用于姿势引导人体图像合成的从粗到细的潜在扩散
摘要
扩散模型是一种很有前景的图像生成方法,已被用于姿势引导人体图像合成(PGPIS),具有具有竞争力的性能。 虽然现有方法只是将人的外观与目标姿势对齐,但由于缺乏对源人图像的高级语义理解,它们很容易过度拟合。 在本文中,我们提出了一种新颖的 PGPIS 粗到细潜在扩散(CFLD)方法。 在缺乏图像标题对和文本提示的情况下,我们开发了一种纯粹基于图像的新颖训练范例来控制预训练的文本到图像扩散模型的生成过程。 感知细化解码器旨在逐步细化一组可学习的查询,并提取人物图像的语义理解作为粗粒度的提示。 这允许在不同阶段解耦细粒度的外观和姿势信息控制,从而避免潜在的过度拟合问题。 为了生成更真实的纹理细节,提出了一种混合粒度注意模块,将多尺度细粒度外观特征编码为偏差项,以增强粗粒度提示。 DeepFashion 基准的定量和定性实验结果都证明了我们的方法相对于 PGPIS 的最新技术的优越性。 代码可在 https://github.com/YanzuoLu/CFLD 获取。
1简介
姿势引导人物图像合成(PGPIS)旨在将源人物图像转换为特定的目标姿势,同时尽可能保留外观。 它的应用范围很广,包括电影制作、虚拟现实、时尚电商等。 大多数现有的方法都是基于生成对抗网络(GAN)[26, 6, 41, 63, 18, 33, 44, 54, 25, 56, 34, 27, 38, 20, 28, 62]。 然而,基于 GAN 的方法可能会受到最小-最大训练目标不稳定的影响,并且难以在单次前向传递中生成高质量图像。

作为 GAN 图像生成的一种有前途的替代方案,扩散模型通过一系列去噪步骤逐步合成更真实的图像。 最近流行的文本到图像潜在扩散模型,例如稳定扩散(SD)[35]现在可以根据给定的文本提示生成引人注目的人物图像。 生成的人的外貌可以通过精心设计的提示[19, 31]或提示学习[60, 59]来确定。 有了更可靠的结构指导[55, 29],合成的人物图像可以进一步约束到特定的姿势。 尽管文本到图像的扩散可以根据具有高级语义的文本提示生成逼真的图像,但其训练范例需要大量的图像标题对,而这些图像标题对的收集对于 PGPIS 来说是非常昂贵的。 更重要的是,由于语言和视觉之间的信息密度不同[11],即使是最详细的文本描述也不可避免地会引入歧义,并且可能无法准确地保留如图所示的外观。 . 1(a)。
最近,针对 PGPIS 出现了几种基于扩散的方法。 PIDM [1]提出了纹理扩散模块来模拟源图像外观与目标姿态之间的复杂对应关系。 由于高分辨率像素级的去噪过程的计算成本很高,PoCoLD [9] 通过使用预训练的变分自动编码器将像素映射到低维潜在空间来降低训练和推理成本( VAE)[7]。 在 PoCoLD 中,基于附加 3D Densepose [8] 注释的姿势约束注意模块进一步利用了对应关系。 虽然 PIDM 和 PoCoLD 都通过将源图像与目标姿势对齐来生成更真实的纹理细节,但它们缺乏对人物图像的高级语义理解。 因此,当合成与源图像差异很大或训练集中罕见的夸张姿势时,它们很容易出现过度拟合和泛化性能差的情况。 如图图1(b)所示,在这些情况下生成的图像变得扭曲且不自然,这与几个GAN-基于的方法。
在这项工作中,我们提出了一种新颖的 PGPIS 粗到细潜在扩散(CFLD)方法。 我们的方法打破了传统的训练范例,利用文本提示来控制预训练 SD 模型的生成过程。 我们不是对人类生成的信号(即高度语义和信息密集的语言)进行调节,而是促进纯粹基于图像的从粗到细的外观控制方法。 为了获得上述针对人物图像的语义理解,我们努力通过引入感知细化解码器来解耦不同阶段的细粒度外观和姿势信息控制。 对源人物图像的感知是通过随机初始化一组可学习查询并通过交叉注意力在后续解码器块中逐步细化它们来实现的。 解码器输出用作描述源图像的粗粒度提示,重点关注不同人物图像之间的共同语义,例如人体部位和属性,例如年龄和性别。 此外,我们设计了一个混合粒度注意模块来有效地将多尺度细粒度外观特征编码为偏差项,以增强粗粒度提示。 这样,在粗粒度提示的指导下,只需补充必要的细粒度细节,源图像就能与目标姿势对齐,从而实现更好的泛化,如 图 1(c) 所示。
我们的主要贡献可总结如下:
-
•
我们在缺乏图像标题对的情况下提出了一种新颖的训练范例,以克服将文本到图像扩散应用于 PGPIS 时的限制。 我们提出了一种感知细化的解码器来提取人物图像的语义理解作为粗粒度的提示。
-
•
我们制定了一个新的混合粒度注意模块,用细粒度的外观特征来偏置粗粒度的提示。 因此,生成图像的纹理细节得到更好的控制,变得更加真实。
-
•
我们在 DeepFashion [21] 基准上进行了广泛的实验,并在定量和定性上实现了最先进的性能。 用户研究和消融验证了我们方法的有效性。
2相关工作
姿势引导的人物图像合成。 Ma 等人. [26]首先提出了姿势引导的人物图像合成任务,并以对抗性方式细化生成的图像。 为了解耦姿势和外观信息,早期的方法[6, 27]提出学习与姿势无关的特征,但无法使用普通卷积神经网络处理复杂的纹理细节。 为了缓解这个问题,引入了辅助信息来提高生成质量,例如解析[28]和UV贴图[38]。 最近的方法[63,44,18,33,20,34]专注于对姿势和外观之间的空间对应关系进行建模,更频繁地使用解析图[54,25,62 ]。 PIDM [1] 和 PoCoLD [9] 是基于扩散模型开发的,以防止生成对抗网络的缺点,包括最小-最大训练目标的不稳定性和合成高分辨率图像的困难。 这两种基于扩散的方法都扩展了空间对应的思想,通过交叉注意机制对源图像的外观和目标姿态之间的关系进行建模。 我们认为,在没有对人物图像进行高级语义理解的情况下,简单地将源外观与目标姿势对齐会导致过度拟合。 更多并发作品,如 MagicAnimate [50]、Animate Anybody [16] 和 PCDMs [39] 需要多阶段和渐进式完全微调,而我们的管道通过冻结大多数参数而更加高效和端到端。 IP-Adatper [52] 的训练范例严重依赖于图像文本对,而这对于 PGPIS 任务来说是不可用的。
可控扩散模型。 扩散模型最近出现并展示了其高分辨率图像合成的潜力。 其核心思想是从简单的噪声向量开始,通过多次去噪迭代逐步将其转化为高质量的图像。 除了无条件生成[15,42,43]之外,还引入了各种方法将用户提供的控制信号合并到生成过程中,从而实现更可控的图像生成。 例如,[5]引入了使用分类器梯度来调节生成,而[14]提出了一种无分类器控制机制,采用条件和条件的加权求和。用于可控合成的无条件输出。 此外,潜在扩散模型(LDM)在潜在空间中进行扩散,并通过特定的编码器和交叉注意力注入调节信号。 基于稳定扩散(SD)[35]等预训练LDM,后续工作探索通过添加额外的控制[55, 29]来偏置潜在空间,以及进一步为用户提供对生成内容的控制[45, 12]。 我们没有在整个生成过程中使用高级调节提示,而是设计了一个从粗到细的调节过程,该过程调整基于 UNet 的预测网络中不同阶段的潜在特征,从而提供更好的可控姿势引导人物图像合成。
3方法
3.1初步
我们的方法建立在文本到图像潜在扩散模型之上,即具有高质量图像生成能力的稳定扩散(SD)[35]。 SD 模型有两个主要阶段:在原始像素空间和低维潜在空间之间映射的变分自动编码器 (VAE) [7] 和基于 UNet 的预测模型 [ 36]用于去噪扩散图像生成。 它遵循去噪扩散概率模型(DDPM)[15]的总体思想,制定了步的前向扩散过程和后向去噪过程。 扩散过程逐渐将随机高斯噪声添加到初始潜在中,在不同时间步将其映射为噪声潜在,
| (1) |
其中源自固定方差表。 去噪过程学习 UNet 来预测噪声并反转此映射,其中 是条件嵌入输出,例如[35] 中的 CLIP [32] 文本编码器。 优化可以表述为:
| (2) |
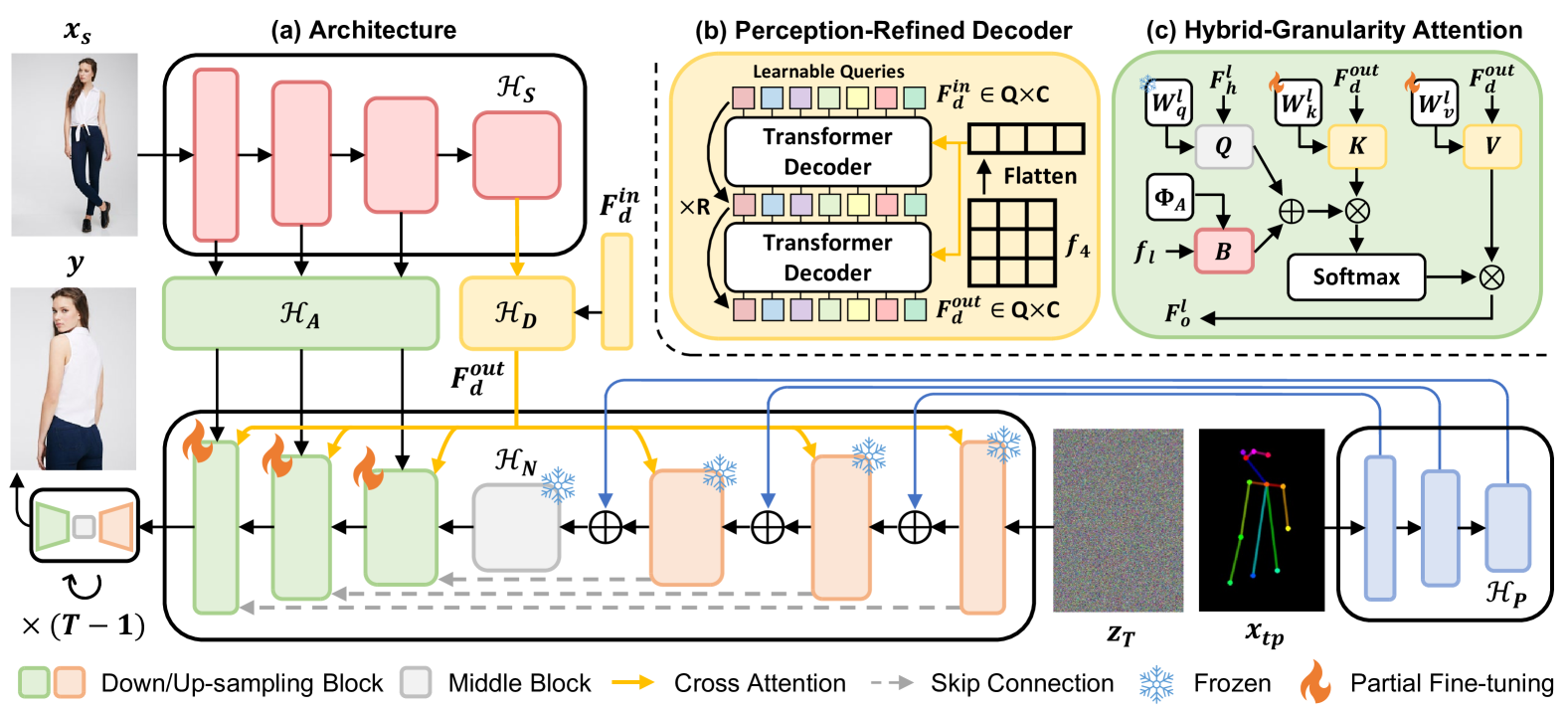
3.2 从粗到细的潜在扩散
架构和概述。 图 2(a) 显示了我们提出的方法的架构。 为了简洁起见,图中我们省略了 VAE [7] 模型的编码器 和解码器 。 在训练阶段,我们得到源图像 、源姿势 、目标姿势 和真实图像 源图像经过图像编码器(例如swin Transformer [22]),从中我们提取一堆多尺度特征图用于从粗到细的外观控制。 粗粒度提示由我们的感知精炼解码器 (PRD) 学习,并用作 UNet 的下采样和上采样块中的条件嵌入。 虽然 中的下采样块在我们的方法中保持不变,但我们使用混合粒度注意力模块 (HGA) 重新构建上采样块,以偏置粗粒度提示细粒度的外观特征以获得更真实的纹理。 有关 和 的更多详细信息将在稍后介绍。
为了高效的姿势控制,我们采用了一个轻量级的姿势适配器,它由多个ResNet块[10]组成。 的输出特征图直接添加到每个下采样块的末尾,如 [29] 中。 这不需要额外的微调,并且明确地解耦细粒度的外观和姿势信息控制。 在不同尺度的下采样下,姿态信息仅与我们的PRD作为条件嵌入给出的相同粗粒度提示对齐,而不是常见实践中不同的多尺度细粒度外观特征[1 ,9]。 这样,HGA模块在上采样阶段就可以学习到所有与姿态无关的纹理细节,并且不容易出现过拟合。 将真实图像的初始潜在状态表示为 。 Eq. 2 中的 MSE 损失因此重写为:
| (3) |
感知精炼解码器。 我们建议将控制与不同阶段的细粒度外观和姿势信息解耦,而不是像现有的基于扩散的方法[1, 9]那样利用多尺度外观特征作为条件嵌入。 因此,我们设计了一个感知精炼解码器(PRD)来提取人物图像的语义理解作为粗粒度提示,给定来自 的扁平化最后尺度输出 ,如下所示图2(b)。 通过重新审视人们对人物形象的感知,我们发现了几个共同的特征,即人体部位、年龄、性别、发型、服装等,如图图 1(a)。 这激励我们维护一组可学习的查询,代表人物图像的不同语义。 它们是使用标准 Transformer 解码器[47]随机初始化并逐步细化的。 源图像调节通过每个解码器块处的交叉注意模块进行交互。 经过块的细化,我们得到粗粒度的提示,它作为条件嵌入以及中下采样和上采样的输入t2>。
混合粒度注意力。 为了精确控制生成图像的纹理细节,我们引入了混合粒度注意力模块(HGA),该模块嵌入在中不同尺度的上采样块中,其中我们请参阅 其输入和输出。 给定来自 的源图像的多尺度特征图 ,HGA 模块旨在补偿粗粒度提示中丢失的必要细节。 为了实现这一目标,我们制定了自然遵循从粗到精的学习课程的 HGA 模块。
具体来说,我们建议通过在上采样块中偏置交叉注意力的查询来注入多尺度纹理细节,如图图2所示t0>(c),即
| (4) |
其中 是维度 的第 尺度上采样块的特定投影层。 是一个细粒度的外观编码器,主要由 Transformer层组成,并在开头和结尾添加了零卷积[55]。 零卷积是一个标准的卷积层,权重和偏置都初始化为零。 它在训练初期保持回到的梯度足够小,使得图像编码器更容易收敛感知细化解码器可以专注于学习以提供与预训练的SD模型兼容的高级语义理解。 由于我们解耦了不同阶段对细粒度外观和姿态信息的控制,因此在下采样过程中可以很好地控制目标姿态,而不会出现过拟合。 因此,这样的设计鼓励 HGA 模块慢慢填充更细粒度的纹理,以便在训练期间更好地将生成与源图像对齐。 请注意,上采样块中的 是可训练参数。 它们是整个中唯一可训练的参数,仅占预训练SD模型中所有参数的1.2%。
3.3优化
为了协助源到目标的姿势转换,我们按照[56]中的见解为训练进行源到源的自重建。 重建损失为,
| (5) |
其中 和 是在时间步 从 映射的噪声潜伏。总体目标写为,
| (6) |
此外,我们采用三次函数作为时间步的分布。增加了采样初期掉落的概率,加强了引导,有助于更快收敛,缩短训练时间。
采样。 一旦学习了条件潜在扩散模型,就可以通过采样随机高斯噪声来执行推理。 在每个时间步 使用去噪网络 将 公式 1 中的时间表反转,即可得到预测的潜变量 。 我们采用累积无分类器指导[9,14,2]来加强源外观和目标姿态指导,即
| (7) | ||||
当源图像 丢失时,我们使用可学习的向量作为条件嵌入。 可学习向量的训练概率为 %,在训练期间同时丢弃 和 。 如果目标姿势 丢失,姿势适配器 的输出将设置为全零。 我们使用 DDPM 调度程序 [15],其步骤与 [9, 1] 中相同,有 50 个步骤。 最后,通过VAE解码器得到生成的图像。
4实验
| Component | Default | Trainable Params. | |
| Swin-B [22] | 87.0M | ||
| 22.5M | |||
| , , | 97.7M | ||
| Adapter [29] | 30.6M | ||
| up-sampling | 10.3M | ||
| Method | Pose Info. & Annotation | Training Epochs | Trainable Params. |
| PIDM [1] | 2D OpenPose [3] | 300 | 688.0M |
| PoCoLD [9] | 3D DensePose [8] | 100 | 395.9M |
| CFLD (Ours) | 2D OpenPose [3] | 100 | 248.2M |
| Method | Venue | FID | LPIPS | SSIM | PSNR |
| Evaluate on 256176 resolution | |||||
| PATN [63] | CVPR 19’ | 20.728 | 0.2533 | 0.6714 | - |
| ADGAN [28] | CVPR 20’ | 14.540 | 0.2255 | 0.6735 | - |
| GFLA [33] | CVPR 20’ | 9.827 | 0.1878 | 0.7082 | - |
| PISE [54] | CVPR 21’ | 11.518 | 0.2244 | 0.6537 | - |
| SPGNet [25] | CVPR 21’ | 16.184 | 0.2256 | 0.6965 | 17.222 |
| DPTN [56] | CVPR 22’ | 17.419 | 0.2093 | 0.6975 | 17.811 |
| NTED [34] | CVPR 22’ | 8.517 | 0.1770 | 0.7156 | 17.740 |
| CASD [62] | ECCV 22’ | 13.137 | 0.1781 | 0.7224 | 17.880 |
| PIDM [1] | CVPR 23’ | 6.812 | 0.2006 | 0.6621 | 15.630 |
| PIDM [1] | CVPR 23’ | 6.440 | 0.1686 | 0.7109 | 17.399 |
| PoCoLD [9] | ICCV 23’ | 8.067 | 0.1642 | 0.7310 | - |
| CFLD (Ours) | 6.804 | 0.1519 | 0.7378 | 18.235 | |
| VAE Reconstructed | 7.967 | 0.0104 | 0.9660 | 33.515 | |
| Ground Truth | 7.847 | 0.0000 | 1.0000 | ||
| Evaluate on 512352 resolution | |||||
| CoCosNet2 [61] | CVPR 21’ | 13.325 | 0.2265 | 0.7236 | - |
| NTED [34] | CVPR 22’ | 7.645 | 0.1999 | 0.7359 | 17.385 |
| PoCoLD [9] | ICCV 23’ | 8.416 | 0.1920 | 0.7430 | - |
| CFLD (Ours) | 7.149 | 0.1819 | 0.7478 |
17.645 |
|
| VAE Reconstructed | 8.187 | 0.0217 | 0.9231 | 30.214 | |
| Ground Truth | 8.010 | 0.0000 | 1.0000 | ||
4.1设置
数据集。 我们按照[9, 34]对DeepFashion的店内服装检索基准[21]进行实验,并在256上进行评估176 和 512352 分辨率。 该数据集包含 52,712 张时尚领域的高分辨率人物图像。 数据集分割与 PATN [63] 中的相同,其中分别选择 101,966 和 8,570 个非重叠对进行训练和测试。
客观指标。 我们使用四种不同的指标来定量评估生成的图像,包括 FID [13]、LPIPS [57]、SSIM [49] 和 PSNR 。 FID 和 LPIPS 都是基于深层特征。 Fréchet Inception Distance (FID) 使用 Inception-v3 [37] 特征计算生成图像和真实图像分布之间的 Wasserstein-2 距离 [46] 和学习到的距离感知图像块相似度 (LPIPS) 利用经过人类判断训练的网络来测量感知领域的重建准确性。 至于结构相似性指数测量(SSIM)和峰值信噪比(PSNR),它们在像素级别量化生成图像和地面实况之间的相似性。
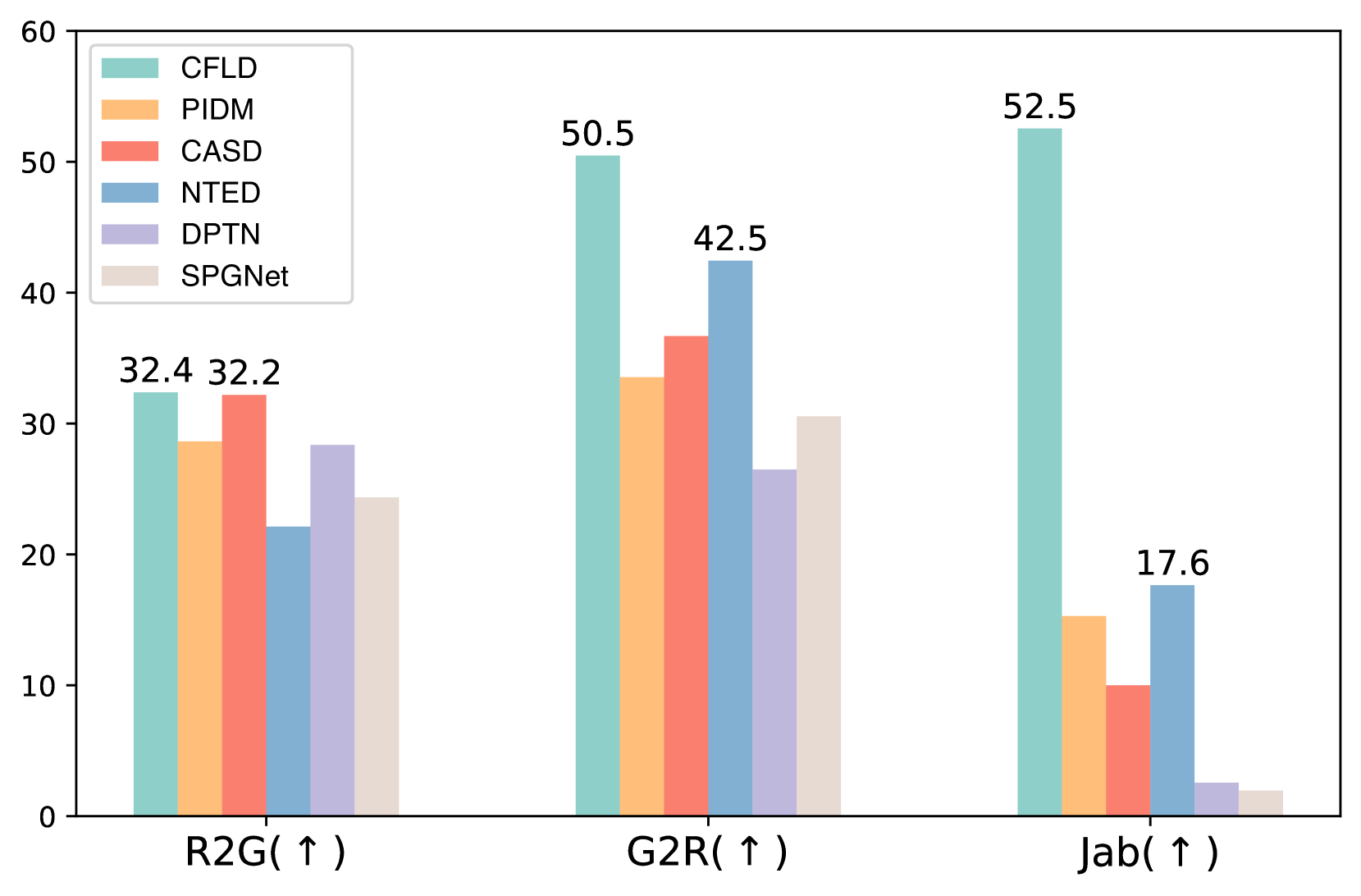
主观指标。 除了客观指标之外,我们还按照 [9] 在用户研究中使用 Jab [25, 62, 1] 指标来计算生成的图像的百分比被认为是所有方法中最好的[1,62,34,56,25]。 此外,为了测量生成的图像和真实数据之间的相似性,我们像许多早期方法一样量化 R2G 和 G2R 指标[26,41,63]。 R2G 表示被认为是生成的真实图像的百分比,G2R 表示被人类认为是真实的生成图像的百分比。
实施细节。 我们的方法是在版本为 1.5 的稳定扩散 [35] 之上使用 PyTorch [30] 和 HuggingFace Diffusers [48] 实现的。 源图像大小调整为 256256,源图像编码器 是在 ImageNet 上预训练的标准 Swin-B [22] 4]。 每个组件中的默认设置和可训练参数的数量总结为 选项卡。 1. 我们使用 Adam [17] 优化器训练 100 个 epoch,基础学习率为 5e-7,按总批量大小缩放。 学习率在前 1,000 个步骤中经历线性预热,并在 50 个时期乘以 0.1。 对于无分类器指导,我们在采样期间将 和 设置为 2.0,并以概率丢弃条件 和 训练期间(%)。
4.2定量比较
4.3定性比较
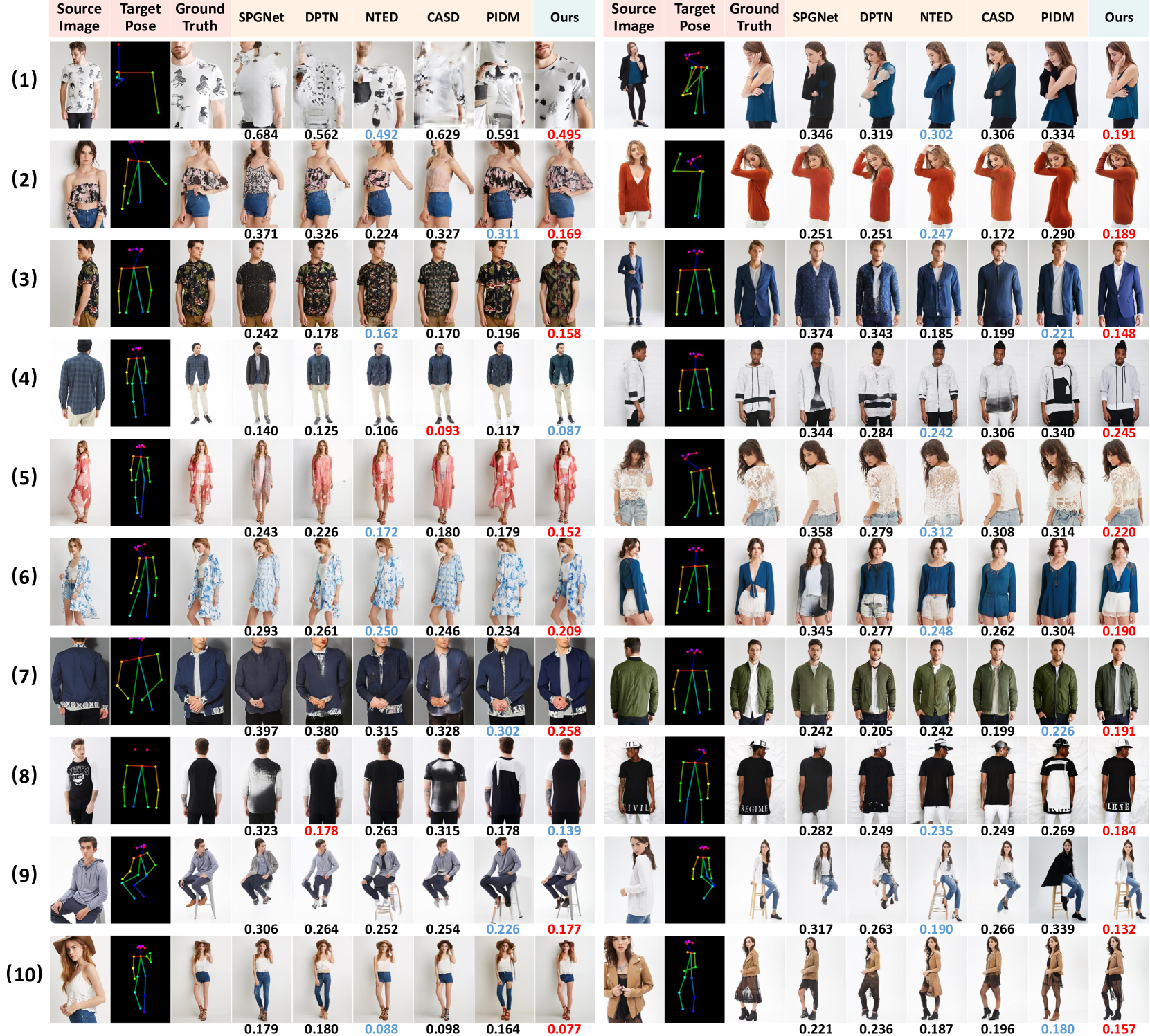
在图 3中,我们对公开可用且可重现的最新方法进行了全面的视觉比较,包括 SPGNet [25] 、DPTN [56]、NTED [34]、CASD [62]及马存保机构[1].
我们的观察可总结如下。
(1) 基于 GAN 和基于扩散的方法都存在过度拟合人体姿势的问题。
当生成训练集中一些极端或不常见的目标姿势时,现有方法显示出严重的扭曲,如第 1-2 行所示。
由于我们解耦了细粒度外观和姿势信息的控制,因此我们的方法规避了潜在的过度拟合问题,并且始终通过条件粗粒度提示和细粒度外观偏差生成合理的姿势。
(2) 对于第 3-6 行中具有更复杂服装的源图像,我们生成的图像可以更好地保留纹理细节,同时与目标姿势对齐,这要归功于强大的粗略算法混合粒度注意力模块的精细化学习课程。
对于其他方法,尽管颜色匹配,但衣服要么表现出模糊和失真(SPGNet、DPTN 和 CASD),要么在纹理上拼接不自然,从而与源图像(NTED 和 PIDM)产生很大差距。
(3) 对于目标姿态需要源图像中不可见区域的可视化的情况,我们的方法表现出很强的理解和泛化能力。
通过感知细化解码器提供的对源图像的语义理解,我们的方法知道当人转身或坐下时应该预测什么,如第 7-10 行所示,例如衣服的正反面、坐椅、下半身的穿着都有不同的图案。
4.4用户研究
为了验证生成图像和真实图像之间的差距以及我们相对于现有技术的优越性,我们招募了超过 100 名志愿者,按照马存保机构 [1] 进行以下两项用户研究。 (1) 对于 R2G 和 G2R 指标,要求志愿者区分测试集中的 30 张生成图像和 30 张真实图像。 每个志愿者只能看到特定方法生成的图像,并且生成的源图像和目标姿势对在不同方法中是一致的,以进行公平比较。 从图4的结果来看,真实图像被识别为生成(R2G)的几率相对较低,超过一半我们生成的图像被识别为真实的(G2R),这表明我们的方法生成了更真实的图像,不太可能被人类判断为假图像。 (2) 对于 Jab 指标,要求每个志愿者从不同方法生成的图像中选择与真实情况的最佳匹配。 与其他方法相比,我们的 Jab 得分达到了 52.5%,明显高于第二名的同行(+34.9),这表明我们的方法更受青睐,可以生成更好的纹理细节和姿势对齐。
| Method | Biasing | Trainable | Prompt | LPIPS | SSIM |
| B1 | M-S | 0.2018 | 0.6959 | ||
| B2 | CLIP | 0.2099 | 0.6944 | ||
| B3 | PRD | 0.1615 | 0.7293 | ||
| B4 | PRD | 0.1742 | 0.7198 | ||
| B5 | Swin | 0.1912 | 0.7038 | ||
| Ours | PRD | 0.1519 | 0.7378 |



4.5消融研究
我们在多个基线上进行消融研究,以与我们的方法进行比较。
定量结果呈现在 选项卡。 3.
B1 引用自其他两种基于扩散的方法 [1, 9],它们合并了多尺度细粒度外观特征作为条件提示。
我们还在 B2 中尝试使用 CLIP 图像编码器 [32] 来为源图像生成描述性的粗粒度提示,这首先是通过图像编辑方法进行探索的[51] 也纯粹以图像为条件。
结合图5中的定性结果,我们可以看到,即使是非常简单的纹理有时也无法保留,这表明这些提示是与预训练的 SD 模型不兼容。
为了提供更具体的人物图像的粗粒度特征,我们将感知精炼解码器(PRD)集成到B3中。
重建指标(即 LPIPS 和 SSIM) 选项卡。 3 揭示了生成图像质量的显着提高,这验证了我们提出的 PRD 的有效性。
虽然这可以在图 5中定性地得到证实,但仍然缺乏红色框所示的纹理细节。
为了解决这个问题,我们在 UNet 中尝试训练更多参数 B4,但结果却观察到性能下降。
这意味着 SD 模型的泛化能力受到损害,这不是我们的预期。
因此,我们提出了混合粒度注意力(HGA)来偏置查询并在定量和定性上实现最先进的结果。
为了验证源图像编码器(即Swin Transformer [22])是否能够为HGA学习足够的信息并给出有用的提示,我们放弃了B5中的PRD.
图 5中的定性结果表明B4和B5都过度拟合,只有我们的方法通过以粗粒度到细粒度的方式学习来规避这个问题。
可视化。 在图7中,我们可视化了中不同查询的有效性。 注意力图反映了可学习查询捕获的人物图像的不同人体部位,这证明我们对源图像有高度的理解,因此不太容易出现过度拟合。
4.6外观编辑
风格转移。 我们的CFLD继承了SD模型强大的生成能力,冻结了其绝大多数参数。 因此,风格迁移可以简单地通过掩蔽来实现,无需额外的训练。 具体来说,我们将参考图像 中的感兴趣区域标记为二进制掩码 。 在采样过程中,噪声预测被分解为 ,其中 基于 的姿势和不同风格的源图像的外观。 令 为从 映射的时间步 处的噪声潜伏,如 Eq. 1。 根据图6(a)中的结果,我们的方法在感兴趣的区域中生成真实且连贯的纹理细节。
风格插值。 此外,我们的 CFLD 支持粗粒度提示和细粒度外观偏差的任意线性插值。 如图图6(b)所示,我们生成的图像忠实地再现了不同的风格并具有平滑的过渡。
5结论
本文提出了一种新颖的用于姿势引导人体图像合成(PGPIS)的从粗到细的潜在扩散(CFLD)方法。 我们通过解耦细粒度的外观和姿势信息控制来规避潜在的过度拟合问题。 我们提出的感知精炼解码器(PRD)和混合粒度注意力模块(HGA)能够对人物图像进行高级语义理解,同时还通过从粗到精的学习课程保留纹理细节。 大量实验表明,CFLD 在数量和质量上均优于 PGPIS 的最新技术。 我们未来的工作将研究 CFLD 是否可以扩展到更多受到劣质数据影响的下游任务,例如人员重新识别 [23, 53] 和领域适应 [24, 40],因为我们的训练范例既产生了预先训练的特征网络,又产生了强大的增强生成器。
致谢。 这项工作得到了国家自然科学基金 (U22A2095, 62276281) 的部分支持。
参考
- Bhunia et al. [2023] Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Jorma Laaksonen, Mubarak Shah, and Fahad Shahbaz Khan. Person image synthesis via denoising diffusion model. In CVPR, page 5968–5976, 2023.
- Brooks et al. [2023] Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. In CVPR, pages 18392–18402, 2023.
- Cao et al. [2017] Zhe Cao, Tomas Simon, Shih-En Wei, and Yaser Sheikh. Realtime multi-person 2d pose estimation using part affinity fields. In CVPR, page 7291–7299, 2017.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, page 248–255, 2009.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alexander Quinn Nichol. Diffusion models beat gans on image synthesis. In NeurIPS, pages 8780–8794, 2021.
- Esser and Sutter [2018] Patrick Esser and Ekaterina Sutter. A variational u-net for conditional appearance and shape generation. In CVPR, page 8857–8866, 2018.
- Esser et al. [2021] Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In CVPR, page 12873–12883, 2021.
- Güler et al. [2018] Rıza Alp Güler, Natalia Neverova, and Iasonas Kokkinos. Densepose: Dense human pose estimation in the wild. In CVPR, pages 7297–7306, 2018.
- Han et al. [2023] Xiao Han, Xiatian Zhu, Jiankang Deng, Yi-Zhe Song, and Tao Xiang. Controllable person image synthesis with pose-constrained latent diffusion. In ICCV, page 22768–22777, 2023.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, page 770–778, 2016.
- He et al. [2022] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. In CVPR, page 16000–16009, 2022.
- Hertz et al. [2022] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. arXiv:2208.01626, 2022.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017.
- Ho and Salimans [2021] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. In NeurIPS Workshops, 2021.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020.
- Hu et al. [2023] Liucheng Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, and Liefeng Bo. Animate anyone: Consistent and controllable image-to-video synthesis for character animation. arXiv:2311.17117, 2023.
- Kingma and Ba [2015] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015.
- Li et al. [2019] Yining Li, Chen Huang, and Chen Change Loy. Dense intrinsic appearance flow for human pose transfer. In CVPR, page 3693–3702, 2019.
- Liu and Chilton [2022] Vivian Liu and Lydia B Chilton. Design guidelines for prompt engineering text-to-image generative models. In CHI, pages 1–23, 2022.
- Liu et al. [2019] Wen Liu, Zhixin Piao, Jie Min, Wenhan Luo, Lin Ma, and Shenghua Gao. Liquid warping gan: A unified framework for human motion imitation, appearance transfer and novel view synthesis. In ICCV, pages 5904–5913, 2019.
- Liu et al. [2016] Ziwei Liu, Ping Luo, Shi Qiu, Xiaogang Wang, and Xiaoou Tang. Deepfashion: Powering robust clothes recognition and retrieval with rich annotations. In CVPR, page 1096–1104, 2016.
- Liu et al. [2021] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, page 10012–10022, 2021.
- Lu et al. [2022] Yanzuo Lu, Manlin Zhang, Yiqi Lin, Andy J Ma, Xiaohua Xie, and Jianhuang Lai. Improving pre-trained masked autoencoder via locality enhancement for person re-identification. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 509–521. Springer, 2022.
- Lu et al. [2024] Yanzuo Lu, Meng Shen, Andy J Ma, Xiaohua Xie, and Jian-Huang Lai. Mlnet: Mutual learning network with neighborhood invariance for universal domain adaptation. In AAAI, 2024.
- Lv et al. [2021] Zhengyao Lv, Xiaoming Li, Xin Li, Fu Li, Tianwei Lin, Dongliang He, and Wangmeng Zuo. Learning semantic person image generation by region-adaptive normalization. In CVPR, page 10806–10815, 2021.
- Ma et al. [2017] Liqian Ma, Xu Jia, Qianru Sun, B. Schiele, T. Tuytelaars, and L. Gool. Pose guided person image generation. In NeurIPS, 2017.
- Ma et al. [2018] Liqian Ma, Qianru Sun, Stamatios Georgoulis, Luc Van Gool, Bernt Schiele, and Mario Fritz. Disentangled person image generation. In CVPR, pages 99–108, 2018.
- Men et al. [2020] Yifang Men, Yiming Mao, Yuning Jiang, Wei-Ying Ma, and Zhouhui Lian. Controllable person image synthesis with attribute-decomposed gan. In CVPR, page 5084–5093, 2020.
- Mou et al. [2023] Chong Mou, Xintao Wang, Liangbin Xie, Jing Zhang, Zhongang Qi, Ying Shan, and Xiaohu Qie. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv:2302.08453, 2023.
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. NeurIPS, 32, 2019.
- Pavlichenko and Ustalov [2023] Nikita Pavlichenko and Dmitry Ustalov. Best prompts for text-to-image models and how to find them. In SIGIR, pages 2067–2071, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In ICML, page 8748–8763, 2021.
- Ren et al. [2020] Yurui Ren, Xiaoming Yu, Junming Chen, Thomas H. Li, and Ge Li. Deep image spatial transformation for person image generation. In CVPR, page 7690–7699, 2020.
- Ren et al. [2022] Yurui Ren, Xiaoqing Fan, Ge Li, Shan Liu, and Thomas H. Li. Neural texture extraction and distribution for controllable person image synthesis. In CVPR, page 13535–13544, 2022.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, page 10684–10695, 2022.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, page 234–241, 2015.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. NeurIPS, 29, 2016.
- Sarkar et al. [2021] Kripasindhu Sarkar, Vladislav Golyanik, Lingjie Liu, and Christian Theobalt. Style and pose control for image synthesis of humans from a single monocular view. arXiv:2102.11263, 2021.
- Shen et al. [2024] Fei Shen, Hu Ye, Jun Zhang, Cong Wang, Xiao Han, and Wei Yang. Advancing pose-guided image synthesis with progressive conditional diffusion models. In ICLR, 2024.
- Shen et al. [2023] Meng Shen, Yanzuo Lu, Yanxu Hu, and Andy J Ma. Collaborative learning of diverse experts for source-free universal domain adaptation. In ACM MM, pages 2054–2065, 2023.
- Siarohin et al. [2018] Aliaksandr Siarohin, Enver Sangineto, Stephane Lathuiliere, and Nicu Sebe. Deformable gans for pose-based human image generation. In CVPR, page 3408–3416, 2018.
- Song et al. [2021a] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In ICLR, 2021a.
- Song et al. [2021b] Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In ICLR, 2021b.
- Tang et al. [2020] Hao Tang, Song Bai, Li Zhang, Philip H. S. Torr, and Nicu Sebe. Xinggan for person image generation. In ECCV, page 717–734, 2020.
- Tumanyan et al. [2023] Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. In CVPR, pages 1921–1930, 2023.
- Vaserstein [1969] Leonid Nisonovich Vaserstein. Markov processes over denumerable products of spaces, describing large systems of automata. Problemy Peredachi Informatsii, 5(3):64–72, 1969.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
- von Platen et al. [2022] Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, and Thomas Wolf. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/diffusers, 2022.
- Wang et al. [2004] Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: From error visibility to structural similarity. TIP, 13(4):600–612, 2004.
- Xu et al. [2023] Zhongcong Xu, Jianfeng Zhang, Jianfeng Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. Magicanimate: Temporally consistent human image animation using diffusion model. arXiv:2311.16498, 2023.
- Yang et al. [2023] Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In CVPR, page 18381–18391, 2023.
- Ye et al. [2023] Hu Ye, Jun Zhang, Siyi Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv:2308.06721, 2023.
- Yuan et al. [2024] Junkun Yuan, Xinyu Zhang, Hao Zhou, Jian Wang, Zhongwei Qiu, Zhiyin Shao, Shaofeng Zhang, Sifan Long, Kun Kuang, Kun Yao, et al. Hap: Structure-aware masked image modeling for human-centric perception. NeurIPS, 36, 2024.
- Zhang et al. [2021] Jinsong Zhang, Kun Li, Yu-Kun Lai, and Jingyu Yang. Pise: Person image synthesis and editing with decoupled gan. In CVPR, page 7982–7990, 2021.
- Zhang et al. [2023] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. In ICCV, page 3836–3847, 2023.
- Zhang et al. [2022] Pengze Zhang, Lingxiao Yang, Jianhuang Lai, and Xiaohua Xie. Exploring dual-task correlation for pose guided person image generation. In CVPR, page 7713–7722, 2022.
- Zhang et al. [2018] Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, page 586–595, 2018.
- Zheng et al. [2015] Liang Zheng, Liyue Shen, Lu Tian, Shengjin Wang, Jingdong Wang, and Qi Tian. Scalable person re-identification: A benchmark. In ICCV, page 1116–1124, 2015.
- Zhou et al. [2022a] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. In CVPR, page 16816–16825, 2022a.
- Zhou et al. [2022b] Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. IJCV, 130(9):2337–2348, 2022b.
- Zhou et al. [2021] Xingran Zhou, Bo Zhang, Ting Zhang, Pan Zhang, Jianmin Bao, Dong Chen, Zhongfei Zhang, and Fang Wen. Cocosnet v2: Full-resolution correspondence learning for image translation. In CVPR, page 11465–11475, 2021.
- Zhou et al. [2022c] Xinyue Zhou, M. Yin, Xinyuan Chen, Li Sun, Changxin Gao, and Qingli Li. Cross attention based style distribution for controllable person image synthesis. In ECCV, page 161–178, 2022c.
- Zhu et al. [2019] Zhen Zhu, Tengteng Huang, Baoguang Shi, Miao Yu, Bofei Wang, and Xiang Bai. Progressive pose attention transfer for person image generation. In CVPR, page 2347–2356, 2019.
对 Market-1501 的评估。 由于基于扩散的方法,包括 PIDM [1]、PoCoLD [9] 和并发 PCDM [39] 都没有发布生成的图像或Market-1501 [58] 上的检查点,我们与可用的基于 GAN 的方法进行公平比较 选项卡。 4. 从这些结果来看,华夏幸福在不同指标上的表现仍然忠实地优于其他指标,这验证了我们的稳健性。
无分类器策略的消融。 在里面 选项卡。 5 我们改变 DeepFashion [21] 上方程(7)的选择。 结果表明,适当增强外观和姿态信息(即增加引导权重)可以有效提高生成图像的质量。
| Method | Venue | FID | LPIPS | SSIM | PSNR |
| GAN-based Methods | |||||
| GFLA | CVPR 20’ | 19.740 | 0.2815 | 0.2808 | 14.337 |
| XingGAN | ECCV 20’ | 22.520 | 0.3058 | 0.3044 | 14.446 |
| SPGNet | CVPR 21’ | 23.057 | 0.2777 | 0.3139 | 14.489 |
| DPTN | CVPR 22’ | 18.995 | 0.2711 | 0.2854 | 14.521 |
| Diffusion-based Methods | |||||
| CFLD (Ours) | 11.972 | 0.2636 | 0.3173 | 14.861 | |
| VAE Reconstructed | 6.028 | 0.0164 | 0.9883 | 36.625 | |
| Ground Truth | 4.845 | 0.0000 | 1.0000 | ||
额外的定性结果。 为了进一步评估我们方法的泛化能力,我们生成从测试集中随机选择的任意姿势的人物图像,如下所示 图 8、9 和 10。 结果表明,我们的方法始终能够生成高质量的人物图像,同时保留源图像中的外观。 即使目标姿态与源图像显着不同,或者需要源图像的不可见区域,生成的图像仍然不失真。 在粗粒度提示的指导下,我们的方法具有高层次的理解,并且不会出现过度拟合,例如强制源图像的纹理细节对齐。 在此基础上,我们嵌入的混合粒度注意力仅补充必要的细粒度外观特征,从而实现更真实和自然的纹理。



更多关于过度拟合和偏差的讨论。 我们的观察是,以前基于扩散的方法会将源图像的空间卷积特征直接拟合到噪声样本中。 但这在实践中没有意义,因为源图像的纹理细节可能不应该出现在目标样本的同一位置,特别是在夸张的姿势转换情况下。 由于模型实际上是在进行复制粘贴,因此生成的代数是扭曲的、不自然的,我们将这种现象称为过拟合和缺乏泛化能力。
为了规避这个问题,我们做了三项努力:1)我们引入预训练的文本到图像扩散作为基础模型,以提高泛化能力,因为它已经暴露于数十亿个图像文本对。 这使模型能够推测目标姿势的某些在源图像中不可见的区域。 2) 请注意,PGPIS 任务的文字描述不可用。 为了促进有效的微调而不影响泛化,我们冻结了扩散模型中的大多数参数(98.8%),从而迫使所提出的 PRD 学习粗粒度语义,就像 CLIP 文本编码器提供的那样。 3)与以前的方法相反,为了将细粒度的外观和姿势信息解耦,我们努力将多尺度卷积特征作为偏差项编码到交叉注意力中。 多尺度偏置是必要的,因为假设U-Net块中每个尺度的条件提示都是相同的,仅由PRD学习的粗粒度提示可能缺乏纹理细节的保留。 我们不对有偏差的查询(等式(4)中的)进行训练,并采用零卷积设计,都是为了降低 HGA 模块的学习速度,从而促进从粗到细的外观控制,如前所述在手稿中。
| Strategy | FID | LPIPS | SSIM | PSNR | ||
| disabled | 1.0 | 1.0 | 8.143 | 0.2000 | 0.7055 | 15.753 |
| appearance only | 1.0 | 2.0 | 8.334 | 0.1921 | 0.7131 | 16.429 |
| pose only | 2.0 | 1.0 | 7.580 | 0.1770 | 0.7256 | 17.611 |
| both | 2.0 | 2.0 | 6.804 | 0.1519 | 0.7378 | 18.235 |
| both | 3.0 | 3.0 | 7.423 | 0.1746 | 0.7250 | 17.706 |