WeakSAM:分割任何东西满足弱监督实例级识别
摘要
使用不精确监督的弱监督视觉识别是一个关键但具有挑战性的学习问题。 它显着降低了人工标记成本,并且传统上依赖于多实例学习和伪标记。 本文介绍了 WeakSAM,并利用视觉基础模型(即分段任意模型(SAM))中包含的预先学习的世界知识来解决弱监督目标检测(WSOD)和分割问题。 WeakSAM 通过自适应 PGT 生成和感兴趣区域 (RoI) 丢弃正则化,解决了传统 WSOD 再训练中的两个关键限制,即伪地面实况 (PGT) 不完整性和嘈杂的 PGT 实例。 它还解决了 SAM 在自动对象检测和分割时需要提示和类别无意识的问题。 我们的结果表明,WeakSAM 在 WSOD 和 WSIS 基准测试中显着超越了之前最先进的方法,并且大幅提升,即平均分别提高了 7.4% 和 8.5%。 代码可在 https://github.com/hustvl/WeakSAM 获取。
1.20.1
1简介
弱监督学习(WSL)(周,2018;王等人,2013;徐等人,2014)是机器学习的重要组成部分。 在由于数据标注成本较高而难以进行强监督标注的任务中,它尤其有价值(Locatello 等人,2020;Schroeter 等人,2019;Fu 等人,2020)。 由于视觉感知中对注释数据的大量需求,WSL 对于开发标签高效的识别系统至关重要。 在标准的弱监督视觉感知范式(Tang等人,2018a;Sui等人,2022)中,训练从不精确的监督开始,例如图像级标签。 随后,训练有素的 WSL 网络用于生成伪地面实况 (PGT),这是一种改进的形式,尽管仍然不准确。 最后,利用PGT作为不准确的监督来启动WSL再训练。 尽管迭代WSL过程取得了显着进展,但仍然受到外部知识缺乏的限制,这限制了WSL的性能并阻碍其匹配全监督学习(FSL)。
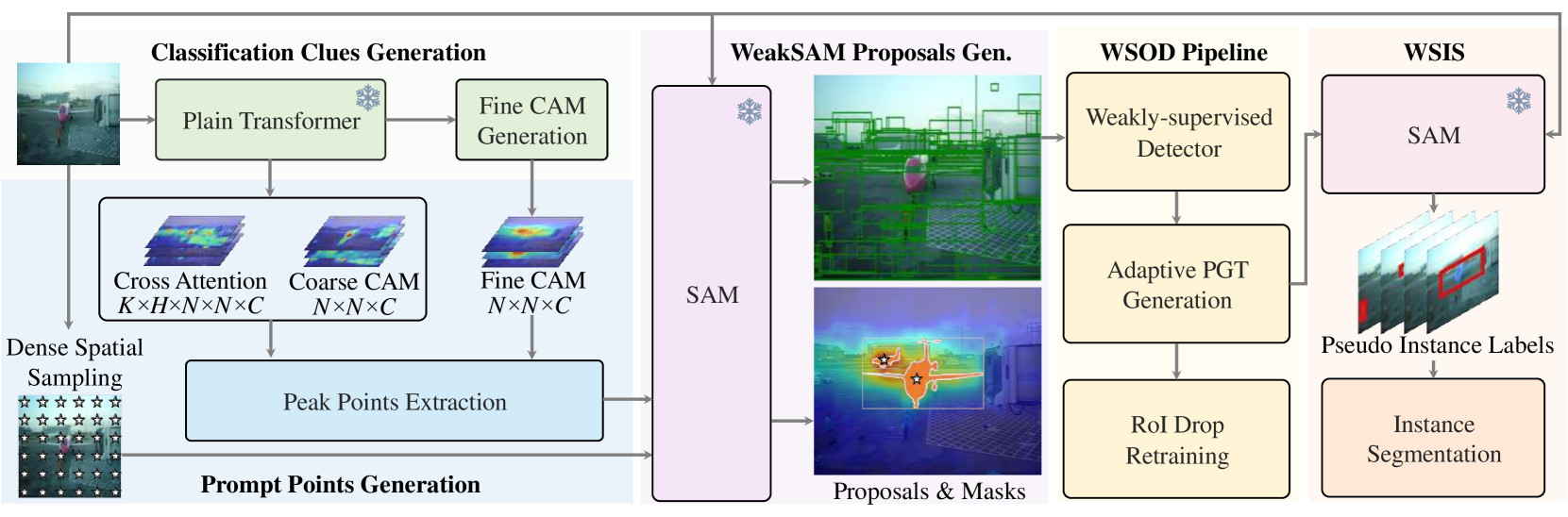
如今,基础模型因其可迁移的预先学习的世界知识而受到越来越多的关注,这可以被视为 WSL 的强大外部知识。 作为视觉基础模型,SAM (Kirillov 等人, 2023) 在交互式、与类别无关的分割方面取得了出色的性能。 SAM 的成功归功于大规模数据集上的快速训练。 然而,SAM 有两个主要缺点:首先,SAM 需要交互式操作作为输入,这意味着它无法在没有人工提示的情况下自动工作。 其次,SAM 生成与类别无关的段,并且无法分配类别标签。 这些缺点严重限制了 SAM 作为通用视觉框架的应用。 作为强有力的补充,WSL擅长通过不精确的监督挖掘分类线索,可以为SAM提供自动提示。 随后,具有 SAM 知识的 WSL 可以进一步带来阶级感知感知。
这促使我们将 SAM 纳入 WSL 范式。 WeakSAM 框架旨在利用 SAM 的可转移知识,从而丰富 WSL 流程。 同时,它还提供向 SAM 提供自动分类线索的功能。 这种双向增强构建了一个有前途的基于基础模型的弱监督视觉感知框架。 具体来说,在弱监督对象检测 (WSOD) 设置中,WeakSAM 使用分类线索作为 SAM 提示来自动生成建议。 然后,这些建议将在 WSOD 训练中用于类别感知感知。
在 WeakSAM 框架的范围内,我们的分析确定了迭代 WSOD 再训练方法中的两个普遍限制:伪地面实况 (PGT) 不完整性问题和噪声 PGT 实例的存在。 前者是PGT不完整性,是指WSOD生成的PGT倾向于省略某些对象或类别,导致这些类别的训练不足。 后者是有噪声的 PGT 实例,与 PGT 中普遍存在的噪声有关,这会对再训练过程产生不利影响。 为了有效缓解这些挑战,我们引入了两个关键策略:自适应 PGT 生成来解决 PGT 不完整性问题,以及感兴趣区域 (RoI) 丢弃正则化来抵消 PGT 实例中的噪声。 此外,WeakSAM 的功能可以扩展到弱监督实例分割(WSIS)领域。 在此背景下,SAM 用于进一步细化 WeakSAM-PGT,从而能够生成伪实例分割标签。 这种方法体现了 WeakSAM 有望构建一个统一的弱监督实例级识别框架。
本文的主要贡献可概括如下:
-
•
我们提出了一个弱监督实例级识别框架(WeakSAM),它通过建议的分类线索自动提示 SAM。 WeakSAM 提案提高了 WSOD 的有效性和效率。
-
•
我们分析了传统 WSOD 再训练的弱点,并提出自适应 PGT 生成和 RoI drop 正则化来分别解决这些问题。 WeakSAM-WSOD 完成后,所提出的 WeakSAM 可以轻松地进一步应用于 WSIS。
-
•
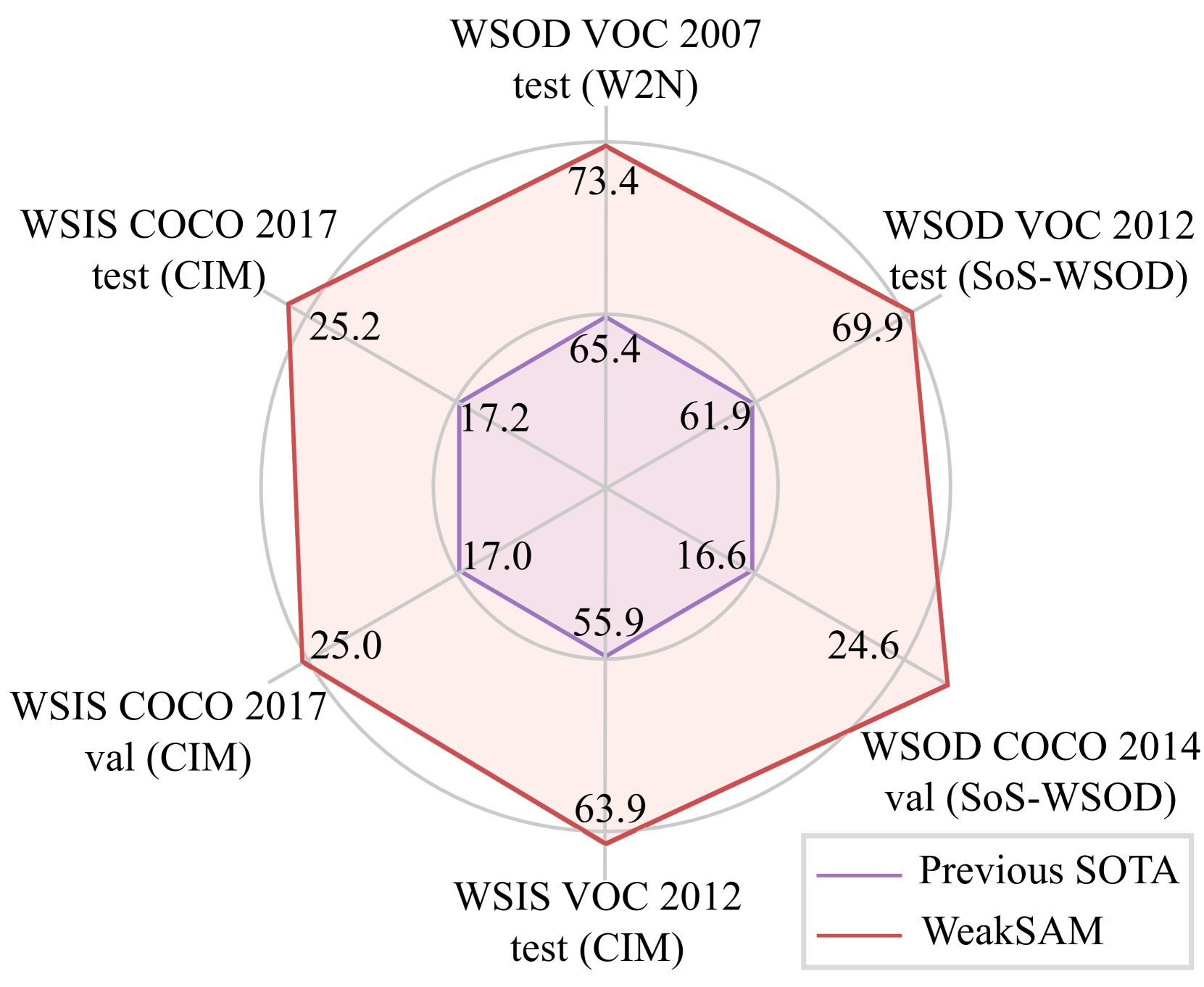
所提出的 WeakSAM 在 WSOD 和 WSIS 基准上取得了最先进的 (SOTA) 结果,显着超越了之前的 SOTA 方法,如图 1 所示。
2相关工作
2.1 细分任何模型
最近的分段任意模型(SAM)(Kirillov 等人,2023)引起了研究人员的极大关注。 SAM 在 SA-1B 上使用超过 10 亿个掩模进行训练,遵循模型在环方式。 此外,SAM具有优越的零样本传输能力,并应用于许多视觉任务,例如FGVP (Yang等人,2023)结合SAM实现零样本细粒度视觉提示,MedSAM (Ma & Wang, 2023) 将 SAM 应用于大规模医学数据集,构建医学基础模型,以及一些方法(Sun 等人, 2023; Jiang & Yang, 2023; Chen 等人, 2023 )利用SAM来处理弱监督语义分割问题。 然而,SAM 是一种交互式分割方法,严重依赖人工提示。
在我们的方法中,我们创新性地提出使用分类线索自动提示 SAM 来提取区域提案。 这种方法产生的高召回率提案在效率和有效性方面都超越了选择性搜索等传统方法。 这一进步代表了 WSOD 框架内提案生成领域的重大改进。
2.2 弱监督目标检测
具有图像级标签的弱监督目标检测(WSOD)(Laptev 等人, ; Diba 等人, 2017; Tang 等人, 2018b; 高 等人, 2018; Wan 等人, 2018; 张 等人, 2018a;李等人,2019;孙等人,2020;万等人,2019)减轻人类的负担。 之前的工作,即 WSDDN (Bilen & Vedaldi, 2016b) 和 OICR (Tang 等人, 2017),提出了多实例学习和在线细化范式。 后期的工作旨在从不同角度提高 WSOD 性能。 如WSOD(Zeng等人, 2019)引入了自下而上的对象证据,PCL(Tang等人, 2018a)提出了聚类提案、MIST (Ren 等人, 2020) 利用了自训练算法等。 此外,一些方法(Tang 等人,2018a;Jie 等人,2017;Li 等人,2016;Sui 等人,2022;Zhang 等人,2018b;Huang 等人,2022)也进行了重新训练具有生成的伪地面实况(PGT)的完全监督的对象检测网络。 然而,他们中的大多数使用了低级方法生成的提案,即 Selective Search (Uijlings 等人, 2013)、EdgeBox (Zitnick & Dollár, 2014)、和MCG (Pont-Tuset等人, 2016),其中包含大量冗余提案并带来优化挑战。
与以前的方法不同,我们的 WeakSAM-proposals 数量更少,召回率更高,这降低了 WSOD 方法找到正确提案的难度。 针对 PGT 不完整性和噪声 PGT 实例的关键问题,我们分别提出自适应 PGT 生成和感兴趣区域(RoI)丢弃正则化来解决它们。
2.3 弱监督实例分割
弱监督实例分割(WSIS)旨在通过弱监督实现实例分割,例如框级监督(Tian 等人,2021;Wang 等人,2021;Cheng 等人,2023;Hsu 等人,2019 ; Liao 等人, 2019; Lee 等人, 2017; Zhu 等人, 2022),以及图像级监督 (葛等人,2019;欧等人,2021;朱等人,2019;刘等人,2020;黄等人,2021;张等人,2021;胡等人,2020;谢等人,2023;Laradji12等人,)。 具有图像级监督的 WSIS 具有挑战性,因为它缺乏准确的实例位置。 一些图像级WSIS方法使用CAM来提取粗略目标位置,例如PRM (Zhou 等人, 2018)、IAM (Zhu 等人, 2019)、IRNet (Ahn 等人, 2019), BESTIE (Kim 等人, 2022), 等等 其他一些图像级 WSIS 方法尝试合并来自额外先验的实例线索,例如 Fan 等人 (Fan 等人, 2018b)、LIID (Liu 等人, 2020)、CIM (Li 等人, 2023)等 然而,它们总是需要复杂的网络,并且缺乏高质量的实例段。
与以前的 WSIS 方法不同,所提出的使用 WeakSAM-PGT 和 SAM 预测的 WSIS 扩展简洁有效。 生成的伪实例标签可以进一步应用于任何完全监督的实例分割方法。
3方法
我们提出了如图2所示的WeakSAM框架。 首先,WeakSAM 根据分类线索和空间样本自动生成提示。 接下来,WeakSAM 向 SAM 发送 WeakSAM 提案的提示。 然后,我们启动弱监督对象检测 (WSOD) 管道,该管道通过 WeakSAM 提案、自适应伪地面实况 (PGT) 生成和 RoI 下降正则化得到增强。 最后,我们使用 WSOD 管道生成的 PGT 框来启动弱监督实例分割扩展。
3.1 分类线索自动提示
以前的 WSOD 方法面临着由冗余提案引起的优化问题,例如 Selective Search (Uijlings 等人, 2013) 和 EdgeBox (Zitnick & Dollár, 2014),因为这些提案仅基于低级功能。 为了解决这个问题,我们建议转移基础模型(即 SAM)中的知识以用于提案生成。 我们利用分类线索自动提示SAM,这也解决了SAM需要交互式提示的缺点
分类线索生成
如图2所示,我们从分类ViT中提取分类线索。 具体来说,我们选择预训练的弱监督语义分割网络WeakTr (Zhu等人,2023a),因为其优越的定位能力来提供分类线索。 首先,我们从自注意力图中提取交叉注意力图,其中是Transformer编码层的数量,是Transformer编码层的数量。每层的注意力头,是视觉标记的空间大小,表示分类类别的总数。 然后,我们从卷积 CAM 头获得粗略 CAM,,该头将最终 Transformer 层的视觉标记作为输入并生成粗略 CAM。 最后,我们使用 WeakTr 制作精细的 CAM,。
提示积分生成
如图2所示,我们从密集采样点、交叉注意力图和CAM中提取提示。 首先,密集采样需要将图像分割成块,并以中心点作为提示。 值得注意的是,密集的采样点提供了空间感知提示,但缺乏对对象和语义的明确引用,这意味着增加 通常会导致大量无效采样点。 然后,我们从交叉注意力图中获取峰值点作为提示。 我们观察到这些地图不仅关注相应类别的对象,而且还关注不同类别的对象。 因此,我们将这些提示标记为实例感知提示。 最后,我们从粗略 CAM 和精细 CAM 中提取峰值作为语义感知提示,这些提示更加精确并且专注于前景对象的区域。
具体来说,我们从交叉注意力图和 CAM 中提取峰值点,如算法 1 所示。 给定交叉注意力图或 CAM 作为输入,我们首先初始化峰值点列表 、峰值列表 、删除列表 、 和最大池操作。 接下来,我们重塑输入图并确保最后两个维度对应于原始图像大小,其他维度对应于第一个维度。 然后,我们在输入映射上应用最大池化,并根据按降序对和进行排序。最后,我们删除激活值低或接近高分点的点。
WeakSAM 提案生成
在WeakSAM提案生成阶段,我们使用三种提示来自动提示SAM。 我们直接将语义感知提示和空间感知提示添加到提示列表中,因为它们通常分别对前景对象和空间位置有清晰的定位。 对于具有一定冗余的实例感知提示,我们将它们进行聚类以过滤重复的提示,然后将它们添加到提示列表中。 最后,提示列表中的所有提示都用于提示 SAM 提出建议。
3.2 WeakSAM WSOD 管道
为了更好地描述所提出的弱监督目标检测(WSOD)管道,我们首先使用 WeakSAM 提案提出弱监督检测器训练。 然后,我们识别了 PGT 不完整性问题,并引入了所提出的自适应 PGT 生成来解决该问题。 最后,我们分析了再训练阶段存在的噪声问题,并提出了兴趣区域(RoI)下降正则化来减轻噪声的影响。
弱监督检测器训练
传统 WSOD 方法的主要挑战是训练效率低,这很大程度上归因于提案的冗余。 传统方法通常涉及感兴趣区域池层处理每个图像的数千个建议,这会损害有效性和效率。 为了解决这个问题,我们的 WeakSAM 提案采用了来自 SAM 和分类线索的转移知识。 所提出的方法侧重于在保持高召回率的同时生成较少数量的提案,从而提高 WSOD 环境中检测过程的整体效率和功效。 我们主要将所提出的 WeakSAM 应用于一些令人信服的 WSOD 方法,包括 OICR (Tang 等人, 2017) 和 MIST (Ren 等人, 2020),这些方法得到了显着的改进。 如表1所示,定量结果表明WeakSAM增强的WSOD可以更精确地注释对象的边界框。
自适应 PGT 生成
生成高质量的伪真实值 (PGT) 是 WSOD 范式的关键。 传统的WSOD方法经常遇到PGT不完整的问题。 发生这种情况是因为这些方法通常选择得分最高的提案作为 PGT 或应用统一的阈值来过滤所有类别的提案。 这种方法可能会导致遗漏对象或整个类别,特别是当某些类别的提案得分较低时。 为了解决这些问题,我们提出了一种自适应 PGT 生成方法来规范提案的分数分布,确保它们落在相似的范围内,如算法所示。 2.
对于框列表 和相应的分数列表 ,我们首先使用特定的分类标签选择它们,然后对分数进行归一化。 是预测框的数量,的第二个维度是类别标签和四个坐标值的组合。 接下来,我们保留分数高于阈值的框。 请注意,归一化使阈值能够自适应地适用于所有类别,因此即使该类别中的所有框得分较低,我们也不会丢失地面实况类别。 然后,我们选择主要部分不包含在一些较大盒子中的盒子。 因为具有较多的盒子往往是某些对象的局部组件。 最后,我们返回框列表作为最终的PGT。
投资回报率下降正则化
WSOD 重新训练阶段的一个公认问题是 PGT 实例的噪声。 这些嘈杂的实例导致 PGT 充当不准确的监督。 缓解这个问题对于提高 WSOD 再训练的性能至关重要。 为了深入分析这个问题,我们首先将 RoIs 划分为不同的损失区间。 然后,我们将相应的 PGT 与地面实况框 IoU 不至少为 70% 的 RoI 标记为错误 RoI。 最后,我们给出如图3所示的统计数据,这表明损失较大的RoI数量较少且错误率较高。
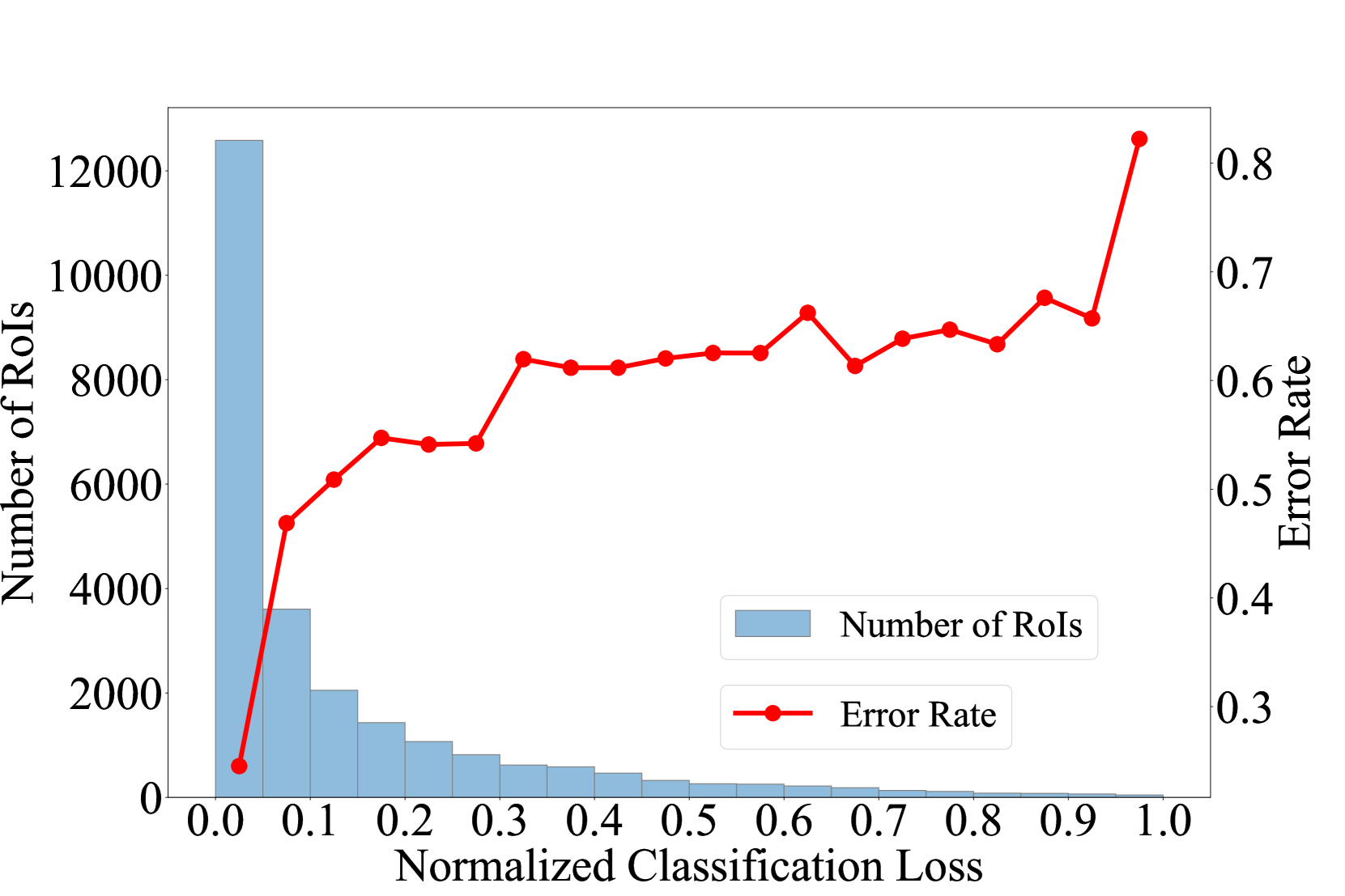
直观上,我们提出了一种称为 RoI drop 正则化的方法,来自适应地丢弃损失较大的 RoI。 值得注意的是,所提出的方法易于实现,并且可以通过其变体查询丢弃正则化进一步帮助基于查询的检测器减轻噪声 PGT 问题。 对于基于锚点的 FSOD 方法,例如 Faster-RCNN (Ren 等人, 2015),我们首先确定分类损失的阈值 和 和回归损失,分别。 然后,我们计算 RoI 的下降信号 。
| (3) |
其中 和 分别表示每个 RoI 的分类损失和回归损失。 当RoI的两个损失都低于其阈值时,我们将其下降信号设置为。 最后,我们将整合到最终损失的计算中。
| (4) |
| Methods | Proposal | Retrain | VOC 07 | VOC 12 | COCO 14 | |||
| Fully-supervised object detection methods. | ||||||||
| Faster R-CNN (Ren et al., 2015) | RPN | – | 69.9 | – | 21.2 | 41.5 | – | |
| WSOD methods with point supervision. | ||||||||
| P2BNet (Chen et al., 2022) | RPN | – | 60.2 | – | 19.4 | 43.5 | – | |
| WSOD methods with image-level supervision. | ||||||||
| C-MIDN (Gao et al., 2019) | SS, MCG | – | 52.6 | 50.2 | 9.6 | 21.4 | – | |
| WSOD (Zeng et al., 2019) | SS | – | 53.6 | 47.2 | 10.8 | 22.7 | – | |
| SLV (Chen et al., 2020) | SS | – | 53.5 | 49.2 | – | – | – | |
| CASD (Huang et al., 2020) | SS | – | 56.8 | 53.6 | 12.8 | 26.4 | – | |
| IM-CFB (Yin et al., 2021) | SS | – | 54.3 | 49.4 | – | – | – | |
| OD-WSCL (Seo et al., 2022) | SS, MCG | – | 56.4 | 54.6 | 13.7 | 27.7 | 11.9 | |
| WSOD-CBL (Yin et al., 2023) | SS | – | 57.4 | 53.5 | 13.6 | 27.6 | – | |
| WSOVOD (Lin et al., 2024) | LO-WSRPN + SAM | – | 59.1 | 59.8 | 18.8 | 27.1 | 19.7 | |
| WSOVOD‡ | LO-WSRPN + SAM | – | 63.4 | 62.1 | 20.5 | 29.1 | 21.4 | |
| Baseline and ours. | ||||||||
| OICR (Tang et al., 2017) | SS, MCG | – | 41.2 | 37.9 | 8.0 | 18.9 | 7.0 | |
| WeakSAM (OICR) | WeakSAM | – | 58.9+17.7 | 58.4+20.5 | 19.9+11.9 | 32.1+13.2 | 20.6+13.6 | |
| Baseline and ours. | ||||||||
| MIST (Ren et al., 2020) | SS, MCG | – | 54.9 | 52.1 | 11.4 | 24.3 | 9.4 | |
| WeakSAM (MIST) | WeakSAM | – | 67.4+12.5 | 66.9+14.8 | 22.9+11.5 | 35.2+10.9 | 24.6+15.2 | |
| WSOD methods with image-level supervision. + Retrain | ||||||||
| W2F (Zhang et al., 2018b) | RPN | Faster R-CNN | 52.4 | 47.8 | – | – | – | |
| SoS-WSOD (Sui et al., 2022) | RPN | Faster R-CNN | 64.4 | 61.9 | 16.6 | 32.8 | 15.2 | |
| W2N (Huang et al., 2022) | RPN | Faster R-CNN | 65.4 | 60.8 | 15.9 | 33.3 | 13.4 | |
| Ours. + Retrain | ||||||||
| WeakSAM (OICR) | RPN | Faster R-CNN | 65.7 | 62.9 | 22.3 | 36.5 | 23.0 | |
| WeakSAM (MIST) | RPN | Faster R-CNN | 71.8 | 69.2 | 23.8 | 38.5 | 25.1 | |
| WeakSAM (OICR) | – | DINO | 66.1 | 63.7 | 24.9 | 36.9 | 26.8 | |
| WeakSAM (MIST) | – | DINO | 73.4 | 70.2 | 26.6 | 39.3 | 29.0 | |
其中,如果框为正,则 为 1;如果框为负,则为 0。 是平衡重。
对于基于查询的 FSOD 方法,例如 DINO (Zhang 等人, 2022),由于查询可以被视为动态 RoIs,因此我们对其应用查询丢弃正则化。 由于只有少数匹配查询需要计算框损失和IoU损失,因此我们仅根据分类损失设置百分位阈值。 只有当查询的损失小于%百分位数的损失,即时,其对应的 设置为 。
| (7) |
| (8) |
3.3 WSIS 的 WeakSAM
| Methods | Backbone | Retrain | VOC 12 | ||||
| Fully-supervised instance segmentation methods. | |||||||
| Mask R-CNN (He et al., 2017) | ResNet-101 | – | 76.7 | 67.9 | 52.5 | 44.9 | |
| WSIS methods with image-level supervision. + Retrain | |||||||
| WISE (Laradji et al., 2019) | ResNet-50 | Mask R-CNN | 49.2 | 41.7 | – | 23.7 | |
| IRNet (Ahn et al., 2019) | ResNet-50 | Mask R-CNN | – | 46.7 | 23.5 | – | |
| LIID (Liu et al., 2020) | ResNet-50 | Mask R-CNN | – | 48.4 | – | 24.9 | |
| Arun et al.(Arun et al., 2020) | ResNet-50 | Mask R-CNN | 59.7 | 50.9 | 30.2 | 28.5 | |
| WS-RCNN (Ou et al., 2021) | VGG-16 | Mask R-CNN | 62.2 | 47.3 | – | 19.8 | |
| BESTIE (Kim et al., 2022) | HRNet-W48 | Mask R-CNN | 61.2 | 51.0 | 31.9 | 26.6 | |
| CIM (Li et al., 2023) | ResNet-50 | Mask R-CNN | 68.7 | 55.9 | 37.1 | 30.9 | |
| Ours. | |||||||
| WeakSAM | ResNet-50 | Mask R-CNN | 70.3 | 59.6 | 43.1 | 36.2 | |
| WeakSAM | ResNet-50 | Mask2Former | 73.4 | 64.4 | 49.7 | 45.3 | |
| Methods | Backbone | Retrain | COCO val 2017 | COCO test-dev | |||||
| Fully-supervised instance segmentation methods. | |||||||||
| Mask R-CNN (He et al., 2017) | ResNet-50 | – | 34.4 | 55.1 | 36.7 | 33.6 | 55.2 | 35.3 | |
| WSIS methods with image-level supervision. | |||||||||
| WS-JDS (Shen et al., 2019) | VGG-16 | – | 6.1 | 11.7 | 5.5 | – | – | – | |
| PDSL (Shen et al., 2021) | ResNet18-WS | – | 6.3 | 13.1 | 5.0 | – | – | – | |
| Fan et al. (Fan et al., 2018a) | ResNet-101 | Mask R-CNN | – | – | – | 13.7 | 25.5 | 13.5 | |
| LIID (Liu et al., 2020) | ResNet-50 | Mask R-CNN | – | – | – | 16.0 | 27.1 | 16.5 | |
| BESTIE (Kim et al., 2022) | HRNet-W48 | Mask R-CNN | 14.3 | 28.0 | 13.2 | 14.4 | 28.0 | 13.5 | |
| CIM (Li et al., 2023) | ResNet-50 | Mask R-CNN | 17.0 | 29.4 | 17.0 | 17.2 | 29.7 | 17.3 | |
| Ours. | |||||||||
| WeakSAM | ResNet-50 | Mask R-CNN | 20.6 | 33.9 | 22.0 | 21.0 | 34.5 | 22.2 | |
| WeakSAM | ResNet-50 | Mask2Former | 25.2 | 38.4 | 27.0 | 25.9 | 39.9 | 27.9 | |
得益于高质量的 WeakSAM-PGT,我们可以直接使用它们来提示 SAM 精确分段作为伪实例标签。 遵循 WeakSAM-WSOD 管道中的实践,我们分别使用基于 R-CNN 和基于查询的实例分割方法来评估 WeakSAM-PGT 的质量。 值得注意的是,我们没有在 WeakSAM-WSIS 中引入更多技术,因为 WeakSAM 伪实例标签足够准确。
4实验
4.1 实验设置
数据集和指标
我们在弱监督对象检测(WSOD)和弱监督实例分割(WSIS)基准上评估了所提出的 WeakSAM。 值得注意的是,不同任务的相同数据集可能具有不同的设置。 对于 WSOD,我们使用三个数据集,即 PASCAL VOC 2007 (Everingham 等人, 2015)、PASCAL VOC 2012 (Everingham 等人, 2015) t2> 和 COCO 2014 (Lin 等人,2014)。 PASCAL VOC 2007 有 2501 个用于训练的图像、2510 个用于评估的图像和 4592 个用于测试的图像。 PASCAL VOC 2012 包含 5717 个训练图像、5823 个验证图像和 10991 个测试图像。 COCO 2014 包括大约 80,000 张用于训练的图像和 40,000 张用于验证的图像。 遵循之前的 WSOD 方法,我们在 和 集上训练 WeakSAM,并在 PASCAL VOC 2007 和 2012 的 集上评估 WeakSAM。 对于 COCO 2014,我们使用 集进行训练,使用 集进行评估。 PASCAL VOC 2007 和 2012 数据集包含 20 个对象类别,COCO 2014 数据集包含 80 个对象类别。 我们报告了这些基准的平均精度 AP 指标。 对于 WSIS,我们使用两个数据集,即 PASCAL VOC 2012 和 COCO 2017。 PASCAL VOC 2012 数据集包括 10582 个用于训练的图像和 1449 个用于评估的图像,包括 20 个对象类别。 COCO 2017 数据集包括 115K 个训练图像、5K 个验证图像和 20K 个测试图像,包含 80 个对象类别。 按照之前的方法,我们报告具有不同交并集 (IoU) 阈值的平均精度 AP 指标。
实施细节
对于 WeakSAM 提案生成,我们采用 WeakTr (Zhu 等人, 2023a) 和 DeiT-S (Touvron 等人, 2021) 模型来生成分类线索,SAM (Kirillov 等人, 2023) 与 ViT-H (Dosovitskiy 等人, 2020) 模型生成提案。 对于 WeakSAM WSOD 管道,我们使用 WSOD 网络,即 OICR (Tang 等人, 2017) 和 MIST (Ren 等人, 2020),以及 VGG- 16 (Han 等人, 2021) 生成伪地面实况 (PGT) 的骨干网和 FSOD 网络,即 Faster R-CNN (Ren 等人, 2015) 和DINO (Zhang 等人, 2022),使用 ResNet-50 (He 等人, 2016) 主干网络进行重新训练。 对于 WeakSAM-WSIS,我们使用 SAM-ViT-H 生成伪实例标签并训练基于 R-CNN 和基于查询的方法,即 Mask R-CNN (He 等人, 2017)<分别为 /t0> 和 Mask2former (Cheng 等人, 2022)。 Alg 中的所有超参数。 1 和 Alg。 2遵循Zhu等人(2023a)和Sui等人(2022)的默认方式。
4.2与最先进方法的比较
| SS | Dense Sample | CAM | CAM | Cross Attn. | Num. | Recall | |||
| IoU=0.50 | IoU=0.75 | IoU=0.90 | |||||||
| ✓ | 2001 | 92.6 | 57.7 | 19.2 | 54.9 | ||||
| ✓ | 129 | 79.6 | 50.7 | 24.3 | 45.2 | ||||
| ✓ | ✓ | 151 | 88.9 | 67.0 | 37.2 | 63.3+18.1 | |||
| ✓ | ✓ | ✓ | 174 | 90.6 | 70.1 | 40.1 | 65.5+20.3 | ||
| ✓ | ✓ | ✓ | ✓ | 213 | 95.6 | 75.0 | 42.1 | 67.4+22.2 | |
| Top-1 PGT | Adaptive PGT | RoI Drop | AP |
| ✓ | 68.4 | ||
| ✓ | 70.7+2.3 | ||
| ✓ | ✓ | 71.8+3.4 |
| Top-1 PGT | Adaptive PGT | Query Drop | AP |
| ✓ | 71.1 | ||
| ✓ | 72.8+1.7 | ||
| ✓ | ✓ | 73.4+2.3 |
弱监督目标检测
我们在表中列出了定量 WSOD 结果。 1. 与我们的 WSOD 基线方法(即 OICR 和 MIST)相比,所提出的 WeakSAM 在所有指标上都实现了超过 10% 的改进。 WeakSAM (MIST) 的结果在所有指标上都超过了所有 WSOD 方法,这证明了 WeakSAM 提案的有效性。 与伪地面真值(PGT)重新训练的 WSOD 方法相比,采用 Faster R-CNN 重新训练的 WeakSAM(MIST)仍然优于 SoS-WSOD (Sui 等人,2022)和 W2N ( Huang 等人,2022) 在所有指标上,采用 DINO 再训练的 WeakSAM (MIST) 甚至具有与完全监督的 Faster R-CNN 相当的性能。 再训练结果证明了所提出的 WSOD 管道的有效性,其中包括自适应 PGT 生成和 RoI drop 再训练。 与同时工作的WSOVOD (Lin 等人, 2024)(也结合了SAM)相比,我们的WeakSAM(MIST)也取得了更好的性能。
弱监督实例分割
我们首先在表 2 中展示 PASCAL VOC 2012 的定量 WSIS 结果。 所提出的带有 Mask R-CNN 再训练的 WeakSAM 达到了最佳性能,这表明 WeakSAM 可以有效地使 WSIS 受益。 此外,WeakSAM 生成的伪实例标签也可以用于现代基于查询的方法,例如 Mask2Former (Cheng 等人, 2022),它取得了最佳结果。
然后,我们展示了 COCO 2017 和 集上的定量 WSIS 结果。 在这些更具挑战性的基准上,采用 Mask R-CNN 再训练的 WeakSAM 取得了比 CIM 更好的结果(Li 等人,2023)。 此外,WeakSAM 与 Mask2Former 也呈现出最佳效果。
4.3消融研究
在本节中,我们提出了消融研究来评估所提出的方法带来的改进,即 WeakSAM 提示、自适应 PGT 生成和 RoI 下降再训练。
由于篇幅限制,我们在补充材料中留下了更多的消融研究,包括效率分析、敏感性分析、定性分析等。
WeakSAM 提示的改进
为了进一步分析所提出的 WeakSAM 提示所带来的改进,我们对表 4 中的不同提示进行了消融实验。 在这里,我们使用选择性搜索(Uijlings等人,2013)作为基线方法。 当仅使用密集采样点时,生成的提案可以实现 5.1% 更高的 Recall(IoU=0.90),并且 MIST 的 AP 降低 9.7%。 添加峰值 CAM 点和峰值交叉注意点作为提示后,我们平均仅通过 213 个提案即可实现更高的召回率和 AP。
WSOD 管道的改进
为了进一步分析所提出的 WeakSAM-WSOD 流程带来的改进,我们对表 5(b) 中的自适应 PGT 生成和 RoI 下降正则化进行了消融实验。 在这里,我们设置一个基线,使用得分为 top-1 的预测框作为 PGT,并使用普通的 Faster R-CNN 作为再训练网络。 结果表明,自适应PGT生成和RoI下降都可以改善Faster R-CNN (Ren等人,2015)和DINO (Zhang等人,2022)的再训练结果, 分别。
5结论
在本文中,我们介绍了 WeakSAM,这是一种利用分段任意模型 (SAM) 进行弱监督实例级识别的新颖框架,在 WSOD 和 WSIS 基准测试中展示了领先的性能。 与原始 SAM 需要交互且无法感知类别不同,WeakSAM 代表了 SAM 与弱监督学习(WSL)的创新融合,克服了 WSOD 提案的冗余问题。 为了进一步解决 WSOD 问题,例如伪真实值 (PGT) 不完整性和嘈杂的 PGT 实例,我们的方法包括自适应 PGT 生成和感兴趣区域 (RoI) 丢弃正则化。 WeakSAM 通过扩展到弱监督实例分割(WSIS)进一步展示了其适应性。 我们的工作旨在激发 SAM 和 WSL 的进一步研究,为弱监督识别通用框架的开发做出重大贡献。
参考
- Ahn et al. (2019) Ahn, J., Cho, S., and Kwak, S. Weakly supervised learning of instance segmentation with inter-pixel relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Arun et al. (2019) Arun, A., Jawahar, C., and Kumar, M. P. Dissimilarity coefficient based weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Arun et al. (2020) Arun, A., Jawahar, C., and Kumar, M. P. Weakly supervised instance segmentation by learning annotation consistent instances. In European Conference on Computer Vision, pp. 254–270. Springer, 2020.
- Bilen & Vedaldi (2016a) Bilen, H. and Vedaldi, A. Weakly supervised deep detection networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2846–2854, 2016a.
- Bilen & Vedaldi (2016b) Bilen, H. and Vedaldi, A. Weakly supervised deep detection networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2846–2854, 2016b.
- Chen et al. (2022) Chen, P., Yu, X., Han, X., Hassan, N., Wang, K., Li, J., Zhao, J., Shi, H., Han, Z., and Ye, Q. Point-to-box network for accurate object detection via single point supervision. In European Conference on Computer Vision, pp. 51–67. Springer, 2022.
- Chen et al. (2023) Chen, T., Mai, Z., Li, R., and Chao, W.-l. Segment anything model (sam) enhanced pseudo labels for weakly supervised semantic segmentation. arXiv preprint arXiv:2305.05803, 2023.
- Chen et al. (2020) Chen, Z., Fu, Z., Jiang, R., Chen, Y., and Hua, X.-S. Slv: Spatial likelihood voting for weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- Cheng et al. (2022) Cheng, B., Misra, I., Schwing, A. G., Kirillov, A., and Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 1290–1299, 2022.
- Cheng et al. (2023) Cheng, T., Wang, X., Chen, S., Zhang, Q., and Liu, W. Boxteacher: Exploring high-quality pseudo labels for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3145–3154, 2023.
- Diba et al. (2017) Diba, A., Sharma, V., Pazandeh, A., Pirsiavash, H., and Van Gool, L. Weakly supervised cascaded convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 914–922, 2017.
- Dosovitskiy et al. (2020) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Everingham et al. (2015) Everingham, M., Eslami, S. A., Van Gool, L., Williams, C. K., Winn, J., and Zisserman, A. The pascal visual object classes challenge: A retrospective. International journal of computer vision, 111:98–136, 2015.
- Fan et al. (2018a) Fan, R., Hou, Q., Cheng, M.-M., Yu, G., Martin, R. R., and Hu, S.-M. Associating inter-image salient instances for weakly supervised semantic segmentation. In Proceedings of the European conference on computer vision (ECCV), pp. 367–383, 2018a.
- Fan et al. (2018b) Fan, R., Hou, Q., Cheng, M.-M., Yu, G., Martin, R. R., and Hu, S.-M. Associating inter-image salient instances for weakly supervised semantic segmentation. In Proceedings of the European conference on computer vision (ECCV), pp. 367–383, 2018b.
- Fu et al. (2020) Fu, D., Chen, M., Sala, F., Hooper, S., Fatahalian, K., and Re, C. Fast and three-rious: Speeding up weak supervision with triplet methods. In III, H. D. and Singh, A. (eds.), Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pp. 3280–3291. PMLR, 13–18 Jul 2020. URL https://proceedings.mlr.press/v119/fu20a.html.
- Gao et al. (2018) Gao, M., Li, A., Yu, R., Morariu, V. I., and Davis, L. S. C-wsl: Count-guided weakly supervised localization. In Proceedings of the European conference on computer vision (ECCV), pp. 152–168, 2018.
- Gao et al. (2019) Gao, Y., Liu, B., Guo, N., Ye, X., Wan, F., You, H., and Fan, D. C-midn: Coupled multiple instance detection network with segmentation guidance for weakly supervised object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9834–9843, 2019.
- Ge et al. (2019) Ge, W., Guo, S., Huang, W., and Scott, M. R. Label-penet: Sequential label propagation and enhancement networks for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3345–3354, 2019.
- Han et al. (2021) Han, K., Xiao, A., Wu, E., Guo, J., Xu, C., and Wang, Y. Transformer in transformer. Advances in Neural Information Processing Systems, 34:15908–15919, 2021.
- He et al. (2016) He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016.
- He et al. (2017) He, K., Gkioxari, G., Dollár, P., and Girshick, R. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pp. 2961–2969, 2017.
- Hsieh et al. (2023) Hsieh, Y.-H., Chen, G.-S., Cai, S.-X., Wei, T.-Y., Yang, H.-F., and Chen, C.-S. Class-incremental continual learning for instance segmentation with image-level weak supervision. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1250–1261, October 2023.
- Hsu et al. (2019) Hsu, C.-C., Hsu, K.-J., Tsai, C.-C., Lin, Y.-Y., and Chuang, Y.-Y. Weakly supervised instance segmentation using the bounding box tightness prior. Advances in Neural Information Processing Systems, 32, 2019.
- Hu et al. (2020) Hu, Z., Liu, Z., Li, G., Ye, L., Zhou, L., and Wang, Y. Weakly supervised instance segmentation using multi-stage erasing refinement and saliency-guided proposals ordering. Journal of Visual Communication and Image Representation, 73:102957, 2020.
- Huang et al. (2020) Huang, Z., Zou, Y., Kumar, B., and Huang, D. Comprehensive attention self-distillation for weakly-supervised object detection. Advances in neural information processing systems, 33:16797–16807, 2020.
- Huang et al. (2022) Huang, Z., Bao, Y., Dong, B., Zhou, E., and Zuo, W. W2n:switching from weak supervision to noisy supervision for object detection, 2022.
- Hwang et al. (2021) Hwang, J., Kim, S., Son, J., and Han, B. Weakly supervised instance segmentation by deep community learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 1020–1029, January 2021.
- Jia et al. (2021) Jia, Q., Wei, S., Ruan, T., Zhao, Y., and Zhao, Y. Gradingnet: Towards providing reliable supervisions for weakly supervised object detection by grading the box candidates. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 1682–1690, 2021.
- Jiang & Yang (2023) Jiang, P.-T. and Yang, Y. Segment anything is a good pseudo-label generator for weakly supervised semantic segmentation. arXiv preprint arXiv:2305.01275, 2023.
- Jie et al. (2017) Jie, Z., Wei, Y., Jin, X., Feng, J., and Liu, W. Deep self-taught learning for weakly supervised object localization. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1377–1385, 2017.
- Khoreva et al. (2017) Khoreva, A., Benenson, R., Hosang, J., Hein, M., and Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
- Kim et al. (2022) Kim, B., Yoo, Y., Rhee, C. E., and Kim, J. Beyond semantic to instance segmentation: Weakly-supervised instance segmentation via semantic knowledge transfer and self-refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4278–4287, June 2022.
- Kirillov et al. (2023) Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., Lo, W.-Y., Dollár, P., and Girshick, R. Segment anything. arXiv:2304.02643, 2023.
- (35) Laptev, I., Kantorov, V., Oquab, M., and Cho, M. Contextlocnet: Context-aware deep network models for weakly supervised localization.
- Laradji et al. (2019) Laradji, I. H., Vazquez, D., and Schmidt, M. Where are the masks: Instance segmentation with image-level supervision. arXiv preprint arXiv:1907.01430, 2019.
- (37) Laradji12, I. H., Vazquez, D., Schmidt, M., and Element, A. Where are the masks: Instance segmentation with image-level supervision.
- Lee et al. (2021) Lee, J., Yi, J., Shin, C., and Yoon, S. Bbam: Bounding box attribution map for weakly supervised semantic and instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2643–2652, June 2021.
- Li et al. (2016) Li, D., Huang, J.-B., Li, Y., Wang, S., and Yang, M.-H. Weakly supervised object localization with progressive domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3512–3520, 2016.
- Li et al. (2022) Li, W., Liu, W., Zhu, J., Cui, M., Hua, X.-S., and Zhang, L. Box-supervised instance segmentation with level set evolution. In European conference on computer vision, pp. 1–18. Springer, 2022.
- Li et al. (2019) Li, X., Kan, M., Shan, S., and Chen, X. Weakly supervised object detection with segmentation collaboration. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- Li et al. (2023) Li, Z., Zeng, Z., Liang, Y., and Yu, J.-G. Complete instances mining for weakly supervised instance segmentation. In International Joint Conference on Artificial Intelligence, 2023.
- Liao et al. (2019) Liao, S., Sun, Y., Gao, C., KP, P. S., Mu, S., Shimamura, J., and Sagata, A. Weakly supervised instance segmentation using hybrid networks. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1917–1921. IEEE, 2019.
- Lin et al. (2024) Lin, J., Shen, Y., Wang, B., Lin, S., Li, K., and Cao, L. Weakly supervised open-vocabulary object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, 2024.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., and Zitnick, C. L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, 2014.
- Lin et al. (2017) Lin, T.-Y., Goyal, P., Girshick, R., He, K., and Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision, pp. 2980–2988, 2017.
- Lin et al. (2023) Lin, Y., Chen, M., Wang, W., Wu, B., Li, K., Lin, B., Liu, H., and He, X. Clip is also an efficient segmenter: A text-driven approach for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15305–15314, 2023.
- Liu et al. (2019) Liu, B., Gao, Y., Guo, N., Ye, X., Wan, F., You, H., and Fan, D. Utilizing the instability in weakly supervised object detection. In CVPR Workshops, 2019.
- Liu et al. (2020) Liu, Y., Wu, Y.-H., Wen, P., Shi, Y., Qiu, Y., and Cheng, M.-M. Leveraging instance-, image-and dataset-level information for weakly supervised instance segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1415–1428, 2020.
- Locatello et al. (2020) Locatello, F., Poole, B., Rätsch, G., Schölkopf, B., Bachem, O., and Tschannen, M. Weakly-supervised disentanglement without compromises. In International Conference on Machine Learning, pp. 6348–6359. PMLR, 2020.
- Loshchilov & Hutter (2017) Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- Ma & Wang (2023) Ma, J. and Wang, B. Segment anything in medical images. arXiv preprint arXiv:2304.12306, 2023.
- Ou et al. (2021) Ou, J.-R., Deng, S.-L., and Yu, J.-G. Ws-rcnn: Learning to score proposals for weakly supervised instance segmentation. Sensors, 21(10):3475, 2021.
- Pont-Tuset et al. (2016) Pont-Tuset, J., Arbelaez, P., Barron, J. T., Marques, F., and Malik, J. Multiscale combinatorial grouping for image segmentation and object proposal generation. IEEE transactions on pattern analysis and machine intelligence, 39(1):128–140, 2016.
- Ren et al. (2015) Ren, S., He, K., Girshick, R., and Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 2015.
- Ren et al. (2020) Ren, Z., Yu, Z., Yang, X., Liu, M.-Y., Lee, Y. J., Schwing, A. G., and Kautz, J. Instance-aware, context-focused, and memory-efficient weakly supervised object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10598–10607, 2020.
- Schroeter et al. (2019) Schroeter, J., Sidorov, K., and Marshall, D. Weakly-supervised temporal localization via occurrence count learning. In International Conference on Machine Learning, pp. 5649–5659. PMLR, 2019.
- Seo et al. (2022) Seo, J., Bae, W., Sutherland, D. J., Noh, J., and Kim, D. Object discovery via contrastive learning for weakly supervised object detection. In European Conference on Computer Vision, pp. 312–329. Springer, 2022.
- Shen et al. (2019) Shen, Y., Ji, R., Wang, Y., Wu, Y., and Cao, L. Cyclic guidance for weakly supervised joint detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 697–707, 2019.
- Shen et al. (2020) Shen, Y., Ji, R., Wang, Y., Chen, Z., Zheng, F., Huang, F., and Wu, Y. Enabling deep residual networks for weakly supervised object detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VIII 16, pp. 118–136. Springer, 2020.
- Shen et al. (2021) Shen, Y., Cao, L., Chen, Z., Zhang, B., Su, C., Wu, Y., Huang, F., and Ji, R. Parallel detection-and-segmentation learning for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8198–8208, 2021.
- Sui et al. (2022) Sui, L., Zhang, C.-L., and Wu, J. Salvage of supervision in weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14227–14236, 2022.
- Sun et al. (2020) Sun, G., Wang, W., Dai, J., and Van Gool, L. Mining cross-image semantics for weakly supervised semantic segmentation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16, pp. 347–365. Springer, 2020.
- Sun et al. (2023) Sun, W., Liu, Z., Zhang, Y., Zhong, Y., and Barnes, N. An alternative to wsss? an empirical study of the segment anything model (sam) on weakly-supervised semantic segmentation problems. arXiv preprint arXiv:2305.01586, 2023.
- Tang et al. (2017) Tang, P., Wang, X., Bai, X., and Liu, W. Multiple instance detection network with online instance classifier refinement. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2843–2851, 2017.
- Tang et al. (2018a) Tang, P., Wang, X., Bai, S., Shen, W., Bai, X., Liu, W., and Yuille, A. Pcl: Proposal cluster learning for weakly supervised object detection. IEEE transactions on pattern analysis and machine intelligence, 42(1):176–191, 2018a.
- Tang et al. (2018b) Tang, P., Wang, X., Wang, A., Yan, Y., Liu, W., Huang, J., and Yuille, A. Weakly supervised region proposal network and object detection. In Proceedings of the European conference on computer vision (ECCV), pp. 352–368, 2018b.
- Tian et al. (2021) Tian, Z., Shen, C., Wang, X., and Chen, H. Boxinst: High-performance instance segmentation with box annotations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5443–5452, 2021.
- Touvron et al. (2021) Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., and Jégou, H. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pp. 10347–10357. PMLR, 2021.
- Uijlings et al. (2013) Uijlings, J. R. R., van de Sande, K. E. A., Gevers, T., and Smeulders, A. W. M. Selective search for object recognition. International Journal of Computer Vision, 104:154 – 171, 2013. URL https://api.semanticscholar.org/CorpusID:216077384.
- Wan et al. (2018) Wan, F., Wei, P., Jiao, J., Han, Z., and Ye, Q. Min-entropy latent model for weakly supervised object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1297–1306, 2018.
- Wan et al. (2019) Wan, F., Liu, C., Ke, W., Ji, X., Jiao, J., and Ye, Q. C-mil: Continuation multiple instance learning for weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2199–2208, 2019.
- Wang et al. (2013) Wang, X., Wang, B., Bai, X., Liu, W., and Tu, Z. Max-margin multiple-instance dictionary learning. In International conference on machine learning, pp. 846–854. PMLR, 2013.
- Wang et al. (2021) Wang, X., Feng, J., Hu, B., Ding, Q., Ran, L., Chen, X., and Liu, W. Weakly-supervised instance segmentation via class-agnostic learning with salient images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10225–10235, 2021.
- Xu et al. (2014) Xu, C., Tao, D., Xu, C., and Rui, Y. Large-margin weakly supervised dimensionality reduction. In International conference on machine learning, pp. 865–873. PMLR, 2014.
- Xu et al. (2022) Xu, L., Ouyang, W., Bennamoun, M., Boussaid, F., and Xu, D. Multi-class token transformer for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4310–4319, 2022.
- Yang et al. (2019) Yang, K., Li, D., and Dou, Y. Towards precise end-to-end weakly supervised object detection network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8372–8381, 2019.
- Yang et al. (2023) Yang, L., Wang, Y., Li, X., Wang, X., and Yang, J. Fine-grained visual prompting. arXiv preprint arXiv:2306.04356, 2023.
- Yin et al. (2021) Yin, Y., Deng, J., Zhou, W., and Li, H. Instance mining with class feature banks for weakly supervised object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pp. 3190–3198, 2021.
- Yin et al. (2023) Yin, Y., Deng, J., Zhou, W., Li, L., and Li, H. Cyclic-bootstrap labeling for weakly supervised object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 7008–7018, 2023.
- Zeng et al. (2019) Zeng, Z., Liu, B., Fu, J., Chao, H., and Zhang, L. Wsod2: Learning bottom-up and top-down objectness distillation for weakly-supervised object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 8292–8300, 2019.
- Zhang et al. (2022) Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J., Ni, L. M., and Shum, H.-Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection, 2022.
- Zhang et al. (2023) Zhang, J., Su, H., He, Y., and Zou, W. Weakly supervised instance segmentation via category-aware centerness learning with localization supervision. Pattern Recognition, 136:109165, 2023.
- Zhang et al. (2021) Zhang, K., Yuan, C., Zhu, Y., Jiang, Y., and Luo, L. Weakly supervised instance segmentation by exploring entire object regions. IEEE Transactions on Multimedia, 2021.
- Zhang et al. (2018a) Zhang, X., Feng, J., Xiong, H., and Tian, Q. Zigzag learning for weakly supervised object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4262–4270, 2018a.
- Zhang et al. (2018b) Zhang, Y., Bai, Y., Ding, M., Li, Y., and Ghanem, B. W2f: A weakly-supervised to fully-supervised framework for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 928–936, 2018b.
- Zhou et al. (2018) Zhou, Y., Zhu, Y., Ye, Q., Qiu, Q., and Jiao, J. Weakly supervised instance segmentation using class peak response. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3791–3800, 2018.
- Zhou (2018) Zhou, Z.-H. A brief introduction to weakly supervised learning. National science review, 5(1):44–53, 2018.
- Zhu et al. (2023a) Zhu, L., Li, Y., Fang, J., Liu, Y., Xin, H., Liu, W., and Wang, X. Weaktr: Exploring plain vision transformer for weakly-supervised semantic segmentation. arXiv preprint arXiv:2304.01184, 2023a.
- Zhu et al. (2023b) Zhu, L., Peng, L., Ding, S., and Liu, Z. An encoder-decoder framework with dynamic convolution for weakly supervised instance segmentation. IET Computer Vision, 2023b.
- Zhu et al. (2019) Zhu, Y., Zhou, Y., Xu, H., Ye, Q., Doermann, D., and Jiao, J. Learning instance activation maps for weakly supervised instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- Zitnick & Dollár (2014) Zitnick, C. L. and Dollár, P. Edge boxes: Locating object proposals from edges. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 391–405. Springer, 2014.
附录 AWeakSAM 提案的更多详细信息
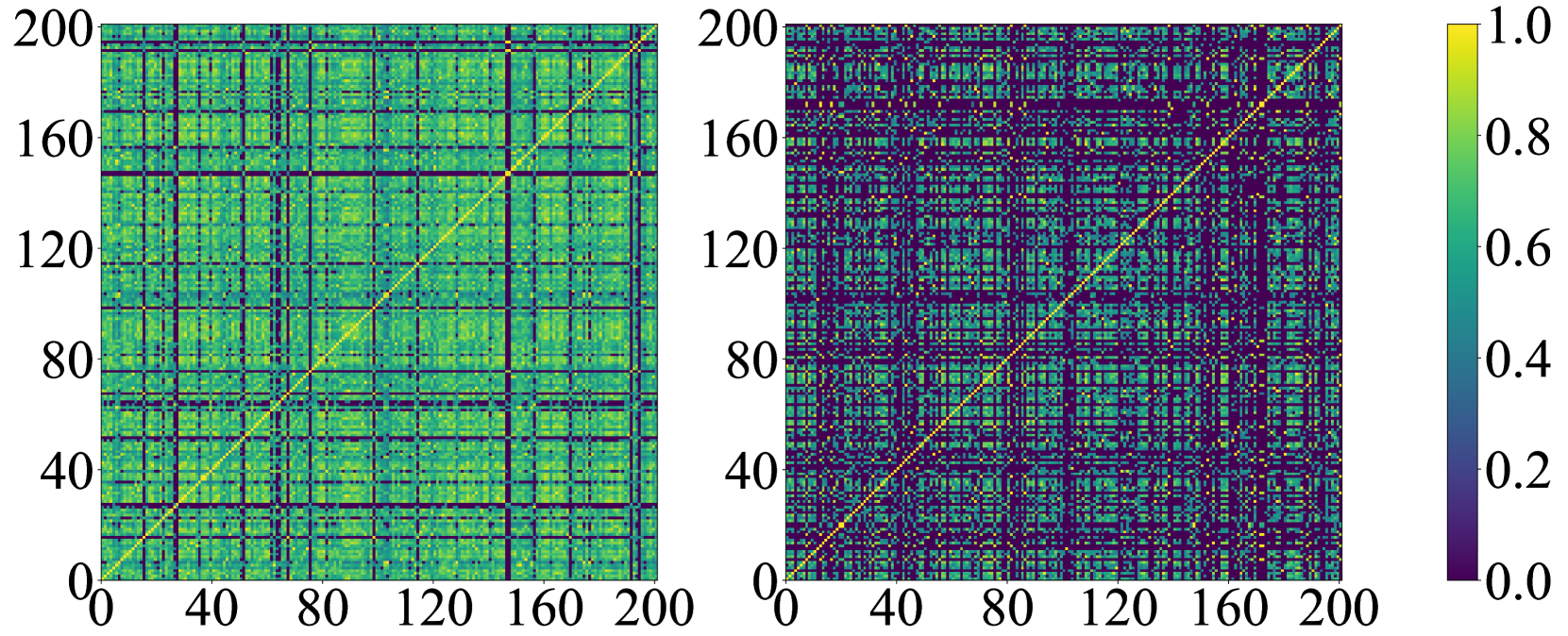
我们进一步分析了不同弱监督目标检测(WSOD)提案中的提案相似性,如图4所示。 我们从选择性搜索(Uijlings等人,2013)提案和WeakSAM提案中随机抽取200个提案特征,然后分别计算它们的余弦相似度。 请注意,所有特征均由 RoI 池化层输出。 可以看出,选择性搜索的特征往往与其他特征具有更高的相似度。 相比之下,WeakSAM 提案中的特征显示出较低的相似性,这通常意味着它具有较少的重叠和冗余。
附录 BRoI Drop 正则化的更多详细信息
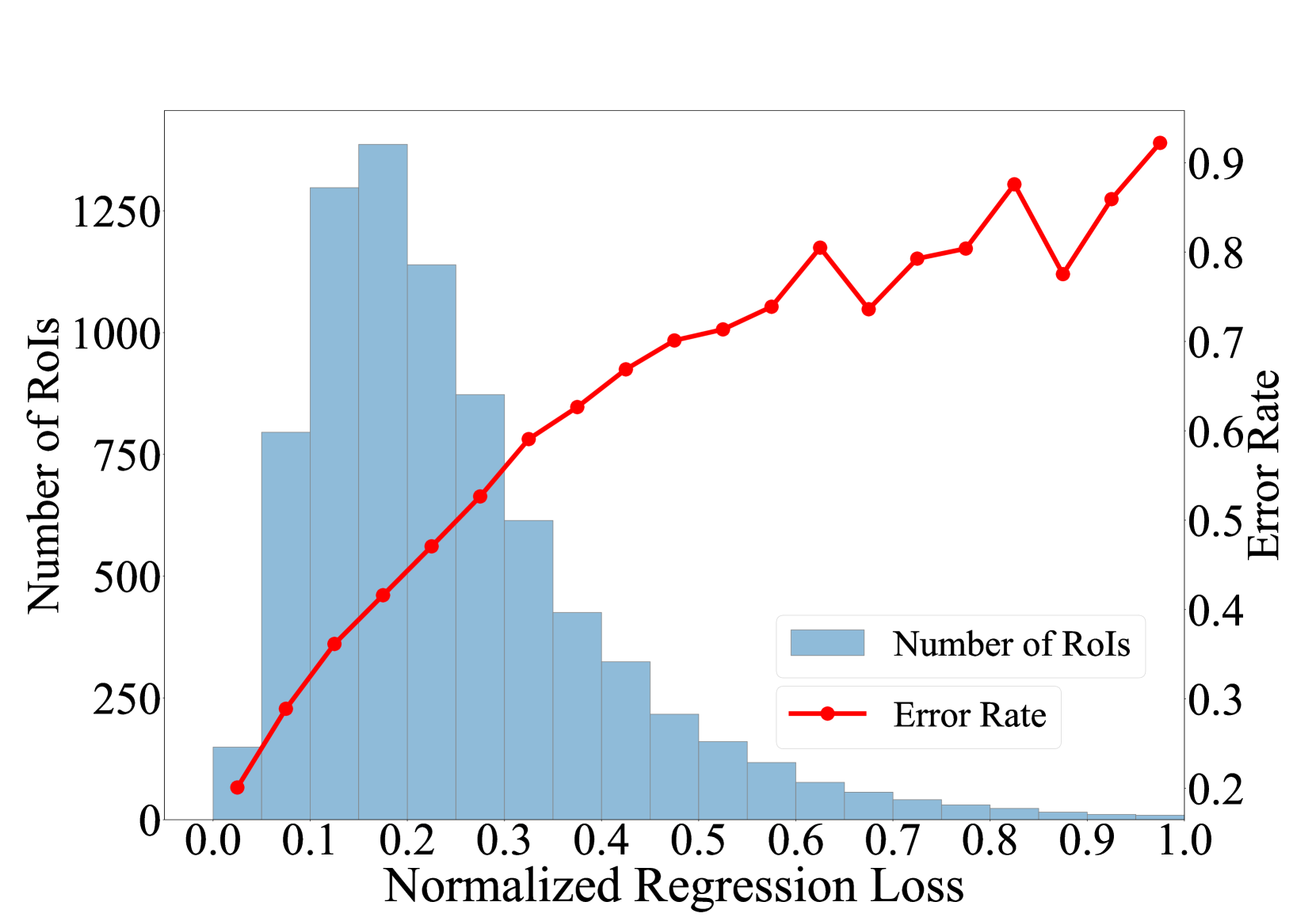
我们进一步在图5中展示了归一化回归损失、相应的RoI数量和相应的错误率之间的关系。 它表明,与分类损失相比,RoI 的回归损失具有不同的数字分布。 然而,它们表现出相似的错误率曲线。 这一观察结果进一步证明了使用回归阈值进行RoI下降正则化的必要性。
附录 C 查询删除正则化的更多详细信息
由于 DINO (Zhang 等人, 2022) 采用焦点损失 (Lin 等人, 2017) 作为分类损失,与背景类相关的查询往往具有更高的预测概率和更低的损失。 这导致直接删除查询时无意中遗漏了大多数前台类别查询。 为了缓解这个问题,我们的第一步涉及对每个训练批次中的前台和后台查询的未加权焦点损失进行归一化,这本质上是二元交叉熵损失。 批次级别的归一化将采样范围从单个图像扩大到批次的大小。 在第二步中,根据规范化后的损失排名删除查询。 这种方法避免了由于删除大多数前台查询而导致模型收敛缓慢。
附录D效率比较
| Num. | T | T | M | |
| SS (Uijlings et al., 2013) | 2001 | 11.6 hrs | 16 hrs | 17810 MiB |
| Ours | 213-89.4% | 4 hrs-65.5% | 9 hrs-43.8% | 5667 MiB-68.2% |
为了进一步分析 WeakSAM 带来的效率提升,我们给出了 Selective Search (Uijlings 等人, 2013) 和我们的 WeakSAM 在 4 个 GPU 卡的机器上的效率比较,如表 6。 我们的 WeakSAM 将提案数量减少了 89.4%,提案生成时间减少了 65.5%,WSOD 网络训练时间减少了 43.8%,GPU 内存成本减少了 68.2%。 结果表明所提出的 WeakSAM 带来了显着的效率提升。
附录 E其他定量结果
| Methods | Proposal | CorLoc | |
| WSDDN (Bilen & Vedaldi, 2016a) | EB (Zitnick & Dollár, 2014) | 53.5 | |
| Yang et al. (Yang et al., 2019) | SS (Uijlings et al., 2013) | 68.0 | |
| C-MIL (Wan et al., 2019) | SS | 65.0 | |
| C-MIDN (Gao et al., 2019) | SS | 53.5 | |
| WSOD2 (Zeng et al., 2019) | SS | 69.5 | |
| CASD (Huang et al., 2020) | SS | 70.4 | |
| OD-WSCL (Seo et al., 2022) | SS | 69.8 | |
| WSOD-CBL (Yin et al., 2023) | SS | 71.8 | |
| WSOVOD (Lin et al., 2024) | LO-WSRPN+SAM | 77.2 | |
| WSOVOD‡ | LO-WSRPN+SAM | 80.1 | |
| OICR (Tang et al., 2017) | SS | 60.6 | |
| WeakSAM (OICR) | WeakSAM | 74.5+13.9 | |
| MIST (Ren et al., 2020) | SS | 68.8 | |
| WeakSAM (MIST) | WeakSAM | 82.9+14.1 |
我们以 CorLoc 的形式对 PASCAL VOC 2007 集进行比较,如表 7 所示。 可以看出,WeakSAM 在 OICR 和 MIST 上分别实现了 13.9% 和 14.1% CorLoc 改进。 WeakSAM (OICR) 的性能比 WSOD-CBL (Yin 等人, 2023) 好 11.1% CorLoc。 结果表明我们的 WeakSAM 带来了显着的效率提升。
附录 F其他消融研究
F.1分类方法的改进
| CLS Methods | Num. | Recall | ||
| IoU=0.50 | IoU=0.75 | IoU=0.90 | ||
| None | 2001 | 92.6 | 57.7 | 19.2 |
| WeakTr (Zhu et al., 2023a) | 213 | 95.6 | 75.0 | 42.1 |
| MCTformer (Xu et al., 2022) | 173 | 93.2 | 74.8 | 43.7 |
| CLIP-ES (Lin et al., 2023) | 205 | 93.8 | 75.6 | 44.5 |
为了进一步分析生成分类线索的方法的影响,我们用 MCTformer 和 CLIP-ES 替换了 WeakSAM 中的 WeakTr。 如表8所示,WeakSAM (MCTformer) 的召回率 (IoU=90) 比 WeakSAM (WeakTr) 高 1.6%。 此外,在 IoU 阈值为 75 和 90 时,WeakSAM (CLIP-ES) 的召回率比 WeakSAM (WeakTr) 分别提高了 0.6% 和 2.4%。 这些结果证明了 WeakSAM 提议生成方法在不同分类方法中的多功能性。 请注意,本研究中使用的所有分类方法都是来自弱监督语义分割 (WSSS) 方法的 CAM 网络。 由于这些网络通常针对特定数据集进行了良好调整,例如 PASCAL VOC 2012 和 COCO 2014,因此它们擅长提供丰富的分类线索。
F.2 RoI 下降正则化的消融研究
| 0.8 | 1.0 | 1.2 | |
| 71.0 | 71.8 | 71.3 | |
| 3.0 | 4.0 | 5.0 | |
| 71.2 | 71.8 | 71.1 | |
为了进一步分析回归阈值和分类阈值对RoI下降正则化的影响,我们进行了表9(b)所示的实验。 据观察,RoI drop正则化的最佳回归阈值和分类阈值分别为1.0和4.0。
F.3 查询删除正则化的消融研究
| Baseline | AP | ||
| ✓ | 72.8 | ||
| ✓ | 73.4+0.6 | ||
| ✓ | ✓ | 73.3+0.5 |


为了分析删除与前景类别和背景类别对应的查询的影响,我们进行了如表10所示的消融。 实验结果表明,仅删除前台查询 () 会带来最佳性能,而删除两种类型的查询会导致性能略有下降。 我们坚持认为,丢弃更多后台查询也可能导致收敛速度变慢。 因此,我们选择仅删除 以获得更好的性能。
我们进一步分析分类阈值对查询丢弃正则化的影响,如表11所示。 定量结果表明 90 是最佳百分位分类阈值。
| (%) | 100 | 90 | 80 |
| 72.8 | 73.4 | 71.8 | |
附录 G其他可视化结果


附录 H 更多实施细节
对于算法1,我们将内核大小设置为128,将激活阈值设置为0.9,遵循WeakTr (朱等人, 2023a)。 对于算法2,我们遵循类似于SoS-WSOD (Sui 等人, 2022)的默认方式,其中设置分数阈值为0.3,重叠阈值设置为0.85。
对于 Faster R-CNN (Ren 等人, 2015) 再训练,我们采用与全监督训练相同的训练策略和超参数。 对于 DINO (Zhang 等人, 2022) 重新训练,我们使用 AdamW (Loshchilov & Hutter, 2017) 优化器的 9e-5 学习率和最大历元共 14 个。 此外,我们在训练和测试中应用了多尺度增强和水平翻转。
对于 Mask R-CNN (He 等人, 2017) 和 Mask2Former (Cheng 等人, 2022) 的实现,我们遵循它们的默认超参数。