ALLaVA:利用 GPT4V 合成数据构建 Lite 视觉语言模型
摘要
大型视觉语言模型 (LVLM) 的最新进展使得能够在语言模型中处理多模式输入,但需要大量的计算资源进行部署,尤其是在边缘设备中。 本研究旨在通过采用高质量的训练数据来缩小传统规模的 LVLM 和资源友好型精简版之间的性能差距。 为此,我们利用 GPT-4V 生成详细说明、复杂推理指令和图像详细答案的能力来创建合成数据集。 使用我们的数据 ALLaVA 训练的结果模型在 12 个基准测试中达到了高达 3B LVLM 的竞争性能。 这项工作强调了采用高质量数据来构建更高效的 LVLM 的可行性。 我们的在线演示位于https://allava.freedomai.cn。
1简介
最近几个月,大视觉语言模型(LVLM)蓬勃发展。 这些模型能够处理视觉和文本输入,类似于人类在现实场景中处理信息的方式。 LVLM 通常由两个关键组件组成,即视觉编码器和大语言模型(大语言模型)。 前者使模型能够看,后者使模型能够处理和说话。 因此,LVLM不仅可以执行传统的任务,例如字幕(Agrawal等人,2019;Young等人,2014)和图像文本检索(Lin等人,2015;Young等人) , 2014),但也能够遵循人类指令并执行复杂的 VQA 任务(Li 等人, 2023a; Liu 等人, 2023c; Ge 等人, 2023; Yu 等人, 2023; Fu等人,2023),使它们成为通用人工智能(AGI)的里程碑。
虽然 LVLM 展示了其卓越的能力,但它们通常需要大量资源来进行训练和部署。 例如,IDEFICS (IDEFICS, 2023) 经过数亿数据的训练; Qwen-VL (Bai 等人, 2023b) 和 CogVLM (Wang 等人, 2023c) 经过超过 10 亿个样本的训练。 巨大的成本阻碍了 LVLM 的民主化。 为了使 LVLM 更加便携,一些研究致力于开发精简版 LVLM (Chu 等人,2023;Zhu 等人,2024)。 尽管这些模型对计算资源稀缺的用户更加友好,但它们在一定程度上伴随着性能损失,表现为正常大小的 LVLM 和精简版 LVLM 之间的性能差距。
因此,在本文中,我们研究一个自然出现的问题: 扩展高质量数据能否填补正常大小的 LVLM 和精简版 LVLM 之间的性能差距? 为了回答这个问题,我们提示 GPT-4V 生成一系列高质量的数据集,包括高质量的标题、说明和答案。 然后,我们利用合成数据在 Phi2 上进行训练111https://huggingface.co/microsoft/phi-2,这是一个仅有 2.7B 个参数的超级模型,但其性能却可与 LLaMA2-7B 相媲美(Touvron 等人,2023 年)、(Hendrycks 等人,2021 年;Chen 等人,2021 年;Cobbe 等人,2021 年)。 我们将结果模型命名为 ALLaVA、A Lite Language 和 Vision A ssistant,我们在缩写中排除了tiny Lite。 受益于我们高质量的训练数据,ALLaVA 在各种基准测试中取得了具有竞争力的表现。
我们的贡献如下:
-
•
数据:我们收集并开源了用于 LVLM 训练的最大 GPT-4V 数据集。 该数据集由 1.4M 数据组成,带有细粒度的标题、复杂的指令和由 GPT-4V 生成的详细答案。
-
•
模型:我们提出ALLaVA,一种在大规模高质量数据上训练的精简版LVLM,在3B LVLM中的12个基准上取得了有竞争力的性能,证明了所提出的数据集的优越性。
2 重新思考现有的 LVLM
在强调输入数据质量重要性的“垃圾输入,垃圾输出”原则的指导下,我们的方法从以数据为中心的角度重新评估多模态语言模型。 在这个框架内 222我们通过仔细检查对齐和视觉指令调整阶段来重新评估广泛采用的解决方案(即 LLaVA Liu 等人 (2023a)),特别注意潜在的问题。,我们关注两个主要策略:对齐和视觉指令调整。 前者主要致力于协助语言模型辨别视觉对象并增强其视觉推理能力。 与此同时,后者侧重于使 LVLM 能够泛化更广泛的指令,特别是涉及视觉输入的指令。
2.1 关于对齐
图像文本对齐相当粗粒度现有工作倾向于使用字幕数据(即图像及其文本描述)来对齐语言模型中的图像和文本。 流行的大规模字幕数据集(Schuhmann 等人, 2022; 2021; Sharma 等人, 2018; Changpinyo 等人, 2021; Ordonez 等人, 2011) 由简短且粗粒度的字幕组成,引入噪声信号并阻碍视觉-语言对齐过程。 为了提高质量,BLIP (Li 等人, 2022) 引入了 CapFilt,它在人工注释的 COCO (Lin 等人, 2015) 数据集上进行训练,以生成更高质量的字幕并删除不满意的字幕。 LLaVA (Liu 等人, 2023b) 采用纯文本 GPT-4 (OpenAI 等人, 2023) 使用 COCO 注释直接生成视觉对话,但详细程度描述的数量受到人工注释的限制,并且扩展成本高昂。 此外,我们发现 COCO 图文对中的跨模态关联有限(Parekh 等人,2020),质疑在 COCO 之上管理高质量数据的有效性。 因此,我们需要一种更合理、可扩展的方法来获取高质量的字幕数据。
对齐数据规模太小,无法学习长尾视觉知识对齐过程是大规模多模态模型的关键步骤。 然而,目前对齐数据尤其是高质量数据的规模相对有限,通常在10万到50万个实例之间。 虽然这足以捕获流行的视觉知识,但它对推广到更广泛的长尾视觉知识提出了挑战。 例如,模型可能能够熟练地讨论金门大桥的照片,但对安吉大桥却视而不见 333https://en.wikipedia.org/wiki/Anji_Bridge,一座国际知名度较低的中国传统桥梁。 扩大对齐数据的数量,特别是来自不同来源的数据,对于实现对长尾视觉知识的细致入微的理解至关重要。 这对于解决模型意识和理解方面的差距尤其重要。
2.2 关于视觉指令
问题相对简单 以 Vision-FLAN (Xu 等人, 2023b) 为例,它包含 101 个数据集的 191 个 VQA 任务,与 WizardLM 相比,其问题相对简单 徐等人(2023a)。 正如 WizardLM Xu 等人 (2023a) 所说,复杂的问题(或称为“指令”)对于语言模型是有益的,特别是在指令遵循方面。 此外,当前的视觉指令调整数据集更注重提高基本能力,而不是复杂推理等更高级的能力。 例如,Visual Genome (Krishna 等人, 2016) 包含边界框定位问题,OCRVQA (Mishra 等人, 2019) 包含书籍封面的简单文本识别任务和 TextVQA (Singh 等人, 2019) 要求为每张图像生成一句话标题。
答案简短且缺乏信息此外,虽然Vision-FLAN中的答案是由人工手动注释的,但它们通常由简短的单词或短语组成,没有格式提示。 有些答案甚至作为一个句子是不完整的(例如,没有句号或大写第一个字母)。 直接学习此类输出会影响模型性能(Liu等人,2023a),这表明需要完善或重新生成Vision-FLAN指令的答案。
3 ALLaVA 方法论
3.1 Lite LVLM 的动机
Lite LVLM 越来越受欢迎,因为它们的训练和部署成本较低。 对于训练,使用 8*A100 40G GPU 训练 7B LLaVA 架构模型需要不到 14 小时的时间来训练 1M 数据(Liu 等人, 2023a)。 训练时间随着可训练参数的数量线性减少,这意味着在相同设置下训练 Phi2-2.7B 主干网只需要不到 7 个小时。 精简版 LVLM 的部署成本比普通尺寸的 LVLM 小得多。 利用量化技术,可以将2.7B LVLM装入8GB RAM的手机中并进行推理(Chu等人,2023),性能良好,这表明lite LVLM的前景广阔。
3.2 ALLaVA的理念
利用高质量数据进行规模补偿 虽然轻量级 LVLM 在计算成本方面比普通尺寸的同类产品具有优势,但由于参数数量减少,它们可能会遇到性能下降的情况。 为了增强 lite LVLM 的有效性,同时保持其效率,我们的目标是构建高质量的数据集,以弥补 lite LVLM 与正常大小的对应数据集相比固有的容量下降。
3.2.1 使用字幕然后QA方式进行数据合成
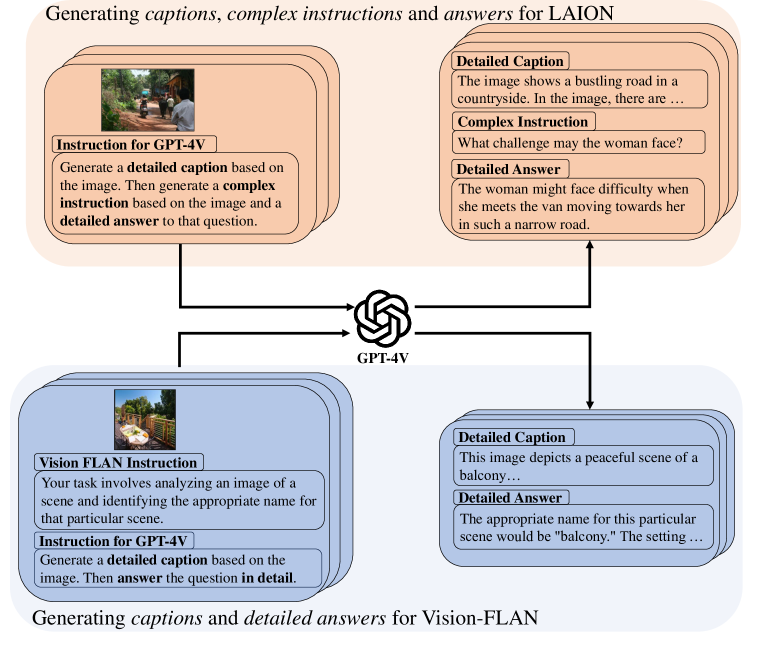
为了生成高质量的标题和 VQA,我们建议在单个会话中提取图像的标题和 QA 对,请参见图 2。 具体来说,我们用图像提示 GPT-4V,并要求它首先生成细粒度的标题,然后生成 VQA 对。 通过这样做,整个数据合成过程包括三个阶段:字幕、提问和回答,这在第 2 节中进行了描述。 3.3。
在典型的 VQA 场景中,合并附加标题是有益的;也就是说,补充说明可以被视为有助于提高答案质量和减少幻觉的额外上下文。 由于图像嵌入和标题分别充当图像的隐式和显式表达,因此答案的生成可以是基于两种类型的表达式,而不仅仅是前者。 通过利用附加信息,模型可以全面了解视觉和文本组件,从而提高其提供准确且与上下文相关的响应的能力。 此外,它可能会减轻幻觉问题,因为提供了更多的上下文。
3.2.2 图像来源
我们在数据合成中选择两个图像源:Vision-FLAN(本文其余部分简称为VFLAN)和LAION。 我们选择前者,因为图像与不同的指令(近 200 个任务)相关联。 后者是首选,因为它是来自“野生”互联网的自然结果,并且图像来源足够多样化;此外,图像来源也与最终用户的实际使用情况保持一致。
-
•
LAION (Schuhmann 等人, 2021) 是一种流行的视觉语言对齐数据集,因为它包含从网页爬取的各种图像。 为了保证图像质量,我们只下载短边分辨率至少为512的图像。
-
•
Vision-FLAN (Xu 等人, 2023b) 是一个集成了 101 个开源数据集的 191 个 VQA 任务的数据集。 它包含对于提高 LVLM 基础能力至关重要的指令,并且可以提高传统基准测试的性能。
3.3管道
3.3.1 第一阶段:字幕
走向细粒度的字幕。 图3显示了字幕提示片段。 它要求 GPT-4V 关注图像的多个方面并尽可能详细地描述图像。 生成的字幕预计细节丰富,由 GPT-4V 按一定逻辑组织。
3.3.2 第二阶段:提问
由于Vision-FLAN已经包含多种指令,因此我们保留其原始指令并且不对其进行问题生成。 我们仅针对来自 LAION 来源的图像生成问题。
提示复杂的问题。 正如第二节所论证的那样。 2.2,我们的目标是生成可能涉及复杂推理的复杂问题。 这是受到 WizardLM Xu 等人 (2023a) 的启发,但我们使用轻量级提示而不是原始指令演化来实现复杂的指令。
针对不同的问题。 在图 4 中,我们演示了使用 LAION 图像生成问题的示例提示。 为了促使 GPT-4V 做出更多样化、需要较强推理能力来回答的指令,我们要求它先生成 5 个候选问题,然后随机选择一个作为最终问题。 我们发现这种策略可以阻止 GPT-4V 提出具有相似模式的问题,从而迫使 LVLM 遵循更多样化的指令。
3.3.3 阶段 3:回答
详细答案 图5 显示了生成给定问题答案的示例提示。 答案文本不仅应该包括纯粹的答案,还应该提供详细的证据、思路和更相关的上下文。 我们认为,从复杂的问题和没有上下文的纯粹答案中学习可能会损害模型,因为从输入到输出的学习映射并不简单,并且可能会引入一些幻觉。
在ALLaVA-VFLAN中重新生成答案而不是原始答案对于Vision-FLAN数据集,原始答案存在格式问题,甚至作为句子不完整;因此,直接学习此类输出可能会损害语言模型的流畅性和连贯性。 因此,我们选择使用强大的 GPT-4V 重新生成其答案。 我们手动检查了一些 GPT-4V 应答输出,其质量令人满意。 背后的另一个基本原理与表面对齐假设Zhou 等人(2023)有关。 该假设指出,视觉指令调整阶段的主要目标是学习与用户交互时响应格式的细分,而不是注入更多知识;因为知识只是从预训练中学到的。
3.4关于道德
在描述特定职业时,解决涉及性别和种族等传统偏见因素的提示至关重要(见图6)。 确保公正的语言和公平的代表性对于减少历史偏见至关重要。 道德考虑是必不可少的,任何试图引起涉及披露个人信息或鼓励对代表性不足群体做出歧视性判断的问题都应被认定为不适当并立即拒绝。 坚持道德标准对于保持负责任和包容性的语言生成方法、在所提供的信息中营造积极和公正的环境至关重要。
3.5 结果数据集
| Type | Name | Subset Name | Source | #Ex. | Total |
| Caption | ALLaVA-Caption-4V | ALLaVA-Caption-LAION-4V | GPT-4V | 513K | 715K |
| ALLaVA-Caption-VFLAN-4V | 202K | ||||
| VQA | ALLaVA-Instruct-4V | ALLaVA-Instruct-LAION-4V | GPT-4V | 513K | 715K |
| ALLaVA-Instruct-VFLAN-4V | 202K | ||||
| Text | - | Evol-Intruct-GPT4-Turbo-143K | GPT4-Turbo | 143K | 143K |
如表1所示,我们按照数据生成管道构建了两个大规模合成数据集:图像标题和视觉指令数据。 此外,我们还提供从 GPT4-Turbo 中提取的纯文本的高质量指令数据。
LAION 图 1 的上半部分说明了使用 GPT-4V ( 在一个提示中对同一图像提取细粒度标题和复杂 VQA 的管道) OpenAI,2023),这是迄今为止 OpenAI 开发的最强大的 LVLM。 我们使用来自 LAION (Schuhmann 等人,2021) 的 513K 图像的子集,其中包含从网页爬取的各种图像。 我们将蒸馏后的标题集命名为 ALLaVA-Caption-LAION-4V,将 VQA 集命名为 ALLaVA-Instruct-LAION-4V。 详细提示参见附录A.1,示例参见附录A.3。
Vision-FLAN 图 1 的下半部分展示了使用 GPT 在一个提示中提取细粒度标题的管道以及对同一图像的给定指令的详细答案-4V。 我们将蒸馏后的字幕集命名为 ALLaVA-Caption-VFLAN-4V,将 VQA 集命名为 ALLaVA-Instruct-VFLAN-4V。 详细提示参见附录A.2,示例参见附录A.3。
Evol-Intruct-GPT4-Turbo-143K 正如(白等人,2023b)所指出的,经过多模态视觉指令调优后,语言模型能力可能会下降。 因此,我们采取添加文本数据来减轻大语言模型的灾难性遗忘。 具体来说,我们选择 WizardLM_evol_instruct_V2 (Xu 等人, 2023a) 作为我们的问题集,并使用 GPT4-Turbo 重新生成答案。 我们将结果数据集命名为 Evol-Intruct-GPT4-Turbo-143K。
4实验
4.1实现细节
| Module | Pretrained Backbone | #Params | Trainability |
|---|---|---|---|
| Vision Encoder | CLIP-ViT-L/14@336 | 303M | ✗ |
| Projector | From Scratch | 6.3M | ✓ |
| LM Backbone | Phi2 | 2.7B | ✓ |
我们的模型架构与 LLaVA-v1.5 (Liu 等人, 2023a) 相同,由视觉编码器、投影仪和大语言模型组成。 我们采用 LLaVA-v1.5 (Liu 等人, 2023a) 的两阶段训练。 我们训练投影仪和 LM 主干网,并在两个阶段冻结视觉编码器。 模块的选择及其可训练性总结在表2中。 更详细的训练超参数显示在附录C中。
表3列出了用于训练的数据,包括149K文本数据、795K字幕数据和1,372K VQA数据。 在预训练阶段,我们混合一份字幕数据副本和两份文本数据副本,并在训练期间从总体中随机抽样。 文本数据的两个副本有助于为基础大语言模型配备指令跟随能力。 在微调阶段,我们将一份 VQA 数据和一份文本数据混合在一起,并在训练过程中进行随机采样。 添加文本数据是为了缓解大语言模型在视觉指令微调过程中的灾难性遗忘问题(Bai等人,2023b)。
| Types | #Ex. | Total | Name | Source |
|---|---|---|---|---|
| Text | 143K | 149K | Evol-Intruct-GPT4-Turbo-143K | GPT4-Turbo |
| 6K | OpenChat (Wang et al., 2023a) | GPT-4 | ||
| Caption | 715K | 795K | ALLAVA-Caption-4V | GPT-4V |
| 80K | ShareGPT4V (Chen et al., 2023) | |||
| VQA | 715K | 1,372K | ALLAVA-Instruct-4V | GPT-4V |
| 657K | llava_instruct_657K (Liu et al., 2023a) | Original |
| Model | LM Backbone | Benchmarks | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Text | Multimodal (Close-ended) | Multimodal (Open-ended) | |||||||||||
| Vicuna-80 | MMB | SEED | MM-Vet | MMMUval | MME | VQAT | GQA | EMTc10 | MB | TS | LLaVAW | ||
| InstructBLIP | Vicuna-13B | - | 44.0 | - | 25.6 | - | 1212.8 | 50.7 | 49.5 | - | 4.0 | 552.4 | 58.2 |
| BLIP-2-T5-XL | FLAN-T5-XL(4B) | - | - | 49.7 | 22.4 | 34.4 | - | - | - | - | 2.1 | - | - |
| Qwen-VL-Chat | Qwen-7B | - | 60.6 | 65.4 | - | 35.9 | 1487.5 | 61.5 | 57.5 | - | 6.2 | 711.6 | - |
| LLaVA-v1.7B | Vicuna-7B | - | 64.3 | - | 31.1 | - | 1510.7 | 58.2 | 62.0 | - | - | 65.4 | |
| LLaVA-v1.5 13B | Vicuna-13B | 22.50 | 67.7 | 68.2 | 35.4 | 36.4 | 1531.3 | 61.3 | 63.3 | 85.0 | 7.4 | 637.7 | 70.7 |
| LVIS-Inst4V 7B | Vicuna-7B | - | 66.2 | - | 31.5 | - | 1528.2 | 58.7 | 62.6 | - | 6.0 | - | 67.0 |
| LVIS-Inst4V 13B | Vicuna-13B | - | 68.0 | - | 37.4 | - | 1574.9 | 62.5 | 63.6 | - | - | - | 71.3 |
| ShareGPT4V 7B | Vicuna-7B | - | 68.8 | 69.7 | 37.6 | - | 1943.8 | 60.4 | 63.3 | - | - | - | 72.6 |
| ShareGPT4V 13B | Vicuna-13B | - | 71.2 | 70.8 | 43.1 | - | 1921.9 | 62.2 | 64.8 | - | - | - | 79.9 |
| TinyGPT-V | Phi2-2.7B | - | - | - | - | - | - | - | 33.6 | - | - | - | - |
| MobileVLM | MobileLLaMA-2.7B | - | 59.6 | - | - | - | 1288.9 | 47.5 | - | - | - | - | - |
| LLaVA-Phi | Phi2-2.7B | - | 59.8 | - | 28.9 | - | 1335.1 | 48.6 | - | - | - | - | - |
| ALLaVA | Phi2-2.7B | 48.8 | 64.0 | 65.2 | 32.2 | 35.3 | 1623.2 | 49.5 | 48.8 | 90.2 | 6.7 | 632.0 | 69.4 |
| ALLaVA-Longer | Phi2-2.7B | 52.5 | 64.6 | 65.6 | 35.5 | 33.2 | 1564.6 | 50.3 | 50.0 | 85.9 | 8.8 | 636.5 | 71.7 |
4.2基准
文本基准
我们评估了 Vicuna-80 上多模态微调后的 LM 能力(Chiang 等人,2023)。 LLaMA2-7B-Chat 提供锚定答案,采用 GPT-4 投票选出更好的答案(详细提示见附录D.1)。 结果显示为候选模型对锚点的获胜率。
多式联运基准
LVLM 的多模态能力通过 8 个基准进行测量(详细信息请参阅附录 B)。最近的研究介绍了几个用于评估多模态和语言模型的基准。 MMBench (刘等人, 2023c)、SEED-Bench-v1 (李等人, 2023a)、MM-Vet (于等人, 2023)、MMMU (Yue 等人, 2023)、MME (Fu 等人, 2023)、TextVQA (Singh 等人, 2019)、GQA (Hudson & Manning, 2019)、MLLM-Bench (Ge 等人, 2023)、TouchStone (Bai 等人, 2023c)、LLaVA-Bench (In-the-Wild)(Liu 等人, 2023b) 和 EMT(Zhai 等人, 2023)0> 涵盖了广泛的问题和任务,从多项选择到开放式,跨越不同的能力维度。 虽然大多数基准测试都采用准确性作为指标,但有些基准测试使用独特的测量方法,例如锚点的获胜率或平均分数。 这些基准共同提供了评估和提高现代多模式和语言模型性能的多种方法。
4.3定量结果
表 4 显示了每个 LVLM 在 12 个基准测试中的性能。 ALLaVA 是我们使用我们的高质量数据在 Phi2-2.7B 上训练的模型。 为了进一步提高性能,我们在视觉指令调整阶段将模型再训练一个 epoch,产生 ALLaVA-Longer。 我们的模型在所有类似规模的 LVLM(即,~3B)(如 TinyGPT-V-2.8B)(Yuan 等人,2023) 中在这 12 个基准测试中实现了最佳性能、MobileVLM-3B (朱等人,2023)和 LLaVA-Phi-3B (朱等人,2024)。 它还在多个基准测试中与更大规模的 LVLM 实现了可比的性能,例如 InstructBLIP-13B (Dai 等人,2023)、BLIP-2 (Li 等人,2023b)、 Qwen-VL-Chat (白 等人, 2023b)、LLaVA-V1.5 (刘 等人, 2023a)、LVIS-Instruct4V (王 等人, 2023b) 和 ShareGPT4V (Chen 等人, 2023)。
我们的模型展示了卓越的语言能力,在 Vicuna-80 上比 LLaMA2-7B-Chat 提供的锚答案获得了 52.5% 的胜率。 这个结果也大大超过了 LLaVA-v1.5-13B,表明我们使用的文本数据的高质量以及从基础模型构建 LVLM 的有效性。
对于多项选择或简答题基准,ALLaVA 在 MMB、SEED 上大幅超越类似规模的 LVLM、MM-Vet、MME 和 GQA。 ALLaVA-Longer 在 MM-Vet、MME 和 EMT 上的性能甚至优于 LLaVA-v1.5-13B,其参数仅为 25%。 对于自由形式生成基准,ALLaVA-Longer 在 MLLM-Bench(探测复杂推理能力的基准)上比 GPT-4V 取得了 8.8% 的 SOTA 胜率。 它在 TouchStone 和 LLaVA (In-the-Wild) 上的性能也与 LLaVA-v1.5-13B 相当。
4.4定性结果
| Example 1: humor comprehension | |
|---|---|
![[Uncaptioned image]](6.png)
|
|
| User | Explain the humor of the image. |
| ALLaVA | The humor in the image arises from the unexpected and whimsical interaction between the two animals and the camera. The squirrel, typically a creature of the forest, is shown engaging with a human-made object, which is a camera. This anthropomorphism creates a playful and amusing scenario, as it is not common to see a squirrel with a camera. The bird, while not directly interacting with the camera, adds to the humor by being perched on the tripod, which is a human-made object, further blurring the lines between the natural and the artificial. The image plays on the idea of animals being curious about human technology and the unexpected ways in which they might interact with it. The humor is also enhanced by the contrast between the natural setting and the human-made objects, creating a surreal and entertaining scene. |
| GPT-4V | The humor in this image comes from the role reversal and anthropomorphism on display. Typically, it’s humans who photograph wildlife, but here, the squirrel is the one operating the camera, aiming it at the bird, as if it’s about to take a picture. The bird, on the other hand, is posing like a subject of a photograph. This unexpected switch, along with the attribution of human-like behavior to the animals, creates a whimsical and amusing scene that deviates from the norm, which is the essence of humor. Additionally, the fact that the camera is set on top of a mushroom adds another layer of fantasy and playfulness to the image. |
| LLaVA-v1.6-34B | The humor in this image comes from the anthropomorphism of the squirrel, which is a technique where human traits, emotions, or intentions are attributed to non-human entities. The squirrel is posed as if it is a photographer, holding a camera and seemingly taking a picture of the bird. This is amusing because it’s a playful and imaginative scenario that suggests the squirrel is engaging in human-like behavior, which is not possible in reality. The juxtaposition of a small, wild animal acting like a human photographer is whimsical and lighthearted, evoking a sense of amusement and wonder. |
| LLaVA-v1.5-13B | The image features a squirrel standing on its hind legs and holding a camera, seemingly taking a picture of a bird. This scene is quite humorous as it portrays the squirrel as a photographer, which is an unusual and amusing sight. The bird, on the other hand, is perched on a mushroom, adding to the whimsical nature of the scene. The combination of the squirrel’s human-like behavior and the bird’s presence creates a light-hearted and entertaining image. |
| Example 2: emotion detection | |
![[Uncaptioned image]](7.jpg)
|
|
| User | Based on the visual cues, what is the facial expression of the woman? |
| ALLaVA | The woman’s facial expression can be described as solemn and introspective. Her eyes are slightly narrowed, and her mouth is closed in a neutral position, which often conveys a sense of seriousness or deep thought. The overall impression is one of quiet contemplation or a moment of reflection. |
| GPT-4V | The woman in the image appears to have a neutral or contemplative expression. Her eyes are slightly downcast, and her mouth is closed in a relaxed manner, which does not convey a strong emotion. The overall impression is one of calmness or pensiveness. |
| LLaVA-v1.6-34B | The woman in the image appears to have a neutral to slightly serious facial expression. Her eyebrows are slightly furrowed, and her mouth is closed, which could suggest a thoughtful or contemplative mood. The white markings on her face, which are often associated with cultural or traditional significance, add a unique and striking element to her appearance. |
| LLaVA-v1.5-13B | The woman in the image has a serious facial expression, as she is looking directly at the camera. |
我们提供两个例子并比较 ALLaVA 与其他 SOTA 模型(包括 GPT-4V、LLaVA-v1.5-13B 和 LLaVA-V1.6-13B)的生成结果444结果于 2024 年 2 月 9 日从 https://llava.hliu.cc/ 获取。. 示例1测试模型的幽默理解能力。 所有四个模型都能够对图像产生令人满意的描述,捕捉松鼠和鸟的姿势并识别它们各自的角色,这为图像增添了幽默感。 示例 2 探讨了检测情绪的能力。 ALLaVA、GPT-4V 和 LLaVA-v1.6-34B 对女性的面部表情和潜在情绪有一致的判断。 然而,LLaVA-v1.5-13B 只有肤浅的描述,并指出她正在看镜头,但事实并非如此。
在这两个示例中,仅具有 3B 个参数的 ALLaVA 就能够与更大的模型实现相当的性能,展示了其从我们的高质量训练集获得的卓越推理能力。
4.5分析
数据消融
| PT w/ ALLaVA-Caption-4V | FT w/ ALLaVA-Instruct-4V | MM-Vet | MME | GQA |
|---|---|---|---|---|
| ✗ | ✗ | 25.8 | 1489.9 | 44.0 |
| ✗ | ✓ | 12.1 | 1199.8 | 39.0 |
| ✓ | ✗ | 30.0 | 1582.1 | 47.7 |
| ✓ | ✓ | 32.2 | 1623.2 | 50.0 |
表 6 详细说明了每个阶段使用或不使用我们的数据训练模型的结果。 基线结果(第 1 行)是通过单独使用 ShareGPT4V 进行对齐和 llava_instruct_657K 进行指令调整获得的。 单独添加 ALLaVA-Instruct-4V(第 2 行)的性能甚至比使用我们的任何一个数据(第 1 行)还要差,但添加两者(第 4 行)的性能比单独添加 ALLaVA-Caption-4V(第 3 行)要好。 这表明无法对未充分对齐的模型进行大规模视觉指令调整。 涉及我们的两个数据集(第 4 行)显着提高了这三个基准上的模型性能,体现了我们数据集的有效性。
| Name (LM backbone) | Vicuna-80 | MM-VET | MME | GQA |
|---|---|---|---|---|
| ALLaVA (Qwen-1.8B) | 40.0 | 28.3 | 1467.0 | 48.7 |
| ALLaVA (StableLM-2-1.6B) | 38.1 | 32.7 | 1539.1 | 49.9 |
| ALLaVA (Phi2-2.7B) | 48.8 | 33.2 | 1623.2 | 50.0 |
LM 主干网的选择
表 7 详细介绍了使用不同 LM 主干的结果。 多模态训练后使用 Phi2-2.7B 的语言性能明显优于使用 Qwen-1.8B (Bai 等人, 2023a) 和 StableLM-2-1.6B (Team, 2023) 。 在多模式基准测试中,使用 Phi2-2.7B 的性能优于 Qwen-1.8B,且比 StableLM-2-1.6B 的优势更大。 这一结果表明采用 StableLM 进行多模式训练的潜力。
5结论
在这项工作中,我们提出了一个同时生成高质量标题、指令和答案的框架,这是一种为 LVLM 训练获取更多数据的可扩展方法。 使用 ALLaVA-Caption-4V 和 ALLaVA-Instruct-4V,我们训练模型 ALLaVA,该模型在 3B 规模 LVLM 的 12 个基准测试中实现了具有竞争力的性能,并且在多个基准测试中与较大的 SOTA 模型(例如 LLaVA-v1.5-13B)具有相当的性能以及。 我们的数据可以显着缩小精简版 LVLM 和普通尺寸 LVLM 之间的性能差距。 我们将我们的模型和数据开源给研究界,以促进该领域的更好发展。
局限性
虽然我们已经提供了近1M的数据,但数据还可以进一步扩大。
参考
- Agrawal et al. (2019) Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. Nocaps: Novel object captioning at scale. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 8948–8957, 2019.
- Bai et al. (2023a) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report, 2023a.
- Bai et al. (2023b) Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, 2023b.
- Bai et al. (2023c) Shuai Bai, Shusheng Yang, Jinze Bai, Peng Wang, Xingxuan Zhang, Junyang Lin, Xinggang Wang, Chang Zhou, and Jingren Zhou. Touchstone: Evaluating vision-language models by language models, 2023c.
- Changpinyo et al. (2021) Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts, 2021.
- Chen et al. (2023) Lin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. arXiv preprint arXiv:2311.12793, 2023.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. Evaluating large language models trained on code, 2021.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Chu et al. (2023) Xiangxiang Chu, Limeng Qiao, Xinyang Lin, Shuang Xu, Yang Yang, Yiming Hu, Fei Wei, Xinyu Zhang, Bo Zhang, Xiaolin Wei, and Chunhua Shen. Mobilevlm : A fast, strong and open vision language assistant for mobile devices, 2023.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021.
- Dai et al. (2023) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- Fu et al. (2023) Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models, 2023.
- Ge et al. (2023) Wentao Ge, Shunian Chen, Guiming Chen, Junying Chen, Zhihong Chen, Shuo Yan, Chenghao Zhu, Ziyue Lin, Wenya Xie, Xidong Wang, Anningzhe Gao, Zhiyi Zhang, Jianquan Li, Xiang Wan, and Benyou Wang. Mllm-bench, evaluating multi-modal llms using gpt-4v, 2023.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021.
- Hudson & Manning (2019) Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering, 2019.
- IDEFICS (2023) IDEFICS. Introducing idefics: An open reproduction of state-of-the-art visual language model. https://huggingface.co/blog/idefics, 2023.
- Kirillov et al. (2023) Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything, 2023.
- Krishna et al. (2016) Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. Visual genome: Connecting language and vision using crowdsourced dense image annotations, 2016.
- Krizhevsky et al. (2009) Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- Li et al. (2023a) Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension, 2023a.
- Li et al. (2022) Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation, 2022.
- Li et al. (2023b) Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023b.
- Lin et al. (2015) Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, and Piotr Dollár. Microsoft coco: Common objects in context, 2015.
- Liu et al. (2023a) Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning, 2023a.
- Liu et al. (2023b) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023b.
- Liu et al. (2023c) Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player?, 2023c.
- Mishra et al. (2019) Anand Mishra, Shashank Shekhar, Ajeet Kumar Singh, and Anirban Chakraborty. Ocr-vqa: Visual question answering by reading text in images. In 2019 international conference on document analysis and recognition (ICDAR), pp. 947–952. IEEE, 2019.
- OpenAI (2023) OpenAI. Gpt-4v(ision) system card. https://cdn.openai.com/papers/GPTV_System_Card.pdf, 2023.
- OpenAI et al. (2023) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mo Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. Gpt-4 technical report, 2023.
- Ordonez et al. (2011) Vicente Ordonez, Girish Kulkarni, and Tamara Berg. Im2text: Describing images using 1 million captioned photographs. Advances in neural information processing systems, 24, 2011.
- Parekh et al. (2020) Zarana Parekh, Jason Baldridge, Daniel Cer, Austin Waters, and Yinfei Yang. Crisscrossed captions: Extended intramodal and intermodal semantic similarity judgments for ms-coco. arXiv preprint arXiv:2004.15020, 2020.
- Schuhmann et al. (2021) Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs, 2021.
- Schuhmann et al. (2022) Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. Laion-5b: An open large-scale dataset for training next generation image-text models, 2022.
- Sharma et al. (2018) Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2556–2565, 2018.
- Singh et al. (2019) Amanpreet Singh, Vivek Natarjan, Meet Shah, Yu Jiang, Xinlei Chen, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8317–8326, 2019.
- Team (2023) Stability AI Language Team. Stable lm 2 1.6b, 2023. URL [https://huggingface.co/stabilityai/stablelm-2-1.6b](https://huggingface.co/stabilityai/stablelm-2-1.6b).
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models, 2023.
- Wang et al. (2023a) Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song, and Yang Liu. Openchat: Advancing open-source language models with mixed-quality data. arXiv preprint arXiv:2309.11235, 2023a.
- Wang et al. (2023b) Junke Wang, Lingchen Meng, Zejia Weng, Bo He, Zuxuan Wu, and Yu-Gang Jiang. To see is to believe: Prompting gpt-4v for better visual instruction tuning, 2023b.
- Wang et al. (2023c) Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, Jiazheng Xu, Bin Xu, Juanzi Li, Yuxiao Dong, Ming Ding, and Jie Tang. Cogvlm: Visual expert for pretrained language models, 2023c.
- Xu et al. (2023a) Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023a.
- Xu et al. (2023b) Zhiyang Xu, Trevor Ashby, Chao Feng, Rulin Shao, Ying Shen, Di Jin, Qifan Wang, and Lifu Huang. Vision-flan:scaling visual instruction tuning, Sep 2023b. URL https://vision-flan.github.io/.
- Young et al. (2014) Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014.
- Yu et al. (2023) Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities, 2023.
- Yuan et al. (2023) Zhengqing Yuan, Zhaoxu Li, and Lichao Sun. Tinygpt-v: Efficient multimodal large language model via small backbones, 2023.
- Yue et al. (2023) Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, Huan Sun, Yu Su, and Wenhu Chen. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. arXiv preprint arXiv:2311.16502, 2023.
- Zhai et al. (2023) Yuexiang Zhai, Shengbang Tong, Xiao Li, Mu Cai, Qing Qu, Yong Jae Lee, and Yi Ma. Investigating the catastrophic forgetting in multimodal large language models, 2023.
- Zhou et al. (2023) Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment. arXiv preprint arXiv:2305.11206, 2023.
- Zhu et al. (2024) Yichen Zhu, Minjie Zhu, Ning Liu, Zhicai Ou, Xiaofeng Mou, and Jian Tang. Llava-: Efficient multi-modal assistant with small language model. arXiv preprint arXiv:2401.02330, 2024.
附录A数据蒸馏
A.1 提示蒸馏 LAION
A.2 提示蒸馏 Vision-FLAN
A.3数据示例
| LAION | |
|---|---|
![[Uncaptioned image]](cupcake.jpg)
|
|
| LAION Caption | Paleo Diet Fig Newton Cupcakes |
| Fine-grained Caption | The image features a close-up view of a single cupcake with a creamy white frosting on top, placed on a dark-colored metal stand with slender, branch-like supports. The cupcake is centered in the frame and is positioned on a circular platform that is part of the stand. On top of the frosting, there is a garnish that appears to be a slice of candied fruit, possibly a fig, with visible seeds and a caramelized exterior, which adds a touch of elegance to the presentation. The cupcake liner has a fluted design and is a golden yellow color, suggesting it might be made of a buttery or vanilla-flavored cake. In the background, slightly out of focus, there is another cupcake with a bite taken out of it, revealing a dark filling, possibly chocolate or fruit jam. The background is a soft, neutral color, providing a contrast that highlights the cupcake in the foreground. |
| Complex Reasoning Instruction | Considering the visual cues present in the image, what might be the flavor profile of the cupcake and how does the garnish on top contribute to the overall taste experience? |
| Detailed Answer | Based on the image, the cupcake likely has a sweet and rich flavor profile, with the golden yellow cake suggesting a vanilla or buttery base. The creamy white frosting adds a layer of sweetness and a smooth texture. The garnish on top appears to be a slice of candied fig, which would contribute a chewy texture and a complex sweetness with hints of caramelization. The seeds within the fig slice would also add a slight crunch, creating a varied mouthfeel. Overall, the garnish not only serves as an aesthetically pleasing decoration but also enhances the flavor experience with its unique taste and texture. |
| Vision-FLAN | |
![[Uncaptioned image]](cow.jpg)
|
|
| Fine-grained Caption | The image depicts a pastoral scene at what appears to be a livestock show. In the foreground, a row of individuals, primarily wearing white coats, are leading a line of large, tan and white animals across a grassy field. These animals, with their distinctive humped backs and white patches, are cattle, likely a specific breed given the context of the event. In the background, there’s a large white tent labeled "Members", suggesting an exclusive area or services for participants or special guests. The landscape features rolling hills, and the sky is partly cloudy, allowing for patches of blue sky and sunlight to enhance the bucolic atmosphere. No other animal species are visible in the frame. |
| Instruction | Given an image of an animal, identify the kind of animal in the image. The picture could be of more popular animals that are visible around zoos or are sometimes domesticated at home. They could also sometimes be found in the wild. Options: (a) This image contains a giraffe (b) This image contains an elephant (c) This image contains a zebra (d) This image contains a sheep (e) This image contains a bear (f) This image contains a horse (g) This image contains a cow (h) This image contains a cat (i) This image contains a dog (j) This image contains a bird |
| VFLAN Answer | (g) This image contains a cow |
| Detailed Answer | The animals in the image are cattle, more commonly referred to as cows. This determination is made clear by their physical characteristics—large size, humped backs, distinctive color patterns, and the presence of horns in some individuals. Given the setting of a livestock show, these cows are likely to be a breed prized for either dairy or beef production. They are being shown off by handlers, which is typical in such events where animals are judged based on breed standards or other criteria. Therefore, the correct answer from the provided options is: (g) This image contains a cow. |
在表 8 中,我们展示了每个数据集中的两个示例,其中包含图像、图像标题、问题和答案。 粗体条目是由 GPT-4V 使用我们的数据生成协议生成的。
附录 B基准详细信息
本研究中采用的基准详述如下。
-
•
MMBench (Liu 等人, 2023c)(开发集)由 20 个能力维度的 4329 个多项选择题组成,以循环评估下的准确性为指标。
-
•
SEED-Bench-v1 (Li 等人, 2023a)(图像集)包含 9 个维度的 14,233 个多项选择题。 采用准确度作为指标。
-
•
MM-Vet (Yu 等人, 2023) 包含 218 个问题,每个问题都需要多种能力来解决,并提供多种基本事实以实现灵活匹配。 采用准确度作为指标。
-
•
MMMU (Yue 等人, 2023)(验证集)由 900 个需要专家级知识才能解决的多项选择题组成。 采用准确度作为指标。
-
•
MME (Fu 等人, 2023) 是一个基准,包含 2,374 个问题,涵盖 14 个子任务。 使用准确度作为指标。
-
•
TextVQA (Singh 等人, 2019) 包含 5,000 个问题,并使用 准确性 作为指标。
-
•
GQA (Hudson & Manning,2019) 包含 12,578 个问题,用于现实世界推理和组合问答。 使用准确度作为指标。
-
•
MLLM-Bench (Ge 等人, 2023) 包含 420 个复杂的视觉推理问题以及帮助 GPT-4V 对每个答案进行评分的每个样本标准。 GPT-4V 的答案充当锚点。 采用主播获胜率作为指标。
-
•
TouchStone (Bai 等人, 2023c) 包含 908 个开放式问题,涵盖 5 个能力和 27 个子任务。 将 LVLM 的答案与预先生成的基于文本的 GPT-4 的答案进行比较,使用基于文本的 GPT-4 作为评委对每个答案进行评分。 使用平均分数作为指标。
-
•
LLaVA-Bench (In-the-Wild) (Liu 等人, 2023b) 包含 60 个开放式问题,并使用基于文本的 GPT-4 (OpenAI 等人, 2023)(OpenAI 等人, 2023) t1> 作为法官以成对的方式对答案进行评分。 采用 GPT-4 的候选答案与锚答案之间的得分比作为指标。
-
•
EMT (Zhai 等人, 2023) (Cifar10 split) 旨在测试视觉指令调整后 LVLM 的灾难性遗忘程度。 使用准确度作为指标。
附录C培训细节
在表9中,我们显示了使用 Phi2-2.7B 作为 LM 主干的 ALLaVA-3B 的详细超参数。
| Stage | Name | Value |
|---|---|---|
| 1 | Global Batch Size | 256 |
| Deepspeed ZeRO Stage | 1 | |
| Optimizer | AdamW | |
| Weight Decay | 0 | |
| Scheduler | Cosine Annealing with Linear Warmup | |
| Warmup Ratio | 0.03 | |
| Max LR | ||
| Min LR | ||
| Precision | BF16 | |
| 2 | Global Batch Size | 128 |
| Deepspeed ZeRO Stage | 1 | |
| Optimizer | AdamW | |
| Weight Decay | 0 | |
| Scheduler | Cosine Annealing with Linear Warmup | |
| Warmup Ratio | 0.03 | |
| Max LR | ||
| Min LR | ||
| Precision | BF16 |