[json]断线
API Pack:用于生成 API 调用的大规模多编程语言数据集
摘要
我们引入了 API Pack,这是一个包含超过 100 万个指令 API 调用对的海量多编程语言数据集,用于提高大型语言模型的 API 调用生成能力。 通过对 API Pack 中 20,000 个 Python 实例上的 CodeLlama-13B 进行微调,我们在生成未见过的 API 调用方面分别比 GPT-3.5 和 GPT-4 提高了约 10% 和 5% 的准确度。 API Pack 上的微调通过利用一种语言的大量数据和其他语言的少量数据来实现跨编程语言泛化。 将训练数据扩展到 100 万个训练实例,进一步提高了模型对期间未遇到的新 API 的泛化能力。 我们在 https://github.com/zguo0525/API-Pack 开源 API Pack 数据集、训练模型和相关源代码,以促进进一步研究。
1简介
大型语言模型(大语言模型)在协助软件工程任务[1, 2, 3, 4, 5, 6, 7, 8, 9]方面表现出了良好的前景,主要关注代码一代[10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26]。 我们的工作建立在这些进步的基础上,但针对的是开发人员在查找应用程序编程接口 (API) 调用代码示例时经常面临的耗时任务。 虽然通过搜索找到合适的 API 相对容易,但挑战在于生成特定的 API 调用代码。 这涉及了解 API 的参数、数据类型和所需的操作,这些参数、数据类型和所需的操作可能很复杂,并且在不同的 API 中差异很大。 目前,开发人员通常在文档或 API 中心中寻找示例[27],筛选冗长的页面以查找相关信息[28]。 这个过程被认为是繁琐且低效的,因为它需要开发人员手动解析示例代码并将其适应其特定用例。 我们的研究旨在通过使用大语言模型来改变这个工作流程,以识别适当的API端点并根据自然语言指令生成相应的API调用,从而自动化理解和调整API调用代码示例的过程。
为了实现这一研究目标,我们创建了API Pack,这是一个旨在提高大语言模型的API调用生成能力的数据集。 这个庞大的多编程语言数据集包含 10 种编程语言的超过 100 万个实例,是迄今为止用于 API 调用生成和 API 调用意图检测的最大开源指令数据集(参见表1)。 我们通过各种实验评估了 API Pack 在改进 API 调用生成方面的有效性(参见第 4 节),发现仅使用 API Pack 中的 20,000 个 Python 实例进行微调的 CodeLlama-13B 的性能优于GPT-3.5 和 GPT-4 为全新 API 生成 API 调用的过程。
API Pack 与之前的作品[29,30,31]的区别在于两个关键方面:多语言性和规模。 API Pack 包括跨 10 种不同编程语言的 API 调用(参见表1),允许对跨语言技能转移进行独特的评估 - 一种语言的改进适用于其他语言的程度。 这对于大语言模型在 API 调用生成中的实际应用至关重要,但在之前的研究中尚未得到充分探索。 此外,与前身相比,API Pack 拥有超过一百万个实例,涵盖更广泛的现实世界 API 和用例,通过控制训练数据量,可以对泛化能力进行更严格的评估。
我们总结了实验的三个主要发现:
| Feature | API Pack (this work) | APIBench (Gorilla) | ToolBench | ToolBench (ToolLLM) | API Bank | ToolAlpaca | ToolFormer |
|---|---|---|---|---|---|---|---|
| API call intent detection? | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| API call code generation? | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Multi-lingual API calls? | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ |
| Multi-API call scenario? | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Data generation method: | custom | self-instruct | self-instruct | custom | custom | custom | custom |
| # of Sources | 4 | 3 | 8 | 1 | 53 | / | 5 |
| # of APIs / Tools | 11,213 | 1,645 | 8 | 16,464 | 53 | 400 | 5 |
| # of API calls | 1,128,599 | 16,450 | / | 37,204 | 568 | 3,938 | 9,400 |
| # of Instances | 1,128,599 | 16,450 | 2,746 | 12,657 | 264 | 3,938 | 22,453 |
-
1.
在 API Pack 中的 20,000 个 Python 实例上对 CodeLlama-13B 进行微调,对于未见过的 API 调用,其准确度分别比 GPT-3.5 和 GPT-4 高出 10% 和 5% 以上。
-
2.
跨语言 API 调用生成可以通过对一种语言的大量数据加上其他语言的少量数据进行模型微调来实现。
-
3.
将指令数据扩展到 100 万个实例可以提高对新 API 的泛化能力,从而证实更大数据集的优势。
2相关作品
2.1 大语言模型生成指令数据的方法
手动创建指令数据是一项劳动密集型工作[32]。 为了自动化这个过程,研究人员建议使用大语言模型,尽管存在生成低质量实例的风险。 两种流行的方法是 Self-Instruct [33] 和 Evol-Instruct [32],这两种方法都涉及实例生成和过滤。 Self-Instruct 使用上下文中的示例来改变种子实例,并根据 ROUGE-L 相似性和其他启发式方法对其进行过滤。 Evol-Instruct 通过有针对性的提示生成实例,并使用预定义的启发式过滤它们。 使用合成数据微调模型时,质量检查至关重要。 专家注释者可以确定实例的正确性[33],或者像ChatGPT这样的强大的大语言模型可以根据小样本的启发式对实例[34]进行评分或分类。 此方法也已用于评估指令复杂性[35, 36]。
2.2 用于 API 调用代码生成和意图检测的 LLM
用于代码生成的大语言模型主要关注一般编码任务,通过 MBPP [37]、HumanEval [38] 及其变体 [39、 40, 41]。 最近的研究在两个领域探索了大语言模型和 API:API 调用意图检测和 API 调用代码生成。 API 调用意图检测可识别自然语言任务的适当 API 端点。 为此目的的大语言模型[31,42,43,44,45]在混合架构中工作,其中大语言模型找到API端点并且其他组件生成代码。 这些研究探索了单 API 和多 API 意图场景,但很少有在后者[31]中取得良好结果。 我们的工作重点是创建大语言模型来生成调用 API 功能的代码,与 API 调用意图检测相比,这方面的探索较少。 Gorilla [30] 生成 API 调用,用于从已知模型中心加载预先训练的机器学习模型。 ToolBench[29]对开源大语言模型的工具操作能力进行基准测试。 另一项工作探索了语言模型[46,47,48](包括 ChatGPT)中的函数调用。 这些模型在执行之前需要预定义的函数,这与我们的场景不同,开发人员依靠语言模型根据自然语言输入引导他们使用适当的函数或 API。
3 API 包
API Pack 是一个拥有超过一百万个实例的指令数据集。 每个实例都包含一个输入输出对以及有关 API 和相应端点的附加信息。 输入是用于查找 API 调用来解决编码任务的指令,包括软件工程语言的任务描述和要使用的 API 的名称。 输出是 API 调用示例,特别是从 OpenAPI 规范 (OAS) 文件中整理的 HTTP 请求代码片段。 API Pack 中的数据来自四个存储 OAS 文件的中心:RapidAPI111https://rapidapi.com/categories, APIGurus222https://apis.guru/、Swaggerhub333https://app.swaggerhub.com/search,以及 IBM 的公共 API Hub444https://developer.ibm.com/apis/。 表 2 总结了 API Pack 中包含的 API 总数、唯一端点和实例总数(采用不同的编程语言)。
| Source | APIs | Unique Endpoints | Total Instances |
|---|---|---|---|
| IBM API Hub | 73 | 2,884 | 17,206 |
| APIs Gurus | 1,980 | 37,097 | 495,533 |
| Swaggerhub | 5,045 | 26,747 | 345,765 |
| RapidAPI | 4,115 | 21,525 | 270,095 |
| Total | 11,213 | 88,253 | 1,128,599 |
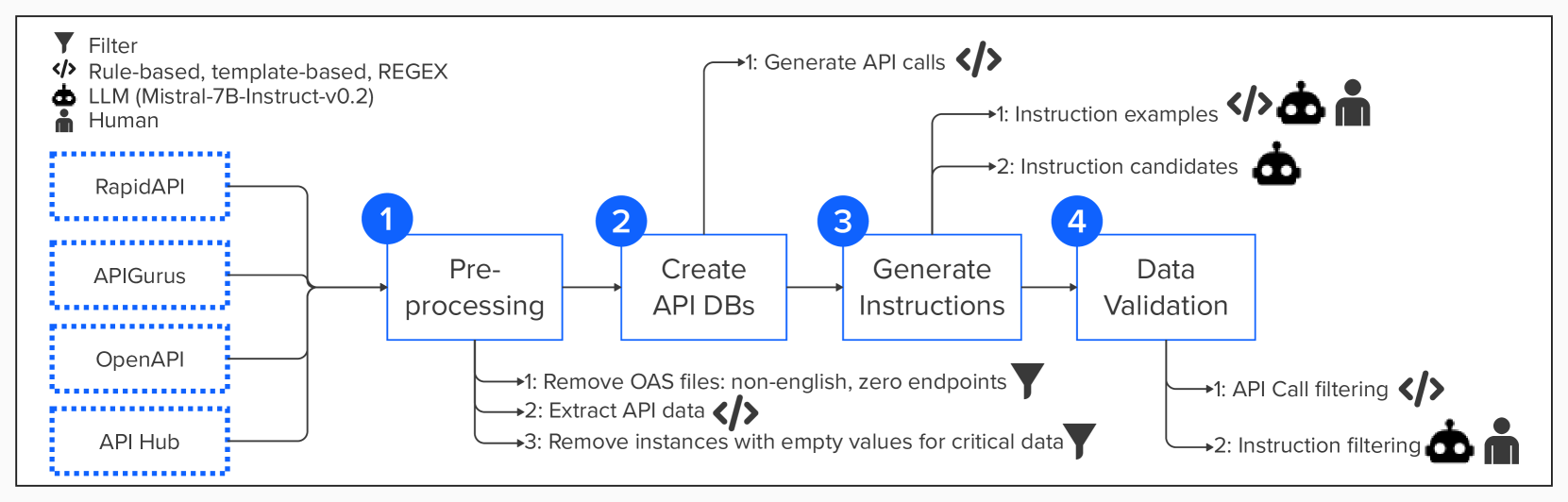
3.1数据预处理
数据预处理阶段涉及两个主要步骤。 首先,我们过滤掉包含非英语数据的 OAS 文件,以保持语言一致性。 我们还删除了零端点的 OAS 文件,因为它们缺乏生成有意义的 API 调用示例或指令所需的信息。 接下来,我们从剩余的 OAS 文件中提取相关信息。 在端点级别,我们收集名称、功能、描述、方法和路径。 在 API 级别,我们收集 API 名称、描述和提供商。 为了进一步确保数据质量,我们应用第二个过滤器来删除缺少生成 API 调用(例如方法、路径或端点名称)和指令(例如功能、描述或端点名称)的关键数据的实例。 此步骤保证数据集中的所有实例都包含生成有用的 API 调用示例和指令所需的信息。
3.2 创建API数据库
我们使用预处理的数据构建一个 API 数据库 (DB),每个实例都包含端点信息、API 详细信息、特定编程语言的 API 调用示例以及语言标识符。 我们使用 OpenAPI Snippet555https://www.npmjs.com/package/openapi-snippet 为来自 RapidAPI、APIGurus 和 OpenAPI 的端点生成 10 种编程语言(cURL、libcurl、Java、Node.js、Python、Go、Ruby、PHP、Swift、JavaScript)的 API 调用,同时直接从 IBM API Hub 的 OAS 文件中提取 API 调用。 附录 9.5 提供有关每个源的 API 数据库实例结构和编程语言多样性的详细信息。
3.3 指令生成
指令生成过程包括两个主要步骤:创建高质量的指令示例和生成候选指令。 这两个步骤的过程对于确保生成精确、清晰和有用的指令至关重要。
首先,我们为每个 API DB 文件创建高质量的指令示例。 我们从每个 API 中随机选择三个端点,并使用它们的信息(例如功能、描述、端点名称、路径)以及相应的 API 名称来填写预定义指令模板的列表。 此过程为每个 API DB 文件生成三个指令示例。 对于 API Gurus 和 IBM API Hub 源,三位作者通过更正语法错误、删除不必要的信息以及确保 API 名称出现在所有示例中来手动审查和完善生成的指令示例。 在此手动审核过程中,我们识别生成的指令中的常见错误模式。 为了简化 Swaggerhub 和 RapidAPI 源的细化过程,我们用大语言模型 (Mistral-7B-Instruct-v0.2666https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)。 我们根据手动审查 API Gurus 和 IBM API Hub 指令示例期间发现的常见错误模式创建提示(附录 9.8 中的提示 1)。 该提示用于指导大语言模型完善Swaggerhub和RapidAPI源的指令示例。
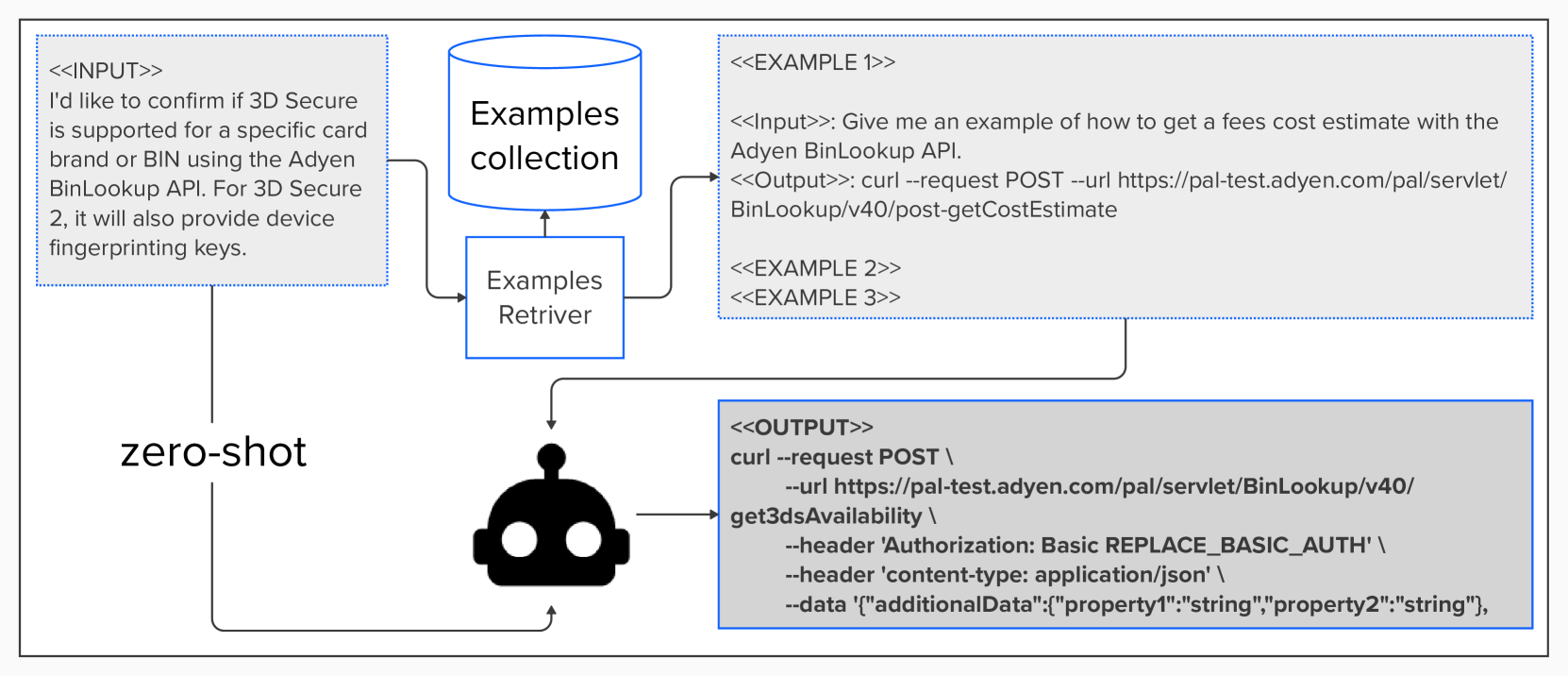
接下来,我们使用高质量的指令示例为 API DB 中的每个实例生成候选指令。 我们以终端信息作为输入,提示大语言模型(Mistral-7B-Instruct-v0.2),并提供高质量的指令示例作为上下文示例(附录 9.8 中的提示 2)。 大语言模型为API DB 中的每个实例生成五个候选指令。 图2显示了生成的候选指令的示例,而附录9.7展示了为同一实例生成的所有五个候选指令。
[fontsize=, breaklines, breakanywhere] bash "instruction_candidates": [ "idx": 1, "candidate": "I’d like to confirm if 3D Secure is supported for a specific card brand or BIN using the Adyen BinLookup API. For 3D Secure 2, it will also provide device fingerprinting keys.", "input_tokens_mean": -0.5497539341557909, , … ], "api_call": "curl –request POST –url https://paltest.adyen.com/pal/servlet/BinLookup/v40/get3dsAvailability –header ’Authorization: Basic REPLACE_BASIC_AUTH’ –header ’content-type: application/json’ –data ’"additionalData":"property1":"string","property2":"string", "brands":["string"], "cardNumber":"string", "merchantAccount":"string", "recurringDetailReference":"string", "shopperReference":"string"’" …
3.4数据验证
数据验证过程涉及三个主要步骤:1)验证给定编程语言中 API 调用作为 HTTP 请求示例的有效性,2)评估生成指令的质量,3)选择最高质量的指令进行微调。
为了验证API调用的有效性,我们首先将API调用的内容与实例数据进行比较,以确保endpoint_name和HTTP方法(例如get、post、put、delete、自定义方法名称)的正确性。 然后,考虑到 URL 域、路径参数或查询参数可能存在占位符字符串,我们使用正则表达式来验证 URL 格式。 此外,我们还会检查 API 调用中的编程语言关键字是否与分配给每个实例的语言字符串 ID 匹配。
为了验证为每个 API 调用生成的指令,我们随机选择了 121 个实例的样本,每个实例包含一个 API 调用和 5 个指令。 这些实例具有独特的功能、描述和端点名称。 其中一位作者手动将 605 条指令(121 个实例 x 5 条指令)标记为好或坏。 对标记为不良指令的分析揭示了三个共同特征:1)包含多个指令而不是单个指令,b)在主指令之前或之后包含不必要的文本,以及c)未能准确使用正确的API名称。 基于这些特征,我们创建了三个提示,其中包含一组固定的上下文示例,以自动标记指令。 为了选择最佳提示,我们使用大语言模型(Mistral-7B-Instruct-v0.2)来标记 605 个手动分类的指令,并将结果与人工标记的结果进行比较。 我们选择性能最佳的提示(附录 9.8 中的提示 4)并指示 Mistral-7B-Instruct-v0.2 将数据集中的所有指令分类为良好或坏的。 少于两条好指令的实例将从数据集中删除。
为了从良好指令的子集中选择最佳候选指令,我们计算了大语言模型重新生成用于生成指令的输入文本的可能性。 我们用每个候选指令提示 Mistral-7B-Instruct-v0.2(附录 9.8 中的提示 3),并获取重新生成的每个词符的对数概率输入文本。 我们计算这些对数概率的平均值 (input_tokens_mean)。 附录9.7显示了五个候选指令及其各自的input_tokens_mean。 我们选择使用最佳 input_token_mean 标记为良好的指令进行微调。 我们的最终数据集包含 1,128,599 个实例,每个实例都有一个有效的 API 调用示例和至少两个高质量指令。 附录9.1显示了在管道的每个阶段过滤掉的数据实例。
4实验和评估框架
为了优化语言模型的指令跟踪能力,我们将 API Pack 后处理为两个指令调优模板:零样本和三镜头。 零样本模板的目标场景是预期输出是根据给定输入的直接推论。 三镜头模板强调了模型通过上下文学习来学习和生成输出的能力。 三镜头模板可在附录5中找到。
4.1实验设置
A。 选择基线: 我们的第一个实验设置的目的是为我们其余的实验选择基本模型。 我们在 API Pack 子集(Python 编程语言中的 20,000 个实例)上使用了 Mistral 7b [49]、CodeLlama 7b 和 13b,以及 Llama 2 13b [50] 。 我们评估在 20k 子集上微调的每个结果模型的性能,并在其余实验中使用性能最佳的微调模型的基础模型。
B. 检索推理: 我们的第二个实验旨在了解检索增强对模型泛化的影响。 我们在测试期间在四种不同的提示设置下评估模型:
-
•
0-shot:没有为模型提供API示例。
-
•
3-shot random:三个随机选择的 API 示例。
-
•
3-shot检索:检索到的三个相关API示例。
-
•
3-shot 检索和重新排序:五个检索的 API 示例,其中三个使用重新排序模型选择。
请注意,这些提示设置用于测试/推理,与微调中使用的指令调整模板不同。 我们使用 bge-large-en-v1.5 [51] 作为检索的嵌入模型,并使用 beg-reranker-large [52]重新排名。 附录9.4说明了用于评估模型性能的推理管道(0-shot、3-shot)。
C. 跨语言泛化: 为了测试模型泛化到新编程语言的能力,我们用 API Pack 中另外九种语言(Go、Java、JavaScript、libcurl、Node.js、PHP、Python、鲁比和斯威夫特。 目标是确定模型是否可以推广到新语言,而无需大量的多编程语言数据。
D. 缩放实验: 我们进行了一项扩展实验,以研究更多的 API 数据是否可以提高模型对未见过的 API 的泛化能力。 我们通过独特的 API 调用在逐渐增大的 API 数据集上进行建模:10k、20k、40k、80k、100k 和 100 万个实例。 我们的假设是,在微调过程中接触更大规模和更多样化的 API 将提高模型泛化到新的、未见过的 API 的能力。
4.2评估
为了衡量 API Pack 实现的泛化能力,我们建立了一个涵盖 API 调用生成的三个复杂程度的综合评估框架:
-
•
级别 1:已查看 API 和端点。 该级别评估对新指令的泛化。
-
•
级别 2:已了解 API 和新端点。 此级别测试对已知 API 新端点的泛化。
-
•
3 级:不可见的 API 和端点。 此级别验证全新 API 的性能。
数据拆分的过程详见附录9.2。 训练超参数在附录9.3中。 每个级别的端点和 API 调用准确性由 SequenceMatcher 衡量,它可以识别最长的匹配子序列,同时排除无关紧要的元素。 这些元素指的是 API 请求的特定部分,这些部分不会影响请求的整体功能或目的,例如空格和格式差异(例如,API 请求中的空格、制表符或换行符的变化)以及特定的命名约定或变量名称(即,重点是 API 请求的结构和参数,而不是变量或函数使用的特定名称,只要它们具有相同的目的)。 应用 0.9 的启发式阈值将生成的输出与地面实况端点和 API 调用进行比较,开发人员应根据高于此阈值的模型响应完成 API 调用。
5结果
| Model | Fine-tuning | Testing | Evaluation Accuracy (%) | |||||
| template | Level 1 | Level 2 | Level 3 | |||||
| Intent | API Call | Intent | API Call | Intent | API Call | |||
| Mistral-7b | zero-shot | 0-shot | 17.2 | 10.9 | 14.1 | 11.4 | 14.3 | 11.2 |
| 3-shot (retre) | 42.0 | 29.7 | 35.4 | 28.7 | 39.1 | 29.1 | ||
| three-shot | 0-shot | 40.5 | 28.5 | 24.0 | 18.3 | 15.2 | 12.1 | |
| 3-shot (retre) | 64.1 | 55.4 | 49.1 | 42.8 | 50.8 | 42.5 | ||
| CodeLlama-7b | zero-shot | 0-shot | 8.1 | 6.1 | 10.0 | 7.0 | 11.0 | 7.8 |
| 3-shot (retre) | 52.6 | 42.6 | 43.6 | 35.9 | 50.2 | 40.1 | ||
| three-shot | 0-shot | 12.1 | 9.3 | 13.7 | 10.2 | 16.8 | 13.0 | |
| 3-shot (retre) | 60.6 | 52.7 | 54.1 | 47.3 | 55.9 | 49.1 | ||
| Llama-2-13b | zero-shot | 0-shot | 9.4 | 6.2 | 11.6 | 9.0 | 10.9 | 8.4 |
| 3-shot (retre) | 44.5 | 33.9 | 45.4 | 35.6 | 46.7 | 39.1 | ||
| three-shot | 0-shot | 15.7 | 10.2 | 14.0 | 11.2 | 11.7 | 9.6 | |
| 3-shot (retre) | 59.5 | 51.5 | 50.8 | 44.3 | 52.7 | 44.2 | ||
| CodeLlama-13b | zero-shot | 0-shot | 9.8 | 6.8 | 10.8 | 8.1 | 12.1 | 8.5 |
| 3-shot (retre) | 55.6 | 44.4 | 50.6 | 43.3 | 52.3 | 44.1 | ||
| three-shot | 0-shot | 14.4 | 10.3 | 15.9 | 13.3 | 14.2 | 8.9 | |
| 3-shot (retre) | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.5 | ||
| gpt-3.5-1106 | none | 0-shot | - | - | - | - | 1.0 | 0.7 |
| none | 3-shot (retre) | - | - | - | - | 47.2 | 39.5 | |
| gpt-4-1106 | none | 0-shot | - | - | - | - | 0.2 | 0.1 |
| none | 3-shot (retre) | - | - | - | - | 53.5 | 44.3 | |
5.1 微调 CodeLlama 在 API 调用生成方面表现出色
表 3 展示了使用 API Pack 中的 20,000 个 Python 实例进行微调的四个模型的评估结果。 经过微调的 CodeLlama-13b 模型在三镜头检索设置的 API 调用生成方面展示了卓越的性能,在所有评估级别上实现了最高的 API 调用准确性。 使用三镜头模板微调的模型始终优于使用零样本模板微调的模型,这表明使用三镜头模板来提高模型的上下文学习能力的重要性。 此外,与 0-shot 相比,在测试时使用 3-shot(撤退)进行提示可以带来显着的改进,这是在所有模型和级别中观察到的趋势。 这一发现凸显了提供相关示例对于提高模型生成 API 调用的准确性的重要性。 值得注意的是,带有 API Pack 的微调 CodeLlama-13b 模型在 3 级(0-shot 和 3-shot(retre))方面的性能超过了 GPT-3.5 和 GPT-4 模型(未微调)。
| Model | Testing | Evaluation Accuracy (%) | |||||
| Level 1 | Level 2 | Level 3 | |||||
| Endpoint | API Call | Endpoint | API Call | Endpoint | API Call | ||
| Mistral-7b | 3-shot (rand) | 54.5 | 41.8 | 48.2 | 41.2 | 45.2 | 37.0 |
| 3-shot (retre) | 64.1 | 55.4 | 49.1 | 42.8 | 50.8 | 42.5 | |
| 3-shot (retre & rerank) | 63.0 | 53.6 | 49.0 | 42.2 | 51.5 | 43.9 | |
| CodeLlama-13b | 3-shot (rand) | 49.2 | 38.6 | 49.8 | 43.6 | 50.0 | 41.4 |
| 3-shot (retre) | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.5 | |
| 3-shot (retre & rerank) | 61.0 | 52.9 | 55.1 | 49.2 | 55.9 | 49.3 | |
5.2 检索增强改进了 API 调用生成
表4说明了不同检索方法对三镜头API调用生成的影响,强调了检索增强在提高模型性能方面的重要性。 使用三镜头模板对 API Pack 中的 20,000 个 Python 实例微调 Mistral-7b 和 CodeLlama-13b 模型的结果表明,三镜头检索是最有效的方法。
5.3 API调用性能的跨语言概括
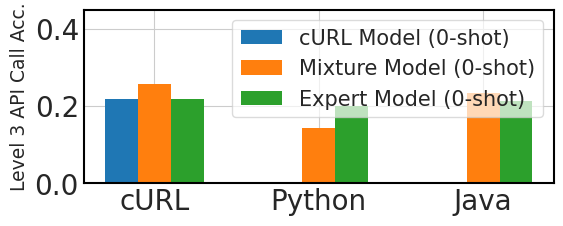
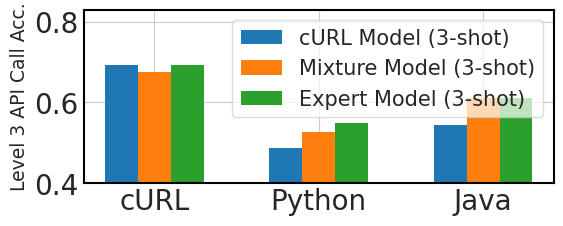

图3比较了跨语言API调用性能的三种微调方法:专门针对100,000个“cURL”数据实例进行微调的模型,或cURL模型,三种专家模型,每个模型分别针对 100,000 个“cURL”、“Python”和“Java”数据样本进行微调,混合模型针对 100,000 个实例进行微调“cURL”数据,其中包含 1,000 个实例的附加样本,每个实例对应 9 种不同的语言。
该图显示,在零样本场景中,在不进行微调的情况下推广到新的编程语言是具有挑战性的。 然而,这些模型在三镜头设置中的表现优于预期,表明具有一定的上下文学习适应性。 混合语言微调可以提高零样本和三样本场景中的性能,这表明即使是少量的各种语言的微调数据也可以提高模型在跨语言 API 调用任务中的有效性。 这些发现表明,跨语言 API 调用生成可以通过对一种语言的大量数据加上其他语言的少量数据微调模型来实现,而不需要每种目标编程语言的大量数据集。 图4说明了模型在十种编程语言中的适应性,其中混合模型在三轮测试中与专家模型表现相当,突出显示它们在多语言编程应用中的潜力。
5.4 扩展指令数据集有助于泛化
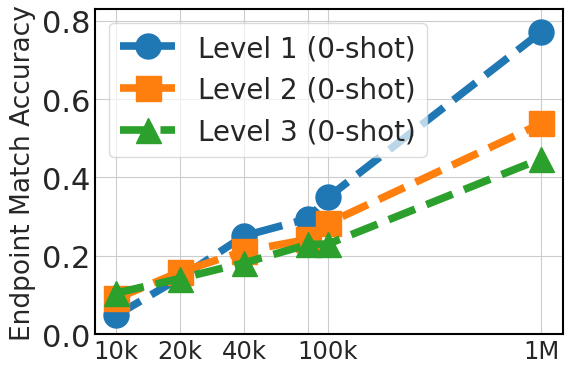
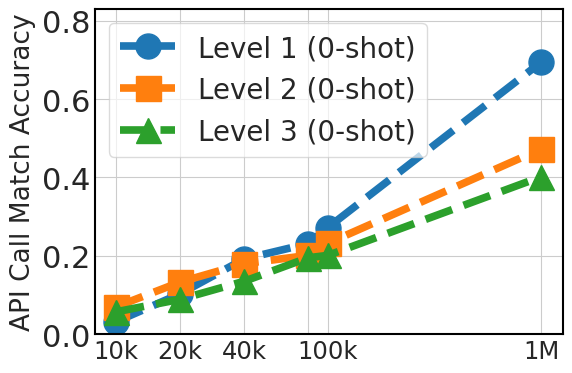
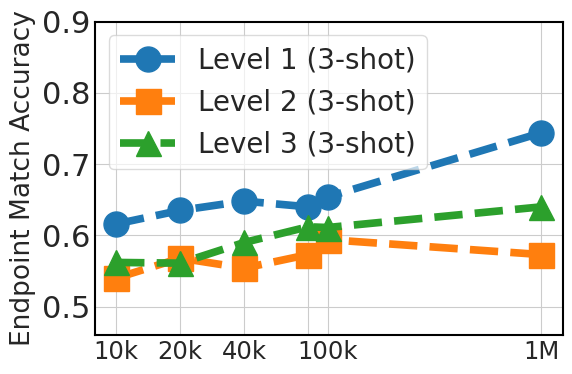
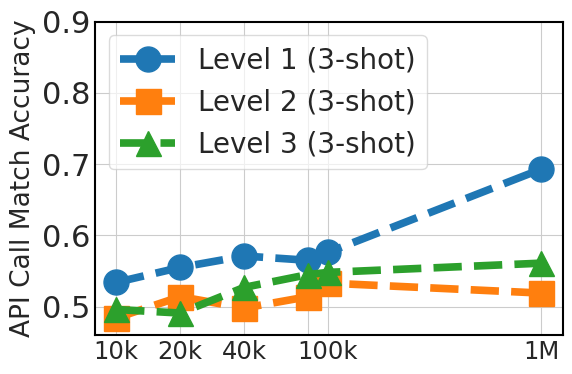
图5清楚地展示了零样本性能的上升趋势,这与微调数据集大小(API Pack 中的 20k、40k、80k、100k 和 100 万个实例)相关。 这一改进凸显了较大数据集在提供多样化示例方面的优势,这对于模型仅依赖于其预先存在的知识的零样本提示至关重要。 对于三镜头提示,该图还显示了随着数据集大小的增加而有所改善,尽管不如零样本情况显着,特别是对于 3 级情况。 这表明,虽然额外的微调数据是有益的,但模型预训练在上下文学习能力中发挥着更关键的作用。
5.5额外的消融实验
| Train | Testing | Evaluation Accuracy | |||||
| Level 1 Endpoint | Level 1 API Call | Level 2 Endpoint | Level 2 API Call | Level 3 Endpoint | Level 3 API Call | ||
| ToolBench | 0-shot | 5.7 | 5.7 | 8.1 | 8.0 | 7.3 | 7.0 |
| 3-shot | 44.5 | 37.8 | 40.7 | 36.4 | 43.7 | 38.1 | |
| API Pack | 0-shot | 14.4 | 10.3 | 15.9 | 13.3 | 14.2 | 8.9 |
| 3-shot | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.1 | |
为了验证 API Pack 的质量,我们在 ToolBench 数据集的 20k 个实例上评估了经过微调的 CodeLlama-13b 模型,该数据集仅包含来自 RapidAPI 的 API。 表 5 中的结果表明,与 API Pack(管理来自四个不同来源的数据)相比,使用 TollBench 等单一来源的 API 会降低 0-shot 和 3-shot 设置中的模型性能。
| Train | Testing | Evaluation Accuracy | |||||
| Level 1 Endpoint | Level 1 API Call | Level 2 Endpoint | Level 2 API Call | Level 3 Endpoint | Level 3 API Call | ||
| none-filtered | 0-shot | 10.3 | 8.3 | 12.8 | 10.3 | 12.2 | 8.4 |
| 3-shot | 62.4 | 54.9 | 54.9 | 48.7 | 55.7 | 49.5 | |
| with-filtered | 0-shot | 14.4 | 10.3 | 15.9 | 13.3 | 14.2 | 8.9 |
| 3-shot | 63.5 | 55.5 | 56.8 | 51.4 | 56.1 | 49.1 | |
此外,为了证明我们的数据过滤管道的有效性,我们用未过滤的指令替换了 45% 的过滤指令,并使用每个指令的 20k 实例对 CodeLlama-13b 进行了微调。 表 6 中的结果证实,随着非过滤指令的引入,0-shot 和 3-shot 性能确实下降。
6结论
在本文中,我们介绍了 API Pack,这是一个包含超过 100 万个指令 API 调用实例的大型多编程语言数据集。 使用此数据集,我们研究模型是否可以在没有大量多语言数据的情况下泛化到新语言,以及在微调过程中接触不同的 API 是否可以提高泛化能力。 我们的结果表明,通过对大量单语言数据进行训练并辅以少量其他语言的数据,可以实现跨语言 API 调用。 此外,增加数据量可以提高泛化能力。 这些发现凸显了大规模、多样化数据集在使大语言模型能够有效识别适当的 API 端点并基于自然语言指令生成相应的 API 调用方面的潜力。
7 限制
API Pack 并非专为多 API 调用场景而设计,因此使用此数据集进行微调的模型可能难以处理涉及多个相互依赖的 API 调用的任务。 此限制限制了 API Pack 在复杂的现实世界软件开发任务中的有效性,这些任务通常需要多 API 集成。 未来的工作应该集中于创建能够有效处理多API调用场景的数据集和模型,从而能够生成更复杂和实用的代码解决方案。
8更广泛的影响声明
我们的研究对软件生产力具有更广泛的影响,因为它旨在通过自动化常规编码任务来加速软件开发工作流程。 除了有望提高生产力之外,将先进的大语言模型集成到软件开发工作流程中也引起了社会技术问题(例如,工作替代、开发人员为确保准确性而进行的持续监督)。 因此,评估和应对潜在危害的负责任的创新视角仍然至关重要。
致谢和资金披露
这项工作得到了 MIT-IBM Watson AI 实验室和 IBM Research 的支持。
参考
- [1] Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, and ZHAO-XIANG ZHANG. Sheetcopilot: Bringing software productivity to the next level through large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 4952–4984. Curran Associates, Inc., 2023.
- [2] Ipek Ozkaya. Application of large language models to software engineering tasks: Opportunities, risks, and implications. IEEE Software, 40(3):4–8, 2023.
- [3] Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. Large language models for software engineering: Survey and open problems. arXiv preprint arXiv:2310.03533, 2023.
- [4] Lenz Belzner, Thomas Gabor, and Martin Wirsing. Large language model assisted software engineering: prospects, challenges, and a case study. In International Conference on Bridging the Gap between AI and Reality, pages 355–374. Springer, 2023.
- [5] Steven I Ross, Fernando Martinez, Stephanie Houde, Michael Muller, and Justin D Weisz. The programmer’s assistant: Conversational interaction with a large language model for software development. In Proceedings of the 28th International Conference on Intelligent User Interfaces, pages 491–514, 2023.
- [6] Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large Language Models for Software Engineering: A Systematic Literature Review, September 2023. arXiv:2308.10620 [cs].
- [7] Christof Ebert and Panos Louridas. Generative AI for Software Practitioners. IEEE Software, 40(4):30–38, July 2023. Conference Name: IEEE Software.
- [8] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. ACM Transactions on Intelligent Systems and Technology, 15(3):1–45, 2024.
- [9] Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. Software testing with large language models: Survey, landscape, and vision. IEEE Transactions on Software Engineering, 2024.
- [10] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [11] Frank F Xu, Uri Alon, Graham Neubig, and Vincent Josua Hellendoorn. A systematic evaluation of large language models of code. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, pages 1–10, 2022.
- [12] Sami Sarsa, Paul Denny, Arto Hellas, and Juho Leinonen. Automatic generation of programming exercises and code explanations using large language models. In Proceedings of the 2022 ACM Conference on International Computing Education Research-Volume 1, pages 27–43, 2022.
- [13] Priyan Vaithilingam, Tianyi Zhang, and Elena L Glassman. Expectation vs. experience: Evaluating the usability of code generation tools powered by large language models. In Chi conference on human factors in computing systems extended abstracts, pages 1–7, 2022.
- [14] Gabriel Poesia, Oleksandr Polozov, Vu Le, Ashish Tiwari, Gustavo Soares, Christopher Meek, and Sumit Gulwani. Synchromesh: Reliable code generation from pre-trained language models. arXiv preprint arXiv:2201.11227, 2022.
- [15] Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi D. Q. Bui, Junnan Li, and Steven C. H. Hoi. CodeT5+: Open Code Large Language Models for Code Understanding and Generation, May 2023. arXiv:2305.07922 [cs].
- [16] Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. Repository-level prompt generation for large language models of code. In International Conference on Machine Learning, pages 31693–31715. PMLR, 2023.
- [17] Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as Policies: Language Model Programs for Embodied Control. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 9493–9500, May 2023.
- [18] Daoguang Zan, Bei Chen, Fengji Zhang, Dianjie Lu, Bingchao Wu, Bei Guan, Wang Yongji, and Jian-Guang Lou. Large Language Models Meet NL2Code: A Survey. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7443–7464, Toronto, Canada, July 2023. Association for Computational Linguistics.
- [19] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and LINGMING ZHANG. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Systems, volume 36, pages 21558–21572. Curran Associates, Inc., 2023.
- [20] Disha Shrivastava, Hugo Larochelle, and Daniel Tarlow. Repository-Level Prompt Generation for Large Language Models of Code. In Proceedings of the 40th International Conference on Machine Learning, pages 31693–31715. PMLR, July 2023. ISSN: 2640-3498.
- [21] Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Source Code Is All You Need, December 2023. arXiv:2312.02120 [cs].
- [22] Niklas Muennighoff, Qian Liu, Armel Zebaze, Qinkai Zheng, Binyuan Hui, Terry Yue Zhuo, Swayam Singh, Xiangru Tang, Leandro von Werra, and Shayne Longpre. OctoPack: Instruction Tuning Code Large Language Models, August 2023. arXiv:2308.07124 [cs].
- [23] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, et al. Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161, 2023.
- [24] Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, et al. Starcoder 2 and the stack v2: The next generation. arXiv preprint arXiv:2402.19173, 2024.
- [25] Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri, and Siddharth Garg. Verigen: A large language model for verilog code generation. ACM Transactions on Design Automation of Electronic Systems, 29(3):1–31, 2024.
- [26] Mayank Mishra, Matt Stallone, Gaoyuan Zhang, Yikang Shen, Aditya Prasad, Adriana Meza Soria, Michele Merler, Parameswaran Selvam, Saptha Surendran, Shivdeep Singh, et al. Granite code models: A family of open foundation models for code intelligence. arXiv preprint arXiv:2405.04324, 2024.
- [27] Caitlin Sadowski, Kathryn T. Stolee, and Sebastian Elbaum. How developers search for code: a case study. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2015, pages 191–201, New York, NY, USA, August 2015. Association for Computing Machinery.
- [28] Michael Meng, Stephanie Steinhardt, and Andreas Schubert. Application Programming Interface Documentation: What Do Software Developers Want? Journal of Technical Writing and Communication, 48(3):295–330, July 2018. Publisher: SAGE Publications Inc.
- [29] Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, and Jian Zhang. On the Tool Manipulation Capability of Open-source Large Language Models, May 2023.
- [30] Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large Language Model Connected with Massive APIs, May 2023. arXiv:2305.15334 [cs].
- [31] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs, July 2023. arXiv:2307.16789 [cs].
- [32] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. WizardLM: Empowering Large Language Models to Follow Complex Instructions, June 2023. arXiv:2304.12244 [cs].
- [33] Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-Instruct: Aligning Language Models with Self-Generated Instructions, May 2023. arXiv:2212.10560 [cs].
- [34] Wei Liu, Weihao Zeng, Keqing He, Yong Jiang, and Junxian He. What Makes Good Data for Alignment? A Comprehensive Study of Automatic Data Selection in Instruction Tuning, December 2023. arXiv:2312.15685 [cs].
- [35] Lichang Chen, Shiyang Li, Jun Yan, Hai Wang, Kalpa Gunaratna, Vikas Yadav, Zheng Tang, Vijay Srinivasan, Tianyi Zhou, Heng Huang, and Hongxia Jin. AlpaGasus: Training A Better Alpaca with Fewer Data, November 2023. arXiv:2307.08701 [cs].
- [36] Keming Lu, Hongyi Yuan, Zheng Yuan, Runji Lin, Junyang Lin, Chuanqi Tan, Chang Zhou, and Jingren Zhou. #InsTag: Instruction Tagging for Analyzing Supervised Fine-tuning of Large Language Models, August 2023. arXiv:2308.07074 [cs].
- [37] Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program Synthesis with Large Language Models, August 2021. arXiv:2108.07732 [cs].
- [38] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating Large Language Models Trained on Code, July 2021. arXiv:2107.03374 [cs].
- [39] Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation, October 2023. arXiv:2305.01210 [cs].
- [40] Qinkai Zheng, Xiao Xia, Xu Zou, Yuxiao Dong, Shan Wang, Yufei Xue, Zihan Wang, Lei Shen, Andi Wang, Yang Li, Teng Su, Zhilin Yang, and Jie Tang. Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x, 2023.
- [41] Qiwei Peng, Yekun Chai, and Xuhong Li. Humaneval-xl: A multilingual code generation benchmark for cross-lingual natural language generalization. arXiv preprint arXiv:2402.16694, 2024.
- [42] Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. API-Bank: A Benchmark for Tool-Augmented LLMs, April 2023. arXiv:2304.08244 [cs].
- [43] Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Boxi Cao, and Le Sun. ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases, September 2023. arXiv:2306.05301 [cs].
- [44] Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction, May 2023. arXiv:2305.18752 [cs].
- [45] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language Models Can Teach Themselves to Use Tools, February 2023. arXiv:2302.04761 [cs].
- [46] Venkat Krishna Srinivasan, Zhen Dong, Banghua Zhu, Brian Yu, Damon Mosk-Aoyama, Kurt Keutzer, Jiantao Jiao, and Jian Zhang. Nexusraven: a commercially-permissive language model for function calling. In NeurIPS 2023 Foundation Models for Decision Making Workshop, 2023.
- [47] Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Yongliang Shen, Ren Kan, Dongsheng Li, and Deqing Yang. Easytool: Enhancing llm-based agents with concise tool instruction. arXiv preprint arXiv:2401.06201, 2024.
- [48] Wei Chen, Zhiyuan Li, and Mingyuan Ma. Octopus: On-device language model for function calling of software apis. arXiv preprint arXiv:2404.01549, 2024.
- [49] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7B, October 2023. arXiv:2310.06825 [cs].
- [50] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open Foundation and Fine-Tuned Chat Models, July 2023. arXiv:2307.09288 [cs].
- [51] Peitian Zhang, Shitao Xiao, Zheng Liu, Zhicheng Dou, and Jian-Yun Nie. Retrieve Anything To Augment Large Language Models, October 2023. arXiv:2310.07554 [cs].
- [52] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-Pack: Packaged Resources To Advance General Chinese Embedding, December 2023. arXiv:2309.07597 [cs].
9附录
9.1 管道每个阶段的数据过滤
| Source/Instances | Before Data Validation | After Removing Invalid API calls | After Removing Instances without Good Instructions |
|---|---|---|---|
| IBM API Hub | 27,635 | 17,712 | 17,206 |
| APIs Gurus | 500,160 | 499,250 | 495,533 |
| Swaggerhub | 351,756 | 351,756 | 345,765 |
| RapidAPI | 274,014 | 273,388 | 270,095 |
| Total | 1,153,565 | 1,142,106 | 1,128,599 |
9.2 1级、2级和3级测试的数据拆分
要分割数据,首先将总数据集复制到total_training中并计算每个API的出现次数。 对于第一级测试数据,从前 20,000 个条目中选择最多 1,000 个数据点,其中 instructions_test 不为“None”且 API 出现超过四次。 对于第二级,迭代前 20,000 个条目,选择尚未选择 API 的数据点,直到收集到 1,000 个唯一的 API,然后从训练数据集中删除它们。 对于第三级,从第 80,000 个条目开始,选择具有第 2 级中未使用的 API 的数据点,最多收集 1,000 个数据点,并从训练数据集中删除具有这些 API 的数据点。
9.3 训练的超参数
我们在一个集群上使用 HuggingFace Transformers 库来构建模型,该集群由 1 个节点和 8 个 NVIDIA H100 80GB GPU 组成,具有完全共享数据并行性 (FSDP)。 使用混合精度、梯度检查点和 AdaFactor 优化器等技术来提高训练效率。 表8总结了关键的超参数。
| Hyperparameter Name | Value |
|---|---|
| Learning rate | |
| Batch size | 128 |
| Max seq length | 4096 |
| Number of epochs | 2 |
| Warmup ratio | 0.03 |
9.4测试管道
图6显示了我们的测试流程的示例,包括零样本和少样本。
9.5 API 数据库实例
图7显示了API数据库实例的结构。 我们使用了 openapi-snippet 777https://www.npmjs.com/package/openapi-snippet,一个开源包,它将 OpenAPI v2.0 或 v3.0.x 规范文件(OAS 文件)作为输入,并将其转换为 HTTP Archive 1.2 请求对象,以生成 API 调用。 我们为 RapidAPI、API Gurus 和 Swaggerhub 使用 10 种不同的编程语言(cURL、libcurl、java、node、python、go、ruby、php、swift、JavaScript)生成 API 调用 (api_call)。 对于公司的公共 API Hub,API 调用是直接从 OAS 文件中提取的。 我们从此源中提取了八种不同编程语言的 API 调用(cURL、java、node、python、go、ruby、php、swift)。
[fontsize=] json "api_name" : "The name of the API the endpoint belongs to", "api_description": "The description of the API the enpoint belongs to", "api_provider": "The API’s provider name", "endpoint_name": "The name of the function to call", "functionality": "A brief description of endpoint’s functionality", "description": "A long description of endpoint’s functionality", "path": "The enpoint’s name plus specific versioning as it appears in the API call’s URL", "method": "HTTP method used in the API call (e.g., get, post, put, delete)", "api_call": "HTTP request code example to invoke an endpoint", "lang": "The programming language in which the API call is written",
9.6 使用 API Pack 改进代码模型
我们评估了将 API Pack 的 50,000 个条目的子集与 Magicoder 数据集和微调的 CodeLlama-13b 模型混合的性能。 生成的模型显示,3 级的 API 调用代码生成准确度提高了 35.3% 以上,特别是在 3-shot 设置下。 这种改进并不以牺牲总体编码效率为代价,因为生成的模型在 HumanEval+ 和 MBPP 等基准测试中仍然表现良好。 有关详细信息,请参阅表9。
| Data Mixture | Bench. (pass@10) | Level 3 (3-shot) | |
|---|---|---|---|
| HumanEval+ | MBPP | Endpoint | |
| - | 47.8 | 58.3 | - |
| Magicoder | 60.8 | 66.4 | 17.0 |
| Magicoder + API Pack | 61.3 | 64.3 | 52.3 |
9.7 指令候选人
图8显示了为实例生成的所有候选者及其各自的id和input_tokens_mean。
[fontsize=] json "instruction_candidates": [ "idx": 1, "candidate": "I’d like to confirm if 3D Secure is supported for a specific card brand or BIN using the Adyen BinLookup API. For 3D Secure 2, it will also provide device fingerprinting keys.", "input_tokens_mean": -0.5497539341557909 , "idx": 2, "candidate": "To confirm if 3D Secure is enabled for a specific card brand or BIN number using the Adyen BinLookup API, you can make use of the ‘post-get3dsAvailability‘ endpoint. This API call will provide you with information about the availability of 3D Secure, along with device fingerprinting keys for 3D Secure 2 transactions. Let me know if you need assistance in forming the request or handling the response.", "input_tokens_mean": -0.5088001283229344 , "idx": 3, "candidate": "To confirm if a specific card brand or BIN supports 3D Secure and retrieves device fingerprinting keys for 3D Secure 2, please utilize the Adyen BinLookup API’s post-get3dsAvailability endpoint.", "input_tokens_mean": -0.5554471563123543 , "idx": 4, "candidate": "To confirm if 3D Secure is supported for a specific card brand or BIN number using the Adyen BinLookup API, please make a POST request to the endpoint ’post-get3dsAvailability’. This API will return whether 3D Secure is enabled and for 3D Secure 2, it will also provide device fingerprinting keys.", "input_tokens_mean": -0.5466722401065375 , "idx": 5, "candidate": "To confirm if 3D Secure is supported by Adyen for a given card brand or BIN number, you can utilize the Adyen BinLookup API. Simply send a POST request to the post-get3dsAvailability endpoint with the required card details. If 3D Secure is available, the response will include device fingerprinting keys for 3D Secure 2.", "input_tokens_mean": -0.5726057469087047 ]