使用大型语言模型的可视化生成:评估
摘要
分析师经常需要在数据分析过程中创建可视化以获取和传达见解。 为了减轻创建可视化的负担,之前的研究开发了多种方法,供分析师根据自然语言查询创建可视化。 最近的研究证明了大型语言模型在自然语言理解和代码生成任务中的能力。 这些能力意味着使用大型语言模型从自然语言查询生成可视化规范的潜力。 在本文中,我们评估了大型语言模型在自然语言可视化(NL2VIS)任务上生成可视化规范的能力。 更具体地说,我们选择 GPT-3.5 和 Vega-Lite 分别代表大型语言模型和可视化规范。 评估是在 nvBench 数据集上进行的。 在评估中,我们采用零样本和少样本提示策略。 结果表明 GPT-3.5 超越了之前的 NL2VIS 方法。 此外,少样本提示的性能高于零样本提示的性能。 我们讨论了 GPT-3.5 在 NL2VIS 上的局限性,例如对数据属性的误解和生成规范中的语法错误。 我们还总结了几个方向,例如纠正真实情况和减少自然语言查询中的歧义,以改进 NL2VIS 基准。
索引术语:
可视化生成、大语言模型、评估、声明性语法1 简介
数据可视化对于数据分析至关重要,有助于发现模式并传达见解[1]。 然而,创建可视化需要了解可视化设计原理和可视化创作工具的技能[2, 3]。 让分析师专注于数据分析本身的一个重要方向是根据用户的自然语言查询自动化数据可视化创建。 因此,大量面向可视化的自然语言界面应运而生,让数据分析师只需使用自然语言即可创建可视化,提升数据分析效率。
自然语言处理(NLP)技术的发展不断提高自然语言可视化(NL2VIS)方法的适用性。 关于NL2VIS的许多研究都是基于自然语言处理的库,例如使用Stanford Parser [5]的Articulate [4],DeepEye [6] 使用 OpenNLP [7],NL4DV [8] 使用 CoreNLP [9]。 它们要么对用户输入有限制,要么无法理解复杂的自然语言查询[10]。 研究人员进一步使用基于深度学习的方法[11, 12]训练神经网络来处理复杂的自然语言。 然而,单一的基于深度学习的方法无法在各种任务上表现良好。
最近,越来越多的大型语言模型(大语言模型,例如、GPT-3.5 [13])被开发出来[14] 。 大语言模型具有卓越的理解自然语言并以用户定义的格式或编程代码生成高质量响应的能力。 他们在各种生成任务中表现出了出色的熟练程度,包括代码生成[15]、推理[16]和数学[17]。 此外,许多研究还从不同方面评估了大语言模型的能力,并采用了思想链[18]、思想纲领[19]等多种提示策略。从少到多[20]。 因此,利用大语言模型来实现NL2VIS任务也是可行的,并且已经开发了一些基于LLM的系统,例如Chat2VIS [21]和LIDA [22],生成 Python 代码来构建数据可视化。 Maddigan 等人[23]进行评估以验证Chat2VIS系统在NL2VIS任务上的能力。
与 Python 一起,JSON 格式的领域特定语言现在广泛用于指定各种应用程序中的可视化[24]。 此外,现有研究[23]尚未评估不同提示构建策略对NL2VIS任务的影响。 尽管大语言模型和基于LLM的NL2VIS方法取得了实质性进展,但评估大语言模型在可视化生成中使用不同提示策略的能力是一个关键要求。 更具体地说,评估 NL2VIS 任务的大语言模型是一个基本步骤,可以了解其实用性、推动改进并确保在各种应用程序中进行负责任和明智的部署。
在本文中,我们进行了评估以验证大语言模型对于 NL2VIS 任务的能力。 我们选择流行的Vega-Lite可视化语法[25]作为生成目标。 我们首先总结现有的提示策略,选择适合NL2VIS任务的零样本和少样本策略来设计提示。 提示由三个主要部分组成:指示大语言模型的角色定义、演示模式的采样数据表以及描述用户任务的查询,包括预期的图表类型和要可视化的数据属性。 对于零样本提示,我们设计了一些静态规则来指示大语言模型修改我们在初步知识评估中发现的错误并生成正确的Vega-Lite规范。 对于少样本提示,我们添加了几个示例来演示不同图表类型的高质量 Vega-Lite 规范。 每个示例都包含一个查询及其相应的规范。 我们选择GPT-3.5作为大语言模型的代表进行评估。 在评估中,我们使用nvBench数据集[26]作为基准,分别考察零样本和少样本提示策略的性能。 对于评估结果,我们计算了 nvBench 中的真实数据与 GPT-3.5 的输出之间的可视化结果的匹配精度。 我们以匹配精度为衡量标准,验证了大语言模型在NL2VIS任务上的潜力。
评估结果表明,GPT-3.5模型的性能超越了现有研究在少样本提示的Vega-Lite生成任务中的表现。 此外,少样本提示的性能明显高于零样本提示的性能。 我们还将 GPT-3.5 的局限性以及现有基准本身的问题进行分类和讨论,作为我们的发现。 首先,GPT-3.5仍然无法完全掌握Vega-Lite语法,部分输出违反语法而出错。 此外,与真实情况相比,GPT-3.5 会生成不正确的结果,因为它无法完全理解数据表中属性的含义。 其次,现有基准中的一些情况需要正确。 更具体地说,某些案例的可视化结果不符合任务描述,并且某些案例的文本查询存在歧义。 这两个方面的局限性都会对大语言模型在 NL2VIS 任务中的性能产生负面影响,我们试图在未来的工作中推广这一任务。
综上所述,本文有以下贡献:
-
•
我们使用各种提示策略评估大语言模型基于 vega-lite 规范的 NL2VIS 任务的能力。 基于NVBench的大语言模型评估结果表明,GPT-3.5具有强大的Vega-Lite规范生成能力。
-
•
我们对大语言模型的评估结果展示了改进 NL2VIS 基准的见解和方向。
2 相关工作
我们回顾了自然语言可视化和大语言模型能力评估方面的文献,以推动我们的研究。
2.1 自然语言到可视化
本节回顾了有关 NL2VIS 的现有研究,将其分为基于规则和基于神经网络的两类。 由于这项工作是评估NL2VIS任务的大语言模型能力,因此我们将基于LLM的算法区分为第三类。
基于规则的方法。 早期的NL2VIS研究大多采用基于规则的算法来实现自然语言理解和用户意图提取。 Cox等人[27]提出了一个原型框架,使用自然语言界面自动生成数据可视化。 然而,他们开发的原型系统对查询有限制,只能生成数据表和条形图。 Articulate [4] 和 DataTone [28] 使用斯坦福解析器库 [5] 分析自然语言查询并将其转换为适当的可视化。 特别是,与 Articulate 相比,DataTone 添加了一个自定义小部件来解决自然语言查询中存在的歧义。 Eviza [29]采用ANTLR解析器[30],增强查询的表达能力,并可以支持用户通过自然语言与数据可视化进行交互。 DeepEye [6] 使用 OpenNLP [7] 解析由关键字组成的未指定查询,并对要选择的多个候选可视化进行排名。 FlowSense [31]利用SEMPER [32]和CoreNLP [9]实现语义解析,让用户能够利用数据流可视化系统的优势通过自然语言交互进行数据分析。 NL4DV [8] 还采用 CoreNLP [9] 从输入查询中提取数据属性并根据查询决定预定义任务,并且与以前的接口无关接近。 虽然基于规则的算法相对容易应用,但它们对自然语言输入有限制或无法理解复杂的查询。 因此,它们的性能被随后的基于神经网络的技术超越。
基于神经网络的方法。 随着深度学习技术的发展并在 NLP 中广泛应用,可视化社区开始探索基于神经网络的方法。 Liu等人提出ADVISor [11],这是一种基于深度学习的方法,结合预定义的规则来生成表格数据的可视化。 输入数据表加上自然语言查询后,用户可以获得带有注释的可视化图表,突出显示用户关心的内容。 罗等人[26]提出了一种综合器,利用现有的大规模NL2SQL基准来综合新的NL2VIS基准,命名为nvBench,以促进该领域的进步。 该基准包含约25,000对(NL、VIS),覆盖百余个领域,其整体高质量通过专家和众包评估得到验证。 他们采用 nvBench 基准测试来训练新的 seq2seq 模型 ncNet [12],该模型输入自然语言查询和数据集并输出 Vega-Lite 规范。 ncNet 还可以接受可选的图表模板输入,以允许用户明确说明预期的图表类型。 Song等人[33]受到代码开发过程和对话系统的启发,提出了RGVisNet,它是基于检索和基于生成的方法论的融合。 实验表明 RGVisNet 的性能超越了之前的 NL2VIS 方法。 Chen 等人[34]结合程序综合和基于BERT的[35] NLP技术,从自然语言查询生成可视化并制作相应的系统Graphy。 他们使用 NLVCorpus [36] 数据集进行的评估表明,他们的方法的性能优于以前基于规则和基于转换器的方法。
基于 LLM 的方法。 随着最近大语言模型的出现,一些研究尝试将大语言模型用于NL2VIS。 Maddigan 等人[21]利用大语言模型生成Python代码来可视化数据。 他们开发了Chat2VIS系统,使用户能够通过自然语言输入数据集和分析意图,然后系统将查询转换为包含数据表描述和自然语言查询的适当提示,最后通过生成的Python代码呈现所需的图表。 此外,他们还通过高级功能改进了 Chat2VIS 系统[23]。 然后,Chat2VIS系统可以将多语言自然语言作为输入,并允许用户基于大语言模型理解长对话的能力迭代地完善其可视化效果。 LIDA [22] 将自动可视化生成定义为一个四阶段任务。 它结合了大语言模型和图像生成模型来解决数据集和分析目标,并可以生成图表和信息图表。 研究人员引入了两个指标来评估生成的可视化:可视化错误率和自评估可视化质量。 Wang等人[37]提出了Data Formulator,一个允许用户输入自然语言或实例,借助大语言模型实现复杂数据转换的系统。 通过这种范例,用户可以从复杂且耗时的数据处理中解放出来。 Wang等人[38]利用ChatGPT进行可视化推荐,以减轻收集大量训练数据的负担。 他们的方法还可以为推荐的可视化生成人类水平的解释,并且实验表明其性能优于或至少类似于以前的方法(例如决策树)。 Ko等人[39]收集了真实世界的Vega-Lite语料库,并提出了一个基于LLM的框架来自动生成具有丰富句法多样性和与原始图表强语义相关性的自然语言数据集,从而做出贡献NL4VIS 的进步。
基于大语言模型的NL2VIS任务最近引起了人们的关注。 目前的研究主要集中在基于 LLM 的 Python 代码生成方法,在探索基于声明性语法的可视化生成技术方面存在空白。 此外,还需要对各种可视化生成提示策略的效率进行更多研究。 在大语言模型的背景下,明显缺乏性能基线。 我们的目标是解决这些差距并加强对这些方面的理解。
2.2 大语言模型能力评估
大语言模型最近在一系列自然语言处理任务中展示了卓越的能力。 然而,大语言模型在不同特定任务中的定量表现尚不清楚,这可能不利于用户利用大语言模型。 评估这些模型的实际质量、功能和局限性对于帮助用户更有效地利用大语言模型是必要的。 以往的研究从代码生成、推理、数学等不同角度系统地评估了大语言模型的能力,但在可视化任务中仍存在空白有待填补。
代码生成。 将自然语言转换为代码通常包括自动代码生成、翻译、代码补全。 生成的代码需要满足多种标准,例如功能要求、语法正确性和编码风格,使得评估成为一项复杂的任务。 Hendrycks 等人[15]介绍了APPS,这是一种新的代码生成基准,用于系统地评估大语言模型直接从自然语言规范生成Python代码的能力。 此外,Cassano等人[40]构建了第一个多语言代码生成基准MultiPL-E,为理解和改进代码生成任务中的多语言语言模型模型提供了重要经验。 此外,刘等人[41]提出了一个扩展评估数据集的框架。 该框架使用生成器获得相当多的测试集来覆盖不同的代码路径和边缘情况,从而严格评估LLM生成代码的准确性。 基于该基准,丁等人[42]提出了一个静态代码完成评估框架。 它分析了预训练的大语言模型在现实世界的Python评估集上所犯的错误,并识别常见的静态错误及其发生频率的趋势。
推理。 推理任务是大语言模型的一项重要挑战。 此类任务要求模型不仅能够理解问题的含义,而且能够进行逻辑和因果推理,以生成具有逻辑结构和正确答案的响应。 Liu等人[16]评估了OpenAI开发的两种语言模型ChatGPT和GPT-4的逻辑推理能力,发现GPT-4在大多数基准测试中表现优于ChatGPT,但其性能下降逻辑推理自然语言推理任务。 Fu 等人[43]介绍了一种用于测量大语言模型推理性能的开源评估。 目前的结果表明,模型大小和推理能力总体上是相关的,呈现出近似对数线性的趋势。 徐等人[44]通过选择不同推理形式的数据集、多个有代表性的大语言模型、不同的样本设置、细化的评价指标、不同的错误类型,综合评价大语言模型的逻辑推理能力,最终呈现出一个完善的总体评价框架。
数学。 评估大语言模型的数学能力是一项重要任务,需要特定的数学问题数据集,包括代数、几何、概率和统计。 数学推理能力通常要求模型对数学概念有深入的理解,而不仅仅是模式匹配。 因此,数学推理能力的评价是综合性的、具有挑战性的。 一方面,许多研究建立了各种数据集来评估大语言模型的能力。 Wei等人[45]构建了一个新的中文数学文本数据集CMATH,用于评估大语言模型的算术和推理能力。 袁等人[17]提出了一个名为MATH 401的算术数据集,该数据集侧重于评估大语言模型的算术能力。 Frieder等人[46]构建了一个新的自然语言数学数据集,基于一系列细粒度的性能指标来测试大语言模型在数学理解方面的不同维度。 另一方面,一些研究制定了评估框架。 吴等人[47]提出了一种基于聊天的大语言模型的对话框架,该框架可以轻松集成不同的提示策略和工具,使模型通过与用户代理的对话来解决数学问题。 Collins等人[48]设计了一个轻量级的交互式评估平台来评估大语言模型辅助数学定理证明的能力。 Dao等人[49]考察了ChatGPT在越南高考数学题中的整体准确率,并具体分析了在不同难度级别和题型上的表现,清晰地揭示了ChatGPT的优缺点。
可视化。 评估大语言模型在可视化生成任务上的能力至关重要,因为评估结果有助于用户了解大语言模型的性能并指导进一步的改进和优化。 Maddigan 等人 [23] 使用 nvBench [26] 和 NLVCorpus 定量评估所提出的 Chat2VIS 系统 [21] 的性能[36] 数据集,结果表明他们的系统与以前的 NL2VIS 方法具有相当的性能。 然而Chat2VIS输出的是Python代码,这并不是可视化创建的主流方式。 而且,他们还没有充分优化现有的各种策略的提示,并且性能无法展现大语言模型在NL2VIS任务中的真正潜力。 在本文中,我们研究了现有的提示策略,并利用适合我们的 NL2VIS 任务的策略来构建不同的高质量提示。 我们选择可视化界流行的可视化创建方法Vega-Lite[25],并使用少样本和零样本提示来评估大语言模型的性能,以探索大语言模型的潜力。 NL2VIS任务中的语言模型完全。
综上所述,虽然人们对大语言模型的评估进行了广泛的研究,但在可视化构建任务的综合检验方面仍存在显着差距。 本工作旨在从声明性语法方面评估NL2VIS任务的性能,为提高基于LLM的可视化生成效率奠定基础。
3 提示设计
在本节中,我们首先总结提示策略并分析策略是否适合NL2VIS任务。 然后,我们介绍了评估的提示以及这些提示的迭代过程。
3.1 提示策略
提示策略涉及制作有效的提示或指令来与大语言模型交互,旨在从模型中引出所需的响应或信息。 合理设计和选择提示可以实现任务定制、控制模型输出、防止误解、节省资源。
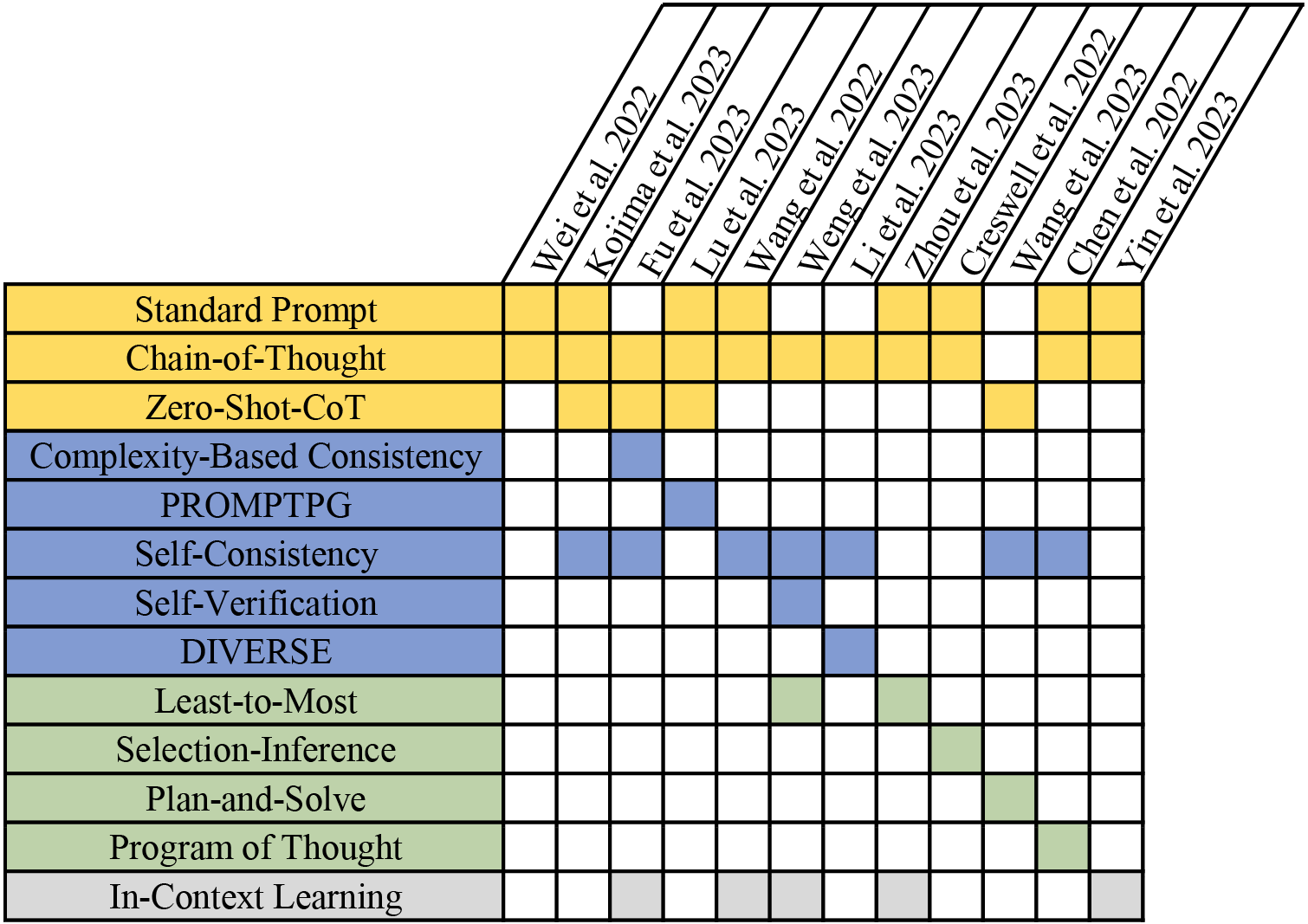
本节将针对特定任务或设置促进大语言模型推理的常用提示技术分为四类(见图1),然后分析每一类是否适合可视化生成任务。 值得强调的是,不同的提示策略可以组合,多阶段提示过程可以集成,但并不总是需要如此。
3.1.1 思想链及其变体
在标准提示中,大语言模型总是被要求在一个步骤中解决复杂的多步骤问题,而人类认知方法则涉及逐步解决复杂的推理问题。 因此,Wei等人[18]引入了思想链(CoT)方法,该方法在生成最终答案之前集成了多个推理路径步骤。 这样,大语言模型还可以展示回答时的推理过程,从而得到更准确、更可解释的结果。
使用少样本方法,CoT 需要特定的人工成本来设计提示。 Kojima 等人[50]证明大语言模型可以作为零样本推理器,只需在每个响应之前附加提示“让我们一步一步思考”即可。 我们还在初级知识学习中探索了一些逐步提示策略,发现它们在性能上没有明显的提升。 因此,我们添加了一些关于 Vega-Lite 语法的规则来构造零样本提示。
3.1.2 基本原理工程
原始的 CoT 提示依赖于人工制作的中间推理步骤示例,并使用贪婪解码来生成连贯的推理过程。 相反,理性工程旨在通过以下三个方面更有效地利用大语言模型的推理能力。
理据细化是指为模型提供更多中间步骤的示例或优化这些示例的结构和表达。 Fu等人[51]提出基于复杂性的一致性,表明推理复杂性较高的提示在多步推理任务上具有较高的性能。 Lu等人[52]提出PROMTPPG,利用策略梯度从训练数据集中策略性地选择上下文中的示例,然后为所选示例构建相应的提示。 我们在少样本提示中特意选择了丰富的样本,涵盖了各个难度级别的所有类别的图表,以提高大语言模型的性能。
Rationale discovery旨在通过发现更多潜在的推理路径来选择最佳的推理链。 Wang等人[53]提出自一致性解码策略,在多个推理路径中进行多数投票以获得最终答案。 然而,本工作中 NL2VIS 任务的中间结果是 Vega-Lite 规范,单个可视化图像可能对应于多个 Vega-Lite 规范。 测量 Vega-Lite 代码之间的相似性具有挑战性,这使得基本原理探索方法不适用于我们的工作。
生成推理链后,可以引入Rationale verify来验证推理步骤的有效性和合理性。 翁等人[54]提出自我验证,使大语言模型具有验证答案的能力。 类似的提示集成策略包括 DIVERSE [55],一个推理步骤验证器,用于过滤掉不正确的答案并独立验证每个推理步骤。 我们不采用合理性验证策略,因为大语言模型在评估时只能以文本形式输出结果,并且在没有相应的可视化图像的情况下无法验证Vega-Lite规范的有效性和正确性。
3.1.3 问题分解
复杂的任务通常需要系统的分析和解决方案。 将复杂问题分解为更小、更容易解决的子问题是一种常见策略,有助于防止大语言模型因问题的规模而感到困惑。 问题分解策略可以分为两种类型。
按处理顺序分解一般包括两个步骤:将问题分解为子问题并按特定顺序解决每个子问题。 根据定义的顺序,先前解决的子问题的答案可以促进下一个子问题的解决。 基于这一思想,周等人[20]提出了从最少到最多的提示,将一个复杂问题解构为一系列多个子问题,并将先前子问题的解作为提示解决后续问题。 Creswell等人[56]引入了一个选择-推理框架,该框架将每个推理步骤分为选择和推理,从而在它们之间交替生成一系列可解释的、任意的推理步骤,最终得出最终结果回答。 王等人[57]提出计划和解决提示,其中制定初始计划,系统地将总体任务分解为更易于管理的子任务,然后按照设计的计划执行它们。 然而,必须注意的是,可视化规范生成任务通常不能分解为连续的步骤,因为查询通常在单个步骤中执行。 因此,顺序分解方法不适合我们的工作。
按任务类型分解是指将整个问题解耦为独立的子问题,每个子问题对应一个特定的任务,然后将子问题的结果聚合形成最终结果。 陈等人[19]提出了思维提示程序(PoT),利用代码预训练的大语言模型来编写程序,从而将计算与推理任务解耦。 我们评估中生成的 Vega-Lite 在单一规范中实现了数据转换和可视化映射。 因此,按任务类型分解并不适用于我们的工作。
3.1.4情境学习
上下文学习(ICL)可以通过任务相关的示例或指令增强上下文信息,从而提高大语言模型的预测性能。 对于 ICL 提示策略,大语言模型接收自然语言模板中描述的示例及其演示上下文作为前缀,然后将查询作为输入,从而生成模仿所提供示例的输出。 ICL 可以与其他提示技术(例如思维链)结合使用,演示上下文涵盖推理过程,而不仅仅是答案。 这种方法可以有效激发大语言模型的推理能力。 Yin等人[58]在NL2Code任务中使用包含笔记本上下文和当前意图的提示,使大语言模型根据提供的实例直接理解任务。
对于 NL2VIS 任务的复杂用例,如果没有额外的规范,输入查询的模糊意图很难正确理解。 受ICL提示策略的启发,我们的提示涉及上下文中的原始数据表样本,以帮助大语言模型理解查询,显着提高大语言模型对结构化知识的基础理解并提高生成准确性。
3.2 评估提示
大语言模型可以将文本作为输入并生成代码。 因此,基于大语言模型来完成NL2VIS任务是一种很有前景的方法。 由于现有的NL2VIS技术是端到端的,即它们接受自然语言查询并输出可视化规范,因此我们在这项工作中仅考虑一轮交互条件来模拟端到端范式并简化评估过程。 因此,我们将基于LLM的NL2VIS的过程定义为两个步骤。 首先,用户输入包含任务描述和相关数据表的提示。 其次,大语言模型返回Vega-Lite规范作为响应,我们进一步得到相应的可视化结果。
为了使大语言模型(本文中为 GPT-3.5)生成正确有效的可视化效果,我们尝试优化提示并比较 nvBench 数据集上的各自性能。 我们的提示符的基本版本很简单:它只是告诉大语言模型它在系统消息中扮演什么角色,任务查询以及在用户消息中需要的数据表,如下所示。
大括号table_name、nl_query、sampled_data中的变量分别是数据表名称、任务描述以及需要的数据表分别从 nvBench 数据集中提取。 由于nvBench中的几个数据表非常大,我们选择将采样数据表转移到GPT-3.5以减少 Token 数量。
我们发现GPT-3.5给出的输出并不是纯粹的Vega-Lite规范,并且总是包含冗余的解释文本。 为了使输出仅具有 Vega-Lite 规范,以便于后续自动处理,我们在提示符末尾添加一条指令,使 GPT-3.5 仅输出 Vega-Lite 规范。
生成的规范在规范输出中始终使用内联数据源,这可能会导致错误,因为提示仅包含从原始数据中采样的部分数据表。 因此,我们在规范中添加另一条指令来控制data属性的格式,以使用URL“data.csv”作为数据源。
我们利用这个版本的提示作为基础来构建以下零样本和少样本提示。
3.2.1 零样本提示
为了评估初始提示的有效性,我们首先对 nvBench 数据集中的一百个实例进行了初步知识研究,发现生成的规范存在多种类型的错误。 为了提高大语言模型的性能,我们补充了一些规则,使大语言模型避免出现此类错误。 因此,零样本提示由三部分组成:任务描述、采样数据表以及指导生成Vega-Lite规范的几条规则。 下面讨论一下提示中的错误以及对应的规则:
(1) 正式确定Vega-Lite的版本。 基于Vega-Lite的可视化规范在$schema属性中规定了其版本。 预备知识研究结果显示,GPT-3.5生成的Vega-Lite版本并不一致,包括版本4和版本5。 此外,Vega-Lite 的语法在不同版本之间也存在一些差异。 为了使生成的Vega-Lite规范的版本一致,我们在提示中添加了以下规则(规则1),以引导输出使用版本5中的Vega-Lite,该规则被可视化社区广泛使用。
(2) 形式化transform属性的位置。 可用的变量默认只包含原始数据表中的属性。 因此,生成的规范始终需要为 transform 属性中列出的转换操作定义一个变量。 然而,在我们的物品知识评估结果中,超过四分之一的生成规范将 transform 属性置于 encoding 属性后面。 这些实例不使用 transform 中为 encoding 中轴的 field 属性定义的名称,从而导致不正确的结果。 因此,我们补充以下规则(规则 2):将 transform 属性放在 encoding 属性之前,以防止生成的规范不使用已定义的变量名称。 结果表明,当 transform 属性位于 encoding 属性之前时,生成的规范可以正确引用先前定义的变量。 此示例意味着生成的 Vega-Lite 规范中指定属性的顺序会影响最终结果。
(3) 提醒在aggregate属性中使用filter转换。 基础知识学习中的任何规范都无法根据查询描述成功过滤输入数据。 我们添加以下规则(规则3)来提醒模型使用filter操作来实现数据选择。 评估结果表明,该指令确实减少了忘记实现所需数据过滤的实例数量。
(4) 提醒在aggregate属性中使用groupby转换。 此外,我们还发现近一半的预备知识结果在 transform 属性中使用 aggregate 操作时忘记指定 groupby 属性。 groupby 属性对于阐明在执行特定转换时要分组的数据字段是必要的。 例如,当您显示不同专业或年级的学生的平均身高时,groupby 属性应分别是专业或年级属性。 因此,缺少 groupby 属性将使 Vega-Lite 使用默认值,并可能导致错误的结果。 为了修复这个错误,我们添加了相应的规则(规则4)来提醒GPT-3.5模型在规范中指定groupby属性。 评估结果表明,使用此规则,GPT-3.5 永远不会忘记指定 aggregate 的 groupby 属性。
(5) 更正sort属性的使用。 涉及排序操作的生成可视化规范中超过 90% 是错误的,因为 GPT-3.5 输出的结果总是在 transform 对象中定义 sort 属性,这违反了 Vega -精简语法。 因此,我们补充以下规则(规则5)来纠正其对sort操作的使用。 尽管这条规则减少了涉及排序操作的错误实例的数量,但是无论我们如何修改该规则的声明,许多此类实例仍然是错误的。 我们也在第二节讨论这个问题。 5.1。 它揭示了单一规则不能总是指导生成的规范结果并使其正确。
此外,添加这条规则后,我们在大语言模型的结果中检测到了幻觉。 更具体地说,当使用排序转换时,生成的规范会更改其将属性映射到轴的模式。 先前的规范通常将名义属性映射到 x 轴,将定量属性映射到 y 轴。 使用新规则,规范将名义属性映射到 y 轴,将定量属性映射到 x 轴,并产生翻转的轴。 尽管翻转的可视化结果在外观上与地面事实不同,但它们呈现的数据是相同的,因此不会对正确性产生负面影响。
3.2.2 少量提示
除了零样本提示外,我们还采用少样本提示策略。 在零样本提示中,我们没有提供GPT-3.5的Vega-Lite规范的示例,只是根据其错误和错误的分析使用了一些规则。 相比之下,少样本提示策略没有添加关于 Vega-Lite 规范的额外规则,而是列出了一些由任务查询和相应的正确 Vega-Lite 规范组成的示例,分别作为训练数据和标签。 查询是从 nvBench 数据集中选择的,我们采用 GPT-3.5 生成的正确规范,使用零样本提示作为训练标签的来源。
我们为 Vega-Lite 中包含的每种图表类型添加一个示例,以避免省略特定图表类型,这可能会导致该类型的性能下降。 此外,我们选择的每种图表类型的示例至少包括一种特定的任务类型,例如排序、过滤和聚合,我们预计 GPT-3.5 能够从每种图表类型示例中提取有关相应任务的规则,并将其推广到其他图表类型图表类型。 在这里,我们展示了我们的少样本提示的开头和第一个示例:
总之,我们的少样本提示由 nvBench 中每种图表类型的(查询、Vega-Lite)对示例、任务描述、查询描述、采样数据表以及指定输出格式的两代规则组成。
4 评估
在本节中,我们首先介绍评估中采用的数据集和大语言模型,然后对评估结果进行展示和分析,并与之前的NL2VIS方法进行比较。
4.1 数据集和模型
我们利用 nvBench [26] 数据集作为我们评估的基准。 nvBench是一个大规模的NL2VIS数据集,涵盖了体育、医疗等100多个应用场景,包含7,247个可视化实例和超过25,000个(NL,VIS)对。 该数据集涵盖七种图表类型:条形图、饼图、折线图、散点图、堆积条形图、分组线图和分组散点图。 该数据集根据所涉及的数据转换的复杂性,将 NL2VIS 任务分为四个难度级别:简单、中等、困难和超困难。 nvBench中的每个实例都包含罗等人[26]提出的自然语言查询描述的任务,可以看作图表类型语句和SQL查询的组合,可视化为基础事实,以及一些自然语言查询。
我们发现nvBench中的部分实例需要连接至少两个数据表才能完成相应的任务。 但是,Vega-Lite 无法在单个可视化规范中支持多个数据源。 因此,我们需要合并多个数据表,使用SQL查询过滤所需的属性,并将数据处理结果作为Vega-Lite规范的输入。 由于本研究仅评估大型语言模型生成可视化规范的能力,因此我们过滤了与多个数据表相关的这些实例,并使用所有剩余实例来实施我们的评估。
对于大语言模型,我们选择GPT-3.5作为大语言模型的代表,因为它比GPT-4更常用且成本更低。 为了防止包含少样本示例和采样数据表的提示超过词符限制,我们采用GPT-3.5-turbo-16k来实施评估。 我们将 GPT-3.5 的温度参数设置为 0 以避免随机性。
4.2 指标
在评估中,我们利用真实情况与 GPT-3.5 生成的结果之间的匹配精度。 具体来说,我们将生成的 Vega-Lite 转换为可视化结果,然后将结果与真实的可视化结果进行比较,以检查它们是否等效。
为了测量以图像形式呈现的两个图表之间的等效性,我们首先使用朴素的度量标准,即基于像素的匹配精度。 基于像素的匹配意味着仅当其图像的每个像素与地面真实图像的相应像素相同时,生成的结果才是正确的。 然而,这种天真的度量过于严格,因为两个图像之间只有一点点差异(例如轴的标题)就可能导致基于像素的不匹配。 如果图表类型和呈现的数据相同,则两个可视化是等效的,这是合理的。 因此,我们采用基于 svg-json 的匹配策略,利用 JSON 格式的 SVG 图像和 Vega-Lite 规范来检查两个可视化的等效性。
首先,我们从相应的 JSON 格式的 Vega-Lite 规范中提取可视化的图表类型。 如果生成结果的图表类型与真实值不同,我们认为生成结果是错误的。 然后,我们从 SVG 显示的可视化中的图形元素中提取基础值,并比较这两个值集。 如果两个值集相等并且图表类型也相同,我们认为生成的结果是正确的。
4.3 评估结果
基于像素的匹配策略的准确率对于零样本策略为3.02%,对于少样本策略为5.63%。 这两个匹配结果都较低,因为即使两个可视化图表的内容相同,但它们的像素可能并不完全相同,并且在某些细微差别上有所不同,例如轴的标题或轴的单位值。
表I给出了基于svg-json的匹配策略的评估结果。 零样本和少样本提示策略在nvBench上的总体匹配准确率分别为43.23%和50.12%,且少样本提示的性能显着高于零样本提示。 对于不同图表类型的性能,零样本提示在散点图上生成的准确度最高,在饼图上的准确度第二高,接下来的排名是对散点图、条形图和堆积条形图进行分组。 对于少样本提示,性能排名从高到低分别是分组散点图、饼图、散点图、条形图、堆积条形图,并且分组散点图的准确率甚至大于90%。
两种提示策略在散点图、分组散点图和饼图上的表现都相对较好,但在条形图和堆积条形图上的准确度相对较低。 特别是对于堆积条形图,生成精度可以略高于20%。 值得注意的是,尽管少样本提示在总体准确度和其他四种图表类型的准确度上的表现高于零样本提示,但其在散点图上的表现却低于零样本提示。 我们分别分析了两个提示输出的散点图的Vega-Lite规格,发现少样本提示的规格与零样本提示相比在数据转换方面存在更多错误。 具体来说,“少样本”提示的部分规范未能按照任务查询的要求实现数据过滤,而“零样本”提示给出的相应规范则正确完成任务。 例如,nvBench 中的查询要求制作散点图来显示表中 abandoned_yn 属性等于 1 的被遗弃狗的年龄和体重。 然而,少样本提示的结果使用了表中的所有项目,而零样本结果正确地选择了abandoned_yn属性等于1的项目。
我们进一步分析为什么少样本提示的规格在数据转换方面比零样本提示的散点图有更多的错误。 如上所述,我们在零样本提示策略的基础上,在规范中添加了规则来实现过滤操作。 对于少样本提示策略,我们在提示中列出了一些示例。 我们发现少样本提示中使用的散点图示例不包含过滤操作。 然而,少样本提示中使用的其他图表类型的示例确实包含过滤操作。 因此,零样本提示优于少样本提示的性能异常可能是因为GPT-3.5未能将过滤操作推广到其他图表类型,特别是生成规格中比例的散点图。
任务难度(nvBench 中定义的“硬度”)也会显着影响评估结果。 如表I所示,两种提示的性能都随着难度的增加而降低。 少样本提示在困难任务上的表现异常低于零样本提示,这与散点图类似。 经过分析,我们发现原因也是相同的。 更具体地说,困难任务包括许多数据转换,例如数据过滤。 但少样本提示给出的结果忘记做所需的变换或者变换操作出错,使得少样本提示的性能相对较低。
| Accuracy | Overall | Chart type | Task difficulty | |||||||
| Bar | Pie | Scatter | Stacked bar | Grouping scatter | Easy | Medium | Hard | Extra hard | ||
| Zero-shot | 43.23% | 46.00% | 57.37% | 69.68% | 21.47% | 51.05% | 48.28% | 47.15% | 37.40% | 10.93% |
| Few-shot | 50.12% | 53.32% | 68.80% | 62.67% | 21.79% | 93.19% | 60.72% | 54.28% | 30.39% | 12.92% |
我们将导致生成结果错误的原因分为四类:无效的 JSON、无效的 Vega-Lite、图表类型不匹配、图表内容不匹配。 表II显示了这四个错误的分布。 无效的 JSON 错误意味着生成的规范不是有效的 JSON 文件,无效的 Vega-Lite 错误意味着该规范是有效的 JSON 文件,但不符合 Vega-Lite 的语法。 关于图表类型不匹配的错误意味着生成结果的图表类型与真实值不同。 图表内容不匹配是指真实结果与生成结果之间的图表类型相同,但底层数据内容不同。
表II展示了零样本和少量简短提示的四种不同错误之间的分布。 可以看出,两次提示结果的主要错误是Vega-Lite无效和图表内容不匹配。 零样本提示的无效Vega-Lite比例明显高于少样本提示,而两者提示的其他三种错误类型的比例略有差异。 尽管我们的零样本提示添加了规则来指导 GPT-3.5 避免语法错误并更正确地完成任务,但零样本策略仍然比少样本策略产生更多的 Vega-Lite 语法错误。 原因可能是添加的规则相互干扰,从而无法按预期工作。
| Invalid JSON | Invalid Vega-Lite | Chart Type Mismatch | Chart Content Mismatch | |
| Zero-shot | 0.11% | 18.71% | 1.38% | 29.79% |
| Few-shot | 0.22% | 14.37% | 0.75% | 28.34% |
4.4 与以前的方法比较
之前的方法与我们使用 GPT-3.5 的零样本和少样本提示策略之间的性能比较如表III所示。 先前方法的性能由 Song 等人 [33] 和 Maddigan 等人 [23] 评估。
我们可以了解到零样本提示的性能略低于以前方法的最先进性能,大约等于 Chat2VIS [21],这也是基于 LLM 的使用未明确优化的简单提示的方法。 少样本提示策略的性能超过了之前方法的最先进性能 50% 以上,展示了 GPT-3.5 在 NL2VIS 任务上的强大潜力。
| Approaches | Accuracy |
| Seq2Vis [26] | 2% |
| Transformer [59] | 3% |
| ncNet [12] | 26% |
| Chat2VIS [21] | 43% |
| RGVisNet [33] | 45% |
| Ours (Zero-shot) | 43% |
| Ours (Few-shot) | 50% |
5 调查结果

在本节中,我们首先对限制 GPT-3.5 在 NL2VIS 任务上的性能的原因进行分类,然后介绍我们在现有 NL2VIS 基准测试中发现的限制。
5.1 NL2VIS大语言模型的局限性
上一节显示 GPT-3.5 在 nvBench 数据集上的性能表现平平。 我们分析错误并将其分为以下三类,以找出GPT-3.5在Vega-Lite生成上的局限性,以方便进一步优化。
错误类型 1:Vega-Lite 规范无效。 这是我们评估结果中最常见的错误,意味着生成的Vega-Lite规范无效并且存在语法错误,导致Vega-Lite规范转换为可视化结果失败。 导致Vega-Lite规范无效的原因分为三种类型。
(1) JSON格式错误。 此类错误滥用了 Vega-Lite 规范的属性并导致无效的 JSON 对象。 图2(a)显示了GPT-3.5生成的示例,该示例违反了有效JSON对象的格式规则。 更具体地说,GPT-3.5 将 mark 和 encoding 属性放入 transform 属性中,并将 encoding 属性视为规范的结尾。 这种误用总是会导致转换末尾缺少方括号,并导致 JSON 格式违规。
(2) 使用 Vega-Lite 规范中不存在的属性。 此类错误会在生成的规范中添加不存在的属性。 图2(b)显示了一个符合JSON格式要求但在transform属性中使用不存在的sort的示例。 根据任务描述,图表应该对Director属性进行升序排序,这可以通过在x属性中定义sort来实现如图2(b) 中使用粗体文本突出显示的那样。 尽管 GPT-3.5 可以理解任务查询以正确定义排序操作,但 transform 属性中 sort 的误用会导致错误的规范。 而且,在需要对某一属性进行排序的任务中,sort属性的错误频繁发生,导致GPT-3.5在此类任务上的性能相对较低。
(3)滥用Vega-Lite变换操作。 错误类型误用了 Vega-Lite 规范中的转换操作。 例如,图2(c)具有正确的JSON格式,并且没有使用不存在的操作,但是在transform<中使用了bin /t3> 属性不正确,输出规范仍然违反 Vega-Lite 语法。 任务查询是按工作日分箱 date_address_to,正确的规范可以通过在 transform 属性中定义 timeUnit 来实现此目标。 GPT-3.5 给出的输出混淆了 bin 和 timeUnit 的功能,并导致无效的规范。
Vega-Lite规范的不正确反映了大语言模型在Vega-Lite输出上存在不可忽视的幻觉[13]问题,例如指定查询中未包含的数据转换或出现语法错误。 上面的例子也启发我们,Vega-Lite可视化规范存在一些语法错误,对可视化规范提供有效的linting策略将提高性能。 大语言模型输出的 linting 技术应重点关注 Vega-Lite 规范的转换。
错误类型 2:不理解 Vega-Lite 规范。 第二类表示生成的Vega-Lite规范没有语法错误,可以成功转换为可视化。 然而,与真实情况相比,生成的可视化结果是不正确的,因为 GPT-3.5 无法完全理解 Vega-Lite 中参数的含义。
不理解 Vega-Lite 操作参数。 此类错误意味着大语言模型无法完全理解Vega-Lite的运行参数。 本例中的查询类似于第三种错误1。 然而,与错误1的规范不同,该规范没有语法错误,但最终生成的图表与真实情况相比仍然不正确。 原因是对 transform 属性中使用的 timeUnit 参数不理解。 尽管查询确实要求按工作日分箱 date_address_to,但 GPT-3.5 通过将 timeUnit 的值定义为 weekday 而不是正确的值来实现此目标参数天。 这个例子揭示了GPT-3.5需要对Vega-Lite语法有全面的了解,并且很容易受到查询的影响而使用不正确的参数分配。
这类错误意味着提高大语言模型在NL4VIS任务上的性能的一个方面是开发更多的策略来促进大语言模型理解和正确使用Vega-Lite规范的参数。 例如,Vega-Lite [60]的文档应该是实现这一目标的重要资源。
错误类型 3:不理解任务描述和数据。 对于此类错误,生成的Vega-Lite规范从语法方面来说是正确的,GPT-3.5也可以正确使用输出规范中的参数。 然而,GPT-3.5可能会误解数据表或任务查询,从而导致不正确的可视化结果。
(1)对输入数据表不理解。 该类型错误表明GPT-3.5无法完全理解输入数据的属性并滥用规范中的属性。 如图2(d)所示,查询是用条形图显示公寓号和每间公寓的房间数,数据表中需要的属性为 apt_number 和 room_count。 通过在 x 轴上显示 apt_number 属性和在 y 轴上显示 room_count 属性,可以轻松完成此任务。 然而,如图2(d)中的Vega-Lite输出所示,GPT-3.5不理解room_count属性的含义,并认为数据中的每一行表描述了公寓中单个房间的信息。 因此,它选择计算每个公寓的行数并生成不正确的结果。 图2(d) 中使用斜体、粗体文本显示了正确的规格。
(2)不理解任务查询。 此类别中的第二种错误是误解任务查询。 图2(e)说明了任务查询不理解的示例。 该查询要求显示银行业公司的排名和市值,GPT-3.5 应首先选择 Main_Industry 属性值等于 Banking 的行。 然而,图2(e)所示的输出没有使用过滤操作并生成了错误的结果,这表明GPT-3.5没有完全捕获任务描述的要求。
上述错误意味着必须全面理解输入数据表和任务描述才能正确生成 Vega-Lite 规范。 这一发现启发我们将基于大语言模型的NL4VIS任务分成不同的步骤,并检查每个步骤结果的正确性。 因此,我们可以将用户交互引入可视化生成过程,并利用更及时的策略,例如Chain-of-Thought,来提高大语言模型的性能。
5.2 重新检查 NL2VIS 基准
我们分析GPT-3.5输出中的不匹配结果,进一步发现nvBench中的部分实例不正确,GPT-3.5的相应故障应归因于nvBench本身。 我们将失败分为五类并进行详细讨论,以启发改进 NL2VIS 任务的基准设计。

查询语句不正确。 图3(a)显示了一个查询中的问题示例,该问题与地面实况图表相结合是不正确且令人困惑的。 图3(a)中的查询询问每个级别的教职人员数量,答案是教授27人,副教授8人,助理教授15人,讲师8人。 地面实况图表显示了完全不同的答案 1:2:2:2,GPT-3.5 成功给出了正确答案 27:8:15:8。
更合理的解释是,groundtruth图表反映了该实例的真实意图,而查询是不正确的。 唯一满足1:2:2:2比例的统计数据是每个等级的性别数量;也就是说,教授的性别属性只有一种,而其他三个职级则有两种性别。 因此,正确的查询应该询问每个等级的性别人数比例。
与可视化内容不匹配的错误查询是 NL2VIS 基准测试中的一个严重问题。 人工设计和自动生成的查询很难完全避免这个问题,因此仔细检查是必不可少的。 考虑到一些基础模型具有多模态能力,使基础模型能够同时理解自然语言和图像,我们可以使用它们来检查查询是否与可视化内容有效匹配。
数据映射不当。 数据映射指示将数据属性编码到适当的视觉通道中。 现有的研究界已经对可视化设计的原理进行了深入的研究和总结[1,61,62]。 有效的可视化结果需要适当的数据映射策略。 然而,我们发现 nvBench 给出的部分 Vega-Lite 规范为数据分配了不适当的类型。 尽管这些不适当的数据映射在我们的评估过程中没有负面影响,但这个问题可能会影响基于可视化图像内容的评估方法。 例如,groundtruth的散点图在x轴上呈现不同专业的数量,并将专业数量视为定量类型。 然而,不同专业的数量通常是离散整数,而不是连续实数。 因此,本例的主编号应该是名义类型。
另一个基本事实错误地使用时态数据作为名义类型,这种情况几乎发生在涉及时态数据的每个实例中。 从可视化设计原理的角度来看,这种情况传达了不合理的数据见解,因为由于标称类型数据按字母顺序排列,因此可能会导致不正确的时间顺序。 因此,时间数据应分类为时间类型或序数类型。
为了纠正可视化中不适当的数据映射,我们可以采用 linting 技术,这类似于解决 5.1 中 Vega-Lite 规范的无效性。我们只能添加有关可视化数据映射的规则,并使用 linting 技术来检查基准测试中的规范并纠正不适当的数据映射。
数据不正确。 nvBench中很多涉及求和、平均等数值计算的实例在计算前直接去掉了原表中数据的小数部分,导致groundtruth与GPT-3.5的输出结果完全不同。
如图3(e)所示,原始数据表中的monthly_rental属性为混合小数。 然而,在最右边所示的nvBench给出的Vega-Lite规范中,最终的求和结果是整数。 经过检查,我们发现nvBench在求和之前去掉了monthly_rental属性的小数部分,导致与正确答案相比绝对误差大于1。
nvBench 基本事实中存在的另一个问题子类型是不正确的标签。 图3(d)显示了一个例子。 该实例询问每个产品名称的产品比例,但根据原始表格,地面实况图显然丢失了 Sony 标签。 相比之下,GPT-3.5的输出实际上是正确的。 由于Vega-Lite规范groundtruth采用内联数据源,因此生成该实例时可能因疏忽而导致标签不正确的问题。
为了使可视化中显示的数据与原始表格一致,我们应该确保data属性的内容与原始表格的内容相同,或者仅使用Vega-Lite规范中的内联数据源。
未说明的时间单位定义。 nvBench 中的某些需要在图表中呈现时态数据的实例具有未明确说明时间单位定义的查询。 因此,GPT-3.5 生成的结果与地面事实相比定义了不同的时间单位,导致这些情况下的准确性较低。
图3(c) 显示了未说明的时间单位定义的示例。 地面真值图表将 date_of_notes 属性(以秒为单位)分箱到一周的时间单位。 然而,这个要求在查询语句中没有明确或隐含地说明,从而使得 GPT-3.5 生成与真实情况完全不同的图表。
此问题类似于不正确的查询问题。 因此,我们还可以使用多模态基础模型来检查生成的可视化结果。 如果基础模型发现可视化定义了相应查询中未说明的时间单位,我们可以修改可视化规范并纠正此问题。
未说明的图表类型。 nvBench 中的大多数查询都需要特定的图表类型,但有些查询没有明确说明图表类型,这对 GPT-3.5 的判断产生负面影响。
图3(b)所示的实例有五个查询,只有第一个和第三个查询明确需要饼图。 GPT-3.5 为这两个查询(第一个和第三个)生成饼图,并为其他三个查询提供条形图。 对于不需要明确要求饼图的三个查询,它们在语句中同时强调比例和数量。 因此,条形图也是合适的。 我们将生成的结果与基本事实之间的不匹配定义为不正确的结果。 因此,未声明图表类型的问题也会降低 GPT-3.5 在 nvBench 上的性能。
nvBench中的查询由NL2SQL-to-NL2VIS合成器[26]自动生成,我们认为自然语言查询的生成过程可以进一步优化,以消除现有图表类型语句的歧义在部分查询中。 例如,我们可以使用大语言模型来检查查询,并将最合适的图表类型添加到有问题的查询中,该图表类型是由大语言模型根据我们在提示中输入的图表类型选择规则确定的。
6 结论
本文选择GPT-3.5和nvBench数据集来评估大语言模型在NL2VIS任务上的性能。 具体来说,我们让 GPT-3.5 生成 Vega-Lite 规范,给定数据表和任务查询作为输入,并使用基于图表类型和可视化中的数据内容的匹配精度作为度量,将生成的可视化与地面事实进行比较。 我们为Vega-Lite一代设计了零样本提示和少样本提示,并分别评估了它们的性能。 我们还总结和归类了GPT-3.5在NL2VIS任务和nvBench本身上的几个缺点,这可以促进NL2VIS的进步。 在未来的工作中,我们尝试通过优化提示并引入与大语言模型的对话交互来提高NL2VIS任务的性能。 本文的主要发现如下:
-
•
评估结果表明,少样本提示的性能明显高于零样本提示,并超越了先前NL2VIS技术的SOTA性能。
-
•
大语言模型在Vega-Lite语法以及对任务描述和数据的理解方面存在缺陷。 可以利用 linting 技术以及用户与大语言模型之间的交互来纠正错误或提高大语言模型输出的质量。 Vega-Lite的文档和规范示例可用于微调大语言模型或添加到提示中以在NL2VIS任务上推广大语言模型。
-
•
现有的NL2VIS基准测试也存在一些缺陷,可能会影响大语言模型在NL2VIS任务上的性能评估和提升。 可以考虑使用大语言模型来提高基准测试中的查询质量。 我们可以添加一些关于查询的规则,例如明确的图表类型语句和时态数据的明确的时间单位定义,并使大语言模型检查和纠正基准查询。
参考
- [1] T. Munzner, Visualization analysis and design. CRC press, 2014.
- [2] J. D. Mackinlay, “Automating the design of graphical presentations of relational information,” ACM Transactions on Graphics, vol. 5, no. 2, pp. 110–141, 1986.
- [3] J. Mackinlay, P. Hanrahan, and C. Stolte, “Show me: Automatic presentation for visual analysis,” IEEE Transactions on Visualization and Computer Graphics, vol. 13, no. 6, pp. 1137–1144, 2007.
- [4] Y. Sun, J. Leigh, A. E. Johnson, and S. Lee, “Articulate: A semi-automated model for translating natural language queries into meaningful visualizations,” in Proc. Int. Symp. Smart Graphics (SG), ser. Lecture Notes in Computer Science, vol. 6133, 2010, pp. 184–195.
- [5] “The stanford parser,” http://nlp.stanford.edu/software/lex-parser.shtml.
- [6] Y. Luo, X. Qin, N. Tang, G. Li, and X. Wang, “DeepEye: Creating good data visualizations by keyword search,” in Proc. Int. ACM Conf. Management of Data (SIGMOD), 2018, pp. 1733–1736.
- [7] “Apache opennlp,” 2017, http://opennlp.apache.org.
- [8] A. Narechania, A. Srinivasan, and J. T. Stasko, “NL4DV: A toolkit for generating analytic specifications for data visualization from natural language queries,” IEEE Transactions on Visualization and Computer Graphics, vol. 27, no. 2, pp. 369–379, 2021.
- [9] C. D. Manning, M. Surdeanu, J. Bauer, J. R. Finkel, S. Bethard, and D. McClosky, “The Stanford CoreNLP natural language processing toolkit,” in Proc. Con. Association for Computational Linguistics (ACL), 2014, pp. 55–60.
- [10] L. Shen, E. Shen, Y. Luo, X. Yang, X. Hu, X. Zhang, Z. Tai, and J. Wang, “Towards natural language interfaces for data visualization: A survey,” IEEE Transactions on Visualization and Computer Graphics, vol. 29, no. 6, pp. 3121–3144, 2023.
- [11] C. Liu, Y. Han, R. Jiang, and X. Yuan, “ADVISor: Automatic visualization answer for natural-language question on tabular data,” in Proc. IEEE Pacific Visualization Symposium (PacificVis), 2021, pp. 11–20.
- [12] Y. Luo, N. Tang, G. Li, J. Tang, C. Chai, and X. Qin, “Natural language to visualization by neural machine translation,” IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 1, pp. 217–226, 2022.
- [13] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “GPT-4 technical report,” preprint arXiv:2303.08774, 2023.
- [14] W. Yang, M. Liu, Z. Wang, and S. Liu, “Foundation models meet visualizations: Challenges and opportunities,” Computational Visual Media, 2024, preprint arXiv:2310.05771.
- [15] D. Hendrycks, S. Basart, S. Kadavath, M. Mazeika, A. Arora, E. Guo, C. Burns, S. Puranik, H. He, D. Song, and J. Steinhardt, “Measuring coding challenge competence with APPS,” preprint arXiv:2105.09938, 2021.
- [16] H. Liu, R. Ning, Z. Teng, J. Liu, Q. Zhou, and Y. Zhang, “Evaluating the logical reasoning ability of chatgpt and GPT-4,” preprint arXiv:2304.03439, 2023.
- [17] Z. Yuan, H. Yuan, C. Tan, W. Wang, and S. Huang, “How well do large language models perform in arithmetic tasks?” preprint arXiv:2304.02015, 2023.
- [18] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in Neural Information Processing Systems, vol. 35, pp. 24 824–24 837, 2022.
- [19] W. Chen, X. Ma, X. Wang, and W. W. Cohen, “Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks,” preprint arXiv:2211.12588, 2022.
- [20] D. Zhou, N. Schärli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. V. Le, and E. H. Chi, “Least-to-most prompting enables complex reasoning in large language models,” in Proc. Int. Con. Learning Representations (ICLR), 2023.
- [21] P. Maddigan and T. Susnjak, “Chat2VIS: Generating data visualizations via natural language using chatgpt, codex and GPT-3 large language models,” IEEE Access, vol. 11, pp. 45 181–45 193, 2023.
- [22] V. Dibia, “LIDA: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models,” in Proc. Con. Association for Computational Linguistics (ALC), 2023, pp. 113–126.
- [23] P. Maddigan and T. Susnjak, “Chat2VIS: Fine-tuning data visualisations using multilingual natural language text and pre-trained large language models,” preprint arXiv:2303.14292, 2023.
- [24] X. Pu, M. Kay, S. M. Drucker, J. Heer, D. Moritz, and A. Satyanarayan, “Special interest group on visualization grammars,” in Extended Abstacts of ACM Conf. Human Factors in Computing Systems, 2021.
- [25] A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer, “Vega-lite: A grammar of interactive graphics,” IEEE Transactions on Visualization and Computer Graphics, vol. 23, no. 1, pp. 341–350, 2017.
- [26] Y. Luo, N. Tang, G. Li, C. Chai, W. Li, and X. Qin, “Synthesizing natural language to visualization (NL2VIS) benchmarks from NL2SQL benchmarks,” in Proc. Int. ACM Conf. Management of Data (SIGMOD), 2021, pp. 1235–1247.
- [27] K. C. Cox, R. E. Grinter, S. Hibino, L. J. Jagadeesan, and D. Mantilla, “A multi-modal natural language interface to an information visualization environment,” International Journal of Speech Technology, vol. 4, no. 3, pp. 297–314, 2001.
- [28] T. Gao, M. Dontcheva, E. Adar, Z. Liu, and K. G. Karahalios, “DataTone: Managing ambiguity in natural language interfaces for data visualization,” in Proc. ACM Conf. Symposium on User Interface Software and Technology (UIST), 2015, pp. 489–500.
- [29] V. Setlur, S. E. Battersby, M. Tory, R. Gossweiler, and A. X. Chang, “Eviza: A natural language interface for visual analysis,” in Proc. ACM Conf. Symposium on User Interface Software and Technology (UIST), 2016, pp. 365–377.
- [30] T. J. Parr and R. W. Quong, “ANTLR: A predicated-LL(k) parser generator,” Software: Practice and Experience, vol. 25, no. 7, pp. 789–810, 1995.
- [31] B. Yu and C. T. Silva, “FlowSense: A natural language interface for visual data exploration within a dataflow system,” IEEE Transactions on Visualization and Computer Graphics, vol. 26, no. 1, pp. 1–11, 2020.
- [32] Y. Zhang, P. Pasupat, and P. Liang, “Macro grammars and holistic triggering for efficient semantic parsing,” in Proc. Conf. on Empirical Methods in Natural Language Processing (EMNLP), 2017, pp. 1214–1223.
- [33] Y. Song, X. Zhao, R. C. Wong, and D. Jiang, “Rgvisnet: A hybrid retrieval-generation neural framework towards automatic data visualization generation,” in Proc. Int. ACM Conf. Management of Data (SIGMOD), 2022, pp. 1646–1655.
- [34] Q. Chen, S. Pailoor, C. Barnaby, A. Criswell, C. Wang, G. Durrett, and I. Dillig, “Type-directed synthesis of visualizations from natural language queries,” Proc. ACM Program. Lang., vol. 6, no. OOPSLA2, pp. 532–559, 2022.
- [35] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in Proc. Conf. North American Chapter of the Association for Computational Linguistics: Human Language Technologies(NAACL-HLT), 2019, pp. 4171–4186.
- [36] A. Srinivasan, N. Nyapathy, B. Lee, S. M. Drucker, and J. T. Stasko, “Collecting and characterizing natural language utterances for specifying data visualizations,” in Proc. ACM Conf. Human Factors in Computing Systems (CHI), 2021, pp. 464:1–464:10.
- [37] C. Wang, J. Thompson, and B. Lee, “Data Formulator: Ai-powered concept-driven visualization authoring,” preprint arXiv:2309.10094, 2023.
- [38] L. Wang, S. Zhang, Y. Wang, E. Lim, and Y. Wang, “LLM4Vis: Explainable visualization recommendation using chatgpt,” preprint arXiv:2310.07652, 2023.
- [39] H. Ko, H. Jeon, G. Park, D. H. Kim, N. W. Kim, J. Kim, and J. Seo, “Natural language dataset generation framework for visualizations powered by large language models,” preprint arXiv:2309.10245, 2023.
- [40] F. Cassano, J. Gouwar, D. Nguyen, S. Nguyen, L. Phipps-Costin, D. Pinckney, M.-H. Yee, Y. Zi, C. J. Anderson, M. Q. Feldman et al., “MultiPL-E: A scalable and extensible approach to benchmarking neural code generation,” preprint arXiv:2208.08227, 2022.
- [41] J. Liu, C. S. Xia, Y. Wang, and L. Zhang, “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,” preprint arXiv:2305.01210, 2023.
- [42] H. Ding, V. Kumar, Y. Tian, Z. Wang, R. Kwiatkowski, X. Li, M. K. Ramanathan, B. Ray, P. Bhatia, and S. Sengupta, “A static evaluation of code completion by large language models,” in Proc. Con. Association for Computational Linguistics (ACL), 2023, pp. 347–360.
- [43] Y. Fu, L. Ou, M. Chen, Y. Wan, H. Peng, and T. Khot, “Chain-of-thought hub: A continuous effort to measure large language models’ reasoning performance,” preprint arXiv:abs/2305.17306, 2023.
- [44] F. Xu, Q. Lin, J. Han, T. Zhao, J. Liu, and E. Cambria, “Are large language models really good logical reasoners? a comprehensive evaluation from deductive, inductive and abductive views,” preprint arXiv:2306.09841, 2023.
- [45] T. Wei, J. Luan, W. Liu, S. Dong, and B. Wang, “CMATH: can your language model pass chinese elementary school math test?” 2023.
- [46] S. Frieder, L. Pinchetti, A. Chevalier, R.-R. Griffiths, T. Salvatori, T. Lukasiewicz, P. C. Petersen, and J. Berner, “Mathematical Capabilities of ChatGPT,” preprint arXiv:2301.13867, 2023.
- [47] Y. Wu, F. Jia, S. Zhang, H. Li, E. Zhu, Y. Wang, Y. T. Lee, R. Peng, Q. Wu, and C. Wang, “An empirical study on challenging math problem solving with GPT-4,” preprint arXiv:2306.01337, 2023.
- [48] K. M. Collins, A. Q. Jiang, S. Frieder, L. Wong, M. Zilka, U. Bhatt, T. Lukasiewicz, Y. Wu, J. B. Tenenbaum, W. Hart, T. Gowers, W. Li, A. Weller, and M. Jamnik, “Evaluating language models for mathematics through interactions,” preprint arXiv:2306.01694, 2023.
- [49] X. Dao and N. Le, “Investigating the effectiveness of chatgpt in mathematical reasoning and problem solving: Evidence from the vietnamese national high school graduation examination,” preprint arXiv:2306.06331, 2023.
- [50] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large language models are zero-shot reasoners,” Advances in neural information processing systems, vol. 35, pp. 22 199–22 213, 2022.
- [51] Y. Fu, H. Peng, A. Sabharwal, P. Clark, and T. Khot, “Complexity-based prompting for multi-step reasoning,” in Proc. Int. Con. Learning Representations (ICLR), 2023.
- [52] P. Lu, L. Qiu, K. Chang, Y. N. Wu, S. Zhu, T. Rajpurohit, P. Clark, and A. Kalyan, “Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning,” in Proc. Int. Con. Learning Representations (ICLR), 2023.
- [53] X. Wang, J. Wei, D. Schuurmans, Q. V. Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,” in Proc. Int. Con. Learning Representations (ICLR), 2023.
- [54] Y. Weng, M. Zhu, F. Xia, B. Li, S. He, K. Liu, and J. Zhao, “Large Language Models are Better Reasoners with Self-Verification,” preprint arXiv:2212.09561, 2023.
- [55] Y. Li, Z. Lin, S. Zhang, Q. Fu, B. Chen, J.-G. Lou, and W. Chen, “Making language models better reasoners with step-aware verifier,” in Proc. Con. Association for Computational Linguistics (ACL), 2023, pp. 5315–5333.
- [56] A. Creswell, M. Shanahan, and I. Higgins, “Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning,” arXiv:2205.09712, 2022.
- [57] L. Wang, W. Xu, Y. Lan, Z. Hu, Y. Lan, R. K. Lee, and E. Lim, “Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models,” in Proc. Con. Association for Computational Linguistics (ACL), 2023, pp. 2609–2634.
- [58] P. Yin, W. Li, K. Xiao, A. Rao, Y. Wen, K. Shi, J. Howland, P. Bailey, M. Catasta, H. Michalewski, O. Polozov, and C. Sutton, “Natural language to code generation in interactive data science notebooks,” in Proc. Con. Association for Computational Linguistics (ACL), 2023, pp. 126–173.
- [59] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Proc. Conf. Neural Information Processing Systems (NeurIPS), 2017, pp. 5998–6008.
- [60] “Vega-lite document,” https://vega.github.io/vega-lite/docs/.
- [61] J. Mackinlay, “Automating the design of graphical presentations of relational information,” ACM Transactions on Graphics, vol. 5, no. 2, p. 110–141, 1986.
- [62] Y. Kim and J. Heer, “Assessing effects of task and data distribution on the effectiveness of visual encodings,” Computer Graphics Forum, vol. 37, no. 3, pp. 157–167, 2018.