通过多模态大语言模型实现语言驱动的视频修复
摘要
我们引入了一项新任务——语言驱动的视频修复,它使用自然语言指令来指导修复过程。 这种方法克服了传统视频修复方法的局限性,传统视频修复方法依赖于手动标记的二进制掩模,这一过程通常是乏味且劳动密集型的。 我们提出了按指令从视频中删除对象 (ROVI) 数据集,其中包含 5,650 个视频和 9,091 个修复结果,以支持此任务的训练和评估。 我们还提出了一种新颖的基于扩散的语言驱动的视频修复框架,这是该任务的第一个端到端基线,集成多模态大语言模型以有效地理解和执行复杂的基于语言的修复请求。 我们的综合结果展示了数据集的多功能性和模型在各种语言指导的修复场景中的有效性。 我们将公开数据集、代码和模型。

1简介
视频修复是一种用于恢复视频帧中丢失或损坏的片段的技术,在视频补全[4]、视频恢复[16]和对象等领域有着广泛的应用删除[6]。 尽管在增强图像质量和修复结果的时间一致性方面不断取得进步[46,11,22,66],但当前的方法主要依赖于手动注释的二进制掩模来识别恢复区域。 对于长视频来说,这个手动过程非常耗时且不切实际。 虽然自动标记工具(例如分割和对象跟踪模型[59,55,61])可以提供一些缓解,但由于标记不完善,它们通常需要手动细化。
也许执行视频修复的更自然的方式是通过自然语言,如图图1所示。 如果我们可以利用自然语言描述来指定修复区域(例如“左边的女人”),从而无需像素级手动注释,那么任务就会变得容易得多。 重要的是,语言驱动的设置可以受益于自然语言的灵活性。 例如,通过更丰富的句子,人们可以轻松引用多个或摘要对象,这比标记蒙版要有效得多。 从这个概念延伸,可以将任务分为两个子任务,即“引用视频修复”和“交互式视频修复”。前者以简单的引用表达式作为输入,后者考虑更复杂的类似对话的交互来完成修复任务。

为了为所提出的任务建立基线模型,必须拥有用于训练和评估的适当数据集。 目前,没有公开可用的数据集包含原始视频、删除表达式和修复视频的三元组。 为了弥补这一差距,我们构建了一个新的数据集,名为“按指令从视频中删除对象”(ROVI) 数据集。 具体来说,我们采用引用对象分割数据集,该数据集预先用对象掩码和描述性表达式进行注释。 这些数据集通过使用最先进的视频修复模型生成的相应修复视频进一步增强。 我们发现现有的交互式视频修复任务的引用表达式过于简单化。 为了解决这一限制,我们采用多模态大型语言模型 (MLLM) [60, 67, 3] 来创建类似对话的对话。 这些对话旨在模拟现实世界的场景,包括用户请求和相应的机器响应。 这种方法丰富了数据集,使其更能代表实际视频修复应用中的复杂性和可变性。
除了数据集之外,我们还为建议的任务引入了第一个端到端基线模型,即语言驱动视频修复(LGVI)。 我们的模型建立在基于扩散的生成模型之上。 特别是,我们通过使用额外的时间维度扩展参数,将文本到图像(T2I)模型膨胀为文本到视频(T2V)架构。 我们提出了一种有效的视觉调节方法,可以最大限度地增加参数数量。 为了进一步增强模型的交互式任务能力,我们将 LGVI 框架扩展为 LGVI-I(交互式)。 此扩展包含专门设计用于处理和理解以类似对话的格式表达的用户请求的 MLLM。 LGVI-I 模型以端到端的方式进行训练。 这种交互式架构使系统能够准确地解释复杂的指令。 因此,它可以在对话上下文中产生适当的修复结果和相关响应,从而为与交互式视频修复系统进行更直观、更灵活的用户交互铺平道路。
总而言之,我们的主要贡献如下:
-
•
我们引入了一种新颖的语言驱动的视频修复任务,显着减少了视频修复应用中对人类标记掩模的依赖。 该任务包括两个不同的子任务:参考视频修复和交互式视频修复。
-
•
我们提出了一个数据集来促进所提出任务的训练和评估。 该数据集是同类数据集中的第一个,包含原始视频、删除表达式和修复视频的三元组,为该领域的研究提供了独特的资源。
-
•
我们提出了一种基于扩散的架构 LGVI,作为所提出任务的基线模型。 我们展示了如何利用 MLLM 来改进交互式视频修复的语言指导。 据我们所知,它是第一个执行端到端语言驱动视频修复的模型。
| Dataset | Task | Scene | #Images | #Videos | #Frames | Annotations | #Objects | #Exprs | #Chats | Source | |||
| mask | expr | inpaint | chat | ||||||||||
| Places [65] | II | Buildings & Places | 10,624,928 | - | - | - | - | - | - | ||||
| CelebA [28] | II | Human Face | 202,599 | - | - | - | - | - | - | ||||
| YouTube-VOS [54] | VI | General | - | 4,453 | 197,272 | 7,755 | - | - | YouTube | ||||
| DAVIS [36] | VI | General | - | 50 | 3,455 | 3,455 | - | - | - | ||||
| GQA-Inpaint [56] | LII | General | 49,311 | - | - | 97,854 | 107,252 | - | GQA [12] | ||||
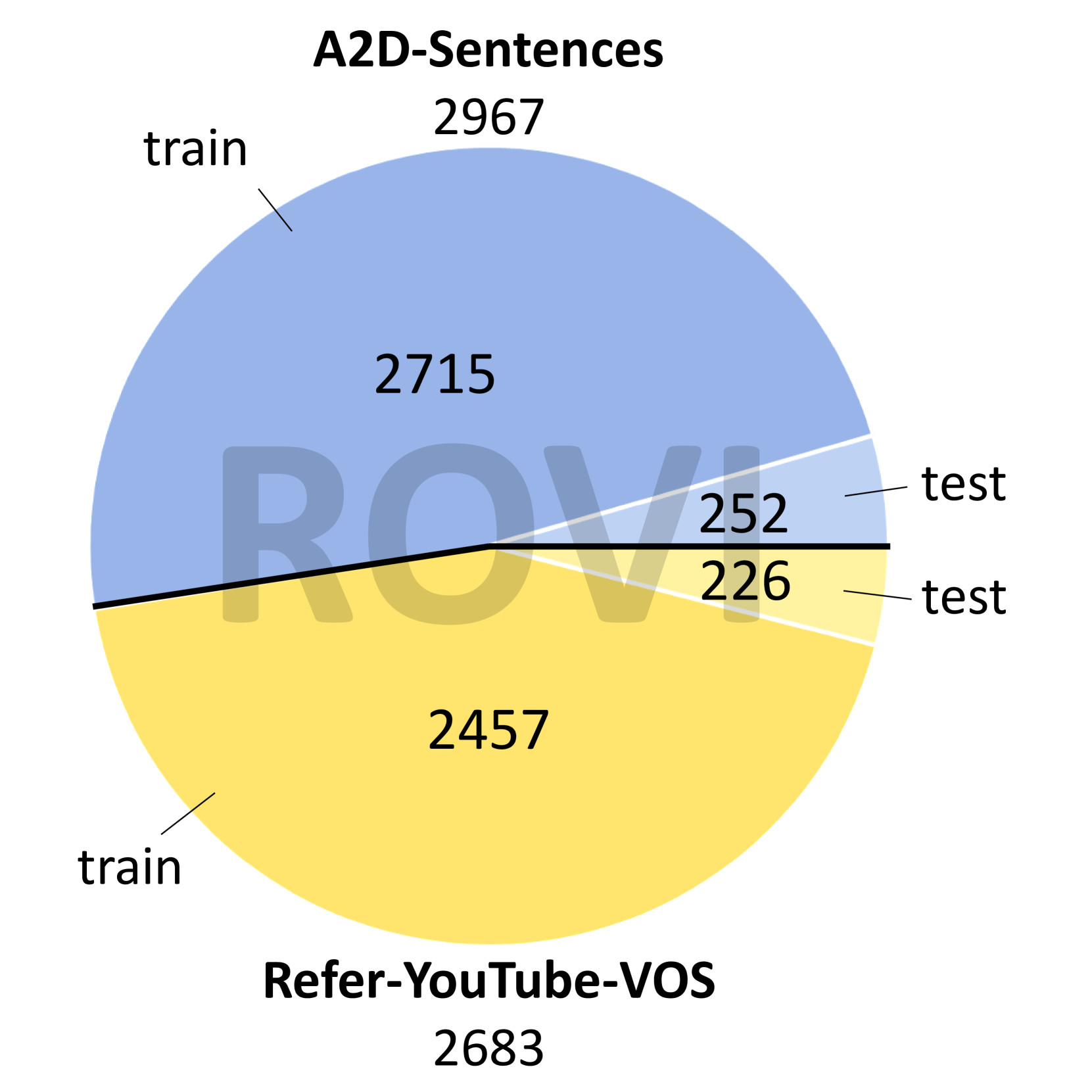
| ROVI | LVI + IVI | General | - | 5,650 | 247,018 | 9,091 | 12,534 | 9,091 | Refer-YouTube-VOS [42] + A2D-Sentences [7] | ||||

2相关工作
视频修复。 视频修复是一种旨在合理地恢复或填充视频中丢失或损坏的部分的技术。 与图像修复方法[35, 58, 23, 24, 19, 20]相关,视频修复技术[26, 4, 46, 11, 22, 62, 17, 66] 将问题扩展到更复杂的移动视觉领域。 该技术可应用于各种应用,例如对象移除、视觉恢复和补全。 随着深度学习的出现,视觉修复网络通常采用卷积神经网络(CNN)[58,46,11]和生成对抗网络(GAN)[35,23,24,19 ]。 最近的工作还应用视觉 Transformers [5, 39, 57, 32, 29] 来增强视觉特征之间的全局交互[20, 22, 62, 17, 66] 。 最先进的方法在恢复丢失的部件和移除物体方面表现出强大的能力。 大多数这些工作需要输入二进制掩码来定义恢复区域[22,20,23,26,62,4]。 然而,类物体掩模的生成,特别是对于长视频,提出了重大且劳动密集型的挑战,
语言驱动的可视化编辑。 基于扩散的文本到图像生成模型[40,33,41,38,43]在按照文本引导生成图像和视频方面表现出了出色的能力。 最近的研究还实现了图像编辑[9,1,31,44,63],图像分割[49,51,50,21]和视频编辑[ 52, 13] 与 DM。 其中,Prompt2Prompt [9] 操纵模型内的交叉注意力图,以实现对象修改、添加和样式转移等各种编辑操作。 InstructPix2Pix [1] 利用这种方法来创建图像编辑数据集。 同样,Tune-A-Video [52] 提出了一种无需训练的架构,可以通过语言参考来编辑视频。 然而,这些作品适用于一般的视觉编辑。 当应用于更具体的挑战时,例如语言驱动的视频修复,它们往往会产生次优的结果。 图2显示了两个示例,其中这些模型在被指示删除对象时产生较差的结果。 一些作品探索了使用 DM 进行图像修复任务。 Repaint [30] 仍然以图像和蒙版作为输入,并让 DM 恢复原始图像。 SmartBrush [53] 将蒙版和文本作为输入来指导蒙版区域上的区域控制生成,其目的是生成新概念而不是删除对象。 最近,Inst-Inpaint[56]提出了一种基于语言描述对图像进行对象去除的方法。 尽管方法创新,但 Inst-Inpaint 的训练样本因缺乏交互表情和视频资源而受到限制,限制了其在复杂场景下的实际效果。
多模态大语言模型。 大型语言模型 (大语言模型) 在各种基于文本的任务和应用中表现出了卓越的性能[3,2,34,45,18,8]。 最近的工作将大语言模型的功能扩展到包括图像处理和计算机视觉。 一个值得注意的例子是 LLaVA [25],它将图像标记转换为语言特征空间,从而将微调模型转换为 MLLM。 这种适应使 MLLM 能够解释和理解视觉内容。 后续研究将 MLLM 用于各种应用,包括视觉推理、对象检测和分割[25,67,37,60,18,8]。 据我们所知,这项研究是第一个将 MLLM 集成到语言驱动的视频修复领域的研究。
3 ROVI数据集
3.1 与现有数据集比较
表1总结了ROVI与相关数据集之间的差异。 在图像和视频修复研究中,流行的训练和评估数据集主要包括以视觉为中心的数据集,例如 Places [65]、CelebA [28]、YouTube-VOS [ 54] 和 DAVIS [36],没有人工注释。 这些数据集通常在训练中采用随机掩码来模拟修复的缺失区域。 然而,对于物体移除任务,专门标记的掩模是必不可少的。 虽然 YouTube-VOS 提供了对象蒙版,但它缺乏相应的修复基本事实。 GQA-Inpaint 数据集[56]虽然具有丰富的对象表达和修复结果,但仅限于图像数据并且不适应视频或交互式上下文。 我们的 ROVI 数据集通过覆盖广泛区域的全面注释解决了这些限制,包括对象掩码、引用表达式、修复结果和类似对话的对话。 与 Places 和 CelebA 专注于建筑物或人脸等特定图像类别不同,ROVI 涵盖更广泛的一般场景,使其更适合各种修复应用。
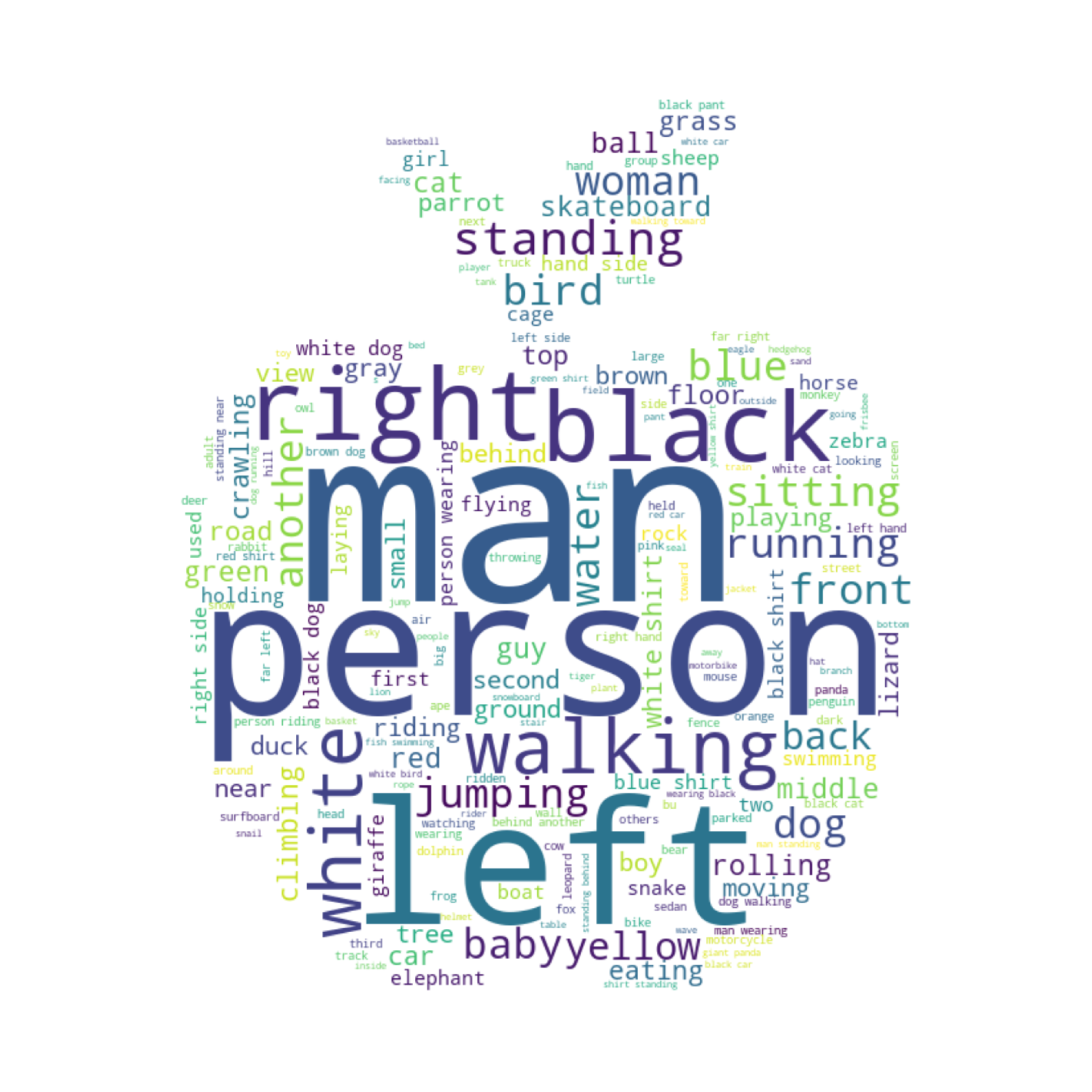
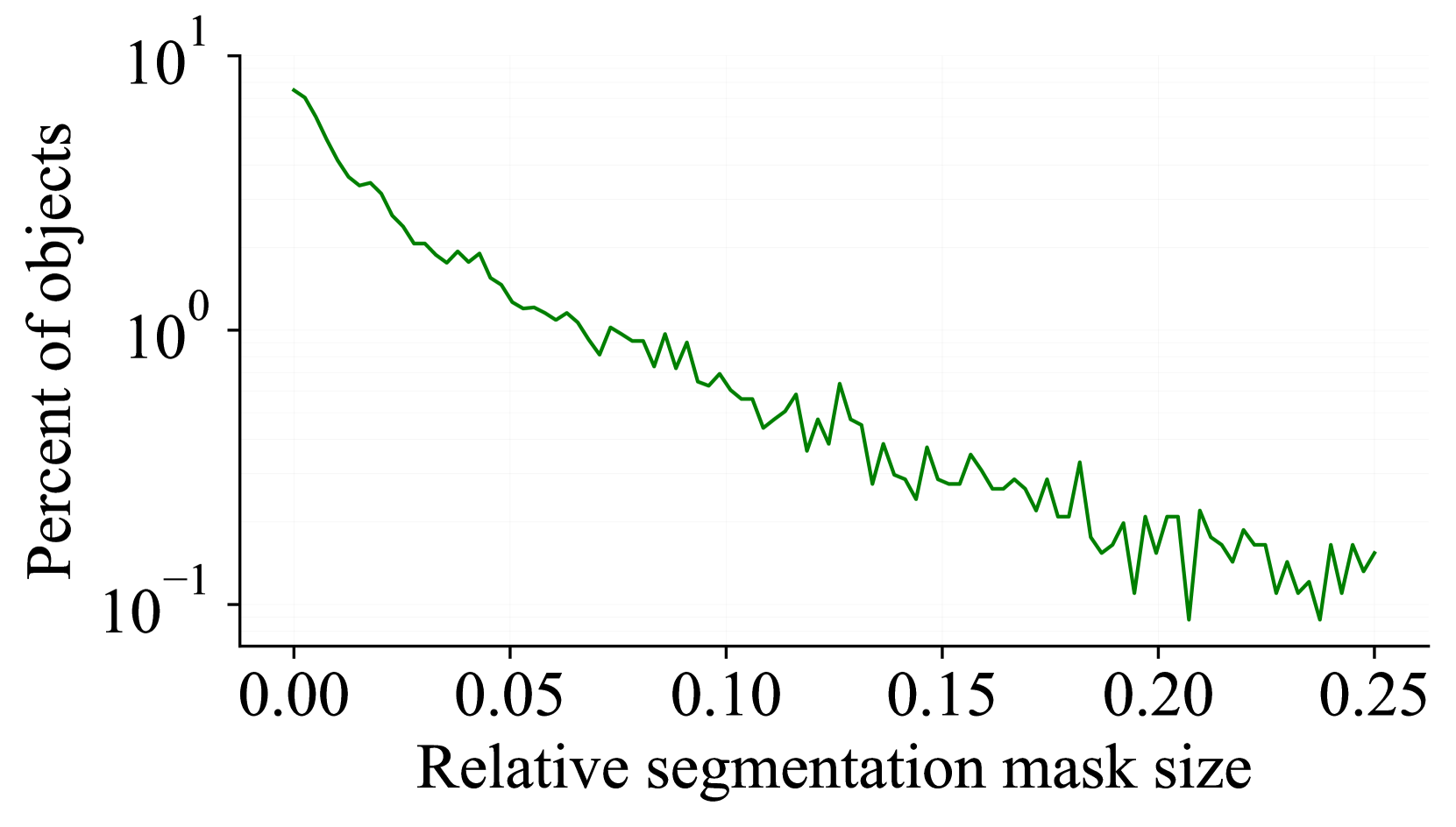
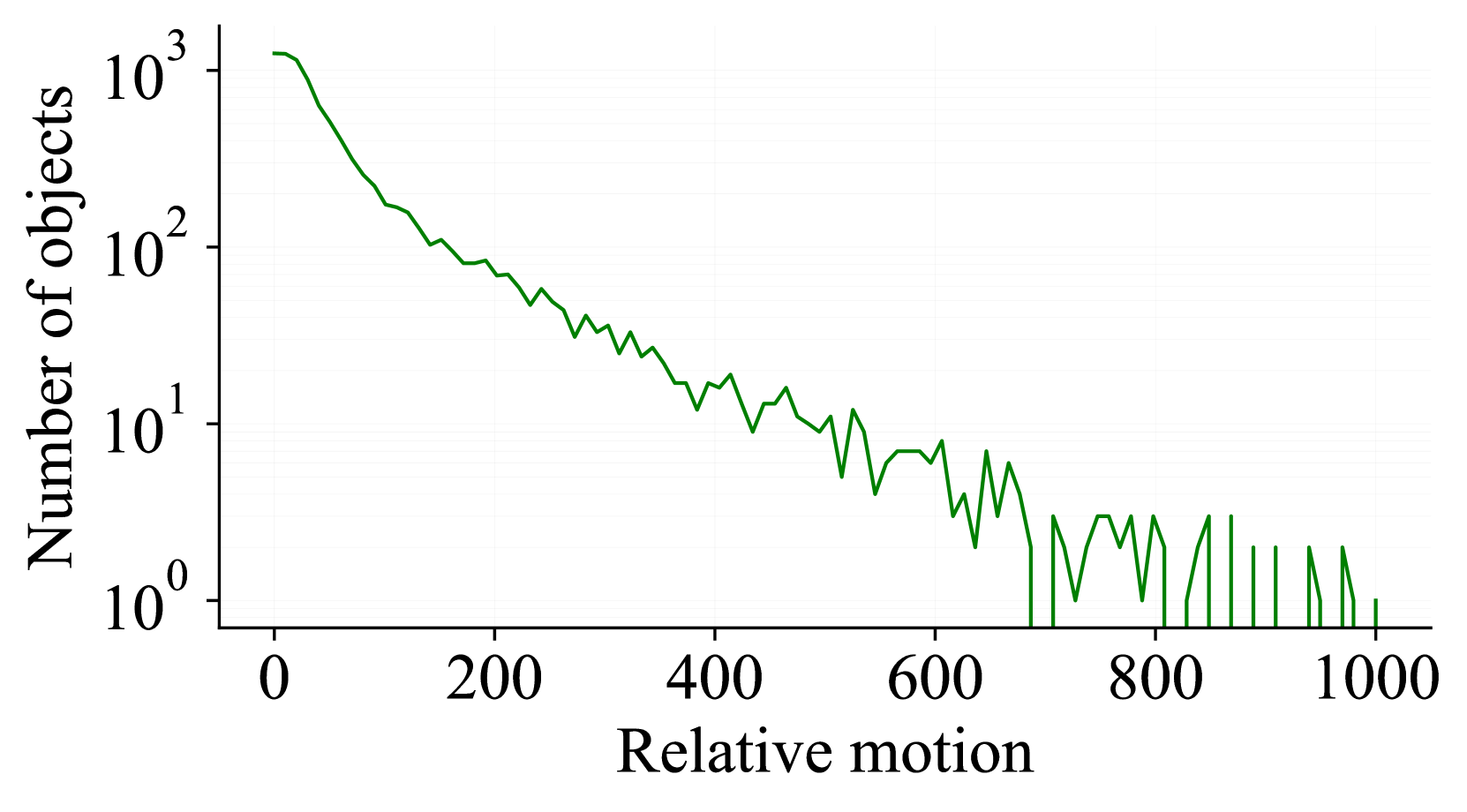
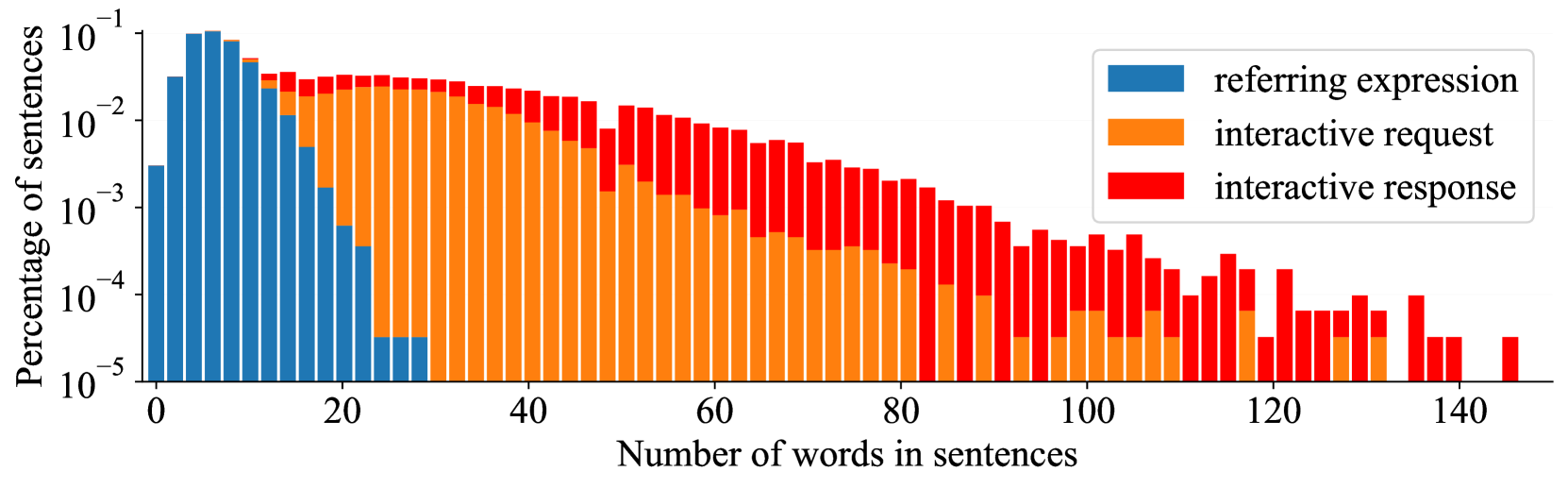
3.2数据集统计
3.3 数据集构建流程
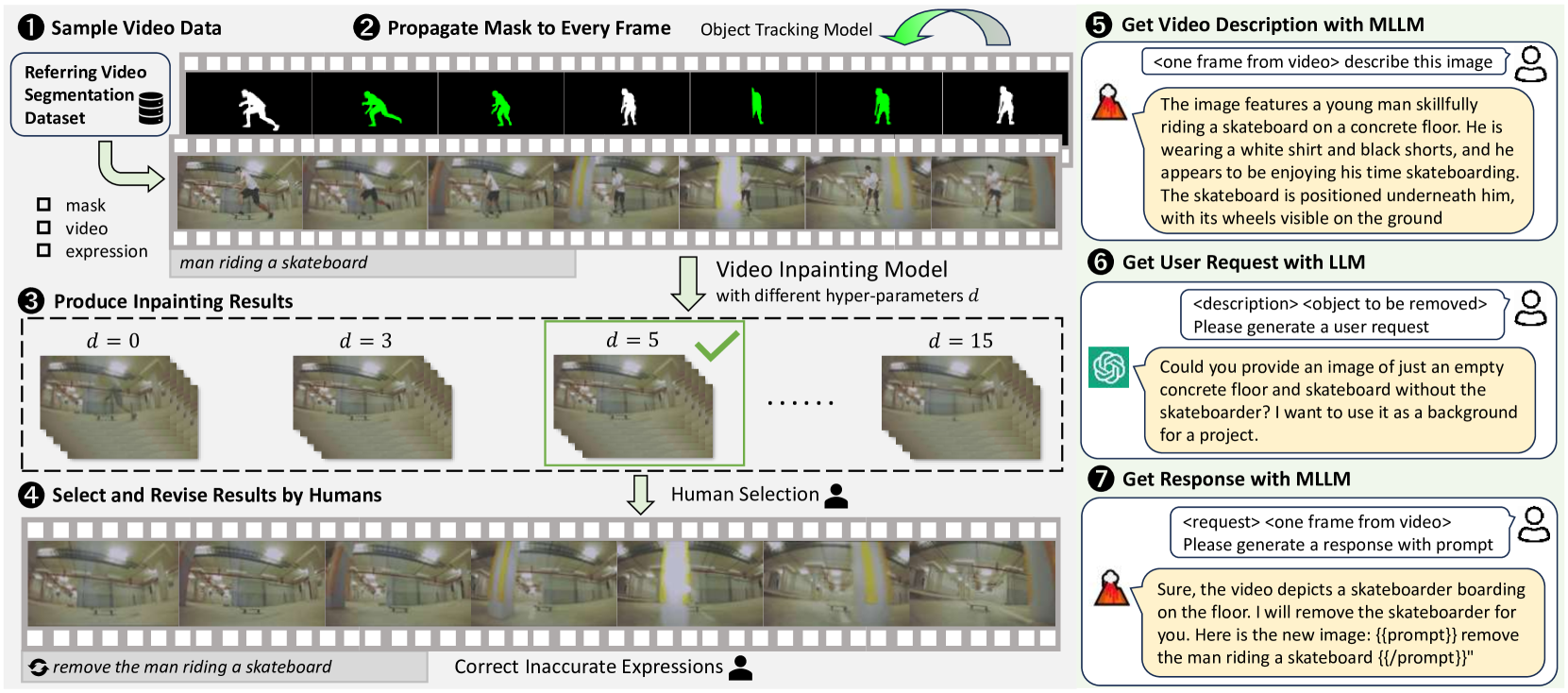
视频数据选择。 如图图4所示,我们选择参考视频对象分割数据集作为视频数据源。 参考视频对象分割旨在分割给定语言描述所参考的对象。 这些数据集具有预先注释的对象掩码和描述性表达式,使它们非常适合所提出的任务。 具体来说,我们选择 Refer-YouTube-VOS [42] 和 A2D-Sentences [7] 作为我们的数据源。
标注管道。 我们使用视频修复模型来生成修复基本事实。 具体来说,我们选择 EFGVI [22](一种最先进的视频修复模型)来生成修复结果。 该模型经过视频数据训练,保证了修复结果的时间一致性。
为了进一步确保基本事实的高质量,我们在修复方法的超参数上纳入了人工选择过程。 具体来说,输入掩码可以扩展为不同的像素大小,表示为。 越大,输入掩模就越大,以便它可以覆盖整个对象。 最佳 值因对象而异,如果设置为固定值,则会导致修复视频的性能不稳定。 因此,在整个数据生成过程中,我们尝试使用各种超参数来为每个对象生成多个结果,并让人类注释者选择最佳结果。 更多详细信息请参阅附录A。
对于交互式注释,我们需要通过聊天式对话来收集表情。 与简单的“删除”句子不同,这些交互式请求应该是隐式的,需要模型识别用户的潜在意图。 我们不是仅仅依靠人类注释者来表达这些请求,而是探索一种更加自动化的方法:我们使用大语言模型和 MLLM 来模拟人类用户并生成潜在的请求和响应。 我们提出了一种多步骤方法,详细信息如图图4所示。 通过采用这种双向的标注管道,ROVI 数据集能够处理复杂的用户请求。
4方法论
在本节中,我们将介绍语言驱动的视频修复框架 (LGVI) 和 MLLM 增强型 LGVI-I(交互式)架构。
4.1LGVI
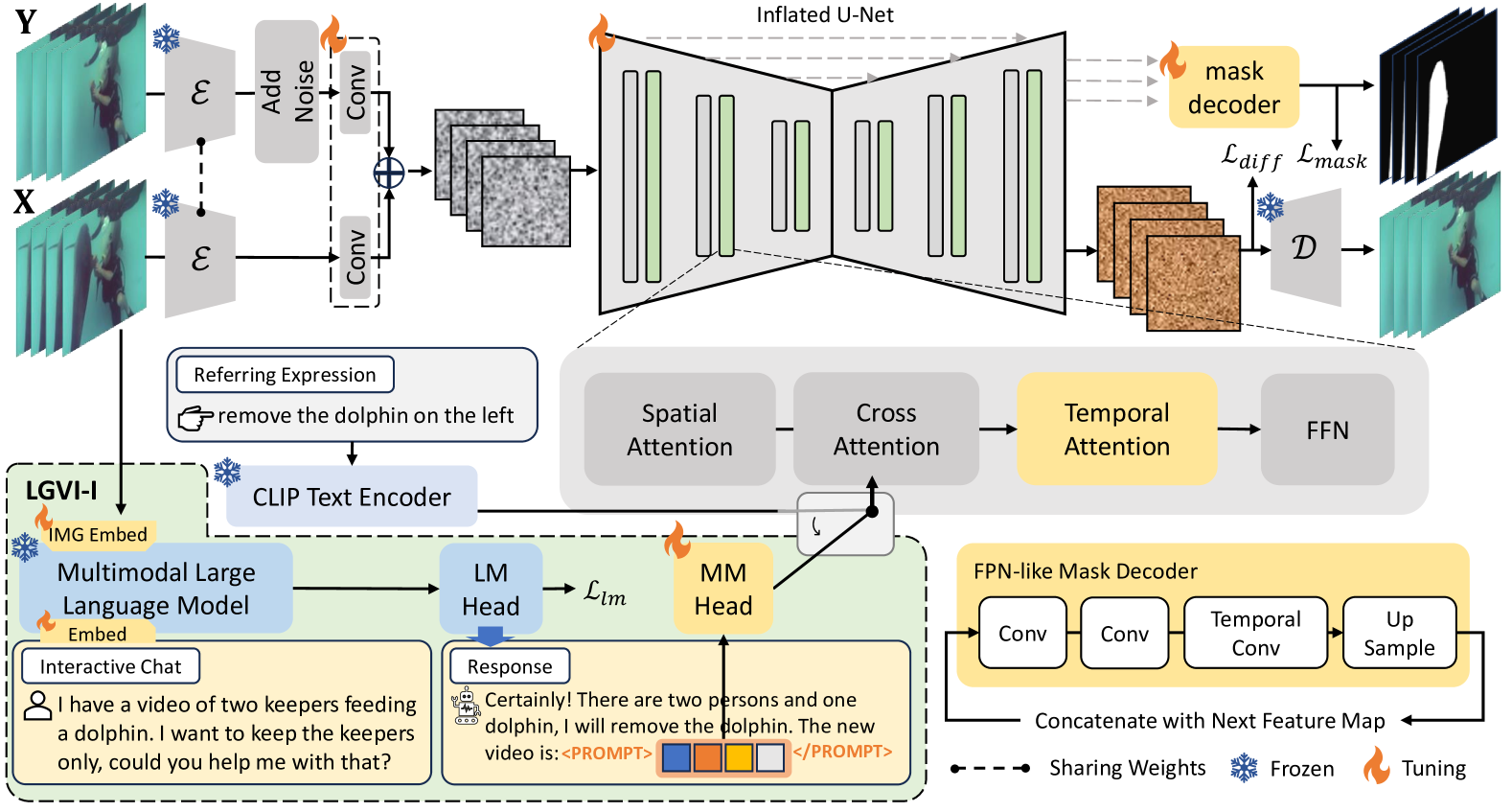
LGVI 框架如图5所示,它建立在稳定扩散[40]的架构之上。 为了将框架扩展到视频输入,我们通过按照 [52, 43] 重新组织网络结构来执行时间膨胀。 对于具有 帧的批量视频输入,表示为 ,其中 是批量大小, 是大小,我们将张量转置为 。 此转换将输入转换为 4 维图像批量输入格式。 预先训练的 2D 网络可以处理视频剪辑,因为它们是单独的图像。 此外,我们引入了位于交叉注意力网络和 FFN 网络之间的参数高效的时间注意力模块。 给定潜在特征 ,其中 是修补视觉标记的长度, 是通道大小,我们将其转置为 。 时间注意力模块的公式如下:
| (1) | ||||
其中 、 和 是可学习矩阵,用于将输入投影到查询、键和值。 时间注意力模块的计算复杂度为,而空间自注意力模块的计算复杂度为。 考虑。 时间注意力模块是一种节省时间的工具,可确保输出视频序列的一致性。
扩散模型学习逐渐消除噪声视频中的噪声。 训练时,目标视频添加噪声,作为噪声视频的起点。 除了带噪声的目标视频输入外,LGVI 还将原始视频作为控制信号输入。 具体来说,我们将原始视频 编码到潜在空间,并将其特征与通道维度中的噪声目标视频连接起来。 请注意,噪声仅添加到潜在的目标视频中,并且在测试过程中,加噪声的目标视频是随机生成的噪声。
| (2) | ||||
其中 是预训练的 VAE 编码器, 是采样时间戳, 和 是带有 内核将潜在代码传输到 U-Net 特征维度。 的初始权重设置为全零。 该技术允许模型在训练期间添加视频条件指导。 由于 ROVI 数据集中的掩码注释,我们可以利用掩码作为 LGVI 框架中的附加监督信号。 具体来说,我们实现一个掩码解码器来预测视频中需要修复或删除的对象的掩码。 该解码器使用 U-Net up-blocks 的输出,由卷积层和时间卷积层组成。 使用掩模监督使模型能够专注于自然语言输入中描述的区域,从而促进精确和有针对性的修复。 掩模监督的有效性可以在Sec.5中看到。 LGVI的训练目标是:
| (3) | ||||
其中和分别是扩散模型训练目标和掩模损失; 是来自指称表达的语言引导特征; 是掩码预测, 是真实掩码。 参数和是平衡损失权重。
4.2LGVI-I 与 MLLM
在交互式视频修复任务中,模型有望从复杂的对话中提取有价值的信息。 为了克服这个问题,我们建议合并 MLLM,将 LGVI 从工作扩展到 LGVI-I(交互式)。 MLLM 在视觉理解和多模态推理方面表现出了强大的能力,使它们非常适合我们提出的交互式视频修复任务。 如图图5所示,MLLM将图像帧和聊天式用户请求作为输入,生成语言响应和一对特殊指示符:PROMPT 和 /PROMPT。 然后,这两个指标之间最后一层的隐藏状态通过 MM 头传递,该头实现为具有激活函数的两层线性层。 转换后的特征被馈送到交叉注意力模块以指导 U-Net 修复过程。 从数学上讲,给定输入视频 和用户请求 ,MLLM 的计算流程可总结如下:
| (4) | ||||
其中是语言词符嵌入,是预先训练的图像主干,用于提取图像特征。 是一个线性层,将图像特征转换为语言词符空间。 是 MLLM 最后一层的隐藏状态。 是通过LM头预测的语言词符分布。 是LM头的权重。 在预测的单词中,我们使用 函数查找 PROMPT 和 /PROMPT指标并提取位于这两个指标之间的隐藏状态。 是MM头的权重。 MM head 将选定的 token 传输到 中,然后将其馈送到 U-Net 交叉注意力模块中。 在此过程中,充当修复过程的视觉感知语言指导。 LGVI-I的训练目标是:
| (5) | ||||
其中 是 MLLM 增强的语言条件, 是语言建模损失,实现为交叉熵损失, 是基本事实句子,并且是语言建模损失的损失权重。 通过将 MLLM 集成到 LGVI 框架中,系统实现了更高级别的用户交互性。 这使得用户能够通过交互式语言指令来指导视觉修复过程,从而为交互式视频修复任务建立一种更加用户友好和易于访问的方法。
| Method | PSNR | SSIM | VFID | |
|---|---|---|---|---|
| Image Models | ||||
| InstructPix2Pix [1] | 18.12 | 0.600 | 0.361 | 1.343 |
| Inst-Inpaint [56] | 19.00 | 0.896 | 0.310 | 1.206 |
| MagicBrush [63] | 20.39 | 0.725 | 0.310 | 0.934 |
| Multi-Stage Video Model | ||||
| Inpaint Anything* [59] | 22.84 | 0.728 | 0.283 | 0.874 |
| One-Stage Video Model | ||||
| LGVI (Ours) | 22.85 | 0.756 | 0.308 | 0.901 |
| Method | PSNR | SSIM | VFID | |
|---|---|---|---|---|
| Image Models | ||||
| InstructPix2Pix [1] | 16.53(-1.59) | 0.558(-0.042) | 0.391(-0.003) | 1.789(-0.446) |
| Inst-Inpaint [56] | 18.96(-0.04) | 0.702 | 0.314(-0.004) | 1.047 |
| MagicBrush [63] | 20.46 | 0.728 | 0.311(-0.001) | 0.901 |
| Multi-Stage Video Model | ||||
| IA* [59] | 20.64(-2.20) | 0.664(-0.064) | 0.312(-0.029) | 1.182(-0.308) |
| One-Stage Video Model | ||||
| LGVI (Ours) | 20.70(-2.15) | 0.707(-0.049) | 0.332(-0.024) | 1.191(-0.290) |
| MLLM-Enhanced Two-Stage Model | ||||
| MB + MLLM | 20.37 | 0.726 | 0.313 | 1.004 |
| IA* + MLLM | 21.37 | 0.722 | 0.291 | 0.875 |
| LGVI + MLLM | 21.45 | 0.738 | 0.311 | 0.923 |
| MLLM-Enhanced End-to-End Model | ||||
| LGVI-I (Ours) | 22.24(+1.54) | 0.732(+0.025) | 0.299(+0.033) | 0.867(+0.324) |




5实验
5.1设置
数据集和指标。 我们使用 ROVI 数据集测试集来执行参考视频修复和交互式视频修复任务。 测试集包含 478 个视频和 758 个对象,每个对象配备 1 个引用表情和 1 个交互表情。 在模型训练过程中,我们引入了参考图像修复数据集 GQA-Inpaint [56],以丰富数据词汇。 我们遵循视频修复工作[26,22,66,62],使用PSNR和SSIM[48]来评估预测结果和真实结果之间的统计相似性。 此外,我们使用 VIFD [47] 来测量感知相似性。 为了评估生成视频的时间一致性和平滑度,我们还应用了 指标 [15]。
基线。 对于基线,我们选择三种语言驱动的图像编辑方法:InstructPix2Pix [1]、Inst-Inpaint [56] 和 MagicBrush [63]。 值得注意的是,InstructPix2Pix 和 MagicBrush 是在广泛的图像编辑数据集上进行预训练的。 Inst-Inpaint 被提出来对图像进行参考图像修复。 我们还与 Inpaint Anything 进行比较,这是一种用于一键视频修复的多阶段方法。 它使用 Segment Anything [14] 和 OSTrack [55] 根据用户点击生成分段蒙版,然后使用修复模型 [61] 修复蒙版区域。 我们实现了 Inpaint Anything*,它将 Inpaint Anything [59] 与 GroundingDINO [27] 结合起来,使其能够处理语言输入。
实施细节。 我们从 MagicBrush [63] 初始化 U-Net 权重。 新引入的模块是从头开始训练的。 在训练过程中,我们以 的比例采样视频和图像数据。 对于MLLM,我们采用LLaVA-7B [25]。 U-Net、掩模解码器和 MLLM 中调整参数的学习率分别为 3e-5、1e-4 和 1e-4。 损失权重设置为、、。 由于它们代表的损失类型不同,这些权重差异很大。 输入和输出视频大小设置为512 320,视频长度为24。 对于 LGVI,我们在 ROVI 数据集上训练 50 个 epoch,视频批量大小为 32,图像批量大小为 768。 对于 LGVI-I,我们加载 LGVI 检查点并在相同批量大小下对其进行 50 个周期的调节。 所有实验均在 8 个 NVIDIA A100 GPU 上进行。
5.2 参考视频修复
定量结果。 我们报告了参考视频修复任务的定量结果。 与基线模型相比,我们的模型是第一个单阶段语言驱动的视频修复模型。 如图所示 选项卡。 2,我们的模型在所有指标上均优于 MagicBrush [63],并且即使 Inpaint Anything* 使用基于蒙版的修复,也能实现与 Inpaint Anything* [59] 同等的结果模型[61]。 结果证明了我们模型的有效性。
定性结果。 图6显示了定性结果。 我们与 MagicBrush [63] 进行比较,这是一种强大的通用语言驱动的图像编辑模型。 在第一个示例中,语言指的是右侧的猫,MagicBrush 模型删除了场景中的所有猫,而我们的模型成功修复了右侧的猫。 在第二个示例中,引用表达式变得更加复杂。 MagicBrush 很难识别需要修复的对象,并在最后一帧中删除了错误的对象(球)。 相比之下,我们的模型生成了合理的输出,证明了其在处理复杂的语言驱动的修复任务方面的卓越性能。 此外,在图7中,我们在涉及多个对象或不存在对象的句子上与Inpaint Anything*进行比较。 Inpaint Anything 由引用分割和视频修复模型的简单组合驱动。 因此,固定为每个句子生成一个掩码。 当引用多个或不存在的对象时,它会输出不准确的结果,而我们的模型会产生正确的输出。 这证明了语言驱动设置的稳健性。
5.3 交互式视频修复
定量结果。 我们报告了交互式视频修复任务的结果 选项卡。 3. 如前 5 行所示,当使用引用表达式训练模型时,它们在此任务中的性能相应下降。 这是直观的,因为交互式表达式更长且更隐含。 对于 MLLM 增强的两阶段模型,我们以零样本的方式将基线模型与 MLLM 结合起来。 只需提示 MLLM,即可将交互式输入转换为较短的引用表达式。 这些模型表现出改进的性能。 我们的 LGVI-I 模型实现了最高性能,证明了所提出架构的有效性。
定性结果。 图8展示了交互式视频修复任务的示例。 用户请求对基线模型的理解提出了重大挑战和复杂性。 特别是,Inpaint Anything* 会预测不正确的蒙版,从而导致结果不准确。 同样,其他基于扩散的模型很难准确解释用户的意图,导致结果不太令人满意。 相比之下,我们的 LGVI-I 模型利用 MLLM 的强大功能,在这些具有挑战性的场景中始终如一地提供最佳性能。 这强调了我们提出的方法的优越性。
5.4消融研究
我们进行了三项消融,包括掩模监督、微调整个 U-Net 以及与图像的联合训练。
口罩监管的好处。 没有面罩监督的模型仅依靠修复地面进行引导,缺乏明确的信号来指导修复区域。 如图图9所示,奔跑的人在所有帧中都保持存在。 值得注意的是,虽然我们在 ROVI 数据集中使用 mask 标注进行训练,但 LGVI 框架在推理过程中不需要 mask 输入。
微调整个 U-Net 的好处。 我们改变整个U-Net,而不是仅仅调整新模块的参数。 如图图9所示,仅对新模块进行微调会阻碍训练收敛,模型难以输出预期结果。 这说明了调整整个模型的必要性。
与图像联合训练的好处。 如图图9所示,没有联合训练的模型产生的输出比我们的伪影更重。 这是因为扩大数据集会给模型带来更多的物体和场景多样性。 展示了联合训练的有效性。
6 结论、挑战和展望
在本文中,我们提出了一种新颖的语言驱动的视频修复任务,该任务使用语言来指导修复区域。 为了训练和评估,我们收集了一个视频数据集,即 ROVI。 全面的统计数据证明了我们数据集的独特性和多样性,特别是由强大的大语言模型和 MLLM 生成的聊天式交互对话。 我们进一步提出了一种基于扩散的基线模型 LGVI。 定量和定性实验结果表明了我们模型的有效性和鲁棒性。
挑战。 (1) 处理语言描述中的歧义。 语言驱动的视频修复在很大程度上依赖于语言输入的准确性和清晰度。 语言描述中的歧义或含糊可能会导致修复结果不准确。 开发能够智能处理或澄清模糊语言输入的模型是一项重大挑战。 (2) 实时处理。 实时环境中的视频修复,尤其是复杂的语言驱动输入,对计算的要求很高。 由于马尔可夫去噪过程,基于扩散的模型也会遇到推理缓慢的问题。 在不影响准确性的情况下提高这些模型的速度和效率是一项至关重要的挑战。 (3) 可扩展性和通用性。 另一个挑战是确保模型能够很好地泛化各种语言和视频类型。 模型可能在训练过的数据集上表现良好,但在处理新的、看不见的数据时却表现不佳。
未来的工作。 一个有前途的方向是解决语言输入中的歧义,可能通过使用视频或先前语言输入中的上下文线索。 此外,研究优化这些模型以进行实时视频修复的方法对于直播或交互式媒体可能很有价值。 未来的另一项重要工作是结合交互式用户反馈机制,使系统能够从用户指示的更正或偏好中学习,从而随着时间的推移提高修复结果的准确性和相关性。 有关更多讨论,请参阅补充。
潜在的社会影响。 这项技术可能会促进电影制作、广告和内容创作等创意领域的发展。 它允许更无缝的编辑和创造性的故事讲述,使创作者能够轻松修改和增强他们的视觉叙事。 它也带来了负面影响。 例如,它可用于制造误导性或虚假媒体以及伦理或道德问题。
7附录
概述。 我们的补充包括以下部分:
视频演示。 我们还提供了我们工作的视频介绍,其中展示了可视化演示。
附录A数据集标注详细信息
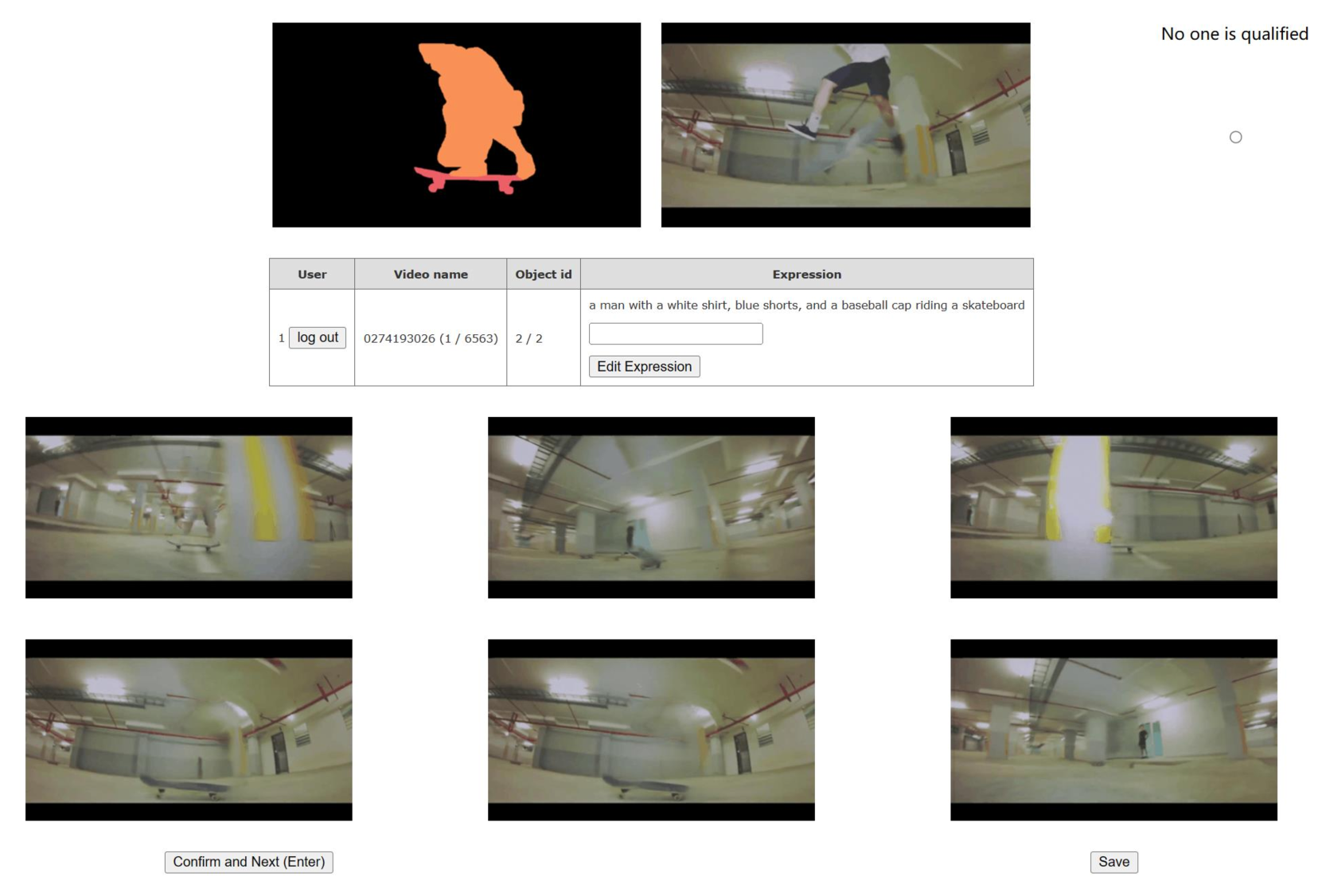
A.1 人类色素
当使用视频修复网络[22]生成修复结果时,输入掩码可以通过不同的像素大小巧妙地扩展,表示为。 越大,输入掩码就开发得越大,以便它可以覆盖整个对象。 最佳 值因对象而异,如果设置为固定值,则会导致修复视频的性能不稳定。 因此,在整个生成过程中,我们尝试使用各种超参数来为每个对象生成多个结果,并让人类注释者选择最佳结果。 特别是,我们为每个对象生成六个带有 的样本。 人类注释者应该在这些示例中选择最好看的结果。 如果所有示例均被评估为不合格,则该对象不会进入 ROVI 数据集。 这种人工标记过程保证了 ROVI 数据集的高质量地面真实性。 图10显示了人类镍接口的图示。
此外,我们发现 Refer-YouTube-VOS 数据集中存在一些错误注释。 在某些视频中,对象标签与对象蒙版和表达式错误匹配。 例如,根据对象标签,人可以对应于“人身边行走的狗”。 因此,人类注释者也会对表达式进行必要的修改,以防注释错误。

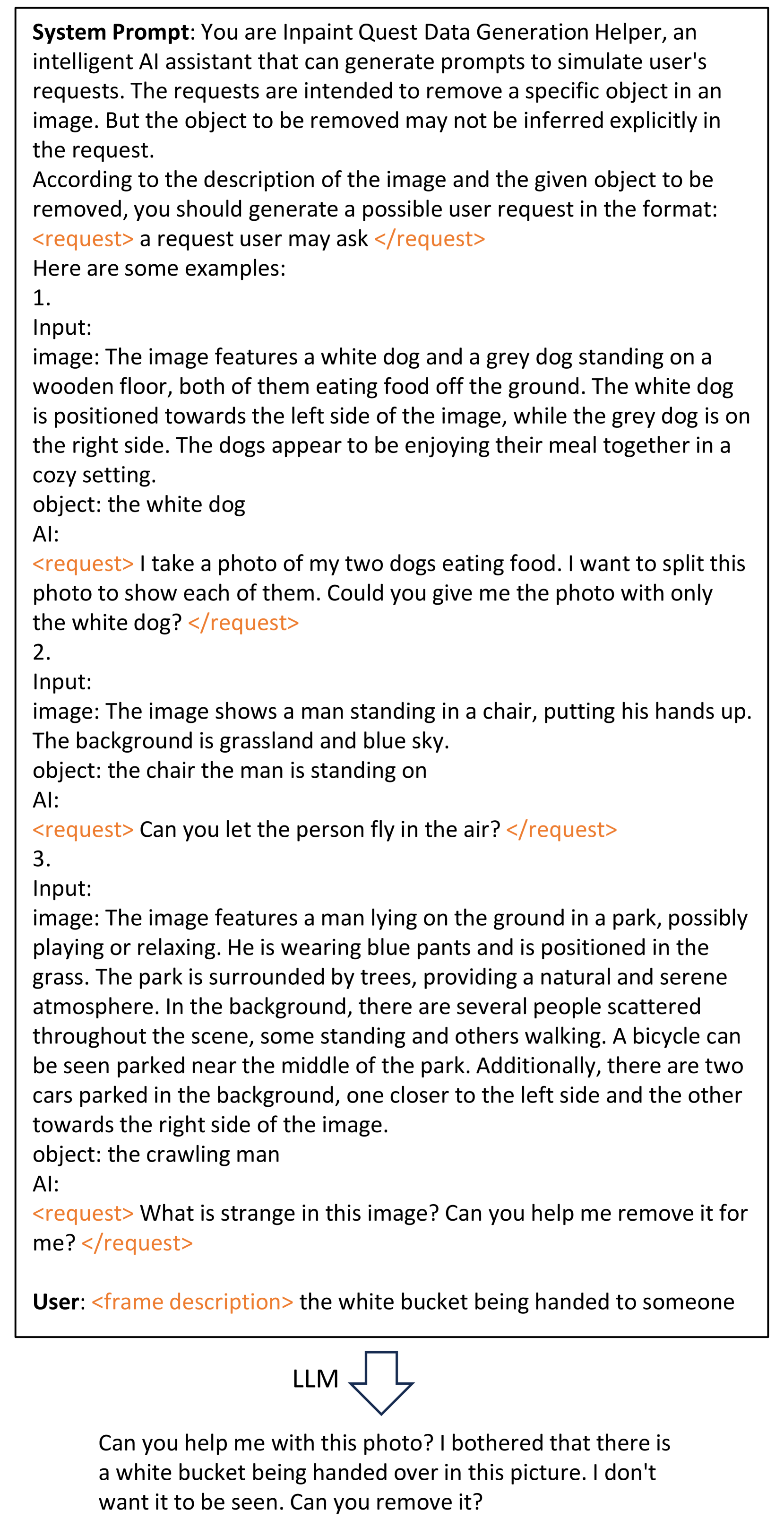

A.2 交互式标注详细信息
附录 B基线详细信息
对于 Inst-Inpaint [56] 基线,我们使用与 LGVI 相同的超参数调整 ROVI 数据集上的已发布检查点。 具体来说,我们在 8 × 80GB NVIDIA A100 GPU 上训练 50 个 epoch,视频和图像批量大小分别为 32 和 768。 我们将输入图像的大小调整为 512 × 320,与 LGVI 保持相同。 对于 InstructPix2Pix [1]、MagicBrush [63] 和 Inpaint Anything* [59],我们直接使用它们已发布的检查点,因为它们是在大规模图像编辑/修复数据集上进行了预训练。
| Method | PSNR | SSIM | VFID | |
|---|---|---|---|---|
| w/o FW | 20.53 | 0.607 | 0.370 | 1.101 |
| w/o MS | 21.80 | 0.631 | 0.358 | 1.059 |
| w/o VF | 22.08 | 0.754 | 0.356 | 1.017 |
| w/o IJ | 22.39 | 0.728 | 0.297 | 0.987 |
| LGVI (Ours) | 22.85 | 0.756 | 0.308 | 0.901 |
附录 C 更多消融研究
我们展示了定量消融结果 选项卡。 4. 该观察结果与主要论文中的消融一致。 除了 VFID 指标略有增加 0.011 之外,没有图像联合训练的性能略有下降。 这可以归因于附加图像数据提供的视觉源的多样性增强。 同时它带来了结果质量和时间一致性之间的折衷。 结果还证明了 LGVI 的 U-Net 通胀和掩模监管修改的必要性。 缺乏这些修改会导致性能明显下降。 当 U-Net 未完全微调而仅训练新添加的参数时,会观察到最显着的性能下降。 这种下降可归因于修复任务和预训练图像生成任务之间的内在差异。 在后者中,语言输入指导模型创建什么,但没有指定需要删除什么。


附录 D更多定性结果

附录E扩散模型的基础知识
去噪扩散概率模型 (DDPM)。 DDPM [10] 的核心涉及迭代地向数据添加噪声,直到它成为简单高斯分布的样本。 模型学习了从噪声生成数据的逆过程。 前向过程,也称为“噪声”过程,通常被建模为马尔可夫链,在一系列时间步骤 内逐渐向数据添加高斯噪声:
| (6) |
其中 是数据分布 中的样本, 表示时间步 处的数据, 是方差表,用于确定每一步添加的噪声量。 是从标准高斯分布 采样的噪声。 逆向过程,即生成过程,旨在通过逆向噪声过程来学习原始数据的分布。 这涉及学习参数化函数,该函数对反向条件概率进行建模。 其逆过程描述如下:
| (7) |
其中 和 是学习到的函数,用于预测 分布的均值和协方差,给定 和时间步长 。的学习通常是通过变分法完成的,即最小化损失函数,该函数是证据下边界(ELBO)的修正版。 该损失函数确保学习到的逆过程非常接近数据的真实分布,可以简化为:
| (8) |
去噪过程可以包含额外的指导,其中模型被训练以生成以一组标签或属性为条件的样本。典型的指导是语言和图像[40, 64]。 损失函数可以更新如下:
| (9) |
其中是控制生成结果的指导。 我们用视频输入 扩展条件输入来控制修复结果。
潜在扩散模型 (LDM)。 潜在扩散模型(LDM)[40]是一种在潜在空间而不是直接在数据空间上运行的生成模型。 主要思想是首先将高维数据(例如图像)编码为低维潜在表示 ,然后在该潜在空间内应用扩散过程。 解码器将潜在值重构回像素分布。
LGVI架构。 我们模型的核心是产生由语言指导和视觉输入驱动的修复结果。 这个核心概念是通用的,可以集成到各种现有架构中,包括基于扩散或 Transformer 范式的架构,只要模型可以融合语言和视觉输入。 我们选择 LDM 架构是因为它可以灵活地扩展到视频模态,并且由于问题的维度降低而提高了样本质量。
附录F未来工作讨论
图16显示了两个LGVI和LGVI-I故障案例。 这些模型仍然面临隐式语言或描述的核心挑战。 在第一个示例中,引用表达式相对较长且难以理解,导致性能较差。 在交互式任务的第二个示例中,即使 MLLM 输出合理的响应并正确预测被移除人员的位置,扩散模型也无法提供正确的输出。 这是因为当前基于扩散的基线模型是对预训练的文本到图像模型的初步知识修改,缺乏对精确位置的理解。 失败案例表明,尽管以前的方法具有相对较强的性能,但我们提出的模型仍然是语言驱动的视频修复领域的基线。 未来的工作预计将开发更先进的方法来克服这些挑战。
参考
- Brooks et al. [2023] Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. In CVPR, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 2020.
- Bubeck et al. [2023] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Chang et al. [2019] Ya-Liang Chang, Zhe Yu Liu, Kuan-Ying Lee, and Winston Hsu. Free-form video inpainting with 3d gated convolution and temporal patchgan. In ICCV, 2019.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
- Ebdelli et al. [2015] Mounira Ebdelli, Olivier Le Meur, and Christine Guillemot. Video inpainting with short-term windows: application to object removal and error concealment. TIP, 2015.
- Gavrilyuk et al. [2018] Kirill Gavrilyuk, Amir Ghodrati, Zhenyang Li, and Cees GM Snoek. Actor and action video segmentation from a sentence. In CVPR, 2018.
- Ge et al. [2023] Yuying Ge, Yixiao Ge, Ziyun Zeng, Xintao Wang, and Ying Shan. Planting a seed of vision in large language model. arXiv preprint arXiv:2307.08041, 2023.
- Hertz et al. [2022] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626, 2022.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. NeurIPS, 2020.
- Hu et al. [2020] Yuan-Ting Hu, Heng Wang, Nicolas Ballas, Kristen Grauman, and Alexander G Schwing. Proposal-based video completion. In ECCV, 2020.
- Hudson and Manning [2019] Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. CVPR, 2019.
- Khachatryan et al. [2023] Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. arXiv preprint arXiv:2303.13439, 2023.
- Kirillov et al. [2023] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023.
- Lai et al. [2018] Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. Learning blind video temporal consistency. In ECCV, 2018.
- Lee et al. [2019] Sungho Lee, Seoung Wug Oh, DaeYeun Won, and Seon Joo Kim. Copy-and-paste networks for deep video inpainting. In ICCV, 2019.
- Li et al. [2020a] Ang Li, Shanshan Zhao, Xingjun Ma, Mingming Gong, Jianzhong Qi, Rui Zhang, Dacheng Tao, and Ramamohanarao Kotagiri. Short-term and long-term context aggregation network for video inpainting. In ECCV, 2020a.
- Li et al. [2023a] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Mimic-it: Multi-modal in-context instruction tuning. arXiv preprint arXiv:2306.05425, 2023a.
- Li et al. [2020b] Jingyuan Li, Ning Wang, Lefei Zhang, Bo Du, and Dacheng Tao. Recurrent feature reasoning for image inpainting. In CVPR, 2020b.
- Li et al. [2022a] Wenbo Li, Zhe Lin, Kun Zhou, Lu Qi, Yi Wang, and Jiaya Jia. MAT: Mask-aware transformer for large hole image inpainting. In CVPR, 2022a.
- Li et al. [2023b] Xiangtai Li, Henghui Ding, Wenwei Zhang, Haobo Yuan, Guangliang Cheng, Pang Jiangmiao, Kai Chen, Ziwei Liu, and Chen Change Loy. Transformer-based visual segmentation: A survey. arXiv pre-print, 2023b.
- Li et al. [2022b] Zhen Li, Cheng-Ze Lu, Jianhua Qin, Chun-Le Guo, and Ming-Ming Cheng. Towards an end-to-end framework for flow-guided video inpainting. In CVPR, 2022b.
- Liu et al. [2018] Guilin Liu, Fitsum A Reda, Kevin J Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro. Image inpainting for irregular holes using partial convolutions. In ECCV, 2018.
- Liu et al. [2022] Guilin Liu, Aysegul Dundar, Kevin J Shih, Ting-Chun Wang, Fitsum A Reda, Karan Sapra, Zhiding Yu, Xiaodong Yang, Andrew Tao, and Bryan Catanzaro. Partial convolution for padding, inpainting, and image synthesis. TPAMI, 2022.
- Liu et al. [2023a] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023a.
- Liu et al. [2021a] Rui Liu, Hanming Deng, Yangyi Huang, Xiaoyu Shi, Lewei Lu, Wenxiu Sun, Xiaogang Wang, Jifeng Dai, and Hongsheng Li. Fuseformer: Fusing fine-grained information in transformers for video inpainting. In ICCV, 2021a.
- Liu et al. [2023b] Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023b.
- Liu et al. [2015] Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. In ICCV, 2015.
- Liu et al. [2021b] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021b.
- Lugmayr et al. [2022] Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. In CVPR, 2022.
- Meng et al. [2021] Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073, 2021.
- Meng et al. [2022] Lingchen Meng, Hengduo Li, Bor-Chun Chen, Shiyi Lan, Zuxuan Wu, Yu-Gang Jiang, and Ser-Nam Lim. AdaViT: Adaptive vision transformers for efficient image recognition. In CVPR, 2022.
- Nichol et al. [2022] Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In ICML, 2022.
- OpenAI [2023] OpenAI. Gpt-4 technical report, 2023.
- Pathak et al. [2016] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. Context encoders: Feature learning by inpainting. In CVPR, 2016.
- Perazzi et al. [2016] Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video object segmentation. In CVPR, 2016.
- Pi et al. [2023] Renjie Pi, Jiahui Gao, Shizhe Diao, Rui Pan, Hanze Dong, Jipeng Zhang, Lewei Yao, Jianhua Han, Hang Xu, and Lingpeng Kong Tong Zhang. Detgpt: Detect what you need via reasoning. arXiv preprint arXiv:2305.14167, 2023.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- Rao et al. [2021] Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. DynamicViT: Efficient vision transformers with dynamic token sparsification. In NeurIPS, 2021.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- Saharia et al. [2022] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. NeurIPS, 2022.
- Seo et al. [2020] Seonguk Seo, Joon-Young Lee, and Bohyung Han. Urvos: Unified referring video object segmentation network with a large-scale benchmark. In ECCV, 2020.
- Singer et al. [2022] Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. arXiv preprint arXiv:2209.14792, 2022.
- Singh et al. [2023] Jaskirat Singh, Stephen Gould, and Liang Zheng. High-fidelity guided image synthesis with latent diffusion models. In CVPR, 2023.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Wang et al. [2019] Chuan Wang, Haibin Huang, Xiaoguang Han, and Jue Wang. Video inpainting by jointly learning temporal structure and spatial details. In AAAI, 2019.
- Wang et al. [2018] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. Video-to-video synthesis. NeurIPS, 2018.
- Wang et al. [2004] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. TIP, 2004.
- Wu et al. [2022] Jianzong Wu, Xiangtai Li, Xia Li, Henghui Ding, Yunhai Tong, and Dacheng Tao. Towards robust referring image segmentation. arXiv preprint arXiv:2209.09554, 2022.
- Wu et al. [2023a] Jianzong Wu, Xiangtai Li, Henghui Ding, Xia Li, Guangliang Cheng, Yunhai Tong, and Chen Change Loy. Betrayed by captions: Joint caption grounding and generation for open vocabulary instance segmentation. ICCV, 2023a.
- Wu et al. [2023b] Jianzong Wu, Xiangtai Li, Shilin Xu, Haobo Yuan, Henghui Ding, Yibo Yang, Xia Li, Jiangning Zhang, Yunhai Tong, Xudong Jiang, Bernard Ghanem, et al. Towards open vocabulary learning: A survey. arXiv preprint arXiv:2306.15880, 2023b.
- Wu et al. [2023c] Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Stan Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation. In ICCV, 2023c.
- Xie et al. [2023] Shaoan Xie, Zhifei Zhang, Zhe Lin, Tobias Hinz, and Kun Zhang. Smartbrush: Text and shape guided object inpainting with diffusion model. In CVPR, 2023.
- Xu et al. [2018] Ning Xu, Linjie Yang, Yuchen Fan, Jianchao Yang, Dingcheng Yue, Yuchen Liang, Brian Price, Scott Cohen, and Thomas Huang. YouTube-VOS: Sequence-to-sequence video object segmentation. In ECCV, 2018.
- Ye et al. [2022] Botao Ye, Hong Chang, Bingpeng Ma, Shiguang Shan, and Xilin Chen. Joint feature learning and relation modeling for tracking: A one-stream framework. In ECCV, 2022.
- Yildirim et al. [2023] Ahmet Burak Yildirim, Vedat Baday, Erkut Erdem, Aykut Erdem, and Aysegul Dundar. Inst-inpaint: Instructing to remove objects with diffusion models. arXiv preprint arXiv:2304.03246, 2023.
- Yin et al. [2022] Hongxu Yin, Arash Vahdat, Jose M Alvarez, Arun Mallya, Jan Kautz, and Pavlo Molchanov. A-ViT: Adaptive tokens for efficient vision transformer. In CVPR, 2022.
- Yu et al. [2019] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S Huang. Free-form image inpainting with gated convolution. In ICCV, 2019.
- Yu et al. [2023] Tao Yu, Runseng Feng, Ruoyu Feng, Jinming Liu, Xin Jin, Wenjun Zeng, and Zhibo Chen. Inpaint anything: Segment anything meets image inpainting. arXiv preprint arXiv:2304.06790, 2023.
- Zang et al. [2023] Yuhang Zang, Wei Li, Jun Han, Kaiyang Zhou, and Chen Change Loy. Contextual object detection with multimodal large language models. arXiv preprint arXiv:2305.18279, 2023.
- Zeng et al. [2020] Yanhong Zeng, Jianlong Fu, and Hongyang Chao. Learning joint spatial-temporal transformations for video inpainting. In ECCV, 2020.
- Zhang et al. [2022] Kaidong Zhang, Jingjing Fu, and Dong Liu. Flow-guided transformer for video inpainting. In ECCV, 2022.
- Zhang et al. [2023a] Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing. In NeurIPS, 2023a.
- Zhang et al. [2023b] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, 2023b.
- Zhou et al. [2017] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. TPAMI, 2017.
- Zhou et al. [2023] Shangchen Zhou, Chongyi Li, Kelvin C.K Chan, and Chen Change Loy. ProPainter: Improving propagation and transformer for video inpainting. In ICCV, 2023.
- Zhu et al. [2023] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023.