ConspEmoLLM:使用基于情感的大语言模型检测阴谋论
摘要
互联网给社会带来了好处,也带来了危害。 后者的一个典型例子是错误信息,包括充斥网络的阴谋论。 自然语言处理的最新进展,特别是大型语言模型(大语言模型)的出现,改善了准确错误信息检测的前景。 然而,大多数基于 LLM 的阴谋论检测方法仅关注二元分类,而未能考虑错误信息和情感特征(即情绪和情绪)之间的重要关系。 通过对阴谋文本的全面分析,揭示其独特的情感特征,我们提出了ConspEmoLLM,这是第一个集成情感信息并能够执行与阴谋论相关的各种任务的开源大语言模型。 这些任务不仅包括阴谋论检测,还包括理论类型的分类和相关讨论的检测(例如,对理论的看法)。 ConspEmoLLM 基于情感导向的大语言模型,使用我们新颖的 ConDID 数据集进行微调,其中包括五个任务来支持大语言模型指令调整和评估。 我们证明,当应用于这些任务时,ConspEmoLLM 在很大程度上优于几个开源通用领域大语言模型和 ChatGPT,以及使用 ConDID 进行微调但不使用情感特征的大语言模型。 该项目将在 https://github.com/lzw108/ConspEmoLLM/ 发布。
ConspEmoLLM:使用基于情感的大语言模型检测阴谋论
Zhiwei Liu, Boyang Liu, Paul Thompson, Kailai Yang, Sophia Ananiadou National Centre for Text Mining, Department of Computer Science The University of Manchester, Manchester, United Kingdom {zhiwei.liu-2, boyang.liu-2, kailai.yang}@postgrad.manchester.ac.uk {paul.thompson, sophia.ananiadou}@manchester.ac.uk
1简介
错误信息已成为社会的主要威胁之一。 互联网和社交媒体的兴起使得错误信息更容易迅速传播。 阴谋论是错误信息的一种,其虚假内容旨在造成伤害Napolitano 和 Reuter (2023)。 流行阴谋论的例子包括那些声称地球是平的和疫苗导致自闭症的阴谋论。 阴谋论者忽视科学证据,倾向于将事件解释为秘密行动Giachanou 等人 (2023)。 在COVID-19大流行期间,阴谋论的传播显着增加(例如,声称5G电信网络激活了病毒),对社会造成了重大负面影响Douglas (2021)。 因此,能够自动检测阴谋论的高性能方法变得越来越紧迫。
此前已有研究表明,错误信息(包括阴谋论)与情感信息,即情绪和情感Liu 等人(2024b)之间存在密切关系。 例如,Dong 等人 (2020) 发现,在 COVID-19 大流行期间,公众愤怒程度与谣言传播的可能性之间存在相关性,而 Zaeem 等人 ( 2020)还观察到负面情绪与假新闻之间存在显着的正相关关系。 基于这样的观察,许多研究采用情感信息作为检测错误信息的手段Liu 等人 (2023);张等人(2021)。 在这里,我们的目标是扩展情感信息的研究,特别是情感和情绪,以加深我们对阴谋论的理解和检测。
预训练语言模型(PLM)如 BERT Devlin 等人 (2018) 和 RoBERTa Liu 等人 (2019) 在应用于各种分类任务时表现出了出色的性能,包括阴谋论侦查 Yanagi 等人 (2021); Peskine 等人 (2021)。 然而,由于它们的参数数量有限。 PLM 在应用于多样化且复杂的任务时无法发挥最佳性能Zhang 等人 (2023)。 最近,拥有大量参数的大语言模型被探索作为解决错误信息问题的一种新方法,并取得了非常有希望的结果 Hu 等人 (2023);帕夫利申科 (2023);张和林(2023)。 然而,这些研究大多集中于根据文本是否传达错误信息对文本进行二元分类,而且,这些先前的研究大多利用简单的提示来测试或进行大语言模型的指令调优,或者采用大语言模型作为其他模型的辅助工具。 据我们所知,现有的 LLM 研究尚未尝试利用错误信息所特有的重要情感特征,或能够对阴谋相关文本进行深入分析。
为了解决这些研究空白,我们构建了一个多任务阴谋检测指令数据集ConDID,以促进大语言模型的指令调整和评估。 基于两个阴谋论数据集的注释,ConDID分为阴谋论判断、阴谋论主题检测和阴谋论意图检测五个任务。 随后,我们提出了一种新颖的开源大语言模型,ConspEmoLLM,专门用于检测阴谋相关信息。 ConspEmoLLM 是通过使用 ConDID 数据集将指令调整方法应用于面向情感的大语言模型而创建的。 使用ConDID测试集对ConspEmoLLM的评估表明,它在其他开源大语言模型以及闭源ChatGPT中实现了最先进(SOTA)的性能。
我们的主要贡献如下:
(1) 我们开发了ConDID,第一个多任务阴谋指令调整数据集。
(2)我们对用于构建ConDID的两个阴谋论数据集进行了情感分析,这提供了证据表明阴谋论文本中的情绪和情感表达与主流文本中的情感和情感表达不同。
(3)我们提出了ConspEmoLLM,第一个开源的基于情感的大语言模型,专门用于各种阴谋论检测任务。 对ConspEmoLLM的评估表明,它在不同任务上的性能优于其他开源大语言模型和ChatGPT。 它还超越了不包含情感特征的指令调整大语言模型的性能,从而证实了情感信息在检测阴谋相关信息方面的有效性和重要性。
2相关工作
2.1 阴谋论和错误信息检测
PLM 已广泛应用于阴谋论和错误信息检测的任务。 例如,Yanagi 等人 (2021) 使用 BERT 作为 COVID-19 阴谋论检测的基础模型,而 Peskine 等人 (2021) 应用了特定领域的 COVID BERT(CT-BERT)可以完成相同的任务。 最近,越来越多的注意力致力于探索大语言模型在检测阴谋论和错误信息方面的应用。 例如,Peskine 等人 (2023) 采用零样本学习来评估 GPT-3 模型对推文进行细粒度多标签阴谋论分类的准确性,而 Hu 等人人(2023)提出了一种假新闻检测框架,利用大语言模型作为辅助工具来提高BERT的预测精度。 与此同时,Pavlyshenko (2023) 采用基于提示的 LLaMA2 微调来检测谣言和假新闻。 Cheung 和 Lam (2023) 用外部知识补充了大语言模型,以增强假新闻检测的性能。 然而,所有这些模型都专注于二元分类,并且没有利用情感信息进行错误信息检测。
2.2情感分析
文本的自动情感分析以前通过多种方式进行,包括使用不同的情感分析工具,例如 VADER Hutto 和 Gilbert (2014) 和 TextBlob111https://textblob.readthedocs.io/。 PLM 还被用于情绪分析。 例如,Hoang 等人 (2019) 使用 BERT 进行基于方面的情感分析,而 Tan 等人 (2022) 提出了一种将 RoBERTa 与LSTM。 最近的工作也开始探索大语言模型在情感分析方面的有效性。 例如,Zhang 等人(2023)和Lei 等人(2023)均利用检索增强大语言模型来增强大语言模型的情感分析能力。分别为财经新闻和对话。 同时,刘等人(2024a)提出了一系列专门用于情感分析的综合性大语言模型(EmoLLMs),能够从五个不同维度(即情感强度、序数)分析情感。情感强度分类、情感强度、情感分类、情感检测)。 EmoLLM 表现出强大的泛化能力,在大多数情感分析任务中超越了 ChatGPT 和 GPT-4。 因此,我们在本研究中使用其中一种 EmoLLM,即 EmoLLaMA 来进行情感分析。
2.3 开源大语言模型
大量的研究致力于开发开源大语言模型,作为众所周知的闭源大语言模型(例如ChatGPT)的替代品,以支持更容易地研究大语言的改进和应用模型。 热门系列开源通用语言模型包括 LLaMA Touvron 等人 (2023)、OPT Zhang 等人 (2022) 和 BLOOM Workshop 等人 (2022) )。 这些模型还辅以一系列特定领域的开源大语言模型,包括金融领域的 FinMA Xie 等人 (2023)、金融领域的 MentalLLaMA Yang 等人 (2023)心理健康,ExTES-LLaMA Zheng 等人 (2023) 用于情感支持聊天机器人,TimeLLaMA Yuan 等人 (2023) 用于时间推理。 在这项工作中,我们通过开发第一个基于情感信息的多任务阴谋论检测开源大语言模型,扩展了特定领域大语言模型的库存。
3方法
3.1 任务形式化
我们将阴谋论检测视为一项生成任务,并使用生成模型作为其基础。 该生成模型是一个自回归语言模型,使用预训练权重进行参数化。 它与之前的判别模型的不同之处在于它能够同时处理多个阴谋论检测任务,即阴谋识别、阴谋意图检测和阴谋主题识别。 每个任务表示为,表示为一组上下文-目标对:,其中上下文是包含该任务的词符序列描述、输入文本和查询, 是包含查询答案的进一步词符序列。 该模型基于合并数据集进行优化,合并了所有任务数据集,旨在最大化条件语言建模的目标,以提高预测性能。
3.2指令调优数据集构建
3.2.1 原始数据
我们使用两个现有的带注释的数据集构建指令调整数据集:
COCO COVID-19 阴谋论 (COCO) 数据集 Langguth 等人 (2023) 是 MediaEval FakeNews: Corona Virus and Conspiracies 中使用的数据集的扩展任务挑战Pogorelov等人(2021)。 COCO 由推文组成,每条推文都被分配了 12 个不同的标签,这些标签描述了推文相对于 12 个不同阴谋论类别的意图 222抑制治疗、行为控制、反疫苗接种、假病毒、故意大流行、有害辐射、人口减少、新世界秩序、深奥的错误信息、撒旦教、其他阴谋论、其他误传。. 每个标签可以有三个可能的值,即不相关:该推文与特定阴谋类别无关。 这类推文包含与阴谋相关的关键词,但它们的使用环境完全不同; 相关:该推文与特定类别相关,但不传播错误信息或阴谋论; 阴谋:该推文与特定类别相关,并积极旨在传播阴谋论。
COCO 中的每条推文还分配有一个整体意图标签,如下所示: Conspiracy 分配给那些 Conspiracy 标签至少分配给 12 个类别之一的推文。 否则,如果将 Related 类别分配给至少一个类别,则使用 Related 的整体标签。 不相关的整体标签仅用于与所有 12 个阴谋类别无关的推文。
LOCOAnnotations The Language of Conspiracy (LOCO) Miani 等人 (2021) 是由从互联网收集的文档组成的语料库(8800 万字),用于研究差异阴谋语言与主流语言之间。 我们使用由 Mompelat 等人 (2022) 创建的 LOCO 带注释子集,我们将其称为 LOCOAnnotations。 该子集由涉及两个不同主题(即桑迪胡克学校枪击事件和冠状病毒)的文档组成,其中分配了两种类型的标签。 第一类标签涉及该文件是否与阴谋论直接相关。 第二种标签反映了与阴谋论的相关程度,使用三种标签(密切相关/广泛相关/不相关)。
3.2.2 任务
使用这两个不同的数据集,我们定义了五个不同的任务。 任务 1-3 基于 COCO 语料库,与 MediaEval FakeNews 挑战中使用的任务类似,而任务 4 和 5 基于 LOCOAnnotations。
任务 1:阴谋意图检测 确定推文针对 COVID-19 阴谋论的总体意图(即无关/相关/阴谋)。
任务 2:阴谋论主题检测 确定推文是否提及或引用任何预定义的阴谋论类别。
任务 3:任务 1 和任务 2 的组合 预测两者阴谋类别和推文的关系(不相关/相关/阴谋)类别。
任务 4:阴谋论检测 确定文档是否与阴谋论直接相关(阴谋/非阴谋)。
任务 5:相关性检测 确定文档与阴谋论的相关性级别(密切相关/广泛相关/不相关)。
3.2.3原始数据情感分析
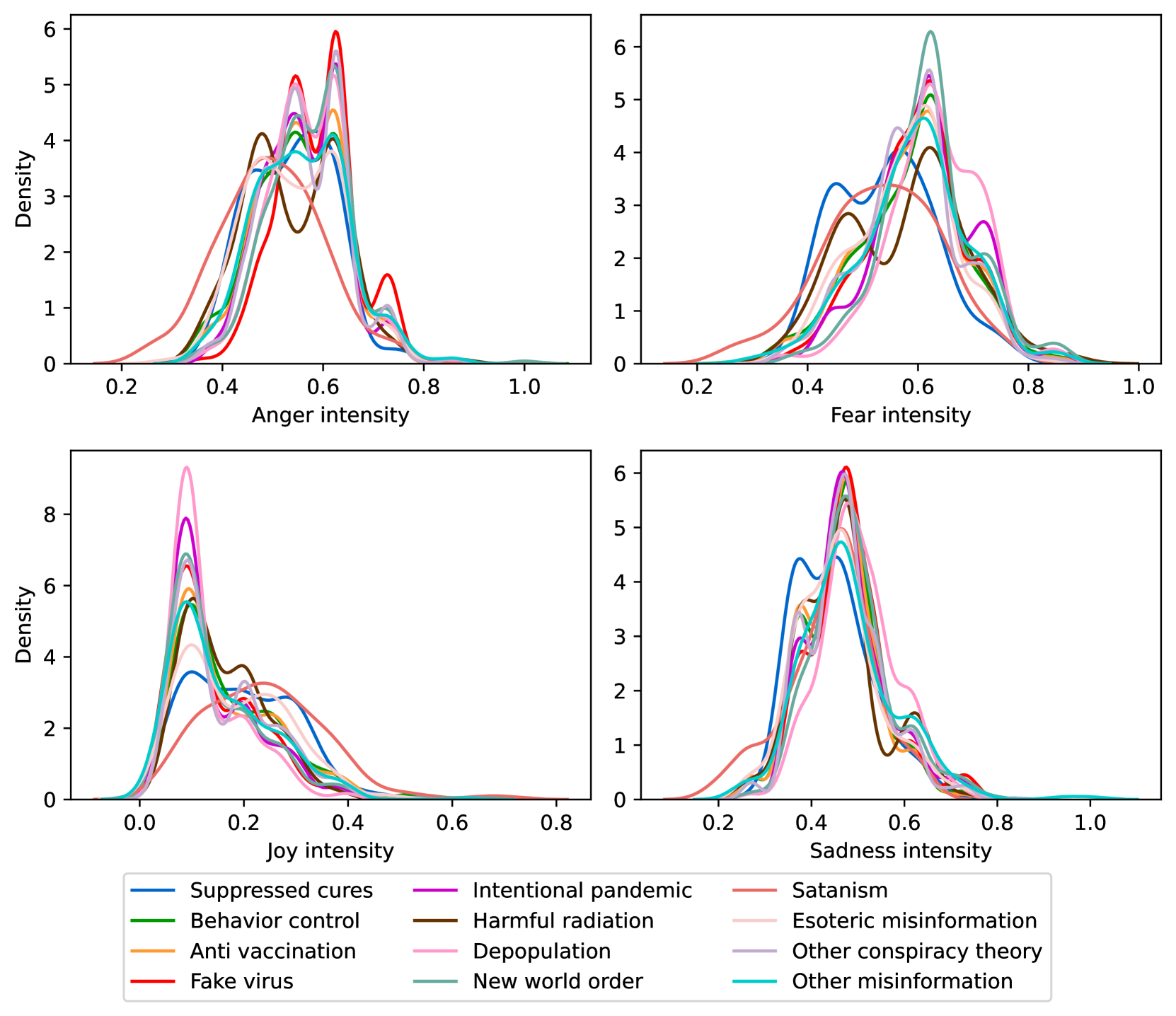
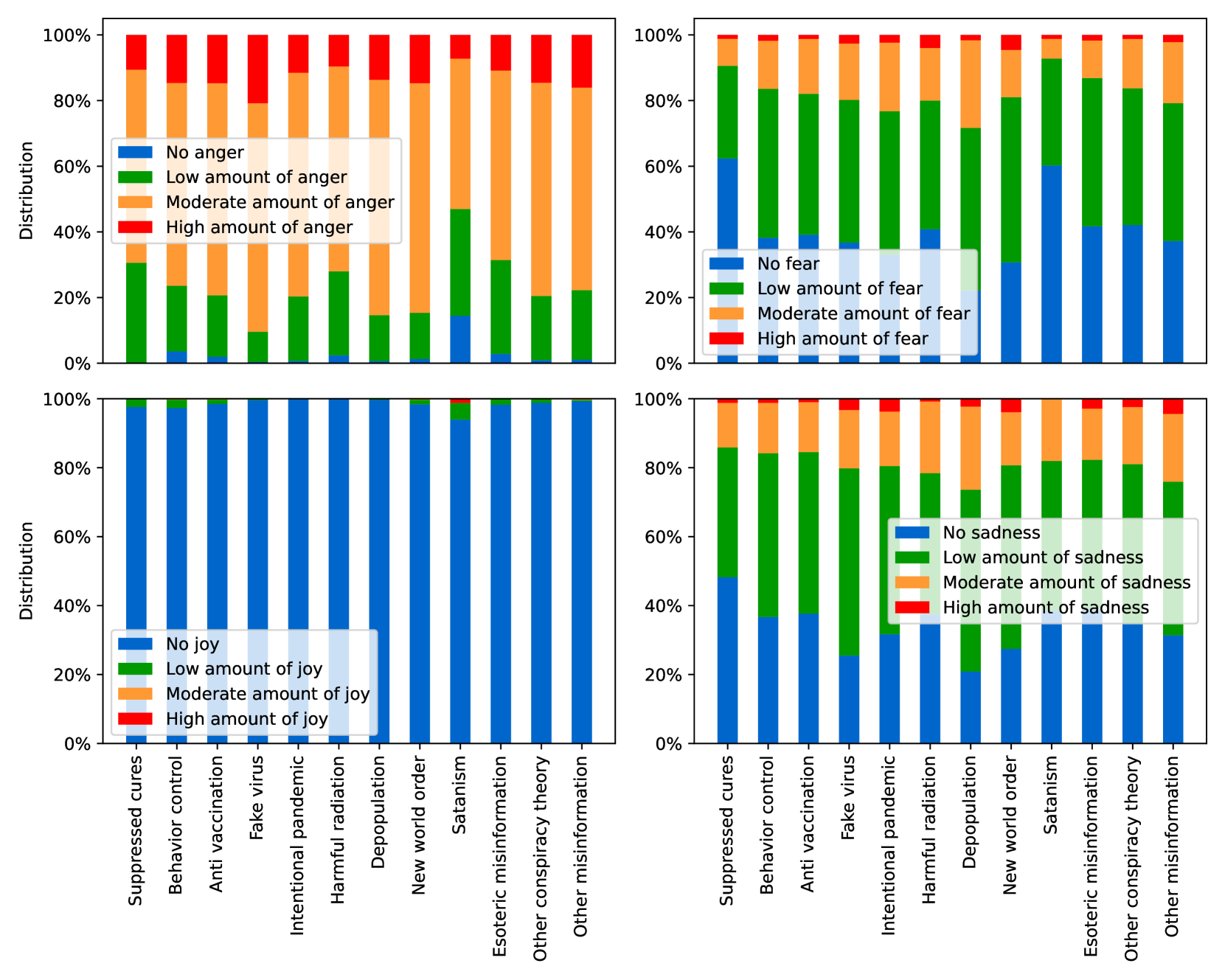
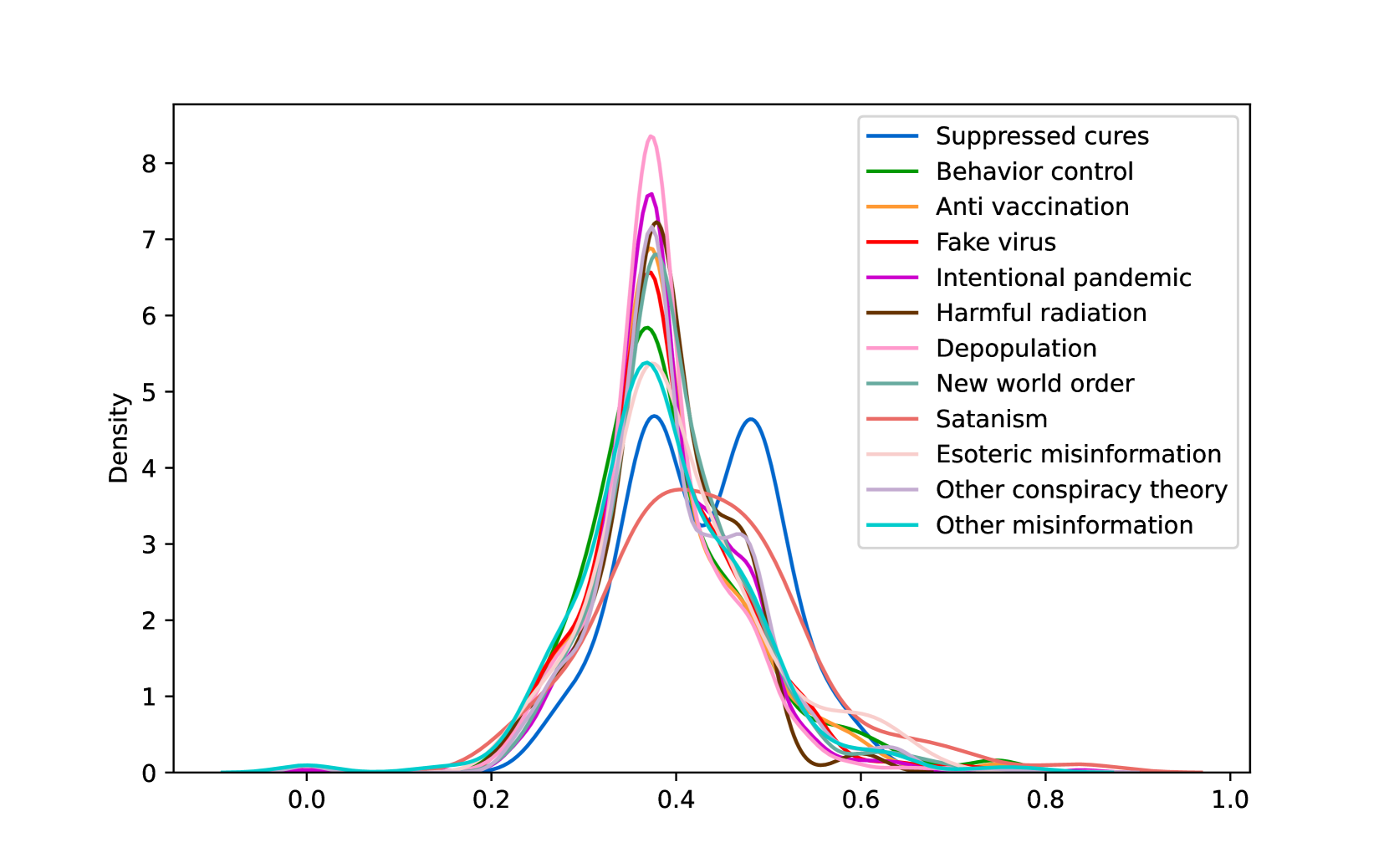
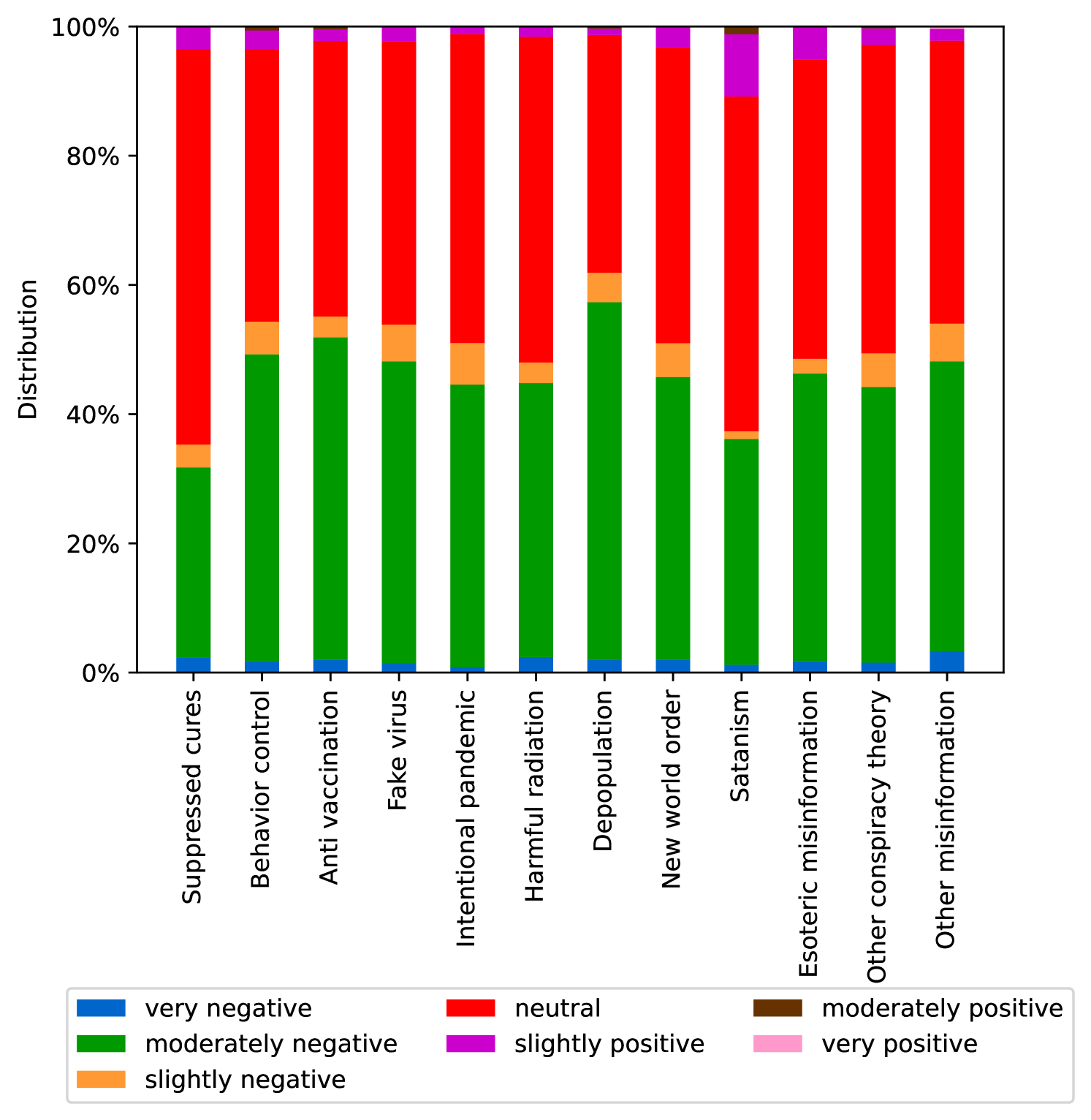
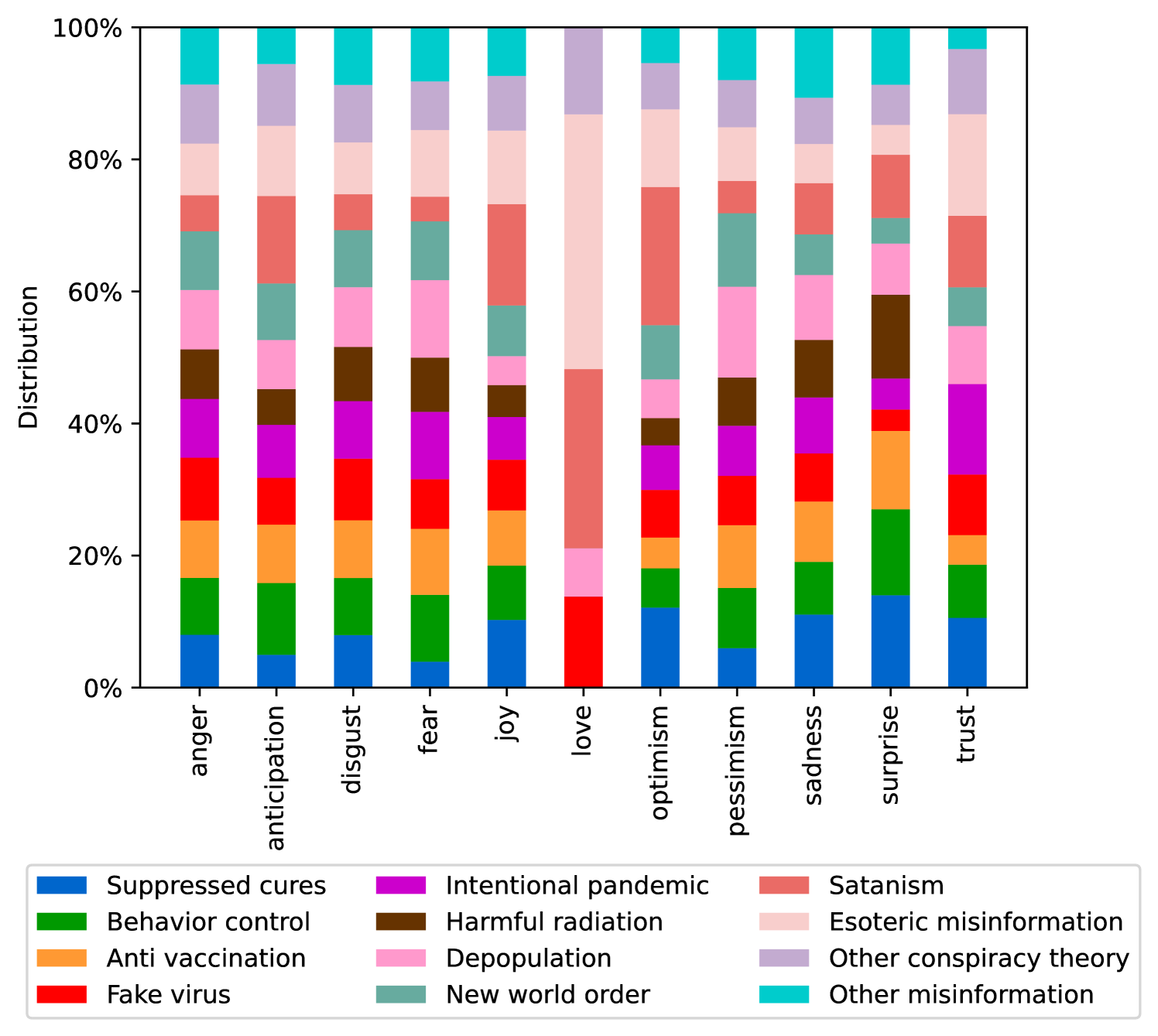
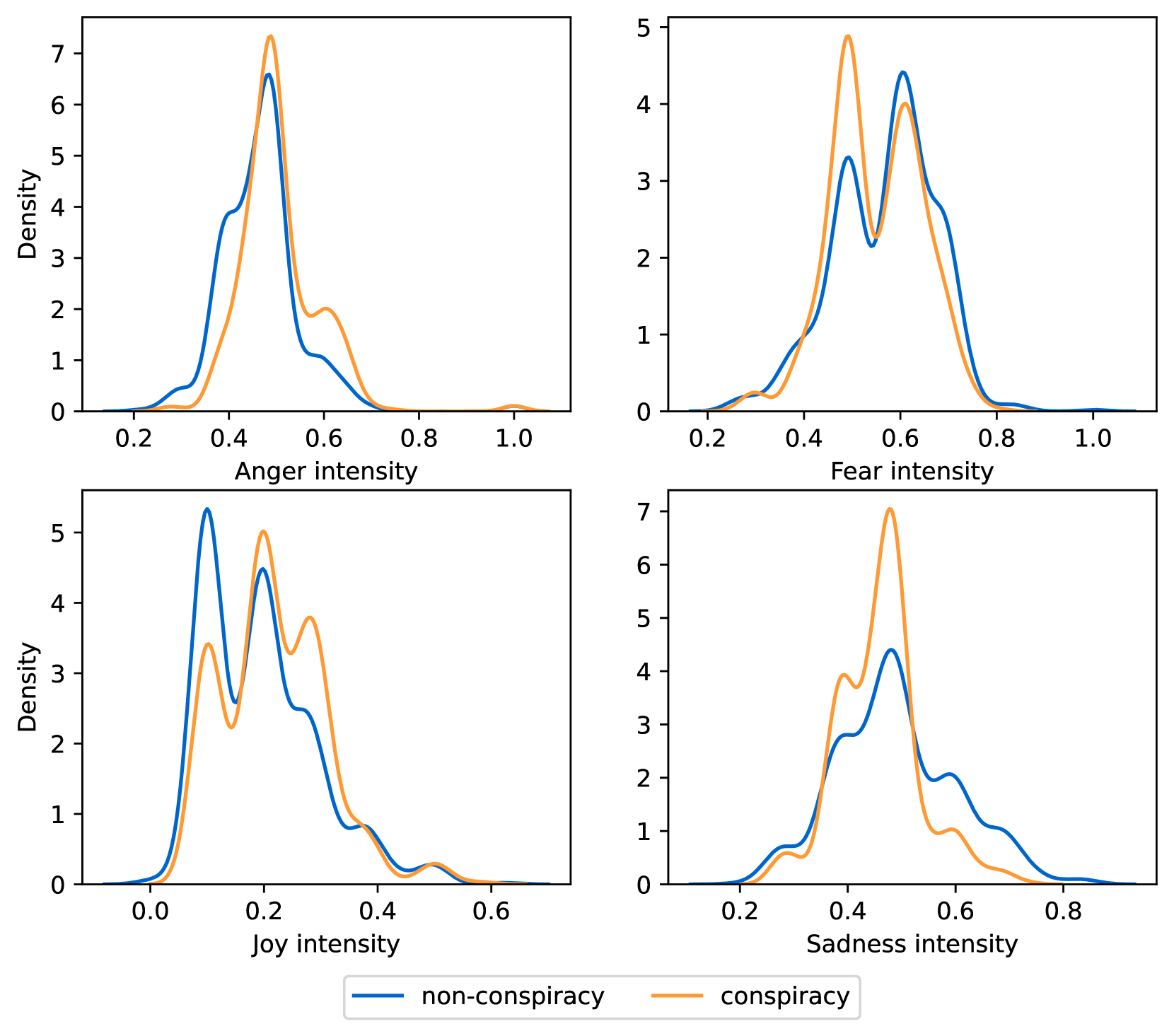
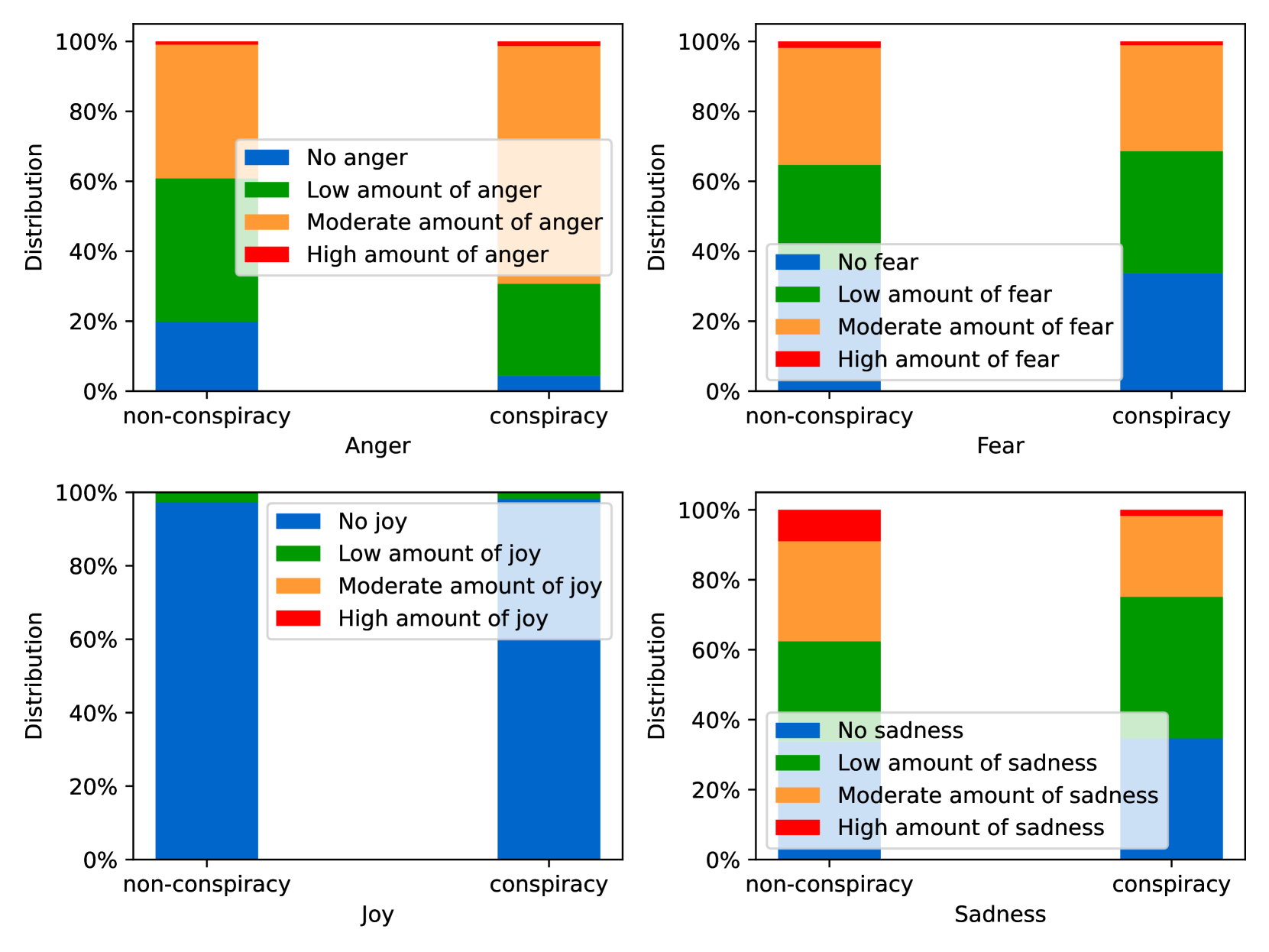
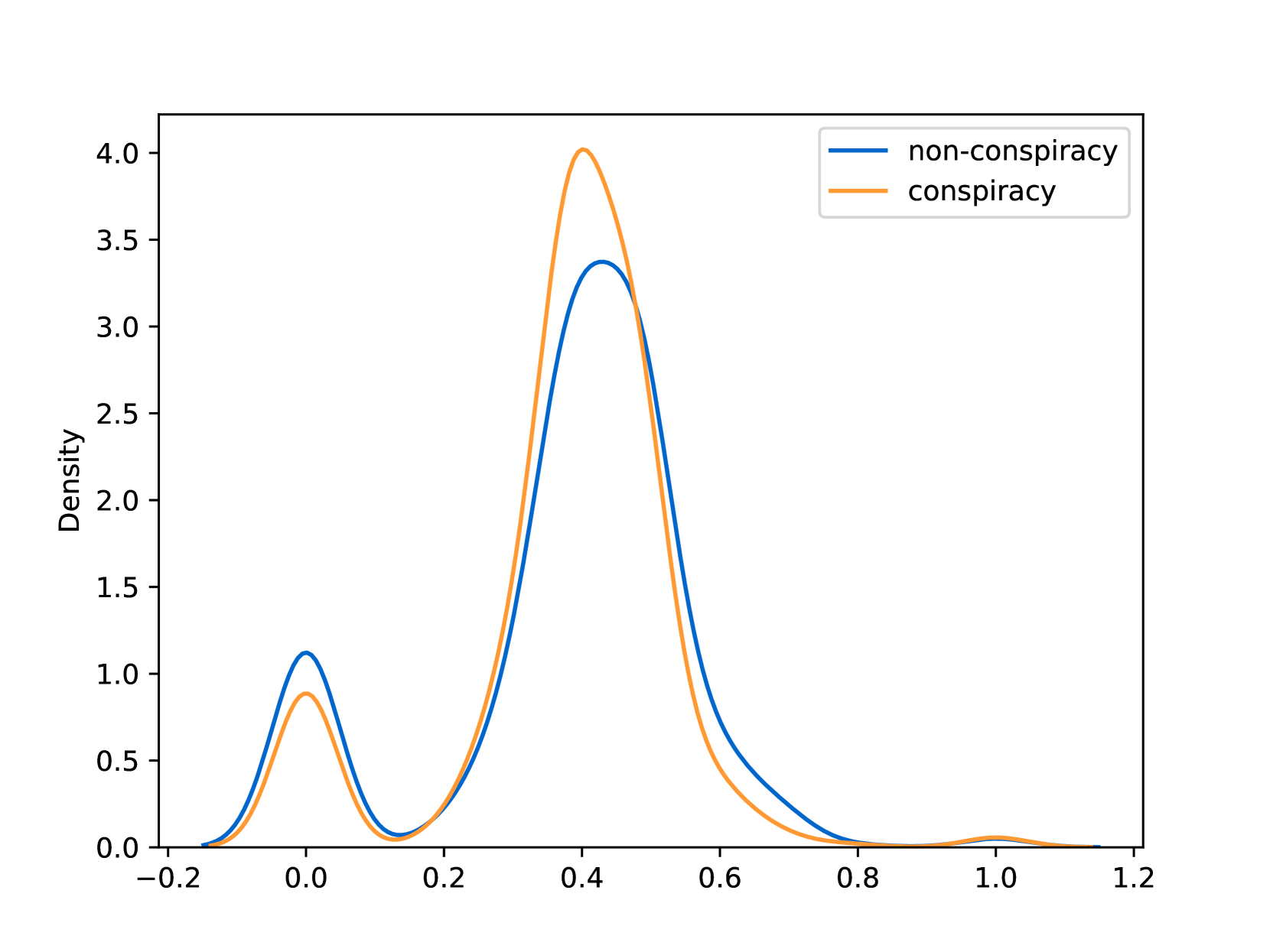
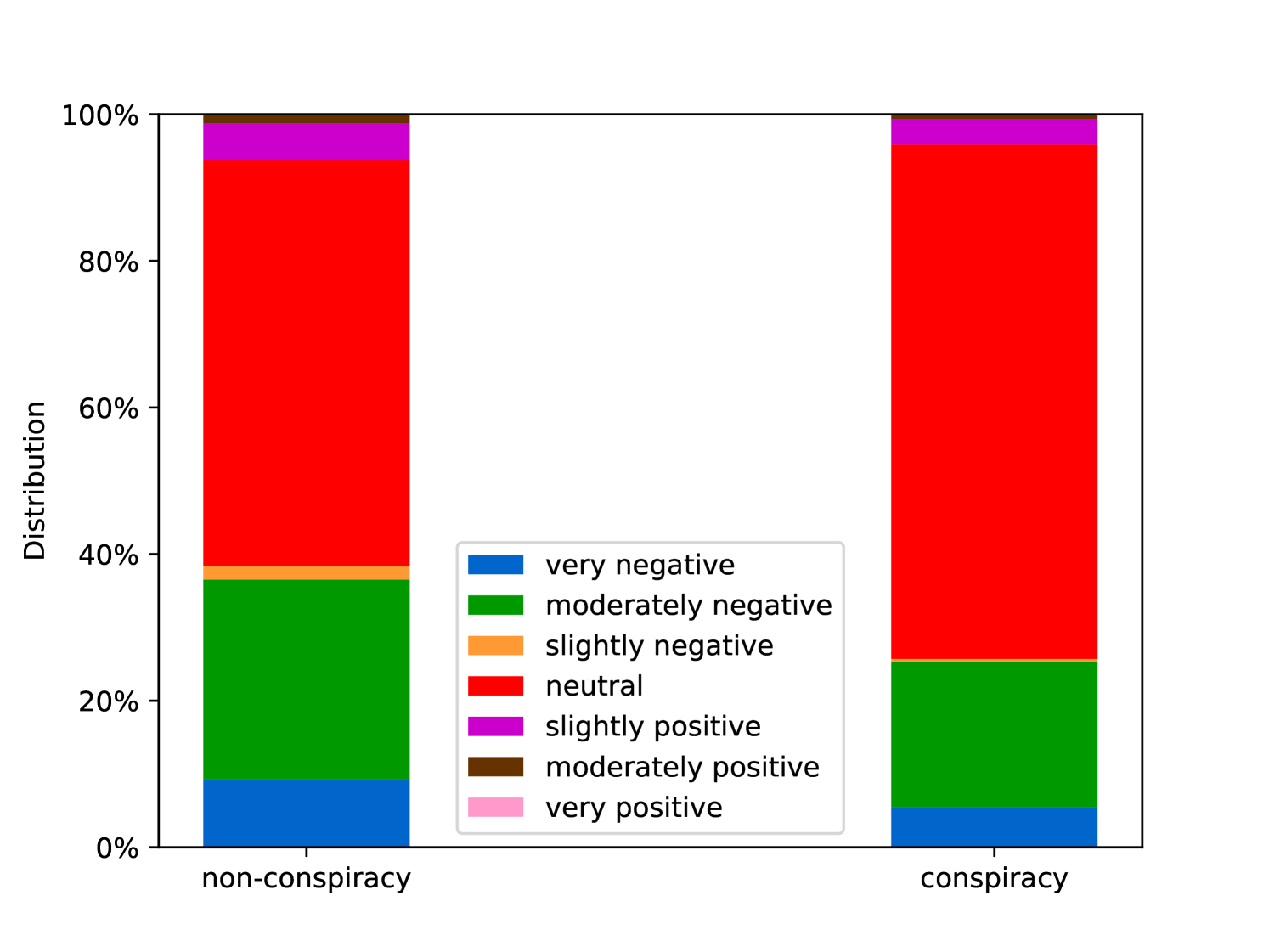
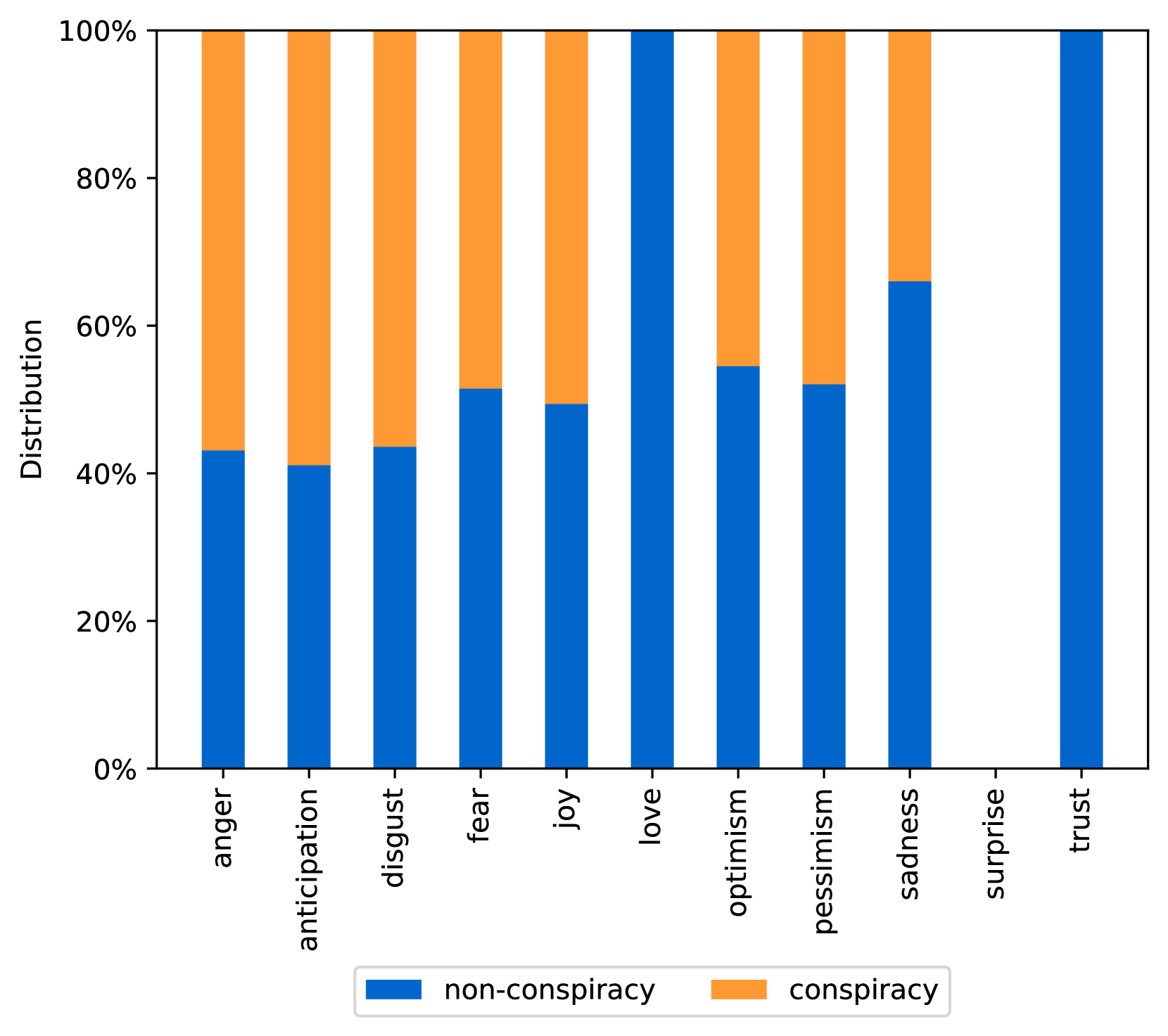
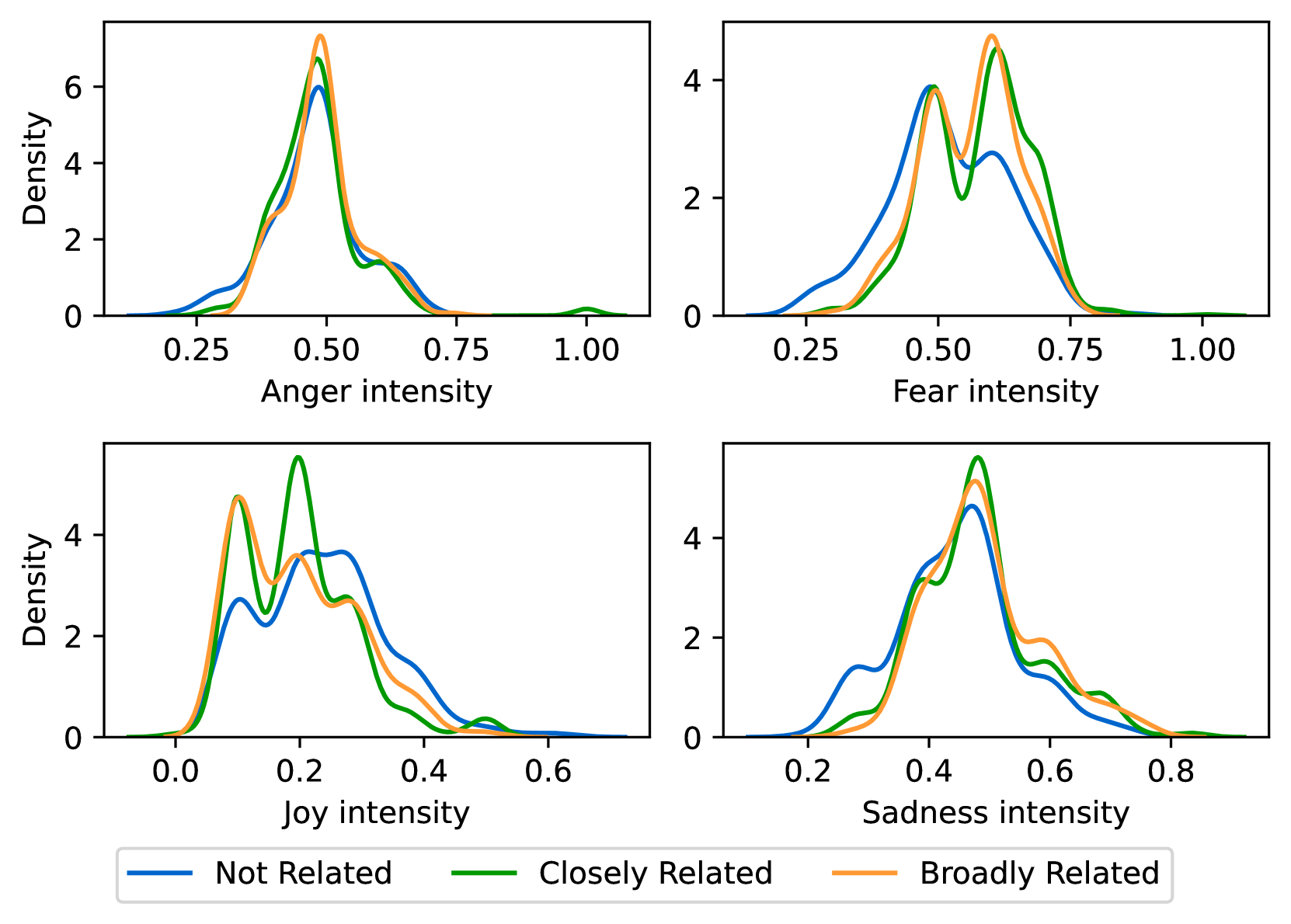
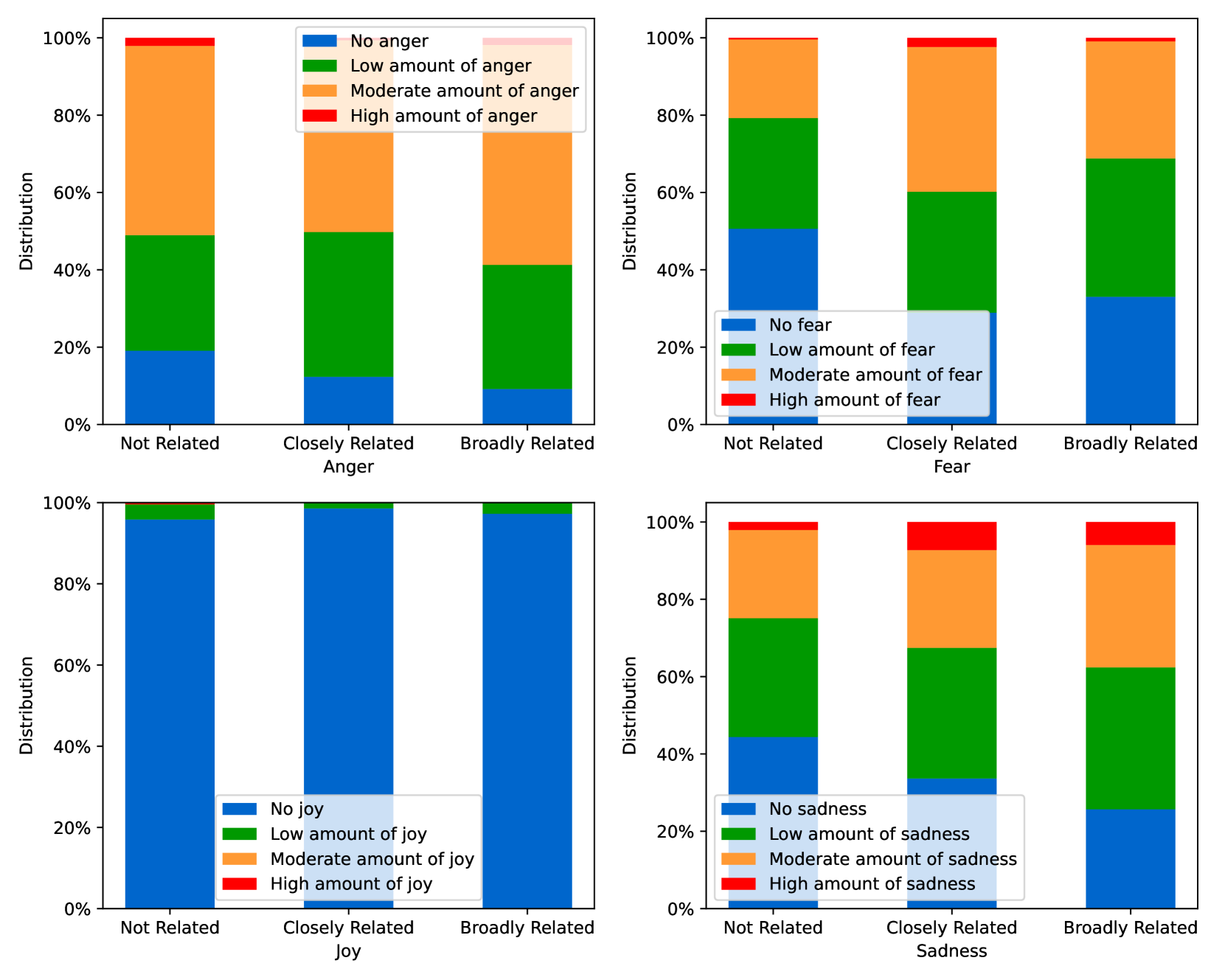
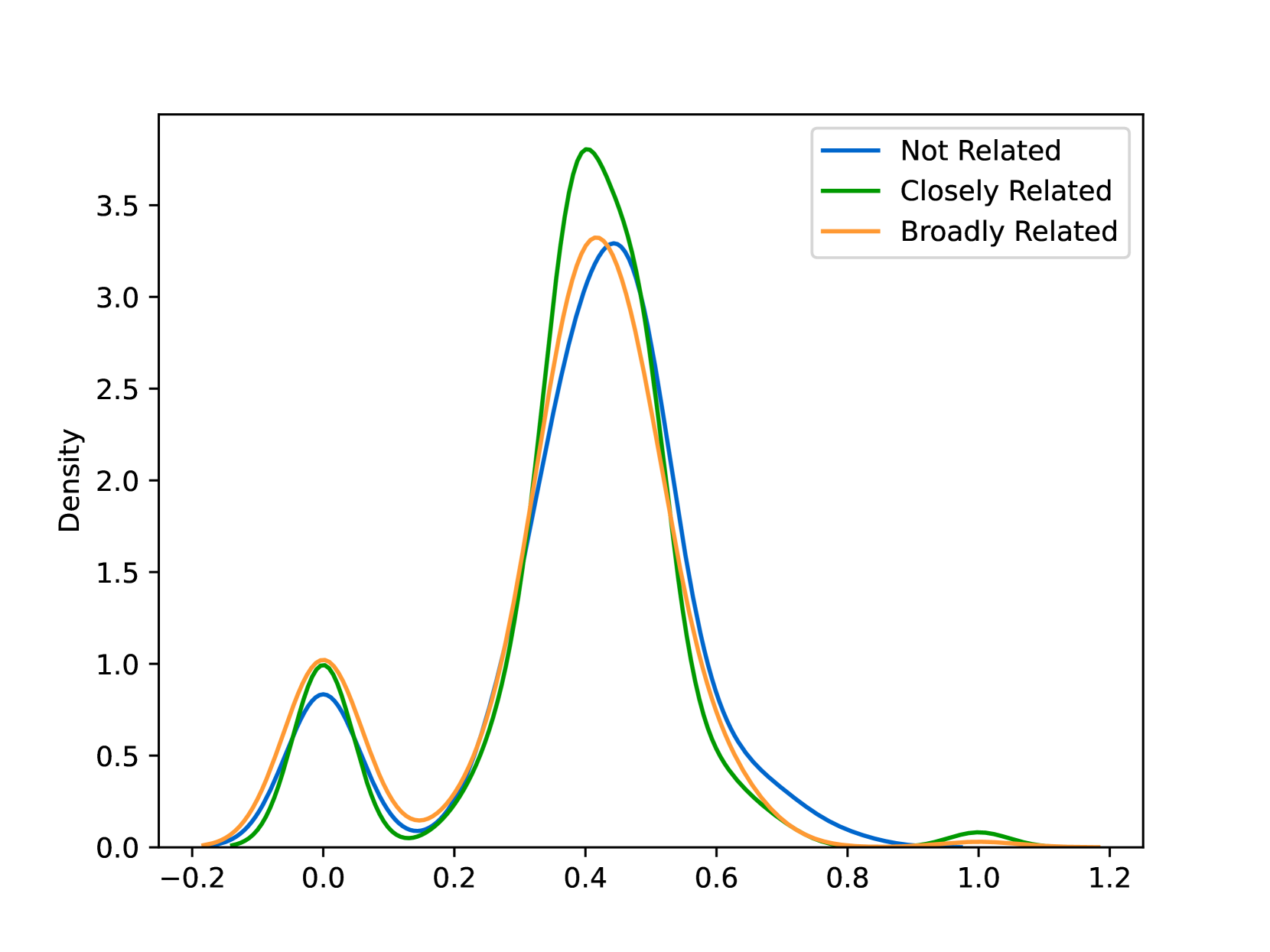
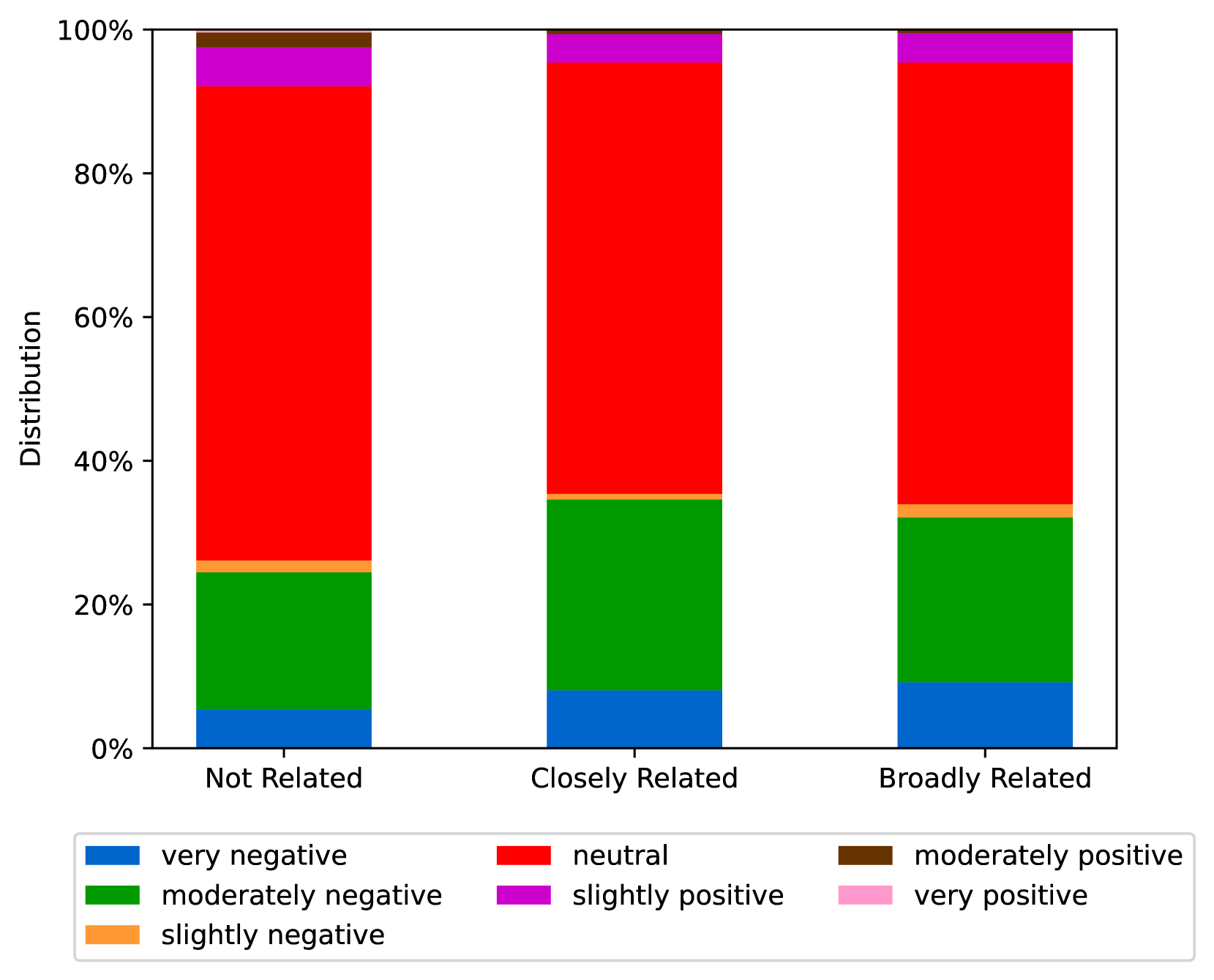
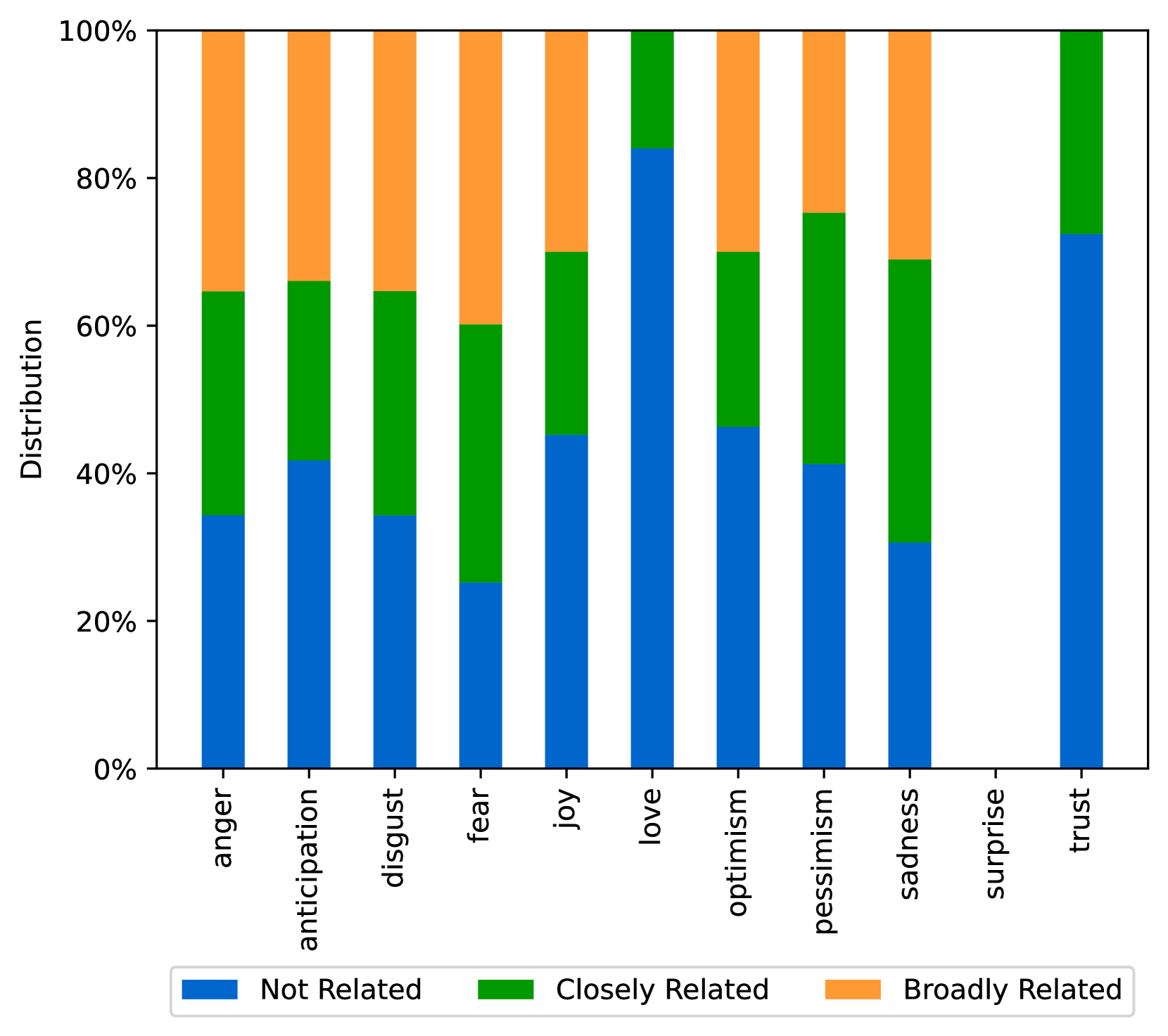
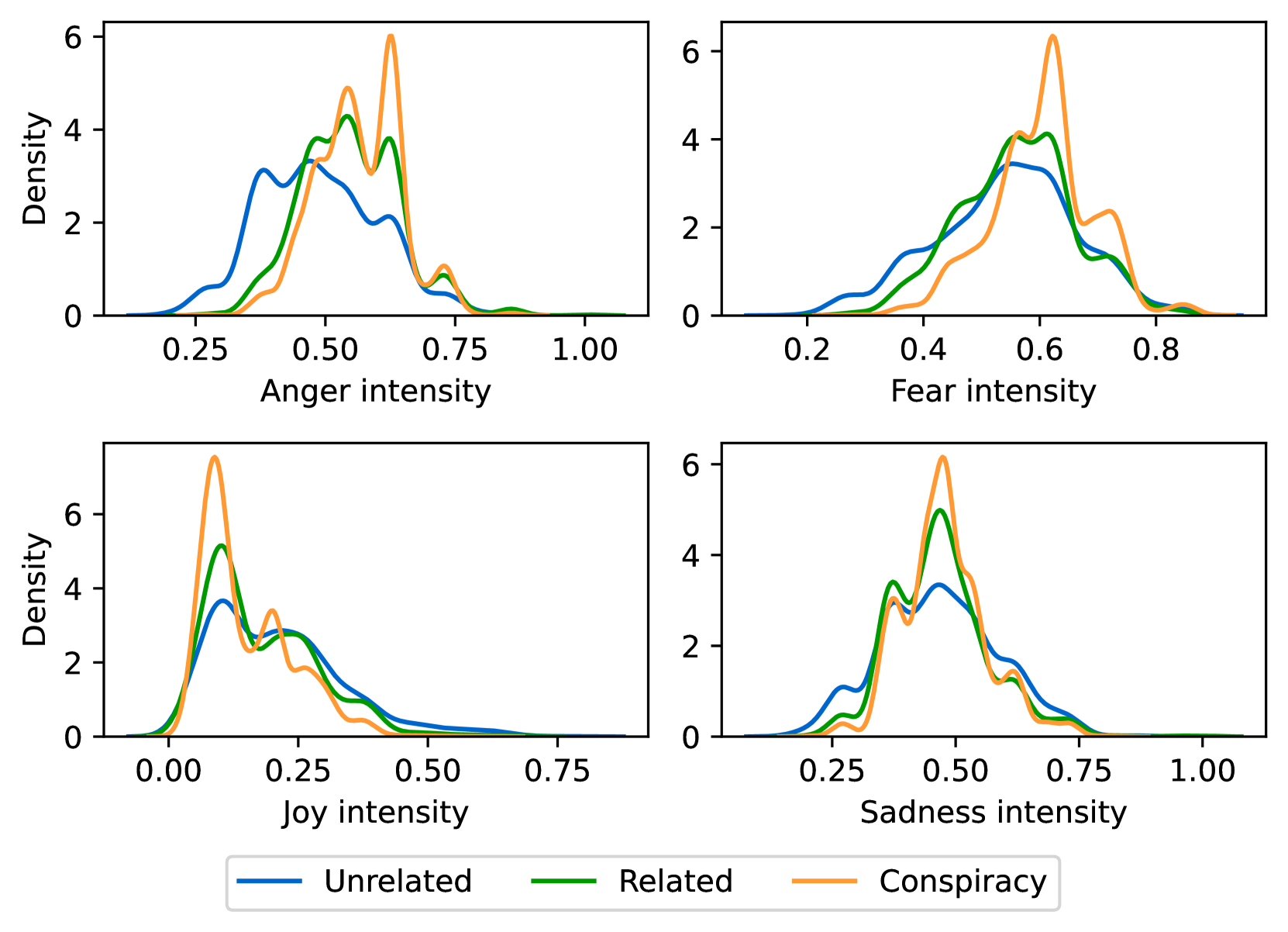
EmoLLMs Liu 等人 (2024a) 是一系列情感分析模型。 我们采用本系列中表现最好的模型(即 EmoLLaMA-chat-7b),对 COCO 和 LOCOAnnotations 进行五个不同维度(即情感强度、情感强度顺序分类、情感强度、情感分类、情感检测)。 该分析的结果如图1至5所示。 由于篇幅限制,这些图仅涉及COCO数据集中的意图分析; COCO数据集和LOCOAnnoations中不同阴谋类别的情感分析数据可以在附录LABEL:appfig:coco_conspiracy和附录LABEL:appfig:loco中找到。 图1至5描述了根据推文意图(即不相关/相关/阴谋)的情感特征之间的差异。 同时,附录LABEL:appfig:coco_conspiracy中的图7至11说明了根据12种不同阴谋类别的情感差异。 附录LABEL:appfig:loco中的图12至21比较了阴谋文本和非阴谋文本之间的情感差异,以及表现出不同程度相关性的文本阴谋论(即不相关/密切相关/广泛相关)。
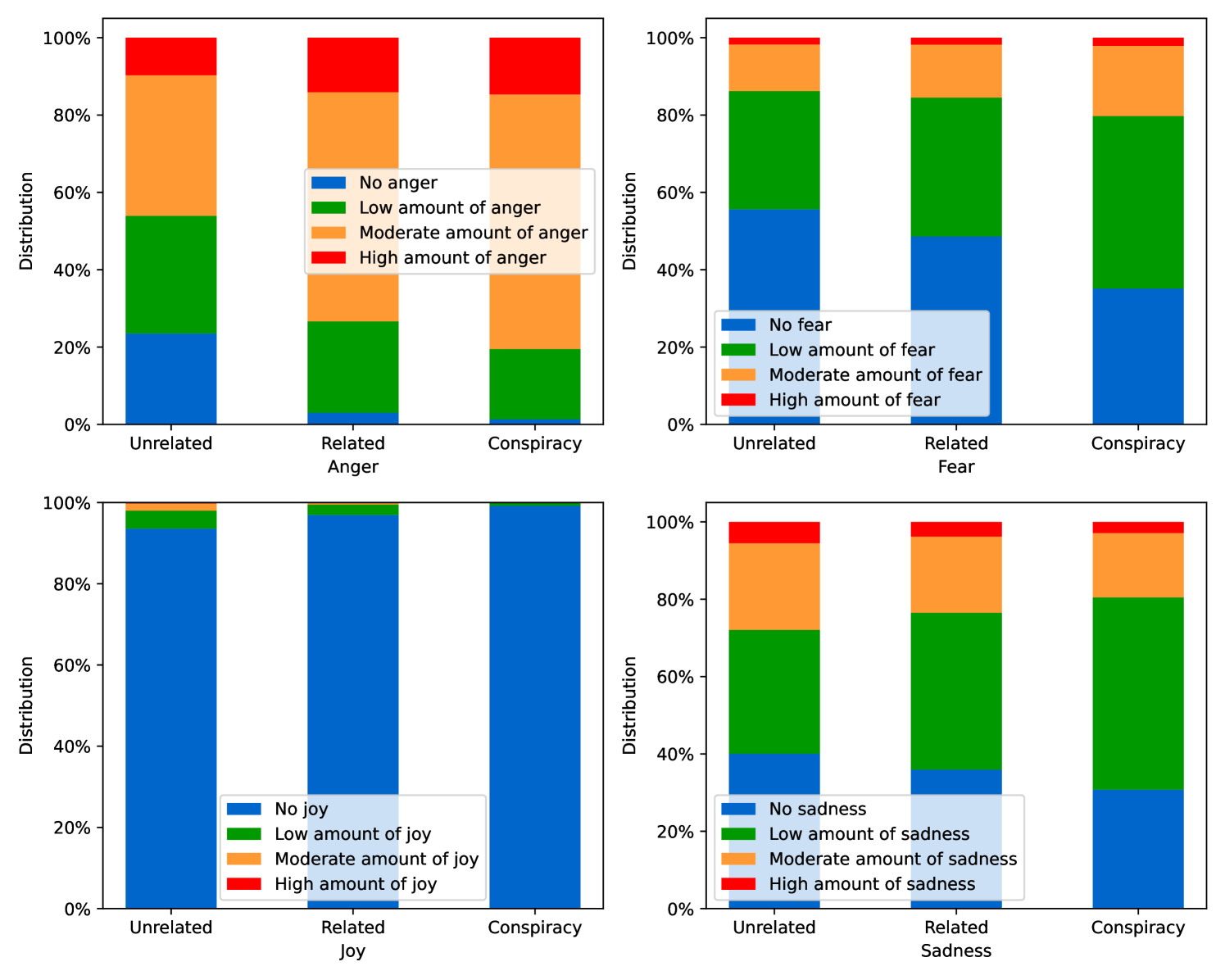
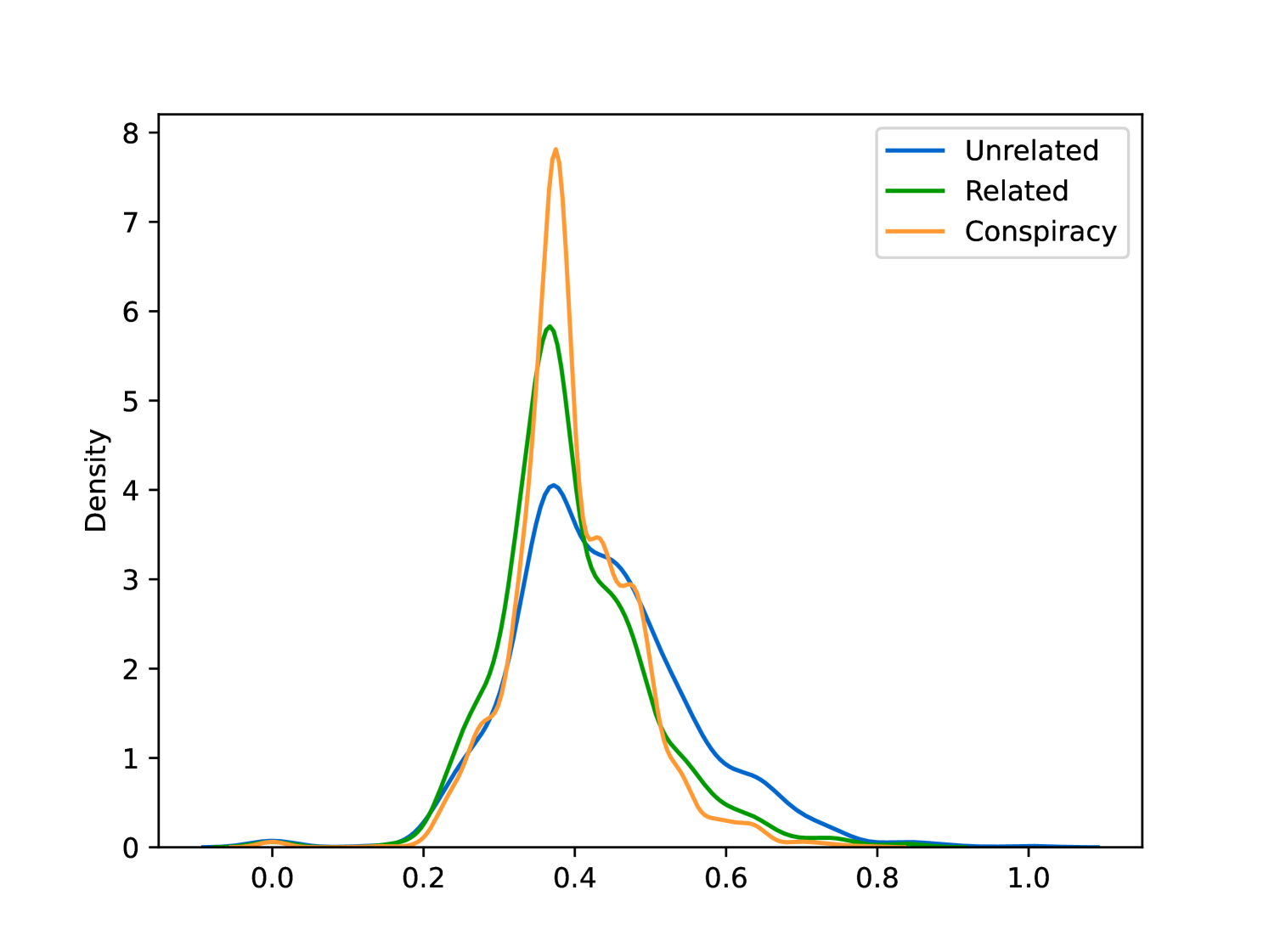
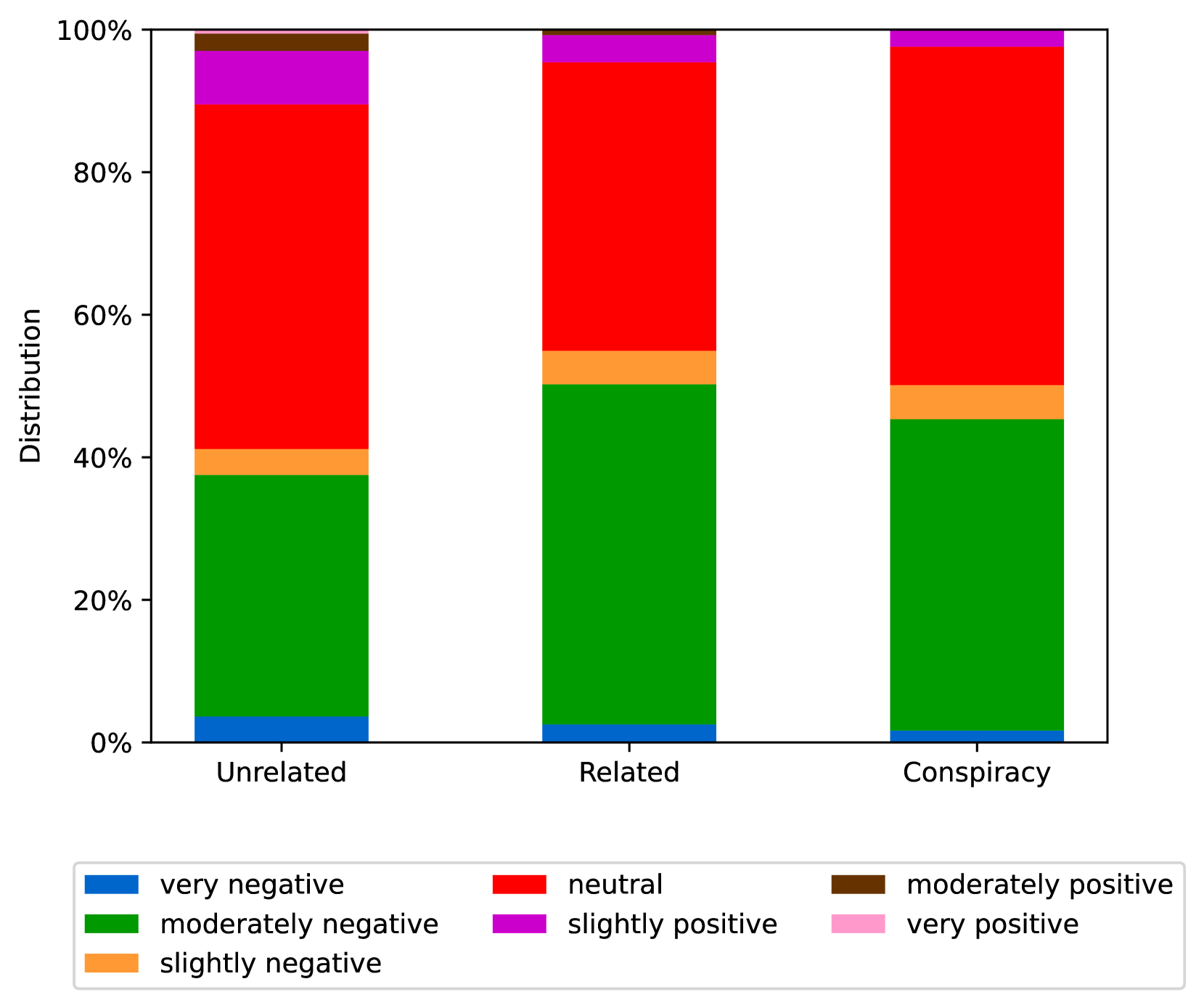
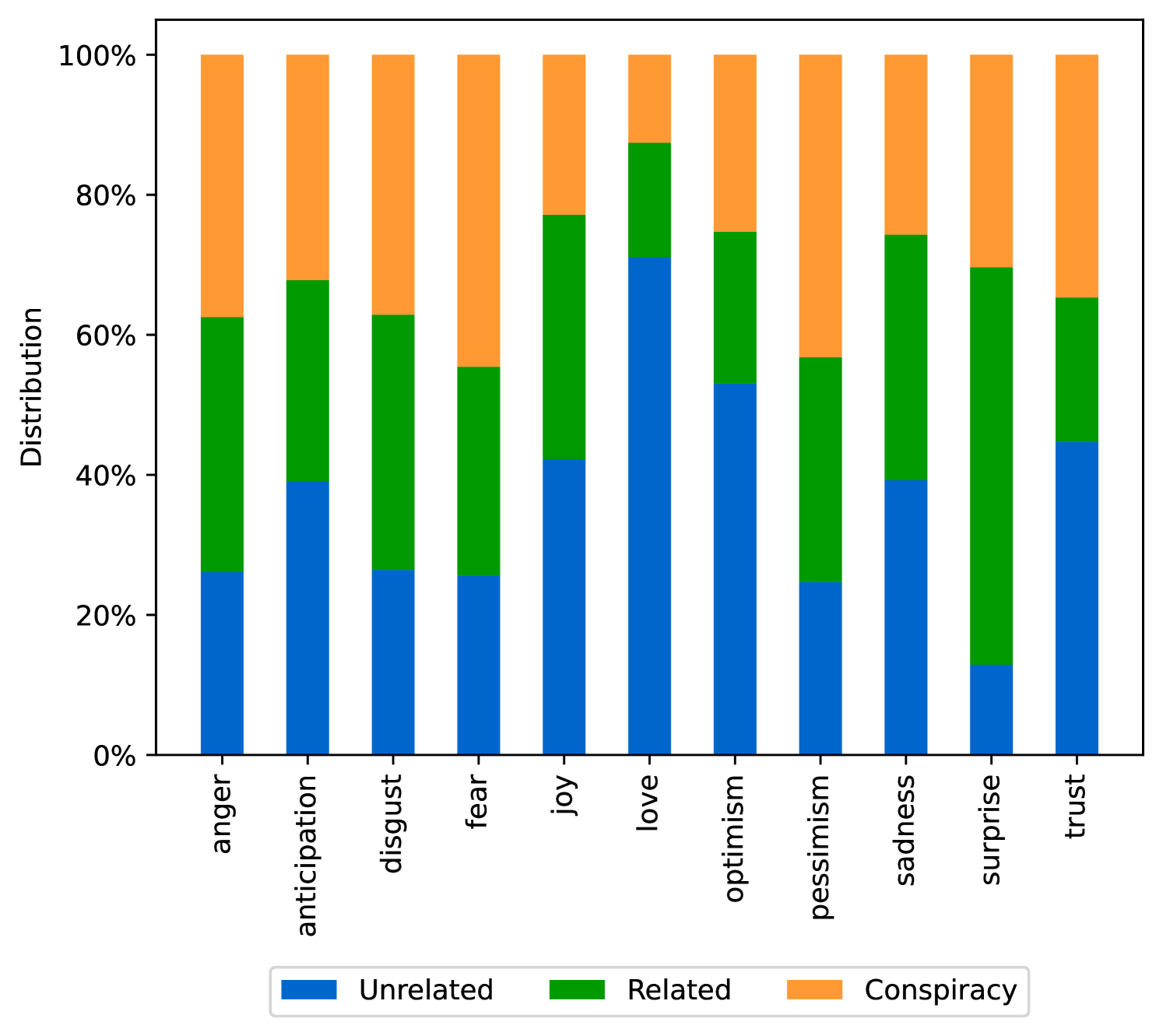
3.2.4ConDID阴谋检测指令数据集构建
| Task | Raw (Train/Dev/Test) | Instruction (Train/Dev/Test) |
|---|---|---|
| Task 1 | 2092/697/698 | |
| Task 2 | 2092/697/698 | 2092/697/698 |
| Task 3 | 25104/8364/8376 | |
| Task 4 | 669/223/233 | |
| Task 5 | 669/223/233 | 669/223/233 |
| Task | Prompt Template |
|---|---|
| Task 1 | Task: Classify the text regarding COVID-19 conspiracy theories or misinformation into one of the following three classes: 0. Unrelated. 1. Related (but not supporting). 2. Conspiracy (related and supporting). |
| Task 2 | Task: detect whether the text in any form mentions or refers to any of the specific categories of COVID-19 conspiracy theories (’suppressed cures’, ’behavior control’, ’anti vaccination’, ’fake virus’, ’intentional pandemic’, ’harmful radiation’, ’depopulation’, ’new world order’, ’satanism’, ’esoteric misinformation’, ’other conspiracy theory’) or other misinformation. If it doesn’t, it is ’no conspiracy. |
| Task 3 | Task: Classify the text regarding the specific category [Specific Conspiracy] into one of the following three classes: 0. Unrelated. 1. Related (but not supporting). 2. Conspiracy (related and supporting). |
| Task 4 | Task: Determine if the text is a conspiracy theory. Classify it into one of the following two classes: 0. non-conspiracy. 1. conspiracy. |
| Task 5 | Task: Determine the relatedness between the text and [conspiracy theory]. Classify it into one of the following three classes: 0. not related. 1. closely related. 2. broadly related. |
| Affective prompt | Task: original task prompt + "You can also refer to the affective information. (1) Emotion intensity: anger: 0.521, fear: 0.625, joy: 0.25, sadness: 0.354. (2) Ordinal classification of emotion intensity: moderate amount of anger can be inferred. low amount of fear can be inferred. no joy can be inferred. no sadness can be inferred. (3) Sentiment intensity: 0.435. (4) Sentiment classification: neutral or mixed mental state can be inferred. (5) The emotions included are: anger, disgust, fear." |
我们使用原始数据集作为构建指令数据集的基础。 我们随机选择20%的数据作为测试集,20%作为验证集。 数据集统计数据如表 1 所示。 对于任务 3,需要为 12 个类别中的每一个类别创建提示,从而产生的数据量是原始语料库大小的 12 倍。 我们基于以下模板为每个任务构建了指令调整数据:
任务:[任务提示] 文本:[文本] 班级/文本提及或提及阴谋:[输出]
3.3 ConspEmoLLM 和 ConspLLM
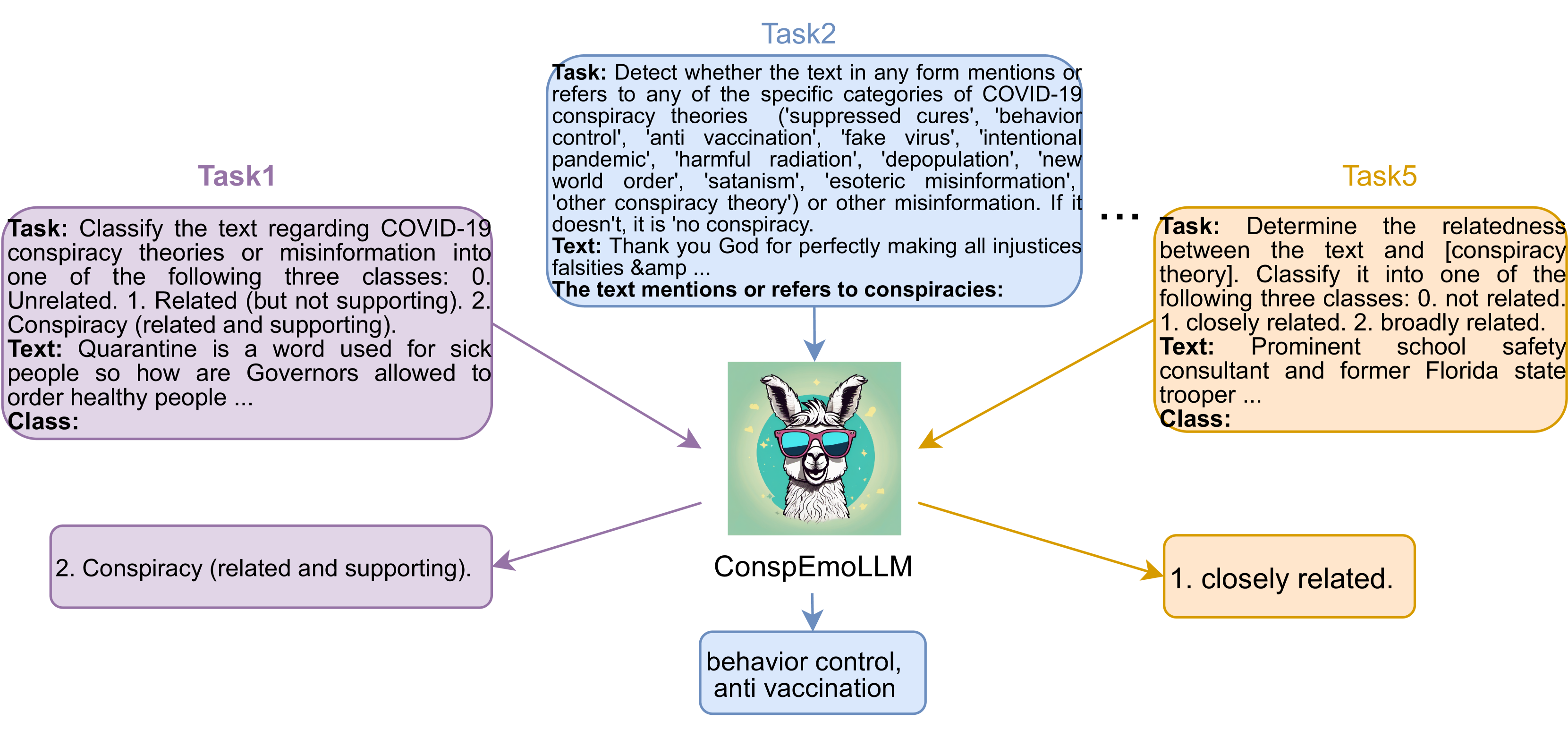
我们通过使用 ConDID 数据集微调 EmoLLaMA-chat-7b Liu 等人 (2024a) 来构建 ConspEmoLLM。 我们还基于 LLaMA2-chat-7b Touvron 等人 (2023) 微调了不使用情感信息的大语言模型 (ConspLLM),同样使用 ConDID。 这些模型基于 AdamW 优化器 Loshchilov 和 Hutter (2017) 进行了三个 epoch 的训练,并使用 DeepSpeed Rasley 等人 (2020) 来减少内存使用。 我们将批量大小设置为 256。 初始学习率设置为1e-6,预热比例为5%,最大模型输入长度设置为4096。 所有模型均在两个 Nvidia Tesla A100 GPU 上进行训练,每个 GPU 具有 80GB 内存。 图6概述了ConspEmoLLM针对不同阴谋检测任务的多任务指令调整。
4实验
4.1 基准模型
PLM:阴谋论检测通常被视为分类任务。 对于我们的基线模型,我们选择了常用的 PLM,它们只能针对单个任务进行微调,即通用语言 BERT 和 RoBERTa,以及 CT-BERT Müller 等人 (2023),这是专为 COVID-19 领域量身定制的。 我们将任务 1 和 5 视为三向分类任务,将任务 4 视为二元分类任务,使用交叉熵损失进行训练。 任务2被视为多标签二元分类问题,可以通过利用具有logits损失的二元交叉熵来实现。 为了解决任务 3,对 12 个不同的分类问题进行微调,每个问题都有自己的交叉熵损失函数。 最后的损失是12次损失的平均值。
大语言模型:大语言模型已被证明能够解决众多任务。 我们将指令数据集上的零样本提示应用于以下开源大语言模型:Falcon-7B-instruct Penedo 等人 (2023)、LLaMA2-chat-7B Touvron 等人 ( 2023)、OPT-7B 张等人 (2022)、BLOOM-7B Workshop 等人 (2022) 和 Vicuna-7B-v1.5333https://huggingface.co/lmsys/vicuna-13b-v1.5 。 我们还利用专有的大语言模型 ChatGPT 进行零样本提示。
4.2评估方法
由于本文解决的任务都是分类问题,因此我们应用常用的指标来评估模型的性能,即准确率(ACC)、精度(PRE)、召回率(REC)和加权F1分数。
4.3结果
| Model | Task1 | Task2 | Task3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ACC | PRE | REC | F1 | ACC | PRE | REC | F1 | ACC | PRE | REC | F1 | |
| BERT | 0.576 | 0.601 | 0.428 | 0.406 | 0.272 | 0.150 | 0.012 | 0.023 | 0.893 | 0.871 | 0.893 | 0.842 |
| RoBERTa | 0.517 | 0.505 | 0.335 | 0.231 | 0.279 | 0.204 | 0.077 | 0.112 | 0.893 | 0.842 | 0.893 | 0.844 |
| CT-BERT | 0.564 | 0.472 | 0.469 | 0.428 | 0.042 | 0.137 | 0.303 | 0.175 | 0.893 | 0.797 | 0.893 | 0.842 |
| Falcon | 0.265 | 0.361 | 0.265 | 0.211 | 0.189 | 0.193 | 0.180 | 0.160 | 0.556 | 0.810 | 0.556 | 0.653 |
| Vicuna | 0.380 | 0.446 | 0.380 | 0.392 | 0.136 | 0.172 | 0.270 | 0.150 | 0.437 | 0.825 | 0.437 | 0.556 |
| LLaMA2-chat | 0.325 | 0.527 | 0.325 | 0.251 | 0.193 | 0.093 | 0.071 | 0.074 | 0.674 | 0.814 | 0.674 | 0.732 |
| OPT | 0.311 | 0.389 | 0.311 | 0.298 | 0.235 | 0.216 | 0.048 | 0.072 | 0.481 | 0.805 | 0.481 | 0.590 |
| BLOOM | 0.328 | 0.389 | 0.328 | 0.318 | 0.268 | 0.000 | 0.000 | 0.000 | 0.114 | 0.810 | 0.114 | 0.146 |
| ChatGPT | 0.638 | 0.677 | 0.638 | 0.596 | 0.324 | 0.546 | 0.333 | 0.332 | 0.208 | 0.896 | 0.208 | 0.240 |
| ChatGPT-aff | 0.583 | 0.647 | 0.583 | 0.525 | 0.312 | 0.449 | 0.326 | 0.308 | 0.150 | 0.898 | 0.150 | 0.146 |
| ConspLLM | 0.662 | 0.757 | 0.662 | 0.675 | 0.328 | 0.685 | 0.320 | 0.334 | 0.893 | 0.886 | 0.893 | 0.864 |
| ConspLLM-aff | 0.517 | 0.483 | 0.517 | 0.354 | 0.203 | 0.404 | 0.330 | 0.301 | 0.077 | 0.901 | 0.077 | 0.015 |
| ConspEmoLLM | 0.695 | 0.755 | 0.695 | 0.705 | 0.340 | 0.699 | 0.345 | 0.364 | 0.897 | 0.884 | 0.897 | 0.860 |
| Model | Task4 | Task5 | ||||||
|---|---|---|---|---|---|---|---|---|
| ACC | PRE | REC | F1 | ACC | PRE | REC | F1 | |
| BERT | 0.691 | 0.677 | 0.642 | 0.645 | 0.614 | 0.623 | 0.356 | 0.296 |
| RoBERTa | 0.677 | 0.664 | 0.670 | 0.666 | 0.601 | 0.200 | 0.333 | 0.250 |
| Falcon | 0.448 | 0.489 | 0.448 | 0.453 | 0.422 | 0.640 | 0.422 | 0.477 |
| Vicuna | 0.529 | 0.524 | 0.529 | 0.526 | 0.274 | 0.633 | 0.274 | 0.279 |
| LLaMA2-chat | 0.583 | 0.611 | 0.583 | 0.588 | 0.291 | 0.634 | 0.291 | 0.314 |
| OPT | 0.466 | 0.509 | 0.466 | 0.470 | 0.507 | 0.676 | 0.507 | 0.554 |
| BLOOM | 0.439 | 0.483 | 0.439 | 0.443 | 0.587 | 0.653 | 0.587 | 0.617 |
| ChatGPT | 0.668 | 0.774 | 0.668 | 0.664 | 0.596 | 0.576 | 0.596 | 0.574 |
| ChatGPT-aff | 0.673 | 0.769 | 0.673 | 0.670 | 0.587 | 0.557 | 0.587 | 0.551 |
| ConspLLM | 0.641 | 0.663 | 0.641 | 0.646 | 0.596 | 0.574 | 0.596 | 0.580 |
| ConspLLM-aff | 0.731 | 0.758 | 0.731 | 0.735 | 0.453 | 0.555 | 0.453 | 0.479 |
| ConspEmoLLM | 0.700 | 0.717 | 0.700 | 0.703 | 0.610 | 0.647 | 0.610 | 0.623 |
表 3 和 4 报告每项任务的结果。 ChatGPT-aff 和 ConspLLM-aff 是使用包含明确情感信息的提示的模型。 从结果表中我们可以观察到,就 F1 分数而言,微调的 ConspLLM 和 ConspEmoLLM 优于所有其他开源模型444应该注意的是,未经指令调整的大语言模型产生了一些不遵循指令的响应,即它们不产生以下类型的输出在提示中要求。 在这种情况下,我们根据任务将其标记为无关或非阴谋。,以及 PLM。 ConspLLM 和 ConspEmoLLM 的性能也均优于 ChatGPT,但任务 4 上的 ConspLLM 除外。 此外,基于大型情感语言模型进行微调的ConspEmoLLM,除任务3稍落后于ConspLLM外,所有任务的F1分数都比ConspLLM高出3%以上。 ChatGPT-aff 和 ConspLLM-aff 的结果表明,使用情感信息显式增强提示会导致除任务 4 之外的所有任务的性能下降。 我们可以推断,明确添加情感信息似乎会分散模型对手头任务的注意力。 相比之下,ConspEmoLLM 隐式使用情感信息在利用情感线索方面更为成功。
5结论
在本文中,我们对两个阴谋论数据集的综合情感分析表明,阴谋论文本表现出与主流文本不同的情感和情感特征。 这一分析的结果激发了我们开发 ConspEmoLLM,这是一个基于情感信息的开源特定领域大语言模型,可以执行各种阴谋论检测任务。 ConspEmoLLM 使用我们新构建的多任务阴谋检测指令数据集 (ConDID) 进行了微调。 对ConDID测试集的评估表明,ConspEmoLLM在所有测试的开源大语言模型以及ChatGPT中均实现了SOTA性能。 它在大多数任务上的性能超过了 ConspLLM 模型,该模型也是使用 ConDID 进行指令调整的,但不使用情感信息。 这些结果提供了强有力的证据,证明情感特征在检测与阴谋论相关的各种类型的信息中的重要性。
作为未来的工作,我们将使用更多阴谋论数据集来扩充 ConDID 数据集,包括来自多个平台、来源、领域和语言的数据。 这应该有助于进一步提高使用 ConspEmoLLM 执行的任务的性能和多样性。 我们还将探索纳入情感信息的替代方法,以进一步提高模型检测阴谋论的能力。 此外,我们将设计更合适的提示,利用更复杂多样的模型结构,更好地利用情感和情绪。
6 限制
我们工作的潜在局限性可总结如下:
(1)由于计算资源有限,我们仅使用7B大语言模型进行阴谋论检测任务的指令调优和评估。 因此,我们没有考虑使用更大或不同的模型架构可能如何影响阴谋论检测任务的性能。
(2)本文使用的数据集主要涉及COVID-19阴谋论,且规模有限。 这些限制可能会影响模型推广到其他类型的数据或域的能力。 然而,正如 5 节中提到的,我们计划通过从不同来源和领域收集更多数据来增加 ConDID 数据集的大小。 希望这将有助于提高模型的性能和通用性。
7道德声明
构建 ConDID 数据集所收集的原始数据集来自公共社交媒体平台和网站。 我们严格遵守隐私协议和道德原则,以保护用户隐私并确保在所有文本中正确应用匿名。
致谢
图 6 中的 ConspEmoLLM 插图是使用 PIXLR555https://pixlr.com/image-generator/。 这项工作得到了曼彻斯特大学计算共享设施和曼彻斯特大学计算机科学系学者奖的支持。 这项工作还得到了曼彻斯特大学数字信任与社会中心、曼彻斯特-墨尔本-多伦多研究基金以及新能源和工业技术发展组织的支持。
参考
- Cheung and Lam (2023) Tsun-Hin Cheung and Kin-Man Lam. 2023. Factllama: Optimizing instruction-following language models with external knowledge for automated fact-checking. In 2023 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pages 846–853. IEEE.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Dong et al. (2020) Wei Dong, Jinhu Tao, Xiaolin Xia, Lin Ye, Hanli Xu, Peiye Jiang, and Yangyang Liu. 2020. Public emotions and rumors spread during the covid-19 epidemic in china: web-based correlation study. Journal of Medical Internet Research, 22(11):e21933.
- Douglas (2021) Karen M Douglas. 2021. Covid-19 conspiracy theories. Group Processes & Intergroup Relations, 24(2):270–275.
- Giachanou et al. (2023) Anastasia Giachanou, Bilal Ghanem, and Paolo Rosso. 2023. Detection of conspiracy propagators using psycho-linguistic characteristics. Journal of Information Science, 49(1):3–17.
- Hoang et al. (2019) Mickel Hoang, Oskar Alija Bihorac, and Jacobo Rouces. 2019. Aspect-based sentiment analysis using bert. In Proceedings of the 22nd nordic conference on computational linguistics, pages 187–196.
- Hu et al. (2023) Beizhe Hu, Qiang Sheng, Juan Cao, Yuhui Shi, Yang Li, Danding Wang, and Peng Qi. 2023. Bad actor, good advisor: Exploring the role of large language models in fake news detection. arXiv preprint arXiv:2309.12247.
- Hutto and Gilbert (2014) Clayton Hutto and Eric Gilbert. 2014. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the international AAAI conference on web and social media, volume 8, pages 216–225.
- Langguth et al. (2023) Johannes Langguth, Daniel Thilo Schroeder, Petra Filkuková, Stefan Brenner, Jesper Phillips, and Konstantin Pogorelov. 2023. Coco: an annotated twitter dataset of covid-19 conspiracy theories. Journal of Computational Social Science, pages 1–42.
- Lei et al. (2023) Shanglin Lei, Guanting Dong, Xiaoping Wang, Keheng Wang, and Sirui Wang. 2023. Instructerc: Reforming emotion recognition in conversation with a retrieval multi-task llms framework. arXiv preprint arXiv:2309.11911.
- Liu et al. (2023) Fei Liu, Xinsheng Zhang, and Qi Liu. 2023. An emotion-aware approach for fake news detection. IEEE Transactions on Computational Social Systems.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Liu et al. (2024a) Zhiwei Liu, Kailai Yang, Tianlin Zhang, Qianqian Xie, Zeping Yu, and Sophia Ananiadou. 2024a. Emollms: A series of emotional large language models and annotation tools for comprehensive affective analysis. arXiv preprint arXiv:2401.08508.
- Liu et al. (2024b) Zhiwei Liu, Tianlin Zhang, Kailai Yang, Paul Thompson, Zeping Yu, and Sophia Ananiadou. 2024b. Emotion detection for misinformation: A review. Information Fusion, page 102300.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Miani et al. (2021) Alessandro Miani, Thomas Hills, and Adrian Bangerter. 2021. Loco: The 88-million-word language of conspiracy corpus. Behavior research methods, pages 1–24.
- Mompelat et al. (2022) Ludovic Mompelat, Zuoyu Tian, Amanda Kessler, Matthew Luettgen, Aaryana Rajanala, Sandra Kübler, and Michelle Seelig. 2022. How “loco” is the loco corpus? annotating the language of conspiracy theories. In Proceedings of the 16th Lingusitic Annotation Workshop (LAW-XVI) within LREC2022, pages 111–119.
- Müller et al. (2023) Martin Müller, Marcel Salathé, and Per E Kummervold. 2023. Covid-twitter-bert: A natural language processing model to analyse covid-19 content on twitter. Frontiers in Artificial Intelligence, 6:1023281.
- Napolitano and Reuter (2023) M Giulia Napolitano and Kevin Reuter. 2023. What is a conspiracy theory? Erkenntnis, 88(5):2035–2062.
- Pavlyshenko (2023) Bohdan M Pavlyshenko. 2023. Analysis of disinformation and fake news detection using fine-tuned large language model. arXiv preprint arXiv:2309.04704.
- Penedo et al. (2023) Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. 2023. The refinedweb dataset for falcon llm: outperforming curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116.
- Peskine et al. (2021) Youri Peskine, Giulio Alfarano, Ismail Harrando, Paolo Papotti, and Raphael Troncy. 2021. Detecting covid-19-related conspiracy theories in tweets. MediaEval.
- Peskine et al. (2023) Youri Peskine, Damir Korenčić, Ivan Grubisic, Paolo Papotti, Raphael Troncy, and Paolo Rosso. 2023. Definitions matter: Guiding gpt for multi-label classification. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4054–4063.
- Pogorelov et al. (2021) Konstantin Pogorelov, Daniel Thilo Schroeder, Stefan Brenner, and Johannes Langguth. 2021. Fakenews: Corona virus and conspiracies multimedia analysis task at mediaeval 2021. In Multimedia Benchmark Workshop, volume 67.
- Rasley et al. (2020) Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506.
- Tan et al. (2022) Kian Long Tan, Chin Poo Lee, Kalaiarasi Sonai Muthu Anbananthen, and Kian Ming Lim. 2022. Roberta-lstm: a hybrid model for sentiment analysis with transformer and recurrent neural network. IEEE Access, 10:21517–21525.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Workshop et al. (2022) BigScience Workshop, Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, et al. 2022. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
- Xie et al. (2023) Qianqian Xie, Weiguang Han, Xiao Zhang, Yanzhao Lai, Min Peng, Alejandro Lopez-Lira, and Jimin Huang. 2023. Pixiu: A large language model, instruction data and evaluation benchmark for finance. arXiv preprint arXiv:2306.05443.
- Yanagi et al. (2021) Yuta Yanagi, Ryohei Orihara, Yasuyuki Tahara, Yuichi Sei, and Akihiko Ohsuga. 2021. Classifying covid-19 conspiracy tweets with word embedding and bert. In Working Notes Proceedings of the MediaEval 2021 Workshop, Online, pages 13–15.
- Yang et al. (2023) Kailai Yang, Tianlin Zhang, Ziyan Kuang, Qianqian Xie, and Sophia Ananiadou. 2023. Mentalllama: Interpretable mental health analysis on social media with large language models. arXiv preprint arXiv:2309.13567.
- Yuan et al. (2023) Chenhan Yuan, Qianqian Xie, Jimin Huang, and Sophia Ananiadou. 2023. Back to the future: Towards explainable temporal reasoning with large language models. arXiv preprint arXiv:2310.01074.
- Zaeem et al. (2020) Razieh Nokhbeh Zaeem, Chengjing Li, and K Suzanne Barber. 2020. On sentiment of online fake news. In 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), pages 760–767. IEEE.
- Zhang et al. (2023) Boyu Zhang, Hongyang Yang, Tianyu Zhou, Muhammad Ali Babar, and Xiao-Yang Liu. 2023. Enhancing financial sentiment analysis via retrieval augmented large language models. In Proceedings of the Fourth ACM International Conference on AI in Finance, pages 349–356.
- Zhang et al. (2022) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
- Zhang et al. (2021) Xueyao Zhang, Juan Cao, Xirong Li, Qiang Sheng, Lei Zhong, and Kai Shu. 2021. Mining dual emotion for fake news detection. In Proceedings of the web conference 2021, pages 3465–3476.
- Zheng et al. (2023) Zhonghua Zheng, Lizi Liao, Yang Deng, and Liqiang Nie. 2023. Building emotional support chatbots in the era of llms. arXiv preprint arXiv:2308.11584.