VALL-T:用于
稳健且解码可控的文本到语音的仅解码器生成传感器
摘要
最近具有仅解码器 Transformer 架构的 TTS 模型(例如 SPEAR-TTS 和 VALL-E)实现了令人印象深刻的自然度,并展示了在给定语音提示的情况下零样本适应的能力。 然而,此类仅解码器的 TTS 模型缺乏单调对齐约束,有时会导致发音错误、跳词和重复等幻觉问题。 为了解决这个限制,我们提出了 VALL-T,一种生成 Transducer 模型,它引入了输入音素序列的移动相对位置嵌入,明确指示单调生成过程,同时保持仅解码器 Transformer 的架构。 因此,VALL-T保留了基于提示的零样本适应能力,并表现出更好的抗幻觉鲁棒性,词错误率相对降低了28.3%。 此外,解码期间 VALL-T 中对齐的可控性有助于使用未转录的语音提示,即使是在未知语言中也是如此。 它还可以通过利用对齐的上下文窗口来合成冗长的语音。 音频示例可从 http://cpdu.github.io/vallt 获取。
1简介
文本到语音 (TTS) 合成是单调的序列到序列任务,在输入音素序列和输出语音序列之间保持严格的顺序。 而且,输出语音序列是帧级的,一个音素可能对应多个语音帧,因此输出序列明显长于其对应的输入音素序列。 主流神经文本转语音模型,如 FastSpeech 2 (Ren 等人, 2020)、GradTTS (Popov 等人, 2021) 和 VoiceFlow (Guo等人, 2024),集成时长预测模块。 在训练之前,目标持续时间通常是使用维特比强制对齐算法导出的。 在训练期间,该模块通过最小化预测持续时间和目标持续时间之间的均方误差 (MSE) 进行优化。 在推理阶段,持续时间预测器模块预测每个输入音素的持续时间,从而相应地建立输入和输出序列之间的对齐。 然后,根据预测的持续时间将编码的输入音素序列扩展到帧级别,并随后传递到语音解码器。 该机制对序列到序列过程强制执行单调对齐约束,确保语音合成的鲁棒性。
过去两年,GSLM (Lakhotia 等人,2021) 和 VQTTS (Du 等人,2022) 提出了利用离散语音标记进行语音生成,为将尖端语言建模技术集成到 TTS 系统中的方法。 受到 GPT 3 (Brown 等人,2020) 和 LLAMA 2 (Touvron 等人,2023) 等仅解码器的大型 Transformer 模型驱动的自然语言处理方面的巨大进步的启发>、Tortoise-TTS (Betker, 2023)、SPEAR-TTS (Kharitonov 等人, 2023)、VALL-E (Wang 等人, 2023a) 和 LauraGPT (Wang 等人, 2023b) 采用纯解码器架构进行 TTS,实现了显着的自然度。 SPEAR-TTS 和 VALL-E 还能够通过给定语音提示的自回归 (AR) 延续来执行零样本扬声器适应。 此外,与传统的神经 TTS 模型不同,这些仅解码器的 TTS 模型规避了显式持续时间建模以及对训练前获得的音素持续时间的要求。 这一特性提供了便利并简化了训练过程,特别是在大规模数据集上训练时。 然而,这些系统中的隐式持续时间建模缺乏单调对齐约束,常常导致发音错误、跳词和重复等幻觉问题。
事实上,我们确实有一个名为 Transducer (Graves, 2012) 的训练方案,专为单调序列到序列任务而设计,并在自动语音识别 (ASR) (He 等人,2019)。 它采用模块化架构,由编码器、预测网络和联合网络组成。 然而,Transducer 的这种模块化架构是专门为 ASR 作为分类任务而设计的,使其不太适合 TTS 作为生成任务。 对这个问题的进一步见解将在第 3 章中讨论。
为了实现两全其美,我们提出了 VALL-T,这是一种利用仅解码器 Transformer 架构的生成 Transducer 模型。 具体来说,除了传统的绝对位置嵌入之外,我们还将额外的相对位置嵌入合并到输入音素序列中。 这里,相对位置 0 指定当前正在合成的音素,允许我们通过从左到右移动相对位置来明确指导单调生成过程。 据我们所知,这是第一个使用仅解码器 Transformer 架构实现 Transducer 的工作。 与之前的 TTS 模型相比,VALL-T 具有以下几个优点:
-
•
VALL-T 引入了单调对齐约束,而不改变仅解码器的架构,从而具有更好的抗幻觉鲁棒性。
-
•
VALL-T 利用隐式持续时间建模,无需在训练前获取音素持续时间。
-
•
VALL-T 在解码过程中的对齐可控性使得即使在未知语言中也能够利用未转录的语音提示。

2相关工作
2.1 仅解码器零样本 TTS,带语音提示
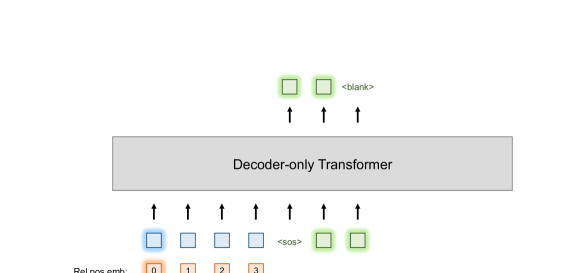
零样本 TTS 是指仅根据看不见的说话者的语音的简短样本来生成该说话者的语音的能力。 仅解码器的 TTS 模型,例如 VALL-E (Wang 等人,2023a),能够通过目标说话人样本的自回归延续来执行零样本说话人自适应。 因此,目标说话人的语音样本也称为语音提示。
具体来说,在训练过程中,如图 1(a) 所示,音素和语音序列沿着时间轴连接起来,并输入到仅解码器的 Transformer 模型中。 假设每个训练单词中说话者的声音保持不变。 在推理阶段,如图1(b)所示,需要语音提示来确定生成语音的语音。 语音提示的音素转录和语音提示本身分别位于输入和输出序列的开头,后面是要生成的输入音素及其对应的音素。输出语音标记。 据信,从语音提示开始的自回归延续过程可以在生成的输出中保留说话者的声音。
2.2传感器
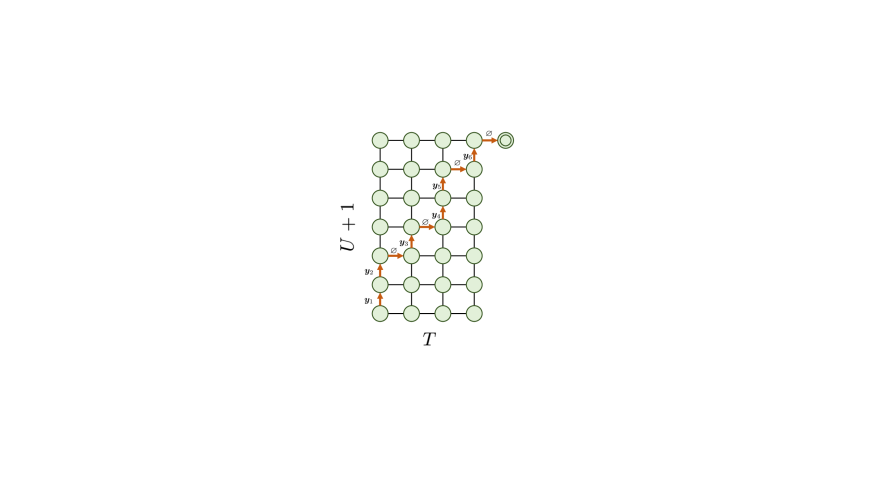
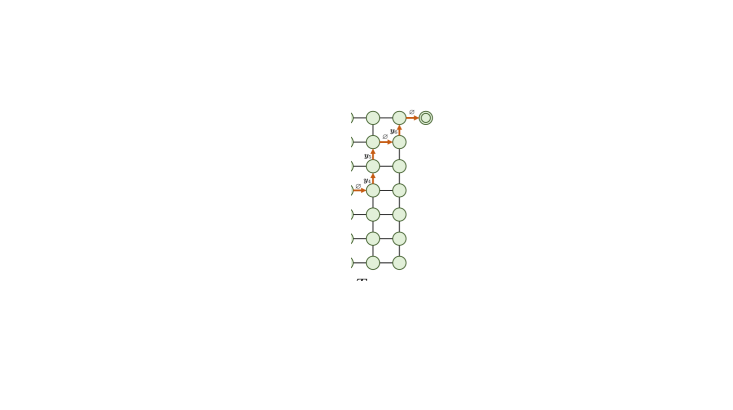
Transducer 模型(Graves,2012),也称为 RNN-T,专为单调序列到序列任务而设计,由三个组件组成:编码器、预测网络和联合网络。 这里,预测网络是自回归网络,例如RNN和LSTM。 Transducer模型还引入了一个特殊的输出词符,称为空白,表示为,它表示输出和输入序列之间的对齐边界。 我们将 定义为输出标记的词汇表,将 定义为扩展词汇表。 此外,我们将输入序列 和输出序列 的长度表示为 和 以及扩展词汇表的大小 为 。
在训练阶段,如图2(a)所示,编码器和预测网络分别对两个序列和进行编码,产生编码后的隐藏层序列 和 。 随后,我们分别在位置和处对隐藏向量和进行切片,然后将它们发送到联合网络进行计算下一个词符预测的概率,其中。 我们迭代两个序列的所有可能的切片隐藏向量,从 到 以及从 到 ,生成一个矩阵 形状为 ,其 处的条目为 。 从左下角到右上角的每条路径 表示 和 之间的对齐,长度为 。 图2(b)展示了的对齐路径的示例。
Transducer模型的训练准则是最大化的概率,它是所有可能的对齐路径的概率之和,即
| (1) | ||||
其中 和 是由对齐路径 指定的相应位置处的切片隐藏向量。 在实践中,可以通过动态规划有效地计算该概率。
在推理阶段,每当出现空白词符 时,预测网络就会根据从 到 的切分输入隐藏向量,自动递归地预测下一个词符。
Transducer 模型在 ASR 领域取得了显着的成功。 然而,其模块化架构不足以适合生成任务。 最近,一些文献探索了Transducer在TTS中的应用(Chen等人,2021;Kim等人,2023),但它们仍然依赖于典型的模块化架构,因此导致性能有限。 与之前的工作不同,我们首次提出使用仅解码器架构来实现 Transducer,以实现更好的性能。
3 VALL-T:仅解码器生成传感器
目前的模块化传感器模型已在 ASR 领域取得了巨大成功。 然而,它对生成任务的适用性是有限的。 通常,联合网络是一个小型网络,仅包含一个或几个线性投影层,预测网络是 LSTM 或 Transformer 块。 该架构引入了一个限制,其中输入条件 在到达联合网络之前不会合并到生成过程中。 更糟糕的是,联合网络太小,无法有效地将输入条件整合到生成过程中。 此外,模块化传感器模型利用切片来表示特定位置。 因此,联合网络无法明确感知输入上下文,进一步导致条件生成任务难以获得令人满意的性能。
为了解决上述问题,我们提出了 VALL-T,它将编码器、预测网络和联合网络集成到一个仅解码器的 Transformer 架构中,并利用相对位置嵌入来表示相应的位置。 我们在下面讨论训练和推理的细节。
3.1训练
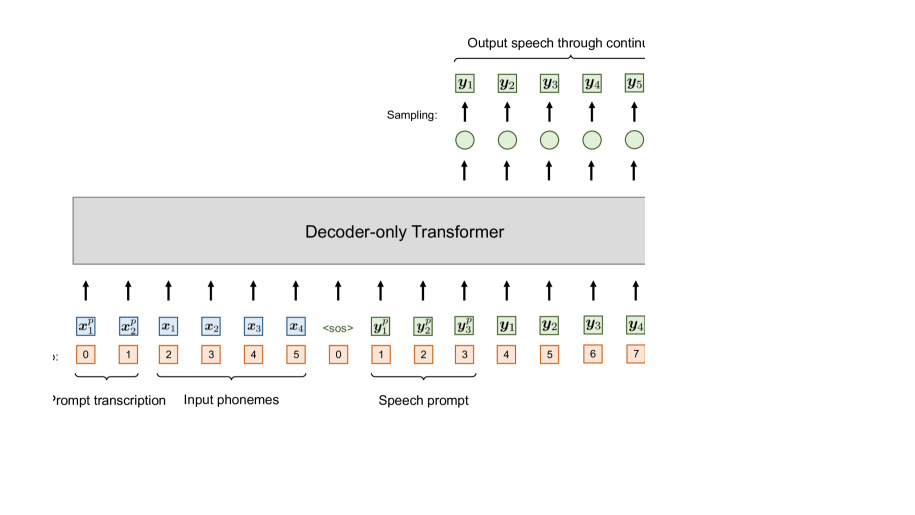
我们对 VALL-T 使用仅解码器架构。 与之前的工作 VALL-E 中的方法类似,我们沿时间轴连接输入音素和输出语音标记,并将它们作为统一序列呈现给模型。 与传统的 RNN 和 LSTM 架构不同,Transformer 缺乏输入标记的特定时间顺序,而是依靠位置嵌入来指示它们的位置。 输入序列的位置索引范围从到,并通过正弦函数(Vaswani等人,2017)转换为位置嵌入。 同样,输出序列采用从 到 的位置索引,包括开头的附加 <sos> 词符。 在 VALL-E 之后,我们对输出序列使用三角形注意掩模,以促进自回归生成。 该掩码确保每个语音词符仅关注先前生成的标记,从而在输出中保持正确的顺序。
除了从 0 开始的典型绝对位置索引之外,我们还在 VALL-T 中为输入标记引入了额外的相对位置索引。 相对位置索引指定当前正在合成的音素。 其左侧的音素被分配从 开始的负位置索引,而其右侧的音素则被分配从 开始的正位置索引。 这些相对位置索引被转换为具有与绝对位置索引相同的正弦函数的相对位置嵌入。 得到的绝对和相对位置嵌入被添加到输入音素嵌入中,然后呈现给仅解码器的 Transformer。 在采用这种方法时,模型获得了对当前正在进行合成的音素的认识,特别是分配了相对位置 的音素,以及充当其前后上下文的音素。
3.2 单调自回归推理
让我们首先考虑没有语音提示的自回归推理过程。 最初,相对位置 被指定为第一个音素,从 <sos> 词符开始语音生成。 然后,模型根据输入音素标记和先前生成的语音标记自动回归生成语音标记,直到出现空白词符。 的出现标志着第一个音素的生成完成,并引发相对位置的移动。 我们迭代地进行上述过程,直到最后一个音素出现,表明输入音素序列的整个生成过程结束。 由于训练过程中 Transducer 损失鼓励模型为分配相对位置 的音素生成语音标记,因此解码过程中的逐步移位操作促进了单调生成过程,从而增强了针对幻觉的鲁棒性。
接下来,我们考虑将语音提示集成到零样本扬声器适应中。 按照 VALL-E 中使用的方法,语音提示的音素转录放置在输入序列的开头,而语音提示本身则放置在输出序列的开头。 这两个序列后面分别是要生成的输入音素及其相应的输出语音标记。 鉴于提供了语音提示,我们将相对位置0分配给提示转录后的第一个音素,如图3所示,并进行语音延续。 同样,每次 出现时,相对位置都会发生变化,重复直到最终音素的生成完成。


3.3 未转录语音提示的伪提示转录
在以前的仅解码器 TTS 模型中,对齐是通过自注意力隐式学习的。 这些模型必须仅根据输入标记和前面的输出标记之间的自注意力来辨别当前在每个时间步骤合成哪个音素。 因此,他们依靠语音提示的正确转录来获得正确的对齐并相应地开始生成。 然而,在实际应用中,获取转录后的语音提示并不方便,因此我们希望直接利用语音提示并消除其转录的需要。
在 VALL-T 中,很明显,在推理过程中对齐是可控的,允许我们通过将位置 分配给我们想要合成的音素来操纵生成过程,而不依赖于配对的语音提示及其转录。 因此,我们可以使用未转录的语音提示进行零样本改编。 具体来说,给定一个未转录的语音提示,我们使用随机单词的音素序列(称为伪提示转录)作为其转录,并将其放置在输入序列的开头。 然后,可以利用与 3.2 节中描述的完全相同的算法来正确开始生成。 使用伪提示转录而不是无提示转录的原因在于输入序列中存在绝对位置嵌入。 从绝对位置嵌入的角度来看,我们需要避免看不见的对齐模式。
此外,由于不需要转录语音提示,因此可以将未转录的语音提示的使用扩展到包括未知语言的提示。 这使得跨语言零样本自适应语音合成成为可能。
3.4 对齐上下文窗口以进行冗长的语音合成
仅解码器的 Transformer 模型泛化到未见过的位置嵌入的能力非常有限。 这意味着如果我们合成的语音超过训练期间遇到的最大长度,性能将会下降。
幸运的是,在 VALL-T 中,对齐在推理期间可用,允许我们使用对齐的上下文窗口来同时约束输入和输出序列长度。 具体来说,在每个解码步骤中,我们仅保留当前音素之前的 音素和其之后的 音素,从而在输入音素上创建受约束的滑动上下文窗口。 此外,在给定对齐的情况下,我们仅保留与前面的 音素相对应的语音标记,并丢弃更远的历史记录,从而在输出序列上形成上下文窗口。 因此,通过利用对齐的上下文窗口,VALL-T 在输入和输出序列上始终保持有限的上下文,从而允许它生成任何长度的语音。
4实验和结果
4.1设置
在我们的实验中,我们利用我们的 Encodec (Défossez 等人, 2022) 语音标记器,其帧移位为 20ms,输出波形的采样率为 16k。 每帧包含 8 个残差矢量量化 (RVQ) 索引。 为了确保 VALL-E 和我们提出的模型 VALL-T 之间的公平比较,我们遵循 VALL-E 中引入的方法,用自回归模型预测第一个 RVQ 指数的序列,然后预测剩余的 7 个 RVQ 指数具有单独的非自回归 (NAR) 模型的第一个 RVQ 指数。 输入和输出序列均使用 BPE (Sennrich 等人, 2016) 算法进行编码,以缩短序列长度并减少 GPU 内存消耗。 VALL-T采用与VALL-E相同的架构,包含12层Transformer块。 每个块包含 12 个注意力头,隐藏维度为 1024。
我们在实验中使用 LibriTTS (Zen 等人, 2019) 数据集,这是一个多说话人转录的英语语音数据集。 其训练集包含来自 2,306 名说话者的约 580 小时的语音数据。 我们使用 ScaledAdam (Yao 等人, 2023) 优化器对模型进行 40 个时期的训练。 学习率调度器为 Eden (Yao 等人, 2023),基本学习率为 ,纪元调度因子为 4,步长调度因子为 5000。
4.2比对分析
我们首先进行对齐分析,以检查 VALL-T 中的相对位置嵌入是否表明对齐符合预期。 给定语音 及其转录 ,我们遍历所有相对位置,计算出 形状的输出分布矩阵 。 然后我们相应地计算前向变量、后向变量和后验概率。 前向变量、后向变量和后验概率的概念最初在隐马尔可夫模型(Young等人,2002)中引入,并在Transducer(Graves,2012)中引入>。 这些值的定义和计算在附录A中详细说明。
| Method | WER(%) | MCD | Naturalness MOS | Similarity MOS | SECS |
|---|---|---|---|---|---|
| Ground-truth | 1.92 | 0 | 4.63 0.07 | 4.23 0.10 | 0.837 |
| Encodec resynthesis | 2.08 | 2.50 | 4.55 0.07 | 4.19 0.11 | 0.835 |
| NAR resynthesis | 3.75 | 2.95 | 4.44 0.07 | 4.24 0.10 | 0.846 |
| Transduce and Speak | 6.14 | 4.38 | 4.07 0.10 | 4.02 0.11 | 0.838 |
| VALL-E | 5.80 | 4.00 | 4.25 0.08 | 4.12 0.10 | 0.857 |
| VALL-T (ours) | 4.16 | 3.98 | 4.26 0.08 | 4.21 0.09 | 0.849 |
| Method | Pseudo Prompt | WER(%) | MCD | Naturalness MOS | Similarity MOS | SECS |
|---|---|---|---|---|---|---|
| Transcription | ||||||
| VALL-E | 68.22 | 4.97 | - | - | 0.795 | |
| 21.01 | 4.28 | - | - | 0.836 | ||
| VALL-T | 30.86 | 4.43 | - | - | 0.836 | |
| 3.48 | 3.97 | 4.29 0.09 | 4.14 0.10 | 0.848 |
| Method | WER(%) | Naturalness MOS | Similarity MOS | SECS |
|---|---|---|---|---|
| VALL-E | 39.83 | - | - | 0.779 |
| VALL-T | 4.22 | 4.25 0.08 | 4.36 0.06 | 0.782 |
| Method | Aligned Context | WER(%) | MCD | Naturalness MOS | Similarity MOS | SECS |
|---|---|---|---|---|---|---|
| Window | ||||||
| Ground-truth | - | 1.68 | 2.50 | 4.81 0.05 | 4.48 0.09 | 0.877 |
| VALL-E | 50.82 | 4.37 | - | - | 0.875 | |
| VALL-T | 14.63 | 4.31 | 4.21 0.08 | 4.31 0.07 | 0.828 | |
| VALL-T | 5.50 | 4.26 | 4.39 0.06 | 4.37 0.07 | 0.847 |
4.3 零样本TTS评估
在本节中,我们在零样本 TTS 任务上对我们的模型进行评估。 该任务是指在给定语音提示及其相应转录的情况下,合成看不见的说话者的声音。 我们的测试集使用与 (Du 等人, 2024) 相同的测试集,包含 LibriTTS 测试集中的 500 个话语并涉及 37 个说话者。 每个发言者都被分配了特定的语音提示。 在评估我们的模型的性能之前,我们使用我们的编码器进行语音重新合成来评估语音标记器。 我们还做了一个名为“NAR 再合成”的实验。 在本实验中,我们将真实的第一个 RVQ 指数发送到 NAR 模型以预测其余 7 个 RVQ 指数。 然后,我们使用 Encodec 解码器将所有 8 个 RVQ 索引转换为波形。 NAR 再合成实验的目的是证明 NAR 模型引入的性能下降,以便我们可以更好地分析整个管道的结果,其中 AR 模型是我们论文的主要关注点。
该实验的基线包括两个模型。 一种是流行的纯解码器 TTS 模型 VALL-E,另一种是最近提出的具有模块化 Transducer 架构的 TTS 模型,称为“Transduce and Speak”(Kim 等人,2023)。 本文的主要评价指标是单词错误率(WER)。 在我们的评估过程中,我们首先为测试集合成语音,然后使用著名的 ASR 模型 Whisper111https://huggingface.co/openai/whisper-medium (Radford 等人,2023)。 然后将从 ASR 模型获得的转录与真实输入文本进行比较,以计算单词错误率。 表1显示VALL-T的WER显着低于基线,与VALL-E相比相对降低了28.3%,仅比NAR再合成高0.41,表明VALL-T的稳健性。
此外,我们在表中提供了梅尔倒谱失真(MCD),作为量化生成的语音与相应的地面实况录音之间距离的度量。 VALL-T 还实现了所有型号中最低的 MCD。 进一步的评估扩展到平均意见得分 (MOS) 听力测试,以评估自然度和说话者相似度。 15 名听众被要求对每篇文章进行评分,评分范围从 1 到 5,分数越高表明自然性和相似性越好。 请注意,说话者相似度是在生成的语音和提供的语音提示之间评估的,而不是在相应的真实语音之间评估的。 这种区别是由于说话者在不同话语中音色的变化而产生的,目标是仅模仿给定提示的音色。 在听力测试中,VALL-T 的自然度得分与 VALL-E 相当,说话人相似度稍好一些。 最后,评估扩展到说话人嵌入余弦相似度 (SECS) 的计算,使用预训练的说话人验证模型进行测量222https://github.com/resemble-ai/Resemblyzer。 该指标通过评估生成的语音的说话人嵌入与提供的语音提示之间的余弦相似度来测量说话人的相似度。 虽然 VALL-T 的 SECS 值略低于 VALL-E,但根据相似性主观听力测试的结果,它仍然优于其他模型,并且不会对人类感知产生不利影响。
4.4 利用未转录的语音提示
VALL-T 的对齐可控性使我们能够利用未转录的语音提示进行零样本 TTS。 在本实验中,我们仍然使用与上一节相同的测试集,排除语音提示的转录,以模拟提示转录不可用的场景。 从 LibriTTS 测试集中随机选择一句话,其音素转录作为伪提示转录,用于生成测试集中的所有话语。 我们将所提出的方法与三个基线进行比较。 第一个基线是使用 VALL-T 生成的,但不使用任何提示转录。 其余两个基线使用 VALL-E,一个使用伪提示转录,另一个不使用提示转录。
结果如表2所示。 我们发现,无论是否提供伪提示转录,在缺乏正确提示转录的情况下,VALL-E 始终无法执行延续。 尽管 VALL-T 表现出改进的稳健性,但在不使用提示转录的情况下,它在连续任务中仍然失败。 这种失败是由绝对位置嵌入视图中看不见的对齐模式引起的。 当提供伪提示转录时,VALL-T 成功完成了语音提示的延续。 WER 显着低于三个基线,甚至低于表1中使用真实即时转录和使用 NAR 再合成获得的结果。 这种改进可能归因于与不同的真实提示转录相比,固定伪提示转录中的噪声减少。 这一结果进一步证明了VALL-T的稳健性。
同样,与其他基线相比,我们观察到采用所提出的方法的 MCD 较低。 我们不对三个基线进行听力测试,因为评估完全错误的生成音频样本的自然度和相似性是没有意义的。 所提出的方法的自然度几乎与使用真实提示转录时观察到的相同,但其说话者相似度稍低。 我们在 SECS 评估中也可以观察到这一点。
接下来,我们将未转录语音提示的使用扩展到未知语言的情况。 具体来说,我们继续使用与之前实验相同的测试集,但利用从多语言 Librispeech 数据集(Pratap 等人,2020)中随机选择的 10 个德语和 10 个西班牙语使用者的语音提示,模拟未知语言的语音提示。 对 VALL-T 和基线 VALL-E 采用与之前实验相同的英语伪提示转录,我们从德语和西班牙语的语音提示中生成延续。 结果列于表3中。 由于未知的提示转录,VALL-E 在一代中继续失败。 相反,VALL-T 仍然成功地根据德语和西班牙语的语音提示执行零样本 TTS,达到 4.22 的 WER。 请注意,由于语音提示的说话者不同,本实验中的相似度MOS和SECS不能与表1和2中的相应结果直接比较。 我们没有对应的真实语音来用德语和西班牙语说话的测试集中的话语,因此我们在本实验中也没有计算 MCD。
4.5 评估冗长的语音生成
我们还评估了我们的模型在超过训练过程中遇到的最大长度的冗长语音合成。 由于GPU内存的限制,训练话语的最大持续时间约为15秒。 本实验的测试集由 85 个话语组成,每个话语由前一个测试集中的 5 个话语连接而成,以模拟长篇文章。 该测试集中生成的语音超过 20 秒。 我们使用 和 作为上下文窗口大小。
检查表 4 中的结果,我们观察到,与 VALL-E 相比,VALL-T 对长语音表现出优异的泛化能力,这归因于它利用相对位置嵌入,即使在没有对齐的上下文窗口的情况下也是如此。 相比之下,VALL-E 经常在生成大约 20 秒的语音后开始咕哝,并且经常在未完成生成的情况下提前终止。 应用对齐的上下文窗口后,VALL-T 的 WER 进一步降低并接近生成正常话语的结果。 此外,生成的语音与真实语音之间的自然度和说话者相似度的 MOS 分数差距也与合成正常话语的结果相当。
5结论
在这项研究中,我们提出了 VALL-T,一种仅解码器的生成式 Transducer 模型,旨在提高 TTS 模型的鲁棒性和可控性。 VALL-T 将单调对齐约束合并到仅解码器的 TTS 框架中,从而实现音素持续时间的隐式建模。 因此,该模型消除了在训练之前获取音素持续时间的需要。 VALL-T 通过在后验概率图上搜索最佳路径,支持给定输入音素和相应的输出语音的强制对齐。 这种对齐在推理过程中是可控的,即使在未知语言中,也可以通过未转录的语音提示来促进零样本合成。 此外,VALL-T 还展示了流式生成的能力,以及用于合成冗长语音的对齐上下文窗口。 这些功能使 VALL-T 成为 TTS 应用程序的强大模型。
参考
- Betker (2023) Betker, J. Better speech synthesis through scaling. arXiv preprint arXiv:2305.07243, 2023.
- Brown et al. (2020) Brown, T. B., Mann, B., Ryder, N., et al. Language models are few-shot learners. In NeurIPS, 2020.
- Chen et al. (2021) Chen, J., Tan, X., Leng, Y., Xu, J., Wen, G., Qin, T., and Liu, T. Speech-T: Transducer for text to speech and beyond. In NeurIPS, pp. 6621–6633, 2021.
- Défossez et al. (2022) Défossez, A., Copet, J., Synnaeve, G., and Adi, Y. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438, 2022.
- Du et al. (2022) Du, C., Guo, Y., Chen, X., and Yu, K. VQTTS: high-fidelity text-to-speech synthesis with self-supervised VQ acoustic feature. In ISCA Interspeech, pp. 1596–1600, 2022.
- Du et al. (2024) Du, C., Guo, Y., Shen, F., Liu, Z., Liang, Z., Chen, X., Wang, S., Zhang, H., and Yu, K. UniCATS: A unified context-aware text-to-speech framework with contextual vq-diffusion and vocoding. AAAI, 2024.
- Graves (2012) Graves, A. Sequence transduction with recurrent neural networks. arXiv preprint arXiv:1211.3711, 2012.
- Guo et al. (2024) Guo, Y., Du, C., Ma, Z., Chen, X., and Yu, K. VoiceFlow: Efficient text-to-speech with rectified flow matching. IEEE ICASSP, 2024.
- He et al. (2019) He, Y., Sainath, T. N., Prabhavalkar, R., et al. Streaming end-to-end speech recognition for mobile devices. In IEEE ICASSP, pp. 6381–6385, 2019.
- Kharitonov et al. (2023) Kharitonov, E., Vincent, D., Borsos, Z., et al. Speak, read and prompt: High-fidelity text-to-speech with minimal supervision. arXiv preprint arXiv:2302.03540, 2023.
- Kim et al. (2023) Kim, M., Jeong, M., Choi, B. J., Lee, D., and Kim, N. S. Transduce and speak: Neural transducer for text-to-speech with semantic token prediction. IEEE ASRU, 2023.
- Lakhotia et al. (2021) Lakhotia, K., Kharitonov, E., Hsu, W.-N., Adi, Y., Polyak, A., Bolte, B., Nguyen, T.-A., Copet, J., Baevski, A., Mohamed, A., et al. On generative spoken language modeling from raw audio. Transactions of the Association for Computational Linguistics, 9:1336–1354, 2021.
- Popov et al. (2021) Popov, V., Vovk, I., Gogoryan, V., Sadekova, T., and Kudinov, M. A. Grad-TTS: A diffusion probabilistic model for text-to-speech. In ICML, volume 139, pp. 8599–8608, 2021.
- Pratap et al. (2020) Pratap, V., Xu, Q., Sriram, A., Synnaeve, G., and Collobert, R. MLS: A large-scale multilingual dataset for speech research. In ISCA Interspeech, pp. 2757–2761, 2020.
- Radford et al. (2023) Radford, A., Kim, J. W., Xu, T., Brockman, G., McLeavey, C., and Sutskever, I. Robust speech recognition via large-scale weak supervision. In ICML, volume 202, pp. 28492–28518, 2023.
- Ren et al. (2020) Ren, Y., Hu, C., Tan, X., Qin, T., Zhao, S., Zhao, Z., and Liu, T.-Y. Fastspeech 2: Fast and high-quality end-to-end text to speech. arXiv preprint arXiv:2006.04558, 2020.
- Sennrich et al. (2016) Sennrich, R., Haddow, B., and Birch, A. Neural machine translation of rare words with subword units. In ACL, 2016.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2005.14165, 2023.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., et al. Attention is all you need. In NIPS, pp. 5998–6008, 2017.
- Wang et al. (2023a) Wang, C., Chen, S., Wu, Y., et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111, 2023a.
- Wang et al. (2023b) Wang, J., Du, Z., Chen, Q., et al. Lauragpt: Listen, attend, understand, and regenerate audio with GPT. arXiv preprint arXiv:2310.04673, 2023b.
- Yao et al. (2023) Yao, Z., Guo, L., Yang, X., Kang, W., Kuang, F., Yang, Y., Jin, Z., Lin, L., and Povey, D. Zipformer: A faster and better encoder for automatic speech recognition. ICLR, 2310.11230, 2023.
- Young et al. (2002) Young, S., Evermann, G., Gales, M., Hain, T., Kershaw, D., Liu, X., Moore, G., Odell, J., Ollason, D., Povey, D., et al. The HTK book. Cambridge university engineering department, 3(175):12, 2002.
- Zen et al. (2019) Zen, H., Dang, V., Clark, R., Zhang, Y., Weiss, R. J., Jia, Y., Chen, Z., and Wu, Y. LibriTTS: A corpus derived from librispeech for text-to-speech. In ISCA Interspeech, pp. 1526–1530, 2019.
附录ATransducer中的前向变量、后向变量和后验概率。
在4.2节中,我们通过计算前向变量、后向变量和后验概率来分析对齐。 在本节中,我们将提供这些变量的定义和计算的更多详细信息。
位置 处的前向变量表示为 ,表示在给定输入 的情况下观察到输出 的概率,其中 和 。 换句话说,它是从开始到结束的所有路径的概率之和。
由于计算所有可能路径的概率的计算复杂性,采用动态规划来提高效率。 前向变量的计算从初始化开始。 随后,根据其左侧和下方的条目归纳计算每个位置的前向变量:
| (2) | ||||
通过计算前向变量,我们还可以知道方程1中定义的的概率:
| (3) |
类似地,我们将位置处的后向变量表示为,表示在给定的情况下观察到输出的概率。换句话说,它是从到的所有路径的概率之和。
后向概率也可以通过动态规划有效地计算,但方向相反。 我们从 开始,根据其上方和右侧的条目归纳计算每个位置的后向变量:
| (4) | ||||
最后,我们将后验概率 定义为在给定整个输入和输出序列 的情况下,在时间步 之前生成 的概率和。 换句话说,它是从开始,经过点并结束于的所有路径的概率之和。 后验概率可以通过前向和后向变量相乘轻松计算出来,即
| (5) |
后验概率表明两个序列 和 之间的潜在对齐关系。 我们在图 4 中绘制了这些值的示例图。
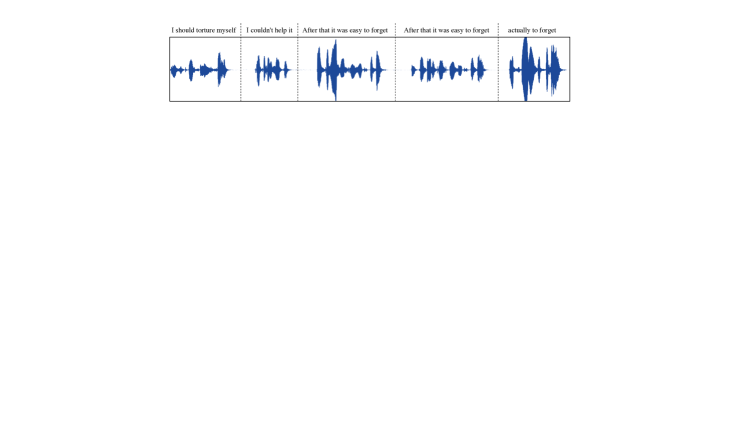

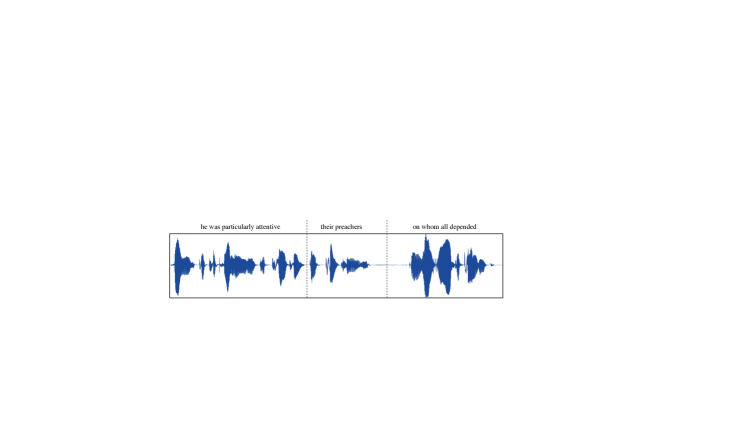
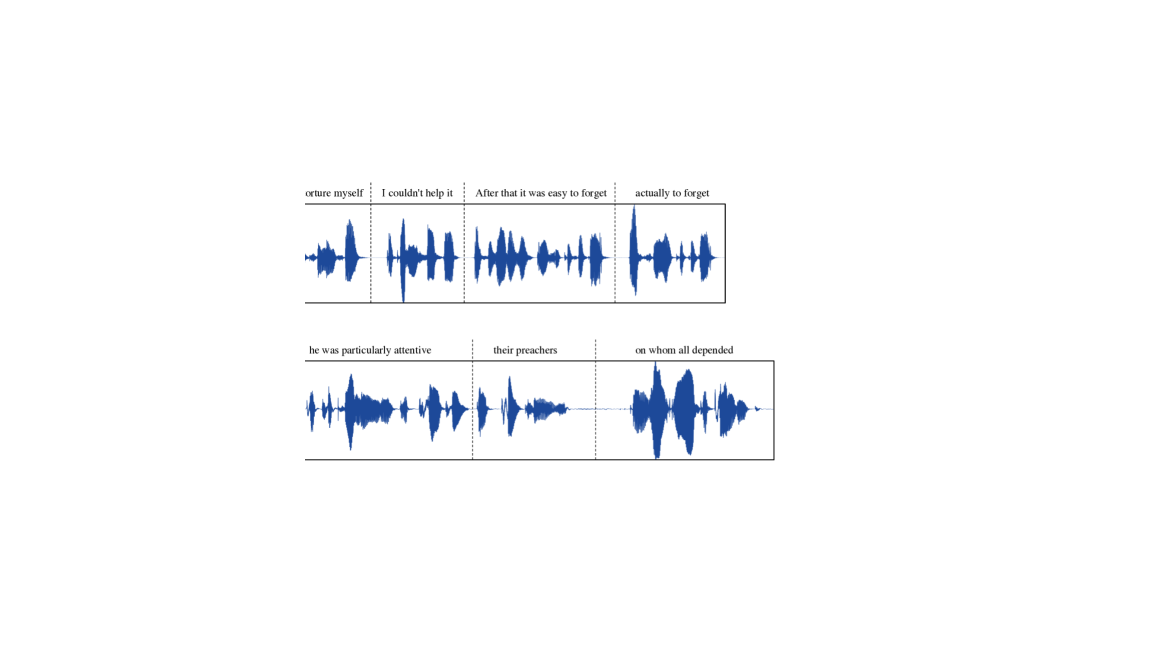
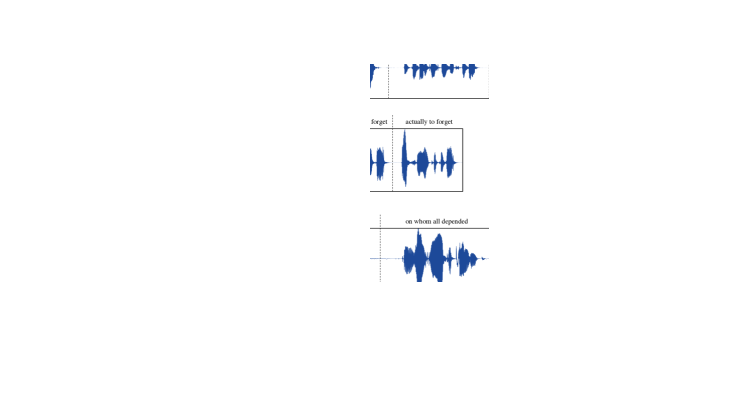
附录BVALL-E中幻觉问题的说明。
在4.3节中,观察到VALL-E有时会出现幻觉问题。 本节通过绘制音频样本的波形及其相应的转录来说明这些情况的一些示例。
附录C长语音生成中的历史上下文窗口大小。
在4.5节中,我们评估了冗长语音合成的模型,其中未来上下文大小被限制为的指定值以促进流生成。 因此,本节仅研究历史上下文大小 对生成输出的影响。
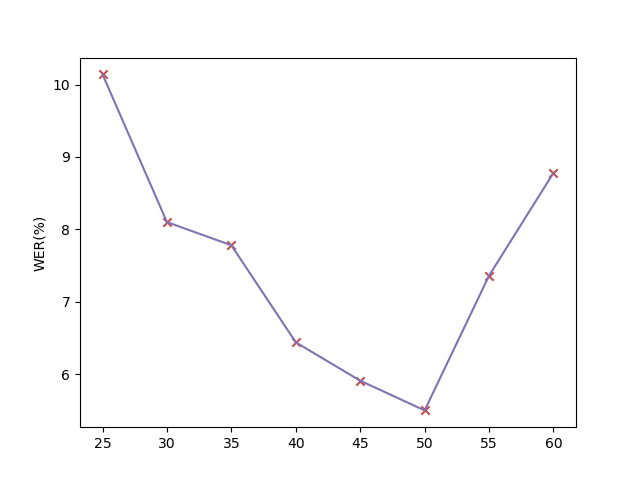
我们在图7中绘制了不同历史上下文大小的误词率曲线。 从图中我们可以看到,随着历史上下文大小的增长,WER 最初会下降。 这一观察结果与我们的直觉一致,因为更多的历史背景为模型提供了额外的信息,从而在解码过程中做出更明智的决策。 然而,超过一定阈值后,我们观察到 WER 随后会增加。 这种现象可以归因于太长的语音序列的复杂性带来的挑战。 因此,在具有对齐上下文窗口的流式生成中,我们需要确定最佳历史上下文大小以实现最佳性能。
附录DVALL-T的伪代码。
Input: A batch of training data .
Parameter: Optimizer , model parameters .
Input: Phoneme sequence , speech prompt and speech prompt transcription .
Parameter: Model parameters .
Output: Speech token sequence corresponding to .