迁移学习的广义用户表示
摘要。
我们提出了一种用于大规模推荐系统中用户表示的新颖框架,旨在以通用方式有效地表示不同的用户品味。 我们的方法采用结合表示学习和迁移学习的两阶段方法。 表示学习模型使用自动编码器将各种用户特征压缩到表示空间中。 在第二阶段,下游特定任务模型通过迁移学习利用用户表示,而不是单独管理用户特征。 我们进一步在表示的输入功能上增强了这种方法,以提高灵活性并实现对用户事件的反应,包括近实时的新用户体验。 此外,我们提出了一种新颖的解决方案来管理该框架在生产模型中的部署,允许下游模型独立工作。 我们通过大规模系统中严格的离线和在线实验来验证我们的框架的性能,展示了其在多个评估任务中的卓越功效。 最后,我们展示了与其他方法相比,所提出的框架如何显着降低基础设施成本。
1. 介绍
近年来,在线音乐流媒体服务日益占据主导地位。 这些服务向数亿用户提供包含数千万首音乐曲目的目录。 虽然其他在线平台利用允许个性化目录导航和发现首选内容的技术(Zhang 等人,2019;Amatriain 和 Basilico,2016;Bell 和 Koren,2007),但用户经常与音乐流媒体互动以不同于其他推荐系统的方式提供服务(Schedl 等人,2018;Schedl,2019;Wang 等人,2018;Cebrián 等人,2010;Vall 等人,2017)。
传统的用户建模通过显式和隐式反馈来捕获和量化潜在的用户兴趣(Koren等人,2009;Batmaz等人,2019;Isinkaye等人,2015;Li和Zhao,2020),但是这些系统当应用于音乐领域时,很容易出现扩展问题。 强大的目录受到季节性影响、外生事件以及不断添加新音乐曲目(改变曲目之间的感知关系)的影响。 这些曲目通常很短,并且可以在聆听会话中一起播放许多曲目,通常没有任何反馈(Schedl 等人,2018)。 用户在重温自己喜欢的曲目和发现新音乐以丰富其聆听体验方面存在利益冲突(Zhang 等人,2012;Schedl 和 Hauger,2015)。 此外,由于交互和消费是推荐系统训练的主要来源,缺乏这些信号使得向新用户的推荐成为一项本质上具有挑战性的任务(Yürekli 等人,2021;Wei 等人,2021) 。 尽管用户建模方面最近取得了进展,但捕获这些用户兴趣并对其进行建模仍然是大规模音乐流媒体服务中的一项具有挑战性的任务。
一种方法是独立处理每个推荐任务:检索可以直接根据长期品味建模;提供多样化的聆听体验将是一个多目标排名问题;新用户可以使用来自粗略早期信号的强盗式方法。 然而,这些模型会隐式地相互影响,而不考虑非线性效应,并且每个额外的模型都会增加基础设施的复杂性和总体成本。 此外,从用户的角度来看,当使用不同的模型时,这可能会导致体验脱节,这对于用户使用流媒体服务的早期体验尤其重要(Passino 等人,2021 年;Kula,2015 年).
截至撰写本文时,人们对所谓的基础模型的兴趣日益浓厚,这些基础模型的灵感来自于通过大型语言模型进行自然语言处理的努力。 这些模型旨在以最小的适应新领域的方式来服务无数的任务。 我们采用这个概念,并提出了一个在超大规模工业音乐推荐系统中用于用户表示的新框架。 在此框架中,各种下游任务继续独立开发,同时保持一致的基础用户表示,以适应新用户和看不见的任务。 通过利用潜在嵌入作为通用接口,考虑到它们易于有效分发,我们能够提供这样的表示。 我们在现实世界的音乐流数据集上展示了我们的结果,并演示了每个模型组件如何有助于在建模用户方面实现最佳结果。 在本文中,我们详细阐述了我们的模型如何构建有效的用户表示,解决该框架所隐含的挑战,并演示该设计如何捕获整体用户兴趣以及当前偏好。
我们的贡献旨在回答以下研究问题:
-
•
[RQ1] 我们如何有效地设计一个模型来捕获大规模推荐系统中丰富的用户表示,该系统包含核心用户兴趣,同时适应各种下游任务?
-
•
[RQ2] 我们如何设计一个适用于冷启动用户并随着用户在平台上更加成熟而改进的用户表示模型?
-
•
[RQ3] 我们如何设计有效的评估策略来衡量向量嵌入空间的功效,以确保我们能够为各种下游任务提供价值?
我们通过设计一个两阶段流程来解决这些问题。 我们开发了一个自动编码器模型,该模型吸收各种用户特征,例如收听历史记录、人口统计数据和上下文信息。 此阶段的主要目标是学习丰富的用户表示,以有效捕获和总结用户兴趣。 为了进一步使这些表示适应各种应用,我们设计了第二阶段,以利用迁移学习范式中学习到的表示。 最后,我们在实证研究部分展示了我们的方法相对于基线的优势。
2. 相关作品
现代推荐系统已经成为许多面向用户的平台的核心引擎。 协同过滤方法是过去几十年来最成功的方法之一。 通过假设具有相似品味的用户消费相似的商品,他们能够根据协作信息提供推荐。 同样,矩阵分解方法已成功应用于整个行业的许多产品和应用(Hu等人,2008;Mnih和Salakhutdinov,2008)。 尽管它们效率很高,但它们本质上是线性的,这限制了它们的推荐能力。 多年来,深度学习的关键进展显着提高了推荐任务的成功率(Gopalan 等人,2015;Liang 等人,2018;Xiao 等人,2015;Koren,2009;Zhou 等人,2019;Sachdeva 等人,2019;张等人,2019)。
推荐系统通过学习隐式和/或显式反馈来向用户提供个性化推荐(Koren 等人,2009;Batmaz 等人,2019;Bell 和 Koren,2007;Amatriain 和 Basilico,2016)。 基于内容的算法利用特定于项目的信息,而混合模型结合协作和基于内容的方法来进一步改进推荐(Aggarwal,2016;Kouki 等人,2015;Çano 和 Morisio,2017)。 自动编码器架构及其变分适应是无监督方法,可以学习未标记数据中的潜在主题。 在推荐系统中,这种属性对于理解潜在的用户兴趣和学习基本的用户-项目交互模式特别有用(Liang 等人,2018;Fazelnia 等人,2022)。 虽然这些模型以无监督的方式熟练地学习用户兴趣,但它们对下游任务固有的不灵活性需要进行额外的修改,以针对特定的推荐目标进行定制。
过去几年,迁移学习在推荐系统应用中变得越来越流行(Fu 等人,2023;Yuan 等人,2021)。 该方法通过预训练和微调阶段解决数据不足和稀疏的问题,取得了良好的效果(Li等人,2009;Pan等人,2011,2010)。 为了学习能够捕获广泛用户兴趣并将其无缝集成到下游应用程序的强大用户表示,我们开发了一个迁移学习框架。 这涉及最初从用户和跟踪特征中学习表示,然后使它们适应各种下游任务。 与最近的作品(Pancha等人,2022;Xia等人,2023)不同,这些作品单独管理用户特征并需要频繁地重新训练模型,我们采取了根本不同的方法,通过构建广义的用户表示和然后利用迁移学习来完成各个任务。 通过使嵌入空间稳定,我们将重新训练频率减少到每隔几个月一次。
这些基础模型通常对输入进行标记,从而形成包含数万个项目的词汇空间。 然而,音乐推荐系统处理由数千万首曲目组成的极其大规模的空间,这使得部署这些模型变得更具挑战性(Afchar等人,2022;Schedl等人,2018;Bonnin和Jannach,2014;Cebrián等人,2010;瓦尔等人,2017)。 为了解决这个问题,我们设计了一个预处理步骤,其中我们通过模态编码器学习轨道的嵌入。 此步骤使我们能够避免显式使用轨道 ID,并显着提高框架的可扩展性。
冷启动用户问题是这些面向用户的服务中最具挑战性的方面之一(Yürekli 等人,2021;Wei 等人,2021)。 缺乏来自新用户的隐式或显式信号给传统推荐系统带来了新的挑战。 尽管冷启动推荐是一个经过充分研究的问题,但之前的大多数工作都集中在冷启动项目上(Panda and Ray,2022)。 人们提出了整合外部信息源的方法,例如社交网络连接(Nie等人,2014)或跨域融合(Zhang等人,2018)。 虽然很有希望,但由于用户匿名和隐私保护政策,这些方法无法应用于我们现实世界的音乐流媒体服务。 在我们的框架中,我们通过近实时更新和批量管理,将冷启动用户的平台加入信号以及已建立用户的所有功能纳入模型中。 这使我们能够显着改善冷启动用户的结果,而不会影响已建立用户的性能。
3. 方法
在本节中,我们从介绍符号开始详细介绍我们的方法。 我们描述了框架的各个组件,并总结了用户表示模型的训练过程。 最后,我们展示了该模型的实现细节。
3.1. 符号
令 为用户集,而 为轨道集。 对于每个用户,我们将特征表示为,其中表示输入特征空间的维度。 让 表示存在于表示空间 中的用户 的用户表示。 为了有效地学习和压缩信息,我们设置。
不失一般性,我们假设我们有一个由用户曲目交互组成的音乐流数据集。 对于每个用户 , 是所有特定于用户的信息(包括上下文、人口统计、亲和力和活动)的串联。 有关这些功能的更多详细信息请参见 3.3 节。 是用户 与之交互的所有轨迹的集合。 对于每个轨迹,我们将轨迹特征定义为。
3.2. 建筑学
在本节中,我们将介绍用户表示模型架构的详细信息。 图1展示了模型架构的概述。 最初,模态编码器对轨道特征进行预处理,如下面 3.2.1 节中所述。 随后,与其他用户特征结合,它们形成输入特征,并经过主模型训练以产生用户表示。 然后可以将这些学习到的表示用作适合各种推荐任务的特征输入。 我们在第 4 节中提供了最后一部分的更多详细信息。
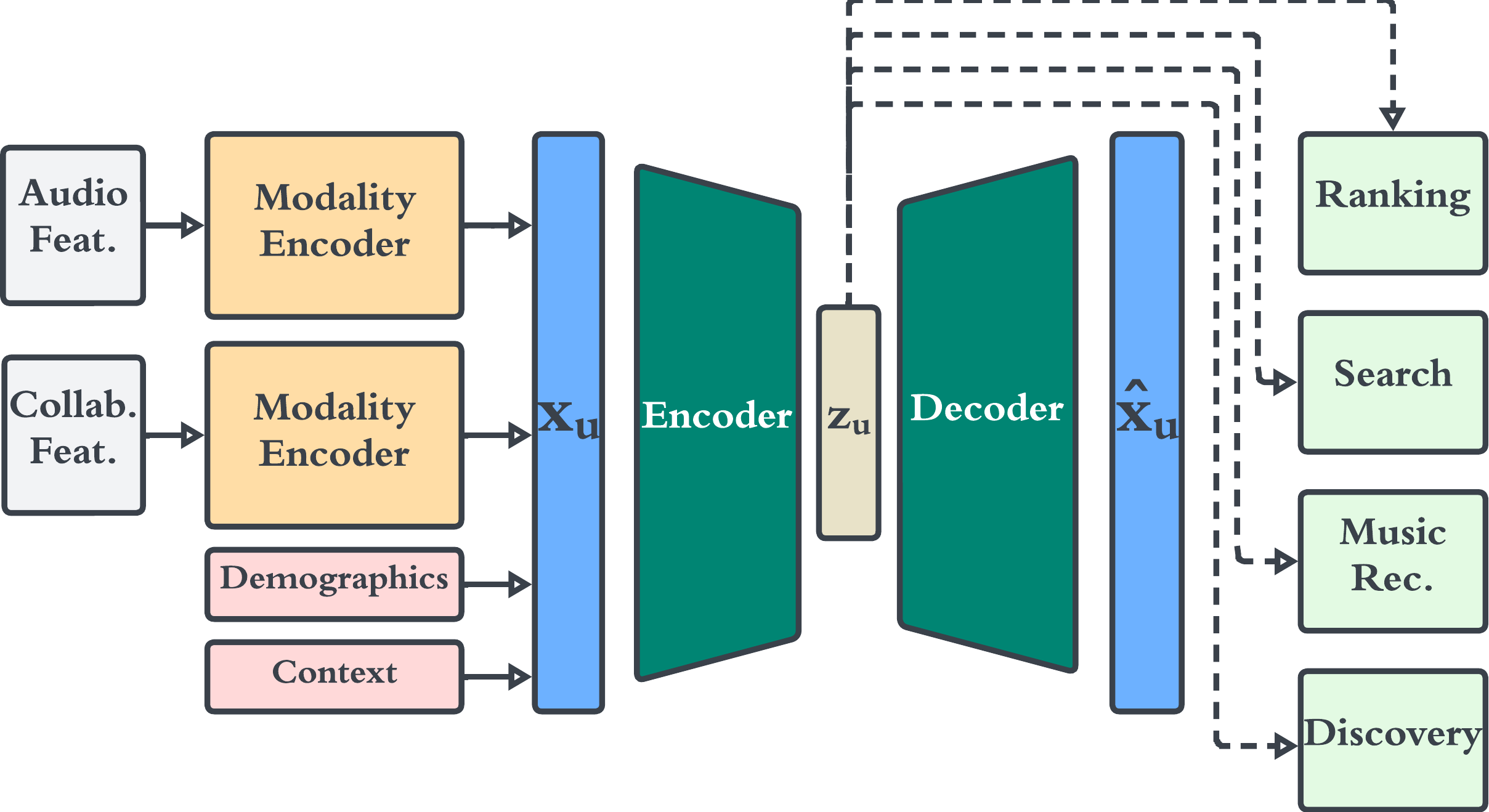
3.2.1. 模态编码器
我们的建模框架的第一步是处理轨道空间。 如前所述,考虑到轨道空间的规模,此步骤是必要的。 轨道音频在模态编码器组件中进行处理,以生成将轨道映射到音频嵌入空间的 80 维实值向量。 此外,我们假设如果两个曲目经常一起出现在播放列表中,则它们具有潜在的相似性,并且比嵌入空间中的两个随机曲目更接近。 为了利用这些信息,我们让每个轨道由在协作模态编码器中获取的另一个 80 维实值向量表示。 这些曲目表示基于播放列表中的曲目共现,这意味着如果两个曲目同时出现在播放列表中,则它们可能在嵌入空间中彼此靠近,反之亦然。 这些特定的嵌入空间之前已被证明非常适合音乐推荐(Mehrotra 等人,2018)。
3.2.2. 输入特性
在使用模态编码器进行预处理步骤之后,我们准备自动编码器模型的输入特征。 我们构建用户 的输入特征并进行向量化,如下所示:
| (1) |
和 分别显示用户 所使用的音频嵌入的聚合和曲目的协作嵌入。
3.2.3. 用于核心用户表示的自动编码器
我们的模型由编码器和解码器组成,它们一起将用户信息压缩到表示空间中。 自动编码器架构以最佳方式从输入特征中学习并将核心用户信息捕获到表示空间中。 该模型的目标是找到 ,从而最小化损失函数:
| (2) |
其中 为最佳编码器 。
我们总结了算法1中的总体训练步骤。 我们对随机批次的用户使用随机优化来训练 autoencdoer 模型并生成用户表示。 我们注意到和。 有关训练的更多详细信息将在下一节中介绍。
3.3. 模型实现
我们展示了我们模型的实现细节。 我们还展示了如何使用户表示可推广,这在几个下游任务中发挥着关键作用。
3.3.1. 训练数据集
离线训练数据集是使用来自我们全球用户群的内部流信息创建的,包含目录中超过 3000 万个项目的 6 亿多个用户的实例。
3.3.2. 输入特性
我们希望输入特征能够捕捉音乐品味的短期和长期趋势,并允许模型同时学习这两种趋势。 我们的功能经过精心设计,使得用户表示可以概括,以在任何给定时间捕获对用户的整体理解。 考虑到这一点,我们的功能如下:
-
•
模态编码器输出不同时间范围内的嵌入。 我们在 1 周、1 个月和 6 个月内汇总这些嵌入。 根据 3.2.1 节,我们使用两种不同类型的模态编码器嵌入,一种是处理音频声学信息的嵌入,我们用捕获播放列表曲目共现信息的嵌入来补充它学习合作兴趣。
-
•
我们将其与人口统计信息(例如注册国家/地区)以及有关所用设备和活动(例如赛道播放次数)的信息结合起来。
-
•
为了考虑新用户的冷启动信号,我们将上述特征与艺术家和语言的新用户入门信息结合起来。
使用基于多个时间范围的特征的一个关键优势是,我们的模型可以保持对用户的“核心”理解,同时对最近的品味变化敏感。 对此的更多研究可以在我们之前的工作(Fazelnia等人,2022)中找到。 图 2 显示了嵌入功能的图解版本。
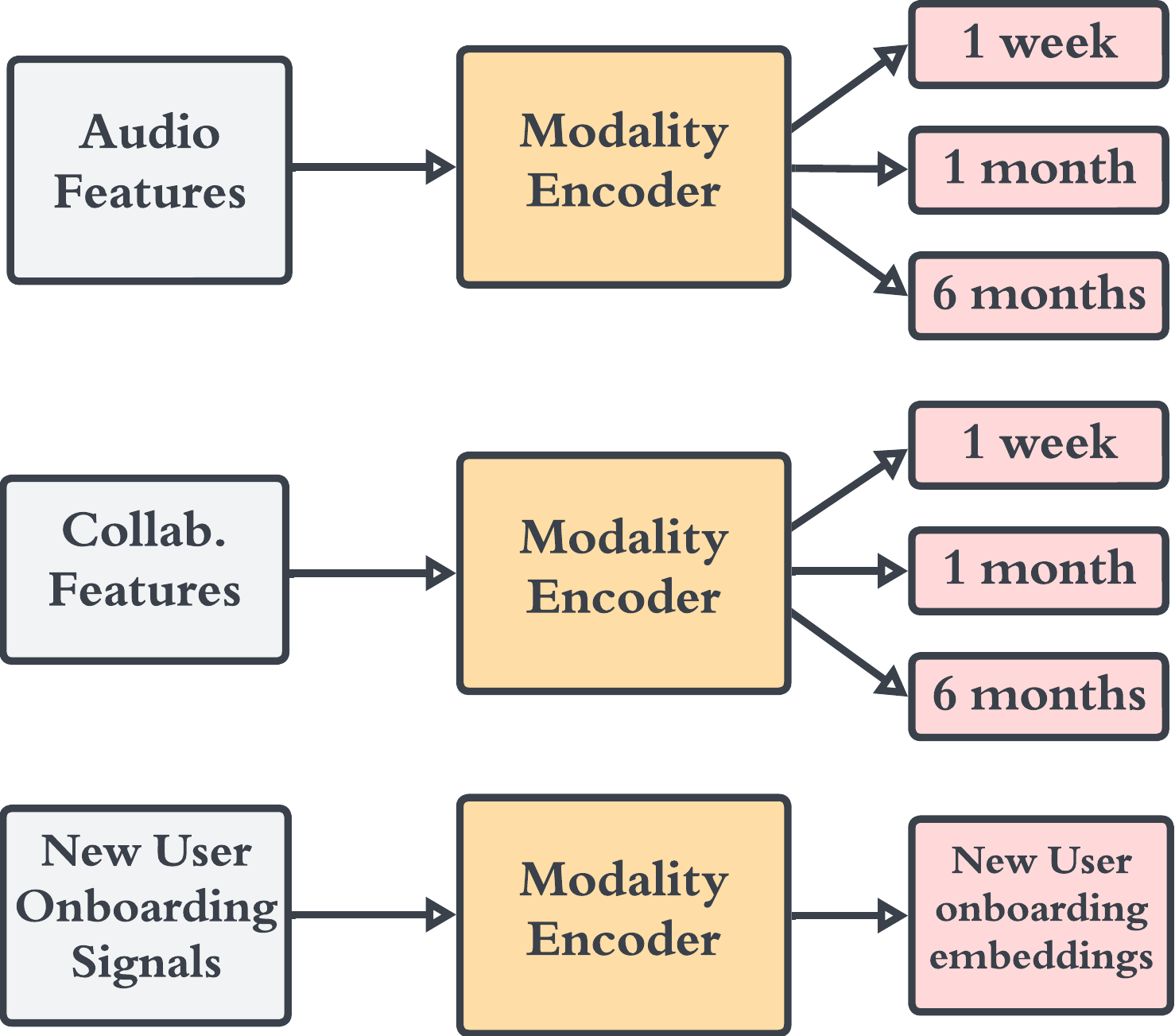
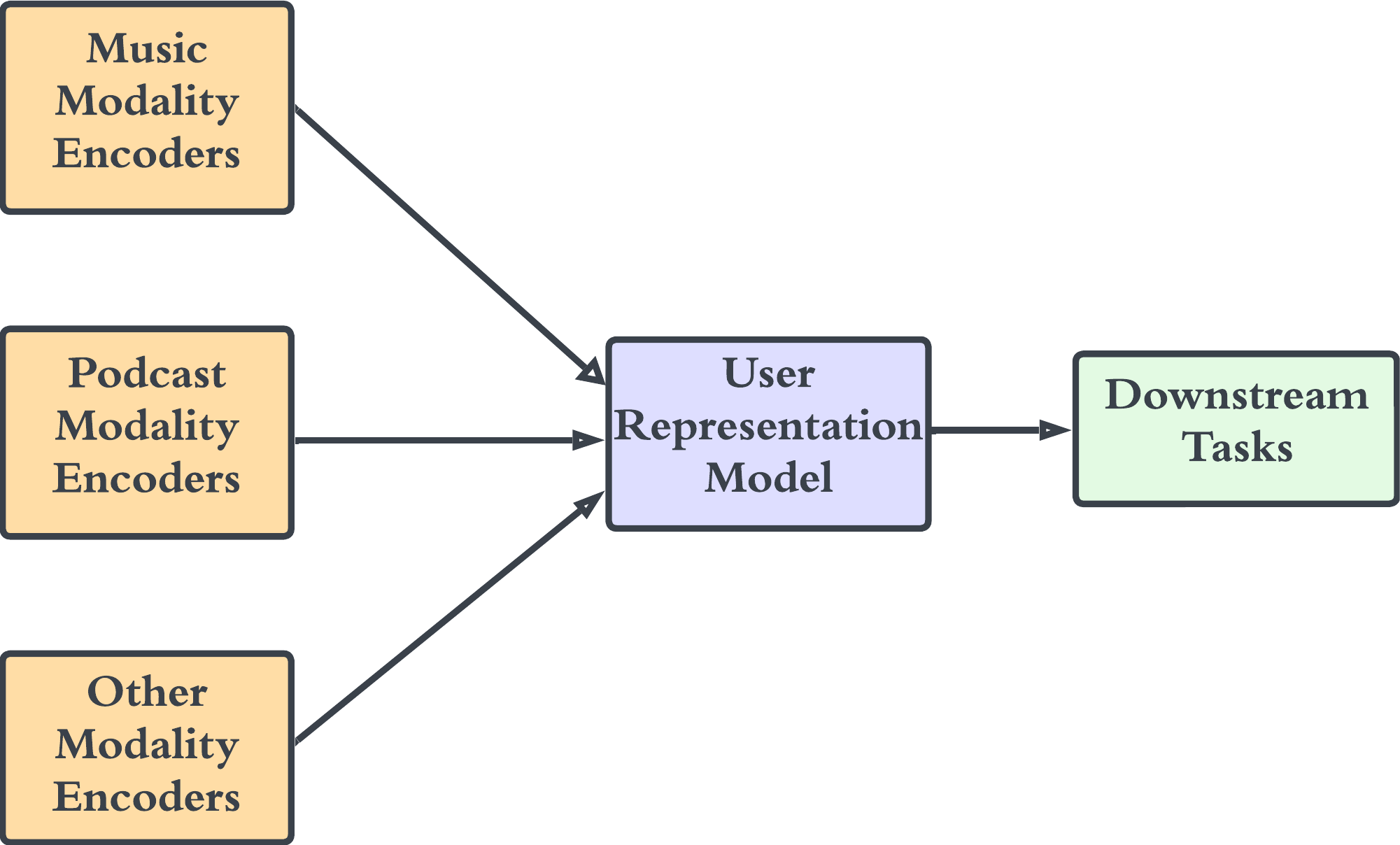
该系统使我们不仅可以接受不同时间帧的音乐流信号,还可以补充来自更多模态编码器的信息,例如平台上其他内容信息的嵌入,例如播客收听。 111Modern streaming platforms often host various content types including music and podcasts这使得用户表示在推荐任务的各种内容类型中普遍有用。 详细信息见图3。
3.3.3. 模型详细信息和重新训练节奏
自动编码器模型的编码器和解码器是由多个隐藏层组成的深度神经网络。 我们通过使用小的 dropout 进行正则化,以确保泛化并避免过度拟合。 我们在编码器和解码器中使用缩放指数线性单元(SELU)激活函数,因为它比其他激活函数提供更好的收敛性。
重建损失允许我们更新模型的权重,以总结用户特征。 这与更喜欢下一项预测的模型架构形成鲜明对比。 这确保我们通过总结来全面了解用户,而不是仅仅擅长预测下一步行动。 为了确保我们全面了解用户,我们评估了多个任务的用户表示,包括预测未来时间窗口中聚合收听的曲目。 详细信息请参见第 5 节。
该模型输出 120 维的用户表示,可用于所有下游推荐任务。
该模型的训练与下游任务隔离,并且每隔几个月重新训练一次。 其重新训练的时间表与上游模态编码器重新训练同步。 一旦用户模型完成再训练,下游模型就会执行自己的再训练。 有关迁移学习模型链稳定性和批量同步的更多详细信息,请参见第 4.4 节。
我们结合批量推理和近实时推理来进行用户表示。 批量推理管道每天为 6 亿多用户运行一次。 根据用户活动,近实时推理全天会发生多次。
4. 迁移学习方法
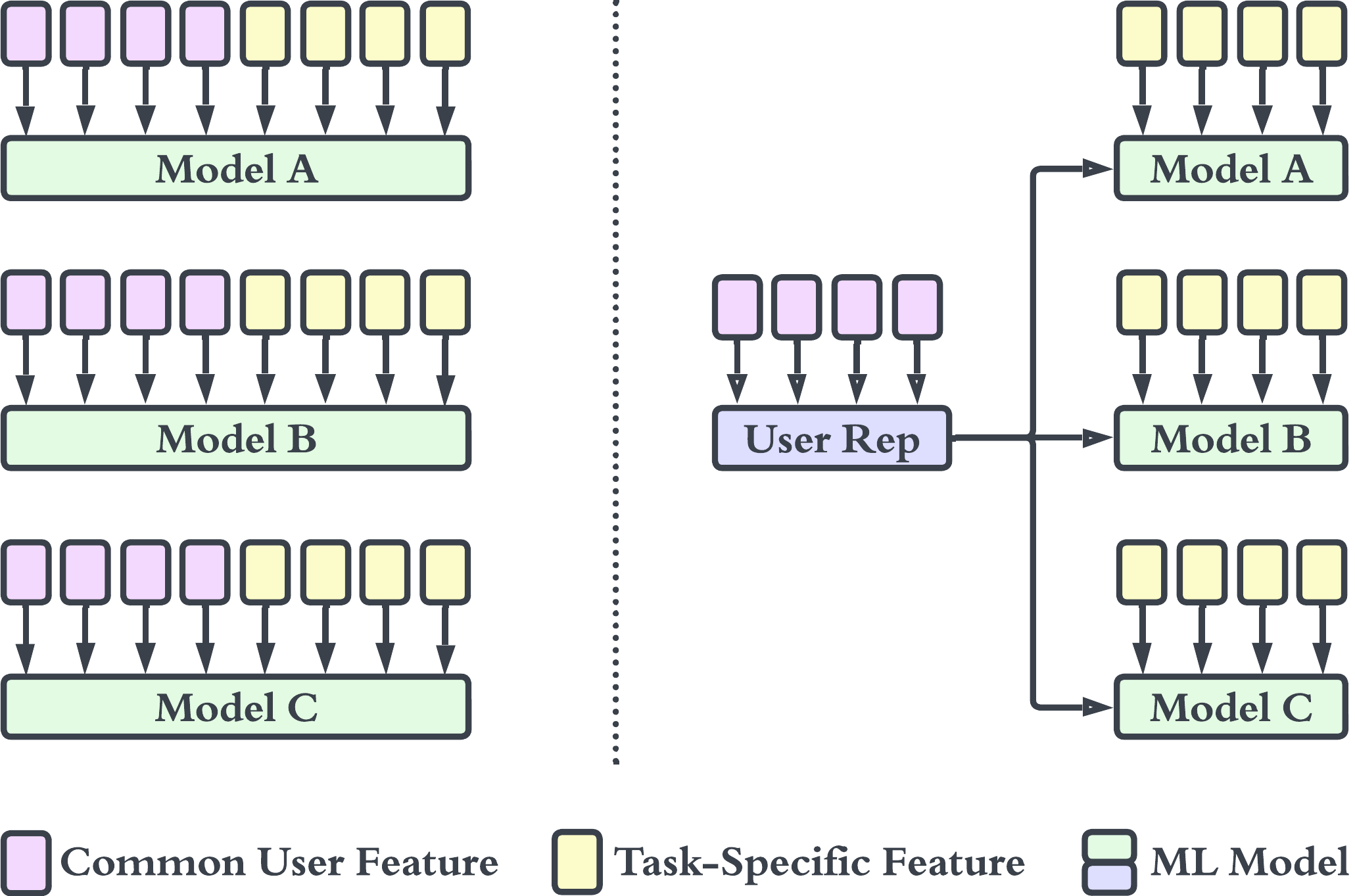
迁移学习可以重用从预先训练的模型中获得的知识来解决下游任务中的新问题,例如排名、搜索、音乐推荐和发现,如图 1 所示。 本节介绍了我们针对大规模推荐任务通过用户表示实现迁移学习的方法。 图4描述了需要用户信息的三个任务。 如果没有迁移学习(左),常见的用户特征将被单独策划并输入到每个模型中。 通过迁移学习(右),常见的用户特征被压缩为通用的用户表示,可以直接输入到下游任务模型中。 通过利用广义的通用用户表示而不是单个用户特征,我们可以减少下游模型所需的特征工程量和模型复杂性。
4.1. 用例
我们提出了推荐任务中迁移学习的三个生产用例,其中用户表示提供了价值。
分类模型
第一个应用是分类模型。 分类模型在需要系统了解内容的亲和力或参与可能性的任务中非常有用。 此类分类器的一个示例是艺术家偏好模型。 它是一个二元分类器,可以预测用户关注艺术家的可能性。 该模型的输出被团队用来对艺术家进行排名,以在播放列表的封面艺术中向用户展示以及在播放列表个性化任务中挑选艺术家。 全面捕捉用户兴趣并快速响应用户兴趣的用户表示对于成功至关重要。
候选生成模型
第二个应用是候选生成模型。 候选生成模型在推荐系统的前几个阶段非常重要,并且涉及通过最近邻居查找来查找与用户接近的多个项目。 候选生成模型的一个示例是两塔模型,用于挑选推荐项目(Covington 等人,2016)。 第一个塔获取用户特征,第二个塔获取项目特征,然后将这些特征传递到密集神经网络的多个隐藏层。 该模型使用两座塔最后一层嵌入的点积进行调整,将它们带入相同的向量空间,以便在候选生成任务中进行最近邻查找。 具有冷启动意识的用户表示对于确保我们能够识别正确的项目以在新用户的前几个会话中向其显示非常重要。
项目排名模型
第三个应用程序是项目排名模型,用于确定应用程序各个部分中内容片段的顺序。 一个示例是排序模型,它对项目执行列表排序并按个性化顺序重新排序。 排名模型可以拥有更简单的架构,同时获得用户表示的所有功能。 在此类模型中,快速响应不断变化的用户品味的用户表示至关重要。
考虑到这些用例,用户表示的特定质量和特征是有价值的。 这些在其余小节中列出。
4.2. 反应能力
用户表示应该对用户的聆听行为和交互做出快速响应。 批量推理系统需要 2-3 天才能响应口味变化,这对于各种下游任务来说还不够快。 任何时间点的表示都应反映我们掌握的有关用户品味的最新信息,并随着活动不断更新。 为了快速响应用户的收听行为和交互,我们使用近实时 (NRT) 推理。
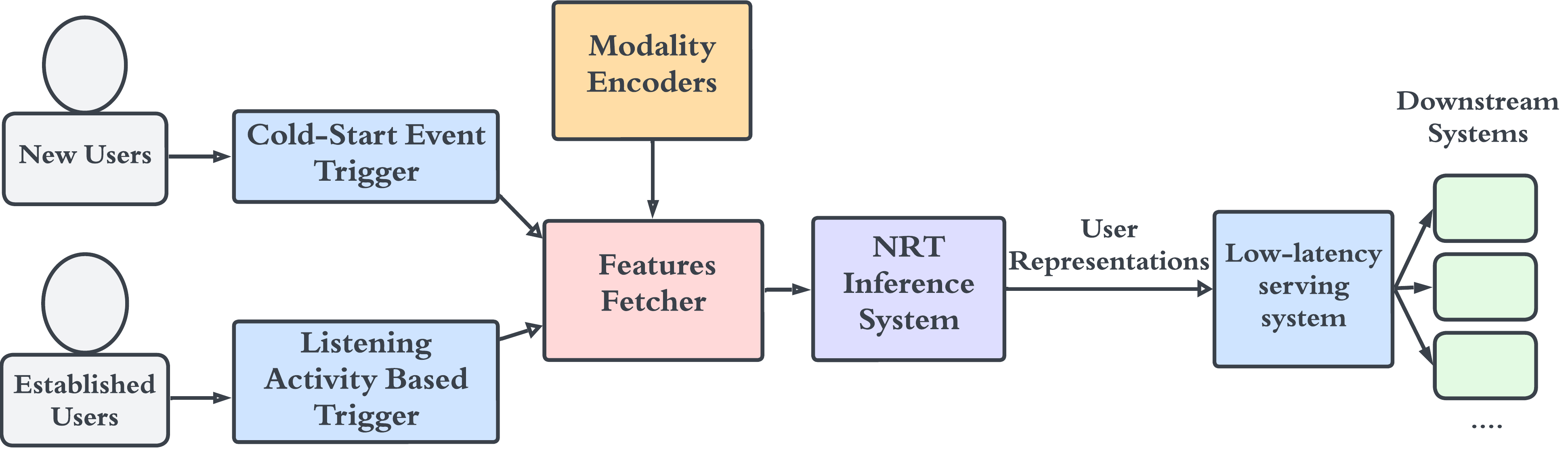
构建事件驱动系统来支持 NRT 推理,使表示能够快速响应用户的品味。 如图5所示,我们有事件流作为触发器并携带基于用户监听活动的输入功能。 该事件队列由我们的后端服务订阅,这些服务将事件预处理为模型可使用的特征,并近乎实时地进行推理。 用户表示被摄取到低延迟服务系统中,该系统提供对所有下游服务的最新表示的访问。 我们将 NRT 和批量推理结合起来,以确保我们为活跃用户以及在一段不活动后返回平台的用户生成表示。
4.3. 冷启动意识
用户表示应该对新用户和老用户一样有效,并且随着时间的推移会变得更好。 在我们的平台上,新用户可以在入职过程中选择艺术家和/或语言。 然而,只有一部分新用户完成了完整的入职流程。
如图5所示,我们使用单独的事件触发器和启动信号。 在入职期间选择的艺术家将被传递到模态编码器,模态编码器将它们转换为嵌入。 语言选择将转换为多热编码列表。 新用户的嵌入是通过与已建立用户相同的模型创建的。 下游模型可以通过我们的低延迟服务系统立即使用嵌入内容。 当新用户加入信号可用时,我们将这些信号与人口统计特征一起使用。 在没有新用户加入信号的情况下,我们会估算这些信号并使用人口统计和其他静态特征。
随着用户在平台上的地位越来越高,我们会在几个月内不断推断新用户选择以及其他收听历史记录。 此后,新用户引导信号不再在用户推理中发挥作用。 这是为了确保个性化体验从用户冷启动到成熟过渡。
4.4. 稳定
在迁移学习中,“上游”模型的输出被输入一个或多个“下游”模型,有效地形成有向无环图。 出于一般性考虑,请注意这些是通用术语,模型既可以充当某些模型的“下游”,也可以充当其他模型的“上游”。 为了使用户表示模型普遍用于迁移学习,用户表示及其各自的模态编码器应该存在于“稳定”向量空间中。 稳定的向量空间是这样一种空间,其中项目嵌入仅在初始训练后添加或更新,而不会显着改变各个向量空间维度的潜在含义。 与每天重新训练的向量空间模型(例如,为了添加和更新项目)相比,下游模型可以安全地解释稳定的向量空间,而无需将下游模型重新训练为新模型物品就产生了。 然而,为了考虑模型漂移、特征和超参数更新等,即使是稳定的向量空间也需要重新训练(Polyzotis 等人,2017),尽管频率要低得多。 因此,迁移学习带来了一个挑战,即上游模型的更改需要重新训练下游模型以保持兼容性。 如果上游模型被重新训练,下游模型也必须效仿,以避免由于数据漂移而导致模型失败或不可预测的结果(Polyzotis 等人,2017)。 为了解决这个问题,我们提出了“批量管理”,这是一种确保迁移学习链中模型之间同步的策略。
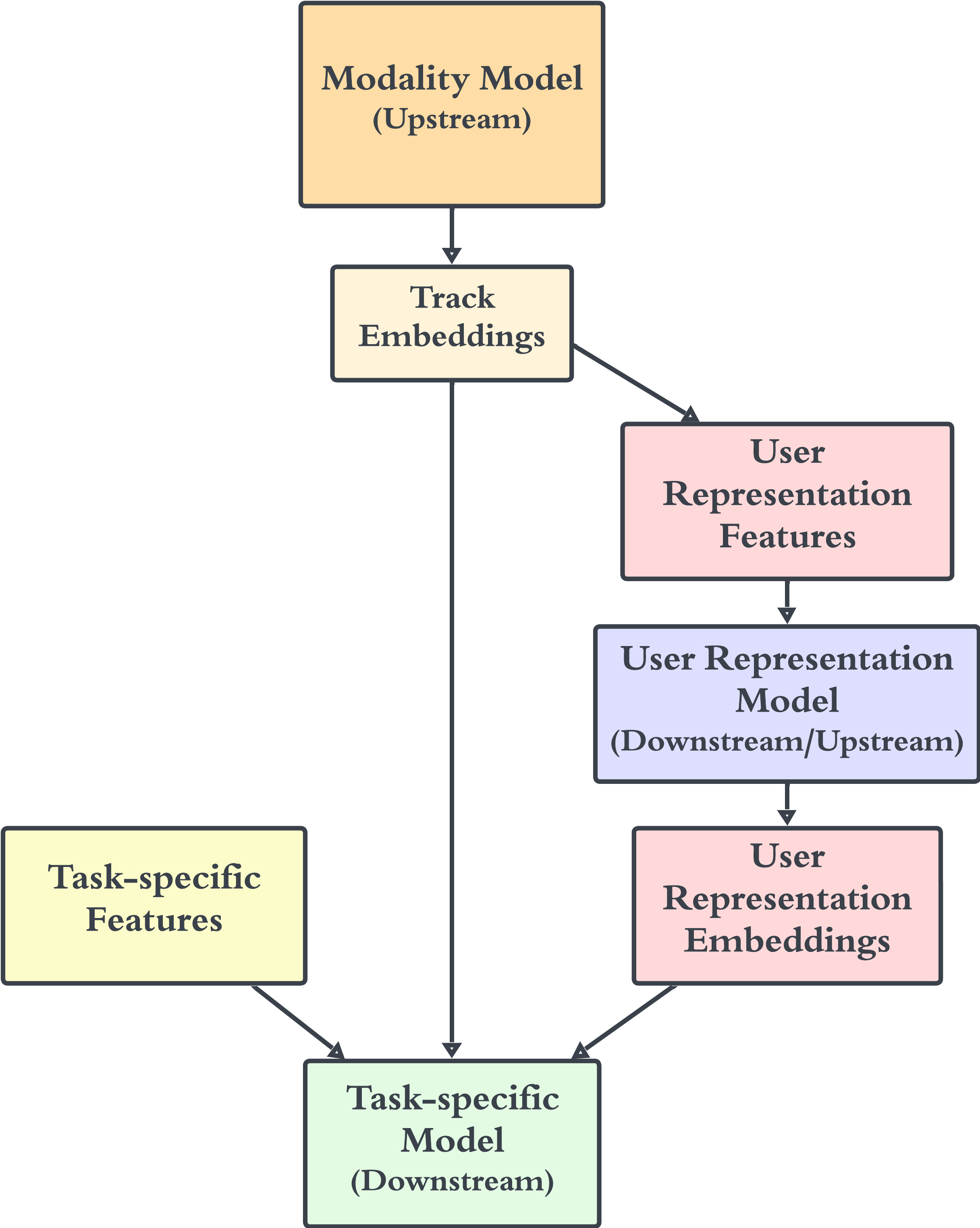
图6说明了一个常见的模型链:模态编码器生成轨道嵌入,并将其输入到用户表示模型中。 由此产生的用户表示与轨道嵌入和其他特定于任务的功能一起进一步输入到特定于任务的下游模型中。 重新训练模态嵌入模型需要随后按特定顺序重新训练用户表示模型和特定于任务的模型。
“批量管理”策略的关键方面如下:
-
1.
批次识别:重新训练嵌入/向量空间模型会产生一个带有跟踪标识符的新“批次”,允许跟踪向量空间维度的变化。
-
2.
同步:迁移学习链中的每个模型都是同步的。 其各自上游模型的模型再训练。
-
3.
Upstream Retrains:模型可以根据需要独立重新训练;然而,当任何上游模型被重新训练时,链中位于其下游的所有模型都必须自动重新训练。
-
4.
一致比较:下游模型应该只比较同一上游批次内的嵌入。
-
5.
训练和推理:下游模型必须使用相同的上游批次进行训练和预测,以确保一致性。
-
6.
持续生产:生产中的模型可以在重新训练期间继续做出最新的预测。
为了管理复杂性和资源消耗,我们将每个模型限制为两个并发批次 - “当前”和“旧”批次。 当模型完成训练时,会发生“批次轮换”,将新模型推送到当前批次,并将上一个批次轮换到旧版。 上游批次轮换后,下游模型切换为使用旧批次进行离线和/或在线推理,同时对当前批次进行重新训练。 一旦重新训练完成,下游模型就会切换回使用当前批次进行生产。
这种编排策略可适应各种用例,例如批量推理、在线推理以及带有在线更新的批量推理。 虽然实施批次管理还存在其他注意事项,但它们超出了本文的范围。
5. 实证研究
我们进行了广泛的评估,以展示我们的框架对于冷启动用户以及跨多个任务和基线的已建立用户的优势。
5.1. 方法
为了回答第 1 节中的上述研究问题,我们将评估方法分类如下:
-
1.
为了回答RQ1在捕获用户兴趣的同时适应下游任务,我们考虑未来听力预测的基本推荐任务。 此任务类似于许多下游模型的目标。 我们还评估下游生产模型,以验证我们对特定任务的迁移学习假设。
-
2.
为了回答关于捕获冷启动用户兴趣的RQ2,我们修改了未来的收听预测任务以反映对冷启动用户最重要的时间线。 我们进一步对完成入职流程的用户和未完成入职流程的用户进行分析。
-
3.
为了回答RQ3设计有效的评估策略来衡量嵌入空间的功效,我们使用基于集群的评估构建了一个内在度量。 这确保了用户表示向量空间本身对于从候选生成到排名的异构下游模型都很有价值。
5.1.1. 评价
我们提出了三种用于验证我们假设的评估。
未来收听预测
此评估的目标是预测用户在接下来的 小时或几天内收听的曲目。 我们设置此评估来预测 上的聚合轨迹,而不是预测下一个项目或项目序列。 这是为了确保我们全面捕获用户的兴趣。 我们在一个简单的分类器模型中使用用户表示,该模型经过训练可以预测未来的收听情况。
我们将其表述为二元分类问题。 我们在评估数据集中执行随机负采样,以创建相同数量的正例和负例。
对于老用户,我们会调查未来 7 天内的表现,以全面、总体地捕捉当前的兴趣。 对于冷启动用户,我们会调查注册后 4 小时内的性能。 其目的是衡量用户加入后的初始会话期间以及仍处于冷启动模式的短时间内推荐的成功程度。
生产模型下游任务
为了验证我们的模型在迁移学习案例中的优势和功效,我们评估了真实生产模型上的用户表示。 我们对此模型进行了多次离线实验,并比较了迁移学习的基础设施优势。
基于聚类的评估来查找相似用户
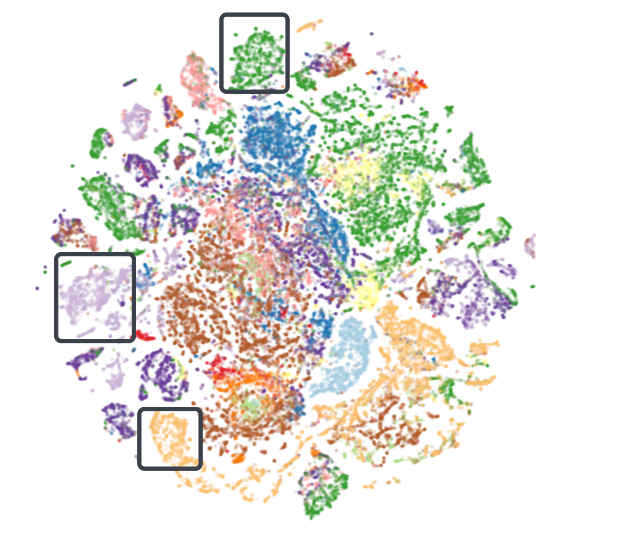
该评估本质上使用表示空间中用户的最近邻查找来评估嵌入。 我们在这个空间内形成集群,并检查表征是否能够识别和捕获它们。 我们选择随机用户样本并进行近似最近邻检索以找到前 50 个邻居。 然后,我们使用归一化折扣累积增益 (nDCG@50) 作为指标来测量这些邻居与预定义集群的重叠程度。 该评估的简化图如图7所示。
5.1.2. 数据
我们使用来自全球用户群的音频流信息创建离线训练数据集。 我们的评估数据集由从全球用户群中随机抽样的几百万用户组成。 这些用户是根据注册国家/地区、免费与高级状态以及注册后天数等属性进行抽样的。
5.2. 结果
我们在本节中介绍实证研究的结果。 我们首先展示已建立用户和冷启动用户在未来听力预测任务上的 ROC 曲线的准确性和 AUC,对这一部分进行分解。 接下来,我们使用用户表示来呈现下游生产模型的离线和在线结果。 接下来,我们使用各种聚类启发法提出基于聚类的 nDCG@50 评估。 最后,我们提出了输入特征的消融研究。
5.2.1. 未来收听预测
我们展示了已建立用户和冷启动用户的未来轨迹预测结果。
已建立的用户
对于已建立的用户,我们使用 7 天的窗口来预测未来的收听情况。 我们将用户表示与其他流行且相对可扩展的推荐系统基线进行比较,例如非负矩阵分解(NMF)(Zhang等人,2006)和基于深度学习的LightFM (Kula, 2015)模型。 我们还使用相同的分类器比较了用户表示的性能与收听历史记录中项目的平均嵌入的性能。 正如我们在表 1 中看到的,我们展示了现有用户在未来 7d 聆听中跨各种基线的改进。 这有助于我们通过类似于下游模型目标的基本任务来回答 RQ1。
| Comparison | Accuracy | AUC |
|---|---|---|
| vs NMF | +15.2% | +18.6% |
| vs LightFM | +26.2% | +37.1% |
| vs average embeddings | +1.8% | +1.6% |
冷启动用户
接下来,对于冷启动用户,我们使用 4 小时的窗口来进行未来的收听预测。 我们首先将我们的用户表示与新用户入职期间选择的艺术家嵌入的平均基线进行比较。 请注意,我们没有针对未完成入职流程的冷启动用户的嵌入。 对于这些用户,我们会使用针对用户人口统计的最热门曲目。 表 2 显示了冷启动用户的性能增益与基线。 可以看出,采用更统一的方法有助于显着提高性能。 这有助于我们回答 RQ2:我们是否抓住了冷启动用户的兴趣,包括那些完成和未完成入职的用户。
| Comparison | Onboarding Status | Accuracy | AUC |
|---|---|---|---|
|
vs popularity heuristic |
Completed |
+26.2% |
+27.0% |
|
vs popularity heuristic |
Not Completed |
+24.6% |
+24.7% |
|
vs average embeddings |
Completed |
+5.0% |
+5.1% |
5.2.2. 下游生产模式
我们用于评估的下游生产模型是艺术家偏好模型:预测用户关注艺术家的可能性的分类器。 有关此模型的更多详细信息将在第 4 节中介绍。
离线结果
为了进行比较,我们的基准是一个使用单独策划的用户特定功能的模型。 这些用户特征包括几个基于静态、活动和收听历史的特征。 我们将其与具有相同训练目标的模型进行比较,该模型通过迁移学习利用我们的用户表示,如图 4 所示。 从表 3 中可以看出,当用我们的用户表示替换所有单个用户特征时,我们展示了迁移学习的优势,AUC 提高了 3.6%。
| Model | Accuracy | AUC |
|---|---|---|
| Transfer Learning with User Rep | +3.8% | +3.6% |
在线结果
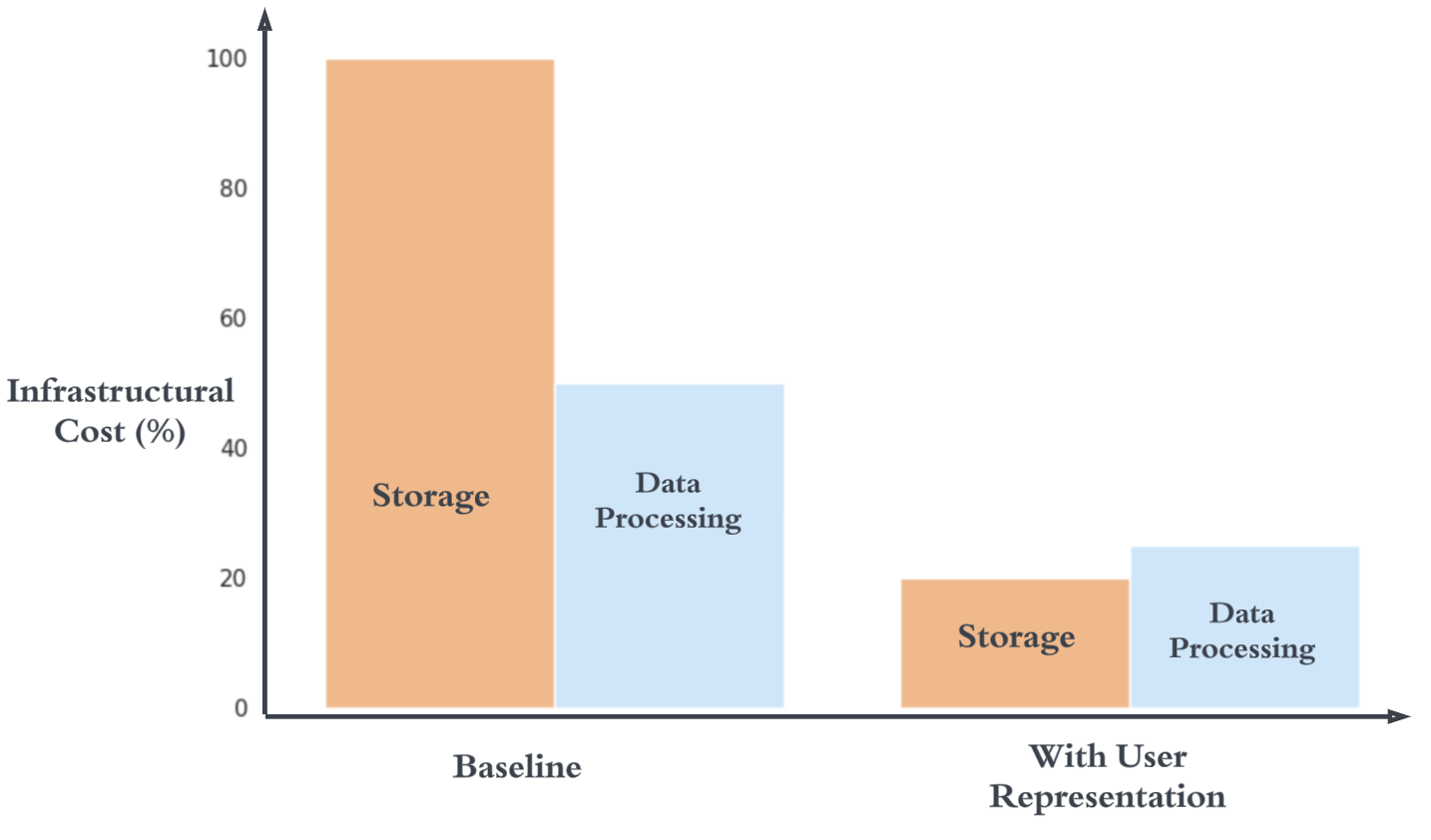
我们使用相同的设置进行了在线测试。 对于类似的性能,我们发现了显着的基础设施优势,包括减少特征存储和推理数据处理成本,以及更轻松的服务和随叫随到的复杂性。 我们还能够利用生态系统中现有的服务系统和其他集中式服务。 这带来了巨大的成本效益,如图8所示。 这些结果表明我们可以在下游生产模型中捕获用户的兴趣,从而帮助我们进一步回答 RQ1。
5.2.3. 基于聚类的评估
我们根据已知属性构建相似用户的集群,并使用用户子集的最近邻查找来查找重叠。 我们将几种类型的簇的 nDCG@50 与用户收听历史记录中项目的平均嵌入进行比较。 正如我们在表 4 中看到的,我们针对不同类型的用户集群的基线进行了改进。 这通过表明表示空间本质上有价值来帮助我们回答 RQ3。
| Cluster Heuristic | nDCG@50 |
|---|---|
| Same favorite artists | +2.9% |
| Same country of most listened artists | +5.5% |
| Same new user onboarding | +26.2% |
5.2.4. 消融研究
最后,为了研究相对特征重要性,我们对输入特征进行了消融研究。 模型的基线具有第 3.3.2 节中列出的特征。 我们删除特征以查看它们对模型的影响。
没有新用户加入信号
如果没有新用户引导冷启动信号,我们发现使用相同新用户引导创建的集群的 nDCG@50 下降了 13.8%。 如果没有引导信号,该模型解读新用户集群的能力就会降低。
没有模态编码器嵌入
如果没有模态编码器嵌入,我们发现 7 天内未来听力评估的 AUC 下降了 4.2%。 我们还发现,由相同喜爱的艺术家制作的集群的 nDCG@50 下降了 37.1%。 这些结果表明模态编码器嵌入对于系统的整体成功至关重要。
没有基于用户的静态功能
如果没有基于用户的静态特征(包括注册国家/地区),我们会发现 nDCG@50 下降了 12.1%,其中大多数收听艺术家来自同一国家/地区。
本节介绍了我们的结果以验证我们的假设。 为了回答 RQ1 和 RQ2,我们展示了通用用户表示如何帮助已建立的用户和冷启动用户在不同时间窗口完成未来的听力预测任务。 我们还展示了下游生产模型的离线和在线结果,显示基础设施成本大幅降低。 最后,为了回答 RQ3,我们使用各种聚类评估展示了用户表示在其嵌入空间中的功效。 通用用户表示现已部署在生产中,并用于为我们的全球用户群提供个性化内容。
6. 结论和未来的工作
在本文中,我们提出了一种在大规模音乐推荐系统中学习广义用户表示的新方法。 这些表示捕获了核心用户兴趣,并且可以使用迁移学习来适应各种下游任务。 为了实现在下游任务中有用的目标,我们通过快速适应用户品味的变化,使用户表示在近实时(NRT)中做出响应。 我们通过响应入职信号以及 NRT 中的人口统计数据,并使用相同的模型来推断新用户和老用户,从而使用户代表具有冷启动意识。 最后,我们使向量空间稳定,以允许下游模型每隔几个月重新训练一次。 我们提出了一种新颖的批量管理方法,以实现向量空间的稳定性,从而允许下游模型独立工作。 我们的方法的有效性已经通过一系列离线和在线实验得到验证。
虽然我们的重点是测试音乐推荐系统,但我们有可能将我们的方法扩展到更广泛的音频领域,包括播客和有声读物推荐。 除了音频推荐之外,在线新闻和电子商务等其他领域也在规模、任务异构性和解决冷启动问题方面面临着类似的挑战。 我们的框架为此类应用程序提供了适应性强的解决方案。 我们的重点主要是使用模态编码器来跟踪特征。 然而,存在合并附加信息源的机会,包括歌词、播放列表和专辑标题等文本数据。 鉴于大型语言模型(大语言模型)的最新进展,集成这些模型生成的嵌入是改善用户表示的另一个潜在途径。
参考
- (1)
- Afchar et al. (2022) Darius Afchar, Alessandro Melchiorre, Markus Schedl, Romain Hennequin, Elena Epure, and Manuel Moussallam. 2022. Explainability in music recommender systems. AI Magazine 43, 2 (2022), 190–208.
- Aggarwal (2016) Charu C Aggarwal. 2016. Content-based recommender systems. In Recommender systems. Springer, 139–166.
- Amatriain and Basilico (2016) Xavier Amatriain and Justin Basilico. 2016. Past, present, and future of recommender systems: An industry perspective. In Proceedings of the 10th ACM Conference on Recommender Systems. 211–214.
- Batmaz et al. (2019) Zeynep Batmaz, Ali Yurekli, Alper Bilge, and Cihan Kaleli. 2019. A review on deep learning for recommender systems: challenges and remedies. Artificial Intelligence Review 52, 1 (2019), 1–37.
- Bell and Koren (2007) Robert M Bell and Yehuda Koren. 2007. Lessons from the Netflix prize challenge. Acm Sigkdd Explorations Newsletter 9, 2 (2007), 75–79.
- Bonnin and Jannach (2014) Geoffray Bonnin and Dietmar Jannach. 2014. Automated generation of music playlists: Survey and experiments. ACM Computing Surveys (CSUR) 47, 2 (2014), 1–35.
- Çano and Morisio (2017) Erion Çano and Maurizio Morisio. 2017. Hybrid recommender systems: A systematic literature review. Intelligent Data Analysis 21, 6 (2017), 1487–1524.
- Cebrián et al. (2010) Toni Cebrián, Marc Planagumà, Paulo Villegas, and Xavier Amatriain. 2010. Music recommendations with temporal context awareness. In Proceedings of the fourth ACM conference on Recommender systems. 349–352.
- Covington et al. (2016) Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM conference on recommender systems. 191–198.
- Fazelnia et al. (2022) Ghazal Fazelnia, Eric Simon, Ian Anderson, Benjamin Carterette, and Mounia Lalmas. 2022. Variational user modeling with slow and fast features. In Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. 271–279.
- Fu et al. (2023) Junchen Fu, Fajie Yuan, Yu Song, Zheng Yuan, Mingyue Cheng, Shenghui Cheng, Jiaqi Zhang, Jie Wang, and Yunzhu Pan. 2023. Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights. arXiv preprint arXiv:2305.15036 (2023).
- Gopalan et al. (2015) Prem Gopalan, Jake M Hofman, and David M Blei. 2015. Scalable Recommendation with Hierarchical Poisson Factorization.. In UAI. 326–335.
- Hu et al. (2008) Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative filtering for implicit feedback datasets. In 2008 Eighth IEEE International Conference on Data Mining. Ieee, 263–272.
- Isinkaye et al. (2015) Folasade Olubusola Isinkaye, YO Folajimi, and Bolande Adefowoke Ojokoh. 2015. Recommendation systems: Principles, methods and evaluation. Egyptian informatics journal 16, 3 (2015), 261–273.
- Koren (2009) Yehuda Koren. 2009. Collaborative filtering with temporal dynamics. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 447–456.
- Koren et al. (2009) Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization techniques for recommender systems. Computer 42, 8 (2009), 30–37.
- Kouki et al. (2015) Pigi Kouki, Shobeir Fakhraei, James Foulds, Magdalini Eirinaki, and Lise Getoor. 2015. Hyper: A flexible and extensible probabilistic framework for hybrid recommender systems. In Proceedings of the 9th ACM Conference on Recommender Systems. 99–106.
- Kula (2015) Maciej Kula. 2015. Metadata Embeddings for User and Item Cold-start Recommendations. In Proceedings of the 2nd Workshop on New Trends on Content-Based Recommender Systems co-located with 9th ACM Conference on Recommender Systems (RecSys 2015), Vienna, Austria, September 16-20, 2015. (CEUR Workshop Proceedings, Vol. 1448), Toine Bogers and Marijn Koolen (Eds.). CEUR-WS.org, 14–21. http://ceur-ws.org/Vol-1448/paper4.pdf
- Li et al. (2009) Bin Li, Qiang Yang, and Xiangyang Xue. 2009. Transfer learning for collaborative filtering via a rating-matrix generative model. In Proceedings of the 26th annual international conference on machine learning. 617–624.
- Li and Zhao (2020) Sheng Li and Handong Zhao. 2020. A Survey on Representation Learning for User Modeling.. In IJCAI. 4997–5003.
- Liang et al. (2018) Dawen Liang, Rahul G Krishnan, Matthew D Hoffman, and Tony Jebara. 2018. Variational autoencoders for collaborative filtering. In Proceedings of the 2018 world wide web conference. 689–698.
- Mehrotra et al. (2018) Rishabh Mehrotra, James McInerney, Hugues Bouchard, Mounia Lalmas, and Fernando Diaz. 2018. Towards a fair marketplace: Counterfactual evaluation of the trade-off between relevance, fairness & satisfaction in recommendation systems. In Proceedings of the 27th acm international conference on information and knowledge management. 2243–2251.
- Mnih and Salakhutdinov (2008) Andriy Mnih and Russ R Salakhutdinov. 2008. Probabilistic matrix factorization. In Advances in neural information processing systems. 1257–1264.
- Nie et al. (2014) Da-Cheng Nie, Zi-Ke Zhang, Qiang Dong, Chongjing Sun, Yan Fu, et al. 2014. Information filtering via biased random walk on coupled social network. The Scientific World Journal 2014 (2014).
- Pan et al. (2011) Weike Pan, Nathan N Liu, Evan W Xiang, and Qiang Yang. 2011. Transfer learning to predict missing ratings via heterogeneous user feedbacks. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Catalonia, Spain. 2318.
- Pan et al. (2010) Weike Pan, Evan Xiang, Nathan Liu, and Qiang Yang. 2010. Transfer learning in collaborative filtering for sparsity reduction. In Proceedings of the AAAI conference on artificial intelligence, Vol. 24. 230–235.
- Pancha et al. (2022) Nikil Pancha, Andrew Zhai, Jure Leskovec, and Charles Rosenberg. 2022. PinnerFormer: Sequence Modeling for User Representation at Pinterest. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 3702–3712.
- Panda and Ray (2022) Deepak Kumar Panda and Sanjog Ray. 2022. Approaches and algorithms to mitigate cold start problems in recommender systems: a systematic literature review. Journal of Intelligent Information Systems 59, 2 (2022), 341–366.
- Passino et al. (2021) Francesco Sanna Passino, Lucas Maystre, Dmitrii Moor, Ashton Anderson, and Mounia Lalmas. 2021. Where To Next? A Dynamic Model of User Preferences. WWW 21 (2021), 19–23.
- Polyzotis et al. (2017) Neoklis Polyzotis, Sudip Roy, Steven Euijong Whang, and Martin Zinkevich. 2017. Data Management Challenges in Production Machine Learning. In Proceedings of the 2017 ACM International Conference on Management of Data (Chicago, Illinois, USA) (SIGMOD ’17). Association for Computing Machinery, New York, NY, USA, 1723–1726. https://doi.org/10.1145/3035918.3054782
- Sachdeva et al. (2019) Noveen Sachdeva, Giuseppe Manco, Ettore Ritacco, and Vikram Pudi. 2019. Sequential variational autoencoders for collaborative filtering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining. 600–608.
- Schedl (2019) Markus Schedl. 2019. Deep learning in music recommendation systems. Frontiers in Applied Mathematics and Statistics 5 (2019), 44.
- Schedl and Hauger (2015) Markus Schedl and David Hauger. 2015. Tailoring music recommendations to users by considering diversity, mainstreaminess, and novelty. In Proceedings of the 38th international acm sigir conference on research and development in information retrieval. 947–950.
- Schedl et al. (2018) Markus Schedl, Hamed Zamani, Ching-Wei Chen, Yashar Deldjoo, and Mehdi Elahi. 2018. Current challenges and visions in music recommender systems research. International Journal of Multimedia Information Retrieval 7, 2 (2018), 95–116.
- Vall et al. (2017) Andreu Vall, Massimo Quadrana, Markus Schedl, Gerhard Widmer, and Paolo Cremonesi. 2017. The Importance of Song Context in Music Playlists.. In RecSys Posters.
- Wang et al. (2018) Dongjing Wang, Shuiguang Deng, and Guandong Xu. 2018. Sequence-based context-aware music recommendation. Information Retrieval Journal 21, 2 (2018), 230–252.
- Wei et al. (2021) Yinwei Wei, Xiang Wang, Qi Li, Liqiang Nie, Yan Li, Xuanping Li, and Tat-Seng Chua. 2021. Contrastive learning for cold-start recommendation. In Proceedings of the 29th ACM International Conference on Multimedia. 5382–5390.
- Xia et al. (2023) Xue Xia, Pong Eksombatchai, Nikil Pancha, Dhruvil Deven Badani, Po-Wei Wang, Neng Gu, Saurabh Vishwas Joshi, Nazanin Farahpour, Zhiyuan Zhang, and Andrew Zhai. 2023. TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest. arXiv preprint arXiv:2306.00248 (2023).
- Xiao et al. (2015) Yingyuan Xiao, Pengqiang Ai, Ching-Hsien Hsu, Hongya Wang, and Xu Jiao. 2015. Time-ordered collaborative filtering for news recommendation. China Communications 12, 12 (2015), 53–62.
- Yuan et al. (2021) Fajie Yuan, Guoxiao Zhang, Alexandros Karatzoglou, Joemon Jose, Beibei Kong, and Yudong Li. 2021. One person, one model, one world: Learning continual user representation without forgetting. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 696–705.
- Yürekli et al. (2021) Ali Yürekli, Cihan Kaleli, and Alper Bilge. 2021. Alleviating the cold-start playlist continuation in music recommendation using latent semantic indexing. International Journal of Multimedia Information Retrieval 10, 3 (2021), 185–198.
- Zhang et al. (2006) Sheng Zhang, Weihong Wang, James Ford, and Fillia Makedon. 2006. Learning from incomplete ratings using non-negative matrix factorization. In Proceedings of the 2006 SIAM international conference on data mining. SIAM, 549–553.
- Zhang et al. (2019) Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep learning based recommender system: A survey and new perspectives. ACM Computing Surveys (CSUR) 52, 1 (2019), 1–38.
- Zhang et al. (2018) Yin Zhang, Xiao Ma, Shaohua Wan, Haider Abbas, and Mohsen Guizani. 2018. CrossRec: Cross-domain recommendations based on social big data and cognitive computing. Mobile networks and applications 23 (2018), 1610–1623.
- Zhang et al. (2012) Yuan Cao Zhang, Diarmuid Ó Séaghdha, Daniele Quercia, and Tamas Jambor. 2012. Auralist: introducing serendipity into music recommendation. In Proceedings of the fifth ACM international conference on Web search and data mining. 13–22.
- Zhou et al. (2019) Fan Zhou, Zijing Wen, Kunpeng Zhang, Goce Trajcevski, and Ting Zhong. 2019. Variational session-based recommendation using normalizing flows. In The World Wide Web Conference. 3476–3475.