[兰花=0009-0000-8760-4381]
[1]
概念化、方法论、软件、验证、形式分析、调查、数据管理、写作 - 原稿 1]organization=新加坡管理大学计算与信息系统学院,地址=80 Stamford Rd,国家/地区=新加坡
[兰花=0000-0003-2028-2407]
概念化、调查、方法论、写作评论和编辑、监督、资金获取
[cor1]通讯作者
利用基于图的神经多任务学习来预测病毒谣言和易受攻击的用户,以进行信息流行病监控
摘要
在信息流行时代,拥有有效监控快速传播的猖獗谣言的工具,以及识别可能更容易传播此类错误信息的弱势用户至关重要。 这种积极主动的做法可以及时采取预防措施,减轻虚假信息对社会的负面影响。 我们提出了一种使用统一图神经网络模型来预测病毒式谣言和易受攻击用户的新颖方法。 我们预先训练基于网络的用户嵌入,并利用用户和帖子之间的交叉注意机制以及社区增强的漏洞传播(CVP)方法来改进用户和传播图表示。 此外,我们采用两种多任务训练策略来减轻不同环境下任务之间的负转移效应,从而提高我们方法的整体性能。 我们还构建了两个数据集,其中包含谣言和非谣言事件中信息病毒性和用户脆弱性的真实注释,这些数据集是从现有谣言检测数据集自动派生的。 我们的联合学习模型的广泛评估结果证实了它在所有三个任务中都优于强基线:谣言检测、病毒性预测和用户漏洞评分。 例如,与基于微博数据集的最佳基线相比,我们的模型在谣言检测的准确性和 MacF1 上分别提高了 3.8% 和 3.0%,并将病毒性预测和用户的均方误差 (MSE) 降低了 23.9% 和 16.5%分别对漏洞进行评分。 我们的研究结果表明,我们的方法有效地捕获了谣言病毒性传播与用户脆弱性之间的相关性,利用这些信息来提高预测性能并为信息流行病监控提供有价值的工具。
关键词:
谣言检测 病毒性预测 用户漏洞 神经多任务学习 信息流行病监测1简介
网络谣言是指在互联网尤其是社交媒体上流传的未经证实的信息。 带有歪曲事实的错误信息的谣言可能会在公众中引起错误的信念和不必要的恐慌。 具体来说,这些病毒式谣言由于其广泛的可达性,可能会导致极其有害的影响,最近一次大流行期间有关 COVID-19 的谣言引发的各种人为悲剧就证明了这一点 ((Islam 等人,2021;Ali, 2020)。
基于机器学习方法的自动谣言检测是近年来的热门研究课题(马等人,2016,2017;卞等人,2020;马等人,2018;王等人,2020) 。 然而,网络谣言监控的潜力受到不加区别地监控所有已识别谣言和参与者的成本效益的限制,而并非所有谣言和参与者在监控中都同等重要。 例如,广泛传播的谣言可以产生更大范围的影响,并且往往对用户更具说服力,因为高病毒性可以通过唤起对社会规范的更大认知来作为做出判断的心理捷径(Kim,2018 ;李和吴,2017);同时,谣言可能会对个别接收者产生不同的影响,具体取决于每个接收者的轻信程度(Mercier,2017),这反过来可能会影响谣言传播的广度和深度。 通过在谣言检测的背景下准确估计信息病毒式传播以及用户脆弱性,我们可以期望在各种社交媒体平台上更经济有效地跟踪值得注意的谣言和用户。
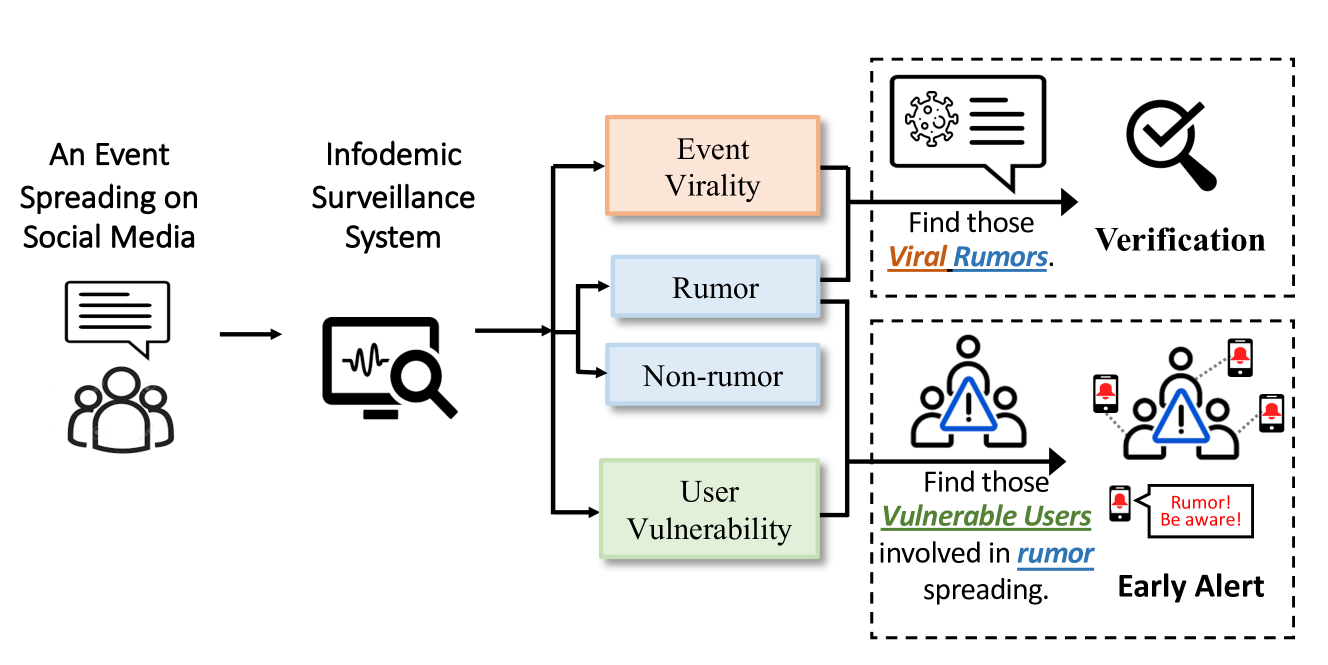
然而,这种需求目前超出了各种现有谣言检测任务的能力,因为它们通常忽略了对谣言潜在影响范围及其传播者危害的评估。 想象一下,如果有一个如图1所示的结合了谣言检测、病毒性预测和漏洞预测的监控系统,通过这样的系统,利益相关者将能够向那些处于危险中的易受攻击的用户发送警报对潜在的病毒性谣言,要求及时进行专业核实,从而更有效地进行信息监测和早期干预。 为了实现这一目标,有必要弥补一些主要差距。
先前的信息传播研究已经调查了一般信息的病毒式传播预测。 例如,Cheng等人(2014)将各种时间和结构特征与机器学习模型相结合,以估计源消息的信息传播图未来可以达到多大。 Li 等人 (2017) 使用神经网络模型来学习表征病毒式传播的特征表示,以实现类似的目的。 然而,这种一般的病毒式传播模型没有考虑谣言和正常信息之间的区别,以及容易受骗的用户对传播的影响,他们更容易被谣言激活。
在错误信息相关的研究中,提出了用户脆弱性(即易受骗性)的概念来衡量激励用户参与传播谣言或虚假新闻的倾向。 例如,Shen 等人 (2019) 尝试使用分类器来预测用户对假新闻的脆弱性,该分类器考虑了帖子内容、用户状态(例如关注者和朋友的数量)和网络连接的特征。 然而,这些作品并没有进一步将用户的脆弱性与谣言的病毒式传播联系起来。 在社交网络分析中,用户对物品采用的敏感性是与拓扑内在因素(Hoang and Lim,2016)一起衡量的,例如用户传播物品的能力和用户采用的潜力项目,这有助于项目在网络中的广泛传播。 虽然这可能有助于从拓扑角度分析信息病毒性与用户传播(或采用)信息强度之间的关系,但谣言病毒性可以说不仅与网络的拓扑结构有关,还与所传播和传播的信息内容有关。用户的认知状态。
基于TWITTER等公共谣言检测数据集111我们将Ma等人(2017)发布的Twitter15和Twitter16数据集合并成一个更大的数据集,即TWITTER。 (Ma 等人, 2017),通常由一组标记为谣言和非谣言的源帖子的传播级联组成,我们观察到病毒性(即参与该活动的用户数量)传播)在某种程度上可能与相关用户的脆弱性之间的相互作用(即用户参与谣言传播的倾向)有关222用户的脆弱性被估计为谣言在用户参与的所有信息中所占的比例。 以及所传播的信息是谣言还是非谣言。 图 2 展示了来自 TWITTER 数据集的四个说明性示例。 总体而言,大多数被非谣言吸引的用户通常比谣言中的用户更不容易受到攻击。 值得注意的是,当涉及的用户总体上更容易受到攻击时,谣言往往会像病毒一样传播,如(a)与(b)所示。 同时,当参与的用户通常不太容易受到攻击时,非谣言往往会更容易传播,如(c)和(d)之间的区别所示。 根据上述观察,关注信息的用户脆弱性、病毒性和谣言/非谣言性质之间似乎存在一些隐含的联系。 如果这是真的,我们就有可能利用它们的关系来促进有关谣言检测、信息病毒性预测和用户脆弱性估计的三项预测任务。 人们通常会认为病毒式传播与相关信息是否是谣言无关,因为谣言和非谣言都可能是病毒式传播(或不是病毒式传播)。 然而,我们认为,考虑到用户的脆弱性作为桥梁,信息的病毒性和谣言/非谣言性质之间的关系可以隐式地建立,并通过相关预测任务的表现进行验证。
为了验证我们的假设,我们提出了一个基于图神经网络(GNN)和分层图池方法的统一多任务学习框架,用于谣言检测、病毒性预测和用户漏洞评分的联合学习。 该框架旨在同时提高三个看似独立的任务的性能,以帮助信息监视和早期干预。 特别是,我们首先将信息传播网络转换为用户交互网络,用于使用基于网络的方法训练用户嵌入。 通过使用用户帖子交叉注意机制合并帖子内容,进一步增强了用户嵌入。 然后,我们使用 DiffPool(Ying 等人, 2018) 来发现具有相似传播谣言行为的用户的潜在社区,并参考潜在社区使用社区增强型漏洞传播(CVP)方法细化用户嵌入。 为了减轻任务之间的负迁移,我们采用了两种截然不同的多任务训练方法,Gradnorm (Chen 等人, 2018) 和元学习 (Buffelli and Vandin, 2020) 完成三个任务。 我们的主要贡献可概括如下:
-
•
据我们所知,这是第一个在信息流行病监测统一框架中进行谣言检测、病毒性预测和用户漏洞评分的研究。
-
•
我们使用归纳 GNN 和分层图池来联合学习这三个任务。 特别是,我们预训练了一般用户嵌入,并提出了一种 CVP 方法来进一步细化用户嵌入
-
•
我们在两种不同的多任务设置下训练框架,即 GradNorm 的并发训练和元学习,用于处理任务训练冲突,即负迁移。
-
•
我们构建了两个大型数据集,其中基于现有的谣言检测数据集注释了病毒性和用户漏洞,在这两个数据集上,我们的方法在所有三个任务上都优于强大的基线333数据和代码可在https://github.com/jadeCurl/Predicting-Viral-Rumors-and-Vulnerable-Users获取。.

2相关工作
我们在本文中的研究涉及多个研究主题,包括多任务学习框架下的谣言检测、信息病毒性预测和用户脆弱性分析,这些主题将在本节中分别进行综述。
2.1谣言检测
多项调查(Cao 等人,2018;Zubiaga 等人,2018;Zannettou 等人,2019;Sharma 等人,2019;Xu 等人,2021)全面回顾了谣言检测的文献。 这里我们介绍一些与我们最相关的作品。 许多关于谣言检测的研究主要从帖子内容、用户档案和传播模式中提取判别性特征,并学习监督分类器进行分类(Castillo等人,2011;Zhao等人,2015b;Ma等人,2017). 后来,表示学习方法通过利用端到端神经网络模型来学习分类的潜在表示,成为主流方法(Ma 等人,2018;Bian 等人,2020;Nguyen 等人,2020;Liu 等人,2020)吴,2020;窦等人,2021;孙等人,2022)。 例如,Bian 等人 (2020) 使用双向图卷积网络(Bi-GCN)来捕获传播树的扩散和色散属性。 Sun等人(2022)提出了一种双动态图卷积网络(DDGCN)模型,可以同时学习消息传播的动态和知识图谱中背景知识的动态。 然而,鉴于网上谣言众多,追踪所有检测到的谣言并不划算,也没有必要。 与旨在区分谣言和非谣言的现有谣言检测方法不同,我们允许系统能够根据谣言和非谣言的唯一用户数量来区分谣言和非谣言的病毒性。可能会实现更具成本效益的监测。
2.2信息病毒式传播预测
据我们所知,很少有工作专注于预测谣言的病毒式传播。 然而,关于信息传播病毒式传播的一般研究非常丰富(Yu 等人,2015;Zhao 等人,2015a;Li 等人,2017;Kefato 等人,2018;Chen 等人,2021;Zhang 等人, 2021;谭等人,2022)。 现有方法通常基于使用原始帖子、共享者和社区结构的特征工程(Jenders 等人,2013;Cheng 等人,2014;Weng 等人,2014)。 基于时间和结构特征,还设计了生成模型(Shen等人,2014;Yu等人,2015)。 例如,Shen等人(2014)将信息扩散建模为强化泊松过程。 这些生成方法对宏观分布和随机过程做出了强有力的假设,这限制了它们在实践中的应用。 为了获得更好的特征表示,深度神经网络在病毒式传播预测方面取得了良好的结果(Li 等人,2017;Kefato 等人,2018;Zhang 等人,2021;Tan 等人,2022)。
然而,这些一般的病毒式传播预测工作并没有考虑到相关用户的脆弱性与所传播的信息是谣言还是非谣言之间的相互作用。 据我们所知,目前还没有专门研究谣言和非谣言信息病毒式传播之间差异的研究。 在假新闻领域,一些研究发现假新闻一般比真实新闻传播得更快、更广(Vosoughi 等人,2018)。 然而,还没有任何工作试图直接预测谣言传播的程度,而且目前还不清楚谣言和非谣言之间的传播程度有何不同。 我们的研究也不区分谣言和非谣言的病毒式传播。 相反,我们对病毒式谣言的预测是通过交叉引用谣言检测任务和病毒式传播预测任务的输出来间接实现的,它们不仅在图级别上共享共同特征,而且还以用户漏洞任务为桥梁。 因此,如果信息类型(即谣言或非谣言)和参与用户的脆弱性特征已知,我们就可以更好地预测信息的病毒式传播。 从信息监控的角度来看,这很有用,因为联合预测使我们能够同时跟踪那些广泛传播的谣言和易受攻击的用户。
2.3用户漏洞分析
现有的工作主要集中在研究用户对社交媒体和社交网络中各种信息源的敏感性(Wald等人,2013;Lee和Lim,2015;Hoang和Lim,2016;Albladi和Weir,2020). 之前很少有关于用户易受谣言和假新闻影响的分析(Rath 等人,2019;Pennycook 和 Rand,2019;Bringula 等人,2021)。 Rath等人(2019)基于计算信任指标衍生的可信度概念,提出了一种社区健康评估模型,用于计算节点和社区对假新闻传播的脆弱性。 Bringula 等人 (2021) 发现技术、内部和外部因素可能会对大学生对政治错误信息的脆弱性产生积极或消极的影响。 在本文中,我们使用统一的神经模型来学习代表用户对谣言的脆弱性的特征,并进一步将用户的脆弱性与信息的病毒性联系起来,这可以帮助谣言检测和估计谣言对网络用户的潜在影响程度。
2.4图神经网络(GNN)
最近,基于矩阵分解的图卷积网络(GCN)在各种图相关任务中展示了最先进的性能(Veličković等人,2018;Sun等人,2022;Warmsley等人,2022;张等人,2023a;何等人,2022;翟等人,2023;王等人,2023)。 这些转导式 GCN 在固定图上运行良好,但很难应用于训练时未出现的未见节点(Defferrard 等人,2016)。 为了克服这个弱点,Hamilton 等人 (2017) 提出了一种归纳 GraphSAGE 模型,该模型聚合来自邻居的节点特征。 可以在 GNN 模型之上添加不同类型的分层池化过程,以从分层图结构中捕获更深层次的信息,以增强学习节点嵌入(Zhang 等人,2023b)。 例如,gPool (Gao 等人, 2019) 和 SAGPoo (Lee 等人, 2019) 选择 top-K 个节点来形成诱导子图,这可能会丢失有用的图结构和节点信息。 EdgePool (Diehl, 2019) 通过将池化图中的节点数固定为原始的一半,减少图中的边以获得池化子图。 上述方法可以通过主动丢弃一些节点和边信息来学习池化的较小图。 相比之下,DiffPool (Ying 等人, 2018) 通过软分配将节点映射到一组社区。 在本文中,我们使用 GraphSAGE 和 DiffPool 来构建我们的多任务学习框架。
3问题定义
“蝙蝠汤引起武汉病毒”等谣言在社交媒体平台上传播可能会造成重大危害。 传播此类虚假信息可能会引发误解、仇恨,甚至种族冲突。 我们的目标是利用最初的传播信息,促进对谣言猖獗传播的监测和预警。 具体来说,我们专注于一系列预测目标:(1)根据对社交媒体平台上信息传播的早期(因此部分)观察来区分谣言和非谣言,(2)根据给定的信息预测相关消息的传播规模在初始阶段对传播进行观察,(3)识别出现在观察到的传播中且更有可能传播此类谣言的脆弱用户,并为其分配脆弱性评分,以及(4)加强对谣言、病毒性的联合预测性能,以及通过改进任务相关特征的表示来解决用户漏洞。
为了解决这些问题,我们将我们的研究问题定义如下。 给定谣言数据集,每个实例都作为与特定社交事件(或声明)相对应的传播网络给出,其中包含源帖子及其通过转发(例如回复和转发)行为传播事件的级联消息 (卞等人,2020;宋等人,2021)。 我们将整个后传播网络定义为图,其中最后一个帖子的时间戳是。此外,考虑到我们任务的预测性质,需要来自后传播早期阶段的信息,我们引入了一个观察到的(即部分)传播网络 ,其中 包括节点和边的集合:
-
•
是参与传播的帖子对应的节点集。 每个 表示在时间戳 ( 时创建 -th 帖子内容 () 的是 -th 用户 () 、其中 是 和 的观察时间窗口大小),而 是出现在 中的唯一用户集合。
-
•
是邻接矩阵,表示帖子之间的转发关系。 矩阵中的每个条目都是一个二进制值(0或1),指示两个相应帖子之间是否存在转发关系。 在不失一般性的情况下,我们省略了消息传播的方向,即 是对称的。
然后,我们制定如下三个预测任务,对应于我们的前三个研究目标:
-
1.
谣言检测: 给定一个观察到的传播网络,我们将此任务表述为一个双向图分类问题,预测最终的传播网络是否是谣言,即任务,其中 是 的真实类别。
-
2.
病毒式传播预测: 给定观察到的传播网络 ,我们将这一任务定义为预测参与传播整个事件 的唯一用户总数的回归问题,记为 ,其中 表示出现在 中的唯一用户集合。根据以前的工作(Tsur 和 Rappoport,2012;Kupavskii 等人,2012;Li 等人,2017),模型将通过压扁网络的绝对规模来拟合地面实况的对数。
-
3.
用户漏洞评分: 给定一个观察到的传播网络 ,我们尝试推断每个唯一用户 的脆弱性,即其对谣言传播的敏感程度,这表示为任务 . 真实用户漏洞被定义为谣言占用户参与的所有信息的比例。
此外,为了解决第四个研究目标,我们提出了一个统一的 GNN 模型,并采用多任务学习框架来联合训练上述三个任务的模型。 为了减轻这些任务之间的训练冲突,我们利用可能表明它们相互可预测性的潜在相关性,这使我们能够在单个模型中有效地集成和优化对谣言、病毒性和用户漏洞的预测。
4方法论
如图3所示,我们的整个框架由四个部分组成:(i)用户交互图构建; (ii) 输入嵌入; (iii) 精细嵌入; (iv) 输出层。

.
4.1 用户交互图构建
为了了解用户传播谣言和非谣言的模式,预测源帖子病毒式传播的可能性,并识别更容易传播错误信息的用户,我们首先需要找到参与传播的用户以及它们之间的关系。他们。 与现有工作(Ratkiewicz 等人,2011;Li 等人,2017)类似,我们基于传播网络构建用户交互图,其中节点为单个用户,如图4所示。 基本上,对于任何一对唯一用户,只要他们在任何帖子传播网络中的帖子之间存在转发行为,我们就会在用户交互网络中在他们之间创建边缘。 形式上,我们将 表示为表示用户之间关系的邻接矩阵。 与关注者/被关注者网络相比,用户交互网络结构反映了用户之间真正活跃的交互。
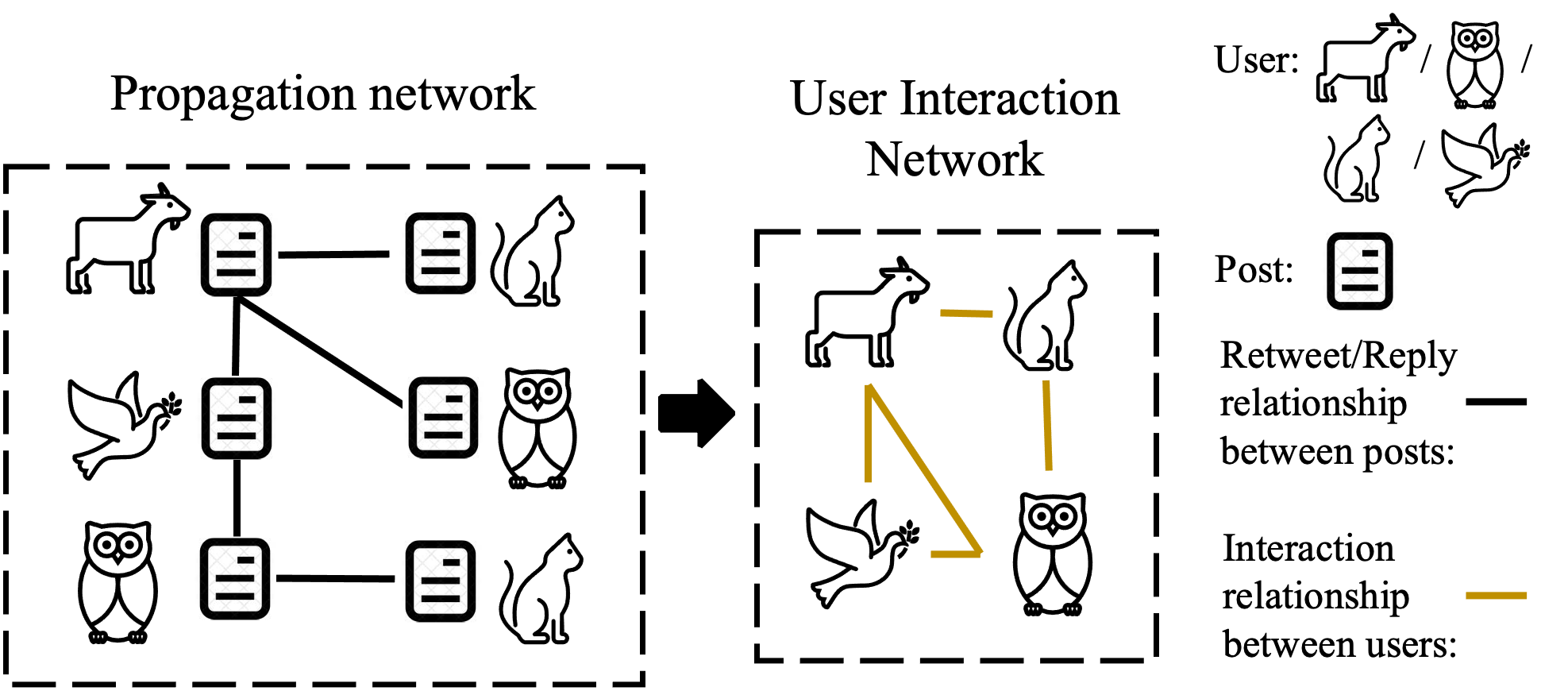
4.2 输入嵌入
输入嵌入层用于捕获每个用户的原始特征。 为了实现这一点,该层被分为两个独立的模块:时间感知后嵌入和基于对比学习的用户嵌入,如图3(b)所示。 主要思想是利用帖子信息和用户的全局交互来改进用户嵌入,从而更准确地表示用户及其行为。
4.2.1 时间感知后嵌入
帖子信息可以揭示用户的内在特征(Rissola 等人,2019)和观点(Zhu 等人,2015),这对于建立用户代表性非常重要,可以进一步帮助谣言检测(Bian等人,2020)和病毒性预测(Chen等人,2019)等任务。 为了获得每个帖子内容的表示,我们使用预训练的基于 BERT 的编码器(Devlin 等人,2019)。 具体来说,我们首先按时间顺序展平传播网络 ,它由一系列帖子组成。 这允许每个帖子表示共同关注不同位置的节点,以更好地捕获语义。 其次,我们在帖子内容的开头和结尾插入两个特殊标记,即[CLS]和[SEP],其中[CLS]词符旨在表示的语义其后的帖子。 取最后一层词符[CLS]的特征来表示,记为。 为了使模型更加高效,我们在训练自己的模型时冻结了 BERT 参数。
除了内容特征之外,每个帖子的时间预计有助于表明信息类型(Nguyen等人,2020)和未来的病毒式传播(Huang等人,2019) 。 因此,我们通过使用全连接(FC)层将 转换为向量 ,并将时间感知后嵌入创建为 ,其中 是连接运算符,从而使后嵌入与时间相关。 让矩阵表示传播网络中所有帖子的嵌入。
4.2.2 通过对比学习预训练用户嵌入
信息扩散过程自然地体现了用户之间丰富的邻近关系(张等人,2018)。 挖掘隐藏在此类关系网络中的深层结构和模式可以帮助学习用户的表示(Pan and Ding,2019)。 在本文中,我们首先基于信息扩散过程构建跨特定事件的全球用户网络,然后通过用户在全球用户网络中的位置和连接来研究用户的一般特征。
具体来说,我们首先通过将不同用户交互图中的相同用户合并到一个节点来创建全局用户图。 我们不假设任何用户级标注可用。 然后我们使用自监督对比学习来学习用户嵌入。 给定一个用户,我们模拟网络中固定长度的随机游走,从沿途遇到的节点中获取正样本,并随机挑选负样本。 由于用户网络规模较大,我们将正样本和负样本的数量限制为一个。 令表示的嵌入,对比学习的目标如下:
| (1) |
其中 和 分别是随机游走中 的正样本和负样本的嵌入。
4.3 精细嵌入
对于每个事件,我们从输入嵌入层获取用户嵌入 和时间感知后嵌入 。 然后,我们使用用户帖子交叉关注(Vaswani等人,2017)机制,将视为查询,将视为键和值。 这基本上使用 中的用户特定特征来指导我们的模型提取 中与相应用户相关的帖子特征,从而用帖子嵌入细化用户嵌入,即表述为:
| (2) |
其中 表示更新后的带有帖子信息的用户嵌入,、 和 是维度为 、 和 。
为了聚合来自本地社区用户的特征以捕获他们的共性以更好地表示用户,我们然后使用 GraphSAGE (Hamilton 等人, 2017) 如下:
| (3) |
其中 是包含用户交互信息的更新后的用户表示。
在我们的模型中,我们在 之上使用 DiffPool (Ying 等人, 2018) 进行图池化。 DiffPool 用于识别可能具有相似观点和漏洞的志同道合用户的潜在集群。 这些集群增强了我们更有效地学习和执行特定任务的能力。 具体来说,DiffPool 用于将图从用户节点粗化到社区节点。 这是通过标准 DiffPool 的两个步骤完成的:1)再次使用 GraphSAGE 计算软社区分配矩阵 ,如下所示:
| (4) |
2)获取新粗化图的社区节点嵌入矩阵。
然后,原始用户图和池化社区图的特征被输入输出层,用于谣言检测、病毒性传播和漏洞预测任务,如图3(c)所示。
4.4 输出层
4.4.1 用于谣言检测和病毒式传播预测的图分类
对于谣言检测和病毒式传播预测,我们在池化图上尝试不同的池化方法,包括总和、平均值、最大值和额外的 DiffPool,以进一步将用户社区图池化为单个图表示。 我们发现求和池表现最好,这可能是因为求和运算对图的大小更敏感。 获得最终的图形表示后,我们使用多层感知器(MLP)在图形级别进行谣言检测和病毒式传播预测。
4.4.2 用户漏洞预测的节点分类
社区信息有望有助于提高用户信息的完整性,因为社区内的用户通常具有相似的行为和兴趣。 对于漏洞预测,我们提出了一种名为社区增强漏洞传播(CVP)的方法来利用潜在社区来细化用户节点表示。 基本思想是将节点表示与其相应的社区表示连接起来。
通过软社区分配矩阵和社区节点嵌入矩阵,我们得到嵌入矩阵,其中每一行是相应节点的社区嵌入在中。 然后,我们通过将原始节点嵌入与其相应的社区嵌入连接来获得更新的用户嵌入。 最后,我们再次将增强的节点表示通过 GraphSAGE 以获得最终的用户表示 ,以便相邻节点的嵌入可以显式地相互影响。
获得最终的节点表示后,我们使用 MLP 来预测每个用户的漏洞。
4.5训练策略
在训练过程中,我们使用均方误差(MSE)损失函数进行用户漏洞预测和病毒性预测,并使用交叉熵损失进行谣言检测。 我们在两种不同的多任务设置下训练联合学习框架,以探索其缓解多个任务训练冲突的能力:1)并发训练,2)基于元学习的元训练。
4.5.1 并发训练
为了处理三个任务之间潜在的训练冲突并进一步提高模型性能,我们使用 Gradnorm (Chen 等人, 2018) 组合三个损失函数,动态调整它们的权重,使得梯度大小任务很接近,并且任务的学习速度相似。
4.5.2 元训练
Input: A set of graphs ; Parameters .
5实验评估
5.1 数据集和设置
| Dataset | Type | # instances | Average # posts | Average # users | Average Vulnerability | Average Virality |
| Rumor | 1,560 | 277.2 | 271.7 | 0.843 | 340.1 | |
| Non-Rumor | 579 | 503.7 | 498.3 | 0.196 | 621.2 | |
| Rumor | 2,311 | 720.7 | 701.2 | 0.904 | 876.4 | |
| Non-Rumor | 2,351 | 577.9 | 568.7 | 0.124 | 711.0 |
5.1.1 数据集
我们基于两个公共数据集构建数据,即 TWITTER (Ma 等人, 2017) 和 WEIBO (Ma 等人, 2016)。 原始数据集是为谣言检测而设计的,仅在图形级别上有谣言/非谣言注释。 我们需要得出真实的病毒性标签和漏洞标签。 我们根据数据集中每个事件的整个传播过程中的唯一用户数量为每个图表建立病毒性标签。 我们的目标是使用其早期传播状态作为输入来预测传播网络的病毒性(例如,当传播的观察百分比 等于 20%、40%、...等时)。 继Liao 等人 (2019)之后,我们的主要表格(表2、3、4和5)显示了时得到的预测结果。 其他比例观测值对应的预测结果如图8所示。 对于用户来说,我们将用户参与的所有事件中谣言的比例作为其黄金漏洞。 仅参与多个传播图的用户被标记,其中 TWITTER 上的用户占 15.5%,WEIBO 上的用户占 16.7%。 性能评估中不考虑未标记的用户。
我们分别按 和 将数据集分为训练集、验证集和测试集。 一个关键的优先事项是消除训练集和验证/测试集之间的用户重叠,从而确保没有数据泄漏。 为了实现这一目标,我们首先检查数据集中的每个图表。 如果某个图仅包含在任何其他图中未找到的用户,则将其指定为非重叠图。 值得注意的是,我们数据集中超过 20% 的图表与任何其他图表都不重叠。 然后,我们从这些非重叠图中随机采样,以便验证集和测试集都包含这些采样的非重叠图,两组中的每一个都代表整个数据集的 10%。 最后,剩余的非重叠图和所有其他图都放入训练集中。 这确保了验证/测试训练集中的用户在过程中保持不可见。 表1给出了我们数据集的统计数据。
5.1.2指标
对于谣言检测任务,由于分类结果的准确性会受到类别不平衡的影响,因此除了准确性之外,我们还使用精度、召回率和宏观平均F1分数(MacF1)分数来提供更全面的性能评估。 同时,对于病毒性预测和漏洞预测任务,我们使用MSE和均方对数误差(MSLE)来评估回归结果。 此外,我们还使用归一化折扣累积增益(nDCG)(Järvelin 和 Kekäläinen,2000) 来根据预测的病毒性和漏洞分数来衡量模型的排名性能,因为 nDCG 考虑了相关性和每个预测项目的排名位置,这对于病毒性和漏洞预测任务尤其重要,其中预测项目的重要性顺序可以显着影响模型的整体有效性。
5.1.3参数设置
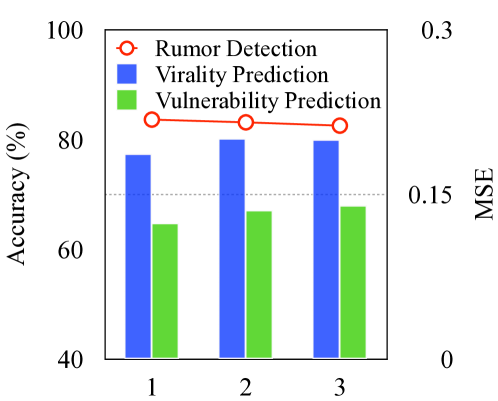
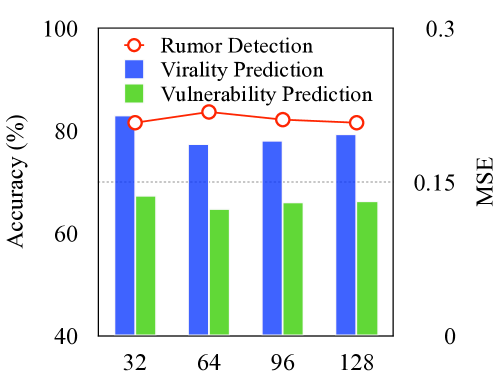
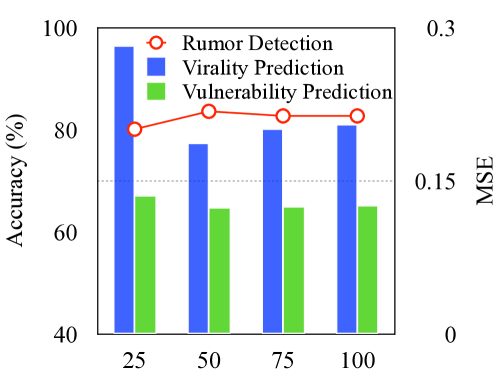
我们使用 DGL444https://www.dgl.ai/,以及所有基于 Pytorch 的深度学习模型555https://pytorch.org/。 我们的方法基于 GraphSAGE (Hamilton 等人, 2017) 和 DiffPool (Ying 等人, 2018) 模型。 在我们的实验中,我们采用随机搜索(Bergstra 和 Bengio,2012) 进行超参数调整,因为它比网格搜索更有效。 我们将随机搜索的迭代次数设置为 100。 我们的重点是一些关键的超参数:1)GraphSAGE 和 CVP 中的层数,取自 ; 2) DiffPool 的池大小,根据中的选择进行调整; 3)嵌入维度,选自; 4)批量大小,选自; 5)学习率,从集合中选择; 6) 丢失率,从集合中采样; 7) 最大帖子长度,从集合中选择。 我们检查这些超参数对验证集的影响。 特别是,其中三个直接决定模型的复杂性,即层数、嵌入维度和最大帖子长度。 我们在图5中具体展示了它们对模型性能的影响。 随机搜索让我们为 GraphSAGE 和 CVP 选择一层,DiffPool 池大小为 50,嵌入维度为 64,批量大小为 8,学习率为 5-3,dropout速率为 0.2,最大帖子长度为 50。
在训练过程中,我们使用随机梯度下降更新模型参数,并通过 Adam 算法优化模型。 实验结果是使用不同种子的五次独立运行的平均值。
5.2谣言检测结果。
| Model | ||||||||
| Acc. | Pre. | Recall | MacF1 | Acc. | Pre. | Recall | MacF1 | |
| GCNFN | 0.772 | 0.664 | 0.714 | 0.731 | 0.902 | 0.885 | 0.930 | 0.908 |
| Bi-GCN | 0.790 | 0.736 | 0.763 | 0.716 | 0.913 | 0.893 | 0.942 | 0.921 |
| RoBERTa | 0.791 | 0.749 | 0.772 | 0.740 | 0.917 | 0.907 | 0.940 | 0.923 |
| UPFD | 0.815 | 0.836 | 0.783 | 0.805 | 0.921 | 0.905 | 0.940 | 0.933 |
| DDGCN | 0.813 | 0.821 | 0.790 | 0.811 | 0.918 | 0.911 | 0.937 | 0.925 |
| Us-DeFake | 0.819 | 0.839 | 0.803 | 0.821 | 0.919 | 0.910 | 0.931 | 0.924 |
| MT-CON (ours) | 0.820 | 0.854 | 0.814 | 0.833 | 0.946 | 0.929 | 0.949 | 0.943 |
| MT-META (ours) |
0.826 |
0.879 |
0.826 |
0.845 |
0.954 |
0.941 |
0.955 |
0.952 |
| Model | ||||||
| MSE | MSLE | nDCG | MSE | MSLE | nDCG | |
| DeepHawkes | 2.011 | 0.067 | 0.521 | 0.994 | 0.048 | 0.783 |
| NPP | 1.199 | 0.020 | 0.867 | 0.867 | 0.022 | 0.984 |
| DeepBlue | 0.918 | 0.016 | 0.894 | 0.824 | 0.017 | 0.985 |
| BERT | 0.960 | 0.019 | 0.891 | 0.835 | 0.018 | 0.989 |
| CasSeqGCN | 0.648 | 0.009 | 0.990 | 0.799 | 0.013 | 0.988 |
| TCAN | 0.588 | 0.008 | 0.992 | 0.792 | 0.017 | 0.989 |
| MT-CON (ours) | 0.320 | 0.006 | 0.996 | 0.716 | 0.013 |
0.995 |
| MT-META (ours) |
0.197 |
0.005 |
0.999 |
0.603 |
0.008 |
0.998 |
| Model | ||||||
| MSE | MSLE | nDCG | MSE | MSLE | nDCG | |
| LING-GAT | 0.121 | 0.062 | 0.989 | 0.168 | 0.074 | 0.972 |
| GraphRfi | 0.151 | 0.075 | 0.985 | 0.179 | 0.079 | 0.963 |
| IMP-GCN | 0.140 | 0.074 | 0.975 | 0.181 | 0.079 | 0.964 |
| U-BERT | 0.124 | 0.065 | 0.983 | 0.166 | 0.084 | 0.974 |
| PinnerFormer | 0.126 | 0.067 | 0.985 | 0.167 | 0.082 | 0.969 |
| CLUE | 0.127 | 0.068 | 0.987 | 0.164 | 0.077 | 0.972 |
| MT-CON (ours) | 0.112 | 0.054 | 0.991 | 0.153 | 0.061 | 0.981 |
| MT-META(ours) |
0.104 |
0.035 |
0.995 |
0.137 |
0.047 |
0.988 |
鉴于我们基于并发训练(MT-CON)和元学习(MT-META)的多任务模型,我们与以下基线模型进行比较:
-
•
GCNFN (Monti 等人, 2019):利用几何深度学习的谣言检测模型。
-
•
Bi-GCN (Bian 等人, 2020):一种基于双向 GCN 的谣言检测方法。
-
•
RoBERTa (Pelrine 等人, 2021):直接微调预训练 RoBERTa 模型的基线,在谣言检测任务上取得了令人惊讶的性能。
-
•
UPFD (Dou 等人, 2021):基于 GCN 的模型,考虑用户偏好来帮助谣言检测。
-
•
DDGCN (Sun 等人, 2022):基于双动态 GCN 的模型,可以对传播网络的动态以及知识图谱中背景知识的动态进行建模。
-
•
Us-DeFake (Su 等人, 2023):一种通过学习传播特征和用户交互特征的谣言检测方法。
如表2所示,我们提出的联合学习模型通常优于两个数据集上的所有基线。 我们有以下观察:
(1) 具有适当设计的 GCN 是谣言检测中一种有前景的方法。 基于GCN的模型可以有效识别谣言和非谣言的传播模式,被广泛用作谣言检测的基础模型。 通过特殊设计整合先验知识可以进一步提高模型在此任务中的性能。 例如,考虑到用户偏好特征,平均而言,UPFD 在准确率方面分别超过 GCNFN 和 Bi-GCN 3.8% 和 2.0%。
(2) 帖子中的内容及其回复为检测谣言提供了有价值的信息。 尽管忽略了复杂的图结构并仅利用内容信息,但对预训练的 RoBERTa 模型进行微调也可以实现与基于 GCN 的 GCNFN 和 Bi-GCN 模型相当的行为。 例如,RoBERTa 在准确率方面超过 GCNFN 2.1%。 这表明用于谣言检测的预训练模型的强大呈现能力所释放的内容信息的重要性。
(3) 分层图池可以帮助利用更多有用的信息。 从两个基本 GCN 学习到的节点表示都是平坦的,因为它们无法通过仅通过节点和边传播信息来以分层方式编码图结构。 我们提出的模型 MT-CON 和 MT-META 在联合学习中利用了用户表示和分层池化,从而击败了所有基线。 例如,MT-META 在准确度方面比最佳基线 Us-DeFake 平均高出 2.4%。
(4) 缓解多个任务的训练冲突可以进一步提高性能。 MT-META 的准确度平均优于 MT-CON 0.8%,这表明与并发训练相比,元学习策略在减轻任务的训练冲突方面表现更好。
5.3病毒式传播预测结果。
我们与以下基准模型进行比较:
-
•
DeepHawkes (Cao 等人, 2017):一种基于 Hawkes 过程的深度学习模型,用于病毒式传播预测。
-
•
NPP (Chen 等人,2019):一种学习流行度和病毒式嵌入的预测模型,同时考虑时间、用户和内容因素。
-
•
DeepBlue (Zhang 等人, 2021):一种基于双层 LSTM 的流行度和病毒式传播方法,它考虑了用户声誉和推文相关特征等历史信息。
-
•
BERT (Tan 等人, 2022):一种基于 Bert 的模型,利用内容特征进行流行度和病毒式传播预测。 原始论文利用了其他模式(例如图像)的特征。 这里我们仅用其文本处理方式进行比较。
-
•
CasSeqGCN (Wang 等人,2022):一种流行度和病毒式传播预测方法,采用 GCN 进行网络结构特征,使用 LSTM 进行时间动态。
-
•
TCAN (Sun 等人, 2023):一种基于显式时间嵌入的流行度和病毒性方法,它采用图注意力编码器和序列注意力编码器来学习传播网络的表示。
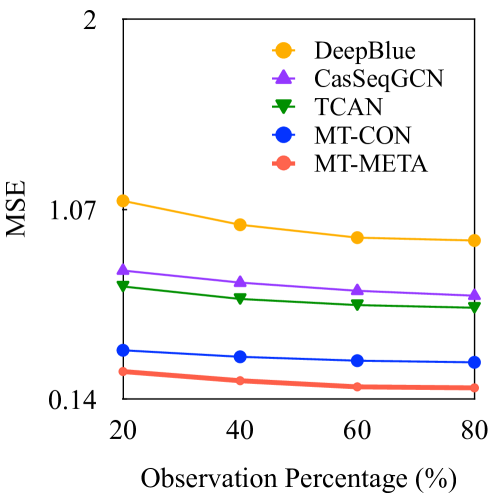
如表2所示,MT-CON 和 MT-Meta 在这两个数据集上总体上优于所有基线。 我们有以下观察:
(1) 传播结构中包含的信息可以帮助病毒式传播预测,但可能还不够。 DeepHawkes 表现最差,MSE 比第二差的模型(即 NPP)高 39.2%,因为它只使用网络结构来建模讨论过程。 考虑更多信息(例如上下文和用户)的模型显然表现更好。
(2) 结合用户和事件特征可以提高病毒式传播预测的性能。 DeepBlue 在 MSE 方面的表现比 NPP 平均低 13.3%,因为它不仅考虑单个推文,还考虑了从历史推文中学习到的有用的用户声誉和帖子相关特征。 此外,我们的模型还考虑了事件的信息类型(即谣言/非谣言)以及参与其传播的用户的脆弱性,以帮助进行病毒式传播预测。
(3) 帖子中的内容及其回复可以预示当前事件未来的病毒式传播。 尽管仅利用内容特征,但预训练的 BERT 模型实现了与 DeepBlue 相当的行为,MSE 仅小幅提高了 3.3%。 这表明文本在病毒式传播预测任务中的重要作用以及预训练模型的优势。
(4) 结合分层池可以更好地理解图的结构,从而提高病毒式传播预测的准确性。 我们的模型 MT-CON 和 MT-META 利用不同特征表示的组合,例如时间、用户和帖子内容以及有关事件类型和用户漏洞的信息,然后将其分层汇集,从而与所有基线相比提高了性能。 例如,MT-META 的 MSE 平均比 TCAN 低 49.3%。
(5) 减少多个任务之间的训练冲突可以提高绩效。 与谣言检测结果中的观察结果类似,在基于元学习的训练策略的帮助下,MT-META 在缓解冲突方面比 MT-CON 表现更好。 平均而言,MT-META 的 MSE 比 MT-CON 低 37.5%。
5.4用户漏洞预测结果
对于此任务,我们与以下基线模型进行比较:
-
•
LING-GAT (Del Tredici 等人,2019):一种用户表示方法,使用 Bi-LSTM 层捕获语言特征,并使用转导图注意网络(GAT)来建模用户的社交关系。
-
•
GraphRfi (Zhang 等人, 2020):使用 GCN 和神经随机森林手工制作的基于特征的用户表示学习框架。
-
•
IMP-GCN (Liu 等人, 2021):一种基于 GCN 的用户兴趣感知表示学习模型。
-
•
U-BERT (Qiu 等人, 2021):受 BERT 模型成功启发的预训练用户嵌入模型。
-
•
PinnerFormer (Pancha 等人, 2022):一种基于用户最近操作序列的用户表示学习方法。 为了使其适应漏洞预测任务,我们将用户的帖子和评论视为他们的操作。
-
•
CLUE (Shin 等人, 2023):一种基于对比学习的通用用户表示学习方法。
为了使现有的基线模型适应预测用户漏洞的回归任务,我们通过删除特定于任务的最终层并用回归层替换它们来修改它们。 这使我们能够使用相同的模型架构,同时将它们重新用于用户漏洞预测的特定任务。
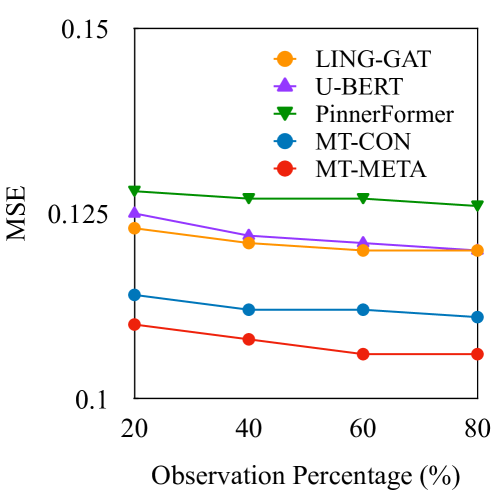
如表2所示,我们提出的模型在漏洞预测方面优于两个数据集上的所有基线。 我们有一些具体的观察:
(1) 手工制作的特征在捕获潜在特征和深层相关性方面受到限制。 由于手工特征的泛化性普遍较弱,GraphRfi 的表现最差,MSE 比第二差的模型(即 IMP-GCN)高 7.1%。
(2) 用户帖子的内容可以揭示他们内心的脆弱。 IMP-GCN 在 MSE 上的表现略好于 GraphRfi,低 6.6%,因为它使用可以传达用户倾向的内容信息。 然而,它在 MSE 方面的表现仍然比另一个基于 GCN 的模型 LING-GAT 差,高出 16.5%,因为 LING-GAT 通过 Bi-LSTM 层深度利用了帖子内容信息。
(3) 预训练和对比学习是用户表示学习中很有前途的方法。 U-BERT 优于所有其他基线,这表明预训练模型对于用户分类的有用性。 有趣的是,PinnerFormer 和 CLUE 不利用传播网络结构,却表现出了令人印象深刻的良好性能。 例如,CLUE 的平均 MSE 分别比考虑更多信息的 GraphRfi 和 IMP-GCN 低 12.6% 和 10.7%。 这表明了对比学习尚未开发的潜力,PinnerFormer 和 CLUE 都采用了这项技术。 我们的模型还通过对比学习来预训练一般用户嵌入,以帮助捕获用户特征。
(4) 减少多项任务的训练冲突可以提高绩效。 这一观察结果与其他两个任务类似。 在漏洞预测任务中,MT-META 的 MSE 比 MT-CON 平均低 8.9%。
5.5分析
5.5.1 消融研究
为了检查我们提出的联合学习方法中每个关键组成部分的影响,我们基于 TWITTER 数据集上最好的完整模型 MT-META 进行了消融研究。 表 3 显示了我们的实验。 我们总结了各个方面,并重点介绍了以下最有趣的发现。
输入嵌入。
我们首先在前四行中展示输入嵌入层中每个组件的效果。 我们可以看到,当预训练的用户嵌入(即 User Emb. 表 3 中的)没有被使用,这表明挖掘隐藏在构建的全局用户图中的深层结构和模式对于我们所有的三个任务来说非常重要。 此外,在我们的模型中,后嵌入中的内容和时间信息都起着不可或缺的作用,删除内容、时间和两种类型的嵌入后性能下降就证明了这一点。
精致嵌入。
如果我们用求和池替换分层池,这意味着我们直接对节点表示求和以获得图表示,性能会下降。 这与我们的假设一致,即学习图的层次结构(即通过模型中的 DiffPool)可以提高模型的性能。
CVP
社区增强和 CVP 中的 GraphSAGE 在用户漏洞预测中都发挥着重要作用。 这进一步证实了我们的假设,即 CVP 可以通过利用潜在社区内用户之间的共享特征来细化节点表示,从而直接帮助预测用户脆弱性。
| # | Input Emb. | Refined Emb. | CVP | Task | |||||||||
| User Emb. | Cnt. Emb. | Time Emb. | Sum Pool | Hier. Pool | Comm. Enh. | Graph- SAGE | Rumor | Virality | Vulnerability | ||||
| Acc | MacF1 | MSE | nDCG | MSE | nDCG | ||||||||
| 1 | ✓ | ✓ | ✓ | ✓ | ✓ | 0.802 | 0.757 | 0.233 | 0.995 | 0.138 | 0.983 | ||
| 2 | ✓ | ✓ | ✓ | ✓ | 0.777 | 0.742 | 0.391 | 0.990 | 0.159 | 0.988 | |||
| 3 | ✓ | ✓ | ✓ | ✓ | ✓ | 0.784 | 0.759 | 0.373 | 0.990 | 0.152 | 0.986 | ||
| 4 | ✓ | ✓ | ✓ | ✓ | ✓ | 0.791 | 0.771 | 0.381 | 0.992 | 0.143 | 0.984 | ||
| 5 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 0.777 | 0.730 | 0.405 | 0.985 | 0.160 | 0.984 | |
| 6 | ✓ | ✓ | ✓ | ✓ | 0.821 | 0.817 | 0.211 | 0.994 | 0.152 | 0.986 | |||
| 7 | ✓ | ✓ | ✓ | ✓ | ✓ | 0.821 | 0.809 | 0.204 | 0.998 | 0.147 | 0.979 | ||
| 8 | ✓ | ✓ | ✓ | ✓ | ✓ | 0.822 | 0.814 | 0.204 | 0.998 | 0.134 | 0.984 | ||
| 9 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
0.826 |
0.845 |
0.197 |
0.999 |
0.104 |
0.995 |
|
5.5.2 不同任务损失配置的影响
为了评估我们提出的联合学习方法中每个任务损失的贡献,我们通过改变损失配置并在 TWITTER 数据集上使用我们最有效的模型 MT-META 进行消融实验,如表 4 所示>。 我们有一些具体的观察:
-
•
病毒式传播与谣言类别(即谣言或非谣言)之间的直接联系很弱。 当仅考虑病毒性损失时,谣言检测的性能最低。 同样,当仅考虑谣言检测损失时,病毒式传播预测的性能最低。
-
•
任务训练冲突可能会导致性能下降。 不适当的联合学习可能会导致一定程度的训练冲突,因为它试图平衡不同任务目标之间的学习过程。 以谣言检测任务为例,当谣言检测损失与病毒性预测损失联合优化时,与仅优化谣言检测损失相比,准确率下降了5.1%,在MacF1中性能下降了0.6%;与漏洞预测损失联合优化时,准确率从0.806小幅下降到0.801,而MacF1从0.796小幅上升到0.8。 这可能表明谣言预测与用户脆弱性的关系比病毒式传播更直接。
-
•
所有三项任务的联合学习对于防止训练冲突至关重要。 这是因为以用户脆弱性为桥梁,可以隐式地建立信息的病毒性和谣言/非谣言性质之间的关系。 在谣言检测任务中,与仅谣言检测损失相比,联合优化所有三个损失时,我们观察到谣言检测任务的准确率和 MacF1 分别提高了 2.5% 和 6.2%。 在其他两项任务中也可以观察到类似程度的改进。 这意味着所有三个任务的联合学习可以防止训练冲突,这可能是由于更多任务的桥梁效应。
| # | Loss | Task | |||||||
| Rumor Detection | Virality Prediction | Vulnerability Prediction | Rumor | Virality | Vulnerability | ||||
| Acc | MacF1 | MSE | nDCG | MSE | nDCG | ||||
| 1 | ✓ | 0.806 | 0.796 | 321.766 | 0.145 | 23.262 | 0.005 | ||
| 2 | ✓ | 0.673 | 0.641 | 0.209 | 0.990 | 1.977 | 0.187 | ||
| 3 | ✓ | 0.739 | 0.704 | 168.336 | 0.275 | 0.122 | 0.972 | ||
| 4 | ✓ | ✓ | 0.748 | 0.710 | 0.201 | 0.998 | 0.137 | 0.961 | |
| 5 | ✓ | ✓ | 0.801 | 0.800 | 9.513 | 0.479 | 0.207 | 0.954 | |
| 6 | ✓ | ✓ | 0.765 | 0.742 | 0.249 | 0.990 | 0.518 | 0.872 | |
| 7 | ✓ | ✓ | ✓ |
0.826 |
0.845 |
0.197 |
0.999 |
0.104 |
0.995 |
5.5.3 边缘方向的影响
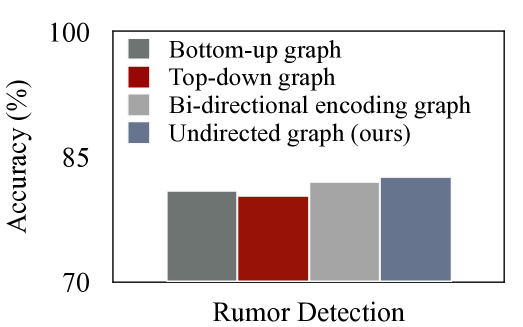
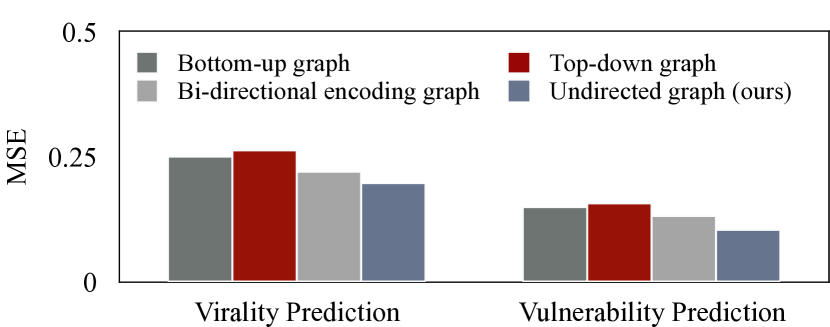
为了研究我们提出的方法中传播网络中边缘方向的影响,我们探索了四种不同的边缘方向设置:(1)自下而上的图,其中边缘遵循所引用信息的方向(Ma等人,2018; Bian 等人, 2020), (2) 自上而下的有向图,其中边沿信息流方向(Ma 等人, 2018; Bian 等人, 2020), (3) 双向编码图,其中两个 GraphSage 编码器同时工作以表示图中沿两个不同方向(即自上而下和自下而上)的特征。 这些编码器产生的嵌入被连接起来形成一个包含双向信息的综合节点表示,类似于 Bi-GCN (Bian 等人, 2020),以及 (4) 我们的无向图,其中每个边虽然没有方向,但表示双向关系,并且图的邻接矩阵明确地表示双向图,因为每条边都是往复的。 如图6所示,我们的研究结果表明,自上而下和自下而上的有向图都比(3)和(4)中的两个双向变体表现出更差的性能。 这可能表明,考虑两个方向的基础模型的特征表示比仅考虑单个方向(无论实际传播方向如何)更好。 此外,(4)中的无向处理优于(3)中的双向情况。 这可能是因为无向图更直接地将两个方向的信息与对称邻接矩阵集成在一起,而不是单独学习然后将它们组合起来。 这种直接集成有助于模型更好地理解节点之间的关系。
5.5.4 GNN 编码器的效果
为了研究 GNN 编码器在我们提出的方法中的影响,我们测试了不同的 GNN 编码器来导出节点表示。 在图7中,我们显示了使用六个不同编码器的性能,即GCN (Defferrard等人,2016),GraphSAGE (Hamilton等人,2017) t3>、GAT (Veličković 等人, 2018)、GIN (Xu 等人, 2018),以及没有 GNN 编码器的情况。 我们观察到,带有 GNN 编码器的变体始终优于没有 GNN 编码器的变体,这表明 GNN 在更新节点特征方面的优势。 此外,我们注意到 GraphSAGE 的性能比其他 GNN 编码器稍好。 我们推测这可能是由于 GraphSAGE 的归纳学习和采样机制,它可能特别适合具有丰富噪声信息的社交网络图。
5.5.5 观察百分比的影响
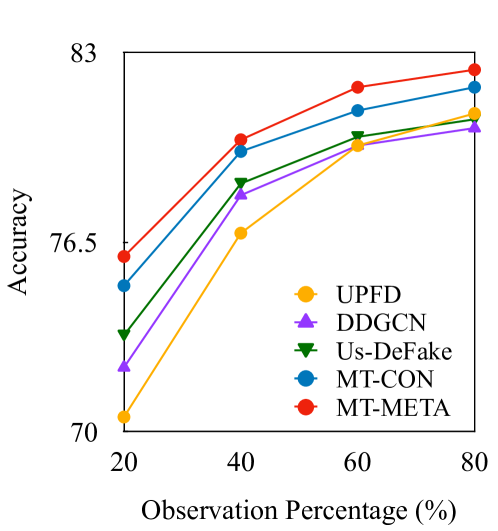
为了清楚起见,我们仅将我们的模型与每项任务的三个表现最佳的基线进行比较。 图8展示了当观察百分比从20%变化到80%时,谣言检测精度以及病毒性和漏洞预测的MSE的变化。 随着百分比的增加,观察到的图表的大小也会增加,从而提高所有三项任务的性能。 从图中我们可以看到,即使仅使用早期传播信息(例如 20%),我们提出的模型 MT-CON 和 MT-META 在这三个任务上都优于基线模型,并具有明显的优势。 特别是,仅用 40% 传播作为观察,MT-META 就可以达到与使用 80% 传播的三个基线相似的谣言检测精度(见图8(a))。
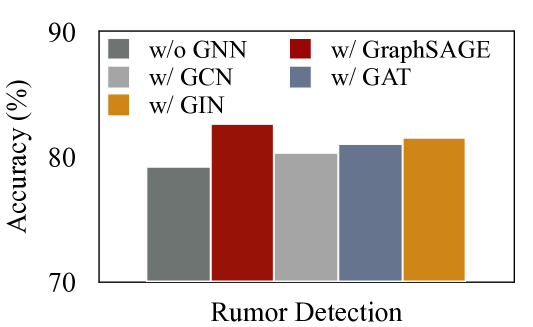
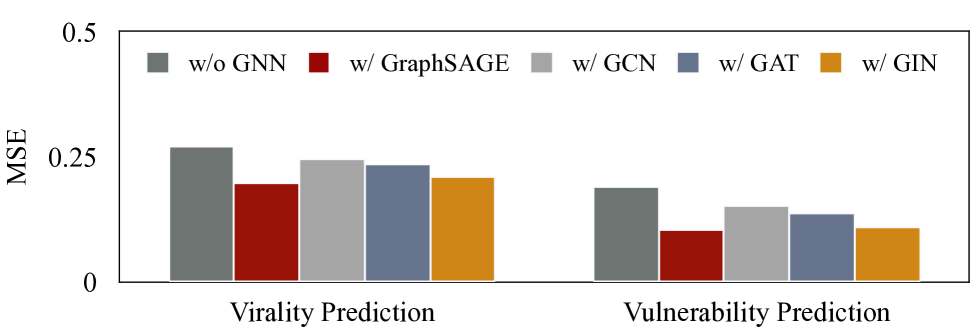
| Setting | Rumor | Virality | Vul. | ||||
| Acc | MacF1 | MSE | nDCG | MSE | nDCG | ||
| STL | - | 0.806 | 0.796 | 0.209 | 0.990 | 0.122 | 0.972 |
| MTL | Basic | 0.793 | 0.784 | 0.228 | 0.981 | 0.126 | 0.973 |
| CON | 0.820 | 0.833 | 0.320 | 0.996 | 0.112 | 0.991 | |
| Meta |
0.826 |
0.845 |
0.197 |
0.999 |
0.104 |
0.995 |
|
5.5.6 训练策略的效果
虽然任务之间存在相关性,但如果没有选择适当的训练策略,可能会发生导致负迁移的训练冲突,而我们的训练方法可以缓解这个问题。 表5显示,当我们通过线性组合三个任务的损失来使用基本多任务训练来训练所有三个任务时,性能低于单独训练它们,这表明存在训练冲突。 Gradnorm,用于并发训练,通过调整梯度来平衡不同任务的学习率,明显改善了基础训练。 然而,与单任务设置相比,它仅略微提高了性能。 相比之下,元学习策略在所有三个任务上都优于基本训练和 Gradnorm 方法,这表明它大大减轻了训练冲突。 这种优越的性能可能归因于以下事实:在元学习中,由于不同任务仅共享 ,因此发生训练冲突的机会较小。
当训练冲突缓解后,即找到合适的训练方法后,我们发现联合学习的结果比单独训练要好。 重要的是,这些结果表明所提出的方法有效地捕获了谣言病毒性和用户脆弱性之间的相关性,并利用这些信息来提高预测性能。 通过识别这些相关性,该模型可以更好地预测错误信息如何传播以及哪些用户更容易受到错误信息的影响。 因此,这可以采取有针对性的干预措施和策略来防止错误信息的传播,从而提高打击在线社区中虚假新闻和谣言的整体有效性。
5.5.7 用户社区可视化
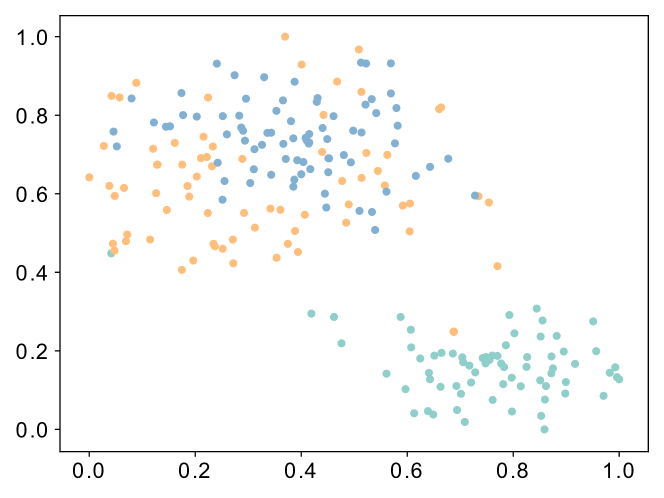
我们使用 MT-META 池化层生成的 t-SNE (Van der Maaten 和 Hinton,2008) 可视化三个最大的用户社区。 由于我们的模型采用软分配,因此我们认为每个用户都被分配到与他们具有最高相似度的社区。 图9显示我们的模型可以有效地将具有相似嵌入的用户聚集在一起,这有助于进一步利用社区隐含的信息(例如,每个社区内用户的共享模式和特征)来帮助我们完成任务。
5.5.8案例研究
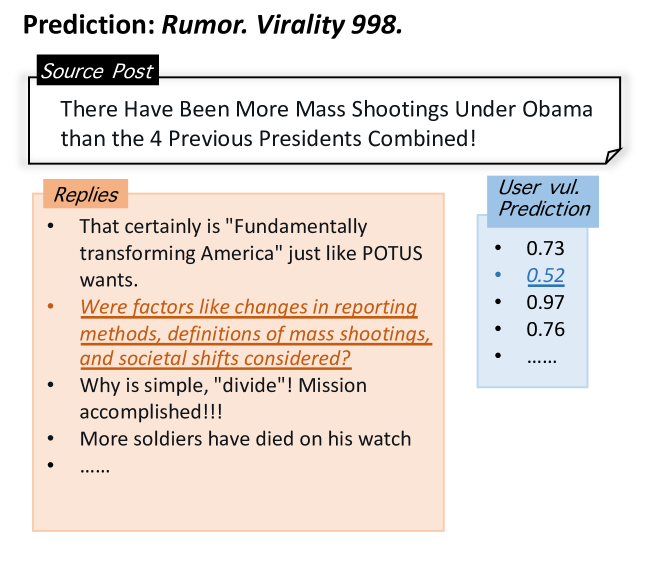
为了更好地说明我们的模型如何利用从三个任务中学习并利用它们之间的关系来提高性能,我们在图 9 中展示了一个示例,使用病毒式谣言图来解释预测结果。
我们可以看到,我们的模型将该事件预测为谣言,这与其用户漏洞预测一致,因为大多数转发来自易受攻击或中度易受攻击的用户。 此外,该事件对于中等或不易受攻击(即漏洞分数低于 0.5)的用户没有吸引力。 用户脆弱性得分高表明人们很容易受到谣言的影响,并且很容易在未经验证的情况下接受和传播谣言,这可以解释为什么谣言会像病毒一样传播。 与易受攻击的用户相比,较不易受攻击的用户(例如,帖子标记为橙色)似乎对声明更为挑剔,因为他们注意到源帖子的争议,而不是简单地同意或重复其他人叙述的内容。 这一观察结果符合用户脆弱性的定义:较低的用户脆弱性意味着用户更频繁地参与非谣言(即经过验证的新闻)而不是谣言(即虚假或未经验证的信息),表明此类用户更可信或理性的。
6 影响
谣言是一种不断演变的现象,需要共同努力来减轻其负面影响。 对于技术贡献,我们提供了一个新的视角,结合了谣言检测、病毒性预测和信息流行病监控的用户漏洞评分三项任务。 在这种情况下,它提出了一种机制,利用 GNN 的力量来同时学习之前独立学习的这三个任务,并捕获它们之间的潜在相关性。 这不仅提高了个人任务的绩效,而且有利于及时有效的信息流行病监测,即利用有限的可用信息对监测需求做出及时、准确的响应。 我们的框架还为未来的信息流行病监测研究提供了新途径。
为了做出实际贡献,我们为在线社交媒体平台上的信息流行病监测提供了可行的策略。 监控系统首先检测事件及其在社交媒体上的传播。 然后,检测到的病毒谣言将发送给事实核查人员进行验证,并且还会向参与谣言传播的弱势用户发出警报,让他们意识到这一点。 这样一来,首先可以在不影响其他用户体验的情况下,精准保护易受攻击的用户。 社交媒体平台是许多人信息和交流的重要来源。 扰乱其他用户的体验可能会导致混乱和不信任,从而加剧信息流行病问题。 因此,我们的方法旨在精确识别和保护易受攻击的用户。 这种有针对性的方法使我们能够为最需要的人提供保护,同时最大限度地减少对更广泛用户群的负面影响。
其次,可以减轻核查负担,从而实现更有效的信息监控和早期干预。 社交媒体平台上传播的信息量巨大,使得手动验证谣言和错误信息变得具有挑战性。 我们的统一预测框架结合了谣言检测、病毒性预测和用户漏洞评分,可以更全面、更准确地分析在线信息。 这意味着我们可以同时预测最具影响力的谣言和易受攻击的用户,从而减少耗时的手动验证的需要,并有可能协助当局更有效地分配资源。
第三,我们的统一预测框架最重要的影响之一是它能够在早期阶段检测谣言并预测其病毒式传播,即使传播信息有限。 这是该模型的一项重要功能,因为它可以及时干预并防止谣言进一步传播,从而可能造成伤害。 及早发现谣言及其潜在影响,使当局和组织能够快速有效地做出反应,从而最大限度地减少社会动荡、政治不稳定和其他不良后果的风险。
7 结论和未来工作
我们提出了一种联合学习方法,用于检测谣言,并在基于图神经网络的统一多任务框架中预测其病毒性和用户脆弱性。 通过利用这些任务的潜在相关性,我们的方法可以预测可能传播的谣言,并帮助找到容易传播谣言的轻信用户,以进行及时有效的信息流行病监测。 评估证实,我们的方法在所有三个任务上都优于最先进的基线,使用两个数据集,以及基于现有谣言检测语料库构建的谣言类别、事件病毒性和用户漏洞的基本事实。
未来,我们计划使用更好的排名算法来代替回归,以进一步提升 nDCG。 我们还将开发嵌入更深层次用户特征的方法,以更好地反映用户对谣言的内部状态(可能是心理层面),从而进行更深入的用户漏洞分析。
竞争利益声明
作者声明,他们没有已知的可能影响本文报告工作的竞争利益。
致谢
这项研究得到了新加坡教育部 (MOE) 学术研究基金 (AcRF) Tier-1 资助(资助号: 19-C220-SMU-013)。 本材料中表达的任何意见、调查结果和结论或建议均为作者的观点,并不反映资助机构的观点。
参考
- Albladi and Weir (2020) Albladi, S.M., Weir, G.R., 2020. Predicting individuals’ vulnerability to social engineering in social networks. Cybersecurity 3, 1–19.
- Ali (2020) Ali, I., 2020. The covid-19 pandemic: Making sense of rumor and fear: Op-ed. Medical anthropology 39, 376–379.
- Alkhodair et al. (2020) Alkhodair, S.A., Ding, S.H., Fung, B.C., Liu, J., 2020. Detecting breaking news rumors of emerging topics in social media. Information Processing & Management 57, 102018.
- Bergstra and Bengio (2012) Bergstra, J., Bengio, Y., 2012. Random search for hyper-parameter optimization. Journal of machine learning research 13.
- Bi et al. (2022) Bi, B., Wang, Y., Zhang, H., Gao, Y., 2022. Microblog-han: A micro-blog rumor detection model based on heterogeneous graph attention network. Plos one 17, e0266598.
- Bian et al. (2020) Bian, T., Xiao, X., Xu, T., Zhao, P., Huang, W., Rong, Y., Huang, J., 2020. Rumor detection on social media with bi-directional graph convolutional networks, in: AAAI, pp. 549–556.
- Bringula et al. (2021) Bringula, R.P., Catacutan-Bangit, A.E., Garcia, M.B., Gonzales, J.P.S., Valderama, A.M.C., 2021. “who is gullible to political disinformation?”: predicting susceptibility of university students to fake news. Journal of Information Technology & Politics , 1–15.
- Buffelli and Vandin (2020) Buffelli, D., Vandin, F., 2020. A meta-learning approach for graph representation learning in multi-task settings. NIPS Workshop on Meta-Learning (MetaLearn) .
- Cao et al. (2018) Cao, J., Guo, J., Li, X., Jin, Z., Guo, H., Li, J., 2018. Automatic rumor detection on microblogs: A survey. arXiv preprint arXiv:1807.03505 .
- Cao et al. (2017) Cao, Q., Shen, H., Cen, K., Ouyang, W., Cheng, X., 2017. Deephawkes: Bridging the gap between prediction and understanding of information cascades, in: CIKM, pp. 1149–1158.
- Castillo et al. (2011) Castillo, C., Mendoza, M., Poblete, B., 2011. Information credibility on twitter, in: WWW, pp. 675–684.
- Chen et al. (2019) Chen, G., Kong, Q., Xu, N., Mao, W., 2019. Npp: A neural popularity prediction model for social media content. Neurocomputing 333, 221–230.
- Chen et al. (2021) Chen, X., Zhou, F., Zhang, F., Bonsangue, M., 2021. Catch me if you can: A participant-level rumor detection framework via fine-grained user representation learning. Information Processing & Management 58, 102678.
- Chen et al. (2018) Chen, Z., Badrinarayanan, V., Lee, C.Y., Rabinovich, A., 2018. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks, in: ICML, pp. 794–803.
- Cheng et al. (2014) Cheng, J., Adamic, L., Dow, P.A., Kleinberg, J.M., Leskovec, J., 2014. Can cascades be predicted?, in: WWW, pp. 925–936.
- Defferrard et al. (2016) Defferrard, M., Bresson, X., Vandergheynst, P., 2016. Convolutional neural networks on graphs with fast localized spectral filtering, in: NIPS, pp. 3844–3852.
- Del Tredici et al. (2019) Del Tredici, M., Marcheggiani, D., im Walde, S.S., Fernández, R., 2019. You shall know a user by the company it keeps: Dynamic representations for social media users in nlp, in: EMNLP, pp. 4707–4717.
- Devlin et al. (2019) Devlin, J., Chang, M.W., Lee, K., Toutanova, K., 2019. Bert: Pre-training of deep bidirectional transformers for language understanding, in: NAACL, pp. 4171–4186.
- Diehl (2019) Diehl, F., 2019. Edge contraction pooling for graph neural networks. arXiv preprint arXiv:1905.10990 .
- Dou et al. (2021) Dou, Y., Shu, K., Xia, C., Yu, P.S., Sun, L., 2021. User preference-aware fake news detection, in: SIGIR, pp. 2051–2055.
- Gao et al. (2019) Gao, H., Chen, Y., Ji, S., 2019. Learning graph pooling and hybrid convolutional operations for text representations, in: WWW, pp. 2743–2749.
- Hamilton et al. (2017) Hamilton, W.L., Ying, R., Leskovec, J., 2017. Inductive representation learning on large graphs, in: NIPS, pp. 1025–1035.
- He et al. (2022) He, L., Xu, G., Jameel, S., Wang, X., Chen, H., 2022. Graph-aware deep fusion networks for online spam review detection. IEEE Transactions on Computational Social Systems .
- Hoang and Lim (2016) Hoang, T.A., Lim, E.P., 2016. Virality and susceptibility in information diffusions, in: ICWSM, pp. 146–153.
- Huang et al. (2019) Huang, Z., Wang, Z., Zhang, R., 2019. Cascade2vec: Learning dynamic cascade representation by recurrent graph neural networks. IEEE Access 7, 144800–144812.
- Islam et al. (2021) Islam, M.S., Kamal, A.H.M., Kabir, A., Southern, D.L., Khan, S.H., Hasan, S.M., Sarkar, T., Sharmin, S., Das, S., Roy, T., et al., 2021. Covid-19 vaccine rumors and conspiracy theories: The need for cognitive inoculation against misinformation to improve vaccine adherence. PloS ONE , e0251605.
- Järvelin and Kekäläinen (2000) Järvelin, K., Kekäläinen, J., 2000. Ir evaluation methods for retrieving highly relevant documents, in: SIGIR, pp. 41–48.
- Jenders et al. (2013) Jenders, M., Kasneci, G., Naumann, F., 2013. Analyzing and predicting viral tweets, in: WWW, pp. 657–664.
- Kefato et al. (2018) Kefato, Z.T., Sheikh, N., Bahri, L., Soliman, A., Montresor, A., Girdzijauskas, S., 2018. Cas2vec: Network-agnostic cascade prediction in online social networks, in: SNAMS, pp. 72–79.
- Kim (2018) Kim, J.W., 2018. Rumor has it: The effects of virality metrics on rumor believability and transmission on twitter. New Media & Society 20, 4807–4825.
- Kupavskii et al. (2012) Kupavskii, A., Ostroumova, L., Umnov, A., Usachev, S., Serdyukov, P., Gusev, G., Kustarev, A., 2012. Prediction of retweet cascade size over time, in: CIKM, pp. 2335–2338.
- Lee and Oh (2017) Lee, H., Oh, H.J., 2017. Normative mechanism of rumor dissemination on twitter. Cyberpsychology, Behavior, and Social Networking 20, 164–171.
- Lee et al. (2019) Lee, J., Lee, I., Kang, J., 2019. Self-attention graph pooling, in: ICML, PMLR. pp. 3734–3743.
- Lee and Lim (2015) Lee, R.K.W., Lim, E.P., 2015. Measuring user influence, susceptibility and cynicalness in sentiment diffusion, in: ECIR, pp. 411–422.
- Li et al. (2017) Li, C., Ma, J., Guo, X., Mei, Q., 2017. Deepcas: An end-to-end predictor of information cascades, in: WWW, pp. 577–586.
- Liao et al. (2019) Liao, D., Xu, J., Li, G., Huang, W., Liu, W., Li, J., 2019. Popularity prediction on online articles with deep fusion of temporal process and content features, in: AAAI, pp. 200–207.
- Liu et al. (2021) Liu, F., Cheng, Z., Zhu, L., Gao, Z., Nie, L., 2021. Interest-aware message-passing gcn for recommendation, in: WWW, pp. 1296–1305.
- Liu and Wu (2020) Liu, Y., Wu, Y.F.B., 2020. Fned: a deep network for fake news early detection on social media. ACM Transactions on Information Systems (TOIS) 38, 1–33.
- Ma et al. (2016) Ma, J., Gao, W., Mitra, P., Kwon, S., Jansen, B.J., Wong, K.F., Cha, M., 2016. Detecting rumors from microblogs with recurrent neural networks, in: IJCAI, pp. 3818–3824.
- Ma et al. (2017) Ma, J., Gao, W., Wong, K.F., 2017. Detect rumors in microblog posts using propagation structure via kernel learning, in: ACL, pp. 708–717.
- Ma et al. (2018) Ma, J., Gao, W., Wong, K.F., 2018. Rumor detection on twitter with tree-structured recursive neural networks, in: ACL, pp. 1980–1989.
- Van der Maaten and Hinton (2008) Van der Maaten, L., Hinton, G., 2008. Visualizing data using t-sne. Journal of machine learning research 9.
- Mercier (2017) Mercier, H., 2017. How gullible are we? a review of the evidence from psychology and social science. Review of General Psychology 21, 103–122.
- Monti et al. (2019) Monti, F., Frasca, F., Eynard, D., Mannion, D., Bronstein, M.M., 2019. Fake news detection on social media using geometric deep learning. ICLR .
- Nguyen et al. (2020) Nguyen, V.H., Sugiyama, K., Nakov, P., Kan, M.Y., 2020. Fang: Leveraging social context for fake news detection using graph representation, in: CIKM, pp. 1165–1174.
- Pan and Ding (2019) Pan, S., Ding, T., 2019. Social media-based user embedding: A literature review, in: IJCAI, pp. 6318–6324.
- Pancha et al. (2022) Pancha, N., Zhai, A., Leskovec, J., Rosenberg, C., 2022. Pinnerformer: Sequence modeling for user representation at pinterest, in: Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 3702–3712.
- Pelrine et al. (2021) Pelrine, K., Danovitch, J., Rabbany, R., 2021. The surprising performance of simple baselines for misinformation detection, in: WWW, pp. 3432–3441.
- Pennycook and Rand (2019) Pennycook, G., Rand, D.G., 2019. Lazy, not biased: Susceptibility to partisan fake news is better explained by lack of reasoning than by motivated reasoning. Cognition 188, 39–50.
- Qiu et al. (2021) Qiu, Z., Wu, X., Gao, J., Fan, W., 2021. U-bert: Pre-training user representations for improved recommendation, in: AAAI, pp. 4320–4327.
- Rath et al. (2019) Rath, B., Gao, W., Srivastava, J., 2019. Evaluating vulnerability to fake news in social networks: A community health assessment model, in: ASONAM, pp. 432–435.
- Ratkiewicz et al. (2011) Ratkiewicz, J., Conover, M., Meiss, M., Gonçalves, B., Patil, S., Flammini, A., Menczer, F., 2011. Truthy: mapping the spread of astroturf in microblog streams, in: WWW, pp. 249–252.
- Rissola et al. (2019) Rissola, E.A., Bahrainian, S.A., Crestani, F., 2019. Personality recognition in conversations using capsule neural networks, in: WI, pp. 180–187.
- Sharma et al. (2019) Sharma, K., Qian, F., Jiang, H., Ruchansky, N., Zhang, M., Liu, Y., 2019. Combating fake news: A survey on identification and mitigation techniques. TIST 10, 1–42.
- Shen et al. (2014) Shen, H., Wang, D., Song, C., Barabási, A.L., 2014. Modeling and predicting popularity dynamics via reinforced poisson processes, in: AAAI, p. 291–297.
- Shen et al. (2019) Shen, T.J., Cowell, R., Gupta, A., Le, T., Yadav, A., Lee, D., 2019. How gullible are you? predicting susceptibility to fake news, in: WebSci, pp. 287–288.
- Shin et al. (2023) Shin, K., Kwak, H., Kim, S.Y., Ramström, M.N., Jeong, J., Ha, J.W., Kim, K.M., 2023. Scaling law for recommendation models: Towards general-purpose user representations, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 4596–4604.
- Song et al. (2021) Song, Y.Z., Chen, Y.S., Chang, Y.T., Weng, S.Y., Shuai, H.H., 2021. Adversary-aware rumor detection, in: ACL, pp. 1371–1382.
- Su et al. (2023) Su, X., Yang, J., Wu, J., Zhang, Y., 2023. Mining user-aware multi-relations for fake news detection in large scale online social networks, in: Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, pp. 51–59.
- Sun et al. (2022) Sun, M., Zhang, X., Zheng, J., Ma, G., 2022. Ddgcn: Dual dynamic graph convolutional networks for rumor detection on social media, in: AAAI, pp. 4611–4619.
- Sun et al. (2023) Sun, X., Zhou, J., Liu, L., Wei, W., 2023. Explicit time embedding based cascade attention network for information popularity prediction. Information Processing & Management 60, 103278.
- Tan et al. (2022) Tan, Y., Liu, F., Li, B., Zhang, Z., Zhang, B., 2022. An efficient multi-view multimodal data processing framework for social media popularity prediction, in: ACM MM, pp. 7200–7204.
- Tsur and Rappoport (2012) Tsur, O., Rappoport, A., 2012. What’s in a hashtag? content based prediction of the spread of ideas in microblogging communities, in: WSDM, pp. 643–652.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I., 2017. Attention is all you need, in: NIPS.
- Veličković et al. (2018) Veličković, P., Cucurull, G., Casanova, A., Romero, A., Liò, P., Bengio, Y., 2018. Graph attention networks, in: ICLR.
- Vosoughi et al. (2018) Vosoughi, S., Roy, D., Aral, S., 2018. The spread of true and false news online. science 359, 1146–1151.
- Wald et al. (2013) Wald, R., Khoshgoftaar, T.M., Napolitano, A., Sumner, C., 2013. Predicting susceptibility to social bots on twitter, in: IRI, IEEE. pp. 6–13.
- Wang et al. (2023) Wang, J., Xie, H., Wang, F.L., Lee, L.K., Wei, M., 2023. Jointly modeling intra-and inter-session dependencies with graph neural networks for session-based recommendations. Information Processing & Management 60, 103209.
- Wang et al. (2020) Wang, Y., Qian, S., Hu, J., Fang, Q., Xu, C., 2020. Fake news detection via knowledge-driven multimodal graph convolutional networks, in: ICMR, pp. 540–547.
- Wang et al. (2022) Wang, Y., Wang, X., Ran, Y., Michalski, R., Jia, T., 2022. Casseqgcn: Combining network structure and temporal sequence to predict information cascades. Expert Systems with Applications 206, 117693.
- Warmsley et al. (2022) Warmsley, D., Waagen, A., Xu, J., Liu, Z., Tong, H., 2022. A survey of explainable graph neural networks for cyber malware analysis, in: 2022 IEEE International Conference on Big Data (Big Data), IEEE. pp. 2932–2939.
- Weng et al. (2014) Weng, L., Menczer, F., Ahn, Y.Y., 2014. Predicting successful memes using network and community structure, in: ICWSM, pp. 535–543.
- Xu et al. (2021) Xu, F., Sheng, V.S., Wang, M., 2021. A unified perspective for disinformation detection and truth discovery in social sensing: A survey. CSUR 55, 1–33.
- Xu et al. (2018) Xu, K., Hu, W., Leskovec, J., Jegelka, S., 2018. How powerful are graph neural networks?, in: International Conference on Learning Representations.
- Ying et al. (2018) Ying, Z., You, J., Morris, C., Ren, X., Hamilton, W., Leskovec, J., 2018. Hierarchical graph representation learning with differentiable pooling. NIPS 31.
- Yu et al. (2015) Yu, L., Cui, P., Wang, F., Song, C., Yang, S., 2015. From micro to macro: Uncovering and predicting information cascading process with behavioral dynamics, in: ICDM, pp. 559–568.
- Zannettou et al. (2019) Zannettou, S., Sirivianos, M., Blackburn, J., Kourtellis, N., 2019. The web of false information: Rumors, fake news, hoaxes, clickbait, and various other shenanigans. JDIQ 11, 1–37.
- Zhai et al. (2023) Zhai, P., Yang, Y., Zhang, C., 2023. Causality-based ctr prediction using graph neural networks. Information Processing & Management 60, 103137.
- Zhang et al. (2023a) Zhang, F., Wu, J., Zhang, P., Ma, R., Yu, H., 2023a. Detecting collusive spammers with heterogeneous graph attention network. Information Processing & Management 60, 103282.
- Zhang et al. (2020) Zhang, S., Yin, H., Chen, T., Hung, Q.V.N., Huang, Z., Cui, L., 2020. Gcn-based user representation learning for unifying robust recommendation and fraudster detection, in: SIGIR, pp. 689–698.
- Zhang et al. (2018) Zhang, Y., Lyu, T., Zhang, Y., 2018. Cosine: Community-preserving social network embedding from information diffusion cascades, in: AAAI.
- Zhang et al. (2023b) Zhang, Z., Bu, J., Ester, M., Zhang, J., Li, Z., Yao, C., Dai, H., Yu, Z., Wang, C., 2023b. Hierarchical multi-view graph pooling with structure learning. TKDE 35, 545–559.
- Zhang et al. (2021) Zhang, Z., Yin, Z., Wen, J., Sun, L., Su, S., Philip, S.Y., 2021. Deepblue: Bi-layered lstm for tweet popularity estimation. TKDE 34, 4737–4752.
- Zhao et al. (2015a) Zhao, Q., Erdogdu, M.A., He, H.Y., Rajaraman, A., Leskovec, J., 2015a. Seismic: A self-exciting point process model for predicting tweet popularity, in: SIGKDD, pp. 1513–1522.
- Zhao et al. (2015b) Zhao, Z., Resnick, P., Mei, Q., 2015b. Enquiring minds: Early detection of rumors in social media from enquiry posts, in: WWW, pp. 1395–1405.
- Zhu et al. (2015) Zhu, L., Gao, S., Pan, S.J., Li, H., Deng, D., Shahabi, C., 2015. The pareto principle is everywhere: Finding informative sentences for opinion summarization through leader detection. Recommendation and search in social networks , 165–187.
- Zubiaga et al. (2018) Zubiaga, A., Aker, A., Bontcheva, K., Liakata, M., Procter, R., 2018. Detection and resolution of rumours in social media: A survey. CSUR 51, 1–36.