用于现实世界图聚类的可证明过滤器
摘要
图聚类是一个重要的无监督问题,已被证明对图神经网络(GNN)的进步更具抵抗力。 此外,几乎所有的聚类方法都关注同亲图而忽略异亲图。 这极大地限制了它们在实践中的适用性,因为现实世界的图表现出结构差异,不能简单地分为同质和异质。 因此,迫切需要一种处理实际图形的原则性方法。 为了填补这一空白,我们提供了一种具有理论支持的新颖解决方案。 有趣的是,我们发现大多数同质和异质边缘可以根据邻居信息正确识别。 受这一发现的启发,我们构建了两个分别高度同质和异质的图。 它们用于构建低通和高通滤波器以捕获整体信息。 挤压和激励模块进一步增强了重要功能。 我们通过对同性图和异性图进行大量实验来验证我们的方法。 经验结果证明了我们的方法与最先进的聚类方法相比的优越性。
索引术语:
结构差异、图神经网络、异质性。我简介
由于图数据的大幅扩展,最近人们对归因图聚类[1]的关注激增。 这种兴趣的增加源于观察到许多现实世界的图表现出边缘的局部不均匀分布,从而导致节点聚集。 事实证明,图聚类在多种应用中具有非凡的价值,包括数据探索[2,3,4]、可视化[5,6]、异常检测[ 7],以及功能发现[8]。 然而,事实证明它对图神经网络 (GNN) 的进步更具抵抗力[9]。 一种流行的方法是基于图自动编码器 [10] 构建节点嵌入,然后将其馈送到传统的聚类方法中。 最近的进展导致了多种变体的出现,例如对抗性方法[11]和生成方法[12]。 对比学习的思想也被广泛用于提高表示的可辨别性。 他们总是预先定义正负对,并最大化正负对之间的相似性,同时增加正负对[13, 14]之间的不相似性。 最后,提出了一些浅层方法来生成新图[15, 16],随后通过聚类技术利用该图来获得聚类。
现有方法面临两个基本但致命的问题。 首先是异质性问题。 大多数方法假设同亲是图的关键特征,即连接的节点来自同一簇,并忽略异亲图,即连接的节点来自不同的簇。 异嗜图在实践中无处不在[17]。 用于同质图的方法一般来说并不有效,并且堆叠 MLP 在异质情况下甚至可以胜过许多 GNN[18]。 实际上,该图本质上包含同源和异源邻居,表现出结构差异[19]。 因此,捕获同亲图中低频信息或异亲图中高频信息的方法相当有限,不可避免地导致信息丢失。 第二个问题是大多数聚类方法只是应用局部图卷积而无法捕获全局结构信息[20]。 当低度节点的邻域有限时,局部信息聚合将变得不太有用,而全局信息传播对于异亲图[21]至关重要。
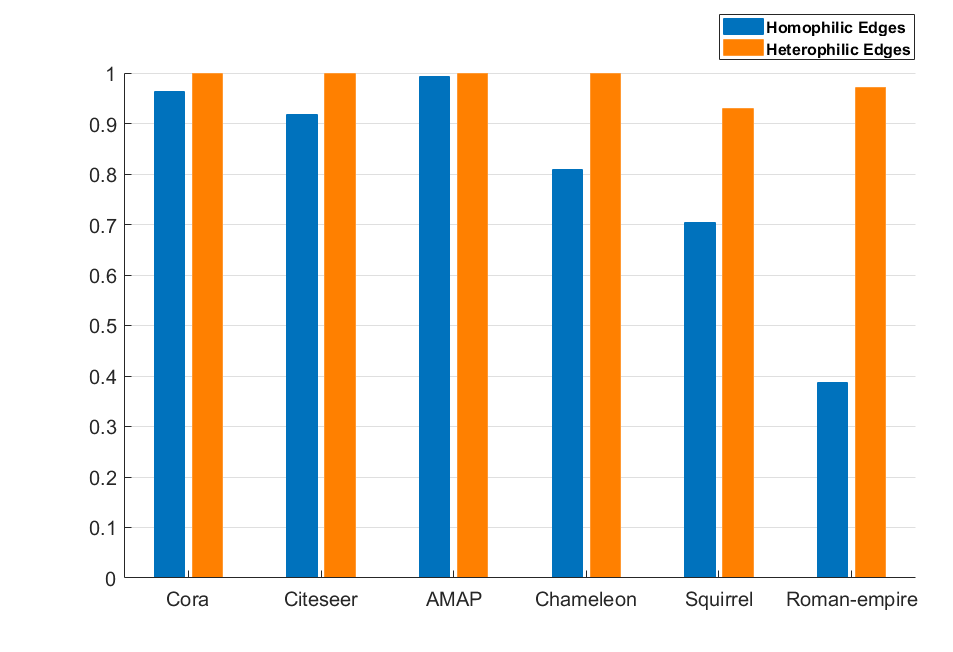
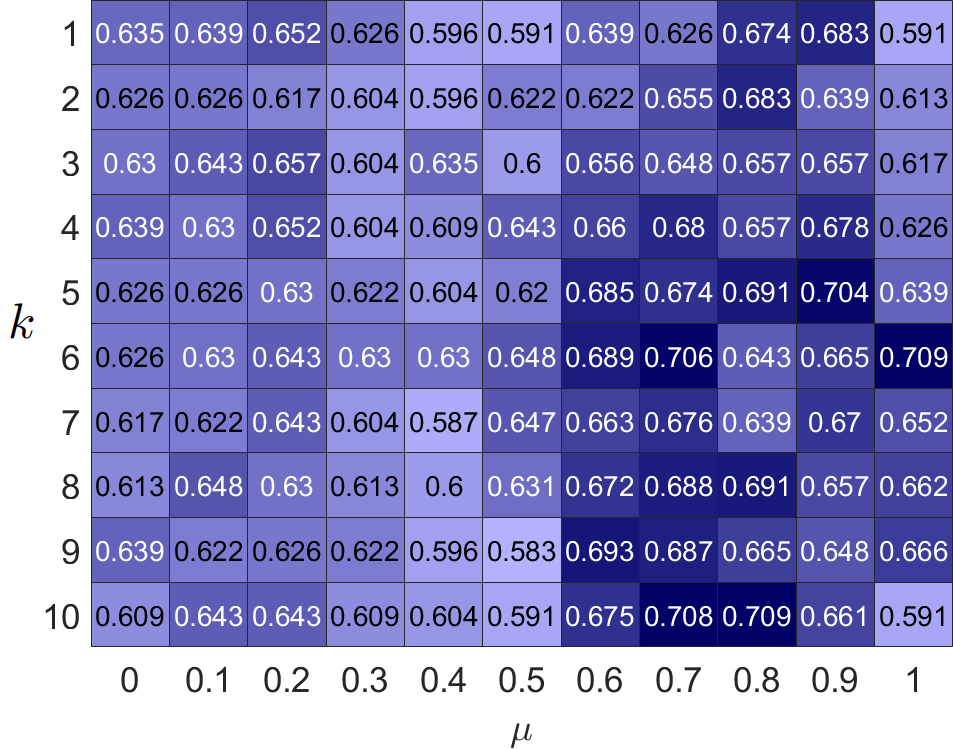
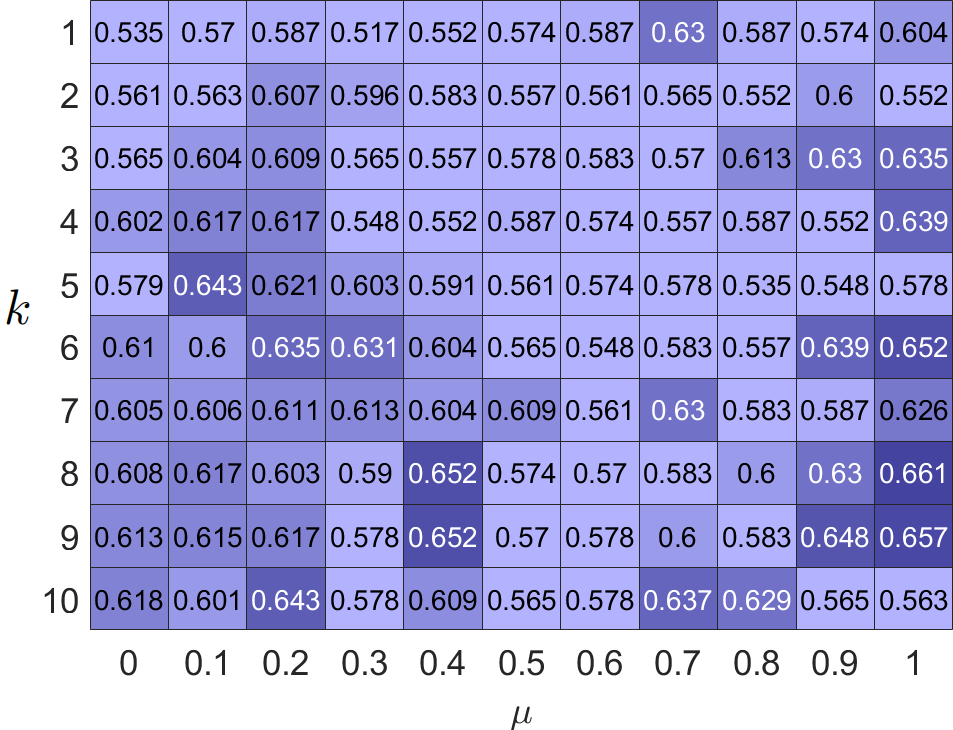
为了克服上述缺点,我们首先通过实证实验研究同亲和异亲图中邻居的共性。 我们的直觉来自平衡理论[22, 23],它指出:“我敌人的敌人是我的朋友,我朋友的朋友也是我的朋友。”因此,对于异亲图,如果两个节点有很多共同的“敌人”,那么这两个节点很有可能被归为一个簇;对于同亲图,共享许多共同“朋友”的两个节点可能来自同一个集群。 我们进行了一些实证实验来验证这一点。 定义一条边,连接两个节点和,它们的邻居是和,分别。 我们计算共同邻居的比例为:。 如果,我们将分类为同亲边。 否则,我们将 视为异嗜边,因为连接的节点没有足够的共同“朋友”或“敌人”。 我们计算了在六个真实的同性和异性数据集中可以正确分类的边缘比例。 从图1可以看出:1)大部分边缘可以通过邻居信息正确区分; 2)可以高精度地识别异性边缘。 这个有趣的发现激励我们在真实的图过程中充分利用邻居信息。
在共性的基础上,我们首先提出了一种简单的方法来构建两个高度同质和异质的图。 然后考虑到它们不同的邻域大小,设计了一种新颖的过滤器,这在理论上被证明有利于聚类。 此外,还采用挤压和激励块来增强基本功能。 我们的主要贡献总结如下。
-
•
我们研究同性图和异性图的邻居的共性。 基于它,我们开发了两种无监督的图重构策略,以从任何类型的图中捕获同质和异质信息。
-
•
我们提出了一种用于现实世界图过滤的新颖过滤器,并提供理论分析来展示其优势。
-
•
我们首次尝试在图聚类中应用挤压和激励思想来增强聚合后的基本特征。
二相关工作
II-A 图聚类
属性图聚类方法大致可以分为两类。 第一类是基于 GNN 的方法。 他们通过采用基于拓扑结构[24]的消息传递机制来学习表示。 DAEGC [25] 是一个目标导向的框架,它将基于注意力的图自动编码器与潜在表示的深度学习相结合。 MSGA [26]引入了多尺度自表达模块,以从每个编码器层获得更具辨别力的系数表示,并引入自监督模块来监督学习过程。 SSGC [27] 使用修改后的马尔可夫扩散内核来捕获每个节点的全局和局部上下文,允许在大邻域中聚合,同时限制严重的过度平滑。 对比学习思想也广泛应用于图聚类中。 CCGC [13] 通过使用具有非共享参数的孪生编码器并利用高置信度聚类信息来仔细选择正样本,解决了语义漂移问题。 SCGC [14] 利用参数非共享暹罗编码器以及使用高斯噪声对节点嵌入的直接扰动。 第二种是不使用神经网络的浅层方法。 [28] 和 [29] 通过使用低通滤波器获得平滑的嵌入。 FGC[16]和MCGC[15]采用低通滤波器,分别为新图学习最近邻信息。 然而,这些方法只关注同质图而忽略异质性,这是有限的,因为现实世界的图总是包含异质边。
II-B 异嗜图学习
异性图给许多基于 GNN 的方法带来了重大挑战,导致性能下降。 异嗜性问题在节点分类任务中得到了广泛的研究。 已经提出了一些方法来扩展感受野以寻找同质邻居。 MixHop [30] 通过迭代混合位于不同距离的邻居的特征表示来克服异质性。 GloGNN [21] 构造一个包含高阶邻居的图,以辨别图结构中的同亲邻居。 此外,还提出了许多方法来修改异嗜图的消息传递架构。 ACM-GCN [31]在每一层自适应地采用聚合、多样化和身份通道来对抗有害的异质性并提高 GNN 的性能。 LINKX [32] 将图和特征表示分离。
尽管这些方法在一定程度上缓解了异性问题,但它们严重依赖于先验知识,例如标签,而这些知识在无监督任务中是无法访问的。 据我们所知,SELENE [33]、CGC [34] 和 DGCN [35] 是唯一考虑异性的图聚类方法。 SELENE [33] 使用双通道特征嵌入管道分别使用节点属性和结构信息来区分 r-ego 网络。 DGCN 和 CGC 使用自适应滤波器来捕获有意义的低频和高频信息。 然而,这些方法基于传统的低通滤波器并忽略全局结构信息。 与我们最相关的工作是 DGCN,它也构建了用于聚类的同质图和异质图。 然而,相对于我们的方法,它具有以下缺点:1)构建图需要计算复杂度,这使得它无法应用于中等大小的图。 2)其同亲图完全基于特征,没有考虑原始结构的性质。 3) 其过滤器未能合并全局结构信息。
III 方法论
符号。 我们定义一个无向图,其中表示节点集,表示具有边的边集。 是特征矩阵, 是通道数。 矩阵表示邻接矩阵,其中 if ;否则,。 另外,矩阵对应于度矩阵。 标准化的是。 归一化拉普拉斯图为 ,其特征值矩阵为 ,其中 。 表示对应的正交特征向量。
III-A 图重构
图聚类面临两个关键挑战:现实世界的图由同质边和异质边的混合组成;图同质性在聚类中是事先未知的。 直接使用原始图进行过滤会对下游聚类产生不利影响。 因此,迫切需要开发一种原则性的方法来对具有不同同质性水平的图进行聚类。 在本文中,我们遵循图重构方法,分别提取同质和异质信息。
III-A1 同亲图构造
基于我们之前发现的共性,我们使用邻域信息来区分同质和异质边缘。 具体来说,我们使用余弦相似度来计算属性和拓扑空间中节点之间的距离:
| (1) | ||||
其中 是 的第 行。 那么同亲图构造如下:
| (2) | ||||
其中是Hadamard乘积,用于筛选属性空间和拓扑空间中的共同邻居。 设置为0.001或0.05以消除一些噪音。
III-A2 异性图构建
我们利用互补图思想构建异亲图如下:
| (3) | ||||
其中 1. 是全 1 的矩阵。 表征拓扑空间中相距较远的相似节点。 我们使用 而不是 ,因为 中的邻居更有可能是同亲邻居。 可能很密集,因此我们为每个节点仅保留 5 条边,对应于前 5 个距离较远的节点。
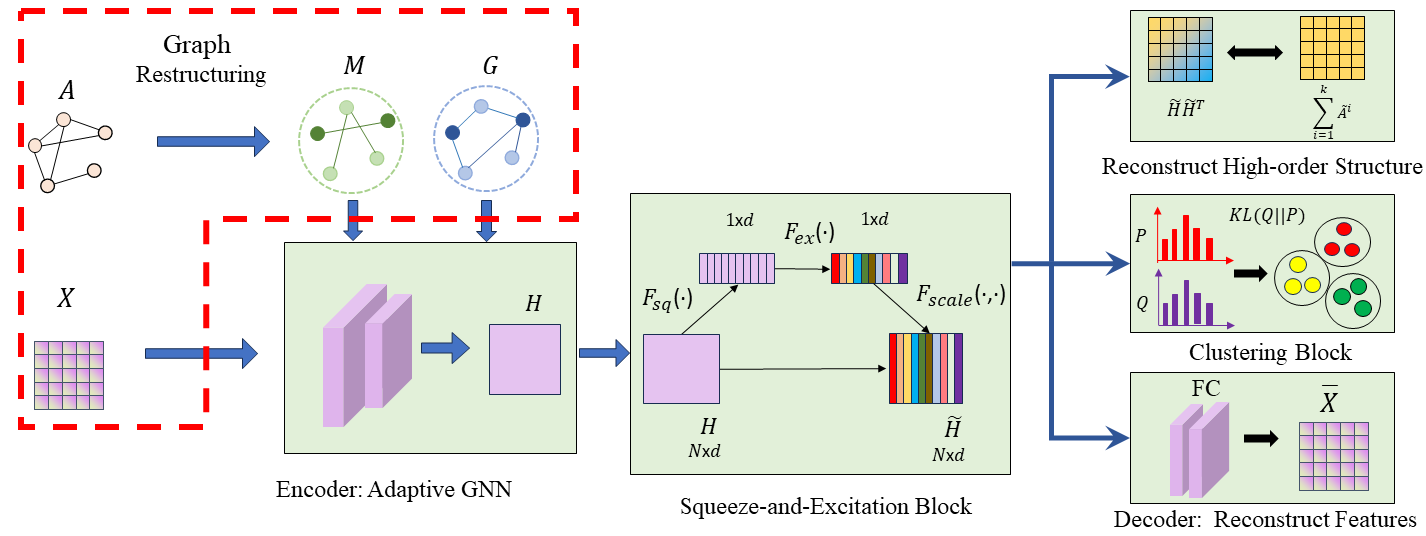
III-B 聚类框架
我们的图聚类任务的总体框架如图2所示。 它首先使用我们构造的图 和 使用新颖的过滤器对节点特征进行编码。然后,我们使用挤压和激励块改进学习的表示,该块由两个步骤组成,即挤压和激励操作。 解码器用于重建原始特征。 应用聚类块来增强聚类性能。
III-B1 图过滤
前期研究发现低频滤波器与同质性呈正相关,而高频滤波器则呈负相关[36]。 对图和进行不同的处理,我们分别进行同性聚合和异性聚合。
同亲聚集: 传统的 GNN[24] 仅聚合局部信息,从而丢失信息。 因此,我们考虑全局滤波器:,其中是可以捕获低频或高频信息的线性滤波器。 为了捕获低频信息,我们采用GCN的过滤器内核,即对于图,我们有,其中是重构后的图 的归一化拉普拉斯矩阵。 那么全局 GNN 就变成:
| (4) |
使用该全局低通滤波器的原因可以通过泰勒展开来解释如下:
| (5) |
如果具有不同跳数的路径连接节点和,则它可以描述从开始的全局信息。 值较高意味着在 跳中, 和 之间存在很大相似性。 阶乘除法通过使用快速接近零的因子来保持数学稳定性,从而保证整个无限和的存在。 因此,随着跳数的增加,重要权重将大幅下降。 这与同亲图的特征是一致的,因为同亲节点的可能性随着跳数的增加而减少[21]。
异嗜聚集: 为了捕获高频信息,我们使用传统的局部 GNN [37]:
| (6) |
其中 是重构图 的归一化拉普拉斯矩阵。 根据之前的工作[37],始终设置为。
自适应 GNN: 同嗜和异嗜相邻节点都出现在同嗜和异嗜图中。 因此,我们结合上述低通滤波器和高通滤波器,并提出第 层的聚合,如下所示:
| (7) | ||||
全局滤波器经过最小-最大归一化,与局部滤波器具有相同的范围,是平衡低频和高频信息的权衡参数。 是原始特征。 通过这种聚合,我们的模型可以自适应地聚合每一层中的低频和高频信息。 在同亲图上使用全局聚合而在异亲图上使用局部聚合的原因在定理III.1中进行了分析。
III-B2 挤压励磁块
编码后,我们将获得的节点表示输入到挤压和激励(SE)块中,这是一种基于属性维度的注意力机制。 重要的节点功能将得到改进。 它由两个主要步骤组成:挤压和激励。
挤压:为了考虑潜在空间中的全局特征,挤压操作将节点表示压缩为。 具体来说,squeeze操作就是全局池化,如下:
| (8) |
其中,被认为是压缩全局特征信息的通道统计。
激励:激励遵循挤压操作,旨在捕获通道之间的所有依赖关系。 激励是一种简单的门控机制,可以灵活地学习通道之间的非线性相互作用。 它使用 sigmoid 函数 来激发压缩的特征图。 首先,维度通过全连接层减小。 然后我们使用ReLU函数和维度递增的全连接层来返回维度,即。 最后,对其应用 sigmoid 函数。 操作总结如下:
| (9) |
Reweight:由于属性维度的选择,激励操作的结果被认为是每个属性的重要性。 接下来,我们通过将每个属性维度乘以初始表示 来完成表示的重新校准。具体重加权操作定义如下:
| (10) |
其中 是 SE 块的输出。
III-B3 聚类模块
现有的工作经常重建原始的拓扑结构[25],这使得相邻节点具有相似的表示。 然而,这是基于同质假设。 重建异性图将使高度不同的节点靠近。 [21]指出,多跳邻居中存在同亲节点。 因此,我们建议如下重建高阶拓扑结构。
| (11) |
其中表示重建阶结构。
解码器用于重建原始特征。 一些“简单”节点在重建过程中显示出很少的特征变化,这表明它们对模型训练的贡献微不足道。 我们采用全连接(FC)层作为解码器,输出,缩放余弦误差(SCE)[38]作为目标函数:
| (12) |
最后,我们利用聚类块进行聚类增强。 软分配分布计算如下:
| (13) |
其中聚类中心 使用表示上的 K 均值进行初始化, 表示学生 分布的自由度。 目标分布计算如下:
| (14) |
我们通过最小化分布 和 之间的 KL 散度,使节点表示更接近聚类中心,从而提高聚类的内聚性,计算公式为:
| (15) |
最终,我们提出的图聚类可证明过滤器(PFGC)方法的目标函数表述为:
| (16) |
其中 和 是平衡三项的权衡参数。 我们最小化上面的目标函数来训练模型,获得节点 的聚类标签为:
| (17) |
III-C 计算复杂度
PFGC的复杂性主要来自于图重构和自适应GNN。 余弦相似度的复杂度为。 可以应用采样策略使其与节点数量成线性。 自适应 GNN 需要图拉普拉斯的特征分解。 根据经验,有两种方法可以提高其速度。 首先,图的特征分解结果可以在一次性计算后存储和访问,因此,我们只需要一次特征分解。 其次,虽然滤波过程发生在谱域中,但根据经验,可以使用多项式近似来近似该过程。 因此,自适应 GNN 的计算复杂度与标准线性 GCN [24] 和图扩散模型 [39] 相当。
III-D 过滤器行为的理论分析
对于图聚类,过滤器和聚类性能之间的理论联系仍未得到充分探索。 为了填补这一空白,我们从理论上分析了如何设计滤波器以更好地适应具有不同同质性水平的实际图。 同亲图和异亲图的特点需要不同的邻域大小来进行过滤。 我们考虑具有较小感受野的局部滤波器和具有较大感受野的全局滤波器。 假设该图是平衡且无向的,每个类别都有 节点和 簇,其中 节点。 其拉普拉斯矩阵为,最大特征值为。 考虑全局过滤器:、和在其他方法中广泛应用的局部过滤器:、。 全局滤波器经过最小-最大归一化,与局部滤波器具有相同的范围,这与我们提出的方法一致。 是同质率。 那么我们有如下定理:
Theorem III.1.
假设分别在具有 和 的图形上应用低通和高通滤波器。 那么与 相比, 的簇将更具区分性,而 比 更能提高簇的区分性。
证明。
是原始图形信号。 是 (i=1,2,3,4) 过滤后的表示。 令和分别为簇内和簇间的总距离; 和是的平均簇内和簇间距离。 和 。 我们可以将信号 表示为特征向量的线性组合:
| (18) |
其中 是系数。 然后滤波后的信号可以计算为:
| (19) | ||||
使用、、、过滤的信号为、 、 、 分别。 相邻节点的平滑度可以计算为:
| (20) |
特征向量的平滑度得分与其对应的特征值是等价的:
| (21) |
我们有:
| (22) | ||||
由于 是任意单位图信号,因此所有 都是独立同分布 (i.i.d.)。 对于 i.i.d. 随机变量 和 (),我们有:
| (23) | ||||
然后,我们可以计算过滤后的相邻节点之间的总距离。 是全局过滤器和局部过滤器之间的距离。 具体来说,和之间的距离可以计算为:
| (24) | ||||
请注意,我们的全局过滤器是最小-最大标准化的,以确保它与本地过滤器具有相同的范围。 定义一个关于的通用函数:
| (25) | ||||
定义和。 显然,相对于单调递减,因此。 因此,我们只需要关注来判断是正数还是负数。 令=0,我们有:
| (26) |
因此, 在 上单调递减,在 上单调递增。 考虑到,在中只有一个根。 因此,当时,当时,其中 是 中与 最接近的一个。 请注意,两个滤波器都应用于重建的同亲图,这表明 非常接近 0。 因此, 和 非常接近 0。 因此,我们假设。 然后我们有以下内容:
| (27) | ||||
我们可以从中得出以下结果:
| (28) | ||||
同样,我们可以用高通滤波器证明以下结论:
| (29) | ||||
将定义为节点的标签。 我们可以计算总的簇内和簇间距离,如下所示:
| (30) | ||||
最后,簇间和簇内节点之间的平均距离可以计算为:
| (31) | ||||
同样,经过高通滤波后,我们有:
| (32) | ||||
显然,。 我们得出以下结论。
(1)如果,则,即
(2) 若,则,即 ∎
因此,在对同性图应用全局过滤器后,簇更具区分性,而在异性图上应用局部过滤器后,簇更具区分性。 同亲图的连接节点更有可能来自同一簇,而异亲图则相反。 因此,全局过滤器和局部过滤器的组合可以通过减少簇内距离和增加簇间距离来使簇更容易区分。 这解释了为什么所提出的自适应 GNN 更适合现实世界的图过程。
IV 实验
IV-A 数据集
为了公平起见,我们选择常用于图聚类任务的基准数据集。 对于同质图,我们选择五个数据集:Cora、CiteSeer、Pubmed [40]、Amazon Photo (AMAP) [41]、USA Air-Traffic (UAT) [42]。 对于异嗜图,选择了六个数据集,Chameleon 和 Squirrel 是专注于来自维基百科[43]的特定主题的页-页网络;卡内基梅隆大学收集了来自各大学多个计算机科学系的网络图表111http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-11/www/wwkb/,包括康奈尔大学、威斯康星州和华盛顿州。 罗马帝国源自英语维基百科上的罗马帝国文章,被选为平台上可用的最长文章之一[44]。 同质率的计算遵循[45],其中值大表示同质度高。 这些数据集的统计数据总结在表I中。
| Graph datasets | Nodes | Dims. | Edges | Clusters | Homophily Ratio | |
|---|---|---|---|---|---|---|
| Heterophilic Graphs | Cornell | 183 | 1703 | 298 | 5 | 0.1220 |
| Wisconsin | 251 | 1703 | 515 | 5 | 0.1703 | |
| Washington | 230 | 1703 | 786 | 5 | 0.1434 | |
| Chameleon | 2277 | 2325 | 31371 | 5 | 0.2299 | |
| Squirrel | 5201 | 2089 | 217073 | 5 | 0.2234 | |
| Roman-empire | 22662 | 300 | 32927 | 18 | 0.0469 | |
| Homophilic Graphs | Cora | 2708 | 1433 | 5429 | 7 | 0.8137 |
| Citeseer | 3327 | 3703 | 4732 | 6 | 0.7392 | |
| Pubmed | 19717 | 500 | 44327 | 3 | 0.8024 | |
| UAT | 1190 | 239 | 13599 | 4 | 0.6978 | |
| AMAP | 7650 | 745 | 119081 | 8 | 0.8272 | |
IV-B 比较方法
为了展示 PFGC 的优越性,我们将其与 18 个基线进行比较以进行性能评估。 这 18 个基线涵盖了五类不同的方法:1)传统的基于 GNN 的方法,例如 DAEGC [25]、MSGA [26]、SSGC [46 ]、GMM [47]、RWR [48]、ARVGA [11]; 2)基于对比学习的方法,如MVGRL [49]、SDCN [50]、DFCN [51]、DCRN [52]、SCGC [14]0> 和 CCGC [13]1>,利用 MLP 和 GNN 一起从增强的角度学习对齐的表示; 3)先进的聚类方法AGE[53]2>,它通过拉普拉斯平滑滤波器和自适应编码器实现聚类友好的嵌入; 4)利用滤波器平滑原始特征并降低噪声的浅层方法,包括MCGC [15]3>、FGC [16]4>和CGC [34]5>; (5)最近统一同质异质的方法,包括SELENE [33]6>和DGCN [35]7>。
| Methods | Cornell | Wisconsin | Washington | Chameleon | Squirrel | Roman-empire | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | |
| DAEGC | 42.56 | 12.37 | 39.62 | 12.02 | 46.96 | 17.03 | 32.06 | 6.45 | 25.55 | 2.36 | 21.23 | 12.67 |
| MSGA | 50.77 | 14.05 | 54.72 | 16.28 | 49.38 | 6.38 | 27.98 | 6.21 | 27.42 | 4.31 | 19.31 | 12.25 |
| FGC | 44.10 | 8.6 | 50.19 | 12.92 | 57.39 | 21.38 | 36.50 | 11.25 | 25.11 | 1.32 | 14.46 | 4.86 |
| GMM | 58.86 | - | 52.08 | 8.89 | 60.86 | 20.56 | - | - | - | - | - | - |
| RWR | 58.29 | - | 53.96 | 16.02 | 63.91 | 23.13 | - | - | - | - | - | - |
| ARVGA | 56.23 | - | 56.23 | 13.73 | 60.87 | 16.19 | - | - | - | - | - | - |
| DCRN | 51.32 | 9.05 | 57.74 | 19.86 | 55.65 | 14.15 | 34.52 | 9.11 | 30.69 | 6.84 | 32.57 | 29.50 |
| SELENE | 57.96 | 17.32 | 71.69 | 39.51 | - | - | 38.97 | 20.63 | - | - | - | - |
| CGC | 44.62 | 14.11 | 55.85 | 23.03 | 63.20 | 25.94 | 36.43 | 11.59 | 27.23 | 2.98 | 30.16 | 27.25 |
| DGCN | 62.29 | 29.93 | 71.71 | 41.29 | 69.13 | 28.22 | 36.14 | 11.23 | 31.34 | 7.24 | OOM | OOM |
| PFGC | 66.12 | 33.04 | 74.10 | 47.53 | 70.43 | 37.99 | 41.28 | 21.62 | 33.05 | 7.58 | 33.98 | 38.80 |
IV-C 实验设置
为了保证公平性,不同数据集中的所有实验设置都遵循DGCN[35],它执行网格搜索以找到最佳结果。 我们的网络使用 Adam 优化器进行 200 轮训练,直到收敛。 根据[21],超过一半的同亲邻居可以包含在5跳中。 因此,超参数在Roman-empire和Pubmed上固定为1以节省计算时间,而在其他数据集上根据经验设置为5。 优化器的学习率设置在 1e-2 和 1e-3 之间。 选择和来平衡[1e-3, 1e-2, 1e-1, 1, 10]中的三种类型的损失。 我们将权衡参数从0.1调整到0.7。 采用准确度(ACC)和标准化互信息(NMI)作为聚类指标。
IV-D 结果
异嗜图中的聚类结果如表II所示。 可以看出,PFGC在所有数据集上都具有主导性能。 特别是,我们的方法优于考虑异性的 SELENE、CGC 和 DGCN。 SELENE 是一种基于 GNN 的方法,DGCN 和 CGC 都使用自适应滤波器。 这验证了我们的自适应滤波器比它们能够更好地利用图形信息。 特别是,这些方法仅关注局部信息,而我们的方法考虑全局聚类结构。 除此之外,PFGC 的 ACC 可以在康奈尔大学、威斯康星州和华盛顿大学超过其他方法高达 9%、16% 和 6%。 这证明考虑异质性可以使模型在现实数据集上更加强大。 此外,传统的基于 GNN 的方法在异嗜图上表现不佳,这与文献中先前的观察结果一致。
同亲图中的聚类结果如表III所示。 可以看出,PFGC表现出有竞争力的性能,在大多数情况下取得了最好的性能,在其余三种情况下排名第二。 据观察,最先进的对比学习方法会产生不稳定的性能。 这种不稳定是由于它们的性能很大程度上基于数据增强策略,该策略需要领域知识并且缺乏跨不同数据集的灵活性。 在浅层方法的情况下,FGC 和 MCGC 仅使用低通滤波器。 它们的性能在不同的数据集之间差异很大。 CGC 是带有自适应滤波器的浅层方法,表现出比 FGC 和 MCGC 更好的性能。 这验证了单个过滤器不适合表现出各种同质性级别的真实图。 在大多数情况下,PFGC 和 DGCN 的表现优于 AGE,这表明仅使用低通滤波器进行滤波是不够的,在同质情况下高频信息也很重要。 PFGC 在所有情况下都可以超越 DGCN。 这部分是因为DGCN中新图的构造没有考虑原始结构属性,这使得DGCN在强同质图中效果较差。
综上所述,PFGC 在同性和异性病例中都取得了稳定且有前途的性能。 这主要是由于图能够捕获图中固有的同性和异性信息。 因此,PFGC 适合对实际图进行聚类,即使同质率未知。
| Methods | Cora | Citeseer | Pubmed | UAT | AMAP | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | |
| DFCN | 36.33 | 19.36 | 69.50 | 43.9 | - | - | 33.61 | 26.49 | 76.88 | 69.21 |
| DCRN | 48.93 | - | 70.86 | 45.86 | - | - | - | - | 79.94 | 73.70 |
| SSGC | 69.60 | 54.71 | 69.11 | 42.87 | - | - | 36.74 | 8.04 | 60.23 | 60.37 |
| MVGRL | 70.47 | 55.57 | 68.66 | 43.66 | - | - | 44.16 | 21.53 | 45.19 | 36.89 |
| SDCN | 60.24 | 50.04 | 65.96 | 38.71 | 65.78 | 29.47 | 52.25 | 21.61 | 53.44 | 44.85 |
| AGE | 73.50 | 57.58 | 70.39 | 44.92 | - | - | 52.37 | 23.64 | 75.98 | - |
| MCGC | 42.85 | 24.11 | 64.76 | 39.11 | 66.95 | 32.45 | 41.93 | 16.64 | 71.64 | 61.54 |
| FGC | 72.90 | 56.12 | 69.01 | 44.02 | 70.01 | 31.56 | 53.03 | 27.06 | 71.04 | - |
| SCGC | 73.88 | 56.10 | 71.02 | 45.25 | 67.73 | 28.65 | 56.58 | 28.07 | 77.48 | 67.67 |
| CCGC | 73.88 | 56.45 | 69.84 | 44.33 | 68.06 | 30.92 | 56.34 | 28.15 | 77.25 | 67.44 |
| CGC | 75.15 | 56.90 | 69.31 | 43.61 | 67.43 | 33.07 | 49.58 | 17.49 | 73.02 | 63.26 |
| DGCN | 72.19 | 56.04 | 71.27 | 44.13 | OOM | OOM | 52.27 | 23.54 | 76.07 | 66.13 |
| PFGC | 76.51 | 58.25 | 71.90 | 45.45 | 72.89 | 33.30 | 56.81 | 29.33 | 78.50 | 70.81 |
| Methods | PFGC w/o SE | PFGC-1 | PFGC-2 | PFGC-3 | PFGC | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | ACC | NMI | |
| Cora | 75.18 | 57.20 | 75.88 | 56.94 | 76.07 | 57.91 | 75.30 | 57.85 | 76.51 | 58.25 |
| AMAP | 75.88 | 67.90 | 75.38 | 67.54 | 78.38 | 70.25 | 76.26 | 67.82 | 78.50 | 70.81 |
| Wisconsin | 72.51 | 47.47 | 72.11 | 47.42 | 70.92 | 43.59 | 68.53 | 34.87 | 74.10 | 47.53 |
| Washington | 68.53 | 35.06 | 67.21 | 36.69 | 64.78 | 33.86 | 61.30 | 32.19 | 70.43 | 37.99 |
V 参数分析
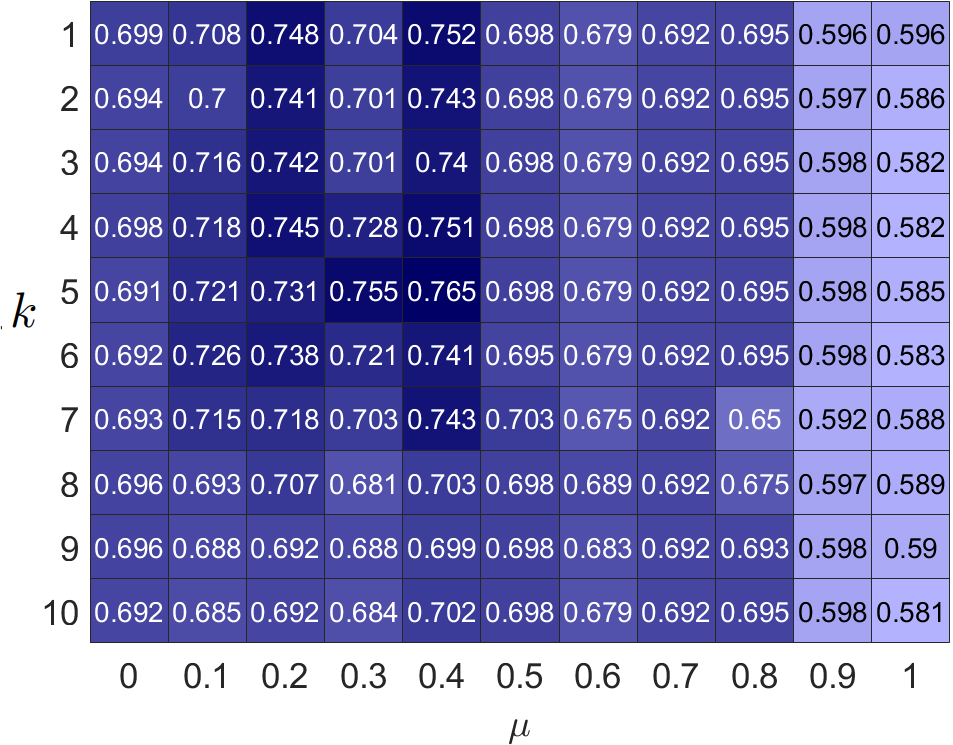
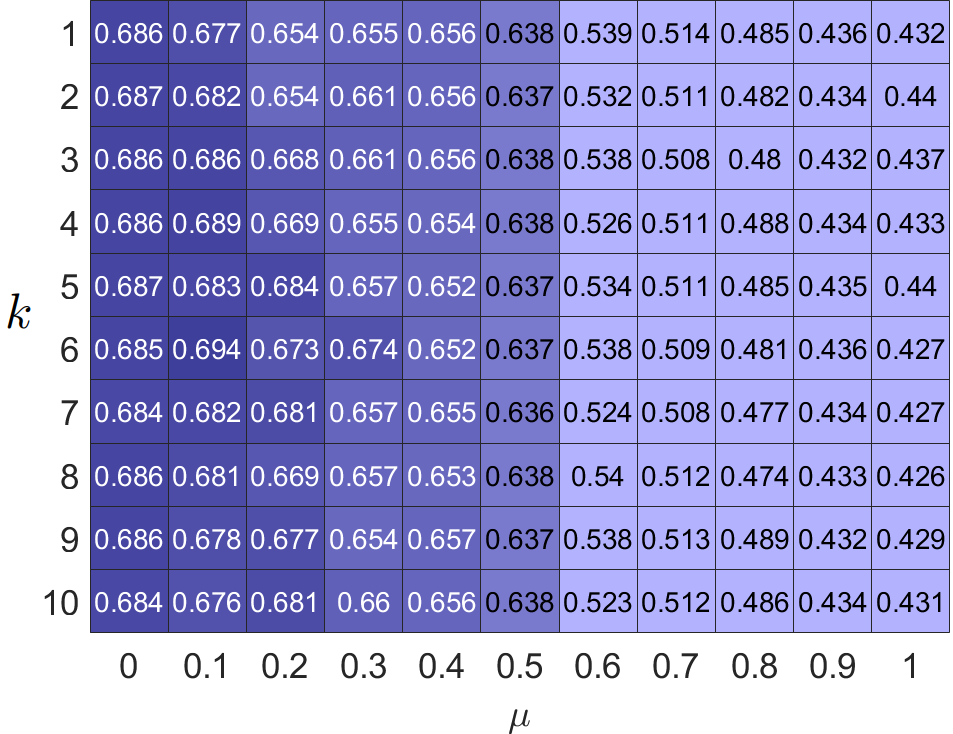
我们的过滤器在新重构的同性和异性图上运行,其中相邻节点表现出相似和不相似的倾向。 此外,我们的损失引入了一种重建阶结构信息的方法。为了证明重构图和高阶结构的有效性,我们评估了不同图中超参数 和 PFGC 的聚类精度。 结果如图3所示。 可以看出,重构图显着增强了同亲图和异亲图上的模型性能。 此外,当 时始终出现最佳性能,这表明集成高频信息的重要性。 当 较小时,同亲图获得最佳性能,而异亲图更喜欢大 ,这表明同亲图倾向于支持低频分量,而异亲图表现出对高频成分的敏感性。 我们还可以看到,在原始同亲图上, 较大时,性能会急剧下降;因此,在同亲图中将相邻节点推得太远是不合理的。 对于,我们的模型更喜欢在科拉使用较小的值,而在华盛顿使用较大的值。 原因是相似的节点在同亲图中距离较近,而在异亲图中距离较远。
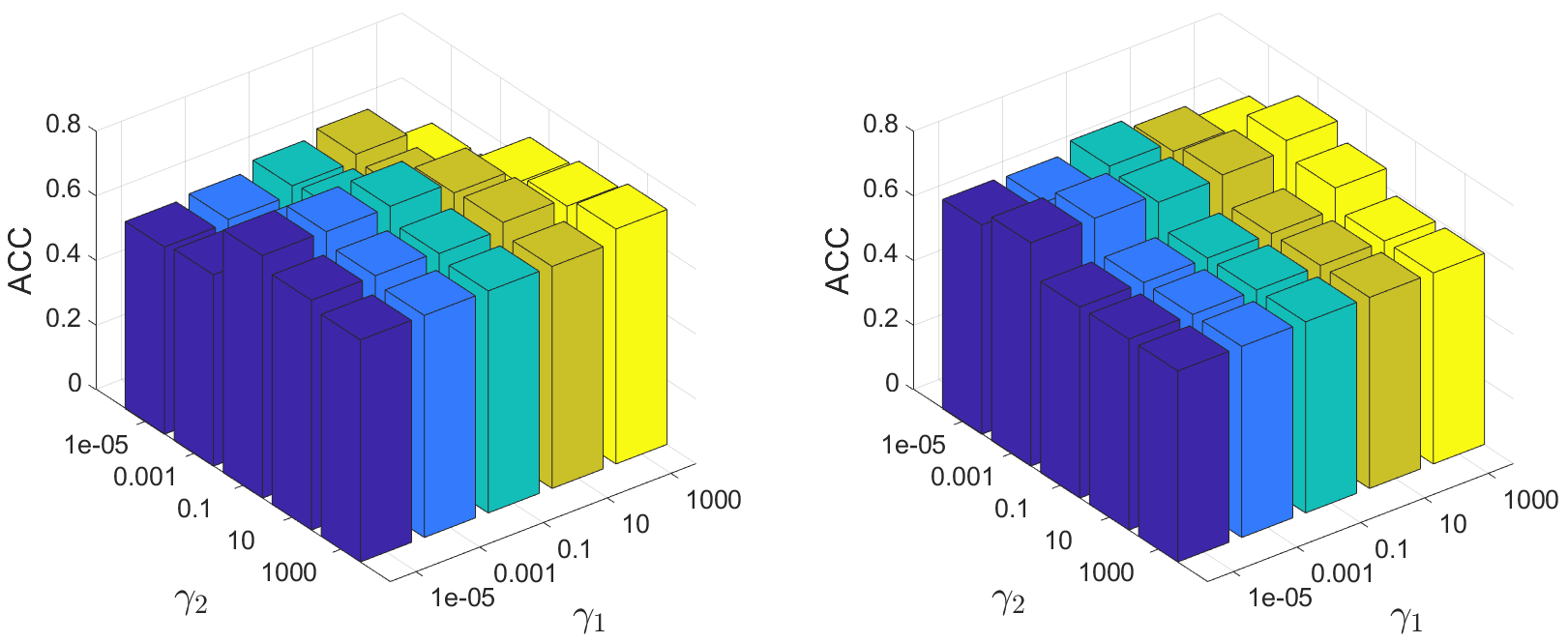
损失函数包括两个平衡参数和。 为了查看它们的效果,我们设置 , =[1e-5, 1e-3, 1e-1, 1e1, 1e3]。 它们对Cora和Washington聚类ACC的影响如图4所示。 我们的技术对于各种参数都有效。 对性能的影响大于,说明集群增强的重要性。
VI 消融研究
为了了解我们提出的自适应 GNN 的影响,我们将 PFGC 与不同的组合进行了比较。 层聚合变为:
| (33) | ||||
分别标记为 PFGC-1、PFGC-2 和 PFGC-3。 结果如表IV所示。 PFGC 在所有情况下都实现了最佳性能。 PFGC 远远超过 PFGC-1,因为 PFGC-1 只考虑传统的局部滤波器。 因此,全局过滤器有利于提高表示的质量。 PFGC-3 在大多数情况下取得了最差的性能,这与我们的定理一致。
原始图和构造图的同质性分数在表V中进行了比较。可以看出,新图是高度同质或异质的。 这表明我们的图重构方法提供了更丰富的信息。
| A | M | G | |
| Cora | 0.8100 | 0.8268 | 0.1046 |
| Citeseer | 0.7355 | 0.7790 | 0.0843 |
| Pubmed | 0.8024 | 0.8204 | 0.2212 |
| AMAP | 0.8272 | 0.8836 | 0.0653 |
| UAT | 0.6978 | 0.7005 | 0.1872 |
| Cornell | 0.1227 | 0.4807 | 0.2142 |
| Wisconsin | 0.1703 | 0.5059 | 0.0360 |
| Washington | 0.1530 | 0.5443 | 0.0653 |
| Chameloen | 0.2299 | 0.5382 | 0.1742 |
| Squirrel | 0.2234 | 0.4781 | 0.1999 |
| Roman-Empire | 0.0469 | 0.5000 | 0.0223 |
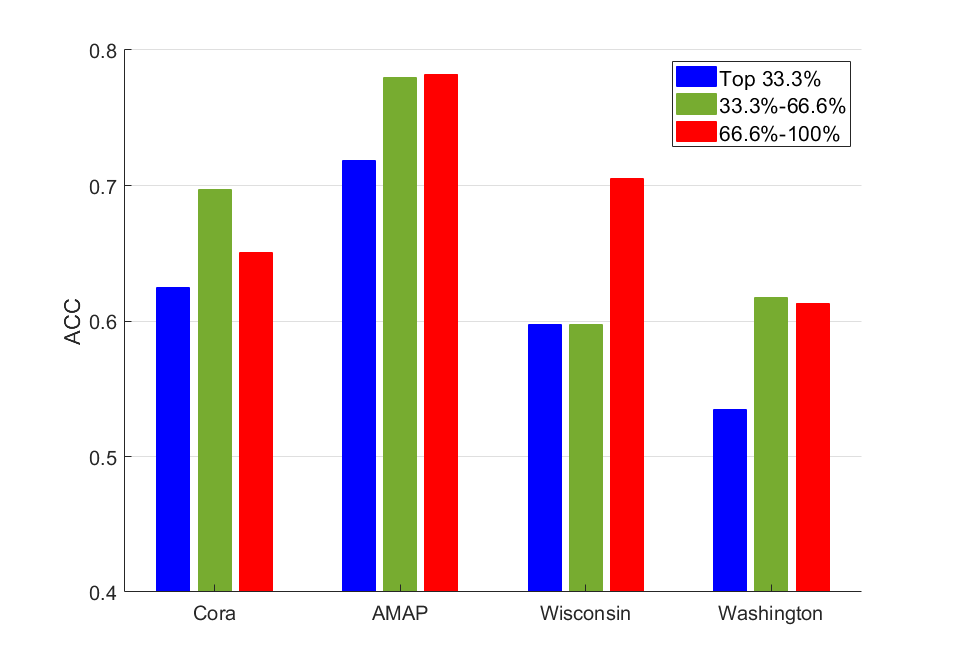
为了测试挤压和激励模块的效果,我们将其移除并将其标记为 PFGC w/o SE。 根据表IV,性能有所下降,表明挤压和激励块提高了表示质量。 我们根据注意力权重(即)掩盖最终特征。 我们将其分为三个区间:前 33.3%(最高)权重的掩蔽特征、从 33.3% 到 66.6% 权重的掩蔽特征以及其余 66.6% 到 100% 的特征。 屏蔽后,我们对特征使用 K 均值以获得 ACC 结果。 如图5所示,当屏蔽最重要的特征(前33.3%)时,性能下降最显着。 这表明与顶级特征相对应的注意力权重至关重要。 33。 3%-66。 6% 和 66。 6%-100%,它们的效果在不同的数据集上有所不同。 因此,我们提出的挤压和激励模块可以成功地增强重要特征,从而提高性能。
七结论
这项研究提出了一种创新的图聚类方法,特别是解决同质和异质图结构带来的挑战。 我们的主要贡献之一是开发用于图重组的无监督策略,从而能够根据图的共性提取同质和异质信息。 此外,我们设计了一个自适应 GNN,以更好地利用重构图的特征。 挤压和激励模块的结合放大了关键特征的重要性,以进一步提高性能,使这一概念首次应用于图聚类。 理论和实证结果验证了我们方法的有效性。
参考
- [1] C. Wang, S. Pan, G. Long, X. Zhu, and J. Jiang, “Mgae: Marginalized graph autoencoder for graph clustering,” in Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, 2017., pp. 889–898.
- [2] S. Fortunato and D. Hric, “Community detection in networks: A user guide,” Physics reports, vol. 659, pp. 1–44, 2016.
- [3] X. Liu, “Incomplete multiple kernel alignment maximization for clustering,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- [4] X. Wang, P. Cui, J. Wang, J. Pei, W. Zhu, and S. Yang, “Community preserving network embedding,” in Proceedings of the AAAI conference on artificial intelligence, vol. 31, no. 1, 2017.
- [5] W. Cui, H. Zhou, H. Qu, P. C. Wong, and X. Li, “Geometry-based edge clustering for graph visualization,” IEEE transactions on visualization and computer graphics, vol. 14, no. 6, pp. 1277–1284, 2008.
- [6] F. Nie, J. Xue, W. Yu, and X. Li, “Fast clustering with anchor guidance,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [7] B. Perozzi and L. Akoglu, “Discovering communities and anomalies in attributed graphs: Interactive visual exploration and summarization,” ACM Transactions on Knowledge Discovery from Data (TKDD), vol. 12, no. 2, pp. 1–40, 2018.
- [8] I. Cabreros, E. Abbe, and A. Tsirigos, “Detecting community structures in hi-c genomic data,” in 2016 Annual Conference on Information Science and Systems (CISS). IEEE, 2016, pp. 584–589.
- [9] A. Tsitsulin, J. Palowitch, B. Perozzi, and E. Müller, “Graph clustering with graph neural networks,” Journal of Machine Learning Research, vol. 24, no. 127, pp. 1–21, 2023.
- [10] F. Tian, B. Gao, Q. Cui, E. Chen, and T.-Y. Liu, “Learning deep representations for graph clustering,” in Proceedings of the AAAI Conference on Artificial Intelligence, no. 1, 2014.
- [11] S. Pan, R. Hu, S.-f. Fung, G. Long, J. Jiang, and C. Zhang, “Learning graph embedding with adversarial training methods,” IEEE transactions on cybernetics, vol. 50, no. 6, pp. 2475–2487, 2019.
- [12] J. Cheng, Q. Wang, Z. Tao, D. Xie, and Q. Gao, “Multi-view attribute graph convolution networks for clustering,” in Proceedings of the twenty-ninth international conference on international joint conferences on artificial intelligence, 2021, pp. 2973–2979.
- [13] X. Yang, Y. Liu, S. Zhou, S. Wang, W. Tu, Q. Zheng, X. Liu, L. Fang, and E. Zhu, “Cluster-guided contrastive graph clustering network,” in Proc. of AAAI, 2023.
- [14] Y. Liu, X. Yang, S. Zhou, X. Liu, S. Wang, K. Liang, W. Tu, and L. Li, “Simple contrastive graph clustering,” IEEE Transactions on Neural Networks and Learning Systems, 2023.
- [15] E. Pan and Z. Kang, “Multi-view contrastive graph clustering,” Advances in neural information processing systems, vol. 34, pp. 2148–2159, 2021.
- [16] Z. Kang, Z. Liu, S. Pan, and L. Tian, “Fine-grained attributed graph clustering,” in Proceedings of the 2022 SIAM International Conference on Data Mining (SDM). SIAM, 2022, pp. 370–378.
- [17] J. Zhu, Y. Yan, L. Zhao, M. Heimann, L. Akoglu, and D. Koutra, “Beyond homophily in graph neural networks: Current limitations and effective designs,” Advances in Neural Information Processing Systems, vol. 33, pp. 7793–7804, 2020.
- [18] ——, “Beyond homophily in graph neural networks: Current limitations and effective designs,” Advances in neural information processing systems, vol. 33, pp. 7793–7804, 2020.
- [19] H. Mao, Z. Chen, W. Jin, H. Han, Y. Ma, T. Zhao, N. Shah, and J. Tang, “Demystifying structural disparity in graph neural networks: Can one size fit all?” Advances in neural information processing systems, 2023.
- [20] Q. Li, Z. Han, and X.-M. Wu, “Deeper insights into graph convolutional networks for semi-supervised learning,” in Proceedings of the AAAI conference on artificial intelligence, vol. 32, no. 1, 2018.
- [21] X. Li, R. Zhu, Y. Cheng, C. Shan, S. Luo, D. Li, and W. Qian, “Finding global homophily in graph neural networks when meeting heterophily,” in International Conference on Machine Learning. PMLR, 2022.
- [22] D. Cartwright and F. Harary, “Structural balance: a generalization of heider’s theory.” Psychological review, vol. 63, no. 5, p. 277, 1956.
- [23] R. Lei, Z. Wang, Y. Li, B. Ding, and Z. Wei, “Evennet: Ignoring odd-hop neighbors improves robustness of graph neural networks,” Advances in Neural Information Processing Systems, 2022.
- [24] M. Welling and T. N. Kipf, “Semi-supervised classification with graph convolutional networks,” in J. International Conference on Learning Representations, 2017.
- [25] C. Wang, S. Pan, R. Hu, G. Long, J. Jiang, and C. Zhang, “Attributed graph clustering: A deep attentional embedding approach,” in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, 2019, pp. 3670–3676.
- [26] T. Wang, J. Wu, Z. Zhang, W. Zhou, G. Chen, and S. Liu, “Multi-scale graph attention subspace clustering network,” Neurocomputing, vol. 459, pp. 302–314, 2021.
- [27] H. Zhu and P. Koniusz, “Simple spectral graph convolution,” in 9th International Conference on Learning Representations, ICLR 2021, 2021.
- [28] Z. Lin and Z. Kang, “Graph filter-based multi-view attributed graph clustering.” in IJCAI, 2021, pp. 2723–2729.
- [29] Z. Lin, Z. Kang, L. Zhang, and L. Tian, “Multi-view attributed graph clustering,” IEEE Transactions on Knowledge and Data Engineering, vol. 35, no. 2, pp. 1872–1880, 2023.
- [30] S. Abu-El-Haija, B. Perozzi, A. Kapoor, N. Alipourfard, K. Lerman, H. Harutyunyan, G. Ver Steeg, and A. Galstyan, “Mixhop: Higher-order graph convolutional architectures via sparsified neighborhood mixing,” in International Conference on Machine Learning. PMLR, 2019, pp. 21–29.
- [31] S. Luan, C. Hua, Q. Lu, J. Zhu, M. Zhao, S. Zhang, X.-W. Chang, and D. Precup, “Is heterophily a real nightmare for graph neural networks to do node classification?” arXiv preprint arXiv:2109.05641, 2021.
- [32] D. Lim, F. Hohne, X. Li, S. L. Huang, V. Gupta, O. Bhalerao, and S. N. Lim, “Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods,” Advances in Neural Information Processing Systems, vol. 34, pp. 20 887–20 902, 2021.
- [33] Z. Zhong, G. Gonzalez, D. Grattarola, and J. Pang, “Unsupervised network embedding beyond homophily,” IEEE Transactions on Machine Learning Research, 2022.
- [34] X. Xie, W. Chen, Z. Kang, and C. Peng, “Contrastive graph clustering with adaptive filter,” Expert Systems with Applications, vol. 219, p. 119645, 2023.
- [35] E. Pan and Z. Kang, “Beyond homophily: Reconstructing structure for graph-agnostic clustering,” in International conference on machine learning, 2023, pp. 1–10.
- [36] J. Xu, E. Dai, D. Luo, X. Zhang, and S. Wang, “Learning graph filters for spectral gnns via newton interpolation,” arXiv preprint arXiv:2310.10064, 2023.
- [37] J. Park, M. Lee, H. J. Chang, K. Lee, and J. Y. Choi, “Symmetric graph convolutional autoencoder for unsupervised graph representation learning,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6519–6528.
- [38] Z. Hou, X. Liu, Y. Dong, C. Wang, J. Tang et al., “Graphmae: Self-supervised masked graph autoencoders,” SIGKDD, 2022.
- [39] B. Chamberlain, J. Rowbottom, M. I. Gorinova, M. Bronstein, S. Webb, and E. Rossi, “Grand: Graph neural diffusion,” in International Conference on Machine Learning. PMLR, 2021, pp. 1407–1418.
- [40] Z. Yang, W. Cohen, and R. Salakhudinov, “Revisiting semi-supervised learning with graph embeddings,” in International Conference on Machine Learning. PMLR, 2016, pp. 40–48.
- [41] Y. Liu, W. Tu, S. Zhou, X. Liu, L. Song, X. Yang, and E. Zhu, “Deep graph clustering via dual correlation reduction,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, 2022, pp. 7603–7611.
- [42] N. Mrabah, M. Bouguessa, M. F. Touati, and R. Ksantini, “Rethinking graph auto-encoder models for attributed graph clustering,” IEEE Transactions on Knowledge and Data Engineering, 2022.
- [43] B. Rozemberczki, C. Allen, and R. Sarkar, “Multi-scale attributed node embedding,” Journal of Complex Networks, vol. 9, no. 2, p. cnab014, 2021.
- [44] O. Platonov, D. Kuznedelev, M. Diskin, A. Babenko, and L. Prokhorenkova, “A critical look at the evaluation of gnns under heterophily: are we really making progress?” in The Eleventh International Conference on Learning Representations, 2023.
- [45] H. Pei, B. Wei, K. C.-C. Chang, Y. Lei, and B. Yang, “Geom-gcn: Geometric graph convolutional networks,” in International Conference on Learning Representations, 2020.
- [46] H. Zhu and P. Koniusz, “Simple spectral graph convolution,” in 9th International Conference on Learning Representations, ICLR 2021,, 2021.
- [47] P. Zhu, J. Li, Y. Wang, B. Xiao, S. Zhao, and Q. Hu, “Collaborative decision-reinforced self-supervision for attributed graph clustering,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [48] P.-Y. Huang, R. Frederking et al., “Rwr-gae: Random walk regularization for graph auto encoders,” arXiv preprint arXiv:1908.04003, 2019.
- [49] K. Hassani and A. H. Khasahmadi, “Contrastive multi-view representation learning on graphs,” in International Conference on Machine Learning. PMLR, 2020, pp. 4116–4126.
- [50] D. Bo, X. Wang, C. Shi, M. Zhu, E. Lu, and P. Cui, “Structural deep clustering network,” in Proceedings of The Web Conference 2020, 2020, pp. 1400–1410.
- [51] W. Tu, S. Zhou, X. Liu, X. Guo, Z. Cai, E. Zhu, and J. Cheng, “Deep fusion clustering network,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 11, 2021, pp. 9978–9987.
- [52] Y. Liu, W. Tu, S. Zhou, X. Liu, L. Song, X. Yang, and E. Zhu, “Deep graph clustering via dual correlation reduction,” in Proc. of AAAI, 2022.
- [53] G. Cui, J. Zhou, C. Yang, and Z. Liu, “Adaptive graph encoder for attributed graph embedding,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 976–985.
VIII 传记部分
![[Uncaptioned image]](x1.png) |
Xuanting Xie 获得理学学士学位 2021 年获得软件工程学士学位,目前正在攻读博士学位。毕业于电子科技大学计算机科学与工程学院,中国成都。 他的主要研究兴趣包括图学习和聚类。 |
![[Uncaptioned image]](x2.png) |
Erlin Pan 获得理学学士学位 2021年获得计算机科学与技术博士学位,目前在中国成都电子科技大学计算机科学与工程学院攻读硕士学位。主要研究兴趣包括图学习、多视图学习和聚类。 |
![[Uncaptioned image]](x3.png) |
赵康获得博士学位2017 年获得美国伊利诺伊州卡本代尔市南伊利诺伊大学卡本代尔分校计算机科学博士学位。 现任电子科技大学计算机科学与工程学院副教授。 他在顶级会议和期刊上发表了80多篇研究论文,包括NeurIPS、AAAI、IJCAI、ICDE、CVPR、SIGKDD、ECCV、ICDM、CIKM、SDM、IEEE TRANSACTIONS ON CYBERNETICS、IEEE Transactions on Image Processing、IEEE Transactions on知识和数据工程,以及 IEEE 神经网络和学习系统汇刊。 他的研究兴趣是机器学习、模式识别和数据挖掘。 康博士曾担任NeurIPS、ICLR、AAAI、IJCAI、CVPR、ICCV、MM、ECCV等多个顶级会议的AC/SPC/PC Member或审稿人。 他定期担任《机器学习研究杂志》、《IEEE 模式分析和机器智能交易》、《IEEE 神经网络和学习系统交易》、《IEEE 控制论交易》、《IEEE 知识和数据工程交易》和《IEEE 多媒体交易》的审稿人。 |
![[Uncaptioned image]](x4.png) |
陈文宇获得博士学位2009年毕业于电子科技大学计算机科学专业,获学士学位。 现任电子科技大学计算机科学与工程学院教授。 他的研究工作集中在模式识别、自然语言处理和神经网络。 |
![[Uncaptioned image]](x5.png) |
李秉恒目前是电子科技大学2020级本科生。 他的研究重点是图聚类和图数据挖掘。 |