具有主要对象提取和上下文视频编码的视频语义通信
摘要
本文研究了一种用于海量通信的端到端视频语义通信系统。 在所考虑的系统中,发送器必须连续将视频发送到接收器,以促进沉浸式应用(例如交互式视频会议)中的角色重建。 然而,传输具有大量数据的原始视频信息对有限的无线资源提出了挑战。 为了解决这个问题,我们通过让发送端从视频中提取语义信息并发送来减少传输的数据量,从而细化视频中的主要对象和时间和空间的相关性。 具体来说,我们首先开发基于主要对象提取(MOE)和上下文视频编码(CVE)的视频语义通信系统,以实现高效的视频传输。 然后,我们使用基于运动估计、上下文提取和熵编码的卷积神经网络设计了 MOE 和 CVE 模块。 仿真结果表明,与传统编码方案相比,该方法可减少传输数据量高达25%,同时将重构视频的峰值信噪比(PSNR)提高高达14%。
索引术语:
语义通信、视频传输、主要对象提取、上下文编码。我简介
B5G/6G通信的发展促进了新型宽带交互应用(如元界)的蓬勃兴起,这些应用需要以不同模态采集和传输海量传感数据[1]。 例如,在沉浸式视频会议等交互应用中,发送方需要向接收方发送包括人物、动作、背景等信息。 然而,交互式应用需要大量的数据传输[2]和严格的传输性能,例如严格的延迟[3]和高质量的体验,这带来了对资源有限的现有无线通信系统带来巨大挑战[4]。 因此,未来的交互应用需要高效的视频传输技术,而语义通信[5]作为一种高效的传输技术正在兴起,以提高宽带交互应用的性能。
以前的工作研究了不同数据类型的语义通信技术。 在[6]中,作者提出了一种基于深度学习(DL)的语义通信系统来减少文本信息数据量。 此外,[7]中的工作提出了基于生成对抗网络(GAN)的图像语义编解码器,通过传输语义信息而不是原始符号来减少图像传输数据量。 扩展单用户场景,[8]的作者提出了一种基于DL的多用户语义通信系统来传输多模态数据。 然而,[6,7,8]中用于传输文本和图像的语义只考虑了一时刻的数据属性,忽略了数据流中时间相关性的语义。 与文本和图像不同,由于视频数据流中多个时刻之间的相关性,视频语义提取具有挑战性。
先前的工作[9,10,11]研究了高效的视频语义通信系统。 在[9]中,作者提出了一种基于端到端深度学习的视频通信模型,该模型获取视频帧之间的运动信息来对视频进行编码。 [10]中的工作提出了一种基于人脸关键点传输的语义视频会议(SVC)模型来表达人脸运动。 [11]中的作者提出了一种方案,在深度视频语义传输(DVST)模型下收集特征域上下文提供的强视频时间相关性,以实现更高效的视频传输。 然而,对于视频会议等交互式应用,静态背景信息往往是多余的,没有必要在每一帧中传输。 因此,根据视频传输中重构内容的需要,去除冗余背景信息,可以减少传输数据量,降低传输时延,这是[9,10,11]中没有考虑到的。
为了解决上述问题,在本文中,我们提出了一种视频语义通信系统,该系统提取视频的主要对象以在接收器处进行字符重建。

本文的主要贡献如下:
(1)我们通过主要对象提取(MOE)-上下文视频编码(CVE)开发视频语义通信系统。 在所考虑的系统中,发送器通过去除冗余静态背景来提取视频中主要对象的语义信息,然后将主要对象的语义信息发送到接收器。 接收器解码语义信息并合成背景。
(2)我们提出了一种使用混合高级和低级语义信息的有效视频语义提取方法,其中高级语义是主要对象信息,低级语义是视频帧中的空间结构。 为了实现上述目标,我们设计了 MOE 模块来提取主要对象,并设计了 CVE 模块来对低语义级别的视频进行语义编码,其中基于上下文的空间结构被提取并通过熵编码进行编码。
(3)仿真结果表明,与传统编码方案相比,所提出的MOE-CVE方案可以减少高达25%的传输数据量,同时将峰值信噪比(PSNR)提高高达14%。
本文的其余部分安排如下。 第二节介绍系统模型。 第三节提供了所提议的网络架构的详细描述。 模拟结果在第四节中给出。 第五节得出结论。
II 系统模型
我们考虑一个支持交互式视频会议的视频语义通信系统,它包括发射器[12]和接收器,如图1所示。 接收端需要准确地重构字符信息,而静态的背景信息不需要及时更新,只有有限的无线带宽可以支持海量的通信。 为此,系统需要高效的视频传输技术,通过提取和传输视频语义信息。 为了实现这一目标,我们考虑通过去除冗余的静态视频背景信息来进行混合的高层和低层语义提取,主要包括三个步骤。 首先,我们在高语义层面提取视频的主要对象,其中视频帧分为前景和背景,静态背景仅传输一次,前景需要实时更新。 其次,前景通过低语义级别的时间和空间相关性进一步编码。 最后,给定传输的前景语义特征,接收器通过将前景中的字符和一帧静态背景组合成完整的视频来重建视频帧。
接下来,我们首先介绍高语义层面的MOE。 然后,我们在低语义级别呈现我们的 CVE。 随后,我们介绍了我们的渠道模型。 最后,我们介绍了视频解码和重建的方法。
II-A 主要对象提取
用表示发送器处感测到的原始视频数据,其中是第视频帧。 和分别是视频帧的高度和宽度。 是通道数。 MOE模块用于从中提取主要对象,主要对象就是前景组件。 用 表示前景估计张量, 可以由下式给出
| (1) |
其中是MOE模块的函数。
随后,我们采用前景提取来获得具有的前景系列,其中第帧经过背景像素去除,并且可以由下式给出
| (2) |
其中 是表示空白背景的白色像素张量, 是 Hadamard 产品。 给定和,可以用提取背景,其中背景可以通过图像生成技术进一步完成。
II-B 上下文视频编码
为了利用前景的时间和空间相关性来进一步减少传输所需的数据量,我们将从像素域转换为潜在的语义特征。域,然后将编码为变长码字进行传输。 在CVE模块中,我们首先使用运动估计网络来学习当前帧和前一帧之间的运动向量,给出经过
| (3) |
其中表示运动估计函数。 由于神经网络可以有效地细化潜在域中的视频特征[13],给定运动向量,我们可以细化原始视频前景系列 进入语义特征系列,它是数据量较小的潜在域表示,如图1所示。 和 之间的关系可以由下式给出
| (4) |
其中表示上下文提取函数,是单帧的语义特征。 最后,通过熵编码算法将编码为码字流通过无线信道传输,可得
| (5) |
其中表示编码功能,为变长码字,为的长度。 我们用作为信道带宽比(CBR)[11]来描述的平均编码率。
II-C 无线频道
当通过无线信道传输时,编码码字流会遭受传输损伤,包括失真和噪声。 假设视频传输使用单个端到端无线链路,则接收到的信号可由下式给出
| (6) |
其中是接收到的具有传输损伤的语义特征码字流,是衰落信道系数,表示高斯信道噪声, 是噪声方差, 是单位矩阵。
II-D 接收者
接收器包括熵解码、上下文恢复和重建器模块。 熵解码用于将接收到的码字流解码为语义特征,其由下式给出
| (7) |
然后使用上下文恢复从语义特征中获取,由下式给出
| (8) |
重建器用于组合直接在接收器处提供的静态背景。 在所考虑的系统中,静态背景可以重复用于多个视频帧。 结果,我们传输一个静态背景帧并将其用作重建视频的背景。 最后,我们将视频帧组合回重建视频,如图1所示。
III 网络架构
在本节中,我们设计系统模块来共同考虑准确的语义提取和各种信道条件来实现所提出的系统。 特别是,我们首先通过语义编码器中基于神经网络的 MOE 提取每个单帧中的高级语义。 然后,我们在语义编码器中通过CVE提取低层语义,考虑帧之间的相关性,并进行自适应各种长度编码,从而减少传输的数据量。 最后,对语义解码器和整个训练算法进行了说明。
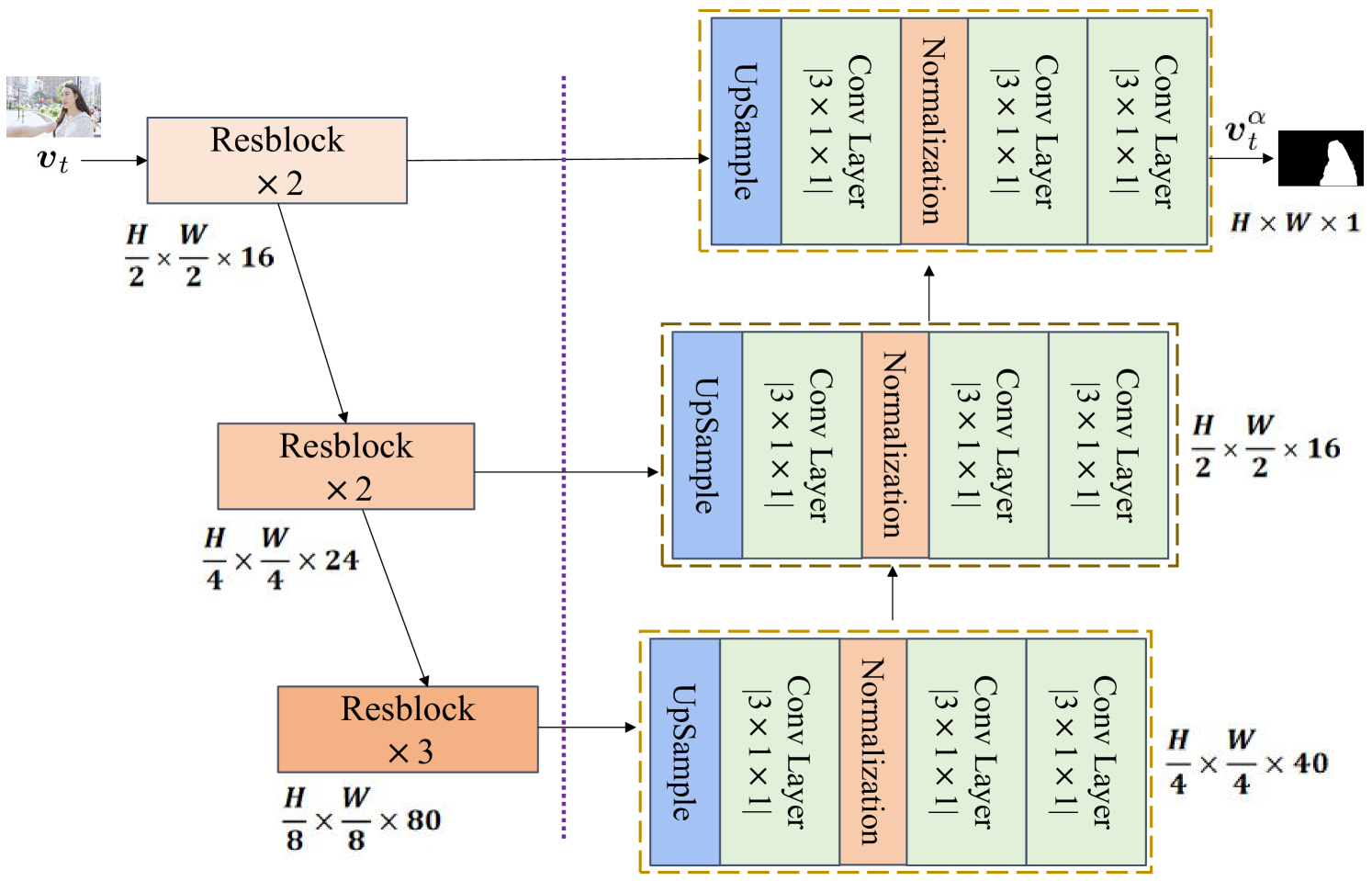
III-A 语义编码器中的 MOE
MOE 模块用于从输入视频帧中执行字符提取。 它首先识别主要对象,然后去除静态背景。 这样,我们将对象级内容视为高级语义。 为了准确识别主要物体,我们提取不同尺度的特征,包括物体的形状和位置。 我们使用 MOE 模块在 (1) 中生成 。 如图2所示,我们使用MobileNetV3-Large [14]作为MOE模块的主干,它由特征提取器和特征融合组成。 特征提取器由残差块组成,分别提取视频帧的 、、 尺度的特征,以准确定位视频主要对象。 特征融合部分通过卷积层融合不同尺度的特征,生成,如图2所示。
为了提高前景估计的准确性,MOE模块对输出的损失函数为
| (9) |
其中 是 的基本事实,并且
| (10) |
是拉普拉斯损失 [15],其中 是第 金字塔层 [15] 的输出。
III-B 语义编码器中的 CVE
在 CVE 中,我们首先使用运动向量 通过上下文提取从 中细化语义特征 。 然后,基于的熵估计,将编码为可变长度码字。 接下来,我们将依次介绍运动估计、上下文提取和熵编码。
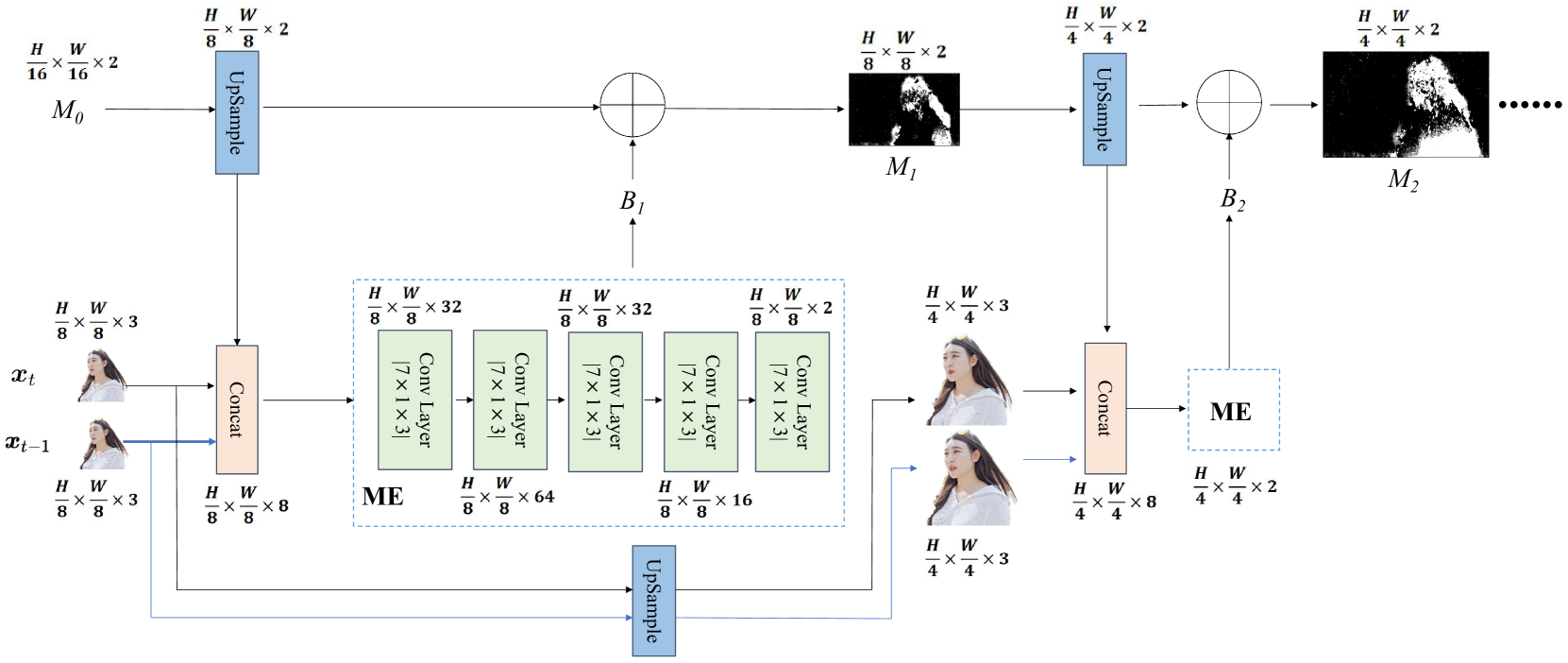
III-B1 运动估计
由于前景在连续视频帧之间具有很强的时间和空间相关性,因此CVE模块进一步提取低级语义特征(时间和空间相关性)以减少传输开销。 为了获得上下文信息(连续视频帧之间的时间和空间相关性的组合),我们首先使用卷积神经网络(CNN)来估计运动向量。 与传统的运动估计(ME)方法相比,神经网络可以融合视频中的颜色、纹理和深度等多维信息,以提高运动估计的准确性,因此我们估计运动向量:美国有线电视新闻网。 ME是像素块的位置变化预测。 在 ME 过程中,我们使用光流估计网络[16]来估计上一帧和当前帧之间的运动矢量。 具体来说,光流估计网络由四个ME模块组成,形成四个金字塔级别[16]。 如图3所示,光流估计采用从粗到细的空间金字塔结构来学习每个金字塔级别的残差流,并且光流 在 金字塔层由下式给出
| (11) |
其中是上采样操作,是ME模块输出的残余流,是作为初始值的零张量。 我们使用ME模块来计算当前级别(第级别)的剩余光流。 依次输入残余光流,对各级光流进行校正。 ME是光流估计的最后一步,最终输出最后的光流作为运动向量,由给出。
III-B2 上下文提取
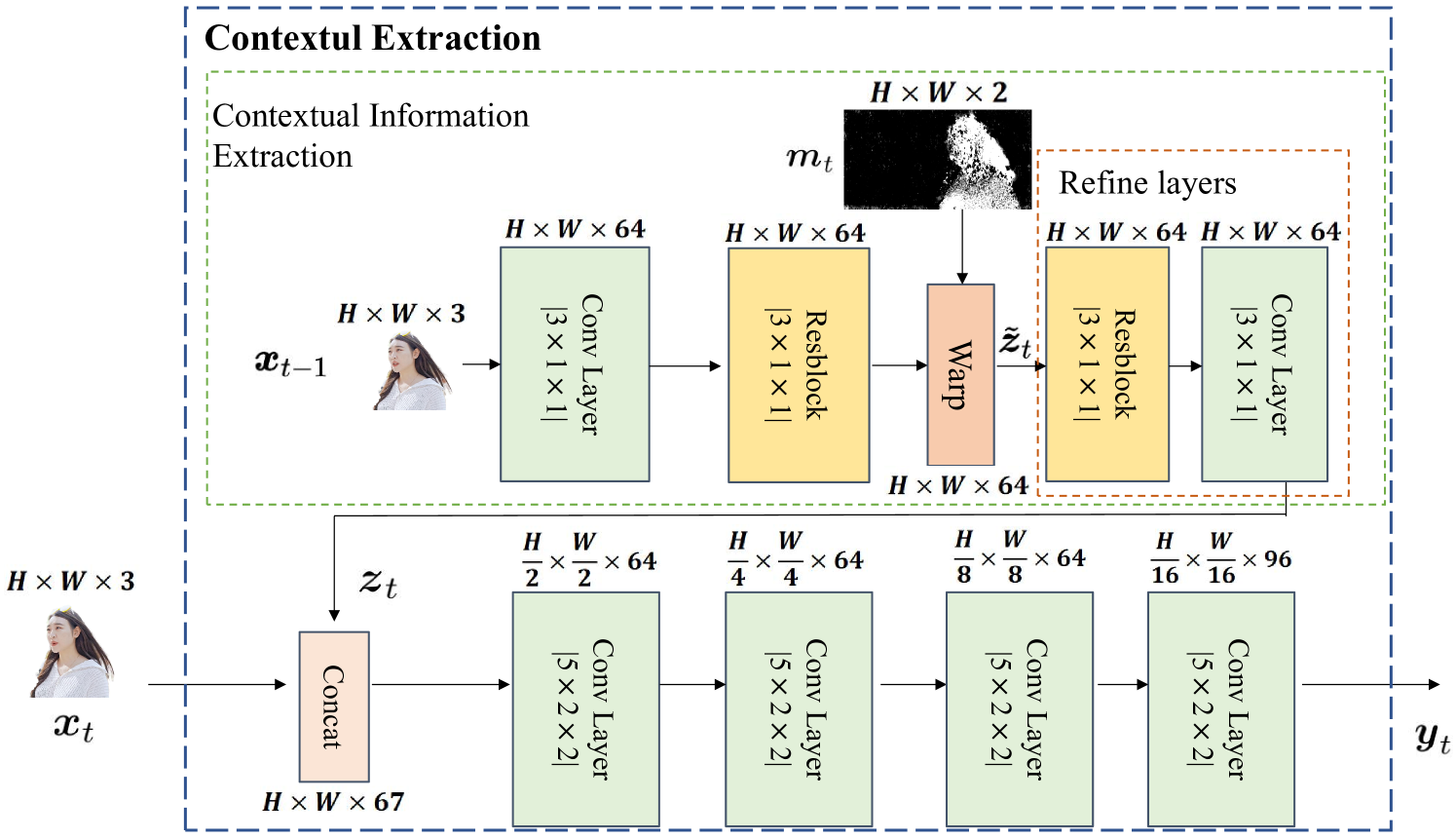
如图4所示,我们使用获得的和前一帧通过卷积层和残差块提取初始上下文信息。 在这里,为了补偿不连续性[11],我们使用细化层来细化包含时间和空间相关性的最终上下文信息。 然后我们使用通过CNN层提取语义特征,其中是在潜在域中的映射特征。 我们没有像传统方法那样直接在像素域对视频帧进行编码,而是考虑跨视频帧区域的时间和空间相关性对语义特征进行编码,这更有利于后续分配的编码权重。
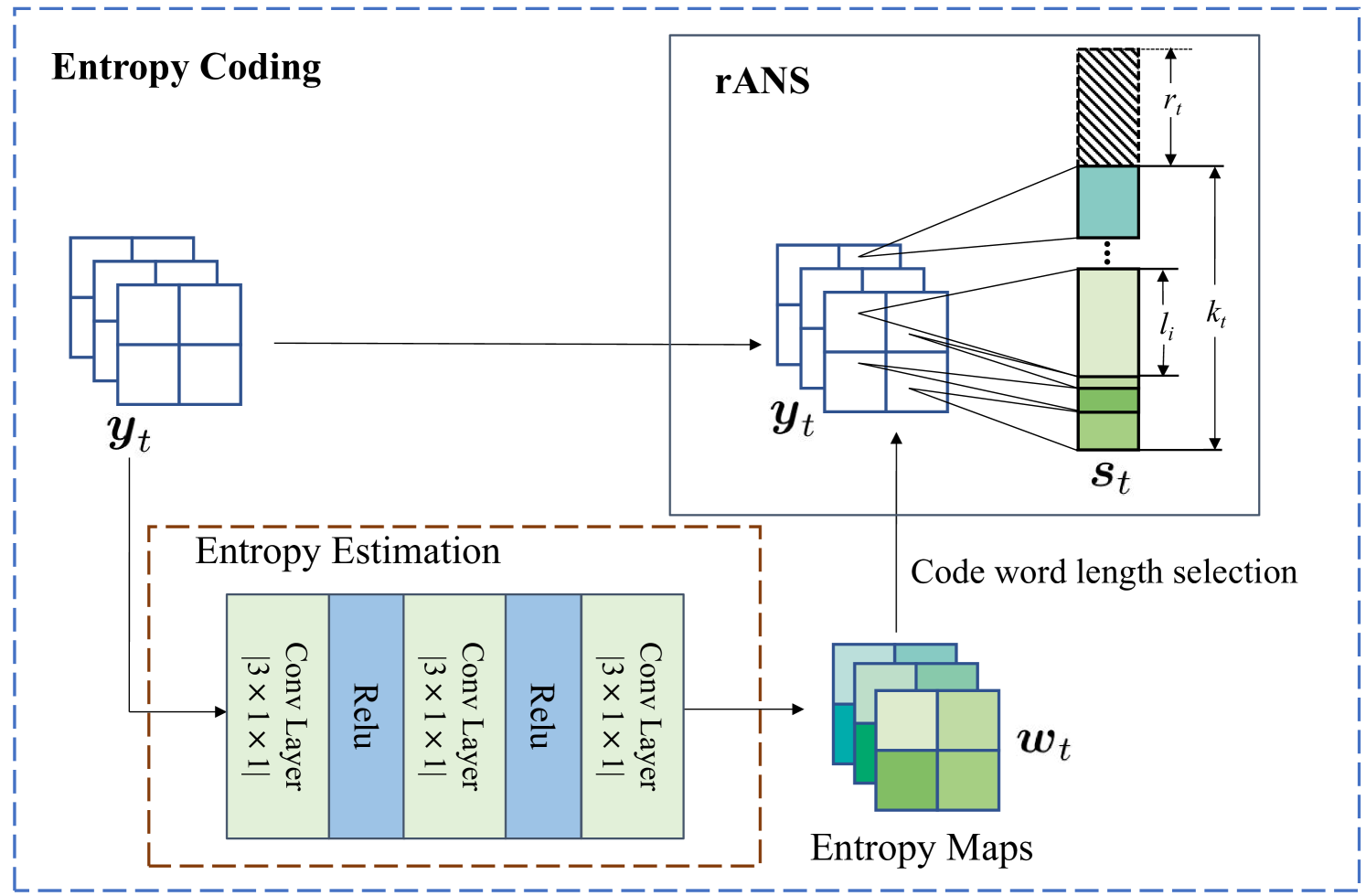
III-B3 熵编码
给定,我们通过熵编码将语义特征编码为变长码字。
III-C 语义解码器
III-D MOE-CVE 训练算法
在所提出的系统中,每个模块都是独立的,我们分别训练带有参数的MOE模块和带有参数的CVE模块。 在MOE训练中,我们使用Adam优化器,其中是的梯度; 为一阶矩估计; 为二阶矩估计; 是。 MOE 和 CVE 模块的学习率 和 均设置为 。 语义特征通过AWGN通道传输后,接收器使用接收到的噪声特征进行训练。 熵解码和上下文恢复以端到端方法与 CVE 同时训练。 整个训练过程总结在算法中。 1.
四仿真与性能分析
在我们的模拟中,考虑了由发射器和接收器组成的视频语义通信系统。 所有网络层的详细信息如图2-5所示。 MOE 模型使用视频数据集 VideoMatte240K [19] 进行训练。 该数据集提供 484 个视频剪辑,我们将数据集分为 475/4/5 个剪辑,用于训练/验证/测试分割。 CVE 模块使用 Vimeo-90k septuplet 数据集 [20] 作为训练数据。 测试数据使用[14]提供的字符数据集,其中包含=1920、=1024和=3。 我们训练了 4 个具有不同 的模型,其中衰落通道的 =0.9 且 SNR=15dB AWGN。 出于比较目的,我们试验了三个基线:a) 高级视频编码 (H.264) + 低密度奇偶校验 (LDPC):用于源编码的 H.264 与用于通道编码的 1/2 速率 LDPC 代码相结合,b)高效视频编码(H.265)+ LDPC 和 c)深度上下文视频压缩(DCVC)+ LDPC 如果可能的话,在这里提供参考是很好的。
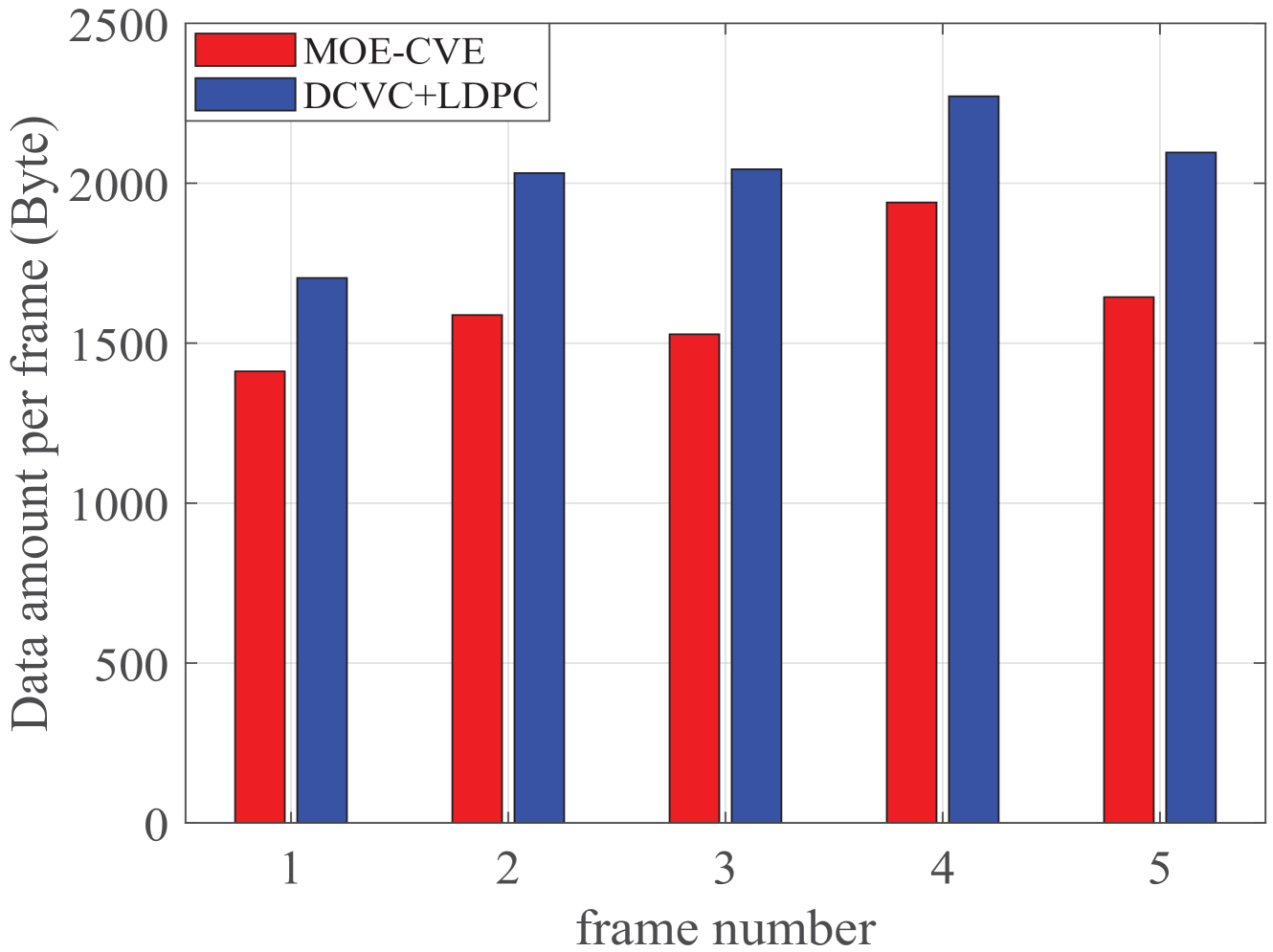
在图6中,我们展示了我们的方法和DCVC+LDPC中不同视频帧的传输数据量。 从图6中我们可以看出,两种方法都使用少量的数据来传输原始视频帧,而我们的方法减少了更多的数据量。 从图6中我们可以看出,与DCVC+LDPC相比,我们的方法将每帧视频的数据量减少了近25%。 这是因为 MOE 去除了多余的背景信息并聚焦于主要对象。 图6表明所提出的MOE-CVE方法显着减少了传输数据量。

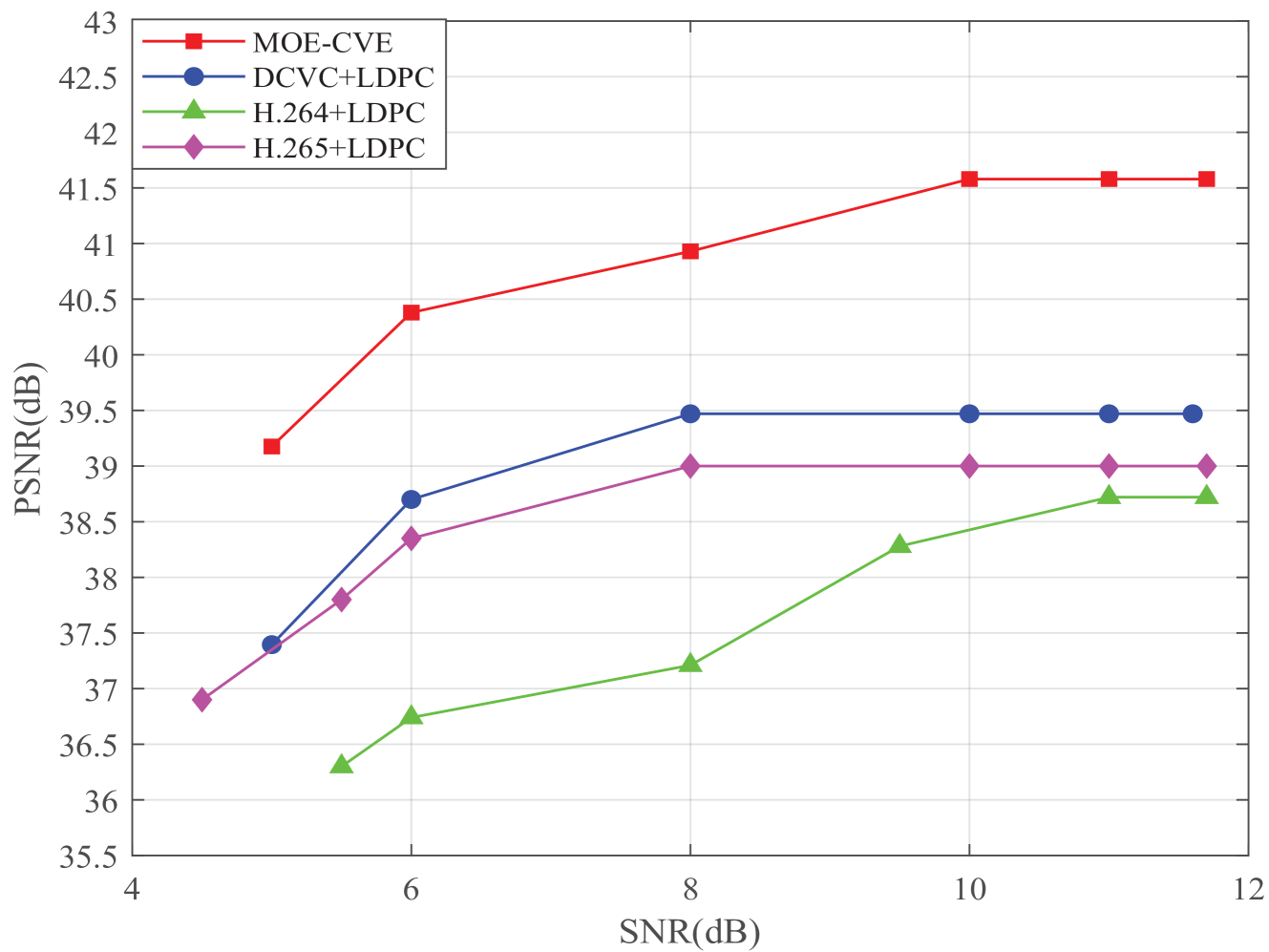
在图7中,我们展示了PSNR如何随着CBR的变化而变化。 从图7我们可以观察到,随着传输CBR的增加,传输PSNR按预期增加,而我们的MOE-CVE增加得更快。 从图7我们还可以看出,当CBR为0.012时,我们的方法的PSNR比H.264+LDPC高14%,比H.265+LDPC高12%。 此外,与DCVC+LDPC相比,我们的方法还实现了PSNR的改进。 这种改进是由于其他算法对视频帧的所有细节进行编码,而我们的 MOE-CVE 专注于主要对象的语义特征,从而在相同 CBR 下实现更好的重建性能。 图7表明该方法可以提高视频重建精度。
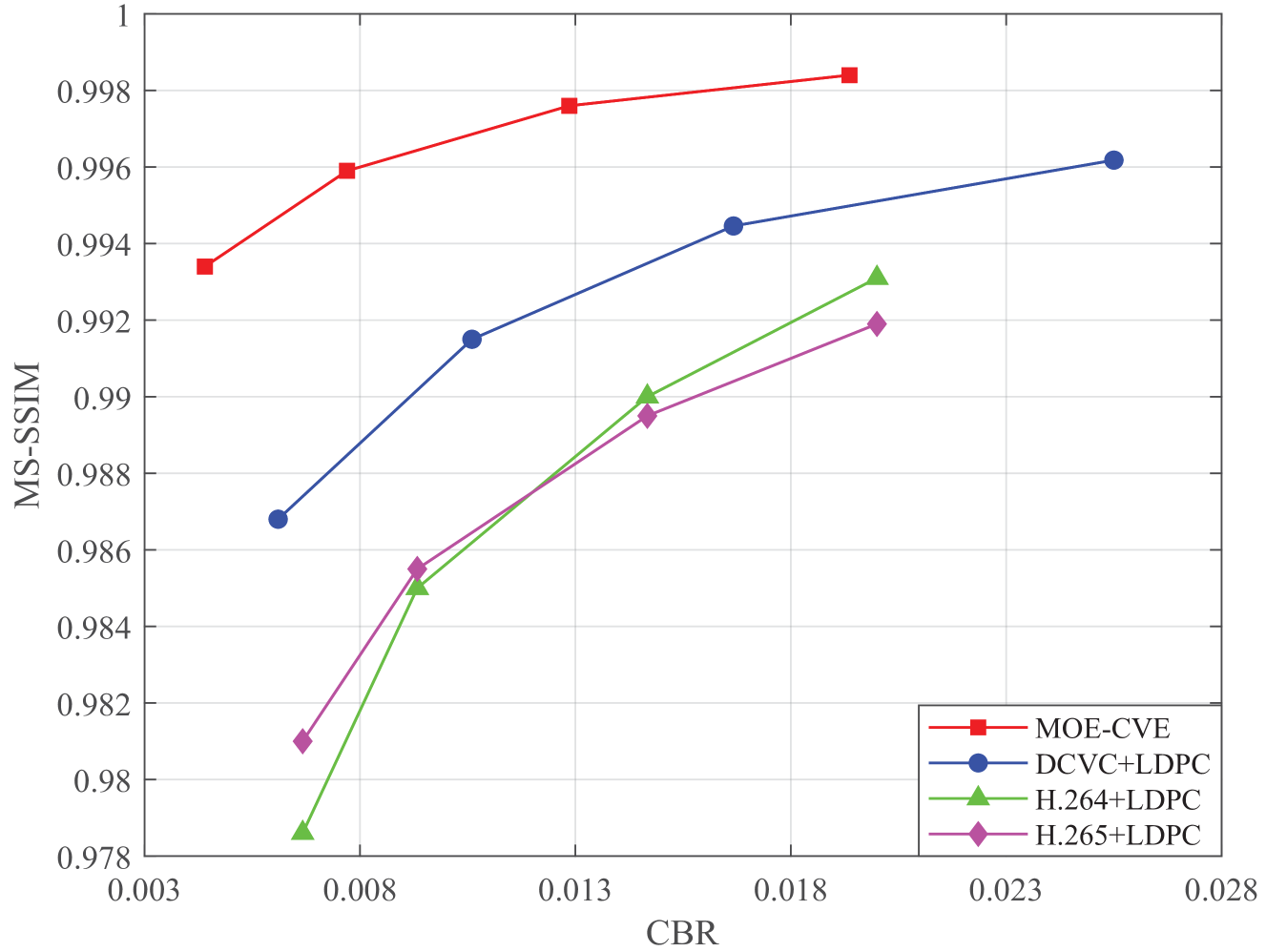
在图8中,我们展示了多尺度结构相似性(MS-SSIM)[18]如何随着CBR的变化而变化。 从图8我们观察到,随着CBR的增加,传输MS-SSIM如预期的那样增加。 从图8我们还可以观察到,与H.264+LDPC相比,我们的方法将MS-SSIM的传输率提高了近0.014。 此外,我们方法的 MS-SSIM 变化比其他方法更平坦。 这是因为我们的方法去除了静态背景,并考虑了相关性进行编码,从而显着改善了 MS-SSIM。
V 结论
在本文中,我们提出了一种用于视频语义通信的 MOE-CVE。 特别是,我们设计了一个 MOE 模块来提取视频的主要对象,并设计了一个 CVE 模块来编码主要对象的语义信息。 仿真结果表明,与传统的编码方案相比,所提出的 MOE-CVE 方案可以在保持 PSNR 和 MS-SSIM 的同时减少高达 25% 的传输数据。 此外,所提出的 MOE-CVE 方案比基线方法表现出更好的对信道损伤的鲁棒性。
参考
- [1] Z. Yang, M. Chen, Z. Zhang, and C. Huang, “Energy efficient semantic communication over wireless networks with rate splitting,” IEEE Journal on Selected Areas in Communications, May 2023.
- [2] S. Yang, F. Li, S. Trajanovski, R. Yahyapour, and X. Fu, “Recent advances of resource allocation in network function virtualization,” IEEE Transactions on Parallel and Distributed Systems, Feb. 2021.
- [3] W. Gong, H. Tong, S. Wang, Z. Yang, X. He, and C. Yin, “Adaptive bitrate video semantic communication over wireless networks,” arXiv preprint arXiv:2308.00531, Aug. 2023.
- [4] A. Pratap, R. Gupta, V. S. S. Nadendla, and S. K. Das, “Bandwidth-constrained task throughput maximization in IoT-enabled 5G networks,” Pervasive and Mobile Computing, Nov. 2020.
- [5] H. Tong, Z. Yang, S. Wang, Y. Hu, W. Saad, and C. Yin, “Federated learning based audio semantic communication over wireless networks,” in 2021 IEEE Global Communications Conference (GLOBECOM), Dec. 2021.
- [6] H. Xie, Z. Qin, G. Y. Li, and B.-H. Juang, “Deep learning enabled semantic communication systems,” IEEE Transactions on Signal Processing, Apr. 2021.
- [7] D. Huang, X. Tao, F. Gao, and J. Lu, “Deep learning-based image semantic coding for semantic communications,” in Proc. Global Communications Conference (GLOBECOM), Dec. 2021.
- [8] H. Xie, Z. Qin, X. Tao, and K. B. Letaief, “Task-oriented multi-user semantic communications,” IEEE Journal on Selected Areas in Communications, Sept. 2022.
- [9] G. Lu, W. Ouyang, D. Xu, X. Zhang, C. Cai, and Z. Gao, “Dvc: An end-to-end deep video compression framework,” in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2019.
- [10] P. Jiang, C.-K. Wen, S. Jin, and G. Y. Li, “Wireless semantic communications for video conferencing,” IEEE Journal on Selected Areas in Communications, Jan. 2023.
- [11] S. Wang, J. Dai, Z. Liang, K. Niu, Z. Si, C. Dong, X. Qin, and P. Zhang, “Wireless deep video semantic transmission,” IEEE Journal on Selected Areas in Communications, Jan. 2023.
- [12] P. Si, J. Zhao, K.-Y. Lam, and Q. Yang, “Uav-assisted semantic communication with hybrid action reinforcement learning,” in Proc. IEEE Global Communications Conference (GLOBECOM), Dec. 2023.
- [13] J. Dai, S. Wang, K. Tan, Z. Si, X. Qin, K. Niu, and P. Zhang, “Nonlinear transform source-channel coding for semantic communications,” IEEE Journal on Selected Areas in Communications, Aug. 2022.
- [14] S. Lin, L. Yang, I. Saleemi, and S. Sengupta, “Robust high-resolution video matting with temporal guidance,” in Proc. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Jan. 2022.
- [15] Q. Hou and F. Liu, “Context-aware image matting for simultaneous foreground and alpha estimation,” in Proc. IEEE/CVF International Conference on Computer Vision (ICCV), Oct. 2019.
- [16] A. Ranjan and M. J. Black, “Optical flow estimation using a spatial pyramid network,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Aug. 2017.
- [17] J. Duda, “Asymmetric numeral systems: entropy coding combining speed of huffman coding with compression rate of arithmetic coding,” arXiv preprint arXiv:1311.2540, Fan. 2014.
- [18] Z. Bao, H. Liang, C. Dong, C. Li, X. Xu, and P. Zhang, “Mdvsc–wireless model division video semantic communication,” arXiv preprint arXiv:2308.05338, May. 2023.
- [19] S. Lin, A. Ryabtsev, S. Sengupta, B. L. Curless, S. M. Seitz, and I. Kemelmacher-Shlizerman, “Real-time high-resolution background matting,” in Proc. the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Aug. 2021.
- [20] T. Xue, B. Chen, J. Wu, D. Wei, and W. T. Freeman, “Video enhancement with task-oriented flow,” International Journal of Computer Vision, Feb. 2019.