使用数据重新上传量子神经网络训练嵌入式量子核
摘要
核方法在机器学习中起着至关重要的作用,嵌入式量子核 (EQKs) 作为对量子系统的扩展,已显示出非常有前景的性能。 然而,为 EQKs 选择合适的嵌入是具有挑战性的。 我们通过提出一个基于数据重新上传的 量子位量子神经网络 (QNN) 来解决这个问题,以识别用于任务 ( 到 ) 的最佳 量子位 EQK。 此方法仅需要构造一次核矩阵,从而提高了效率。 特别地,我们关注两种情况: 到 ,其中我们提出了一种可扩展的方法来训练 量子位 QNN,以及 到 ,证明了单个量子位 QNN 的训练可以用来构建强大的 EQKs。
I 引言
量子计算是一种很有前途的计算范式,用于解决经典上难以解决的一些复杂计算问题。 特别是,它在增强机器学习任务方面的潜力已引起广泛关注 Biamonte et al. (2017); Carleo et al. (2019); Dunjko and Briegel (2018); Dalzell et al. (2023),其中参数化量子电路是最常见的方法 Benedetti et al. (2019); Skolik et al. (2022); Schuld et al. (2020); Farhi and Neven (2018)。 尽管有一些证据表明在一些定制问题中存在量子优势 Sweke et al. (2021); Jerbi et al. (2021); Pirnay et al. (2023); Gyurik and Dunjko (2023),但对于实际应用而言,与经典对应物的优势仍然是活跃的研究领域。
在探索量子机器学习模型的过程中,先前的研究,特别是在参考文献 Havlíček et al. (2019); Schuld and Killoran (2019) 中,已经将分类划分为显式模型和隐式模型。 在显式模型中,数据被编码到量子态中,然后进行参数化测量。 相反,隐式或核模型是基于编码数据点之间内积的加权求和。 参数化量子电路中一个专门的类别,可以单独考虑,包括数据重新上传模型 Pérez-Salinas et al. (2020)。 此架构的特点是在编码和处理酉算子之间交替,从而产生表达能力强的模型,这些模型已被广泛使用 Schuld et al. (2021a); Caro et al. (2021); Ono et al. (2023)。 然而,Jerbi 等人 (2023) 指出,这些模型可以映射到一个显式模型上,从而在希尔伯特空间内线性模型框架内统一这三种方法。
除了这个总体的理论框架之外,人们还致力于研究量子核方法的性能 Huang 等人 (2021); Peters 等人 (2021); Bartkiewicz 等人 (2020); Kusumoto 等人 (2021)。 此外,人们还将它们作为解释量子机器学习模型的一种方式进行了理论化 Schuld 和 Killoran (2019); Schuld (2021); Schuld 等人 (2021b)。 这种兴趣有几个令人信服的因素。 首先,将数据嵌入量子态中,可以直接访问指数级庞大的量子希尔伯特空间,其中可以高效地计算内积。 其次,创建嵌入式量子核,它们对经典计算而言是难以处理的,但也具有量子优势的潜力 Liu 等人 (2021)。 最后,在经典机器学习和核方法中,表示定理 Schölkopf 和 Smola (2001) 确保它们始终实现的训练损失低于或等于显式模型的训练损失,前提是使用相同的编码和训练集。 然而,值得注意的是,这种增强的表达能力可能会伴随着泛化能力的降低,这一点在参考文献 Jerbi 等人 (2023) 中进行了探讨和讨论。
虽然以上论点可能表明更偏向于使用核或隐式模型而不是显式模型,但实际问题依然存在。 首先,构建核矩阵相关的计算复杂度与训练样本数量成二次方增长。 此外,选择定义核函数的合适嵌入取决于具体问题,需要谨慎考虑。 关于最后一个问题,人们已经考虑了两种方法来训练针对数据集定制的核:多核学习和核目标对齐。 在前者中,训练多个核函数的组合来最小化经验风险函数 Vedaie 等人 (2020); Ghukasyan 等人 (2023)。 在后者中,使用一个嵌入式假设定义一个核,该核经过训练以与理想核对齐 Hubregtsen 等人 (2022)。 但是,这些技术需要在每次训练迭代中计算核矩阵,从而导致大量的计算成本。
在这篇文章中,我们使用量子神经网络 (QNN) 来创建一个嵌入式量子核 (EQK)。 此策略利用 QNN 训练来构建相应的核矩阵,与在每个训练步骤中构建核矩阵相比,显着降低了计算成本。 特别是,我们利用了 QNN 的数据重新上传架构,并提出了一种方法来直接将训练扩展到 量子比特 QNN。 在对给定数据集进行训练后,此 QNN 用于生成 量子比特 EQK。 此构造表示为 到 方法。 在这里,我们将重点关注两种特定情况: 到 和 到 。 前者具有根本意义,因为我们可以证明,随着 的增加,QNN 的分类精度不会下降,并且纠缠在该精度中起作用。 此外,我们已经通过经验观察到,EQK 的分类精度不仅如预期的那样高于 QNN,而且不会随着 的增加而下降。 我们还建议使用单个量子比特 QNN 的训练来创建具有纠缠的 量子比特 EQK,称为 到 方法。 我们用数值证据证实了我们的提议,证明了小型 QNN 的训练(甚至可能在经典上进行模拟)能够熟练地选择参数来形成一个针对特定任务的强大 EQK。 我们的结果考虑了最多 10 个量子比特,表明我们的方法规避了与扩展参数化量子电路相关的典型训练挑战。
本文组织如下。 我们首先介绍量子核方法和 EQK。 之后,我们介绍了数据重新上传架构以及我们将该架构扩展到 量子比特 QNN 的方法。 随后,我们详细介绍了从这些 QNN 训练中推导出的 EQK 的构建。 最后,我们展示了支持我们方法可行性的数值结果。
II 量子核方法
量子机器学习模型可以分为显式模型和隐式模型,如参考文献中所述。 Schuld 和 Killoran (2019); Havlíček 等人 (2019). 显式模型基于参数化的量子电路 Benedetti 等人 (2019); Abbas 等人 (2021); Cerezo 等人 (2021); Bharti 等人 (2022),它们专门用于处理经典信息 ,编码成量子状态为 ,其中 指的是某种量子嵌入。 这些模型已被证明对噪声具有弹性 Sharma 等人 (2020),这使得它们在寻求近期限量子处理器中的量子优势方面极具吸引力。 但是,由于训练期间的贫瘠高原问题,它们面临着可扩展性挑战 McClean 等人 (2018); Cerezo 等人 (2021); Holmes 等人 (2022); Anschuetz 和 Kiani (2022); Ragone 等人 (2023)。 另一方面,隐式或核模型由线性组合定义
| (1) |
其中 是核函数,而 表示来自训练集 的训练点。 来自经典机器学习理论的一个重要见解被代表定理所捕获。 该定理断言,当提供特征编码和训练集时,以等式 1 形式的隐式模型始终能获得等于或低于显式量子模型的训练损失。
确定隐式模型的最佳 参数涉及解决一个凸优化问题,需要构造具有条目 的核矩阵 。 为此,必须在量子计算机上评估所有训练点之间的内积 Buhrman 等人 (2001); Fanizza 等人 (2020); Cincio 等人 (2018),涉及 次评估。 尽管在某些情况下可以计算这些内积而无需显式构建特征映射,但我们这里主要关注的是嵌入量子核 (EQKs)。 EQKs 在量子核文献中很普遍,并且在参考文献 Gil-Fuster 等人 (2023) 中被证明是通用的,它们的构建方式如下:
| (2) |
其中 。 这些重叠评估作为支持向量机 (SVM) 算法的输入。 尽管已经探索了量子 SVM 方法 Rebentrost 等人 (2014); Park 等人 (2023),但在本工作中,我们假设对此步骤进行经典计算,其时间复杂度为 。
鉴于代表定理和量子设备固有的访问指数级大特征空间的能力,量子核方法成为最优量子机器学习模型的有希望的候选者 Schuld (2021)。 然而,它们也面临着挑战,例如核值的指数衰减 Thanasilp et al. (2022); Kübler et al. (2021),以及,正如本文所述,选择适合特定任务的核的至关重要问题。
为了识别最佳内核,通用策略涉及使用参数化量子嵌入 Lloyd et al. (2020),其中 代表可训练参数。 此嵌入定义了一个可训练的量子内核 ,然后根据特定的优值指标对其进行优化。 在 Hubregtsen 等人的研究中 Hubregtsen et al. (2022),优化问题是使用内核目标对齐来制定的。 另一种在诸如 Vedaie et al. (2020); Ghukasyan et al. (2023) 的作品中探讨的途径涉及多内核学习,其目标是确定针对特定任务的不同内核的最佳组合。 然而,这些方法要求在每个训练步骤中构建内核矩阵,这意味着计算成本很高。 在我们的工作中,我们提出了一种新颖的方法来训练嵌入式量子内核,该方法只需要构建内核矩阵一次。
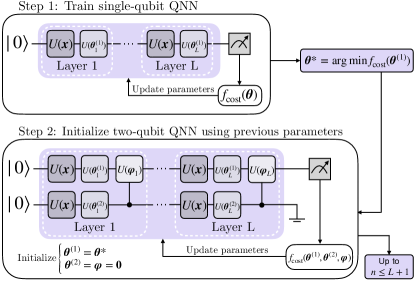
III 为 量子比特 QNN 扩展数据重新上传
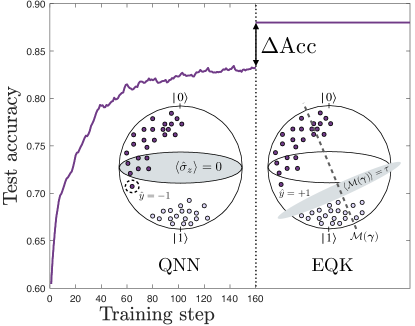
正如 Pérez-Salinas 等人在参考文献 Pérez-Salinas et al. (2020) 中所报道的那样,数据重新上传模型包含由数据编码和训练酉算子组成的层。 这种方法有效地将非线性引入模型,允许捕捉数据上的复杂模式 Schuld et al. (2021a); Casas and Cervera-Lierta (2023); Caro et al. (2021); Barthe and Pérez-Salinas (2023)。 事实上,已经证明单量子比特量子分类器具有通用能力 Pérez-Salinas et al. (2021)。
虽然可以为这种架构考虑各种编码策略,但我们专门采用最简单的定义
| (3) |
这里, 表示层数, 表示一般的 酉算子,向量 包含可训练参数。 为了利用此模型构建二元分类器,必须选择在希尔伯特空间中最大分离的两个标签状态。 训练目标包括指示模型将属于同一类的点集体旋转,使它们更靠近其相应的标签状态。
从数据重新上传单量子比特 QNN 架构开始,我们可以自然地将其扩展以创建多量子比特 QNN。 引入更多量子比特通过增加每层可训练参数的数量来增强模型的表达能力,并提供量子比特之间纠缠的可能性,从而增强模型的表达能力 Panadero et al. (2023)。
在这项工作中,我们提出了一种用于多量子比特 QNN 的迭代训练方法。 在我们的构造中,-量子比特 QNN 定义为
| (4) |
其中 表示一般 酉算子的受控版本,控制在第 个量子比特,目标在第 个量子比特, 和 分别指代单量子比特和双量子比特门的可训练参数。 此架构中可训练参数的总数为 。
为了训练 量子比特的 QNN,我们提出了一种从单个量子比特 QNN 开始的迭代构建方法。 初始化过程如图 1 所示。 最初,我们训练一个单量子比特 QNN,并利用其参数来初始化双量子比特 QNN。 在初始化双量子比特 QNN 期间,我们为所有 设置 ,使用从单量子比特训练步骤中获得的参数初始化第一个量子比特的参数。 因此,纠缠层没有任何作用,确保在对第一个量子比特进行局部测量时,我们从单量子比特 QNN 训练的输出状态开始。
此过程可用于扩展 QNN 架构,允许构建具有高达 个量子比特的 QNN。 添加一个额外的量子比特时,补充纠缠门被初始化为单位矩阵,训练从前一步获得的最优参数开始。 本质上,这种形式化方法表明,通过添加每个额外的量子比特,QNN 的性能得到了系统且可扩展的提高。
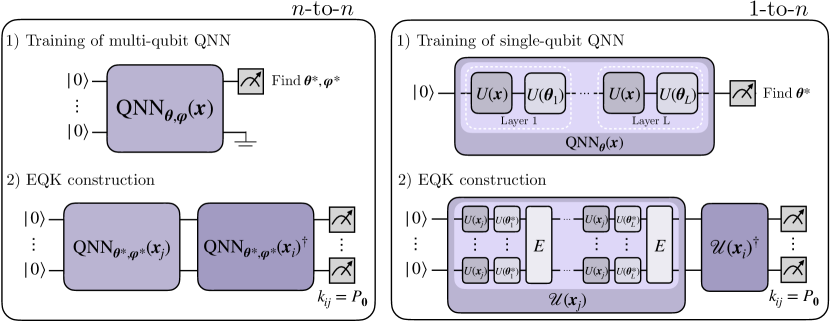
IV 从 QNN 训练中构建 EQK
在本节中,我们提出了一种使用数据重新上传量子神经网络 (QNN) 构建训练后的嵌入量子核 (EQK) 的方法。 想法是训练 QNN 用于分类任务,并利用其架构生成针对特定任务的 EQK,从而提高给定数据集上的性能。 将这两种二元分类方法(QNN 和核方法)结合起来的动机源于两个方面。
首先,我们研究 QNN 是否可以有效地为特定任务选择合适的嵌入核。 与以前的方法相比,这种方法可能导致更有效的核训练,因为我们只需要构建一次核矩阵。 其次,QNN 的性能取决于其训练。 利用相应的 EQK 构造,与仅依赖 QNN 相比,即使在训练过程未达到最佳状态的情况下,也可能产生更好的结果。 可以在附录 E 中找到说明此结果的数值结果。
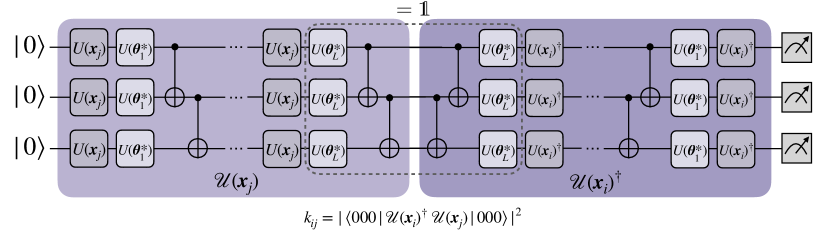
该方法的基本概念在附录中进行了形式化,并在图 2 中进行了说明,特别是针对单量子比特场景。 最初,QNN 会将同一类的数据点旋转到其标签状态附近,同时保持决策超平面固定。 此超平面被视为布洛赫球的赤道,即 。 训练 QNN 后,通过保留训练期间获得的参数来获得最终的特征图。 然后利用此特征图来构建 EQK。 随后,使用此核的 SVM 算法旨在识别特征空间中的最佳分离超平面。 在这种情况下,优化等同于调整最佳测量 ,同时保持数据点固定。
基于这种见解,我们提出了使用 QNN 训练构建 EQK 的两种方法: 到 方法和 到 。 在第一个方法中,使用前面提出的迭代方法训练 量子比特 QNN,以直接构建 量子比特的相应 EQK。 如图 3 所示,一个具有 Eq. 4 形式的多量子比特 QNN 在固定嵌入 和 的可训练参数的情况下进行训练。 然后,这些参数随后用于构建一个由
| (5) |
此方法允许我们在训练期间尽可能地扩展 QNN,当它达到性能平稳期时,我们可以利用训练后的特征映射来构建 EQK。
在 到 的构造中,我们从 Eq. 3 训练一个单量子比特 ,固定 ,并利用这种训练来构建内核
| (6) |
其中 表示一个纠缠操作,例如 或 门的级联,以及其他可能性。 值得注意的是,训练是针对单量子比特 QNN 进行的,并没有明确考虑纠缠。 然而,我们将展示数值结果,证明这种训练本身就足以选择参数来构建针对特定任务的定制多量子比特内核。
当然,可以将 到 和 到 架构结合起来,并将其推广到 到 ,其中 代表某个整数。 在这种情况下,训练了一个 量子比特 QNN,并用于实现与 到 构造中相同的设计。 然而,在这种情况下,QNN 的每个量子比特都嵌入到 个量子比特中,在层之间引入了纠缠。
V 数值结果
现在让我们探索我们方法的实际实现,并评估它们在附录 F 中详细介绍的各种数据集上的性能。训练集和测试集都包含 500 个数据点。
对于本节中的 QNN 训练,我们采用 Adam 优化器,批次大小为 24。 在 QNN 训练的初始步骤 () 中,我们使用 0.05 的学习率,并考虑 30 个时期。 对于 ,我们使用 0.005 的学习率和 10 个时期。
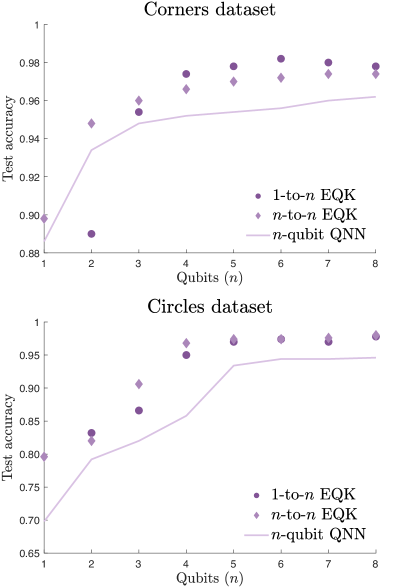
图 4 中展示的结果演示了两个不同数据集(角落数据集和圆圈数据集)的测试准确率,分别针对 到 和 到 的构造,作为量子比特数量 的函数。这些实验考虑了 层,将 QNN 扩展到 。 在 到 结构中,我们使用一系列 CNOT 门来引入层之间的纠缠,定义为
| (7) |
其中下标表示控制量子位,上标表示目标量子位。
数值实验表明,随着两个数据集引入更多量子位, 量子神经网络的性能始终得到改善。 此外,由 到 结构表示的相应内核与单独的量子神经网络相比,性能有所提升。 有趣的是, 到 结构表现出色,在少量量子位的情况下,性能迅速提高,尽管最终会达到平稳状态。 虽然 到 场景的改进速度较慢,但其性能始终优于量子神经网络,并且该模型的扩展是持续且严格的。 有关其他数值实验,请参阅附录 G。
这些结果一方面证明了数据重新上传量子神经网络的可扩展性以及构建相应 EQK 所实现的性能提升。 另一方面,它们突出了通过训练简单的量子神经网络架构来创建复杂内核的能力。 尽管可以使用经典计算机训练小型量子神经网络,但所获得的参数可用于构建经典上难以嵌入的量子内核。
VI 结论
我们已经解决了训练 量子位嵌入量子内核的挑战,引入了一种实用方法,从数据重新上传 量子位量子神经网络构建它们。 与之前的技术相比,该方法显着降低了计算成本,在之前的技术中,内核矩阵在每个训练步骤中都构建。 我们专注于构建嵌入式量子核的两种特定情况,即 到 和 到 的情况。 第一种方法涉及直接使用 量子神经网络 (QNN) 训练的输出作为特征映射(称为 到 方法),我们为此提出了一种可扩展的训练方法。 第二种方法能够通过单个量子神经网络 (QNN) 的训练创建具有纠缠的多量子比特 EQK(称为 到 方法)。 鉴于当前参数化量子电路扩展方面的局限性,我们的组合方法为创建可训练的可扩展内核作为量子机器学习模型提供了一种替代方案,减轻了与它们的可扩展性相关的挑战,并减少了对训练以实现模型成功的依赖。 此外, 到 方法可以被视为一种量子启发的方案,为探索从小型架构的训练中构建经典难以估计的内核铺平了道路,即使这些架构可以使用经典计算机模拟。
VII 致谢
作者要感谢 Maria Schuld 的宝贵意见,这些意见使我们能够更清晰地呈现结果,并感谢 Sofiene Yerbi 和 Adrián Pérez-Salinas 在 QTML 2023 期间的宝贵见解。 PR 和 YB 感谢 CDTI 在 Misiones 2021 项目和科学与创新部在“CUCO:量子计算及其在战略产业中的应用”项目下根据恢复、转型和复原计划 - 下一代欧盟的财务支持。 PR 和 MS 感谢欧盟 FET Open 项目 EPIQUS(899368)和 HORIZON-CL4-2022-QUANTUM01-SGA 项目 101113946 OpenSuperQPlus100 的支持,该项目是欧盟量子技术旗舰项目的一部分,西班牙拉蒙·卡哈尔奖助金 RYC-2020-030503-I,项目资助号 PID2021-125823NA-I00 由 MCIN/AEI/10.13039/501100011033 资助,并由“欧洲发展基金”和“欧洲发展基金投资你的未来”资助,以及通过巴斯克政府教育部的伊克巴斯基金会和 BCAM 之间的合作协议在 IKUR 战略下的支持。 该项目还获得了西班牙经济事务和数字转型部通过 QUANTUM ENIA 项目计划 - 西班牙量子计划,以及欧盟通过恢复、转型和复原计划 - 下一代欧盟的支持。 YB 感谢西班牙政府通过 PID2021-126694NA-C22 项目(MCIU/AEI/FEDER,欧盟)提供的支持。
参考文献
- Biamonte et al. (2017) J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Nature 549, 195 (2017).
- Carleo et al. (2019) G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborová , Reviews of Modern Physics 91 (2019), 10.1103/revmodphys.91.045002.
- Dunjko and Briegel (2018) V. Dunjko and H. J. Briegel, Reports on Progress in Physics 81, 074001 (2018).
- Dalzell et al. (2023) A. M. Dalzell, S. McArdle, M. Berta, P. Bienias, C.-F. Chen, A. Gilyén, C. T. Hann, M. J. Kastoryano, E. T. Khabiboulline, A. Kubica, G. Salton, S. Wang, and F. G. S. L. Brandão, “Quantum algorithms: A survey of applications and end-to-end complexities,” (2023), arXiv:2310.03011 [quant-ph] .
- Benedetti et al. (2019) M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Quantum Science and Technology 4, 043001 (2019).
- Skolik et al. (2022) A. Skolik, S. Jerbi, and V. Dunjko, Quantum 6, 720 (2022).
- Schuld et al. (2020) M. Schuld, A. Bocharov, K. M. Svore, and N. Wiebe, Physical Review A 101 (2020), 10.1103/physreva.101.032308.
- Farhi and Neven (2018) E. Farhi and H. Neven, “Classification with quantum neural networks on near term processors,” (2018), arXiv:1802.06002 [quant-ph] .
- Sweke et al. (2021) R. Sweke, J.-P. Seifert, D. Hangleiter, and J. Eisert, Quantum 5, 417 (2021).
- Jerbi et al. (2021) S. Jerbi, L. M. Trenkwalder, H. Poulsen Nautrup, H. J. Briegel, and V. Dunjko, PRX Quantum 2 (2021), 10.1103/prxquantum.2.010328.
- Pirnay et al. (2023) N. Pirnay, R. Sweke, J. Eisert, and J.-P. Seifert, Physical Review A 107 (2023), 10.1103/physreva.107.042416.
- Gyurik and Dunjko (2023) C. Gyurik and V. Dunjko, “On establishing learning separations between classical and quantum machine learning with classical data,” (2023), arXiv:2208.06339 [quant-ph] .
- Havlíček et al. (2019) V. Havlíček, A. D. Córcoles, K. Temme, A. W. Harrow, A. Kandala, J. M. Chow, and J. M. Gambetta, Nature 567, 209 (2019).
- Schuld and Killoran (2019) M. Schuld and N. Killoran, Physical review letters 122, 040504 (2019).
- Pérez-Salinas et al. (2020) A. Pérez-Salinas, A. Cervera-Lierta, E. Gil-Fuster, and J. I. Latorre, Quantum 4, 226 (2020).
- Schuld et al. (2021a) M. Schuld, R. Sweke, and J. J. Meyer, Physical Review A 103 (2021a), 10.1103/physreva.103.032430.
- Caro et al. (2021) M. C. Caro, E. Gil-Fuster, J. J. Meyer, J. Eisert, and R. Sweke, Quantum 5, 582 (2021).
- Ono et al. (2023) T. Ono, W. Roga, K. Wakui, M. Fujiwara, S. Miki, H. Terai, and M. Takeoka, Physical Review Letters 131 (2023), 10.1103/physrevlett.131.013601.
- Jerbi et al. (2023) S. Jerbi, L. J. Fiderer, H. Poulsen Nautrup, J. M. Kübler, H. J. Briegel, and V. Dunjko, Nature Communications 14, 517 (2023).
- Huang et al. (2021) H.-Y. Huang, M. Broughton, M. Mohseni, R. Babbush, S. Boixo, H. Neven, and J. R. McClean, Nature Communications 12 (2021), 10.1038/s41467-021-22539-9.
- Peters et al. (2021) E. Peters, J. Caldeira, A. Ho, S. Leichenauer, M. Mohseni, H. Neven, P. Spentzouris, D. Strain, and G. N. Perdue, “Machine learning of high dimensional data on a noisy quantum processor,” (2021), arXiv:2101.09581 [quant-ph] .
- Bartkiewicz et al. (2020) K. Bartkiewicz, C. Gneiting, A. Černoch, K. Jiráková, K. Lemr, and F. Nori, Scientific Reports 10 (2020), 10.1038/s41598-020-68911-5.
- Kusumoto et al. (2021) T. Kusumoto, K. Mitarai, K. Fujii, M. Kitagawa, and M. Negoro, npj Quantum Information 7 (2021), 10.1038/s41534-021-00423-0.
- Schuld (2021) M. Schuld, arXiv preprint arXiv:2101.11020 (2021).
- Schuld et al. (2021b) M. Schuld, F. Petruccione, M. Schuld, and F. Petruccione, Machine Learning with Quantum Computers , 217 (2021b).
- Liu et al. (2021) Y. Liu, S. Arunachalam, and K. Temme, Nature Physics 17, 1013 (2021).
- Schölkopf and Smola (2001) B. Schölkopf and A. Smola, Smola, A.: Learning with Kernels - Support Vector Machines, Regularization, Optimization and Beyond. MIT Press, Cambridge, MA, Vol. 98 (2001).
- Vedaie et al. (2020) S. S. Vedaie, M. Noori, J. S. Oberoi, B. C. Sanders, and E. Zahedinejad, “Quantum multiple kernel learning,” (2020), arXiv:2011.09694 [quant-ph] .
- Ghukasyan et al. (2023) A. Ghukasyan, J. S. Baker, O. Goktas, J. Carrasquilla, and S. K. Radha, “Quantum-classical multiple kernel learning,” (2023), arXiv:2305.17707 [quant-ph] .
- Hubregtsen et al. (2022) T. Hubregtsen, D. Wierichs, E. Gil-Fuster, P.-J. H. S. Derks, P. K. Faehrmann, and J. J. Meyer, Physical Review A 106 (2022), 10.1103/physreva.106.042431.
- Abbas et al. (2021) A. Abbas, D. Sutter, C. Zoufal, A. Lucchi, A. Figalli, and S. Woerner, Nature Computational Science 1, 403–409 (2021).
- Cerezo et al. (2021) M. Cerezo, A. Sone, T. Volkoff, L. Cincio, and P. J. Coles, Nature Communications 12 (2021), 10.1038/s41467-021-21728-w.
- Bharti et al. (2022) K. Bharti, A. Cervera-Lierta, T. H. Kyaw, T. Haug, S. Alperin-Lea, A. Anand, M. Degroote, H. Heimonen, J. S. Kottmann, T. Menke, et al., Reviews of Modern Physics 94, 015004 (2022).
- Sharma et al. (2020) K. Sharma, S. Khatri, M. Cerezo, and P. J. Coles, New Journal of Physics 22, 043006 (2020).
- McClean et al. (2018) J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Babbush, and H. Neven, Nature Communications 9 (2018), 10.1038/s41467-018-07090-4.
- Holmes et al. (2022) Z. Holmes, K. Sharma, M. Cerezo, and P. J. Coles, PRX Quantum 3 (2022), 10.1103/prxquantum.3.010313.
- Anschuetz and Kiani (2022) E. R. Anschuetz and B. T. Kiani, Nature Communications 13 (2022), 10.1038/s41467-022-35364-5.
- Ragone et al. (2023) M. Ragone, B. N. Bakalov, F. Sauvage, A. F. Kemper, C. O. Marrero, M. Larocca, and M. Cerezo, “A unified theory of barren plateaus for deep parametrized quantum circuits,” (2023), arXiv:2309.09342 [quant-ph] .
- Buhrman et al. (2001) H. Buhrman, R. Cleve, J. Watrous, and R. de Wolf, Physical Review Letters 87 (2001), 10.1103/physrevlett.87.167902.
- Fanizza et al. (2020) M. Fanizza, M. Rosati, M. Skotiniotis, J. Calsamiglia, and V. Giovannetti, Physical Review Letters 124 (2020), 10.1103/physrevlett.124.060503.
- Cincio et al. (2018) L. Cincio, Y. Subaşı, A. T. Sornborger, and P. J. Coles, New Journal of Physics 20, 113022 (2018).
- Gil-Fuster et al. (2023) E. Gil-Fuster, J. Eisert, and V. Dunjko, arXiv preprint arXiv:2309.14419 (2023).
- Rebentrost et al. (2014) P. Rebentrost, M. Mohseni, and S. Lloyd, Physical review letters 113, 130503 (2014).
- Park et al. (2023) S. Park, D. K. Park, and J.-K. K. Rhee, Scientific Reports 13, 3288 (2023).
- Thanasilp et al. (2022) S. Thanasilp, S. Wang, M. Cerezo, and Z. Holmes, “Exponential concentration and untrainability in quantum kernel methods,” (2022), arXiv:2208.11060 [quant-ph] .
- Kübler et al. (2021) J. M. Kübler, S. Buchholz, and B. Schölkopf, “The inductive bias of quantum kernels,” (2021), arXiv:2106.03747 [quant-ph] .
- Lloyd et al. (2020) S. Lloyd, M. Schuld, A. Ijaz, J. Izaac, and N. Killoran, “Quantum embeddings for machine learning,” (2020), arXiv:2001.03622 [quant-ph] .
- Casas and Cervera-Lierta (2023) B. Casas and A. Cervera-Lierta, Physical Review A 107 (2023), 10.1103/physreva.107.062612.
- Barthe and Pérez-Salinas (2023) A. Barthe and A. Pérez-Salinas, “Gradients and frequency profiles of quantum re-uploading models,” (2023), arXiv:2311.10822 [quant-ph] .
- Pérez-Salinas et al. (2021) A. Pérez-Salinas, D. López-Núñez, A. García-Sáez, P. Forn-Díaz, and J. I. Latorre, Physical Review A 104 (2021), 10.1103/physreva.104.012405.
- Panadero et al. (2023) I. Panadero, Y. Ban, H. Espinós, R. Puebla, J. Casanova, and E. Torrontegui, “Regressions on quantum neural networks at maximal expressivity,” (2023), arXiv:2311.06090 [quant-ph] .
- Holmes and Jain (2006) D. E. Holmes and L. C. Jain, Innovations in machine learning (Springer, 2006).
附录 A 关于量子内核训练的相关工作
量子内核方法的主要缺点之一是确定最佳内核,这取决于具体的问题。 在没有关于输入数据的先验知识的情况下,已经开发出了一些方法来构建针对特定任务训练的参数化嵌入式量子内核。 这些核训练方法基于多核学习 Vedaie et al. (2020); Ghukasyan et al. (2023) 和核目标对齐 Hubregtsen et al. (2022)。
A.1 多核学习
多核学习方法涉及创建组合核
| (8) |
其中 表示一组参数化的嵌入量子核,而 是一个组合函数。 此函数的两种常见选择分别导致线性核组合
| (9) |
或乘法核组合
| (10) |
在选择模型参数时,在 Ref. Vedaie et al. (2020) 中,他们使用经验风险函数进行最小化,而在 Ref. Ghukasyan et al. (2023) 中,作者选择了一个凸最小化问题。 但是,在这两种构造中,在每个优化步骤中都会计算完整的核矩阵。
A.2 核目标对齐
使用核目标对齐训练核基于两个核矩阵之间的相似度度量,分别表示为 和 。 这种相似度度量,称为核对齐 Holmes and Jain (2006),定义为
| (11) |
并且对应于核矩阵之间的角度的余弦,如果我们将它们视为具有希尔伯特-施密特内积的矩阵空间中的向量。 使用核对齐来训练核是通过定义理想的核矩阵 ,其条目为 。 给定一个参数化的量子嵌入核 ,其核矩阵名为 ,核目标对齐定义为 与理想核之间的核对齐,即
| (12) |
其中我们使用 与标签无关,而 是训练点的数量。 因此,Ref. Hubregtsen et al. (2022) 中的作者使用此量作为成本函数,该函数使用梯度下降在 参数上最小化。 这种策略与参考文献 Lloyd 等人 (2020) 中概述的方法密切相关,其中作者探索了构建量子特征图以最大限度地扩大希尔伯特空间中不同类别之间距离的目标。 然而,在核目标对齐策略的情况下,类似于多核学习,在每个训练步骤中都需要构建核矩阵(或至少其子集)。
附录 B 数据重新上传
为了构建用于二元分类的数据重新上传 QNN,每个标签都与一个唯一的量子态相关联,旨在最大限度地扩大 Bloch 球体中的分离。 对于单量子比特量子分类器,标签 +1 和 -1 分别由计算基态 和 表示。 目标是适当地调整定义状态 的参数。
| (13) |
将同一类的数点旋转到其对应的标签状态附近。 为此,我们使用保真度成本函数
| (14) |
其中 表示数据点 的正确标签状态。 此优化过程在经典处理器上进行。 模型训练完成后,量子电路将应用于测试数据点 ,并测量获得其中一个标签状态的概率。 如果该概率超过某个阈值(在本例中设置为 1/2),则数据点将被分类到相应的标签状态类别中。 正式地说,决策规则可以表示为
| (15) |
当考虑多量子比特体系结构时,其想法是相同的,但我们需要适当地选择相应的标签状态。 在这项工作中,对于 量子比特 QNN,我们考虑由投影仪 和 定义的标签状态,这对应于第一个量子比特的局部测量。
附录 C 与代表定理的联系
本节,我们旨在利用代表定理来证明,从数据重新上传量子神经网络 (QNN) 衍生的内核将至少与相应的 QNN 一样有效。 在我们的构造中, 量子比特 QNN 在正文的公式 4 中定义。 那里,我们可以提取最后一层,将其分成一个变分部分(当我们定义相应的量子模型时将被吸收到测量中)和一个编码部分(将为内核的构造定义量子特征映射)。 这对应于
| (16) |
其中我们定义了 和 。 这种公式与参考文献中定义的量子模型一致。 舒尔德(2021),
| (17) |
在我们的案例中,,以及变分测量 。
一旦这个模型在数据集上训练完成,我们就确定最小化上一节定义的 的参数,固定 和 。 如果我们现在使用相应的特征映射 来构建一个嵌入量子内核,我们实际上是将优化 中的测量替换为最优测量
| (18) |
根据代表定理,它定义了最优量子模型
| (19) |
使正则化的经验风险函数最小化。 因此,我们证明了,从 QNN 训练构建嵌入量子内核在训练损失方面将与 QNN 本身一样好或更好。
附录 D 布洛赫球体中定义的超平面
数据重新上传量子神经网络 (QNN) 的目标是将所有标记为 +1 的点映射到布洛赫球体上的 状态,同时将标记为 -1 的点映射到 状态。 在理想情况下,所有 +1 点将被旋转到 状态,所有 -1 点将被旋转到 状态。 使用此特征图构建嵌入量子核,所有点将成为与相同拉格朗日乘子 关联的支持向量。 SVM 生成由以下等式定义的分隔超平面
| (20) |
在这种情况下,假设平衡数据集转化为每个类别具有相同数量的支持向量,表示为 ,由于对称性,导致 。 通过分别考虑 +1 类 () 和 -1 类 () 的支持向量之和来处理此等式,我们得到
| (21) |
这等效于由以下等式定义的超平面
| (22) |
反映 QNN 部分的决策边界。 因此,在完美训练的情况下,SVM 就变得多余了。 即使点没有完美地映射到它们的标签状态,并且 SVM 的分隔超平面不完全是来自等式 22 的超平面,只要 QNN 正确地对所有点进行分类,SVM 就会产生相同的结果。 因此,SVM 部分仅在单量子比特 QNN 构建单量子比特 EQK 案例时才有意义,此时 QNN 训练不是最优的,需要调整决策边界的测量。
附录 E 噪声模拟
我们已经介绍了一种用于二元分类的组合协议。 值得注意的是,核估计部分涉及使用深度是 QNN 部分两倍的量子电路。 在当前噪声中型量子设备上的实际实现中,需要仔细考虑更大的电路。 这是因为更大的电路容易受到噪声水平升高的影响,这可能会影响整体性能。
如前所述,增加模型中的层数可以提高其表达能力。 但是,当使用大量层构建内核时,噪声会对性能产生不利影响,导致组合协议的结果比仅使用 QNN 更差。 因此,在本节中,我们的目标是执行模拟以可视化 QNN 中层数与使用组合协议之间的权衡。
为了表征这些模拟中包含的噪声,我们采用了噪声通道 作用于量子态 的算子求和表示,
| (23) |
其中 代表相应的克劳斯算子。 在我们的模拟中,我们考虑了两个在每个量子门之后应用的单量子比特噪声通道。 首先,我们考虑由克劳斯算子描述的幅度衰减误差
| (24) | ||||
| (25) |
这里, 是幅度衰减概率,可以定义为 ,其中 代表热弛豫时间, 代表量子门的应用持续时间。 我们考虑的第二个噪声源是相位翻转误差,它可以用以下克劳斯算子描述
| (26) | ||||
| (27) |
在这种情况下, 代表相位翻转误差的概率,可以定义为 ,其中 代表自旋自旋弛豫时间或退相干时间。 的值也落在区间 内。
超导量子处理器噪声参数的最新实验值如下: 位于 的范围内, 位于 的范围内, 从 变化。 重要的是要注意,当 和 减小和/或 增加时,噪声会更加明显。 为了探索具有最差噪声的情况,我们考虑这些范围内的极值,导致 和 。
在我们的模拟中,为了简单起见,我们通过定义一个噪声强度参数 来简化噪声表征。 我们选择单量子比特数据重新上传量子神经网络 (QNN) 作为内核选择部分。 为了观察一个不再有利于包含支持向量机 (SVM) 部分的转变,我们探索了从 到 范围内的 值,步长为 ,同时还包括无噪声情况,其中 。 这些值对应于检查范围 和 。 值得注意的是,即使在这些高度不利条件下,这些条件比当前实际硬件量子设备的条件要糟糕得多,我们发现组合协议仍然适用。 这一结论与预期相符,因为该协议仅使用少量量子比特和量子门。
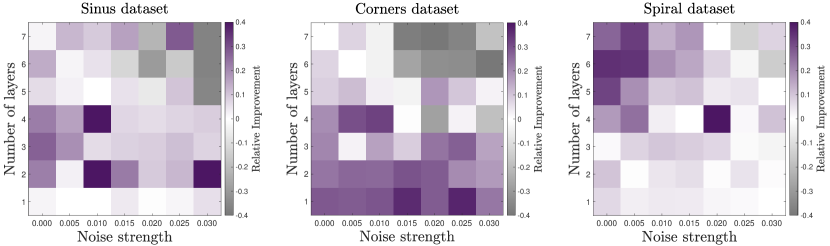
在图 E.1 中,我们展示了相对改进,表示为
| (28) |
绘制为噪声强度参数 和层数 的函数。 所使用的体系结构对应于 到 的情况,使用 门进行层间纠缠。 在这种情况下,我们将 QNN 训练限制为两个 epoch,学习率为 0.05。 目的是证明由此产生的 EQK 不高度依赖于相应 QNN 的训练细节,即使是次优的 QNN 训练也可以导致针对特定任务的强大 EQK。
相对改进因所考虑的数据集而异,范围从 到 。 正如预期的那样,组合协议的最差性能在更高的噪声水平和更多层的层数下观察到,对应于更深层的量子电路。 再次强调,这些高噪声强度值远远超过了当前量子设备的噪声参数。 因此,即使组合协议需要运行一个双层电路,并且有更多量子比特,考虑到前面描述的噪声模型,它仍然适合实际的量子设备。
附录 F 数据集
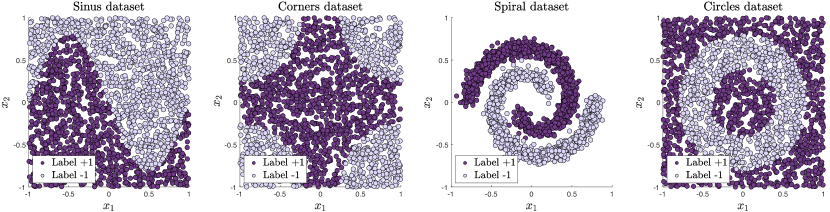
在这项工作中,我们使用了四个人工数据集来评估提出的嵌入式量子核的性能。 以下解释了它们是如何创建的:
-
•
正弦数据集:正弦数据集由正弦函数定义,具体来说是 。 位于此正弦曲线之上的点被归类为 -1 类,而位于其之下的点被归类为 +1 类。
-
•
角数据集:角数据集包含圆周的四个象限,半径为 0.75,位于正方形的角上。 位于这些圆形区域内部的点被标记为 -1 类,而位于外部的点被标记为 +1 类。
-
•
螺旋数据集:螺旋数据集包含两个螺旋,这些螺旋由沿着极坐标定义的轨迹排列的点形成。 第一个螺旋,表示为 +1 类,起源于原点 (0, 0),并以逆时针方向向外螺旋,形成一条曲线。 第二个螺旋,标记为 -1 类,镜像第一个螺旋,但以顺时针方向向内螺旋。 这些螺旋是通过改变极角生成的,随机选择以创建数据点。 每个点到原点的径向距离取决于角度,从而形成特征螺旋形状。 通过向数据点引入随机扰动来添加噪声,以确保它们不会完全沿着螺旋排列。
-
•
圆数据集:圆数据集是使用两个同心圆来创建的,这两个同心圆定义了一个环形区域。 内圆的半径为 ,外圆的半径为 。 位于环形区域内的点被标记为 -1,而位于区域外的点被标记为 +1。
附录 G 数值实验
在正文中,我们提供了两个数据集的数值结果,针对 到 和 到 结构,最高可达 8 个量子比特。 在这里,我们提供了更多数值实验的表格,使用相同的超参数:对于 QNN,学习率为 0.05,迭代次数为 30 次;对于 ,学习率为 0.005,迭代次数为 10 次。 在这里,我们提供了更多针对不同数据集的结果,并且也考虑了 CZ 作为纠缠源。 所有准确率都指测试准确率。
| Dataset | QNN accuracy | EQK type | EQK accuracy |
|---|---|---|---|
| Sinus | 0.890 | 0.960 | |
| Sinus | 0.948 | ||
| Corners | 0.886 | 0.954 | |
| Corners | 0.940 | ||
| Spiral | 0.800 | 0.994 | |
| Spiral | 0.866 | ||
| Circles | 0.698 | 0.866 | |
| Circles | 0.864 |
在表 1 中,结果表明,当通过 门或 门引入纠缠时,结果表现出惊人的相似性,螺旋形数据集除外。 鉴于关于纠缠引入方法的模糊性,人们可能会考虑使用具有随机参数的受控旋转作为纠缠的潜在来源。 值得注意的是,人们观察到,即使从一个单量子比特 QNN 开始,其准确率低于 ,但构建 EQKs 仍然可以获得超过 的准确率。
| Dataset | n=2 | n=3 | n=4 | n=5 | n=6 | n=7 | n=8 | n=9 | n=10 |
|---|---|---|---|---|---|---|---|---|---|
| Corners | 0.890 | 0.954 | 0.974 | 0.978 | 0.982 | 0.980 | 0.978 | 0.978 | 0.978 |
| Circles | 0.832 | 0.866 | 0.950 | 0.970 | 0.974 | 0.970 | 0.978 | 0.966 | 0.962 |
在表 2 中针对角落数据集和圆形数据集呈现的 到 结构中,我们观察到随着量子比特的增加,准确率迅速上升,并在 处达到峰值。 随后,准确率趋于稳定,在角落数据集的 和圆形数据集的 处达到最大值。 在达到这些点之后,准确率随着额外量子比特的增加而逐渐下降。
| Dataset | n=1 | n=2 | n=3 | n=4 | n=5 | n=6 | n=7 | n=8 |
|---|---|---|---|---|---|---|---|---|
| Corners (QNN) | 0.886 | 0.934 | 0.948 | 0.952 | 0.954 | 0.956 | 0.960 | 0.962 |
| Corners (EQK) | 0.898 | 0.948 | 0.960 | 0.966 | 0.970 | 0.972 | 0.974 | 0.974 |
| Circles (QNN) | 0.698 | 0.792 | 0.820 | 0.858 | 0.934 | 0.944 | 0.944 | 0.946 |
| Circles (EQK) | 0.796 | 0.820 | 0.906 | 0.968 | 0.974 | 0.974 | 0.976 | 0.980 |
在表 3 中所示的 到 方法中,对于 QNN 和 EQK,准确率随着量子比特的增加而持续提高。 此外,正如正文所述,对于相同的 值,EQK 的性能始终优于相应的 QNN 架构。
| Dataset | Layers | QNN accuracy | EQK accuracy |
|---|---|---|---|
| Sinus | 0.948 | 0.970 | |
| Sinus | 0.956 | 0.964 | |
| Sinus | 0.966 | 0.972 | |
| Sinus | 0.958 | 0.964 | |
| Corners | 0.948 | 0.970 | |
| Corners | 0.936 | 0.950 | |
| Corners | 0.934 | 0.948 | |
| Corners | 0.916 | 0.920 | |
| Spiral | 0.952 | 0.996 | |
| Spiral | 0.974 | 0.998 | |
| Spiral | 0.978 | 1.000 | |
| Spiral | 0.980 | 0.998 | |
| Circles | 0.786 | 0.812 | |
| Circles | 0.808 | 0.814 | |
| Circles | 0.792 | 0.820 | |
| Circles | 0.844 | 0.902 |
最后,在表 4 中,我们针对四个数据集呈现了结果,这些结果考虑了 到 架构的层数,其中 。 添加层数会提高 QNN 的表达能力,但不能保证更高的准确率,正如我们所观察到的。 同样,我们看到 EQK 的性能始终优于 QNN。