通过数据净化和动态激活函数设计推进分布外检测
摘要
在机器学习和深度学习的动态领域,模型的稳健性和可靠性至关重要,尤其是在关键的现实应用中。 该领域的一个基本挑战是管理分布外 (OOD) 样本,这会显着增加模型错误分类和不确定性的风险。 我们的工作通过增强神经网络中 OOD 样本的检测和管理来应对这一挑战。 我们引入了 OOD-R(Out-of-Distribution-Rectified),这是一个精心策划的开源数据集集合,具有增强的降噪特性。 现有 OOD 数据集中的分布内 (ID) 噪声可能会导致检测算法的评估不准确。 认识到这一点,OOD-R 结合了噪声过滤技术来细化数据集,确保对 OOD 检测算法进行更准确、更可靠的评估。 这种方法不仅提高了数据的整体质量,还有助于更好地区分 OOD 和 ID 样本,从而使模型准确度提高高达 2.5%,误报率至少减少 3.2%。 此外,我们还提出了 ActFun,这是一种创新方法,可以微调模型对不同输入的响应,从而提高特征提取的稳定性并最大限度地减少特异性问题。 ActFun 通过策略性地减少隐藏单元的影响,解决了 OOD 检测中模型过度自信的常见问题,从而增强了模型更准确地估计 OOD 不确定性的能力。 在 OOD-R 数据集中实现 ActFun 带来了显着的性能提升,包括 GradNorm 方法的 AUROC 提高了 18.42%,Energy 方法的 FPR95 降低了 16.93%。 总的来说,我们的研究不仅推进了 OOD 检测的方法,而且强调了数据集完整性对于准确算法评估的重要性。 通过细化分布内和分布外数据之间的区别,我们的贡献旨在提高模型识别和概括未知数据的能力,从而确保模型在不同应用中具有更高的可靠性。
索引术语:
分布外检测、OOD 数据集、分布内数据集、OOD 评估。我简介
深度神经网络中的分布外 (OOD) 检测在增强网络安全性和可靠性方面发挥着至关重要的作用[11,25,45,46],其重要性日益凸显。 尽管深度神经网络的能力令人印象深刻,但当遇到训练分布之外的输入时,它可能会产生不可靠的预测。 这种不可靠性在安全关键型应用中带来了相当大的风险,例如医疗诊断[34]和自动驾驶汽车[19],在这些应用中分类器的可靠性至关重要。
OOD 检测主要关注区分不确定的 OOD 预测和更可靠的分布内 (ID) 预测。 OOD 检测在确保机器学习系统安全部署方面的重要作用得到了强调,特别是在输入数据分布本质上不可预测的开放世界环境中[8]。 它具有双重目的:减少错误预测的可能性,并增强模型在实际应用中的可信度和实用性。 OOD 检测取决于准确估计数据密度或描述分布中的特征,而数据分布的复杂性使这项任务变得具有挑战性。 通常,模型是根据分布内 (ID) 数据进行预训练的,这些数据通常覆盖有限的范围,与现实世界数据的多样性和多方面性形成鲜明对比。
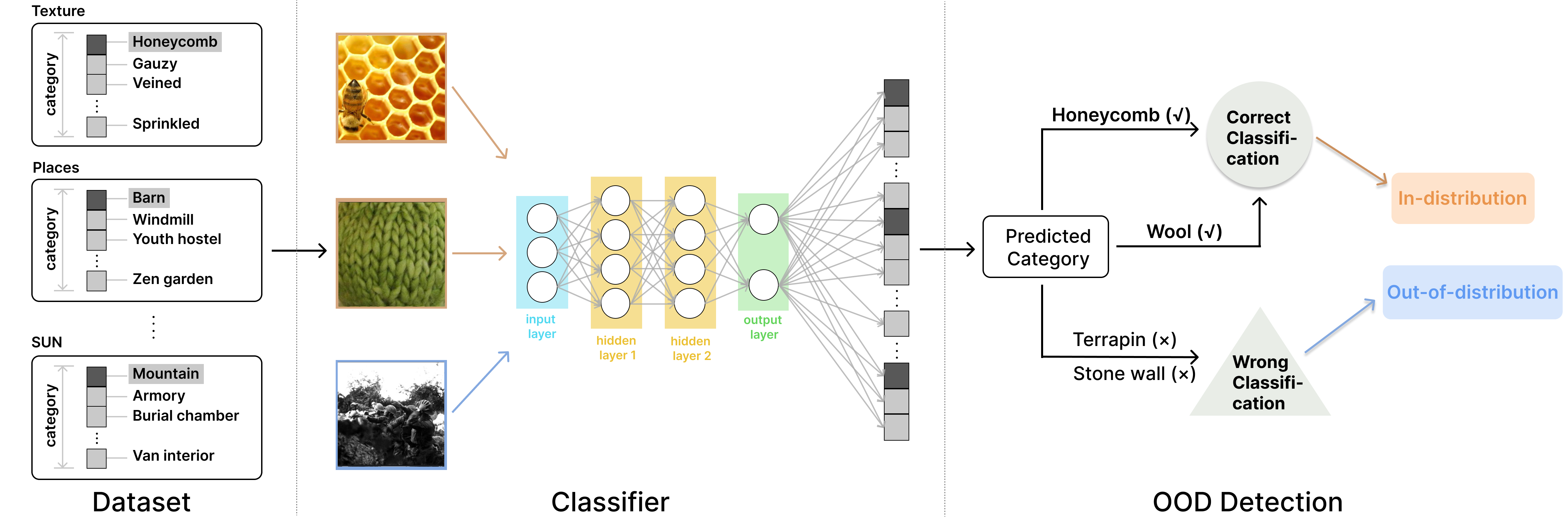
在日益受到严格审查的 OOD 检测任务领域,评估各种检测算法的性能成为一个关键话题,这决定了如何进行公平有效的比较。 然而,我们注意到一个关键问题:传统评估中常用的OOD数据集总是包含大量ID样本,如图1所示。 传统的评估方法需要检测算法来区分 OOD 数据集和 ID 数据集。 然而,当 OOD 数据集包含 ID 样本(噪声数据)时,预期的行为是将这些噪声数据识别为 ID 样本,并将 OOD 数据集的其余部分识别为 OOD。 然而,这种方法可能会产生较低的评估结果,因为传统的评估方法要求检测算法将 OOD 数据集中的所有样本分类为 OOD 样本。
为了解决这些问题,我们承担了纯化 OOD 数据集的关键任务。 此纯化过程涉及仔细去除标记错误的 ID 样本,从而确保 OOD 数据集的完整性和清晰度。 使用纯化的 OOD 数据集训练模型可以更好地反映现实世界的条件,其中 ID 和 OOD 数据之间的分离并不总是清晰的。 在此类纯化数据集上使用预训练模型的目的是增强其鲁棒性,与 OOD 检测的核心目标保持一致——有效地泛化各种环境并可靠地识别新的、未见过的 OOD 实例。
这种方法不仅强调了 OOD 检测中数据集纯度的重要性,还强调了我们致力于改进方法,以在实际应用中实现更准确、更可靠的模型性能。
在分析了数据集中的噪声对 OOD 检测任务的潜在负面影响并构建了纯化的数据集之后,我们进一步研究了增强现有 OOD 检测算法性能的方法,称为 ActFun。 OOD检测是一项单样本假设检验任务,其中单个样本的检测结果可能会受到样本特异性的影响,导致稳健性较低。 因此,我们建议在输入的邻域内进行检测。 具体来说,我们不是计算单个输入的激活,而是计算输入邻域内的期望。 此外,我们还推导了一个简化的公式来从理论上计算该期望。 ActFun 的一个主要优点是能够提高 ID 和 OOD 数据分布之间的可分离性,从而使受试者工作特征曲线下面积 (AUROC) 显着增强,从 49.35% 增加到 67.77%,并且错误率显着降低。当分布内(正)样本的真阳性率高达 95%(FPR95)时,OOD(负)样本的阳性率从 82.6% 上升到 65.67%。
此外,我们的研究还包括一项分析,探索 ActFun 对 OOD 检测贡献的潜在机制。 我们证明了 ActFun 的有效性,特别是在 OOD 激活与 ID 激活相比表现出更高的混乱度和正偏度的情况下(这是在众多 OOD 数据集中经常观察到的特征)。 对广泛认可的 OOD 检测基准的综合评估证实了 ActFun 相对于已建立的基线方法的优越性能。
总之,我们的研究解决了 OOD 检测中数据集噪声和评估技术的完善等紧迫问题,将这些关键贡献视为该领域的关键进展:
-
1.
我们提出了 OOD-R 数据集,它是现有开源数据集的创新合并,以其低噪声水平而著称。 该校正后的数据集通过策略性噪声过滤,为 OOD 检测提供了增强的数据质量,为研究和模型开发提供了更清晰、更可靠的样本。
-
2.
我们还引入了 ActFun 激活结构,它在各种网络中用 ReLU 的期望版本替代传统的 ReLU。 这一变化显着提高了 OOD 检测的特异性和准确性。 值得注意的是,ActFun 在评估方法上表现出了相当大的改进,AUROC 提高了高达 18.42%,FPR95 降低了 16.93%,凸显了精确超参数校准在优化 OOD 检测中的重要性。
-
3.
我们的研究考察了超参数 对不同 OOD 检测算法的影响。 我们发现该参数与每种方法的性能之间存在很强的相关性,这凸显了精确超参数调整的必要性,特别是在修改激活函数时,以增强 OOD 检测效果。
II 相关工作
OOD检测[48, 49]在确保机器学习模型的可靠性和鲁棒性方面发挥着关键作用,尤其是在计算机视觉领域。 在以不可预测的变化为特征的现实场景中,准确识别和处理显着偏离训练分布的数据至关重要。 本节深入研究 OOD 检测领域内的数据集、核心方法和关键发现,强调它们在推动该领域向前发展方面的贡献和局限性。
用于 OOD 模型评估的多样化数据集。 在我们的研究中,我们利用 ImageNet[5] 作为主要 ID 数据集,包含 20,000 多个类别的约 1400 万张图像。 ImageNet 在视觉对象识别研究中的广泛使用使其成为众多计算机视觉工作的基石数据集。 我们整合了五个不同的开源数据集进行 OOD 评估,每个数据集都提供了独特的挑战和观点。 其中包括以其各种自然纹理而闻名的纹理[4]; ImageNet-O[13],ImageNet 的一个子集,专门针对其具有挑战性的 OOD 属性而设计; iNaturalist[40],涵盖广泛的生物物种; Places365[47],具有各种自然和城市场景;以及 SUN 子集[43],重点关注广泛的室内环境。 这些数据集与 ImageNet 类别不同,对于评估我们的模型在不同场景下的分类能力是不可或缺的。
生成模型的策略。 生成模型是 OOD 检测中值得注意的策略,可估计输入数据的概率密度[17,38,32,7,39,16]。 然而,它们有时会将 OOD 数据错误分类为高可能性[28],并在训练和优化方面提出挑战,与判别模型相比,通常表现不佳。 因此,我们的工作集中于基于判别性的 OOD 检测方法。 尽管生成模型在理论上很有吸引力[18,31,33,35,42,44],但其局限性使其不太适合大规模 OOD 检测目标。 人们优先考虑增强方法的稳健性和可扩展性。 另一个研究方向涉及合并辅助离群数据以进行模型正则化[1, 9, 26, 27, 36, 25]。 这包括真实的[12,27,30,25,2]和由 GAN[21] 生成的合成图像。 我们的方法的不同之处在于,仅使用分布内数据来完善模型,避免编译和集成外部异常数据集的复杂性,并简化模型开发过程,同时专注于有效 OOD 检测的实用、可扩展的解决方案。
OOD检测评估方法的开发。近年来,OOD 检测领域取得了重大进展。 Nguyen 等人[29]强调了深度神经网络对对抗性攻击的敏感性,介绍了使用对抗性样本评估网络可靠性的方法。 Hendrycks 和 Gimpel[11] 使用 MSP[11] 设置基线,利用 softmax 输出固有的不确定性进行 OOD 检测。 Lee等人[22]使用特征空间内的马哈拉诺比斯距离改进了OOD检测。 刘等人[25]的基于能量的方法通过利用网络能量估计进行OOD识别,进一步推进了这一进展。 广义 ODIN 方法[14, 23] 引入了温度缩放和峰值调整以增强性能。 最近的发展包括 Wang 等人[41] 的方法,将虚拟对抗训练与逻辑概率匹配相结合,以及 Hendrycks 等人[10] 的 KL-Matching 方法,关注未知数据评估的概率分布差异。 Sun等人[37]的ReAct模型采用事后单元激活修改,使激活模式与最佳性能场景保持一致。 相比之下,我们的 ActFun 方法有助于学习特征表示的平滑过渡,从而增强 OOD 检测。 Lin等人[24]的多级特征提取技术和模型输出统计[15]方法在OOD检测中显示出了前景。 然而,每种方法都有其局限性和优点,特别是在不同数据集大小的可扩展性和有效性方面。
三方法
在人工智能 (AI) 蓬勃发展的时代,数据集的质量和完整性变得至关重要。 随着人工智能模型的发展,超越基本的模式识别以实现细致入微的理解和推理,数据集的作用,特别是那些处理 OOD 样本的数据集,对于确保模型的稳健性和可靠性至关重要。 OOD 数据集以其可变性和噪声为特征,反映了现实世界场景的不可预测性和复杂性。 在这样的环境中[50],清理和完善 OOD 数据集势在必行,而不仅仅是程序性的。 忽视这一重要方面可能会使模型在面对意外数据时容易被误解、准确性降低和稳健性受损。 因此,干净的 OOD 数据集对于让人工智能模型能够熟练地导航和适应多样化和动态的现实世界环境至关重要。
III-A 用于增强 OOD 检测的数据集优化
我们的研究重点是完善五个著名的开源数据集,以提高分布外(OOD)检测评估的公平性和准确性。 此细化过程需要在每个数据集中进行严格的图像验证,确保与我们初始分析中确定的相应同义词集保持一致。 我们的数据集选择包括 Places365[47]、Texture[4]、iNaturalist[40]、SUN 子集[43] 和 ImageNet-O[13].. 这种集成的主要目标是提高数据集评估中类分类的准确性,确保它真正代表图像的真实性质。
我们的方法将这些数据集中的图像分为 ImageNet-1K 分类模型可识别的 1,000 个类别。 这种细致的分类过程旨在将每张图像准确地分配到其正确的类型,尽管存在诸如遮挡、分散注意力的元素以及许多图像中的多种类型等挑战。 我们采用多用户独立分类系统来确保广泛的表示和精确的标签。 仅当图像在审阅者中获得绝大多数共识时,才会被归类为分发中 (ID);如果没有达成共识,则被视为 OOD 样本。 这种方法降低了低置信度分类的风险。
此外,我们还提供 OOD 数据集中 ID 数据类别标签的全面文档,并利用余弦相似度度量进行视觉相似度分析。 实施了多种方法来进一步提高注释的质量。 不确定图像类别的注释者可以将其标记为“未分类”,表明需要进一步审查。 每张图像都经过至少五个独立注释者的评估,并以一致的结果指导其最终分类。 该过程包括多轮过滤和定期质量检查,以维持高标注标准。 对于特别具有挑战性的图像,特别是在 ImageNet-O[13] 中,我们寻求额外的审阅者输入以更准确地捕获类别复杂性。
我们方法的一个重要方面是从 OOD 数据集中仔细分离和消除 ID 数据。 如图2所示,这种细致的分类过程产生了一个主要由真实的OOD样本组成的数据集,增强了我们的图像分类和OOD检测评估的有效性和公平性。 经过广泛的优化,我们精心策划的数据集显着降低了噪声,从而实现更可靠的 OOD 检测。 这个增强的数据集代表了图像分类任务中深度特征提取和语义分析的新颖组合,确保了 OOD 检测模型的公平和准确评估。
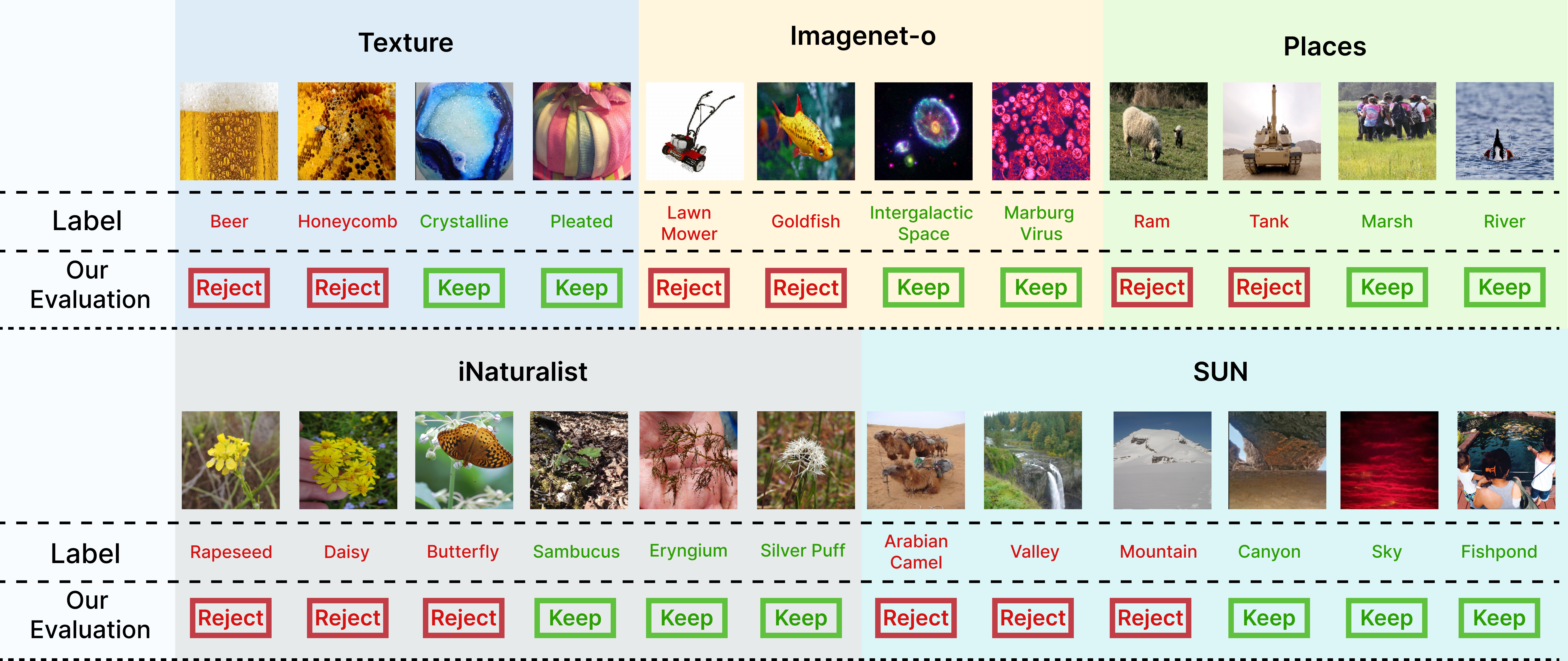
OOD-R 数据集是我们精心策划和评估的结果,构成了我们评估方法和模型改进的基础。 该数据集是 ID 和 OOD 数据的平衡组合,经过了严格和多方面的评估,以确保其多样性、完整性和在增强神经网络模型内 OOD 检测能力方面的有效性。
III-B OOD 检测的激活函数设计
利用 OOD-R 数据集,我们使用了 BiT[20] 和 VGG[6] 等模型,充分利用了它们卓越的分类和特征提取功能。 我们的评估范式集成了一套 OOD 评分函数,包括 MSP[11]、MaxLogit[10]、Energy[25]、ReAct[37]、ViM[41]、残差、GradNorm、Mahalanobis[22] 和 KL 匹配[10]. 利用 OOD-R 数据集进行评估有助于公平评估模型在分布外 (OOD) 环境中的适应性和泛化能力。
考虑到分布外样本检测是一项单样本假设检验任务(评估单个样本以产生其 OOD 分数),单个样本的特异性可能会降低检测性能。 因此,我们的目标是通过计算某个邻域内单个样本的期望来减轻特异性的影响。 具体来说,我们不再使用普通的 ReLU 激活函数,该函数仅计算单个输入的激活值。 在本文中,我们计算输入邻域内的预期激活值,如下所示:
| (1) |
其中 是隐式定义的。 因此,确定测试样本是否是 OOD 样本不再仅仅依赖于单个输入的激活,而是计算整个邻域的平均激活。 这种方法有助于获得更稳健的测试结果。 在实际应用中,为了简化计算过程,我们进行如下推导和化简。 方程。 (1) 可以用积分形式重新表示为:
| (2) |
对于,方程的微分。 2 是:
| (3) |
这里,我们选择为:
| (4) |
然后方程。 (3) 可以表示为:
| (5) |
对方程两边积分,可得:
| (6) |
这是Softplus函数的计算公式。 结合方程。 (6) 和 (1),我们得到了输入邻域内激活期望的替代方案,这在实践中很方便。
正如我们详细的方程和分析所示,ActFun 结构强调了激活动态,在 OOD 检测中培养更熟练的神经网络架构。 我们利用 Softplus 功能的内在属性来确保更平滑、适应性更强的激活。 这种方法优化了模型对不同输入的响应,从而提高了其在数据不可预测的环境中的准确性和可靠性。 在实验部分,我们广泛讨论了等式中超参数 的影响。 (6)。
| Dataset | Texture | ImageNet-O | iNaturalist | Places365 | SUN subset |
|---|---|---|---|---|---|
| OOD | 5640 | 2000 | 10000 | 10000 | 10000 |
| OOD-R | 5253 | 1933 | 9905 | 9449 | 9579 |
IV 实验
在本节中,我们在综合 OOD 检测任务的框架内仔细评估了我们策划的数据集 OOD-R 的有效性和适用性。 我们的评估策略是多方面的,旨在彻底审查各种测试范例中数据集的稳健性和有效性。 最初,我们的重点是利用 ImageNet 数据集建立完善的大规模 OOD 检测基准[15]。 这一阶段(A 节中详细介绍)提供了对 OOD-R 数据集性能特征的基础见解,在公认的基准测试环境中提供了可靠的分析。 这确保了我们的研究结果在更广泛的研究界内是全面且具有可比性的。 接下来,在 B 节中,我们将更深入地研究评估集成到我们方法中的增强功能。 在这里,我们将我们的方法与 BiT[20] 和 VGG[6] 网络上的现有模型进行比较,以证明这些改进对 OOD 检测能力的影响。 最后,我们发现在不同超参数 的影响下,我们提出的数据集的先前使用结果有所不同,请参见第 C 节。本节中呈现的结果突出了我们方法的进步,有助于对OOD-R数据集的性能和适用性。
IV-A 增强数据集以提高数据质量标准
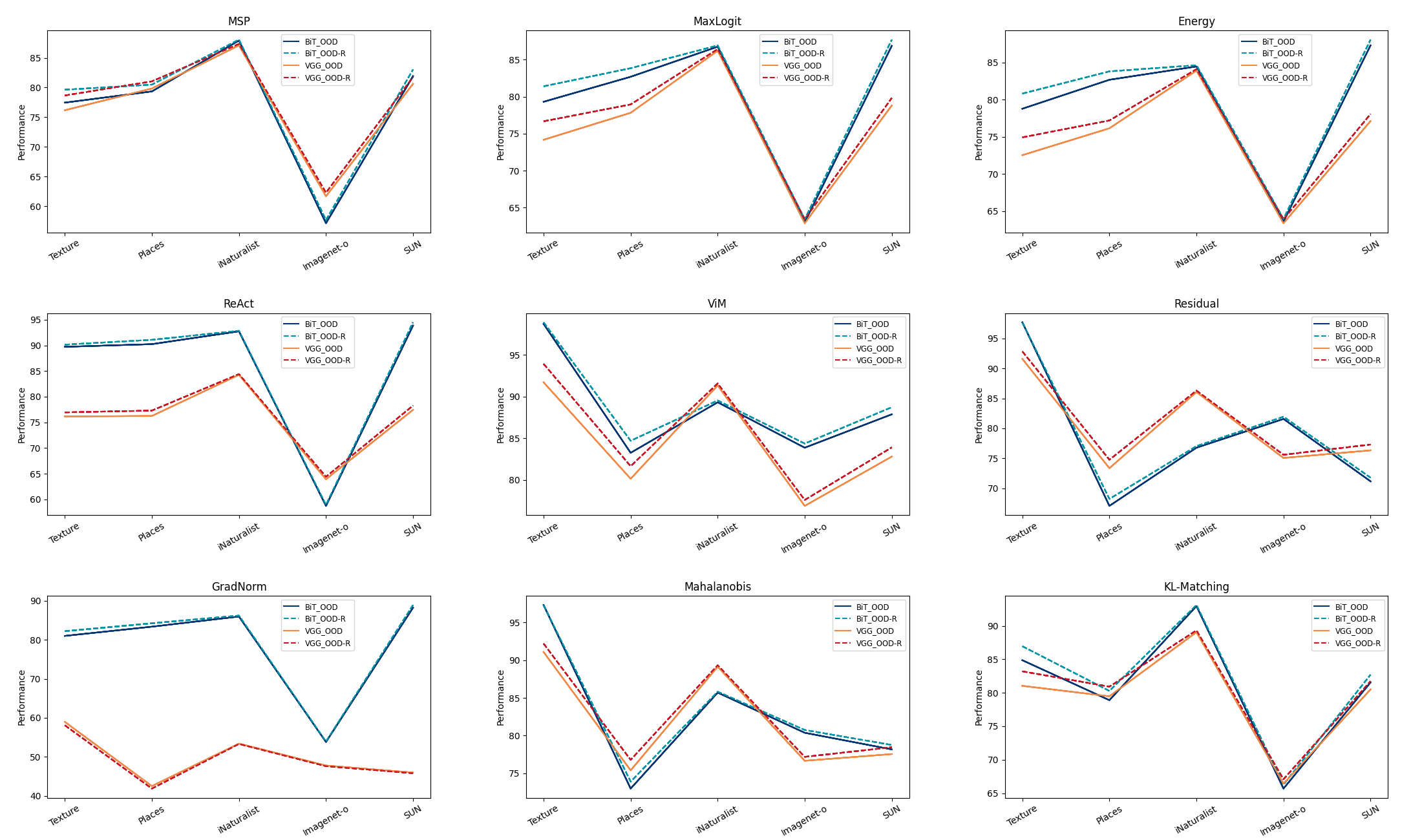
为了提高数据质量标准并解决噪声带来的限制,我们引入了开源数据集 OOD-R,如表 I 所示。 这个创新的数据集采用噪声过滤技术来提供具有更高清晰度和可靠性的样本存储库。 我们使用 BiT[20] 和 VGG[6] 等模型进行的综合评估显示了显着的改进。 我们观察到,使用 MaxLogit[10] 时 AUROC 增加了 2.5%,使用 ViM[41] 时 FPR95 显着降低了 3.2%。 图3以图形方式展示了这些发现,强调了数据集在提高评估准确性和可靠性方面的关键作用。 我们的数据集独特的低噪声特征在结果部分进行了广泛讨论,为理解这些实验结果提供了背景,并强调了其对提高 OOD 检测方法的准确性和可信度的贡献。
| Method | Texture | Places | iNaturalist | Imagenet-o | SUN | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | |
| GradNorm | 82.20 | 57.15 | 84.22 | 59.89 | 86.19 | 58.22 | 53.92 | 91.77 | 88.90 | 43.81 | 79.09 | 62.17 |
| GradNorm_ActFun | 85.12(+2.92) | 50.64(-6.51) | 87.51(+3.29) | 50.5(-9.39) | 90.74(+4.55) | 42.48(-15.74) | 59.39(+5.47) | 88.72(-3.05) | 92.18(+3.28) | 33.78(-10.03) | 82.99(+3.90) | 53.23(-8.94) |
| ReAct | 90.15 | 44.53 | 91.08 | 46.64 | 92.85 | 38.56 | 58.91 | 89.24 | 94.49 | 29.55 | 85.50 | 49.70 |
| ReAct_ActFun | 93.23(+3.08) | 33.87(-10.66) | 91.62(+0.54) | 42.70(-3.94) | 95.11(+2.26) | 26.13(-12.43) | 63.23(+4.32) | 85.46(-3.78) | 95.06(+0.57) | 26.08(-3.47) | 87.65(+2.15) | 42.85(-6.85) |
| Mahalanobis | 97.31 | 14.32 | 73.88 | 81.84 | 85.82 | 64.79 | 80.74 | 69.63 | 78.75 | 72.78 | 83.30 | 60.67 |
| Mahalanobis_ActFun | 98.31(+1.00) | 8.32(-6.00) | 74.23(+0.35) | 80.07(-1.77) | 87.83(+2.01) | 59.72(-5.07) | 82.74(+2.00) | 63.99(-5.64) | 80.20(+1.45) | 68.78(-4.00) | 84.66(+1.36) | 56.18(-4.49) |
| Energy | 80.83 | 74.41 | 83.82 | 72.02 | 84.65 | 74.77 | 63.97 | 96.22 | 88.09 | 59.69 | 80.27 | 75.42 |
| Energy_ActFun | 82.69(+1.86) | 68.34(-6.07) | 83.60 | 71.69(-0.33) | 85.74(+1.09) | 70.16(-4.61) | 66.12(+2.15) | 95.45(-0.77) | 88.21(+0.12) | 58.94(-0.75) | 81.27(+1.00) | 72.92(-3.50) |
| MaxLogit | 81.40 | 74.05 | 83.85 | 73.16 | 86.93 | 70.32 | 63.42 | 96.84 | 87.71 | 62.39 | 80.66 | 75.35 |
| MaxLogit_ActFun | 82.64(+1.24) | 69.88(-4.17) | 83.73 | 72.21(-0.95) | 88.04(+1.11) | 64.26(-6.06) | 65.31(+1.89) | 95.91(-0.93) | 87.87(+0.16) | 61.49(-0.90) | 81.52(+0.86) | 72.75(-2.60) |
| MSP | 79.63 | 77.42 | 80.49 | 78.02 | 88.07 | 64.38 | 57.67 | 96.90 | 83.04 | 70.92 | 77.78 | 77.53 |
| MSP_ActFun | 79.56 | 75.56(-1.86) | 80.56(+0.07) | 77.25(-0.77) | 88.55(+0.48) | 61.34(-3.04) | 57.49 | 96.90 | 83.09(+0.05) | 69.89(-1.03) | 77.85(+0.07) | 76.19(-1.34) |
| Method | Texture | Places | iNaturalist | Imagenet-o | SUN | Average | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | AUROC | FPR95 | |
| GradNorm | 58.10 | 91.28 | 41.89 | 98.88 | 53.33 | 98.20 | 47.63 | 95.65 | 45.83 | 98.20 | 49.35 | 96.44 |
| GradNorm_ActFun | 70.46(+12.36) | 87.40(-3.88) | 67.29(+25.40) | 91.67(-7.21) | 76.56(+23.23) | 90.12(-8.08) | 50.66(+3.03) | 95.29(-0.36) | 73.86(+28.03) | 87.91(-10.29) | 67.77(+18.42) | 90.48(-5.96) |
| Energy | 74.94 | 82.73 | 77.21 | 83.37 | 84.11 | 75.40 | 63.91 | 87.84 | 78.08 | 83.63 | 75.65 | 82.60 |
| Energy_ActFun | 79.11(+4.17) | 69.07(-13.66) | 84.42 (+7.21) | 63.93(-19.44) | 90.12(+6.01) | 50.22(-25.18) | 63.82 | 85.36(-2.48) | 86.17(+8.09) | 59.80(-23.83) | 80.73(+5.08) | 65.67(-16.93) |
| ReAct | 76.95 | 82.12 | 77.30 | 83.13 | 84.40 | 74.81 | 64.41 | 87.74 | 78.27 | 83.03 | 76.27 | 82.17 |
| ReAct_ActFun | 81.09(+4.14) | 68.15(-13.97) | 84.18(+6.88) | 63.75(-19.38) | 90.23(+5.83) | 49.39(-25.42) | 64.27 | 85.31(-2.31) | 85.97(+7.70) | 59.46(-23.57) | 81.15(+4.88) | 65.21(-16.96) |
| MaxLogit | 76.67 | 76.66 | 78.95 | 77.36 | 86.43 | 61.91 | 63.43 | 89.71 | 79.83 | 77.00 | 77.06 | 76.53 |
| MaxLogit_ActFun | 79.98(+3.31) | 66.70(-9.96) | 84.81(+5.86) | 62.48(-14.88) | 91.47(+5.04) | 41.53(-20.38) | 63.43 | 88.00(-1.71) | 86.37(+6.54) | 59.09(-17.91) | 81.21(+4.15) | 63.56(-12.97) |
| MSP | 78.66 | 72.64 | 81.04 | 74.03 | 87.34 | 54.65 | 62.27 | 91.41 | 81.76 | 72.86 | 78.22 | 73.12 |
| MSP_ActFun | 80.41(+1.75) | 67.33(-5.31) | 84.03(+2.99) | 64.57(-9.46) | 91.09(+3.75) | 41.15(-13.50) | 62.82(+0.55) | 89.91(-1.50) | 85.30(+3.54) | 62.30(-10.56) | 80.73(+2.51) | 65.05(-8.07) |
| KL-Matching | 83.21 | 61.55 | 80.92 | 74.78 | 89.33 | 41.95 | 67.08 | 84.69 | 81.73 | 74.03 | 80.45 | 67.40 |
| KL-Matching_ActFun | 83.37(+0.16) | 61.96 | 81.00(+0.08) | 75.20 | 89.51(+0.18) | 41.29(-0.66) | 67.10(0.02) | 84.27(-0.42) | 81.80(+0.07) | 74.11 | 80.56(+0.11) | 67.37(-0.03) |
在数据集优化中,观察到的对 OOD 检测算法的影响与每个算法利用的独特属性密切相关。 MaxLogit[10]、Energy[25]、Mahalanobis[22] 和 KL-Matching[10] 等算法t3> 由于依赖模型置信度和数据分布假设而表现出显着的性能变化。 MaxLogit[10] 和 Energy[25] 受模型预测置信度影响很大;因此,改变决策边界或置信度得分的优化可以显着影响其有效性。 Mahalanobis[22] 方法假定数据点聚集在特征空间中的中心均值周围,并且数据集大小的减小可以改变均值和协方差估计,从而通过距离计算的变化深刻影响性能。 同样,KL-Matching[10] 评估分布内样本和 OOD 样本的预测概率之间的差异,数据集优化可能会导致更均匀的分布,从而提高 KL 散度对剩余样本的敏感性数据点,极大地影响算法性能。
相反,MSP[11]、ReAct[37] 和 GradNorm 在数据集上表现出稳定性,尽管大小有所减小。 MSP[11] 对最大 softmax 概率输出的依赖意味着数据集缩小不一定会破坏这些概率的分布,从而保持稳定的性能。 ReAct[37] 的方法通过调整网络激活来减轻对抗性扰动,较少依赖于精确的数据分布,更多地依赖于网络激活模式,使其对数据集大小变化具有固有的鲁棒性。 同样,GradNorm 将梯度范数作为 OOD 信号,与数据分布的联系较少,而与模型的响应联系较多,因此其性能相对不受数据集大小减小的影响。 总体而言,数据集优化对 OOD 检测方法的不同影响源于每种算法与数据集的统计属性和模型置信度度量的交互。 利用数据集详细统计分析的算法对其变化表现出更高的敏感性。 相比之下,那些采用更广泛的数据特征或模型动态的人在面对数据集变化时表现出一致的性能弹性。 这种理解对于根据每种 OOD 检测算法的特定要求和优势定制数据集优化策略至关重要。
IV-B 评价方法比较
在计算机视觉中,模型有效处理来自不同来源的数据的能力至关重要,这强调了评估模型对未知数据的鲁棒性和泛化能力的重要性。 为此,我们使用大规模 OOD 检测基准,结合各种 OOD 测试数据集进行了全面评估。 其中包括来自 Places365[47]、Texture[4]、iNaturalist[40]、SUN 和 ImageNet-O[ 13]。 结果如表II和III所示,详细分析了模型在不同场景下的性能,旨在增强其在实际应用中的鲁棒性和泛化能力。
我们的研究批判性地研究了 OOD 检测任务中的 BiT[20] 和 VGG[6] 模型,强调了从传统 ReLU 激活到 Softplus 的转变。 此修改旨在利用 Softplus 的梯度保持和可微分属性,从而提高模型对 OOD 实例的敏感性。 正如两个表中所述,我们观察到 GradNorm、ReAct[37] 和 MaxLogit[10] 等方法显着受益于 Softplus 一致的梯度流和平滑的过渡激活。 这种适应增强了它们区分分布内数据和 OOD 数据的能力。 同样,Energy[25] 方法和 MSP[11] 也显示出改进,这归因于扩大的 logit 范围和信息更丰富的 softmax 概率,从而实现更精确的 OOD 检测。
Softplus 在 VGG 模型中的应用证实了这些发现。 这些结果凸显了为 OOD 检测选择适当的激活函数的复杂性,强调对某些方法有利的增强可能会对其他方法产生不利影响。 通过用 Softplus 取代传统的 ReLU,ActFun 旨在利用后者一致的梯度和平滑的激活转换。 这种集成显着增强了 FPR95 和 AUROC 等性能指标。 具体来说,GradNorm 展示了显着的改进,表现为更好的 AUROC 分数和降低的 FPR95,这表明区分分布内数据和 OOD 数据之间细微差异的准确性有所提高。 ReAct[37] 方法还表现出改进的性能,特别是在 iNaturalist[40] 和 SUN[43] 等数据集中,受益于改进的对 Softplus 启用的网络激活的控制。 这些发现验证了 ActFun 可以有效地增强 OOD 检测方法,利用 Softplus 的可微性质及其保留梯度信息的能力,这对于 GradNorm 等基于梯度的方法和 ReAct[37]< 等基于梯度的方法和激活调整技术至关重要。 /t0>.
IV-C 超参数 对结果的影响
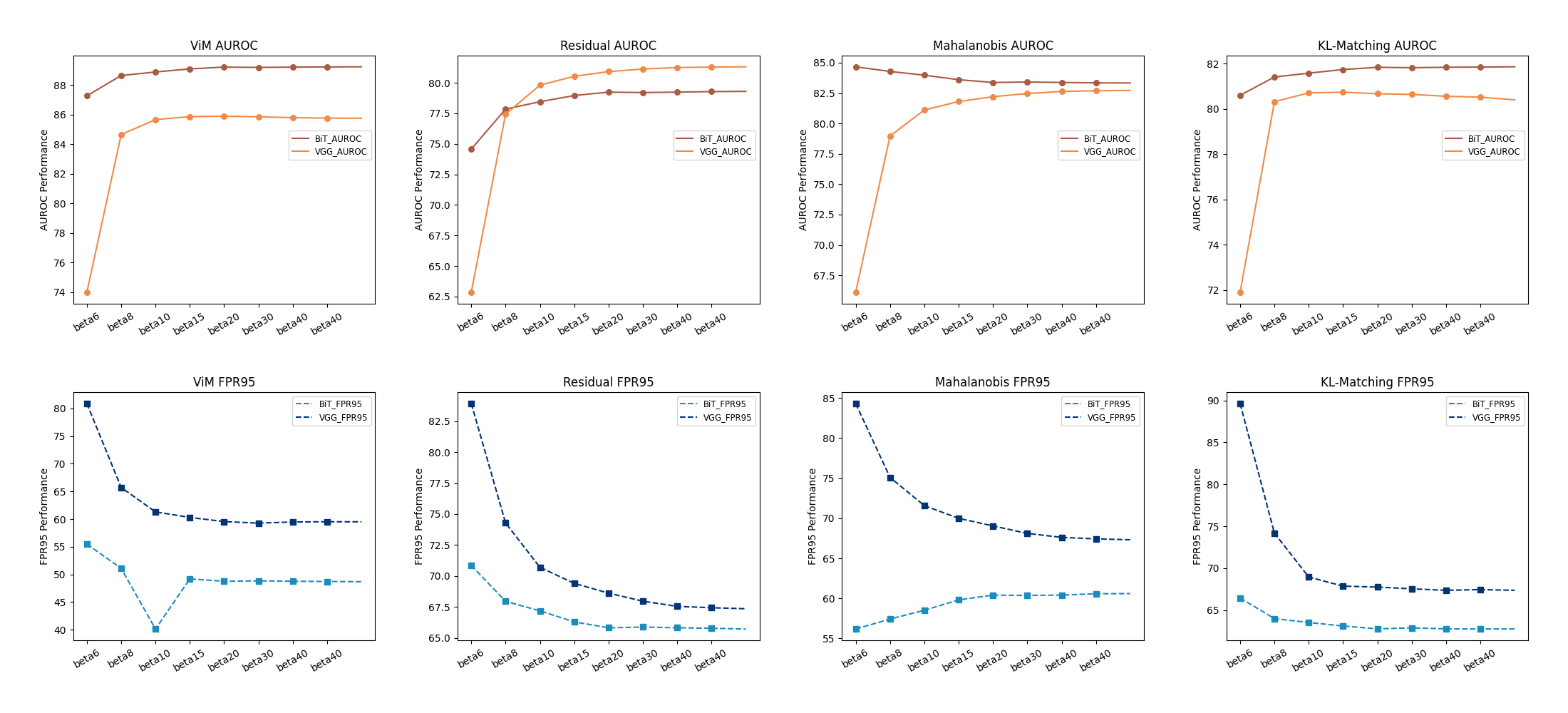
图4中的实验数据阐明了Softplus激活函数的超参数对OOD检测方法的影响。 ViM[41] 方法采用不确定性概率模型,随着 的增加,AUROC 值有所改善或稳定,并且 FPR95 有所下降。 这一趋势表明,激活函数中较小的斜率有助于更好地表示数据的概率方面,从而导致更准确的不确定性估计,这是 OOD 检测的关键因素。
KL-Matching[10] 依赖 Kullback-Leibler 散度来测量 ID 和 OOD 概率分布之间的差异。 AUROC 在不同 值上的维持表明 KL-Matching 对于激活平滑度变化的鲁棒性。 然而,随着 值的增加,FPR95 降低意味着更明显的激活响应增强了该方法区分数据分布的能力,从而提高了 OOD 拒绝率。
残差方法采用跳跃连接来维持梯度流并获得高 AUROC 分数,这意味着有效的 OOD 样本识别。 尽管如此,在较大的 值下观察到的 FPR95 的增加表明特征空间内可能存在过度平滑,可能会削弱残差连接旨在保留的独特特征,并导致 ID-OOD 分离不那么清晰决策边界。
Mahalanobis[22] 方法因其在高维空间中的有效性而闻名,并且基于 ID 数据的高斯分布假设,显示 FPR95 随着 值的增加而增加。 这种敏感性表明,较大的 值(更接近 ReLU)可能会扰乱特征空间中的高斯分布假设,从而损害 OOD 检测所需的区分清晰度。
总之,ViM[41] 和 KL-Matching[10] 方法似乎利用了 Softplus 函数提供的平滑度的增加和减少。 相比之下,Residual 和 Mahalanobis[22] 方法对 表现出细微的响应,其中前者在 值较高时会出现误报增加,后者表现出性能下降,可能是由于高斯分布假设不一致。 和 OOD 检测功效之间复杂的相互作用凸显了特定于方法的超参数调整的重要性。 理解每个算法的核心机制和激活函数之间的相互作用对于调节性能至关重要,特别是在修改激活函数等关键模型组件时。
V 结论
我们的工作引入了开源数据集 OOD-R 和新颖的方法 ActFun,标志着在增强神经网络中的 OOD 检测方面取得了重大进展。 凭借其噪声过滤技术,OOD-R 具有低噪声特性,可在给定网络中实现高达 2.5% 的准确度提升和至少 3.2% 的误报减少。 它有助于提取更清洁、更可靠的样品。 这会带来更准确、更值得信赖的评估。 来自各个领域和任务的严格实验和分析的经验证据表明,我们的方法具有显着的性能改进。 此外,ActFun 融合了创新技术调整和深刻的理论见解,重新校准了神经网络的输入响应。 这给OOD-R数据集带来了显着的改进,GradNorm方法的性能提高了18.42%,Energy方法的误报率降低了16.93%。 它有效地减少了隐藏单元对OOD输出的影响,增强了数据的可分离性,从而改善了特定网络的结果。 此外,我们的研究阐明了超参数 与各种 OOD 检测算法的功效之间复杂的相互作用。 我们强调细致的超参数调整和深入了解每种算法的基本原理的必要性。 ActFun 的理论基础为 OOD 场景中的神经网络机制提供了宝贵的见解,使其成为图像和多类分类应用的实用且适应性强的方法。 我们的方法有助于当前对神经网络中 OOD 检测的理解,并为未来的研究开辟了途径。 我们预计将这些方法扩展到图像分类之外,以深化和丰富跨各种神经网络应用的 OOD 检测机制的探索。
参考
- [1] Petra Bevandić, Ivan Krešo, Marin Oršić, and Siniša Šegvić. Discriminative out-of-distribution detection for semantic segmentation, 2018.
- [2] Jiefeng Chen, Yixuan Li, Xi Wu, Yingyu Liang, and Somesh Jha. Robust out-of-distribution detection via informative outlier mining. arXiv preprint arXiv:2006.15207, 1(2):7, 2020.
- [3] Hyunsun Choi and Eric Jang. Generative ensembles for robust anomaly detection. 2018.
- [4] Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014.
- [5] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- [6] Xiaohan Ding, Xiangyu Zhang, Ningning Ma, Jungong Han, Guiguang Ding, and Jian Sun. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13733–13742, 2021.
- [7] Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp. arXiv preprint arXiv:1605.08803, 2016.
- [8] Nick Drummond and Rob Shearer. The open world assumption. In eSI Workshop: The Closed World of Databases meets the Open World of the Semantic Web, volume 15, page 1, 2006.
- [9] Yonatan Geifman and Ran El-Yaniv. Selectivenet: A deep neural network with an integrated reject option, 2019.
- [10] Dan Hendrycks, Steven Basart, Mantas Mazeika, Andy Zou, Joe Kwon, Mohammadreza Mostajabi, Jacob Steinhardt, and Dawn Song. Scaling out-of-distribution detection for real-world settings. arXiv preprint arXiv:1911.11132, 2019.
- [11] Dan Hendrycks and Kevin Gimpel. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136, 2016.
- [12] Dan Hendrycks, Mantas Mazeika, and Thomas Dietterich. Deep anomaly detection with outlier exposure. arXiv preprint arXiv:1812.04606, 2018.
- [13] Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15262–15271, 2021.
- [14] Yen-Chang Hsu, Yilin Shen, Hongxia Jin, and Zsolt Kira. Generalized odin: Detecting out-of-distribution image without learning from out-of-distribution data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10951–10960, 2020.
- [15] Rui Huang and Yixuan Li. Mos: Towards scaling out-of-distribution detection for large semantic space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8710–8719, 2021.
- [16] Xun Huang, Yixuan Li, Omid Poursaeed, John Hopcroft, and Serge Belongie. Stacked generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5077–5086, 2017.
- [17] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [18] Polina Kirichenko, Pavel Izmailov, and Andrew G Wilson. Why normalizing flows fail to detect out-of-distribution data. Advances in neural information processing systems, 33:20578–20589, 2020.
- [19] Bernd Kitt, Andreas Geiger, and Henning Lategahn. Visual odometry based on stereo image sequences with ransac-based outlier rejection scheme. In 2010 ieee intelligent vehicles symposium, pages 486–492. IEEE, 2010.
- [20] Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (bit): General visual representation learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16, pages 491–507. Springer, 2020.
- [21] Kimin Lee, Honglak Lee, Kibok Lee, and Jinwoo Shin. Training confidence-calibrated classifiers for detecting out-of-distribution samples. arXiv preprint arXiv:1711.09325, 2017.
- [22] Kimin Lee, Kibok Lee, Honglak Lee, and Jinwoo Shin. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. Advances in neural information processing systems, 31, 2018.
- [23] Shiyu Liang, Yixuan Li, and Rayadurgam Srikant. Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv preprint arXiv:1706.02690, 2017.
- [24] Ziqian Lin, Sreya Dutta Roy, and Yixuan Li. Mood: Multi-level out-of-distribution detection, 2021.
- [25] Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detection. Advances in neural information processing systems, 33:21464–21475, 2020.
- [26] Andrey Malinin and Mark Gales. Predictive uncertainty estimation via prior networks, 2018.
- [27] Sina Mohseni, Mandar Pitale, JBS Yadawa, and Zhangyang Wang. Self-supervised learning for generalizable out-of-distribution detection. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 5216–5223, 2020.
- [28] Eric Nalisnick, Akihiro Matsukawa, Yee Whye Teh, Dilan Gorur, and Balaji Lakshminarayanan. Do deep generative models know what they don’t know? arXiv preprint arXiv:1810.09136, 2018.
- [29] Anh Nguyen, Jason Yosinski, and Jeff Clune. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 427–436, 2015.
- [30] Aristotelis-Angelos Papadopoulos, Mohammad Reza Rajati, Nazim Shaikh, and Jiamian Wang. Outlier exposure with confidence control for out-of-distribution detection. Neurocomputing, 441:138–150, 2021.
- [31] Jie Ren, Peter J Liu, Emily Fertig, Jasper Snoek, Ryan Poplin, Mark Depristo, Joshua Dillon, and Balaji Lakshminarayanan. Likelihood ratios for out-of-distribution detection. Advances in neural information processing systems, 32, 2019.
- [32] Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generative models. In International conference on machine learning, pages 1278–1286. PMLR, 2014.
- [33] Robin Schirrmeister, Yuxuan Zhou, Tonio Ball, and Dan Zhang. Understanding anomaly detection with deep invertible networks through hierarchies of distributions and features. Advances in Neural Information Processing Systems, 33:21038–21049, 2020.
- [34] Thomas Schlegl, Philipp Seeböck, Sebastian M Waldstein, Ursula Schmidt-Erfurth, and Georg Langs. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In International conference on information processing in medical imaging, pages 146–157. Springer, 2017.
- [35] Joan Serrà, David Álvarez, Vicenç Gómez, Olga Slizovskaia, José F Núñez, and Jordi Luque. Input complexity and out-of-distribution detection with likelihood-based generative models. arXiv preprint arXiv:1909.11480, 2019.
- [36] Akshayvarun Subramanya, Suraj Srinivas, and R Venkatesh Babu. Confidence estimation in deep neural networks via density modelling. arXiv preprint arXiv:1707.07013, 2017.
- [37] Yiyou Sun, Chuan Guo, and Yixuan Li. React: Out-of-distribution detection with rectified activations. Advances in Neural Information Processing Systems, 34:144–157, 2021.
- [38] Esteban G Tabak and Cristina V Turner. A family of nonparametric density estimation algorithms. Communications on Pure and Applied Mathematics, 66(2):145–164, 2013.
- [39] Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image generation with pixelcnn decoders. Advances in neural information processing systems, 29, 2016.
- [40] Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui, Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and Serge Belongie. The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8769–8778, 2018.
- [41] Haoqi Wang, Zhizhong Li, Litong Feng, and Wayne Zhang. Vim: Out-of-distribution with virtual-logit matching. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4921–4930, 2022.
- [42] Ziyu Wang, Bin Dai, David Wipf, and Jun Zhu. Further analysis of outlier detection with deep generative models. Advances in Neural Information Processing Systems, 33:8982–8992, 2020.
- [43] Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In 2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE, 2010.
- [44] Zhisheng Xiao, Qing Yan, and Yali Amit. Likelihood regret: An out-of-distribution detection score for variational auto-encoder. Advances in neural information processing systems, 33:20685–20696, 2020.
- [45] J Yang, K Zhou, Y Li, and Z Liu. Generalized out-of-distribution detection: A survey. arxiv. arXiv preprint arXiv:2110.11334, 2021.
- [46] Jingkang Yang, Pengyun Wang, Dejian Zou, Zitang Zhou, Kunyuan Ding, Wenxuan Peng, Haoqi Wang, Guangyao Chen, Bo Li, Yiyou Sun, et al. Openood: Benchmarking generalized out-of-distribution detection. Advances in Neural Information Processing Systems, 35:32598–32611, 2022.
- [47] Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition. IEEE transactions on pattern analysis and machine intelligence, 40(6):1452–1464, 2017.
- [48] Yao Zhu, Yuefeng Chen, Xiaodan Li, Rong Zhang, Hui Xue, Xiang Tian, Rongxin Jiang, Bolun Zheng, and Yaowu Chen. Rethinking out-of-distribution detection from a human-centric perspective. arXiv preprint arXiv:2211.16778, 2022.
- [49] Yao Zhu, YueFeng Chen, Chuanlong Xie, Xiaodan Li, Rong Zhang, Hui Xue, Xiang Tian, Yaowu Chen, et al. Boosting out-of-distribution detection with typical features. Advances in Neural Information Processing Systems, 35:20758–20769, 2022.
- [50] Yao Zhu, Jiacheng Sun, and Zhenguo Li. Rethinking adversarial transferability from a data distribution perspective. In International Conference on Learning Representations, 2021.