EmoLLMs:一系列用于综合情感分析的情感大语言模型和标注工具
摘要。
情感分析和情绪检测是自然语言处理(NLP)中的重要研究课题,并使许多下游任务受益。 随着大语言模型的广泛应用,研究人员开始探索基于指令调优的大语言模型在情感分析领域的应用。 然而,这些模型仅关注情感分类任务的单个方面(例如情感极性或分类情感),而忽略了回归任务(例如情感强度或情感强度),这导致下游任务的性能不佳。 主要原因是缺乏全面的情感指令调优数据集和评估基准,涵盖各种情感分类和回归任务。 此外,虽然情感信息对下游任务有用,但现有的下游数据集缺乏高质量和全面的情感注释。 在本文中,我们提出了EmoLLM,这是第一个开源的指令跟踪大语言模型,用于基于指令数据微调各种大语言模型的综合情感分析,第一个多任务情感分析指令数据集(AAID)基于3个分类任务和2个回归任务的234K数据样本支持大语言模型指令调优,以及来自不同来源和领域的8个回归任务和6个分类任务的综合情感评估基准(AEB)来测试大语言模型的泛化能力语言模型。 我们通过使用 AAID 微调大语言模型,提出了一系列 EmoLLM 来解决各种情感教学任务。 我们将我们的模型与 AEB 上的各种大语言模型和情感分析工具进行比较,我们的模型优于所有其他开源大语言模型和情感分析工具,并且在大多数任务中超越了 ChatGPT 和 GPT-4,这表明系列EmoLLM在情感分析任务上实现了ChatGPT级和GPT-4级泛化能力,并证明我们的模型可以用作情感标注工具。 该项目位于 https://github.com/lzw108/EmoLLMs/。
1. 介绍
情绪和情感在塑造我们的生活中起着至关重要的作用。 我们的言语和行为是我们情绪状态的指标(Liu,2020)。 利用情绪检测(ED)和情绪分析(SA)等自然语言处理(NLP)技术,我们可以深入分析人类互动,使我们能够理解人们对特定主题的情绪反应(Hakak等人, 2017)。 具体来说,SA 任务通常涉及预测极性(通常是积极、消极或中性)以及这种语气的强度(Thelwall 等人,2010),而情绪检测任务通常涉及将数据分类为细粒度的情绪类别(例如Ekman (Ekman,1992),Plutchik (Plutchik,1980))或预测情绪强度(Xie等人,2018) )。 这些情感信息被证明对许多下游任务都是有用的特征,包括心理健康分析(Zhang 等人,2023b)、错误信息检测(Liu 等人,2023),以及同理心对话系统(马等人,2020)。
预训练语言模型(PLM),例如 BERT (Devlin 等人,2018)和 RoBERTa (Liu 等人,2019),在分类任务中表现出了出色的性能。 许多研究已将其应用于情感分析或情绪检测任务(Bello等人,2023;Liao等人,2021;Yin等人,2020)。 然而,这些PLM受到模型参数规模和训练语料库的限制,导致缺乏对复杂任务的全面理解和泛化能力(张等人,2023c),限制了PLM的有效性情感分析,尤其是情感回归任务(Zhang 等人,2020)。 与PLM相比,大语言模型具有参数规模巨大的特点,通常达到数千亿甚至更多,这使得它们在下游任务中具有更强的泛化能力,使其能够处理复杂复杂的任务(张等人,2023a)。 许多研究者开始探索大语言模型在情感分析领域的应用,通过对开源大语言模型在情感分析任务上的微调,取得了优异的性能(Zhang 等人, 2023c, a; Lei 等人,2023)。 然而,这些研究仅关注情感/情感分类任务,而忽略了回归任务(例如情感强度、情感强度),回归任务提供了更细粒度的情感特征(Akhtar等人,2020)并被证明在很多场景下都很有用(Zhang 等人,2021;Qureshi 等人,2020;Consoli 等人,2022)。 主要原因是缺乏全面的基于指令的情感分析数据集和评估基准。
此外,尽管情感信息被证明对下游任务有用,但现有的下游数据集缺乏与情感相关的资源,例如情感/情感标签。 因此,许多作品都使用情感分析工具(例如VADER (Hutto and Gilbert, 2014a)、TextBlob111https://textblob.readthedocs.io/)提供情感注释。 例如,在(Govindasamy 和 Palanichamy,2021) 中,作者利用 TextBlob 库来计算情绪分数,并将其输入抑郁症检测分类器。 此外,一些研究采用迁移学习方法,通过应用在其他情感分析或情感标记数据集上训练的模型来自动注释下游任务数据集中表达的情感(Chan等人,2023;Dong等人,2022). 然而,这些工具或方法只能标注情感分析任务的某一方面,导致情感特征的覆盖范围有限。
为了解决上述问题,我们提出了一套大语言模型、指令调优数据集和多任务情感分析的评估基准。 我们首先构建了具有 234K 数据样本的多任务情感分析指令数据集(AAID)来支持大语言模型指令调优,该数据集基于 SemEval-2018 Task1:Affect in Tweet (Mohammad 等人,2018;Mohammad 和Kiritchenko,2018),包括五个任务:情感强度回归、情感强度顺序分类、情感强度回归、情感分类和多标签情感分类。 基于AAID数据集,我们通过对大语言模型进行多任务指令调优,提出了一系列情感大语言模型(EmoLLMs),这是第一个用于全面情感分析的开源指令跟踪大语言模型。 为了评估EmoLLM的性能和泛化性,我们还基于从不同平台和来源收集的14个情感分析数据集构建了情感评估基准(AEB),其中包括8个回归任务和6个分类任务。
基于AEB,我们评估了EmoLLM、各种开源大语言模型、闭源大语言模型(即ChatGPT和GPT-4)以及几种情感分析工具。 实验结果表明,EmoLLM系列超越了所有其他开源大语言模型和情感分析工具,并在7个回归任务和4个分类任务上超过了ChatGPT和GPT-4。 这些结果表明,EmoLLM 在大多数情感分析任务中实现了与 ChatGPT 和 GPT-4 相当的能力。 EmoLLM 可以作为全面的情感标注工具,用于注释来自不同平台和来源的数据。
我们的主要贡献如下:
-
•
我们构建了AAID(第一个多任务情感分析指令调优数据)和AEB(第一个情感泛化测试指令基准)。
-
•
我们推出了一系列EmoLLM,这是继大语言模型之后第一个用于全面情感分析的开源指令。
-
•
我们将 EmoLLM 与 AEB 上的其他大语言模型进行比较。 此外,我们对ChatGPT和GPT-4的情感分析能力进行了全面分析。 与其他开源大语言模型相比,我们的模型在 AEB 数据集上实现了 SOTA 性能,并具有 ChatGPT 级别和 GPT-4 级别的泛化能力,确立了其作为情感标注有效工具的潜力。
2. 相关工作
2.1. 情感分析模型
人们已经提出了各种情感分析工具,例如 VADER (Hutto 和 Gilbert,2014a) 和 TextBlob。 这些工具虽然使用方便,但在情感分析方面的效果并不理想(何等人,2022)。 近年来,许多研究都集中在对 PLM 进行微调以增强其在情感分析领域的能力。 Bello 等人 (Bello 等人, 2023) 将 BERT 与其他深度学习模型(例如 CNN、RNN、LSTM)相结合,提高模型在简短文本情感分析方面的能力。 Liao 等人 (Liao 等人, 2021) 提出了一种基于 RoBERTa 的多任务模型,用于方面类别情感分析。 尹等人(Yin 等人, 2020)提出SentiBERT模型,专注于情感分析领域。 SentiBERT 在 BERT 的基础上集成了递归选区树,以更好地捕获成分情感语义。 最近,许多研究开始调查大语言模型在情感分析中的应用,在情感分析任务中取得了显着的性能提升。 张等人(Zhang 等人, 2023c)提出了一种用于金融情绪分析的检索增强大语言模型,该模型利用了来自外部来源的额外背景信息,并且比大语言模型基线分别提高了15%和48% 。 同样,雷等人(Lei 等人, 2023)也使用简单而有效的检索模块来增强大语言模型在对话中的情感识别能力。 张等人(Zhang 等人, 2023a)开发了一个上下文和情感知识调优的大语言模型,即DialogueLLM,通过多模态(即文本和视频)情感微调大语言模型获得对话,在三个对话情绪识别 (ERC) 数据集上取得了 SOTA 结果。 然而,这些PLM和大语言模型只关注情感分析的个体方面,缺乏预测情感强度和情绪强度的能力。
2.2. 开源大型语言模型
尽管ChatGPT和GPT-4在各个领域都表现出了优异的性能,但其闭源可用性影响了科学研究的进展。 因此,大量的研究致力于大语言模型的民主化,例如LLaMA系列(Touvron等人,2023a,b),OPT系列(Zhang等人,2022) 、 BLOOM 系列(Workshop 等人,2022)、Falcon (Penedo 等人,2023)。 基于开源大语言模型,人们通过在广泛的指令调优数据集(例如 Alpaca222https://crfm.stanford.edu/2023/03/13/alpaca.html和骆马333https://lmsys.org/blog/2023-03-30-vicuna/)。 最近,出现了很多特定领域的工作,旨在通过在特定领域的指令数据集上进行训练来提高大语言模型在特定领域的性能。 如金融领域的FinMA (Xie 等人, 2023)、心理健康领域的MentalLLaMA (Yang 等人, 2023)、TimeLlaMA (Yuan 等人, 2023) 用于时间推理,ExTES-LLaMA (Zheng 等人, 2023) 用于情感支持聊天机器人。 我们的工作是第一个用于综合多任务情感分析的开源大语言模型系列。
3. 方法
这项工作的目标是评估和增强大语言模型的综合复杂情感分析能力。 为了实现这一目标,我们构建了第一个情感分析指令数据集(AAID)来支持综合情感分析任务的大语言模型调优。 我们提出了EmoLLMs,这是在AAID的基础上微调大语言模型的一系列情感大语言模型。 此外,我们构建了综合情感评估基准来测试大语言模型的泛化能力。
3.1. 任务定义
与处理心理健康分析任务中的(Yang 等人, 2023)类似,我们也将情感分析视为生成任务,其中生成模型(即自回归语言模型 由预训练权重参数化)作为基础,这与之前的判别模型和回归模型不同。 该模型能够同时解决情感分析任务,例如情感极性和强度预测、情感分类和强度预测。 每个任务 t 由训练上下文目标对的子集表示:,其中 是包含任务描述、目标文本和查询的词符序列, 是包含查询答案(即分类结果或回归结果)的另一个序列。 所有子集都组合成一个训练数据集:。该模型基于这些合并数据进行优化,旨在最大化条件语言建模目标,以提高预测的准确性。
3.2. 指令参数 数据构建
我们基于 SemEval-2018 任务 1:推文中的影响构建指令数据集,其中包括一系列高度注释的情感分析子任务(Mohammad 等人,2018;Mohammad 和 Kiritchenko,2018)。
3.2.1. 原始数据
SemEval 2018 Task1 包含 5 个子任务:1. 情绪强度回归(EI-reg),2. 情绪强度序数分类(EI-oc),3. 效价(情绪) ) 回归 (V-reg),4. 效价(情感)序数分类 (V-oc),以及 5. 情感分类 (E-c) >)。
EI-reg:给定一条推文和一种情绪 E(愤怒、恐惧、喜悦、悲伤),确定最能代表推文者心理状态的 E 强度——0 之间的实值分数(E 最少)和 1(E 最多);
EI-oc:给定一条推文和一种情绪 E(愤怒、恐惧、喜悦、悲伤),将该推文分类为四个序数类之一(0:无法推断出 E。 1:可以推断E的含量较低。 2:可以推断出中等量的E。 3:可以推断出高E量)最能代表高音扬声器心理状态的E强度;
V-reg:给定一条推文,确定最能代表推文者心理状态的情感强度或效价 (V),即介于 0(最负面)和 1(最负面)之间的实际得分积极的);
V-oc:给定一条推文,将其分类为七个序数类别之一(从 -3:非常消极到 3:非常积极),对应于不同级别的积极和消极情绪强度,最好代表高音扬声器的精神状态;
E-c:给定一条推文,将其分类为“中性或无情感”或十一种给定情感中的一种或多种(愤怒、期待、厌恶、恐惧、喜悦、爱、乐观、悲观、悲伤、惊讶、信任)最能代表高音扬声器的心理状态。
| Task | Raw (Train/Dev) | Instruction (Train/Dev) | Source |
|---|---|---|---|
| EI-reg, EI-oc | |||
| anger | 1701/388 | 17010/3880 | |
| fear | 2252/389 | 22520/3890 | |
| joy | 1616/290 | 16160/2900 | |
| sadness | 1533/397 | 15330/3970 | |
| V-reg, V-oc | 1181/449 | 11810/4490 | |
| E-c | 6838/886 | 68380/8860 |
3.2.2. AAID:情感分析指令数据集
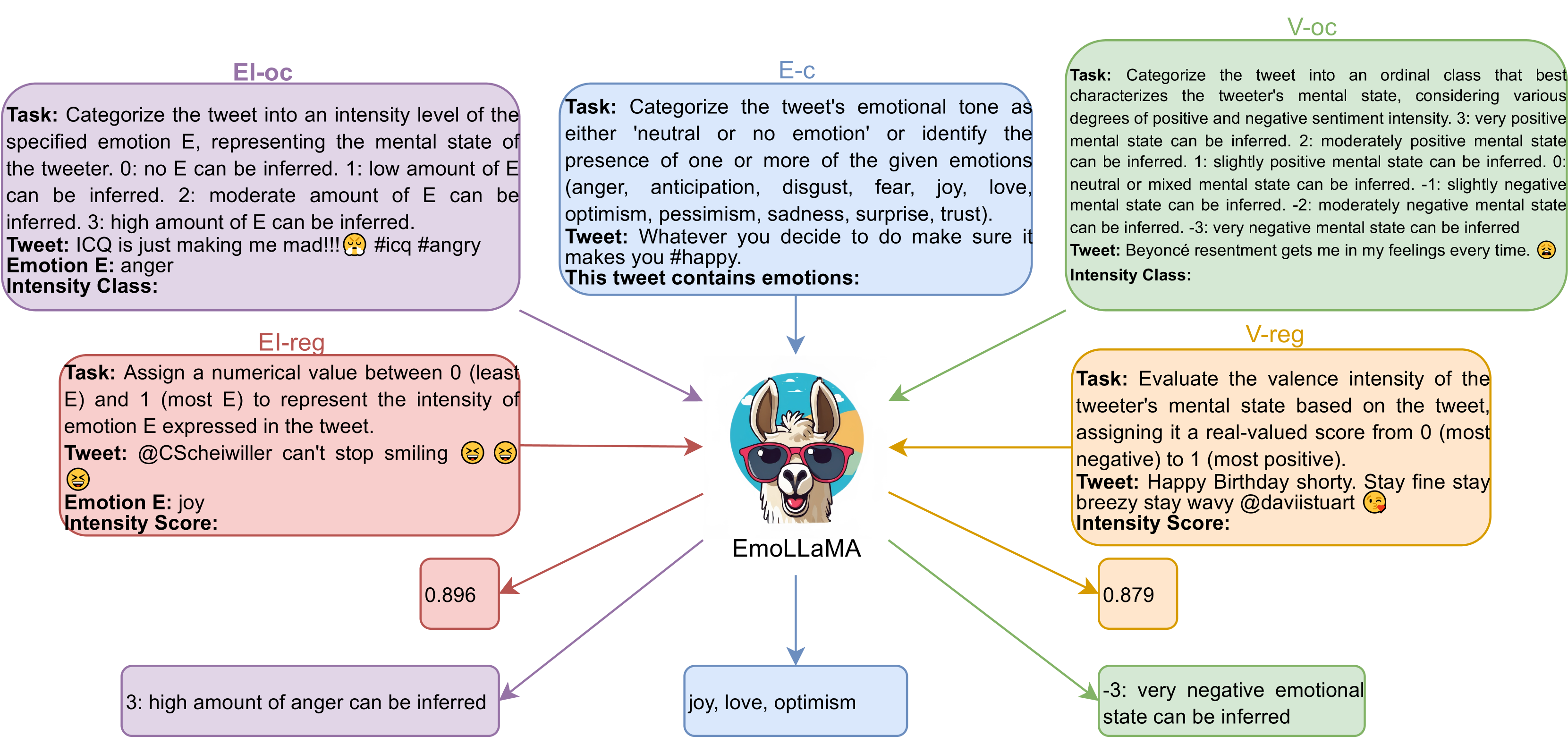
我们根据原始数据构建指令数据集。 由于原始数据集数量有限,我们为每个任务使用 10 个不同的任务指令来扩充训练集和验证集。 数据统计如表1所示。 具体来说,我们基于一些模板构建指令调整示例。 表2描述了每个任务的具体指令模板,图1提供了相应的示例(以EmoLLaMA为例,每个任务选择一个[任务提示] 为例)。 [任务提示]描述每个特定任务的说明。 “Tweet”一词可以根据实际任务进行调整。 [输入文本]指的是原始数据的内容。 最终的[输出]应根据具体任务进行调整,以提供情感分类、情感强度、情感分类或情感强度。
| Task | Prompt Template |
|---|---|
| EI-reg | Task: [task prompt] Tweet: [input text] Emotion E: [emotion] Intensity score: [output] |
| EI-oc | Task: [task prompt] Tweet: [input text] Emotion E: [emotion] Intensity class: [output] |
| V-reg | Task: [task prompt] Tweet: [input text] Intensity score: [output] |
| V-oc | Task: [task prompt] Tweet: [input text] Intensity class: [output] |
| E-c | Task: [task prompt] Tweet: [input text] This tweet contains emotions: [output] |
3.3. AEB:情感评估基准构建
| Dataset | Size | Type | Source | Dataset | Size | Type | Source | Dataset | Size | Type | Source |
|---|---|---|---|---|---|---|---|---|---|---|---|
| EI-reg | 4068 | R[0,1] | V-Amazon | 1000 | R [-4,4] | Amazon | SST | 2210 | R [0,1] | Movie reviews | |
| EI-oc | 4068 | EC(4) | V-Movies | 1000 | R [-4,4] | Movies reviews | SST-5 | 2210 | SC (5) | Movie reviews | |
| V-reg | 937 | R[0,1] | V-NYT | 1000 | R [-4,4] | New York Times | TDT | 692 | SC (3) | ||
| V-oc | 937 | SC(7) | V-Tweet | 1000 | R [-4,4] | GoEmotion | 5427 | EC (7) | |||
| E-c | 3259 | EC(11) | EmoBank | 1000 | R [1,5] | News, blogs. etc. |
| Dataset | Task prompt |
|---|---|
| EI-reg | Assign a numerical value between 0 (least E) and 1 (most E) to represent the intensity of emotion E expressed in the tweet. |
| EI-oc | Categorize the tweet into an intensity level of the specified emotion E, representing the mental state of the tweeter. 0: no E can be inferred. 1: low amount of E can be inferred. 2: moderate amount of E can be inferred. 3: high amount of E can be inferred. |
| V-reg | Evaluate the valence intensity of the tweeter’s mental state based on the tweet, assigning it a real-valued score from 0 (most negative) to 1 (most positive). |
| V-oc | Categorize the tweet into an ordinal class that best characterizes the tweeter’s mental state, considering various degrees of positive and negative sentiment intensity. 3: very positive mental state can be inferred. 2: moderately positive mental state can be inferred. 1: slightly positive mental state can be inferred. 0: neutral or mixed mental state can be inferred. -1: slightly negative mental state can be inferred. -2: moderately negative mental state can be inferred. -3: very negative mental state can be inferred. |
| E-c | Categorize the tweet’s emotional tone as either ’neutral or no emotion’ or identify the presence of one or more of the given emotions (anger, anticipation, disgust, fear, joy, love, optimism, pessimism, sadness, surprise, trust). |
| V-A, V-M, V-NYT, V-T | Calculate the sentiment intensity or valence score of the text, which should be a real number between -4 (extremely negative) and 4 (extremely positive). |
| SST | Calculate the sentiment score of the text, which should be a real number between 0 (extremely negative) and 1 (extremely positive). |
| Emobank | Determine the valence/arousal/dominance intensity of the writer’s mental state on a scale of 1 (most negative) to 5 (most positive). |
| GoEmotion | Categorize the text’s emotional expression, classifying it as either ’neutral’ or as one or more of the specified emotions (anger, disgust, fear, joy, sadness, surprise) that reflect the writer’s state of mind. |
| SST5 | Classify the text into one of five classes of sentiment that best represents the mental state of the text. 0: very negative, 1: negative, 2: neutral, 3: positive, 4: very positive. |
| TDT | Classify the text into one of three classes of sentiment that best represents the mental state of the text. -1: negative, 0: neutral, 1: positive. |
我们首先从 SemEval-2018 任务 1:推文中的影响中收集测试数据。 为了测试我们模型的稳健性,为测试集中的每个实例选择增强中使用的十个指令中的随机训练指令。 我们还从各种来源和领域收集额外的情感分析或情绪检测数据集,以测试我们模型的普遍性。 我们按照表2中提供的模板格式构建AEB。 表4显示了每个数据集的任务提示示例。 除VADER的四个数据集外,其他数据集均使用原始测试数据集。 表3显示了统计详细信息。
用于情绪推理的效价感知词典 (VADER) 中使用的数据集 (Hutto 和 Gilbert,2014b):有来自不同社交媒体平台的四个数据集,具有情绪强度(效价)分数[-4,4] 内:V-Amazon(亚马逊评论片段)、V-Movies(电影评论片段,收集自 rotten.tomatoes.com)、V-NYT(纽约时报社论片段),V-Tweet(推文)。 我们从每个数据集中随机抽取 1000 个实例进行普遍性测试。
EmoBank (Buechel and Hahn,2022,2017):该数据集是从新闻、博客、小说、信件等中收集的,包含三个维度,并手动标注了情感根据心理价-唤起-支配方案,得分在 [1,5] 范围内。
Stanford Sentiment Treebank (SST) (Socher 等人, 2013):从电影评论中收集,这是第一个完全标记解析树的语料库,可以全面语言情感的构成性分析。 在 SST444https://huggingface.co/datasets/sst,每个句子都分配有一个浮点标签,表示积极情绪的程度,范围从 0.0 到 1.0。在 SST5 中555https://huggingface.co/datasets/SetFit/sst5 ,每句话都标注了五个标签:非常积极、积极、中立、消极、非常消极。
Target Dependent Twitter Sentiment Classification (TDT) (Dong 等人, 2014):这是一个从名人、产品和公司的帖子评论中收集的 Twitter 情感分类数据集,它是用三个标签(负面、中性、正面)手动注释的。 为了便于我们的泛化性测试,我们恢复了原始数据中隐藏的实体,创建了标准的句子级情感分析数据集。
GoEmotion (Demszky 等人, 2020):它是一个从 Reddit 评论中收集的多标签分类数据集,由 28 个情感标签组成,包括中性情感标签。 然而,具有 28 个情感标签的原始数据集是不平衡的。 为了缓解这个问题,我们从作者提供的数据集中选择了“Ekman”选项,该选项由 7 个情绪标签组成,包括中性情绪标签。
由于前5个数据集与AAID的来源相同,其余数据来自不同的平台和来源,因此我们将AEB分为两部分进行比较。 前者被称为AEB-1,用于测试模型的训练效果。 后者称为AEB-2,适合测试模型的泛化能力。
3.4. LLM
我们通过基于AAID微调各种大语言模型来构建EmoLLM。 我们基于 LLaMA2 (Touvron 等人, 2023b) 训练了三个 EmoLLaMA 模型:EmoLLaMA-7B、EmoLLaMA-chat-7B、EmoLLaMA-chat-13B,通过微调 LLaMA2-7B、LLaMA2-chat- 7B,LLaMA2-chat-13B,其中LLaMA2-chat-7B和LLaMA2-chat-13B是第一个通过人类反馈强化学习(RLHF)进行调优的开源大语言模型(Stiennon等人,2020). 我们还分别基于 OPT-13B (Zhang 等人, 2022) 和 BLOOM-7B (Workshop 等人, 2022)) 训练 EmoOPT 和 EmoBLOOM。 所有模型均基于 AdamW 优化器(Loshchilov 和 Hutter,2017) 进行三个 epoch 的训练,利用早期停止技术(Dodge 等人,2020) 来防止过度拟合,并利用DeepSpeed (Rasley 等人, 2020; Yao 等人, 2023) 以减少内存使用。 我们将批量大小设置为 256。 初始学习率设置为1e-6,预热比例为5%,最大模型输入长度设置为2048。 所有模型均在两个 Nvidia Tesla A100 GPU 上进行训练,每个 GPU 具有 80GB 内存。
4. 评估
4.1. 基础型号
PLM:情感分析和情绪检测通常被视为分类任务,而强度预测被视为回归任务。 我们选择一些常用的 PLM 作为基线模型,这些模型只能对单个任务进行微调,包括 BERT、RoBERTa 和一个特定领域的预训练模型(即 SentiBERT (Yin 等人, 2020))。 我们为每个模型添加一个完全连接的神经层,用于分类或回归。 对于 EI-reg 和 V-reg 任务,我们利用均方误差 (MSE) 损失函数。 对于 EI-oc 和 V-oc 任务,我们使用交叉熵损失。 对于多标签任务E-c,我们采用带有logits损失的二元交叉熵。
零样本/few-shot 方法(无需微调的大语言模型): 随着大语言模型的出现,零样本和少样本学习成为解决众多任务的有效途径。 我们选择Falcon-7b-instruct (Penedo等人, 2023)、Vicuna-13b-v1.5666https://huggingface.co/lmsys/vicuna-13b-v1.5,LLaMA2-chat-7B 和 LLaMA2-chat-13B 执行零样本对指令数据集进行提示。 此外,我们还采用闭源大语言模型ChatGPT (gpt-3.5-turbo) 和GPT-4 (gpt-4-1106-preview) 的零样本和少样本提示方法。 我们为每个情绪类别或标签类别至少选择一条数据作为少样本提示。
基于情感的指令调整方法: 除了 EmoLLMs 系列模型之外,我们还使用与基线模型相同的指令数据集对 BART (Lewis 等人,2019 年)、T5 (Raffel 等人,2020 年) 进行了微调,以进一步评估我们模型的有效性。
4.2. 评价方法
对于 AEB-1,我们使用官方评估指标777https://competitions.codalab.org/competitions/17751,皮尔逊相关系数(pcc),作为EI-reg、EI-oc、V-reg、V-oc的评价指标以及使用准确度,micro-F1(mi -F1),宏-F1 (ma-F1) 用于 E-c。此外,官方评估还纳入了二次评估指标。 对于回归任务,他们还对测试集的子集使用皮尔逊相关性,该子集仅包含强度得分大于或等于 0.5 的推文。 对于序数分类任务,他们还对测试集的子集使用皮尔逊相关性,该子集仅包含强度类别为低 X、中 X 或高 X(其中 X 是情感)的推文,并在完整的测试集,并对测试集的某些情感子集采用加权二次kappa。 限于篇幅,我们没有列出二次评价,其结论与初步评价结果一致。
对于 AEB-2,我们应用准确性和宏 F1 作为情感分类任务的评估指标。 对于回归任务,我们使用皮尔逊相关系数(pcc)(Cohen等人,2009)作为评估指标。
| model | EI-reg | EI-oc | V-reg | V-oc | E-c | ||||||||||
| ave | anger | fear | joy | sadness | ave | anger | fear | joy | sadness | valence | valence | acc | mi-F1 | ma-F1 | |
| Leaderboard(1) | 0.799 | 0.827 | 0.779 | 0.792 | 0.798 | 0.695 | 0.706 | 0.637 | 0.720 | 0.717 | 0.873 | 0.856 | 0.609 | 0.724 | 0.592 |
| PLMs | |||||||||||||||
| BERT-base | 0.785 | 0.800 | 0.781 | 0.783 | 0.742 | 0.683 | 0.698 | 0.656 | 0.712 | 0.665 | 0.840 | 0.805 | 0.567 | 0.718 | 0.568 |
| RoBERTa-base | 0.717 | 0.670 | 0.736 | 0.769 | 0.694 | 0.664 | - | - | - | - | 0.845 | 0.772 | 0.563 | 0.721 | 0.536 |
| SentiBERT | 0.722 | 0.724 | 0.740 | 0.731 | 0.691 | 0.665 | - | - | - | - | 0.835 | 0.763 | 0.535 | 0.700 | 0.522 |
| Zero-shot/few-shot methods | |||||||||||||||
| Falcon | 0.114 | 0.147 | 0.082 | 0.095 | 0.131 | 0.033 | 0.022 | 0.017 | 0.031 | 0.061 | 0.135 | 0.189 | 0.190 | 0.318 | 0.253 |
| Vicuna | 0.281 | 0.307 | 0.257 | 0.260 | 0.299 | 0.214 | 0.238 | 0.193 | 0.186 | 0.241 | 0.298 | 0.579 | 0.220 | 0.359 | 0.253 |
| LLaMA2-7B-chat | 0.194 | 0.176 | 0.257 | 0.097 | 0.247 | 0.120 | 0.112 | 0.138 | 0.115 | 0.114 | 0.094 | 0.497 | 0.257 | 0.414 | 0.286 |
| LLaMA2-13B-chat | 0.488 | 0.524 | 0.506 | 0.398 | 0.526 | 0.194 | 0.262 | 0.178 | 0.119 | 0.216 | 0.312 | 0.568 | 0.274 | 0.424 | 0.302 |
| ChatGPT | 0.599 | 0.637 | 0.573 | 0.569 | 0.618 | 0.455 | 0.500 | 0.428 | 0.363 | 0.529 | 0.637 | 0.748 | 0.382 | 0.546 | 0.429 |
| ChatGPT-FS | 0.550 | 0.572 | 0.482 | 0.587 | 0.560 | 0.473 | 0.502 | 0.410 | 0.407 | 0.573 | 0.739 | 0.791 | 0.413 | 0.563 | 0.466 |
| GPT-4 | 0.656 | 0.699 | 0.575 | 0.686 | 0.667 | 0.620 | 0.656 | 0.579 | 0.618 | 0.629 | 0.811 | 0.788 | 0.444 | 0.572 | 0.497 |
| GPT-4-FS | 0.679 | 0.704 | 0.654 | 0.679 | 0.678 | 0.562 | 0.623 | 0.523 | 0.515 | 0.585 | 0.825 | 0.793 | 0.460 | 0.582 | 0.515 |
| Emotion-based instruction-tuning methods | |||||||||||||||
| EmoBART | 0.795 | 0.798 | 0.803 | 0.795 | 0.782 | 0.725 | 0.705 | 0.742 | 0.723 | 0.729 | 0.851 | 0.835 | 0.528 | 0.686 | 0.548 |
| EmoT5 | 0.783 | 0.785 | 0.797 | 0.798 | 0.751 | 0.717 | 0.703 | 0.733 | 0.726 | 0.707 | 0.852 | 0.836 | 0.559 | 0.712 | 0.568 |
| EmoOPT | 0.825 | 0.827 | 0.830 | 0.837 | 0.805 | 0.753 | 0.739 | 0.751 | 0.762 | 0.759 | 0.887 | 0.843 | 0.532 | 0.680 | 0.550 |
| EmoBLOOM | 0.791 | 0.802 | 0.797 | 0.790 | 0.776 | 0.732 | 0.725 | 0.717 | 0.746 | 0.740 | 0.857 | 0.822 | 0.528 | 0.683 | 0.552 |
| EmoLLaMA-7B | 0.822 | 0.819 | 0.821 | 0.837 | 0.809 | 0.743 | 0.738 | 0.722 | 0.768 | 0.745 | 0.879 | 0.843 | 0.545 | 0.695 | 0.563 |
| EmoLLaMA-chat-7B | 0.824 | 0.825 | 0.830 | 0.832 | 0.810 | 0.751 | 0.748 | 0.754 | 0.764 | 0.739 | 0.876 | 0.827 | 0.534 | 0.693 | 0.540 |
| EmoLLaMA-chat-13B | 0.831 | 0.827 | 0.835 | 0.843 | 0.817 | 0.763 | 0.755 | 0.764 | 0.777 | 0.755 | 0.886 | 0.860 | 0.537 | 0.696 | 0.545 |
4.3. 结果
4.3.1. AEB-1 的结果
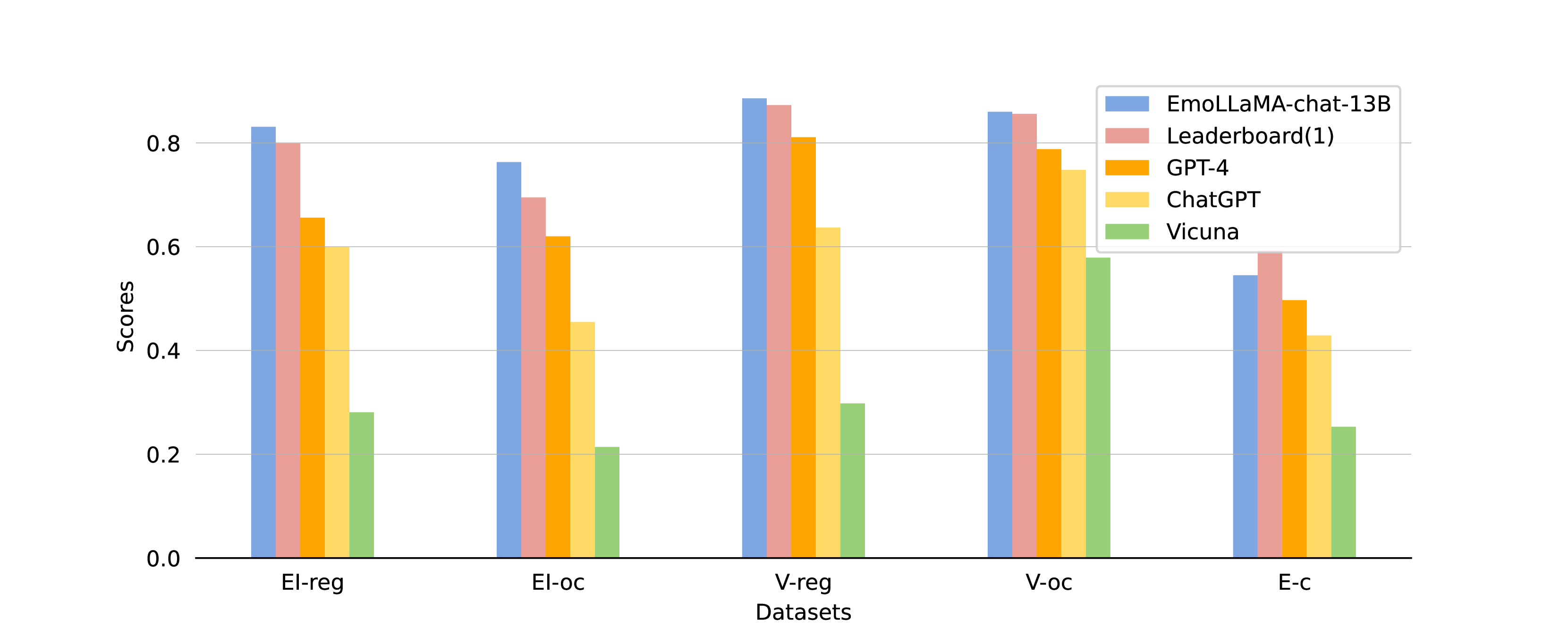
AEB-1的评估结果如表5所示(开源模型的结果为五次运行的平均值)。 第一行是 SemEval-2018 Task1 排行榜前 1 名的得分。
EmoLLM 和 PLM 之间的比较,零样本/少样本方法: 图2展示了几种不同方法在AEB-1上的结果。 对于 EmoLLM,我们选择了 EmoLLaMA-chat-13B,它显示出最佳的整体性能,与其他类别进行比较。 表5的结果表明EmoLLaMA-chat-13B优于所有其他大语言模型并超越排名第一888Seernet (Duppada 等人, 2018) 在 SemEval-2018 Task1 的前四项任务中获得第一名。 它基于传统的机器学习方法,执行全面的数据预处理,并应用堆叠技术来集成多种机器学习方法(例如 XG Boost、随机森林)。 在 AEB-1 的前四项任务中。 对于复杂任务 EI-reg 和 EI-oc,EmoLLaMA-chat-13B 与 top 1 相比显示出很高的改进,分别提高了 3.2%(EmoLLaMA:0.831,top1:0.799)和 6.8%(EmoLLaMA:0.763,top1: 0.695)。 对于独立的原始任务微调方法,尽管这些 PLM 在广泛的数据集上进行训练并针对每个任务单独进行微调,但结果并没有超过原始的 top 1 分数。 研究结果表明,与大语言模型相比,通用 PLM 在处理情感回归任务和细粒度情感分类任务时更容易忽略重要信息。 对于零样本/少样本方法,我们可以观察到此类方法与其他微调方法相比表现较差,特别是在 EI-reg 和 EI-oc 任务中。 这表明没有微调的大语言模型很难有效地处理情绪强度问题(我们也在零样本和少样本方法中测试了BART、T5、OPT和BLOOM,但它们的响应高度无关)。
EmoLLM之间的比较: 从表5中我们可以观察到,与没有进行微调的大语言模型相比,EmoLLM 都表现良好。 EmoT5 在情感分类任务 E-c (ma-F1) 上表现最好(EmoT5:0.568,EmoLLaMA:0.545),但在回归任务上表现不如其他模型(例如 EI-reg(ave): EmoT5:0.783 ,EmoLLaMA:0.831)。 尽管 EmoOPT 在一些回归任务中略优于 EmoLLaMA(例如 V-reg:EmoOPT:0.887,EmoLLaMA:0.886),但在大多数任务中它仍然落后于 EmoLLaMA。
总之,我们提出的情感分析任务指令调优策略优于 PLM 和所有未经微调的大语言模型,实现了最佳综合性能。 与其他指令调整的 EmoLLM 相比,EmoLLaMA 在情感分析方面表现出更全面和集成的能力。
4.3.2. AEB-2 的结果
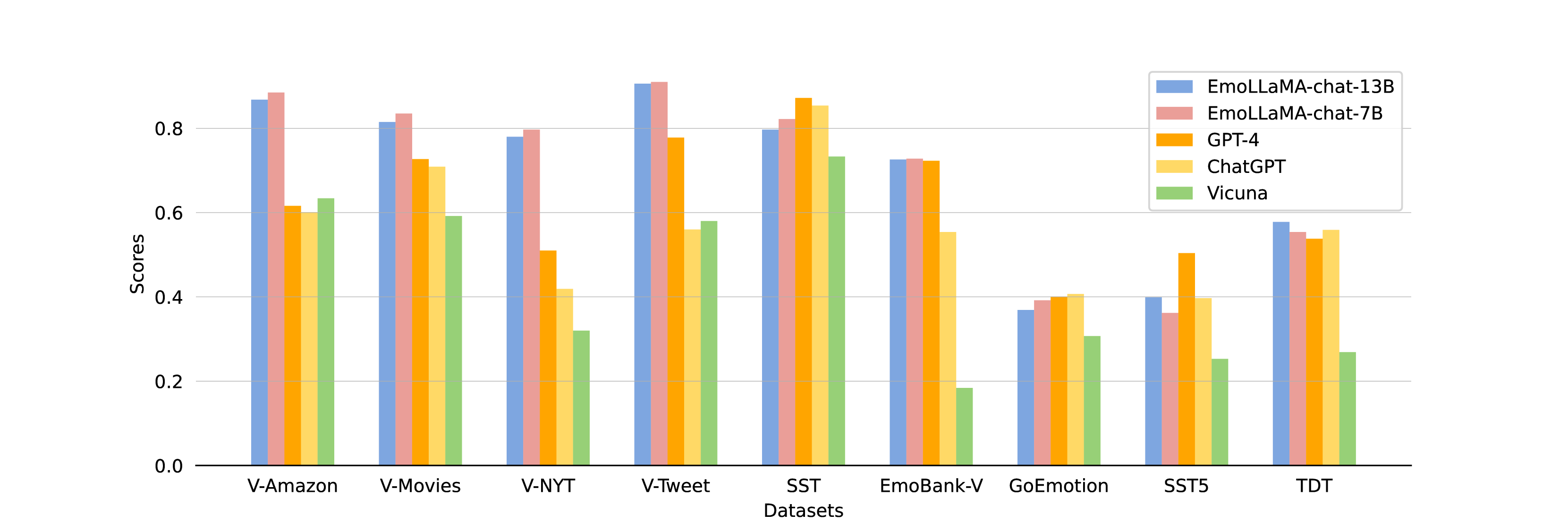
为了评估EmoLLM的泛化性,我们在训练过程中未包含的AEB-2上进行了实验(详细描述见表3)。 所有型号均采用零样本方法。 我们将 EmoLLM 系列与 ChatGPT、GPT4、几个开源大语言模型(即 LLaMA2-chat、Falcon 和 Vicuna)以及几个情感分析工具(即 VADER、TextBlob)进行比较。 表6给出了实验结果(开源模型的结果是五次运行的平均值)。 对于 EmoLLM,值得注意的是,由于我们在回归数据集上微调模型时使用 0 到 1 范围内的标签,因此我们在回归任务的泛化测试期间也使用 0 到 1 范围内的预测。 然后,我们将这些预测映射到数据的相应范围。
EmoLLMs和大语言模型未经微调的比较: 图3展示了几种不同类型方法在AEB-2上的结果。 我们仍然选择EmoLLaMA作为EmoLLMs的代表。 从表6可以看出,在大多数回归任务中,EmoLLaMA系列在没有进行微调的情况下优于ChatGPT、GPT-4和大语言模型。 在前四个回归任务中,EmoLLaMA 超过 GPT-4 10% 以上。 尽管 EmoLLaMA 在 SST 和 Emobank-Arousal 方面的表现不如 ChatGPT 和 GPT-4,但差异小于 5%。 对于分类任务,EmoLLaMA系列在TDT任务中表现优于ChatGPT和GPT-4。 在 GoEmotion 中,EmoLLaMA 的性能与 ChatGPT 和 GPT-4 相比相差在 5% 以内。 在SST5任务中,GPT-4表现得非常好(acc:0.543,ma-F1:0.504),我们可以看到ChatGPT,GPT-4在SST5和SST任务中都优于其他模型。 可能的原因是SST数据集很受欢迎,大语言模型在预训练时也接触过类似的语料库,这使得它们能够使用零样本方法表现得更好。
EmoLLM 之间的比较: 表6显示除EmoBART和EmoT5外,所有指令调优大语言模型在AEB-2上均表现良好,并且具有良好的可迁移性。 EmoBART 和 EmoT5 的表现与它们在 AEB-1 数据集上的表现相似,在回归任务中表现不佳。 有趣的是,EmoLLaMA-chat-7B 在 AEB-2 的大多数任务中表现最好,甚至在大多数回归任务中优于 EmoLLaMA-chat-13B。 一个可能的原因是,参数较多的模型在微调过程中往往会过度拟合,从而影响其总体性能。
值得注意的是,在 AEB-2 数据集中,只有 TDT 和 V-Tweet 来自 Twitter,其他则来自不同平台和域。 尽管EmoLLMs的训练数据仅来自Twitter,但在其他平台和领域上表现良好,这表明了其出色的可移植性。 结果还表明,当前情感分析工具(即 VADER、TextBlob)的性能明显逊色于 EmoLLM。 总体而言,AEB-2上的实验结果说明EmoLLMs系列达到了ChatGPT级别和GPT-4级别的通用能力(尤其是EmoLLaMA),可以作为情感标注工具。
| model | V-A | V-M | V-NYT | V-T | SST | EmoBank | GoEmotion | SST5 | TDT | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| pcc | pcc | pcc | pcc | pcc | V-pcc | A-pcc | D-pcc | acc | ma-F1 | acc | ma-F1 | acc | ma-F1 | |
| VADER | 0.565 | 0.446 | 0.464 | 0.862 | 0.450 | - | - | - | - | - | - | - | 0.510 | 0.266 |
| TextBlob | 0.490 | 0.372 | 0.288 | 0.666 | 0.408 | - | - | - | - | - | - | - | 0.434 | 0.435 |
| Falcon | 0.492 | 0.530 | 0.340 | 0.449 | 0.205 | 0.092 | 0.059 | 0.009 | 0.168 | 0.223 | 0.231 | 0.179 | 0.355 | 0.285 |
| Vicuna | 0.634 | 0.592 | 0.320 | 0.580 | 0.733 | 0.184 | 0.140 | 0.002 | 0.250 | 0.307 | 0.293 | 0.253 | 0.312 | 0.269 |
| LLaMA2-chat-13B | 0.348 | 0.479 | -0.011 | 0.300 | 0.811 | 0.237 | 0.248 | -0.036 | 0.278 | 0.337 | 0.346 | 0.281 | 0.436 | 0.437 |
| ChatGPT | 0.601 | 0.709 | 0.419 | 0.560 | 0.854 | 0.554 | 0.320 | -0.121 | 0.342 | 0.407 | 0.500 | 0.397 | 0.552 | 0.559 |
| GPT4 | 0.616 | 0.727 | 0.510 | 0.778 | 0.872 | 0.723 | 0.364 | 0.193 | 0.327 | 0.401 | 0.543 | 0.504 | 0.532 | 0.538 |
| EmoBART | 0.770 | 0.661 | 0.650 | 0.853 | 0.634 | 0.670 | 0.059 | 0.101 | 0.318 | 0.366 | 0.341 | 0.323 | 0.529 | 0.535 |
| EmoT5 | 0.838 | 0.728 | 0.668 | 0.889 | 0.724 | 0.714 | 0.239 | 0.064 | 0.327 | 0.374 | 0.373 | 0.376 | 0.578 | 0.583 |
| EmoOPT | 0.883 | 0.842 | 0.767 | 0.904 | 0.815 | 0.713 | 0.120 | 0.247 | 0.287 | 0.331 | 0.286 | 0.255 | 0.573 | 0.528 |
| EmoBLOOM | 0.848 | 0.852 | 0.649 | 0.856 | 0.807 | 0.663 | 0.106 | 0.243 | 0.302 | 0.348 | 0.409 | 0.353 | 0.546 | 0.551 |
| EmoLLaMA-7B | 0.866 | 0.838 | 0.732 | 0.902 | 0.819 | 0.717 | 0.219 | 0.209 | 0.330 | 0.366 | 0.296 | 0.260 | 0.599 | 0.579 |
| EmoLLaMA-chat-7B | 0.885 | 0.835 | 0.797 | 0.910 | 0.822 | 0.728 | 0.192 | 0.226 | 0.371 | 0.392 | 0.400 | 0.362 | 0.554 | 0.554 |
| EmoLLaMA-chat-13B | 0.868 | 0.815 | 0.780 | 0.906 | 0.797 | 0.726 | 0.332 | 0.218 | 0.350 | 0.369 | 0.412 | 0.399 | 0.574 | 0.578 |
4.3.3. Chatgpt 和 GPT-4 分析
在 AEB-1 数据集上,表 5 显示 GPT-4 和 GPT-4-FS 在零样本/少样本方法中表现最佳,其次是 ChatGPT 和 ChatGPT-FS。 这说明目前开源的大语言模型在复杂任务上与ChatGPT和GPT-4还有很大差距(例如GPT-4和Vicuna之间的差距:EI-reg(ave): 0.375,EI-oc(ave): 0.426,V-reg:0.406,V-oc:0.513,E-c(宏-F1):0.244)。 一个有趣的现象是,在大多数任务中,ChatGPT 和 GPT-4 使用少样本方法比零样本方法表现更好。 然而,在EI-reg中,ChatGPT的零样本方法优于少样本,而在EI-oc中,GPT-4的零样本方法优于少样本。 一个可能的原因是EI-reg和EI-oc任务更加复杂,少样本学习需要精心设计才能提高模型的性能。 对于不同的模型,对少样本示例的理解可能会有所不同。 因此,对于复杂的任务,有必要针对不同的大语言模型设计有针对性的少样本。
在AEB-2数据集上,GPT-4和ChatGPT在大多数任务中无需微调的情况下也比其他开源大语言模型表现更好。 然而,与 AEB-1 数据集上的性能相比,ChatGPT、GPT-4 和其他未经微调的大语言模型之间的性能差距在几个任务中变得更小(例如 GPT-4 和 Vicuna 之间的差距:V-A:- 0.018,V-M:0.135,GoEmotion(acc):0.077)。 一个可能的原因是这些任务比 AEB-1 中的任务更简单。 这进一步表明,与其他开源大语言模型相比,ChatGPT和GPT-4更擅长处理复杂任务。
综上所述,目前开源的大语言模型与ChatGPT、GPT-4在情感分析任务上还存在一定的差距。 目前,我们只能通过对特定任务进行微调来超越 ChatGPT 和 GPT-4。
5. 结论
在本文中,我们提出了 EmoLLM,一系列全面的情感分析模型和标注工具。 我们还构建了多任务情感分析指令数据集(AAID)和情感评估基准(AEB)。 我们对EmoLLM以及各种大语言模型在AEB基准上的表现进行了全面的分析。 结果表明,EmoLLM在情感分析回归任务和分类任务上都表现出色,与其他开源大语言模型相比,达到了SOTA,并且EmoLLM表现出很强的可迁移性,实现了ChatGPT和GPT-4的泛化能力在各种看不见的情感分析任务中。 结果还表明,目前开源的大语言模型与ChatGPT、GPT-4在特定领域仍存在一定差距。 解决这个问题的一个理想的解决方案是本文采用的指令调优策略,它可以极大地提高大语言模型在特定领域的性能,并在大多数任务中超越ChatGPT和GPT-4。
6. 讨论
实际应用。 EmoLLMs可以自动提供高质量和多种情感信息,可用于各种实际应用。 例如,(1)错误信息检测:谣言或假新闻常常传达特定的情绪。 情感特征可以帮助验证错误信息(刘等人,2023)。 (2)医疗保健(如心理健康):抑郁症状的严重程度与情绪密切相关。 主要原因是有抑郁症状的人常常难以调节自己的情绪,导致情绪复杂性下降。 因此,情绪信息对于精神障碍的诊断很有用(张等人,2023b)。 (3)客户服务(例如网购):对产品评论进行情感分析,可以为产品和服务质量以及客户体验提供有价值的见解(阿里等人,2024)。
局限性和未来的工作。 大多数公开可用的数据集来自互联网和社交媒体,与其他类型的文本内容相比,它们具有不同的表达形式、文本格式和风格。 因此,当应用于现实世界时,可能会存在一些偏差。 此外,当前的 EmoLLM 仅限于英文文本内容,缺乏其他语言和模式的内容。 未来,我们将引入更多来自不同平台、领域、模式和语言的数据集作为指令调优数据,以进一步增强 EmoLLM 的能力。
致谢。
本项目代码基于百丽代码(BELLEGroup, 2023; Ji 等人, 2023; Wen 等人, 2023)。 图1中的EmoLLaMA图片是由PIXLR999https://pixlr.com/image-generator/。 这项工作得到了曼彻斯特大学计算共享设施和曼彻斯特大学计算机科学系学者奖的支持。 这项工作得到了新能源和工业技术发展组织 (NEDO)、曼彻斯特大学数字信任与社会中心以及曼彻斯特-墨尔本-多伦多研究基金的 JPNP20006 项目的支持。参考
- (1)
- Akhtar et al. (2020) Md Shad Akhtar, Asif Ekbal, and Erik Cambria. 2020. How intense are you? Predicting intensities of emotions and sentiments using stacked ensemble [application notes]. IEEE Computational Intelligence Magazine 15, 1 (2020), 64–75.
- Ali et al. (2024) Hashir Ali, Ehtesham Hashmi, Sule Yayilgan Yildirim, and Sarang Shaikh. 2024. Analyzing amazon products sentiment: a comparative study of machine and deep learning, and transformer-based techniques. Electronics 13, 7 (2024), 1305.
- BELLEGroup (2023) BELLEGroup. 2023. BELLE: Be Everyone’s Large Language model Engine. https://github.com/LianjiaTech/BELLE.
- Bello et al. (2023) Abayomi Bello, Sin-Chun Ng, and Man-Fai Leung. 2023. A BERT framework to sentiment analysis of tweets. Sensors 23, 1 (2023), 506.
- Buechel and Hahn (2017) Sven Buechel and Udo Hahn. 2017. Readers vs. writers vs. texts: Coping with different perspectives of text understanding in emotion annotation. In Proceedings of the 11th linguistic annotation workshop. 1–12.
- Buechel and Hahn (2022) Sven Buechel and Udo Hahn. 2022. Emobank: Studying the impact of annotation perspective and representation format on dimensional emotion analysis. arXiv preprint arXiv:2205.01996 (2022).
- Chan et al. (2023) Jireh Yi-Le Chan, Khean Thye Bea, Steven Mun Hong Leow, Seuk Wai Phoong, and Wai Khuen Cheng. 2023. State of the art: a review of sentiment analysis based on sequential transfer learning. Artificial Intelligence Review 56, 1 (2023), 749–780.
- Cohen et al. (2009) Israel Cohen, Yiteng Huang, Jingdong Chen, Jacob Benesty, Jacob Benesty, Jingdong Chen, Yiteng Huang, and Israel Cohen. 2009. Pearson correlation coefficient. Noise reduction in speech processing (2009), 1–4.
- Consoli et al. (2022) Sergio Consoli, Luca Barbaglia, and Sebastiano Manzan. 2022. Fine-grained, aspect-based sentiment analysis on economic and financial lexicon. Knowledge-Based Systems 247 (2022), 108781.
- Demszky et al. (2020) Dorottya Demszky, Dana Movshovitz-Attias, Jeongwoo Ko, Alan Cowen, Gaurav Nemade, and Sujith Ravi. 2020. GoEmotions: A dataset of fine-grained emotions. arXiv preprint arXiv:2005.00547 (2020).
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Dodge et al. (2020) Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. 2020. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. arXiv preprint arXiv:2002.06305 (2020).
- Dong et al. (2022) Diwen Dong, Fuqiang Lin, Guowei Li, and Bo Liu. 2022. Sentiment-Aware Fake News Detection on Social Media with Hypergraph Attention Networks. In 2022 IEEE International Conference on Systems, Man, and Cybernetics (SMC). IEEE, 2174–2180.
- Dong et al. (2014) Li Dong, Furu Wei, Chuanqi Tan, Duyu Tang, Ming Zhou, and Ke Xu. 2014. Adaptive recursive neural network for target-dependent twitter sentiment classification. In Proceedings of the 52nd annual meeting of the association for computational linguistics (volume 2: Short papers). 49–54.
- Duppada et al. (2018) Venkatesh Duppada, Royal Jain, and Sushant Hiray. 2018. SeerNet at SemEval-2018 Task 1: Domain Adaptation for Affect in Tweets. In Proceedings of the 12th International Workshop on Semantic Evaluation. 18–23.
- Ekman (1992) Paul Ekman. 1992. An argument for basic emotions. Cognition & emotion 6, 3-4 (1992), 169–200.
- Govindasamy and Palanichamy (2021) Kuhaneswaran AL Govindasamy and Naveen Palanichamy. 2021. Depression detection using machine learning techniques on twitter data. In 2021 5th international conference on intelligent computing and control systems (ICICCS). IEEE, 960–966.
- Hakak et al. (2017) Nida Manzoor Hakak, Mohsin Mohd, Mahira Kirmani, and Mudasir Mohd. 2017. Emotion analysis: A survey. In 2017 International Conference on Computer, Communications and Electronics (Comptelix). 397–402. https://doi.org/10.1109/COMPTELIX.2017.8004002
- He et al. (2022) Lu He, Tingjue Yin, and Kai Zheng. 2022. They May Not Work! An evaluation of eleven sentiment analysis tools on seven social media datasets. Journal of Biomedical Informatics 132 (2022), 104142.
- Htait and Azzopardi (2021) Amal Htait and Leif Azzopardi. 2021. Sentiment intensity prediction using neural word embeddings. In Proceedings of the 2021 ACM SIGIR International Conference on Theory of Information Retrieval. 93–102.
- Hutto and Gilbert (2014a) Clayton Hutto and Eric Gilbert. 2014a. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the international AAAI conference on web and social media, Vol. 8. 216–225.
- Hutto and Gilbert (2014b) Clayton Hutto and Eric Gilbert. 2014b. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the international AAAI conference on web and social media, Vol. 8. 216–225.
- Ji et al. (2023) Yunjie Ji, Yong Deng, Yan Gong, Yiping Peng, Qiang Niu, Lei Zhang, Baochang Ma, and Xiangang Li. 2023. Exploring the impact of instruction data scaling on large language models: An empirical study on real-world use cases. arXiv preprint arXiv:2303.14742 (2023).
- Lei et al. (2023) Shanglin Lei, Guanting Dong, Xiaoping Wang, Keheng Wang, and Sirui Wang. 2023. Instructerc: Reforming emotion recognition in conversation with a retrieval multi-task llms framework. arXiv preprint arXiv:2309.11911 (2023).
- Lewis et al. (2019) Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461 (2019).
- Liao et al. (2021) Wenxiong Liao, Bi Zeng, Xiuwen Yin, and Pengfei Wei. 2021. An improved aspect-category sentiment analysis model for text sentiment analysis based on RoBERTa. Applied Intelligence 51 (2021), 3522–3533.
- Liu (2020) Bing Liu. 2020. Sentiment analysis: Mining opinions, sentiments, and emotions. Cambridge university press.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
- Liu et al. (2023) Zhiwei Liu, Tianlin Zhang, Kailai Yang, Paul Thompson, Zeping Yu, and Sophia Ananiadou. 2023. Emotion Detection for Misinformation: A Review. arXiv preprint arXiv:2311.00671 (2023).
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
- Ma et al. (2020) Yukun Ma, Khanh Linh Nguyen, Frank Z Xing, and Erik Cambria. 2020. A survey on empathetic dialogue systems. Information Fusion 64 (2020), 50–70.
- Mohammad et al. (2018) Saif Mohammad, Felipe Bravo-Marquez, Mohammad Salameh, and Svetlana Kiritchenko. 2018. Semeval-2018 task 1: Affect in tweets. In Proceedings of the 12th international workshop on semantic evaluation. 1–17.
- Mohammad and Kiritchenko (2018) Saif Mohammad and Svetlana Kiritchenko. 2018. Understanding Emotions: A Dataset of Tweets to Study Interactions between Affect Categories. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). European Language Resources Association (ELRA), Miyazaki, Japan. https://aclanthology.org/L18-1030
- Penedo et al. (2023) Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. 2023. The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116 (2023).
- Plutchik (1980) Robert Plutchik. 1980. A general psychoevolutionary theory of emotion. In Theories of emotion. Elsevier, 3–33.
- Qureshi et al. (2020) Syed Arbaaz Qureshi, Gael Dias, Mohammed Hasanuzzaman, and Sriparna Saha. 2020. Improving depression level estimation by concurrently learning emotion intensity. IEEE Computational Intelligence Magazine 15, 3 (2020), 47–59.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research 21, 1 (2020), 5485–5551.
- Rasley et al. (2020) Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 3505–3506.
- Socher et al. (2013) Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Y Ng, and Christopher Potts. 2013. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing. 1631–1642.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback. Advances in Neural Information Processing Systems 33 (2020), 3008–3021.
- Thelwall et al. (2010) Mike Thelwall, Kevan Buckley, Georgios Paltoglou, Di Cai, and Arvid Kappas. 2010. Sentiment strength detection in short informal text. Journal of the American society for information science and technology 61, 12 (2010), 2544–2558.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023).
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Wen et al. (2023) Cheng Wen, Xianghui Sun, Shuaijiang Zhao, Xiaoquan Fang, Liangyu Chen, and Wei Zou. 2023. ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation. arXiv preprint arXiv:2307.15290 (2023).
- Workshop et al. (2022) BigScience Workshop, Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, et al. 2022. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100 (2022).
- Xie et al. (2018) Hongliang Xie, Shi Feng, Daling Wang, and Yifei Zhang. 2018. A novel attention based CNN model for emotion intensity prediction. In Natural Language Processing and Chinese Computing: 7th CCF International Conference, NLPCC 2018, Hohhot, China, August 26–30, 2018, Proceedings, Part I 7. Springer, 365–377.
- Xie et al. (2023) Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. 2023. PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark for Finance. arXiv preprint arXiv:2306.05443 (2023).
- Yang et al. (2023) Kailai Yang, Tianlin Zhang, Ziyan Kuang, Qianqian Xie, and Sophia Ananiadou. 2023. Mentalllama: Interpretable mental health analysis on social media with large language models. arXiv preprint arXiv:2309.13567 (2023).
- Yao et al. (2023) Zhewei Yao, Reza Yazdani Aminabadi, Olatunji Ruwase, Samyam Rajbhandari, Xiaoxia Wu, Ammar Ahmad Awan, Jeff Rasley, Minjia Zhang, Conglong Li, Connor Holmes, et al. 2023. DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales. arXiv preprint arXiv:2308.01320 (2023).
- Yin et al. (2020) Da Yin, Tao Meng, and Kai-Wei Chang. 2020. Sentibert: A transferable transformer-based architecture for compositional sentiment semantics. arXiv preprint arXiv:2005.04114 (2020).
- Yuan et al. (2023) Chenhan Yuan, Qianqian Xie, Jimin Huang, and Sophia Ananiadou. 2023. Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models. arXiv preprint arXiv:2310.01074 (2023).
- Zhang et al. (2023c) Boyu Zhang, Hongyang Yang, Tianyu Zhou, Muhammad Ali Babar, and Xiao-Yang Liu. 2023c. Enhancing financial sentiment analysis via retrieval augmented large language models. In Proceedings of the Fourth ACM International Conference on AI in Finance. 349–356.
- Zhang et al. (2020) Linrui Zhang, Hsin-Lun Huang, Yang Yu, and Dan Moldovan. 2020. Affect in Tweets: A Transfer Learning Approach. In Proceedings of the Twelfth Language Resources and Evaluation Conference. 1511–1516.
- Zhang et al. (2022) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068 (2022).
- Zhang et al. (2023b) Tianlin Zhang, Kailai Yang, Shaoxiong Ji, and Sophia Ananiadou. 2023b. Emotion fusion for mental illness detection from social media: A survey. Information Fusion 92 (2023), 231–246.
- Zhang et al. (2021) Xueyao Zhang, Juan Cao, Xirong Li, Qiang Sheng, Lei Zhong, and Kai Shu. 2021. Mining dual emotion for fake news detection. In Proceedings of the web conference 2021. 3465–3476.
- Zhang et al. (2023a) Yazhou Zhang, Mengyao Wang, Prayag Tiwari, Qiuchi Li, Benyou Wang, and Jing Qin. 2023a. DialogueLLM: Context and Emotion Knowledge-Tuned LLaMA Models for Emotion Recognition in Conversations. arXiv preprint arXiv:2310.11374 (2023).
- Zheng et al. (2023) Zhonghua Zheng, Lizi Liao, Yang Deng, and Liqiang Nie. 2023. Building emotional support chatbots in the era of llms. arXiv preprint arXiv:2308.11584 (2023).