KnowPhish:大型语言模型与多模态知识图相结合,增强基于参考的网络钓鱼检测
摘要
网络钓鱼攻击给个人和企业造成了巨大损失,因此需要开发强大且高效的自动网络钓鱼检测方法。 基于参考的网络钓鱼检测器 (RBPD) 可将目标网页上的徽标与一组已知的徽标进行比较,已成为最先进的方法。 然而,现有RBPD的一个主要限制是它们依赖于手动构建的品牌知识库,使其无法扩展到大量品牌,从而由于知识库的品牌覆盖率不足而导致假阴性错误。 为了解决这个问题,我们提出了一个自动化的知识收集管道,通过它我们收集并发布了一个大规模的多模式品牌知识库KnowPhish,其中包含2万个品牌,每个品牌都有丰富的信息。 KnowPhish 可用于以即插即用的方式提升现有 RBPD 的性能。 现有 RBPD 的第二个限制是它们仅依赖于图像模态,忽略了网页 HTML 中存在的有用文本信息。 为了利用这些文本信息,我们提出了一种基于大语言模型(大语言模型)的方法来从文本中提取网页的品牌信息。 我们的多模式网络钓鱼检测方法 KnowPhish Detector (KPD) 可以检测带有或不带有徽标的网络钓鱼网页。 我们在手动验证的数据集以及新加坡当地背景下的实地研究中评估了 KnowPhish 和 KPD,结果表明与最先进的基线相比,其有效性和效率有了显着提高。 111预印本。 正在审核中。 代码和数据将在稍后发布。
1简介
网络钓鱼攻击是最具影响力的诈骗类型之一,对个人和企业都造成损害:2023 年,全球消费者在诈骗中损失了约 1.026 万亿美元[5],其中网络钓鱼诈骗是其中之一最常见的类型。 网络钓鱼诈骗还占组织[11]数据泄露的约 90%。 自动网络钓鱼工具包的激增加剧了这一问题,使恶意行为者能够轻松模仿真实页面,同时使用对策[64]逃避检测。 因此,与上一年相比,2022 年网络钓鱼攻击数量增加了 47.2%[65]。 这些强调了解决该问题的重要性和紧迫性,以及有效的自动网络钓鱼检测方法的必要性。
人们已经做出了许多努力来应对网络钓鱼攻击,包括反网络钓鱼黑名单、基于启发式和基于特征的模型[14]。 基于黑名单的方法[40,42,45]将输入 URL 与预定义的恶意 URL 黑名单进行比较,但这些是反应性方法,需要首先报告或通过其他方式检测网络钓鱼站点。 基于启发式的[13]和基于特征的模型[28,37,18,61,31,54,35]提取特征以主动识别新的网络钓鱼网页。 然而,由于它们不利用徽标信息,因此它们检测大量网络钓鱼页面的能力受到极大限制,这些页面主要通过徽标[33]的存在来识别。 此外,由于它们依赖统计特征来检测网络钓鱼页面,因此由于网络钓鱼活动的性质不断变化,它们很容易受到分布变化的影响。
相比之下,基于参考的网络钓鱼检测器 (RBPD) 通过将目标网页上的徽标与一组已知的徽标进行比较来工作,已被确立为最先进的网络钓鱼检测范例,吸引了大量的研究关注[1,32,33]。 具体来说,RBPD 由包含品牌信息(品牌徽标和合法域名)的品牌知识库 (BKB) 和使用此 BKB 中的信息进行网络钓鱼的检测器主干组成检测。 为了检测网页是否为网络钓鱼或良性页面,RBPD 首先识别网页的品牌意图,即网页呈现的品牌(例如,带有 Adobe 徽标和外观的网页具有Adobe 的品牌意图)。 然后,如果检测到该网页具有某个品牌的意图,但其域名与该品牌的合法域名不匹配,则该网页被归类为网络钓鱼。 由于几乎所有网络钓鱼页面都不利用原始品牌的合法域名,因此这种方法通常可以获得高精度。 此外,由于该方法基于不随时间变化的不变量,因此对于分布偏移[32, 33]相对稳健。
挑战。
尽管 RBPD 具有诸多优点,但它们有两个我们重点关注的主要局限性。 (1) 第一个限制是有限规模的 BKB:RBPD 从根本上依赖其 BKB 来识别网站的品牌意图。 然而,手动构建和维护大规模的BKB是劳动密集型的。 Phishpedia [32] 和 PhishIntention [33] 依赖于手动管理,因此仅限于包含 277 个品牌的小型 BKB。 最近的方法 DynaPhish [34] 提出在部署期间动态扩展 BKB。 然而,这会导致运行时间极长,例如,在我们的实验中,每个样本平均需要 秒。 此外,它无法识别那些看不见的品牌的徽标变体,从而导致潜在的漏报。 (2)第二个限制是文本品牌意图:网络钓鱼网页可以通过文本而不是徽标来传达其品牌意图。 图1显示了一个没有徽标的网页,但其目标品牌澳大利亚邮政以 HTML 形式呈现。 其品牌意图对于页面访问者来说是清楚的,但现有的 RBPD 无法识别它,因为它们仅在图像模式内运行。
目前的工作。
在本文中,我们寻求解决这两个问题。 首先,我们提出了一个自动化知识收集管道,通过它构建并公开发布一个名为 KnowPhish 的大规模多模式 BKB,其中包含每个品牌的丰富徽标变体、别名和域名信息。 KnowPhish 是根据我们的实证分析构建的,我们发现网络钓鱼目标大多属于少数高价值行业,并且随着时间的推移是稳定的。 因此,利用根据公开知识库 Wikidata 建模的品牌与行业关系,我们可以预测性地搜索一组潜在的网络钓鱼目标及其品牌知识,从而生成涵盖大约 20k 个潜在网络钓鱼目标的 BKB。 正如我们的实验所证明的,KnowPhish 可用于以即插即用的方式提高现有 RBPD 的性能。
接下来,为了解决文本品牌意图问题,我们开发了一种基于大语言模型(大语言模型)的方法,结合 KnowPhish 知识库中的别名信息来识别网页的品牌意图。 我们的方法可以直接与任何标准视觉 RBPD [33] 集成,将其增强以形成一个多模式 RBPD,通过视觉和文本模式检测品牌意图。 我们最终的多模式网络钓鱼检测方法名为 KnowPhish Detector (KPD),能够检测带有或不带有徽标的网络钓鱼网页。
然后,我们在 TR-OP 上评估 KnowPhish 和 KPD 的有效性和效率,TR-OP 是一个手动验证的数据集,包含我们公开发布的 5k 良性网页和 5k 网络钓鱼网页。 我们还评估了我们在新加坡当地背景下进行实地研究的方法,以研究不同方法如何推广到这样的当地背景。 生成的数据(我们称之为 SG-SCAN)包含 6 个月内来自新加坡本地网页流量的 10k 个网页。 在两个数据集上的实验中,KnowPhish 显着提高了 RBPD 的效率,并且在配备基于图像的 RBPD 时,速度比部署框架 DynaPhish [34] 快 30 倍或更多。 此外,结合我们的多模式方法 KPD 可以大幅增加检测到的网络钓鱼网页的数量。
总之,我们的贡献有三方面:
-
•
多式联运品牌知识库。 我们提出了 KnowPhish,这是第一个用于网络钓鱼检测的大规模多模式 BKB 及其自动化构建方法。 KnowPhish 可用于任何 RBPD,以即插即用的方式提升其品牌知识。
-
•
基于多模态参考的网络钓鱼检测器。 我们提出了一种基于 LLM 的方法来识别 HTML 中的文本品牌,以处理无徽标的网络钓鱼网页。 我们的方法直接与任何现有的 RBPD 集成,将其增强以形成多模式 RBPD,可以检测无徽标的网络钓鱼网页。
-
•
有效性和效率。 大量实验表明,与最先进的基线相比,我们的方法显着提高了网络钓鱼检测的有效性和效率。 我们还在现场研究中证明了其有效性,并验证了对抗性攻击的稳健性。
2 形式化
威胁模型。
在网络钓鱼攻击中,恶意行为者会误导访问者相信他们的网页来自合法品牌,从而误导用户提供其凭据(例如用户名和密码)。 请注意,我们不认为其他类型的攻击(例如不符合上述描述的恶意软件或其他诈骗)属于我们的范围。
在我们的威胁模型中,我们假设攻击者完全控制他们的网页。 然而,为了保持网页误导用户的有效性,网页需要传达其品牌意图,即向访问者展示自己是一个特定的可识别品牌。 此外,网页需要以某种方式凭证接收:例如,通过用户名和密码字段,但存在不太常见的方法,例如按钮或二维码。 偏离这两个条件中的任何一个都会导致网络钓鱼攻击成功的可能性较小,并且我们的经验观察支持这两个条件在网络钓鱼网页中始终成立。
正式地,考虑一个网页 ,它由屏幕截图 (w.screenshot)、页面 HTML (w.html) 及其域组成(w.domain)。 如上所述,网页需要传达其品牌意图,将自己呈现为属于品牌。 这可以通过视觉形式(例如,通过屏幕截图中的徽标)或文本形式(例如,通过 HTML 中的文本)来完成,因此品牌信息可能会出现在 w.screenshot 或 w.html(或两者)。
基于参考的网络钓鱼检测。
由于网络钓鱼网页需要传达品牌意图,最先进的 RBPD 方法依赖于通过将页面上的图像与一组已知的参考徽标进行比较来识别该品牌意图。 形式上,RBPD 由品牌知识库 (BKB) 和利用该 BKB 的检测器主干组成。
BKB [32,33,34]存储品牌相关知识,采用品牌列表的形式:。 对于每个品牌 ,我们存储其名称 (b.name)、徽标图像 (b.logos) 及其合法域名 (b.domains)。 在我们的工作中,为了便于检测文本品牌意图,我们进一步添加了文本别名列表,即用于指代品牌的常见备用名称列表(b.aliases),从而得到在增强的BKB中。 形式上,给定品牌 ,增强的 BKB 为:
例如,对于品牌 PayPal,这可能包含:(PayPal, (logo1, logo2), ( www.paypal.com), (PYPL)),其中 logo1 和 logo2 是两个 PayPal 徽标图像。
接下来,给定网页 和 BKB , 检测器主干 输出 预测的品牌意向,或 "空 "表示没有预测的品牌意向:。
最后,RBPD(表示为 )将网页 分类为网络钓鱼或良性。 如果 的检测器主干 检测到 显示了品牌意图 ,但 的域与 中记录的品牌 的任何合法域不一致(即 ),则 会将 归类为网络钓鱼。 否则, 被分类为良性。 正式:
躲避攻击。
攻击者可能尝试通过以下方法绕过:
T1:使用徽标变体进行网络钓鱼。 为了规避 的在线知识扩展方法(例如 DynaPhish[34]),攻击者可以使用 的其他合法徽标变体来代替显示在的官方网页上。
T2:使用文本品牌进行网络钓鱼。 攻击者可以依靠文本 w.html 来展示其品牌意图,而不是使用徽标来展示其品牌意图,从而使基于图像的网络钓鱼检测器完全失败。
T3:HTML 混淆。 网络钓鱼攻击者可能会对 HTML 内容采用规避技术,以阻碍基于文本的方法有效提取信息。
我们通过构建一个具有丰富徽标信息(即每个品牌多个徽标)的大型多模式 BKB 来解决 T1。 我们通过开发基于 LLM 的方法从 HTML 中提取文本品牌来解决 T2 问题。 对于 T3,我们在第 5.5 部分中表明,我们基于 LLM 的方法对于 HTML 中不同类型的对抗性噪声具有鲁棒性。
3KnowPhish建设
在本节中,我们将介绍如何构建大规模多模态 BKB KnowPhish。 我们首先对不同时期的网络钓鱼源进行实证分析,寻找前瞻性指标,主动寻找潜在的网络钓鱼目标。 根据我们的实证研究结果,我们描述了如何使用可公开访问的多模态知识图自动构建 KnowPhish。
3.1 经验动机
我们的实证分析旨在解决以下问题:
问题 1。 网络钓鱼目标随时间变化有多大?
问题 2。 不同时间间隔的网络钓鱼源共有哪些持久特征?
3.1.1数据
为了实现这一目标,我们使用两个不同的网络钓鱼数据集进行了一项研究。 第一个数据集 包含 [32] 三年前收集的网络钓鱼网页。 它包含总共 29,496 个针对 283 个不同品牌的网络钓鱼实例。 第二个数据集 包含 2022 年底从 APWG[6] 获取的网络钓鱼样本。 该数据集总共包含 5,167 个针对 391 个独特品牌的网络钓鱼示例。
此外,我们手动将每个网络钓鱼目标分类为以下不同行业之一,即:1) 金融、2) 在线服务、3) 电信、4) 电子商务、5) 社交媒体、6) 邮政服务、7 ) 政府,8) 门户网站,9) 视频游戏,以及 10) 赌博。 对于不能归入这十类中任何一类的品牌,我们将其归类为11)其他业务。 例如,美国银行被归类为金融类别,而肯德基则被归类为其他业务。
3.1.2分析
我们对两个网络钓鱼数据集中网络钓鱼目标的差异及其各自行业的分布进行了彻底检查。 我们的观察如下。
观察1。 三年后,网络钓鱼目标发生了显着变化。
特别是,在图2中,我们观察到网络钓鱼目标与三年前相比发生了显着变化,中的 391 个品牌中只有 118 个是存在于中。 一些以前的网络钓鱼目标(例如 EMS 和 De Volksbank)已不复存在,而新的目标(例如 Bitkub 和 USPS)已经出现。 这种变化趋势与[34]之前的研究结果一致。
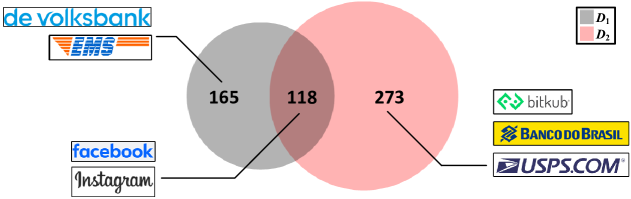
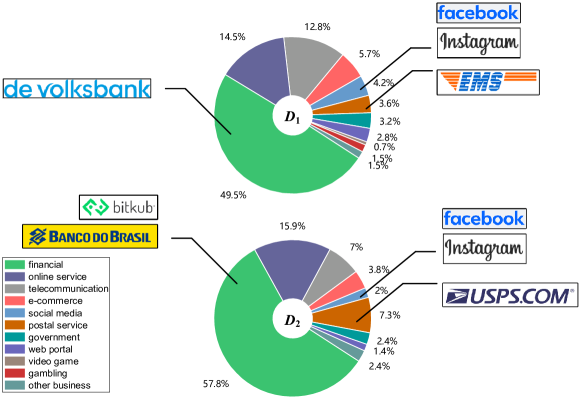
观察2。 尽管大量新兴网络钓鱼目标出现,但网络钓鱼目标的行业并没有发生明显变化。
然而,图3中一个有趣的发现是,尽管网络钓鱼目标的格局发生了变化,但这些网络钓鱼攻击所针对的行业基本保持一致。 例如,De Volksbank()、Bitkub 和 Banco Do Brazil()都是银行组织,尽管它们在不同时间成为网络钓鱼目标。 中的几乎所有钓鱼目标仍然可以归入十大行业。 这些目标大多数仍然属于历史上网络钓鱼攻击重点的行业,例如金融、电信和邮政服务等,而只有肯德基、Hydroquebec 等少数品牌无法被覆盖。十大产业。 我们在附录A中的表8中提供了更多属于不同行业的网络钓鱼目标示例。
值得注意的是,这一观察与社会工程所依赖的六大影响原则[10]相呼应,即权威在成功说服中的重要性。 在社会工程背景下,包括网络钓鱼攻击者在内的威胁行为者往往将精力集中在授权和高价值实体上,以最大限度地提高非法获取敏感信息的收益,而不是冒充信誉较差和价值较低的公司。
3.1.3 连接到维基数据知识图谱
网络钓鱼攻击持续针对特定行业,可以为预测性构建 BKB 奠定宝贵的基础。 品牌与行业的关系可以被视为存储在知识图谱中的事实三元组。 在这项工作中,我们使用最大的可公开访问的知识库维基数据[55][46, 43]来探索网络钓鱼目标与知识图谱之间的联系。 我们的重点在于检查维基数据中的 instance_of 关系,因为我们凭经验发现它提供了有关实体所属类型或类别的最全面的信息。 例如,Bank of America 品牌属于银行类别,可以表示为。 形式上,如果知识图中存在这样的事实,我们使用来表示品牌属于类别。
为了更深入地了解这些网络钓鱼目标所属的维基数据类别,我们在 数据集中执行搜索。 具体来说,对于每个网络钓鱼目标,我们搜索与其关联的类别,表示为。 此过程会生成类别集合 ,其中包含 APWG 网络钓鱼数据集中所有网络钓鱼目标的类别。 在图4中,我们展示了中30个最常出现的类别的可视化。 我们的观察表明,某些类别代表特定行业,例如银行、邮政服务和互联网服务提供商,而其他类别,例如商业、上市公司和企业,则传达更一般的语义。
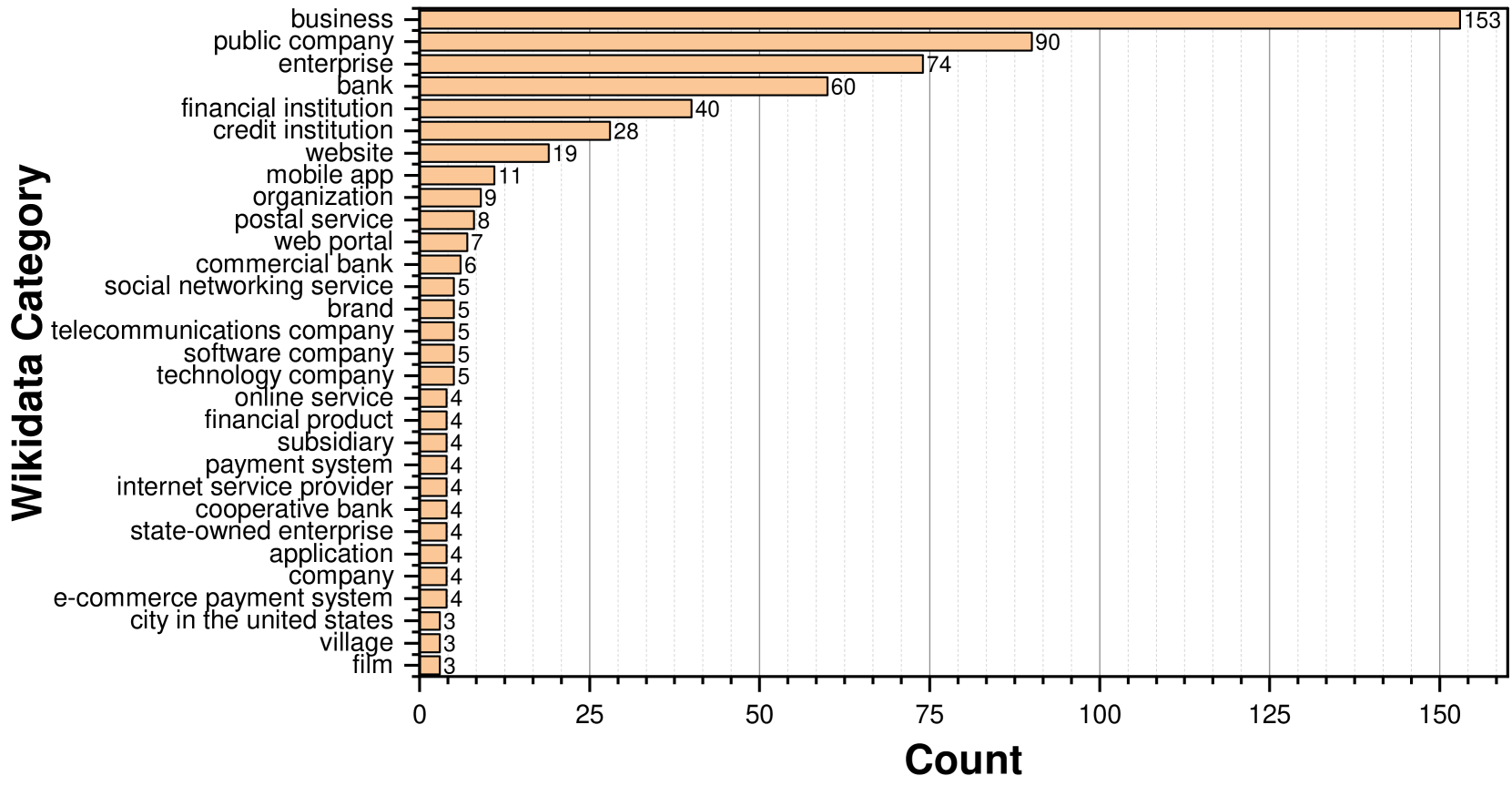
基于这一观察,我们整理了两个类别列表:1) 窄类别 ,例如代表较窄行业领域的“银行”,以及 2) 一般类别 例如“business”,将用于构建我们的品牌知识库 KnowPhish。 The detailed lists can be found in Table 9 and Table 10 in Appendix A.
3.2方法概述
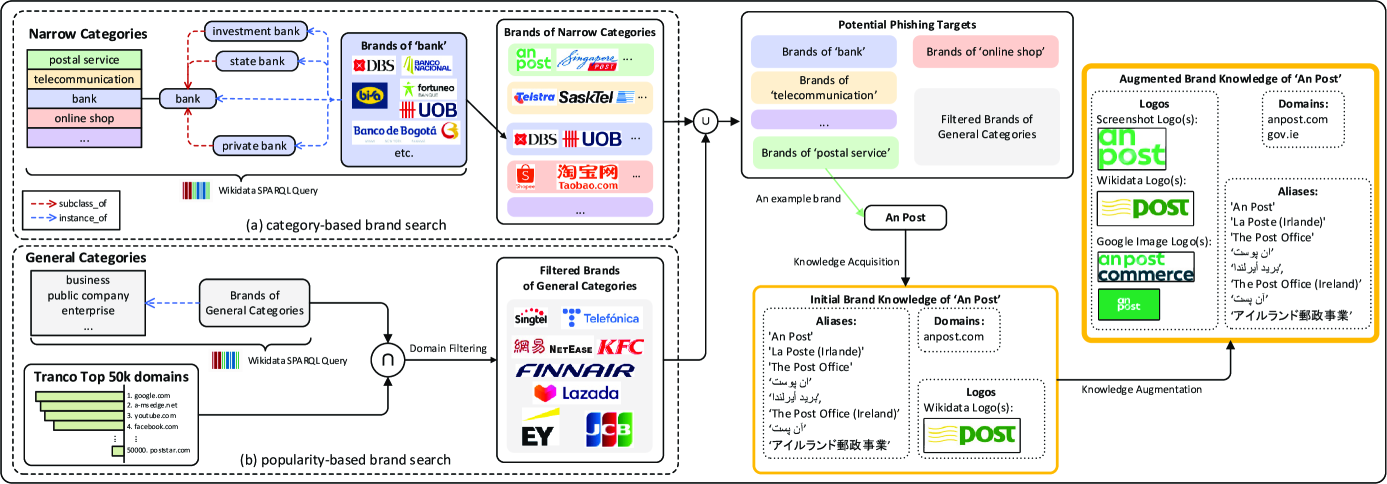
3.3品牌搜索
识别广泛的潜在钓鱼目标对于KnowPhish的构建至关重要。 如果BKB中不存在钓鱼目标,则RBPD可能无法识别其对应的钓鱼网页,从而导致漏报。 我们的品牌搜索模块旨在优先考虑价值较高的网络钓鱼目标品牌,并由两个并发组件组成:
-
(A)
基于类别的品牌搜索识别特定行业(即窄类别)内运营的品牌,以查找品牌。
-
(二)
基于受欢迎程度的品牌搜索考虑更广泛的常规类别,并按受欢迎程度对品牌进行排名,以生成品牌列表。
通过结合(a)和(b),我们获得了更全面的潜在网络钓鱼目标列表,表示为。
3.3.1 基于类别的品牌搜索
基于类别的品牌搜索是由我们的经验观察推动的,即网络钓鱼攻击者经常选择冒充高价值行业中的品牌。 因此,我们收集与窄类别 相关的所有品牌。 例如,当关注“银行”类别时,我们的目标是找到维基数据中列出的所有银行。
因此,对于每个窄类别,我们搜索属于及其子类别的相应品牌,其中subclass_of表示维基数据图中两个类别之间的层次关系。 形式上,与类别 相关的品牌列表是:
| (1) |
我们在这里引入子类别是因为窄类别子类别中的品牌也是网络钓鱼攻击者的潜在目标。 例如,哥斯达黎加国家银行在维基数据中被归类为国家银行(银行的子类别),尽管它无疑属于银行类别,并且是潜在的网络钓鱼目标。
3.3.2 基于流行度的品牌搜索
尽管行业类别是潜在网络钓鱼目标的关键指标,但维基数据中可能无法准确维护每个品牌的此类信息。 例如,新加坡电信公司 Singtel 按逻辑应该属于电信类别。 然而,维基数据中的唯一类别是“商业”、“上市公司”和“企业”。 因此,仅依赖窄类别 是不够的。
为了解决这个问题,我们引入了基于流行度的品牌搜索,其中结合了域排名来选择品牌。 我们使用基于域排名的过滤有两个原因:1) 并非一般类别 中的所有品牌都是高价值实体,2) 品牌声誉越高,就越有可能成为高价值实体。网络钓鱼目标。 因此,对于每个一般类别,我们生成具有域排名约束的相应品牌列表:
其中 是热门域名排名列表, 使用 计算 b.domains 中最热门域名的域名排名>,是域名排名阈值。 在这里,我们用 Tranco 域排名列表 [44] 实例化 。
通过基于类别的品牌搜索(表示为)和基于流行度的品牌搜索(表示为)获得的品牌被合并到我们的最终列表中>。
3.4知识获取和增强
RBPD 从根本上依赖于其品牌知识来实现准确的网络钓鱼检测。 接下来,我们通过有关 1) 徽标、2) 域名 和 3) 别名(或备用名称)相关知识来扩充我们收集的品牌与每个品牌。 请注意,现有 BKB [32, 33, 34] 中不存在别名,但我们引入它们是为了方便检测文本品牌意图,如第 4。
3.4.1知识获取
我们收集的每个品牌都是一个具有丰富属性信息的维基数据实体。 因此,我们利用这些现成的数据来建立初始品牌知识。 具体来说,对于每个 ,我们从维基数据图 中获取初始品牌知识:
其中徽标图像、官方网站和 标签222标签 在 SPARQL 中实例化为“rdfs:label”,而不是属性关系。 中的属性关系分别表示实体的徽标、官网URL以及不同语言的别名。
3.4.2 知识增强
维基数据中维护的信息可能不完整,尤其是徽标和域名。 品牌可以在其在线展示中使用多种合法的徽标变体和域名变体。 当网络钓鱼页面包含知识库中不存在的徽标变体时,网络钓鱼检测器可能无法识别其品牌,从而导致漏报。 同样,如果我们的检测器检查具有维基数据中未记录的合法域的良性网页,则可能会引发误报。 因此,需要进一步增强徽标和域上的,以减少此类误报和漏报。
标志变体。
为了捕获徽标变体,我们采用两种方法。 第一个涉及访问品牌的关联域并通过训练有素的网页布局检测器[33](表示为)捕获该网页上显示的徽标。 第二种方法利用 Google 图片搜索[17]。 我们通过将品牌名称与术语“徽标”相结合来发起搜索查询,然后过滤结果以包含 URL 与品牌域名匹配的图像。 通过这种方式,我们将我们的徽标集合扩展到维基数据徽标图像之外:
| (2) |
域变体。
为了获取其他域名变体,我们利用 Tranco 域名排名列表 和 Whois 服务[15]。 具体来说,我们对 KnowPhish 和 中的所有域运行 Whois 查找,以收集每个域的 Whois 信息。 然后,对于每个品牌 ,我们通过将与原始 共享相同组织详细信息的域合并到 中来扩展其合法域列表:
| (3) |
这里,指的是域的Whois信息。请注意,Whois 信息中的组织条目指定域的所有者。 因此,同一实体拥有的内的域可以有效地补充我们的域变体列表。
域传播。
我们进一步提出了一种在共享子公司关系的品牌对之间传播域信息的方法,因为品牌的合法网站也可能显示其子公司的徽标(反之亦然)。 例如,“facebook.com”可以被视为 Meta 的域名变体。 当访问“facebook.com”时,出现 Meta 徽标是合理的;但如果我们不知道这个域名变体,我们就会将其归类为具有 Meta 的品牌意图,从而将其归类为网络钓鱼攻击,从而导致误报。
为了解决这个问题,我们在中使用owned_by和parent_organization属性关系下的从属关系。 对于每个 ,其“传播域”被定义为这些关系图上其 1 跳邻域中的所有域;那是:
代表与品牌 共享附属关系的品牌集合中的域。 在域传播结束时,我们将原始域 (b.domains) 替换为上面的传播域。
至此,KnowPhish 已完成构建,并准备好配备基于图像的 [32, 33] 和基于文本的网络钓鱼检测器(在第 4 节中讨论) )。
适应不断变化的网络钓鱼目标。
新品牌不断出现,成为新的潜在网络钓鱼目标。 由于KnowPhish是以全自动方式构建的,因此可以通过定期重建KnowPhish以在之外搜索新的潜在网络钓鱼目标来简单地处理这种信息过时的情况。 这种定期更新使得 RBPD 方法能够有效抵御针对这些新兴品牌的攻击。
4KnowPhish 检测器
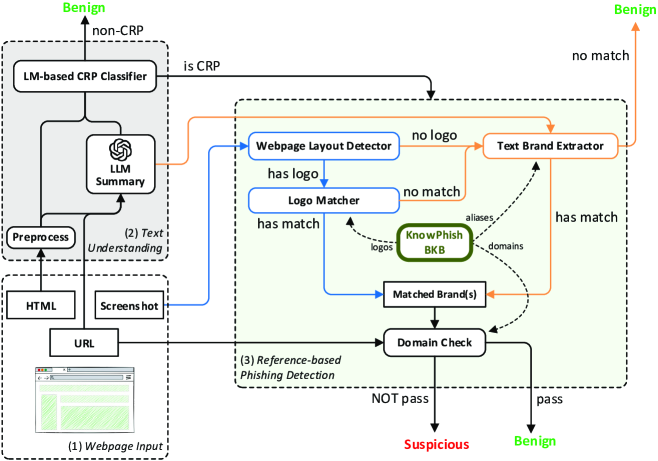
结合我们的多模态 BKB KnowPhish,我们进一步提出了 KnowPhish Detector (KPD),这是一种具有多阶段分析的多模态 RBPD。 图6提供了KPD的概述,算法1进一步阐述了其分析步骤。 具体来说,对于输入网页 ,KPD 首先利用大语言模型使用其 HTML 和 URL 生成 的摘要。 然后,将摘要和 HTML 输入到训练有素的小语言模型中,以对 是否是需要凭据的页面 (CRP) 进行分类。 如果被检测为CRP,KPD将继续从屏幕截图或大语言模型摘要中提取其品牌意图。 然后使用提取的 品牌意图来检索合法域列表,将其与 域进行比较,以确定 是否是网络钓鱼或不是。 值得注意的是,KPD 具有新颖的基于文本的模块来分析隐式 CRP 并从无徽标网页中提取品牌意图,这将在第4.2节和第4.3。
4.1 基于LLM的网页摘要
4.2 基于文本的 CRP 分类
正如第 2 节中所述,网络钓鱼网页始终传达需要凭据的意图。 虽然之前的研究已经开发了基于图像的 CRP 分类器[33],但我们凭经验发现,它会在部署过程中错误地将网络钓鱼网页分类为非 CRP,从而导致大量漏报,其中大多数假阴性都是隐含的 CRP。 图7提供了显式CRP和隐式CRP之间的比较,其中显式CRP直接显示凭证获取元素(例如,用户名和密码的输入字段),而隐式CRP仅显示凭证获取元素(例如,用户名和密码的输入字段)呈现重定向到潜在显式 CRP 的元素(例如登录按钮)。 虽然需要凭据的意图对于页面访问者来说是显而易见的,但 [33] 中的 CRP 分类器无法识别它,因为它专门专注于识别显式 CRP。

针对这一限制,我们建议使用小型 LM (XLM-RoBERTa[12]) 来识别文本中需要凭证的意图。 具体来说,小型LM将处理后的HTML和大语言模型摘要作为输入,并输出网页是否是CRP的二进制预测。 这种将原文及其大语言模型摘要整合为较小 LM 的输入的设计旨在受益于大语言模型的通用推理和指令跟踪能力,以及小型 LM [ 的可训练性。 20]。 因此,我们基于文本的分类器可以更好地理解网页文本中的凭证需求意图,从而促进显式和隐式 CRP 的检测。 分类为非 CRP 的网页被视为良性;对于那些被归类为 CRP 的人,我们继续进行品牌提取步骤。
4.3 品牌提取器
接下来,我们的目标是提取网页的品牌意图。 回想一下,我们的方法与现有的 RBPD 集成,后者通过徽标直观地识别品牌,我们将其称为徽标品牌提取器 (LBE)。 具体来说,现有的 LBE [32, 33] 由一个用于从屏幕截图中定位徽标的网页布局检测器和一个用于匹配的徽标匹配器组成。该标志为 BKB 中的一个品牌。 我们发现,现有的 RBPD 在识别品牌意图时遇到限制:1)网页中显示的徽标与 BKB 中存储的徽标不同,或者 2)甚至无法检测到徽标(例如,图 1)。
为了解决这个问题,我们引入了文本品牌提取器(TBE),当 LBE 无法从屏幕截图中识别品牌时,它充当额外的组件。 TBE通过解析已经包含品牌意图预测的大语言模型摘要来直接提取文本品牌。 预测的文本品牌与 KnowPhish 中的所有别名进行精确匹配。 与匹配的别名相关联的品牌在品牌识别步骤期间成为识别的品牌。 如果多个别名匹配,则所有相应的品牌都会被识别。
当LBE无法检测到网页上的徽标或找不到匹配的徽标时,TBE就会被激活以提取品牌意图,从而提高召回率。
4.4 域名检查
一旦确认需要凭证的意图和品牌意图,最后一步就是执行域检查。 我们从 KnowPhish 检索匹配品牌的所有合法域名,并将它们与输入网页的域名进行比较。 如果输入的域名与我们检索到的所有合法域名不一致,则该网页将被归类为钓鱼网站;否则,预测为良性。 请注意,被分类为非 CRP 或没有品牌意图的网页也被视为良性的。
5实验
我们进行实验来回答以下研究问题:
-
•
[RQ1]有效性和效率:KnowPhish 和 KPD 能否有效提高现有网络钓鱼检测器的网络钓鱼检测性能?
-
•
[RQ2] 实地研究:KnowPhish 和 KPD 在实际场景中部署时效果如何?
-
•
[RQ3] 对抗鲁棒性:基于文本的网络钓鱼检测器针对 HTML 文本中的对抗噪音的鲁棒性如何?
-
•
[RQ4] 消融研究:KPD 的每个组成部分对其整体性能有何贡献?
5.1数据集
我们利用两个数据集进行主要的网络钓鱼检测实验。 1) TR-OP:手动标记和平衡的数据集,其中良性样本来自 Tranco[44],网络钓鱼样本来自 OpenPhish[40 ]。 网络钓鱼样本是在2023年7月至12月的6个月内爬取并验证的,覆盖了440个独特的网络钓鱼目标。 请注意,此处的网络钓鱼样本与第3.1中的APWG网络钓鱼数据集不同。 2)SG-SCAN:未标记的数据集,样本来自新加坡本地网页流量。 我们随机抽取了 2023 年 8 月中旬至 2024 年 1 月中旬的 10,000 个网页样本。 它用于评估本地环境中的网络钓鱼检测方法。 表1提供了这两个数据集的概述。
| Dataset | #Samples | #Benign | #Phishing | Used in |
|---|---|---|---|---|
| TR-OP | 10k | 5000 | 5000 | RQ1,3, and 4 |
| SG-SCAN | 10k | Unknown | Unknown | RQ2 and 4 |
此外,我们还手动提取并标记了 2555 个样本,以训练基于文本的 CRP 分类器 XLM-RoBERTa [12]。 该数据集包含来自 的 1094 个网络钓鱼样本和来自 Alexa Ranking [4] 的 1461 个良性样本。 这1094个钓鱼样本都是CRP。 在1461个良性样本中,1297个是非CRP,其余164个是CRP。 组合这些样本后,它们被分为 0.8/0.1/0.1 训练/有效/测试分割。
5.2基线
我们选择两种最先进的方法,Phishpedia[32] 和 PhishIntention[33],以及我们提出的 KPD 作为 RBPD 主干。 Phishpedia 和 PhishIntention 都可以配备其原始参考列表(包含 277 个品牌)、DynaPhish[34] 或我们建议的 KnowPhish,作为用于网络钓鱼检测的 BKB。 由于需要别名信息,KPD 将仅配备 KnowPhish。 为了公平比较,KnowPhish 和 DynaPhish 都将从空的 BKB 构建知识,因为人们总是可以通过手动添加经过严格检查的品牌知识来提高这两种知识扩展方法的性能。
我们在所有实验中都假设静态环境(即网页上唯一可用的数据是其 URL、屏幕截图和 HTML)。 此时,PhishIntention中的动态分析模块和DynaPhish中的网页交互模块将被禁用。 有关实现的更多详细信息,请参阅附录C。
5.3 RQ1:有效性和效率
| Detector | BKB | ACC | F1 | Precision | Recall | Time |
|
Original |
68.17 |
53.54 |
99.08 |
36.68 |
0.22s |
|
|
Phishpedia |
DynaPhish |
66.40 |
52.52 |
89.50 |
37.16 |
10.92s |
|
KnowPhish |
85.79 |
83.67 |
98.27 |
72.80 |
0.22s |
|
|
Original |
64.97 |
46.15 |
99.73 |
30.02 |
0.24s |
|
|
PhishIntention |
DynaPhish |
62.51 |
41.16 |
95.62 |
26.22 |
10.67s |
|
KnowPhish |
77.84 |
71.60 |
99.67 |
55.84 |
0.26s |
|
|
KPD |
KnowPhish |
92.49 | 92.05 |
97.84 |
86.90 |
2.02s |
我们通过准确度、F1 分数、精确度、召回率、检测到的品牌数量以及基于每个样本的平均运行时间的效率来评估不同 RBPD 的有效性。 具体来说,检测到的品牌数量有助于了解每个 RBPD 可以从网络钓鱼网页中识别出多少个独特品牌,因为识别网页的目标是 RBPD 的一项关键任务。
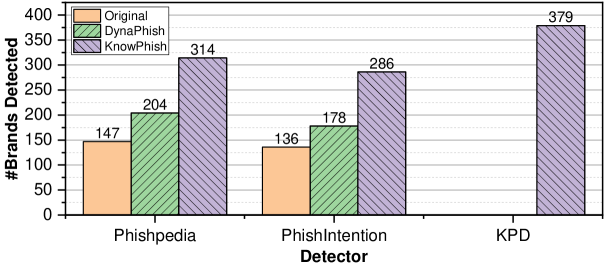
表2显示了三种具有不同BKB的RBPD的网络钓鱼检测性能。 我们观察到 KnowPhish 和 KPD 具有以下主要优势:
-
•
与其他 BKB 基线相比,KnowPhish 将 Phishpedia 的 F1 分数大幅提高了 30%,PhishIntention 提高了 25%,召回率也提高了 25%,而对精确率的影响很小。 KnowPhish 比 DynaPhish 性能优越的主要因素是 KnowPhish 包含更多徽标变体。 相比之下,DynaPhish 只能识别与官方网页上显示的徽标相同的徽标(图8中提供了一些示例)。
-
•
KPD 提供了最高的 F1 分数(92.02%)和召回率(86.90%),大大优于其他方法。 KPD 受益于 KnowPhish 的别名信息,使其能够检测无徽标的网络钓鱼页面。 因此,KPD 比 DynaPhish 识别出更多的网络钓鱼目标,如图图9所示。
-
•
KnowPhish 通过将 BKB 构造与网络钓鱼检测器解耦来实现运行时效率。 与需要在部署期间抓取额外网页的 DynaPhish 不同,KnowPhish 在本地识别潜在的网络钓鱼目标,与 Phishpedia 和 PhishIntention 集成时,运行时间可缩短约 50 倍。 即使配备具有额外大语言模型查询开销的 KPD,KnowPhish 仍比具有基于图像的 RBPD 的 DynaPhish 快 5 倍。
总体而言,KnowPhish 和 KPD 增加了品牌及其徽标的覆盖范围,并使我们能够检测无徽标的页面,从而显着提高检测性能,同时保持可接受的运行时开销。
5.4RQ2:实地研究
为了进一步了解不同 RBPD 的网络钓鱼检测性能推广到本地环境的效果如何,我们对 SG-SCAN 数据集进行了实地研究。 该实地研究还纳入了 URLScan[53](一种广泛认可的商业网络钓鱼检测器)作为评估 KnowPhish 和 KPD 在行业内影响的基线。 请注意,该数据集未标记,因此我们仅手动验证网络钓鱼检测器报告的样本。 这使我们能够计算真正的阳性计数和评估精度(但不是召回率)。
| Detector | BKB | #P | #TP | Precision | Time |
| Original | 54 | 17 | 31.48 | 0.16s | |
| Phishpedia | DynaPhish | 583 | 481 | 82.67 | 5.98s |
| KnowPhish | 353 | 333 | 94.33 | 0.16s | |
| Original | 25 | 8 | 32.00 | 0.18s | |
| PhishIntention | DynaPhish | 163 | 140 | 85.89 | 5.91s |
| KnowPhish | 138 | 133 | 96.37 | 0.19s | |
| URLScan | NA | 517 | 495 | 95.74 | NA |
| KPD | KnowPhish | 699 | 681 | 97.42 | 1.64s |
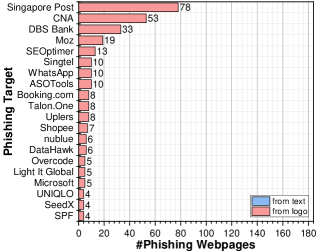
主要结果如表3和图10所示,我们的实地研究得出以下观察结果:
- •
-
•
KnowPhish 涵盖了新加坡的许多本地网络钓鱼目标(例如星展银行、华侨银行、Shopee、Lazada、Singtel、Qoo10)。 这些钓鱼目标均属于我们在第3.1节中提到的十大高价值行业,这进一步验证了我们的实证观察。
-
•
与 KnowPhish 集成时,Phishpedia 和 PhishIntention 检测到的网络钓鱼网页略少于与 DynaPhish 集成。 我们的手动检查发现,当遇到维基数据中未维护的鲜为人知的品牌(例如 SEOptimer 和 ASOTools)时,DynaPhish 往往更有效,而 KnowPhish 在识别使用徽标变体或文本品牌的网络钓鱼网页方面表现更好。
总而言之,我们的实地研究强调了对可以在文本模式下运行的 RBPD 的需求,并证明了 KnowPhish 和 KPD 在本地环境中的有效性和效率。
5.5 RQ3:对抗鲁棒性
我们研究基于文本的组件针对 HTML 混淆作为规避技术的稳健性。 我们设计了两种混淆 HTML 的方法:
-
•
插入。 我们遵循[27]中介绍的技术来生成随机 Token 。 5 个随机噪声标记将被放置为前缀或后缀。
- •
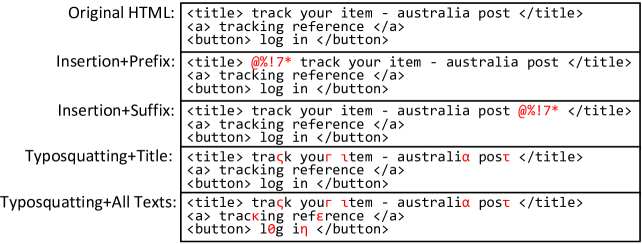
这两种攻击技术的目的都是通过在输入文本中引入噪声来破坏基于文本的模型,同时保持与原始文本的相似性。 图11显示了HTML混淆的四种设置的几个示例。
对于品牌提取,我们使用 TR-OP 数据集中的 200 个随机钓鱼网页样本来评估 1)NIR,测试样本中品牌不可识别的样本比例,以及 2)品牌提取准确性。 由于对品牌意图的正确预测可能有多种形式(例如,“星展银行”或“星展银行”是对品牌星展银行的正确预测),因此评估品牌提取的准确性需要人工验证。 因此,评估集的大小被限制为较小的数量。 对于CRP分类,我们以148/276/154显式/隐式/非CRP分割对SG-SCAN数据集中的578个网页进行采样和注释,评估指标是分类准确性。
| Task | Attack Type | Position | NIR | ACC |
| None | None | 12.00 | 81.00 | |
| Brand | Insertion | Prefix | 13.00 | 79.00 |
| Extraction | Suffix | 14.00 | 78.50 | |
| Typosquatting | Title | 13.50 | 78.00 | |
| All Texts | 18.00 | 72.00 | ||
| CRP | None | None | NA | 93.94 |
| Classif. | Typosquatting | All Texts | NA | 91.00 |
表4显示了采用对抗性攻击后的结果。 总体而言,我们基于 LLM 的方法对于此类攻击具有很强的鲁棒性。 对于品牌提取任务,作为对抗性攻击的插入仅导致 ACC 下降 2-3%,NIR 增加 1-2%。 当我们引入拼写错误时,性能差距会稍微大一些,尤其是在 HTML 中的所有文本中使用它时。 然而,在所有类型的攻击下,整体品牌提取 ACC 仍然高于 70%。 我们认为这是因为大语言模型可以从 HTML 的多个部分中寻找有用的信息,甚至在 Token 损坏时使用其内部知识来纠正品牌名称。 同样,对于 CRP 分类,即使 HTML 文本中的每个单词都被误植,我们基于 LLM 的 CRP 分类器也可以保持相对较高的分类精度。
总之,我们的对抗性攻击实验表明,我们基于 LLM 的组件对于四种类型的 HTML 混淆具有鲁棒性。
5.6 RQ4:消融研究
5.6.1 KPD组件的消融
我们的多模式网络钓鱼检测器 KPD 采用 LBE 和 TBE 构建,用于品牌识别。 因此,我们分别删除了 LBE 和 TBE,以研究它们在管道中的各自效用。 我们还单独删除了基于文本的 CRP 分类器,以检查其消除误报的有效性。 我们使用 TP-OP 数据集和 SG-SCAN 数据集来评估我们的消融模型。
| Dataset | Detector | Recall | Precision | #P | #TP |
| TR-OP | KPD | 86.90 | 97.84 | 4441 | 4345 |
| w/o TBE | 69.96 | 98.54 | 3550 | 3498 | |
| w/o LBE | 71.72 | 98.35 | 3646 | 3586 | |
| w/o CRP Classifier | 91.20 | 97.42 | 4781 | 4560 | |
| SG-SCAN | KPD | Unknown | 97.42 | 699 | 681 |
| w/o CRP Classifier | Unknown | 85.11 | 873 | 743 |
表5显示,排除 LBE 或 TBE 会显着损害 TR-OP 上的召回率。 这种结果是预料之中的,因为许多网络钓鱼网页通过徽标或文本(但不一定同时两者)传达其品牌意图。 关于基于文本的 CRP 分类器,结果表明,其删除不会严重影响精度,但会大大提高 TR-OP 的召回率。 尽管如此,我们认为该组件在现实场景中仍然不可或缺,其中良性网页的数量明显多于网络钓鱼网页。 SG-SCAN 数据集的结果证实了这一点,表明缺乏基于文本的 CRP 分类器会明显影响精度。
5.6.2 不同大语言模型架构的效果
我们还尝试了不同的大语言模型架构,以研究它们对网络钓鱼检测的影响。
| Detector | ACC | F1 | Precision | Recall |
|---|---|---|---|---|
| KPD (GPT-3.5-turbo-instruct) | 92.49 | 92.05 | 97.84 | 86.90 |
| w/ GPT-3.5-turbo | 91.84 | 91.29 | 97.94 | 85.48 |
| w/ GPT-4 | 92.31 | 91.82 | 98.05 | 86.34 |
| w/ LLaMA-2-7B | 91.23 | 90.68 | 96.69 | 85.38 |
结果如表6所示。 虽然 GPT-4 的精度最高,但我们目前使用的大语言模型 (GPT-3.5-turbo-instruct) 的召回率最高。 一般来说,较大的模型在精度和召回率方面都比 LLaMA-2-7B 等较小的模型表现更好。 根据我们的观察,LLaMA-2-7B 倾向于更频繁地混合上下文演示中的信息,并预测实际样本的目标品牌是演示中的品牌。 当此类错误发生在良性样本上时,可能会导致域名品牌不一致,从而导致误报预测。 此外,较小的模型的指令跟踪能力较差,并且在更多情况下无法遵守所需的输出格式。
5.6.3CRP分类器分析
除了主要组件之外,我们还仔细研究了不同 CRP 分类器的性能。 我们基于文本的 CRP 分类器是一个经过良好训练的 XLM-RoBERTa 模型,它接收样本的 HTML 和由大语言模型 (GPT-3.5-instruct) 生成的 CRP 摘要。 我们用其他架构替换当前的大语言模型摘要器,以研究 CRP 摘要器的选择是否重要。 此外,我们还删除了 CRP 摘要,并使用 HTML 作为 XLM-RoBERTa 模型的唯一输入,以检查其在独立设置中的性能。 由于[33]还提出了一种基于图像的CRP分类器,可以根据屏幕截图生成CRP预测,因此我们也将其作为单独的基线。
| Detector | ACC | F1 | Precision | Recall |
|---|---|---|---|---|
| Text-based CRP Classifier | 93.94 | 95.95 | 94.31 | 97.64 |
| w/ GPT-3.5-turbo Summary | 93.43 | 95.58 | 94.27 | 96.93 |
| w/ GPT-4 Summary | 94.12 | 96.05 | 94.72 | 97.41 |
| w/ LLaMA-2-7B Summary | 86.85 | 91.72 | 85.22 | 99.29 |
| w/o LLM Summary | 93.43 | 95.63 | 93.27 | 98.11 |
| Image-based CRP Classifier[33] | 51.90 | 51.91 | 97.40 | 35.38 |
然后我们的模型在第5.5中的相同CRP数据集上进行评估,结果如表7所示。 在基于 NLP 的方法中,由较大的大语言模型(GPT-3.5-instruct、GPT-3.5-turbo、GPT-4)生成的摘要具有相似的性能。 然而,将大语言模型摘要器切换为LLaMA-2-7B时,精度和准确度明显下降。 这可能是由摘要中的幻觉引起的,幻觉误导了我们的 XLM-RoBERTa 分类器(请参阅第 6 中的讨论)。 删除大语言模型摘要仅对精度和准确度产生轻微影响。 这意味着我们的 CRP 分类器可以单独正常运行,而大语言模型摘要则增加了额外的保护措施,防止分类器的训练样本在推理过程中出现潜在的分布变化。 与基于图像的方法相比,虽然我们基于文本的方法在精度上稍有滞后,但它具有更高的召回率和准确性,并且可以检测更多的 CRP,尤其是隐式 CRP。
6 限制
6.1错误分析
本节深入分析KnowPhish和KPD的误报和漏报情况。
误报
通过手动检查 KPD 的所有 97 个误报,我们查明了两个主要原因:品牌代表冲突和域变体包含不完整,分别占 45.36% 和 43.30%分别为误报总数。
品牌表示冲突要么是网页的屏幕截图,要么是 HTML 与错误的品牌匹配。 徽标匹配器和文本品牌提取器都不是完美的,并且可能会通过不匹配徽标或从与真实品牌意图不匹配的文本中提取品牌来错误识别网页的品牌意图。
对于第二个问题,KnowPhish 中可能会缺少域名变体,因为 Whois 所有者信息并非适用于所有域名。 我们发现 KnowPhish 中最多 30.79% 的域名拥有可用的所有者信息。 这种缺陷可能会导致品牌的域变体列表不完整,当当前页面的域被忽略为知识库中的合法域时,会导致误报。
最后,大多数剩余的误报与之前研究中概述的常见问题一致,例如将广告徽标误识别为主要徽标[32, 33]。
假阴性
我们还检查了 KPD 在 TR-OP 数据集上的所有 655 个假阴性样本,揭示了这些错误预测背后的三个主要原因。
当徽标品牌提取器和文本品牌提取器都无法识别输入网页的任何品牌意图时,大多数(53.84%)的误报就会出现。 当网页上显示的徽标与 KnowPhish 中的徽标不同、从屏幕截图中无法识别徽标、大语言模型错误地提取文本品牌或无法完全从 HTML 中提取文本品牌时,可能会出现这种情况。 如果无法从网页中识别出品牌意图,KPD 和任何现有的 RBPD 都会将该网页归类为良性。
此外,CRP 分类器的负分类也会导致 30.2% 的假阴性。 大多数失败案例都伴随着极其隐含的凭证要求意图。 附录C中的图14显示了一个示例,其中我们的文本品牌提取器检测到品牌意图为 Telegram,但是我们的 CRP 分类器将其分类为非 CRP。
KnowPhish 有限的品牌覆盖率是造成剩余漏报的原因。 Bank Promerica、Minnesota Unemployment Insurance 和 Battleground Mobile India 等网络钓鱼目标甚至没有包含在维基数据中。 虽然 KnowPhish 增强了现有 RBPD 的性能,甚至超越了 DynaPhish,但某些网络钓鱼目标将超出 BKB。 在这种情况下,任何 RBPD 都将面临检测网络钓鱼网页的挑战。
6.2 外部数据库的不完整性
我们在第 6.1 节中的错误分析指出,品牌知识限制(包括徽标、别名和域名变体)是由于 Wikidata 和 Whois 的限制而产生的主要错误来源服务。 最直接的解决方案是整合其他品牌数据库,例如 WIPO 全球品牌数据库[60]。 或者,我们可以依靠大语言模型[50,39,36,23]的隐性知识或大语言模型与在线搜索相结合的方法[56,48,38,26] 。
为了进一步处理误报,我们还可以引入辅助验证器,例如基于搜索引擎的过滤器,以在 RBPD 将网页报告为网络钓鱼之前验证该网页的受欢迎程度:即,如果某个网页被 RBPD 报告为网络钓鱼但发现成为搜索引擎流行的网页,很可能是良性的。 先前的研究表明,基于搜索引擎的验证器可以识别超过 60% 的良性网页[13, 34],而运行时开销可以忽略不计。
6.3 大语言模型的错误
我们观察到我们的大语言模型犯了两种主要类型的错误。 首先,当 HTML 包含多个品牌名称时,他们偶尔会提取错误的品牌(参见表4)。 这可以通过更好的提示或从大语言模型中引出更好的推理来解决。 目标品牌的文本跨度通常具有将其与非品牌区分开来的形态(例如,每个字符的大写)或上下文特征。 因此,我们可以利用现有技术[58,57,62]来指导大语言模型对这些特征进行识别和推理,从而更准确地提取目标品牌。 其次,我们观察到大语言模型可以构造不存在的 HTML 元素,例如表明凭证获取意图的输入字段和重定向按钮。 这指向幻觉,这是大语言模型[22]的一个已知问题。 为了解决这个问题,可以使用许多策略[51,49,8]将我们的模型的注意力引导到与凭证获取意图相关的 HTML 部分,并使它们的生成更好地锚定在页面内容。
7相关工作
网络钓鱼检测
最简单的网络钓鱼检测方法依赖于恶意 URL 黑名单[45,40,42],这是一种反应式方法。 主动方法包括基于特征工程的方法,这些方法依赖于 URL [28, 37, 54]、HTML [18, 61] 或两者的手工制作特征[31,35,29]。 这些方法受到无法使用徽标的限制,并且容易受到分布变化的影响。 RBPD 依靠手动收集的小型 BKB,通过屏幕截图 [16, 3, 1] 或徽标[32, 33] 提取网页的品牌意图。 最近,DynaPhish[34]提出在部署过程中动态扩展BKB。 然而,部署过程中的这种交互会导致检测器的运行时间大幅增加,例如每个样本 10.6 秒。 相比之下,我们的多模态 BKB 在部署之前就已完全构建,使我们的检测器更加高效。
大语言模型与知识密集型应用
大语言模型在广泛的语言和代码相关任务上表现出了卓越的性能[2, 9],并已扩展到大型多模态模型(LMM)[63]. 最近的一些工作将大语言模型应用于网络钓鱼检测[25, 59]。 然而,这些都是非 RBPD 方法,并且不能使用徽标。 它们也不与知识库集成,因此其可用知识的广度受到限制。
为了提高大语言模型在知识密集型任务上的性能,丰富的工作线将它们与知识图谱[21, 41]结合起来。 这可以减少幻觉[52],提高可解释性,并允许知识更新[41]。 网络钓鱼检测本质上是一项知识密集型任务,其中品牌知识是一个非常重要的组成部分;此外,可解释性和知识更新在现实世界的网络钓鱼检测中具有很高的实际重要性,这促使我们开发用于网络钓鱼检测的大规模多模态知识图。 据我们所知,现有的工作还没有将知识图谱集成到用于网络钓鱼检测的标准徽标数据库之外,这使得这是一个重要的研究空白。 在检测器方面,现有的工作还没有开发利用图像和文本模态的多模态 RBPD。
值得关注的是,大语言模型也被滥用来开发网络钓鱼攻击[24],特别是鱼叉式网络钓鱼电子邮件[19, 7]、模仿某些品牌的网络钓鱼网页以及规避当前的网络钓鱼攻击。反网络钓鱼工具[47]。 他们能够大规模生成恶意网页,同时避免人为创建的网络钓鱼网页的传统指标,这对网络安全构成了严重且不断演变的威胁。 这就需要开发更好的检测工具,这些工具具有主动性、对抗性强、可扩展至大量网页。
8结论
在这项工作中,我们提出了 KnowPhish,这是一个大规模的多模式品牌知识库,涵盖超过 20k 的潜在网络钓鱼目标,可以以即插即用的方式与任何 RBPD 集成。 我们进一步提出 KPD,一种在文本和图像模式下运行的多模式 RBPD,用于检测带有或不带有徽标的网络钓鱼网页。 大量实验证明了 KnowPhish 和 KPD 在多种设置下的有效性和效率。 展望未来,我们预计集成其他知识源和 LLM 相关增强功能(例如检索增强 [30])可以进一步提高性能。
致谢
这项研究得到了新加坡国家研究基金会、智能国家和数字政府办公室智能国家和数字政府研发资助计划 (TRANS) 2.0 (TRANS2023-TGC01) 以及新加坡国家研究基金会 NCS Pte 的支持。 有限公司和新加坡国立大学下属的 NUS-NCS 联合实验室(Grant A-0008542-00-00)。
参考
- [1] Sahar Abdelnabi, Katharina Krombholz, and Mario Fritz. Visualphishnet: Zero-day phishing website detection by visual similarity. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, CCS ’20, page 1681–1698, New York, NY, USA, 2020. Association for Computing Machinery.
- [2] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [3] Sadia Afroz and Rachel Greenstadt. Phishzoo: Detecting phishing websites by looking at them. In 2011 IEEE Fifth International Conference on Semantic Computing, pages 368–375, 2011.
- [4] Alexa ranking. https://www.alexa.com/siteinfo.
- [5] Global Anti-Scam Alliance. The global state of scams report, 2023.
- [6] Anti-phishing working group. https://apwg.org/.
- [7] Mazal Bethany, Athanasios Galiopoulos, Emet Bethany, Mohammad Bahrami Karkevandi, Nishant Vishwamitra, and Peyman Najafirad. Large language model lateral spear phishing: A comparative study in large-scale organizational settings. arXiv preprint arXiv:2401.09727, 2024.
- [8] Chung-Ching Chang, David Reitter, Renat Aksitov, and Yun-Hsuan Sung. Kl-divergence guided temperature sampling, 2023.
- [9] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- [10] Robert Cialdini and Brad J. B. Sagarin. Psychological Insights and Perspectives. Sage Publications, Inc, 2005.
- [11] Cisco. Cybersecurity threat trends report, 2022.
- [12] Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Francisco Guzmán Guillaume Wenzek, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020.
- [13] Yan Ding, Nurbol Luktarhan, Keqin Li, and Wushour Slamu. A keyword-based combination approach for detecting phishing webpages. Comput. Secur., 84(C):256–275, jul 2019.
- [14] D. Divakaran and A. Oest. Phishing detection leveraging machine learning and deep learning: A review. IEEE Security & Privacy, 20(5):2–11, jun 5555.
- [15] Free whois lookup. https://www.whois.com/whois/.
- [16] Anthony Y. Fu, Liu Wenyin, and Xiaotie Deng. Detecting phishing web pages with visual similarity assessment based on earth mover’s distance (emd). IEEE Transactions on Dependable and Secure Computing, 3(4):301–311, 2006.
- [17] Google images search. https://pypi.org/project/Google-Images-Search/.
- [18] Bingyang Guo, Yunyi Zhang, Chengxi Xu, Fan Shi, Yuwei Li, and Min Zhang. Hinphish: An effective phishing detection approach based on heterogeneous information networks. Applied Sciences, 11(20), 2021.
- [19] Julian Hazell. Large language models can be used to effectively scale spear phishing campaigns. arXiv preprint arXiv:2305.06972, 2023.
- [20] Xiaoxin He, Xavier Bresson, Thomas Laurent, Adam Perold, Yann LeCun, and Bryan Hooi. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning, 2023.
- [21] Linmei Hu, Zeyi Liu, Ziwang Zhao, Lei Hou, Liqiang Nie, and Juanzi Li. A survey of knowledge enhanced pre-trained language models. IEEE Transactions on Knowledge and Data Engineering, 2023.
- [22] Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1––38, 2022.
- [23] Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. Large language models struggle to learn long-tail knowledge. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors, Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 15696–15707. PMLR, 23–29 Jul 2023.
- [24] Rabimba Karanjai. Targeted phishing campaigns using large scale language models. arXiv preprint arXiv:2301.00665, 2022.
- [25] Takashi Koide, Naoki Fukushi, Hiroki Nakano, and Daiki Chiba. Detecting phishing sites using chatgpt, 2023.
- [26] Mojtaba Komeili, Kurt Shuster, and Jason Weston. Internet-augmented dialogue generation. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors, Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8460–8478, Dublin, Ireland, May 2022. Association for Computational Linguistics.
- [27] Aounon Kumar, Chirag Agarwal, Suraj Srinivas, Aaron Jiaxun Li, Soheil Feizi, and Himabindu Lakkaraju. Certifying llm safety against adversarial prompting, 2023.
- [28] Hung Le, Quang Pham, Doyen Sahoo, and Steven C. H. Hoi. Urlnet: Learning a url representation with deep learning for malicious url detection, 2018.
- [29] Jehyun Lee, Farren Tang, Pingxiao Ye, Fahim Abbasi, Phil Hay, and Dinil Mon Divakaran. D-fence: A flexible, efficient, and comprehensive phishing email detection system. In 2021 IEEE European Symposium on Security and Privacy (EuroS&P), pages 578–597, 2021.
- [30] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [31] Yukun Li, Zhenguo Yang, Xu Chen, Huaping Yuan, and Wenyin Liu. A stacking model using url and html features for phishing webpage detection. Future Gener. Comput. Syst., 94(C):27–39, may 2019.
- [32] Yun Lin, Ruofan Liu, Dinil Mon Divakaran, Jun Yang Ng, Qing Zhou Chan, Yiwen Lu, Yuxuan Si, Fan Zhang, and Jin Song Dong. Phishpedia: A hybrid deep learning based approach to visually identify phishing webpages. In 30th USENIX Security Symposium (USENIX Security 21), pages 3793–3810. USENIX Association, August 2021.
- [33] Ruofan Liu, Yun Lin, Xianglin Yang, Siang Hwee Ng, Dinil Mon Divakaran, and Jin Song Dong. Inferring phishing intention via webpage appearance and dynamics: A deep vision based approach. In 31st USENIX Security Symposium (USENIX Security 22), pages 1633–1650, Boston, MA, August 2022. USENIX Association.
- [34] Ruofan Liu, Yun Lin, Yifan Zhang, Penn Han Lee, and Jin Song Dong. Knowledge expansion and counterfactual interaction for Reference-Based phishing detection. In 32nd USENIX Security Symposium (USENIX Security 23), pages 4139–4156, Anaheim, CA, August 2023. USENIX Association.
- [35] Christian Ludl, Sean McAllister, Engin Kirda, and Christopher Kruegel. On the effectiveness of techniques to detect phishing sites. In Bernhard M. Hämmerli and Robin Sommer, editors, Detection of Intrusions and Malware, and Vulnerability Assessment, pages 20–39, Berlin, Heidelberg, 2007. Springer Berlin Heidelberg.
- [36] Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, Toronto, Canada, July 2023. Association for Computational Linguistics.
- [37] Pranav Maneriker, Jack W. Stokes, Edir Garcia Lazo, Diana Carutasu, Farid Tajaddodianfar, and Arun Gururajan. Urltran: Improving phishing url detection using transformers. In MILCOM 2021 - 2021 IEEE Military Communications Conference (MILCOM), pages 197–204, 2021.
- [38] Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback, 2022.
- [39] Reham Omar, Omij Mangukiya, Panos Kalnis, and Essam Mansour. Chatgpt versus traditional question answering for knowledge graphs: Current status and future directions towards knowledge graph chatbots, 2023.
- [40] Openphish - phishing intelligence. https://openphish.com/.
- [41] Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. Unifying large language models and knowledge graphs: A roadmap. IEEE Transactions on Knowledge and Data Engineering, 2024.
- [42] Phishtank | join the fight against phishing. https://phishtank.org/.
- [43] Sini Govinda Pillai, Lay-Ki Soon, and Su-Cheng Haw. Comparing dbpedia, wikidata, and yago for web information retrieval. In Vincenzo Piuri, Valentina Emilia Balas, Samarjeet Borah, and Sharifah Sakinah Syed Ahmad, editors, Intelligent and Interactive Computing, pages 525–535, Singapore, 2019. Springer Singapore.
- [44] Victor Le Pochat, Tom Van Goethem, Samaneh Tajalizadehkhoob, Maciej Korczynski, and Wouter Joosen. Tranco: A research-oriented top sites ranking hardened against manipulation. In Proceedings 2019 Network and Distributed System Security Symposium. Internet Society, 2019.
- [45] Niels Provos, Dean McNamee, Panayiotis Mavrommatis, Ke Wang, and Nagendra Modadugu. The ghost in the browser: Analysis of web-based malware. In First Workshop on Hot Topics in Understanding Botnets (HotBots 07), Cambridge, MA, April 2007. USENIX Association.
- [46] Daniel Ringler and Heiko Paulheim. One knowledge graph to rule them all? analyzing the differences between dbpedia, yago, wikidata & co. In Gabriele Kern-Isberner, Johannes Fürnkranz, and Matthias Thimm, editors, KI 2017: Advances in Artificial Intelligence, pages 366–372, Cham, 2017. Springer International Publishing.
- [47] Sayak Saha Roy, Poojitha Thota, Krishna Vamsi Naragam, and Shirin Nilizadeh. From chatbots to phishbots?–preventing phishing scams created using chatgpt, google bard and claude. arXiv preprint arXiv:2310.19181, 2023.
- [48] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023.
- [49] Weijia Shi, Xiaochuang Han, Mike Lewis, Luke Zettlemoyer Yulia Tsvetkov, and Scott Wen tau Yih. Trusting your evidence: Hallucinate less with context-aware decoding, 2023.
- [50] Kai Sun, Yifan Ethan Xu, Hanwen Zha, Yue Liu, and Xin Luna Dong. Head-to-tail: How knowledgeable are large language models (llm)? a.k.a. will llms replace knowledge graphs?, 2023.
- [51] Ran Tian, Shashi Narayan, Thibault Sellam, and Ankur P Parikh. Sticking to the facts: Confident decoding for faithful data-to-text generation., 2019.
- [52] SM Tonmoy, SM Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, and Amitava Das. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.01313, 2024.
- [53] Url and website scanner - urlscan.io. https://urlscan.io/.
- [54] Rakesh Verma and Keith Dyer. On the character of phishing urls: Accurate and robust statistical learning classifiers. In Proceedings of the 5th ACM Conference on Data and Application Security and Privacy, CODASPY ’15, page 111–122, New York, NY, USA, 2015. Association for Computing Machinery.
- [55] Denny Vrandečić and Markus Krötzsch. Wikidata: A free collaborative knowledgebase. Commun. ACM, 57(10):78–85, sep 2014.
- [56] Xintao Wang, Qianwen Yang, Yongting Qiu, Jiaqing Liang, Qianyu He, Zhouhong Gu, Yanghua Xiao, and Wei Wang. Knowledgpt: Enhancing large language models with retrieval and storage access on knowledge bases, 2023.
- [57] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In Proceedings of the 11th International Conference on Learning Representations (ICLR)., 2023.
- [58] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Conference on Neural Information Processing Systems (NeurIPS), 2022.
- [59] What does chatgpt know about phishing? https://securelist.com/chatgpt-anti-phishing/109590/.
- [60] Wipo global brand database. https://www.wipo.int/portal/en/index.html.
- [61] Guang Xiang, Jason Hong, Carolyn P. Rose, and Lorrie Cranor. Cantina+: A feature-rich machine learning framework for detecting phishing web sites. ACM Trans. Inf. Syst. Secur., 14(2), sep 2011.
- [62] Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, and Junxian He. Decomposition enhances reasoning via self-evaluation guided decoding. In CoRR, 2023.
- [63] Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models. arXiv preprint arXiv:2306.13549, 2023.
- [64] Rasha Zieni, Luisa Massari, and Maria Carla Calzarossa. Phishing or not phishing? a survey on the detection of phishing websites. IEEE Access, 11:18499–18519, 2023.
- [65] Zscaler. Zscaler threatlabz 2023 phishing report, 2023.
附录 A有关 KnowPhish 构建的其他详细信息
不同行业的钓鱼目标
我们在表8中提供了每个数据集上十一个行业品牌的更多详细信息。
| Industries | ||
|---|---|---|
|
financial |
Bank of America, Paypal, Credit Agricole, PostFinance |
Bitkub, Credit Saison, Denizbank, Banco Do Brasil, GCash |
|
online services |
Outlook, Microsoft 365, Dropbox, Adobe, Onedrive |
WeTransfer, Booking.com, Intuit, Biglobe, Mailchimp |
|
telecommunication |
AT&T, BT Group, Orange, Cox Communication |
Shaw Communication, Swisscom, Singtel, Bell, Etisalat |
|
e-commerce |
Amazon, eBay, Rakuten, Americanas |
Brooks Sports, Tesco, Loungefly, Shopee |
|
social media |
Instagram, Facebook, LinkedIn |
WeChat, VKontakte |
|
postal service |
DHL, EMS, FedEx, La Poste |
Australia Post, USPS, UPS, An Post, DPD |
|
government |
UK Gov, IRS, French Health Insurance, |
Turkey Gov, Australia Gov, LTA Singapore |
|
web portal |
Google, Daum, AOL |
Naver |
|
video game |
Steam, RuneScape, League of Legends |
/ |
|
gambling |
Bet365 |
/ |
|
other business |
Delta Airline |
KFC, AirNZ, Hydroqubec |
KnowPhish 构建的维基数据类别
我们在表9中提供了窄类别的完整列表,在表10中提供了一般类别的完整列表。 我们将两个维基数据类别“在线服务”和“政府组织”放入中,因为我们凭经验发现这会导致品牌数量过多。 我们通过调节它们的受欢迎程度来处理这个问题,这与将它们放入 中相同。
| Industries | Wikidata Category | Wikidata ID |
|
financial |
bank |
Q22687 |
|
financial institution |
Q650241 |
|
|
credit institution |
Q730038 |
|
|
federal credit union |
Q116763799 |
|
|
payment system |
Q986008 |
|
|
digital wallet |
Q1147226 |
|
|
cryptocurrency exchange |
Q25401607 |
|
|
online service |
webmail |
Q327618 |
|
web service |
Q193424 |
|
|
mobile app |
Q620615 |
|
|
office suite |
Q207170 |
|
|
telecommunication |
telecommunication company |
Q2401749 |
|
mobile network |
Q15360302 |
|
|
mobile network operator |
Q1941618 |
|
|
internet service provider |
Q11371 |
|
|
e-commerce |
online shop |
Q4382945 |
|
online marketplace |
Q3390477 |
|
|
social media |
social media |
Q202833 |
|
social networking service |
Q3220391 |
|
|
online video platform |
Q559856 |
|
|
postal service |
postal service |
Q1529128 |
|
package delivery |
Q1447463 |
|
|
government |
government |
Q7188 |
|
web portal |
web portal |
Q186165 |
|
web search engine |
Q4182287 |
|
|
video game |
video game distribution platform |
Q81989119 |
|
gambling |
gambling |
Q11416 |
| Industries | Wikidata Category | Wikidata ID |
|---|---|---|
|
other business |
business |
Q4830453 |
|
public company |
Q891723 |
|
|
enterprise |
Q6881511 |
|
|
online service |
Q19967801 |
|
|
government organization |
Q2659904 |
KnowPhish构建算法
完整的KnowPhish构建算法如算法2所示。
附录 B有关 KnowPhish 检测器的其他详细信息
大语言模型摘要生成提示模板 表11提供了为输入网页生成大语言模型摘要的完整提示模板。
Instruction: Define targeted brand as a brand that a webpage belongs to. Define credential-taking intention as a webpage’s intention to take users’ credentials, such as their email addresses, passwords, and so on. A credential-taking intention can be explicit or implicit, where explicit means having forms and input fields to submit user credentials directly, and implicit means not having explicit credential-taking intention, but instead having buttons or links redirecting users to another credential-taking webpage. Additionally, keywords related to user credentials, such as "Sign in", "Log in", "Register", "Account", "Assets", and "Password", are usually strong indicators of a credential-taking intention. Note that the texts in the HTML may be obfuscated into similar characters (e.g., ’a’ is obfuscated into ’’, or ’b’ is obfuscated into ’’). If such obfuscation exists, please deobfuscate it and correctify your output. Given the URL and HTML of a webpage P, answer (1) What the targeted brand of P is. If it is not identifiable, put "Not identifiable". Extract the brand name only and do not include extra details such as affiliated products, countries, or additional abbreviations; (2) What forms or input fields to submit user credentials are present; (3) What buttons or links are present that redirect users to another credential-taking webpage; (4) What important keywords are present; (5) Whether there is a credential-taking intention; (6) Reason to the answer in (5). Start the answer to each of (1) to (6) on a new line.
URL: https://1staskyoude2-gopnumze9.top/
HTML: <title> Adobe-PDF Singapore sell everything you need </title> <a> </a> <a> </a> © 2023 Adobe. All brands are the property of their respective owners.
Answer:
(1) Adobe
(2) There are no forms or input fields to submit user credentials.
(3) There are no buttons or links directing the user to another credential-taking page.
(4) There are no important keywords.
(5) no intention
(6) The answer is according to (2), (3), and (4).
URL: https://cryptoinex.com/h5/
HTML: <title> Home - Cryptoin Online For Business - CPT </title> 本站点必须要开启JavaScript才能运行 Cryptoin currency Total assets equivalent (USD) 0.00 Announcement on Delisting SGB/USDT Token Pair Announcement on Delisting Selected Token Pairs Announcement on Supporting Ethereum London Hard Fork locked mining more 3day USDT lock up to earn coins 10 start 3% Daily rate of return 1day USDT lock up to earn coins 100 start 7% Daily rate of return 15day USDT lock up to earn coins 1000 start 15% Daily rate of return 30day USDT lock up to earn coins 10000 start 30% Daily rate of return 60day USDT lock up to earn coins 100000 start 60% Daily rate of return Quote more BTC/USDT -0.54% 22437.79000 DTC/USDT -0.49% 1570.48000 XRP/USDT +0.87% 0.37054 LTC/USDT -1.39% 87.52000 EOS/USDT -1.00% 1.21330 YMT/USDT -0.61% 1.26965 BCH/USDT +0.02% 124.50000 Quote more trading pair Latest Price Today change XRP /USDT 24H: 11681739.60651 0.37054 +0.87% LTC /USDT 24H: 5219.74600 87.52000 -1.39% EOS /USDT 24H: 204125.08287 1.21330 -1.00% YMT /USDT 24H: 490.15695 1.26965 -0.61% BCH /USDT 24H: 1079.22726 124.50000 +0.02% Home Markets Trade Finance Assets Cancel OK
Answer:
(1) Cryptoin
(2) There are no forms or input fields to submit user credentials.
(3) There are no buttons or links directing the user to another credential-taking page.
(4) There is a keyword "Assets" related to user assets.
(5) implicit intention
(6) The answer is according to (4).
URL: https://app.afe-n2jhk.com/index/login/login/token
HTML: English Chinese English <form> <inputtxt> </inputtxt> <inputpwd> </inputpwd> The account or password is wrong, please re-enter!! <button> Login </button> </form> <a> Open an account now </a> <a> Online service </a> <a> ©1998-2021 Rights Reserved </a> <a> AFE ©1998-2021 Rights Reserved </a>
Answer:
(1) AFE
(2) There is a form containing account and password input fields.
(3) There is a button with the label "Login" and a link with the text "Open an account now".
(4) There are keywords "account", "password", and "Login" related to user credentials.
(5) explicit intention
(6) The answer is according to (2).
URL: {U}
HTML: {H}
Answer:
大语言模型查询的预估成本
KPD 中的大语言模型 Summarizer 利用 GPT-3.5-turbo-instruct 作为其大语言模型骨干。 在这里,我们提供了这个大语言模型查询所产生的成本的估计。 以我们的 TR-OP 数据集为例:平均每个网页样本有 2,588 个输入标记和 108 个输出标记。 API 定价为每 1,000 个输入 Token 0.0015 美元,每 1,000 个输出 Token 0.0020 美元,每个网页样本的大语言模型摘要的估计价格计算如下:
| Cost | |||
因此,在整个 TR-OP 数据集上运行 KPD 的预计成本约为 41 美元。
附录 C有关实验的其他详细信息
实施细节
对于 KnowPhish 构建,我们使用与 [33] 相同的网页布局检测器从网页中提取徽标图像,作为 DetectLogo() 函数的实例化。 我们将顶级域列表 的大小限制为 50k(即 =50k)。 品牌搜索算法因此返回 20514 个潜在的网络钓鱼目标。 对于KPD,我们还使用[33]中的相同模块实例化网页布局检测器和徽标匹配器,并使用GPT-3.5-turbo-instruct作为大语言模型骨干。
所有实验均在配备 2 个 AMD EPYC 7543 32 核处理器 @ 2.8GHz 和 8 个 Nvidia A40 48GB GPU 的 Ubuntu 服务器中进行。
HTML 混淆的激励示例
图12提供了一个拼写错误的示例,基于此我们开展了本文中的HTML混淆技术研究。
实地研究中的无徽标网络钓鱼网页
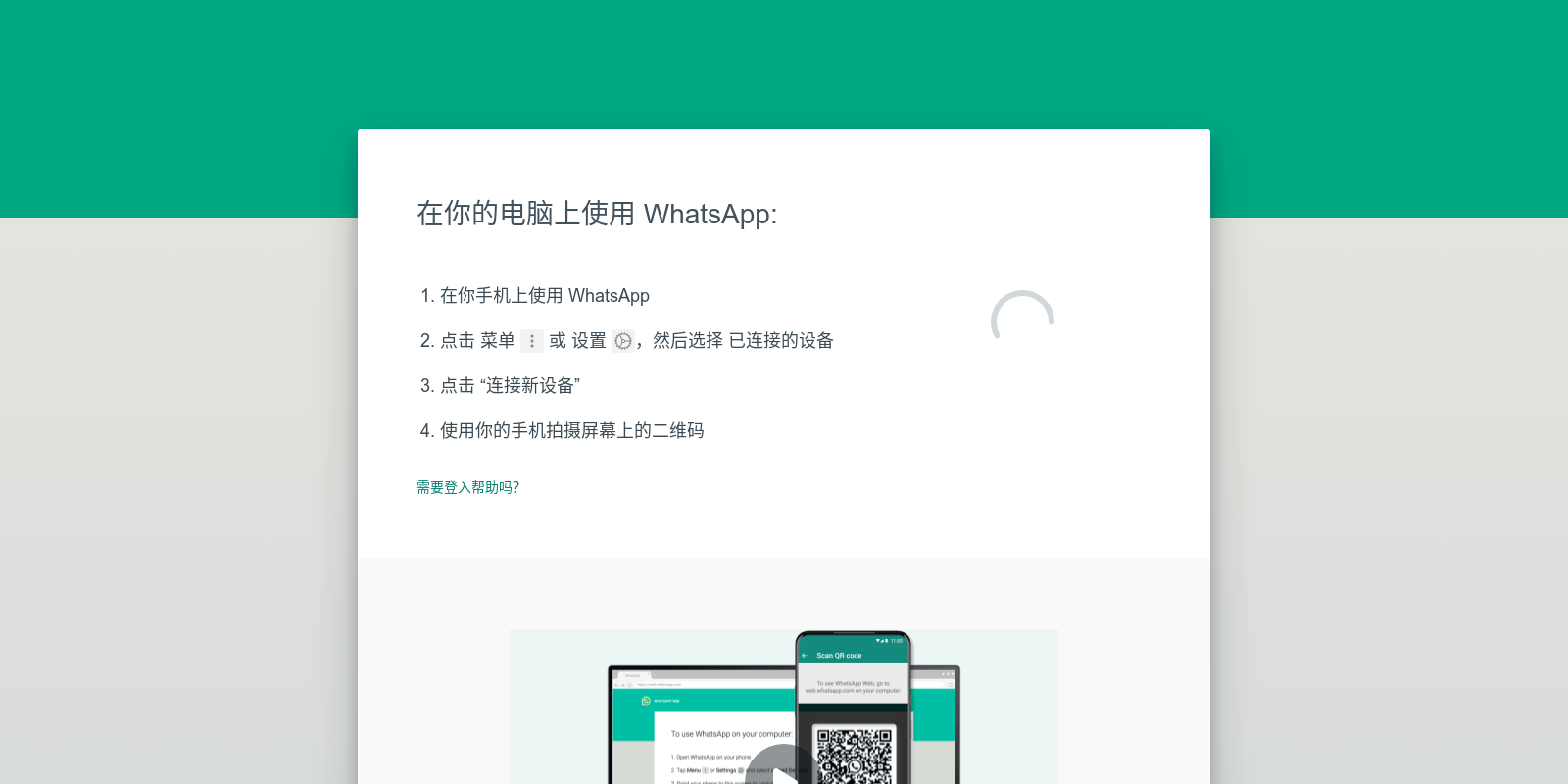
图13显示了 KPD 在 SG-SCAN 数据集上检测到的无徽标网络钓鱼网页的一些示例。
误差分析
图14是我们基于文本的CRP分类器无法检测到的极其隐式CRP的示例。