22institutetext:出发。 东京大学信息科学技术学部
33institutetext:出发。 哥伦比亚大学机械工程系
44institutetext:出发。 东京大学机械工学部
55institutetext:出发。 上海交通大学自动化学院
SGS-SLAM:神经密集 SLAM 的语义高斯泼溅
摘要
我们提出了 SGS-SLAM,这是第一个基于高斯 Splatting 的语义视觉 SLAM 系统。 它通过多通道优化融合了外观、几何和语义特征,解决了神经隐式 SLAM 系统在高质量渲染、场景理解和对象级几何方面的过度平滑限制。 我们引入了一种独特的语义特征损失,有效弥补了传统深度和颜色损失在对象优化中的缺点。 通过语义引导的关键帧选择策略,我们可以防止累积错误导致的错误重建。 大量实验表明,SGS-SLAM 在相机姿态估计、地图重建、精确语义分割和对象级几何精度方面提供了最先进的性能,同时确保了实时渲染能力。
关键词:
SLAM 3D 重建 3D 语义 3D 分割1简介

密集视觉同步定位与建图(SLAM)是计算机视觉领域的一个关键问题。 它的目标是在不可见的环境中重建密集的 3D 地图,同时实时跟踪相机姿势。 传统的视觉SLAM系统[6,29,32,27,39,9]在使用点云和体素的稀疏重建方面表现出色,但在密集重建方面却表现不佳。 为了提取密集的几何信息以获得高质量的表示,基于学习的 SLAM 方法[1, 36]受到了广泛的关注。 他们展示了生成良好 3D 全球地图的能力,同时展示了对噪声和异常值的鲁棒性。 此外,从神经辐射场(NeRF)[25]的进展中汲取灵感,基于NeRF的SLAM方法[35,47,18,44,19,37,8] 取得了进一步的进展。 他们擅长通过可微分渲染捕获密集的光度信息来产生准确和高保真度的全局重建。
然而,基于 NeRF 的 SLAM 方法采用多层感知器(MLP)作为场景的隐式神经表示,这引入了一些具有挑战性的局限性。 首先,MLP 模型面临着对象边缘的过度平滑问题,导致地图中缺乏细粒度的细节。 这一挑战还给解开对象的表示带来了困难,使得分割、编辑和操作场景中的对象变得非常困难。 此外,当应用于更大的场景时,MLP 模型很容易出现灾难性遗忘。 这意味着合并新场景可能会对先前学习的模型的精度产生不利影响,从而降低整体性能。 此外,基于 NeRF 的方法计算效率低下。 由于整个场景是通过一个或多个 MLP 进行建模的,因此需要进行大量的模型调整来添加或更新场景。
在这种情况下,与基于 NeRF 的神经表示相反,我们的探索转向基于 3D 高斯辐射场 [17] 的体积表示。 这种方法标志着一个重大转变,并在场景表示方面提供了显着的优势。
受益于 3D 图元的光栅化,Gaussian Splatting 表现出非常快的渲染速度,并允许直接梯度流到每个高斯参数。 这导致优化过程中密集光度损失和参数之间几乎呈线性投影,这与 NeRF 模型中看到的分层像素采样和通过多个非线性层的间接梯度流不同。 此外,直接投影功能简化了将新参数作为单独通道添加到高斯场的过程,从而实现动态多通道渲染。 至关重要的是,我们将语义图集成到 3D 高斯场中,这对于机器人和混合现实的应用至关重要。 这种集成允许实时渲染外观、深度和语义颜色。
与神经隐式语义SLAM系统(例如DNS-SLAM [19]和SNI-SLAM [46])相比,我们的系统在渲染速度方面表现出显着的优越性,重建质量和分割精度。 利用这些优势,我们的方法可以精确编辑和操作特定场景元素,同时保持整体渲染的高保真度。 此外,使用明确的空间和语义信息来识别场景内容有助于优化相机跟踪。 特别是,我们结合了基于关键帧选择的几何和语义标准的两级调整。 这个过程依赖于识别之前在轨迹中看到的物体。 在合成和真实场景基准上进行了大量的实验。 这些实验将我们的方法与基于隐式 NeRF 的方法[41,47,37,15]和基于 3D-Gaussian 的新颖方法[16]进行比较,评估性能映射、跟踪和语义分割。
总的来说,我们的工作提出了几个关键贡献,总结如下:
-
•
我们介绍 SGS-SLAM,这是第一个基于 3D 高斯的语义密集视觉 SLAM 系统。 SGS-SLAM 采用显式体积表示,可实现快速实时的摄像机跟踪和场景映射。 更重要的是,它利用 2D 语义图来学习高斯表达的 3D 语义表示。 与之前基于 NeRF 的方法提供的物体边缘过于平滑的情况相比,SGS-SLAM 提供了高保真重建和最佳分割精度。
-
•
在SGS-SLAM中,语义图为优化参数和选择关键帧提供额外的监督。 我们采用多通道参数优化策略,其中外观、几何和语义信号共同有助于相机跟踪和场景重建。 此外,SGS-SLAM 在跟踪阶段利用这些不同的通道进行关键帧选择,专注于主动识别轨迹中较早看到的物体。 这种方法可以根据所选关键帧实现高效、高质量的地图重建。
-
•
SGS-SLAM 利用语义表示,在 3D 场景中提供高度准确的解缠结对象表示,为场景编辑和操作等下游任务奠定坚实的基础。 SGS-SLAM 有助于实时动态移动、旋转或移除地图中的物体。 这是通过指定对象的语义标签对高斯进行分组来实现的。
2相关工作
2.1语义SLAM
语义信息对于 SLAM 系统非常重要[27,12,38,30],这是机器人和 VR 或 AR 领域应用的关键要求。 实时密集语义SLAM系统[32,1,31]将语义信息集成到3D几何表示中。 传统的语义SLAM系统依赖于稀疏的3D语义表达,例如体素[13]、点云[28]和有符号距离场[28]。 由于语义理解有限,这些方法很难准确解释复杂的环境。 这导致环境特征的简化分类,可能无法捕获空间内所有对象及其关系。 此外,这些方法在重建速度、高保真模型采集和内存使用方面表现出局限性。
2.2神经隐式SLAM
基于 NeRF [24] 的方法,处理复杂的拓扑结构和可微的场景表示方法,引起了广泛的关注,导致了神经隐式 SLAM 方法的发展[3, 21, 7, 20, 45]。 iMAP [35] 使用单个 MLP 进行场景表示,这在大规模场景中显示出局限性。 NICE-SLAM [47] 使用预训练的多个 MLP 进行分层场景表示。 Co-SLAM [37] 将基于像素集的关键帧跟踪与 one-blob 编码相结合。 Go-SLAM [44] 使用 Droid-SLAM 作为前端跟踪系统和多分辨率哈希编码 [26] 进行映射,同时集成闭环检测和全局优化。 然而,这些方法无法利用地图中的语义信息。 NIDS-SLAM [11] 利用 ORB-SLAM3 [2] 和 Instant-NGP [26] 成熟的前端跟踪进行映射但没有优化 3D 重建的联合语义特征。 DNS-SLAM[19]提出了一种2D语义先验系统,该系统提供多视图几何约束,但没有利用语义特征优化3D重建。 SNI-SLAM [46] 是与我们并行的工作,它引入了几何监督的语义损失,但仍然受到 NeRF 体积渲染的效率限制。
2.33D高斯泼溅SLAM
3D高斯溅射[17]出色的性能和快速光栅化能力使场景重建的效率和精度更高。 然而,现有的基于3D-高斯的SLAM系统[40,16,14]缺乏传统的有效跟踪优化,限制了跟踪精度和识别场景中语义信息的能力。 我们将语义特征融合到几何和外观中,并在跟踪过程中的关键帧选择期间集成 3D 语义特征。 这使我们能够在保持实时性能的同时获得更有效、更高分辨率的场景分割结果。
3方法
SGS-SLAM是一种基于高斯的语义视觉SLAM系统。 Sec. 3.1介绍了用于联合参数优化的多通道高斯表示。 与之前的 SLAM 技术一样,我们的方法可以分为两个过程:跟踪和建图。 跟踪过程估计每帧的相机姿态,同时保持场景参数固定。 映射根据估计的相机姿势优化场景表示。 Sec. 3.2详细解释了分解步骤。 此外,Sec. 3.3 将场景操作作为下游任务的案例研究。 图 1显示了我们系统的概述。
3.1多通道高斯表示
场景在地图上使用高斯影响函数 表示,为简单起见,这些高斯函数是各向同性的,如 [16] 中提出的:
| (1) |
这里,表示不透明度,表示中心位置,表示半径。 每个高斯还带有 RGB 颜色 。
为了优化高斯函数的参数来表示场景,我们需要以可微分的方式将高斯函数渲染成2D图像。 我们使用 [22] 中的 render 方法,提供渲染颜色深度的扩展功能。 它的工作原理是通过近似影响函数 沿像素坐标深度维度的积分投影,将 3D 高斯分布到图像平面中。 高斯 的中心、半径 和深度 (在相机坐标中)使用标准点渲染公式进行喷溅:
| (2) |
其中 是相机内在矩阵, 是捕获相机在帧 、 处旋转和平移的外在矩阵是焦距。 可以通过将高斯按深度顺序排序并使用最大体绘制公式[23]进行从前到后的体绘制来组合所有高斯对该像素的影响:
| (3) |
像素级渲染颜色 是每个高斯 颜色的总和,并由影响函数 加权(替换 3D 均值和协方差矩阵与 2D splatted 版本),乘以遮挡项,考虑到当前高斯前面的所有高斯的影响。 类似地,深度可以表示为:
| (4) |
其中表示每个高斯的深度。 通过设置,我们可以计算出轮廓,它有助于确定像素在当前视图[16]中是否可见。 可见性的这一方面对于相机姿态估计至关重要,因为它依赖于当前重建的地图。 此外,它还用于地图重建,其中在缺乏足够信息的像素中引入新的高斯。
虽然获取 3D 语义信息具有挑战性并且通常需要大量的手动标记,但 2D 语义标签更容易访问。 在我们的方法中,我们利用 2D 语义标签,这些标签通常在数据集中提供,或者可以使用现成的方法轻松获得。 我们为高斯参数分配不同的通道来表示它们的语义标签和颜色。 在渲染过程中,可以从重建的3D场景中渲染2D语义图,如下所示:
| (5) |
其中 表示与高斯相关的语义颜色。 在映射过程中,该语义颜色与外观颜色和深度共同优化。
SGS-SLAM 中采用的高斯表示有助于以高渲染速度进行高质量重建,从而以卓越的细节和效率捕获复杂的纹理和几何图形,从而提供卓越的精度。 此外,我们的方法中语义特征的集成显着提高了最佳场景解释和精确的对象级几何形状,有效缓解了 NeRF 模型中普遍存在的过度平滑问题。
3.2跟踪和绘图
3.2.1 相机姿态估计
给定第一帧,相机姿态被设置为恒等并用作以下跟踪和映射过程的参考坐标。 在新的时间步评估 RGB-D 视图的相机位姿时,初始相机位姿是通过向前一个位姿添加位移来确定的,假设速度恒定,如 。 接下来,通过最小化地面真实颜色()、深度图像()和语义图()之间的跟踪损失来迭代地细化当前姿态。 t2>) 及其不同的渲染视图:
| (6) |
在这里,只有那些具有足够大轮廓的渲染像素才会被纳入损失计算中。 阈值旨在利用之前已经优化过的地图,并且在当前相机视图中具有很高的确定性。
3.2.2 关键帧选择和加权
在 SLAM 系统的跟踪阶段,关键帧被同时识别和存储。 这些关键帧提供了对象的不同视图,对于映射以完善 3D 场景重建至关重要。 SGS-SLAM 以恒定的时间间隔捕获并存储关键帧。 随后,基于几何和语义约束选择与当前帧相关联的关键帧。 具体来说,我们从当前帧中随机选择像素并在 3D 场景中提取它们对应的高斯 。 然后,这些高斯函数 被投影到关键帧的摄像机视图上,作为 。 根据几何重叠率进行评估:
| (7) |
它表示在关键帧的相机视图中捕获的高斯比例。 和 是相机视图的宽度和高度。 低于特定阈值的候选者将被删除。 在最初的基于几何的选择之后,基于语义标准进行第二次过滤。 我们丢弃语义图 与当前帧的语义图相同的关键帧,如高 mIoU 分数所示。 这个阈值表示为,旨在从不同的角度增强地图优化,优先选择具有低 mIoU 重叠的视图。 剩余的候选者被随机采样以作为与当前帧相关联的选定关键帧。 此外,我们计算每个关键帧的不确定性得分,定义为,其中表示关键帧的时间戳,是衰减系数。 该不确定性分数用于对映射损失进行加权。 这背后的直觉是,由于相机跟踪误差沿着轨迹累积,具有较晚时间戳索引的关键帧在重建中具有更高的不确定性。
3.2.3 地图重建
该场景使用三个不同通道的高斯模型进行建模:(1) 它们的平均坐标表示场景的几何信息,(2) 它们的外观颜色描述场景的视觉外观,(3) 它们的语义颜色表示对象的语义标签。 这些跨通道的参数在高斯致密化和优化过程中被联合优化,而通过跟踪确定的相机位姿保持固定。
从第一帧开始,所有像素都有助于初始化地图。 在新时间步的地图重建过程中,新的高斯函数被引入到地图中密度不够或在先前估计的地图前面显示新几何形状的区域。 新高斯的添加是通过对像素应用掩模来调节的,其中(ii)轮廓值低于某个阈值,表示可见性的高度不确定性,或者(ii)地面实况深度比估计深度小得多,表明存在新的几何实体。
致密化后,通过最小化贴图损失来优化贴图参数:
| (8) |
其中和是关于外观图像和语义图像的加权SSIM损失[17]:
| (9) |
、、 和 是预定义的超参数, 是定义在秒 3.2.2。
与现有基于 NeRF 的方法[47,15,19,46]需要复杂的模型架构和特征融合策略相比,SGS-SLAM 采用显式高斯表示进行映射。 这种方法允许直接梯度流到每个参数,从而实现高渲染速度和最佳重建质量。 与最近基于高斯的方法[16, 40]相比,SGS-SLAM融合了几何、外观和语义特征以进行多通道渲染。 这使得能够跨不同通道联合优化参数,显着提高映射和分割过程的效率和有效性。
3.3 通过对象级几何图形进行场景操作
鉴于场景由高斯明确表示,直接编辑和操作目标高斯组变得可行。 在我们的例子中,高斯群是根据语义标签来识别的。 映射过程生成这些高斯函数,如 Eq. 1 中所定义,允许按以下方式进行进一步操作:
| (10) |
其中编辑后的高斯函数 受到可见性掩模 、转换函数 和高斯函数语义标签 的影响。 可见性掩码根据确定是否应保留高斯(1)或删除(0)。 转换函数 对所选 上的高斯坐标进行变换,从而实现空间操作。
4实验
4.1 实验设置
4.1.1 数据集
我们在合成数据集和真实数据集上评估我们的方法。 为了与其他神经隐式 SLAM 方法进行比较,我们评估了来自 Replica 数据集 [34] 的合成场景以及来自 ScanNet [4] 和 ScanNet++ [43 的真实世界场景]数据集。 Replica 的地面实况相机位姿和语义图由仿真提供,ScanNet 的地面实况相机位姿由 BundleFusion [5] 生成。 真实的 2D 语义标签由数据集提供。
4.1.2指标
我们使用 PSNR、Depth-L1(在 2D 深度图上)、SSIM 和 LPIPS 来评估重建质量。 对于相机位姿的评估,我们采用平均绝对轨迹误差(ATE RMSE)。 对于语义分割,我们计算 mIoU 分数。
4.1.3 基线
我们将跟踪和建图与最先进的方法 iMap [35]、NICE-SLAM [47]、Co-SLAM [37] 进行比较、ESLAM [15] 和 SplaTAM [16]。 对于语义分割精度,我们与 NIDS-SLAM [11]、DNS-SLAM [19] 和 SNI-SLAM [46] 进行比较。
4.2测绘和定位评估
我们使用副本数据集[34]展示了重建质量的定量测量 选项卡。 1. 我们的方法展示了最先进的性能。 与其他基线方法相比,我们的方法取得了显着优异的结果,PSNR 比它们高出 10dB。
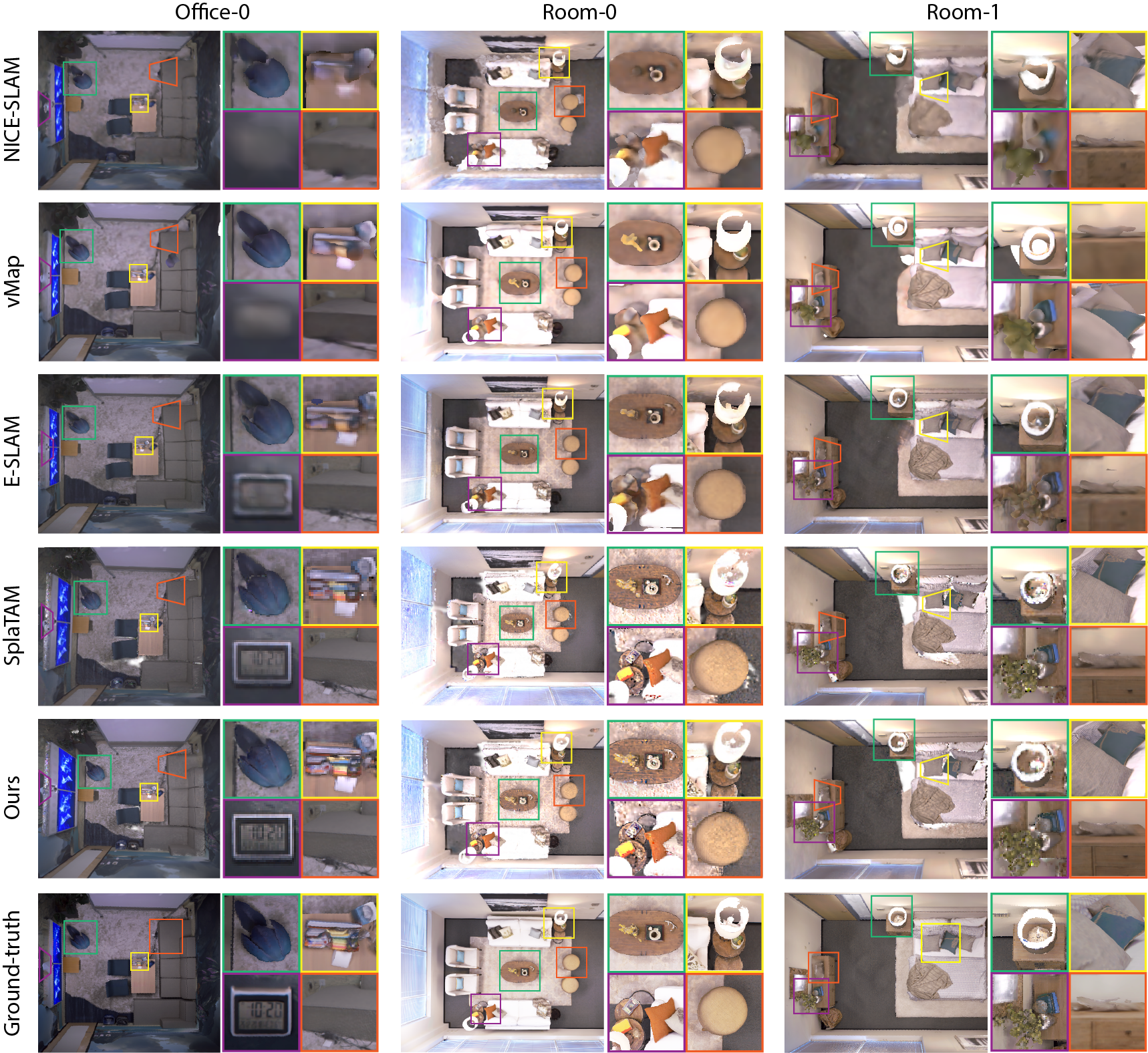
在图2中,我们展示了三个选定场景的重建结果,其中感兴趣的区域用各种颜色的框强调。 我们的方法展示了高保真重建结果。 具体来说,对于时钟、插座、茶几上的书和灯等小型、纹理复杂的物体,我们的方法比基于 NeRF 的方法显示出显着的准确性。 这是因为高斯能够表示具有复杂纹理和表面的对象。 此外,基于 NeRF 的方法经常遇到过度平滑问题,导致对象边缘模糊。 相比之下,通过利用显式高斯表示,SGS-SLAM 可以精确捕获边缘清晰的物体,无论其大小如何。 与同样基于高斯的模型 SplaTAM [16] 相比,我们的方法利用语义信息来辨别对象类别,识别视觉外观以确定纹理,并应用几何约束来保留准确的形状。 这种组合使我们的方法能够实现对象及其周围环境的彻底建模。 这些约束的结合使 SGS-SLAM 能够捕获物体的细粒度细节,从而提供高保真度和准确的重建。
| Methods | Metrics | Avg. | Room0 | Room1 | Room2 | Office0 | Office1 | Office2 | Office3 | Office4 |
| PSNR | 24.42 | 22.12 | 22.47 | 24.52 | 29.07 | 30.34 | 19.66 | 22.23 | 24.94 | |
| NICE-SLAM | SSIM | 0.809 | 0.689 | 0.757 | 0.814 | 0.874 | 0.886 | 0.797 | 0.801 | 0.856 |
| LPIPS | 0.233 | 0.330 | 0.271 | 0.208 | 0.229 | 0.181 | 0.235 | 0.209 | 0.198 | |
| PSNR | 30.24 | 27.27 | 28.45 | 29.06 | 34.14 | 34.87 | 28.43 | 28.76 | 30.91 | |
| Co-SLAM | SSIM | 0.939 | 0.910 | 0.909 | 0.932 | 0.961 | 0.969 | 0.938 | 0.941 | 0.955 |
| LPIPS | 0.252 | 0.324 | 0.294 | 0.266 | 0.209 | 0.196 | 0.258 | 0.229 | 0.236 | |
| PSNR | 29.08 | 25.32 | 27.77 | 29.08 | 33.71 | 30.20 | 28.09 | 28.77 | 29.71 | |
| ESLAM | SSIM | 0.929 | 0.875 | 0.902 | 0.932 | 0.960 | 0.923 | 0.943 | 0.948 | 0.945 |
| LPIPS | 0.336 | 0.313 | 0.298 | 0.248 | 0.184 | 0.228 | 0.241 | 0.196 | 0.204 | |
| PSNR | 33.98 | 32.48 | 33.72 | 34.96 | 38.34 | 39.04 | 31.90 | 29.70 | 31.68 | |
| SplaTAM | SSIM | 0.969 | 0.975 | 0.970 | 0.982 | 0.982 | 0.982 | 0.965 | 0.950 | 0.946 |
| LPIPS | 0.099 | 0.072 | 0.096 | 0.074 | 0.083 | 0.093 | 0.100 | 0.118 | 0.155 | |
| PSNR | 34.66 | 32.50 | 34.25 | 35.10 | 38.54 | 39.20 | 32.90 | 32.05 | 32.75 | |
| Ours | SSIM | 0.973 | 0.976 | 0.978 | 0.981 | 0.984 | 0.980 | 0.967 | 0.966 | 0.949 |
| LPIPS | 0.096 | 0.070 | 0.094 | 0.070 | 0.086 | 0.087 | 0.101 | 0.115 | 0.148 | |
| Methods | Depth L1 [cm] | ATE Mean [cm] | ATE RMSE [cm] | Track. FPS Unit | Map. FPS Unit | SLAM FPS Unit |
| iMAP | 4.645 | 3.118 | 4.153 | 9.92 | 2.23 | 1.82 |
| NICE-SLAM | 1.903 | 1.795 | 2.503 | 13.70 | 0.20 | 0.20 |
| Co-SLAM | 1.513 | 0.935 | 1.059 | 17.24 | 10.20 | 6.41 |
| ESLAM | 1.180 | 0.520 | 0.630 | 18.11 | 3.62 | 3.02 |
| Ours | 0.356 | 0.327 | 0.412 | 5.27 | 3.52 | 2.11 |
选项卡。 2 显示副本数据集[34]上的跟踪评估结果。 我们的方法擅长实现最高水平的深度 L1 损失 (cm) 和最小的 ATE 误差,在深度损失方面超过基线方法 70%,在 ATE RMSE (cm) 方面超过基线方法 34%。 这种卓越的性能可归因于我们精确的场景重建,它提供了精细的渲染结果。 反过来,高质量渲染可以防止错误的几何重建,从而有助于基于已建立的地图进行准确的相机姿态估计,否则可能会导致不准确的跟踪结果。 此外,利用高斯不同通道的特征,例如几何、外观和语义信息,提供了多个级别的监督,从而产生更强大和更准确的跟踪能力。
4.3语义分割评估
选项卡。 3 显示了我们的方法与其他神经语义 SLAM 方法相比的定量评估。 值得注意的是,我们只展示了四个场景,因为之前基于 NeRF 的语义模型仅报告这些场景的结果。 与之前的这些方法相比,SGS-SLAM 展示了最先进的性能,比初始基线高出 10% 以上。 显着的增强凸显了显式高斯表示相对于基于 NeRF 的方法的关键优势。 高斯可以精确地隔离对象边界,从而实现高度准确的 3D 场景分割。 相比之下,基于 NeRF 的方法通常很难识别单个对象,并且通常需要复杂的多级模型设计和广泛的特征融合。 我们的方法提供了无与伦比的能力来识别分解表示中的 3D 对象,这可以作为未来时间步骤中跟踪和映射的 3D 先验,并且非常适合进一步的下游任务。
| Methods | Avg. mIoU | Room0 [%] | Room1 [%] | Room2 [%] | Office0 [%] |
| NIDS-SLAM | 82.37 | 82.45 | 84.08 | 76.99 | 85.94 |
| DNS-SLAM | 84.77 | 88.32 | 84.90 | 81.20 | 84.66 |
| SNI-SLAM | 87.41 | 88.42 | 87.43 | 86.16 | 87.63 |
| Ours | 92.72 | 92.95 | 92.91 | 92.10 | 92.90 |
4.4关键帧优化评估

在现实世界的数据集中,跟踪误差往往会沿着轨迹累积,使得稍后时间戳的姿态估计不太可靠。 这种不准确性可能会影响地图重建的质量,从而对之前完善的场景产生负面影响。 一个典型的例子是 ScanNet 数据集 [4] 中的 scene0000,其中自行车和吉他等对象在轨迹的早期和晚期阶段被重新访问。 后续序列中的关键帧受不准确的相机姿势的影响,可能会破坏之前准确的重建。 图3说明了场景0000的新颖视图评估。 与基于 NeRF 和 3D 高斯的 ESLAM [15] 和 SplaTAM [16] 相比,我们的方法提供了更准确的重建结果。 自行车、垃圾桶和吉他都被准确渲染,同时保留了细节。 我们的方法有助于根据几何和语义约束选择关键帧,并在所选关键帧的优化过程中纳入不确定性加权。 该策略证明了其从不同角度进行地图优化的有效性,同时防止具有高不确定性的不可靠关键帧显着改变早期准确重建的地图。
4.5场景操作
所获得的 3D 场景内的语义掩模对于后续任务具有一系列应用。 作为说明性示例,我们演示了由 Eq. 10 定义的简单但高效的高斯编辑方法,这对于实现机器人场景操作至关重要或混合现实应用程序。

与需要对整个网络进行微调的基于 NeRF 的方法相比,SGS-SLAM 利用解耦的场景表示,可以编辑场景中的特定对象,同时保持训练有素的其余不相关环境的固定。 如图图 4所示,我们可以直接操作与编辑目标相关的高斯,例如擦除、移动、旋转罐子和桌子上的鲜花。 此外,我们可以通过选择对象的语义掩码并应用转换来对对象进行分组,例如旋转表格和上述对象,如补充材料中所示。 这种编辑功能不需要训练或微调,因此可以轻松用于下游应用程序。
4.6消融研究
我们在 ScanNet 数据集 [4] 的 scene0000 上执行 SGS-SLAM 消融,以评估多通道特征监督和关键帧优化策略的有效性。
| Settings | Depth L1 [cm] | ATE RMSE [cm] | PSNR [dB] | mIoU [%] |
| without color image () | 7.44 | 24.59 | ✗ | 68.19 |
| without depth map () | 47.66 | 40.47 | 15.14 | 54.52 |
| without semantic map () | 9.15 | 13.81 | 17.52 | ✗ |
| without silhouette threshold () | 29.12 | 357.48 | 12.06 | 28.07 |
| with multi-channel optimization | 6.18 | 11.26 | 19.47 | 70.27 |
| Settings | Depth L1 [cm] | ATE RMSE [cm] | PSNR [dB] | mIoU [%] |
| without geometric threshold () | 6.66 | 15.55 | 19.21 | 68.93 |
| without semantic threshold () | 8.44 | 12.89 | 17.84 | 69.85 |
| without uncertainty weighting () | 6.87 | 11.43 | 18.72 | 70.12 |
| with keyframe selection | 6.18 | 11.26 | 19.47 | 70.27 |
4.6.1 多渠道优化效果
选项卡。 4 显示了多通道参数优化的消融研究。 结果表明,我们的优化策略可以显着提高定位和建图性能。 具体来说,没有外观颜色的系统无法提供渲染视图,而相机姿势和深度仍然可以通过利用深度和语义输入来估计。 缺乏深度数据会导致最差的深度估计,凸显了几何监督的重要性。 此外,缺少输入语义图会禁用 3D 语义分割,并显着降低跟踪和映射的性能。 此外,轮廓阈值对于评估场景可见性至关重要,对于系统稳定性也至关重要。 如果没有这个阈值,系统的跟踪和绘图效率就会显着下降。
4.6.2 关键帧优化效果
选项卡。 5 呈现关键帧选择消融的结果。 我们的两级关键帧选择策略表明,忽略几何或语义约束会导致跟踪和映射性能显着下降。 此外,如果不结合不确定性加权,系统的性能与其完全实施相比会有所下降。
5 结论和局限性
我们提出了 SGS-SLAM,这是第一个基于 3D 高斯表示的语义密集视觉 SLAM 系统。 我们建议利用多通道参数优化,将外观、几何和语义约束相结合,以强制执行高精度 3D 语义分割和高保真密集地图重建,同时有效地产生稳健的相机位姿估计。 SGS-SLAM 利用最佳关键帧优化,实现可靠的重建质量。 大量的实验表明,我们的方法提供了最先进的跟踪和映射结果,同时保持快速的渲染速度。 此外,我们的系统生成的高质量场景重建和精确的 3D 语义标签为场景编辑等下游任务奠定了坚实的基础,为机器人或混合现实应用提供了坚实的先验知识。
5.0.1限制
SGS-SLAM 响应深度和 2D 语义信号输入以进行跟踪和绘图。 在这些信息稀缺或难以访问的情况下,系统的有效性将会受到影响。 此外,我们的方法在部署到大型场景时会产生大量内存消耗。 解决这些限制将是未来研究的目标。
参考
- [1] Bloesch, M., Czarnowski, J., Clark, R., Leutenegger, S., Davison, A.J.: Codeslam—learning a compact, optimisable representation for dense visual slam. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2560–2568 (2018)
- [2] Campos, C., Elvira, R., Rodríguez, J.J.G., Montiel, J.M., Tardós, J.D.: Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Transactions on Robotics 37(6), 1874–1890 (2021)
- [3] Chung, C.M., Tseng, Y.C., Hsu, Y.C., Shi, X.Q., Hua, Y.H., Yeh, J.F., Chen, W.C., Chen, Y.T., Hsu, W.H.: Orbeez-slam: A real-time monocular visual slam with orb features and nerf-realized mapping. In: 2023 IEEE International Conference on Robotics and Automation (ICRA). pp. 9400–9406. IEEE (2023)
- [4] Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: Scannet: Richly-annotated 3d reconstructions of indoor scenes. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5828–5839 (2017)
- [5] Dai, A., Nießner, M., Zollhöfer, M., Izadi, S., Theobalt, C.: Bundlefusion: Real-time globally consistent 3d reconstruction using on-the-fly surface reintegration. ACM Transactions on Graphics (ToG) 36(4), 1 (2017)
- [6] Davison, A.J., Reid, I.D., Molton, N.D., Stasse, O.: Monoslam: Real-time single camera slam. IEEE transactions on pattern analysis and machine intelligence 29(6), 1052–1067 (2007)
- [7] Deng, T., Liu, S., Wang, X., Liu, Y., Wang, D., Chen, W.: Prosgnerf: Progressive dynamic neural scene graph with frequency modulated auto-encoder in urban scenes. arXiv preprint arXiv:2312.09076 (2023)
- [8] Deng, T., Shen, G., Qin, T., Wang, J., Zhao, W., Wang, J., Wang, D., Chen, W.: Plgslam: Progressive neural scene represenation with local to global bundle adjustment. arXiv preprint arXiv:2312.09866 (2023)
- [9] Deng, T., Xie, H., Wang, J., Chen, W.: Long-term visual simultaneous localization and mapping: Using a bayesian persistence filter-based global map prediction. IEEE Robotics and Automation Magazine 30(1), 36–49 (2023)
- [10] Freda, L.: Plvs: A slam system with points, lines, volumetric mapping, and 3d incremental segmentation. arXiv preprint arXiv:2309.10896 (2023)
- [11] Haghighi, Y., Kumar, S., Thiran, J.P., Van Gool, L.: Neural implicit dense semantic slam. arXiv preprint arXiv:2304.14560 (2023)
- [12] He, J., Li, M., Wang, Y., Wang, H.: Ovd-slam: An online visual slam for dynamic environments. IEEE Sensors Journal (2023)
- [13] Hermans, A., Floros, G., Leibe, B.: Dense 3d semantic mapping of indoor scenes from rgb-d images. In: 2014 IEEE International Conference on Robotics and Automation (ICRA). pp. 2631–2638. IEEE (2014)
- [14] Huang, H., Li, L., Cheng, H., Yeung, S.K.: Photo-slam: Real-time simultaneous localization and photorealistic mapping for monocular, stereo, and rgb-d cameras. arXiv preprint arXiv:2311.16728 (2023)
- [15] Johari, M.M., Carta, C., Fleuret, F.: Eslam: Efficient dense slam system based on hybrid representation of signed distance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 17408–17419 (2023)
- [16] Keetha, N., Karhade, J., Jatavallabhula, K.M., Yang, G., Scherer, S., Ramanan, D., Luiten, J.: Splatam: Splat, track & map 3d gaussians for dense rgb-d slam. arXiv preprint arXiv:2312.02126 (2023)
- [17] Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics 42(4) (2023)
- [18] Kong, X., Liu, S., Taher, M., Davison, A.J.: vmap: Vectorised object mapping for neural field slam. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 952–961 (2023)
- [19] Li, K., Niemeyer, M., Navab, N., Tombari, F.: Dns slam: Dense neural semantic-informed slam. arXiv preprint arXiv:2312.00204 (2023)
- [20] Li, M., He, J., Jiang, G., Wang, H.: Ddn-slam: Real-time dense dynamic neural implicit slam with joint semantic encoding. arXiv preprint arXiv:2401.01545 (2024)
- [21] Li, M., He, J., Wang, Y., Wang, H.: End-to-end rgb-d slam with multi-mlps dense neural implicit representations. IEEE Robotics and Automation Letters 8(11), 7138–7145 (2023)
- [22] Luiten, J., Kopanas, G., Leibe, B., Ramanan, D.: Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. In: 3DV (2024)
- [23] Max, N.: Optical models for direct volume rendering. IEEE Transactions on Visualization and Computer Graphics 1(2), 99–108 (1995)
- [24] McCormac, J., Clark, R., Bloesch, M., Davison, A., Leutenegger, S.: Fusion++: Volumetric object-level slam. In: 2018 international conference on 3D vision (3DV). pp. 32–41. IEEE (2018)
- [25] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM 65(1), 99–106 (2021)
- [26] Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (ToG) 41(4), 1–15 (2022)
- [27] Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: Orb-slam: a versatile and accurate monocular slam system. IEEE transactions on robotics 31(5), 1147–1163 (2015)
- [28] Narita, G., Seno, T., Ishikawa, T., Kaji, Y.: Panopticfusion: Online volumetric semantic mapping at the level of stuff and things. In: 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 4205–4212. IEEE (2019)
- [29] Newcombe, R.A., Lovegrove, S.J., Davison, A.J.: Dtam: Dense tracking and mapping in real-time. In: 2011 international conference on computer vision. pp. 2320–2327. IEEE (2011)
- [30] Qin, T., Li, P., Shen, S.: Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Transactions on Robotics 34(4), 1004–1020 (2018)
- [31] Rosinol, A., Abate, M., Chang, Y., Carlone, L.: Kimera: an open-source library for real-time metric-semantic localization and mapping. In: 2020 IEEE International Conference on Robotics and Automation (ICRA). pp. 1689–1696. IEEE (2020)
- [32] Salas-Moreno, R.F., Newcombe, R.A., Strasdat, H., Kelly, P.H., Davison, A.J.: Slam++: Simultaneous localisation and mapping at the level of objects. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1352–1359 (2013)
- [33] Sandström, E., Li, Y., Van Gool, L., Oswald, M.R.: Point-slam: Dense neural point cloud-based slam. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18433–18444 (2023)
- [34] Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., et al.: The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797 (2019)
- [35] Sucar, E., Liu, S., Ortiz, J., Davison, A.J.: imap: Implicit mapping and positioning in real-time. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 6229–6238 (2021)
- [36] Sucar, E., Wada, K., Davison, A.: Nodeslam: Neural object descriptors for multi-view shape reconstruction. In: 2020 International Conference on 3D Vision (3DV). pp. 949–958. IEEE (2020)
- [37] Wang, H., Wang, J., Agapito, L.: Co-slam: Joint coordinate and sparse parametric encodings for neural real-time slam. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13293–13302 (2023)
- [38] Whelan, T., Leutenegger, S., Salas-Moreno, R., Glocker, B., Davison, A.: Elasticfusion: Dense slam without a pose graph. In: Proceedings of Robotics: Science and Systems. Robotics: Science and Systems (2015)
- [39] Xie, H., Deng, T., Wang, J., Chen, W.: Robust incremental long-term visual topological localization in changing environments. IEEE Transactions on Instrumentation and Measurement 72, 1–14 (2023)
- [40] Yan, C., Qu, D., Wang, D., Xu, D., Wang, Z., Zhao, B., Li, X.: Gs-slam: Dense visual slam with 3d gaussian splatting. arXiv preprint arXiv:2311.11700 (2023)
- [41] Yang, X., Li, H., Zhai, H., Ming, Y., Liu, Y., Zhang, G.: Vox-fusion: Dense tracking and mapping with voxel-based neural implicit representation. In: 2022 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). pp. 499–507. IEEE (2022)
- [42] Ye, M., Danelljan, M., Yu, F., Ke, L.: Gaussian grouping: Segment and edit anything in 3d scenes. arXiv preprint arXiv:2312.00732 (2023)
- [43] Yeshwanth, C., Liu, Y.C., Nießner, M., Dai, A.: Scannet++: A high-fidelity dataset of 3d indoor scenes. In: Proceedings of the International Conference on Computer Vision (ICCV) (2023)
- [44] Zhang, Y., Tosi, F., Mattoccia, S., Poggi, M.: Go-slam: Global optimization for consistent 3d instant reconstruction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3727–3737 (2023)
- [45] Zhou, H., Guo, Z., Liu, S., Zhang, L., Wang, Q., Ren, Y., Li, M.: Mod-slam: Monocular dense mapping for unbounded 3d scene reconstruction. arXiv preprint arXiv:2402.03762 (2024)
- [46] Zhu, S., Wang, G., Blum, H., Liu, J., Song, L., Pollefeys, M., Wang, H.: Sni-slam: Semantic neural implicit slam. arXiv preprint arXiv:2311.11016 (2023)
- [47] Zhu, Z., Peng, S., Larsson, V., Xu, W., Bao, H., Cui, Z., Oswald, M.R., Pollefeys, M.: Nice-slam: Neural implicit scalable encoding for slam. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12786–12796 (2022)
SGS-SLAM:神经密集 SLAM 的语义高斯泼溅
— 补充材料 —
6 实验设置
在本节中,我们概述了我们研究中应用的实验设置和超参数。 实验在配备 NVIDIA A100-40GB GPU 的服务器上进行。 然而,对于本研究中呈现的场景,我们的方法通常需要不到 12 GB 的内存,因此它与任何具有超过此内存量的 GPU 兼容。 我们比较的地面实况结果,特别是对于新颖的视图渲染,是从数据集中提供的地面实况网格获得的,该网格是以离线方式生成的。 因此,在真实结果中可以观察到一些缺陷。 该代码即将发布。
6.0.1SGS-SLAM
默认情况下,每帧都会进行映射和跟踪操作。 在跟踪阶段,我们将轮廓可见性阈值 设置为 0.99。 多通道优化涉及三个参数:深度、颜色、语义损失,其中语义损失权重较低。现实世界语义标签的典型噪音。 在整个跟踪过程中,多通道高斯参数保持不变,仅调整学习率为2e-3的相机参数进行过渡。 关键帧最初以每 5 帧的间隔选择,然后根据几何和语义标准进行细化。 几何重叠阈值 定义为 0.05,语义平均交并 (mIoU) 阈值 定义为 0.7。 考虑到计算速度,每帧的最大关键帧数限制为 25。 不确定性衰减系数 随着输入帧系列的长度而变化。 在建图过程中,轮廓阈值调整为0.5。 光度损失的权重设置为、和。 这里,相机参数固定,高斯参数优化,3D位置的具体学习率为1e-4,颜色为2.5e-3,高斯旋转为1e-3,logit不透明度为0.05,对数比例为1e-3 。 每 5 帧评估一次跟踪和映射的性能指标,并以相同的频率评估 mIoU 分数。
映射和跟踪迭代步骤特定于每个数据集,对于副本数据集[34],跟踪和映射的迭代次数设置为 40 和 60。 对于 ScanNet 数据集 [4],跟踪和映射设置为 120 和 40。 在增强的 ScanNet++ 数据集[43]中,每帧之间的相机过渡较大,跟踪和映射迭代次数调整为 220 和 50。
6.0.2基线
我们遵循他们论文中报告的每个基线的默认配置。 跟踪和映射的评估指标与我们的方法中应用的评估指标一致。 对于未公开实施的基线,我们提供其论文中报告的结果。
7 其他实验结果
我们在秒7.1中提供了对摄像机跟踪的额外定量分析。 Sec. 7.2 中介绍了语义分割与基于 NeRF 的方法的可视化比较。 Sec. 7.3 中说明了更多定性新颖的视图渲染结果。 我们将我们的方法与 Vox-Fusion [41]、NICE-SLAM [47]、Co-SLAM [37]、ESLAM [15] 和 Point-SLAM [33] 用于 ATE RMSE 评估。 对于 3D 语义分割,我们可视化了与 DNS-SLAM [19] 的比较。
7.1相机跟踪
在本节中,我们将详细分析 Replica [34]、ScanNet [4] 和 ScanNet++ [43]< 上的 ATE RMSE [cm] 的定量分析。 /t2> 数据集。 选项卡。 6, 选项卡。 7, 和 选项卡。 8 展示我们的 SGS-SLAM 针对每个数据集上的基线模型的评估。 我们通过直接优化密集光度损失的梯度来估计相机姿态的方法在具有高质量 RGB-D 图像的数据集上实现了最先进的跟踪性能。 特别是,在 ScanNet++ 数据集 [43] 上,连续帧之间存在较大的相机过渡,基于 NeRF 的方法(如 ESLAM)无法跟踪。 相反,SGS-SLAM 展示了强大而准确的跟踪能力。
| Methods | Avg. | Room0 | Room1 | Room2 | Office0 | Office1 | Office2 | Office3 | Office4 |
| Vox-Fusion | 3.09 | 1.37 | 4.70 | 1.47 | 8.48 | 2.04 | 2.58 | 1.11 | 2.94 |
| NICE-SLAM | 2.50 | 2.25 | 2.86 | 2.34 | 1.98 | 2.12 | 2.83 | 2.68 | 2.96 |
| Co-SLAM | 0.86 | 0.65 | 1.13 | 1.43 | 0.55 | 0.50 | 0.46 | 1.40 | 0.77 |
| ESLAM | 0.63 | 0.71 | 0.70 | 0.52 | 0.57 | 0.55 | 0.58 | 0.72 | 0.63 |
| Point-SLAM | 0.52 | 0.61 | 0.41 | 0.37 | 0.38 | 0.48 | 0.54 | 0.69 | 0.72 |
| Ours | 0.41 | 0.46 | 0.45 | 0.29 | 0.46 | 0.23 | 0.45 | 0.42 | 0.55 |
| Methods | Avg. | 0000 | 0059 | 0106 | 0169 | 0181 | 0207 |
| Vox-Fusion | 26.90 | 68.84 | 24.18 | 8.41 | 27.28 | 23.30 | 9.41 |
| NICE-SLAM | 10.70 | 12.00 | 14.00 | 7.90 | 10.90 | 13.40 | 6.20 |
| Co-SLAM | 9.73 | 12.29 | 9.57 | 6.62 | 13.43 | 7.13 | 9.37 |
| ESLAM | 7.88 | 8.47 | 8.70 | 7.58 | 7.45 | 8.87 | 6.20 |
| Point-SLAM | 12.19 | 10.24 | 7.81 | 8.65 | 22.16 | 14.77 | 9.54 |
| Ours | 9.87 | 11.15 | 9.54 | 10.43 | 10.70 | 11.28 | 6.11 |
| Methods | Avg. [cm] | 8b5caf3398 [cm] | b20a261fdf [cm] |
| ESLAM | 170.06 | 185.15 | 156.96 |
| Ours | 1.62 | 0.65 | 2.34 |
7.2语义分割

在本节中,对副本数据集 [34] 上的语义分割结果进行可视化,并与基于 NeRF 的方法 DNS-SLAM [19] 进行比较。 如图所示,我们的方法提供了准确和详细的分割,而 DNS-SLAM 由于 NeRF 的过度平滑问题而面临边缘挑战。
7.3 新颖的视图渲染
我们展示了使用我们的方法在 Replica [34]、ScanNet [4] 和 ScanNet++ [43] 数据集上进行新颖视图渲染的其他结果,与 ESLAM [15] 进行比较。 图 6、图 7<中提供了可视化效果/t3>、图8和图0>91> 具有语义分割结果。 我们的方法始终为合成数据集和真实数据集提供高质量的渲染结果。 值得注意的是,在具有挑战性的现实世界 ScanNet++ 数据集上,ESLAM [15] 难以重建场景。 相比之下,SGS-SLAM 提供准确的高保真场景重建以及精确的分割结果。 请注意,地面实况分割标签是从实例级别的地面实况网格中检索的,因此,我们的结果也显示实例级分割。




7.4 场景操作
在本节中,我们通过使用语义掩码对高斯进行分组来可视化场景操作结果。 如图图10,对于对象去除,我们可以直接擦除与编辑目标相关的高斯,比如在删除表格的同时保留其上的所有物品。 此外,我们可以通过选择语义掩码并应用平移和旋转来对对象进行分组,例如将表格和上述对象移动和旋转到不同的位置。
值得注意的是,在移除或转移对象时,我们可以观察到该位置留下的孔洞。 比如我们拆掉桌子时在地上留下的洞。 这是由于使用 3D 高斯的显式场景表示,其中来自轨迹的多视图中未观察到的几何形状不可避免地会丢失。 这种缺陷源于 3D 高斯表示的特征,提出了一个具有挑战性的问题。 它被确定为未来研究的一个领域,通过使用 3D 几何先验 [10] 或场景修复 [42] 技术提供潜在的解决方案。
