用于重排序推荐的非自回归生成模型
摘要。
现代推荐系统旨在通过提供符合用户特定需求或兴趣的定制项目列表来满足用户的需求。 在多阶段推荐系统中,重新排名通过对项目之间的列表内相关性进行建模而发挥着至关重要的作用。 重新排序的关键挑战在于探索排列组合空间内的最佳序列。 最近的研究提出了一种生成器评估器学习范式,其中生成器生成多个可行序列,评估器根据估计的列表分数挑选出最佳序列。 生成器至关重要,生成模型非常适合生成器功能。 当前的生成模型采用自回归策略来生成序列。 然而,在实时工业系统中部署自回归模型具有挑战性。 首先,生成器只能一项一项地生成目标项,因此推理速度较慢。 其次,训练与推理的差异带来了误差积累。 最后,从左到右的一代忽略了后续项目的信息,导致性能不佳。
为了解决这些问题,我们提出了一个Non-AutoR回归生成模型来重新排序R推荐( NAR4Rec)旨在提高效率和效果。 为了解决稀疏训练样本和动态候选等挑战,我们引入了匹配模型。 考虑到用户反馈的多样性,我们采用序列级可能性训练目标来区分可行序列和不可行序列。 此外,为了克服关于目标项目的非自回归模型中缺乏依赖性建模的问题,我们引入对比解码来捕获这些项目之间的相关性。 大量的离线实验验证了 NAR4Rec 相对于最先进的重新排序方法的优越性能。 在线A/B测试表明NAR4Rec显着增强了用户体验。 此外,NAR4Rec已全面部署在日活跃用户超过3亿的热门视频应用快手中。
1. 介绍
推荐系统为用户提供适合其兴趣的个性化项目列表。 人们提出了各种方法来捕获用户兴趣,重点关注特征交互(Cheng等人,2016;Guo等人,2017;Lian等人,2018)、用户偏好建模(Zhou等)人,2018,2019b),等等。 然而,大多数现有方法单独处理各个项目,忽略了它们的相互影响并导致次优结果。 认识到用户与某个项目的交互可能与推荐列表中的其他项目相关(Pei 等人,2019),引入重新排名来考虑上下文信息并生成推荐项目的最佳序列。
重新排序的主要挑战是在广阔的排列空间中探索最佳序列。 重新排序方法通常分为阶段方法和两阶段方法。 一阶段方法(Ai等人,2018;Pei等人,2019)将候选者作为输入,估计排列中每个项目的精细分数,并根据这些分数对它们进行贪婪地重新排序。 然而,一阶段方法遇到了一个固有的矛盾(Feng 等人,2021;Xi 等人,2021):重排序操作本质上改变了排列,与初始排列相比,引入了项目之间不同的相互影响。 因此,以初始排列为条件的细化分数被认为是难以置信的。
为了应对这一挑战,两阶段方法利用了生成器评估器框架。 在这里,生成器创建多个可行序列,评估器根据估计的列表分数选择最佳序列。 在生成器-评估器框架中,生成器起着至关重要的作用。 生成模型(Bello 等人,2018;Feng 等人,2021;Gong 等人,2022;Zhang 等人,2018)优于启发式方法(Feng 等人,2021;Lin等人, 2023; Xi 等人, 2021; Shi 等人, 2023) 由于项目排列的解空间广阔。 生成模型通常采用自回归策略来生成序列。
然而,在实时工业推荐系统中部署自回归模型面临着挑战。 首先,自回归模型的推理效率受到影响。 自回归模型采用顺序方法逐项生成目标序列,由于时间复杂度随着序列长度线性增加,导致推理缓慢。 其次,自回归模型中的训练与推理差异引起了一个关键问题。 虽然这些模型经过训练,可以根据迄今为止的事实来预测下一个项目。 然而,在推理过程中,它们接收自己先前生成的输出作为输入。 这种错位会引入累积误差,其中早期时间步长中产生的误差会随着时间的推移而传播和累积。 因此,这种积累导致序列偏离目标序列的真实分布。 此外,自回归模型的信息利用率有限。 顺序解码过程仅关注前面的项目,忽略后续项目的信息。 由于模型无法充分利用可用上下文,因此这种限制会导致性能不佳。
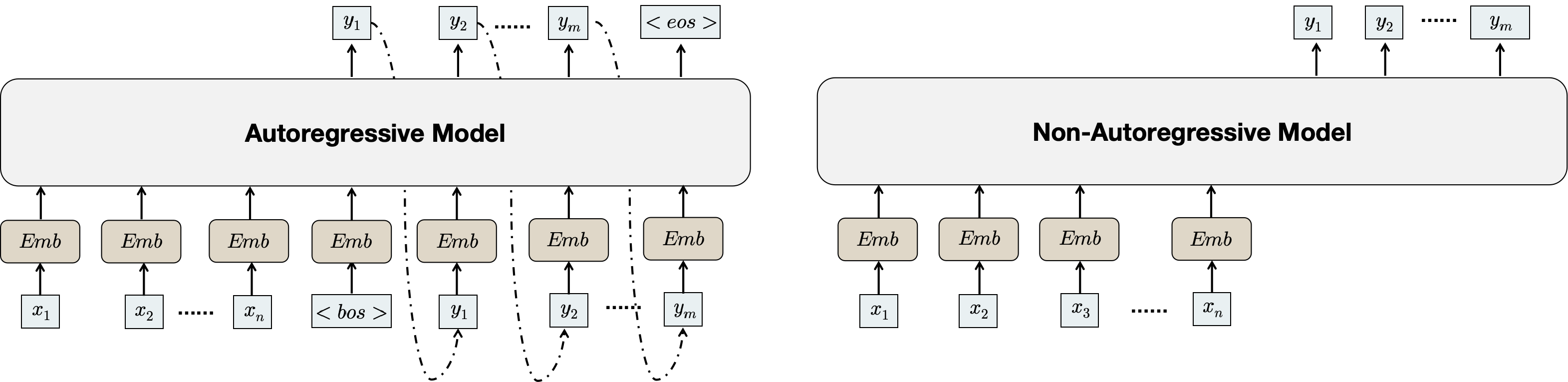
为了应对这些挑战,我们提出Non-AutoR用于重新排名R推荐的渐进生成模型(NAR4Rec )。 与自回归模型不同,自回归模型依赖于自己之前的输出逐步生成序列,NAR4Rec 会同时生成目标序列中的所有项目。
然而,我们发现在推荐系统中部署非自回归并不简单。 首先,推荐系统中的稀疏性和动态候选给学习收敛带来了困难,我们通过共享位置嵌入并引入匹配模型来解决这个问题。 其次,用户反馈的多样性(包括积极和消极的互动)使得最大似然训练不太适合。 我们提出不太可能训练来区分所需序列和不需要的序列。 最后,非自回归模型假设序列中每个位置的项目都是独立选择的,这在建模列表内相关性时是不够的。 因此,我们提出对比解码来捕获项目之间的依赖关系。
总而言之,我们的贡献如下:
-
•
我们首次尝试采用非自回归模型进行重排序,显着加快了推理速度,满足了实时推荐系统的要求。
-
•
我们提出了一种匹配模型来增强收敛性,一种序列级似然性训练方法来指导生成的序列提高整体效用,以及一种对比解码方法来细化当前具有列表内相关性的解码策略。
-
•
大量的离线实验表明,NAR4Rec 的性能优于最先进的方法。 在线A/B测试进一步验证了NAR4Rec的有效性。 此外,NAR4Rec已在日活跃用户超过3亿的真实视频应用快手中全面部署,显着改善了用户体验。
2. 相关工作
2.1. 推荐系统中的重新排名
与匹配和排名(Burges 等人,2005 年;Liu 等人,2009 年)等早期阶段相比,推荐系统中重新排名的核心在于对曝光列表中的相关性进行建模。 重新排名(Pang 等人, 2020; Pei 等人, 2019; Xi 等人, 2021),基于排名阶段的候选项目,选择一个子集并确定其顺序,以确保暴露最合适的项目给用户。 现有的重排序研究可以系统地分为两大类:一阶段方法(Ai 等人,2018;Pei 等人,2019;Pang 等人,2020)和两阶段方法(冯等人,2021;石等人,2023;林等人,2023;奚等人,2021)。
单阶段方法将重新排名视为一项检索任务,根据排名模型的分数推荐前 k 个项目。 这些方法使用列表信息细化初始列表分布,优化整体推荐质量。 随后,以贪婪的方式根据细化的逐项得分对候选者进行重新排序。 区别在于捕获列表信息的网络架构,例如DLCM中的GRU(Ai等人,2018)和PRM中的Transformer(Pei等人,2019) t1>. 然而,用户对公开列表的反馈不仅受到项目兴趣的影响,还受到安排和周围环境的影响(Joachims 等人,2017;Lorigo 等人,2008,2006;Yang,2017)。 重新排序操作修改排列,从而引入与初始排列不同的影响。 此外,专门对初始排列进行建模的单阶段方法无法捕获替代排列。 因此,这些方法很难最大化总体用户反馈(Xi 等人,2021)。
两阶段方法(Feng 等人,2021;Shi 等人,2023;Lin 等人,2023;Xi 等人,2021)包含生成器评估器框架。 在此框架中,生成器通过生成多个可行序列来启动该过程,随后评估器根据估计的列表分数选择最佳序列。 该框架允许对各种可行序列进行全面探索,并根据列表考虑明智地选择最佳序列。 生成器的作用对于生成序列尤其重要。 生成器的常见方法可分为启发式方法(Feng 等人,2021;Lin 等人,2023;Xi 等人,2021;Shi 等人,2023),例如集束搜索或项目交换,以及生成模型(Bello等人,2018;Feng等人,2021;Gong等人,2022;庄等人,2018)。 考虑到巨大的排列空间,生成模型比启发式方法更适合重新排序。 这些生成模型通常采用逐步贪心策略,自回归决定每个位置的显示结果。 然而,在线推理的高计算复杂性限制了它们在实时推荐系统中的应用。
为了解决与自回归生成模型相关的挑战,我们的工作研究了生成器评估器框架内非自回归生成模型的可行性。 非自回归生成模型生成目标序列一次,以减轻计算复杂性。
2.2. 非自回归序列生成
非自回归序列生成(Gu 等人,2018)最初被引入机器翻译中以加快解码过程。 此后,它在自然语言处理领域获得了越来越多的关注,例如:文本摘要(Gu 等人, 2019; Awasthi 等人, 2019)、文本纠错(Leng 等人, 2021b, a)。 具体来说,工作重点是解决非自回归模型中目标信息缺失的问题。 策略包括增强训练语料库以减轻目标端依赖性(Gu 等人, 2018; Zhou 等人, 2019a) 和细化训练方法(Ghazvininejad 等人, 2019; Stern 等人, 2019)缓解学习困难。
尽管非自回归生成已经在文本中进行了探索,但这些传统技术并不直接适用于推荐系统。 我们解决推荐系统中遇到的挑战,以提高非自回归模型的收敛性和性能,并首次尝试将非自回归模型集成到实时推荐系统中的重排序中。
3. 初步知识
3.1. 重新排序问题表述
对于集合 中的每个用户 ,请求包含一组用户个人资料特征(例如用户 ID、性别、年龄)、最近的交互历史记录和 候选人项目表示为,其中 是候选人数量。 给定候选 ,重新排名的目标是提出一个项目序列 ,为用户 引发最有利的反馈,其中 是序列长度, 是重排序模型的推荐列表。 我们将重排序模型表示为 ,其中相应的参数为 。 在实时推荐系统中,重新排名是提供最终推荐项目列表的最后阶段。 通常, 显着超过 , 小于 10, 范围从几十到几百。
在多交互场景中,用户可能会对每个项目曝光表现出不同类型的交互(例如,点击、点赞、评论)。 形式上,我们将用户交互集定义为,表示用户对有关交互的项目的响应。 给定,每个项目都有一个多交互响应。 对于所有项目 ,总体用户响应为:
| (1) |
整体效用被量化为各个项目效用的总和,表示为。 与每个项目相关联的实用程序可以对应于特定的交互类型,例如点击、观看时间或喜欢。 在这种情况下,项目效用表示为。 或者,项目效用可以表示为不同交互的加权和,其中表示每个交互的权重。
重新排名的目标是最大化给定用户的总体效用:
| (2) |
重排序引入了指数大小的排列空间,表示为,其中表示候选数,表示要选择和排序的项目数。 每个排列代表了项目的潜在排列,并且用户为每个排列提供独特的反馈。 然而,在实际场景中,用户通常只会遇到一种排列。 因此,重新排序的主要挑战在于,在给定巨大的解决方案空间但作为训练样本的真实用户反馈极其稀疏的情况下,高效且有效地确定最佳排列。
3.2. 自回归序列生成
给定一组表示为 的候选项,自回归模型将潜在生成序列 上的分布分解为一系列条件概率:
| (3) |
其中特殊标记 (例如,¡bos¿)和 (例如,¡eos¿)表示目标序列的开头和结尾。 重要的是,生成的序列的长度是预先确定和固定的,这与文本中的可变长度不同。
自回归分解序列生成输出分布会导致在每个时间步具有交叉熵损失的最大似然训练:
| (4) |
训练目标旨在优化个体条件概率。 在训练中,当目标序列已知时,这些概率是根据较早的目标项而不是模型生成的项来计算的,从而实现高效的并行化。 在推理过程中,自回归模型依次逐项生成目标序列,有效捕获目标序列的分布。 这使得它们非常适合重新排序任务,特别是考虑到可能的排列空间很大。
虽然自回归模型已被证明是有效的,但将它们部署到工业推荐系统中具有挑战性。 首先,它们的顺序解码过程导致推理缓慢,引入延迟,阻碍实时应用。 其次,这些模型经过训练可以根据真实情况进行预测,当它们收到自己生成的输出作为输入时,它们在推理过程中会面临差异。 这种错位可能会导致复合错误,因为早期时间步长中产生的不准确性会随着时间的推移而累积,从而导致序列不一致或发散,从而偏离目标序列的真实分布。 第三,自回归模型依赖于从左到右的因果注意机制,限制了隐藏表示的表达能力,因为每个项目仅编码来自先前项目的信息(Sun等人,2019)。 这种约束阻碍了最佳表示学习,导致性能不佳。
3.3. 非自回归序列生成
为了解决上述挑战,非自回归序列生成消除了现有模型的自回归依赖性。 每个元素的分布仅取决于候选:
| (5) |
那么非自回归模型的损失函数为:
| (6) |
尽管去除了自回归结构,模型仍保留了显式的似然函数。 模型的训练对每个输出分布采用单独的交叉熵损失。 至关重要的是,这些分布可以在推理过程中同时计算,这与自回归模型的顺序过程显着不同。 这种非自回归方法减少了推理延迟,从而提高了推荐系统在实际应用中的效率。
4. 方法
在本节中,我们将详细介绍 NAR4Rec。 我们将首先讨论我们的非自回归模型结构,它通过部分4.1中的匹配模型来估计概率。 然后,我们深入研究不太可能训练,这是一种旨在识别部分 4.2中推荐序列内的反馈的方法。 最后,我们提出对比解码来对部分4.3中目标序列的依赖性进行建模。 我们的生成器-评估器框架中的序列评估器在部分4.4中介绍。
4.1. 配套型号
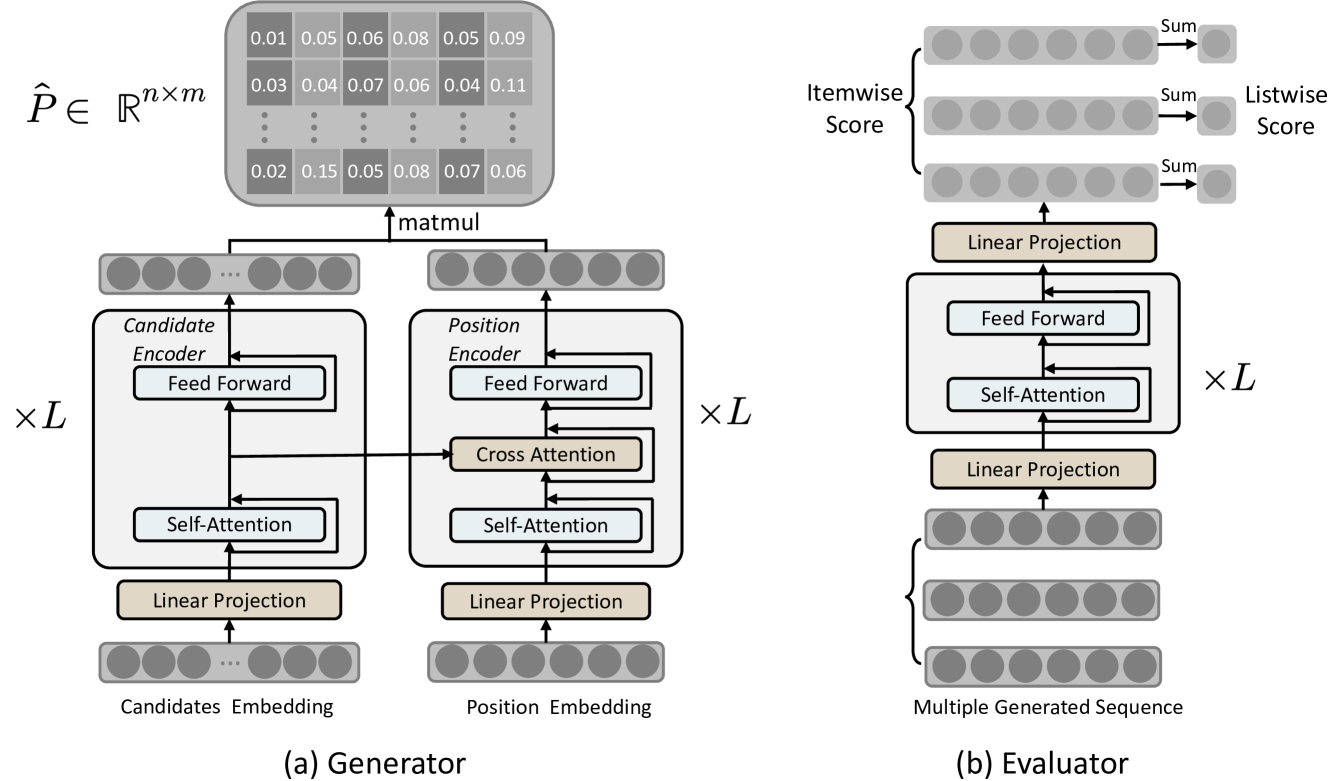
由于两个主要原因,非自回归模型在训练收敛方面遇到挑战。 首先,训练序列的稀疏性带来了学习困难。 与通常共享语言结构的文本序列不同,训练样本中的推荐列表很少有相同的暴露,这给从有限的数据中有效学习带来了挑战。 其次,在重新排名阶段,候选者的相同索引可能表示不同的项目,导致词汇表变化,因为要排名的候选者因样本而异。
传统模型可能难以有效地处理此类变化。 为了应对这些挑战,我们在模型中引入了两个关键组件:用于有效编码候选表示的候选编码器和用于捕获目标内特定位置信息的位置编码器顺序。 最初,我们随机初始化目标序列中每个位置的嵌入。 值得注意的是,我们在训练数据中共享这些位置嵌入,以增强对稀疏数据的学习。 随后,我们集成双向自注意力和交叉注意力模块,利用候选人的信息来获取每个职位的表示。
此外,为了解决样本中候选者变化所带来的动态词汇带来的挑战,我们采用了一种匹配机制。 具体来说,我们将每个候选者与目标序列中的每个位置进行匹配,从而产生每个位置处每个候选者的概率。 下面我们详细阐述NAR4Rec的结构。
给定用户 和候选人 , 的隐藏表示为 。 我们将 一起堆叠成矩阵 。 此外,我们将每个位置 的嵌入向量随机初始化为 。 此外,我们将 堆叠到 中。 为了将 的嵌入维度与 的嵌入维度对齐,我们通过线性投影层将它们投影到相同的隐藏维度 中。 然后是和。 因此, 表示为 , 表示为 。
候选编码器。 候选编码器采用标准 Transformer 架构(Vaswani 等人,2017),通过堆叠 Transformer 层。 在每一层中,该架构主要由两个块组成,一个自注意力块和一个前馈网络。 自注意力块的输入被线性转换为查询()、键()和值()如下:
| (7) |
其中、和表示权重矩阵。 然后,自注意力操作应用为:
| (8) |
对于多头版本的自注意力机制,输入以 次线性投影到 、 和 中使用单独的线性投影到小尺寸(例如 )。 最后,self-attention(SAN)的输出为
| (9) | SAN | |||
前馈网络通常放置在自注意力块之后,
| (10) |
其中和表示两个线性投影的权重矩阵。
位置编码器。 位置编码器采用与候选编码器类似的 Transformer 架构。 它们之间的关键区别在于,位置编码器在每个 Transformer 层的自注意力块和前馈网络之间插入了一个交叉注意力块。 如图2所示,在每一层中,交叉注意块从两个编码器的自注意块接收隐藏表示,并通过交叉注意操作对其进行处理。 具体来说,候选编码器和位置编码器的隐藏表示分别表示为和。 与自注意力块类似,我们最初对它们应用线性投影:
| (11) |
然后,我们将 eq. 9 中的公式应用于 、 和 获取输出隐藏表示。 引入交叉注意力来捕获候选序列和目标序列之间的相关性。
概率矩阵。 为了计算概率矩阵,我们对候选编码器(表示为 )和位置编码器(表示为 )的输出隐藏表示执行矩阵乘法。 随后,我们应用逐列 softmax 函数来标准化分数。 形式上,将第 个候选项放置到第 个位置的概率得分计算如下:
| (12) |
训练目标 NAR4Rec通过交叉熵损失函数进行训练,定义如下:
| (13) |
其中,如果 位于 位置,则 为 1,否则为 0。
4.2. 可能性训练
文本和项目序列之间的差异阻碍了生成模型从文本到项目推荐的直接应用。 这种差异源于推荐场景中用户交互的独特特征。 与自然语言文本的结构化性质不同,由于用户交互的不同性质,推荐序列中的反馈是多种多样的。 虽然文本序列通常遵循传统的语言结构来传达信息或构建连贯的叙述,但推荐序列中的用户反馈以点击或点赞等不同动作为特征,反映了多样化且细致入微的反馈。
因此,最大似然训练(如eq. 5)和重新排序(如eq. 2)在目标上的差异带来了巨大的挑战。 尽管最大似然训练有效地捕获了文本序列中的模式,但在用户偏好动态且主观的推荐场景中,其适用性会减弱。 高质量推荐的本质不仅在于训练数据的序列模式,更重要的是在于推荐列表的用户效用。 用户与推荐项目的交互是主观的并且是上下文驱动的,这增加了将目标与所需模型行为保持一致的训练复杂性。 为了应对这一挑战,我们提出了不太可能的训练,指导模型将较低的概率分配给不需要的世代。 这种调整使训练过程与复杂的反馈模式保持一致。
Likelihood 训练降低了模型生成负序列的概率。 给定候选 和负序列 ,可能性损失为:
| (14) |
损失随着的减小而减小。
与消息清晰且以内容为中心的文本生成不同,管理输出文本中的主题、风格和情感等属性非常简单(Li 等人,2020;Welleck 等人,2019)。 然而,推荐序列涉及带有隐式信号的用户反馈。 例如,缺乏与推荐项目的互动可能表明不感兴趣。 这凸显了模型需要理解用户反馈中的显式和隐式提示。 有效控制推荐序列的生成对于根据用户偏好和行为定制输出至关重要,从而增强个性化推荐。 具体来说,我们根据部分 3.1中定义的整体效用将项目序列分类为正或负,相应的损失如下:
| (15) |
其中是正序列和负序列的阈值。
总之,除了通过序列似然学习正序列模式的主要目标之外,可能性训练还引入了一个额外的目标,即降低生成低效用序列的可能性,有效地训练推荐模型以辨别推荐序列中的反馈。
4.3. 对比解码
与自回归生成相比,非自回归方法显着提高了计算效率,并且可以在实时推荐系统中部署。 然而,非自回归生成引入了条件独立假设:每个目标项的分布仅取决于候选项。 这种与自回归模型的偏差对捕获有效目标序列分布的固有多模态性质提出了挑战。 以机器翻译为例,将短语“谢谢”翻译成德语时可能会产生多个有效翻译,例如“Vielen Dank”和“Danke”。 然而,非自回归模型可能会生成不合理的翻译,例如“Danke Dank”。 eq. 5中的条件独立性假设限制了模型有效掌握目标序列中多模态分布的能力。
从本质上讲,条件独立性的假设限制了模型导航巨大解决方案空间以及从给定候选集的众多有效选项中识别最合适排列的能力。 这种限制在推荐中尤其明显,其中合理目标序列的数量远远超过文本中遇到的数量。 因此,非自回归框架努力应对减轻条件独立性影响的挑战,以提高生成多样化且适合上下文的目标序列的能力。 为了解决这个问题,我们提出对比解码来建模项目之间的共现关系,从而改善目标依赖性。
对比解码结合了调节序列解码过程的多样性先验。 这是基于这样的直觉:有效的推荐列表需要由各种各样的项目组成。 事实上,对比解码在解码时利用相似性得分函数作为调节器,捕获目标序列中各个位置之间的相互依赖性。
形式上,给定前面的上下文 ,在时间步 ,输出 的选择如下
| (16) |
其中。 在 eq. 16 中,第一项称为模型置信度,表示候选 预测的概率模型。 第二项称为相似性惩罚,量化与先前选择的项目有关的独特性候选 ,其中 计算如下:
| (17) |
具体来说,相似度惩罚被定义为的表示与中的所有项目之间的最大相似度。 NAR4Rec 利用点积项嵌入和位置嵌入来计算概率矩阵。 项目之间较高的嵌入相似度通常意味着某个位置的相似概率。 我们引入这样的惩罚来引入列表内相关性。
此外,为了鼓励语言模型学习有区别的和各向同性的项目表示,我们将对比目标纳入到语言模型的训练中。 具体来说,给定序列 , 和 定义为:
| (18) |
其中 是预定义的边距, 是候选编码器中项目 的隐藏表示。
| (19) |
其中 是位置编码器中位置 的隐藏表示。 直观地说,通过使用 进行训练,模型学会拉近不同标记表示之间的距离。111根据定义,相同词符的余弦相似度为。 因此,可以获得判别性且各向同性的模型表示空间。
4.4. 序列评估器
序列评估器模型旨在评估给定序列的整体效用,如图图2所示。 首先使用自注意力和前馈层对生成器生成的序列进行编码以捕获上下文信息。 然后,隐藏表示通过线性投影层来预测特定目标的分数。 总体效用计算为逐项得分的加权和。 最终,选择具有最高总体效用的序列来交付给用户。
5. 实验
在本节中,我们进行了大量的离线实验和在线 A/B 测试来证明 NAR4Rec 的有效性。 我们首先在部分5.1中描述我们的实验设置和基线。 对于部分 5.2中的离线实验,我们将 NAR4Rec 与现有基线的性能、训练和推理时间进行比较。 然后我们交替超参数来分析NAR4Rec的超参数敏感性。 为了进一步展示 NAR4Rec 在实时推荐系统中的有效性,我们进行了在线 A/B 测试来消除我们在部分 5.3中提出的方法。
5.1. 实验详情
| Dataset | #Requests | #Users | #Ads |
|---|---|---|---|
| Avito | 53,562,269 | 1,324,103 | 23,562,269 |
| Meituan | 230,525,531 | 3,201,922 | 98,525,531 |
数据集:为了评估重排序推荐,我们期望数据集的每个样本都是向用户公开的序列,而不是手动构建的序列。 对于公共数据集,我们选择 Avito 数据集。 对于工业数据集,我们使用从快手短视频平台收集的真实世界数据。 详细介绍见表1。
-
•
阿维托222https://www.kaggle.com/c/avito-context-ad-clicks/data:Avito 数据集是来自 avito.ru 的用户搜索日志的公开集合。 该数据集包含超过 5300 万个列表、130 万用户和 3600 万条广告。 每个样本对应一个包含多个广告的搜索页面。 前21天的用户搜索日志作为训练集,最近7天的搜索日志作为测试集。 Avito 中的序列长度为 5。
-
•
快手:快手数据集源自快手,快手是一款广泛使用的短视频应用,日活跃用户超过3亿。 数据集中的每个样本代表一个实际的用户请求日志,其中包含用户信息(例如用户 ID、年龄、性别)、候选项目以及用户与公开项目的交互。 该数据集总共包含 82,230,788 个用户、26,835,337 个项目和 1,811,625,438 个请求。 每个请求包含公开项目序列中的 6 个项目和排名中的 60 个候选项目。
5.2. 离线实验
基线 我们将提出的 NAR4Rec 与 6 种最先进的重新排序方法进行比较。 我们选择DNN、DCN作为逐点基线,PRM作为一阶段列表基线,Edge-Rerank、PIER、Seq2slate作为两阶段基线。 至关重要的是,Seq2slate 是一种自回归生成模型。 这些基线方法的简要概述如下:
-
•
DNN(Covington 等人, 2016):DNN 是点击率预测的基本方法,它应用多层感知来学习特征交互。
-
•
DCN(Wang 等人,2017):DCN 在每一层都引入了特征交叉,消除了手动特征工程的需要,同时将 DNN 模型增加的复杂性降至最低。
-
•
PRM(Pei 等人, 2019):PRM利用自注意力机制对item之间的相互相关性进行建模,然后根据估计分数对item进行排序,生成item顺序。
-
•
Edge-Rerank(Gong 等人, 2022):Edge-Rerank 通过估计分数的自适应波束搜索生成上下文感知序列。
-
•
Seq2Slate(Bello 等人, 2018):Seq2Slate 利用指针网络,这是具有注意机制的 seq2seq 模型,可以在给定已选择的项目的情况下预测下一个项目。
-
•
PIER(Shi 等人, 2023):PIER应用哈希算法根据用户兴趣从全排列中选择top-k候选者。 然后联合训练生成器和评估器以生成更好的排列。
指标 由于没有通用的推荐序列生成指标,我们遵循之前的工作(Shi等人,2023;Lin等人,2023)并使用三个常用的模型来评估这些模型采用的指标:Avito 数据集上的 AUC、LogLoss 和 NDCG。 对于 Avito 数据集,其中 和 相等 (5),任务是在给定列表输入的情况下预测逐项点击率。 对于快手数据集,其中和分别是和,我们采用Recall@6、Recall@10和LogLoss作为评价指标。 快手数据集的任务是预测某个项目是否被选择为公开的 项目之一。
超参数 对于 Avito 数据集,学习率为 10-3,优化器为 Adam,批量大小为 1024。 对于快手数据集,学习率和优化器与Avito相同,但batch size为256。
5.2.1. 性能对比
在这里,我们展示了我们提出的方法 NAR4Rec 的结果。 可以看出 table 2 和 table 3,NAR4Rec 优于 5 个基线,包括最近的强大重排序方法(Pei 等人,2019;Bello 等人,2018;Shi 等人,2023)。 PRM 通过有效捕捉项目之间的相互影响,优于 DNN 和 DCN。 此外,Edge-rerank 通过使用先前项目信息进行自适应波束搜索,超越了 DNN 和 DCN。 通过每个类别的交互,PIER 表现出了优于其他基线的优势。 值得注意的是,与其他基线模型相比,我们提出的方法表现出最高的改进,AUC 指标显着增加了 0.0125。 table 3显示了我们在快手上离线实验的结果。 本实验使用的评估指标包括Recall@6、Recall@10和损失。 与其他基线模型相比,我们的方法在所有指标上都取得了优异的结果。
| AUC | LogLoss | NDCG | |
|---|---|---|---|
| DNN | 0.6614 | 0.0598 | 0.6920 |
| DCN | 0.6623 | 0.0598 | 0.7004 |
| PRM | 0.6881 | 0.0594 | 0.7380 |
| Edge-rerank | 0.6953 | 0.0574 | 0.7203 |
| PIER | 0.7109 | 0.0409 | 0.7401 |
| Seq2Slate | 0.7034 | 0.0486 | 0.7225 |
| NAR4Rec | 0.7234 | 0.0384 | 0.7409 |
| Recall@6 | Recall@10 | LogLoss | |
|---|---|---|---|
| DNN | 66.47% | 86.65% | 0.6764 |
| DCN | 68.22% | 87.95% | 0.6809 |
| PRM | 73.17% | 92.25% | 0.5328 |
| Edge-rerank | 73.63 % | 92.90% | 0.5252 |
| PIER | 73.50% | 92.44% | 0.5361 |
| NAR4Rec | 74.86% | 93.16% | 0.5199 |
5.2.2. 训练和推理时间比较
鉴于 NAR4Rec 与自回归模型密切相关,我们与自回归模型 Seq2Slate 进行比较。 我们比较了 Seq2slate 和 NAR4Rec 在 Avito 数据集上的训练和推理时间。 我们还在 table 4 中给出了其他基线中生成器的训练和推理时间。 由于Seq2slate使用循环神经网络作为其骨干网络,因此训练和推理过程都采用自回归方式。 NAR4Rec 相对于 Seq2slate 的推理加速几乎与训练相同。 NAR4Rec 仅需要 58 分钟即可完成训练,而 Seq2Slate 则需要 283 分钟。 训练时间的显着减少(即大约 5 加速)凸显了 NAR4Rec 的计算效率。 以 Seq2Slate 为代表的自回归模型逐项生成目标序列,而我们的非自回归 NAR4Rec 一次生成所有项目。 因此,当生成长度为 5 的序列时,NAR4Rec 显示出大约 5 加速。
| Training Time | Inference Time | |
|---|---|---|
| DNN | 0.102s | 0.034s |
| DCN | 0.106s | 0.035s |
| PRM | 0.109s | 0.036s |
| Edge-rerank | 0.105s | 0.035s |
| PIER | 0.160s | 0.053s |
| Seq2Slate | 0.558s | 0.186s |
| NAR4Rec | 0.112s | 0.037s |
5.2.3. NAR4Rec的超参数分析
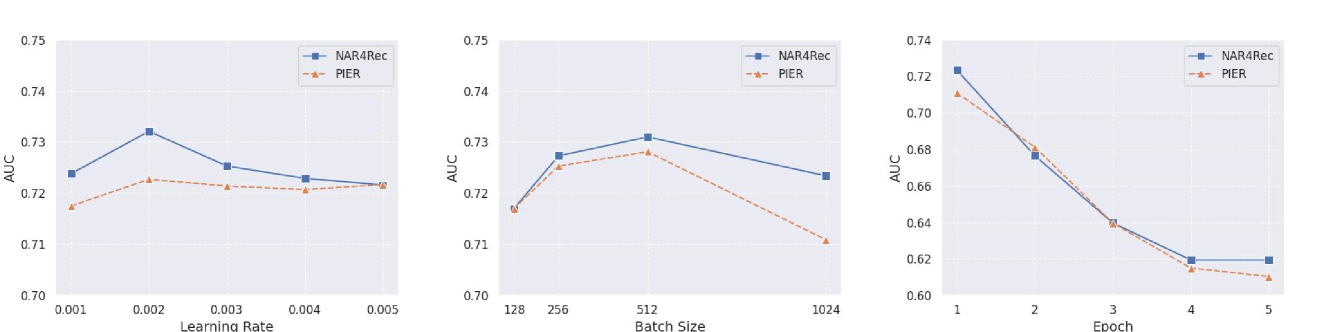
我们进一步分析 NAR4Rec 上的超参数敏感性。 在这里,我们在 NAR4Rec 和 PIER 上进行了一系列实验。 如图图 3所示,我们证明我们的实验结果对学习率、批量大小和历元的变化不敏感。
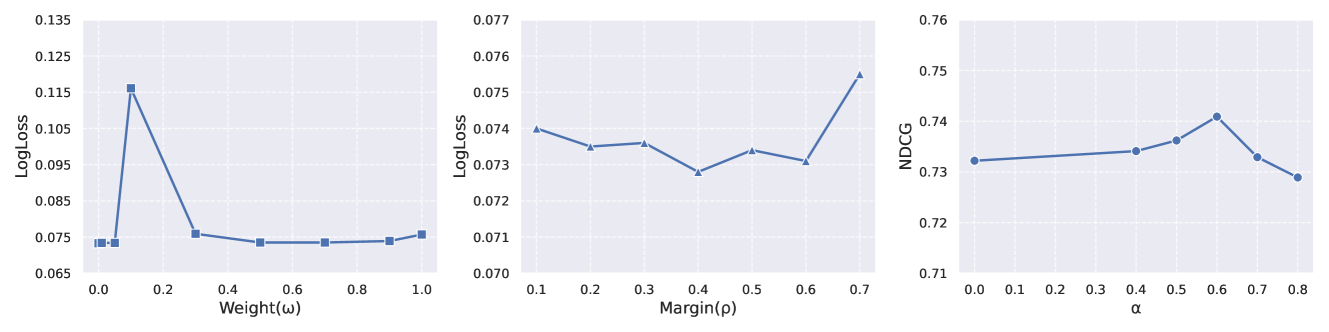
然后,我们分析了权重和余量对对比损失的影响以及惩罚参数对对比解码的影响。 图 4显示了我们的实验结果。 对比损失,我们在固定=0.5的同时改变,在固定=0.01的同时改变。 当对比解码中改变时,我们将=0.5和=0.01设置为默认参数。
5.3. 在线实验
文本序列生成通常通过人工标记来评估。 在推荐方面,我们通过在线A/B实验来获取用户的反馈来证明我们的有效性。
5.3.1. 实验设置
在线A/B实验中,我们将整个App的流量均分为十个桶。 线上基线为 Edge-rerank(Gong 等人, 2022),其中 20% 的流量分配给 NAR4Rec,其余流量分配给 Edge-rerank。
5.3.2. 实验结果
实验已在系统上启动十天,结果列于表5中。 NAR4Rec 的性能大幅优于 Edge-rerank(Gong 等人,2022)。 NAR4Rec 表明,与 (Gong 等) 相比,用户观看了更多(即更高的观看次数)视频,在每个视频上花费了更多的时间(即更多的长观看和完整观看)以及更积极的用户反馈(即点赞、关注方面的改进)人,2022)。
| Views | Likes | Follows | Long Views | Complete Views |
| +1.161% | +1.71% | +1.15% | +1.82% | +2.45% |
5.3.3. 可能性消融研究训练
为了显示不可能性训练的有效性,我们将所有公开序列上的普通训练与不可能性训练进行比较。 可能性显示出更多的观看次数和更长的观看时间。
| Views | Watch Time | |
| Vanilla training | -0.370%* | -0.277%* |
5.3.4. 对比解码的消融研究
在这里,我们比较了文本序列中的常见解码算法和基于多样性的算法(即 深度 DPP)与对比解码。 这些解码算法显示观看和观看时间显着下降,表明用户反馈较差。
| Views | Watch Time | |
|---|---|---|
| Deep DPP | -0.363%* | -0.361%* |
| Beam Search | -0.327%* | -0.214%* |
| Greedy Search | -0.216%* | -0.178%* |
| Top-k Sampling | -0.254%* | -0.131% |
6. 结论
在本文中,我们概述了推荐系统中与重新排名相关的当前表述和挑战。 尽管在自然语言处理中已经探索了非自回归生成,但传统技术并不能直接应用于推荐系统。 我们解决了推荐中的挑战,以提高非自回归模型的收敛性和性能,并首次尝试将非自回归模型集成到实时推荐系统的重新排名中。 广泛的在线和离线 A/B 实验证明了 NAR4Rec 作为生成具有增强实用性的序列的多功能框架的有效性和效率。 展望未来,我们未来的工作将集中于完善序列效用的建模,以进一步增强 NAR4Rec 的功能。
参考
- (1)
- Ai et al. (2018) Qingyao Ai, Keping Bi, Jiafeng Guo, and W Bruce Croft. 2018. Learning a deep listwise context model for ranking refinement. In The 41st international ACM SIGIR conference on research & development in information retrieval. 135–144.
- Awasthi et al. (2019) Abhijeet Awasthi, Sunita Sarawagi, Rasna Goyal, Sabyasachi Ghosh, and Vihari Piratla. 2019. Parallel Iterative Edit Models for Local Sequence Transduction. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 4260–4270.
- Bello et al. (2018) Irwan Bello, Sayali Kulkarni, Sagar Jain, Craig Boutilier, Ed Chi, Elad Eban, Xiyang Luo, Alan Mackey, and Ofer Meshi. 2018. Seq2Slate: Re-ranking and slate optimization with RNNs. arXiv preprint arXiv:1810.02019 (2018).
- Burges et al. (2005) Chris Burges, Tal Shaked, Erin Renshaw, Ari Lazier, Matt Deeds, Nicole Hamilton, and Greg Hullender. 2005. Learning to rank using gradient descent. In Proceedings of the 22nd international conference on Machine learning. 89–96.
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems. 7–10.
- Covington et al. (2016) Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems. 191–198.
- Feng et al. (2021) Yufei Feng, Binbin Hu, Yu Gong, Fei Sun, Qingwen Liu, and Wenwu Ou. 2021. GRN: Generative Rerank Network for Context-wise Recommendation. arXiv preprint arXiv:2104.00860 (2021).
- Ghazvininejad et al. (2019) Marjan Ghazvininejad, Omer Levy, Yinhan Liu, and Luke Zettlemoyer. 2019. Mask-Predict: Parallel Decoding of Conditional Masked Language Models. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 6112–6121.
- Gong et al. (2022) Xudong Gong, Qinlin Feng, Yuan Zhang, Jiangling Qin, Weijie Ding, Biao Li, Peng Jiang, and Kun Gai. 2022. Real-time Short Video Recommendation on Mobile Devices. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 3103–3112.
- Gu et al. (2018) Jiatao Gu, James Bradbury, Caiming Xiong, Victor OK Li, and Richard Socher. 2018. Non-Autoregressive Neural Machine Translation. In International Conference on Learning Representations.
- Gu et al. (2019) Jiatao Gu, Changhan Wang, and Junbo Zhao. 2019. Levenshtein transformer. Advances in Neural Information Processing Systems 32 (2019).
- Guo et al. (2017) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence. 1725–1731.
- Joachims et al. (2017) Thorsten Joachims, Laura Granka, Bing Pan, Helene Hembrooke, and Geri Gay. 2017. Accurately interpreting clickthrough data as implicit feedback. In Acm Sigir Forum, Vol. 51. Acm New York, NY, USA, 4–11.
- Leng et al. (2021a) Yichong Leng, Xu Tan, Rui Wang, Linchen Zhu, Jin Xu, Wenjie Liu, Linquan Liu, Xiang-Yang Li, Tao Qin, Edward Lin, et al. 2021a. FastCorrect 2: Fast Error Correction on Multiple Candidates for Automatic Speech Recognition. In Findings of the Association for Computational Linguistics: EMNLP 2021. 4328–4337.
- Leng et al. (2021b) Yichong Leng, Xu Tan, Linchen Zhu, Jin Xu, Renqian Luo, Linquan Liu, Tao Qin, Xiangyang Li, Edward Lin, and Tie-Yan Liu. 2021b. Fastcorrect: Fast error correction with edit alignment for automatic speech recognition. Advances in Neural Information Processing Systems 34 (2021), 21708–21719.
- Li et al. (2020) Margaret Li, Stephen Roller, Ilia Kulikov, Sean Welleck, Y-Lan Boureau, Kyunghyun Cho, and Jason Weston. 2020. Don’t Say That! Making Inconsistent Dialogue Unlikely with Unlikelihood Training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 4715–4728.
- Lian et al. (2018) Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1754–1763.
- Lin et al. (2023) Xiao Lin, Xiaokai Chen, Chenyang Wang, Hantao Shu, Linfeng Song, Biao Li, et al. 2023. Discrete Conditional Diffusion for Reranking in Recommendation. arXiv preprint arXiv:2308.06982 (2023).
- Liu et al. (2009) Tie-Yan Liu et al. 2009. Learning to rank for information retrieval. Foundations and Trends® in Information Retrieval 3, 3 (2009), 225–331.
- Lorigo et al. (2008) Lori Lorigo, Maya Haridasan, Hrönn Brynjarsdóttir, Ling Xia, Thorsten Joachims, Geri Gay, Laura Granka, Fabio Pellacini, and Bing Pan. 2008. Eye tracking and online search: Lessons learned and challenges ahead. Journal of the American Society for Information Science and Technology 59, 7 (2008), 1041–1052.
- Lorigo et al. (2006) Lori Lorigo, Bing Pan, Helene Hembrooke, Thorsten Joachims, Laura Granka, and Geri Gay. 2006. The influence of task and gender on search and evaluation behavior using Google. Information processing & management 42, 4 (2006), 1123–1131.
- Pang et al. (2020) Liang Pang, Jun Xu, Qingyao Ai, Yanyan Lan, Xueqi Cheng, and Jirong Wen. 2020. Setrank: Learning a permutation-invariant ranking model for information retrieval. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 499–508.
- Pei et al. (2019) Changhua Pei, Yi Zhang, Yongfeng Zhang, Fei Sun, Xiao Lin, Hanxiao Sun, Jian Wu, Peng Jiang, Junfeng Ge, Wenwu Ou, et al. 2019. Personalized re-ranking for recommendation. In Proceedings of the 13th ACM conference on recommender systems. 3–11.
- Shi et al. (2023) Xiaowen Shi, Fan Yang, Ze Wang, Xiaoxu Wu, Muzhi Guan, Guogang Liao, Wang Yongkang, Xingxing Wang, and Dong Wang. 2023. PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 4823–4831.
- Stern et al. (2019) Mitchell Stern, William Chan, Jamie Kiros, and Jakob Uszkoreit. 2019. Insertion transformer: Flexible sequence generation via insertion operations. In International Conference on Machine Learning. PMLR, 5976–5985.
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Wang et al. (2017) Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17. 1–7.
- Welleck et al. (2019) Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. 2019. Neural Text Generation With Unlikelihood Training. In International Conference on Learning Representations.
- Xi et al. (2021) Yunjia Xi, Weiwen Liu, Xinyi Dai, Ruiming Tang, Weinan Zhang, Qing Liu, Xiuqiang He, and Yong Yu. 2021. Context-aware reranking with utility maximization for recommendation. arXiv preprint arXiv:2110.09059 (2021).
- Yang (2017) Ziying Yang. 2017. Relevance judgments: Preferences, scores and ties. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1373–1373.
- Zhou et al. (2019a) Chunting Zhou, Jiatao Gu, and Graham Neubig. 2019a. Understanding Knowledge Distillation in Non-autoregressive Machine Translation. In International Conference on Learning Representations.
- Zhou et al. (2019b) Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019b. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948.
- Zhou et al. (2018) Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1059–1068.
- Zhuang et al. (2018) Tao Zhuang, Wenwu Ou, and Zhirong Wang. 2018. Globally optimized mutual influence aware ranking in e-commerce search. arXiv preprint arXiv:1805.08524 (2018).