- 奥罗克
- 接收者操作特征曲线下面积
- 体重指数
- 体重指数
- CXR
- 胸部 X 光
- LLM
- 大型语言模型
- MIM
- 遮蔽图像建模
- 个人健康指数
- 受保护的健康信息
- PTX
- 气胸
- SSL协议
- 自监督学习
- 索塔
- 最先进的
- 维特
- 视觉Transformer
- 质量保证
- 视觉问答
: 探索可扩展的医学图像编码器,超越文本监督
摘要
语言监督预训练已被证明是一种从图像中提取语义上有意义特征的宝贵方法,它作为计算机视觉和医学影像领域内多模式系统的基础元素。 然而,得到的特征受到文本中包含的信息的限制。 这在医学影像中尤其成问题,因为放射科医生的书面发现集中在特定观察结果上;由于担心泄露个人健康信息,配对的图像-文本数据稀缺,这一挑战加剧了。 在这项工作中,我们从根本上挑战了学习通用生物医学图像编码器对语言监督的普遍依赖。 我们引入了 ,一个仅在单模态生物医学影像数据上预训练的生物医学图像编码器,在各种基准测试中取得了与最先进的生物医学语言监督模型相似或更高的性能。 具体来说,学习到的表示的质量是在标准影像任务(分类和语义分割)和视觉-语言对齐任务(从图像生成文本报告)上评估的。 为了进一步证明语言监督的缺点,我们表明特征与其他医疗记录(例如性别或年龄)的相关性比语言监督模型更好,而放射学报告中通常没有提到这些模型。 最后,我们进行一系列的消融,确定影响性能的因素;值得注意的是,我们观察到它的下游性能随着训练数据的数量和多样性而很好地扩展,这表明仅图像监督是训练基础生物医学图像编码器的可扩展方法。
† †*贡献相同。 对应作者:ozan.oktay@microsoft.com1 引言
在视觉-语言深度学习不断发展的领域中,文本监督的普遍使用[1, 2]一直是学习用于下游应用[2, 3]的新型视觉描述符的基石,包括生物医学领域[4, 5, 6, 7]。 随着large language models的出现,这些视觉描述符正越来越多地被集成作为多模态推理的静态输入符元,以执行Visual Question Answering (VQA) 和文本字幕任务[8, 9, 10]。
随着重点转向在更大规模的数据集和模型[11]上实现state-of-the-art (SOTA) 性能,模型的可扩展性与不断增加的数据集规模以及高质量数据集的可用性密切相关[12, 13]。 但是,这种转变在特定领域的应用中带来了实际挑战,例如医疗保健,特别是在图像-文本对的大规模数据集的获取和整理方面。 公共多模态医学数据集的有限可用性以及对protected health information (PHI) 匿名性的担忧阻碍了研究界扩展医学基础模型的努力。 此外,缺乏像素级监督,特别是在图像分割的文本数据不可用时,是一个重大挑战。 缺乏详细的文本标注阻碍了图像编码器在需要精确图像分析的任务(如 2D 或 3D 医学扫描中的结节检测和定位)中的性能提升。
此外,在某些情况下,文本监督可能会成为一个限制因素,具体取决于字幕的描述性,特别是在省略放射学发现(描述放射科医生对图像的关键观察结果(目标类别))时。 这可能导致表示崩溃,以牺牲图像-文本对齐[14, 15, 16]为代价,其中类内变化可能无法保留。 例如,放射学短语“无心肺过程”经常用于报告 MIMIC-CXR [17] 数据集中健康的chest X-ray。 因此,它与图像特征的对比对齐[18, 19]可能会对跨个体观察到的解剖学变化引入不希望有的不变性。 但是,这些信息对于超出标准文本生成的临床应用来说可能是宝贵的,从图像分割到治疗的生物标志物发现,都需要理解每个人的独特性 [20, 21]。 如果没有这种背景,学习到的图像编码器的适用性可能无法推广到更广泛的医疗保健应用,最终需要重新训练网络。 事实上,最近的一项研究 [15] 表明,虽然图像-文本数据可以在语言和视觉世界之间建立对应关系,但它可能不够精确和清晰,无法生成 SOTA 图像描述符,以用于下游视觉任务。 类似于 [15],我们探索了这样一个假设:可能不需要文本监督来学习单模态和多模态医学应用所需的判别性视觉描述符:一旦使用大规模成像数据单独执行特征的视觉聚类,就可以根据下游应用在两种模态之间进行后续对齐。
为此,我们提出了图像编码器,它通过采用 DINOv2 仅图像 self-supervised learning (SSL) 方法 [22] 持续预训练医学扫描。 我们评估了其可扩展性,其预训练数据集大小与下游单模态和多模态应用相匹配,包括图像级和像素级预测任务。 它利用两个互补的训练目标:masked image modelling (MIM) 和自监督对比学习。 这种混合设计使学习到的特征能够迁移到全局和局部下游任务,而无需外部文本监督 [23, 24, 25]。 特别地,我们通过在多个医学数据集上将其与一系列 SOTA 基线图像编码器(使用文本监督训练)进行基准测试,从经验上验证了上述假设。 在图像分类方面,我们证明了在大多数情况下,可以始终如一地实现或甚至超过类似的性能水平,而无需使用成对的图像-文本数据集进行训练。 这些发现被推广到下游多模态应用,其中图像到文本生成的生成结果使用冻结的图像骨干网络进行评估。 此外,我们证明了有希望的语义分割性能,无需使用 U-Net [26] 或 Swin Transformer [27] 等分层编码器架构,而是通过在预训练编码器之上训练现成的解码器头 [28, 29],突出了对大规模、密集标注的训练数据集的需求降低。 最后,我们表明,通常在文本中未提及的患者人口统计信息,可以从 的编码中比语言监督模型更准确地预测出来,这表明仅图像模型如 对更广泛的临床应用更有用。
更重要的是,进行了一系列消融研究,以了解 的每个组件对其性能的贡献,包括:(I) 使用 DINOv2 的预训练权重的域迁移的有益影响,(II) MIM 对图像分割的重要作用,以及 (III) 输入图像分辨率对检测某些类别的重要性。 特别是,最近的生物医学基准测试工作 [30, 31] 表明,大型通用模型(例如 ViT-G [22])显示出强大的域迁移能力,尽管仅在自然图像上进行训练。 最后,我们分析了所提出的方法如何随着大型且多样化的仅图像数据集而扩展,因为这可以实现一种统一的方法,而无需依赖于为特定医学成像模态提出的手工 SSL 预文本任务 [32, 33]。
总之,我们的主要发现如下:
-
•
我们表明,使用文本数据的弱监督并非必要,甚至可能阻碍学习下游多模态生物医学应用所需的视觉特征。 相反,人们可以使用仅包含图像数据的自监督,例如使用 DINOv2,来实现可比或更好的性能,并通过利用海量图像数据的可用性进一步扩展。
-
•
此外,DINOv2 的特征与临床信息(例如患者病历)之间表现出更强的相关性,这超越了放射学报告中通常发现的数据,但在诊断目的中被常规依赖。 这种能力可以使未来的多模态应用包含 EHR 数据。
-
•
最后,我们通过一组消融实验证明,DINOv2 的性能随着训练数据集大小、多样性和更高输入分辨率的增加而扩展,为训练大规模基础生物医学图像编码器提供了一种可行的解决方案。
2 预备知识和实验设置
恐龙v2:
在这项工作中,我们利用 DINOv2,一种 state-of-the-art 仅图像自监督学习方法,专门用于预训练 vision transformers [22]。 这种方法使用一个孪生网络,将教师网络的预测提炼到学生网络中。 为了学习对全局和局部下游任务都有用的图像表示,无需文本标题,图像级和补丁级目标同时使用 [23, 24]。 对于补丁级目标,使用 masked image modelling (MIM),其中学生网络被馈送一个包含随机掩码补丁的图像,并且必须预测教师网络对每个补丁的特征。 对于图像级目标,使用对比训练目标:学生网络分别被馈送图像的多个裁剪(多裁剪),并且必须将它的局部特征表示与教师网络对图像的全局视图预测的特征表示对齐。 教师网络使用指数移动平均 (EMA) [34] 通过学生网络的参数更新,梯度反向传播仅限于学生网络。
这些目标的结合在 DINOv2 的 SOTA 性能方面发挥着关键作用,优于传统 SSL 技术,这些技术仅依赖于对比目标(例如,CLIP [2]、SimCLR [19])或掩码建模目标(BEiT [35])。 此外,使用多裁剪有助于使生成的骨干网络学习密集预测任务 [25] 所需的独特局部特征,例如语义分割和深度估计。 为了防止模式崩溃,在两个分支中应用了非对称设计选择,包括不同的增强视图、居中和温度缩放(有关进一步分析,请参见 [36])。 居中技术的非对称性有助于学习过程的鲁棒性。 此外,DINOv2 使用 KoLeo 正则化器 [37],它促进了特征的均匀分布。 这对于与聚类相关的任务(例如最近邻图像检索)特别有利。
训练设置:
我们使用一组大规模的仅包含放射学图像的数据集,即 Multi-CXR,该数据集包含来自多个公共和私人来源的多个数据集,在发现和人口统计方面具有广泛的多样性(有关概述,请参见 表 B.1)。 预先训练的 DINOv2 ViT-B 模型使用这些 chest X-ray (CXR) 图像进行额外 60k 训练步骤的持续训练,批次大小为 640。 与 [22] 中使用的从低分辨率到高分辨率的两阶段学习计划相比,由于我们的持续训练时间较短,输入分辨率在整个训练过程中保持不变。 双视图增强已调整为满足特定领域的要求,因为目标类别(疾病发现)需要纹理和上下文信息,导致教师分支上的裁剪尺寸更大,模糊程度更低(参见 部分 C.1)。 这种方法与 [38] 中关于 X 射线的发现以及 [23] 中关于自然图像的发现一致。
| Model type | Model | Arch. | # Params. | Training dataset | # Images | # Text | Image resolution |
| Image & Text | CLIP@224 [2] | ViT-L/14 | 304 M | WebImageText | 400 M | 400 M | 224 224 |
| Image & Text | CLIP@336 [2] | ViT-L/14 | 304 M | WebImageText | 400 M | 400 M | 336 336 |
| Image & Text | BioViL-T [39] | ResNet50 | 27 M | MIMIC-CXR | 197 k | 174 k | 512 512 |
| Image & Text | BiomedCLIP [40] | ViT-B/16 | 86 M | PMC-15M | 15 M | 15 M | 224 224 |
| Image & Text | MRM [7] | ViT-B/16 | 86 M | MIMIC-CXR | 377 k | 227 k | 448 448 |
| Image Only | DINO-v2 [22] | ViT-G/14 | 1.1 B | LVD | 142 M | - | 518 518 |
| Image Only | -Control | ViT-B/14 | 87 M | MIMIC-CXR | 197 k | - | 518 518 |
| Image Only | ViT-B/14 | 87 M | Multi-CXR | 838 k | - | 518 518 |
基线方法:
一系列基线方法(参见 表 1)被选用于实验分析,如 表 1 中所述。 具体而言,CLIP 中图像文本对的普遍使用(BioViL-T [39] 和 BiomedCLIP [40])以及多模态掩蔽建模 (MRM [7]) 指导了我们的选择。 我们主要目的是调查以下假设:文本监督可能不是学习单模态和多模态下游应用所需的图像编码器所必需的。 此外,这种多样的选择有助于分析输入图像分辨率、训练数据集大小以及对特定领域预训练的需求等因素。 与仅图像的 SSL 方法的比较不在本研究范围内,因为在现有技术中已得到广泛研究 [22, 23, 41]。 此外,在同一框架内评估 CLIP@336 和 CLIP@224 突出了当前医学多模态学习文献 [8, 9] 的局限性,这些文献主要依赖于基于静态 CLIP 的图像编码器。 实验利用公开可用的模型检查点(见 部分 C.2),保持一致的训练-测试拆分和评估指标。
下游评估任务:
图像级和像素级预测任务通常需要不同的特征不变性 [42],因此需要补充的预训练目标 [23, 22]。 为了评估学习特征的全局和纹理特征,我们使用语义图像分割和线性探测来进行具有冻结主干网络的图像分类任务,并结合外部数据集和一些长尾发现(不常观察到的案例)。 至关重要的是,我们还评估了学习特征对多模态预测任务的有用性,即图像到文本的生成;这还使我们能够确定仅图像任务与文本相关任务的相关程度。 为此,Vicuna-1.5 7B LLM [43] 在 LLaVA 样式设置中针对每个冻结图像主干进行微调 [44, 45](更多详细信息见 部分 4.2)。
评估数据集和指标:
在所有应用中,数据拆分都经过仔细构建,以确保来自每个受试者的图像都被限制在单个拆分中,从而防止潜在的数据泄漏。 图像分类使用外部数据集进行评估,包括 VinDr-CXR [46]、CANDID-PTX [47] 和 RSNA-Pneumonia [48]。 对于 VinDr-CXR,选择了六个发现的子集,强调多样性(住院/门诊)和流行度,因为该数据集的分布是长尾的。 与其他公共数据集相比,该数据集特别用于消融研究,因为它具有不同的数据分布,包括各种发现和患者人口统计学,有关数据集的更多详细信息,请参见 部分 B.2。 结果使用 AUPRC 指标报告,由于存在明显的类不平衡,因此选择 AUPRC 指标而不是 AUROC 或依赖于阈值的精度/F1 值。 值得注意的是,目标类别不是相互排斥的。 为了更方便地可视化和比较,消融研究中展示了宏观 AUPRC 结果。
在分割任务中,专门的解码器头从头开始训练。 使用 Dice 分数在各种解剖学和病理学类别中对chest X-rays进行评估,包括左肺和右肺[49]、六个肺区[50]、气胸[47]、胸管[47]和肋骨[51]。 有关其各自数据集的更多信息,请参见部分B.2。 对于文本报告生成,由于缺乏可公开获取的大规模图像-文本对,这些文本对对于LLM微调至关重要,因此专门使用了 MIMIC-CXR [17] 数据集。 使用标准词汇和事实性指标量化性能,并在官方测试拆分上报告结果。
3 消融研究
不同图像网络的实验分析可能会受到图像分辨率、训练数据集和权重初始化等因素的影响,这会导致不完整,有时甚至会导致误导性的发现。 因此,本研究旨在首先了解这些因素对基准结果的影响及其隔离效果,然后在考虑这些因素的情况下,对基线生物医学模型进行广泛的评估。 在这方面,以下小节介绍了我们从在 VinDr-CXR 数据集上运行多类线性分类得出的消融结果。
3.1 对图像分辨率的依赖性
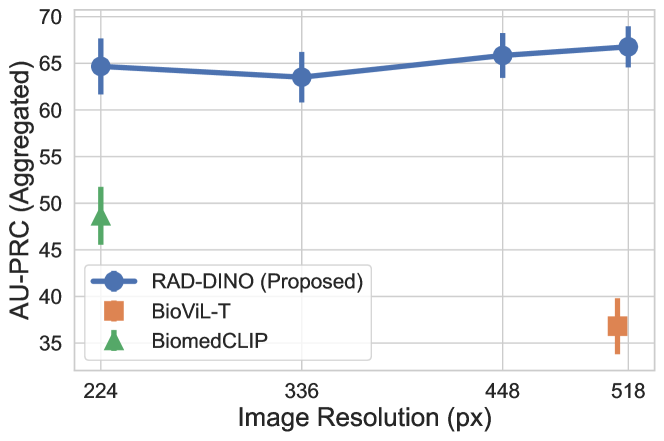
图像分辨率已被证明是下游预测任务中的一个重要因素[52, 53],并且它可能是我们实验中观察到的和基线图像编码器之间的性能差距的一个混淆因素。 在本节中,我们研究了图像分辨率对 VinDr-CXR [46] 数据集中的大规模或明显发现(例如心肌肥大和不透明度)的影响,输入分辨率范围为 224 到 518 像素。 对每个数据集中的发现进行线性探测,并使用不同种子进行多次运行,将 AUPRC 结果汇总。 从 DINOv2 (ViT-B) 初始化以进行此消融。 图 1 显示,对于如此大规模的发现,的性能改进并不一定归因于其对编码更高分辨率输入的能力——只要输入信号与目标目标相关,例如在图像的大区域上表现出来的发现。 相反,在 第 A.1 节中,对潜在的小或微妙的发现(包括 pneumothorax (PTX) 和胸腔引流管)重复了相同的实验,这些发现是在 CANDID-PTX [47] 数据集中发现的,其中需要更高的输入分辨率(参见 图 A.1)。 在这种情况下,我们观察到性能下降,因为细粒度细节丢失了,但仅图像学习仍然优于基线方法。
需要注意的是,过去关于 VQA [8, 9, 10] 和文本生成 [10, 54] 的研究工作,这些工作利用了较低分辨率的图像主干,很可能受到输入信号模糊性的阻碍。 这种模糊性可能导致幻觉和性能限制,尽管努力在图像嵌入之上使用数十亿个模型参数来适应大规模文本解码器。
3.2 模型权重初始化
进行了一系列消融以检查在使用 chest X-ray 图像进行域内训练之前,对来自超过 10 亿张图像的大规模通用领域数据集(例如,LVD-142M)进行预训练的作用。 通过使用随机权重和 ViT-B 初始化编码器参数,并在相同设置中比较大规模 DINO-v2 模型(ViT-G 和 ViT-B),在相同的 VinDR 基准上执行线性分类实验。
| Model | LO | CM | PL-T | AE | PF | TB | Agg |
| DINOv2 (ViT-B) [22] | p m 1.36 | p m 1.62 | p m 3.71 | p m 1.4 | p m 1.06 | p m 0.9 | 39.46 |
| DINOv2 (ViT-G) [22] | p m 5.98 | p m 1.54 | p m 2.33 | p m 2.26 | p m 1.62 | p m 3.29 | 43.36 |
| (Random init.) | p m 2.8 | p m 1.13 | p m 3.91 | p m 0.86 | p m 1.78 | p m 2.47 | 59.82 |
| (Continual) | p m 2.96 | p m 1.66 | p m 4.98 | p m 0.73 | p m 2.29 | p m 3.51 | 66.63 |
LO:肺部不透明,CM:心肌肥大,PL-T:胸膜增厚,AE:主动脉扩大,
PF:肺纤维化,TB:结核病,Agg:宏观平均值
3.3 对训练数据集大小的依赖
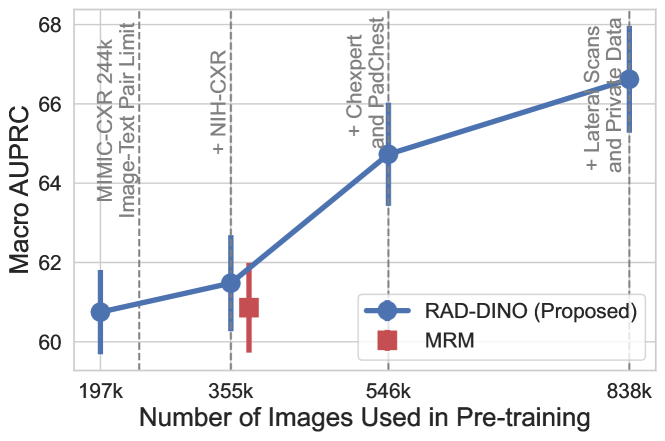
在这里,我们通过系统地用更多样化的示例(例如门诊研究)来丰富训练数据集,从而改变训练数据集的多样性和大小。 这种数据增量添加使得能够与使用配对图像-文本数据集的不同基线方法进行比较。 尽管与使用完整数据集相比性能有所下降(表 2 和 3),但我们观察到,使用较小规模数据(MIMIC-CXR:197k)训练的模型在不使用文本输入进行训练的情况下,仍然保持其优于基线方法的性能(见 图 2)。 为了与其他消融研究保持一致,我们使用了相同的主干模型、基准和指标。 鉴于模型倾向于在较小的数据集大小下过度拟合,通过监控在 CANDID-PTX 分类任务中通过线性探测计算的验证损失来应用早期停止。
对于最多 546k 个样本,只使用正位 chest X-ray 扫描(AP/PA),因为我们凭经验观察到这些扫描在测试集完全由正位图像组成的情况下会产生最大的收益(见 图 2)。 同样,包含 PadChest [57] 数据集会提供额外的性能提升,因为门诊数据集中的发现多样性增加。 在最后阶段,使用侧位扫描和一个额外的私有数据集来观察所提出的方法如何在数据集数量增加的情况下进行扩展。
4 基准测试结果
4.1 转移到图像分类
实验设置:
使用线性探测法将主干网络与其他通用领域和特定领域的图像网络进行比较,以比较不同的 SSL 方法,并评估它们在每个生物医学基准测试中的最佳性能,尽管预训练数据集存在差异。 所有评估都在三个外部 CXR 数据集上进行,这些数据集收集自门诊和住院环境(VinDr-CXR、CANDID-PTX 和 RSNA 肺炎),因此适合测试网络的泛化能力。 该分析没有侧重于比较不同的仅图像 SSL 方法,因为现有研究已经表明,MIM [58] 和对比方法 [41] 的组合(如 iBoT [59] 和 DINOv2 [22] 的情况)可实现最先进的性能。
| VinDr-CXR [46] (AUPRC) | |||||||
| Model | LO | CM | PL-T | AE | PF | TB | Agg |
| CLIP@224 [2] | p m 1.17 | p m 1.53 | p m 2.33 | p m 2.02 | p m 1.35 | p m 1.43 | 33.03 |
| CLIP@336 [2] | p m 1.05 | p m 1.40 | p m 3.61 | p m 1.62 | p m 0.69 | p m 1.99 | 34.54 |
| BioViL-T [39] | p m 3.20 | p m 1.94 | p m 4.32 | p m 1.19 | p m 2.38 | p m 3.65 | 34.19 |
| BiomedCLIP [40] | p m 1.93 | p m 0.95 | p m 3.57 | p m 1.9 | p m 3.85 | p m 4.85 | 45.42 |
| MRM [7] | p m 2.36 | p m 1.43 | p m 4.94 | p m 1.3 | p m 3.44 | p m 4.15 | 60.86 |
| p m 2.96 | p m 1.66 | p m 4.98 | p m 0.73 | p m 2.29 | p m 3.51 | 66.63 | |
| +4.17 | +0.47 | +1.08 | +8.39 | +14.55 | +5.94 | +5.77 | |
LO:肺部不透明度,CM:心脏扩大,PL-T:胸膜增厚,AE:主动脉扩大,
PF:肺纤维化,TB:结核病,Agg:宏观平均值
VinDr-CXR 基准测试:
在基准测试上收集的 表 3 中的结果表明,包括 MRM [7] 在内的掩码建模方法,与仅图像文本对比方法相比,产生了更强的性能。 第 3.3 节的消融实验表明,随着数据集大小和多样性的增加,它也能很好地扩展,这与现有文献 [60] 一致。 MRM 与(用 显示)之间的性能差异在域外发现中更为明显,例如门诊研究中看到的慢性或偶然发现;这是由于多模态公共数据集的可用性有限,因此 MRM 仅在 MIMIC-CXR [17] 上进行训练,而 MIMIC-CXR 缺乏多样性。 特别是,对 MIMIC-CXR 中所有 227.8k 个研究报告进行关键字搜索发现,“纤维化”(PF)、“主动脉扩大”(AE)和“结核病”(TB)很少被报告(<1%)。 尽管如此,-Control,通过使用 MIMIC-CXR 的子集进行训练(仅 197k 个图像,参见 第 3.3 节)获得的,在没有使用任何文本报告并且训练图像更少的情况下(197k 对 377k),其性能与 MRM 相当(60.75 对 60.86 AUPRC)。 请注意,[7] 中的消融实验表明,MRM 的性能更多地依赖于图像重建和建模预训练任务,而不是文本建模,这支持了文本对于强图像表示可能不是必要的这一论点。
此外,基线结果强调了数据质量的重要性及其对下游任务的相关性,因为 BiomedCLIP [40] 使用从 PubMed 文章中检索到的超过 10 个图像-文本对进行训练,其中 222k 个包含 X 光片。 最后,当我们将 DINOv2 (ViT-G) (部分 3.2) 与 CLIP@336 [2] 进行比较时,通用领域编码器网络的性能随着容量和训练数据的增加而提升 [55, 56]。
CANDID-PTX 和 RSNA 肺炎基准:
在这两个基准上进行的线性分类实验(见 表 4)评估了模型对其他外部数据集的泛化能力以及对更局部发现(如气胸)的分类。 请注意,输入图像分辨率对 CANDID-PTX 具有重要作用,如 图 A.1 中的消融研究所示;然而,我们观察到,尽管性能有所下降,但 224 像素版本仍然比图像-文本对比基线表现得更好。 肋骨骨折的较低 AUPRC 值主要归因于正例数量较少(不到 2%)以及发现的粒度,这可能需要以更高分辨率对图像进行编码。 在 RSNA 肺炎数据集上,与 SOTA 相当,尽管不需要文本监督。 与基线相比,缺乏显著改进可能是由于公共数据集中肺不透明度和肺炎相关图像的丰富性,导致性能差距较小。
| CANDID-PTX [47] (AUPRC) | RSNA Pneumonia [48] | |||||
| Model | Arch | PTX | Chest Tube | Fracture | AUPRC | AUROC |
| CLIP@224 [2] | ViT-L | p m 1.57 | p m 0.98 | p m 1.14 | p m 2.01 | p m 0.71 |
| CLIP@336 [2] | ViT-L | p m 1.15 | p m 1.67 | p m 1.97 | p m 1.7 | p m 0.37 |
| BioViL-T [39] | ResNet50 | p m 1.48 | p m 3.40 | p m 1.88 | p m 1.51 | p m 0.45 |
| BiomedCLIP [40] | ViT-B | p m 1.99 | p m 4.43 | p m 2.46 | p m 1.68 | p m 0.40 |
| MRM [7] | ViT-B | p m 2.37 | p m 4.89 | p m 7.11 | p m 1.49 | p m 0.51 |
| ViT-B | p m 1.55 | p m 1.56 | p m 4.10 | p m 1.75 | p m 0.63 | |
| +5.20 | +32.64 | +1.18 | -0.45 | -0.60 | ||
侧位 CXR 扫描:
对于这两个分类实验,仅使用正面 chest X-ray。 但是,侧位扫描可以捕获某些异常,因此也常用于消除发现歧义,两张图像使用相同的文本报告。 由于许多书面发现无法在侧位扫描中清晰可见 [61, 62],这大大降低了互信息并增加了学习过程中的噪声,从而降低了语言监督方法的有效性。 我们在 表 A.1 中以类似的方式对其进行评估,方法是训练一个线性分类器来检测在侧视图扫描中可见的异常,并观察到基于 MIM 和 MRM 的方法大大优于 CLIP 风格的模型。
学习目标的影响:
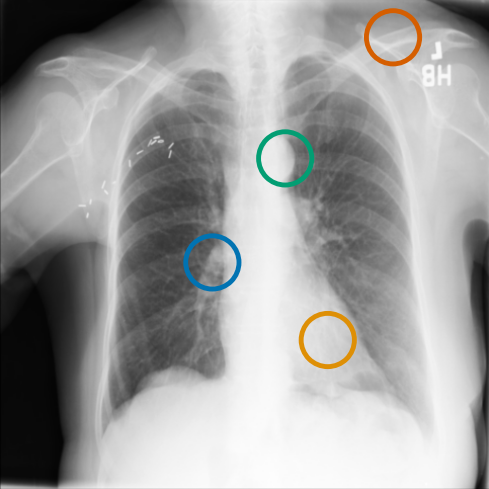
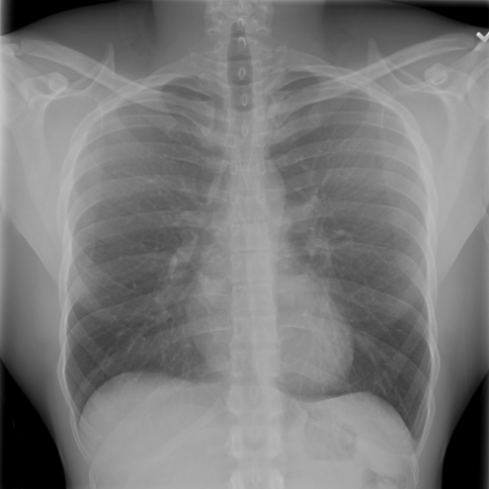
正如 图 A.2 中所示的自注意力图所证明的那样,观察到训练会提取局部纹理,我们将其归因于 MIM [22, 59] 和多作物对比训练 [63]。 同样,图 3 显示了来自不同受试者的扫描中补丁嵌入之间的对应关系,其中解剖语义在训练期间被捕获,请参阅 第 A.4 节以获取显示发现和解剖地标之间匹配的更多示例。 特别是,[25] 表明 DINO 受益于其多作物训练设置,因为它专门训练为对结构的局部和全局尺度都不变,而 [24] 强调了 MIM 在学习图像中存在的高频信息方面的重要性,而对比目标则有利于学习全局形状表示。 此外,在肺炎线性探测任务中,我们观察到 CLIP 风格的骨干网络表现出热启动和更快的收敛,这归因于公共基准中肺炎相关图像发现(例如不透明度)的广泛可用性和放射学报告中对其的详细描述。 这种可用性可能有助于观察到的不同基线之间性能差距更小。
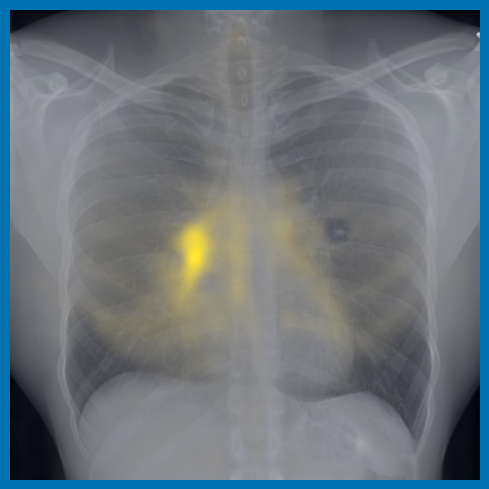
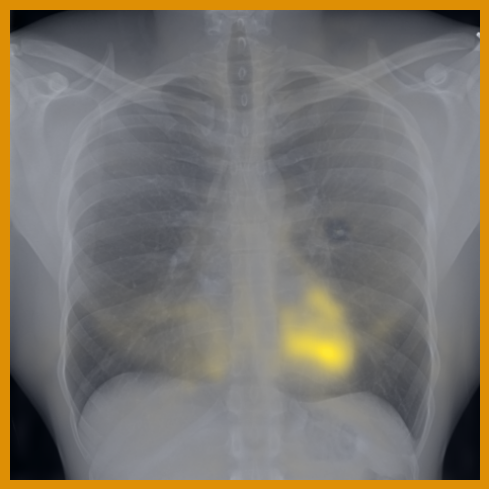
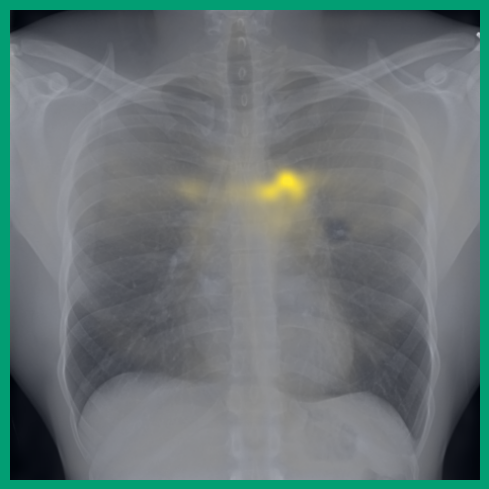
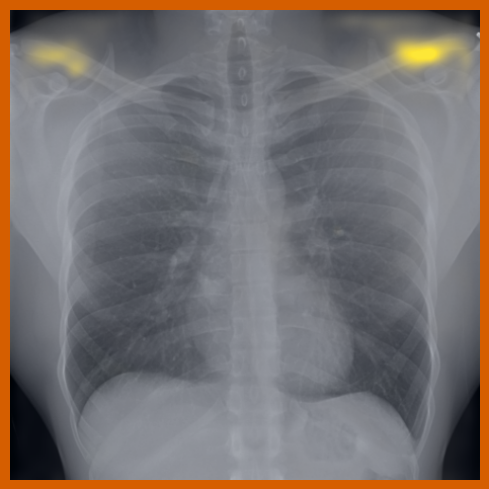
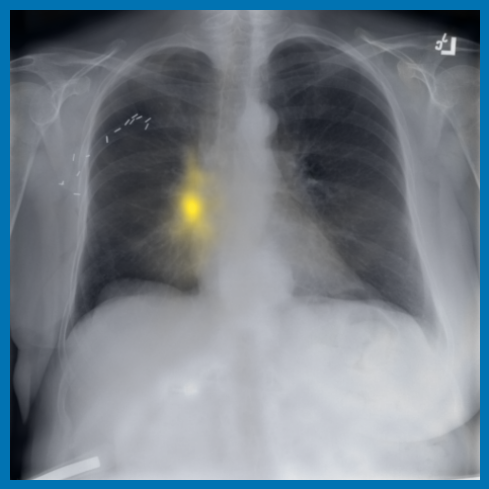
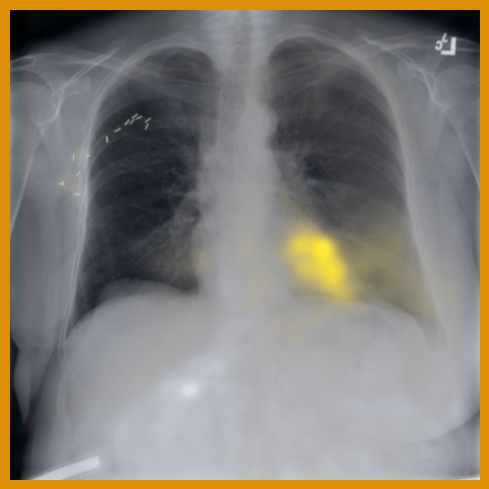
4.2 转移到视觉-语言任务:从图像生成文本报告
实验设置:
CLIP 式多模态预训练 [2] 旨在实现图像和文本嵌入之间的对称对齐。 在这里,我们询问这是否是视觉-语言下游任务(即生成正面 chest X-ray 报告的“发现”部分)的必要步骤。 为此,我们使用 MIMIC-CXR 数据集 [17],遵循与用于 的数据一致的官方测试和训练分割,删除所有非 AP/PA 扫描,并删除没有发现部分的样本,导致 146,909 / 7,250 / 2,461 个图像-文本对用于语言解码器微调的训练、验证和测试。 MRM 基线 [7] 在此分析中被排除在外,因为主干网络是用 MIMIC-CXR 中的完整图像-文本对集进行训练的。
我们遵循 LLaVA 式架构 [45, 44] 来生成多模态模型:来自冻结图像编码器的补丁嵌入被投影并与指令串联以生成输出报告:“image_tokens 提供放射影像中发现的描述。” 遵循 LLaVA-1.5 [44],我们使用两层全连接 (MLP) 投影机和 Vicuna-7B (v1.5) [43] 作为语言模型。 投影网络使用随机权重初始化,并在与解码器模型一起训练,而图像编码器保持冻结。 输入 LLM 的信息保持最少,以专注于对图像表示质量的评估——通过应用数据增强 [64] 或提供其他临床信息(包括先前报告 [39])可以获得更高的性能。
结果分析:
表 5 显示了基准图像编码器的详细性能。 除了放射学特定的 RGER [67] 和 CheXbert 基于的 [68] Macro-F1-14 [69](将“不确定”标签映射为负值)之外,我们报告标准词汇指标 (ROUGE-L [65]、BLEU-4 [66]) 以衡量生成的发现和相应的真实发现部分的单词重叠。 Macro-F1-14 指标衡量了 14 个不同类别中报告的发现的事实性。 在所有计算出的词汇和临床指标方面,都优于所有其他图像编码器。 特别地,我们观察到对专门基线 BiomedCLIP 和 BioViL-T 的显着改进,这些基线是使用语言监督进行预训练的。 Macro-F1-14 的大幅提升表明,专用编码器提供的嵌入有效地捕获了相关病理,产生了更具事实性的正确报告。 结果突出了 DINO 风格的纯图像预训练的有效性,该方法学习了生成胸部 X 光片发现的准确描述所需的特征。 顺便说一下,这些结果也为 [70] 中的发现提供了额外的支持,即图像分辨率比标记数量更重要;这种体系结构设计可能有助于实现更大的可扩展性。
| Image encoder | Input resolution | # of Tokens | ROUGE-L | BLEU-4 | RGER | Macro-F1-14 |
| CLIP@224 | 224 224 | 23.0 [22.7, 23.4] | 8.3 [7.9, 8.6] | 20.3 [19.8, 20.7] | 24.7 [23.6, 26.0] | |
| CLIP@336 | 316 316 | 23.3 [22.9, 23.7] | 8.4 [8.0, 8.7] | 20.4 [19.9, 20.9] | 25.3 [24.2, 26.5] | |
| DINOv2 | 518 518 | 22.7 [22.4, 23.2] | 7.6 [7.3, 7.9] | 18.5 [18.1, 19.1] | 18.6 [17.8, 19.5] | |
| BiomedCLIP | 224 224 | 23.1 [22.8, 23.5] | 7.9 [7.5, 8.2] | 20.4 [19.9, 20.8] | 24.9 [23.8, 26.1] | |
| BioViL-T | 512 512 | 23.5 [23.2, 23.9] | 7.3 [7.0, 7.6] | 22.4 [21.9, 22.8] | 28.4 [27.2, 29.8] | |
| -Control | 518 518 | 24.2 [23.8, 24.6] | 9.0 [8.7, 9.4] | 22.4 [21.9, 22.9] | 31.5 [30.1, 32.9] | |
| 518 518 | 24.6 [24.2, 25.0] | 9.3 [8.9, 9.7] | 22.8 [22.3, 23.3] | 31.9 [30.4, 33.3] | ||
| +1.1 | +1.4 | +0.4 | +3.5 |
训练数据集的平衡:
为了评估在域内数据上训练的重要性,在 表 5 中,我们进行了一个受控实验(称为 -Control),仅在较小的域内 MIMIC-CXR 数据集上进行训练,类似于 BioViL-T。 再次,我们见证了在这种情况下性能得到增强,表明相对于基线的改进不仅仅是由于在广泛的放射学数据上进行训练,而是 masked image modelling 本身的力量。 此外,我们观察到控制和全数据方案之间的差距很小,这可能是因为控制训练数据已经与 MIMIC-CXR 测试集对齐。 总体而言,这些结果表明是放射学领域下游视觉语言任务的强大编码器选择。
4.3 转移到语义分割
实验设置:
为了进一步探究 的补丁级表示能力,我们使用常见的胸部 X 光片数据集(CANDID-PTX 和从 MIMIC-CXR 派生的数据集;更多详细信息请参见 第 B.2 节)评估其在下游分割任务上的性能。 我们在编码器-解码器框架中使用每个冻结骨干,并使用不同的解码器头:线性 [22]、ViTDet [28] 和 UPerNet [29]。 此选择旨在衡量补丁嵌入的线性区分以及使用特征金字塔网络 [71] 和标准视觉转换器实现的顶级性能。 与之前的实验类似,在新的设置中,比较了相同的一组主干网络。 为了进一步了解性能的潜在上限 [72],我们使用不同的图像编码器,NN-UNet [26] 和 EfficientNet-B6 [74],对 U-Net [26] 编码器-解码器网络进行端到端训练和评估,每个结构,主要是因为它们能够通过编码器和解码器层之间的跳跃连接在降采样过程中保留高分辨率的空间信息。
结果分析:
masked image modelling (MIM) 的重要性:
通过对没有 MIM 目标的训练进行消融,我们进一步研究了部分中讨论的两个训练目标的互补性[24] t5> 2,其中仅使用全球作物和多本地作物之间的对比项来训练模型。 对比目标更侧重于全局关系(例如,形状),但 MIM 更倾向于局部关系(例如,纹理),因此,特别是对于密集的下游任务,例如语义分割,MIM 可能特别重要。 如 表 6 所示,MIM 目标有助于提高所有结构和数据集的分割性能,表明 MIM 为我们的密集任务产生了有效的表示。
Encoder Decoder # Features Frozen backbone Lungs Lung zones Pneumothorax Chest tubes Ribs NN-UNet [73] Unet — ✗ 98.0 (1.1) 92.6 (10.2) 89.3 (27.3) 93.1 (21.8) 86.2 (2.8) EfficientNet-B6 [74] Unet — ✗ 98.3 (1.1) 92.7 (10.1) 89.5 (26.9) 95.2 (17.2) 88.9 (2.6) BioViL-T [39] Linear 2048 ✓ 83.2 (3.2) 69.4 (9.0) 76.0 (39.9) 83.0 (37.0) 59.1 (4.7) BiomedCLIP [40] Linear 768 ✓ 90.4 (2.6) 76.2 (10.2) 27.4 (41.3) 67.6 (46.4) 67.4 (4.5) (no MIM) Linear 768 ✓ 91.3 (2.5) 78.8 (9.6) 37.5 (45.4) 78.5 (39.6) 67.3 (4.7) Linear 768 ✓ 95.9 (1.5) 85.7 (9.8) 47.4 (46.7) 90.4 (26.8) 73.4 (3.6) ViTDet 4 768 ✓ 97.8 (1.2) 90.7 (10.0) 52.5 (46.9) 85.6 (32.7) 83.6 (2.9) UPerNet 4 768 ✓ 98.0 (1.1) 91.2 (10.1) 87.2 (29.4) 94.4 (20.0) 85.3 (2.6)
编码器-解码器选择的作用:
图像特征金字塔网络 (FPN) 的变体 [71],包括用于设置性能上限的 U-Net 方法,一直应用于密集定位和分割任务,因为它们有效地利用了低级和高级语义特征。 在这方面,ViT 并不是这种目的的最佳选择,因为它在整个网络中只有一个尺度的特征图,因此我们将它与基于 FPN 的解码器头(例如,UPerNet)组合,以观察其最大性能。
我们观察到,预训练本身是学习可迁移冻结特征的一个好选择,类似于 DINOv2 特征在无需微调的情况下就可以表现良好的方式 [22],并且与专门针对下游任务训练的端到端网络具有竞争力,例如 表 6 中的 U-Net 和其他最近的 chest X-ray 分割模型 [76, 77, 78, 79]。 同样,对于更小的结构,使用中间激活和基于 FPN 的解码器头也会带来较大的性能提升,我们推测,通过在图像编码阶段引入特征金字塔,例如使用 Swin Transformer [27] 这样的架构,可以实现进一步的提升。
需要较少的分割标签:
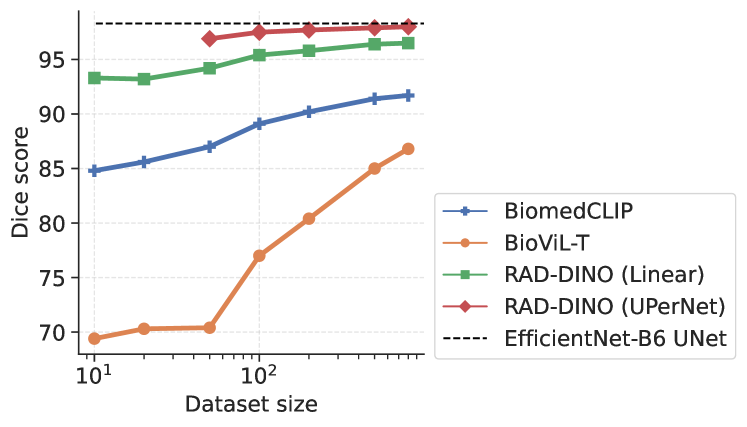
进行了额外的消融研究,以了解图像网络到分割任务的少样本迁移;因此,之前的实验组仅针对左肺和右肺的分割进行了重复,并使用了不同大小的手动注释用于训练。 图 4 显示,与使用线性解码器的视觉预训练编码器相比,基线方法(BioViL-T 和 BiomedCLIP)的少样本迁移不是最优的 [22]。 我们看到 Dice 得分在随着训练数据集大小的增加而变化较小,即使使用很少的样本也能达到接近最优的分割性能。 当与 UPerNet 解码器结合使用时,性能进一步提高。 这意味着大规模仅图像预训练可以潜在地减少对下游语义分割应用的密集标注医学扫描的需求,这些应用需要医学专业知识,并且收集起来非常耗时。
4.4 成像特征与患者元数据的相关性
实验设置:
虽然患者人口统计学特征和病历,如性别、年龄、体重和 body mass index (BMI),通常不会包含在 chest X-ray 报告中,但放射科医生在图像解释、辐射剂量决定 [80] 和后续干预过程中会考虑这些因素。 然而,患者的元数据通常与成像特征相关,例如在 3D 断层扫描中,二维侦察图像可以提供有用的近似值 [81, 82]。 我们的假设是,使用基于文本的弱监督训练的图像编码器(例如,BiomedCLIP 和 BioViL-T)可能无法捕获此患者信息,即使它存在于像素数据中。 我们比较了使用冻结编码器的线性分类器的性能,以及使用冻结 BiomedCLIP 和 BioViL-T 编码器的性能。 我们选择 MIMIC-CXR 数据集的一个子集(N = 60.1k),其中放射学报告中指出“无发现”。 然后,我们将匿名主题信息与 MIMIC-IV 数据集中提供的病历进行关联 [83]。
Encoder Sex Age Weight BMI BioViL-T [39] 75.1 (0.3) 60.8 (0.5) 43.8 (0.5) 47.6 (0.1) BiomedCLIP [40] 86.0 (0.3) 56.5 (0.5) 52.8 (0.4) 54.2 (0.1) 99.6 (0.1) 72.3 (0.3) 62.4 (0.4) 71.3 (0.2)
结果分析:
5 相关工作
表征学习:
表征学习的进步来自多个方向,最近的方法通过组合方法获得了所需的属性。 对于仅图像预训练,对比目标对于学习有用的全局表示很有效 [19];最近,对负样本的依赖已被不对称架构 [84, 85] 和聚类 [63, 41] 所取代。 对于局部特征学习,这对诸如分割之类的任务很有用,生成性任务,即掩盖图像建模已被证明更有用 [35, 86],其数据扩展特性在 [60] 中进行了研究。 这种局部 MIM 和全局对比目标可以有效地结合起来,以捕获对更多样化任务有用的特征 [59, 22, 23]。 最近 [58] 表明,仅 MIM 学习加上高级掩蔽和潜在预测策略可以提高模型收敛速度并减少对多视图对比目标的依赖。 对比方法同样流行于图像文本预训练,将两种模态映射到相同的全局特征空间(CLIP; [2]),并且已被证明对各种下游任务有效。 改进建议包括使用外部知识库 [87],鼓励更精细的级联对齐 [88],以及绑定多种模态 [89]。 通过生成性任务(如标题生成)可以获得学习表示中的额外粒度 [90, 91, 92, 93]。 结合仅图像目标和图像文本目标也被证明是有益的 [15, 94, 95, 96]。
生物医学视觉语言模型:
其他一些工作已经开发了专门用于医疗任务的基础模型。 其中许多是基于多模态对比学习 [6] 的,ChexZero [97]、GLoRIA [5] 和 BioViL [4] 仅在 X 射线数据集上训练,展示了 CLIP 目标的图像和补丁级变体。 BioViL-T [39] 将时间知识引入学习过程,以利用多个 X 射线和条件报告。 Med-UniC [31] 将这些方法扩展到多语言数据集,取得了优异的性能。 在 [98] 中,作者通过从每种模态中提取临床实体三元组并对齐它们,为多模态样本引入了一个联合空间。 一组研究集中在构建新的更大规模的配对图像-文本数据集,以匹配自然图像 CLIP 模型观察到的缩放:BiomedCLIP [40] 通过从 PubMed 文章中提取图表构建了一个更大的图像-文本对数据集;PMC-CLIP [99] 做类似的事情,并增加了数据整理阶段以过滤掉主要是 X 射线图像。 MedCLIP [100] 通过解耦图像和文本进行多模态对比学习,从而以低成本大幅扩展可用训练数据,解决了医疗数据稀缺问题。 同样,掩码建模也在该领域找到了应用,在各种基准测试中取得了优异的性能 [7]。 最后,基于生成式字幕的视觉-语言模型已经开发出来 [90],Med-Flamingo [9] 在配对/交错的图像-文本数据上微调了 Flamingo [101] 模型。
基于图像的自监督学习:
医疗数据的仅图像预训练已被广泛研究,许多最近的工作重点是选择对感兴趣的下游应用类别有用的预训练目标。 例如,对于分类,[38, 102, 103] 展示了使用 SimCLR [19] 和 DINO-v.1 [41] 对比方法来学习可迁移的图像特征以供下游微调(还构建了更多信息量更大的正对);而对于分割,Tang 等人 [33] 通过对局部区域应用对比/预测目标来学习对 CT 和 MR 图像分割有用的局部特征,并且 [32, 104] 使用像素级掩码图像建模 [86, 105] 在不同的成像模态中展示了强大的性能。 为了学习对多尺度医疗任务有用的特征,Hosseinzadeh Taher 等人 [106] 以粗到细的方式分解图像并利用对比预测编码 [18],而 Zhou 等人 [7] 将掩码图像建模与掩码语言建模相结合,以学习联合分布并改进模态融合。 最近的大规模预训练图像网络也与之相关,这些网络专门用于组织病理学领域,该领域以其大量可用的成像数据而著称;在类似的研究中,[107, 108] 中的作者分别训练了 iBoT [59] 和 DINOv2 [22] 模型,认为对比方法不适合罕见病理,因为学习到的表示的线性可分离性对于类不平衡数据来说很差。
深度网络在放射学中的应用:
关于胸部 X 光的调查研究 [109] 概述了以往研究中使用的各种应用和基准数据集。 Sellergren 等人 [110] 研究了将预训练的 SSL 特征转移到分类任务中,以减少对人工标签的需求。 同样,早期的工作 [69, 111] 探讨了在大型数据集(NIH-CXR-14 和 Chexpert)上使用神经网络进行图像分类。 在这些基准测试中,诊断标签是使用解析器从放射学报告中提取的,导致了显著的标签噪声 [112, 113]。 因此,基准测试仅在包含专家标注的基准测试中进行评估。 对于医学图像分割,特别是 U-Net [26] 模型仍然很流行 [72],而特定领域的方法 [114] 使用了针对胸部 X 光片的先验信息。 发现的分割也用于减轻网络学习到的潜在捷径和偏差,以将异常与治疗干预区分开来 [115]。 最后,图像主干被用于放射学报告生成 [10, 39, 116, 117] 和 VQA 应用 [8, 9],以提取可以与其他临床输入数据或文本提示一起推理以生成文本输出的视觉描述符。
6 讨论和结论
在本研究中,我们证明了高质量的通用生物医学图像编码器对于各种下游任务都有用,可以仅使用单峰图像数据进行训练。 这与之前最先进的生物医学方法形成对比,后者依赖于语言监督。 为了实现这一目标,我们通过不断地使用特定领域的增强和数据集对 DINOv2 进行预训练,而没有专门针对特定的模态集或特定任务的监督目标,而是仅使用原始图像数据。 多个基准测试的实验结果表明,该方法在性能上可与最先进的方法相媲美或优于最先进的方法,这一区别归因于它独立于文本监督质量,以及它能够大规模地捕捉更广泛的图像特征。
为了解释该方法的性能,我们推测,依赖于额外的模态不仅可能不是必要的,而且实际上可能成为学习医学扫描的丰富视觉表示的潜在限制;在文本报告的情况下,这取决于其描述性和完整性。 此外,语言监督模型可能无法推广到发现报告中所述内容之外的内容。 例如,通过将没有任何异常的扫描映射到相同的潜在表示,CLIP 样式的图像网络可能无法将图像数据与其他临床数据模态关联起来,探索新的图像生物标志物,以及实现需要医学扫描的预后。 为了加强这些发现,我们进行了一些消融实验,发现:没有领域内生物医学知识的预先存在的基于大型视觉 Transformer 的图像编码器已经能够很好地推广到胸部 X 光数据集,产生的结果与一些已建立的生物医学基准相当,呼应了 [30, 31] 中的发现;该方法的图像特征与患者病历的相关性比 CLIP 样式模型更好;并且与 CLIP 样式模型不同,该方法可以自然地处理从正面和侧面扫描同时学习的挑战,而无需融合多个视图或将文本短语分别与每个视图相关联。
该方法的另一个优势是它允许利用大量的仅包含医学影像的数据,从而可以训练更大规模的模型。 这规避了公共数据集图像-文本对稀缺的已知问题,同时还开辟了包括组织病理学和超声检查在内的应用领域,这些领域很少有文本。 仅依赖图像自监督还可以实现分辨率和维度更高的应用(例如,全身 3D CT 图像);在这些应用中,文本数据的弱监督信号可能会变得稀疏且不可靠,需要多实例学习或特定于应用程序的预处理解决方案,从而限制了它们的扩展性。 出于这个原因,我们推测自监督训练,使用或其他 MIM 方法,将更容易随着来自其他成像模态的数据的添加而扩展,同时实现与当前 SOTA 方法相似或更好的结果。 此外,我们对输入图像分辨率的分析强调了根据目标类别细分结果分析的重要性:一些发现子集需要对纹理进行细粒度分析;例如,在这项工作中 pneumothorax 和胸管,其中没有显示出主要的局限性。 图像分辨率的重要性预计在描述发现属性(例如严重程度和时间进展)的背景下将更加突出,这在一定程度上在我们报告生成实验中进行了量化。 但是,尽管明显重要,但 的优越性能并不完全归因于图像分辨率。
随着大规模计算的增长和大量训练数据的可用性,我们开始见证大规模模型在超越其初始范围的任务中的潜力,能够从少量示例中学习特定于应用程序的任务 [118, 119]。 我们预计类似的趋势将在医疗领域展开 [120]。 我们的工作在这方面取得了进展;与其为一组狭窄的应用程序微调如此庞大的网络,产生多个结果编码器,我们主张在不同的环境中将它们与特定于任务的头部(例如,分割、语言解码)一起重复使用,作为一种更有效、更高效的策略,以在更广泛的医疗保健环境中实现 AI 解决方案。 这还需要在广泛的应用中进行补充基准测试工作,就像我们研究中一样,不仅仅关注单模态评估 [7, 31],还包括文本报告生成等多模态任务。 由于我们研究的范围有限,我们没有研究替代编码器架构调整,例如 Swin Transformers;但是,我们预计在我们的方法中使用这种多尺度骨干将为图像分割提供进一步的性能提升,而不会影响其他基准的性能。 同样,通过聚合中间层和微调更高容量的适应层,如 [121] 中所述,可以进一步提高图像主干的报告生成性能,以便更好地将图像表示适应 LLM。 我们将把此留作将来工作。
参考文献
- Desai and Johnson [2021] Karan Desai and Justin Johnson. Virtex: Learning visual representations from textual annotations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11162–11173, 2021.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Yu et al. [2022a] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. Trans. Mach. Learn. Res., 2022, 2022a. URL https://openreview.net/pdf?id=Ee277P3AYC.
- Boecking et al. [2022] Benedikt Boecking, Naoto Usuyama, Shruthi Bannur, Daniel C Castro, Anton Schwaighofer, Stephanie Hyland, Maria Wetscherek, Tristan Naumann, Aditya Nori, Javier Alvarez-Valle, et al. Making the most of text semantics to improve biomedical vision–language processing. In European conference on computer vision, pages 1–21. Springer, 2022.
- Huang et al. [2021] Shih-Cheng Huang, Liyue Shen, Matthew P Lungren, and Serena Yeung. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3942–3951, 2021.
- Zhang et al. [2022] Yuhao Zhang, Hang Jiang, Yasuhide Miura, Christopher D Manning, and Curtis P Langlotz. Contrastive learning of medical visual representations from paired images and text. In Machine Learning for Healthcare Conference, pages 2–25. PMLR, 2022.
- Zhou et al. [2023] Hong-Yu Zhou, Chenyu Lian, Liansheng Wang, and Yizhou Yu. Advancing radiograph representation learning with masked record modeling. In The Eleventh International Conference on Learning Representations, 2023.
- Li et al. [2023] Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. arXiv preprint arXiv:2306.00890, 2023. URL https://arxiv.org/pdf/2306.00890.pdf.
- Moor et al. [2023a] Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Cyril Zakka, Yash Dalmia, Eduardo Pontes Reis, Pranav Rajpurkar, and Jure Leskovec. Med-flamingo: a multimodal medical few-shot learner. arXiv preprint arXiv:2307.15189, 2023a. URL https://arxiv.org/pdf/2307.15189.pdf.
- Tu et al. [2023] Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaekermann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Chuck Lau, Ryutaro Tanno, Ira Ktena, et al. Towards generalist biomedical ai. arXiv preprint arXiv:2307.14334, 2023. URL https://arxiv.org/pdf/2307.14334.pdf.
- Moor et al. [2023b] Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, and Pranav Rajpurkar. Foundation models for generalist medical artificial intelligence. Nature, 616(7956):259–265, 2023b.
- Dehghani et al. [2023] Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Peter Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. In International Conference on Machine Learning, pages 7480–7512. PMLR, 2023.
- Zhai et al. [2022a] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lucas Beyer. Scaling vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12104–12113, 2022a.
- Yang et al. [2022] Jinyu Yang, Jiali Duan, Son Tran, Yi Xu, Sampath Chanda, Liqun Chen, Belinda Zeng, Trishul Chilimbi, and Junzhou Huang. Vision-language pre-training with triple contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15671–15680, 2022.
- Zhai et al. [2022b] Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18123–18133, 2022b.
- Liang et al. [2022] Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35:17612–17625, 2022.
- Johnson et al. [2019] Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data, 6(1):317, 2019. URL https://physionet.org/content/mimic-cxr/2.0.0/.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018. URL https://arxiv.org/pdf/1807.03748.pdf.
- Chen et al. [2020] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020. URL https://proceedings.mlr.press/v119/chen20j/chen20j.pdf.
- Acosta et al. [2022] Julián N Acosta, Guido J Falcone, Pranav Rajpurkar, and Eric J Topol. Multimodal biomedical ai. Nature Medicine, 28(9):1773–1784, 2022.
- Langlotz [2023] Curtis P Langlotz. The future of ai and informatics in radiology: 10 predictions, 2023.
- Oquab et al. [2023] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Hervé Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, and Piotr Bojanowski. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. URL https://arxiv.org/pdf/2304.07193.pdf.
- Huang et al. [2023] Zhicheng Huang, Xiaojie Jin, Chengze Lu, Qibin Hou, Ming-Ming Cheng, Dongmei Fu, Xiaohui Shen, and Jiashi Feng. Contrastive masked autoencoders are stronger vision learners. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- Park et al. [2023] Namuk Park, Wonjae Kim, Byeongho Heo, Taekyung Kim, and Sangdoo Yun. What do self-supervised vision transformers learn? In The Eleventh International Conference on Learning Representations, 2023.
- Shekhar et al. [2023] Shashank Shekhar, Florian Bordes, Pascal Vincent, and Ari S Morcos. Objectives matter: Understanding the impact of self-supervised objectives on vision transformer representations. In ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models, 2023.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- Liu et al. [2021] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021.
- Li et al. [2022] Yanghao Li, Hanzi Mao, Ross Girshick, and Kaiming He. Exploring plain vision transformer backbones for object detection. In European Conference on Computer Vision, pages 280–296. Springer, 2022.
- Xiao et al. [2018] Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. In Proceedings of the European conference on computer vision (ECCV), pages 418–434, 2018. URL https://openaccess.thecvf.com/content_ECCV_2018/papers/Tete_Xiao_Unified_Perceptual_Parsing_ECCV_2018_paper.pdf.
- Huix et al. [2024] Joana Palés Huix, Adithya Raju Ganeshan, Johan Fredin Haslum, Magnus Söderberg, Christos Matsoukas, and Kevin Smith. Are natural domain foundation models useful for medical image classification? In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 7634–7643, 2024.
- Wan et al. [2023] Zhongwei Wan, Che Liu, Mi Zhang, Jie Fu, Benyou Wang, Sibo Cheng, Lei Ma, Cesar C’esar Quilodr’an-Casas, and Rossella Arcucci. Med-unic: Unifying cross-lingual medical vision-language pre-training by diminishing bias. Advances in Neural Information Processing Systems, 2023.
- Zhou et al. [2019] Zongwei Zhou, Vatsal Sodha, Md Mahfuzur Rahman Siddiquee, Ruibin Feng, Nima Tajbakhsh, Michael B Gotway, and Jianming Liang. Models genesis: Generic autodidactic models for 3d medical image analysis. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, October 13–17, 2019, Proceedings, Part IV 22, pages 384–393. Springer, 2019.
- Tang et al. [2022] Yucheng Tang, Dong Yang, Wenqi Li, Holger R Roth, Bennett Landman, Daguang Xu, Vishwesh Nath, and Ali Hatamizadeh. Self-supervised pre-training of swin transformers for 3d medical image analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20730–20740, 2022.
- Tarvainen and Valpola [2017] Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Advances in neural information processing systems, 30, 2017.
- Bao et al. [2021] Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image transformers. In International Conference on Learning Representations, 2021.
- Wang et al. [2022a] Xiao Wang, Haoqi Fan, Yuandong Tian, Daisuke Kihara, and Xinlei Chen. On the importance of asymmetry for siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16570–16579, 2022a.
- Sablayrolles et al. [2018] Alexandre Sablayrolles, Matthijs Douze, Cordelia Schmid, and Hervé Jégou. Spreading vectors for similarity search. In International Conference on Learning Representations, 2018.
- Park et al. [2022] Sangjoon Park, Gwanghyun Kim, Yujin Oh, Joon Beom Seo, Sang Min Lee, Jin Hwan Kim, Sungjun Moon, Jae-Kwang Lim, Chang Min Park, and Jong Chul Ye. Self-evolving vision transformer for chest x-ray diagnosis through knowledge distillation. Nature communications, 13(1):3848, 2022.
- Bannur et al. [2023] Shruthi Bannur, Stephanie Hyland, Qianchu Liu, Fernando Perez-Garcia, Maximilian Ilse, Daniel C Castro, Benedikt Boecking, Harshita Sharma, Kenza Bouzid, Anja Thieme, et al. Learning to exploit temporal structure for biomedical vision-language processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15016–15027, 2023.
- Zhang et al. [2023a] Sheng Zhang, Yanbo Xu, Naoto Usuyama, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, Cliff Wong, et al. Large-scale domain-specific pretraining for biomedical vision-language processing. arXiv preprint arXiv:2303.00915, 2023a. URL https://arxiv.org/pdf/2303.00915.pdf.
- Caron et al. [2021] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021.
- Bardes et al. [2022] Adrien Bardes, Jean Ponce, and Yann LeCun. Vicregl: Self-supervised learning of local visual features. Advances in Neural Information Processing Systems, 35:8799–8810, 2022.
- Chiang et al. [2023] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Liu et al. [2023a] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023a. URL http://arxiv.org/pdf/2310.03744.pdf.
- Liu et al. [2023b] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023b. URL http://arxiv.org/abs/2304.08485.
- Nguyen et al. [2022] Ha Q Nguyen, Khanh Lam, Linh T Le, Hieu H Pham, Dat Q Tran, Dung B Nguyen, Dung D Le, Chi M Pham, Hang TT Tong, Diep H Dinh, et al. Vindr-cxr: An open dataset of chest x-rays with radiologist’s annotations. Scientific Data, 9(1):429, 2022.
- Feng et al. [2021] Sijing Feng, Damian Azzollini, Ji Soo Kim, Cheng-Kai Jin, Simon P Gordon, Jason Yeoh, Eve Kim, Mina Han, Andrew Lee, Aakash Patel, et al. Curation of the candid-ptx dataset with free-text reports. Radiology: Artificial Intelligence, 3(6):e210136, 2021.
- MD et al. [2018] Anouk Stein MD, Carol Wu, Chris Carr, George Shih, Jamie Dulkowski, kalpathy, Leon Chen, Luciano Prevedello, Marc Kohli MD, Mark McDonald, Peter, Phil Culliton, Safwan Halabi MD, and Tian Xia. Rsna pneumonia detection challenge, 2018. URL https://kaggle.com/competitions/rsna-pneumonia-detection-challenge.
- Chen et al. [2022] Li-Ching Chen, Po-Chih Kuo, Ryan Wang, Judy Gichoya, and Leo Anthony Celi. Chest x-ray segmentation images based on mimic-cxr, 2022. URL https://physionet.org/content/lung-segment-mimic-cxr/1.0.0/.
- Wu et al. [2021] Joy T Wu, Nkechinyere N Agu, Ismini Lourentzou, Arjun Sharma, Joseph A Paguio, Jasper S Yao, Edward C Dee, William Mitchell, Satyananda Kashyap, Andrea Giovannini, et al. Chest imagenome dataset (version 1.0. 0). PhysioNet, 5:18, 2021.
- Nguyen et al. [2021] Hoang C. Nguyen, Tung T. Le, Hieu H. Pham, and Ha Q. Nguyen. Vindr-ribcxr: A benchmark dataset for automatic segmentation and labeling of individual ribs on chest x-rays, 2021.
- Haque et al. [2023] Md Inzamam Ul Haque, Abhishek K Dubey, Ioana Danciu, Amy C Justice, Olga S Ovchinnikova, and Jacob D Hinkle. Effect of image resolution on automated classification of chest x-rays. Journal of Medical Imaging, 10(4):044503–044503, 2023.
- Sabottke and Spieler [2020] Carl F Sabottke and Bradley M Spieler. The effect of image resolution on deep learning in radiography. Radiology: Artificial Intelligence, 2(1):e190015, 2020.
- Tanno et al. [2023] Ryutaro Tanno, David GT Barrett, Andrew Sellergren, Sumedh Ghaisas, Sumanth Dathathri, Abigail See, Johannes Welbl, Karan Singhal, Shekoofeh Azizi, Tao Tu, et al. Consensus, dissensus and synergy between clinicians and specialist foundation models in radiology report generation. arXiv preprint arXiv:2311.18260, 2023. URL https://arxiv.org/pdf/2311.18260.pdf.
- Cherti and Jitsev [2022] Mehdi Cherti and Jenia Jitsev. Effect of pre-training scale on intra-and inter-domain, full and few-shot transfer learning for natural and x-ray chest images. In 2022 International Joint Conference on Neural Networks (IJCNN), pages 1–9. IEEE, 2022. URL https://arxiv.org/pdf/2106.00116.pdf.
- Mustafa et al. [2021] Basil Mustafa, Aaron Loh, Jan Freyberg, Patricia MacWilliams, Megan Wilson, Scott Mayer McKinney, Marcin Sieniek, Jim Winkens, Yuan Liu, Peggy Bui, et al. Supervised transfer learning at scale for medical imaging. arXiv preprint arXiv:2101.05913, 2021. URL https://arxiv.org/pdf/2101.05913.pdf.
- Bustos et al. [2020] Aurelia Bustos, Antonio Pertusa, Jose-Maria Salinas, and Maria de la Iglesia-Vayá. PadChest: A large chest x-ray image dataset with multi-label annotated reports. Medical Image Analysis, 66:101797, December 2020. ISSN 1361-8415. doi:10.1016/j.media.2020.101797. URL http://dx.doi.org/10.1016/j.media.2020.101797.
- Assran et al. [2023] Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023.
- Zhou et al. [2022] Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. iBOT: image BERT pre-training with online tokenizer. In International Conference on Learning Representations, 2022.
- Xie et al. [2023] Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Yixuan Wei, Qi Dai, and Han Hu. On data scaling in masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10365–10374, 2023.
- Bertrand et al. [2019] Hadrien Bertrand, Mohammad Hashir, and Joseph Paul Cohen. Do lateral views help automated chest x-ray predictions? arXiv preprint arXiv:1904.08534, 2019. URL https://arxiv.org/pdf/1904.08534.pdf.
- Hashir et al. [2020] Mohammad Hashir, Hadrien Bertrand, and Joseph Paul Cohen. Quantifying the value of lateral views in deep learning for chest x-rays. In Medical Imaging with Deep Learning, pages 288–303. PMLR, 2020. URL https://proceedings.mlr.press/v121/hashir20a/hashir20a.pdf.
- Caron et al. [2020] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. Advances in neural information processing systems, 33:9912–9924, 2020.
- Yang et al. [2023] Ziyu Yang, Santhosh Cherian, and Slobodan Vucetic. Data augmentation for radiology report simplification. In Findings of the Association for Computational Linguistics: EACL 2023, pages 1877–1887, 2023.
- Lin [2004] Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81. Association for Computational Linguistics, July 2004. URL https://aclanthology.org/W04-1013.
- Papineni et al. [2002] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318. Association for Computational Linguistics, July 2002. doi:10.3115/1073083.1073135.
- Delbrouck et al. [2022] Jean-Benoit Delbrouck, Pierre Chambon, Christian Bluethgen, Emily Tsai, Omar Almusa, and Curtis Langlotz. Improving the factual correctness of radiology report generation with semantic rewards. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 4348–4360. ACL, December 2022. doi:10.18653/v1/2022.findings-emnlp.319.
- Smit et al. [2020] Akshay Smit, Saahil Jain, Pranav Rajpurkar, Anuj Pareek, Andrew Ng, and Matthew Lungren. Combining automatic labelers and expert annotations for accurate radiology report labeling using BERT. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1500–1519. ACL, November 2020. doi:10.18653/v1/2020.emnlp-main.117.
- Irvin et al. [2019] Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn L. Ball, Katie Shpanskaya, Jayne Seekins, David A. Mong, Safwan S. Halabi, Jesse K. Sandberg, Ricky Jones, David B. Larson, Curtis P. Langlotz, Bhavik N. Patel, Matthew P. Lungren, and Andrew Y. Ng. CheXpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2019), volume 33, pages 590–597. AAAI Press, July 2019. doi:10.1609/aaai.v33i01.3301590.
- Lin et al. [2023a] Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. arXiv preprint arXiv:2312.07533, 2023a. URL https://arxiv.org/pdf/2312.07533.pdf.
- Lin et al. [2017] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017.
- Azad et al. [2022] Reza Azad, Ehsan Khodapanah Aghdam, Amelie Rauland, Yiwei Jia, Atlas Haddadi Avval, Afshin Bozorgpour, Sanaz Karimijafarbigloo, Joseph Paul Cohen, Ehsan Adeli, and Dorit Merhof. Medical image segmentation review: The success of u-net, 2022.
- Isensee et al. [2018] Fabian Isensee, Jens Petersen, Andre Klein, David Zimmerer, Paul F. Jaeger, Simon Kohl, Jakob Wasserthal, Gregor Koehler, Tobias Norajitra, Sebastian Wirkert, and Klaus H. Maier-Hein. nnu-net: Self-adapting framework for u-net-based medical image segmentation. arXiv preprint arXiv:1809.10486, 2018. URL https://arxiv.org/pdf/1809.10486.pdf.
- Tan and Le [2020] Mingxing Tan and Quoc V. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2020. URL https://arxiv.org/pdf/1905.11946.pdf.
- Ilharco et al. [2022] Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. OpenCLIP, September 2022. URL https://doi.org/10.5281/zenodo.7086307.
- Wang et al. [2024] Hongyu Wang, Dandan Zhang, Jun Feng, Lucia Cascone, Michele Nappi, and Shaohua Wan. A multi-objective segmentation method for chest x-rays based on collaborative learning from multiple partially annotated datasets. Information Fusion, 102:102016, 2024.
- Zhang et al. [2023b] Dandan Zhang, Hongyu Wang, Jiahui Deng, Tonghui Wang, Cong Shen, and Jun Feng. Cams-net: An attention-guided feature selection network for rib segmentation in chest x-rays. Computers in Biology and Medicine, 156:106702, 2023b.
- Pal et al. [2023] Debojyoti Pal, Tanushree Meena, and Sudipta Roy. A fully connected reproducible se-uresnet for multiorgan chest radiographs segmentation. In 2023 IEEE 24th International Conference on Information Reuse and Integration for Data Science (IRI), pages 261–266. IEEE, 2023.
- Brioso et al. [2023] Ricardo Coimbra Brioso, João Pedrosa, Ana Maria Mendonça, and Aurélio Campilho. Semi-supervised multi-structure segmentation in chest x-ray imaging. In 2023 IEEE 36th International Symposium on Computer-Based Medical Systems (CBMS), pages 814–820. IEEE, 2023.
- Boos et al. [2016] Johannes Boos, Rotem S Lanzman, Philipp Heusch, Joel Aissa, Christoph Schleich, Christoph Thomas, Lino M Sawicki, Gerald Antoch, and Patric Kröpil. Does body mass index outperform body weight as a surrogate parameter in the calculation of size-specific dose estimates in adult body ct? The British Journal of Radiology, 89(1059):20150734, 2016.
- Demircioğlu et al. [2023] Aydin Demircioğlu, Anton S Quinsten, Lale Umutlu, Michael Forsting, Kai Nassenstein, and Denise Bos. Determining body height and weight from thoracic and abdominal ct localizers in pediatric and young adult patients using deep learning. Scientific Reports, 13(1):19010, 2023.
- Ichikawa et al. [2021] Shota Ichikawa, Misaki Hamada, and Hiroyuki Sugimori. A deep-learning method using computed tomography scout images for estimating patient body weight. Scientific reports, 11(1):15627, 2021.
- Johnson et al. [2023] Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Steven Horng, Leo Anthony Celi, and Roger Mark. Mimic-iv, 2023. URL https://physionet.org/content/mimiciv/2.2/.
- Grill et al. [2020] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33:21271–21284, 2020.
- Chen and He [2021] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021.
- He et al. [2022] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022.
- Shen et al. [2022] Sheng Shen, Chunyuan Li, Xiaowei Hu, Yujia Xie, Jianwei Yang, Pengchuan Zhang, Zhe Gan, Lijuan Wang, Lu Yuan, Ce Liu, et al. K-lite: Learning transferable visual models with external knowledge. Advances in Neural Information Processing Systems, 35:15558–15573, 2022.
- Yao et al. [2021] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training. In International Conference on Learning Representations, 2021.
- Girdhar et al. [2023] Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15180–15190, 2023.
- Yu et al. [2022b] Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models. Transactions on Machine Learning Research, 2022b. ISSN 2835-8856.
- Wang et al. [2022b] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. SimVLM: Simple visual language model pretraining with weak supervision. In International Conference on Learning Representations, 2022b.
- Singh et al. [2022] Amanpreet Singh, Ronghang Hu, Vedanuj Goswami, Guillaume Couairon, Wojciech Galuba, Marcus Rohrbach, and Douwe Kiela. Flava: A foundational language and vision alignment model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15638–15650, 2022.
- Tschannen et al. [2023] Michael Tschannen, Manoj Kumar, Andreas Steiner, Xiaohua Zhai, Neil Houlsby, and Lucas Beyer. Image captioners are scalable vision learners too. arXiv preprint arXiv:2306.07915, 2023. URL https://arxiv.org/pdf/2306.07915.pdf.
- Li et al. [2021] Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. In International Conference on Learning Representations, 2021.
- Weers et al. [2023] Floris Weers, Vaishaal Shankar, Angelos Katharopoulos, Yinfei Yang, and Tom Gunter. Masked autoencoding does not help natural language supervision at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23432–23444, 2023.
- Mu et al. [2022] Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. Slip: Self-supervision meets language-image pre-training. In European Conference on Computer Vision, pages 529–544. Springer, 2022.
- E. et al. [2022] Tiu E., Talius E., Patel P., et al. Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning. Nat. Biomed. Eng 6, 1399–1406, 2022.
- Wu et al. [2023] Chaoyi Wu, Xiaoman Zhang, Ya Zhang, Yanfeng Wang, and Weidi Xie. Medklip: Medical knowledge enhanced language-image pre-training for x-ray diagnosis. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 21372–21383, October 2023. URL https://openaccess.thecvf.com/content/ICCV2023/papers/Wu_MedKLIP_Medical_Knowledge_Enhanced_Language-Image_Pre-Training_for_X-ray_Diagnosis_ICCV_2023_paper.pdf.
- Lin et al. [2023b] Weixiong Lin, Ziheng Zhao, Xiaoman Zhang, Chaoyi Wu, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-clip: Contrastive language-image pre-training using biomedical documents. arXiv preprint arXiv:2303.07240, 2023b. URL https://arxiv.org/pdf/2303.07240.pdf.
- Wang et al. [2022c] Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text, 2022c. URL https://arxiv.org/pdf/2210.10163.pdf.
- Alayrac et al. [2022] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716–23736, 2022.
- Azizi et al. [2021] Shekoofeh Azizi, Basil Mustafa, Fiona Ryan, Zachary Beaver, Jan Freyberg, Jonathan Deaton, Aaron Loh, Alan Karthikesalingam, Simon Kornblith, Ting Chen, et al. Big self-supervised models advance medical image classification. In Proceedings of the IEEE/CVF international conference on computer vision, pages 3478–3488, 2021.
- Azizi et al. [2023] Shekoofeh Azizi, Laura Culp, Jan Freyberg, Basil Mustafa, Sebastien Baur, Simon Kornblith, Ting Chen, Nenad Tomasev, Jovana Mitrović, Patricia Strachan, et al. Robust and data-efficient generalization of self-supervised machine learning for diagnostic imaging. Nature Biomedical Engineering, pages 1–24, 2023.
- Chen et al. [2023] Zekai Chen, Devansh Agarwal, Kshitij Aggarwal, Wiem Safta, Mariann Micsinai Balan, and Kevin Brown. Masked image modeling advances 3d medical image analysis. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1970–1980, 2023.
- Xie et al. [2022] Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9653–9663, 2022.
- Hosseinzadeh Taher et al. [2023] Mohammad Reza Hosseinzadeh Taher, Michael B Gotway, and Jianming Liang. Towards foundation models learned from anatomy in medical imaging via self-supervision. In MICCAI Workshop on Domain Adaptation and Representation Transfer, pages 94–104. Springer, 2023.
- Filiot et al. [2023] Alexandre Filiot, Ridouane Ghermi, Antoine Olivier, Paul Jacob, Lucas Fidon, Alice Mac Kain, Charlie Saillard, and Jean-Baptiste Schiratti. Scaling self-supervised learning for histopathology with masked image modeling. medRxiv, pages 2023–07, 2023. URL https://www.medrxiv.org/content/10.1101/2023.07.21.23292757v2.full.pdf.
- Vorontsov et al. [2023] Eugene Vorontsov, Alican Bozkurt, Adam Casson, George Shaikovski, Michal Zelechowski, Siqi Liu, Philippe Mathieu, Alexander van Eck, Donghun Lee, Julian Viret, Eric Robert, Yi Kan Wang, Jeremy D. Kunz, Matthew C. H. Lee, Jan Bernhard, Ran A. Godrich, Gerard Oakley, Ewan Millar, Matthew Hanna, Juan Retamero, William A. Moye, Razik Yousfi, Christopher Kanan, David Klimstra, Brandon Rothrock, and Thomas J. Fuchs. Virchow: A million-slide digital pathology foundation model. arXiv preprint arXiv:2309.07778, 2023. URL https://arxiv.org/pdf/2309.07778.pdf.
- Çallı et al. [2021] Erdi Çallı, Ecem Sogancioglu, Bram van Ginneken, Kicky G van Leeuwen, and Keelin Murphy. Deep learning for chest x-ray analysis: A survey. Medical Image Analysis, 72:102125, 2021.
- Sellergren et al. [2022] Andrew B Sellergren, Christina Chen, Zaid Nabulsi, Yuanzhen Li, Aaron Maschinot, Aaron Sarna, Jenny Huang, Charles Lau, Sreenivasa Raju Kalidindi, Mozziyar Etemadi, et al. Simplified transfer learning for chest radiography models using less data. Radiology, 305(2):454–465, 2022.
- Wang et al. [2017] Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2097–2106, 2017.
- Oakden-Rayner [2020] Luke Oakden-Rayner. Exploring large-scale public medical image datasets. Academic radiology, 27(1):106–112, 2020.
- Majkowska et al. [2020] Anna Majkowska, Sid Mittal, David F Steiner, Joshua J Reicher, Scott Mayer McKinney, Gavin E Duggan, Krish Eswaran, Po-Hsuan Cameron Chen, Yun Liu, Sreenivasa Raju Kalidindi, et al. Chest radiograph interpretation with deep learning models: assessment with radiologist-adjudicated reference standards and population-adjusted evaluation. Radiology, 294(2):421–431, 2020.
- Gaggion et al. [2023] Nicolás Gaggion, Candelaria Mosquera, Lucas Mansilla, Martina Aineseder, Diego H Milone, and Enzo Ferrante. Chexmask: a large-scale dataset of anatomical segmentation masks for multi-center chest x-ray images. arXiv preprint arXiv:2307.03293, 2023. URL https://arxiv.org/pdf/2307.03293.pdf.
- Rueckel et al. [2021] Johannes Rueckel, Christian Huemmer, Andreas Fieselmann, Florin-Cristian Ghesu, Awais Mansoor, Balthasar Schachtner, Philipp Wesp, Lena Trappmann, Basel Munawwar, Jens Ricke, et al. Pneumothorax detection in chest radiographs: optimizing artificial intelligence system for accuracy and confounding bias reduction using in-image annotations in algorithm training. European radiology, pages 1–13, 2021.
- Endo et al. [2021] Mark Endo, Rayan Krishnan, Viswesh Krishna, Andrew Y Ng, and Pranav Rajpurkar. Retrieval-based chest x-ray report generation using a pre-trained contrastive language-image model. In Machine Learning for Health, pages 209–219. PMLR, 2021.
- Miura et al. [2021] Yasuhide Miura, Yuhao Zhang, Emily Tsai, Curtis Langlotz, and Dan Jurafsky. Improving factual completeness and consistency of image-to-text radiology report generation. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5288–5304, 2021.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Achiam et al. [2023] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. URL https://arxiv.org/pdf/2303.08774.pdf.
- Nori et al. [2023] Harsha Nori, Yin Tat Lee, Sheng Zhang, Dean Carignan, Richard Edgar, Nicolo Fusi, Nicholas King, Jonathan Larson, Yuanzhi Li, Weishung Liu, et al. Can generalist foundation models outcompete special-purpose tuning? case study in medicine. arXiv preprint arXiv:2311.16452, 2023. URL https://arxiv.org/pdf/2311.16452.pdf.
- Jiang et al. [2023] Dongsheng Jiang, Yuchen Liu, Songlin Liu, Xiaopeng Zhang, Jin Li, Hongkai Xiong, and Qi Tian. From clip to dino: Visual encoders shout in multi-modal large language models, 2023. URL https://arxiv.org/pdf/2310.08825v1.pdf.
- Reis et al. [2022] Eduardo P Reis, Joselisa PQ de Paiva, Maria CB da Silva, Guilherme AS Ribeiro, Victor F Paiva, Lucas Bulgarelli, Henrique MH Lee, Paulo V Santos, Vanessa M Brito, Lucas TW Amaral, et al. BRAX, Brazilian labeled chest x-ray dataset. Scientific Data, 9(1):487, 2022.
- Pedregosa et al. [2011] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
附录 A 模型行为和结果的进一步分析
A.1 图像分辨率对细微发现的影响
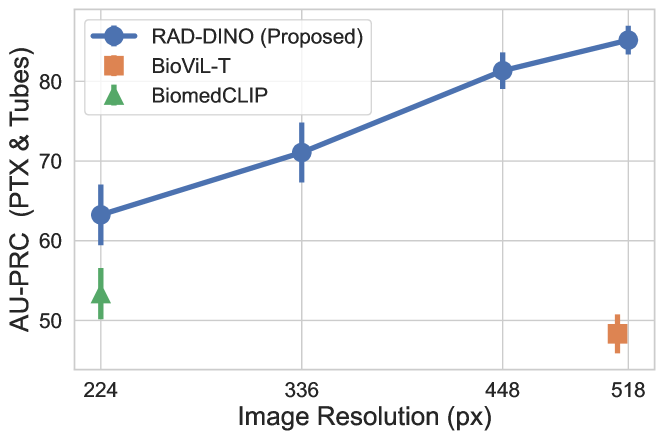
我们还扩展了在 第 3.1 节 中报道的分辨率消融研究,以使用 CANDID-PTX 数据集 [47] 包含气胸和胸管等细微发现。 如 图 A.1 中 所述,结果表明,由于输入图像中的模糊和细节丢失,编码器的性能在较低分辨率下会下降,这突出了高分辨率对于准确检测这种细微发现的必要性。 与 BiomedCLIP 和 BioViL-T 等其他基线方法相比,仅图像预训练的编码器在各种分辨率(分别为 224 px 和 512 px)下始终表现出优越的性能。 这表明编码器有效利用更高分辨率可以在下游任务(如 VQA 和文本生成)中带来更高的性能,超过在有限分辨率下训练的编码器 [9, 10]。 此外,分析不同发现的结果细分对于全面了解输入分辨率的影响至关重要。
A.2 使用侧位胸片进行的实验
我们假设对于侧位扫描和放射学文本数据,图像-文本对齐可能具有挑战性,因为这两种数据模态之间通常共享的互信息有限。 具体而言,放射学文本报告中报告的某些发现可能在侧位扫描中不可见,或者可以通过仅依赖正面扫描来评估。 在这种情况下,仅图像 SSL 技术(例如)可以作为一种有用的替代方案,在预训练期间同时从正面和侧位成像视图中学习丰富的成像特征集。
为此,我们使用了 PadChest 数据集的一个子集,仅选择了包含特定发现的侧位扫描,并将这些研究从预训练中排除。 发现的选择以仅基于侧位扫描检测它们的可能性为指导,以减少任务模糊。 出于这些原因,以下发现是根据先前研究工作 [61, 62] 中证明侧位扫描在识别它们方面的独特价值而选择的:“椎体退行性改变”(VDC)、“胸腔积液”(PE)和“肋膈角变钝”(CAB)。 通过从数据集的其余部分随机采样负侧向扫描,每个二元任务的正负类别分布保持平衡。 总数据集大小为 N=11.9k,数据集按主题标识符随机分配,在训练/验证/测试中分别占 80/10/10%。 由于该数据集中并非所有图像都存在所有类别标签,因此对每个发现使用数据集的一个子集来测试模型:VDC 为 N=373,PE 为 N=542,CAB 为 N=503。
在 表 A.1 中的结果表明,BioViL-T 在以前未见过的发现(如 VDC)上的表现几乎与随机分类器相当,这可能是因为它主要使用来自 MIMIC-CXR 的正面扫描进行训练。 相反,BiomedCLIP 的训练数据集包含更平衡的正面和侧向扫描组合。 总之,我们观察到基于掩蔽建模的方法(如 MRM 和 )始终提供强大的分类结果。 这证明了 MIM 目标在适应各种成像视图方面的有效性。 此外,重要的是要注意,可以在预训练期间无需文本监督的情况下实现这种性能。
| PadChest [57] (AUPRC) | |||||
| Image Encoder | Pre-trained with Laterals | Vertebral Deg. Changes | Pleural Effusion | Costophrenic Angle Blunting | Agg |
| BioViL-T [39] | ✗ | p m 2.44 | p m 2.36 | p m 2.21 | 69.64 |
| BiomedCLIP [40] | ✓ | p m 1.24 | p m 1.02 | p m 2.92 | 78.62 |
| MRM [7] | ✓ | p m 1.75 | p m 0.98 | p m 2.85 | 85.50 |
| ✓ | p m 1.32 | p m 0.95 | p m 2.63 | 86.14 | |
A.3 定性结果
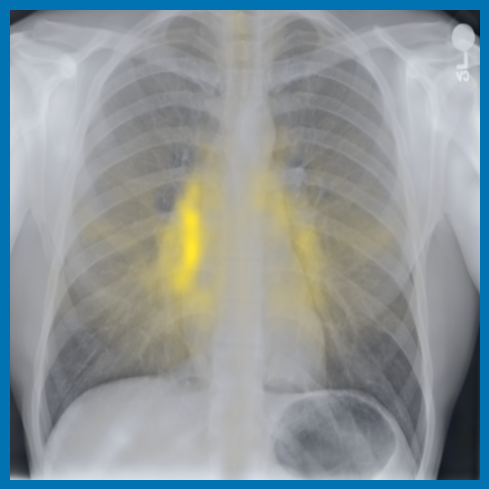
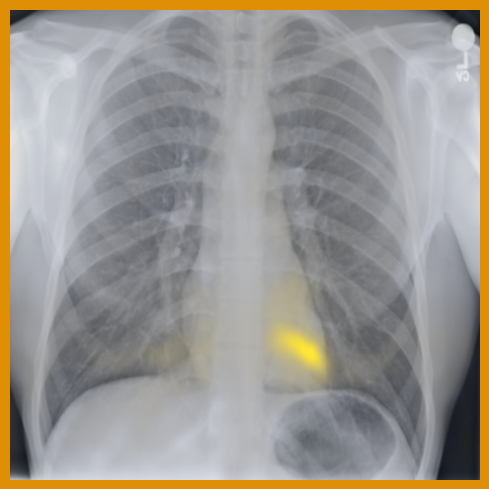
A.3.1 自注意的可视化
图 A.2 显示了 [CLS] 符元关于使用编码器提取的补丁嵌入的自注意。 顶行展示了 的能力,可以准确地关注和追踪不同类型的支撑设备。 底行显示,在有胸腔积液和不透明度的图像上,注意力头集中在肺野内,包括底部和肺门区域。


A.4 补丁嵌入对应关系
图 A.3 和 A.4 提供了来自不同受试者的 chest X-ray 图像对之间补丁嵌入匹配的额外定性示例。 特别地,我们看到解剖对应关系 (图 A.3) 尽管存在诸如局限性右胸膜积液等发现,但仍然保留得很好。
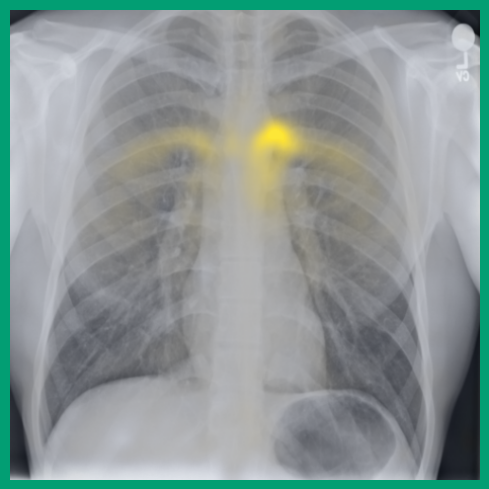
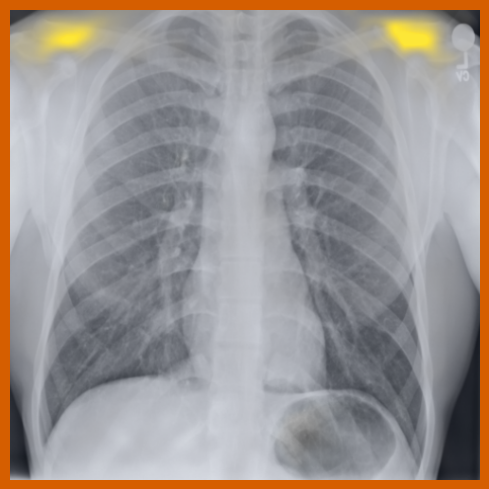
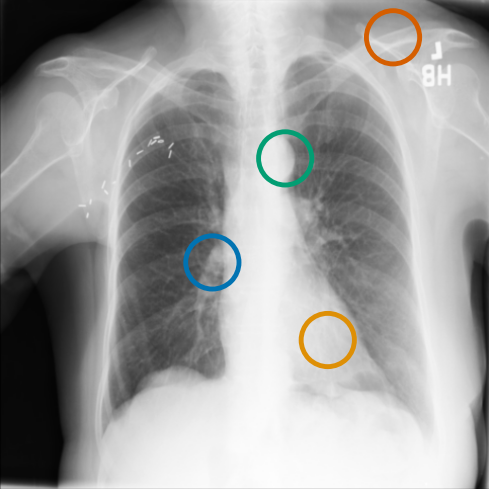
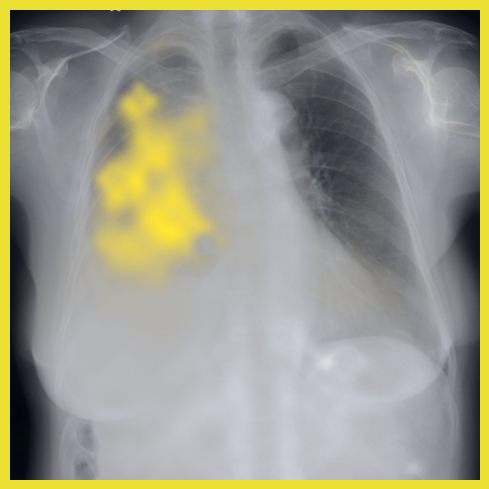
同样,异常发现(如固结和结节)的局部补丁嵌入可以在扫描之间很好地对齐,见 图 A.4。 我们还观察到,当解剖区域与异常发现(例如,肋膈角处的胸膜积液)重叠时,解剖对应点的最近邻匹配会受到影响。 这导致嵌入同时捕获两种类型的信息。
A.4.1 定性分割结果
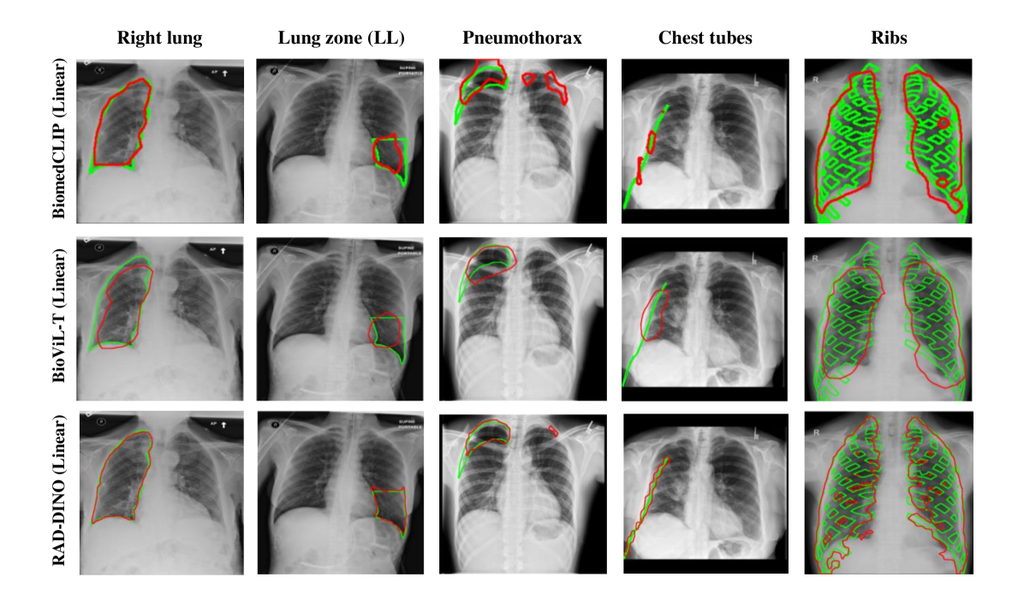
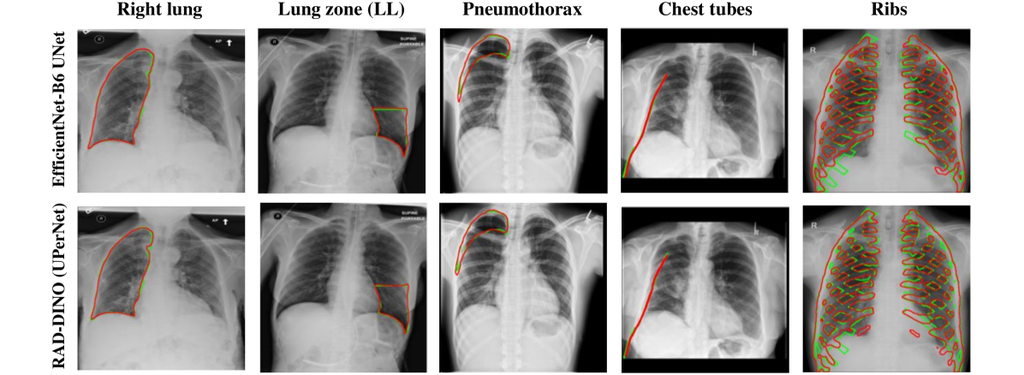
与使用线性解码器头的图像-文本对比训练编码器 BioViL-T 和 BiomedCLIP 相比,使用预训练编码器的定性结果在所有任务中明显更好 (图 4(a))。 具体而言,我们看到预测的分割掩码中对形状和边缘的更多细节(在较小的结构(如胸管和肺区)中更明显地看到)。 相反,BioViL-T 和 BiomedCLIP 预测的掩码中没有保留细粒度的边缘和形状细节。 BiomedCLIP 生成的分割掩码显示出断开的组件(类似于 [22] 中 OpenCLIP 分割的定性结果)。 此外,使用带有 UPerNet 解码器的编码器预测的分割掩码保留了每个结构的细粒度细节,并且在视觉质量上接近性能最佳的分割模型 EfficientNet-B6 UNet 预测的掩码 (图 4(b))。
附录 B 数据集
B.1 预训练
为了训练图像编码器,我们使用 表 B.1 中概述的 chest X-ray 数据集的组合。 BRAX 数据集 [122] 包含 24,959 张高质量数字胸部 X 光片研究,这些研究是在 COVID-19 大流行之前从一家大型巴西综合医院的 19,351 名患者身上获得的。 由于 BRAX 来自一家巴西医院,因此它可以帮助解决某些人群在医疗数据集中的代表性不足问题。 MIMIC-CXR [17] 包含胸部 X 光片研究,包括从重症监护病房 (ICU) 收集的放射学报告,其中观察到临床发现的子集。 它一直是现有技术 [5, 39, 7] 中主要的预训练数据资源。 同样,NIH-CXR [111] 由 NIH 编译,包含来自超过 30,000 名患者的胸部 X 光片扫描,其中包括许多患有晚期肺病的患者。 PadChest [57] 包含医学图像及其相关的报告,这些报告来自在圣胡安医院(西班牙)报告的受试者,其中这些报告被标记为 174 种不同的放射学发现、19 种鉴别诊断和 104 个解剖位置,这些位置被组织成一个层次分类法。 由于 PadChest 数据集包含从门诊病房和住院病房收集的研究,因此其多样性对于泛化到 ICU 环境之外观察到的发现非常有价值。 请注意,尽管评估主要评估正面扫描中看到的发现,但横向扫描并未从训练中排除。 最后,我们利用一组从门诊收集的内部 chest X-ray 成像数据集来进一步评估训练数据集大小的可扩展性模型。
综上所述,大型组合预训练数据集包含从具有不同报告放射学发现的受试者那里获得的胸部 X 光图像,这些图像来自不同地理位置和时间段的不同患者群体。 除了 MIMIC-CXR [17] 之外,所有图像都用于从给定数据集中进行预训练,其中使用了他们推荐的训练拆分。
| Dataset | View | Patient cohort | Number of subjects | Number of images |
| BRAX [122] | frontal, lateral | all available in institutional PACS | 19,351 | 41,620 |
| CheXpert [69] | frontal, lateral | inpatient and outpatient | 65,240 | 223,648 |
| MIMIC-CXR [17] | frontal | ICU | 188,546 | 210,491 |
| NIH-CXR [111] | frontal | not specified | 32,717 | 112,120 |
| PadChest [57] | frontal, lateral | all available | 67,000 | 160,817 |
| Private | frontal, lateral | outpatient | 66,323 | 90,000 |
| Total | 439,177 | 838,336 |
B.2 下游评估任务
对于图像分类任务,我们使用 VinDr-CXR [46]、CANDID-PTX [47] 和 RSNA-Pneumonia [48]。 VinDr-CXR 子集包含六个报告发现,由来自相同数量受试者的 18,000 张图像组成。 CANDID-PTX [47] 包含来自相同数量受试者的 19,237 张图像。 RSNA-Pneumonia [48] 包含来自相同数量受试者的 26,684 张图像。 对于语义分割任务,我们训练和评估编码器-解码器网络,用于左肺和右肺、肺区、气胸、胸管和肋骨。 对于肺和肺区分割,肺掩码在基于 MIMIC-CXR 的肺分割数据集 [49] 中提供。 为了从肺掩码中提取肺区掩码,基于 MIMIC-CXR 的 Chest Imagenome 数据集 [50] 中获得了六个肺区(左上、左中、左下、右上、右中、右下)的边界框。 相应的胸部 X 光图像直接从 MIMIC-CXR 数据库 [17] 中提取。 肺和肺区分割数据集包含来自相同数量受试者的 1,138 幅图像。 对于气胸和胸管,我们使用来自 CANDID-PTX 的胸部 X 光图像和掩码 [47],包含来自相同数量受试者的 19,237 幅图像。 VinDR-RibCXR 数据集 [51] 包含从 245 名受试者收集的图像中 20 根肋骨(L1-L10、R1-R10)的肋骨分割。
附录 C 实现细节
C.1 预训练
我们在 4 个计算节点上训练编码器,每个节点有 4 个 NVIDIA A100 GPU。 为了预训练编码器 (ViT-B/14),我们使用 640 的训练批次大小(每个 GPU 40),AdamW 优化器,基础学习率 0.001 和具有线性预热余弦学习率调度器。 对于 518 518 大小的输入图像,我们通过提取大小从 (259, 518) 中采样的随机裁剪,并将其上采样回 518 518 来生成全局视图。 对于局部视图,我们使用 (104, 259) 并上采样到 196 196。 编码器经过 100 个 epochs 的训练。 部分2中提供了包括增强在内的更多详细信息。
C.2 基线图像编码器
基线图像编码器的源代码和预训练权重从公共资源获取:CLIP@224 111https://huggingface.co/openai/clip-vit-large-patch14,CLIP@336 222https://huggingface.co/openai/clip-vit-large-patch14-336,BioViL-T 333https://huggingface.co/microsoft/BiomedVLP-BioViL-T,BiomedCLIP 444https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224,MRM 555https://github.com/RL4M/MRM-pytorch,以及DINOv2 666https://github.com/facebookresearch/dinov2。 对于每个基线,我们使用了其对应的图像预处理管道和图像推理实现(如果有提供)。 如果网络在对比学习预训练期间使用了特殊符元,例如[CLS],则在线性探测实验中使用它来获得更好的基线性能。 对于MRM基线,我们观察到在池化后的patch嵌入上进行探测时,下游性能更好,这些嵌入在预训练期间被用于掩码图像和文本建模目标。 由于基线评估侧重于解释单个图像,因此BioViL-T模型在静态模式下进行评估,而不是在对两个连续扫描进行时间分析。
C.3 下游评估任务
以下提供了第 4节中介绍的每个下游网络训练和评估的实施细节:
图像分类:
我们使用96(每个GPU 12)的训练批次大小,AdamW优化器,基本学习率和余弦学习率调度器。 我们使用以下预处理和增强:中心裁剪和调整大小(对于BiomedCLIP除外,我们调整大小为224 224,其他所有编码器为518 518),随机水平翻转,随机裁剪,随机仿射变换,随机颜色抖动和随机高斯噪声。 对于实验,我们使用从MIMIC-CXR [17]中所有图像计算的统计数据来规范化强度。 分类模型训练100个epoch。 我们选择最后一个检查点用于测试集上的推理,因为我们在监控验证损失时没有观察到过拟合。
语义图像分割:
我们使用80(每个GPU 10)的训练批次大小,Adam优化器,基本学习率和余弦学习率调度器。 我们使用以下预处理和增强:中心裁剪和调整大小(对于BiomedCLIP除外,我们调整大小为224 224,其他所有编码器为518 518),随机水平翻转(左肺和右肺以及肺区除外),随机仿射变换,弹性变换,随机亮度和对比度抖动以及随机伽马调整。 为了进行实验,我们使用从 MIMIC-CXR [17] 中所有图像计算的统计数据来规范化强度。 分割模型训练了 100 个 epoch。 我们分别使用 70/15/15 的主题分割来创建训练集、验证集和测试集,并在测试集上报告指标(对于肋骨分割,我们使用提供的分割数据,即 196 个训练样本,49 个测试样本)。 在验证集上损失最小的模型用于在测试集上进行推理。
文本报告生成:
训练在具有 80GB RAM 的 4 个 NVIDIA A100 GPU 的计算节点上执行。 我们使用与 LLaVa-1.5 [44] 中相同的超参数集。 即,我们使用 128 的批次大小(每个 GPU 32),以及在训练步骤的 3% 期间进行预热和基础学习率的余弦学习率调度器 。 我们只对三个 epochs 执行单阶段微调,其中图像编码器被冻结,而 LLM 以及适配器则被更新。 最后,在推理过程中,我们使用 32 位全精度来解码最多 150 个符元,批次大小为 1。
患者元数据的实验:
首先,我们从 MIMIC-CXR 数据集中选择一个子集,其中放射学报告中注明“无发现”。 然后,我们将匿名主题信息与 MIMIC-IV 数据集中提供的医疗记录联系起来。 产生的数据集包含 60.1k 个具有 AP/PA 视图的图像。 其次,我们计算 BioViL-T、BiomedCLIP 和 的嵌入。 第三,我们训练一个逻辑回归模型来预测元数据变量:性别、年龄、体重和 BMI,使用图像嵌入。 该模型使用五折交叉验证进行评估,数据按照 80/20 的比例划分,并使用默认设置训练了 100 个 epoch(我们使用了 scikit-learn [123] 中的 LogisticRegression 模块)。 性别是一个二元变量,类别为女性(N = 29.3k)和男性(N = 30.8k)。 连续变量年龄、体重和 BMI 分别被离散化为五个箱。 数据集在这些箱中的分布如下:
-
•
年龄(岁):< 20 (N = 0.8k),20–40 (N = 11.1k),40–60 (N = 23.2k),60–80 (N = 20.4k),> 80 (N = 4.6k)
-
•
体重(kg):< 50 (2.7k),50–65 (11.3k),65–80 (17.9k),80–95 (14.2k),> 95 (13.8k)
-
•
BMI (): < 18.5 (1.9k),18.5–25 (17.4k),25–30 (18.8k),30–35 (11.4k),> 35 (10.4k)