LLM4EDA:电子设计自动化大型语言模型的新进展
摘要
在摩尔定律的推动下,现代芯片设计的复杂性和规模正在迅速增加。 电子设计自动化(EDA)已被广泛应用来解决整个芯片设计过程中遇到的挑战。 然而,超大规模集成电路的发展使得芯片设计变得耗时且资源密集,需要大量的先验专业知识。 此外,中间人类控制活动对于寻求最佳解决方案至关重要。 在系统设计阶段,电路通常用硬件描述语言(HDL)作为文本格式来表示。 最近,大型语言模型(大语言模型)展示了其在上下文理解、逻辑推理和答案生成方面的能力。 由于电路可以用HDL以文本格式表示,因此有理由质疑大语言模型是否可以在EDA领域利用来实现全自动芯片设计并生成具有改进的功耗、性能和面积(PPA)的电路。 本文对大语言模型在EDA领域的应用进行了系统的研究,将其分为以下几类案例:1)助理聊天机器人,2)HDL和脚本生成,3)HDL验证和分析。 此外,我们还强调了未来的研究方向,重点是大语言模型在逻辑综合、物理设计、多模态特征提取和电路对齐方面的应用。 我们通过以下链接收集该领域的最新相关论文:https://github.com/Thinklab-SJTU/Awesome-LLM4EDA。
1简介
在过去的几十年里,电子设计自动化(EDA)算法和工具取得了长足的进步,芯片设计生产力得到了显着提高。 与此同时,在摩尔定律的推动下,电路尺寸呈指数级增长,给芯片工程师实现数十亿晶体管的超大规模集成(VLSI)带来了新的挑战。 除了规模之外,满足功耗、性能和面积 (PPA)、规格和其他约束的要求也变得越来越具有挑战性,特别是在整个漫长的 EDA 设计流程中。 在这个漫长的设计流程中,涉及大量中间过程,需要大量时间和成本的人工干预,通常需要与自然语言或编程语言接口进行迭代交互。 这些过程会产生丰富多样的输出和富含文本信息的日志,需要工程师理解、处理和决策以遵循指导和命令。 因此,完整的设计流程还远未实现完全自动化。 同时,芯片设计对工程师也提出了很高的要求,通常需要数年时间才能培养出一名经验丰富的工程专业人才。 如何实现电路设计过程的完全自动化,减少对经验丰富的电路设计工程师的依赖,成为研究的重点焦点。
深度学习作为一种不断发展的技术,已在不同领域和场景中得到广泛应用,包括分类、检测、预测和生成。 值得注意的是,它在为 EDA 领域常见的许多 NP 完全 (NPC) 问题生成高质量解决方案方面表现出巨大的潜力。 传统方法在有效解决这些问题方面遇到了挑战,因为它们对计算资源和时间要求很高,特别是在 VLSI 领域。 与无需积累知识而独立解决每个问题的传统方法不同,深度学习方法擅长提取相似或相关案例之间共享的高级特征和表示。 利用这些功能可以在整个问题解决过程中重复使用和应用它们,从而提高速度并提高解决方案质量。 因此,整合深度学习技术来帮助和加速 EDA 问题的解决代表了一个非常有前途的研究方向。
目前,深度学习在芯片设计流程中得到了广泛的应用,包括逻辑综合(Hosny等人,2020;Yuan等人,2023)、布局规划(Amini等人,2022) ,布局(Lin 等人,2019;Mirhoseini 等人,2021;Cheng 等人,2021;Cheng 等人,2022;Lai 等人,2022),时钟树综合(卢等人,2021;梁等人,2023)路由(程等人,2022;杜等人,2023a)和PPA预测(郭等人, 2022;柴等人,2023;钟等人,2024)。 同时,许多工作关注电路的通用表示学习(Li 等人,2022a;Shi 等人,2023;Wang 等人,2022)。 它将电路的功能和结构信息嵌入为向量,并且这些表示可以在各种下游任务中进一步利用,而不是从头开始学习每个任务的特定模型。 为了支持神经网络训练对海量训练数据的需求,并在 EDA 中实现更强的泛化能力,开源数据集如 Circuit (Chai 等人, 2023) 和 Circuit 2.0 (Anonymous, 2024 ) 已提供给研究界。 这些数据集提供跨阶段和跨设计样本,有助于全面探索电子设计自动化人工智能(AI4EDA)的进步。 我们收集了有关AI4EDA的论文并保持实时更新 111https://github.com/Thinklab-SJTU/awesome-ai4eda。
最近,大语言模型展示了上下文理解、问答和逻辑推理等多方面的能力。 商业(ChatGPT、Bard 等)和开源(LLaMA2 (Touvron 等人, 2023))方案都在该领域取得了显着进展。 由于电路可以用编程语言、硬件描述语言 (HDL)、规范和通过 EDA 流程的许多中间输出来描述,因此也可以用文本格式来表示。 人们自然会问大语言模型是否可以用于EDA来协助工程师进行芯片设计。
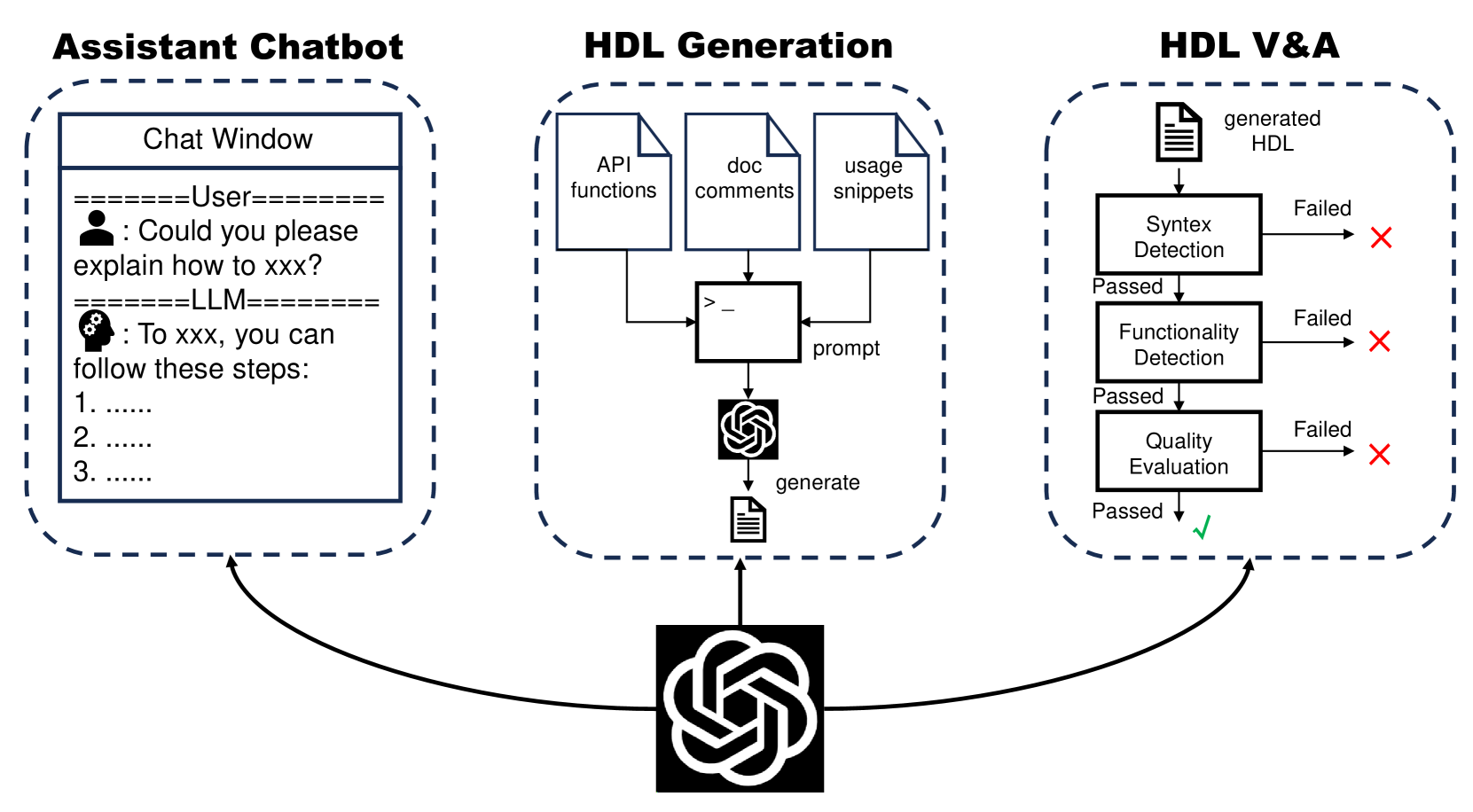
在本次调查中,我们对电子设计自动化大型语言模型(LLM4EDA)的进展和应用进行了全面、详细的调查。 如图1所示,我们将目前大语言模型在EDA中的应用和探索分为以下三个方向:
-
•
助理聊天机器人。 用户可以与大语言模型进行交互,进行知识获取和问答,无需花费时间等待或主动寻找答案。 我们展示了一些著名的作品,旨在提供用户友好且易于交互的助理聊天机器人,并为我们带来 EDA 软件的新交互范例。
-
•
HDL 和脚本生成。 给定语言格式规范和要求,大语言模型将生成RTL代码和EDA控制脚本。 这种自动化过程通过减少传统上编写代码和脚本所涉及的手动工作来简化电路设计的开发,从而提高芯片设计的效率和生产力。 此外,如何评估生成代码的质量仍然是一个开放的研究热点,其中语法正确性和功能等效性是关键因素。 在 EDA 领域,存在更多指标需要考虑,例如功耗、性能和面积(PPA)以及安全问题。 因此,考虑各方面的新的评估框架也是必要的。
-
•
HDL 验证和分析。 我们还研究了大语言模型在代码分析中的广泛应用,例如错误检测和修复、代码摘要和安全检查。 此外,大语言模型还表现出了强大的验证能力,例如: 基于断言的验证。
除了上述进步之外,从大语言模型的角度来看,EDA 流程中的其他关键流程也表现出了良好的潜力。 具体来说,我们提供以下概述:
-
•
逻辑综合。 当硬件描述语言(HDL)和提示被视为输入时,大语言模型具有生成优化序列以及逻辑综合中相应参数的潜力。
-
•
物理设计。 目前布局布线(P&R)的复杂性使得直接应用大语言模型具有挑战性。 然而,采用图划分和聚类等策略可以减少问题的规模并加速求解过程,从而使大语言模型的使用变得可行。 大语言模型还可以用于优化模块或充当强化学习代理的奖励系统。
2 预赛
2.1 大型语言模型
大语言模型(Large Language Models)(OpenAI, 2023b; Touvron 等人, 2023)是一类具有大量参数特征的人工智能模型。 这些模型在延长的 GPU 时间内接受了大量文本数据的训练。 该领域的先驱是OpenAI的GPT系列(Brown 等人, 2020; Ouyang 等人, 2022; OpenAI, 2023b),其中GPT-3 (Brown 等人, 2020) 是一个拥有 1750 亿个参数的自回归语言模型,在规模上显着优于其他当代模型。 在此基础上,GPT-3.5 (Ouyang 等人, 2022) 重点对 GPT-3 进行微调,特别是结合了人类反馈的强化学习 (RLHF) (Christiano 等人, 2017;Stiennon 等人,2020),以增强与人类偏好的一致性。 虽然这些模型表现出了令人印象深刻的性能,但大语言模型的官方激增可归因于 ChatGPT 的出现 222https://openai.com/blog/chatgpt/,将GPT-3.5适配于对话,取得了显着的效果和应用。 针对ChatGPT的广泛关注,OpenAI开发了GPT-4(OpenAI, 2023b),这是一个比ChatGPT更强大的大语言模型,支持多模态、更长、更逻辑的输入/输出。
GPT系列的成功带动了其他各种大语言模型的发展,例如LLaMA (Touvron 等人, 2023)和Gemini 333https://deepmind.google/technologies/gemini/ 由不同的公司和机构提供。 凭借大量的数据、大量的参数和较长的训练时间,大语言模型可以在给定一定输入的情况下生成类似人类的文本。 它们不仅能够执行翻译、角色模拟、生成诗歌、故事等创意内容等任务,还能够回答问题并处理生成可执行代码和脚本等高难度任务。 大语言模型的潜力是巨大的,而且还远未完全发挥出来。
2.2电子设计自动化的设计流程
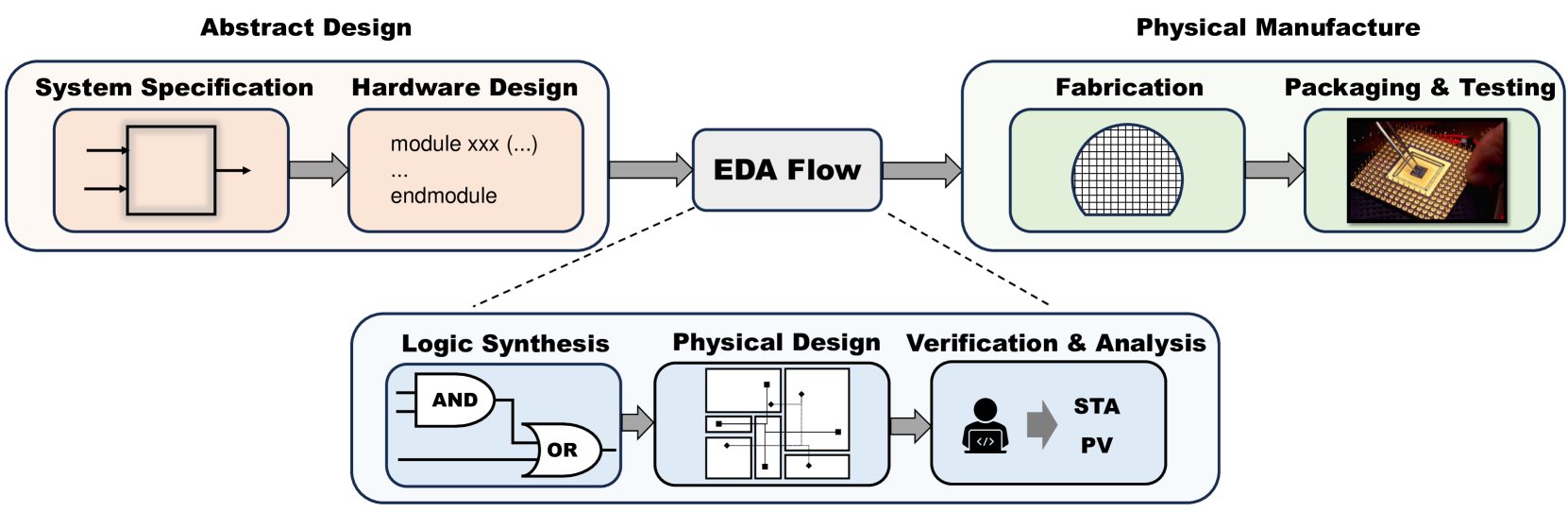
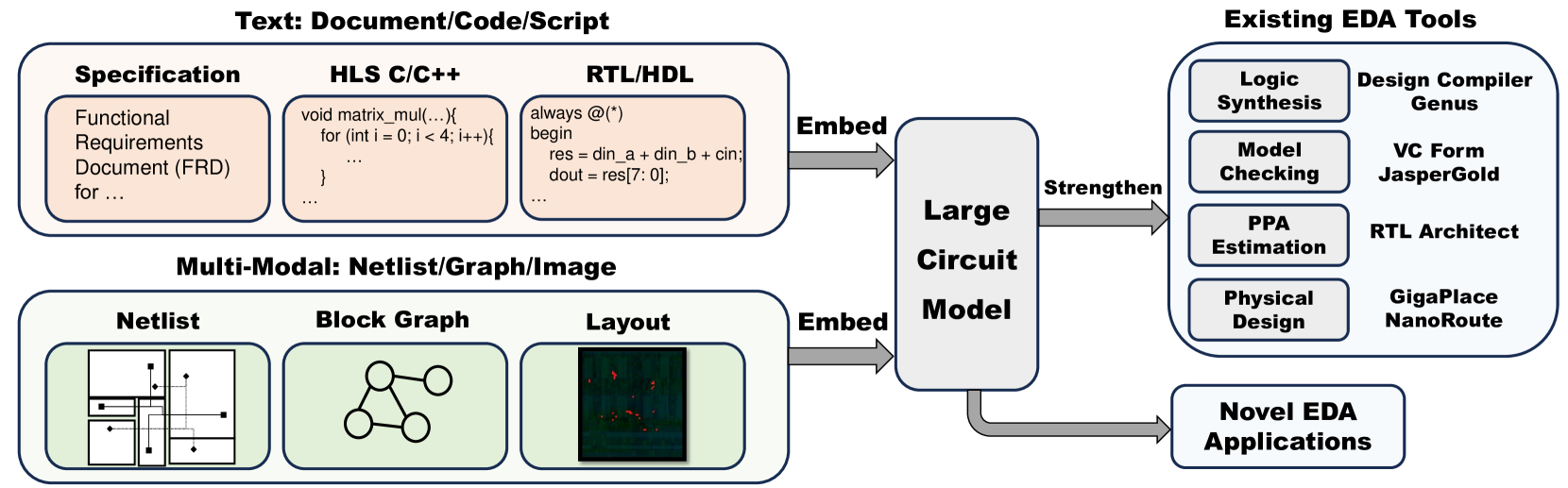
芯片设计过程错综复杂且涉及多个方面,通常分为几个不同的阶段(Anonymous,2024)。 如图2所示,这些阶段包括抽象设计、EDA流程和物理制造。 EDA流程本身可以进一步细分为逻辑综合、物理设计、验证和分析,每一个环节对于芯片的成功创建都起着至关重要的作用。 我们还设想一个大型电路模型,被视为 EDA 引导的大语言模型,可以联合不同阶段并输出 EDA 流程中的通用解决方案。 具体来说,我们的方法利用数据驱动的大型模型,其中文本和多模态信息都集成到潜在空间中。 文本数据包括规范文档、HLS 代码和 RTL 脚本,而多模态信息包括网表、图形和图像。 大电路模型可以从头开始训练,也可以使用这些数据对现有的语言大模型(大语言模型)进行微调。 经过训练,该模型可以增强现有 EDA 工具的功能并促进各种下游应用程序。 基于大电路模型的理想工作流程如图3所示。 然而,值得注意的是,实现我们的最终目标仍有很长的路要走。
3LLM4EDA的应用
根据主流研究兴趣,我们将近期文献综合为四个方面,包括1)助理聊天机器人; 2)HDL和脚本生成; 3) 生成代码的评估,以及 4) 代码验证和分析。 相关论文如图4所示。
对于tree=grow'=east,绘制,圆角,节点选项=font=,fill=blue!20,edge=thick,color=blue!50,l sep+=0.8cm,s sep+ =0.1cm,父锚点=东,子锚点=西,锚点=西,边缘路径= [绘制,边缘] (!u.父锚点) – +(5pt,0) |- (.子锚点)边缘标签; ,[LLM4EDA,填充=黑色!20 [ Assistant Chatbot ,对于tree=fill=green!20 [ChipNeMo (刘等人, 2023a),对于tree=fill=black!5] [Smarton-AI ( Han 等人, 2023), for tree=fill=black!5] [RapidGPT (PrimisAI, 2023), for tree=fill=black!5] ] [ HDL Generation ,对于tree=fill=red!20 [ChatEDA (He 等人, 2023),对于tree=fill=black!5] [ChipGPT (Chang 等人, 2023), 对于tree=fill=black!5] [VerilogEval (Liu 等人, 2023b), 对于tree=fill=black!5] [GPT4AIGChip ( Fu 等人, 2023), for tree=fill=black!5] [Chip-Chat (Blocklove 等人, 2023), for tree=fill=black!5] [AutoChip (Thakur 等人, 2023c), for tree=fill=black!5] [RTLLM (Lu 等人, 2023), for tree=fill=black!5] [Thakur 等人 (2023a),用于 tree=fill=black!5] [VeriGen (Thakur 等人,2023b),用于 tree=fill=black!5] [RapidGPT (PrimisAI, 2023)0>,对于 tree=fill=black!5] ] [ Code Verification & Analysis ,对于tree=fill=blue!20 [ChipNeMo (Liu 等人, 2023a),对于tree=fill=black!5] [RTLFixer (Tsai 等)人, 2023), 对于tree=fill=black!5] [AutoSVA (Orenes-Vera 等人, 2021), 对于tree=fill=black!5] [ Kande 等人 (2023), for tree=fill=black!5] [NSPG (Meng 等人, 2023), for tree=fill=black!5] [DIVAS (Paria 等人, 2023), for tree=fill=black!5] [Ahmad 等人 (2023), for tree=fill=black!5] ] ]
3.1 助理聊天机器人
完整的芯片设计流程需要大量的先验专业知识,这需要多年的研究和积累。 为了帮助工程师获得与架构、设计、工具和验证相关的问题的答案,工程助理聊天机器人可以有效地满足他们的需求。 尽管当前的大语言模型是针对各种类型的文本进行预训练并充当通用聊天机器人,但它们可能缺乏对 EDA 等特定领域的深刻而准确的理解。 因此,开发一个工程助理聊天机器人,结合从内部设计文档、代码以及与设计和技术通信相关的记录数据中提取的知识,可以大大提高设计效率。
人们普遍认为,大语言模型可能会产生不准确的答案,给人以正确的印象,但往往会导致严重的误解。 这种现象通常被称为幻觉(Ji等人,2023)。 虽然幻觉的确切原因尚未完全了解,但必须解决这个问题,特别是在工程领域,特别是 EDA 领域。 这些生成的答案的准确性在工程中具有重要意义,强调了减少幻觉发生的必要性。
代表作品是ChipNeMo (Liu 等人, 2023a)。 他们建议利用检索增强生成(RAG)(Lewis等人,2020)方法来减轻幻觉。 此外,他们发现使用适量的领域特定训练数据对现成的无监督预训练密集检索模型进行微调可以显着提高检索准确性。 他们利用这些技术对预训练的大语言模型进行构建,以构建芯片设计专用的助理聊天机器人。 因此,工程师可以更加专注于集思广益、设计和编写代码,而不是等待答案或搜索他们缺乏的知识。 RapidGPT (PrimisAI,2023)是另一项值得注意的工作,它是业界第一个为 FPGA 工程师量身定制的基于人工智能的配对设计器。 作为智能代码助手,RapidGPT 利用 AI 算法提供准确且上下文感知的代码建议,使 FPGA 工程师能够更高效地编写 Verilog 代码。 RapidGPT 还通过提供聊天面板将对话功能提升到新的水平,使用户可以轻松地与该工具进行通信。 该聊天面板可用于以对话方式编写或改进 HDL 代码。
从与大语言模型交互的角度来看,Smart-AI (Han 等人,2023 年)提出了在复杂软件中利用大语言模型的新交互范式,包括主子 GPT 和问答 GPT。 主 GPT 根据自然语言格式的用户输入识别最相关的任务。 所有子 GPT 形成专家混合 (MoE) (Masoudnia 和 Ebrahimpour,2014) 系统。 每个子 GPT 专用于主 GPT 中确定的任务,并为此任务生成学习文档。 Q&A GPT 负责处理子 GPT 生成的学习文档。 它充当助理聊天机器人,利用从这些文档派生的输入来促进用户交互并以问答形式提供相关信息。
3.2 HDL生成和评估
3.2.1 HDL生成
现代芯片设计通常源自人类自然语言给出的规范,然后转化为硬件描述语言(HDL),例如 Verilog。 这些翻译通常需要高技能的硬件工程师,并且会遇到人为错误和大量劳动力。 自动化硬件设计可以有效减少人为错误并加速设计转化过程。 大语言模型已被经验证明可以有效生成高质量的上下文,因此很自然地将大语言模型应用于语言翻译和其他相关的脚本生成。
HDL和脚本生成的大语言模型最近的工作主要强调两个方面:1)工作流程,2)目标是什么。
其中,ChatEDA(何等人,2023)致力于实现从寄存器传输级(RTL)到图形数据系统版本II(GDSII)的流程自动化,将流程拆分为任务规划由于整个流程的复杂性,脚本生成和任务执行。 具体来说,ChatEDA将自然语言作为输入,然后通过EDA工具生成有效的代码来执行任务。 ChipGPT(Chang 等人, 2023)中也可以观察到类似的流程拆分,该框架报告了一个四阶段逻辑设计框架,包括生成提示、生成初始 Verilog 程序、纠正和优化这些程序以及选择根据目标指标进行优化设计。 GPT4AIGChip (Fu 等人, 2023) 构建了一个旨在民主化 AI 加速器设计的框架。 通过研究当前大语言模型的弱点,特别是无法处理冗长的代码,GPT4AIGChip还解耦了AI加速器设计的各种硬件模块和功能,以实现LLM驱动的设计自动化。 Chip-Chat (Blocklove 等人,2023) 针对基于新型 8 位累加器的微处理器架构的情况,并将任务划分为生成 Verilog 代码和生成大部分处理器规范。
为了使生成的代码在功能上更加准确,AutoChip (Thakur 等人, 2023c)在将大语言模型的交互合并到输出中时,更多地关注编译错误和调试内容的上下文。 Verilog 模拟。 与 AutoChip (Thakur 等人, 2023c) 和大多数其他以设计正确性为目标的基于 LLM 的方法不同,RTLLM (Lu 等人, 2023) 作为生成指令设计RTL,更关注设计品质,在实践中更公平。 除了基于度量的目标外,考虑到空间限制,Chip-Chat (Blocklove 等人, 2023) 寻求具有 32 字节内存的冯诺依曼型设计。 针对硬件设计中的安全问题和漏洞,Nair 等人 (2023) 为 ChatGPT 构建了健壮的提示,以生成抗设计的常见漏洞枚举(CWE)。
VerilogEval (Liu 等人, 2023b) 利用 GPT-3.5 (Ouyang 等人, 2022) 构建了一个综合监督微调数据集,生成与 Verilog 代码配对的问题描述。 RTLCoder (Liu 等人, 2023c)遵循这种综合方法,提出了一种利用质量分数反馈的新的大语言模型微调算法。 此外,他们还将大语言模型量化为4位,总大小为4GB,使其可以在单台笔记本电脑上运行,而性能仅略有下降。 同时,许多工作注重即时工程和反馈,直接利用现有的通用大语言模型,而无需进一步微调。 ChipGPT (Chang 等人, 2023) 使用基于模板的提示,提供原始规范的详细信息和目的。 它还包含一个输出管理器,为大语言模型提供 PPA 或其他人类指定的目标作为反馈。 杜等人(2023b)提出在复杂的FPGA设计中利用情境学习和思维链提示技术来解决挑战,包括子任务调度和多步骤思维问题。 Chip-Chat(Blocklove等人,2023)提出了对话流技术,将大型设计分解为子任务,并将先前子任务的输出提供给大语言模型作为基础规范和反馈。
3.2.2 HDL评估
一旦开发了用于代码生成的大语言模型,评估其质量就变得至关重要。 此评估过程涉及检查语法正确性和功能正确性。 语法正确性确保生成的代码遵循正确的编程语言语法规则,而功能正确性确保代码准确地执行预期任务。
除了这些检查之外,在处理 EDA 领域的代码时,进行进一步的测试以评估其最终的功耗、性能和面积 (PPA) 特性也至关重要。 该测试过程通常在整个设计流程完成后进行。 它们用于验证最终的电路设计是否满足指定的要求和相应的约束,例如面积利用率和时序约束。
以RTLLM(Lu等人, 2023)为例:它提供了一个公共基准,从以下三个角度评估生成的代码:
-
1.
语法目标。 这意味着生成的RTL设计至少应该是正确的,这可以通过检查设计是否可以正确综合到网表中来验证。
-
2.
功能目标。 这意味着生成的 RTL 的功能应该与用户的期望完全相同。 这个目标可以通过综合测试平台进行检查。
-
3.
设计质量目标。 如果生成的RTL通过了上述两个单元测试,我们需要进一步检查其设计质量,例如购电协议。 可以通过检查RTL综合和布局后的PPA值来验证。
Dataset Task Size Description Chat Gen. V&A ChipNeMo (Liu et al., 2023a) 24.1 B tokens Data from NVBugs (NVIDIA’s internal bug database), bug summary, design source, documentation, verification. LLaMA2 tokenizer is adapted and approximately 9K new tokens are added to improve tokenization efficiency. ChatEDA (He et al., 2023) ✓ 1,500 instructions Instruction tuning: Query GPT-4 to generate and collect instructions. The core controller, AutoMage is further fine-tuned on these instructions. GPT4AIGChip (Fu et al., 2023) ✓ 7,000 snippets Open-source HLS code snippets from GitHub and customized HLS templates with implementation instructions to fine-tune LLMs. VeriGen (Thakur et al., 2023b) ✓ 400 MB From Verilog textbooks and open-source GitHub repositories. Training samples are further generated through overlapped sliding windows on module blocks. Dehaerne et al. (2023) ✓ 100,000 files Verilog and SystemVerilog from GitHub open-source repositories. The dataset consists of two unlabeled subsets, file-level data and snippet-level data, and a labeled subset of snippet definition and body pairs VerilogEval (Liu et al., 2023b) ✓ 8,502 samples Designs generated from GPT-3.5 for SFT data, containing description and corresponding code. MinHash algorithm with Jaccard similarity is also performed to realize approximate deduplication. RTLCoder (Liu et al., 2023c) ✓ 10,000 designs Generated from GPT-3.5, each sample consists of an description and corresponding RTL code. Conditional log probability based quality score is also incorporated for fine-tuning. NSPG (Meng et al., 2023) ✓ 20,000 sentences Documentation collected from OpenTitan, RISC-V, OpenRISC, MIPS, OpenSPARC. This dataset is further augmented with Random Deletion, Random Swap, Synonym Replacement and Random Insertion.
基于上述单元测试,VerilogEval (Liu 等人, 2023b)提出使用pass@k度量来进一步反映生成的RTL代码的正确性:
| (1) |
我们为每个任务生成 个样本,其中 个样本通过了单元测试。
之前的一些作品,包括 AutoChip (Thakur 等人, 2023c)、ChipGPT (Chang 等人, 2023)、Thakur 等人 (2023a) ,将问题集分类为难度类型:例如简单、中级和困难。 在不同的难度设置下,他们根据语法目标、功能目标、设计质量目标来评估生成的 RTL 代码。
3.3HDL验证与分析
大语言模型在 EDA 中的另一个有前景的应用是利用大语言模型来理解、分析和总结输入的 RTL 代码。 与第二节不同。 3.2.2通过外部工具评估生成的代码,大语言模型将输入作为RTL代码和用户指定的查询,并根据该输入向用户提供响应。 这种方法允许用户直接与大语言模型交互,进行输入代码的分析。
为了帮助工程师进行错误总结和分析,ChipNeMo (Liu 等人, 2023a) 基于 NVIDIA 内部错误数据库 NVBugs 构建了特定领域的 SFT 数据集。 考虑到错误描述对于上下文窗口来说可能太大,他们用短别名替换长路径名,并将摘要任务拆分为增量任务。
除了 bug 总结和分析之外,RTLFixer (Tsai 等人, 2023) 提出了一种直接修复错误的 Verilog 代码的范例。 制定输入提示,然后利用检索增强生成(RAG)和ReAct提示机制(Yao等人,2022),代理修正错误的Verilog代码。 如果语法错误仍然存在,则会提供来自编译器的错误日志以及从数据库检索到的人工指导作为反馈。
大语言模型还展示了断言检查的能力,可以有效地发现复杂的RTL错误和安全问题。 它是一种流行的验证技术,其中将被测设计的规范编码为硬件描述语言中的断言或属性。 每个断言将侧重于验证单独的功能和逻辑。 此外,它还能够检测安全漏洞以防御攻击。 Orenes-Vera 等人 (2023) 提出了一种基于形式属性验证的迭代方法,从给定的 RTL 模块生成 SystemVerilog 断言 (SVA)。 他们还将这种断言生成流程集成到开源框架 AutoSVA (Orenes-Vera 等人,2021) 中。 Kande等人(2023)以类似的流程实现了SVA,包括提示构造、基于LLM的断言生成和模拟。 他们还根据大语言模型对“常见陷阱”的定性分析,自动修复小错误的词汇工具。
考虑到硬件设计中的安全问题,NSPG(Meng等人,2023)提出了一个框架,用于从知识产权(IP)核文档中识别基本属性。 它们是预训练的大语言模型和由硬件文档组成的数据集上的序列分类模型,后者负责识别文档中的句子是否是属性,其中包含操作员行为和安全的基本信息。 DIVAS (Paria 等人, 2023) 提出了一种基于 LLM 的端到端框架,用于识别给定片上系统 (SoC) 规范的 CWE,并采用了一种新颖的基于 LLM 的技术确定相关的CWE,最后使用大语言模型转化为SystemVerilog Assertions进行验证。 (Ahmad 等人, 2023) 利用检测器工具提取或直接获取 bug 的位置和 CWE 类型。 这些Bug信息、Bug前的代码以及注释中的Bug代码组合成大语言模型提示,辅助大语言模型修复该硬件Bug。
4 LLM4EDA数据集
使用广泛且准确的特定领域数据对通用大语言模型进行微调将产生更好的性能。 一些工作已经通过收集现有数据构建相应的数据集,包括公共设计源代码、文档、内部错误日志和错误摘要。 同时,其他工作通过查询现有的通用大语言模型的电路或设计指令来生成综合数据集。 在表1中,我们展示了一些利用特定领域数据集探索大语言模型微调的代表性作品。
5 LLM4EDA 的主干
我们在表2中展示了应用于EDA的大语言模型的任务、主干和微调技术。 由于计算资源和可用数据集的限制,当前的工作主要集中在利用现有大语言模型的 API。 对于特定领域的数据,他们要么收集现有的 RTL 代码(Liu 等人,2023a;Fu 等人,2023;Thakur 等人,2023b;Dehaerne 等人,2023;Meng 等人,2023),或从预训练的通用大语言模型(Liu等人,2023c,b)生成综合设计。
Method Task Type Size Fine-tune Chat Gen. V&A RTLCoder (Liu et al., 2023c) ✓ Zephyr 7 B Quality Score VerilogEval (Liu et al., 2023b) ✓ CodeGen 16 B SFT Ahmad et al. (2023) ✓ CodeGen 16 B Thakur et al. (2023a) ✓ CodeGen 16 B AI21 Studio ChipNeMo (Liu et al., 2023a) ✓ ✓ ✓ LLaMA2 13 B SFT ChatEDA (He et al., 2023) ✓ LLaMA2 70 B QLoRA ChipGPT (Chang et al., 2023) ✓ GPT-3.5 DIVAS (Paria et al., 2023) ✓ GPT-3.5 Schäfer et al. (2023) ✓ GPT-3.5 Nair et al. (2023) ✓ GPT-3.5 Du et al. (2023b) ✓ ✓ GPT-3.5 Kande et al. (2023) ✓ GPT-3.5 RTLFixer (Tsai et al., 2023) ✓ GPT-3.5 RTLLM (Lu et al., 2023) ✓ GPT-4 GPT4AIGChip (Fu et al., 2023) ✓ GPT-4 AutoChip (Thakur et al., 2023c) ✓ GPT-4 Chip-Chat (Blocklove et al., 2023) ✓ GPT-4 VeriGen (Thakur et al., 2023b) ✓ GPT-4 Orenes-Vera et al. (2023) ✓ GPT-4
6展望
6.1 逻辑综合 LLM
逻辑综合转换设计的高级描述,例如Verilog,转化为优化的门级表示。 主要包括三个步骤,即映射前优化、技术映射和映射后优化。 需要对综合优化流程进行广泛的调整,包括使用哪些优化、它们相应的参数和调用顺序。 这个过程可以被视为参数化动作空间中的顺序决策问题(Fan等人,2019)。 由于可能的优化排列数量呈指数级增长,有效的设计空间探索具有挑战性。 因此,它在很大程度上依赖于经验丰富的工程师。
目前的工作利用启发式(Li 等人,2022b),贝叶斯优化(BO)(Grosnit 等人,2022)强化学习(RL)(Hosny 等人) , 2020; Yuan 等人, 2023) 来搜索性能良好的优化序列。 对于大语言模型,以设计的HDL和适当的提示作为输入(例如,包含目标PPA),大语言模型可以生成优化序列及其各自的参数。 此外,最终或估计的PPA可以作为大语言模型的反馈,从而迭代提高结果质量(QoR)。
6.2物理设计 LLM
在物理设计中,布局算法确定每个模块的位置,包括宏模块和标准单元。 其目的是在密度限制下最大限度地降低线长成本。 放置后,(电线)布线步骤添加正确连接放置的组件所需的电线,同时遵守所有设计规则。 主要目标是连接所有需要的连接,并在此基础上减少布线长度和溢出。 布局布线 (P&R) 在物理设计过程中消耗了大部分时间和计算资源,并对最终的 PPA 产生重大影响。
由于大规模问题带来的固有挑战,大语言模型在布局布线 (P&R) 中的应用相对尚未被探索。 当代设计通常包含数百万个单元和网络(Lin等人,2019),这使得大语言模型直接解决每个组件的位置和布线分配是不切实际的。 采用图分区和聚类算法提供了减少问题规模的可行方法。 虽然这些方法可能会导致细粒度细节的损失和潜在的约束违规,但由此产生的“粗略”布局可以作为传统 P&R 算法的初始解决方案,从而加快求解过程。
另一种策略可能涉及优化模块,这些模块数量很少,但受到许多复杂的约束。 在这种情况下,大语言模型可以起到双重作用:它们可以用来生成最佳结果,或者可以充当黑盒奖励系统,为强化学习代理提供反馈。
6.3特征提取与对齐
目前,电路通常使用硬件描述语言来表达,以文本格式表示。 综合过程完成后,电路将转换为等效网表,通常表示为有向无环图 (DAG)。 随后,执行布局和布线操作以生成布局,建立组件的物理位置和互连。
这些表示源于相同的底层实体,并分别对应于基于语言、基于图形和基于图像的表示。 然而,迄今为止,这些多模态内容的提取和对齐尚未得到彻底研究。 大图模型(Zhang 等人,2023;Tang 等人,2023)和大视觉模型(Wang 等人,2023a;OpenAI,2023a)展示了强大的潜力分别从网表和布局中提取信息特征和表示。 我们还可以构建一个大规模的多模态预训练模型(Wang等人,2023b)来实现不同模态特征的对齐。 对比学习等技术,例如 可以采用 CLIP(对比语言-图像预训练)(Radford 等人,2021),或涉及从其他模态中屏蔽和重建某些模态的方法来实现内容对齐。
6.4 PPA 的长链反馈
在大语言模型的帮助下,我们的目标是改进芯片设计中的PPA。 然而,由于需要综合、布局和布线等众多中间过程,在系统设计阶段预测和优化 PPA 仍然存在很大差距。 这种冗长的反馈链对从初始阶段优化 PPA 提出了挑战。 我们认为这个问题可以从以下几个角度来解决:
-
1.
使用 PPA 的领域特定数据集。 包含 PPA 指标的特定领域数据集引起了人们的关注。 用于微调通用预训练大语言模型的现有数据集通常包括源代码和相应的描述。 然而,他们缺乏对购电协议考虑因素的认识(Chang 等人,2023)。 通过使用最终 PPA 指标来扩充这些数据集,它们可以作为更准确的设计规范或目标,并提供受监督的标签。 这种增强将弥合 RTL 设计与其相应的最终 PPA 之间的差距,从而增强用于 fune-tuning PPA 感知大语言模型的数据集的有效性和适用性。
-
2.
利用 PPA 作为反馈。 对于人类工程师来说,PPA 是一种重要的反馈,可以作为迭代和重复设计过程的指导。 同样,在与大语言模型的交互过程中,我们可以1)通过外部验证工具高精度评估最终的PPA,或者2)以增强的计算速度预测PPA,例如使用基于神经网络的方法(郭等人,2022;杨等人,2022;钟等人,2024)。 这些PPA可以作为大语言模型的反馈,指导他们生成或完善设计以提高质量。
-
3.
及时进行工程和任务规划。 与大语言模型交互尤其是EDA领域查询的提示问题(Chang等人,2023;He等人,2023;Pearce等人,2020)。 我们可以通过指定PPA目标、纳入成本约束、整合设计规则来构造更多信息提示,促进大语言模型更好地理解和实现我们的目的。 为了充分利用上下文窗口,通过任务规划将大型设计分解为子任务是有益的,每个子任务都有自己的与其他任务通信的接口。 此外,先前任务生成的输出可以作为后续子任务处理的基本规范和指导,从而促进连贯且高效的设计工作流程。
7结论
本文对电子设计自动化(EDA)领域中的语言模型(大语言模型)集成进行了全面的调查。 此次调查涵盖了大语言模型在EDA中的一系列应用,即:1)助理聊天机器人,2)HDL代码和EDA流程脚本的生成,3)HDL代码的验证和分析。 此外,我们还强调了未来的研究方向,重点是大语言模型在逻辑综合和物理设计中的应用,解决PPA的长反馈、多模态特征提取和电路对齐。 我们坚信大规模多模态预训练模型的最终实现,不仅适用于 EDA。
参考
- Ahmad et al. [2023] Baleegh Ahmad, Shailja Thakur, Benjamin Tan, Ramesh Karri, and Hammond Pearce. Fixing hardware security bugs with large language models. arXiv preprint arXiv:2302.01215, 2023.
- Amini et al. [2022] Mohammad Amini, Zhanguang Zhang, Surya Penmetsa, Yingxue Zhang, Jianye Hao, and Wulong Liu. Generalizable floorplanner through corner block list representation and hypergraph embedding. In SIGKDD, 2022.
- Anonymous [2024] Anonymous. Circuitnet 2.0: An advanced dataset for promoting machine learning innovations in realistic chip design environment. In Submitted to The 12th ICLR, 2024. URL https://openreview.net/forum?id=nMFSUjxMIl. Under Review.
- Blocklove et al. [2023] Jason Blocklove, Siddharth Garg, Ramesh Karri, and Hammond Pearce. Chip-chat: Challenges and opportunities in conversational hardware design. arXiv preprint arXiv:2305.13243, 2023.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NeurIPS, 2020.
- Chai et al. [2023] Zhuomin Chai, Yuxiang Zhao, Wei Liu, Yibo Lin, Runsheng Wang, and Ru Huang. Circuitnet: An open-source dataset for machine learning in vlsi cad applications with improved domain-specific evaluation metric and learning strategies. TCAD, 2023.
- Chang et al. [2023] Kaiyan Chang, Ying Wang, Haimeng Ren, Mengdi Wang, Shengwen Liang, Yinhe Han, Huawei Li, and Xiaowei Li. Chipgpt: How far are we from natural language hardware design. arXiv preprint arXiv:2305.14019, 2023.
- Cheng and Yan [2021] Ruoyu Cheng and Junchi Yan. On joint learning for solving placement and routing in chip design. NeurIPS, 2021.
- Cheng et al. [2022] Ruoyu Cheng, Xianglong Lyu, Yang Li, Junjie Ye, Jianye Hao, and Junchi Yan. The policy-gradient placement and generative routing neural networks for chip design. NeurIPS, 2022.
- Christiano et al. [2017] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. NeurIPS, 2017.
- Dehaerne et al. [2023] Enrique Dehaerne, Bappaditya Dey, Sandip Halder, and Stefan De Gendt. A deep learning framework for verilog autocompletion towards design and verification automation. arXiv preprint arXiv:2304.13840, 2023.
- Du et al. [2023a] Xingbo Du, Chonghua Wang, Ruizhe Zhong, and Junchi Yan. Hubrouter: Learning global routing via hub generation and pin-hub connection. In NeurIPS, 2023a.
- Du et al. [2023b] Yuyang Du, Soung Chang Liew, Kexin Chen, and Yulin Shao. The power of large language models for wireless communication system development: A case study on fpga platforms. arXiv preprint arXiv:2307.07319, 2023b.
- Fan et al. [2019] Zhou Fan, Rui Su, Weinan Zhang, and Yong Yu. Hybrid actor-critic reinforcement learning in parameterized action space. In IJCAI, 2019.
- Fu et al. [2023] Yonggan Fu, Yongan Zhang, Zhongzhi Yu, Sixu Li, Zhifan Ye, Chaojian Li, Cheng Wan, and Yingyan Celine Lin. Gpt4aigchip: Towards next-generation ai accelerator design automation via large language models. In ICCAD, 2023.
- Grosnit et al. [2022] Antoine Grosnit, Cedric Malherbe, Rasul Tutunov, Xingchen Wan, Jun Wang, and Haitham Bou Ammar. Boils: Bayesian optimisation for logic synthesis. In DATE. IEEE, 2022.
- Guo et al. [2022] Zizheng Guo, Mingjie Liu, Jiaqi Gu, Shuhan Zhang, David Z Pan, and Yibo Lin. A timing engine inspired graph neural network model for pre-routing slack prediction. In DAC, 2022.
- Han et al. [2023] Boyu Han, Xinyu Wang, Yifan Wang, Junyu Yan, and Yidong Tian. New interaction paradigm for complex eda software leveraging gpt. arXiv preprint arXiv:2307.14740, 2023.
- He et al. [2023] Zhuolun He, Haoyuan Wu, Xinyun Zhang, Xufeng Yao, Su Zheng, Haisheng Zheng, and Bei Yu. Chateda: A large language model powered autonomous agent for eda. In MLCAD, 2023.
- Hosny et al. [2020] Abdelrahman Hosny, Soheil Hashemi, Mohamed Shalan, and Sherief Reda. Drills: Deep reinforcement learning for logic synthesis. In ASP-DAC, 2020.
- Ji et al. [2023] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 2023.
- Kande et al. [2023] Rahul Kande, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Shailja Thakur, Ramesh Karri, and Jeyavijayan Rajendran. Llm-assisted generation of hardware assertions. arXiv preprint arXiv:2306.14027, 2023.
- Lai et al. [2022] Yao Lai, Yao Mu, and Ping Luo. Maskplace: Fast chip placement via reinforced visual representation learning. NeurIPS, 35, 2022.
- Lewis et al. [2020] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. NeurIPS, 2020.
- Li et al. [2022a] Min Li, Sadaf Khan, Zhengyuan Shi, Naixing Wang, Huang Yu, and Qiang Xu. Deepgate: Learning neural representations of logic gates. In DAC, 2022a.
- Li et al. [2022b] Xing Li, Lei Chen, Fan Yang, Mingxuan Yuan, Hongli Yan, and Yupeng Wan. Himap: A heuristic and iterative logic synthesis approach. In DAC, 2022b.
- Liang et al. [2023] Rongjian Liang, Siddhartha Nath, Anand Rajaram, Jiang Hu, and Haoxing Ren. Bufformer: A generative ml framework for scalable buffering. In ASP-DAC, 2023.
- Lin et al. [2019] Yibo Lin, Shounak Dhar, Wuxi Li, Haoxing Ren, Brucek Khailany, and David Z Pan. Dreamplace: Deep learning toolkit-enabled gpu acceleration for modern vlsi placement. In DAC, 2019.
- Liu et al. [2023a] Mingjie Liu, Teodor-Dumitru Ene, Robert Kirby, Chris Cheng, Nathaniel Pinckney, Rongjian Liang, Jonah Alben, Himyanshu Anand, Sanmitra Banerjee, Ismet Bayraktaroglu, et al. Chipnemo: Domain-adapted llms for chip design. arXiv preprint arXiv:2311.00176, 2023a.
- Liu et al. [2023b] Mingjie Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. Verilogeval: Evaluating large language models for verilog code generation. In ICCAD, 2023b.
- Liu et al. [2023c] Shang Liu, Wenji Fang, Yao Lu, Qijun Zhang, Hongce Zhang, and Zhiyao Xie. Rtlcoder: Outperforming gpt-3.5 in design rtl generation with our open-source dataset and lightweight solution. arXiv preprint arXiv:2312.08617, 2023c.
- Lu et al. [2023] Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. Rtllm: An open-source benchmark for design rtl generation with large language model. arXiv preprint arXiv:2308.05345, 2023.
- Lu et al. [2021] Yi-Chen Lu, Jeehyun Lee, Anthony Agnesina, Kambiz Samadi, and Sung Kyu Lim. A clock tree prediction and optimization framework using generative adversarial learning. TCAD, 2021.
- Masoudnia and Ebrahimpour [2014] Saeed Masoudnia and Reza Ebrahimpour. Mixture of experts: a literature survey. Artificial Intelligence Review, 2014.
- Meng et al. [2023] Xingyu Meng, Amisha Srivastava, Ayush Arunachalam, Avik Ray, Pedro Henrique Silva, Rafail Psiakis, Yiorgos Makris, and Kanad Basu. Unlocking hardware security assurance: The potential of llms. arXiv preprint arXiv:2308.11042, 2023.
- Mirhoseini et al. [2021] Azalia Mirhoseini, Anna Goldie, Mustafa Yazgan, Joe Wenjie Jiang, Ebrahim Songhori, Shen Wang, Young-Joon Lee, Eric Johnson, Omkar Pathak, Azade Nazi, et al. A graph placement methodology for fast chip design. Nature, 2021.
- Nair et al. [2023] Madhav Nair, Rajat Sadhukhan, and Debdeep Mukhopadhyay. Generating secure hardware using chatgpt resistant to cwes. Cryptology ePrint Archive, 2023.
- OpenAI [2023a] OpenAI. Gpt-vision. https://platform.openai.com/docs/guides/vision, 2023a.
- OpenAI [2023b] OpenAI. Gpt-4 technical report, 2023b.
- Orenes-Vera et al. [2021] Marcelo Orenes-Vera, Aninda Manocha, David Wentzlaff, and Margaret Martonosi. Autosva: Democratizing formal verification of rtl module interactions. In DAC, 2021.
- Orenes-Vera et al. [2023] Marcelo Orenes-Vera, Margaret Martonosi, and David Wentzlaff. Using llms to facilitate formal verification of rtl. arXiv e-prints, 2023.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In NeurIPS, 2022.
- Paria et al. [2023] Sudipta Paria, Aritra Dasgupta, and Swarup Bhunia. Divas: An llm-based end-to-end framework for soc security analysis and policy-based protection. arXiv preprint arXiv:2308.06932, 2023.
- Pearce et al. [2020] Hammond Pearce, Benjamin Tan, and Ramesh Karri. Dave: Deriving automatically verilog from english. In MLCAD, 2020.
- PrimisAI [2023] PrimisAI. Rapidgpt: Your ultimate hdl pair-designer. https://primis.ai/, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021.
- Schäfer et al. [2023] Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. An empirical evaluation of using large language models for automated unit test generation. IEEE Transactions on Software Engineering, 2023.
- Shi et al. [2023] Zhengyuan Shi, Hongyang Pan, Sadaf Khan, Min Li, Yi Liu, Junhua Huang, Hui-Ling Zhen, Mingxuan Yuan, Zhufei Chu, and Qiang Xu. Deepgate2: Functionality-aware circuit representation learning. arXiv preprint arXiv:2305.16373, 2023.
- Stiennon et al. [2020] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. NeurIPS, 2020.
- Tang et al. [2023] Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. Graphgpt: Graph instruction tuning for large language models. arXiv preprint arXiv:2310.13023, 2023.
- Thakur et al. [2023a] Shailja Thakur, Baleegh Ahmad, Zhenxing Fan, Hammond Pearce, Benjamin Tan, Ramesh Karri, Brendan Dolan-Gavitt, and Siddharth Garg. Benchmarking large language models for automated verilog rtl code generation. In DATE, 2023a.
- Thakur et al. [2023b] Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri, and Siddharth Garg. Verigen: A large language model for verilog code generation. arXiv preprint arXiv:2308.00708, 2023b.
- Thakur et al. [2023c] Shailja Thakur, Jason Blocklove, Hammond Pearce, Benjamin Tan, Siddharth Garg, and Ramesh Karri. Autochip: Automating hdl generation using llm feedback. arXiv preprint arXiv:2311.04887, 2023c.
- Touvron et al. [2023] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Tsai et al. [2023] YunDa Tsai, Mingjie Liu, and Haoxing Ren. Rtlfixer: Automatically fixing rtl syntax errors with large language models. arXiv preprint arXiv:2311.16543, 2023.
- Wang et al. [2023a] Jiaqi Wang, Zhengliang Liu, Lin Zhao, Zihao Wu, Chong Ma, Sigang Yu, Haixing Dai, Qiushi Yang, Yiheng Liu, Songyao Zhang, et al. Review of large vision models and visual prompt engineering. Meta-Radiology, 2023a.
- Wang et al. [2023b] Xiao Wang, Guangyao Chen, Guangwu Qian, Pengcheng Gao, Xiao-Yong Wei, Yaowei Wang, Yonghong Tian, and Wen Gao. Large-scale multi-modal pre-trained models: A comprehensive survey. Machine Intelligence Research, 2023b.
- Wang et al. [2022] Ziyi Wang, Chen Bai, Zhuolun He, Guangliang Zhang, Qiang Xu, Tsung-Yi Ho, Bei Yu, and Yu Huang. Functionality matters in netlist representation learning. In DAC, 2022.
- Yang et al. [2022] Zhihao Yang, Dong Li, Yingxueff Zhang, Zhanguang Zhang, Guojie Song, Jianye Hao, et al. Versatile multi-stage graph neural network for circuit representation. NeurIPS, 2022.
- Yao et al. [2022] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Yuan et al. [2023] Jianyong Yuan, Peiyu Wang, Junjie Ye, Mingxuan Yuan, Jianye Hao, and Junchi Yan. Easyso: Exploration-enhanced reinforcement learning for logic synthesis sequence optimization and a comprehensive rl environment. In ICCAD, 2023.
- Zhang et al. [2023] Ziwei Zhang, Haoyang Li, Zeyang Zhang, Yijian Qin, Xin Wang, and Wenwu Zhu. Large graph models: A perspective. arXiv preprint arXiv:2308.14522, 2023.
- Zhong et al. [2024] Ruizhe Zhong, Junjie Ye, Zhentao Tang, Shixiong Kai, Mingxuan Yuan, Jianye Hao, and Junchi Yan. Preroutgnn for timing prediction with order preserving partition: Global circuit pre-training, local delay learning and attentional cell modeling. In AAAI, 2024.