同样的任务,更多的词符:输入长度对大型语言模型
推理性能的影响
摘要
本文探讨了扩展输入长度对大型语言模型(大语言模型)能力的影响。 尽管大语言模型近年来取得了进步,但它们在不同输入长度上的性能一致性尚不清楚。 我们通过引入一种新颖的 QA 推理框架来研究这个方面,该框架专门用于评估输入长度的影响。 我们使用同一样本的多个版本来隔离输入长度的影响,每个版本都使用不同长度、类型和位置的填充进行扩展。 我们的研究结果表明,在比技术最大值短得多的输入长度下,大语言模型的推理性能显着下降。 我们表明,退化趋势出现在数据集的每个版本中,尽管强度不同。 此外,我们的研究表明,传统的困惑度指标与大语言模型在长输入推理任务中的表现并不相关。 我们分析结果并确定故障模式,这些模式可以作为未来研究的有用指南,并有可能为解决大语言模型中观察到的局限性提供策略。
同样的任务,更多的词符:输入长度对大型语言模型
推理性能的影响
Mosh Levy††thanks: These authors contributed equally to this work. Alon Jacoby11footnotemark: 1 Yoav Goldberg Bar-Ilan University Allen Institute for AI {moshe0110, alonj4}@gmail.com
1简介
大型语言模型(大语言模型)的最新进展在一系列任务中显示出令人印象深刻的性能OpenAI(2023); Anil 等人 (2023); Jiang 等人 (2024),包括正确回答需要多个推理步骤的复杂问题Kojima 等人 (2022);魏等人(2022)。 这些模型还声称支持越来越长的输入。 这一发展强调了需要检查它们在技术上支持的较长输入上的性能。
一个合理的假设是,对长输入的支持将跨任务转移,并使模型能够在短输入提示中擅长解决任务,而在嵌入较长提示时执行相同的任务。 这个假设成立吗?
最近的研究对涉及较长输入的任务(包括推理任务)的模型进行了基准测试,表明模型确实经常难以对长输入进行推理(Shaham 等人,2023;Li 等人,2023;Bai 等人,2023). 然而,这些研究没有正确控制其变量,并且改变了输入长度和要执行的相关任务。 这使得很难说性能下降是由于需要使用更长的输入,还是由于任务通常更困难。
在这项工作中,我们研究了增加输入长度对模型性能的影响,同时保持其他因素尽可能恒定。
我们采用一种方法来衡量模型性能趋势作为输入长度的函数,通过将其隔离为变量,同时保持底层任务完整(§2)。
为此,我们引入了F灵活LENgth Q问题A回答数据集(FLenQA)111https://github.com/alonj/Same-Task-More-Tokens,用于基于文本推理的 QA 数据集 (§3 对于每个样本,由一个对/错问题和回答它所需的两条信息(上下文)组成,我们通过将上下文部分嵌入到较长的、不相关的文本中来创建不同长度的多个版本。 为了确保模型利用其全部输入,数据集由任务组成,对于这些任务,两条信息必须一起推理才能正确回答问题。 同时,我们保持任务足够简单,以便当信息片段单独呈现时,模型可以正确回答大多数任务,而无需额外填充。
我们表明,即使输入长度为 3000 个标记,大语言模型的推理能力也会迅速下降,这比其技术最大值短得多(所有测试模型的平均精度从 下降到)。
此外,我们还探讨了将信息片段嵌入到上下文中的不同位置以及两种上下文中的效果:与信息片段相似,或与信息片段不相似(§4)。 我们发现,无论实验设置如何,都存在类似的降解趋势。
我们还表明,模型在长输入上的下一个单词预测性能与其在长输入推理的下游任务上的性能不相关(§5)。
此外,我们发现,虽然思想链(CoT)提示(Kojima等人,2022;Wei等人,2022)提高了短输入的性能,但在大多数情况下当输入较长时,它不会减轻性能下降的模型:虽然 CoT 提示比非 CoT 提示提高了准确性,但增加的量在不同上下文长度上大致一致,并且远未消除由于长上下文而导致的性能下降( §6)。 唯一的例外是 GPT4222我们将模型gpt-4-1106-preview、gpt-3.5-turbo-1106相应地称为GPT4和GPT3.5。,其中 CoT 与正常提示之间的差距随着输入时间的延长而增加。
最后,我们分析结果并确定模型响应中的几种故障模式 (§7)。 我们发现,对于较长的输入,模型往往不遵循输入中的特定指令,要么不提供答案,要么在 CoT 提示的情况下,在概述推理步骤之前呈现最终答案。 我们还观察到,随着输入长度的增加,模型会倾向于回答“错误”,并且模型在其响应中纳入相关信息的能力会下降。
2 所需的数据属性
我们的目标是在相关信息保持不变的情况下,了解输入长度如何影响大语言模型对文本的推理能力。 因此,我们使用需要模型对给定文本进行推理的问答任务。 为了使研究同时适用于开放模型和封闭模型,我们选择了依赖于输入干预的行为方法(Holtzman等人,2023)。
我们的目标是我们的数据满足以下要求:
确保模型对输入进行推理。
为了检查模型在长输入上的性能,我们要求只能通过从文本 (Huang 和 Chang,2022) 中的证据得出结论来正确解决任务。
-
1.
每个数据样本应包含几个相关的文本范围,这些文本范围对于正确解决任务来说是必要且充分的。
-
2.
所有相关跨度必须共同协商才能达成成功的解决方案。 一些任务,例如文本摘要,可以使用“分而治之”的方法来解决(Gidiotis 和 Tsoumakas,2020;Liu 等人,2022;Wolhandler 等人,2022),其中每个相关span 被单独识别,然后解释并添加到输出中。 我们希望避免这种可分解的任务,因为它们实际上并不需要对长输入进行推理。
-
3.
避免模型依赖参数化知识而非文本,避免数据污染Jacovi 等人 (2023) 问题和支持相关的跨度应包含训练中未见过的新事实。333模型通常会正确回答问题,即使其输入中没有或仅存在一个所需的支持事实。 我们在附录A中进一步讨论这一点。
隔离长度因子。
为了隔离长度的影响,我们提出以下要求:
-
1.
所需的推理应独立于样本的长度:相关跨度应在所有长度变化中保持相同。
-
2.
添加的材料(又名“填充”,为控制样本长度而添加的文本)不应与相关文本范围的推理相矛盾或干扰。
-
3.
输入内每个相关跨度的位置应该是可控的。
保持自然的输入。
输入应该反映用户可能在大语言模型提示中自然使用的内容。 例如,一系列不相关的句子是不自然的。 相反,一系列不相关的段落但每个段落都有凝聚力则更为自然,因为这样的输入可能是通过从多个来源收集相关信息而产生的。 为了在更改输入长度的同时最好地保持输入的自然性,我们要求输入至少在段落级别应该具有凝聚力。
3FLenQA
我们引入了F灵活LENgth Q问题A回答数据集(FLenQA),它遵循中设置的要求§2。
FlenQA 由三个推理任务组成:单调关系(一项新任务)、People In Rooms(一项新任务)和简化版本的 Ruletaker (Clark 等人,2021) (§3.2)。 每个任务由 100 个基本实例组成,我们从中创建不同长度、不同背景文本以及背景文本中不同事实分布的变体 (§3.3)。
每个任务的标签分布(“True”和“False”)完全平衡,并且我们确保其中的大多数基本实例在以未展开的形式呈现时能够被大语言模型正确解决(§3.4)。
我们发布数据集以支持未来的推理和长输入性能研究。 任务的详细信息和统计数据显示在附录B中。
3.1 基础实例。
每个基本实例由(1)一个可选前缀(例如介绍任务或支持事实)组成; (2) 两个关键段落,每个段落主题连贯,并以解决任务所需的关键句子开头; (3) 一个可选后缀(例如,询问有关前面上下文的问题)。444可选性位于任务级别,任务中的所有实例要么有前缀/后缀,要么没有。 对于每个实例,不同的部分都通过换行符连接起来并输入到大语言模型中。
在整个文本中,关键段落以红色排版,其中的支持句子以深红色排版,可选的前缀和后缀以黑色排版。 每个数据集使用的完整提示位于附录D中。
导出关键段落
每个任务都依赖于两个事实,并以简单的句子表达。 然后将每个句子扩展为主题连贯的段落,以确保自然性要求。 这种扩展是使用 GPT-4 执行的,我们提示扩展句子而不添加新信息,然后由作者对结果进行手动验证。
3.2任务
单调关系(MonoRel)
每个关键句子都是在单调尺度上比较两个人名,例如“X 大于 Y”,“Y 大于 Z”。 后缀是一个真/假问题,询问出现在不同句子中的两个实体之间的关系(它们在文本中没有明确比较)。 这些关系本质上是传递的和单调的。
MonoRel 示例:
朱莉·贝克比朱利安·巴顿年轻。 这是一个不变的事实,就像北极星一样不变。 这是一个再清楚不过的事实,她 ...
萨曼莎·阿诺德比朱莉·贝克年轻。 这意味着萨曼莎·阿诺德的生日比朱莉·贝克少。 ...
萨曼莎·阿诺德比朱利安·巴顿年轻吗?
该数据的灵感来自 Sinha 等人 2018 引入的描述亲属关系的不同单调关系。 我们在这项工作中定义了一组新的关系类型。 根据§2中的要求,回答问题需要对两个关键句子进行推理。 数据是通过从 Faker python 库(Faraglia 和 Contributors,2012) 中随机抽取名称以及手工制作的关系列表中的关系来以编程方式创建的。
房间内人员 (PIR)
在任务的每个样本中,在一个关键句子中,据说人位于一个指定的房间中(“X 在旧图书馆中”),另一个关键句子描述了该房间有一个某些财产(“旧图书馆有木地板”)。 然后,任务是推断给定的人是否位于具有给定财产的房间中。
PIR 示例:
约翰的客厅铺有大理石地板, 这是建筑的本质,就像它的地基一样。 此时此刻 ...
伊森·华盛顿在约翰的客厅里, 这一事实已经成为这个地方的一部分,就像墙壁和天花板一样。 伊森华盛顿在约翰生活中的真相 ...
伊森华盛顿在大理石地板的房间里吗?
该数据集的灵感来自 bAbI 任务集(Weston 等人,2016),其中推理是在一个或多个代理所采取的路径上进行的。 PIR 是任务的简化,仅涉及一名代理。 任务中人员的姓名是随机抽取的(Faraglia 和 Contributors,2012)。 房间和属性是手工选择的,是相互排斥的(例如,房间要么是蓝墙,要么是红墙),因此不会创建不明确的示例。
简化的规则制定者
我们采用 Ruletaker Clark 等人 (2021) 的任务表述,这是一个为在自然语言中呈现明确逻辑理论的文本中进行定理证明而设计的基准。 每个实例由一个逻辑规则、两个句子(每个句子介绍一个事实)以及一个关于规则和事实的问题组成。555初步实验表明,大多数大语言模型仍然难以处理涉及多个规则或两个以上事实的实例。 我们的简化规则制定者任务由符合这些标准的生成样本组成。
简化的规则制定者示例:
事实:
艾琳是毛茸茸的。 艾琳以毛茸茸而闻名。 他有很多皮毛并且 ...
艾琳很好。 艾琳一直以他的优秀而闻名。 他的良善体现在生活的方方面面 ...
规则:如果 X 大并且 X 好,那么 X 就高。
问题:“艾琳很高”这一说法可以从规则和事实中推导出来吗?
3.3 长度变化
我们将每个基本实例扩展为大约 250、500、1000、2000 和 3000 个 Token 的输入长度。666如果 GPT4 分词器测量的词符计数在 中,则我们认为样本的长度为 N。 为了将输入扩展到这些目标,我们添加了与问题无关的背景文本(“padding”,§2)。 对于每个基本实例和长度对,我们创建不同的版本,这些版本的背景文本来源不同:重复、相似或不同实例的关键段落。 对于每一个,我们还改变了背景文本中关键段落的分散程度。
3.3.1 背景文本
复制。
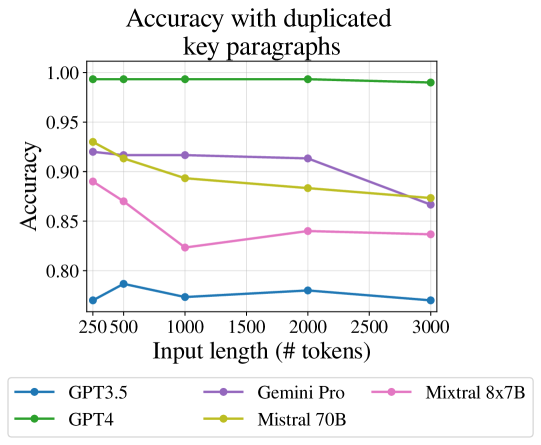
为了评估长度发生变化但信息保持不变的极端情况,我们进行了一个实验,其中每个长度的文本都由关键段落的多个副本组成。 我们复制每个关键段落而不进行任何修改,以达到输入的目标长度。 两个重复的段落以交替顺序出现,直到达到所需的样本长度。 在这种情况下,在 QA 推理的两个子任务中——识别关键信息并对其进行推理,第一个子任务是微不足道的。
相似:从同一任务中重新采样。
为了获得与关键段落相似的背景文本,我们使用从同一任务的其他基本实例中采样的段落进行填充。 为了避免产生矛盾,我们排除了包含关键段落中出现的实体的段落。 因此,这种填充不会产生样本的对抗性或模糊版本。
不同:书籍语料库。
为了获取与关键段落不同的背景文本,我们使用图书语料库(朱等人,2015)中的文本。 我们从图书语料库中抽取随机(连续)文本,并将每个关键段落注入其中,同时尊重句子边界。

3.3.2 文本中关键段落的位置
我们考虑关键段落在背景文本中分散的四种不同方式:在前三种情况下,关键段落彼此相邻,而在第四种情况下,关键段落被不同长度的中间文本分隔开。
(1) 关键段落在前:关键段落出现在文本的开头,后面填充;
(2) Key paragraphs middle:一半的padding贴在关键段落之前,一半贴在关键段落之后,但不在关键段落之间(关键段落正好在中间);
(3) Key paragraphs last:关键段落出现在文本的末尾,前面添加 padding 作为前缀;
(4) 随机放置:在段落之前、之间和之后添加填充,间隔随机。
图2提供了视觉表示。
3.4 基础实例是可负责的
我们通过评估数据集中每个样本的最小文本(仅包括问题和与其相关的关键段落)的大语言模型来估计基线准确性。 我们发现,即使使用非 CoT 提示,五个模型中的四个也能达到很高的准确率 (>0.89)。 性能最低的模型 (GPT3.5) 达到了足够高的精度,可以观察到性能下降 (0.77)。 完整结果可在附录C中找到。
4主要实验
我们报告所有三个任务的平均准确度,并在所有输入长度上保持相同的设置(提示、温度等)。 我们评估了五个最新的大语言模型:GPT4、GPT3.5、Gemini-Pro、Mistral 70B 和 Mixtral 8x7B。 请参阅附录 E 了解我们的设置参数的详细信息。
4.1 长度和位置的影响
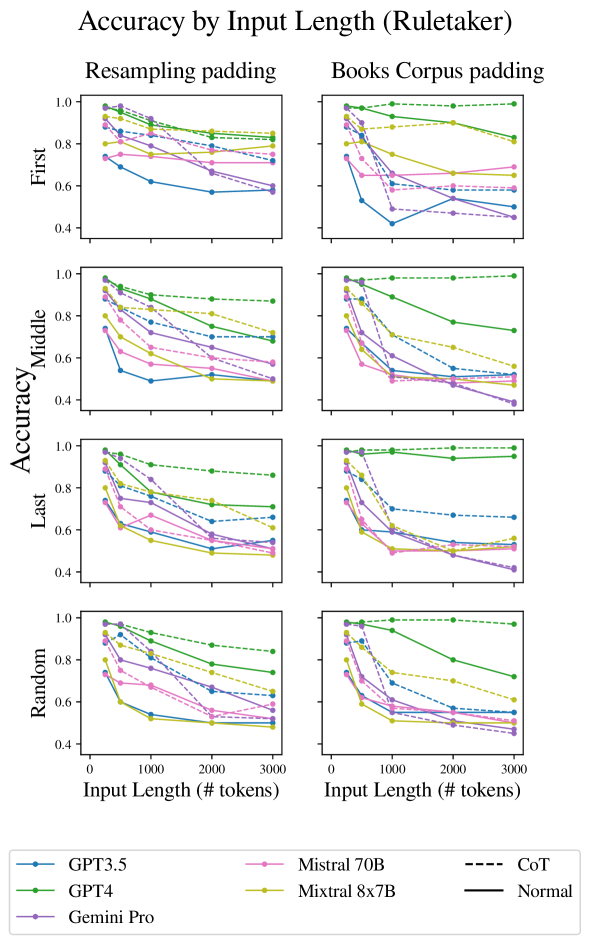
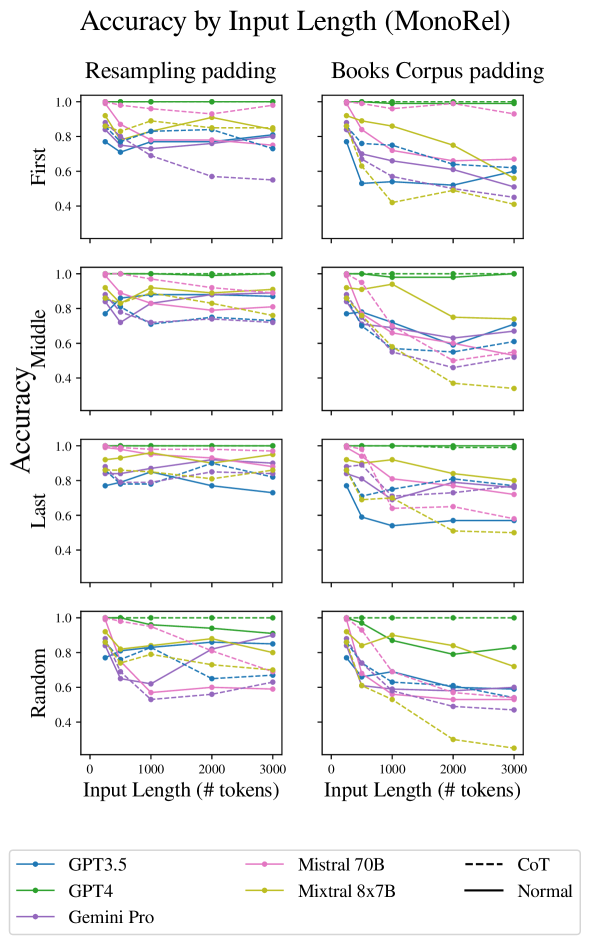
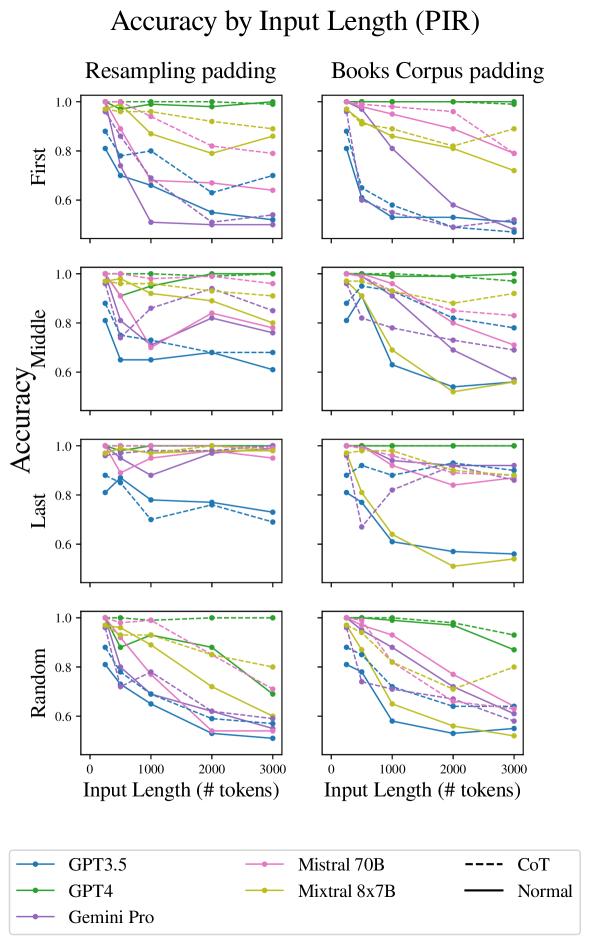
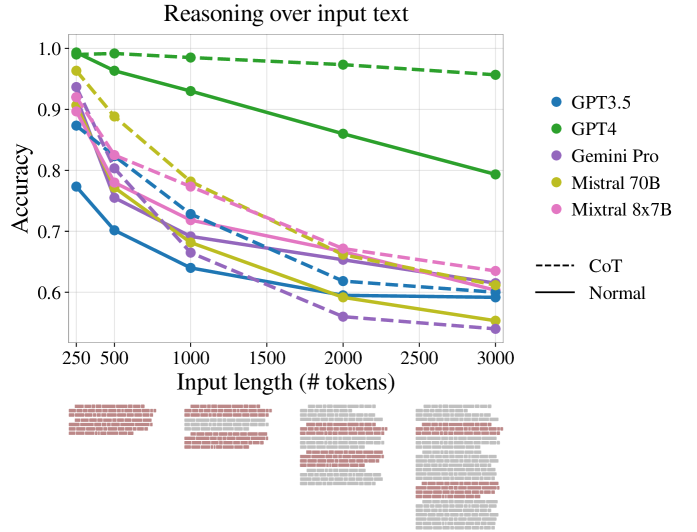
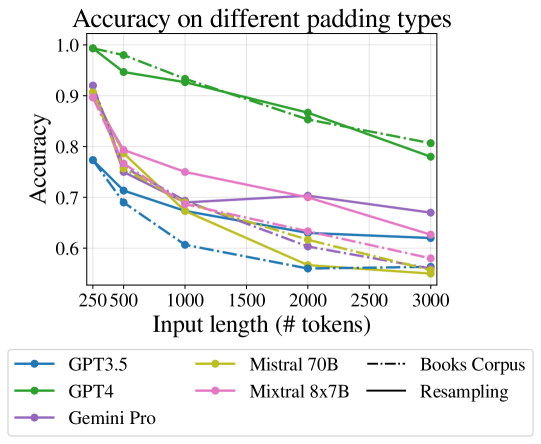
我们首先在各种实验设置中验证输入长度对大语言模型推理性能的影响(图1)。
没有不相关的段落
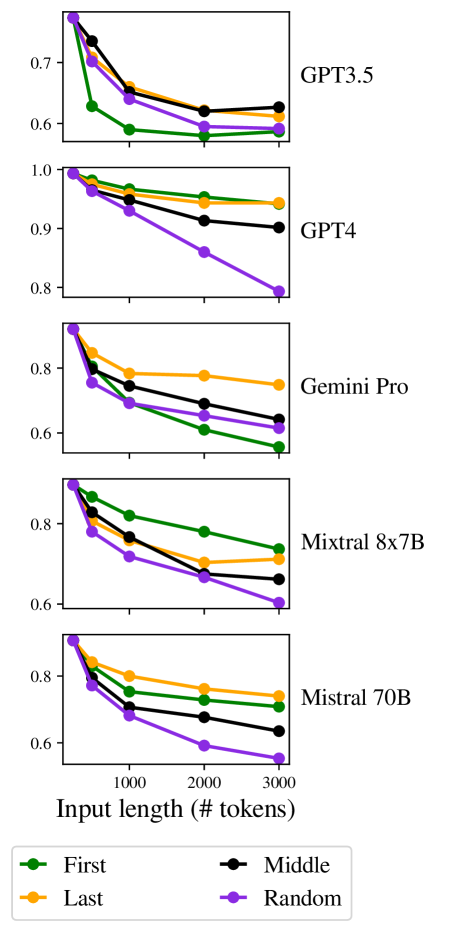
我们首先研究仅添加相关标记的极端情况(“重复填充”)。 Shi 等人 (2023) 证明将不相关的文本附加到推理任务 (GSM-8K Cobbe 等人 (2021)) 的输入会大大降低模型性能。 我们通过测试一个设置来隔离相关性的影响,其中填充是关键段落的确切文本的重复。 在这种设置中,大语言模型不需要“搜索”输入来查找关键段落,因此对任何位置的任何偏见都变得无关Liu 等人 (2023b)。 此外,关键段落之间的距离可能带来的任何困难也变得无关紧要。 因此,我们预计性能不会下降。 令人惊讶的是,图 3 中显示的结果表明,即使在这种设置中,长度也确实起到了影响作用,并且所有模型的准确度都随着长度的增加而降低 。
相邻段落被不相关的段落包围
我们现在转向更现实的情况,其中提示包括关键段落以及其他不相关的段落。 在第一组实验中,我们保持关键段落彼此相邻:大语言模型只需要关注并操作输入的单个区域,而忽略其余部分。 Liu 等人(2023b)发现在抽取式QA任务中,答案在文本中的位置影响模型正确回答的能力。 因此,我们尝试了三种场景:将两个关键段落放置在文本的开头、结尾或中间。 在所有情况下,我们都会对两种类型的不相关填充进行平均。
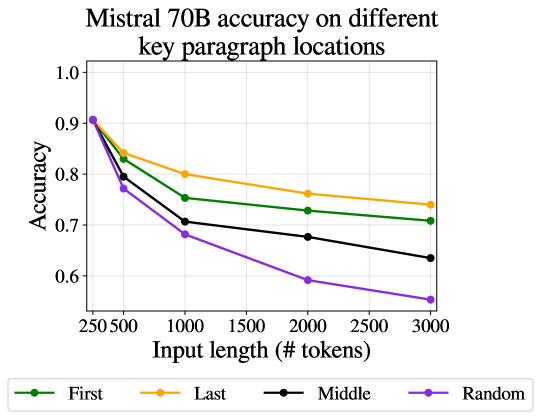
图 4 中的结果显示,随着长度增加超过 500 个标记,准确度显着下降。 对于大多数模型来说,关键段落的相邻性会产生更高的准确性,并且当关键段落出现在最后时,准确性通常最高(表明新近度偏差)。
不相邻的相关段落。
最后,我们测试需要从文本中两个不相邻位置收集相关事实的场景。
这里,图1中的结果显示,随着长度的增加,性能下降非常大,这表明当大语言模型需要收集证据时,推理任务变得更加困难。较大上下文长度中的两个不同位置。
4.2 不相关材料的种类
我们现在只关注不相邻关键段落的情况,并探讨这种不相关文本的效果。 我们考虑两种情况:当不相关的段落与相关段落相似(取自同一任务)时,以及当它们不同(取自书籍语料库)时。
我们最初的期望是,不相关段落与相关段落不同的设置对于模型来说会更容易,因为不相关段落将更容易被丢弃,从而有助于关注相关段落。 然而,结果(图5)表明情况并非如此:不同设置的下降大多大于类似设置的下降。
5 与下一个单词预测的相关性
使用困惑度作为主要基准来表明模型利用其整个输入 Anil 等人 (2023);江等人(2024)。 然而,研究表明,下游任务的表现并不一定与模型复杂度相关(Liu 等人,2023a;Xia 等人,2022;Tay 等人,2022)。 在这里,我们将利用数据集的灵活性来理解困惑度和推理准确性之间的相关性。
在封闭模型中,我们无法获得完整的词汇词符概率,因此无法测量模型的复杂性,因此我们求助于测量数据的下一个单词的准确性。 我们提示模型完成给定文本中的下一个单词,如果它与真正的下一个单词完全匹配,则输出是正确的。 我们使用数据集中的样本(没有问题)作为文本,并将结果与相同样本的推理性能进行比较。
我们的方法发现下一个单词预测任务的趋势与其他作品 Anil 等人 (2023) 中显示的趋势相似; Jiang等人(2024),即输入越长,准确性越高。 然而,如图 1 所示,下一个单词的准确性与 FlenQA 上的推理呈负相关 777, 。
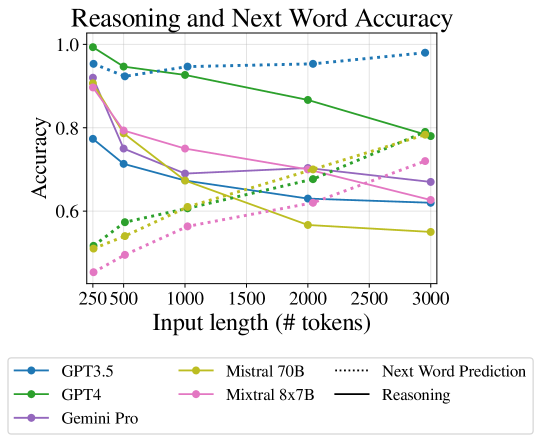
这意味着测量下一个单词的预测以及类似的困惑度不能替代对长输入的下游任务评估。
6 思想链有帮助吗?
思想链(CoT)提示,由Kojima等人(2022)提出; Wei 等人 (2022) 是一种在得出问题的正确答案之前推动大语言模型生成包含推理步骤的文本的技术。 Zhou 等人 (2022) 发现了一个更具体、更优化的指令(“让我们一步一步地解决这个问题,以确保我们得到正确的答案。”)。
CoT 技术被证明可以显着提高许多基于推理的问答设置的准确性。 使用它会改变趋势并使大语言模型能够在更长的输入上有效地执行吗? 我们使用 Zhou 等人 (2022) 的引出字符串进行 CoT 实验。
结果表明(图1)CoT对不同的大语言模型有不同的影响,总体上并不能缓解由于长度导致的性能下降。 在大多数情况下(GPT4、Mixtral 8x7B、Mistral 70B 和 GPT3.5),它可以提高性能,但仅在 GPT4 中,随着长度的增加,它的效果也会增强,这使其成为一种有限的缓解技术。 在 Gemini-Pro 的情况下,我们看到 CoT 随着输入长度的增加而降低性能,尽管它提高了短长度的性能。
CoT 提示所有任务和设置的完整结果可在附录 E 中找到。
7 长度引起的故障模式
我们在结果中发现四种故障模式:888所有故障模式都可以使用我们存储库中的代码自动测量。 与错误响应相关的一致模式。
无法回答
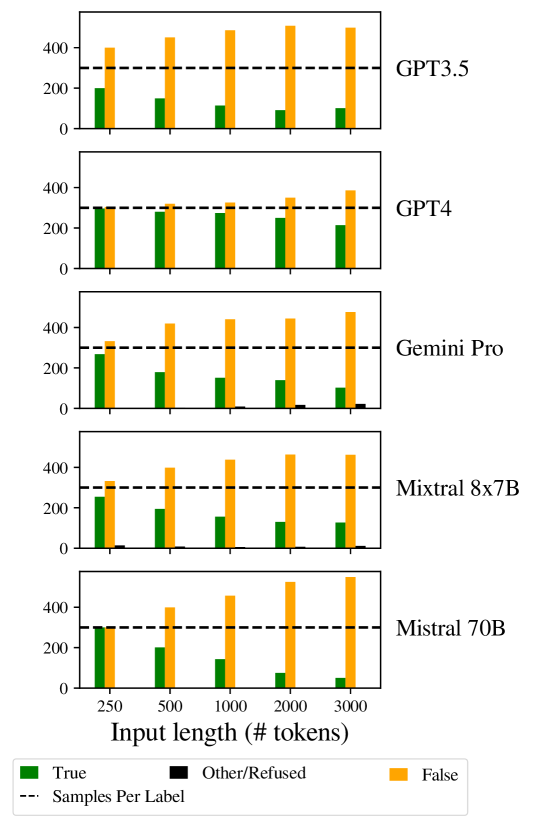
按照我们的提示(附录D)中的说明,数据集中的所有样本都可以回答“True”或“False”。 然而,一些大语言模型的回答是拒绝回答这个问题,并经常在前面加上诸如“文本中没有足够的信息”之类的句子。 这种趋势随着输入长度的增加而增长,表明未能遵守指定“True”和“False”之间明确选择的指令。 图 7 展示了这一趋势,附录 16 中显示了所有模型的结果。
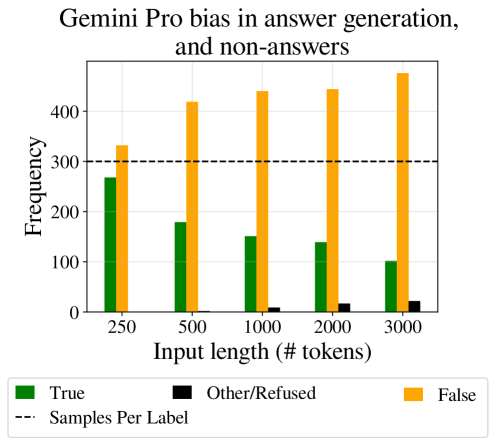
标签偏差
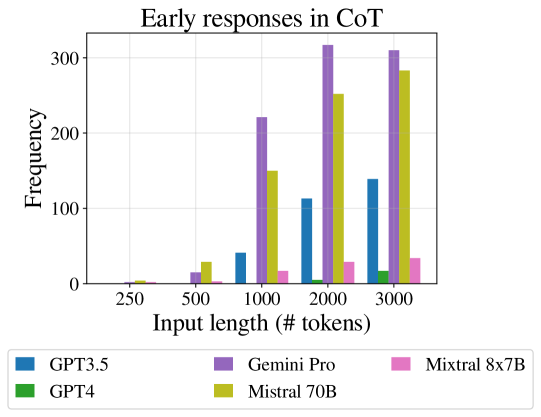
先回答,后推理
当使用思想链提示时,随着输入变长,一些大语言模型更有可能在预期的推理步骤之前输出最终的真/假答案。 在最近的工作中,Kojima 等人 2022 发现,当引出模型在答案后提供推理步骤时,它们的性能不会提高(正如使用仅关注早期标记的自回归模型时所预期的那样) 。 这可以看作是随着长度的增加而未能遵循提示说明(参见附录D中的提示说明)的情况。 在测试中,我们发现错误的反应在统计上取决于推理步骤之前答案的出现999通过Fisher精确检验得到,对应的优势比为3.643。.
思想链缺乏覆盖
FlenQA中的所有任务都需要大语言模型来:(1)在输入中定位相关文本; (2)对其进行相关推理。 理想情况下,CoT提示会引导大语言模型首先找到每个相关文本并将其复制到“步骤”部分,从而避免长输入对推理的影响。 然而,我们发现随着输入长度的增加,大语言模型的能力会下降(图9)。
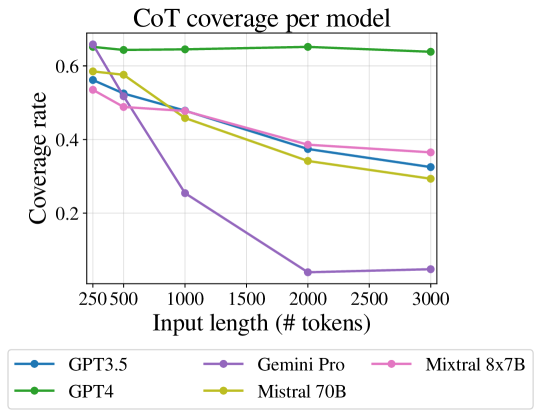
我们通过计算模型输出的“步骤”部分中相关文本(每个样本中的关键句子)的覆盖率来衡量这一点(详细信息参见附录D.4)。 我们发现,在大多数模型中,随着输入长度变长,在输入中定位相关文本的能力会降低。 我们发现错误的回答在统计上取决于事实的不完整覆盖101010通过Fisher精确检验得到,对应的优势比为3.138。.
8相关工作
大语言模型对长输入的评估遵循两条不同的路径:下游任务的基准和下一个单词的预测。 在基准领域,研究提出了可用于评估模型的长输入样本数据集 Shaham 等人 (2023, 2022);安等人(2023b,a)。 这些数据集是根据不同但固定长度的输入来组织的。 这种方法虽然简单,但限制了我们输入不同长度的能力,这给理解输入长度对模型性能的真正影响带来了挑战。 另一方面,下一个词预测评估确实提供了关于模型如何处理不同长度输入的见解(例如 Anil 等人 2023; Jiang 等人 2024 中所做的)。 然而,该任务与下游绩效的相关性并不一致(Liu等人,2023a;Xia等人,2022;Tay等人,2022)。 在本文中,我们在延长长度方面重现了这一发现。
这项研究建立在先前研究的基础上,通过输入干预检查不同方面,研究任务的语义内容(主题)(Dasgupta等人,2022),提示策略(Kojima等人,2022) ; Yao 等人, 2023; Jin 等人, 2024) 以及 QA 任务 (Levy 等人, 2023) 的各种属性。 我们的调查重点是输入长度,将其隔离,以揭示其对性能的影响。
9讨论
我们研究输入长度对当前大型语言模型(大语言模型)推理性能的影响。 我们的研究结果表明,输入较长时,性能会显着下降,这种情况发生在达到模型的最大输入长度容量之前。 我们的实验依赖于 FLenQA,这是我们构建的一个数据集,可以通过调整输入中与任务无关的部分来隔离长度因子。 我们表明,无论我们如何调整样本,长度对推理性能仍然有很大的影响。
最后,我们确定了特定的故障模式,包括遵循扩展说明的困难以及对不太相关的信息的偏见。 我们的分析揭示了具体的缺陷,为未来研究解决和纠正大语言模型中发现的弱点提供了可能的方向。
总之,我们的工作表明,基于单个输入长度评估模型的性能并不能提供全面的信息,需要更细致的评估。 我们认为,要使模型具有远距离能力,它必须在技术支持的任何长度上保持其性能。
局限性
由于行为测试的性质,观察到的随输入长度变化而出现的性能下降仍然无法解释;由于无法访问许多模型,我们怀疑这个方向将继续受到限制。 其次,我们的方法旨在创建一个跨不同大语言模型的普遍适用的测试,从而选择满足最低公分母的任务。 这种方法可能会忽略更复杂的推理任务(例如 5 个关键段落)中细微的性能差异,例如,与我们的研究结果相比,更强的模型可能会在更短的输入长度下表现出性能下降。 此外,我们还关注推理任务类型的子集,它们在行为上可能与其他类型不同。 最后,我们的研究没有测试关键段落之间的距离,因此大语言模型表现的一个方面没有得到探索,我们留待未来的研究。
致谢
参考
- An et al. (2023a) Chen An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. 2023a. L-eval: Instituting standardized evaluation for long context language models. ArXiv, abs/2307.11088.
- An et al. (2023b) Chenxin An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. 2023b. L-eval: Instituting standardized evaluation for long context language models.
- Anil et al. (2023) Rohan Anil, Sebastian Borgeaud, Yonghui Wu, and Gemini Team Google. 2023. Gemini: A family of highly capable multimodal models. ArXiv, abs/2312.11805.
- Bai et al. (2023) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. 2023. Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508.
- Chen and Durrett (2019) Jifan Chen and Greg Durrett. 2019. Understanding dataset design choices for multi-hop reasoning. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers).
- Clark et al. (2021) Peter Clark, Oyvind Tafjord, and Kyle Richardson. 2021. Transformers as soft reasoners over language. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, pages 3882–3890.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Dasgupta et al. (2022) Ishita Dasgupta, Andrew K Lampinen, Stephanie CY Chan, Antonia Creswell, Dharshan Kumaran, James L McClelland, and Felix Hill. 2022. Language models show human-like content effects on reasoning. arXiv preprint arXiv:2207.07051.
- Faraglia and Contributors (2012) Daniele Faraglia and Other Contributors. 2012. Faker.
- Gidiotis and Tsoumakas (2020) Alexios Gidiotis and Grigorios Tsoumakas. 2020. A divide-and-conquer approach to the summarization of long documents. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:3029–3040.
- Holtzman et al. (2023) Ari Holtzman, Peter West, and Luke Zettlemoyer. 2023. Generative models as a complex systems science: How can we make sense of large language model behavior? arXiv preprint arXiv:2308.00189.
- Huang and Chang (2022) Jie Huang and Kevin Chen-Chuan Chang. 2022. Towards reasoning in large language models: A survey. arXiv preprint arXiv:2212.10403.
- Jacovi et al. (2023) Alon Jacovi, Avi Caciularu, Omer Goldman, and Yoav Goldberg. 2023. Stop uploading test data in plain text: Practical strategies for mitigating data contamination by evaluation benchmarks. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5075–5084, Singapore. Association for Computational Linguistics.
- Jiang et al. (2024) Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2024. Mixtral of experts.
- Jin et al. (2024) Mingyu Jin, Qinkai Yu, Haiyan Zhao, Wenyue Hua, Yanda Meng, Yongfeng Zhang, Mengnan Du, et al. 2024. The impact of reasoning step length on large language models. arXiv preprint arXiv:2401.04925.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. Advances in neural information processing systems, 35:22199–22213.
- Levy et al. (2023) Mosh Levy, Shauli Ravfogel, and Yoav Goldberg. 2023. Guiding llm to fool itself: Automatically manipulating machine reading comprehension shortcut triggers. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 8495–8505.
- Li et al. (2023) Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. 2023. Loogle: Can long-context language models understand long contexts? ArXiv, abs/2311.04939.
- Liu et al. (2023a) Hong Liu, Sang Michael Xie, Zhiyuan Li, and Tengyu Ma. 2023a. Same pre-training loss, better downstream: Implicit bias matters for language models. In International Conference on Machine Learning, pages 22188–22214. PMLR.
- Liu et al. (2023b) Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023b. Lost in the middle: How language models use long contexts. arXiv preprint arXiv:2307.03172.
- Liu et al. (2022) Yang Liu, Chenguang Zhu, and Michael Zeng. 2022. End-to-end segmentation-based news summarization. In Findings of the Association for Computational Linguistics: ACL 2022, pages 544–554.
- Min et al. (2019) Sewon Min, Eric Wallace, Sameer Singh, Matt Gardner, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2019. Compositional questions do not necessitate multi-hop reasoning. In Annual Meeting of the Association for Computational Linguistics.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Sainz et al. (2023) Oscar Sainz, Jon Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. 2023. Nlp evaluation in trouble: On the need to measure llm data contamination for each benchmark. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787.
- Shaham et al. (2023) Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. 2023. Zeroscrolls: A zero-shot benchmark for long text understanding. arXiv preprint arXiv:2305.14196.
- Shaham et al. (2022) Uri Shaham, Elad Segal, Maor Ivgi, Avia Efrat, Ori Yoran, Adi Haviv, Ankit Gupta, Wenhan Xiong, Mor Geva, Jonathan Berant, et al. 2022. Scrolls: Standardized comparison over long language sequences. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 12007–12021.
- Shi et al. (2023) Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. In International Conference on Machine Learning, pages 31210–31227. PMLR.
- Sinha et al. (2018) Koustuv Sinha, Shagun Sodhani, William L. Hamilton, and Joelle Pineau. 2018. Compositional language understanding with text-based relational reasoning. ArXiv, abs/1811.02959.
- Tay et al. (2022) Yi Tay, Mostafa Dehghani, Samira Abnar, Hyung Won Chung, William Fedus, Jinfeng Rao, Sharan Narang, Vinh Q Tran, Dani Yogatama, and Donald Metzler. 2022. Scaling laws vs model architectures: How does inductive bias influence scaling? arXiv preprint arXiv:2207.10551.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- Weston et al. (2016) Jason Weston, Antoine Bordes, Sumit Chopra, Alexander M Rush, Bart Van Merriënboer, Armand Joulin, and Tomas Mikolov. 2016. Towards ai-complete question answering: A set of prerequisite toy tasks. In 4th International Conference on Learning Representations, ICLR 2016.
- Wolhandler et al. (2022) Ruben Wolhandler, Arie Cattan, Ori Ernst, and Ido Dagan. 2022. How “multi” is multi-document summarization? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5761–5769.
- Xia et al. (2022) Mengzhou Xia, Mikel Artetxe, Chunting Zhou, Xi Victoria Lin, Ramakanth Pasunuru, Danqi Chen, Luke Zettlemoyer, and Ves Stoyanov. 2022. Training trajectories of language models across scales. arXiv preprint arXiv:2212.09803.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601.
- Zhou et al. (2022) Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2022. Large language models are human-level prompt engineers. arXiv preprint arXiv:2211.01910.
- Zhu et al. (2015) Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In The IEEE International Conference on Computer Vision (ICCV).
附录A推理任务中的训练污染
数据污染是评估模型时的一个主要问题(Sainz 等人,2023;Jacovi 等人,2023)。 确保任务需要跨多个文本范围进行推理是比需要多跳推理的任务更严格的要求 (§2)。 使用参数知识来评估模型回答的问题会阻止我们评估他们的推理能力。 来自互联网来源的数据集特别容易受到污染,从而破坏了对模型推理新事实能力的评估。
此外,研究表明,当给定任务所需的一些部分之一时,小型模型可以回答现有的推理数据集(Chen 和 Durrett,2019;Min 等人,2019)。 这就提出了一个问题:这些数据集可以在多大程度上用于评估长度的影响,其中我们要求对文本的多个部分进行推理。
我们的结论是,在评估基于文本的推理能力时应考虑参数知识。 在这项工作中,我们引入了 FlenQA,它由新颖的生成数据组成,以确保需要对输入进行推理。
附录 B数据集
以下每个任务包含 100 个基本实例。 在每个示例中,都有两个段落长度的文本(关键段落)。 为了获得相似长度的段落,我们通过截断超出特定长度的句子来编辑它们,从而使平均段落长度为 125 个标记。
B.1 规则制定者
任务中的关键段落作为推理任务的证据、规则和问题。 在原始数据Clark等人(2021)中,样本包含不同数量的推理步骤。 在这项研究中,我们生成了新的、更简单的任务样本:每个样本仅由两个事实和一个逻辑规则组成。 我们生成的样本与原始 Ruletaker 数据中存在的样本具有相似的风格,但是使用新的陈述、规则和事实生成的。 关键段落和填充内容显示为每个样本的事实。
| Padding | Target Input | Mean Number |
| Type | Length | Tokens |
| Books | 250 | 249.8 |
| 500 | 508.78 | |
| 1000 | 1009.56 | |
| 2000 | 2009.64 | |
| 3000 | 3008.38 | |
| Same | 250 | 249.8 |
| 500 | 503.535 | |
| 1000 | 1004.41 | |
| 2000 | 2005.51 | |
| 3000 | 3005.125 |
B.2MonoRel
任务中的关键段落充当推理任务的证据和问题。 两个关键段落都描述了两个人之间的单调关系,其中一个人由两个人共享。 关键段落嵌入到填充文本中以创建文本混合。
| Padding | Target Input | Mean Number |
| Type | Length | Tokens |
| Books | 250 | 238.06 |
| 500 | 490.84 | |
| 1000 | 991.41 | |
| 2000 | 1990.34 | |
| 3000 | 2990.95 | |
| Same | 250 | 238.06 |
| 500 | 491.69 | |
| 1000 | 991.43 | |
| 2000 | 1991.31 | |
| 3000 | 2991.44 |
B.3 房间内人员 (PIR)
一个关键段落描述了个人的位置,另一段描述了该位置的某些属性。 关键段落嵌入到填充文本中以创建文本混合。
| Padding | Target Input | Mean Number |
| Type | Length | Tokens |
| Books | 250 | 305.36 |
| 500 | 491.85 | |
| 1000 | 989.91 | |
| 2000 | 1992.00 | |
| 3000 | 2988.67 | |
| Same | 250 | 305.36 |
| 500 | 484.63 | |
| 1000 | 985.82 | |
| 2000 | 1985.04 | |
| 3000 | 2984.80 |
附录 C基础实例结果
| Model | Prompt | MonoRel | PIR | Ruletaker* |
|---|---|---|---|---|
| GPT3.5 Turbo | Direct | 0.77 | 0.81 | 0.74 |
| CoT | 0.86 | 0.88 | 0.88 | |
| GPT4 Turbo | Direct | 1.00 | 1.00 | 0.98 |
| CoT | 1.00 | 1.00 | 0.97 | |
| Gemini Pro | Direct | 0.84 | 1.00 | 0.92 |
| CoT | 0.88 | 0.96 | 0.97 | |
| Mistral 70B | Direct | 0.99 | 1.00 | 0.73 |
| CoT | 1.00 | 1.00 | 0.89 | |
| Mixtral 8x7B | Direct | 0.92 | 0.97 | 0.80 |
| CoT | 0.86 | 0.97 | 0.93 |
附录 D完整评估设置
D.1提示
规则制定者提示 - 正常:
回答陈述{陈述}是否可以从规则和事实中推导出来。 回答“正确”或“错误”。
规则:{规则}
事实:{事实 + 填充}
回答“对”或“错”。
规则制定者提示 - CoT:
回答陈述{陈述}是否可以从规则和事实中推导出来。
显示您的步骤,然后回答“正确”或“错误”。
规则:{规则}
事实:{事实 + 填充}
回答“对”或“错”。 让我们一步一步地解决这个问题,以确保我们得到正确的答案。
PIR 提示 - 正常:
{事实+填充}
对/错问题:{问题}
仅回答对或错。
PIR 提示 - CoT:
显示您的步骤,然后回答“对”或“错”。
{事实+填充}
对/错问题:{问题}
让我们一步一步地解决这个问题,以确保我们得到正确的答案。
MonoRel 提示 - 正常:
以下是一些事实。 根据文本准确回答以下问题:{question} 准确回答问题。 {事实+填充}
{问题}
仅回答对或错。
MonoRel 提示 - CoT:
以下是一些事实。 根据文本准确回答以下问题:{question} 准确回答问题。
显示您的步骤,然后回答“对”或“错”。
{事实+填充}
{问题}
让我们一步一步地解决这个问题,以确保我们得到正确的答案。 展示你的作品,最后回答“对”或“错”。 最后一步应包括问题和答案的确切文本。
D.2参数
所有模型均在温度为 0 且“top p”为 0 的情况下进行评估,以使结果尽可能具有可重复性。 此外,我们将 Gemini Pro 配置为忽略安全护栏(“HARM_CATEGORY”配置),以克服某些示例中的空白答案。
D.3 在模型的回复中找到答案
为了识别模型响应中的答案,我们搜索了“假”或“真”的出现情况,不考虑大小写。 如果这些词多次出现,则只有最后一个实例被认为是相关的。 我们通过手动检查 100 个响应的随机样本来测试该方法的可靠性,并确认其在所有情况下的准确性。
D.4 评估 CoT 中关键事实的覆盖范围
通过在每个模型的输出中搜索关键段落中关键句子的(不区分大小写)匹配来完成 CoT 输出中与推理任务相关的关键事实的覆盖。 完全覆盖意味着输入中的两个关键句子都出现在 CoT 输出中。 我们通过 100 个响应样本手动验证了该方法的可靠性。
附录 E完整结果