Smaug:使用 DPO-Positive 修复偏好优化的失败模式
摘要
直接偏好优化 (DPO) 可有效显着提高大型语言模型 (LLM) 在推理、摘要和对齐等下游任务上的性能。 DPO 使用成对的首选和不首选数据来模拟选择一个响应而不是另一个响应的相对概率。 在这项工作中,首先我们从理论上证明,只要首选类和非首选类之间的相对概率增加,标准 DPO 损失就会导致模型对首选示例的可能性降低。 然后,我们凭经验证明,当在常见数据集上微调 LLM 时,尤其是在完成对之间的编辑距离较低的数据集上,会发生这种现象。 利用这些见解,我们设计了 DPO-Positive (DPOP),这是一种新的损失函数和训练程序,可以避免这种故障模式。 令人惊讶的是,我们还发现 DPOP 在各种数据集和下游任务中显着优于 DPO,包括完成之间编辑距离较高的数据集。 通过使用 DPOP 进行微调,我们创建并发布了 Smaug-34B 和 Smaug-72B,它们实现了最先进的开源性能。 值得注意的是,Smaug-72B 在 HuggingFace 开放大语言模型排行榜上比任何其他开源模型都要好近 2%,成为第一个平均准确率超过 80% 的开源大语言模型。
1简介
将大型语言模型 (LLM) 与人类偏好保持一致对于其流畅性和对许多任务的适用性非常重要,自然语言处理文献使用许多技术来整合人类反馈[Christiano 等人,2017 ,Stiennon 等人,2020,欧阳等人,2022]。 通常,在大语言模型对齐中,我们首先收集大量偏好数据,包括上下文和两个潜在的完成;其中一个被标记为首选完成,另一个被标记为不首选。 我们使用这些数据来学习在给定上下文中生成补全的一般策略。 直接偏好优化 (DPO) [Rafailov 等人,2023] 是一种根据人类偏好学习的流行方法,并且已被证明可以有效提高预训练的性能负责推理、总结和对齐等下游任务的法学硕士[Wang et al, 2023, Tunstall et al, 2023]。 DPO 的理论动机基于偏好排序模型,该模型具有隐式奖励函数,该函数对选择首选完成而不是不首选的相对概率进行建模。
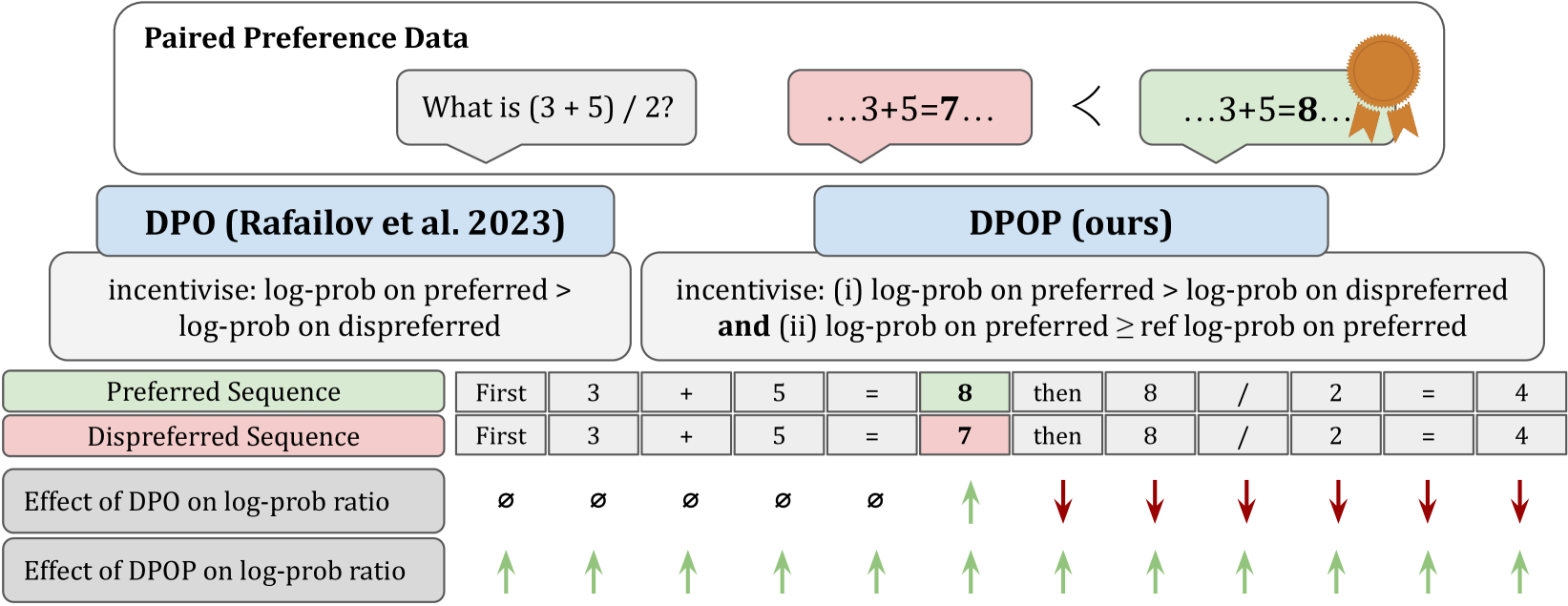
在这项工作中,我们首先从理论上证明了标准 DPO 损失会导致模型对首选补全的可能性降低(只要首选类和非首选类之间的相对概率增加),并从经验上证明了在常见数据集上微调当前 LLM 时会出现这种现象。 我们对这种现象的理论解释表明,该问题最常发生在每对完成之间编辑距离较小的偏好数据集中,例如基于数学的偏好数据集。
利用这些见解,我们设计了一个新的损失函数:DPO-Positive (DPOP),它在损失函数中添加了一个新术语,用于惩罚降低积极完成的概率。 我们还基于 ARC [Clark 等人,2018]、HellaSwag [Zellers 等人,2019]< 创建新的偏好数据集/t2> 和 MetaMath [Yu et al, 2023] 并将它们与 DPOP 一起使用来创建新模型。
我们介绍 Smaug 类模型,它使用 DPOP 并实现最先进的开源性能。 我们在新数据集上建立了 72B、34B 和 7B 模型,结果表明 DPOP 远远优于 DPO。 我们在多个基准上评估我们的结果模型,包括 HuggingFace Open 大语言模型排行榜[Beeching et al, 2023,Gao et al, 2021] ,它汇总了 MMLU [Hendrycks 等人,2021] 和 GSM8K [Cobbe 等人,2021] 和 MT-Bench [Zheng et al, 2023],这是一个具有挑战性的基准,它使用强大的大语言模型对八个不同类别的候选模型响应进行评分表现。 在HuggingFace开放大语言模型排行榜上,Smaug-72B平均准确率达到80.48%,成为第一个超过80%平均准确率的开源大语言模型,比第二名的开源大语言模型提高了近2%。源模型,而我们的 Smaug-34B 模型是同类参数数量相似的模型中最好的。 我们在 https://github.com/abacusai/smaug 发布了我们的代码和预训练模型。
我们的贡献。
-
•
我们从理论上和经验上展示了 DPO 的一种令人惊讶的失败模式:在完成之间编辑距离较小的偏好数据集上运行 DPO 可能会导致准确性的灾难性下降。
-
•
我们引入了 DPO-Positive (DPOP),我们从理论上和经验上都表明它可以改善性能下降。 特别是,即使在完成之间编辑距离较高的偏好数据集上,DPOP 的性能通常也优于 DPO。
-
•
我们创建了新的基于偏好的 ARC、HellaSwag 和 MetaMath 版本。
-
•
使用 DPOP 和我们的新数据集,我们创建并发布了 Smaug 类模型,其中 Smaug-72B 成为 HuggingFace 开放大语言模型排行榜上第一个平均准确率达到 80% 的开源模型。 我们开源经过训练的模型、数据集和代码。
2 背景及相关工作
大型语言模型 (LLM) 已显示出令人印象深刻的零样本和少样本性能[Radford 等人,2019,Brown 等人,2020,Bubeck 等人,2023]。 最近,研究人员通过使用人工编写的补全内容对下游任务的预训练 LLM 进行了微调[Chung 等人,2022,Mishra 等人,2021] 或使用相对于其他补全标记为人类首选补全的数据集[Ouyang et al, 2022, Bai et al, 2022, Ziegler et al, 2020]。 这些技术已用于提高各种下游任务的性能,例如翻译[Kreutzer 等人,2018] 和摘要[Stiennon 等人,2020],以及创建通用模型,例如 Zephyr [Tunstall 等人,2023]。 从人类偏好数据中学习的两种最流行的技术是从人类反馈中进行强化学习 (RLHF) [Ouyang et al, 2022, Bai et al, 2022 ,Ziegler 等人,2020] 和直接偏好优化 (DPO) [Rafailov 等人,2023]。 我们总结了这些方法如下。
RLHF
Consider a dataset of pairwise-preference ranked data where are prompts and and are respectively the preferred and dispreferred completions conditioned on that prompt. 我们有一个初始大语言模型 参数化分布 。 通常,我们将 初始化为经过监督微调(SFT)的大语言模型,以提高下游任务的性能)。
RLHF 首先利用布拉德利-特里模型 [布拉德利和特里,1952],对偏好 而不偏好 的概率进行建模,该模型假设了以下概率形式:
其中, 是逻辑函数, 对应于某个潜在奖励函数,假定在提示 时,完成 的奖励函数是存在的。 给定 ,我们可以通过最小化数据集的负对数似然来学习 的参数化估计:
对于 RLHF,我们使用强化学习基于学习到的奖励函数 进行优化(使用正则化 KL 约束来防止模型崩溃) ,得到新的大语言模型分布。
数据保护组织
Rafailov 等人 [2023] 表明,可以优化与 RLHF 中相同的 KL 约束奖励函数,而无需学习显式奖励函数。 相反,问题直接转化为分布 的最大似然优化,目标为:
| (1) |
其中是对应于RLHF中KL正则化强度的正则化项。 在这种情况下,隐式奖励参数化为 ,以及 Rafailov 等人 [20235>]4> 进一步表明 Plackett-Luce 模型下的所有奖励类别[Plackett, 19757>, Luce, 20058>]6>(例如 Bradley- Terry) 在此参数化下是可表示的。 对于缩写,我们定义
自 DPO 发布以来,人们提出了各种替代方案。 我们在下面和附录A中讨论与我们的工作最相关的内容。
首次公开募股
Azar 等人 [2023] 旨在了解 RLHF 和 DPO 的理论基础。 他们发现,在首选示例相对于不首选示例的偏好概率接近 1 的情况下,DPO 可能容易出现过度拟合。 他们提出了另一种形式的成对偏好损失——“身份-PO(IPO)”。 IPO 试图通过惩罚超出此正则化值的优惠幅度来防止过度拟合偏好数据集。 相反,我们发现 DPO 也会导致欠拟合,甚至性能完全下降。
3DPO的故障模式
在本节中,我们后退一步,检查方程 1中的 DPO 损失,特别着眼于它如何降低概率的首选完成。 损失仅是对数比率差异的函数,这意味着即使 降低到 1 以下,只要 这意味着首选完成的对数似然降低到低于参考模型的原始对数似然!
为什么这是一个问题? RLHF 的原始用例并未明确表示首选补全也是理想补全(而不仅仅是两个选择中的首选补全 和 ),因此 DPO 目标是一个很好的建模选择。 然而,从那时起,大量工作集中在将强大模型的知识提炼为更小或更弱的模型,同时也表明使用 RLHF/DPO 这样做优于 SFT [Taori 等人,2023、Tunstall 等人,2023、Xu 等人、2023、Chiang 等人、2023]。 在这种范式中,通常的情况是,在每对完成中,两者中较好的一个确实也是理想的完成。 此外,一种新技术是将标准标记数据集转换为成对偏好数据集[Ivison et al, 2023, Tunstall et al, 2023],它还具有以下性质:对于每对完成,其中一个是理想完成。
编辑距离 1
虽然上面说明了一个假设情况,但现在我们提供一个具体案例,其中 DPO 可能会导致更好完成的概率降低。 考虑通过比较“2+2=4”和“2+2=5”的完成来尝试提高模型的数学或推理能力的情况。此过程创建一对首选和非首选补全,其编辑(汉明)距离为 1,即补全中的所有标记除了一个之外都是相同的。 接下来,我们将探讨不同词符的位置如何影响 DPO 损失的计算。 为了便于论证,我们将研究当不同的词符是第一个词符时会发生什么,尽管如果它出现在其他地方,论证也会遵循。
For preliminaries, consider two completions with an edit distance of 1 which differ at token with , i.e., consider and . 表示 和 Assume that the vocabulary length of the LLM is . Let represent the probability of the -th token in the model’s vocabulary given the input . 虽然大语言模型模型参数很多,但我们将注意力限制在logits上, 。
方程 1相对于的梯度与以下成比例:
We note first that for , all tokens from 1 to have no effect on the gradient, simply because for all , , causing these tokens’ contribution to the gradient to cancel out. 因此,在不失一般性的情况下,假设 ,即 和 不失一般性,我们还假设 占据词汇位置 1。 然后,对于每个 ,我们有以下内容(在 Section 中推导) t7>B.1):
| (2) |
As we typically run DPO after SFT, the model is likely to be reasonably well optimised, so we should have for and . 因此,虽然此分析仅扩展到相对于 logit 的梯度,但我们看到梯度向量在正确的 logit 维度中减少,并在错误的 logit 维度中增加。 Surprisingly, this suggests that under DPO, all tokens that follow a mismatched token should have reduced probability of emitting the correct token when compared to . 我们稍后将在部分5和图3中给出这方面的经验证据t5>。
4 DPOP
现在,我们介绍DPO-Positive(DPOP),它是修复上一节中描述的故障模式的解决方案。 虽然 DPO 没有动力维持首选完成的高对数似然,但 DPOP 添加了惩罚项 造成损失。 当 ,并且当比率低于 1 时增加。 因此,DPOP损失函数为:
| (3) | ||||
其中 是可以调整的超参数。 这种形式的损失保留了我们在 Bradley-Terry 模型下对偏好数据进行参数拟合的属性。 隐式奖励参数化为
通过应用这种优化压力,模型不再能够通过显着降低不优选示例的对数似然来最小化损失,而不是显着降低优选示例的对数似然;它还必须确保优选示例的对数似然相对于参考模型下的对数似然保持较高。
现在,我们展示 方程 3 减轻了上一节中的故障模式示例。 回想一下部分 3,我们重点关注两个完成,和,在位置 我们在方程 2中表明,对于标准DPO,补全中第个词符的梯度相对于第 个 logit 为 。 但是,对于 DPOP,如果 ,梯度变为
其中是词符的词汇索引。 Since , for the case , the gradient is guaranteed to be positive for a large enough choice of . 类似地,对于 的情况,对于足够大的 (只要 )。 因此,这解决了 Section 3 中的问题。 上述推导在部分B.1中给出。
与对比损失的联系
5 DPOP 数据集和实验
在本节中,我们通过经验验证故障模式确实在实践中出现,并且 DPOP 能够减轻故障。 我们还表明,即使编辑距离很大并且 DPO 没有表现出性能下降,DPOP 仍然可以在下游任务评估中表现出色。
5.1 数据集创建
在我们的实证分析中,我们重点关注 GSM8K、ARC 和 HellaSwag 的下游任务,并引入并发布相关的配对偏好排序数据集。
GSM8K [Cobbe 等人,2021] 是各种小学数学应用题的数据集,已被采用作为衡量数学和法学硕士的推理能力[Chowdhery et al, 2023, Touvron et al, 2023b, a, Beeching et al, 2023,高等人,2021]。 我们创建了 MetaMath [Yu et al, 2023] 的配对偏好排名版本,这是 GSM8K 训练数据 [An et al, 2023,Yu 等人,2023]。 MetaMath 数据集中的正确完成由一系列导致最终答案的步骤组成。 为了创建一个不受欢迎的版本,我们随机破坏了中间计算的结果之一。 该数据集的编辑距离较低(标准化)为 6.5%。
ARC [Clark et al, 2018] 是一个测试小学水平的科学理解水平的数据集。 我们特别关注 ARC-Challenge,这是 ARC 两个小节中较难的一个,它已被广泛采用作为大语言模型推理和世界理解的衡量标准[Chowdhery et al, 2023 , Touvron 等人, 2023b, a, Beeching 等人, 2023, Cobbe 等人, 2021]. ARC-Challenge 数据集包含每个问题的四种答案选择,其中之一是正确的。 为了创建配对的偏好排序数据集,对于训练分割中的每个正确响应,我们使用每个错误响应创建三对。 由于响应的差异,该数据集的归一化编辑距离高达 90%。
HellaSwag [Zellers et al, 2019] 是一个数据集,其中包含已知对法学硕士来说很难的常识推理问题。 与 ARC 类似,每个问题都有一个正确的完成和三个不正确的完成,因此我们通过为训练分割中的每个正确响应创建三对来创建配对的偏好排序数据集。 有关我们新发布的数据集的更多详细信息和文档,请参阅附录 D。
5.2实验
在本节中,我们将在上述数据集上比较训练 DPO、IPO 和 DPOP,并在相应的任务上对它们进行评估。 我们将每种偏好训练方法应用于 Mistral7B [Jiang et al, 2023] 的基础模型。 我们使用大语言模型评估工具[Gao et al,2021]对GSM8K和ARC测试集进行评估。
损失函数比较
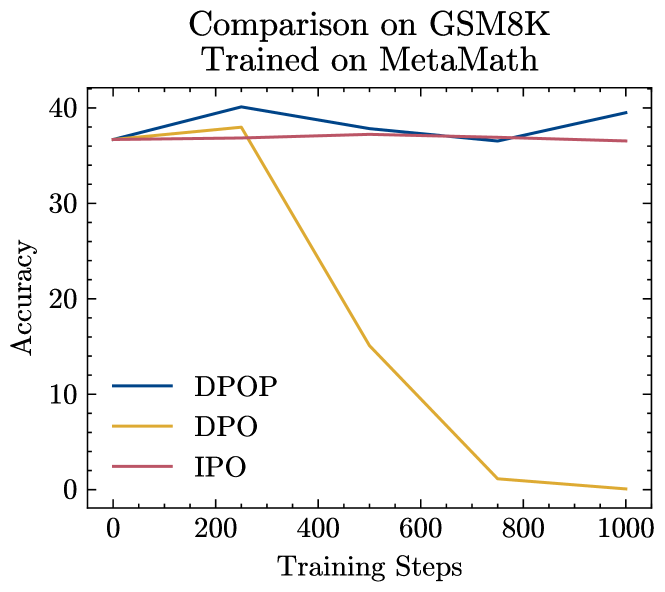
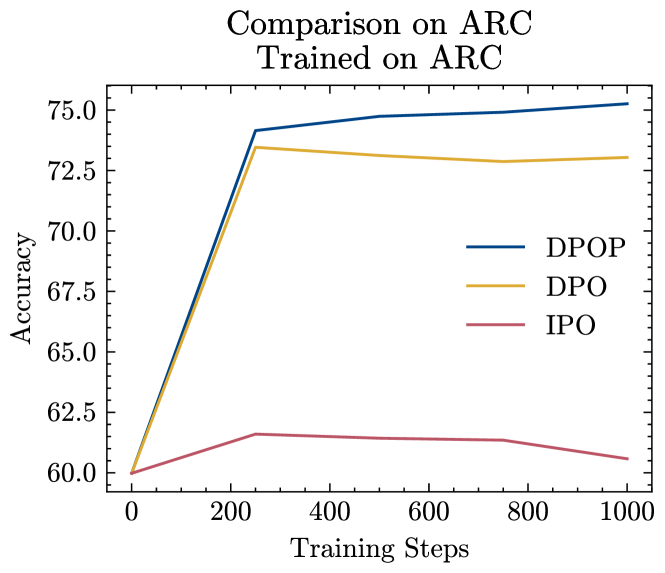
首先,我们在 MetaMath 和 ARC 上训练时比较 DPO、IPO 和 DPOP;参见图2。 我们发现,当在 MetaMath 上训练时,DPO 会灾难性地失败,而 IPO 不会提高性能。 DPOP 是唯一比基本模型提高性能的模型。 当在 ARC 上训练时,如上一节所述,ARC 具有更高的编辑距离,DPO 和 DPOP 都能够在基础模型上显着改进;然而,DPOP 表现更好。
的消融研究
关于如何防止 MetaMath 上 DPO 退化的一种潜在假设是通过修改正则化参数 的强度。 We test , and although a larger does induce a slower decrease, the performance with DPO still plummets, while DPOP shows strong and consistent performance with different values of (see Appendix Figure 4).
代币层面分析
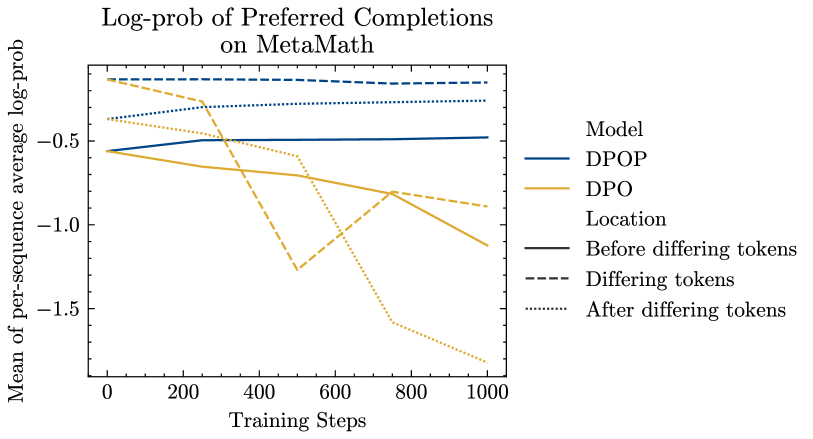
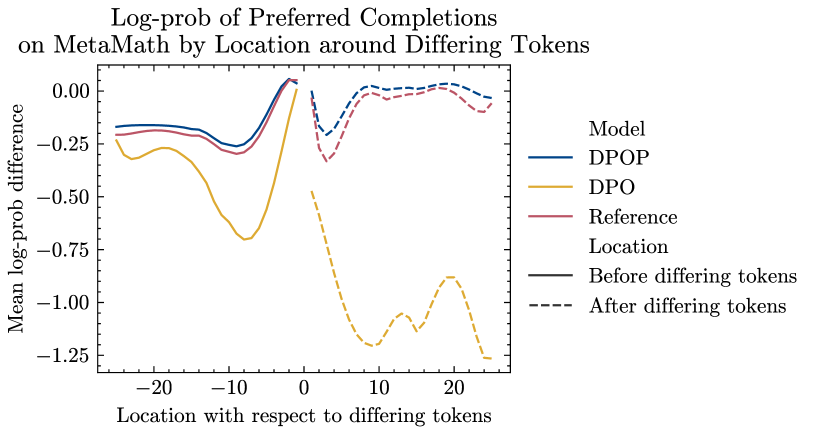
回想一下,在部分 3中,我们给出了为什么 DPO 可能在低编辑距离数据集上表现不佳的理论动机。 现在,我们在 MetaMath 数据集上分析超过 1000 个样本的词符级别训练模型的对数概率,以实证支持我们的论点。 让我们用 来表示首选完成和不首选完成之间不同的第一个词符的索引。
我们建议 为 We find this is indeed the case—the average log-prob after training of tokens after is for the reference model and for DPOP, but for DPO on the preferred completions (see (Figure 3) (left)). 也许最具启发性的是,对于参考模型和 DPOP,在图3(右)中,我们看到编辑索引后的标记显示更高比编辑索引之前的对数似然性——这表明语言建模表现良好,随着更多标记添加到上下文中,困惑度更低。 相比之下,DPO 显示了相反的模式——编辑索引后对数似然实际上减少了。 这表明语言建模出现了更深层次的崩溃,我们认为这是由我们在 Section 3 中概述的错误方向梯度促成的。 Finally, we are also able to substantiate our assumption from Section 3 that ; we find from our analysis that for the baseline model, the tokens after the edit have an average log-likelihood of on the preferred completion, but this drops to on the dispreferred completion.
6 史矛革
在本节中,我们介绍 Smaug 系列模型。 我们使用 DPOP 训练 7B、34B 和 72B 参数大小的模型。 我们使用 7B 类来直接比较 DPOP 与 DPO,包括现有的和广泛使用的配对优先排序数据集。 由于训练较大模型需要计算资源,我们仅在 34B 和 72B 上执行 DPOP,并与 HuggingFace Open 大语言模型排行榜上的其他模型进行比较。 出于同样的原因,我们也不进行任何超参数调整;例如,使用不同的 值有可能获得更好的性能。
6.1Smaug-34B 和 Smaug-72B
| Model | Size | Avg. | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|---|---|---|---|---|---|---|---|---|
| Smaug-72B (Ours) | 72B+ | 80.48 | 76.02 | 89.27 | 77.15 | 76.67 | 85.08 | 78.70 |
| MoMo-72B-lora-1.8.7-DPO | 72B+ | 78.55 | 70.82 | 85.96 | 77.13 | 74.71 | 84.06 | 78.62 |
| TomGrc_FusionNet_34Bx2_MoE_v0.1_DPO_f16 | 72B+ | 77.91 | 74.06 | 86.74 | 76.65 | 72.24 | 83.35 | 74.45 |
| TomGrc_FusionNet_34Bx2_MoE_v0.1_full_linear_DPO | 72B+ | 77.52 | 74.06 | 86.67 | 76.69 | 71.32 | 83.43 | 72.93 |
| Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B | 72B+ | 77.44 | 74.91 | 89.30 | 64.67 | 78.02 | 88.24 | 69.52 |
Smaug-34B 是基础模型 Bagel-34B-v0.2 [Durbin, 2024a] 的修改版本,其本身是 Yi-34B-200k 的 SFT 版本[01.AI,2024]。 我们首先使用 Bagel-34B-v0.2 并使用三个数据集的组合执行 SFT:MetaMath [Yu et al, 2023]、ORCA-Chat [Es, 2024] 和 ShareGPT 数据集 [Z., 2024]。 接下来,我们使用五个数据集执行 DPOP:部分5中描述的成对 MetaMath DPO、ARC DPO 和 HellaSwag DPO 数据集,即 ORCA DPO数据集 [Intel,2024] 和 UltraFeedback 二值化数据集 [AllenAI,2024]。 最后,我们使用 Truthy DPO 数据集 [Durbin, 2024b] 执行标准 DPO。 我们使用 8 个 H100 GPU 运行这些实验。 We set , , a learning rate of , and the AdamW optimizer [Loshchilov and Hutter, 2017], and we run 1000 steps for all DPOP routines. 所有步骤的总训练时间为 108 小时。
对于 72B,我们从 MoMo-72b-lora-1.8.7-DPO [Moreh, 2024] 开始,它本身就是 Qwen-72B [ Bai 等人,2023]。 MoMo-72b-lora-1.8.7-DPO 已经进行了 SFT,因此我们只需像 Smaug-34B 中那样运行五个 DPOP 例程。 总训练时间为144小时。
HuggingFace开放大语言模型排行榜
我们使用广泛使用的基准 HuggingFace Open 大语言模型排行榜 [Beeching et al, 2023, Gau et al, 2021] 进行评估集合了六个流行基准的套件:ARC [Clark 等人,2018]、GSM8K [Cobbe 等人,2021]、HellaSwag [Zellers 等人,2019]、MMLU [Hendrycks 等人、20210>]、TruthfulQA [Lin 等人,20222>]1> 和 WinoGrande [Sakaguchi 等人,20204>]3>。 我们直接在 HuggingFace 中进行评估,它使用大语言模型评估工具[Gao et al, 2021]。 它对这些任务的测试集执行少样本提示,并检查模型是否给出正确的答案。 我们根据 HuggingFace 开放大语言模型排行榜将 Smaug-72B 与前 5 名开放权重 LLM 的评估分数进行比较[Beeching et al, 2023,Gao et al, 2021]截至2024年2月1日;参见表1。 Smaug-72B 的平均准确率达到 80.48%,成为第一个平均准确率超过 80% 的开源大语言模型,比第二好的开源模型提高了近 2%。 与其他类似或更小尺寸的型号相比,Smaug-34B 还实现了同类最佳的性能(参见附录E)。
MT-Bench
接下来,我们使用 MT-Bench [Zheng et al, 2023] 进行评估,这是一个使用 GPT-4 [OpenAI, 202320232023 的具有挑战性的基准t3>] 对八个不同性能类别的候选模型响应进行评分。 正如其他作品[Zheng et al, 2023, Rafailov et al, 2023]所示,GPT-4等强LLM表现出良好的一致性与人类的喜好。 我们使用 Llama-2 对话模板 [Touvron 等人,2023b] 运行 MT-Bench。 请参阅表2,根据截至 2024 年 2 月 1 日的 Arena Elo 与最先进的法学硕士进行比较。 Smaug-72B 在表2中的开源模型中获得了最高的 MMLU 分数和第三好的 MT 基准分数。 在附录 E中,我们给出了 Smaug-72B 完成 MT-Bench 问题的示例。
| Model | Arena Elo | MT-bench | MMLU | Organization | License |
|---|---|---|---|---|---|
| GPT-4-1290-preview | 1253 | OpenAI | Proprietary | ||
| GPT-4-1106-preview | 1252 | 9.32 | OpenAI | Proprietary | |
| Bard (Gemini Pro) | 1224 | Proprietary | |||
| GPT-4-0314 | 1190 | 8.96 | 86.4 | OpenAI | Proprietary |
| GPT-4-0613 | 1162 | 9.18 | OpenAI | Proprietary | |
| Mistral Medium | 1150 | 8.61 | 75.3 | Mistral | Proprietary |
| Claude-1 | 1149 | 7.9 | 77 | Anthropic | Proprietary |
| Claude-2.0 | 1132 | 8.06 | 78.5 | Anthropic | Proprietary |
| Gemini Pro (Dev API) | 1120 | 71.8 | Proprietary | ||
| Claude-2.1 | 1119 | 8.18 | Anthropic | Proprietary | |
| GPT-3.5-Turbo-0613 | 1118 | 8.39 | OpenAI | Proprietary | |
| Mixtral-8x7b-Instruct-v0.1 | 1118 | 8.3 | 70.6 | Mistral | Apache 2.0 |
| Yi-34B-Chat | 1115 | 73.5 | 01 AI | Yi License | |
| Gemini Pro | 1114 | 71.8 | Proprietary | ||
| Claude-Instant-1 | 1109 | 7.85 | 73.4 | Anthropic | Proprietary |
| GPT-3.5-Turbo-0314 | 1105 | 7.94 | 70 | OpenAI | Proprietary |
| WizardLM-70B-v1.0 | 1105 | 7.71 | 63.7 | Microsoft | Llama 2 Community |
| Tulu-2-DPO-70B | 1104 | 7.89 | AllenAI/UW | AI2 ImpACT Low-risk | |
| Vicuna-33B | 1093 | 7.12 | 59.2 | LMSYS | Non-commercial |
| Starling-LM-7B-alpha | 1090 | 8.09 | 63.9 | UC Berkeley | CC-BY-NC-4.0 |
| Smaug-72B | 7.76 | 77.15 | Abacus.AI | tongyi-qianwen-license-agreement |
6.2使用 7B 模型的比较
我们从 Llama 2-chat [Touvron et al, 2023b] 的基础上构建了 Smaug-7B。 由于 Llama 2-chat 已经进行了指令微调,因此我们直接使用上一节中描述的相同数据集执行 DPO 和 DPOP。 我们在 1xGH200 上训练 2000 步。
MT 工作台
我们在 MT-Bench 上以与上一节所述相同的设置评估 Smaug-7B。 我们发现 DPOP 的首轮得分为 7.275,而 DPO 的首轮得分为 7.076。
7 结论、局限性和影响
在这项工作中,我们提出了关于 DPO 严重失效模式的新理论和实证发现,其中微调会导致首选示例的概率降低。 为了缓解这个问题,我们设计了一种新技术 DPOP,我们证明它克服了 DPO 的故障模式,并且即使在这种故障模式之外也能优于 DPO。 通过在 ARC、HellaSwag 和 MetaMath 的新成对偏好版本上使用 DPOP 进行微调,我们创建了一个新的大语言模型,该模型实现了最先进的性能。 特别是,它是 HuggingFace 开放大语言模型排行榜上第一个平均准确率超过 80% 的开放权重模型,比之前的开放权重大语言模型提高了近 2%。
将来,创建其他数据集的基于成对偏好的版本,并使用这些数据集运行 DPOP,可以使开源 LLM 的能力更加接近 GPT-4 等专有模型的性能[OpenAI,2023]。 此外,在其他数学数据集上使用 DPOP 是未来工作的一个令人兴奋的领域,因为它有可能进一步提高法学硕士的数学推理能力。
局限性
虽然我们的工作提供了有关 DPO 故障模式的理论和经验证据以及提出的解决方案,但它仍然存在局限性。 首先,我们无法对 72B 模型进行完整的消融研究。 在 72B 模型上运行多个微调实验是不可行的,因为每个微调实验可能需要五天以上的时间才能完成。 因此,我们假设我们对较小模型的消融在规模上仍然有效。 此外,虽然我们期望 DPOP 在任何偏好数据集(尤其是编辑距离较小的数据集)上实现强劲的性能,但我们仅在五个英语数据集上展示了其性能。 我们希望未来的工作能够在更多数据集上验证其有效性,特别是在非英语数据集上。
更广泛的影响
本文提出了一种使用偏好数据对LLMs进行优化的技术,发布了三个基于数学和推理的偏好数据集,并发布了根据偏好数据进行微调的新LLMs。 与任何发布微调技术或大语言模型的论文一样,存在固有的风险。 对手可以使用这种技术来创建经过微调的模型,以产生有害、有毒或非法内容。 然而,我们乐观地认为我们的工作将产生积极的净影响。 特别是,DPOP 在与数学或推理数据集一起使用时特别有用,其中首选和次首选完成之间只有少数标记不同。 此外,我们给出了 DPO 失败案例的理论直觉,以及避免这种失败案例的方法,从而朝着更全面地理解基于偏好优化的技术迈进。 最近在人工智能安全方面做出了广泛的努力[Huang et al, 2023, Yao et al, 2023, Weidinger et al, 2021] ,我们希望基于偏好优化的技术能够对社会产生积极的影响。 最后,我们注意到我们发布的模型性能低于当前顶级专有模型,例如 GPT-4 [OpenAI, 2023],因此减少了发布的负面影响我们的模型。
参考
- 01.AI [2024] 01.AI. Yi-34b-200k, 2024. URL https://huggingface.co/01-ai/Yi-34B-200K.
- AllenAI [2024] AllenAI. Ultrafeedback binarized clean, 2024. URL https://huggingface.co/datasets/allenai/ultrafeedback_binarized_cleaned.
- An et al. [2023] Shengnan An, Zexiong Ma, Zeqi Lin, Nanning Zheng, Jian-Guang Lou, and Weizhu Chen. Learning from mistakes makes llm better reasoner. arXiv preprint arXiv:2310.20689, 2023.
- Azar et al. [2023] Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. A general theoretical paradigm to understand learning from human preferences, 2023.
- Bai et al. [2023] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- Bai et al. [2022] Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, Ben Mann, and Jared Kaplan. Training a helpful and harmless assistant with reinforcement learning from human feedback, 2022.
- Beeching et al. [2023] Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. Open llm leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard, 2023.
- Bradley and Terry [1952] R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952. doi: 10.2307/2334029.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Bubeck et al. [2023] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Chen et al. [2020] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020.
- Chiang et al. [2023] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Chowdhery et al. [2023] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Christiano et al. [2017] Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30, 2017.
- Chung et al. [2022] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416, 2022.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021.
- Durbin [2024a] Jon Durbin. Bagel-34b-v0.2, 2024a. URL https://huggingface.co/jondurbin/bagel-34b-v0.2.
- Durbin [2024b] Jon Durbin. Truthy dpo, 2024b. URL https://huggingface.co/datasets/jondurbin/truthy-dpo-v0.1.
- Es [2024] Shahul Es. Orca-chat, 2024. URL https://huggingface.co/datasets/shahules786/orca-chat.
- Ethayarajh et al. [2023] Kawin Ethayarajh, Winnie Xu, Dan Jurafsky, and Douwe Kiela. Human-centered loss functions (halos). Technical report, Contextual AI, 2023.
- Gao et al. [2021] Leo Gao, Jonathan Tow, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Kyle McDonell, Niklas Muennighoff, Jason Phang, Laria Reynolds, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, September 2021.
- Hadsell et al. [2006] R. Hadsell, S. Chopra, and Y. LeCun. Dimensionality reduction by learning an invariant mapping. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pages 1735–1742, 2006. doi: 10.1109/CVPR.2006.100.
- He et al. [2020] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020.
- Hendrycks et al. [2021] Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. Measuring coding challenge competence with apps. arXiv preprint arXiv:2105.09938, 2021.
- Huang et al. [2023] Xiaowei Huang, Wenjie Ruan, Wei Huang, Gaojie Jin, Yi Dong, Changshun Wu, Saddek Bensalem, Ronghui Mu, Yi Qi, Xingyu Zhao, et al. A survey of safety and trustworthiness of large language models through the lens of verification and validation. arXiv preprint arXiv:2305.11391, 2023.
- Intel [2024] Intel. Orca dpo pairs, 2024. URL https://huggingface.co/datasets/Intel/orca_dpo_pairs.
- Ivison et al. [2023] Hamish Ivison, Yizhong Wang, Valentina Pyatkin, Nathan Lambert, Matthew Peters, Pradeep Dasigi, Joel Jang, David Wadden, Noah A Smith, Iz Beltagy, et al. Camels in a changing climate: Enhancing lm adaptation with tulu 2. arXiv preprint arXiv:2311.10702, 2023.
- Jiang et al. [2023] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023.
- Kreutzer et al. [2018] Julia Kreutzer, Joshua Uyheng, and Stefan Riezler. Reliability and learnability of human bandit feedback for sequence-to-sequence reinforcement learning. arXiv preprint arXiv:1805.10627, 2018.
- Lin et al. [2022] Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2022.
- Loshchilov and Hutter [2017] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Luce [2005] R Duncan Luce. Individual choice behavior: A theoretical analysis. Courier Corporation, 2005.
- Mishra et al. [2021] Swaroop Mishra, Daniel Khashabi, Chitta Baral, and Hannaneh Hajishirzi. Cross-task generalization via natural language crowdsourcing instructions. arXiv preprint arXiv:2104.08773, 2021.
- Moreh [2024] Moreh. Momo-72b-lora-1.8.7-dpo, 2024. URL https://huggingface.co/moreh/MoMo-72B-lora-1.8.7-DPO.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- OpenAI [2023] OpenAI. Gpt-4 technical report. Technical Report, 2023.
- Ouyang et al. [2022] Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback, 2022.
- Plackett [1975] Robin L Plackett. The analysis of permutations. Journal of the Royal Statistical Society Series C: Applied Statistics, 24(2):193–202, 1975.
- Radford et al. [2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Rafailov et al. [2023] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), 2023.
- Sakaguchi et al. [2020] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Proceedings of the AAAI Conference on Artificial Intelligence, 34, 2020.
- Saunshi et al. [2019] Nikunj Saunshi, Orestis Plevrakis, Sanjeev Arora, Mikhail Khodak, and Hrishikesh Khandeparkar. A theoretical analysis of contrastive unsupervised representation learning. In International Conference on Machine Learning, pages 5628–5637. PMLR, 2019.
- Schroff et al. [2015] Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 815–823, 2015. doi: 10.1109/CVPR.2015.7298682.
- Stiennon et al. [2020] Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), 2020.
- Taori et al. [2023] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpaca: A strong, replicable instruction-following model. Stanford Center for Research on Foundation Models. https://crfm. stanford. edu/2023/03/13/alpaca. html, 3(6):7, 2023.
- Touvron et al. [2023a] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023a.
- Touvron et al. [2023b] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Tunstall et al. [2023] Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, and Thomas Wolf. Zephyr: Direct distillation of lm alignment, 2023.
- Tversky and Kahneman [1992] Amos Tversky and Daniel Kahneman. Advances in prospect theory: Cumulative representation of uncertainty. Journal of Risk and Uncertainty, 5(4):297–323, 1992.
- Wang and Liu [2021] Feng Wang and Huaping Liu. Understanding the behaviour of contrastive loss. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2495–2504, 2021.
- Wang et al. [2023] Peiyi Wang, Lei Li, Liang Chen, Feifan Song, Binghuai Lin, Yunbo Cao, Tianyu Liu, and Zhifang Sui. Making large language models better reasoners with alignment. arXiv preprint arXiv:2309.02144, 2023.
- Wang and Isola [2020] Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In International Conference on Machine Learning, pages 9929–9939. PMLR, 2020.
- Wei et al. [2023] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023.
- Weidinger et al. [2021] Laura Weidinger, John Mellor, Maribeth Rauh, Conor Griffin, Jonathan Uesato, Po-Sen Huang, Myra Cheng, Mia Glaese, Borja Balle, Atoosa Kasirzadeh, et al. Ethical and social risks of harm from language models. arXiv preprint arXiv:2112.04359, 2021.
- Xu et al. [2023] Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, and Daxin Jiang. Wizardlm: Empowering large language models to follow complex instructions. arXiv preprint arXiv:2304.12244, 2023.
- Xu et al. [2024] Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation. arXiv preprint arXiv:2401.08417, 2024.
- Yao et al. [2023] Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Eric Sun, and Yue Zhang. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. arXiv preprint arXiv:2312.02003, 2023.
- Yu et al. [2023] Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models, 2023.
- Z. [2024] Z. Sharegpt_vicuna_unfiltered, 2024. URL https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered.
- Zellers et al. [2019] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1472. URL https://www.aclweb.org/anthology/P19-1472.
- Zheng et al. [2023] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023.
- Ziegler et al. [2020] Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences, 2020.
附录A相关工作仍在继续
在本节中,我们继续讨论部分2中的相关工作。
非洲金融时报
Wang 等人 [2023] 寻求调整法学硕士以正确地“评分”(就困惑度而言)他们自己的一代人。 他们通过对每个提示生成多个思想链[Wei et al, 2023]响应来实现这一点,并根据是否回答问题将其分类为首选或不首选。正确提问。 他们提出的“对齐微调(AFT)”范例在标准中添加了对齐目标 微调损失,定义为
其中 是一组首选示例, 是一组不受欢迎的示例。 通过最小化 ,鼓励优选示例的对数似然大于对数似然不受欢迎的示例的可能性,类似于 DPO。 然而,Wang 等人 [2023] 对我们采取了相反的动机:他们特别关心不受欢迎的示例的对数似然被过分下推的问题
我们的工作与 AFT 的不同之处在于三个关键点。 首先,尽管 Wang 等人 [2023] 在附录中讨论了 DPO,但他们没有展示他们的方法如何扩展到重新制定其目标;他们还将实验仅集中在监督微调上。 接下来,我们使用不同的约束机制——他们的机制是对不喜欢的示例与首选示例的对数概率距离的软边距约束,而我们的则是对偏离参考模型的软惩罚。 最后,他们特别关注自我生成的大语言模型CoT反应的情况,并校准大语言模型对其自身反应的困惑度。
光环
Ethayarajh 等人 [2023] 试图在“以人为中心的损失函数 (HALO)”的背景下理解对齐方法,包括 DPO。 通过将对齐方法与Tversky 和 Kahneman [1992] 在前景理论中的工作进行等价,他们将该论文中的“人类价值函数”调整为语言模型设置:
其中定义 为
和
此方法与 DPO 的主要区别在于它不需要配对偏好数据。 只要标签单独标记为正或负,上述损失函数就可以用于任何数据集。
首席采购官
最近,并行工作[Xu 等人,2024] 建议在 DPO 损失函数中添加一个新术语,以便让 DPO 能够更好地拒绝“更差”的完成质量很好,但并不完美。 具体来说,它们包括术语
虽然相似,但他们的工作使用了具有不同动机的不同损失函数,而且他们只考虑了最多 13B 个参数的机器翻译模型。
附录Blogit梯度的推导
B.1 DPO 的推导
考虑长度为 且编辑(汉明)距离为 1 的两个完成,其在词符 处不同,且 。 输入 和 输入 和 请注意,方程 1相对于的导数与以下各项成正比:
根据链式法则,我们有
并使用对数恒等式
当我们将其代入 ,我们观察到
Assume that the vocabulary length of the LLM is . This means that corresponds to a vector of length and represents the softmax output of the final layer of the LLM, i.e., . 请注意,如果上下文很明显,我们可以从 的表示法中删除 。 Therefore, represents the probability of the -th token in the model’s vocabulary given the input context .
虽然大语言模型模型参数很多,但让我们将注意力限制在logits上,我们将其表示为 与 和 是 softmax 的输入。 有了这个假设,我们知道
| (4) |
考虑 和 的情况> 仅在第一个词符处不同,即 在本例中,我们有 :
不失一般性,假设 占据词汇位置 1。 然后从方程 4,我们有:
| (5) |
As we typically run DPO after SFT the model is likely to be reasonably well optimised, so we should have for and . 因此,虽然此分析仅扩展到相对于 logit 的梯度,但我们看到梯度向量在正确的 logit 维度中减少,并在错误的 logit 维度中增加。 In particular, this derivation suggests that under DPO, all tokens that follow a difference at at any point should have reduced probability of emitting the correct token when compared to .
B.2 DPOP 的推导
我们可以遵循类似的推理来计算 相对于它的 logits,我们再次用 表示>。
Again taking token position for illustrative purposes and assuming that takes vocabulary position , in the case when ,
当 ,那么我们就得到了
附录C动机:对比损失
虽然 DPOP 的主要动机是避免部分3中描述的故障模式,但我们也注意到它与对比损失. 对比学习被广泛使用[Wang and Liu, 2021, Wang and Isola, 2020, Saunshi et al, 2019, Oord et al, 2018, Chen et al, 2020, He et al, 2020],通常用于嵌入学习应用程序。 对比损失表述通常包括两个主要术语:一个鼓励类似输入的接近,另一个鼓励不同可分类数据的分歧。
此外,在这些术语之一后面引入余量通常可以确保更稳定的训练过程。 一旦超过特定值阈值,该裕度就可以作为对点位移漠不关心的指标。 当附加到相似点项时,边距建立了一个最小阈值,超过该阈值我们不关心将点拉近。 或者,如果添加到不同点项上,则裕度设置最大阈值。
我们证明了 DPO 损失的结构使得在 DPO 训练期间学习概率相当于学习对比损失公式中的嵌入。 然而,标准DPO仅使用术语计算不相似点之间的距离,并且不包括相似点术语或间隔。 因此,可以预见的是,传统 DPO 的低效率反映了当缺少一个组成项时对比训练的已知缺点。 DPOP 是我们改进的 DPO 公式,通过添加缺席项和边距来解决此问题。
Hadsell 等人 [2006] 中定义了对比损失。 如果我们将保证金保留在相似点的条件下,则可以写成如下:
回想一下,标准 DPO 损失(方程 1)如下:
假设我们指定一个嵌入函数 :
我们定义一个距离函数如下:
标准DPO在对比损失公式的类比下仅具有相异点项。 为了更强大的训练,我们适应类似的嵌入术语。 我们对正点和负点都使用锚点或嵌入的概念,如三元组损失 Schroff 等人 [2015] 中所示。 这些点是我们希望点实现的已知理想嵌入。 在我们的等价中,它们分别具有 1 和 0 的概率,具体取决于它们是首选样本还是不首选样本。
因此,DPOP 损失可以表述为:
如果我们设置边距 ,第二项是:
这种裕度的选择在数学上相当于选择一个阈值,该阈值确保当学习模型在首选响应上的表现比基本模型差时,相似性项只会造成损失。
我们可以在训练过程中忽略第三项,主要原因有两个。 首先,它试图将负样本的对数概率推至负无穷大,这在训练过程中可能不稳定。 其次,本质上,它对负样本的可能性产生负面影响。 然而,考虑到我们的目标是在不减少阳性样本可能性的情况下延长阳性样本和阴性样本之间的距离,因此牺牲此信号是可以接受的。 在最坏的情况下,虽然负面的概率可能会增加,但前两项确保了正面概率的随之增加,从而使牺牲是可以接受的。
附录D数据集详细信息
在本节中,我们将提供我们发布的三个数据集的更多详细信息和示例。 我们根据 Apache 2.0 许可证发布所有数据集。
元数学
GSM8K [Cobbe et al, 2021] 是各种小学数学应用题的数据集,通常被用来衡量法学硕士的数学和推理技能[Chowdhery 等人,2023、Touvron 等人,2023b、a、Beeching 等人,2023 ,高等人,2021]。 MetaMath 数据集分为查询和响应,其中查询是涉及数学计算或推理的问题,响应是最终得出最终答案的一系列逻辑步骤和计算。 为了构建我们的配对偏好版本的 MetaMath,我们将查询作为提示 ,将响应作为首选完成 。 我们通过随机破坏中间计算结果之一来修改响应,使其不正确,从而创建 ;然而,我们对答案保持不变。
示例如下::“考虑到每个球员需要一件 25 美元的球衣、一条 15.20 美元的短裤和一件一双袜子售价 6.80 美元?” :“每位球员需要一件 25 美元的球衣、一条 15.20 美元的短裤和一双袜子售价 6.80 美元。 因此,每个玩家的总成本为 $25 + $15.20 + $6.80 = $47。 由于足球队有 16 名球员,因此所有球员的总成本为 16 * 47 美元 = 752 美元。 #### 752 答案是:752" :“每个球员需要一件 25 美元的球衣、一条 15.20 美元的短裤,以及一双袜子售价 6.80 美元。 因此,每个玩家的总成本为 $25 + $15.20 + $6.80 = $52。 由于足球队有 16 名球员,因此所有球员的总成本为 16 * 47 美元 = 752 美元。 #### 752 答案是:752”
该数据集包含 393 999 个训练示例和 1 000 个评估示例。 我们构建此数据集的动机是使模型在中间计算中保持精确。 该数据集的编辑距离较低——标准化编辑距离约为 6.5%。
弧
ARC [Clark et al, 2018] 是一个数据集,用于测试大约小学水平的科学理解水平。 我们特别关注 ARC 的“挑战”小节,这是两个小节中较难的一个,它已被广泛采用作为大语言模型推理和世界理解的衡量标准[Chowdhery 等人,2023、Touvron 等人、2023b、a、Beeching 等人、2023、Gao 等人、2021 ,Cobbe 等人,2021]。 我们根据 ARC-Challenge 的训练分割创建了一个配对的偏好排序数据集。 数据集被划分为我们作为提示 的问题,以及每个问题的四种答案选择,其中只有一个是正确答案。 正确的响应被视为,错误的响应被视为;由于每个提示都有 3 个不正确的响应,因此我们对每个提示重复 该数据集包含 3357 个训练示例和 895 个评估示例。 该数据集具有约 90% 的高归一化编辑距离。
海拉斯瓦格
最后,我们考虑 HellaSwag 数据集[Zellers et al, 2019],这是一个包含已知对法学硕士来说很难的常识推理问题的数据集。 一个示例提示是“然后,男人在车窗上的雪上写字,穿着冬衣的女人微笑着。 然后”,潜在的完成是”,该男子在挡风玻璃上添加蜡并切割它。“,”,一个人登上滑雪缆车,同时两名男子支撑着穿着冬装的人的头部当我们女孩们拉雪橇时,衣服下雪了。“,”,男人穿上了一件用网编织的圣诞外套。“,”,男人继续清除车上的积雪。 该数据集包含 119 715 个训练示例和 30 126 个评估示例。
附录 E其他实验和详细信息
E.1 其他训练详细信息
创建 Smaug-34B 或 Smaug-72B 时未进行超参数调整。 DPOP 有两个超参数, 和 。 我们选择 ,类似于之前的工作 [Rafailov 等人,2023 ],我们选择了,没有尝试其他值。 例如,使用不同的 值有可能实现更好的性能。
在这里,我们给出了用于训练 Smaug 系列模型的所有模型的许可证。
Smaug-7B 从 Llama 2-chat [Touvron et al, 2023b] 开始。 因此,我们根据 Llama 2 许可证 (https://ai.meta.com/llama/license/) 发布它。
Smaug-34B 从 Bagel-34B-v0.2 [Durbin, 2024a] 开始,它本身是 Yi-34B-200k [01 的 SFT 版本。 AI,2024]。 因此,我们根据 Yi 系列模型社区许可协议 (https://github.com/01-ai/Yi/blob/main/MODEL_LICENSE_AGREEMENT.txt) 发布 Smaug-34B。
Smaug-72B 从 MoMo-72b-lora-1.8.7-DPO [Moreh, 2024] 开始,它本身就是 Qwen-72B [Bai等人,2023]。 因此,我们在 Qwen 许可下发布 Smaug-72B (https://github.com/QwenLM/Qwen/blob/main/Tongyi%20Qianwen%20LICENSE%20AGREEMENT)。
E.2 其他结果
消融研究
在部分5中,我们描述了一项关于的消融研究,以拒绝关于DPO降解如何影响的一个潜在假设。可以通过修改正则化参数的强度来防止MetaMath。 在这里,我们介绍一下情节;参见图4。 我们测试 。 尽管较大的 确实会导致较慢的下降,但 DPO 的性能仍然会直线下降。 另一方面,DPOP 在不同的 值下表现出强大且一致的性能。
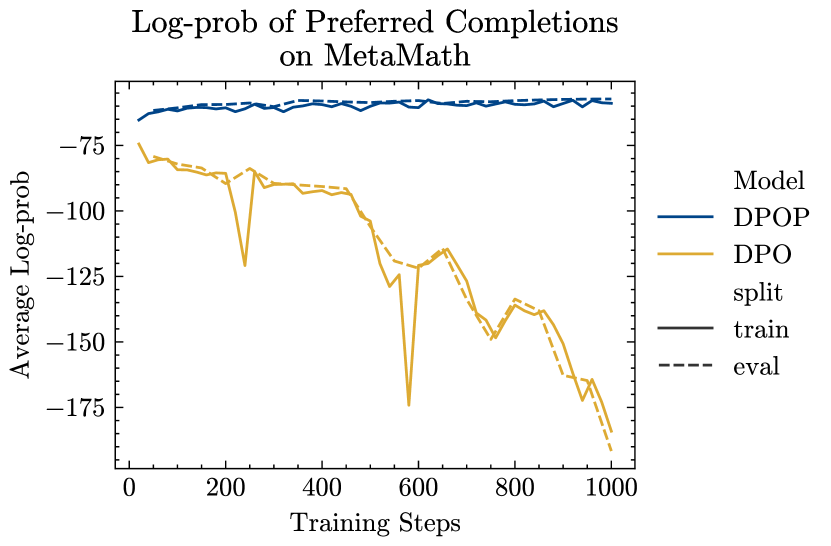
首选完成的对数概率
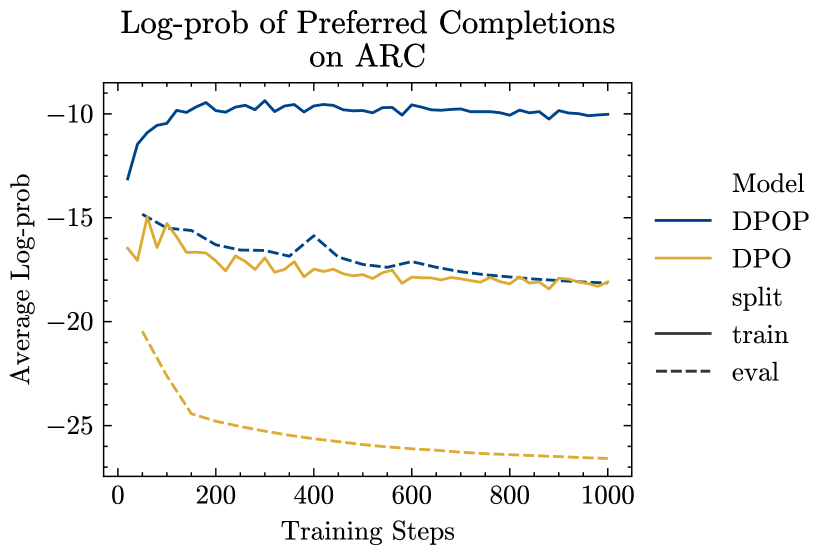
在图 5中,我们显示了在 MetaMath 上训练期间首选完成训练和评估集的对数概率。 我们以比图 3中更精细的粒度绘制对数概率。 我们确认了部分 4中的理论见解——DPO中首选完成的对数概率大幅下降,而DPOP则增加——训练集和评估集。 对于 ARC,我们在图 6中看到,DPOP 保持较高的训练集对数概率,而训练集和评估集对数概率DPO 减少。 值得注意的是,尽管 DPOP 的 eval set log-probs 确实有所下降,但它们仍然高于 DPO 的训练集 log-probs。
附加表
在Table3中,我们给出了Table1<的扩展/t3> (其实验细节位于部分6)。 在表4中,我们给出了相同的表,但尺寸为34B或更低的型号除外。
| Model | Avg. | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|---|---|---|---|---|---|---|---|
| Smaug-72B (Ours) | 80.48 | 76.02 | 89.27 | 77.15 | 76.67 | 85.08 | 78.70 |
| MoMo-72B-lora-1.8.7-DPO | 78.55 | 70.82 | 85.96 | 77.13 | 74.71 | 84.06 | 78.62 |
| TomGrc_FusionNet_34Bx2_MoE_v0.1_DPO_f16 | 77.91 | 74.06 | 86.74 | 76.65 | 72.24 | 83.35 | 74.45 |
| TomGrc_FusionNet_34Bx2_MoE_v0.1_full_linear_DPO | 77.52 | 74.06 | 86.67 | 76.69 | 71.32 | 83.43 | 72.93 |
| Truthful_DPO_TomGrc_FusionNet_7Bx2_MoE_13B | 77.44 | 74.91 | 89.30 | 64.67 | 78.02 | 88.24 | 69.52 |
| CCK_Asura_v1 | 77.43 | 73.89 | 89.07 | 75.44 | 71.75 | 86.35 | 68.08 |
| FusionNet_34Bx2_MoE_v0.1 | 77.38 | 73.72 | 86.46 | 76.72 | 71.01 | 83.35 | 73.01 |
| MoMo-72B-lora-1.8.6-DPO | 77.29 | 70.14 | 86.03 | 77.40 | 69.00 | 84.37 | 76.80 |
| Smaug-34B-v0.1 (Ours) | 77.29 | 74.23 | 86.76 | 76.66 | 70.22 | 83.66 | 72.18 |
| Truthful_DPO_TomGrc_FusionNet_34Bx2_MoE | 77.28 | 72.87 | 86.52 | 76.96 | 73.28 | 83.19 | 70.89 |
| DARE_TIES_13B | 77.10 | 74.32 | 89.5 | 64.47 | 78.66 | 88.08 | 67.55 |
| 13B_MATH_DPO | 77.08 | 74.66 | 89.51 | 64.53 | 78.63 | 88.08 | 67.10 |
| FusionNet_34Bx2_MoE | 77.07 | 72.95 | 86.22 | 77.05 | 71.31 | 83.98 | 70.89 |
| MoE_13B_DPO | 77.05 | 74.32 | 89.39 | 64.48 | 78.47 | 88.00 | 67.63 |
| 4bit_quant_TomGrc_FusionNet_34Bx2_MoE_v0.1_DPO | 76.95 | 73.21 | 86.11 | 75.44 | 72.78 | 82.95 | 71.19 |
| MixTAO-7Bx2-MoE-Instruct-v7.0 | 76.55 | 74.23 | 89.37 | 64.54 | 74.26 | 87.77 | 69.14 |
| Truthful_DPO_cloudyu_Mixtral_34Bx2_MoE_60B0 | 76.48 | 71.25 | 85.24 | 77.28 | 66.74 | 84.29 | 74.07 |
| MoMo-72B-lora-1.8.4-DPO | 76.23 | 69.62 | 85.35 | 77.33 | 64.64 | 84.14 | 76.27 |
| FusionNet_7Bx2_MoE_v0.1 | 76.16 | 74.06 | 88.90 | 65.00 | 71.20 | 87.53 | 70.28 |
| MBX-7B-v3-DPO | 76.13 | 73.55 | 89.11 | 64.91 | 74.00 | 85.56 | 69.67 |
| Model | Size | Avg. | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
|---|---|---|---|---|---|---|---|---|
| Smaug-34B-v0.1 (Ours) | <35B | 77.29 | 74.23 | 86.76 | 76.66 | 70.22 | 83.66 | 72.18 |
| DARE_TIES_13B | <35B | 77.10 | 74.32 | 89.50 | 64.47 | 78.66 | 88.08 | 67.55 |
| 13B_MATH_DPO | <35B | 77.08 | 74.66 | 89.51 | 64.53 | 78.63 | 88.08 | 67.10 |
| MoE_13B_DPO | <35B | 77.05 | 74.32 | 89.39 | 64.48 | 78.47 | 88.00 | 67.63 |
| 4bit_quant_TomGrc_FusionNet_34Bx2_MoE_v0.1_DPO | <35B | 76.95 | 73.21 | 86.11 | 75.44 | 72.78 | 82.95 | 71.19 |
附录 F完成示例
在本节中,我们将给出 Smaug-72B 对 MT-Bench [Zheng et al, 2023] 中问题的补全示例。 请注意,这些并不是精心挑选的——它们包括好的和坏的完成示例。