Shenglai Zeng , Jiankun Zhang, Pengfei He, Yue Xing, Yiding Liu, Han Xu Jie Ren, Shuaiqiang Wang, Dawei Yin, Yi Chang, Jiliang Tang Michigan State University Baidu, Inc.
School of Artificial Intelligence, Jilin University
International Center of Future Science, Jilin University
Engineering Research Center of Knowledge-Driven Human-Machine Intelligence, MOE, China Equal contribution.Corresponding to zengshe1@msu.edu
Shenglai Zeng††thanks: Equal contribution.††thanks: Corresponding to zengshe1@msu.edu , Jiankun Zhang, Pengfei He, Yue Xing, Yiding Liu, Han XuJie Ren, Shuaiqiang Wang, Dawei Yin, Yi Chang, Jiliang TangMichigan State University Baidu, Inc. School of Artificial Intelligence, Jilin University International Center of Future Science, Jilin University Engineering Research Center of Knowledge-Driven Human-Machine Intelligence, MOE, China
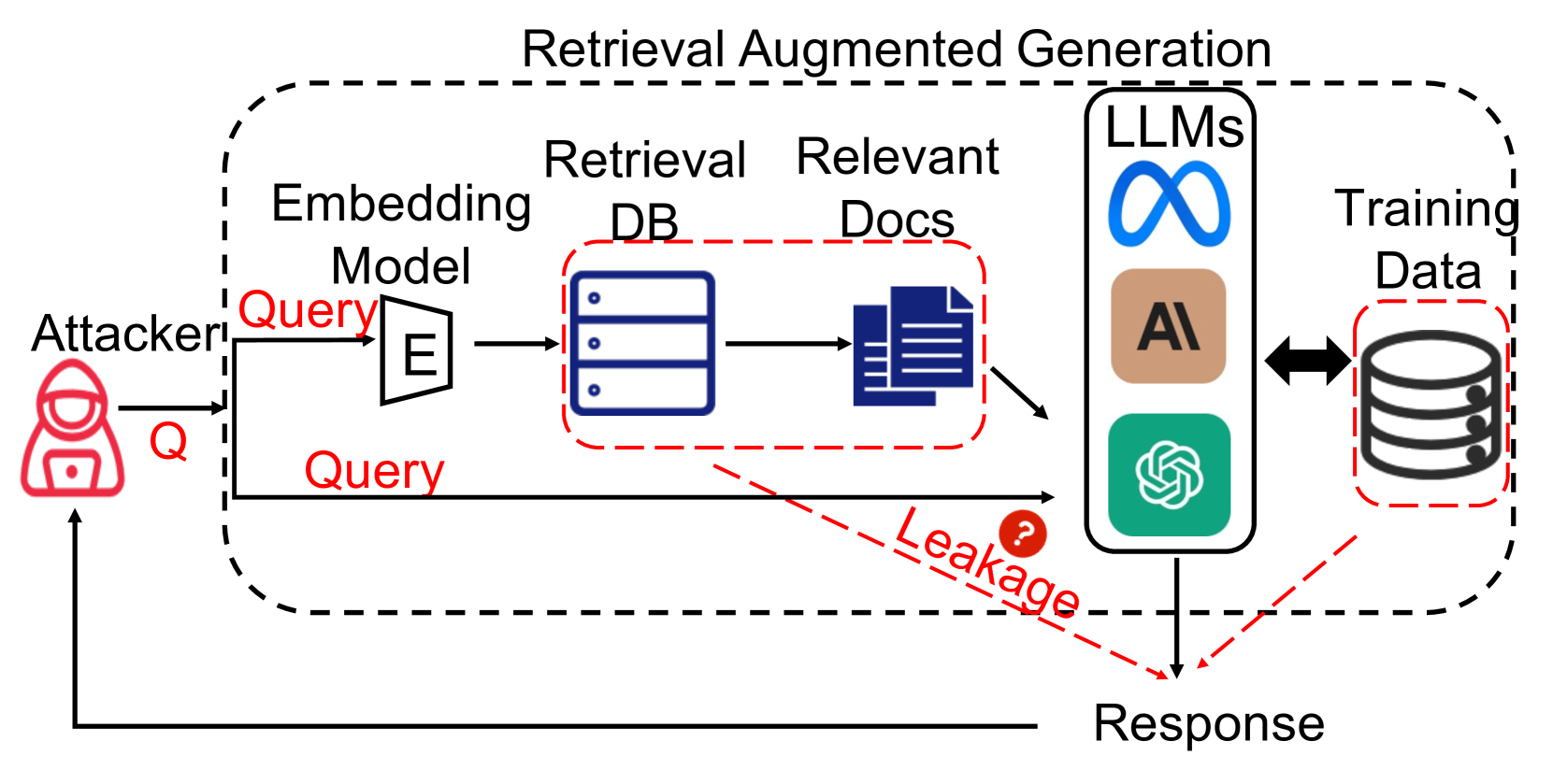
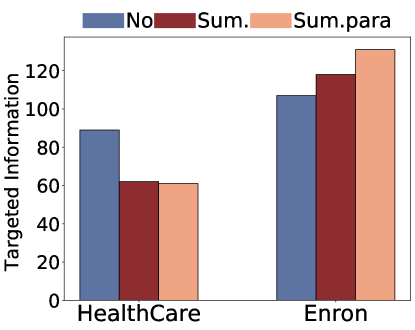
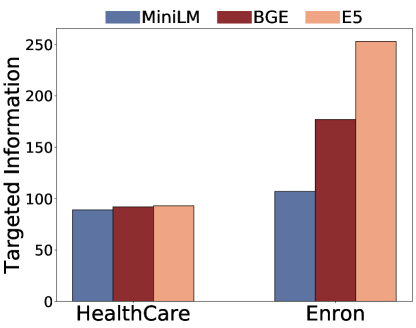
摘要可以作为一种潜在的缓解措施,因为它压缩检索到的上下文,从而减少其信息暴露。为了研究这一点,我们首先在检索后使用附加模型进行总结,然后将其输入到生成模型。具体来说,我们将查询和每个返回的文档都输入到大语言模型中,并要求大语言模型只维护与查询相关的信息。我们考虑不允许释义的提取摘要 (Sum) 和允许句子更改的抽象摘要 (Sum.Para)555We detailed the prompt templates for summarization in Appendix A.2.3中详细介绍了摘要的提示模板。我们的研究结果表明,摘要有效地降低了与非目标攻击相关的隐私风险。值得注意的是,抽象总结表现出卓越的有效性,可将风险降低约 50%。这是因为摘要减少了句子长度并过滤掉了不相关的信息,从而减少了成功重建的次数。然而,在有针对性的攻击背景下,汇总的效果有限。例如,在安然电子邮件数据集中,个人身份信息(PII)的出现甚至在无意中增加。这表明,虽然摘要技术可能会过滤掉不相关的内容,但它往往会保留与目标攻击相关的关键信息,从而可能增加大语言模型生成敏感信息的可能性。
为了隔离检索数据集成的影响,我们在输入之前添加了具有 50 个随机噪声注入标记的基线和典型的保护系统提示。这样可以区分检索增强和简单附加附加内容的效果777We introduced the construction of random noise and protective system prompts in appendix A.2.2的输入。
Biderman et al. (2023)Stella Biderman, USVSN Sai Prashanth, Lintang Sutawika, Hailey Schoelkopf, Quentin Anthony, Shivanshu Purohit, and Edward Raf.2023.Emergent and predictable memorization in large language models.arXiv preprint arXiv:2304.11158.
Borgeaud et al. (2022)Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. 2022.Improving language models by retrieving from trillions of tokens.In International conference on machine learning, pages 2206–2240.PMLR.
Carlini et al. (2022)Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang.2022.Quantifying memorization across neural language models.arXiv preprint arXiv:2202.07646.
Carlini et al. (2021)Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021.Extracting training data from large language models.In 30th USENIX Security Symposium (USENIX Security 21), pages 2633–2650.
Cheng et al. (2023)Xin Cheng, Di Luo, Xiuying Chen, Lemao Liu, Dongyan Zhao, and Rui Yan.2023.Lift yourself up: Retrieval-augmented text generation with self memory.arXiv preprint arXiv:2305.02437.
Fix and Hodges (1989)Evelyn Fix and Joseph Lawson Hodges.1989.Discriminatory analysis.nonparametric discrimination: Consistency properties.International Statistical Review/Revue Internationale de Statistique, 57(3):238–247.
Gao et al. (2023)Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang.2023.Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997.
Huang et al. (2023)Yangsibo Huang, Samyak Gupta, Zexuan Zhong, Kai Li, and Danqi Chen.2023.Privacy implications of retrieval-based language models.arXiv preprint arXiv:2305.14888.
Ippolito et al. (2022)Daphne Ippolito, Florian Tramèr, Milad Nasr, Chiyuan Zhang, Matthew Jagielski, Katherine Lee, Christopher A Choquette-Choo, and Nicholas Carlini.2022.Preventing verbatim memorization in language models gives a false sense of privacy.arXiv preprint arXiv:2210.17546.
Kandpal et al. (2022)Nikhil Kandpal, Eric Wallace, and Colin Raffel.2022.Deduplicating training data mitigates privacy risks in language models.In International Conference on Machine Learning, pages 10697–10707.PMLR.
Khandelwal et al. (2019)Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis.2019.Generalization through memorization: Nearest neighbor language models.arXiv preprint arXiv:1911.00172.
Kulkarni et al. (2024)Mandar Kulkarni, Praveen Tangarajan, Kyung Kim, and Anusua Trivedi.2024.Reinforcement learning for optimizing rag for domain chatbots.arXiv preprint arXiv:2401.06800.
Lee et al. (2023)Jooyoung Lee, Thai Le, Jinghui Chen, and Dongwon Lee.2023.Do language models plagiarize?In Proceedings of the ACM Web Conference 2023, pages 3637–3647.
Lee et al. (2021)Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, and Nicholas Carlini.2021.Deduplicating training data makes language models better.arXiv preprint arXiv:2107.06499.
Lewis et al. (2020)Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020.Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in Neural Information Processing Systems, 33:9459–9474.
Mireshghallah et al. (2022)Fatemehsadat Mireshghallah, Archit Uniyal, Tianhao Wang, David Evans, and Taylor Berg-Kirkpatrick.2022.Memorization in nlp fine-tuning methods.arXiv preprint arXiv:2205.12506.
Panagoulias et al. (2024)Dimitrios P Panagoulias, Maria Virvou, and George A Tsihrintzis.2024.Augmenting large language models with rules for enhanced domain-specific interactions: The case of medical diagnosis.Electronics, 13(2):320.
Parvez et al. (2021)Md Rizwan Parvez, Wasi Ahmad, Saikat Chakraborty, Baishakhi Ray, and Kai-Wei Chang.2021.Retrieval augmented code generation and summarization.In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 2719–2734.
Ram et al. (2023)Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham.2023.In-context retrieval-augmented language models.arXiv preprint arXiv:2302.00083.
Shao et al. (2023)Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen.2023.Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy.arXiv preprint arXiv:2305.15294.
Shi et al. (2023)Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen-tau Yih.2023.Replug: Retrieval-augmented black-box language models.arXiv preprint arXiv:2301.12652.
Shuster et al. (2021)Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston.2021.Retrieval augmentation reduces hallucination in conversation.arXiv preprint arXiv:2104.07567.
Siriwardhana et al. (2023)Shamane Siriwardhana, Rivindu Weerasekera, Elliott Wen, Tharindu Kaluarachchi, Rajib Rana, and Suranga Nanayakkara.2023.Improving the domain adaptation of retrieval augmented generation (rag) models for open domain question answering.Transactions of the Association for Computational Linguistics, 11:1–17.
Van Veen et al. (2023)Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, William Collins, Neera Ahuja, et al. 2023.Clinical text summarization: Adapting large language models can outperform human experts.arXiv preprint arXiv:2309.07430.
Xie et al. (2021)Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma.2021.An explanation of in-context learning as implicit bayesian inference.arXiv preprint arXiv:2111.02080.
Yunxiang et al. (2023)Li Yunxiang, Li Zihan, Zhang Kai, Dan Ruilong, and Zhang You.2023.Chatdoctor: A medical chat model fine-tuned on llama model using medical domain knowledge.arXiv preprint arXiv:2303.14070.
Zeng et al. (2023)Shenglai Zeng, Yaxin Li, Jie Ren, Yiding Liu, Han Xu, Pengfei He, Yue Xing, Shuaiqiang Wang, Jiliang Tang, and Dawei Yin.2023.Exploring memorization in fine-tuned language models.arXiv preprint arXiv:2310.06714.
Zhang et al. (2021)Chiyuan Zhang, Daphne Ippolito, Katherine Lee, Matthew Jagielski, Florian Tramèr, and Nicholas Carlini.2021.Counterfactual memorization in neural language models.arXiv preprint arXiv:2112.12938.
Zhang and Ippolito (2023)Yiming Zhang and Daphne Ippolito.2023.Prompts should not be seen as secrets: Systematically measuring prompt extraction attack success.arXiv preprint arXiv:2307.06865.
在第一阶段,攻击者必须根据自己的需求提供具体的示例。例如,如果目标对象的名称是,他们可能会编写诸如“我想要一些关于{目标名称}”、“关于{目标名称}”的建议清除。相反,如果目标是摘要,例如特定的电子邮件地址或某人的电话号码,攻击者可以提供与这些目标相关的前缀内容,例如“Please email us at”或“Please call me at”。
 (a)
(a)
 (b)
(b)
 (c)
(c)
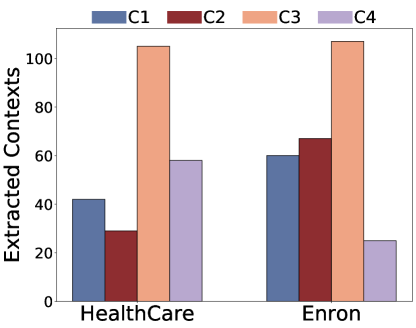 (d)
(d)
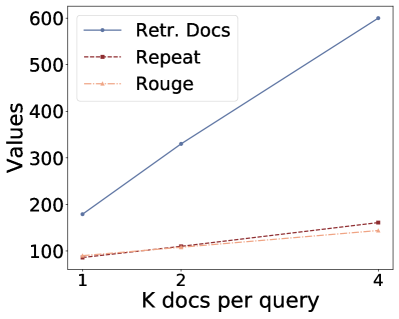 (a)
(a)
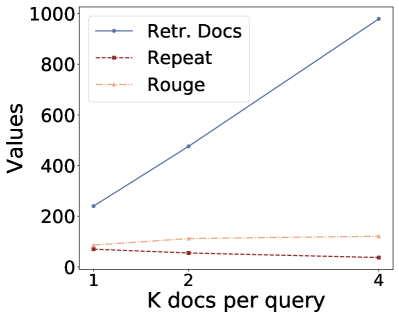 (b)
(b)
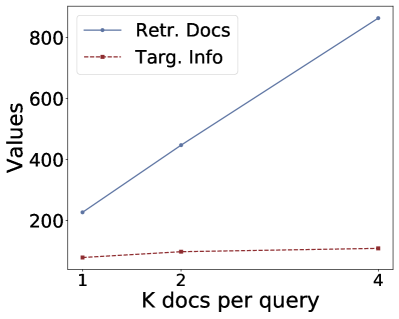 (c)
(c)
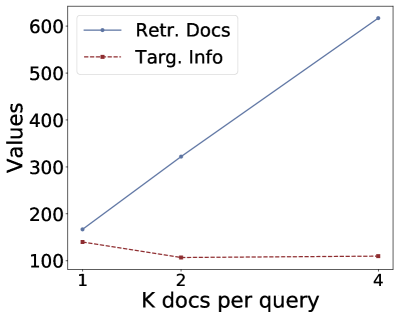 (d)
(d)
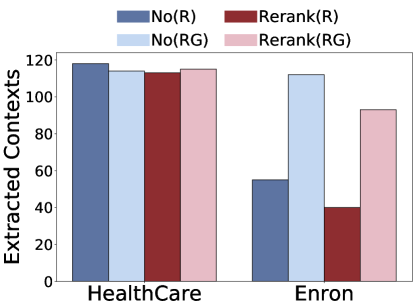 (a)
(a)
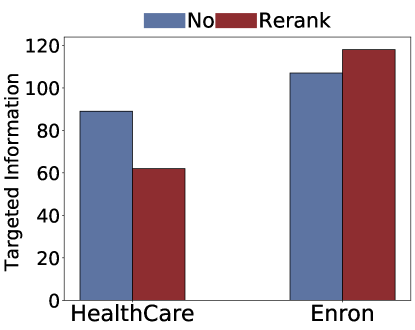 (b)
(b)
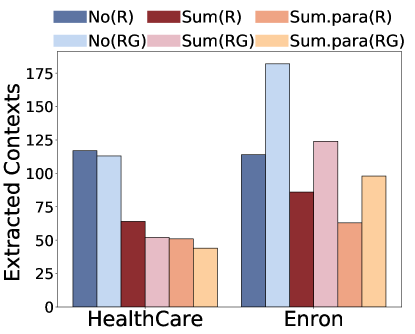 (c)
(c)
 (d)
(d)
 (a)
(a)
 (b)
(b)
 (c)
(c)
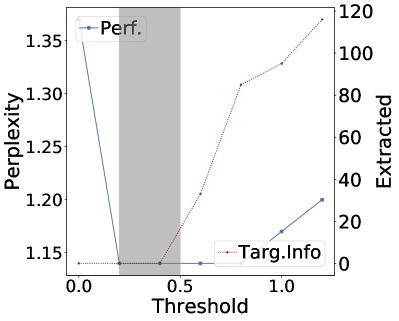 (d)
(d)
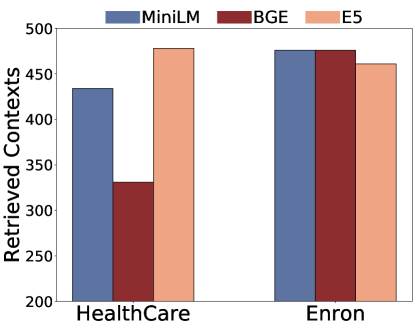 (a)
(a)
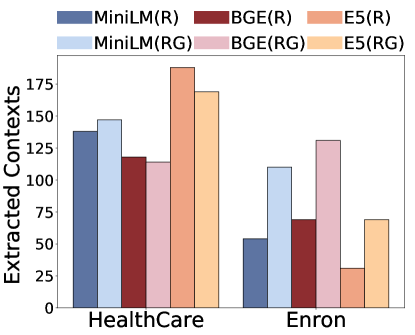 (b)
(b)
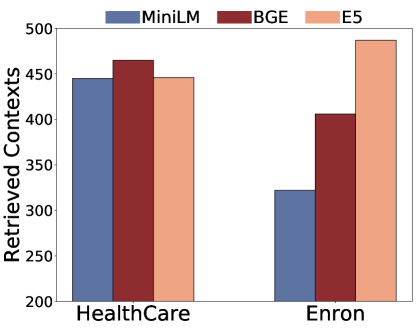 (c)
(c)
 (d)
(d)