图基础模型
摘要
图基础模型(GFM)是图领域的一个新趋势研究主题,旨在开发一种能够泛化不同图和任务的图模型。 然而,通用的 GFM 尚未实现。 构建 GFM 的关键挑战是如何实现具有不同结构模式的图之间的正迁移。 受 CV 和 NLP 领域现有基础模型的启发,我们通过倡导“图词汇”为 GFM 开发提出了一种新的视角,其中图底层的基本可转移单元编码图上的不变性。 我们从网络分析、理论基础和稳定性等基本方面奠定了图词汇构建的基础。 这样的词汇视角有可能推动未来遵循神经尺度法则的 GFM 设计。
1简介
基础模型(Bommasani等人,2021)经过海量数据预训练,可以适应广泛的下游任务,在计算机视觉等各个领域取得了无与伦比的成功(CV) (Radford 等人, 2021) 和自然语言处理 (NLP) (Bubeck 等人, 2023; Touvron 等人, 2023)。 通常,基础模型可以有效地利用预训练阶段获得的先验知识和下游任务的数据来实现更好的性能(Han等人,2021),甚至可以在少样本的情况下提供有希望的效果任务演示(董等人,2022)。
同时,图是重要且独特的数据结构,封装了非欧几里得和复杂的对象关系。 鉴于各种图体现了独特的关系,大多数图学习方法都是针对特定图上的单个任务从头开始训练。 这种方法需要为每个单独的图和任务收集和部署数据。 于是,一个有趣的问题出现了: 是否有可能设计一个能够泛化不同图和任务的图基础模型(GFM)?
尽管其他领域的基础模型取得了重大进展,但 GFM 的发展仍处于婴儿阶段。 最近的研究证明了 GFM 在专业领域的潜力,例如知识图(Galkin 等人,2023)和分子结构(Beaini 等人,2023)。 然而,这些模型通常集中于有限的场景:它们可能跨多个数据集应用,但仅限于单个任务,跨越单个域内的各种任务,或者仅限于一小组数据集和任务。 迄今为止,可以泛化广泛的基于图的应用程序的多功能 GFM 尚未实现。
实现 GFM 的关键困难是如何在从社交网络到具有无数结构模式的分子图的各种图数据之间实现正迁移。 CV 和 NLP 领域的答案是共享词汇表。 在 NLP 基础模型中,文本首先根据词汇被分解为更小的单元,词汇可以是单词、短语或符号。 在CV基础模型中,基于视觉词符词汇将图像映射到一系列离散图像标记(Yu等人,2023a;Bai等人,2023)。 词汇表定义了特定领域中的基本单元,可以跨不同的任务和数据集转移。 因此,实现 GFM 的关键挑战缩小到我们如何找到图词汇,即图底层的基本可转移单元,用于对图上的不变性进行编码。
然而,找到一个适用于不同图的合适的图词汇是具有挑战性的,这也是本文的主要焦点。
我们的贡献: 在本文中,我们提出了一个词汇视角来清楚地阐述 GFM 的立场。 特别是,我们将原始 GFM 的现有成功归因于在第 2 节中图的特定可迁移性原则指导下的适当词汇构建。 3节对图的可迁移性原则进行了全面的回顾,为我们未来的词汇构建和GFM设计提供了原则。
与过去相关文献的比较与我们的立场文件同时,Jin 等人 (2023a); Li 等人 (2023b);张等人(2023c)回顾了那些针对图采用大语言模型的方法,这些方法没有显示出传输能力,因此偏离了我们构建以图为中心的GFM的范围。 Liu 等人 (2023e) 进一步讨论了现有的图预训练和适应技术,重点关注其实现。 我们的工作更多地关注基本原理,而不是技术细节,例如跨数据集的几何不变性。 在原则指导下,我们描绘了 GFM 发展的有希望和相对难以捉摸的方向。
2 现有的原始 GFM 以及现有成功的关键原因
GFM 在 Liu 等人 (2023e) 中正式定义,它期望 GFM 能够跨所有图任务和数据集进行传输。
尽管如此,目前还没有这样的 GFM 满足上述定义。 相比之下,我们观察到现有模型(Galkin等人,2023;Zheng等人,2023a)已经取得了初步成功,在某些方面获得了GFM所需的能力。
2.1 现有的原始GFM
基于跨领域和跨任务的模型可迁移性,我们可以将现有的原始 GFM 大致分为三类:特定任务、特定领域和原型 GFM。 我们为每个类别提供了定义和示例,并在附录 B 中提供了更多说明。
特定于任务/特定于域的 GFM 应可跨特定任务/域转移,从而适应不同的下游数据集和特定于域的任务。 特定于任务的 GFM 的一个著名示例是 ULTRA (Galkin 等人,2023),它在各个领域的数据集上实现了卓越的零样本知识图谱完成 (KGC) 性能。 特定领域的 GFM 实例 DiG (Zheng 等人, 2023a) 通过利用特定领域的知识来学习跨各种化学任务的通用表示。
原型 GFM 表现出泛化到有限数量的数据集和任务的能力。 一个值得注意的例子是 PRODIGY (Huang 等人, 2023a),它可以对文本属性图上的节点分类和链接预测执行少量样本上下文学习。 然而,由于 Huang 等人 (2023a) 采用浅层 GNN 作为其核心模型,鉴于其适度的模型大小,额外数据集和任务的可扩展性和灵活性仍然不确定。
与此同时,人们也在努力(Li 等人,2023b)利用大语言模型来执行图相关任务。 尽管大语言模型在 NLP 领域表现出色,但直接简单地扁平化图结构并提示大语言模型会产生次优结果,这在文本属性 (Chen 等人, 2023b) 和非文本属性的研究中得到了证明。 -归因图(Wang等人,2023a)。 一个值得注意的方法是 GraphText (Zhao 等人, 2023b) 采用基于树的提示设计,保留结构语义,提供令人满意的少样本上下文学习性能。 然而,大语言模型在解决图数据方面遇到了基本问题(Saparov & He, 2022; Dziri 等人, 2023)。 我们在5节中进一步讨论了大语言模型在图领域的使用。
2.2现有GFM成功的关键原因。
尽管原始 GFM 取得了经验上的成功,但其根本原因仍不清楚。 特别是,我们研究了 ULTRA (Galkin 等人,2023) 的机制,这是一种专注于知识图谱完成(KGC)任务的特定于任务的 GFM。 KGC任务旨在推断缺失的三元组(边),表示为,其中是查询关系,和 分别是头实体和尾实体。 KGC 模型旨在回答查询 通过预测尾部实体。
其成功的第一个原因是利用 NBFNet (Zhu 等人, 2021b) 主干模型,该模型能够归纳推广到具有表达性关系词汇的新图。 NBFNet 提出了一种条件消息传递,可以学习以头实体节点和查询关系为条件的成对节点表示。
Huang 等人 (2023c) 展示了这种基于关系 Weisfeiler-Leman 算法的条件消息传递,理论上与标准、无条件 GNN 相比,在 KGC 中提供了更高的表达能力 (Li 等人, 2022 )。 这种表达能力有助于区分具有不同结构特征的知识图之间的差异,从而产生合适的关系词汇。 相比之下,Barcelo 等人 (2022) 表示那些无条件 GNN,例如 R-GCN (Schlichtkrull 等人, 2018) 和 CompGCN (Vashishth 等人) ,2019),将非同构节点对映射到相同的表示中,从而产生收缩的关系词汇表。 这种收缩的词汇可能会导致负迁移,从而在具有固有差异的非同构节点对之间不适当地概括知识。
然而,这种表达关系词汇仅考虑预定义的关系类型,在推理过程中无法泛化到具有新关系类型的场景。 为了扩展现有的关系词汇,包括新的关系类型,Galkin 等人 (2023) 构建了一个关系图,捕获独立于任何图特定关系类型的基本交互,这是其成功的第二个原因。 关系图具有理论基础(Gao 等人,2023),旨在学习双排列等变表示。 这种表示与节点实体和边关系类型的排列等价。 这种等变性可以类比于共享的关系词汇表。 它将新的看不见的关系类型连接到现有的关系类型,并将等变节点对映射到相同的表示,尽管关系类型不同,从而导致正迁移。
综上所述,我们可以得出结论,ULTRA 实现良好可迁移性的关键是为 KGC 找到合适的词汇表,满足两个原则:(1)词汇表不应该被压缩,这会导致不同的节点对共享表示,从而导致潜在的负迁移。 (2) 词汇表应该具有足够的包容性,能够将新的、未知的关系映射到现有词汇表上,从而有可能实现正向迁移。
寻找合适的词汇表来构建 GFM 的有效性也可以在其他现有的原始 GFM 中找到,并有以下证据。 GraphGPT (Zhao 等人, 2023c) 构造一个数据集特定的词汇表,其中每个节点对应一个唯一的节点 ID。 值得注意的是,GraphGPT 需要对每个数据集进行特定的预训练和微调。 MoleBERT (Xia 等人, 2023)是分子图的基础模型,它手动设计了一个词汇表,将原子属性转换为具有化学意义的代码。 同样,OFA (Liu 等人, 2023b) 手动将所有节点特征转换为有意义的文本描述。
3 底层可转移性原则
在最后一节中,我们研究了目前构建 GFM 成功的关键原因。 构建 GFM 的关键原则是构建合适的图词汇表,以保持跨数据集和任务的基本不变性。 尽管已经取得了成功,
更多的图可转移性原则可以发现不同的不变性,并为未来的 GFM 构建新的合适的图词汇提供指导。
以下讨论安排如下:
我们首先在3.1节中对图可转移性原理进行一般性介绍。 关于节点分类、链接预测和图分类任务的详细任务特定原则可以分别参见3.2、3.3和3.4节。 我们最后在3.5节中讨论了任务可转移性的原则。 值得注意的是,以下讨论主要集中在图结构的可转移性上。
3.1 图可迁移性原则
在本小节中,我们介绍实现图可迁移性的原理,重点关注三个关键方面:网络分析、表达性和稳定性。
网络分析通过识别基本图形模式(例如网络主题(Menczer等人,2020))并建立关键原则(例如三元图),提供对网络系统的传统理解封闭原则(黄等人,2015)和同质原则,在不同领域普遍有效。 这些原则通常被用来指导高级 GNN 的设计。 例如,最先进的用于链接预测的 GNN(Wang 等人,2023b) 是一种神经公共邻居,受到三元闭包原理的启发。 尽管网络分析很有效,但它严重依赖于专家知识,而没有可证明的保证。
表现力提供了图神经架构一般可以对哪些函数进行建模的理论背景,例如,GNN 的图级性能受 Weisfeiler-Leman 测试限制的众所周知的连接(Xu等人,2019;莫里斯等人,2019,2023)。 最具表现力的结构表示(Srinivasan & Ribeiro,2019)是描述两个节点集的表示应保持不变的关键概念,当且仅当节点集对称并具有置换等价。 这种最具表现力的结构表示是设计合适的图词汇的重要原则,可以完美地区分多元预测任务中的所有非同构结构模式。
稳定性 (Ruiz 等人, 2023) 评估表示对图形扰动的敏感性。 它的目的是在较小的扰动下保持对预测的有界差距,而不是仅区分同构和非同构情况的表现力。 稳定性施加了更严格的约束,从而导致更好的泛化。 它可以类比图词汇表的约束,其中相似的结构模式应该具有相似的表示。
此外,还有一些其他挑战会影响更深层次的 GNN 设计以包含更多高阶信息。 更深的 GNN 可能会出现性能下降并且无法捕获高阶结构信息。 主要存在三个问题:(i)过度挤压问题(Topping等人,2021)说明节点表示对来自重要但遥远节点的信息不敏感。 (ii)过度平滑问题(Oono&Suzuki,2019;Cai&Wang,2020)说明更多的聚合导致节点表示收敛到唯一的平衡,从而失去了不同节点之间的区别。 (iii) 未触及的(Barceló等人, 2020)说明未能探索、覆盖或影响图中的所有相关节点,导致信息损失。 提出了各种技术来识别根本原因(Di Giovanni 等人,2023;Wu 等人,2023)并通过新的 GNN 解决表达性问题(Yang 等人,2021) t1> 和 graph Transformer (Wu 等人,2022;Müller 等人,2023) 架构设计。
3.2 节点分类中的可传递性原则
网络分析。 同质性 (Khanam 等人,2020)描述了链接节点通常具有相似特征的现象(“物以类聚”),是社会科学中的一个长期存在的原理。 它可以作为从传统的 pagerank (Chien 等人,2021) 和标签传播 (Chawla & Karakoulas,2005) 到最近先进的 GNN 等方法的原则指导。 现有的 GNN 架构通常基于同质原理构建,在不同领域的不同同质图上表现出强大的性能。 这种对同质性的坚持不仅增强了模型的有效性,而且还促进了同质图数据集之间模型的可转移性。 值得注意的是,Ying 等人 (2018) 证明了这些图之间的成功转移。
虽然同质性在网络分析中占主导地位,但这并不是普遍规则。 在许多现实世界的场景中,“异性相吸”,导致网络具有异质性,其中节点更有可能与不同的节点连接。 使用同质原理构建的 GNN 通常会与异质网络发生斗争,除非是“良好的异质性”(Ma 等人,2021;Luan 等人,2021),其中 GNN 可以识别并利用一致的模式不同节点之间的连接。 然而,大多数异亲网络都是复杂多样的,由于其不规则且错综复杂的交互模式,给 GNN 带来了挑战(Luan 等人,2023;Wang 等人,2024;Mao 等人,2023a)。 因此,GNN 的可迁移性在同亲图中更有保证,但在异亲图中面临着重大挑战。
稳定性。 尤等人(2023)从理论上建立了可传递性与网络稳定性之间的关系,证明了具有增强谱平滑性和较小最大频率响应的图滤波器分别在节点特征和结构方面表现出改善的可传递性。 特别是,谱平滑度(以相应 GNN 的图滤波器函数的 Lipschitz 常数为特征)表明了针对边缘扰动的稳定性。 最大频率响应反映了应用图形滤波器后的最高频谱频率(本质上是拉普拉斯矩阵的最大特征值),描述了针对特征扰动的稳定性。
3.3 链接预测中的可转移性原则
网络分析。 重要的网络分析原理(毛等人,2023b)分为三个主要概念,包括:(1)对应三元闭合原理的局部结构邻近性(黄等人,2015),朋友的朋友自己也成为朋友。 它启发了包括 CN、RA、AA 在内的众所周知的常规方法(Adamic & Adar,2003)。 (2)全局结构邻近性,对应于衰减因子原理,其中两个节点之间的短路径越多,连接的概率就越高。 它启发了著名的传统方法,例如 Simrank 和 Katz (Katz,1953;Jeh & Widom,2002)。 (3)特征接近性对应于同质性原则(Murase等人,2019),在相关个体中可以找到共同的信念和想法。
这些原则指导着链接预测算法的演变,从基本启发式到复杂的 GNN (Chamberlain 等人,2022;Li 等人,2023a)。 受这些原则的启发,GNN 在多个领域的不同图上表现良好。 此外,Zheng 等人(2023b)提供了支持这些指导原则有益的可转移性的经验证据。
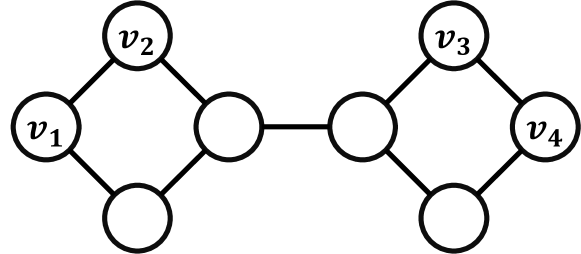
表现力。 仅配备单节点排列等价的普通 GNN 由于缺乏表达性而无法实现链路预测任务的可转移性。 图 1 中显示了展示此类失败的示例,其中包含无特征的图表。 和 由普通 GNN 表示相同,因为它们具有相同的邻域结构。
因此,和之间的相似性将与和之间的相似性相同,从而导致相同的表示和预测对于链接 和 而言,但是,根据全局结构邻近度,距离较短为 1 的 应该更有可能被连接。 普通 GNN 仅从其邻域计算 的表示,忽略了与 的结构依赖性。 因此,这可能会导致负迁移,即 GNN 可能会错误地预测两个链接都存在或都不存在,而更有可能只有 有链接。
为了考虑节点对之间所有可能的依赖关系,我们的目标是为链路预测提供最具表现力的结构表示。 当且仅当链接对称时,这种表示形式才应该是不变的。 Zhang & Chen (2018) 通过结合依赖于链接中源节点和目标节点的节点标记特征来实现这种结构表示。 Zhang等人(2021)进一步强调了节点标签设计的关键方面,包括:(1)目标节点区分,其中源节点和目标节点与其他节点相比具有不同的标签; (2)排列等方差。 满足这些标准的节点标记方法,例如双半径节点标记(DRNL)和零一(ZO)标记,可以产生最具表现力的结构表示。 表达性表示可以找到完整的不同关系集来区分所有非同构节点对,从而减轻标准 GNN 中负迁移的风险。 Huang 等人 (2023c) 扩展了关系 Weisfeiler-Leman 框架 (Barcelo 等人, 2022) 以链接预测并将标签技巧的概念纳入多关系图。
稳定性。 对于那些同样具有表达能力的结构表示,其稳定性可能仍然存在差距。 例如,经验证据(Zhang等人,2021)表明带有DRNL标记的GNN优于带有ZO标记的GNN。 从稳定性的角度来看,在小扰动下保持对预测的有限差距至关重要。 Wang 等人 (2021) 提供了理论分析,识别了稳定位置编码的关键属性(GNN 应该与位置编码具有旋转和排列等变性),从而增强泛化能力。
3.4图分类中的可传递性原理
网络分析。 网络主题通常由小型且经常出现的子图组成,通常被视为图的构建块(Milo 等人,2002;Benson 等人,2016)。 正确选择主题集可以涵盖特定数据集的最重要知识。 图内核(Vishwanathan等人,2010)被提出来量化主题计数或其他预定义的图结构特征,然后利用提取的特征来构建分类器,例如SVM。 尽管来自不同领域的基本主题集通常不同,但可能存在跨不同领域共享的统一主题集。 在这种情况下,可以在均匀集上找到正迁移,其中 Battiston 等人 (2020) 显示了跨神经元连接网络、食物网和电子电路的正迁移。 因此,我们推测网络主题可能是图分类词汇表(一组不变元素)的基本单位,因为它既是可解释的,又可能在图之间共享。
表现力。 Zhang 等人 (2024) 提出了一个统一的框架来理解不同 GNN 检测和计算图子结构(motif)的能力。 更具表现力的 GNN,可以检测更多不同的主题并构建更丰富的图形词汇。 与统一主题集类比,我们推测表达 GNN 更有可能找到统一主题集并实现更好的可迁移性。
稳定性。 Huang 等人 (2023d) 提出了一种可证明稳定的位置编码,超越了表达符号和不变编码 (Kreuzer 等人, 2021) 和建模 (Lim 等人) ,2022),在拉普拉斯算子的微小修改上实现对位置编码的最小改变。 关键的创新是应用特征向量的加权和,而不是独立处理每个特征子空间。 在非分布分子图预测上可以观察到令人满意的性能。
3.5 跨任务的可转移性
通常采用统一的任务制定来促进各种任务之间的可转移性。 对齐任务公式的重要性在以下示例中显而易见:Jin 等人 (2020b) 表明直接使用链接预测作为借口任务会导致节点分类的负迁移。 然而,通过将节点分类重新表述为链接预测问题(Sun等人,2022;Huang等人,2023a),其中节点的类成员资格被视为节点和标签节点之间的链接可能性,实现正向迁移。
刘等人 (2023g); Sun等人(2023)进一步提出了一种子图视图,将节点分类调整为自我图分类,并将链接预测调整为目标节点对的归纳子图上的二元分类。
图2提供了这两个统一视图的说明性示例。 统一的任务制定使得能够(1)通过将不同下游任务的数据集转换为一来扩大数据集大小,以及(2)利用一个预训练模型来服务不同的任务。
除了统一的表述之外,不同任务还有以下共同原则:(1)节点分类和链路预测任务共享特征同质性作为重要原则。 (2) Liu 等人(2023d)指出链路预测上的全局结构邻近原理可以提高非同亲图上的节点分类性能。 (3) 链接预测中的三元闭包是图分类中使用的特定网络主题。 图分类和链接预测任务上都有更多的共享主题(Hibshman 等人,2021;Dong 等人,2017;AbuOda 等人,2020;Kriege 等人,2020)。
4 遵循神经尺度定律走向 GFM
基础模型的成功可以归因于神经缩放定律(Kaplan等人,2020)的有效性,该定律表明随着模型规模和数据规模的增加,性能得到增强。 在本节中,我们首先从图词汇的角度讨论4.1节中的神经缩放定律何时发生。 然后,我们分别在 4.2 和 4.3 节中讨论成功数据扩展和模型扩展的技术。 最后在4.4节中讨论了前置任务的设计。
4.1 当神经标度定律发生时
在第 3 节中,我们讨论指导未来词汇构建的基本可迁移原则。 这样的原理指导使得在几何先验的帮助下,在材料科学领域取得了成功的缩放行为(Shoghi 等人,2023;Zhang 等人,2023a;Batia 等人,2023)。 尽管如此,我们仍然对现有的成功是否可以扩展到图领域持谨慎态度。 关键问题是图能否严格遵循这些原则。 人类定义的图构建标准存在不确定性(Brugere等人,2018)。 例如,依赖专家知识的构造知识可能会导致边的不确定性(叶等人,2022)。 Chen 等人 (2023b); Li等人(2023c)观察到,错误标记的样本广泛存在于各个数据集中,其中流行的CiteSeer数据集有超过15个。尽管存在上述不确定性,但手工设计的不同图构造可以遵循相反的结果原则。 例如,Ogbn-arxiv (Hu 等人, 2020) 和 Arxiv-year (Lim 等人, 2021) t3>是具有相同图信息的两个节点分类数据集。 唯一的区别在于标签,其中Ogbn-arxiv使用论文类别,而Arxiv-year使用出版年份作为标签,导致同质和异质属性发生冲突(毛等人,2023a)。 因此,当存在不确定性和相反的图结构时,由于数据不遵守图可转移原则,缩放行为可能不会发生。
4.2 数据缩放
Chen 等人 (2023a); Huang 等人 (2023a) 初步验证了以监督和自监督方式训练的 GNN 遵循分子属性预测的数据缩放定律以及文本属性图的节点分类。 Xu等人(2023)进一步表明,预训练数据与下游任务数据之间的相似性是图上数据缩放的先决条件。 具体来说,Cao 等人 (2023); Xu等人(2023)分别就如何通过图子信号分析和基本网络属性(即网络熵)选择预训练数据提供了具体指导。 当数据在图形空间中或具有共享网络属性时表现出相似性时,可以发现正迁移。
当前数据扩展研究的一个局限性是数据集规模较小,特别是与大语言模型(Raffel等人,2019)的预训练相比。 这种差异可能归因于图领域高质量数据的稀缺。 NetworkRepository(Rossi & Ahmed,2015)是目前最大的图数据库,可以支持更大规模的预训练,但需要繁重的预处理来清理那些嘈杂且无序的数据。 此外,我们在附录A中展示了一系列有用的数据集。 然后我们展示现有的解决方案如下。
解决特征异构性。 由于缺失特征和不同语义空间导致的异构特征,现有图数据集无法统一用于预训练。 特征插补技术(Taguchi等人,2021;Um等人,2023;Gupta等人,2023)通常适用于基于邻近特征预测缺失属性。 然而,这些技术要求每个特征维度共享相同的语义。 当特征未在同一语义空间对齐时,Liu 等人(2023b)手动将原始特征与文本描述进行转换,然后使用大语言模型对嵌入进行编码。 此外,在预训练模型输入和测试数据之间的推理阶段也可以发现特征错位。 Jing 等人 (2023) 在下游任务特征上连接一个可学习的填充特征,以与预训练的 GNN 保持一致。 然而,这种技术无法适应特征空间未对齐的情况。 Zhao等人(2023b)直接放弃原有特征,利用特征相似度作为指导。
生成合成图是增强数据缩放和扩大训练数据大小的另一种途径。 传统的图生成模型(Albert & Barabási, 2002; Robins 等人, 2007; Airoldi 等人, 2008; Leskovec 等人, 2010)能够生成满足某些统计特性的图,仍然发挥着作用在节点级和链路级任务中发挥重要作用。
图上的深度生成模型(Jin 等人,2020a;Luo 等人,2021;Jo 等人,2022;Vignac 等人,2023)在生成高质量合成图方面取得了巨大成功,这有助于通过提供对图分布空间的更全面的描述来完成图级任务。
Liu 等人 (2023a) 利用扩散模型生成特定于任务的数据论证,以增强图级任务上的 GNN,并获得显着的性能提升。 有了对来自其他领域的合成数据进行预训练的成功证据(Mishra 等人,2022;Trinh 等人,2024),我们预计有潜力为大规模预训练生成高质量的合成图。 -GFM 培训。
4.3模型缩放
之前的 NLP 研究表明,除了数据之外,主干模型也是扩展的基础(Kaplan 等人,2020)。 Liu 等人 (2024) 主要在监督设置下验证各种图任务和模型架构的神经缩放定律。
然而,Kim 等人 (2022) 表明,与较小参数相比,参数数量较多的 GAT (Veličković 等人, 2017) 在图回归任务上表现不佳。大小对应。 相比之下,几何 GNN 可以很好地预测材料科学中的原子势(Shoghi 等人,2023;Zhang 等人,2023a;Batia 等人,2023)。 这种矛盾现象表明 GNN 的几何先验与特定任务之间的一致性可能会影响模型的缩放。
Graph Transformer 是模型架构的另一种流行选择,其中几何先验通过 GNN 或位置编码显式建模(Müller 等人,2023)。 硕士等人 (2022); Lu 等人 (2023) 表明,图转换器在监督设置下对分子数据表现出正缩放能力。 最近,Zhao 等人 (2023c) 展示了普通 Transformer 在蛋白质和分子特性预测方面的有效性。 特别是,它将图视为形成欧拉路径(Edmonds&Johnson,1973)的 Token 序列,这确保了无损序列化,然后采用下一个 Token 预测来预训练 Transformer 。 经过微调,它在蛋白质关联预测和分子特性预测上取得了可喜的结果,并表明普通变形金刚也遵循模型缩放定律(Kaplan等人,2020)。 尽管如此,这种纯粹的 Transformer 在其他任务上的有效性仍不清楚。
4.4借口任务设计
鉴于标记数据的稀缺性,能够有效利用无监督数据的借口任务是更大规模神经扩展的基石。 我们对代表性的借口设计进行了简要回顾。
图对比学习设计了借口任务(Sun 等人, 2019; Veličković 等人, 2018; Hassani & Khasahmadi, 2020; You 等人, 2020),通过对比原始视图和增强视图来获得等价性图形而不实质改变输入的语义内容。 对这些前置任务的初步统一理解(刘等人,2022)表明现有的前置任务侧重于保持图谱上低频的不变性。 尽管如此,不同的借口任务仍然不同,朱等人(2021a)观察到令人满意的性能需要借口任务和下游任务具有相似的理念,例如同质性。 为了获得有利于不同下游任务的预训练模型,Ju等人(2023)通过多任务学习框架自适应地将不同哲学的借口任务结合起来。
生成式自监督学习设计了前置任务(Hou等人,2022;Hu等人,2019;Kipf&Welling,2016)来捕获不同任务之间共享的数据生成过程。 特别是,他们尝试使用剩余的结构和特征来预测图形的屏蔽部分。 刘等人 (2023f); Xia等人(2023)进一步观察到任务粒度在生成建模中也发挥着重要作用。 具体来说,采用节点级借口任务可能会导致模型仅学习低级特征(Liu等人,2023f),而忽略图级任务所必需的全局信息。 为了解决这个问题,他们采用基于 GNN 的分词器在预训练阶段对高级信息进行显式建模,从而提高下游任务性能。
最近,下一个词符预测(NTP)前置文本任务(Zhao等人,2023c)在分子图上取得了初步成功。 值得注意的是,这是第一个展示模型扩展经验证据的借口任务。 其成功的潜在原因可能是(1)构建固定词符集,将问题空间缩小到有限集中,仅预测离散词符;(2)选择 Transformer 作为骨干模型。 然而,目前尚不清楚这种成功是否可以轻松扩展到更多任务。
5 见解和开放式问题
大语言模型在图领域的应用。 随着大语言模型(Bubeck等人,2023)在NLP领域的成功,一个自然的问题是我们是否可以直接将其原始的以语言为中心的能力应用到图上。 大语言模型的初步探索集中在文本属性图上。 Chen 等人 (2023b);他等人(2023)将节点分类视为目标节点上的文本分类,即使没有任何结构信息,也说明了零样本设置上有希望的结果。 对于没有文本属性的图形,Fatemi 等人 (2023); Wang等人(2023a)通过用自然语言描述图结构将数据输入到大语言模型中。 观察表明,大语言模型在理解基本图结构方面的能力有限。 关键原因是大语言模型需要依次贪婪地解决问题(McCoy 等人, 2023),从而得到捷径解决方案(Saparov & He, 2022; Dziri 等人, 2023)而不是对图结构的正式分析。 此外,Yue等人(2023)指出了利用大语言模型进行推荐(下游链接预测任务)的效率问题。
唐等人 (2023);叶等人 (2023); Chai等人(2023)因此利用GNN对图结构知识进行编码,然后引入线性层将从GNN获得的嵌入转换到文本空间作为提示词符。 虽然这些模型可以表现良好,但它们仍然有两个缺点:(1)处理结构的能力受到 GNN 能力的限制; (2)指令调优成本高昂,而调优后的模型只能处理相应的下游任务,不能转移到其他任务和数据集,这使得它们的能力与 GFM 相去甚远。 我们同意大语言模型展示了文本节点特征理解的优越性能。 尽管如此,目前尚不清楚大语言模型是否应该在构建 GFM 中发挥关键作用,或者只是作为更好的文本特征编码器。
多模态基础模型的成功可以启发大语言模型有效处理图结构的潜在策略(Liu等人,2023c)。 关键思想(Yu等人,2023b)是通过预先训练的标记器将图结构映射到一系列离散标记,该标记器可以将图转换为大语言模型可以理解的格式。 更多讨论可以在附录C中找到。
基于子图的方法的效率问题。 基于子图的提取是一种广泛采用的技术,用于实现归纳推理(Zeng等人,2021)并统一不同的任务公式(Sun等人,2023)。 然而,基于子图的提取会导致以下问题:(1)高阶邻域的信息损失; (2)重复子图信息,内存消耗过多,(3)普通子图提取的时间复杂度随着跳数呈指数增长。 这些问题阻碍了基于子图的方法的适用性。 (Zeng 等人, 2019) 和全局状态向量 (Fey 等人, 2021) 等图采样技术可以帮助缓解这些问题。
前置任务和架构设计的潜在冗余。 实现可迁移性主要有两种方法:(1)设计具有特定几何属性的 GNN 进行迁移,例如 ULTRA (Galkin 等人,2023),以及(2)创建借口任务来自动学习这些属性特性。 (Jin 等人, 2020b) 表明这些方法之间存在重叠,这表明鉴于 GNN 本身通常对本地结构信息进行编码,因此针对局部结构信息的借口任务可能是不必要的。 研究这些技术的优点和局限性,并为其选择提供实用指导,可能是一个有价值的研究方向。 一个假设可能是模型设计方法更适合严格遵守几何先验的数据,而借口任务设计在相反的情况下更有效。
GFM的必要性。 可以根据不同的标准(例如节点对之间的相似性或影响力)以不同的方式定义图(Brugere等人,2018)。 然后,我们可以根据标准的可观察性对图表进行分类。 可观察图是明确已知的,例如,一篇论文是否在引文图中引用了另一篇论文。 文本和图像也可以被视为可观察图表的特定情况。 相比之下,不可观察的任务是通过对关系的模糊描述来手动进行的,例如,一个基因是否在基因调控图中调节另一个基因的表达。 这些图可能并不自然存在于世界中,导致缺乏不变原理的不确定性。 我们不确定 GFM 中是否应考虑此类图表。
此外,人们担心在既不来自同一域也不共享相同下游任务的图上训练 GFM 的好处。 一方面,对他们的训练似乎同时没有显示出正转移的好处,同时增加了负转移的风险。 另一方面,我们并没有意识到潜在的未被发现的可转移性会导致成功。
更多应用上的 GFM。 在本文中,我们主要关注传统的图任务,例如节点分类、链接预测、图分类以及在它们上构建 GFM 的原理。 然而,图表示能力是通用的表示能力,可以很容易地扩展到不同的领域,例如CV的场景图(Zhai等人,2023;Zhong等人,2021),线性规划的二部图(Chen 等人,2022),以及用于理解物理机制的物理图(Shi 等人,2022)。 每个领域都有其需要特定图词汇构建的原则。 现有的成功可以在材料科学中找到(Zhang 等人, 2023a; Batatia 等人, 2023)。 例如,(Batatia等人,2023)利用等变图张量网络可以编码原子几何的多体信息,可以跨不同化学物质进行分子动力学模拟。 GFM 的一个潜在应用是帮助生成场景图(Zhong 等人,2021),涉及预测局部对象之间的关系。 知识图谱基础模型(Galkin等人,2023)可以泛化到看不见的实体和关系,可以有效地对关系进行建模,从而生成高质量的场景图。
6结论
从图的可转移性原则出发,我们回顾了现有的 GFM,并从词汇表的角度分析了它们的有效性,以找到一组跨图和任务的基本可转移单元。 我们的主要观点可以总结如下:(1)构建通用的 GFM 具有挑战性,但是特定领域/任务的 GFM 在通常可用的特定词汇表的情况下是可以实现的。 (2) 一项挑战是遵循神经尺度法则开发 GFM,这需要在数据工程、架构和借口任务中进行原则驱动的设计。 本文总结了当前的立场和下一步面临的挑战,这可能是 GFM 启发相关研究的蓝图。
7影响陈述
在本文中,我们为图基础模型的开发提供了原则指导,该模型可以成为支持自然科学和电子商务等多种应用的关键基础设施。 图基础模型可以减少与训练大量特定任务模型相关的资源消耗。 此外,它可能会大大减少对手动标注的需求,特别是在分子特性预测等领域。 我们预计我们的贡献将推动旨在开发具有更好通用性和公平性的下一代图基础模型的持续努力。
参考
- AbuOda et al. (2020) AbuOda, G., De Francisci Morales, G., and Aboulnaga, A. Link prediction via higher-order motif features. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2019, Würzburg, Germany, September 16–20, 2019, Proceedings, Part I, pp. 412–429. Springer, 2020.
- Adamic & Adar (2003) Adamic, L. A. and Adar, E. Friends and neighbors on the web. Social networks, 25(3):211–230, 2003.
- Airoldi et al. (2008) Airoldi, E. M., Blei, D., Fienberg, S., and Xing, E. Mixed membership stochastic blockmodels. Advances in neural information processing systems, 21, 2008.
- Albert & Barabási (2002) Albert, R. and Barabási, A.-L. Statistical mechanics of complex networks. Reviews of modern physics, 74(1):47, 2002.
- Bai et al. (2023) Bai, Y., Geng, X., Mangalam, K., Bar, A., Yuille, A., Darrell, T., Malik, J., and Efros, A. A. Sequential modeling enables scalable learning for large vision models. arXiv preprint arXiv:2312.00785, 2023.
- Barcelo et al. (2022) Barcelo, P., Galkin, M., Morris, C., and Orth, M. R. Weisfeiler and leman go relational. In Learning on Graphs Conference, pp. 46–1. PMLR, 2022.
- Barceló et al. (2020) Barceló, P., Kostylev, E. V., Monet, M., Pérez, J., Reutter, J., and Silva, J. P. The logical expressiveness of graph neural networks. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=r1lZ7AEKvB.
- Batatia et al. (2023) Batatia, I., Benner, P., Chiang, Y., Elena, A. M., Kovács, D. P., Riebesell, J., Advincula, X. R., Asta, M., Baldwin, W. J., Bernstein, N., Bhowmik, A., Blau, S. M., Cărare, V., Darby, J. P., De, S., Pia, F. D., Deringer, V. L., Elijošius, R., El-Machachi, Z., Fako, E., Ferrari, A. C., Genreith-Schriever, A., George, J., Goodall, R. E. A., Grey, C. P., Han, S., Handley, W., Heenen, H. H., Hermansson, K., Holm, C., Jaafar, J., Hofmann, S., Jakob, K. S., Jung, H., Kapil, V., Kaplan, A. D., Karimitari, N., Kroupa, N., Kullgren, J., Kuner, M. C., Kuryla, D., Liepuoniute, G., Margraf, J. T., Magdău, I.-B., Michaelides, A., Moore, J. H., Naik, A. A., Niblett, S. P., Norwood, S. W., O’Neill, N., Ortner, C., Persson, K. A., Reuter, K., Rosen, A. S., Schaaf, L. L., Schran, C., Sivonxay, E., Stenczel, T. K., Svahn, V., Sutton, C., van der Oord, C., Varga-Umbrich, E., Vegge, T., Vondrák, M., Wang, Y., Witt, W. C., Zills, F., and Csányi, G. A foundation model for atomistic materials chemistry, 2023.
- Battiston et al. (2020) Battiston, F., Cencetti, G., Iacopini, I., Latora, V., Lucas, M., Patania, A., Young, J.-G., and Petri, G. Networks beyond pairwise interactions: Structure and dynamics. Physics Reports, 874:1–92, 2020.
- Beaini et al. (2023) Beaini, D., Huang, S., Cunha, J. A., Moisescu-Pareja, G., Dymov, O., Maddrell-Mander, S., McLean, C., Wenkel, F., Müller, L., Mohamud, J. H., et al. Towards foundational models for molecular learning on large-scale multi-task datasets. arXiv preprint arXiv:2310.04292, 2023.
- Benson et al. (2016) Benson, A. R., Gleich, D. F., and Leskovec, J. Higher-order organization of complex networks. Science, 353(6295):163–166, 2016.
- Bommasani et al. (2021) Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Brugere et al. (2018) Brugere, I., Gallagher, B., and Berger-Wolf, T. Y. Network structure inference, a survey: Motivations, methods, and applications. ACM Computing Surveys (CSUR), 51(2):1–39, 2018.
- Bubeck et al. (2023) Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Cai & Wang (2020) Cai, C. and Wang, Y. A note on over-smoothing for graph neural networks. arXiv preprint arXiv:2006.13318, 2020.
- Cao et al. (2023) Cao, Y., Xu, J., Yang, C., Wang, J., Zhang, Y., Wang, C., Chen, L., and Yang, Y. When to pre-train graph neural networks? an answer from data generation perspective! arXiv preprint arXiv:2303.16458, 2023.
- Chai et al. (2023) Chai, Z., Zhang, T., Wu, L., Han, K., Hu, X., Huang, X., and Yang, Y. Graphllm: Boosting graph reasoning ability of large language model. arXiv preprint arXiv:2310.05845, 2023.
- Chamberlain et al. (2022) Chamberlain, B. P., Shirobokov, S., Rossi, E., Frasca, F., Markovich, T., Hammerla, N., Bronstein, M. M., and Hansmire, M. Graph neural networks for link prediction with subgraph sketching. arXiv preprint arXiv:2209.15486, 2022.
- Chawla & Karakoulas (2005) Chawla, N. V. and Karakoulas, G. Learning from labeled and unlabeled data: An empirical study across techniques and domains. Journal of Artificial Intelligence Research, 23:331–366, 2005.
- Chen et al. (2023a) Chen, D., Zhu, Y., Zhang, J., Du, Y., Li, Z., Liu, Q., Wu, S., and Wang, L. Uncovering neural scaling laws in molecular representation learning. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023a. URL https://openreview.net/forum?id=Ys8RmfF9w1.
- Chen et al. (2022) Chen, Z., Liu, J., Wang, X., and Yin, W. On representing linear programs by graph neural networks. In The Eleventh International Conference on Learning Representations, 2022.
- Chen et al. (2023b) Chen, Z., Mao, H., Li, H., Jin, W., Wen, H., Wei, X., Wang, S., Yin, D., Fan, W., Liu, H., and Tang, J. Exploring the potential of large language models (llms) in learning on graphs. ArXiv, abs/2307.03393, 2023b.
- Chen et al. (2023c) Chen, Z., Mao, H., Wen, H., Han, H., Jin, W., Zhang, H., Liu, H., and Tang, J. Label-free node classification on graphs with large language models (llms). arXiv preprint arXiv:2310.04668, 2023c.
- Chien et al. (2021) Chien, E., Peng, J., Li, P., and Milenkovic, O. Adaptive universal generalized pagerank graph neural network. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=n6jl7fLxrP.
- Dessí et al. (2022) Dessí, D., Osborne, F., Recupero, D. R., Buscaldi, D., and Motta, E. Cs-kg: A large-scale knowledge graph of research entities and claims in computer science. In International Workshop on the Semantic Web, 2022. URL https://api.semanticscholar.org/CorpusID:253021556.
- Di Giovanni et al. (2023) Di Giovanni, F., Rusch, T. K., Bronstein, M. M., Deac, A., Lackenby, M., Mishra, S., and Veličković, P. How does over-squashing affect the power of gnns? arXiv preprint arXiv:2306.03589, 2023.
- Dong et al. (2022) Dong, Q., Li, L., Dai, D., Zheng, C., Wu, Z., Chang, B., Sun, X., Xu, J., and Sui, Z. A survey for in-context learning. arXiv preprint arXiv:2301.00234, 2022.
- Dong et al. (2017) Dong, Y., Johnson, R. A., Xu, J., and Chawla, N. V. Structural diversity and homophily: A study across more than one hundred big networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 807–816, 2017.
- Dziri et al. (2023) Dziri, N., Lu, X., Sclar, M., Li, X. L., Jian, L., Lin, B. Y., West, P., Bhagavatula, C., Bras, R. L., Hwang, J. D., et al. Faith and fate: Limits of transformers on compositionality. arXiv preprint arXiv:2305.18654, 2023.
- Edmonds & Johnson (1973) Edmonds, J. and Johnson, E. L. Matching, euler tours and the chinese postman. Mathematical Programming, 5:88–124, 1973. URL https://api.semanticscholar.org/CorpusID:15249924.
- Fatemi et al. (2023) Fatemi, B., Halcrow, J., and Perozzi, B. Talk like a graph: Encoding graphs for large language models. arXiv preprint arXiv:2310.04560, 2023.
- Fey & Lenssen (2019) Fey, M. and Lenssen, J. E. Fast graph representation learning with pytorch geometric. arXiv preprint arXiv:1903.02428, 2019.
- Fey et al. (2021) Fey, M., Lenssen, J. E., Weichert, F., and Leskovec, J. Gnnautoscale: Scalable and expressive graph neural networks via historical embeddings. In International conference on machine learning, pp. 3294–3304. PMLR, 2021.
- Freitas et al. (2021) Freitas, S., Duggal, R., and Chau, D. H. Malnet: A large-scale image database of malicious software. arXiv preprint arXiv:2102.01072, 2021.
- Galkin et al. (2023) Galkin, M., Yuan, X., Mostafa, H., Tang, J., and Zhu, Z. Towards foundation models for knowledge graph reasoning. arXiv preprint arXiv:2310.04562, 2023.
- Gao et al. (2023) Gao, J., Zhou, Y., Zhou, J., and Ribeiro, B. Double equivariance for inductive link prediction for both new nodes and new relation types. In NeurIPS 2023 Workshop: New Frontiers in Graph Learning, 2023.
- Gupta et al. (2023) Gupta, S., Manchanda, S., Ranu, S., and Bedathur, S. J. Grafenne: learning on graphs with heterogeneous and dynamic feature sets. In International Conference on Machine Learning, pp. 12165–12181. PMLR, 2023.
- Han et al. (2021) Han, X., Zhang, Z., Ding, N., Gu, Y., Liu, X., Huo, Y., Qiu, J., Yao, Y., Zhang, A., Zhang, L., et al. Pre-trained models: Past, present and future. AI Open, 2:225–250, 2021.
- Hassani & Khasahmadi (2020) Hassani, K. and Khasahmadi, A. H. Contrastive multi-view representation learning on graphs. In Proceedings of International Conference on Machine Learning, pp. 3451–3461. 2020.
- He et al. (2023) He, X., Bresson, X., Laurent, T., Perold, A., LeCun, Y., and Hooi, B. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning, 2023.
- Hibshman et al. (2021) Hibshman, J. I., Gonzalez, D., Sikdar, S., and Weninger, T. Joint subgraph-to-subgraph transitions: Generalizing triadic closure for powerful and interpretable graph modeling. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, pp. 815–823, 2021.
- Hou et al. (2022) Hou, Z., Liu, X., Cen, Y., Dong, Y., Yang, H., Wang, C., and Tang, J. Graphmae: Self-supervised masked graph autoencoders. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 594–604, 2022.
- Hu et al. (2019) Hu, W., Liu, B., Gomes, J., Zitnik, M., Liang, P., Pande, V., and Leskovec, J. Strategies for pre-training graph neural networks. arXiv preprint arXiv:1905.12265, 2019.
- Hu et al. (2020) Hu, W., Fey, M., Zitnik, M., Dong, Y., Ren, H., Liu, B., Catasta, M., and Leskovec, J. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020.
- Huang et al. (2015) Huang, H., Tang, J., Liu, L., Luo, J., and Fu, X. Triadic closure pattern analysis and prediction in social networks. IEEE Transactions on Knowledge and Data Engineering, 27(12):3374–3389, 2015.
- Huang et al. (2023a) Huang, Q., Ren, H., Chen, P., Kržmanc, G., Zeng, D., Liang, P., and Leskovec, J. Prodigy: Enabling in-context learning over graphs. arXiv preprint arXiv:2305.12600, 2023a.
- Huang et al. (2023b) Huang, S., Poursafaei, F., Danovitch, J., Fey, M., Hu, W., Rossi, E., Leskovec, J., Bronstein, M., Rabusseau, G., and Rabbany, R. Temporal graph benchmark for machine learning on temporal graphs. arXiv preprint arXiv:2307.01026, 2023b.
- Huang et al. (2023c) Huang, X., Orth, M. R., Ceylan, İ. İ., and Barceló, P. A theory of link prediction via relational weisfeiler-leman. arXiv preprint arXiv:2302.02209, 2023c.
- Huang et al. (2023d) Huang, Y., Lu, W., Robinson, J., Yang, Y., Zhang, M., Jegelka, S., and Li, P. On the stability of expressive positional encodings for graph neural networks. arXiv preprint arXiv:2310.02579, 2023d.
- Jeh & Widom (2002) Jeh, G. and Widom, J. Simrank: a measure of structural-context similarity. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 538–543, 2002.
- Jin et al. (2023a) Jin, B., Liu, G., Han, C., Jiang, M., Ji, H., and Han, J. Large language models on graphs: A comprehensive survey. arXiv preprint arXiv:2312.02783, 2023a.
- Jin et al. (2023b) Jin, B., Zhang, W., Zhang, Y., Meng, Y., Zhang, X., Zhu, Q., and Han, J. Patton: Language model pretraining on text-rich networks. arXiv preprint arXiv:2305.12268, 2023b.
- Jin et al. (2020a) Jin, W., Barzilay, R., and Jaakkola, T. Hierarchical generation of molecular graphs using structural motifs. In International conference on machine learning, pp. 4839–4848. PMLR, 2020a.
- Jin et al. (2020b) Jin, W., Derr, T., Liu, H., Wang, Y., Wang, S., Liu, Z., and Tang, J. Self-supervised learning on graphs: Deep insights and new direction. arXiv preprint arXiv:2006.10141, 2020b.
- Jing et al. (2023) Jing, Y., Yuan, C., Ju, L., Yang, Y., Wang, X., and Tao, D. Deep graph reprogramming. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 24345–24354, 2023.
- Jo et al. (2022) Jo, J., Lee, S., and Hwang, S. J. Score-based generative modeling of graphs via the system of stochastic differential equations. In International Conference on Machine Learning, pp. 10362–10383. PMLR, 2022.
- Ju et al. (2023) Ju, M., Zhao, T., Wen, Q., Yu, W., Shah, N., Ye, Y., and Zhang, C. Multi-task self-supervised graph neural networks enable stronger task generalization. 2023.
- Kaplan et al. (2020) Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Katz (1953) Katz, L. A new status index derived from sociometric analysis. Psychometrika, 18(1):39–43, 1953.
- Khanam et al. (2020) Khanam, K. Z., Srivastava, G., and Mago, V. The homophily principle in social network analysis. arXiv preprint arXiv:2008.10383, 2020.
- Kim et al. (2022) Kim, J., Nguyen, T. D., Min, S., Cho, S., Lee, M., Lee, H., and Hong, S. Pure transformers are powerful graph learners. arXiv, abs/2207.02505, 2022. URL https://arxiv.org/abs/2207.02505.
- Kipf & Welling (2016) Kipf, T. N. and Welling, M. Variational graph auto-encoders. arXiv preprint arXiv:1611.07308, 2016.
- Kreuzer et al. (2021) Kreuzer, D., Beaini, D., Hamilton, W., Létourneau, V., and Tossou, P. Rethinking graph transformers with spectral attention. Advances in Neural Information Processing Systems, 34:21618–21629, 2021.
- Kriege et al. (2020) Kriege, N. M., Johansson, F. D., and Morris, C. A survey on graph kernels. Applied Network Science, 5(1):1–42, 2020.
- Leskovec & Krevl (2014) Leskovec, J. and Krevl, A. SNAP Datasets: Stanford large network dataset collection. http://snap.stanford.edu/data, June 2014.
- Leskovec et al. (2010) Leskovec, J., Chakrabarti, D., Kleinberg, J., Faloutsos, C., and Ghahramani, Z. Kronecker graphs: an approach to modeling networks. Journal of Machine Learning Research, 11(2), 2010.
- Li et al. (2022) Li, J., Shomer, H., Ding, J., Wang, Y., Ma, Y., Shah, N., Tang, J., and Yin, D. Are graph neural networks really helpful for knowledge graph completion? arXiv preprint arXiv:2205.10652, 2022.
- Li et al. (2023a) Li, J., Shomer, H., Mao, H., Zeng, S., Ma, Y., Shah, N., Tang, J., and Yin, D. Evaluating graph neural networks for link prediction: Current pitfalls and new benchmarking. arXiv preprint arXiv:2306.10453, 2023a.
- Li et al. (2023b) Li, Y., Li, Z., Wang, P., Li, J., Sun, X., Cheng, H., and Yu, J. X. A survey of graph meets large language model: Progress and future directions. arXiv preprint arXiv:2311.12399, 2023b.
- Li et al. (2023c) Li, Y., Xiong, M., and Hooi, B. Graphcleaner: Detecting mislabelled samples in popular graph learning benchmarks. arXiv preprint arXiv:2306.00015, 2023c.
- Lim et al. (2021) Lim, D., Hohne, F., Li, X., Huang, S. L., Gupta, V., Bhalerao, O., and Lim, S. N. Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods. Advances in Neural Information Processing Systems, 34:20887–20902, 2021.
- Lim et al. (2022) Lim, D., Robinson, J. D., Zhao, L., Smidt, T., Sra, S., Maron, H., and Jegelka, S. Sign and basis invariant networks for spectral graph representation learning. In The Eleventh International Conference on Learning Representations, 2022.
- Liu et al. (2023a) Liu, G., Inae, E., Zhao, T., Xu, J., Luo, T., and Jiang, M. Data-centric learning from unlabeled graphs with diffusion model. arXiv preprint arXiv:2303.10108, 2023a.
- Liu et al. (2023b) Liu, H., Feng, J., Kong, L., Liang, N., Tao, D., Chen, Y., and Zhang, M. One for all: Towards training one graph model for all classification tasks. arXiv preprint arXiv:2310.00149, 2023b.
- Liu et al. (2023c) Liu, H., Li, C., Wu, Q., and Lee, Y. J. Visual instruction tuning. In NeurIPS, 2023c.
- Liu et al. (2023d) Liu, H., Liao, N., and Luo, S. Simga: A simple and effective heterophilous graph neural network with efficient global aggregation. arXiv preprint arXiv:2305.09958, 2023d.
- Liu et al. (2023e) Liu, J., Yang, C., Lu, Z., Chen, J., Li, Y., Zhang, M., Bai, T., Fang, Y., Sun, L., Yu, P. S., et al. Towards graph foundation models: A survey and beyond. arXiv preprint arXiv:2310.11829, 2023e.
- Liu et al. (2024) Liu, J., Mao, H., Chen, Z., Zhao, T., Shah, N., and Tang, J. Neural scaling laws on graphs. 2024.
- Liu et al. (2022) Liu, N., Wang, X., Bo, D., Shi, C., and Pei, J. Revisiting graph contrastive learning from the perspective of graph spectrum. Advances in Neural Information Processing Systems, 35:2972–2983, 2022.
- Liu et al. (2023f) Liu, Z., Shi, Y., Zhang, A., Zhang, E., Kawaguchi, K., Wang, X., and Chua, T.-S. Rethinking tokenizer and decoder in masked graph modeling for molecules. In NeurIPS, 2023f. URL https://openreview.net/forum?id=fWLf8DV0fI.
- Liu et al. (2023g) Liu, Z., Yu, X., Fang, Y., and Zhang, X. Graphprompt: Unifying pre-training and downstream tasks for graph neural networks. In Proceedings of the ACM Web Conference 2023, pp. 417–428, 2023g.
- Lu et al. (2023) Lu, S., Gao, Z., He, D., Zhang, L., and Ke, G. Highly accurate quantum chemical property prediction with uni-mol+. arXiv preprint arXiv:2303.16982, 2023.
- Luan et al. (2021) Luan, S., Hua, C., Lu, Q., Zhu, J., Zhao, M., Zhang, S., Chang, X.-W., and Precup, D. Is heterophily a real nightmare for graph neural networks to do node classification? arXiv preprint arXiv:2109.05641, 2021.
- Luan et al. (2023) Luan, S., Hua, C., Xu, M., Lu, Q., Zhu, J., Chang, X.-W., Fu, J., Leskovec, J., and Precup, D. When do graph neural networks help with node classification: Investigating the homophily principle on node distinguishability. arXiv preprint arXiv:2304.14274, 2023.
- Luo et al. (2021) Luo, Y., Yan, K., and Ji, S. Graphdf: A discrete flow model for molecular graph generation. In International Conference on Machine Learning, pp. 7192–7203. PMLR, 2021.
- Ma et al. (2021) Ma, Y., Liu, X., Shah, N., and Tang, J. Is homophily a necessity for graph neural networks? arXiv preprint arXiv:2106.06134, 2021.
- Mao et al. (2023a) Mao, H., Chen, Z., Jin, W., Han, H., Ma, Y., Zhao, T., Shah, N., and Tang, J. Demystifying structural disparity in graph neural networks: Can one size fit all? arXiv preprint arXiv:2306.01323, 2023a.
- Mao et al. (2023b) Mao, H., Li, J., Shomer, H., Li, B., Fan, W., Ma, Y., Zhao, T., Shah, N., and Tang, J. Revisiting link prediction: A data perspective. arXiv preprint arXiv:2310.00793, 2023b.
- Masters et al. (2022) Masters, D., Dean, J., Klaser, K., Li, Z., Maddrell-Mander, S., Sanders, A., Helal, H., Beker, D., Rampášek, L., and Beaini, D. Gps++: An optimised hybrid mpnn/transformer for molecular property prediction. arXiv preprint arXiv:2212.02229, 2022.
- McCoy et al. (2023) McCoy, R. T., Yao, S., Friedman, D., Hardy, M., and Griffiths, T. L. Embers of autoregression: Understanding large language models through the problem they are trained to solve. arXiv preprint arXiv:2309.13638, 2023.
- Menczer et al. (2020) Menczer, F., Fortunato, S., and Davis, C. A. A First Course in Network Science. Cambridge University Press, 2020.
- Milo et al. (2002) Milo, R., Shen-Orr, S., Itzkovitz, S., Kashtan, N., Chklovskii, D., and Alon, U. Network motifs: simple building blocks of complex networks. Science, 298(5594):824–827, 2002.
- Mishra et al. (2022) Mishra, S., Panda, R., Phoo, C. P., Chen, C.-F. R., Karlinsky, L., Saenko, K., Saligrama, V., and Feris, R. S. Task2sim: Towards effective pre-training and transfer from synthetic data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9194–9204, 2022.
- Morris et al. (2019) Morris, C., Ritzert, M., Fey, M., Hamilton, W. L., Lenssen, J. E., Rattan, G., and Grohe, M. Weisfeiler and leman go neural: Higher-order graph neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pp. 4602–4609, 2019.
- Morris et al. (2020) Morris, C., Kriege, N. M., Bause, F., Kersting, K., Mutzel, P., and Neumann, M. Tudataset: A collection of benchmark datasets for learning with graphs. In ICML 2020 Workshop on Graph Representation Learning and Beyond (GRL+ 2020), 2020. URL www.graphlearning.io.
- Morris et al. (2023) Morris, C., Lipman, Y., Maron, H., Rieck, B., Kriege, N. M., Grohe, M., Fey, M., and Borgwardt, K. Weisfeiler and leman go machine learning: The story so far. Journal of Machine Learning Research, 24(333):1–59, 2023. URL http://jmlr.org/papers/v24/22-0240.html.
- Müller et al. (2023) Müller, L., Galkin, M., Morris, C., and Rampášek, L. Attending to graph transformers. arXiv preprint arXiv:2302.04181, 2023.
- Murase et al. (2019) Murase, Y., Jo, H. H., Török, J., Kertész, J., Kaski, K., et al. Structural transition in social networks. 2019.
- Oono & Suzuki (2019) Oono, K. and Suzuki, T. Graph neural networks exponentially lose expressive power for node classification. In International Conference on Learning Representations, 2019.
- (100) Project, U. C. R. Recommender systems and personalization datasets. URL https://cseweb.ucsd.edu/~jmcauley/datasets.html.
- Radford et al. (2021) Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp. 8748–8763. PMLR, 2021.
- Raffel et al. (2019) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv e-prints, 2019.
- Ramsundar et al. (2019) Ramsundar, B., Eastman, P., Walters, P., Pande, V., Leswing, K., and Wu, Z. Deep Learning for the Life Sciences. O’Reilly Media, 2019. https://www.amazon.com/Deep-Learning-Life-Sciences-Microscopy/dp/1492039837.
- Robins et al. (2007) Robins, G., Pattison, P., Kalish, Y., and Lusher, D. An introduction to exponential random graph (p*) models for social networks. Social networks, 29(2):173–191, 2007.
- Rossi & Ahmed (2015) Rossi, R. A. and Ahmed, N. K. The network data repository with interactive graph analytics and visualization. In AAAI, 2015. URL http://networkrepository.com.
- Ruiz et al. (2023) Ruiz, L., Chamon, L. F. O., and Ribeiro, A. Transferability properties of graph neural networks. IEEE Transactions on Signal Processing, 71:3474–3489, 2023. doi: 10.1109/TSP.2023.3297848.
- Saparov & He (2022) Saparov, A. and He, H. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. arXiv preprint arXiv:2210.01240, 2022.
- Schlichtkrull et al. (2018) Schlichtkrull, M., Kipf, T. N., Bloem, P., Van Den Berg, R., Titov, I., and Welling, M. Modeling relational data with graph convolutional networks. In The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, Proceedings 15, pp. 593–607. Springer, 2018.
- Shi et al. (2022) Shi, H., Ding, J., Cao, Y., Liu, L., Li, Y., et al. Learning symbolic models for graph-structured physical mechanism. In The Eleventh International Conference on Learning Representations, 2022.
- Shoghi et al. (2023) Shoghi, N., Kolluru, A., Kitchin, J. R., Ulissi, Z. W., Zitnick, C. L., and Wood, B. M. From molecules to materials: Pre-training large generalizable models for atomic property prediction, 2023.
- Srinivasan & Ribeiro (2019) Srinivasan, B. and Ribeiro, B. On the equivalence between positional node embeddings and structural graph representations. arXiv preprint arXiv:1910.00452, 2019.
- Sun et al. (2019) Sun, F.-Y., Hoffmann, J., Verma, V., and Tang, J. Infograph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization. arXiv preprint arXiv:1908.01000, 2019.
- Sun et al. (2022) Sun, M., Zhou, K., He, X., Wang, Y., and Wang, X. Gppt: Graph pre-training and prompt tuning to generalize graph neural networks. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’22, pp. 1717–1727, New York, NY, USA, 2022. Association for Computing Machinery. ISBN 9781450393850. doi: 10.1145/3534678.3539249. URL https://doi.org/10.1145/3534678.3539249.
- Sun et al. (2023) Sun, X., Cheng, H., Li, J., Liu, B., and Guan, J. All in one: Multi-task prompting for graph neural networks. 2023.
- Taguchi et al. (2021) Taguchi, H., Liu, X., and Murata, T. Graph convolutional networks for graphs containing missing features. Future Generation Computer Systems, 117:155–168, 2021.
- Tang (2016) Tang, J. Aminer: Toward understanding big scholar data. In Proceedings of the Ninth ACM International Conference on Web Search and Data Mining, WSDM ’16, pp. 467, New York, NY, USA, 2016. Association for Computing Machinery. ISBN 9781450337168. doi: 10.1145/2835776.2835849. URL https://doi.org/10.1145/2835776.2835849.
- Tang et al. (2023) Tang, J., Yang, Y., Wei, W., Shi, L., Su, L., Cheng, S., Yin, D., and Huang, C. Graphgpt: Graph instruction tuning for large language models. arXiv preprint arXiv:2310.13023, 2023.
- Topping et al. (2021) Topping, J., Di Giovanni, F., Chamberlain, B. P., Dong, X., and Bronstein, M. M. Understanding over-squashing and bottlenecks on graphs via curvature. In International Conference on Learning Representations, 2021.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Trinh et al. (2024) Trinh, T. H., Wu, Y., Le, Q. V., He, H., and Luong, T. Solving olympiad geometry without human demonstrations. Nature, 625(7995):476–482, 2024.
- Um et al. (2023) Um, D., Park, J., Park, S., and young Choi, J. Confidence-based feature imputation for graphs with partially known features. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=YPKBIILy-Kt.
- Vashishth et al. (2019) Vashishth, S., Sanyal, S., Nitin, V., and Talukdar, P. Composition-based multi-relational graph convolutional networks. In International Conference on Learning Representations, 2019.
- Veličković et al. (2017) Veličković, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., and Bengio, Y. Graph attention networks. arXiv preprint arXiv:1710.10903, 2017.
- Veličković et al. (2018) Veličković, P., Fedus, W., Hamilton, W. L., Liò, P., Bengio, Y., and Hjelm, R. D. Deep graph infomax. arXiv preprint arXiv:1809.10341, 2018.
- Vignac et al. (2023) Vignac, C., Krawczuk, I., Siraudin, A., Wang, B., Cevher, V., and Frossard, P. Digress: Discrete denoising diffusion for graph generation. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=UaAD-Nu86WX.
- Vishwanathan et al. (2010) Vishwanathan, S. V. N., Schraudolph, N. N., Kondor, R., and Borgwardt, K. M. Graph kernels. Journal of Machine Learning Research, 11:1201–1242, 2010.
- Wang et al. (2021) Wang, H., Yin, H., Zhang, M., and Li, P. Equivariant and stable positional encoding for more powerful graph neural networks. In International Conference on Learning Representations, 2021.
- Wang et al. (2023a) Wang, H., Feng, S., He, T., Tan, Z., Han, X., and Tsvetkov, Y. Can language models solve graph problems in natural language? In Thirty-seventh Conference on Neural Information Processing Systems, 2023a. URL https://openreview.net/forum?id=UDqHhbqYJV.
- Wang et al. (2024) Wang, J., Guo, Y., Yang, L., and Wang, Y. Understanding heterophily for graph neural networks. arXiv preprint arXiv:2401.09125, 2024.
- Wang et al. (2023b) Wang, X., Yang, H., and Zhang, M. Neural common neighbor with completion for link prediction. arXiv preprint arXiv:2302.00890, 2023b.
- Wu et al. (2022) Wu, Q., Zhao, W., Li, Z., Wipf, D. P., and Yan, J. Nodeformer: A scalable graph structure learning transformer for node classification. Advances in Neural Information Processing Systems, 35:27387–27401, 2022.
- Wu et al. (2023) Wu, X., Ajorlou, A., Wu, Z., and Jadbabaie, A. Demystifying oversmoothing in attention-based graph neural networks. arXiv preprint arXiv:2305.16102, 2023.
- Xia et al. (2023) Xia, J., Zhao, C., Hu, B., Gao, Z., Tan, C., Liu, Y., Li, S., and Li, S. Z. Mole-BERT: Rethinking pre-training graph neural networks for molecules. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=jevY-DtiZTR.
- Xie et al. (2023) Xie, H., Zheng, D., Ma, J., Zhang, H., Ioannidis, V. N., Song, X., Ping, Q., Wang, S., Yang, C., Xu, Y., et al. Graph-aware language model pre-training on a large graph corpus can help multiple graph applications. arXiv preprint arXiv:2306.02592, 2023.
- Xu et al. (2023) Xu, J., Huang, R., Jiang, X., Cao, Y., Yang, C., Wang, C., and Yang, Y. Better with less: A data-active perspective on pre-training graph neural networks. arXiv preprint arXiv:2311.01038, 2023.
- Xu et al. (2019) Xu, K., Hu, W., Leskovec, J., and Jegelka, S. How powerful are graph neural networks? In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=ryGs6iA5Km.
- Yang et al. (2021) Yang, Y., Liu, T., Wang, Y., Zhou, J., Gan, Q., Wei, Z., Zhang, Z., Huang, Z., and Wipf, D. Graph neural networks inspired by classical iterative algorithms. In International Conference on Machine Learning, pp. 11773–11783. PMLR, 2021.
- Yasunaga et al. (2022a) Yasunaga, M., Bosselut, A., Ren, H., Zhang, X., Manning, C. D., Liang, P., and Leskovec, J. Deep bidirectional language-knowledge graph pretraining. In Neural Information Processing Systems (NeurIPS), 2022a.
- Yasunaga et al. (2022b) Yasunaga, M., Leskovec, J., and Liang, P. Linkbert: Pretraining language models with document links. arXiv preprint arXiv:2203.15827, 2022b.
- Ye et al. (2022) Ye, H., Zhang, N., Chen, H., and Chen, H. Generative knowledge graph construction: A review. arXiv preprint arXiv:2210.12714, 2022.
- Ye et al. (2023) Ye, R., Zhang, C., Wang, R., Xu, S., and Zhang, Y. Natural language is all a graph needs. arXiv:2308.07134, 2023.
- Ying et al. (2018) Ying, R., He, R., Chen, K., Eksombatchai, P., Hamilton, W. L., and Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pp. 974–983, 2018.
- You et al. (2020) You, Y., Chen, T., Sui, Y., Chen, T., Wang, Z., and Shen, Y. Graph contrastive learning with augmentations. Advances in neural information processing systems, 33:5812–5823, 2020.
- You et al. (2023) You, Y., Chen, T., Wang, Z., and Shen, Y. Graph domain adaptation via theory-grounded spectral regularization. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=OysfLgrk8mk.
- Yu et al. (2023a) Yu, L., Lezama, J., Gundavarapu, N. B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Gupta, A., Gu, X., Hauptmann, A. G., et al. Language model beats diffusion–tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737, 2023a.
- Yu et al. (2023b) Yu, L., Lezama, J., Gundavarapu, N. B., Versari, L., Sohn, K., Minnen, D., Cheng, Y., Gupta, A., Gu, X., Hauptmann, A. G., et al. Language model beats diffusion–tokenizer is key to visual generation. arXiv preprint arXiv:2310.05737, 2023b.
- Yue et al. (2023) Yue, Z., Rabhi, S., Moreira, G. d. S. P., Wang, D., and Oldridge, E. Llamarec: Two-stage recommendation using large language models for ranking. arXiv preprint arXiv:2311.02089, 2023.
- Zeng et al. (2019) Zeng, H., Zhou, H., Srivastava, A., Kannan, R., and Prasanna, V. Graphsaint: Graph sampling based inductive learning method. arXiv preprint arXiv:1907.04931, 2019.
- Zeng et al. (2021) Zeng, H., Zhang, M., Xia, Y., Srivastava, A., Malevich, A., Kannan, R., Prasanna, V., Jin, L., and Chen, R. Decoupling the depth and scope of graph neural networks. In Beygelzimer, A., Dauphin, Y., Liang, P., and Vaughan, J. W. (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=d0MtHWY0NZ.
- Zhai et al. (2023) Zhai, G., Örnek, E. P., Wu, S.-C., Di, Y., Tombari, F., Navab, N., and Busam, B. Commonscenes: Generating commonsense 3d indoor scenes with scene graphs. arXiv preprint arXiv:2305.16283, 2023.
- Zhang et al. (2024) Zhang, B., Gai, J., Du, Y., Ye, Q., He, D., and Wang, L. Beyond weisfeiler-lehman: A quantitative framework for gnn expressiveness. arXiv preprint arXiv:2401.08514, 2024.
- Zhang et al. (2023a) Zhang, D., Liu, X., Zhang, X., Zhang, C., Cai, C., Bi, H., Du, Y., Qin, X., Huang, J., Li, B., Shan, Y., Zeng, J., Zhang, Y., Liu, S., Li, Y., Chang, J., Wang, X., Zhou, S., Liu, J., Luo, X., Wang, Z., Jiang, W., Wu, J., Yang, Y., Yang, J., Yang, M., Gong, F.-Q., Zhang, L., Shi, M., Dai, F.-Z., York, D. M., Liu, S., Zhu, T., Zhong, Z., Lv, J., Cheng, J., Jia, W., Chen, M., Ke, G., E, W., Zhang, L., and Wang, H. Dpa-2: Towards a universal large atomic model for molecular and material simulation. arXiv preprint arXiv:2312.15492, 2023a.
- Zhang et al. (2023b) Zhang, F., Liu, X., Tang, J., Dong, Y., Yao, P., Zhang, J., Gu, X., Wang, Y., Kharlamov, E., Shao, B., Li, R., and Wang, K. Oag: Linking entities across large-scale heterogeneous knowledge graphs. IEEE Transactions on Knowledge and Data Engineering, 35(9):9225–9239, 2023b. doi: 10.1109/TKDE.2022.3222168.
- Zhang & Chen (2018) Zhang, M. and Chen, Y. Link prediction based on graph neural networks. Advances in neural information processing systems, 31, 2018.
- Zhang et al. (2021) Zhang, M., Li, P., Xia, Y., Wang, K., and Jin, L. Labeling trick: A theory of using graph neural networks for multi-node representation learning. Advances in Neural Information Processing Systems, 34:9061–9073, 2021.
- Zhang et al. (2023c) Zhang, Z., Li, H., Zhang, Z., Qin, Y., Wang, X., and Zhu, W. Graph meets llms: Towards large graph models. In NeurIPS 2023 Workshop: New Frontiers in Graph Learning, 2023c.
- Zhang et al. (2023d) Zhang, Z., Luo, B., Lu, S., and He, B. Live graph lab: Towards open, dynamic and real transaction graphs with nft. arXiv preprint arXiv:2310.11709, 2023d.
- Zhao et al. (2023a) Zhao, H., Liu, S., Ma, C., Xu, H., Fu, J., Deng, Z.-H., Kong, L., and Liu, Q. Gimlet: A unified graph-text model for instruction-based molecule zero-shot learning. bioRxiv, pp. 2023–05, 2023a.
- Zhao et al. (2023b) Zhao, J., Zhuo, L., Shen, Y., Qu, M., Liu, K., Bronstein, M., Zhu, Z., and Tang, J. Graphtext: Graph reasoning in text space. arXiv preprint arXiv:2310.01089, 2023b.
- Zhao et al. (2023c) Zhao, Q., Ren, W., Li, T., Xu, X., and Liu, H. Graphgpt: Graph learning with generative pre-trained transformers. arXiv preprint arXiv:2401.00529, 2023c.
- Zheng et al. (2023a) Zheng, S., He, J., Liu, C., Shi, Y., Lu, Z., Feng, W., Ju, F., Wang, J., Zhu, J., Min, Y., Zhang, H., Tang, S., Hao, H., Jin, P., Chen, C., Noé, F., Liu, H., and Liu, T.-Y. Towards predicting equilibrium distributions for molecular systems with deep learning. arXiv preprint arXiv:2306.05445, 2023a.
- Zheng et al. (2023b) Zheng, W., Huang, E. W., Rao, N., Wang, Z., and Subbian, K. You only transfer what you share: Intersection-induced graph transfer learning for link prediction. arXiv preprint arXiv:2302.14189, 2023b.
- Zhong et al. (2021) Zhong, Y., Shi, J., Yang, J., Xu, C., and Li, Y. Learning to generate scene graph from natural language supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1823–1834, 2021.
- Zhu et al. (2021a) Zhu, Y., Xu, Y., Liu, Q., and Wu, S. An empirical study of graph contrastive learning. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021a.
- Zhu et al. (2021b) Zhu, Z., Zhang, Z., Xhonneux, L.-P., and Tang, J. Neural bellman-ford networks: A general graph neural network framework for link prediction. Advances in Neural Information Processing Systems, 34:29476–29490, 2021b.
附录A支持大规模预训练的数据集集合
在本节中,我们展示了来自各个领域的大规模图数据集的集合,以支持预训练大规模图基础模型。
| Name | URL | Description |
|---|---|---|
| TU-Dataset (Morris et al., 2020) | https://chrsmrrs.github.io/datasets/ | A collection of graph-level prediction datasets |
| NetworkRepository (Rossi & Ahmed, 2015) | https://networkrepository.com/ | The largest graph datasets, with graphs coming from 30+ different domains |
| Open Graph Benchmark (Hu et al., 2020) | https://ogb.stanford.edu/ | Contains a bunch of large-scale graph benchmarks |
| Pyg (Fey & Lenssen, 2019) | https://pytorch-geometric.readthedocs.io | Official datasets provided by PYG, containing popular datasets for benchmark |
| SNAP (Leskovec & Krevl, 2014) | https://snap.stanford.edu/data/ | Mainly focus on social network |
| Aminer (Tang, 2016) | https://www.aminer.cn/data/ | A collection of academic graphs |
| OAG (Zhang et al., 2023b) | https://www.aminer.cn/open-academic-graph | A large-scale academic graph |
| MalNet (Freitas et al., 2021) | https://www.mal-net.org/#home | A large-scale function calling graph for malware detection |
| ScholKG (Dessí et al., 2022) | https://scholkg.kmi.open.ac.uk/ | A large-scale scholarly knowledge graph |
| Graphium (Beaini et al., 2023) | https://github.com/datamol-io/graphium | A massive dataset for molecular property prediction |
| Live Graph Lab (Zhang et al., 2023d) | https://livegraphlab.github.io/ | A large-scale temporal graph for NFT transactions |
| Temporal Graph Benchmark (Huang et al., 2023b) | https://docs.tgb.complexdatalab.com/ | A large-scale benchmark for temporal graph learning |
| MoleculeNet (Ramsundar et al., 2019) | https://moleculenet.org/ | A benchmark for molecular machine learning |
| Recsys data (Project, ) | https://cseweb.ucsd.edu/~jmcauley/datasets.html | A collection of datasets for recommender systems |
| LINKX (Lim et al., 2021) | https://github.com/CUAI/Non-Homophily-Large-Scale | A collection of large-scale non-homophilous graphs |
附录 B 现有 GFM
在本节中,我们将演示现有的代表性 GFM,并将其分类为原型 GFM、特定领域 GFM 和特定任务 GFM,如图所示在表2中。
| Name | Domain | Task | |||||
| Prototype GFM | PRODIGY (Huang et al., 2023a) |
|
|
||||
| OneForAll (Liu et al., 2023b) |
|
|
|||||
| GraphText (Zhao et al., 2023b) | General graph | Node classification | |||||
| Domain-specific GFM | DIG (Zheng et al., 2023a) | Molecule |
|
||||
| MACE-MP-0 (Batatia et al., 2023) | Material Science |
|
|||||
| JMP-1 (Shoghi et al., 2023) | Material Science | Atomic property prediction | |||||
| DPA-2 (Zhang et al., 2023a) | Material Science | Molecular simulation | |||||
| MoleBERT (Xia et al., 2023) | Molecule | Molecule property prediction | |||||
|
ULTRA (Galkin et al., 2023) | Knowledge graph | Knowledge graph reasoning |
附录C关于大语言模型应用于图的更全面的讨论
在这篇立场文件中,我们主要讨论如何构建以图为中心的基础模型。 很多人也将图基础模型理解为图与其他基础模型的结合(金等人,2023a;李等人,2023b;刘等人,2023e)。 在这一部分中,我们将介绍这些代表性作品。 具体来说,当前图模型和基础模型的集成遵循两个主要途径。 第一个涉及使用图表来增强其他基础模型的功能。 第二个采用基础模型来解决图机器学习中遇到的挑战。
第一类工作侧重于通过图来增强基础模型的能力。 Yasunaga 等人 (2022a, b); Jin 等人 (2023b); Xie 等人 (2023) 通过结构感知借口任务进一步在文本属性图上预训练大语言模型。 例如,Yasunaga 等人 (2022b) 训练一个大语言模型来预测屏蔽边缘,其形式化为两个端节点属性的配对分类。 结构感知训练可以有效增强语言模型在需要结构推理的任务(例如多跳推理)上的能力。 这些作品仍然将图视为提供辅助信息的二等公民,并更加强调以文本为中心的任务,例如问答(Yasunaga等人,2022a,b)。 唐等人 (2023);叶等人 (2023); Chai 等人 (2023) 通过指令调优提高了大语言模型处理图形相关问题的能力。 他们采用线性映射将 GNN 生成的嵌入作为提示词符注入,然后根据下游任务调整大语言模型。 这些工作的一个显着缺点在于,调整后的模型在引入计算开销的同时不具备 GNN 之外的功能。
第二条工作采用大语言模型的能力来解决图领域的挑战。 Chen 等人 (2023b); He等人(2023)采用大语言模型作为编码器来增强节点属性并增强GNN在节点分类上的性能。 Chen 等人(2023c)旨在解决节点分类中的冷启动问题,并表明利用大语言模型主动注释节点可以显着提高GNN的零样本推理能力。 Zhao 等人 (2023a) 通过指令调整统一分子的图形和文本表示,从而在属性预测方面实现有希望的零样本性能。
然后我们对大语言模型上图的积极潜力进行了更全面的讨论。 正如2.1节所讨论的,通过自然语言描述直接将大语言模型应用于图学习并不理想。 主要问题是大语言模型倾向于以连续贪婪的心态来处理问题(McCoy等人,2023),这常常导致肤浅的“捷径”解决方案(Saparov&He, 2022; Dziri 等人, 2023) 而不是深入的结构分析。 因此,采用大语言模型作为 GFM 的主要挑战是使它们能够有效地理解图结构。 一种有希望的解决方案涉及大语言模型可以处理的结构化格式化提示。 例如,GraphText (Zhao 等人, 2023b) 引入了一种基于树的提示格式,可以允许大语言模型在保留结构语义的同时执行图形推理。 大语言模型作为GFM仍然具有积极的潜力。