使用 SURT 进行说话人归因
摘要
流式分离和识别传感器 (SURT) 最近已成为连续、流式、多说话者语音识别 (ASR) 的流行框架。 随着架构、目标和混合模拟方法的进步,SURT 被证明可以成为一种高效的流式处理方法 与说话者无关 真实会议的转录。 在这项工作中,我们通过提出执行方法来进一步推动该框架 说话者归因 使用 SURT 进行转录,适用于短混合物和长录音。 我们通过向 SURT 添加辅助说话者分支,并通过 HAT 式空白分解将其标签预测与 ASR 词符预测同步来实现这一目标。 为了确保录音中不同话语组的相关说话人标签的一致性,我们提出“说话人前缀”——在每个块上附加先前块中识别的说话人的高置信度帧,以建立相对顺序。 我们对合成 LibriSpeech 混合物进行了广泛的消融实验,以验证我们的设计选择,并证明我们最终模型在 AMI 语料库上的有效性。
索引术语:多人 ASR、SURT、发言者归属、会议转录。
1简介
说话者归因的多说话者语音识别 (ASR) 或“谁说了啥”的任务是转录多说话者对话中的所有语音以及相关说话者属性。 该任务有多种应用,例如会议转录和摘要、协作学习和晚宴对话[1,2,3]。 由于重叠语音、轮流和远场音频的存在,通常需要特殊的建模技术[4,5,6]。 研究人员从模块化(即基于管道)和端到端的角度研究了说话者归因的转录。 在前者中,它被分解为说话者分类和 ASR 子任务,并利用每个领域的进步[7,8,9]独立解决。 然而,这种方法可能不是最佳的,因为组件是独立优化的,导致错误传播,并且还可能需要更多的工程工作来维护[10]。
由于模块化系统的这些局限性,研究人员提出了联合优化模型,将二值化和 ASR 结合起来,直接解决说话者归因的转录问题。 其中最流行的是基于基于注意力的编码器-解码器 (AED) 的说话者归因 ASR (SA-ASR) [11]。 它使用序列化输出训练 (SOT) 来处理重叠语音,并使用注册的说话人配置文件(称为说话人库存)来处理说话人属性 [12, 13]。 对该模型的一些修改利用了基于 Transformer 的编码器[14]和大规模预训练[15],并提出了长记录推理方法[16] 不依赖发言者库存[17]。 人们对 SA-ASR 中的说话人归因方法及其对多通道和情境化 ASR 的扩展进行了进一步研究[18,19,20]。 通过将 SOT 修改为在 token 级别执行(称为 t-SOT),Kanda 等人[21]执行了重叠语音的流式转录,这对于话语级别序列化来说是不可行的。 以这种方式增强单调性还允许这些模型建立在神经传感器[22]而不是 AED 上。 然而,t-SOT 需要基于时间戳的复杂 Token 交织/反序列化,以适应单个输出通道上的重叠语音,并且使用“通道更改” Token 可能会对 ASR 训练产生不利影响。
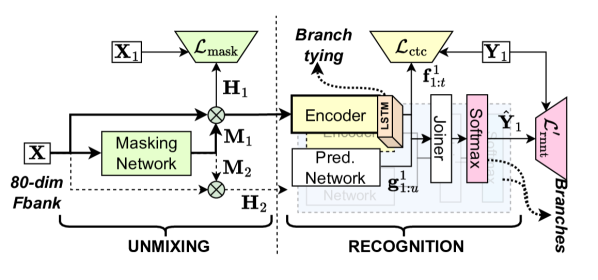
连续、流式、多说话者 ASR 的另一种方法涉及通过在模型内分解重叠的话语来转录并行输出通道上的重叠话语。 这种两分支策略的例子有流解混合和识别传感器 (SURT) [24] 和多转 RNN-T (MT-RNNT) [25] 等模型>,但为了不失一般性,我们在本文中将它们称为 SURT。 SURT 已扩展为处理长格式多轮录音 [26, 25],并联合执行端点和分段 [27, 28]。 卢等人[29]也提出了与SURT联合说话人识别,但他们的模型依赖于说话人库存并且仅用于单轮合成混合物。 如图所示。 1,SURT 模型由一个“解混”组件和一个“识别”组件组成,“解混”组件将混合音频分离为不重叠的流,而“识别”组件则转录每个流。 由于在此建模方案中没有明确发出说话者标签,SURT 迄今为止仅限于 与说话人无关转录。在本文中,我们的目标是将 SURT 模型扩展为说话者归因 在没有任何说话人库存的情况下转录任意数量的说话人。
我们通过在 SURT 的识别模块中添加辅助扬声器传感器来实现这一点。 我们限制该分支发出与使用输出 logits 的 HAT 式空白分解预测的每个 ASR 词符相对应的说话者标签。 我们还提出了一种新颖的“说话人前缀”方法,以确保录音中不同话语组的说话人标签保持一致。 我们通过对 LibriSpeech 混合物进行消融实验来验证我们的方法,并最终在 AMI 语料库的真实会议上演示流式发言者归因转录。 我们将通过开源的方式发布代码 icefall工具包111https://github.com/k2-fsa/icefall。
2 初步:SURT
2.1 神经传感器的语音识别
在单说话者 ASR 中,分段话语的音频特征 ( 和 分别表示时间帧的数量和输入特征维度)作为输入提供,系统预测转录本,其中是输出单位,例如字素或单词片段,0> 是标签序列的长度。 对于判别训练,我们通过最小化负条件对数似然来实现这一点, 。由于 和 之间的排列方式未知,转换器通过对所有排列方式的集合 进行边际化来计算 ,其中 和 的排列方式为 称为空白标签。 正式地,
| (1) |
其中是从比对到输出序列。传感器参数化 带有编码器、预测网络和连接器(参见图 1 中的“识别”组件)。 1)。编码器将映射为隐藏表示,而预测网络将映射为。连接器结合编码器和预测网络的输出,计算对数,并将其输入软最大函数,以生成的后验分布。在流式编码器的假设下,我们可以将 (1) 展开为
| (2) | ||||
| (3) |
其中表示时间时标签序列中的索引. 该表达式的负对数称为 RNN-T 或传感器损失。 在实践中,为了使训练更加节省内存,我们经常近似总和,例如使用修剪后的传感器损失[30]。 我们将这种损失表示为 本文的其余部分。
2.2 使用 SURT 的多说话者 ASR
In multi-talker ASR, the input is an unsegmented mixture containing utterances from speakers, i.e., , where is the -th utterance ordered by start time, shifted and zero-padded to the length of . The desired output is , where is the reference corresponding to . Assuming at most two-speaker overlap, the heuristic error assignment training (HEAT) 范式 [24] 用于创建通道引用 和 通过分配 按开始时间的顺序转到第一个可用频道。 SURT估计 如下。 首先,分解模块计算 和 为
| (4) | ||||
是每个通道的软掩码, 是阿达玛产品。 和 被输入基于传感器的 ASR,生成 logits 和。最后,
| (5) | ||||
其中 和 分别表示编码器[31]上的辅助CTC损失和掩蔽网络上的均方误差损失,并且 是超参数。 在原来的公式中,SURT仅执行 与说话者无关 转录,并使用 ORC-WER 进行评估(参见 部分 4.4) [25]。
3方法论
对于说话者归因的 ASR,所需的输出为 ,其中 是混合物中说话者的数量。 SURT估计 通过将话语映射到两个通道 和 ,如中所述第2.2节. 在多说话者设置中,一种流行的说话者归因方法是预测说话者变化标记,将输出分段为特定于说话者的区域,然后为每个片段分配说话者标签。 然而,这种训练很容易高估说话人变化标记,也可能对 ASR 性能产生不利影响。 相反,我们希望在不影响 ASR 分支的输出的情况下执行说话人归因,例如通过预测发出的每个 ASR 词符的说话人标签。
为了与转录一起执行这种流式说话者归因,出现了以下问题:(i)我们如何处理重叠语音? (ii) 我们如何将说话人标签预测与 ASR 词符预测同步? (iii) 如何协调长录音中不同话语组的相关说话人标签? 我们将在以下小节中回答每个问题。
3.1辅助扬声器传感器
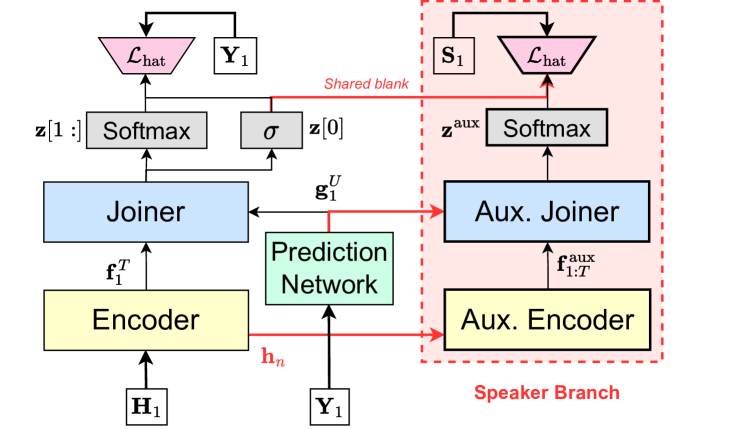
我们根据HEAT策略将说话者标签映射到两个通道,得到和 。在训练过程中,我们重复 次数,次数与 中的标记相同,即我们想要预测每个 ASR 词符的说话人标签。 此后,我们使用非重叠流 估计 采用与 ASR 传感器相同的两分支方法。 为此,我们在识别模块的两个分支中分别添加一个辅助扬声器传感器,如图 1 所示。 2. Intermediate representations from the layer of the main encoder are fed into an auxiliary encoder, producing . An auxiliary joiner combines with to produce auxiliary logits ,用于获取说话者标签和空白标签的分布。 将辅助编码器表示与 ASR 预测网络的表示相结合,使说话者分支能够利用词汇内容来预测说话者标签。 这种词汇信息的使用已被证明有利于使用基于聚类的[32, 33]或端到端神经方法[34]进行说话人二值化。
3.2 将说话者标签与 ASR Token 同步
由于传感器使用空白标签执行帧同步解码,因此上述公式存在几个问题。 首先,我们无法保证ASR Token 的数量 在分支上预测等于说话人标签的数量. 即使我们可以确保这一点,为 ASR 标记分配说话者标签也可能很困难,从以下包含两个说话者说“hello”和“hi”的示例可以明显看出:
![[Uncaptioned image]](x6.png)
即使我们预测了正确的说话者标签,也很难将它们分配给相应的 ASR 标记,因为它们不是按帧同步的。 为了解决这些问题,我们需要确保 SURT 在 ASR 和说话人分支的相同帧上发出空白标签。 我们通过以混合自回归传感器(HAT)模型[35]的风格单独分解空白标签来实现这一点,即,我们替换对齐后验 在 (3) 与
| (6) |
其中 和 表示 sigmoid 函数。 通过设置 ,即通过共享 ASR 和扬声器输出的空白 logit,我们确保两个分支之间的空白发射同步。 说话人分支接受类似 HAT 损失的训练,即
| (7) |
最近也提出了这样的同步策略,用于使用转换器[36]执行字级二值化。 对于 ASR 和说话者分支,我们使用 HAT 损失的修剪版本,类似于修剪的 RNNT [30]。
3.3 跨词组维护状态
推理长格式音频的常见方法是以某种方式进行分块(例如,在静音或固定长度的块),单独处理每个块,然后组合输出。 对于 SURT,我们假设录音已在静音时被分块以创建话语组,这些话语组是通过说话者重叠连接的话语集。 对于多说话者 ASR 方法,例如 SA-ASR(参见 部分 1) 预测 绝对 使用外部说话人配置文件来识别说话人身份,组合分块输出相对简单,因为不存在说话人标签排列的问题。 然而,SURT 中的辅助说话人分支经过训练可以预测 相对的 该块内的说话者标签按 FIFO 顺序排列,并且这些标签必须在录音内的所有块之间进行协调,以获得最终的说话者归属转录本。
3.3.1 辅助编码器编码什么?
跨不同块的说话人标签协调以实现长格式分类或说话人归因的 ASR 通常是通过对从块估计的说话人嵌入进行聚类来完成的。 例如,用于说话人二值化的 EEND-VC 模型通过在分块说话人向量 [37] 上应用聚类,扩展了长录音二值化的 EEND。 该方法将输出预测至少延迟到块的末尾,以便可以完成重新聚类。 为了解决这个问题,基于 t-SOT 的 SA-ASR 根据连续说话人向量之间的余弦相似度来估计说话人的变化,并在每次检测到说话人变化时对所有向量进行重新聚类[21] 。 然而,通过这种聚类解决标签排列要求逐块说话人向量应该表示绝对说话人身份。 在 SURT 模型中可能无法满足此要求,因为辅助说话者分支被训练为按照其在混合物中出现的顺序来预测相关说话者标签。
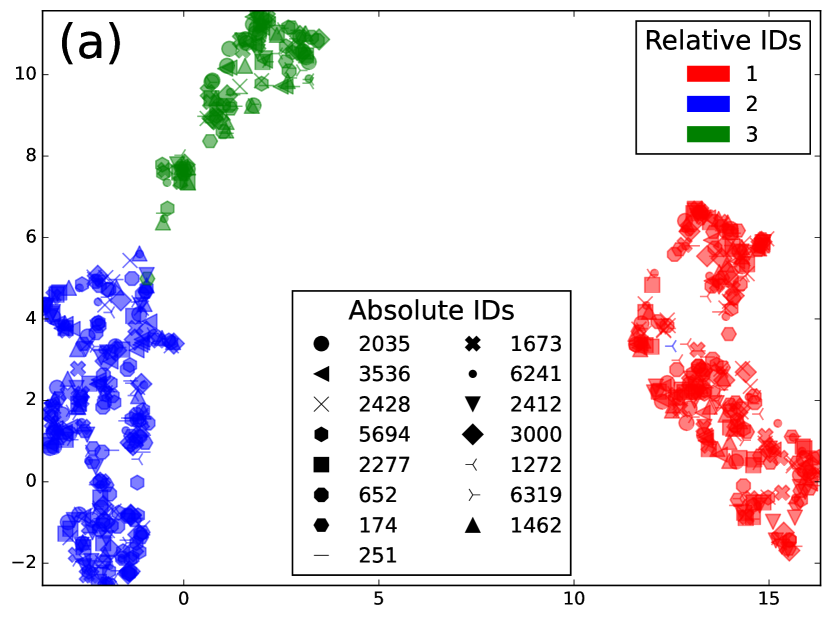
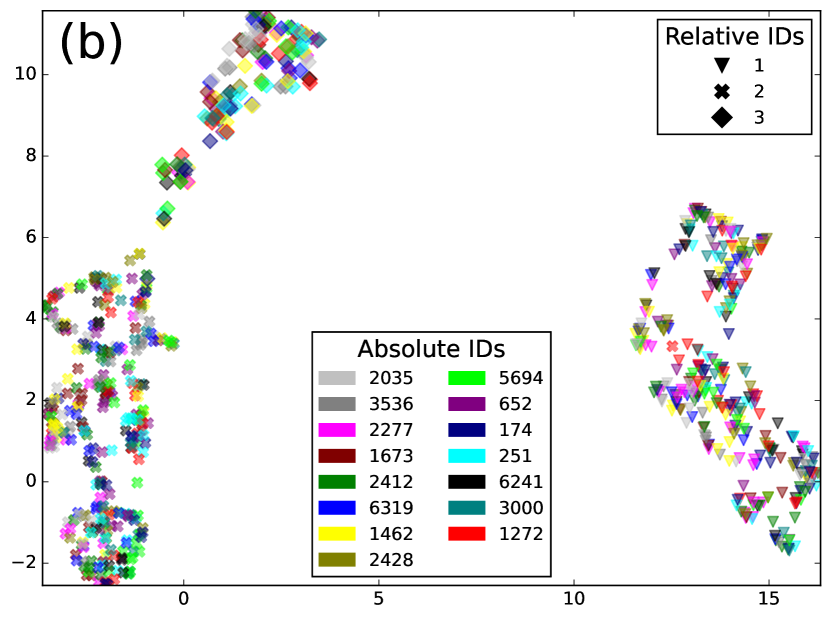
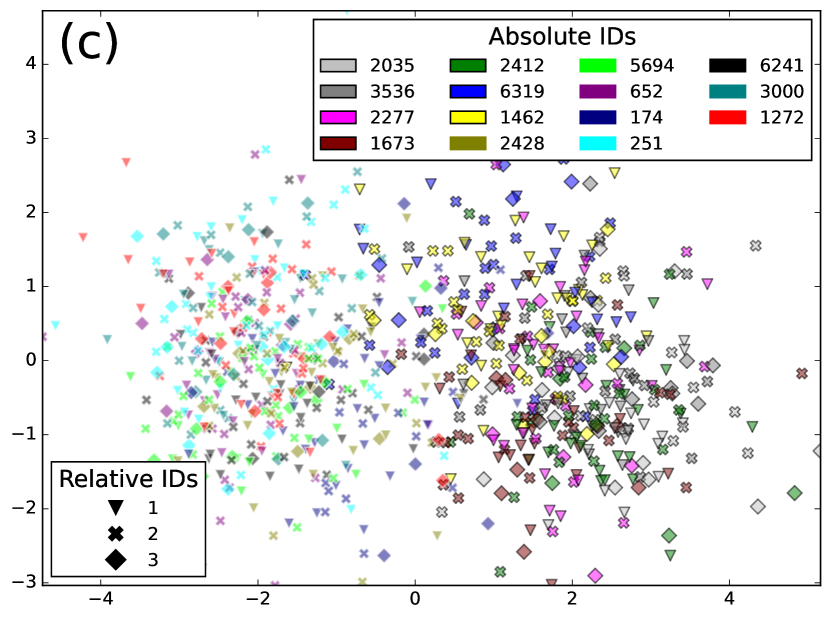
为了验证这一点,我们将 SURT 与辅助扬声器分支应用于 LibriSpeech 话语的合成混合物(如第 4.2 节中所述))每个混合物由 2 或 3 个扬声器组成。 我们收集了辅助分支预测说话者标签的帧的 256 维编码器表示,并对每个说话者的混合嵌入进行平均。 在图中。 3,我们展示了 LSMix 中 15 个不同说话者的这些嵌入的 UMAP 和 LDA 投影dev 放。 在图中。 3(a),三种颜色表示在 SURT 推理期间分配给说话者的相对说话者标签,标记表示绝对说话者身份。 如图。 3(b) 显示相同的图,但在这种情况下,颜色表示绝对说话者身份,标记表示块内的相对顺序。 很容易看出,嵌入是通过相对说话者标签而不是绝对说话者身份进行聚类的,这验证了我们的猜想,即辅助编码器提取了块中的相对说话者位置。 即使使用绝对说话者标签的LDA用于低维投影(如图1所示)。 3(c)),我们没有找到绝对说话者标签的簇。 有趣的是,嵌入确实保留了有关说话者性别的信息。 在图中,有和没有黑色边框的点分别表示女性和男性说话者,并且它们看起来很好地分成基于性别的集群。
3.3.2 说话者前缀方法
受到 EEND 模型中使用说话人跟踪缓冲区进行在线分类的启发[38],我们提出了一种新颖的方法 说话人前缀 解决跨词组的说话人标签排列问题的策略。 说话人前缀的想法是在块的输入特征之前按照其预测标签的顺序附加我们迄今为止在录音中看到的说话人的高置信度帧。 正式地,让 是录音中与 话语组对应的输入特征,使得 .对于某些块 ,让 是迄今为止在录音中看到的发言者数量。 我们定义一些函数 选择先前块中给定说话者的帧,即
| (8) |
其中 是 发言者之一,,对于某些(这是一个超参数),类似于扬声器“缓冲区”。然后,块 的说话者前缀输入给出为 0>
| (9) |
哪里 表示转置。 我们用 而不是 作为该块的输入,推测扬声器缓冲区将强制当前块中扬声器之间的相对排序。 在主编码器和辅助编码器的输出处,我们删除了与前缀相对应的表示,该表示的长度为 ,其中 是编码器的子采样因子。 在推理过程中,我们设置 选择具有最大置信值总和的 帧序列(来自之前的块),如其 logit < 预测的那样/t3>。训练时,我们随机选择 批次中所有发言者的前缀。 这种策略模仿了预期的推理时间场景,其中并非所有带前缀的说话者都会在每个块中看到。 对于每个选定的说话人,我们随机采样一系列 来自该扬声器的所有段的帧。
4实验设置
4.1网络架构
主要的 SURT 模型遵循早期的工作[23]。 掩蔽网络包含四个 256 维 DP-LSTM 层[39]。 掩码特征通过卷积层减少到原始长度的一半,并且子采样特征被输入到 zipformer 编码器[40]中。 ASR 编码器由 6 个 zipformer 块组成,这些块以不同的帧速率(中间高达 8 倍)进行二次采样。 编码器输出被进一步下采样,使得整体下采样因子为 4 倍。 来自 ASR 编码器中间层的表示被传递到辅助编码器。 这是另一个 zipformer,包含 3 个具有较小注意力和前馈维度的块。 使用单向 LSTM 层 [23] 在两个编码器的输出处使用分支绑定。 ASR 预测网络包含单个 512 维 Conv1D 层。 完整的SURT模型包含38.0M参数,其中掩蔽网络、ASR分支和说话人分支分别分为6.0M、23.6M和8.4M。 内部 LSTM 和 Zipformer 的块大小设置为 32 帧,导致建模延迟为 320 毫秒。
4.2数据
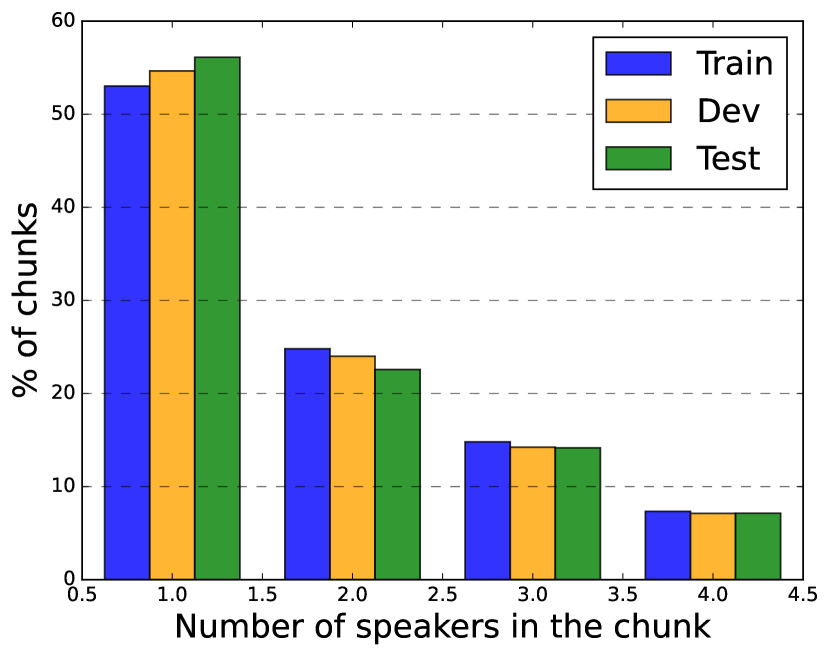
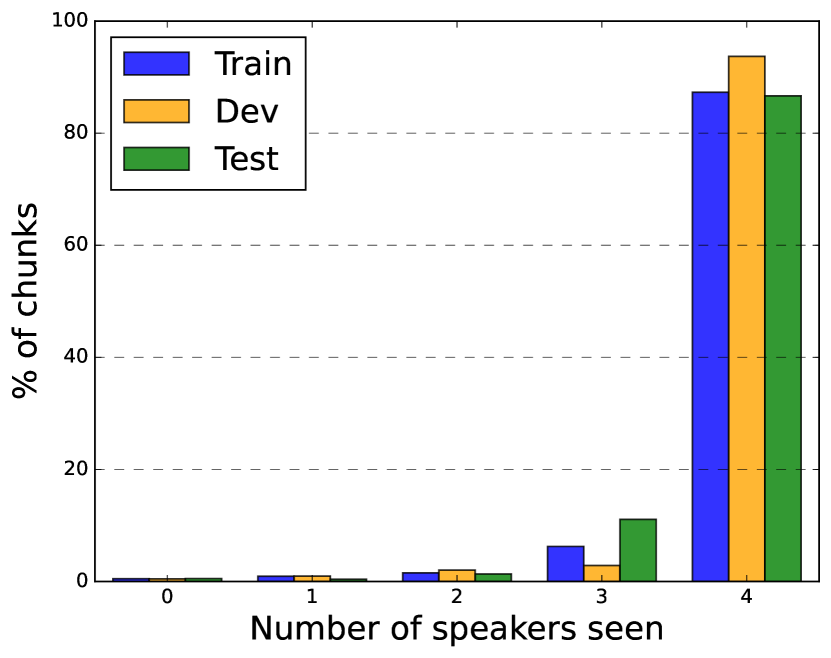
我们在综合混合 LibriSpeech 话语(称为 LSMix)和 AMI 会议语料库上进行了实验,其统计数据如表1. 为了创建 LSMix,我们首先以 0.2 秒的停顿来剪切 LibriSpeech 话语,然后使用 [23] 中描述的算法混合这些片段的速度扰动版本。 由此产生的混合物平均长度为 17 秒,包含 2-3 个说话者和最多 9 轮对话。 我们创造了 训练和dev 使用相应的 LibriSpeech 分区对 LSMix 进行分割。 我们使用此评估数据来执行消融,以在 SURT 中开发辅助扬声器分支。 AMI 由 100 小时的录制会议组成,每个会议有 4 或 5 名发言人[4]。 会议通过近距离通话(耳机和领夹)麦克风以及 2 个线性阵列(每个阵列包含 8 个麦克风)进行录制。 我们在实验中使用了三种不同的麦克风设置:IHM-Mix(数字混合独立耳机麦克风)、SDM(阵列 1 的第一个通道)和 MDM(波束成形阵列 1),其中最后一个设置使用官方提供的波束成形录音[41]。 为了训练 AMI 的 SURT 模型,我们使用了 AMI 和 ICSI [42] 话语的合成混合物(称为 AIMix),如 [23] 中所述。 我们首先在 1841h 的 AIMix 数据上训练模型,然后在真实环境中对其进行调整 训练会话。对于使用扬声器缓冲区的训练,我们将 固定为每个扬声器 128 帧,并选择 从 [0,4] 开始,概率为 [0.05,0.05,0.1,0.2,0.6]。 这是因为在推理过程中,大多数块将使用 4 个扬声器缓冲区进行处理,如图 1 所示。 4.
LSMix AMI Train Dev Train Dev Test Duration (h:m) 2193:57 4:19 79:23 9:40 9:03 Num. sessions 486440 897 133 18 16 Silence (%) 3.4 3.2 18.1 21.5 19.6 Overlap (%) 28.4 26.0 24.5 25.7 27.0
4.3培训详情
辅助损失尺度为 (LABEL:eq:heat)、 和 ,分别设置为 0.2。 我们按照标准 zipformer-transducer 配方使用 ScaledAdam 优化器训练模型 冰瀑布 [40]。 这是 Adam 的一个变体,其中每个参数的更新与该参数的范数成比例。 经过 5000 次迭代,学习率升至 0.004,此后呈指数衰减。 如节中所述 5.2,我们尝试了顺序和联合训练策略。 对于前者,SURT 模型训练了 40 个 epoch。 对于后者,ASR 分支首先训练了 30 个 epoch;然后将其冻结,并对扬声器分支进行 20 个 epoch 的训练。 在所有情况下,ASR 传感器都是从预先训练的传感器模型初始化的,在 LibriSpeech 上训练 10 个 epoch,因为这对于快速收敛很有用[23]。 我们对最后 5 个时期的模型检查点进行平均以进行推理,并使用贪婪解码来报告所有结果。 为了对 AMI 进行评估,我们使用在 LSMix 上训练的 SURT 模型的参数初始化掩蔽网络和 ASR 分支。 然后,我们在 AIMix 上按顺序过程训练该模型,即先进行 ASR 分支,然后进行说话人分支,然后适应真实的 AMI 训练会话。
4.4评估
对于与说话者无关的转录,使用[25]和[26]中独立提出的最佳参考组合词错误率(ORC-WER)度量来评估SURT。 ORC-WER 计算使用参考话语到输出通道的最佳分配获得的最小总 WER。 在本文中,由于我们扩展了 SURT 来执行说话者归因转录,因此我们使用级联最小排列 WER (cpWER) [3] 来衡量其性能。 该指标找到参考和假设说话者的最佳排列,从而最大限度地减少所有说话者的总 WER。
我们还希望独立于转录错误来测量说话者归因错误。 对此的传统度量称为二值化错误率(DER),并测量预测说话者与参考说话者不匹配的说话时间的持续时间比率。 然而,由于 SURT 是一种流模型,因此与实际参考时间戳相比,ASR Token 和相应说话者标签的发出可能会有一些延迟。 即使说话者归因错误很少,这也会人为地升级 DER。 为了解决这个问题,我们报告了受 [43] 启发的单词级二值化错误率 (WDER)。 最初,WDER 被定义为具有错误说话人标签的正确识别单词的比例。 我们通过使用 ORC-WER 参考分配来修改 SURT 的度量,以识别正确的单词,并使用 cpWER 计算中的说话者映射来检查说话者的等效性。
5 结果与讨论
5.1 RNN-T 与 HAT 用于与说话者无关的 ASR
由于我们的公式需要用 (63) /t4>),我们希望确保模型的与说话人无关的 ASR 性能不会降低。 为了验证这一点,我们使用以下方法训练了 SURT(没有辅助分支) 和 在 LSMix 训练 集上,并评估生成的模型在 dev 集上。我们发现HAT模型获得了8.53%的ORC-WER,相比之下使用常规 RNN-T 为 8.59%。 错误细分显示插入略高但删除较少,这可能是由于空白词符的显式建模所致。
Strategy ORC-WER WDER cpWER Sequential 8.53 3.99 14.96 Joint 8.43 4.46 14.95 Seq. + Joint 9.17 4.25 15.33
5.2 顺序训练与联合训练
5.3辅助编码器位置
Ins. Del. Sub. cpWER WDER 3.34 6.04 7.28 16.66 5.36 2.91 5.20 6.85 14.96 3.99 4.58 6.77 8.24 19.59 6.73 5.95 8.23 9.41 23.59 8.35
输入 辅助编码器是从主编码器的中间表示获得的。 我们训练了几个具有不同位置辅助输入的SURT模型,以找到说话人分支的最佳表示,结果如表所示 3. 模型按顺序进行训练,ORC-WER 为 8.53%(与之前相同)。 我们发现,如果我们使用更深层次的表示,cpWER 和 WDER 都会变得越来越差,这可能是因为通过主编码器丢失了说话人信息。 有趣的是, (即第一个 zipformer 块的输出)表现出比 更好的性能 (卷积嵌入层的输出)。 我们推测输入 辅助编码器需要上下文表示 因为说话者标签需要在两个分支之间同步。 这些发现反映了最近的研究表明声学模型的中间层最适合提取说话人信息[36]。 此类分析还激发了使用 Wav2Vec 2.0 [44] 等自监督编码器进行 ASR 和说话人分类的“串联”多任务学习。
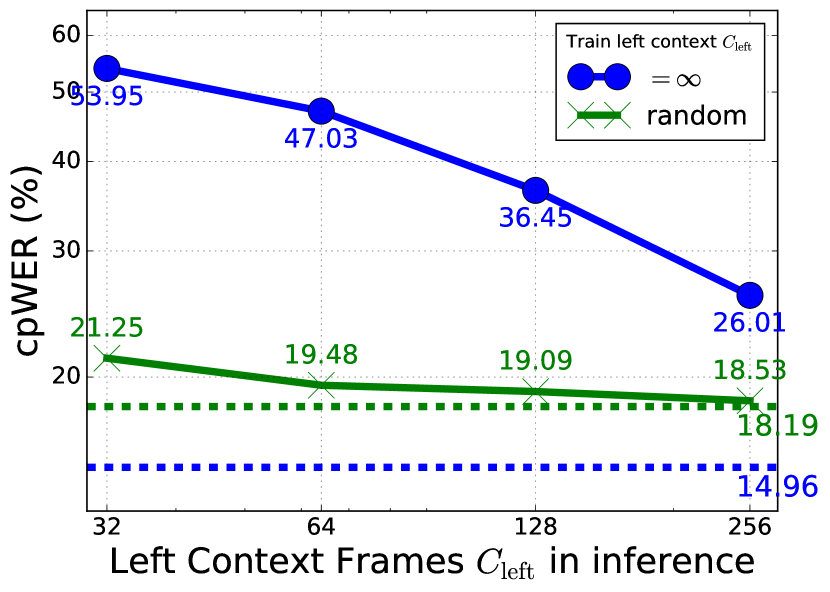
5.4 左侧上下文的影响
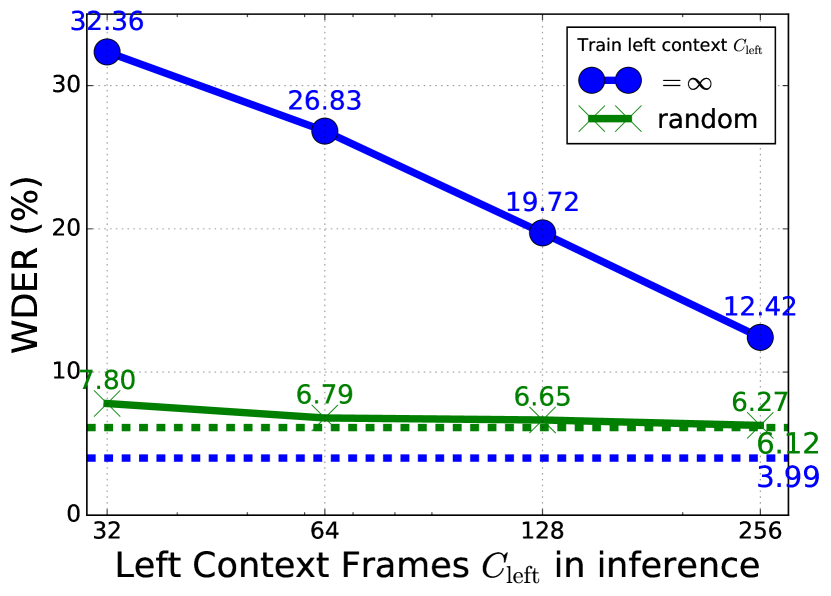
SURT模型的ASR编码器使用有限的左上下文(=128帧)在推理过程中的自注意力计算中。 虽然 ASR 词符预测通常是本地决策,但说话者标签预测需要查看完整历史记录才能同步相关 FIFO 标签。 我们用不同的历史记录进行了训练和解码实验,结果如图 2 所示。 5。对于用无限训练的模型 (蓝实线),在推理过程中限制它会迅速降低 WDER 和 cpWER 性能。 当模型接受随机训练时 (绿实线),降解不太明显。 然而,它无法在推理时充分利用无限历史,并且仅获得 6.12% 的 WDER,而使用无限训练的模型则为 3.99% 。这表明在推理过程中使用无限左上下文非常重要 用于辅助扬声器编码器。
Prefix IHM-Mix SDM MDM ID Train/Decode ORC WDER cpWER ORC WDER cpWER ORC WDER cpWER A ✗ / ✗ 34.9 9.3 42.9 43.2 10.9 50.3 40.5 9.9 47.3 B ✗ / ✓ 34.9 22.5 61.2 43.2 23.1 68.2 40.5 22.6 64.8 C ✓ / ✓ 34.9 14.0 49.9 43.2 16.3 58.9 40.5 15.5 56.0
#spk 1 2 3 4 Avg. WDER () 0.1 3.4 13.0 23.9 9.3 Count. () 98.6 61.9 26.8 44.0 75.9 cpWER () 17.2 32.4 51.1 63.6 42.9
5.5AMI 的话语组评估
我们在话语组场景下的 AMI 会议语料库的不同麦克风设置上评估 SURT 模型,结果如表5 就 ORC-WER、WDER 和 cpWER 而言。 综合来看,性能 从 IHM-Mix 降级为 SDM 设置,这是预期的,因为 SDM 除了重叠之外还包含远场伪影。 使用多个麦克风的波束形成部分消除了背景噪声和混响,从而提供了比 SDM 稍微容易的条件。 对于系统 A,在没有说话人前缀的情况下进行训练和解码,我们在三种条件下获得的平均 cpWER 为 46.8%。 当我们使用相同的模型对说话者前缀(系统 B)进行解码时,cpWER 性能相对于前者下降了 38.2%。 由于模型在训练时没有看到短的说话者缓冲区,因此辅助编码器不擅长使用这些缓冲区来生成上下文表示。
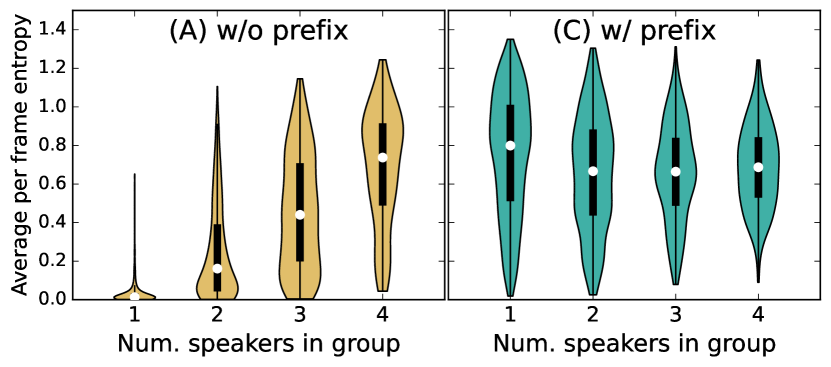
接下来,我们使用说话者前缀训练相同的 SURT 模型,如第 4.3 节中所述,并发现由于匹配的训练和测试条件,它显着提高了性能。 尽管如此,这个模型还是 比原来差7-8% 绝对 cpWER 性能方面的模型。 为了进一步研究这一点,我们计算了 IHM-Mix 中所有话语组的说话者标签的平均帧熵 测试 设置,并按组中发言者的数量对它们进行分组。 如图。 6 显示了有和没有说话人前缀的 SURT 模型的这些熵的分布。 我们发现对于没有前缀的模型, 对于只有一个说话者的话语组来说,熵非常低,并随着发言者的数量逐渐增加。 这表明该模型对少数说话人情况的预测非常有信心。 对于具有说话人前缀的模型,出现了相反的趋势,其中单说话人情况的熵最高。 这是因为对于每一帧,模型需要决定该帧应该分配给 4 个前缀说话者中的哪一个,这可能会导致预测的置信度较低。
总的来说,我们发现随着组中说话者数量的增加,所有模型的性能逐渐变差,如表5 对于系统 A。有趣的是,与说话者计数精度相比,WDER 的下降很小。 这可能是因为有几个词组,其中一些说话者只用几个词参与,这可能很难让系统识别,但对总体说话者归因错误贡献不大。
5.6AMI 完整会话评估
最后,我们对完整的 AMI 测试会话进行了推理,并在表6中报告了相应的 cpWER. 在这种情况下计算 ORC-WER 和 WDER 是不可行的,因为它们的计算复杂性取决于参考中的段数。 首先,我们看到没有说话人前缀的模型获得了非常高的错误率,因为它无法正确协调不同话语组中的说话人标签。 通过说话人前缀,我们得到 15.1% 相对 cpWER 改进 整个麦克风设置的平均值。 对于说话人前缀,我们使用以下方法训练和评估模型 每个扬声器 128 帧或 1.28 秒。
在会议转录设置中,由于事先知道参与者,因此我们通常可以获得每个发言者的注册话语。 如果我们从这些注册话语中选择说话者前缀,而不是从之前的块中选择说话者前缀,我们会获得进一步的 相对 cpWER 提高 29.2%, 一般。 我们推测,当不使用注册话语时,早期块中的说话者归因错误可能会对当前块的性能产生不利影响,因为缓冲帧用于指导相对顺序。 尽管如此,全场评估和话语小组评估之间仍然存在约 10-12% 绝对 cpWER 的显着差距(如表所示) 5)。
Method IHM-Mix SDM MDM w/o prefix 100.11 97.15 96.26 w/ prefix 82.77 83.94 82.28 + enrollment 53.04 61.22 59.59
6结论
SURT 框架允许对多说话者对话进行连续、流式识别,但它只能用于与说话者无关的转录。 在本文中,我们展示了如何使用 SURT 执行流式单词级说话人标记,从而使用相同的模型实现说话人归因转录。 我们通过向模型的识别组件添加辅助说话人编码器来实现这一目标,并使用相同的两分支策略来处理重叠语音。 我们通过分解空白逻辑并在分支之间共享它来解决 ASR 和扬声器分支输出之间的同步问题。 由于该模型以 FIFO 顺序预测相对说话者标签,因此协调录音中不同单词组的标签就成为一项挑战。 我们表明,为识别的说话人添加高置信度说话人帧前缀的简单策略可以部分缓解这个问题,但需要进一步研究以使会话级错误率更接近于话语组的错误率。
参考
- [1] J. Barker, R. Marxer, E. Vincent, and S. Watanabe, “The third ‘CHiME’ speech separation and recognition challenge: Dataset, task and baselines,” in IEEE ASRU, 2015.
- [2] K. Kinoshita, M. Delcroix, T. Yoshioka, T. Nakatani, A. Sehr, W. Kellermann, and R. Maas, “The REVERB challenge: A common evaluation framework for dereverberation and recognition of reverberant speech,” in IEEE WASPAA, 2013.
- [3] S. Watanabe, M. Mandel, J. Barker, and E. Vincent, “CHiME-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings,” ArXiv, 2020.
- [4] J. Carletta et al., “The AMI meeting corpus: A pre-announcement,” in MLMI, 2005.
- [5] E. Shriberg, A. Stolcke, and D. Baron, “Observations on overlap: findings and implications for automatic processing of multi-party conversation,” in Interspeech, 2001.
- [6] T. Yoshioka, D. Dimitriadis, A. Stolcke, W. Hinthorn, Z. Chen, M. Zeng, and X. Huang, “Meeting transcription using asynchronous distant microphones,” in Interspeech, 2019.
- [7] D. Raj, D. Povey, and S. Khudanpur, “GPU-accelerated guided source separation for meeting transcription,” in Interspeech, 2023.
- [8] D. Raj, P. Denisov, et al., “Integration of speech separation, diarization, and recognition for multi-speaker meetings: System description, comparison, and analysis,” in IEEE SLT, 2021.
- [9] N. Kanda, S. Horiguchi, Y. Fujita, Y. Xue, K. Nagamatsu, and S. Watanabe, “Simultaneous speech recognition and speaker diarization for monaural dialogue recordings with target-speaker acoustic models,” in IEEE ASRU, 2019, pp. 31–38.
- [10] J. Wu, Z. Chen, S. Chen, Y. Wu, T. Yoshioka, N. Kanda, S. Liu, and J. Li, “Investigation of practical aspects of single channel speech separation for ASR,” in Interspeech, 2021.
- [11] J. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y. Bengio, “Attention-based models for speech recognition,” in NIPS, 2015.
- [12] N. Kanda, Y. Gaur, X. Wang, Z. Meng, and T. Yoshioka, “Serialized output training for end-to-end overlapped speech recognition,” in Interspeech, 2020.
- [13] N. Kanda, Y. Gaur, et al., “Joint speaker counting, speech recognition, and speaker identification for overlapped speech of any number of speakers,” in Interspeech, 2020.
- [14] N. Kanda, G. Ye, Y. Gaur, X. Wang, Z. Meng, Z. Chen, and T. Yoshioka, “End-to-end speaker-attributed ASR with transformer,” in Interspeech, 2021.
- [15] N. Kanda, X. Xiao, J. Wu, T. Zhou, Y. Gaur, X. Wang, Z. Meng, Z. Chen, and T. Yoshioka, “A comparative study of modular and joint approaches for speaker-attributed asr on monaural long-form audio,” in IEEE ASRU, 2021, pp. 296–303.
- [16] X. Chang, N. Kanda, Y. Gaur, X. Wang, Z. Meng, and T. Yoshioka, “Hypothesis stitcher for end-to-end speaker-attributed ASR on long-form multi-talker recordings,” in IEEE ICASSP, 2021.
- [17] N. Kanda, X. Chang, Y. Gaur, X. Wang, Z. Meng, Z. Chen, and T. Yoshioka, “Investigation of end-to-end speaker-attributed ASR for continuous multi-talker recordings,” in IEEE SLT, 2020.
- [18] F. Yu, Z. Du, S. Zhang, Y. Lin, and L. Xie, “A comparative study on speaker-attributed automatic speech recognition in multi-party meetings,” in Interspeech, 2022.
- [19] M. Shi, J. Zhang, Z. Du, F. Yu, S. Zhang, and L. Dai, “A comparative study on multichannel speaker-attributed automatic speech recognition in multi-party meetings,” in APSIPA ASC, 2022, pp. 1943–1948.
- [20] M. Shi, Z. Du, Q. Chen, F. Yu, Y. Li, S. Zhang, J. Zhang, and L. Dai, “Casa-asr: Context-aware speaker-attributed asr,” in Interspeech, 2023.
- [21] N. Kanda, J. Wu, Y. Wu, X. Xiao, Z. Meng, X. Wang, Y. Gaur, Z. Chen, J. Li, and T. Yoshioka, “Streaming speaker-attributed ASR with token-level speaker embeddings,” in Interspeech, 2022.
- [22] A. Graves, “Sequence transduction with recurrent neural networks,” in ICML Representation Learning Workshop, 2012.
- [23] D. Raj, D. Povey, and S. Khudanpur, “SURT 2.0: Advances in transducer-based multi-talker speech recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 3800–3813, 2023.
- [24] L. Lu, N. Kanda, J. Li, and Y. Gong, “Streaming end-to-end multi-talker speech recognition,” IEEE Signal Processing Letters, vol. 28, pp. 803–807, 2020.
- [25] I. Sklyar, A. Piunova, X. Zheng, and Y. Liu, “Multi-turn RNN-T for streaming recognition of multi-party speech,” in IEEE ICASSP, 2021.
- [26] D. Raj, L. Lu, Z. Chen, Y. Gaur, and J. Li, “Continuous streaming multi-talker ASR with dual-path transducers,” in IEEE ICASSP, 2022.
- [27] L. Lu, J. Li, and Y. Gong, “Endpoint detection for streaming end-to-end multi-talker ASR,” in IEEE ICASSP, 2022.
- [28] I. Sklyar, A. Piunova, and C. Osendorfer, “Separator-transducer-segmenter: Streaming recognition and segmentation of multi-party speech,” in Interspeech, 2022.
- [29] L. Lu, N. Kanda, J. Li, and Y. Gong, “Streaming multi-talker speech recognition with joint speaker identification,” in Interspeech, 2021.
- [30] F. Kuang, L. Guo, W. Kang, L. Lin, M. Luo, Z. Yao, and D. Povey, “Pruned RNN-T for fast, memory-efficient ASR training,” in Interspeech, 2022.
- [31] A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” in ICML, 2006.
- [32] N. Flemotomos, P. G. Georgiou, and S. S. Narayanan, “Language aided speaker diarization using speaker role information,” in Speaker Odyssey, 2020.
- [33] T. J. Park, K. J. Han, J. Huang, X. He, B. Zhou, P. G. Georgiou, and S. S. Narayanan, “Speaker diarization with lexical information,” in Interspeech, 2019.
- [34] A. Khare, E. Han, Y. Yang, and A. Stolcke, “Asr-aware end-to-end neural diarization,” in IEEE ICASSP, 2022, pp. 8092–8096.
- [35] E. Variani, D. Rybach, C. Allauzen, and M. Riley, “Hybrid autoregressive transducer (hat),” in IEEE ICASSP, 2020, pp. 6139–6143.
- [36] Y. Huang, W. Wang, G. Zhao, H. Liao, W. Xia, and Q. Wang, “Towards word-level end-to-end neural speaker diarization with auxiliary network,” ArXiv, vol. abs/2309.08489, 2023.
- [37] K. Kinoshita, M. Delcroix, and N. Tawara, “Integrating end-to-end neural and clustering-based diarization: Getting the best of both worlds,” in IEEE ICASSP, 2020, pp. 7198–7202.
- [38] Y. Xue, S. Horiguchi, Y. Fujita, S. Watanabe, and K. Nagamatsu, “Online end-to-end neural diarization with speaker-tracing buffer,” in IEEE SLT, 2021, pp. 841–848.
- [39] Y. Luo, Z. Chen, and T. Yoshioka, “Dual-path RNN: Efficient long sequence modeling for time-domain single-channel speech separation,” in IEEE ICASSP, 2019.
- [40] Z. Yao, L. Guo, X. Yang, W. Kang, F. Kuang, Y. Yang, Z. Jin, L. Lin, and D. Povey, “Zipformer: A faster and better encoder for automatic speech recognition,” ArXiv, vol. abs/2310.11230, 2023.
- [41] X. A. Miró, C. Wooters, and J. Hernando, “Acoustic beamforming for speaker diarization of meetings,” IEEE TASLP, vol. 15, pp. 2011–2022, 2007.
- [42] A. L. Janin, D. Baron, J. Edwards, D. P. W. Ellis, D. Gelbart, N. Morgan, B. Peskin, T. Pfau, E. Shriberg, A. Stolcke, and C. Wooters, “The ICSI meeting corpus,” in IEEE ICASSP, 2003.
- [43] L. E. Shafey, H. Soltau, and I. Shafran, “Joint speech recognition and speaker diarization via sequence transduction,” in Interspeech, 2019.
- [44] X. Zheng, C. Zhang, and P. C. Woodland, “Tandem multitask training of speaker diarisation and speech recognition for meeting transcription,” in Interspeech, 2022.