RepoAgent:用于存储库级代码文档生成的 LLM 支持的开源框架
摘要
生成模型在软件工程中展示了巨大的潜力,特别是在代码生成和调试等任务中。 然而,它们在代码文档生成领域的利用仍未得到充分探索。 为此,我们引入了RepoAgent,这是一个大型语言模型驱动的开源框架,旨在主动生成、维护和更新代码文档。 通过定性和定量评估,我们验证了我们方法的有效性,表明 RepoAgent 在生成高质量存储库级文档方面表现出色。 代码和结果可通过 https://github.com/OpenBMB/RepoAgent 公开访问。
1简介
开发人员通常花费大约 58% 的时间用于程序理解,而高质量的代码文档在减少此时间方面发挥着重要作用(Xia 等人,2018;de Souza 等人,2005)。 然而,维护代码文档也会消耗大量的时间、金钱和人力(Zhi等人,2015),而且并非所有项目都有资源或热情将文档作为首要关注点。
为了减轻维护代码文档的负担,自动文档生成的早期尝试旨在为源代码提供描述性摘要(Sridhara 等人,2010;Rai 等人,2022;Khan 和 Uddin,2022;Zhang 等人,2022 ),如图1所示。 然而,它们仍然存在很大的局限性,特别是在以下方面:(1)总结性差。 以前的方法主要侧重于总结孤立的代码片段,忽略了更广泛的存储库级别上下文中代码的依赖关系。 生成的代码摘要过于摘要和碎片化,导致难以准确传达代码语义以及将代码摘要编译成文档。 (2)指导不足。 好的文档不仅能准确描述代码的功能,还能细致地指导开发者正确使用所描述的代码(Khan and Uddin,2022;Wang等人,2023)。 这包括但不限于澄清功能边界、强调潜在的误用以及提供输入和输出的示例。 以前的方法仍然无法提供如此全面的指导。 (3)被动更新。 雷曼软件演化第一定律指出,正在使用的程序将不断演化以满足新的用户需求(Lehman,1980)。 因此,及时更新文档以与代码更改保持一致至关重要,这是以前的方法忽略的功能。 最近,大语言模型(Large Language Models)取得了重大进展(OpenAI,2022,2023),特别是在代码理解和生成方面(Nijkamp 等人,2023;Li 等人,2023 ; Chen 等人, 2021; Rozière 等人, 2023; Xu 等人, 2024; Sun 等人, 2023; Wang 等人, 2023; Khan 和 Uddin, 2022)。 鉴于这些进步,人们很自然地会问: 大语言模型能否用于生成和维护存储库级代码文档,解决上述限制?
在本研究中,我们介绍了RepoAgent,这是第一个由大语言模型支持的框架,旨在主动生成和维护整个存储库的综合文档。 图1中演示了一个运行示例。 RepoAgent提供以下功能: (1) 存储库级文档: RepoAgent利用全局上下文来推断整个存储库中目标代码对象的功能语义,从而能够生成准确且语义一致的结构化文档。 (2) 实践指导: RepoAgent不仅描述了代码的功能,还提供了实用的指导,包括代码使用说明、输入输出示例等,方便开发者快速理解代码库。 (3)维护自动化: RepoAgent可以无缝集成到使用 Git 管理的团队软件开发工作流程中,并主动接管文档维护,确保代码和文档保持同步。 这个过程是自动化的,不需要人工干预。
我们定性地展示了 RepoAgent 为真实的 Python 存储库生成的代码文档。 结果表明,RepoAgent 擅长生成与人类创建的质量相当的文档。 从数量上看,在两次盲目偏好测试中,RepoAgent生成的文档比人类编写的文档更受青睐,在 Transformers 和 LlamaIndex 存储库上分别达到了 70% 和 91.33% 的偏好率。 这些评估结果表明了所提出的RepoAgent在自动代码文档生成方面的实用性。
2 RepoAgent
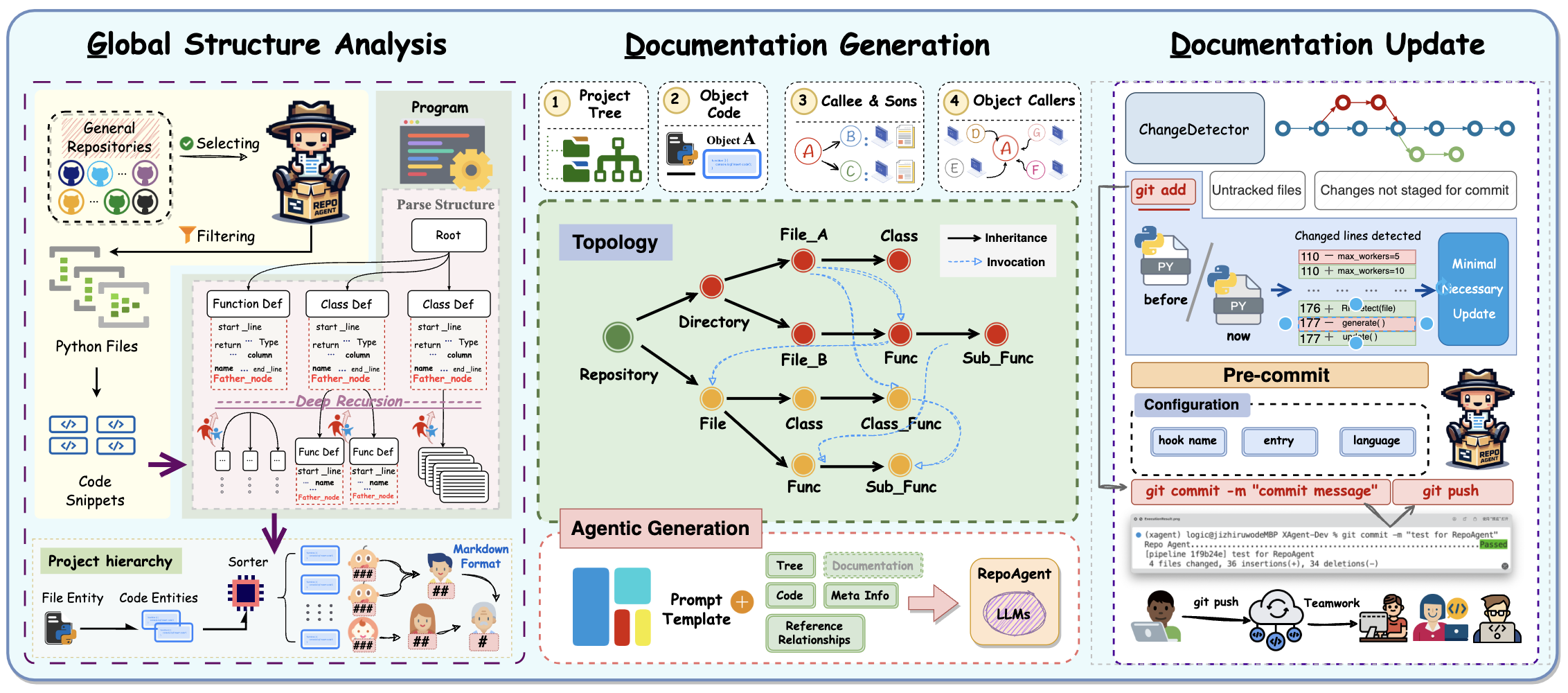
RepoAgent由三个关键阶段组成:全局结构分析、文档生成和文档更新。 2展示了RepoAgent的整体设计。 全局结构分析阶段涉及从源代码中解析必要的元信息和全局上下文关系,为RepoAgent推断目标代码的功能语义奠定基础。 在文档生成阶段,我们设计了一套复杂的策略,利用解析的元信息和全局上下文关系来促使大语言模型生成具有实际指导意义的细粒度文档。 在文档更新阶段,RepoAgent利用Git工具跟踪代码变更并相应更新文档,确保代码和文档在整个项目生命周期中保持同步。
2.1全局结构分析
生成准确且细粒度的代码文档的一个重要先决条件是对代码结构的全面理解。 为了实现这一目标,我们提出了项目树,这是一种数据结构,用于维护存储库中的所有代码对象,同时保留它们的语义层次关系。 首先,我们过滤掉存储库中的所有非 Python 文件。 对于每个Python文件,我们应用摘要语法树(AST)分析(Zhang等人,2019)来递归解析文件中所有类和函数的元信息,包括它们的类型、名称、代码片段等 这些与其元信息关联的类和函数被用作文档生成的原子对象。 值得注意的是,大多数设计良好的存储库的文件结构都反映了代码的功能语义。 因此,我们首先利用它来初始化项目树,其根节点代表整个存储库,中间节点和叶子节点分别代表目录和Python文件。 然后,我们将解析后的类和函数作为新的叶节点(或子树)添加到相应的Python文件节点中,形成最终的项目树。
除了代码结构之外,代码内部的引用关系作为一种重要的全局上下文信息,也可以帮助大语言模型识别代码的功能语义。 此外,对目标函数的引用可以被视为自然的上下文学习示例(Wei等人,2022)来教大语言模型使用目标函数,从而帮助生成实用的文档指导。 我们考虑两种类型的引用关系:Caller 和 Callee。 我们使用 Jedi 库111https://github.com/davidhalter/jedi 通过替换代码解析工具,可扩展到Python以外的编程语言。 提取存储库中的所有双向引用关系,然后将它们接地到项目树中相应的叶节点。 通过引用关系增强的项目树形成有向无环图222我们只是忽略了循环依赖以避免循环,因为大多数情况都可能存在错误。 (有向无环图)。
2.2文档生成


RepoAgent旨在生成具有实用指导意义的细粒度文档,其中包括详细的功能、参数、代码说明、注释和示例。 后端大语言模型利用前一阶段解析的元信息和参考关系,使用精心设计的提示模板生成具有所需结构的文档。 图 3 显示了一个说明性的提示模板,LABEL:lst:prompt_template 中给出了完整的真实提示示例。
提示模板主要需要以下参数: Project Tree帮助RepoAgent感知存储库级别的上下文。 代码片段充当RepoAgent生成文档的主要信息来源。 参考关系提供代码对象之间的语义调用关系,并协助RepoAgent生成指导说明和示例。 元信息表示目标对象的类型、名称、相对文件路径等必要信息,用于文档的后处理。 另外,我们可以将之前生成的对象直接子节点的文档作为辅助信息来帮助理解代码。 这是可选的,因为省略它可以显着节省成本。
RepoAgent遵循从下到上的拓扑顺序为DAG中的所有代码对象生成文档,确保每个节点的子节点以及它引用的节点都在之前生成了文档它。 文档生成后,RepoAgent将其编译为人类友好的 Markdown 格式。 例如,不同级别的对象与不同的 Markdown 标题相关联(例如,##、###)。 最后,RepoAgent利用 GitBook333https://www.gitbook.com/ 将 Markdown 格式的文档呈现为方便的 Web 图形界面,为文档读者提供轻松的导航和可读性。
2.3文档更新
RepoAgent通过与 Git 无缝协作支持自动跟踪和更新文档。 Git 的预提交钩子用于使 RepoAgent 能够检测任何代码更改并执行文档更新。 更新后,挂钩会提交代码和文档更改,确保代码和文档保持同步。 这个过程是完全自动化的,不需要人工干预。
由于低耦合原则,本地代码的更改一般不会影响其他代码,不需要每次较小的代码更新都重新生成整个文档。 RepoAgent仅更新受影响对象的文档。 当 (1) 对象的源代码被修改时,会触发更新; (2) 对象的引用者不再引用它;或者 (3) 一个对象获得新的引用。 值得注意的是,当对象的引用对象发生变化时,不会触发更新,因为我们遵循依赖倒置原则(Martin,1996),该原则规定高层模块不应依赖于低级模块的实现。
3实验
3.1实验设置
我们选择了 9 个不同规模的 Python 存储库来生成文档,代码量从不到 1,000 行到超过 10,000 行不等。 这些存储库以其经典地位或在 GitHub 上的高人气而闻名,其特点是高质量的代码和相当大的项目复杂性。 §A.1中提供了存储库的详细统计信息。 我们采用了基于API的大语言模型 gpt-3.5-turbo (OpenAI, 2022) 和 gpt-4-0125 ( OpenAI, 2023),以及开源大语言模型 Llama-2-7b 和 Llama-2-70b (Touvron 等人,2023) 作为 RepoAgent 的后端模型。
3.2案例研究
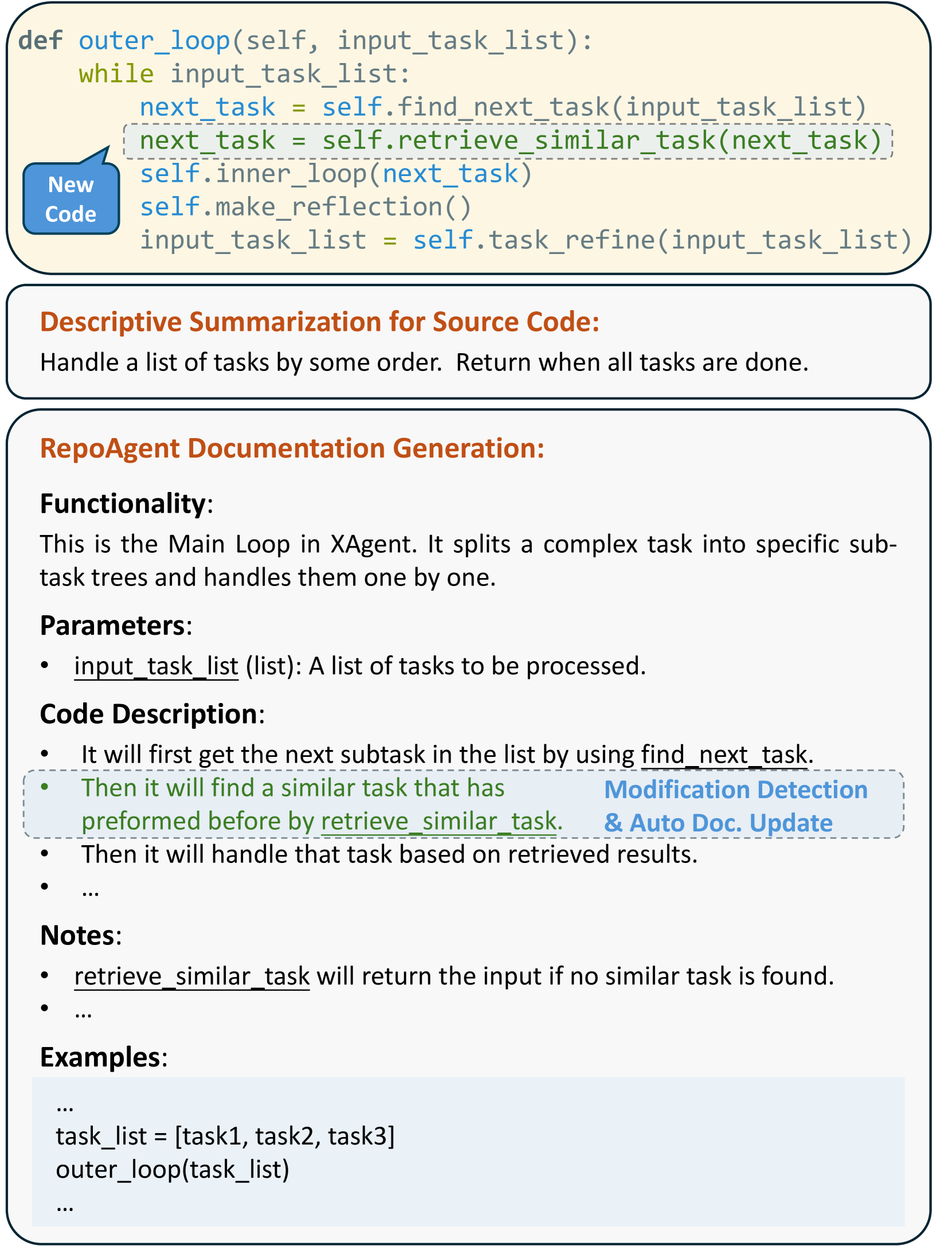
我们使用 ChatDev 存储库 Qian 等人 (2023) 和 gpt-4-0125 后端进行案例研究。 生成的文档如图图4所示。 RepoAgent 生成的文档分为几个部分,首先是一个清晰、简洁的句子,阐明了对象的功能。 接下来,参数部分枚举所有相关参数及其描述,帮助开发人员了解如何利用所提供的代码。 此外,代码描述部分全面阐述了代码的各个方面,隐式或显式地展示了对象的角色及其与全局上下文中其他代码的关联。 此外,注释部分通过涵盖手头对象的使用注意事项进一步丰富了这些描述。 值得注意的是,它突出显示了代码中的任何逻辑错误或潜在的优化,从而提示高级开发人员进行修改。 最后,如果当前对象产生返回值,模型将生成一个示例部分,其中填充模拟内容以清楚地演示预期输出。 这对于开发人员来说非常有利,有助于高效的代码重用和单元测试构建。
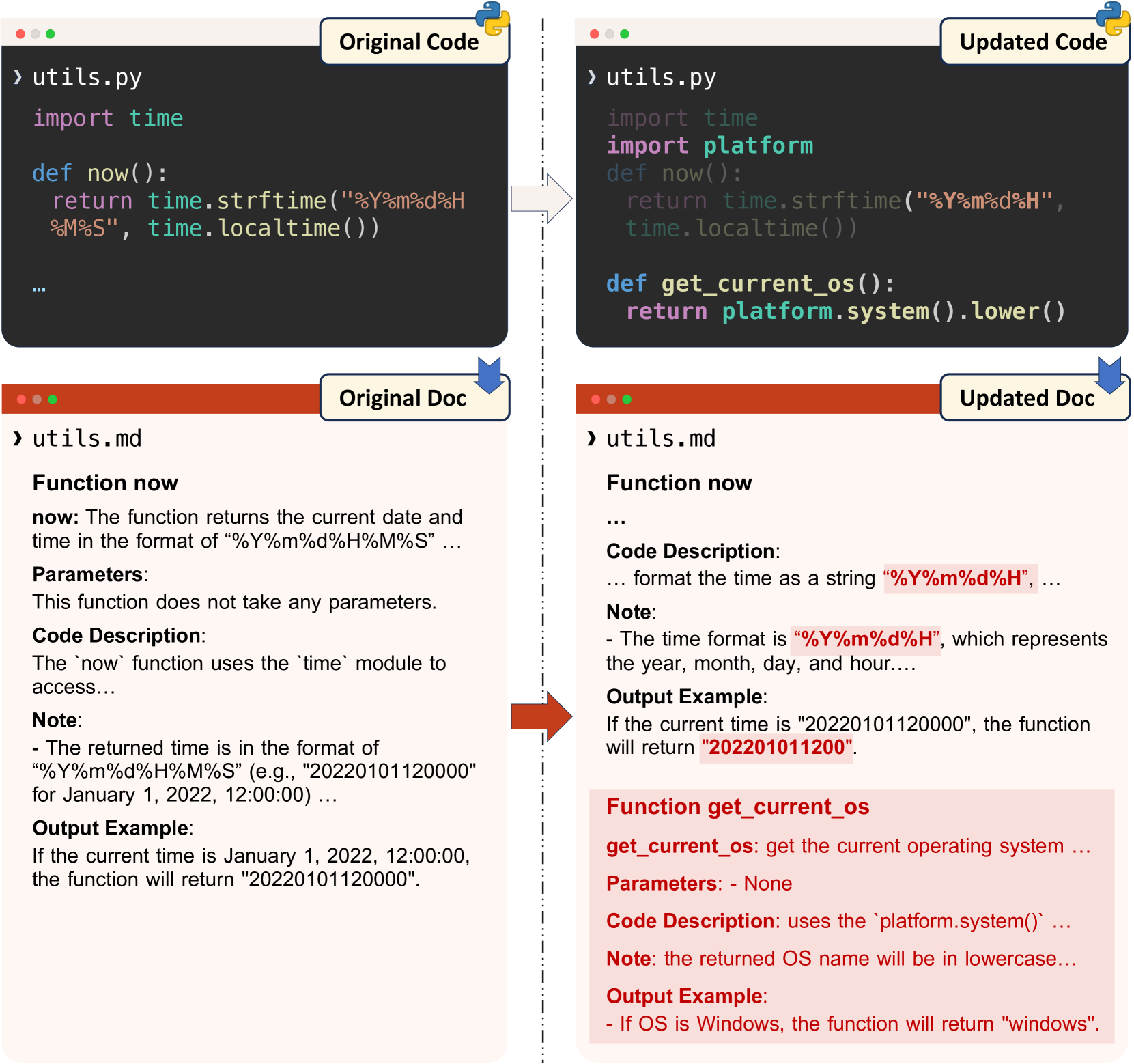
一旦代码发生更改,就会触发文档更新,如图图5所示。 在暂存区域中发生代码更改时,RepoAgent会识别受影响的对象及其双向引用,更新受影响范围最小的文档,并将这些更新集成到新的 Markdown 文件中,其中包括对象的添加或全局删除' 文档。 这种自动化扩展到集成 Git 的预提交挂钩来检测代码更改和更新文档,从而在项目开发的同时无缝维护文档。 具体来说,当代码更新暂存并提交时,会触发 RepoAgent,自动刷新文档并暂存以进行提交。 它通过“通过”指示器确认该过程,无需额外的命令或手动干预,从而保留了开发人员通常的工作流程。
3.3人类评价
由于缺乏有效的评估方法,我们采用人工评估来评估生成文档的质量。 我们进行了偏好测试来比较人类编写的代码文档和模型生成的代码文档。 我们分别从 Transformers 和 LlamaIndex 存储库中随机抽取了 150 份文档内容,其中包括 100 个类对象和 50 个函数级对象。 招募了三名评估员来评估这两个文档集的质量,详细的评估协议在 § A.2.2 中概述。 § 3.3 中提供的结果强调了 RepoAgent 在生成超越人类创作内容的文档方面的显着效率,实现了 和 。
lcccc 人体模型总胜率
变形金刚 150 45 105 0.70
LlamaIndex 150 13 137 0.91
3.4定量分析
参考回忆。
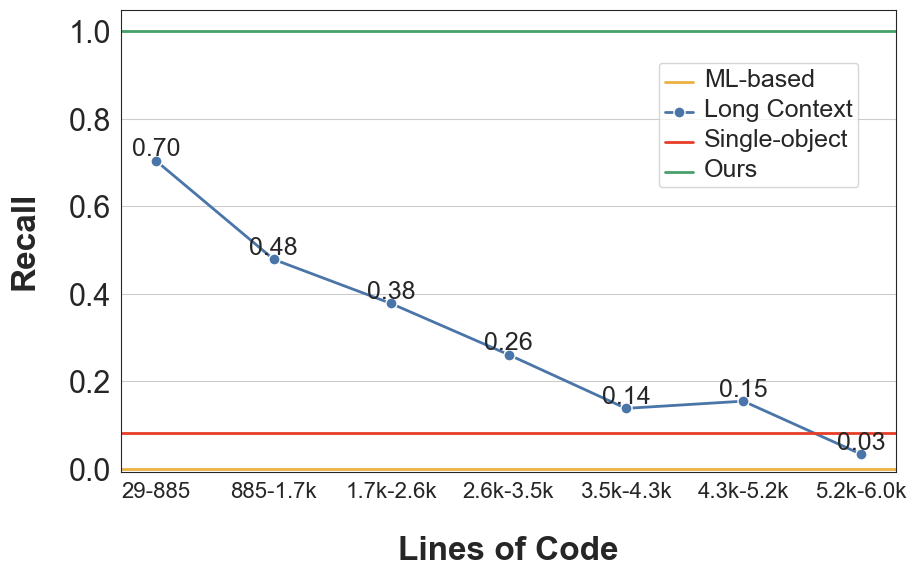
我们通过计算识别代码对象引用关系的召回率来评估模型对全局上下文的感知。 我们从 9 个存储库中每个存储库中采样了 20 个对象,并比较了 3 种文档生成方法在全局调用者和被调用者识别中的召回情况。 比较方法包括基于机器学习的方法,使用 LSTM 进行评论生成(Iyer 等人,2016),利用大语言模型进行长上下文串联,上下文长度高达 128k 上下文长度来处理整个项目代码以进行识别调用关系,单对象生成方法,只向大语言模型提供代码片段。
图6展示了识别参考关系的召回率。 基于机器学习的方法无法识别引用关系,而单对象方法部分识别被调用者,但不能识别调用者。 尽管长上下文方法提供了广泛的代码内容,但仅实现了对引用的部分和非全面识别,并且随着上下文的增加,召回率下降。 相比之下,我们的方法利用确定性工具 Jedi 和双向解析来准确传达全局引用关系,有效克服其他方法在生成存储库级代码文档时遇到的范围限制。
lcccc 存储库 Llama-2-7b Llama-2-70b gpt-3.5-turbo gpt-4-0125
unoconv 0.0000 0.5000 1.0000 1.0000
simdjson 0.4298 0.6336 1.0000 0.9644
greenlet 0.5000 0.7482 0.9252 0.9615
code2flow 0.5145 0.6171 0.9735 0.9803
AutoGen 0.3049 0.5157 0.8633 0.9545
AutoGPT 0.4243 0.5611 0.8918 0.9527
ChatDev 0.5387 0.6980 0.9164 0.9695
MemGPT 0.4582 0.5729 0.9285 0.9911
MetaGPT 0.3920 0.5819 0.9066 0.9708
格式对齐。
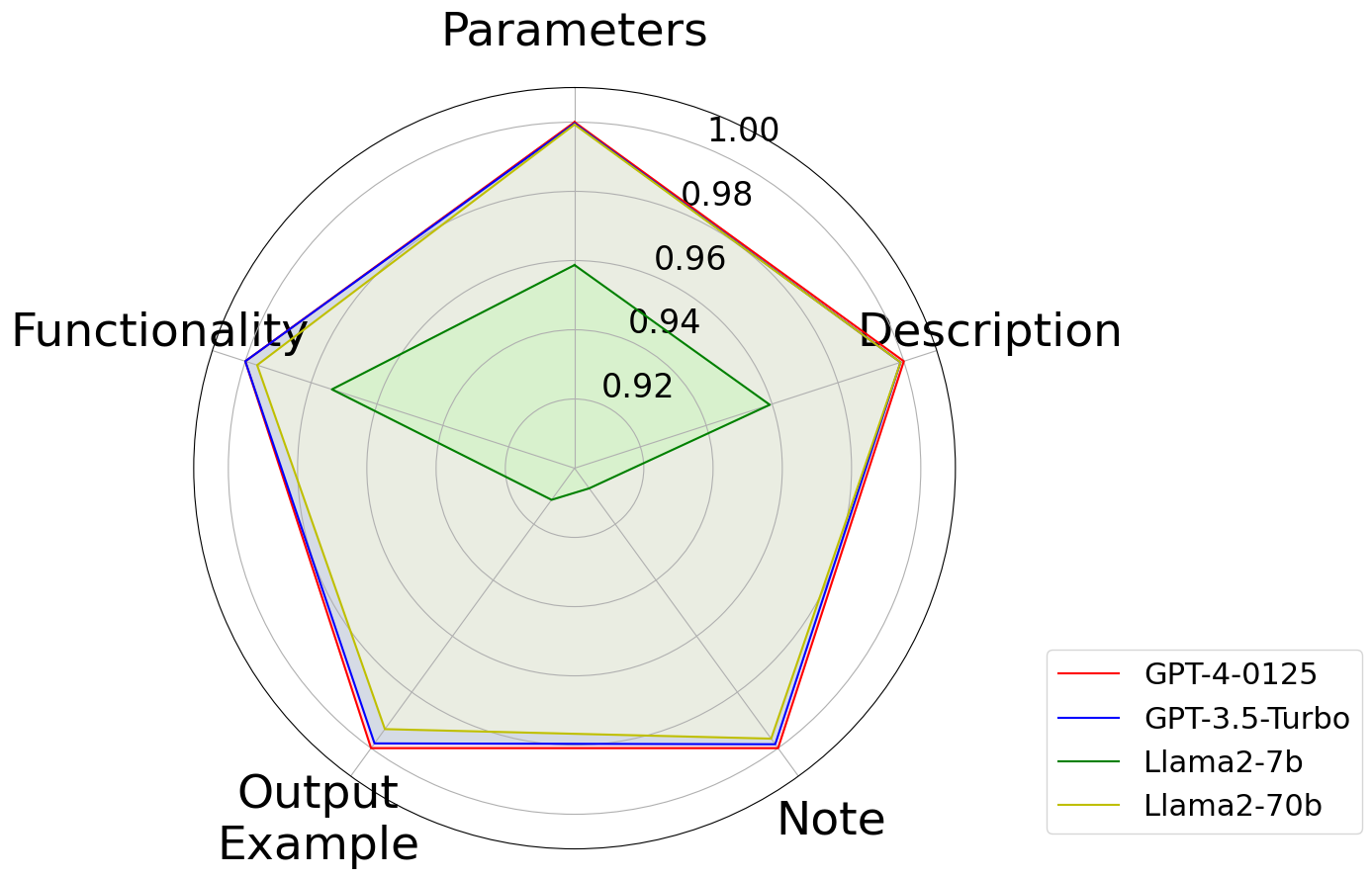
遵守格式对于文档生成至关重要。 生成的文档应由 5 个基本部分组成,其中 Examples 是动态的,具体取决于代码对象是否有返回值。 我们使用全部9个存储库评估了大语言模型遵循格式的能力,结果如图图7所示。 像GPT系列和Llama-2-70b这样的大型模型在格式对齐方面表现非常好,而小型模型Llama-2-7b表现不佳,尤其是在示例方面。
参数识别。
我们进一步评估了模型识别所有 9 个存储库上的参数的能力,结果如 § 3.4 所示。 值得注意的是,我们报告的是准确性而不是召回率,因为模型可能会产生不存在的参数,这一点应该考虑在内。 从表中可以看出,GPT系列在参数识别方面明显优于LLaMA系列,其中gpt-4-0125表现最好。
4相关工作
代码总结。
该领域专注于生成简洁、人类可读的代码摘要。 早期的方法是基于规则或模板驱动的 Haiduc 等人 (2010); Sridhara 等人 (2010);莫雷诺等人 (2013); Rodeghero 等人 (2014)。 随着机器学习的进步,出现了基于学习的方法,例如利用 LSTM 单元的 CODE-NN,用于摘要创建Iyer 等人 (2016)。 随着注意力机制和 Transformer 模型的出现,该领域进一步发展,显着增强了对远程依赖关系进行建模的能力 Allamanis 等人 (2016); Vaswani 等人 (2017),表明转向更加上下文感知和灵活的摘要技术。
大语言模型开发。
大语言模型的发展和应用给自然语言处理和软件工程领域带来了革命性的变革。 最初,该领域被诸如 BERT Devlin 等人 (2019) 这样的屏蔽语言模型所改变,随后编码器-解码器模型的进步,例如 T5 系列 Raffel 等人 (2020),以及 GPT 系列 Radford 等人 (2018) 等自回归模型。 自回归模型以其序列生成能力而闻名,已被有效地应用于代码生成 Nijkamp 等人 (2023);李等人 (2023);陈 等人 (2021); Rozière 等人 (2023); Xu 等人 (2024),代码摘要 Sun 等人 (2023),以及文档生成 Wang 等人 (2023); Khan 和 Uddin (2022),强调了它们在编程和文档任务中的多功能性。 同时,基于 LLM 的代理已变得无处不在 XAgent (2023);秦等人 (2024);吕等人 (2023);叶等人 (2023);秦等人 (2023),尤其是软件工程Chen 等人 (2024);钱 等人 (2023); Hong 等人 (2024),通过角色扮演和自动生成代理Wu 等人 (2023) 促进开发,从而增强存储库级代码理解、生成甚至调试 t3>Tian 等人 (2024). 随着基于 LLM 的代理的开发,存储库级文档生成可以作为代理任务来解决。
5结论与讨论
在本文中,我们介绍了RepoAgent,这是一个开源框架,旨在生成细粒度的存储库级代码文档,促进改进团队协作。 实验结果表明,RepoAgent能够为整个项目生成并主动维护高质量的文档。 RepoAgent有望将开发人员从这项繁琐的任务中解放出来,从而提高他们的生产力和创新潜力。
在未来的工作中,我们会考虑如何有效地利用这个工具,并探索如何将RepoAgent应用到未来更广泛的下游应用中。 为此,我们相信聊天可以作为在代码和人类之间建立沟通桥梁的天然工具。 目前,通过采用我们的检索增强生成方法,结合了代码、文档和参考关系,我们已经在所谓的“Chat With Repo”中取得了初步的知识成果,这标志着一种新颖的编码范式的出现。
局限性
编程语言的限制。
RepoAgent目前依赖于 Jedi 参考识别工具,限制了其仅适用于 Python 项目。 能够适应多种编程语言的更通用的开源工具将能够在各种代码库中得到更广泛的采用,这将在未来的迭代中得到解决。
人类监督的要求。
人工智能生成的文档可能仍需要人工审查和修改,以确保其准确性和完整性。 技术复杂性、特定于项目的约定和特定于领域的术语可能需要手动干预来提高生成文档的质量。
对语言模型功能的依赖。
RepoAgent的性能很大程度上取决于后端大语言模型和相关技术。 尽管目前的结果显示基于 API 的大语言模型(如 GPT 系列)取得了可喜的进展,但使用开源模型的长期稳定性和可持续性仍需要进一步验证和研究。
缺乏评估标准。
对于生成文档的专业性、准确性、规范性,很难建立统一的定量评价方法。 此外,值得注意的是,学术界目前缺乏典型人类文档的基准和数据集。 此外,文档的主观性质进一步限制了质量评估方面的当前方法。
更广泛的影响
提高生产力和创新。
RepoAgent自动生成、更新和维护代码文档,这对于开发人员来说传统上是一项耗时的任务。 通过将开发人员从这种负担中解放出来,我们的工具不仅提高了生产力,而且还为软件开发中的创造性和创新性工作提供了更多时间。
提高软件质量和协作。
高质量的文档对于理解、使用和贡献软件项目至关重要,有助于开发人员快速理解项目。 RepoAgent的能力保证了代码文档的长期高一致性。 我们认为,将 RepoAgent 与项目开发过程紧密集成可以引入一种新的范式,用于标准化并使存储库更具可读性。 反过来,这有望刺激社区的积极贡献和快速发展,提高软件项目的整体质量。
教育福利。
RepoAgent可以作为一种教育工具,为代码库提供清晰一致的文档,使学生和新手程序员更容易学习软件开发实践并理解复杂的代码库。
偏见和不准确。
虽然 RepoAgent 旨在生成高质量的文档,但存在由于模型幻觉而生成有偏见或不准确内容的潜在风险。
安全和隐私问题。
目前,RepoAgent主要依赖基于远程API的大语言模型,它将有机会访问用户的代码数据。 这可能会引起安全和隐私问题,特别是对于专有软件。 确保数据保护和代码安全处理至关重要。
致谢
我们感谢所有同学和社区朋友的建议和帮助,包括Arno(冯邦胜)、张果、郭强、杨力、杨娇等人。
参考
- Allamanis et al. (2016) Miltiadis Allamanis, Hao Peng, and Charles Sutton. 2016. A convolutional attention network for extreme summarization of source code. In Proceedings of the 33nd International Conference on Machine Learning, volume 48, pages 2091–2100, New York City, NY, USA.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Joshua Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, and Wojciech Zaremba. 2021. Evaluating large language models trained on code. Computing Research Repository, arXiv:2107.03374.
- Chen et al. (2024) Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, Yujia Qin, Xin Cong, Ruobing Xie, Zhiyuan Liu, Maosong Sun, and Jie Zhou. 2024. AgentVerse: Facilitating multi-agent collaboration and exploring emergent behaviors. In Proceedings of the the 12th International Conference on Learning Representations, Vienna, Austria.
- de Souza et al. (2005) Sergio Cozzetti B. de Souza, Nicolas Anquetil, and Káthia Marçal de Oliveira. 2005. A study of the documentation essential to software maintenance. In Proceedings of the 23rd Annual International Conference on Design of Communication: documenting & Designing for Pervasive Information, pages 68–75, Coventry, UK.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Haiduc et al. (2010) Sonia Haiduc, Jairo Aponte, Laura Moreno, and Andrian Marcus. 2010. On the use of automated text summarization techniques for summarizing source code. In Proceedings of the 17th Working Conference on Reverse Engineering, pages 35–44, Beverly, MA, USA.
- Hong et al. (2024) Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. 2024. MetaGPT: Meta programming for multi-agent collaborative framework. In Proceedings of the the 12th International Conference on Learning Representations, Vienna, Austria.
- Iyer et al. (2016) Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, and Luke Zettlemoyer. 2016. Summarizing source code using a neural attention model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2073–2083, Berlin, Germany. Association for Computational Linguistics.
- Khan and Uddin (2022) Junaed Younus Khan and Gias Uddin. 2022. Automatic code documentation generation using GPT-3. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, pages 174:1–174:6, Rochester, MI, USA.
- Lehman (1980) M.M. Lehman. 1980. Programs, life cycles, and laws of software evolution. Proceedings of the IEEE, 68(9):1060–1076.
- Li et al. (2023) Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, Nicolas Gontier, Nicholas Meade, Armel Zebaze, Ming-Ho Yee, Logesh Kumar Umapathi, Jian Zhu, Benjamin Lipkin, Muhtasham Oblokulov, Zhiruo Wang, Rudra Murthy V, Jason Stillerman, Siva Sankalp Patel, Dmitry Abulkhanov, Marco Zocca, Manan Dey, Zhihan Zhang, Nour Moustafa-Fahmy, Urvashi Bhattacharyya, Wenhao Yu, Swayam Singh, Sasha Luccioni, Paulo Villegas, Maxim Kunakov, Fedor Zhdanov, Manuel Romero, Tony Lee, Nadav Timor, Jennifer Ding, Claire Schlesinger, Hailey Schoelkopf, Jan Ebert, Tri Dao, Mayank Mishra, Alex Gu, Jennifer Robinson, Carolyn Jane Anderson, Brendan Dolan-Gavitt, Danish Contractor, Siva Reddy, Daniel Fried, Dzmitry Bahdanau, Yacine Jernite, Carlos Muñoz Ferrandis, Sean Hughes, Thomas Wolf, Arjun Guha, Leandro von Werra, and Harm de Vries. 2023. StarCoder: may the source be with you! Computing Research Repository, arXiv:2305.06161.
- Lyu et al. (2023) Bohan Lyu, Xin Cong, Heyang Yu, Pan Yang, Yujia Qin, Yining Ye, Yaxi Lu, Zhong Zhang, Yukun Yan, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2023. Gitagent: Facilitating autonomous agent with github by tool extension. Computing Research Repository, arXiv:2312.17294.
- Martin (1996) Robert C Martin. 1996. The dependency inversion principle. C++ Report, 8(6):61–66.
- Moreno et al. (2013) Laura Moreno, Jairo Aponte, Giriprasad Sridhara, Andrian Marcus, Lori L. Pollock, and K. Vijay-Shanker. 2013. Automatic generation of natural language summaries for Java classes. In Proceedings of the IEEE 21st International Conference on Program Comprehension, pages 23–32, San Francisco, CA, USA.
- Nijkamp et al. (2023) Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, and Caiming Xiong. 2023. CodeGen: An open large language model for code with multi-turn program synthesis. In Proceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda.
- OpenAI (2022) OpenAI. 2022. OpenAI: Introducing ChatGPT.
- OpenAI (2023) OpenAI. 2023. GPT-4 technical report. Computing Research Repository, arXiv:2303.08774.
- Qian et al. (2023) Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. 2023. Communicative agents for software development. Computing Research Repository,, arXiv:2307.07924.
- Qin et al. (2023) Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weilin Zhao, Yuxiang Huang, Junxi Yan, Xu Han, Xian Sun, Dahai Li, Jason Phang, Cheng Yang, Tongshuang Wu, Heng Ji, Zhiyuan Liu, and Maosong Sun. 2023. Tool learning with foundation models. Computing Research Repository, arXiv:2304.08354.
- Qin et al. (2024) Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Sun. 2024. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. In The Twelfth International Conference on Learning Representations, Vienna, Austria.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training. Preprint.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67.
- Rai et al. (2022) Sawan Rai, Ramesh Chandra Belwal, and Atul Gupta. 2022. A review on source code documentation. ACM Transactions on Intelligent Systems and Technology, 13(5):1 – 44.
- Rodeghero et al. (2014) Paige Rodeghero, Collin McMillan, Paul W. McBurney, Nigel Bosch, and Sidney K. D’Mello. 2014. Improving automated source code summarization via an eye-tracking study of programmers. In Proceedings of the 36th International Conference on Software Engineering, pages 390–401, Hyderabad, India.
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. 2023. Code Llama: Open foundation models for code. Computing Research Repository,, arXiv:2308.12950.
- Sridhara et al. (2010) Giriprasad Sridhara, Emily Hill, Divya Muppaneni, Lori L. Pollock, and K. Vijay-Shanker. 2010. Towards automatically generating summary comments for java methods. In Proceedings of the 25th IEEE/ACM international conference on Automated software engineering, pages 43–52, Antwerp, Belgium.
- Sun et al. (2023) Weisong Sun, Chunrong Fang, Yudu You, Yuchen Chen, Yi Liu, Chong Wang, Jian Zhang, Quanjun Zhang, Hanwei Qian, Wei Zhao, et al. 2023. A prompt learning framework for source code summarization. Computing Research Repository, arXiv:2312.16066.
- Tian et al. (2024) Runchu Tian, Yining Ye, Yujia Qin, Xin Cong, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2024. DebugBench: Evaluating debugging capability of large language models. Computing Research Repository, arXiv:2401.04621.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open foundation and fine-tuned chat models. Computing Research Repository, arXiv:2307.09288.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, pages 5998–6008, Long Beach, CA, USA.
- Wang et al. (2023) Shujun Wang, Yongqiang Tian, and Dengcheng He. 2023. gDoc: Automatic generation of structured API documentation. In Companion Proceedings of the ACM Web Conference 2023, pages 53–56, Austin, TX, USA.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, pages 24824–24837, New Orleans, LA, USA.
- Wu et al. (2023) Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023. AutoGen: Enabling next-gen llm applications via multi-agent conversation framework. Computing Research Repository,, arXiv:2308.08155.
- XAgent (2023) XAgent. 2023. Xagent: An autonomous agent for complex task solving.
- Xia et al. (2018) Xin Xia, Lingfeng Bao, David Lo, Zhenchang Xing, Ahmed E. Hassan, and Shanping Li. 2018. Measuring program comprehension: A large-scale field study with professionals. IEEE Transactions on Software Engineering, 44(10):951–976.
- Xu et al. (2024) Yiheng Xu, Hongjin Su, Chen Xing, Boyu Mi, Qian Liu, Weijia Shi, Binyuan Hui, Fan Zhou, Yitao Liu, Tianbao Xie, et al. 2024. Lemur: Harmonizing natural language and code for language agents. In Proceedings of the 12th International Conference on Learning Representations, Vienna, Austria.
- Ye et al. (2023) Yining Ye, Xin Cong, Shizuo Tian, Jiannan Cao, Hao Wang, Yujia Qin, Yaxi Lu, Heyang Yu, Huadong Wang, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2023. Proagent: From robotic process automation to agentic process automation. Computing Research Repository, arXiv:2311.10751.
- Zhang et al. (2022) Chunyan Zhang, Junchao Wang, Qinglei Zhou, Ting Xu, Ke Tang, Hairen Gui, and Fudong Liu. 2022. A survey of automatic source code summarization. Symmetry, 14(3):471.
- Zhang et al. (2019) Jian Zhang, Xu Wang, Hongyu Zhang, Hailong Sun, Kaixuan Wang, and Xudong Liu. 2019. A novel neural source code representation based on abstract syntax tree. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering, pages 783–794, Montréal, Québec, Canada.
- Zhi et al. (2015) Junji Zhi, Vahid Garousi-Yusifoğlu, Bo Sun, Golara Garousi, Shawn Shahnewaz, and Guenther Ruhe. 2015. Cost, benefits and quality of software development documentation: A systematic mapping. Journal of Systems and Software, 99:175–198.
附录 A附录:实验细节
A.1实施细节
表A.2.2列出了所选存储库的详细统计数据以及与初始文档制作相关的词符成本。 这些存储库既来自于 GitHub 上成熟的、高星级的项目,也来自于新出现的、表现最好的项目。 存储库的特点是代码行数、类和函数的数量。 包含项目目录结构和双向引用等全局信息会导致很长的提示(详见附录C)。 尽管如此,生成的文档完整而简洁,长度通常在 0.4k 到 1k 标记之间。
在实际生成过程中,我们解决了不同模型的文本长度不同的问题。 当使用上下文长度较短的模型(例如,gpt-3.5-turbo和LLaMA系列)时,RepoAgent自适应地切换到上下文长度较大的模型(例如, gpt-3.5-16k 或 gpt-4-32k)根据当前提示的长度,以应对合并全局视角的词符开销。 即使超出了这些模型的限制,RepoAgent也会通过简化项目的目录结构并删除双向参考代码来截断内容,然后再重新启动文档生成任务。 当使用具有最长上下文 (128k) 的模型(例如 gpt-4-1106 或 gpt-4-0125)时,此类措施并不常见。 这种动态调度策略,结合可变的网络条件,可能会影响词符的消耗。 尽管如此,RepoAgent在保证文档完整性的同时,最大程度地追求成本效益。
A.2设置
A.2.1技术环境
所有实验均在 Python 3.11.4 环境中进行。 该系统安装了 CUDA 11.7,并配备 8 个 NVIDIA A100 40GB GPU。
A.2.2人类评估协议
我们招募了三名人工评估员来评估RepoAgent生成的代码文档,并指示所有人工评估员根据表中所示的一组评估标准进行总体评估4。 我们从存储库中随机抽取了 150 份文档。 随后,为每位人类评估员分配了 50 对文档,每对包含一份人工编写的文档和一份模型生成的文档。 人类评估者需要为每一对选择更好的文档。
lcccccc
Repository
Model
Prompt Tokens
Completion
Tokens
Class
Numbers
Function
Numbers
Code Lines
unoconv gpt-4-0125 4020 2550 0 1 1k
gpt-3.5-turbo 2743
Llama-2-7b 1180 2916
Llama-2-70b 437
simdjson gpt-4-0125 45344 35068 6 55 1k
gpt-3.5-turbo 29736
Llama-2-7b 49615 27562
Llama-2-70b 32961
greenlet gpt-4-0125 86587 79113 59 319 1k 10k
gpt-3.5-turbo 260464
Llama-2-7b 33177 31561
Llama-2-70b 225595
code2flow gpt-4-0125 185511 134462 51 257 1k 10k
gpt-3.5-turbo 234101
Llama-2-7b 354574 431761
Llama-2-70b 187835
AutoGen gpt-4-0125 4939388 516975 64 590 1k 10k
gpt-3.5-turbo 288609
Llama-2-7b 889050 630139
Llama-2-70b 410256
AutoGPT gpt-4-0125 4116296 888223 318 1170 10k
gpt-3.5-turbo 799380
Llama-2-7b 1838425 1893041
Llama-2-70b 927946
ChatDev gpt-4-0125 2021168 602474 183 729 10k
gpt-3.5-turbo 519226
Llama-2-7b 1122400 946131
Llama-2-70b 531838
MemGPT gpt-4-0125 628482 345109 74 478 10k
gpt-3.5-turbo 234101
Llama-2-7b 742591 740783
Llama-2-70b 352940
MetaGPT gpt-4-0125 154364 111159 291 885 10k
gpt-3.5-turbo 134101
Llama-2-7b 1904244 2265991
Llama-2-70b 1009996