自动驾驶混合预测综合规划
摘要
自动驾驶系统需要能够充分理解和预测周围环境,以便在复杂场景下做出明智的决策。 基于学习的系统的最新进展凸显了集成预测和规划模块的重要性。 然而,这种整合带来了三大挑战:单一预测固有的权衡、预测模式之间的一致性以及预测和规划的社会一致性。 为了应对这些挑战,我们引入了混合预测综合规划(HPP)系统,该系统拥有三个新颖设计的模块。 首先,我们引入边际条件占用预测,以使联合占用与智能体感知保持一致。 我们提出的 MS-OccFormer 模块实现了每个占用预测的多阶段对齐,并具有智能体运动预测的一致意识。 其次,我们提出了一种博弈论运动预测器 GTFormer,通过联合预测意识来模拟个体代理之间的交互未来。 第三,混合预测模式同时与 Ego Planner 集成,并通过预测指导进行优化。 HPP 在 nuScenes 数据集上实现了最先进的性能,展示了预测和规划中端到端范例的卓越准确性和一致性。 此外,我们在 Waymo 开放运动数据集和 CARLA 基准上测试了 HPP 的长期开环和闭环性能,以增强的准确性和兼容性超越了其他集成预测和规划管道。 项目网站:https://georeliu233.github.io/HPP
索引术语:
占用预测、运动预测、综合预测与规划、自动驾驶。我简介
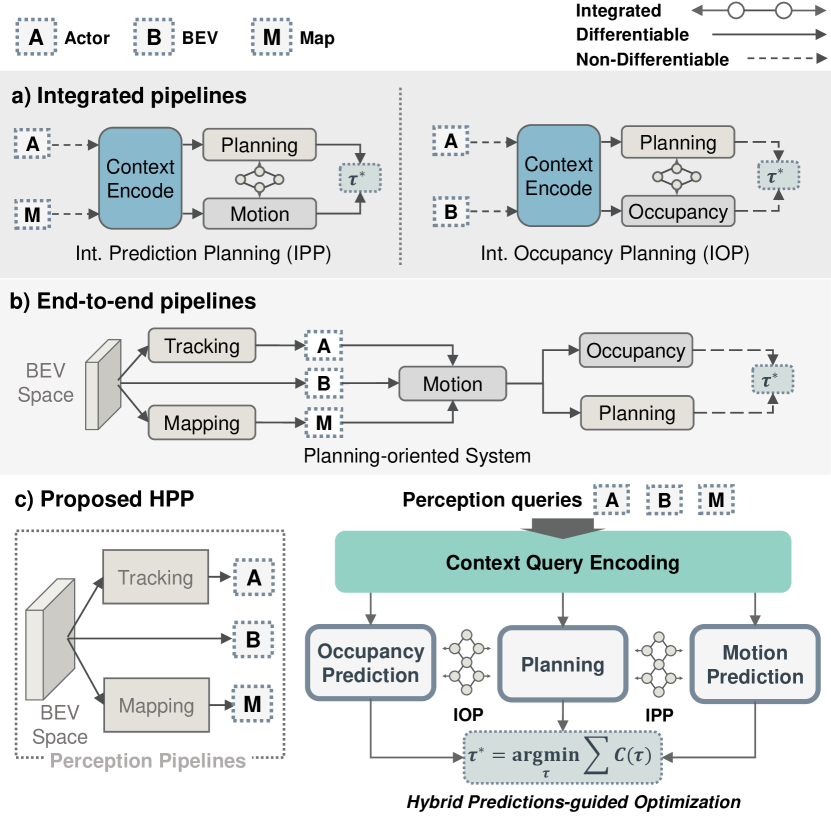
得益于学习范式的进步[1],自动驾驶系统(ADS)在感知、预测和规划方面取得了重大进展。 然而,这些独立任务的性能增长已经停止,促使人们重新考虑模块化设计优化[2,3,4,5]。 在自动驾驶车辆和交通参与者之间固有的相互作用的推动下,最近的研究非常重视预测和规划任务的集成[6]。 他们寻求在预测和规划方面同时取得进步。
集成管道(图1a)通常连接规划和奇异预测模块,涉及智能体运动轨迹(IPP)[3,7,8]或全场景占用概率(IOP)[9,10,11]。 然而,依靠单一的预测格式不可避免地会面临各自的不足。 具体来说,运动预测对每个智能体跟踪的连续时间轨迹进行建模,但在边缘智能体[12]的联合社交模式中遇到不一致和指数成本。 相反,独占占用可以准确预测鸟瞰(BEV)感知下整个场景智能体的对齐关节模式,但智能体可处理性的损失会导致关键智能体的时间冲突和遗漏风险[13] 。 这一特性凸显了运动和占用预测的互补性。 单一预测模式中出现的不一致给 IPP 和 IOP 带来了挑战,导致共同学习的规划不兼容以及预测不一致。
集成系统的局限性促使人们重新关注端到端管道(图1b)[14]。 面向规划的系统采用组织良好的模块化设计,在统一的 BEV 几何结构和基于查询的中间交互[2,5,15]下解决规划指导问题。 虽然这种方法证明了规划的优越性并考虑了预测和规划的混合格式,但它在解决不同预测之间的潜在冲突方面存在不足。 此外,预测和规划之间缺乏交互式协同设计会导致被动操作,并阻碍系统学习以实现社会兼容性。 不同模块的集成带来了三大挑战:固有的权衡,包括单独预测的不一致和遗漏风险;预测中的联合模式和边缘模式之间的差异,限制了准确性并阻碍了安全和自然驾驶操作的学习;考虑到混合预测的依赖性,缺乏兼容规划的交互式协同设计。
为了解决上述挑战,我们提出了一种新颖的集成管道(图1c),名为Hybrid-Prediction Integrated P lanning (HPP),在协同设计过程中优化预测和规划。 通过将 IPP 和 IOP 相结合,HPP 提供一致的规划,同时确保混合预测一致地相互告知。 为了实现这一目标,HPP 利用基于 Transformer 的查询来引导和聚合模块之间的交互。 此外,我们还开发了一个细化流程,指导安全规划与混合预测的交互。 具体来说,我们建议 MS-OccFormer 执行边缘条件联合占用预测,与边缘运动预测一致地进行对齐和细化。 我们利用 GTFormer,它的灵感来自模拟自我车辆和联合占用的边缘运动预测的博弈论迭代推理。 HPP 同时对 Ego Planner 中集成混合预测模式的细粒度交互进行建模,我们最终设计出一种混合预测引导的细化机制,以促进安全且兼容的规划。 主要贡献如下:
-
1.
我们提出 HPP,一种模块化协同设计优化 ADS 范例,它在边际预测模式和联合预测模式与规划之间持续相互作用。
-
2.
我们引入了 MS-OccFormer,这是一个模型,可以预测 BEV 几何中的联合占用模式,同时了解边际预测。 我们还提出了 GTFormer,这是一个模型,可以在边际运动预测中执行博弈论推理,并与规划和占用预测相协调。 自我规划器是在混合预测的交互式指导下设计的。
-
3.
HPP 在多个大规模现实世界基准上进行了测试,广泛的测试结果证明了其在预测和规划的准确性、安全性和一致性方面的最先进的性能。
II 相关工作
II-A ADS 中的预测和规划
传统 ADS 模型中的预测和规划模块是分开的。 预测通常将不断演变的转变定义为安全规划的条件。 基于学习的预测模型擅长对不同代理和场景上下文之间的交互进行建模[12]。 按表示分类,稀疏预测可预测多智能体轨迹 (MATP) 以及检测到的参与者。 利用 Transformer [16, 17] 或 GNN [7, 18] 构建社交交互图 [7] 或循环精炼 [19],MATP 在对每个智能体的边际预测组合进行评分时过滤多智能体预测。 在实现智能体准确性的同时,MATP 引入了指数计算和轨迹方面的不一致。 密集预测直接根据以自我为中心的占用率[9,20,21]共同估计智能体的未来分布。 一个值得注意的问题是智能体可处理性的损失。 通过热图采样轨迹[22]或联合轨迹学习[23]的增强表现出类似的一致性问题。 在 ADS 规划中,各种方法都是有根据的,包括采样[24]、优化[25]以及通过模仿学习[26]<的基于学习的技术/t2> 或强化学习[27]。 尽管如此,在规划中实现安全且与社会兼容的驾驶操作需要从符合规划的预测中获得交互式意识和安全保证。 此外,独立预测和规划带来的累积误差凸显了开发集成 ADS 的必要性。
II-B ADS 中的集成预测和规划
在密集的交互式交通中导航需要集成的 ADS,它可以对社交代理和自动驾驶车辆之间的同步驾驶行为进行建模。 直觉思维是将自我车辆与社会主体的预测堆叠在一起并学习统一的轨迹。 所有交互均由基于 Transformer 的 IPP [8, 28] 或 IOP 管道下的后处理占用预测[23] 隐式建模。 为了考虑预测和规划之间不断变化的交互行为,条件方法对从自我车辆到社会代理预测的行为响应进行了单独建模[29]。 然后将条件运动预测集成到计划重新安排中[24, 30]或建模为非合作博弈[31]。 尽管如此,这些单向交互绕过了与所有代理的相互一致性。 此外,迭代双层优化[32]显着减慢了学习速度。 为了避免智能体之间的冲突,分层博弈论方法对迭代推理过程进行建模[33],同时更新所有智能体的相互行为[34]。 然而,统一的智能体推理缺乏预测和规划之间的规范,而预测和规划应该是目标驱动的。 在 HPP 中,我们通过引入代理条件占用来调节社会代理的联合行为来整合推理。 以及用于交互式规划的自我规划器。 这种集成的协同设计可以灵活地学习预测和规划,同时通过迭代推理保持相互意识。
最近的范例侧重于利用输出响应进行预测,以增强规划保证。 在联合运动预测和规划之间采用对抗性目标,考虑可能的[3, 35]或安全关键模式[36]以实现相互可微优化。 然而,MATP 面临的类似一致性问题带来了额外的优化挑战。 一些方法将密集占用联合预测为规划指导的潜在成本[11,9,10]。 然而,棘手的问题会带来风险并且需要费力的过滤。 另一个挑战是缺乏集成建模会导致不一致,并限制交互过程仅在优化中。 在 HPP 中,ADS 协同设计和输出优化同时考虑集成。 通过系统协同设计灵活一致的混合预测和规划,联合利用混合预测来细化规划,持续增强安全性。
II-C 自动驾驶端到端系统和大语言模型
端到端方法考虑从原始传感器到感知理解下的预测和规划的直接映射[14]。 典型的系统由模块序列化,并与每个目标[37, 4]联合学习。 然而,模块化误差会累积,并且几何形状会因未对准的预测和规划而受到阻碍。 因此,规划是通过预测[38]在轨迹检索中进行采样的。 BEV 感知方面的突出优势[39,40,41]可实现统一 BEV 几何结构下的模块化集成和学习[42]。 这进一步催生了一个面向规划的系统,该系统在视觉[2,15,43]或矢量化[5]感知下组织和服务针对规划的所有中间模块。 基于查询的设计通道和传播模块化集成。 这促使最近的工作将大型语言模型(大语言模型)作为运动规划器[44]或路由代理[45]。 尽管如此,当前的端到端系统更多地侧重于与感知的集成,从而使预测和规划保持一致,从而使范式讨论纳入大语言模型[46]。 在 HPP 中,我们更加强调模块化协同设计优化、学习交互式混合预测以及基于查询的集成下的感知规划。
三混合预测综合规划
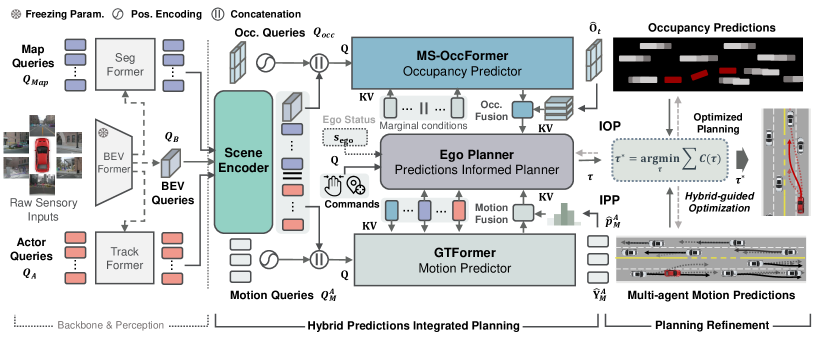
我们提出的HPP的概述如图2所示,它在第2节中定义。 III-A 基于 ADS 的基于查询的模块化协同设计和优化。 在接下来的部分中,由第二节中展示的 BEV 感知管道提供信息。 III-B,HPP 管理第 2 节中 MS-OccFormer 的框架协同设计。 III-C用于联合占用预测,与GTFormer中的运动预测共享一致性。 在这里,我们在第 2 节中详细阐述了用于交互式预测和规划的分层推理模型。 III-D。 其次是混合预测感知Ego Planner(第 2 节)。 III-E,我们在第 2 节中构建了 HPP 计算混合预测指导的学习和优化过程。 III-F。
III-A 问题表述
如图2所示,HPP专注于解决ADS的综合预测和规划挑战。 这个基于学习的系统以 BEV 几何下的感知为基础,通过模块化协同设计和优化而建立。 HPP 以 Transformer 为基础进行模块化,利用分类查询 通过多头注意力机制将模块化输出和通道交互聚合为键和值 。
给定多视角图像输入后,HPP 的协同设计将从 BEV 特征 的感知骨干开始。BEV 感知进一步定义了一个以 为中心的自我区域,其地图为 和 在当前时间步 检测到的代理 ,其中 表示自我车辆。 基于场景上下文,HPP旨在同时学习和优化混合预测和规划模块。 具体来说,在未来的范围和一组查询中,联合预测被定义为所有邻居代理的每步占用概率。 同时,所有智能体的边际未来运动由表示多模式未来轨迹的和考虑模式的概率定义的不确定性。 混合预测感知规划由计划上下文查询。 随后,HPP 制定了模块化学习的集体目标,以及优化混合预测引导规划的成本标准。 一般来说,HPP 的公式为:
| (1) | ||||
其中表示HPP的协同设计,是模型参数。 HPP 中每个模块的具体协同设计和构成将在以下部分中进行说明。
III-B 感知场景编码
HPP 中的感知管道旨在使用 BEV 几何下的原始图像输入捕获场景上下文 。 然后场景上下文被联合编码以捕捉它们的全局关系。
III-B1 纯电动汽车感知
在 HPP 中,多视图图像特征 是通过共享主干网 [47] 从原始图像输入中提取的。 我们利用 BEV 编码器 [39] 通过循环自上而下的 BEV 查询 将 转换为 BEV 功能 ,其中 表示隐藏维度。 基于 BEV 主干网,我们利用两个类 DETR 感知解码器[2],在 代理查询 和 地图查询 之后,从 中提取代理 和地图 的场景上下文特征。 请注意,HPP 侧重于综合预测和规划。 因此,使用更先进的 BEV 感知单元的 HPP 预计会获得更好的结果。
III-B2 场景编码
为了对具有 BEV 感知的场景元素之间的全局交互进行建模,我们继承了之前的工作 [48, 9] 来收集和编码单独的视觉和矢量化场景上下文特征。 具体来说,视觉特征由 BEV 查询 编码,地图和代理的场景特征被连接并编码为 ,其中 表示连接。 然后,编码结果 将作为集成预测和规划的 HPP 协同设计的输入。
III-C 女士-OccFormer
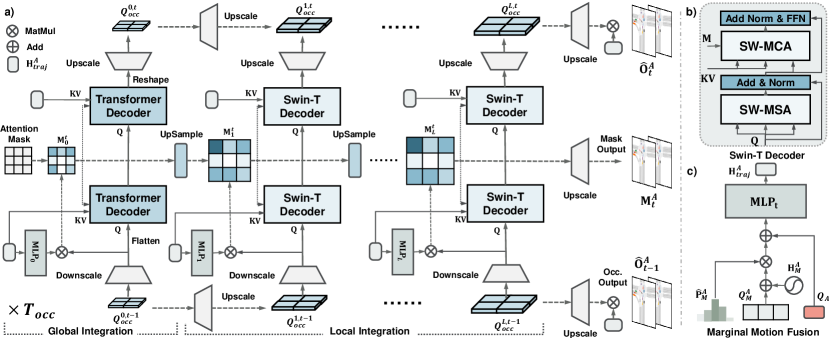
HPP 将联合预测制定为占用率,与感知中的 BEV 几何结构一致。 为了进一步解决混合预测之间的一致性挑战,在 HPP 中,我们提出 MS-OccFormer 重点关注两个方面,即定义易于处理的预测的边际条件占用率,以及处理不同粒度的交互式对齐的多尺度预测明智集成。 如图3所示,MS-OccFormer利用基于流的管道来推出未来地平线,并基于解码每步占用预测> 成功步骤功能的级别集成。
III-C1 模块化查询
我们在多尺度聚合中利用占用查询来获取位置和感知特征:。 位置网格 使用正弦 进行编码,并通过多层感知器 (MLP) 进行转换。 我们在 级别 下进一步对 进行下采样,以循环查询多尺度交互。
III-C2 边际依赖性
III-C3 边际条件占用
制定 的主要挑战在于难以处理导致联合不一致的边际预测。 受实例级占用率[2]和条件方法[24]的启发,我们提出了边际条件占用率预测任务。 该模型对基于智能体边际预测的一致联合占用率 进行了建模。 为了将不确定性和相互交互联系起来,给定最终联合解码特征和边缘特征,边缘条件占用率最终将通过点积建模:
| (3) |
其中 表示每个网格概率的 sigmoid 函数。 然后可以将原始任务转换回以协同设计其他HPP模块:
III-C4 多尺度预测智能集成
旨在在解码中迭代对齐混合预测之间的多尺度交互特征。在图3a中,多尺度成功占用特征查询对齐通过两级 Transformer 解码器的不同粒度的注意力来获得边缘特征。
全局集成阶段利用普通 Transformer 解码器从扁平的高级联合特征 与边缘特征执行每个网格的交互。 随后,随着占用特征 的升级,局部集成阶段的重点是捕获具有边缘特征的部分联合行为的一致性。 这促使我们设计移位窗口多头交叉注意(SW-MCA),其灵感来自于[49]中的SW-MSA。 如图3b所示,我们采用滚动过程来同时捕获转移窗口注意力下的局部交互。
为了确保跨多尺度集成的交互一致性,我们为 Transformer 解码器设计了一个可学习的注意力掩模,它迭代地改进了先前尺度的交互结果。 这根据之前的结果调整了注意力模型,如图 3a 所示,对于每个级别,注意力掩模都会根据当前规模级别上的代理条件占用率进行更新:
| (4) |
然后,注意力掩码将按以下方式迭代更新:
| (5) |
其中 是更新因子。 一般来说,给定特定阶段的 Transformer 解码器为 ,时间步 的尺度 下的预测积分定义为:
| (6) |
输出联合占用特征最终将通过等式融合。 3 用于条件占用预测。
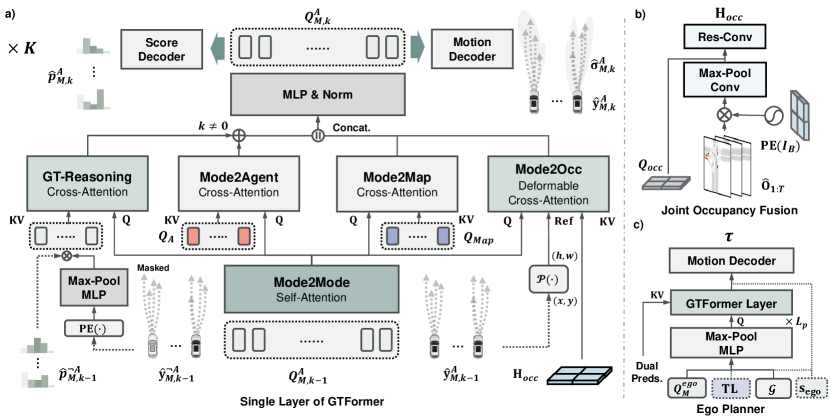
III-D GT前任
在 HPP 中,确保运动预测和规划之间的交互一致性涉及 GTFormer 的引入。 如图4所示,GTFormer将未来的交互行为制定为博弈论推理过程,通过层堆叠的Transformer解码器模拟分层推理。 除了我们之前的工作[34]的统一智能体推理模型之外,GTFormer 与 MS-OccFormer(第 III-C 节)合作,对占用交互进行建模以调节关节每个推理水平的未来行为。
III-D1 模块化查询
我们利用运动查询来初始化具有多模式运动意图和代理感知特征的智能体交互推理:。
III-D2 联合依赖
我们将联合占用预测 与位置特征 进行转换,以与连续几何图形对齐以进行预测和规划。 如图 4b 所示,我们使用 max-pooling 进行乘法,以使用 BEV 语义对占用位置特征进行编码:
| (7) |
其中 和 分别表示卷积投影和残差层。 然后,联合特征 与所有代理进行交互。
III-D3 博弈论 Transformer 层
我们采用 k 级游戏对 GTFormer 层进行建模(见图4a),以了解所有代理的未来交互行为。 继承于我们之前的工作[34],我们将智能体多模式预测和规划表示为玩家策略。 对于每个玩家 ,推理过程被定义为 次策略迭代,以来自最后推理级别的对手 策略为条件:。 具体来说,0 级策略是独立推理的:。 我们利用高斯混合模型 (GMM) 将预测和规划政策的不确定性概述为:
| (8) |
其中 和 分别表示二维高斯分布的密度函数和方差。
具体来说,GTFormer 的单层由级别 策略(图4a)在所有代理之间共享。 层以多头自注意力 (MHSA) 开始,名为 Mode2Mode,用于最后一级运动查询 ,以对未来跨模态的交互进行建模。 为 设计了四个多头交叉注意(MHCA),分别聚合策略条件进行推理。 (1) GT 推理与最后一级组件策略交互。 由等式融合。 2与和,组件特征通过未来掩码[34]过滤,以查询未来推理行为为。 (2) Mode2Agent 和 (3) Mode2Map 概述了代理 的场景上下文交互,并将 映射为 和。 (4) Mode2Occ 利用可变形 MHCA (DCA) [39] 来模拟未来与关节占用特征的交互。 通过转换为像素坐标的 引用的一组偏移量 进行查询。 然后,每个客服人员的 参考占用率将聚合为 。 一般来说,所有交互特征都会串联起来以更新运动查询:
| (9) |
其中 表示残差 MLP 和层范数的前馈层。 对于独立的未来策略,我们省略了 在 处的推理注意力。 最终,更新的运动查询 通过分数和轨迹解码器传递,以实现合理的 GMM 预测和规划策略。
III-E 自我规划师
HPP 引入了图4c 所示的自我规划器。自我规划器根据规划推理策略指定面向规划的条件。 HPP 的共同设计促进了混合预测感知的 Ego Planner,它与 GTFormer 和 MS-OccFormer 协作,定义为 。 这是至关重要的,因为 GTFormer(第 III-D 节)中的博弈论过程只是简单地与其他代理统一建模自我规划。
III-E1 模块化查询
在目标驱动规划的背景下,我们定义计划查询,通过最大池融合使用计划上下文集成规划推理功能: 。 这里,包含用于编码导航命令或坐标的全局目标特征、交通灯特征以及用于编码导航命令或坐标的可选自我状态自我速度和航向。
III-E2 混合预测依赖性
我们直接利用 GTFormer 层中的一堆 交互 Transformers 部件(图 4a)来模拟未来的联合交互 和边缘交互 ,通过合理的规划功能和目标条件的规划查询来通知。 GT-Reasoning 模块结合了边缘运动交互 的混合预测意识,而 Mode2Occ 模块则处理联合占用交互 。通过聚合来自混合预测的交互式未来行为,计划查询通过相同的运动解码器,从而产生细化的计划轨迹。
III-F 系统学习与优化设计
我们提出了 HPP 系统的协作学习和优化范例。 通过分离的 BEV 主干,共同设计的框架经历了两个阶段的训练过程:1)使用感知目标 [2] 对两个感知解码器进行预热学习; 2)使用所有模块化目标进行端到端监督学习:
| (10) |
在推理过程中,混合预测引导优化通过最小化成本函数 来细化规划 。 下面,我们详细阐述模块化目标、成本和协同优化策略。
III-F1 模块化物镜
为了精确预测 MS-OccFormer 中的边际条件占用率 ,我们针对 和 联合使用了 top-k BCE 损失和 Dice 损失 [2] 组合,以均衡预测占用概率:,以及 。
为了捕获 GTFormer 中所有代理的分层推理过程, 级别策略的最小-最大目标包括 、最小化模仿行为和 ,最大化交互距离。 总体目标定义为。 这里,表示推理策略的负对数似然(NLL)损失,每个代理的最接近的最终位移误差(FDE)作为正混合:
| (11) |
其中表示正索引,定义为:
| (12) |
这里是和。 我们利用 的交叉熵损失来更新评分。 对于交互式损失 ,它是通过在最后一级组件策略下最大化 内最近轨迹的 L2 距离 来建模的:
| (13) |
为了在 Ego Planner 中执行精细化规划 ,需要通过 L2 距离 : 进行学习。
III-F2 成本概况
成本函数概况包含不同的成本项,考虑到规划绩效的各个方面,分类为:推动进度、舒适度、遵守规则[9],并且最重要的是, 安全。 重要的是,规划安全性由包含联合 和边际 预测的高斯势场定义。 在混合预测的补充安全指导的推动下,明确的目录如下:
| (14) |
这里,表示高斯密度函数,如等式1所示。 8. 表示占用坐标,是根据的推理结果得出的。 每个势场都受到朝向规划轨迹的距离阈值 的屏蔽。
III-F3 优化
混合预测引导规划的优化被定义为有限视野下的开环优化问题。 一般公式如下:
| (15) |
其中是计划变量,表示成本函数的权重。 对于广义 ADS,HPP 根据不同的标准解决这个优化问题:
参考路线: 假设可访问的参考路线是密集插值的,HPP会在Frenet坐标下转换所有成本曲线以减轻优化困难。 每个参考点都分配有切向和法向向量:。 然后可以通过以下方式将笛卡尔坐标 转换为 :
| (16) |
路径规划:这处理自我车辆的较低频率的轨迹。 从 Ego Planner 对 执行直接优化,生成优化路径 。 本次操作仅考虑安全成本。
运动规划:这解决了自我车辆每一步的未来状态。 使用模型预测控制 (MPC) 对基于逆动态的控制操作 进行优化: [36]。 然后,优化后通过前向动力学将最佳运动规划转换回来:。
为了解决这个非线性优化问题,如方程所示。 15,我们利用高斯-牛顿方法[50]。 迭代地细化规划变量作为初始值。 成本权重可以精心设计或直接学习,因为整个优化过程是完全可微的[3]。
IV 实验
在本节中,我们首先介绍所提出的 HPP 的实验设置,包括测试基准、评估指标和详细实现。 随后,HPP 与现有最先进的预测和规划方法和系统进行了定量比较。 关于消融研究的讨论揭示了 HPP 模块化协同设计优化的有效性和机制。 定性结果进一步削弱了 HPP 与某些最先进基线的特征。
IV-A 实验装置
IV-A1 测试基准
为了发现HPP在预测和规划方面的综合表现,我们总结了基准测试需要解决的三个问题:(1)HPP作为全栈ADS在交互式真实场景下的能力如何? (2)HPP在交互式现实场景中的长期表现如何? (3)HPP在连续的现实场景中的长期驾驶效果如何? 这些提示相应的基准:
(1) nuScenes数据集 [51]:该数据集是全栈自动驾驶中最大、应用最广泛的数据集之一。 它包括 1,000 多个以 2 Hz 注释的 20 秒驾驶场景帧,覆盖全球四个城市。 基准评估[2]涉及开环设置下 ADS 所有任务的 6,019 帧。 测试范围定义为运动预测的 和 。
(2) Waymo 开放运动数据集 (WOMD) [52]: 用于长期运动评估,它是现实世界中最大的运动数据集交互式场景的数据集。 它由代表独特场景的 104,000 个 20 秒帧组成,以 10 Hz 标记,涵盖超过 570 公里的行驶里程和 1750 公里的道路。 为了评估规划和运动预测的长期现实性能,在 SMARTS 基准[34]中系统地进行了评估。 其中包括 400 个高度互动的场景,每个场景持续 9 秒,具有代表性的行为。 自动驾驶车辆的任务是在开环和闭环配置中进行 5 秒的长期规划和预测。 闭环测试涉及利用日志模拟器重放在线交互的驾驶场景。 为了进一步检查 HPP 中联合预测的性能,系统在 Waymo 占用预测基准[53]上进行了测试。 这涉及在 8 秒时间范围内以 1 Hz 的频率预测超过 44,000 个驾驶场景的占用和流量。
| Methods | Collision rate (%) | Planning error (m) | ||||||
|---|---|---|---|---|---|---|---|---|
| @1 s | @2 s | @3 s | Avg. | @1 s | @2 s | @3 s | Avg. | |
| NMP† [54] | - | - | 1.92 | - | - | - | 2.31 | - |
| SA-NMP† [54] | - | - | 1.59 | - | - | - | 2.05 | - |
| FusionAD†‡ [15] | 0.02 | 0.08 | 0.27 | 0.12 | - | - | - | 0.81 |
| FF† [55] | 0.06 | 0.17 | 1.07 | 0.43 | 0.55 | 1.20 | 2.54 | 1.43 |
| EO† [56] | 0.04 | 0.09 | 0.88 | 0.33 | 0.67 | 1.36 | 2.78 | 1.60 |
| OccNet [57] | 0.21 | 0.59 | 1.37 | 0.72 | 1.29 | 2.13 | 2.99 | 2.13 |
| UniAD [2] | 0.05 | 0.17 | 0.71 | 0.31 | 0.48 | 0.96 | 1.65 | 1.03 |
| HPP‡ | 0.03 | 0.07 | 0.35 | 0.15 | 0.30 | 0.61 | 1.15 | 0.72 |
| HPP | 0.03 | 0.17 | 0.68 | 0.29 | 0.48 | 0.91 | 1.54 | 0.97 |
| Avg. Metrics | @1 s | @2 s | @3 s | Avg. | @1 s | @2 s | @3 s | Avg. |
| ST-P3 [4] | 0.23 | 0.62 | 1.27 | 0.71 | 1.33 | 2.11 | 2.90 | 2.11 |
| VAD-Base‡ [5] | 0.07 | 0.10 | 0.24 | 0.14 | 0.17 | 0.34 | 0.60 | 0.37 |
| VAD-Base [5] | 0.07 | 0.17 | 0.41 | 0.22 | 0.41 | 0.70 | 1.05 | 0.72 |
| DeepEM∗ [58] | 0.05 | 0.15 | 0.36 | 0.19 | 0.25 | 0.45 | 0.73 | 0.48 |
| HPP‡ | 0.02 | 0.04 | 0.11 | 0.06 | 0.26 | 0.37 | 0.59 | 0.40 |
| HPP | 0.03 | 0.08 | 0.24 | 0.12 | 0.41 | 0.61 | 0.86 | 0.63 |
(3) CARLA模拟器 [59]:我们利用Longest6基准[60]进行长期驾驶评价。 自动驾驶车辆被分配了地平线闭环规划任务,跨越 36 条路线,范围从 1.6 公里到 1.8 公里,在 6 个 CARLA 城镇的各种驾驶条件下进行。
IV-A2 测试指标
我们在测试指标配置中遵循原始基准。 与 HPP 的贡献相一致,所设计的指标主要关注预测和规划的准确性、一致性和安全性三个方面。 详细指标如下:
(1) 入住预测: 并集交集 (IoU) 和曲线下面积 (AUC) [61] 量化总体和每个网格的占用率预测精度。 采用视频全景质量(VPQ)[62]来评估边缘代理和感知的占用一致性。
(2) 运动预测: 使用轨迹的最小平均和最终位移误差(minADE、minFDE)以及每个智能体的错过率 (MR) 来评估预测精度[52]。 通过所有代理[34]的关节位移误差(JADE、JFDE)以及感知上的端到端预测精度(EPA)[63]来测试一致性。
(3) 规划:对于开环测试,使用位移误差(DE)[2]和平均距离[5]来评估规划精度t2>。 通过碰撞率 (CR) [64] 评估预测和安全性的一致性。 在闭环设置中,外部测量包括违规 (IS)、车辆碰撞 (CV)、路线完成 (RC) 和包含整体驾驶性能的驾驶分数 (DS)[59]。
IV-A3 实施细节
为了公平比较,HPP 根据每个基准进行配置,并精心设计学习管道和系统架构。 在 nuScenes 数据集中,进行全尺寸训练,总批量大小为 4。 为了进行规划,随机采样完整训练集的 10%,并将完整训练集用于 WOMD 中的占用基准。 学习以 24 个为一组进行。 CARLA基准[28]的专家数据集在不同城镇收集,直接用于32个批次的训练。
所有基准测试的训练策略均在四个 NVIDIA A100 GPU 上使用分布式策略进行调整。 采用 AdamW 优化器,初始学习率为 1e-4,并应用余弦退火学习率策略。 训练 epoch 的总数设置为 20。 我们对 nuScenes 和 WOMD 应用相同的 GPU 设备进行测试。 CARLA 基准测试是在一台 NVIDIA RTX 3080 GPU 上进行的。
对于系统架构,HPP 在 nuScenes 中 50 m 的 内建立以自我为中心的 BEV 感知。 在 WOMD 和 CARLA 基准测试中,假设了特权感知。 因此,根据我们之前的工作[34, 65],通过对完美场景上下文输入进行编码来开发HPP。 对于 CARLA 基准,BEV 在 的 米内仍然以自我为中心。 WOMD 的 BEV 设置遵循官方基准指南。 无需了解 nuScenes 和 CARLA 中的参考路线即可优化路径规划。 在 WOMD 中,运动规划是根据参考信息进行的。 nuScenes 中的全栈 HPP 考虑了代理的各种查询。 在 WOMD 和 CARLA 中,代理按 进行排序和过滤。 我们选择 ReLU 激活函数并应用 0.1 的 dropout 率。 我们在表XII中引用了更详细的参数和符号。
IV-B 主要结果
IV-B1 全栈 ADS 性能
我们根据 nuScenes 数据集上最新的方法报告 HPP 的测试性能。 HPP 在预测和规划方面的各种关键指标上都取得了最先进的结果。
| Methods | Collision rate (%) | Planning error (m) | ||||||
|---|---|---|---|---|---|---|---|---|
| @1 s | @2 s | @3 s | Avg. | @1 s | @2 s | @3 s | Avg. | |
| GPTDriver‡ [44] | 0.07 | 0.15 | 1.10 | 0.44 | 0.27 | 0.74 | 1.52 | 0.84 |
| Agent-Driver‡ [45] | 0.02 | 0.13 | 0.48 | 0.21 | 0.22 | 0.65 | 1.34 | 0.74 |
| HPP‡ | 0.03 | 0.07 | 0.35 | 0.30 | 0.61 | 1.15 | 0.72 | 0.15 |
| Methods | IoU-n. | IoU-f. | VPQ-n. | VPQ-f. |
|---|---|---|---|---|
| FIERY[66] | 59.4 | 36.7 | 50.2 | 29.9 |
| StretchBEV[41] | 55.5 | 37.1 | 46.0 | 29.0 |
| ST-P3[4] | - | 38.9 | - | 32.1 |
| BEVerse[40] | 61.4 | 40.9 | 54.3 | 36.1 |
| PowerBEV[67] | 62.5 | 39.4 | 55.5 | 33.8 |
| UniAD[2] | 63.4 | 40.2 | 54.7 | 33.5 |
| HPP | 64.8 | 40.5 | 56.4 | 34.7 |
(1) 规划成果: 如表 I 所示,HPP 在所有规划范围 (@1 s-@3 s) 中针对各种自动驾驶系统在绝对指标 方面均实现了最先进 (SOTA) 结果[2] 和平均 [5]。 具体而言,与使用相同 BEV 的 UniAD [2] 相比,HPP 的平均 L2 错误降低了 5.9%,平均冲突率降低了 6.5%的看法。 这展示了 HPP 模块化协同设计在预测和规划方面的有效性。
在平均指标中,HPP 报告相对于 VAD [5],规划错误改善了 12.5%,这凸显了卓越的感知模块。 与 DeepEM [58] 相比,HPP 的推理设计的碰撞率降低了 30%,DeepEM 还具有通过 EM 解码进行推理和额外的去噪增强的功能。 与利用自我状态的方法相比,HPP的一种变体在自我规划器中添加自我状态(表示为HPP‡)(第III-E节) >) 训练有素,成绩斐然。 HPP‡ 不包括 [5] 中的加速度作为地面实况的泄漏。 与依赖于过度 LIDAR 融合的 FusionAD [15] 相比,HPP 的规划误差也降低了 11.8%,且安全性相当。 与大语言模型方法相比,我们的系统还表现出了2.8%较低的错误率和近20%较低的冲突率(参见表II)。 这进一步证实了以规划为导向的目标中预测的模块化集成的有效性,因为大语言模型基线更注重语言知识的对齐。
(2) 预测结果: 占用预测的联合结果在以自动驾驶车辆为中心的两个范围(近:米;远:米)进行测试。 如表III所示,与[2]相比,HPP具有先进的精度+2.5%和一致性+3.7% ,感谢提出的与运动预测相互集成的 Ms-OccFormer。 与 [67]< 相比,HPP 中模块化协同设计的有效性通过 +4% 和 +1.6% 的 IoU 和 VPQ 改进而得到进一步证明,而无需额外的增强。 /t2> 学习单人占用任务。
运动预测的边缘结果如表IV所示。 在这里,我们比较所有车辆 (-v.) 的平均预测结果,并测量按类别加权的完整代理 (-f.) 结果。 HPP 报告称,车辆预测中的 minADE 降低了 2.8%,EPA 提高了 +3.2%,其中 3.7% 和 +6% 与相同感知设置下的基线[2]相比,预测所有智能体的性能得到提高。 这凸显了通过 GTFormer 中的博弈论推理和联合依赖关系实现的性能增益(第 III-D 节)。
| Methods | minADE | minFDE | MR. | EPA |
|---|---|---|---|---|
| ViP3D[63] | 1.15 | 1.95 | 22.6 | 0.222 |
| PnPNet[38] | 2.05 | 2.84 | 24.6 | 0.226 |
| UniAD-v.[2] | 0.71 | 1.02 | 15.1 | 0.456 |
| UniAD-f.[2] | 0.911 | 1.236 | 15.1 | 0.314 |
| HPP-v. | 0.682 | 0.947 | 13.8 | 0.471 |
| HPP-f. | 0.878 | 1.205 | 14.5 | 0.334 |
| Methods | AUC | AUC | EPE | AUC |
|---|---|---|---|---|
| -obs. | -occ. | -f. | -FT | |
| MotionPerceiver | 77.1 | - | - | - |
| OFMPNet | 77.0 | 16.5 | 3.58 | 76.1 |
| STCNN | 74.4 | 16.8 | 3.87 | 73.3 |
| HOPE[20] | 80.3 | 16.5 | 3.67 | 83.9 |
| STrajNet[48] | 77.8 | 17.8 | 3.20 | 78.5 |
| VectorFlow[21] | 75.4 | 17.3 | 3.58 | 76.7 |
| HPP | 79.7 | 19.4 | 2.95 | 80.2 |
值得注意的是,HPP 侧重于预测和规划,而不是感知。 通过更好的感知[5]或额外的激光雷达输入[15],预测结果可能会得到进一步增强。 然而,HPP 在最终规划结果中仍然表现出色,这表明我们的贡献体现了更好的社会责任感。
IV-B2 长视互动表演
我们在 WOMD 下对 HPP 的长期性能进行了基准测试。 HPP 强调了在预测和规划方面相对于众多 SOTA 方法的先进性能。
(1) 入住结果: 如表V所示,HPP表现出卓越的预测精度(+8.8% AUC-occ。) 考虑联合流量预测时,流量误差较低 (9.1% EPE-f.)。 与我们之前的工作[65]相比,HPP中MS-OccFormer的显式设计证明了其强大的准确性,该工作仅进行全局交互而没有边际意识。 HPP 的 AUC-obs 提高了 +2.4%。 流量追踪占用率+2.2%。
| Method | Collision rate | Miss rate | Planning error (m) | Prediction error (m) | |||
|---|---|---|---|---|---|---|---|
| (%) | (%) | @1 s | @3 s | @5 s | JADE | JFDE | |
| Vanilla IL [3] | 4.25 | 15.61 | 0.216 | 1.273 | 3.175 | – | – |
| DIM [68] | 4.96 | 17.68 | 0.483 | 1.869 | 3.683 | – | – |
| OPGP [9] | 3.79 | 12.89 | 0.245 | 1.672 | 3.099 | – | – |
| MultiPath++ [69] | 2.86 | 8.61 | 0.146 | 0.948 | 2.719 | – | – |
| MTR-e2e [19] | 2.32 | 8.88 | 0.141 | 0.888 | 2.698 | – | – |
| DIPP [3] | 2.33 | 8.44 | 0.135 | 0.928 | 2.803 | 0.925 | 2.059 |
| GameFormer [34] | 1.98 | 7.53 | 0.129 | 0.836 | 2.451 | 0.853 | 1.919 |
| HPP | 1.85 | 7.58 | 0.092 | 0.881 | 2.667 | 0.829 | 1.965 |
| Method | Success rate | Progress | Acceleration | Jerk | Lateral acc. | Position error to expert driver () | ||
| (%) | () | () | () | @3 s | @5 s | @8 s | ||
| Expert | - | 54.52 | 0.529 | 1.020 | 0.103 | - | - | |
| Vanilla IL [3] | 0 | 6.23 | 1.588 | 16.24 | 0.661 | 9.355 | 20.52 | 46.33 |
| RIP [68] | 19.5 | 12.85 | 1.445 | 14.97 | 0.355 | 7.035 | 17.13 | 38.25 |
| CQL [70] | 10 | 8.28 | 3.158 | 25.31 | 0.152 | 10.86 | 21.18 | 40.17 |
| DIPP [3] | 68.125.51 | 41.085.88 | 1.440.18 | 12.583.23 | 0.310.11 | 6.220.52 | 15.551.12 | 26.103.88 |
| GameFormer [34] | 73.166.14 | 44.947.69 | 1.190.15 | 13.632.88 | 0.320.09 | 5.890.78 | 12.430.51 | 21.022.48 |
| HPP | 74.285.49 | 47.178.92 | 1.330.18 | 11.682.76 | 0.350.09 | 4.930.78 | 10.240.82 | 18.993.05 |
| DIPP (optim.) | 92.160.62 | 51.850.14 | 0.580.03 | 1.540.19 | 0.110.01 | 2.260.10 | 5.550.24 | 12.530.48 |
| GameFormer (optim.) | 94.500.66 | 52.670.33 | 0.530.02 | 1.560.23 | 0.100.01 | 2.110.21 | 4.870.18 | 11.130.33 |
| HPP (optim.) | 92.250.85 | 52.190.41 | 0.660.02 | 1.870.28 | 0.100.01 | 2.130.29 | 4.900.26 | 12.890.38 |
(2) 开环结果: 表 VI 揭示了 HPP 在开环预测和规划方面相对于众多最先进 (SOTA) 方法的令人信服的结果。 与折扣预测的模仿学习基线 [3, 68] 相比,HPP 的碰撞次数显着减少了 50% 以上,规划错误显着减少了 26% 。 与作为模仿规划器的 SOTA 运动预测基线相比,HPP 还证明规划误差减少了 2.3% 到 17.6%,碰撞减少了 21.1%。 这强调了综合预测和规划的重要性。
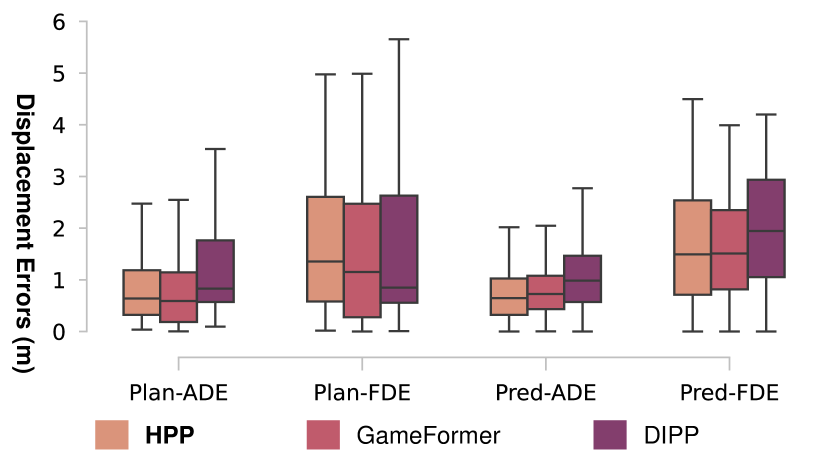
与综合基线相比,HPP 相对于 IOP 框架[9]有了显着的改进,因为缺乏未来的规划交互,并且 IOP 中的棘手占用阻碍了正常指导。 与 IPP 系统相比,HPP 在碰撞率 (6.6%)、联合预测误差 (2.9%) 和可比较的规划误差方面具有卓越的性能。 与我们之前的工作[3, 34]的最新结果相比,该工作专注于对未来交互和推理进行建模(见图5), HPP 表现出卓越的短期性能并减少了方差。 这进一步验证了 HPP 中联合预测和推理规划的协同设计集成的有效性。
(3) 闭环结果: 在表 VII 中,HPP 在重放模拟器中针对最先进的 IPP 系统 [34]、IL 方法 [68] 进行了测试>,RL 接近 [70]。 由于与环境的闭环相互作用中累积的分布变化,IL 和 RL 结果受到显着影响。 与我们之前的方法[34]相比,HPP 表现出更高的成功率 (+1.5%) 和更低的计划错误 (13.2%),谢谢到根据目标上下文设计的混合预测感知规划器。 通过在线优化,闭环性能得到大幅提升。 由于原始数据占用过程成本较高,通过2Hz在线细化重新规划HPP。 测试结果表明,我们之前的方法 [34] 具有强大的性能,该方法以 10 Hz 更频繁地重新规划,将闭环位置误差降低 8.5% [3]。
| Methods | DS | RC∗ | IS | CV |
|---|---|---|---|---|
| Rule-Based[59] | 38.0 | 29.1 | 0.84 | 0.64 |
| KING[36] | 45.1 | 78.3 | 0.55 | 1.67 |
| Roach[71] | 55.3 | 88.2 | 0.62 | 0.72 |
| PlanT∗[28] | 70.9 | 83.1 | 0.87 | 0.31 |
| HPP∗ | 65.5 | 79.2 | 0.82 | 0.51 |
| ID | MS-OccFormer(wo.) | GTFormer(wo.) | EgoPlanner (wo.) | Occupancy Prediction | Motion Prediction | Planning | |||||||||||
| Score | Motion | AC-Occ. | Score | Motion | Occ. | Motion | Occ. | IoU-n. | IoU-f. | VPQ-n. | VPQ-f. | minADE | MR | EPA | ADE | CR | |
| 1 | ✗ | - | - | - | - | - | - | - | 63.5 | 40.0 | 54.5 | 33.7 | 0.733 | 16.1 | 45.6 | 0.989 | 0.428 |
| 2 | - | ✗ | - | - | - | - | - | - | 63.1 | 39.4 | 53.6 | 32.8 | 0.739 | 16.2 | 44.8 | 0.994 | 0.441 |
| 3 | - | ✗ | ✗ | - | - | - | - | - | 61.9 | 39.6 | 50.8 | 30.9 | 0.748 | 16.6 | 43.8 | 1.015 | 0.466 |
| 4 | - | - | - | ✗ | - | - | - | - | 63.7 | 39.8 | 55.0 | 33.3 | 0.728 | 15.9 | 45.0 | 0.986 | 0.402 |
| 5 | - | - | - | - | ✗ | - | - | - | 63.5 | 39.5 | 54.6 | 33.5 | 0.734 | 16.4 | 44.8 | 0.992 | 0.432 |
| 6 | - | - | - | - | ✗ | ✗ | - | - | 63.5 | 39.6 | 54.8 | 33.0 | 0.747 | 16.2 | 44.2 | 0.998 | 0.436 |
| 7 | - | - | - | - | - | - | ✗ | - | 63.6 | 39.8 | 55.0 | 33.4 | 0.726 | 16.0 | 45.7 | 0.989 | 0.414 |
| 8 | - | - | - | - | - | - | - | ✗ | 63.5 | 39.7 | 54.7 | 33.3 | 0.721 | 15.6 | 45.4 | 1.012 | 0.458 |
| 9 | - | - | - | - | - | - | ✗ | ✗ | 63.5 | 39.8 | 54.8 | 33.4 | 0.726 | 15.9 | 45.7 | 0.997 | 0.449 |
| 0 | - | - | - | - | - | - | - | - | 63.7 | 39.8 | 55.0 | 33.5 | 0.724 | 15.9 | 45.8 | 0.985 | 0.402 |
IV-B3 长期驾驶性能
HPP 展示了与 CARLA 基准中最先进的方法 [28] 相当的驱动能力(表 VIII)。 与基于规则的代理[59]相比,HPP 有了显着改进,与 IPP 方法[36]相比,HPP 实现了驾驶分数,IPP 方法通过以下方式指导规划对抗性预测,以及与 RL 方法[71]相比的改进。 注意到 HPP 和复制的 [28] (*) 都显示出受损的路线完成 (RC),可能是由于 GPU 推理问题111https://github.com/autonomousvision/plant/issues/17。
IV-C 消融研究和讨论
为了释放 HPP 的内部有效性,在 nuScenes 中进行了全面的消融研究,重点讨论模块化协同设计的作用以及规划指导中混合预测的特征。
IV-C1 模块化协同设计中的角色
为了得出每个模块之间协同设计的有效性,如表IX所示,我们有目的地删除了跨每个子模块集成的某些关键设计。 参考 ID 1-9,所有消融基线均与原始 HPP (ID.0) 进行比较。 详细讨论如下:
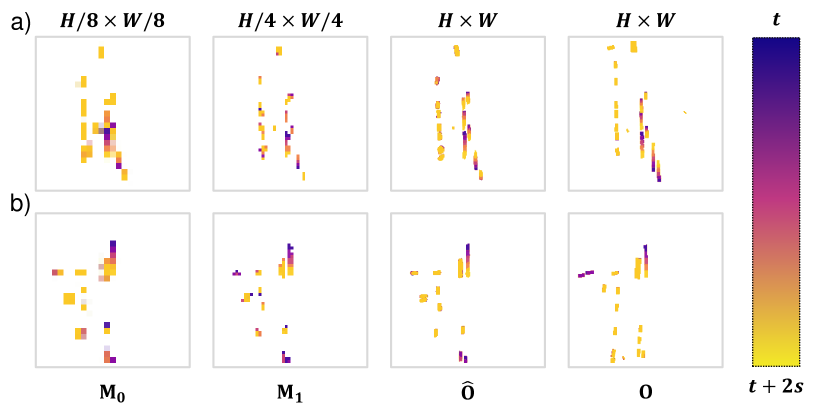
(1) Ms-OccFormer 中的效果: 对于边际依赖性(第 III-C2 节),当删除分数缩放(ID.3 与 ID.0)时,我们观察到占用率下存在轻微的权衡范围(-0.5 VPQ-n. vs. +0.2 VPQ-f.),碰撞增加 ()。 这表明缩放捕获了用于联合预测的多模态特征,并增强了附近的共享占用区域。 删除运动融合(ID.2)会因缺乏边缘对齐而导致包容性下降。 在去除代理条件占用模型时观察到更大的下降(-1.2 IoU-n.和-3.7 VPQ-n.)。 它强调了未来交互的重要性,并验证了运动预测的一致性( 预测误差较低)。 规划结果也反映了近尺度联合预测交互对规划的更多贡献。 比较ID.2和ID.3,在不牺牲远尺度占用率(-1.2 IoU.-n vs. +0.2 IoU-f.)的情况下,规划错误和碰撞随着近尺度预测精度的下降而增加。 对于多尺度预测集成的关键设计,定性(见图6)和定量消融(表X)已经证明了多尺度注意力掩模更新的显着改进设计(+1.2 IoU-n.)以及局部集成(+1.0 VPQ-n.)以实现预测一致性。
(2) GTFormer 中的效果: 作为实现一致预测和规划的推理能力的核心模块,我们尝试通过去除 GTFormer 中的边际和联合预测来发现角色。 ID.4与ID.5相比,推理模块的去除彻底下降,尤其是规划( CR)和运动预测( MR)。 这凸显了推理的一致性和准确性对于未来交互的重要性。 同时,考虑 ID.5 和 ID.6,预测误差 ( minADE) 的增加意味着联合依赖关系 (Sec. III-D2) 是基于 GT 推理的一致运动预测的关键。 这反映了联合和边际预测器协同设计之间的交互建模所调节的增强的相互一致性。
| Baselines | IoU-n. | IoU-f. | VPQ-n. | VPQ-f. |
|---|---|---|---|---|
| w/o. global integration | 61.6 | 38.8 | 52.0 | 31.9 |
| w/o. local integration | 61.8 | 38.8 | 52.8 | 32.1 |
| w/o. attn. mask | 62.5 | 39.0 | 53.8 | 32.4 |
| HPP | 63.7 | 39.8 | 55.0 | 33.5 |
| ID | Occ. | Most-likely | Full-motion | Collision rate (%) | Planning error (m) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| @1 s | @2 s | @3 s | Avg. | @1 s | @2 s | @3 s | Avg. | |||||
| 1 | - | - | - | - | 0.11 | 0.31 | 0.73 | 0.39 | 0.19 | 0.53 | 1.13 | 0.61 |
| 2 | ✓ | - | - | - | 0.07 | 0.22 | 0.64 | 0.31 | 0.18 | 0.52 | 1.09 | 0.60 |
| 3 | ✓ | - | ✓ | - | 0.05 | 0.11 | 0.60 | 0.25 | 0.19 | 0.52 | 1.10 | 0.60 |
| 4 | ✓ | - | - | ✓ | 0.04 | 0.09 | 0.53 | 0.20 | 0.19 | 0.52 | 1.10 | 0.60 |
| 5 | ✓ | ✓ | - | - | 0.03 | 0.14 | 0.45 | 0.20 | 0.30 | 0.61 | 1.16 | 0.72 |
| 6 | ✓ | ✓ | ✓ | - | 0.03 | 0.14 | 0.44 | 0.20 | 0.31 | 0.61 | 1.17 | 0.72 |
| 0 | ✓ | ✓ | - | ✓ | 0.03 | 0.07 | 0.35 | 0.15 | 0.30 | 0.61 | 1.15 | 0.72 |
(3) 自我规划器中的效果: 与我们之前的工作[34]相比,验证计划调节设计的作用。 IV-B2,我们进一步研究了混合预测交互的影响。 在 ID.9 中,我们观察到预测的边际改进(+0.2 IoU,+0.1 EPA)以及包含混合预测交互的规划的更显着增强( CR)。 这强调了 HPP 设计所贡献的一致性建模。 ID.7 和 ID.8 的消融进一步表明,与边际特征 ( CR) 相比,占用预测特征 ( CR) 的交互对规划具有重大影响。 仅运动条件规划(ID.8)输出过于乐观的运动预测(-0.3 MR)。 这反过来又损害了原始的博弈论推理,导致较差的规划( CR)。 这些结果强调了联合依赖性对规划和运动预测的一致性的调节作用。
IV-C2 混合预测中的作用
为了进一步深入研究表XI中列出的边际预测和联合预测的特征,原始HPP(ID.0)是用消融(ID.1-6)指导来测量的:推理损失();边际预测(最有可能,完整);和联合预测(Occ.) 在学习和优化过程中。 主要发现总结如下:
(1) 一致的推理: 比较 ID.1 和 ID.2,显着的安全性改进 ( CR) 凸显了推理学习中边际预测的一致性作用 ()。 HPP 中的联合预测用于指导调节规划的内部边际一致性。
(2) 互补影响: 与 ID.4 和 ID.5 中的单独指导 ( CR) 相比,相互覆盖收益中的混合预测效益规划。 HPP 中的一致性设计增强了这一点。 1) 与 ID.3 相比,全运动预测引导 (ID.2) 产生安全规划 ( CR),且不会牺牲准确性。 2) 混合预测中的良好对齐导致 ID.5 和 ID.6 中的性能接近,添加了最可能的边缘预测。 这些相互影响确定了混合预测由于以下原因而无法发挥作用的情况下的规划性能:(1) 位姿和速度的状态误差; (2) 未来的不确定性; (3) 在时空范围内终止。
IV-D 定性结果
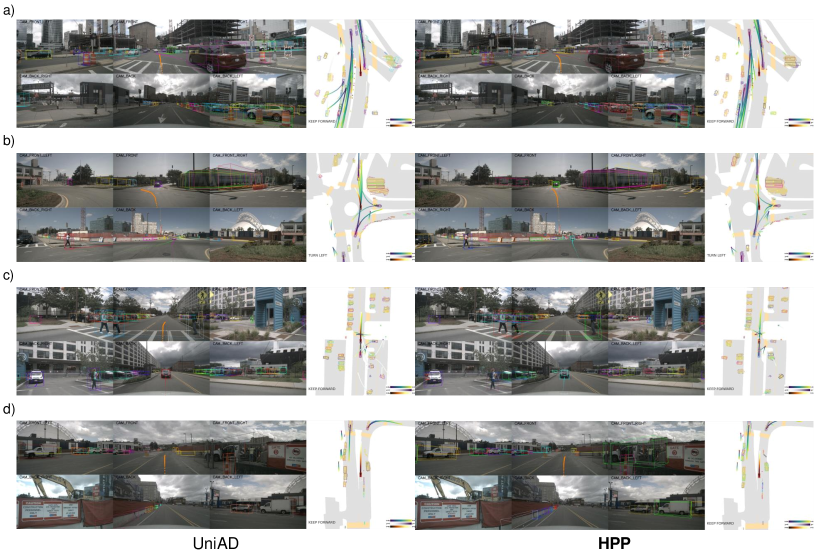
无花果。 7 和 8 展示了在 nuScenes [51] 和 WOMD [52] 中集成混合预测的定性优势分别为基准。 在图7a所示的综合测试场景中,来自占用者的联合引导确保了巡航期间一致的运动预测。 值得注意的是,图7b表明混合预测意识有助于一致的规划,增强平滑巡航的推理行为,而不会过度保守的回避,从而减轻车道边界附近的风险。 图7c进一步说明了互补效应,当占用情况不确定时,运动预测优先指导规划。 相互影响在图7d中很明显,其中自我车辆保持在车道上而不是避开,因为后面骑自行车的人的占用预测受到边缘预测的限制,遵循直线轨迹,保持与自我车辆的安全距离。
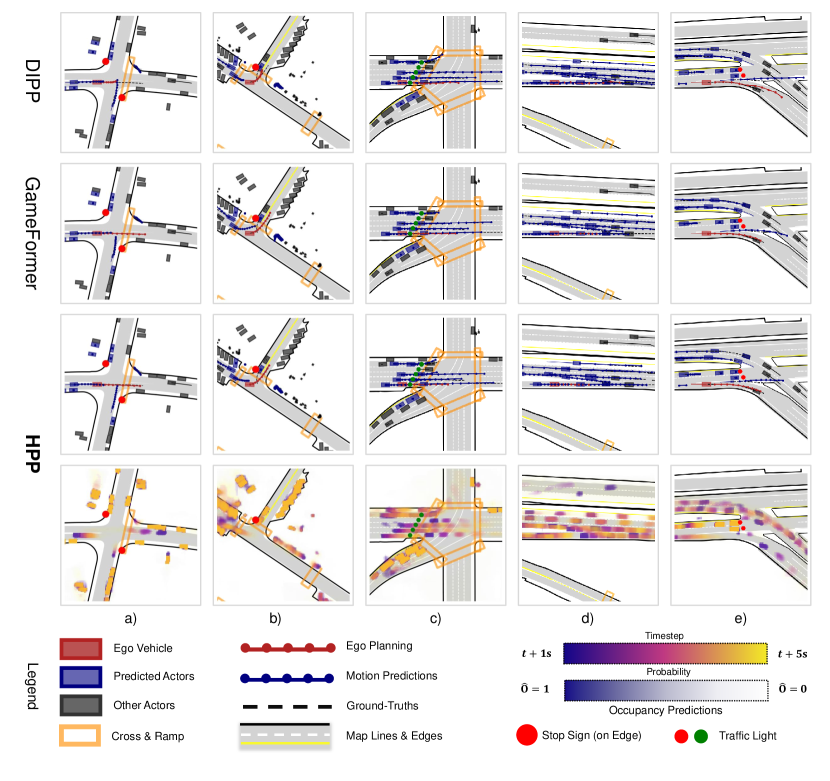
在图8中,WOMD交互场景的定性评估强调了HPP卓越的推理能力和安全意识规划。 在图8a中,DIPP[3]在紧急停止时遇到故障,暴露出运动预测和规划之间缺乏一致性,而HPP和GameFormer[ 34] 围绕障碍物进行更顺畅的规划。 HPP 中的运动预测通过 [34] 运行得更加平稳,因为占用预测会调节关节行为。 这很重要,因为推理的运动预测[34]可能会为了安全性(图8b)和准确性(图8c)而牺牲一致性)。 高速情况(图8d、图8e)进一步证明了HPP运动预测和规划之间的相互一致性,展示了其在不同驾驶环境中的适应性和鲁棒性。 这些结果强调了 HPP 在增强自动驾驶系统的一致性和安全性方面的功效。
IV-E 未来展望
在引入 HPP 时,我们主张采用模块化协同设计和优化原则来塑造 ADS。 随着面向规划的模块化学习系统的概念越来越受欢迎,强调反映现实场景复杂性的组织良好且同时集成的模块的重要性至关重要。 未来,我们会看到基于代理的模型,例如大语言模型,促进各个模块之间的连接,以确保无缝集成。 HPP为模块级集成奠定了基础,未来的工作将深入探索预测和规划之间的中间级集成和指导。
V 结论
在本文中,我们开发了 HPP,一种用于自动驾驶系统的模块化协同设计优化框架。 HPP的主要重点是集成混合预测和规划,其中三个子模块,即MS-OccFormer、GTFormer和Ego Planner利用混合预测引导学习和优化管道解决一致性问题并增强适应性。 HPP 已在不同的基准上进行了广泛的评估,结果一致证明了与最先进的方法相比,它在预测和规划指标方面的卓越性能。 HPP 中的混合预测意识结合了联合行为和占用预测,提高了现实场景中的质量一致性、安全性和可行性。 通过阐明模块化协同设计中的作用以及通过混合预测增强规划的互补效应,HPP 展示了其通过解决预测和规划挑战来推进该领域发展的潜力,为自动驾驶框架的持续发展做出贡献。
| Notation | Meaning | Testing Benchmarks | ||
| nuScenes | WOMD | CARLA | ||
| Size of BEV space | 200 | 128/256 | 128 | |
| BEV length (m) | 50 | 64 | 64 | |
| Max number of agents | - | 11/33 | 11 | |
| Max number of map | - | 100 | 50 | |
| Future Horizons (s) | 3/2/6 | 5/8 | 2 | |
| Future frequency (Hz) | 2 | 2/1 | 2 | |
| Number of modalities | 6 | 6 | 6 | |
| Occ integration levels | 3 | 3 | 3 | |
| Reasoning levels | 3 | 3 | 3 | |
| Layers in Ego Planner | 3 | 3 | 3 | |
| Number of attention heads | 8 | 8 | 8 | |
| Embedding size | 256 | 256 | 256 | |
| Activation function | ||||
| Dropout rate | 0.1 | 0.1 | 0.1 | |
| Batch size | 4 | 24 | 32 | |
| Learning rate | ||||
| Training epochs | 20 | 20 | 20 | |
参考
- [1] L. Chen, Y. Li, C. Huang, B. Li, Y. Xing, D. Tian, L. Li, Z. Hu, X. Na, Z. Li et al., “Milestones in autonomous driving and intelligent vehicles: Survey of surveys,” IEEE Transactions on Intelligent Vehicles, 2022.
- [2] Y. Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang et al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 853–17 862.
- [3] Z. Huang, H. Liu, J. Wu, and C. Lv, “Differentiable integrated motion prediction and planning with learnable cost function for autonomous driving,” arXiv preprint arXiv:2207.10422, 2022.
- [4] S. Hu, L. Chen, P. Wu, H. Li, J. Yan, and D. Tao, “St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning,” in European Conference on Computer Vision. Springer, 2022, pp. 533–549.
- [5] B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” arXiv preprint arXiv:2303.12077, 2023.
- [6] S. Hagedorn, M. Hallgarten, M. Stoll, and A. Condurache, “Rethinking integration of prediction and planning in deep learning-based automated driving systems: a review,” arXiv preprint arXiv:2308.05731, 2023.
- [7] X. Mo, Z. Huang, Y. Xing, and C. Lv, “Multi-agent trajectory prediction with heterogeneous edge-enhanced graph attention network,” IEEE Transactions on Intelligent Transportation Systems, 2022.
- [8] S. Pini, C. S. Perone, A. Ahuja, A. S. R. Ferreira, M. Niendorf, and S. Zagoruyko, “Safe real-world autonomous driving by learning to predict and plan with a mixture of experts,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 10 069–10 075.
- [9] H. Liu, Z. Huang, and C. Lv, “Occupancy prediction-guided neural planner for autonomous driving,” arXiv preprint arXiv:2305.03303, 2023.
- [10] Y. Hu, K. Li, P. Liang, J. Qian, Z. Yang, H. Zhang, W. Shao, Z. Ding, W. Xu, and Q. Liu, “Imitation with spatial-temporal heatmap: 2nd place solution for nuplan challenge,” arXiv preprint arXiv:2306.15700, 2023.
- [11] M. Bansal, A. Krizhevsky, and A. Ogale, “Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst,” arXiv preprint arXiv:1812.03079, 2018.
- [12] S. Mozaffari, O. Y. Al-Jarrah, M. Dianati, P. Jennings, and A. Mouzakitis, “Deep learning-based vehicle behavior prediction for autonomous driving applications: A review,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 1, pp. 33–47, 2020.
- [13] J. Kim, R. Mahjourian, S. Ettinger, M. Bansal, B. White, B. Sapp, and D. Anguelov, “Stopnet: Scalable trajectory and occupancy prediction for urban autonomous driving,” arXiv preprint arXiv:2206.00991, 2022.
- [14] L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,” arXiv preprint arXiv:2306.16927, 2023.
- [15] T. Ye, W. Jing, C. Hu, S. Huang, L. Gao, F. Li, J. Wang, K. Guo, W. Xiao, W. Mao et al., “Fusionad: Multi-modality fusion for prediction and planning tasks of autonomous driving,” arXiv preprint arXiv:2308.01006, 2023.
- [16] X. Jia, P. Wu, L. Chen, Y. Liu, H. Li, and J. Yan, “Hdgt: Heterogeneous driving graph transformer for multi-agent trajectory prediction via scene encoding,” IEEE transactions on pattern analysis and machine intelligence, 2023.
- [17] Z. Huang, X. Mo, and C. Lv, “Multi-modal motion prediction with transformer-based neural network for autonomous driving,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 2605–2611.
- [18] X. Mo, Y. Xing, H. Liu, and C. Lv, “Map-adaptive multimodal trajectory prediction using hierarchical graph neural networks,” IEEE Robotics and Automation Letters, 2023.
- [19] S. Shi, L. Jiang, D. Dai, and B. Schiele, “Motion transformer with global intention localization and local movement refinement,” Advances in Neural Information Processing Systems, 2022.
- [20] Y. Hu, W. Shao, B. Jiang, J. Chen, S. Chai, Z. Yang, J. Qian, H. Zhou, and Q. Liu, “Hope: Hierarchical spatial-temporal network for occupancy flow prediction,” arXiv preprint arXiv:2206.10118, 2022.
- [21] X. Huang, X. Tian, J. Gu, Q. Sun, and H. Zhao, “Vectorflow: Combining images and vectors for traffic occupancy and flow prediction,” arXiv preprint arXiv:2208.04530, 2022.
- [22] T. Gilles, S. Sabatini, D. Tsishkou, B. Stanciulescu, and F. Moutarde, “Thomas: Trajectory heatmap output with learned multi-agent sampling,” arXiv preprint arXiv:2110.06607, 2021.
- [23] A. Kamenev, L. Wang, O. B. Bohan, I. Kulkarni, B. Kartal, A. Molchanov, S. Birchfield, D. Nistér, and N. Smolyanskiy, “Predictionnet: Real-time joint probabilistic traffic prediction for planning, control, and simulation,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 8936–8942.
- [24] Z. Huang, H. Liu, J. Wu, and C. Lv, “Conditional predictive behavior planning with inverse reinforcement learning for human-like autonomous driving,” IEEE Transactions on Intelligent Transportation Systems, 2023.
- [25] P. Hang, C. Lv, C. Huang, J. Cai, Z. Hu, and Y. Xing, “An integrated framework of decision making and motion planning for autonomous vehicles considering social behaviors,” IEEE transactions on vehicular technology, vol. 69, no. 12, pp. 14 458–14 469, 2020.
- [26] D. Xu, Y. Chen, B. Ivanovic, and M. Pavone, “Bits: Bi-level imitation for traffic simulation,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 2929–2936.
- [27] H. Liu, Z. Huang, X. Mo, and C. Lv, “Augmenting reinforcement learning with transformer-based scene representation learning for decision-making of autonomous driving,” arXiv preprint arXiv:2208.12263, 2022.
- [28] K. Renz, K. Chitta, O.-B. Mercea, A. Koepke, Z. Akata, and A. Geiger, “Plant: Explainable planning transformers via object-level representations,” arXiv preprint arXiv:2210.14222, 2022.
- [29] N. Rhinehart, R. McAllister, K. Kitani, and S. Levine, “Precog: Prediction conditioned on goals in visual multi-agent settings,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 2821–2830.
- [30] Z. Huang, H. Liu, J. Wu, W. Huang, and C. Lv, “Learning interaction-aware motion prediction model for decision-making in autonomous driving,” arXiv preprint arXiv:2302.03939, 2023.
- [31] J. L. V. Espinoza, A. Liniger, W. Schwarting, D. Rus, and L. Van Gool, “Deep interactive motion prediction and planning: Playing games with motion prediction models,” in Learning for Dynamics and Control Conference. PMLR, 2022, pp. 1006–1019.
- [32] C. Burger, J. Fischer, F. Bieder, Ö. Ş. Taş, and C. Stiller, “Interaction-aware game-theoretic motion planning for automated vehicles using bi-level optimization,” in 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2022, pp. 3978–3985.
- [33] W. Wang, L. Wang, C. Zhang, C. Liu, L. Sun et al., “Social interactions for autonomous driving: A review and perspectives,” Foundations and Trends® in Robotics, vol. 10, no. 3-4, pp. 198–376, 2022.
- [34] Z. Huang, H. Liu, and C. Lv, “Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving,” arXiv preprint arXiv:2303.05760, 2023.
- [35] P. Karkus, B. Ivanovic, S. Mannor, and M. Pavone, “Diffstack: A differentiable and modular control stack for autonomous vehicles,” in Conference on Robot Learning. PMLR, 2023, pp. 2170–2180.
- [36] N. Hanselmann, K. Renz, K. Chitta, A. Bhattacharyya, and A. Geiger, “King: Generating safety-critical driving scenarios for robust imitation via kinematics gradients,” in European Conference on Computer Vision. Springer, 2022, pp. 335–352.
- [37] S. Casas, A. Sadat, and R. Urtasun, “Mp3: A unified model to map, perceive, predict and plan,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 403–14 412.
- [38] M. Liang, B. Yang, W. Zeng, Y. Chen, R. Hu, S. Casas, and R. Urtasun, “Pnpnet: End-to-end perception and prediction with tracking in the loop,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 553–11 562.
- [39] Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Y. Qiao, and J. Dai, “Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers,” in European conference on computer vision. Springer, 2022, pp. 1–18.
- [40] Y. Zhang, Z. Zhu, W. Zheng, J. Huang, G. Huang, J. Zhou, and J. Lu, “Beverse: Unified perception and prediction in birds-eye-view for vision-centric autonomous driving,” arXiv preprint arXiv:2205.09743, 2022.
- [41] A. K. Akan and F. Güney, “Stretchbev: Stretching future instance prediction spatially and temporally,” in European Conference on Computer Vision. Springer, 2022, pp. 444–460.
- [42] H. Li, C. Sima, J. Dai, W. Wang, L. Lu, H. Wang, J. Zeng, Z. Li, J. Yang, H. Deng et al., “Delving into the devils of bird’s-eye-view perception: A review, evaluation and recipe,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [43] X. Jia, Y. Gao, L. Chen, J. Yan, P. L. Liu, and H. Li, “Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7953–7963.
- [44] J. Mao, Y. Qian, H. Zhao, and Y. Wang, “Gpt-driver: Learning to drive with gpt,” arXiv preprint arXiv:2310.01415, 2023.
- [45] J. Mao, J. Ye, Y. Qian, M. Pavone, and Y. Wang, “A language agent for autonomous driving,” arXiv preprint arXiv:2311.10813, 2023.
- [46] C. Sima, K. Renz, K. Chitta, L. Chen, H. Zhang, C. Xie, P. Luo, A. Geiger, and H. Li, “Drivelm: Driving with graph visual question answering,” arXiv preprint arXiv:2312.14150, 2023.
- [47] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [48] H. Liu, Z. Huang, and C. Lv, “Multi-modal hierarchical transformer for occupancy flow field prediction in autonomous driving,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 1449–1455.
- [49] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022.
- [50] M. Bhardwaj, B. Boots, and M. Mukadam, “Differentiable gaussian process motion planning,” in 2020 IEEE international conference on robotics and automation (ICRA). IEEE, 2020, pp. 10 598–10 604.
- [51] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631.
- [52] S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y. Chai, B. Sapp, C. R. Qi, Y. Zhou et al., “Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9710–9719.
- [53] R. Mahjourian, J. Kim, Y. Chai, M. Tan, B. Sapp, and D. Anguelov, “Occupancy flow fields for motion forecasting in autonomous driving,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 5639–5646, 2022.
- [54] W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Urtasun, “End-to-end interpretable neural motion planner,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8660–8669.
- [55] P. Hu, A. Huang, J. Dolan, D. Held, and D. Ramanan, “Safe local motion planning with self-supervised freespace forecasting,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 732–12 741.
- [56] T. Khurana, P. Hu, A. Dave, J. Ziglar, D. Held, and D. Ramanan, “Differentiable raycasting for self-supervised occupancy forecasting,” in European Conference on Computer Vision. Springer, 2022, pp. 353–369.
- [57] W. Tong, C. Sima, T. Wang, L. Chen, S. Wu, H. Deng, Y. Gu, L. Lu, P. Luo, D. Lin et al., “Scene as occupancy,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8406–8415.
- [58] Z. Chen, M. Ye, S. Xu, T. Cao, and Q. Chen, “Deepemplanner: An em motion planner with iterative interactions,” arXiv preprint arXiv:2311.08100, 2023.
- [59] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “Carla: An open urban driving simulator,” in Conference on robot learning. PMLR, 2017, pp. 1–16.
- [60] K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for autonomous driving,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- [61] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 4, pp. 834–848, 2017.
- [62] D. Kim, S. Woo, J.-Y. Lee, and I. S. Kweon, “Video panoptic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 9859–9868.
- [63] J. Gu, C. Hu, T. Zhang, X. Chen, Y. Wang, Y. Wang, and H. Zhao, “Vip3d: End-to-end visual trajectory prediction via 3d agent queries,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5496–5506.
- [64] O. Scheel, L. Bergamini, M. Wolczyk, B. Osiński, and P. Ondruska, “Urban driver: Learning to drive from real-world demonstrations using policy gradients,” in Conference on Robot Learning. PMLR, 2022, pp. 718–728.
- [65] Y. Liu, J. Zhang, L. Fang, Q. Jiang, and B. Zhou, “Multimodal motion prediction with stacked transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7577–7586.
- [66] A. Hu, Z. Murez, N. Mohan, S. Dudas, J. Hawke, V. Badrinarayanan, R. Cipolla, and A. Kendall, “Fiery: Future instance prediction in bird’s-eye view from surround monocular cameras,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 273–15 282.
- [67] P. Li, S. Ding, X. Chen, N. Hanselmann, M. Cordts, and J. Gall, “Powerbev: A powerful yet lightweight framework for instance prediction in bird’s-eye view,” arXiv preprint arXiv:2306.10761, 2023.
- [68] N. Rhinehart, R. McAllister, and S. Levine, “Deep imitative models for flexible inference, planning, and control,” arXiv preprint arXiv:1810.06544, 2018.
- [69] B. Varadarajan, A. Hefny, A. Srivastava, K. S. Refaat, N. Nayakanti, A. Cornman, K. Chen, B. Douillard, C. P. Lam, D. Anguelov et al., “Multipath++: Efficient information fusion and trajectory aggregation for behavior prediction,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 7814–7821.
- [70] A. Kumar, A. Zhou, G. Tucker, and S. Levine, “Conservative q-learning for offline reinforcement learning,” Advances in Neural Information Processing Systems, vol. 33, pp. 1179–1191, 2020.
- [71] Z. Zhang, A. Liniger, D. Dai, F. Yu, and L. Van Gool, “End-to-end urban driving by imitating a reinforcement learning coach,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15 222–15 232.