DynaVis:用于可视化编辑的动态合成 UI 小部件
摘要。
用户经常依靠 GUI 来编辑可视化并与之交互——由于编辑选项空间很大,这是一项艰巨的任务。 因此,用户要么被复杂的 UI 淹没,要么被带有定制的、固定的选项子集且编辑灵活性有限的自定义 UI 所限制。 自然语言界面 (NLI) 正在成为用户指定编辑的可行替代方案。 然而,NLI 放弃了传统 GUI 的优势:探索和重复编辑以及查看即时视觉反馈的能力。
我们引入DynaVis,它融合了自然语言和动态合成的 UI 小部件。 当用户用自然语言描述编辑任务时,DynaVis 会执行编辑并合成一个持久小部件,用户可以与之交互以进行进一步修改。 研究参与者 (n=) 更喜欢 DynaVis,而不是纯 NLI 界面,理由是由于即时视觉反馈,可以轻松进行进一步编辑并增强编辑信心。
DynaVis in action
1. 介绍
现代交互式可视化创作工具(例如 Tableau (tab,2023)、PowerBI (pow,2023a)、Lyra (Satyanarayan 和 Heer,2014)、Charticulator (Ren 等人, 2018)) 大大减少了从数据创建初始可视化的工作量。 使用这些工具,作者只需指定从数据字段到视觉属性的高级映射,并且在幕后,这些工具会自动提供“智能默认值”(Wilkinson,2005;Satyanarayan 等人,2016) 填写数百个图表参数——隐藏底层细节。
虽然这些智能默认设置通常足以进行探索性分析,但想要细化可视化以更好地传达他们的见解的作者和想要自定义可视化以回答其分析目标的读者通常会发现自己需要编辑这些默认的可视化效果。 例如,为了防止较长的标签在折线图中重叠,用户必须在 轴上旋转标签。 或者,用户必须添加过滤器以仅包含给定日期范围内的数据(参见图2)。
这些编辑通常被认为是可视化的“小调整”,但这些长尾编辑可能非常具有挑战性。 首先,用户需要区分哪些选项将产生所需的编辑效果(例如,了解他们需要“勾选”选项而不是“缩放”或“图例”来编辑标签角度),这需要低水平的专业知识层次可视化语法。 然后,用户需要发现工具中的编辑选项,该选项可能隐藏在工具 GUI 中的菜单和面板层中(例如,用户需要右键单击 轴)打开其属性编辑器,找到刻度上的子面板,找到旋转选项以更改标签角度),如果没有良好的工具专业知识,这可能很难实现。 结果,用户要么看到一个复杂的用户界面,其中充满了选项,要么看到一个旨在简化导航的定制界面,但他们经常发现自己受到太多限制,无法执行所需的自定义。
解决这一可视化编辑和细化挑战的新兴方法是设计自然语言界面 (NLI),允许用户用自然语言描述编辑效果。 然后,根据用户的指令,工具会自动推断必要的选项和相应的值以应用编辑。 例如,用户可以发出自然语言命令“将 轴标题移动到轴的左侧”,这将转换为更改“”编码为值“start”。 然而,虽然 NLI 解决了发现和导航挑战,但它们放弃了 GUI 的优势,尤其是执行细粒度编辑、从编辑结果获取即时视觉反馈以及快速撤消和重新应用编辑的能力。 例如,如果用户想要使折线图中的笔划宽度更粗,他们并不总是考虑到确切的尺寸,并且在选择尺寸之前常常会尝试不同的尺寸。 或者,如果用户想要更改条形图的颜色,他们可能不知道要提供的确切的十六进制(或 RGB)值。 这些限制限制了 NLI 在可视化编辑中的应用。
为了解决可视化编辑和细化的挑战,我们设计了一种新的交互方法,通过动态合成的 GUI 小部件进行交互,并开发了一个名为 DynaVis 的可视化编辑工具。 我们的关键设计见解是将自然语言界面与交互式 GUI 小部件融合在一起,以便用户可以从 NLI 减少执行鸿沟(nn-,2023)和 GUI 交互性中受益。 要执行可视化编辑任务,用户首先描述他们想要执行的编辑(例如,“将 轴标签旋转 45 度”)或直接请求他们想要执行的 GUI 小部件编辑(例如,“给我一个滑块来控制 轴标签角度”);无论哪种方式,DynaVis 都会使用大型语言模型(大语言模型)合成 GUI 小部件(以及前一种情况下用户规范中的预设值),供用户探索和执行后续编辑。
除了减少导航开销和探索编辑效果的交互性等直接好处外,用户还可以使用动态小部件轻松组合和协调多个编辑,因为它们在合成后仍然存在,以便快速编辑访问。 在幕后,我们设计了一个由大型语言模型提供支持的小部件合成引擎,该模型将用户输入转换为小部件的 HTML 实现,以及将小部件输入连接到可视化属性的回调函数。 DynaVis 具有很强的表现力,支持图表设计编辑(例如,调整刻度间距、图例位置、配色方案、标签和标题字体属性),以便作者完善可视化效果,还支持与数据相关的编辑(例如,生成过滤器、缩放控制器和排序),让读者能够交互式地探索可视化效果,而无需预先构建的交互式小部件。 我们对 24 名参与者进行的研究表明,与纯 NLI 界面相比,参与者更喜欢使用 DynaVis,因为易于重复编辑,并且由于即时视觉反馈,使用 GUI 进行编辑时更有信心。
我们的贡献如下:
-
•
一种用于可视化编辑的新交互式方法,即动态小部件,它将 NLI 与 GUI 小部件相结合,以减少执行鸿沟并增强交互性。
-
•
一个小部件合成引擎,利用大型语言模型将自然语言输入转换为小部件和控制功能。
-
•
一项用户研究,旨在评估用户如何使用 DynaVis 来解决可视化编辑任务。
2. 使用场景
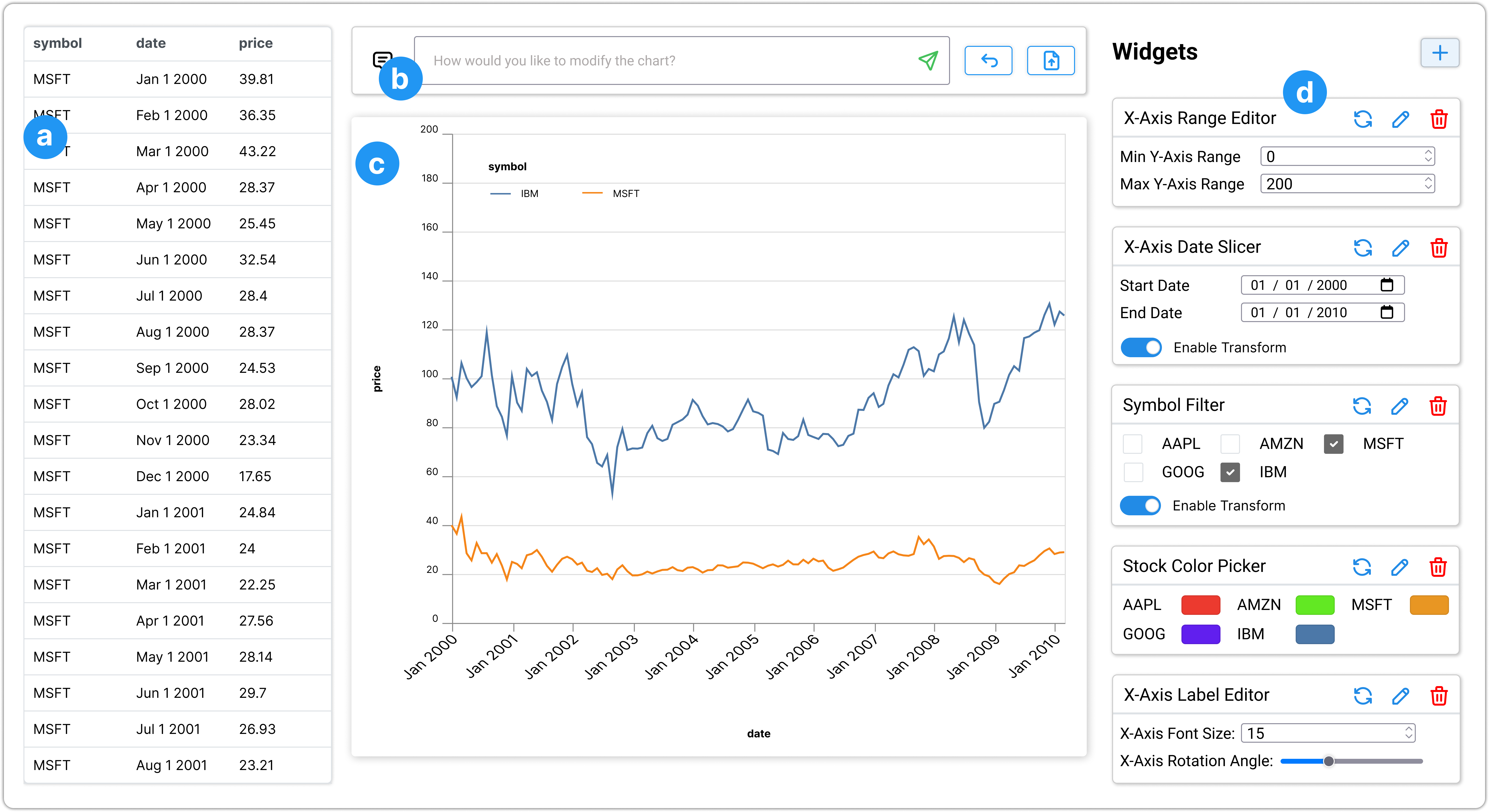
Alice 是一名使用电子表格分析科技公司股票趋势的顾问,她需要创建可视化效果以向合作者展示她的分析结果。 下面,我们描述 Alice 使用 DynaVis 编辑和增强图表的经验。 Figure 1显示了DynaVis的UI,它包含四个主要组件:(a)数据面板,(b)用于指定可视化和编辑命令的命令栏,(c) ) 显示当前工作图表的可视化面板,以及 (d) 合成动态小部件面板,用户可以使用它来管理小部件和编辑工作图表。
初始图表。
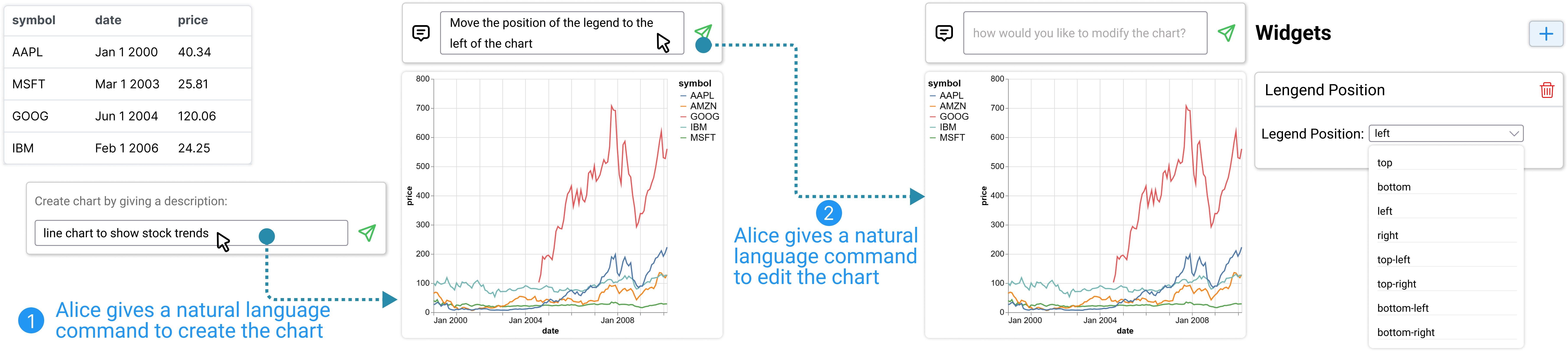
通过图表编辑命令调整图例位置。
Alice 首先想要调整图例位置,以将图例保留在主图表画布内。 她决定使用图表编辑命令来描述她想要应用的更改。 为此,她通过自然语言命令栏提供了指令“将图例移至图表左侧”。 根据指令,DynaVis 更新可视化规范以重新定位图例。 此外,DynaVis 还会自动生成一个小部件,其中包含预先填充的各种图例位置的下拉菜单。 如图Figure 3-(2)所示,使用这个小部件,Alice 尝试了多个图例位置,然后最终确定了“左上角”的最终选择,这实际上是一个比“离开”是爱丽丝一开始没想到的。
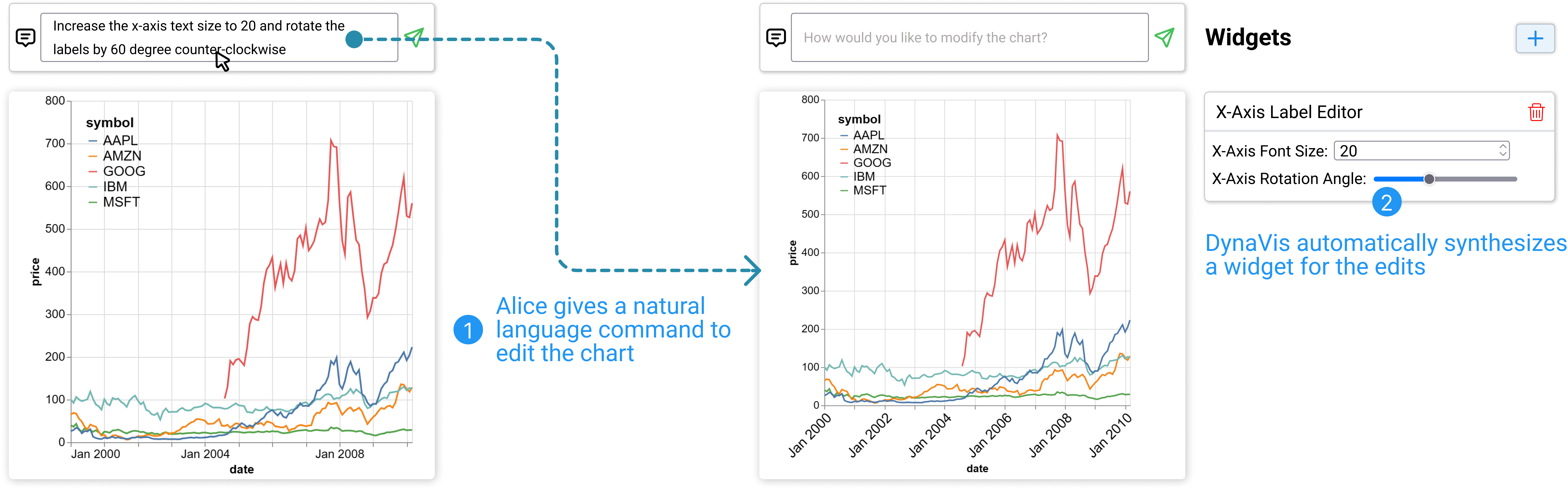
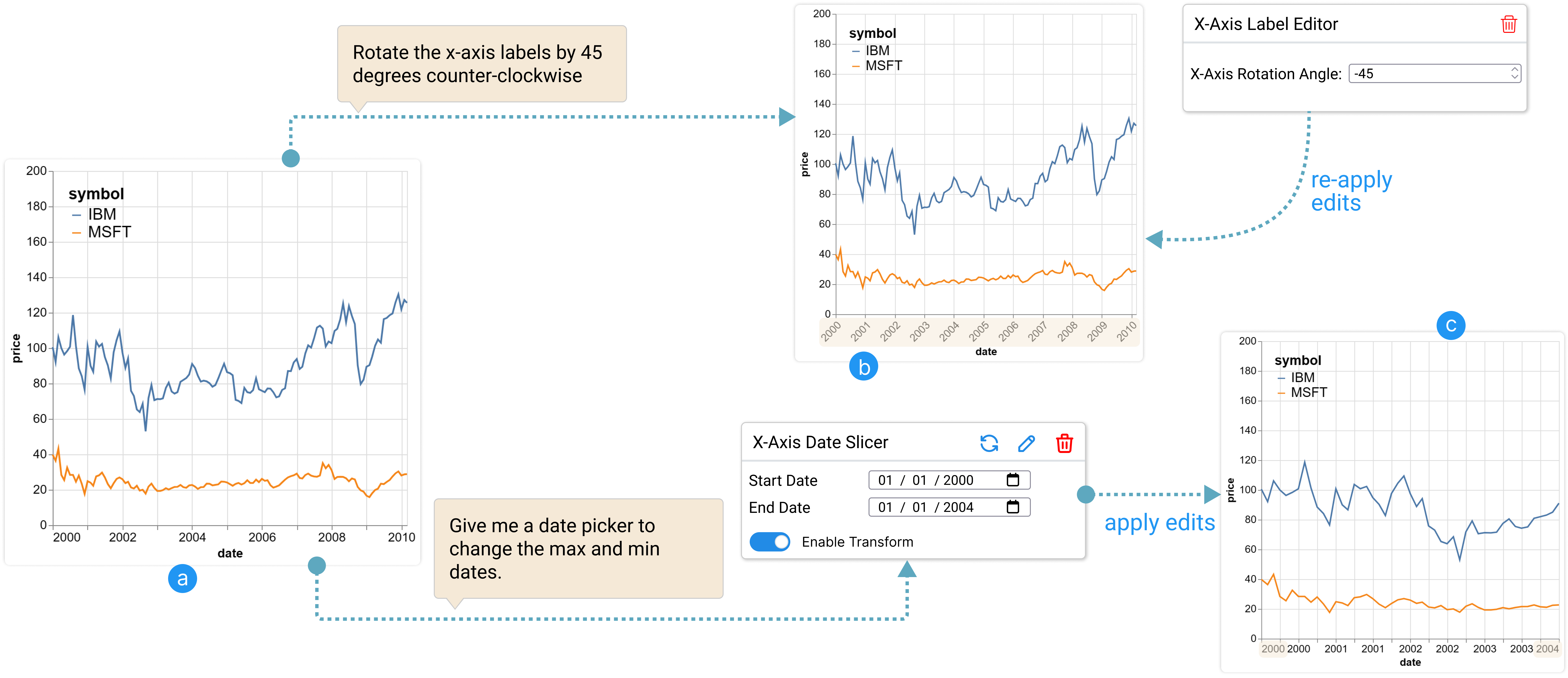
协调编辑轴标签的文本大小和旋转角度。
接下来,Alice 希望解决 轴标签的问题,这些标签目前太小而无法阅读。 然而,这可能是一个相当具有挑战性的编辑:增加字体大小很可能会使标签彼此重叠;虽然可以通过旋转标签角度来解决重叠问题,但旋转过多会降低其可读性。 因此,Alice 需要协调标签字体大小和旋转角度的编辑,以找到正确的平衡。 Alice 还不清楚什么是最佳组合,因此她从一个探索性命令开始:“将 轴文本大小增加到 并旋转标签度”。 DynaVis 根据命令更新图表,并为她提供一个 “ 轴标签编辑器” 小部件,让她可以编辑文本大小和角度同时显示 轴标签(见图 4)。 这样,Alice 就可以轻松尝试多种组合,而无需重新发出编辑指令。 经过反复试验,她确定了适合她需要的字体大小 和旋转角度 。

通过小部件创建命令选择颜色。
现在,Alice 想要修改图表的默认调色板。 由于 Alice 心里还没有具体的颜色,她决定使用 DynaVis 的小部件创建功能来请求小部件来探索颜色选项。 为此,她单击小部件面板顶部的“+”按钮(Figure 5)打开小部件创建命令框,然后输入提示“更改每个股票代码的颜色”。 DynaVis 了解图表的当前上下文和当前数据集,生成一个定制的“股票颜色选择器” 小部件,该小部件允许她为图表中的每个股票代码选择颜色图表(见图5)。 DynaVis 甚至知道属于她当前数据集的所有符号,并且可以为她生成定制的小部件。 Alice 可以使用此小部件尝试不同的颜色,获得即时视觉反馈,并为她的图表选择所需的颜色。
使用数据过滤器小部件进行数据探索。
Alice 完成定制后,将可视化结果通过电子邮件发送给她的合作者 Alex,后者计划将可视化结果包含在他正在撰写的新闻文章中。 经过一番分析后,Alex 希望比较 MSFT 和 IBM 的股票趋势,以获得更深入的见解。 Alex 没有回去要求 Alice 这样做,而是导入 DynaVis 中的可视化规范来执行编辑(一个 JSON Vega-Lite 规范,其中包含section 3)。 导入后,Alex 提供命令“仅比较 MSFT 和 IBM”,DynaVis 快速更新图表以运行过滤器转换,以仅显示 MSFT 的数据和IBM。 DynaVis 还提供了一个“Symbol Filter” 小部件,其中每个股票代码都有一个复选框,Alex 可以使用它继续比较不同的股票趋势,选择一个或多个代码进行比较(Figure 1,第三个小部件)。 DynaVis 还可以智能地识别该小部件具有数据过滤转换,并为用户提供切换器以启用或禁用转换。
评论:
得益于 DynaVis 的以下优势,Alice 和 Alex 可以轻松完成可视化细化和探索任务。
-
•
在传统的 GUI 中,Alice 需要导航菜单和面板来定位小部件以执行编辑,这需要她精通 GUI 和可视化术语。 DynaVis 允许 Alice 通过自然语言描述获取所需的小部件,从而降低了这一障碍。
-
•
合成的小部件允许 Alice 执行细粒度编辑并从编辑结果中获取即时视觉反馈,这使她能够探索和协调编辑选项。 这使她能够通过反复试验找到她以前不准确的编辑(例如颜色、旋转角度和文本)的最佳编辑。 Alice 将无法使用 NLI 轻松探索编辑选项,因为它要求她描述具体的参数值并且具有延迟的规范反馈周期。
-
•
DynaVis 具有很强的表现力,支持作者 Alice 的图表细化编辑和读者 Alex 的数据操作编辑。 如果没有 DynaVis,Alex 要么每次想要图表的更新版本时都必须与 Alice 交互,要么要求 Alice 创建交互式可视化,这需要额外的努力来定制选项。
-
•
由于动态小部件在创建后仍然存在并且完全组合,因此 Alice 和 Alex 可以返回并重复编辑(例如,随着分析目标更改而更新 轴范围)或恢复某些编辑(例如,撤消数据过滤) 。 这对于 NLI 来说可能具有挑战性,因为更改是非组合性的,并且每次更新都需要新的编辑命令。 或者,使用传统的 GUI,他们需要跟踪所做的所有编辑,以便重复或重做编辑。
3. DynaVis系统设计与实现
在本节中,我们首先描述小部件核心概念背后的设计原则。 然后我们描述用于动态生成这些小部件的综合框架。 DynaVis 是一个跨平台 Web 应用程序,使用 React 和 Typescript 实现前端用户界面,使用 Python 实现后端服务器。
3.1. 动态小部件
小部件作为模块化子组件。
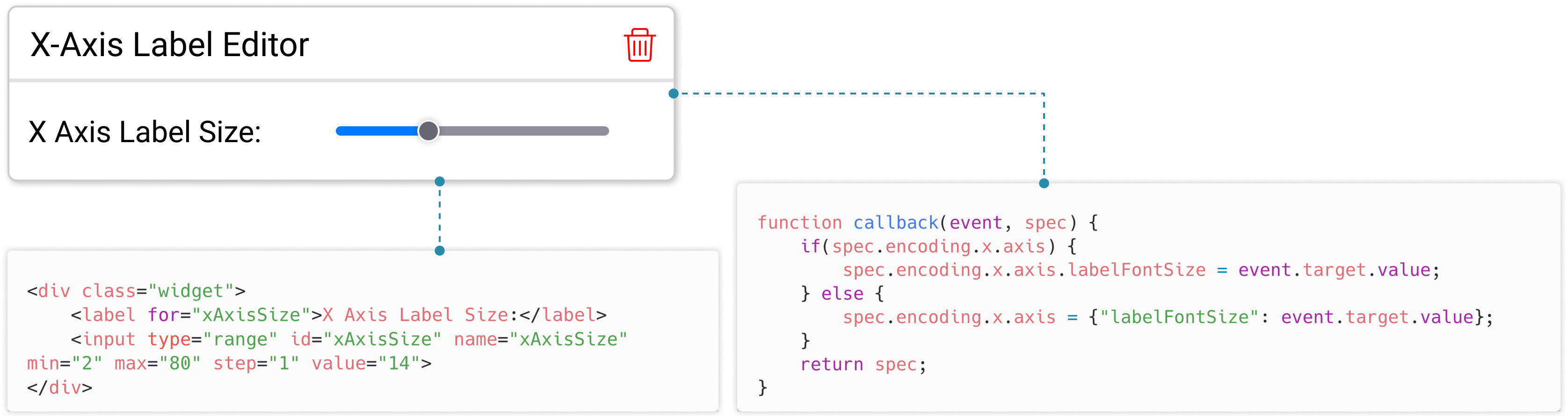
通过 DynaVis,我们引入了动态小部件,它们是小型模块化 UI 组件,专注于手头的特定编辑或交互任务。 编辑可以涉及对一个或多个图表属性的简单更改,例如更改图例或切片的位置,或者可以涉及在图表渲染之前对数据执行的数据转换操作,例如过滤轴上的特定范围。 从高层次来看,小部件有两个组件:
-
•
一个 HTML 脚本,描述用户将与之交互以操作可视化的小部件的 UI 元素。 例如,包含滑块类型的 ¡input¿ 元素的 HTML 脚本,用于更改图表的 x 轴标签大小(参见图 6)。
-
•
JavaScript 回调函数,其中包含每当用户与小部件交互时将执行以操作可视化和/或数据的代码。 此回调函数的形式为 callback(event, Chart) =¿ (transforms, Chart),它接受 HTML 事件对象和当前图表作为输入,并生成可选的转换列表和更新图表作为输出。 此回调函数附加到 HTML 脚本中所有输入元素的 onChange 事件处理程序。
图 6 显示了动态小部件的示例及其 HTML 脚本和 Javascript 回调函数。
我们系统的主要设计选择之一是确保小部件的模块化,以便两个不同小部件的编辑不会发生冲突或以意外的方式操纵图表。 此要求对我们处理图表和转换的方式有影响:
处理图表。
为了确保每个小部件仅更改图表的一小部分,我们认识到使用声明性图表表示比命令性图表表示更可取。 一种这样的声明性表示是使用 JSON 对象(称为规范)对图表的属性进行编码。 例如,使用 JSON 表示形式,要更改 x 轴标题,只需将图表规范编辑为 spec.encoding.x.title = ”axis title”,而无需更改有关 x 轴标题的任何其他内容图表。
在本文中,我们使用 Vega-Lite 规范(Satyanarayan 等人,2016) 来表示图表,因为它为我们提供了简洁且声明性的可视化表示,同时又保持了表现力。 Vega-Lite 还提供了一个支持良好的渲染引擎,与所有主要的 Web 框架兼容。
处理数据转换。
数据转换是可视化编辑的重要组成部分。 DynaVis 处理所有 Vega-Lite 数据转换,例如过滤、折叠、展平等。 在DynaVis中,变换被表示为类似于Vega-Lite的对象列表。 每个小部件的回调都会输出一个转换列表。 转换按照此列表中指定的顺序执行。 如果有多个具有转换的小部件,我们将按照小部件的时间顺序执行转换。 为了实现这一点,我们保留小部件到其最近回调的输出转换的映射,以便我们可以在每次编辑渲染图表之前按上述顺序执行所有小部件的最新转换。 对于向图表添加转换的每个小部件,DynaVis 添加一个开关,以便用户可以启用或禁用转换。 例如,让我们以第 2 节中的 Alex 为例。 当他们请求小部件对日期范围进行切片时,合成的小部件会在数据上添加过滤器转换。 DynaVis 将其标识为特殊的转换小部件,并允许 Alex 动态启用或禁用转换以查看原始图表和过滤后的图表。
3.2. 综合框架
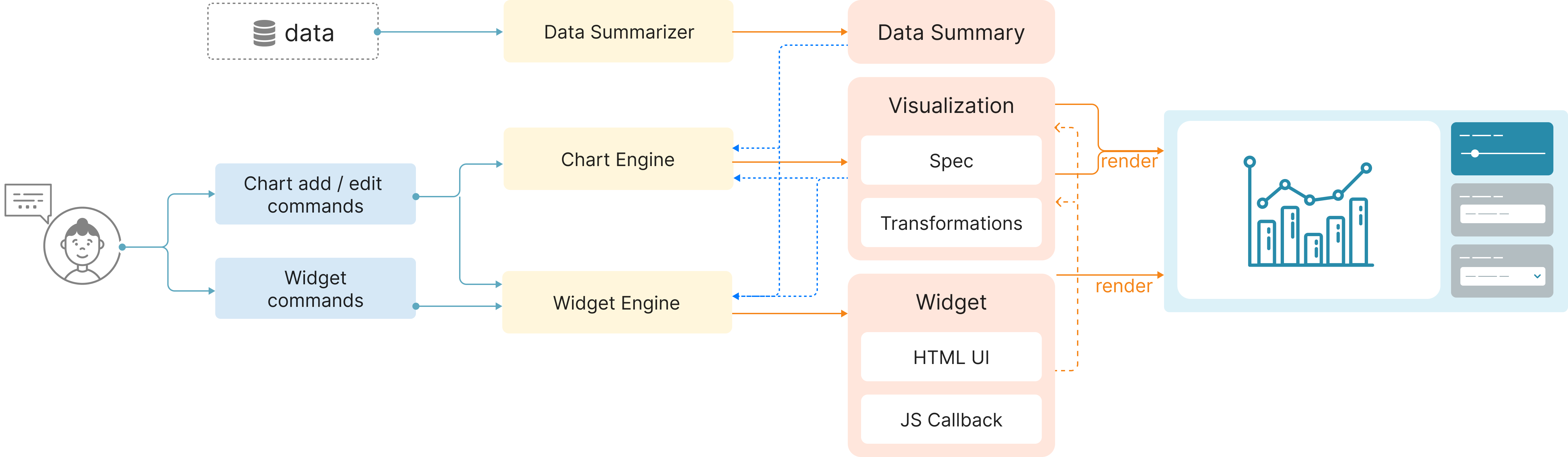
下面我们通过将其分为三个阶段来描述我们的合成框架:预处理、基于 LLM 的合成和后处理。 我们的框架由 3 个主要模块组成:数据摘要器、图表引擎和小部件引擎,如图 7 所示。

3.2.1. 预处理:数据汇总和可视化预处理
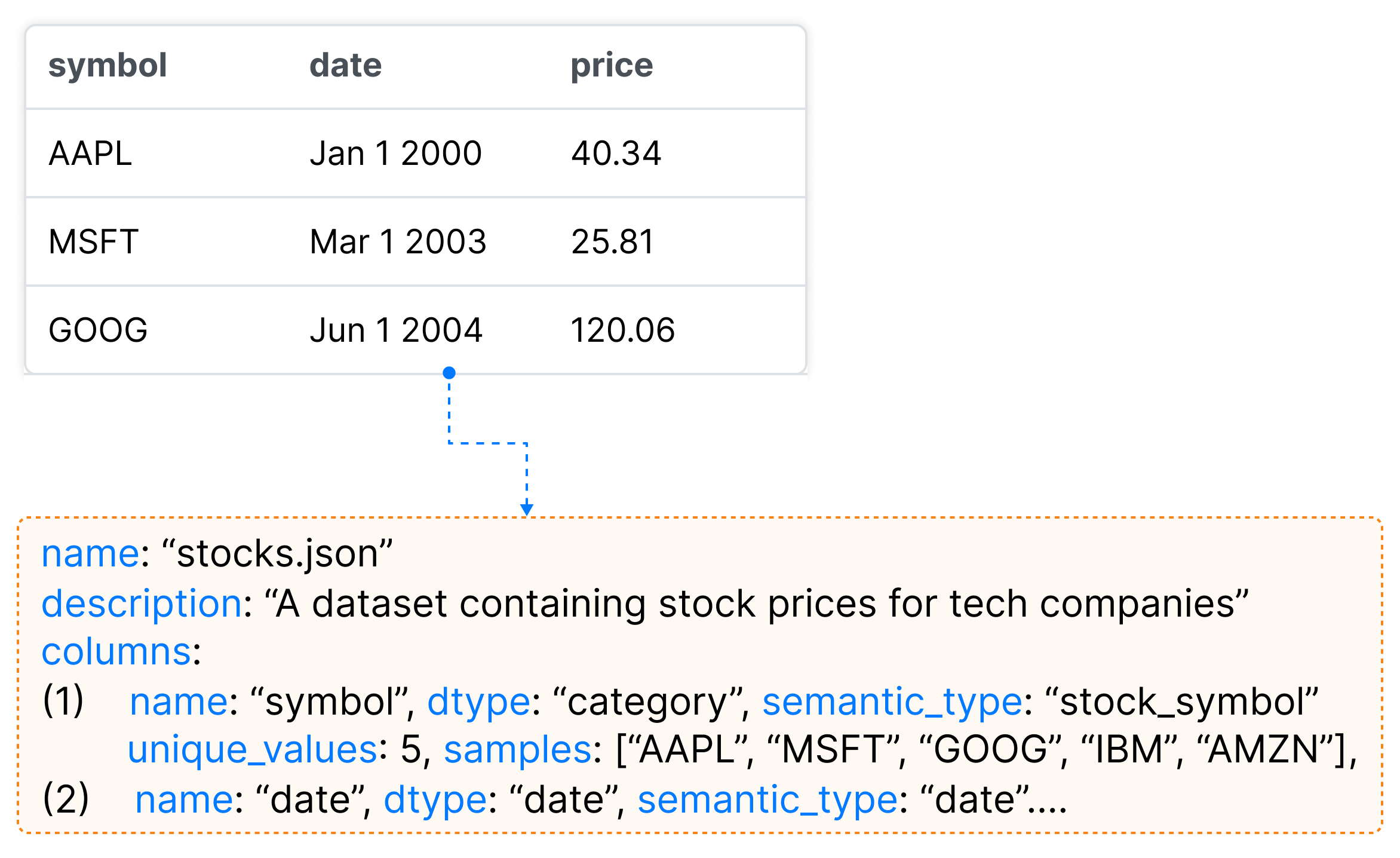
为了生成可视化效果并合成动态小部件,大语言模型需要用户正在使用的数据的准确上下文。 然而,由于大语言模型支持的上下文窗口有限,我们无法将整个数据传递给大语言模型。 因此,为了用数据的基础上下文来增强大语言模型,我们借用了 Lida (Dibia,2023) 的 Data Summarizer。 该摘要器用于为任何给定数据集生成密集而紧凑的摘要,该摘要可用作可视化任务的基础上下文。 对于后续步骤中的每个大语言模型查询,我们传递数据摘要而不是数据。 首先,摘要器应用规则来提取数据集属性,包括原子类型(例如整数、字符串、布尔值)、一般统计数据(最小值、最大值、唯一值等)以及使用 pandas 的每列的 n 个样本的随机列表python 库(pan,2023)。 然后,通过大语言模型丰富基本摘要,以包括数据集的语义描述(例如,10 年来排名前 5 的科技公司的股票价格数据集)和字段(例如,以美元计价的股票价格)以及字段语义类型预测(张等人,2019)(见图9)。
在向大语言模型发送任何编辑或小部件综合查询之前,DynaVis 将数据与可视化规范以及任何其他不必要的图表属性(如宽度、高度等配置属性)分开,以防止上下文溢出。 这也确保了渲染引擎能够保持对 UI 变化的响应。
3.2.2. 基于 LLM 的可视化和动态小部件综合
综合可视化。
图表引擎主要负责合成可视化效果——新的可视化效果或根据用户的自然语言提示编辑现有的可视化效果。 图表引擎使用来自摘要器的丰富数据摘要、用户提示以及可选的现有 Vega-Lite 规范来返回使用大语言模型的 Vega-Lite 规范 [图 9]。 为了确保大语言模型生成有效的 Vega-Lite 规范,并防止基于版本的错误,我们指示模型仅使用 Vega-Lite Schema v5 并生成有效的 JSON 输出采用带有语言描述符的 Markdown 代码块格式。 由于基于聊天的模型(例如 GPT 3.5)经过训练可以生成详细输出,因此使用 Markdown 代码块格式可确保我们能够可靠地提取代码块。 为了保持输出的一致性,我们提供了一些 Vega-Lite 规范的少样本学习示例及其对模型的描述。
合成动态小部件。
Widget Engine主要负责合成动态Widget。 小部件引擎使用数据摘要、当前的 Vega-Lite 图表规范以及用户提示来返回小部件组件 - HTML 脚本和 Javascript 回调函数。
为了确保大语言模型为小部件生成有效的程序,我们为 HTML 和 JavaScript 提供了严格的模板。 HTML 模板定义带有注释指令的空 ¡div¿ 存根。 JavaScript 模板有一个空的 JS 函数存根,带有预定义的返回值。 该模板提高了生成的代码的可靠性和可预测性。 模板还可以帮助我们在下一步的程序分析中验证代码。 我们还向模型提供了少量 HTML 和 JS 代码示例,以保持输出的一致性。
3.2.3. 通过程序分析进行后处理
处理可视化
从 Markdown 输出中提取 JSON 规范后,我们会解析该规范以检查 JSON 格式错误,然后编译 Vega-Lite 规范以检查合成规范中的语法或模式错误。 如果出现错误,我们会提供错误消息并要求模型在同一对话上下文中修复错误。 如果这不起作用,我们会再次尝试提示。
处理动态小部件
为了防止错误,并确保小部件的有效性,DynaVis通过程序分析对大语言模型合成的HTML和JS代码进行了一系列后处理步骤。 我们在下面提到后处理阶段涉及的许多步骤中的一些步骤。 每个步骤都是通过将 HTML 和 JS 代码解析为抽象语法树 (AST) 并操作 AST 来实现的。
-
•
解析 HTML 代码,确保合成的小部件与之前的小部件之间的 HTML“ID”属性不存在冲突。 如果发现冲突,我们以编程方式修改ID属性并修改相应的JS回调函数。
-
•
解析合成的 JS 回调函数,确保其具有正确的函数名称和有效的函数参数。
-
•
识别并替换在 HTML 脚本中修改的回调函数中使用的 HTML ID。
-
•
DynaVis 确保正在编辑的图表的属性已存在于当前图表中,或者回调函数正确处理 null 情况。
3.3. 用户界面实现
DynaVis 使用 React 和 Typescript 实现为 Web 应用程序。 我们使用 html-react-parser (npm, 2023) 库在创建和删除小部件时动态附加和分离小部件。 DynaVis 的支持主机数据摘要器(在 pandas 中实现)实现为 Flask Web 服务器,使用 REST API 与前端进行通信。 我们使用 OpenAI API (ope, 2020) 向大语言模型发出查询。 我们选择 gpt-3.5-turbo 作为当前 OpenAI 实施中的目标大语言模型,因为它在准确性与速度之间取得了适当的平衡。 由于我们必须在交互时间内进行编辑和合成小部件,以防止打扰用户,因此 GPT-3.5 模型的响应速度足够快且足够准确,足以满足我们的需求。 我们还使用更先进的 GPT-4 模型测试了我们的工具,该模型支持更长的上下文,并具有更好的指令跟踪能力,可以更准确地生成小部件。 然而,延迟太高,无法流畅交互。
4. 用户研究设计
为了了解用户如何使用 DynaVis 来解决可视化编辑任务,我们对 24 名参与者进行了一项受试者内实验室研究。 在这项研究中,用户被要求解决两组五个可视化编辑任务,一组使用 DynaVis,另一组使用基于 NLI 的基线工具。 我们的目标是回答以下研究问题:
-
RQ1
DynaVis 是否减少了用户编辑可视化的工作量?
-
RQ2
与基线工具相比,用户在哪些场景下更喜欢使用动态小部件?
-
RQ3
用户使用动态小部件的策略是什么?
4.1. 参加者
我们通过两所研究型大学的邮件列表招募了 24 名参与者(13 名女性、10 名男性、1 名选择不透露)。 在 24 名参与者中,2 名参与者每天至少进行一次数据可视化,4 名参与者每周进行一次可视化,14 名参与者每月至少进行一次可视化,4 名参与者频率较低但仍偶尔进行数据可视化。 参与者提到他们之前有使用各种可视化工具和库的经验,包括 matplotlib (Python)、Seaborn (Python)、ggplot (R)、Tableau、Excel、D3 等。 没有一个参与者有任何使用 Vega-Lite 或 Vega 库的经验。 24 名参与者中有 3 名表示他们每天进行数据分析,6 名参与者每周进行一次,8 名参与者每月至少进行几次,7 名参与者偶尔进行(每月少于几次)。 参与者收到了一张价值 25 美元的亚马逊礼品卡,作为对他们时间的补偿。
4.2. 学习条件
我们在用户研究中考虑以下两个条件。 我们选择基于 NL 的可视化编辑方法作为基线(Dibia 和 Demiralp,2019)。
-
•
基线条件 (): 我们修改了 DynaVis 界面,支持自然语言命令以及一组用于基本图表操作(例如图表标题、轴范围等)的预填充 UI 小部件,并删除了对动态小部件。 通过提供 NL 和基本 UI 支持供用户自由选择,我们相信这是一个公平的、最先进的研究基线工具。 预填充的小部件类似于用户用于编辑可视化效果的静态 UI(例如 Excel、Google Sheets 等)。 对于编辑任务,用户可以使用自然语言命令和预填充小部件的组合来编辑图表。
-
•
实验条件(): 这是 DynaVis,在 之上支持动态小部件。 通过此 UI,用户可以使用自然语言命令编辑图表、添加自定义动态小部件或使用同一组预填充小部件。 此外,每当用户向人工智能提供自然语言编辑命令时,我们都会合成并自动添加动态小部件。 我们按时间倒序显示合成的小部件,因此最新合成的小部件显示在顶部。
请注意,我们没有基于现有可视化工具明确设置仅包含小部件的基线,因为这需要我们将参与者限制为只有具有某种可视化工具经验的人员,从而限制了参与者的多样性。 不过,我们确实在采访中收集了用户的反馈,了解他们对 DynaVis 的体验与他们最喜欢的工具有何不同的看法。
4.3. 任务
我们选择了来自流行数据集的三个数据可视化任务。 由于我们的重点是可视化编辑任务,而不是创作任务,因此参与者从基础数据集和基础可视化开始每个任务。 根据 Wang 等人 (2022) 进行的形成性研究,参与者必须对可视化进行一系列编辑。 每个任务包含五个子任务,其中包含对基本可视化执行编辑的说明。 我们包括以下三种类型的问题:(1)使用具体编辑任务编辑可视化,(2)探索性编辑任务(例如,尝试一些选项,然后选择最佳笔画宽度),以及(3)使用根据图表回答的问题(例如,放大时间窗口或范围、过滤数据等)。
任务 1(股票趋势)。
给定十年来排名前五的科技公司的股票价格数据集以及下面可视化股票趋势的基线图表,要求用户完成以下子任务。
![[Uncaptioned image]](task1.png) (1)
将图表标题更改为“股票趋势”。
(2)
尝试不同的线条笔划宽度,找到最适合您的一种。
(3)
编辑图表以仅显示 AAPL 和 MSFT 的股票趋势。
(4)
将 y 轴最大范围更改为 250 以获取放大视图。 然后,回答问题:“通过查看图表,即可获得 AAPL 和 MSFT 的最低和最高股价”。
(5)
现在仅在 IBM 和 MSFT 之间进行比较。 然后,回答问题:“通过查看图表,找到两家公司股价差异最大的月份和年份”。
(1)
将图表标题更改为“股票趋势”。
(2)
尝试不同的线条笔划宽度,找到最适合您的一种。
(3)
编辑图表以仅显示 AAPL 和 MSFT 的股票趋势。
(4)
将 y 轴最大范围更改为 250 以获取放大视图。 然后,回答问题:“通过查看图表,即可获得 AAPL 和 MSFT 的最低和最高股价”。
(5)
现在仅在 IBM 和 MSFT 之间进行比较。 然后,回答问题:“通过查看图表,找到两家公司股价差异最大的月份和年份”。
任务 2(失业数据)
给定美国多个部门的失业统计数据集和下面可视化失业人数分布的堆积面积图,要求用户完成以下子任务。
![[Uncaptioned image]](task2.png) (1)
将 x 轴标题更改为“时间轴”。
(2)
尝试不同的图例位置(图表内部和外部)以选择最适合您的位置。
(3)
编辑图表以仅显示建筑和农业部门的趋势。
(4)
将 y 轴最大日期编辑为 06/01/2004(2004 年 6 月)。 然后,回答问题:“通过查看图表,获得两个部门之间失业率差异最大的大致月份和年份”。
(5)
现在仅比较金融和建筑业。 然后,回答问题:“通过查看图表,获得两个部门之间失业率差异最大的大致月份和年份”。
(1)
将 x 轴标题更改为“时间轴”。
(2)
尝试不同的图例位置(图表内部和外部)以选择最适合您的位置。
(3)
编辑图表以仅显示建筑和农业部门的趋势。
(4)
将 y 轴最大日期编辑为 06/01/2004(2004 年 6 月)。 然后,回答问题:“通过查看图表,获得两个部门之间失业率差异最大的大致月份和年份”。
(5)
现在仅比较金融和建筑业。 然后,回答问题:“通过查看图表,获得两个部门之间失业率差异最大的大致月份和年份”。
任务 3(天气数据)。
给定西雅图十年天气的数据集和下面可视化每个月天气聚合分布的堆积条形图,要求用户完成以下子任务:
![[Uncaptioned image]](task3.png) (1)
将 y 轴标题更改为“记录数”。
(2)
将 x 轴标签旋转 45、65 和 90 度,然后选择最适合您的一个。
(3)
将每种天气类型的颜色更改为以下颜色:太阳更改为黄色,雪更改为灰色,雨更改为蓝色,雾更改为绿色,毛毛雨更改为紫色。
(4)
编辑图表以仅显示所有月份的“雪”天气。 然后,回答问题:“通过查看图表,找到降雪天数最少的月份”。
(5)
编辑图表以仅显示所有月份的“雾”天气。 然后,回答问题:“通过查看图表,找到雾日最高的月份”。
(1)
将 y 轴标题更改为“记录数”。
(2)
将 x 轴标签旋转 45、65 和 90 度,然后选择最适合您的一个。
(3)
将每种天气类型的颜色更改为以下颜色:太阳更改为黄色,雪更改为灰色,雨更改为蓝色,雾更改为绿色,毛毛雨更改为紫色。
(4)
编辑图表以仅显示所有月份的“雪”天气。 然后,回答问题:“通过查看图表,找到降雪天数最少的月份”。
(5)
编辑图表以仅显示所有月份的“雾”天气。 然后,回答问题:“通过查看图表,找到雾日最高的月份”。
4.4. 学习程序
为了轻松访问 DynaVis,我们在线托管了该工具的控制版和实验版,参与者可以通过网络浏览器访问这些版本。 在获得用户同意后,我们录制了每个参与者的音频和屏幕截图,并鼓励用户在研究过程中大声思考。 在每次研究中,参与者使用控制条件完成三项任务中的一项,并使用实验条件完成另一项任务。 为了减轻学习效果,通过随机分配在参与者之间平衡任务分配的顺序和工具分配的顺序。 因此,对于 3 个任务和 2 个条件的每个独特组合,我们有 8 个参与者数据点。 在学习课程中的每项任务之前,都会向参与者提供指定工具的教程,并允许他们使用测试数据集探索该工具 5 分钟。 在开始每项任务之前,我们还解释了数据集和基础可视化,并为参与者提供了探索和理解数据集的时间。 我们为每项任务设定了 15 分钟的时间限制。 每项任务完成后,参与者都会填写一份任务后调查,以反思他们使用该工具的体验。 完成这两项任务后,参与者回答了最终调查,以直接比较两种情况。 在每次研究结束时,我们还在研究结束时进行了简短的非正式访谈,以获取参与者参与研究的主观体验以及对该工具的反馈。
4.5. 测量和分析
我们在用户研究期间记录了定量和定性指标。 我们测量了参与者必须执行的每个编辑子任务的成功/失败。 如果参与者多次尝试使用该工具仍无法完成任务,则认为子任务失败。 他们可以根据自己的喜好重试多次。 通过应用程序遥测,我们还记录了用户向工具提供的所有自然语言命令以及与工具中小部件的交互。 在用户在每项任务后填写的任务后调查中,我们记录了自我报告的 NASA 任务负荷指数、自我报告的 Likert 分数以轻松完成任务,以及人工智能对他们意图的理解程度(有关调查问题,请参见表1)。 在用户在两项任务结束时填写的研究后调查中,我们记录了参与者自我报告的偏好,并修改了 NASA 任务负荷指数,该指数直接侧重于比较他们在两种工具之间的体验(有关调查问题,请参见表2)。 对于定性分析,第一作者对参与者的回答和音频记录进行开放编码以识别主题,然后与共同作者讨论以在多个会话中完善主题。 这些主题用于解释定性结果。 我们使用配对 t 检验来衡量定量指标的统计显着性。
| Q1.1. It was easy to complete the tasks using the tool provided. (1-Strongly Disagree, 7 - Strongly Agree) |
| Q1.2. The AI understood my intent and made the right edits. (1-Strongly Disagree, 7-Strongly Agree) |
| Q2.1. How mentally demanding was this task with this tool? (1—Very Low, 7—Very High) |
| Q2.2. How hurried or rushed were you during this task? (1—Very Low, 7—Very High) |
| Q2.3. How successful would you rate yourself in accomplishing this task? (1—Perfect, 7—Failure) |
| Q2.4. How hard did you have to work to accomplish your level of performance? (1—Very Low, 7—Very High) |
| Q2.5. How insecure, discouraged, irritated, stressed, and annoyed were you? (1—Very Low, 7—Very High) |
| Q1.1. Which tool would you prefer to use? (1-, 7-) |
| Q2.1. Which tool was more mentally demanding to communicate? (1-, 7-) |
| Q2.2. Which tool made you feel hurried or rushed during the task? (1-, 7-) |
| Q2.3. Which tool made you feel successful in accomplishing the task? (1-, 7-) |
| Q2.4. For which tool did you work harder to accomplish your level of performance? (1-, 7-) |
| Q2.5. Which tool made you feel more insecure, discouraged, irritated, stressed, and annoyed? (1-, 7-) |
5. 用户研究结果
5.1. 任务完成情况
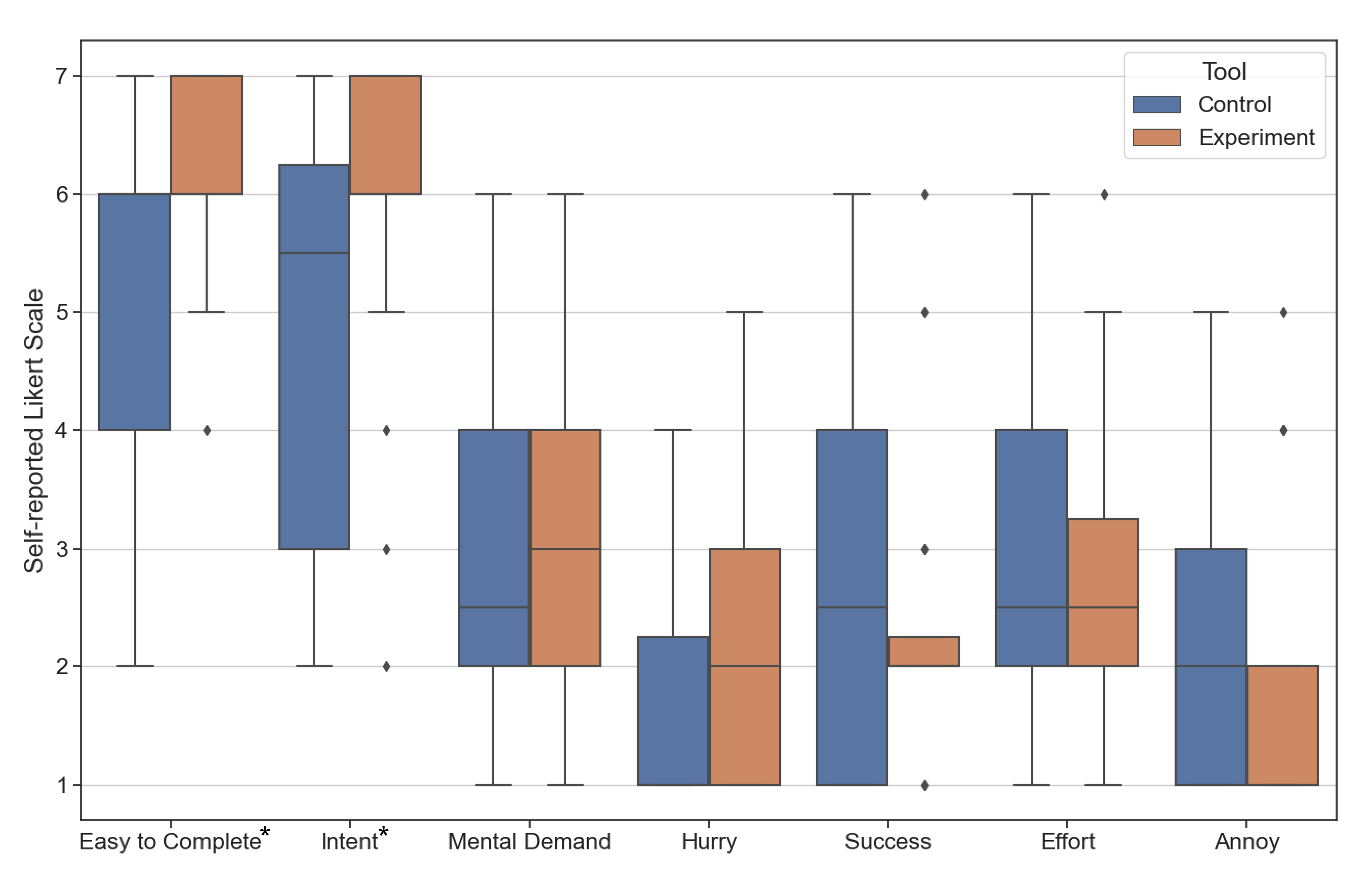
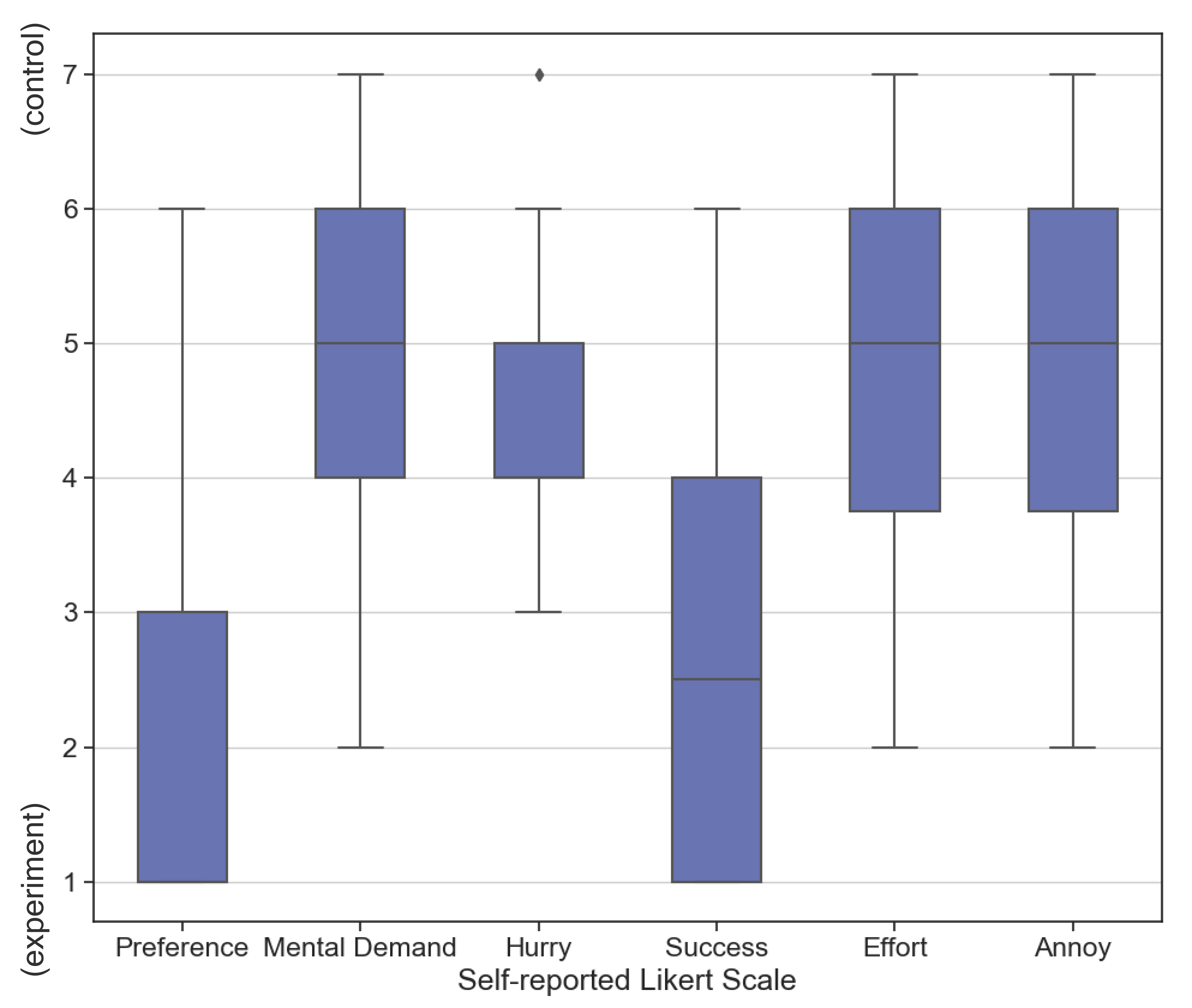
使用工具的参与者比使用工具的参与者更多未能完成子任务。 使用 工具时,与使用 工具。 在研究期间,没有一个参与者在一项以上的子任务上失败。 值得注意的是,尽管参与者根据自己的意愿多次重试任务,但仍会出现失败。 图11显示了自我报告的分数(李克特量表;越高越好),以方便使用针对每种情况提供的工具完成任务。 与使用 的参与者(, )相比,使用 的参与者明显()更容易完成任务(, )。
中参与者完成任务的平均时间为7分22秒(, 和 )。 在条件下,参与者平均花费6分36秒(、和)来完成任务。 两种情况下任务完成时间的差异不具有统计显着性。 请注意,某些子任务(例如任务 1.3)的探索性质鼓励参与者花时间探索可视化,并且完成速度并不是绩效的明确衡量标准。 我们在此报告完成时间,作为了解用户工作的设置,这将在以下部分中讨论。
我们分析了会话记录,以确定这些任务失败的根本原因。 条件下的七次失败中的六次以及 条件下的两次失败都发生在任务 2.4 中,其中参与者必须对图表的日期范围进行切片。 这是因为在通过 NL 命令编辑 Vega-Lite 规范时,模型以不正确的格式返回了日期。 Vega-Lite 使用特定的 JSON 日期格式,例如{''date'': 14, ''month'': 3, ''year'': 2004},而模型在许多情况下使用字符串来表示日期(例如 ''2004-03-14''),导致错误。 生成小部件时,与直接编辑图表规范相比,模型似乎犯此错误的次数更少。 条件中的剩余故障发生在任务 1.5 期间,参与者必须将过滤值从 [MSFT, AAPL] 更改为 [MSFT, IBM]。 在本例中,模型添加了额外的冲突过滤器转换,而不是编辑现有转换。
5.2. 自我报告的认知任务负荷指数
5.3. 用户行为
5.3.1. 自然语言命令对比 动态小部件的使用
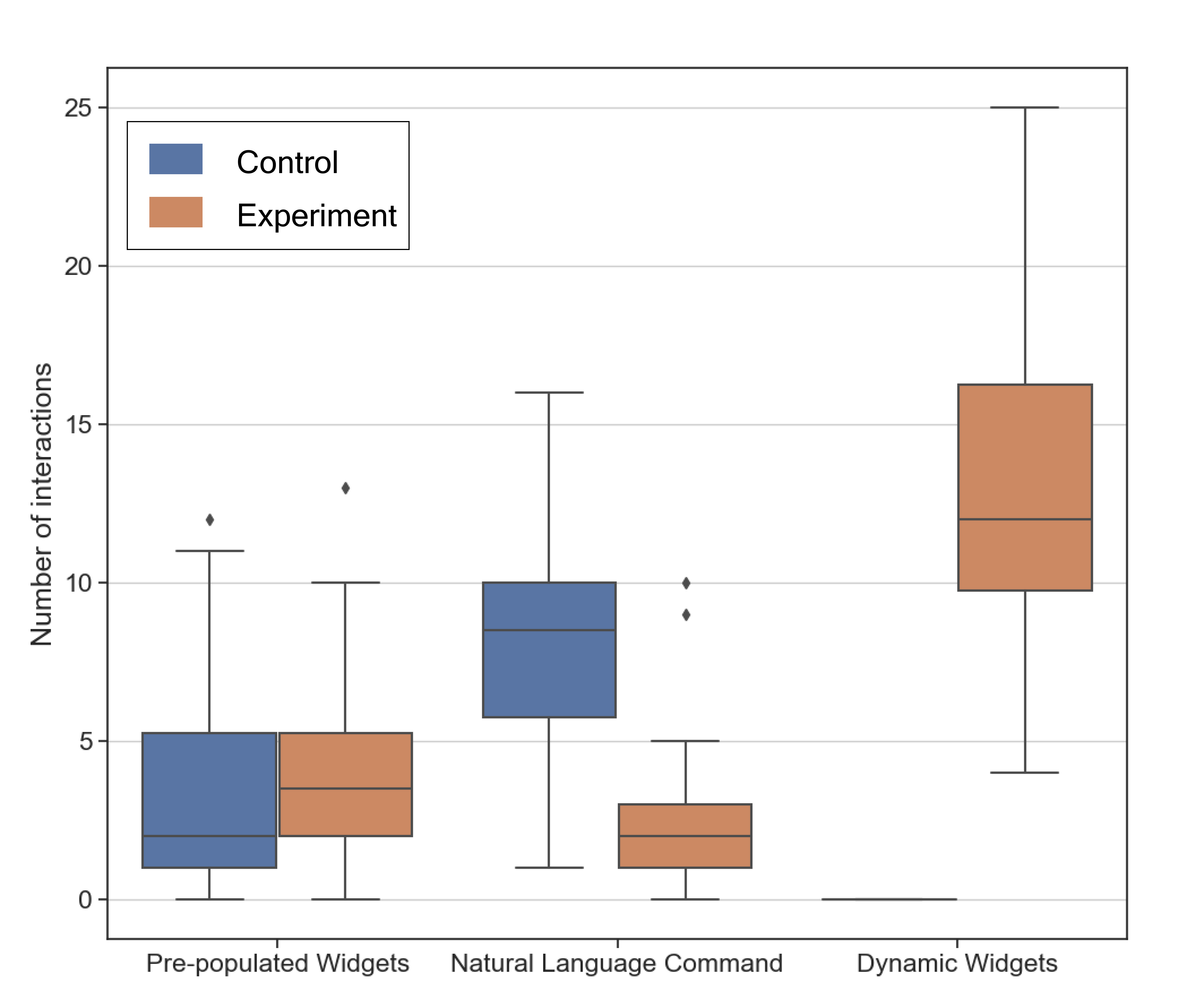
图12显示了参与者调用的自然语言命令数量以及与动态小部件和预填充小部件的交互数量的使用数据。
在 条件下,参与者在每个任务(包括所有子任务)中平均使用 8.4 个自然语言命令来编辑可视化。 当使用 条件时,这种使用量显着减少 (),仅 2.67 个自然语言命令。 这确实被动态小部件的使用所取代,在使用 条件时,参与者平均使用它 13.25 次。 这证实了我们观察到参与者在使用 条件时进行微调的次数有所增加。 这些小部件减少了在进行编辑之前尝试许多不同值的障碍。 例如,P6 说“对于动态小部件,我喜欢它可以轻松切换或以小增量进行编辑并尝试许多不同的值。 我可以看到我正在点击的内容并进行细粒度的控制。” 两种情况下预填充小部件的使用没有显着差异。
5.3.2. 用户策略
在条件下,我们观察到参与者执行任务时使用的两种主要策略。 24 名参与者中的 6 名(P7、P9、P12、P13、P15、P17)始终使用自然语言命令来编辑可视化,而不管任何预填充的小部件可用于执行编辑。 而其他 18 名参与者首先寻找预先填充的小部件来执行编辑,然后再诉诸自然语言命令。
在实验条件中,我们观察到参与者使用的两种主要策略。 九名参与者(P2、P3、P4、P5、P6、P8、P17、P18、P21)更喜欢仅使用小部件来进行所有编辑。 这些参与者仅使用人工智能来合成动态小部件而不进行编辑,然后选择通过与合成的小部件交互来进行编辑。 十名参与者(P7、P10、P12、P13、P16、P19、P20、P22、P23、P24)更喜欢使用自然语言命令进行广泛编辑,然后使用自动合成的动态小部件进行细粒度编辑。 P23 表示“我更愿意第一次使用编辑提示,并使用动态小部件进行进一步的编辑和调整”。 P15 选择仅使用自然语言命令进行编辑并表示“我认为 [ ] 更容易使用。 使用AI命令可以轻松快速地进行编辑”。 其余参与者使用小部件和 NL 命令的组合,没有特别的偏好。
5.3.3. 提示策略
参与者在提示人工智能编辑图表时通常向人工智能提供他们的意图(目标)。 对于所有子任务,他们将提示构造为 [ACTION VERB] + [CHART PROPERTY] + [VALUE]。 一些示例包括“将描边宽度更改为 5”、“将 x 轴标签旋转到 65 度”、“将 x 轴标签更改为时间轴” ”。
然而,我们确实注意到用于基于过滤的子任务的各种自然语言命令(任务 1.3、1.5、2.3、2.5、3.4、3.5)。 一些与会者直接提到了要保留的价值观。 例如,“仅显示金融和建筑行业”。 一些参与者提到要删除的值。 例如,“删除除 MSFT 和 AAPL 之外的所有内容”或“删除 AAPL 的绘图。 让我看看 IBM 的变体”。 一些不精通图表库的参与者使用了不正确的图表属性名称,例如“仅选择 MSFT 和 AAPL 的笔画可见性”、“删除除建筑和农业之外的所有图例类别” t1>”。 在三个这样的实例中,模型仍然执行正确的过滤器转换。 对于两个实例,模型尝试修改可见性,导致图表不正确。
当提示人工智能使用小部件时,参与者会跳过在提示中提供值并直接通过 UI 进行操作。 他们的提示通常结构为[ACTION VERB] + [CHART PROPERTY]。 一些示例包括“更改 x 轴限制”、“更改日期范围”、“更改 x 轴最大日期”。 例如,P3 说“只是一个操作以及需要编辑的图表部分。”。 P23 说“我让它尽可能短。 与 [edit] 命令类似,但没有数据。在下一小节中,我们将展示如何比使用自然语言命令直接编辑图表更容易提示小部件的证据。 通过利用数据上下文、域约束以及使用DynaVis中的模板进行巧妙的提示工程,我们只需用户(Zamfirescu-Pereira等人的简单指令)就可以生成几乎没有歧义的动态小部件,2023)。
5.4. 用户偏好
在任务后调查中,用户被要求对 和 条件之间的偏好进行评分。 与基线工具相比,除 P15 (96%) 之外的所有参与者都强烈倾向于使用 DynaVis。 非正式访谈和调查回复揭示了我们在本小节中讨论的原因。
发现 1:动态小部件使重复编辑变得更加容易。
十六位参与者(P1、P3、P4、P5、P6、P7、P9、P11、P13、P14、P17、P18、P19、P21、P22、P23)明确提到动态小部件大大减少了执行重复编辑所需的工作量。 通过使用动态小部件,他们减少了需要输入的自然语言命令的数量——这是非常耗时的。 P5 说:“我宁愿只与动态小部件交互。 与键入命令相比,我最终只会与 UI 进行交互。”。 P7 评论道“一旦小部件用于某种类型的任务,我更喜欢使用小部件,因为单击比清晰表达和打字更方便。此外,在使用动态小部件时,参与者在创建小部件时仅与大语言模型交互一次。 与使用NL命令相比,后续编辑是立即执行的,每次执行编辑时都必须等待大语言模型的响应。 P6 说:“动态小部件是我进行编辑的基础,我可以根据需要进行多次编辑。 比一次又一次询问人工智能更快。”。 这也解释了(第 5.3.1 节)中提到的动态小部件的使用增加的原因。 使用 的用户尝试了更多的探索性子任务值,因为与使用 相比,重复编辑更容易。
发现 2:视觉反馈增强理解和探索
九名参与者(P2、P4、P5、P8、P11、P17、P18、P23、P24)提到,他们更喜欢使用动态小部件,因为小部件在执行编辑时提供即时视觉反馈。 这种视觉反馈是双向的。 首先,当用户使用动态小部件进行编辑时,编辑会立即反映在图表上,因为我们不需要等待大语言模型的响应。 P23 总结道:“小部件的实时更新,而不是等待人工智能,真是太酷了。 我可以交互式地查看图表发生了什么。”。 值得注意的是,这些可视化本质上是静态的,没有交互性,但通过创建和使用动态小部件,参与者可以与本质上静态的可视化进行交互。
其次,UI通过保留UI状态中的编辑信息来提供视觉反馈。 P24 解释道:“通过动态小部件,我还可以直观地看到变化。 例如,如果我更改颜色,我只能在小部件中看到颜色。 这非常有帮助,效率很高。”。 动态小部件提供图表(系统)状态的清晰可视性,改善视觉反馈(Nielsen,2020)。 换句话说,动态小部件帮助用户克服评估鸿沟的可用性挑战(了解系统状态)(nn-,2023;Norman,1986)。
发现 3:提示创建动态小部件更容易、更可靠
图11显示了参与者自我报告的人工智能对参与者意图理解程度的得分(李克特量表;越高越好)。 使用 工具(, Likert 量表)的参与者表示,人工智能对其意图的理解()明显优于使用 工具(, Likert 量表)的参与者。 使用 的 24 名参与者中,有 18 名至少有 1 个失败的自然语言编辑命令,24 名参与者中有 8 名有超过 2 个失败的自然语言编辑命令。 相比之下,只有九名使用 的参与者至少有一个错误的小部件,并且没有参与者在执行任务时有超过 2 个错误的小部件。
12 位参与者(P1、P2、P3、P5、P6、P11、P14、P16、P17、P21、P22、P24)明确指出,提示动态小部件比仅使用自然语言编辑小部件更容易、更可靠。可视化。 例如,P3 评论道:“对于 [ ],我必须提供尽可能具体的聊天命令以防止错误。 但是对于 [ ] 中的动态小部件,我不必非常具体。”。 P6 评论其可靠性时说:“我喜欢使用动态小部件执行编辑的能力,而不是使用人工智能来随意执行编辑。”
提高可靠性的一个可能原因可能是:当仅使用自然语言命令时,大语言模型必须为响应中的整个图表生成修改后的 Vega-Lite 规范。 这增加了出错的可能性,因为在生成过程中,大语言模型可能会更改规范中任何其他不相关的属性。 而在生成动态小部件时,该模型会合成一个 JavaScript 回调函数,该函数仅编辑 Vega-Lite 规范的一个(或几个)属性,从而大大降低了出错的可能性。
发现4:动态小部件增强NL的控制感
七名参与者(P3、P5、P6、P8、P10、P16、P20)提到,使用动态小部件使他们在编辑可视化时可以更好地控制结果。 用户认为这些小部件为所执行的编辑提供了一种结构感和一种自主感。 P8 说“与人工智能相比,这些小部件给了我一种自主感,可以做出更多改变。 它创建了某种结构来实现变革。”。 此外,P6 表示“输入文本命令有点不理想。 没有小部件让我感觉我无法控制编辑。 [自然语言]命令让人感觉存在一定程度的不确定性。”
发现 5:动态小部件支持自定义,但对于长期使用来说可能会让人不知所措
九名参与者(P1、P3、P6、P9、P10、P11、P16、P14、P18)提到他们喜欢使用动态小部件,因为它允许他们自定义自己的 UI 以适应他们的编辑意图。 P7 说“动态小部件非常酷。 这就像为自己编写一个完整的工具,但不是编写代码,而是立即可用。“由于我们按照小部件创建的相反时间顺序呈现这些小部件,P18 说“我喜欢动态小部件,因为它存储了我所做编辑的历史记录。 如果我不喜欢,我可以随时更改它。”。
与传统的静态UI相比,动态界面是不断变化的。 五名参与者(P21、P17、P18、P8、P23)指出,创建动态小部件可能会在长时间的编辑会话中变得难以承受,并且小部件面板不断更改,并且希望通过某种方式暂停小部件创建或能够对小部件进行分类和控制显示的内容。 例如,P23 说“ 如果我制作了很多[动态小部件],那么它可能会变得棘手。 如果能够根据小部件所做的编辑类型进行自动分组,那就太好了。” 同样,P8 说“最好能够像 Photoshop 一样对多个相关的小部件进行分组、折叠或创建,以便更好地进行定制。” 相比之下,P7 表示“如果这是一系列很长的任务,我可能更喜欢稳定的界面。”,P15 说——“对于 [ ],我不确定动态小部件有什么用处。 使用命令更加简单。”
5.5. 工具性能
为了了解使用 GPT3.5 模型的 DynaVis 的性能,我们进行了事后分析,以测量参与者因模型响应时间而面临的延迟,以及生成模型所需的自动重试次数正确的 Vega-Lite 规范和小部件代码。 我们通过重播参与者在用户研究期间提供的所有 NL 可视化编辑 命令和 NL 添加小部件 命令来测量这一点。 平均而言,对 GPT3.5 模型的每次查询都会增加 秒( 秒)的延迟。 此外,平均而言,对于每个 NL 编辑/添加小部件命令,DynaVis 必须自动重试 1.16 次( 次)以修复语法或语义错误,然后才能生成正确的输出。
6. 讨论和未来的工作
NL 和 UI 小部件之外的模式
DynaVis 采用两种不同的方式让用户指定他们想要对图表进行的编辑类型:自然语言命令和通过动态小部件进行交互。 这种设计结合了两种模式的优势,因此用户可以更好地将意图传达给人工智能代理,并快速对可视化进行重复的精确编辑。 这在研究中反映在参与者对工具的偏好以及他们如何与这两种方式互动。
未来一个有趣的方向是通过添加对语音命令以及手势和图表直接操作的支持,将模式扩展到自然语言和小部件交互之外。 例如,用户无需发出 NL 命令“将图例移至图表底部”,用户只需单击并拖动(通过鼠标、触摸或数字笔)图例即可将图例移动到图表底部。图表底部进行编辑。 用户不需要知道他们必须修改图例,而他们可以简单地向我们指出它。 同样,DynaVis 也有可能包含示例规范,让用户通过编辑可视化的某些部分来演示编辑示例,然后让工具将编辑泛化到可视化的其他部分。
然而,多种模式也带来了挑战。 例如,用户并不总是容易确定使用哪种方式以及何时使用。 因此,需要更多的研究来帮助用户了解每种方式的优点和缺点,以便他们做出明智的选择。
静态对比 动态用户界面
与传统静态 UI 相比,使用自然语言命令和动态小部件的好处之一是能够缓解执行鸿沟。 使用静态 UI,用户必须知道如何以及在何处执行编辑,这可能对认知要求很高(Budiu,2014)。 而对于 NLI 和动态小部件,用户只需要指定他们的意图。 这个论点的另一面是,尽管有学习曲线,但随着时间的推移,用户将学习并习惯静态 UI。 然而,对于动态 UI,界面会不断变化,这可能会增加用户的认知负担,尤其是在长时间的编辑会话中以及对于具有编辑专业知识的用户而言。 该研究的一些参与者确实表达了这种担忧,并建议采用一种可预测的方式对小部件进行分类。 长期可用性研究将为了解不断变化的用户界面如何影响可用性提供见解。 与传统界面不同,DynaVis 和其他纯粹基于 NL 的界面的另一个限制是它们不会始终向用户呈现所有可能的选项。 这是一把双刃剑;由于 NL 界面的临时性质,用于添加小部件/编辑可视化的 NL 命令有时可以帮助用户发现以前未知的特征(类似于 (Barke 等人, 2023) 中的观察结果),以及其他有时可能会将发现工具功能的责任转移给用户,从而导致不信任和不信任(Parasuraman 和 Riley,1997)。 需要更多的研究来研究和寻找克服这些限制的方法。
另一个有趣的未来方向是检查我们如何利用动态 UI 小部件的低编程要求,将最终用户转变为“无代码开发人员”,并能够自定义/DIY 交互面板以增强静态 GUI。 例如,通过动态小部件,最终用户可以构建自己的最适合其日常任务的面板,作为复杂任务的快捷方式。 例如,经常进行地理数据分析的用户可以使用专门用于地图操作功能的动态小部件创建自定义面板,以减少地图编辑工作。
支持命令式绘图库和较低级别的可视化语法
动态小部件是围绕声明性高级可视化语法设计的,以实现组合编辑(例如,VegaLite 的可视化对象的 JSON 表示)。 声明性语法有助于将小部件模块化并按照用户希望的任何顺序进行合成和使用。 尽管有其优点,高级语法比低级语法或命令式库公开的选项更少,用于更复杂的可视化编辑任务(例如,要使线条的一部分变成虚线,而其余部分变成实线,则需要访问线条如何表达的较低级别细节)被代表)。 为了支持这些低级语言的可视化编辑,我们设想将 DynaVis 与双向编辑方法相结合,利用程序分析和综合技术将表面级编辑要求传播到程序结构或参数的编辑。
用于辅助功能和其他应用程序的动态小部件
先前关于动态合成 UI 的工作源于辅助功能研究,例如 SUPPLE (Gajos 和 Weld,2004) 和 SUPPLE++ (Gajos 等人,2007),以适应运动和视觉功能。 在用于可视化任务的动态小部件空间中,有许多可能的 UI 可以执行相同的任务(例如,用于控制字体大小的滑块与数字输入)。 每种类型的 UI 都有基于用户需求的可访问性权衡。 未来,我们可以想象 DynaVis 的一个版本,它允许用户提供他们的界面约束和偏好,并且 DynaVis 自动合成匹配这些约束的 UI。 之前的工作如(Lukes等人,2021;Vaiithilingam和Guo,2019)已经基于示例或演示完成了UI合成。 一个潜在的研究方向是添加可访问性约束并利用大语言模型的常识来创建可访问的小部件。
虽然DynaVis是为可视化编辑任务而设计的,但我们相信动态小部件也可以使具有广泛配置选项的通用应用程序(例如文档处理软件、视频处理应用程序)受益。 用户还可以利用动态小部件在无代码/低代码工具(如 Excel/Tableau)中的低编程要求,并能够自定义或 DIY 交互面板以增强现有的静态 UI。 研究如何在不同的应用程序领域中推广动态小部件将是未来值得研究的。
DynaVis设计机会
未来有很多改进 DynaVis 的机会,我们在此重点介绍其中的一些机会。 在 情况下,一些参与者预计会重复编辑并在提交之前复制 NL 命令以供重复使用。 在 DynaVis 的未来版本中,我们可以让用户访问 NL 命令的历史记录,以便用户更轻松地重新运行经过少量编辑的 NL 命令。 参与者最需要的功能之一是提供更多方式来定制和管理大量动态小部件。 这可能涉及按主题对小部件进行分类(例如 Adobe Photoshop),以及折叠/展开小部件(的部分)。 另一个有用的功能是保存并重新访问某些小部件组合。 我们还可以更进一步,允许用户导出可视化规范以及与其他用户共享的小部件,类似于 Bespoke (Vaithilingam 和Guo,2019)。
7. 相关工作
可视化创作工具
现代可视化创作工具(tab, 2023; pow, 2023a; Ren 等人, 2018; Satyanarayan and Heer, 2014; Liu 等人, 2018)和语法(Satyanarayan 等人, 2016; ggp,2023) 围绕图形语法构建(Wilkinson,2005) 允许用户通过将数据字段映射到可视化来指定高级可视化意图,从而大大减少可视化创作工作特性。 例如,Tableau或PowerBI的用户可以轻松地将数据字段拖放到视觉属性的编码架中以指定映射,而Vega-Lite的用户可以将映射简洁地提供为JSON对象。 然后,基于高级规范,这些工具自动提供“智能默认值”来填充低级可视化属性(例如,笔画、条形间距),并将可视化规范编译为低级可视化语法,例如 D3 (d3, 2023) 用于渲染。 虽然此类设计降低了初始可视化创作的复杂性,但可视化编辑和细化仍然具有挑战性,因为用户需要拆箱高级语法并浏览大量编辑选项来执行编辑。 DynaVis 旨在解决可视化编辑挑战,它补充了现有创作系统的优势。 我们设想 DynaVis 可以与现有工具相结合,用户可以从高级规范开始描述可视化意图,然后利用动态小部件执行后续编辑以细化图表。
用于可视化的自然语言界面 (V-NLI)
自然语言界面已被广泛采用来提高可视化系统的可用性(沉等人,2022)。 即使是基于 GUI 的商业工具,例如 Tableau (Markas,[n. d.])、Microsoft Power BI (pow,2023b) 和 Google Spreadsheets (Dhamdhere 等人, 2017)自动将自然语言查询翻译为数据查询,并以可视化方式呈现查询结果。 然而,这些系统将自然语言交互限制为数据查询和相应的标准图表。
自然语言处理(NLP)技术的快速发展(Young等人,2018;Belinkov和Glass,2019)为探索基于自然语言的数据可视化交互提供了绝佳的机会。 采用自然语言界面来提高可视化系统可用性的研究非常活跃(Shen 等人,2022;Dhamdhere 等人,2017;Gao 等人,2015;Setlur 等人,2016;Srinivasan 和 Stasko,2017 ;于和席尔瓦,2019)。 借助先进的 NLP 工具包(ope, 2023; goo, 2023; Loper and Bird, 2002; spa, 2023; Manning 等人, 2014),面向可视化的自然语言界面涌现(V-NLI)已经出现。 基于 V-NLI 的创作系统接受用户的自然语言查询或命令作为输入并输出适当的可视化。 研究人员探索了多种技术,从基于启发式的方法到端到端的学习方法。
基于启发式的方法在生成潜在可视化空间时探索数据的属性(Wongsuphasawat等人,2017),并根据质量属性对这些可视化空间进行排名(Luo等人,2018;Moritz)等人,2018)并将它们呈现给用户。 进一步的工作考虑了任务分解方法,其中用户查询被分解为多个任务。 然后单独求解,然后聚合以产生最终的可视化(Narechania 等人,2020;Chen 等人,2022b;Wang 等人,2022)。 最后,基于端到端学习的方法寻求直接从数据学习映射以生成可视化(Dibia 和 Demiralp,2019)。 最近,随着大型语言模型(大语言模型)的进步,像 Lida (Dibia,2023) 这样的系统在利用大语言模型从大量语言和代码数据集中学习到的模式方面取得了巨大成功。从自然语言命令创建可视化。 大语言模型排除了应用启发式方法或将自定义模型与自定义训练和数据配对的训练的要求。 作为扩展,许多 V-NLI 创作工具还支持可视化编辑,以自然语言为主要形式。
可定制的动态用户界面
先前在可访问性和普适计算等领域的研究主要针对自动生成 UI 的系统。 SUPPLE (Gajos 和 Weld,2004) 和 SUPPLE++ (Gajos 等人,2007) 为用户生成自定义 UI,以根据用户提供的规范和条件来适应他们的运动和视觉功能。活动痕迹。 UNIFORM (Nichols 等人, 2006a) 和个人通用控制器 (PUC) (Nichols 等人, 2003) 等项目为媒体控制台等设备生成自定义 UI根据每个人的喜好和交互历史定制的打印机。 Huddle (Nichols 等人, 2006b) 构建在 PUC 之上,生成 UI 来协调多个家用电器。 Mavo (Verou 等人, 2016) 允许用户无需编程,只需添加特殊的 HTML 属性即可创建交互式 HTML 页面,并且还根据属性的类型提供不同的编辑小部件。 DynaVis 与这些系统的目标相同,即根据个人用户的意图创建专门的 UI。
最近关于动态界面的工作遵循“放松”方法来创建通用的 UI 小部件。 松弛方法涉及创建 UI 小部件以直接操作函数或查询中的变量。 Bespoke (Vaithilingam 和Guo,2019) 通过使用用户演示为命令行应用程序合成自定义 GUI。 他们采用基于规则的启发式方法来推断 bash 命令中参数的语义类型,以创建用于编辑参数的动态小部件。 类似地,Heer 等人 (2008) 使用查询松弛生成动态 UI,使用户能够概括他们的选择。 一套名为精确接口的工作(Chen,2020;Chen 和 Wu,2022;Zhang 等人,2018) 使用 SQL 查询作为代理,从一系列输入查询生成交互式小部件。 最新迭代 NL2Interface (Chen 等人, 2022a) 从 NL 命令生成 SQL 查询,并创建通用 UI 来编辑 SQL 查询中的参数/变量。 BOLT (Srinivasan 和 Setlur,2023) 和 EVIZA (Setlur 等人,2016) 生成歧义小部件,这些小部件提供了一个简单的 UI,用于操作不明确的推断变量的值。 例如,对于 NL 命令“加利福尼亚州最大的地震”,将地震分类为大地震的阈值不明确。 然而,在 BOLT 和 EVIZA 中,自然语言命令都受到预定义语法的限制。 这些工具凸显了 NL 界面附带的补充 GUI 工具的重要性。 DynaVis 建立在这些系统的基础上,并使用大语言模型来合成动态小部件,可以直接操作可视化属性。 使用大语言模型生成动态小部件给我们带来了三个明显的优势:
-
(1)
通过向大语言模型提供用户上下文的准确表示,DynaVis 对用户提供的自然语言命令中的错误或歧义不太敏感。
-
(2)
我们没有一套固定的规则,或启发法,或依赖于查询松弛。 大语言模型不是合成一个仅允许用户编辑一个变量的 UI,而是可以合成一些小部件,这些小部件甚至可以捕获复杂的关系,例如一次操作多个属性。
-
(3)
与以前的系统不同,我们不限制空间或可以生成的 UI 类型。 随着大语言模型变得越来越强大,这可以实现复杂界面的合成,而不仅仅是传统的 HTML 输入元素。
多模式用户界面
多模式交互技术的优点是可以让用户通过多种方式更好地传达他们的意图,从而减少总体工作量。 Pumice (Li 等人, 2019) 允许用户使用自然语言来描述最终用户开发场景中的编程任务,然后通过提供示例来补充 NL 的模糊性来细化意图。 DIY Assistant(Fischer 等人,2021)让用户可以结合 NL 和编程规范来创建个人助理。 Lee 等人 (2019) 在草图的帮助下,可以通过视觉查询系统更好地理解意义。 ShapeSearch (Siddiqui 等人, 2020) 让用户可以使用 NL 和正则表达式来使用查询形状——极大地提高了形状搜索查询的表达能力。 PanaromicData (Zgraggen 等人, 2014) 和 Vizdom (Crotty 等人, 2015) 等工具允许用户使用笔和触摸分别直接进行数据聚合和分析数字白板。 DynaVis 建立在支持多种交互方式的理念之上。 DynaVis 利用基于 NL 的交互来减少执行鸿沟,并利用基于 UI 的交互来增强交互性。 未来,DynaVis可以进一步结合笔和触摸,直接控制画布上的视觉元素,并通过草图来演示编辑效果。
8. 结论
在本文中,我们介绍了 DynaVis,它融合了自然语言和动态合成的 UI 小部件,以缓解执行困难并增强交互性。 给定可视化编辑命令或小部件创建命令,DynaVis 会合成一个 UI 小部件,用户可以与之交互以执行可视化编辑。 我们对 参与者的研究表明,与纯 NLI 界面相比,参与者更喜欢 DynaVis,因为由于即时视觉反馈,可以轻松进行进一步编辑并增强编辑信心。
参考
- (1)
- ope (2020) 2020. OpenAI API. https://openai.com/blog/openai-api. Accessed: 2023-9-13.
- ope (2023) 2023. Apache OpenNLP. https://opennlp.apache.org/. Accessed: 2023-9-13.
- goo (2023) 2023. Cloud Natural Language. https://cloud.google.com/natural-language. Accessed: 2023-9-13.
- d3 (2023) 2023. D3 by Observable. https://d3js.org/. Accessed: 2023-9-14.
- ggp (2023) 2023. ggplot2. https://ggplot2.tidyverse.org/. Accessed: 2023-9-14.
- pow (2023a) 2023a. Microsoft PowerBI. https://powerbi.microsoft.com/en-us/. Accessed: 2023-9-14.
- npm (2023) 2023. npm: html-react-parser. https://www.npmjs.com/package/html-react-parser. Accessed: 2023-12-6.
- pan (2023) 2023. pandas documentation — pandas 2.1.0 documentation. https://pandas.pydata.org/docs/index.html. Accessed: 2023-9-14.
- spa (2023) 2023. spaCy - Industrial-strength Natural Language Processing in Python. https://spacy.io/. Accessed: 2023-9-13.
- tab (2023) 2023. Tableau: Business Intelligence and Analytics Software. https://www.tableau.com/. Accessed: 2023-9-14.
- nn- (2023) 2023. The Two UX Gulfs: Evaluation and Execution. https://www.nngroup.com/articles/two-ux-gulfs-evaluation-execution/. Accessed: 2023-9-14.
- pow (2023b) 2023b. Use natural language to explore data with Power BI Q&A - Power BI. https://learn.microsoft.com/en-us/power-bi/natural-language/q-and-a-intro. Accessed: 2023-9-13.
- Barke et al. (2023) Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2023. Grounded Copilot: How Programmers Interact with Code-Generating Models. Proc. ACM Program. Lang. 7, OOPSLA1, Article 78 (apr 2023), 27 pages. https://doi.org/10.1145/3586030
- Belinkov and Glass (2019) Yonatan Belinkov and James Glass. 2019. Analysis methods in neural language processing: A survey. Transactions of the Association for Computational Linguistics 7 (2019), 49–72.
- Budiu (2014) Raluca Budiu. 2014. Memory Recognition and Recall in User Interfaces. https://www.nngroup.com/articles/recognition-and-recall/. Accessed: 2023-9-12.
- Chen et al. (2022b) Qiaochu Chen, Shankara Pailoor, Celeste Barnaby, Abby Criswell, Chenglong Wang, Greg Durrett, and Işil Dillig. 2022b. Type-directed synthesis of visualizations from natural language queries. Proceedings of the ACM on Programming Languages 6, OOPSLA2 (2022), 532–559.
- Chen (2020) Yiru Chen. 2020. Monte carlo tree search for generating interactive data analysis interfaces. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2837–2839.
- Chen et al. (2022a) Yiru Chen, Ryan Li, Austin Mac, Tianbao Xie, Tao Yu, and Eugene Wu. 2022a. NL2INTERFACE: Interactive Visualization Interface Generation from Natural Language Queries. ArXiv abs/2209.08834 (2022). https://api.semanticscholar.org/CorpusID:252367337
- Chen and Wu (2022) Yiru Chen and Eugene Wu. 2022. Pi2: End-to-end interactive visualization interface generation from queries. In Proceedings of the 2022 International Conference on Management of Data. 1711–1725.
- Crotty et al. (2015) Andrew Crotty, Alex Galakatos, Emanuel Zgraggen, Carsten Binnig, and Tim Kraska. 2015. Vizdom: interactive analytics through pen and touch. Proceedings of the VLDB Endowment 8, 12 (2015), 2024–2027.
- Dhamdhere et al. (2017) Kedar Dhamdhere, Kevin S McCurley, Ralfi Nahmias, Mukund Sundararajan, and Qiqi Yan. 2017. Analyza: Exploring data with conversation. In Proceedings of the 22nd International Conference on Intelligent User Interfaces. 493–504.
- Dibia (2023) Victor Dibia. 2023. LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models. (6 March 2023). arXiv:2303.02927 [cs.AI]
- Dibia and Demiralp (2019) Victor Dibia and Çağatay Demiralp. 2019. Data2vis: Automatic generation of data visualizations using sequence-to-sequence recurrent neural networks. IEEE computer graphics and applications 39, 5 (2019), 33–46.
- Fischer et al. (2021) Michael H Fischer, Giovanni Campagna, Euirim Choi, and Monica S Lam. 2021. DIY assistant: a multi-modal end-user programmable virtual assistant. In Proceedings of the 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation. 312–327.
- Gajos and Weld (2004) Krzysztof Gajos and Daniel S Weld. 2004. SUPPLE: automatically generating user interfaces. In Proceedings of the 9th international conference on Intelligent user interfaces. 93–100.
- Gajos et al. (2007) Krzysztof Z Gajos, Jacob O Wobbrock, and Daniel S Weld. 2007. Automatically generating user interfaces adapted to users’ motor and vision capabilities. In Proceedings of the 20th annual ACM symposium on User interface software and technology. 231–240.
- Gao et al. (2015) Tong Gao, Mira Dontcheva, Eytan Adar, Zhicheng Liu, and Karrie G Karahalios. 2015. Datatone: Managing ambiguity in natural language interfaces for data visualization. In Proceedings of the 28th annual acm symposium on user interface software & technology. 489–500.
- Heer et al. (2008) Jeffrey Heer, Maneesh Agrawala, and Wesley Willett. 2008. Generalized selection via interactive query relaxation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 959–968.
- Lee et al. (2019) Doris Jung-Lin Lee, John Lee, Tarique Siddiqui, Jaewoo Kim, Karrie Karahalios, and Aditya Parameswaran. 2019. You can’t always sketch what you want: Understanding sensemaking in visual query systems. IEEE transactions on visualization and computer graphics 26, 1 (2019), 1267–1277.
- Li et al. (2019) Toby Jia-Jun Li, Marissa Radensky, Justin Jia, Kirielle Singarajah, Tom M Mitchell, and Brad A Myers. 2019. Pumice: A multi-modal agent that learns concepts and conditionals from natural language and demonstrations. In Proceedings of the 32nd annual ACM symposium on user interface software and technology. 577–589.
- Liu et al. (2018) Zhicheng Liu, John Thompson, Alan Wilson, Mira Dontcheva, James Delorey, Sam Grigg, Bernard Kerr, and John Stasko. 2018. Data illustrator: Augmenting vector design tools with lazy data binding for expressive visualization authoring. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems. 1–13.
- Loper and Bird (2002) Edward Loper and Steven Bird. 2002. Nltk: The natural language toolkit. arXiv preprint cs/0205028 (2002).
- Lukes et al. (2021) Dylan Lukes, John Sarracino, Cora Coleman, Hila Peleg, Sorin Lerner, and Nadia Polikarpova. 2021. Synthesis of web layouts from examples. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. 651–663.
- Luo et al. (2018) Yuyu Luo, Xuedi Qin, Nan Tang, Guoliang Li, and Xinran Wang. 2018. Deepeye: Creating good data visualizations by keyword search. In Proceedings of the 2018 International Conference on Management of Data. 1733–1736.
- Manning et al. (2014) Christopher D Manning, Mihai Surdeanu, John Bauer, Jenny Rose Finkel, Steven Bethard, and David McClosky. 2014. The Stanford CoreNLP natural language processing toolkit. In Proceedings of 52nd annual meeting of the association for computational linguistics: system demonstrations. 55–60.
- Markas ([n. d.]) Ruhaab Markas. [n. d.]. Ask Data: Simplifying analytics with natural language. https://www.tableau.com/blog/ask-data-simplifying-analytics-natural-language-98655. Accessed: 2023-9-13.
- Moritz et al. (2018) Dominik Moritz, Chenglong Wang, Greg L Nelson, Halden Lin, Adam M Smith, Bill Howe, and Jeffrey Heer. 2018. Formalizing visualization design knowledge as constraints: Actionable and extensible models in draco. IEEE transactions on visualization and computer graphics 25, 1 (2018), 438–448.
- Narechania et al. (2020) Arpit Narechania, Arjun Srinivasan, and John Stasko. 2020. NL4DV: A toolkit for generating analytic specifications for data visualization from natural language queries. IEEE Transactions on Visualization and Computer Graphics 27, 2 (2020), 369–379.
- Nichols et al. (2003) Jeffrey Nichols, Brad A Myers, Michael Higgins, Joseph Hughes, Thomas K Harris, Roni Rosenfeld, and Kevin Litwack. 2003. Personal universal controllers: controlling complex appliances with GUIs and speech. In CHI’03 Extended Abstracts on Human Factors in Computing Systems. 624–625.
- Nichols et al. (2006a) Jeffrey Nichols, Brad A Myers, and Brandon Rothrock. 2006a. UNIFORM: automatically generating consistent remote control user interfaces. In Proceedings of the SIGCHI conference on Human Factors in computing systems. 611–620.
- Nichols et al. (2006b) Jeffrey Nichols, Brandon Rothrock, Duen Horng Chau, and Brad A Myers. 2006b. Huddle: automatically generating interfaces for systems of multiple connected appliances. In Proceedings of the 19th annual ACM symposium on User interface software and technology. 279–288.
- Nielsen (2020) Jakob Nielsen. 2020. 10 Usability Heuristics for User Interface Design. https://www.nngroup.com/articles/ten-usability-heuristics/. Accessed: 2023-9-13.
- Norman (1986) Donald Norman. 1986. User centered system design. New perspectives on human-computer interaction (1986).
- Parasuraman and Riley (1997) Raja Parasuraman and Victor Riley. 1997. Humans and automation: Use, misuse, disuse, abuse. Human factors 39, 2 (1997), 230–253.
- Ren et al. (2018) Donghao Ren, Bongshin Lee, and Matthew Brehmer. 2018. Charticulator: Interactive construction of bespoke chart layouts. IEEE transactions on visualization and computer graphics 25, 1 (2018), 789–799.
- Satyanarayan and Heer (2014) Arvind Satyanarayan and Jeffrey Heer. 2014. Lyra: An interactive visualization design environment. In Computer graphics forum, Vol. 33. Wiley Online Library, 351–360.
- Satyanarayan et al. (2016) Arvind Satyanarayan, Dominik Moritz, Kanit Wongsuphasawat, and Jeffrey Heer. 2016. Vega-lite: A grammar of interactive graphics. IEEE transactions on visualization and computer graphics 23, 1 (2016), 341–350.
- Setlur et al. (2016) Vidya Setlur, Sarah E Battersby, Melanie Tory, Rich Gossweiler, and Angel X Chang. 2016. Eviza: A natural language interface for visual analysis. In Proceedings of the 29th annual symposium on user interface software and technology. 365–377.
- Shen et al. (2022) Leixian Shen, Enya Shen, Yuyu Luo, Xiaocong Yang, Xuming Hu, Xiongshuai Zhang, Zhiwei Tai, and Jianmin Wang. 2022. Towards natural language interfaces for data visualization: A survey. IEEE transactions on visualization and computer graphics (2022).
- Siddiqui et al. (2020) Tarique Siddiqui, Paul Luh, Zesheng Wang, Karrie Karahalios, and Aditya Parameswaran. 2020. Shapesearch: A flexible and efficient system for shape-based exploration of trendlines. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 51–65.
- Srinivasan and Setlur (2023) Arjun Srinivasan and Vidya Setlur. 2023. BOLT: A Natural Language Interface for Dashboard Authoring. (2023).
- Srinivasan and Stasko (2017) Arjun Srinivasan and John Stasko. 2017. Natural language interfaces for data analysis with visualization: Considering what has and could be asked. In Proceedings of the Eurographics/IEEE VGTC conference on visualization: Short papers. 55–59.
- Vaithilingam and Guo (2019) Priyan Vaithilingam and Philip J Guo. 2019. Bespoke: Interactively synthesizing custom GUIs from command-line applications by demonstration. In Proceedings of the 32nd annual ACM symposium on user interface software and technology. 563–576.
- Verou et al. (2016) Lea Verou, Amy X. Zhang, and David R. Karger. 2016. Mavo: Creating Interactive Data-Driven Web Applications by Authoring HTML. In Proceedings of the 29th Annual Symposium on User Interface Software and Technology (Tokyo, Japan) (UIST ’16). Association for Computing Machinery, New York, NY, USA, 483–496. https://doi.org/10.1145/2984511.2984551
- Wang et al. (2022) Yun Wang, Zhitao Hou, Leixian Shen, Tongshuang Wu, Jiaqi Wang, He Huang, Haidong Zhang, and Dongmei Zhang. 2022. Towards natural language-based visualization authoring. IEEE Transactions on Visualization and Computer Graphics 29, 1 (2022), 1222–1232.
- Wilkinson (2005) Leland Wilkinson. 2005. The Grammar of Graphics, Second Edition. Springer.
- Wongsuphasawat et al. (2017) Kanit Wongsuphasawat, Zening Qu, Dominik Moritz, Riley Chang, Felix Ouk, Anushka Anand, Jock Mackinlay, Bill Howe, and Jeffrey Heer. 2017. Voyager 2: Augmenting visual analysis with partial view specifications. In Proceedings of the 2017 chi conference on human factors in computing systems. 2648–2659.
- Young et al. (2018) Tom Young, Devamanyu Hazarika, Soujanya Poria, and Erik Cambria. 2018. Recent trends in deep learning based natural language processing. ieee Computational intelligenCe magazine 13, 3 (2018), 55–75.
- Yu and Silva (2019) Bowen Yu and Cláudio T Silva. 2019. FlowSense: A natural language interface for visual data exploration within a dataflow system. IEEE transactions on visualization and computer graphics 26, 1 (2019), 1–11.
- Zamfirescu-Pereira et al. (2023) JD Zamfirescu-Pereira, Richmond Y Wong, Bjoern Hartmann, and Qian Yang. 2023. Why Johnny can’t prompt: how non-AI experts try (and fail) to design LLM prompts. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–21.
- Zgraggen et al. (2014) Emanuel Zgraggen, Robert Zeleznik, and Steven M Drucker. 2014. Panoramicdata: Data analysis through pen & touch. IEEE transactions on visualization and computer graphics 20, 12 (2014), 2112–2121.
- Zhang et al. (2019) Dan Zhang, Yoshihiko Suhara, Jinfeng Li, Madelon Hulsebos, Çağatay Demiralp, and Wang-Chiew Tan. 2019. Sato: Contextual semantic type detection in tables. arXiv preprint arXiv:1911.06311 (2019).
- Zhang et al. (2018) Haoci Zhang, Viraj Raj, Thibault Sellam, and Eugene Wu. 2018. Precision interfaces for different modalities. In Proceedings of the 2018 International Conference on Management of Data. 1777–1780.