![[Uncaptioned image]](x1.png) InstructGraph:通过以图形为中心的指令参数和偏好调整来提升大型语言模型
InstructGraph:通过以图形为中心的指令参数和偏好调整来提升大型语言模型
摘要
当前的大语言模型是否可以通过参数更新更好地解决图推理和生成任务? 在本文中,我们提出了InstructGraph,这是一个通过指令调优和偏好对齐赋予大语言模型图形推理和生成能力的框架。 具体来说,我们首先提出一种结构化格式语言器,将所有图数据统一为通用的类似代码的格式,它可以简单地表示图,而无需任何外部特定于图的编码器。 此外,还引入了图指令调优阶段来指导大语言模型解决图推理和生成任务。 最后,我们识别图任务中潜在的幻觉问题,并对负面实例进行采样以进行偏好对齐,其目标是增强模型输出的可靠性。 跨多个以图为中心的任务的大量实验表明,InstructGraph 可以实现最佳性能,并且分别优于 GPT-4 和 LLaMA2 13% 和 38% 以上 111我们已在https://github.com/wjn1996/InstructGraph中发布了资源代码。.
InstructGraph:通过以图形为中心的指令参数和偏好调整来提升大型语言模型
Jianing Wang††thanks: Work done during visiting at UC San Diego., Junda Wu, Yupeng Hou, Yao Liu††thanks: Corresponding Author., Ming Gao, Julian McAuley East China Normal University, Shanghai, China University of California San Diego, La Jolla, USA lygwjn@gmail.com, {juw069, yphou}@ucsd.edu liuyao@cc.ecnu.edu.cn, mgao@dase.ecnu.edu.cn, jmcauley@ucsd.edu
1简介
目前,大语言模型已经成功地对文本数据进行推理 Brown 等人 (2020);开放人工智能(2023a); Touvron 等人 (2023b);赵等人(2023c)。 然而,图数据中也存在丰富的信息,难以用纯文本Jin 等人(2023)来表示,例如知识图谱Schneider 等人(2022) 、符号图Saba (2023)、社交网络Wang 等人(2023d)以及隐式思维图Besta 等人(2023)。
为了赋予大语言模型解决图任务的能力,一系列的工作重点是设计大语言模型在图数据上的接口(例如提示工程),使其在不进行参数优化的情况下理解语义 Ye 等人(2023);韩等人 (2023);张等人 (2023b);张(2023); Kim 等人 (2023);江等人 (2023);王等人 (2023b); Luo 等人 (2023),或者通过图神经网络 (GNN) 将图嵌入注入到大语言模型的部分参数中 Zhang 等人 (2022); Chai 等人 (2023);唐等人 (2023); Perozzi 等人 (2024)。 尽管取得了重大进展,我们仍探讨了以下两个挑战:1)图和文本之间仍然存在语义差距,这可能会阻碍大语言模型在图推理和生成方面的发展。 2)大语言模型容易产生幻觉,这可能是由于捏造的错误输入或缺乏相关知识造成的。 它可以被视为图形幻觉问题。
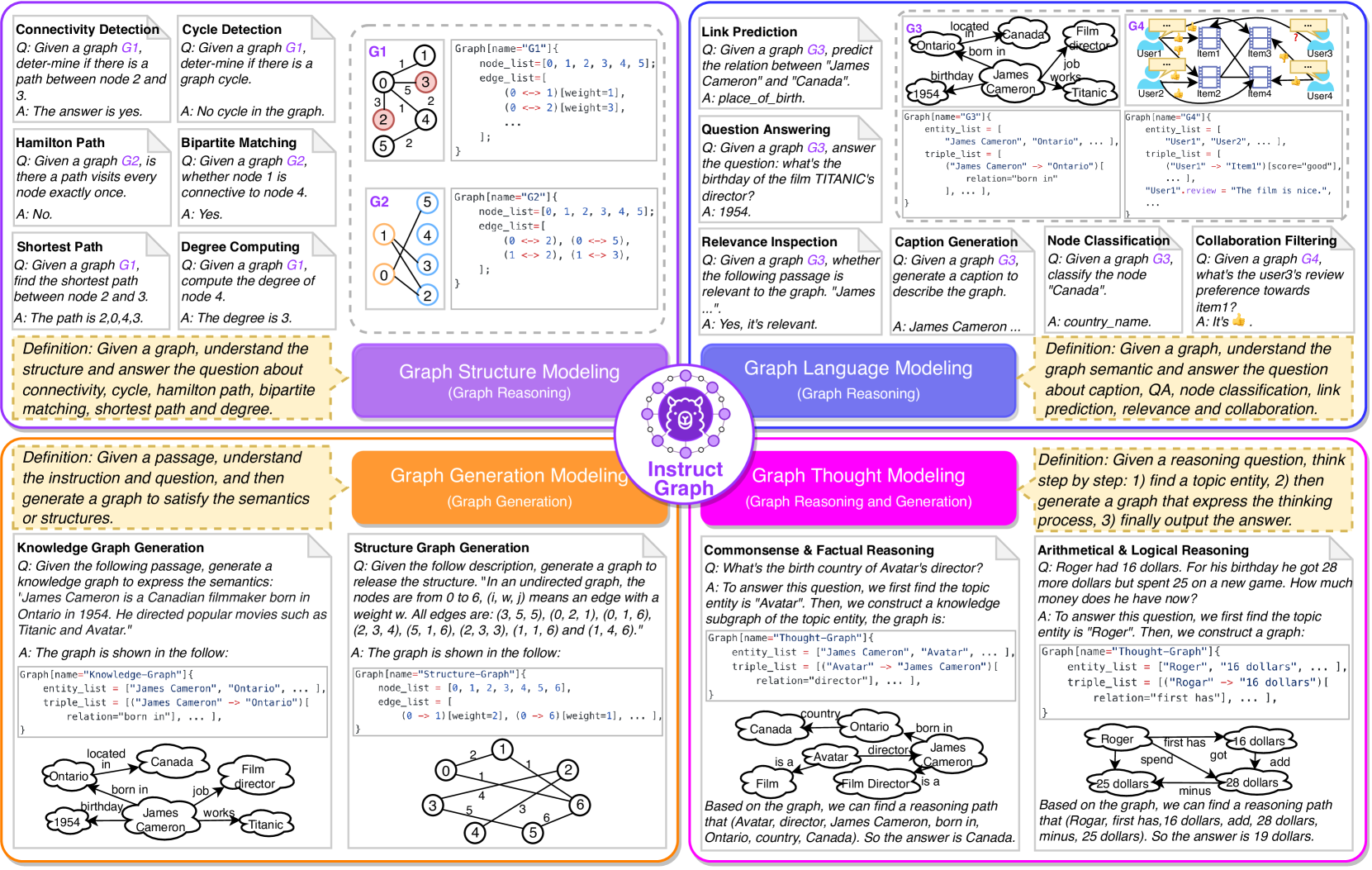
为了克服这些挑战,我们提出了一个名为 InstructGraph 的框架,该框架通过指令调整和偏好对齐来增强大语言模型。 解决第一个挑战的一个简单方法是使用图描述 Ye 等人 (2023) 或图嵌入 Chai 等人 (2023),但是,这些方法需要大量的手动模板来描述图表。 通过嵌入表示大型或复杂的图可能会导致信息损失。 此外,大语言模型用这些方法生成的响应很难解析成实际的图 Jin 等人 (2023);赵等人(2023c)。 目前的研究表明,大语言模型具有很强的代码理解和生成能力 Gao 等人 (2023);马等人 (2023);黄等人 (2023);杨等人(2024)。 受它们的启发,我们可以将图数据统一为类似代码的通用格式,以增强大语言模型对图任务的理解和生成性能。 如图1所示,每个图都可以转化为带有基本变量的代码,如node_list(或entity_list)、 edge_list(或triple_list)和可选属性。 为此,引入图形指令调整阶段来在这些公式化数据上训练大语言模型。
此外,之前的研究发现,大语言模型在遵循指令时会产生幻觉反应,通常指捏造的错误输入或缺乏内在知识Dziri 等人 (2022);张等人 (2023a);吉等人(2023)。 例如,当在缺乏关键信息的图表上提问时,大语言模型可能得出错误的答案,或者大语言模型可能生成包含错误事实、冲突或缺失信息的图表。 然而,如何在图推理和生成中减少这种影响仍处于探索之中。 因此,我们引入图偏好对齐来缓解大语言模型推理和生成中的幻觉问题。 具体来说,我们遵循直接偏好优化(DPO)算法Rafailov 等人(2023)来优化大语言模型以做出更好的偏好。 为了自动对 DPO 中的负面实例进行采样,我们探索了各种场景,例如非事实图、冲突图和缺失图。 ,模拟图形幻觉问题。
为了评估我们框架的有效性,我们对多个图形推理和生成任务进行了广泛的实验。 结果表明,所提出的 InstructGraph 在以图为中心的指令和偏好任务上均实现了最佳性能,并且优于 GPT-4 OpenAI (2023b) 和 LLaMA2 Touvron 等人 (2023b) 分别超过 13% 和 38%。
2方法论
框架如图2所示,可以分解为图输入工程、图指令调优和图偏好对齐三个模块。
2.1 符号
假设有个图任务,每个任务对应的数据集可以表示为,其中表示的例子个数,是对应的指令 222我们手动设计每个数据集的指令。,是具有1个节点(实体)集合、1个可选关系集合、1个边(三元组)集合的图>,以及一个可选的文本属性集,是可选段落,是最终答案 333特别地,答案不仅可以是独立文本,还可以是和.

2.2图输入工程
第一个挑战是如何将图与文本对齐以满足大语言模型的序列接口,之前的工作通过使用图描述Ye等人(2023)或嵌入融合解决了这个问题Chai 等人 (2023),这可能会使生成的响应难以解析为实际图表。
受当前可以同时理解和生成代码的大语言模型的启发,我们引入了一种结构化格式语言化策略,将图转换为简单的类似代码的格式。 形式上,给定一个任务图,我们将表示为结构化格式语言描述器,并且原始图可以映射为序列。 对于基本格式,所有节点(或实体)都列为带有变量node_list(或entity_list)的序列,而所有边(或三元组)都列为序列与变量edge_list(或triple_list)。 对于包含边信息的图,我们可以模拟面向对象语言来表达节点(或实体)。 以图1中的图表为例,评论文本“这部电影很好”。节点“User1”的属性可以表示为“User1.review=The film is Nice.”,其中“.review”可以替换为图中的属性名称。 因此,我们可以将所有图形统一为统一格式,以与文本数据保持一致。
2.3 Graph配置参数
如图1所示,我们首先定义了四组不同的以图为中心的指令任务来增强大语言模型在图上的能力,包括图结构建模、图语言建模、图生成建模、和图形思维建模。 前两组专注于图推理,第三组是典型的图生成,最后一组同时针对图推理和生成 444我们只选择前三组任务进行指令调优。 图思维建模的任务仅用于评估。. 经过图输入工程后,我们可以直接重用标准因果语言建模(CLM)目标来不断调整此类群体的大语言模型。 形式上,给定一个任务数据集,大语言模型可以通过最大似然进行优化:
| (1) |
其中表示具有可训练参数的大语言模型,是模型输出,和 分别代表输入序列和参考标签,这取决于具体的任务定义。 表1列出了所有任务组和相应的集群,以显示任务定义、模型输入和输出。 由此,我们可以得到一个基于指令的图大语言模型,命名为InstructGraph-INS。
| Task Groups | Task Clusters | Task Definition | Task Input | Task Output |
| Graph Structure Modeling | Connection Detection, Cycle Detection, Hamilton Path, Bipartite Matching, Shortest Path, Degree Computing | The tasks in this group aim to make LLMs better understand some basic graph structures. The input only contains nodes, directed or un-directed edges, and optional weights. | ||
| Graph Language Modeling | Graph Caption Generation | The task aims to generate a caption passage to describe the graph . | ||
| Graph Question Answering | The task aims to reason on the whole graph and find an entity as the final answer . | |||
| Graph Node Classification | The task aims to classify the target node into pre- defined classes based on . | |||
| Graph Link Prediction | The task aims to predict the relation between two given nodes based on . | |||
| Graph Relevance Inspection | The task aims to detect whether the graph is relevant to the passage , we have . | |||
| Graph Collaboration Filtering | The task aims to predict whether the target user prefers the target item based on the whole graph , the answer can be set as a score. | |||
| Graph Generation Modeling | Knowledge Graph Generation | The task aims to given a passage that describes a piece of factual or commonsense information, the task aims to extract entities and relations from to generate a graph . | ||
| Structure Graph Generation | The task aims to generate a graph to meet the structure information described in the passage . | |||
| Graph Thought Modeling | Arithmetic Symbolic Robotic Logic | The task aims to solve the general reasoning task in three think steps: 1) first find the question subject, 2) then generate a thought graph to express the rationale and 3) finally output the result based on the graph. |
2.4 图形偏好对齐
最近,NLP 界通过偏好优化,幻觉显着减少Ouyang 等人 (2022);赵等人 (2023e);拉斐洛夫等人 (2023); MacGlashan 等人 (2017)。 在此之后,我们提出图偏好对齐来减轻大语言模型在图上的幻觉。 如图2所示,我们直观地设计了四种典型的图推理和生成的幻觉情况,并对每个图任务进行负采样。
图推理中的幻觉
通常,指令版大语言模型可能是一个很强的指令遵循者,但有时会因为错误输入或缺乏知识而陷入幻觉:1)正确的图表但错误的答案表示大语言即使输入合法,模型也会做出错误的预测,2)非事实图但错误答案表示由对外部知识语义不忠实的图导致的错误答案,3)冲突图但错误答案表示输入图中存在冲突信息,4)缺少图但答案错误表示输入图缺少与答案相关的一些关键信息。
为了模拟第一种情况,我们可以从其他示例中随机选择一个结果来形成负输出。 其余的,我们可以随机替换、添加或删除图中的一些节点(实体)或边(三元组)并构造一个带有原始指令和段落的新输入。 因此,原始答案可以被视为否定和肯定,定义为“抱歉,输入图表包含错误信息,因此该问题无法直接回答”。
图生成中的幻觉
图生成比推理更难,因为大语言模型需要输出完整且准确的类似代码的格式序列。 以下是三种错误生成的图:非事实图、冲突图和缺失图。 我们可以通过执行replace、add和remove运算符直接构建错误的图作为最终输出,这与图推理类似。 原始图表示为正。 此外,如果由于输入错误而导致错误答案,我们可以用数据集中不相关的输入替换原始输入,该输入不会影响答案图。 然后将原始答案图视为负输出。
接下来我们使用 DPO 算法来减少幻觉。 具体来说,给定一个指令示例 和相应的否定 ,我们可以将 Bradley-Terry Bradley and Terry (1952) 下的偏好模型定义为:
| (2) | ||||
其中为平衡因子,表示偏好模型,和分别表示策略和参考模型,可以由指令版大语言模型初始化。 因此,我们可以通过最大似然优化大语言模型:
| (3) | ||||
我们将策略 表示为 InstructGraph-PRE。
| Clusters | Tasks | Metrics | GPT-3.5 | GPT-4 | LLaMA2 | Vicuna | InstructGraph-INS |
| Structure | Conn. Dect. | ACC | 81.45 | 80.47 | 54.01 | 54.85 | 83.54 |
| Cycle Dect. | ACC | 59.02 | 61.44 | 50.79 | 52.88 | 91.10 | |
| Hami. Path | ACC | 21.03 | 29.10 | 1.23 | 1.23 | 34.80 | |
| Bipt. Match | ACC | 50.23 | 66.11 | 0.00 | 0.00 | 76.36 | |
| Shrt. Path | ACC | 38.99 | 49.03 | 0.00 | 0.00 | 66.29 | |
| Degree Comp. | ACC | 41.18 | 70.59 | 18.13 | 19.57 | 65.65 | |
| Caption | Wikipedia | BLEU | 91.99 | 93.85 | 77.15 | 82.94 | 95.81 |
| WebNLG | BLEU | 99.51 | 99.29 | 88.67 | 89.33 | 97.35 | |
| GenWiki | BLEU | 98.60 | 98.65 | 79.72 | 87.67 | 97.71 | |
| EventNA | BLEU | 62.66 | 61.75 | 53.39 | 75.52 | 81.64 | |
| Xalign | BLEU | 86.77 | 88.59 | 84.05 | 86.05 | 93.08 | |
| Graph QA | PathQSP | EM | 52.54 | 68.64 | 42.70 | 31.90 | 86.40 |
| GrailQA | EM | 43.92 | 60.17 | 15.83 | 17.95 | 81.30 | |
| WebQSP | EM | 53.73 | 61.57 | 40.07 | 26.42 | 73.30 | |
| WikiTQ | EM | 49.02 | 60.78 | 29.94 | 35.76 | 47.82 | |
| Node CLS | Cora | EM | 74.51 | 64.17 | 83.04 | 84.08 | 89.33 |
| Citeseer | EM | 70.39 | 74.94 | 68.24 | 67.94 | 71.65 | |
| Pubmed | EM | 74.63 | 77.16 | 79.78 | 80.18 | 81.09 | |
| Arxiv | EM | 70.59 | 74.51 | 45.50 | 57.75 | 81.50 | |
| Products | EM | 68.82 | 84.16 | 29.34 | 79.50 | 95.20 | |
| Link Pred. | Wikidata | Hits@1 | 43.73 | 62.94 | 10.75 | 10.38 | 96.52 |
| FB15K-237 | Hits@1 | 60.34 | 66.88 | 0.00 | 0.00 | 98.91 | |
| ConceptNet | Hits@1 | 31.33 | 38.30 | 8.30 | 8.19 | 59.86 | |
| Relevance | Wikipedia | ACC | 94.40 | 100 | 69.27 | 68.12 | 100 |
| RecSys | Amazon | Hits@1 | 27.09 | 59.77 | 44.40 | 16.40 | 78.80 |
| IE | Wikipedia | F1 | 50.97 | 46.89 | 40.76 | 38.84 | 83.56 |
| UIE | F1 | 24.41 | 26.22 | 20.21 | 26.11 | 76.82 | |
| InstructKGC | F1 | 21.44 | 21.86 | 19.26 | 16.6 | 38.98 | |
| Graph Gen. | NLGraph | F1 | 80.86 | 88.17 | 3.64 | 42.21 | 91.05 |
| Avg. | 59.45 | 66.76 | 41.65 | 46.06 | 79.84 | ||
3实验
在本节中,我们进行了大量的实验来评估 InstructGraph 在图任务和一般 NLP 任务上的有效性。
3.1实现设置
我们构建了大约 160 万个用于图指令调整的示例和 10 万个用于图偏好对齐的示例。 默认情况下,我们从 HuggingFace555https://huggingface.co/meta-llama. 中选择 LLaMA2-7B-HF Touvron 等人 (2023b). 作为支柱。 最大长度设置为。 优化器是 AdamW。 在图指令调整阶段,学习率设置为,衰减率为,在图偏好对齐阶段将更改为。 为了加速训练666实现参考https://github.com/facebookresearch/llama-recipes。,我们利用 FSDP Zhao 等人 (2023d) 和 CPU 卸载 Tsog 等人 (2021)、FlashAttention Dao 等人 (2022),以及BFloat16 技术,并利用 LoRA Hu 等人 (2022) 与 和 进行参数高效学习。
|
|

|
| Methods (7B) | Is Align | Structure | Caption | Graph QA | Nodel CLS | IE | Avg. |
| LLaMA2 | ✗ | 38.64 | 57.96 | 70.70 | 74.68 | 37.40 | 55.88 |
| Vicuna | ✗ | 39.12 | 62.37 | 64.38 | 77.63 | 40.8 | 56.86 |
| InstructGraph-INS | ✗ | 50.32 | 81.15 | 77.85 | 83.16 | 69.14 | 72.32 |
| InstructGraph-PRE | ✓ | 57.80 | 87.44 | 84.44 | 88.98 | 91.44 | 82.02 |
| Methods | Is Align | HaluEval | Anthropic-HH | TruthfulQA | Avg. | ||||
| Dialogue | General | QA | Abstract | Harmless | Helpful | ||||
| GPT-3.5 | ✓ | 72.40 | 79.44 | 62.59 | 58.53 | - | - | 47.50 | - |
| GPT-4 | ✓ | - | - | - | - | - | - | 59.80 | - |
| LLaMA2-7B | ✗ | 43.99 | 20.46 | 49.60 | 49.55 | 54.28 | 60.49 | 33.29 | 44.52 |
| Vicuna-7B | ✗ | 46.35 | 19.48 | 60.34 | 45.62 | 55.70 | 58.71 | 30.10 | 45.19 |
| InstructGraph-INS | ✗ | 44.88 | 21.35 | 52.90 | 51.10 | 56.33 | 59.10 | 35.35 | 45.86 |
| InstructGraph-PRE | ✓ | 47.03 | 21.61 | 52.88 | 51.39 | 58.40 | 60.12 | 35.77 | 46.74 |
3.2 图指令任务的主要结果
在本节中,我们将在零样本设置中详尽地评估 InstructGraph-INS 在多个图形推理和生成任务上的性能。 我们使用类似代码的格式来统一所有图并构建指令调整测试集。 数据统计结果如表10所示,具体内容参见附录A.1。 为了与类似规模的大语言模型进行比较,我们选择广泛使用的LLaMA2-7B和Vicuna-7B作为开源基线。 为了考察AGI时代InstructGraph的性能水平,我们还选择了GPT-3.5(turbo)欧阳等人(2022)和GPT-4OpenAI(2023b) 作为强基线777https://platform.openai.com/.。
表2展示了图推理和生成的主要结果,因此我们得出以下结论:1)InstructGraph-INS取得了最好的总体结果并且比GPT-4优于。 2)与相同规模的大语言模型相比,我们的框架在所有图任务上表现最好,这表明对设计良好的图任务进行进一步的指令调优可以更好地提高推理和生成能力。 3) 对于 DegreeComputing、WebNLG、GenWiki、WikiTQ 和 Citseer 任务,InstructGraph-INS 的表现低于 GPT-3.5 和 GPT-4。 由于具有大规模参数的大语言模型存储了更多的相似知识。 尽管如此,InstructGraph-INS 在其他推理任务上仍然表现出大约 10% 的性能提升。
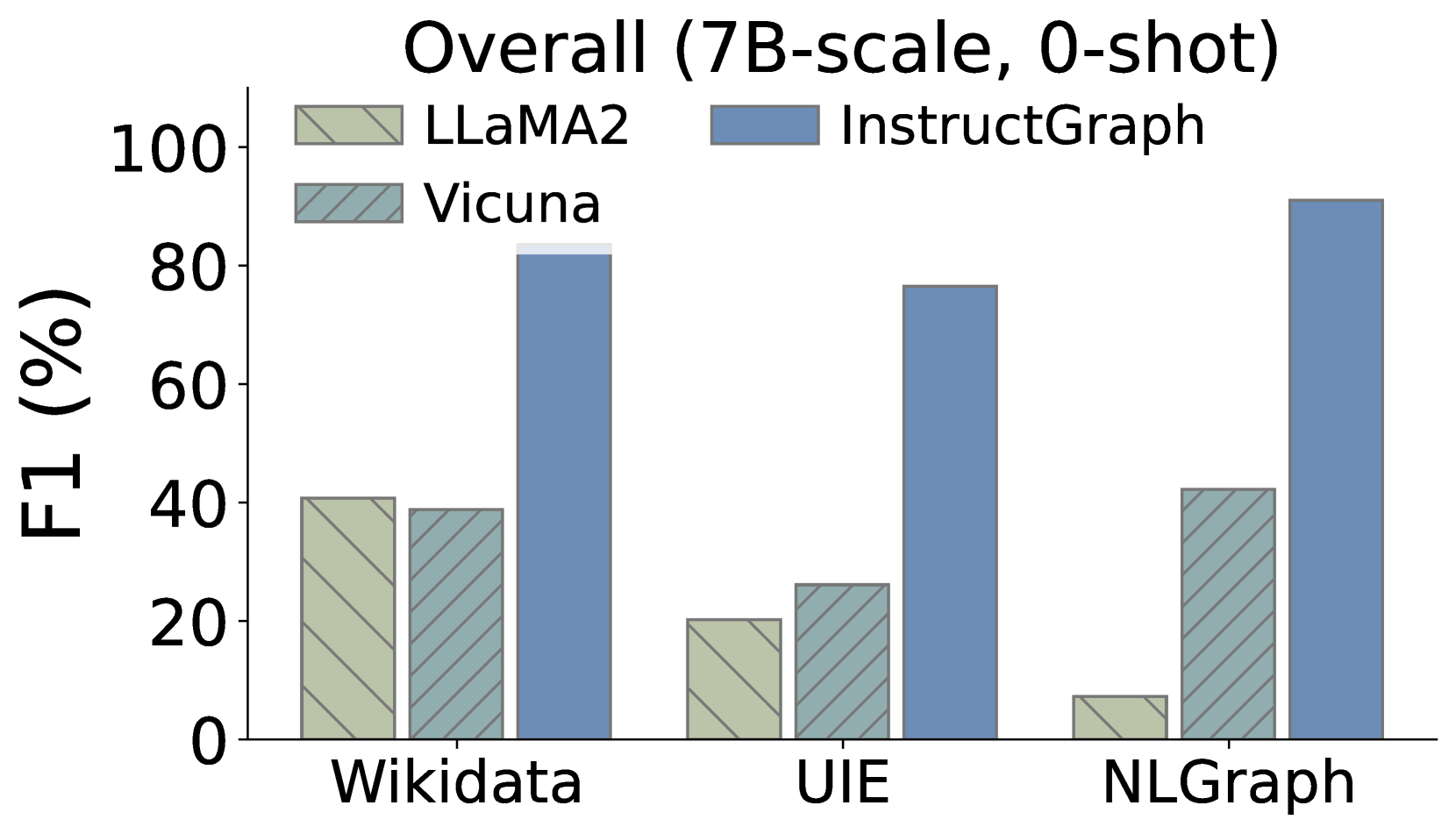
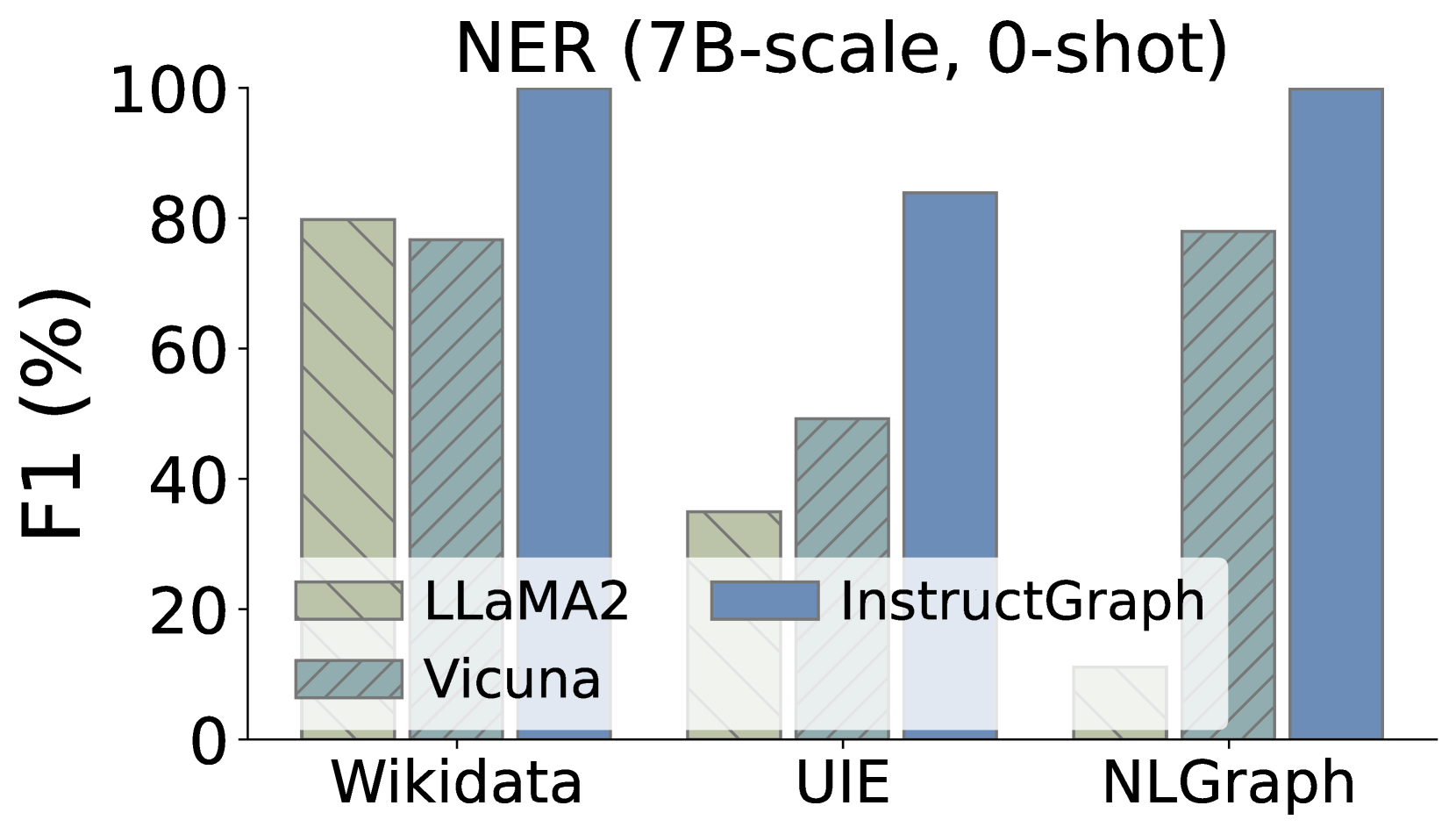
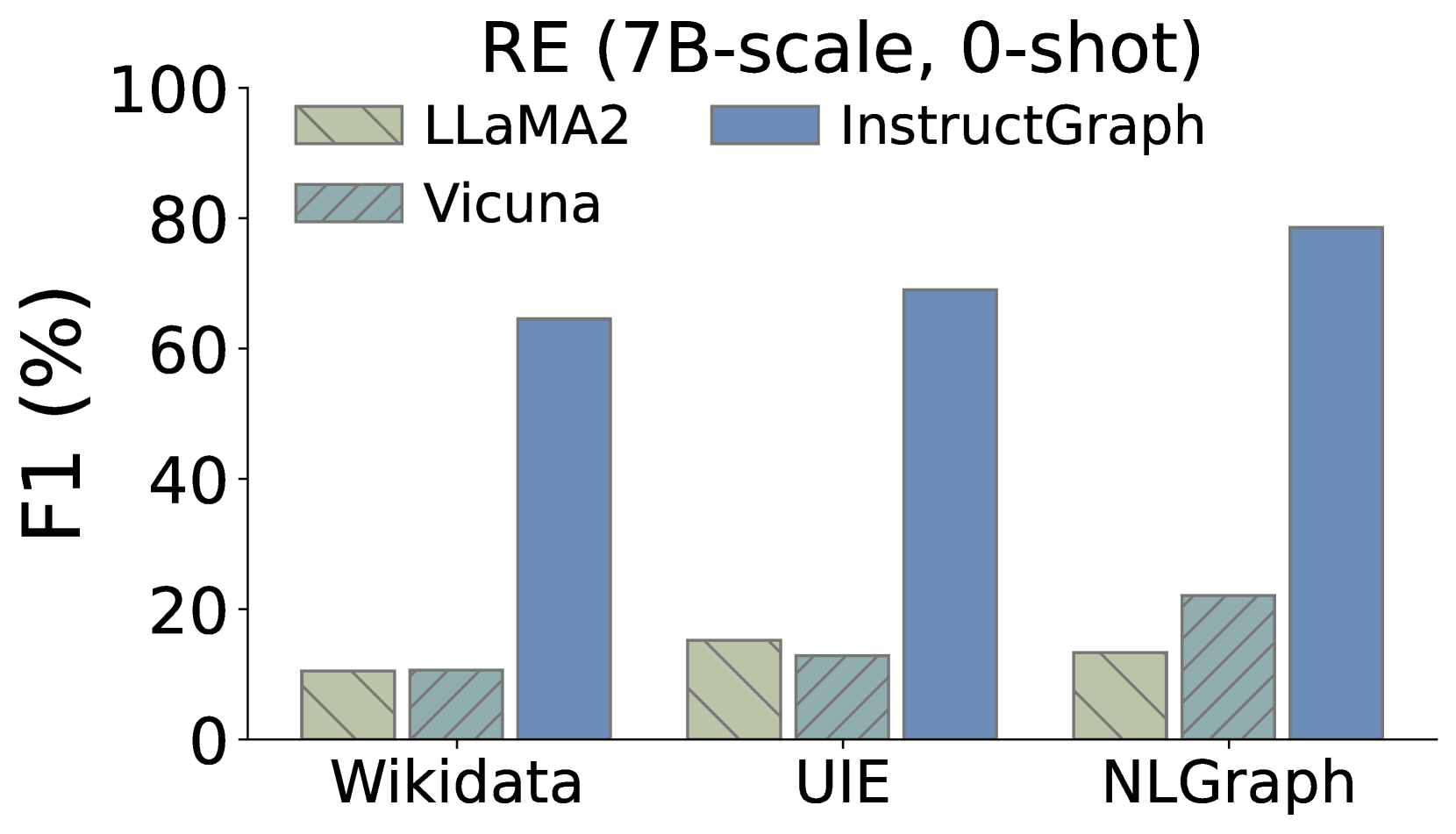
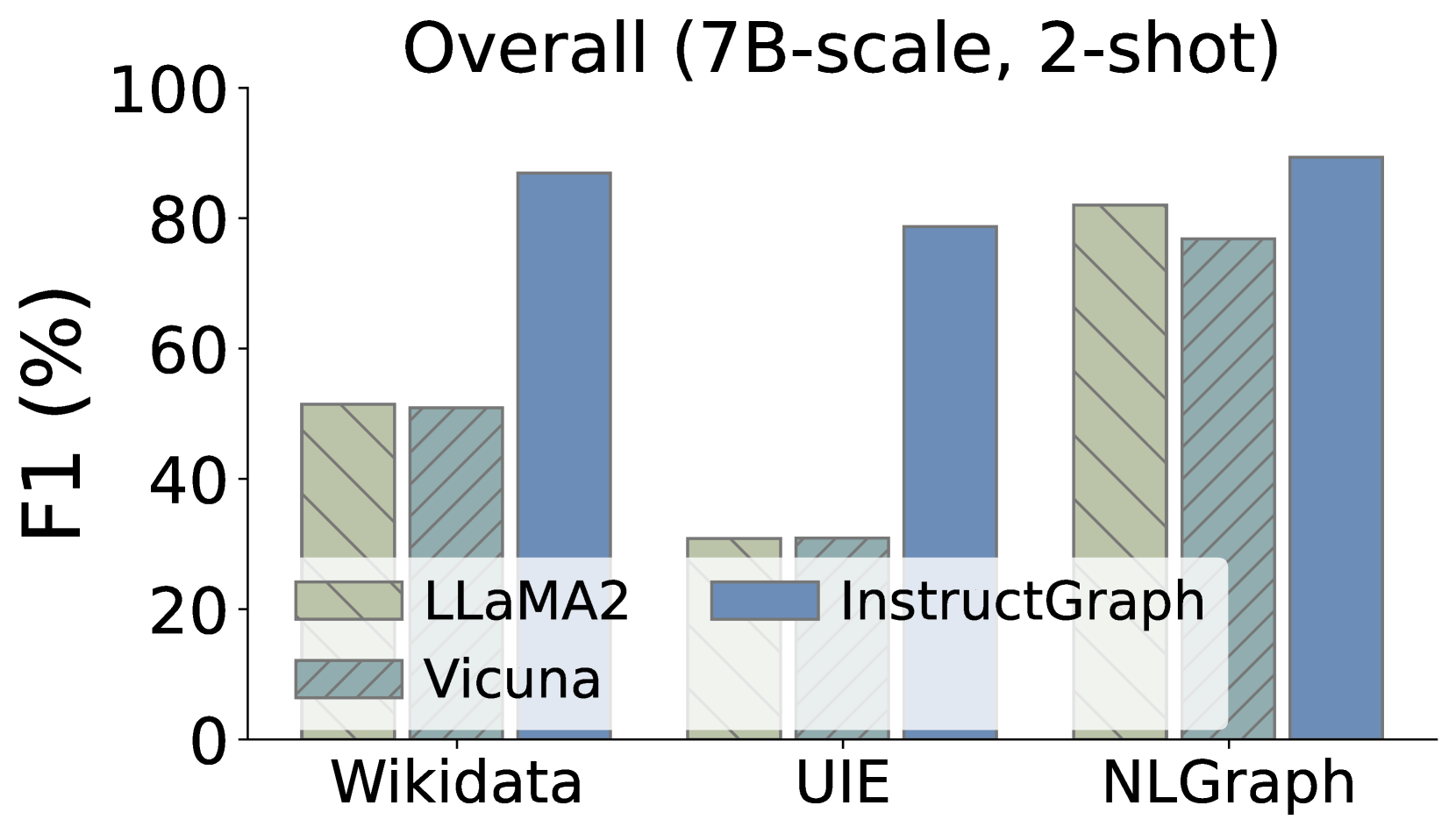
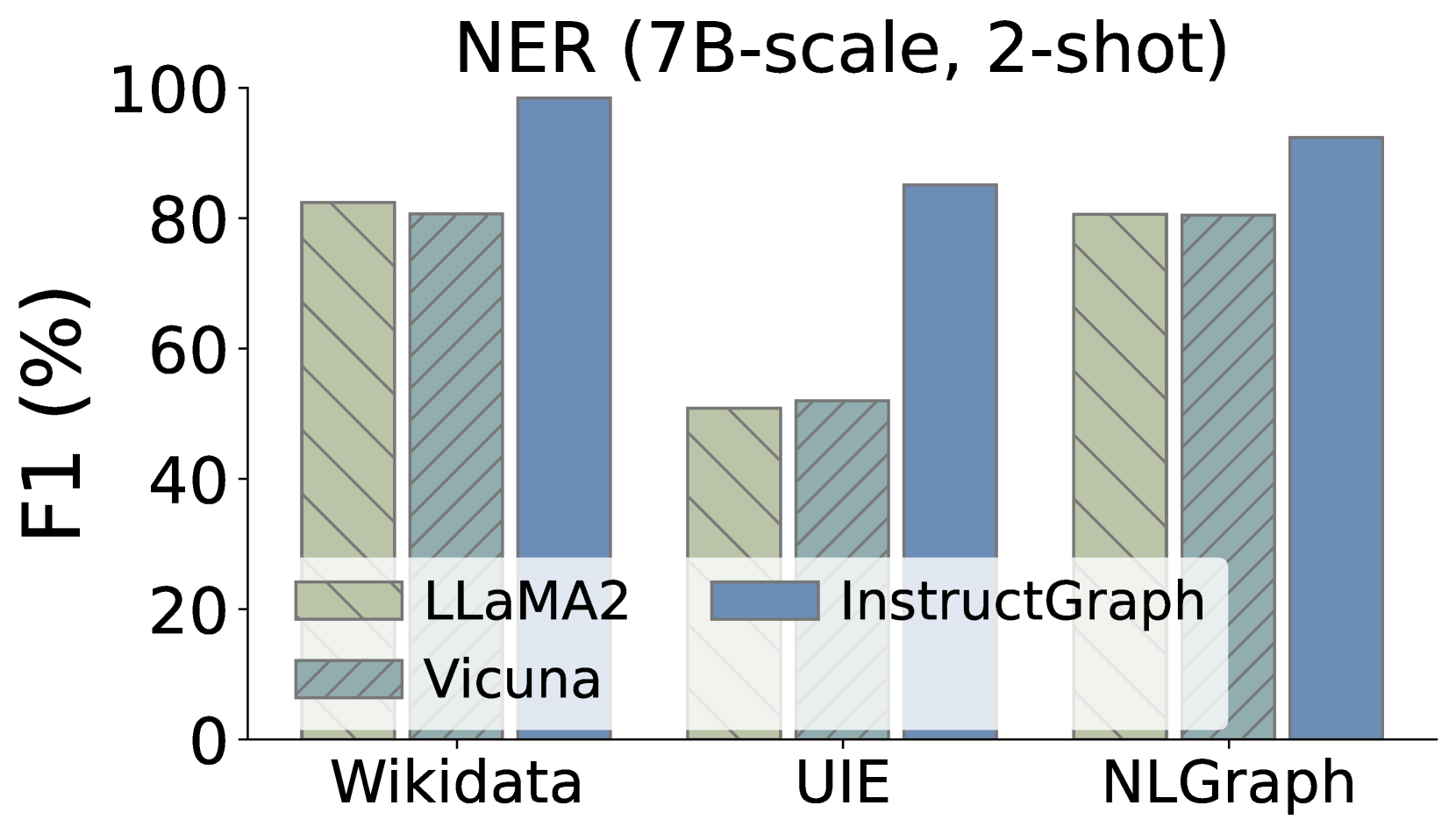
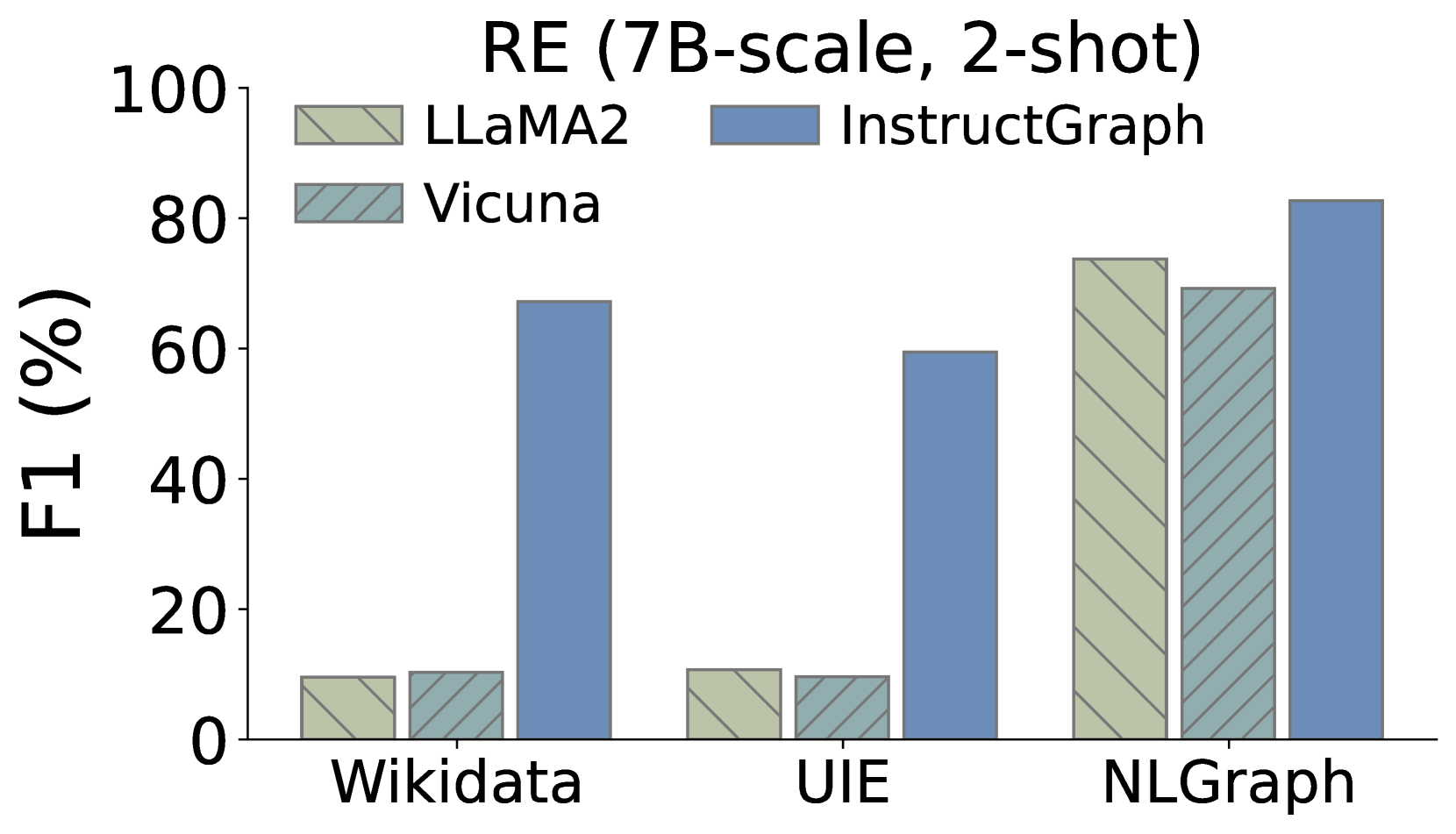
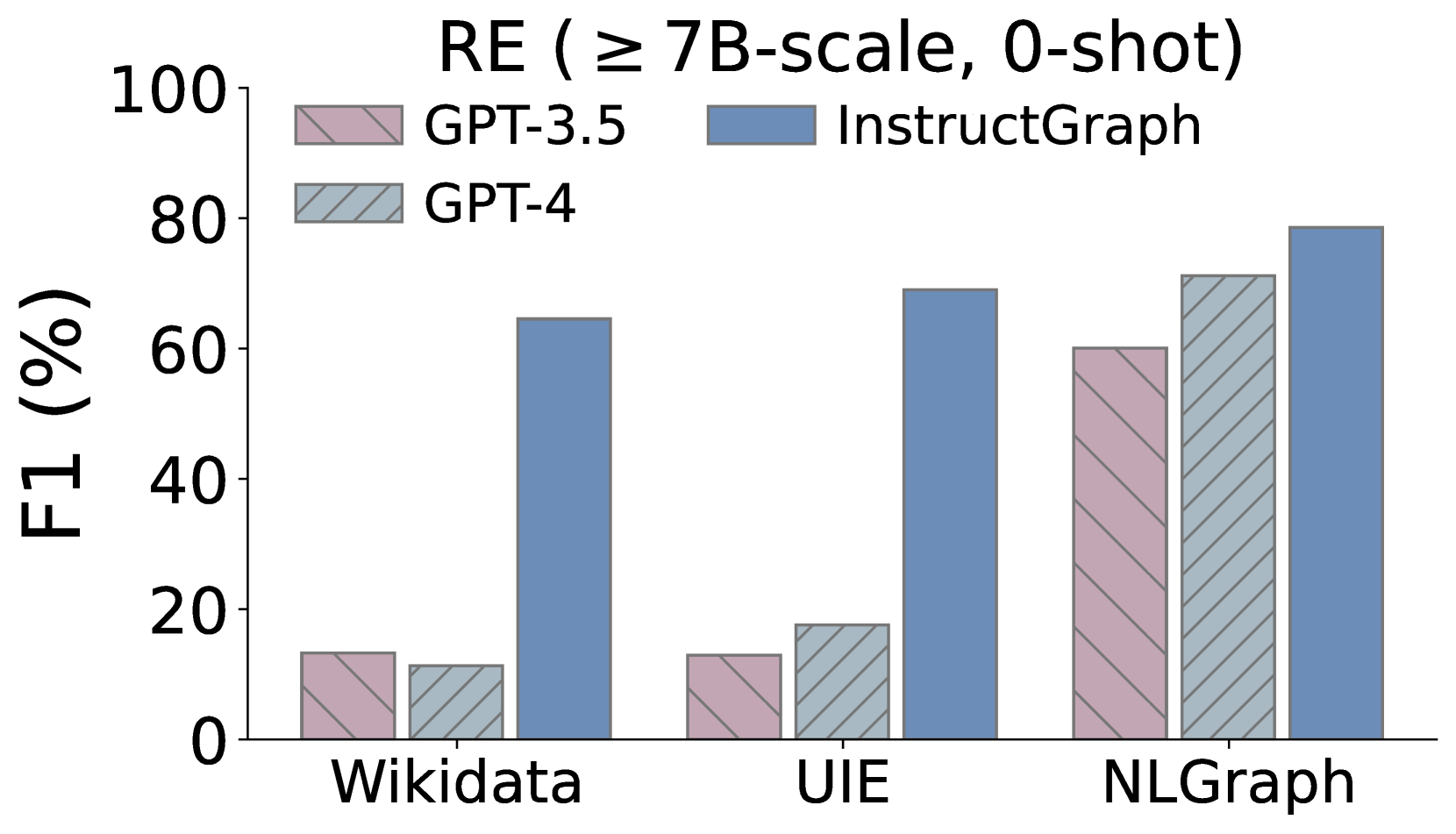
此外,我们还希望深入研究InstructGraph-INS是否实现了图生成任务的改进,我们选择两种外部方式来评估结果:1)NER表示命名实体识别,2)RE表示关系提取。 如图3所示,我们可视化了三个图生成任务的比较性能,其中Wikidata和UIE属于知识图构建,NLGraph专注于结构图生成。 我们观察到:1)InstructGraph-INS 可以为 LLaMA2 和 Vicuna 带来显着的改进,表明图生成能力涵盖 NER 和 RE。 2)我们还将所有基线与 2-shot 范例进行整合,结果表明 InstructGraph-INS 的性能始终是最高的。 3)RE对NER来说更具挑战性,因为它涉及理解生成的节点(实体)的语义并根据它们的关系或权重做出决策。 尽管如此,RE 的改进还是比 NER 更大,这意味着图特定的优化可以更好地赋能大语言模型构建三元组。
| Methods (7B) | Arithmetic | Symbolic | Robotic | Logic | |||||
| GSM8K | SVAMP | AQuA | Letter | Coin | Termes | Floortile | ProofWriter | FOLIO | |
| (4-shot) | (4-shot) | (4-shot) | (4-shot) | (4-shot) | (4-shot) | (4-shot) | (4-shot) | (4-shot) | |
| LLaMA2 w/. CoT | 11.89 | 23.30 | 18.60 | 0.00 | 0.00 | 0.00 | 0.00 | 30.64 | 32.40 |
| Vicuna w/. CoT | 14.33 | 24.19 | 17.80 | 1.50 | 0.00 | 0.00 | 0.00 | 28.77 | 33.15 |
| InstructGraph-INS w/. CoT | 17.52 | 28.80 | 22.33 | 8.70 | 6.20 | 30.00 | 50.00 | 55.80 | 41.68 |
| LLaMA2 w/. GTM | 14.38 | 23.10 | 20.13 | 2.00 | 0.00 | 0.00 | 0.00 | 33.19 | 34.80 |
| Vicuna w/. GTM | 15.10 | 24.84 | 19.60 | 1.50 | 0.00 | 0.00 | 0.00 | 31.50 | 36.19 |
| InstructGraph-INS w/. GTM | 19.46 | 27.10 | 23.80 | 7.40 | 9.40 | 30.00 | 50.00 | 52.77 | 43.06 |
3.3 图偏好任务的主要结果
接下来我们探讨 InstructGraph 是否可以减少图幻觉问题。 我们从相应的集群中抽取一些任务来构建幻觉测试集,包括结构、标题、图形问答和节点分类。 数据统计结果如表10所示,具体内容参见附录A.2。 具体来说,每个例子都由一个正确答案和一个错误答案组成,我们计算大语言模型对这些答案的困惑度(PPL),并选择PPL得分最低的选项作为偏好结果。 因此,准确度指标可以反映幻觉缓解的性能。
如表3所示,我们选择LLaMA2、Vicuna以及InstructGraph的两个变体进行比较。 InstructGraph-INS 的性能分别优于 LLaMA2 和 Vicuna % 和 %,这表明我们的框架仅通过图形指令调整就可以更好地解决偏好任务。 这表明将任务相关知识注入大语言模型的内在参数可能是减少幻觉的重要因素之一。 此外,InstructGraph-PRE将指令版本模型显着增强了约10%,这表明精心设计的偏好优化可以达到上限,并赋予大语言模型缓解幻觉陷阱的能力。
我们还深入研究了图数据的偏好优化是否会阻碍一般领域的有效性。 为了实现这一目标,我们选择了三个外部偏好和幻觉任务。 1) HaluEval 李等人 (2023a) 888https://github.com/RUCAIBox/HaluEval. 侧重于对话、一般理解、问题回答和文本摘要中的幻觉评估(摘要)。 2) TruthfulQA 林等人 (2022) 999https://github.com/sylinrl/TruthfulQA. 旨在测试大语言模型在知识密集型任务上的真实性。 我们选择MC1作为测试。 3) Anthropic-HH 白 等人 (2022) 101010https://github.com/anthropics/hh-rlhf. 发布了无害和有益观点的评估集。 对于这些任务,我们不执行特定于任务的微调来显示零样本性能。 表 4 中的结果表明,我们的框架在某些任务上有时会优于样本规模基线,这满足了我们的需求。
3.4思想规划的有效性
回想图指令调优,我们渴望大语言模型能够解决思维规划任务,包括算术、符号、机器人和逻辑。 我们设计了两个少样本场景:1)思想链(CoT)直接对少样本样本进行采样,并手动注释序列原理以形成提示。 2)图思维建模(GTM)将序列原理分解为三个阶段,即查找主题实体或关键词、构建图来表达思想、输出最终答案。 比较结果如表5所示,我们可以观察到InstructGraph-INS在CoT和GTM提示引发时实现了最佳性能。 此外,GTM 在 SVAMP、Letter 和 ProofWriter 任务中有时表现低于预期。 我们认为这些任务很难用明确的图来表达来传达思维过程。
3.5一般 NLP 任务的表现
接下来我们评估 InstructGraph 在一般 NLP 任务上的性能。 我们选择 Big-Bench-Hard (BBH) Suzgun 等人 (2023) 和 Massive Multitask Language Understanding (MMLU) Hendrycks 等人 (2021) 基准测试,样本样本较少进行推理。 如表6所示,尽管这些任务不属于图领域,但与其他同规模的开源大语言模型相比,我们仍然可以获得有竞争力的结果。
| Methods | BBH | MMLU |
| (3-shot) | (5-shot) | |
| GPT-3.5 | - | 70.00 |
| GPT-4 | - | 86.40 |
| MPT-7B | 31.00 | 26.80 |
| Falcon-7B | 28.00 | 26.20 |
| LLaMA-7B | 30.30 | 35.10 |
| LLaMA2-7B | 32.58 | 45.65 |
| Vicuna-7B | 31.54 | 50.34 |
| InstructGraph-INS | 33.06 | 51.62 |
4分析
4.1 参数高效学习研究
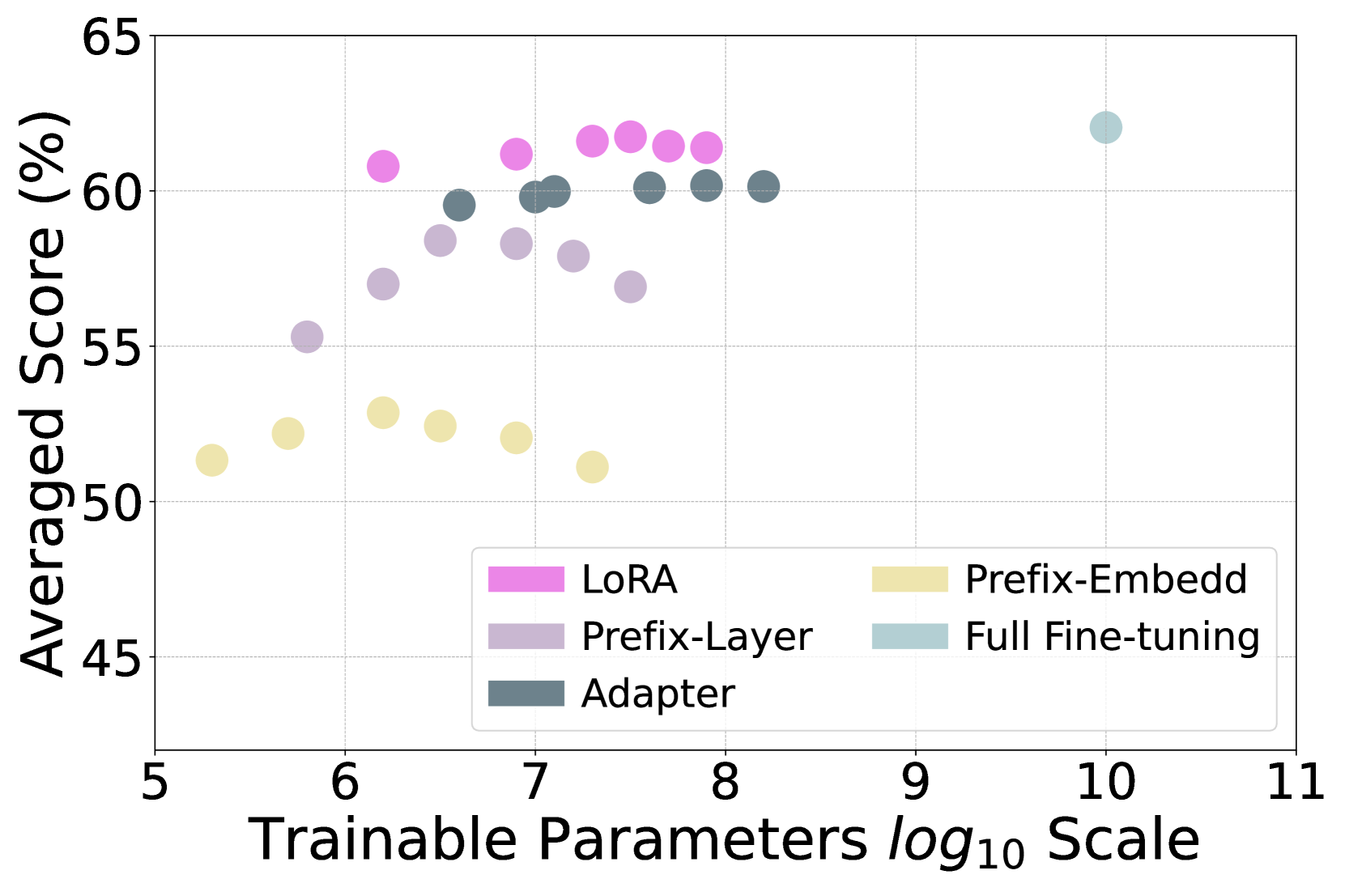
为了在资源限制下加快训练速度并减少内存使用,我们利用参数高效学习(PEL)技术为原始大语言模型配备少量可训练参数。 为了研究不同 PEL 方法的选择,我们将 LoRA 与其他 PEL 方法进行比较,例如 Prefix-tuning Li and Liang (2021) 111111Prefix-Embedd:仅调整输入嵌入层; Prefix-Layer:调整每个 Transformer 层。,以及适配器 Houlsby 等人 (2019)。 对于每种方法,我们选择六种不同的尺度,并对 10% 的训练数据进行图形指令调整。 可训练参数和平均结果之间的平衡如图4所示。 我们可以看到,无论可训练参数的规模如何,LoRA 都可以实现最佳性能,并且类似于完全微调。
| Methods | PathQSP | WebNLG | CoRA | UIE |
| GPT-4 | ||||
| Template | 58.20 | 96.13 | 58.58 | 0.00 |
| Code Format | 68.64 | 99.29 | 64.17 | 26.22 |
| LLaMA2 | ||||
| Template | 20.36 | 59.15 | 27.44 | 0.00 |
| Code Format | 42.70 | 88.67 | 83.04 | 20.21 |
| Baselines | Graph QA | Node CLS | IE |
| Graph Instruction Testing | |||
| InstructGraph-INS | 72.21 | 83.75 | 66.45 |
| w/. only GSM | 71.89 | 83.04 | 63.77 |
| w/. only GLM | 69.32 | 78.40 | 66.13 |
| w/. only GGM | 72.09 | 83.66 | 39.10 |
| w/. only GTM | 69.30 | 81.90 | 66.33 |
| Graph Preference Testing | |||
| InstructGraph-PRE | 84.44 | 88.98 | 91.44 |
| w/o. only unfactual | 82.10 | 84.52 | 84.33 |
| w/o. only conflict | 83.70 | 85.17 | 81.11 |
| w/o. only missing | 79.35 | 83.55 | 78.40 |
| w/o. ALL | 77.85 | 83.16 | 69.14 |
4.2代码格式图的有效性
在这一部分中,我们评估在将图结构与文本大语言模型对齐时结构化格式语言器的使用。 我们选择了四种经典的图推理和生成任务,即 PathQSP、WebNLG、CoRA 和 UIE。 为了与结构化格式语言器进行比较,我们直接选择InstructGLM Ye等人(2023)引入的启发式模板来描述图中的每条路径。 例如,路径“(, , ), (, , )”可以表述为“通过在两跳内与连接,并且特征关系 和 我们使用这个模板来提示GPT-4和LLaMA2显示性能。 表 7 中的结果表明,我们的结构化格式语言表达器在所有任务中都优于传统模板。 特别是,传统模板的大语言模型无法支持图形生成,而结构化格式语言器可以实现这一目标。
|
| Instruction (Graph Caption) | LLaMA2 Output | InstructGraph Output | Reference |
|
You are a good graph reasoner. Give you a graph language that describes a graph structure and node information. You need to understand the graph and the task definition and answer the question. n“‘nGraph[name=’wikipedia-knowledge-graph’] n entity_list = [’clown beetle’, ’euspilotus cribrum’, ’america’, ’the family’, ’species’, ’histeridae’];n triple_list = [(’euspilotus cribrum’ -> ’species’)[relation=’taxon rank’], (’the family’ -> ’america’)[relation=’country’]];nn“‘n Task definition: given a knowledge graph with all entities and structure triples representing factual and commonsense knowledge. Please leverage this graph to generate an encyclopedia passage. Note that do not list all knowledge in a running account.n Q: Please generate an encyclopedia passage for the knowledge graph.n A: |
The relation between Euspilotus cribrum and species is ’taxon rank’, and the family country is America. [Human Evaluation]: This answer directly states each fact triple from the given graph separately. It is accurate but not natural and satisfied as a whole. |
Euspilotus cribrum is a species of clown beetle in the family Histeridae which is found in North America. [Human Evaluation]: This answer naturally describes the factual knowledge. Overall, it is very similar to an encyclopedia document and makes the reading experience better. |
Euspilotus cribrum is a species of clown beetle in the family Histeridae. It is found in North America. |
| Instruction (Graph Generation) | LLaMA2 Output | InstructGraph Output | Reference |
|
You are a good graph generator. You need to understand the task definition and generate a graph language to answer the question. n Task definition: given a passage, extract some corresponding structure factual triples from the passage to form a knowledge graph, and generate a graph language to describe the graph. Note that: 1) the graph is a directed graph and the name is ’knowledge-graph’. 2) The entities must be mentioned in the passage. 3) The candidate relation type must be one of ’publication date’, ’country of origin’, ’publisher’, ’performer’. 4) The generated graph language should be a code-like structure, and the skeleton format can be expressed as the following:n “‘n Graph[name=’knowledge-graph’] {n entity_list = [’xxx’, ];n triple_list = [(’xxx’ -> ’xxx’)[relation=’xxx’], ];n }n“‘n Passage: "’Bluesman’ is the 12th original album of Tak Matsumoto, the guitarist of the Japanese music group B’z. It was released by VERMILLION RECORDS on September 2, 2020.".n Q: Given you a passage, please generate a corresponding knowledge graph.n A: |
Graph[name=’knowledge-graph’] {n entity_list = [’Bluesman’, ’Tak Matsumoto’, ’B’z’];n triple_list = [(’Bluesman’ -> ’Tak Matsumoto) [relation=’performer’], n (’Bluesman’ -> ’B’z’) [relation=’performer’], n (Tak Matsumoto’ -> ’B’z)́ [relation=’performer’],n (’Tak Matsumoto’ -> ’VERMILLION RECORDS’) [relation=’publisher’]];} [Human Evaluation]: This answer sometimes contains wrong triples or missing some entities. |
Graph[name=ḱnowledge-graph]́ {n entity_list = [B́luesman,́ T́ak Matsumoto,́ B́’z,́ V́ERMILLION RECORDS,́ Śeptember 2, 2020]́;n triple_list = [(B́luesman-́> Śeptember 2, 2020)́ [relation=ṕublication date]́, (B́luesman-́> T́ak Matsumoto)́ [relation=ṕerformer]́, (B́luesman-́> V́ERMILLION RECORDS)́ [relation=ṕublisher]́, (B́luesman-́> J́apan)́ [relation=ćountry of origin]́];n} [Human Evaluation]: This answer looks satisfying. |
Graph[name=ḱnowledge-graph]́ {n entity_list = [ćountry of origin,́ ṕerformer,́ ṕublication date,́ B́luesman,́ ṕublisher]́;n triple_list = [(B́luesman-́> J́apan)́ [relation=ćountry of origin]́, (B́luesman-́> V́ERMILLION RECORDS)́ [relation=ṕublisher]́, (B́luesman-́> Śeptember 2, 2020)́ [relation=ṕublication date]́, (B́luesman-́> T́ak Matsumoto)́ [relation=ṕerformer]́];n} |
4.3消融研究
在本节中,我们重点关注消融研究,以显示每个组件对性能的贡献程度。 我们选择三个集群进行测试,即 Graph QA、Node CLS 和 IE。 对于图指令测试,我们验证每个建模任务的有效性,测试集来自指令语料库。 对于图偏好测试,我们评估了三种幻觉采样策略,包括非事实图、冲突图和缺失图,测试集来自偏好语料库。
如表8所示,结果表明,当移除其中一个组件时,性能会下降。 对于指令调优测试,我们可以观察到图语言建模在图 QA 和 Node CLS 集群中发挥着重要作用,而图生成建模有利于 IE 的性能。 对于偏好测试,我们可以看到 w/o 的性能。 missing graph显着下降,表明产生幻觉的主要因素是输入图或生成图中缺少关键信息。
4.4 不同骨干网的有效性
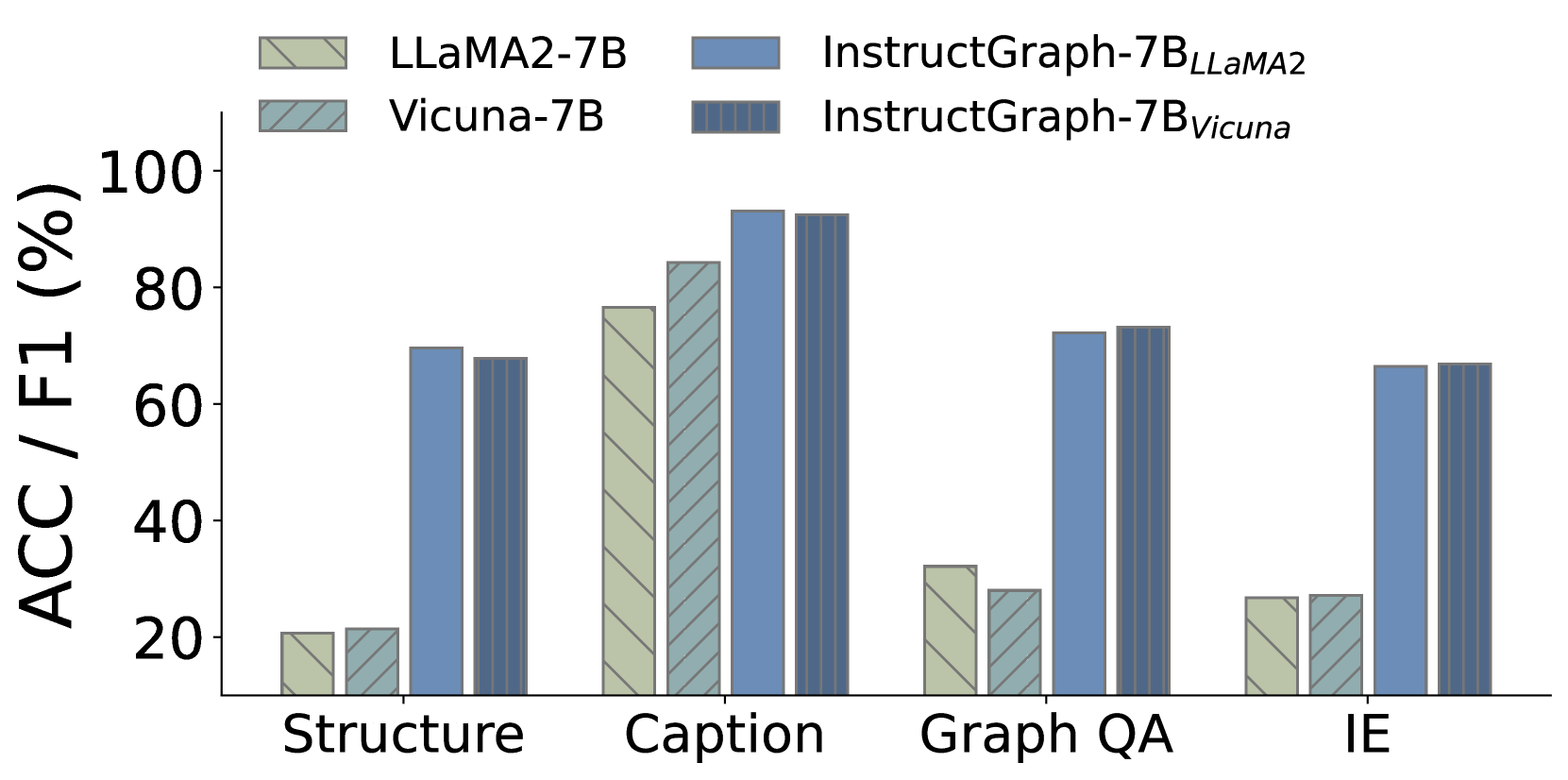
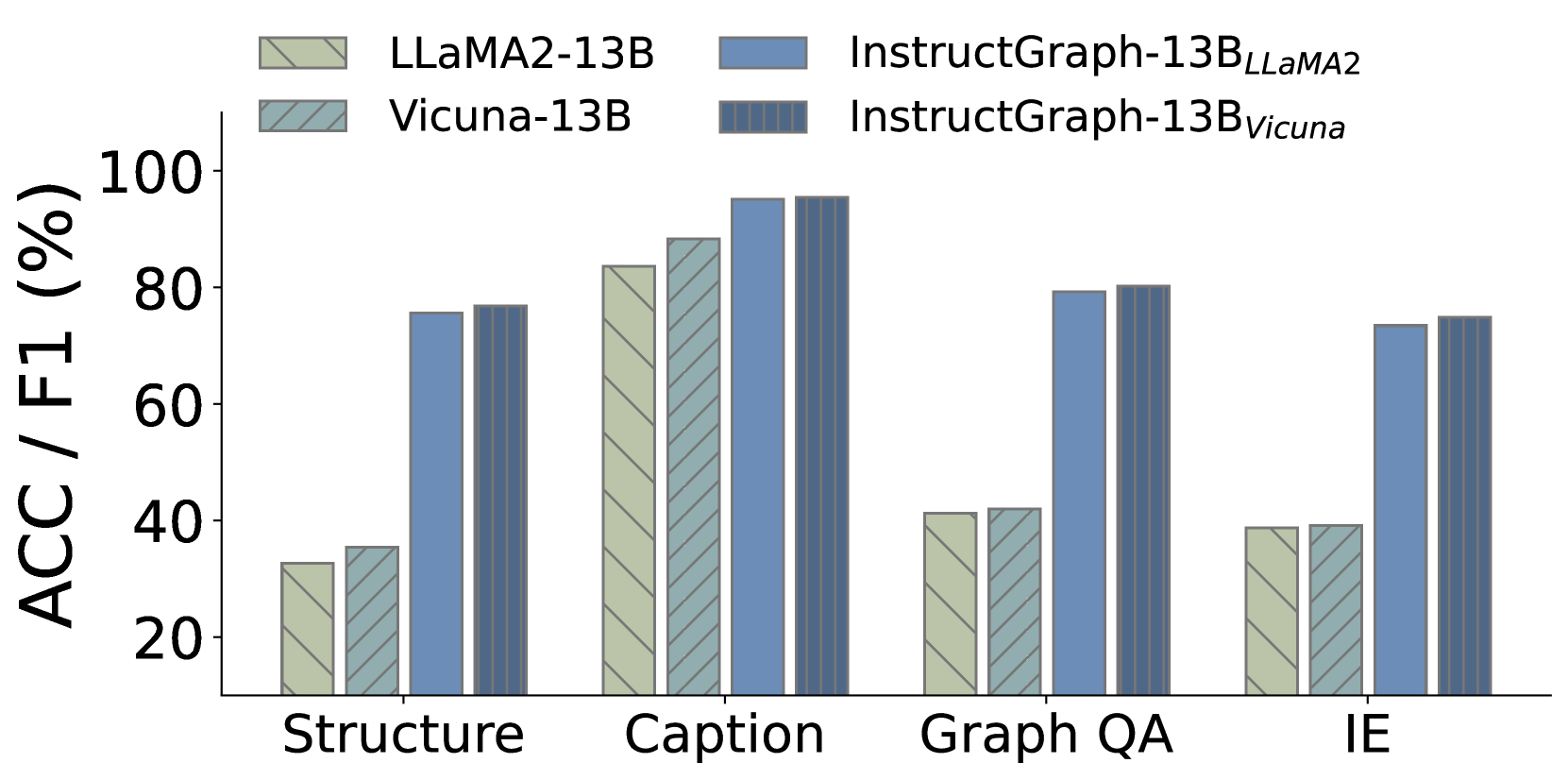
为了研究所提出的 InstructGraph 是否能够持续提高不同大语言模型的图推理和生成能力,我们选择 LLaMA2-7B、LLaMA2-13B、Vicuna-7B 和 Vicuna-13B 作为起始检查点。 为了提高实验效率,我们随机选择10%的训练数据进行图指令调优,并与相应的vanilla大语言模型进行比较。 图 5 中的结果表明,InstructGraph 可以对任意主干网和尺度持续实现实质性改进。 此外,我们观察到 Vicuna 最初的性能比 LLaMA2 更好。 然而,经过图形指令调整后,这种趋势发生了逆转。 经过进一步分析,我们发现LLaMA2和Vicuna都是在LLaMA Touvron等人(2023a)的基础上重新优化的。 Vicuna 的优化涉及使用监督微调(SFT)将领域知识和大量对话数据注入 LLaMA。 同时,LLaMA2重点重构模型架构和预训练策略,以提高模型的通用性。 因此,Vicuna 可能比 LLaMA2 具有更好的理解指令的能力。 尽管如此,LLaMA2 可以成为通过参数更新增强大语言模型图推理和生成任务的更好的起始检查点。
4.5人类评价
我们以一个案例研究结束本节,以展示大语言模型在解决图推理和生成任务时的性能。 我们选择LLaMA2(7B)进行比较,并分别从图标题生成和知识图生成中选择一个示例。 为了找到答案,我们进行了人工评估来估计 InstructGraph 的有效性。 如表9所示,InstructGraph 的性能优于所有基线。 具体来说,与 LLaMA2 相比,InstructGraph 可以生成更自然且可读的标题来描述事实信息。 对于图生成,InstructGraph 可以提供准确的实体和三元组。
5相关工作
5.1 图学习 LLM
一系列工作研究了如何利用大语言模型解决以图为中心的任务Jin等人(2023),可以分解为以下几类:1)即时工程。 一系列工作旨在设计界面以引出大语言模型,以更好地理解和推理图 Ye 等人 (2023);韩等人 (2023);张等人 (2023b);张(2023); Kim 等人 (2023);王等人 (2023b);罗等人 (2023);王等人 (2023a);郭等人 (2023);赵等人(2023b)。 2) 使用可训练的 GNN 提升大语言模型。 这种方法的重点是用可训练的 GNN 增强大语言模型,它可以捕获图的任意尺度 Zhang 等人 (2022); Chai 等人 (2023);唐等人 (2023);赵等人 (2023a);田等人 (2023);秦等人 (2023). 3)图数据的指令调整。 与我们类似的是,Xu 等人 (2023);江等人 (2023); Fang 等人 (2023); Zeng等人(2023)直接收集一些图形或符号数据形成指令语料库,然后不断地预训练大语言模型。 与它们不同的是,我们的InstructGraph通过类似代码的通用格式的图形指令调优以及通过偏好对齐精心设计的幻觉缓解策略进一步为大语言模型赋能。
5.2 大语言模型中的幻觉
最近的研究表明,幻觉可能会降低大语言模型在执行指令推理时的性能。 大语言模型通常会产生看似合理的答案,这被称为幻觉 Ji 等人 (2023);张等人(2023a)。 幻觉现象包括编造错误的用户输入、不忠实于先前生成的上下文以及不真实的外部知识和常识。 为了估计幻觉,Kryscinski 等人 (2020);李等人 (2023a); Tam 等人 (2023); Min 等人 (2023) 利用外部工具或神经网络(例如 BERT-NLI、GPT-4)对模型输出的可信度和真实性进行评分。 最近,许多工作集中在通过检索增强生成(RAG)Lewis 等人(2020)、对比学习Sun 等人(2023)、矛盾评估来抑制这个问题。 t2>Mündler 等人 (2023),以及解码策略 Lee 等人 (2022);石等人 (2023);李等人(2023b)。 与他们不同的是,我们的目标是通过偏好对齐来解决图任务上的幻觉问题。
6结论
本文提出了一种新颖的InstructGraph框架,使大语言模型具有解决图推理和生成任务的能力。 为了弥合图数据和文本语言模型之间的差距,我们引入了一种结构化格式语言器,将每个图转换为类似代码的 foema,并根据从 29 个图任务收集的指令数据集不断调整大语言模型。 此外,我们还引入了图形偏好对齐阶段,以进一步减轻推理或生成图形时的幻觉问题。 大量实验表明,InstructGraph能够充分发挥大语言模型的图推理和生成能力,并实质上达到最佳性能。 在未来的工作中,我们的目标是进一步提高框架在以图为中心和通用 NLP 任务上的性能,并将其扩展到其他大语言模型。
参考
- Abhishek et al. (2022) Tushar Abhishek, Shivprasad Sagare, Bhavyajeet Singh, Anubhav Sharma, Manish Gupta, and Vasudeva Varma. 2022. Xalign: Cross-lingual fact-to-text alignment and generation for low-resource languages. In Companion of The Web Conference 2022, Virtual Event / Lyon, France, April 25 - 29, 2022, pages 171–175. ACM.
- Bai et al. (2022) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom B. Brown, Jack Clark, Sam McCandlish, Chris Olah, Benjamin Mann, and Jared Kaplan. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. CoRR, abs/2204.05862.
- Berant et al. (2013) Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, EMNLP 2013, 18-21 October 2013, Grand Hyatt Seattle, Seattle, Washington, USA, A meeting of SIGDAT, a Special Interest Group of the ACL, pages 1533–1544. ACL.
- Besta et al. (2023) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. 2023. Graph of thoughts: Solving elaborate problems with large language models. CoRR, abs/2308.09687.
- Bollacker et al. (2008) Kurt D. Bollacker, Colin Evans, Praveen K. Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2008, Vancouver, BC, Canada, June 10-12, 2008, pages 1247–1250. ACM.
- Bradley and Terry (1952) Ralph Allan Bradley and Milton E Terry. 1952. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Chai et al. (2023) Ziwei Chai, Tianjie Zhang, Liang Wu, Kaiqiao Han, Xiaohai Hu, Xuanwen Huang, and Yang Yang. 2023. Graphllm: Boosting graph reasoning ability of large language model. CoRR, abs/2310.05845.
- Colas et al. (2021) Anthony Colas, Ali Sadeghian, Yue Wang, and Daisy Zhe Wang. 2021. Eventnarrative: A large-scale event-centric dataset for knowledge graph-to-text generation. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual.
- Dao et al. (2022) Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Dziri et al. (2022) Nouha Dziri, Sivan Milton, Mo Yu, Osmar R. Zaïane, and Siva Reddy. 2022. On the origin of hallucinations in conversational models: Is it the datasets or the models? In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, WA, United States, July 10-15, 2022, pages 5271–5285. Association for Computational Linguistics.
- Fang et al. (2023) Yin Fang, Xiaozhuan Liang, Ningyu Zhang, Kangwei Liu, Rui Huang, Zhuo Chen, Xiaohui Fan, and Huajun Chen. 2023. Mol-instructions: A large-scale biomolecular instruction dataset for large language models. CoRR, abs/2306.08018.
- Gao et al. (2023) Shuzheng Gao, Xin-Cheng Wen, Cuiyun Gao, Wenxuan Wang, Hongyu Zhang, and Michael R. Lyu. 2023. What makes good in-context demonstrations for code intelligence tasks with llms? In 38th IEEE/ACM International Conference on Automated Software Engineering, ASE 2023, Luxembourg, September 11-15, 2023, pages 761–773. IEEE.
- Gardent et al. (2017) Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. Creating training corpora for NLG micro-planners. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Papers, pages 179–188. Association for Computational Linguistics.
- Giles et al. (1998) C. Lee Giles, Kurt D. Bollacker, and Steve Lawrence. 1998. Citeseer: An automatic citation indexing system. In Proceedings of the 3rd ACM International Conference on Digital Libraries, June 23-26, 1998, Pittsburgh, PA, USA, pages 89–98. ACM.
- Gu et al. (2021) Yu Gu, Sue Kase, Michelle Vanni, Brian M. Sadler, Percy Liang, Xifeng Yan, and Yu Su. 2021. Beyond I.I.D.: three levels of generalization for question answering on knowledge bases. In WWW ’21: The Web Conference 2021, Virtual Event / Ljubljana, Slovenia, April 19-23, 2021, pages 3477–3488. ACM / IW3C2.
- Gui et al. (2023) Honghao Gui, Jintian Zhang, Hongbin Ye, and Ningyu Zhang. 2023. Instructie: A chinese instruction-based information extraction dataset. CoRR, abs/2305.11527.
- Guo et al. (2023) Jiayan Guo, Lun Du, and Hengyu Liu. 2023. Gpt4graph: Can large language models understand graph structured data ? an empirical evaluation and benchmarking. CoRR, abs/2305.15066.
- Han et al. (2023) Jiuzhou Han, Nigel Collier, Wray L. Buntine, and Ehsan Shareghi. 2023. Pive: Prompting with iterative verification improving graph-based generative capability of llms. CoRR, abs/2305.12392.
- He and McAuley (2016) Ruining He and Julian J. McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In Proceedings of the 25th International Conference on World Wide Web, WWW 2016, Montreal, Canada, April 11 - 15, 2016, pages 507–517. ACM.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net.
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Proceedings of Machine Learning Research, pages 2790–2799. PMLR.
- Hu et al. (2022) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Hu et al. (2020) Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. 2020. Open graph benchmark: Datasets for machine learning on graphs. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Ji et al. (2023) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Yejin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Comput. Surv., 55(12):248:1–248:38.
- Jiang et al. (2023) Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Xin Zhao, and Ji-Rong Wen. 2023. Structgpt: A general framework for large language model to reason over structured data. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 9237–9251. Association for Computational Linguistics.
- Jin et al. (2023) Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. 2023. Large language models on graphs: A comprehensive survey. CoRR, abs/2312.02783.
- Jin et al. (2020) Zhijing Jin, Qipeng Guo, Xipeng Qiu, and Zheng Zhang. 2020. Genwiki: A dataset of 1.3 million content-sharing text and graphs for unsupervised graph-to-text generation. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, pages 2398–2409. International Committee on Computational Linguistics.
- Kim et al. (2023) Jiho Kim, Yeonsu Kwon, Yohan Jo, and Edward Choi. 2023. KG-GPT: A general framework for reasoning on knowledge graphs using large language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 9410–9421. Association for Computational Linguistics.
- Kryscinski et al. (2020) Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. 2020. Evaluating the factual consistency of abstractive text summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, pages 9332–9346. Association for Computational Linguistics.
- Lee et al. (2022) Nayeon Lee, Wei Ping, Peng Xu, Mostofa Patwary, Pascale Fung, Mohammad Shoeybi, and Bryan Catanzaro. 2022. Factuality enhanced language models for open-ended text generation. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Lewis et al. (2020) Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Li et al. (2023a) Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. 2023a. Halueval: A large-scale hallucination evaluation benchmark for large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 6449–6464. Association for Computational Linguistics.
- Li et al. (2023b) Kenneth Li, Oam Patel, Fernanda B. Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023b. Inference-time intervention: Eliciting truthful answers from a language model. CoRR, abs/2306.03341.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021, pages 4582–4597. Association for Computational Linguistics.
- Lin et al. (2022) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, pages 3214–3252. Association for Computational Linguistics.
- Luo et al. (2023) Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. 2023. Reasoning on graphs: Faithful and interpretable large language model reasoning. CoRR, abs/2310.01061.
- Ma et al. (2023) Yingwei Ma, Yue Liu, Yue Yu, Yuanliang Zhang, Yu Jiang, Changjian Wang, and Shanshan Li. 2023. At which training stage does code data help llms reasoning? CoRR, abs/2309.16298.
- MacGlashan et al. (2017) James MacGlashan, Mark K. Ho, Robert Tyler Loftin, Bei Peng, Guan Wang, David L. Roberts, Matthew E. Taylor, and Michael L. Littman. 2017. Interactive learning from policy-dependent human feedback. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pages 2285–2294. PMLR.
- McCallum et al. (2000) Andrew McCallum, Kamal Nigam, Jason Rennie, and Kristie Seymore. 2000. Automating the construction of internet portals with machine learning. Inf. Retr., 3(2):127–163.
- Min et al. (2023) Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 12076–12100. Association for Computational Linguistics.
- Mündler et al. (2023) Niels Mündler, Jingxuan He, Slobodan Jenko, and Martin T. Vechev. 2023. Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation. CoRR, abs/2305.15852.
- OpenAI (2023a) OpenAI. 2023a. GPT-4 technical report. CoRR, abs/2303.08774.
- OpenAI (2023b) OpenAI. 2023b. GPT-4 technical report. CoRR, abs/2303.08774.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Pasupat and Liang (2015) Panupong Pasupat and Percy Liang. 2015. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, ACL 2015, July 26-31, 2015, Beijing, China, Volume 1: Long Papers, pages 1470–1480. The Association for Computer Linguistics.
- Perozzi et al. (2024) Bryan Perozzi, Bahare Fatemi, Dustin Zelle, Anton Tsitsulin, Mehran Kazemi, Rami Al-Rfou, and Jonathan Halcrow. 2024. Let your graph do the talking: Encoding structured data for llms. arXiv preprint arXiv:2402.05862.
- Qin et al. (2023) Yijian Qin, Xin Wang, Ziwei Zhang, and Wenwu Zhu. 2023. Disentangled representation learning with large language models for text-attributed graphs. CoRR, abs/2310.18152.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. CoRR, abs/2305.18290.
- Saba (2023) Walid S. Saba. 2023. Stochastic llms do not understand language: Towards symbolic, explainable and ontologically based llms. In Conceptual Modeling - 42nd International Conference, ER 2023, Lisbon, Portugal, November 6-9, 2023, Proceedings, volume 14320 of Lecture Notes in Computer Science, pages 3–19. Springer.
- Schneider et al. (2022) Phillip Schneider, Tim Schopf, Juraj Vladika, Mikhail Galkin, Elena Simperl, and Florian Matthes. 2022. A decade of knowledge graphs in natural language processing: A survey. CoRR, abs/2210.00105.
- Sen et al. (2008) Prithviraj Sen, Galileo Namata, Mustafa Bilgic, Lise Getoor, Brian Gallagher, and Tina Eliassi-Rad. 2008. Collective classification in network data. AI Mag., 29(3):93–106.
- Shi et al. (2023) Weijia Shi, Xiaochuang Han, Mike Lewis, Yulia Tsvetkov, Luke Zettlemoyer, and Scott Wen-tau Yih. 2023. Trusting your evidence: Hallucinate less with context-aware decoding. CoRR, abs/2305.14739.
- Speer et al. (2017) Robyn Speer, Joshua Chin, and Catherine Havasi. 2017. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA, pages 4444–4451. AAAI Press.
- Sun et al. (2023) Weiwei Sun, Zhengliang Shi, Shen Gao, Pengjie Ren, Maarten de Rijke, and Zhaochun Ren. 2023. Contrastive learning reduces hallucination in conversations. In Thirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2023, Washington, DC, USA, February 7-14, 2023, pages 13618–13626. AAAI Press.
- Suzgun et al. (2023) Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed Chi, Denny Zhou, and Jason Wei. 2023. Challenging big-bench tasks and whether chain-of-thought can solve them. In Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 13003–13051. Association for Computational Linguistics.
- Tam et al. (2023) Derek Tam, Anisha Mascarenhas, Shiyue Zhang, Sarah Kwan, Mohit Bansal, and Colin Raffel. 2023. Evaluating the factual consistency of large language models through news summarization. In Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 5220–5255. Association for Computational Linguistics.
- Tang et al. (2023) Jiabin Tang, Yuhao Yang, Wei Wei, Lei Shi, Lixin Su, Suqi Cheng, Dawei Yin, and Chao Huang. 2023. Graphgpt: Graph instruction tuning for large language models. CoRR, abs/2310.13023.
- Tian et al. (2023) Yijun Tian, Huan Song, Zichen Wang, Haozhu Wang, Ziqing Hu, Fang Wang, Nitesh V. Chawla, and Panpan Xu. 2023. Graph neural prompting with large language models. CoRR, abs/2309.15427.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023b. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288.
- Tsog et al. (2021) Nandinbaatar Tsog, Saad Mubeen, Fredrik Bruhn, Moris Behnam, and Mikael Sjödin. 2021. Offloading accelerator-intensive workloads in CPU-GPU heterogeneous processors. In 26th IEEE International Conference on Emerging Technologies and Factory Automation, ETFA 2021, Vasteras, Sweden, September 7-10, 2021, pages 1–8. IEEE.
- Wang et al. (2023a) Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. 2023a. Can language models solve graph problems in natural language? CoRR, abs/2305.10037.
- Wang et al. (2022) Jianing Wang, Wenkang Huang, Minghui Qiu, Qiuhui Shi, Hongbin Wang, Xiang Li, and Ming Gao. 2022. Knowledge prompting in pre-trained language model for natural language understanding. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 3164–3177. Association for Computational Linguistics.
- Wang et al. (2023b) Jianing Wang, Qiushi Sun, Nuo Chen, Xiang Li, and Ming Gao. 2023b. Boosting language models reasoning with chain-of-knowledge prompting. CoRR, abs/2306.06427.
- Wang et al. (2023c) Xiao Wang, Weikang Zhou, Can Zu, Han Xia, Tianze Chen, Yuansen Zhang, Rui Zheng, Junjie Ye, Qi Zhang, Tao Gui, Jihua Kang, Jingsheng Yang, Siyuan Li, and Chunsai Du. 2023c. Instructuie: Multi-task instruction tuning for unified information extraction. CoRR, abs/2304.08085.
- Wang et al. (2023d) Xiaolei Wang, Xinyu Tang, Xin Zhao, Jingyuan Wang, and Ji-Rong Wen. 2023d. Rethinking the evaluation for conversational recommendation in the era of large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 10052–10065. Association for Computational Linguistics.
- Wang et al. (2021) Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian Tang. 2021. KEPLER: A unified model for knowledge embedding and pre-trained language representation. Trans. Assoc. Comput. Linguistics, 9:176–194.
- Wong et al. (2023) Man-Fai Wong, Shangxin Guo, Ching Nam Hang, Siu-Wai Ho, and Chee-Wei Tan. 2023. Natural language generation and understanding of big code for ai-assisted programming: A review. Entropy, 25(6):888.
- Xu et al. (2023) Fangzhi Xu, Zhiyong Wu, Qiushi Sun, Siyu Ren, Fei Yuan, Shuai Yuan, Qika Lin, Yu Qiao, and Jun Liu. 2023. Symbol-llm: Towards foundational symbol-centric interface for large language models. CoRR, abs/2311.09278.
- Yang et al. (2024) Ke Yang, Jiateng Liu, John Wu, Chaoqi Yang, Yi R. Fung, Sha Li, Zixuan Huang, Xu Cao, Xingyao Wang, Yiquan Wang, Heng Ji, and Chengxiang Zhai. 2024. If LLM is the wizard, then code is the wand: A survey on how code empowers large language models to serve as intelligent agents. CoRR, abs/2401.00812.
- Ye et al. (2023) Ruosong Ye, Caiqi Zhang, Runhui Wang, Shuyuan Xu, and Yongfeng Zhang. 2023. Natural language is all a graph needs. CoRR, abs/2308.07134.
- Zeng et al. (2023) Zheni Zeng, Bangchen Yin, Shipeng Wang, Jiarui Liu, Cheng Yang, Haishen Yao, Xingzhi Sun, Maosong Sun, Guotong Xie, and Zhiyuan Liu. 2023. Interactive molecular discovery with natural language. CoRR, abs/2306.11976.
- Zhang (2023) Jiawei Zhang. 2023. Graph-toolformer: To empower llms with graph reasoning ability via prompt augmented by chatgpt. CoRR, abs/2304.11116.
- Zhang et al. (2022) Xikun Zhang, Antoine Bosselut, Michihiro Yasunaga, Hongyu Ren, Percy Liang, Christopher D. Manning, and Jure Leskovec. 2022. Greaselm: Graph reasoning enhanced language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net.
- Zhang et al. (2023a) Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, Longyue Wang, Anh Tuan Luu, Wei Bi, Freda Shi, and Shuming Shi. 2023a. Siren’s song in the AI ocean: A survey on hallucination in large language models. CoRR, abs/2309.01219.
- Zhang et al. (2023b) Zeyang Zhang, Xin Wang, Ziwei Zhang, Haoyang Li, Yijian Qin, Simin Wu, and Wenwu Zhu. 2023b. Llm4dyg: Can large language models solve problems on dynamic graphs? CoRR, abs/2310.17110.
- Zhao et al. (2023a) Haiteng Zhao, Shengchao Liu, Chang Ma, Hannan Xu, Jie Fu, Zhi-Hong Deng, Lingpeng Kong, and Qi Liu. 2023a. GIMLET: A unified graph-text model for instruction-based molecule zero-shot learning. CoRR, abs/2306.13089.
- Zhao et al. (2023b) Jianan Zhao, Le Zhuo, Yikang Shen, Meng Qu, Kai Liu, Michael M. Bronstein, Zhaocheng Zhu, and Jian Tang. 2023b. Graphtext: Graph reasoning in text space. CoRR, abs/2310.01089.
- Zhao et al. (2023c) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023c. A survey of large language models. CoRR, abs/2303.18223.
- Zhao et al. (2023d) Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023d. Pytorch FSDP: experiences on scaling fully sharded data parallel. Proc. VLDB Endow., 16(12):3848–3860.
- Zhao et al. (2023e) Zhiyuan Zhao, Bin Wang, Linke Ouyang, Xiaoyi Dong, Jiaqi Wang, and Conghui He. 2023e. Beyond hallucinations: Enhancing lvlms through hallucination-aware direct preference optimization. CoRR, abs/2311.16839.
- Zhou et al. (2018) Mantong Zhou, Minlie Huang, and Xiaoyan Zhu. 2018. An interpretable reasoning network for multi-relation question answering. In Proceedings of the 27th International Conference on Computational Linguistics, COLING 2018, Santa Fe, New Mexico, USA, August 20-26, 2018, pages 2010–2022. Association for Computational Linguistics.
| Clusters | Tasks | Source | Sampling | Instruction Dataset | Preference Dataset | ||
| #Train | #Test | #Train | #Test | ||||
| Structure | Conn. Dect. | Wang et al. (2023a) | Up | 3,737 | 237 | 2,227 | 463 |
| Cycle Dect. | Wang et al. (2023a) | Up | 2,877 | 191 | 863 | 191 | |
| Hami. Path | Wang et al. (2023a) | Up | 1,315 | 55 | - | - | |
| Bipt. Match | Wang et al. (2023a) | Up | 1,755 | 71 | - | - | |
| Shrt. Path | Wang et al. (2023a) | Up | 1,580 | 64 | 948 | 128 | |
| Degree Comp. | Wang et al. (2023a) | Up | 2,435 | 230 | 1,429 | 445 | |
| Caption | Wikipedia | Wang et al. (2022) | Down | 516,585 | 1,979 | 15,208 | 4,785 |
| WebNLG | Gardent et al. (2017) | 12,237 | 2,000 | 6,040 | 2,616 | ||
| GenWiki | Jin et al. (2020) | 99,997 | 1,000 | - | - | ||
| EventNA | Colas et al. (2021) | 58,733 | 1,952 | - | - | ||
| Xalign | Abhishek et al. (2022) | 30,000 | 470 | - | - | ||
| Graph QA | PathQSP | Zhou et al. (2018) | Down | 30,530 | 1,000 | 27477 | 3,000 |
| GrailQA | Gu et al. (2021) | Down | 13,797 | 1,421 | - | - | |
| WebQSP | Berant et al. (2013) | Down | 13,152 | 1,465 | - | - | |
| WikiTQ | Pasupat and Liang (2015) | Down | 2,780 | 688 | - | - | |
| Node CLS | Cora | McCallum et al. (2000) | Down | 548 | 961 | 166 | 965 |
| Citeseer | Giles et al. (1998) | Down | 943 | 995 | 284 | 990 | |
| Pubmed | Sen et al. (2008) | Down | 9,736 | 1,756 | 2,988 | 1,789 | |
| Arxiv | Hu et al. (2020) | Down | 9,710 | 400 | 2,705 | 325 | |
| Products | Hu et al. (2020) | Down | 19,975 | 1,688 | 5,995 | 1,719 | |
| Link Pred. | Wikidata | Wang et al. (2022) | Down | 49,320 | 3,190 | - | - |
| FB15K-237 | Bollacker et al. (2008) | Down | 2,988 | 92 | - | - | |
| ConceptNet | Speer et al. (2017) | Down | 21,240 | 598 | - | - | |
| Relevance | Wikipedia | Wang et al. (2022) | Down | 39,672 | 1,991 | - | - |
| RecSys | Amazon | He and McAuley (2016) | Down | 2,424 | 250 | - | - |
| IE | Wikipedia | Wang et al. (2022) | Down | 73,101 | 1,814 | 19,490 | 1,589 |
| UIE | Wang et al. (2023c) | 100% | 285,877 | 3,000 | - | - | |
| InstructKGC | Gui et al. (2023) | Down | 31,605 | 994 | - | - | |
| Graph Gen. | NLGraph | Wang et al. (2023a) | Down | 3,056 | 407 | - | - |
| The total number of the corpus | 1,341,885 | 30,959 | 85,820 | 19,005 | |||
附录 AInstructGraph 语料库详细信息
在本节中,我们提供语料库构建的一些细节,包括指令和偏好视角。
A.1 配置参数数据集
为了合并所有面向图的推理和生成任务,我们收集并构建了 29 个任务以形成指令数据。 我们不构建用于图思维建模的训练集。
图结构建模
图结构建模旨在促使大语言模型理解图的结构以及相应的特定任务指令。 为了实现这一目标,我们收集了结构数据集 NLGraph Wang 等人 (2023a)。 The original dataset consists of 8 different tasks, such as Connectivity Detection, Cycle Detection, Topological Sorting, Shortest Path Computing, Maximum Flow Computing, Bipartite Graph Matching, Hamilton Path Detection and GNN Embedding. 然而,作者Wang 等人(2023a)提到,目前的大语言模型很难执行更复杂的图推理,例如拓扑排序、最大值流计算和GNN嵌入,所以我们删除它们。 此外,我们还随机采样了NLGraph的一些图,并构造了一个度计算任务。
-
•
连通性检测:检测图中两个节点之间是否存在路径。 该任务是二元分类,答案应该是“答案是”或“答案是否”。
-
•
环路检测:判断该图中是否存在环路。 该任务是二元分类,答案应该是“是”或“否”。
-
•
拓扑排序:确定是否存在一条路径恰好访问该图中的每个节点一次。 该任务是二元分类,答案应该是“是”或“否”。
-
•
二分图匹配:检测二分图中两个给定节点之间是否存在边。 该任务是二元分类,答案应该是“是”或“否”。
-
•
最短路径计算:求图中两个节点之间的最短路径,并计算最短路径中的权重之和。 答案是具有值的路径序列。
-
•
图度计算:计算图中目标节点的度。 答案是一个整数值。
| Task Name | Hallucination Type | Positive Answer | Negative Answer |
| Conn. Dect. Cycle Detect. Shrt. Path Degree Comp. | Correct graph but wrong answer | <The original answer> | <Randomly sampled from other examples> |
| Unfactual graph but wrong answer | Sorry, the graph contains some wrong knowledge in the follow: <list all unfactual triples>. So the question is unanswerable, you had better provide a correct graph. | <The original answer> | |
| Conflict graph but wrong answer | Sorry, the graph contains some conflict edges in the follow: <list all conflict triples>. So the question is unanswerable, you had better provide a correct graph. | <The original answer> | |
| Missing graph but wrong answer | Sorry, the graph does not exist node node name. So the question is unanswerable, you had better provide a correct graph. | <The original answer> | |
| Caption | Correct graph but wrong answer | <The original answer> | <Randomly sampled from other examples> |
| Unfactual graph but wrong answer | Sorry, the graph contains some wrong knowledge in the follow: <list all unfactual triples>. based on the corrected graph, the answer can be <The original answer>. | <The original answer> | |
| Conflict graph but wrong answer | Sorry, the graph contains some conflict edges in the follow: <list all conflict triples>. So the question is unanswerable, you had better provide a correct graph. | <The original answer> | |
| Graph QA | Correct graph but wrong answer | <The original answer> | <Randomly sampled from other examples> |
| Unfactual graph but wrong answer | Sorry, the graph contains some wrong knowledge in the follow: <list all unfactual triples>. based on the corrected graph, the answer can be <The original answer>. | <The original answer> | |
| Conflict graph but wrong answer | Sorry, the graph contains some conflict edges in the follow: <list all conflict triples>. So the question is unanswerable, you had better provide a correct graph. | <The original answer> | |
| Missing graph but wrong answer | Based on the world knowledge, the correct answer to the question is <The original answer>, but the answer does not exist in the graph. | <The original answer> | |
| Node CLS | Correct graph but wrong answer | <The original answer> | <Randomly sampled from other examples> |
| IE | Wrong input but wrong graph | <The original graph> | <Randomly sampled from other examples> |
| Correct input but unfaithful graph | <The original graph> | <Randomly edit entities in the original graph> | |
| Correct input but unfactual graph | <Randomly edit edges in the original graph> | <The original graph> | |
| Correct input but missing or redundant information in graph | <Randomly remove or add edges in the original graph> | <The original graph> |
图语言建模
图语言建模旨在教会大语言模型理解图的结构和语义知识并回答问题。 我们将这组任务分解为 6 种任务,包括图标题生成、图问答、图节点分类、图链接预测、图相关性检查和图协作过滤。
-
•
图标题生成:当给定一个知识图时,生成一个百科全书段落,其中所有实体和结构三元组代表事实和常识知识。 我们直接从WebNLG Gardent 等人 (2017)、GenWiki Jin 等人 (2020)、EventNarrative Colas 等人 (2021) 中选择数据集, XAlign Abhishek 等人 (2022). 此外,我们还按照Wang等人(2022)收集维基百科语料库和相应的维基数据知识图谱来构建字幕任务。 具体来说,我们使用AC自动机器算法来识别段落中的所有实体,并基于主题实体构建2跳子图。
-
•
图问答:在图中找到实体和推理路径来回答问题。 我们直接从 PathQuestions Zhou 等人 (2018)、GrailQA Gu 等人 (2021)、WebQuestions Berant 等人 (2013) 收集语料,维基表格问题Pasupat 和Liang (2015)。 特别是,WikiTableQuestions 是一个表格理解任务,可根据表格回答问题。 为了使我们的框架支持此类任务,我们执行预处理,将表格的每一行转换为单个图形,其中表头是关系名称,每个单元格是实体。
-
•
图节点分类:根据对应的图对目标节点进行分类。 我们直接选择 Cora McCallum 等人 (2000)、Citeseer Giles 等人 (1998)、Pubmed Sen 等人 (2008)、OGBN -ArXiv 和 OGBN-Products Hu 等人 (2020)。 由于这些任务中的图太大,我们只采样以每个目标节点为中心的2跳子图。 我们还对每个任务执行下采样。
-
•
图链接预测:根据图对两个给定节点(实体)之间的边(关系)进行分类。 我们选择了三个主要的知识图谱,例如Wikidata Wang 等人 (2021)、Freebase Bollacker 等人 (2008)、ConceptNet Speer 等人 (2017). 具体来说,我们随机采样三元组的子集,然后提取并合并分别以两个实体为中心的两个 2 跳子图。
-
•
图相关性检查:检查标题与图是否相关。 该任务是具有两个类别的二元分类,即“相关”和“不相关”。 我们在图形标题生成任务中直接使用维基百科Wang等人(2022)中的相同语料库。 对于每个图的负采样,我们直接选择其他标题。
-
•
图协作过滤:根据协作图预测用户节点相对于目标项目节点的偏好分数。 我们选择广泛使用的亚马逊 He and McAuley (2016) 作为语料库。 由于亚马逊数据集不提供任何图形数据,因此我们执行预处理阶段来构建协作图。 具体来说,我们根据每对用户的偏好项计算他们之间的 Jaccard 相似度,然后为每个用户回忆前 10 个相似度用户,形成一个图。 因此,我们可以将这个图注入到大语言模型中,让它知道如何根据所有潜在用户推荐一些项目。
图生成建模
该小组旨在指导大语言模型生成类似代码格式的图。 我们考虑两个具有挑战性的图生成领域,包括知识图生成和结构图生成。
-
•
知识图生成:类似于信息提取,旨在在给定一篇文章时提取实体和关系。 我们直接从统一信息提取(UIE)Wang等人(2023c)中选择语料库; Gui等人(2023),由21个使用的命名实体识别(NER)任务、10个使用的关系提取(RE)和4个使用的事件提取(EE)任务组成。
-
•
结构图生成:根据描述生成结构图。 例如,当给定图描述为“请生成一个具有 0 到 3 四个节点的全连接无向图”时,预期的类似代码格式图为“Graph[name='structural-graph']节点列表=[0,1,2,3]; edge_list=[(0 <-> 1), (0 <-> 2), (0 <-> 3), (1 <-> 2), (1 <-> 3), (2 <-> 3) ];”。 我们可以直接重用 NLGraph Wang 等人 (2023a) 中的语料库并采样子集来构建此任务。
A.2 偏好对齐数据集
我们从图形指令调整数据集中选择了部分数据集以进行偏好对齐。 该数据集包括连接检测、循环检测、最短路径计算、度计算、Wikipedia 和 WebNLG 的图形标题、PathQSP 的图形 QA、Cora、Citeseer、Pubmed、Arxiv 和 Products 的 Node CLS,以及 Wikipedia 的 IE。
对于每项任务,我们都会设计积极和消极的答案来支持偏好一致。 详情如表11所示。