capbtabbox表[][]
Diffusion-ES:自动驾驶扩散的无梯度规划和零样本指令遵循
摘要
扩散模型擅长对复杂的多模态轨迹分布进行建模,以进行决策和控制。 最近提出了奖励梯度引导去噪,以生成最大化可微奖励函数和扩散模型捕获的数据分布下的可能性的轨迹。 奖励梯度引导去噪需要一个适合干净样本和噪声样本的可微奖励函数,限制了其作为通用轨迹优化器的适用性。 在本文中,我们提出了 Diffusion-ES,一种将无梯度优化与轨迹去噪相结合的方法,以优化黑盒不可微目标,同时保持在数据流形中。 Diffusion-ES 在进化搜索过程中从扩散模型中采样轨迹,并使用黑盒奖励函数对其进行评分。 它使用截断的扩散过程来改变高分轨迹,该过程应用少量的噪声和去噪步骤,从而可以更有效地探索解决方案空间。 我们展示了 Diffusion-ES 在 nuPlan(已建立的自动驾驶闭环规划基准)上实现了最先进的性能。 Diffusion-ES 优于现有的基于采样的规划器、反应性确定性或基于扩散的策略以及奖励梯度指导。 此外,我们表明,与之前的指导方法不同,我们的方法可以优化由少样本大语言模型提示生成的不可微语言形奖励函数。 当由人类老师发出指令进行指导时,我们的方法可以生成新颖的、高度复杂的行为,例如攻击性的车道编织,而这在训练数据中是不存在的。 这使我们能够解决最困难的 nuPlan 场景,这些场景超出了现有轨迹优化方法和驾驶策略的能力。 111Project page: diffusion-es.github.io
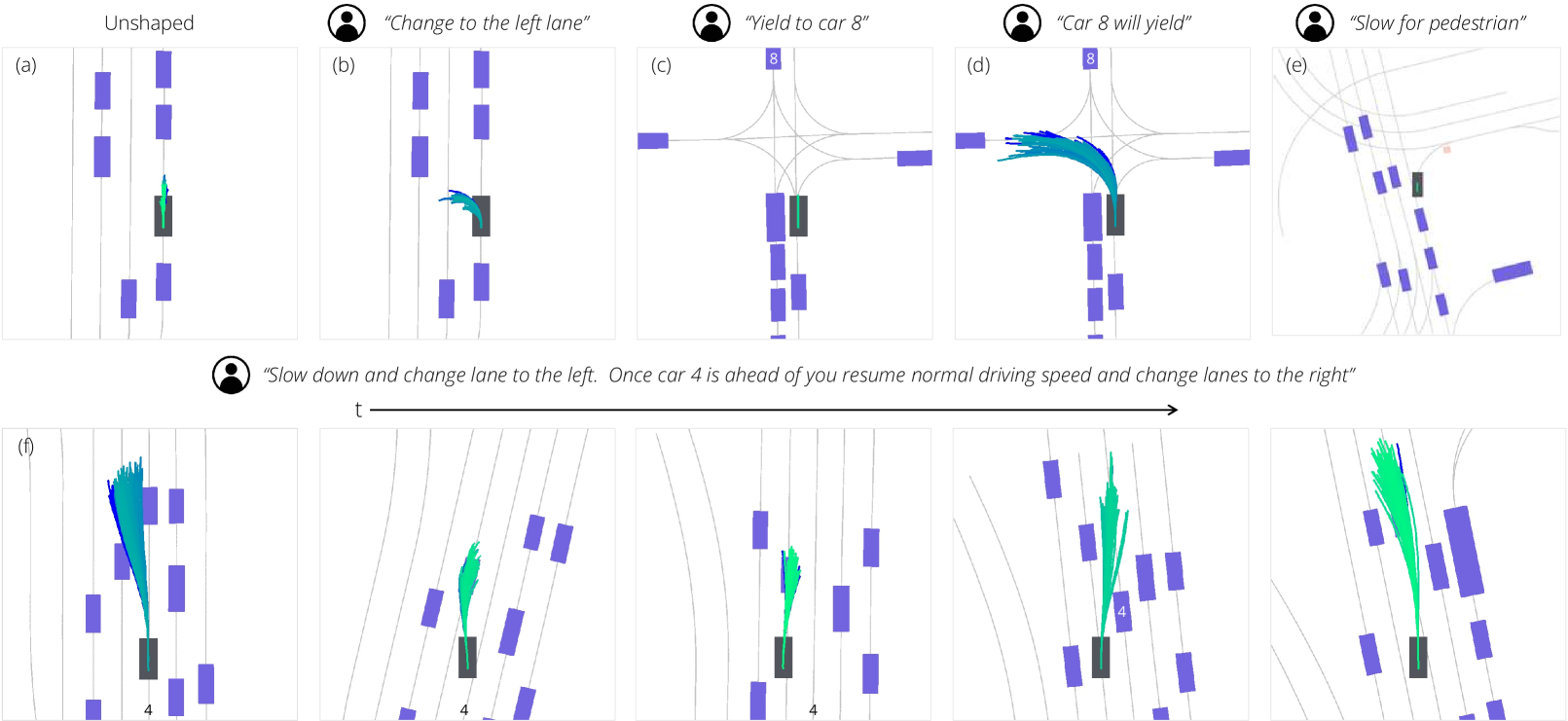
1简介
扩散模型已被证明擅长对高度复杂的多模态轨迹分布进行建模,以进行决策和控制[26, 1]。 奖励梯度指导[26,62,34]已用于通过在去噪扩散步骤和反向传播奖励梯度到噪声轨迹之间交替来测试时间优化可微奖励函数。 通过这种方式,采样的轨迹被推向轨迹数据流形,同时也最大化现有的奖励函数[26]。 奖励函数与轨迹扩散的这种解耦允许使用单个轨迹扩散模型来在测试时最大化各种奖励函数。 奖励梯度指导要求奖励函数是可微分的,并且适合噪声和干净的轨迹,这通常需要重新训练。 这限制了它作为轨迹优化通用求解器的适用性。
我们提出了 Diffusion-ES,一种奖励引导的去噪方法,用于优化不可微的黑盒目标,该方法使用扩散模型对轨迹进行采样和变异,并由仅对干净的最终去噪样本进行操作的奖励函数引导。 天真地将扩散与基于采样的优化结合起来是行不通的:基于采样的优化器,如 CEM [50] 或 MPPI [66],通常需要大量样本多次迭代选择和变异以收敛到好的解决方案,当与去噪推理的计算成本相结合时,会导致搜索过程极其缓慢。 在 Diffusion-ES 中,使用截断的扩散去噪过程来突变高分轨迹,通过添加少量噪声并对其进行去噪,如图 2 所示对。 添加的噪声量在搜索迭代中逐渐减少,使得 Diffusion-ES 在计算上可行。
用于 Diffusion-ES 中测试时间优化的轨迹扩散模型原则上可以以任何场景相关信息为条件,将采样范围缩小到场景相关轨迹的分布。 事实上,条件信息的数量控制着先训练后测试的学习和测试时间规划之间的连续体,以及推理速度和分布外 (OOD) 泛化之间的相应权衡:1. 条件信息越多,从中提取轨迹样本的分布越窄,搜索速度就越快。 在极端情况下,不使用测试时奖励优化,并且我们的扩散模型在测试时作为反应策略运行。 事实上,许多方法将扩散策略[9]训练为条件扩散轨迹预测模型,使用奖励作为轨迹扩散模型[1]的条件信息或通过强化学习[63, 36]或模仿学习[41]微调扩散策略。 虽然这些方法可以处理黑盒奖励函数或模仿的良好行为,但我们表明,按原样使用它们或在测试时使用奖励指导通常无法实现无条件扩散的奖励引导去噪模型,它将轨迹和奖励建模完全解耦。 2. 条件信息越少,提取轨迹样本的分布越宽,搜索速度越慢,但对 OOD 任务和场景的泛化效果就越好,这些任务和场景需要新的轨迹和场景上下文配对,而这些配对不存在于训练数据。 事实上,这是测试时规划优于训练后测试学习的前提:能量函数组合的测试时优化[18, 14],这里是轨迹数据的能量任意奖励函数的分布和能量,应该能够合成训练时未见过的新行为。
我们展示了 Diffusion-ES 如何与轨迹上的无条件扩散模型相结合,纯粹通过扩散引导的黑盒奖励最大化来实现最先进的规划性能。 我们的方法在 nuPlan [5] 上进行评估,这是一个建立在真实驾驶日志和估计的地面真实感知基础上的既定驾驶基准。 我们实现了最先进的闭环驱动性能,与之前的 SOTA、PDM-Closed(根据 nuPlan 基准[12]量身定制的基于采样的规划器)的性能相匹配,如下所示:以及基于确定性或扩散的反应性驱动策略[53, 46]。 此外,我们通过测试时优化使用少样本大语言模型提示生成的语言形奖励函数来说明 Diffusion-ES 的灵活性。 使用语言指令,我们可以解决最具挑战性的 nuPlan 场景,并合成全新的驾驶行为。 然后,我们测试我们的模型和基线优化生成的奖励函数以引发所需行为的能力。 使用我们的方法执行指令生成的行为的定性示例可以在图 1 中找到。 我们展示了 Diffusion-ES 的性能显着优于 PDM-Closed、其他基于采样的规划器,以及 Diffusion-ES 的烧蚀版本,它们要么在周围场景上调节扩散模型,要么根本不使用任何指导。
总之,我们的贡献如下:
-
1.
我们引入了 Diffusion-ES,这是一种用于优化黑盒目标的轨迹优化方法,该方法使用轨迹扩散模型在基于采样的搜索过程中进行采样和变异轨迹提案。 我们表明,Diffusion-ES 与 nuPlan 闭环驾驶中工程规划器的 SOTA 性能相匹配,并且在优化需要灵活驾驶行为(超越车道跟随)的更复杂奖励函数时,其性能远远优于它们。 据我们所知,这是第一个将进化搜索与扩散模型相结合的工作。
-
2.
我们证明,Diffusion-ES 可用于遵循语言指令并通过优化 LLM 形状的奖励函数来引导自动驾驶车辆的闭环驾驶行为,无需任何语言和动作数据。 我们证明,这种遵循指令可以解决 nuPlan 中最具挑战性的驾驶场景。
-
3.
我们展示了我们的模型与不同数量的条件信息的广泛消融,这清楚地揭示了驾驶中推理速度和分布外(OOD)泛化之间的权衡。
我们相信 Diffusion-ES 将作为通用轨迹优化器对社区有用,其适用性超出了驾驶范围。 我们的代码和模型将在发布后公开,以帮助项目网页的可重复性:diffusion-es.github.io。
2相关工作
用于决策和轨迹优化的扩散模型 扩散模型[57,21,58,40]通过迭代去噪过程学习近似数据分布,并显示出令人印象深刻的结果关于图像生成[13,51,49,45]。 它们已用于操作任务[9,47,41,67]的模仿学习,用于可控车辆运动生成[74,27,6]以及视频生成操作任务[15, 70]。 [75, 28]的作品使用扩散模型来预测离线车辆轨迹。 据我们所知,这是第一个在闭环驱动中使用扩散模型的工作。
自动驾驶的学习与规划 通过模仿驾驶演示来学习驾驶在自动驾驶汽车的研发中非常普遍[10, 32, 2, 46, 73, 43, 3, 8, 7, 44]。 许多卓越的模仿方法都假设潜在的动作分布是单峰的,这在从多峰专家演示中进行训练时会出现问题。 已经提出了可以更好地处理多模态轨迹预测的目标和架构[39,56,31,61,17,11]。 我们证明扩散模型非常适合驾驶,并且可用于从多模态演示中合成丰富的复杂行为。
另一方面,传统的自治堆栈根本不依赖于学习来进行决策,而是依赖于在线优化手动设计的成本函数[16,38,77]。 最近,PDM-Closed [12] 仅依靠测试时间规划和启发式方法来选择轨迹建议,在 nuPlan 驾驶基准上实现了最先进的性能。 其他先前的工作旨在通过对学习的成本图执行基于采样的规划[72]或对学习的动态模型进行基于梯度的优化[,将离线学习的优势融入到测试时间规划中。 48]。 我们通过展示如何将基于扩散的生成模型与基于采样的规划相结合来扩展这一工作范围。
自动驾驶语言条件策略 最近,驾驶语言条件策略取得了重大进展。 GAIA-1 [22] 是一种能够生成多模态视频的生成世界模型,它利用视频、语言和动作来合成符合给定语言指令的驾驶场景。 然而,GAIA-1 不执行任何实际的控制输入。
根据互联网规模文本训练的大语言模型在适当的提示下,在没有任何权重微调的情况下,对各种下游语言任务表现出了令人印象深刻的零样本推理能力[64,35,4]。 最近的工作表明,大语言模型可以提示将语言指令映射到语言子目标[76,68,23,24]动作程序[33,60,19]或成本图[25]以及适当的类似计划或类似程序的提示。 我们的工作遵循大语言模型的少样本提示来塑造驱动奖励函数。 我们通过使用 Python 生成器来扩展以前的方法来生成奖励函数,该函数在调用之间维护内部状态。 [37,65,69]的作品使用大语言模型来预测给定高级场景描述和语言指令的低级控制信号。 然而,这些方法都没有评估它们在闭环驾驶方面的性能,这比开环轨迹预测[12]要困难得多。 [55] 与我们类似,但仅考虑高度简化的驾驶设置,并且不报告具有强基线的标准化基准的结果。
3方法
3.1背景
扩散模型扩散模型通过前向扩散过程的反转来捕获概率分布,该过程逐渐将高斯噪声添加到初始样本 添加的噪声量取决于预定义的方差表 ,其中 表示扩散时间步的总数。 在扩散时间步处,前向扩散过程使用公式将噪声添加到中,其中是来自高斯分布的样本与 具有相同维度的分布。 这里是和。 对于去噪,神经网络 将输入作为噪声样本 和扩散时间步长 ,并学习预测添加的噪声 . 要从学习分布 中生成样本,我们首先要从先验分布 中提取样本,然后用 对该样本进行 次迭代去噪。 的应用取决于指定的采样时间表 [21, 58],该采样时间表以从 采样的 结束。 通过向去噪神经网络 添加额外的输入,可以很容易地将扩散模型扩展到 模型,其中 c 是一些条件信号,如预期的未来奖励 ,。
进化策略进化策略(ES)是一系列基于群体的无梯度优化算法,可以最大化任意黑盒奖励函数而无需任何训练,其中 是我们优化的变量。 ES 迭代更新搜索分布 以最大化预期奖励 。 虽然基于分布的 ES 方法(例如 CEM 和 CMA-ES)明确地表示 (通常作为单峰高斯),但我们也可以非参数地将 表示为一组高斯函数。执行解决方案而不对 的函数形式做出强有力的假设。
3.2扩散-ES
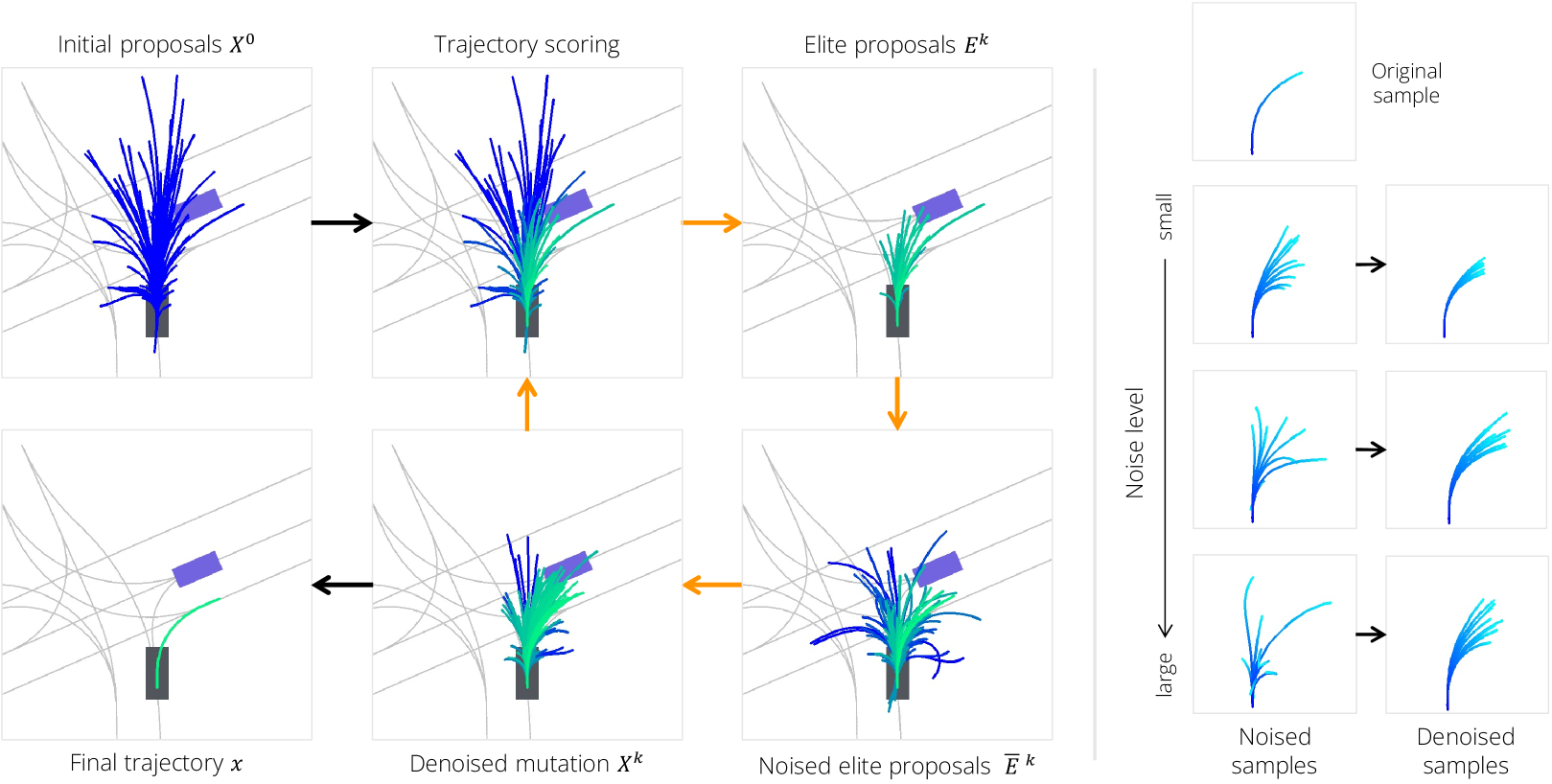
Diffusion-ES 是一种轨迹优化方法,利用无梯度进化搜索,针对任何黑盒奖励函数 ,从经过训练的扩散模型执行奖励引导采样。 具体来说,我们使用经过训练的扩散模型来初始化样本总体,并使用截断的扩散去噪过程来变异样本,同时保留在数据流形中。 Diffusion-ES 的控制流程如图2(左)和算法1所示。
通过扩散采样初始化总体 我们首先使用扩散模型对 轨迹样本的初始总体 进行采样:
| (1) |
其中 是迭代 时的总体。这涉及完整的反向扩散过程。 鉴于我们使用无条件扩散模型,这些样本与场景无关,并且始终可以使用而无需在每个时间步重新采样。 我们还可以通过包含其他方法生成的样本或混合前一个时间步的解决方案来修改初始群体以热启动我们的优化。
样本评分 在每次迭代时,我们都会对总体中的样本进行评分。 请注意,我们的群体由“干净”样本组成,因此我们不需要可以处理“嘈杂”样本的奖励函数,与执行基于分类器的指导的指导方法相比,这为我们提供了显着的灵活性。
选择 我们使用奖励来决定应该选择哪些样本来传播到下一次迭代。 与 MPPI [66] 类似,我们对 进行重新采样,如下所示:
| (2) | ||||
| (3) |
其中 代表我们的精英集,它在迭代 中保留, 是控制 锐度的可调温度参数。
使用截断扩散去噪的突变我们对应用随机突变进行探索。 先前的进化搜索方法诉诸于朴素高斯扰动,其不利用有关数据流形的任何先验知识。 我们的主要见解是利用截断的扩散去噪过程来改变轨迹,从而产生的突变是数据流形的一部分。 我们可以运行前向扩散过程的前步骤来获得噪声精英样本:
| (4) |
其中。 然后我们可以运行反向扩散过程的最后步骤来再次对样本进行去噪,从而得到干净的样本:
| (5) |
实际上,截断扩散过程的时间步数是一个可调的时间相关超参数,它控制每次迭代的突变强度。图2(右)对此进行了可视化。 我们发现,在我们的实验中,在 20 个搜索步骤中,将突变扩散步骤数 从 5 线性衰减到 1 效果最好。
3.3 用大语言模型提示将语言指令映射到奖励函数
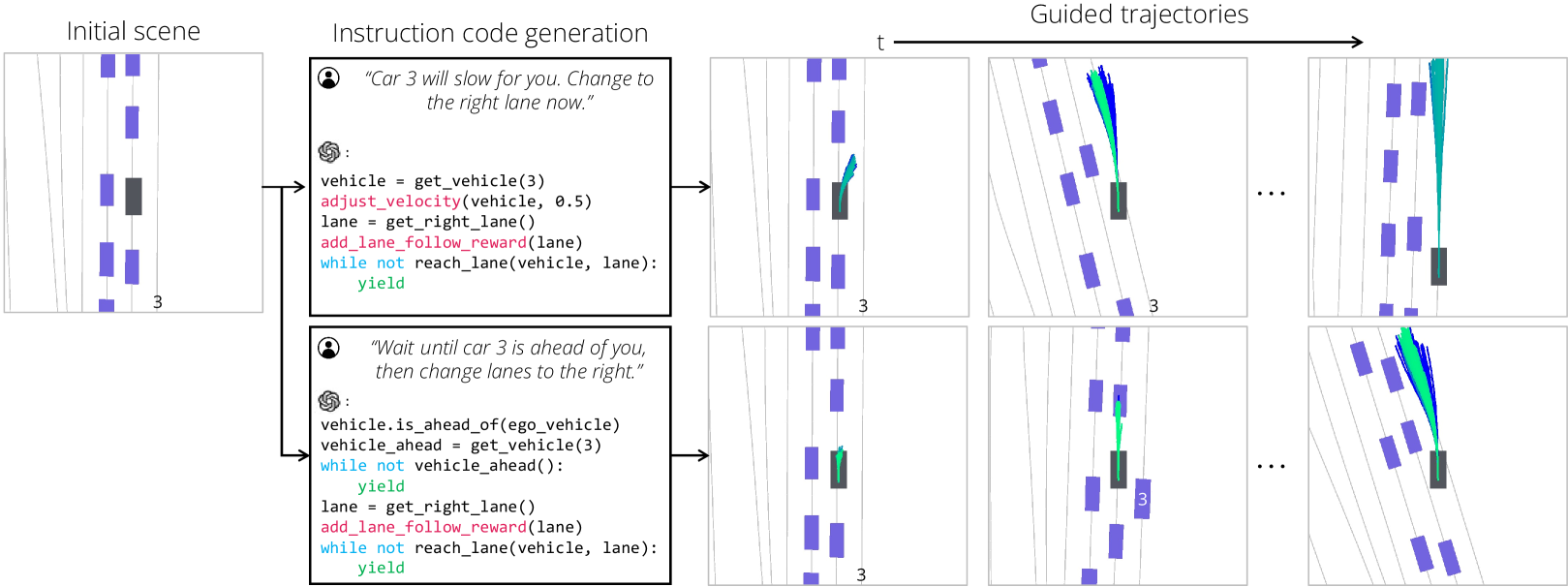
为了遵循自然语言给出的驾驶指令,我们将它们映射到黑盒奖励函数,并使用 Diffusion-ES 进行优化。 我们采用与[71, 29]类似的方法,使用大语言模型从语言指令中合成奖励函数。 奖励函数是可组合的,使我们能够将语言指导与其他约束无缝结合起来。 这对于我们不断同时优化许多不同目标(例如安全性、驾驶员舒适度、路线遵守)的驾驶至关重要。
与之前的工作类似,我们公开了一个 Python API,可用于提取有关道路场景中实体的信息。 由于驾驶中的许多基本奖励信号不会因场景而变化(例如,避免碰撞或可驾驶区域合规性),因此我们允许大语言模型编写奖励塑造代码来修改基本奖励函数,而不是从头开始生成所有内容。 奖励塑造可以添加辅助奖励条款(例如,密集的到达车道奖励)或重新加权现有奖励条款。 我们在图 3 中显示了生成的代码示例。
我们的目标是处理具有时间依赖性的一般和复杂的语言指令,例如“向左改变车道,然后通过右侧的汽车,然后驶出出口”。 之前的工作[71, 25]产生了一个固定的奖励函数,即在规划期间固定的奖励函数。 这使得仅通过奖励来表达连续计划变得具有挑战性。 我们发现在代码中捕获这些计划的一种更自然和简洁的方法是使用生成器函数,它保留调用之间的内部状态。 我们所有的提示和代码示例都可以在补充文件中找到。 在第4节中,我们展示了如何优化这些语言形状的奖励函数可以合成符合语言指令的丰富而复杂的驾驶行为。
4实验
我们首先在 nuPlan [5] 中评估闭环驾驶的 Diffusion-ES,这是一个既定的基准,使用车辆、行人、车道和交通标志的估计感知。 我们的模型和基线根据其安全高效驾驶的能力进行评估,同时能够访问数据集提供的接近真实的感知输出。 我们还考虑了一套遵循任务的驾驶指导。 我们在大语言模型提示下将指令映射到成形的奖励函数,并评估 Diffusion-ES 和基线优化生成的奖励函数并准确遵循指令的能力。 我们的实验旨在回答以下问题:
-
1.
Diffusion-ES 与现有的基于采样的规划器和用于轨迹优化的奖励梯度指导相比如何?
-
2.
Diffusion-ES 与直接将环境状态映射到车辆轨迹的 SOTA 反应式驾驶策略相比如何?
-
3.
最困难的 nuPlan 驾驶场景是否可以通过假设有一位人类老师以自然语言进行指导而无需任何额外的训练数据来解决?
-
4.
扩散模型的场景调节是否有利于 Diffusion-ES?
4.1闭环驱动
我们在 nuPlan Val14 规划基准 [12] 上评估我们的模型。 我们特别考虑 nuPlan 基准的反应代理跟踪,因为它是 nuPlan 中最困难和最现实的评估设置。
模型设置和超参数
对于 Diffusion-ES,我们在由 2D 姿势 组成的自我车辆轨迹上训练扩散模型,以 2Hz 预测未来 8 秒,导致整体动作维度为 48。 与之前的工作[26]不同,我们仅对动作的分布进行建模,而不是对状态和动作进行建模。 我们在实验中使用的群体大小为 。 我们的扩散模型是通过 去噪步骤进行训练的。
奖励功能
我们采用 PDM-Closed [12] 中使用的评分函数的修改版本作为我们的奖励函数。 为了计算奖励,我们使用 LQR 跟踪器将预测轨迹转换为低级控制输入。 这些控制输入被输入到运动学自行车模型[42]中,该模型传播自我车辆的动力学。 我们遵循[12]并通过假设恒定速度来预测其他智能体的运动。 然后根据 nuPlan 基准评估指标对这些模拟部署进行评分。 我们还添加了辅助奖励条款,以惩罚接近领先代理并强制执行速度限制。
请注意,由于跟踪器和使用不可微启发法来评估交通违规行为,此奖励函数不可微。 此外,训练回归奖励的模型具有挑战性,因为 nuPlan 数据集不包含严重交通违规的实例。
评估指标
我们使用驾驶分数来报告结果,该分数汇总了与交通规则合规性、安全性、路线进度和骑手舒适度相关的多个规划指标。 这是 nuPlan 中使用的标准评估指标。
基线
我们考虑以下基线:
-
•
UrbanDriverOL [52],一种通过行为克隆和增强进行训练的确定性 Transformer 策略。 与[52]训练不同,nuPlan实现不执行闭环。
-
•
PlanCNN [46] 一种确定性模仿策略,使用 CNN 主干对光栅化 BEV 地图进行编码。
-
•
IDM [20]:一种基于规则的启发式规划器,可调整其速度以与领先车辆保持安全距离。 它还用于控制 nuPlan 中代理的行为。
-
•
PDM-Closed [12]:基于 MPC 的规划器,它使用车道中心线生成路径建议,并与我们类似地推出轨迹。 PDM-Closed 不是迭代地优化奖励,而是在一轮评分后简单地执行表现最好的提案。 它是 nuPlan Val14 基准测试中当前最先进的。
-
•
扩散策略:我们考虑场景特征的条件来直接预测车辆轨迹的扩散模型。 我们使用 Urban Driver [53] 中的 Transformer 特征主干对场景特征进行编码。 我们通过模仿学习和增强来训练它。 这类似于 Diffusion-ES 中的无条件轨迹模型,并对场景特征进行了额外的调节。
| Method | Driving Score () | |
|---|---|---|
| Train-then-test | UrbanDriverOL [53] | 65 |
| PlanCNN [46] | 72 | |
| Diffusion policy | 50 | |
| Test-time optimize | IDM [50] | 77 |
| PDM-Closed [12] | 92 | |
| Diffusion-ES (ours) | 92 |
我们在表 1 中显示了定量结果。 我们得出以下结论:
1。 Diffusion-ES 与之前最先进的 PDM-Closed 相匹配,并且大大优于所有其他基线。 PDM-Closed 是一种基于采样的规划器,它依赖于特定领域的启发式方法来生成轨迹建议,而 Diffusion-ES 从数据中学习这些建议。 两者都对场景中的代理使用类似的奖励函数和动态模型。
2。最近的工作[12]也指出,反应式神经策略和测试时间规划器之间的性能存在很大差距。 我们假设这是因为与其他控制基准相比,nuPlan 具有更丰富的观察空间,因为场景中充满了动态参与者,其中许多与自我代理无关。 这使得基于学习的方法难以泛化,从而激发了测试时优化的需要。
3. 扩散-ES 的性能明显优于扩散策略。 定性地讲,我们的扩散政策有随机改变车道的倾向,这导致自我车辆更快地到达分布外的场景。 Diffusion-ES 利用生成模型的表现力,同时使用测试时优化来提高泛化能力。
4.2 语言说明如下
nuPlan 驾驶基准的一个缺点是鼓励高度保守的驾驶行为。 例如,PDM-Closed [12] 拥有 nuPlan Val14 基准中的最先进技术,但无法更改车道,因为其路径建议仅考虑自我车辆所在的车道目前开启。 然而,在当前的 nuPlan 基准测试中,变道并不是获得良好驾驶性能所必需的。
为了评估 Diffusion-ES 和基线优化任意奖励函数的能力,我们考虑了八种语言指令跟踪任务,每个任务都取自 nuPlan 基准中的现有驾驶日志。 在每项任务中,语言指令都要求自我车辆执行特定的驾驶操作,以解决具有挑战性的驾驶场景。 在大多数情况下,nuPlan 中的任何位置都不会提供指示行为的示例。 例如,车道编织任务要求自动车辆在密集的城市交通中积极改变多条车道。 附录中提供了任务描述、语言说明和提示。 我们使用3中描述的方法来生成可执行的Python代码,给定一个语言指令,该指令适应第4.1节的初始奖励函数,为我们提供了每个语言形状的奖励函数设想。 我们的模型和基线将优化相同的语言形状的奖励函数。
评估指标
我们使用任务成功率来评估我们的模型和基线,它衡量代理能够成功完成指定任务的频率。 为了增加任务的难度,我们通过在每个情节中不定期地向其他车辆智能体的 IDM 参数添加噪声来随机化其他车辆智能体的行为。 报告的所有分数都是十个随机种子的平均值。
基线
我们与以下基线进行比较:
-
•
PDM-Closed:通过使用我们的语言形状奖励函数代替原始奖励函数来适应此设置。
-
•
PDM-Closed-Multilane:PDM-Closed 的修改变体,它考虑更广泛的横向偏移路径,允许车道变更。
-
•
Conditional Diffusion-ES:使用条件扩散模型而不是无条件扩散模型的扩散-ES。
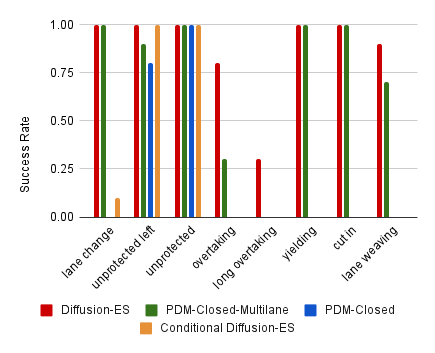
图4显示了可控性任务的成功率。 我们得出以下结论:
1。 Diffusion-ES 优于所有基线。 尽管由于轨迹建议更加多样化,PDM-Closed-Multilane 与 PDM-Closed 相比,性能有了显着提高,但在 8 个任务中的 4 个上,它仍然弱于 Diffusion-ES。 这凸显了依靠手工制定的规则来生成提案的弱点。 2. 条件扩散模型的扩散-ES 表现明显较差。 条件扩散模型更难指导,因为场景上下文导致分布中的样本较少。
4.3车道跟随
为了将 Diffusion-ES 与奖励梯度引导进行比较,我们考虑一个具有可微奖励函数的简化车道跟随任务,该任务由两项组成:一项惩罚偏离车道的横向偏差(车道错误),以及与目标速度的一次惩罚偏差(速度错误)。 我们对 14 个场景进行了采样,nuPlan 中每种场景类型之一,并报告所有场景的平均规划成本。
基线
我们考虑以下基线:
-
•
CEM [50]:一种广泛使用的 ES 方法,它将搜索分布 参数化为高斯分布。 CEM 在从 采样和将 拟合到最佳样本之间进行迭代。
-
•
MPPI [66]:与 CEM 类似,但不是保留固定数量的精英,MPPI 样本与奖励成比例。
-
•
奖励梯度指导 [26]:我们在去噪过程中直接使用梯度下降来优化地面实况规划目标。
| Method | Lane Error | Speed Error |
|---|---|---|
| CEM | 2.34 | 2.05 |
| MPPI | 3.29 | 2.74 |
| Reward-gradient guidance | 1.22 | 0.96 |
| Diffusion-ES (ours) | 0.61 | 0.79 |
我们在表2中显示了定量结果。 我们得出以下结论:1.Diffusion-ES 优于可微奖励梯度指导基线即使目标是可微的。 我们假设这是因为虽然地面实况奖励函数可用,但它可能无法为中间噪声轨迹提供合适的指导。 这凸显了我们的方法相对于之前的工作的一个关键优势,即我们可以优化新颖的目标,而无需在噪声样本上训练奖励回归器。 2。两种基于扩散的方法都明显优于不利用扩散的基于采样的规划器。 这与我们的假设一致,即扩散引导可以比传统 ES 方法更有效地优化轨迹。 我们的方法在所有实验设置中驱动的视频可以在我们的项目页面 diffusion-es.github.io 中找到。
4.4运行时分析
| Method | Wallclock time (s) |
|---|---|
| Diffusion | 1.11 0.02 |
| Diffusion-ES | 5.85 0.11 |
| Diffusion-ES (optimized) | 0.50 0.01 |
Diffusion-ES 可以通过一些小的优化来实时使用。 通过使用更少的扩散步骤、更小的群体规模和更少的迭代,我们的方法可以以与模拟器相同的频率(2 Hz)运行性能成本很小(nuPlan 驾驶分数从 92 下降到 91)。 我们在表 3 中报告了超过 100 次试验的每个时间步的平均推理时间。
4.5讨论 - 局限性 - 未来的工作
如 4.4 节所示,我们的方法确实引入了计算开销。 我们相信,通过结合扩散建模的最新进展(例如更快的采样器)可以缓解这些问题。 我们的奖励函数假设其他代理将以匀速行驶,这显然可以改进。 这还假设其他智能体无法对自我车辆做出反应,这已被证明是自动驾驶规划者的主要限制[48]。 然而,我们的实验指导表明,即使我们无法完美预测,我们也可以使用语言形式的奖励来解决最困难的驾驶场景。 我们的目标是在未来的工作中探索记忆促进的类比奖励塑造,以在没有人类老师的情况下处理长尾场景。
5结论
我们提出了 Diffusion-ES,一种黑盒奖励引导扩散采样的方法。 我们表明,Diffusion-ES 可以有效地优化 nuPlan 中用于驱动和指令遵循的奖励函数,并且优于基于工程采样的规划器、反应性确定性或扩散策略以及可微奖励梯度指导。 我们展示了如何在没有任何语言动作轨迹数据的情况下使用我们的方法来遵循语言指令,只需使用大语言模型提示来生成用于测试时间优化的成形奖励图。 我们未来的工作将探索检索正确的奖励塑造,以优化在没有人类教师的情况下处理长尾驾驶场景。 我们的实验展示了扩散策略场景调节期间推理速度和 OOD 泛化之间的权衡。 我们未来的工作将探索如何将此类搜索的结果摊销到快速反应策略,并平衡两个极端,以便可以根据场景花费可变的计算量。
致谢
本材料基于 NSF 职业奖、AFOSR FA95502310257 奖、ONR 奖 N000142312415 和 ARL 奖 No 48987.3.1130233 支持的工作。 本材料中表达的任何观点、发现和结论或建议均为作者的观点,并不一定反映美国陆军、国家科学基金会或美国空军的观点。
参考
- Ajay et al. [2022] Anurag Ajay, Yilun Du, Abhi Gupta, Joshua B. Tenenbaum, T. Jaakkola, and Pulkit Agrawal. Is conditional generative modeling all you need for decision-making? ArXiv, abs/2211.15657, 2022.
- Bansal et al. [2018] Mayank Bansal, Alex Krizhevsky, and Abhijit S. Ogale. Chauffeurnet: Learning to drive by imitating the best and synthesizing the worst. CoRR, abs/1812.03079, 2018.
- Bojarski et al. [2016] Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D. Jackel, Mathew Monfort, Urs Muller, Jiakai Zhang, Xin Zhang, Jake Zhao, and Karol Zieba. End to end learning for self-driving cars, 2016.
- Brown et al. [2020] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020.
- Caesar et al. [2022] Holger Caesar, Juraj Kabzan, Kok Seang Tan, Whye Kit Fong, Eric Wolff, Alex Lang, Luke Fletcher, Oscar Beijbom, and Sammy Omari. Nuplan: A closed-loop ml-based planning benchmark for autonomous vehicles, 2022.
- Carvalho et al. [2023] João Carvalho, An T. Le, Mark Baierl, Dorothea Koert, and Jan Peters. Motion planning diffusion: Learning and planning of robot motions with diffusion models. ArXiv, abs/2308.01557, 2023.
- Chen and Krähenbühl [2022] Dian Chen and Philipp Krähenbühl. Learning from all vehicles, 2022.
- Chen et al. [2019] Dian Chen, Brady Zhou, Vladlen Koltun, and Philipp Krähenbühl. Learning by cheating. ArXiv, abs/1912.12294, 2019.
- Chi et al. [2023] Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion, 2023.
- Codevilla et al. [2017] Felipe Codevilla, Matthias Müller, Alexey Dosovitskiy, Antonio M. López, and Vladlen Koltun. End-to-end driving via conditional imitation learning. CoRR, abs/1710.02410, 2017.
- Cui et al. [2021] Alexander Cui, Abbas Sadat, Sergio Casas, Renjie Liao, and Raquel Urtasun. Lookout: Diverse multi-future prediction and planning for self-driving. CoRR, abs/2101.06547, 2021.
- Dauner et al. [2023] Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with misconceptions about learning-based vehicle motion planning, 2023.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. ArXiv, abs/2105.05233, 2021.
- Du et al. [2023a] Yilun Du, Conor Durkan, Robin Strudel, Joshua B. Tenenbaum, Sander Dieleman, Rob Fergus, Jascha Sohl-Dickstein, Arnaud Doucet, and Will Grathwohl. Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc, 2023a.
- Du et al. [2023b] Yilun Du, Mengjiao Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Joshua B. Tenenbaum, Dale Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation. ArXiv, abs/2302.00111, 2023b.
- Fan et al. [2018] Haoyang Fan, Fan Zhu, Changchun Liu, Liangliang Zhang, Li Zhuang, Dong Li, Weicheng Zhu, Jiangtao Hu, Hongye Li, and Qi Kong. Baidu apollo em motion planner. arXiv preprint arXiv:1807.08048, 2018.
- Fragkiadaki et al. [2017] Katerina Fragkiadaki, Jonathan Huang, Alex Alemi, Sudheendra Vijayanarasimhan, Susanna Ricco, and Rahul Sukthankar. Motion prediction under multimodality with conditional stochastic networks, 2017.
- Gkanatsios et al. [2023] Nikolaos Gkanatsios, Ayush Jain, Zhou Xian, Yunchu Zhang, Christopher Atkeson, and Katerina Fragkiadaki. Energy-based Models are Zero-Shot Planners for Compositional Scene Rearrangement. In Robotics: Science and Systems, 2023.
- Gupta and Kembhavi [2023] Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14953–14962, 2023.
- Helbing and Tilch [1998] Dirk Helbing and Benno Tilch. Generalized force model of traffic dynamics. Physical review E, 58(1):133, 1998.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- Hu et al. [2023] Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023.
- Huang et al. [2022a] Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. arXiv preprint arXiv:2201.07207, 2022a.
- Huang et al. [2022b] Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. Inner monologue: Embodied reasoning through planning with language models, 2022b.
- Huang et al. [2023] Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. Voxposer: Composable 3d value maps for robotic manipulation with language models. arXiv preprint arXiv:2307.05973, 2023.
- Janner et al. [2022] Michael Janner, Yilun Du, Joshua Tenenbaum, and Sergey Levine. Planning with diffusion for flexible behavior synthesis. In International Conference on Machine Learning, 2022.
- Jiang et al. [2023a] Chiyu Jiang, Andre Cornman, Cheolho Park, Benjamin Sapp, Yin Zhou, and Dragomir Anguelov. Motiondiffuser: Controllable multi-agent motion prediction using diffusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9644–9653, 2023a.
- Jiang et al. [2023b] Chiyu “Max” Jiang, Andre Cornman, Cheolho Park, Benjamin Sapp, Yin Zhou, and Dragomir Anguelov. Motiondiffuser: Controllable multi-agent motion prediction using diffusion, 2023b.
- Katara et al. [2023] Pushkal Katara, Zhou Xian, and Katerina Fragkiadaki. Gen2sim: Scaling up robot learning in simulation with generative models, 2023.
- Khattab et al. [2023] Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714, 2023.
- Kim et al. [2023] Sanmin Kim, Hyeongseok Jeon, Jun Won Choi, and Dongsuk Kum. Diverse multiple trajectory prediction using a two-stage prediction network trained with lane loss. IEEE Robotics and Automation Letters, 8(4):2038–2045, 2023.
- Kuefler et al. [2017] Alex Kuefler, Jeremy Morton, Tim Allan Wheeler, and Mykel John Kochenderfer. Imitating driver behavior with generative adversarial networks. CoRR, abs/1701.06699, 2017.
- Liang et al. [2022] Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. arXiv preprint arXiv:2209.07753, 2022.
- Liang et al. [2023] Zhixuan Liang, Yao Mu, Mingyu Ding, Fei Ni, Masayoshi Tomizuka, and Ping Luo. Adaptdiffuser: Diffusion models as adaptive self-evolving planners. In ICML, 2023.
- Liu et al. [2021] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. CoRR, abs/2107.13586, 2021.
- Lu et al. [2023] Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. arXiv preprint arXiv:2304.12824, 2023.
- Mao et al. [2023] Jiageng Mao, Yuxi Qian, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415, 2023.
- Montremerlo et al. [2008] M Montremerlo, J Beeker, S Bhat, and H Dahlkamp. The stanford entry in the urban challenge. Journal of Field Robotics, 7(9):468–492, 2008.
- Nayakanti et al. [2022] Nigamaa Nayakanti, Rami Al-Rfou, Aurick Zhou, Kratarth Goel, Khaled S. Refaat, and Benjamin Sapp. Wayformer: Motion forecasting via simple and efficient attention networks, 2022.
- Nichol and Dhariwal [2021] Alexander Quinn Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In International Conference on Machine Learning, pages 8162–8171. PMLR, 2021.
- Pearce et al. [2023] Tim Pearce, Tabish Rashid, Anssi Kanervisto, Dave Bignell, Mingfei Sun, Raluca Georgescu, Sergio Valcarcel Macua, Shan Zheng Tan, Ida Momennejad, Katja Hofmann, and Sam Devlin. Imitating human behaviour with diffusion models, 2023.
- Polack et al. [2017] Philip Polack, Florent Altché, Brigitte d’Andréa Novel, and Arnaud de La Fortelle. The kinematic bicycle model: A consistent model for planning feasible trajectories for autonomous vehicles? In 2017 IEEE intelligent vehicles symposium (IV), pages 812–818. IEEE, 2017.
- Pomerleau [1989] Dean A. Pomerleau. ALVINN: an autonomous land vehicle in a neural network. In Advances in Neural Information Processing Systems 1, pages 305–313. San Francisco, CA: Morgan Kaufmann, 1989.
- Prakash et al. [2021] Aditya Prakash, Kashyap Chitta, and Andreas Geiger. Multi-modal fusion transformer for end-to-end autonomous driving. CoRR, abs/2104.09224, 2021.
- Ramesh et al. [2022] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. ArXiv, abs/2204.06125, 2022.
- Renz et al. [2022] Katrin Renz, Kashyap Chitta, Otniel-Bogdan Mercea, A. Sophia Koepke, Zeynep Akata, and Andreas Geiger. Plant: Explainable planning transformers via object-level representations. In 6th Annual Conference on Robot Learning, 2022.
- Reuss et al. [2023] Moritz Reuss, Maximilian Li, Xiaogang Jia, and Rudolf Lioutikov. Goal-conditioned imitation learning using score-based diffusion policies. arXiv preprint arXiv:2304.02532, 2023.
- Rhinehart et al. [2021] Nicholas Rhinehart, Jeff He, Charles Packer, Matthew A Wright, Rowan McAllister, Joseph E Gonzalez, and Sergey Levine. Contingencies from observations: Tractable contingency planning with learned behavior models. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13663–13669. IEEE, 2021.
- Rombach et al. [2022] Robin Rombach, A. Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674–10685, 2022.
- Rubinstein [1997] Reuven Y Rubinstein. Optimization of computer simulation models with rare events. European Journal of Operational Research, 99(1):89–112, 1997.
- Saharia et al. [2022] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L. Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, Seyedeh Sara Mahdavi, Raphael Gontijo Lopes, Tim Salimans, Jonathan Ho, David J. Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding. ArXiv, abs/2205.11487, 2022.
- Scheel et al. [2021] Oliver Scheel, Luca Bergamini, Maciej Wołczyk, Bla.zej Osi’nski, and Peter Ondruska. Urban driver: Learning to drive from real-world demonstrations using policy gradients. In Conference on Robot Learning, 2021.
- Scheel et al. [2022] Oliver Scheel, Luca Bergamini, Maciej Wolczyk, Błażej Osiński, and Peter Ondruska. Urban driver: Learning to drive from real-world demonstrations using policy gradients. In Conference on Robot Learning, pages 718–728. PMLR, 2022.
- Seff et al. [2023] Ari Seff, Brian Cera, Dian Chen, Mason Ng, Aurick Zhou, Nigamaa Nayakanti, Khaled S Refaat, Rami Al-Rfou, and Benjamin Sapp. Motionlm: Multi-agent motion forecasting as language modeling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8579–8590, 2023.
- Sha et al. [2023] Hao Sha, Yao Mu, Yuxuan Jiang, Li Chen, Chenfeng Xu, Ping Luo, Shengbo Eben Li, Masayoshi Tomizuka, Wei Zhan, and Mingyu Ding. Languagempc: Large language models as decision makers for autonomous driving. arXiv preprint arXiv:2310.03026, 2023.
- Shafiullah et al. [2022] Nur Muhammad Mahi Shafiullah, Zichen Jeff Cui, Ariuntuya Altanzaya, and Lerrel Pinto. Behavior transformers: Cloning modes with one stone, 2022.
- Sohl-Dickstein et al. [2015] Jascha Narain Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. ArXiv, abs/1503.03585, 2015.
- Song et al. [2020] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- Su et al. [2021] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864, 2021.
- Surís et al. [2023] Dídac Surís, Sachit Menon, and Carl Vondrick. Vipergpt: Visual inference via python execution for reasoning, 2023.
- Tang and Salakhutdinov [2019] Yichuan Charlie Tang and Ruslan Salakhutdinov. Multiple futures prediction. CoRR, abs/1911.00997, 2019.
- Urain et al. [2023] Julen Urain, Niklas Funk, Georgia Chalvatzaki, and Jan Peters. Se (3)-diffusionfields: Learning cost functions for joint grasp and motion optimization through diffusion. ICRA, 2023.
- Wang et al. [2022] Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. arXiv preprint arXiv:2208.06193, 2022.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. CoRR, abs/2201.11903, 2022.
- Wen et al. [2023] Licheng Wen, Xuemeng Yang, Daocheng Fu, Xiaofeng Wang, Pinlong Cai, Xin Li, Tao Ma, Yingxuan Li, Linran Xu, Dengke Shang, et al. On the road with gpt-4v (ision): Early explorations of visual-language model on autonomous driving. arXiv preprint arXiv:2311.05332, 2023.
- Williams et al. [2015] Grady Williams, Andrew Aldrich, and Evangelos Theodorou. Model predictive path integral control using covariance variable importance sampling. arXiv preprint arXiv:1509.01149, 2015.
- [67] Zhou Xian, Nikolaos Gkanatsios, Théophile Gervet, Tsung-Wei Ke, and Katerina Fragkiadaki. Chaineddiffuser: Unifying trajectory diffusion and keypose prediction for robotic manipulation. In CoRL 2023.
- Xu et al. [2019] Danfei Xu, Roberto Martín-Martín, De-An Huang, Yuke Zhu, Silvio Savarese, and Li Fei-Fei. Regression planning networks. CoRR, abs/1909.13072, 2019.
- Xu et al. [2023] Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kenneth KY Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. arXiv preprint arXiv:2310.01412, 2023.
- Yang et al. [2023] Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. ArXiv, abs/2310.06114, 2023.
- Yu et al. [2023] Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, et al. Language to rewards for robotic skill synthesis. arXiv preprint arXiv:2306.08647, 2023.
- Zeng et al. [2019] Wenyuan Zeng, Wenjie Luo, Simon Suo, Abbas Sadat, Bin Yang, Sergio Casas, and Raquel Urtasun. End-to-end interpretable neural motion planner. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8660–8669, 2019.
- Zhang et al. [2021] Zhejun Zhang, Alexander Liniger, Dengxin Dai, Fisher Yu, and Luc Van Gool. End-to-end urban driving by imitating a reinforcement learning coach. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- Zhong et al. [2022a] Ziyuan Zhong, Davis Rempe, Danfei Xu, Yuxiao Chen, Sushant Veer, Tong Che, Baishakhi Ray, and Marco Pavone. Guided conditional diffusion for controllable traffic simulation. ArXiv, abs/2210.17366, 2022a.
- Zhong et al. [2022b] Ziyuan Zhong, Davis Rempe, Danfei Xu, Yuxiao Chen, Sushant Veer, Tong Che, Baishakhi Ray, and Marco Pavone. Guided conditional diffusion for controllable traffic simulation. ArXiv, abs/2210.17366, 2022b.
- Zhu et al. [2020] Yifeng Zhu, Jonathan Tremblay, Stan Birchfield, and Yuke Zhu. Hierarchical planning for long-horizon manipulation with geometric and symbolic scene graphs. CoRR, abs/2012.07277, 2020.
- Ziegler et al. [2014] Julius Ziegler, Philipp Bender, Thao Dang, and Christoph Stiller. Trajectory planning for bertha—a local, continuous method. In 2014 IEEE intelligent vehicles symposium proceedings, pages 450–457. IEEE, 2014.
6附录
6.1 模型训练详情
我们在已发布的 nuPlan 训练数据的 1% 上训练扩散模型,该数据从原始 20Hz 二次采样到 0.5Hz。 我们的扩散模型是使用 扩散步骤训练的 DDIM [58]。 我们使用缩放的线性 beta 计划并预测 。 我们的模型是在 PyTorch 中实现的,我们使用 HuggingFace Diffusers 库来实现我们的扩散模型。
我们的基础扩散架构如下。 每个轨迹路点都线性投影到隐藏大小为 256 的潜在特征。 噪声水平采用正弦位置嵌入进行编码,后跟 2 层 MLP。 通过将噪声特征连接到沿特征维度的所有轨迹特征并投影回隐藏大小 256,将噪声特征与轨迹标记融合。 我们还将旋转位置嵌入 [59] 应用于轨迹标记作为时间嵌入。 然后,我们将所有轨迹标记传递给 8 个 Transformer 编码器层,每个轨迹词符被解码为相应的路点。 最终轨迹由堆叠的航路点预测组成。 我们的条件扩散策略基线使用类似的架构,不同之处在于我们使用 Urban Driver [53] 的 nuPlan 重新实现的主干来对场景进行特征化,并将这些标记传递到自注意力层中。
我们使用批量大小 256 训练模型,并使用学习率 1e-4、权重衰减 5e-4 和 的 AdamW 优化器。
我们的轨迹由 16 个 2D 位姿路径点组成,每个路径点具有 3 个特征 ()。 我们通过应用 MotionLM [54] 中描述的 Verlet 包裹来预处理这些轨迹特征,我们发现它可以通过鼓励平滑轨迹来提高性能。
6.2 任务后的语言教学
在这里,我们详细描述每项可控性任务。 对于每个任务,我们列出了任务目标以及所使用的特定语言指令。
-
1.
车道变换:自我车辆必须执行车道变换。 语言指令为“向左变道”。 如果自我车辆到达左侧车道,则该事件被认为是成功的。
-
2.
无保护左转:自我车辆必须执行无保护左转。 语言指令是 “如果 18 号车在 20 米以内,请让行。 否则你的速度会变慢”,其中 18 号车是来车。 如果自我车辆在迎面而来的汽车之前完成转弯,或者迎面而来的汽车自由地通过自我表明成功让道,则该事件被认为是成功的。 由于代理行为是随机的,因此并不总是能够安全地执行此任务中的回合。
-
3.
无保护右转:自我车辆必须执行无保护右转。 语言指令为“Change to Lane 33.”,其中33车道为目标车道。 如果自我车辆完成右转,则该事件被认为是成功的。
-
4.
超车:本车必须超越目标车。 语言指令是“21号车会为你减慢速度。” 变更至右侧车道。 一旦超过 4 号车,就换到左车道。”,其中 21 号车是右车道的迎面而来的车,4 号车是目标车。 如果本车在同一车道上领先于目标车,则该事件被认为是成功的。
-
5.
延长超车:本车必须跨越多条交通密集的车道超越目标车。 语言指令是 “向左改变两条车道。 然后,如果您领先于 3 号车,请向右变道”. 如果本车在同一车道上领先于目标车,则该事件被认为是成功的。
-
6.
让行:自我车辆必须允许从后面快速接近的汽车变道通过。 语言指令是 “减速并向左变道。 然后,一旦 8 号车在前面,就向右变道。”,其中 8 号车是来车。 如果自我车辆位于目标汽车后面,则该事件被认为是成功的。
-
7.
切入:自我车辆必须切入一列汽车中。 语言指令是 “减速。 2 号车会减慢你的速度。 向左改变两条车道”,其中 2 号车是我们要插在前面的车。 如果自我车辆位于目标汽车前面并且在同一车道上,则该事件被认为是成功的。
-
8.
车道编织:自我车辆必须穿过几条交通密集的车道,到达两辆车之间的特定间隙。 语言指令是 “一旦前面 12 号车就向左变道。 然后减速很多并向左变道。 一旦 9 号车在您前面几米处,就向左变道”. 如果自我车辆成功到达目标间隙,则该事件被认为是成功的。
6.3根据提示进行语言教学
我们总共收集了 24 个指令-程序对,它们的完整内容如下所示。 为了组织和管理我们的提示,我们使用 DSPy [30]。