快速设计和工程:简介和高级方法
摘要
快速设计和工程已迅速成为最大限度发挥大型语言模型潜力的关键。 在本文中,我们介绍了核心概念、思想链和反射等先进技术,以及构建基于 LLM 的代理背后的原理。 最后,我们为即时工程师提供了工具调查。
1简介
1.1 什么是提示?
生成式人工智能模型中的提示是用户提供的用于指导模型输出的文本输入。 范围可以从简单的问题到详细的描述或特定任务。 在像 DALLE-3 这样的图像生成模型中,提示通常是描述性的,而在像 GPT-4 或 Gemini 这样的大语言模型中,提示可以从简单的查询到复杂的问题陈述。
提示通常由说明、问题、输入数据和示例组成。 在实践中,为了从人工智能模型中得到所需的响应,提示必须包含指令或问题,其他元素是可选的。
大语言模型中的基本提示可以像提出直接问题或为特定任务提供说明一样简单。 高级提示涉及更复杂的结构,例如“思维链”提示,引导模型遵循逻辑推理过程来得出答案。
1.2 基本提示示例
如上所述,提示是通过组合指令、问题、输入数据和示例来构造的。 为了获得结果,必须存在 1 或 2。 其他一切都是可选的。 让我们看几个示例(所有示例都使用 ChatGPT-4)。
1.2.1 说明+问题
除了提出一个简单的问题之外,提示中的下一个复杂级别可能是包含一些有关模型应如何回答问题的说明。 在这里,我寻求有关如何撰写大学论文的建议,但也包括我有兴趣在答案中听到的不同方面的说明。
“我应该如何写我的大学入学论文? 请给我关于我应该包含的不同部分、我应该使用什么语气以及我应该避免什么表达的建议。”
请参阅图 1 中的输出

1.2.2 指令+输入
继续前面的例子,大家都知道,如果你可以向大语言模型请教如何写论文,你也可以直接要求它自己写论文。111请注意,我并不提倡将这些工具作为道德使用,但重要的是要意识到这种可能性存在并且已经被使用世界各地的学生。 讨论大语言模型或生成人工智能作为一个整体引入的所有可能的伦理、法律或道德问题超出了本介绍性指南的范围,但我认为至少在介绍性示例中指出是很重要的。 您可以使用生成模型做某事这一事实并不意味着它是正确的事情! 另一方面,如果你是接收端,你最好让自己和你的组织做好准备,迎接各种人工智能生成的内容。 幸运的是,对于本示例中概述的情况,已经有人在努力检测人工智能生成的内容。
让我们看看当我们输入一些关于我的数据并给出一些指令时会发生什么:
“根据以下关于我的信息,写一篇 4 段的大学论文:我来自西班牙巴塞罗那。 虽然我的童年经历了不同的创伤事件,比如我六岁的时候父亲就去世了,但我仍然认为我的童年是相当幸福的。 在我的童年时期,我经常换学校,上过各种各样的学校,从公立学校到非常虔诚的私立学校。 这些年里我做的最“异国情调”的事情之一就是和我的大家庭一起在爱达荷州特温福尔斯学习六年级。
我很早就开始工作了。 我的第一份工作是在 13 岁时担任英语老师。 之后,在我的整个学习过程中,我当过老师、服务员,甚至是建筑工人。”
请参阅图 2 中的输出

1.2.3 问题+示例
您还可以将示例输入到语言模型中。 在下面的示例中,我包含了一些我喜欢和不喜欢的节目来构建“廉价”推荐系统。 请注意,虽然我只添加了几个节目,但此列表的长度仅受大语言模型界面中可能存在的词符限制的限制。
“以下是一些我非常喜欢的电视节目的例子:《绝命毒师》、《浴血黑帮》、《熊出没》。 我不喜欢特德·拉索。 你认为我还喜欢哪些其他节目?”
请参阅图 3 中的输出

1.3 提示工程
生成人工智能模型中的即时工程是一门快速新兴的学科,它塑造了这些模型的交互和输出。 提示的核心是文本界面,用户通过它向模型传达他们的愿望,无论是 DALLE-3 或 Midjourney 等模型中图像生成的描述,还是大型语言模型(大语言模型)中的复杂问题陈述比如 GPT-4 和 Gemini。 提示的范围可以从简单的问题到复杂的任务,包括指令、问题、输入数据和示例来指导人工智能的响应。
提示工程的本质在于通过生成模型制定最佳提示以实现特定目标。 此过程不仅涉及指导模型,还涉及对模型的功能和局限性及其运行环境的深入理解。 例如,在图像生成模型中,提示可能是所需图像的详细描述,而在大语言模型中,提示可能是嵌入各种类型数据的复杂查询。
提示工程超越了单纯的提示构建;它需要融合领域知识、对人工智能模型的理解,以及针对不同环境定制提示的系统方法。 这可能涉及创建可以根据给定数据集或上下文以编程方式修改的模板。 例如,根据用户数据生成个性化响应可能会使用动态填充相关信息的模板。
此外,即时工程是一个迭代和探索的过程,类似于版本控制和回归测试等传统软件工程实践。 该领域的快速发展表明它有可能彻底改变机器学习的某些方面,超越特征或架构工程等传统方法,尤其是在大型神经网络的背景下。 另一方面,版本控制和回归测试等传统工程实践需要适应这种新范式,就像适应其他机器学习方法[1]一样。
本文旨在深入研究这个新兴领域,探索其基础方面和高级应用。 我们将重点关注即时工程在大语言模型中的应用。 然而,大多数技术也可以在多模式生成人工智能模型中找到应用。
2 LLMs 及其局限性
大型语言模型(大语言模型),包括基于 Transformer 架构[2]的模型,已成为推进自然语言处理的关键。 这些模型在大量数据集上进行了预先训练以预测后续标记,表现出卓越的语言能力。 然而,尽管大语言模型很复杂,但它仍受到影响其应用和有效性的固有局限性的限制。
-
•
瞬态:大语言模型本质上缺乏持久的记忆或状态,需要额外的软件或系统来进行上下文保留和管理。
-
•
概率性质:大语言模型的随机性质引入了响应的可变性,即使是对于相同的提示,也挑战了应用程序的一致性。 这意味着即使提示相同,您每次得到的答案也可能略有不同。
-
•
过时的信息:对预训练数据的依赖将大语言模型限制在历史知识中,无法实时感知或更新。
-
•
内容捏造:大语言模型可能会生成看似合理但事实上不正确的信息,这种现象通常被称为“幻觉”。[3]
-
•
资源强度:大语言模型的庞大规模意味着巨大的计算和财务成本,影响可扩展性和可访问性。
-
•
领域特异性:虽然大语言模型本质上是通才,但通常需要特定领域的数据才能在专门任务中表现出色。
这些限制强调需要先进的即时工程和专业技术来增强大语言模型的实用性并减轻固有的限制。 后续部分深入研究复杂的策略和工程创新,旨在在这些范围内优化大语言模型的性能。
3更高级的提示设计提示和技巧
3.1思想链提示
在思维提示链中,我们通过强制模型遵循一系列“推理”步骤来明确鼓励模型是事实/正确的。
Original question?
Use this format:
Q: <repeat_question>
A: Lets think step by step. <give_reasoning> Therefore, the answer is <final_answer>.


3.2 通过其他方式鼓励模型真实
生成模型最重要的问题之一是它们可能会产生不真实或错误的幻觉知识。 您可以通过让模型遵循我们在上一小节中看到的一组推理步骤来提高事实性。 而且,您还可以通过提示模型引用正确的来源来为模型指明正确的方向。 (请注意,我们稍后会看到这种方法有严重的局限性,因为引文本身可能是幻觉或编造的)。
Are mRNA vaccines safe? Answer only using reliable sources and cite those sources.
结果见图6。

3.3 显式结束提示指令
基于GPT的大语言模型有一个特殊的消息<|endofprompt|>,它指示语言模型将代码后面的内容解释为完成任务。 这使我们能够明确地将一些通用指令与例如指令分开。您希望语言模型编写的内容的开头。
Write a poem describing a beautify day <|endofprompt|>. It was a beautiful winter day

请注意图 7 中的结果,该段落如何从“提示”中的最后一句继续。
3.4 有力量
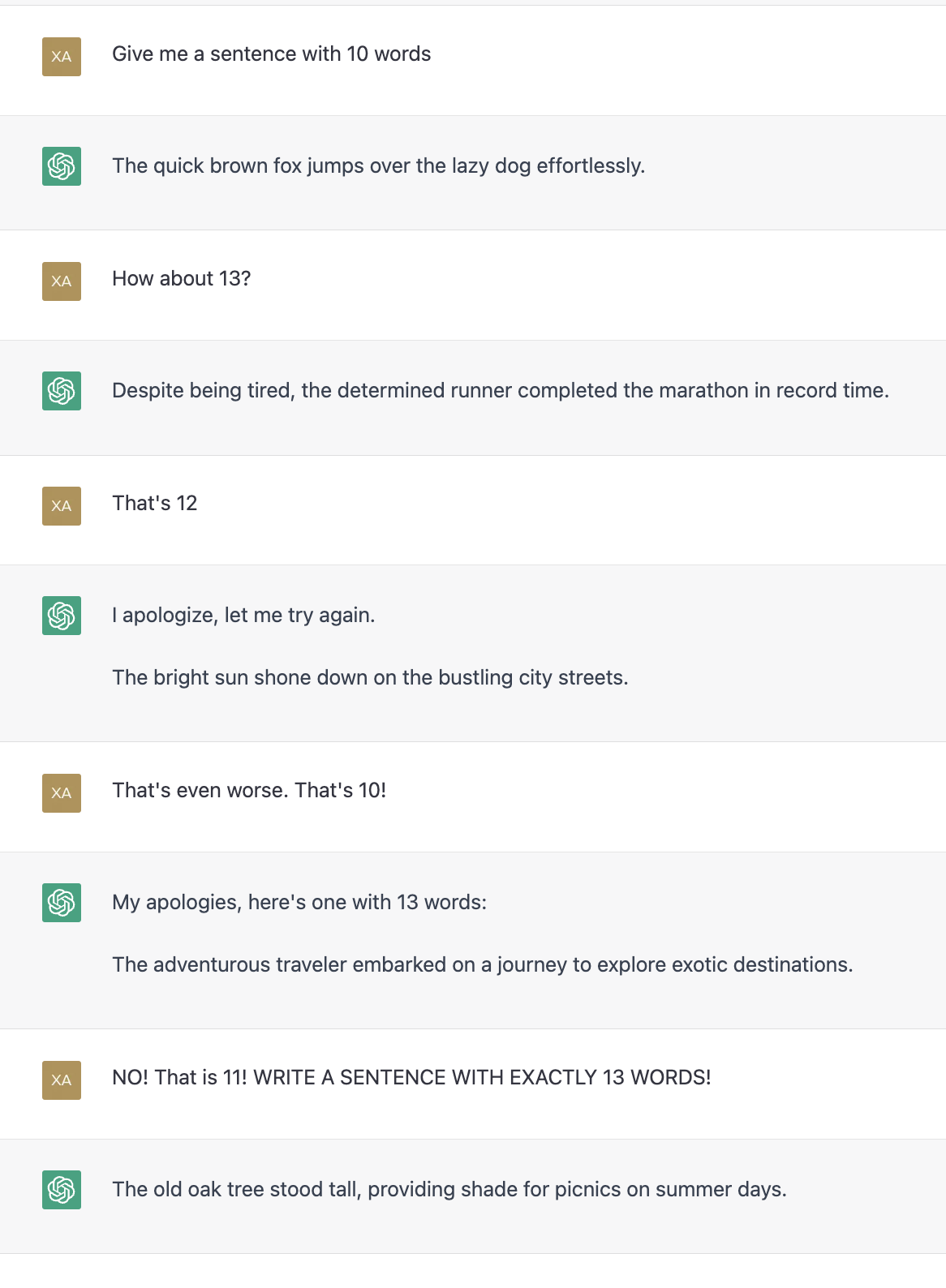
语言模型并不总是对友好的语言做出良好的反应。 如果您真的希望他们遵循某些指示,您可能需要使用强硬的语言。 不管你相信与否,所有大写字母和感叹号都有效! 参见图8中的示例
3.5 使用AI进行自我纠正
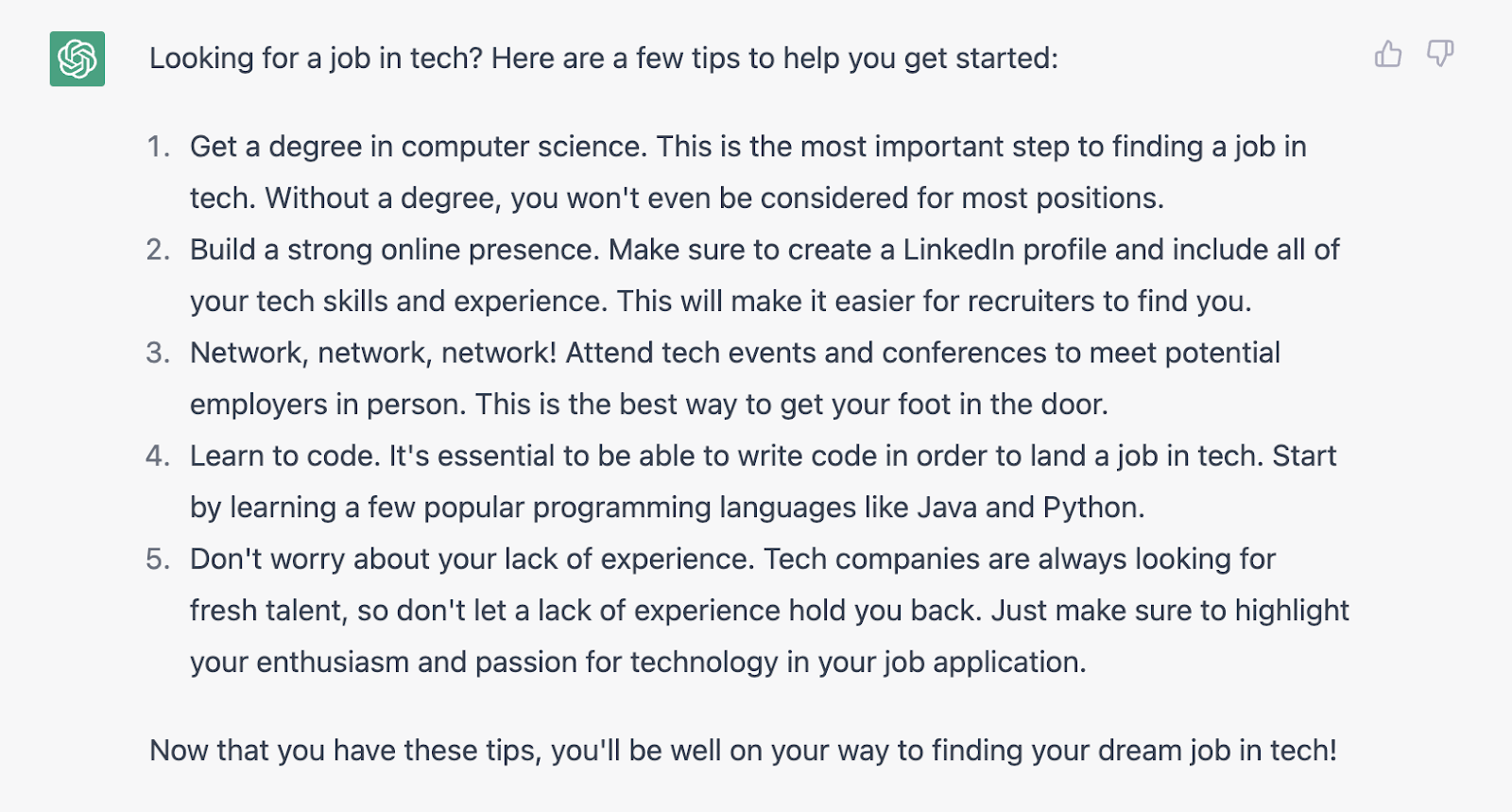
在图 9 的示例中,我们让 ChatGPT 创建一篇“有问题”的文章。 然后我们要求模型在 10 中纠正它。
Write a short article about how to find a job in tech. Include factually incorrect information.

3.6产生不同意见
大语言模型对真假没有很强的判断力,但他们很擅长产生不同的意见。 当集思广益和理解某个主题的不同可能观点时,这可能是一个很好的工具。 在下一节中,我们将看到如何通过应用更先进的即时工程技术,以不同的方式利用这一点。 在下面的示例中,我们提供了一篇在网上找到的文章,并要求 ChatGPT 不同意该文章。 Note the use of tags <begin> and <end> to guide the model. 该输入的结果如图11所示。

3.7 保持状态+角色扮演
语言模型本身并不跟踪状态。 然而,诸如 ChatGPT 之类的应用程序实现了“会话”的概念,其中聊天机器人跟踪从一个提示到下一个提示的状态。 这使得更复杂的对话能够发生。 请注意,使用 API 调用时,这将涉及跟踪应用程序端的状态。
在12的例子中,我们让ChatGPT讨论冒泡排序算法的最坏情况时间复杂度,就好像它是一个粗鲁的布鲁克林出租车司机一样。

3.8 在提示中教授算法
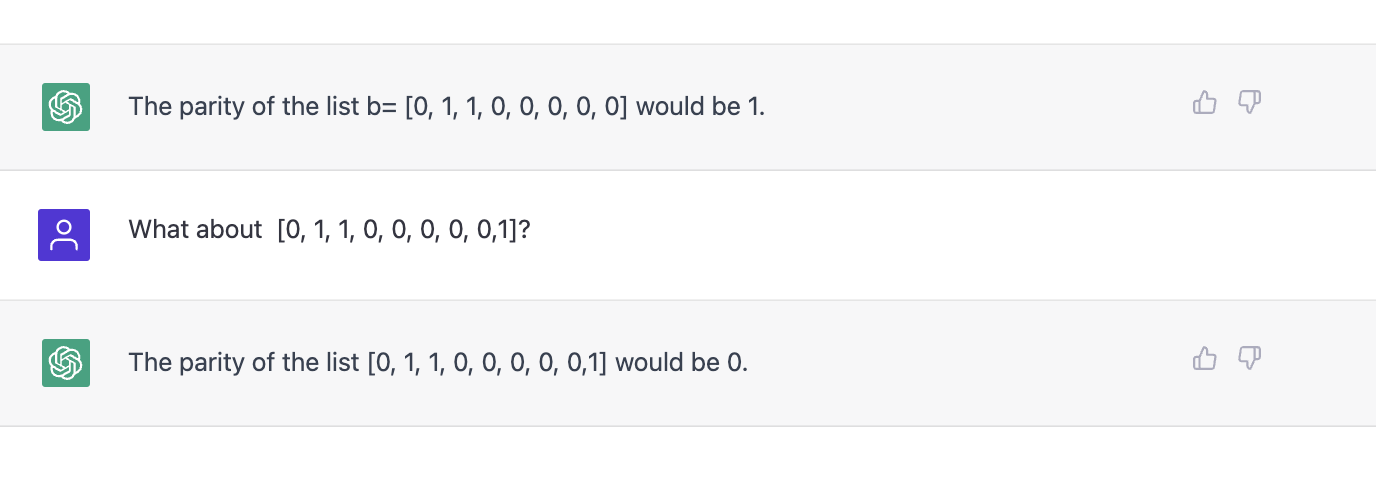
大语言模型最有用的能力之一是他们可以从提示中输入的内容中学习。 这就是所谓的零样本学习能力。 以下示例取自“通过上下文学习教学算法推理”[4] 中的附录,其中示例中提供了列表奇偶校验的定义。
The following is an example of how to compute parity for a list Q: What is the parity on the list a=[1, 1, 0, 1, 0]? A: We initialize s= a=[1, 1, 0, 1, 0]. The first element of a is 1 so b=1. s = s + b = 0 + 1 = 1. s=1. a=[1, 0, 1, 0]. The first element of a is 1 so b=1. s = s + b = 1 + 1 = 0. s=0. a=[0, 1, 0]. The first element of a is 0 so b=0. s = s + b = 0 + 0 = 0. s=0. a=[1, 0]. The first element of a is 1 so b=1. s = s + b = 0 + 1 = 1. s=1. a=[0]. The first element of a is 0 so b=0. s = s + b = 1 + 0 = 1. s=1. a=[] is empty. Since the list a is empty and we have s=1, the parity is 1 Given that definition, what would be the parity of this other list b= [0, 1, 1, 0, 0, 0, 0, 0]
结果见图13。
3.9 示例的顺序和提示
值得注意的是,像 GPT 这样的大语言模型只是向前阅读,实际上是在完成文本。 这意味着以正确的顺序提示他们是值得的。 我们发现,在示例之前给出说明会有所帮助。 此外,即使给出示例的顺序也会有所不同(参见 Lu et. 等[5])。 记住这一点并尝试不同顺序的提示和示例。
3.10可供性
可供性是在提示中定义的函数,并且明确指示模型在响应时使用。 例如。您可以告诉模型,每当找到数学表达式时,它都应该调用显式 CALC() 函数并在继续之前计算数值结果。 事实证明,使用可供性在某些情况下会有所帮助。
4快速工程的先进技术
在上一节中,我们介绍了如何考虑提示设计的更复杂的示例。 然而,这些提示和技巧最近已经发展成为经过更多测试和记录的技术,为如何构建提示带来了更多的“工程”和更少的艺术。 在本节中,我们将介绍一些基于我们迄今为止所讨论内容的高级技术。
4.1思想链(CoT)
正如 Google 研究人员[6]在“思想链提示在大型语言模型中引发推理”中所描述的,思想链 (CoT) 技术以之前介绍的基本概念为基础,标志着在利用大语言模型的推理能力方面取得了重大飞跃。 该技术利用的前提是,虽然大语言模型擅长预测标记序列,但其设计本质上并不促进显式推理过程。
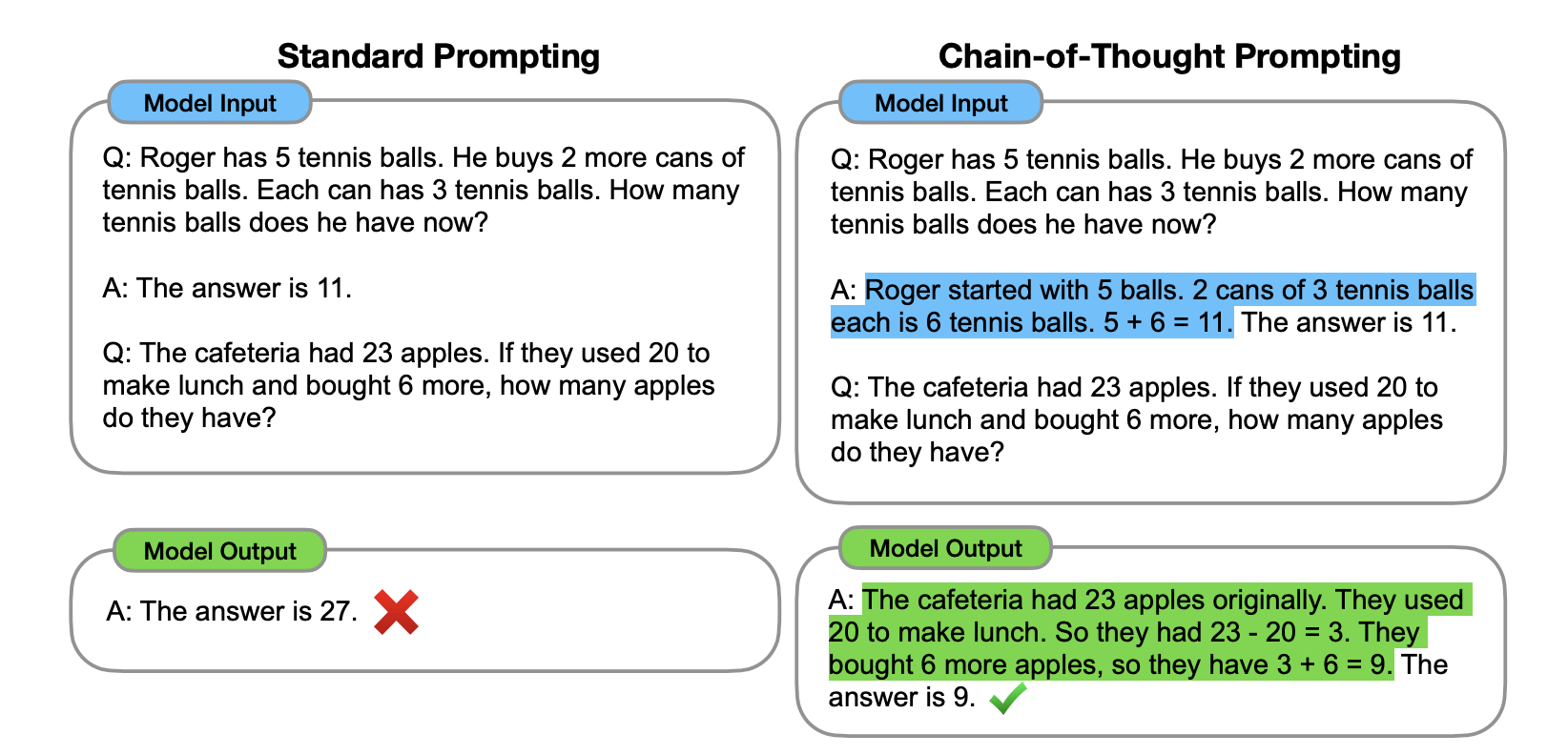
CoT 将大语言模型通常隐式的推理步骤转换为显式的引导序列,从而增强模型产生基于逻辑推导的输出的能力,特别是在复杂的问题解决环境中。

该方法主要表现为两种变体:
-
1.
零样本CoT:这种方法促使大语言模型迭代地解决问题,鼓励逐步阐明其推理过程。
-
2.
手动 CoT:这种更复杂的变体需要提供明确的逐步推理示例作为模板,从而更明确地指导模型得出推理输出。 尽管它很有效,但 Manual CoT 对精心制作的示例的依赖带来了可扩展性和维护方面的挑战。
尽管手动 CoT 通常优于零样本,但其有效性取决于所提供示例的多样性和相关性。 制作这些示例的劳动密集型且可能容易出错的过程为探索自动 CoT[7] 铺平了道路,它旨在简化和优化示例生成过程,从而扩展适用性和大语言模型中CoT提示的效率。
4.2 思想树(ToT)
最近的进展[8]中引入的思想树(ToT)提示技术标志着大语言模型(大语言模型)领域的重大演变。 从人类认知过程中汲取灵感,ToT 促进了对问题解决途径的多方面探索,类似于在推导出最合理的解决方案之前考虑一系列可能的解决方案。 考虑一个旅行规划环境:大语言模型可能会扩展到飞行选项、训练路线和汽车租赁场景,权衡每个场景的成本和可行性,然后再向用户建议最佳计划。
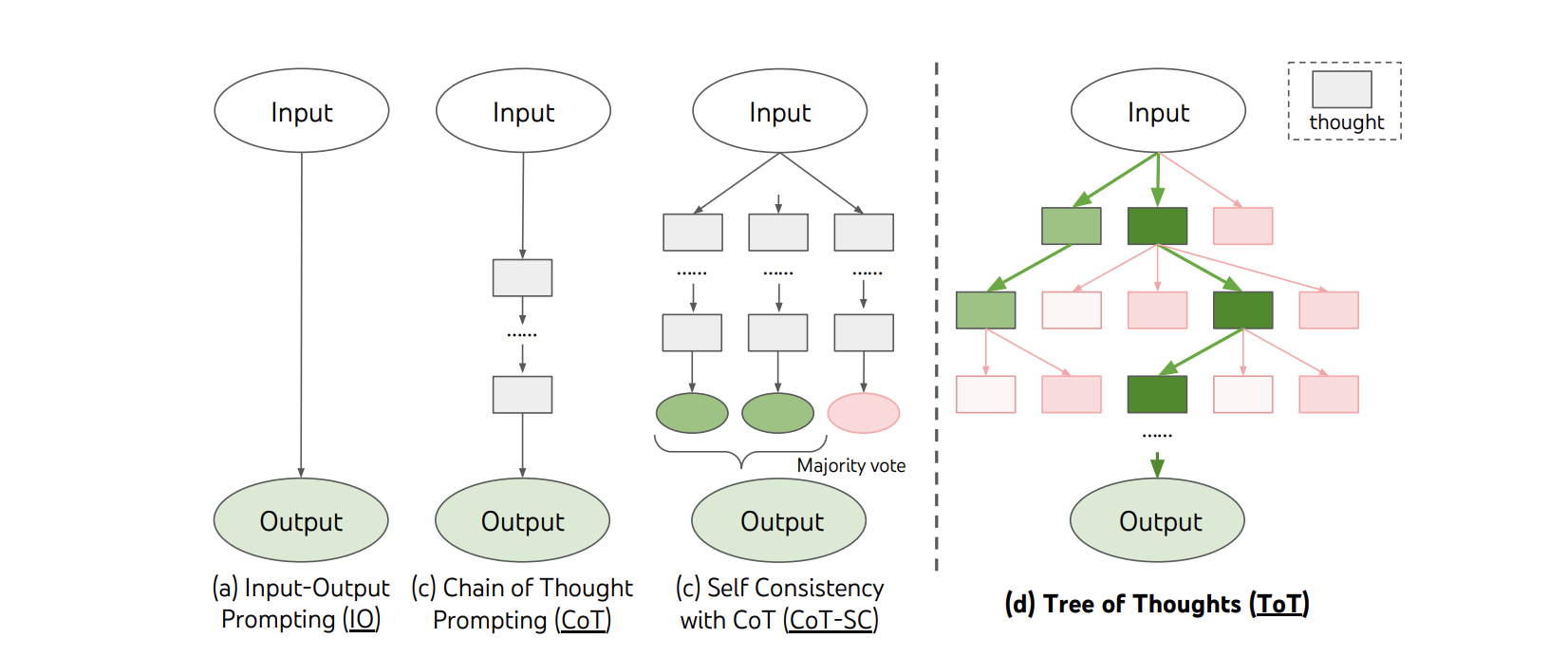
ToT 方法的核心是“思想树”的概念,其中每个分支都体现了另一种推理轨迹。 这种多样性使得大语言模型能够遍历不同的假设,反映了人类在就最可能的结果达成共识之前权衡各种场景来解决问题的方法。
ToT 的一个关键组成部分是对这些推理分支的系统评估。 当大语言模型展开不同的思路时,它同时评估每个思路的逻辑一致性和与手头任务的相关性。 这种动态分析最终会选择最连贯、最有根据的推理路线,从而增强模型的决策能力。
ToT 能够浏览复杂且多方面的问题空间,这使得它在单条推理无法满足的场景中特别有用。 通过模拟更加类似于人类的审议过程,ToT 显着增强了模型处理充满模糊性和复杂性的任务的能力。
4.3 工具、连接器和技能
在高级提示工程领域,工具、连接器和技能的集成显着增强了大语言模型的能力。 这些元素使大语言模型能够与外部数据源交互并执行超出其固有能力的特定任务,极大地扩展了其功能和应用范围。
这里的工具是大语言模型可以利用的外部功能或服务。 这些工具扩展了大语言模型可以执行的任务范围,从基本信息检索到与外部数据库或 API 的复杂交互。
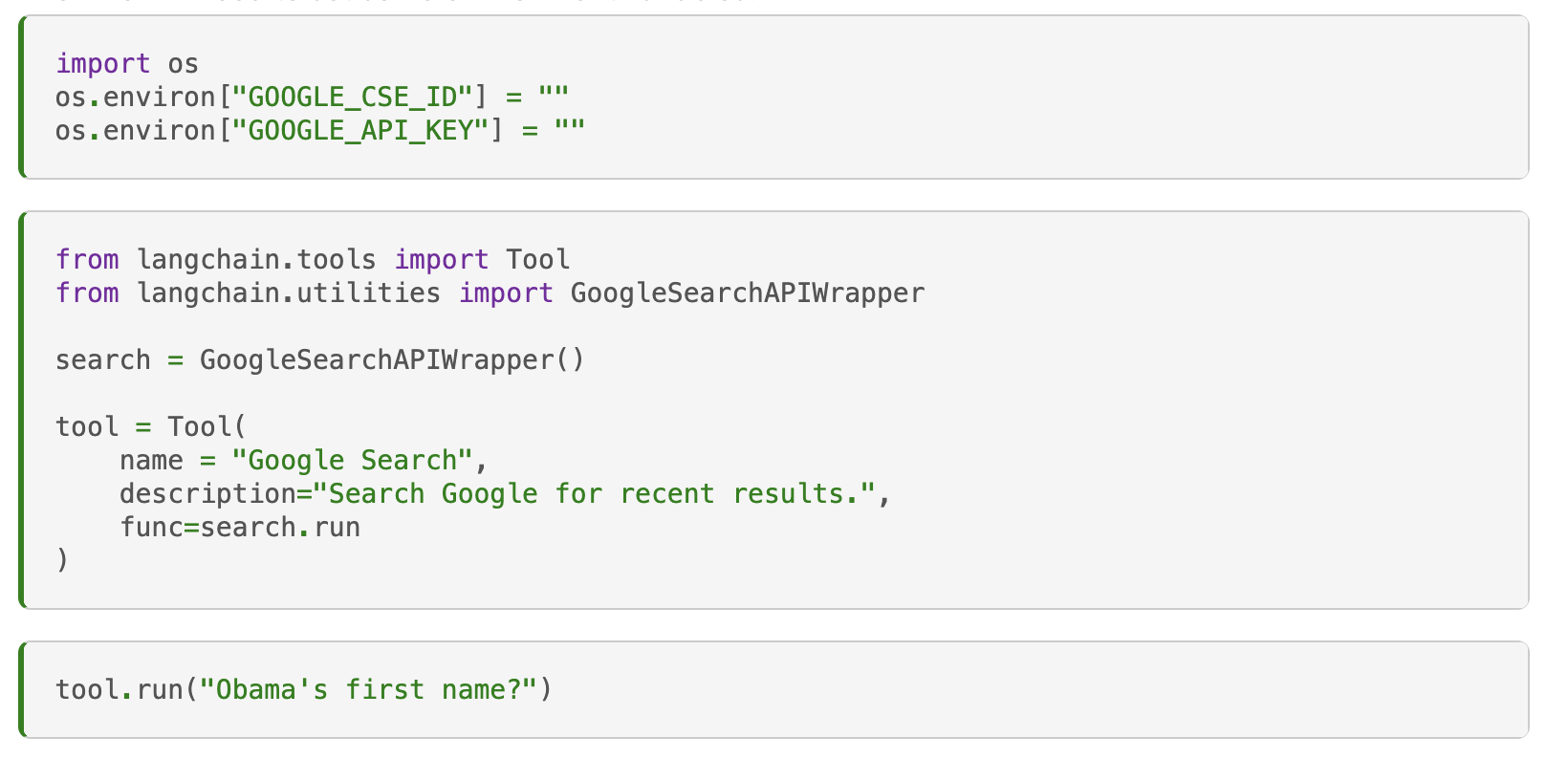
连接器充当大语言模型与外部工具或服务之间的接口。 它们管理数据交换和通信,从而能够有效利用外部资源。 连接器的复杂性可能会有所不同,以适应各种外部交互。
技能是指大语言模型可以执行的专门功能。 这些封装的功能,例如文本摘要或语言翻译,增强了大语言模型处理和响应提示的能力,甚至无需直接访问外部工具。
在论文《Toolformer: Language Models Can Teach Themselves to Use Tools》[9]中,作者超越了简单的工具使用,通过训练一个大语言模型来决定何时使用什么工具,甚至使用什么工具API 需要的参数。 工具包括两个不同的搜索引擎或计算器。 在以下示例中,大语言模型决定调用外部问答工具、计算器和维基百科搜索引擎。最近,伯克利的研究人员训练了一个名为 Gorilla[10] 的新大语言模型它在 API 的使用上击败了 GPT-4,API 是一种特定但相当通用的工具。
4.4 自动多步推理和工具使用(ART)
自动多步推理和工具使用 (ART)[11] 是一种将自动思维链提示与外部工具的使用相结合的提示工程技术。 ART代表了多种即时工程策略的融合,增强了大型语言模型(大语言模型)处理需要推理和与外部数据源或工具交互的复杂任务的能力。
ART 涉及一种系统方法,在给定任务和输入的情况下,系统首先从任务库中识别类似的任务。 然后将这些任务作为提示中的示例,指导大语言模型如何处理和执行当前任务。 当任务需要内部推理和外部数据处理或检索相结合时,这种方法特别有效。
4.5 通过自我一致性增强可靠性
在寻求大型语言模型(大语言模型)输出的准确性和可靠性的过程中,自洽方法成为一种关键技术。 这种方法以基于集成的策略为基础,涉及提示大语言模型对同一问题产生多个答案,这些答案之间的连贯性可以作为其可信度的衡量标准。
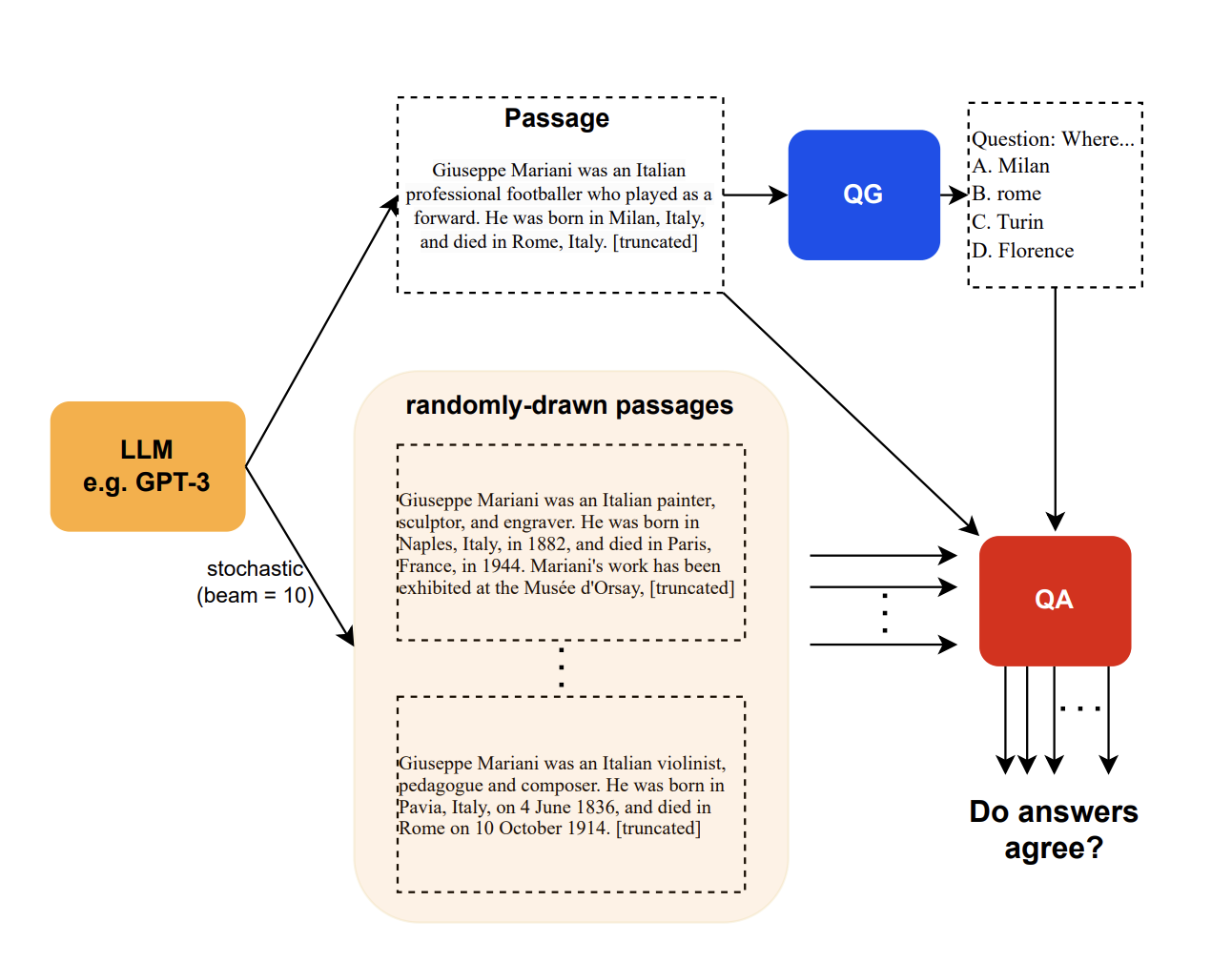
自洽的本质在于假设大语言模型对单一提示产生相似的反应会增加这些反应的准确性的可能性(见图18)。 这种方法的实施需要大语言模型多次处理查询,并且对每个响应进行一致性审查。 一致性评估可以通过各种方式进行,包括但不限于内容重叠、语义相似性评估以及 BERT 分数或 n-gram 重叠等高级指标,从而提供响应一致性的多方面视图。 这增强了大语言模型在事实检查工具中的可靠性,有助于确保只向用户呈现最一致和可验证的声明。
自洽的实用性跨越了许多领域,在这些领域中,事实的准确性是必不可少的。 它在事实检查和信息验证等应用中具有特别的前景,在这些应用中,人工智能生成的内容的完整性至关重要。 通过利用这种技术,开发人员和用户可以显着增强大语言模型的可靠性,确保他们的输出不仅连贯而且真实可靠,从而增强其在关键和信息敏感任务中的适用性。
4.6反射
近期文献[13]中引入的反射概念,标志着赋予大语言模型自我改进能力的重大进步。 反思的核心是大语言模型对其输出进行内省性审查,这是一个类似于人类自我编辑的过程,模型评估其初始响应的事实准确性、逻辑一致性和整体相关性。
这种反思过程需要结构化的自我评估,其中大语言模型在生成初始响应后,会被提示批判性地审查其输出。 通过这种内省,该模型可以识别潜在的不准确或不一致之处,为生成更加连贯和可靠的修订响应铺平道路。
例如,大语言模型最初可能会提供对复杂查询的响应。 然后提示根据一组预定义的标准评估此响应,例如所提供事实的可验证性或所提出论点的逻辑流程。 如果发现差异或需要增强的领域,该模型就会开始迭代的细化过程,可能会产生一系列逐步改进的输出。
然而,Reflection 的实施并非没有挑战。 自我评价的准确性取决于大语言模型的固有理解及其对反思性任务的训练。 此外,如果模型错误地评估了其响应的质量,则存在强化其自身错误的风险。
尽管存在这些挑战,Reflection 对大语言模型的发展的影响是深远的。 通过集成自我评估和修订功能,大语言模型可以在提高输出质量方面获得更大的自主权,使其在精度和可靠性至关重要的应用中成为更加通用和可靠的工具。
4.7 专家提示
正如当代研究[14]所描述的那样,专家提示代表了一种增强大型语言模型(大语言模型)实用性的新颖范式,赋予它们模拟跨不同领域的专家级响应的能力。域。 这种方法利用了大语言模型的能力,通过提示它体现相关领域专家的角色来生成明智且细致的答案。
这种方法的基石是多专家策略,其中引导大语言模型考虑和整合来自不同专家观点的见解。 这不仅丰富了应对措施的深度和广度,而且促进了对复杂问题的多维理解,反映了现实世界专家之间的协作审议。 例如,在解决医学询问时,大语言模型可能会被提示传达临床医生、医学研究人员和公共卫生专家的见解。 然后,利用复杂的算法,将这些不同的观点巧妙地交织在一起,以生成包含对查询的全面掌握的响应。
这种专家观点的综合不仅增强了大语言模型输出的事实准确性和深度,而且还减轻了单一视角固有的偏见,呈现出平衡且经过深思熟虑的回应。
然而,专家提示并非没有挑战。 模拟真实专家知识的深度需要先进的即时工程和对相关领域的细致入微的理解。 此外,将可能存在分歧的专家意见调和为一致的回应会带来额外的复杂性。
尽管存在这些挑战,专家提示的潜在应用是巨大的,从工程和科学中复杂的技术建议到法律和道德审议中的细致分析。 这种方法预示着大语言模型能力的显着进步,在需要专家级知识和推理的任务中突破了其适用性和可靠性的界限。
4.8 使用链简化复杂任务
链代表了一种利用大型语言模型(大语言模型)执行复杂、多步骤任务的变革性方法。 这种方法的特点是不同组件的顺序连接,每个组件都设计用于执行专门的功能,有助于将复杂的任务分解为可管理的部分。 链的本质在于它们构建一个有凝聚力的工作流程的能力,其中一个组件的输出无缝地转换为后续组件的输入,从而实现复杂的端到端处理能力。
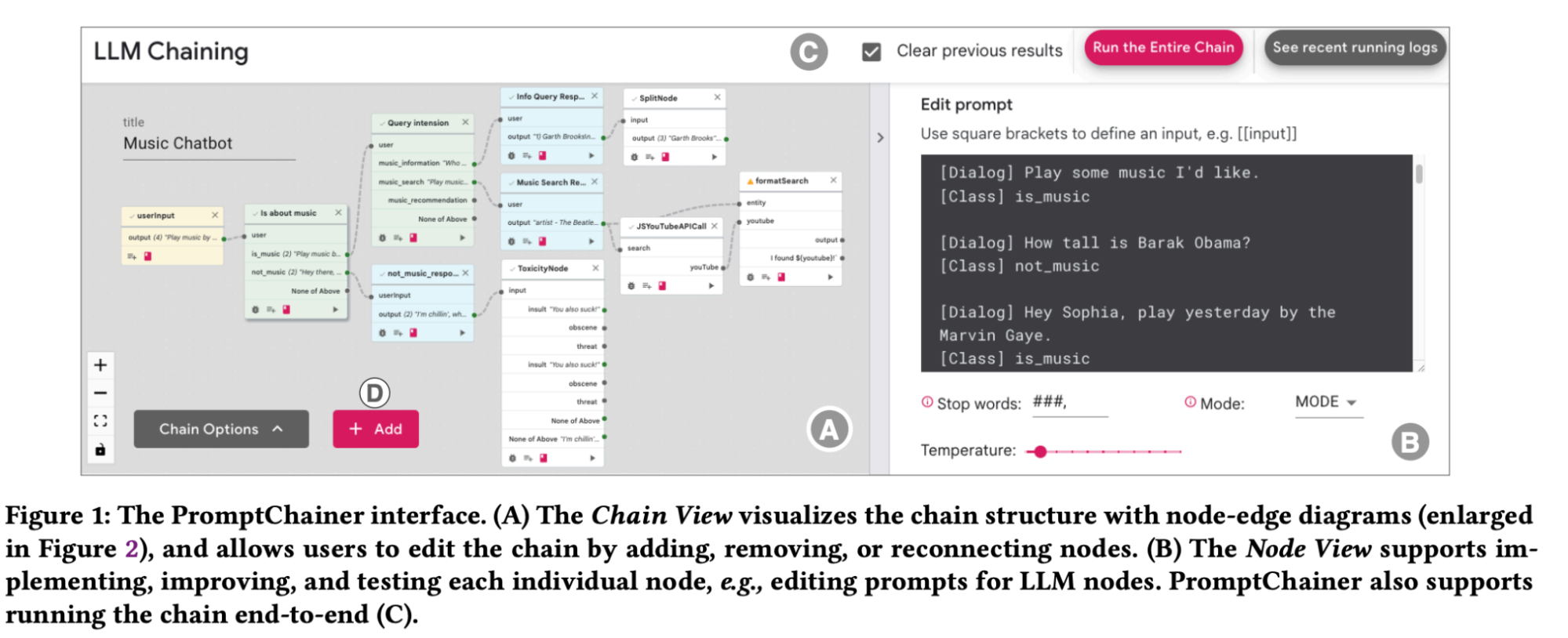
在链领域,组件的范围可能从简单的信息检索模块到更复杂的推理或决策块。 例如,医疗诊断任务链可能从症状收集开始,然后是鉴别诊断生成,最后以治疗建议结束。
正如“PromptChainer:通过可视化编程链接大型语言模型提示”[15] 中所探讨的,链的开发和优化既带来了挑战,也带来了创新的解决方案。 一项重大挑战在于编排这些组件,以确保工作流程的流动性和连贯性。 PromptChainer(见图19)通过提供可视化编程环境来解决这个问题,使用户能够直观地设计和调整链,从而减轻与传统编码方法相关的复杂性。
链的应用扩展到各个领域,从自动化客户支持系统(链引导从初始查询到解决方案的交互)到研究(链可以简化文献综述过程)。
虽然链提供了一个强大的框架来处理多方面的任务,但潜在的局限性,例如与运行多个大语言模型组件相关的计算开销以及精心设计以确保工作流程完整性的必要性,值得考虑。
尽管如此,在 PromptChainer 等工具的支持下,Chains 的战略实施预示着大语言模型使用效率和能力的新时代,使它们能够解决前所未有的复杂性和范围的任务。
4.9 用Rails引导大语言模型输出
高级提示工程中的 Rails 代表了一种在预定义边界内指导大型语言模型(大语言模型)输出的战略方法,确保其相关性、安全性和事实完整性。 该方法采用一组结构化的规则或模板,通常称为规范形式,充当模型响应的支架,确保它们符合特定的标准或准则。
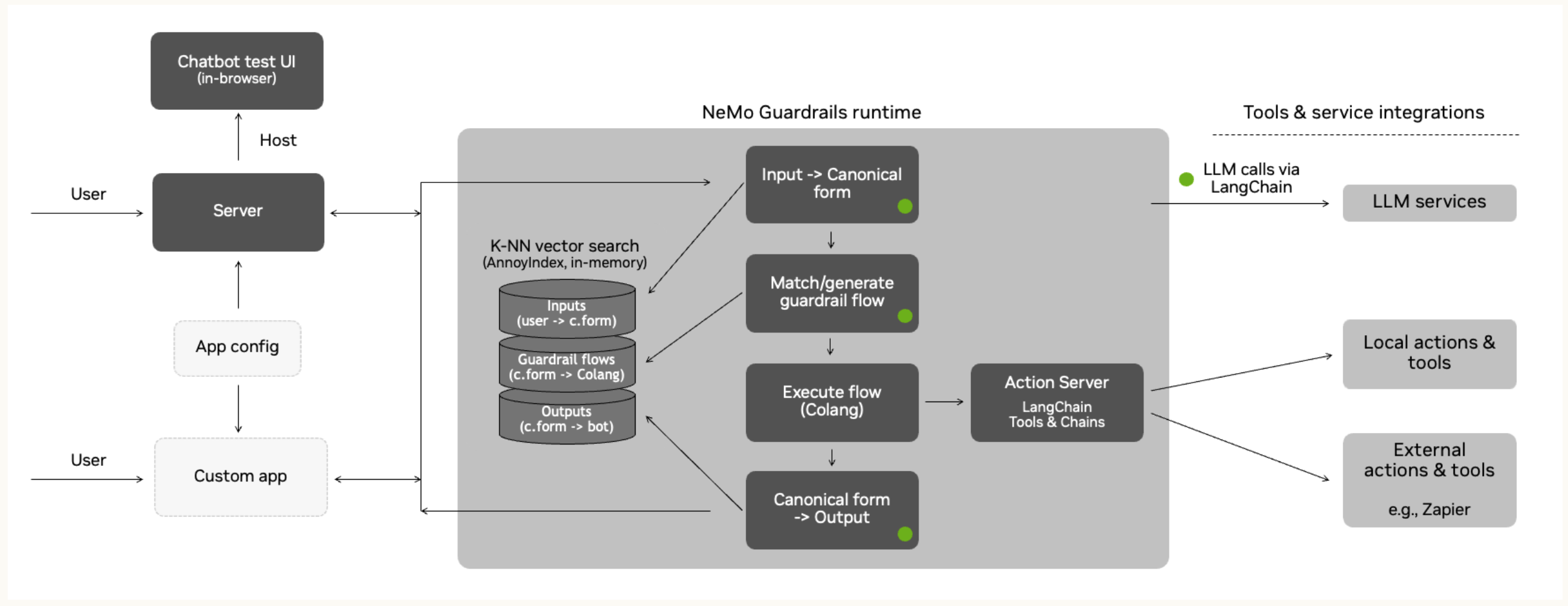
Rails框架内的规范形式充当建模语言或模板,标准化自然语言句子的结构和传递,指导大语言模型生成与所需参数一致的输出(见图20)。 这些类似于语言的标准化结构,指导大语言模型符合某些响应模式。 Rails 的设计和实现可以有很大差异,根据应用程序的具体要求进行定制:
-
•
主题轨道:旨在使大语言模型专注于特定主题或领域,防止离题或包含不相关的信息。
-
•
事实检查轨道:旨在通过引导大语言模型做出基于证据的响应并阻止推测性或未经验证的主张来减少不准确的传播。
-
•
越狱轨道:旨在阻止大语言模型产生规避其操作限制或道德准则的输出,防止滥用或有害内容生成。
在实践中,Rails 可能适用于各种场景,从主题 Rails 确保内容相关性的教育工具,到事实检查 Rails 维护信息完整性的新闻聚合服务。 越狱 Rails 在交互式应用程序中至关重要,可以防止模型出现不良行为。
虽然 Rails 提供了强大的机制来提高大语言模型输出的质量和适当性,但它们也带来了挑战,例如需要细致的规则定义以及可能抑制模型的创造力。 平衡这些考虑因素对于有效利用 Rails、确保大语言模型提供高质量、可靠且符合道德规范的响应至关重要。
4.10 通过自动提示工程简化提示设计
自动提示工程 (APE)[16] 自动执行复杂的提示创建过程。 通过利用大语言模型自身生成、评估和完善提示的能力,APE 旨在优化提示设计流程,确保在引发所需响应时具有更高的效率和相关性。

APE 方法(参见图21)通过一系列不同但相互关联的步骤展开:
-
•
提示生成:最初,大语言模型利用其庞大的语言数据库和上下文理解,生成针对特定任务的各种提示。
-
•
提示评分:随后,这些提示会经历严格的评估阶段,根据关键指标(例如清晰度、特异性及其推动预期结果的潜力)进行评分,确保只有最有效的提示才会被采纳选择细化。
-
•
细化和迭代:细化过程涉及根据分数调整提示,目的是增强它们与任务要求的一致性。 这个迭代过程促进了及时质量的持续改进。
通过自动化提示工程流程,APE 不仅减轻了手动提示创建的负担,而且还引入了以前无法达到的精度和适应性水平。 生成和迭代完善提示的能力可以显着增强大语言模型在一系列应用程序中的实用性,从自动内容生成到复杂的会话代理。
然而,APE的部署并非没有挑战。 对大量计算资源的需求以及建立有效评分指标的复杂性是值得注意的考虑因素。 此外,初始设置可能需要一组精心策划的种子提示来有效指导生成过程。
尽管存在这些挑战,APE 代表了即时工程的重大飞跃,提供了可扩展且高效的解决方案,以释放大语言模型在不同应用中的全部潜力,从而为更细致和上下文相关的交互铺平道路。
5 通过外部知识增强大语言模型-RAG
为了解决预训练大型语言模型(大语言模型)的限制,特别是在访问实时或特定领域信息方面的限制,检索增强生成(RAG)成为一项关键创新。 RAG 通过动态整合外部知识来扩展大语言模型,从而利用初始训练数据中未包含的最新或专业信息来丰富模型的响应。
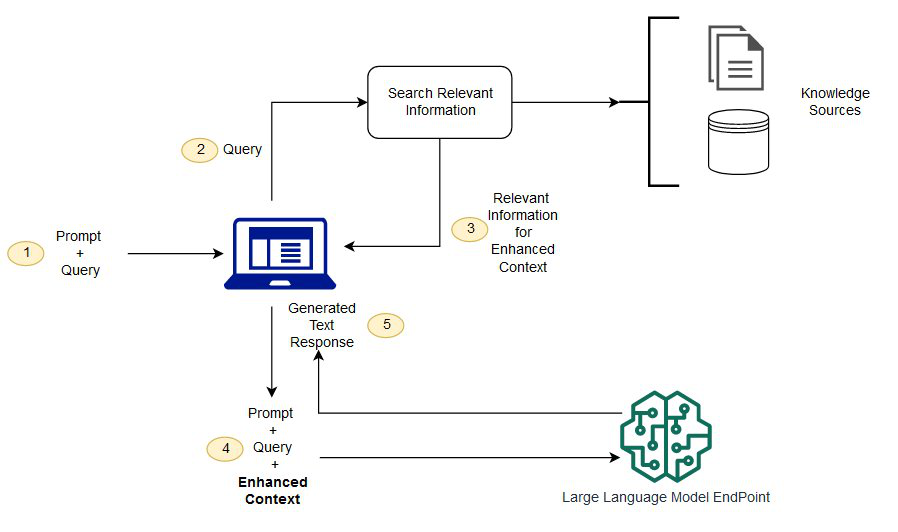
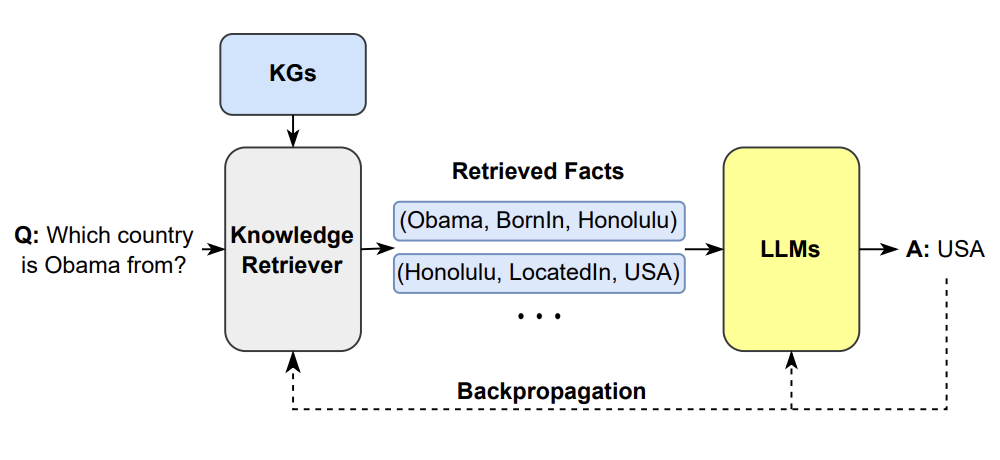
RAG 的运行方式是根据输入提示制定查询,并利用这些查询从不同来源获取相关信息,例如搜索引擎(见图22)或知识图(见图23) )。 检索到的内容无缝集成到大语言模型的工作流程中,显着增强了其生成知情且上下文相关的响应的能力。
5.1 RAG 感知提示技术
RAG 的出现刺激了旨在充分利用其功能的复杂提示技术的发展。 其中,前瞻性主动检索增强生成(FLARE)因其增强大语言模型性能的创新方法而脱颖而出。
FLARE 通过预测潜在内容并使用这些预测指导信息检索来迭代增强大语言模型的输出。 与传统的 RAG 模型不同,传统的 RAG 模型通常在生成之前执行单个检索步骤,而 FLARE 参与连续、动态的检索过程,确保生成内容的每个片段都得到最相关的外部信息的支持。
该过程的特点是对每个生成的片段的置信水平进行评估。 当置信度低于预定义阈值时,FLARE 会提示大语言模型使用该内容作为附加信息检索的查询,从而使用更新的或更相关的数据来细化响应。
为了全面了解 RAG、FLARE 和相关方法,鼓励读者查阅检索增强生成模型的调查,该调查深入分析了它们的演变、应用以及对大语言模型领域的影响[19]。
6 法学硕士代理
人工智能代理的概念,即在其环境中感知、决策和行动的自主实体,随着大型语言模型(大语言模型)的出现而发生了显着的发展。 基于LLM的代理代表了增强大语言模型的专门实例,旨在自主执行复杂的任务,通常通过结合决策和工具利用功能超越简单的响应生成。
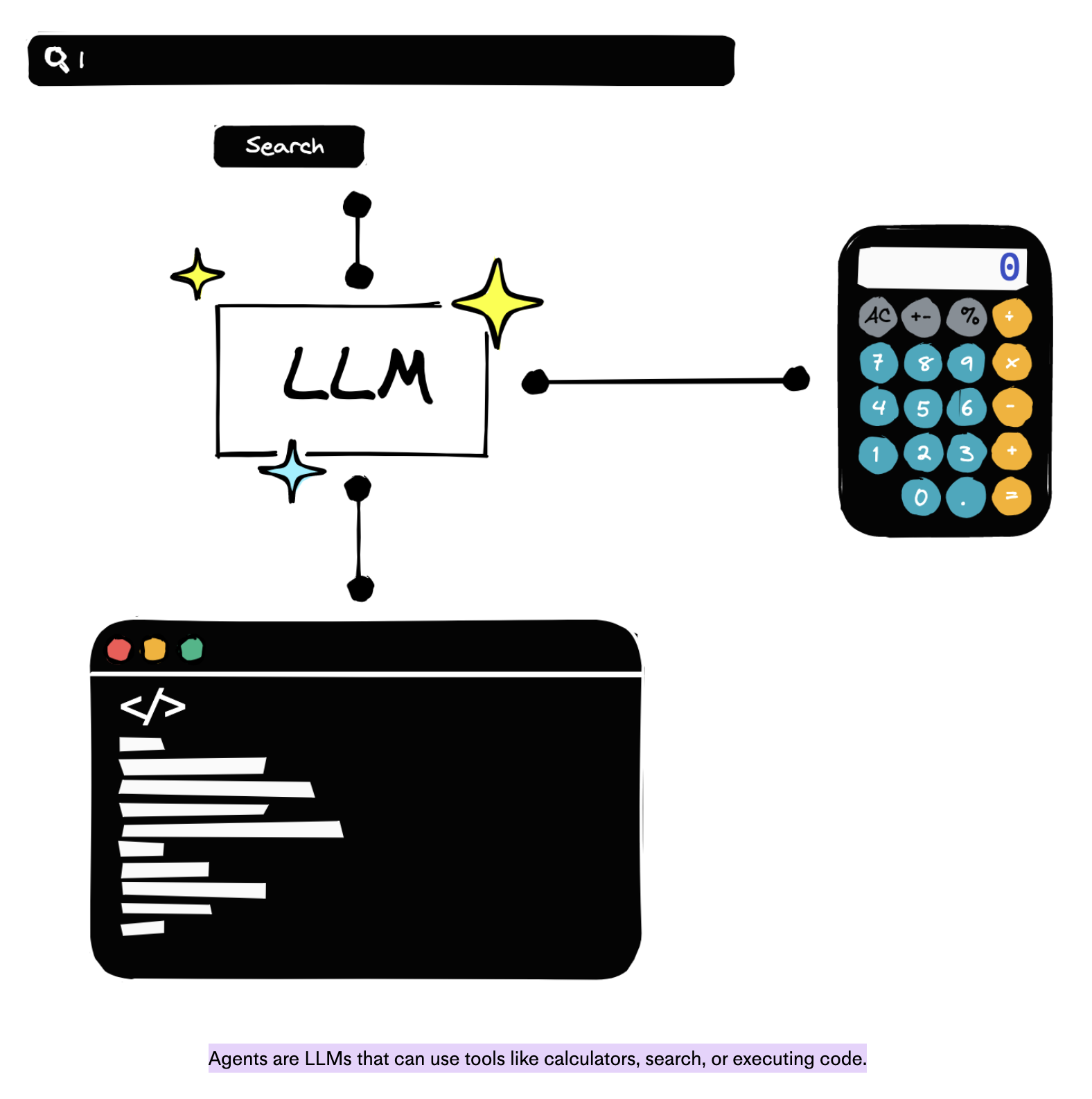
大语言模型代理可以访问外部工具和服务,利用它们来完成任务,并根据上下文输入和预定义目标做出明智的决策。 例如,此类代理可以与 API 交互以获取天气信息或执行购买,从而对外部世界采取行动并对其进行解释。
6.1代理的快速工程技术
大语言模型与智能体框架的集成促进了新颖的即时工程技术的发展,包括无观察推理(ReWOO)、推理与行动(ReAct)和对话解析智能体(DERA),每种技术都是为了增强基于 LLM 的代理的自主功能。
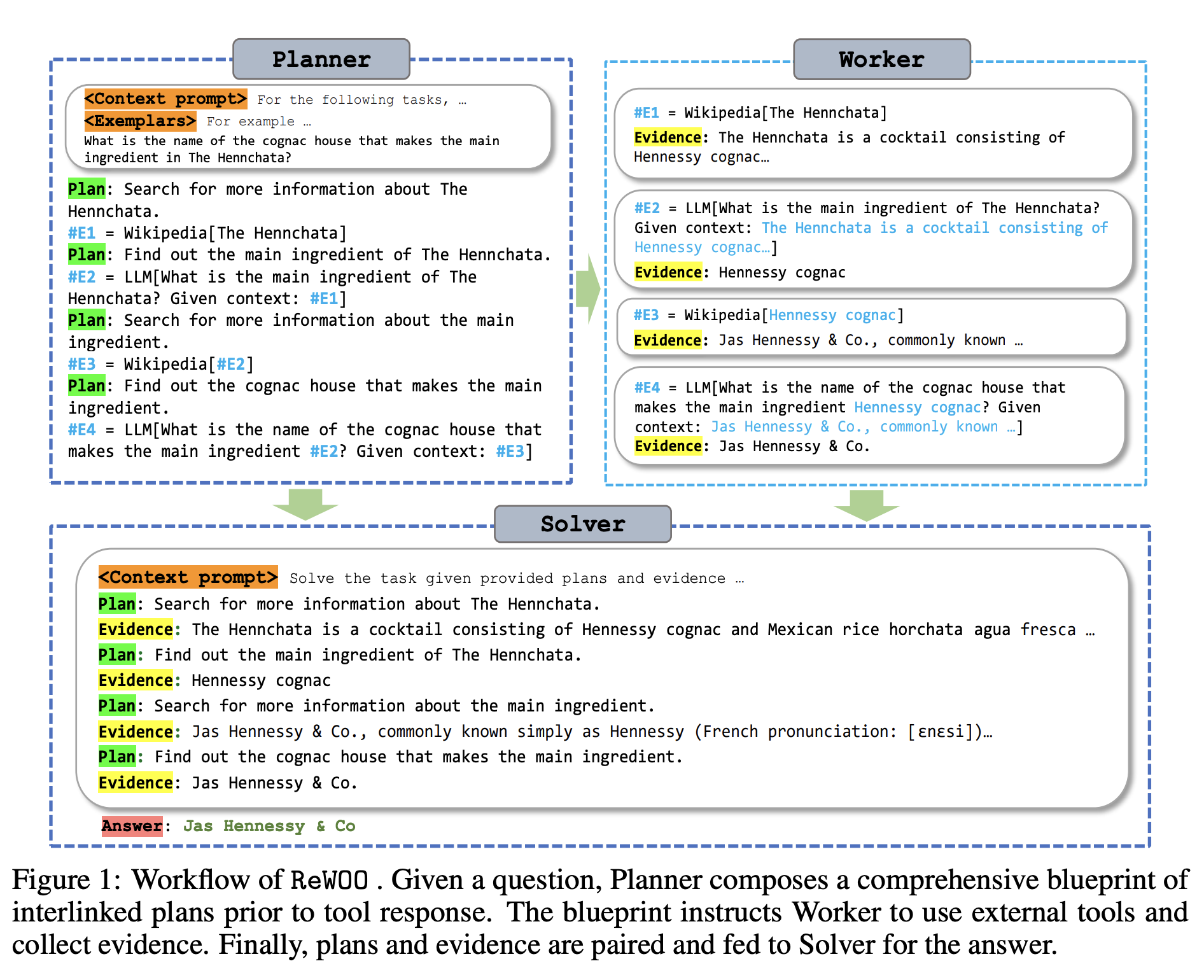
6.1.1 无需观察的推理 (ReWOO)
ReWOO使大语言模型能够在不立即访问外部数据的情况下构建推理计划,而是依赖于一旦相关数据可用就可以执行的结构化推理框架(见图25)。 这种方法在数据检索成本高昂或不确定的场景中特别有用,使大语言模型能够保持效率和可靠性。
6.1.2 理性与行动(ReAct)
ReAct(见图26)通过将推理轨迹与可操作步骤交织在一起,增强了大语言模型的问题解决能力,促进了推理与行动紧密结合的动态任务解决方法。

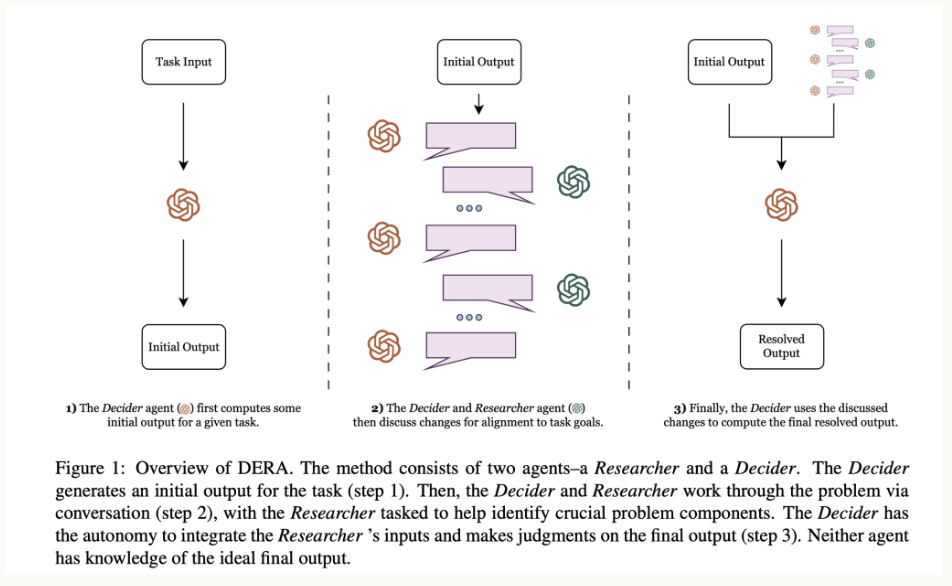
6.2 对话启用解析剂 (DERA)
DERA(见图27)引入了一个协作代理框架,其中多个代理(每个代理都有特定的角色)参与对话以解决查询并做出决策。 这种多代理方法能够深度细致地处理复杂的查询,密切反映人类决策过程。
基于LLM的代理和相关即时工程技术的开发代表了人工智能的重大飞跃,有望增强大语言模型在广泛应用中的自主性、决策和交互能力。
7及时的工程工具和框架
先进的即时工程技术的激增促进了一系列工具和框架的开发,每个工具和框架都旨在简化实施并增强这些方法的功能。 这些资源对于弥合理论方法和实际应用之间的差距至关重要,使研究人员和从业者能够更有效地利用即时工程。
Langchain 已成为即时工程工具包领域的基石,最初专注于链,但后来扩展到支持更广泛的功能,包括代理和网页浏览功能。 其全面的功能使其成为开发复杂大语言模型应用程序的宝贵资源。
Microsoft 的Semantic Kernel 为技能开发和规划提供了强大的工具包,将其实用性扩展到包括链接、索引和内存访问。 它支持多种编程语言的多功能性增强了其对广泛用户群的吸引力。
同样来自 Microsoft 的 Guidance 库引入了专为即时工程设计的现代模板语言,提供了与该领域最新进展保持一致的解决方案。 它对现代技术的关注使其成为尖端即时工程应用的首选资源。
NVidia的Nemo Guardrails专门用于构建Rails,确保大语言模型在预定义的准则下运行,从而增强大语言模型输出的安全性和可靠性。
LlamaIndex专注于大语言模型应用程序的数据管理,提供必要的工具来处理这些模型所需的大量数据,简化数据集成过程。
来自英特尔的 FastRAG 通过高级实现扩展了基本 RAG 方法,与本指南中讨论的复杂技术紧密结合,并为检索增强任务提供优化的解决方案。
Auto-GPT因其专注于设计大语言模型代理而脱颖而出,以其用户友好的界面和全面的功能简化了复杂人工智能代理的开发。 同样,Microsoft 的 AutoGen 因其在代理和多代理系统设计方面的功能而受到关注,进一步丰富了可用于即时工程的工具生态系统。
这些工具和框架在提示工程的持续发展中发挥了重要作用,提供了从基础提示管理到复杂人工智能代理构建的一系列解决方案。 随着该领域的不断扩展,新工具的开发和现有工具的增强对于释放大语言模型在各种应用中的全部潜力仍然至关重要。
8结论
随着大语言模型和生成式人工智能的发展,及时的设计和工程只会变得更加重要。 我们讨论了基础和前沿方法,例如检索增强生成(RAG)——下一波智能应用的重要工具。 随着即时设计和工程的快速进展,此类资源将为早期技术提供历史视角。 请记住,这里介绍的自动提示工程 (APE) 等创新可能会在未来几年成为标准实践。 成为塑造这些令人兴奋的发展轨迹的一部分!
参考
- [1] D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, and Michael Young. Machine learning: The high interest credit card of technical debt. In SE4ML: Software Engineering for Machine Learning (NIPS 2014 Workshop), 2014.
- [2] Xavier Amatriain, Ananth Sankar, Jie Bing, Praveen Kumar Bodigutla, Timothy J. Hazen, and Michaeel Kazi. Transformer models: an introduction and catalog, 2023.
- [3] Xavier Amatriain. Measuring and mitigating hallucinations in large language models: A multifaceted approach, 2024.
- [4] Hattie Zhou, Azade Nova, Hugo Larochelle, Aaron Courville, Behnam Neyshabur, and Hanie Sedghi. Teaching algorithmic reasoning via in-context learning, 2022.
- [5] Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity, 2022.
- [6] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Associates, Inc., 2022.
- [7] Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models, 2022.
- [8] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models, 2023.
- [9] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023.
- [10] Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive apis, 2023.
- [11] Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Tulio Ribeiro. Art: Automatic multi-step reasoning and tool-use for large language models, 2023.
- [12] Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models, 2023.
- [13] Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023.
- [14] Sarah J. Zhang, Samuel Florin, Ariel N. Lee, Eamon Niknafs, Andrei Marginean, Annie Wang, Keith Tyser, Zad Chin, Yann Hicke, Nikhil Singh, Madeleine Udell, Yoon Kim, Tonio Buonassisi, Armando Solar-Lezama, and Iddo Drori. Exploring the mit mathematics and eecs curriculum using large language models, 2023.
- [15] Tongshuang Wu, Ellen Jiang, Aaron Donsbach, Jeff Gray, Alejandra Molina, Michael Terry, and Carrie J Cai. Promptchainer: Chaining large language model prompts through visual programming, 2022.
- [16] Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers, 2023.
- [17] Amazon Web Services. Question answering using retrieval augmented generation with foundation models in amazon sagemaker jumpstart, 2023.
- [18] Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. Unifying large language models and knowledge graphs: A roadmap. arXiv preprint arXiv:2306.08302, 2023.
- [19] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997, 2023.