CT2Rep:用于3D医学影像的自动放射学报告生成
摘要
医学影像在诊断中起着至关重要的作用,放射学报告是重要的文件。 自动生成报告已成为缓解放射科医生工作量的迫切需求。 虽然机器学习促进了 2D 医学影像的报告生成,但由于计算复杂性和数据稀缺,将其扩展到 3D 尚未得到探索。 我们介绍了第一个为 3D 医学影像生成放射学报告的方法,专门针对胸部 CT 体积。 鉴于缺乏可比方法,我们使用医学影像中先进的 3D 视觉编码器建立了一个基线,以证明我们方法的有效性,该方法利用了一种新颖的自回归因果 Transformer。 此外,认识到利用先前访问信息的好处,我们通过基于交叉注意力的多模态融合模块和层次记忆增强 CT2Rep,从而能够合并纵向多模态数据。 访问我们的代码:https://github.com/ibrahimethemhamamci/CT2Rep。
关键词:
3D 医学影像,胸部 CT 体积,放射学报告,CT-RATE 数据集,报告生成,纵向,Transformer1 引言
由于大量公共数据集[28, 14, 12]的推动,机器学习在放射学中的整合显著增强了疾病分类和分割[30, 25, 10, 6]。 此外,最近的进展已经能够开发出许多利用公共数据集[16, 23]为 2D 医学影像生成放射学报告的方法[4, 26, 20, 15, 27]。 然而,由于计算复杂性[8]以及缺乏与放射学报告配对的数据集[3],报告生成方面的这一进展尚未扩展到 3D 医学影像。
与二维成像相比,三维医学成像,如计算机断层扫描 (CT) 和磁共振成像,提供了对患者病情的更详细的视角 [22]. 因此,手动报告生成对于传达诊断结果至关重要,变得更加耗时且容易出错,这突出了自动化的必要性。 开发此类框架的挑战之一在于三维医学成像数据集与报告配对的稀缺性 [19]. 此外,三维图像的性质涉及体积数据,这需要更复杂的算法来解释额外的维度。 这种复杂性为生成描述性且临床相关的报告提出了独特的障碍,这些报告有效地捕捉了三维图像的细节。
认识到这一差距,我们的工作引入了 CT2Rep,这是第一个针对三维医学成像,特别是针对胸部 CT 体积进行自动放射学报告生成的方案。 CT2Rep 利用了一种新颖的三维自回归因果视觉特征提取器,该提取器针对处理体积数据进行了优化。 我们还整合了关系记忆,以利用来自先前报告生成的的信息,使用记忆驱动的条件层归一化将此数据整合到我们的框架中。 为了训练我们的框架,我们利用了 CT-RATE 数据集 [9],该数据集包含 25,692 个非对比度胸部 CT 体积,通过各种重建扩展到 50,188 个,来自 21,304 个独特的患者,以及相应的放射学报告。 CT2Rep 的独特性在于,它是三维医学成像领域中首屈一指的,这意味着不存在直接可比的方法。 尽管如此,为了证明我们框架的有效性,我们合理地设计了一个基线,使用最先进的用于三维胸部 CT 体积解释的视觉编码器 CT-Net [6] 进行报告生成。 CT2Rep 优于这种设计精良的基线方法,展示了我们新方法的有效性。
放射科医师通常会评估三维胸部 CT 体积以及同一患者之前的所有体积和报告,因为在临床实践中多次访问很常见。 纵向体积及其报告包含有价值的信息,利用这种多模式数据可以潜在地增强报告生成。 因此,我们通过结合基于交叉注意力的多模式融合模块以及分层记忆驱动的解码器扩展了 CT2Rep。 这种扩展不仅解决了与三维图像分析相关的计算挑战,而且促进了纵向多模式患者数据的纳入,丰富了生成的报告的上下文和准确性。 我们对这个扩展版本(名为 CT2RepLong)进行了全面的消融研究,以强调历史影像和报告在为当前诊断解释提供信息方面的重要性。 我们的贡献可以概括如下:
-
•
我们提出了 CT2Rep,这是第一个用于 3D 医学影像的放射学报告生成框架,它采用了一种新颖的自回归因果 Transformer。
-
•
由于 CT2Rep 是同类中的第一个,并且没有可比方法存在,因此我们设计了一个基线,该基线采用胸部 CT 分类中使用的最先进的 3D 视觉编码器来对我们的方法进行基准测试,并证明其有效性。
-
•
我们使用基于交叉注意的多模态融合模块和分层记忆驱动的解码器来增强 CT2Rep,以利用常见的纵向数据,并辅以全面的消融研究,展示了将纵向数据纳入报告生成中的有效性。
-
•
我们公开发布了我们训练的模型和源代码,以促进 3D 胸部 CT 体积的开箱即用报告生成。
2 方法
尽管 3D 医学影像(例如 3D 胸部 CT 体积)比其 2D 对应物(如胸部 X 光片)提供更全面的信息,但目前尚无针对 3D 影像生成放射学报告的解决方案,因为数据稀缺且计算复杂。 为了解决这一差距,我们开发了一个 3D 序列到序列生成模型,详细介绍见第 2.1 节,利用第 2.3 节概述的数据。 此外,我们还增强了我们的方法,以纳入来自先前访问的纵向多模态数据,如第 2.2 节所述。
2.1 所提出的方法
该模型 () 接受输入 3D 体积 作为一系列 CT 补丁 来预测目标序列 。 这里, 表示 CT 特征数量, 表示符元数量, 表示可能的符元词汇表。 图 1 中描述的 CT2Rep 包含三个关键组件,下面将分别详细说明。
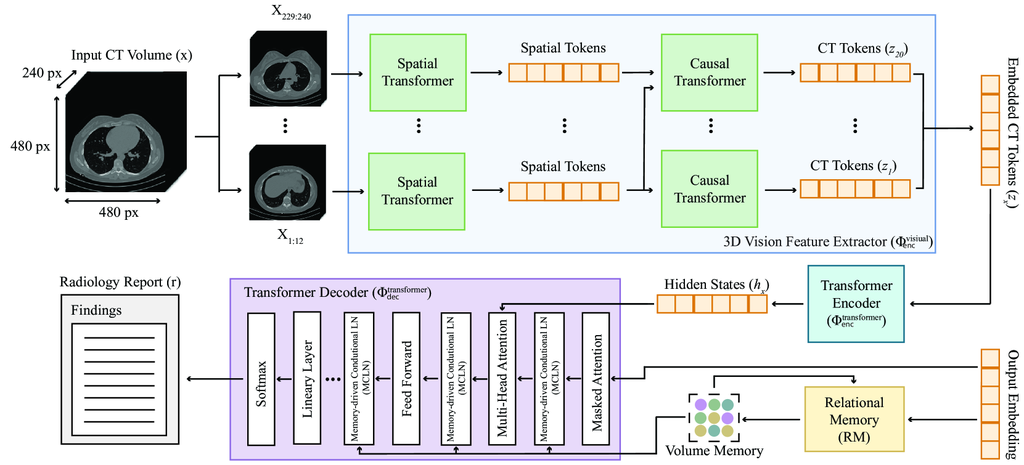
3D 视觉特征提取器。 作为我们框架的一个关键组件和主要贡献,这个网络 () 通过将数据分割成不同的块并将它们转换为低维潜在空间,从而促进从 3D 胸部 CT 体积中提取嵌入式 CT 符元,其灵感来自 [1]。 这些符元捕获了基本信息,促进了后续的分析。
该网络接收一个 3D CT 体积 () 并生成嵌入式 CT 符元 ,首先从 中提取 个不重叠的块。 然后将每个块映射到 维空间, 设置为 。 然后,根据之前的一项工作 [11],将这些块重新整形并线性转换为 。 这里, 表示时间块大小, 表示时间块的数量, 是批次大小, 和 分别是切片的宽度和高度, 和 表示空间块大小。 在块嵌入之后,结果张量大小为 。 然后,这个张量被连续地由两个 Transformer 网络处理。 首先,空间 Transformer 对大小为 的重新整形张量进行操作,生成具有相同维度的张量。 随后,因果 Transformer 处理这个重新整形为 的输出,并生成一个保持这些维度的输出。 这种方法确保在每一层之后都保留空间和潜在维度,从而在整个网络的处理阶段中保留 3D 体积信息。 整个 3D 胸部 CT 体积特征提取过程,正式定义为 ,确保 3D 体积信息被保留,便于有效构建用于报告生成的序列到序列模型。
Transformer 编码器。 我们使用一个传统的 Transformer () 来编码由 提取的 CT 特征。 这个网络通过注意力机制处理这些特征,以生成编码的隐藏状态,这对于捕获特征的相互依赖性至关重要。 编码的隐藏状态表示为:
其中每个 代表一个 patch 的编码状态, 为总的 patch 数量。 Transformer 中的注意力机制定义为 ,其中 、 和 分别代表查询、键和值矩阵, 是键的维度。
Transformer 解码器。 我们将传统的 Transformer 网络作为解码器 (),并进行了两个显著的改进。 首先,我们集成了关系记忆 (RM) [4],它需要利用矩阵来封装和传播跨生成步骤的模式信息。 此矩阵中的每一行存储特定模式的详细信息,这些信息通过更新迭代地细化,更新包括来自先前步骤的输出。 更新机制涉及使用先前步骤的矩阵作为查询,并将它与先前输出连接起来,作为 Transformer 多头注意力模块的键和值。 从数学上讲,这个过程是通过多头注意力实现的,其中 、 和 。 这里, 表示先前步骤输出的嵌入,而 、 和 分别代表查询、键和值变换的可训练权重。 因此,模型有效地学习了保守的报告模式,例如 "Trachea, both main bronchi are open.",在相似的 CT 体积内。 其次,我们采用了基于记忆的条件层归一化 (MCLN) [17],将 RM 直接集成到解码器的缩放 () 和移位 () 参数中。 这使得模型更能感知上下文,并且更擅长生成准确的文本输出。 解码过程定义为:
推断。 训练后,CT2Rep () 能够为给定的 3D 胸部 CT 体积 () 生成放射学报告 (),正式定义如下:
2.2 纵向数据利用
为了利用来自先前访问的多模态数据,我们使用基于交叉注意力的融合模块 [31] 对 CT2Rep 进行了增强,该模块允许通过整合先前 CT 体积 () 及其相应先前报告 () 的表征,来预测给定新的 3D 胸部 CT 体积 () 的结果序列 。 通过和计算先前卷和报告表示之间的交叉注意力来促进融合过程,其中和是分别涉及纵向卷和报告的特征。 这些特征被连接起来,以创建一个全面的多模态纵向表示 。 这种集成方法通过利用先前访问的时空信息,显著增强了纵向框架 的性能,如 Fig. 2 中所述。
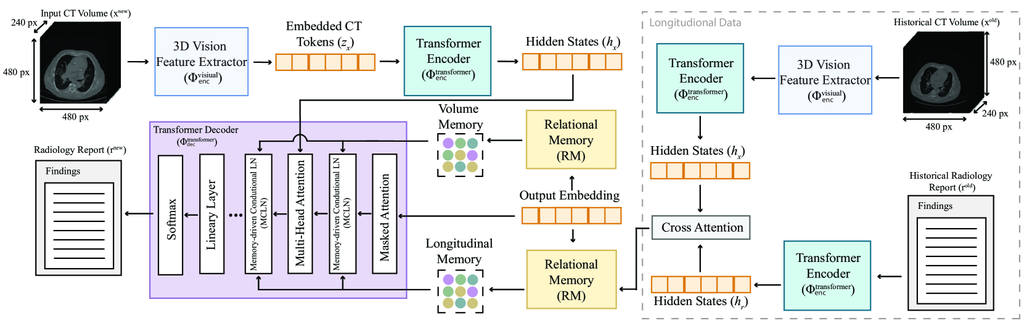
2.2.1 多模态 Transformer 解码器。
的解码器与 的解码器非常相似。 但是, 采用另外两种交叉注意力机制,共同定义为 ,来分析先前报告 () 和体积 () 之间的关系,反之亦然。 输出被连接起来,然后根据 Sec. 2.1 中描述的过程,将 RM 应用于新的报告。 随后,另一个交叉注意力 () 用于 RM 与来自先前体积和报告的交叉注意力输出之间。 然后,将得到的交叉注意力输出用于 MCLN,其形式化为:
|
|
2.2.2 推断。
训练后, 可以为给定的新体积 () 生成报告 (),以及先前体积及其相应的报告:
2.3 数据集准备。
我们利用公开的 CT-RATE 数据集 [9] 中的 3D 胸部 CT 体积以及相应的放射学报告。 为了开发 CT2Rep,我们使用了 CT-RATE 初始版本的所有体积和报告。 我们的数据集包含来自 21,314 个独特患者的 25,701 个非对比 3D 胸部 CT 体积,在应用针对不同窗口设置的多个重建后,该数据集扩展到 49,138 个体积 [29]。 每个体积在轴向平面上的分辨率为 像素,切片数量范围从 100 到 600。 与每个体积相关的放射学报告被分成四个部分:临床信息、技术、发现和印象;然而,只有发现部分被用于报告生成训练。 同一个放射学报告被用于单个 CT 体积的每个重建体积。 数据集被分成一个包含 20,000 个患者的训练集和一个包含 1,314 个患者的验证集,确保两者之间没有重叠。 使用元数据中的斜率和截距值,将 CT 体积转换为豪斯菲尔德单位 (HU),并裁剪到 以表示 HU 量表的实际诊断极限 [5]。 随后,每个体积被调整大小以在 x 和 y 轴上实现 0.75 mm 的均匀间距,在 z 轴上实现 1.5 mm 的均匀间距。 体积被中心裁剪或填充以实现 的一致分辨率。
创建纵向数据集。 我们针对访问次数超过两次的患者,分别从 2,638 个和 169 个独特患者中获得了 6,766 个和 429 个 3D 胸部 CT 体积,用于训练集和验证集。 在应用各种重建后,这些体积分别增加到训练集的 13,354 个和验证集的 849 个。 我们使用 StudyTime 元数据属性按时间顺序排列每个患者的体积,并将每个患者的两个可能的纵向体积配对,从而产生 28,441 个训练对和 1,689 个验证对。
3 实验和结果
| NLG Metrics | CE Metrics | ||||||||
| Method | BL-1 | BL-2 | BL-3 | BL-4 | M | R | P | R | F1 |
| Base w/ CT-Net | 0.443 | 0.399 | 0.375 | 0.354 | 0.286 | 0.442 | 0.513 | 0.531 | 0.456 |
| mycolor CT2Rep (Ours) | 0.460 | 0.415 | 0.390 | 0.369 | 0.295 | 0.459 | 0.749 | 0.548 | 0.534 |
| methods below utilize longitudinal data | |||||||||
| Baseline | 0.372 | 0.317 | 0.282 | 0.251 | 0.238 | 0.353 | 0.666 | 0.465 | 0.525 |
| report | 0.330 | 0.284 | 0.260 | 0.241 | 0.213 | 0.313 | 0.623 | 0.410 | 0.524 |
| volume | 0.305 | 0.261 | 0.238 | 0.220 | 0.204 | 0.291 | 0.662 | 0.434 | 0.530 |
| report volume | 0.365 | 0.319 | 0.292 | 0.271 | 0.239 | 0.351 | 0.658 | 0.410 | 0.533 |
| mycolor CT2RepLong (Ours) | 0.374 | 0.327 | 0.304 | 0.401 | 0.285 | 0.263 | 0.727 | 0.511 | 0.536 |
为了评估模型在生成放射学报告方面的有效性,我们采用了自然语言生成 (NLG) 和临床疗效 (CE) 指标。 NLG 指标包括 BLEU (BL) [24]、METEOR (M) [18] 和 ROUGE-L (R) [21],分别评估词语重叠、同义词使用和词语顺序以及序列匹配。 对于 CE 指标,我们对 CXR-Bert 模型 [2] 进行了微调,用于对 18 种异常的报告进行多标签分类,如补充材料中所述。 然后,我们预测了真实数据和生成的报告的异常标签,并计算了包括精确度 (P)、召回率 (R) 和 F1 分数在内的分类分数,以衡量生成的报告的临床准确性。
3.1 与基线方法的比较
鉴于缺乏直接可比较的方法,进一步突出了我们方法的新颖性,我们通过实现最先进的视觉编码器 CT-Net [7] 为放射学报告生成建立了一个基准,该编码器用于 3D 医学影像。 CT-Net 是第一个也是唯一一个为分类 3D 胸部 CT 体积而开发的模型。 它的架构包括一个 ResNet-18 特征提取器 [13],由旨在简化 ResNet 特征的 3D 卷积块增强,然后是最终的分类层。 在我们的方法中,我们利用了 CT-Net 的特征提取能力,将这些特征作为我们 3D 体积转换器的输入,将其确立为我们研究的基准。 表格 1 表明,由于我们作为 3D 视觉特征提取器使用的新的自回归因果转换器,我们的 CT2Rep 明显优于该基线。
案例研究。 我们通过对测试集中随机选择的案例进行定性分析,比较生成的报告与真实情况,来评估我们模型的性能。 图 3 说明了 CT2Rep 准确地生成了内容流畅、医学术语与放射科医生撰写的报告非常相似的报告,明显超过了使用 CT-Net 建立的基线。

3.2 纵向数据利用的消融研究
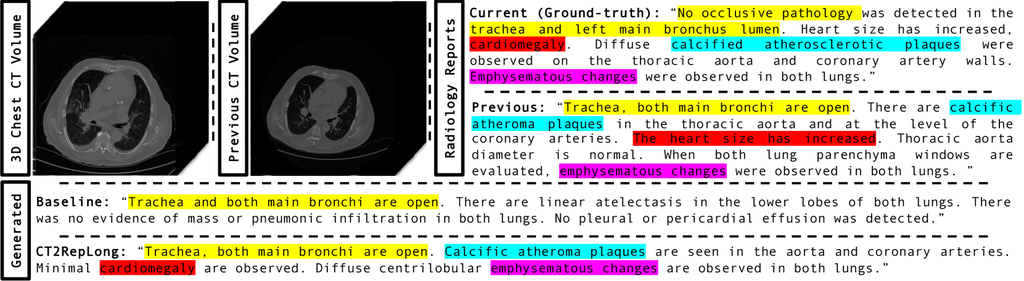
我们通过消融研究评估了CT2RepLong的性能以及整合先前数据的影響。 首先,我们仅在纵向数据集上训练CT2Rep,而没有使用任何先验数据,从而建立了基线。 然后,我们通过三种策略增强了该基线:利用来自先前报告的嵌入、先前体积嵌入,以及通过简单融合(不包括我们的纵向交叉注意力机制)的组合。 表1展示了先验多模态数据的优势以及我们独特的交叉注意力机制。 R的例外可以归因于它对序列长度的重视,而不是对来自纵向数据集成的丰富内容和多样性的重视。 此外,尽管纵向数据量有限——只有13%的患者(参见第2.3节)——CT2RepLong的性能与原始CT2Rep相当,证明了它的有效性,即使在数据集受限的情况下也是如此。
案例研究。 对一个随机测试案例的定性分析(图4)表明,CT2RepLong显著受益于整合纵向数据。 诸如“心肌肥大”和“钙化性动脉粥样硬化斑块”之类的关键词出现在当前和先前报告中,从而提高了生成报告的准确性。 值得注意的是,基线模型遗漏的术语,例如“心肌肥大”,被CT2RepLong包含在内,与真实情况一致,并证明了利用纵向数据的扩展方法在提高报告生成可靠性方面的有效性。
3.3 实现细节
CT2Rep和基线方法(参见第3.1节)在49,138个3D CT体积及其相应的报告(第2.3节)上进行了训练。 我们使用Adam优化器,和超参数分别设置为0.9和0.99。 视觉提取器的学习率设置为 0.00005,其他参数的学习率设置为 0.0001。 使用了带伽马值为 0.1 的 StepLR 调度器,批次大小为 1,调度器的最大符元计数为 300。 CT2RepLong 和消融方法(3.2 节)在 28,441 对(2.3 节)上训练,使用了与 CT2Rep 相同的超参数。 所有模型的训练时间为一周,在一个 NVIDIA A100 GPU 上进行,共训练了 20 个 epochs。 CT2Rep 的推断时间约为 35 秒,CT2RepLong 的推断时间约为 50 秒。
4 讨论与结论
总之,我们介绍了 CT2Rep,这是一个用于自动生成 3D 医学影像报告的第一个框架,重点是胸部 CT 卷。 CT2Rep 利用创新的自回归因果 Transformer 架构并整合关系记忆,提高了报告生成的准确性。 作为同类产品中的第一个,我们使用 3D 胸部 CT 卷解释中最先进的视觉编码器建立了一个基准,以展示 CT2Rep 的有效性。 此外,我们通过纵向数据集成扩展了它的功能,从而产生了 CT2RepLong,进一步增强了上下文和准确性。 我们将我们训练好的模型和代码完全开源,为进一步研究打下坚实的基础。
4.0.1 致谢
我们感谢海尔穆特·霍顿基金会对我们研究的大力支持。 此外,我们还要感谢伊斯坦布尔梅迪波尔大学提供 CT-RATE 数据集。
4.0.2
作者声明没有与本文内容相关的竞争利益。
参考文献
- [1] Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., Schmid, C.: Vivit: A video vision transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 6836–6846 (2021)
- [2] Boecking, B., Usuyama, N., Bannur, S., Castro, D.C., Schwaighofer, A., Hyland, S., Wetscherek, M., Naumann, T., Nori, A., Alvarez-Valle, J., et al.: Making the most of text semantics to improve biomedical vision–language processing. In: European conference on computer vision. pp. 1–21. Springer (2022)
- [3] Chen, X., Wang, X., Zhang, K., Fung, K.M., Thai, T.C., Moore, K., Mannel, R.S., Liu, H., Zheng, B., Qiu, Y.: Recent advances and clinical applications of deep learning in medical image analysis. Medical Image Analysis 79, 102444 (2022)
- [4] Chen, Z., Song, Y., Chang, T.H., Wan, X.: Generating radiology reports via memory-driven transformer. arXiv preprint arXiv:2010.16056 (2020)
- [5] DenOtter, T.D., Schubert, J.: Hounsfield unit (2019)
- [6] Draelos, R.L., Dov, D., Mazurowski, M.A., Lo, J.Y., Henao, R., Rubin, G.D., Carin, L.: Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes. Medical image analysis 67, 101857 (2021)
- [7] Draelos, R.L., Dov, D., Mazurowski, M.A., Lo, J.Y., Henao, R., Rubin, G.D., Carin, L.: Machine-learning-based multiple abnormality prediction with large-scale chest computed tomography volumes. Medical image analysis 67, 101857 (2021)
- [8] Gao, J., Shen, T., Wang, Z., Chen, W., Yin, K., Li, D., Litany, O., Gojcic, Z., Fidler, S.: Get3d: A generative model of high quality 3d textured shapes learned from images. Advances In Neural Information Processing Systems 35, 31841–31854 (2022)
- [9] Hamamci, I.E., Er, S., Almas, F., Simsek, A.G., Esirgun, S.N., Dogan, I., Dasdelen, M.F., Wittmann, B., Simsar, E., Simsar, M., et al.: A foundation model utilizing chest ct volumes and radiology reports for supervised-level zero-shot detection of abnormalities. arXiv preprint arXiv:2403.17834 (2024)
- [10] Hamamci, I.E., Er, S., Simsar, E., Sekuboyina, A., Gundogar, M., Stadlinger, B., Mehl, A., Menze, B.: Diffusion-based hierarchical multi-label object detection to analyze panoramic dental x-rays. In: Greenspan, H., Madabhushi, A., Mousavi, P., Salcudean, S., Duncan, J., Syeda-Mahmood, T., Taylor, R. (eds.) Medical Image Computing and Computer Assisted Intervention – MICCAI 2023. pp. 389–399. Springer Nature Switzerland, Cham (2023)
- [11] Hamamci, I.E., Er, S., Simsar, E., Tezcan, A., Simsek, A.G., Almas, F., Esirgun, S.N., Reynaud, H., Pati, S., Bluethgen, C., et al.: Generatect: Text-guided 3d chest ct generation. arXiv preprint arXiv:2305.16037 (2023)
- [12] Hamamci, I.E., Er, S., Simsar, E., Yuksel, A.E., Gultekin, S., Ozdemir, S.D., Yang, K., Li, H.B., Pati, S., Stadlinger, B., et al.: Dentex: An abnormal tooth detection with dental enumeration and diagnosis benchmark for panoramic x-rays. arXiv preprint arXiv:2305.19112 (2023)
- [13] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
- [14] Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 590–597 (2019)
- [15] Jing, B., Xie, P., Xing, E.: On the automatic generation of medical imaging reports. arXiv preprint arXiv:1711.08195 (2017)
- [16] Johnson, A.E., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Mark, R.G., Horng, S.: Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data 6(1), 317 (2019)
- [17] Lample, G., Sablayrolles, A., Ranzato, M., Denoyer, L., Jégou, H.: Large memory layers with product keys. Advances in Neural Information Processing Systems 32 (2019)
- [18] Lavie, A., Denkowski, M.J.: The meteor metric for automatic evaluation of machine translation. Machine translation 23, 105–115 (2009)
- [19] Li, J., Zhu, G., Hua, C., Feng, M., Bennamoun, B., Li, P., Lu, X., Song, J., Shen, P., Xu, X., et al.: A systematic collection of medical image datasets for deep learning. ACM Computing Surveys 56(5), 1–51 (2023)
- [20] Li, M., Lin, B., Chen, Z., Lin, H., Liang, X., Chang, X.: Dynamic graph enhanced contrastive learning for chest x-ray report generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3334–3343 (2023)
- [21] Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text summarization branches out. pp. 74–81 (2004)
- [22] Müller, N.: Computed tomography and magnetic resonance imaging: past, present and future. European Respiratory Journal 19(35 suppl), 3s–12s (2002)
- [23] Nguyen, H.Q., Lam, K., Le, L.T., Pham, H.H., Tran, D.Q., Nguyen, D.B., Le, D.D., Pham, C.M., Tong, H.T., Dinh, D.H., et al.: Vindr-cxr: An open dataset of chest x-rays with radiologist’s annotations. Scientific Data 9(1), 429 (2022)
- [24] Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics. pp. 311–318 (2002)
- [25] Pati, S., Thakur, S.P., Hamamcı, İ.E., Baid, U., Baheti, B., Bhalerao, M., Güley, O., Mouchtaris, S., Lang, D., Thermos, S., et al.: Gandlf: the generally nuanced deep learning framework for scalable end-to-end clinical workflows. Communications Engineering 2(1), 23 (2023)
- [26] Thirunavukarasu, A.J., Ting, D.S.J., Elangovan, K., Gutierrez, L., Tan, T.F., Ting, D.S.W.: Large language models in medicine. Nature medicine 29(8), 1930–1940 (2023)
- [27] Wang, J., Bhalerao, A., He, Y.: Cross-modal prototype driven network for radiology report generation. In: European Conference on Computer Vision. pp. 563–579. Springer (2022)
- [28] Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M., Summers, R.M.: Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2097–2106 (2017)
- [29] Willemink, M.J., Noël, P.B.: The evolution of image reconstruction for ct—from filtered back projection to artificial intelligence. European radiology 29, 2185–2195 (2019)
- [30] Yüksel, A.E., Gültekin, S., Simsar, E., Özdemir, S.D., Gündogar, M., Tokgöz, S.B., Hamamci, I.E.: Dental enumeration and multiple treatment detection on panoramic X-rays using deep learning. Scientific Reports (2021). https://doi.org/10.1038/s41598-021-90386-1
- [31] Zhu, Q., Mathai, T.S., Mukherjee, P., Peng, Y., Summers, R.M., Lu, Z.: Utilizing longitudinal chest x-rays and reports to pre-fill radiology reports. arXiv preprint arXiv:2306.08749 (2023)
补充材料
| Base w/ CT-Net | CT2Rep (Ours) | ||||||
|---|---|---|---|---|---|---|---|
| Abnormality | P | R | F1 | P | R | F1 | Test Set |
| Medical material | |||||||
| Arterial wall calcification | |||||||
| Cardiomegaly | |||||||
| Pericardial effusion | |||||||
| Coronary artery wall calcification | |||||||
| Hiatal hernia | |||||||
| Lymphadenopathy | |||||||
| Emphysema | |||||||
| Atelectasis | |||||||
| Lung nodule | |||||||
| Lung opacity | |||||||
| Pulmonary fibrotic sequela | |||||||
| Pleural effusion | |||||||
| Mosaic attenuation pattern | |||||||
| Peribronchial thickening | |||||||
| Consolidation | |||||||
| Bronchiectasis | |||||||
| Interlobular septal thickening | |||||||
| Mean | |||||||
| Baseline | CT2RepLong | ||||||
|---|---|---|---|---|---|---|---|
| Abnormality | P | R | F1 | P | R | F1 | Test Set |
| Medical material | |||||||
| Arterial wall calcification | |||||||
| Cardiomegaly | |||||||
| Pericardial effusion | |||||||
| Coronary artery wall calcification | |||||||
| Hiatal hernia | |||||||
| Lymphadenopathy | |||||||
| Emphysema | |||||||
| Atelectasis | |||||||
| Lung nodule | |||||||
| Lung opacity | |||||||
| Pulmonary fibrotic sequela | |||||||
| Pleural effusion | |||||||
| Mosaic attenuation pattern | |||||||
| Peribronchial thickening | |||||||
| Consolidation | |||||||
| Bronchiectasis | |||||||
| Interlobular septal thickening | |||||||
| Mean | |||||||