通过函数调用将大型语言模型作为零样本
对话状态跟踪器
摘要
大语言模型(LLM)在一般情况下具有高级理解和生成能力,因此在会话系统中越来越普遍。 然而,它们在面向任务的对话(TOD)中的效果仍然不太令人满意,因为这种对话不仅需要生成响应,还需要在特定任务和领域内进行有效的对话状态跟踪(DST)。 在这项工作中,我们提出了一种新方法FnCTOD,用于通过函数调用解决带有 LLM 的 DST。 这种方法改进了零样本 DST,无需大量数据收集或模型调整,即可适应不同领域。 我们的实验结果表明,我们的方法在使用大小适中的开源 LLM 和专有 LLM 时都取得了优异的性能:通过上下文提示,它使各种 7B 或 13B 参数模型超越了 ChatGPT 以前取得的最先进水平(SOTA),并将 ChatGPT 的性能提高了 5.6% Avg,超越了 SOTA。 JGA. GPT-3.5 和 GPT-4 的单个模型结果分别提高了 4.8% 和 14%。 我们还证明,通过对一小部分不同任务导向的对话进行微调,我们可以使规模适中的模型(特别是 13B 参数的 LLaMA2-Chat 模型)具备与 ChatGPT 相当的函数调用能力和 DST 性能,同时保持其聊天功能。 我们将开源实验代码和模型。
1导言
近年来,大型语言模型(LLM)得到了快速发展,这些模型展现了卓越的自然语言理解和生成能力。 将 LLM 集成到行业应用中,特别是作为对话助手,是一个值得注意的趋势。 这些模型通过用户与助手之间的对话进行微调,进一步与人类的偏好保持一致,从而提高了助手对用户询问做出流畅、有益和礼貌回答的能力。 著名的例子包括 ChatGPT111http://chatgpt.openai.com/ 和 Claude222https://www.anthropic.com/index/introducing-claude,以及 LLaMA2-Chat Touvron 等 (2023)、Vicuna Chiang 等 (2023)、Baichuan Baichuan (2023)等开源模型。
| Zero-shot DST Paradigms | Base Model | Fine-tuning | Prompting | Plug-&-Play |
| Domain transfer approaches (Lin et al., 2021b, c; Zhao et al., 2022a) | Small LMs | ✓ | ✗ | ✗ |
| Previous prompting approaches Heck et al. (2023); Chung et al. (2023) | Advanced proprietary LLMs | ✗ | ✓ | ✗ |
| FnCTOD (Ours) | Modestly-sized open-source LLMs & Advanced proprietary LLMs | ✓ | ✓ | ✓ |
这些经过聊天调整的 LLM 的主要重点通常是在一般情况下做出回应。 然而,对于另一种重要的对话类型--面向任务的对话(TOD)--来说,模型需要提取用户在对话每一个轮次上的意图,并将其表示为每个领域预定义模式的槽值对;这一过程被称为对话状态跟踪(DST)。 挑战在于该模型能否在多次对话中准确概括用户需求,并严格遵守特定领域的本体。 最直接的解决方案Hosseini-Asl 等人(2020);Peng 等人(2020);Su 等人(2021)必须在经过策划的特定领域标注数据上进行训练,而这一过程是出了名的高成本和劳动密集型。 尽管在使用 GPT-3 Li 等人 (2022) 自动创建数据集方面做出了努力,但这些方法仍难以推广到未见领域。 为了实现未见域的零样本 DST,先前的方法通常涉及领域转移方法 (Campagna 等,20;Lin 等,2021a;Zhao 等,2022b)。 然而,这些训练仍需要在类似领域的数据上进行训练,其表现远不能令人满意。
LLM 在处理各种任务时表现出非凡的能力,无需针对具体任务进行微调,因此非常适合零样本 DST。 然而,虽然已经有人开始利用 ChatGPT 进行零样本 DST Hu等人(2022);Hudeček和Dušek(2023);Heck等人(2023);Chung等人(2023),但这些方法倾向于将DST视为独立任务,而不是聊天完成任务,而聊天完成任务是模型,尤其是chat-tuned 模型更擅长的。 它们通常将整个对话作为输入,并附上详细说明,以特定领域的格式生成。 由于任务背景较长,且有特定的输出要求,这种设置带来了挑战。 因此,这种方法只适用于高级 ChatGPT 或 Codex 模型,却不适用于功能较弱的 LLM Hudeček 和 Dušek (2023)。
在这项工作中,我们引入了一种新方法 FnCTOD,以解决带有 LLM 的零样本 DST 问题。 我们的方法无缝集成了 DST,使其成为聊天完成过程中助手输出的一部分。 具体来说,我们将每个任务导向对话领域的模式视为一个特定函数,而该领域的 DST 则是 "调用 "相应函数的过程。 因此,我们指示 LLM 在助手的输出中生成函数调用和响应。 为此,我们将领域模式转换为函数规范,其中包括函数的描述和所需参数,并将其纳入大语言模型的 系统提示中。 此外,我们还将这些函数调用整合到助手在 对话上下文 中的输出中。
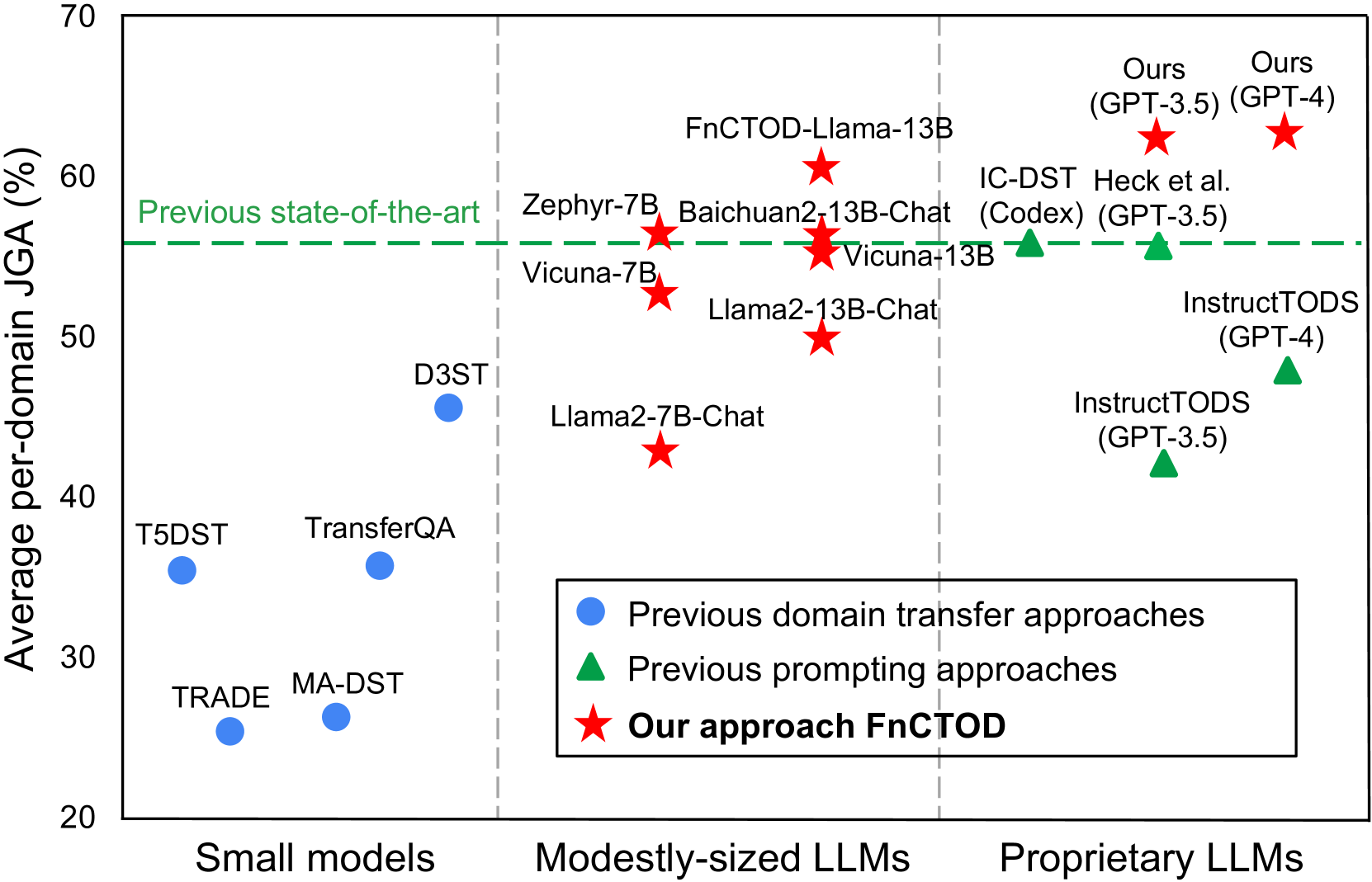
如图1所示,MultiWOZ 基准Budzianowski 等人(2018)的实验结果是一个重要的里程碑。 我们的方法是第一种无需进一步微调就能使规模适中的开源 LLM(7B 或 13B 参数)达到与以前的最先进(SOTA)提示方法相当或更优性能的方法,这些方法完全依赖于先进的专有 LLM,例如 ChatGPT 和 Codex Hudeček 和 Dušek (2023); Heck 等人 (2023; Chung 等人 (2023) .(2023); Chung 等人 (2023)。 此外,我们的方法比之前的零样本 SOTA 方法高出 5.6% Av。 JGA,牢牢树立了新标准。 它提高了 ChatGPT 的性能;分别比之前 GPT-3.5 和 GPT-4 的单项最佳结果高出 4.8% 和 14%。
此外,我们还展示了通过使用 7,200 个任务导向对话集合(包括从异构 TOD 数据集中随机选择的涵盖 36 个不同领域的 200 个对话)对 13B LLaMA2-Chat 模型进行微调,我们可以使其具备与 ChatGPT 不相上下的函数调用 DST 能力,同时仍能保持其响应生成能力。
2相关工作
2.1对话状态跟踪
在建造 TOD 系统的过程中,DST 是一项必不可少但又极具挑战性的任务。 其主要目的是在整个对话过程中的每一个转折点提取和跟踪用户目标。 跟踪到的对话状态通常用特定领域预定义模式的槽值来表示。 这就要求槽值严格遵守特定域模式。 因此,以前的方法依赖于收集和标注特定领域的对话来进行模型训练 Lee 等 (2019); Wu 等 (2019); Heck 等 (20); Hosseini-Asl 等 (20); Peng 等 (20); Lin 等 (20) .(20); Peng 等 (20); Lin 等 (20) 然而,即使是利用 GPT-3 自动模拟此类数据的方法,获取训练数据的成本也是出了名的高 Li 等 (2022) 。 此外,这些方法仅限于处理训练数据所涵盖的领域。
2.2利用 LLM 完成对话任务
LLMs Brown等人(2020);Chowdhery等人(2023);OpenAI(2023)在处理各种任务时表现出了非凡的能力,无需进一步微调。 最近的聊天/指令调整模型在会话语境中进一步表现出令人印象深刻的性能Touvron 等人(2023);Chiang 等人(2023);Yang 等人(2023)。 然而,当前的聊天模型主要关注一般对话,往往忽略了任务导向对话(TOD)。 TOD 与一般对话的不同之处在于,它要求模型不仅能生成回复,还能根据特定领域的模式跟踪对话状态。 尽管 ChatGPT 在 TOD 中的回复生成表现出效果,如李等人(2023)所示,但他们在零-shot DST方面的表现,正如最近关于提示方法的研究所探讨的那样,如胡等人(2022);Bang等人(2023);Hudeček和Dušek(2023);Heck等人(2023);Zhang等人(2023);Chung等人(2023);仍然不尽人意,这仍然是一个重大挑战。
2.3在 LLM 中使用工具
有关工具使用的早期工作 Parisi 等人 (2022); Schick 等人 (2023) 以及最近推出的 GPT-4 插件和函数调用功能 OpenAI (2023) 都强调了函数调用对于 LLM 的重要性,从而鼓励了后续工作 Patil 等人 (2023; Shen 等人 (2023; Li 等人 (2023a) 的开展。(2023); Shen 等人 (2023); Li 等人 (2023a)。 常见的集成工具包括网络浏览器、计算器Cobbe et al. (2021)、翻译系统等。 我们是第一个利用这种工具使用/功能调用能力来解决具有挑战性的 DST 任务的 TOD LLMs,缩小了一般对话和任务导向对话之间的差距。
3背景
3.1经过聊天调整的 LLM
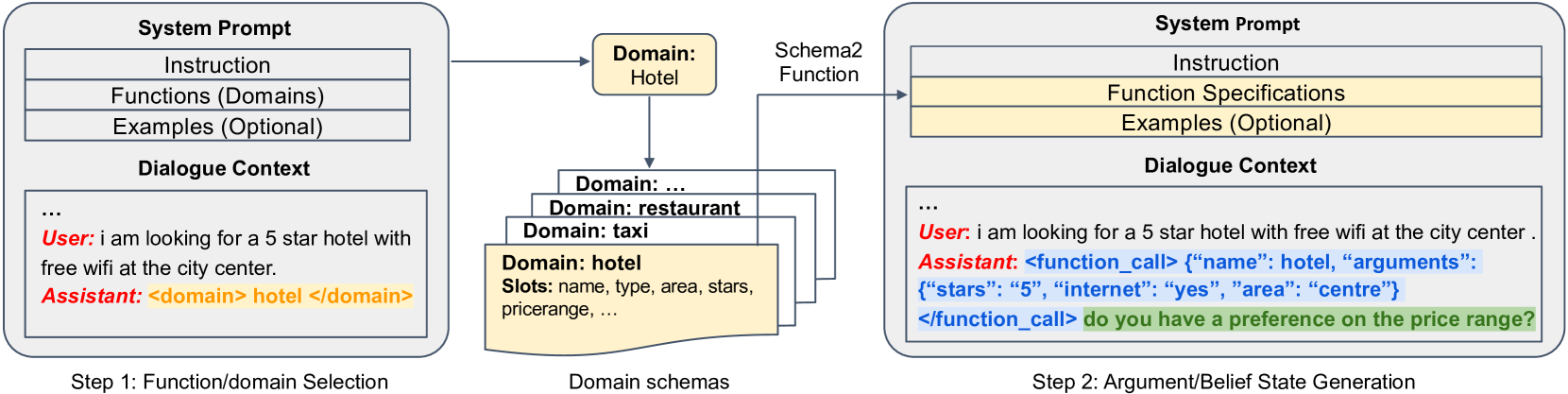
经过聊天调整的 LLM 是专门为以对话方式与用户交互而微调的模型。 这类模型包括 ChatGPT 和 Claude 等专有模型,以及 Vicuna Chiang 等人 (2023)、LLaMA2-Chat Touvron 等人 (2023) 和 Baichuan Yang 等人 (2023) 等开源模型。 这些聊天模型通常从基础模型开始,通过对话格式进一步微调,使其能够有效地作为对话代理发挥作用。 如图 2 所示,对话格式通常包含三个不同的角色:(1) 系统提示部分中的系统角色,它定义了助手的角色、职责和预期行为;以及 (2) 对话上下文部分中的用户和助手角色,包括他们的对话。 模型的典型任务是根据 用户的输入生成 助手的响应。 这些聊天模型的主要目的是为一般用户询问生成有用、详细和友好的回复,而不是像 TOD 那样处理特定任务的对话。
3.2制定 DST 任务
在 TOD 中,每轮对话时,DST 的任务是总结对话状态 ,给定对话上下文 ,其中和分别代表用户在轮次中的话语和助手的回应。 为简单起见,我们将在随后的讨论中省略轮次索引 。 对话状态 是一组槽值对:
| (1) |
其中,是 域中的第 个插槽、而 是其跟踪值。 每个域 都对应于特定服务、API 调用或数据库查询(如餐厅预订)的一组插槽。 就 restaurant 域而言,槽位可能包括 "restaurant-food"、"restaurant-area"、"restaurant-pricerange "等。我们使用 表示域 的跟踪槽。

4方法
我们的方法将 DST 重新定义为函数调用,将每个域视为一个不同的函数,并将域内的槽值作为其参数。 如图 2 所示,这一范例在聊天调整模型中的表现形式是在系统提示中嵌入函数规范,如图 3 所示。 如图 4 所示,该模型的任务是生成函数调用和响应。 下文将详细介绍我们的方法。
DST 作为函数调用
在我们的形式化中,DST 被概念化为函数调用。 每个域 都被建模为一个唯一的函数 ,相关的槽值作为参数。 因此,在对话的每一个轮次,DST 任务都会转变为识别正确的函数 及其参数 :
| (2) | |||
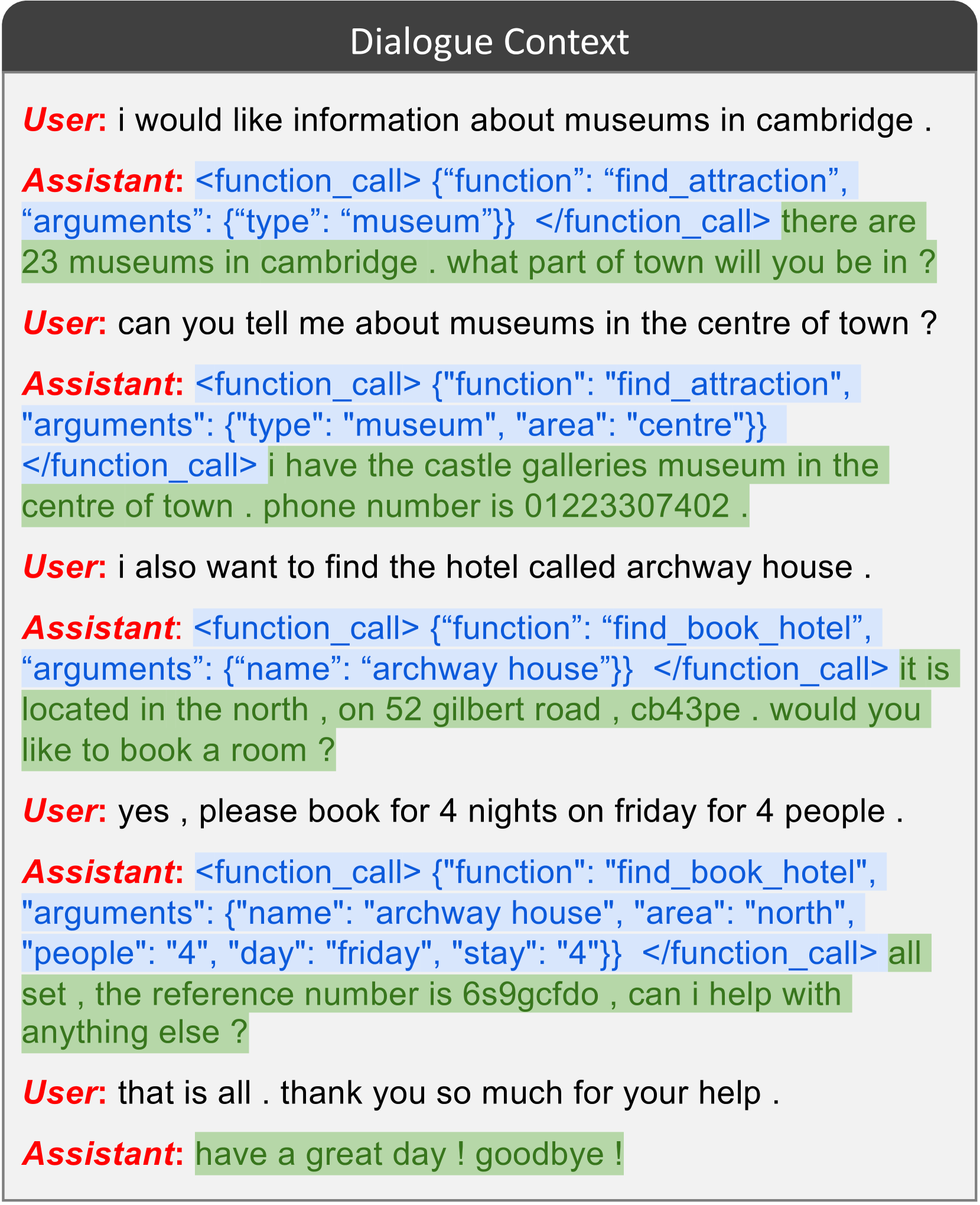
其中"<fn_call>"和"</fn_call>"为特殊词符。 在实践中,我们使用"<function_call>"和"</function_call>"来表示它们,并生成 JSON 格式的函数调用。 图 4 显示了对话中产生的函数调用的一些示例。
对话提示格式
函数调用分解
如前所述,该模型不仅需要预测调用哪个函数(例如即函数名),但也会为预测函数生成参数。 为了简化这一过程并加强控制,我们将其分为两个连续的步骤:函数选择和参数生成。 如图 2 所示,对话每进行一轮,模型首先会从支持的函数中选择一个函数 。 在这一步中,我们只在 系统提示符中包含函数描述,并提示模型只生成选定的域/函数,并用特殊词符"<域>"和"</域>"包围。 随后,我们在 系统提示符中加入所选函数 的完整说明,促使模型生成函数 的相应参数。
上下文提示
由于目前的开源模型没有专门针对生成函数调用进行微调,因此无法保证模型总是能生成正确的格式。 为了解决这个问题,我们还包括了上下文示例对话,如图4所示,以及在系统提示中预测的函数的规范说明。 我们为每个支持的领域手动选择了一些示范示例。
模型微调
为了使开源模型无需演示示例即可具备函数调用功能,我们使用一系列面向任务的异构对话数据集对 LLaMA2-13B-Chat 模型进行了微调,这些数据集包括 WOZ Mrkšić 等人(2016)、CamRest676 Wen 等人(2016b)a。(2016), CamRest676 Wen et al. (2016b, a), MSR-E2E Li et al.(2018), TaskMaster Byrne 等 (2019) 和 Schema-Guided Dialogues (SGD) Rastogi 等 (20). 请注意,我们特意排除了整个目标测试数据集。 我们从这些数据集中选择了 36 个具有高质量标注的不同领域/功能。 我们没有使用这些数据集中的所有数据,而是从这些数据集中的每个领域中随机抽取了 200 个对话,共计 7 200 个对话用于训练。 这一样本量已被证明足以取得有效成果。
在训练过程中,我们会在每个对话的 系统提示中加入所有调用函数的规范。 我们的损失计算只侧重于助手生成的函数调用方面。 考虑到 LLMs 在做出连贯反应方面的现有能力,以及数据集中函数调用示例的稀缺性,我们没有对反应生成部分进行微调。 微调模型被命名为FnCTOD-LaMA2-13B。
| Model | Attraction | Hotel | Restaurant | Taxi | Train | JGA | ||||||
| JGA | Slot-F1 | JGA | Slot-F1 | JGA | Slot-F1 | JGA | Slot-F1 | JGA | Slot-F1 | Average | Overall | |
| Cross-domain Transfer approaches | ||||||||||||
| TRADE Wu et al. (2019) | 20.06 | – | 14.20 | – | 12.59 | – | 59.21 | – | 22.39 | – | 25.69 | – |
| MA-DST Kumar et al. (2020) | 22.46 | – | 16.28 | – | 13.56 | – | 59.27 | – | 22.76 | – | 26.87 | – |
| TransferQA Lin et al. (2021b) | 31.25 | – | 22.72 | – | 26.28 | – | 61.87 | – | 36.72 | – | 35.77 | – |
| T5DST Lin et al. (2021c) | 33.09 | – | 21.21 | – | 21.65 | – | 64.62 | – | 35.43 | – | 35.20 | – |
| D3ST Zhao et al. (2022a) | 56.40 | – | 21.80 | – | 38.20 | – | 78.40 | – | 38.70 | – | 46.70 | – |
| Previous Prompting approaches | ||||||||||||
| IC-DST (Codex) | 60.00 | – | 46.70 | – | 57.30 | – | 71.40 | – | 49.40 | – | 56.96 | – |
| Heck et al. (2023) (GPT-3.5) | 52.70 | – | 42.00 | – | 55.80 | – | 70.90 | – | 60.80 | – | 56.44 | 31.50 |
| InstructTODS (GPT-3.5) | 30.23 | 65.38 | 26.77 | 76.28 | 48.28 | 82.90 | 56.22 | 75.33 | 53.75 | 83.64 | 42.02 | – |
| InstructTODS (GPT-4) | 39.53 | 78.99 | 31.23 | 84.07 | 55.86 | 88.23 | 63.24 | 82.71 | 59.83 | 89.72 | 48.16 | – |
| Our approach FnCTOD | ||||||||||||
| ChatGPT (GPT-3.5) | 67.15 | 87.20 | 37.56 | 82.86 | 60.12 | 90.21 | 74.43 | 86.90 | 67.29 | 92.48 | 61.31 | 38.56 |
| ChatGPT (GPT-4) | 58.77 | 81.84 | 45.15 | 85.07 | 63.18 | 91.06 | 76.39 | 87.73 | 69.48 | 90.16 | 62.59 | 38.71 |
| FnCTOD-LLaMA2-13B | 62.24 | 84.99 | 46.83 | 85.39 | 60.27 | 88.69 | 67.48 | 80.39 | 60.90 | 89.88 | 59.54 | 37.67 |
| Zephyr-7B-Beta | 56.50 | 81.97 | 38.43 | 79.52 | 63.18 | 91.19 | 74.10 | 86.56 | 56.20 | 90.00 | 57.68 | 32.11 |
| Vicuna-7B-v1.5 | 50.66 | 74.93 | 35.00 | 73.66 | 52.76 | 85.25 | 67.02 | 80.36 | 59.66 | 89.05 | 53.02 | 29.45 |
| Vicuna-13B-v1.5 | 54.25 | 80.99 | 38.43 | 79.96 | 56.44 | 87.26 | 69.11 | 83.37 | 58.82 | 89.26 | 55.41 | 31.84 |
| Baichuan2-13B-Chat | 53.67 | 79.57 | 40.15 | 81.36 | 59.02 | 87.82 | 69.31 | 81.95 | 60.67 | 89.45 | 56.56 | 33.21 |
| LLaMA2-7B-Chat | 42.64 | 70.18 | 30.47 | 69.37 | 37.60 | 78.63 | 63.20 | 73.80 | 44.17 | 82.18 | 43.44 | 16.78 |
| LLaMA2-13B-Chat | 49.76 | 76.80 | 29.50 | 67.60 | 48.87 | 81.33 | 64.66 | 68.97 | 53.59 | 85.09 | 49.28 | 25.68 |
| LLaMA2-70B-Chat | 50.66 | 78.26 | 34.03 | 76.61 | 54.48 | 86.18 | 66.10 | 72.60 | 56.53 | 87.39 | 52.36 | 28.38 |
5实验
5.1实验设置
数据集和衡量标准
基线
我们将我们的方法与两种不同的方法进行了比较:(1) 跨域转移方法,即在 MultiWOZ 上进行训练,但排除一个域,然后在保留域上进行评估。 这类方法包括 TRADE Wu等人 (2019)、MA-DST Kumar等人 (2020)、TransferQA Lin等人 (2021b)、T5DST Lin等人 (2021c)和TransferQA。(2021b), T5DST Lin 等人 (2021c), 和 D3ST Zhao 等人 (2022a). (2) 以前的提示方法只对高级 ChatGPT 和 Codex 有效。 其中包括使用 Codex 的 IC-DST Hu 等人(2022)、Heck 等人(2023)和使用 ChatGPT (GPT-3.5/4) 的 InstructTODS Chung 等人(2023)。
评估模型
我们在专有 ChatGPT 和各种开源模型上对我们的方法进行了评估。 对于 ChatGPT,我们评估了 GPT-3.5-Turbo (gpt-3.5-turbo-1106) 和 GPT-4 (gpt-4-1106-preview),这两个版本都已具备函数调用功能。 关于开源模型,我们评估了几个广为人知的不同规模的聊天调谐模型,包括 7B 参数模型 Zephyr-7B-Beta (Tunstall 等,2023)、7B 和 13B 版本的 Vicuna-v1.5 (Chiang 等,2023)、7B、13B 和 70B 版本的 LLaMA2-Chat (Touvv、2023),LLaMA2-Chat 的 7B、13B 和 70B 版本 (Touvron 等,2023),以及 13B 参数模型 Baichuan2-13B-Chat Baichuan(2023)。 这些模型的详细说明和 Huggingface 模型路径见附录。
此外,我们还对微调模型FnCTOD-LaMA2-13B进行了评估。 值得注意的是,与这些领域转移基线不同,我们的模型完全是在来自 MultiWOZ 以外的数据集的 7200 个对话中训练的,因此设置更加真实,也更具挑战性。
推理细节
对于具有函数调用功能的 ChatGPT 和经过微调的 FnCTOD-LaMA2-13B,我们可以执行零样本提示,不包括系统提示中的上下文示例。 对于其他开源模型,我们默认使用五个样本(5-shot)进行少样本提示。 值得注意的是,零样本/少样本提示中的样本指的是提示模型时使用的上下文中样本的数量,而零样本 DST 中的样本指的是训练数据中看到的域内样本的数量。
5.2零样本 DST 评估
表 2 列出了零样本 DST 性能比较,观察结果总结如下。
我们的方法使中等规模的开源模型能够超越以前使用高级 ChatGPT 实现的 SOTA 结果。
以往的提示方法仅在使用高级专有模型时显示出良好效果,但在使用较低级模型时则表现不佳Hudeček 和 Dušek (2023)。 与以前使用高级 ChatGPT 和 Codex 获得的 SOTA 结果相比,我们的方法首次使中等规模的开源模型实现了相当或更优的性能。 具体来说,7B 参数 Zephyr-7B-Beta 和 13B 参数 Baichuan2-13B-Chat 模型的性能优于之前的 SOTA。 这一重大进展标志着 DST 和 TOD 在实际应用法律硕士方面的一个里程碑。
与之前的提示方法相比,我们的方法大大提高了 ChatGPT 的性能。
与之前报告的结果相比,我们的方法在 GPT-3.5 和 GPT-4 模型中分别提高了 4.8%(平均 JGA)和 14%。 我们使用 GPT-4 的结果比之前使用 Codex 的 SOTA 提示方法高出 5.6% 的平均 JGA。
我们经过微调的 13B 参数模型与 ChatGPT 的性能相匹配。
很明显,我们微调后的 FnCTOD-LLaMA2-13B 比其基础模型 LLaMA2-13B-Chat 有了显著提高,性能可与 ChatGPT 相媲美。 这表明,我们可以轻松地使中等规模的开源 LLM 具备与 ChatGPT 相当的函数调用能力和零样本 DST 性能,这标志着我们在弥合开源模型和专有模型之间的差距方面取得了令人振奋的进展。
5.3零样本端到端 TOD 评估
在实际应用中,TOD 系统会使用跟踪到的对话状态来查询知识库或应用程序接口,以获得响应。 我们对 DST 和响应生成进行了端到端评估,这是一种更现实、更具挑战性的设置。 我们的 FnCTOD 方法可以生成这两种对话状态、 即在助手的输出中会出现函数调用、和响应。 这与通常将 DST 作为独立任务的提示方法形成了鲜明对比。 与之前的端到端零样本 TOD 评估工作Hudeček 和 Dušek (2023)一致,我们使用 MultiWOZ 2.2 数据集Zang 等人 (2020)进行了去词汇化应答评估。 我们的评估指标包括 DST 的 JGA 和生成响应的 成功率。 成功率是指完全达到用户目标的对话所占的百分比。 结果见表 3。
| Model | JGA | Success |
| ChatGPT Hudeček and Dušek (2023) | 21.0 | 20.0 |
| FnCTOD-LLaMA2-13B | 37.9 | 44.4 |
| Zephyr-7B-Beta | 32.3 | 57.5 |
| Vicuna-7B-v1.5 | 29.4 | 37.7 |
| Vicuna-13B-v1.5 | 33.8 | 23.1 |
| Baichuan2-13B-Chat | 33.0 | 45.7 |
| LLaMA2-7B-Chat | 16.7 | 24.9 |
| LLaMA2-13B-Chat | 25.8 | 27.7 |
5.4消融研究
不同数量的上下文示例的影响
我们最初的研究重点是在使用开源模型进行少样本提示时,改变上下文中示例数量的影响,这些模型最初并不是为函数调用生成而训练的。 我们使用不同数量的上下文示例(从 0 到 5 个不等)对各种模型的性能进行了评估。 我们注意到,使用五个以上的例子可能会超出某些模型的上下文窗口容量(如 4096 个词符)。 图 LABEL:fig:nshot说明了研究结果。 结果表明,与零样本提示相比,利用上下文中的样本时,模型的表现明显更好。 此外,在大多数领域和模型中,随着示例数量的增加,性能也在不断提高。 这突出表明,在利用开源模型通过函数调用实现 DST 时,上下文示例起着至关重要的作用,这也是合理的,因为这些模型并没有经过微调,无法完全根据系统提示中的函数规范生成所需格式的函数调用。
| Attr. | Hotel | Rest. | Taxi | Train | |
| ChatGPT (GPT-3.5) | |||||
| w/o decomp. | 59.64 | 32.24 | 61.39 | 74.87 | 49.91 |
| w/ decomp. | 67.15 | 37.56 | 60.12 | 74.43 | 67.29 |
| FnCTOD-LLaMA2-13B | |||||
| w/o decomp. | 34.77 | 32.02 | 56.63 | 65.40 | 36.21 |
| w/ decomp. | 62.24 | 46.83 | 60.27 | 67.48 | 60.90 |
函数调用分解的影响
在每个对话回合中,模型首先需要确定要调用的适当函数(函数选择),然后为其生成相应的参数(参数生成)。 我们将我们的两步法与非分解法进行了比较,在非分解法中,所有支持的函数都直接包含在提示中,模型的任务是在一个步骤中生成包含函数名和参数的整个函数调用。 这一比较是在 ChatGPT 和我们经过微调的 FnCTOD-LaMA2-13B上进行的,后者支持零样本提示。 值得注意的是,在使用 ChatGPT 时,非分解方法是默认的。 表4中的结果表明,这种分解方法始终能提高性能,从而凸显了我们策略的有效性。
| #Data | Attr. | Hotel | Rest. | Taxi | Train | Avg. |
| 100 | 59.61 | 44.40 | 54.33 | 67.02 | 54.33 | 55.94 |
| 200 | 62.24 | 46.83 | 60.27 | 67.48 | 60.90 | 59.54 |
| 300 | 69.19 | 43.68 | 57.06 | 64.98 | 57.60 | 58.50 |
| 400 | 60.80 | 43.21 | 57.39 | 65.70 | 53.78 | 56.18 |
训练数据大小的影响
我们的结果表明,在每个域中只需使用少至 200 个样本,即在 36 个域中总共使用 7,200 个对话的情况下,我们就能对 LLaMA2-13B-Chat 模型进行微调,使其与 ChatGPT 的零样本 DST 性能相匹配。 我们使用不同数量的样本(每个域 100 到 400 个不等)探索了该模型的性能。 表 5 所示的结果表明,每个域使用 200 个样本就能达到最佳性能。 我们推测,超过这一点后,训练样本的数量会导致模型过度拟合训练数据中的域,从而降低零样本泛化的效果。
6结论
我们引入了一种新方法,利用 LLM 解决零样本 DST 这一具有挑战性的任务,使它们能够处理不同领域中的一般对话和任务导向型对话,而无需额外的数据收集。 我们在 MultiWOZ 上的实验结果表明,我们的方法不仅能在高级 ChatGPT 模型中实现卓越性能(树立了新的基准),还能在一系列中等规模的开源 LLM 中实现卓越性能。 此外,我们还证明,只需使用来自 36 个不同领域的 7,200 个训练样本,我们就可以对开源模型 LLaMA-2-13B-Chat 进行微调,从而得到 FnCTOD-LaMA2-13B,它实现了与 ChatGPT 不相上下的函数调用、零样本 DST 性能。
7限制条件
在这项工作中,我们提出了一种利用 LLM 解决零样本 DST 的新方法。 我们的方法在使用各种 LLM(包括规模适中的开源 LLM 和先进的专有 LLM)时都取得了出色的性能,开创了新的先河。 不过,必须认识到,目前的精度可能还不足以实际部署这种零样本系统。 我们预计,随着基础 LLM 的 NLU 和 NLG 能力的进一步提高,我们的方法可以达到更高的性能水平。 此外,虽然我们的方法可以同时处理 DST 和 TOD 中的应答生成任务,但值得注意的是,由于目前缺乏针对 TOD 中应答生成的更真实的评估环境,我们使用了去词汇化应答进行评估,因为这在之前的工作中已被广泛使用。 这种设置和相关的度量标准有一些已知的不足之处,如可以用非自然反应来博弈度量标准,以及与 LLM 的训练方式存在数据不匹配。 在 LLM 时代,我们主张为 TOD 中的全自然语言应答生成开发更切合实际的评估方法。
参考资料
- Baichuan (2023) Baichuan. 2023. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305.
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. 2023. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Budzianowski et al. (2018) Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Inigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gašić. 2018. Multiwoz–a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. arXiv preprint arXiv:1810.00278.
- Byrne et al. (2019) Bill Byrne, Karthik Krishnamoorthi, Chinnadhurai Sankar, Arvind Neelakantan, Daniel Duckworth, Semih Yavuz, Ben Goodrich, Amit Dubey, Andy Cedilnik, and Kyu-Young Kim. 2019. Taskmaster-1: Toward a realistic and diverse dialog dataset. arXiv preprint arXiv:1909.05358.
- Campagna et al. (2020) Giovanni Campagna, Agata Foryciarz, Mehrad Moradshahi, and Monica S Lam. 2020. Zero-shot transfer learning with synthesized data for multi-domain dialogue state tracking. arXiv preprint arXiv:2005.00891.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Chung et al. (2023) Willy Chung, Samuel Cahyawijaya, Bryan Wilie, Holy Lovenia, and Pascale Fung. 2023. Instructtods: Large language models for end-to-end task-oriented dialogue systems. arXiv preprint arXiv:2310.08885.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Eric et al. (2020) Mihail Eric, Rahul Goel, Shachi Paul, Abhishek Sethi, Sanchit Agarwal, Shuyang Gao, Adarsh Kumar, Anuj Goyal, Peter Ku, and Dilek Hakkani-Tur. 2020. MultiWOZ 2.1: A consolidated multi-domain dialogue dataset with state corrections and state tracking baselines. In Proceedings of the Twelfth Language Resources and Evaluation Conference, pages 422–428, Marseille, France. European Language Resources Association.
- Heck et al. (2023) Michael Heck, Nurul Lubis, Benjamin Ruppik, Renato Vukovic, Shutong Feng, Christian Geishauser, Hsien-Chin Lin, Carel van Niekerk, and Milica Gašić. 2023. Chatgpt for zero-shot dialogue state tracking: A solution or an opportunity? arXiv preprint arXiv:2306.01386.
- Heck et al. (2020) Michael Heck, Carel van Niekerk, Nurul Lubis, Christian Geishauser, Hsien-Chin Lin, Marco Moresi, and Milica Gašić. 2020. Trippy: A triple copy strategy for value independent neural dialog state tracking. arXiv preprint arXiv:2005.02877.
- Hosseini-Asl et al. (2020) Ehsan Hosseini-Asl, Bryan McCann, Chien-Sheng Wu, Semih Yavuz, and Richard Socher. 2020. A simple language model for task-oriented dialogue. Advances in Neural Information Processing Systems, 33:20179–20191.
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685.
- Hu et al. (2022) Yushi Hu, Chia-Hsuan Lee, Tianbao Xie, Tao Yu, Noah A Smith, and Mari Ostendorf. 2022. In-context learning for few-shot dialogue state tracking. arXiv preprint arXiv:2203.08568.
- Hudeček and Dušek (2023) Vojtěch Hudeček and Ondřej Dušek. 2023. Are llms all you need for task-oriented dialogue? arXiv preprint arXiv:2304.06556.
- Jiang et al. (2023) Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. 2023. Mistral 7b. arXiv preprint arXiv:2310.06825.
- Kumar et al. (2020) Adarsh Kumar, Peter Ku, Anuj Goyal, Angeliki Metallinou, and Dilek Hakkani-Tur. 2020. Ma-dst: Multi-attention-based scalable dialog state tracking. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 8107–8114.
- Lee et al. (2019) Hwaran Lee, Jinsik Lee, and Tae-Yoon Kim. 2019. Sumbt: Slot-utterance matching for universal and scalable belief tracking. arXiv preprint arXiv:1907.07421.
- Li et al. (2023a) Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. 2023a. Api-bank: A comprehensive benchmark for tool-augmented llms. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3102–3116.
- Li et al. (2018) Xiujun Li, Sarah Panda, Jingjing Liu, and Jianfeng Gao. 2018. Microsoft dialogue challenge: Building end-to-end task-completion dialogue systems. arXiv preprint arXiv:1807.11125.
- Li et al. (2023b) Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023b. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval.
- Li et al. (2022) Zekun Li, Wenhu Chen, Shiyang Li, Hong Wang, Jing Qian, and Xifeng Yan. 2022. Controllable dialogue simulation with in-context learning. arXiv preprint arXiv:2210.04185.
- Li et al. (2023c) Zekun Li, Baolin Peng, Pengcheng He, Michel Galley, Jianfeng Gao, and Xifeng Yan. 2023c. Guiding large language models via directional stimulus prompting. arXiv preprint arXiv:2302.11520.
- Lin et al. (2021a) Zhaojiang Lin, Bing Liu, Andrea Madotto, Seungwhan Moon, Paul Crook, Zhenpeng Zhou, Zhiguang Wang, Zhou Yu, Eunjoon Cho, Rajen Subba, et al. 2021a. Zero-shot dialogue state tracking via cross-task transfer. arXiv preprint arXiv:2109.04655.
- Lin et al. (2021b) Zhaojiang Lin, Bing Liu, Andrea Madotto, Seungwhan Moon, Zhenpeng Zhou, Paul Crook, Zhiguang Wang, Zhou Yu, Eunjoon Cho, Rajen Subba, and Pascale Fung. 2021b. Zero-shot dialogue state tracking via cross-task transfer. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7890–7900, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Lin et al. (2021c) Zhaojiang Lin, Bing Liu, Seungwhan Moon, Paul Crook, Zhenpeng Zhou, Zhiguang Wang, Zhou Yu, Andrea Madotto, Eunjoon Cho, and Rajen Subba. 2021c. Leveraging slot descriptions for zero-shot cross-domain dialogue StateTracking. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5640–5648, Online. Association for Computational Linguistics.
- Lin et al. (2020) Zhaojiang Lin, Andrea Madotto, Genta Indra Winata, and Pascale Fung. 2020. Mintl: Minimalist transfer learning for task-oriented dialogue systems. arXiv preprint arXiv:2009.12005.
- Mrkšić et al. (2016) Nikola Mrkšić, Diarmuid O Séaghdha, Tsung-Hsien Wen, Blaise Thomson, and Steve Young. 2016. Neural belief tracker: Data-driven dialogue state tracking. arXiv preprint arXiv:1606.03777.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Parisi et al. (2022) Aaron Parisi, Yao Zhao, and Noah Fiedel. 2022. Talm: Tool augmented language models. arXiv preprint arXiv:2205.12255.
- Patil et al. (2023) Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2023. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334.
- Peng et al. (2020) Baolin Peng, Chunyuan Li, Jinchao Li, Shahin Shayandeh, Lars Liden, and Jianfeng Gao. 2020. Soloist: Few-shot task-oriented dialog with a single pretrained auto-regressive model. arXiv preprint arXiv:2005.05298, 3.
- Rastogi et al. (2020) Abhinav Rastogi, Xiaoxue Zang, Srinivas Sunkara, Raghav Gupta, and Pranav Khaitan. 2020. Towards scalable multi-domain conversational agents: The schema-guided dialogue dataset. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 8689–8696.
- Schick et al. (2023) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761.
- Shen et al. (2023) Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. arXiv preprint arXiv:2303.17580.
- Shin et al. (2022) Jamin Shin, Hangyeol Yu, Hyeongdon Moon, Andrea Madotto, and Juneyoung Park. 2022. Dialogue summaries as dialogue states (DS2), template-guided summarization for few-shot dialogue state tracking. In Findings of the Association for Computational Linguistics: ACL 2022, pages 3824–3846, Dublin, Ireland. Association for Computational Linguistics.
- Su et al. (2021) Yixuan Su, Lei Shu, Elman Mansimov, Arshit Gupta, Deng Cai, Yi-An Lai, and Yi Zhang. 2021. Multi-task pre-training for plug-and-play task-oriented dialogue system. arXiv preprint arXiv:2109.14739.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Tunstall et al. (2023) Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, et al. 2023. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944.
- Wen et al. (2016a) Tsung-Hsien Wen, Milica Gašić, Nikola Mrkšić, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, David Vandyke, and Steve Young. 2016a. Conditional generation and snapshot learning in neural dialogue systems. arXiv preprint: 1606.03352.
- Wen et al. (2016b) Tsung-Hsien Wen, David Vandyke, Nikola Mrkšić, Milica Gašić, Lina M. Rojas-Barahona, Pei-Hao Su, Stefan Ultes, and Steve Young. 2016b. A network-based end-to-end trainable task-oriented dialogue system. arXiv preprint: 1604.04562.
- Wu et al. (2020) Chien-Sheng Wu, Steven C.H. Hoi, and Caiming Xiong. 2020. Improving limited labeled dialogue state tracking with self-supervision. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4462–4472, Online. Association for Computational Linguistics.
- Wu et al. (2019) Chien-Sheng Wu, Andrea Madotto, Ehsan Hosseini-Asl, Caiming Xiong, Richard Socher, and Pascale Fung. 2019. Transferable multi-domain state generator for task-oriented dialogue systems. arXiv preprint arXiv:1905.08743.
- Yang et al. (2023) Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, Fan Yang, et al. 2023. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305.
- Zang et al. (2020) Xiaoxue Zang, Abhinav Rastogi, Srinivas Sunkara, Raghav Gupta, Jianguo Zhang, and Jindong Chen. 2020. Multiwoz 2.2: A dialogue dataset with additional annotation corrections and state tracking baselines. arXiv preprint arXiv:2007.12720.
- Zhang et al. (2023) Xiaoying Zhang, Baolin Peng, Kun Li, Jingyan Zhou, and Helen Meng. 2023. Sgp-tod: Building task bots effortlessly via schema-guided llm prompting. arXiv preprint arXiv:2305.09067.
- Zhao et al. (2022a) Jeffrey Zhao, Raghav Gupta, Yuan Cao, Dian Yu, Mingqiu Wang, Harrison Lee, Abhinav Rastogi, Izhak Shafran, and Yonghui Wu. 2022a. Description-driven task-oriented dialog modeling. arXiv preprint arXiv:2201.08904.
- Zhao et al. (2022b) Jeffrey Zhao, Raghav Gupta, Yuan Cao, Dian Yu, Mingqiu Wang, Harrison Lee, Abhinav Rastogi, Izhak Shafran, and Yonghui Wu. 2022b. Description-driven task-oriented dialog modeling. arXiv preprint arXiv:2201.08904.
附录 A Appendix
A.1评估细节
我们评估了两个版本的 ChatGPT 和六个主要的聊天/指令调整 LLM,它们代表了不同的规模、指令遵循和对话能力。 已评估的六个开源模型包括Zephyr-7B-Beta(Tunstall 等人,2023)是 Mistral-7B 的指令调整版本 (Jiang 等人,2023),它是 AlpacaEval 排行榜上同类模型中的佼佼者 Li等人 (2023b)。 Vicuna-7B-v1.5和Vicuna-13B-v1.5 (Chiang 等人,2023)是根据 ChatGPT 的用户对话微调的 LLaMA-2 模型。 LLaMA2-7B-Chat和LLaMA2-13B-Chat是大小不同的LLaMA2模型的聊天调整版本(Touvron 等人,2023)。 Baichuan2-13B-Chat 也是在广泛的语料库 Baichuan (2023) 上进一步微调的 LLaMA2-13B 模型。 我们利用了 Huggingface 上提供的检查点333https://huggingface.co/models。 表 8 详细列出了这些模型的具体路径。 推理时,温度固定为 0.3,top_p 为 0.2,max_tokens 为 128。 对于每个测试案例,我们都进行了一次推理运行。 所有推论均在配备了 8 个 48G NVIDIA RTX A6000 GPU 的集群上执行。
A.2训练细节
训练数据
为了构建微调数据集,我们选择了除 MultiWOZ 之外的五个高质量、多轮 TOD 语料库,详见表 9 。 每个数据集包含一个或多个领域。 我们排除了几个标注质量较低的域,共保留了 36 个域。 为了进行微调,我们专门从这些数据集的训练集中抽取数据,构成我们的训练数据。
| Hyperparameter | Values |
| batch size | |
| epochs | |
| learning rate | |
| learning rate scheduler | cosine |
| weight decay | |
| cutoff_len | |
| lora_r | |
| lora_alpha | |
| lora_dropout | |
| lora_target_modules | q_proj, v_proj |
| Model | Accuracy |
| ChatGPT (GPT-3.5) | 95.54 |
| ChatGPT (GPT-4) | 88.62 |
| FnCTOD-LLaMA2-13B | 91.68 |
| Zephyr-7B-Beta | 92.77 |
| Vicuna-7B-v1.5 | 94.75 |
| Vicuna-13B-v1.5 | 91.82 |
| Baichuan2-13B-Chat | 92.50 |
| LLaMA2-7B-Chat | 91.90 |
| LLaMA2-13B-Chat | 89.34 |
| LLaMA2-70B-Chat | 90.25 |
| Model | Model versioning/path |
| GPT-3.5-Turbo | gpt-3.5-turbo-1106 |
| GPT-4 | gpt-4-1106-preview |
| Zephyr-7B-Beta | https://huggingface.co/HuggingFaceH4/zephyr-7b-beta |
| Vicuna-7B-v1.5 | https://huggingface.co/lmsys/vicuna-7b-v1.5 |
| Vicuna-13B-v1.5 | https://huggingface.co/lmsys/vicuna-13b-v1.5 |
| Baichuan2-13B-Chat | https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat |
| LLaMA2-7B-Chat | https://huggingface.co/meta-llama/Llama-2-7b-chat-hf |
| LLaMA2-13B-Chat | https://huggingface.co/meta-llama/Llama-2-13b-chat-hf |
| Dataset | Domains | #Domains |
| Schema-Guided Rastogi et al. (2020) | RentalCars_1, RentalCars_2, Buses_1, Buses_2, Events_1, Events_2, | 26 |
| Services_1, Services_2, Services_3, Media_1, RideSharing_1, RideSharing_2, | ||
| Travel_1, Hotels_1, Hotels_2, Hotels_3, Flights_1, Flights_2, Restaurants_1, | ||
| Calendar_1, Music_1, Music_2, Weather_1, Movies_1, Homes_1, Banks_1 | ||
| CamRest676 Wen et al. (2016b) | Restaurant | 1 |
| MSR-E2E Li et al. (2018) | Restaurant, Movie, Taxi | 3 |
| TaskMaster Byrne et al. (2019) | pizza_ordering, movie_ticket, auto_repair, uber_lyft, coffee_ordering | 5 |
| WOZ Mrkšić et al. (2016) | Restaurant | 1 |
超参数
我们对 Hugginface.444https://huggingface.co/meta-LLaMA/LLaMA-2-13b-chat-hf 中的 LLaMA-2-13b-Chat 检查点进行了微调。 我们利用低秩逼近(LoRA)Hu et al. (2021),并将微调限制在q_proj和v_proj模块中的参数。 有关微调超参数的更多详情,请参见表 6 。 微调在 4 个 A6000 48GB GPU 上进行。
A.3更多结果
A.3.1功能选择精度
A.3.2消融研究
我们进行了更多的调查,重点是有效的提示策略,包括有效的对话提示格式和描述支持功能的方法。
统一对话提示的影响
我们首先利用开源模型对情境提示的有效提示策略进行了分析。 在我们的方法中,我们将功能调用无缝集成到助手的输出中,将其纳入对话语境,而不是将其作为一项单独的任务。 为了评估其影响,我们比较了对话上下文中包含或不包含函数调用的情况。 图 LABEL:fig:fs_ablation 中描述的结果强调了在对话上下文中嵌入函数调用的有效性。
功能规范类型的影响
除了在提示中直接包含 JSON 格式的函数说明外,我们还尝试将数据翻译成更易于人类理解的自然语言描述。 图 LABEL:fig:fs_ablation展示了直接使用 JSON 格式(json)和将其转换为自然语言描述(文本)之间的比较。 结果表明,使用这两种函数说明方法,模型的表现类似。
A.4提示
对话背景
我们采用了每个被评估的大语言模型在其微调中使用的特定聊天格式,关于对话在提示中的格式。555https://github.com/lm-sys/FastChat
系统提示
在评估中,我们使用了以下系统提示模板:
括号内用蓝色高亮显示的部分为占位符,由与该功能/领域相关的具体功能说明和对话示例取代。 示例部分仅用于少样本提示,模型未针对功能调用进行微调。
功能规格
对于提示符中系统提示符内的功能说明,我们遵循 ChatGPT 的格式。 为了提高模型的理解能力,我们还尝试将 JSON 格式翻译成自然语言描述,以纳入系统提示。 图 5 是一个示例,说明了特定领域的 JSON 格式及其相应的自然语言描述。
完整提示
结合所有组件,图 6 显示了完整对话提示的示例。 为了更清楚地说明问题,我们采用了一种更便于人类阅读的对话格式,其中不包括特定模型对话格式中使用的特殊词符。

