API Pack:用于 API 调用生成的海量多语言数据集
摘要
我们推出了 API Pack,这是一个多语言数据集,具有超过一百万个指令 API 调用对,旨在提高大型语言模型的 API 调用生成功能。 通过实验,我们证明了 API Pack 在增强此专门任务的模型方面的功效,同时保持了一般编码的整体熟练程度。 仅在 20,000 个 Python 实例上对 CodeLlama-13B 进行微调,在生成未见过的 API 调用方面,准确率分别比 GPT-3.5 和 GPT-4 高 10% 和 5% 以上。 扩展到 100k 个示例可以提高对训练期间未见过的新 API 的泛化能力。 此外,无需每种语言的大量数据即可实现跨语言 API 调用生成。 数据集、微调模型和整体代码库可在 https://github.com/zguo0525/API-Pack 上公开获取。
1简介
大型语言模型(大语言模型)在协助软件工程任务(Hou 等人,2023;Ebert & Louridas,2023)方面显示出前景,主要关注代码生成(Wang等人,2023b;Zan 等人,2023;Shrivastava 等人,2023;Muennighoff 等人,2023)。 我们的工作建立在这些进步的基础上,但针对的是开发人员在查找 API 调用代码示例时经常面临的耗时任务。 目前,开发人员通常在文档网站或 API 中心寻找示例(Sadowski 等人,2015),筛选冗长的页面以查找相关信息(Meng 等人,2018) 。 这个过程被认为是繁琐且低效的。 我们的研究旨在通过探索大语言模型识别适当的 API 端点并根据自然语言提示生成相应的 API 调用的功能来改变此工作流程。
为了实现我们的研究目标,我们创建了 API Pack,这是一个旨在提升大语言模型 API 调用生成功能的数据集。 该多语言数据集包含超过 100 万个实例和 10 种编程语言,是迄今为止用于 API 调用生成和 API 调用意图检测的最大开源指令数据集(参见表 1)(根据自然语言提示识别适当的 API 端点来解决任务)。 我们通过多种方式评估了 API Pack 对 API 调用生成的影响(请参阅第 4 节)。 我们的一项微调实验表明,仅使用 20,000 个 API Pack 实例(全部采用 Python)进行微调的 CodeLlama-13B 在针对未见过的新 API 的 API 调用生成方面超越了 GPT-3.5 和 GPT-4。
API Pack 与之前的作品(Xu 等人,2023b;Patil 等人,2023;Qin 等人,2023) 的区别在于两个不同的方面:规模和多语言性。 API Pack 拥有超过一百万个示例,涵盖比前身更多的真实 API 和用例,通过控制训练数据量,API Pack 有助于严格评估泛化能力。 此外,API Pack 还包括跨 10 种不同编程语言的 API 调用(请参阅表1)。 这可以对跨语言技能转移进行罕见的评估——一种语言的收益如何应用于其他语言。 这种转移至关重要,但在之前的研究中尚未得到充分探索。
| Feature | API Pack (this work) | APIBench (Gorilla) | ToolBench | ToolBench (ToolLLM) | API Bank | ToolAlpaca | ToolFormer |
|---|---|---|---|---|---|---|---|
| API call intent detection? | ✓(*) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| API call code generation? | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Multi-lingual API calls? | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Multi-API call scenario? | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Data generation method: | custom | self-instruct | self-instruct | custom | custom | custom | custom |
| # of Sources | 4 | 3 | 8 | 1 | 53 | / | 5 |
| # of APIs / Tools | 11,213 | 1,645 | 8 | 16,464 | 53 | 400 | 5 |
| # of API calls | 1,128,599 | 16,450 | / | 37,204 | 568 | 3,938 | 9,400 |
| # of Instances | 1,128,599 | 16,450 | 2,746 | 12,657 | 264 | 3,938 | 22,453 |
我们总结了实验的三个亮点:
-
•
对于未见过的 API 调用,在 20,000 个 Python 实例上微调 CodeLlama-13B 的准确率分别比 GPT-3.5 和 GPT-4 高 10% 和 5% 以上。
-
•
将指令数据扩展到 100,000 个 Python 实例可以提高对新 API 的泛化能力,从而证实了更大数据集的优势。
-
•
跨语言 API 调用生成可以通过对一种语言的大量数据加上其他语言的少量数据进行模型微调来实现。 每种目标编程语言的数据量过多并不重要。
我们还结合其他指令数据集(Magicoder-OSS-Instruct-75K 和 Magicoder-Evol-Instruct-110K (Wei 等人, 2023))评估了 API Pack 的性能。 我们的结果表明,API Pack 改进了 API 调用生成,而不影响 HumanEval+ (Liu 等人,2023a) 和 MBPP (Austin 等人,2021) 基准测试上的代码生成性能。
2相关工作
2.1 大语言模型生成指令数据的方法
由于手动制作指令数据是一个劳动密集型过程(徐等人,2023a),越来越多的工作趋势提出使用大语言模型作为减少创建所需人力的手段指令数据集。 一方面,大语言模型使得自动生成大量指令数据成为可能。 另一方面,使用大语言模型生成合成数据会增加引入错误数据、缺乏复杂性或多样性不足的实例的风险。 研究人员针对这些问题进行了研究,并提出了不同的方法来创建和过滤 LLM 生成的数据。 广泛采用的两种方法是 Self-Instruct (Wang 等人, 2023a) 和 Evol-Instruct (Xu 等人, 2023a)。 后者尤其解决了创建开放域指令的挑战。
实例生成和过滤这两个阶段对于使用 Self-Instruct (Wang 等人, 2023a) 和 Evol-Instruct (Xu 等人, 2023a) 创建合成指令数据至关重要>。 在自我指导中,创建了一个小的实例池,并且大语言模型用上下文中的示例来改变选定的实例。 仅当新实例通过过滤时,才会将其添加回池中。 Self-Instruct 根据 ROUGE-L 相似性和其他启发式过滤实例。 Evol-Instruct通过大语言模型提示生成新实例,提示具有特定目标。 该方法通过基于一组启发式对指令进行分类来实现实例过滤。 对于这两种方法,例如过滤的启发式都是通过数据的手动分析来确定的。 尽管 Self-Instruct (Wang 等人, 2023a) 和 Evol-Instruct (Xu 等人, 2023a) 已成为创建指令数据的标准,但这些的自定义版本方法还用于为特定领域创建指令数据集。
除了数据过滤之外,为了将合成数据用于参数模型,执行质量检查仍然至关重要。 执行此质量审核的一种简单但耗时的方法是要求专家注释者(人类)确定生成的每个实例的正确性(Wang 等人,2023a)。 人类方法的另一种替代方法是根据手动审查小样本确定的启发式,通过评分或分类指令来提示强大的大语言模型(即 ChatGPT)(Liu 等人,2023b)生成的数据。 这种评分方法也被用来确定指令复杂性(Chen 等人,2023;Lu 等人,2023)。
2.2 用于 API 调用代码生成和意图检测的 LLM
越来越多的研究探索大型语言模型(大语言模型)和应用程序接口(API)的集成。 这项工作的一部分重点是API 调用意图检测,准确识别适当的 API 端点来解决自然语言任务。 然而,其他研究工作的重点是创建大语言模型,生成调用 API 功能的代码(例如,(Patil 等人, 2023)、(Xu 等人, 2023b))。 我们的工作也对第二种方法做出了贡献,该方法将开发人员作为最终用户,并寻求改善他们在查找 API 调用代码示例方面的体验。
API调用意图检测大语言模型(例如,(Qin 等人, 2023)、(Li 等人, 2023a)、(Tang 等人, 2023 )、(Yang 等人, 2023)、(Schick 等人, 2023)) 通常作为混合架构的一部分,大语言模型在其中找到使用适当的 API 端点,其他软件组件(例如检索器、API 代码数据库、代码生成库)生成调用它们的代码。 在这种混合方法中,API 调用在内部执行以向用户返回最终答案。 API 调用意图检测研究探索了单个和多个 API 意图场景。 对于后者,只有少数研究取得了良好的结果(即(Qin等人, 2023))。
API 调用代码生成在研究中很少涉及,因为只有少数研究对其进行了探索。 其中之一是 Gorilla 项目(Patil 等人,2023),该项目创建了一个大语言模型来生成 API 调用,用于从三个已知模型中心(Torch Hub、TensorFlow)加载预训练的机器学习模型集线器 v2、HuggingFace)。 另一项重要工作是ToolBench数据集(徐等人, 2023b),它作为增强开源大语言模型工具操作能力的基准。
2.3 代码相关任务的数据集
由于人们担心只有闭源模型(例如 Code-Davinci002、Google 的 Bard)在流行的代码基准测试上表现良好(例如 HumanEval (Chen 等人, 2021)、HumanEval+ (Liu 等人, 2023a), MBPP (Austin 等人, 2021)) 开源社区为代码相关任务创建了开源指令数据集,试图平衡开源代码大语言模型与闭源模型的性能。 WizardCoder 训练集 (Luo 等人, 2023) 就是其中之一。 该数据集是通过在代码领域定制 Evol-Instruct(Xu 等人, 2023a) 方法来构建的,并用于模拟 StarCoder 模型 (Li 等人, 2023b) 。 生成的模型 WizardCoder 的性能非常接近 GPT4 和 GPT3.5 模型。 同样,CommitPack (Muennighoff 等人,2023)(一个包含 350 种编程语言的 4 TB Git 提交的指令数据集)也用于微调 StarCoder。 生成的模型在 HumanEval Python 基准测试中取得了良好的性能。 出于同一目标的另一个重要贡献是 OSS-INSTRUCT (Wei 等人,2023),一种生成更加多样化、真实且可控的编码指令数据的方法。 OSS-INSTRUCT 是基于开源代码片段(输出)的种子创建的。 然后,教师模型的任务是为代码片段(输入)创建编码问题。 该指令数据集用于微调 Magicoder 模型系列,这些模型在 HumanEval+ (Liu 等人,2023a) 基准测试上超越了 ChatGPT。
3 API 包
API Pack 是一个拥有超过一百万个实例的指令数据集。 在 API Pack 中,实例包含输入-输出对以及有关 API 和相应端点的附加信息。 输入是查找 API 调用以解决编码任务的指令。 它们包括软件工程语言的任务描述和要使用的 API 的名称。 相反,输出是 API 调用示例,特别是从 OpenAPI 规范 (OAS) 文件中整理的 HTTP 请求代码片段。
API Pack 从存储 OAS 文件的四个中心收集数据:RapidAPI 111https://rapidapi.com/categories, APIGurus 222https://apis.guru/、Swaggerhub 333https://app.swaggerhub.com/search 以及公司的公共 API Hub 444https://{anonymous_url}。 表 2 显示 API Pack 包含的 API 总数、唯一端点和实例总数(采用不同的编程语言)。
| Source | APIs | Unique Endpoints | Total Instances |
|---|---|---|---|
| Company API Hub | 73 | 2,884 | 17,206 |
| APIs Gurus | 1,980 | 37,097 | 495,533 |
| Swaggerhub | 5,045 | 26,747 | 345,765 |
| RapidAPI | 4,115 | 21,525 | 270,095 |
| Total | 11,213 | 88,253 | 1,128,599 |
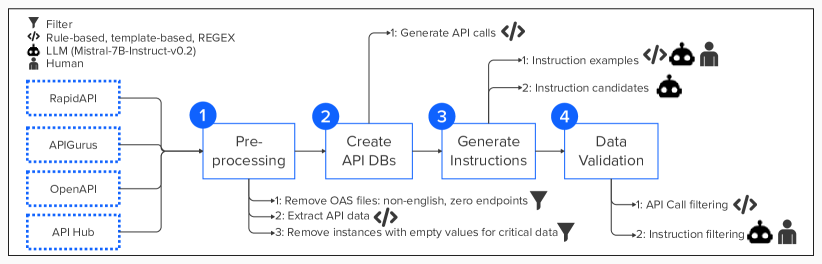
3.1数据预处理
首先,我们过滤掉所有收集到的 OAS 文件中包含非英语数据或零端点的文件。 其次,我们提取了每个 OAS 文件包含的端点信息:名称、功能、描述、方法和路径。 我们还提取了 API 级别的信息。 具体来说,我们收集了 API 名称、API 描述和 API 提供商。 此信息对于 OAS 文件中存在的所有端点都是相同的。 虽然 OAS 文件提供了标准结构来记录 API 的设计,但并非所有信息字段都是强制性的。 因此,我们应用了第二个过滤器来删除具有关键数据的实例,以生成空的 API 调用(例如,方法、路径或端点名称)。 我们还过滤掉功能、描述和端点名称为空的实例,因为必须存在这些值中的至少一个才能生成指令。
3.2 创建API DB
从 OAS 文件中提取相关数据后,我们用提取的数据构建了 API DB。 API DB 包含 JSON 格式的独立实例数组。 每个实例包含与端点相关的所有信息(端点名称、功能、描述、路径、方法)以及每个端点所属的 API(API 名称、API 描述、API 提供者)。 这些信息直接从原始 OAS 文件中提取。 每个实例还包含给定编程语言的 API 调用示例,以及标识编程语言的字符串(例如 cURL、python、java)。 我们使用 openapi-snippet 555 https://www.npmjs.com/package/openapi-snippet 为三个数据源的端点生成 10 种不同编程语言(cURL、libcurl、java、node、python、go、ruby、php、swift、JavaScript)的 API 调用 (api_call)。 对于一个数据源,我们直接从 OAS 文件中提取 API 调用。 附录 F 显示 API 数据库实例的结构,并提供有关每个源的编程语言多样性的详细信息。
图 2 显示了 cURL 中 API 调用的示例。 请注意,此示例不包括实参值。 相反,字符串(例如 REPLACE_BASIC_AUTH、[“string”]、“string”)用作占位符来指示是否需要参数。 这是 API 文档库将 API 调用代码示例集成到文档中的标准方式(例如 swagger-codegen 666https://github.com/swagger-api/swagger-codegen Sphinx 文档 777https://www.sphinx-doc.org/en/master/,DocFX 83>88https://github.com/dotnet/docfx 开发人员通常复制这些示例并替换占位符字符串来测试 API 调用代码片段。
3.3 指令生成
生成指令的过程包括两个步骤:1)创建高质量的指令示例,2)生成候选指令。
我们创建了如下指令示例。 首先,我们从每个 API DB 文件中随机选择三个端点。 然后,我们通过将其信息(例如功能、描述、端点名称、路径)和相应的 API 名称引导到不同的模板中,为所选的每个端点创建了一个指令示例。 通过这种方法,我们获得了每个API DB的三个指令示例。 请注意,没有提示大语言模型生成这些示例的初始版本。 我们通过两种方式改进了教学示例。 对于 API Gurus 和公司的 API Hub,三人(本文的所有作者)纠正了语法错误,删除了不必要的信息(即指令中的 URL),并验证了 API 名称是所有指令示例的一部分。 在手动检查这两个来源的示例后,我们注意到发现的错误是重复的。 因此,对于其他两个来源(Swaggerhub 和 RapidAPI),我们用大型语言模型(大语言模型)Mistral-7B-Instruct-v0.2999https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2。 用于细化这些指令示例的提示(附录 H 中的提示 LABEL:lst:prompt_refinement)是从研究人员通过为 API 大师纠正指令示例而识别的错误模式中提炼出来的以及公司的 API 中心。
我们使用这些高质量的指令示例为每个 API DB 中的实例生成候选指令。 我们通过提供端点信息作为输入以及为每个 API DB 创建的高质量指令(请参阅上一段)作为上下文示例(请参阅附录H中的提示LABEL:lst:prompt_ Generation)。 对于每个 API DB,我们为每个实例生成了 5 个候选指令。 图2显示了生成的候选指令之一(附录G显示了为同一实例生成的所有候选指令)。
3.4数据验证
数据验证过程包括三个步骤:1) 验证 API 调用是否是给定编程语言中的有效 HTTP 请求示例,2) 验证指令是否具有高质量,以及 3) 选择训练质量最佳的指令。
为了验证 API 调用是否是有效的 HTTP 请求示例,我们首先将 API 调用的内容与实例数据进行比较,以检查端点名称和所使用的方法(例如 get、post、put、delete、自定义方法名称)的正确性)。 然后,我们使用正则表达式来验证 url 格式。 由于这些 API 调用是代码示例,我们认为 url 域、路径参数或查询参数可能存在占位符字符串。 我们还检查了 API 调用中的编程语言关键字是否与分配给每个实例的语言字符串 ID 相对应。
为了验证为每个 API 调用生成的指令集,我们首先随机选择了 121 个实例样本,每个实例包含一个 API 调用和 5 个指令。 所选的 121 个实例包含独特的功能、描述和端点名称。 其中一位作者将这 121 个实例(总共 605 条指令)的指令标记为好或坏。 通过分析标记为不良的指令,我们注意到它们至少符合以下三个特征之一:
-
•
包含多个指令而不是单个指令。
-
•
在主要指令之前或之后包含不必要的文本(例如,“用户查询”、“查询”、“指令:”)。
-
•
未能准确使用正确的API名称。
考虑到这些特征,我们创建了三个提示来自动标记指令。 所有提示都包含一组固定的上下文示例。 为了选择冠军提示,我们使用大语言模型(Mistral-7B-Instruct-v0.2)来标记作者之一手动分类为好或坏的 605 条指令。 我们对每个提示重复这个过程,并将结果与我们人工制作的预言机进行比较。 我们使用显示最佳结果的提示(附录H中的提示LABEL:lst:prompt_scoring)对Mistral-7B-Instruct-v0.2进行任务,并对所有指令进行分类在我们的数据集中是好是坏。 我们从数据集中删除了少于两个良好指令的实例。
为了从良好指令(子)集中选择用于训练的最佳候选者,我们计算了大语言模型重新创建用于生成每条指令的输入文本的可能性。 我们提示了一个大语言模型Mistral-7B-Instruct-v0.2来完成这个任务(参见附录H中的提示LABEL:lst:prompt_backtranslation);用作输入的文本是每个候选指令本身。 大语言模型返回重新生成的输入文本的每个词符的对数概率。 我们计算了这些对数概率的平均值 (input_tokens_mean),并将该指标链接到相应的候选指令。 附录G显示了五个候选指令及其各自的input_tokens_mean。 我们选择了标记为良好且具有最佳 input_token_mean(值接近于零)的指令进行训练。
我们的最终数据集包含 1,128,599 个实例,每个实例都有一个有效的 API 调用示例和至少两个高质量指令。 附录A显示了在管道的每个阶段过滤掉的数据实例。
4实验和评估框架
在本节中,我们介绍我们的实验设置和评估框架。
4.1序言
为了优化使用我们的数据集微调的语言模型的指令跟踪能力,我们将 API Pack 后处理为两个指令调优模板,我们将其称为零样本和三镜头模板。 第一个模板(零样本)针对的场景是输出预计是给定输入的直接推断,这突出了模型的直接指令跟踪能力。 第二个模板(三镜头)强调模型通过上下文学习来学习和生成输出的能力。 我们为下面的每个模板提供了数学表示:
零样本:此模板对输入 (x) 和输出 (y) 之间的直接概率关系进行建模。 公式表示为:
| (1) |
式中,是输入指令到对应输出的语言模型映射。
三步:此模板通过合并上下文对 () 来扩展模型的容量。 它由等式表示:
| (2) |
在此公式中, 考虑主要输入 x 以及来自三个附加对 的上下文。 三镜头模板可在附录 LABEL:lst:prompt_eval 中找到。
4.2实验设置
A。 选择基线: 我们的第一个实验设置的目的是为我们其余的实验选择基本模型。 为此,我们对 Mistral 7b (Jiang 等人,2023)、CodeLlama 7b 和 13b,以及 Llama 2 13b (Touvron 等人,2023) 进行了测试API Pack 的子集(Python 编程语言中的 20,000 个实例)。 我们评估每个 20k 微调结果模型的性能。 我们使用各自的基本模型作为微调模型,该模型在其余实验中显示出最佳性能。
B. 检索推理: 我们的第二个实验的目标是了解检索增强对模型泛化的影响。 因此,我们在测试期间在四种不同的提示设置下评估模型:
-
•
0-shot:没有为模型提供API示例。
-
•
3-shot random:3 个随机选择的 API 示例。
-
•
检索到3次:检索到3个相关API示例。
-
•
3-shot 检索和重新排序:5 个检索的 API 示例,使用重新排序模型从 5 个示例中选择 3 个。
请注意,这些提示设置用于测试/推理,与微调时使用的指令调优模板不同。 这里,我们使用 bge-large-en-v1.5 (Zhang 等人, 2023) 作为检索的嵌入模型,beg-reranker-large (Xiao 等人, 2023) 重新排名。 附录C说明了我们用于评估模型性能的推理管道(0-shot、3-shot)。
C. 缩放实验: 我们进行了一项扩展实验,以研究更多的 API 数据是否可以提高模型对未见过的 API 数据的泛化能力。 在本实验中,我们在逐渐增大的 API 数据集上进行建模,所有数据集都使用 Python 中的独特 API 调用。 具体来说,我们分别使用 20k、40k、80k 和 100k 实例对模型进行微调。 我们的假设是,在微调过程中接触更多样化的 API 将提高模型泛化到新的、未见过的 API 的能力。
D. 跨语言泛化: 为了测试模型泛化到新编程语言的能力,我们用来自九种附加语言中的每一种的 1000 个实例来补充包含 100,000 个实例的 cURL 数据集:Go、Java、JavaScript、libcurl、Node.js、PHP、Python、Ruby 和API 包中的 Swift。 目标是看看模型是否可以推广到新语言而不需要大量的多语言数据。
E. API Pack 与 Magicoder 的集成: 本实验研究了 API Pack 与现有指令数据集相结合的效果。 我们将 API Pack 中 50,000 个条目的子集集成到 Magicoder 数据集(Magicoder-OSS-Instruct 加上 Magicoder-Evol-Instruct)和 CodeLlama-13b 模型中。 重点是评估 API 调用代码生成的改进,特别是对于 3 次提示下的 3 级任务。
4.3评估
为了衡量 API Pack 实现的泛化能力,我们建立了一个涵盖 API 调用生成的三个复杂程度的综合评估框架。
-
•
级别 1,所见 API 和端点评估熟悉 API 中新指令的泛化能力。
-
•
级别 2,已看到的 API 和新端点测试对已知 API 的新端点的泛化。
-
•
3 级,看不见的 API 和端点验证全新 API 的性能。
每个级别的端点和 API 调用准确性由 SequenceMatcher 衡量,它可以识别最长的匹配子序列,同时排除无关紧要的元素。 应用 0.9 的阈值将生成的输出与真实端点和 API 调用进行比较。
| Model | Fine-tuning | Testing | Evaluation Accuracy (%) | |||||
| template | Level 1 | Level 2 | Level 3 | |||||
| Intent | API Call | Intent | API Call | Intent | API Call | |||
| Mistral-7b | zero-shot | 0-shot | 17.2 | 10.9 | 14.1 | 11.4 | 14.3 | 11.2 |
| 3-shot (retre) | 42.0 | 29.7 | 35.4 | 28.7 | 39.1 | 29.1 | ||
| three-shot | 0-shot | 40.5 | 28.5 | 24.0 | 18.3 | 15.2 | 12.1 | |
| 3-shot (retre) | 64.1 | 55.4 | 49.1 | 42.8 | 50.8 | 42.5 | ||
| CodeLlama-7b | zero-shot | 0-shot | 8.1 | 6.1 | 10.0 | 7.0 | 11.0 | 7.8 |
| 3-shot (retre) | 52.6 | 42.6 | 43.6 | 35.9 | 50.2 | 40.1 | ||
| three-shot | 0-shot | 12.1 | 9.3 | 13.7 | 10.2 | 16.8 | 13.0 | |
| 3-shot (retre) | 60.6 | 52.7 | 54.1 | 47.3 | 55.9 | 49.1 | ||
| Llama-2-13b | zero-shot | 0-shot | 9.4 | 6.2 | 11.6 | 9.0 | 10.9 | 8.4 |
| 3-shot (retre) | 44.5 | 33.9 | 45.4 | 35.6 | 46.7 | 39.1 | ||
| three-shot | 0-shot | 15.7 | 10.2 | 14.0 | 11.2 | 11.7 | 9.6 | |
| 3-shot (retre) | 59.5 | 51.5 | 50.8 | 44.3 | 52.7 | 44.2 | ||
| CodeLlama-13b | zero-shot | 0-shot | 9.8 | 6.8 | 10.8 | 8.1 | 12.1 | 8.5 |
| 3-shot (retre) | 55.6 | 44.4 | 50.6 | 43.3 | 52.3 | 44.1 | ||
| three-shot | 0-shot | 14.4 | 10.3 | 15.9 | 13.3 | 14.2 | 8.9 | |
| 3-shot (retre) | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.5 | ||
| gpt-3.5-1106 | none | 3-shot (retre) | - | - | - | - | 47.2 | 39.5 |
| gpt-4-1106 | none | 3-shot (retre) | - | - | - | - | 53.5 | 44.3 |
5结果
在本节中,我们将介绍并简要讨论第 4 节中描述的实验结果。
5.1 微调 CodeLlama 在 API 调用生成方面表现出色
表3显示了使用Python中的20,000个API Pack实例进行微调的四个模型的评估结果。 总体而言,请注意,CodeLlama-13b 的微调在三镜头检索设置的 API 调用(代码生成)方面表现出色,在三个评估级别中实现了最高的评价率(级别 1 为 55.5%,级别 2 为 51.4%) ,3 级为 49.5%)。 另请注意,使用三镜头模板微调的模型始终表现出比使用零样本模板微调的模型更好的性能。 这一结果表明,使用三镜头模板引导数据对于提高模型的上下文学习能力非常重要。 另一个关键的见解是在测试时观察到 3 次(撤退)提示相对于 0 次提示的显着改进。 这一趋势在所有模型和级别上都是一致的,这表明为模型提供相关示例可以提高其生成 API 调用的准确性。 最后,请注意,对于 3 级,使用 API Pack 进行微调的 CodeLlama-13b 优于 GPT-3.5 和 GPT-4 模型(未微调)。
5.2 检索增强改进了 API 调用生成
使用三镜头模板对 Mistral-7b 和 CodeLlama-13b 模型以及 20,000 个 Python API 数据集进行微调的结果表明,三镜头检索是提高 API 调用生成准确性的最佳方法。 有关更多详细信息,请参阅附录D。
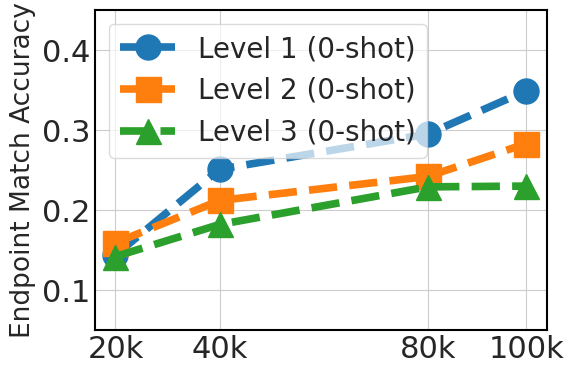
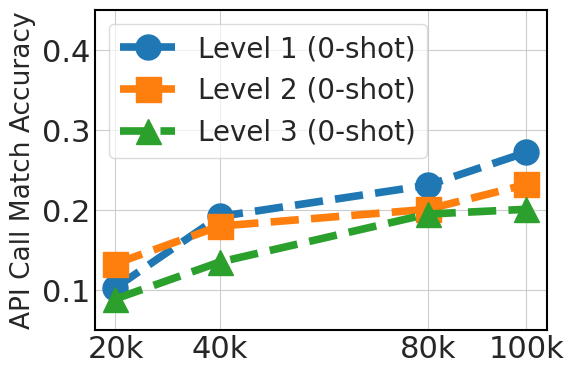
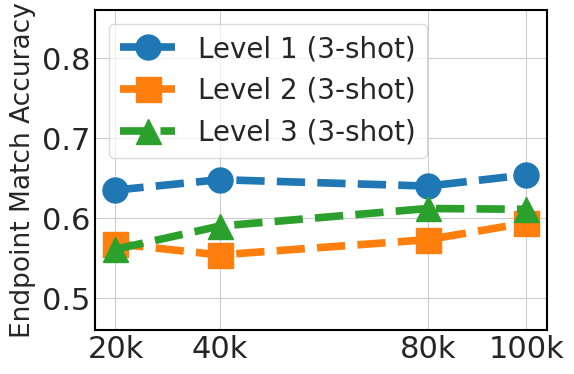
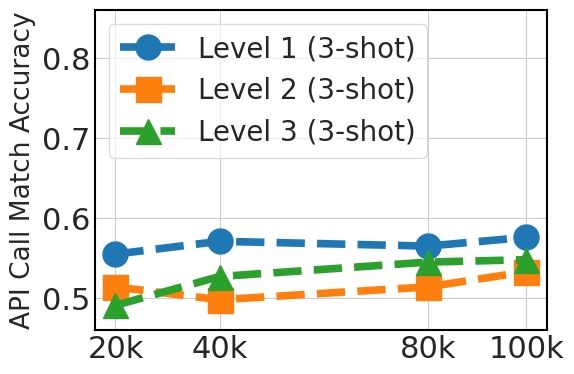
5.3 扩展指令数据集有助于泛化
图3清楚地显示了与数据集大小(20k、40k、80k 和 100k Python API 数据)相关的 0-shot 性能的上升趋势。 这一改进反映了较大数据集在提供多样化示例方面的优势,这对于模型完全依赖于其预先存在的知识的 0-shot 提示至关重要。 对于 3-shot,该图还显示了随着数据集大小的增加而得到的改进,尽管不如 0-shot 情况那么显着。 这表明,虽然额外的微调数据是有益的,但模型预训练对于少样本学习能力更有帮助。
5.4 API调用性能的多语言概括
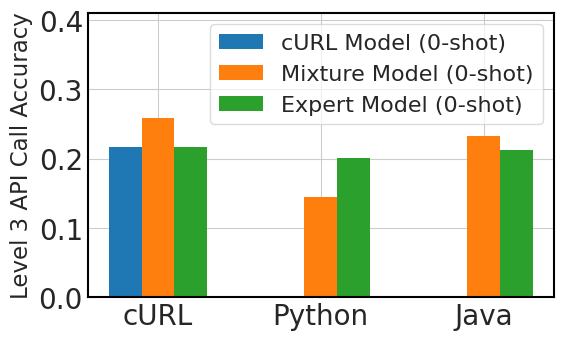
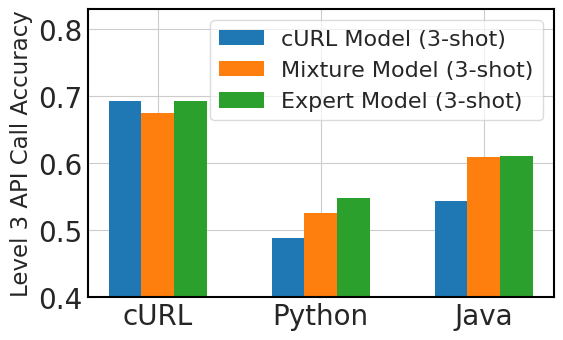
图4比较了多语言API调用性能的三种微调方法:专门针对100,000个“cURL”数据实例进行微调的模型,或cURL模型,三种专家模型,每个模型分别针对 100,000 个“cURL”、“Python”和“Java”数据样本进行微调,混合模型针对 100,000 个实例进行微调“cURL”数据,其中包含 9,000 个实例的附加样本,每个实例对应九种不同的语言。
我们从这张图中提炼出三个关键观察结果。 首先,在零样本场景中,在没有事先接触的情况下推广到新的编程语言仍然是一个挑战。 其次,尽管存在零样本限制,但模型在三镜头环境中表现出优于预期的性能,表明即使没有特定的语言微调,也具有一定程度的环境学习适应性。 第三,混合语言微调提高了零样本和三镜头场景中的性能,这表明即使是各种语言的少量微调数据也可以有助于模型在 API 调用任务中的整体语言多功能性和有效性。
我们还分析了模型在十种编程语言中的适应性。 我们将此分析的结果包含在附录 E 中。
5.5 使用 API Pack 改进代码模型
我们还评估了将 API Pack 的 50,000 个条目的子集与 Magicoder 数据集和微调的 CodeLlama-13b 模型混合的性能。 生成的模型显示,3 级的 API 调用代码生成准确度提高了 35.3% 以上,特别是在 3-shot 设置下。 这种改进并不以牺牲总体编码效率为代价,因为生成的模型在 HumanEval+ 和 MBPP 等基准测试中仍然表现良好。 有关详细信息,请参阅表4。
| Data Mixture | Bench. (pass@10) | Level 3 (3-shot) | |
|---|---|---|---|
| HumanEval+ | MBPP | Endpoint | |
| - | 47.8 | 58.3 | - |
| Magicoder | 60.8 | 66.4 | 17.0 |
| Magicoder + API Pack | 61.3 | 64.3 | 52.3 |
6结论
在本文中,我们介绍了 API Pack,这是一个包含超过一百万个指令 API 调用实例的多语言数据集,旨在提高模型的代码生成能力。 利用这种前所未有的规模和多样性,我们探索了两个关键的研究问题:(1)在微调过程中接触更多样化的 API 是否可以提高模型对新 API 数据的泛化能力? (2)模型能否在不需要大量多语言数据的情况下泛化到新语言? 我们的结果表明,增加数据量确实可以提高泛化能力,并且可以通过仅使用一种编程语言加上少量其他语言的数据进行训练来实现跨语言代码生成。 此外,我们还探讨了 API Pack 与其他代码指令数据集的可用性。 我们的结果表明,API Pack 改进了 API 调用代码生成,而不影响其他代码生成任务的总体性能。
7 限制
在通过 API 调用集成推进代码生成领域的同时,我们的研究也存在局限性:
-
•
API Pack 指令必须包含 API 名称才能实现正确的意图检测。 这种限制阻碍了模型直观解释和响应不完整查询的能力。
-
•
多 API 调用场景的挑战。 由于 API Pack 不是多 API 调用数据集,因此使用该数据集微调的模型可能会难以应对涉及多个相互依赖的 API 调用的场景。 这限制了 API Pack 在复杂的现实软件开发任务中的有效性。
8未来的工作
基于这些有希望的发现,我们提出了三个未来的研究方向:
-
•
丰富的API分类。 消除数据集指令中对 API 名称的显式需求,以实现基于上下文的直观翻译,更好地类似于自然编码工作流程。
-
•
论证增强。 将 API 调用与参数结合起来,以获得全面的功能示例。 这种扩展的范围使模型能够生成开发人员可以测试的详细的、可操作的代码。
-
•
多步骤 API 场景。 包括多 API 调用序列,以反映高级开发设置中现实世界的复杂性和依赖性。
9 更广泛的影响声明
我们的研究对软件生产力具有更广泛的影响,因为它旨在通过自动化常规编码任务来加速软件开发工作流程。 除了有望提高生产力之外,将先进的大语言模型集成到软件开发工作流程中也引起了社会技术问题(例如,工作替代、开发人员为确保准确性而进行的持续监督)。 因此,评估和应对潜在危害的负责任的创新视角仍然至关重要。
参考
- Austin et al. (2021) Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., and Sutton, C. Program Synthesis with Large Language Models, August 2021. URL http://arxiv.org/abs/2108.07732. arXiv:2108.07732 [cs].
- Chen et al. (2023) Chen, L., Li, S., Yan, J., Wang, H., Gunaratna, K., Yadav, V., Tang, Z., Srinivasan, V., Zhou, T., Huang, H., and Jin, H. AlpaGasus: Training A Better Alpaca with Fewer Data, November 2023. URL http://arxiv.org/abs/2307.08701. arXiv:2307.08701 [cs].
- Chen et al. (2021) Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Chantzis, F., Barnes, E., Herbert-Voss, A., Guss, W. H., Nichol, A., Paino, A., Tezak, N., Tang, J., Babuschkin, I., Balaji, S., Jain, S., Saunders, W., Hesse, C., Carr, A. N., Leike, J., Achiam, J., Misra, V., Morikawa, E., Radford, A., Knight, M., Brundage, M., Murati, M., Mayer, K., Welinder, P., McGrew, B., Amodei, D., McCandlish, S., Sutskever, I., and Zaremba, W. Evaluating Large Language Models Trained on Code, July 2021. URL http://arxiv.org/abs/2107.03374. arXiv:2107.03374 [cs].
- Ebert & Louridas (2023) Ebert, C. and Louridas, P. Generative AI for Software Practitioners. IEEE Software, 40(4):30–38, July 2023. ISSN 1937-4194. doi: 10.1109/MS.2023.3265877. URL https://ieeexplore.ieee.org/abstract/document/10176168?casa_token=JPr1zeiL9IYAAAAA:noU0xEJ-kpRsoaLTTNiSFttcQ_Fw1lBtZRQWnykXIz6rRNvIW4qW-5nljQZYP7H_dH1yJ-3qc-bW. Conference Name: IEEE Software.
- Hou et al. (2023) Hou, X., Zhao, Y., Liu, Y., Yang, Z., Wang, K., Li, L., Luo, X., Lo, D., Grundy, J., and Wang, H. Large Language Models for Software Engineering: A Systematic Literature Review, September 2023. URL http://arxiv.org/abs/2308.10620. arXiv:2308.10620 [cs].
- Jiang et al. (2023) Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. d. l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7B, October 2023. URL http://arxiv.org/abs/2310.06825. arXiv:2310.06825 [cs].
- Li et al. (2023a) Li, M., Song, F., Yu, B., Yu, H., Li, Z., Huang, F., and Li, Y. API-Bank: A Benchmark for Tool-Augmented LLMs, April 2023a. URL http://arxiv.org/abs/2304.08244. arXiv:2304.08244 [cs].
- Li et al. (2023b) Li, R., Allal, L. B., Zi, Y., Muennighoff, N., Kocetkov, D., Mou, C., Marone, M., Akiki, C., Li, J., Chim, J., Liu, Q., Zheltonozhskii, E., Zhuo, T. Y., Wang, T., Dehaene, O., Davaadorj, M., Lamy-Poirier, J., Monteiro, J., Shliazhko, O., Gontier, N., Meade, N., Zebaze, A., Yee, M.-H., Umapathi, L. K., Zhu, J., Lipkin, B., Oblokulov, M., Wang, Z., Murthy, R., Stillerman, J., Patel, S. S., Abulkhanov, D., Zocca, M., Dey, M., Zhang, Z., Fahmy, N., Bhattacharyya, U., Yu, W., Singh, S., Luccioni, S., Villegas, P., Kunakov, M., Zhdanov, F., Romero, M., Lee, T., Timor, N., Ding, J., Schlesinger, C., Schoelkopf, H., Ebert, J., Dao, T., Mishra, M., Gu, A., Robinson, J., Anderson, C. J., Dolan-Gavitt, B., Contractor, D., Reddy, S., Fried, D., Bahdanau, D., Jernite, Y., Ferrandis, C. M., Hughes, S., Wolf, T., Guha, A., von Werra, L., and de Vries, H. StarCoder: may the source be with you!, December 2023b. URL http://arxiv.org/abs/2305.06161. arXiv:2305.06161 [cs].
- Liang et al. (2023) Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., Florence, P., and Zeng, A. Code as Policies: Language Model Programs for Embodied Control. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 9493–9500, May 2023. doi: 10.1109/ICRA48891.2023.10160591. URL https://ieeexplore.ieee.org/abstract/document/10160591?casa_token=NZCPW7T2O5QAAAAA:lnnQxWsEhgimKw52mjcQJ-GMER2nOCA11yJHSUvZGA_VZiHcM_qYfKBnd2GCRDbNcLGakL2SgQ.
- Liu et al. (2023a) Liu, J., Xia, C. S., Wang, Y., and Zhang, L. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation, October 2023a. URL http://arxiv.org/abs/2305.01210. arXiv:2305.01210 [cs].
- Liu et al. (2023b) Liu, W., Zeng, W., He, K., Jiang, Y., and He, J. What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, December 2023b. URL http://arxiv.org/abs/2312.15685. arXiv:2312.15685 [cs].
- Lu et al. (2023) Lu, K., Yuan, H., Yuan, Z., Lin, R., Lin, J., Tan, C., Zhou, C., and Zhou, J. #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models, August 2023. URL http://arxiv.org/abs/2308.07074. arXiv:2308.07074 [cs].
- Luo et al. (2023) Luo, Z., Xu, C., Zhao, P., Sun, Q., Geng, X., Hu, W., Tao, C., Ma, J., Lin, Q., and Jiang, D. WizardCoder: Empowering Code Large Language Models with Evol-Instruct, June 2023. URL http://arxiv.org/abs/2306.08568. arXiv:2306.08568 [cs].
- Meng et al. (2018) Meng, M., Steinhardt, S., and Schubert, A. Application Programming Interface Documentation: What Do Software Developers Want? Journal of Technical Writing and Communication, 48(3):295–330, July 2018. ISSN 0047-2816. doi: 10.1177/0047281617721853. URL https://doi.org/10.1177/0047281617721853. Publisher: SAGE Publications Inc.
- Muennighoff et al. (2023) Muennighoff, N., Liu, Q., Zebaze, A., Zheng, Q., Hui, B., Zhuo, T. Y., Singh, S., Tang, X., von Werra, L., and Longpre, S. OctoPack: Instruction Tuning Code Large Language Models, August 2023. URL http://arxiv.org/abs/2308.07124. arXiv:2308.07124 [cs].
- Patil et al. (2023) Patil, S. G., Zhang, T., Wang, X., and Gonzalez, J. E. Gorilla: Large Language Model Connected with Massive APIs, May 2023. URL http://arxiv.org/abs/2305.15334. arXiv:2305.15334 [cs].
- Qin et al. (2023) Qin, Y., Liang, S., Ye, Y., Zhu, K., Yan, L., Lu, Y., Lin, Y., Cong, X., Tang, X., Qian, B., Zhao, S., Tian, R., Xie, R., Zhou, J., Gerstein, M., Li, D., Liu, Z., and Sun, M. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, July 2023. URL http://arxiv.org/abs/2307.16789. arXiv:2307.16789 [cs].
- Sadowski et al. (2015) Sadowski, C., Stolee, K. T., and Elbaum, S. How developers search for code: a case study. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2015, pp. 191–201, New York, NY, USA, August 2015. Association for Computing Machinery. ISBN 978-1-4503-3675-8. doi: 10.1145/2786805.2786855. URL https://dl.acm.org/doi/10.1145/2786805.2786855.
- Schick et al. (2023) Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T. Toolformer: Language Models Can Teach Themselves to Use Tools, February 2023. URL http://arxiv.org/abs/2302.04761. arXiv:2302.04761 [cs].
- Shrivastava et al. (2023) Shrivastava, D., Larochelle, H., and Tarlow, D. Repository-Level Prompt Generation for Large Language Models of Code. In Proceedings of the 40th International Conference on Machine Learning, pp. 31693–31715. PMLR, July 2023. URL https://proceedings.mlr.press/v202/shrivastava23a.html. ISSN: 2640-3498.
- Tang et al. (2023) Tang, Q., Deng, Z., Lin, H., Han, X., Liang, Q., Cao, B., and Sun, L. ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases, September 2023. URL http://arxiv.org/abs/2306.05301. arXiv:2306.05301 [cs].
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa, M., Kloumann, I., Korenev, A., Koura, P. S., Lachaux, M.-A., Lavril, T., Lee, J., Liskovich, D., Lu, Y., Mao, Y., Martinet, X., Mihaylov, T., Mishra, P., Molybog, I., Nie, Y., Poulton, A., Reizenstein, J., Rungta, R., Saladi, K., Schelten, A., Silva, R., Smith, E. M., Subramanian, R., Tan, X. E., Tang, B., Taylor, R., Williams, A., Kuan, J. X., Xu, P., Yan, Z., Zarov, I., Zhang, Y., Fan, A., Kambadur, M., Narang, S., Rodriguez, A., Stojnic, R., Edunov, S., and Scialom, T. Llama 2: Open Foundation and Fine-Tuned Chat Models, July 2023. URL http://arxiv.org/abs/2307.09288. arXiv:2307.09288 [cs].
- Wang et al. (2023a) Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H. Self-Instruct: Aligning Language Models with Self-Generated Instructions, May 2023a. URL http://arxiv.org/abs/2212.10560. arXiv:2212.10560 [cs].
- Wang et al. (2023b) Wang, Y., Le, H., Gotmare, A. D., Bui, N. D. Q., Li, J., and Hoi, S. C. H. CodeT5+: Open Code Large Language Models for Code Understanding and Generation, May 2023b. URL http://arxiv.org/abs/2305.07922. arXiv:2305.07922 [cs].
- Wei et al. (2023) Wei, Y., Wang, Z., Liu, J., Ding, Y., and Zhang, L. Magicoder: Source Code Is All You Need, December 2023. URL http://arxiv.org/abs/2312.02120. arXiv:2312.02120 [cs].
- Xiao et al. (2023) Xiao, S., Liu, Z., Zhang, P., and Muennighoff, N. C-Pack: Packaged Resources To Advance General Chinese Embedding, December 2023. URL http://arxiv.org/abs/2309.07597. arXiv:2309.07597 [cs].
- Xu et al. (2023a) Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., and Jiang, D. WizardLM: Empowering Large Language Models to Follow Complex Instructions, June 2023a. URL http://arxiv.org/abs/2304.12244. arXiv:2304.12244 [cs].
- Xu et al. (2023b) Xu, Q., Hong, F., Li, B., Hu, C., Chen, Z., and Zhang, J. On the Tool Manipulation Capability of Open-source Large Language Models, May 2023b. URL https://arxiv.org/abs/2305.16504v1.
- Yang et al. (2023) Yang, R., Song, L., Li, Y., Zhao, S., Ge, Y., Li, X., and Shan, Y. GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction, May 2023. URL http://arxiv.org/abs/2305.18752. arXiv:2305.18752 [cs].
- Zan et al. (2023) Zan, D., Chen, B., Zhang, F., Lu, D., Wu, B., Guan, B., Yongji, W., and Lou, J.-G. Large Language Models Meet NL2Code: A Survey. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 7443–7464, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.411. URL https://aclanthology.org/2023.acl-long.411.
- Zhang et al. (2023) Zhang, P., Xiao, S., Liu, Z., Dou, Z., and Nie, J.-Y. Retrieve Anything To Augment Large Language Models, October 2023. URL http://arxiv.org/abs/2310.07554. arXiv:2310.07554 [cs].
附录
附录A管道每个阶段的数据过滤
| Source/Instances | Before Data Validation | After Removing Invalid API calls | After Removing Instances without Good Instructions |
|---|---|---|---|
| API Hub | 27,635 | 17,712 | 17,206 |
| APIs Gurus | 500,160 | 499,250 | 495,533 |
| Swaggerhub | 351,756 | 351,756 | 345,765 |
| RapidAPI | 274,014 | 273,388 | 270,095 |
| Total | 1,153,565 | 1,142,106 | 1,128,599 |
附录B训练的超参数
我们在一个集群上使用 HuggingFace Transformers 库来构建模型,该集群由 1 个节点和 8 个 NVIDIA H100 80GB GPU 组成,具有完全共享数据并行性 (FSDP)。 使用混合精度、梯度检查点和 AdaFactor 优化器等技术来提高训练效率。 表6总结了关键的超参数。
| Hyperparameter Name | Value |
|---|---|
| Learning rate | |
| Batch size | 128 |
| Max seq length | 4096 |
| Number of epochs | 2 |
| Warmup ratio | 0.03 |
附录 C测试管道
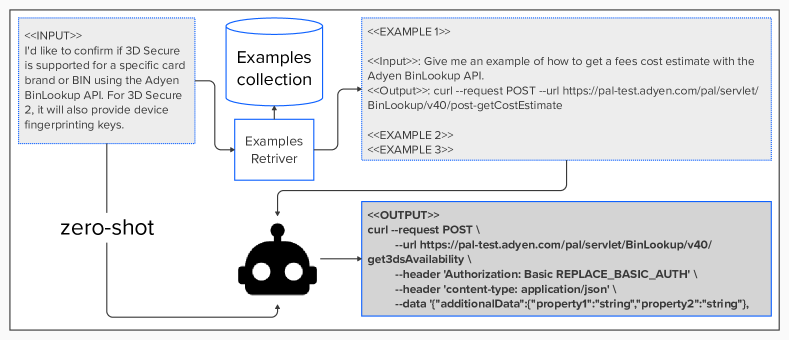
图5显示了我们的测试流程的示例,包括零样本和少样本。
附录D检索方法比较
图 7 说明了不同检索方法对三次 API 调用生成的影响。
| Model | Testing | Evaluation Accuracy (%) | |||||
| Level 1 | Level 2 | Level 3 | |||||
| Endpoint | API Call | Endpoint | API Call | Endpoint | API Call | ||
| Mistral-7b | 3-shot (rand) | 54.5 | 41.8 | 48.2 | 41.2 | 45.2 | 37.0 |
| 3-shot (retre) | 64.1 | 55.4 | 49.1 | 42.8 | 50.8 | 42.5 | |
| 3-shot (retre & rerank) | 63.0 | 53.6 | 49.0 | 42.2 | 51.5 | 43.9 | |
| CodeLlama-13b | 3-shot (rand) | 49.2 | 38.6 | 49.8 | 43.6 | 50.0 | 41.4 |
| 3-shot (retre) | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.5 | |
| 3-shot (retre & rerank) | 61.0 | 52.9 | 55.1 | 49.2 | 55.9 | 49.3 | |
附录E跨语言灵活性分析
图6说明了模型在十种编程语言中的适应性。 在三轮测试中,混合模型与专家模型相当,凸显了模型在多语言编程应用中的潜力。

附录 F API 数据库实例
图7显示了API数据库实例的结构。 我们使用了 openapi-snippet 101010https://www.npmjs.com/package/openapi-snippet,一个开源包,它将 OpenAPI v2.0 或 v3.0.x 规范文件(OAS 文件)作为输入,并将其转换为 HTTP Archive 1.2 请求对象,以生成 API 调用。 我们为 RapidAPI、API Gurus 和 Swaggerhub 使用 10 种不同的编程语言(cURL、libcurl、java、node、python、go、ruby、php、swift、JavaScript)生成 API 调用 (api_call)。 对于公司的公共 API Hub,API 调用是直接从 OAS 文件中提取的。 我们从此源中提取了八种不同编程语言的 API 调用(cURL、java、node、python、go、ruby、php、swift)。
附录 G候选指令
图8显示了为实例生成的所有候选者及其各自的id和input_tokens_mean。