PRILoRA:修剪和等级增加的低等级适应
摘要
随着大型预训练语言模型 (PLM) 的激增,微调所有模型参数变得越来越低效,特别是在处理大量需要大量训练和存储成本的下游任务时。 已经提出了几种旨在实现参数高效微调(PEFT)的方法。 其中,低秩适应(LoRA)作为一种原型方法脱颖而出,它将可训练的秩分解矩阵合并到每个目标模块中。 尽管如此,LoRA 并没有考虑每一层的不同重要性。 为了解决这些挑战,我们引入了 PRILoRA,它以递增的方式为每一层线性分配不同的排名,并在整个训练过程中执行剪枝,同时考虑权重的临时大小和任何给定层输入的累积统计数据。 我们通过八个 GLUE 基准的广泛实验验证了 PRILoRA 的有效性,设定了新的技术水平。
PRILoRA:修剪和等级增加的低等级适应
Nadav Benedek Tel Aviv University nadavbenedek@mail.tau.ac.il Lior Wolf Tel Aviv University wolf@cs.tau.ac.il
1简介
当前自然语言处理任务的范式是利用预先训练的模型,这些模型是使用大量数据和昂贵的资源进行训练的,并将它们调整到各种下游任务(Brown等人,2020;Liu等人,2019) ; Radford 等人, 2019; He 等人, 2021b; Devlin 等人, 2019)。 这种微调传统上是通过模型所有参数的梯度更新来进行的(Dodge等人,2020;Raffel等人,2020;Qiu等人,2020)。 随着模型尺寸的不断增大,例如 Llama 7B-65B (Touvron 等人,2023)、Palm 540B (Chowdhery 等人,2022) 等,训练由于资源由数百个并行 GPU 组成,仅某些机构和公司可以使用,因此全面的微调可能会变得令人望而却步、冗长且碳足迹高(Luccioni 等人,2022)。 此外,以这种方式进行完全微调需要存储每个下游任务的微调模型的所有参数。
为了应对上述挑战,提出了参数高效微调(PEFT)的一些研究方向。 这些方向旨在保持甚至提高完整微调方法的准确性,而仅训练一小部分参数。 一种方法是向基本模型添加小模块,该模型在整个训练过程中保持冻结。 这种适配器调优技术(Rebuffi等人,2017;Houlsby等人,2019;Pfeiffer等人,2020;He等人,2022)在层之间添加模块。 由于模型深度增加,这意味着训练时间更长,推理期间的延迟更高。 或者,提示和前缀调整(Lester等人,2021;Li和Liang,2021)将可训练标记附加到模型中各层的开头,从而可能减少其有效的最大词符长度。
LoRA (Hu 等人, 2022) 通过将每一层视为权重矩阵 、冻结它并添加一个小的秩矩阵来微调线性层,其中与原始权重矩阵形状相同,由两个低秩矩阵 和 的乘积获得。 选择低秩 远小于该层的输入维度,从而显着减少可训练参数的数量。 在 LoRA 训练期间,仅更新两个低秩矩阵,通常是原始参数计数的 0.01% 到 1.00%,具体取决于两个矩阵的低秩。 该方法除了高效且常常超过全微调(Hu 等人, 2022)的性能外,还有一个优点是能够在推理过程中合并回原始矩阵,而无需增加延迟。 LoRA已成功应用于各种下游任务(Schwartz等人,2022;Lawton等人,2023;Dettmers等人,2023)
LoRA 的一个限制是低秩 是一个任意设置的参数,在原始 LoRA 中它被设置为跨层和权重固定。
致力于解决LoRA的固定等级问题。 AdaLoRA (Zhang 等人, 2023) 从初始参数预算开始,该预算略高于最终预算,然后逐渐减少,直到通过基于 SVD 去除权重来匹配目标。
在这项工作中,我们鼓励使用从一层到下一层线性增加等级,同时遵守相同的参数预算。 正如我们所展示的,该策略提供了比统一放置甚至学习替代方案更好的学习参数分布。
第二个贡献是通过修剪矩阵获得的。 这是通过考虑 的元素和层输入的指数移动平均值来完成的。 尽管在大多数情况下我们会修剪的一半元素,但我们通过修剪寻求提高的主要指标是修剪后获得的整体准确性。
我们对八个不同的通用语言理解评估(Wang等人,2019)基准进行了广泛的实验,并提供了证据表明所提出的方法优于LoRA及其最近的变体,即排名的线性分布和特定的修剪方法是有益的,并且该方法训练不需要比传统 LoRA 更多的 GPU 内存或时间,这与 LoRA 最近的扩展不同。
2相关工作
近年来,参数高效微调(PEFT)作为一种减少微调和存储大规模预训练模型相关费用以及训练所需时间的方法,引起了研究人员越来越多的兴趣。 已经出现了各种方法,每种方法都表现出与推理过程中的内存利用率、存储要求和计算开销相关的独特特征。 根据原始模型参数是否在训练阶段进行微调,这些方法可以分为两大类,即选择性 PEFT 方法和附加 PEFT 方法。
选择性方法涉及根据模型的原始参数选择和修改模型。 这一概念的早期实例是在仅对网络顶层的一个子集进行微调时观察到的,如 Donahue 等人 (2014) 以及最近的工作 所证明的那样(Gheini 等人,2021)。 在最近的发展中,已经提出了各种方法,每种方法都针对模型的特定层或内部模块。 例如,BitFit 方法(Zaken 等人, 2021) 仅更新偏差参数,导致可训练参数数量大幅减少,但代价是性能不佳。 其他方法在选择可训练参数时使用评分函数(Guo 等人,2020;Sung 等人,2021;Vucetic 等人,2022),而其他方法则根据 Fisher 信息计算选择顶级参数(宋等人,2021)。
加法方法代表了通过在主干网络中引入额外的可训练参数来替代全参数微调的方法。 适配器是一种可训练组件,最初由 Rebuffi 等人 (2017) 应用于多域图像分类环境中,随后集成到 Transformer 网络中,特别是在注意力层和前馈层中(Houlsby 等人,2019)。 前缀调整和提示调整(Li和Liang,2021;Lester等人,2021)涉及在所有层的隐藏状态序列之前添加可训练参数。 LST(Ladder Side-Tuning)(Sung 等人,2022)通过将原始网络中的隐藏状态缩短为紧凑的可训练侧网络来运行,从而消除了通过主干网络反向传播梯度的需要。
LoRA (Hu 等人, 2022) 通过两个低秩矩阵的相乘来模拟模型中权重矩阵的调整。 值得注意的是,从此过程中产生的训练参数可以在推理阶段无缝地合并到原始网络中,而不会产生额外的计算开销。
最近,出现了混合方法,将选择性方法和附加方法相结合,并提出了统一的框架(Chen等人,2023;He等人,2022;Mao等人,2021)。 其他方法基于 PEFT 模块中存在参数冗余的假设,从而修剪可训练参数以实现优异的微调性能(Bai 等人,2022)。
网络剪枝方法(Molchanov等人,2016;Hassibi等人,1993;Frankle和Carbin,2019;Liu等人,2018;Han等人,2015b)减少通过从网络中删除或缩小矩阵来调整网络的大小,这实际上相当于将它们设置为零。 此类方法需要进一步完全重新训练或其他计算密集型迭代。
幅度剪枝 (Han 等人, 2015a; Gale 等人, 2019) 当幅度低于某个阈值时删除单个参数权重。 阈值的确定要么基于与同一参数或层中其他权重的相对大小(Zhu and Gupta,2018),要么针对整个网络(Liu等人,2018).
3背景
Transformer 模型。 Transformer (Vaswani 等人, 2017) 是一种利用自注意力的序列到序列架构。 通常,它由多个堆叠块组成,其中每个块包含两个子模块:多头注意力(MultiHead)和全连接前馈网络(FFN)。 给定维度 的 个标记的输入序列 ,MultiHead 使用 头执行注意力功能,允许 空间来关注另一个词符的不同价值投影:
其中方括号表示沿第二维的串联, 和 是每个块的 head 的参数,softmax 应用于每一行。 通常设置为 。 MultiHead 的输出被输入 FFN,由两个线性变换组成,中间有一个 ReLU 非线性:
,其中和是块的参数。 最后,应用残差连接和层归一化(Ba等人,2016)。
适配器。 (Houlsby 等人,2019 年;Pfeiffer 等人,2020 年)适配器技术在 Transformer 层之间注入一个模块,从而使用 将输入向下投射到低维空间,然后是非线性 ,再使用 向上投射,结合残差连接:
| (1) |
低阶适应。 LoRA (Hu 等人, 2022) 冻结了预训练的模型权重,并将两个可训练的秩分解矩阵注入到 Transformer 架构的每一层中,大大减少了微调任务的可训练参数的数量。 对于线性层,LoRA修改的前向函数为:
| (2) |
其中 、 和 以及 。 是高斯初始化的, 是零初始化的,以便在微调训练开始时有 。 Hu 等人 (2022) 将 LoRA 应用于多头注意力中的查询和值参数(即 和 ),而不修改其他重量。 He 等人 (2022) 将其扩展到前馈网络的其他权重矩阵,以提高性能。
4方法
我们提出的方法 PRILoRA(修剪和秩增加低秩适应)由与 LoRA 微调集成的两个主要组件组成:(i)跨网络层的低秩线性分布,以及(ii) ) 根据层的输入激活和 LoRA 矩阵的权重,持续修剪 LoRA 的 矩阵。
4.1 排名的线性分布
虽然 LoRA 统一分配学习到的参数,但也可以不同地分配这些参数。 例如,可以向某些层分配较低的等级,而向其他层分配较高的等级。
回想一下,LoRA 中的可训练参数是矩阵 和 。 每个层都有一个根据层结构固定的维度,以及一个低阶 维度。由于层的时间复杂度(训练或测试)和内存复杂度与各层的输入和输出维度均呈线性关系,而且 和 中只有一个维度取决于 ,因此 LoRA 的总体复杂度与所有修改层的秩总和呈线性关系。
我们分配学习参数的方式受到 Zhang 等人 (2023) 提供的结果的启发,这表明顶层需要更多的适应。 考虑到不能只关注顶层,因为其他层也需要适应(参见第 6 节),并且为了简化,我们采用线性分布的等级。
在排名的线性分布中,我们以线性增加的方式为模型中的每一层分配不同的低排名。 具体来说,对于基于 DeBERTaV3 的模型,我们从第一层开始,应用低秩 ,并线性增长,直到第十二层,应用 ,使得跨层的平均等级为 8。 无论矩阵类型(查询、键、值等)如何,我们都为给定层中的所有权重分配相同的低秩。 这使得参数总数与 LoRA 方法相同。
4.2 持续的基于重要性的 A 权重修剪
我们采用剪枝作为动态特征选择的一种形式,这使得微调过程能够在每次剪枝迭代时专注于每个瓶颈索引处的一些层输入。 直觉是,由于更新矩阵 的容量较低,因此仅关注重要的输入维度将是有益的。
4.2.1 重要性矩阵
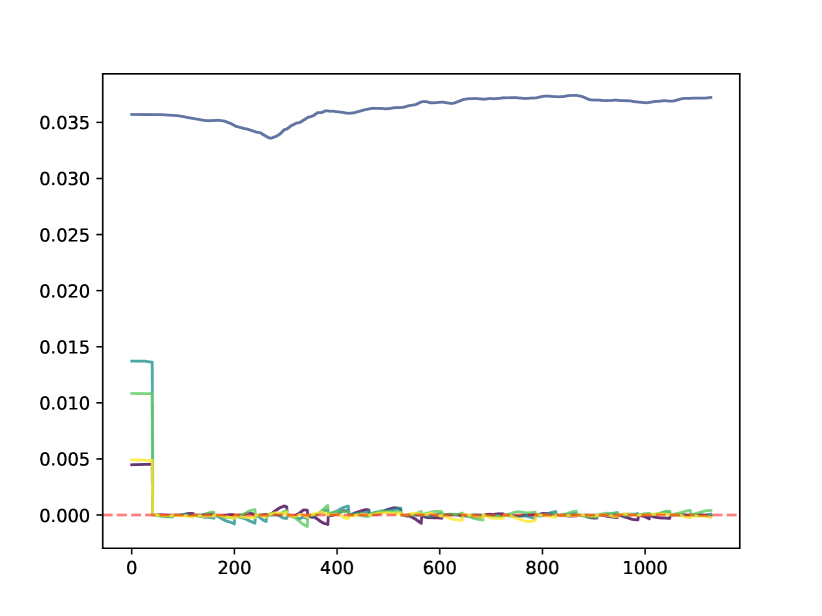
每个 Transformer 层,无论是与键、查询或值关联的投影,还是 FFN 层之一,都有一些权重矩阵 。 它还具有一些输入 ,其中 是批量大小, 是 Token 数量, 是维度。 我们稍微滥用了该符号,并为 FFN 的第二层编写了 ,尽管在本例中,维度为 ,通常大于 。在我们的框架中,我们在整个训练过程中维护每个此类输入 行的 范数的指数移动平均值,如图 1
对于每个批次,我们考虑维度为 的张量,对所有元素求平方,对第一维和第二维求和,获得大小为 的向量,并取平方每个向量元素的根,得到。
指数移动平均线按以下规则在批次之间更新
| (3) |
接下来,我们将针对每个权重矩阵 ,或者更具体地说,针对 (即 的相关半分解),计算与 大小相同的重要性矩阵 。 受到万达 (Sun 等人,2023 年) 的启发,是 的绝对值与相关移动平均向量 的元素相乘(请注意,每个权重矩阵 都有一个 ):
| (4) |
请注意, 的所有值都是正数,因为它们代表平均范数。 因此, 的所有元素也都是正数。
 |
 |
| (a) | (b) |
 |
 |
| (c) | (d) |
4.2.2 修剪
训练过程中每 40 个步骤,我们都会根据相关的重要性矩阵 修剪每个 矩阵。 为此,我们考虑 的每行 的 最低元素,并创建一个二进制掩码 。 每个掩码元素指示是否在的行的最低值之中。 由剪枝率决定;比率越高意味着更多的权重被归零。 然后,我们使用掩码 将 中的元素清零。
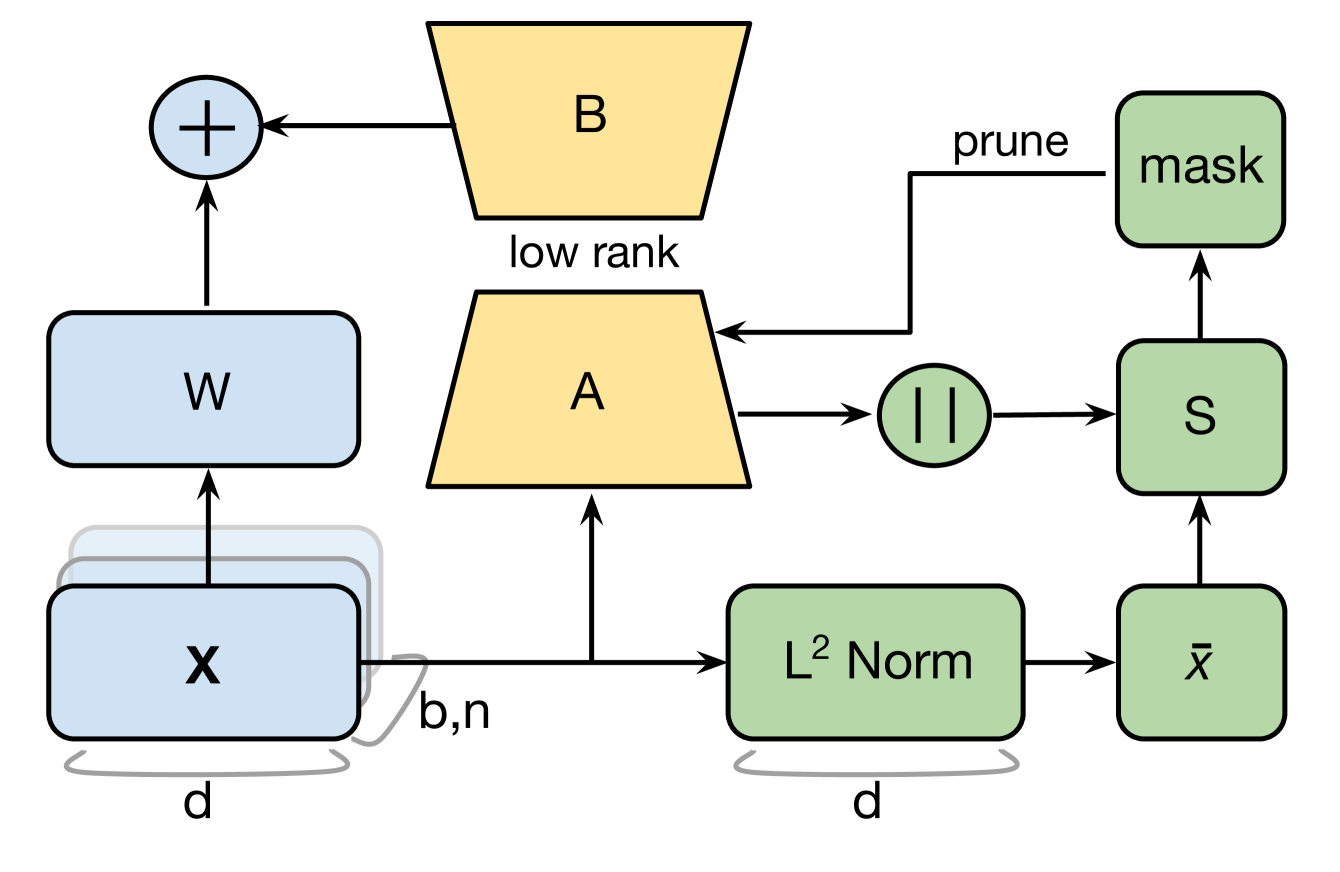
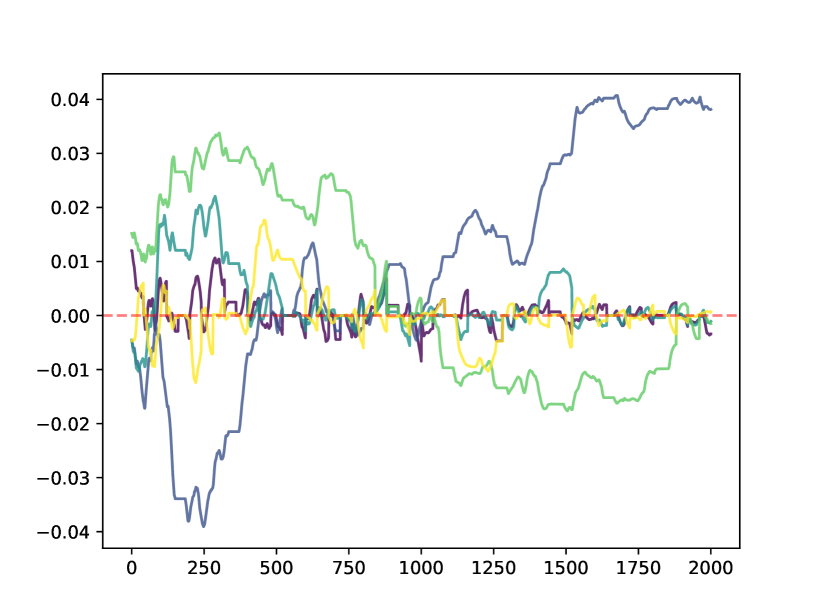
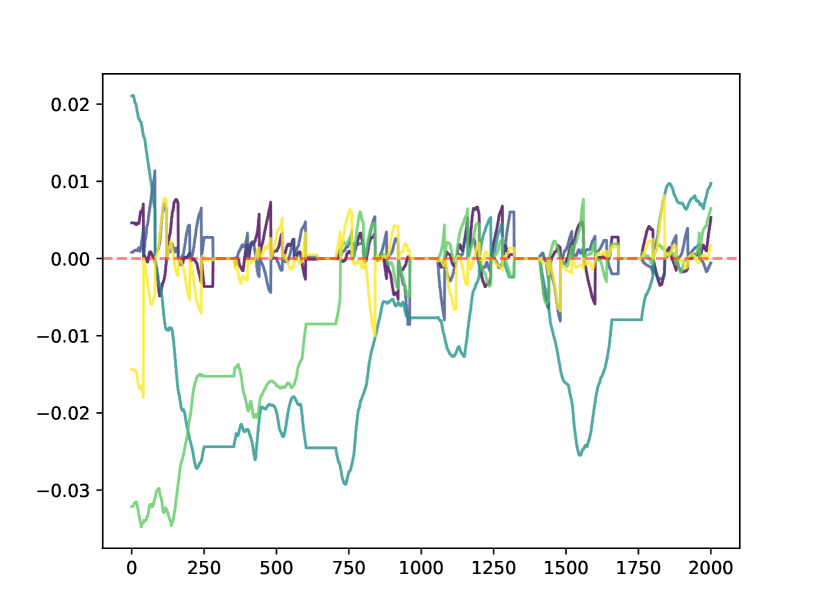
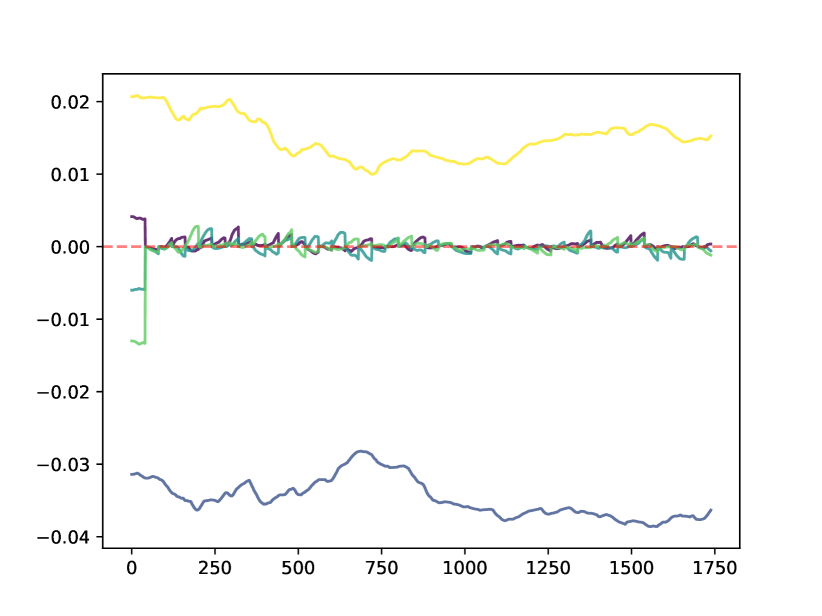
请注意,将 的元素清零并不会阻止该元素在下一个训练步骤中立即变为非零。 然而,以这种方式修剪会改变训练动态并鼓励 变得稀疏。 图2显示了不同数据集训练过程中的五个随机权重。 可以看出,一些权重可以在剪枝后幸存下来,一些权重由于无法足够快地逃逸而保留在剪枝区域中,而一些权重则避免了完全剪枝。
5实验
我们将 PRILoRA 应用于 DeBERTaV3-base (He 等人, 2021a)(1.84 亿个参数),并在通用语言理解评估 - GLUE ( 中包含的八个自然语言理解基准上评估该方法)王等人,2019)。 GLUE 基准测试摘要可在表 6 中找到。 我们使用 PyTorch (Paszke 等人, 2019) 和 Hugging Face Transformers (Wolf 等人, 2019) 来实现算法。 所有实验均在 NVIDIA GeForce RTX 2080 Ti GPU 上进行。 由于 GPU 内存大小有限,我们将 T5-3B、Llama 等大型模型的类似分析留待未来研究。
5.1基线
完全微调:在微调阶段,使用预训练的参数初始化模型,所有模型参数都经过梯度更新。
Bitfit:(Zaken 等人,2021) 一种稀疏微调方法,仅修改模型的偏差项(或其子集)。
HAdapter: (Houlsby 等人, 2019) 在自注意力模块、FFN 模块和后续残差连接之间插入适配器层。 有两个完全连接的层,在适配器层中存在偏差,其间存在非线性。
PAdapter: (Pfeiffer 等人, 2020) 在 FNN 模块和 LayerNorm 之后插入适配器。
LoRA: (Hu 等人, 2022) 与现有权重矩阵并行添加可训练的秩分解矩阵对。 可训练参数的数量由等级和原始参数的形状决定。
AdaLoRA: (Zhang 等人, 2023) 对于给定的参数,以奇异值分解的形式参数化增量更新。
5.2实施细节
在我们的研究中,我们在保持参数总数不变的情况下尝试了不同的分布,发现配置 以及表 7 中指定的超参数是最佳的>。 事实上,较高层需要更多参数来进行 LoRA 微调,这可能表明基于 Transfomer 的模型中较高层可以捕获更深层次的理解,因此在微调预训练语言模型时,必须更多关注更深层次与需要较少修改或适应相关下游任务的较低层相比。
5.3 主要结果
我们将 PRILoRA 与基线方法进行比较。 表 1 显示了我们在 GLUE 开发集上的结果(附录 A)。 PRILoRA 在 8 个数据集中的 6 个数据集中取得了最好的平均分数和最佳结果,并且在所有数据集中都比 HAdapter、PAdapter 和 LoRA 的结果更好,参数数量大致相同。
请注意,在计算参数数量时,我们不会对修剪后的参数进行折扣。 然而,在大多数基准测试中,剪枝率为 0.5 时,四分之一的学习参数( 矩阵的一半参数)为零。 因此,更精确的参数计数将接近 100 万个参数,而不是 1.33M。
| Method | #Param | MNLI | SST-2 | CoLA | QQP | QNLI | RTE | MRPC | STS-B | All |
|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Acc | Mcc | Acc | Acc | Acc | Acc | Corr | Avg. | ||
| Full FT | 184M | 89.90 | 95.63 | 69.19 | 92.40 | 94.03 | 83.75 | 89.46 | 91.60 | 88.25 |
| BitFit | 0.1M | 89.37 | 94.84 | 66.96 | 88.41 | 92.24 | 78.70 | 87.75 | 91.35 | 86.20 |
| HAdapter | 1.22M | 90.13 | 95.53 | 68.64 | 91.91 | 94.11 | 84.48 | 89.95 | 91.48 | 88.28 |
| PAdapter | 1.18M | 90.33 | 95.61 | 68.77 | 92.04 | 94.29 | 85.20 | 89.46 | 91.54 | 88.41 |
| 1.33M | 90.65 | 94.95 | 69.82 | 91.99 | 93.87 | 85.20 | 89.95 | 91.60 | 88.50 | |
| AdaLoRA | 1.27M | 90.76 | 96.10 | 71.45 | 92.23 | 94.55 | 88.09 | 90.69 | 91.84 | 89.46 |
| PRILoRA | 1.33M | 90.75 | 96.21 | 72.79 | 92.45 | 94.44 | 89.05 | 92.49 | 91.92 | 90.01 |
| [PRILoRA SD] | 0.03 | 0.30 | 1.28 | 0.05 | 0.14 | 1.04 | 0.57 | 0.14 | 0.44 | |
| SST-2 | CoLA | RTE | MRPC | |
| PRILoRA | 96.44 | 73.08 | 90.25 | 93.14 |
| Fixed distribution | 96.10 | 72.17 | 88.81 | 92.16 |
| Inverted distribution | 95.99 | 69.73 | 88.09 | 91.91 |
| Concentrated dist. | 95.07 | 69.92 | 87.73 | 89.95 |
| No pruning | 96.22 | 71.31 | 89.89 | 92.09 |
| Prune B rows | 96.10 | 71.41 | 89.89 | 91.67 |
| Prune B cols. | 96.22 | 71.46 | 88.81 | 91.42 |
| Prune A rand cols. | 94.84 | 70.75 | 88.09 | 89.22 |
| SST-2 | CoLA | RTE | MRPC | |
|---|---|---|---|---|
| Prune 0.25 | 96.10 0.34 | 71.43 0.30 | 87.73 1.25 | 91.34 0.99 |
| Prune 0.50 | 96.21 0.30 | 72.79 1.28 | 89.05 1.04 | 92.49 0.57 |
| Prune 0.75 | 95.95 0.17 | 70.63 1.56 | 87.73 0.73 | 90.85 0.51 |
| Dataset | Method | GPU Mem | Time/epoch |
|---|---|---|---|
| MNLI | LoRA | 9.559 GB | 117 min |
| PRILoRA | 9.559 GB | 120 min | |
| SST-2 | LoRA | 9.559 GB | 24 min |
| PRILoRA | 9.559 GB | 23 min | |
| QQP | LoRA | 9.559 GB | 109 min |
| PRILoRA | 9.559 GB | 110 min |
| SST-2 | CoLA | RTE | MRPC | |
|---|---|---|---|---|
| PRILoRA | 9875 | 12375 | 1875 | 1750 |
| LoRA | 6500 | 8000 | 3250 | 1250 |
5.3.1 消融研究
在表 2 中,我们提出了 PRILoRA 的消融研究,涉及四个 GLUE 任务:SST-2、CoLA、RTE 和 MRPC。 我们的目标是分析跨层的排名分布和剪枝方法。
对于秩分布研究,我们:(i)删除我们方法的线性分布组件,仅保留剪枝组件,并在每一层具有相同的秩; (ii) 替换 412 按 12 分配4; (iii) 仅将 LoRA 适配器附加到最后一层,最高等级为 24(集中分布)。
对于剪枝方法研究,我们:(i)删除重要性剪枝成分,保留递增的等级分布 4 12;(ii) 通过收集 输入规范的指数移动平均值来修剪 矩阵的行,而不是 ,而不是 (或层)的输入;(iii) 类似地,修剪 列,而不是行;(iv) 随机修剪 列,而不是 PRILoRA 方法,但 修剪率相同。 在所有消融测试期间,根据基准测试,我们保留相同的超参数并仅更改单个组件。 对于表中的所有单元格,使用相同的单个种子。
排名分布
可以看出,去除低秩的线性分布并在所有层上固定一个恒定的秩,使得参数总数保持与 LoRA 中相同,但应用剪枝会减少所有测试的结果。 尽管如此,去除线性分布的效果仍然优于 LoRA 结果,这表明修剪确实是该方法的重要组成部分。 例如,没有线性分布的 PRILoRA 在 SST-2 基准上达到 96.10,而 LoRA 为 94.95,在 CoLA 上为 72.17 对 69.82。
有趣的是,将排名分配的顺序更改为 124、性能大幅降低;例如减少 73.08 CoLA 基准为 69.73,93.14 MRPC 基准测试结果为 91.91。 反转排名分配顺序会降低跨层固定排名分配的性能。 这为需要向顶层分配更多参数提供了额外的支持。
最后,仅将 LoRA 附加到最后一层会在整个等级分布消融研究中产生最低的平均结果,例如,当使用完整方法时,MRPC 上的结果为 89.95 与 93.14。
修剪方法
完全消除修剪会降低性能。 例如,在 CoLA 上,它减少了 73.08 71.31. 这高于 LoRA(69.82),表明排名增加分布的积极作用。 当我们修剪矩阵 而不是 时,我们得到的结果类似于根本没有修剪,这表明修剪 没有产生任何明显的好处。
一个合理的论点是, 和 的输入激活形状非常不同,例如,在 DeBERTaV3 基础模型中大多数权重和较低权重的情况下,分别为 768 与 8。 -排名第8。 选择以 0.5 的 修剪比率 来对矩阵 进行行修剪,本质上意味着消除每 行中 8 个单元中的 4 个,这也可能是挑衅的。 此外,对 列执行相同的过程可能会导致 的整行被清零,这意味着 LoRA 的相应输出单元也将为零。 此外,矩阵 的压缩低秩潜在输入已经封装了基本信息,因此修剪它会降低性能。
最后,以相同的修剪比率对中的列进行随机修剪,在修剪方法消融研究中产生最低结果。
5.3.2 PRILoRA剪枝率研究
我们想了解应该如何积极地修剪,即应该向 LoRA 权重注入多少稀疏性才能达到峰值性能。 我们选择了四个 GLUE 任务,对于每个任务和 {0.25, 0.50, 0.75} 中的每个修剪比率,我们运行了三次微调,每次都使用不同的种子。 我们报告不同种子的平均结果和标准差。
5.3.3 PRILoRA 培训成本研究
我们使用基于 DeBERTaV3 的模型,在 NVIDIA GeForce RTX 2080 Ti GPU 上展示 PRILoRA 和 LoRA 之间的训练成本比较。 对于这两种方法,批量大小均为 32。
表 4 显示,与 LoRA 相比,PRILoRA 可训练参数数量的增加为零,并且每轮训练时间的增加可以忽略不计。
相比之下,AdaLoRA (Zhang 等人, 2023) 每批速度在 MNLI 基准测试中比 LoRA 慢 11%,在 SST-2 基准测试中慢 16%,并且内存占用稍大。
然而,分析每批次的训练时间是不够的。 一旦我们知道 PRILoRA 中的训练步骤时间与 LoRA 类似,我们就想要更深入地研究并分析所需的步骤数,直到在评估指标上达到峰值性能。
表5列出了每种方法达到其峰值评估性能所需的步骤数。 显然,就达到最佳性能所需的步数或时间而言,没有明显的赢家。 LoRA 和 PRILoRA 具有相同的数量级。 由于人们经常训练超过峰值,因此该表并不表明在这方面一种方法优于另一种方法。
6讨论
从一项任务转移到另一项任务需要调整输入和输出域。 虽然大型语言模型的输入域可能足够全面以支持新的下游任务,但输出的生成在很大程度上依赖于上下文和任务。
因此,微调需要对顶层进行更多的调整也就不足为奇了,因为顶层比早期的输入处理层更接近输出。
然而,如果只改变顶层,正如我们在消融研究中所示,那么早期层就没有足够的共同适应能力,无法使顶层产生所需的输出。 因此,逐步增加分配的资源似乎是一个合理的策略。
7结论
在本文中,我们介绍了 PRILoRA,这是一种新颖、简单且参数高效的方法,用于在微调过程中改善低秩自适应。 我们的广泛实验涵盖了多个种子的八个 GLUE 基准,说明了 PRILoRA 的有效性。 值得注意的是,与最先进的指标相比,我们实现了卓越的性能,同时保持相同数量的可训练参数,在大多数基准测试中将非零参数减少四分之一,并遵守相同的内存约束和每个周期的运行时间。
8 限制
我们的工作有一些局限性。 我们利用 NVIDIA GeForce RTX 2080 Ti GPU 突破了计算资源的限制,在八个 GLUE 基准测试中进行了本研究中提出的实验。 我们采用了 PRILoRA 修改的 DeBERTaV3 模型,该模型由 1.84 亿个参数组成。
这些实验与最相关的工作(Zhang等人,2023)具有相同的规模。 然而,该方法的全部潜力可以在更广泛的数据集上训练的更大模型上实现,并通过使用可以放入 GPU 内存的更大批次,从而允许在其他下游任务(例如问答和文本摘要)上检查该方法。
参考
- Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. 2016. Layer normalization. arXiv preprint arXiv:1607.06450.
- Bai et al. (2022) Yue Bai, Huan Wang, Xu Ma, Yitian Zhang, Zhiqiang Tao, and Yun Fu. 2022. Parameter-efficient masking networks. Advances in Neural Information Processing Systems, 35:10217–10229.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Chen et al. (2023) Jiaao Chen, Aston Zhang, Xingjian Shi, Mu Li, Alex Smola, and Diyi Yang. 2023. Parameter-efficient fine-tuning design spaces. arXiv preprint arXiv:2301.01821.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311.
- Dettmers et al. (2023) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dodge et al. (2020) Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah Smith. 2020. Fine-tuning pretrained language models: Weight initializations, data orders, and early stopping. arXiv preprint arXiv:2002.06305.
- Donahue et al. (2014) Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, and Trevor Darrell. 2014. Decaf: A deep convolutional activation feature for generic visual recognition. In International conference on machine learning, pages 647–655. PMLR.
- Frankle and Carbin (2019) Jonathan Frankle and Michael Carbin. 2019. The lottery ticket hypothesis: Finding sparse, trainable neural networks. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.
- Gale et al. (2019) Trevor Gale, Erich Elsen, and Sara Hooker. 2019. The state of sparsity in deep neural networks. arXiv preprint arXiv:1902.09574.
- Gheini et al. (2021) Mozhdeh Gheini, Xiang Ren, and Jonathan May. 2021. Cross-attention is all you need: Adapting pretrained transformers for machine translation. arXiv preprint arXiv:2104.08771.
- Guo et al. (2020) Demi Guo, Alexander M Rush, and Yoon Kim. 2020. Parameter-efficient transfer learning with diff pruning. arXiv preprint arXiv:2012.07463.
- Han et al. (2015a) Song Han, Huizi Mao, and William J Dally. 2015a. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149.
- Han et al. (2015b) Song Han, Jeff Pool, John Tran, and William J. Dally. 2015b. Learning both weights and connections for efficient neural network. In Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pages 1135–1143.
- Hassibi et al. (1993) Babak Hassibi, David G Stork, and Gregory J Wolff. 1993. Optimal brain surgeon and general network pruning. In IEEE international conference on neural networks, pages 293–299. IEEE.
- He et al. (2022) Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. 2022. Towards a unified view of parameter-efficient transfer learning. In International Conference on Learning Representations.
- He et al. (2021a) Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2021a. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing. arXiv preprint arXiv:2111.09543.
- He et al. (2021b) Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021b. Deberta: Decoding-enhanced bert with disentangled attention. In International Conference on Learning Representations.
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
- Hu et al. (2022) Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations.
- Lawton et al. (2023) Neal Lawton, Anoop Kumar, Govind Thattai, Aram Galstyan, and Greg Ver Steeg. 2023. Neural architecture search for parameter-efficient fine-tuning of large pre-trained language models. arXiv preprint arXiv:2305.16597.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pages 4582–4597. Association for Computational Linguistics.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Liu et al. (2018) Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. 2018. Rethinking the value of network pruning. arXiv preprint arXiv:1810.05270.
- Luccioni et al. (2022) Alexandra Sasha Luccioni, Sylvain Viguier, and Anne-Laure Ligozat. 2022. Estimating the carbon footprint of bloom, a 176b parameter language model. arXiv preprint arXiv:2211.02001.
- Mao et al. (2021) Yuning Mao, Lambert Mathias, Rui Hou, Amjad Almahairi, Hao Ma, Jiawei Han, Wen-tau Yih, and Madian Khabsa. 2021. Unipelt: A unified framework for parameter-efficient language model tuning. arXiv preprint arXiv:2110.07577.
- Molchanov et al. (2016) Pavlo Molchanov, Stephen Tyree, Tero Karras, Timo Aila, and Jan Kautz. 2016. Pruning convolutional neural networks for resource efficient inference. arXiv preprint arXiv:1611.06440.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. Pytorch: An imperative style, high-performance deep learning library. In Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, pages 8024–8035.
- Pfeiffer et al. (2020) Jonas Pfeiffer, Aishwarya Kamath, Andreas Rücklé, Kyunghyun Cho, and Iryna Gurevych. 2020. Adapterfusion: Non-destructive task composition for transfer learning. arXiv preprint arXiv:2005.00247.
- Qiu et al. (2020) Xipeng Qiu, Tianxiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. 2020. Pre-trained models for natural language processing: A survey. Science China Technological Sciences, 63(10):1872–1897.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67.
- Rebuffi et al. (2017) Sylvestre-Alvise Rebuffi, Hakan Bilen, and Andrea Vedaldi. 2017. Learning multiple visual domains with residual adapters. Advances in neural information processing systems, 30.
- Schwartz et al. (2022) Eli Schwartz, Assaf Arbelle, Leonid Karlinsky, Sivan Harary, Florian Scheidegger, Sivan Doveh, and Raja Giryes. 2022. Maeday: Mae for few and zero shot anomaly-detection. arXiv preprint arXiv:2211.14307.
- Sun et al. (2023) Mingjie Sun, Zhuang Liu, Anna Bair, and J Zico Kolter. 2023. A simple and effective pruning approach for large language models. arXiv preprint arXiv:2306.11695.
- Sung et al. (2022) Yi-Lin Sung, Jaemin Cho, and Mohit Bansal. 2022. Lst: Ladder side-tuning for parameter and memory efficient transfer learning. Advances in Neural Information Processing Systems, 35:12991–13005.
- Sung et al. (2021) Yi-Lin Sung, Varun Nair, and Colin A Raffel. 2021. Training neural networks with fixed sparse masks. Advances in Neural Information Processing Systems, 34:24193–24205.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Vucetic et al. (2022) Danilo Vucetic, Mohammadreza Tayaranian, Maryam Ziaeefard, James J Clark, Brett H Meyer, and Warren J Gross. 2022. Efficient fine-tuning of bert models on the edge. In 2022 IEEE International Symposium on Circuits and Systems (ISCAS), pages 1838–1842. IEEE.
- Wang et al. (2019) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.
- Wolf et al. (2019) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. 2019. Huggingface’s transformers: State-of-the-art natural language processing. ArXiv preprint, abs/1910.03771.
- Zaken et al. (2021) Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. 2021. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. arXiv preprint arXiv:2106.10199.
- Zhang et al. (2023) Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023. Adaptive budget allocation for parameter-efficient fine-tuning. In The Eleventh International Conference on Learning Representations.
- Zhu and Gupta (2018) Michael Zhu and Suyog Gupta. 2018. To prune, or not to prune: Exploring the efficacy of pruning for model compression. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Workshop Track Proceedings. OpenReview.net.
附录 AGLUE 数据集
以下是我们从 GLUE (Wang 等人,2019) 数据集中使用的基准和指标的摘要。
| Corpus | Task | #Train | #Dev | #Label | Metrics |
| Single-Sentence Tasks | |||||
| CoLA | Grammatical Acceptability | 8.5k | 1k | 2 | Matthews corr |
| SST-2 | Sentiment | 67.3k | 872 | 2 | Accuracy |
| Pairwise Text Tasks | |||||
| MNLI | NLI (Entailment) | 392k | 9.8k | 3 | Matched Accuracy |
| RTE | NLI (Entailment) | 2.5k | 277 | 2 | Accuracy |
| QQP | Semantic Equivalence | 364k | 40k | 2 | Accuracy |
| MRPC | Semantic Equivalence | 3.7k | 408 | 2 | Accuracy |
| QNLI | Question Answering | 105k | 5.5k | 2 | Accuracy |
| STS-B | Similarity | 5.7k | 1.5k | 1 | Pearson/Spearman corr |
附录 B PRILoRA GLUE 训练详细信息
对于所有基准测试,我们使用从 4 到 12 的线性排名分布 (4,5,6,6,7,8,8,9,10,10,11,12),因此平均排名为 8(排名四舍五入为整数)。 所有八个基准测试均使用线性学习率调度进行训练,初始学习率报告为学习率,调度程序的纪元数记为纪元。 运行在 stop epoch epoch 之后停止。 在 空间中随机搜索超参数:学习率、批量大小、历时次数、衰减和剪枝率。 对于所有基准测试和方法,最大 seq 长度 为 128。
| Dataset | learning rate | batch size | # epochs | stop epoch | decay | prune ratio |
|---|---|---|---|---|---|---|
| MNLI | 32 | 70 | 5 | 0.01 | 0.50 | |
| RTE | 32 | 70 | 25 | 0.01 | 0.50 | |
| QNLI | 32 | 60 | 3 | 0.01 | 0.50 | |
| MRPC | 32 | 60 | 15 | 0.01 | 0.50 | |
| QQP | 32 | 10 | 10 | 0.01 | 0.50 | |
| SST-2 | 32 | 60 | 5 | 0.01 | 0.50 | |
| CoLA | 4 | 70 | 6 | 0.01 | 0.50 | |
| STS-B | 32 | 30 | 30 | 0.10 | 0.75 |