上海交通大学,上海,200240,中国
11email: yi.hong@sjtu.edu.cn
Med3DInsight:利用2D多模态大型语言模型增强3D医学图像理解
摘要
理解3D医学图像体积是医学领域的一项关键任务。 然而,现有的基于3D卷积和Transformer的方法对图像体积的语义理解有限,并且需要大量体积进行训练。 多模态大型语言模型(MLLMs)的最新进展为利用文本描述理解图像提供了一种新的有前景的方法。 然而,目前大多数MLLMs都是为2D自然图像设计的。 为了利用2D MLLMs增强3D医学图像理解,我们提出了一种新颖的预训练框架,称为Med3DInsight,它将现有的3D图像编码器与2D MLLMs结合起来,并通过设计的Plane-Slice-Aware Transformer(PSAT)模块将它们连接起来。 广泛的实验表明了我们在两个下游分割和分类任务上的SOTA性能,包括三个带有CT和MRI模态的公共数据集,以及与十多个基线的比较。 Med3DInsight可以轻松地集成到任何现有的3D医学图像理解网络中,并能显著提升其性能。 我们的源代码可在https://github.com/Qybc/Med3DInsight上公开获取。
关键词:
3D医学图像理解 多模态大型语言模型 自监督学习1 引言
在医学研究中,分析和解释三维医学图像是一项关键任务,它提取了有价值的信息,用于诊断、治疗计划以及医疗保健领域的其它研究。 为了理解 3D 医学图像,研究人员通常根据特定目的设计不同的模型,例如 3D 图像分类模型 [14, 2]、3D 医学图像分割模型 [6, 10, 30]。 此外,在深度学习时代,这些模型对 3D 医学图像的语义理解有限,其特征提取被视为黑盒。 我们的目标是设计一个用于学习通用 3D 医学图像表示的预训练框架,该框架增强了对 3D 扫描中医学内容的语义理解,可以应用于多个下游任务,包括图像分类和分割。
语言描述是通过整合自然语言处理和计算机视觉技术来提高图像理解的有效方法。 最近,多模态大型语言模型 (MLLM) [16, 1, 22] 在使自然语言能够讨论和理解各种视觉场景方面展现出令人印象深刻的能力。 尽管 MLLM 在处理 2D 图像内容方面表现出色,但它们对更具挑战性的 3D 医学体积的理解仍然是一个悬而未决的问题。 一些研究探索了利用现有 MLLM 进行 3D 医学理解的潜力,例如 MedBLIP [5]、GTGM [7] 和 T3D [17]。 这些方法要么将 3D 图像投影到 2D 表示作为 MLLM 的输入 [7],要么用 3D 适配器增强 2D MLLM [5],它们不是纯粹的 3D 表示学习器,失去了对整个 3D 图像的理解。 虽然这些方法对齐了图像和文本特征,但与 MLLM 中的图像编码器不同,它们缺乏对 3D 图像的语义理解。
为了解决上述挑战,我们建议使用 MLLM 中的图像-文本对齐技术来增强 3D 图像编码器。 但是,与计算机视觉领域不同,具有 3D 医学扫描图像-文本对的医学数据集非常稀缺,即使收集大量 2D 医学图像-文本对也是一项非平凡的任务。 此外,在为二维自然图像设计的当前MLLM与三维医学图像理解之间存在很大差距。 幸运的是,GPT-4V(ision) [22] 视觉已经发展出对二维医学图像解释的能力 [28]. 因此,我们引入了一个新的三维医学图像表示学习框架,即Med3DInsight,它借助二维MLLM来对齐三维图像理解,如图 1所示。
Mde3DInsight通过对比学习 [24]将三维体积特征与二维图像和文本特征对齐。 为了弥合三维和二维特征空间之间的差距,我们设计了一个平面切片感知Transformer (PSAT)模块,该模块在三维体积中嵌入切片的平面和切片位置,并采用可学习的查询技术 [3]将三维特征投影到二维特征空间以进行映射。 我们采用GPT-4V(ision) [22]为从三维图像扫描中提取的二维医学切片生成详细的文本描述。 为了在同一个特征空间中对齐图像和文本模态 [27],我们使用GPT-4V生成的切片-文本对对CLIP [24]的图像和文本编码器进行微调。 在预训练期间,我们保持GPT-4V和CLIP模型冻结,并训练三维图像编码器和PSAT模块,从而得到一个用于下游分割和分类任务的预训练三维图像编码器。
总体而言,我们的贡献总结如下:
-
•
我们提出了一个新的框架Med3DInsight,它利用二维MLLM来增强现有三维编码器的医学图像理解。 我们的框架是通用的,它改进了多个最近的模型,在MM-WHS [31]、CHAOS [15]和OASIS [20]数据集上都获得了最先进的(SOTA)性能,用于三维分割和分类。
-
•
我们设计了一个平面切片感知Transformer (PSAT)模块,它将三维医学图像编码器与二维视觉-语言模型连接起来。 该模块允许学习一个感知视觉特征空间方向的映射,该映射可以应用于其他需要建立二维和三维特征映射的应用中。
2 方法
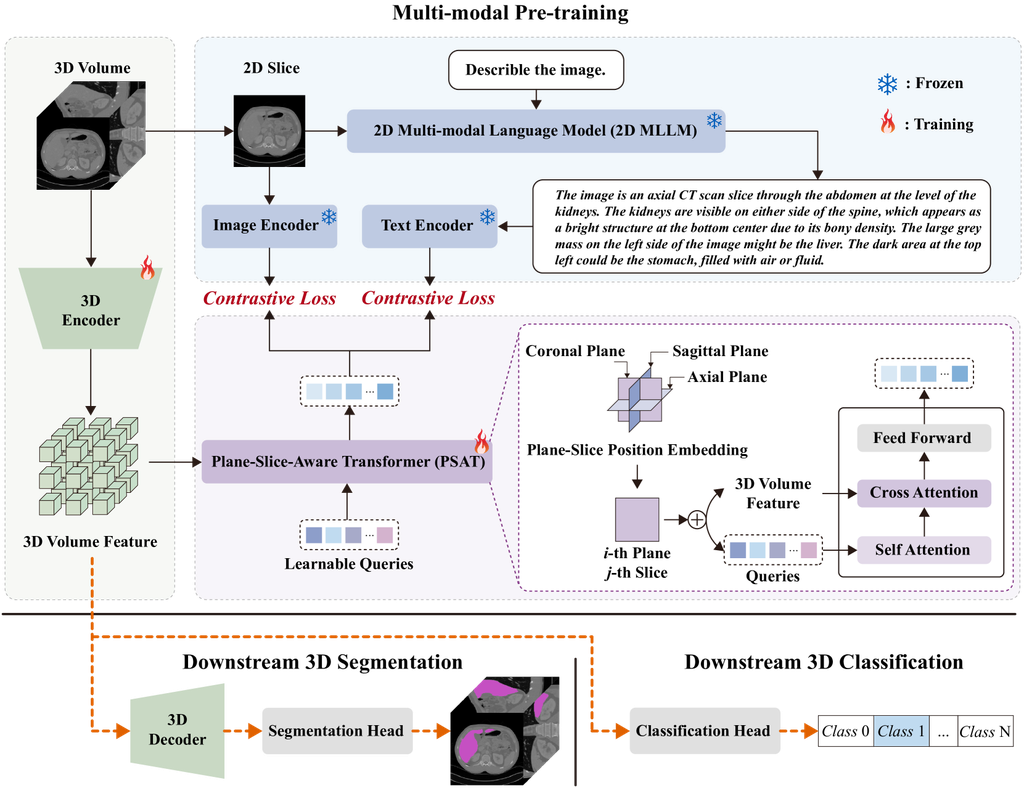
图 1展示了Med3DInsight框架的概述,该框架可以分为预训练和下游任务。 预训练包括三个组件,即三维图像编码器、二维MLLM和平面切片感知Transformer (PSAT)模块。 关于 3D 图像编码器,我们可以选择现有模型的编码器,例如 SETR [29]、UNETR [10]、nnFormer [30]、Vit [8]、Swin-ViT [18] 等。 基于用于预训练的图像体积,我们首先为 2D MLLM 创建切片和文本对,然后使用 PSAT 模块建立 2D 和 3D 特征空间之间的联系。
数据收集和 2D 特征提取。 我们选择一个公开的 3D 医学数据集 3DSeg-8 [6] 用于预训练。 该数据集包含 2K 张不同模态的图像,例如 MRI、CT 和不同身体部位,包括大脑、心脏、前列腺、脾脏等。 这些图像扫描来自多个中心,具有不同的空间分辨率和强度范围。 对于此数据集中每个 3D 医学体积图像 ,我们创建一个三元组 ,其中包括医学体积 、从第 i 个平面(即冠状、矢状或轴状平面)的第 j 个切片中提取的图像切片 ,以及其相应的文本描述 。
(1) 切片和特征提取。 为了获得图像切片集 ,我们从所有三个平面中提取每个图像体积 的所有图像切片。 在预训练的每次迭代中,我们从图像体积的一个平面中随机选择一个图像切片作为 ,并将其作为从 CLIP 中采用的图像编码器 的输入,以提取其特征 ,如图 1 所示。
(2) 文本生成和特征提取。 我们采用一个 2D MLLM(例如 GPT-4V [22])来生成特定 2D 切片 的文本描述 ,如图 1 所示。 然后,我们将此文本描述输入到从 CLIP 中采用的文本编码器 中,并获得图像切片的文本特征表示 ,即 。
通过这种方式,我们将一个三元组数据 转换为一个三元组特征集 ,其中 和 是选定的 3D 图像编码器。
PSAT 对齐。 在特征集 中,我们既有 3D 图像特征 ,也有 2D 图像和文本特征对 ,需要对齐以弥合 2D 和 3D 之间的差距,并允许基于对比学习的自训练。 在这里,我们采用查询技术 [3],该技术通过了解随机选择的图像切片的平面-切片位置来增强。
如图 1 所示,PSAT 模块包含一组 可学习的查询嵌入。 在实验中,我们将 设置为 300,以便将 CLIP 的图像和文本嵌入空间方便地投影。 这些可学习的查询通过自注意力层相互作用,然后通过交叉注意力层与体积特征 相互作用,并生成一个输出 编码的视觉向量,每个查询嵌入对应一个。 然后,这些向量通过多层感知器 (MLP) 进行处理,从而生成体积嵌入的投影,该投影通过对比损失 [24] 送入与图像切片和文本嵌入的对齐。
由于图像切片是从图像体积中提取的,并且位于第平面的第切片,3D-2D 投影应该了解图像体积和切片之间的这种方向关系。 因此,我们为体积特征引入了一个平面-切片位置嵌入,以提高模型学习方向和几何关系的能力。
具体而言,我们首先构建平面-切片位置嵌入 ,其初始参数为零,其中 是模型的嵌入维数, 是平面的数量, 是切片的数量。 在预训练期间,当处理一个切片图像 时,例如,当处理与冠状平面 (即 ) 的第八个切片 (即 ) 相关的样本时,我们只将第八个切片注入冠状平面位置嵌入 中的体积特征和查询,遵循一般的方位编码 [26]。
通过与 2D 图像切片和文本特征对齐,我们以自学习的方式增强了 3D 医学图像理解。 同时,它有可能减少图像体积的数据需求,因为该模型建立在预训练的 2D MLLM 之上,我们拥有来自预训练数据集的 2K 个图像体积的数百万个 2D 图像切片,这在我们的实验中得到了证明。
3 实验
为了证明我们的预训练 3D 框架 Med3DInsight 的有效性,我们对两组下游任务进行了实验:3D 分割,包括心脏结构分割、腹部器官分割和脑分割,以及阿尔茨海默病 (AD) 和正常对照 (NC) 的 3D 分类。 然后,我们提供了详细的消融研究和定性分析,以更深入地了解我们的方法。
3.1 数据集和实验设置
MM-WHS [31]。 对于心脏分割,我们使用了 2017 年多模态全心脏分割 (MM-WHS) 挑战数据集 [31],该数据集包含在真实临床环境中获取的 20 个未配对的 CT 和 20 个 MRI 扫描,并具有地面真实像素级标注,包括五个标签,即左心室血腔 (LVC)、右心室血腔 (RVC)、左心房血腔 (LAC)、右心房血腔 (LAC) 和升主动脉 (AA)。 在此实验中,我们使用 CT,包含 177 到 363 个切片,每个切片大小为 512×512 像素,体素间距范围为 0.3 到 0.6 毫米。
CHAOS [15]。 对于腹部器官分割,我们使用由 ISBI 2019 CHAOS 挑战赛 [15] 中的 20 张腹部 CT 图像组成的训练数据集,其中仅包含一个腹部器官,即肝脏,用于分割。 每个 CT 扫描包含 81 到 266 个切片,每个切片大小为 512×512 像素,体素间距范围为 0.6 到 2.0 毫米。
OASIS [20]。 对于脑部分割,我们使用公开的 OASIS1 数据集 [20],包括 414 个使用 FreeSurfer [9] 和 SAMSEG [23] 预处理的受试者。 我们的方法被应用于分割四个脑部子结构,即皮层、灰质 (GM)、白质 (WM) 和脑脊液 (CSF)。 每个 MRI 扫描的图像大小为 160×192×224,体素间距为 1.0 毫米。 对于阿尔茨海默病分类,我们使用公开的 OASIS2 数据集 [19],包含来自 135 个受试者的 335 个 T1 加权 sMRI 扫描,包括 AD 受试者和健康志愿者。 每个 MRI 扫描的图像大小为 224×224×224,体素间距为 1.75 毫米。
由于下游数据集中使用的图像体积具有不同的图像分辨率和间距,因此所有图像体积都被重新采样到每个维度 1.0 毫米的各向同性体素间距,体积的图像大小范围从 144×144×161 到 400×400×256。 然后将图像的体素强度归一化为 [0,1] 范围。 为了简化预处理步骤,首先将所有图像填充为立方体形状,然后缩放为统一大小 128 × 128 × 128 作为输入。 我们 按受试者 将数据按 7:1:2 的比例划分为训练集、验证集和测试集。
主干网络、基线和其它设置。 对于 3D 图像编码器,我们采用最先进的 3D 主干网络,例如 SETR [29]、UNETR [10] 和 nnFormer [30] 用于分割,ViT [8] 和 Swin-ViT [18] 用于分类。 对于分割任务,我们通过简单地对它们进行平均来利用交叉熵损失和骰子损失。 对于分类任务,我们利用交叉熵损失。 所有实验都在 NVIDIA GeForce RTX 3090 GPU 上进行。 为了比较,我们选择了 5 个 3D 图像分割的基线,包括 UNet [25]、AttUNet [21]、Med3D [6]、TransUNet [4]、nnUNet [13],以及 5 个分类的基线,包括 3D ResNet50 [11]、3D DenseNet121 [12]、MRNet [2]、MedicalNet [6] 和 M3T [14]。 对于 PSAT 模块,我们将可学习查询的符元数量设置为 300,符元的维度为 512。 Med3DInsight 训练了 300 个 epochs。 我们将批次大小设置为 32,学习率设置为 。 AdamW 是我们用于训练 Med3DInsight 的优化器。
| Methods | MM-WHS | CHAOS | OASIS | |||||||||
| LVC | RVC | LAC | RAC | AA | Avg. | Liver | Cortex | GM | WM | CSF | Avg. | |
| UNet [25] | 80.9 | 78.1 | 76.6 | 72.3 | 74.7 | 76.5 | 79.9 | 70.9 | 83.3 | 83.2 | 80.5 | 79.5 |
| AttUNet [21] | 81.0 | 78.9 | 77.1 | 74.2 | 75.2 | 77.3 | 79.7 | 70.8 | 83.1 | 83.1 | 79.8 | 79.2 |
| Med3D [6] | 83.0 | 77.1 | 81.6 | 74.9 | 77.9 | 78.9 | 81.2 | 76.4 | 85.5 | 87.7 | 84.5 | 83.5 |
| TransUNet [4] | 82.9 | 76.9 | 80.8 | 76.1 | 78.6 | 79.1 | 82.6 | 76.6 | 85.6 | 87.3 | 84.7 | 83.6 |
| nnUNet [13] | 83.9 | 76.6 | 78.9 | 76.8 | 81.9 | 79.6 | 84.8 | 77.2 | 86.0 | 88.0 | 85.5 | 84.2 |
| SETR [29] | 85.1 | 77.2 | 80.5 | 75.7 | 81.7 | 80.0 | 86.2 | 81.5 | 86.9 | 84.5 | 87.2 | 85.0 |
| +Med3DInsight | 85.2 | 81.5 | 81.6 | 80.4 | 85.7 | 82.9 | 89.8 | 82.6 | 89.1 | 88.3 | 90.1 | 87.5 |
| +2.9 | +3.6 | +2.5 | ||||||||||
| UNetr [10] | 85.9 | 81.0 | 83.4 | 80.2 | 87.2 | 83.5 | 89.9 | 80.3 | 88.0 | 89.5 | 88.2 | 86.5 |
| +Med3DInsight | 86.5 | 81.2 | 85.3 | 83.5 | 89.7 | 85.2 | 91.2 | 83.0 | 90.1 | 91.3 | 90.4 | 88.7 |
| +1.7 | +1.3 | +2.2 | ||||||||||
| nnFormer [30] | 85.2 | 83.3 | 85.5 | 85.0 | 90.6 | 85.9 | 91.9 | 89.1 | 93.1 | 94.6 | 92.8 | 92.4 |
| +Med3DInsight | 89.3 | 89.1 | 86.5 | 87.4 | 90.5 | 88.6 | 94.1 | 92.6 | 94.2 | 96.8 | 95.3 | 94.7 |
| +2.7 | +2.2 | +2.3 | ||||||||||
| Methods | OASIS | |
| Accuracy(%) | AUC(%) | |
| 3D ResNet50 [11] | 66.2 | 65.9 |
| 3D DenseNet121 [12] | 72.3 | 72.7 |
| MRNet [2] | 70.8 | 71.9 |
| MedicalNet [6] | 73.9 | 72.7 |
| M3T [14] | 80.2 | 81.7 |
| ViT [8] | 80.5 | 82.6 |
| +Med3DInsight | 81.4 | 84.3 |
| +0.9 | +1.7 | |
| Swin-ViT [18] | 82.8 | 84.4 |
| +Med3DInsight | 84.1 | 85.7 |
| +1.3 | +1.3 | |
3.2 实验结果和消融研究
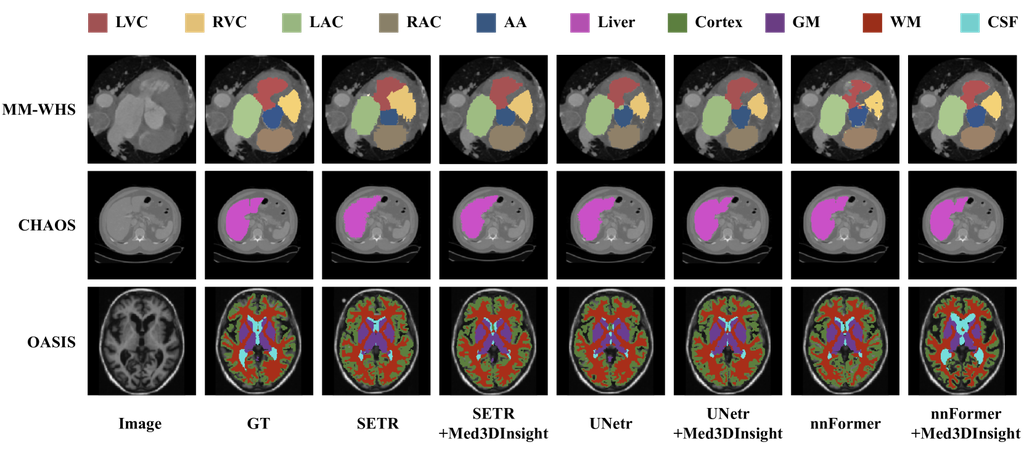
表 1 报告了 MM-WHS、CHAOS 和 OASIS 数据集上的 3D 分割结果,表 2 报告了 OASIS 上的 3D 分类结果。 实验结果表明,Med3DInsight 增强了所有主干网络,并将分割和分类结果分别提高了 2% 以上的平均 Dice 系数和 1% 的分类准确率。 此外,所有经过 Med3DInsight 增强的模型都优于所有基线模型。 对于 3D 分割,Med3DInsight 与 nnFormer 的组合在所有三个分割任务中实现了最先进的性能。 对于 3D 分类,Swin-ViT 与 Med3DInsight 的组合在 OASIS 数据集上表现最佳。 图 2 展示了 3D 分割结果的定性比较。 Med3DInsight 显示了基线模型的分割性能得到改进。 具体而言,我们的模型在捕获器官或子结构的细粒度细节方面表现出更好的性能。
PSAT 模型的有效性。 为了证明 PSAT 中每个组件的有效性,我们在 OASIS 3D 分割任务上进行了消融研究。 如表 3 所示, 表示不存在任何 Transformer 结构和位置嵌入。 在这种情况下,3D 图像特征直接输入到投影层以对齐维度,然后馈送到计算对比损失,以与 CLIP 的 2D 视觉语言特征对齐。 在 中,使用查询 Transformer,我们观察到 Dice 得分达到 93.9%。 结果表明,查询 Transformer 的结构可以更好地将 3D 医学图像特征与 2D 视觉语言特征对齐。 与 和 相比,引入平面切片位置嵌入使 Dice 得分提高了 0.8%。 这组结果证实,将平面切片位置嵌入纳入模型有助于模型更好地理解 3D 场景和空间关系。
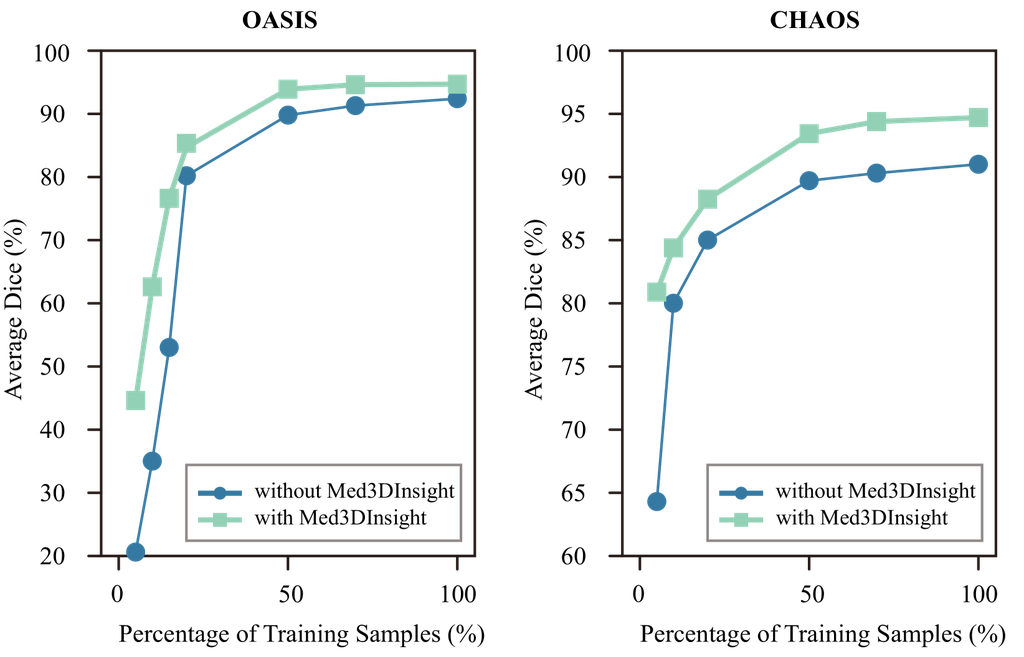
数据效率。 模型预训练有可能减少下游任务对标记数据的需求。 我们通过比较基于 nnFormer 的 Med3DInsight 在不同微调样本数量下的有效性来验证数据效率。 图 3 展示了对比结果,表明在 Med3DInsight 框架下进行预训练时,nnFormer 的性能在低数据情况下得到了显著提高。 我们观察到,Med3DInsight 在使用不到 20% 的训练数据时,在 CHAOS 上的表现优于 OASIS 数据集。 这可能是因为我们的模型是在 3DSeg-8 数据集上进行预训练的,该数据集包含大量腹部 CT 图像。 即使在这种情况下,Med3DInsight 仍然在 OASIS 上取得了显著的性能提升。
4结论与讨论
在本文中,我们提出了一种新的预训练框架 Med3DInsight,它利用 2D MLLMs 来增强医学图像理解,并提高多个当前 3D 图像理解网络的下游分割和分类性能。 为了弥合 3D 图像编码器和 2D MLLMs 之间的特征空间差距,我们基于可学习查询技术引入了平面切片感知 Transformer (PSAT)。 实验结果证明了我们的方法在下游任务中取得了持续的改进。 在未来的工作中,我们考虑通过整合大型语言模型来进行 3D 图像字幕或 3D 图像问答,进一步探索我们框架中 3D 图像体积的语义理解。
参考文献
- [1] Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems 35, 23716–23736 (2022)
- [2] Bien, N., Rajpurkar, P., Ball, R.L., Irvin, J., Park, A., Jones, E., Bereket, M., Patel, B.N., Yeom, K.W., Shpanskaya, K., et al.: Deep-learning-assisted diagnosis for knee magnetic resonance imaging: development and retrospective validation of mrnet. PLoS medicine 15(11), e1002699 (2018)
- [3] Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., Zagoruyko, S.: End-to-end object detection with transformers. In: European conference on computer vision. pp. 213–229. Springer (2020)
- [4] Chen, J., Lu, Y., Yu, Q., Luo, X., Adeli, E., Wang, Y., Lu, L., Yuille, A.L., Zhou, Y.: Transunet: Transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306 (2021)
- [5] Chen, Q., Hu, X., Wang, Z., Hong, Y.: Medblip: Bootstrapping language-image pre-training from 3d medical images and texts. arXiv preprint arXiv:2305.10799 (2023)
- [6] Chen, S., Ma, K., Zheng, Y.: Med3d: Transfer learning for 3d medical image analysis. arXiv preprint arXiv:1904.00625 (2019)
- [7] Chen, Y., Liu, C., Huang, W., Cheng, S., Arcucci, R., Xiong, Z.: Generative text-guided 3d vision-language pretraining for unified medical image segmentation. arXiv preprint arXiv:2306.04811 (2023)
- [8] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
- [9] Fischl, B.: Freesurfer. Neuroimage 62(2), 774–781 (2012)
- [10] Hatamizadeh, A., Tang, Y., Nath, V., Yang, D., Myronenko, A., Landman, B., Roth, H.R., Xu, D.: Unetr: Transformers for 3d medical image segmentation. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 574–584 (2022)
- [11] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
- [12] Iandola, F., Moskewicz, M., Karayev, S., Girshick, R., Darrell, T., Keutzer, K.: Densenet: Implementing efficient convnet descriptor pyramids. arXiv preprint arXiv:1404.1869 (2014)
- [13] Isensee, F., Jaeger, P.F., Kohl, S.A., Petersen, J., Maier-Hein, K.H.: nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature methods 18(2), 203–211 (2021)
- [14] Jang, J., Hwang, D.: M3t: three-dimensional medical image classifier using multi-plane and multi-slice transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20718–20729 (2022)
- [15] Kavur, A.E., Gezer, N.S., Barış, M., Aslan, S., Conze, P.H., Groza, V., Pham, D.D., Chatterjee, S., Ernst, P., Özkan, S., et al.: Chaos challenge-combined (ct-mr) healthy abdominal organ segmentation. Medical Image Analysis 69, 101950 (2021)
- [16] Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597 (2023)
- [17] Liu, C., Ouyang, C., Chen, Y., Quilodrán-Casas, C.C., Ma, L., Fu, J., Guo, Y., Shah, A., Bai, W., Arcucci, R.: T3d: Towards 3d medical image understanding through vision-language pre-training. arXiv preprint arXiv:2312.01529 (2023)
- [18] Liu, Z., Ning, J., Cao, Y., Wei, Y., Zhang, Z., Lin, S., Hu, H.: Video swin transformer. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3202–3211 (2022)
- [19] Marcus, D.S., Fotenos, A.F., Csernansky, J.G., Morris, J.C., Buckner, R.L.: Open access series of imaging studies: longitudinal mri data in nondemented and demented older adults. Journal of cognitive neuroscience 22(12), 2677–2684 (2010)
- [20] Marcus, D.S., Wang, T.H., Parker, J., Csernansky, J.G., Morris, J.C., Buckner, R.L.: Open access series of imaging studies (oasis): cross-sectional mri data in young, middle aged, nondemented, and demented older adults. Journal of cognitive neuroscience 19(9), 1498–1507 (2007)
- [21] Oktay, O., Schlemper, J., Folgoc, L.L., Lee, M., Heinrich, M., Misawa, K., Mori, K., McDonagh, S., Hammerla, N.Y., Kainz, B., et al.: Attention u-net: Learning where to look for the pancreas. arXiv preprint arXiv:1804.03999 (2018)
- [22] OpenAI: Gpt-4v(ision) system card (2023)
- [23] Puonti, O., Iglesias, J.E., Van Leemput, K.: Fast and sequence-adaptive whole-brain segmentation using parametric bayesian modeling. NeuroImage 143, 235–249 (2016)
- [24] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
- [25] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. pp. 234–241. Springer (2015)
- [26] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
- [27] Xue, L., Gao, M., Xing, C., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., Savarese, S.: Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1179–1189 (2023)
- [28] Yang, Z., Yao, Z., Tasmin, M., Vashisht, P., Jang, W.S., Ouyang, F., Wang, B., Berlowitz, D., Yu, H.: Performance of multimodal gpt-4v on usmle with image: Potential for imaging diagnostic support with explanations. medRxiv pp. 2023–10 (2023)
- [29] Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu, Y., Feng, J., Xiang, T., Torr, P.H., et al.: Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6881–6890 (2021)
- [30] Zhou, H.Y., Guo, J., Zhang, Y., Han, X., Yu, L., Wang, L., Yu, Y.: nnformer: Volumetric medical image segmentation via a 3d transformer. IEEE Transactions on Image Processing (2023)
- [31] Zhuang, X., Shen, J.: Multi-scale patch and multi-modality atlases for whole heart segmentation of mri. Medical image analysis 31, 77–87 (2016)