数据大型语言模型标注:一项调查
摘要
数据标注是用相关信息对原始数据进行标记或标记,这对于提高机器学习模型的效率至关重要。 然而,该过程是劳动密集型且昂贵的。 以 GPT-4 为代表的先进大型语言模型(大语言模型)的出现,为彻底改变和自动化复杂的数据标注过程提供了前所未有的机会。 虽然现有的调查广泛涵盖了大语言模型架构、训练和一般应用,但本文特别关注它们对数据标注的特定用途。 这项调查致力于三个核心方面:基于LLM的数据、评估LLM生成的注释以及利用LLM生成的注释进行学习。 此外,本文还对采用大语言模型进行数据标注的方法进行了深入的分类,对纳入 LLM 生成注释的模型的学习策略进行了全面回顾,并详细讨论了使用大语言模型进行标注相关的主要挑战和局限性。数据标注。 作为一个关键指南,本次调查旨在指导研究人员和从业者探索最新大语言模型在数据标注方面的潜力,促进这一关键领域的未来进步。 我们在 https://github.com/Zhen-Tan-dmml/LLM4Annotation.git 提供了全面的论文列表。
1简介
在机器学习和 NLP 的复杂领域中,数据标注是一个关键但具有挑战性的步骤,它超越了简单的标签附件,涵盖了丰富的辅助预测信息。 这个详细的过程通常涉及❶使用类别或任务标签对原始数据进行基本分类,❷添加上下文深度的中间标签Yu等人(2022),❸分配置信度分数以衡量标注可靠性 Lin 等人 (2022),❹ 应用对齐或偏好标签来根据特定标准或用户需求定制输出,❺ 注释实体关系以了解数据集中的实体如何相互交互 Wadhwa 等人 (2023 ),❻标记语义角色以定义实体在句子中扮演的底层角色Larionov 等人 (2019),❼标记时间序列以捕获事件或动作的顺序于等人(2023)。
由于数据的复杂性、主观性和多样性,数据标注对当前的机器学习模型提出了重大挑战,需要领域专业知识以及手动标记大型数据集的资源密集型特性。 先进的大语言模型,如GPT-4 OpenAI (2023)、Gemini Team 等人 (2023) 和 Llama-2 Touvron 等人 (2023b) t2> 提供了一个彻底改变数据的有希望的机会。 大语言模型不仅仅是工具,而且在提高数据有效性和准确性方面发挥着至关重要的作用。 他们能够自动执行标注任务(Zhang 等人,2022),确保大量数据的一致性(Hou 等人,2023),并通过微调或调整来适应针对特定领域的提示(宋等人,2023),显着减少了传统标注方法遇到的挑战,为 NLP 领域可实现的目标设定了新标准。 这项调查深入探讨了使用大语言模型进行数据标注的细微差别,探索了这种变革方法中的方法、学习策略和相关挑战。 通过这次探索,我们的目标是阐明采用大语言模型作为重新定义机器学习和自然语言处理中数据标注景观的催化剂背后的动机。
我们利用最新的大语言模型进行数据标注。 该调查有四个主要贡献:
-
•
基于 LLM 的数据标注:我们深入研究特定属性(例如,语言理解、上下文理解)、能力(例如文本生成、上下文推理)和精细- GPT-4 和 Llama-2 等较新的大语言模型的调整或提示策略(例如提示工程、特定领域的微调)使它们特别适合标注任务。
-
•
评估 LLM 生成的注释:我们探索了评估标注质量的各种方法,以及如何从众多选项中选择高质量的注释。
-
•
使用LLM生成的注释进行学习:我们研究了基于大语言模型生成的注释训练机器学习模型的方法,评估质量、可靠性以及对下游任务的影响。
-
•
挑战和道德考虑:我们识别并讨论从采样偏差和幻觉等技术限制到社会偏见等道德困境和更广泛的社会影响等挑战。
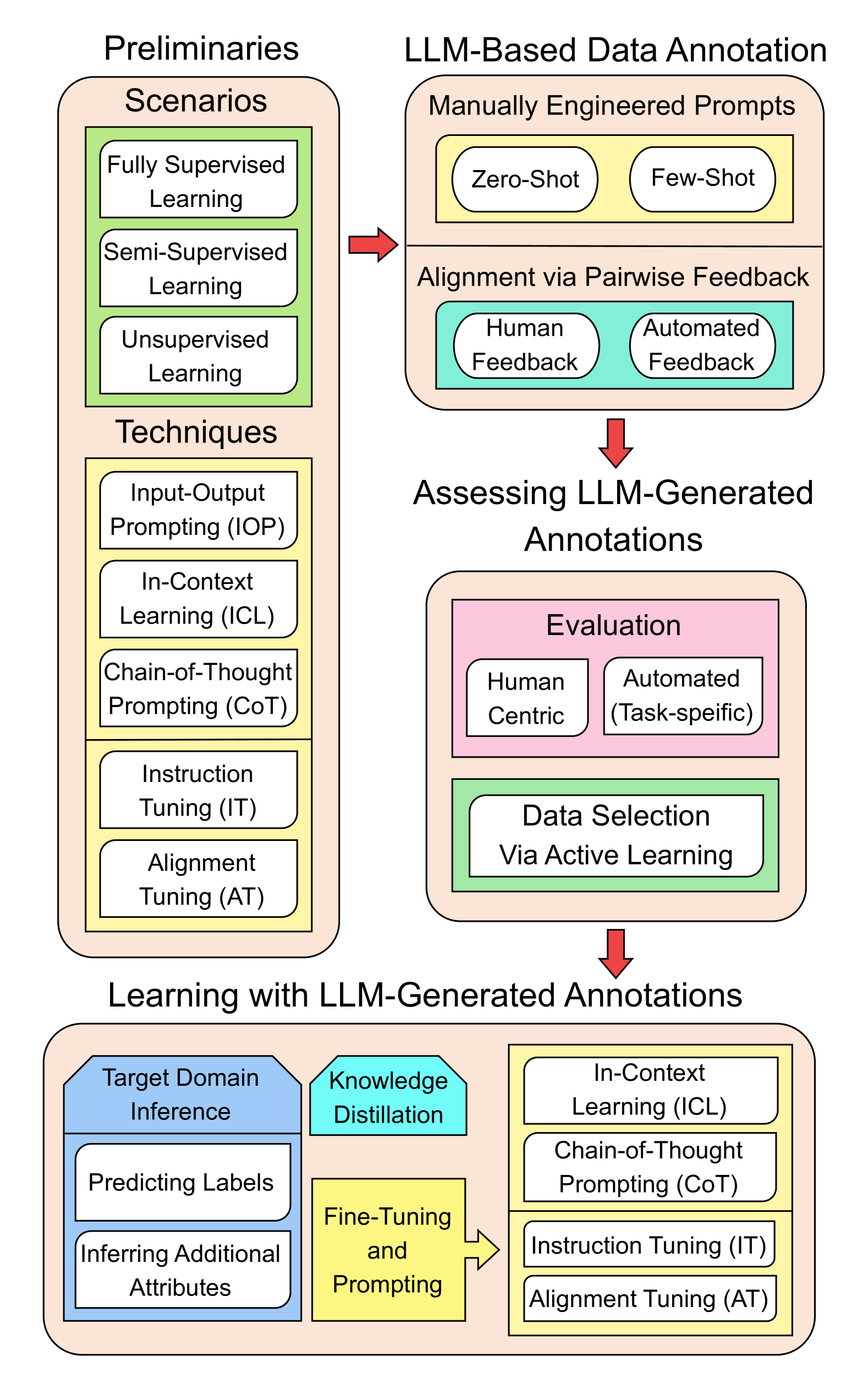
该调查针对大语言模型应用中代表性不足的这一方面,旨在为打算为标注部署大语言模型的学者和从业者提供有价值的指导。 请注意,在本次调查中,我们主要关注纯语言模型。 因此,我们没有考虑最近出现的多模态大语言模型,例如 LLaVA Liu 等人 (2023b)。 图1说明了本次调查的总体结构。 附录A中包含了利用大语言模型进行标注的潜在工具列表以及解释性示例。
与其他 LLM 相关调查的差异虽然大语言模型的现有调查广泛涵盖架构上的细微差别Zhao 等人 (2023),但训练方法Liu 等人 (2023d) 、与大语言模型相关的知识编辑Wang 等人(2023c)以及评估协议Chang 等人(2023),主要关注的是能力用于特定最终任务的模型,例如机器翻译 Min 等人 (2021)、对齐 Wang 等人 (2023d)、代码生成 Zan 等人 (2023) ,以及医学Thirunavukarasu 等人 (2023)。 相比之下,这项调查的与众不同之处在于,它强调了这些强大的下一代大语言模型在复杂的数据领域的应用,这是一个至关重要但尚未得到充分探索的领域。
2 符号和基础知识
在本节中,我们将介绍本文中使用的重要符号和基本知识。 符号及其定义可以在表1中找到。
2.1问题框架
在本节中,我们将深入探讨标注流程的方法。 我们引入两个核心模型:一个注释器模型,表示为 ,它将输入数据映射到注释;以及一个任务学习器,表示为 ,从这些注释数据中学习以完成任务具体任务。 我们的主要重点是利用先进的大语言模型,如 GPT-4 (OpenAI, 2023) 和 LLaMA (Touvron 等人, 2023a) 作为注释器 (),而任务学习器()可能涉及不太复杂的模型,例如 BERT (Devlin 等人,2018),它从这些带注释的数据中学习以执行指定的操作任务。 LLM 生成的注释包含分类标签,并通过一系列全面的辅助信号增强原始数据点。 这些注释(包括置信度分数、上下文详细信息和其他元数据)超出了传统的分类标签的范围。
2.2场景
鉴于 NLP 任务的多样性,我们在本次调查中主要关注分类任务。 然而,我们的方法可以扩展到其他领域,例如文本生成,其中显式标签 可能不适用。 为了说明我们的方法,让 表示未标记的数据池, 表示手动标记的数据集,其中 和 表示它们的大小,这可能因场景而异。 在分类任务中,我们探索以下设置:
-
1.
完全监督学习:。 注释器为中的数据点生成辅助信号并将其转换为。 形式上,,其中 。 然后学习者 在 上进行训练。 例如,在情感分析任务中,生成的属性可以突出显示电影评论中的关键短语和情感强度,帮助任务学习者进行分类准确地评价为正面或负面。
-
2.
无监督学习:。 在本例中, 对 进行操作,生成定义为 的 ,其中 。 任务学习器 在此数据集上进行训练。
-
3.
半监督学习:,通常是。 这里,注释器可以对和之一或两者进行操作以生成组合数据集。 然后任务学习器 在 上进行训练。
这些场景有两个共同元素:(1)大语言模型注释者 的标注流程和(2)基于 的 的学习策略注释。 随后的部分详细介绍了一种新颖的分类法,该分类法根据这些方面组织方法。 附录B中提供了分类论文集。
| Notations | Definitions or Descriptions |
|---|---|
| Concatenation operator. | |
| A data point. | |
| A ground truth label. | |
| A predicted label. | |
| An annotator model used for annotation. | |
| A task learner that learns a specific task. | |
| A prompt. | |
| An output of an LLM. | |
| A reasoning pathway. | |
| An instruction(s) generated by humans. | |
| A description of a specific task. | |
| A human preference score. | |
| A dataset. | |
| An unlabeled dataset. | |
| A manually labeled dataset. | |
| The augmented by LLM annotations. | |
| The augmented by LLM annotations. | |
| The size of an unlabeled dataset. | |
| The size of a manually labeled dataset. | |
| A sequence of demonstrations. | |
| An acquisition function. | |
| A prompt generation function. |
2.3 大语言模型提示与调优技巧
本小节形式化了与大语言模型交互时常用的技术。 给定输入和特定于任务的数据集,可以使用函数手动或算法生成提示,表示为。
输入输出提示(IO)(Kojima等人,2022)作为与大语言模型的基本交互模式,用函数表示>。 提供提示以获得输出。
情境学习 (ICL) 以 IO 为基础,通过一系列演示或示例对丰富提示,从而引导大语言模型获得所需的输出。
思想链提示 (CoT) 通过在 中的每个演示附加推理路径 进一步增强 ICL,从而产生 . 这种增强可以提高大语言模型的推理能力。
请注意, 表示串联,这意味着在 ICL 和 CoT 中,示例对 都集成到提示符 中以形成扩展提示符。 此外,值得注意的是,ICL 可以被视为 IO 的一种特殊形式,而 CoT 可以被视为 ICL 的一种特殊形式。
指令性能 (IT) 被引入到基于任务特定指令的大语言模型中,使它们能够泛化到各种下游任务。 该过程可以表述为,其中代表任务描述。
Alignment Tuning (AT) 旨在使大语言模型的行为与人类偏好保持一致。 除了人工标记的数据外,研究人员还利用 LLM 生成的注释进行微调。 一般来说,基于LLM的标注流程可以表示为,其中和表示大语言模型生成的两个候选答案,代表任务描述。 表示表示人类偏好的分数,通常建模为 0 到 1 之间的值。 此评级 是根据特定奖励 生成的,表示对更好的候选响应 进行基于人的比较,其中 Dubois 等人 (2023)。
3 基于 LLM 的数据标注
大型语言模型的出现引发了人们对其高质量、上下文敏感数据能力的极大兴趣。 本节探讨通过大语言模型用于数据标注的各种技术和方法。
3.1 手动设计的提示
手动设计的提示对于大语言模型的标注任务至关重要,旨在引出特定注释。 它们被归类为缺乏演示的零样本或包含Dong 等人 (2023) 的少样本。
零样本。 在大语言模型研究的早期阶段,零样本提示因其简单性和有效性而受到关注。 形式上,注释是通过将精心设计的提示 映射到标注 来派生的。 提示可能包括概述任务的指令以及基本事实标签。 例如,ZEROGEN Ye 等人 (2022) 的研究展示了零样本提示的实用性,使用诸如“积极情绪的电影评论是:”之类的短语来指导大语言模型生成文本 与标签 对齐。
样本少。 此类别涉及使用上下文学习 (ICL) 来生成注释。 ICL 可以被视为提示工程的高级形式,它将人类生成的指令 与从 采样的演示相结合。 在少样本场景中,示范样本的选择至关重要Liu 等人(2023c)。 例如,在少样本语义解析中,Shin 等人 (2021) 使用 GPT-3 从训练集中选择随机样本作为演示。 Rubin 等人 (2022) 的另一种方法使用评分大语言模型 来评估演示样本的潜在有用性。 这里,给定目标实例,模型将候选样本的分数评估为。 这些分数用于训练无监督演示检索器,通过对比学习从 BERT 基础进行初始化。
此外,还有一些工作将其他类型的注释集成到 ICL 中。 例如,SuperICL Xu 等人 (2023) 将较小语言模型的置信度分数纳入演示中,进一步增强了标注过程。
3.2 通过成对反馈进行对齐
人们越来越认识到大语言模型与以人为中心的属性相结合的重要性。 这些属性,包括乐于助人、诚实和无害,对于用于公共交互的大语言模型来说是必不可少的,超出了其固有的 NLP 技能Zhao 等人 (2023)。 传统的无监督学习方法,例如下一个单词预测,无法灌输这些品质。
人类反馈。 将这些特征嵌入到大语言模型中的主导策略是根据人类偏好进行微调Dai 等人(2023)。 一种流行但资源密集型的技术需要收集特定大语言模型响应的定量反馈Ziegler 等人 (2019)。 尽管有效,但这种方法成本高昂,并且需要付出相当大的努力Bakker 等人 (2022)。 Sparrow Glaese 等人 (2022) 等举措为人类注释者设定了标准,但研究人员意图和注释者感知之间的差异可能会影响反馈质量。
自动反馈。 因此,最近的进展旨在自动化反馈机制,经常利用另一个大语言模型或相同的大语言模型来注释不同的输出 Bakker 等人 (2022);王等人(2023b)。 这种方法通常涉及一个作为奖励模型的大语言模型,由人类偏好数据 Menick 等人 (2022) 提供信息。 例如,OpenAI 和 DeepMind 分别实现了 6B GPT-3 和 7B Gopher 模型作为奖励模型。 各种研究深入探讨了这种自动化方法的各个方面。 例如,Stiennon 等人 (2020) 的研究收集了人类对摘要的比较判断,以训练奖励模型。 然后利用该模型通过强化学习来完善摘要策略。 此外,Askell 等人 (2021) 评估了奖励模型的不同训练目标,发现排名偏好建模往往比模仿学习更有效地随着模型大小而改进。 该模型利用各种社会福利函数来合并这些个人偏好。 最新的研究(Rafailov等人,2023)采用Bradley-Terry模型来指导大语言模型评估人类注释者做出的选择。
4评估 LLM 生成的注释
对大语言模型生成的注释进行有效评估对于充分发挥其潜力至关重要。 本节主要关注两个方面:
4.1 评估 LLM 生成的注释
本小节探讨了评估标注质量的各种方法,从人工方法到自动化方法。
一般方法: 研究调查了评估大语言模型注释的多种方法。 Efrat 和 Levy (2020) 的“Turking Test”评估了大语言模型对数据标注指南的遵守情况,人工注释者将大语言模型的输出与 SNLI Bowman 等人等基准进行比较( 2015)、SQuAD Rajpurkar 等人 (2016) 和 NewsQA Trischler 等人 (2016)。 同样,Honovich 等人(2022a)手动检查了大语言模型创建的数据集的原创性、准确性和多样性,重点关注他们对指令的响应。 此外,Alizadeh 等人 (2023) 等人的研究衡量了开源大语言模型在相关性和主题检测等任务中针对人工注释标签的性能。
针对特定任务的评估: 方法因应用而异。 例如,在知识图增强中,词符排名指标评估大语言模型在事实完成方面的贡献。 此外,反事实生成的评估通常利用 Self-BLEU Chen 等人 (2023) 等多样性指标,而代码生成则依赖于 Pass@k Nijkamp 等人 (2022) 等指标t1>. 在需要大量数据集的场景中,LLM 生成的注释的质量与小型标记子集中的黄金标准标签进行比较 Zhao 等人 (2021); Agrawal 等人 (2022);他等人(2023)。
4.2 通过主动学习进行数据选择
从众多选项中选择高质量的注释至关重要。 主动学习 (AL) 成为一项关键技术,尤其是在将大语言模型集成到 AL 流程中时。 本节介绍了学习标注框架内基于池的 AL,其中存在大量未标记数据和较小的标记数据集。 AL 策略性地从池中选择信息最丰富的样本,以增强学习模型的性能或直到达到预算限制。
大语言模型作为习得函数: 存在各种类型的获取函数,分类为(a)多样性、(b)不确定性和(c)相似性。 这方面的著名研究包括 Shelmanov 等人 (2021) 的研究; Tamkin 等人 (2022); Margatina 等人 (2023),每个人都研究使用大语言模型作为习得函数的不同方面。
作为 Oracle Annotators 的大语言模型: 创新研究Bansal 和 Sharma (2023); Wu 等人 (2023a) 在 AL 设置中采用大语言模型作为预言机注释器,增强了 NLP 模型的领域泛化和上下文学习。 此外,Kim 等人(2023)提出利用大语言模型来注释输入文本对之间的特定于任务的偏好,促进与任务标签的联合学习。
5 使用 LLM 生成的注释进行学习
LLM 生成的注释为各种机器学习任务提供了宝贵的标记数据资源。 本节探讨使用 LLM 生成的注释进行学习的方法。
5.1 目标域推断:直接利用注释
在本节中,我们将探讨 LLM 生成的注释在各种下游任务中的实际应用。 通过精心设计的提示从大语言模型中提取的注释为广泛的下游应用程序提供了有价值的预测。 这种用法可以根据第 2 节中的定义进行分类: 监督:标签以任何形式使用。 b.无监督:注释充当预测,不涉及标签,例如零样本场景。
预测标签。 利用手动设计的提示,大语言模型以两种不同的方式生成预测标签。 首先,他们在考虑演示样本的同时预测标签,表示为 。 其次,他们在不依赖演示样本的情况下进行预测,表示为 。 根据这些演示样本的来源(可能是 或 ),可以将其分类为有监督或无监督Sorensen 等人 (2022)。 这项技术使大语言模型能够为广泛的任务做出贡献,涵盖推理、知识库、因果推理、推荐系统、医疗保健,甚至视觉语言模型Wei等人(2022a);小岛等人 (2022); Petroni 等人 (2019); Kıcıman 等人 (2023);侯等人 (2023);顾等人(2023a)。
推断附加属性。 同样,大语言模型巧妙地将提示与特定属性或概念相关联,在监督和非监督环境中都有效 Sorensen 等人 (2022)。 这种能力在诸如概念瓶颈模型 Tan 等人 (2023c, b) 等模型的情况下被证明特别有利,该模型通过识别潜在概念来生成预测。 在此背景下,大语言模型有效地解决了数据集注释有限的问题。 在视觉语言任务中,大语言模型可用于自动生成图像分类的文本描述 Radford 等人 (2021);梅农和冯德里克 (2022)。
5.2 知识蒸馏:桥接大语言模型和特定任务模型
知识蒸馏(KD)扩展了之前关于直接使用注释的讨论,成为利用大语言模型功能的另一种方法。 KD 有助于将专业知识从较大的“教师”模型(通常是大语言模型)转移到较小的、更集中的“学生”模型。 尽管资源需求较低,但该技术使学生模型能够匹配甚至超越教师的表现。
模型增强。 目前,一些研究已经采用 KD 来丰富特定于任务的学习者模型(表示为 ),并利用基于 LLM 的注释器(称为 )的见解。 例如,像Magister等人(2022)这样的研究工作;福等人 (2023);孙等人 (2023); Li 等人 (2024) 重点关注使用 注释的数据集训练 。相反,Hsieh 等人(2023)采用“任务难度”作为提供的辅助标签来增强的学习过程。 值得注意的是,Alpaca Taori 等人 (2023a) 和 GPT4All Anand 等人 (2023) 使用 LLM 生成的语料库来训练其轻量级学生模型,以取得令人印象深刻的性能。
KD 创新。 在工具方面,GKD Tan 等人 (2023a) 作为最近开发的库脱颖而出,它利用大语言模型简化了 KD 流程。 这一动态领域的进步包括黑盒 Jiang 等人 (2023b) 和白盒 Gu 等人 (2023c) 作为教师模型的大语言模型,以及效率 Jha 等人 (2023),并扩展到专业领域,例如生物医学知识提取 Gu 等人 (2023b)、代码生成 Gunasekar 等人 (2023a) 、网页内容过滤Vörös 等人 (2023) 和数学推理 Fu 等人 (2023)。
总之,采用 KD 进行训练任务特定模型具有减少计算需求和持续性能的双重优势,使其成为当代自然语言处理中非常有前途的途径。
5.3 利用大语言模型注释进行微调和提示
使用LLM生成的注释在大语言模型适应中进行微调或提示越来越受欢迎,遵循知识蒸馏原则来释放大语言模型的潜力。 研究表明,用于监督微调的更大数据集可以增强大语言模型的泛化能力 Sanh 等人 (2021); Wei 等人 (2021),强调了 LLM 注释数据 Wang 等人 (2022c) 日益增长的重要性。 这些方法主要分为四类:
情境学习。
源于 GPT-3 模型 Brown 等人 (2020),上下文学习(ICL)已被广泛应用于提高大语言模型在各种任务中的性能。 该方法通常采用特殊格式的提示,其中包括任务说明以及说明性演示Dong 等人 (2022)。 这些提示有助于大语言模型推断新的、未见过的任务,而不需要显式的参数更新。 虽然有效,但通常很难实现 Margatina 等人 (2023)。 因此,基于大语言模型洪金等人(2022)生成的注释来获取有用提示的有效方法。 由于任务指令对于 ICL 的性能至关重要,因此提出了多项工作来自动生成指令,而无需人工操作的繁琐过程Zhao 等人(2023)。 在 Honovich 等人 (2022b) 中,作者观察到,通过提供几个演示示例,大语言模型可以学习生成各种任务的指令,从而提高 ICL 性能。
除了利用 LLM 生成的注释作为指令的方法外,其他工作还探讨了利用 LLM 生成的 ICL Dong 等人 (2022) 演示的可能性。 其中,最近一篇名为合成提示Shao等人(2023)的作品受到关注。 该技术根据给定输入问题的推理链构建新问题,然后采用聚类方法来选择最多样化和最复杂的演示。 Chen 等人 (2022) 利用原始文本数据集作为热身,介绍了一种创建自我监督数据的方法,该数据与各种下游任务的 ICL 学习格式保持一致。
思想链提示。 它代表了 ICL 中的一种专门方法,专门增强了大语言模型在复杂推理任务上的性能,例如算术推理 Miao 等人 (2021)、常识推理 Talmor 等人 (2018) ,以及符号推理Wei等人(2022b)。 与传统的 ICL 不同,CoT 在提示中引入了中间推理步骤。 这些步骤旨在对最终输出做出有意义的贡献。 这种区别强调了 CoT 对推理机制的关注。 人们普遍认为,创建有效的 CoT 提示对于解锁大语言模型复杂的推理能力至关重要Dong 等人 (2022)。 由于手动创建此类提示可能既昂贵又耗时 Wei 等人 (2022b),最近的工作普遍提出通过大语言模型自动生成 CoT 提示。 例如,在零样本CoT Kojima 等人(2022)中,大语言模型提示“让我们一步一步思考”以生成推理步骤,然后提示“因此,答案是”即可得出结论。 Auto-CoT Zhang 等人 (2022) 通过将聚类策略应用于训练问题来确定每个聚类中最具代表性的问题,从而改进了这种方法。 一项相关研究 Wang 等人 (2022a) 通过考虑即时置信度来扩展这一点,发现多样化的推理路径对于有效的 CoT 至关重要。 另一方面,Fu 等人 (2023) 建议将 LLM 生成的 CoT 和少样本演示结合起来,以保留 ICL 功能,同时增强使用不同提示格式的推理性能。 王等人(2023a)探索使用LLM注释的原理进行基于CoT提示的知识蒸馏。 尽管有不相关或空洞的理由,作者还是使用对比解码来显着提高使用这些增强数据训练的学生模型的推理能力。
指令执行。 ICL 通过改变输入结构来适应大语言模型,而指令调优则采取不同的方法,在监督学习环境中对各种任务的模型进行微调Zhao 等人 (2023)。 多项研究表明,大语言模型在对 Chung 等人 (2022) 进行微调后,在泛化到不熟悉的任务方面表现出了显着的能力; Muennighoff 等人 (2022)。 然而,获取指令调节的高质量训练数据的过程通常需要大量的人力,这在特定的现实场景中是不切实际的Lou等人(2023)。 为了避免获取人工注释的繁琐过程,最近的工作采用了 LLM 生成的注释。 作为一个典型的例子,在《Self-Instruct Wang 等人 (2022b)》中,大语言模型被提示自主生成新的教学输入输出对。 这些随后被过滤并用于 T5 模型 Brown 等人 (2020) 的微调。 这个两阶段管道生成指令,过滤掉无效或冗余实例,并利用其余部分进行模型微调。 Alpaca Taori 等人 (2023b) 以指令跟踪演示的形式利用 LLM 生成的注释来构建 LLaMA 模型 Touvron 等人 (2023a)。 值得注意的是,GopherCite 模型 Menick 等人 (2022) 在训练大语言模型中引入了强化学习框架,以引用证据支持的答案形式生成注释,从而增强其答案的可验证性。 Chiang 和 Lee (2023) 提出了一项关于使用 LLM 生成的注释在各种 NLP 任务中进行类人评估的可靠性的研究。
对准调整。 对齐调整旨在通过将大语言模型与人类期望对齐来消除大语言模型的不良行为Zhao等人(2023)。 然而,在实践中,收集人类反馈通常既昂贵又费力Ziegler 等人 (2019)。 因此,现有的工作通常学习一种替代奖励模型,该模型可以在一对输入(成对反馈)中模仿人类的偏好。 为了训练注释奖励模型,研究人员通常会首先从人类注释者那里收集带标签的成对反馈数据集。 然后基于不同的策略,很多算法直接向Keskar等人(2019)学习;刘等人 (2023a); Korbak 等人 (2023),而其他算法 Christiano 等人 (2017);欧阳等人(2022)从学习代理奖励模型,并用它来自动注释大语言模型生成的未标记成对反馈。 为了使大语言模型与注释保持一致,现有工作通常利用强化学习策略OpenAI (2023); Touvron 等人 (2023b),即 RLHF(来自人类反馈的强化学习)。 作为一个经典的例子,InstructGPT Ouyang 等人 (2022) 利用 PPO 策略 Schulman 等人 (2017),并在每次更新中计算 Kullback–Leibler (KL) 散度当前大语言模型输出与之前更新的输出之间的差异。 通过这种方式,可以以更稳健的方式优化框架。 另一方面,ILQL Snell 等人 (2022) 探索了离线环境下对 LLM 生成的注释进行对齐调整的应用,与流行的在线 RL 场景形成鲜明对比。 在 GopherCite Menick 等人 (2022) 中,作者利用人类偏好的强化学习 (RLHP) 来训练 QA 模型,该模型生成答案并同时引用具体证据来支持他们的主张,从而促进准确性的评估。 最近,RLAIF Lee 等人 (2023) 利用现成的大语言模型代替人类标记的偏好,实现了与使用人类标记数据类似的性能。
6 挑战
在本节中,我们概述了大语言模型数据面临的严峻挑战,包括技术障碍、准确性问题以及劳动力流失和偏见传播等社会影响。 解决这些问题对于推进大语言模型标注应用至关重要。
模型模仿中的复合误差。
为了缩小 ChatGPT 等专有大语言模型与 LLaMA 等开源模型之间性能差距的努力,通常涉及通过使用更强大的模型的输出进行训练来增强后者的能力 Sun 等人 (2023 ); Gunasekar 等人 (2023b); Hsieh 等人 (2023); Honovich 等人 (2022a);蒋等人 (2023);耿等人 (2023). 虽然这种策略产生了不同的结果,但模仿模型通常会复制风格元素,而无法达到卓越模型 Gudibande 等人 (2023) 的事实精度。 研究强调模仿的失败主要是由于模型崩溃,即模仿模型逐渐偏离其试图复制的模型的数据分布Shumailov等人(2023)。 这种分歧是由两个主要问题造成的:由于样本量有限而产生的统计近似误差,以及由于模型容量受限而产生的函数近似误差。 这两个错误往往会在连续的训练周期Alemohammad 等人 (2023) 中放大。 模型崩溃和近似误差的影响延伸到社会领域。 在未来的模型训练中传播和利用 LLM 生成的带有这些不准确的注释可能会导致数据污染。 随着时间的推移,这种情况可能会破坏大语言模型的可信度,影响其在关键应用中的效用。 在未来的研究中解决这些问题对于构建下一代大语言模型,或者更广泛的人工智能(AGI)来说越来越重要。
幻觉对大语言模型注释的影响。
大语言模型中的幻觉现象严重破坏了其生成注释的完整性和可靠性Alkaissi and McFarlane (2023); Azamfirei 等人 (2023)。 脱离实际数据的输出可能会导致错误信息和注释不准确,从而在医疗保健、法律分析和金融领域等敏感领域带来巨大风险 Jiang 等人 (2023a);陈和舒(2023)。 解决幻觉需要综合策略,包括完善大语言模型训练流程以减少无根据内容的出现,并通过自动和手动验证实施注释验证机制Liao and Vaughan (2023);潘等人 (2023);卞等人(2023)。 然而,大语言模型固有的不透明性使得查明和纠正幻觉原因的工作变得复杂,在部署大语言模型担任关键角色时造成了伦理困境。 这强调了持续研究的必要性,以减轻幻觉,同时平衡大语言模型应用领域的性能收益与伦理问题。
社会影响。
LLM 生成的注释在现实世界领域的激增,例如金融 Yang 等人 (2023)、法学 Cui 等人 (2023) 和医疗保健 Eloundou等人 (2023) 有潜力显着提高效率和生产力。 然而,这种自动化带来了社会挑战,特别是在劳动力流失、标注质量和社会发展影响方面。 向自动注释的转变可能会导致人类注释者角色变得多余,从而可能加剧收入差距并影响低技能就业部门Dillion 等人 (2023)。 此外,尽管大语言模型标注的生成速度很快,但人类洞察力的缺乏可能会导致输出缺乏深度,导致研究结果有偏见或不公平Wu等人(2023b);阿比德等人 (2021);程 等人 (2021);李等人(2023)。 此外,传统上由人类管理的任务依赖大语言模型,需要采取谨慎的方法,以确保技术进步不会无意中加剧社会不平等或降低质量标准。 未来的研究应该旨在协调技术进步与其更广泛的社会影响。
7结论
大语言模型对数据标注的探索揭示了自然语言处理领域令人兴奋的前沿,为数据稀缺等长期挑战提供了新颖的解决方案,并提高了标注质量和流程效率。 这项调查仔细审查了与大语言模型使用相关的方法、应用和障碍,包括快速工程和特定领域调整等创新策略。 它评估 LLM 生成的注释对训练机器学习模型的影响,同时解决偏见和社会影响等技术和道德问题。 这项工作强调了我们对大语言模型方法的新颖分类、利用 LLM 生成的注释的策略以及对挑战的批判性讨论,旨在引导这一关键领域的未来进展。 此外,我们引入了全面的技术分类,并编译了广泛的基准数据集来支持正在进行的研究工作,最后对持续存在的挑战和悬而未决的问题进行了检查,为该领域未来的研究活动铺平了道路。
局限性
采样偏差和幻觉。 大语言模型可能会出现抽样偏差,导致数据不正确或“幻觉”,影响判别任务注释的可靠性和质量。
社会偏见和道德困境。 训练数据中固有的偏见可能会被大语言模型延续和放大,从而导致道德问题和通过注释数据传播社会偏见。 这在需要公平和公正的任务中尤其成问题。
对高质量数据的依赖。 大语言模型在生成注释方面的有用性取决于大型、高质量的数据集。 但整理这些数据集是劳动密集型的,这给基于 LLM 的标注工作带来了可扩展性挑战。
调整和快速工程的复杂性。 成功利用大语言模型进行数据标注需要复杂的即时工程和微调技术。 这可能会对没有 NLP 和机器学习方面丰富专业知识的从业者和研究人员构成进入障碍。
泛化和过度拟合虽然大语言模型可以成为标注的强大工具,但存在对训练数据过度拟合的风险,限制了它们泛化到未见过的数据或不同上下文的能力。 这是判别性任务的一个关键限制,其目标是开发在不同数据集和领域中表现良好的模型。
计算和资源要求。 最先进的数据标注大语言模型的训练和部署需要大量的计算资源,而这些资源可能并非所有研究人员和组织都可以获得,从而限制了广泛采用。
道德声明
对公平的承诺。 确保大语言数据模型的开发和应用遵循促进公平和防止偏见的道德原则,认识到数据的多样性并避免歧视性结果。
透明度和问责制。 保持大语言模型方法、训练数据和标注流程的透明度。 提供清晰的文档和问责机制,以解决大语言模型引入的潜在错误或偏见。
隐私和数据保护。 维护强大的数据隐私协议,确保训练和标注数据集的机密性和同意。
人类监督。 利用人工监督来审查 LLM 生成的注释,确保准确性、道德合规性,并降低错误传播或偏见的风险。
持续监控偏差和错误。 定期评估和更新大语言模型,以识别和纠正偏见、不准确或道德问题,利用多样化的数据集和反馈机制来提高模型的公平性和可靠性。
社会影响和责任。 考虑为数据部署大语言模型所带来的更广泛的社会影响,包括工作岗位流失的可能性以及敏感领域自动化系统的道德使用。 致力于开发能够增强人类福祉的对社会有益的技术。
协作和参与。 与广泛的利益相关者合作,包括伦理学家、领域专家和受影响的社区,收集不同的观点和见解,确保数据标注的大语言模型应用服务于公共利益和道德标准。
参考
- Abid et al. (2021) Abubakar Abid, Maheen Farooqi, and James Zou. 2021. Persistent anti-muslim bias in large language models. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pages 298–306.
- Aceituno and Rosinol (2022) Bernardo Aceituno and Antoni Rosinol. 2022. Stack ai: The middle-layer of ai.
- Agrawal et al. (2022) Monica Agrawal, Stefan Hegselmann, Hunter Lang, Yoon Kim, and David Sontag. 2022. Large language models are zero-shot clinical information extractors. arXiv preprint arXiv:2205.12689.
- Alemohammad et al. (2023) Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossein Reza Babaei, Daniel LeJeune, Ali Siahkoohi, and Richard Baraniuk. 2023. Self-consuming generative models go mad. ArXiv, abs/2307.01850.
- Alizadeh et al. (2023) Meysam Alizadeh, Maël Kubli, Zeynab Samei, Shirin Dehghani, Juan Diego Bermeo, Maria Korobeynikova, and Fabrizio Gilardi. 2023. Open-source large language models outperform crowd workers and approach chatgpt in text-annotation tasks. arXiv preprint arXiv:2307.02179.
- Alkaissi and McFarlane (2023) Hussam Alkaissi and Samy I McFarlane. 2023. Artificial hallucinations in chatgpt: implications in scientific writing. Cureus, 15(2).
- Amamou (2021) Walid Amamou. 2021. Ubiai: Text annotation tool.
- Anand et al. (2023) Yuvanesh Anand, Zach Nussbaum, Brandon Duderstadt, Benjamin Schmidt, and Andriy Mulyar. 2023. Gpt4all: Training an assistant-style chatbot with large scale data distillation from gpt-3.5-turbo. GitHub.
- Askell et al. (2021) Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. 2021. A general language assistant as a laboratory for alignment. arXiv preprint arXiv:2112.00861.
- Azamfirei et al. (2023) Razvan Azamfirei, Sapna R Kudchadkar, and James Fackler. 2023. Large language models and the perils of their hallucinations. Critical Care, 27(1):1–2.
- Bakker et al. (2022) Michiel Bakker, Martin Chadwick, Hannah Sheahan, Michael Tessler, Lucy Campbell-Gillingham, Jan Balaguer, Nat McAleese, Amelia Glaese, John Aslanides, Matt Botvinick, et al. 2022. Fine-tuning language models to find agreement among humans with diverse preferences. Advances in Neural Information Processing Systems, 35:38176–38189.
- Bansal and Sharma (2023) Parikshit Bansal and Amit Sharma. 2023. Large language models as annotators: Enhancing generalization of nlp models at minimal cost. arXiv preprint arXiv:2306.15766.
- Bian et al. (2023) Ning Bian, Peilin Liu, Xianpei Han, Hongyu Lin, Yaojie Lu, Ben He, and Le Sun. 2023. A drop of ink may make a million think: The spread of false information in large language models. arXiv preprint arXiv:2305.04812.
- Bowman et al. (2015) Samuel R Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. 2015. A large annotated corpus for learning natural language inference. arXiv preprint arXiv:1508.05326.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Chang et al. (2023) Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. 2023. A survey on evaluation of large language models.
- Chen and Shu (2023) Canyu Chen and Kai Shu. 2023. Can llm-generated misinformation be detected? arXiv preprint arXiv:2309.13788.
- Chen et al. (2022) Mingda Chen, Jingfei Du, Ramakanth Pasunuru, Todor Mihaylov, Srini Iyer, Veselin Stoyanov, and Zornitsa Kozareva. 2022. Improving in-context few-shot learning via self-supervised training. In NAACL.
- Chen et al. (2023) Zeming Chen, Qiyue Gao, Antoine Bosselut, Ashish Sabharwal, and Kyle Richardson. 2023. Disco: Distilling counterfactuals with large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5514–5528.
- Cheng et al. (2021) Lu Cheng, Kush R Varshney, and Huan Liu. 2021. Socially responsible ai algorithms: Issues, purposes, and challenges. Journal of Artificial Intelligence Research, 71:1137–1181.
- Chiang and Lee (2023) Cheng-Han Chiang and Hung-yi Lee. 2023. Can large language models be an alternative to human evaluations? arXiv preprint arXiv:2305.01937.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open-source chatbot impressing GPT-4 with 90%* chatgpt quality.
- Christiano et al. (2017) Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
- Chung et al. (2022) Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
- Cui et al. (2023) Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, and Li Yuan. 2023. Chatlaw: Open-source legal large language model with integrated external knowledge bases. arXiv preprint arXiv:2306.16092.
- Dai et al. (2023) Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. 2023. Why can gpt learn in-context? language models secretly perform gradient descent as meta-optimizers. In Findings of the Association for Computational Linguistics: ACL 2023, pages 4005–4019.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Dillion et al. (2023) Danica Dillion, Niket Tandon, Yuling Gu, and Kurt Gray. 2023. Can ai language models replace human participants? Trends in Cognitive Sciences.
- Dong et al. (2023) Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. 2023. Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767.
- Dong et al. (2022) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2022. A survey for in-context learning. arXiv preprint arXiv:2301.00234.
- Dubois et al. (2023) Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. 2023. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387.
- Efrat and Levy (2020) Avia Efrat and Omer Levy. 2020. The turking test: Can language models understand instructions? arXiv preprint arXiv:2010.11982.
- Eloundou et al. (2023) Tyna Eloundou, Sam Manning, Pamela Mishkin, and Daniel Rock. 2023. Gpts are gpts: An early look at the labor market impact potential of large language models. arXiv preprint arXiv:2303.10130.
- Fu et al. (2023) Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. 2023. Specializing smaller language models towards multi-step reasoning. arXiv preprint arXiv:2301.12726.
- Geng et al. (2023) Xinyang Geng, Arnav Gudibande, Hao Liu, Eric Wallace, Pieter Abbeel, Sergey Levine, and Dawn Song. 2023. Koala: A dialogue model for academic research. BAIR Blog.
- Glaese et al. (2022) Amelia Glaese, Nat McAleese, Maja Trębacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, et al. 2022. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375.
- Gu et al. (2023a) Jindong Gu, Zhen Han, Shuo Chen, Ahmad Beirami, Bailan He, Gengyuan Zhang, Ruotong Liao, Yao Qin, Volker Tresp, and Philip Torr. 2023a. A systematic survey of prompt engineering on vision-language foundation models. arXiv preprint arXiv:2307.12980.
- Gu et al. (2023b) Yu Gu, Sheng Zhang, Naoto Usuyama, Yonas Woldesenbet, Cliff Wong, Praneeth Sanapathi, Mu Wei, Naveen Valluri, Erika Strandberg, Tristan Naumann, et al. 2023b. Distilling large language models for biomedical knowledge extraction: A case study on adverse drug events. arXiv preprint arXiv:2307.06439.
- Gu et al. (2023c) Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2023c. Knowledge distillation of large language models. arXiv preprint arXiv:2306.08543.
- Gudibande et al. (2023) Arnav Gudibande, Eric Wallace, Charles Burton Snell, Xinyang Geng, Hao Liu, P. Abbeel, Sergey Levine, and Dawn Song. 2023. The false promise of imitating proprietary llms. ArXiv, abs/2305.15717.
- Gunasekar et al. (2023a) Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, et al. 2023a. Textbooks are all you need. arXiv preprint arXiv:2306.11644.
- Gunasekar et al. (2023b) Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio Cesar Teodoro Mendes, Allison Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero C. Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, S. Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee, and Yuan-Fang Li. 2023b. Textbooks are all you need. ArXiv, abs/2306.11644.
- Harrison (2022) Chase Harrison. 2022. Langchain.
- He et al. (2023) Xingwei He, Zhenghao Lin, Yeyun Gong, Alex Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen, et al. 2023. Annollm: Making large language models to be better crowdsourced annotators. arXiv preprint arXiv:2303.16854.
- Hongjin et al. (2022) SU Hongjin, Jungo Kasai, Chen Henry Wu, Weijia Shi, Tianlu Wang, Jiayi Xin, Rui Zhang, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, et al. 2022. Selective annotation makes language models better few-shot learners. In ICLR.
- Honnibal and Montani (2017) Matthew Honnibal and Ines Montani. 2017. spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing. To appear.
- Honovich et al. (2022a) Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. 2022a. Unnatural instructions: Tuning language models with (almost) no human labor. arXiv preprint arXiv:2212.09689.
- Honovich et al. (2022b) Or Honovich, Uri Shaham, Samuel R Bowman, and Omer Levy. 2022b. Instruction induction: From few examples to natural language task descriptions. arXiv preprint arXiv:2205.10782.
- Hou et al. (2023) Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. 2023. Large language models are zero-shot rankers for recommender systems. arXiv preprint arXiv:2305.08845.
- Hsieh et al. (2023) Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alexander Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. 2023. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. arXiv preprint arXiv:2305.02301.
- Jha et al. (2023) Ananya Harsh Jha, Dirk Groeneveld, Emma Strubell, and Iz Beltagy. 2023. Large language model distillation doesn’t need a teacher. arXiv preprint arXiv:2305.14864.
- Jiang et al. (2023a) Bohan Jiang, Zhen Tan, Ayushi Nirmal, and Huan Liu. 2023a. Disinformation detection: An evolving challenge in the age of llms. arXiv preprint arXiv:2309.15847.
- Jiang et al. (2023b) Yuxin Jiang, Chunkit Chan, Mingyang Chen, and Wei Wang. 2023b. Lion: Adversarial distillation of closed-source large language model. arXiv preprint arXiv:2305.12870.
- Keskar et al. (2019) Nitish Shirish Keskar, Bryan McCann, Lav R Varshney, Caiming Xiong, and Richard Socher. 2019. Ctrl: A conditional transformer language model for controllable generation. arXiv preprint arXiv:1909.05858.
- Kıcıman et al. (2023) Emre Kıcıman, Robert Ness, Amit Sharma, and Chenhao Tan. 2023. Causal reasoning and large language models: Opening a new frontier for causality. arXiv preprint arXiv:2305.00050.
- Kim et al. (2023) Jaehyung Kim, Jinwoo Shin, and Dongyeop Kang. 2023. Prefer to classify: Improving text classifiers via auxiliary preference learning. arXiv preprint arXiv:2306.04925.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213.
- Korbak et al. (2023) Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Vinayak Bhalerao, Christopher Buckley, Jason Phang, Samuel R Bowman, and Ethan Perez. 2023. Pretraining language models with human preferences. In International Conference on Machine Learning, pages 17506–17533. PMLR.
- Larionov et al. (2019) Daniil Larionov, Artem Shelmanov, Elena Chistova, and Ivan Smirnov. 2019. Semantic role labeling with pretrained language models for known and unknown predicates. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), pages 619–628.
- Lee et al. (2023) Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Lu, Thomas Mesnard, Colton Bishop, Victor Carbune, and Abhinav Rastogi. 2023. Rlaif: Scaling reinforcement learning from human feedback with ai feedback.
- Li et al. (2024) Dawei Li, Zhen Tan, Tianlong Chen, and Huan Liu. 2024. Contextualization distillation from large language model for knowledge graph completion. arXiv preprint arXiv:2402.01729.
- Li et al. (2023) Yingji Li, Mengnan Du, Rui Song, Xin Wang, and Ying Wang. 2023. A survey on fairness in large language models. arXiv preprint arXiv:2308.10149.
- Liao and Vaughan (2023) Q Vera Liao and Jennifer Wortman Vaughan. 2023. Ai transparency in the age of llms: A human-centered research roadmap. arXiv preprint arXiv:2306.01941.
- Lin et al. (2022) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Teaching models to express their uncertainty in words. arXiv preprint arXiv:2205.14334.
- Liu et al. (2023a) Hao Liu, Carmelo Sferrazza, and Pieter Abbeel. 2023a. Chain of hindsight aligns language models with feedback. arXiv preprint arXiv:2302.02676, 3.
- Liu et al. (2023b) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023b. Visual instruction tuning. arXiv preprint arXiv:2304.08485.
- Liu et al. (2023c) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023c. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35.
- Liu et al. (2023d) Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo Hao Cheng, Yegor Klochkov, Muhammad Faaiz Taufiq, and Hang Li. 2023d. Trustworthy llms: a survey and guideline for evaluating large language models’ alignment. arXiv preprint arXiv:2308.05374.
- Lou et al. (2023) Renze Lou, Kai Zhang, and Wenpeng Yin. 2023. Is prompt all you need? no. a comprehensive and broader view of instruction learning. arXiv preprint arXiv:2303.10475.
- Magister et al. (2022) Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adamek, Eric Malmi, and Aliaksei Severyn. 2022. Teaching small language models to reason. arXiv preprint arXiv:2212.08410.
- Margatina et al. (2023) Katerina Margatina, Timo Schick, Nikolaos Aletras, and Jane Dwivedi-Yu. 2023. Active learning principles for in-context learning with large language models. arXiv preprint arXiv:2305.14264.
- Menick et al. (2022) Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, et al. 2022. Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147.
- Menon and Vondrick (2022) Sachit Menon and Carl Vondrick. 2022. Visual classification via description from large language models. arXiv preprint arXiv:2210.07183.
- Miao et al. (2021) Shen-Yun Miao, Chao-Chun Liang, and Keh-Yih Su. 2021. A diverse corpus for evaluating and developing english math word problem solvers. arXiv preprint arXiv:2106.15772.
- Min et al. (2021) Bonan Min, Hayley Ross, Elior Sulem, Amir Pouran Ben Veyseh, Thien Huu Nguyen, Oscar Sainz, Eneko Agirre, Ilana Heintz, and Dan Roth. 2021. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Computing Surveys.
- Montani and Honnibal (2018) Ines Montani and Matthew Honnibal. 2018. Prodigy: A new annotation tool for radically efficient machine teaching. Artificial Intelligence, to appear.
- Muennighoff et al. (2022) Niklas Muennighoff, Thomas Wang, Lintang Sutawika, Adam Roberts, Stella Biderman, Teven Le Scao, M Saiful Bari, Sheng Shen, Zheng-Xin Yong, Hailey Schoelkopf, et al. 2022. Crosslingual generalization through multitask finetuning. arXiv preprint arXiv:2211.01786.
- Nijkamp et al. (2022) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2022. Codegen: An open large language model for code with multi-turn program synthesis. arXiv preprint arXiv:2203.13474.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Pan et al. (2023) Yikang Pan, Liangming Pan, Wenhu Chen, Preslav Nakov, Min-Yen Kan, and William Yang Wang. 2023. On the risk of misinformation pollution with large language models. arXiv preprint arXiv:2305.13661.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. 2019. Language models as knowledge bases? arXiv preprint arXiv:1909.01066.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250.
- Rubin et al. (2022) Ohad Rubin, Jonathan Herzig, and Jonathan Berant. 2022. Learning to retrieve prompts for in-context learning. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2655–2671.
- Sanh et al. (2021) Victor Sanh, Albert Webson, Colin Raffel, Stephen H Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Teven Le Scao, Arun Raja, et al. 2021. Multitask prompted training enables zero-shot task generalization. arXiv preprint arXiv:2110.08207.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Shao et al. (2023) Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Synthetic prompting: Generating chain-of-thought demonstrations for large language models. arXiv preprint arXiv:2302.00618.
- Shelmanov et al. (2021) A Shelmanov, D Puzyrev, L Kupriyanova, N Khromov, DV Dylov, A Panchenko, D Belyakov, D Larionov, E Artemova, and O Kozlova. 2021. Active learning for sequence tagging with deep pre-trained models and bayesian uncertainty estimates. In EACL 2021-16th Conference of the European Chapter of the Association for Computational Linguistics, Proceedings of the Conference, pages 1698–1712.
- Shin et al. (2021) Richard Shin, Christopher Lin, Sam Thomson, Charles Chen Jr, Subhro Roy, Emmanouil Antonios Platanios, Adam Pauls, Dan Klein, Jason Eisner, and Benjamin Van Durme. 2021. Constrained language models yield few-shot semantic parsers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7699–7715.
- Shumailov et al. (2023) Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. 2023. The curse of recursion: Training on generated data makes models forget. ArXiv, abs/2305.17493.
- Snell et al. (2022) Charlie Snell, Ilya Kostrikov, Yi Su, Mengjiao Yang, and Sergey Levine. 2022. Offline rl for natural language generation with implicit language q learning. arXiv preprint arXiv:2206.11871.
- Song et al. (2023) Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, and Houfeng Wang. 2023. Preference ranking optimization for human alignment. arXiv preprint arXiv:2306.17492.
- Sorensen et al. (2022) Taylor Sorensen, Joshua Robinson, Christopher Michael Rytting, Alexander Glenn Shaw, Kyle Jeffrey Rogers, Alexia Pauline Delorey, Mahmoud Khalil, Nancy Fulda, and David Wingate. 2022. An information-theoretic approach to prompt engineering without ground truth labels. arXiv preprint arXiv:2203.11364.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. 2020. Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33:3008–3021.
- Sun et al. (2023) Weiwei Sun, Lingyong Yan, Xinyu Ma, Pengjie Ren, Dawei Yin, and Zhaochun Ren. 2023. Is chatgpt good at search? investigating large language models as re-ranking agent. arXiv preprint arXiv:2304.09542.
- Talmor et al. (2018) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2018. Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937.
- Tamkin et al. (2022) Alex Tamkin, Dat Nguyen, Salil Deshpande, Jesse Mu, and Noah Goodman. 2022. Active learning helps pretrained models learn the intended task. Advances in Neural Information Processing Systems, 35:28140–28153.
- Tan et al. (2023a) Shicheng Tan, Weng Lam Tam, Yuanchun Wang, Wenwen Gong, Yang Yang, Hongyin Tang, Keqing He, Jiahao Liu, Jingang Wang, Shu Zhao, et al. 2023a. Gkd: A general knowledge distillation framework for large-scale pre-trained language model. arXiv preprint arXiv:2306.06629.
- Tan et al. (2023b) Zhen Tan, Tianlong Chen, Zhenyu Zhang, and Huan Liu. 2023b. Sparsity-guided holistic explanation for llms with interpretable inference-time intervention. arXiv preprint arXiv:2312.15033.
- Tan et al. (2023c) Zhen Tan, Lu Cheng, Song Wang, Yuan Bo, Jundong Li, and Huan Liu. 2023c. Interpreting pretrained language models via concept bottlenecks. arXiv preprint arXiv:2311.05014.
- Taori et al. (2023a) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023a. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
- Taori et al. (2023b) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. 2023b. Stanford alpaca: An instruction-following llama model.
- Team et al. (2023) Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- Thirunavukarasu et al. (2023) Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. 2023. Large language models in medicine. Nature Medicine, pages 1–11.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Trischler et al. (2016) Adam Trischler, Tong Wang, Xingdi Yuan, Justin Harris, Alessandro Sordoni, Philip Bachman, and Kaheer Suleman. 2016. Newsqa: A machine comprehension dataset. arXiv preprint arXiv:1611.09830.
- Vörös et al. (2023) Tamás Vörös, Sean Paul Bergeron, and Konstantin Berlin. 2023. Web content filtering through knowledge distillation of large language models. arXiv preprint arXiv:2305.05027.
- Wadhwa et al. (2023) Somin Wadhwa, Silvio Amir, and Byron C Wallace. 2023. Revisiting relation extraction in the era of large language models. arXiv preprint arXiv:2305.05003.
- Wang et al. (2023a) Peifeng Wang, Zhengyang Wang, Zheng Li, Yifan Gao, Bing Yin, and Xiang Ren. 2023a. Scott: Self-consistent chain-of-thought distillation. arXiv preprint arXiv:2305.01879.
- Wang et al. (2023b) Song Wang, Zhen Tan, Ruocheng Guo, and Jundong Li. 2023b. Noise-robust fine-tuning of pretrained language models via external guidance. arXiv preprint arXiv:2311.01108.
- Wang et al. (2023c) Song Wang, Yaochen Zhu, Haochen Liu, Zaiyi Zheng, Chen Chen, et al. 2023c. Knowledge editing for large language models: A survey. arXiv preprint arXiv:2310.16218.
- Wang et al. (2022a) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. 2022a. Rationale-augmented ensembles in language models. arXiv preprint arXiv:2207.00747.
- Wang et al. (2022b) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. 2022b. Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560.
- Wang et al. (2022c) Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. 2022c. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. arXiv preprint arXiv:2204.07705.
- Wang et al. (2023d) Yufei Wang, Wanjun Zhong, Liangyou Li, Fei Mi, Xingshan Zeng, Wenyong Huang, Lifeng Shang, Xin Jiang, and Qun Liu. 2023d. Aligning large language models with human: A survey. arXiv preprint arXiv:2307.12966.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. 2021. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652.
- Wei et al. (2022a) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. 2022a. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
- Wei et al. (2022b) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022b. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. 2020. Huggingface’s transformers: State-of-the-art natural language processing.
- Wu et al. (2023a) Sherry Wu, Hua Shen, Daniel S Weld, Jeffrey Heer, and Marco Tulio Ribeiro. 2023a. Scattershot: Interactive in-context example curation for text transformation. In Proceedings of the 28th International Conference on Intelligent User Interfaces, pages 353–367.
- Wu et al. (2023b) Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. 2023b. Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564.
- Xu et al. (2023) Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu, and Julian McAuley. 2023. Small models are valuable plug-ins for large language models. arXiv preprint arXiv:2305.08848.
- Yang et al. (2023) Hongyang Yang, Xiao-Yang Liu, and Christina Dan Wang. 2023. Fingpt: Open-source financial large language models. arXiv preprint arXiv:2306.06031.
- Ye et al. (2022) Jiacheng Ye, Jiahui Gao, Qintong Li, Hang Xu, Jiangtao Feng, Zhiyong Wu, Tao Yu, and Lingpeng Kong. 2022. Zerogen: Efficient zero-shot learning via dataset generation. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11653–11669.
- Yu et al. (2022) Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, and Meng Jiang. 2022. Generate rather than retrieve: Large language models are strong context generators. arXiv preprint arXiv:2209.10063.
- Yu et al. (2023) Xinli Yu, Zheng Chen, Yuan Ling, Shujing Dong, Zongyi Liu, and Yanbin Lu. 2023. Temporal data meets llm–explainable financial time series forecasting. arXiv preprint arXiv:2306.11025.
- Zan et al. (2023) Daoguang Zan, Bei Chen, Fengji Zhang, Dianjie Lu, Bingchao Wu, Bei Guan, Wang Yongji, and Jian-Guang Lou. 2023. Large language models meet nl2code: A survey. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7443–7464.
- Zhang et al. (2022) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2022. Automatic chain of thought prompting in large language models. arXiv preprint arXiv:2210.03493.
- Zhao et al. (2021) Mengjie Zhao, Fei Mi, Yasheng Wang, Minglei Li, Xin Jiang, Qun Liu, and Hinrich Schütze. 2021. Lmturk: Few-shot learners as crowdsourcing workers in a language-model-as-a-service framework. arXiv preprint arXiv:2112.07522.
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023. A survey of large language models.
- Ziegler et al. (2019) Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.
附录A LLM 辅助的标注工具和软件
LLM 辅助的标注工具和软件是宝贵的资源,专门为促进各种 NLP 任务的标注流程而设计。 它们的主要属性之一是直观且用户友好的界面,使工程师甚至非技术注释者可以轻松处理复杂的文本数据。 这些工具旨在支持多种标签类型,从简单的二进制标签到更复杂的层次结构。 这些工具的主要目标是简化标签流程、提高标签质量并提高数据标签的整体生产力。
下面,我们将介绍一系列支持标注流程大型语言模型的库和工具:
-
•
LangChain:LangChain Harrison (2022)是一个开源库111目前仅适用于 JavaScript/TypeScript 和 Python 语言。 它提供了一系列旨在促进 LLM 相关管道和工作流程构建的工具。 该库专门提供带有代理的大型语言模型,以便与其环境以及各种外部数据源有效交互。 因此,提供动态且上下文适当的响应,超出了单个大语言模型调用的范围。
就标注过程而言,它们的力量主要在于通过创建称为链的模块化结构来促进标注。 在链接技术中,复杂的问题被分解为更小的子任务。 然后将从一个或多个步骤获得的结果进行汇总并用作链中后续操作的输入提示。
-
•
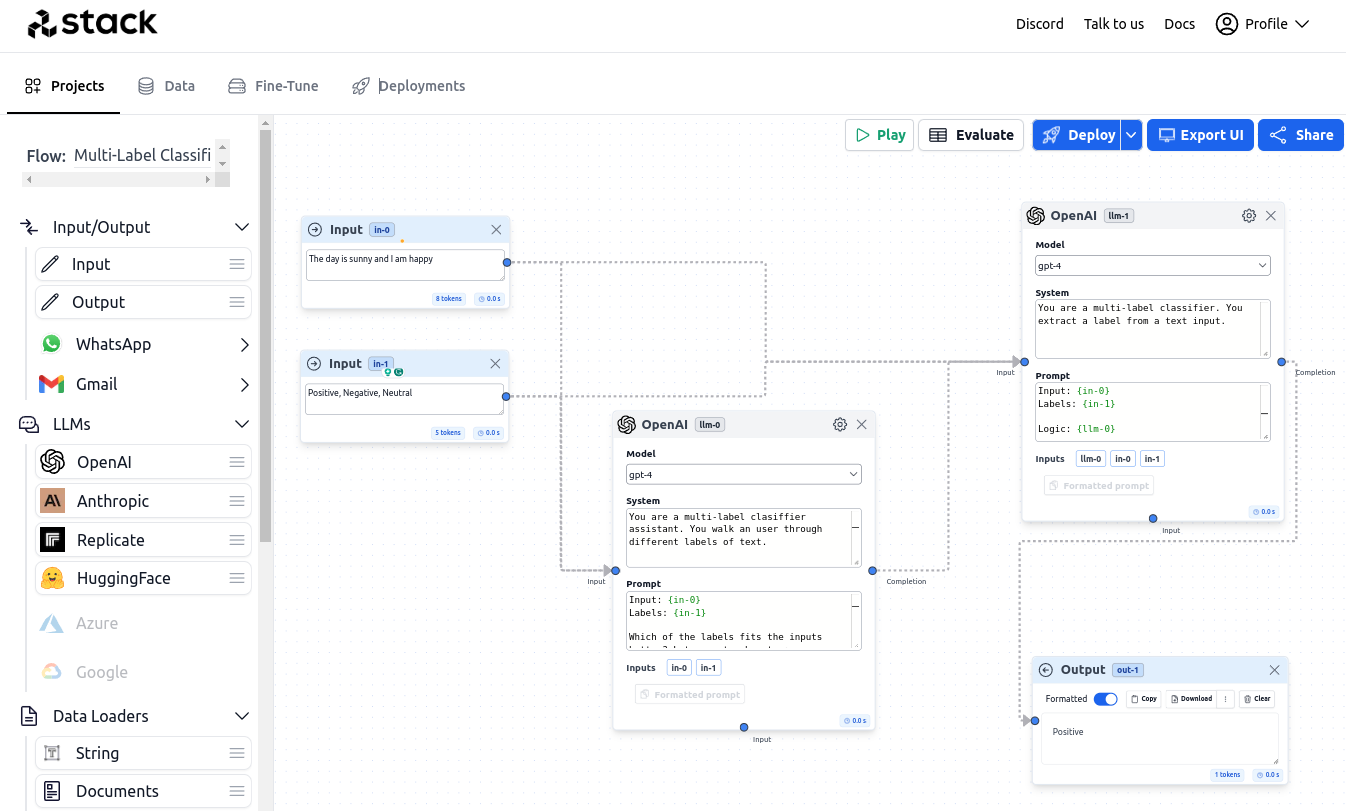
Stack AI:Stack AI Aceituno 和 Rosinol (2022) 是一项付费服务,提供人工智能驱动的数据平台。 它专门为自动化业务流程而设计,使他们能够最大限度地提高效率。 他们平台的本质在于能够通过大型语言模型的顺利集成来可视化设计、测试和部署人工智能工作流程。 其用户友好的图形界面(图2)允许用户创建与各种任务相关的应用程序和工作流程,从内容创建和数据标签到对话式人工智能应用程序和文档处理。 此外,Stack AI 利用弱监督机器学习模型来加快数据准备过程。
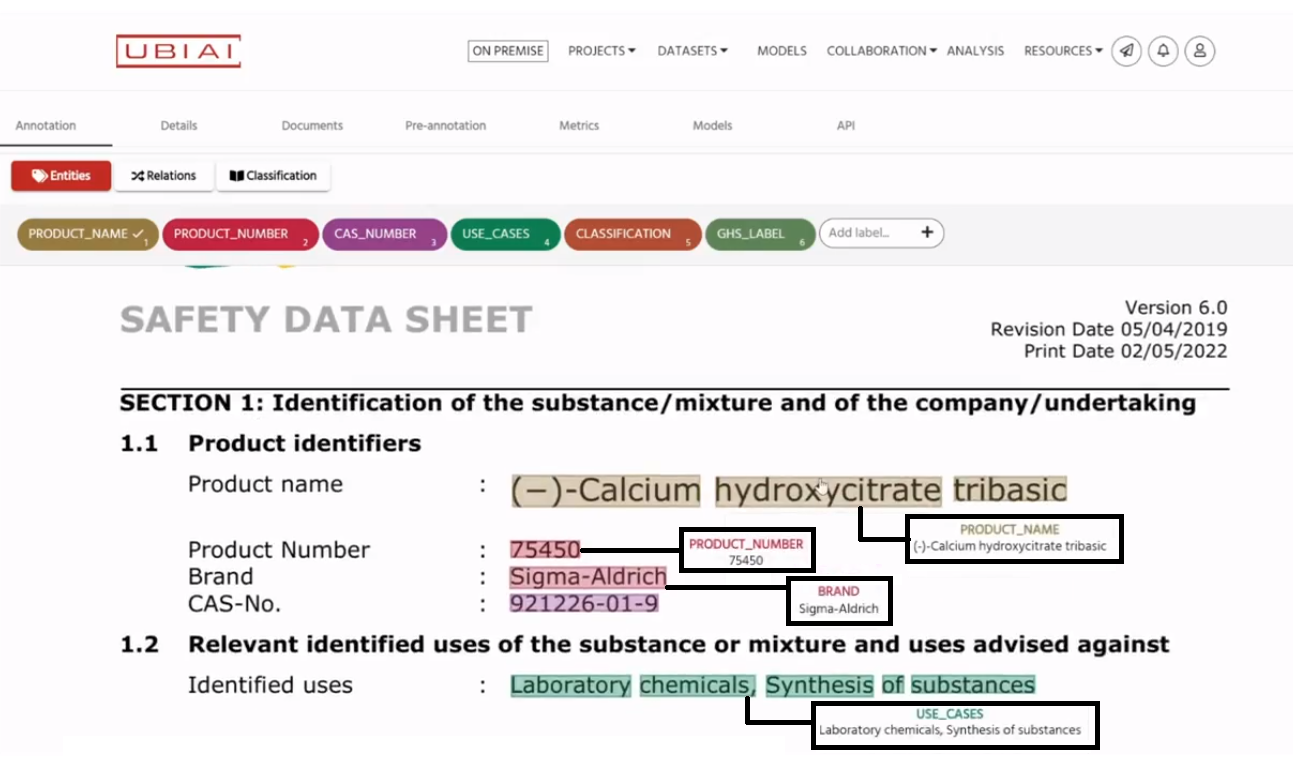
图3: UBIAI 在 pdf 文档上标注结果。 文档文本中的所有实体都已根据类型进行了标识、注释和颜色编码。 该图像借用自 UBIAI 文档 Amamou (2021) 中提供的视频。 -
•
UBIAI:UBIAI Amamou (2021) 是一款付费标注工具,提供自然语言处理方面的多语言基于云的解决方案和服务。 该公司旨在帮助用户从非结构化文档中提取有价值的见解。 该工具不仅提供了方便手动标记的用户界面,还提供了多种自动标记功能,例如 LLM 辅助的零样本和少样本标记以及模型辅助标记。 它们还提供了与 Huggingface Wolf 等人 (2020) 上各种模型的集成,以及在用户标记数据上调整不同模型的环境。
-
•
Prodigy:Prodigy Montani 和 Honnibal (2018) 由 spaCy 库 Honnibal 和 Montani (2017) 的创建者设计,提供基于规则的、统计模型,以及 LLM 辅助的标注方法。 该工具提供简单、灵活且强大的标注选项,例如命名实体识别、跨度分类以及针对不同模式(包括文本、音频和视觉)的分类/标记。 此外,它可以轻松地与能够进行零样本或少样本学习的大型语言模型集成,同时还提供服务和可量化的方法来制作提示以解决任何嘈杂的结果。 该工具不是开源的。
附录B数据标注大语言模型论文集
该表格集合提供了使用大型语言模型(大语言模型)进行数据标注的简明概述,包括最先进的技术、方法和实际应用。 表2列出了基于LLM数据标注的重要论文,详细介绍了它们的方法、核心技术、发表地点和资源链接。 表3重点评估LLM生成的注释的质量。 表 4、5、6 探索使用 LLM 生成的注释进行学习的策略,涵盖特定领域的推理、知识蒸馏、微调、以及诸如上下文学习和配置参数之类的提示技术。 每个表格都清楚地概述了场景、技巧、技术、场地和可用资源,作为 LLM 驱动数据的最新指南及其对自动化数据处理和机器学习研究的未来的影响。
| Paper | Scenario | Technique | Backbone | Venue | Code/Data Link |
| Manually Engineered Prompts | |||||
| RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment | Unsupervised | Zero-Shot | LLaMA | Arxiv’23 | Link |
| ZeroGen: Efficient Zero-shot Learning via Dataset Generation | Unsupervised | Zero-Shot | GPT-2 | EMNLP’22 | Link |
| Constrained Language Models Yield Few-Shot Semantic Parsers | Supervised | Alignment Tuning Few-Shot | BART GPT-2 GPT-3 | EMNLP’21 | Link |
| Learning To Retrieve Prompts for In-Context Learning | Unsupervised | Few-Shot | BERT | NAACL-HLT’22 | Link |
| Small Models are Valuable Plug-ins for Large Language Models | Supervised | Few-Shot | RoBERTa XLM-V | Arxiv’23 | Link |
| Alignment via Pairwise Feedback | |||||
| Why can GPT learn in-context? language models secretly perform gradient descent as meta-optimizers | Supervised | Human Feedback | GPT 1.3B GPT 2.7B | ACL’23 | Link |
| Fine-Tuning Language Models from Human Preferences | Unsupervised | Human Feedback | GPT-2 | Arxiv’19 | Link |
| Fine-tuning language models to find agreement among humans with diverse preferences | Unsupervised | Zero-Shot Few-Shot Human Feedback | Chinchilla | NeurIPS’22 | Not Available |
| Teaching language models to support answers with verified quotes | Unsupervised | Automated Feedback | Gopher | Arxiv’22 | Link |
| Learning to summarize with human feedback | Supervised | Zero-Shot Automated Feedback | GPT-3 | NeurIPS’20 | Link |
-
•
Note: Dong et al. (2023); Ye et al. (2022); Shin et al. (2021); Rubin et al. (2022); Xu et al. (2023); Dai et al. (2023); Ziegler et al. (2019); Bakker et al. (2022); Menick et al. (2022); Stiennon et al. (2020); .
| Paper | Scenario | Technique | Backbone | Venue | Code/Data Link |
| Evaluation | |||||
| The Turking Test: Can Language Models Understand Instructions? | Supervised | Human Centric | GPT-2 | Arixv’20 | Not Available |
| Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor | Unsupervised | Human Centric | T5 | Arixv’22 | Link |
| Open-Source Large Language Models Outperform Crowd Workers and Approach ChatGPT in Text-Annotation Tasks | unsupervised | Automatic Huamn Centric | ChatGP | Arixv’23 | Not Available |
| Data Selection Via Active Learning | |||||
| Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates | Semi-Supervised | In-Context Learning | BiLSTM BERT Distill-BERT ELECTRA | EACL’21 | Not Available |
| Active learning helps pretrained models learn the intended task | Semi-Supervised | In-Context Learning | BiT Roberta | Arxiv’22 | Link |
| Active Learning Principles for In-Context Learning with Large Language Models | Supervised | In-Contect Learning | GPT OPT | EMNLP’23 | Not Available |
| Large Language Models as Annotators: Enhancing Generalization of NLP Models at Minimal Cost | Semi-Supervised | In-Context Learning | GPT-3.5 turbo | Arxiv’23 | Not Available |
| ScatterShot: Interactive In-context Example Curation for Text Transformation | Unsupervised | In-Context Learning | GPT-3 | IUI’23 | Link |
| Prefer to Classify: Improving Text Classifiers via Auxiliary Preference Learning | Supervised | In-Context Learning | GPT-3 | ICML’23 | Link |
-
•
Note: Efrat and Levy (2020); Honovich et al. (2022a); Alizadeh et al. (2023); Shelmanov et al. (2021); Tamkin et al. (2022); Margatina et al. (2023); Bansal and Sharma (2023); Wu et al. (2023a); Kim et al. (2023);.
| Paper | Scenario | Technique | Backbone | Venue | Code/Data Link |
| Target Domain Inference | |||||
| An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels | Unsupervised | Predicting Labels | GPT2 GPT3 GPT-Neo GPT-J | ACL’22 | Link |
| Emergent Abilities of Large Language Models | Unsupervised | Predicting Labels | GPT-3 PaLM FLAN LaMDA Chinchilla | TMLR’22 | Not Available |
| Large Language Models are Zero-Shot Reasoners | Unsupervised | Predicting Labels | GPT3 PaLM GPT-Neo GPT-J OPT | NeurIPS’22 | Link |
| Language Models as Knowledge Bases? | Unsupervised | Predicting Labels | ELMo BERT | EMNLP’19 | Link |
| Causal Reasoning and Large Language Models: Opening a New Frontier for Causality | Unsupervised | Predicting Labels | GPT3.5 GPT4 | Arixv’23 | Not Available |
| Large Language Models are Zero-Shot Rankers for Recommender Systems | Unsupervised | Predicting Labels | Alpaca Vicuna LLama2 GPT3.5 GPT4 | ECIR’24 | Link |
| Learning Transferable Visual Models From Natural Language Supervision | Unsupervised | Inferring Additional Attributes | Transformer | PMLR’21 | Link |
| Visual Classification via Description from Large Language Models | Unsupervised | Inferring Additional Attributes | GPT3 | Arixv’22 | Not Available |
| Knowledge Distillation | |||||
| Teaching Small Language Models to Reason | Unsupervised | Chain-of-Thought | PaLM GPT-3 T5 | Arxiv’22 | Not Available |
| Specializing Smaller Language Models towards Multi-Step Reasoning | Unsupervised | Chain-of-Thought | GPT-3.5 T5 | Arxiv’23 | Not Available |
| Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents | Unsupervised | Chain-of-Thought | ChatGPT GPT-4 | EMNLP’23 | Not Available |
| Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes | Semi-Supervised | Chain-of-Thought | PaLM T5 | ACL’23 | Link |
| GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo | Unsupervised | Input-Output Prompting | GPT-3.5-Turbo LLaMA LoRA | GitHub’23 | Link |
| GKD: A General Knowledge Distillation Framework for Large-scale Pre-trained Language Model | Unsupervised Semi-supervised Supervised | Input-Output Prompt | BERT GLM | ACL’23 | Link |
| Lion: Adversarial Distillation of Proprietary Large Language Models | Unsupervised | Instruction Tuning Chain-of-Thought | ChatGPT GPT-4 | EMNLP’23 | Link |
| Knowledge Distillation of Large Language Models | Supervised | Instruction Tuning | GPT2 OPT LLama GPT-J | Arxiv’23 | Link |
| Distilling Large Language Models for Biomedical Knowledge Extraction: A Case Study on Adverse Drug Events | Supervised | Instruction Tuning | GPT3.5 GPT4 | Arxiv’23 | Not Available |
| Web Content Filtering through knowledge distillation of Large Language Models | Supervised | Input-Output Prompt | T5 GPT3 | Arxiv’23 | Not Available |
-
•
Note: Sorensen et al. (2022); Wei et al. (2022a); Kojima et al. (2022); Petroni et al. (2019); Kıcıman et al. (2023); Hou et al. (2023); Radford et al. (2021); Menon and Vondrick (2022); Magister et al. (2022); Fu et al. (2023); Sun et al. (2023) Hsieh et al. (2023); Anand et al. (2023); Tan et al. (2023a); Jiang et al. (2023b); Gu et al. (2023c); Gu et al. (2023b); Vörös et al. (2023); .
| Paper | Scenario | Technique | Backbone | Venue | Code/Data Link |
| Fine-Tuning and Prompting - In-Context Learning | |||||
| Language Models are Few-Shot Learners | Supervised | In-Context Learning | GPT-3 | NeurIPS’20 | Not Available |
| Active Learning Principles for In-Context Learning with Large Language Models | Supervised | In-Context Learning | GPT OPT | EMNLP’23 | Not Available |
| Selective Annotation Makes Language Models Better Few-Shot Learners | Supervised | In-Contect Learning | GPT-J Codex-davinci-002 | Arxiv’22 | Link |
| Instruction Induction: From Few Examples to Natural Language Task Descriptions | Unsupervised | In-Context Learning | GPT-3 InstructGPT | Arxiv’22 | Link |
| Synthetic Prompting: Generating Chain-of-Thought Demonstrations for Large Language Models | Unsupervised | In-Context Learning | InstructGPT | ICML’23 | Not Available |
| Improving In-Context Few-Shot Learning via Self-Supervised Training | Supervised | In-Context Learning | RoBERTa | NAACL’22 | Not Available |
| Fine-Tuning and Prompting - Chain-of-Thought Prompting | |||||
| A Diverse Corpus for Evaluating and Developing English Math Word Problem Solvers | Supervised | Chain-of-Thought | LCA++ UnitDep GTS | ACL’20 | Link |
| Chain-of-Thought Prompting Elicits Reasoning in Large Language Models | Supervised | Chain-of-Thought | GPT-3 LaMDA PaLM UL2 20B Codex | NeurIPS’22 | Not Available |
| Large Language Models are Zero-Shot Reasoners | Unsupervised | Chain-of-Thought | Instruct-GPT3 GPT-2 GPT-Neo GPT-J T0 OPT | NeurIPS’22 | Not Available |
| Automatic chain of thought prompting in large language models | Supervised Unsupervised | Chain-of-Thought | GPT-3 Codex | ICLR’23 | Link |
| Rationale-augmented ensembles in language models | Semi-Supervised | Chain-of-Thought | PaLM GPT-3 | Arxiv’22 | Not Available |
| Specializing Smaller Language Models towards Multi-Step Reasoning | Unsupervised | Chain-of-Thought | GPT-3.5 T5 | Arxiv’23 | Not Available |
| SCOTT: Self-Consistent Chain-of-Thought Distillation | Supervised | Chain-of-Thought | GPT-neox T5 | Arxiv’22 | Not Available |
-
•
Note: Brown et al. (2020); Margatina et al. (2023); Hongjin et al. (2022); Honovich et al. (2022b); Shao et al. (2023); Chen et al. (2022); Miao et al. (2021); Wei et al. (2022b); Kojima et al. (2022); Zhang et al. (2022); Wang et al. (2022a); Fu et al. (2023); Wang et al. (2023a); .
| Paper | Scenario | Technique | Backbone | Venue | Code/Data Link |
| Fine-Tuning and Prompting - Instruction Tuning | |||||
| Scaling Instruction-finetuned Language Models | Unsupervised | Instruction Tuning | T5 PaLM U-PaLM | Arxiv’22 | Link |
| Crosslingual Generalization through Multitask Finetuning | Supervised | Instruction Tuning | BLOOM T5 | ACL’23 | Link |
| Self-Instruct: Aligning Language Models with Self-Generated Instructions | Supervised | Instruction Tuning | GPT-3 | ACL’23 | Link |
| Language Models are Few-Shot Learners | Supervised | Instruction Tuning | GPT-3 | NeurIPS’20 | Not Available |
| LLaMA: Open and Efficient Foundation Language Models | Unsupervised | Instruction Tuning | LLaMA | Arxiv’23 | Link |
| Can Large Language Models Be an Alternative to Human Evaluations? | Unsupervised | Instruction Tuning | GPT-2 | ACL’23 | Not Available |
| Super-NaturalInstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks | Supervised | Instruction Tuning | GPT-3 T5 | EMNLP’22 | Link |
| Fine-Tuning and Prompting - Alignment Tuning | |||||
| Fine-Tuning Language Models from Human Preferences | Supervised | Alignment Tuning | GPT-2 | Arxiv’19 | Link |
| CTRL: A Conditional Transformer Language Model for Controllable Generation | Supervised | Alignment Tuning | CTRL | Arxiv’19 | Link |
| Chain of hindsight aligns language models with feedback | Supervised | Alignment Tuning | GPT-J OPT | Arxiv’23 | Link |
| Pretraining Language Models with Human Preferences | Supervised | Alignment Tuning | GPT-2 | PMLR’23 | Link |
| Training language models to follow instructions with human feedback | Supervised | Alignment Tuning | GPT-3 | NeurIPS’22 | Not Available |
| Llama 2: Open Foundation and Fine-Tuned Chat Models | Supervised | Alignment Tuning | Llama 1 | Arxiv’23 | Link |
| Offline RL for Natural Language Generation with Implicit Language Q Learning | Supervised | Alignment Tuning | GPT-2 | ICLR’23 | Link |
| Teaching language models to support answers with verified quotes | Supervised | Alignment Tuning | Gopher | Arxiv’22 | Link |
| RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback | Supervised | Alignment Tuning | PaLM 2 | Arxiv’23 | Not Available |
-
•
Note: Chung et al. (2022); Muennighoff et al. (2022); Wang et al. (2022b); Brown et al. (2020); Touvron et al. (2023a); Chiang and Lee (2023); Wang et al. (2022c); Ziegler et al. (2019); Keskar et al. (2019); Liu et al. (2023a); Korbak et al. (2023); Ouyang et al. (2022); Touvron et al. (2023b); Snell et al. (2022); Menick et al. (2022); Lee et al. (2023) .