Dolma![[Uncaptioned image]](x1.png) :用于语言模型预训练研究的三万亿 Token 开放语料库
:用于语言模型预训练研究的三万亿 Token 开放语料库
摘要
语言模型已成为解决各种自然语言处理任务的关键技术,但有关如何开发性能最佳的语言模型的许多细节尚未报道。 特别是,有关预训练语料库的信息很少被讨论:商业语言模型很少提供有关其数据的任何信息;即使是开放模型也很少发布它们所训练的数据集,或者重现它们的确切方法。 因此,进行某些语言建模研究是具有挑战性的,例如了解训练数据如何影响模型功能并形成其局限性。 为了促进语言模型预训练的开放研究,我们发布了 Dolma,这是一个包含 3 万亿个 Token 的英语语料库,由网络内容、科学论文、代码、公共领域书籍、社交媒体和百科全书材料的多种组合构建而成。 此外,我们还开源数据管理工具包,以便进一步实验和复制我们的工作。 在这份报告中,我们记录下 Dolma,包括其设计原理、构造细节以及内容摘要。 我们在本报告中穿插了在 Dolma 中间状态上训练语言模型的分析和实验结果,以分享我们在重要数据整理实践方面的心得,包括内容或质量过滤器、重复数据删除和多源混合的作用。 Dolma 已用于训练 OLMo,这是一种最先进的开放语言模型和框架,旨在构建和研究语言建模科学。
| Dataset | v. 1.6 | huggingface.co/datasets/allenai/dolma | |
| Toolkit | v. 1.0 | github.com/allenai/dolma |
| Source | Doc Type |
|
|
|
|
|||||||||||
|
web pages | 9,022 | 3,370 | 1,775 | 2,281 | |||||||||||
|
code | 1,043 | 210 | 260 | 411 | |||||||||||
|
web pages | 790 | 364 | 153 | 198 | |||||||||||
|
|
social media | 339 | 377 | 72 | 89 | |||||||||||
|
STEM papers | 268 | 38.8 | 50 | 70 | |||||||||||
|
books | 20.4 | 0.056 | 4.0 | 6.0 | |||||||||||
|
encyclopedic | 16.2 | 6.2 | 3.7 | 4.3 | |||||||||||
| Total | 11,519 | 4,367 | 2,318 | 3,059 | ||||||||||||
1简介
语言模型现在是解决无数自然语言处理任务的核心,包括少样本学习、摘要、问题回答等。 最强大的语言模型越来越多地由少数保留大部分模型开发细节的组织构建(Anthropic,2023;OpenAI,2023;Anil 等人,2023;Gemini Team 等人,2023)。 特别是,语言模型预训练数据的组成往往是含糊其辞的,即使模型本身被发布供公众使用,例如 LLaMA 2 (Touvron 等人, 2023b)。 这阻碍了对预训练语料库组成对模型能力和局限性的影响的理解,从而阻碍了对模型本身的影响,对科学进步以及与这些模型交互的公众产生了影响。 相反,我们的目标是开放和透明,发布并记录了包含 3 万亿 Token 的数据集以及重现、审查和扩展我们工作的工具。
我们的目标是让更多的个人和组织参与语言模型的研究和开发。
-
•
数据透明度可帮助依赖语言模型的应用程序的开发者和用户做出更明智的决策(Gebru 等人,2021)。 例如,语言模型预训练数据中文档或术语的流行程度增加与相关任务的更好表现(Razeghi 等人,2022;Kandpal 等人,2023)以及预训练中的社会偏见有关训练数据(Feng 等人, 2023; Navigli 等人, 2023; Seshadri 等人, 2023) 在某些领域可能需要额外考虑。
-
•
通过实证研究探索数据构成如何影响模型行为,开放预训练数据对于分析是必要的,允许建模社区质疑和改进当前的数据管理实践(Longpre等人,2023;Gao, 2021;Elazar 等人,2023)。 这项研究的例子包括记忆(Carlini 等人,2022b;Chang 等人,2023)、重复数据删除(Lee 等人,2022)、对抗性攻击(Wallace)等人,2021)、基准污染(Magar 和 Schwartz,2022)、训练数据归因 (Hammoudeh 和 Lowd,2022;Grosse 等人,2023)
-
•
开放语言模型的成功开发需要访问数据。 例如,较新的语言模型可能会提供将生成归属于预训练数据(Borgeaud 等人,2022 年)等功能。
为了支持这些研究领域更广泛的参与和探究,我们给出 Data for Open Language Models’ Appetite (Dolma),一个包含 3 万亿个 Token 的开放语料库,旨在支持语言模型预训练研究。 预训练数据混合通常是出于捕捉所谓“通用”英语的愿望。 我们的大部分数据来源与过去工作中的来源类似,包括 Common Crawl 的网络文本、Semantic Scholar 的科学研究、GitHub 的代码、公共领域书籍、Reddit 的社交媒体帖子以及来自 Reddit 的百科全书材料维基百科。 我们将我们的数据集与公开可用的各种流行预训练语料库进行比较,发现 Dolma 提供了更大的 Token 池,且具有相当的质量和同样多样化的数据构成。 Dolma 已经用于预训练 OLMo (Groeneveld 等人, 2024),这是一系列旨在促进语言建模科学的最先进模型。
总之,我们的贡献有两个方面:
-
•
我们发布了 Dolma 语料库,这是一个多样化、多源的语料库,包含从 7 个不同数据源获取的 5B 文档中的 3T Token,这些 Token(i)通常用于大规模语言模型预训练,(ii)可供公众访问。 表 1 提供了每个来源的数据量的高级概述。
-
•
我们开源了 Dolma Toolkit,这是一种高性能、便携式工具,旨在有效地管理用于语言模型预训练的大型数据集。 通过这个工具包,从业者可以重现我们的管理工作并开发自己的数据管理管道。
2Dolma 设计目标
为了支持大规模的 LM 预训练研究,我们围绕开放性、与先前工作的一致性、规模和风险缓解设定了四个设计要求。 我们依次讨论每一个。
Dolma 的设计应该与之前的语言模型预训练方案一致。
通过匹配创建其他语言模型语料库的数据源和方法,在已知的范围内,我们让更广泛的研究社区能够使用我们的语料库和生成的模型工件来研究(和审查)当今正在开发的语言模型,甚至是那些已闭门开发的语言模型。 在这项复制工作中,我们遵循已知的既定实践(即,使用数据源和技术来预处理和过滤在语言建模工作中经常出现的内容) ,并在不知道最佳实践或实现方式存在细微差别时遵循分析、实验和有根据的猜测。111我们注意到这种复制工作并不寻求复制特定语言模型预训练数据实现。 相反,我们重现了一系列数据管理主题。 值得注意的是,这也意味着将 Dolma 的范围限定为纯英语文本,以更好地利用已知的管理实践,并最大限度地提高 Dolma 上的科学工作对现有语言模型的通用性。222认识到这一重点强化了英语作为“默认”语言的假设,我们希望将来将卓玛扩展到更多语言。 我们发布数据管理工具来支持此类努力。 为了说明这一再现工作的开放性质,在附录 §C 中,我们给出一份详细的总结,涵盖最大的私有模型(例如 GPT-4 (OpenAI, 2023), PaLM 2 (Anil et al., 2023), Claude (Anthropic, 2023))和开放模型(例如 OPT (Zhang, 2022), LLaMA (Touvron et al., 2023a), Llama 2 (Touvron et al., 2023b))的已知(和未知)数据管理实践。
Dolma 应该支持大型模型的训练。
Hoffmann 等人 (2022) 建议,可以通过保持语言模型大小(以参数表示)与最小训练标记数之间的固定比率来训练计算最优模型。 最近遵循这些“缩放法则”的模型,例如 LLaMA 2 (Touvron 等人, 2023b),似乎表明通过增加训练标记的数量仍有提升性能的空间。333参见Touvron等人(2023b)中的图5,其中即使在2T代币下损失也没有收敛。 由于这是一个活跃的研究领域,我们的目标是拥有足够大的语料库,以便进一步研究模型和数据集大小之间的关系 - 2-3T Tokens。
Dolma 应该为开放语料库做出贡献。
缺乏预训练语料库以及相应的语言模型一直是更广泛的研究界的主要障碍。 近年来发布的数百个开放模型中,很少有随训练数据一起发布的:T5 和 C4 (Raffel 等人, 2020)、BLOOM 和 ROOTS (Leong 等人, 2022) ;Piktus 等人, 2023), GPT-J/GPT-NeoX/Pythia 和 Pile (Wang 和 Komatsuzaki, 2021;Black 等人, 2022;Biderman 等人, 2023;Gao 等人, 2020 )、INCITE 和 RedPajama v1 (Together Computer,2023b,c)。 然而,这些先前语料库的局限性激发了对新数据集(例如卓玛)的需求:
-
•
C4 (Raffel 等人,2020 年)、Pile (Gao 等人,2020 年)和 Falcon (Almazrouei 等人,2023 年)都是高质量的数据集,已证明可用于训练语言模型,但遗憾的是规模有限。 ROOTS (Piktus 训练等人, 2023) 规模庞大且多样化,但考虑到其多语言重点,其纯英语部分对于纯英语模型来说也太小了。
-
•
RedPajama v2 (Together Computer,2023a) 符合我们的规模标准,但没有反映在策划最大语言模型(例如科学论文、代码)时常见的内容来源的代表性分布。
-
•
RedPajama v1 (Together Computer,2023c)与我们的努力最相似,也是设计卓玛时的灵感来源。 虽然 RedPajama v1 是 LLaMA (Touvron 等人, 2023a) 训练数据的复制,但我们有一个更广泛的复制目标,需要深入研究 RedPajama v1 没有追求的数据源,包括更大的科学集合论文和 Reddit 等对话论坛。
总之,我们通过创建迄今为止最大的精选开放预训练语料库来扩展这些工作。 我们将开放性定义为 (i) 共享数据本身,这反过来又告知我们对数据源的选择,以及 (ii) 记录用于策划它的过程,包括做出有理由的决策,以及开源实现,以允许其他人复制我们的工作并创建新的语料库。 由此产生的开源高性能工具包使研究人员能够实现自己的数据管道,以进一步完善卓玛或处理自己的数据集。
Dolma 的设计应尽量减少对个人造成伤害的风险
策划预训练语料库可能会给个人带来风险,无论是通过促进对语料库中存在的信息的访问,还是通过允许有害模型的训练。 为了在实现我们既定目标的同时最大限度地降低这些风险,我们在项目早期就与组织内部的法律和道德专家进行了接触,并根据他们的反馈逐案评估了数据设计决策。 一般来说,我们会遵循可行的公认做法(例如,屏蔽某些个人身份信息),并在文献中存在分歧意见时采取谨慎的方法(例如,最有效的方法)识别和去除有毒成分的方法)。 此外,我们还提供了请求数据删除的工具444Available at the following URL: forms.gle/FzpUXLJhE57JLJ3f8 随着数据和人工智能领域的不断发展,我们并不声称我们的决策是正确的。 尽管如此,我们确实相信在对个人造成重大伤害的情况下,应该牺牲所需的研究工件属性,例如模型的可重复性、性能和可扩展性。
即使有了这些设计目标来帮助我们确定工作范围,我们在策划卓玛时仍然必须做出无数决定。 由于之前的工作没有一个明确的方法可供遵循,我们依靠两个原则来指导我们的决策:
-
(i)
明智地使用评估套件。 作为 OLMo 项目 Groeneveld 等人 (2024) 的一部分,我们开发了一套评估套件(Groeneveld 等人,2023;详细信息参见Appendix D )在预训练期间提供一系列能力和任务的指导。 只要有可能,就会做出数据决策来改进其指标。 然而,我们的评估套件并不完美。 例如,它无法完全衡量指令调优后添加有利于模型的数据源的效果555 例如,在模型能够生成可执行代码之前,无法完全测量向预训练数据添加代码的效果。 然而,这种能力通常是在模型进一步微调到遵循指令(Muennighoff等人,2023a)后观察到的。 . 在这些情况下,我们确保任何一项决策都不会大幅降低套件中任何任务的性能。
-
(ii)
赞成推动我们组织感兴趣的研究方向的决策。 如果上述原则无法提供指导,我们将寻求建立一个对像作者这样的学术或非营利组织的研究最有用的语料库。 这并不一定意味着最大化基准性能;许多理想的数据集干预措施彼此不一致666 例如,我们希望卓玛支持未来对预训练对代码影响的调查;虽然我们当前的评估套件设计不正确,无法充分评估代码数据的影响,但我们仍然将代码包含在我们的语料库中,以进一步研究该主题。 同样,虽然之前的研究表明去除 .
3创建 Dolma
预训练数据的整理通常需要定义复杂的管道,将来自多个来源的原始数据转换为经过清理的纯文本文件的单一集合。 这样的管道应支持获取来自不同来源的内容(例如、抓取、API 摄取、批量处理)、数据清理 通过使用过滤启发式方法和内容分类器,以及 混合到最终数据集(例如、重复数据删除、上/下采样的来源)。
在策划 Dolma 时,我们创建了一个高性能工具包,以促进对数百 TB 文本内容的高效处理。 该工具包专为高可移植性而设计:它可以运行从消费类硬件(从而促进新管道的开发)到分布式集群环境(非常适合处理 Dolma 等大型数据集)的任何平台。 通过 Dolma 的整理,我们实现了常用的清理和混合步骤,这些步骤可用于重现和管理与 Gopher、C4、和 OpenWebText。
使用我们的工具包,我们开发并组合了四种与我们在 § 2 中介绍的 Dolma desiderata 相匹配的数据转换:
-
•
语言过滤。 为了创建纯英语语料库,我们依靠可扩展的工具进行自动语言识别。 使用fastText的(Joulin等人, 2016a)语言ID模型进行识别。 根据每个来源中文档的长度,我们要么立即处理整个文本,要么对段落的分数进行平均。 英语分数足够低的文档将被删除。777保持较低的阈值有助于减轻语言检测器对少数群体使用的英语方言的固有偏见(Blodgett 等人,2016) 。 每个来源使用的分数将在后续部分中报告。 我们不会对已预先过滤为纯英语文档的数据集执行任何语言识别。888这些数据集可能已使用其他分类器和阈值过滤为英语内容。 我们注意到,语言过滤永远不会完美,多语言训练数据永远不会从预语料库中完全删除(Blevins 和 Zettlemoyer,2022)。
-
•
质量过滤。 删除被认为是“低质量”的文本是常见的做法,尽管对于这意味着什么或如何最好地使用自动化工具来实施这一点还没有达成广泛的共识。999术语“质量过滤器”虽然在文献中广泛使用,但并没有适当地描述过滤数据集的结果。 质量可能被视为对信息性、全面性或人类重视的其他特征的评论。 然而,Dolma 和其他语言模型中使用的过滤器会根据固有的观念标准来选择文本(Gururangan 等人,2022 年)。 对于网络来源,我们遵循 Gopher (Rae 等人,2021) 和 Falcon (Almazrouei 等人,2023) 中的建议,即避免使用基于模型的质量过滤器,如 LLaMA (Touvron 等人,2023a) 和 GPT-3 (Brown 等人,2020)。 相反,我们重新实现并应用了 C4 (Raffel 等人,2020) 和 Gopher (Rae 等人,2021) 中用于处理 Common Crawl 的启发式方法。 对于其他来源,我们建议读者参阅相应的部分,作为每个所需的定制质量过滤策略。
-
•
内容过滤。 除了去除低质量、不自然的内容之外,标准做法是从预训练数据中过滤有毒内容,以降低有毒物质生成的风险(Anil 等人,2023;Rae 等人,2021;Thoppilan 等人,2022;Hoffmann等人,2022;Longpre 等人,2023)。 我们遵循这种做法,并根据来源实施基于规则和分类器的毒性过滤技术的组合。101010 与“质量”的情况一样,“毒性”没有单一的定义;相反,具体定义取决于任务(Vidgen和Derczynski,2020)和数据集管理者的社会身份(Santy等人,2023);注释者的信念也会影响有毒语言检测(Sap等人,2021)使用模型识别有毒内容仍然具有挑战性(Welbl等人,2021;Markov等人,2023a) ,并且现有方法已被证明存在对少数群体的歧视(Xu等人,2021)。 . 大型预训练语料库还被证明包含个人身份信息(PII;Elazar 等人,2023),模型能够在推理时重现(Carlini 等人,2022a;Chen等人,2023b)。 在 Dolma 中,我们通过使用 Jigsaw Toxic Comments (cjadams 等人,2017) 和一系列针对 Subramani 等人 (2023) 中的 PII 类别的正则表达式进行训练的 fastText 分类器来识别要删除的内容; Elazar 等人 (2023)。
-
•
重复数据删除。 预训练语料去重已被证明是模型期间提高词符效率的有效技术(Lee 等人,2022;Abbas 等人,2023;Tirumala 等人,2023)。 在准备 Dolma 时,我们结合使用 URL、文档和段落级重复数据删除。 我们通过使用布隆过滤器(Bloom,1970)实现线性时间重复数据删除。 我们跨同一子集的文件执行重复数据删除(例如,对 Web 子集中的所有文档进行重复数据删除),但不会跨源执行此重复数据删除(例如,不检查是否有任何 Web 文档也出现在代码子集中)。
在本节的剩下内容中,我们详细解释了如何针对Table 1中所示的每个数据源实施上述步骤。 为了支持我们的决策,我们利用两种工具。 首先,我们使用 WIMBD 工具检查管道的输出(Elazar 等人,2023)。 这种方法使我们能够有效地发现问题,而无需训练任何模型。
然后,我们使用经过 1500 亿个 Token 训练的 10 亿参数解码器模型进行数据消融;我们在§ D.1中提供了我们实验设置的详细描述。 通过这些消融,我们可以比较评估套件上数据管道的结果。 该评估套件由 18 个领域组成,我们在这些领域上测量困惑度以估计语言适合度(Magnusson 等人,2023;在 § D.2 中描述),以及 7 个领域我们评估结果模型的问答、推理和常识能力的下游任务(在§ D.3中描述)。 对于本节的剩下内容,我们提供了评估套件的结果子集;我们将所有实验结果包含在Appendix K中。在做出决策时,我们优先考虑优化下游任务指标的干预措施,而不是语言契合度。
3.1 网络管道

Dolma 的网页子集来自 Common Crawl。111111commoncrawl.org Common Crawl 是一个包含超过 2500 亿个页面的集合,这些页面自 2007 年以来一直在爬取。 它以快照形式组织,每个快照都对应于对其种子 URL 的完整抓取。 2023 年 11 月,有 89 个快照。 Dolma 由 25 个快照组成。121212我们使用足够的快照来满足§ 2中描述的数量目标——至少2T代币。 收集时间为 2020-05 至 2023-06。
3.1.1 数据采集和语言过滤
遵循用于开发 LLaMA (Touvron 等人, 2023a) 的数据管理实践,我们的网页管道利用 CCNet (Wenzek 等人, 2020b) 来执行语言过滤和初始内容重复数据删除。 此工具还用于 RedPajama v1 (Together Computer,2023c) 和 RedPajama v2 (Together Computer,2023a) 的 Common Crawl 子集。 CCNet 使用 fastText 语言识别模型131313https://fasttext.cc/docs/en/language-identification.html 处理每个网页,以确定每个文档的主要语言; 我们保留所有英语文档得分大于或等于 0.5 的页面(按大小删除了 61.7% 的网页)。 此外,CCNet 通过将每个快照中的分片分组为小集合并删除每个集合中的重复段落来识别并删除非常常见的段落。 此步骤删除了大约 70% 的段落,主要包括标题和导航元素。 总体而言,CCNet 管道过滤掉了 Common Crawl 中 84.2% 的内容,从 175.1 TB 到 27.7 TB。 附录J.4提供了更多详细信息。
3.1.2 质量过滤
网络爬取数据需要进行大量清理才能用于语言模型预训练。 此步骤会删除从 HTML 转换为纯文本时引入的工件(例如 页眉、格式不正确的文本),并丢弃不包含足够“散文式”文本的页面(例如重复文本、短片段)。 首先,CCNet 本身提供了一个质量过滤器,使用 KenLM (Heafield,2011) 困惑度根据维基百科的相似性将文档分组到存储桶中;该类别通常被解释为高 (21.9%)、中 (28.5%) 或低 (49.6%) 质量上下文。 然而,根据 Rae 等人 (2021) 和 Almazrouei 等人 (2023) 中针对基于模型的质量过滤器提出的论点,以及我们自己对分发的内容进行的手动检查在这些类别之间,我们选择不使用这些 CCNet 质量分数。 相反,在 Dolma 中,我们通过结合 Gopher (Rae 等人, 2021) 和 C4 (Raffel 等人, 2020) 引入的启发式方法来实现质量过滤。 具体来说,我们保留所有 Gopher 规则(此后称为 Gopher All),并保留 C4 中的单个启发式规则,旨在删除不以标点符号结尾的段落 (C4 NoPunc;相反至 C4 全部)。 过滤规则的详细说明参见附录J.4。
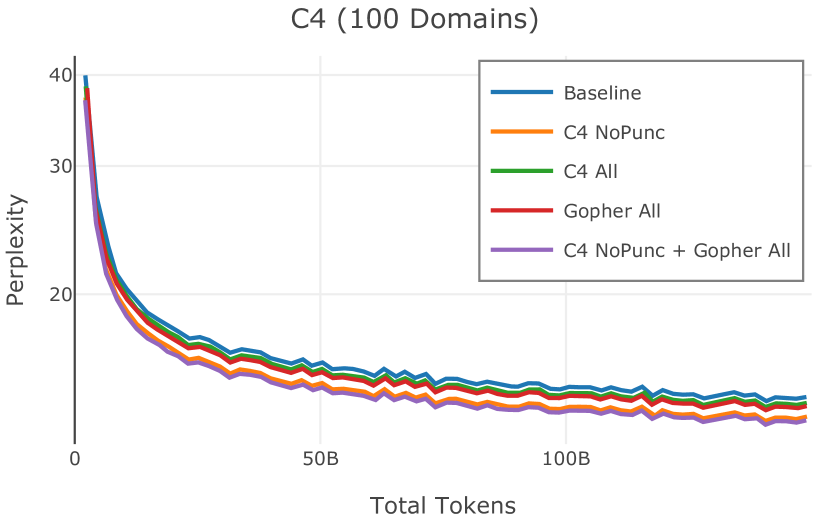
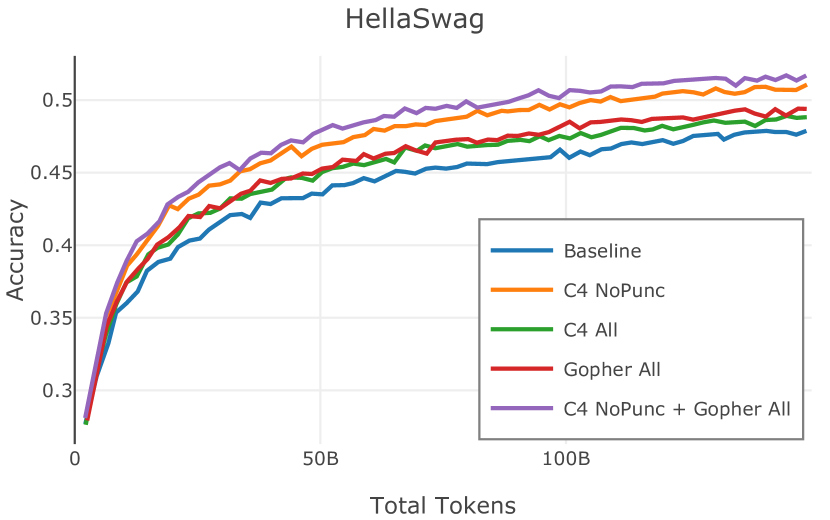
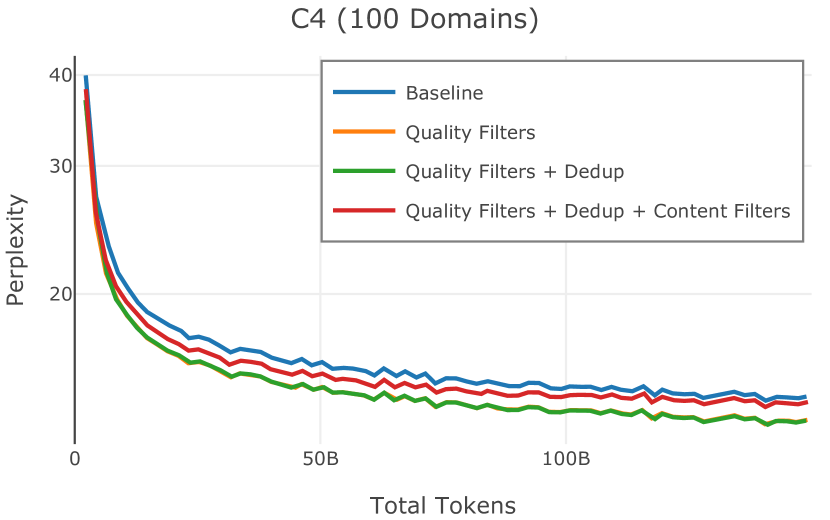
Figure 2 中显示的消融结果验证了我们的过滤策略:我们发现在困惑度和下游任务上 C4 NoPunc 本身的性能优于 C4 All 以及 Gopher All 。 最后,组合 Gopher All + C4 NoPunc 可提供最佳性能。 总之,Gopher 规则标记了 15.23% 的 UTF-8 字符进行删除,而 C4 规则标记了 22.73% 的字符进行删除。 当将我们的启发式方法与 CCNet 的质量分数进行比较时,过滤后的剩余文档落入 CCNet 的高 (22.8%)、中 (26.2%) 和低 (51.0%) 质量类别,表明模型和基于启发式的质量过滤器之间的相关性非常小。
使用 Elazar 等人 (2023) 中的工具,我们检查过滤后的数据集是否出现重复的 -gram。 尽管使用Gopher和C4规则进行过滤,我们仍然发现不需要的文本,例如重复序列“-”100次,出现超过6000万次,或重复序列“bla”,出现1910万次(见表2)。 基于此,我们实现了-gram启发法来识别和删除包含这些序列的文档;具体来说,我们删除任何长度超过 100 个 UTF-8 字符的重复序列。 虽然这只删除了数据集中总字符数的 0.003%,但删除这些文档可以防止训练过程中出现损失峰值,正如经验发现的那样。141414更多信息请访问 Scao等(2022)中的 github.com/bigscience-workshop/bigscience/blob/master/train/tr8-104B-wide/chronicles.md。 我们还注意到,这是一种相当保守的启发式方法,使得数据集中仍有许多重复序列;我们通过人工检查这些序列发现,它们往往是网页布局元素,而不是不规则的解析。
| Repeated -gram sequence |
| - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - … |
| * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * … |
| / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / / … |
| . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . … |
| = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = … |
| # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # … |
3.1.3 内容过滤
过滤有毒内容
从互联网采集的数据可能包含有害或有毒内容(Matic 等人,2020;Luccioni 和 Viviano,2021;Birhane 等人,2023a, b)。 正如§ 2中所强调的,我们过滤Dolma以减少有毒内容的训练语言模型可能产生的危害。 我们使用 Jigsaw Toxic Comments 数据集 (cjadams 等人 2017),这个数据包含带有(多标签)类别的论坛评论,类别包括toxic、severe toxic、threat、insult、obscene 和/或 identity hate 以及未标记的评论,训练两个 fastText 分类器 —— 二元 hate 检测器和二元 NSFW 检测器:
-
1.
对于我们的“仇恨”检测器,我们将所有未标记的评论和仅“淫秽”的评论分组为负面评论,并将其余评论作为正面评论。
-
2.
对于我们的“NSFW”检测器,我们将所有标记为“淫秽”的评论视为正面评论,并将其他剩余评论视为负面评论。 请务必注意,此检测器仅过滤提及性或淫秽主题的有毒内容,而不是一般性内容。
对于这两个模型,我们在 Common Crawl 句子上运行它们151515使用 BlingFire 句子分割器(Microsoft,2019)进行识别。 基于手动阈值调整的过滤阈值为 0.40。 我们选择阈值,寻求以下两者之间的平衡:(1)通过检查 Common Crawl 的单个快照上预测的有毒句子来最大化精确度和召回率,以及(2)最小化过多的数据删除。161616例如,“hate”和“NSFW”检测器过滤掉了 34.9% 和 29.1% Common Crawl 的代币阈值分别为 0.0004 和 0.00017。 我们总是只删除被标记为有毒的范围,而不是完整的文档。 我们公开提供这两种模型。1717 17“NSFW” fastText 标签器 和 “hate” fastText 标签器.
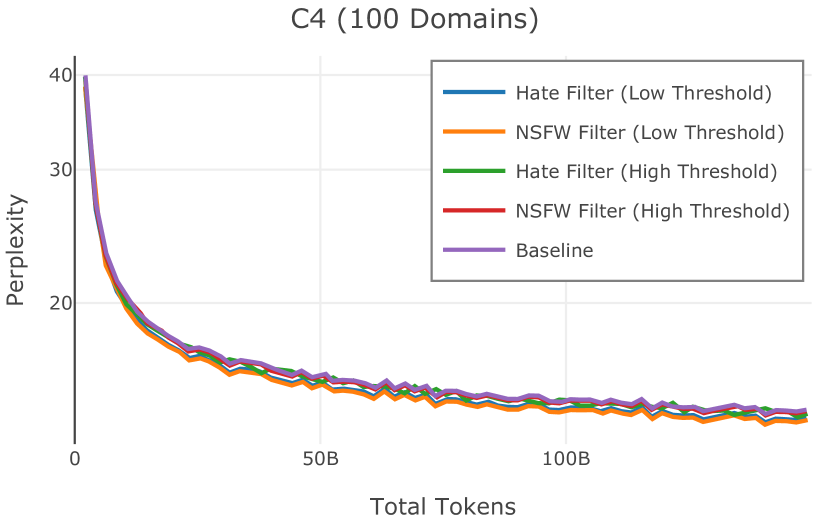
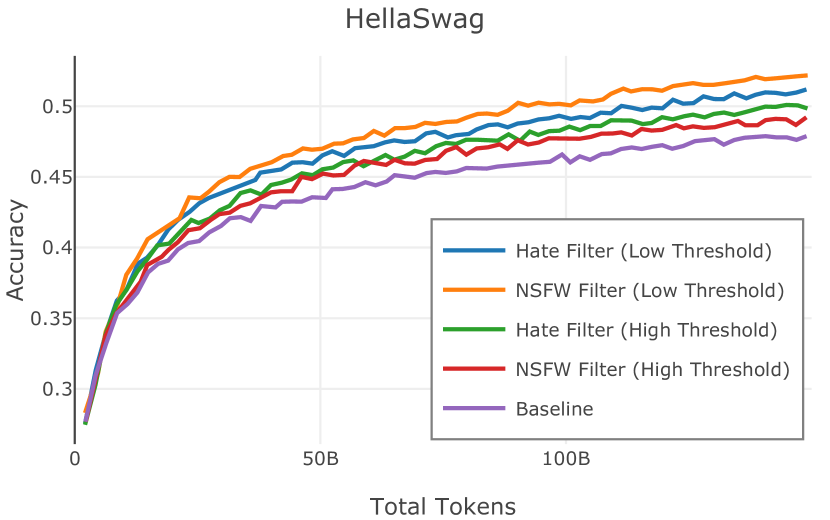
在Figure 3中,我们比较了“hate”和“NSFW”检测器的两个不同阈值的效果。 “高阈值”配置删除较少内容,但通常会导致评估集更高的复杂性和更低的下游性能。 “低阈值”配置会删除更多内容,通常具有更高的性能,但会删除更多文本单元(对于 ''hate'' 和 ''NSFW'' UTF-8 字符)。 由于较低的阈值可能会导致误报,而通过将内容过滤器与质量和重复数据删除过滤器相结合可以提高性能,因此我们使用“hate”和“”的“高阈值”版本NSFW”过滤器,删除任何得分大于或等于 0.4 的句子。
过滤个人身份信息
从互联网采样的数据还可能泄露用户的个人身份信息 (PII)(Luccioni 和 Viviano,2021;Subramani 等人,2023);此类 PII 在大规模数据集中非常丰富(Elazar 等人,2023)。
PII检测可以使用基于模型的工具来完成(Dernoncourt等人,2017;Microsoft,2018;Hathurusinghe等人,2021;Lison等人,2021;Lukas等人,2023;Mazzarino等人,2023) 或基于规则的方法(Aura 等人,2006;Elazar 等人,2023)。 前者通常提供更好的性能,而后者则更快。
Dolma 的规模使得使用基于模型的工具变得不切实际;相反,我们依赖精心设计的正则表达式。
根据 Subramani 等人 (2023) 的研究结果,我们标记了三种可以足够准确地检测到的 PII:电子邮件地址181818Regex:
[.\s@,?!;:)(]*([\^\s@]+@[\^\s@,?!;:)(]+?)[.\s@,?!;:)(]?[\s\n\r]
,IP 地址 191919Regex: \s+\(?(\d{3})\)?[-\. ]*(\d{3})[-. ]?(\d{4}) 和电话号码202020正则表达式: (?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9]{1,2})\.){3}
(?:25[0-5]|2[0-4][0-9]|[01]?[0-9]{1,2}).
当文本范围标记之后,我们就会根据每个文档的密度采用不同的处理策略:
-
•
检测到 5 个或更少的 PII 文本范围:我们用特殊标记 | | |EMAIL_ADDRESS| | |、| | |PHONE_NUMBER| | | 和 | | |IP_ADDRESS| | | 分别表示电子邮件地址、电话号码和 IP 地址替换页面上的所有文本范围212121当在 Dolma 上训练模型时,我们将这些特殊标记添加到标记器词汇表中。 对于本文中显示的所有结果,我们使用 allenai/gpt-neox-olmo-dolma-v1\_5。. 总的来说,我们发现 25 个 Common Crawl 快照中有 0.02% 的文档与此过滤器匹配。
-
•
检测到 6 个或更多 PII 范围:我们会删除包含 6 个或更多匹配 PII 范围的任何文档。 我们采用这种方法是因为包含大量电话号码和电子邮件地址的页面可能会带来更大的泄露其他 PII 类别的风险。 25 个常见爬网快照中有 0.001% 的文档与此过滤器匹配。
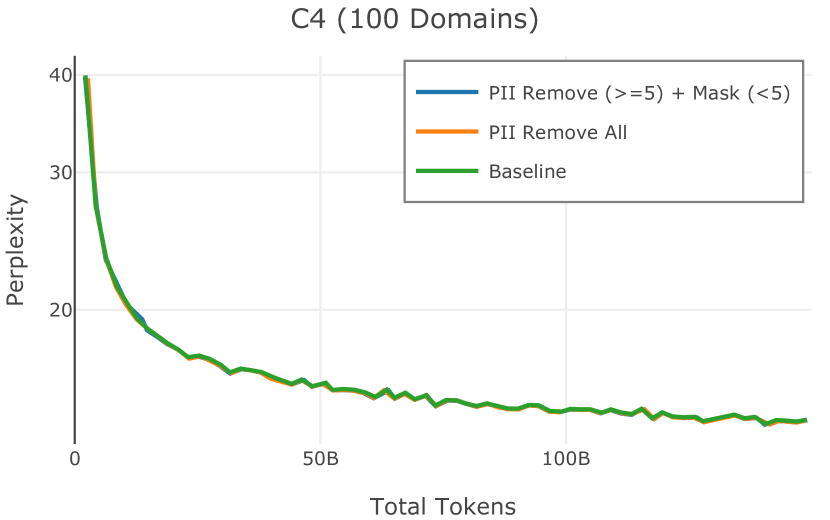
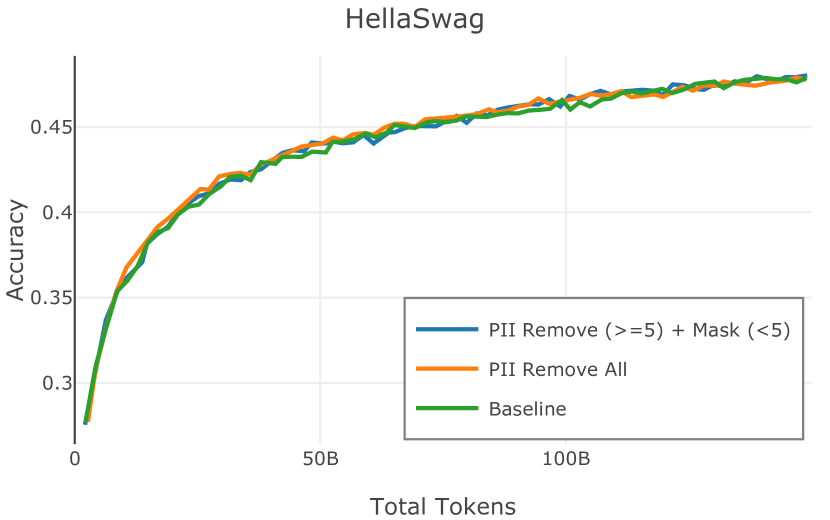
在图 4 中,我们展示了旨在量化 PII 策略影响的实验结果。 总体而言,我们发现,在语言建模和下游任务中,PII 删除和屏蔽对模型性能没有明显影响。
3.1.4 重复数据删除
最近的研究表明,数据去重可以提高语言模型的训练效率(Lee 等人,2022)。 遵循这一原则,我们对 Web 管道中的数据进行重复数据删除。 我们执行重复数据删除的三个阶段:
-
(i)
精确 URL 重复数据删除:标记共享相同 URL 的页面。 不执行标准化。 此过滤器主要用于删除已被多次抓取的页面。 总体而言,它删除了用于创建 Dolma 的 25 个快照中 53.2% 的文档。 由于计算效率高,URL 重复数据删除通常被用作网络爬虫的第一阶段(Agarwal 等人,2009;Koppula 等人,2010;Penedo 等人,2023)。
-
(ii)
精确文档去重:标记包含相同文本的页面。 没有删除标点符号或空格。 空文档算作重复项。 总体而言,在 URL 重复数据删除后,它额外删除了 14.9% 的文档。
-
(iii)
精确段落重复数据删除:将跨页面的相同段落标记为重复项。 我们保持该单元的定义与之前的过滤器一致:段落是由换行符 UTF-8 字符 ‘‘\n’’ 分隔的一段文本。 总体而言,此过滤器将 URL 重复数据删除集中 18.7% 的文档标记为重复。
3.1.5 将它们放在一起
管道中的步骤如何组成?
总的来说,Dolma 网络管道通过首先执行 URL 和文档级去重,然后进行质量过滤(Gopher,C4 NoPunc),内容过滤(有害内容,PII),最后进行段落级去重来转换 CCNet 的输出。 但是过滤的综合结果是什么?
数据分布
我们使用Elazar等人(2023)中的工具来检查Figure 6中的最终数据组成。 我们特别分析网站域名、年份和语言分布。
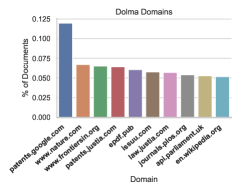
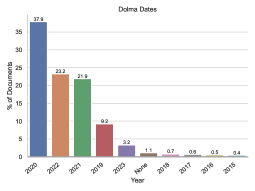
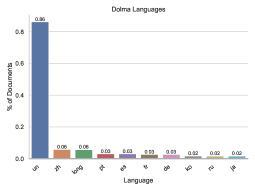
我们注意到 Dolma 包含来自广泛互联网域的文档,大部分来自 2020 年、2022 年和 2021 年。 根据 Token,Dolma 最常见的互联网域名是 patents.google.com,其次是 www.nature.com 和 www.frontiersin.org。 事实上,与 Elazar 等人 (2023) 中报告的其他语料库类似,Dolma 63.6% 的网页文档来自“.com”网站(其次是“.org”和“.co.uk” 网站)。 最后,由于所有语言识别工具都不完善,我们总结了仅英语过滤后剩下的语言:我们发现英语后最常见的语言没有被很好地识别(“un”),占文档的 0.86%,其次是 0.06%被识别为中文的文件。
质量过滤器和内容过滤器有类似的效果吗?
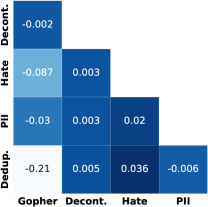
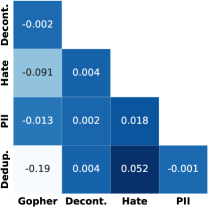
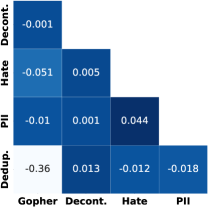
图 7 描述了我们的通用爬网过滤器标记为删除的文档之间的相关性。 我们发现相关性通常很低,因此我们的过滤器选择相当不同的文档并且不是冗余的。 我们的 PII(个人身份信息)过滤器和消除仇恨言论的过滤器之间存在某种正相关性。 这可能是因为仇恨言论通常是针对人的。 Gopher 过滤规则与我们的重复数据删除负相关,尤其是对于数据的高复杂度尾部部分。 这是因为 Gopher 规则删除了许多高复杂度文档,例如随机字符串,这些文档由于其随机性而未被重复数据删除捕获。 由于这些随机字符串可能无助于更好地理解语言,因此将它们过滤掉非常重要,因此依赖于重复数据删除之外的过滤器。
3.2 代码管道
3.2.1 数据采集和语言过滤
我们从 The Stack (Kocetkov 等人,2022)(一组许可的 GitHub 存储库)中派生出 Dolma 的代码子集。 我们使用接近重复数据删除的版本作为起点,从而无需自己执行重复数据删除。 该数据集的原始版本于 2023 年 3 月收集。 我们通过删除带有 JSON 和 CSV 等扩展名的文件来过滤数据量大的文档。
3.2.2 质量过滤
我们应用源自 RedPajama v1 (Together Computer,2023c) 和 StarCoder (Li 等人,2023) 数据集的启发式方法。 前者包含删除重复文件前导码的规则,例如许可证声明222222我们将此信息保存在与卓玛中每个文档关联的元数据中。 以及行数过长或内容大部分为数字的文档。 总体而言,RedPajama 规则 (RPJ) 旨在删除主要是数据或通过模板生成的文件。 为了进一步选择高质量的代码片段,我们利用 StarCoder 管道中的规则;这些启发式方法会过滤没有或很少有星星的 GitHub 存储库、评论太少或太多的文件以及代码与文本比率低的 HTML 文件。 有关这些规则的详细说明,请参阅§ J.4。
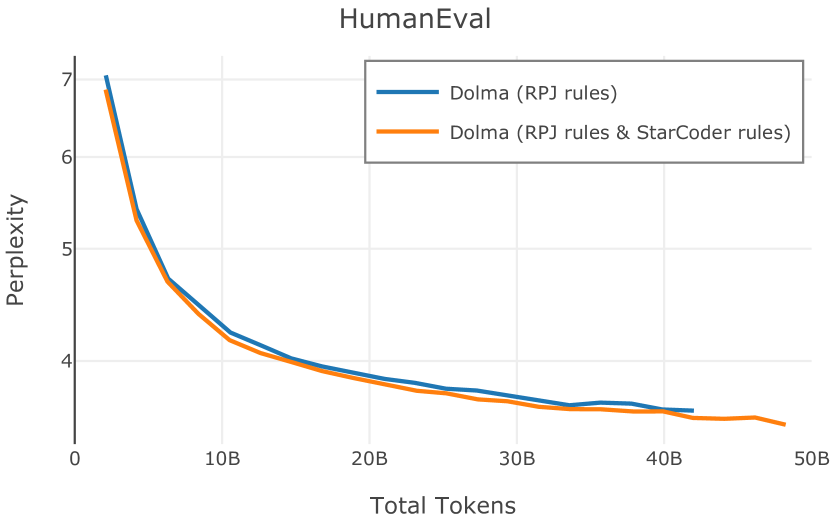
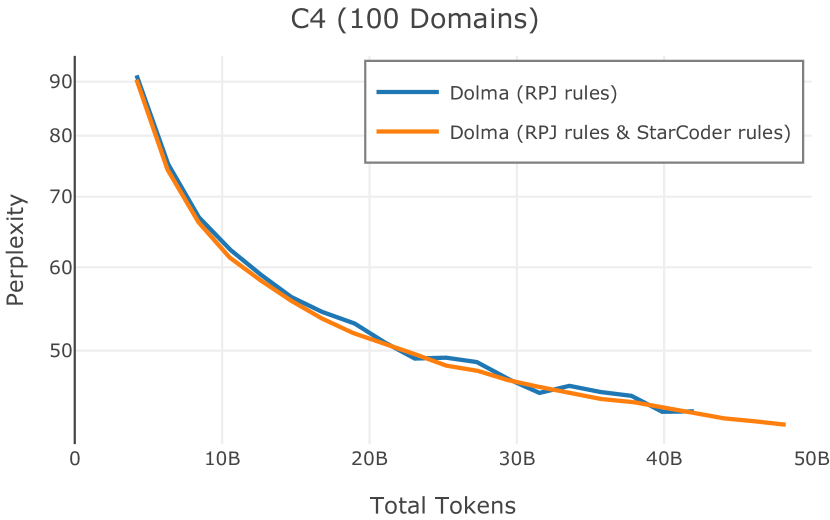
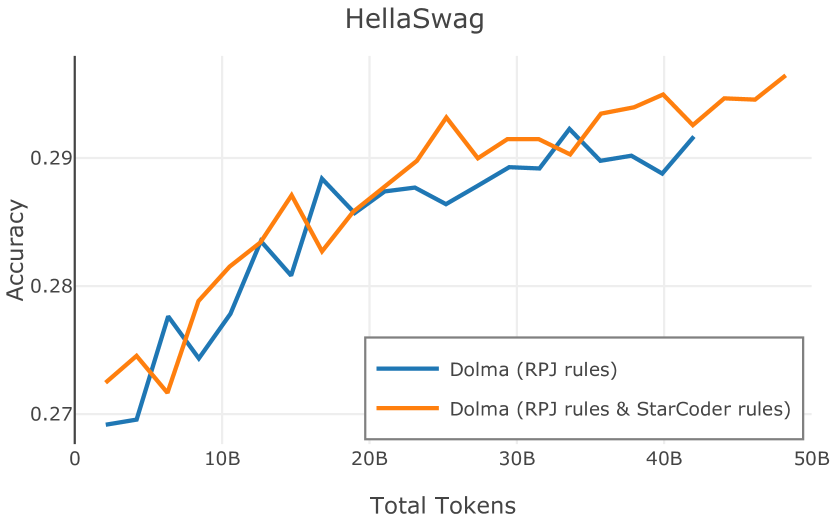
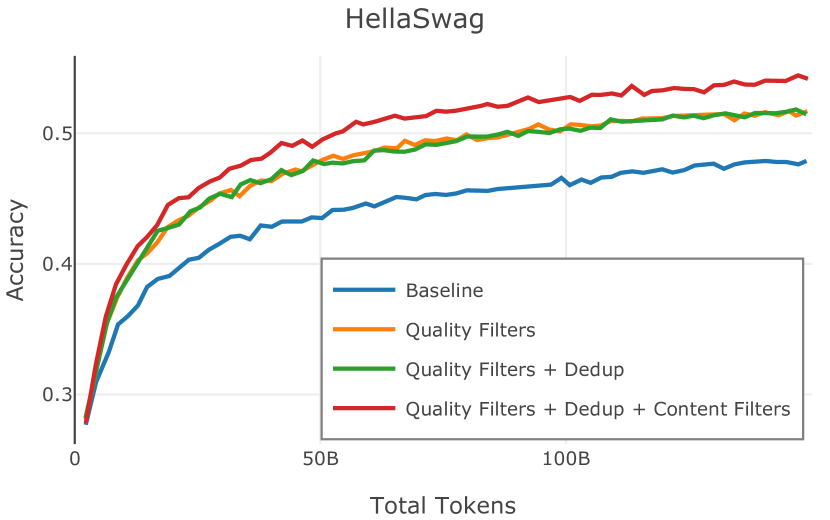
在Figure 9中,我们展示了RedPajama (RPJ)和StarCoder规则之间的比较。 在我们的消融中,我们发现,与单独的 RPJ 规则相比,RPJ 和 StarCoder 组合可以降低代码数据集的困惑度(例如, HumanEval; Chen 等人, 2021b),在非代码测试集上训练时困惑度更稳定(例如,C4 100 Domains Paloma 子集;Magnusson 等人,2023),并提高了下游性能(例如,HellaSwag;Zellers 等人,2019)。 因此,我们在为 Dolma 制作最终混音时选择使用这种组合。
3.2.3 内容过滤
我们对网络管道 (§ 3.1) 应用相同的过滤规则来掩盖个人身份信息 (PII)。 具有超过 5 个 PII 实例的文档将从 Dolma 中删除。 在所有其他情况下,电子邮件、电话号码和 IP 地址均使用特殊 Token 进行屏蔽。
我们还删除代码机密或个人信息。 为此,我们使用 detect-secrets (Yelp, 2013) 库并删除任何匹配的文档。
3.2.4 重复数据删除
我们使用 Kocetkov 等人 (2022) 发布的已进行重复数据删除的 The Stack 版本;他们的方法使用 Allal 等人 (2023) 首次引入的管道,该管道使用 MinHash Broder (2002) 和本地敏感哈希来查找相似文档。
3.3 对话论坛管道

3.3.1 数据采集和语言过滤
Dolma 的对话子集源自 Pushshift Reddit 数据集 (Baumgartner 等人,2020b),这是通过 Reddit 的数据 API 收集并由 Pushshift 分发的大量论坛对话集合项目。 我们从 2005 年 12 月到 2023 年 3 月期间 Reddit 上的 3.78 亿条帖子中得出了卓玛的对话子集。 我们在数据集中包含了提交(Reddit 对话中的初始消息)和评论(对消息的回复)。 我们将所有提交和评论视为独立文档,与它们出现的线程没有任何结构或联系;在我们的评估中,这种简化的表示可以在下游任务上产生更好的性能。 附录E对此权衡进行了讨论。
为了保持一致性,我们使用与网络管道相同的策略来过滤非英语内容。 特别是,我们保留英语分数大于0.5的提交和评论。
3.3.2 质量过滤
对话论坛数据必须经过充分清理,以删除太短、重复或被提交到的社区负面排名的内容。 我们使用 Henderson 等人 (2019) 引入的管道来使用 Google Dataflow232323https://cloud.google.com/dataflow 促进提交和评论的清理。 我们删除短于 500 个字符的评论以及短于 400 个字符的提交内容242424对数据的定性检查表明,提交的质量高于评论;因此,我们使用更宽松的最小长度。. 我们还删除长度超过 40,000 个字符的文档。
我们删除了少于 3 票的评论252525通过计算赞成票(也称为“赞成票”、反对票或“反对票”)之间的差值来获得每个文档的总票数。,因为较低的分数与深层嵌套在对话线程中的评论(Weninger等人,2013)或更有可能导致情绪激动的话语(Davis和Graham, 2021)。 投票已被用作构建 WebText (Radford 等人,2019) 和 OpenWebText (Peterson,2020) 语料库的信号。 我们丢弃已被作者删除或被版主删除的文档;此外,被作者标记为“超过 18 岁” 的文档也被删除。 我们排除源自 26,123 个被禁止且不适合工作的 Reddit 子版块的任何文档262626该列表位于https://github.com/allenai/dolma/blob/main/sources/reddit/atomic_content_v5/subreddit_blocklist.txt. 该列表是通过合并多个追踪被禁 subreddit 的来源(主要来自 Reddit 本身的帖子)而获得的。 我们还测量了 Reddit 子版块中标记为 NSFW 的帖子比例,并在该比例超过 10% 时屏蔽了 Reddit 子版块。 我们策划的。
3.3.3 内容过滤
我们应用与网络管道 (§ 3.1.3) 中使用的相同过滤规则来删除有毒内容并掩盖 PII。 与网络管道的情况不同,如果文档的一部分被标记为有毒,我们将完全删除该文档。 我们采用这种策略是因为 Reddit 的内容长度较短,因此被归类为有毒的单个句子更有可能强烈表明整个文档也有毒。
3.3.4 重复数据删除
我们采用与 Web 管道相同的策略 (§ 3.1.4)。 由于提交和评论比网络文档短,因此我们仅在文档级别进行重复数据删除。 此策略有助于减少“复制意大利面”(为了达到喜剧效果而在许多评论和 Reddit 子版块中经常重复的文本块)和其他重复信息的发生率。
3.4 其他数据源
C4 用于整洁的 Web 内容
学术文献 PeS2o
PeS2o 数据集(Soldaini 和 Lo,2023) 是大约 4000 万篇开放获取学术论文的集合,这些论文经过清理、过滤和格式化,用于语言模型的预训练。 它源自语义学者开放研究语料库(S2ORC)(Lo 等人,2020)。 由于该数据集是为了语言建模目的而创建的,因此我们按原样使用它。
古腾堡图书计划
古腾堡计划是一个包含 7 万多本公共领域书籍的存储库。 我们于 2023 年 4 月收集了古腾堡计划的档案。 我们使用相同的基于 fastText 的语言识别模型来识别英语书籍并将其包含在 Dolma 中。 更多详细信息,请参阅我们的数据表 § J。
百科全书内容的维基百科和维基教科书
该数据集源自 2023 年 3 月的维基媒体转储。 我们使用维基百科和维基教科书的“英语”和“简单”版本作为卓玛百科全书子集的基础。 来源是使用 WikiExtractor 进行处理的272727github.com/attardi/wikiextractor, v. 3.0.7,提交前缀 8f1b434。 . 我们删除任何包含 25 个或更少 UTF-8 分段单词的文档,因为我们发现较短的页面可能是短模板页面的结果(例如,仅包含几个单词和一个信息框)或 XML 解析错误。
4在 Dolma 上训练语言模型
作为 Dolma 管道的最后验证步骤,我们训练、评估并发布一个仅解码器的自回归语言模型,我们称之为 Olmo-1b。 在本节中,我们将讨论特定于模型训练的额外数据集管理决策的潜在方法。 在§ 4.1中,我们介绍了一种从 Dolma 中移除基准任务的数据 — 即 decontaminate — 的方法。 然后,在§ 4.2中,我们讨论了组合(即混合)Dolma中的各种文档子集以获得最终预训练语料库时的注意事项。 最后,在§ 4.3中,我们展示了所得Olmo-1b模型的实验结果。 Olmo-1b 使用 GPT-NeoX 分词器 (Black 等人, 2022),我们发现它非常适合 Dolma;我们在Appendix F中提供了支持我们决定的结果。
4.1Dolma 消除基准数据的策略
在本节中,我们尝试从预训练中消除基准数据污染的方法,并选择最终在 Olmo-1b 中使用的方法。 大规模语言数据集包含通常用于评估语言模型基准数据的副本(Dodge 等人,2021;Yang 等人,2023;Elazar 等人,2023)。 目前对这种污染的影响存在争议。 例如,Lee 等人 (2022) 表明,从 C4 预训练中删除重复的验证数据会增加对先前重复的验证数据的困惑。 与此同时,对受污染和未受污染下游数据之间事后性能差异的研究发现,没有一致的正面或负面影响(Chowdhery 等人,2022;Brown 等人,2020;OpenAI,2023)。 首先,我们专注于消除困惑基准数据污染,并测量下游任务污染的程度。 我们尝试消除早期版本 Paloma (Magnusson 等人,2023) 的污染,这是一个包含 585 个文本域的基准,旨在评估适合不同来源的语言模型。 Appendix D 中详细介绍了这种困惑度评估的选择。
用于困惑度评估的消除基准数据策略
使用 § 3.1.4 中描述的段落重复数据删除工具,如果 (i) 长度超过 13 个 Unicode 分段标记,我们会将 Dolma 中的任何段落标记为受污染的282828就像Elazar 等人 (2023) 一样,我们只考虑足够长度的段落以避免误报匹配。 (ii) 它出现在 Paloma 的任何文档中。 在针对 Paloma 早期版本的 C4 (Raffel 等人, 2020) 净化知识实验中,我们将上述基于段落的净化技术与精确匹配的整个文档进行了比较。 结果表明,基于文档的净化产生的匹配率较低,12 个子集中只有 1 个子集的污染文档大于 1%292929C4 100 Domains子集,直接由C4构建。. 然而,当考虑基于段落的净化时,12 个困惑任务中有 6 个的文档污染率超过 1%。 由于后者更能反映预期的污染率,因此我们选择它作为本节的剩余内容。
最后,我们考虑消除污染数据的两种方法。 在 C4 上的初步实验中,我们发现通过从文档中排除受污染的段落来删除它们会删除 0.01% 的 Token,而删除带有任何污染的整个文档会删除 0.02% 的 Token。 无论哪种情况,都有 0.01% 的文档受到影响。 鉴于每个文档的影响相对较小,我们选择删除完整的文档以避免扰乱阅读顺序,尽管这确实偏向于删除较长的文档。
| Avg ppl over subsets (↓) | Largest subset ppl diff (ptb ↓) | Avg acc on end tasks (↑) | Largest acc diff on end task (sciq ↑) | |
| Decontaminated | 25.6 | 22.3 | 59.2 | 84.8 |
| Not Decontaminated | 25.7 | 22.0 | 56.37 | 86.3 |
| Difference | -0.1 | 0.3 | 2.8 | -1.5 |
用于困惑度评估的消除污染数据结果
为了评估我们消除污染数据方法的风险,我们训练了303030 本实验使用Appendix D 中描述的设置,包括模型配置、优化器和评估设置。 RedPajama v1 (Together Computer,2023c) 的 221B Token 子集上的两个 1B 参数模型,该语料库与 Dolma 在实验时的预期构图最相似。 第一个模型按原样在 RedPajama v1 上进行训练,而第二个模型使用相同的语料库但是在上述段落匹配、文档删除方法净化。 在这个子集中,我们的净化方法删除了 2.17% 的 unicode 令牌和 0.66% 的文档。 在表 3 中,我们表明困惑度和下游任务绩效的差异很小,并且趋势并不总是积极或消极。 对于困惑度,7 个来源会降低,6 个来源会改善;对于下游任务,5 个降级,4 个提高。 Penn Tree Bank 上困惑源的最大降级为 22.0 至 22.3。 下游任务中最大的降级是 SCIQ 准确率下降 1.5% 至 84.8%。 总之,结果显示没有一致的证据表明净化后性能会下降。
Olmo-1b 中的污染数据消除
由于我们的实验已经降低了我们清除基准污染方法的风险,我们将其应用于我们在Dolma上训练的模型。 Magnusson 等人 (2023) 详细介绍了消除与 Paloma 重叠的最终方法。 它应用本节讨论的步骤,并添加一个过滤器,忽略仅包含标点符号、空格和表情符号的重叠文本。 这些类型的 Token 可以在文本格式中任意重复,导致常见的 n-gram 大于我们的 13-gram 阈值。 在用于训练 Olmo-1b 的最终 Dolma 语料库中,我们的方法发现训练数据中不到 0.001% 的字符受到污染,并删除不到 0.02% 的文档。
测量下游任务可能受到的数据污染
我们测量 Dolma 的数据污染情况。 我们遵循 WIMBD (Elazar 等人,2023) 中的相同设置,并计算可在单个文档中找到的具有两个或多个输入(例如,自然语言推理)的任务的实例百分比。 这是 Dolma 中精确匹配数据污染的上限。 我们考虑了 PromptSource (Bach 等人, 2022) 中的 82 个数据集,并报告这些数据集至少有 5% 的测试集可以在 Dolma 中找到。 我们在图11中报告了结果。
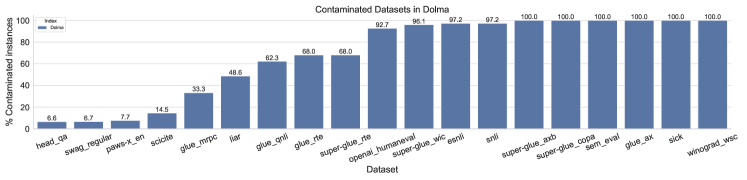
结果表明 Promptsource 中的部分数据集出现在 Dolma 中。 六个数据集完全被污染(100%):Winograd Schema Challenge (Levesque 等人,2012)、Sick (Marelli 等人,2014)、来自 GLUE 的 AX (Wang 等人, 2018)、SemEval(特别是 2014 年的任务 1)、SuperGLUE 的 COPA (Roemmele 等人, 2011) 和 AXb(诊断任务)来自 SuperGLUE (Wang 等人,2019)。 此外,其他数据集大多受到污染,超过 90% 的测试集出现在 Dolma 文档中:OpenAI HumanEval (Chen 等人, 2021a)、SuperGLUE 的 WIC (Pilehvar 和 Camacho- Collados, 2019)、ESNLI (Camburu 等人, 2018) 和 SNLI (Bowman 等人, 2015)。 我们注意到,受污染的数据集已被排除在我们用于模型评估的下游任务之外(c.r.f. Appendix D)。
4.2使用 Dolma 进行子集混合和上采样的策略
与几乎所有大型语言模型的预训练语料库一样,卓玛是一个多源数据集。 因此,Dolma 上的训练需要一种混合策略,确定要包含每个源的多少数据,以及可能要对哪些源进行上采样。 与其他多源语料库一样(例如,ROOTS (Laurenccon 等人, 2023)、Pile (Gao 等人, 2020)、RedPajama v1 (Together Computer , 2023c)),313131RedPajama v1 是 LLaMA (Touvron 等人,2023a) 中使用的多源语料库的复制品。 RedPajama v2 (Together Computer,2023a) 仅专注于 Common Crawl,因此是单一来源。 卓玛并没有规定单一的混合策略。 我们建议读者参考 Rae 等人 (2021),了解如何以编程方式搜索混合配置以最大限度地提高性能的示例。 在这里,我们进行混合实验,以此作为回答一些有关不同数据源如何交互的研究问题的机会。 我们使用§ 3中描述的相同消融设置。
多少代码对于预训练很重要?
即使代码生成不是预期任务,语言模型也会对一定数量的代码进行预训练,这是常见的做法。 一些研究表明,将代码混合到纯文本文档的训练中可以提高推理任务的性能(Madaan 等人,2022)。 我们调查这一观察结果是否适用于在 Dolma 上训练的模型,如果是,需要多少代码?
| Dataset | 0% Code | 5% Code | 15% Code |
| bAbI (ICL) | 0.0 ± 0.0 | 8.8 ± 0.9 | 10.1 ± 2.8 |
| WebNLG (ICL) | 16.8 ± 1.1 | 19.3 ± 1.1 | 22.0 ± 1.3 |
| GSM8K (FT) | 0.0 ± 0.0 | 0.0 ± 0.0 | 0.0 ± 0.0 |
| GSM8K+PAL (FT) | 11.8 ± 0.8 | 14.2 ± 1.3 | 14.7 ± 0.9 |
我们从包含 0%、5% 和 15% 代码数据的 C4 和 Stack 子集创建三种混合。 在每个模型上,我们训练一个 1B 模型。 我们在三个不同的推理任务上评估这些模型:bAbI (Weston 等人, 2015)、WebNLG Gardent 等人 (2017) 和 GSM8k Cobbe 等人 (2021) )。 对于前两项任务,我们遵循 Muennighoff 等人 (2023b) 的实验设置,并通过 5 个随机种子的不断变化的演示次数 (0-5) 来评估 ICL 设置中的每个模型。 Muennighoff 等人 (2023b) 表明,向预训练数据添加代码可以提高 bAbI 和 WebNLG 上的 ICL 性能,并且他们建议代码可以提高远程状态跟踪能力。 我们的实验(如表 4 所示)证实了这些发现:虽然纯 C4 模型在所有 bAbI 任务上都失败了,但添加代码可以提高性能,WebNLG 的趋势类似。
在更困难的 GSM8k 基准测试中,所有模型都无法在 ICL 设置中获得任何正确答案,甚至在整个训练集上微调模型时也是如此。 然而,我们发现,通过对程序辅助输出进行微调,通过编写 Python 代码片段来解决问题,如 Gao 等人 (2022) 中所述,代码模型优于纯 C4 模型。 这些结果表明,即使原始任务不直接涉及代码,在代码上预训练的模型也可以利用代码生成来回答具有挑战性的推理任务。
评估 Dolma 上预训练的混合策略
虽然卓玛没有规定具体的来源混合物,但我们分析了一些常用的策略323232 我们没有在这些组合中包含任何社交数据,因为在本实验时尚未准备好。 并使用 Paloma 评估套件(Magnusson 等人,2023)比较其效果。 具体来说,我们在Table 5 中呈现并评估了四种可能的数据混合物。
| Mix Name | 描述 | Sampling | Proportion | ||||||||||||||||
| Naïve | Sample each source in Table 1 equally. |
|
|
||||||||||||||||
| Web Only | 与 Ayoola 等人 (2022) 类似,我们测试了仅使用网络数据的混合物。 |
|
|
||||||||||||||||
| Reference+ | 在编写训练混合物时,上传知识密集型文档是常见的做法。 在我们的例子中,我们将 PeS2o 论文、维基百科、维基教科书和古腾堡书籍子集的采样提高了 2 倍。 |
|
|
||||||||||||||||
| Gopher-like | 继Rae等人(2021)之后,我们创建了一个严重偏向参考材料的组合。 由于我们无法访问相同的来源,因此不可能精确复制它们的组合。 |
|
|
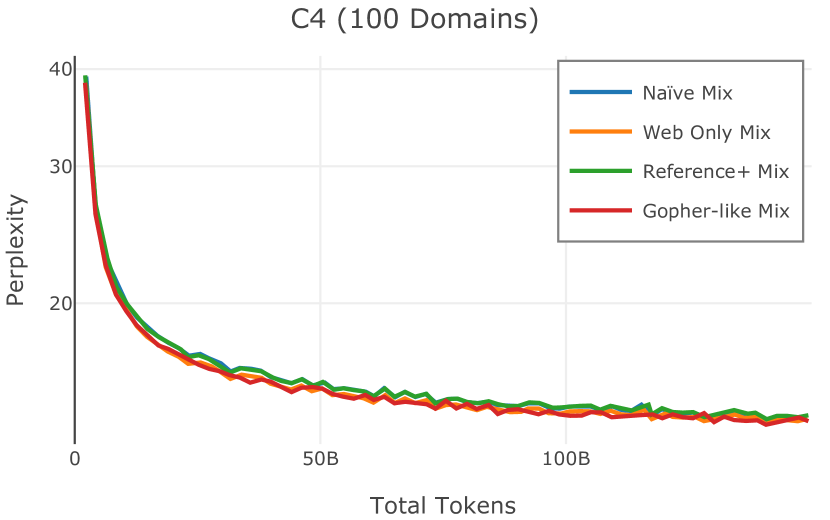
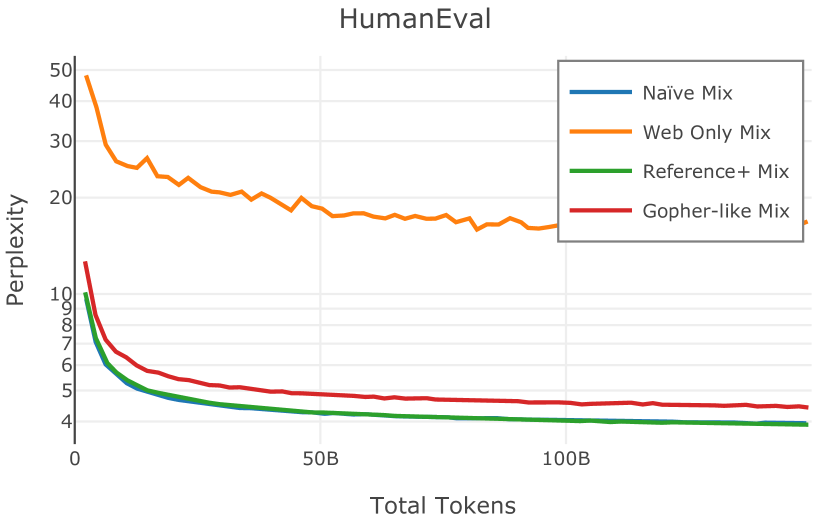
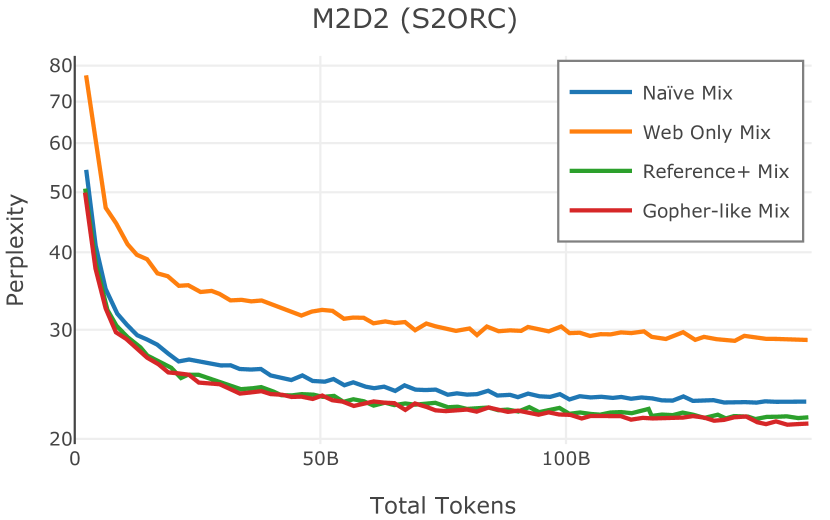
我们在Figure 12 中显示了混合物的结果。 总的来说,我们观察到不同的混合物对所得模型捕获特定子域的能力有影响。 所有混合物在从 C4 的 100 个域中采样的页面上都显示出相似的困惑度分数(Figure 12,左),表明它们在建模 Web 文档方面的总体有效性。 另一方面,我们注意到模型如何努力对专门领域进行建模,除非它们接触到这些领域。 例如,在仅 Web 混合上训练的模型很难表示代码域中的数据(Figure 12,中心,HumanEval)。 最后,我们使用 M2D2 的 S2ORC 子集(由学术论文组成)的结果来说明不同的数据混合如何影响困惑度。 与代码的情况一样,仅 Web 模型由于域不匹配而表现出更高的复杂性。 另一方面,在 Reference+ 和 Gopher-like 混合上训练的模型比在 Naïve 混合上训练的模型实现更低的困惑度,因为更多域内内容。 然而,我们注意到,尽管 Reference+ 和 Gopher-like 之间的学术论文数量存在显着差异(4.9% vs 24.2%),但它们取得的结果几乎相同,这表明即使域内数据的比例相对较小,也足以实现良好的域拟合。
4.3 评估Olmo-1b
|
|
|
|
|
|||||||||
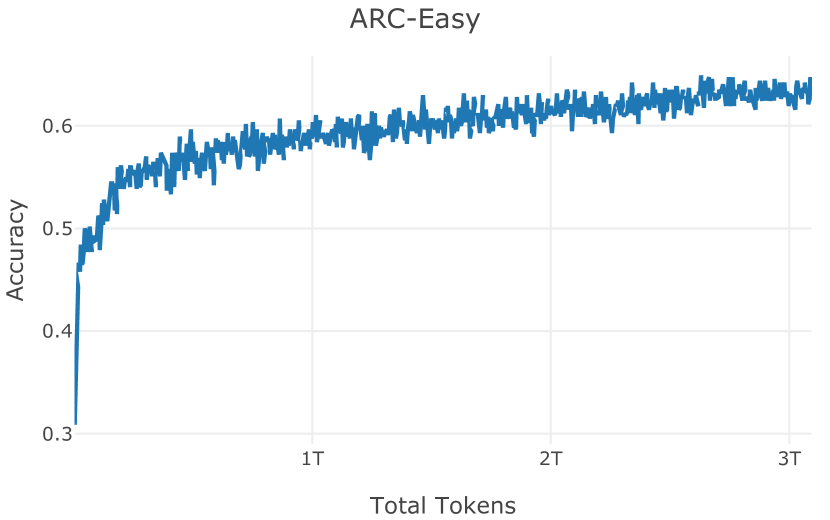
| ARC-E (Clark et al., 2018) | 63.7 | 50.2 | 53.2 | 58.1 | |||||||||
| ARC-C (Clark et al., 2018) | 43.8 | 33.1 | 34.8 | 34.5 | |||||||||
| BoolQ (Clark et al., 2019) | 76.6 | 61.8 | 64.6 | 60.7 | |||||||||
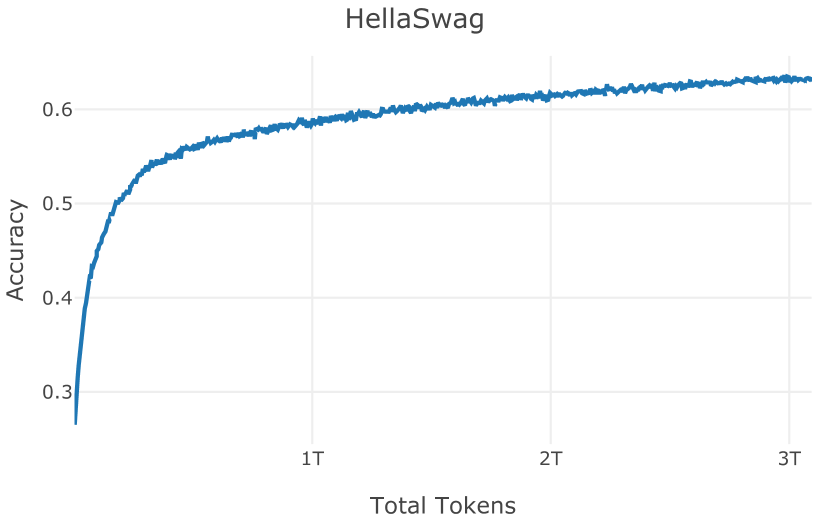
| HellaSwag (Zellers et al., 2019) | 68.2 | 44.7 | 58.7 | 62.5 | |||||||||
| OpenBookQA (Mihaylov et al., 2018) | 45.8 | 37.8 | 43.6 | 46.4 | |||||||||
| PIQA (Bisk et al., 2019) | 74.0 | 69.1 | 71.1 | 73.7 | |||||||||
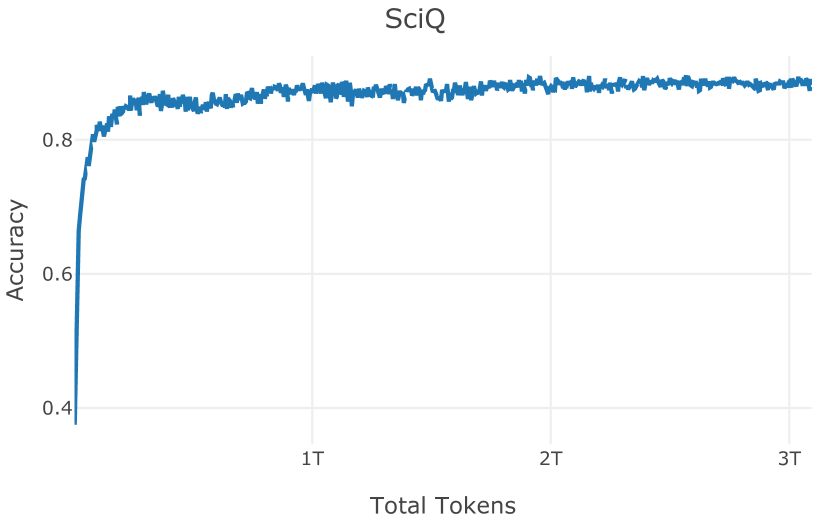
| SciQ (Welbl et al., 2017) | 94.7 | 86 | 90.5 | 88.1 | |||||||||
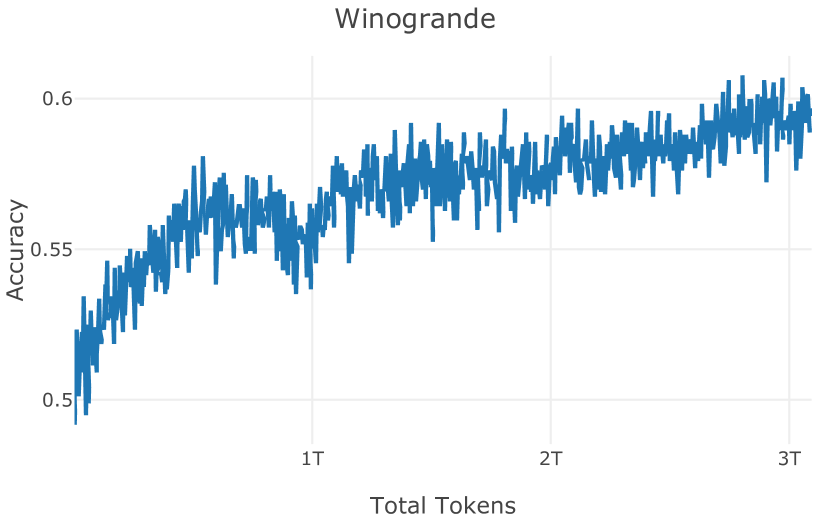
| WinoGrande (Sakaguchi et al., 2019) | 64.9 | 53.3 | 58.9 | 58.9 | |||||||||
| Average | 66.5 | 54.5 | 59.4 | 60.3 |
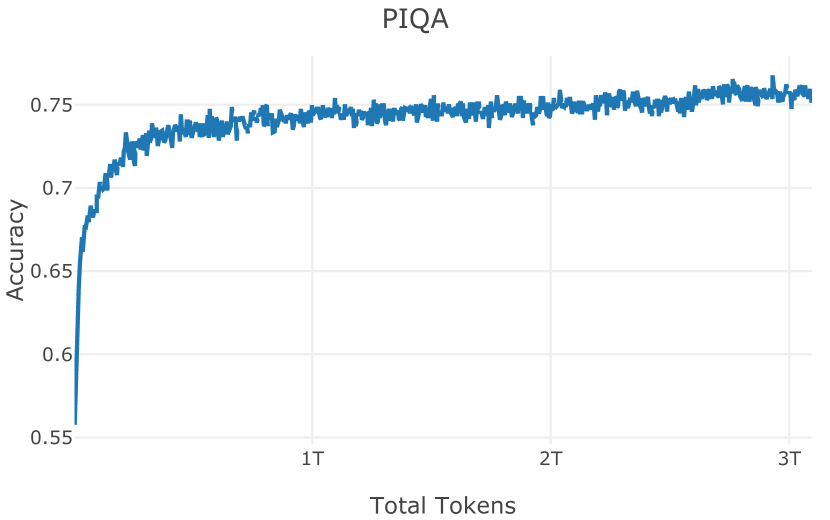
在Table 6中,我们将Olmo-1b与其他1B模型进行了比较。 请注意,虽然此处参数计数是匹配的,但只有 TinyLlama 接受了相当数量的标记的训练,而 Pythia 1B 接受了近 10 倍的标记训练,并且 StableLM2 的数据组成未知。 尽管如此,我们发现 Olmo-1b 的平均表现比最具可比性的模型 TinyLlama 更好,在 8 项任务中有 4 项表现优于它。 尽管下游任务的零样本评估对于这些相对较小的 1B 模型来说通常具有挑战性,但所有模型上所有任务的性能都高于朴素随机性能。 有关下游任务的更多详细信息包含在Appendix D 中。
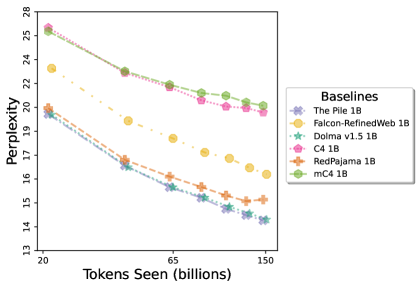
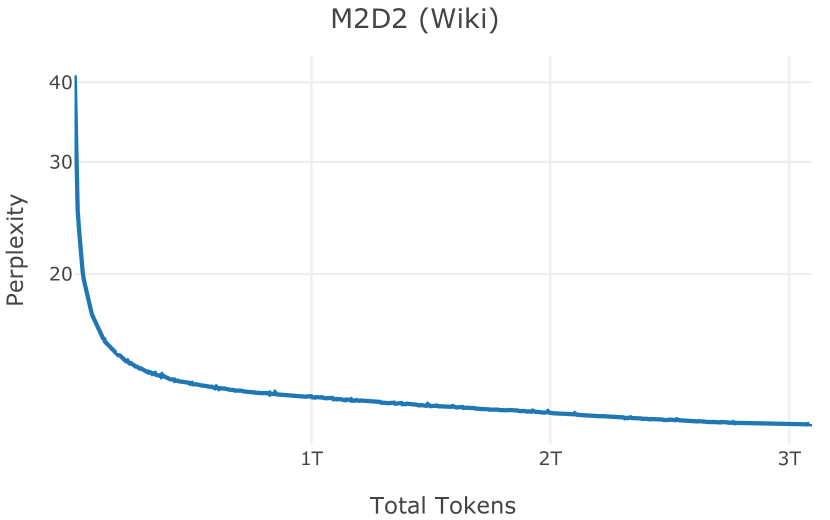
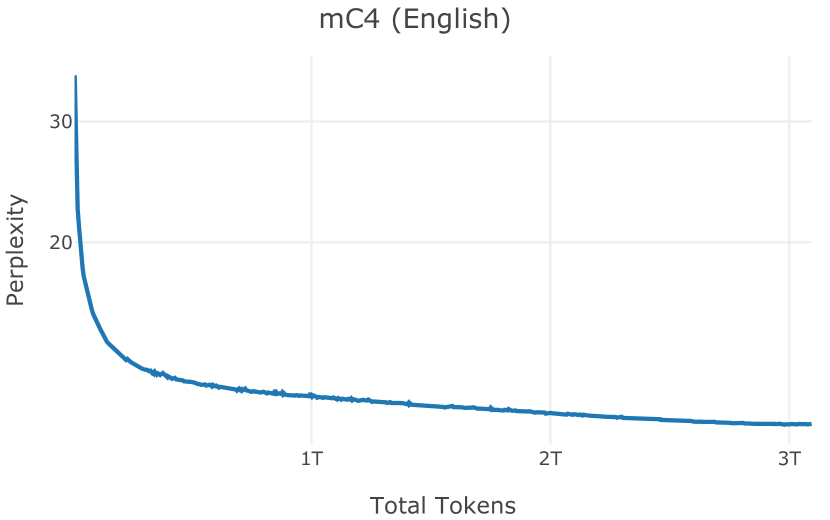
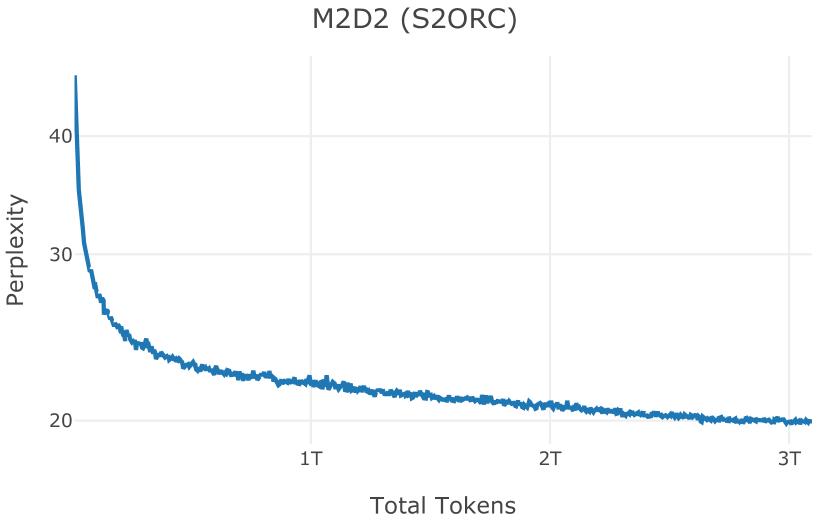
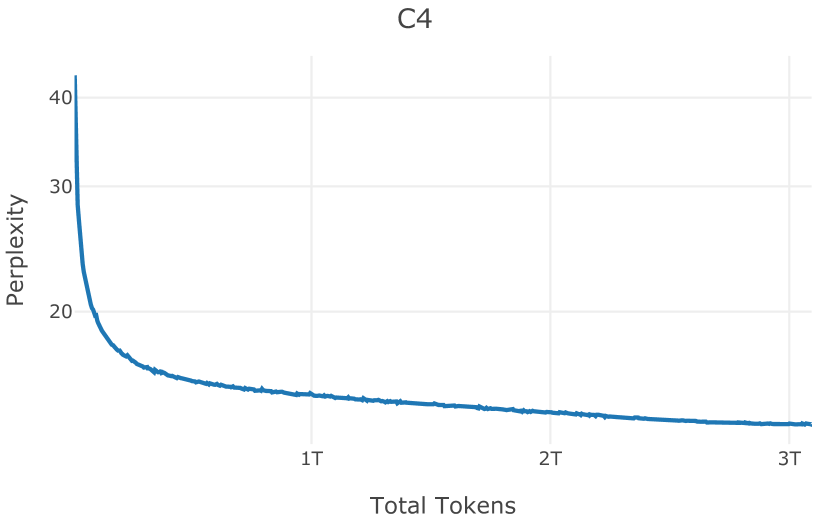
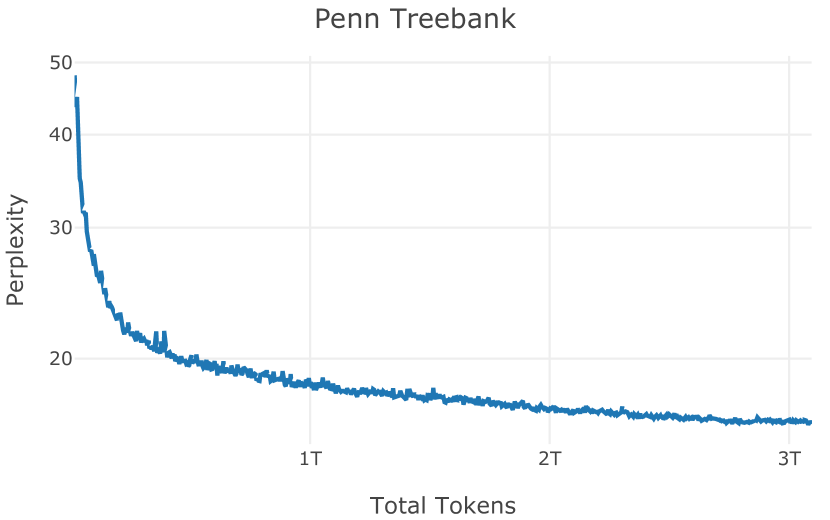
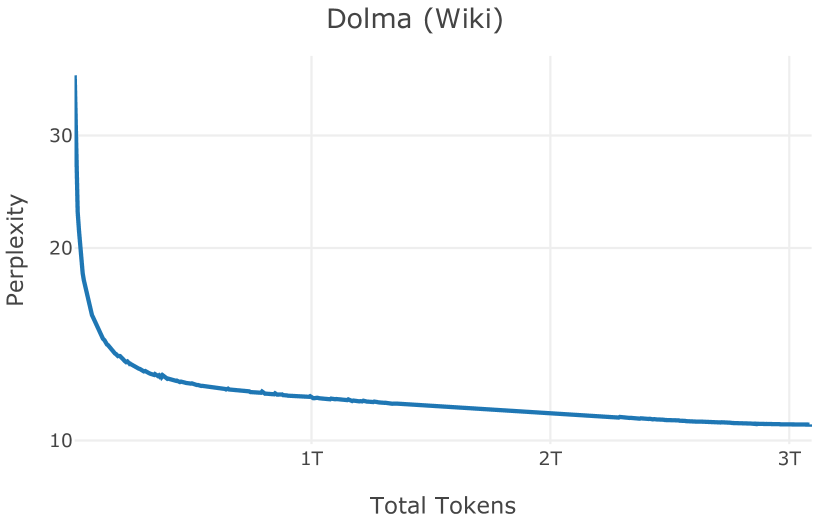
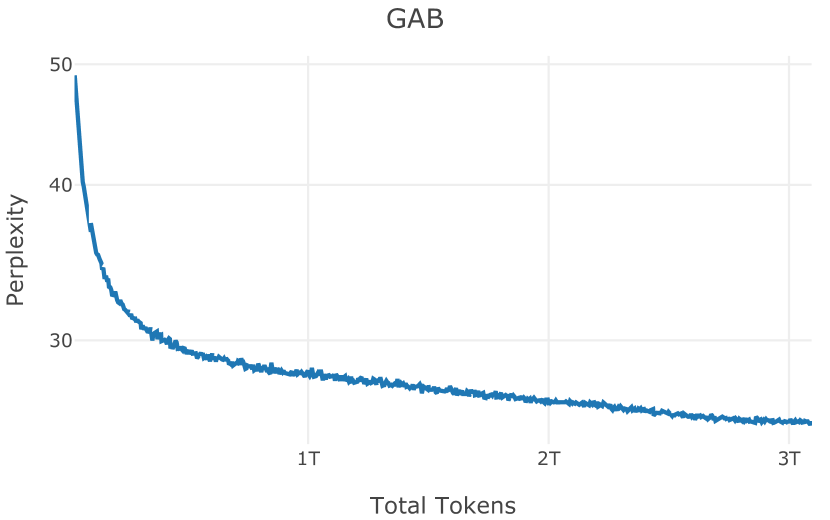
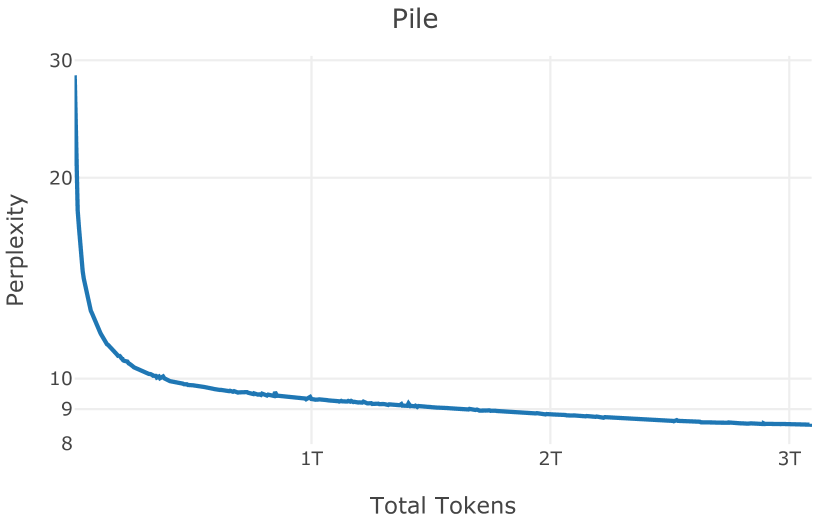
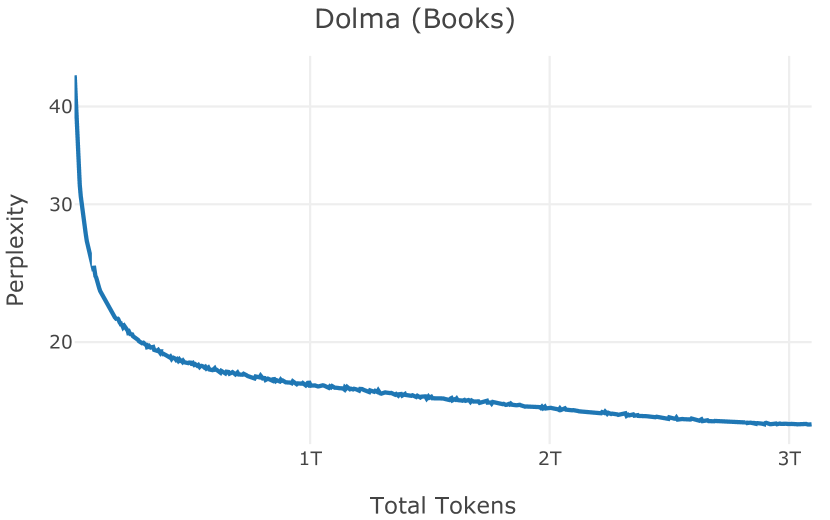
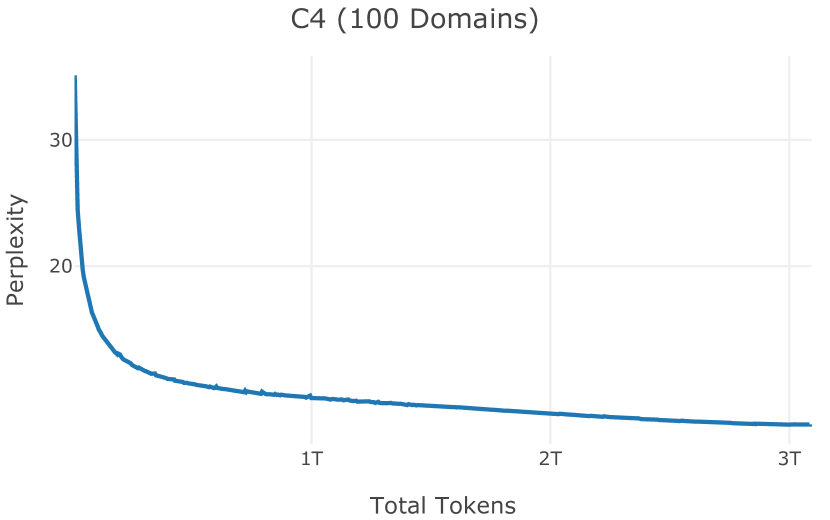
在图13中,我们评估了用于训练Olmo-1b的Dolma mix与其他流行的预训练语料库在模型困惑度方面的比较,其中除预之外的所有其他变量训练数据受到控制。 特别是,我们将每个模型训练的令牌数量固定为 150B,以便数据规模和学习率计划的差异不会与我们打算研究的数据组合的效果相混淆。 此分析使用 Paloma 的 1B 基线并评估 Paloma 的最高级别指标,该指标计算来自 11 个数据源的测试集组合的困惑度。 比较这些基线的其他更细粒度的困惑结果可在 Magnusson 等人 (2023) 中找到。 目前的分析排除了未公开的、涉及边缘或有毒文本的来源,或者包含我们使用的基准净化方法不支持的代码数据的来源。 剩下 C4 (Raffel 等人, 2020)、mC4-en (Chung 等人, 2023)、Wikitext 103 (Merity 等人, 2016) t2>、Penn Treebank (Marcus 等人, 1999; Nunes, 2020)、RedPajama (Together Computer, 2023c)、Falcon-RefinedWeb (Penedo 等人, 2023)、卓玛(本作品)、M2D2 S2ORC (Reid 等人, 2022)、M2D2 Wikipedia (Reid 等人, 2022)、C4 100 域(Chronopoulou 等人,2022),以及 Dolma 100 Subreddits(本作品)。
我们的受控困惑度分析揭示了包含来自不同来源的非常见爬网数据的重要性。 我们使用 Paloma 的指标揭示了模型如何适应更异构的数据,因为它平等地对每个源中的标记域进行采样,而不是按照源中的不等比例进行采样。 直观上,在 Pile 上训练的基线非常适合此类数据,因为预训练语料库主要来自此类较小的、精心挑选的来源。 但由于我们希望扩展语料库中的标记总数,因此面临的挑战是如何集成更多可用的 Common Crawl 数据,同时又不损失诸如 Paloma 指标等各种评估的样本效率。 在这种情况下,我们看到 Dolma 基线几乎与 Pile 基线的性能曲线匹配,尽管所包含的 Common Crawl 数据的比例要高出 4 倍多。
5发布 Dolma
风险缓解
我们认识到,从大型网络爬取中获得的任何数据集都将包含事实不正确的信息、有毒语言、仇恨言论、PII 和其他类型的有害内容。 虽然我们已经考虑到这一点,努力整理该数据集,但我们认为最好从多个方向来降低风险,包括仔细考虑许可证和访问控制。
版权
虽然我们使用的大多数数据集都是在考虑版权和许可的情况下进行策划的(例如,peS2o 中的开放获取论文(Soldaini 和 Lo,2023)、Stack 中的开源存储库(Kocetkov 等人, 2022))或已经获得许可(例如,维基百科是在知识共享许可下发布的),我们认识到大型网络抓取也将包含受版权保护的材料。 然而,鉴于当前的工具,不可能在如此规模的语料库中可靠或可扩展地检测受版权保护的材料。 我们决定公开发布 Dolma 是出于多种考虑,包括我们所有的数据源都是公开的,并且已经在大规模语言模型预训练(开放和封闭)中使用,我们建议读者参考我们对人工智能和人工智能的公开立场合理使用(Farhadi 等人,2023)。
我们认识到人工智能的法律和道德环境正在迅速变化,我们计划在新信息出现时重新审视我们的选择。
参考
- Abbas et al. (2023) Amro Abbas, Kushal Tirumala, Daniel Simig, Surya Ganguli, and Ari S. Morcos. Semdedup: Data-efficient learning at web-scale through semantic deduplication. ArXiv, abs/2303.09540, 2023. URL https://api.semanticscholar.org/CorpusID:257557221.
- Acs (2019) Judit Acs. Exploring BERT’s Vocabulary, 2019.
- Agarwal et al. (2009) Amit Agarwal, Hema Swetha Koppula, Krishna P. Leela, Krishna Prasad Chitrapura, Sachin Garg, Pavan Kumar GM, Chittaranjan Haty, Anirban Roy, and Amit Sasturkar. Url normalization for de-duplication of web pages. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, CIKM ’09, page 1987–1990, New York, NY, USA, 2009. Association for Computing Machinery. ISBN 9781605585123. doi: 10.1145/1645953.1646283. URL https://doi.org/10.1145/1645953.1646283.
- Ahia et al. (2023) Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David R. Mortensen, Noah A. Smith, and Yulia Tsvetkov. Do all languages cost the same? tokenization in the era of commercial language models, 2023.
- Allal et al. (2023) Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferrandis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo García del Río, Qian Liu, Shamik Bose, Urvashi Bhattacharyya, Terry Yue Zhuo, Ian Yu, Paulo Villegas, Marco Zocca, Sourab Mangrulkar, David Lansky, Huu Nguyen, Danish Contractor, Luis Villa, Jia Li, Dzmitry Bahdanau, Yacine Jernite, Sean Hughes, Daniel Fried, Arjun Guha, Harm de Vries, and Leandro von Werra. SantaCoder: don’t reach for the stars! arXiv [cs.SE], January 2023.
- Almazrouei et al. (2023) Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Merouane Debbah, Etienne Goffinet, Daniel Heslow, Julien Launay, Quentin Malartic, Badreddine Noune, Baptiste Pannier, and Guilherme Penedo. Falcon-40B: an open large language model with state-of-the-art performance. TII UAE, 2023.
- Angelescu, Radu (2013) Angelescu, Radu. GutenbergPy. https://github.com/raduangelescu/gutenbergpy, 2013. Version 0.3.5 [accessed August 2023].
- Anil et al. (2023) Rohan Anil, Andrew M. Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Tachard Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Z. Chen, Eric Chu, J. Clark, Laurent El Shafey, Yanping Huang, Kathleen S. Meier-Hellstern, Gaurav Mishra, Erica Moreira, Mark Omernick, Kevin Robinson, Sebastian Ruder, Yi Tay, Kefan Xiao, Yuanzhong Xu, Yujing Zhang, Gustavo Hernandez Abrego, Junwhan Ahn, Jacob Austin, Paul Barham, Jan A. Botha, James Bradbury, Siddhartha Brahma, Kevin Michael Brooks, Michele Catasta, Yongzhou Cheng, Colin Cherry, Christopher A. Choquette-Choo, Aakanksha Chowdhery, C Crépy, Shachi Dave, Mostafa Dehghani, Sunipa Dev, Jacob Devlin, M. C. D’iaz, Nan Du, Ethan Dyer, Vladimir Feinberg, Fan Feng, Vlad Fienber, Markus Freitag, Xavier García, Sebastian Gehrmann, Lucas González, Guy Gur-Ari, Steven Hand, Hadi Hashemi, Le Hou, Joshua Howland, An Ren Hu, Jeffrey Hui, Jeremy Hurwitz, Michael Isard, Abe Ittycheriah, Matthew Jagielski, Wen Hao Jia, Kathleen Kenealy, Maxim Krikun, Sneha Kudugunta, Chang Lan, Katherine Lee, Benjamin Lee, Eric Li, Mu-Li Li, Wei Li, Yaguang Li, Jun Yu Li, Hyeontaek Lim, Han Lin, Zhong-Zhong Liu, Frederick Liu, Marcello Maggioni, Aroma Mahendru, Joshua Maynez, Vedant Misra, Maysam Moussalem, Zachary Nado, John Nham, Eric Ni, Andrew Nystrom, Alicia Parrish, Marie Pellat, Martin Polacek, Alex Polozov, Reiner Pope, Siyuan Qiao, Emily Reif, Bryan Richter, Parker Riley, Alexandra Ros, Aurko Roy, Brennan Saeta, Rajkumar Samuel, Renee Marie Shelby, Ambrose Slone, Daniel Smilkov, David R. So, Daniela Sohn, Simon Tokumine, Dasha Valter, Vijay Vasudevan, Kiran Vodrahalli, Xuezhi Wang, Pidong Wang, Zirui Wang, Tao Wang, John Wieting, Yuhuai Wu, Ke Xu, Yunhan Xu, Lin Wu Xue, Pengcheng Yin, Jiahui Yu, Qiaoling Zhang, Steven Zheng, Ce Zheng, Wei Zhou, Denny Zhou, Slav Petrov, and Yonghui Wu. Palm 2 technical report. ArXiv, abs/2305.10403, 2023. URL https://api.semanticscholar.org/CorpusID:258740735.
- Anthropic (2023) Anthropic. Introducing Claude. https://www.anthropic.com/index/introducing-claude, 2023.
- Aura et al. (2006) Tuomas Aura, Thomas A. Kuhn, and Michael Roe. Scanning electronic documents for personally identifiable information. Association for Computing Machinery, Inc., October 2006. URL https://www.microsoft.com/en-us/research/publication/scanning-electronic-documents-for-personally-identifiable-information/.
- Ayoola et al. (2022) Tom Ayoola, Shubhi Tyagi, Joseph Fisher, Christos Christodoulopoulos, and Andrea Pierleoni. ReFinED: An efficient zero-shot-capable approach to end-to-end entity linking. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Track, pages 209–220, Hybrid: Seattle, Washington + Online, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-industry.24. URL https://aclanthology.org/2022.naacl-industry.24.
- Bach et al. (2022) Stephen Bach, Victor Sanh, Zheng Xin Yong, Albert Webson, Colin Raffel, Nihal V. Nayak, Abheesht Sharma, Taewoon Kim, M Saiful Bari, Thibault Fevry, Zaid Alyafeai, Manan Dey, Andrea Santilli, Zhiqing Sun, Srulik Ben-david, Canwen Xu, Gunjan Chhablani, Han Wang, Jason Fries, Maged Al-shaibani, Shanya Sharma, Urmish Thakker, Khalid Almubarak, Xiangru Tang, Dragomir Radev, Mike Tian-jian Jiang, and Alexander Rush. PromptSource: An integrated development environment and repository for natural language prompts. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 93–104, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-demo.9. URL https://aclanthology.org/2022.acl-demo.9.
- Baumgartner et al. (2020a) Jason Baumgartner, Savvas Zannettou, Brian Keegan, Megan Squire, and Jeremy Blackburn. The pushshift reddit dataset. ArXiv, abs/2001.08435, 2020a. URL https://api.semanticscholar.org/CorpusID:210868223.
- Baumgartner et al. (2020b) Jason Baumgartner, Savvas Zannettou, Brian Keegan, Megan Squire, and Jeremy Blackburn. The pushshift reddit dataset. arXiv [cs.SI], January 2020b.
- Biderman et al. (2023) Stella Rose Biderman, Hailey Schoelkopf, Quentin G. Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling. ArXiv, abs/2304.01373, 2023. URL https://api.semanticscholar.org/CorpusID:257921893.
- Birhane et al. (2023a) Abeba Birhane, Vinay Prabhu, Sang Han, Vishnu Naresh Boddeti, and Alexandra Sasha Luccioni. Into the laions den: Investigating hate in multimodal datasets. ArXiv, abs/2311.03449, 2023a. URL https://api.semanticscholar.org/CorpusID:265043448.
- Birhane et al. (2023b) Abeba Birhane, Vinay Uday Prabhu, Sanghyun Han, and Vishnu Naresh Boddeti. On hate scaling laws for data-swamps. ArXiv, abs/2306.13141, 2023b. URL https://api.semanticscholar.org/CorpusID:259243810.
- Bisk et al. (2019) Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. arXiv [cs.CL], November 2019.
- Black et al. (2022) Sid Black, Stella Rose Biderman, Eric Hallahan, Quentin G. Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Martin Pieler, USVSN Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Benqi Wang, and Samuel Weinbach. Gpt-neox-20b: An open-source autoregressive language model. ArXiv, abs/2204.06745, 2022. URL https://api.semanticscholar.org/CorpusID:248177957.
- Blevins and Zettlemoyer (2022) Terra Blevins and Luke Zettlemoyer. Language contamination helps explains the cross-lingual capabilities of English pretrained models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3563–3574, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.233.
- Blodgett et al. (2016) Su Lin Blodgett, Lisa Green, and Brendan O’Connor. Demographic dialectal variation in social media: A case study of African-American English. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1119–1130, Austin, Texas, November 2016. Association for Computational Linguistics. doi: 10.18653/v1/D16-1120. URL https://aclanthology.org/D16-1120.
- Bloom (1970) Burton H Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7):422–426, July 1970. ISSN 0001-0782,1557-7317. doi: 10.1145/362686.362692.
- Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack Rae, Erich Elsen, and Laurent Sifre. Improving language models by retrieving from trillions of tokens. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors, Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 2206–2240. PMLR, 17–23 Jul 2022. URL https://proceedings.mlr.press/v162/borgeaud22a.html.
- Bowman et al. (2015) Samuel Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 632–642, 2015.
- Broder (2002) A Z Broder. On the resemblance and containment of documents. In Proceedings. Compression and Complexity of SEQUENCES 1997 (Cat. No.97TB100171), pages 21–29. IEEE Comput. Soc, 2002. ISBN 9780818681325. doi: 10.1109/sequen.1997.666900.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, T. J. Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeff Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. ArXiv, abs/2005.14165, 2020. URL https://api.semanticscholar.org/CorpusID:218971783.
- Camburu et al. (2018) Oana-Maria Camburu, Tim Rocktäschel, Thomas Lukasiewicz, and Phil Blunsom. e-snli: Natural language inference with natural language explanations. Advances in Neural Information Processing Systems, 31, 2018.
- Carlini et al. (2022a) Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. Quantifying memorization across neural language models. arXiv [cs.LG], February 2022a.
- Carlini et al. (2022b) Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramèr, and Chiyuan Zhang. Quantifying memorization across neural language models. ArXiv, abs/2202.07646, 2022b. URL https://api.semanticscholar.org/CorpusID:246863735.
- Caselli et al. (2021) Tommaso Caselli, Valerio Basile, Jelena Mitrović, and Michael Granitzer. HateBERT: Retraining BERT for abusive language detection in English. In Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021), pages 17–25, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.woah-1.3. URL https://aclanthology.org/2021.woah-1.3.
- Chang et al. (2023) Kent K. Chang, Mackenzie Cramer, Sandeep Soni, and David Bamman. Speak, memory: An archaeology of books known to chatgpt/gpt-4. ArXiv, abs/2305.00118, 2023. URL https://api.semanticscholar.org/CorpusID:258426273.
- Chen et al. (2021a) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code, 2021a.
- Chen et al. (2021b) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code. July 2021b.
- Chen et al. (2023a) Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Yao Liu, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V Le. Symbolic discovery of optimization algorithms. February 2023a.
- Chen et al. (2023b) Yang Chen, Ethan Mendes, Sauvik Das, Wei Xu, and Alan Ritter. Can language models be instructed to protect personal information? arXiv [cs.CL], October 2023b.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam M. Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Benton C. Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier García, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Díaz, Orhan Firat, Michele Catasta, Jason Wei, Kathleen S. Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. Palm: Scaling language modeling with pathways. ArXiv, abs/2204.02311, 2022. URL https://api.semanticscholar.org/CorpusID:247951931.
- Chronopoulou et al. (2022) Alexandra Chronopoulou, Matthew Peters, and Jesse Dodge. Efficient hierarchical domain adaptation for pretrained language models. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1336–1351, Seattle, United States, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.96. URL https://aclanthology.org/2022.naacl-main.96.
- Chung et al. (2023) Hyung Won Chung, Noah Constant, Xavier García, Adam Roberts, Yi Tay, Sharan Narang, and Orhan Firat. Unimax: Fairer and more effective language sampling for large-scale multilingual pretraining. ArXiv, abs/2304.09151, 2023. URL https://api.semanticscholar.org/CorpusID:258187051.
- cjadams et al. (2017) cjadams, Jeffrey Sorensen, Julia Elliott, Lucas Dixon, Mark McDonald, nithum, and Will Cukierski. Toxic comment classification challenge, 2017. URL https://kaggle.com/competitions/jigsaw-toxic-comment-classification-challenge.
- Clark et al. (2019) Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044, 2019.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge. March 2018.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. ArXiv, abs/2110.14168, 2021. URL https://api.semanticscholar.org/CorpusID:239998651.
- Common Crawl (2016) Common Crawl. cc-crawl-statistics. https://github.com/commoncrawl/cc-crawl-statistics, 2016. [accessed August 2023].
- Creative Commons (2013) Creative Commons. Attribution-ShareAlike 4.0 International. https://creativecommons.org/licenses/by-sa/4.0/legalcode, 2013. [accessed August 2023].
- Davis and Graham (2021) Jenny L Davis and Timothy Graham. Emotional consequences and attention rewards: the social effects of ratings on reddit. Information, communication and society, 24(5):649–666, April 2021. ISSN 1369-118X,1468-4462. doi: 10.1080/1369118x.2021.1874476.
- Dernoncourt et al. (2017) Franck Dernoncourt, Ji Young Lee, Ozlem Uzuner, and Peter Szolovits. De-identification of patient notes with recurrent neural networks. Journal of the American Medical Informatics Association: JAMIA, 24(3):596–606, May 2017. ISSN 1067-5027,1527-974X. doi: 10.1093/jamia/ocw156.
- Dodge et al. (2021) Jesse Dodge, Maarten Sap, Ana Marasović, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. Documenting large webtext corpora: A case study on the colossal clean crawled corpus. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 1286–1305, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.98. URL https://aclanthology.org/2021.emnlp-main.98.
- Elazar et al. (2023) Yanai Elazar, Akshita Bhagia, Ian Magnusson, Abhilasha Ravichander, Dustin Schwenk, Alane Suhr, Pete Walsh, Dirk Groeneveld, Luca Soldaini, Sameer Singh, et al. What’s in my big data? arXiv preprint arXiv:2310.20707, 2023. URL https://arxiv.org/abs/2310.20707.
- Farhadi et al. (2023) Ali Farhadi, David Atkinson, Chris Callison-Burch, Nicole DeCario, Jennifer Dumas, Kyle Lo, Crystal Nam, and Luca Soldaini. AI2 Response to Notice of Inquiry and Request for Comments, 2023. URL https://www.regulations.gov/comment/COLC-2023-0006-8762.
- Feng et al. (2023) Shangbin Feng, Chan Young Park, Yuhan Liu, and Yulia Tsvetkov. From pretraining data to language models to downstream tasks: Tracking the trails of political biases leading to unfair NLP models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11737–11762, Toronto, Canada, July 2023. Association for Computational Linguistics. URL https://aclanthology.org/2023.acl-long.656.
- Gao (2021) Leo Gao. An empirical exploration in quality filtering of text data. CoRR, abs/2109.00698, 2021. URL https://arxiv.org/abs/2109.00698.
- Gao et al. (2020) Leo Gao, Stella Rose Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. ArXiv, abs/2101.00027, 2020. URL https://api.semanticscholar.org/CorpusID:230435736.
- Gao et al. (2022) Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. arXiv preprint arXiv:2211.10435, 2022.
- Gardent et al. (2017) Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. Creating training corpora for NLG micro-planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 179–188, Vancouver, Canada, July 2017. Association for Computational Linguistics. doi: 10.18653/v1/P17-1017. URL https://aclanthology.org/P17-1017.
- Gebru et al. (2021) Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. Datasheets for datasets. Communications of the ACM, 64(12):86–92, 2021.
- Gehman et al. (2020) Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. RealToxicityPrompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.301. URL https://aclanthology.org/2020.findings-emnlp.301.
- Gemini Team et al. (2023) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, David Silver, Slav Petrov, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy Lillicrap, Angeliki Lazaridou, Orhan Firat, James Molloy, Michael Isard, Paul R Barham, Tom Hennigan, Benjamin Lee, Fabio Viola, Malcolm Reynolds, Yuanzhong Xu, Ryan Doherty, Eli Collins, Clemens Meyer, Eliza Rutherford, Erica Moreira, Kareem Ayoub, Megha Goel, George Tucker, Enrique Piqueras, Maxim Krikun, Iain Barr, Nikolay Savinov, Ivo Danihelka, Becca Roelofs, Anaïs White, Anders Andreassen, Tamara von Glehn, Lakshman Yagati, Mehran Kazemi, Lucas Gonzalez, Misha Khalman, Jakub Sygnowski, Alexandre Frechette, Charlotte Smith, Laura Culp, Lev Proleev, Yi Luan, Xi Chen, James Lottes, Nathan Schucher, Federico Lebron, Alban Rrustemi, Natalie Clay, Phil Crone, Tomas Kocisky, Jeffrey Zhao, Bartek Perz, Dian Yu, Heidi Howard, Adam Bloniarz, Jack W Rae, Han Lu, Laurent Sifre, Marcello Maggioni, Fred Alcober, Dan Garrette, Megan Barnes, Shantanu Thakoor, Jacob Austin, Gabriel Barth-Maron, William Wong, Rishabh Joshi, Rahma Chaabouni, Deeni Fatiha, Arun Ahuja, Ruibo Liu, Yunxuan Li, Sarah Cogan, Jeremy Chen, Chao Jia, Chenjie Gu, Qiao Zhang, Jordan Grimstad, Ale Jakse Hartman, Martin Chadwick, Gaurav Singh Tomar, Xavier Garcia, Evan Senter, Emanuel Taropa, Thanumalayan Sankaranarayana Pillai, Jacob Devlin, Michael Laskin, Diego de Las Casas, Dasha Valter, Connie Tao, Lorenzo Blanco, Adrià Puigdomènech Badia, David Reitter, Mianna Chen, Jenny Brennan, Clara Rivera, Sergey Brin, Shariq Iqbal, Gabriela Surita, Jane Labanowski, Abhi Rao, Stephanie Winkler, Emilio Parisotto, Yiming Gu, Kate Olszewska, Yujing Zhang, Ravi Addanki, Antoine Miech, Annie Louis, Laurent El Shafey, Denis Teplyashin, Geoff Brown, Elliot Catt, Nithya Attaluri, Jan Balaguer, Jackie Xiang, Pidong Wang, Zoe Ashwood, Anton Briukhov, Albert Webson, Sanjay Ganapathy, Smit Sanghavi, Ajay Kannan, Ming-Wei Chang, Axel Stjerngren, Josip Djolonga, Yuting Sun, Ankur Bapna, Matthew Aitchison, Pedram Pejman, Henryk Michalewski, Tianhe Yu, Cindy Wang, Juliette Love, Junwhan Ahn, Dawn Bloxwich, Kehang Han, Peter Humphreys, Thibault Sellam, James Bradbury, Varun Godbole, Sina Samangooei, Bogdan Damoc, Alex Kaskasoli, Sébastien M R Arnold, Vijay Vasudevan, Shubham Agrawal, Jason Riesa, Dmitry Lepikhin, Richard Tanburn, Srivatsan Srinivasan, Hyeontaek Lim, Sarah Hodkinson, Pranav Shyam, Johan Ferret, Steven Hand, Ankush Garg, Tom Le Paine, Jian Li, Yujia Li, Minh Giang, Alexander Neitz, Zaheer Abbas, Sarah York, Machel Reid, Elizabeth Cole, Aakanksha Chowdhery, Dipanjan Das, Dominika Rogozińska, Vitaly Nikolaev, Pablo Sprechmann, Zachary Nado, Lukas Zilka, Flavien Prost, Luheng He, Marianne Monteiro, Gaurav Mishra, Chris Welty, Josh Newlan, Dawei Jia, Miltiadis Allamanis, Clara Huiyi Hu, Raoul de Liedekerke, Justin Gilmer, Carl Saroufim, Shruti Rijhwani, Shaobo Hou, Disha Shrivastava, Anirudh Baddepudi, Alex Goldin, Adnan Ozturel, Albin Cassirer, Yunhan Xu, Daniel Sohn, Devendra Sachan, Reinald Kim Amplayo, Craig Swanson, Dessie Petrova, Shashi Narayan, Arthur Guez, Siddhartha Brahma, Jessica Landon, Miteyan Patel, Ruizhe Zhao, Kevin Villela, Luyu Wang, Wenhao Jia, Matthew Rahtz, Mai Giménez, Legg Yeung, Hanzhao Lin, James Keeling, Petko Georgiev, Diana Mincu, Boxi Wu, Salem Haykal, Rachel Saputro, Kiran Vodrahalli, James Qin, Zeynep Cankara, Abhanshu Sharma, Nick Fernando, Will Hawkins, Behnam Neyshabur, Solomon Kim, Adrian Hutter, Priyanka Agrawal, Alex Castro-Ros, George van den Driessche, Tao Wang, Fan Yang, Shuo-Yiin Chang, Paul Komarek, Ross McIlroy, Mario Lučić, Guodong Zhang, Wael Farhan, Michael Sharman, Paul Natsev, Paul Michel, Yong Cheng, Yamini Bansal, Siyuan Qiao, Kris Cao, Siamak Shakeri, Christina Butterfield, Justin Chung, Paul Kishan Rubenstein, Shivani Agrawal, Arthur Mensch, Kedar Soparkar, Karel Lenc, Timothy Chung, Aedan Pope, Loren Maggiore, Jackie Kay, Priya Jhakra, Shibo Wang, Joshua Maynez, Mary Phuong, Taylor Tobin, Andrea Tacchetti, Maja Trebacz, Kevin Robinson, Yash Katariya, Sebastian Riedel, Paige Bailey, Kefan Xiao, Nimesh Ghelani, Lora Aroyo, Ambrose Slone, Neil Houlsby, Xuehan Xiong, Zhen Yang, Elena Gribovskaya, Jonas Adler, Mateo Wirth, Lisa Lee, Music Li, Thais Kagohara, Jay Pavagadhi, Sophie Bridgers, Anna Bortsova, Sanjay Ghemawat, Zafarali Ahmed, Tianqi Liu, Richard Powell, Vijay Bolina, Mariko Iinuma, Polina Zablotskaia, James Besley, Da-Woon Chung, Timothy Dozat, Ramona Comanescu, Xiance Si, Jeremy Greer, Guolong Su, Martin Polacek, Raphaël Lopez Kaufman, Simon Tokumine, Hexiang Hu, Elena Buchatskaya, Yingjie Miao, Mohamed Elhawaty, Aditya Siddhant, Nenad Tomasev, Jinwei Xing, Christina Greer, Helen Miller, Shereen Ashraf, Aurko Roy, Zizhao Zhang, Ada Ma, Angelos Filos, Milos Besta, Rory Blevins, Ted Klimenko, Chih-Kuan Yeh, Soravit Changpinyo, Jiaqi Mu, Oscar Chang, Mantas Pajarskas, Carrie Muir, Vered Cohen, Charline Le Lan, Krishna Haridasan, Amit Marathe, Steven Hansen, Sholto Douglas, Rajkumar Samuel, Mingqiu Wang, Sophia Austin, Chang Lan, Jiepu Jiang, Justin Chiu, Jaime Alonso Lorenzo, Lars Lowe Sjösund, Sébastien Cevey, Zach Gleicher, Thi Avrahami, Anudhyan Boral, Hansa Srinivasan, Vittorio Selo, Rhys May, Konstantinos Aisopos, Léonard Hussenot, Livio Baldini Soares, Kate Baumli, Michael B Chang, Adrià Recasens, Ben Caine, Alexander Pritzel, Filip Pavetic, Fabio Pardo, Anita Gergely, Justin Frye, Vinay Ramasesh, Dan Horgan, Kartikeya Badola, Nora Kassner, Subhrajit Roy, Ethan Dyer, Víctor Campos, Alex Tomala, Yunhao Tang, Dalia El Badawy, Elspeth White, Basil Mustafa, Oran Lang, Abhishek Jindal, Sharad Vikram, Zhitao Gong, Sergi Caelles, Ross Hemsley, Gregory Thornton, Fangxiaoyu Feng, Wojciech Stokowiec, Ce Zheng, Phoebe Thacker, Çağlar Ünlü, Zhishuai Zhang, Mohammad Saleh, James Svensson, Max Bileschi, Piyush Patil, Ankesh Anand, Roman Ring, Katerina Tsihlas, Arpi Vezer, Marco Selvi, Toby Shevlane, Mikel Rodriguez, Tom Kwiatkowski, Samira Daruki, Keran Rong, Allan Dafoe, Nicholas FitzGerald, Keren Gu-Lemberg, Mina Khan, Lisa Anne Hendricks, Marie Pellat, Vladimir Feinberg, James Cobon-Kerr, Tara Sainath, Maribeth Rauh, Sayed Hadi Hashemi, Richard Ives, Yana Hasson, Yaguang Li, Eric Noland, Yuan Cao, Nathan Byrd, Le Hou, Qingze Wang, Thibault Sottiaux, Michela Paganini, Jean-Baptiste Lespiau, Alexandre Moufarek, Samer Hassan, Kaushik Shivakumar, Joost van Amersfoort, Amol Mandhane, Pratik Joshi, Anirudh Goyal, Matthew Tung, Andrew Brock, Hannah Sheahan, Vedant Misra, Cheng Li, Nemanja Rakićević, Mostafa Dehghani, Fangyu Liu, Sid Mittal, Junhyuk Oh, Seb Noury, Eren Sezener, Fantine Huot, Matthew Lamm, Nicola De Cao, Charlie Chen, Gamaleldin Elsayed, Ed Chi, Mahdis Mahdieh, Ian Tenney, Nan Hua, Ivan Petrychenko, Patrick Kane, Dylan Scandinaro, Rishub Jain, Jonathan Uesato, Romina Datta, Adam Sadovsky, Oskar Bunyan, Dominik Rabiej, Shimu Wu, John Zhang, Gautam Vasudevan, Edouard Leurent, Mahmoud Alnahlawi, Ionut Georgescu, Nan Wei, Ivy Zheng, Betty Chan, Pam G Rabinovitch, Piotr Stanczyk, Ye Zhang, David Steiner, Subhajit Naskar, Michael Azzam, Matthew Johnson, Adam Paszke, Chung-Cheng Chiu, Jaume Sanchez Elias, Afroz Mohiuddin, Faizan Muhammad, Jin Miao, Andrew Lee, Nino Vieillard, Sahitya Potluri, Jane Park, Elnaz Davoodi, Jiageng Zhang, Jeff Stanway, Drew Garmon, Abhijit Karmarkar, Zhe Dong, Jong Lee, Aviral Kumar, Luowei Zhou, Jonathan Evens, William Isaac, Zhe Chen, Johnson Jia, Anselm Levskaya, Zhenkai Zhu, Chris Gorgolewski, Peter Grabowski, Yu Mao, Alberto Magni, Kaisheng Yao, Javier Snaider, Norman Casagrande, Paul Suganthan, Evan Palmer, Geoffrey Irving, Edward Loper, Manaal Faruqui, Isha Arkatkar, Nanxin Chen, Izhak Shafran, Michael Fink, Alfonso Castaño, Irene Giannoumis, Wooyeol Kim, Mikołaj Rybiński, Ashwin Sreevatsa, Jennifer Prendki, David Soergel, Adrian Goedeckemeyer, Willi Gierke, Mohsen Jafari, Meenu Gaba, Jeremy Wiesner, Diana Gage Wright, Yawen Wei, Harsha Vashisht, Yana Kulizhskaya, Jay Hoover, Maigo Le, Lu Li, Chimezie Iwuanyanwu, Lu Liu, Kevin Ramirez, Andrey Khorlin, Albert Cui, Tian Lin, Marin Georgiev, Marcus Wu, Ricardo Aguilar, Keith Pallo, Abhishek Chakladar, Alena Repina, Xihui Wu, Tom van der Weide, Priya Ponnapalli, Caroline Kaplan, Jiri Simsa, Shuangfeng Li, Olivier Dousse, Fan Yang, Jeff Piper, Nathan Ie, Minnie Lui, Rama Pasumarthi, Nathan Lintz, Anitha Vijayakumar, Lam Nguyen Thiet, Daniel Andor, Pedro Valenzuela, Cosmin Paduraru, Daiyi Peng, Katherine Lee, Shuyuan Zhang, Somer Greene, Duc Dung Nguyen, Paula Kurylowicz, Sarmishta Velury, Sebastian Krause, Cassidy Hardin, Lucas Dixon, Lili Janzer, Kiam Choo, Ziqiang Feng, Biao Zhang, Achintya Singhal, Tejasi Latkar, Mingyang Zhang, Quoc Le, Elena Allica Abellan, Dayou Du, Dan McKinnon, Natasha Antropova, Tolga Bolukbasi, Orgad Keller, David Reid, Daniel Finchelstein, Maria Abi Raad, Remi Crocker, Peter Hawkins, Robert Dadashi, Colin Gaffney, Sid Lall, Ken Franko, Egor Filonov, Anna Bulanova, Rémi Leblond, Vikas Yadav, Shirley Chung, Harry Askham, Luis C Cobo, Kelvin Xu, Felix Fischer, Jun Xu, Christina Sorokin, Chris Alberti, Chu-Cheng Lin, Colin Evans, Hao Zhou, Alek Dimitriev, Hannah Forbes, Dylan Banarse, Zora Tung, Jeremiah Liu, Mark Omernick, Colton Bishop, Chintu Kumar, Rachel Sterneck, Ryan Foley, Rohan Jain, Swaroop Mishra, Jiawei Xia, Taylor Bos, Geoffrey Cideron, Ehsan Amid, Francesco Piccinno, Xingyu Wang, Praseem Banzal, Petru Gurita, Hila Noga, Premal Shah, Daniel J Mankowitz, Alex Polozov, Nate Kushman, Victoria Krakovna, Sasha Brown, Mohammadhossein Bateni, Dennis Duan, Vlad Firoiu, Meghana Thotakuri, Tom Natan, Anhad Mohananey, Matthieu Geist, Sidharth Mudgal, Sertan Girgin, Hui Li, Jiayu Ye, Ofir Roval, Reiko Tojo, Michael Kwong, James Lee-Thorp, Christopher Yew, Quan Yuan, Sumit Bagri, Danila Sinopalnikov, Sabela Ramos, John Mellor, Abhishek Sharma, Aliaksei Severyn, Jonathan Lai, Kathy Wu, Heng-Tze Cheng, David Miller, Nicolas Sonnerat, Denis Vnukov, Rory Greig, Jennifer Beattie, Emily Caveness, Libin Bai, Julian Eisenschlos, Alex Korchemniy, Tomy Tsai, Mimi Jasarevic, Weize Kong, Phuong Dao, Zeyu Zheng, Frederick Liu, Fan Yang, Rui Zhu, Mark Geller, Tian Huey Teh, Jason Sanmiya, Evgeny Gladchenko, Nejc Trdin, Andrei Sozanschi, Daniel Toyama, Evan Rosen, Sasan Tavakkol, Linting Xue, Chen Elkind, Oliver Woodman, John Carpenter, George Papamakarios, Rupert Kemp, Sushant Kafle, Tanya Grunina, Rishika Sinha, Alice Talbert, Abhimanyu Goyal, Diane Wu, Denese Owusu-Afriyie, Cosmo Du, Chloe Thornton, Jordi Pont-Tuset, Pradyumna Narayana, Jing Li, Sabaer Fatehi, John Wieting, Omar Ajmeri, Benigno Uria, Tao Zhu, Yeongil Ko, Laura Knight, Amélie Héliou, Ning Niu, Shane Gu, Chenxi Pang, Dustin Tran, Yeqing Li, Nir Levine, Ariel Stolovich, Norbert Kalb, Rebeca Santamaria-Fernandez, Sonam Goenka, Wenny Yustalim, Robin Strudel, Ali Elqursh, Balaji Lakshminarayanan, Charlie Deck, Shyam Upadhyay, Hyo Lee, Mike Dusenberry, Zonglin Li, Xuezhi Wang, Kyle Levin, Raphael Hoffmann, Dan Holtmann-Rice, Olivier Bachem, Summer Yue, Sho Arora, Eric Malmi, Daniil Mirylenka, Qijun Tan, Christy Koh, Soheil Hassas Yeganeh, Siim Põder, Steven Zheng, Francesco Pongetti, Mukarram Tariq, Yanhua Sun, Lucian Ionita, Mojtaba Seyedhosseini, Pouya Tafti, Ragha Kotikalapudi, Zhiyu Liu, Anmol Gulati, Jasmine Liu, Xinyu Ye, Bart Chrzaszcz, Lily Wang, Nikhil Sethi, Tianrun Li, Ben Brown, Shreya Singh, Wei Fan, Aaron Parisi, Joe Stanton, Chenkai Kuang, Vinod Koverkathu, Christopher A Choquette-Choo, Yunjie Li, T J Lu, Abe Ittycheriah, Prakash Shroff, Pei Sun, Mani Varadarajan, Sanaz Bahargam, Rob Willoughby, David Gaddy, Ishita Dasgupta, Guillaume Desjardins, Marco Cornero, Brona Robenek, Bhavishya Mittal, Ben Albrecht, Ashish Shenoy, Fedor Moiseev, Henrik Jacobsson, Alireza Ghaffarkhah, Morgane Rivière, Alanna Walton, Clément Crepy, Alicia Parrish, Yuan Liu, Zongwei Zhou, Clement Farabet, Carey Radebaugh, Praveen Srinivasan, Claudia van der Salm, Andreas Fidjeland, Salvatore Scellato, Eri Latorre-Chimoto, Hanna Klimczak-Plucińska, David Bridson, Dario de Cesare, Tom Hudson, Piermaria Mendolicchio, Lexi Walker, Alex Morris, Ivo Penchev, Matthew Mauger, Alexey Guseynov, Alison Reid, Seth Odoom, Lucia Loher, Victor Cotruta, Madhavi Yenugula, Dominik Grewe, Anastasia Petrushkina, Tom Duerig, Antonio Sanchez, Steve Yadlowsky, Amy Shen, Amir Globerson, Adam Kurzrok, Lynette Webb, Sahil Dua, Dong Li, Preethi Lahoti, Surya Bhupatiraju, Dan Hurt, Haroon Qureshi, Ananth Agarwal, Tomer Shani, Matan Eyal, Anuj Khare, Shreyas Rammohan Belle, Lei Wang, Chetan Tekur, Mihir Sanjay Kale, Jinliang Wei, Ruoxin Sang, Brennan Saeta, Tyler Liechty, Yi Sun, Yao Zhao, Stephan Lee, Pandu Nayak, Doug Fritz, Manish Reddy Vuyyuru, John Aslanides, Nidhi Vyas, Martin Wicke, Xiao Ma, Taylan Bilal, Evgenii Eltyshev, Daniel Balle, Nina Martin, Hardie Cate, James Manyika, Keyvan Amiri, Yelin Kim, Xi Xiong, Kai Kang, Florian Luisier, Nilesh Tripuraneni, David Madras, Mandy Guo, Austin Waters, Oliver Wang, Joshua Ainslie, Jason Baldridge, Han Zhang, Garima Pruthi, Jakob Bauer, Feng Yang, Riham Mansour, Jason Gelman, Yang Xu, George Polovets, Ji Liu, Honglong Cai, Warren Chen, Xianghai Sheng, Emily Xue, Sherjil Ozair, Adams Yu, Christof Angermueller, Xiaowei Li, Weiren Wang, Julia Wiesinger, Emmanouil Koukoumidis, Yuan Tian, Anand Iyer, Madhu Gurumurthy, Mark Goldenson, Parashar Shah, M K Blake, Hongkun Yu, Anthony Urbanowicz, Jennimaria Palomaki, Chrisantha Fernando, Kevin Brooks, Ken Durden, Harsh Mehta, Nikola Momchev, Elahe Rahimtoroghi, Maria Georgaki, Amit Raul, Sebastian Ruder, Morgan Redshaw, Jinhyuk Lee, Komal Jalan, Dinghua Li, Ginger Perng, Blake Hechtman, Parker Schuh, Milad Nasr, Mia Chen, Kieran Milan, Vladimir Mikulik, Trevor Strohman, Juliana Franco, Tim Green, Demis Hassabis, Koray Kavukcuoglu, Jeffrey Dean, and Oriol Vinyals. Gemini: A family of highly capable multimodal models. arXiv [cs.CL], December 2023.
- Gordon et al. (2012) Andrew Gordon, Zornitsa Kozareva, and Melissa Roemmele. SemEval-2012 task 7: Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In Eneko Agirre, Johan Bos, Mona Diab, Suresh Manandhar, Yuval Marton, and Deniz Yuret, editors, *SEM 2012: The First Joint Conference on Lexical and Computational Semantics – Volume 1: Proceedings of the main conference and the shared task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012), pages 394–398, Montréal, Canada, 7-8 June 2012. Association for Computational Linguistics. URL https://aclanthology.org/S12-1052.
- Greenbaum (1991) Sidney Greenbaum. Ice: The international corpus of english. English Today, 7(4):3–7, 1991.
- Groeneveld et al. (2023) Dirk Groeneveld, Anas Awadalla, Iz Beltagy, Akshita Bhagia, Ian Magnusson, Hao Peng, Oyvind Tafjord, Pete Walsh, Kyle Richardson, and Jesse Dodge. Catwalk: A unified language model evaluation framework for many datasets. arXiv [cs.CL], December 2023.
- Groeneveld et al. (2024) Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, and Hannaneh Hajishirzi. OLMo: Accelerating the Science of Language Models. arXiv preprint, 2024.
- Grosse et al. (2023) Roger Baker Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, Evan Hubinger, Kamil.e Lukovsiut.e, Karina Nguyen, Nicholas Joseph, Sam McCandlish, Jared Kaplan, and Sam Bowman. Studying large language model generalization with influence functions. 2023. URL https://api.semanticscholar.org/CorpusID:260682872.
- Gururangan et al. (2022) Suchin Gururangan, Dallas Card, Sarah Dreier, Emily Gade, Leroy Wang, Zeyu Wang, Luke Zettlemoyer, and Noah A. Smith. Whose language counts as high quality? measuring language ideologies in text data selection. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2562–2580, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.165.
- Hammoudeh and Lowd (2022) Zayd Hammoudeh and Daniel Lowd. Training data influence analysis and estimation: A survey. ArXiv, abs/2212.04612, 2022. URL https://api.semanticscholar.org/CorpusID:254535627.
- Hartvigsen et al. (2022) Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar. ToxiGen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3309–3326, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.234. URL https://aclanthology.org/2022.acl-long.234.
- Hathurusinghe et al. (2021) Rajitha Hathurusinghe, Isar Nejadgholi, and Miodrag Bolic. A privacy-preserving approach to extraction of personal information through automatic annotation and federated learning. In Proceedings of the Third Workshop on Privacy in Natural Language Processing, pages 36–45, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.privatenlp-1.5. URL https://aclanthology.org/2021.privatenlp-1.5.
- Heafield (2011) Kenneth Heafield. KenLM: Faster and smaller language model queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, pages 187–197, Edinburgh, Scotland, July 2011. Association for Computational Linguistics. URL https://aclanthology.org/W11-2123.
- Henderson et al. (2019) Matthew Henderson, Paweł Budzianowski, Iñigo Casanueva, Sam Coope, Daniela Gerz, Girish Kumar, Nikola Mrkšić, Georgios Spithourakis, Pei-Hao Su, Ivan Vulic, and Tsung-Hsien Wen. A repository of conversational datasets. In Proceedings of the Workshop on NLP for Conversational AI, jul 2019. URL https://arxiv.org/abs/1904.06472. Data available at github.com/PolyAI-LDN/conversational-datasets.
- Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and L. Sifre. Training compute-optimal large language models. ArXiv, abs/2203.15556, 2022. URL https://api.semanticscholar.org/CorpusID:247778764.
- Hong et al. (2021) Jimin Hong, TaeHee Kim, Hyesu Lim, and Jaegul Choo. AVocaDo: Strategy for adapting vocabulary to downstream domain. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4692–4700, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.385. URL https://aclanthology.org/2021.emnlp-main.385.
- Joulin et al. (2016a) Armand Joulin, Edouard Grave, Piotr Bojanowski, Matthijs Douze, Hérve Jégou, and Tomas Mikolov. Fasttext.zip: Compressing text classification models. arXiv preprint arXiv:1612.03651, 2016a.
- Joulin et al. (2016b) Armand Joulin, Edouard Grave, Piotr Bojanowski, and Tomas Mikolov. Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759, 2016b.
- Kandpal et al. (2023) Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. Large language models struggle to learn long-tail knowledge. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 15696–15707. PMLR, 23–29 Jul 2023. URL https://proceedings.mlr.press/v202/kandpal23a.html.
- Kinney et al. (2023) Rodney Kinney, Chloe Anastasiades, Russell Authur, Iz Beltagy, Jonathan Bragg, Alexandra Buraczynski, Isabel Cachola, Stefan Candra, Yoganand Chandrasekhar, Arman Cohan, Miles Crawford, Doug Downey, Jason Dunkelberger, Oren Etzioni, Rob Evans, Sergey Feldman, Joseph Gorney, David Graham, Fangzhou Hu, Regan Huff, Daniel King, Sebastian Kohlmeier, Bailey Kuehl, Michael Langan, Daniel Lin, Haokun Liu, Kyle Lo, Jaron Lochner, Kelsey MacMillan, Tyler Murray, Chris Newell, Smita Rao, Shaurya Rohatgi, Paul Sayre, Zejiang Shen, Amanpreet Singh, Luca Soldaini, Shivashankar Subramanian, Amber Tanaka, Alex D. Wade, Linda Wagner, Lucy Lu Wang, Chris Wilhelm, Caroline Wu, Jiangjiang Yang, Angele Zamarron, Madeleine Van Zuylen, and Daniel S. Weld Weld. The Semantic Scholar Open Data Platform. arXiv preprint arXiv:2301.10140, 2023.
- Kirk and Nelson (2018) John Kirk and Gerald Nelson. The international corpus of english project: A progress report. World Englishes, 2018. URL https://api.semanticscholar.org/CorpusID:150172629.
- Kocetkov et al. (2022) Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, et al. The Stack: 3 TB of permissively licensed source code. arXiv preprint arXiv:2211.15533, 2022.
- Koppula et al. (2010) Hema Swetha Koppula, Krishna P. Leela, Amit Agarwal, Krishna Prasad Chitrapura, Sachin Garg, and Amit Sasturkar. Learning url patterns for webpage de-duplication. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, WSDM ’10, page 381–390, New York, NY, USA, 2010. Association for Computing Machinery. ISBN 9781605588896. doi: 10.1145/1718487.1718535. URL https://doi.org/10.1145/1718487.1718535.
- Kudo (2018) Taku Kudo. Subword regularization: Improving neural network translation models with multiple subword candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 66–75, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1007. URL https://aclanthology.org/P18-1007.
- Kudo and Richardson (2018) Taku Kudo and John Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71, Brussels, Belgium, November 2018. Association for Computational Linguistics. doi: 10.18653/v1/D18-2012. URL https://aclanthology.org/D18-2012.
- Laurenccon et al. (2023) Hugo Laurenccon, Lucile Saulnier, Thomas Wang, Christopher Akiki, Albert Villanova del Moral, Teven Le Scao, Leandro von Werra, Chenghao Mou, Eduardo Gonz’alez Ponferrada, Huu Nguyen, Jorg Frohberg, Mario vSavsko, Quentin Lhoest, Angelina McMillan-Major, Gérard Dupont, Stella Rose Biderman, Anna Rogers, Loubna Ben Allal, Francesco De Toni, Giada Pistilli, Olivier Nguyen, Somaieh Nikpoor, Maraim Masoud, Pierre Colombo, Javier de la Rosa, Paulo Villegas, Tristan Thrush, S. Longpre, Sebastian Nagel, Leon Weber, Manuel Sevilla Muñoz, Jian Zhu, Daniel Alexander van Strien, Zaid Alyafeai, Khalid Almubarak, Minh Chien Vu, Itziar Gonzalez-Dios, Aitor Soroa Etxabe, Kyle Lo, Manan Dey, Pedro Ortiz Suarez, Aaron Gokaslan, Shamik Bose, David Ifeoluwa Adelani, Long Phan, Hieu Trung Tran, Ian Yu, Suhas Pai, Jenny Chim, Violette Lepercq, Suzana Ilic, Margaret Mitchell, Sasha Luccioni, and Yacine Jernite. The bigscience roots corpus: A 1.6tb composite multilingual dataset. ArXiv, abs/2303.03915, 2023. URL https://api.semanticscholar.org/CorpusID:257378329.
- Le Scao et al. (2022) Teven Le Scao, Thomas Wang, Daniel Hesslow, Stas Bekman, M Saiful Bari, Stella Biderman, Hady Elsahar, Niklas Muennighoff, Jason Phang, Ofir Press, Colin Raffel, Victor Sanh, Sheng Shen, Lintang Sutawika, Jaesung Tae, Zheng Xin Yong, Julien Launay, and Iz Beltagy. What language model to train if you have one million GPU hours? In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 765–782, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.findings-emnlp.54.
- Lee et al. (2022) Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini. Deduplicating training data makes language models better. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8424–8445, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.577. URL https://aclanthology.org/2022.acl-long.577.
- Leong et al. (2022) Colin Leong, Joshua Nemecek, Jacob Mansdorfer, Anna Filighera, Abraham Owodunni, and Daniel Whitenack. Bloom library: Multimodal datasets in 300+ languages for a variety of downstream tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 8608–8621, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.590.
- Levesque et al. (2012) Hector J. Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge. In Proceedings of the Thirteenth International Conference on Principles of Knowledge Representation and Reasoning, KR’12, page 552–561. AAAI Press, 2012. ISBN 9781577355601. URL https://dl.acm.org/doi/10.5555/3031843.3031909.
- Lhoest et al. (2021) Quentin Lhoest, Albert Villanova del Moral, Patrick von Platen, Thomas Wolf, Mario Šaško, Yacine Jernite, Abhishek Thakur, Lewis Tunstall, Suraj Patil, Mariama Drame, Julien Chaumond, Julien Plu, Joe Davison, Simon Brandeis, Victor Sanh, Teven Le Scao, Kevin Canwen Xu, Nicolas Patry, Steven Liu, Angelina McMillan-Major, Philipp Schmid, Sylvain Gugger, Nathan Raw, Sylvain Lesage, Anton Lozhkov, Matthew Carrigan, Théo Matussière, Leandro von Werra, Lysandre Debut, Stas Bekman, and Clément Delangue. Datasets: A Community Library for Natural Language Processing. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 175–184. Association for Computational Linguistics, November 2021. URL https://aclanthology.org/2021.emnlp-demo.21.
- Li et al. (2023) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulov, Zhiruo Wang, Rudra Murthy, Jason Stillerman, Siva Sankalp Patel, Dmitry Abulkhanov, Marco Zocca, Manan Dey, Zhihan Zhang, Nourhan Fahmy, Urvashi Bhattacharyya, W. Yu, Swayam Singh, Sasha Luccioni, Paulo Villegas, Maxim Kunakov, Fedor Zhdanov, Manuel Romero, Tony Lee, Nadav Timor, Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jana Ebert, Tri Dao, Mayank Mishra, Alexander Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor, Siva Reddy, Daniel Fried, Dzmitry Bahdanau, Yacine Jernite, Carlos Muñoz Ferrandis, Sean M. Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries. Starcoder: may the source be with you! ArXiv, abs/2305.06161, 2023. URL https://api.semanticscholar.org/CorpusID:258588247.
- Lison et al. (2021) Pierre Lison, Ildikó Pilán, David Sanchez, Montserrat Batet, and Lilja Øvrelid. Anonymisation models for text data: State of the art, challenges and future directions. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4188–4203, Stroudsburg, PA, USA, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.323.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. ArXiv, abs/1907.11692, 2019. URL https://api.semanticscholar.org/CorpusID:198953378.
- Lo et al. (2020) Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. S2ORC: The semantic scholar open research corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4969–4983, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.447. URL https://aclanthology.org/2020.acl-main.447.
- Longpre et al. (2023) S. Longpre, Gregory Yauney, Emily Reif, Katherine Lee, Adam Roberts, Barret Zoph, Denny Zhou, Jason Wei, Kevin Robinson, David M. Mimno, and Daphne Ippolito. A pretrainer’s guide to training data: Measuring the effects of data age, domain coverage, quality, & toxicity. ArXiv, abs/2305.13169, 2023. URL https://api.semanticscholar.org/CorpusID:258832491.
- Luccioni and Viviano (2021) Alexandra Luccioni and Joseph Viviano. What’s in the box? an analysis of undesirable content in the Common Crawl corpus. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 182–189, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-short.24. URL https://aclanthology.org/2021.acl-short.24.
- Lukas et al. (2023) Nils Lukas, Ahmed Salem, Robert Sim, Shruti Tople, Lukas Wutschitz, and Santiago Zanella-Béguelin. Analyzing leakage of personally identifiable information in language models. arXiv [cs.LG], February 2023.
- Madaan et al. (2022) Aman Madaan, Shuyan Zhou, Uri Alon, Yiming Yang, and Graham Neubig. Language models of code are few-shot commonsense learners. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 1384–1403, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.90.
- Magar and Schwartz (2022) Inbal Magar and Roy Schwartz. Data contamination: From memorization to exploitation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 157–165, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-short.18. URL https://aclanthology.org/2022.acl-short.18.
- Magnusson et al. (2023) Ian Magnusson, Akshita Bhagia, Valentin Hofmann, Luca Soldaini, Ananya Harsh Jha, Oyvind Tafjord, Dustin Schwenk, Evan Pete Walsh, Yanai Elazar, Kyle Lo, Dirk Groeneveld, Iz Beltagy, Hannaneh Hajishirzi, Noah A Smith, Kyle Richardson, and Jesse Dodge. Paloma: A benchmark for evaluating language model fit. arXiv [cs.CL], December 2023. URL https://paloma.allen.ai.
- Marcus et al. (1994) Mitchell Marcus, Grace Kim, Mary Ann Marcinkiewicz, Robert MacIntyre, Ann Bies, Mark Ferguson, Karen Katz, and Britta Schasberger. The Penn Treebank: Annotating predicate argument structure. In Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994, 1994. URL https://aclanthology.org/H94-1020.
- Marcus et al. (1999) Mitchell P. Marcus, Beatrice Santorini, Mary Ann Marcinkiewicz, and Ann Taylor. Treebank-3, 1999. URL https://catalog.ldc.upenn.edu/LDC99T42.
- Marelli et al. (2014) Marco Marelli, Stefano Menini, Marco Baroni, Luisa Bentivogli, Raffaella Bernardi, and Roberto Zamparelli. A SICK cure for the evaluation of compositional distributional semantic models. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), pages 216–223, Reykjavik, Iceland, May 2014. European Language Resources Association (ELRA). URL http://www.lrec-conf.org/proceedings/lrec2014/pdf/363_Paper.pdf.
- Markov et al. (2023a) Todor Markov, Chong Zhang, Sandhini Agarwal, Florentine Eloundou Nekoul, Theodore Lee, Steven Adler, Angela Jiang, and Lilian Weng. A holistic approach to undesired content detection in the real world. Proceedings of the … AAAI Conference on Artificial Intelligence. AAAI Conference on Artificial Intelligence, 37(12):15009–15018, June 2023a. ISSN 2159-5399,2374-3468. doi: 10.1609/aaai.v37i12.26752.
- Markov et al. (2023b) Todor Markov, Chong Zhang, Sandhini Agarwal, Florentine Eloundou Nekoul, Theodore Lee, Steven Adler, Angela Jiang, and Lilian Weng. A holistic approach to undesired content detection in the real world. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificial Intelligence, AAAI’23/IAAI’23/EAAI’23. AAAI Press, 2023b. ISBN 978-1-57735-880-0. doi: 10.1609/aaai.v37i12.26752. URL https://doi.org/10.1609/aaai.v37i12.26752.
- Matic et al. (2020) Srdjan Matic, Costas Iordanou, Georgios Smaragdakis, and Nikolaos Laoutaris. Identifying sensitive urls at web-scale. Proceedings of the ACM Internet Measurement Conference, 2020. URL https://api.semanticscholar.org/CorpusID:225042878.
- Mazzarino et al. (2023) Simona Mazzarino, Andrea Minieri, and Luca Gilli. Nerpii: A python library to perform named entity recognition and generate personal identifiable information. 2023.
- Merity et al. (2016) Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer Sentinel Mixture Models. arXiv preprint arXiv:1609.07843, 2016.
- Microsoft (2018) Microsoft. Presidio - data protection and de-identification sdk, 2018. URL https://microsoft.github.io/presidio/.
- Microsoft (2019) Microsoft. Blingfire: A lightning fast Finite State machine and REgular expression manipulation library. https://github.com/microsoft/BlingFire, 2019.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv [cs.CL], September 2018.
- Muennighoff et al. (2023a) Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro Von Werra, and Shayne Longpre. Octopack: Instruction tuning code large language models. arXiv preprint arXiv:2308.07124, 2023a.
- Muennighoff et al. (2023b) Niklas Muennighoff, Alexander M Rush, Boaz Barak, Teven Le Scao, Aleksandra Piktus, Nouamane Tazi, Sampo Pyysalo, Thomas Wolf, and Colin Raffel. Scaling data-constrained language models. arXiv preprint arXiv:2305.16264, 2023b.
- Navigli et al. (2023) Roberto Navigli, Simone Conia, and Björn Ross. Biases in large language models: Origins, inventory, and discussion. J. Data and Information Quality, 15(2), jun 2023. ISSN 1936-1955. doi: 10.1145/3597307. URL https://doi.org/10.1145/3597307.
- Nunes (2020) Davide Nunes. Preprocessed penn tree bank, 2020. URL https://zenodo.org/record/3910021.
- Ofir Press et al. (2021) Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. August 2021.
- Open Data Commons (2010) Open Data Commons. Open Data Commons Attribution License (ODC-By) v1.0. https://opendatacommons.org/licenses/by/1-0/, 2010. Announcement. [accessed August 2023].
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023. URL https://api.semanticscholar.org/CorpusID:257532815.
- Papasavva et al. (2020) Antonis Papasavva, Savvas Zannettou, Emiliano De Cristofaro, Gianluca Stringhini, and Jeremy Blackburn. Raiders of the lost kek: 3.5 years of augmented 4chan posts from the politically incorrect board. 14th International AAAI Conference On Web And Social Media (ICWSM), 2020, 2020.
- Penedo et al. (2023) Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra-Aimée Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. The refinedweb dataset for falcon llm: Outperforming curated corpora with web data, and web data only. ArXiv, abs/2306.01116, 2023. URL https://api.semanticscholar.org/CorpusID:259063761.
- Peterson (2020) Joshua Peterson. openwebtext: Open clone of OpenAI’s unreleased WebText dataset scraper. this version uses pushshift.io files instead of the API for speed, 2020.
- Petrov et al. (2023) Aleksandar Petrov, Emanuele La Malfa, Philip H. S. Torr, and Adel Bibi. Language model tokenizers introduce unfairness between languages, 2023.
- Piktus et al. (2023) Aleksandra Piktus, Christopher Akiki, Paulo Villegas, Hugo Laurençon, Gérard Dupont, Sasha Luccioni, Yacine Jernite, and Anna Rogers. The ROOTS search tool: Data transparency for LLMs. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 304–314, Toronto, Canada, July 2023. Association for Computational Linguistics. URL https://aclanthology.org/2023.acl-demo.29.
- Pilehvar and Camacho-Collados (2019) Mohammad Taher Pilehvar and Jose Camacho-Collados. Wic: the word-in-context dataset for evaluating context-sensitive meaning representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1267–1273, 2019.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. February 2019.
- Rae et al. (2021) Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, Eliza Rutherford, Tom Hennigan, Jacob Menick, Albin Cassirer, Richard Powell, George van den Driessche, Lisa Anne Hendricks, Maribeth Rauh, Po-Sen Huang, Amelia Glaese, Johannes Welbl, Sumanth Dathathri, Saffron Huang, Jonathan Uesato, John F. J. Mellor, Irina Higgins, Antonia Creswell, Nathan McAleese, Amy Wu, Erich Elsen, Siddhant M. Jayakumar, Elena Buchatskaya, David Budden, Esme Sutherland, Karen Simonyan, Michela Paganini, L. Sifre, Lena Martens, Xiang Lorraine Li, Adhiguna Kuncoro, Aida Nematzadeh, Elena Gribovskaya, Domenic Donato, Angeliki Lazaridou, Arthur Mensch, Jean-Baptiste Lespiau, Maria Tsimpoukelli, N. K. Grigorev, Doug Fritz, Thibault Sottiaux, Mantas Pajarskas, Tobias Pohlen, Zhitao Gong, Daniel Toyama, Cyprien de Masson d’Autume, Yujia Li, Tayfun Terzi, Vladimir Mikulik, Igor Babuschkin, Aidan Clark, Diego de Las Casas, Aurelia Guy, Chris Jones, James Bradbury, Matthew G. Johnson, Blake A. Hechtman, Laura Weidinger, Iason Gabriel, William S. Isaac, Edward Lockhart, Simon Osindero, Laura Rimell, Chris Dyer, Oriol Vinyals, Kareem W. Ayoub, Jeff Stanway, L. L. Bennett, Demis Hassabis, Koray Kavukcuoglu, and Geoffrey Irving. Scaling language models: Methods, analysis & insights from training gopher. ArXiv, abs/2112.11446, 2021. URL https://api.semanticscholar.org/CorpusID:245353475.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- Rajaraman and Ullman (2011) Anand Rajaraman and Jeffrey David Ullman. Mining of Massive Datasets. Cambridge University Press, USA, 2011. ISBN 1107015359.
- Razeghi et al. (2022) Yasaman Razeghi, Robert L Logan IV, Matt Gardner, and Sameer Singh. Impact of pretraining term frequencies on few-shot numerical reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 840–854, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.findings-emnlp.59.
- Reid et al. (2022) Machel Reid, Victor Zhong, Suchin Gururangan, and Luke Zettlemoyer. M2D2: A massively multi-domain language modeling dataset. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 964–975, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.63.
- Ribeiro et al. (2021) Manoel Horta Ribeiro, Jeremy Blackburn, Barry Bradlyn, Emiliano De Cristofaro, Gianluca Stringhini, Summer Long, Stephanie Greenberg, and Savvas Zannettou. The evolution of the manosphere across the web. In Proceedings of the International AAAI Conference on Web and Social Media, volume 15, pages 196–207, 2021.
- Roemmele et al. (2011) Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S Gordon. Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In 2011 AAAI Spring Symposium Series, 2011.
- Roller et al. (2021) Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Eric Michael Smith, Y-Lan Boureau, and Jason Weston. Recipes for building an open-domain chatbot. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 300–325, Online, April 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.eacl-main.24. URL https://aclanthology.org/2021.eacl-main.24.
- Sakaguchi et al. (2019) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial winograd schema challenge at scale. arXiv [cs.CL], July 2019.
- Santy et al. (2023) Sebastin Santy, Jenny T Liang, Ronan Le Bras, Katharina Reinecke, and Maarten Sap. NLPositionality: Characterizing design biases of datasets and models. arXiv [cs.CL], June 2023. doi: 10.48550/arXiv.2306.01943.
- Sap et al. (2021) Maarten Sap, Swabha Swayamdipta, Laura Vianna, Xuhui Zhou, Yejin Choi, and Noah A Smith. Annotators with attitudes: How annotator beliefs and identities bias toxic language detection. arXiv [cs.CL], November 2021.
- Scao et al. (2022) Teven Le Scao, Angela Fan, Christopher Akiki, Elizabeth-Jane Pavlick, Suzana Ili’c, Daniel Hesslow, Roman Castagn’e, Alexandra Sasha Luccioni, Franccois Yvon, Matthias Gallé, Jonathan Tow, Alexander M. Rush, Stella Rose Biderman, Albert Webson, Pawan Sasanka Ammanamanchi, Thomas Wang, Benoît Sagot, Niklas Muennighoff, Albert Villanova del Moral, Olatunji Ruwase, Rachel Bawden, Stas Bekman, Angelina McMillan-Major, Iz Beltagy, Huu Nguyen, Lucile Saulnier, Samson Tan, Pedro Ortiz Suarez, Victor Sanh, Hugo Laurenccon, Yacine Jernite, Julien Launay, Margaret Mitchell, Colin Raffel, Aaron Gokaslan, Adi Simhi, Aitor Soroa Etxabe, Alham Fikri Aji, Amit Alfassy, Anna Rogers, Ariel Kreisberg Nitzav, Canwen Xu, Chenghao Mou, Chris C. Emezue, Christopher Klamm, Colin Leong, Daniel Alexander van Strien, David Ifeoluwa Adelani, Dragomir R. Radev, Eduardo Gonz’alez Ponferrada, Efrat Levkovizh, Ethan Kim, Eyal Bar Natan, Francesco De Toni, Gérard Dupont, Germán Kruszewski, Giada Pistilli, Hady ElSahar, Hamza Benyamina, Hieu Trung Tran, Ian Yu, Idris Abdulmumin, Isaac Johnson, Itziar Gonzalez-Dios, Javier de la Rosa, Jenny Chim, Jesse Dodge, Jian Zhu, Jonathan Chang, Jorg Frohberg, Josephine L. Tobing, Joydeep Bhattacharjee, Khalid Almubarak, Kimbo Chen, Kyle Lo, Leandro von Werra, Leon Weber, Long Phan, Loubna Ben Allal, Ludovic Tanguy, Manan Dey, Manuel Romero Muñoz, Maraim Masoud, Mar’ia Grandury, Mario vSavsko, Max Huang, Maximin Coavoux, Mayank Singh, Mike Tian-Jian Jiang, Minh Chien Vu, Mohammad Ali Jauhar, Mustafa Ghaleb, Nishant Subramani, Nora Kassner, Nurulaqilla Khamis, Olivier Nguyen, Omar Espejel, Ona de Gibert, Paulo Villegas, Peter Henderson, Pierre Colombo, Priscilla A. Amuok, Quentin Lhoest, Rheza Harliman, Rishi Bommasani, Roberto L’opez, Rui Ribeiro, Salomey Osei, Sampo Pyysalo, Sebastian Nagel, Shamik Bose, Shamsuddeen Hassan Muhammad, Shanya Sharma, S. Longpre, Somaieh Nikpoor, S. Silberberg, Suhas Pai, Sydney Zink, Tiago Timponi Torrent, Timo Schick, Tristan Thrush, Valentin Danchev, Vassilina Nikoulina, Veronika Laippala, Violette Lepercq, Vrinda Prabhu, Zaid Alyafeai, Zeerak Talat, Arun Raja, Benjamin Heinzerling, Chenglei Si, Elizabeth Salesky, Sabrina J. Mielke, Wilson Y. Lee, Abheesht Sharma, Andrea Santilli, Antoine Chaffin, Arnaud Stiegler, Debajyoti Datta, Eliza Szczechla, Gunjan Chhablani, Han Wang, Harshit Pandey, Hendrik Strobelt, Jason Alan Fries, Jos Rozen, Leo Gao, Lintang Sutawika, M Saiful Bari, Maged S. Al-shaibani, Matteo Manica, Nihal V. Nayak, Ryan Teehan, Samuel Albanie, Sheng Shen, Srulik Ben-David, Stephen H. Bach, Taewoon Kim, Tali Bers, Thibault Févry, Trishala Neeraj, Urmish Thakker, Vikas Raunak, Xiang Tang, Zheng Xin Yong, Zhiqing Sun, Shaked Brody, Y Uri, Hadar Tojarieh, Adam Roberts, Hyung Won Chung, Jaesung Tae, Jason Phang, Ofir Press, Conglong Li, Deepak Narayanan, Hatim Bourfoune, Jared Casper, Jeff Rasley, Max Ryabinin, Mayank Mishra, Minjia Zhang, Mohammad Shoeybi, Myriam Peyrounette, Nicolas Patry, Nouamane Tazi, Omar Sanseviero, Patrick von Platen, Pierre Cornette, Pierre Franccois Lavall’ee, Rémi Lacroix, Samyam Rajbhandari, Sanchit Gandhi, Shaden Smith, Stéphane Requena, Suraj Patil, Tim Dettmers, Ahmed Baruwa, Amanpreet Singh, Anastasia Cheveleva, Anne-Laure Ligozat, Arjun Subramonian, Aur’elie N’ev’eol, Charles Lovering, Daniel H Garrette, Deepak R. Tunuguntla, Ehud Reiter, Ekaterina Taktasheva, Ekaterina Voloshina, Eli Bogdanov, Genta Indra Winata, Hailey Schoelkopf, Jan-Christoph Kalo, Jekaterina Novikova, Jessica Zosa Forde, Xiangru Tang, Jungo Kasai, Ken Kawamura, Liam Hazan, Marine Carpuat, Miruna Clinciu, Najoung Kim, Newton Cheng, Oleg Serikov, Omer Antverg, Oskar van der Wal, Rui Zhang, Ruochen Zhang, Sebastian Gehrmann, Shachar Mirkin, S. Osher Pais, Tatiana Shavrina, Thomas Scialom, Tian Yun, Tomasz Limisiewicz, Verena Rieser, Vitaly Protasov, Vladislav Mikhailov, Yada Pruksachatkun, Yonatan Belinkov, Zachary Bamberger, Zdenvek Kasner, Alice Rueda, Amanda Pestana, Amir Feizpour, Ammar Khan, Amy Faranak, Ananda Santa Rosa Santos, Anthony Hevia, Antigona Unldreaj, Arash Aghagol, Arezoo Abdollahi, Aycha Tammour, Azadeh HajiHosseini, Bahareh Behroozi, Benjamin Olusola Ajibade, Bharat Kumar Saxena, Carlos Muñoz Ferrandis, Danish Contractor, David M. Lansky, Davis David, Douwe Kiela, Duong Anh Nguyen, Edward Tan, Emily Baylor, Ezinwanne Ozoani, Fatim Tahirah Mirza, Frankline Ononiwu, Habib Rezanejad, H.A. Jones, Indrani Bhattacharya, Irene Solaiman, Irina Sedenko, Isar Nejadgholi, Jan Passmore, Joshua Seltzer, Julio Bonis Sanz, Karen Fort, Lívia Macedo Dutra, Mairon Samagaio, Maraim Elbadri, Margot Mieskes, Marissa Gerchick, Martha Akinlolu, Michael McKenna, Mike Qiu, M. K. K. Ghauri, Mykola Burynok, Nafis Abrar, Nazneen Rajani, Nour Elkott, Nourhan Fahmy, Olanrewaju Samuel, Ran An, R. P. Kromann, Ryan Hao, Samira Alizadeh, Sarmad Shubber, Silas L. Wang, Sourav Roy, Sylvain Viguier, Thanh-Cong Le, Tobi Oyebade, Trieu Nguyen Hai Le, Yoyo Yang, Zachary Kyle Nguyen, Abhinav Ramesh Kashyap, A. Palasciano, Alison Callahan, Anima Shukla, Antonio Miranda-Escalada, Ayush Kumar Singh, Benjamin Beilharz, Bo Wang, Caio Matheus Fonseca de Brito, Chenxi Zhou, Chirag Jain, Chuxin Xu, Clémentine Fourrier, Daniel Le’on Perin’an, Daniel Molano, Dian Yu, Enrique Manjavacas, Fabio Barth, Florian Fuhrimann, Gabriel Altay, Giyaseddin Bayrak, Gully Burns, Helena U. Vrabec, Iman I.B. Bello, Isha Dash, Ji Soo Kang, John Giorgi, Jonas Golde, Jose David Posada, Karthi Sivaraman, Lokesh Bulchandani, Lu Liu, Luisa Shinzato, Madeleine Hahn de Bykhovetz, Maiko Takeuchi, Marc Pàmies, María Andrea Castillo, Marianna Nezhurina, Mario Sanger, Matthias Samwald, Michael Cullan, Michael Weinberg, M Wolf, Mina Mihaljcic, Minna Liu, Moritz Freidank, Myungsun Kang, Natasha Seelam, Nathan Dahlberg, Nicholas Michio Broad, Nikolaus Muellner, Pascale Fung, Patricia Haller, R. Chandrasekhar, Renata Eisenberg, Robert Martin, Rodrigo L. Canalli, Rosaline Su, Ruisi Su, Samuel Cahyawijaya, Samuele Garda, Shlok S Deshmukh, Shubhanshu Mishra, Sid Kiblawi, Simon Ott, Sinee Sang-aroonsiri, Srishti Kumar, Stefan Schweter, Sushil Pratap Bharati, T. A. Laud, Th’eo Gigant, Tomoya Kainuma, Wojciech Kusa, Yanis Labrak, Yashasvi Bajaj, Y. Venkatraman, Yifan Xu, Ying Xu, Yu Xu, Zhee Xao Tan, Zhongli Xie, Zifan Ye, Mathilde Bras, Younes Belkada, and Thomas Wolf. Bloom: A 176b-parameter open-access multilingual language model. ArXiv, abs/2211.05100, 2022. URL https://api.semanticscholar.org/CorpusID:253420279.
- Sennrich et al. (2016) Rico Sennrich, Barry Haddow, and Alexandra Birch. Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, Berlin, Germany, August 2016. Association for Computational Linguistics. doi: 10.18653/v1/P16-1162. URL https://aclanthology.org/P16-1162.
- Seshadri et al. (2023) Preethi Seshadri, Sameer Singh, and Yanai Elazar. The bias amplification paradox in text-to-image generation. arXiv preprint arXiv:2308.00755, 2023.
- Shazeer (2020) Noam Shazeer. GLU variants improve transformer. February 2020.
- Soldaini and Lo (2023) Luca Soldaini and Kyle Lo. peS2o (Pretraining Efficiently on S2ORC) Dataset. Technical report, Allen Institute for AI, 2023. ODC-By, https://github.com/allenai/pes2o.
- Srivastava et al. (2023) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Amanda Askell, Amanda Dsouza, Ambrose Slone, Ameet Rahane, Anantharaman S. Iyer, Anders Johan Andreassen, Andrea Madotto, Andrea Santilli, Andreas Stuhlmüller, Andrew M. Dai, Andrew La, Andrew Lampinen, Andy Zou, Angela Jiang, Angelica Chen, Anh Vuong, Animesh Gupta, Anna Gottardi, Antonio Norelli, Anu Venkatesh, Arash Gholamidavoodi, Arfa Tabassum, Arul Menezes, Arun Kirubarajan, Asher Mullokandov, Ashish Sabharwal, Austin Herrick, Avia Efrat, Aykut Erdem, Ayla Karakaş, B. Ryan Roberts, Bao Sheng Loe, Barret Zoph, Bartłomiej Bojanowski, Batuhan Özyurt, Behnam Hedayatnia, Behnam Neyshabur, Benjamin Inden, Benno Stein, Berk Ekmekci, Bill Yuchen Lin, Blake Howald, Bryan Orinion, Cameron Diao, Cameron Dour, Catherine Stinson, Cedrick Argueta, Cesar Ferri, Chandan Singh, Charles Rathkopf, Chenlin Meng, Chitta Baral, Chiyu Wu, Chris Callison-Burch, Christopher Waites, Christian Voigt, Christopher D Manning, Christopher Potts, Cindy Ramirez, Clara E. Rivera, Clemencia Siro, Colin Raffel, Courtney Ashcraft, Cristina Garbacea, Damien Sileo, Dan Garrette, Dan Hendrycks, Dan Kilman, Dan Roth, C. Daniel Freeman, Daniel Khashabi, Daniel Levy, Daniel Moseguí González, Danielle Perszyk, Danny Hernandez, Danqi Chen, Daphne Ippolito, Dar Gilboa, David Dohan, David Drakard, David Jurgens, Debajyoti Datta, Deep Ganguli, Denis Emelin, Denis Kleyko, Deniz Yuret, Derek Chen, Derek Tam, Dieuwke Hupkes, Diganta Misra, Dilyar Buzan, Dimitri Coelho Mollo, Diyi Yang, Dong-Ho Lee, Dylan Schrader, Ekaterina Shutova, Ekin Dogus Cubuk, Elad Segal, Eleanor Hagerman, Elizabeth Barnes, Elizabeth Donoway, Ellie Pavlick, Emanuele Rodolà, Emma Lam, Eric Chu, Eric Tang, Erkut Erdem, Ernie Chang, Ethan A Chi, Ethan Dyer, Ethan Jerzak, Ethan Kim, Eunice Engefu Manyasi, Evgenii Zheltonozhskii, Fanyue Xia, Fatemeh Siar, Fernando Martínez-Plumed, Francesca Happé, Francois Chollet, Frieda Rong, Gaurav Mishra, Genta Indra Winata, Gerard de Melo, Germán Kruszewski, Giambattista Parascandolo, Giorgio Mariani, Gloria Xinyue Wang, Gonzalo Jaimovitch-Lopez, Gregor Betz, Guy Gur-Ari, Hana Galijasevic, Hannah Kim, Hannah Rashkin, Hannaneh Hajishirzi, Harsh Mehta, Hayden Bogar, Henry Francis Anthony Shevlin, Hinrich Schuetze, Hiromu Yakura, Hongming Zhang, Hugh Mee Wong, Ian Ng, Isaac Noble, Jaap Jumelet, Jack Geissinger, Jackson Kernion, Jacob Hilton, Jaehoon Lee, Jaime Fernández Fisac, James B Simon, James Koppel, James Zheng, James Zou, Jan Kocon, Jana Thompson, Janelle Wingfield, Jared Kaplan, Jarema Radom, Jascha Sohl-Dickstein, Jason Phang, Jason Wei, Jason Yosinski, Jekaterina Novikova, Jelle Bosscher, Jennifer Marsh, Jeremy Kim, Jeroen Taal, Jesse Engel, Jesujoba Alabi, Jiacheng Xu, Jiaming Song, Jillian Tang, Joan Waweru, John Burden, John Miller, John U. Balis, Jonathan Batchelder, Jonathan Berant, Jörg Frohberg, Jos Rozen, Jose Hernandez-Orallo, Joseph Boudeman, Joseph Guerr, Joseph Jones, Joshua B. Tenenbaum, Joshua S. Rule, Joyce Chua, Kamil Kanclerz, Karen Livescu, Karl Krauth, Karthik Gopalakrishnan, Katerina Ignatyeva, Katja Markert, Kaustubh Dhole, Kevin Gimpel, Kevin Omondi, Kory Wallace Mathewson, Kristen Chiafullo, Ksenia Shkaruta, Kumar Shridhar, Kyle McDonell, Kyle Richardson, Laria Reynolds, Leo Gao, Li Zhang, Liam Dugan, Lianhui Qin, Lidia Contreras-Ochando, Louis-Philippe Morency, Luca Moschella, Lucas Lam, Lucy Noble, Ludwig Schmidt, Luheng He, Luis Oliveros-Colón, Luke Metz, Lütfi Kerem Senel, Maarten Bosma, Maarten Sap, Maartje Ter Hoeve, Maheen Farooqi, Manaal Faruqui, Mantas Mazeika, Marco Baturan, Marco Marelli, Marco Maru, Maria Jose Ramirez-Quintana, Marie Tolkiehn, Mario Giulianelli, Martha Lewis, Martin Potthast, Matthew L Leavitt, Matthias Hagen, Mátyás Schubert, Medina Orduna Baitemirova, Melody Arnaud, Melvin McElrath, Michael Andrew Yee, Michael Cohen, Michael Gu, Michael Ivanitskiy, Michael Starritt, Michael Strube, Michał Swędrowski, Michele Bevilacqua, Michihiro Yasunaga, Mihir Kale, Mike Cain, Mimee Xu, Mirac Suzgun, Mitch Walker, Mo Tiwari, Mohit Bansal, Moin Aminnaseri, Mor Geva, Mozhdeh Gheini, Mukund Varma T, Nanyun Peng, Nathan Andrew Chi, Nayeon Lee, Neta Gur-Ari Krakover, Nicholas Cameron, Nicholas Roberts, Nick Doiron, Nicole Martinez, Nikita Nangia, Niklas Deckers, Niklas Muennighoff, Nitish Shirish Keskar, Niveditha S. Iyer, Noah Constant, Noah Fiedel, Nuan Wen, Oliver Zhang, Omar Agha, Omar Elbaghdadi, Omer Levy, Owain Evans, Pablo Antonio Moreno Casares, Parth Doshi, Pascale Fung, Paul Pu Liang, Paul Vicol, Pegah Alipoormolabashi, Peiyuan Liao, Percy Liang, Peter W Chang, Peter Eckersley, Phu Mon Htut, Pinyu Hwang, Piotr Miłkowski, Piyush Patil, Pouya Pezeshkpour, Priti Oli, Qiaozhu Mei, Qing Lyu, Qinlang Chen, Rabin Banjade, Rachel Etta Rudolph, Raefer Gabriel, Rahel Habacker, Ramon Risco, Raphaël Millière, Rhythm Garg, Richard Barnes, Rif A. Saurous, Riku Arakawa, Robbe Raymaekers, Robert Frank, Rohan Sikand, Roman Novak, Roman Sitelew, Ronan Le Bras, Rosanne Liu, Rowan Jacobs, Rui Zhang, Russ Salakhutdinov, Ryan Andrew Chi, Seungjae Ryan Lee, Ryan Stovall, Ryan Teehan, Rylan Yang, Sahib Singh, Saif M. Mohammad, Sajant Anand, Sam Dillavou, Sam Shleifer, Sam Wiseman, Samuel Gruetter, Samuel R. Bowman, Samuel Stern Schoenholz, Sanghyun Han, Sanjeev Kwatra, Sarah A. Rous, Sarik Ghazarian, Sayan Ghosh, Sean Casey, Sebastian Bischoff, Sebastian Gehrmann, Sebastian Schuster, Sepideh Sadeghi, Shadi Hamdan, Sharon Zhou, Shashank Srivastava, Sherry Shi, Shikhar Singh, Shima Asaadi, Shixiang Shane Gu, Shubh Pachchigar, Shubham Toshniwal, Shyam Upadhyay, Shyamolima Shammie Debnath, Siamak Shakeri, Simon Thormeyer, Simone Melzi, Siva Reddy, Sneha Priscilla Makini, Soo-Hwan Lee, Spencer Torene, Sriharsha Hatwar, Stanislas Dehaene, Stefan Divic, Stefano Ermon, Stella Biderman, Stephanie Lin, Stephen Prasad, Steven Piantadosi, Stuart Shieber, Summer Misherghi, Svetlana Kiritchenko, Swaroop Mishra, Tal Linzen, Tal Schuster, Tao Li, Tao Yu, Tariq Ali, Tatsunori Hashimoto, Te-Lin Wu, Théo Desbordes, Theodore Rothschild, Thomas Phan, Tianle Wang, Tiberius Nkinyili, Timo Schick, Timofei Kornev, Titus Tunduny, Tobias Gerstenberg, Trenton Chang, Trishala Neeraj, Tushar Khot, Tyler Shultz, Uri Shaham, Vedant Misra, Vera Demberg, Victoria Nyamai, Vikas Raunak, Vinay Venkatesh Ramasesh, vinay uday prabhu, Vishakh Padmakumar, Vivek Srikumar, William Fedus, William Saunders, William Zhang, Wout Vossen, Xiang Ren, Xiaoyu Tong, Xinran Zhao, Xinyi Wu, Xudong Shen, Yadollah Yaghoobzadeh, Yair Lakretz, Yangqiu Song, Yasaman Bahri, Yejin Choi, Yichi Yang, Yiding Hao, Yifu Chen, Yonatan Belinkov, Yu Hou, Yufang Hou, Yuntao Bai, Zachary Seid, Zhuoye Zhao, Zijian Wang, Zijie J. Wang, Zirui Wang, and Ziyi Wu. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=uyTL5Bvosj.
- Stability AI (2024) Stability AI. Introducing Stable LM 2 1.6B. https://github.com/kingoflolz/mesh-transformer-jax, 2024.
- Subramani et al. (2023) Nishant Subramani, Sasha Luccioni, Jesse Dodge, and Margaret Mitchell. Detecting personal information in training corpora: an analysis. In Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023), pages 208–220, Toronto, Canada, July 2023. Association for Computational Linguistics. URL https://aclanthology.org/2023.trustnlp-1.18.
- Thoppilan et al. (2022) Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, Yaguang Li, Hongrae Lee, Huaixiu Steven Zheng, Amin Ghafouri, Marcelo Menegali, Yanping Huang, Maxim Krikun, Dmitry Lepikhin, James Qin, Dehao Chen, Yuanzhong Xu, Zhifeng Chen, Adam Roberts, Maarten Bosma, Vincent Zhao, Yanqi Zhou, Chung-Ching Chang, Igor Krivokon, Will Rusch, Marc Pickett, Pranesh Srinivasan, Laichee Man, Kathleen Meier-Hellstern, Meredith Ringel Morris, Tulsee Doshi, Renelito Delos Santos, Toju Duke, Johnny Soraker, Ben Zevenbergen, Vinodkumar Prabhakaran, Mark Diaz, Ben Hutchinson, Kristen Olson, Alejandra Molina, Erin Hoffman-John, Josh Lee, Lora Aroyo, Ravi Rajakumar, Alena Butryna, Matthew Lamm, Viktoriya Kuzmina, Joe Fenton, Aaron Cohen, Rachel Bernstein, Ray Kurzweil, Blaise Aguera-Arcas, Claire Cui, Marian Croak, Ed Chi, and Quoc Le. LaMDA: Language models for dialog applications. arXiv [cs.CL], January 2022.
- Tirumala et al. (2023) Kushal Tirumala, Daniel Simig, Armen Aghajanyan, and Ari S. Morcos. D4: Improving llm pretraining via document de-duplication and diversification. ArXiv, abs/2308.12284, 2023. URL https://api.semanticscholar.org/CorpusID:261076313.
- Together Computer (2023a) Together Computer. Redpajama-data-v2, 10 2023a. URL https://huggingface.co/datasets/togethercomputer/RedPajama-Data-V2.
- Together Computer (2023b) Together Computer. Redpajama-incite-base-3b-v1, 5 2023b. URL https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-3B-v1.
- Together Computer (2023c) Together Computer. Redpajama-data-1t, 4 2023c. URL https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023a. URL https://api.semanticscholar.org/CorpusID:257219404.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S. Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023b. URL https://api.semanticscholar.org/CorpusID:259950998.
- Vidgen and Derczynski (2020) Bertie Vidgen and Leon Derczynski. Directions in abusive language training data, a systematic review: Garbage in, garbage out. PloS one, 15(12):e0243300, December 2020. ISSN 1932-6203. doi: 10.1371/journal.pone.0243300.
- Wallace et al. (2021) Eric Wallace, Tony Zhao, Shi Feng, and Sameer Singh. Concealed data poisoning attacks on NLP models. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 139–150, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.13. URL https://aclanthology.org/2021.naacl-main.13.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- Wang et al. (2019) Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems, 32, 2019.
- Wang and Komatsuzaki (2021) Ben Wang and Aran Komatsuzaki. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://stability.ai/news/introducing-stable-lm-2, May 2021.
- Welbl et al. (2017) Johannes Welbl, Nelson F Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. arXiv [cs.HC], July 2017.
- Welbl et al. (2021) Johannes Welbl, Amelia Glaese, Jonathan Uesato, Sumanth Dathathri, John Mellor, Lisa Anne Hendricks, Kirsty Anderson, Pushmeet Kohli, Ben Coppin, and Po-Sen Huang. Challenges in detoxifying language models. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 2447–2469, Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.findings-emnlp.210. URL https://aclanthology.org/2021.findings-emnlp.210.
- Weninger et al. (2013) Tim Weninger, Xihao Avi Zhu, and Jiawei Han. An exploration of discussion threads in social news sites. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, New York, NY, USA, August 2013. ACM. ISBN 9781450322409. doi: 10.1145/2492517.2492646.
- Wenzek et al. (2020a) Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Edouard Grave. CCNet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 4003–4012, Marseille, France, May 2020a. European Language Resources Association. ISBN 979-10-95546-34-4. URL https://aclanthology.org/2020.lrec-1.494.
- Wenzek et al. (2020b) Guillaume Wenzek, Marie-Anne Lachaux, Alexis Conneau, Vishrav Chaudhary, Francisco Guzmán, Armand Joulin, and Édouard Grave. Ccnet: Extracting high quality monolingual datasets from web crawl data. In Proceedings of The 12th Language Resources and Evaluation Conference, pages 4003–4012, 2020b.
- Weston et al. (2015) Jason Weston, Antoine Bordes, Sumit Chopra, and Tomas Mikolov. Towards ai-complete question answering: A set of prerequisite toy tasks. arXiv: Artificial Intelligence, 2015. URL https://api.semanticscholar.org/CorpusID:3178759.
- Xu et al. (2021) Albert Xu, Eshaan Pathak, Eric Wallace, Suchin Gururangan, Maarten Sap, and Dan Klein. Detoxifying language models risks marginalizing minority voices. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2390–2397, Online, June 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.190. URL https://aclanthology.org/2021.naacl-main.190.
- Xue et al. (2020) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mT5: A massively multilingual pre-trained text-to-text transformer. arXiv [cs.CL], October 2020.
- Yang et al. (2023) Shuo Yang, Wei-Lin Chiang, Lianmin Zheng, Joseph E. Gonzalez, and Ion Stoica. Rethinking benchmark and contamination for language models with rephrased samples. ArXiv, abs/2311.04850, 2023. URL https://api.semanticscholar.org/CorpusID:265050721.
- Yelp (2013) Yelp. Detect secrets. https://github.com/Yelp/detect-secrets, 2013. v1.4.0.
- Zannettou et al. (2018) Savvas Zannettou, Barry Bradlyn, Emiliano De Cristofaro, Haewoon Kwak, Michael Sirivianos, Gianluca Stringini, and Jeremy Blackburn. What is gab: A bastion of free speech or an alt-right echo chamber. In Companion Proceedings of the The Web Conference 2018, WWW ’18, page 1007–1014, Republic and Canton of Geneva, CHE, 2018. International World Wide Web Conferences Steering Committee. ISBN 9781450356404. doi: 10.1145/3184558.3191531. URL https://doi.org/10.1145/3184558.3191531.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
- Zhang (2022) Hao Zhang. Language model decomposition: Quantifying the dependency and correlation of language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2508–2517, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. URL https://aclanthology.org/2022.emnlp-main.161.
- Zhang et al. (2024) Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. TinyLlama: An open-source small language model. arXiv [cs.CL], January 2024.
附录 A致谢
如果没有许多个人和机构的支持,卓玛的诞生是不可能的。 这项工作的实验组件是通过与 AMD 和 CSC 的合作实现的,从而能够使用 LUMI 超级计算机。 我们感谢 Jonathan Frankle、Cody Blakeney、Matthew Leavitt 和 Daniel King 以及 MosaicML 团队的其他成员分享了我们数据的简单知识版本的实验结果。 我们感谢 Vitaliy Chiley 在 Twitter 上向我们发送建议,以解决影响我们数据洗牌的随机数生成器错误。 我们感谢 Erfan Al-Hossami、Shayne Longpre 和 Gregory Yauney 分享了他们自己的大规模预训练数据实验的发现。 我们感谢Together AI 的张策和莫里斯·韦伯对开放数据集和数据分发格式进行了深思熟虑的讨论。 我们感谢 Stella Biderman 和 Aviya Skowron 围绕数据许可和数据处理框架进行的讨论。 我们感谢 AI2 Nicole DeCario、Matt Latzke、Darrell Plessas、Kelsey MacMillan、Carissa Schoenick、Sam Skjonsberg 和 Michael Schmitz 的团队成员在网站、设计、内部和外部沟通、预算和其他支持顺利进展的活动方面提供的帮助在这个项目上。 最后,我们还要感谢 AI2 的队友和密切合作者的有益讨论和反馈,包括 Prithviraj (Raj) Ammanabrolu、Maria Antoniak、Chris Callison-Burch、Peter Clark、Pradeep Dasigi、Nicole DeCario、Doug Downey、Ali Farhadi 、Suchin Gururangan、Sydney Levine、Maarten Sap、Ludwig Schmidt、Will Smith、Yulia Tsvetkov 和 Daniel S. Weld。
附录 B作者贡献
如果没有我们众多队友和合作者的帮助,卓玛不可能成功。 AI2 的任何人都可以访问每周项目会议、消息应用程序和文档。 关于卓玛的重大决定通常是在这些渠道中做出的,但某些主题(例如法律、资金)除外。 虽然许多人都参与了卓玛的工作(参见致谢 §A),但本文的作者是那些拥有并交付了这一难题的关键部分的人。 我们在下面详细介绍他们的贡献(按作者字母顺序排列):
数据采集和特定源数据处理的贡献者包括 Akshita Bhagia、Dirk Groeneveld、Rodney Kinney、Kyle Lo、Dustin Schwenk 和 Luca Soldaini。 每个人都对可用来源和最佳实践的文献综述以及围绕要追求的来源的决策做出了贡献。 Akshita Bhagia、Rodney Kinney、Dustin Schwenk 和 Luca Soldaini 使用 1B 模型处理了大量数据采集、处理和消融实验,以做出特定源的设计决策。 Kyle Lo 和 Luca Soldaini 与法律部门进行了讨论,以告知我们对来源的选择。
基础设施和工具的贡献者包括 Russell Authur、Dirk Groeneveld、Rodney Kinney、Kyle Lo 和 Luca Soldaini。 Rodney Kinney、Kyle Lo 和 Luca Soldaini 设计并实现了用于大规模处理我们的语料库的共享工具包。 Dirk Groeneveld 编写了用于重复数据删除和净化的布隆过滤器。 Russell Authur 编写了一个用于获取和存储 Common Crawl 数据的工具包。
源无关数据处理的贡献者包括 Kyathi Chandu、Yanai Elazar、Rodney Kinney、Kyle Lo、Xinxi Lyu、Ian Magnusson、Aakanksha Naik、Abhilasha Ravichander、Zejian Shen 和 Luca Soldaini。 Khyathi Chandu 和 Aakanksha Naik 开发了有毒文本过滤器。 Kyle Lo、Xinxi Lyu 帮助评估。 Luca Soldaini 开发了语言过滤方法。 Rodney Kinney、Zejian Shen 和 Luca Soldaini 开发了“优质”过滤器。 Yanai Elazar 识别出重复的 -gram 序列。 Abhilasha Ravichander、Kyle Lo 和 Luca Soldaini 开发了 PII 过滤器。 Jesse Dodge 和 Ian Magnusson 开发了评估集净化方法。
消融实验的贡献者包括 Iz Beltagy、Akshita Bhagia、Jesse Dodge、Dirk Groeneveld、Rodney Kinney、Kyle Lo、Ian Magnusson、Matthew Peters、Kyle Richardson、Dustin Schwenk、Luca Soldaini、Nishant Subramani、Oyvind Tafjord和皮特·沃尔什。 这项工作包括在给定计算约束的情况下设计实验并确定实验优先级、实施和运行 1B 模型实验以及解释结果。 特别是,Oyvind Tafjord 在评估工具包方面的工作和 Pete Walsh 在模型实施方面的工作至关重要。
对卓玛最终文物进行事后实验和分析的贡献者。 Ben Bogin 在 Kyle Lo 和 Niklas Muennighoff 的支持下领导了 1B 模型权重的探索实验,以评估不同代码混合的影响。 Yanai Elazar 运行数据分析工具来总结和记录卓玛的创作。 Valentin Hofmann 在 Kyle Lo 的支持下领导了代币化生育率分析。 Ananya Harsh Jha 和 Ian Magnusson 在 Luca Soldaini 的支持下在其他开放数据集上进行了实验训练和评估基线 1B 模型。 Sachin Kumar 和 Jacob Morrison 在 Kyle Lo 的支持下对我们选择的语言识别和毒性分类器中的系统问题进行了分析。 在 Kyle Lo 和 Luca Soldaini 的支持下,Niklas Muennighoff 领导了对 Common Crawl 数据使用的不同过滤器之间的相关性分析。
许可和发布政策的贡献者包括 David Atkinson、Jesse Dodge、Jennifer Dumas、Nathan Lambert、Kyle Lo、Crystal Nam 和 Luca Soldaini。 David Atkinson、Jesse Dodge、Jennifer Dumas 和 Crystal Nam 领导了大部分工作,包括数据许可证的研究、预训练数据的风险级别确定以及定义发布政策。 Kyle Lo 和 Luca Soldaini 在整个过程中提供了反馈,并处理了发布所需的技术细节。 Nathan Lambert 提供了有关发布过程的反馈并处理了实际的发布策略,特别是围绕外部沟通。
上述所有贡献者都帮助编写了各自组件的文档和编写。 特别是,Li Lucy 对语言模型、开放语料库和预训练语料库创建实践进行了广泛的文献综述。 艾玛·斯特鲁贝尔对我们的手稿提出了宝贵的反馈。 内森·兰伯特 (Nathan Lambert) 帮助提供了有关卓玛的博客文章和其他形式的外部沟通的反馈。
Hannaneh Hajishirzi、Noah Smith 和 Luke Zettlemoyer 为该项目提供了建议,包括总体战略、写作、招聘和提供资源。 作为 OLMo 项目的领导者,Iz Beltagy、Jesse Dodge 和 Dirk Groeneveld 帮助提高与其他关键 OLMo 项目工作流的可见性和协调。 值得注意的是,我们将卓玛这个名字归功于诺亚·史密斯(Noah Smith)。
最后,Kyle Lo 和 Luca Soldaini 领导整个 Dolma 项目并参与各个方面,包括项目管理、规划和设计、与法律和道德委员会的讨论、数据和计算合作伙伴关系、基础设施、工具、实施、实验、写作/文档等。
附录C有关最大LM背后的预训练数据的详细信息
我们对最大的 LM 的预训练数据管理实践(或缺乏报告)进行了高级概述,以说明围绕数据集管理对清晰文档和透明度的需求。
C.1 Llama 2 (Touvron 等人, 2023b)
Touvron 等人训练 (2023b) 提供了有关 Llama 2 的预数据的有限信息;我们总结了从他们的手稿第 2.1、4.1 和 A.6 节中收集到的信息:
-
1.
语料库大小。 2T Token。
-
2.
数据来源。 除了他们避免使用元用户数据之外,不适用。
-
3.
PII。 报告称某些已知包含大量 PII 的网站排除了数据,但这些网站的具体内容并未披露。
-
4.
毒性。 没有明确讨论,但似乎没有执行毒性过滤,而是选择在稍后的训练阶段处理有毒文本生成。 他们确实报告了事后分析的结果,其中使用在 ToxiGen (Hartvigsen 等人,2022) 上微调的 HateBERT (Caselli 等人,2021) 分类器对每个分类器进行评分文档行(并平均以产生文档级分数)。
-
5.
语言 ID。 没有说明在预训练数据管理中使用,但它们使用 fastText 语言 ID 提供预训练数据集的事后分析,检测到的语言阈值为 0.5。 我们假设这可能与他们用于预训练数据管理的协议相同,因为它也出现在 CCNet 库 (Wenzek 等人, 2020a) 中,该库用于 Llama (Touvron 等人,2023a)。
-
6.
质量。 N/A.
-
7.
重复数据删除。 N/A.
-
8.
净化。 他们提供了有关重复数据删除方法的广泛报告,该方法依赖于 Lee 等人 (2022) 的 ngram 重复数据删除工具的修改版本。
-
9.
其他。 报告对某些来源进行了上采样,但没有进一步的细节。 他们还报告了与 PaLM 2 (Anil 等人,2023) 中有关人口身份和英语代词汇总统计的类似分析。
C.2 PaLM 2 (Anil 等人,2023)
Anil 等人 (2023) 提供了有关用于 PaLM 2 的预训练数据的有限信息;我们总结了从他们的手稿第 3 节和 D1 节中收集到的信息:
-
1.
语料库大小。 未报道,只是它比用于训练 PaLM (Chowdhery 等人, 2022) 的要大
-
2.
数据来源。 除了他们使用网络文档、书籍、代码、数学和对话数据之外,没有被报道。
-
3.
PII。 报告称已执行过滤,但没有进一步的详细信息。
-
4.
毒性。 使用 Perspective API 识别出有毒文本,但缺乏复制所需的详细信息(即文本单位、阈值)。 没有关于删除的详细信息。 他们确实报告了通过使用控制令牌来解决毒性问题,但没有提供有关此方法的足够详细信息。
-
5.
语言 ID。 报告最常用的语言及其频率。 缺乏复制所需的详细信息(即文本单元、使用的工具、阈值)。
-
6.
质量。 报告称已执行过滤,但没有进一步的详细信息。
-
7.
重复数据删除。 报告称已执行过滤,但没有进一步的详细信息。
-
8.
净化。 N/A.
-
9.
其他。 Anil 等人 (2023) 报告某些人口统计身份在数据中出现(或未出现)的频率的汇总统计数据。 此类统计数据包括身份(例如美国人)或英语代词。 这些是使用 KnowYourData 或 GoogleCloud 等工具识别的,但手稿缺乏复制所需的细节。
C.3 GPT-4 (OpenAI,2023)
OpenAI (2023) 提供有关 GPT-4 预训练数据的有限信息;我们总结了从他们的手稿第 2 节、附录 C 和 D、脚注 5、6、10 和 27 以及系统卡中的第 1.1 和 3.1 节中收集到的内容:
-
1.
语料库大小。 N/A
-
2.
数据来源。 不适用,除了报告 (1) 数据来源于互联网和第三方提供商,(2) 数据主要来源于 2021 年 9 月之前,并有少量更新的数据,以及 (3) 包括 GSM -8K (Cobbe 等人, 2021) 作为总预训练组合的一小部分。
-
3.
PII。 N/A.
-
4.
毒性。 使用基于词典的启发式方法和遵循 Markov 等人 (2023b) 的定制分类器相结合,从预训练中删除了违反使用政策的文档,包括“色情内容”。
-
5.
语言 ID。 除了报告大部分预训练数据都是英文之外,不适用。
-
6.
质量。 N/A.
-
7.
重复数据删除。 N/A.
-
8.
混合物。
-
9.
净化。 没有讨论净化程序,而是报告了衡量专业和学术考试污染程度的事后统计数据,以及一些学术基准。 基于测试示例与预训练数据示例的精确子字符串匹配(删除空格后)来识别污染的方法。 他们报告了 BIG-Bench 的一些污染(Srivastava 等人,2023)。
-
10.
其他。 有很多作品对 GPT-4 进行“数据考古”,即试图通过记忆探针收集 GPT-4 中使用的预训练数据的信息。 例如,Chang 等人 (2023) 表明 GPT-4 可以从受版权保护的书籍生成序列。 我们并不试图调查所有这些调查工作。
C.4 Claude (Anthropic, 2023)
不幸的是,我们对克劳德使用的预训练数据几乎一无所知。
C.5 LLaMA (Touvron 等人, 2023a)
Touvron 等人训练 (2023a) 提供了一些用于训练 LLaMA 的预数据信息;我们总结了从他们的手稿第 2.1 节中可以收集到的信息。
-
1.
语料库大小。 1.4T Token。
-
2.
数据来源。 LLaMA 使用来源已知的数据,包括 2017 年至 2020 年期间 CommonCrawl 的五个分片、C4 (Raffel 等人,2020)、来自 Google BigQuery 公共数据集 的 GitHub 代码(仅限于Apache、BSD 和 MIT 许可证)、维基百科从 2022 年 6 月到 2022 年 8 月的转储、Project Gutenberg 书籍、来自 The Pile (高等人,2020)的 Books3、来自 arXiv 的 LaTeX 文件和 StackExchange 页面。
-
3.
PII。 N/A.
-
4.
毒性。 N/A. 报告对 RealToxicityPrompts (Gehman 等人,2020) 基准的评估。
-
5.
语言 ID。 报告使用 CCNet 库 (Wenzek 等人, 2020b),该库采用 fastText (Joulin 等人, 2016a) 分类器来删除非英语文本(低于 0.5 阈值) )。 没有报告 C4、GitHub、Books、arXiv 和 StackExchange 集的其他语言 ID。 对于维基百科,报告限制使用拉丁文或西里尔文脚本的页面:bg、ca、cs、da、de、en、es、fr、hr、hu、it、nl、pl、pt、ro、ru、sl、sr ,sv,英国。
-
6.
质量。 报告使用 CCNet 库(Wenzek 等人,2020b)从 CommonCrawl 中删除低质量内容; CCNet 使用 KenLM (Heafield, 2011)(一种 -gram 语言模型)对文本的困惑度进行评分,作为与维基百科文本的相似性度量。 他们不报告他们选择的过滤阈值。 他们还报告使用经过训练的线性模型来将页面分类为类似维基百科参考或非类似维基百科参考。 他们还报告了对 GitHub 和 Wikipedia 子集的样板内容的轻度启发式过滤。
-
7.
重复数据删除。 报告使用 CCNet 库(Wenzek 等人,2020b) 来识别 Common Crawl 文本的重复行、GitHub 代码的文件级精确匹配重复数据删除以及 Gutenberg 和 Books3 中超过 90% 的书籍重复数据删除子集。
-
8.
净化。 N/A.
-
9.
混合物。 该手稿报告了 67% CommonCrawl、15% C4、4.5% GitHub、4.5% Wikipedia、4.5% Books、2.5% arXiv 和 2.0% StackExchange 的混合。 除了维基百科和书籍的上采样(2 个时期)之外,模型训练是该混合物的单个时期。
-
10.
其他。
C.6 OPT (Zhang, 2022)
根据Zhang (2022)的手稿和提供的数据表(Gebru等人, 2021),我们总结如下:
OPT 模型在来自已知来源的数据源的180B 令牌上进行训练:用于 RoBERTa (Liu 等人,2019) 的数据集, Pile (Gao 等人, 2020) 的子集,以及由 (Roller 等人, 2021) 处理的 Pushshift Reddit 数据集 (Baumgartner 等人, 2020a) )。 他们对这些来源做了一些显着的更改:
-
1.
RoBERTa. (Zhang,2022)将 CC-News 合集更新至 2021 年 9 月。
-
2.
Pile. (Zhang,2022)仅限于以下集合:CommonCrawl、DM Mathematics、Project Gutenberg、HackerNews、OpenSubtitles、OpenWebText2、USPTO 和 Wikipedia。 (Zhang,2022)报告由于 1B 模型尺度的梯度范数峰值而遗漏了其他 Pile 子集。
-
3.
Pushshift Reddit。 (Zhang, 2022) 仅限于每个线程中最长的评论链;据报道,该操作将数据集减少了 66%。
(Zhang,2022)还描述:(1)重复数据删除使用MinHashLSH(Rajaraman和Ullman,2011),Jaccard相似度阈值为0.95, (2) 语言 ID 过滤纯英文文本,尽管它们没有描述所使用的方法。
他们没有讨论是否进行(或不)进行任何PII、毒性、质量或净化处理处理 t3>.
附录 D实验设置
D.1 消融设置
对于本节中描述的所有数据消融,我们在最多 150B 代币上训练 1B 参数模型。 这与之前的工作(Le Scao 等人,2022)中用于消融的类似模型尺寸一致。 每个模型都是仅解码器的 Transformer 模型,具有 16 层、16 个注意力头和 2048 维。 我们使用 ALiBi 位置嵌入(Ofir Press 等人,2021)、SwiGLU 激活(Shazeer,2020)和混合精度;模型上下文大小设置为 标记。 我们使用 EleutherAI 的 GPT NeoX 分词器(Black 等人, 2022)。 该模型使用 LionW 优化器 (Chen 等人, 2023a) 进行训练,具有 峰值学习率、 步骤的预热、余弦衰减、和权重衰减。 批量大小设置为。 虽然我们将最大步数设置为 95k(大约为 200B 令牌),但我们以 150B 令牌结束实验。
我们使用 64 个 AMD Instinct MI250X 加速器。 每个MI250X加速器包含两个逻辑节点;因此,从我们的训练代码的角度来看,我们的实验在分为 16 个节点的 128 个计算单元上运行。 对于每个逻辑单元,我们使用 8 的微批量大小。 我们使用 OLMo 代码库 实施我们的实验。
D.2困惑度评估套件
在训练过程中,我们使用 Paloma 基准的早期版本(Magnusson 等人,2023) 来跟踪困惑度。 除非另有说明,否则对帕洛玛的引用均指此早期版本。 此版本的 Paloma 源自以下数据集:
-
•
C4 (Raffel 等人, 2020; Dodge 等人, 2021):从 2019 年 4 月的 Common Crawl 抓取中自动筛选出的标准当代 LM 预训练语料库。
-
•
mC4 (薛等人, 2020); 英语子集:从 71 个 Common Crawl 抓取中自动过滤的预训练语料库的英语部分。
-
•
Pile (Gao 等人, 2020)、验证集:广泛使用的语言建模预训练语料库;包含从多个来源(包括多个非网络来源)整理的文档。
-
•
WikiText 103 (Merity 等人,2016):维基百科上经过验证的“好”和“精选”文章的标准集合。
-
•
Penn Tree Bank (Marcus 等人,1994):广泛使用的 NLP 语料库,源自《华尔街日报》的文章。
-
•
M2D2 (Reid 等人, 2022)、S2ORC 子集:来自语义学者的论文 (Lo 等人, 2020) 按层次学术领域类别分组。
-
•
M2D2 (Reid等人,2022),Wiki子集:按维基百科本体中的层次类别分组的维基百科文章
-
•
C4 100 个域名 (Chronopoulou 等人, 2022):C4 中前 100 个域名的平衡样本。
-
•
Gab (Zannettou 等人, 2018):来自另类右翼、言论自由的社交媒体平台的 2016-2018 年数据,该平台已被证明包含更多仇恨言论高于主流平台。
-
•
ICE (Greenbaum,1991):由当地专家策划的来自世界各地的英语,其中包括加拿大、东非、香港、印度、爱尔兰、牙买加、菲律宾、新加坡、美国。
-
•
Twitter AAE (Blodgett 等人, 2016):标记为非裔美国人或白人英语的平衡推文集。
-
•
Manosphere (Ribeiro 等人,2021):9 个论坛的样本,在过去十年中发展了一系列相关的男性主义意识形态。
-
•
4chan (Papasavva 等人,2020):来自一个匿名论坛的 2016-2019 年政治板块的数据被发现含有高比例的有毒内容。
在一些实验中,我们使用 Magnusson 等人 (2023) 中发布的 Paloma 最终版本。 这包含从以下附加数据集中采样的评估数据:
-
•
Dolma(这项工作),统一样本:来自 Dolma 语料库所有子集的 8,358 个文档样本(13 个来自书籍,1,642 个来自 Common Crawl 网页,4,545 个 Reddit提交的内容、450 篇科学文章、1,708 个维基百科和维基教科书条目)。
-
•
RedPajama v1 (Together Computer,2023a):LLaMA 1 (Touvron 等人,2023a) 预训练语料库的 1 万亿个代币复制。
-
•
Falcon RefinedWeb (Penedo 等人,2023):从 2023 年 6 月之前的所有 Common Crawl 抓取中采样的英语语料库,比 C4 和 mC4-en 更积极地过滤和去重。
-
•
Dolma 100 Subreddits(这项工作):按帖子数量平衡前 100 个 Reddit 子集的样本,源自 Dolma Reddit 子集。
-
•
Dolma 100 编程语言(这项工作):按令牌数量平衡前 100 种编程语言的样本,源自 Dolma Stack 子集。
D.3下游评估套件
我们还使用 Catwalk 框架在以下下游任务数据集上评估模型(Groeneveld 等人,2023):
-
•
AI2 Reasoning Challenge (Clark 等人,2018):科学问答数据集,分为简单和挑战子集。 在线评估中仅使用简单子集。 然而,挑战子集包含在离线评估中。
-
•
BoolQ (Clark 等人, 2019):由自然发生的是/否布尔问题和背景上下文组成的阅读理解数据集。
-
•
HellaSwag (Zellers 等人, 2019):一个测试情境理解和常识的多项选择问答数据集。
-
•
OpenBookQA (Mihaylov 等人,2018):以开卷科学考试为模型的多项选择题问答数据集。
-
•
物理交互:问答(PIQA) (Bisk等人,2019):一个专注于物理常识和朴素物理学的多项选择问答数据集。
-
•
SciQ (Welbl 等人,2017):众包多项选择问答数据集,包含有关物理、化学和生物学以及其他科学领域的日常问题。
-
•
WinoGrande (Sakaguchi 等人, 2019):涉及各种形式常识的代词解析问题数据集。 仿照 Levesque 等人 (2012) 的 Winograd 挑战。
D.4 Olmo-1b 的训练设置
对于 Olmo-1b,我们遵循Appendix D 中数据集消融实验概述的实验设置,但存在以下差异:
-
•
我们将最大步数设置为 739,328(大约为 3.1T 代币)。
-
•
我们将批量大小加倍到 ,并通过扩展到 256 个计算单元(我们用于数据消融的两倍)来实现这一点。
-
•
由于我们发现 LionW 优化器不稳定,我们改用 AdamW。
附录E论坛数据中会话线程的构建
内容来自 Reddit 的数据 API,以两种独立但链接的形式:提交和评论。 提交内容可以是指向外部内容(例如新闻文章、博客甚至多媒体内容)的“链接帖子”,也可以是“自我帖子”(由发布者撰写的提交内容,旨在发起有关某个主题的讨论线程) 。 评论是用户对发起帖子(顶级评论)或其他用户评论的回复。 帖子、顶级评论和评论回复形成一个嵌套的对话线程,其根为提交帖子,评论分支为多个可能的对话树。
Reddit 线程的树状结构允许多种可能的数据格式,具体取决于线程的各个组件的组合方式。
我们研究了三种格式作为 LM 预训练数据的潜力:
-
•
原子含量。 这种简单的格式将所有评论和提交视为独立文档,没有任何结构或与其出现的线程的连接。
-
•
部分线程。 这种格式将来自同一线程的评论组合成用户之间结构化的多轮对话。 提交的内容将作为单独的文件保留。 组装的对话仅限于最大父深度,并且生成的文档只是其原始线程的片段(分布在多个文档中)。
-
•
完整线程。 这种复杂的格式将给定的提交及其所有子评论合并到包含整个线程的单个文档中。 类似代码的缩进用于指示线程层次结构中评论的深度。
我们在Figure 14 中对这些组装文档的策略进行了实验评估。 我们发现,出于语言建模的目的,与部分线程和完整线程相比,将评论和提交视为原子单元会带来更好的下游性能。 我们假设处理对话所需的更复杂的格式可能会引入语言建模不需要的内容,例如简短和重复的评论。 我们将针对语言建模的论坛内容更好的格式的研究留给未来的工作。
附录FTokenization 分析
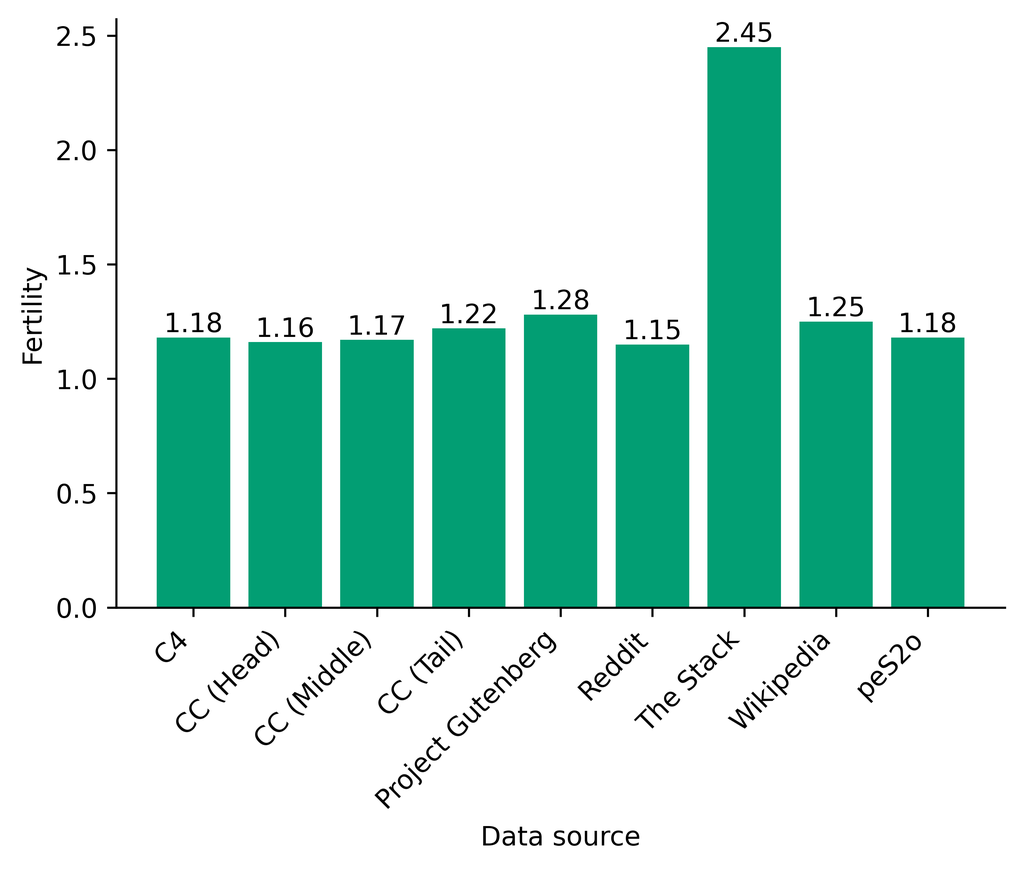
使用语言模型处理文本的第一步是标记化,即将文本映射到具有相应输入嵌入的标记序列(Sennrich 等人,2016;Kudo,2018;Kudo 和 Richardson, 2018)。 最近,人们对 LM 分词器如何适应不同数据源的问题越来越感兴趣(例如,不同语言的数据;Ahia 等人,2023;Petrov 等人,2023)作为新兴的工作领域,我们对应用于 Dolma 的 GPTNeoX tokenizer (Black 等人,2022) 进行了探索性分析,这提供了第一张图片,说明 Dolma 包含的不同数据源对于当前的挑战有多大LM 分词器。
我们首先从全局角度审视分词器与 Dolma 的契合度。 在标记器词汇表中的 50,280 个标记中,有 50,057 个存在于 Dolma 的标记化文本中。 换句话说,有 223 个标记从未被使用过,大约占标记器词汇量的 0.4%。 223 个标记主要由空格字符的组合组成(例如,“\n\n ”,两个换行符后跟两个空格字符)。 请注意,当在 Dolma 上使用经过检查的标记器训练 LM 时,与这些标记相对应的输入嵌入不会更新。 在符元计数分布方面,我们发现 ID 较小的符元在 Dolma 中往往具有更高的计数(见图 15(a)),这也反映在 (i) 基于 Dolma 中计数对符元进行排序和 (ii) 符元 ID ( 0.638, 0.001) 之间的强斯皮尔曼相关性中。 考虑到分词器的训练方式(Sennrich 等人,2016;Black 等人,2022),较小的 ID 对应于较早合并的字节对,因此这些 Token 在分词器训练数据中出现频率更高。 总体而言,这些结果建议 GPTNeoX 分词器与 Dolma 非常匹配。
这个分词器是否同样适合 Dolma 中包含的所有数据源? 为了研究这个问题,我们对派生率进行分析,派生率被定义为分词器(Acs,2019;Scao等人,2022)为每个词生成的 Token 平均数目,在我们的案例中,派生率是在特定数据源上测量的。 我们发现大多数数据源的派生率相似,范围在 1.15(会话论坛子集)和 1.28(书籍子集)之间,但代码子集除外,其派生率要高得多,为 2.45(见图 15(b))。 这意味着处理代码子集的成本 - 无论是计算成本还是财务成本(Petrov 等人,2023) - 与其他数据源相比要高出两倍多。
造成这种差异的原因是什么? 我们发现,在代码子集中(主要包含代码),单词前面通常有空白字符,而不是空格(例如,换行符、制表符、回车符)。 至关重要的是,虽然单词之前的空格被标记为该单词的一部分(例如,I love you “I”, “ love”, “ you”),但其他空白字符产生单独的 Token(例如,I love you “I”, “\t”, “love”, “\t”, “you”)。 这也可以通过按数据源绘制表示空白字符的标记的相对频率来看出,与大多数其他数据源相比,The Stack 的频率要高出一个数量级(参见图 15(c)) 。 因此,当在 Stack 上训练 LM(或更一般的代码)时,建议向分词器 添加特殊标记(例如,“\nif”;Hong 等人,2021)。 值得注意的是,这一观察结果适用于当今使用的大多数分词器(例如,GPT-4 使用的分词器),它们往往缺少诸如“\nif”之类的标记。
附录 G评估语言识别
为了分析 fastText 语言识别分类器的影响,我们对国际英语语料库 (ICE) (Kirk 和 Nelson,2018) 进行了外部审计,该数据集包含来自九个国家的口语和书面英语世界各地。 我们对 ICE 数据集中的所有文档运行语言 ID 工具,以估计每个区域有多少文档被错误过滤。 此分析的基本事实是每个文档都是英文的,并且应该如此分类。 有趣的是,我们发现,在我们相当宽松的阈值(保持英语得分至少为 0.5 的文档)下,ICE 中的所有英语文档都正确识别为英语,无论其来自哪个地区。
附录H评估毒性分类
为了测量拼图毒性分类器中的方言偏差,我们分析了其将不同国家所说的英语变体预测为有毒的倾向。 从未经过滤的 Reddit 语料库开始,我们创建了来自基于位置的 subreddits 的评论数据集,过滤了包含超过 50K 条评论的特定国家/地区的 subreddits。 该数据集可以作为不同英语方言的粗略代理,假设大多数评论者居住在各自的位置并讲不同的英语方言。 我们进一步假设每个 Reddit 子版块中实际有毒评论的比例大致相同。 我们使用拼图分类器计算此数据集中每个评论的毒性分数,并在Figure 17 中报告针对不同分类器阈值标记为有毒的评论的百分比。 对于所有阈值,对于任何两个位置,我们发现标记为有毒的评论比例的差异 <5%,表明几乎没有偏见。 此外,我们绘制了每个 Reddit 子版块中评论的毒性分数分布,发现分配给评论的分数通常落在极端值(接近 0 或接近 1),这表明任何合理的阈值(介于 0.1 到 0.9 之间)预测毒性会导致类似的结果。
附录一代码管道过滤器分析
在表 LABEL:tab:stackfilters 中,我们显示了 The Stack 的两组过滤器标记的文档数量以及它们的相关性。 我们发现,对于大多数语言,RedPajama v1 过滤器标记的文档比 StarCoder 过滤器标记的文档多得多。 然而,对于 Java、JavaScript 和 Python,我们从 StarCoder 派生的过滤器标记了大量文档。 这是因为它包含其他语言未采用的附加代码与文本比率过滤器。 这两组过滤器通常具有较低的相关性,但少数语言除外,例如 txl,它们完全相关。
| Language | RPJ % | SC % | RPJ SC | Language | RPJ % | SC % | RPJ SC |
| Flag | Flag | Corr. | Flag | Flag | Corr. | ||
| abap | 1.4 | 0.0 | N/A | lookml | 0.0 | 0.0 | N/A |
| actionscript | 1.3 | 0.0 | N/A | lsl | 3.2 | 1.3 | 0.05 |
| ada | 1.5 | 2.6 | -0.02 | lua | 4.6 | 0.0 | N/A |
| agda | 25.4 | 0.0 | N/A | m | 35.1 | 0.0 | N/A |
| ags-script | 4.7 | 0.0 | N/A | m4 | 2.7 | 0.1 | 0.003 |
| alloy | 3.5 | 0.1 | -0.005 | makefile | 2.3 | 0.0 | N/A |
| ampl | 24.0 | 0.0 | N/A | mako | 2.3 | 0.7 | -0.013 |
| antlr | 6.0 | 0.0 | N/A | maple | 18.2 | 44.2 | -0.414 |
| apacheconf | 0.5 | 0.0 | N/A | markdown | 8.0 | 0.0 | N/A |
| api-blueprint | 3.8 | 0.0 | N/A | mask | 16.6 | 0.0 | N/A |
| apl | 28.2 | 0.0 | N/A | mathematica | 66.3 | 0.0 | N/A |
| applescript | 2.1 | 0.0 | N/A | matlab | 94.7 | 0.0 | N/A |
| arc | 17.7 | 8.8 | -0.144 | max | 91.2 | 0.1 | -0.033 |
| arduino | 2.5 | 0.0 | N/A | maxscript | 4.0 | 0.5 | -0.014 |
| asciidoc | 4.0 | 0.0 | N/A | mediawiki | 6.6 | 0.0 | N/A |
| asp | 16.4 | 0.1 | -0.01 | metal | 5.4 | 0.0 | N/A |
| aspectj | 0.9 | 0.0 | N/A | mirah | 25.3 | 0.0 | N/A |
| assembly | 50.1 | 0.0 | N/A | modelica | 10.3 | 0.0 | N/A |
| ats | 5.3 | 0.0 | N/A | mms | 3.2 | 0.0 | N/A |
| augeas | 7.2 | 4.8 | -0.063 | monkey | 6.5 | 0.0 | N/A |
| autohotkey | 4.9 | 0.0 | N/A | moonscript | 5.1 | 0.0 | N/A |
| autoit | 3.0 | 0.0 | N/A | mtml | 4.5 | 2.1 | -0.031 |
| awk | 36.4 | 0.1 | -0.02 | muf | 18.9 | 0.0 | N/A |
| batchfile | 9.8 | 0.0 | N/A | mupad | 13.8 | 1.7 | 0.006 |
| befunge | 100.0 | 0.0 | N/A | myghty | 27.3 | 0.0 | N/A |
| bison | 2.8 | 0.0 | N/A | nesc | 7.9 | 0.0 | N/A |
| bitbake | 0.9 | 0.0 | N/A | netlinx | 15.4 | 0.0 | N/A |
| blitzbasic | 56.6 | 0.0 | N/A | netlogo | 12.5 | 0.0 | N/A |
| blitzmax | 1.2 | 0.0 | N/A | nginx | 0.0 | 0.0 | N/A |
| bluespec | 2.8 | 0.0 | N/A | nimrod | 4.5 | 0.0 | N/A |
| boo | 10.3 | 0.3 | 0.136 | ninja | 36.8 | 0.0 | N/A |
| brainfuck | 73.8 | 0.3 | -0.003 | nit | 3.4 | 0.0 | N/A |
| brightscript | 2.8 | 0.0 | N/A | nix | 1.6 | 0.0 | N/A |
| bro | 3.3 | 0.0 | N/A | nsis | 3.0 | 0.0 | N/A |
| c | 3.7 | 0.0 | N/A | nu | 15.1 | 0.0 | N/A |
| c++ | 5.6 | 0.0 | N/A | numpy | 0.0 | 0.0 | N/A |
| c-sharp | 0.5 | 0.0 | N/A | objdump | 77.5 | 0.0 | N/A |
| c2hs-haskell | 1.7 | 0.0 | N/A | objective-c++ | 5.6 | 0.1 | 0.023 |
| cap’n-proto | 4.7 | 0.0 | N/A | objective-j | 48.7 | 0.0 | N/A |
| cartocss | 15.9 | 0.2 | -0.021 | ocaml | 7.8 | 0.0 | N/A |
| ceylon | 2.1 | 0.0 | N/A | octave | 61.2 | 3.0 | -0.22 |
| chapel | 20.4 | 0.0 | N/A | omgrofl | 0.0 | 0.0 | N/A |
| chuck | 13.0 | 0.0 | N/A | ooc | 4.3 | 0.0 | N/A |
| cirru | 31.0 | 0.0 | N/A | opa | 0.3 | 0.0 | N/A |
| clarion | 0.6 | 0.0 | N/A | opal | 11.4 | 1.9 | -0.05 |
| clean | 12.0 | 0.5 | -0.026 | opencl | 14.6 | 0.0 | N/A |
| click | 17.8 | 0.3 | -0.024 | openscad | 31.4 | 0.0 | N/A |
| clips | 13.9 | 0.1 | -0.01 | org | 11.1 | 0.1 | 0.002 |
| clojure | 4.7 | 0.0 | N/A | ox | 43.6 | 8.4 | 0.315 |
| cmake | 2.0 | 0.0 | N/A | oxygene | 0.0 | 94.5 | N/A |
| cobol | 9.8 | 0.3 | -0.017 | oz | 8.4 | 0.2 | -0.012 |
| coffeescript | 4.0 | 0.0 | N/A | pan | 1.8 | 18.0 | 0.095 |
| coldfusion | 2.5 | 1.2 | -0.014 | papyrus | 10.8 | 0.1 | 0.01 |
| coldfusion-cfc | 1.1 | 0.0 | N/A | parrot | 20.0 | 0.0 | N/A |
| common-lisp | 6.4 | 0.0 | N/A | parrot-assembly | 6.0 | 0.0 | N/A |
| component-pascal | 37.1 | 84.1 | 0.144 | pir | 8.4 | 0.0 | N/A |
| coq | 17.5 | 0.0 | N/A | pascal | 2.5 | 0.0 | N/A |
| creole | 41.8 | 0.0 | N/A | pawn | 13.3 | 0.0 | N/A |
| crystal | 2.8 | 0.1 | -0.006 | perl | 7.8 | 0.1 | 0.022 |
| csound | 6.7 | 3.9 | -0.041 | perl6 | 15.3 | 0.0 | N/A |
| css | 10.9 | 0.0 | N/A | php | 2.1 | 0.0 | N/A |
| csv | 87.2 | 0.0 | N/A | piglatin | 5.5 | 0.0 | N/A |
| cucumber | 2.3 | 0.8 | 0.41 | pike | 11.9 | 0.0 | N/A |
| cuda | 2.6 | 0.0 | N/A | pod | 3.0 | 0.0 | N/A |
| cycript | 25.3 | 0.0 | N/A | pogoscript | 2.2 | 0.0 | N/A |
| cython | 2.0 | 0.0 | N/A | pony | 18.5 | 0.0 | N/A |
| d | 15.5 | 7.0 | 0.008 | postscript | 44.8 | 0.0 | N/A |
| darcs-patch | 3.0 | 0.0 | N/A | pov-ray-sdl | 36.7 | 0.0 | N/A |
| dart | 0.9 | 0.0 | N/A | powershell | 2.0 | 0.0 | N/A |
| desktop | 0.8 | 0.0 | N/A | processing | 12.0 | 0.0 | N/A |
| diff | 11.5 | 0.0 | N/A | prolog | 20.2 | 0.0 | N/A |
| dcl | 42.4 | 0.2 | -0.005 | propeller-spin | 9.7 | 0.0 | N/A |
| dm | 7.7 | 0.0 | N/A | protocol-buffer | 1.2 | 0.0 | N/A |
| dns-zone | 56.4 | 0.0 | N/A | pure-data | 79.8 | 0.1 | -0.035 |
| dockerfile | 1.5 | 0.0 | N/A | purebasic | 61.9 | 0.0 | N/A |
| dogescript | 3.3 | 0.0 | N/A | purescript | 2.0 | 0.0 | N/A |
| dylan | 1.5 | 0.0 | N/A | python | 2.9 | 26.3 | 0.091 |
| eagle | 82.8 | 40.1 | 0.076 | pt | 33.3 | 0.0 | N/A |
| ec | 10.1 | 0.2 | -0.014 | qmake | 4.1 | 0.0 | N/A |
| ecere-projects | 4.9 | 0.0 | N/A | qml | 1.2 | 0.0 | N/A |
| ecl | 4.3 | 0.0 | N/A | r | 11.2 | 0.1 | -0.002 |
| edn | 36.9 | 0.0 | N/A | racket | 6.4 | 0.0 | N/A |
| eiffel | 22.4 | 0.0 | N/A | rirh | 11.9 | 0.1 | -0.009 |
| elixir | 1.5 | 0.0 | N/A | raml | 2.7 | 0.0 | N/A |
| elm | 3.7 | 0.0 | N/A | rdoc | 1.8 | 0.0 | N/A |
| emacs-lisp | 9.1 | 0.0 | N/A | realbasic | 0.9 | 0.0 | N/A |
| emberscript | 9.1 | 1.1 | -0.016 | rebol | 20.3 | 0.1 | -0.018 |
| erlang | 5.2 | 0.0 | N/A | red | 14.3 | 0.2 | -0.02 |
| f-sharp | 5.1 | 0.0 | N/A | redcode | 20.9 | 0.0 | N/A |
| factor | 7.7 | 0.0 | N/A | ren’py | 2.3 | 0.0 | N/A |
| fancy | 9.9 | 0.0 | N/A | renderscript | 16.1 | 0.0 | N/A |
| fantom | 5.2 | 0.1 | -0.006 | rt | 2.7 | 0.2 | -0.002 |
| fish | 2.4 | 0.0 | N/A | rhtml | 4.2 | 0.6 | 0.001 |
| flux | 35.9 | 0.0 | N/A | rmarkdown | 8.1 | 0.0 | N/A |
| forth | 11.2 | 0.0 | N/A | rf | 0.8 | 0.2 | 0.117 |
| fortran | 15.4 | 0.0 | N/A | rouge | 14.8 | 0.0 | N/A |
| freemarker | 3.2 | 2.8 | 0.035 | ruby | 1.2 | 0.0 | N/A |
| g-code | 43.7 | 0.1 | -0.004 | rust | 2.6 | 0.1 | -0.004 |
| gams | 53.9 | 0.0 | N/A | sage | 32.1 | 0.0 | N/A |
| gap | 20.7 | 0.0 | N/A | saltstack | 1.9 | 0.0 | N/A |
| gas | 17.6 | 0.0 | N/A | sas | 20.3 | 0.0 | N/A |
| gdscript | 0.7 | 0.0 | N/A | sass | 2.9 | 0.0 | N/A |
| genshi | 9.0 | 12.3 | -0.092 | scala | 1.6 | 0.0 | N/A |
| gentoo-ebuild | 0.3 | 0.0 | N/A | scaml | 5.3 | 0.0 | N/A |
| gentoo-eclass | 0.5 | 0.0 | N/A | scheme | 15.4 | 5.6 | 0.011 |
| gettext-catalog | 1.3 | 0.0 | N/A | scilab | 32.1 | 0.7 | -0.058 |
| glsl | 9.4 | 0.5 | -0.015 | scss | 4.5 | 0.0 | N/A |
| glyph | 0.0 | 0.0 | N/A | self | 5.9 | 0.0 | N/A |
| gnuplot | 68.9 | 0.1 | -0.041 | shell | 5.3 | 0.0 | N/A |
| go | 2.0 | 0.0 | N/A | shellsession | 30.0 | 0.0 | N/A |
| golo | 1.7 | 0.0 | N/A | shen | 16.3 | 0.0 | N/A |
| gosu | 3.1 | 42.5 | -0.153 | slash | 40.8 | 0.0 | N/A |
| grace | 34.5 | 0.0 | N/A | slim | 2.3 | 0.0 | N/A |
| gf | 11.0 | 0.0 | N/A | smali | 1.0 | 0.0 | N/A |
| graphql | 1.6 | 0.0 | N/A | smalltalk | 1.6 | 0.1 | 0.195 |
| graphviz-(dot) | 43.1 | 0.0 | N/A | smarty | 4.4 | 0.8 | 0.001 |
| groff | 19.9 | 0.6 | 0.009 | smt | 34.8 | 0.0 | N/A |
| groovy | 0.9 | 0.0 | N/A | solidity | 13.7 | 0.0 | N/A |
| gsp | 2.5 | 0.2 | 0.001 | sourcepawn | 13.5 | 0.0 | N/A |
| haml | 2.3 | 0.0 | N/A | sparql | 10.1 | 0.0 | N/A |
| handlebars | 4.9 | 0.1 | 0.031 | sqf | 3.3 | 0.0 | N/A |
| harbour | 5.6 | 0.0 | N/A | sql | 11.0 | 0.0 | N/A |
| haskell | 3.4 | 0.0 | N/A | squirrel | 7.3 | 0.0 | N/A |
| haxe | 1.1 | 0.0 | N/A | stan | 15.2 | 0.0 | N/A |
| hcl | 1.3 | 0.0 | N/A | standard-ml | 49.8 | 0.1 | 0.008 |
| hlsl | 3.8 | 0.0 | N/A | stata | 8.2 | 6.1 | -0.073 |
| html | 22.5 | 1.9 | 0.082 | ston | 11.9 | 0.0 | N/A |
| html+django | 5.9 | 1.0 | 0.001 | stylus | 3.3 | 0.0 | N/A |
| html+eex | 4.7 | 0.6 | 0.019 | supercollider | 33.4 | 1.6 | -0.066 |
| html+erb | 4.0 | 0.4 | 0.006 | svg | 92.5 | 49.0 | -0.14 |
| html+php | 3.4 | 0.1 | 0.002 | swift | 0.6 | 0.0 | N/A |
| http | 4.3 | 0.0 | N/A | systemverilog | 4.9 | 0.0 | N/A |
| hy | 9.5 | 0.0 | N/A | tcl | 7.4 | 0.0 | N/A |
| idl | 74.2 | 0.0 | N/A | tcsh | 6.3 | 0.0 | N/A |
| idris | 4.1 | 0.0 | N/A | tea | 5.2 | 0.0 | N/A |
| igor-pro | 2.5 | 0.0 | N/A | tex | 18.6 | 0.0 | N/A |
| inform-7 | 14.0 | 0.2 | -0.019 | text | 56.5 | 0.6 | 0.061 |
| ini | 8.3 | 0.9 | 0.027 | textile | 8.2 | 0.0 | N/A |
| inno-setup | 2.4 | 0.0 | N/A | thrift | 1.2 | 0.0 | N/A |
| io | 18.9 | 0.1 | 0.012 | toml | 11.9 | 0.0 | N/A |
| ioke | 13.4 | 0.0 | N/A | turing | 4.3 | 0.0 | N/A |
| irc-log | 39.6 | 0.0 | N/A | turtle | 25.1 | 0.0 | N/A |
| isabelle | 3.6 | 0.1 | -0.007 | twig | 2.7 | 0.2 | 0.013 |
| j | 27.0 | 0.0 | N/A | txl | 7.4 | 7.4 | 1.0 |
| jade | 2.5 | 0.0 | N/A | typescript | 2.2 | 0.1 | 0.02 |
| jasmin | 20.0 | 0.0 | N/A | upc | 12.3 | 0.0 | N/A |
| java | 0.7 | 30.2 | 0.037 | unity3d-asset | 1.1 | 0.1 | 0.003 |
| jsp | 1.4 | 0.6 | -0.003 | uno | 0.8 | 0.0 | N/A |
| javascript | 9.3 | 52.1 | 0.13 | unrealscript | 2.6 | 0.0 | N/A |
| jflex | 2.6 | 0.3 | 0.333 | urweb | 19.2 | 1.7 | -0.064 |
| json | 44.8 | 0.0 | N/A | vala | 1.4 | 0.0 | N/A |
| json5 | 20.8 | 0.0 | N/A | vcl | 6.8 | 0.0 | N/A |
| jsoniq | 29.5 | 0.0 | N/A | verilog | 1.8 | 0.0 | N/A |
| jsonld | 11.6 | 0.0 | N/A | vhdl | 4.1 | 0.0 | N/A |
| jsx | 2.4 | 0.0 | N/A | viml | 2.6 | 0.0 | N/A |
| julia | 8.6 | 0.0 | N/A | visual-basic | 4.3 | 0.1 | 0.07 |
| jupyter-notebook | 62.5 | 0.0 | N/A | volt | 2.4 | 0.1 | -0.005 |
| kicad | 98.2 | 0.0 | N/A | vue | 3.0 | 0.0 | N/A |
| kit | 6.3 | 0.3 | 0.041 | owl | 10.4 | 85.6 | -0.146 |
| kotlin | 0.7 | 0.0 | N/A | webassembly | 30.3 | 0.0 | N/A |
| krl | 2.7 | 0.0 | N/A | webidl | 0.3 | 0.0 | N/A |
| labview | 39.0 | 100.0 | 0.017 | wisp | 13.8 | 0.0 | N/A |
| lasso | 33.5 | 4.4 | -0.001 | x10 | 8.9 | 1.0 | -0.031 |
| latte | 4.9 | 0.4 | 0.034 | xbase | 2.5 | 0.5 | -0.011 |
| lean | 8.2 | 0.0 | N/A | xc | 14.2 | 0.0 | N/A |
| less | 4.7 | 0.0 | N/A | xml | 13.5 | 65.3 | -0.016 |
| lex | 31.8 | 0.2 | -0.02 | xojo | 2.3 | 0.0 | N/A |
| lfe | 10.2 | 0.0 | N/A | xpages | 0.0 | 95.6 | N/A |
| lilypond | 37.1 | 0.0 | N/A | xproc | 9.9 | 59.5 | -0.375 |
| linker-script | 10.2 | 0.0 | N/A | xquery | 9.1 | 4.4 | -0.065 |
| liquid | 9.6 | 0.6 | 0.074 | xs | 1.6 | 5.9 | -0.032 |
| literate-agda | 23.4 | 0.0 | N/A | xslt | 2.2 | 85.1 | -0.041 |
| lcs | 1.3 | 0.0 | N/A | xtend | 0.3 | 0.0 | N/A |
| literate-haskell | 3.8 | 0.0 | N/A | yacc | 17.5 | 0.0 | N/A |
| livescript | 12.8 | 0.0 | N/A | yaml | 5.1 | 0.0 | N/A |
| llvm | 29.9 | 0.0 | N/A | yang | 0.7 | 0.0 | N/A |
| logos | 24.2 | 0.2 | -0.023 | zephir | 0.4 | 0.0 | N/A |
| logtalk | 4.3 | 0.0 | N/A | zig | 4.8 | 0.0 | N/A |
| lolcode | 14.4 | 4.8 | -0.092 | zimpl | 75.5 | 0.0 | N/A |
附录 J数据表
J.1 数据集创建的动机
为什么创建数据集?
创建 Dolma 的主要目的是训练 AI2 的自回归语言模型 OLMo。 它是来自多个数据源的文档的混合体。 使用基于规则和统计工具的组合来转换文档,以提取文本内容、删除布局信息并过滤英语内容。
卓玛包含来自不同领域的数据。 特别是,它包含从网络抓取中获取的文本、从学术 PDF 中提取的科学内容及其相关元数据、各种编程语言的代码、来自维基百科和维基教科书的参考资料以及来自古腾堡计划的公共领域书籍的混合体。
该数据集可以用于哪些(其他)任务?
我们希望该数据集对训练其他语言模型有用,无论是以其当前形式还是通过进一步过滤并将其与其他数据集组合。
除了语言模型训练之外,该数据集还可用于研究预训练语料库和在其上训练的模型之间的交互。 例如,人们可以从模型中研究世代的起源,或者进行进一步的语料库分析。
Dolma 的特定子集可用于训练特定领域的模型。 例如,代码子集可用于训练人工智能编程助手。
是否有明显不应该使用它的任务?
由于对原始源材料进行了无数次转换来导出我们的数据集,我们认为它不适合作为寻求直接消费原始内容的用户的替代品。 我们建议数据集的用户参考 HuggingFace Hub huggingface.co/datasets/allenai/dolma 上的许可和条款,其中详细说明了任何使用限制。
该数据集是否已用于任何任务?
尚未公开发布在此数据集上训练的模型。
如果是这样,结果在哪里以便其他人可以比较?
手稿即将出版。
谁资助了数据集的创建?
所有负责该数据集的人员均受雇于艾伦人工智能研究所。 同样,计算资源由AI2提供。
如果有关联的补助金,请提供补助金编号。
OLMo 项目的计算由 AMD 和 CSC 提供,使用 LUMI 超级计算机上的 GPU。
J.2 数据集组成
有哪些事例? 是否存在多种类型的实例?
实例是英文文本或计算机代码的纯文本跨度。 每个实例都是通过处理网页(可能包括新闻、文档、论坛等)、学术文章、GitHub 的计算机代码、维基百科的百科全书内容或古腾堡计划书籍获得的。
数据中实例之间的关系是否明确?
卓玛子集的元数据可用于重建项目之间的关系:
-
•
普通抓取。 每个文档都使用从中提取该文档的网页的 URL 作为其标识符;因此,它可以用来识别文档之间的关系。
-
•
C4。 从中提取文档的每个网页的 URL 作为元数据包含在内;因此,它可以用来识别文档之间的关系。
-
•
Reddit。 文档的原始 subreddits 和线程 ID 包含在元数据中。
-
•
peS2o。 每个文档的id是其对应稿件的语义学者语料库ID。 每篇稿件的元数据可以使用语义学者 API (Kinney 等人,2023) 获取。
-
•
堆栈。 每个文档所属的 GitHub 存储库的名称作为元数据包含在内。
-
•
古腾堡计划。 每本书的标题都包含在每个文档的第一行。
-
•
维基百科、维基教科书。 对于这两者,元数据包括与从中提取的页面内容相对应的 URL。 通过URL可以恢复文档之间的结构和联系。
每种类型有多少个实例?
表1中报告了汇总统计数据。
每个实例包含哪些数据? “原始”数据(例如,未经处理的文本或图像)? 特征/属性?
对于每个来源,原始数据无法直接获得,但可以使用特定于来源的方法来恢复:
-
•
普通抓取。 我们从2020年5月到2023年6月的常见抓取快照中获取数据。 Common Crawl 中的 WARC 文件可以与 Dolma id 相交以恢复原始 HTML 文件。
-
•
C4。 我们从 HuggingFace Hub333333https://huggingface.co/datasets/allenai/c4 获得了这个语料库。 反过来,C4 中的文档源自 04/2019 的 Common Crawl 快照。 C4 中的 URL 可用于恢复 HTML 文件。
-
•
Reddit。 这项工作中使用的完整的每月数据转储集不再由 Pushshift 分发,但仍然可以通过 torrent 和一些公共网络档案获得。
-
•
peS2o。 peS2o 源自 S2ORC Lo 等人 (2020)。 可以通过提取S2ORC中与peS2o共享相同ID的文档来获得原始解析文档。 此外,S2ORC中的元数据可用于获取原始PDF。
-
•
堆栈(已删除重复数据)。 文件名和存储库名称都在元数据中可用,可用于恢复原始文件内容。
-
•
古腾堡计划。 每本书的标题是每个文档的第一行。
-
•
维基百科、维基教科书。 对于这两者,元数据包括与从中提取的页面内容相对应的 URL。 通过URL可以恢复文档之间的结构和联系。
是否有与实例关联的标签/目标? 如果实例与人有关,是否确定了亚群(例如,按年龄、性别等)以及它们的分布是什么?
没有与实例关联的标签。 许多文本实例可能是由个人或人群创建的,但在绝大多数情况下,作者身份信息不可用,更不用说子群体元数据了。 我们将这些统计数据的汇总和报告留给未来的工作。
是否包含所有内容或数据依赖于外部资源? (例如,网站、推文、数据集)如果是外部资源,a) 是否能保证它们将存在并随着时间的推移保持不变; b) 有官方存档版本吗? 是否有与任何数据相关的许可、费用或权利?
数据源自网络,原始资源可能不会随着时间的推移而保留。 但是,每个源都代表该数据的存档快照,该快照应保持固定且可用:
-
•
普通抓取。 Common Crawl 数据作为亚马逊网络服务开放数据赞助计划的一部分,在 Amazon S3 上提供,可免费下载343434https://commoncrawl.org/the-data/get-started/。 我们遵循 Common Crawl 的使用条款353535https://commoncrawl.org/terms-of-use/。
-
•
C4。 该语料库可以从 HuggingFace Hub33 获取,并在 ODC-By 1.0 (Open Data Commons,2010) 下发布。
-
•
Reddit。 由于 Reddit API 条款的更改,Pushshift 不再分发此数据集。 数据的非官方副本可以通过种子和一些公共网络档案获得。 Pushshift 数据转储继承363636https://www.reddit.com/r/pushshift/comments/d6luj5/comment/f0ugpqp 它们收集时 Reddit API 的使用条款(2023 年 3 月)。
-
•
peS2o。 peS2o 源自 S2ORC Lo 等人 (2020)。 S2ORC 通过语义学者公共 API373737https://www.semanticscholar.org/product/api 发布,根据 ODC-By 1.0 (Open Data Commons, 2010)。
-
•
堆栈(已删除重复数据)。 该语料库在 HuggingFace Hub383838https://huggingface.co/datasets/bigcode/the-stack-dedup 上提供,包含以各种宽松许可证发布的代码。 上面链接的数据卡中提供了更多详细信息,包括托管或共享语料库的使用条款。
-
•
古腾堡计划。 古腾堡计划包含不受美国版权法保护的书籍。 该语料库可从 gutenberg.org 获取。
-
•
维基百科、维基教科书。 维基百科数据转储393939https://dumps.wikimedia.org 可免费获取,并根据 CC BY-SA 4.0 许可证(Creative Commons, 2013) 发布。
是否有推荐的数据分割或评估措施? (例如,训练、开发、测试;准确性/AUC)
不。 经过净化处理的卓玛单独评估套件将于稍后发布。 该数据集的下游用户可以使用任何替代评估套件。
最初在此数据集上运行了哪些实验? 对这些结果进行总结,如果有的话,请在此处提供包含更多信息的论文链接。
即将发表的手稿将详细介绍为指导该数据集的创建而进行的消融和其他实验。
J.3数据收集过程
数据是如何收集的? (例如,硬件设备/传感器、人工管理、软件程序、软件接口/API;如何验证这些构造/措施/方法?)
每个子集的数据采集如下:
-
•
普通抓取。 快照是从 Common Crawl 的官方 S3 存储桶404040s3://commoncrawl/ 使用 cc_net 管道(Wenzek 等人,2020b)。 数据获取日期为2023年3月17日至3月27日。
-
•
C4。 我们使用带有 Git-LFS 扩展的 Git 从 HuggingFace Hub33 克隆 C4。 存储库于 2023 年 5 月 24 克隆。
-
•
Reddit。 Reddit 以 Pushshift 项目414141https://files.pushshift.io/reddit/submissions/ 收集和分发的每月评论和提交数据转储的形式被收购424242https://files.pushshift.io/reddit/comments/。 我们使用了 2005 年 6 月至 2023 年 3 月期间的整套 422 个公开可用的转储(208 条评论、214 条提交)。 大多数转储是在 2023 年 3 月获取的,最后一次转储是在 2023 年 5 月下载的。
-
•
peS2o。 我们使用 Git 和 Git-LFS 扩展从 HuggingFace Hub434343https://huggingface.co/datasets/allenai/peS2o 克隆 peS2o。 我们使用pes2o V2。 存储库于 2023 年 6 月 30 克隆。
-
•
堆栈(已删除重复数据)。 我们使用带有 Git-LFS 扩展的 Git 从 HuggingFace Hub38 克隆 Stack(已删除重复)。 存储库于 2023 年 5 月 28 克隆。
-
•
古腾堡计划。 数据直接从 gutenberg.org 下载。 我们使用 GutenbergPy (Angelescu, Radu, 2013) 来提取书籍。 网站访问日期:2023 年 4 月 3 日。
-
•
维基百科、维基教科书。 转储是从维基媒体网站39下载的。 我们使用 2023 年 3 月 20 日 的转储。
谁参与了数据收集过程? (例如学生、众包工作者)他们如何获得报酬? (例如,众包工作者的工资是多少?)
数据由艾伦人工智能研究所的全职员工收集和后处理。 此数据集中没有手动注释的实例。
数据是在什么时间范围内收集的? 收集时间范围与创建时间范围相符吗?
请参阅上面的列表。
与每个实例相关的数据是如何获取的? 数据是直接可观察的(例如,原始文本、电影评级)、由受试者报告(例如,调查回复),还是从其他数据间接推断/导出(例如,词性标签;基于模型的年龄或语言猜测) ? 如果是后两者,它们是否经过验证/验证?如果是,如何验证/验证?
与每个实例关联的任何元数据都是直接从每个源获取的。
数据集是否包含所有可能的实例? 或者,例如,它是来自较大实例集的样本(不一定是随机的)吗? 如果数据集是样本,那么总体是多少? 抽样策略是什么(例如,确定性、具有特定抽样概率的概率性)? 样本是否代表更大的集合(例如地理覆盖范围)? 如果不是,为什么不呢(例如,为了涵盖更多样化的实例)? 这对可能的用途有何影响?
每个子集的采样如下:
-
•
普通抓取。 Common Crawl 并不是网络的代表性样本。 有关 Common Crawl 的摘要统计信息通过 cc-crawl-statistics (Common Crawl,2016) 项目报告,可在 commoncrawl.github.io/cc-crawl 获取-统计。 卓玛使用 2020-05 的 Common Crawl 快照来 2023年6月444444常见抓取快照遵循命名约定xxxx-yy,其中xxxx是快照最终确定的年份,yy是周,范围从010> 至 1>522>。3>.
-
•
C4。 我们完全使用C4。
-
•
Reddit。 我们使用 06/2005 至 03/2023 期间所有可用的 Reddit 内容。
-
•
堆栈(已删除重复数据)。 我们完整地使用堆栈(重复数据删除)。
-
•
peS2o。 我们完整地使用 pes2o V2。
-
•
古腾堡计划。 我们处理所有古腾堡书籍。
-
•
维基百科、维基教科书。 我们完整地使用维基百科和维基教科书的英语和简单子集。
数据集中是否缺少信息以及原因? (这不包括故意删除的实例;它可能包括,例如,经过编辑的文本、保留的文档)此数据是否因为不可用而丢失?
Common Crawl 是我们唯一没有完整使用的来源。 我们只使用了所有可用快照的大约四分之一。 考虑到我们可用的计算量,这个数量被认为足以实现 OLMo 项目的目标(训练一个具有多达 700 亿个参数的自回归语言模型)。 我们决定使用 24 个最新的 Common Crawl 快照。
数据中是否存在任何已知的错误、噪声源或冗余?
据我们所知,尽管由于 S3 存储的网络问题,Common Crawl 数据的一小部分可能会丢失。 在访问 Common Crawl 时,我们实现了重试机制,但复制可能会因超出重试限制而失败。
J.4数据预处理
进行了哪些预处理/清洁? (例如,离散化或分桶、标记化、词性标记、SIFT 特征提取、实例删除、缺失值处理等)
所有数据源均使用FastText语言识别模型(Joulin等人,2016a,b)进行过滤,英语阈值为0.5。
对于Common Crawl和C4子集,我们使用以下过滤器(图1)来大幅修改原始数据。 请注意,数据可能会被标记为由一个或多个过滤器删除。
-
•
只有 Common Crawl,作为其分发管道的部分:将所有 HTML 线性化为纯文本文件(WET 文件生成454545https://commoncrawl.org/get-started);
-
•
仅Common Crawl,作为 CCNet 管道的一部分:我们通过识别每个快照的小子集上的重复段落来删除 Common Crawl 中频繁出现的段落。 此步骤消除了多个页面共享的标题,例如导航标题。 删除操作如下:给定每个快照组成的分片,将分片分组为集合;然后,删除 中段落的精确重复项。段落被定义为以换行符分隔的文档切片,并使用其 SHA1 进行比较。 我们选择使得每组最多20GB464646这是对原始CCNet管道的轻微修改,其中选择,以便每组是快照的2%。 我们选择使用固定的分片大小,而不是语料库的一定百分比,因为固定大小在资源使用方面更可预测,从而导致代码不易出错。 从概念上讲,这相当于对一段出现的绝对概率设置一个阈值. (删除了大约 70% 的段落);
-
•
仅限普通抓取,按 URL 进行重复数据删除:我们按 URL 进行页面重复数据删除(删除了 53% 的重复内容);
-
•
语言识别:删除所有由FastText语言识别模型确定的英语分数低于0.5的文档(Joulin等人,2016a,b)(删除了61.69按大小划分的网页百分比);
-
•
品质过滤器474747术语“质量过滤器”虽然在文献中广泛使用,但并没有适当地描述过滤数据集的结果。 质量可能被视为对信息性、全面性或人类重视的其他特征的评论。 然而,Dolma 和其他语言模型中使用的过滤器会根据固有的观念标准来选择文本(Gururangan 等人,2022 年)。:删除半数以上行不以“.”、“?”、“!”或““”。 (22.73% 的字符被标记为删除);
-
•
质量过滤器47:删除任何未通过任何 Gopher 规则的文档(Rae 等人, 2021) (15.23%标记为删除的字符);
-
–
最常见 ngram 中字符的比例大于阈值484848对于二元组,阈值为 0.20。 对于三元组,为 0.18。 4 克为 0.16。
-
–
重复 ngram 中的字符比例大于阈值494949对于 5 克,0.15。 对于 6 克,为 0.14。 对于 7 克,为 0.13。 8 克为 0.12。 对于 9 克,为 0.11。 10 克为 0.10。
-
–
包含少于 50 或超过 100K 字
-
–
中位字长小于 3 或大于 10
-
–
符号与文字的比率大于 0.10
-
–
字母字符小于 0.80 的单词比例
-
–
包含少于 2 个必需单词505050“the”, “be”, “to”, “of”, “and”, “that”, “have”, “with”
-
–
文档中以大于 0.90 的项目符号点开头的行的分数
-
–
文档中以省略号结尾的行的比例大于 0.30
-
–
文档中重复行数大于 0.30 的部分
-
–
重复行中字符的比例大于 0.30
-
–
-
•
质量过滤器47:删除任何包含词符或重复超过 100 次的标记序列的文档515151我们使用allenai/gpt-neox-olmo-dolma-v1_5来获取代币。 (标记为删除的字符的 0.003%);
-
•
内容过滤器:删除被 FastText 分类器评为有毒的句子(得分高于 )。 我们在 Jigsaw 数据集 (cjadams 等人, 2017) 上训练二元分类器(标记为删除的数据的 1.01%);
-
•
内容过滤器:使用识别电子邮件、电话号码和 IP 地址的正则表达式屏蔽个人身份信息 (PII);包含 6 个或更多 PII 的页面从语料库中完全删除(0.05% 标记为屏蔽,0.11% 标记为删除);
-
•
精确文档去重:重复文档相同的文本。 没有删除标点符号或空格。 空文档被视为重复文档(标记为删除的文档的 14.9%)。
-
•
仅限常见爬网,按段落重复数据删除:我们使用布隆过滤器在段落级别对 Web 子集进行重复数据删除(标记为删除的 UTF-8 字符的 19.1%)。
对于 Reddit 子集,我们使用以下过滤器来大幅减少原始数据。
-
•
语言识别:删除由 FastText 语言识别模型确定的英语分数低于 0.5 的所有文档。
-
•
质量过滤器47:删除长度短于 500 个字符的评论和提交内容。
-
•
质量过滤器47:删除点赞数少于三张的用户评论(Reddit 用户对提交和评论的质量进行投票)。
-
•
内容过滤器47:删除来自被禁止、有毒或 NSFW subreddit 的评论和提交内容。
-
•
内容过滤器47:删除被 FastText 分类器列为有毒或仇恨言论的句子(得分高于 )。
-
•
内容过滤器:使用识别电子邮件、电话号码和 IP 地址的正则表达式屏蔽个人身份信息 (PII)
-
•
重复数据删除:我们使用布隆过滤器在段落级别(联合)删除评论和提交的重复数据。
对于从 The Stack 派生的代码子集(已删除重复数据),我们使用以下过滤器(图 8):
-
•
语言过滤器:删除了与以下编程语言关联的文件:
-
–
数据或数字内容:csv、json、json5、jsonld、jsoniq、svg
-
–
汇编代码:汇编
-
–
-
•
质量过滤器47:从文档序言中删除了代码文件中的版权声明525252代码许可和出处仍在元数据中跟踪。;
-
•
质量过滤器47:删除了与任何 RedPajama v1 (Together Computer, 2023c) 代码过滤器匹配的文档(标记的数据的 41.49%用于删除):
-
–
最大行长度 > 1000 个字符。
-
–
平均行长度 > 100 个字符。
-
–
字母数字字符的比例 < 0.25。
-
–
字母字符与标记数量的比率 < 1.5535353Tokens counted using whitespace tokenizer.
-
–
-
•
质量过滤器47:删除了与以下任意 Starcoder 过滤器匹配的文档(Li 等人,2023):
-
–
包含 XML 模板代码。
-
–
HTML 代码与文本的比率 <= 0.2。
-
–
Java、Javascript、Python 代码与注释之比 <= 0.01 或 > 0.8。
-
–
-
•
内容过滤器:使用识别电子邮件、电话号码和 IP 地址的正则表达式屏蔽个人身份信息 (PII);包含 6 个或更多 PII 的页面将从语料库中完全删除。
对于维基百科和维基教科书子集,我们删除了包含少于 25 个 UTF-8 单词的页面。
对于 Gutenberg 子集:
-
•
语言识别:对于每个段落(定义为换行符分隔的文本范围),我们使用 FastText 来执行语言识别。 然后,我们通过平均所有段落的分数来计算平均语言分数。 如果文档的语言分数低于,则将其丢弃;
-
•
质量过滤器47:我们会删除包含少于 25 个 UTF-8 单词的页面;
- •
对于 PeS2o 子集,我们删除任何包含词符或重复超过 100 次的标记序列51 的文档。
对于卓玛版本1.0和1.5,我们对卓玛的所有子集进行净化。 特别是,我们删除了与 Paloma 评估套件 Magnusson 等人 (2023) 中的文档共享的段落。 总体而言,由于该评估集的污染,我们的数据集仅删除了 0.003%。 卓玛版本1.6未净化。
除了预处理/清理的数据之外,是否还保存了“原始”数据? (例如,支持未来意外的用途)
原始数据适用于除 Common Crawl 之外的所有子集。 由于空间限制,我们仅保留 Common Crawl 快照的线性化版本,并按如上所述的语言 ID 进行过滤。
原始数据不可在艾伦人工智能研究所之外下载。 如果感兴趣的人需要访问原始数据,可以联系本文的作者。
有预处理软件吗?
是的,所有预处理软件都可以在 GitHub 上获得,地址为github.com/allenai/dolma,也可以在 PyPI545454https://pypi.org/project/dolma/ 上获得。
此数据集收集/处理过程是否实现了创建本数据表第一部分中所述数据集的动机?
是的,它确实。
J.5数据集分布
数据集是如何分布的? (例如网站、API 等;数据是否有 DOI;是否冗余存档?)
Dolma 通过 HuggingFace Hub 进行分发,该 Hub 提供通过数据集 (Lhoest 等人,2021) Python 包、直接下载和使用 Git-LFS 扩展的 Git 的访问。 此外,艾伦人工智能研究所的云存储中还存储了一份副本。
数据集何时发布/首次分发? (这个数据集有规范的论文/参考吗?)
该数据集现已可用。 本手稿可作为数据集的参考。
它是根据什么许可证(如果有)分发的? 数据有版权吗?
有关与 Dolma 关联的许可证的信息,请参见 HuggingFace Hub 上的发布页面:huggingface.co/datasets/allenai/dolma。
是否有任何费用或访问/出口限制?
该数据集是免费分发的。 用户应在 HuggingFace Hub 上验证其发布页面上的任何限制:huggingface.co/datasets/allenai/dolma。
J.6数据集维护
谁支持/托管/维护数据集? 如何联系数据集的所有者/管理者/管理者(例如电子邮件地址或其他联系信息)?
艾伦人工智能研究所维护该数据集。 对于支持问题,用户可以打开 GitHub 上的 issue555555https://github.com/allenai/dolma/issues 或者在数据集页面565656https://huggingface.co/datasets/allenai/dolma/discussions 的社区标签上(前者优先于后者)。 任何其他询问应发送至ai2-info@allenai.org。
数据集会更新吗? 多久一次以及由谁进行? 如何记录和传达更新/修订(例如,邮件列表、GitHub)? 有勘误吗?
数据集将由艾伦人工智能研究所的维护人员根据需要上传。 数据集的新版本将被相应地标记。 数据集的最新版本以及变更日志将从第一个修订版开始提供。
如果数据集过时,将如何传达? 是否有一个存储库可以链接到使用该数据集的任何/所有论文/系统?
用户应跟踪正在使用的数据集的版本。 有关最新版本 Dolma 的信息可在 HuggingFace Hub 的发布页面上找到:huggingface.co/datasets/allenai/dolma。 卓玛用户在使用此数据时应引用此手稿。
如果其他人想要扩展/增强/构建这个数据集,是否有一种机制可以让他们这样做? 如果是,是否有跟踪/评估这些贡献质量的流程。 向用户传达/分发这些贡献的过程是什么?
上文描述了衍生品的创建和分发。 如果贡献者希望将他们的改进返回到未来的卓玛版本中,他们应该联系本手稿的相应作者。
J.7 法律和道德考虑
如果数据集与人相关(例如,他们的属性)或由人生成,他们是否了解数据收集? (例如,收集文字、照片、交互、交易等的数据集)
来自网络数据的卓玛子集可能是由个人或群体创建的,但作者信息通常不可用。
作者没有直接获悉数据收集情况。 对于百科全书和网络内容,网络服务器的日志将包含 Common Crawl 运行的蜘蛛程序的记录。 对于学术内容,pes2o 子集(Soldaini 和 Lo,2023) 来自作者授权许可分发的手稿。 Reddit 内容是通过遵守服务条款的公共 API 获取的;我们并未直接联系 Reddit 帖子的个别作者。 最后,艾伦人工智能研究所没有联系古腾堡计划。
如果涉及其他受道德保护的主体,是否履行了适当的义务? (例如,医疗数据可能包括从动物收集的信息)
由于卓玛的性质和规模,无法确定哪些义务(如果有)是适当的。
如果与人有关,是否有任何伦理审查申请/审查/批准? (例如机构审查委员会申请)如果与人有关,他们是否被告知数据集将用于什么目的并且他们是否同意? 对于从人类通信中收集的数据存在哪些社区规范? 如果获得同意,如何获得同意? 是否为人们提供了任何机制来在未来或出于某些用途撤销他们的同意?
OLMo 项目包括由艾伦人工智能研究所内部和外部成员组成的道德委员会。 卓玛的创建计划经过了委员会的审查,我们采纳了他们的建议。
按照类似工作中建立的做法,没有收集数据集中可能代表的个人的同意。 我们提供了一个表单575757https://forms.gle/q4BNUUxUxKwKkfdT6 供希望从数据集中删除自己信息的个人使用。
如果它与人有关,该数据集是否会使人们受到伤害或采取法律行动? (例如,金融、社会或其他方面)采取了哪些措施来减轻或减少潜在的伤害?
Dolma 包含从 Common Crawl 从网络上爬取的网页派生的文本实例。 内容可能包含敏感信息,包括个人信息或网络用户选择公开发布的财务信息。 这些数据仅从公共场所获取,因此可以通过浏览网络访问或已经可以访问相同的数据。 我们测量了各种类型的个人信息,并专门构建了工具来删除某些类型的敏感信息,并通过我们的许可证限制用户可以使用这些数据执行哪些操作。
如果个人希望删除自己的信息,我们建议他们通过我们的表单57提交请求。
如果它与人有关,它是否会不公平地使特定社会群体受益或不利? 以什么方式? 这是如何缓解的?
卓玛并非其任何来源的代表性样本。 它可能在互联网上代表性不足或过多;此外,peS2o 子集中的论文偏向于 STEM 学科;古腾堡图书馆的书籍大部分来自公共领域(出版时为1927年之前出版的书籍);最后,维基百科和维基教科书的英语和简单子集可能会偏向于来自北半球的事件和人物。
我们并没有试图改变卓玛社会群体的分布。 纠正大型数据集中的社会偏见的大规模干预措施仍然具有挑战性,有待未来的工作。
如果涉及到人,是否为他们提供了隐私保障? 如果有,有哪些保证以及如何保证这些保证?
该数据集包含源自 Common Crawl 从网络上抓取的网页的文本。 对于大部分数据,无法识别作者身份。 在许多情况下,创作者故意选择在网上匿名发布,因此推断作者身份可能会在道德上引起争议。 我们提供对我们数据的访问,并鼓励任何可能删除其数据或有关其数据的创作者与我们联系。
数据集是否符合欧盟通用数据保护条例 (GDPR)? 它是否符合任何其他标准,例如美国平等就业机会法案?
我们总体创建了这个数据集,而不是单独识别任何个人的内容或信息。 我们采取了合理的措施来删除可以可靠检测的个人信息类型。 我们限制谁有权访问这些数据,并根据禁止可能被视为歧视性的使用的许可证发布这些数据。 我们还为任何人提供联系我们的途径,以便从我们的语料库中删除来自他们或关于他们的文本57。
数据集是否包含可能被视为敏感或机密的信息? (例如,个人识别信息)数据集是否包含可能被认为不适当或具有攻击性的信息?
该数据集包含源自 Common Crawl 从网络上抓取的网页的文本。 因此,它可以包含互联网上的创建者在公共网站上发布的文本。 如果作者公开发布个人信息或攻击性内容,则可能会包含在该数据集中。 我们采取了合理的措施来删除可以可靠检测的个人信息类型。 我们还删除了包含被归类为有毒句子的文件。
附录 K所有原始消融结果
K.1 卓玛与其他语料库的比较
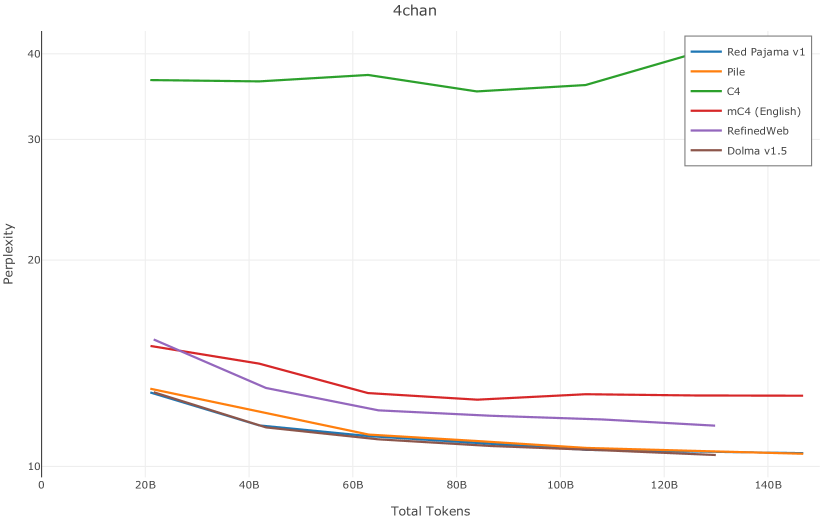
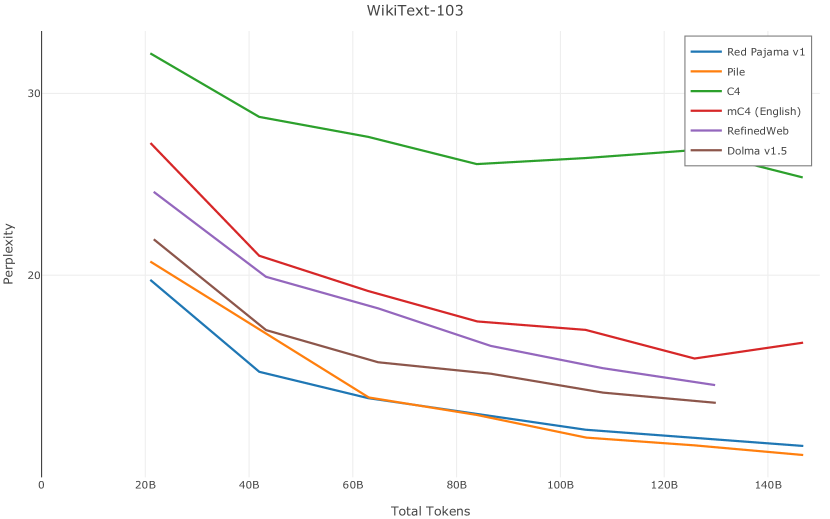
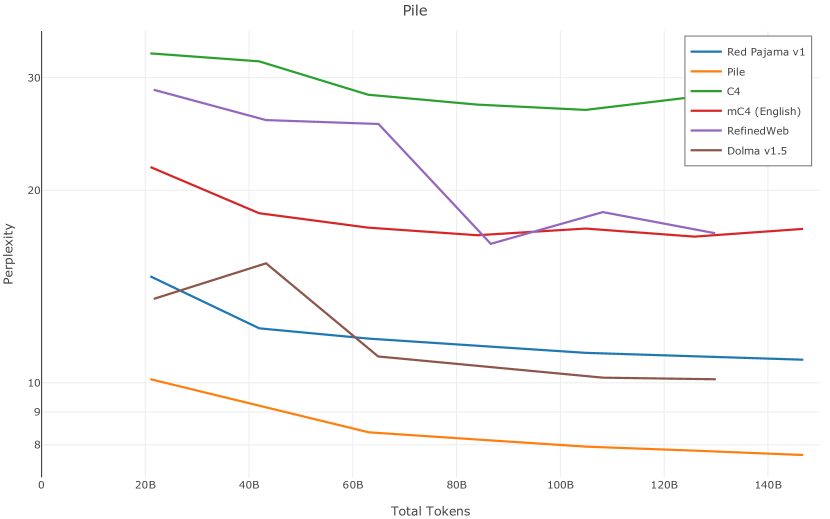
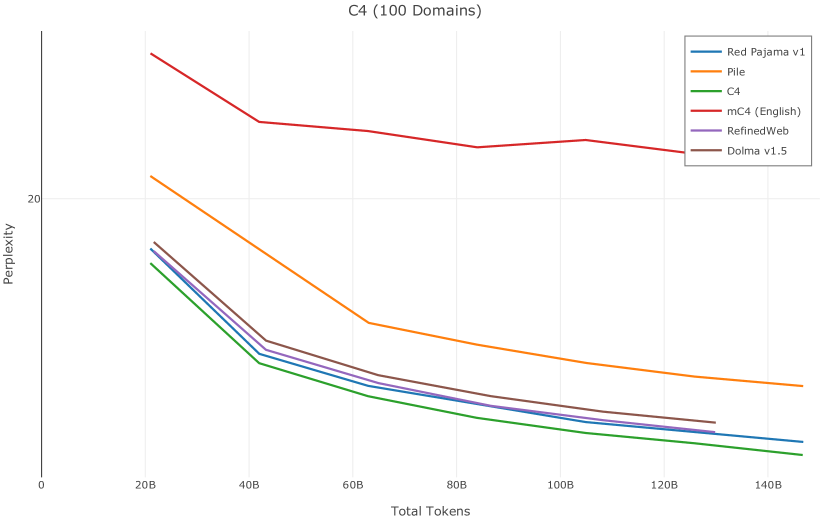
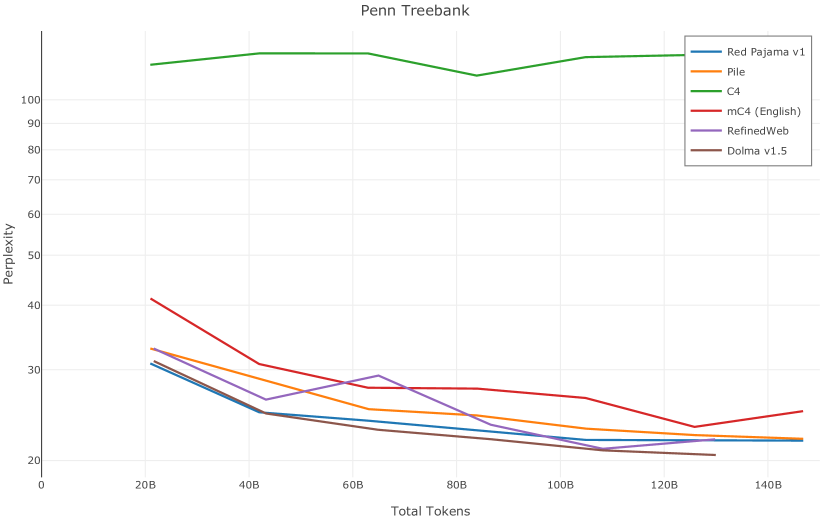
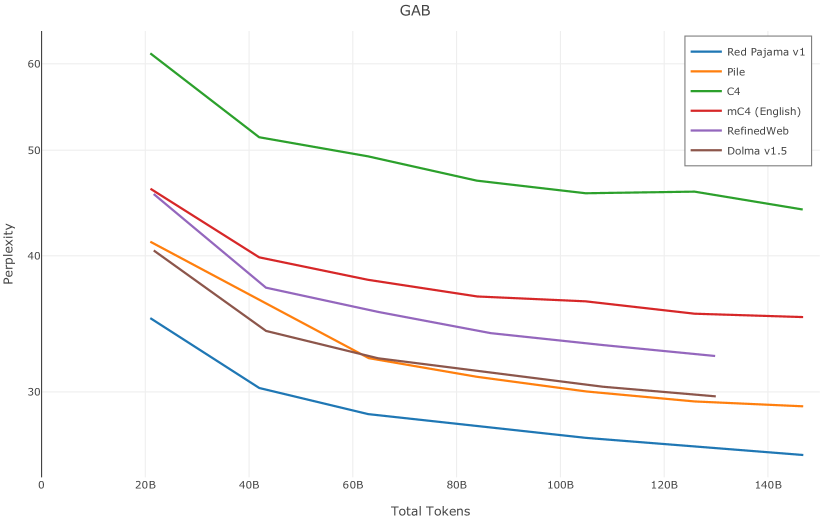
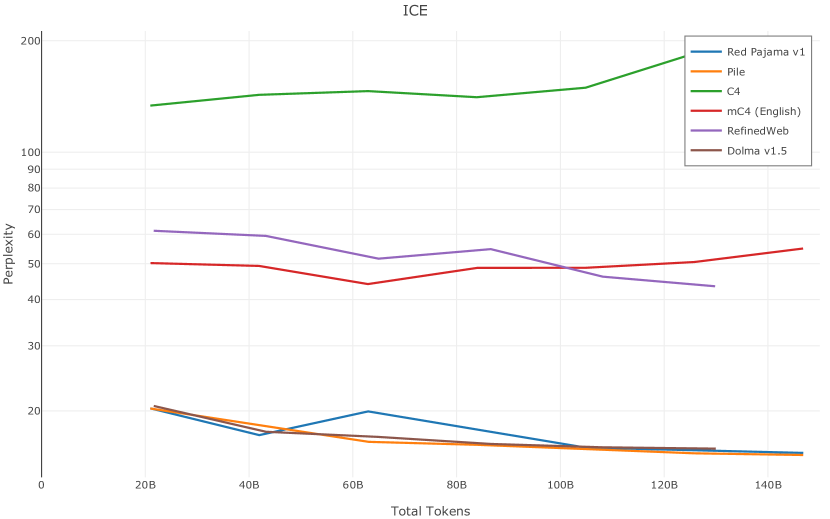
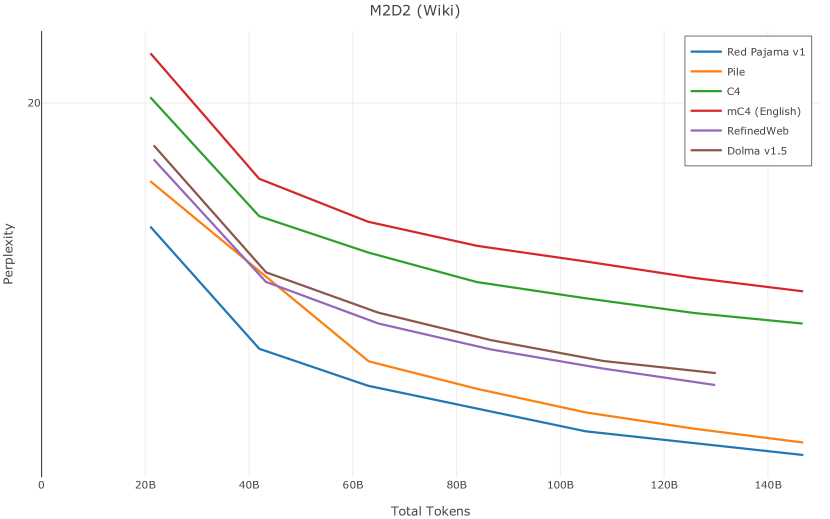
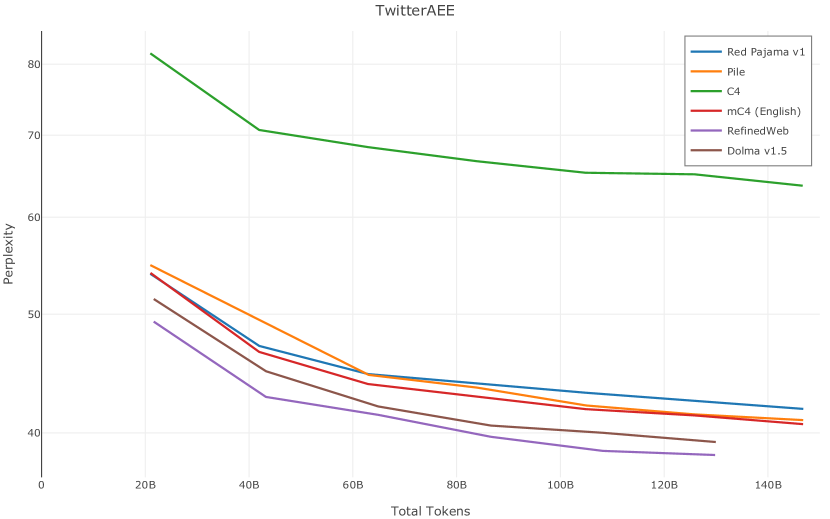
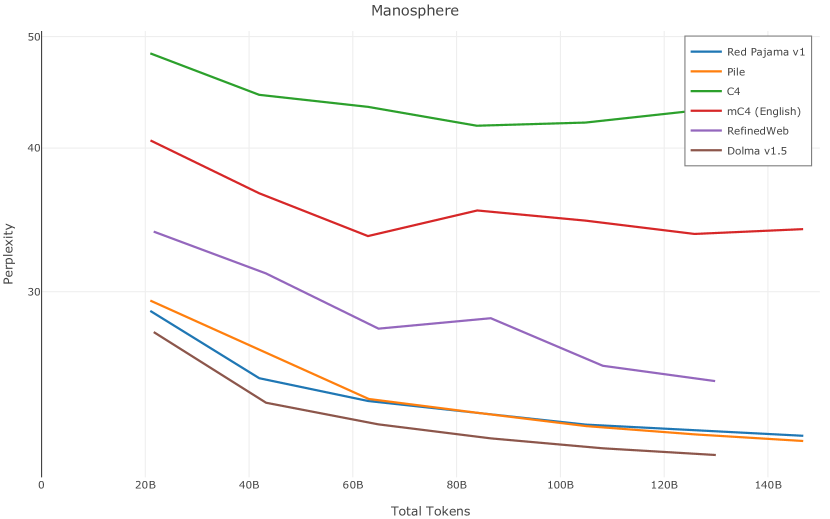
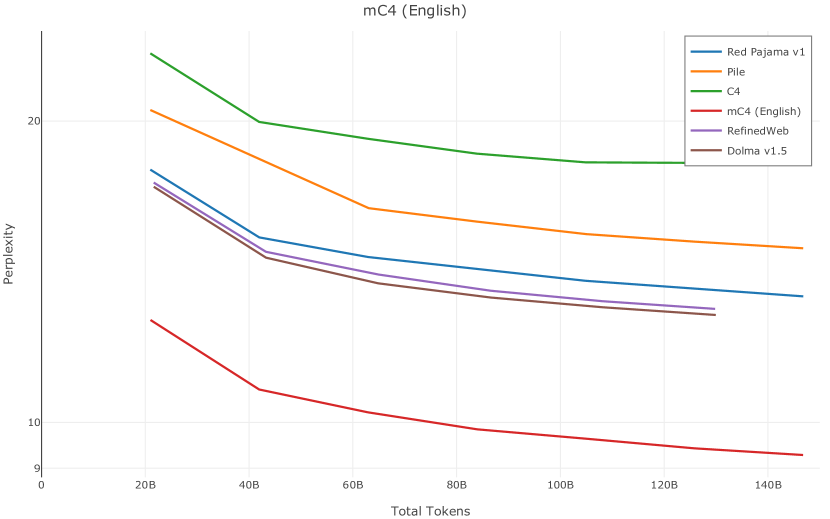
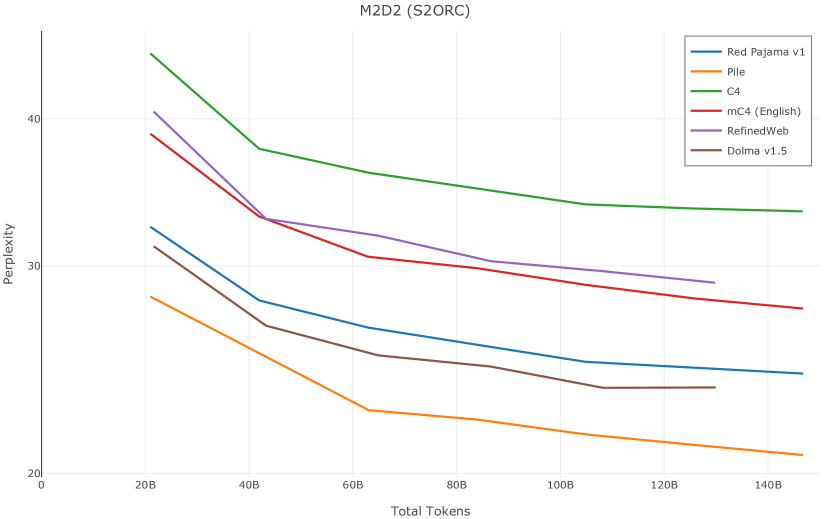
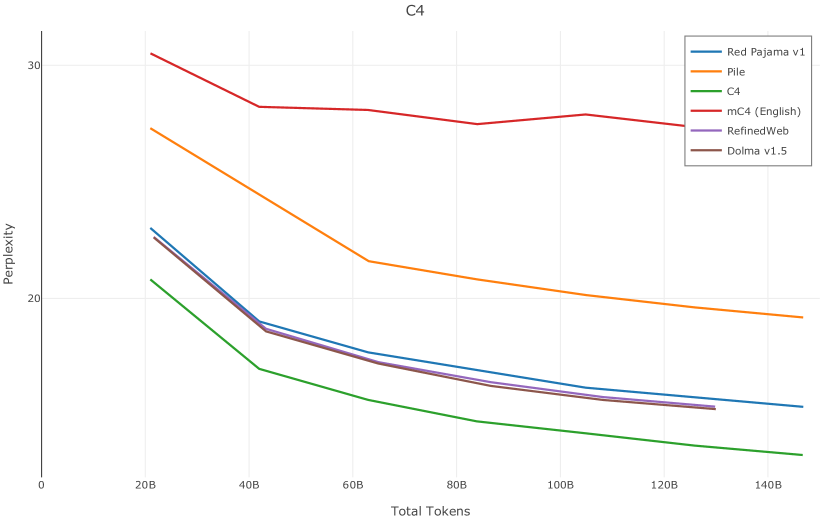
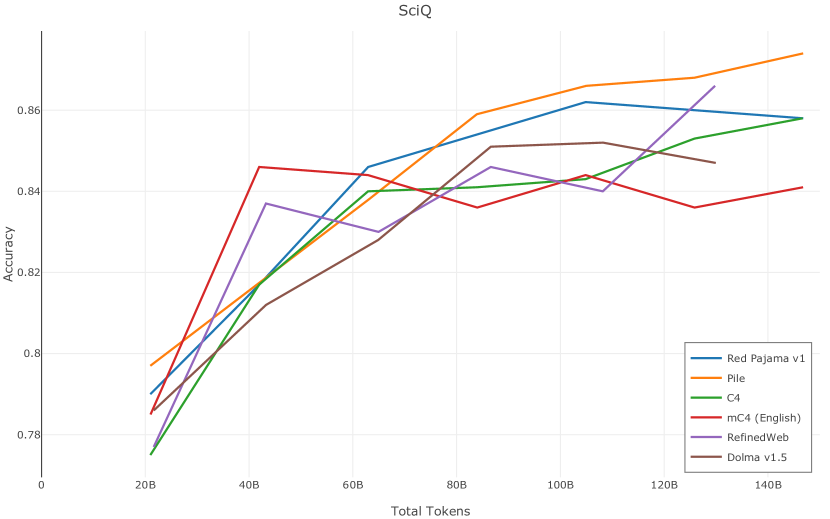
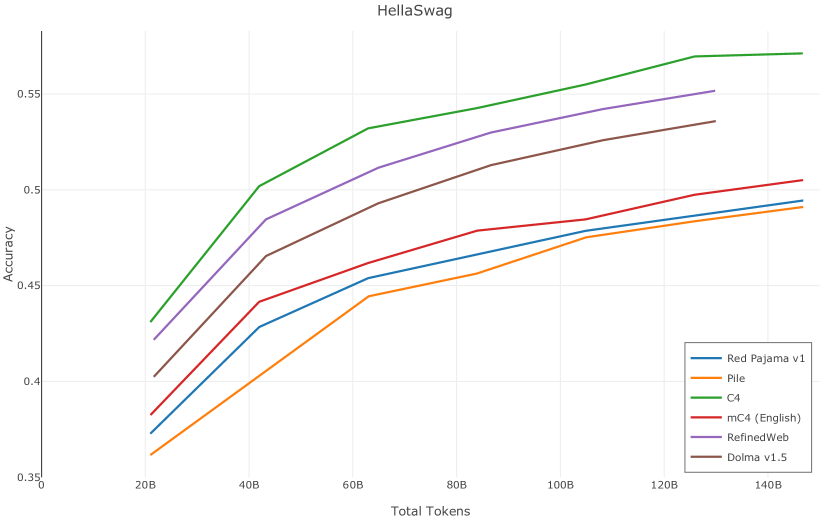
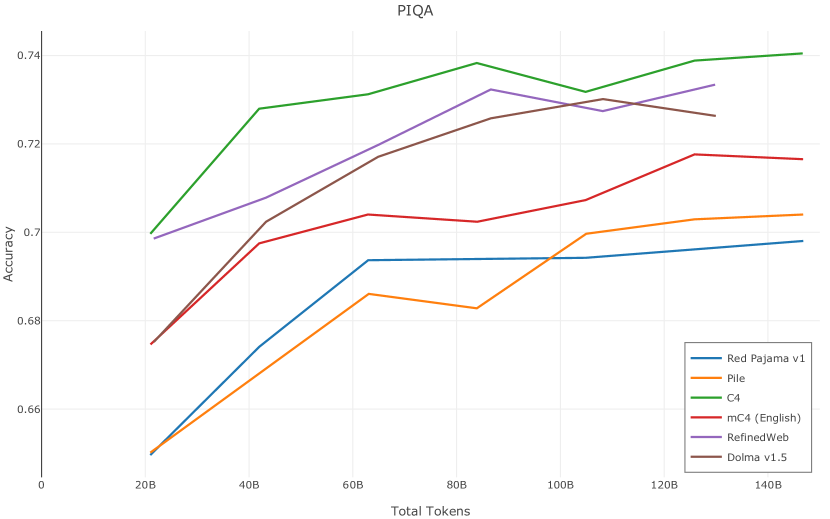
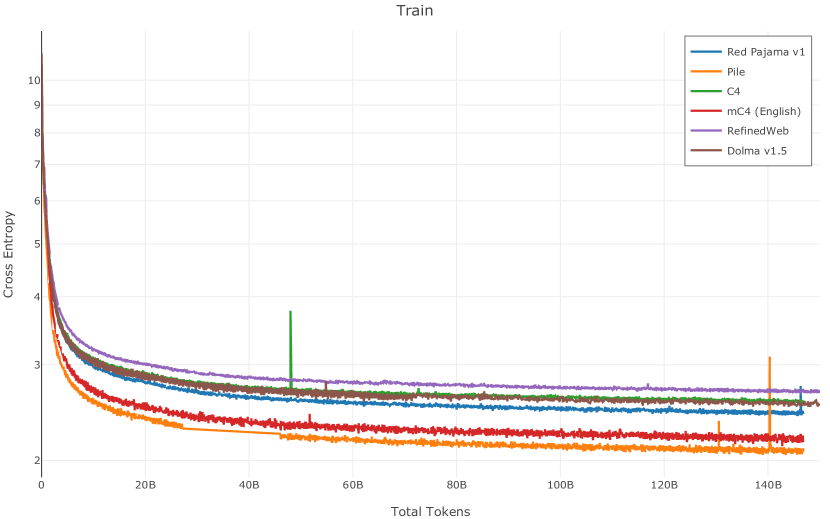
K.2 重复数据删除策略
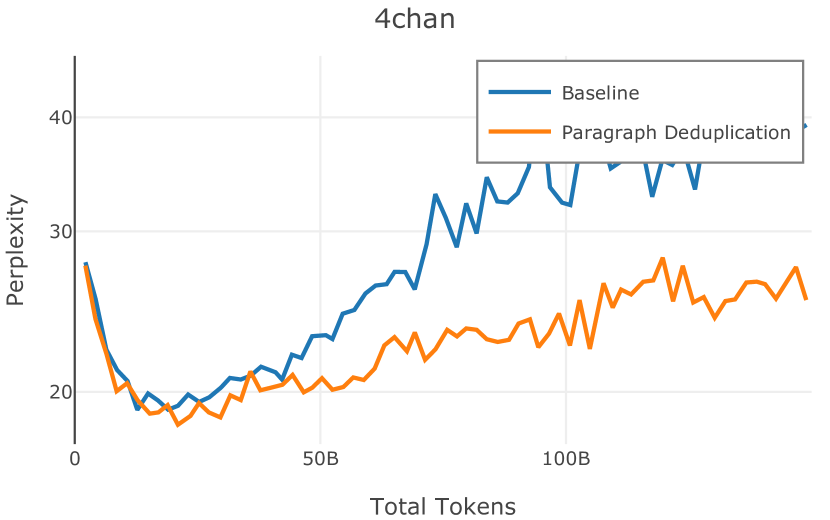
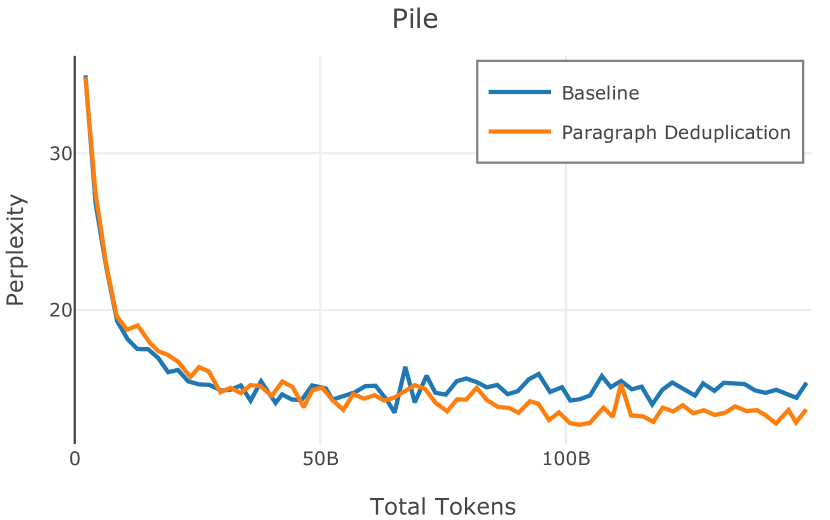
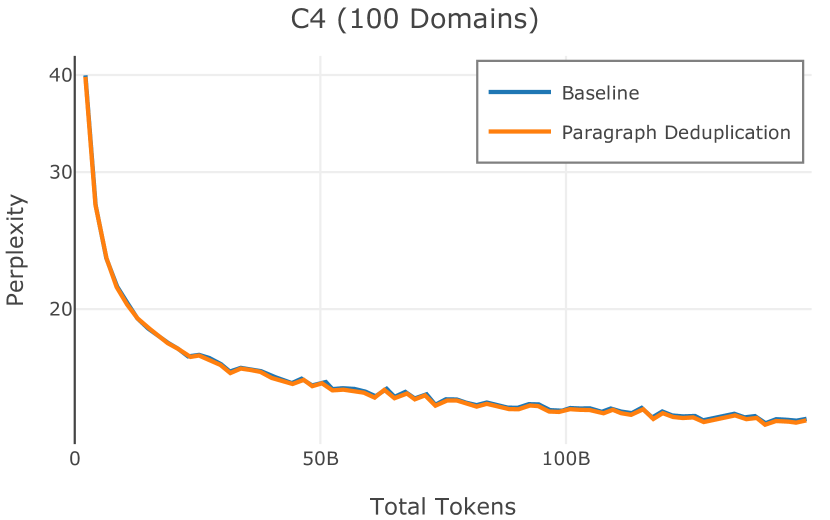
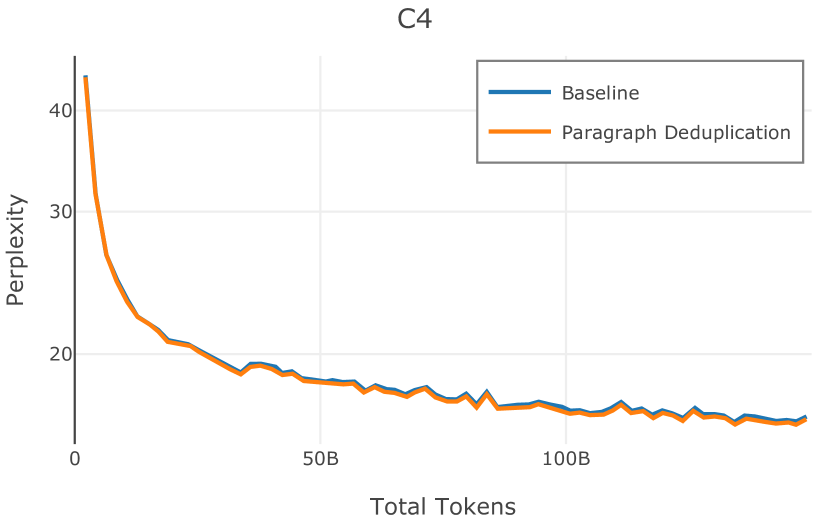
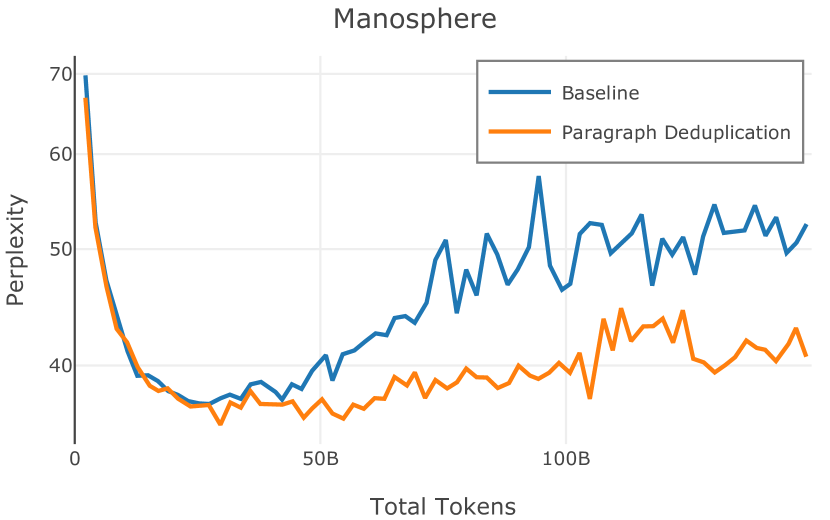
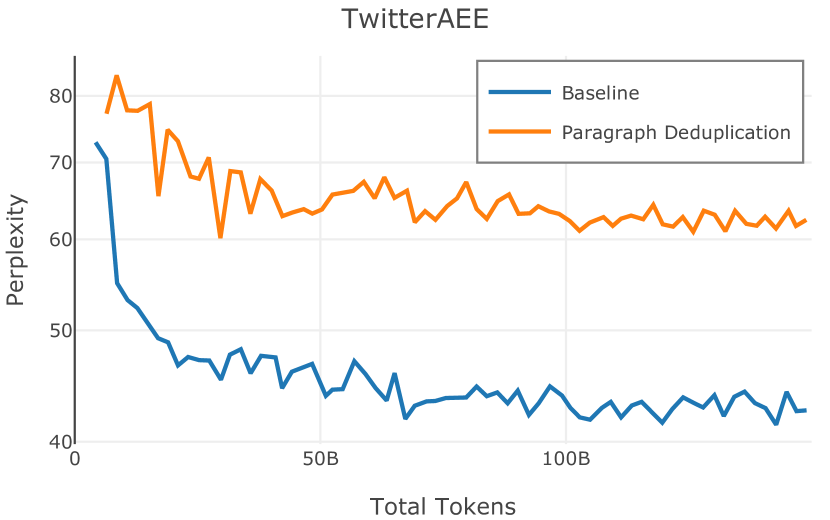
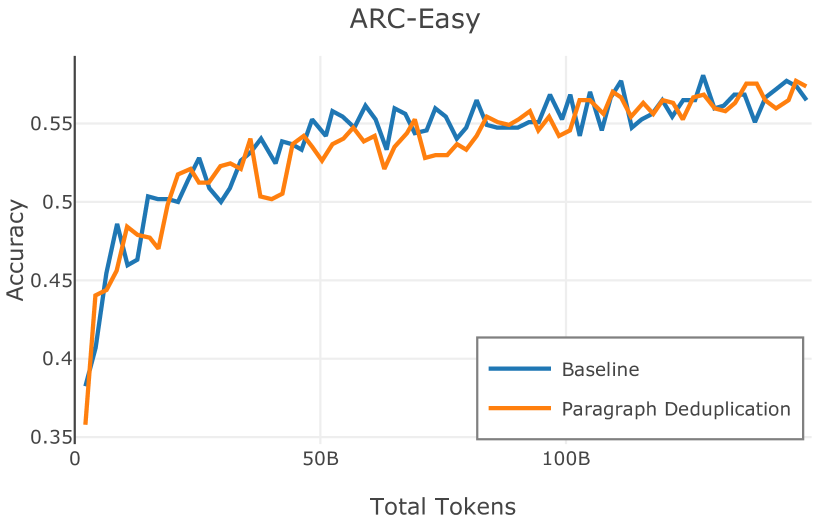
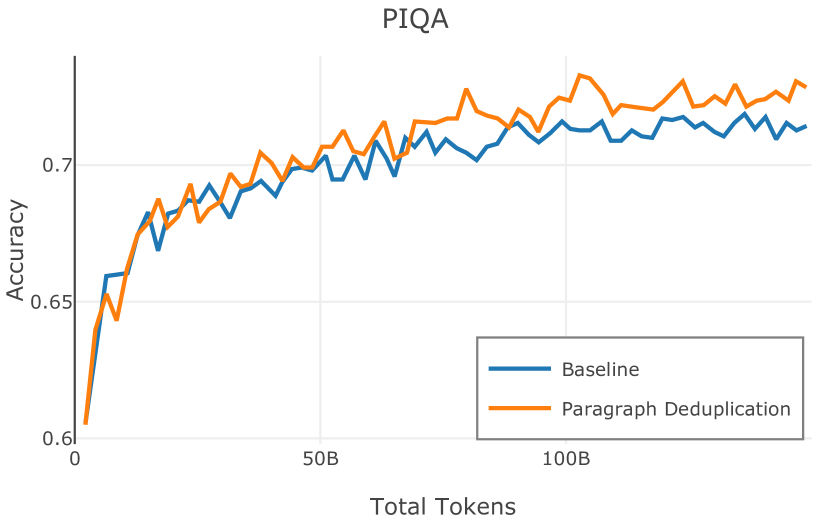
K.3 个人身份信息的过滤
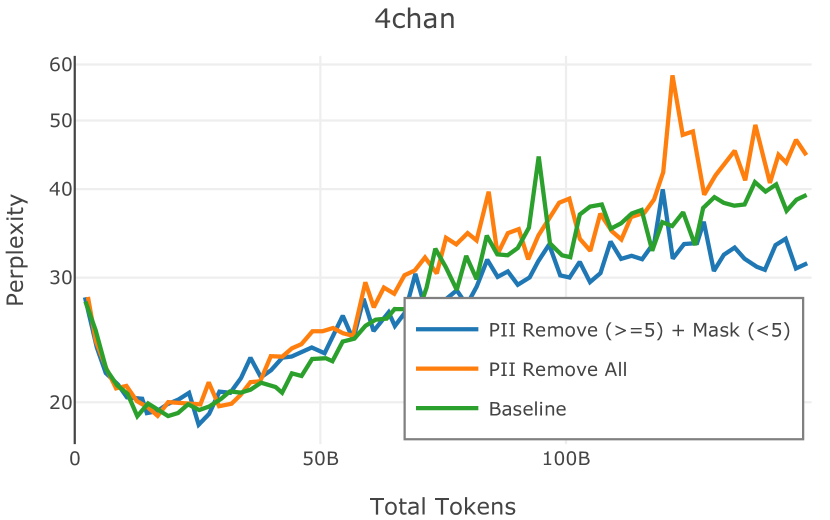
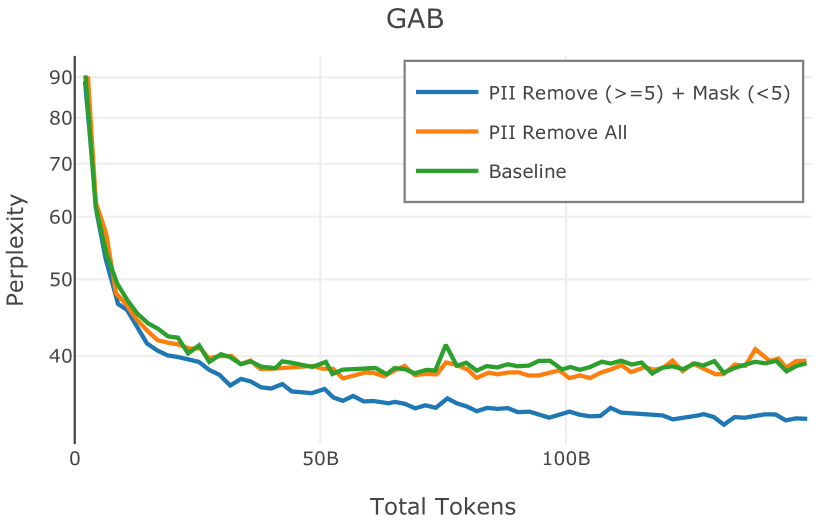
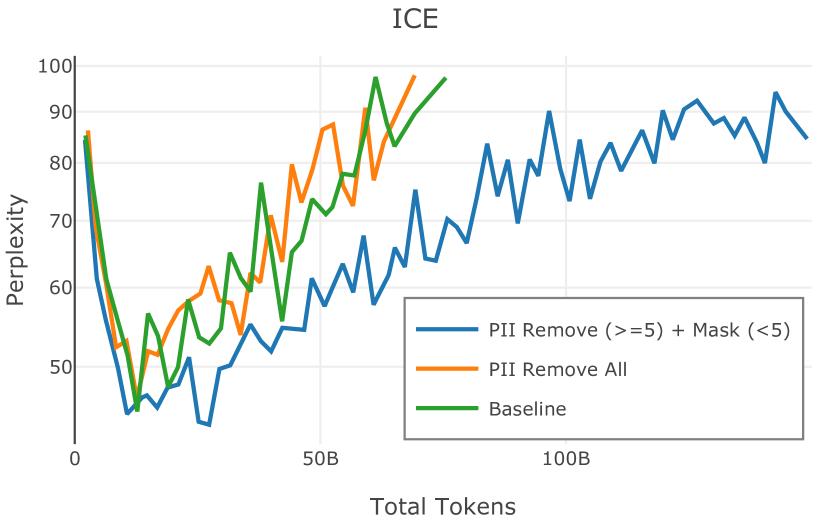
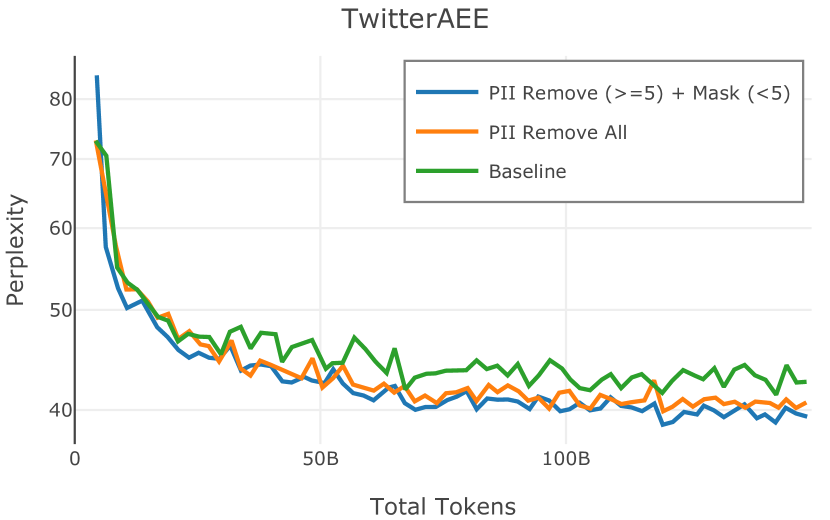
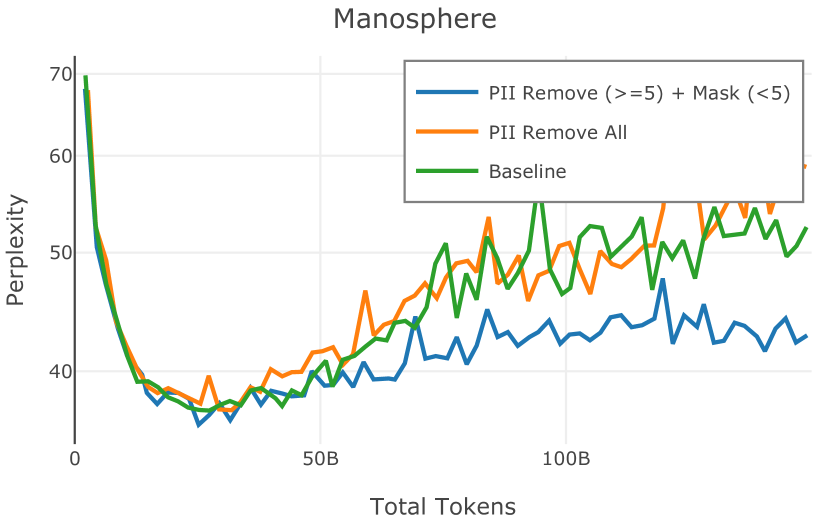
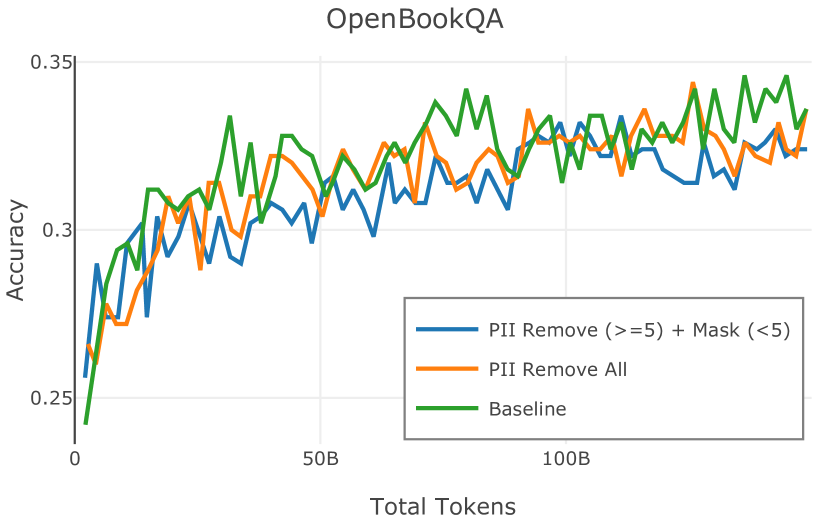
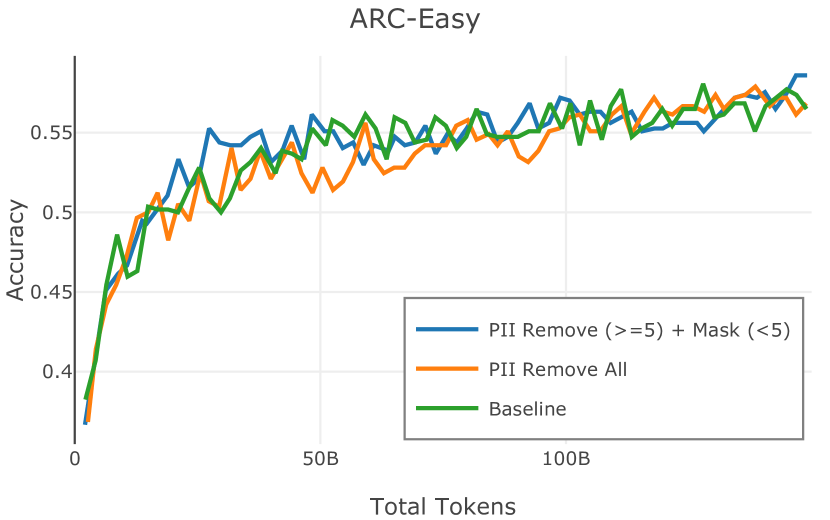
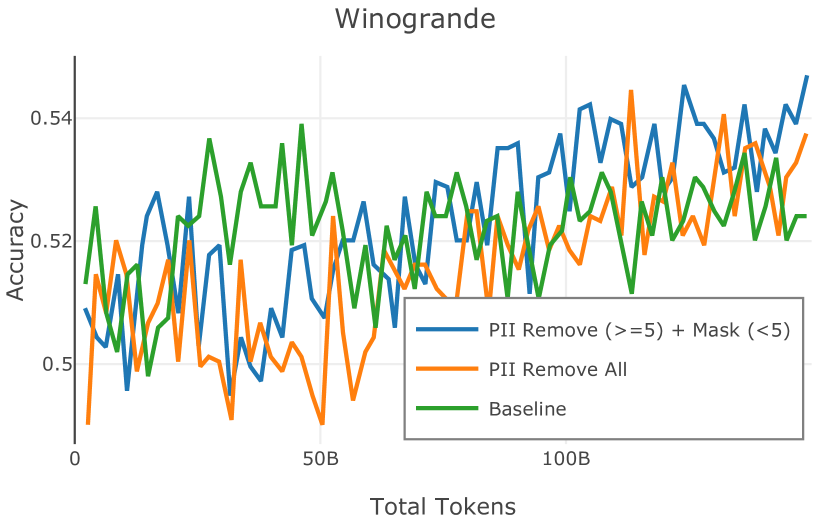
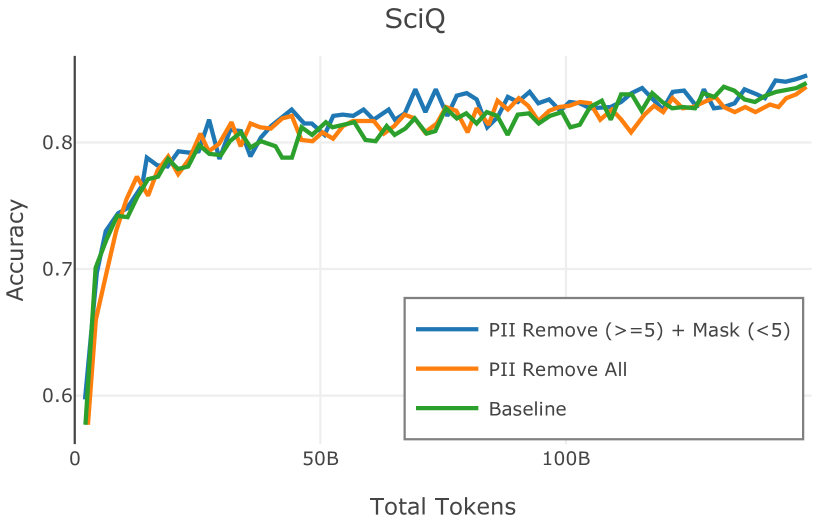
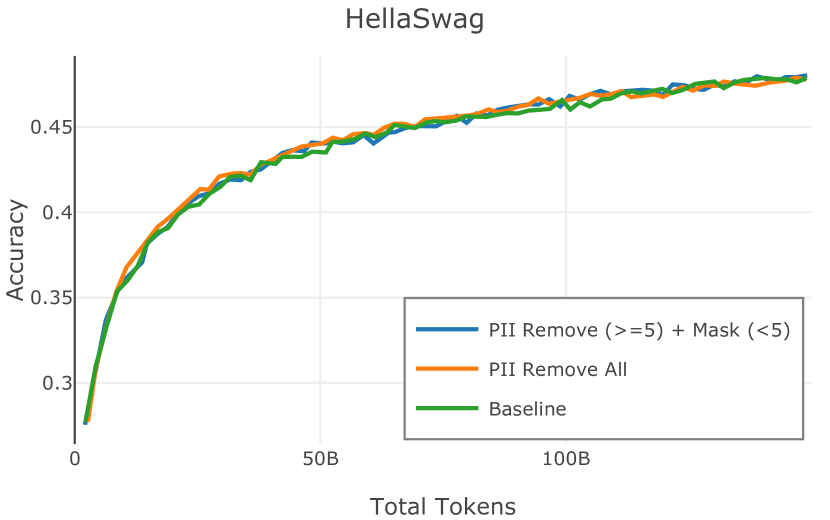
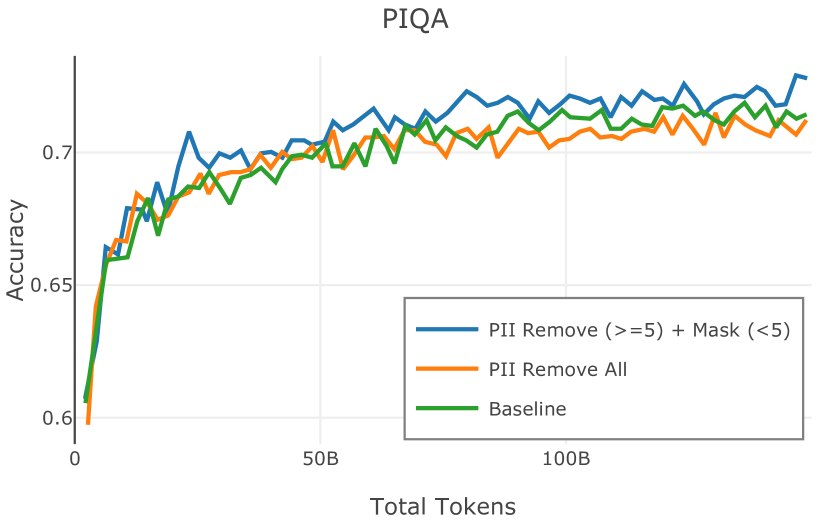
K.4 比较 Web 管道的质量过滤器
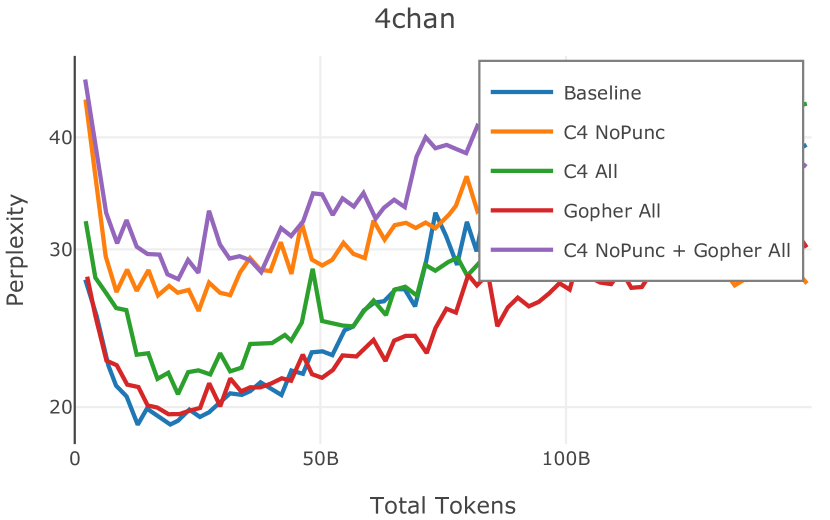
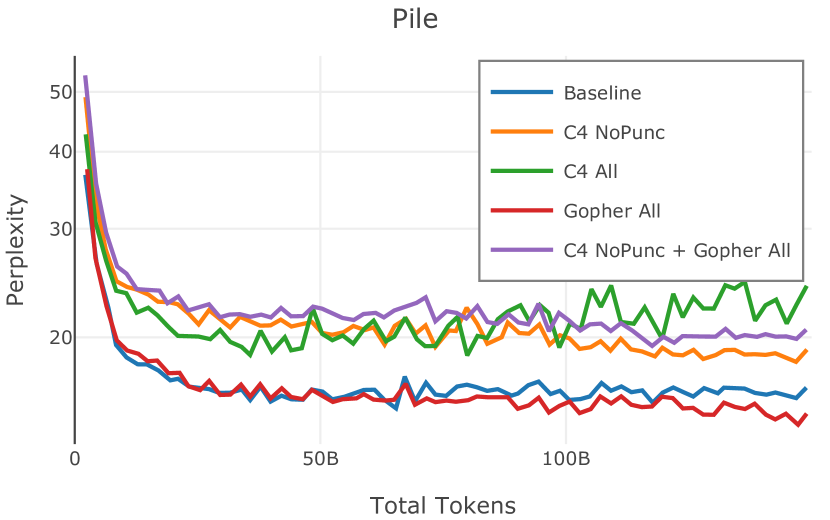
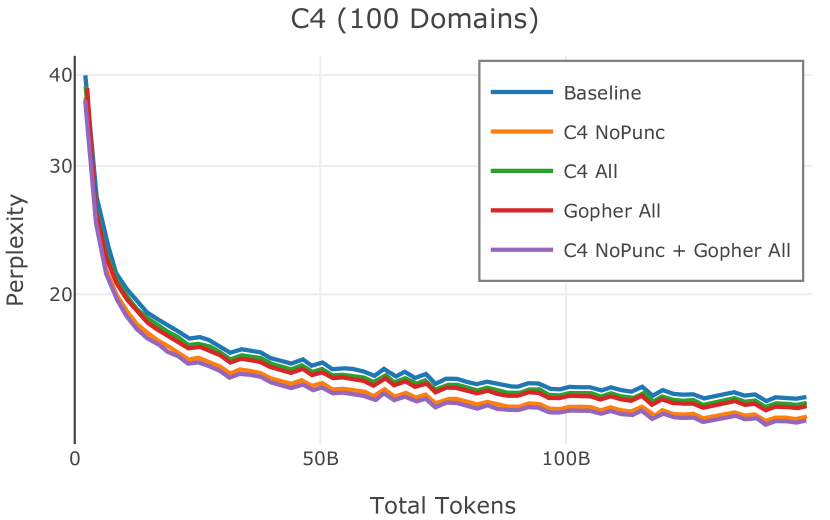
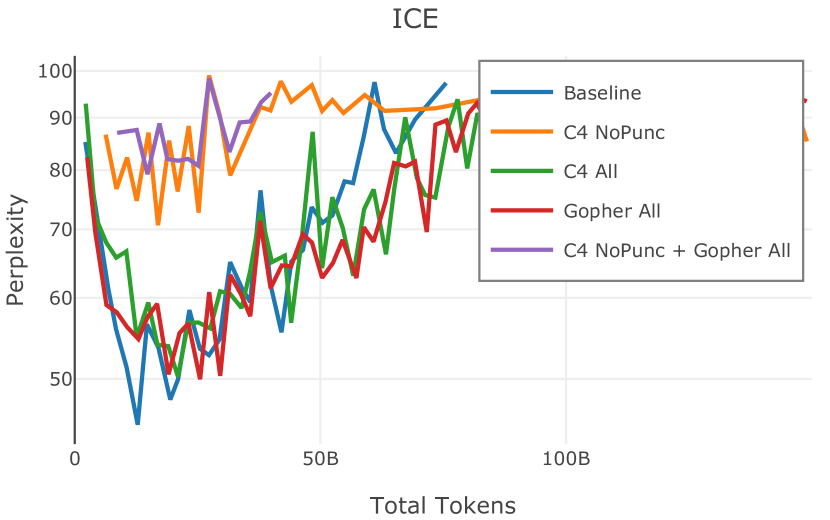
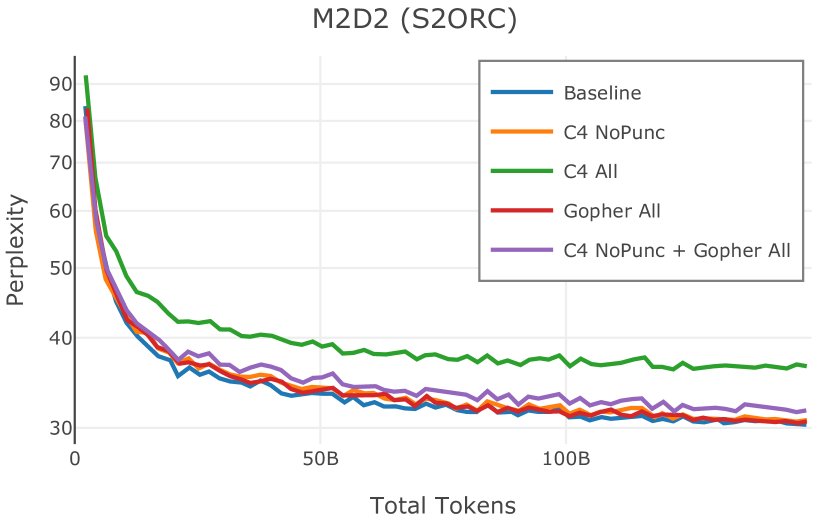
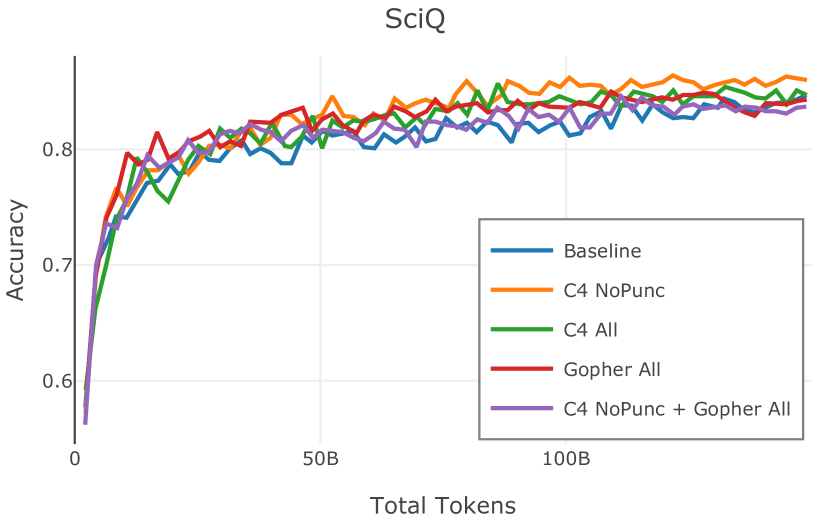
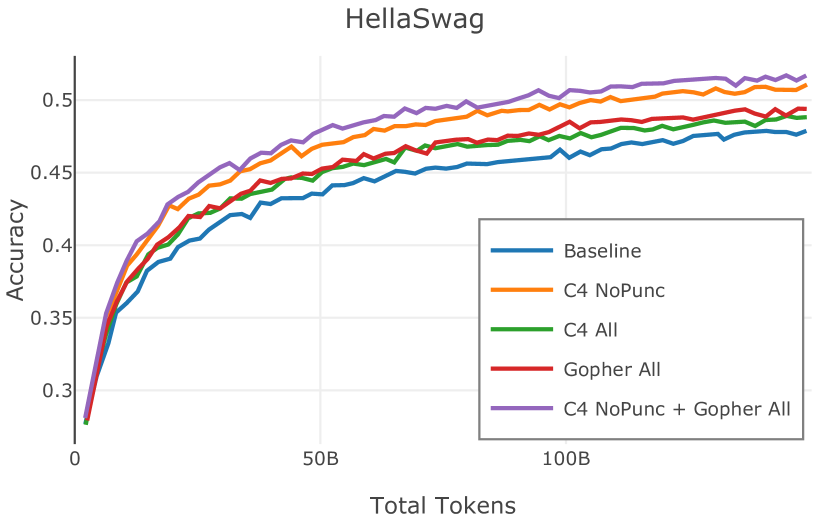
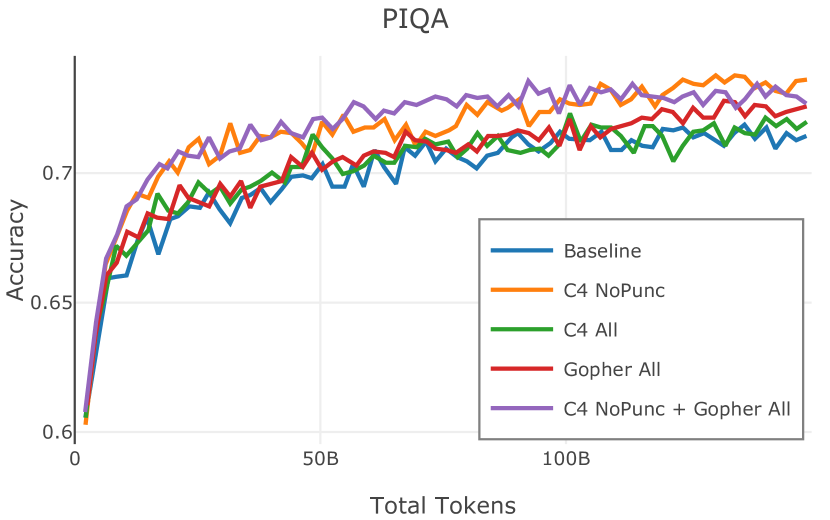
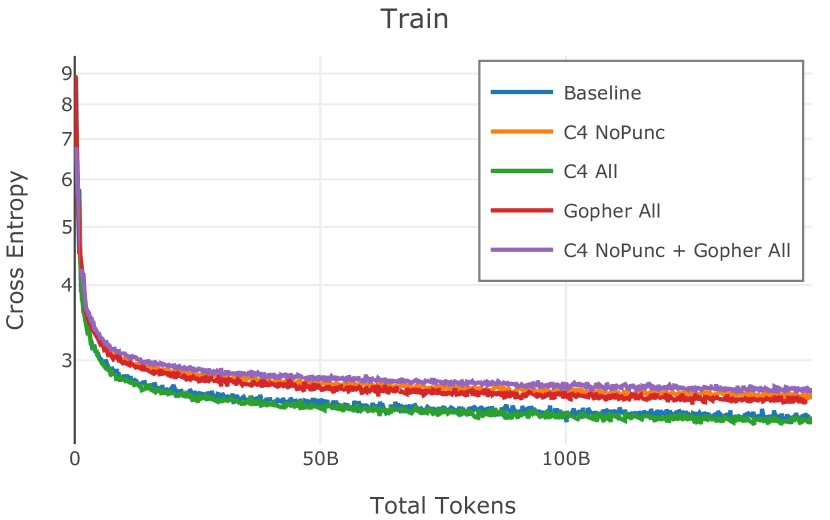
K.5 Web Pipeline 的全面比较
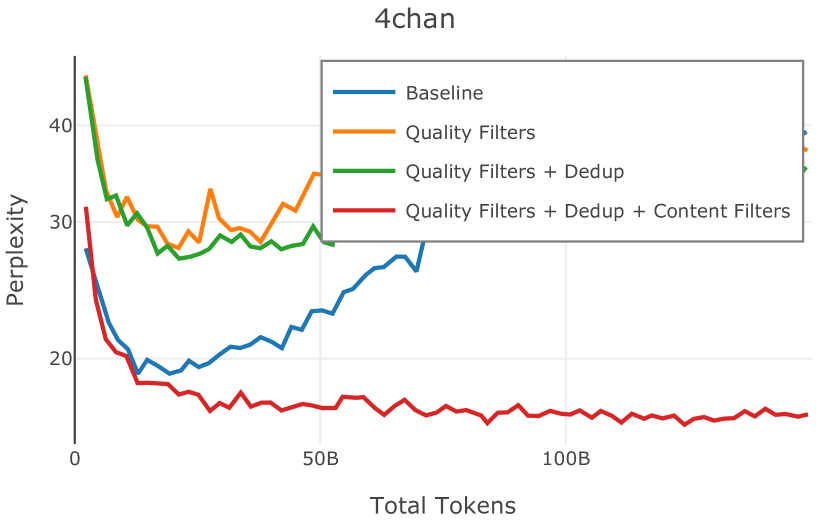
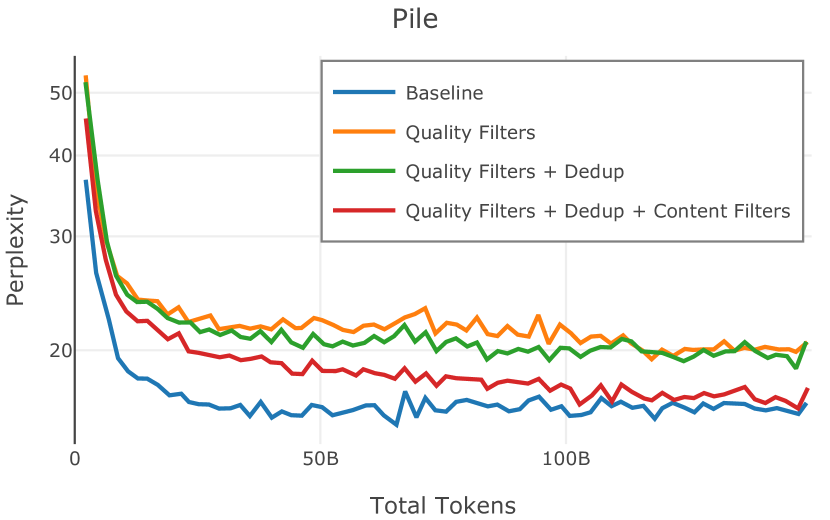
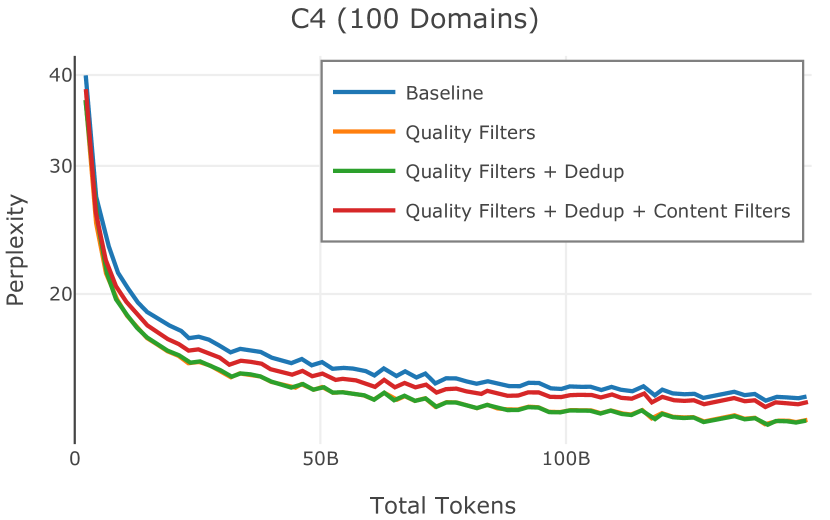
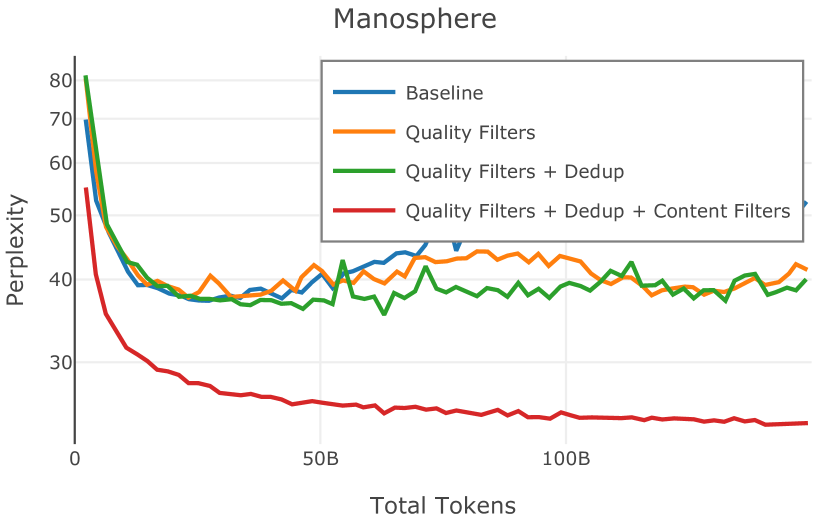
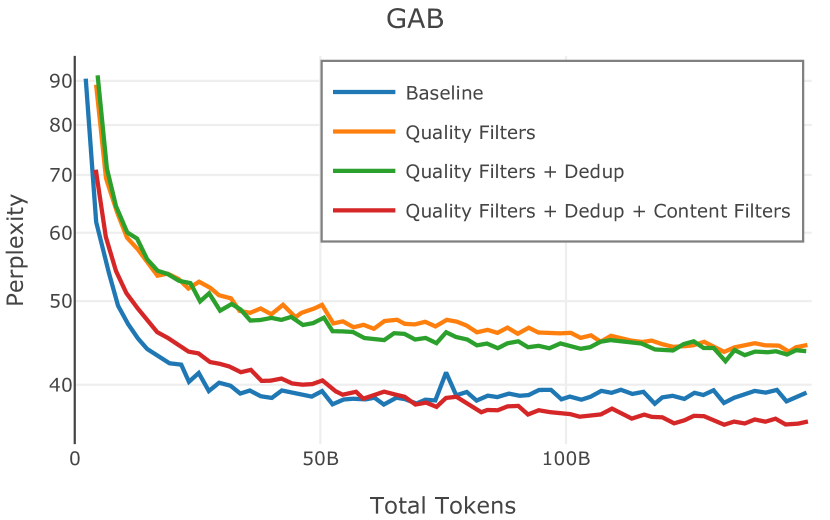
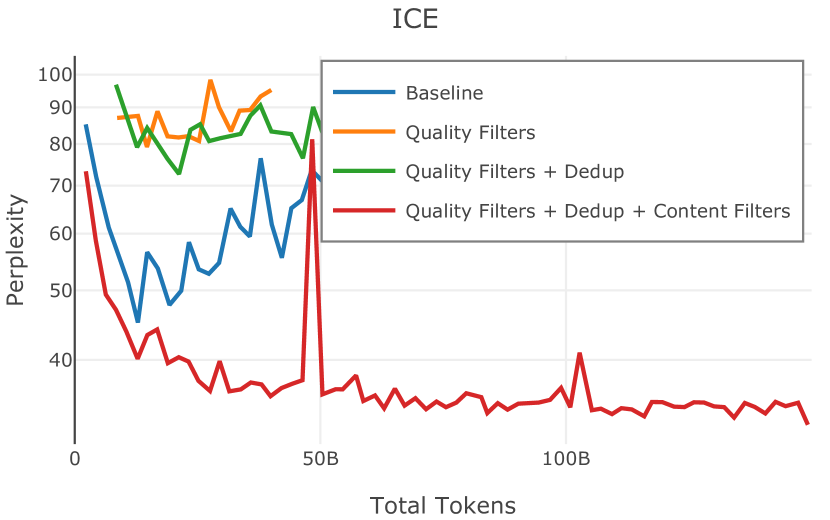
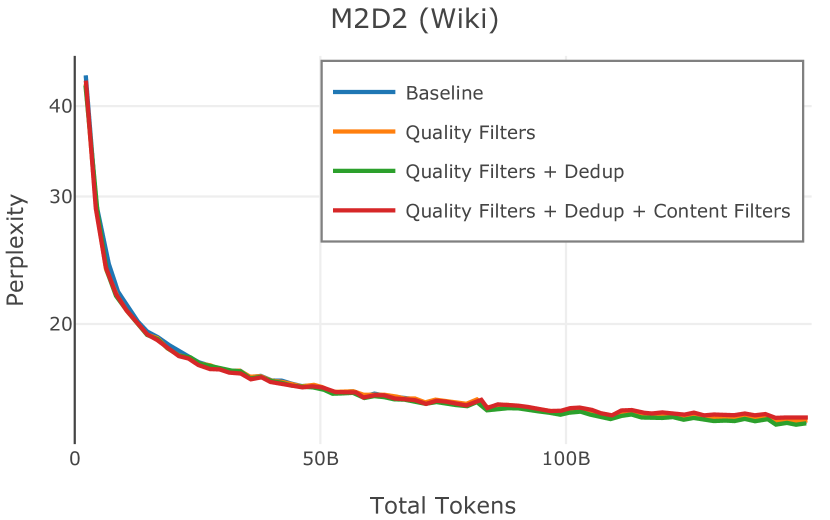
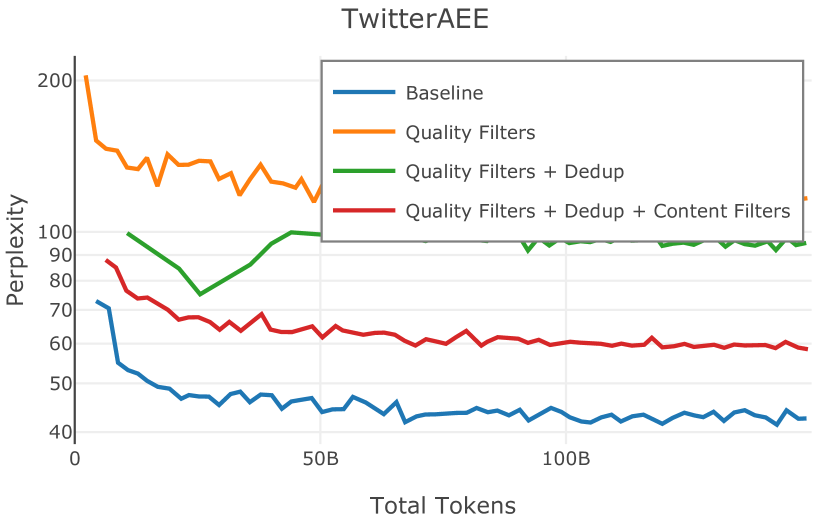
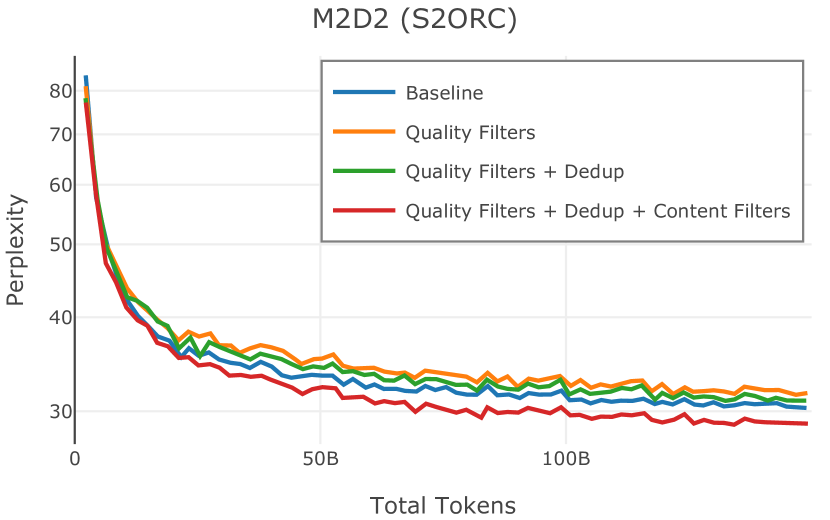
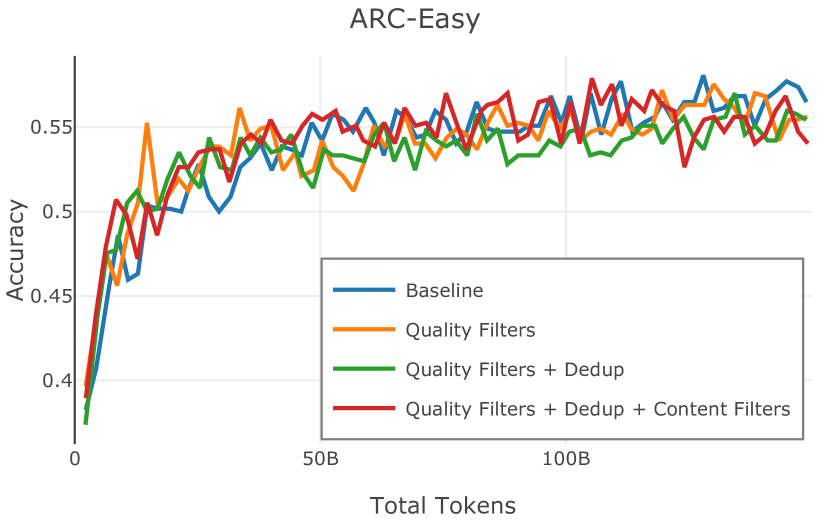
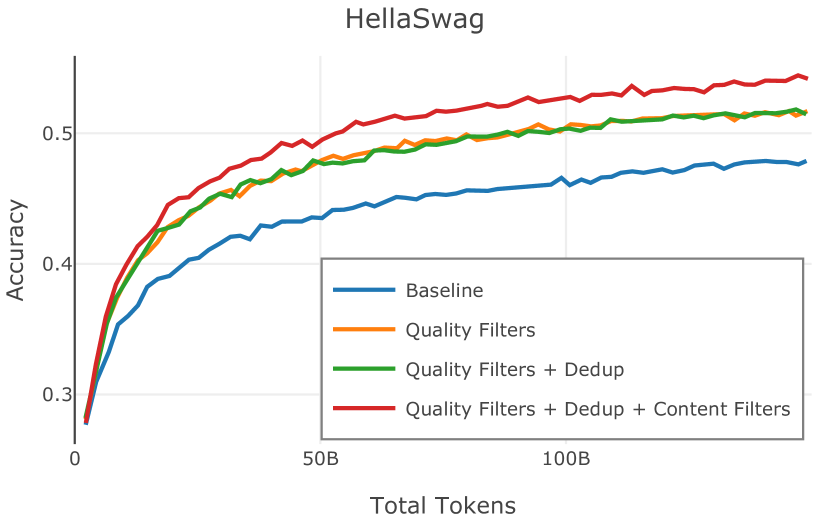
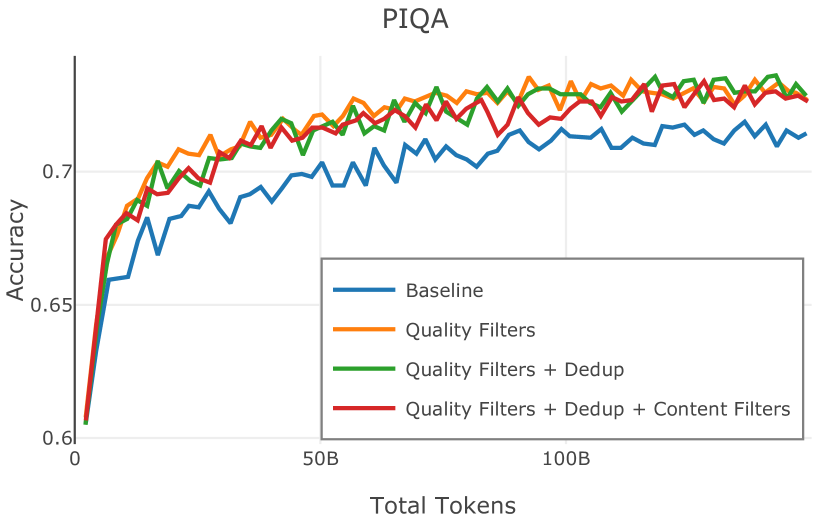
K.6 Web管道中的毒性过滤
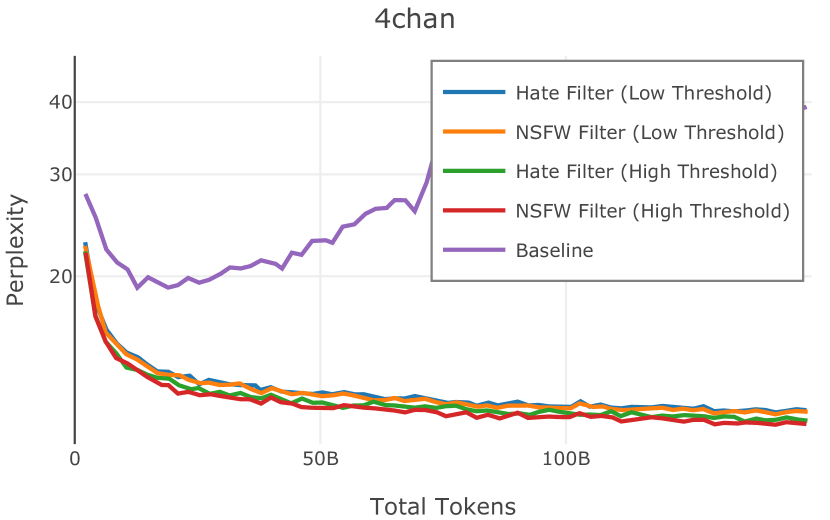
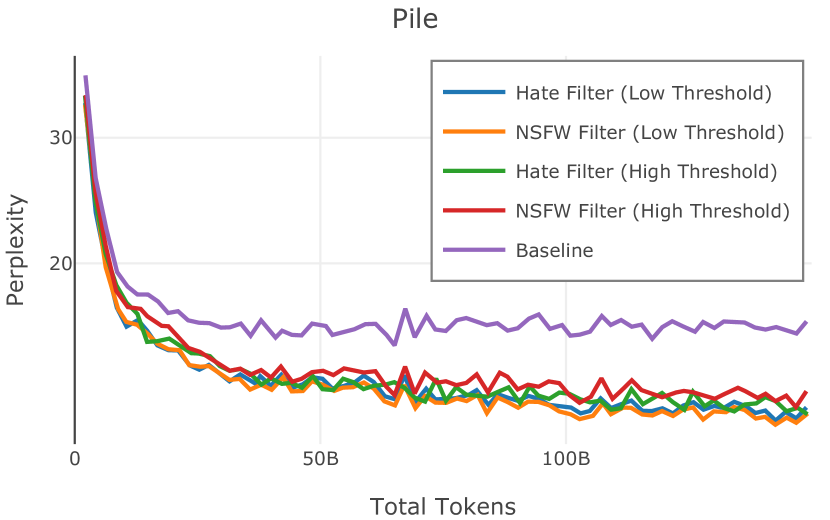
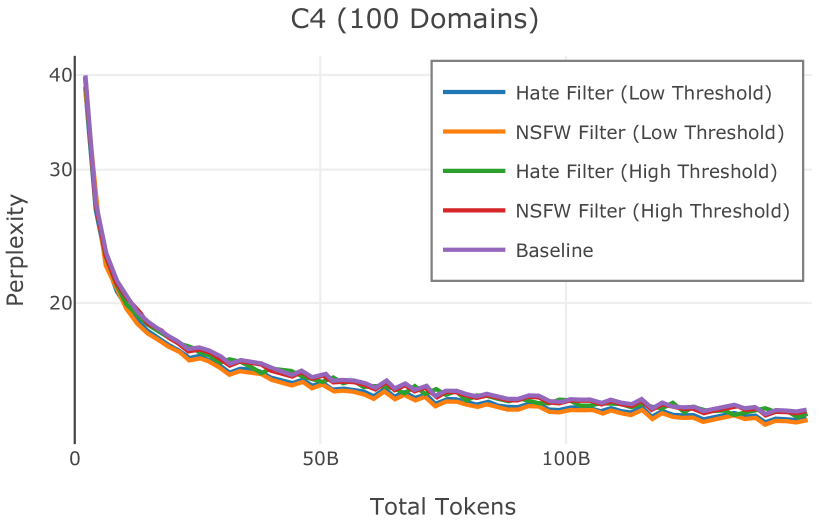
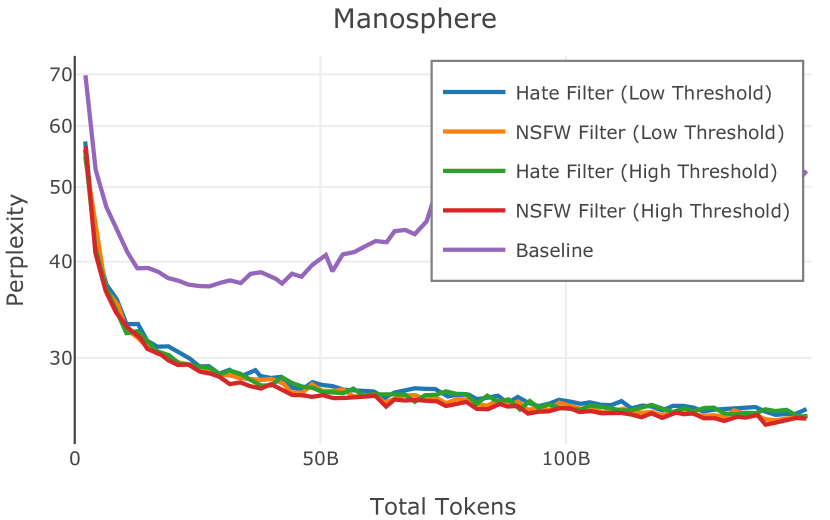
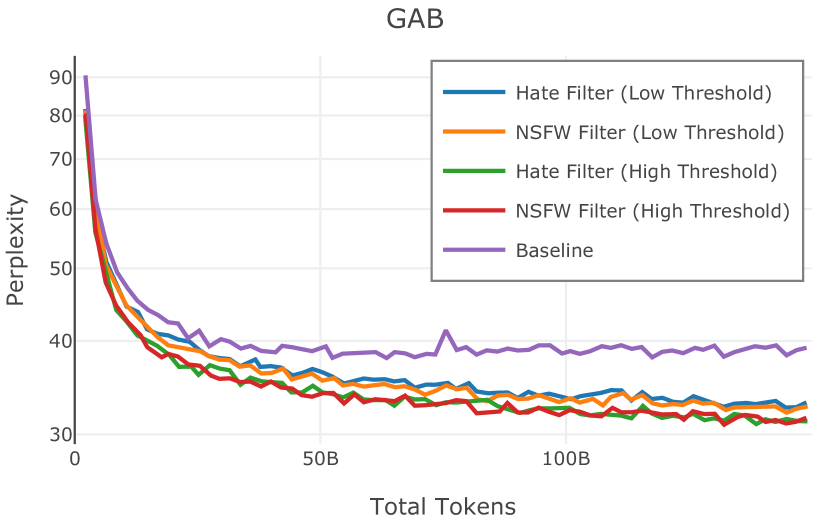
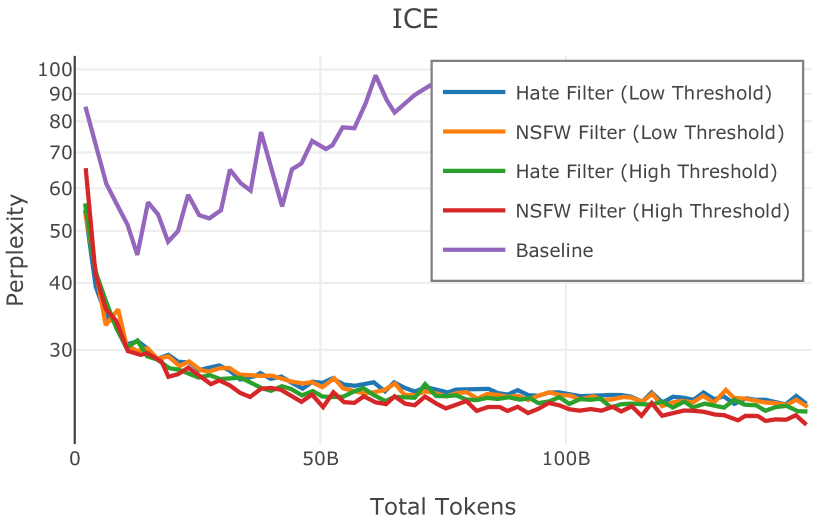
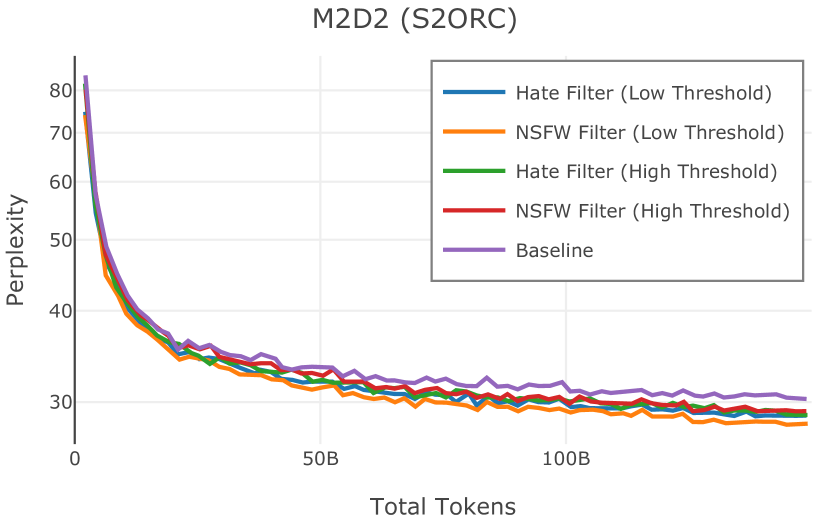
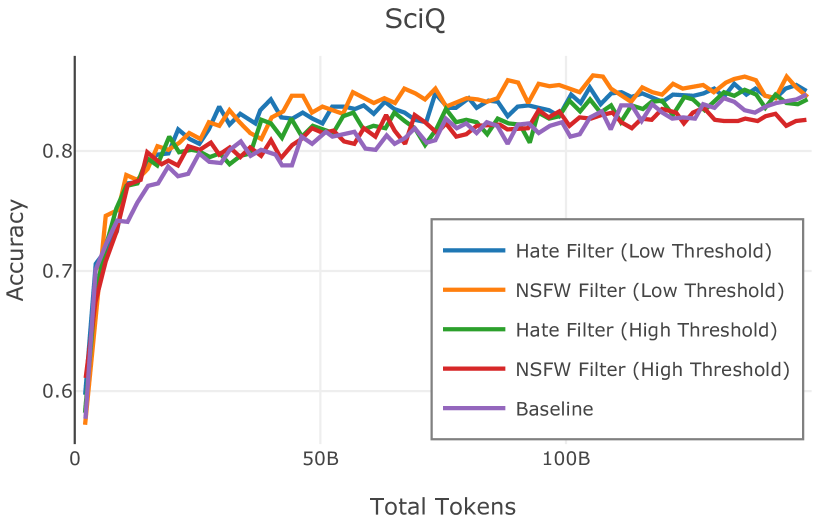
K.7 比较代码处理管道
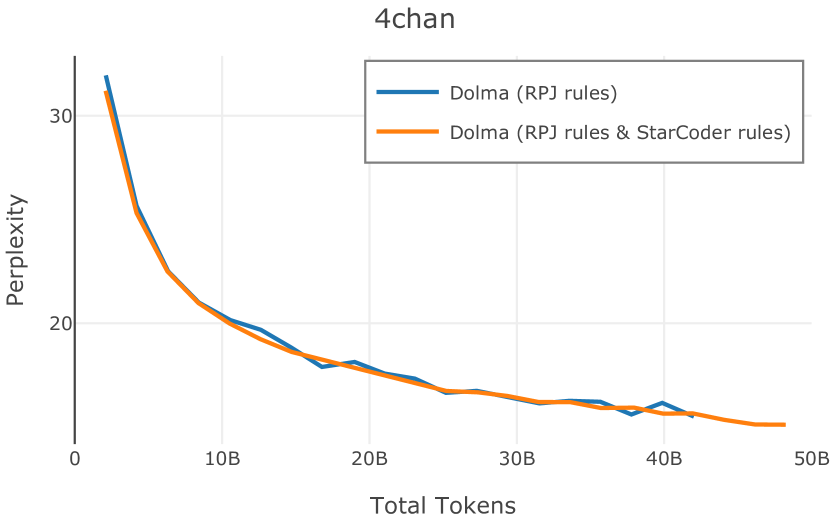
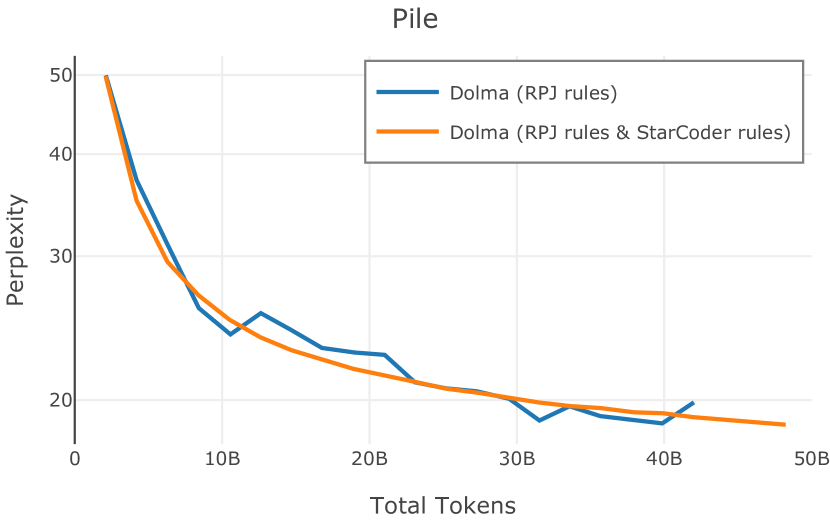
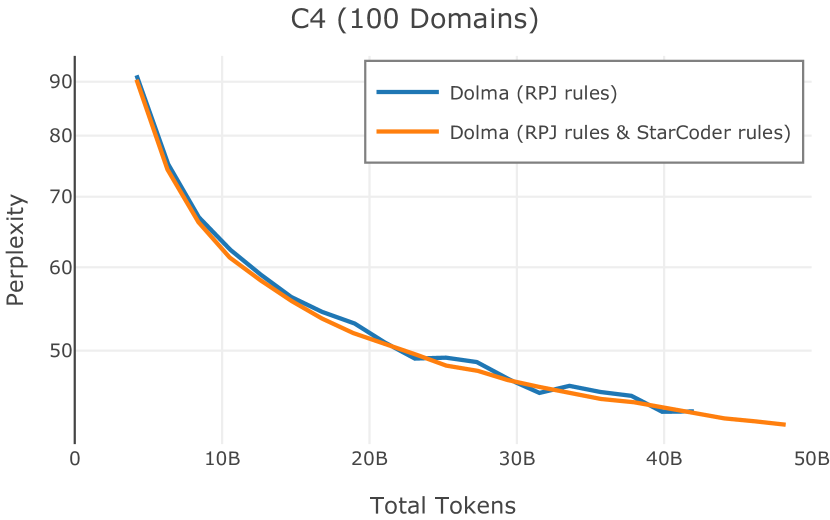
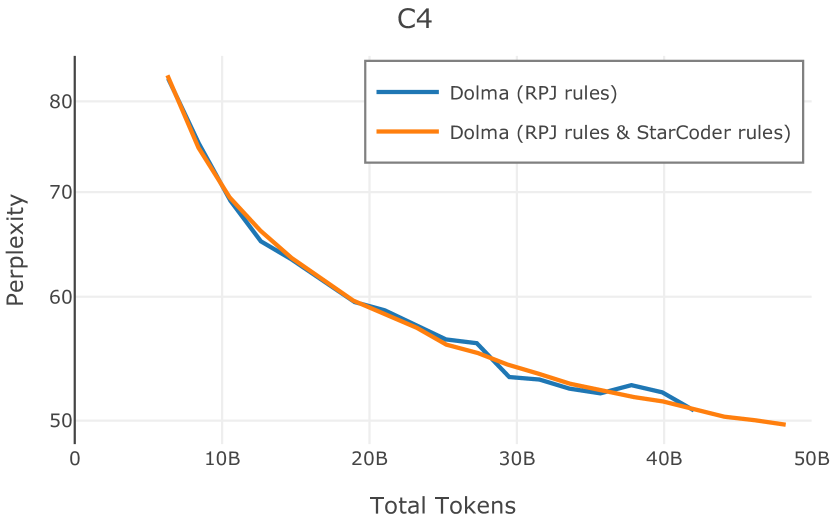
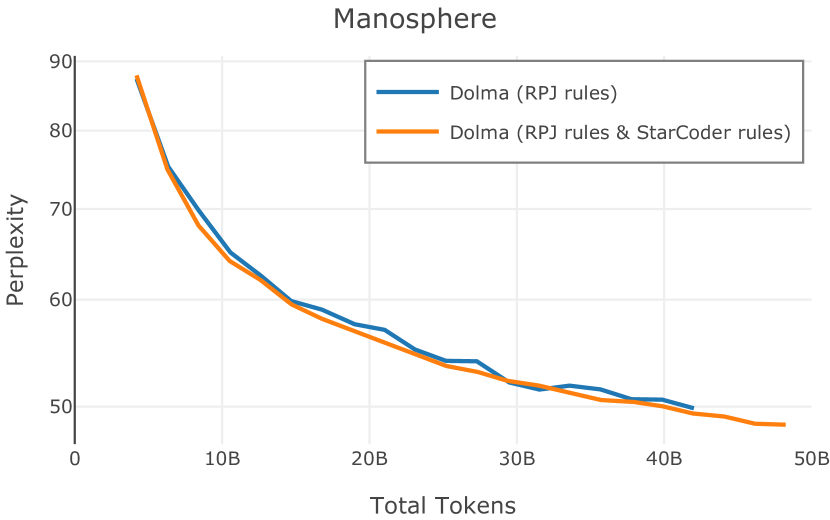
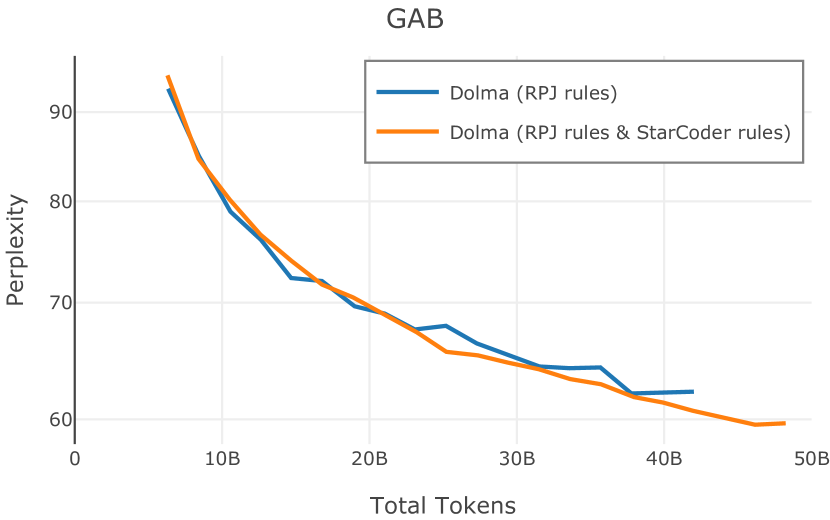
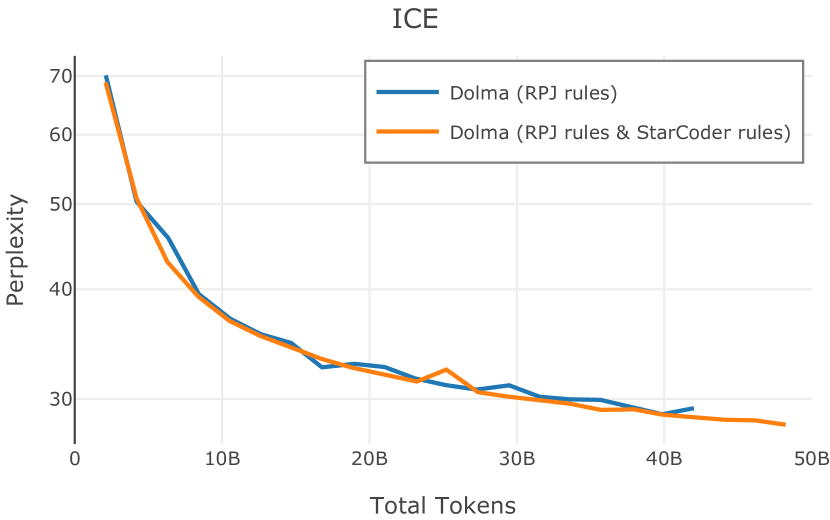
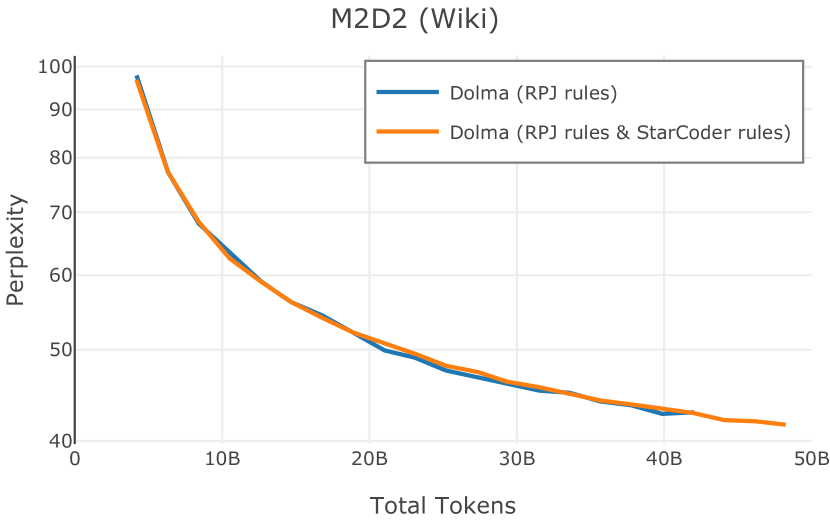
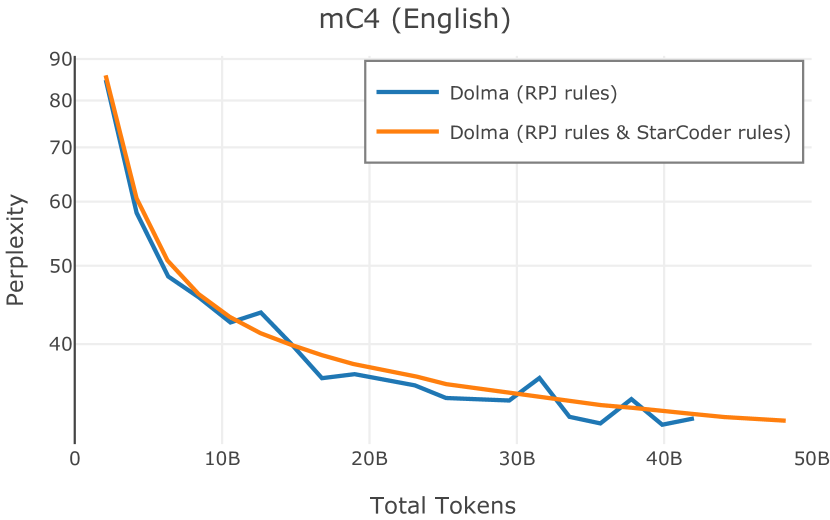
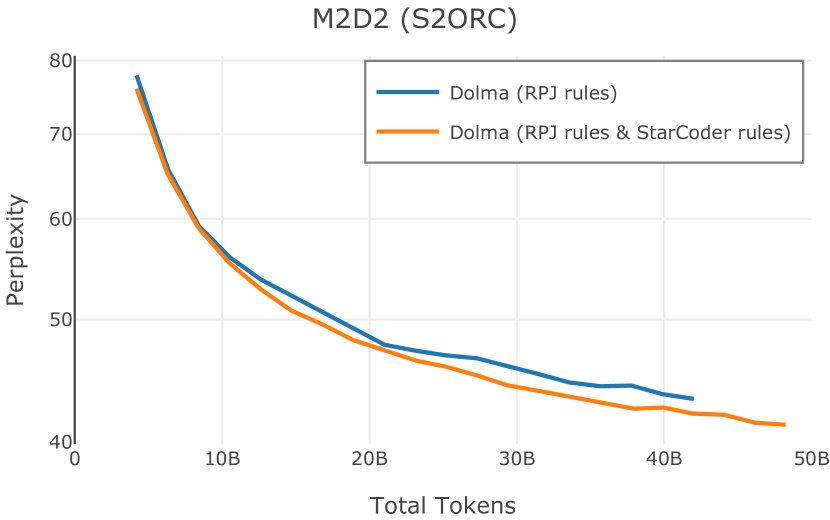
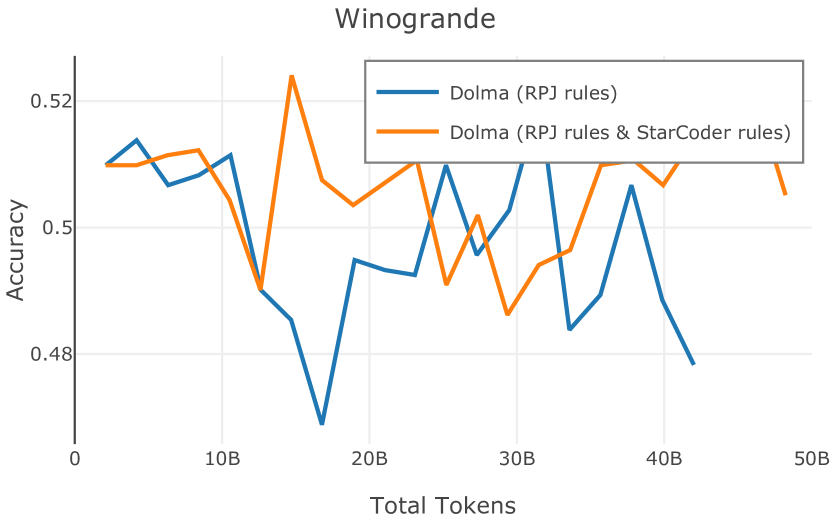
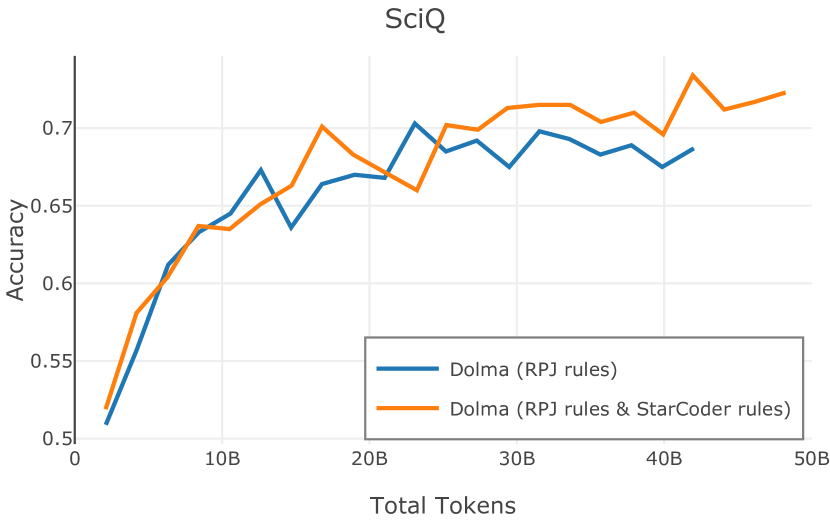
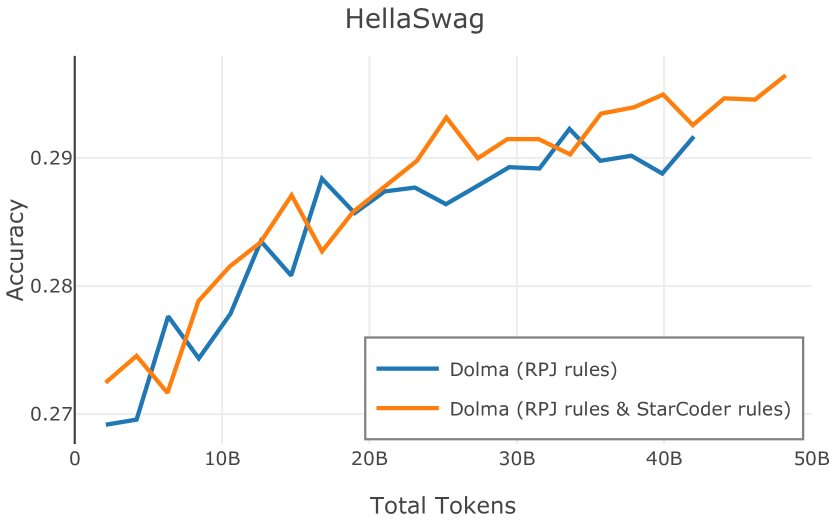
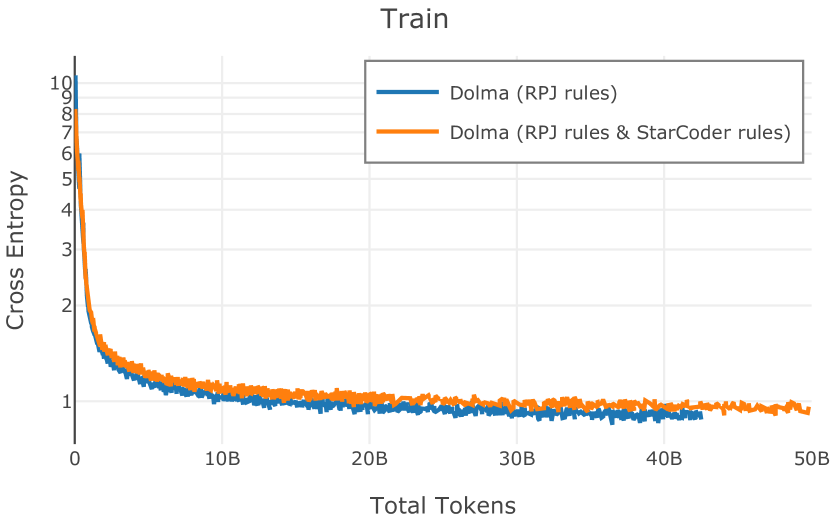
K.8 研究卓玛合剂
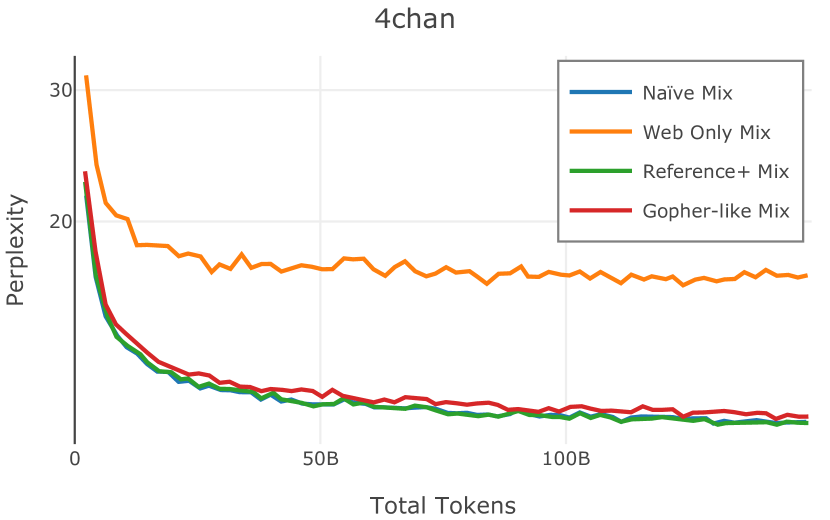
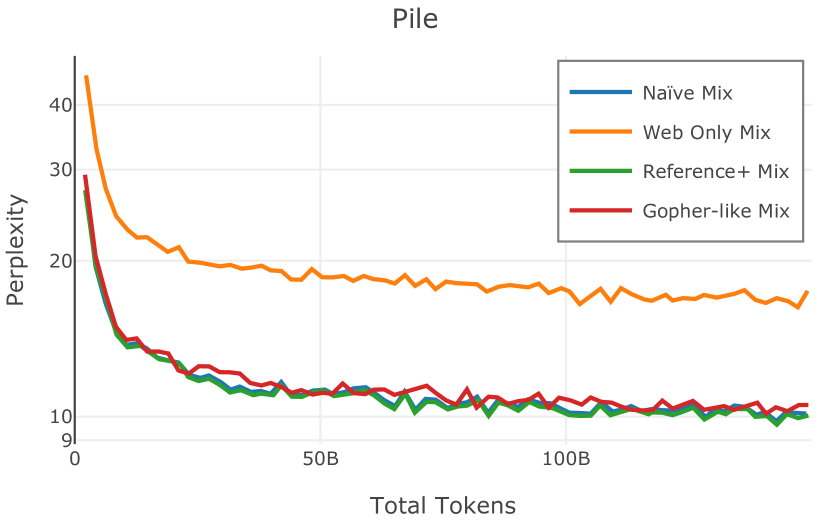
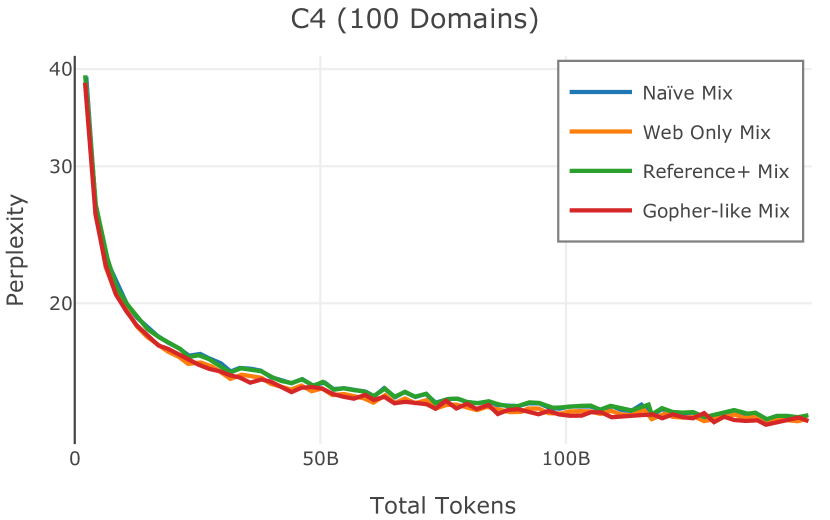
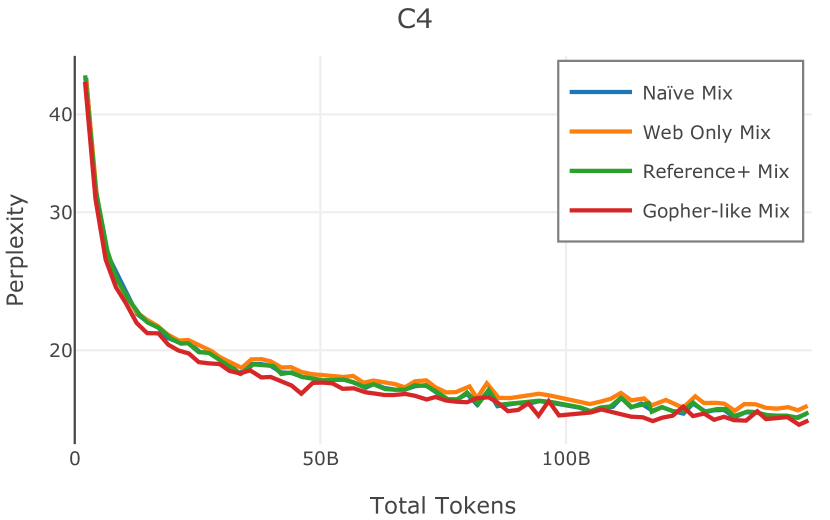
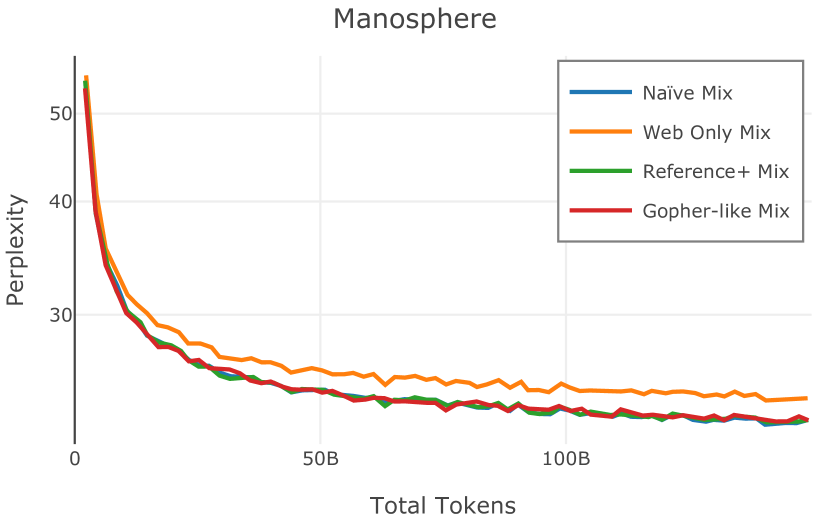
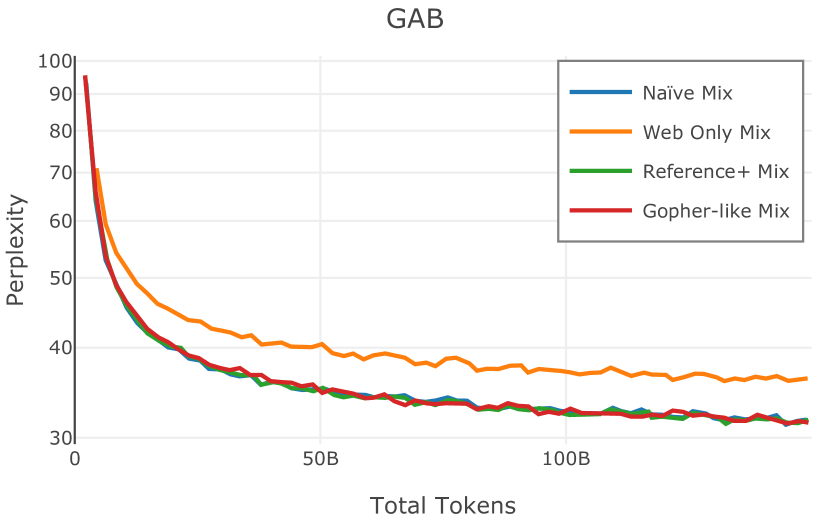
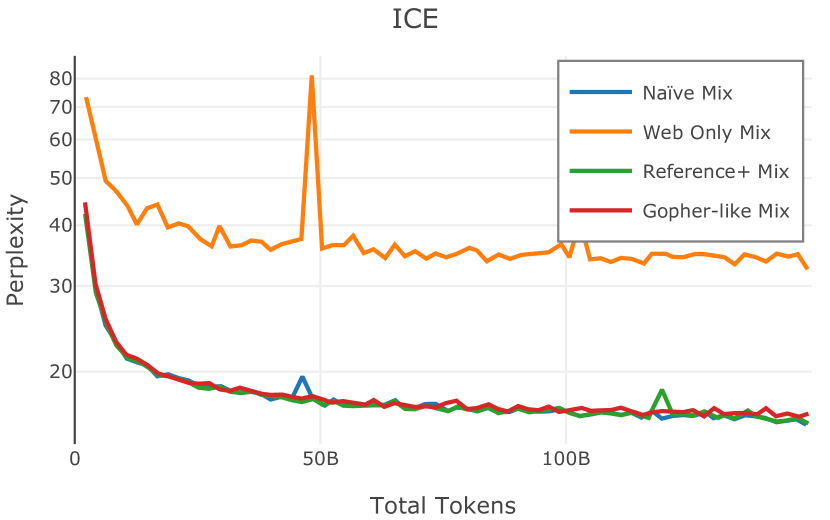
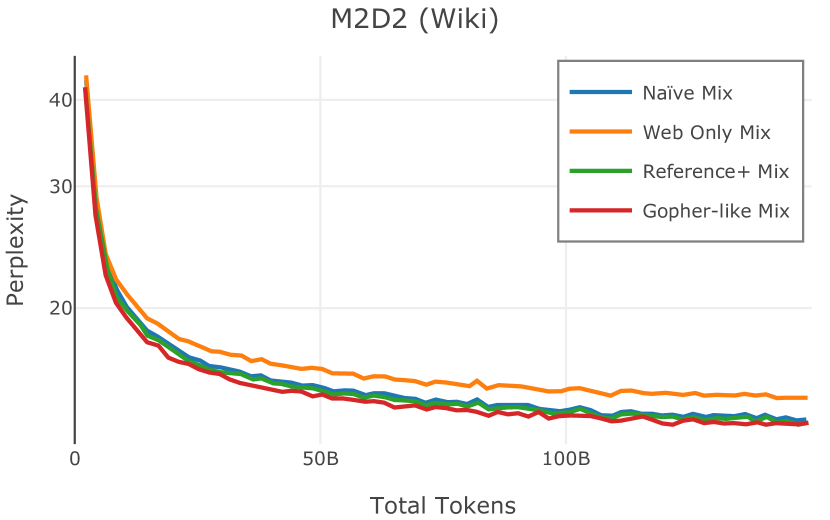
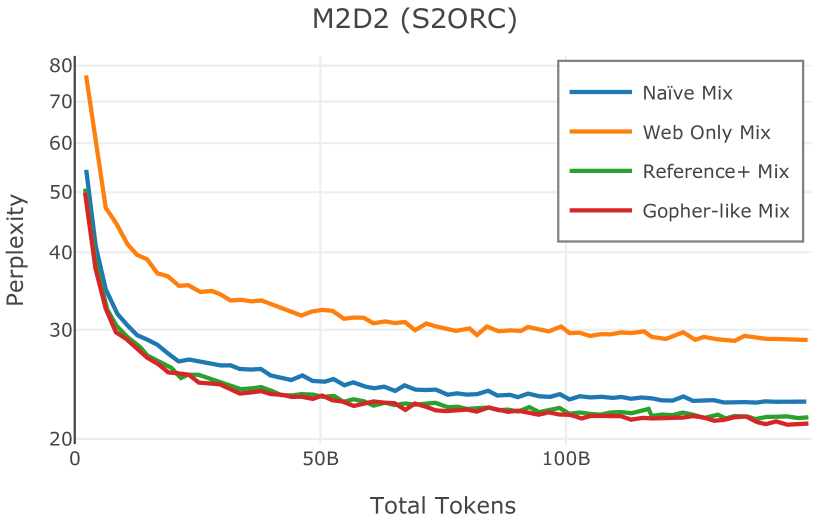
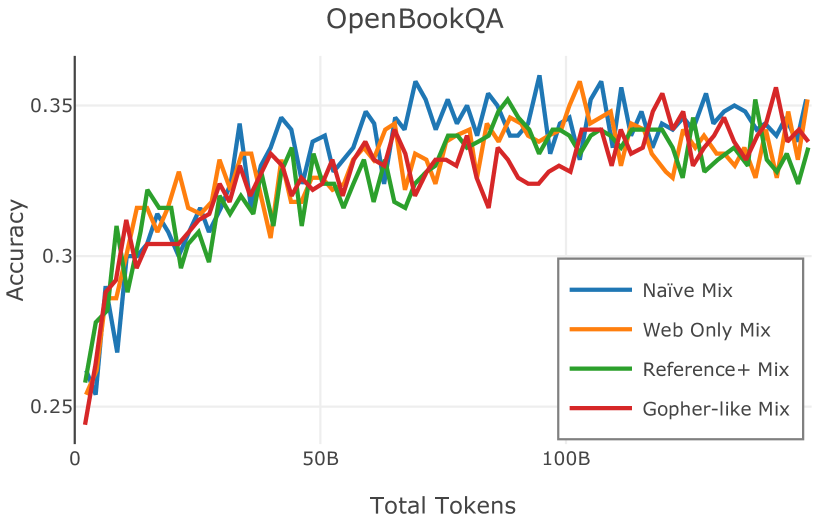
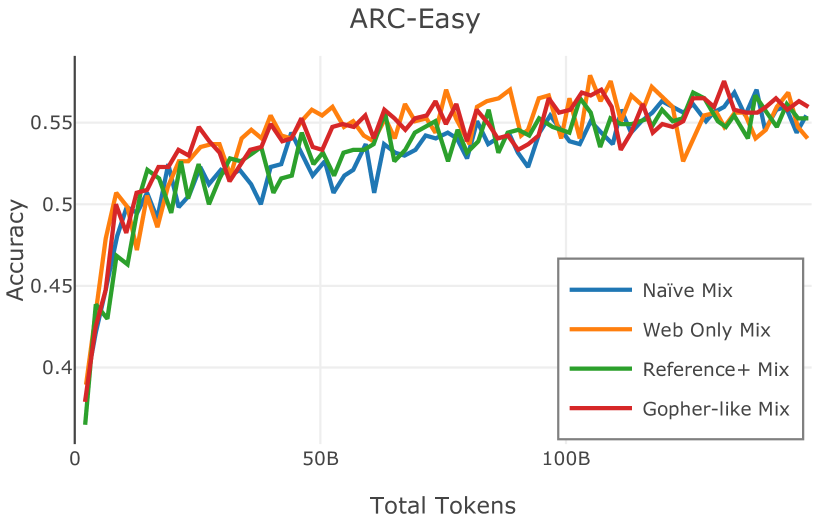
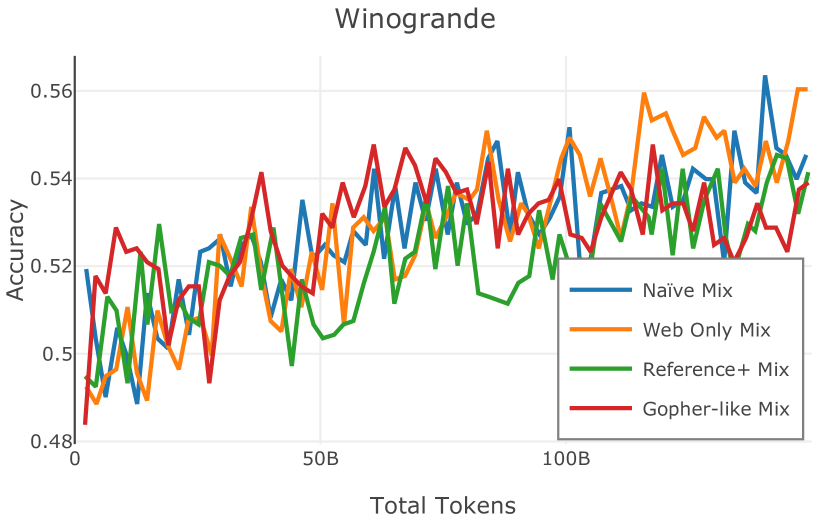
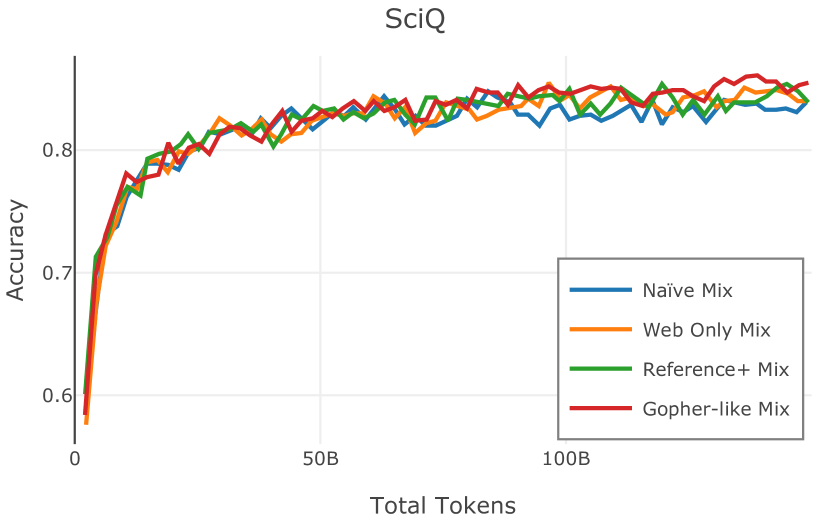
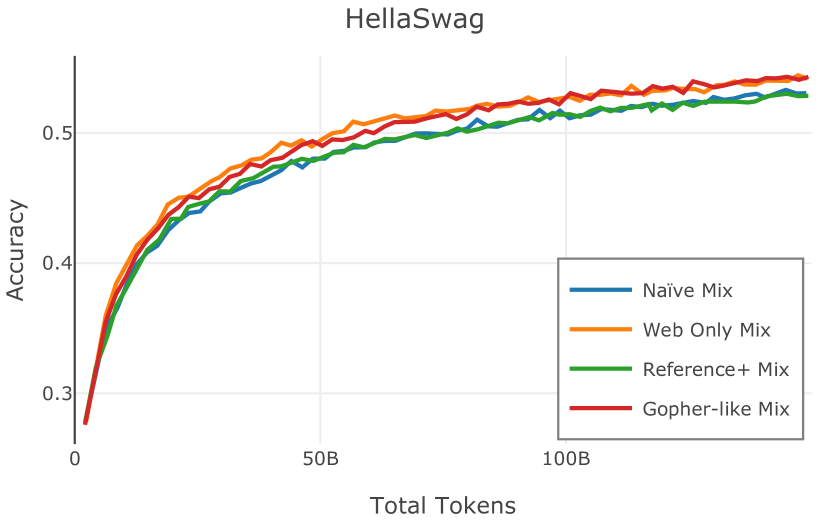
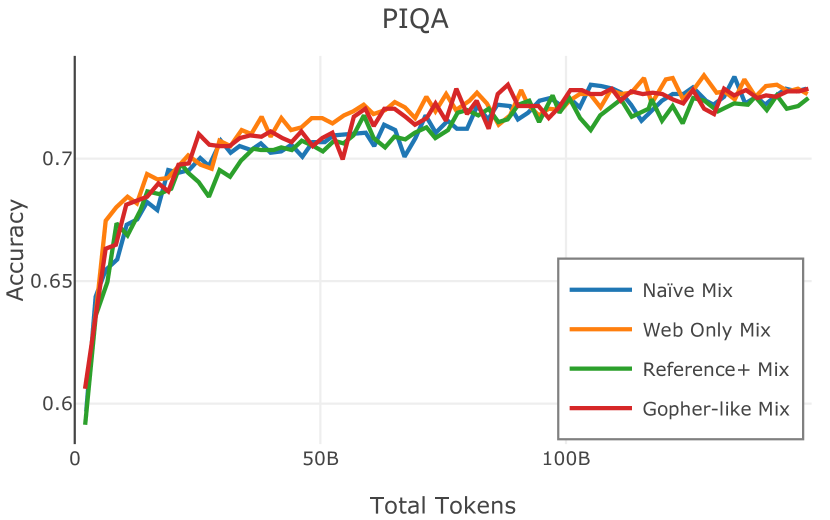
K.9 格式化对话论坛管道的策略
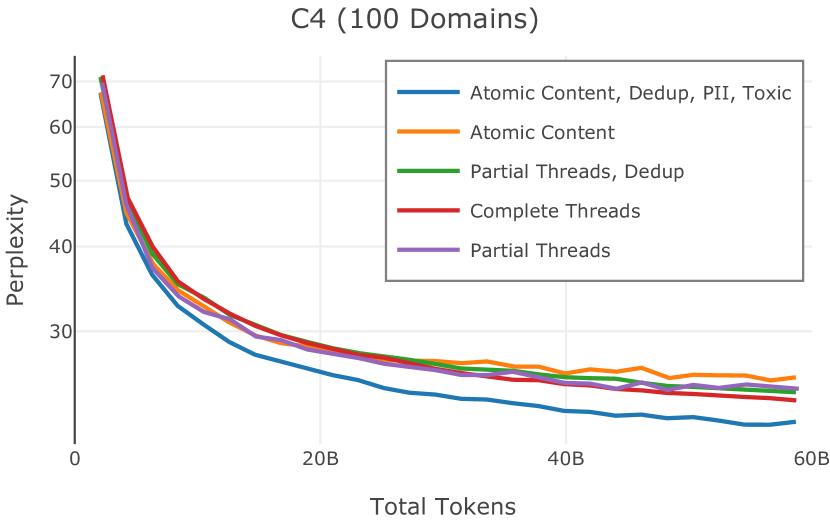
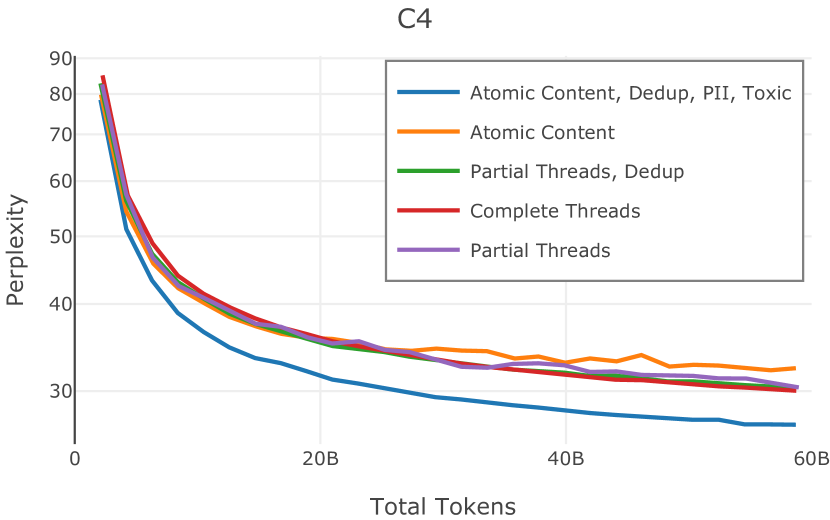
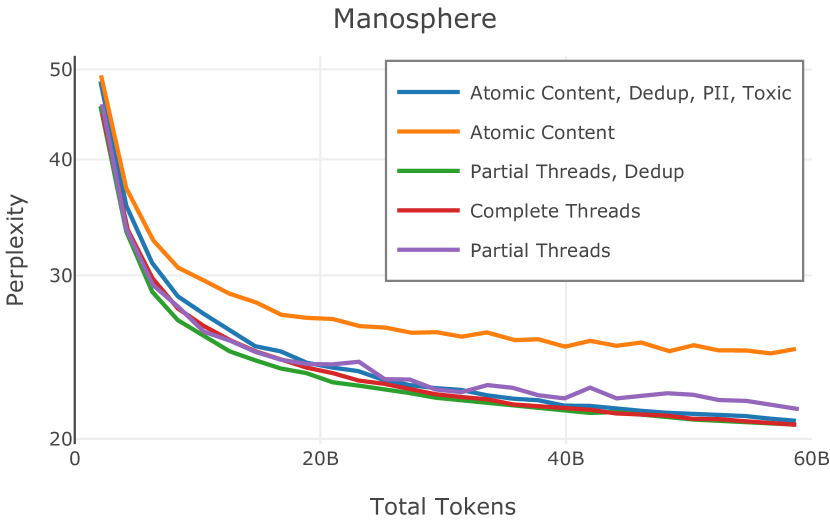
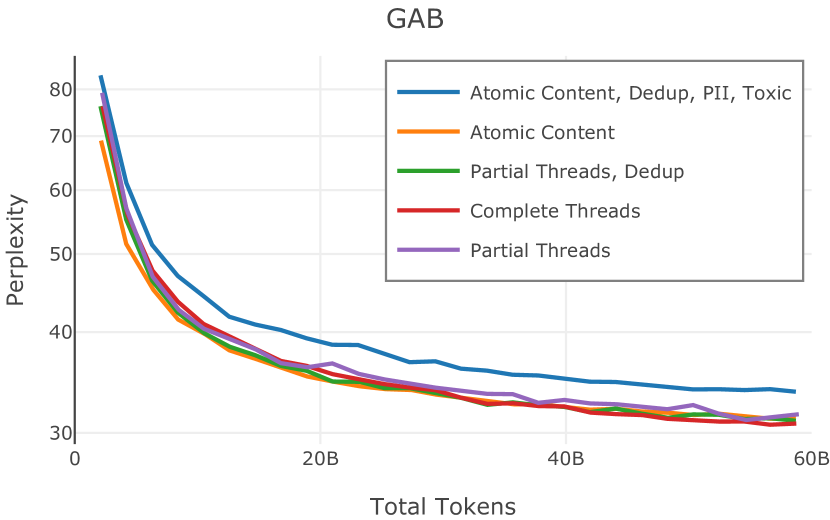
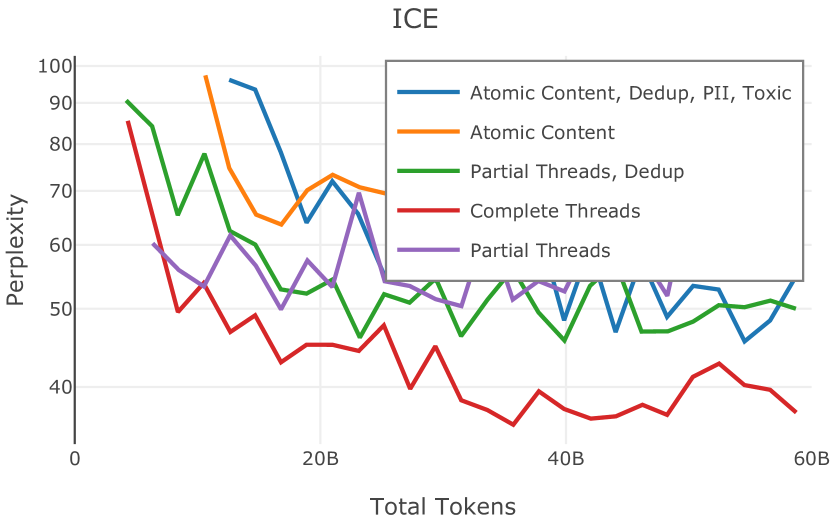
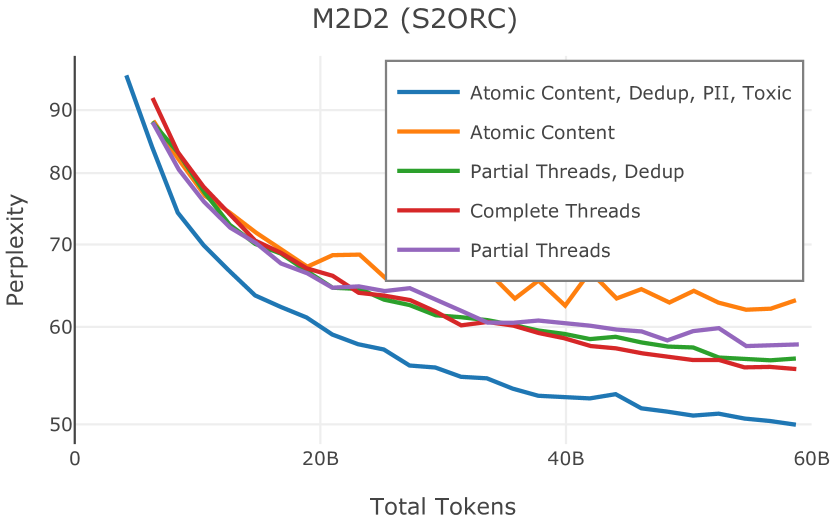
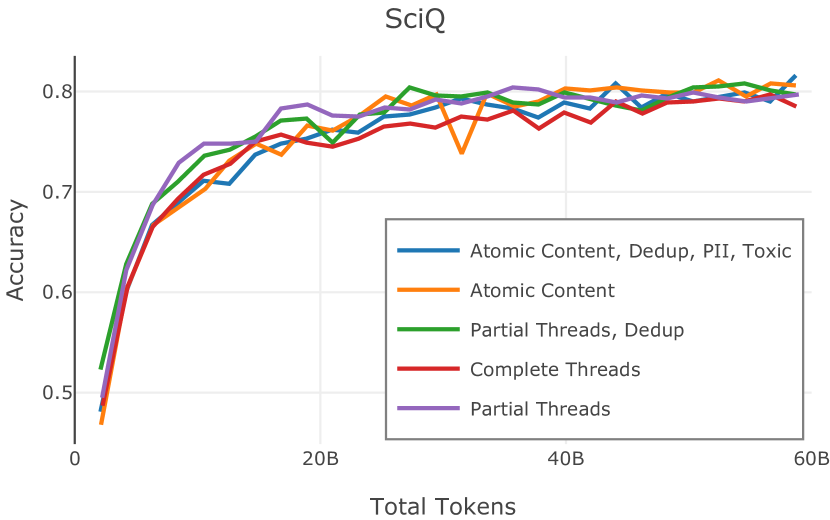
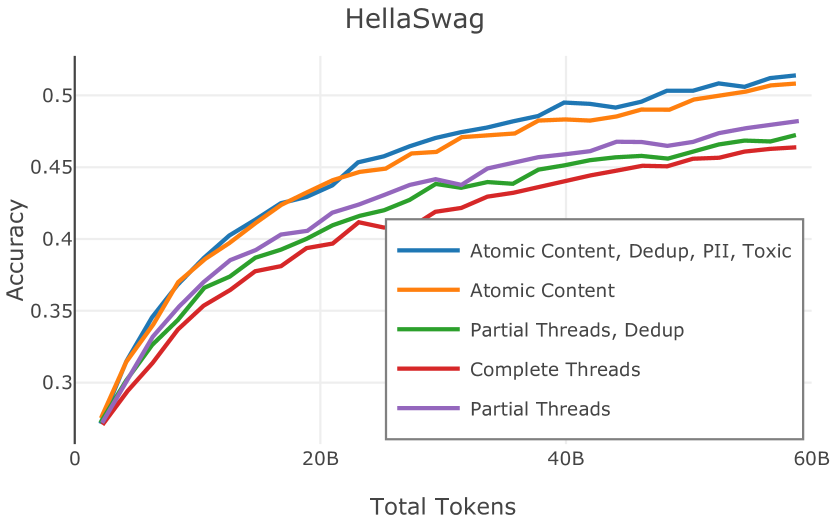
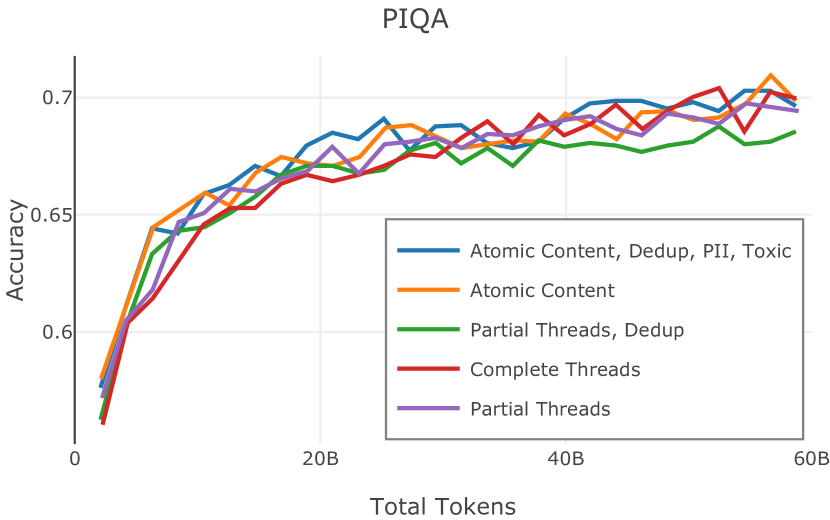
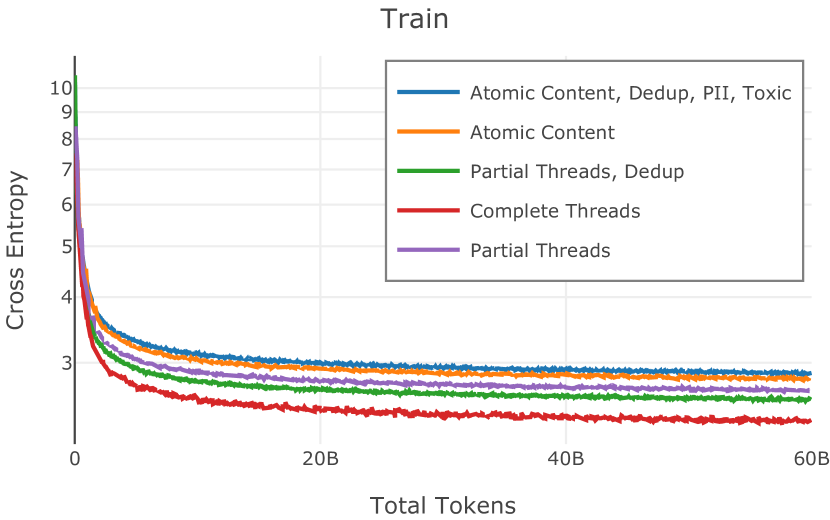
K.10 评估对话论坛管道中的毒性过滤
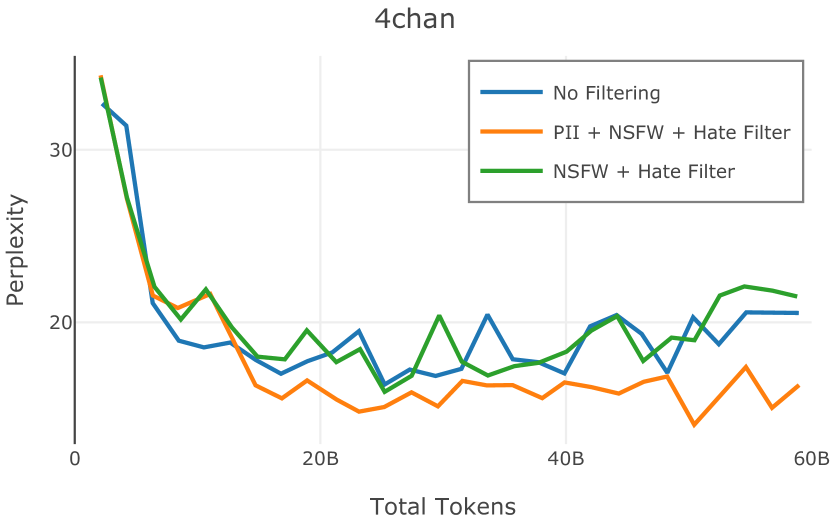
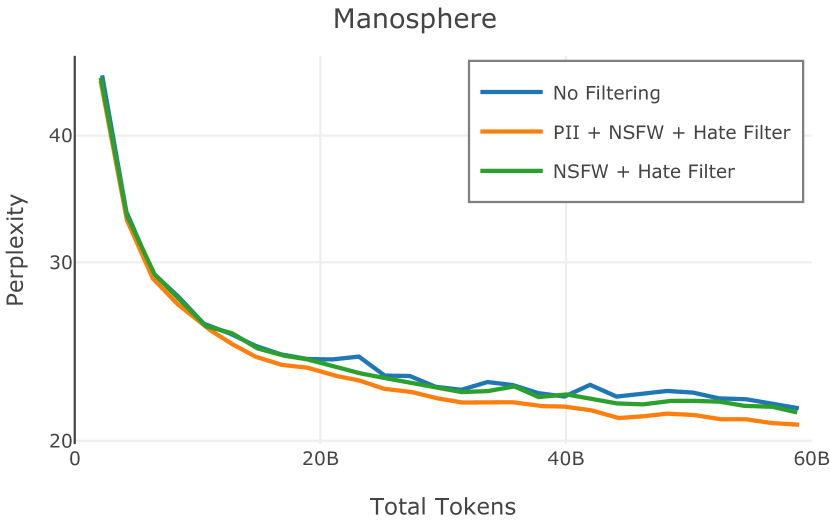
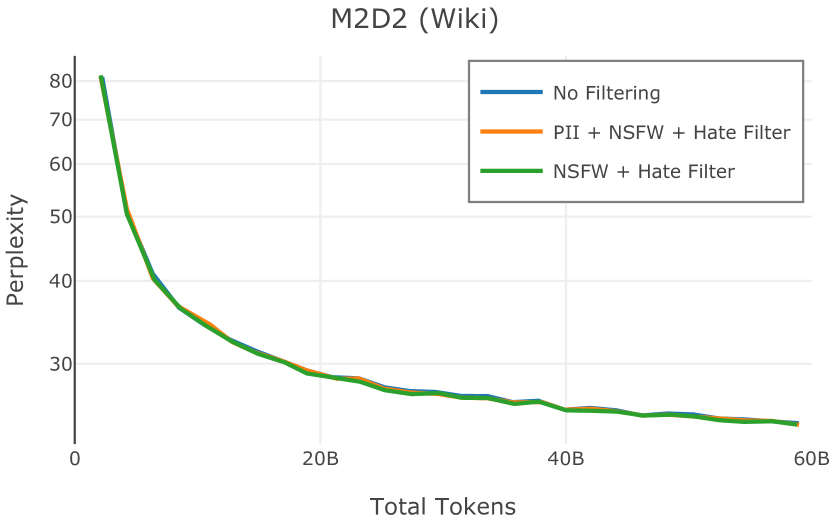
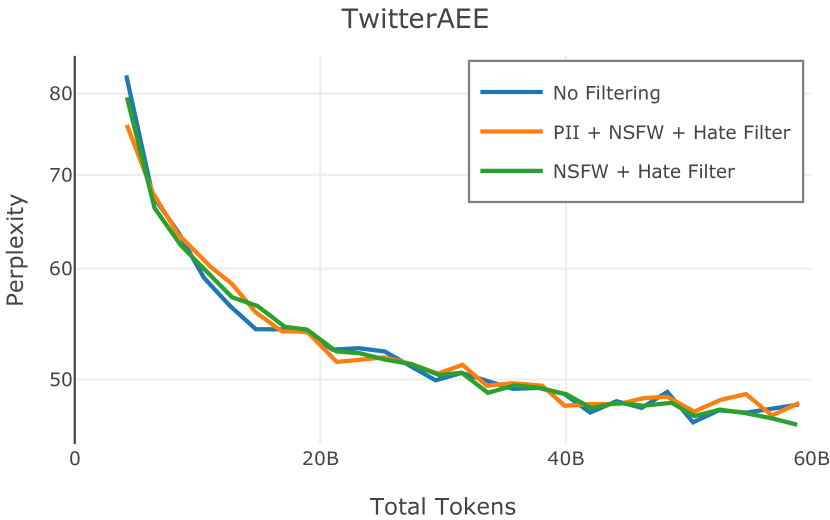
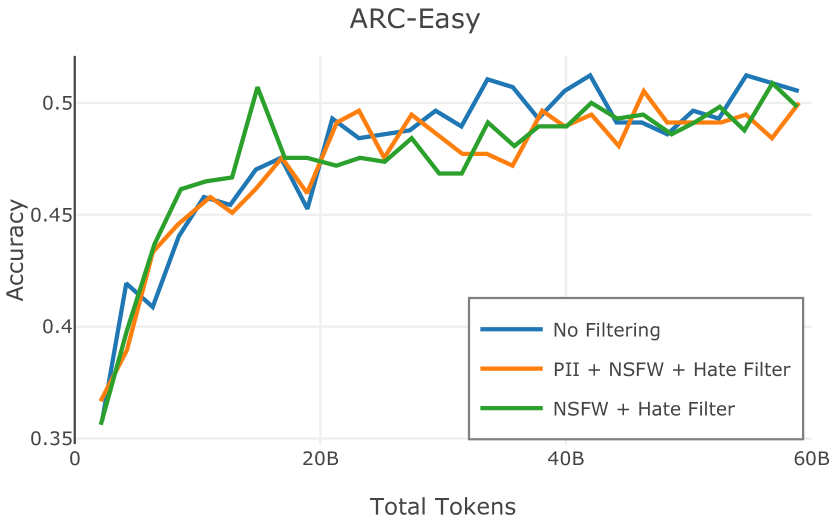
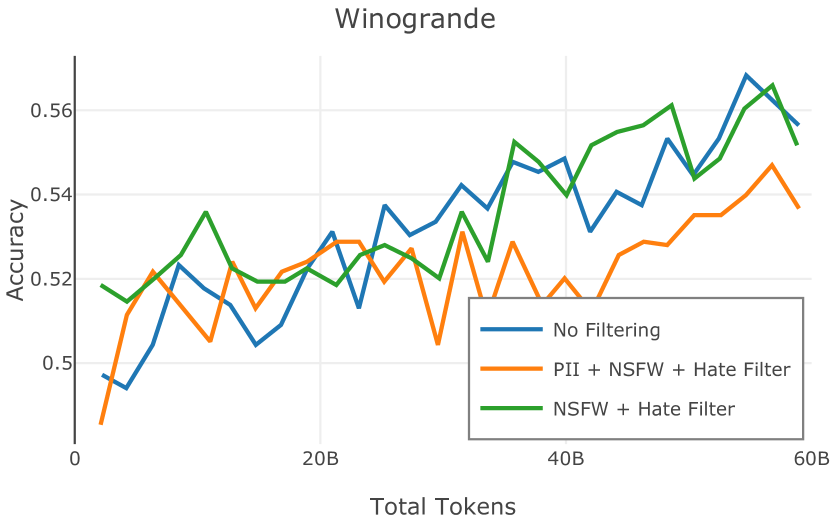
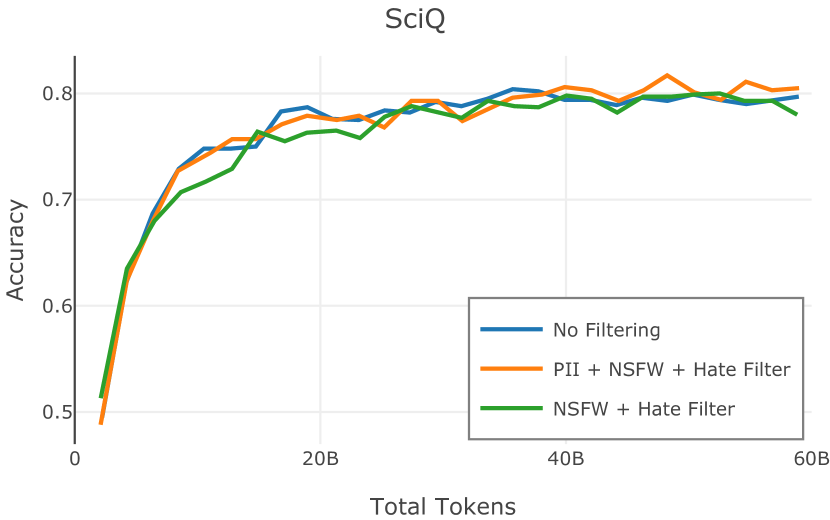
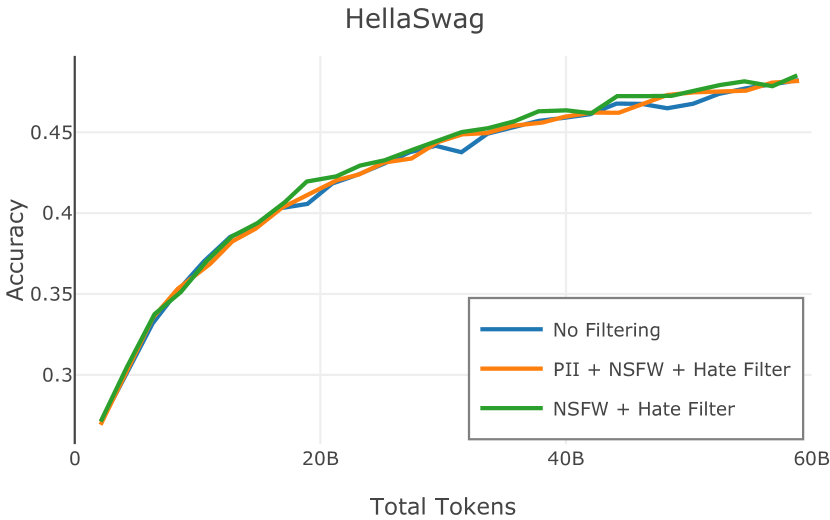
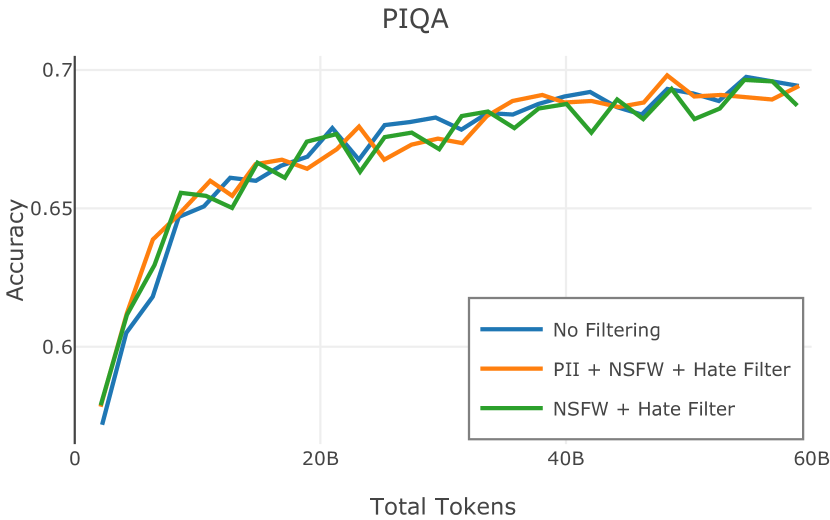
K.11 训练Olmo-1b