TextMonkey:用于理解文档的无 OCR 大型多模态模型
摘要
我们推出了 TextMonkey,这是一个专为以文本为中心的任务而定制的大型多模态模型 (LMM)。 我们的方法引入了跨多个维度的增强:通过采用零初始化的转移窗口注意力,我们在更高的输入分辨率下实现了跨窗口连接并稳定了早期训练;我们假设图像可能包含冗余标记,通过使用相似性过滤掉重要标记,我们不仅可以简化词符长度,还可以提高模型的性能。 此外,通过扩展模型的功能以涵盖文本识别和基础,并将位置信息纳入响应中,我们增强了可解释性。 它还学习通过微调来执行屏幕截图任务。 对 12 个基准的评估显示出显着的改进:以场景文本为中心的任务(包括 STVQA、TextVQA 和 OCRVQA)提高了 5.2%,面向文档的任务(如 DocVQA、InfoVQA、ChartVQA、DeepForm、Kleister Charity 和 WikiTableQuestions)提高了 6.9% ,关键信息提取任务(包括 FUNSD、SROIE 和 POIE)为 2.8%。 它在场景文本识别方面表现出色,提升了 10.9%,并在 OCRBench 上树立了新标准。 OCRBench 是一个由 29 个 OCR 相关评估组成的综合基准,得分为 561,超过了之前用于文档理解的开源大型多模态模型。 代码将在https://github.com/Yuliang-Liu/Monkey发布。
索引术语:
大型多模态模型、文档分析、场景文本、分辨率、OCRBench1 简介
从各种来源(包括表格、表单和发票等文档以及野外文本)提取关键信息对于行业和学术研究至关重要,旨在自动化和完善基于文档和场景文本的工作流程。 该领域需要文档图像和现实场景中的文本检测和识别、语言理解以及视觉和语言的融合。
许多早期方法[1, 2]尝试使用两阶段方法来解决任务:1)使用外部系统检测和识别文本; 2)基于文本结果和图像融合的文档理解。 然而,处理管道中文本读取的各个步骤可能会导致错误的累积。 此外,依赖现成的 OCR 模型/API (OCR 模型) 会带来额外的工程复杂性,限制文本与其周围上下文之间的连接,并可能增加计算成本。 为了减轻外部系统在理解之前的缺陷,OCR-Free 解决方案[3, 4]最近引起了越来越多的关注。
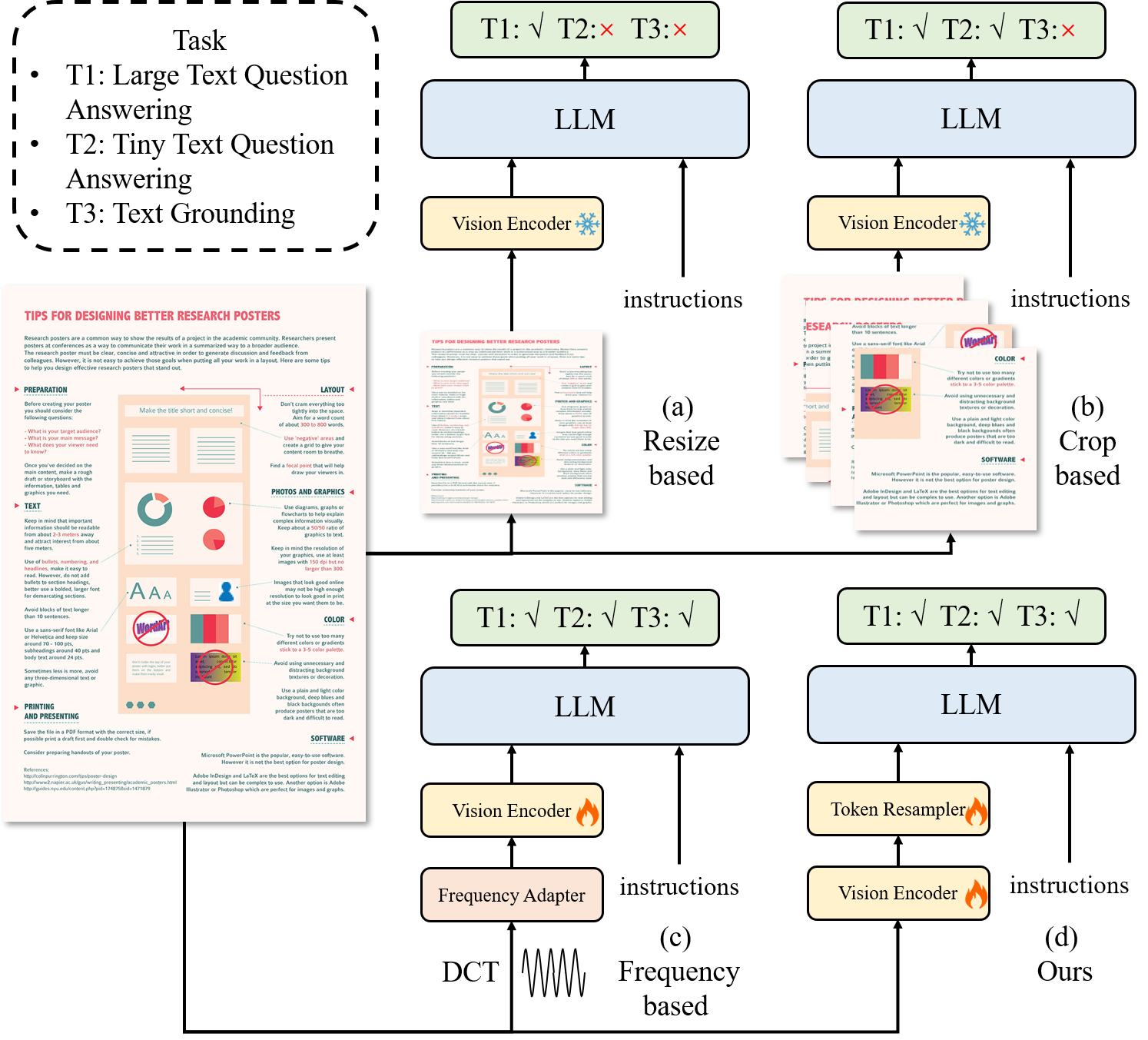
大型多模态模型(LMM)[5, 6]领域由于其处理不同类型数据的强大能力而正在迅速发展。 然而,它们在处理文本相关任务时仍然存在局限性。 如图1(a)所示,几种方法,包括LLaVAR [7]、UniDoc [8]、TGDoc [ 9] 和 mPLUG-DocOwl [10] 严重依赖预训练的 CLIP [11] 进行视觉编码。 然而,这些编码器的输入分辨率为224或336,不足以满足包含大量小文本[12]的文档的需求。 因此,它们只能识别大文本,而难以识别图像中的小文本。 为了解决小文本的限制,URaer [13]和Monkey [14]采取裁剪策略来扩大输入分辨率,如图1 (b)。 然而,这种裁剪策略可能会无意中分割相关单词,导致语义不连贯。 例如,“Backup”这个词可能被分成“Back”和“up”,使得即使在融合之后也无法恢复其原始含义。 此外,这种分裂造成的空间分离也使得处理与文本位置相关的任务(例如文本接地)变得具有挑战性。 如图1(c)所示,DocPedia[15]直接在频域而不是像素空间处理视觉输入。 由于频域的特性,可以快速扩大分辨率而不丢失信息。 然而,由于特征空间的变换,很难利用现有的预训练模型,增加了对资源的需求。
我们希望继承 Monkey [14] 高效的图像分辨率缩放功能,但解决上述文档缺少的跨窗口上下文问题。 为此,我们引入了TextMonkey,如图1(d)所示。 TextMonkey 利用分割模块,使用滑动窗口方法将高分辨率图像分割成窗口块。 受[16]的启发,我们将CLIP中的每个自注意力层视为非重叠窗口中的自注意力。 为了引入跨窗口关系,同时保持高效计算,我们使用零初始化的转移窗口注意力来构建跨窗口连接。 这种方法使我们能够维护编码器的训练数据分布并处理高分辨率文档图像,同时降低从头开始训练的计算成本。 另一方面,分割模块的使用仍然构成重大挑战,因为它会导致词符长度显着增加。 我们观察到有许多重复的图像特征与语言空间一致,类似于语言本身的某些重复元素。 因此,我们提出了一个词符重采样器来压缩这些特征,同时保留尽可能多的最重要的特征。 我们使用重要的标记作为查询,使用原始特征作为键值对,从而促进特征的重新聚合。 在减少token数量的基础上,我们的模块相比随机查询还可以显着提高性能。
另一方面,由于文本的不言自明性,在大多数情况下,人类能够找到答案本身的位置。 为了进一步缓解大型语言模型中的幻觉问题,我们要求模型不仅能够提供准确的答案,而且还需要找到支持其响应的特定视觉证据。 我们还引入了各种与文本相关的任务,以加深文本信息和视觉信息之间的联系,例如文本识别和文本接地。 此外,将位置线索纳入答案中可以进一步增强模型的可靠性和可解释性。
我们总结我们的方法的优点如下:
-
•
增强跨窗口关系。 我们采用Shfited Window Attention来成功合并跨窗口连接,同时扩展输入分辨率。 此外,我们在转移训练窗口注意力机制中引入了零初始化,使模型能够避免对早期的大幅修改。
-
•
词符压缩。 我们展示了一些冗余标记的放大解析结果。 通过使用相似性作为标准,我们能够找到用作词符重采样器查询的重要标记。 该模块不仅减少了词符长度,还提高了模型的性能。 此外,与使用随机查询相比,它显着提高了性能。
-
•
支持文本接地。 我们将范围扩展到基于文本的问答之外的任务,包括阅读文本、文本识别和文本基础。 此外,我们发现将位置信息纳入答案中可以提高模型的可解释性。 TextMonkey 还可以进行微调以理解屏幕截图点击的命令。
-
•
我们在 12 个公认的基准测试中评估了 TextMonkey 的性能,观察到多个领域的显着改进。 首先,在STVQA、TextVQA、OCRVQA等以场景文本为中心的任务中,TextMonkey实现了5.2%的性能提升。 对于面向文档的任务,包括 DocVQA、InfoVQA、ChartVQA、DeepForm、Kleister Charity 和 WikiTableQuestions,它显示出 6.9% 的改进。 在 FUNSD、SROIE 和 POIE 等关键信息提取任务领域,我们注意到增长了 2.8%。 特别值得注意的是它在注重转录准确性的场景文本识别任务(Total-Text、CTW1500 和 ICDAR 2015)中的表现,提高了 10.9%。 此外,TextMonkey 在包含 29 项 OCR 相关评估的综合基准 OCRBench 上创下了 561 分的新高,显着超越了之前专为文档理解而设计的开源大规模多模态模型的性能。 这一成就强调了 TextMonkey 在文档分析和理解领域的有效性和进步。
2 相关作品
旨在理解带有文本信息的图像的模型可大致分为两种类型:OCR 模型驱动方法和 OCR 免费方法。
2.1 OCR 模型驱动方法
OCR 模型驱动方法使用 OCR 工具获取文本和边界框信息。 随后,他们依靠模型来集成文本、布局和视觉数据。 同时,设计了多种预训练任务来增强视觉和文本输入之间的跨模式对齐。 StrucTexT [17]在预训练任务的设计中注重图像内的细粒度语义信息和全局布局信息。 ERNIE-Layout[18]基于布局知识增强技术,创新性地提出了两个自监督预训练任务:阅读顺序预测和细粒度图文匹配。 LayoutLM [19,20,2]系列通过集成预训练的文本、布局和视觉特征,并引入统一的模型架构和预训练目标,不断改进。 这增强了模型在各种文档理解任务中的性能并简化了整体设计。 UDOP [1] 通过 VTL Transformer 和统一的生成预训练任务统一视觉、文本和布局。 Wukong-reader [21] 提出了文本行区域对比学习和专门设计的预训练任务来提取细粒度的文本行信息。 DocFormerv2 [22] 设计了一种非对称预训练方法和一个用于视觉文档理解的简化视觉分支。 DocLLM [23] 仅关注位置信息以合并空间布局结构,使用分解的注意力机制来构建文本和空间模态之间的交叉对齐。
虽然已经取得了进步,但 OCR 模型驱动方法依赖于从外部系统提取文本,这需要增加计算资源并延长处理持续时间。 此外,这些模型可能会继承 OCR 的不准确性,从而给文档理解和分析任务带来挑战。
2.2 免 OCR 方法
无 OCR 方法不需要现成的 OCR 引擎/API。 Donut [3] 首先提出了一种基于 Transformer 的端到端训练方法,无需 OCR。 Dessurt [24]基于类似于Donut的架构,融合了双向交叉注意力并采用了不同的预训练方法。 Pix2Struct [4] 通过学习将网页的屏蔽屏幕截图解析为简化的 HTML 进行预训练,引入可变分辨率输入表示以及更灵活的方式来集成语言和视觉输入。 StrucTexTv2 [25] 引入了一种新颖的自监督预训练框架,采用文本区域级文档图像掩蔽来学习端到端的视觉文本表示。
虽然这些方法不需要 OCR 工具限制,但它们仍然需要针对特定任务进行微调。 在多模态大型语言模型(MLLM)快速发展的时代,一些模型在视觉文本理解数据集上进行显式训练,并使用指令进行微调。 LLaVAR [7]、mPLUG-DocOwl [10] 和 UniDoc [8] 创建新颖的指令跟踪数据集,以增强调优过程并改进理解富含文本的图像。 我们还付出了额外的努力来捕获更复杂的文本细节。 UReader [13] 设计了一个形状自适应裁剪模块,利用冻结的低分辨率视觉编码器来处理高分辨率图像。 DocPedia [15] 在频域而不是像素空间中处理视觉输入,以处理具有有限视觉标记的更高分辨率图像。 通过在大量数据上训练视觉词汇,Vary [26] 扩展了其分辨率并取得了令人印象深刻的结果。 最近,TGDoc [9]使用文本接地来增强文档理解,表明文本接地可以提高模型解释文本内容的能力,从而增强其对富含文本信息的图像的理解。
3 方法论
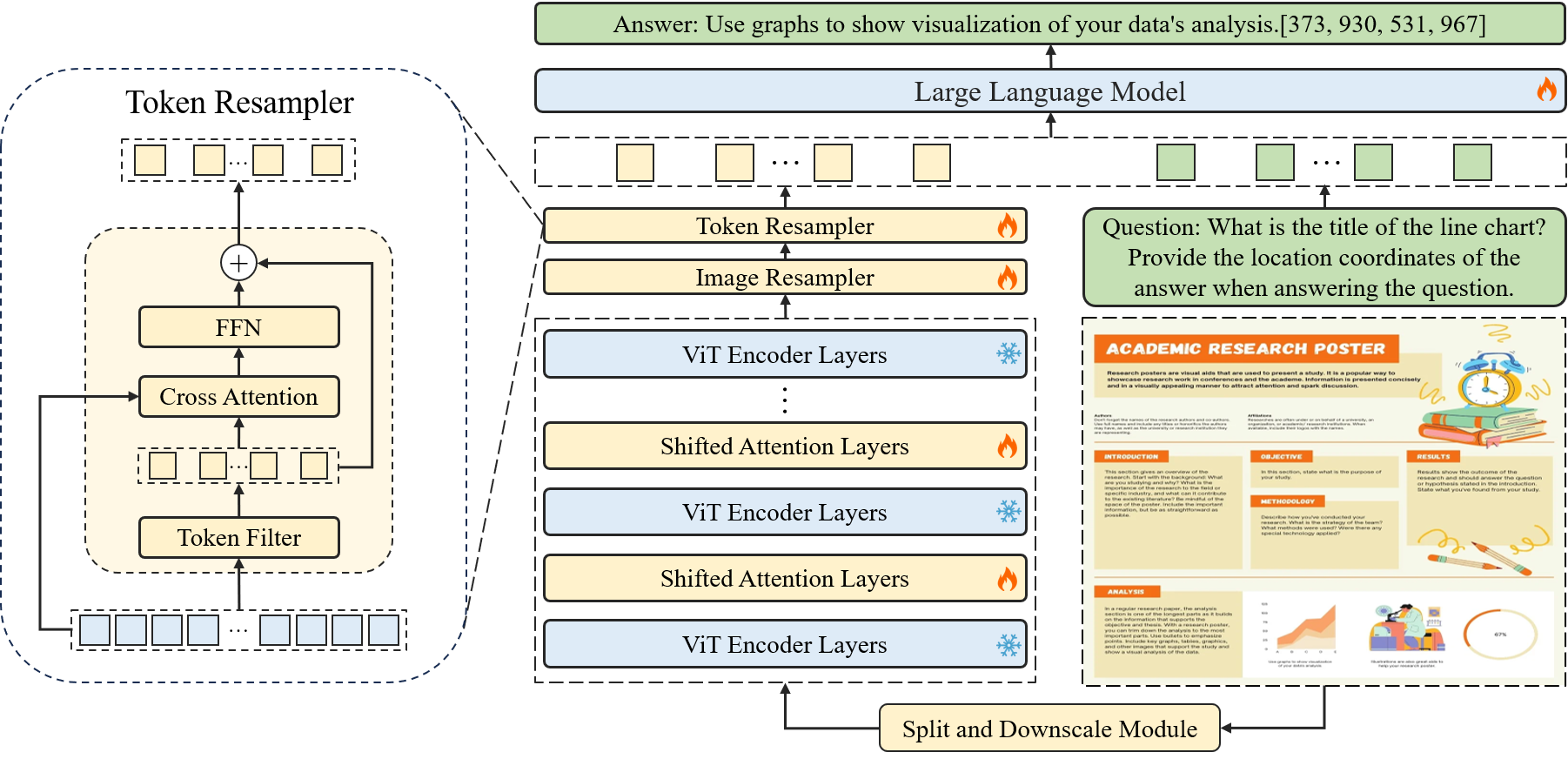
图2中提出的方法首先使用滑动窗口模块将输入图像划分为不重叠的块,每个块的大小为448x448像素。 这些补丁进一步细分为 14x14 像素的更小的补丁,每个补丁都被视为一个词符。 利用继承自预训练 CLIP 模型的 Transformer 块,我们分别处理每个窗口补丁上的这些标记。 为了在各种窗口补丁之间建立连接,转移窗口注意力以特定间隔集成在 Transformer 块内。 为了生成分层表示,输入图像大小调整为 448x448 并输入 CLIP 以提取全局特征,如 [14] 所建议。 然后,该全局特征与子图像的特征一起由共享图像重采样器处理,以与语言域保持一致。 然后,采用词符重采样器通过压缩标记的长度来进一步最小化语言空间中的冗余。 最终,这些处理后的特征与输入问题相结合,由大型语言模型(大语言模型)进行分析,以产生所需的答案。
3.1 转移窗口注意力
先前的研究强调了输入分辨率对于精确文档理解的重要性[15, 12]。 为了提高训练效率,最近的方法[14, 13]采用了滑动窗口技术来增强图像分辨率。 虽然由于其本地化内容而可以有效地分析自然场景,但这种策略可能会导致文档分析中连接文本的碎片化,从而破坏语义连续性。 此外,空间分离给依赖文本定位的任务(例如文本定位)带来了挑战。
为了缓解上述问题,我们采用转移窗口注意力[16]来增强CLIP模型的视觉处理能力。 具体来说,对于输入图像,我们的方法将图像分割成不重叠的窗口。 该切片是使用滑动窗口 实现的,其中 和 表示窗口的大小。 在每个窗口中,我们独立地应用 CLIP 架构中的 Transformer 块,该架构最初不考虑跨窗口关系。 为了整合不同窗口之间的交互并增强模型对图像的上下文理解,我们采用了转移窗口注意力(SWA)机制。 正如[16]中提到的,滑动窗口向左上方向循环移位,从而产生新的窗口。 通过掩蔽机制进行自注意力计算,将自注意力计算限制在新窗口内。
为了实现更平滑的训练初始化,我们对转移的窗口注意力进行了修改,允许它们从零初始化开始学习,避免在初始阶段对早期特征进行过度转换。 特别是,受 [27] 的启发,我们将 MLP 中的常规初始化修改为零初始化,以实现更平滑的训练:
| (1) |
其中B和A指的是两个线性层的权重。 我们对 A 使用随机高斯初始化,对 B 使用零初始化。 这种方法保证了图像编码器的参数在初始阶段保持稳定,有利于更流畅的训练体验。
3.2 图像重采样器
为了最初减少图像特征的冗余,我们继承了 Qwen-VL [28] 的图像重采样器,该图像重采样器在每个窗口上使用。 该模块采用一组可训练参数作为查询向量,并利用视觉编码器的图像特征作为交叉注意操作的键和值。 此过程有助于将视觉特征序列压缩到固定长度 256。 此外,为了保留对细粒度图像理解至关重要的位置信息,二维绝对位置编码被集成到交叉注意机制的查询密钥对中。
3.3 Token 重采样器
随着分辨率的提高, Token 的数量也显着增加,使用滑动窗口机制。 然而,由于某些语言模型的输入长度限制和训练时间限制,减少标记数量变得必要。 在常见的视觉场景中,之前的方法[29]已经证明了合并词符方法的可行性。
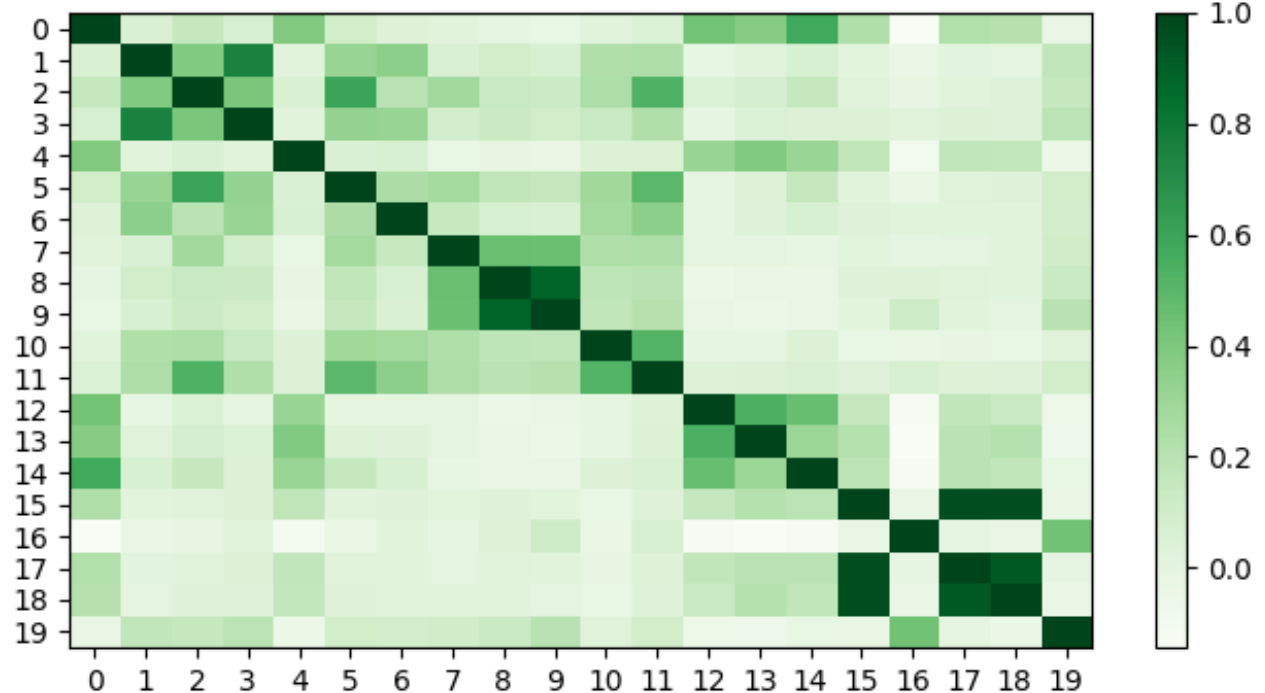
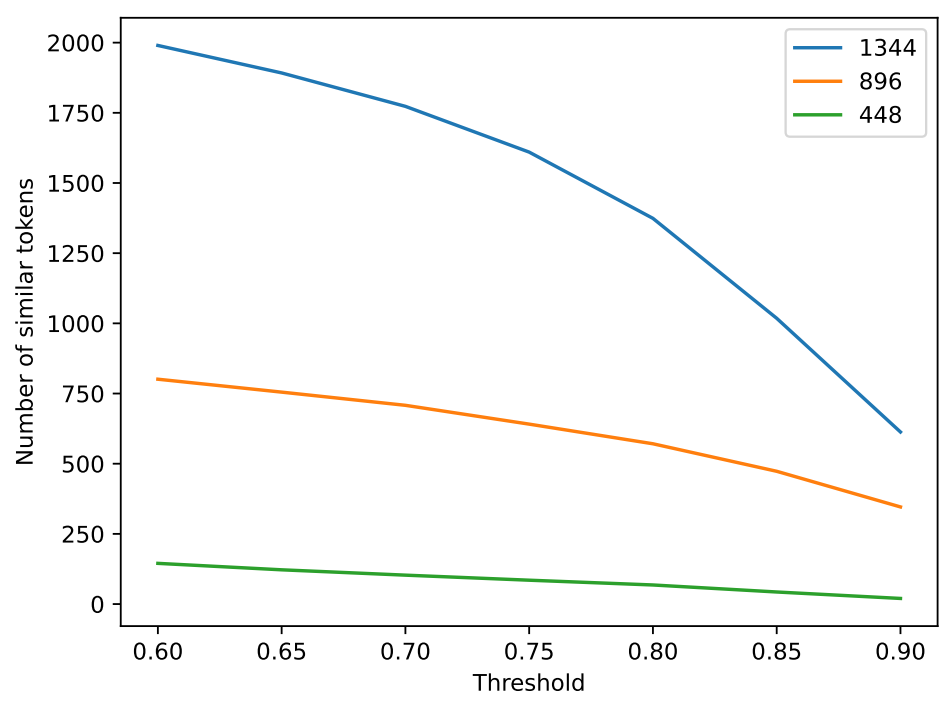
对于自然语言,冗余信息可能是重复的语言元素。 假设通过扩大图像的分辨率,就会存在冗余的视觉信息。 在确定两个语言元素之间的相似性时,我们经常测量它们嵌入的相似性。 为了评估图像特征的冗余性,我们测量已经映射到语言空间的图像标记的相似性。 我们在图像重采样后随机选择 20 个有序特征,并使用余弦相似度比较成对相似度,如图 3 所示。 通过比较图像标记的相似度,我们可以观察到许多图像标记表现出多个相似标记的模式。 此外,我们定量比较了不同分辨率下 Token 的冗余度,如图4所示。 根据经验,我们选择阈值 0.8 作为相似度阈值,在分辨率为 448、896 和 1334 时,我们观察到 68/256 (26.6%)、571/1024 (55.8%) 和 1373/2304 (59.5%)分别是冗余标记。 如图4所示,随着分辨率的提高,重复标记的出现率更高。 这验证了我们的假设,即扩大分辨率虽然可以实现更清晰的可视性,但也引入了一些冗余特征。
然而,我们如何识别重要的token并剔除多余的token呢? 我们观察到某些标记非常独特并且缺乏非常相似的对应物,例如图3中的第五个词符。 这表明这个词符是独特的。 我们假设这些令牌携带重要且独特的信息,这在后续实验中得到进一步验证。 因此,我们利用相似性作为识别重要标记的指标。
为了避免直接丢弃其他令牌造成的信息损失,我们利用重要的令牌作为查询,并采用交叉注意力来进一步聚合所有特征。 基于词符数量的减少,与随机查询相比,我们的模块还可以显着提高性能。
3.4 位置相关任务
为了缓解大语言模型(大语言模型)中的幻觉问题(大语言模型可能会产生与所提供图像无关的错误响应),我们的目标是增强它们分析视觉信息并将其合并到回复中的能力。 考虑到基于文本的任务的答案通常可以在图像本身中找到,我们预计大型模型不仅会产生精确的响应,还会识别支撑其答案的特定视觉证据。
此外,我们还对现有的问答数据集进行了修改。 具体来说,我们在图像中找到了大多数答案的位置。 这些位置线索已被提取并无缝集成到答案本身中。 为了保留原来的直接对话能力,我们还保留了原来的问答任务。
为了更好地感知文本的空间位置,需要模型具有很强的空间理解能力。 在上述模型设计的基础上,我们添加了额外的训练任务来提高模型对文本位置的感知,例如文本识别和阅读文本。 具体任务和提示如选项卡所示。 I。 为了保证文本和位置数据之间的紧密联系,我们严格保持它们的对齐,确保文本信息始终位于任何关联的位置详细信息之前。
为了标准化不同比例的图像,我们使用 (0, 1000) 的比例来表示位置信息。 因此,在分辨率为()的图像中,文本坐标(x,y)将被归一化为,y也是如此。 恢复过程涉及逆操作。
| Type | Prompt |
|---|---|
| Read All Text | Read all the text in the image. |
| Text Spotting | OCR with grounding: |
| Original Tasks | {Question}. Answer: |
| Position of text | <ref>text</ref> |
| Text Recognition | <ref>This</ref> |
| <box>(x1,y1),(x2,y2)</box>is | |
| VQA Grounding | {Question}. Provide the location coordinates |
| of the answer when answering the question. |
3.5 数据集构建
在我们的训练过程中,我们仅利用开源数据并将各种特定于任务的增强应用于不同的数据集。 通过整合各种数据集并对不同的任务采用不同的指令,我们增强了模型的学习能力和训练效率。 对于场景文本场景,我们选择 COCOText [30]、TextOCR [31]、HierText [32]、TextVQA [33] 和 MLT [34] 用于训练。 对于文档图像,我们选择 IIT-CDIP [35]、DocVQA [36]、ChartQA [37]、InfoVQA [38 ]、DeepForm [39]、Kleister Charity (KLC) [40] 和 WikiTableQuestions (WTQ) [41]。 为了加快训练速度,我们借鉴 LLaVA [5] 中介绍的成功方法,将单图像问答转变为基于多轮图像的问答,显着提高了图像特征的利用率。 我们的训练数据的详细信息如表所示。 II。 我们的数据集中共有 409.1k 对对话数据和 210 万对问答数据来训练我们的模型。
为了进一步增强模型处理结构化文本的能力,我们用结构化数据对 TextMonkey 进行了 1 epoch 的处理,以增强其结构化能力,从而产生了 TextMonkey†。 微调数据主要是前一阶段5%的数据,以及部分结构化数据,包括文档、表格、图表等。 结构化数据图像也来自公开可用的数据集,并使用其结构信息生成。 因此,我们总共有 55.7k 条结构化数据。
| Task | Dataset | Samples |
| Scene Text | COCOText [30] | 16.2k |
| TextOCR [31] | 42.7k | |
| HierText [32] | 59.9k | |
| TextVQA [33] | 42.6k | |
| MLT [34] | 11.6k | |
| Document | IIT-CDIP [35] | 154.6k |
| DocVQA [36] | 22.7k | |
| ChartQA [37] | 36.6k | |
| InfoVQA [38] | 10.9k | |
| DeepForm [39] | 1.4k | |
| KLC [40] | 5.2k | |
| WTQ [41] | 4.7k | |
| Total | - | 409.1k |
3.6 损失
由于 TextMonkey 与其他大语言模型一样被训练来预测下一个标记,因此它只需要在训练时最大化损失的可能性。
| (2) |
其中I是输入图像,Q是问题序列,是输出序列,s是输入序列,是输出序列的长度。
| Method | Scene Text-Centric VQA | Document-Oriented VQA | KIE | OCRBench | ||||||
| STVQA | TextVQA | OCRVQA | DocVQA | InfoVQA | ChartQA | FUNSD | SROIE | POIE | ||
| BLIP2-OPT-6.7B [42] | 20.9 | 23.5 | 9.7 | 3.2 | 11.3 | 3.4 | 0.2 | 0.1 | 0.3 | 235 |
| mPLUG-Owl [43] | 30.5 | 34.0 | 21.1 | 7.4 | 20.0 | 7.9 | 0.5 | 1.7 | 2.5 | 297 |
| InstructBLIP [44] | 27.4 | 29.1 | 41.3 | 4.5 | 16.4 | 5.3 | 0.2 | 0.6 | 1.0 | 276 |
| LLaVAR [7] | 39.2 | 41.8 | 24.0 | 12.3 | 16.5 | 12.2 | 0.5 | 5.2 | 5.9 | 346 |
| BLIVA [45] | 32.1 | 33.3 | 50.7 | 5.8 | 23.6 | 8.7 | 0.2 | 0.7 | 2.1 | 291 |
| mPLUG-Owl2 [46] | 49.8 | 53.9 | 58.7 | 17.9 | 18.9 | 19.4 | 1.4 | 3.2 | 9.9 | 366 |
| LLaVA1.5-7B [47] | 38.1 | 38.7 | 58.1 | 8.5 | 14.7 | 9.3 | 0.2 | 1.7 | 2.5 | 297 |
| TGDoc [9] | 36.3 | 46.2 | 37.2 | 9.0 | 12.8 | 12.7 | 1.4 | 3.0 | 22.2 | - |
| UniDoc [8] | 35.2 | 46.2 | 36.8 | 7.7 | 14.7 | 10.9 | 1.0 | 2.9 | 5.1 | - |
| DocPedia [15] | 45.5 | 60.2 | 57.2 | 47.1 | 15.2 | 46.9 | 29.9 | 21.4 | 39.9 | - |
| Monkey [14] | 54.7 | 64.3 | 64.4 | 50.1 | 25.8 | 54.0 | 24.1 | 41.9 | 19.9 | 514 |
| InternVL [48] | 62.2 | 59.8 | 30.5 | 28.7 | 23.6 | 45.6 | 6.5 | 26.4 | 25.9 | 517 |
| InternLM-XComposer2 [49] | 59.6 | 62.2 | 49.6 | 39.7 | 28.6 | 51.6 | 15.3 | 34.2 | 49.3 | 511 |
| TextMonkey | 61.8 | 65.9 | 71.3 | 64.3 | 28.2 | 58.2 | 32.3 | 47.0 | 27.9 | 561 |
| TextMonkey† | 61.2 | 64.3 | 72.2 | 66.7 | 28.6 | 59.9 | 42.9 | 46.2 | 32.0 | 558 |
4 实验
4.1 实现细节
型号配置。 在我们的实验中,我们使用了 Qwen-VL [28] 中训练有素的 Vit-BigG 和大语言模型,这是一个预训练的大型多模态模型。 我们将图像输入的高度和宽度(、)配置为 448,以与 Qwen-VL 的编码器规范保持一致。 我们的图像重采样器配备了 256 个可学习查询,词符重采样器的比率 (r) 对于分辨率为 896 的图像设置为 512,对于分辨率为 1344 的图像增加到 1024。 为了最大限度地提高训练效率,我们的主要实验重点是使用 TextMonkey 并在 896 分辨率设置下评估结果。
TextMonkey由7.7B参数的大型语言模型、90M参数的图像重采样器模块、13M参数的词符重采样器模块、1.9B参数的编码器和45M参数的Shifted Window Attention组成。 总体来说,TextMonkey共有9.7B个参数。
训练。 在训练阶段,我们利用 AdamW [50] 优化器,将初始阶段的学习率设置为 1e-5,后续阶段将学习率降低到 5e-6,同时采用余弦学习费率表。 参数和分别配置为0.9和0.95。 包含 150 个步骤的预热期,我们以 128 个批次处理数据。 为了降低过度拟合的风险,我们应用了 0.1 的权重衰减因子。 综合训练过程跨越 12 A800 天来完成一个 epoch。
评估。 为了便于与其他方法进行更公平的比较,我们采用了准确性指标,其中如果我们的模型产生的响应包含基本事实,则该响应被认为是正确的。 测试数据集的选择和评估标准的制定按照[12]中描述的方法进行。 为了确保与其他方法进行更公平的比较,我们还利用某些数据集的原始指标(例如 F1 分数和 ANLS(平均标准化编辑相似度))对某些数据集进行了补充评估。
| Method | Document | Table | Chart | Scene | ||
|---|---|---|---|---|---|---|
| DocVQA | DF | KLC | WTQ | ChartQA | TextVQA | |
| Donut [3] | 67.5 | 61.6 | 30.0 | 18.8 | 41.8 | 43.5 |
| Pix2Struct [4] | 72.1 | - | - | - | 56.0 | - |
| UReader [13] | 65.4 | 49.5 | 32.8 | 29.4 | 59.3 | 57.6 |
| Qwen-VL [28] | 65.1 | 3.1 | 13.9 | 21.6 | 65.7 | 63.8 |
| Monkey [14] | 66.5 | 40.5 | 33.9 | 25.3 | 65.1 | 67.6 |
| TextMonkey | 71.5 | 61.6 | 37.8 | 30.6 | 65.5 | 68.0 |
| TextMonkey† | 73.0 | 59.7 | 37.8 | 31.9 | 66.9 | 65.6 |
4.2 结果
OCRBench 结果。 我们对我们的方法与最近的大型多模态模型进行了比较分析。 为了进行评估,我们利用三个以场景文本为中心的 VQA 数据集:STVQA [51]、TextVQA [33] 和 OCRVQA [52] ;三个面向文档的 VQA 数据集:DocVQA [36]、InfoVQA [38] 和 ChartQA [37];以及三个关键信息提取(KIE)数据集:FUNSD [53]、SROIE [54] 和 POIE [55]。 为了对性能进行全面评估,我们的评估包括 OCRBench [12],这是一个最近专门开发的基准,用于评估大型多模态模型的光学字符识别 (OCR) 功能。 OCRBench 涵盖广泛的文本相关视觉任务,包含 29 个数据集,旨在生成总体分数。
如表所示。 III,与现有的大型多模态模型相比,我们的模型表现出了优越的性能,特别是在文本密集且较小的场景中。 我们的方法本质上增强了许多当前的评估数据集,使得以场景文本为中心的 VQA、面向文档的 VQA 和 KIE 的众多基线方法的平均性能分别提高了 5.2%、6.9% 和 2.8%。 TextMonkey 在 DocVQA 上可以达到 64.3%,在 ChartQA 上可以达到 58.2%。 具体来说,我们的模型在 OCRBench 上获得了 561 分。 两项具有挑战性的下游任务和 OCRBench 的性能证明了其在文本相关任务中的有效性。 我们发现我们的模型倾向于提供没有单位的数字答案,这导致 POIE 的性能下降。
| Method | Total-Text [56] | CTW1500 [57] | ICDAR 2015 [58] | |||
|---|---|---|---|---|---|---|
| Trans | Pos | Trans | Pos | Trans | Pos | |
| TOSS [59] | 61.5 | 65.1 | 51.4 | 54.2 | 47.1 | 52.4 |
| TTS [60] | - | 75.1 | - | - | - | 70.1 |
| SPTS v2 [61] | 64.7 | 75.5 | 55.4 | 63.6 | 55.6 | 72.6 |
| TextMonkey | 78.2 | 61.4 | 63.2 | 57.5 | 66.9 | 45.1 |
记录基准测试结果。 为了进一步比较和评估我们方法的功能,我们利用论文中提供的具体评估指标对其他数据集进行测试:Deepform 和 KLC 的 F1 分数、WTQ 的准确性、ChartQA 的宽松准确性测量、DocVQA 的 ANLS 以及TextVQA 的 VQA 分数。
结果如表所示。 IV,表明我们的模型在这些数据集上的性能领先,优于其他模型。 在不同领域,TextMonkey 在 DocVQA 中获得了 71.5 分,在 WTQ 中获得了 30.6 分,在 ChartQA 中获得了 65.5 分,在 TextVQA 中获得了 68.0 分。 它显示了我们的模型处理文档、表格、图表和场景文本的能力。
文本识别结果。 为了展示我们模型的广泛功能,我们在没有微调的情况下评估了其在文本识别数据集上的性能,如表 1 所示。 V。鉴于我们的模型专注于识别完整的文本段落,我们将预测的内容分割成单个单词进行分析。 我们采用两种评估方法来评估我们模型的性能。 在“Trans”模式下,如果答案包含该单词,则文本被认为是正确的。 相反,“Pos”模式需要根据之前的方法[62]考虑位置信息。 对于这两个指标,由于输出的粒度问题(TextMonkey 经常生成完整的段落,而其他指标仅生成所需的单词),指标无法严格遵循评估设置;然而,两者应该非常相似,因为计算中的错误和正确情况都是匹配的。
为了保持 TextMonkey 的一致性能,我们没有使用下游文本发现数据对其进行微调,这与针对“Trans”或“Pos”指标优化的其他方法不同。 我们的结果显示,对于“Trans”指标,TextMonkey 的表现优于 SPTS v2 10.9%。 关于“Pos”指标,它展示了强大的文本识别能力,显示了其理解文本内容和空间定位的能力。
4.3 可视化
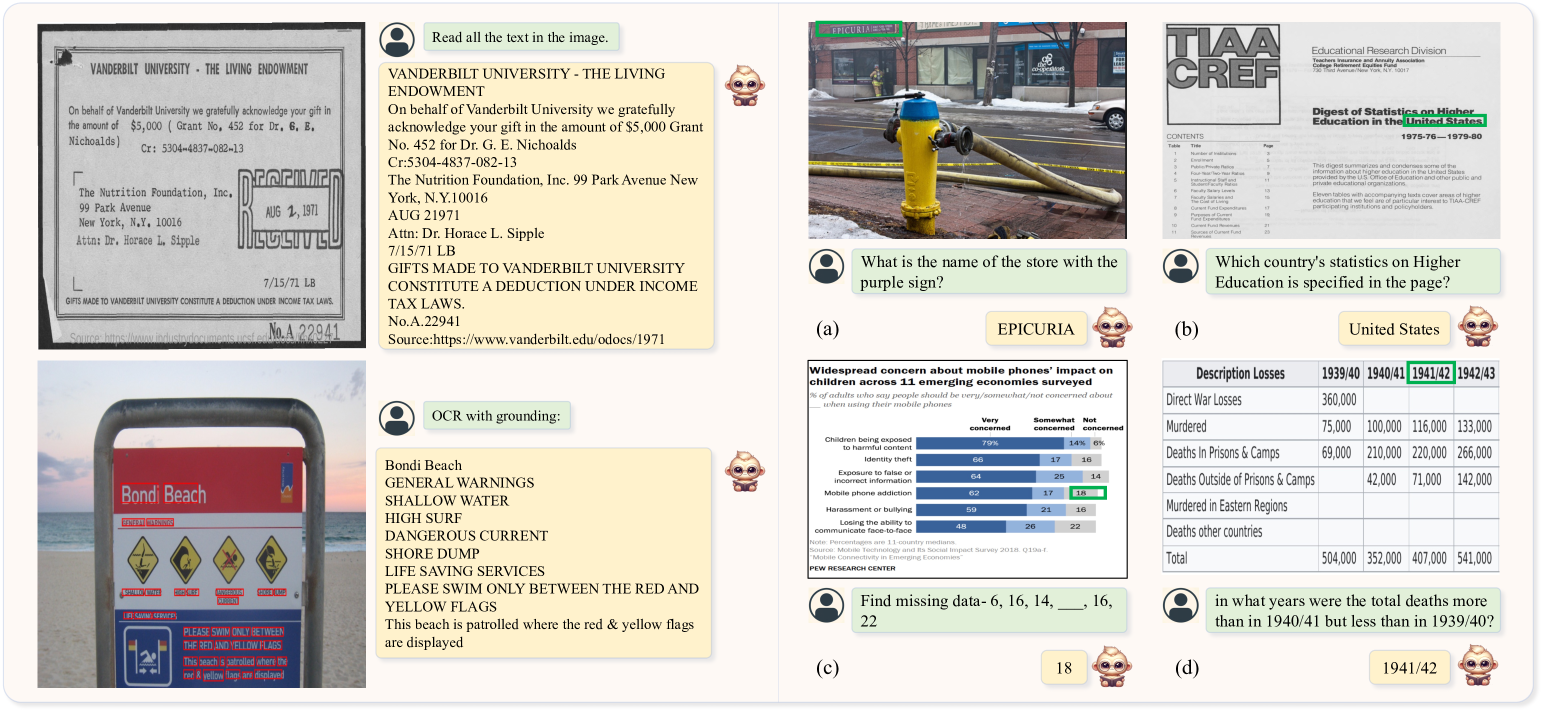
我们对 TextMonkey 进行了跨各种场景的定性评估,包括自然场景和文档图像。 如图5左侧所示,TextMonkey无论是在场景图像还是文档图像中都能准确定位和识别文本。 此外,图5(a)中的自然图像,图5(b)中的文档,图5(c)中的图表,以及图 5 (d) 中的表格例证了 TextMonkey 在各种场景中辨别和解释视觉和文本信息的能力。 总体而言,TextMonkey 在不同场景中的表现证明了其在各种视觉环境中感知和理解文本信息的有效性。
| Zero Initialization | SROIE | DocVQA | TextVQA | ChartVQA |
|---|---|---|---|---|
| 46.8 | 64.1 | 65.7 | 57.6 | |
| 47.0 | 64.3 | 65.9 | 58.2 |
| W-Attn | T-Resampler | SROIE | DocVQA | TextVQA |
|---|---|---|---|---|
| 45.9 | 62.6 | 62.4 | ||
| 46.0 | 64.1 | 64.8 | ||
| 47.0 | 64.3 | 65.9 |
| Method | SROIE | DocVQA | TextVQA |
|---|---|---|---|
| w/o token filter | 32.9 | 46.7 | 59.5 |
| w/o resampler | 44.9 | 63.5 | 62.5 |
| w unsorted token filter | 46.8 | 62.1 | 64.2 |
| ours | 47.0 | 64.3 | 65.9 |
4.4 消融研究
零初始化的消融研究。 由于 CLIP 已经经过预训练,因此建议在早期训练阶段避免特征发生剧烈变化。 如表所示。 VI,结合这种零初始化方法可以在 ChartQA 上产生 0.6% 的性能增益。
不同成分的消融研究。 如表所示。 VII,通过引入跨窗口连接,我们在 SROIE 上实现了 0.1% 的提升,在 DocVQA 上提升了 1.5%,在 TextVQA 上提升了 2.4%。 可以看出,跨窗口连接部分补偿了分块引起的不连续性,并有助于更好地理解图像。 基于词符重采样器,我们的方法展示了更好的性能,在 SROIE、DocVQA 和 TextVQA 上实现了 1.0%、0.2% 和 1.1% 的性能增益。 这表明我们的方法有效地保留了基本信息,同时消除了冗余标记,从而简化了模型的学习过程。
减少词符长度策略的消融研究 如表所示。 VIII,用随机标记替换重要标记(不使用词符过滤器)会导致性能平均下降约 12.7%。 这种下降归因于优化随机查询的复杂性增加,与利用重要标记相比,这需要更多的数据集来实现广义表示。 仅仅关注关键特征(不使用重采样器)并直接消除特征会导致一些信息丢失,表现出性能下降,例如 SROIE 下降 2.1%。 此外,由于语言模型具有组织无序标记的固有能力,忽略标记的顺序(使用未排序的词符过滤器)不会明显影响性能。 尽管如此,缺乏词符顺序仍然会导致性能下降,尤其是在 DocVQA 的结果中,性能下降了 2.2%。
输入分辨率和令牌数量之间的相互作用仍然存在。 如表所示。 IX,直接提高分辨率而不压缩 token 实际上会导致性能持续恶化,尤其是在 DocVQA 中性能下降了 9.2%。 我们推测,分辨率的提高会导致冗余标记的显着增加,从而使在我们的环境中找到关键信息变得更加困难。 因此,合理压缩token可以带来更高的性能。 考虑到大尺寸图像信息的稀疏性,还需要考虑针对不同的输入分辨率选择合适的“r”值。 此外,提高输入分辨率给包含许多大尺寸图像的数据集带来了好处,DocVQA 的性能增益为 0.2%,InfoVQA 的性能增益为 3.2%。 然而,对于像 TextVQA 和 SROIE 这样包含小得多的图像的数据集,直接提高输入分辨率不会产生任何增益。
| Resolution | r | SROIE | DocVQA | TextVQA | InfoVQA |
|---|---|---|---|---|---|
| 896 | - | 46.0 | 64.1 | 64.8 | 29.1 |
| 896 | 256 | 47.0 | 60.9 | 65.2 | 25.9 |
| 896 | 512 | 47.0 | 64.3 | 65.9 | 28.2 |
| 1344 | - | 42.9 | 54.9 | 62.5 | 28.9 |
| 1344 | 512 | 44.9 | 59.7 | 64.2 | 28.0 |
| 1344 | 1024 | 46.0 | 64.5 | 65.1 | 31.4 |
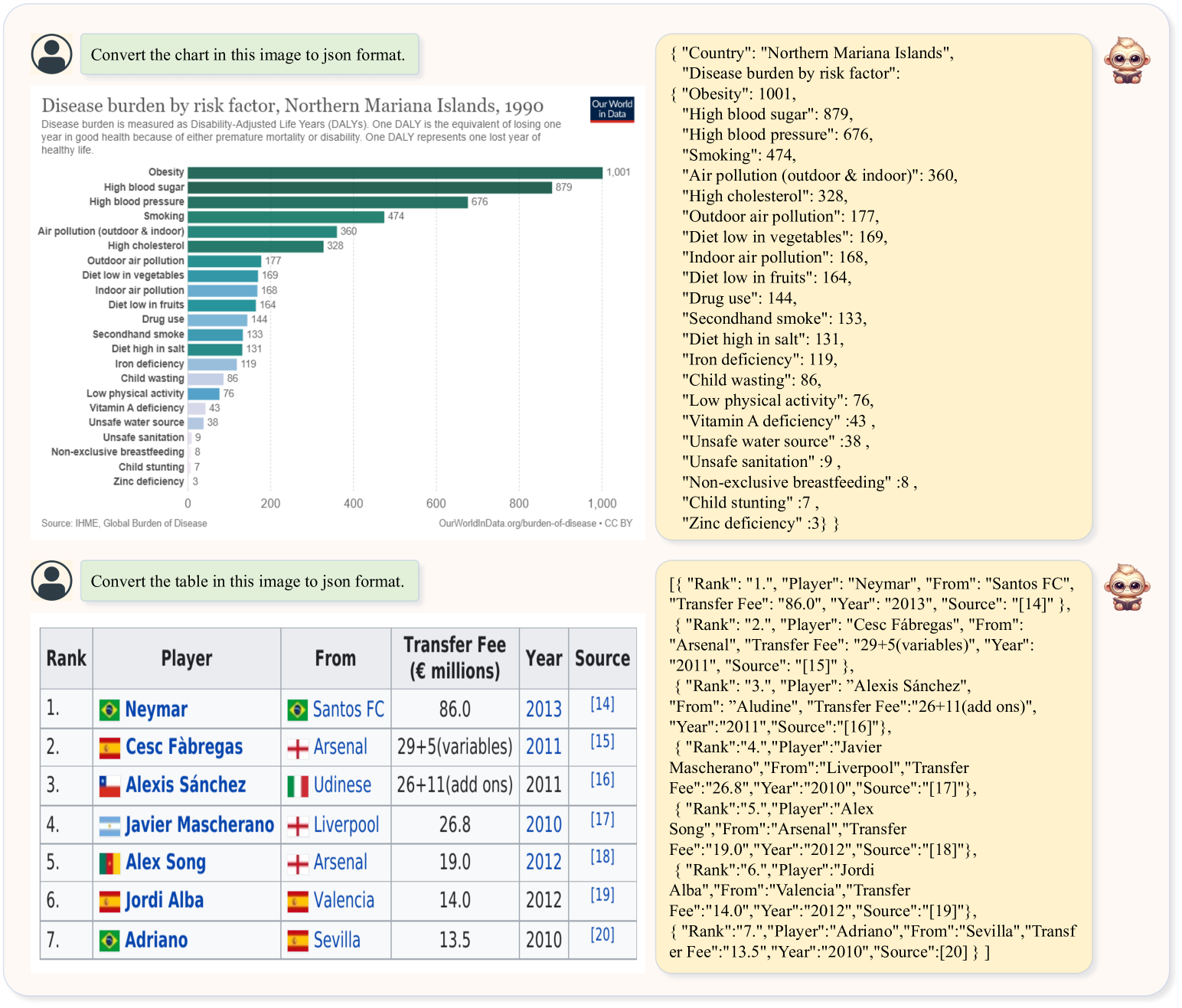
4.5 结构化
图表和表格的结构化具有很大的实用价值。 结构化的图表和表格以清晰的格式呈现数据,通过从图像中提取结构信息,计算机可以准确地解析和提取数据。 这使得数据分析、统计和建模更加高效和精确。 它还有助于降低信息的复杂性并提高其可理解性。 如图6所示,我们的模型能够将图表和表格构建为 JSON 格式,展示了其对下游应用程序的潜力。 根据选项卡。 IV,TextMonkey† 在表格和图表上分别表现出 1.3% 和 1.4% 的性能提升。 这强调了高质量的数据不仅可以实现模型的结构化能力,还可以增强相关基准的有效性。 但值得注意的是,此类数据主要受益于其自身域内的数据,从而导致跨域TextVQA的性能下降。
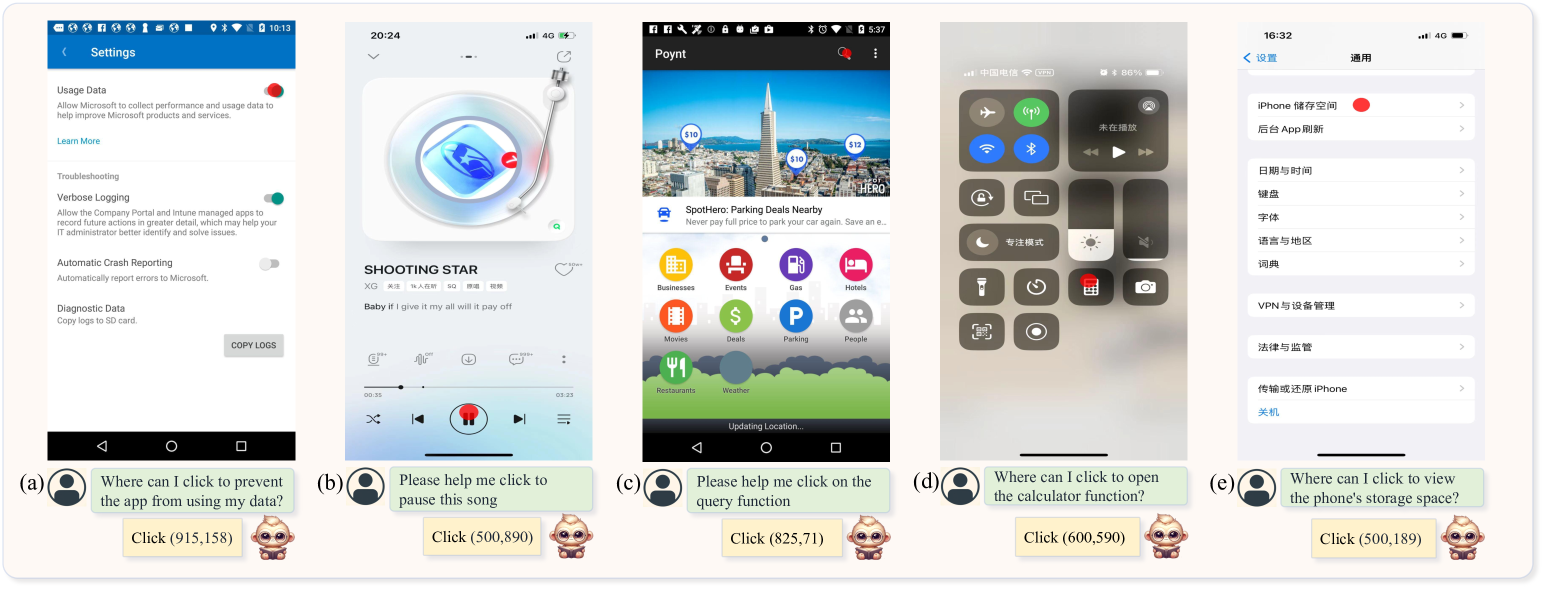
4.6 应用程序代理
最近,使用 LMM 来充当智能手机应用程序代理的任务受到了广泛关注[63,64,65]。 与 Siri 等通过系统后端访问和功能调用进行操作的现有智能手机助手不同,该代理以类似人类的方式与智能手机应用程序进行交互,使用诸如在图形用户界面(GUI)上单击和滑动等低级操作)。 它消除了对系统后端访问的需要,增强了安全性和隐私性,因为代理不需要深入的系统集成。 GUI主要由图标和文本组成,我们探讨TextMonkey在这方面的可行性。 我们转换了 Rico [66] 数据集中的 15k 用户点击数据,并使用 TextMonkey 进行了下游微调。 如图7定性所示,我们的模型能够理解用户意图并点击相应的图标,这表明该模型具有通过使用下游数据充当应用程序代理的潜力。
| Method | DocVQA | SROIE | ChartQA | InfoVQA |
|---|---|---|---|---|
| w position | 64.5 | 47.2 | 57.8 | 27.7 |
| w/o position | 64.3 | 47.0 | 58.2 | 28.2 |

5 讨论
5.1 可解释性
5.2 思想链
我们还对几个数据集进行了实验,如果我们需要一个模型来提供答案的位置,就会观察到不一致的改进,如表 1 所示。 X。 在大多数答案基于图像内信息的数据集中,例如 DocVQA 和 SROIE,要求模型提供答案的位置有明显的好处。 然而,对于涉及推理任务的数据集,例如 ChartQA 和 InfoVQA,其中的问题需要比较或定量分析(例如,“A 比 B 多多少?”),要求位置答案实际上可能会导致有害效果。 经过对错误答案的进一步检查,我们认为接地的要求可能部分影响了某些推理需求。 因此,在决定是否强加位置答案的要求时,必须考虑数据集的性质和所提出问题的类型。
此外,我们相信在后续步骤中自动化构建思维链[67]的过程可能是未来研究的一个有希望的方向。 通过开发自动生成连贯推理链的机制,我们可以潜在地增强模型的整体性能和推理能力。
| Representation | SROIE | DocVQA | TextVQA | ChartVQA |
|---|---|---|---|---|
| Polygon | 47.2 | 64.0 | 65.7 | 57.9 |
| Rect | 47.0 | 64.3 | 65.9 | 58.2 |
| Point | 47.9 | 65.0 | 66.0 | 58.3 |
5.3 不同位置表示方式的比较
最近,一些方法[61]使用点来代替矩形和多边形来表示位置。 首先,直观上来说,与生成矩形和多边形相比,在推理过程中生成点的成本会更低,因为其他形式的边界框需要生成 Nx 个点。 我们的目标是进一步研究并通过实验验证哪种形式更适合 LMM 学习。 为了在实验中保持严格的一致性,我们仅对数据应用转换,同时保持其他训练超参数相同。 对于这些点,我们选择了最有意义的边界框的中心点。
如表XI所示,使用点作为视觉提示比矩形显着提高了性能。 在 Docvqa 中,提高了 0.7%,而在 SROIE 中,提高了 0.9%。 此外,矩形在性能上通常优于多边形。 这可能归因于之前讨论的问题,即冗余图像标记可能会增加模型学习过程的复杂性。 同样,广泛的立场表达也可能面临类似的障碍。 考虑到这些考虑因素以及相关的推理成本,利用点作为表示对于适当的任务来说可能是一种可行的策略。
6 结论
本文引入 TextMonkey 来解决与文本密集型任务(例如文档问答和细粒度文本分析)相关的挑战。 我们采用零初始化的转移窗口注意力来帮助建立关系,同时使用滑动窗口提高输入分辨率。 提高分辨率的同时也会增加令牌的数量。 通过分析令牌的冗余性,我们提出的词符重采样器有效地减少了令牌的数量。 此外,通过同时执行多个面向文本的任务,TextMonkey 增强了其对空间关系的感知和理解,从而提高了可解释性并支持单击屏幕截图。 通过将我们的模型与各种 LMM 进行比较,我们的模型在多个基准测试中取得了优异的结果。 值得一提的是,我们还发现直接提高输入分辨率并不总是能带来改进,特别是对于较小的图像。 这强调了创建一种有效方法来缩放尺寸变化可能剧烈的文档分辨率的必要性。
参考
- [1] Z. Tang, Z. Yang, G. Wang, Y. Fang, Y. Liu, C. Zhu, M. Zeng, C. Zhang, and M. Bansal, “Unifying vision, text, and layout for universal document processing,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 19 254–19 264.
- [2] Y. Huang, T. Lv, L. Cui, Y. Lu, and F. Wei, “Layoutlmv3: Pre-training for document AI with unified text and image masking,” in MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, October 10 - 14, 2022. ACM, 2022, pp. 4083–4091.
- [3] G. Kim, T. Hong, M. Yim, J. Nam, J. Park, J. Yim, W. Hwang, S. Yun, D. Han, and S. Park, “Ocr-free document understanding transformer,” in European Conference on Computer Vision. Springer, 2022, pp. 498–517.
- [4] K. Lee, M. Joshi, I. R. Turc, H. Hu, F. Liu, J. M. Eisenschlos, U. Khandelwal, P. Shaw, M.-W. Chang, and K. Toutanova, “Pix2struct: Screenshot parsing as pretraining for visual language understanding,” in International Conference on Machine Learning. PMLR, 2023, pp. 18 893–18 912.
- [5] H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [6] D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,” The International Conference on Learning Representations (ICLR), 2024.
- [7] Y. Zhang, R. Zhang, J. Gu, Y. Zhou, N. Lipka, D. Yang, and T. Sun, “Llavar: Enhanced visual instruction tuning for text-rich image understanding,” arXiv preprint arXiv:2306.17107, 2023.
- [8] H. Feng, Z. Wang, J. Tang, J. Lu, W. Zhou, H. Li, and C. Huang, “Unidoc: A universal large multimodal model for simultaneous text detection, recognition, spotting and understanding,” arXiv preprint arXiv:2308.11592, 2023.
- [9] Y. Wang, W. Zhou, H. Feng, K. Zhou, and H. Li, “Towards improving document understanding: An exploration on text-grounding via mllms,” arXiv preprint arXiv:2311.13194, 2023.
- [10] J. Ye, A. Hu, H. Xu, Q. Ye, M. Yan, Y. Dan, C. Zhao, G. Xu, C. Li, J. Tian et al., “mplug-docowl: Modularized multimodal large language model for document understanding,” arXiv preprint arXiv:2307.02499, 2023.
- [11] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [12] Y. Liu, Z. Li, H. Li, W. Yu, M. Huang, D. Peng, M. Liu, M. Chen, C. Li, L. Jin et al., “On the hidden mystery of ocr in large multimodal models,” arXiv preprint arXiv:2305.07895, 2023.
- [13] J. Ye, A. Hu, H. Xu, Q. Ye, M. Yan, G. Xu, C. Li, J. Tian, Q. Qian, J. Zhang et al., “Ureader: Universal ocr-free visually-situated language understanding with multimodal large language model,” in The 2023 Conference on Empirical Methods in Natural Language Processing, 2023.
- [14] Z. Li, B. Yang, Q. Liu, Z. Ma, S. Zhang, J. Yang, Y. Sun, Y. Liu, and X. Bai, “Monkey: Image resolution and text label are important things for large multi-modal models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [15] H. Feng, Q. Liu, H. Liu, W. Zhou, H. Li, and C. Huang, “Docpedia: Unleashing the power of large multimodal model in the frequency domain for versatile document understanding,” arXiv preprint arXiv:2311.11810, 2023.
- [16] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022.
- [17] Y. Li, Y. Qian, Y. Yu, X. Qin, C. Zhang, Y. Liu, K. Yao, J. Han, J. Liu, and E. Ding, “Structext: Structured text understanding with multi-modal transformers,” in Proceedings of the 29th ACM International Conference on Multimedia, 2021, pp. 1912–1920.
- [18] Q. Peng, Y. Pan, W. Wang, B. Luo, Z. Zhang, Z. Huang, Y. Cao, W. Yin, Y. Chen, Y. Zhang et al., “Ernie-layout: Layout knowledge enhanced pre-training for visually-rich document understanding,” in Findings of the Association for Computational Linguistics: EMNLP 2022, 2022, pp. 3744–3756.
- [19] Y. Xu, M. Li, L. Cui, S. Huang, F. Wei, and M. Zhou, “Layoutlm: Pre-training of text and layout for document image understanding,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 1192–1200.
- [20] Y. Xu, Y. Xu, T. Lv, L. Cui, F. Wei, G. Wang, Y. Lu, D. A. F. Florêncio, C. Zhang, W. Che, M. Zhang, and L. Zhou, “Layoutlmv2: Multi-modal pre-training for visually-rich document understanding,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, August 1-6, 2021. Association for Computational Linguistics, 2021, pp. 2579–2591.
- [21] H. Bai, Z. Liu, X. Meng, W. Li, S. Liu, Y. Luo, N. Xie, R. Zheng, L. Wang, L. Hou, J. Wei, X. Jiang, and Q. Liu, “Wukong-reader: Multi-modal pre-training for fine-grained visual document understanding,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023. Association for Computational Linguistics, 2023, pp. 13 386–13 401.
- [22] S. Appalaraju, P. Tang, Q. Dong, N. Sankaran, Y. Zhou, and R. Manmatha, “Docformerv2: Local features for document understanding,” arXiv preprint arXiv:2306.01733, 2023.
- [23] D. Wang, N. Raman, M. Sibue, Z. Ma, P. Babkin, S. Kaur, Y. Pei, A. Nourbakhsh, and X. Liu, “Docllm: A layout-aware generative language model for multimodal document understanding,” arXiv preprint arXiv:2401.00908, 2023.
- [24] B. Davis, B. Morse, B. Price, C. Tensmeyer, C. Wigington, and V. Morariu, “End-to-end document recognition and understanding with dessurt,” in European Conference on Computer Vision. Springer, 2022, pp. 280–296.
- [25] Y. Yu, Y. Li, C. Zhang, X. Zhang, Z. Guo, X. Qin, K. Yao, J. Han, E. Ding, and J. Wang, “Structextv2: Masked visual-textual prediction for document image pre-training,” in The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
- [26] H. Wei, L. Kong, J. Chen, L. Zhao, Z. Ge, J. Yang, J. Sun, C. Han, and X. Zhang, “Vary: Scaling up the vision vocabulary for large vision-language models,” arXiv preprint arXiv:2312.06109, 2023.
- [27] E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,” in The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.
- [28] J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,” arXiv preprint arXiv:2308.12966, 2023.
- [29] D. Bolya, C.-Y. Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token merging: Your vit but faster,” in The Eleventh International Conference on Learning Representations, 2022.
- [30] A. Veit, T. Matera, L. Neumann, J. Matas, and S. Belongie, “Coco-text: Dataset and benchmark for text detection and recognition in natural images,” 2016.
- [31] A. Singh, G. Pang, M. Toh, J. Huang, W. Galuba, and T. Hassner, “Textocr: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8802–8812.
- [32] S. Long, S. Qin, D. Panteleev, A. Bissacco, Y. Fujii, and M. Raptis, “Towards end-to-end unified scene text detection and layout analysis,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1049–1059.
- [33] A. Singh, V. Natarajan, M. Shah, Y. Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach, “Towards vqa models that can read,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 8317–8326.
- [34] N. Nayef, Y. Patel, M. Busta, P. N. Chowdhury, D. Karatzas, W. Khlif, J. Matas, U. Pal, J.-C. Burie, C.-l. Liu et al., “Icdar2019 robust reading challenge on multi-lingual scene text detection and recognition—rrc-mlt-2019,” in 2019 International conference on document analysis and recognition (ICDAR). IEEE, 2019, pp. 1582–1587.
- [35] D. Lewis, G. Agam, S. Argamon, O. Frieder, D. Grossman, and J. Heard, “Building a test collection for complex document information processing,” in Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, 2006, pp. 665–666.
- [36] M. Mathew, D. Karatzas, and C. Jawahar, “Docvqa: A dataset for vqa on document images,” in Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2021, pp. 2200–2209.
- [37] A. Masry, X. L. Do, J. Q. Tan, S. Joty, and E. Hoque, “Chartqa: A benchmark for question answering about charts with visual and logical reasoning,” in Findings of the Association for Computational Linguistics: ACL 2022, 2022, pp. 2263–2279.
- [38] M. Mathew, V. Bagal, R. Tito, D. Karatzas, E. Valveny, and C. Jawahar, “Infographicvqa,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 1697–1706.
- [39] S. Svetlichnaya, “Deepform: Understand structured documents at scale,” 2020.
- [40] T. Stanisławek, F. Graliński, A. Wróblewska, D. Lipiński, A. Kaliska, P. Rosalska, B. Topolski, and P. Biecek, “Kleister: key information extraction datasets involving long documents with complex layouts,” in International Conference on Document Analysis and Recognition. Springer, 2021, pp. 564–579.
- [41] P. Pasupat and P. Liang, “Compositional semantic parsing on semi-structured tables,” in Annual Meeting of the Association for Computational Linguistics, 2015.
- [42] J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in International conference on machine learning. PMLR, 2023, pp. 19 730–19 742.
- [43] Q. Ye, H. Xu, G. Xu, J. Ye, M. Yan, Y. Zhou, J. Wang, A. Hu, P. Shi, Y. Shi et al., “mplug-owl: Modularization empowers large language models with multimodality,” arXiv preprint arXiv:2304.14178, 2023.
- [44] W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, “InstructBLIP: Towards general-purpose vision-language models with instruction tuning,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- [45] W. Hu, Y. Xu, Y. Li, W. Li, Z. Chen, and Z. Tu, “Bliva: A simple multimodal llm for better handling of text-rich visual questions,” in Proceedings of the AAAI Conference on Artificial Intelligence, 2024.
- [46] Q. Ye, H. Xu, J. Ye, M. Yan, H. Liu, Q. Qian, J. Zhang, F. Huang, and J. Zhou, “mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [47] H. Liu, C. Li, Y. Li, and Y. J. Lee, “Improved baselines with visual instruction tuning,” arXiv preprint arXiv:2310.03744, 2023.
- [48] Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. Li, P. Luo, T. Lu, Y. Qiao, and J. Dai, “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024.
- [49] X. Dong, P. Zhang, Y. Zang, Y. Cao, B. Wang, L. Ouyang, X. Wei, S. Zhang, H. Duan, M. Cao et al., “Internlm-xcomposer2: Mastering free-form text-image composition and comprehension in vision-language large model,” arXiv preprint arXiv:2401.16420, 2024.
- [50] I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in International Conference on Learning Representations, 2017.
- [51] A. F. Biten, R. Tito, A. Mafla, L. Gomez, M. Rusinol, E. Valveny, C. Jawahar, and D. Karatzas, “Scene text visual question answering,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4291–4301.
- [52] A. Mishra, S. Shekhar, A. K. Singh, and A. Chakraborty, “Ocr-vqa: Visual question answering by reading text in images,” in 2019 international conference on document analysis and recognition (ICDAR). IEEE, 2019, pp. 947–952.
- [53] G. Jaume, H. Kemal Ekenel, and J.-P. Thiran, “Funsd: A dataset for form understanding in noisy scanned documents,” in 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW), vol. 2, 2019, pp. 1–6.
- [54] Z. Huang, K. Chen, J. He, X. Bai, D. Karatzas, S. Lu, and C. V. Jawahar, “ICDAR 2019 competition on scanned receipt ocr and information extraction,” in 2019 International Conference on Document Analysis and Recognition (ICDAR), 2019, pp. 1516–1520.
- [55] J. Kuang, W. Hua, D. Liang, M. Yang, D. Jiang, B. Ren, and X. Bai, “Visual information extraction in the wild: practical dataset and end-to-end solution,” in International Conference on Document Analysis and Recognition. Springer, 2023, pp. 36–53.
- [56] C. K. Ch’ng and C. S. Chan, “Total-text: A comprehensive dataset for scene text detection and recognition,” in 2017 14th IAPR international conference on document analysis and recognition (ICDAR), vol. 1. IEEE, 2017, pp. 935–942.
- [57] Y. Liu, L. Jin, S. Zhang, C. Luo, and S. Zhang, “Curved scene text detection via transverse and longitudinal sequence connection,” Pattern Recognition, vol. 90, pp. 337–345, 2019.
- [58] D. Karatzas, L. Gomez-Bigorda, A. Nicolaou, S. Ghosh, A. Bagdanov, M. Iwamura, J. Matas, L. Neumann, V. R. Chandrasekhar, S. Lu et al., “Icdar 2015 competition on robust reading,” in 2015 13th international conference on document analysis and recognition (ICDAR). IEEE, 2015, pp. 1156–1160.
- [59] J. Tang, S. Qiao, B. Cui, Y. Ma, S. Zhang, and D. Kanoulas, “You can even annotate text with voice: Transcription-only-supervised text spotting,” in Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 4154–4163.
- [60] Y. Kittenplon, I. Lavi, S. Fogel, Y. Bar, R. Manmatha, and P. Perona, “Towards weakly-supervised text spotting using a multi-task transformer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 4604–4613.
- [61] Y. Liu, J. Zhang, D. Peng, M. Huang, X. Wang, J. Tang, C. Huang, D. Lin, C. Shen, X. Bai et al., “Spts v2: single-point scene text spotting,” arXiv preprint arXiv:2301.01635, 2023.
- [62] Y. Liu, C. Shen, L. Jin, T. He, P. Chen, C. Liu, and H. Chen, “ABCNet v2: Adaptive bezier-curve network for real-time end-to-end text spotting,” vol. 44, no. 11, pp. 8048–8064, 2022.
- [63] Z. Yang, J. Liu, Y. Han, X. Chen, Z. Huang, B. Fu, and G. Yu, “Appagent: Multimodal agents as smartphone users,” arXiv preprint arXiv:2312.13771, 2023.
- [64] J. Wang, H. Xu, J. Ye, M. Yan, W. Shen, J. Zhang, F. Huang, and J. Sang, “Mobile-agent: Autonomous multi-modal mobile device agent with visual perception,” arXiv preprint arXiv:2401.16158, 2024.
- [65] R. Niu, J. Li, S. Wang, Y. Fu, X. Hu, X. Leng, H. Kong, Y. Chang, and Q. Wang, “Screenagent: A vision language model-driven computer control agent,” arXiv preprint arXiv:2402.07945, 2024.
- [66] B. Deka, Z. Huang, C. Franzen, J. Hibschman, D. Afergan, Y. Li, J. Nichols, and R. Kumar, “Rico: A mobile app dataset for building data-driven design applications,” in Proceedings of the 30th annual ACM symposium on user interface software and technology, 2017, pp. 845–854.
- [67] J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou et al., “Chain-of-thought prompting elicits reasoning in large language models,” Advances in Neural Information Processing Systems, vol. 35, pp. 24 824–24 837, 2022.