重新审视
内存高效大语言模型微调的零阶优化:基准
摘要
在不断发展的自然语言处理 (NLP) 领域,使用 SGD 和 Adam 等一阶 (FO) 优化器微调预训练的大型语言模型 (大语言模型) 已成为标准。 然而,随着大语言模型规模的增大,FO 梯度计算的反向传播 (BP) 产生的大量内存开销提出了重大挑战。 解决这个问题至关重要,特别是对于像设备上训练这样内存效率至关重要的应用程序。 本文基于 Malladi 等人 (2023) 引入的初始概念,提出转向无 BP、零阶 (ZO) 优化作为大语言模型微调过程中降低内存成本的解决方案。 t0>. 与传统的 ZO-SGD 方法不同,我们的工作通过对五个大语言模型家族(Roberta、OPT、LLaMA、Vicuna、Mistral)进行全面、首创的基准测试研究,将探索扩展到更广泛的 ZO 优化技术)、三种任务复杂性和五种微调方案。 我们的研究揭示了以前被忽视的优化原理,强调了任务对齐的重要性、前向梯度方法的作用以及算法复杂性和微调性能之间的平衡。 我们进一步引入了 ZO 优化的新颖增强功能,包括训练分块下降、混合和梯度稀疏性。 我们的研究为进一步实现记忆高效的大语言模型微调提供了一个有希望的方向。 重现我们所有实验的代码位于 https://github.com/ZO-Bench/ZO-LLM。
1简介
微调预训练大语言模型(大语言模型)已成为当前自然语言处理 (NLP) 范例中事实上的标准(Raffel 等人,2023;Sanh等人,2022)。 一阶 (FO) 优化器,例如、SGD (Amari,1993) 和 Adam (Kingma & Ba,2014),已经成为大语言模型微调的主要选择。 然而,随着大语言模型不断扩展,由于 FO 梯度计算所需的反向传播 (BP),它们会遇到显着的内存开销。 例如,计算大语言模型OPT-13B的梯度比模型推理需要更多的内存成本。 这导致了在大语言模型中实现内存效率微调的挑战。 解决这一挑战的进步还可以促进相关领域的技术突破,例如对内存效率有很高要求的设备上训练(Han 等人,2015;Zhu 等人,2023)。
为了提高内存效率,一种新兴的解决方案是在大语言模型微调过程中用无BP优化器代替需要BP的FO优化方法。 这最初由 Malladi 等人 (2023) 提出,其中 FO 梯度是使用函数值的有限差分来近似的。 尽管在大语言模型微调中得到了新的应用,Malladi 等人 (2023) 中使用的底层优化原理通常被称为零阶 (ZO) 优化,基于函数值的梯度估计称为ZO梯度估计(Flaxman等人, 2005; Nesterov & Spokoiny, 2017; Duchi等人, 2015; Ghadimi & Lan, 2013; Liu等人, 2020) 。 Malladi 等人 (2023) 采用经典的 ZO 随机梯度下降 (ZO-SGD) 算法(Ghadimi & Lan, 2013)(称为 MeZO)来描述预训练的大语言模型并利用ZO优化的无BP特性来降低内存成本。 然而,从ZO优化的角度来看,除了ZO-SGD之外,很多其他的ZO优化方法还没有在大语言模型微调的背景下进行探索。 因此,通过大语言模型微调的 ZO 优化基准研究是否可以实现准确性和/或效率的潜在改进仍然难以捉摸。 这就产生了要探讨的主要问题:
(问)我们能否在大语言模型微调中建立ZO优化的基准,探索被忽视的优化原理,并推进当前的技术水平?
为了解决(Q),与最相关的工作(Malladi等人,2023)相比,我们的工作引入了几项关键创新。 我们探索了 ZO-SGD 之外更广泛的 ZO 优化方法,并检查了各种任务和模型类型以及评估指标。 我们对不同的 ZO 优化方法进行了详细的比较分析,重点介绍了大语言模型微调中经常被忽视的前向梯度法(任等人,2022)以及其他 ZO 优化技术。 这项基准研究有助于揭示这些方法在准确性和效率方面的优缺点。 根据所获得的见解,我们建议使用分块下降、混合 ZO 和 FO 训练以及梯度稀疏性技术进一步改进基于 ZO 优化的大语言模型微调。 总之,我们的主要贡献列于下方。
我们在大语言模型微调的背景下创建了第一个 ZO 优化基准。 该基准测试包括我们对无BP或ZO优化方法、大语言模型系列、不同复杂度的任务以及
在我们的基准测试的帮助下,我们揭示了一系列以前被忽视的优化原则和通过 ZO 优化进行大语言模型微调的见解。 其中包括对齐任务以增强 ZO 优化的重要性、前向梯度作为大语言模型微调基线的作用,以及算法复杂性、微调精度、查询和内存效率之间的权衡。
除了对现有大语言模型微调的 ZO 优化方法进行全面评估之外,我们还引入了 ZO 优化的新颖增强功能,包括分块 ZO 优化、混合 ZO 和 FO 微调以及稀疏性引起的 ZO 优化。 这些提出的技术旨在提高 ZO 大语言模型微调的准确性,同时保持内存效率。
2相关工作
参数高效微调(PEFT)。 早期的工作(Houlsby 等人,2019;Lin 等人,2020)涉及在预训练模型的各层之间插入可训练适配器,它们是紧凑的前馈网络。 最近,人们提出了各种 PEFT 策略。 例如,基于Adapter的方法(Houlsby 等人, 2019; Chen 等人, 2022; Luo 等人, 2023; Karimi Mahabadi 等人, 2021; Pfeiffer 等人, 2020) 将一些可调节但高度紧凑的模块插入到预先训练的模型中。 LoRA (Hu 等人, 2021a) 对预训练模型采用可训练的低秩权重扰动,有效减少所需的微调参数数量。 基于提示的学习 (Gao 等人,2020;Hu 等人,2021b;Tan 等人,2021)在各种 NLP 任务中证明了有效性。 此外,还有提示调整 (Lester等人,2021)和前缀调整 (Li&Liang,2021)等方法> 将可学习的连续嵌入合并到模型的隐藏状态中,以针对特定的下游任务调节冻结模型。 以下工作(Liu等人,2021)展示了其在各种模型尺度上的适用性。 虽然这些最先进的 PEFT 技术大大减少了微调所需的参数数量,但由于使用了反向传播(BP)(Malladi 等人,2023 年),它们仍然会产生与缓存大量激活相关的内存成本。
零阶优化。 零阶 (ZO) 优化是一种使用有限差分来估计梯度的技术。 此类算法仅利用函数值预言机,但与基于一阶 (FO) 梯度的对应方法共享相似的算法结构。 ZO 优化通常享有可证明的(维度相关的)收敛保证,正如各种著作中所讨论的(Flaxman 等人,2005;Nesterov & Spokoiny,2017;Duchi 等人,2015;Ghadimi & Lan,2013) 。 这些方法因其在广泛的现代机器学习(ML)挑战中的有效性而引起了广泛关注(Liu等人,2020),包括对抗性攻击和防御(Chen等人) ,2017;叶等人,2018;张等人,2023;霍根等人,2022; ),与模型无关的对比解释(Dhurandhar等人,2019),通过视觉提示增强迁移学习(Tsai等人,2020),计算图展开(Vicol 等人,2023),并优化自动化机器学习流程(Gu 等人,2021a;Wang 等人,2022)。 除了标准机器学习之外,它还应用于强化学习中的策略搜索(Vemula等人,2019)、网络资源管理(Liu等人,2018)、基于机器学习的优化科学工作流程(Hoffman 等人,2022;Tsaknakis 等人,2022;Chen 等人,2024),以及片上学习增强(Gu 等人,2021b) 。
尽管其用例范围广泛,但 ZO 优化在 ML 中的应用主要仅限于小模型规模。 这种限制归因于与 ZO 优化相关的高方差和缓慢收敛,而模型维度加剧了这种情况。 为了扩大 ZO 优化的规模,人们提出了几种加速技术。 其中包括整合历史数据来完善 ZO 梯度估计器(Meier 等人,2019;Cheng 等人,2021),利用梯度结构信息(Singhal 等人,2023) 或稀疏性来减少 ZO 优化对问题规模的依赖 (Wang 等人, 2017; Cai 等人, 2022, 2021; Balasubramanian & Ghadimi, 2018; Ohta 等人, 2020; Gu 等人, 2021b; Chen等人, 2024),在优化中重用中间特征(Chen 等人, 2024)和随机扰动向量(Malladi 等人, 2023)过程。 这些进步表明 ZO 优化在更复杂和大规模的机器学习问题中的应用潜力越来越大。
针对大型模型的无 BP 训练。 训练大型模型,特别是大语言模型,由于涉及大量的BP计算图(Ren等人,2021;Kim等人,2023),因此非常消耗内存。 因此,无 BP 方法最近成为深度学习(DL)社区的焦点。 前向梯度学习(Baydin 等人,2022;Ren 等人,2022;Silver 等人,2021;Belouze,2022),建立在前向模式自动微分(AD)的基础上,提供了一种替代方案无 BP 训练的 ZO 优化。 与 ZO 优化不同,它依赖于前向模式 AD 来计算前向(方向)梯度。 然而,前向梯度的一个主要限制是它需要完全访问 AD 软件和深度模型,这使得它的内存效率低于 ZO 优化,并且对于解决黑盒问题来说不切实际(Chen 等人,2024 )。 无BP方法的规范包括贪婪分层学习(Nøkland & Eidnes, 2019)、输入权重对齐(Boopathy & Fiete, 2022)、前向前向算法(Hinton, 2022)、合成梯度(Jaderberg 等人, 2017)、BBT/BBTv2 进化算法(Sun 等人, 2022a, b) t4>、利用神经网络特殊低维结构的梯度猜测(Singhal 等人, 2023)以及其他优化提示的黑盒方法(Prasad 等人, 2023; Deng 等人,2022;柴等人,2022)。 其中许多算法的动机也是寻求深度学习的生物学解释。
将 ZO 优化应用于预训练的大语言模型特别有趣,因为它结合了无 BP 和利用预训练的优点。 这提高了 ZO 优化对大规模大语言模型的可扩展性,同时保持内存效率。 MeZO (Malladi 等人, 2023) 在参数高达 600 亿个参数的大语言模型中引入了 ZO-SGD 算法,与 LoRA 等一阶优化方法和结构化微调方法相比非常具有竞争力。 他们还提供了为什么 ZO 方法对大语言模型有效的理论见解。 这为高效的无BP大语言模型微调打开了大门,并在很大程度上激发了我们ZO基准研究。
3 回顾 ZO 优化及其他
这项工作的核心目标是在大语言模型微调中基准测试和利用ZO(零阶)优化的潜力,消除微调过程中对(一阶)反向传播(BP)的需要,从而实现内存效率 (Malladi 等人,2023)。 值得注意的是,(Malladi等人,2023)中使用的ZO优化技术主要是基本版本,具体来说,ZO随机梯度下降(ZO-SGD)。 还有更先进的 ZO 优化方法可用,如(Liu 等人,2020)中所总结。 因此,本节致力于回顾更广泛的 ZO 优化方法,并阐明之前被忽视的大语言模型微调原则。
ZO 优化的基础知识。 ZO 优化作为一阶 (FO) 优化的无梯度替代方案,通过基于函数值的梯度估计来近似 FO 梯度,我们将其称为 ZO 梯度估计,如 中所述( Flaxman 等人, 2004; Ghadimi & Lan, 2013; Duchi 等人, 2015)。 因此,ZO 优化方法通常反映其相应 FO 优化对应物的算法框架。 然而,它用 ZO 梯度估计代替 FO 梯度作为下降方向。
存在多种用于执行 ZO 梯度估计的技术。 在本文中,我们重点关注随机梯度估计器 (RGE) (Nesterov & Spokoiny, 2017; Duchi 等人, 2015),依赖于沿随机选择的方向向量的函数值的有限差分的方法。 Malladi 等人 (2023) 也使用 RGE 来实现大语言模型的内存高效微调。 它在大语言模型微调中的偏爱归因于它的查询效率,即,函数查询数量较少。 给定一个标量值函数 ,其中 的维度为 ,RGE(称为 )使用中心差来表示:
| (RGE) |
其中 是通常从标准高斯分布 中得出的随机方向向量, 是函数查询的数量,是一个小扰动步长(也称为平滑参数)。 Malladi 等人 (2023) 通过设置和来使用RGE。 然而,值得注意的是,查询数在ZO梯度估计方差和查询复杂度之间取得了平衡。 (Duchi 等人, 2015; Liu 等人, 2018)表明RGE的方差大致为量级,其中 表示大O 符号。
RGE背后的原理源于方向导数的概念 (Duchi 等人, 2015): As (令 ),(RGE)中函数值的有限差分趋于,表示沿随机方向 随后,RGE 产生 作为。 此外,方向导数为我们提供了 的无偏梯度估计:
| (1) |
在上述背景下,RGE可以被解释为使用方向导数的FO梯度的近似。
前向梯度:大语言模型微调中缺失的无 BP 基线。
作为将 RGE 连接到 (1) 的副产品,我们获得基于方向导数的梯度估计 ,称为 前向梯度 (Forward-Grad) (Baydin 等人, 2022; Ren 等人, 2022)。 与仅依赖函数值的有限差分的RGE不同,Forward-Grad需要使用前向模式自动微分(AD),但在深度模型细化的实现中无需后向求值——调整或训练。 换句话说,Forward-Grad是无BP的,可以作为另一种替代梯度估计方法,提高大语言模型微调的记忆效率。 我们强调,Forward-Grad 是一个可能被忽视的无 BP 优化器。 鉴于其无偏性(1)所示,理论上它可以作为 ZO 优化的性能上限。
ZO 优化方法的重点系列。 接下来,我们简要概述本工作中要关注的 ZO 优化方法。 具体来说,我们将包括:Malladi 等人 (2023) 在大语言模型中采用的 ZO-SGD (Ghadimi & Lan, 2013)微调,使用基于sign的梯度估计的ZO-SGD(ZO-SGD-Sign)(Liu等人,2019a),ZO -SGD 与 momentum (ZO-SGD-MMT) (Malladi 等人,2023)0>,具有保守1>梯度更新的 ZO-SGD(ZO-SGD-Cons2>),以及 Adam< 的 ZO 变体3> 优化器 (ZO-Adam4>) (Chen 等人, 2019)5>。
上述方法在求解时可以统一为以下通用优化框架:
| (2) |
其中表示第次迭代时的更新解,是学习率,是某个下降方向后-加工操作。 在 (2) 中,为了便于演示,我们省略了用于经验风险最小化的随机小批量的包含。 例如,当时,ZO-SGD可以表示为(2)。 类似地,如果 则可以导出 ZO-SGD-Sign,其中 表示逐元素符号运算。 另一个例子是设置的ZO-SGD-Cons。 我们建议读者参阅附录A,了解应用于 ZO 优化方法的 (2) 的更多算法细节。
我们选择上述 ZO 优化方法进行大语言模型微调的理由基于两个关键考虑因素:(1)我们优先考虑对现有 FO 优化器进行最少修改的 ZO 优化方法,确保简便性大语言模型微调的实现。 (2)我们专注于具有独特算法特征的方法,使我们能够探索多种优化策略来提高大语言模型的性能。 关于(2),我们包括 ZO-SGD-Sign,因为它采用 1 位梯度量化并代表最简单的 ZO 优化方法之一。 此外,我们还包括 ZO-SGD-MMT 和 ZO-SGD-Con,因为它们将某些形式的“自适应学习”纳入下降步骤更新中。 前者利用基于历史梯度信息的动量,而后者允许基于启发式的下降方向选择。 此外,由于利用了移动平均值和自适应学习率,ZO-Adam 是最复杂的 ZO 优化器之一。
大语言模型微调ZO优化中的任务对齐。 正如 (Chen 等人, 2024) 中所讨论的,扩大深度模型训练的 ZO 优化非常具有挑战性,因为它的方差很大,而方差取决于模型大小。 尽管如此,大语言模型预训练提供了独特的优势,它使微调器能够从优化良好的预训练模型状态开始。 这种优雅的模型初始化使得 ZO 优化有可能扩展到大语言模型微调任务(Malladi 等人,2023)。 即使在这种预训练-微调范式中,我们称之为"任务对齐"的另一个关键因素仍然在实现令人满意的 ZO 微调性能方面发挥着关键作用。 “任务对齐”是指将微调任务与预训练任务的格式对齐,由下一个词符或句子预测给出。 例如,Gao 等人 (2020); Malladi 等人 (2023) 通过引入精心设计的输入提示,将下游文本分类任务转化为下一个词符预测任务。 这些提示充当了协调微调任务与预训练任务的桥梁,促进从预训练模型启动时的 ZO 优化。
| Method | SST2 | RTE | ||||
| ✓ | ✗ | Difference | ✓ | ✗ | Difference | |
| FO-SGD | 91.6 | 91.5 | 0.1 | 70.9 | 61.4 | 9.5 |
| ZO-SGD | 89.4 | 79.2 | 10.2 | 68.7 | 60.4 | 8.3 |
| ZO-Adam | 89.8 | 79.2 | 10.6 | 69.2 | 58.7 | 10.5 |
作为热身实验, 标签。 1 通过比较使用预定义的使用和不使用场景,实证证明了将ZO优化应用于大语言模型微调简单二元分类任务时任务对齐的重要性提示实现任务协调。 我们在 SST2 (Socher 等人, 2013) 和 RTE (Wang 等人, 2019) 上对整个 Roberta-Large (Liu 等人, 2019b) 模型进行了仿真 具有两种选定 ZO 方法的数据集:ZO-SGD(即、(Malladi 等人,2023)中的 MeZO)和 ZO-Adam。 我们将它们的性能与 FO 方法 (FO-SGD) 的性能进行比较。 任务对齐通过模板 <CLS>SENTENCE 实现。它是[可怕的|伟大的].<SEP>用于 SST 数据集,另一个模板 <CLS>SENTENCE1?[是|否],SENTENCE2.<SEP>用于 RTE。 正如我们所看到的,如果没有基于提示的文本对齐,ZO 微调方法的性能会大幅下降。 ZO-SGD 和 ZO-Adam 在 SST2 和 RTE 上分别产生 和 精度下降。 相比之下,FO-SGD 由于缺乏任务协调而受到的影响较小。 这表明任务对齐特别有利于ZO大语言模型的微调。 还值得注意的是,为任务对齐制作有效的提示可能并不简单,因为提示设计依赖于上下文,并且可能会影响微调性能。 在这项工作中,我们按照 (Gao 等人, 2020) 和 (Malladi 等人, 2023) 将微调任务与预训练任务对齐。
4 LLM微调基准
在本节中,我们深入研究 ZO 优化在大语言模型微调中的实证表现。 我们的基准测试工作包括评估准确性和效率、考虑不同的下游任务复杂性(从简单的分类到更复杂的推理任务)以及考虑各种语言模型类型。
4.1 基准设置
大语言模型微调任务、方案和模型。 我们首先介绍任务和微调方案。 我们关注三个任务,从低到高考虑其复杂性,其中包括(1)最简单的二元分类任务,Stanford Sentiment Treebank v2(SST2)(Socher等人,2013), (2) 问答任务,Choice Of Plausible Alternatives (COPA) (Roemmele 等人, 2011), (3) 常识推理任务,WinoGrande (Sakaguchi 等人,2021),(4)多句阅读理解(MultiRC)(Khashabi 等人,2018)(仅用于效率评估)。 对于大语言模型在这些任务上的微调,我们探索了四种参数高效的微调(PEFT)方案:对整个预训练模型进行微调的全调优(FT)、低-通过施加低秩权重扰动来进行秩适应(LoRA)(胡等人,2021a),通过在词符嵌入中附加可学习参数来进行前缀调整(Prefix)(Li&Liang, 2021),以及提示调优(Prompt)(Liu 等人,2022),通过引入一系列附加到输入的可学习标记来使固定模型适应下游任务。 我们建议读者参阅 Appx。 B 了解详细信息。 此外,我们还整合了几种代表性语言模型,包括 Roberta-Large (Liu 等人, 2019b)、OPT (Zhang 等人, 2022a)、LLaMA2 (Touvron等人, 2023)、Vicuna (郑等人, 2023)、Mistral (Jiang 等人, 2023)。
设置和实施细节。 为了训练前面提到的大语言模型微调器,我们利用了第 2 节中介绍的 ZO 优化方法。 3。 其中包括 ZO-SGD(即 MeZO (Malladi 等人,2023))、ZO-SGD-Sign、ZO-SGD-MMT、ZO-SGD-Cons 和ZO-亚当。 为了进行比较,我们还展示了 Forward-Grad 的性能,它依赖于前向模式自动微分而不是 BP。 我们还提供了两个 FO 优化器的性能:(FO-)SGD 和 (FO-)Adam。 在将上述优化器应用于大语言模型微调任务之前,我们按照(Gao等人,2020;Malladi等人,2023)将微调任务格式与词符或基于句子预测的预训练任务,如表所示。 1。 我们分别运行 ZO(或无 BP)优化器和 FO 优化器进行 20000 次和 625 次迭代,如 (2) 中所述。 请注意,ZO 优化需要较长的收敛时间,如(Liu 等人,2020)所示。 在实现(RGE)时,除非另有说明,我们将每个梯度估计的查询预算设置为。 我们通过每种方法的网格搜索来确定其他超参数的值,例如平滑参数和学习率。 除非另有说明,以下(Malladi 等人, 2023)中,ZO 和 FO 方法分别默认采用半精度训练(F16)和混合精度训练(FP16),以减少内存消耗。 对于 FP16,模型以全精度加载,而训练以半精度进行,而 F16 表示模型和训练均采用 float16。 更多实现细节可以在 Appx 中找到。 C.2,以及它们对内存效率的影响将在第 2 节中讨论。 4.3。
评估指标。 我们使用两组指标来评估 ZO 大语言模型的微调:准确性和效率。 准确性衡量微调模型在特定任务中的测试时性能,例如分类任务中的测试准确性。 效率包括各种衡量指标,例如内存效率(就峰值内存使用量和 GPU 成本而言)、查询效率(即,ZO 优化所需的函数查询数量)和运行时效率。 这些指标共同提供了对ZO大语言模型微调所需资源的洞察,有助于评估其在实际场景中的可行性和成本效益。
4.2实验结果
| SST2 | Roberta-Large | OPT-1.3B | ||||||
| FT | LoRA | Prefix | Prompt | FT | LoRA | Prefix | Prompt | |
| FO-SGD | ||||||||
| Forward-Grad | ||||||||
| ZO-SGD | ||||||||
| ZO-SGD-MMT | ||||||||
| ZO-SGD-Cons | ||||||||
| ZO-SGD-Sign | ||||||||
| ZO-Adam | ||||||||
ZO 对 SST2 的微调:一项试点研究。 在 标签。 2进行了实验,比较不同的无 BP 和基于 BP (FO-SGD) 方法在最简单的大语言模型下游任务之一:SST2 数据集的二元分类任务上的性能。 我们研究了两种模型架构:中型 Roberta-Large 和较大的模型 OPT-1.3B。 下面总结了几个关键结果。
首先,ZO-Adam 似乎是最有效的 ZO 方法,在 8 种微调设置中的 4 种中实现了最佳性能。 然而,正如稍后将要展示的,这是以额外的内存消耗为代价实现的。 考虑到 ZO-Adam 具有最高的算法复杂性,这并不奇怪,如第 2 节中所述。 3。
第二,与 ZO 方法相比,Forward-Grad 是一种有竞争力的方法,特别是在 FT(全调优)设置中。 这表明Forward-Grad可能适用于更大规模的问题,并使其成为ZO大语言模型微调的引人注目的基线。 此外,当微调方案的复杂性降低时(例如,Prompt),Forward-Grad 相对于基于函数值的 ZO 方法的优势就会减弱。
第三,尽管已经进行了广泛的超参数搜索工作,但 ZO 方法的性能表现出很高的方差,不同实验场景中相对排名的波动就证明了这一点。 例如,ZO-Adam 的有效性在(OPT-1.3B,提示)设置中急剧下降。 此外,(Malladi 等人, 2023)中使用的MeZO方法(即,ZO-SGD)并不总是不出现在顶部-执行ZO优化器以在各种设置中对大语言模型进行微调。 这并不奇怪,很大程度上归因于 RGE 的高方差(Nesterov & Spokoiny,2017;Duchi 等人,2015)。
第四,ZO-SGD-Cons和ZO-SGD-MMT在大语言模型微调中也表现出了作为ZO优化器的强大性能。 然而,最简单的 ZO 优化方法 ZO-SGD-Sign 往往是最弱的方法,除了最简单的微调设置 Prompt 之外。 上述观察结果激励我们扩大探索范围,研究 ZO 方法在更广泛的模型和更复杂的任务中的有效性。
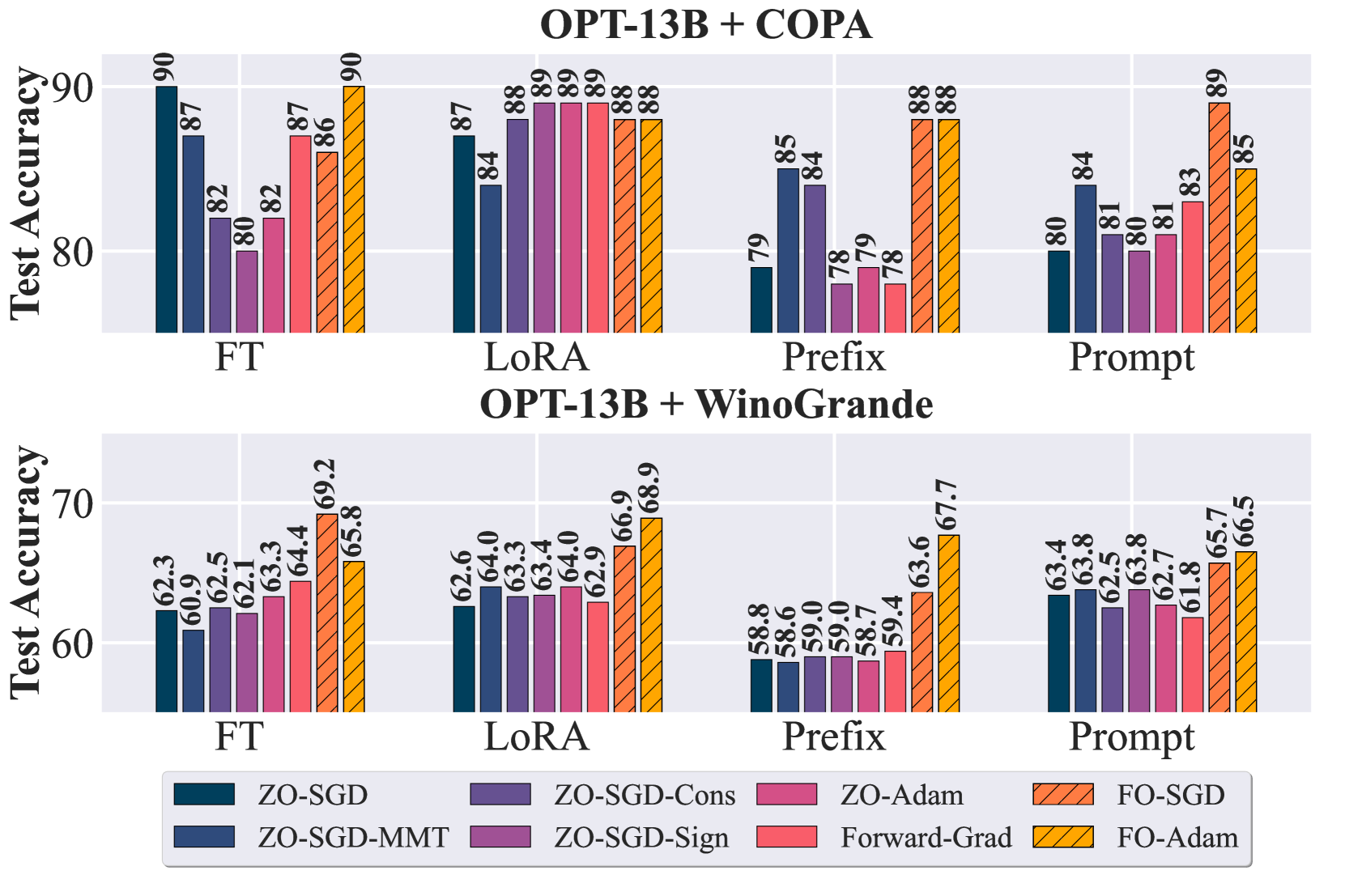
ZO 对 OPT-13B 下的下游任务 COPA 和 WinoGrande 进行微调。 从 SST2 的实验延伸而来,图 1。 1 展示了使用更大的模型 OPT-13B 在 COPA 和 WinoGrande 数据集上的微调性能。 当问题扩大并变得更加复杂时,我们总结了我们的主要观察结果。
首先,与之前的结果相比,不同ZO方法之间的性能差距被放大了很多。 同时,FO和ZO方法之间的性能差距也拉大了。 例如,在 WinoGrande 的实验中,FO 方法(FO-SGD 和 FO-Adam)大幅优于所有其他 ZO 方法。 这一观察结果表明,在处理更大的模型和/或更复杂的任务时,ZO 方法固有的可扩展性瓶颈。
其次,某些 ZO 方法在不同条件下表现出卓越的稳定性:尽管存在变异性的总体趋势,但特定的 ZO 方法,例如,ZO-Adam 和 ZO-SGD-MMT,证明了他们的表现的稳定性。 这可能是因为这些算法将方差减少的优化技术(例如动量和自适应学习率)集成到 ZO 优化中,并且对 ZO 梯度估计的方差具有更强的适应性和弹性(Chen 等人,2019)。
第三,LoRA 调优与各种 ZO 算法配合使用时始终保持稳健。 这种跨不同 ZO 方法的弹性表明 LoRA 的机制本质上更适合各种 ZO 优化策略,在不同的设置中提供稳定可靠的调优方法。 下面我们就来看看LoRA的表现。
| OPT-13B | LLaMA2-7B | Vicuna-7B | Mistral-7B | |
| COPA | ||||
| FO-SGD | ||||
| FO-Adam | ||||
| Forward-Grad | ||||
| ZO-SGD | ||||
| ZO-SGD-CONS | ||||
| ZO-Adam | ||||
| WinoGrande | ||||
| FO-SGD | ||||
| FO-Adam | ||||
| Forward-Grad | ||||
| ZO-SGD | ||||
| ZO-SGD-CONS | ||||
| ZO-Adam | ||||
在 标签。 3中,我们展示了不同的 ZO 方法如何在各种大语言模型家族中(LoRA、COPA)和(LoRA、WinoGrande)上执行。 为了便于计算,我们关注 ZO 优化方法的子集,包括 ZO-SGD、ZO-SGD-CONS 和 ZO-Adam。 正如我们所看到的,在 COPA 数据集的某些场景中,一些无 BP 方法表现出与 FO 方法(FO-SGD 和 FO-Adam)相当甚至优于 FO 方法的有效性。 例如,Forward-Grad 和 ZO-Adam 在模型 OPT-13B 和 Vicuna-7B 上的性能优于最佳 FO 方法。 相反,对于更困难的任务 WinoGrande,不同模型之间 FO 和 ZO 方法之间仍然存在 的性能差距。
效率分析。 在 标签。 4中,我们比较了在批量大小为 的 MultiRC 数据集上微调完整 OPT-13B 模型时各种 ZO/FO 优化器的效率性能。 我们从以下维度评估效率:内存成本(以 GB 为单位)、GPU 资源消耗(GPU 数量)以及每次优化迭代的运行时间成本(以秒为单位)。 所有实验均在同一环境下进行。 首先,从内存效率的角度来看,ZO-SGD、ZO-SGD-Cons 和 ZO-SGD-Sign 表现出相似的效率水平,并且只需要单个 GPU( A100) 用于大语言模型微调 这并不奇怪,因为这些 ZO 方法采用相对简单的优化步骤,并且主要依赖于 RGE 的利用。 第二,Forward-Grad 似乎是 ZO 优化方法失去其相对 FO 方法的内存效率优势的阈值,例如 ZO-Adam。 第三,与 FO 方法相比,ZO-SGD 与 FO-SGD 相比,ZO 优化将每次迭代的运行时间成本降低 。
| Optimizer | Memory | Consumed GPUs | Runtime Cost |
| ZO-SGD | GB | A100 | s |
| ZO-SGD-Cons | GB | A100 | s |
| ZO-SGD-Sign | GB | A100 | s |
| ZO-SGD-MMT | GB | A100 | s |
| Forward-Grad | GB | A100 | s |
| FO-SGD | GB | A100 | s |
| ZO-Adam | GB | A100 | s |
| FO-Adam | GB | A100 | s |
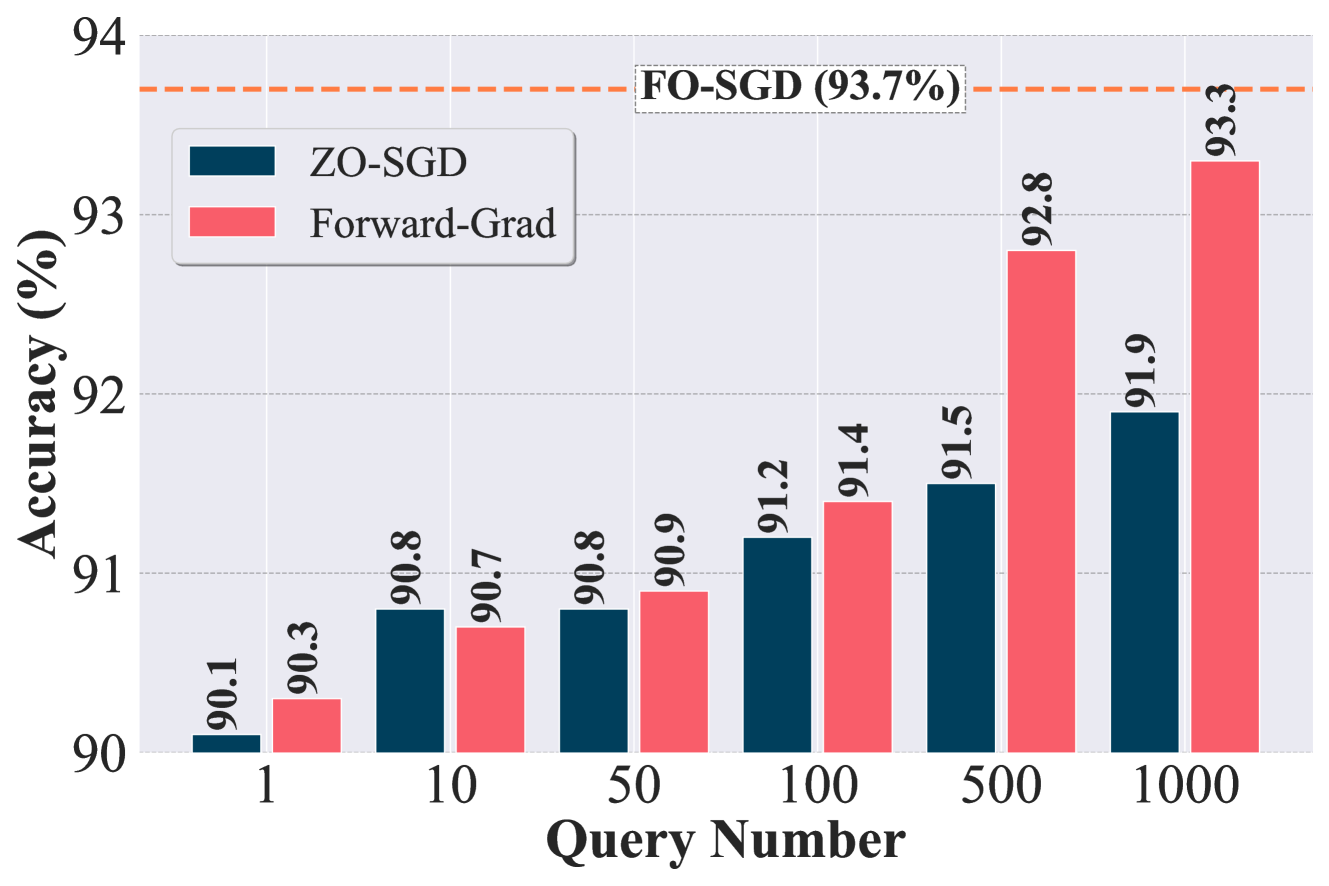
查询预算的消融研究。 回想一下 (1),Forward-Grad 为我们提供了关于 FO 梯度的无偏梯度估计,与基于函数值的有偏 ZO 梯度估计相反。 然而,在上述实验中,我们并没有观察到Forward-Grad带来的显着优势。 我们假设这是由于我们使用了最小的查询预算,尽管它的查询效率很高,但可能无法完全展示无偏的好处。 受上述启发,图。 2 探讨了不同查询预算 () 对 Forward-Grad 和 ZO-SGD(即、MeZO )。 正如我们所看到的,Forward-Grad 和 ZO-SGD 的准确性都随着查询预算的增加而提高。 然而,Forward-Grad 的性能提升更为明显。 例如,当查询数大于时,Forward-Grad 的性能大幅优于 ZO-SGD ,并接近 FO-SGD。 这些观察结果强调,只有当使用足够数量的查询时,前向梯度的固有优势才会变得明显。 使用较高查询预算的缺点是计算成本较高,该成本随 线性扩展。
| Optimizer | Weight Mem. | Dynamic Mem (Grad.&Opt.) | Opt. State Mem. |
| Optimizer in Full Precision | |||
| FO-SGD | 0 | ||
| FO-Adam w/o fast foreach | |||
| FO-Adam | |||
| Forward-Grad | |||
| Vanilla ZO-SGD | 0 | ||
| ZO-SGD | 0 | ||
| ZO-SGD MMT | |||
| ZO-Adam | |||
| Optimizer in Mixed Precision Training (FP16) | |||
| FO-SGD (FP16) | 0 | ||
| FO-Adam (FP16) | |||
| Optimizer with Half Precision Model (F16) | |||
| ZO-SGD (F16) | 0 | ||
| ZO-SGD-MMT (F16) | |||
| ZO-Adam (F16) | |||
4.3 内存效率的深入剖析
在本节中,我们将从理论上和经验上为 ZO 和 FO 方法提供整体内存配置文件。 我们将讨论本工作中采用的实现细节如何影响内存效率,包括 F16(半精度模型)和 FP16(混合精度训练)。
理论分析。 具有和不具有内存节省技巧的所有方法的理论内存效率列于 标签。 5. 我们建议读者参阅 Appx。 C.1 查看这些结果的详细分析。 可以总结出几个关键的见解。 首先,与FO优化器(包括Forward-Grad)相比,ZO优化器的内存效率主要来自两个角度:(1)ZO方法可以避免保存中间结果(模型状态)。 正如我们稍后将看到的,当语言模型的序列长度很大时,这种减少是相当可观的; (2) ZO方法可以分层估计梯度,从而避免存储整个模型的梯度。 其次,在FO方法中使用FP16只能减少中间结果的内存消耗(即,中的Tab.1)。 5),但不是来自模型加载或优化状态存储的。 相比之下,ZO 方法可以轻松配备 F16,从而减少 内存。 第三,尽管Forward-Grad也是一种无BP方法,但其相对于其他FO优化器的内存效率优势并不显着,主要是由于其对存储中间结果的要求(即,计算图)。 最后,虽然ZO-Adam与ZO-SGD相比是内存密集型的,但通过使用F16可以大大提高它,并取得比FO-SGD(FP16)更好的效率。
实证结果分析。 我们在表中进一步比较了完全微调的理论和经验内存成本。 Tab 中的 A1 和 LoRA 微调。 A2。 值得注意的是,实证结果通常与理论分析一致。 ZO 方法通常比 FO 方法更有效,并且可以通过加载半精度模型(使用 F16)进一步减少开销。
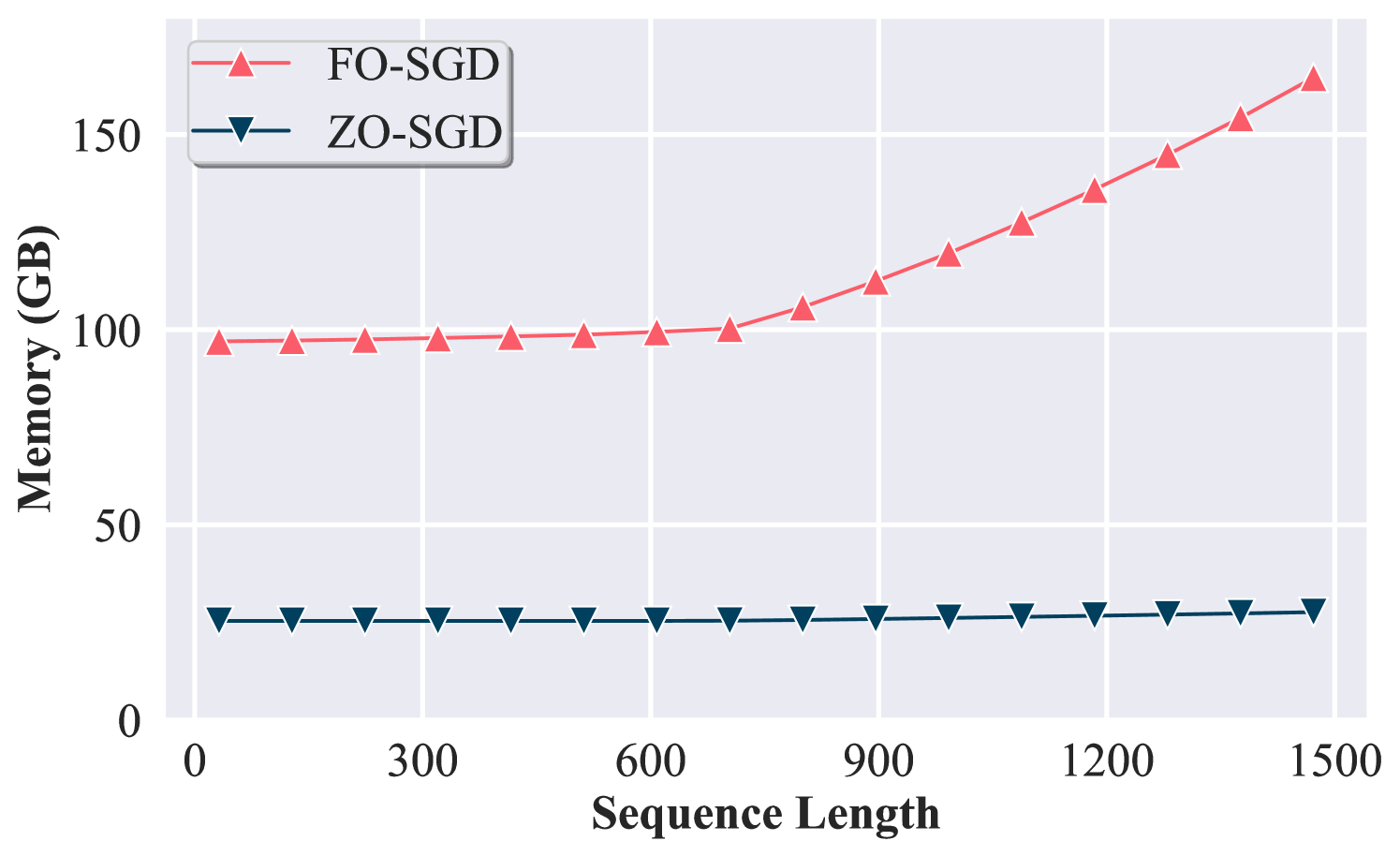
较大的序列长度增强了 ZO 方法的记忆优势。 我们注意到表中的实证结果。 A1 和选项卡。 A2 取决于输入序列长度。 一般来说,较大的序列长度会直接导致较大的激活内存消耗。 为了研究其影响,我们进一步探讨了输入序列长度的缩放如何通过增加激活内存来影响内存使用,结果如图3所示。 此外,我们还检查了大语言模型微调的内存成本与输入序列长度的关系。 在图中3,我们比较了 ZO-SGD 和 FO-SGD 在不同序列长度(即每个样本的词符数量)上的存储效率。 我们可以看到,ZO-SGD 的内存消耗保持了一致的水平,因为其峰值内存消耗仅由模型参数大小(即,基数)决定。并且与中间结果的大小无关(即、),请参见表 1。 5。 相反,随着序列长度的增加,FO-SGD 的峰值内存消耗首先保持不变,然后开始增加。 出现这种现象是因为 FO-SGD 的峰值内存消耗是由每层激活存储和梯度存储中较大的一个(即、)决定的。 当序列长度增加时,前者开始增长并最终在某个点超过后者(例如,超过700)。 因此,ZO-SGD 在上下文长度较长的设置中将表现出更好的效率优势。
5 改进 ZO 微调的扩展研究
超越第二节的基准测试工作。 4,我们将探索算法改进,进一步提高ZO大语言模型微调的有效性。 我们将利用以下技术:(1)逐块 ZO 微调; (2) 混合ZO和FO微调; (3)稀疏性引起的ZO梯度估计。 这些设计旨在减少使用 ZO 算法时梯度估计中的大方差。
逐块 ZO 优化增强了微调性能。 (Liu 等人, 2018) 表明,使用坐标确定性梯度估计器可以减少 ZO 优化方差,尽管该方案难以扩展。 同样,我们问RGE在逐块估计FO梯度时是否也可以提高ZO优化的性能。 关键思想是将大语言模型分成不同的块,然后将 ZO 梯度估计器应用于每个参数块。 例如,OPT-1.3B 需要 参数块,需要 前向传递以进行每个微调步骤的 ZO 梯度估计。 我们的理由是,通过分块进行梯度估计,所得梯度估计的方差将减少,从而有可能提高微调性能。
在 标签。 6因此,我们将 ZO 微调基线 MeZO (Malladi 等人,2023 年)(在第 4 章中对应于查询预算为 的 ZO-SGD)的性能与其基于块的 RGE 变体(我们称之为 ZO-SGD-Block)进行了比较。 为了在查询复杂性方面与 ZO-SGD-Block 进行公平比较,我们还展示了 ZO-SGD 的另一个变体的性能,该变体使用完整的模型 RGE 但采用相同的查询数 作为每次迭代的 ZO-SGD-Block。 值得注意的是,ZO-SGD-Block 在不同的微调任务中的不同查询预算设置中优于 ZO-SGD,显示了按块 ZO 调优的优势。
| Optimizer | Forward Pass # | SST2 | WinoGrande |
| MeZO | |||
| ZO-SGD () | |||
| ZO-SGD-Block |
通过混合 ZO-FO 训练在性能和内存效率之间进行权衡。 大语言模型微调中内存成本的主要来源来自BP,涉及将梯度从模型的深层传递到浅层。 为了节省内存,一种可能的方法是将 BP 限制在深层内而不将其传播到浅层。 此外,ZO优化可以用于浅层而不需要BP。 上述将深层 FO 优化和浅层 ZO 优化相结合的方法产生了大语言模型的混合 ZO-FO 微调方案。
| Memory (GB) | Accuracy () | |||
| ZO Layer # | Memory | Memory | Accuracy | Accuracy |
| (FO-SGD) | ||||
| (ZO-SGD) | ||||
标签。 7 展示了在(OPT-1.3B、SST2)上使用混合 ZO-FO 微调方案的性能。 我们通过决定在 ZO 优化(对于浅层)和 FO 优化(对于深层)之间划分的“where”来检查这种混合方案的不同变体。 假设模型由层组成,我们指定前层用于ZO优化,而剩余的层分配用于FO优化。 纯ZO优化方法对应于。 结果显示在表中。 7 证明仅在模型层的前三分之一(即、)上采用 ZO 优化可以产生与充分利用 ZO 优化所获得的性能相当的性能FO 优化的同时还减少了大约 10% 的内存使用量。 此外,当一半层采用 ZO 优化(即、)时,所获得的性能与完全 ZO 微调的性能相似。
梯度修剪有利于性能。 接下来我们探索梯度剪枝,这是一种在不影响收敛性的情况下加速模型训练的技术(McDanel 等人,2022)。 我们的关键思想是引入稀疏参数扰动,以减少 RGE 中的梯度估计方差。 我们首先利用基于幅度的剪枝(Frankle & Carbin,2018;Chen 等人,2020)来获得分层稀疏率。 然后,我们生成随机修剪掩模(遵循这些分层稀疏率)并将其应用于每个 ZO 微调步骤的 RGE 中的权重扰动。 标签。 8 显示了大语言模型微调中稀疏性引起的 ZO 梯度估计的性能作为总体稀疏率的函数。 很明显,选择适度的稀疏率(例如、)可以比普通 ZO 优化器 ZO-SGD 提高性能。
| COPA | ||||||||||
| Sparsity () | ||||||||||
| Accuracy () | ||||||||||
| SST2 | ||||||||||
| Sparsity () | ||||||||||
| Accuracy () | ||||||||||
6结论
这项工作探索了零阶(ZO)优化在大语言模型微调中的应用。 ZO 优化使用损失差异来近似梯度,从而消除了反向传播和激活存储的需要。 虽然 MeZO (Malladi 等人, 2023) 在适应大语言模型的 ZO 优化方面取得了长足的进步,但理解完整的 ZO 景观仍然是一个悬而未决的问题。 为了解决这个问题,我们通过考虑各种 ZO 优化方法、任务类型和评估指标来扩大范围。 我们对不同的 ZO 优化技术进行了首次基准研究,揭示了它们的准确性和效率。 我们还揭示了被忽视的 ZO 优化原理,例如任务对齐和前向梯度的作用。 利用这些见解,我们提出了诸如分块下降、混合 ZO 和 FO 训练以及梯度稀疏性等技术来增强基于 ZO 优化的大语言模型微调。 所提出的增强功能可以进一步提高微调精度,同时保持内存效率。
影响报告
本文旨在推进大型语言模型(大语言模型)内存效率微调的优化基础。 其潜在影响取决于如何利用这些经过微调的大语言模型。 从积极的一面来看,在大语言模型微调过程中实现内存效率可以显着降低能耗,有助于绿色人工智能的发展,并在资源有限的环境中提高性能。 然而,滥用方面存在潜在的负面影响,因为经过微调的模型可能会被用来生成错误信息、网络钓鱼攻击或发布受版权保护的私人信息。 然而,考虑到这项工作的技术重点,这里没有需要强调的直接源于它的具体社会后果。
致谢
Y.Zhang 和 S.Liu 的工作得到了美国能源部劳伦斯利弗莫尔国家实验室的部分支持。 J. D. Lee 和 Z. Wang 的工作部分得到了 NSF AI 机器学习基础研究所 (IFML) 的支持。 M. Hong 和 J. Li 的工作部分得到 NSF 拨款 CCF-1910385 和 CNS-2003033 的支持。 这项工作还得到了亚马逊 AWS 礼品奖的支持。
参考
- Amari (1993) Amari, S.-i. Backpropagation and stochastic gradient descent method. Neurocomputing, 5(4-5):185–196, 1993.
- Balasubramanian & Ghadimi (2018) Balasubramanian, K. and Ghadimi, S. Zeroth-order (non)-convex stochastic optimization via conditional gradient and gradient updates. Advances in Neural Information Processing Systems, 31, 2018.
- Baydin et al. (2022) Baydin, A. G., Pearlmutter, B. A., Syme, D., Wood, F., and Torr, P. Gradients without backpropagation. arXiv preprint arXiv:2202.08587, 2022.
- Belouze (2022) Belouze, G. Optimization without backpropagation. arXiv preprint arXiv:2209.06302, 2022.
- Boopathy & Fiete (2022) Boopathy, A. and Fiete, I. How to train your wide neural network without backprop: An input-weight alignment perspective. In International Conference on Machine Learning, pp. 2178–2205. PMLR, 2022.
- Cai et al. (2021) Cai, H., Lou, Y., McKenzie, D., and Yin, W. A zeroth-order block coordinate descent algorithm for huge-scale black-box optimization. arXiv preprint arXiv:2102.10707, 2021.
- Cai et al. (2022) Cai, H., Mckenzie, D., Yin, W., and Zhang, Z. Zeroth-order regularized optimization (zoro): Approximately sparse gradients and adaptive sampling. SIAM Journal on Optimization, 32(2):687–714, 2022.
- Chai et al. (2022) Chai, Y., Wang, S., Sun, Y., Tian, H., Wu, H., and Wang, H. Clip-tuning: Towards derivative-free prompt learning with a mixture of rewards, 2022.
- Chen et al. (2024) Chen, A., Zhang, Y., Jia, J., Diffenderfer, J., Liu, J., Parasyris, K., Zhang, Y., Zhang, Z., Kailkhura, B., and Liu, S. Deepzero: Scaling up zeroth-order optimization for deep model training. ICLR, 2024.
- Chen et al. (2017) Chen, P.-Y., Zhang, H., Sharma, Y., Yi, J., and Hsieh, C.-J. Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models. In Proceedings of the 10th ACM workshop on artificial intelligence and security, pp. 15–26, 2017.
- Chen et al. (2022) Chen, S., Ge, C., Tong, Z., Wang, J., Song, Y., Wang, J., and Luo, P. Adaptformer: Adapting vision transformers for scalable visual recognition. Advances in Neural Information Processing Systems, 35:16664–16678, 2022.
- Chen et al. (2020) Chen, T., Frankle, J., Chang, S., Liu, S., Zhang, Y., Wang, Z., and Carbin, M. The lottery ticket hypothesis for pre-trained bert networks. Advances in neural information processing systems, 33:15834–15846, 2020.
- Chen et al. (2019) Chen, X., Liu, S., Xu, K., Li, X., Lin, X., Hong, M., and Cox, D. Zo-adamm: Zeroth-order adaptive momentum method for black-box optimization. NeurIPS, 2019.
- Cheng et al. (2021) Cheng, S., Wu, G., and Zhu, J. On the convergence of prior-guided zeroth-order optimization algorithms. Advances in Neural Information Processing Systems, 34:14620–14631, 2021.
- Deng et al. (2022) Deng, M., Wang, J., Hsieh, C.-P., Wang, Y., Guo, H., Shu, T., Song, M., Xing, E. P., and Hu, Z. Rlprompt: Optimizing discrete text prompts with reinforcement learning, 2022.
- Dhurandhar et al. (2019) Dhurandhar, A., Pedapati, T., Balakrishnan, A., Chen, P.-Y., Shanmugam, K., and Puri, R. Model agnostic contrastive explanations for structured data. arXiv preprint arXiv:1906.00117, 2019.
- Duchi et al. (2015) Duchi, J. C., Jordan, M. I., Wainwright, M. J., and Wibisono, A. Optimal rates for zero-order convex optimization: The power of two function evaluations. IEEE Transactions on Information Theory, 61(5):2788–2806, 2015.
- Flaxman et al. (2004) Flaxman, A. D., Kalai, A. T., and McMahan, H. B. Online convex optimization in the bandit setting: gradient descent without a gradient. arXiv preprint cs/0408007, 2004.
- Flaxman et al. (2005) Flaxman, A. D., Kalai, A. T., and McMahan, H. B. Online convex optimization in the bandit setting: Gradient descent without a gradient. In Proceedings of the sixteenth annual ACM-SIAM symposium on Discrete algorithms, pp. 385–394, 2005.
- Frankle & Carbin (2018) Frankle, J. and Carbin, M. The lottery ticket hypothesis: Finding sparse, trainable neural networks. arXiv preprint arXiv:1803.03635, 2018.
- Gao et al. (2020) Gao, T., Fisch, A., and Chen, D. Making pre-trained language models better few-shot learners. arXiv preprint arXiv:2012.15723, 2020.
- Ghadimi & Lan (2013) Ghadimi, S. and Lan, G. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM Journal on Optimization, 23(4):2341–2368, 2013.
- Gu et al. (2021a) Gu, B., Liu, G., Zhang, Y., Geng, X., and Huang, H. Optimizing large-scale hyperparameters via automated learning algorithm. arXiv preprint arXiv:2102.09026, 2021a.
- Gu et al. (2021b) Gu, J., Feng, C., Zhao, Z., Ying, Z., Chen, R. T., and Pan, D. Z. Efficient on-chip learning for optical neural networks through power-aware sparse zeroth-order optimization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 7583–7591, 2021b.
- Han et al. (2015) Han, S., Mao, H., and Dally, W. J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
- Hinton (2022) Hinton, G. The forward-forward algorithm: Some preliminary investigations. arXiv preprint arXiv:2212.13345, 2022.
- Hoffman et al. (2022) Hoffman, S. C., Chenthamarakshan, V., Wadhawan, K., Chen, P.-Y., and Das, P. Optimizing molecules using efficient queries from property evaluations. Nature Machine Intelligence, 4(1):21–31, 2022.
- Hogan & Kailkhura (2018) Hogan, T. A. and Kailkhura, B. Universal decision-based black-box perturbations: Breaking security-through-obscurity defenses. arXiv preprint arXiv:1811.03733, 2018.
- Houlsby et al. (2019) Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., Attariyan, M., and Gelly, S. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pp. 2790–2799. PMLR, 2019.
- Hu et al. (2021a) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models, 2021a.
- Hu et al. (2021b) Hu, S., Ding, N., Wang, H., Liu, Z., Wang, J., Li, J., Wu, W., and Sun, M. Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification. arXiv preprint arXiv:2108.02035, 2021b.
- Huang et al. (2022) Huang, F., Gao, S., Pei, J., and Huang, H. Accelerated zeroth-order and first-order momentum methods from mini to minimax optimization. The Journal of Machine Learning Research, 23(1):1616–1685, 2022.
- Ilyas et al. (2018) Ilyas, A., Engstrom, L., Athalye, A., and Lin, J. Black-box adversarial attacks with limited queries and information. In International conference on machine learning, pp. 2137–2146. PMLR, 2018.
- Jaderberg et al. (2017) Jaderberg, M., Czarnecki, W. M., Osindero, S., Vinyals, O., Graves, A., Silver, D., and Kavukcuoglu, K. Decoupled neural interfaces using synthetic gradients. In International conference on machine learning, pp. 1627–1635. PMLR, 2017.
- Jiang et al. (2023) Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., Casas, D. d. l., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- Karimi Mahabadi et al. (2021) Karimi Mahabadi, R., Henderson, J., and Ruder, S. Compacter: Efficient low-rank hypercomplex adapter layers. Advances in Neural Information Processing Systems, 34:1022–1035, 2021.
- Khashabi et al. (2018) Khashabi, D., Chaturvedi, S., Roth, M., Upadhyay, S., and Roth, D. Looking beyond the surface:a challenge set for reading comprehension over multiple sentences. In Proceedings of North American Chapter of the Association for Computational Linguistics (NAACL), 2018.
- Kim et al. (2021) Kim, B., Cai, H., McKenzie, D., and Yin, W. Curvature-aware derivative-free optimization. arXiv preprint arXiv:2109.13391, 2021.
- Kim et al. (2023) Kim, T., Kim, H., Yu, G.-I., and Chun, B.-G. BPipe: Memory-balanced pipeline parallelism for training large language models. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp. 16639–16653. PMLR, 23–29 Jul 2023.
- Kingma & Ba (2014) Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Lester et al. (2021) Lester, B., Al-Rfou, R., and Constant, N. The power of scale for parameter-efficient prompt tuning, 2021.
- Li & Liang (2021) Li, X. L. and Liang, P. Prefix-tuning: Optimizing continuous prompts for generation, 2021.
- Lin et al. (2020) Lin, Z., Madotto, A., and Fung, P. Exploring versatile generative language model via parameter-efficient transfer learning, 2020.
- Liu et al. (2018) Liu, S., Kailkhura, B., Chen, P.-Y., Ting, P., Chang, S., and Amini, L. Zeroth-order stochastic variance reduction for nonconvex optimization. volume 31, 2018.
- Liu et al. (2019a) Liu, S., Chen, P.-Y., Chen, X., and Hong, M. signSGD via zeroth-order oracle. In International Conference on Learning Representations, 2019a.
- Liu et al. (2020) Liu, S., Chen, P.-Y., Kailkhura, B., Zhang, G., Hero III, A. O., and Varshney, P. K. A primer on zeroth-order optimization in signal processing and machine learning: Principals, recent advances, and applications. volume 37, pp. 43–54. IEEE, 2020.
- Liu et al. (2021) Liu, X., Ji, K., Fu, Y., Tam, W. L., Du, Z., Yang, Z., and Tang, J. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv preprint arXiv:2110.07602, 2021.
- Liu et al. (2022) Liu, X., Ji, K., Fu, Y., Tam, W., Du, Z., Yang, Z., and Tang, J. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 61–68, 2022.
- Liu et al. (2019b) Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019b.
- Luo et al. (2023) Luo, G., Huang, M., Zhou, Y., Sun, X., Jiang, G., Wang, Z., and Ji, R. Towards efficient visual adaption via structural re-parameterization. arXiv preprint arXiv:2302.08106, 2023.
- Malladi et al. (2023) Malladi, S., Gao, T., Nichani, E., Damian, A., Lee, J. D., Chen, D., and Arora, S. Fine-tuning language models with just forward passes. arXiv preprint arXiv:2305.17333, 2023.
- McDanel et al. (2022) McDanel, B., Dinh, H., and Magallanes, J. Accelerating dnn training with structured data gradient pruning. In 2022 26th International Conference on Pattern Recognition (ICPR), pp. 2293–2299. IEEE, 2022.
- Meier et al. (2019) Meier, F., Mujika, A., Gauy, M. M., and Steger, A. Improving gradient estimation in evolutionary strategies with past descent directions. arXiv preprint arXiv:1910.05268, 2019.
- Nesterov & Spokoiny (2017) Nesterov, Y. and Spokoiny, V. Random gradient-free minimization of convex functions. Foundations of Computational Mathematics, 17:527–566, 2017.
- Nøkland & Eidnes (2019) Nøkland, A. and Eidnes, L. H. Training neural networks with local error signals. In International conference on machine learning, pp. 4839–4850. PMLR, 2019.
- Ohta et al. (2020) Ohta, M., Berger, N., Sokolov, A., and Riezler, S. Sparse perturbations for improved convergence in stochastic zeroth-order optimization. In Machine Learning, Optimization, and Data Science: 6th International Conference, LOD 2020, Siena, Italy, July 19–23, 2020, Revised Selected Papers, Part II 6, pp. 39–64. Springer, 2020.
- Pfeiffer et al. (2020) Pfeiffer, J., Rücklé, A., Poth, C., Kamath, A., Vulić, I., Ruder, S., Cho, K., and Gurevych, I. Adapterhub: A framework for adapting transformers. arXiv preprint arXiv:2007.07779, 2020.
- Prasad et al. (2023) Prasad, A., Hase, P., Zhou, X., and Bansal, M. Grips: Gradient-free, edit-based instruction search for prompting large language models, 2023.
- Raffel et al. (2023) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer, 2023.
- Ren et al. (2021) Ren, J., Rajbhandari, S., Aminabadi, R. Y., Ruwase, O., Yang, S., Zhang, M., Li, D., and He, Y. Zero-offload: Democratizing billion-scale model training, 2021.
- Ren et al. (2022) Ren, M., Kornblith, S., Liao, R., and Hinton, G. Scaling forward gradient with local losses. arXiv preprint arXiv:2210.03310, 2022.
- Roemmele et al. (2011) Roemmele, M., Bejan, C. A., and Gordon, A. S. Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In 2011 AAAI Spring Symposium Series, 2011.
- Sakaguchi et al. (2021) Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- Sanh et al. (2022) Sanh, V., Webson, A., Raffel, C., Bach, S. H., Sutawika, L., Alyafeai, Z., Chaffin, A., Stiegler, A., Scao, T. L., Raja, A., Dey, M., Bari, M. S., Xu, C., Thakker, U., Sharma, S. S., Szczechla, E., Kim, T., Chhablani, G., Nayak, N., Datta, D., Chang, J., Jiang, M. T.-J., Wang, H., Manica, M., Shen, S., Yong, Z. X., Pandey, H., Bawden, R., Wang, T., Neeraj, T., Rozen, J., Sharma, A., Santilli, A., Fevry, T., Fries, J. A., Teehan, R., Bers, T., Biderman, S., Gao, L., Wolf, T., and Rush, A. M. Multitask prompted training enables zero-shot task generalization, 2022.
- Shu et al. (2022) Shu, Y., Dai, Z., Sng, W., Verma, A., Jaillet, P., and Low, B. K. H. Zeroth-order optimization with trajectory-informed derivative estimation. In The Eleventh International Conference on Learning Representations, 2022.
- Silver et al. (2021) Silver, D., Goyal, A., Danihelka, I., Hessel, M., and van Hasselt, H. Learning by directional gradient descent. In International Conference on Learning Representations, 2021.
- Singhal et al. (2023) Singhal, U., Cheung, B., Chandra, K., Ragan-Kelley, J., Tenenbaum, J. B., Poggio, T. A., and Yu, S. X. How to guess a gradient. arXiv preprint arXiv:2312.04709, 2023.
- Socher et al. (2013) Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A. Y., and Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 conference on empirical methods in natural language processing, pp. 1631–1642, 2013.
- Sun et al. (2022a) Sun, T., He, Z., Qian, H., Zhou, Y., Huang, X., and Qiu, X. Bbtv2: Towards a gradient-free future with large language models, 2022a.
- Sun et al. (2022b) Sun, T., Shao, Y., Qian, H., Huang, X., and Qiu, X. Black-box tuning for language-model-as-a-service. In International Conference on Machine Learning, pp. 20841–20855. PMLR, 2022b.
- Tan et al. (2021) Tan, Z., Zhang, X., Wang, S., and Liu, Y. Msp: Multi-stage prompting for making pre-trained language models better translators. arXiv preprint arXiv:2110.06609, 2021.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Tsai et al. (2020) Tsai, Y.-Y., Chen, P.-Y., and Ho, T.-Y. Transfer learning without knowing: Reprogramming black-box machine learning models with scarce data and limited resources. In International Conference on Machine Learning, pp. 9614–9624. PMLR, 2020.
- Tsaknakis et al. (2022) Tsaknakis, I., Kailkhura, B., Liu, S., Loveland, D., Diffenderfer, J., Hiszpanski, A. M., and Hong, M. Zeroth-order sciml: Non-intrusive integration of scientific software with deep learning. arXiv preprint arXiv:2206.02785, 2022.
- Tu et al. (2019) Tu, C.-C., Ting, P., Chen, P.-Y., Liu, S., Zhang, H., Yi, J., Hsieh, C.-J., and Cheng, S.-M. Autozoom: Autoencoder-based zeroth order optimization method for attacking black-box neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, pp. 742–749, 2019.
- Vemula et al. (2019) Vemula, A., Sun, W., and Bagnell, J. Contrasting exploration in parameter and action space: A zeroth-order optimization perspective. In The 22nd International Conference on Artificial Intelligence and Statistics, pp. 2926–2935. PMLR, 2019.
- Verma et al. (2023) Verma, A., Bangar, S., Subramanyam, A., Lal, N., Shah, R. R., and Satoh, S. Certified zeroth-order black-box defense with robust unet denoiser. arXiv preprint arXiv:2304.06430, 2023.
- Vicol et al. (2023) Vicol, P., Kolter, Z., and Swersky, K. Low-variance gradient estimation in unrolled computation graphs with es-single. arXiv preprint arXiv:2304.11153, 2023.
- Wang et al. (2019) Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. 2019. In the Proceedings of ICLR.
- Wang et al. (2022) Wang, X., Guo, W., Su, J., Yang, X., and Yan, J. Zarts: On zero-order optimization for neural architecture search. Advances in Neural Information Processing Systems, 35:12868–12880, 2022.
- Wang et al. (2017) Wang, Y., Du, S., Balakrishnan, S., and Singh, A. Stochastic zeroth-order optimization in high dimensions. arXiv preprint arXiv:1710.10551, 2017.
- Ye et al. (2018) Ye, H., Huang, Z., Fang, C., Li, C. J., and Zhang, T. Hessian-aware zeroth-order optimization for black-box adversarial attack. arXiv preprint arXiv:1812.11377, 2018.
- Zhang et al. (2022a) Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X. V., et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022a.
- Zhang et al. (2022b) Zhang, Y., Yao, Y., Jia, J., Yi, J., Hong, M., Chang, S., and Liu, S. How to robustify black-box ml models? a zeroth-order optimization perspective. ICLR, 2022b.
- Zhao et al. (2019) Zhao, P., Liu, S., Chen, P.-Y., Hoang, N., Xu, K., Kailkhura, B., and Lin, X. On the design of black-box adversarial examples by leveraging gradient-free optimization and operator splitting method. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 121–130, 2019.
- Zheng et al. (2023) Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., et al. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023.
- Zhu et al. (2023) Zhu, S., Voigt, T., Ko, J., and Rahimian, F. On-device training: A first overview on existing systems, 2023.
附录
A 零阶优化算法
零阶优化在不使用导数的情况下解决目标函数 的最小化或最大化:
当函数不可微分、梯度计算昂贵或函数评估有噪声时,这些方法至关重要。 随机梯度估计 (RGE) 通过采样函数评估为零阶优化中的梯度提供替代。 点处的梯度可近似为:
其中 是标准高斯向量, 是小标量。 这种估计有利于使用仅基于函数评估的基于梯度的方法。 利用这个梯度估计器,我们总结现有的第零其他算法如下
ZO-SGD。 (Ghadimi & Lan, 2013) 该方法直接通过估计梯度更新参数:
ZO-Sign-SGD。 (Liu 等人, 2019a) ZO-Sign-SGD 的直觉是使梯度估计对噪声更加鲁棒,因为符号运算可以减轻(坐标方面)梯度噪声的负面影响方差大。 ZO-Sign-SGD使用两侧RGE并更新参数如下,
其中 是标准高斯向量。
ZO-SGD 具有动量。 (Huang 等人, 2022) 从一批中估计的随机梯度可能会出现很大的方差。 Momentum 使用移动平均值来估计全局梯度并通过以下方式更新参数
动量定义为
具有保守梯度更新的 ZO-SGD。 (Kim 等人, 2021) 该方法改编自 (Kim 等人, 2021) 以保守的方式更新参数:我们选取对应的点最小的损失值。 更新写道:
由于零阶 RGE 估计器引入的较大方差,我们相信保守更新可以纠正 ZO-SGD 的错误步骤,产生更好的收敛结果。
ZO-亚当。 (Chen 等人, 2019) 与带有动量的 ZO-SGD 类似,ZO-Adam 使用动量来估计梯度。 此外,ZO-Adam 通过对角矩阵 自适应地惩罚学习率以减少噪声。 总之,参数将通过以下方式更新
其中动量、第二个原始动量估计和归一化矩阵定义为
前向梯度。(Baydin等人,2022) 提出前向梯度以获得方向导数的无偏随机估计。 更新公式为
,其中 是标准高斯随机向量。 虽然前向梯度使用一阶梯度,但它在训练的前向传递过程中使用雅可比向量积(JVP)以减少计算和内存消耗。 因此,与基于反向传播的方法相比,内存复杂度仍然相对较低。
B 参数高效微调(PEFT)的预备知识
在我们的基准测试中,我们考虑了三种 PEFT 方法,包括 {LoRA、前缀调整、提示调整}。
)低阶适应(LoRA)。
LoRA 通过引入可训练的低秩矩阵来修改预训练模型,从而能够在有限的参数预算下进行微调。 给定 Transformer 模型中的权重矩阵 ,LoRA 将其分解为:
| (A1) |
其中是原始权重矩阵,和是低秩矩阵,表示秩。 在微调期间,仅更新 和 ,保持 冻结。
) 提示调整。
提示调整引入了一系列可训练的标记或提示来指导模型的预测。 令 为输入序列, 为表示提示嵌入的矩阵,其中 为提示的长度, 为嵌入维度。 则模型输入为:
| (A2) |
其中 是原始输入 的嵌入, 表示提示和原始输入的串联输入。 在微调期间,仅学习提示嵌入 ,其余模型参数保持冻结。
) 前缀调整。
前缀调整将提示调整的思想扩展到 Transformer 模型的注意力机制。 给定输入序列 ,模型使用额外的上下文向量 和 来处理它,作为注意机制中的键和值:
| (A3) |
其中、和表示注意力机制中的查询、键和值矩阵,、,是前缀的长度。 训练过程中,仅更新和,原始模型参数被冻结。
C 如何实现内存高效的 ZO/FO 优化器?
优化器的内存效率在很大程度上取决于其实现细节。 在本节中,我们将讨论这些实现细节并提供上述所有优化器的整体内存配置文件。 我们注意到本节中的讨论基于 PyTorch 框架。 一般来说,优化器的内存效率是由特定设置下训练期间消耗的峰值内存来定义的,这主要取决于在某个时间点存储的变量的最大数量。 为了剖析不同优化器的内存消耗,我们在算法A1中总结了一个通用的模型参数更新管道,其中包括四个主要步骤。 首先,程序需要使用全精度或半精度的完整参数加载模型。 这是所有优化器不可避免的消耗。 其次,前向传递将产生损失值并存储模型的任何涉及的中间状态。 此过程可能还需要存储任何其他临时变量(例如 FO-SGD FP16中模型权重的float16中的额外副本),该变量将在转发完成后立即释放完全的。 第三,利用存储的状态以反向模式反向传播损失。 类似地,该过程涉及存储后向状态和临时存储。 计算出梯度和状态后,的内存消耗将立即释放。 最后,根据计算出的梯度和状态,参数和优化器状态将被更新,并且的内存将被释放。 通常, 将是存储的渐变。 由于前向状态和梯度是逐层计算的,因此内存消耗将从状态顺序传输到梯度。 根据生命周期,内存消耗可归纳为两种:恒定内存,存在于整个训练生命周期;动态分配,仅存在于一个训练生命周期中。迭代主要用于梯度计算。 虽然动态分配只是暂时存在,但它可以增加峰值内存。 因此,我们将峰值内存消耗总结为
如果每层计算前向和后向,并且临时状态可以无效,则术语 将被 替换,其中 代表任何层数,导致内存消耗如下所示:
接下来,我们将详细介绍本工作中考虑的所有 FO/ZO 优化器,并一一讨论它们的内存效率。
C.1不同优化器的理论内存效率分析
FO-SGD FP16。 我们使用 和 分别表示 16 位版本的 和 (半精度)。 状态定义为:
这里,除了存储在 float16 中用于向后计算的激活值 之外,在混合精度训练中,float16 中还存在模型权重的额外副本。 模型权重的这个额外副本是前向计算期间的临时存储器。 因此,总内存消耗为
香草 ZO-SGD。 对于 ZO-SGD 的普通实现,前向状态包括随机向量 和投影梯度 ,即
投影梯度是通过区分两个前向传递来计算的,其中随机向量由下式给出:
与模型参数 具有相同的维度。 然后,后向状态是由 估计的梯度,并且不涉及优化器状态,即
因此,总内存消耗为:
ZO-SGD 带内存减少技巧(ZO-SGD)。 在这项工作中,ZO-SGD 方法默认使用 MeZO (Malladi 等人,2023) 中概述的随机状态技巧来实现,以减少内存消耗。 这个技巧的关键思想是保存用于生成随机向量的随机种子,而不是直接保存随机向量本身。 通过手动设置随机种子,可以按需生成每层的相同对应随机向量,并用于扰动,而不会产生任何额外的存储:
其中 rng 是伪随机变量生成器。 因此,需要的所有状态是:
由此得出总内存消耗:
为简单起见,我们在整篇论文中使用名称 ZO-SGD 来表示带有内存缩减技巧的 ZO-SGD。
ZO-SGD-动量。 ZO-SGD with Momentum 与 ZO-SGD 类似,但它会消耗额外的内存用于动量存储,动量存储与模型参数共享相同的大小。 这在算法A1中被视为优化器状态。 因此,状态被定义为:
与ZO-SGD类似,总内存消耗为:
前向梯度。 对于FG,前向状态包括随机向量和投影梯度。 投影梯度由雅可比向量积 (JVP) 和前向梯度计算,即、,其中随机向量为:
除了和之外,JVP本身还需要存储中间结果。 例如,考虑一个简化的两层网络。 假设第一层的输出是。 相应的JVP可以表示为
其中是在第一层计算的,需要占用大小的内存。 现在,我们可以将前向状态 所需的内存总结为
那么,后向状态就是估计的梯度,即,
因此,总内存消耗为
PyTorch 不支持无状态的前向梯度 (FG)。 这是因为PyTorch需要预先计算,因此无法简化为无状态实现。 因此,如果我们使用 PyTorch 前向模式自动微分(前向模式 AD)提供的前向梯度,则无法实现。
尽管使用 PyTorch 内置的自动微分工具不可能实现,但没有状态的 FG 仍然是可能的。 具体来说,对于每一层,我们保持计算时的顺序,然后可以根据需要计算。 在实践中追求更节省内存的 FG 计算仍然是一个悬而未决的问题,保留给未来的工作。
C.2 其他实施细节
半精度 (F16)。 大多数现代大语言模型都以 16 位浮点精度提供服务。 默认情况下,模型将以全精度(即 32 位)加载。 为了加快推理速度并提高内存效率,可以以 16 位精度加载模型,即 F16。 我们对不需要微分的 ZO 方法进行 F16。 请注意,对于前向梯度,无法加载 F16 进行自动微分。 对于 FO 方法,出于同样的原因不允许使用半精度。
混合精度 (FP16)。 对于 FO 方法,混合精度是加速梯度计算和降低内存复杂性的常见做法。 我们将混合精度(即计算梯度时的 16 位)表示为 FP16。 请注意,FP16 不会减少存储模型或梯度的内存消耗,而只会影响梯度计算和中间结果。
对于FO-SGD(FP16),计算梯度的内存消耗为
其中 是 16 位模型和激活的内存, 是激活和全精度梯度的内存。
Adam 的“foreach”实现。 Adam 的 PyTorch 实现将使用所谓的“foreach”实现来加速计算。 在较高层次上,foreach 实现将在 Adam 更新期间将所有层的权重合并为一个张量。 虽然 foreach 可以加快计算速度,但它需要额外的内存来存储所有权重。
| Optimizer | Theoretical Mem. | Empirical Mem. |
| FO-SGD | GB | |
| FO-Adam w/o fast foreach | GB | |
| FO-Adam | GB | |
| Forward Grad | GB | |
| Vanilla ZO-SGD | GB | |
| ZO-SGD | GB | |
| ZO-SGD MMT | GB | |
| ZO-Adam | GB | |
| FO-SGD (FP16) | GB | |
| FO-Adam (FP16) | GB | |
| ZO-SGD (F16) | GB | |
| ZO-SGD-MMT (F16) | GB | |
| ZO-Adam (F16) | GB |
| Optimizer | Theoretical Mem. | Empirical Mem. |
| FO-SGD | GB | |
| FO-Adam w/o fast foreach | GB | |
| FO-Adam | GB | |
| Forward Grad | GB | |
| Vanilla ZO-SGD | GB | |
| ZO-SGD | GB | |
| ZO-SGD MMT | GB | |
| ZO-Adam | GB | |
| FO-SGD (FP16) | GB | |
| FO-Adam (FP16) | GB | |
| ZO-SGD (F16) | GB | |
| ZO-SGD-MMT (F16) | GB | |
| ZO-Adam (F16) | GB |