ToolNet: 通过工具图将大型语言模型
与海量工具连接
摘要
尽管在广泛的任务中取得了显著的进展,但大型语言模型 (LLM) 在正确使用海量外部工具方面仍然存在很大的局限性。 现有的上下文学习方法只是将工具格式化为纯文本描述列表并输入到 LLM 中,LLM 从中生成一系列工具调用以逐步解决问题。 这种范式忽略了工具之间的内在依赖关系,并将所有推理负载都卸载到 LLM 上,使其仅限于数量有限的专门设计的工具。 因此,LLM 在海量工具库上运行仍然具有挑战性,这在面对现实场景时构成了巨大的局限性。 本文提出 ToolNet,这是一个即插即用的框架,可以在适度增加符元消耗的情况下将工具数量扩展到数千个。 ToolNet 将工具组织成一个有向图。 每个节点代表一个工具,加权边表示工具转换。 从初始工具节点开始,LLM 通过迭代地从其后继节点中选择下一个节点在图中导航,直到任务解决。 广泛的实验表明,ToolNet 可以在具有挑战性的多跳工具学习数据集中取得令人印象深刻的结果,并且对工具故障具有弹性。
ToolNet: 通过工具图将大型语言模型
与海量工具连接
Xukun Liu Northwestern University xukunliu2025@u.northwestern.edu Zhiyuan Peng North Carolina State University jerrypeng1937@gmail.com Xiaoyuan Yi Microsoft Research Asia xiaoyuanyi@microsoft.com
Xing Xie Microsoft Research Asia xingx@microsoft.com Lirong Xiang North Carolina State University lxiang3@ncsu.edu Yuchen Liu North Carolina State University yuchen.liu@ncsu.edu Dongkuan Xu North Carolina State University dxu27@ncsu.edu
1 简介
越来越多的兴趣 秦等人 (2023); 宋等人 (2023); 姚等人 (2022); Patil等人 (2023); 杨等人 (2023) 在释放大型语言模型 (LLM) 的力量以有效地与各种工具(或 API)交互以完成现实世界任务。 当工具增强型 LLM 与海量 API 可行地连接时,它们可以充当普通人与复杂工具之间的中间接口,最终可能会重塑庞大的应用程序生态系统。 这项工作已经取得了一些令人印象深刻的工业成果,例如搜索引擎 New Bing 微软公司 (2023b),办公助手 Copilot 微软公司 (2023a),机器人控制器 RT-2 Brohan等人 (2023),以及网页浏览代理 WebGPT 中野等人。 .
尽管取得了显著进展,但工具增强型 LLM 仍处于实验阶段,尚未准备好完全满足现实世界的需求。 值得注意的是,虽然 LLM 被设计为针对多种任务的通才,但 LLM 驱动的代理通常会针对狭窄的目的用少量样本进行上下文示例定制。 它们仅限于连接少量专门设计的工具。 例如,Toolformer Schick 等人 (2023) 精通 5 种工具,例如计算器、问答引擎、日历等。Chameleon Lu 等人 (2023) 专注于使用一套精心策划的工具(例如表格语言化器和图像字幕器)完成两个知识密集型问答任务。
将工具数量扩展到数千个对于 LLM 来说是一个挑战。 这不仅仅是因为当工具作为输入提示给 LLM 时,令牌消耗激增,这通常超过了它们的令牌限制。 更重要的是,LLM 无法通过简单的上下文学习从大量的工具库中选择正确的工具。 根据 Hao 等人 (2023),随着工具数量的增加,LLM 往往会在调用工具时出现幻觉和错误,导致性能持续下降。 作为回应,研究人员投入了大量精力来训练 LLM 以掌握大量工具 秦等人 (2023); Patil等人 (2023); Hao等人 (2023)。 尽管这种方法可以产生有希望的结果,但它带来了高昂的计算成本,并且缺乏对新工具或功能不断更新的工具的适应性。 此外,在一个庞大的工具库中,确实应该考虑到低质量的工具。 当被工具误导时,LLM 很容易出现幻觉。 为了应对这个问题, Xie 等人(2023 年) 使用束搜索来探索最合适的工具。 但是,符元消耗量会成倍增加,并且如果没有显式的记忆机制,探索经验就不能用于后续的任务。 为了解决上述问题,我们提出了以下问题:
问题 1。 如何使 LLM 能够处理大量的工具,同时保持符元的效率?
我们分析了 ToolBench 中的多跳工具使用轨迹 Qin 等人(2023 年),该轨迹被认为是最广泛的公开可用的专注于工具学习的数据集。 如图 2 所示,我们的分析表明,工具通常具有一组有限的潜在后续工具可供调用。 这一观察结果表明工具之间的稀疏转换。 从本质上讲,当调用特定工具时,要调用的后续工具可以限制在一组非常有限的选项中。 本研究利用这种工具使用模式将 LLM 与大量工具连接起来,并保持符元的效率。
问题 2。 LLM 如何识别无效的工具并为未来的任务修改其工具使用策略?
Shinn 等人(2023 年) 表明,LLM 可以口头反映其工具使用轨迹,以在正在进行的交互或事件中进行改进。 在这项工作中,我们考虑了工具层面的细粒度反射。 每个工具使用步骤都由 LLM 探测和评分。 分数将用于调整工具转换权重,其中低质量工具将被限制,其转换权重将被降低。 值得注意的是, Shao 等人 (2023) 表明,为 LLM 提供候选答案的分数会带来显著的性能提升。 同样,我们用工具的转换权重提示 LLM。 通过这种方式,通过将经验编码到工具图中,可以显着减少对低质量工具的失败调用。
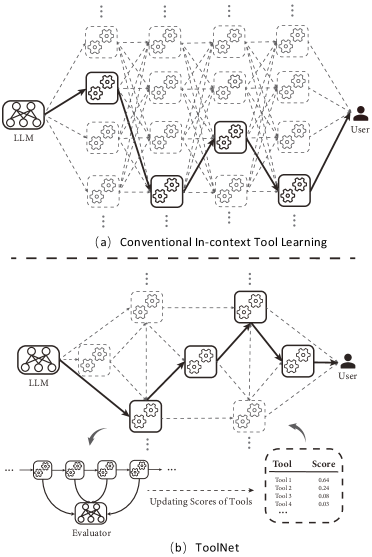
为此,本文提出了 ToolNet,这是一种简单但有效的范式,它可以帮助 LLM 处理大量工具,学习选择合适的工具,并避免调用损坏的工具。 表 1 中提供了 ToolNet 与其他方法的比较。 如图 5 所示,ToolNet 将工具组织在一个加权有向图中。 该图是基于 LLM 生成的工具使用轨迹构建的。 反过来,LLM 使用该图来推理其工具调用,这个过程可以被概念化为在这个图中导航。 此外,该图可以进行在线更新,从而使其能够适应工具的频繁更新或新任务的引入。 在五个不同的数据集上进行了广泛的实验:SciQA Lu 等人 (2022a)、TabMWP Lu 等人 (2022b)、MATH Hendrycks 等人 (2021)、APIBank Li 等人 (2023) 和 ToolBench Qin 等人 (2023)。 结果表明,ToolNet 在整体性能方面始终优于其对应方法。 值得注意的是,它表现出对噪声工具干扰的显著抵抗力,并在利用显著更少的符元的同时实现了这种卓越的性能。
| Method | API/Tool Use | Framework | ||||||
|---|---|---|---|---|---|---|---|---|
| #APIs | Adapt. |
|
Planning |
|
||||
| Toolformer | 5 | – | + | - | ✗ | |||
| ReAct | 3 | + | - | NL | ✓ | |||
| ToT | - | – | – | NL | ✓ | |||
| Reflexion | - | + | – | NL | ✓ | |||
| Chameleon | 15 | - | - | NL | ✓ | |||
| HuggingGPT | 24 | + | - | NL | ✓ | |||
| Gorilla | 1645 | - | + | - | ✗ | |||
| RestGPT | 100+ | + | - | NL | ✓ | |||
| ToolNet (ours) | 3992 | ++ | + | NL+Graph | ✓ | |||
2 问题公式
工具增强的 LLM 通过自然语言中的结构化文本与环境交互。 一般交互过程可以描述如下:在步骤 中,LLM 以当前环境观察 以及交互活动的历史 作为输入,并产生一个口头想法 。 然后,LLM 通过采取行动 与环境交互,该行动可以描述为一个工具名称及其参数的元组,例如, = ,其中 。 随后,LLM 从环境 中获得新的观察结果 。 通过迭代交互过程,LLM 最终可能会解决给定的任务。
LLM 主要无状态。 交互历史 通常被制定为 LLM 输入的一部分。 它有助于 LLM 回忆之前的过程并推断下一个行动 。 我们将 定义为大小为 的队列,包含过去观察、想法和行动,例如, = 。 在每一步,将新的想法、行动和观察的元组追加到 ,如果达到最大容量,则弹出最早的元组。 除了 之外,可用的工具集 也需要包含在输入上下文中,LLM 可以从中选择合适的工具。
| Tool | Category | #Successors |
|---|---|---|
| jokes/random | Social | 49 |
| jokes/search | Social | 33 |
| weather/current | Search | 31 |
| soundcloud | Search | 29 |
| currency exchange | Search | 26 |
| Reddit meme | Social | 24 |
| Date | Search | 22 |
| weather/forecast | Search | 22 |
| nutrition analysis | Health | 20 |
令 表示具有参数 的工具增强型 LLM。 形式上,上述交互过程可以表述如下。
| (1) | ||||
| (2) | ||||
| (3) |
现有工具增强型 LLM 的一个主要问题是它们对符元的消耗量很大,这在很大程度上归因于 和 的较长输入上下文。 一个典型的解决方案是将 的长文本分割成段落,并将它们压缩成语义嵌入。 随后,可以计算候选段落与当前观察结果 之间的语义相似度得分并进行排名。 最后,将公式 1- 2 中的 替换为最相关的段落,作为 LLM 的输入。 直观地说,此解决方案可以扩展到 ,例如,在 中搜索与想法 最相关的工具。 但是,根据等式 1, 的生成没有 的全部知识。 中的语义信息可能与 中的任何工具无关。 此外,在一个庞大的 API 函数库中,可能存在许多工具具有相似的语义信息,但在功能上略有不同。 当 变大时,通过语义嵌入搜索工具可能很粗略且不准确。 因此,现有的工具学习方法要么局限于数量有限的专门设计的工具,要么使用指令微调来增强 LLM ,使其具有 的先验知识,这在计算上可能很密集。
3工具网
ToolNet 的想法很简单。 与将 中的所有工具输入到 中(如等式 2 中)不同,我们只提供一个子集 ,该子集根据策略 和先前动作 ,即
| (4) |
其中 = 。 马尔可夫假设在 的生成中起作用。 我们将 描述为一个加权有向图 = ,它连接了 中的所有工具。 和 分别表示节点和边的集合。 中的每个工具都被视为 中的唯一节点。 此外,两个特殊节点 和 被添加到 中。 换句话说, = 。 边 = 连接节点 到节点 ,其中 表示转换权重。 请注意,工具以及转换权重被格式化为大语言模型(LLM)的输入文本。 除 和 节点外,所有节点都具有指向自身的自循环边。 节点指向所有其他节点,而其他节点则指向 。
为此,执行操作的 LLM 等同于在图 中进行遍历。 假设 LLM 在上次迭代中使用了 = 。 下一步可用的工具 只是 的外邻节点,例如, = 。 如果图 是稀疏的,,从而提高了工具增强型 LLM 的令牌效率。 值得注意的是, 节点连接所有工具。 换句话说,LLM 从 = 开始,这会限制令牌的消耗,并且随着 的增长变得不切实际。 为了解决这个问题,我们利用了第 2 节中提到的语义相似性搜索方法。 每个工具的描述都被压缩成语义嵌入,然后根据其与初始任务描述 的嵌入的相似性进行排名。 只保留了最相关的 个工具来设置 。
ToolNet 引入的另一个好处是 中工具的转换权重,这些权重衡量了工具的先验偏好。 根据权重,可以对工具进行排序并格式化为输入上下文。 LLM 可以参考偏好分数进行选择。 相反,现有的方法(例如 ReAct 和 Reflexion)为 LLM 提供了具有相同偏好的工具。 大语言模型完全依靠其内部推理能力做出选择。
3.1 图构建
图的构建对于性能和效率至关重要。 如果中的所有工具都以相等的边权相互连接,则ToolNet将变得没有信息量,并退化为简单的ReAct方法。 一个好的图应该是稀疏的,即节点的出邻节点数量很少。 应该降低不再有效的过时工具的权重。 值得注意的是,图的构建可以灵活。 本文考虑了静态和动态图构建方法。 其他图操作,例如组合、修剪和分区,值得探索,但不在本文范围内。
3.2 静态构建
静态构建需要大量的工具使用轨迹,例如GitHub上大量调用PyTorch API函数的手写代码片段。 API函数调用顺序可用于构建。 工具增强的LLM也可以生成工具使用轨迹。 多步推理轨迹表示工具调用的序列。 一些现有工作,例如ToolBenchQin等人(2023)、APIBenchPeng等人(2022)、API-BankLi等人(2023)和ToolAlpaca Tang等人 ,已发布了他们精心策划的工具使用实例,可以从中构建ToolNet。 不幸的是,从 LLM 生成的轨迹的质量令人担忧。
的静态构建很简单。 它与 2-gram 语言建模相同。 将 表示为一组已完成任务的工具使用轨迹。 轨迹有一系列工具使用,例如,,其中,为简单起见,我们将 视为一种普通工具。 从节点 到节点 的转换权重 计算如下:
| (5) |
中的 节点是单独设置的。 它以相等的权重连接所有工具,除了 。 当工具变得庞大时,可以采用基于语义相似性搜索的工具检索器来选择第一个工具,,如第 3 节所述。
3.3 动态构建
工具是动态变化的。 它们有生命周期,可能不再由开发人员维护。 因此, 的边权重需要及时微调,使得静态构建不可行。 此外,通常缺乏大量的工具使用轨迹,特别是对于 ChatGPT 上新出现的插件。 在这种情况下, 的动态构建要求很高。
可以通过静态构建或作为具有完全连接工具的非信息性图来初始化。 然后,动态构建在生成工具使用轨迹和更新之间迭代。 轨迹生成的流程与第3节中解释的相同。 的更新很重要。 由于工具使用轨迹的数量有限,因此需要对轨迹进行细粒度检查。 一个 LLM 充当工具评估器,以整个轨迹作为输入,并对所使用的每个工具进行评分。 这些分数是中的离散整数。 评估工具等同于评估中访问的节点。 我们使用表示评估器在第次迭代中对节点的评分。 令表示累积分数,例如, = 。 转换权重按如下方式更新。
| (6) | ||||
| (7) | ||||
| (10) |
其中将累积分数映射到。 表示用于更新转换权重的归一化梯度。 和是超参数。 控制更新速度。 在先验权重和从动态构建中学习的权重之间进行插值。
4 实验
4.1 设置
数据集. 我们在五个数据集上进行实验: (1) SciQA Lu 等人 (2022a),一个在各个科学领域(包括生物学、地理学和生态系统等多个学科)的问答基准。 (2) TabMWP Lu 等人 (2022b),一个问答基准,其中 LLM 应该根据给定的表格回答问题。 (3) MATH Hendrycks 等人 (2021),一个涵盖数学领域的问答基准,包括 7 个类别:初等代数、代数、数论、计数与概率、几何、中级代数和微积分预备课程。 (4) APIBank Li 等人 (2023),一个由各种工具组成的多任务基准,用于评估工具增强型 LLM 的性能。 (5) ToolBench Qin 等人 (2023),一个大型基准,包含 3451 个跨越不同领域的 API。 出于成本考虑,我们选择了这些数据集的子集用于评估。 我们从 SciQA 数据集中随机选择了 1,000 个问题用于评估。 对于 TabMWP,我们使用了 test1k 子集。 在 MATH 数据集中,我们只考虑了级别为 5 的问题,这些问题代表了最高难度级别。 此外,我们排除了与几何相关的题目,这与之前研究 Drori 等人 (2022); Wu 等人 (2023)保持一致。 对于 APIBank,我们专注于一个特定的子集,特别是属于 lv1-lv2-samples 类别的测试数据,总计 212 个问题。 在 ToolBench 数据集中,我们从 G1 集中随机选择了 1,000 个问题。
基准. (1) ReAct Yao 等人 (2022). 配备了各种工具,LLM 策略性地每次为每个步骤选择一个工具来解决特定任务或问题,确保采用循序渐进、重点关注的方法来解决问题。 (2) Reflexion Shinn 等人 (2023)). 与 ReAct 类似,LLM 在几个步骤中与多个工具交互。 当 LLM 无法完成任务时,将提示它口头反思其推理轨迹。 经过自我完善的 LLM 可以从先前的错误中学习,并不断重试,直到提交正确答案或达到最大重试次数。 (3) 树形思维 (ToT) Yao 等人 (2023). 它将 LLM 推理过程表述为一个思维树,其中树中的每个节点都代表解决方案的一部分。 在任何给定的节点上,一个思维生成器模块负责创建新的节点,有效地扩展解决方案空间。 随后,这些新节点中的每一个都将进行评估。 这种思维树的扩展和发展由特定的搜索算法控制,例如深度优先搜索 (DFS),它规定了节点扩展和探索的顺序和方式。 实施细节。 我们在所有实验中都使用 gpt-3.5-turbo 作为 LLM。 给定一个问题或任务指令,LLM 迭代地从可用工具中选择一个,直到调用 答案/完成 工具来提交其答案或在达到最大迭代次数 8 时声明任务失败。
指标。 评估是在答案质量和符元消耗方面进行的。 精确匹配 (EM) 用于将 LLM 生成的答案与 SciQA、TabMWP、MATH 和 APIBank 中提供的真实情况进行比较。 在 ToolBench 中没有唯一的真实答案,因此采用 胜率。 它衡量的是由外部 LLM 驱动的评估器识别为正确的答案的比例。 在 ToolBench 中,采用内置的 ToolEval(由 gpt-3.5-turbo 提供支持)来计算胜率。 此外,我们还测量了 LLM 用于完成任务的符元数量。 它考虑了输入提示和用于推理和回答的生成符元。
| Tool | Description | Dataset | ||
| SciQA | TabMWP | MATH | ||
| GoogleSearch | Search by google | ✓ | ✗ | ✗ |
| WikiPediaSearch | Search in Wikipedia | ✓ | ✗ | ✗ |
| ExecuteCode | Execute math expressions | ✗ | ✓ | ✓ |
| RunPython | Run python code | ✗ | ✓ | ✓ |
| Search∗ | Return ’Nothing Found’ | ✗ | ✗ | ✗ |
| LoopUp∗ | Return ’Nothing Found’ | ✗ | ✗ | ✗ |
| Calculator∗ | Return random numbers | ✗ | ✗ | ✗ |
| ∗ means this tool is on purpose designed to be noisy. | ||||
4.2 结果和分析
4.2.1 特定任务数据集上的评估
在实践中,当 LLM 与大量工具连接时,不可避免地会存在噪声和与任务无关的工具。 为了模拟这种情况,我们首先在三个特定任务的 QA 数据集上进行了实验,即 SciQA、TabMWP 和 MATH。 LLM,gpt-3.5-turbo,与 16 个工具连接,其中大多数与数据集设计用于执行的任务无关。 表 2 列出了使用的一些典型工具。 据我们所知,在这些数据集上没有公开可用的工具使用轨迹。 因此,ToolNet 通过动态构建创建工具图,从具有相等边分数的全连接图开始。
表格 3 比较了现有的工具学习方法(ReAct、Relfexion 和 ToT)与提出的 ToolNet。 与 Reflexion 相比,ToolNet 在 TabMWP 和 MATH 上分别只使用 和 符元。 在答案质量方面(通过 EM 衡量),ToolNet 在 SciQA 和 TabMWP 上显著优于所有其他竞争方法,实现了至少 的绝对改进。 诚然,Reflexion 在 MATH 上略优于 ToolNet,但其符元消耗显著增加,推理步骤也更多。 此外,我们研究了噪声工具对工具增强型 LLM 的影响,并以 ReAct(干净)为例进行说明。 它表示通过在三个数据集上删除所有噪声工具来运行 ReAct。 与 ReAct(干净)相比,ReAct 的答案质量显著下降,符元消耗增加,推理步骤更长,表明它在处理噪声和与任务无关的工具方面效率低下。
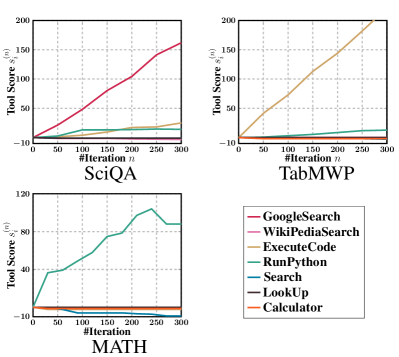
在我们对 ToolNet 生成的工具得分 的分析中,如图 3 所示,我们观察到一个明显的模式。 对于每个特定任务的数据集,有效工具的得分持续增加,而无关工具的得分保持在零左右。 这种模式证明了 ToolNet 在为不同任务选择最合适的工具方面的熟练程度。 具体来说,GoogleSearch 成为 SciQA 数据集的首选工具。 相反,对于 TabMWP 和 MATH 数据集,ExecuteCode 和 RunPython 分别被确定为最合适的工具。 此外,ToolNet 有效地降低了噪声工具的权重,进一步优化了工具选择过程。
| Dataset | Size | #APIs | Metric | ReAct |
|
Reflexion | ToT |
|
||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SciQA | 1000 | 16 | EM | 0.45 | 0.48 | - | 0.12 | 0.61 | ||||
| #Tokens | 8270 | 7318 | - | 23070 | 5945 | |||||||
| #Steps | 5.8 | 5.4 | - | 8.9 | 4.0 | |||||||
| TabMWP | 1000 | 16 | EM | 0.26 | 0.50 | 0.57 | 0.09 | 0.67 | ||||
| #Tokens | 8936 | 6594 | 24710 | 19669 | 4062 | |||||||
| #Steps | 6.1 | 5.3 | 11.3∗ | 8.7 | 3.7 | |||||||
| MATH | 675 | 16 | EM | 0.13 | 0.20 | 0.29 | 0.07 | 0.25 | ||||
| #Tokens | 9216 | 8382 | 28886 | 18090 | 6602 | |||||||
| #Steps | 6.9 | 6.8 | 9.5 | 8.2 | 5.4 |
4.2.2 在具有海量工具的多任务数据集上的评估
然后,我们在 APIBank 和 ToolBench 上评估 ToolNet,这两个具有挑战性的数据集包含各种任务,并且拥有大量可用的工具。 ToolBench 中的海量工具使得 LLM 难以选择起始工具。 我们遵循 ToolBench 中的默认设置,使用经过微调的 BERT 模型 Tool Retriever 来推荐 最合适的起始工具给 LLM。 我们将 设置为 以增强 ReAct 和 Reflexion 在 ToolBench 上的效果,并将 设置为 以增强其在 APIBank 上的效果。 对于 ToolNet 和 ToT,仅提供最推荐的工具作为起始工具。 工具图首先根据数据集提供的轨迹静态构建,正如第 3.2 节中所解释的那样。 之后,图在每次迭代中动态更新。
如表 4 所示,ToolNet 在胜率方面与 Reflexion 相当,但使用的符元显著更少(在 APIBank 上仅为 38.5%,在 ToolBench 上仅为 49.7%,相比之下 Reflexion 使用的符元更多)。 此外,Reflexion 的方法与 ToolNet 相互补充。 当整合到 ToolNet 中时,它进一步提高了答案质量,从而在两个数据集上都获得了最高的胜率。
这两个数据集提供的海量工具和多样化任务,使得人们无法直观地解释工具得分,也无法手动选择工具。 同时,工具也处于活跃状态并不断发展。 有些工具可能会偶尔崩溃,无法再使用。 这就要求 ToolNet 自适应地提高其他一些备份工具的分数。 我们展示了动态构建可以缓解这种问题。 在图 4 中,我们在 APIBank 上模拟了一个工具在第 50 次迭代时突然崩溃的场景。 崩溃工具的分数大幅下降,而备份工具则迅速激活,有效地取代了受损工具。 这种转变突出了 ToolNet 中固有的强大适应性。 在这方面,工具冗余是增强系统可靠性的一个关键特征。
| Dataset | Size | #APIs | Metric | ReAct | Reflexion | ToT | ToolNet (Ours) | |
|---|---|---|---|---|---|---|---|---|
| +Reflexion | ||||||||
| APIBank | 212 | 49 | EM | 0.70 | 0.77 | 0.63 | 0.75 | 0.83 |
| #Tokens | 1720 | 4286 | 2013 | 1649 | 3353 | |||
| ToolBench | 1000 | 3992 | Win Rate | 0.61 | 0.71 | 0.60 | 0.69 | 0.75 |
| #Tokens | 8636 | 13217 | 10167 | 6575 | 12548 | |||
4.2.3 Effect of Transition Weights
Tools along with the transition weights are formatted as the input contexts to LLMs. The transition weights indicate the priorities of tools, thus playing a vital role in tool selection. This section analyses how the transition weights affect the overall performance. As shown in Table 5, five test conditions are considered: removing weights from the input to LLMs (No weight), weights divided by 100 with decimals kept (), weights divided by 10 with decimals kept (), removing decimal parts of weights (Integer), and multiplying weights by 10 (×10). Experiments in each condition were repeated three times to reduce randomness.
| Modification of Transition Weights | |||||
| Metric | No weight | Integer | |||
| EM | 0.70 | 0.70 | 0.71 | 0.75 | 0.75 |
| #Tokens | 1710 | 1682 | 1664 | 1649 | 1645 |
Worst performance is attained when the weights are removed or scaled down into decimals. This suggests the importance of a proper format of weights. Moreover, there is a general increase in EM when scaling up the transition weights. This suggests that LLMs are more sensitive to the difference between integers or large numbers than the subtle difference between decimals. The token consumption is also gradually reduced when scaling up the weights. These observations may indicate a potential optimization pathway for tool learning. Notably, there is an upper-performance limit when scaling up the weights, e.g., the performance saturates at .
5 Related Work
Fine-tuning LLMs to use tools. Early research heavily relied on model fine-tuning for domain-specific tool learning and retrieval-augmented generation. Prominent works in this area include REALM Guu et al. (2020), RETRO Borgeaud et al. (2022),VisualGPT Chen et al. (2022), etc. Notably, WebGPT Nakano et al. , a GPT-3 finetuned on human web search behaviors, can effectively utilize web browsers for question answering. Furthermore, there has been a notable shift in research towards tuning LLMs on a broader spectrum of general tools. Example works include Toolformer Schick et al. (2023), ToolkenGPT Hao et al. (2023), Gorilla Patil et al. (2023), ToolLLM Qin et al. (2023) etc. However, it is important to acknowledge that collecting tool-use data for fine-tuning can be prohibitively expensive, and these fine-tuned LLMs often struggle to generalize to emergent or updated tools.
Prompting LLMs to use tools. The remarkable in-context learning ability of LLMs motivates prompt engineering approaches for tool learning Mialon et al. (2023). This is achieved by showing tool descriptions and demonstrations in context. Building on this idea, reasoning chains can be incorporated to tackle more complex problems, such as arithmetic calculation Cobbe et al. (2021), code execution Gao et al. (2023), and complex mathematical theory verification Jiang et al. (2022). More specifically, Plan-and-Solve Wang et al. (2023) enhances CoT with an explicit planning stage. Self-reflection Shinn et al. (2023); Madaan et al. (2023); Paul et al. (2023) and self-evaluation Xie et al. (2023) were introduced recently to self-correct mistakes in reasoning, showing enhanced performance in code generation and computer operation tasks. These paradigms have given rise to popular industry products such as ChatGPT Store and LangChain Chase (2023), as well as pioneering experimental products such as AutoGPT Richards (2023), MetaGPT Hong et al. (2023), etc. Furthermore, by calling tools to interact with the virtual or physical world, LLMs are capable of guiding embodied agents to accomplish various household tasks Huang et al. (2022a, b); Singh et al. (2023). Recent studies utilize LLMs as the central controller to coordinate multiple neural models, achieving promising results in multi-modal reasoning tasks Lu et al. (2023); Shen et al. (2023). Nevertheless, all methods based on in-context learning suffer from inferior performance in complex scenarios, where the tools are unfamiliar or numerous.
6 Conclusion
We introduce ToolNet, a novel plug-and-play method to organize massive tools into a directed graph, facilitating their use by LLMs via in-context learning. A key feature of ToolNet is its adaptive tool transition weights, which can be initially set and continually updated. This adaptability ensures rapid integration of new tools and alignment with the changing environment of extensive tool repositories. Comprehensive evaluations on both task-specific datasets and complex, multi-task tool learning datasets have shown that ToolNet consistently enhances performance and achieves up to x greater token efficiency. We believe that this research will inspire future studies to develop more advanced tool-augmented LLMs that can intelligently connect massive real-world tools to fulfill diverse human requirements.
7 Limitations and Future Work
While simple and extensible to concurrent tool learning methods, this work has limitations. First, the proposed graph construction demands tool-use trajectories, which can be costly to collect. Second, it requires that the trajectories include multi-hop tool-use cases to model tool transition. However, existing benchmarks are primarily designed to be task-specific and consist mainly of single tool use cases. Third, due to cost considerations, we only use gpt-3.5-turbo in our experiments. Exploring more powerful LLMs such as GPT-4 and the open-source Mixtrial model Mistral AI Team (2023) has the potential to further improve performance.
References
- Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. 2022. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR.
- Brohan et al. (2023) Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818.
- Chase (2023) Harrison Chase. 2023. LangChain: Next Generation Language Processing.
- Chen et al. (2022) Jun Chen, Han Guo, Kai Yi, Boyang Li, and Mohamed Elhoseiny. 2022. Visualgpt: Data-efficient adaptation of pretrained language models for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18030–18040.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Drori et al. (2022) Iddo Drori, Sarah Zhang, Reece Shuttleworth, Leonard Tang, Albert Lu, Elizabeth Ke, Kevin Liu, Linda Chen, Sunny Tran, Newman Cheng, et al. 2022. A neural network solves, explains, and generates university math problems by program synthesis and few-shot learning at human level. Proceedings of the National Academy of Sciences, 119(32):e2123433119.
- Gao et al. (2023) Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Pal: Program-aided language models. In International Conference on Machine Learning, pages 10764–10799. PMLR.
- Guu et al. (2020) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. Retrieval augmented language model pre-training. In International conference on machine learning, pages 3929–3938. PMLR.
- Hao et al. (2023) Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. 2023. Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings. arXiv preprint arXiv:2305.11554.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. NeurIPS.
- Hong et al. (2023) Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, and Chenglin Wu. 2023. Metagpt: Meta programming for multi-agent collaborative framework.
- Huang et al. (2022a) Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. 2022a. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In International Conference on Machine Learning, pages 9118–9147. PMLR.
- Huang et al. (2022b) Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. 2022b. Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608.
- Jiang et al. (2022) Albert Q Jiang, Sean Welleck, Jin Peng Zhou, Wenda Li, Jiacheng Liu, Mateja Jamnik, Timothée Lacroix, Yuhuai Wu, and Guillaume Lample. 2022. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs. arXiv preprint arXiv:2210.12283.
- Li et al. (2023) Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. 2023. Api-bank: A benchmark for tool-augmented llms. arXiv preprint arXiv:2304.08244.
- Lu et al. (2022a) Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022a. Learn to explain: Multimodal reasoning via thought chains for science question answering. In The 36th Conference on Neural Information Processing Systems (NeurIPS).
- Lu et al. (2023) Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. 2023. Chameleon: Plug-and-play compositional reasoning with large language models. arXiv preprint arXiv:2304.09842.
- Lu et al. (2022b) Pan Lu, Liang Qiu, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Tanmay Rajpurohit, Peter Clark, and Ashwin Kalyan. 2022b. Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning. In The Eleventh International Conference on Learning Representations.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2023. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651.
- Mialon et al. (2023) Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, et al. 2023. Augmented language models: a survey. arXiv preprint arXiv:2302.07842.
- Microsoft Corporation (2023a) Microsoft Corporation. 2023a. Microsoft copilot. Accessed: 2023-12-13.
- Microsoft Corporation (2023b) Microsoft Corporation. 2023b. New bing. https://www.bing.com/new. Accessed: 2023-12-13.
- Mistral AI Team (2023) Mistral AI Team. 2023. Mixtral of experts. Accessed: 2023-12-14.
- (24) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: browser-assisted question-answering with human feedback (2021). URL https://arxiv. org/abs/2112.09332.
- Patil et al. (2023) Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2023. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334.
- Paul et al. (2023) Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. 2023. Refiner: Reasoning feedback on intermediate representations. arXiv preprint arXiv:2304.01904.
- Peng et al. (2022) Yun Peng, Shuqing Li, Wenwei Gu, Yichen Li, Wenxuan Wang, Cuiyun Gao, and Michael R Lyu. 2022. Revisiting, benchmarking and exploring api recommendation: How far are we? IEEE Transactions on Software Engineering, 49(4):1876–1897.
- Qin et al. (2023) Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. 2023. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789.
- Richards (2023) Toran Bruce Richards. 2023. Auto-GPT: An Autonomous GPT-4 Experiment.
- Schick et al. (2023) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761.
- Shao et al. (2023) Zhenwei Shao, Zhou Yu, Meng Wang, and Jun Yu. 2023. Prompting large language models with answer heuristics for knowledge-based visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14974–14983.
- Shen et al. (2023) Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. arXiv preprint arXiv:2303.17580.
- Shinn et al. (2023) Noah Shinn, Beck Labash, and Ashwin Gopinath. 2023. Reflexion: an autonomous agent with dynamic memory and self-reflection. arXiv preprint arXiv:2303.11366.
- Singh et al. (2023) Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. 2023. Progprompt: Generating situated robot task plans using large language models. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 11523–11530. IEEE.
- Song et al. (2023) Yifan Song, Weimin Xiong, Dawei Zhu, Cheng Li, Ke Wang, Ye Tian, and Sujian Li. 2023. Restgpt: Connecting large language models with real-world applications via restful apis. arXiv preprint arXiv:2306.06624.
- (36) Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, and Le Sun. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. corr, abs/2306.05301, 2023. doi: 10.48550. arXiv preprint arXiv.2306.05301.
- Wang et al. (2023) Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. 2023. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. arXiv preprint arXiv:2305.04091.
- Wu et al. (2023) Yiran Wu, Feiran Jia, Shaokun Zhang, Qingyun Wu, Hangyu Li, Erkang Zhu, Yue Wang, Yin Tat Lee, Richard Peng, and Chi Wang. 2023. An empirical study on challenging math problem solving with gpt-4. arXiv preprint arXiv:2306.01337.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. 2023. Decomposition enhances reasoning via self-evaluation guided decoding. arXiv preprint arXiv:2305.00633.
- Yang et al. (2023) Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. 2023. Mm-react: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601.
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations.
Appendix
Appendix A Implementation Details
A.1 Prompt of ToolNet
Hereby we disclose the prompt and exemplars used in ToolNet. The tool descriptions and exemplars are subject to setups at run time. Notably, This prompt is a general paradigm and we encourage readers and users to adjust the prompt tailored to their own needs.
You are AutoGPT, you can use many tools(functions) to do the following task.
First I will give you the task description, and your task start.
At each step, you need to give your thought to analyze the status now and what to do next, with a function call to actually excute your step.
After the call, you will get the call result, and you are now in a new state.
Then you will analyze your status now, then decide what to do next…
After many (Thought-call) pairs, you finally perform the task, then you can give your finial answer.
Remember:
1.the state change is irreversible, you can’t go back to one of the former state, if you want to restart the task, call "Finish" function and say "I give up and restart".
2.All the thought is short, at most in 5 sentence.
3.You can do more then one trys, so if your plan is to continusly try some conditions, you can do one of the conditions per try.
Let’s Begin!
Task description: You should use functions to help handle the real time user querys. Remember:
1.ALWAYS call "Finish" function at the end of the task. And the final answer should contain enough information to show to the user,If you can’t handle the task, or you find that function calls always fail(the function is not valid now), use function Finishgive_up_and_restart.
2.Do not use origin tool names, use only subfunctions names.
The confidence scores of tools are listed here. The tools with higher scores are more recommended to use. Note that ’Finish’ tool is always useful, the score of which will not be provided explicitly.
<QUERY>
Begin!
A.2 Dynamic Construction
The Tool Evaluator is an integral component of the Dynamic Construction method in ToolNet. It functions by dynamically assessing the effectiveness of various tools within the network, contributing to an adaptive and efficient tool selection process. This process is crucial for maintaining the robustness and flexibility of ToolNet in diverse computational scenarios.
A.2.1 Prompt of Tool Evaluator
You are an judger who need to judge each tool and provide the scores of each tool.
According to the performance of these tools, provide your scores of each tool.
1. If the final answer of agent is valid, you should determine which tool is helpful and provide higher score.
2. If the final answer of agent is incorrect or not given, you should determine which tool is noisy and provide lower score.
3. Some tools may provide errors. You should discover them and provide lower scores to these tools.
The history of reasoning is listed here.
<HISTORY>
Now based on the reasoning history, provide your scores to each tool and your reasons by using Evaluate tool.
A.2.2 Function of Submiting Score
A.3 Overall Example
Query: I’m creating a playlist and I need to include the tracks from a particular album. Can you provide me with the tracks of the album with ID ’3IBcauSj5M2A6lTeffJzdv’? I would like to know the names, durations, and artists of these tracks. Additionally, please provide the cover art of the album.
Current Tool: Begin
Next Tools: album_tracks_for_spotify_data, Finish
Score: /
Action: album_tracks_for_spotify_data
Arguments:
Observation:
Current Tool: album_tracks_for_spotify_data
Next Tools: album_metadata_for_spotify_data, Finish, album_tracks_for_spotify_data
Score: album_metadata_for_spotify_data = 100
Action: album_metadata_for_spotify_data
Arguments:
Observation:
Current Tool: album_metadata_for_spotify_data
Next Tools: Finish, album_metadata_for_spotify_data
Score: Finish = 100
Action: Finish
Arguments:
Observation:
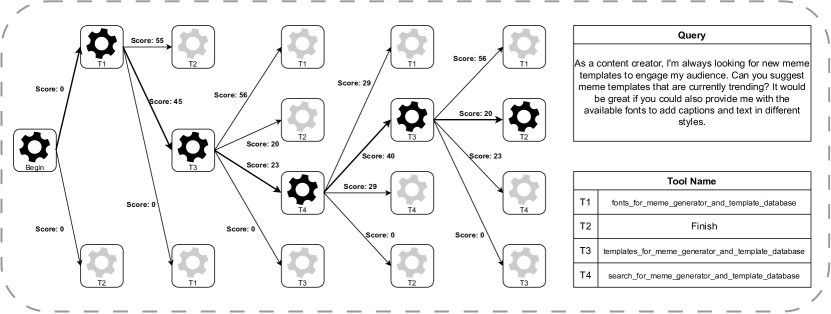
Appendix B Visualization of ToolNet’s Reasoning Process
In this section, we provide a detailed visualization of the reasoning process employed by ToolNet, using a real-world example from the ToolBench dataset. This visualization elucidates the graph structure generated during reasoning, and the corresponding scores associated with each node.
One can observe that the tools suggested by the graph are highly relevant to the task at hand. Moreover, it is evident that the model takes into account both the context of the problem and the information in the graph when invoking a tool. This illustrates the robustness of our approach, as it is capable of integrating diverse sources of information to make informed decisions about tool invocation.
It’s worth noting that the large language model’s inherent understanding capabilities complement the graph structure. The two work synergistically, with the language model providing the semantic understanding necessary to interpret the problem, and the graph structure offering a systematic way to explore potential solutions. This interplay forms the foundation for the progress we observe in our model’s performance.