ShortGPT:大型语言模型中的层比您预期的更加冗余
摘要
随着大语言模型性能的不断提高,其规模也显着增大,目前的大语言模型包含数十亿甚至数万亿的参数。 然而,在这项研究中,我们发现大语言模型的许多层表现出很高的相似性,并且某些层在网络功能中发挥的作用可以忽略不计。 基于这一观察,我们定义了一个称为区块影响力(BI)的指标来衡量大语言模型中每一层的重要性。 然后,我们提出了一种直接的剪枝方法:层删除,其中我们根据 BI 分数直接删除大语言模型中的冗余层。 实验表明,我们的方法(我们称之为 ShortGPT)在模型剪枝方面显着优于先前最先进的(SOTA)方法。 此外,ShortGPT 与类量化方法正交,可以进一步减少参数和计算量。 与更复杂的修剪技术相比,通过简单的层去除获得更好结果的能力表明模型架构中存在高度冗余。
1简介
大语言模型领域近年来发展迅速,大语言模型在各个领域都取得了令人瞩目的表现。 在先前工作(Kaplan等人,2020;Hoffmann等人,2022)中确定的缩放定律的指导下,当前的大语言模型研究倾向于不断增加模型参数以提高性能。 然而,由此产生的包含数十亿甚至数万亿参数的海量模型对硬件提出了严格的要求,阻碍了其实际部署和使用。 为了减轻部署大规模训练模型的硬件要求,许多研究人员专注于降低推理成本的模型压缩技术(朱等人,2023)。 模型压缩方法大致可分为两类:量化(Liu 等人, 2021; Gholami 等人, 2022; Dettmers 等人, 2022, 2024)和剪枝(LeCun 等人, 1989;韩等人,2015)。 量化方法将权重和激活量化到较低的精度。 然而,量化的加速优势取决于硬件支持,有时需要额外的微调才能保持良好的性能。 相反,剪枝方法删除冗余模型参数以减少总体参数数量。 剪枝可以直接应用于经过训练的模型,无需重新训练,并且通常比量化方法对硬件更友好。 虽然最近基于模型剪枝的大型语言模型压缩方法取得了重大进展,但现有方法通常设计得相对复杂。 有些需要使用梯度信息(Zhang 等人,2023)或只关注宽度压缩(Ashkboos 等人,2024),使得它们对于实际应用来说过于复杂。 因此,需要探索专为大型语言模型量身定制的简单高效的模型剪枝方法。 识别有效的模型剪枝技术需要研究模型冗余(Huang等人,2021;Dalvi等人,2020)。 先前关于模型冗余的研究通常集中在相对较小的模型上,例如卷积神经网络(CNN)或小型 Transformer。 对于大语言模型中的模型剪枝,之前的大多数工作都集中在张量冗余分析上,研究每个参数张量内的冗余。 然而,本文的一个关键发现是,大语言模型在层级别表现出显着的冗余,使得可以简单地删除整个层,而不会显着影响下游任务的性能。 例如,当从 LLaMA 2-13B 模型中删除最后 10 层(总共 40 层的 25%)时,MMLU 基准(Hendrycks 等人,2020) 的结果仅从 55.0 下降至 52.2(保留率为 95%)。 此外,通过删除最后 22 层(总共 40 层的 55%),得到 56 亿个参数的模型,我们仍然可以在不进行任何微调的情况下在 MMLU 上获得 47.2 的分数,甚至优于 LLaMA 2-7B 模型。 在本文中,我们建议通过块影响(BI)的镜头来分析分层冗余,它测量大语言模型建模过程中的隐藏状态转换。 我们发现BI是大语言模型中层重要性更相关的指标,我们可以通过简单地用BI删除冗余层来进行模型剪枝。 这种删除特定层的简单行为明显优于以前更复杂的修剪方法。 我们的研究结果强调了当前大语言模型架构中存在大量冗余,并为未来更高效的大语言模型训练提供了机会。 我们论文的主要贡献总结如下:
-
•
我们分析了大型语言模型(大语言模型)中的冗余,发现它们在层级别表现出显着的冗余。 这一见解启发我们通过简单地删除冗余层来修剪大语言模型。
-
•
我们提出了一种称为区块影响力(BI)的指标作为层重要性的有效指标。 通过定量分析,我们证明大语言模型在深度(层)和宽度(层内参数)上都具有冗余性。
-
•
基于 BI 指标,我们提出了一种简单而有效的修剪策略,即删除 BI 分数较低的层。 实验结果表明,我们的方法保持了 92% 的性能,同时减少了约 25% 的参数和计算量,优于之前最先进的方法。
-
•
此外,我们证明了我们的层剪枝方法与量化方法正交,这意味着它可以与量化技术相结合,以进一步减少大语言模型的部署开销。
2方法论
在本节中,我们提出了大语言模型的层删除方法的方法框架,阐明了所采用的基本原理和技术。 我们首先量化当前著名的大语言模型中存在的层冗余问题,例如 LLaMA 2 和 Baichuan 2。 然后,我们引入了一个称为块影响(BI)的指标,旨在评估大语言模型推理过程中每一层隐藏状态的转换。 在BI的基础上,我们将层删除应用于大语言模型,从而在不影响其预测准确性或语言能力的情况下降低其推理成本。
2.1层冗余
目前主流的大语言模型主要基于Transformer(Vaswani等人,2017)。 Transformer 架构基于注意力机制,通常由几个相互堆叠的剩余层组成。 Transformer是序列到序列的映射,可以定义为,其中、、是序列的长度序列,是词汇量,是可学习参数。 L层Transformer的形式化表达如下:
| Y | (1) |
其中是词嵌入矩阵,是Transformer的输出投影矩阵,有时与(Chowdhery等人, 2023), 是 Transformer 的隐藏暗淡。 ATTN指的是注意力层,FFN指的是前馈层,是层的隐藏状态。 鉴于 Transformer 结构由几个相同的层组成,一个自然的问题是这些相同层的功能和角色之间的差异和联系是什么。 之前的工作发现 Transformer 在早期层中具有一定的语义能力(Hasan 等人,2021)。 在这项工作中,我们发现 Transformer 各层之间存在显着的冗余。
层冗余:高冗余度的网络应该包含一些冗余层,这些层对网络最终性能的影响最小。 这可能是因为与网络中的其他层相比,这些层具有同质化的功能。 通过省略特定层,我们发现当前大语言模型存在高度冗余。
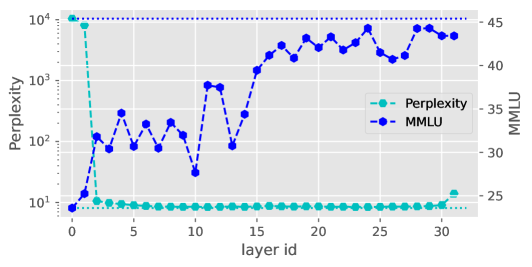
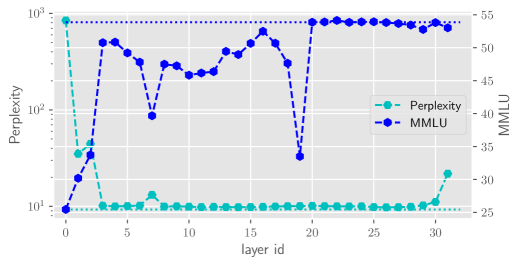
我们观察到,在许多情况下,网络对 的预测基本保持不变。 这种现象表明 Transformer 各层之间存在显着的冗余。 图3展示了Llama2-7B-Base(Touvron等人,2023)中省略某一层的困惑度和MMLU(Hendrycks等人,2020)得分),一个基于英语的大语言模型,以及主要针对中文的Baichuan2-7B-Base (Yang 等人,2023)。 更多基准测试结果请参阅3部分。 从图3可以看出,有些层在大语言模型中并没有起到至关重要的作用。 从大语言模型中删除某一层可能对最终结果的影响很小,对于困惑度也是如此。 而且,这种冗余主要体现在网络的中后期层,其中初始层和最后层往往更为关键。
2.2 层重要性
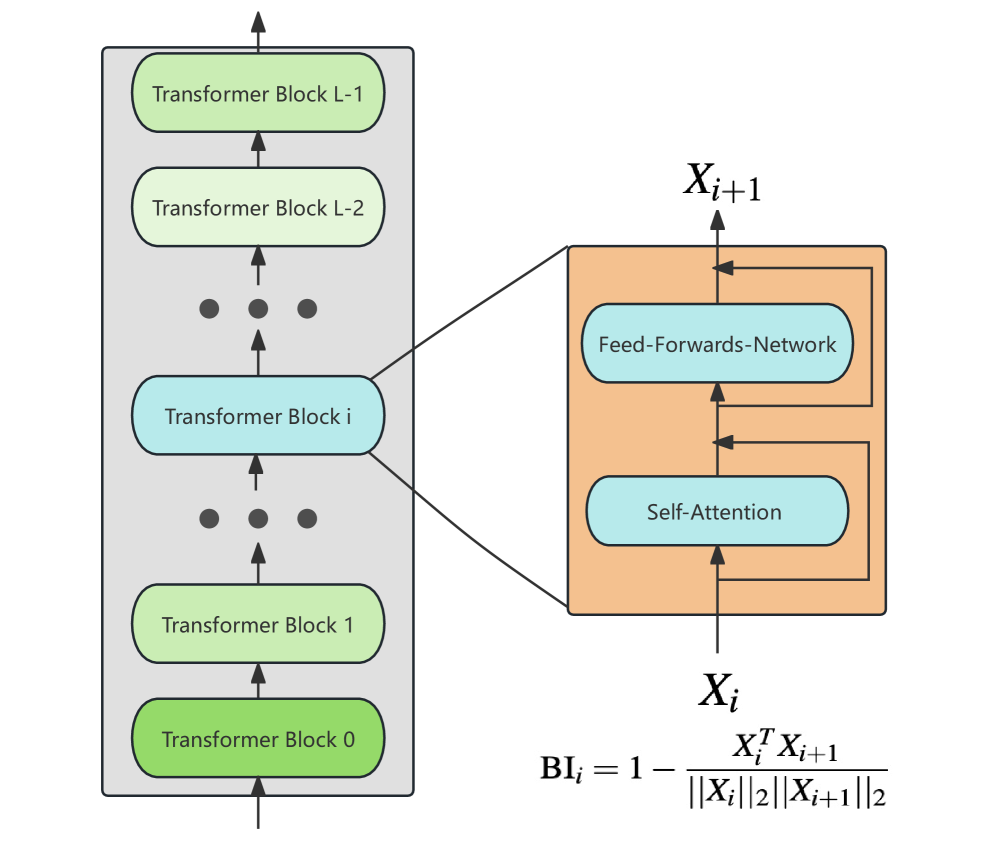
如上一节所述,大语言模型的各层表现出冗余,不同层之间的冗余程度不同。 值得注意的是,更深的层表现出更高水平的冗余。 为了删除这些冗余层,我们需要一个模型固有的度量来衡量层的重要性。 一种直观的方法是使用每层输出的幅度来衡量其重要性,因为幅度越大意味着激活的神经元越多。 在(Samragh等人, 2023)中,他们提出使用相对幅度来衡量层的重要性。 表征某一层的影响。 我们定义了一个新的指标,即区块影响力(BI),假设 Transformer 区块改变隐藏状态越多,该层的影响力就越大。 如图4所示,块的BI分数可以计算如下:
| (2) |
其中 表示 的 行。 我们的经验证据支持,BI 有效地反映了图层的重要性。 图8详细显示了这些不同的指标。
2.3图层去除
3实验
3.1实验设置
3.1.1模型
为了验证我们方法的有效性,我们对现有流行的开源语言模型进行了实验,包括 Llama2-7B (Touvron 等人, 2023)、Llama2-13B、Baichuan2-7B 和 Baichuan2- 13B。 它们都是基于仅解码器 Transformer 架构的大型语言模型。 LLaMA 2 接受了超过 2 万亿个 Token 的训练。 百川系列主要用中文进行训练,其 130 亿模型用 ALiBi (Press 等人,2021)取代了 RoPE (Su 等人,2024)位置嵌入。
3.1.2基准
为了综合评价大语言模型剪枝前后能力的变化,我们对最常用的Benchmark MMLU(Hendrycks等人, 2020)、CMMLU(Li等人,2024) 用于评估大型模型。 此外,我们还遵循 LaCo (Yang 等人, 2024) 来评估更广泛的数据集。
MMLU (Hendrycks 等人, 2020) 是一个基准,旨在通过专门评估零样本和少样本设置中的模型来衡量预训练期间获得的知识。 这使得基准测试更具挑战性,并且类似于我们评估人类的方式。 该基准涵盖STEM、人文、社会科学等57个学科,难度从初级到高级专业水平,测试世界知识和解决问题的能力。
CMMLU (Li 等人, 2024)是一个综合性汉语评估数据集,专门用于评估大语言模型在汉语和文化背景下的高级知识和推理能力。 CMMLU 涵盖 67 个主题,从小学到大学或专业水平。 包括自然科学,也包括人文社会科学,也包括很多具有中国特色的内容。
CMNLI (Xu 等人, 2020) 是汉语理解评估基准的一部分。 它由两部分组成:XNLI 和 MNLI。 HellaSwag (HeSw) (Zellers 等人, 2019) 是一个具有挑战性的数据集,用于评估常识 NLI,这对于最先进的模型来说尤其困难,尽管它的问题对于人类来说都是微不足道的。 PIQA (Bisk 等人, 2020) 是一个专注于日常场景的多选问答数据集。 该数据集通过日常场景探索模型对现实物理世界规律的把握。 CHID (Zheng 等人, 2019)是一个成语完形填空测试数据集,主要关注候选词的选择和成语的表示。 CoQA (Reddy 等人, 2019) 是一个用于会话问答任务的大规模数据集,包含超过 127000 个问题及其对应答案。 BoolQ (Clark 等人, 2019) 是一个问答数据集,包含 15942 个是/否问题的示例。 这些问题是自然发生的——它们是在无声无息、不受约束的环境中产生的。 Race (Lai 等人, 2017)是一个从中国英语考试中收集的大规模阅读理解数据集,专为中学生和高中生设计。 XSum(Hasan 等人, 2021) 用于评估 Abstract 单文档摘要系统。 目标是用一个简短的一句话来概括文章的内容。 C3 (Sun 等人, 2020) 是一个多选机器阅读理解数据集,由选择题、汉语水平考试阅读材料和华裔考试组成。 PG19 (Rae 等人, 2019) 是来自书籍的长文档数据集,用于测试语言建模的有效性。
3.1.3基线
为了评估我们方法的有效性,我们比较了几种针对大型语言模型的结构化剪枝方法,然后是 LaCo (Yang 等人,2024)。 对于我们的方法,我们使用 PG19 进行层重要性和困惑度计算。
LLM 普鲁。 (马等人, 2024)采用结构剪枝,根据梯度信息有选择地去除非关键耦合结构,最大限度地保留了大语言模型的大部分功能。 LLM 普鲁。 将 post 训练应用于修剪后的模型,但为了公平比较,我们不对其应用 post 训练。
SliceGPT (Ashkboos 等人, 2024) 是一种训练后稀疏化方案,用较小的矩阵替换每个权重矩阵,从而减少网络的嵌入维数。 具体来说,他们将PCA应用于从浅层到深层的隐藏表示,并将降维矩阵纳入现有的网络参数中。
LaCo (Yang 等人, 2024)是一种基于约简层数的大型语言模型剪枝方法。 LaCo由深到浅逐渐合并相似的层,并设置阈值以避免连续合并过多的层。
| LLM | Method | Ratio | Benchmarks | Ave. | Per. | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CMNLI | HeSw | PIQA | CHID | WSC | CoQA | BoolQ | Race-H | Race-M | XSum | C3 | MMLU | CMMLU | |||||
| Llama2-7B | Dense | 0.00% | 32.99 | 71.26 | 77.91 | 41.66 | 50.00 | 64.62 | 71.62 | 35.71 | 34.19 | 19.40 | 43.56 | 45.39 | 32.92 | 44.52 | 100.00 |
| LLMPrun. | 27.0% | 34.33 | 56.46 | 71.22 | 25.25 | 36.54 | 42.51 | 55.20 | 22.56 | 22.35 | 11.51 | 25.64 | 23.33 | 25.25 | 32.84 | 73.76 | |
| SliceGPT | 26.4% | 31.70 | 50.27 | 66.21 | 20.79 | 36.54 | 41.36 | 38.32 | 21.07 | 21.66 | 4.89 | 39.78 | 28.92 | 25.37 | 32.84 | 73.76 | |
| LaCo | 27.1% | 34.43 | 55.69 | 69.80 | 36.14 | 40.38 | 45.70 | 64.07 | 22.61 | 23.61 | 15.64 | 39.67 | 26.45 | 25.24 | 38.41 | 86.28 | |
| ShortGPT | 27.1% | 32.95 | 53.02 | 66.43 | 24.68 | 52.46 | 47.99 | 74.71 | 32.25 | 35.17 | 0.67 | 39.62 | 43.96 | 32.25 | 42.60 | 95.69 | |
| Llama2-13B | Dense | 0.00% | 32.99 | 74.78 | 79.71 | 47.35 | 50.00 | 66.91 | 82.39 | 57.95 | 60.38 | 23.45 | 47.51 | 55.00 | 38.40 | 51.91 | 100.00 |
| LLMPrun. | 24.4% | 33.03 | 67.76 | 76.66 | 35.64 | 40.38 | 50.86 | 56.42 | 22.47 | 22.08 | 19.17 | 32.33 | 25.21 | 24.71 | 38.97 | 75.07 | |
| SliceGPT | 23.6% | 29.82 | 55.71 | 69.04 | 19.31 | 36.54 | 47.26 | 37.86 | 23.41 | 24.03 | 5.27 | 41.92 | 37.14 | 25.79 | 34.84 | 67.11 | |
| LaCo | 24.6% | 32.86 | 64.39 | 74.27 | 40.10 | 52.88 | 52.66 | 63.98 | 54.49 | 56.55 | 14.45 | 44.93 | 45.93 | 32.62 | 48.30 | 93.05 | |
| ShortGPT | 24.6% | 33.00 | 66.64 | 73.45 | 36.61 | 50.00 | 58.64 | 62.48 | 58.35 | 60.17 | 17.59 | 46.90 | 54.69 | 38.38 | 50.53 | 97.34 | |
| Baichuan2-7B | Dense | 0.00% | 33.37 | 67.56 | 76.17 | 85.56 | 50.00 | 63.14 | 74.10 | 26.96 | 24.09 | 20.82 | 64.55 | 53.87 | 56.95 | 53.63 | 100.00 |
| LLMPrun. | 24.2% | 32.28 | 53.66 | 71.82 | 69.80 | 53.85 | 47.83 | 61.19 | 21.96 | 22.28 | 15.98 | 41.64 | 24.93 | 25.69 | 41.76 | 77.87 | |
| SliceGPT | 22.2% | 32.07 | 25.29 | 50.33 | 14.85 | 36.54 | 19.57 | 39.30 | 23.53 | 22.49 | 0.00 | 26.58 | 25.18 | 25.25 | 26.23 | 56.38 | |
| LaCo | 24.2% | 33.00 | 52.28 | 68.50 | 76.24 | 42.31 | 47.26 | 56.15 | 28.99 | 27.72 | 12.03 | 50.85 | 31.53 | 31.24 | 42.93 | 80.05 | |
| ShortGPT | 24.2% | 33.30 | 56.96 | 67.68 | 65.63 | 50.00 | 46.70 | 67.83 | 53.26 | 46.76 | 0.04 | 56.33 | 45.77 | 47.87 | 49.08 | 91.52 | |
| Baichuan2-13B | Dense | 0.00% | 33.21 | 71.10 | 78.07 | 86.51 | 50.00 | 65.6 | 77.89 | 67.27 | 68.94 | 25.02 | 65.64 | 59.50 | 61.30 | 62.31 | 100.00 |
| LLMPrun. | 24.3% | 33.80 | 53.57 | 71.82 | 72.77 | 37.50 | 38.82 | 56.54 | 21.17 | 21.61 | 13.67 | 39.89 | 23.19 | 25.18 | 39.20 | 62.91 | |
| SliceGPT | 22.8% | 32.07 | 25.85 | 51.03 | 10.40 | 36.54 | 18.02 | 37.83 | 21.56 | 21.52 | 0.00 | 24.99 | 22.95 | 25.26 | 25.03 | 40.17 | |
| LaCo | 24.7% | 33.03 | 60.71 | 68.88 | 76.73 | 44.23 | 55.45 | 62.35 | 56.92 | 57.80 | 12.32 | 61.10 | 51.35 | 53.65 | 53.43 | 85.75 | |
| ShortGPT | 24.7% | 32.81 | 60.55 | 71.60 | 80.17 | 47.13 | 54.30 | 62.54 | 55.77 | 56.41 | 15.14 | 60.16 | 52.11 | 58.86 | 54.43 | 87.33 | |
3.2 主要结果
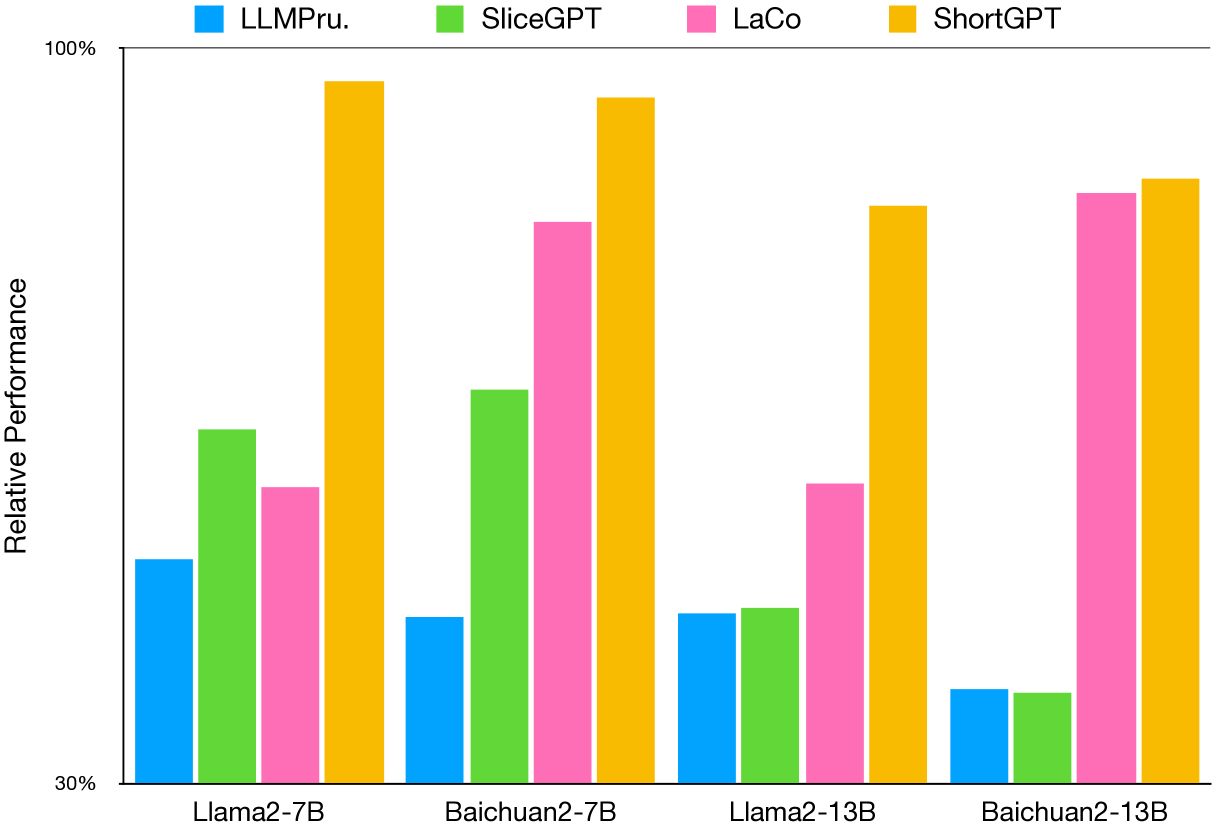
为了验证我们提出的方法的有效性,我们针对大型语言模型评估中常用的基准和基线技术进行了比较实验。 考虑到目前的结构化剪枝方法一般减少参数不超过30%,我们进行了大约剪枝1/4参数的实验。 实验结果如表1所示。 探索不同参数减少比例的其他实验将在后续部分讨论。
结果表明,我们的方法剪枝后的模型性能显着优于基线方法,最大程度地保持了大型语言模型的大部分能力,例如推理、语言理解、知识保留和考试成绩。 此外,我们注意到减少层数的方法(ShortGPT/LaCo)优于减少嵌入维度的方法(LLMPru./SliceGPT),这意味着该模型在深度上表现出比在宽度上更多的冗余。 进一步的实验分析将在接下来的部分中介绍。
4分析
4.1 不同的修剪比率
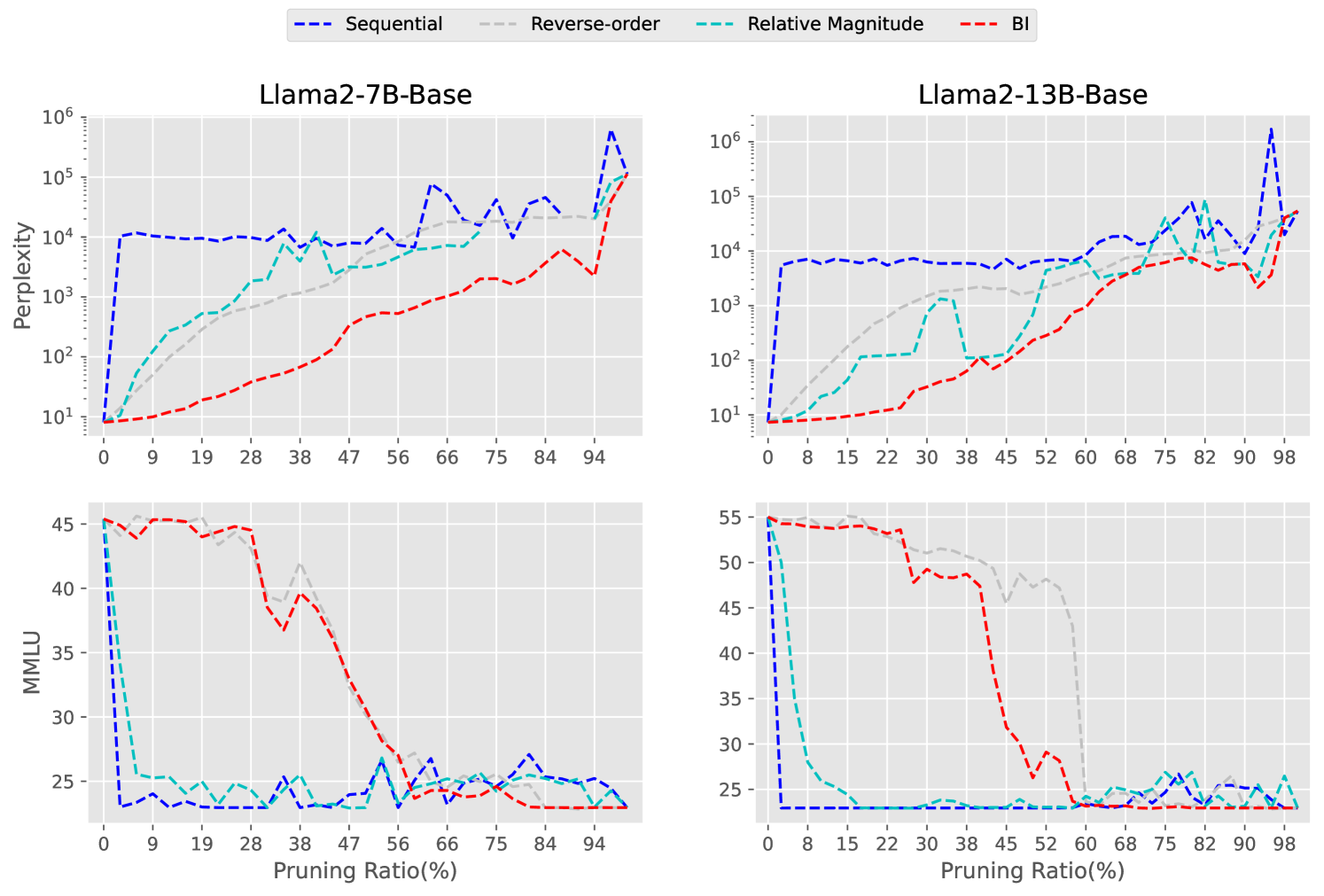
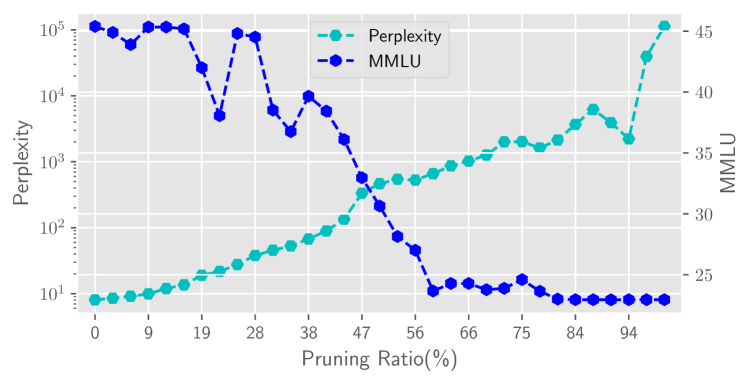
作为剪枝方法,我们进一步验证了不同剪枝比例对模型性能的影响。 在 Llama2-7B-Base 和 Baichuan2-7B-Base 模型上进行实验,观察 Perplexity 和 MMLU。 剪枝率范围从0%到97%,采用本文提出的基于重要性删除层的策略,得到1到32层的模型。 图5的结果表明,随着剪枝率的增加,模型的性能下降。 然而,MMLU 分数在某一层显着下降,这可能意味着网络中存在某些发挥至关重要作用的特殊层。
4.2 深度冗余与深度冗余 宽度冗余
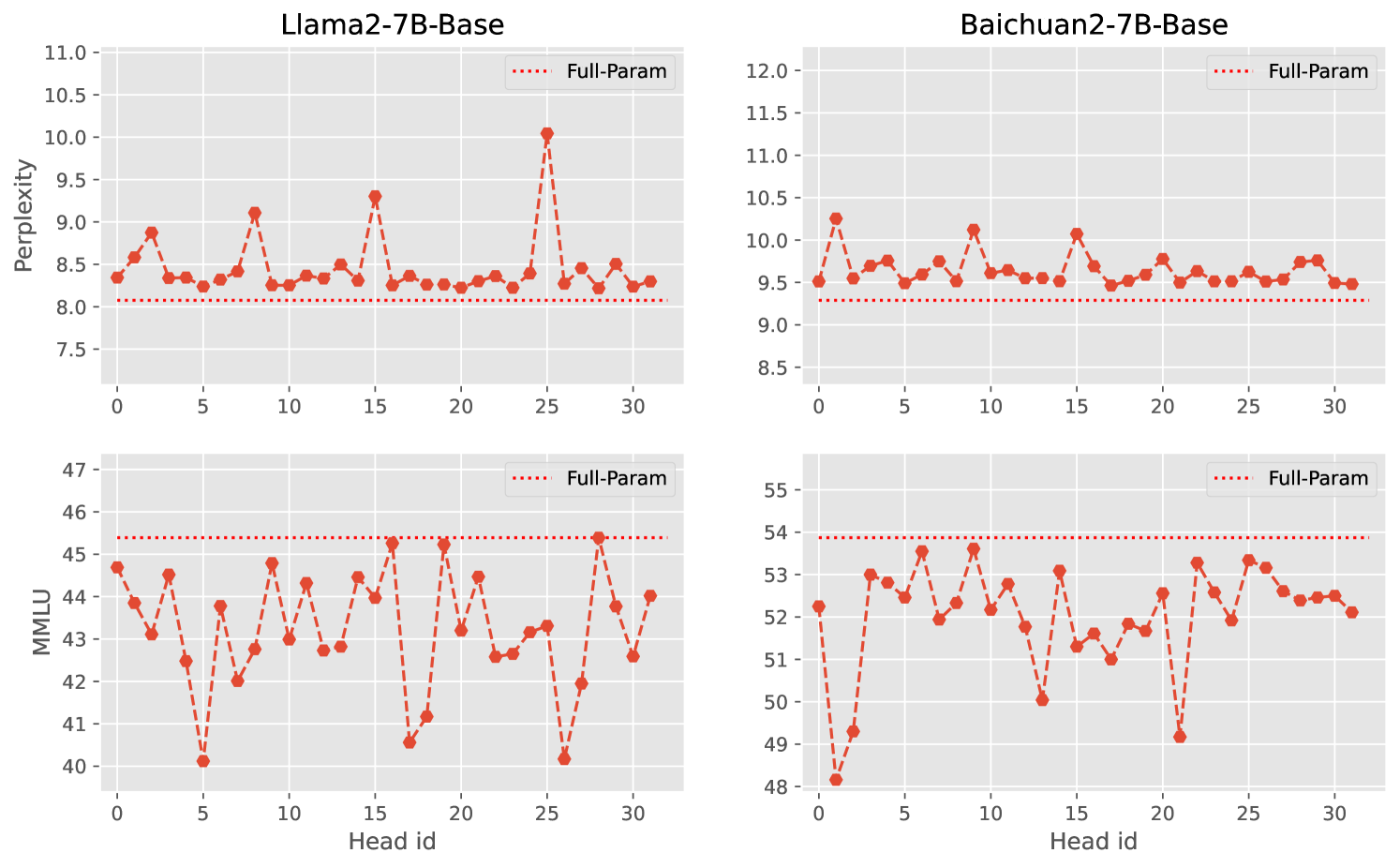
在前面的章节中,我们从深度(层次)上对大语言模型(大语言模型)的冗余进行了分析和探索。 然而,我们还研究了宽度方面的冗余,特别关注注意力头。 我们的方法包括从多头注意力机制中顺序移除每个头,并调整注意力输出投影的参数,以确保注意力块的输出形状保持不变。 前馈网络(FFN)保持不变。 与2.1节中的方法类似,我们观察每个头的移除对网络最终性能的影响。 图6说明了每个头被移除后 Perplexity 和 MMLU 分数的变化。 结果表明,大语言模型在宽度上表现出高度的冗余,与深度上的冗余相当。 然而,这种宽度冗余并不遵循任何可辨别的模式,并且在不同的模型中有所不同。 我们假设这种差异可能归因于头部之间的对称性。
4.3 非 Transformer 大语言模型的冗余

我们进一步研究了深度观察到的冗余是否是 Transformer 架构的结果。 鉴于目前流行的大语言模型绝大多数都是基于Transformer结构。 我们选择了(Peng等人,2023)中提出的RWKV-7B模型,它是Transformer架构的强大竞争对手,在一定程度上确实由相同的层组成。 我们使用2.1中的方法分析了该模型。 图 7 显示了 RWKV-7B 的冗余 111 We use rwkv-v5-world-7B from https://huggingface.co/BlinkDL/rwkv-5-world 模型。 通过该图,我们可以观察到RWKV-7B模型也表现出了很高的冗余度。 这可能表明冗余在大语言模型中是普遍存在的。
4.4重要性指标
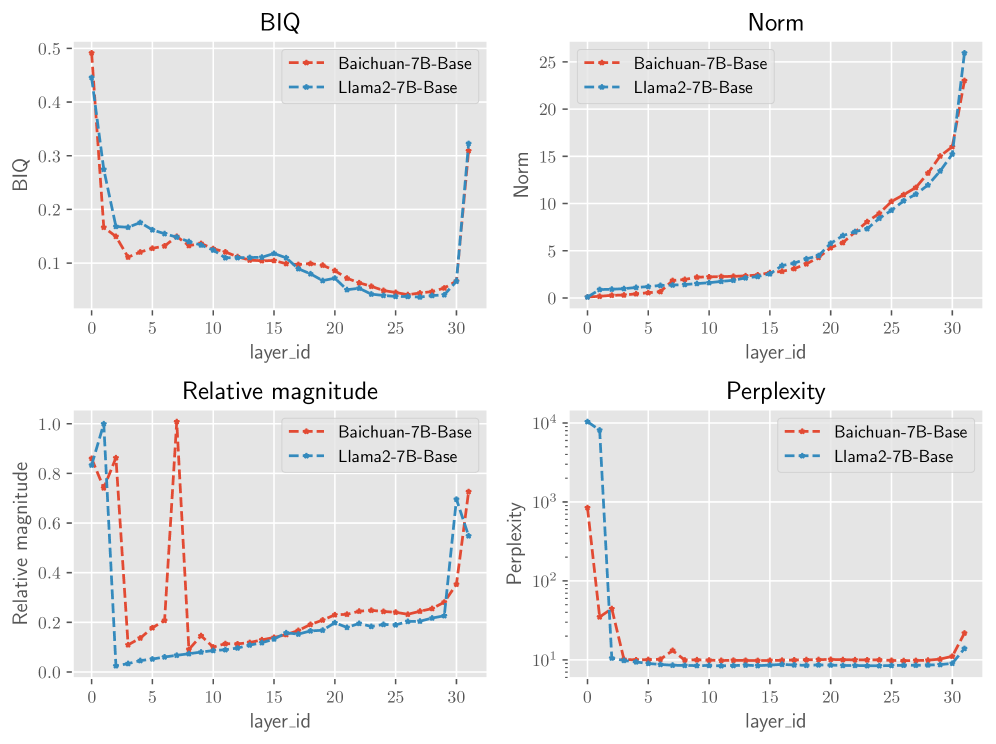
我们方法的总体概念是按重要性对层进行排序并删除不太重要的层。 重要性指标的定义对结果有深远的影响。 在本节中,我们定义并比较各种重要指标:
Sequential:重要性与序列顺序成正比,越浅的层越重要。 这可以通过将每层索引的负数作为重要性度量来实现。
逆序/规范:该指标假定重要性与序列顺序成反比。 受图 3 的启发,它为较浅的层分配了更高的重要性分数。 此方法给出的顺序与 LABEL:layerimportacne 中提到的通过隐藏状态范数测量重要性的顺序相同。 在这里,重要性指标是图层的索引本身。
相对幅度:在(Samragh等人,2023)中提出,该指标假设具有较大的层具有更高的重要性,其中 是图层转换函数。
BI:上一节2.2中提到的BI。
4.5 正交于量化
在本节中,我们将展示我们的方法与量化方法正交。 我们将我们的方法应用于模型 222We take the model from https://huggingface.co/TheBloke/Llama-2-7B-GPTQ 由 GPTQ 算法量化。 表2显示我们的方法与类量化方法兼容,这可以进一步减少占用空间。
| Model | Ratio/Layer | Perplexity | MMLU |
|---|---|---|---|
| Baseline | 0%/32 | 8.4999 | 37.99 |
| ShortGPT | 27.1%/23 | 42.6951 | 36.69 |
5限制
尽管我们的方法与当前的剪枝方法相比表现出强大的竞争力,一些基准测试甚至表明删除某些层对最终结果没有影响,但这并不意味着层删除没有缺点。 由于基准测试的局限性,当前的评估可能无法完全捕捉层去除对模型性能的影响。 我们的实验表明,与多项选择任务相比,层去除的效果在生成任务上更加明显。 在 GSM8K (Cobbe 等人, 2021) 和 HumanEval (Chen 等人, 2021) 等基准测试中,删除 25% 的层通常会导致性能严重下降,分数接近于零。 尽管如此,这项研究证明模型在层去除后仍保持强大的语义理解和处理能力。 训练后技术可能会进一步减轻性能损失,这是一个正在进行的研究领域。
6相关作品
为了降低大型语言模型的推理成本并增加其实际应用,最近出现了许多关于压缩模型的工作,可分为四类:模型剪枝、知识蒸馏、量化和低秩分解。
模型剪枝: 模型剪枝(LeCun等人,1989;Han等人,2015)是一种经典且有效的减少模型冗余模块以压缩模型的方法。 模型剪枝方法主要包括非结构化剪枝和结构化剪枝。 非结构化剪枝通过删除特定参数而不考虑其内部结构来简化大语言模型,例如 SparseGPT (Frantar and Alistarh, 2023) 和 LoRAPrune (Zhang 等人, 2023)。 然而,该方法忽视了大语言模型的整体结构,导致模型组成不规则稀疏。 另一种更实用的方法是结构化剪枝,GUM(Syed 等人, 2023)对纯解码器大语言模型的几种结构化剪枝方法进行了分析。 LLM-Pruner(Ma等人, 2024)根据梯度信息选择性地去除非关键结构。 ShearedLLaMA (Xia 等人, 2023) 采用有针对性的结构化剪枝和动态批量加载。 LaCo (Yang 等人, 2024) 使用图层合并来压缩模型。 与之前的方法相比,我们的方法是一种简单高效的结构化剪枝方法。
知识蒸馏: 知识蒸馏(KD)(Hinton 等人,2015;Gou 等人,2021)是压缩模型的另一种方式,其中较大的教师网络向较小的学生网络提供知识。 使用大语言模型API的提示响应对来模拟小模型可以获得预期的结果(李等人,2022)。 此外,当我们能够访问透明的教师模型时,结果可以得到更大的改善。 MiniLLM (Gu 等人, 2023) 使用反向 Kullback-Leibler 散度来防止学生模型高估教师分布的低概率区域。 DistlLLM (Ko 等人, 2024) 使用自适应离策略方法,旨在提高利用学生生成的输出的效率。 然而,与模型剪枝相比,这种方法通常需要更高的计算资源。
量化:量化(Liu 等人, 2021; Gholami 等人, 2022; Dettmers 等人, 2022, 2024) 是模型压缩领域广泛接受的技术,可以显着节省深度学习模型的存储和计算成本。 传统模型通常存储为浮点数,但量化将它们转换为整数或其他离散形式。 LUT-GEMM (Park 等人, 2022) 使用 BCQ 格式仅量化权重并优化大语言模型中的矩阵乘法。 SPQR (Dettmers 等人, 2023) 识别并隔离异常权重,以更高的精度存储它们,并将所有其他权重压缩为 3-4 位。 我们的模型剪枝方法和量化方法是正交的,这意味着基于我们剪枝模型的量化可以进一步压缩模型。
低阶因式分解: 低秩分解(Cheng 等人,2017;Povey 等人,2018)是一种模型压缩技术,旨在通过将给定的权重矩阵分解为两个或多个维度显着降低的较小矩阵来逼近给定的权重矩阵。 TensorGPT (Xu 等人, 2023) 以低秩张量格式存储大型嵌入,降低了大语言模型的空间复杂度,并使它们可以在边缘设备上使用。 最近,SliceGPT(Ashkboos等人,2024)也实现了基于隐藏状态矩阵分解的模型的结构化压缩,并将新矩阵吸收到原始网络的参数中。
模型冗余: 研究人员很早就注意到非线性模型中的显着冗余(Catchpole 和 Morgan,1997)。 近年来,Transformer模型架构得到了广泛的应用,研究人员也对其冗余性进行了研究。 在(Bian等人,2021)中,研究人员分析了注意机制中的冗余,在注意头之间观察到清晰且相似的冗余模式(簇结构)。 在(Dalvi等人,2020)中,研究人员剖析了两个预训练模型:BERT(Devlin等人,2018)和XLNet(Yang等人,2019) ),研究它们在表示级别和更细粒度的神经元级别上表现出多少冗余。 然而,当前基于仅解码器结构的大型语言模型中的冗余仍然需要探索。
7结论
这项工作引入了一种基于层冗余和定义为注意力熵的“重要性”度量来修剪大型语言模型(大语言模型)的新方法。 我们的研究揭示了大语言模型中存在显着程度的分层冗余,这表明某些层对整体网络功能的贡献最小,因此可以在不显着影响模型性能的情况下将其删除。 通过采用以计算出的每层重要性为指导的简单的层删除策略,我们已经证明可以保持大语言模型高达 95% 的性能,同时将模型的参数数量和计算要求减少约 25%。 这一成果不仅超越了之前最先进的剪枝方法,而且强调了大语言模型部署策略进一步优化的潜力。
我们的研究结果表明,大语言模型固有的冗余很大程度上是基于深度的,而不是基于宽度的,这为未来研究神经网络结构效率提供了一条途径。 此外,我们的剪枝方法以其简单性和有效性为特点,与量化等其他压缩技术兼容,为减少模型大小提供了一种既重要又通用的复合途径。
我们研究的意义超出了学术兴趣,为在资源有限的环境中部署先进的大语言模型提供了实用的解决方案。 通过启用更高效的模型架构,而不需要进行大量的再训练,我们的修剪方法有助于跨各种平台和设备更广泛地访问尖端人工智能功能。
总之,我们对层冗余的研究和基于重要性的修剪策略的开发代表了大型语言模型优化方面的有意义的进步。 随着对复杂人工智能工具的需求不断增长,像我们这样的方法将在使这些技术更容易获得和可持续方面发挥关键作用。 未来的工作将集中于完善我们对模型冗余的理解,并探索提高神经网络模型效率的其他方法。
参考
- Ashkboos et al. (2024) Saleh Ashkboos, Maximilian L Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. 2024. Slicegpt: Compress large language models by deleting rows and columns. arXiv preprint arXiv:2401.15024.
- Bian et al. (2021) Yuchen Bian, Jiaji Huang, Xingyu Cai, Jiahong Yuan, and Kenneth Church. 2021. On attention redundancy: A comprehensive study. In Proceedings of the 2021 conference of the north american chapter of the association for computational linguistics: human language technologies, pages 930–945.
- Bisk et al. (2020) Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. 2020. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, pages 7432–7439.
- Catchpole and Morgan (1997) Edward A Catchpole and Byron JT Morgan. 1997. Detecting parameter redundancy. Biometrika, 84(1):187–196.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Cheng et al. (2017) Yu Cheng, Duo Wang, Pan Zhou, and Tao Zhang. 2017. A survey of model compression and acceleration for deep neural networks. arXiv preprint arXiv:1710.09282.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Clark et al. (2019) Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. Boolq: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2924–2936.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Dalvi et al. (2020) Fahim Dalvi, Hassan Sajjad, Nadir Durrani, and Yonatan Belinkov. 2020. Analyzing redundancy in pretrained transformer models.
- Dettmers et al. (2022) Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Llm. int8 (): 8-bit matrix multiplication for transformers at scale. arXiv preprint arXiv:2208.07339.
- Dettmers et al. (2024) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2024. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36.
- Dettmers et al. (2023) Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. 2023. Spqr: A sparse-quantized representation for near-lossless llm weight compression. arXiv preprint arXiv:2306.03078.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Frantar and Alistarh (2023) Elias Frantar and Dan Alistarh. 2023. Massive language models can be accurately pruned in one-shot. arXiv preprint arXiv:2301.00774.
- Gholami et al. (2022) Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. 2022. A survey of quantization methods for efficient neural network inference. In Low-Power Computer Vision, pages 291–326. Chapman and Hall/CRC.
- Gou et al. (2021) Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. 2021. Knowledge distillation: A survey. International Journal of Computer Vision, 129:1789–1819.
- Gu et al. (2023) Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. 2023. Knowledge distillation of large language models. arXiv preprint arXiv:2306.08543.
- Han et al. (2015) Song Han, Jeff Pool, John Tran, and William Dally. 2015. Learning both weights and connections for efficient neural network. Advances in neural information processing systems, 28.
- Hasan et al. (2021) Tahmid Hasan, Abhik Bhattacharjee, Md Saiful Islam, Kazi Mubasshir, Yuan-Fang Li, Yong-Bin Kang, M Sohel Rahman, and Rifat Shahriyar. 2021. Xl-sum: Large-scale multilingual abstractive summarization for 44 languages. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4693–4703.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300.
- Hinton et al. (2015) Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531.
- Hoffmann et al. (2022) Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre. 2022. Training compute-optimal large language models.
- Huang et al. (2021) Feiqing Huang, Yuefeng Si, Yao Zheng, and Guodong Li. 2021. A new measure of model redundancy for compressed convolutional neural networks.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.
- Ko et al. (2024) Jongwoo Ko, Sungnyun Kim, Tianyi Chen, and Se-Young Yun. 2024. Distillm: Towards streamlined distillation for large language models. arXiv preprint arXiv:2402.03898.
- Lai et al. (2017) Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. 2017. Race: Large-scale reading comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 785–794.
- LeCun et al. (1989) Yann LeCun, John Denker, and Sara Solla. 1989. Optimal brain damage. Advances in neural information processing systems, 2.
- Li et al. (2024) Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin. 2024. Cmmlu: Measuring massive multitask language understanding in chinese.
- Li et al. (2022) Shiyang Li, Jianshu Chen, Yelong Shen, Zhiyu Chen, Xinlu Zhang, Zekun Li, Hong Wang, Jing Qian, Baolin Peng, Yi Mao, et al. 2022. Explanations from large language models make small reasoners better. arXiv preprint arXiv:2210.06726.
- Liu et al. (2021) Zhenhua Liu, Yunhe Wang, Kai Han, Wei Zhang, Siwei Ma, and Wen Gao. 2021. Post-training quantization for vision transformer. Advances in Neural Information Processing Systems, 34:28092–28103.
- Ma et al. (2024) Xinyin Ma, Gongfan Fang, and Xinchao Wang. 2024. Llm-pruner: On the structural pruning of large language models. Advances in neural information processing systems, 36.
- Park et al. (2022) Gunho Park, Baeseong Park, Se Jung Kwon, Byeongwook Kim, Youngjoo Lee, and Dongsoo Lee. 2022. nuqmm: Quantized matmul for efficient inference of large-scale generative language models. arXiv preprint arXiv:2206.09557.
- Peng et al. (2023) Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, et al. 2023. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048.
- Povey et al. (2018) Daniel Povey, Gaofeng Cheng, Yiming Wang, Ke Li, Hainan Xu, Mahsa Yarmohammadi, and Sanjeev Khudanpur. 2018. Semi-orthogonal low-rank matrix factorization for deep neural networks. In Interspeech, pages 3743–3747.
- Press et al. (2021) Ofir Press, Noah A Smith, and Mike Lewis. 2021. Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409.
- Rae et al. (2019) Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, Chloe Hillier, and Timothy P Lillicrap. 2019. Compressive transformers for long-range sequence modelling. In International Conference on Learning Representations.
- Reddy et al. (2019) Siva Reddy, Danqi Chen, and Christopher D Manning. 2019. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7:249–266.
- Samragh et al. (2023) Mohammad Samragh, Mehrdad Farajtabar, Sachin Mehta, Raviteja Vemulapalli, Fartash Faghri, Devang Naik, Oncel Tuzel, and Mohammad Rastegari. 2023. Weight subcloning: direct initialization of transformers using larger pretrained ones.
- Su et al. (2024) Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063.
- Sun et al. (2020) Kai Sun, Dian Yu, Dong Yu, and Claire Cardie. 2020. Investigating prior knowledge for challenging chinese machine reading comprehension. Transactions of the Association for Computational Linguistics, 8:141–155.
- Syed et al. (2023) Aaquib Syed, Phillip Huang Guo, and Vijaykaarti Sundarapandiyan. 2023. Prune and tune: Improving efficient pruning techniques for massive language models. Arxiv.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Xia et al. (2023) Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. 2023. Sheared llama: Accelerating language model pre-training via structured pruning. arXiv preprint arXiv:2310.06694.
- Xu et al. (2020) Liang Xu, Hai Hu, Xuanwei Zhang, Lu Li, Chenjie Cao, Yudong Li, Yechen Xu, Kai Sun, Dian Yu, Cong Yu, et al. 2020. Clue: A chinese language understanding evaluation benchmark. In Proceedings of the 28th International Conference on Computational Linguistics, pages 4762–4772.
- Xu et al. (2023) Mingxue Xu, Yao Lei Xu, and Danilo P Mandic. 2023. Tensorgpt: Efficient compression of the embedding layer in llms based on the tensor-train decomposition. arXiv preprint arXiv:2307.00526.
- Yang et al. (2023) Aiyuan Yang, Bin Xiao, Bingning Wang, Borong Zhang, Ce Bian, Chao Yin, Chenxu Lv, Da Pan, Dian Wang, Dong Yan, et al. 2023. Baichuan 2: Open large-scale language models. arXiv preprint arXiv:2309.10305.
- Yang et al. (2024) Yifei Yang, Zouying Cao, and Hai Zhao. 2024. Laco: Large language model pruning via layer collapse.
- Yang et al. (2019) Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Russ R Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pretraining for language understanding. Advances in neural information processing systems, 32.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800.
- Zhang et al. (2023) Mingyang Zhang, Chunhua Shen, Zhen Yang, Linlin Ou, Xinyi Yu, Bohan Zhuang, et al. 2023. Pruning meets low-rank parameter-efficient fine-tuning. arXiv preprint arXiv:2305.18403.
- Zheng et al. (2019) Chujie Zheng, Minlie Huang, and Aixin Sun. 2019. Chid: A large-scale chinese idiom dataset for cloze test. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 778–787.
- Zhu et al. (2023) Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. 2023. A survey on model compression for large language models.
附录A层去除的详细策略
| Strategy |
Description |
|---|---|
| Sequential |
Layers are removed sequentially from the beginning of the model. The process starts with layer 0 and progressively includes more layers for removal (e.g., {0}, {0, 1}, …). |
| Reverse-order |
This strategy involves starting from the model’s final layer and progressively removing layers in reverse order (e.g., {-1}, {-1, -2}, …). |
| Relative Magnitude |
Layers are removed in ascending order based on their Relative Magnitude values. The removal process accumulates layers from those with the smallest to the largest values, mirroring the sequential strategy’s accumulation method. |
| BI (Block Influence) |
Follows a similar accumulation approach as the Sequential strategy, but layers are ordered and removed according to their BI values, starting from the lowest and moving to the highest. |
附录 B已删除层的基准设置
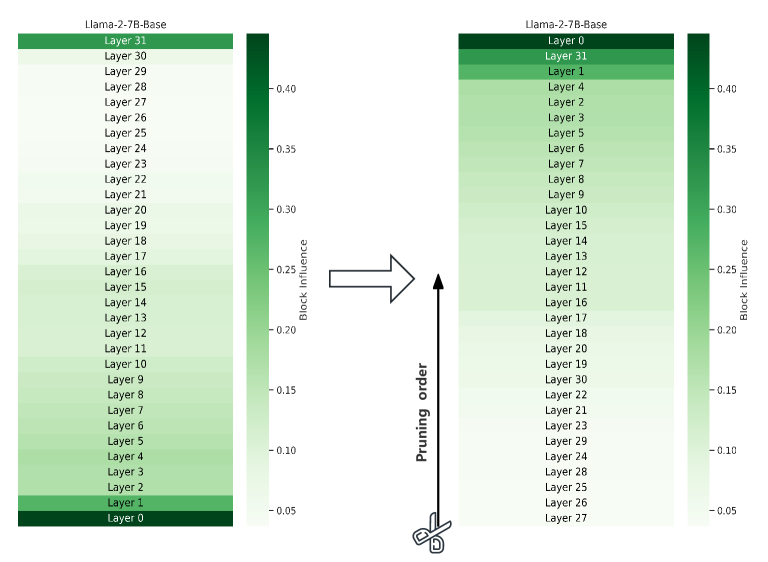
在描述基准模型中的特定层去除配置之前,有必要对结构修改进行简要概述。 Llama-2-7B 和 Baichuan-2-7B 模型最初设计为 32 层,现已精简为 9 层,相当于总层框架减少了 28%。 13B变体最初由40层组成,减少了10层,减少了25%。 层移除的选择标准基于递增的块影响 (BI) 值,确保采用数据驱动的方法来实现最小化。 这个前提支撑了基准配置。
| Model | Removed Layers |
|---|---|
| Llama-2-7B | 27, 26, 25, 28, 24, 29, 23, 21, 22 |
| Llama-2-13B | 33, 31, 32, 30, 29, 34, 28, 35, 27, 26 |
| Baichuan-2-7B | 26, 27, 25, 28, 24, 29, 23, 22, 30 |
| Baichuan-2-13B | 32, 31, 33, 30, 34, 29, 28, 35, 27, 26 |
附录C百川2系列机型去层
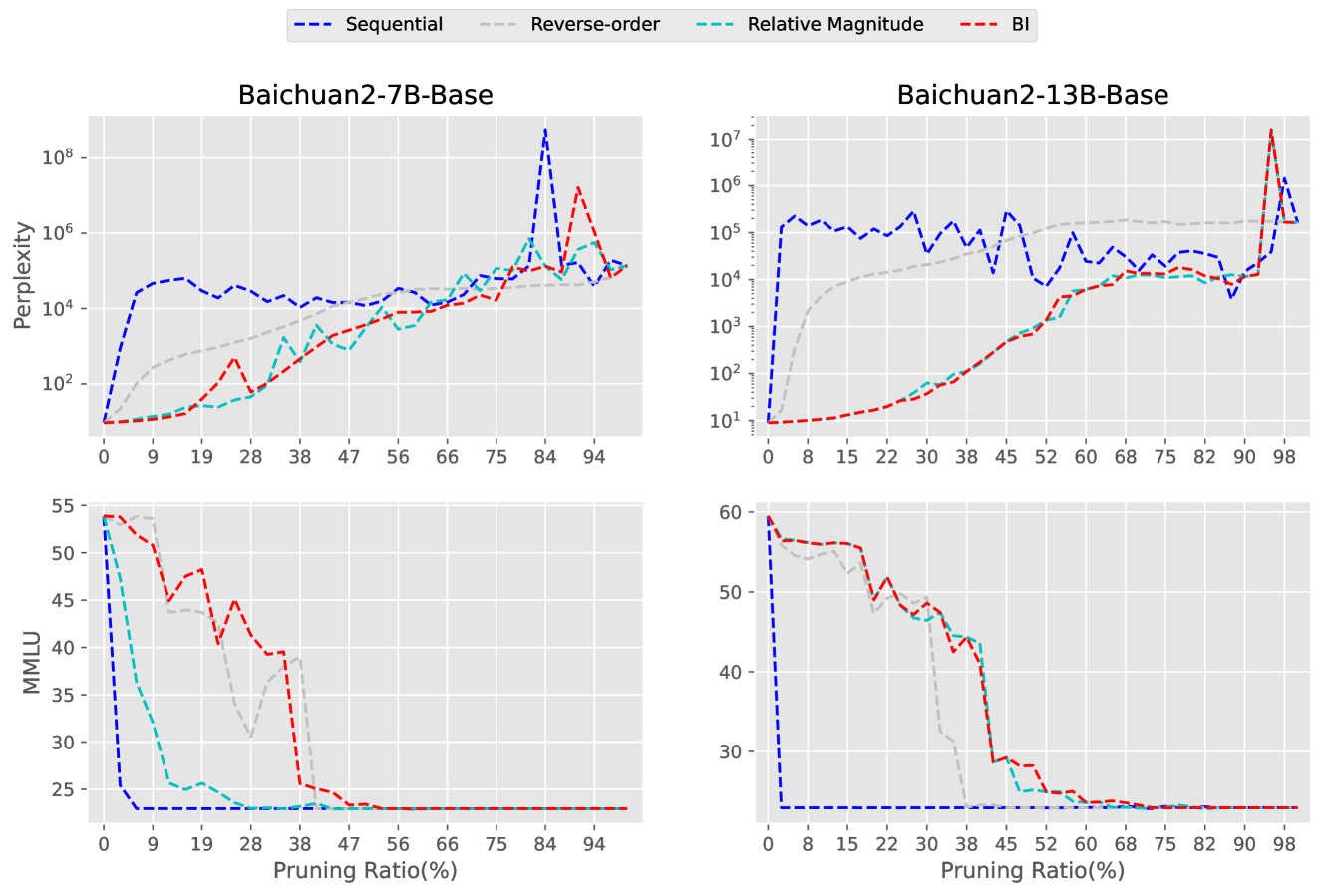
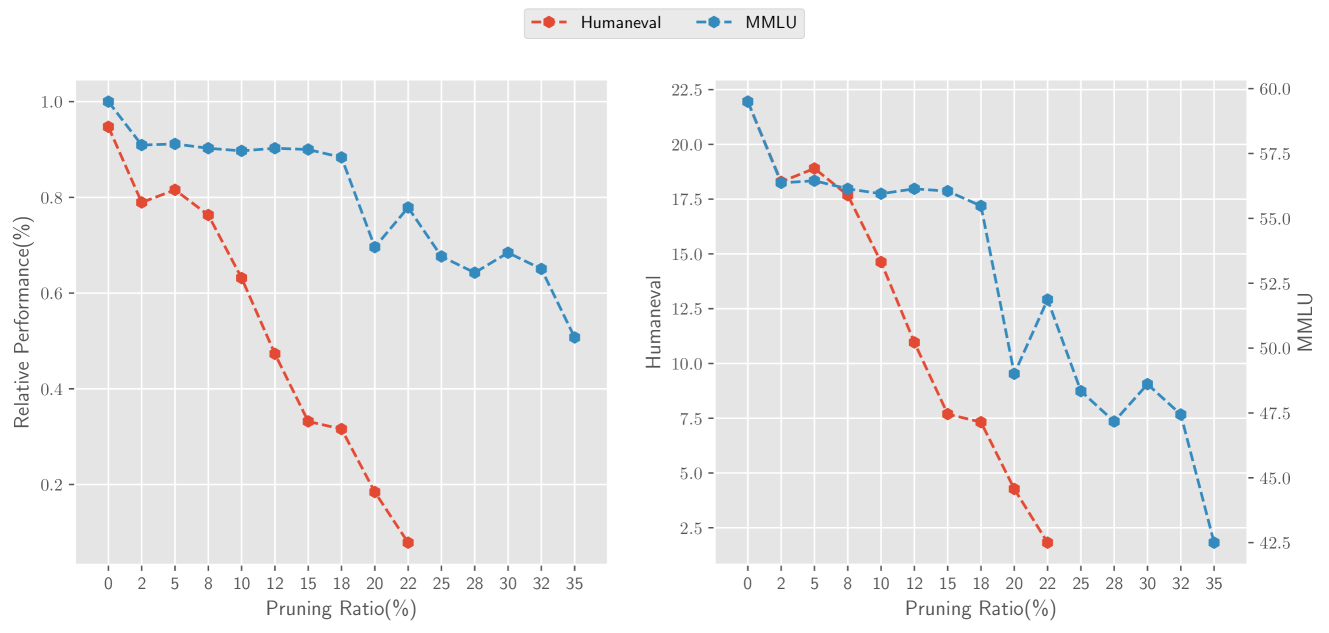
附录 DHumanEval 上的层删除。
我们还发现,层去除对生成任务中模型的性能有显着影响。 具体来说,我们在用于评估代码生成模型性能的数据集HumanEval(Chen等人,2021)上对Baichuan2-13B模型进行了实验。 结果如图 10 所示。 移除 10 层后,HumanEval 的性能几乎完全下降。 我们推测这可能是由于生成任务中的重大累积错误造成的。