SWAG:用行动指导讲故事
摘要
自动长篇故事生成通常采用长上下文大语言模型(大语言模型)进行一次性创作,可以产生有凝聚力但不一定引人入胜的内容。 我们介绍行动指导讲故事(SWAG),这是一种用大语言模型讲故事的新颖方法。 我们的方法通过两个模型反馈循环将故事写作简化为搜索问题:一个大语言模型生成故事内容,另一个辅助大语言模型用于选择下一个最佳“动作”来引导故事的未来方向。 我们的结果表明,当通过 GPT-4 和人工评估进行评估时,SWAG 可以大大优于以前的端到端故事生成技术,并且我们的 SWAG 管道仅使用开放式源模型超越了 GPT-3.5-Turbo。
语言=bash、keywordstyle=、basicstyle=、stringstyle=、showstringspaces=false
1简介
大型语言模型(大语言模型)最近改变了内容生成的格局。 许多作品提出了短篇小说生成技术(Fan 等人,2018;Wilmot & Keller,2021;Rashkin 等人,2020;Xu 等人,2018)。 然而,生成连贯且有趣的长篇故事一直是人工智能面临的重大挑战(Oatley,1995;Charniak,2004;Alabdulkarim 等)人,2021a)。 对于 GPT-4 (OpenAI, 2023)、Llama-2 (Touvron 等人, 2023) 和 Mistral 等 SoTA 大语言模型来说,这仍然是一个挑战(江等人,2023)。
虽然新的大语言模型具有令人印象深刻的内容生成能力,但由于其无监督的训练目标,这些模型可能会产生不稳定的输出。 大语言模型对齐技术的最新进展允许对输出生成进行更多控制。 人类反馈强化学习 (RLHF) (Christiano 等人, 2023) 是一种流行的对齐范式,需要在人类偏好数据集上训练奖励模型,并微调大语言模型以最大化奖励,同时确保模型不会偏离原始预训练模型太远。 这个过程可能复杂且昂贵,由于不完善的奖励模型或近似 KL 散度惩罚的其他问题,会产生不稳定的结果。 直接偏好优化 (DPO) (Rafailov 等人, 2023) 是另一种对齐语言模型的技术,它可以在策略训练的单个步骤中优化 RLHF 中的约束奖励最大化问题。 与现有的 RLHF 技术(例如具有近端策略优化(PPO)的 RLHF)相比,DPO 的计算效率更高、更稳定,具有相似或改进的性能(Schulman 等人,2017)。
我们提出了SWAG,一种使用大语言模型迭代生成引人入胜的故事的算法。 在我们的工作中,我们将讲故事构建为一个搜索问题。 这种范式允许我们将问题表述为在给定故事想法的可能故事的搜索空间中寻找“最佳路径”。 通过在故事写作过程中让另一个模型指导大语言模型,我们可以提高对故事方向的控制并创造出更具吸引力的内容。 在高层次上,我们训练一个动作鉴别器大语言模型(AD大语言模型)来确定给定故事当前状态的下一个最佳动作。 使用生成的动作,我们提示另一个大语言模型根据给定的动作编写故事的下一部分。 这种反馈循环可以生成引人入胜、读起来有趣的长上下文故事。 我们系统的主要组成部分是AD大语言模型,它通过选择下一个最佳“动作”来继续故事,从而为故事铺平道路。 该AD大语言模型可以与任何开源模型(例如Llama-2-7B、Mistral-7B)或封闭模型(例如OpenAI的GPT-4)配对来生成故事。 我们的算法提供了一种简化的讲故事方法,允许对故事内容进展进行细粒度控制,同时提供集成自定义模型来编写故事或通过 API 使用其他公司提供的大语言模型服务的灵活性。
2相关工作
先前的作品尝试以各种方式提高故事生成的质量和/或多样性。
通过强化学习讲故事
在内容生成中,强化主要用于微调(Chang等人,2023;Bai等人,2022)或辅助模型指导(Peng等人,2022;Castricato)等人,2022)。
也许与我们的工作最相似的是涉及动态推理时间选项选择和/或分类的方法(Alabdulkarim 等人,2021b;Tambwekar 等人,2019;Peng 等人,2022)。 我们的方法与之前的方法不同,我们的模型(1)使用改编的大语言模型来解释当前故事的内部表征; (2)高度模块化; (3)是基于提示的。 尽管我们的方法具有如此简单、灵活的结构,但这些方面有助于我们的方法产生多样化的故事。
受控文本生成(通过提示)
语言模型的最新进展极大地提高了(更简单的)提示方法(例如思维链)的流行度。 提示可以是手动设计的(Brown等人,2020)或自动设计的(Shin等人,2020;Zou等人,2021);提示也可能是一个迭代过程(Wei等人,2022)。 一些作品如(Qin & Eisner, 2021; Lester 等人, 2021)也探索了连续的软提示。 与之前的工作相比,我们的贡献是一种基于迭代反馈提示的方法,利用辅助大语言模型进行控制,从而实现更多样化的故事讲述。
人机交互故事生成
与自动故事生成相反,之前的一些作品使用人机循环的方法来生成有趣的长故事(Goldfarb-Tarrant 等人, 2019; Coenen 等人, 2021; Chung 等人, 2022; Mirowski 等人,2022;Martin 等人,2017;Lin 和 Riedl,2021)。 我们强调,虽然我们的方法是完全自动的,无需任何人为干预,但 AD 动作空间的灵活性使得人类合作者可以非常直观地根据自己的喜好“调整”我们的方法。
3方法
我们的创意讲故事方法由两个主要部分组成:故事生成模型和动作判别模型(AD大语言模型)。 SWAG允许使用任何开源大语言模型或大语言模型服务来生成故事。 我们通过收集故事动作的偏好数据来创建 AD 大语言模型,并根据我们的偏好数据集调整预训练的大语言模型。 我们在下面的图 1 中可视化我们的训练管道。
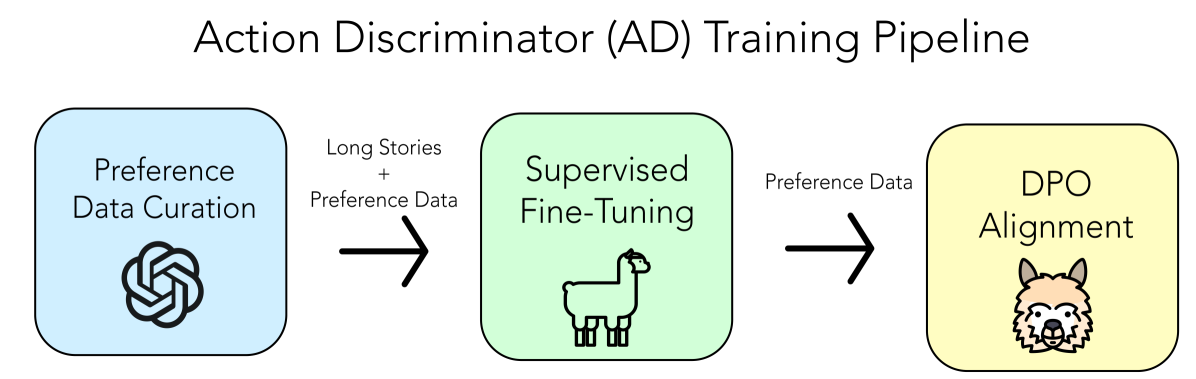
3.1 偏好数据收集
我们使用故事动作的偏好数据集来训练模型,以学习如何为故事的下一部分选择动作。 给定一个动作列表,我们希望我们的 AD 大语言模型能够选择最好的动作,让读者参与到故事中。 多个数据集包含数千个故事提示和想法,但没有用于选择故事下一个方向的偏好数据集。
为了有效地生成这些数据,我们开发了一个管道,提示 OpenAI 的 GPT-4 和 Mixtral-87B (Jiang 等人,2024),选择给定的下一个最佳操作“故事状态”。 我们将故事状态定义为
其中 是故事提示, 是故事提示的当前延续。 我们使用写作提示(范等人,2018)数据集的随机子集来获取一组不同的故事提示。 对于此子集中的每个故事提示,我们提示 GPT-4 和 Mixtral-87B 编写初始段落 ,形成数据集
这些故事状态为 AD 大语言模型提供了一个简单而全面的起点,以找到继续生成给定故事的最佳路径。
在策划初始故事状态后,我们生成有关继续故事的下一个最佳行动的偏好数据。 我们通过对每个故事状态进行“选择”和“拒绝”操作来对偏好数据进行建模。 对于故事状态,选择的动作是我们希望大语言模型在决定故事的下一个最佳方向时选择的动作,而拒绝的动作 是我们希望大语言模型在故事的下一部分中避免走的路。 这些偏好数据使我们的模型能够了解如何针对测试期间遇到的不同故事提示集的不同操作进行排名。
为了生成排名数据,我们使用初始故事状态 和“动作”列表 提示 GPT-4 和 Mixtral-87B选择故事下一段的最佳方向。 GPT-4 用于生成下一段的操作被设置为所选操作,然后我们从剩余操作中随机选择一个操作作为拒绝操作。 我们提取多个数据集进行监督微调(SFT)、直接偏好优化(DPO)和评估。
3.2监督微调(SFT)
在 SFT 阶段,我们遵循典型的设置,从预训练的大语言模型开始,通过监督学习对其进行微调,有效地使用最大似然目标。 我们在使用 GPT-4 和 Mixtral-87B 策划的偏好数据集上对动作辨别的下游任务进行了大语言模型的处理。
使用开源大语言模型的一个问题是它们不一定准备好处理长上下文输入。 例如,Llama-2-7B 模型的最大上下文长度默认为 4096。 为了缓解这个问题,我们使用 LongLoRA (Chen 等人, 2023) 中提出的 SFT 方法。 我们用转移的稀疏注意力替换默认的 Llama-2-7B 注意力,以实现计算高效的长上下文微调。 标准的自注意力算法需要计算,这导致长上下文微调的内存和时间成本很高。 作者建议,通过在较小的标记组中使用短注意力,并通过将组划分移动一半注意力头中的组大小,我们可以以更低的成本有效地近似完全自注意力。 这种-Attn方法很容易实现,并且消除了由于转移机制(Chen等人,2023)而导致特定注意力模式过度拟合的任何可能性。 我们将嵌入和归一化设置为低秩适应(LoRA)训练(Hu等人,2021)期间的可训练参数。 这项技术使我们的模型能够更好地理解较长故事的最佳下一个故事方向,而不需要大量的计算资源。
我们分两个阶段进行 SFT。 在第一阶段,我们在长故事数据集上构建了 AD 大语言模型。 我们训练模型以提示作为输入并生成长上下文故事。 此过程确保像 Llama-2-7B 这样的模型具有较短的默认上下文长度,可以准确地处理较长的数据序列。 在第二阶段,我们在偏好数据集上调整新的长上下文 AD 大语言模型,并为下一个故事方向选择和拒绝动作。 此阶段有助于模型更好地理解我们要为其构建偏好模型的下游任务。
3.3直接偏好优化 (DPO)
我们利用 DPO 进一步细化我们的动作鉴别器模型的结果。 在 DPO 中,我们希望我们的策略 能够了解如何在偏好模型框架中对选择的响应 与拒绝的响应 进行排名。 在 PPO 中,我们使用学习奖励模型 ,通过静态偏好数据集的最大似然来估计参数。 相反,DPO 允许我们定义从最优奖励模型到语言模型策略的映射,使我们的语言模型的训练能够通过单个交叉熵损失直接满足我们的偏好(Rafailov 等人,2023). 更具体地说,在适当的偏好模型下,我们可以根据最优语言模型策略 、原始 SFT 策略 、常数 和分区函数 得出如下最优奖励函数:
然后,我们可以将此奖励插入到我们的偏好模型中,在偏好数据集 上提供一个简单的训练过程:
|
|
(1) |
因此,在 DPO 过程中,我们根据 和 DPO 模型计算 和 的概率,然后我们可以计算式(1)。 1 并反向传播更新 (Tunstall 等人, 2023)。 使用 DPO,我们可以在偏好数据集上优化 SFT 模型,以生成与 GPT-4 和 Mixtral-87B 选择的操作更好地一致的操作。
3.4 SWAG反馈循环
我们方法中的主要算法是启用动作指导机制的 SWAG 反馈循环。 该反馈循环是一个三步过程,可以配置为使用开源大语言模型、闭源大语言模型或两者的混合来进行推理(超越故事生成)。
首先,我们通过将故事提示 传递到故事生成模型 来生成初始故事状态 ,以产生初始段落 。 接下来,我们将 传递到 AD 大语言模型 以及(预定义的)可能操作列表(包含在附录 B 中),并且 生成下一个最佳动作来继续故事。
生成下一个最佳动作后,我们将故事状态更新为
为了生成故事,我们迭代地重复这个过程:(1) 通过 生成故事中的下一段,(2) 通过 生成要采取的最佳后续操作。 请参阅算法 1,了解 SWAG 反馈循环的伪代码实现。
SWAG 反馈循环可以根据需要运行任意多次,直到达到所需的故事长度 - 我们可以自由选择。这种反馈机制可以在任何两个大语言模型(故事和AD)之间实现,从而增强故事内容生成的模块化程度。
3.5消融
我们对 和 执行多次消融来测试我们算法的性能。 具体来说,我们对 和 模型的不同组合进行成对比较,以衡量 SWAG 生成的故事的质量。
在消融中,我们测试不同的模型以生成具有固定的故事。 我们使用多个开源和闭源大语言模型作为运行SWAG推理循环。 这种消融可以让我们深入了解不同基础模型的故事质量的改进程度。
在消融中,我们测试不同的模型以生成具有固定的下一个故事动作。 我们使用相同的 SFT 和 DPO 偏好数据集为此消融训练了两个不同的 AD 大语言模型。
为了在闭源大语言模型上测试 SWAG,我们还使用 GPT-3.5-Turbo 和 GPT-4-Turbo 建立了推理管道。 在这里,我们简单地将 GPT-3.5-Turbo 和 GPT-4-Turbo 设置为 SWAG 反馈循环中的 和 。 通过这些实验,我们的目标是即使不将 AD 作为偏好模型进行微调,也能证明 SWAG 的有效性。
4实验
4.1 实验设置
在我们的实验中,我们的目的是评估我们的推理管道使用不同的模型和 AD 设置组合生成的故事的质量。 我们还探讨了 GPT-4 在对偏好数据集的故事动作进行排名时是否存在任何偏差,以及这种偏差对我们的 AD 大语言模型的影响。
4.2数据集
为了训练一个可以处理长篇内容的 AD 大语言模型,我们在长故事数据集上对模型进行了微调。 我们使用 WritePrompts 数据集中的提示示例从 Llama-2-7B、Mistral-7B 和 Mixtral-87B 中提取了这个长故事数据集。 我们从这些模型中生成了 20,000 个长故事,为 SFT 提供了多样化的故事分布。 我们在这个长篇故事数据集上对 Llama-2-7B 和 Mistral-7B 进行了微调,使它们的上下文长度达到 32,768 个标记。
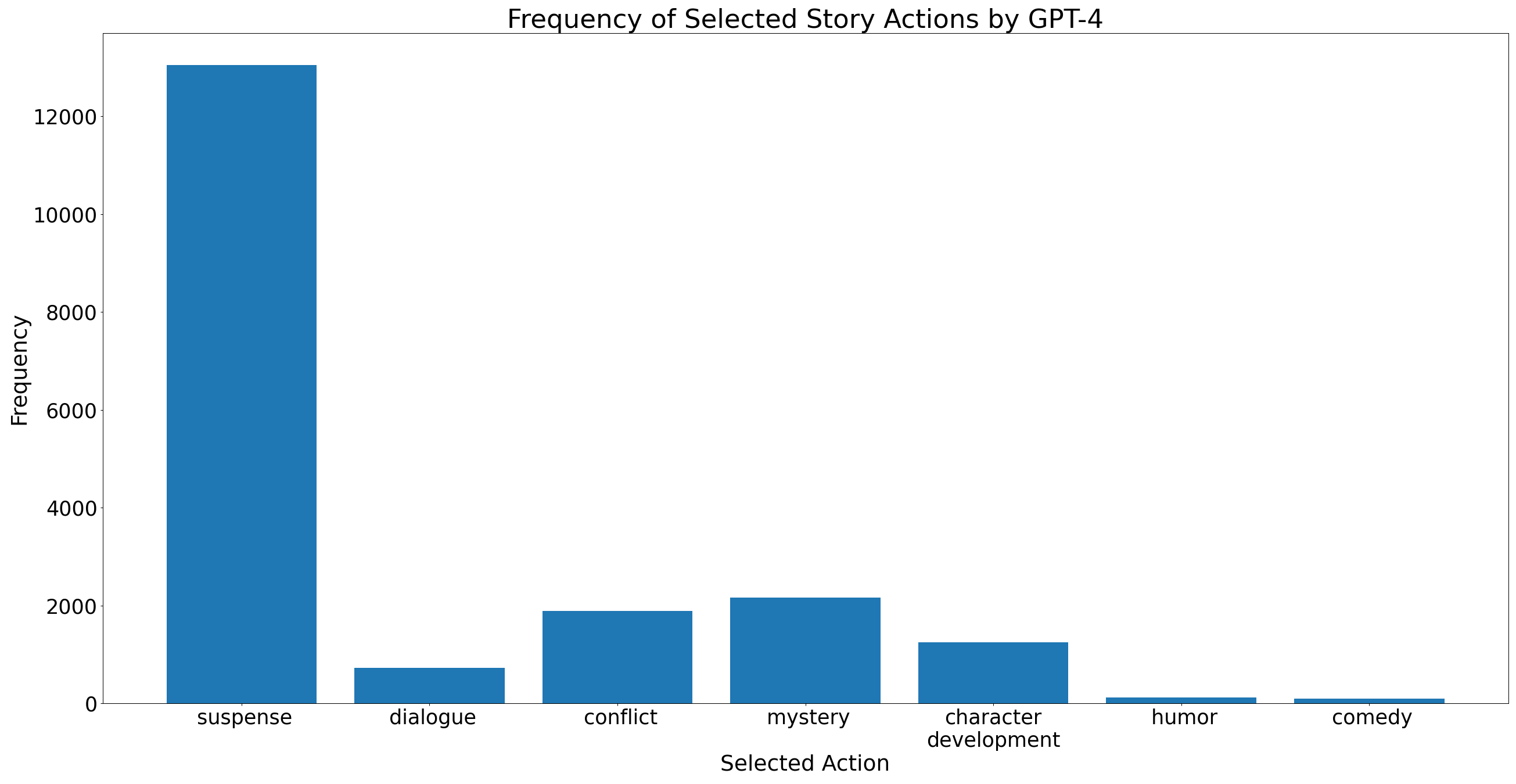
对于我们的 DPO 偏好数据集,我们提示 GPT-4 和 Mixtral-87B 针对 WritePrompts 数据集中大约 60,000 个提示的样本生成偏好数据。 该偏好数据的一个关键方面是故事动作的潜在选项。 我们从 GPT-4 中提取了 50 个不同的故事训练动作列表,并将这组动作用于所有实验。 集合中的一些动作示例包括“添加悬念”、“添加神秘感”、“添加角色发展”等。我们使用 34,000 个偏好数据样本对 AD 大语言模型进行微调,以了解选择下一个的下游任务故事方向,我们使用 25,000 个样本使用 DPO 训练偏好模型。 在 DPO 数据集中,我们注意到 GPT-4 所选操作的分布不平衡。 在图2中,我们可以看到选择“添加悬念”的故事数量与其他选项相比存在显着差异。 这一观察结果表明,GPT-4 在选择继续故事的行动时存在固有偏见。
为了减轻这种影响,我们从 GPT-4 中生成了更多偏好数据,但这一次,我们删除了为故事添加悬念的选项。 这将迫使 GPT-4 也关注其他操作,从而导致操作分布更加分散。 生成新数据后,我们从原始偏好数据集中随机抽取了 3,000 个提示,并将“添加悬念”作为所选操作,并将其与新数据集合并。 在图 3中,我们可以查看故事动作的新分布,并注意到它更加分散,从而允许未来有更多的变化故事方向。
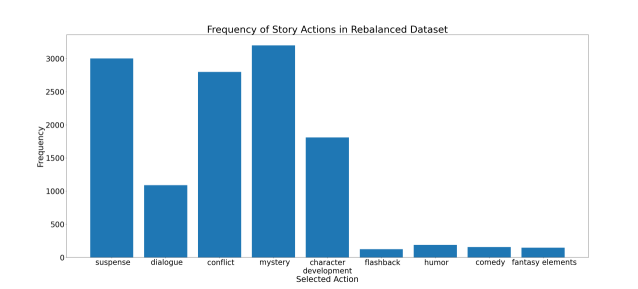
我们收集了三个不同的数据集用于 SFT、DPO 和评估。 重新平衡仅在 DPO 数据集上完成,但类似的方法也可以用于 SFT 数据集。 由于 GPT-4 API 的限制,我们无法生成足够的数据来重新平衡 SFT 数据集。 然而,值得注意的是,SFT 过程可以让我们的模型更好地理解下游任务,但 DPO 过程对于生成偏好模型更为关键,该模型可以产生有用的结果,如后面的实验所示。
4.3训练
对于我们的 AD 大语言模型训练,我们首先使用长故事数据集来调整我们的模型,以处理长上下文序列。 然后,我们使用为 SFT 收集的单独偏好数据集来调整我们的基础 AD 大语言模型。 我们使用了大约 34,000 个 SFT 排名样本,并训练模型在给定初始故事状态的情况下预测下一个最佳动作。 我们在此数据集上对 Llama-2-7B 进行了 5300 个步骤的微调,其中小批量大小为 1,使用 8 个 A100 80GB GPU 进行 64 个梯度累积步骤(因此一步处理 64 个故事,并且530 步大约是一个 epoch)。 完成每个模型的 SFT 过程大约需要 36 小时。 我们使用 LongLoRA (Chen 等人, 2023) 方法和 Flash Attention 2.0 (Dao, 2023) 进行 SFT,以在有限的计算上实现快速微调。 我们使用了 AdamW 优化器 (Loshchilov & Hutter, 2019) 和 ,学习率为 3e-5,并具有恒定学习率调度程序的 30 个预热步骤。
我们使用 DPO 在两个 SFT 模型检查点上训练偏好模型,分别训练了 2650 和 5300 步。 DPO 训练在我们的偏好数据集的大约 25,000 个样本上为每个模型运行了 1000 个步骤。 我们使用了 5e-4 的学习率以及 AdamW 优化器和余弦退火调度器,两者的默认设置都是 。 我们还在两个检查点的 DPO 训练中使用了 LoRA,其中 、 和 0.05 的 dropout。 我们使用 Hugging Face Transformers 强化学习 (TRL) (von Werra 等人, 2020) 库进行 DPO 训练,设置与 SFT 类似,配备 8 个 A100 80GB GPU,但小批量大小为 1 和 8 梯度累积步骤。 在重新平衡的偏好数据集上进行此设置后,每次 DPO 训练大约需要 12 小时,并且我们每 100 个训练步骤检查一次模型。 在大约 800 步的训练后,两个检查点的 DPO 都显示出收敛。
4.4推断
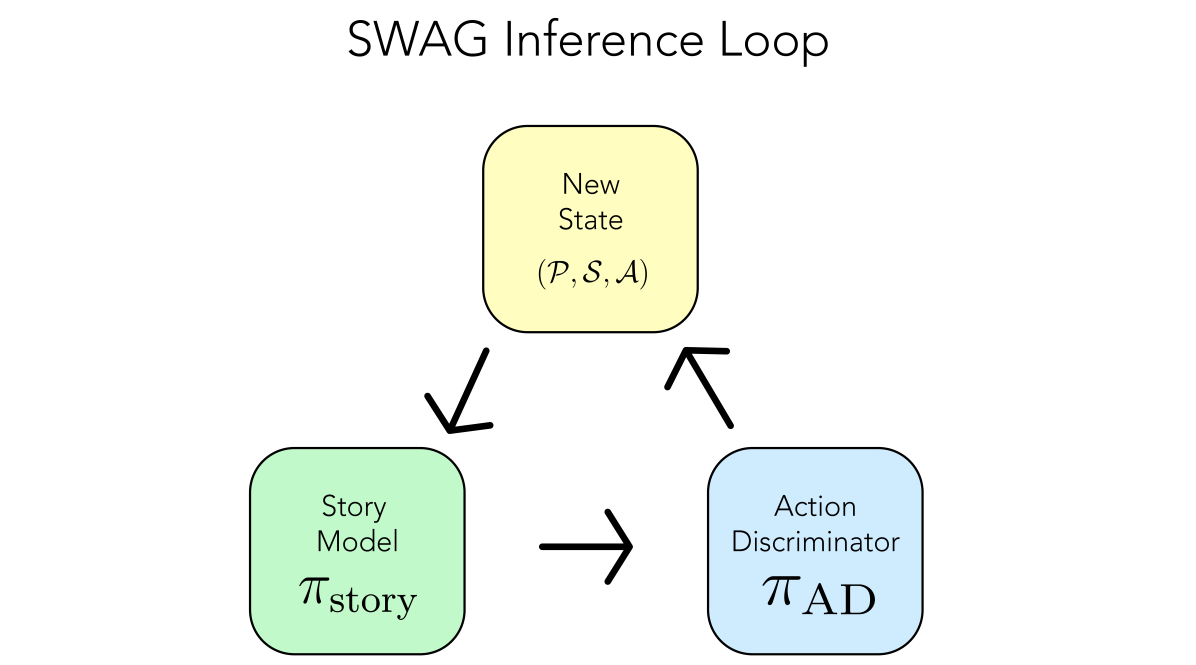
我们的推理管道需要两个模型:动作鉴别器 和故事生成模型 。 我们在这两个模型之间创建一个反馈循环来生成我们的故事。
在我们的实验中,我们评估了 和 的不同组合在一组测试故事提示中的性能。 对于每个故事提示,我们要求编写初始段落,然后,通过这个初始故事状态,我们指示 为后续段落选择最佳操作。
在动作鉴别器模型消融中,我们使用了我们自己微调和对齐的Llama-2-7B和Mistral-7B AD大语言模型和GPT-4-Turbo。 对于故事生成模型 消融,我们使用了基础 Llama-2-7B、Mistral-7B、GPT-3.5-Turbo 和 GPT-4-Turbo 模型。 对于我们的开源模型代,我们还比较了使用使用不同基本模型作为 进行调整的 时的性能。
为了分析故事生成的基线性能,我们通过给出初始故事提示并反复提示它继续故事来生成每个 的故事。 这些端到端(E2E)生成消融的结果如表2所示。
最后,我们分析我们的 模型在选择动作方面是否比随机选择更好。 我们的 AD 大语言模型使用 DPO 进行训练,在 SFT 和 DPO 期间只有 30 个动作可供选择。 通过这 30 个操作,我们使用 SWAG 管道从基本 Llama-2-7B 和 Mistral-7B 模型生成故事。 然而,在此消融中,我们替换了 ,而是从循环的每个步骤的列表中随机选择一个操作。
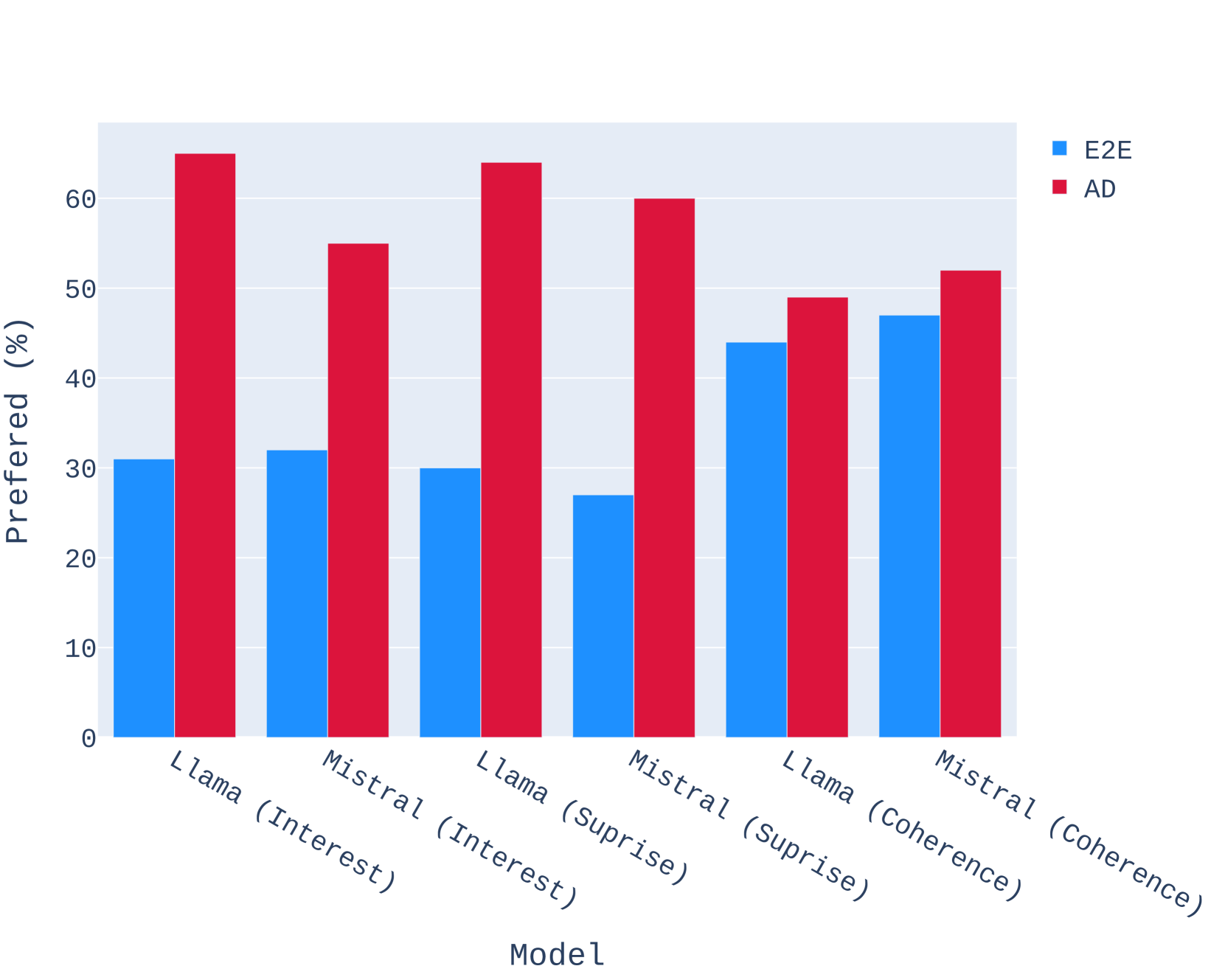
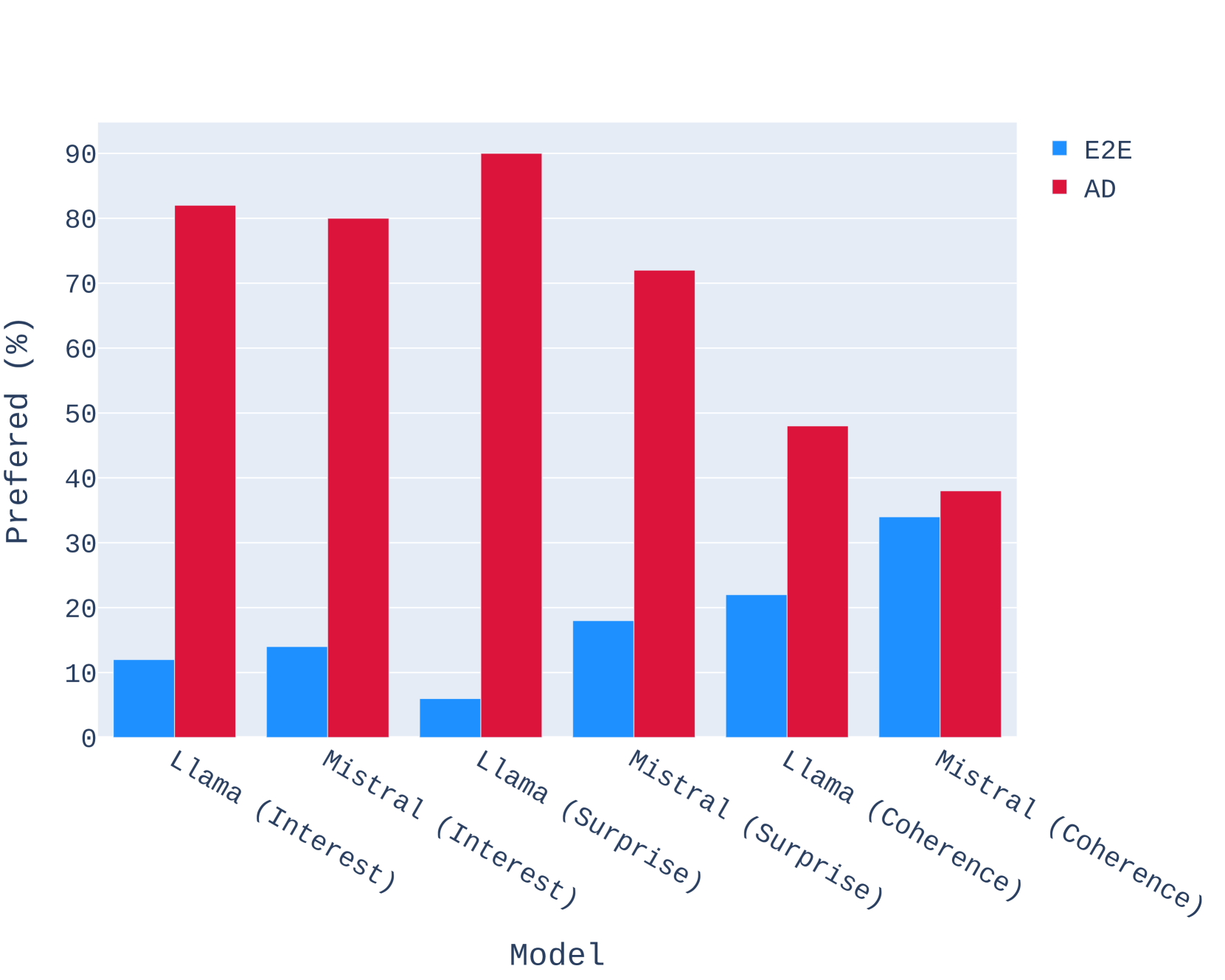
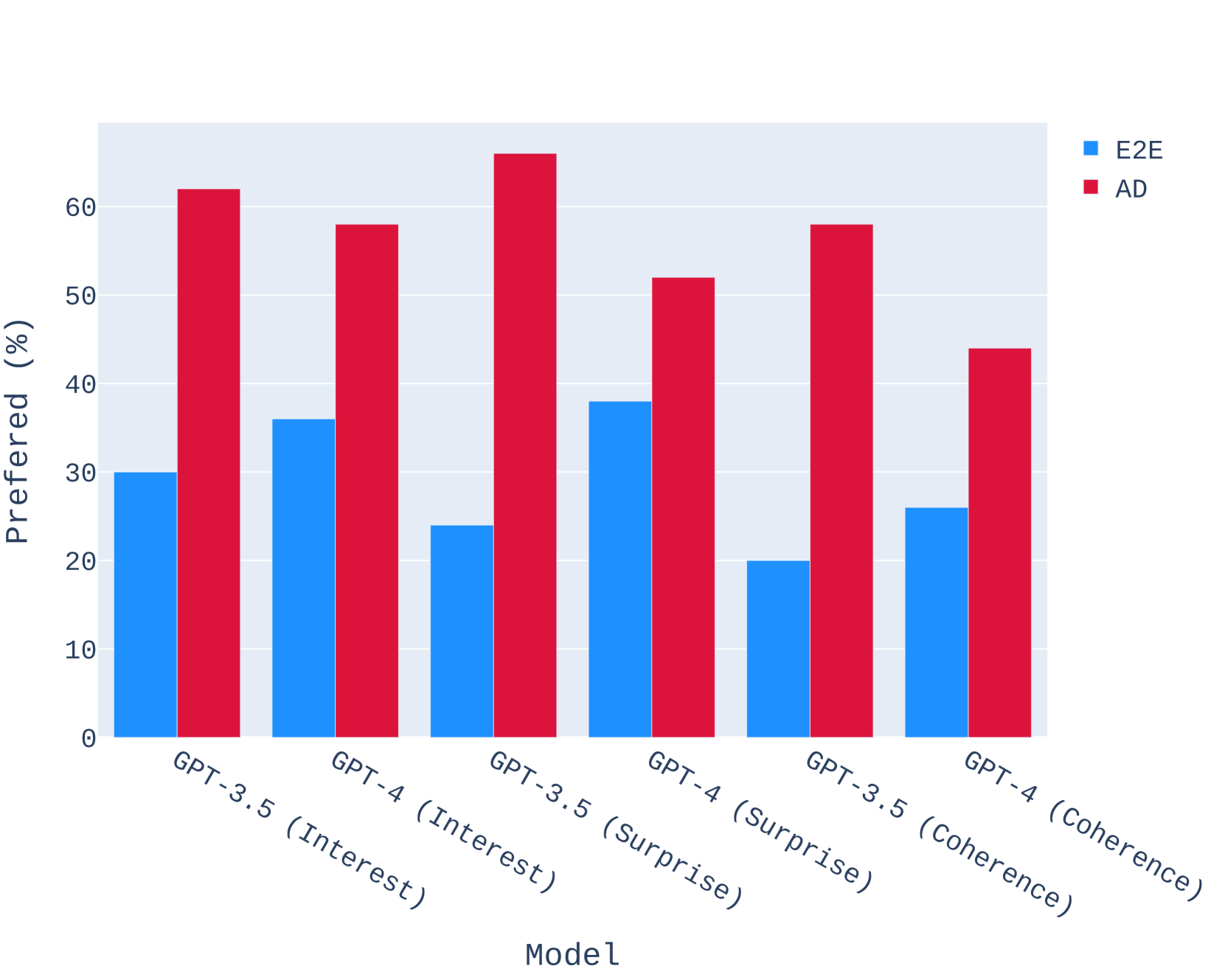
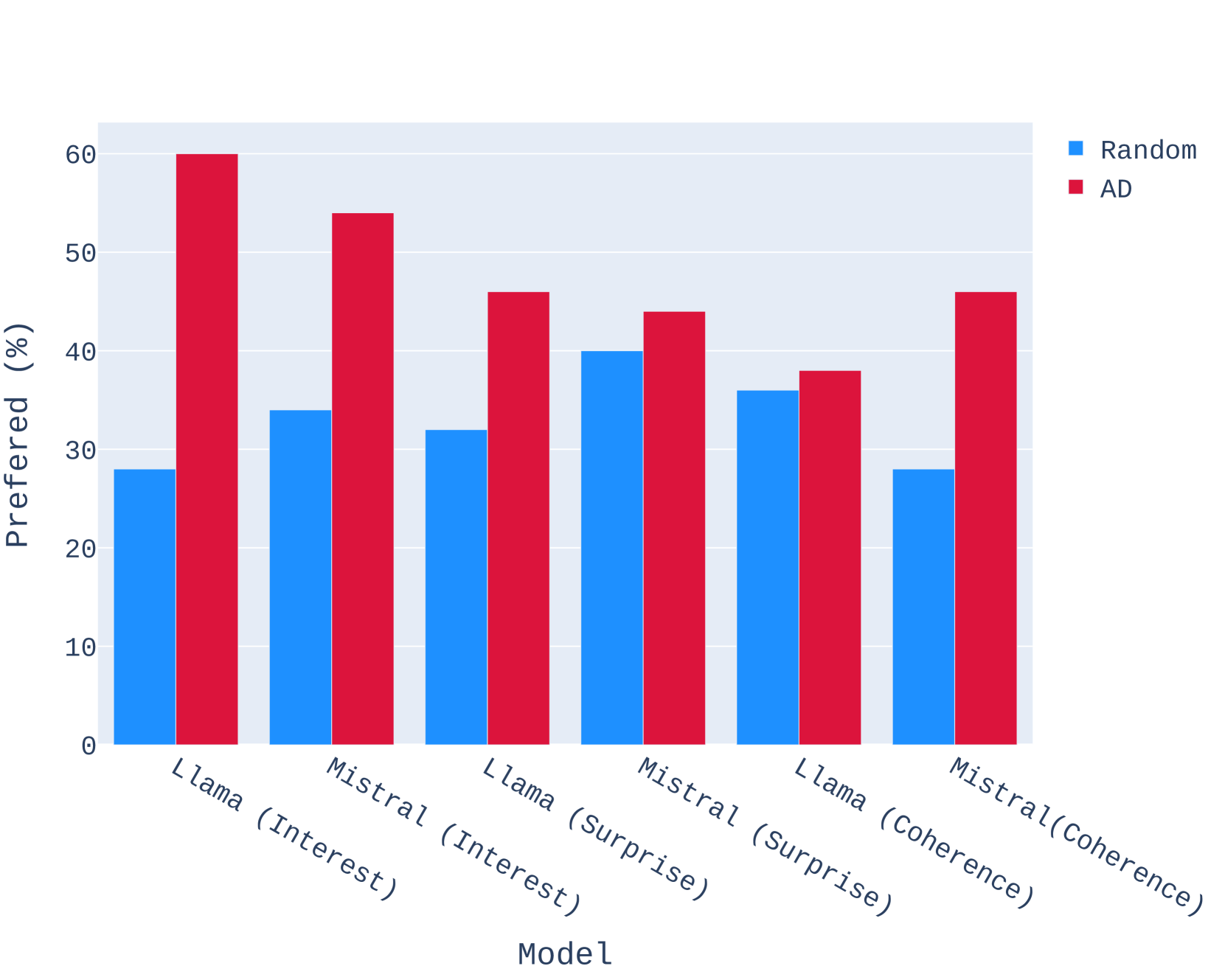
4.5人类评价
我们的人工评估设置很大程度上受到(Zhu等人,2023)的启发。 我们对通过不同方法生成的故事进行人工评估,从三个方面进行比较:趣味性、惊喜性和连贯性。 对于两种方法的 12 个成对比较中的每一个,我们要求 Surge AI 工作人员回答关于我们比较的方法生成的 50 对故事的三个偏好问题。 我们在表 1 中显示偏好问题,其中每个问题对应故事质量的一个方面。 我们在图 5-8 中展示了我们的人类标注结果。
| Q1 |
Which story plot is more interesting to you overall? |
|---|---|
| Q2 |
Which story created more suspense and surprise? |
| Q3 |
Which story is more coherent and consistent in terms of plot structure? |
4.6机器(GPT-4-Turbo)评估
开放式基准测试的最新发展在评估大语言模型的响应方面取得了可喜的成果,越来越多地使用 GPT-4 来代替人类法官,例如 MT-Bench (Zheng 等人,2023)和 AlpacaEval (Dubois 等人, 2023)。 采用类似的策略,我们以 GPT-4-Turbo 作为评判者进行评估,成对比较两个故事,并选择更有趣、更有吸引力、更一致的故事或平局。 系统提示见附录A.3。 我们根据不同的基线(随机操作、GPT-3.5-Turbo 等)评估了 AD 大语言模型的几个开放和专有变体,结果如表 2 所示。
| AD vs E2E | Win-Rate (AD) | AD | E2E | Tie |
|---|---|---|---|---|
| Mistral-7B | 68.0% | 58 | 22 | 20 |
| Llama-2-7B | 54.5% | 47 | 38 | 15 |
| GPT-3.5-Turbo | 77.5% | 66 | 8 | 23 |
| GPT-4-Turbo | 61.5% | 49 | 24 | 25 |
| AD vs Random | Win-Rate (AD) | AD | Random | Tie |
| Llama-2-7B | 53.0% | 45 | 39 | 16 |
| Mistral-7B | 67.5% | 61 | 26 | 13 |
| AD vs GPT-3.5 | Win-Rate (AD) | AD | GPT-3.5 | Tie |
| Mistral-7B | 19.5% | 11 | 72 | 17 |
| Llama-2-7B | 31.0% | 19 | 57 | 24 |
| E2E vs GPT-3.5 | Win-Rate (E2E) | E2E | GPT-3.5 | Tie |
| Mistral-7B | 9.5% | 3 | 84 | 13 |
| Llama-2-7B | 23.5% | 14 | 67 | 19 |
5讨论
5.1机器评估结果
表2显示了使用GPT-4-Turbo作为判断者的成对评估结果。 获胜率列指定 SWAG 生成的故事在比较中被 LM 评委优先的百分比。 对于 AD 与随机比较,GPT-4 更喜欢使用 SWAG 的 Llama-2-7B 和 Mistral-7B,而不是使用随机选择的操作。 这说明SWAG中的AD大语言模型为故事生成大语言模型提供了有用的信号,指导故事的走向。
在 AD 与 E2E 比较中,SWAG 在所有模型中都优于 E2E 方法。 我们注意到 Mistral-7B、GPT-3.5-Turbo 和 GPT-4-Turbo 的 SWAG 结果中的胜率非常高,并且 Llama-2-7B 的胜率略高于 E2E 。 这表明与在没有指导的情况下生成长篇故事相比,SWAG 极大地提高了故事参与度。
各种消融的结果展示了 SWAG 的有效性以及简单的反馈循环如何提高故事中的内容质量。 在每次评估中,GPT-4-Turbo 都为其故事偏好排名提供推理。 使用 SWAG 生成的故事始终被认为具有更好的悬念、惊喜和参与度。 GPT-4-Turbo 推理的示例可以参见附录E。
5.2人类评估结果
然后,我们以人类作为评判者,从有趣性、惊喜性和连贯性方面再次评估这些故事。 特别要求人类评估者通过回答表1中的问题来分别对每个方面进行评分。 我们在附录C中提供了完整的结果。对于开源和闭源模型,SWAG 制作的故事以压倒性优势击败了 E2E 同行。 我们发现,SWAG Llama-2-7B 的故事和 SWAG Mistral-7B 的故事在兴趣和惊喜方面均明显优于 GPT-3.5-Turbo 的故事,同时在连贯性。
比较 GPT-4-Turbo 和人类评估,无论评审如何,AD 始终优于其基线,这证明了 SWAG 的有效性。 然而,与作为法官的 GPT-4-Turbo 相比,人类评估中的偏好差距更大。 如表2和表4所示,开源AD大语言模型与GPT-3.5-Turbo的两两比较偏好存在显着差异,仅14当判断 GPT-4-Turbo 时,Llama-2-7B AD 的 % 优于 GPT-3.5-Turbo,而在这 3 个方面,超过 50% 的 Llama-2-7B AD 被首选。 这很可能是由于 GPT-4-Turbo 对 GPT-3.5-Turbo 固有的偏见,而人类评估者对任何特定的大语言模型没有偏见。 GPT-4-Turbo 和人类评审之间的这些不一致表明,即使是最强大的专有模型在质量和可信度方面也仍然落后于人类评估者。
5.3扩展
除了使用SWAG自动生成故事之外,用户还可以干预故事生成过程。 我们的方法可以随时“暂停”,之后人们可以继续编写故事,甚至可以通过 SWAG 与故事模型来回协作。 随着自动生成能力的进步,我们很高兴能够探索人与 LLM 互动的新形式。
为了进一步定制SWAG推理循环,用户还可以根据自己的需要定制AD大语言模型的操作列表。 例如,如果用户希望他们的 AD 大语言模型专注于导演特定类型(如恐怖)的故事,他们可以添加更适合该主题的动作。 选择操作的灵活性使 SWAG 成为一个多功能系统,适用于跨各种类型的各种内容生成任务。
根据我们的实验和评估,我们相信,如果在 SFT 和 DPO 训练和推理时间期间采取更细粒度的操作,我们的结果可以进一步改进。 细粒度的操作可以实现一致的控制,并可以增加故事的深度和复杂性,从而增加与读者的互动。 使用更详细的动作可以通过允许更细致的角色发展、情节曲折和详细的设置来产生更丰富的叙述。
6 限制
由于计算限制,我们只能使用DPO进行AD大语言模型对齐。 DPO 比 PPO 轻量得多,因为它是一种离线 RL 算法。 但是,通过PPO的在线采样过程以及强大的奖励模型,我们可能能够取得更好的结果。 我们还希望扩大消融的范围,可能尝试更多种类的开源和闭源模型以及更多的多样化和细粒度的操作。
对于我们的评估,由于资源限制,我们只能针对 100 个测试故事提示生成机器评估,并针对 50 个测试故事提示生成人工评估。 评估更大的故事集,尤其是机器评估,可以让我们更好地了解 SWAG 生成的故事的质量。
7结论
本文提出了SWAG,一个简单的基于反馈的创意故事生成框架。 经过微调的动作判别器大语言模型可以实现更有趣和令人兴奋的情节发展,而几乎不牺牲连贯性或一致性。 机器和人类评估都证明了我们的方法与 SoTA 端到端生成方法相比的有效性,即使使用最强大的闭源模型也是如此。 我们预计我们的贡献将进一步推动内容生成,特别是通过迭代反馈机制。
参考
- Alabdulkarim et al. (2021a) Alabdulkarim, A., Li, S., and Peng, X. Automatic story generation: Challenges and attempts, 2021a.
- Alabdulkarim et al. (2021b) Alabdulkarim, A., Li, W., Martin, L. J., and Riedl, M. O. Goal-directed story generation: Augmenting generative language models with reinforcement learning, 2021b.
- Bai et al. (2022) Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., Drain, D., Fort, S., Ganguli, D., Henighan, T., Joseph, N., Kadavath, S., Kernion, J., Conerly, T., El-Showk, S., Elhage, N., Hatfield-Dodds, Z., Hernandez, D., Hume, T., Johnston, S., Kravec, S., Lovitt, L., Nanda, N., Olsson, C., Amodei, D., Brown, T., Clark, J., McCandlish, S., Olah, C., Mann, B., and Kaplan, J. Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022.
- Brown et al. (2020) Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. Language models are few-shot learners. CoRR, abs/2005.14165, 2020. URL https://arxiv.org/abs/2005.14165.
- Castricato et al. (2022) Castricato, L., Havrilla, A., Matiana, S., Pieler, M., Ye, A., Yang, I., Frazier, S., and Riedl, M. Robust preference learning for storytelling via contrastive reinforcement learning, 2022.
- Chang et al. (2023) Chang, J. D., Brantley, K., Ramamurthy, R., Misra, D., and Sun, W. Learning to generate better than your llm, 2023.
- Charniak (2004) Charniak, E. Toward a model of children’s story comprehension. 10 2004.
- Chen et al. (2023) Chen, Y., Qian, S., Tang, H., Lai, X., Liu, Z., Han, S., and Jia, J. Longlora: Efficient fine-tuning of long-context large language models, 2023.
- Christiano et al. (2023) Christiano, P., Leike, J., Brown, T. B., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences, 2023.
- Chung et al. (2022) Chung, J. J. Y., Kim, W., Yoo, K. M., Lee, H., Adar, E., and Chang, M. Talebrush: Sketching stories with generative pretrained language models. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pp. 1–19, 2022.
- Coenen et al. (2021) Coenen, A., Davis, L., Ippolito, D., Reif, E., and Yuan, A. Wordcraft: a human-ai collaborative editor for story writing, 2021.
- Dao (2023) Dao, T. Flashattention-2: Faster attention with better parallelism and work partitioning, 2023.
- Dubois et al. (2023) Dubois, Y., Li, X., Taori, R., Zhang, T., Gulrajani, I., Ba, J., Guestrin, C., Liang, P., and Hashimoto, T. B. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387, 2023.
- Fan et al. (2018) Fan, A., Lewis, M., and Dauphin, Y. Hierarchical neural story generation, 2018.
- Goldfarb-Tarrant et al. (2019) Goldfarb-Tarrant, S., Feng, H., and Peng, N. Plan, write, and revise: an interactive system for open-domain story generation. In Ammar, W., Louis, A., and Mostafazadeh, N. (eds.), Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), pp. 89–97, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-4016. URL https://aclanthology.org/N19-4016.
- Hu et al. (2021) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models, 2021.
- Jiang et al. (2023) Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7b, 2023.
- Jiang et al. (2024) Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de las Casas, D., Hanna, E. B., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L. R., Saulnier, L., Lachaux, M.-A., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Scao, T. L., Gervet, T., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mixtral of experts, 2024.
- Lester et al. (2021) Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv preprint arXiv:2104.08691, 2021.
- Lin & Riedl (2021) Lin, Z. and Riedl, M. O. Plug-and-blend: A framework for plug-and-play controllable story generation with sketches. In Artificial Intelligence and Interactive Digital Entertainment Conference, 2021. URL https://api.semanticscholar.org/CorpusID:236470168.
- Loshchilov & Hutter (2019) Loshchilov, I. and Hutter, F. Decoupled weight decay regularization, 2019.
- Martin et al. (2017) Martin, L. J., Ammanabrolu, P., Wang, X., Singh, S., Harrison, B., Dhuliawala, M., Tambwekar, P., Mehta, A., Arora, R., Dass, N., et al. Improvisational storytelling agents. In Workshop on Machine Learning for Creativity and Design (NeurIPS 2017), volume 8, 2017.
- Mirowski et al. (2022) Mirowski, P., Mathewson, K. W., Pittman, J., and Evans, R. Co-writing screenplays and theatre scripts with language models: An evaluation by industry professionals, 2022.
- Oatley (1995) Oatley, K. Book reviews: The creative process: A computer model of storytelling and creativity. Computational Linguistics, 21(4), 1995. URL https://aclanthology.org/J95-4007.
- OpenAI (2023) OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023. URL https://arxiv.org/abs/2303.08774.
- Peng et al. (2022) Peng, X., Xie, K., Alabdulkarim, A., Kayam, H., Dani, S., and Riedl, M. O. Guiding neural story generation with reader models, 2022.
- Qin & Eisner (2021) Qin, G. and Eisner, J. Learning how to ask: Querying lms with mixtures of soft prompts. arXiv preprint arXiv:2104.06599, 2021.
- Rafailov et al. (2023) Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. Direct preference optimization: Your language model is secretly a reward model, 2023.
- Rashkin et al. (2020) Rashkin, H., Celikyilmaz, A., Choi, Y., and Gao, J. Plotmachines: Outline-conditioned generation with dynamic plot state tracking, 2020.
- Schulman et al. (2017) Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms, 2017.
- Shin et al. (2020) Shin, T., Razeghi, Y., au2, R. L. L. I., Wallace, E., and Singh, S. Autoprompt: Eliciting knowledge from language models with automatically generated prompts, 2020.
- Tambwekar et al. (2019) Tambwekar, P., Dhuliawala, M., Martin, L. J., Mehta, A., Harrison, B., and Riedl, M. O. Controllable neural story plot generation via reward shaping. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-2019. International Joint Conferences on Artificial Intelligence Organization, August 2019. doi: 10.24963/ijcai.2019/829. URL http://dx.doi.org/10.24963/ijcai.2019/829.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa, M., Kloumann, I., Korenev, A., Koura, P. S., Lachaux, M.-A., Lavril, T., Lee, J., Liskovich, D., Lu, Y., Mao, Y., Martinet, X., Mihaylov, T., Mishra, P., Molybog, I., Nie, Y., Poulton, A., Reizenstein, J., Rungta, R., Saladi, K., Schelten, A., Silva, R., Smith, E. M., Subramanian, R., Tan, X. E., Tang, B., Taylor, R., Williams, A., Kuan, J. X., Xu, P., Yan, Z., Zarov, I., Zhang, Y., Fan, A., Kambadur, M., Narang, S., Rodriguez, A., Stojnic, R., Edunov, S., and Scialom, T. Llama 2: Open foundation and fine-tuned chat models, 2023.
- Tunstall et al. (2023) Tunstall, L., Beeching, E., Lambert, N., Rajani, N., Rasul, K., Belkada, Y., Huang, S., von Werra, L., Fourrier, C., Habib, N., Sarrazin, N., Sanseviero, O., Rush, A. M., and Wolf, T. Zephyr: Direct distillation of lm alignment, 2023.
- von Werra et al. (2020) von Werra, L., Belkada, Y., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., and Huang, S. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020.
- Wang & Gordon (2023) Wang, T. S. and Gordon, A. S. Playing story creation games with large language models: Experiments with gpt-3.5. In International Conference on Interactive Digital Storytelling, pp. 297–305. Springer, 2023.
- Wei et al. (2022) Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. 2022. doi: 10.48550/ARXIV.2201.11903. URL https://arxiv.org/abs/2201.11903.
- Wilmot & Keller (2021) Wilmot, D. and Keller, F. A temporal variational model for story generation, 2021.
- Xu et al. (2018) Xu, J., Ren, X., Zhang, Y., Zeng, Q., Cai, X., and Sun, X. A skeleton-based model for promoting coherence among sentences in narrative story generation, 2018.
- Zheng et al. (2023) Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., and Stoica, I. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- Zhu et al. (2023) Zhu, H., Cohen, A., Wang, D., Yang, K., Yang, X., Jiao, J., and Tian, Y. End-to-end story plot generator, 2023.
- Zou et al. (2021) Zou, X., Yin, D., Zhong, Q., Yang, H., Yang, Z., and Tang, J. Controllable generation from pre-trained language models via inverse prompting. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD ’21, pp. 2450–2460, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450383325. doi: 10.1145/3447548.3467418. URL https://doi.org/10.1145/3447548.3467418.
附录A提示
A.1 AD大语言模型提示
A.2 故事模型提示
A.3系统提示评估
为了进一步避免位置偏差,我们还随机打乱提交给 GPT-4-Turbo 评委的故事的位置。 例如,在E2E和AD之间的100个成对比较中,随机选择50个比较将E2E呈现为故事A,而另外50个比较将AD呈现为故事A。
附录 B操作
我们的行动空间由以下 30 个短语组成:
附录 C完整的人类评估结果
| Llama-2_E2E (A) vs GPT-3.5_E2E (B) | Mistral_E2E (A) vs GPT-3.5_E2E (B) | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
22% |
60% |
18% |
26% |
62% |
12% |
| Surprise |
24% |
64% |
12% |
22% |
68% |
10% |
| Coherence |
36% |
48% |
16% |
38% |
44% |
18% |
| Llama-2_AD_Llama-2_GEN (A) vs GPT-3.5_E2E (B) | Mistral_AD_Mistral_GEN (A) vs GPT-3.5_E2E (B) | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
62% |
32% |
6% |
48% |
38% |
14% |
| Surprise |
56% |
30% |
16% |
52% |
36% |
16% |
| Coherence |
34% |
36% |
30% |
38% |
34% |
28% |
| Rnd_AD_Llama-2_GEN vs Llama-2_AD_Llama-2_GEN | Rnd_AD_Mistral_GEN vs Mistral_AD_Mistral_GEN | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
28% |
60% |
12% |
34% |
54% |
12% |
| Surprise |
32% |
46% |
22% |
40% |
44% |
16% |
| Coherence |
36% |
38% |
26% |
28% |
46% |
26% |
| GPT-4_E2E vs GPT-4_AD_GPT-4_GEN | GPT-3.5_E2E vs GPT-3.5_AD_GPT-3.5_GEN | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
36% |
58% |
6% |
30% |
62% |
8% |
| Surprise |
38% |
52% |
10% |
24% |
66% |
10% |
| Coherence |
26% |
44% |
30% |
20% |
58% |
22% |
| Llama-2_E2E vs Llama-2_AD_Llama_GEN | Mistral_E2E vs Mistral_AD_Mistral_GEN | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
12% |
82% |
6% |
14% |
80% |
6% |
| Surprise |
6% |
90% |
4% |
18% |
72% |
10% |
| Coherence |
22% |
48% |
30% |
34% |
38% |
24% |
| Llama-2_AD_Llama_GEN vs Llama-2_AD_Mistral_GEN | Mistral_AD_Mistral_GEN vs Mistral_AD_Llama_GEN | |||||
| Aspect | Story A | Story B | Tie | Story A | Story B | Tie |
| Interest |
52% |
30% |
18% |
40% |
34% |
26% |
| Surprise |
50% |
34% |
16% |
44% |
32% |
24% |
| Coherence |
44% |
30% |
26% |
38% |
28% |
34% |
附录D人类评估实验细节
我们根据估计的 18 美元/小时向参与者支付费用,考虑到这项任务和美国工人的人口结构,我们认为这是合理的报酬。 数据收集协议被确定免除道德审查委员会的审查。
|
We are a group of AI/NLP researchers working on methods to improve the quality and creativity of stories generated by language models. In this task we ask you to look at pairs of (lengthy) stories written by different AI based on the same initial premise, and respond to the following comparison questions about each story pair: (1) Which story is more interesting to you overall? (2) Which story created more suspense and surprise? (3) Which story is more coherent and consistent in terms of plot structure? For all these questions, we just need high-level judgements, so please quickly skim both stories. In other words, there is no need to read each story carefully (they can be up to 5000 words in length); we expect you to spend at most ten minutes per story. |
附录EGPT-4-涡轮推理
示例1: GPT-4-Turbo 的判断示例,对作为故事 A 的 GPT-3.5-Turbo E2E 和作为故事 B 的 GPT-3.5-Turbo AD 进行成对比较。
示例2: GPT-4-Turbo 的判断示例,对作为故事 A 的 GPT-3.5-Turbo E2E 和作为故事 B 的 GPT-3.5-Turbo AD 进行成对比较。
附录F完整故事
示例: GPT-4-Turbo 的响应,以及对以下写作提示的行动指导:“人类在三十分钟内输掉了战争……最糟糕的是伊兹拉齐帝国的技术是如此先进,即使他们的仆人人类在战前比国王生活得更好。”
附录 G使用的模型
我们使用了 Llama-2-7B、Mistral-7B、Mixtral-8x7B、GPT-3.5-Turbo、GPT-4 和 GPT-4-Turbo。
附录 H 许可证和软件
WritePrompts 数据集使用 MIT 许可证。
所有模型均在 PyTorch 中实现; Llama-2 使用 GPL 许可证,Mistral 使用 Apache 2.0 许可证。 Mixtral-8x7B 由 Huggingface 使用,它遵循 Apache License 2.0。
我们对数据集和模型的使用与其预期用途一致。