HAM-TTS:基于标记的零样本文本到语音的分层声学建模,具有模型和数据缩放功能
摘要
基于标记的文本转语音 (TTS) 模型已成为生成自然和真实语音的有前景的途径,但它们面临着发音准确性低、说话风格和音色不一致以及对多样化训练数据的巨大需求等问题。 为此,我们引入了一种新颖的分层声学建模方法,辅以定制的数据增强策略,并结合真实数据和合成数据对其进行训练,将数据大小扩展到 65 万小时,从而形成具有 0.8B 参数的零样本 TTS 模型。 具体来说,我们的方法通过预测器将包含基于精炼自监督学习 (SSL) 离散单元的补充声学信息的潜在变量序列合并到 TTS 模型中。 这显着减少了合成语音中的发音错误和风格突变。 在训练过程中,我们有策略地替换和复制数据片段,以增强音色的均匀性。 此外,利用预训练的少样本语音转换模型来生成大量内容相同但音色不同的语音。 这有助于显式学习话语级一对多映射,丰富语音多样性并确保音色的一致性。 对比实验111Demo page: https://anonymous.4open.science/w/ham-tts/ 证明了我们的模型在发音精度、保持说话风格以及音色连续性方面优于 VALL-E。
HAM-TTS:基于标记的零样本文本到语音的分层声学建模,具有模型和数据缩放功能
王春晖111这些作者对这项工作做出了同等贡献。 1,曾畅111这些作者对这项工作做出了同等贡献。 2 3,张博文111这些作者对这项工作做出了同等贡献。 1,马紫阳111这些作者对这项工作做出了同等贡献。 4, 朱业帆1、蔡子峰1、赵健1、姜忠林1、陈勇1 中国吉利,日本国家信息研究所, 日本SOKENDAI,中国上海交通大学 {Chunhui.Wang5,bowen.zhang3}@geely.com, zengchang@nii.ac.jp, zym.22@sjtu.edu.cn {Yefan.Zhu, Zifeng.Cai, Jian.Zhao9, zhonglin.jiang, yong.chen}@geely.com
1简介
在过去的十年中,取得了显着的进步 Goodfellow 等人 (2014);金玛和威灵 (2014); Van Den Oord 等人 (2017); Dinh 等人 (2015); Vaswani 等人 (2017);何等人(2020)在深度学习和神经网络技术方面取得了进展,使文本转语音(TTS)从声学模型的级联方式演变而来王等人( 2017);李等人 (2019); Kim 等人 (2020); Popov 等人 (2021) 和声码器 van den Oord 等人 (2016);孔等人 (2020);王等人 (2022); Kong 等人 (2021) 到完全端到端 (E2E) 风格 Ren 等人 (2021); Kim 等人 (2021);王等人 (2023a);江等人 (2023);谭等人 (2021). 这些方法不仅能够快速生成高质量的语音,而且擅长合成更具挑战性的声音表达,例如唱歌Lu等人(2020);王等人(2023b,d)。 然而,大多数TTS系统利用频域中的MFCC等连续声学特征作为建模的中间表示,由于语义和声学信息的混合以及难以解开,阻碍了在音色零样本场景中生成高质量的语音Zhang 等人 (2023);杨等人 (2023b).
最近,基于代币的 TTS Borsos 等人 (2022);王等人 (2023a);杨等人 (2023a);沉等人 (2023);王等人 (2023c); Song等人(2024)方法因其在零样本场景中合成高质量语音的潜力而受到学术界和工业界的广泛关注。 其中,神经音频编解码器Zeghidour等人(2021); Défossez 等人 (2022); Yang 等人 (2023b) 已展现出作为 TTS 建模中间表示的巨大潜力。 例如,VALL-E Wang 等人 (2023a) 利用大语言模型 Radford 等人 (2019);布朗等人 (2020); Touvron 等人 (2023a, b) 可以近似神经音频编解码器 Défossez 等人 (2022) 的分布,并且可以在短短三秒内合成非常模仿目标说话者声音的语音样本。 然而,尽管它们的能力很有前途,但我们观察到这些模型常常难以保持准确的发音、一致的说话风格以及合成语音的音色。 此外,对大量且多样化的训练数据的大量需求进一步限制了它们的广泛采用。
为了解决这些问题,我们提出了一种H层次A声学M建模方法,即HAM-TTS,并为基于代币的 TTS 模型 Borsos 等人 (2022);王等人 (2023a);杨等人(2023a)。 具体来说,为了减轻之前研究中直接建模从文本到神经音频编解码器的映射的难度,我们基于 HuBERT Hsu 等人 (2021) 结合了包含补充声学信息的潜在变量序列(LVS)特征进入TTS模型。 文本到 LVS 预测器与 TTS 模型同时优化。 在推理阶段,预测器将文本提示转换为 LVS,以提供命令式声学信息以减少发音错误。
不幸的是,由于HuBERT特征中包含的个性化信息干扰了音频提示,因此基于简单的HuBERT特征生成LVS无法解决合成语音中说话风格不一致的问题。 因此,我们应用 K-Means Ahmed 等人 (2020) 聚类方法来细化 HuBERT 特征,以去除说话风格等个性化信息,使 TTS 模型能够利用剩余的声学信息来改进发音准确,同时在整个合成语音中保持一致的说话风格和音频提示。
音色不一致是基于 token 的 TTS 系统的另一个严重问题Borsos 等人 (2022)。 我们设计了一种音色一致性数据增强策略来训练所提出的 HAM-TTS 系统以对其进行修改。 具体来说,我们用从其他训练话语中选择的一小部分随机替换训练样本的连续片段,或者复制训练样本的连续片段,同时迫使模型预测原始话语。 它增强了零样本场景中合成语音的音色一致性。
如Borsos 等人 (2022) 所示;王等人 (2023a); Shen 等人 (2023),基于 token 的 TTS 方法需要大量的训练数据来赋予模型合成多样化和高质量语音的能力。 在本文中,我们没有单独使用大量真实语音数据进行训练,而是利用预训练的基于 UNet 的 Ronneberger 等人 (2015) 少样本语音转换模型来生成内容相同但音色不同的语音作为补充数据集,使模型能够显式学习一对多映射知识,有利于提高生成语音的多样性和音色一致性。
我们在大规模的中国国内数据集上训练了许多具有不同配置的模型,并在公共 AISHELL1 数据集 Bu 等人 (2017) 上对其进行了评估。 我们将 HAM-TTS 与作为我们基线的最先进 (SOTA) VALL-E 模型进行了严格比较。 这些实验在大量数据集上进行,结果清楚地表明了我们的方法相对于基线模型的优势,展示了 HAM-TTS 的增强功能,特别是在挑战零时的发音准确性、说话风格一致性和音色连续性方面。样本场景。
2相关作品
虽然有很多研究Tokuda等人(2013);理与禅(2016);王等人 (2017);李等人 (2019);任 等人 (2021); Kim 等人 (2021); Wang等人(2023a)专注于TTS,在本节中,我们仅简要回顾一些关于神经音频编解码器和基于它们的语音生成模型的代表性工作,以便与我们的工作更紧密地联系。
2.1神经音频编解码器
神经音频编解码器的最新进展,如 Zeghidour 等人 (2021) 所示; Défossez 等人 (2022); Yang等人(2023b),显着增强了语音合成领域的能力。 这些研究共同强调了神经编解码器在编码和解码音频数据方面的效率,与传统方法相比,提供了更紧凑、更灵活的表示。
Soundstream Zeghidour 等人 (2021) 引入了一种新颖的端到端神经音频编解码器框架,演示了通过残差矢量量化将音频信号有效压缩到离散潜在空间中。 这一进步有助于从紧凑的表示中生成高质量的音频,突出了编解码器在各种音频应用中的多功能性。
Encodec Défossez 等人 (2022) 进一步探索了这一领域,强调了编解码器在有效压缩音频数据同时保持质量方面的作用。 它的方法展示了神经编解码器在处理复杂音频任务时减少数据需求的潜力,这是资源受限环境中的一个关键因素。
在我们的研究中,这些对神经音频编解码器的见解为开发稳健且高效的基于令牌的 TTS 模型奠定了基础。 神经编解码器增强的保真度和效率直接影响我们的方法,使我们能够实现卓越的语音合成质量,特别是在零样本场景中。
2.2基于标记的语音生成模型
越来越多的研究Borsos 等人 (2022);王等人 (2023a);沉等人 (2023);王等人 (2023c); Song等人(2024)开始尝试使用神经音频编解码器作为语音生成的中间表示。 这些方法凸显了该领域关于神经编解码器在处理复杂任务方面的有效性日益增长的共识。
AudioLM Borsos 等人 (2022) 代表了通过采用语言建模方法来生成音频的重大飞跃。 它特别突出的是它能够生成连贯且上下文适当的语音,这归因于它对输入条件下的潜在向量的高级使用。 该模型演示了神经编解码器 Zeghidour 等人 (2021) 的集成如何促进多样化、高质量语音的生成。
另一方面,VALL-E Wang 等人 (2023a) 利用神经编解码器 Défossez 等人 (2022) 的能力来近似大型语言模型,从而实现综合从最小样本中密切模仿目标说话者的声音的语音。
NaturalSpeech2 Shen 等人 (2023) 通过将神经音频编解码器与扩散模型等附加组件集成,进一步发展了这些概念。 它对零样本合成功能和韵律的重视凸显了该模型的稳健性和多功能性,特别是在生成不同的语音风格并在各种场景下保持语音质量方面。
这些研究共同强调了神经编解码器在语音生成中的重要性,并为我们的研究铺平了道路。 在我们的工作中,我们在此基础上提出了一种新颖的分层声学建模方法,以提高发音准确性和说话风格的一致性,同时利用数据增强策略和合成数据来强调生成声音的音色一致性和多样性。
3HAM-TTS
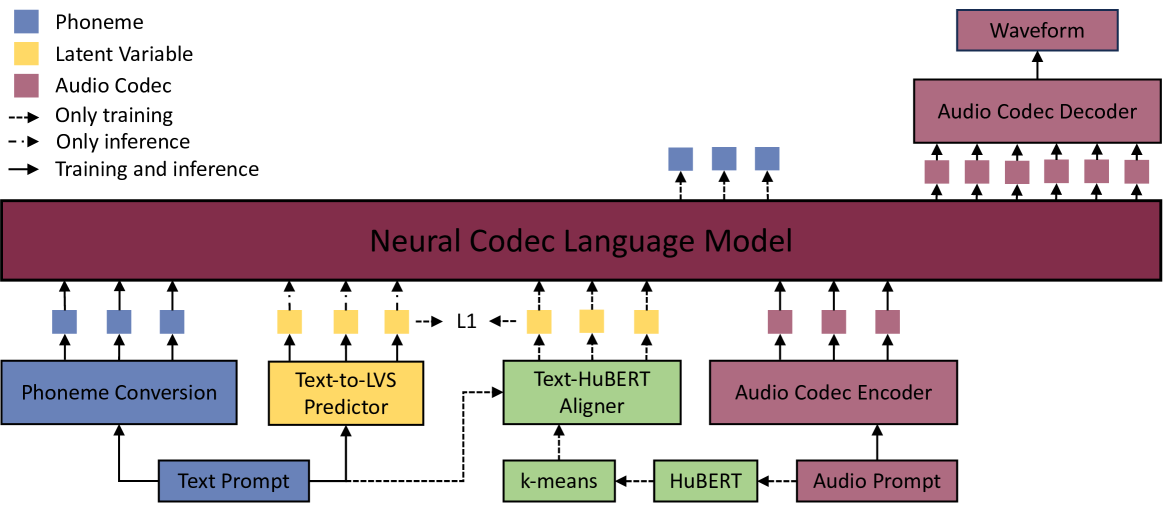
本节介绍 HAM-TTS 模型。 如图1所示,除了源自现有TTS模型(如VALL-E)的音素转换和音频编解码器编码器组件之外,我们还设计了一个预测器来直接将文本提示转换为潜在变量序列(LVS)在推理阶段将补充声学信息合并到神经编解码器语言模型中。 预测器在训练阶段通过 Text-HuBERT 对齐器输出的监督信号与 TTS 模型联合优化,该对齐器利用交叉注意力机制 Li 等人 (2023) 来对齐音素序列和通过 K-Means 聚类细化的 HuBERT 特征来生成 LVS。 3.1 节介绍了 Text-HuBERT 对齐器和 Text-to-LVS 预测器的详细设计。 音色一致性数据增强策略是我们对修正合成语音中音色不一致问题的工作的另一个重要贡献。 具体参见3.2节。 最后,由预训练的少样本语音转换模型生成的补充合成数据集在3.3节中详细阐述。 我们实验中使用的模型的详细配置将在附录A.1中说明。
3.1 分层声学建模
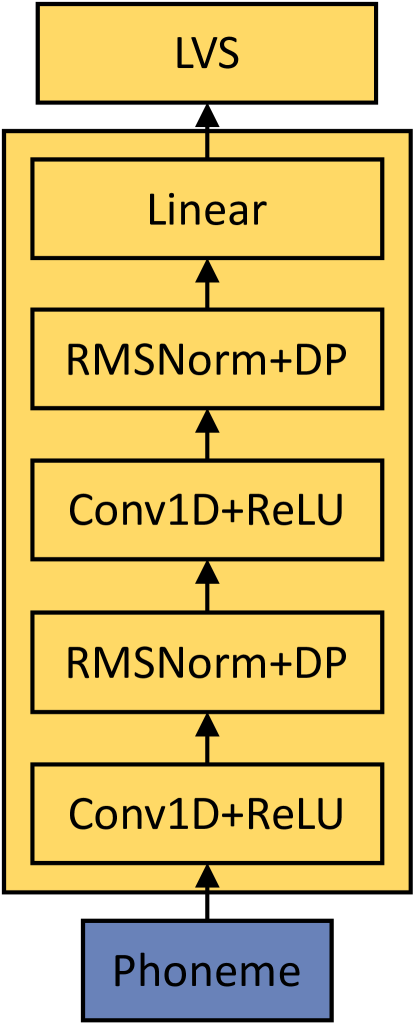
我们观察到,之前的研究如 AudioLM Borsos 等人 (2022) 和 VALL-E Wang 等人 (2023a) 偶尔会产生发音不正确的语音。 这主要是由于在没有足够的声学信息的情况下直接将文本映射到神经音频编解码器序列的局限性。 为了解决这个问题,如图2所示的Text-to-LVS预测器被提出来在推理阶段生成包含来自音素序列的命令性声学信息的潜在变量序列,其可以表示为:
| (1) |
其中 表示具有 个音素单元的音素序列。 表示预测器变换的函数。 是生成的与音素序列长度相同的LVS。 LVS 与相应的音素序列连接。 在此串联之后,组合序列通过卷积层进行转换,以与神经音频编解码器所需的维度对齐,然后将其馈送到编解码器语言模型。 它可以表示为,
| (2) |
其中 是与音频编解码器的维度对齐的输出。
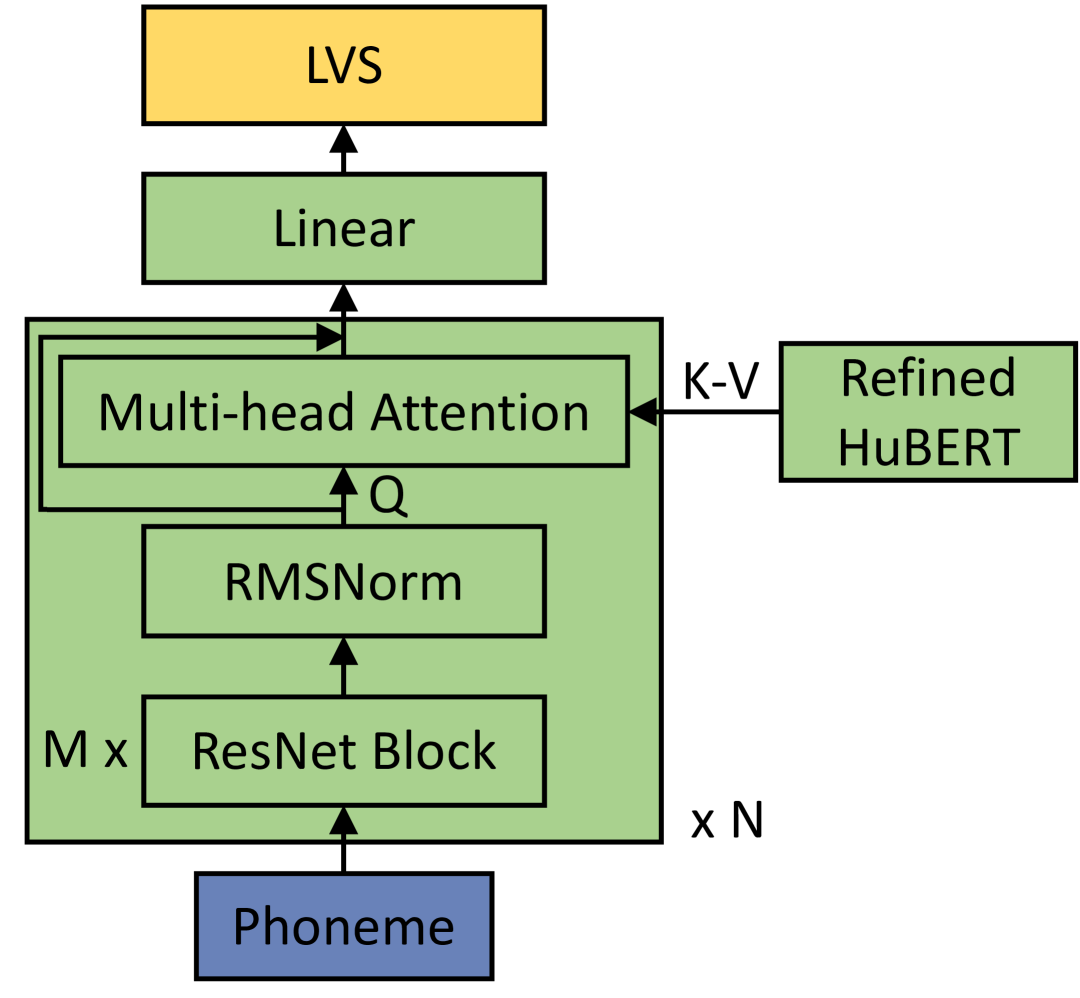
如图1所示,在训练阶段,文本到LVS预测器通过另一个新模块(即Text-HuBERT对齐器)生成的监督信号与神经编解码器语言模型同时进行优化。 对齐器由具有相同架构的块组成,如图3所示。 每个块包含个残差卷积网络He等人(2015)在图中表示为ResNet Block,后面跟着一个均方根层归一化(RMSNorm)张和Sennrich (2019),最后利用多头注意力层 Vaswani 等人 (2017) 将 RMSNorm 的输出序列与 HuBERT Hsu 等人 (2021) 对齐) 通过 K-Means 聚类细化的特征(键和值)。 与 Transformer 模型 Vaswani 等人 (2017) 中使用的标准层归一化不同,我们在对齐器中采用了 RMSNorm,增强了其处理复杂序列的能力并实现更快的收敛。 具有相同长度的音素序列的监督 LVS 可以通过以下方式计算:
| (3) |
其中 是长度为 的精炼 HuBERT 特征序列, 表示监督 LVS。 表示Text-HuBERT对齐器模块的功能。 请注意,必须利用 K-Means 聚类从原始 HuBERT 特征中删除个性化信息,以修正零样本场景中合成语音中说话风格的突变。
和 之间的近似值通过 L1 损失函数测量,如下所示:
| (4) |
其中 是衡量 与 接近程度的指标。
3.2音色一致性数据增强
尽管当代基于标记的 TTS 系统 Wang 等人 (2023a);但在零样本场景中,合成语音的音色不一致一直是困扰 TTS 系统的一个不可忽视的问题。 Yang等人(2023a)声称可以实现音色克隆。 在本节中,我们将说明针对此问题提出的音色一致性数据增强策略。
为了确保合成语音的音色一致性,我们对训练数据实施了数据增强策略。 具体来说,在加载一批语音数据的过程中,对于10%的部分,我们要么从另一个样本中随机选择一个连续的片段来替换当前样本中的片段,要么从同一样本中随机复制一个片段并将其连接到该部分的结尾。 在损失计算中,来自没有数据增强的样本的神经音频编解码器被视为用于使用生成的编解码器计算交叉熵损失的基本事实。 这种方法使模型能够对音色扰动产生强大的抵抗力。 因此,它可以防止短期音色变化影响整个生成语音片段的音色,从而保证合成语音的音色一致性。
3.3 补充综合数据集
训练 TTS 模型需要大量语音数据,这一事实让许多学术研究人员望而却步。 例如,Audiobox Vyas 等人 (2023) 将训练数据规模扩大到 10 万小时,这对于学术机构来说收集这么多数据是一个沉重的负担。 同时,未经授权使用真实数据也存在诸多法律风险。 这些事实促使我们考虑使用合成数据来训练 TTS 模型。 在本节中,我们将展示如何生成合成数据作为真实数据的补充数据集。
现实世界中对于音色单一、持续时间较长的语音,尤其是十几秒以上的语音,很难采集到大量的数据,这导致训练语音合成模型时,对于持续时间较长的语音数据稀疏,也使得训练的难度更大。模型在生成长语音时很难保证整个句子音色的一致性。 考虑到这一点,我们利用预训练的基于 UNet 的 Ronneberger 等人 (2015) 少样本语音转换模型,具体说明在附录 A.2 中,以生成一个大型语音转换模型。大量的长语音数据来弥补真实数据的缺乏。 我们从真实数据中随机选择 1,000 个具有几分钟语音的说话者作为候选者,并为每个候选者转换训练数据集中大约 500 小时的真实语音,其持续时间范围为 10 到 20 秒。 因此,大量的合成数据通过明确地为长语音场景提供一对多映射,提高了训练数据的多样性,这与之前的研究不同 Wang 等人 (2017);任 等人 (2021); Borsos 等人 (2022); Wang等人(2023a),其中仅考虑音素级多样性。
3.4损失函数
我们遵循 VALL-E Wang 等人 (2023a) 的训练策略,将 TTS 作为条件编解码器语言建模任务。 两个 Transformer Vaswani 等人 (2017) 仅解码器编解码器语言模型分别经过自回归 (AR) 和非自回归 (NAR) 建模的训练。 我们利用交叉熵(CE)损失函数来测量编解码器的真实分布和学习分布之间的距离。 它可以表述为,
| (5) |
其中 和 分别表示真实值和合成值的编解码器序列。 表示编解码序列的长度。 是编解码器生成的损失。
此外,为了增强HAM-TTS处理语义信息的能力,在AR编解码器LM和NAR编解码器LM上计算教师强迫损失以拟合输入文本的分布,相应的CE损失函数如下所示:
| (6) |
其中表示合成的音素序列。 是文本生成的损失。
4实验
| Model | #Params | CER%() | NMOS() | SMOS() | MOS() |
|---|---|---|---|---|---|
| GT | - | 2.6 | 4.030.08 | 4.300.06 | 4.450.07 |
| VALL-E | 426M | 5.5 | 3.650.15 | 4.030.12 | 4.050.10 |
| HAM-TTS-S | 421M | 4.0 | 3.790.11 | 4.120.10 | 4.270.08 |
| HAM-TTS-L | 827M | 3.2 | 4.010.07 | 4.260.09 | 4.450.07 |
4.1 实验设置
数据集:所有 TTS 模型均在我们内部的中文语音数据集(包括真实语音和合成语音)上进行训练。 该数据集包括 15 万小时的真实语音和 50 万小时的合成语音。 真实的语音组件包含大约 20,000 个说话者,每个音频片段的长度在 5 到 20 秒之间,采样率为 24kHz。 另一方面,合成语音数据集来自 1,000 个说话者,每个音频片段的长度从 10 到 20 秒不等。 这个广泛且多样化的数据集在我们模型的稳健训练和性能中发挥着关键作用。 测试数据方面,我们从公开的 AISHELL1 数据集 Bu 等人 (2017) 中选取了 50 个说话者,每个说话者有 5 个句子,持续时间从 5 到 20 秒不等。 由于我们的训练数据与公共数据集没有重叠,因此所有测试说话者都是看不见的,旨在展示我们模型的零样本能力。
基线:VALL-E Wang 等人 (2023a) 被用作我们实验中的基线模型,因为它是基于 token 的 TTS 系统的代表性 SOTA 工作。 由于没有可用的官方实现,我们在内部数据集上复制并训练了它。
评估指标:我们从三个方面评估所有模型:发音准确性、说话风格一致性和音色一致性。 发音准确度以字符错误率 (CER) 指标表示,该指标由预训练的 Whisper Radford 等人 (2023) 模型222https://huggingface.co/espnet/pengcheng_aishell_asr_tra
in_asr_whisper_medium_finetune_raw_zh_whisper_multilin
gual_sp由 ESPNet Watanabe 等人 (2018)0> 提供。 说话风格的一致性是通过关于语音自然度的平均意见得分(NMOS)来评估的,因为说话风格的突变是可以从听众的反馈中感知到的。 音色一致性通过说话者相似度 MOS (SMOS) 指标来评估。 此外,我们还要求所有听众对测试数据的整体质量进行评估,包括自然度、音频质量和发音准确性。 它以 MOS 指标表示。 至于听众人数,我们雇佣了60人参加测试。 每个听众都会评估所有话语的表现。 我们相信,如此规模的听力测试将为实验提供一个相对客观的结果。
4.2初步实验结果
在我们的实验分析中,如表 1 所示,所有模型均专门基于 15 万小时的真实数据进行训练。 HAM-TTS 模型设计有两种变体:HAM-TTS-S 和 HAM-TTS-L,探索不同规模的参数化。 HAM-TTS-S 与 VALL-E 匹配 421M 参数,确保公平比较,而 HAM-TTS-L 则扩展到 827M 参数,旨在释放 HAM-TTS 的全部潜力。 这种缩放对于评估我们的模型在各种参数配置中的有效性至关重要。
在表中,我们复制的 VALL-E 的 CER 为 5.5%,NMOS 为 3.65,SMOS 为 4.03,总体 MOS 为 4.05,与原始 VALL-E 论文 Wang 等人中提出的结果一致(2023a),表明我们实验设置的可靠性。 这些结果证明了 VALL-E 在生成语音方面的熟练程度,但也突出了需要改进的地方,特别是与 GT 的结果相比,在发音准确性和自然度方面。 HAM-TTS-S模型的CER为4.0%,低于VALL-E的5.5%,表明发音准确性更好。 其 NMOS 为 3.79,SMOS 为 4.12 也超过了 VALL-E,这表明感知质量和说话者相似度有所提高。 HAM-TTS-L 进一步改进了这些指标,记录了 3.2% 的 CER,NMOS 和 SMOS 分数与 GT 相当,说明了 HAM-TTS 模型在生成高质量、真实语音方面的可扩展性和有效性。 这些结果证明了HAM-TTS模型在发音准确性以及说话风格和音色一致性方面的优越性。
4.3K-Means的消融研究
| Model | CER%() | NMOS() | MOS() |
|---|---|---|---|
| GT | 2.6 | 4.300.06 | 4.450.09 |
| w/o K-Means | 4.2 | 3.630.12 | 4.140.08 |
| HAM-TTS-S | 4.0 | 3.790.11 | 4.270.08 |
在我们的 HAM-TTS 模型中,我们采用 K-Means 聚类技术来细化 HuBERT 特征。 该方法旨在去除说话风格等个性化信息,使TTS模型能够专注于核心声学信息,以提高发音准确性,并在整个合成语音中保持与音频提示一致的说话风格。
我们的实验结果中的表2展示了我们模型中K-Means聚类的有效性。 我们比较了应用和不应用 K-Means 聚类的 HAM-TTS-S 的性能。 结果表明,K-Means聚类的应用进一步提高了模型的性能。 具体来说,没有 K-Means 聚类的 HAM-TTS-S 的 CER 为 4.2%,而实施 K-Means 聚类将 CER 降低到 4.0%。 CER 的降低表明发音准确性的提高,这是改进的 HuBERT 功能提供更准确的声学信息的直接结果。
此外,通过使用 K-Means 聚类,NMOS 和整体 MOS 也略有改善。 NMOS从3.63增加到3.79,MOS从4.14增加到4.27,这表明用细化特征合成的语音被听众认为更自然、质量更高。 这些结果清楚地说明了 K-Means 聚类在增强 HAM-TTS-S 整体性能方面的影响,证实了其在合成语音中提供更准确和一致的说话风格方面的有效性。
4.4合成数据的消融研究
| Training data | CER%() | SMOS() | MOS() |
|---|---|---|---|
| GT | 2.6 | 4.300.06 | 4.450.07 |
| 150k(R) | 4.0 | 4.120.10 | 4.270.08 |
| 150k(R)+150k(S) | 3.6 | 4.260.09 | 4.320.07 |
| 150k(R)+500k(S) | 2.8 | 4.320.07 | 4.490.08 |
| 150k(S) | 4.5 | 4.050.10 | 4.100.13 |
| 300k(S) | 4.1 | 4.130.07 | 4.250.08 |
| 500k(S) | 3.3 | 4.250.06 | 4.350.06 |
在我们的 HAM-TTS 模型中,合成数据在增强生成语音的多样性和质量方面发挥着关键作用。 我们通过一系列实验重点展示了这些合成数据的影响,其结果详见表 3。
实验使用 HAM-TTS-S 模型进行,并根据真实数据和合成数据的不同组合和大小进行训练。 我们的研究结果清楚地表明了合成数据给模型性能带来的显着改进。 当仅使用 15 万小时的真实数据进行训练时,HAM-TTS-S 模型的 CER 为 4.0%,SMOS 为 4.12,总体 MOS 为 4.27。 然而,当使用合成数据进行增强时,所有指标都有显着改善。
具体来说,使用额外 150k 小时的合成数据 (150k(R)+150k(S)) 进行训练可将 CER 降低至 3.6%,并进一步将 SMOS 提高至 4.26,MOS 提高至 4.32。 当模型使用额外 50 万小时的合成数据 (150k(R)+500k(S)) 进行训练时,这种改进更加明显,导致 CER 为 2.8%,SMOS 为 4.32,MOS 为 4.49。 这些结果清楚地表明,合成数据不仅有助于减少发音错误,而且还显着提高了合成语音的质量,因为它使模型能够显式学习话语级一对多映射的知识。
此外,结果强调了仅基于合成数据训练 HAM-TTS 模型的前景。 当使用不同数量的合成数据(150k(S)、300k(S) 和 500k(S))训练模型时,我们观察到所有评估指标都在稳步提高,接近在真实数据上训练的模型的性能水平。 使用 50 万小时的合成数据训练的模型实现了 3.3% 的 CER,与使用真实数据和合成数据组合训练的模型的 2.8% CER 非常接近。 这一发现特别有前景,因为它表明即使在访问大量真实语音数据受到限制的情况下也可以开发高质量的 TTS 系统,这凸显了合成数据在训练有效语音合成模型中的潜力。
这些发现说明了合成数据在提高 HAM-TTS 模型性能方面的显着影响,无论是与真实数据结合使用还是单独使用时,都标志着语音合成领域的重大进步。
5 结论和未来工作
在这项研究中,我们引入了 HAM-TTS,这是一种利用分层声学建模方法的新型文本转语音系统。 该系统集成了先进的技术,例如用于细化 HuBERT 特征的 K-Means 聚类,以及结合真实数据和合成数据的综合策略。 我们的实验证明了 HAM-TTS 在提高零样本场景中的发音准确性、说话风格一致性和音色一致性方面的有效性。
尽管取得了这些重大进展,未来的工作可以探索合成数据在说话者多样性和每个说话者持续时间方面的最佳组合。 这方面可能会进一步增强处理各种语音变化的能力。 此外,优化 HAM-TTS 模型的推理速度对于增强其实际可用性、使其适合实时应用和用户交互至关重要。 对这些途径的探索将为语音合成领域的发展做出重大贡献。
局限性
我们承认,虽然我们的 HAM-TTS 模型已展现出显着的进步,但某些方面仍未得到探索,并为未来的研究提供了机会。 其中一个领域是在说话者多样性和每个说话者持续时间方面的合成数据的最佳组合。 我们尚未调查是否更多的发言者(每个发言者的持续时间较短)或更少的发言者但每个发言者的持续时间更长(更有利)。 这方面对于增强模型处理各种语音变化的能力至关重要,并有可能进一步提高模型的性能。
另一个限制是 HAM-TTS 模型的推理速度。 尽管该模型实现了高质量的语音合成,但当前的推理过程并没有达到应有的效率。 这一领域还有很大的改进空间,特别是在减少生成语音所需的时间方面。 优化模型架构和简化推理流程可以显着增强 HAM-TTS 的实际可用性,使其更适合实时应用和用户交互。
解决这些限制将是我们未来工作的重点,旨在进一步完善HAM-TTS模型并扩展其在各种语音合成场景中的适用性。
道德声明
这项研究遵循人工智能和语音合成的道德标准,强调数据隐私、同意和包容性。 我们解决数据集中可能存在的偏见,并确保不同声音的公平性。 认识到滥用的风险,我们提倡负责任的使用和方法的透明度。 我们的工作旨在为技术进步做出积极贡献,平衡创新与社会和个人福祉。
参考
- Ahmed et al. (2020) Mohiuddin Ahmed, Raihan Seraj, and Syed Mohammed Shamsul Islam. 2020. The K-Means Algorithm: A Comprehensive Survey And Performance Evaluation. Electronics, 9(8):1295.
- Borsos et al. (2022) Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matthew Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, and Neil Zeghidour. 2022. AudioLM: A Language Modeling Approach to Audio Generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:2523–2533.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language Models Are Few-Shot Learners. Advances in neural information processing systems, 33:1877–1901.
- Bu et al. (2017) Hui Bu, Jiayu Du, Xingyu Na, Bengu Wu, and Hao Zheng. 2017. AISHELL-1: An Open-Source Mandarin Speech Corpus and A Speech Recognition Baseline. In 2017 20th conference of the oriental chapter of the international coordinating committee on speech databases and speech I/O systems and assessment (O-COCOSDA), pages 1–5. IEEE.
- Défossez et al. (2022) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2022. High Fidelity Neural Audio Compression. arXiv preprint arXiv:2210.13438.
- Dinh et al. (2015) Laurent Dinh, David Krueger, and Yoshua Bengio. 2015. NICE: Non-linear Independent Components Estimation.
- Goodfellow et al. (2014) Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. Generative Adversarial Networks. Advances in neural information processing systems, 27.
- He et al. (2015) Kaiming He, X. Zhang, Shaoqing Ren, and Jian Sun. 2015. Deep Residual Learning for Image Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778.
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising Diffusion Probabilistic Models. Advances in neural information processing systems, 33:6840–6851.
- Hsu et al. (2021) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. Hubert: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29:3451–3460.
- Jang et al. (2021) Won Jang, Daniel Chung Yong Lim, Jaesam Yoon, Bongwan Kim, and Juntae Kim. 2021. UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation. In Interspeech.
- Jiang et al. (2023) Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Chen Zhang, Zhenhui Ye, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, et al. 2023. Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts. arXiv preprint arXiv:2307.07218.
- Kim et al. (2020) Jaehyeon Kim, Sungwon Kim, Jungil Kong, and Sungroh Yoon. 2020. Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search. Advances in Neural Information Processing Systems, 33:8067–8077.
- Kim et al. (2021) Jaehyeon Kim, Jungil Kong, and Juhee Son. 2021. Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech. In International Conference on Machine Learning, pages 5530–5540. PMLR.
- Kingma and Ba (2015) Diederik Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In International Conference on Learning Representations (ICLR).
- Kingma and Welling (2014) Diederik P. Kingma and Max Welling. 2014. Auto-Encoding Variational Bayes. In 2nd International Conference on Learning Representations, ICLR 2014.
- Kong et al. (2020) Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. 2020. HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis. Advances in Neural Information Processing Systems, 33:17022–17033.
- Kong et al. (2021) Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. 2021. DiffWave: A Versatile Diffusion Model for Audio Synthesis. In 9th International Conference on Learning Representations, ICLR 2021.
- Li and Zen (2016) Bo Li and Heiga Zen. 2016. Multi-Language Multi-Speaker Acoustic Modeling for LSTM-RNN Based Statistical Parametric Speech Synthesis. In Interspeech.
- Li et al. (2023) Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models. In Proceedings of the 40th International Conference on Machine Learning (ICML) 2023. JMLR.
- Li et al. (2019) Naihan Li, Shujie Liu, Yanqing Liu, Sheng Zhao, and Ming Liu. 2019. Neural Speech Synthesis with Transformer Network. Proceedings of the AAAI Conference on Artificial Intelligence, page 6706–6713.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. SGDR: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations.
- Lu et al. (2020) Peiling Lu, Jie Wu, Jian Luan, Xu Tan, and Li Jun Zhou. 2020. XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System. In Interspeech.
- Popov et al. (2021) Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail Kudinov. 2021. Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech. In International Conference on Machine Learning, pages 8599–8608. PMLR.
- Radford et al. (2023) Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2023. Robust Speech Recognition via Large-Scale Weak Supervision. In Proceedings of the 40th International Conference on Machine Learning. JMLR.org.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language Models Are Unsupervised Multitask Learners. OpenAI blog, 1(8):9.
- Ren et al. (2021) Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2021. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. In 9th International Conference on Learning Representations, ICLR 2021.
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer.
- Shen et al. (2023) Kai Shen, Zeqian Ju, Xu Tan, Yanqing Liu, Yichong Leng, Lei He, Tao Qin, Sheng Zhao, and Jiang Bian. 2023. NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers. arXiv preprint arXiv:2304.09116.
- Song et al. (2024) Yakun Song, Zhuo Chen, Xiaofei Wang, Ziyang Ma, and Xie Chen. 2024. Ella-v: Stable neural codec language modeling with alignment-guided sequence reordering. arXiv preprint arXiv:2401.07333.
- Srivastava et al. (2014) Nitish Srivastava, Geoffrey E. Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res., 15:1929–1958.
- Tan et al. (2021) Xu Tan, Tao Qin, Frank Soong, and Tie-Yan Liu. 2021. A Survey on Neural Speech Synthesis. arXiv preprint arXiv:2106.15561.
- Tokuda et al. (2013) Keiichi Tokuda, Yoshihiko Nankaku, Tomoki Toda, Heiga Zen, Junichi Yamagishi, and Keiichiro Oura. 2013. Speech Synthesis Based on Hidden Markov Models. Proceedings of the IEEE, 101(5):1234–1252.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. LLaMA 2: Open Foundation and Fine-Tuned Chat Models. arXiv preprint arXiv:2307.09288.
- van den Oord et al. (2016) Aäron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew W. Senior, and Koray Kavukcuoglu. 2016. WaveNet: A Generative Model for Raw Audio. In The 9th ISCA Speech Synthesis Workshop, page 125.
- Van Den Oord et al. (2017) Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural Discrete Representation Learning. Advances in neural information processing systems, 30.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention Is All You Need. Advances in neural information processing systems, 30.
- Vyas et al. (2023) Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, et al. 2023. Audiobox: Unified Audio Generation with Natural Language Prompts. arXiv preprint arXiv:2312.15821.
- Wang et al. (2023a) Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. 2023a. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. arXiv preprint arXiv:2301.02111.
- Wang et al. (2022) Chunhui Wang, Chang Zeng, Jun Chen, and Xing He. 2022. HiFi-WaveGAN: Generative Adversarial Network with Auxiliary Spectrogram-Phase Loss for High-Fidelity Singing Voice Generation. arXiv preprint arXiv:2210.12740.
- Wang et al. (2023b) Chunhui Wang, Chang Zeng, and Xing He. 2023b. Xiaoicesing 2: A High-Fidelity Singing Voice Synthesizer Based on Generative Adversarial Network. In Proc. Interspeech 2023, pages 5401–5405.
- Wang et al. (2023c) Jiaming Wang, Zhihao Du, Qian Chen, Yunfei Chu, Zhifu Gao, Zerui Li, Kai Hu, Xiaohuan Zhou, Jin Xu, Ziyang Ma, et al. 2023c. LauraGPT: Listen, attend, understand, and regenerate audio with GPT. arXiv preprint arXiv:2310.04673.
- Wang et al. (2023d) Xintong Wang, Chang Zeng, Jun Chen, and Chunhui Wang. 2023d. Crosssinger: A Cross-Lingual Multi-Singer High-Fidelity Singing Voice Synthesizer Trained on Monolingual Singers. In 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pages 1–6. IEEE.
- Wang et al. (2017) Yuxuan Wang, R. J. Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Z. Chen, Samy Bengio, Quoc V. Le, Yannis Agiomyrgiannakis, Robert A. J. Clark, and Rif A. Saurous. 2017. Tacotron: Towards End-to-End Speech Synthesis. In Interspeech.
- Watanabe et al. (2018) Shinji Watanabe, Takaaki Hori, Shigeki Karita, Tomoki Hayashi, Jiro Nishitoba, Yuya Unno, Nelson Enrique Yalta Soplin, Jahn Heymann, Matthew Wiesner, Nanxin Chen, Adithya Renduchintala, and Tsubasa Ochiai. 2018. ESPnet: End-to-end speech processing toolkit. In Proceedings of Interspeech, pages 2207–2211.
- Yang et al. (2023a) Dongchao Yang, Songxiang Liu, Rongjie Huang, Guangzhi Lei, Chao Weng, Helen Meng, and Dong Yu. 2023a. InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt. arXiv preprint arXiv:2301.13662.
- Yang et al. (2023b) Dongchao Yang, Songxiang Liu, Rongjie Huang, Jinchuan Tian, Chao Weng, and Yuexian Zou. 2023b. HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec. arXiv preprint arXiv:2305.02765.
- Zeghidour et al. (2021) Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. 2021. Soundstream: An End-to-End Neural Audio Codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:495–507.
- Zhang and Sennrich (2019) Biao Zhang and Rico Sennrich. 2019. Root Mean Square Layer Normalization. Advances in Neural Information Processing Systems, 32.
- Zhang et al. (2023) Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. 2023. SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities. arXiv preprint arXiv:2305.11000.
附录A附录
A.1型号详细信息
| Component | Config | Value |
| Phoneme Conversion | Embedding Layer | 1024 |
| Audio Codec EncoderDéfossez et al. (2022) | Quantizer | 8 |
| Codebook Size | 1024 | |
| Codebook Dimension | 1024 | |
| Codec Language Model | Attention Block | 14333为了与HAM-TTS-S模型进行公平比较,我们通过增加两个额外参数将VALL-E的参数数量增加到可比较的水平注意力块。 |
| Heads | 16 | |
| Hidden Size | 4096 | |
| Dropout | 0.1 | |
| Output Affine Layer | 1024 |
HAM-TTS基于VALL-E框架构建,继承了某些关键架构特征。 与 VALL-E 类似,HAM-TTS 包含两个不同的 Transformer 解码器。 这些解码器是模型设计不可或缺的一部分,每个解码器在语音合成过程中都有特定的用途。
HAM-TTS 中的 Transformer 解码器之一专用于自回归建模。 该解码器在基于先前生成的元素顺序预测输出的每个元素方面发挥着至关重要的作用,从而捕获语音序列中的时间依赖性。
HAM-TTS 中的另一个 Transformer 解码器用于非自回归建模。 这种方法允许并行生成输出元素,这可以通过减少对顺序生成过程的依赖来显着提高模型的效率。
| Component | Config | Value |
| Phoneme Conversion | Embedding Layer | 1024 |
| Audio Codec EncoderDéfossez et al. (2022) | Quantizer | 8 |
| Codebook Size | 1024 | |
| Codebook Dimension | 1024 | |
| Codec Language Model | Attention Block | 12 |
| Heads | 16 | |
| Hidden Size | 4096 | |
| Dropout | 0.1 | |
| Output Affine Layer | 1024 | |
| Text-to-LVS Predictor | Conv1D Layers | 2 |
| Conv1D Kernel Size | 3 | |
| Dropout | 0.1 | |
| Output Affine Layer | 2 | |
| Text-HuBERT Aligner | Attention Block | 10 |
| Heads | 8 | |
| Hidden Size | 4096 | |
| Dropout | 0.1 | |
| ResNet Block | 3 | |
| Conv1D Layer | 2 | |
| Conv1D Kernel Size | 3 | |
| Output Affine Layer | 2 |
| Component | Config | Value |
| Phoneme Conversion | Embedding Layer | 1024 |
| Audio Codec EncoderDéfossez et al. (2022) | Quantizer | 8 |
| Codebook Size | 1024 | |
| Codebook Dimension | 1024 | |
| Codec Language Model | Attention Block | 24 |
| Heads | 16 | |
| Hidden Size | 4096 | |
| Dropout | 0.1 | |
| Output Affine Layer | 1024 | |
| Text-to-LVS Predictor | Conv1D Layers | 2 |
| Conv1D Kernel Size | 3 | |
| Dropout | 0.1 | |
| Output Affine Layer | 2 | |
| Text-HuBERT Aligner | Attention Block | 10 |
| Heads | 8 | |
| Hidden Size | 4096 | |
| Dropout | 0.1 | |
| ResNet Block | 3 | |
| Conv1D Layer | 2 | |
| Conv1D Kernel Size | 3 | |
| Output Affine Layer | 2 |
A.2预训练的语音转换模型
我们采用图 4 所示的基于 UNet 的 Ronneberger 等人 (2015) 语音转换模型来生成 50 万小时的训练语音数据。
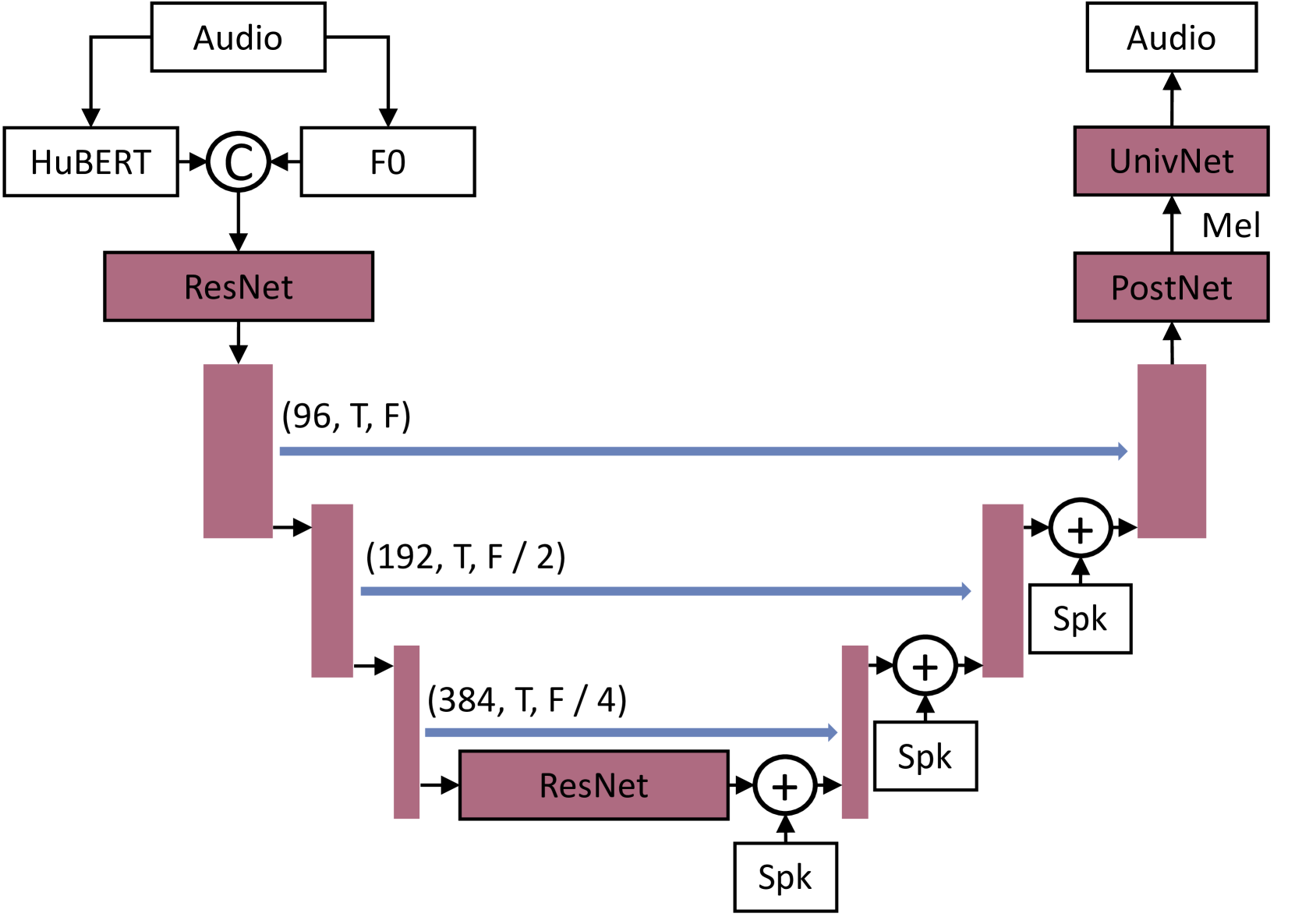
在此语音转换模型中,初始处理阶段涉及从输入音频中提取 HuBERT 和 F0 特征。 然后将这些提取的特征连接起来并输入到 ResNet 模块中进行预处理。 ResNet模块旨在对这些特征进行变换和细化,以(96,T,F)的维度输出它们,其中“T”和“F”分别代表时间和频率维度。
然后将该输出特征引入 UNet 架构的编码器中。 编码器对频率维度执行两次下采样,产生维度为 (384, T, F / 4) 的输出。 接下来,使用另一个 ResNet 模块来进一步细化编码器的输出。 然后将细化后的特征传递给 UNet 的解码器。
在解码过程中,频率维度经历了两阶段的上采样。 在每个上采样步骤之前,扬声器特性被集成到输入中。 这种集成对于确保合成语音保留说话者声音的独特属性至关重要。 解码器的最终输出的维度为(96,T,F),有效地恢复了原始频率维度。
值得注意的是,在整个 UNet 架构中,使用的卷积核的大小为 (1,7)。 这种特定的内核大小有助于捕获语音信号的基本时间和频谱特征。
下一阶段涉及将这些处理后的特征转换为最终波形。 这是通过使用 PostNet 和 UnivNet 声码器 Jang 等人 (2021) 来实现的,它们共同确保合成语音听起来自然,并且在音色和韵律方面与原始音频紧密匹配。
A.3训练方法
我们遵循 VALL-E 中使用的训练策略,采用双重训练方法来优化 HAM-TTS 模型在自回归 (AR) 和非自回归 (NAR) 建模中的性能。
AR 训练:AR 模型是在编码解码器模型 Défossez 等人(2022 年) 的第一个量化器中的序列 和音频编码解码器序列 的串联上训练的。 它可以表述为,
| (8) | |||
NAR训练:NAR模型用于从第二个到最后一个量化器的音频编解码器。 该模型以 、声音提示 以及来自先前码本的预测声音标记 为条件。 每个训练步骤都会随机采样量化器 ,并且训练模型以适应所选量化器码本中编解码器的分布。 它可以表述为,
| (9) | |||
| (10) |
AR 和 NAR 模型均使用 Adam 优化器 Kingma 和 Ba (2015) 进行优化,学习率设置为 0.03,并在前 15,000 个步骤中进行预热。 预热阶段后,使用 CosineAnnealingLR 调度程序 Loshchilov 和 Hutter (2017) 管理学习率。 该训练是在 512 个 NVIDIA A100 80GB GPU 的强大设置上进行的,模型处理的批量大小为 8k 声学标记。 这次大规模训练总共进行了 40 万步,利用 A100 GPU 强大的计算能力来有效处理大批量和大量训练步骤。