超越记忆:语言模型中随机内存访问
的挑战
摘要
语言模型 (LM) 的最新发展已显示出其在 NLP 任务中的有效性,特别是在知识密集型任务中。 然而,其参数内知识存储和内存访问的底层机制仍然难以捉摸。 在本文中,我们研究了生成式 LM(例如 GPT-2)是否能够顺序或随机访问其内存。 通过精心设计的综合任务,涵盖完整背诵、选择性背诵和扎根问答的场景,我们揭示了语言学习者设法顺序访问他们的记忆,同时在随机访问记忆内容方面遇到挑战。 我们发现包括重述和排列在内的技术提高了 LM 的随机存储器访问能力。 此外,通过将这种干预应用于开放域问答的现实场景,我们验证了通过背诵增强随机访问会导致问答的显着改善。 重现我们实验的代码可以在 https://github.com/sail-sg/lm-random-memory-access 找到。
超越记忆:语言模型中随机内存访问
的挑战
Tongyao Zhu1,2 Qian Liu1††thanks: Corresponding authors. Liang Pang3∗ Zhengbao Jiang4 Min-Yen Kan2 Min Lin1 1Sea AI Lab 2National University of Singapore 3Institute of Computing Technology, CAS 4Carnegie Mellon University tongyao.zhu@u.nus.edu {liuqian,linmin}@sea.com pangliang@ict.ac.cn zhengbaj@cs.cmu.edu knmnyn@nus.edu.sg
1简介
语言模型(LM)最近在 NLP 任务中展示了出色的能力,其参数中存储了大量内存(Brown 等人,2020;Ouyang 等人,2022)。 通过对大型文本语料库的预训练,语言模型能够记住关于世界的事实知识(周等人,2023)。 因此,它们在知识密集型任务(Petroni等人,2021)中表现出色,例如开放域问答(Kamalloo等人,2023;Ziems等人,2023;Mallen等人,2023)。 人们越来越有兴趣将语言模型视为知识库(Wang 等人,2021;Heinzerling 和 Inui,2021;Petroni 等人,2019;Cao 等人,2021;AlKhamassi 等人,2022)。 尽管最近在应用 LM 解决下游任务方面取得了进展,但 LM 如何在其参数中存储知识和访问内存的基本原理仍然是正在进行的研究和兴趣的主题 (Tirumala 等人,2022;Zhu 和 Li,2023;Allen -Zhu 和 Li,2023;Berglund 等人,2023)。
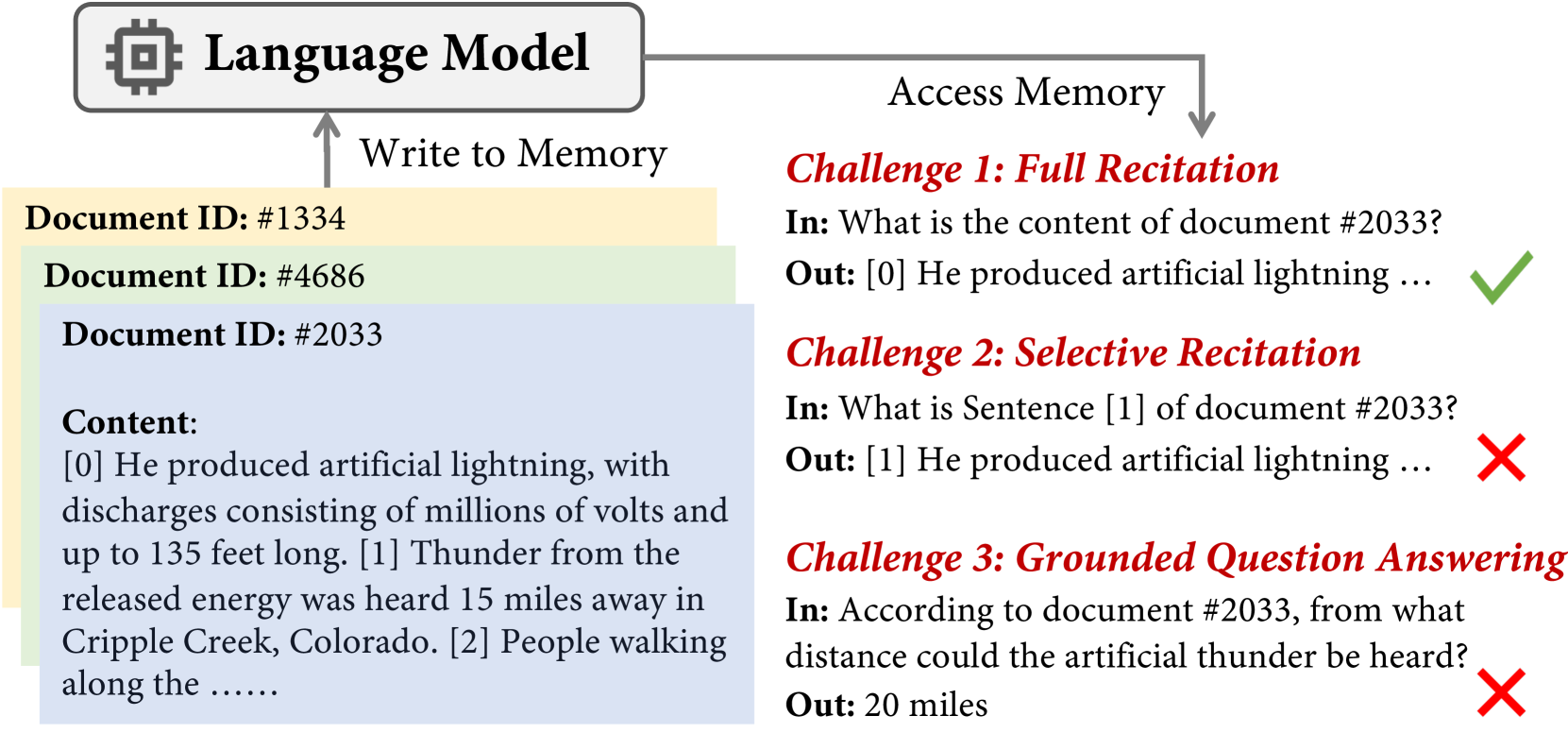
在本文中,我们从计算机系统中观察到的内存访问模式中汲取灵感,探索 LM 是否能够以顺序或随机方式访问其参数内存。 我们推断这些概念来研究 LM 并描述两种内存访问模式:顺序内存访问意味着模型从记忆序列的开头开始,按连续顺序依次浏览内容。 相反,随机内存访问表示模型可以从存储内容中的任何位置开始,而不需要从头开始。 例如,逐行背诵一首记忆的诗被认为是顺序访问,而直接从第三行开始则属于随机访问。
借助这些概念,我们使用合成数据和真实数据设计实验,以评估语言模型对记忆内容执行顺序或随机访问的能力,如图 1 所示。 我们将我们的研究限制在仅解码器的语言模型上,因为它们越来越受欢迎和能力(Radford等人,2019;Brown等人,2020;Touvron等人,2023a,b;Jiang等人,2023)。 我们首先要求模型记住各种类型的键值对,并表明该模型能够以令人满意的程度顺序读取所存储的内容。 接下来,我们通过训练模型背诵句子或在记忆的段落中找到问题的答案来测试模型的随机访问能力。 在此类任务中,当需要提取段落中间的跨度时,模型的性能会急剧下降,这表明它无法随机访问其内存。
鉴于语言模型难以对其记忆进行随机访问,我们寻求两种缓解方法:推理时的背诵和训练期间的排列。 背诵使模型能够在执行任务之前首先顺序读取其参数内存。 因此,可以通过利用上下文窗口中的背诵内容来增强模型的性能。 我们还表明,在训练过程中简单地排列段落中的句子来记忆内容也可以提高表现。
我们最终通过开放域问答的案例研究验证了随机访问的挑战。 我们通过允许模型记住具有真实答案的段落来降低任务的难度,但我们发现当允许模型背诵相关段落然后回答问题时,模型从这种记忆中受益最大。 总的来说,我们为进一步理解仅解码器语言模型的内存访问机制做出了一些贡献:
-
•
我们证明语言模型可以顺序访问其内存并可以重现记忆的内容,但在随机内存访问方面遇到重大挑战。
-
•
我们找到了通过在执行任务之前排列记忆内容或明确背诵记忆来减轻随机访问挑战的解决方案。
-
•
我们证明了开放域问答中随机记忆访问能力差的影响,表明这一挑战可能对语言模型的应用产生更广泛的影响。
2相关工作
语言模型中的记忆。
大型语言模型在其参数中存储了大量知识(Petroni 等人,2019;Heinzerling 和 Inui,2021)。 他们会记住事实和常识等有用知识(Zhao 等人, 2023),但也会记住电子邮件或电话号码等敏感个人信息(Carlini 等人, 2020; Huang 等人, 2022 )。 理解记忆的现有方法包括细粒度分析以定位与知识相关的神经元(Meng等人,2022;Liu等人,2024)或宏观分析以了解记忆的整体动态(Tirumala 等人,2022;Speicher 等人,2024)。 在这项研究中,我们的目的不是分析写入语言模型记忆的机制。 相反,我们将语言模型视为黑盒内存存储,并主要关注模型如何访问其内存。
知识注入。
我们的调查需要将新内容写入模型的参数存储器。 在不改变模型架构的情况下执行此类知识注入主要有两种方法(Ovadia等人,2024;Balaguer等人,2024):微调或检索增强。 检索增强(Lewis等人, 2020; Shi等人, 2023)检索相关信息并将其放入模型上下文中,同时微调直接更新模型参数。 由于我们研究的目标是研究模型在写入内存后如何访问其参数内存,因此我们选择微调作为向模型引入新知识的方法。
知识检索。
先前的研究表明,使用提示可以有效地检索存储在大型语言模型中的知识(Bouraoui等人,2019;Jiang等人,2021;Wang等人,2021)。 我们遵循早期的工作,使用提示来查询模型以访问和重新生成记忆的内容。 然而,一个显着的区别是,先前的工作侧重于寻找优化方法来引出模型在预训练期间获得的知识(Youssef 等人, 2023; Liu 等人, 2023; Yu 等人, 2023),而我们直接使用唯一的密钥来记忆和检索内容。
作为文档索引的语言模型。
我们将语言模型视为段落的记忆存储,这与采用语言模型作为文档存储和检索的索引的最新进展有关(Metzler等人,2021;Tay等人,2022;Wang等人,2023;曾等人,2023)。 在此类索引中,每个文档都与一个文档标识符 (ID) 相关联,该标识符可以是关键字 (Ren 等人, 2023; Bevilacqua 等人, 2022; Lee 等人, 2023b, a) 或数字(Tay等人,2022;王等人,2023;庄等人,2022;周等人,2022)。 我们也遵循惯例,为每个文档分配一个ID,用于存储和检索文档。 但是,我们不会要求模型检索问题的相关 ID。 相反,我们在输入中提供 ID,并研究顺序或随机访问相应文档内容的可能性。
3 研究顺序和随机内存访问
在本节中,我们研究语言模型顺序或随机访问存储在参数中的内存的能力。 首先,我们提供了作为段落记忆库的语言模型的公式(§3.1)。 在此框架内,我们将顺序内存访问定义为从记忆段落的开头开始并逐步生成后续内容的过程。 相比之下,我们将随机内存访问概念化为模型从记忆段落中的任何选定位置启动回忆并准确重新生成后续内容的能力。 基于这些定义,我们首先通过要求模型逐字背诵完整段落来研究模型的顺序记忆访问能力(§3.2)。 接下来,我们通过要求模型背诵记忆段落中选定的句子来测试模型的随机记忆访问能力(§3.3)。 我们通过涉及问答的更具挑战性的任务进一步评估模型的随机访问能力(§3.4)。
3.1 任务制定
我们将语言模型抽象为记忆库,并研究其顺序或随机访问能力。 我们采用存储体的简单定义作为键值存储,其中表示分配给内容的唯一标识符(ID) > 第一段111我们交替使用“文档”和“段落”来指代一段文本。.
存储体需要支持两个核心功能:读和写。 鉴于我们的记忆库体现为语言模型,因此写入和读取模型的记忆并不简单。 继之前的工作(Zhu and Li,2023;Wang等人,2021)之后,为了写入到存储体,我们使用微调来更新模型的参数。 对于阅读,我们使用提示来激发模型的记忆。 具体来说,对于每个段落 及其相应的标识符 ,我们创建两种类型的数据实例:writing、 和 阅读、,其中和表示附录A.1中详细提示。
由于我们研究的主要目标是测试模型是否可以顺序或随机读取(访问)其存储的内容,因此我们在不同的实验中改变读取功能。 给定一个由 段落组成的语料库,我们将语料库分为两个子集: 训练段落和 验证段落。 我们采用 Zhu 和 Li (2023) 描述的混合训练策略:在训练阶段,我们包含 的 和 实例T 训练段落,以及 V 验证段落的 实例。 我们的目标是让模型通过对段落的阅读和写作实例进行训练,学习将每个训练标识符与其段落内容相关联。 在评估过程中,我们使用 V 验证通道的 实例提示模型来测试模型的内存访问模式。
3.2顺序访问:完整背诵
我们通过要求语言模型再现完整的段落内容来测试语言模型的顺序访问能力。 具体来说,给定一个ID,系统会提示模型从相应记忆段落的开头开始,连续生成 Token 。 我们评估模型在 验证段落上重现内容的性能,这要求模型既记住段落内容,又使用提供的密钥顺序访问内存。
设置。
为了研究模型是否可以处理不同类型的标识符和段落内容,我们设置 和 并考虑以下变化。 对于段落内容类型,我们检查两个类别:(1)自然语言(NL),包括来自SQuAD 的维基百科段落(Rajpurkar等人,2016) ,以及 (2) 随机字符串 (Rand),其中每个 NL 段落都替换为空格分隔的字母数字字符串,保持相同数量的标记。 关于的类型(即段落ID),我们探索三种形式:(1)数字字符串(Num),例如“#123”; (2)稀有随机token(Rare),采用Ruiz等人(2022)的方法,随机采样三个稀有token; (3) 文章所属维基百科页面的文章标题 (Title)。
我们采用具有774M参数的GPT2-large模型(Radford等人,2019)作为基础模型。 为了获得更好的字符串记忆能力(Stevens and Su,2023),我们使用预训练的检查点222https://huggingface.co/gpt2而不是从头开始训练模型。 我们对模型进行了 100 个 epoch,以确保模型完全收敛,学习率为 。 我们使用 BLEU 分数 (Papineni 等人,2002) 和精确匹配(EM)分数来衡量记忆力,表明生成的内容与真实段落之间的相似性。
| Title (ID) | Num (ID) | Rare (ID) | |
|---|---|---|---|
| psg=NL | 96.2 / 85.0 | 96.7 / 95.0 | 73.4 / 72.5 |
| psg=Rand | 96.7 / 95.0 | 96.7 / 95.0 | 96.7 / 95.0 |
讨论。
表 1 显示该模型能够顺序访问存储的内容,并且验证通道上的 BLEU 和 EM 较高。 该模型的顺序访问能力通过其对不同类型的 ID 和段落的适应性得到了进一步证明。 具体来说,使用标题或数字作为自然语言段落的关键字比使用稀有标记可以获得更高的性能。 我们怀疑模型可能难以将稀有标记与自然语言内容相关联。 值得注意的是,该模型的访问能力扩展到由随机字符 () 组成的段落。
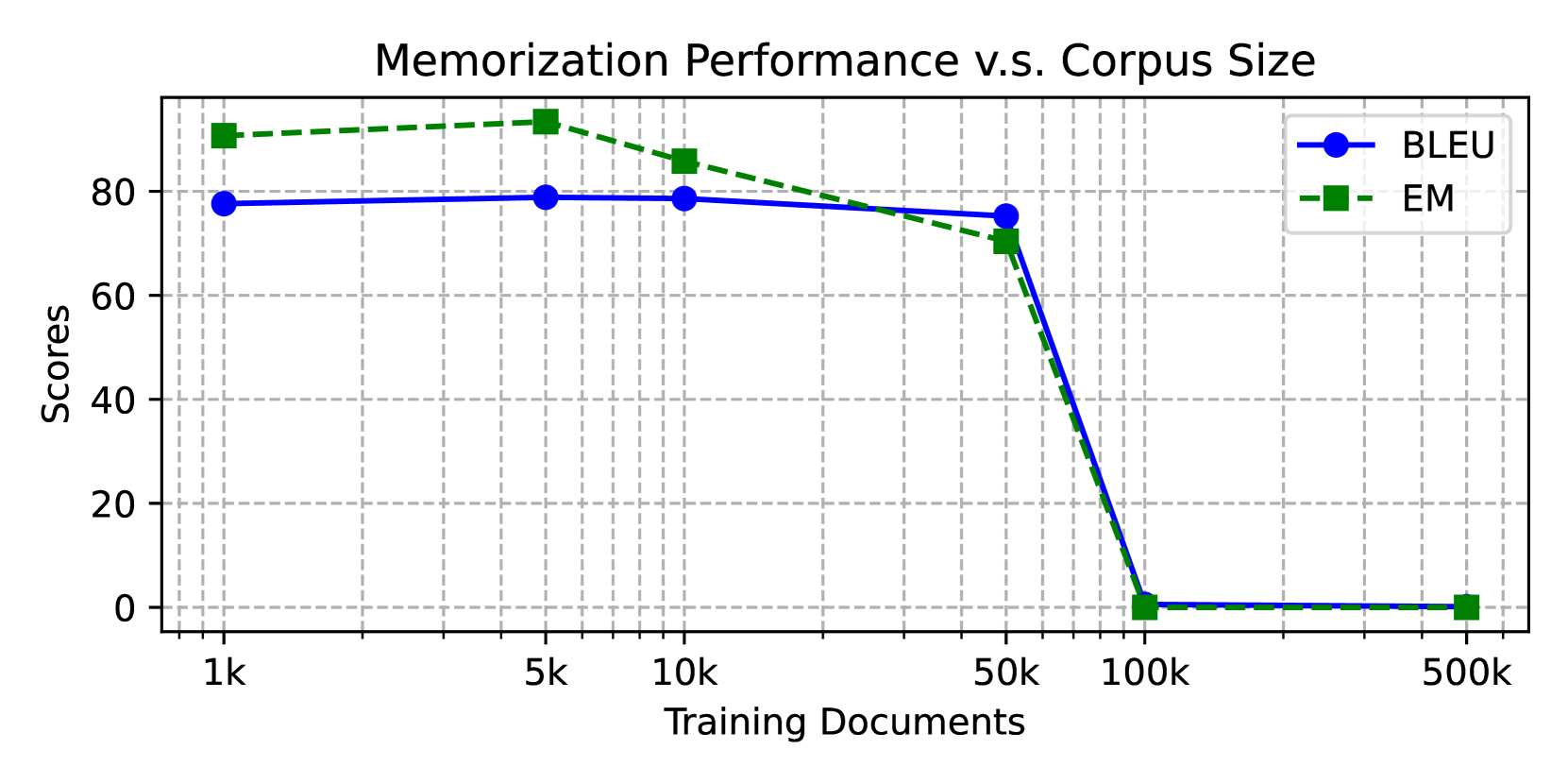
为了进一步测试模型的记忆容量,我们进行了一项额外的实验,将段落类型设置为 ,将标识符类型设置为 ,并构建每个段落具有 25 个随机标记。 如图2所示,我们将固定为1k,并将从1k逐渐增加到500k,以考察顺序内存访问的能力。
我们观察到,即使训练段落数为 50k,GPT2-large 模型也能准确再现超过 70% 的记忆验证段落。 然而,参数内存也存在一个瓶颈:当通道数超过100k时,性能几乎下降到零。 我们将这个瓶颈归因于训练的难度,因为模型无法集中于记住所有段落。 因此,在后续的实验中,我们仔细管理语料库大小,以确保模型记住所有段落。
3.3随机访问:选择性背诵
选择性背诵是一项简单的综合任务:要求语言模型重现所记忆段落的特定句子。 该任务的设计是为了简单,因为它不需要模型理解段落内容。 重点仅在于模型访问记忆段落中的片段的能力。 成功的随机访问将通过模型从记忆的段落中再现任何句子的能力来表明,无论位置如何。
设置。
我们按照 Mallick 等人 (2023) 在每个句子的边界放置标记,这些标记是由 NLTK 句子分割器333https://www.nltk.org/api/nltk.tokenize.sent_tokenize.html:格式化段落如“[0]已发送0[0][1]已发送1[1],...,”。 在这种情况下,模型只需要学习复制这些标记之间的内容。 我们的选择性背诵任务要求模型根据给定的段落 ID 背诵段落 的第 句。 现在的读取函数是,如“文件 #2033 的句子 [1] 是什么?”如图1所示。 作为参考,我们还在上下文窗口中提供段落内容的基线中测试模型的性能。
当我们测试精确记忆时,我们使用 BLEU 和 EM 分数来评估模型。 与§3.2类似,我们使用和验证段落,分别有1994个句子和200个句子。 我们将ID的类型设置为,并且只包含超过3个句子的段落。 所有其他超参数与§3.2相同。
| Title (ID Type) | Rare (ID Type) | Num (ID Type) | ||||
| Setup | EM | F1 | EM | F1 | EM | F1 |
| w/o passage memorization | ||||||
| Closed-Book QA (lower bound) | 9.0 | 16.6 | 9.0 | 16.6 | 9.0 | 16.6 |
| Open-Book QA (upper bound) | 73.7 | 79.3 | 73.7 | 79.3 | 73.7 | 79.3 |
| w/ passage memorization | ||||||
| Grounded QA w/ Golden ID | 26.7 | 35.6 | 20.7 | 28.7 | 24.3 | 32.6 |
| Recitation | 59.7 | 68.0 | 54.7 | 62.1 | 57.7 | 66.2 |
| Grounded QA w/ Random ID | 20.7 | 28.9 | 20.7 | 28.3 | 23.3 | 31.6 |
| Recitation | 16.0 | 20.4 | 18.7 | 23.6 | 18.7 | 23.1 |
| Grounded QA w/o ID | 22.0 | 31.0 | 22.0 | 31.0 | 22.0 | 31.0 |
| Recitation | 26.3 | 33.1 | 26.3 | 33.1 | 26.3 | 33.1 |
讨论。
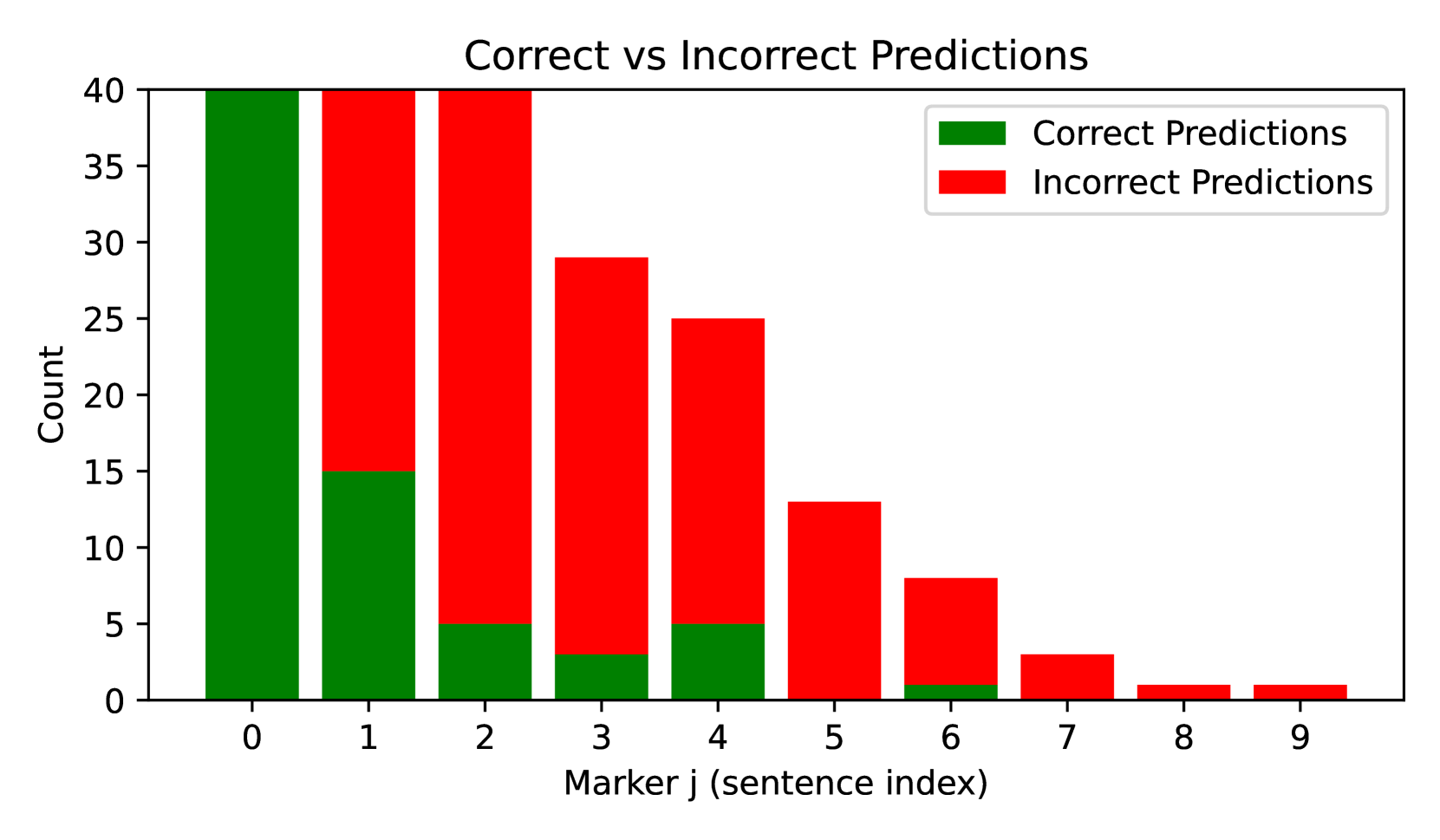
我们发现提供段落 ID 并不能让模型选择性地背诵所请求的句子。 它的得分很低,EM 为 34.5,BLEU 为 47.1,而当段落内容包含在上下文中时,EM 和 BLEU 得分要高得多,分别为 97.0 和 97.3。 详细分析图3表明,正确的预测主要是背诵第一句话()。 这验证了模型可以顺序访问内容以重现第一句话。 然而,随着标记索引的增加,模型需要跳过前面的句子并直接访问段落中间的句子。 该模型的性能急剧下降,表明它无法随机访问记忆段落中的中间或后面的句子。
3.4 随机访问:扎根问答
基于我们之前的发现§3.2,即模型可以记住许多段落,每个段落都链接到一个唯一的 ID,我们开始执行一项更务实的任务:基于特定段落 ID 的问答。 该任务旨在评估模型是否可以通过从内存中提取跨度来提供问题的答案。 例如,一个问题可能被表述为“根据文件#3022,肖邦于哪一年成为法国公民?”,答案是 ID #3022 的段落中的“1835”。 我们假设,如果 LM 能够进行随机内存访问,它们应该使用提供的 ID 导航到相应的段落并提取相关的跨度来回答问题。
设置。
我们使用著名的 SQuAD-v1 (Rajpurkar 等人, 2016) 数据集进行实验,因为它的许多问题都密切依赖于文章,例如“战争是如何开始的?”。 如果没有参考文章,问题可能会含糊不清且无法回答。 这种设计迫使模型依赖于记忆的 ID 和段落,而不是预先存在的知识。 我们探索扎根的 QA 任务,其变体包括:(1) 黄金段落的 ID 和答案,(2) 随机的非黄金 ID 和 (3) 无 ID。 为了进行比较,我们还考虑了不涉及将段落写入模型参数存储器的设置。 其中包括 (1) 闭卷 QA,其中模型仅在 QA 对上进行微调,作为下限基线来评估模型对回答问题的先验知识的依赖程度,以及 (2) 开卷 QA,其中黄金段落内容与问题连接起来,设置了抽取式 QA 性能的上限。
我们尝试不同类型的通道 ID。 为了确保使用标题作为段落 ID 的唯一性,我们从完整的 SQuAD 数据集中选择 段落和 段落,分别包含超过 2,000 和 300 个问题。 该模型按照原始 SQuAD 评估脚本在 F1 和 EM 上进行评估。 其他超参数与§3.2中提到的相同。
讨论。
结果如表2所示(“+Reitation”的设置将在后面的章节中讨论)。 正如预期的那样,该模型在开卷环境中表现最好,因为它只需要在黄金段落中找到答案。 相比之下,闭卷 QA 设置的性能最差,因为该模型无法访问段落,并且仅依赖于预训练期间存储的参数知识。
有趣的是,所提供的通道 ID 的形式对性能的影响最小。 无论是否提供黄金 ID,我们都会观察到相似的性能,但 ID 类型为 Title 时除外。 在这种情况下,提供随机的错误 ID 会损害性能。 我们怀疑这是因为标题通常是与文章主题相关的实体,因此提供了有用的线索。 在 ID 不携带语义的情况下(即 Rare 和 Num),ID 的正确性或存在不会显着影响性能,其性能仍然大大低于尽管模型记住了所有段落,但还是打开的书本设置。 这进一步验证了模型无法有效访问随机内存,因为即使提供了正确的段落 ID,它也很难提取答案。
总之,我们的研究结果验证了这样的假设:LM 可以有效地充当内存库,从而能够对其内存进行顺序访问。 然而,模型随机访问其内存的能力存在很大的限制。 在简单的选择性背诵和复杂的基础问答任务中,尽管明确提供了相应的段落 ID,但该模型始终无法利用其记忆来完成任务。
| Setup | BLEU | EM |
|---|---|---|
| Baseline | 47.1 | 34.5 |
| Duplication (dup-J) | 36.0 | 23.5 |
| Recitation | 99.3 | 98.5 |
| Permutation (first) | 100.0 | 100.0 |
| Permutation (random) | 98.0 | 97.0 |
4 缓解随机访问挑战
我们早期的实验表明,一般来说,语言模型在顺序访问其参数内存方面表现良好,但在随机内存访问方面遇到了挑战。 这自然提出了一个问题:我们如何减轻随机内存访问的缺点?
4.1 建议的方法
为了应对这一挑战,我们从 LM 作为内存存储支持的两种操作开始:读取和写入。 在写作阶段,我们假设对段落内容进行排列可以自然地增强模型的随机访问能力:内容的任何部分都可以作为记忆序列的起点。 在此设置中,我们更改段落内容的顺序以实现随机访问。
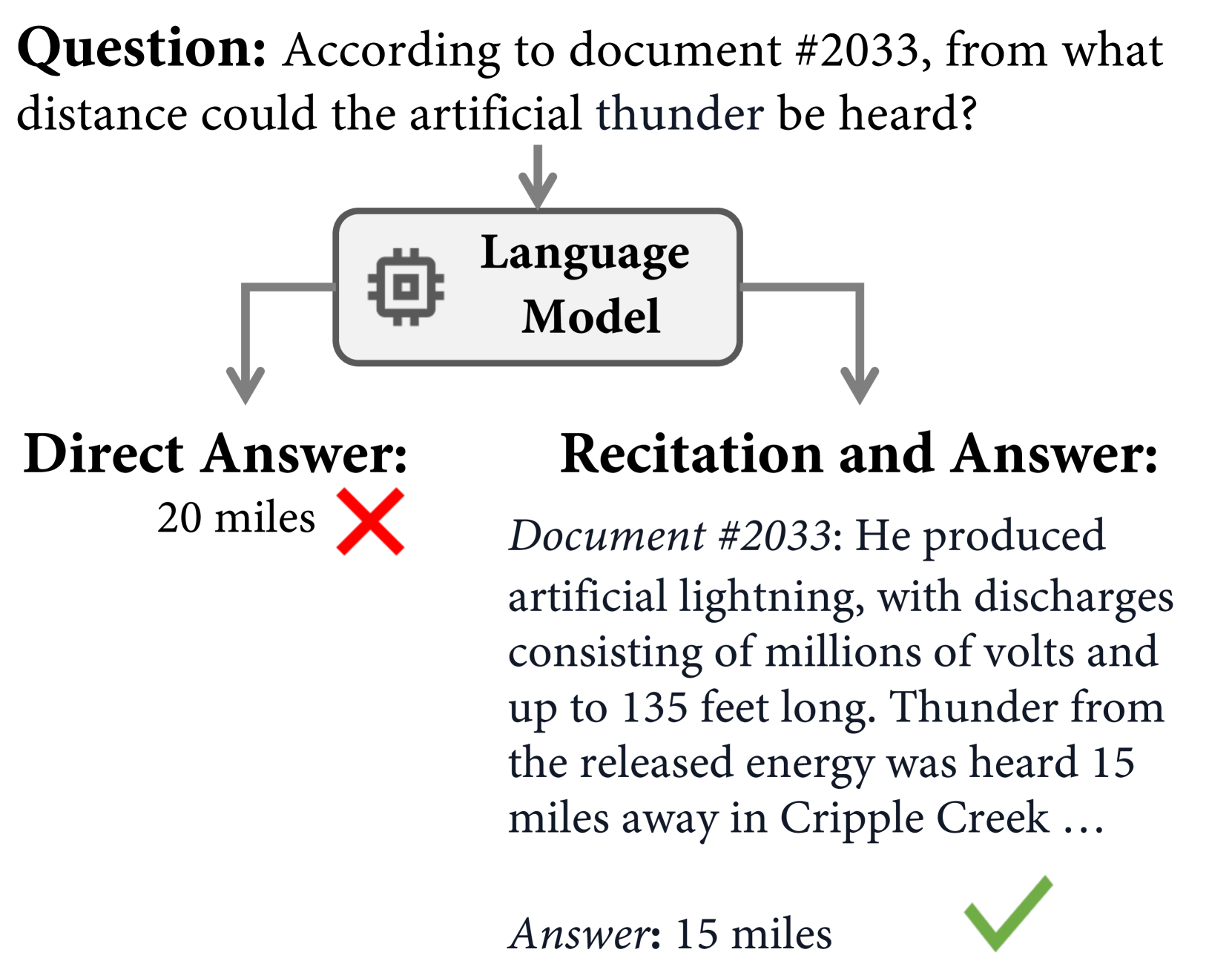
另一方面,在阅读阶段,利用模型的上下文窗口提供了一种可行的策略。 注意力机制(Vaswani 等人, 2017) 使模型能够访问上下文窗口内的任何词符,从而本质上支持随机访问(Packer 等人, 2023; Ge 等人, 2023 )。 对于具有给定 ID 的任务,我们可以要求模型先按顺序复述段落,将其置于上下文中,然后查询模型以利用此上下文执行跨度提取任务,如图4所示。 我们后续的实验旨在评估这两种方法的有效性。 通过实证评估,我们验证了写作过程中的内容排列或阅读过程中的背诵可以在很大程度上减轻随机内存访问的挑战并提高性能。
设置。
我们通过将背诵和排列整合到各自的阅读和写作阶段来扩展早期的实验。
首先,我们在选择性句子背诵任务中添加一个设置:根据给定的ID,模型的任务是先背诵相应段落的全部内容,然后背诵特定句子,将阅读操作更改为。 同样,对于扎根 QA 任务,我们要求模型在回答问题之前背诵与输入段落 ID 相关的段落。 在没有 ID 的设置中,模型仍然接受背诵黄金段落的训练。
为了探索在写作阶段排列的效果,我们在段落中的句子之间进行排列以创建不同的 实例。 对于 句子段落,我们测试: (1) first,将每个句子移动到段落的开头以创建 唯一实例; (2) random-k,随机打乱句子次以创建实例,其中设置为4默认。 为了表明排列的效果不仅仅是由于更多的训练数据,我们还包括一个基线 dup-J,其中每个段落在训练数据中重复 次。
讨论。
背诵段落内容可以有效提高选择性背诵的表现,如表3所示。 通过背诵,模型首先使用提供的段落 ID 从内存中顺序访问内容,然后在上下文中加载该段落以允许随机访问。 因此,根据上下文中背诵的内容,模型可以轻松识别正确的句子。
同样,明确背诵黄金段落可以显着提高问答能力,如表2(+背诵)所示。 这一观察结果在所有三种类型的通道 ID 中都是一致的。 相反,故意促使模型背诵随机段落会导致性能下降。 这可能是因为随机段落引入了不相关的信息并混淆了模型。 令人惊讶的是,即使没有 ID,背诵相关段落也能提高表现,尽管进步幅度小于黄金 ID。 这验证了背诵在更一般的问答场景中的有效性。
增强随机访问的另一种方法是执行句子排列,如表3所示。 只需将每个句子放在段落的开头一次(first)或多次随机排列句子(random)有助于解决访问段落中间内容的挑战。通道。 相反,简单地复制原始段落无助于增强随机访问。 我们还观察到,写入期间的排列增强了基础 QA 性能(表 4),该性能随着随机排列的数量单调增加。 然而,值得注意的是,排列不会改变参数存储器固有的顺序访问模式。 相反,通过排列句子并打乱其原始顺序,我们允许通过 ID 顺序访问段落中间或末尾的更多句子。
我们还验证了结论可以推广到更大的仅解码器 LM。 在附录D中,我们在Qwen1.5-4b(Bai等人,2023)和Llama2-7B(Touvron等人)中观察到类似的随机访问挑战, 2023b) 跨不同的任务。 此外,我们观察到,我们提出的背诵和排列方法可以有效缓解此类挑战。
| Title (ID Type) | Rare (ID Type) | Num (ID Type) | ||||
|---|---|---|---|---|---|---|
| Setup | EM | F1 | EM | F1 | EM | F1 |
| Grounded QA w. Golden ID | 26.7 | 35.6 | 20.7 | 28.7 | 24.3 | 32.6 |
| Duplication (dup-J) | 26.7 | 36.8 | 20.7 | 28.3 | 22.3 | 30.6 |
| Permutation (first) | 27.7 | 39.8 | 27.0 | 37.7 | 27.7 | 37.7 |
| Permutation (random-1) | 25.7 | 35.0 | 19.0 | 27.5 | 19.7 | 28.1 |
| Permutation (random-2) | 26.0 | 35.6 | 25.7 | 33.7 | 23.7 | 32.8 |
| Permutation (random-4) | 29.7 | 38.5 | 25.3 | 35.6 | 25.0 | 34.2 |
| Permutation (random-8) | 31.3 | 40.1 | 27.7 | 36.7 | 29.0 | 38.3 |
5 案例研究:开放域问答
| NQ | Hotpot QA | |||||
| EM | F1 | Recite BLEU | EM | F1 | Recite BLEU | |
| Closed-Book QA | 10.1 | 14.8 | - | 13.1 | 20.1 | - |
| Closed-Book QA w. Mixed Training | 12.6 | 18.2 | - | 15.7 | 22.8 | |
| Recitation | 16.1 | 20.1 | 28.6 | 21.0 | 28.4 | 51.3 |
| Closed-Book QA w. Continual Training | 10.3 | 15.5 | - | 15.1 | 22.4 | - |
| Recitation | 13.4 | 16.9 | 25.6 | 18.1 | 25.2 | 48.3 |
我们的研究结果表明,语言模型很难应对随机内存访问,除非明确地背诵内存并加载到可以随机访问的上下文中。 基于这一见解,我们将研究扩展到开放域问答任务,这是一项具有挑战性的任务,要求模型首先检索相关记忆并对其进行推理。 这与之前的实验不同,因为不再提供通道 ID 作为输入:读取操作变为 。 因此,模型需要在不借助段落 ID 的情况下找到与查询相关的段落,这是一项艰巨的任务(Pradeep 等人,2023)。 由于我们研究的目标不是检索性能,并且我们早期的结果(§3.3)表明该模型的记忆能力有限,因此我们通过限制写入的段落数量来降低检索难度。模型的记忆:我们只包含包含至少一个问题答案的积极段落。
我们的目标是测试模型在实际应用中执行随机访问的能力。 具体来说,我们研究了模型在记住了许多段落后是否能够准确地从记忆中提取答案。 与之前的实验类似,我们也旨在观察模型在训练背诵相关段落并随后回答问题时性能的差异。 我们选择不尝试排列,因为与大量段落中的句子排列相关的训练成本很高,并将这一途径留给未来的工作。
5.1实验设置
我们使用 Karpukhin 等人 (2020) 处理的自然问题 (Kwiatkowski 等人, 2019) 进行单跳 QA,选择 6000 个训练问题和所有 6489 个验证问题,总共 10.9k 段。 对于多跳问答,我们使用 HotpotQA (Yang 等人, 2018),其中每个问题都有两个黄金段落。 我们选择 8k 训练和 distractor 子集中的所有 7405 个验证问题,总共 26.9k 段。
我们从一个基线设置开始,其中训练仅涉及 QA 对,即闭卷 QA,它评估从预训练中获得的模型的先验知识。 接下来,我们考虑两种类型的训练策略来将段落写入内存。 在 mixed 设置中,模型在所有段落和 QA 对的 实例的混合上进行微调。 在连续设置中,模型首先对所有段落的实例进行微调,然后对QA进行微调。 为了测试背诵的有效性,我们还包括训练模型在回答之前背诵黄金段落的设置。
由于该任务要求模型同时执行段落检索和问题回答,因此我们期望模型大小应该足够大。 因此,我们将大语言模型升级为GPT2-XL,参数为1.5B。 在混合设置中,我们以 3e-5 的学习率训练模型 20 个时期。 在连续设置中,我们首先在段落上训练 20 个 epoch,然后在 QA 对上训练另外 20 个 epoch。 我们根据验证问题的 EM 分数报告最佳表现。
5.2结果与讨论
表 5 表明,将黄金段落写入模型的内存中,可以提高混合训练或连续训练的基准闭卷设置的性能。 这符合我们的期望,因为我们故意将包含问题答案的段落注入记忆中,丰富了模型的知识。
此外,背诵显着增强了模型利用和访问记忆段落的能力,从而显着提高了性能。 在混合训练和连续训练设置中都可以观察到这一点。 在单跳和多跳 QA 中,精确匹配分数显着提高了 3% 以上。 当模型明确地背诵段落并将其加载到上下文中进行随机访问时,原始的开放域 QA 任务就简化为更简单的提取 QA 任务。 然而,较低的背诵 BLEU 分数表明该模型并不总是准确背诵黄金段落。 我们预计,如果它能够准确地从记忆中检索相关段落,性能将进一步提高。
混合训练策略优于连续训练设置。 这可能是因为模型对段落内容的记忆在混合训练中不断刷新。 相比之下,在连续训练过程中,第二阶段训练仅涉及段落上的问答对,可能会导致验证段落的记忆衰退。 因此,背诵变得不太准确,如 BLEU 分数下降所示。
我们的结果与 Wei 等人 (2023) 和 Sun 等人 (2023) 的研究结果一致且互补:引入中间步骤或生成相关段落有助于提高模型性能在各种任务上。 我们对这种现象提供了另一种解释:将参数记忆加载到上下文窗口中有助于增强对记忆信息的随机访问,并且模型受益于这种增强。
6结论
我们凭经验研究语言模型如何访问其参数记忆。 我们对合成数据和真实数据的实验表明,虽然语言模型可以按顺序充分再现记忆的内容,但它们难以随机访问记忆内容中间的片段。 我们确定了两种有效的背诵和排列策略来减轻随机内存访问的限制。 此外,通过开放域问答的受控案例研究,我们证明允许模型背诵和随机访问其内存可以显着提高性能。 总的来说,我们的研究不仅提供了对语言模型中的内存访问模式的更深入的理解,而且还强调了有限的随机内存访问能力在语言模型的实际应用中的影响。
局限性
在这项工作中,我们主要探索仅解码器语言模型的内存访问模式。 未来的研究需要了解我们的结论是否适用于基于转换器的其他类型的语言模型,例如仅编码器模型和编码器-解码器模型。 此外,由于计算资源的限制,我们不会将研究扩展到超过 70 亿个参数的更大模型。 在更大的语言模型中探索内存访问模式的进一步扩展行为可能是值得的。 此外,我们主要在固定大小的文本语料库上进行对照实验。 可能需要进一步调查来探索如何将研究结果应用于大规模预训练语料库及其对预训练语言模型的影响。
道德考虑
由于该方法提出了增强对模型记忆的访问的技术,因此可能会恶意使用背诵方法从模型的记忆中提取敏感的个人信息。 我们使用开源英语数据集,包括来自 SQuAD-v1 (Rajpurkar 等人, 2016)、Natural Questions (Kwiatkowski 等人, 2019) 和 Hotpot QA 的问题和上下文(杨等人,2018)。 我们还使用开源英语语言模型 GPT2,具有不同的大小(Radford 等人,2019)。 这些数据集和模型可能存在潜在偏差。
致谢
我们感谢杜宣龙、秦艳霞、苗一松以及 NUS WING 其他成员的建议和意见。 朱同耀获得海洋人工智能实验室行业博士项目资助。
参考
- AlKhamissi et al. (2022) Badr AlKhamissi, Millicent Li, Asli Celikyilmaz, Mona T. Diab, and Marjan Ghazvininejad. 2022. A review on language models as knowledge bases. ArXiv, abs/2204.06031.
- Allen-Zhu and Li (2023) Zeyuan Allen-Zhu and Yuanzhi Li. 2023. Physics of language models: Part 3.2, knowledge manipulation. ArXiv, abs/2309.14402.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609.
- Balaguer et al. (2024) Angels Balaguer, Vinamra Benara, Renato Luiz de Freitas Cunha, Roberto de M. Estevão Filho, Todd Hendry, Daniel Holstein, Jennifer Marsman, Nick Mecklenburg, Sara Malvar, Leonardo O. Nunes, Rafael Padilha, Morris Sharp, Bruno Silva, Swati Sharma, Vijay Aski, and Ranveer Chandra. 2024. RAG vs fine-tuning: Pipelines, tradeoffs, and a case study on agriculture.
- Berglund et al. (2023) Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. 2023. The reversal curse: LLMs trained on "A is B" fail to learn "B is A".
- Bevilacqua et al. (2022) Michele Bevilacqua, Giuseppe Ottaviano, Patrick Lewis, Scott Yih, Sebastian Riedel, and Fabio Petroni. 2022. Autoregressive search engines: Generating substrings as document identifiers. In Advances in Neural Information Processing Systems, volume 35, pages 31668–31683. Curran Associates, Inc.
- Bouraoui et al. (2019) Zied Bouraoui, José Camacho-Collados, and Steven Schockaert. 2019. Inducing Relational Knowledge from BERT. In AAAI Conference on Artificial Intelligence.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Cao et al. (2021) Boxi Cao, Hongyu Lin, Xianpei Han, Le Sun, Lingyong Yan, Meng Liao, Tong Xue, and Jin Xu. 2021. Knowledgeable or educated guess? revisiting language models as knowledge bases. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1860–1874, Online. Association for Computational Linguistics.
- Carlini et al. (2020) Nicholas Carlini, Florian Tramèr, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom B. Brown, Dawn Xiaodong Song, Úlfar Erlingsson, Alina Oprea, and Colin Raffel. 2020. Extracting training data from large language models. In USENIX Security Symposium.
- Ge et al. (2023) Yingqiang Ge, Yujie Ren, Wenyue Hua, Shuyuan Xu, Juntao Tan, and Yongfeng Zhang. 2023. LLM as OS, agents as apps: Envisioning AIOS, agents and the AIOS-agent ecosystem. ArXiv, abs/2312.03815.
- Heinzerling and Inui (2021) Benjamin Heinzerling and Kentaro Inui. 2021. Language models as knowledge bases: On entity representations, storage capacity, and paraphrased queries. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 1772–1791, Online. Association for Computational Linguistics.
- Hu et al. (2022) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations.
- Huang et al. (2022) Jie Huang, Hanyin Shao, and Kevin Chen-Chuan Chang. 2022. Are large pre-trained language models leaking your personal information? In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 2038–2047, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Jiang et al. (2023) Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L’elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b. ArXiv, abs/2310.06825.
- Jiang et al. (2021) Zhengbao Jiang, Jun Araki, Haibo Ding, and Graham Neubig. 2021. How can we know when language models know? on the calibration of language models for question answering. Transactions of the Association for Computational Linguistics, 9:962–977.
- Kamalloo et al. (2023) Ehsan Kamalloo, Nouha Dziri, Charles Clarke, and Davood Rafiei. 2023. Evaluating open-domain question answering in the era of large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5591–5606, Toronto, Canada. Association for Computational Linguistics.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, Online. Association for Computational Linguistics.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466.
- Lee et al. (2023a) Hyunji Lee, JaeYoung Kim, Hoyeon Chang, Hanseok Oh, Sohee Yang, Vladimir Karpukhin, Yi Lu, and Minjoon Seo. 2023a. Nonparametric decoding for generative retrieval. In Findings of the Association for Computational Linguistics: ACL 2023, pages 12642–12661, Toronto, Canada. Association for Computational Linguistics.
- Lee et al. (2023b) Sunkyung Lee, Minjin Choi, and Jongwuk Lee. 2023b. GLEN: Generative retrieval via lexical index learning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7693–7704, Singapore. Association for Computational Linguistics.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems, volume 33, pages 9459–9474. Curran Associates, Inc.
- Liu et al. (2023) Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv., 55(9).
- Liu et al. (2024) Yan Liu, Yu Liu, Xiaokang Chen, Pin-Yu Chen, Daoguang Zan, Min-Yen Kan, and Tsung-Yi Ho. 2024. The devil is in the neurons: Interpreting and mitigating social biases in language models. In The Twelfth International Conference on Learning Representations.
- Mallen et al. (2023) Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9802–9822, Toronto, Canada. Association for Computational Linguistics.
- Mallick et al. (2023) Prabir Mallick, Tapas Nayak, and Indrajit Bhattacharya. 2023. Adapting pre-trained generative models for extractive question answering. ArXiv, abs/2311.02961.
- Meng et al. (2022) Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. In Advances in Neural Information Processing Systems, volume 35, pages 17359–17372. Curran Associates, Inc.
- Metzler et al. (2021) Donald Metzler, Yi Tay, Dara Bahri, and Marc Najork. 2021. Rethinking search: making domain experts out of dilettantes. SIGIR Forum, 55(1).
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744.
- Ovadia et al. (2024) Oded Ovadia, Menachem Brief, Moshik Mishaeli, and Oren Elisha. 2024. Fine-tuning or retrieval? comparing knowledge injection in LLMs.
- Packer et al. (2023) Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. 2023. MemGPT: Towards LLMs as operating systems. ArXiv, abs/2310.08560.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311–318, Philadelphia, Pennsylvania, USA. Association for Computational Linguistics.
- Petroni et al. (2021) Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, Vassilis Plachouras, Tim Rocktäschel, and Sebastian Riedel. 2021. KILT: a benchmark for knowledge intensive language tasks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2523–2544, Online. Association for Computational Linguistics.
- Petroni et al. (2019) Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2463–2473, Hong Kong, China. Association for Computational Linguistics.
- Pradeep et al. (2023) Ronak Pradeep, Kai Hui, Jai Gupta, Adam Lelkes, Honglei Zhuang, Jimmy Lin, Donald Metzler, and Vinh Tran. 2023. How does generative retrieval scale to millions of passages? In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 1305–1321, Singapore. Association for Computational Linguistics.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas. Association for Computational Linguistics.
- Ren et al. (2023) Ruiyang Ren, Wayne Xin Zhao, Jing Liu, Hua Wu, Ji-Rong Wen, and Haifeng Wang. 2023. TOME: A two-stage approach for model-based retrieval. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6102–6114, Toronto, Canada. Association for Computational Linguistics.
- Ruiz et al. (2022) Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2022. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22500–22510.
- Shi et al. (2023) Weijia Shi, Sewon Min, Michihiro Yasunaga, Minjoon Seo, Rich James, Mike Lewis, Luke Zettlemoyer, and Wen tau Yih. 2023. REPLUG: Retrieval-Augmented Black-Box Language Models.
- Speicher et al. (2024) Till Speicher, Aflah Mohammad Khan, Qinyuan Wu, Vedant Nanda, Soumi Das, Bishwamittra Ghosh, Krishna P. Gummadi, and Evimaria Terzi. 2024. Understanding the mechanics and dynamics of memorisation in large language models: A case study with random strings.
- Stevens and Su (2023) Samuel Stevens and Yung-Chun Su. 2023. Memorization for good: Encryption with autoregressive language models. ArXiv, abs/2305.10445.
- Sun et al. (2023) Zhiqing Sun, Xuezhi Wang, Yi Tay, Yiming Yang, and Denny Zhou. 2023. Recitation-augmented language models. In International Conference on Learning Representations.
- Tay et al. (2022) Yi Tay, Vinh Q. Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. 2022. Transformer memory as a differentiable search index.
- Tirumala et al. (2022) Kushal Tirumala, Aram H. Markosyan, Luke Zettlemoyer, and Armen Aghajanyan. 2022. Memorization without overfitting: Analyzing the training dynamics of large language models. ArXiv, abs/2205.10770.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open and efficient foundation language models.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023b. Llama 2: Open Foundation and Fine-Tuned Chat Models.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Wang et al. (2021) Cunxiang Wang, Pai Liu, and Yue Zhang. 2021. Can generative pre-trained language models serve as knowledge bases for closed-book QA? In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3241–3251, Online. Association for Computational Linguistics.
- Wang et al. (2023) Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Hao Sun, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, Xing Xie, Hao Allen Sun, Weiwei Deng, Qi Zhang, and Mao Yang. 2023. A neural corpus indexer for document retrieval.
- Wei et al. (2023) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2023. Chain-of-thought prompting elicits reasoning in large language models.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, Brussels, Belgium. Association for Computational Linguistics.
- Youssef et al. (2023) Paul Youssef, Osman Koraş, Meijie Li, Jörg Schlötterer, and Christin Seifert. 2023. Give me the facts! a survey on factual knowledge probing in pre-trained language models. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 15588–15605, Singapore. Association for Computational Linguistics.
- Yu et al. (2023) Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, and Meng Jiang. 2023. Generate rather than retrieve: Large language models are strong context generators. In International Conference for Learning Representation (ICLR).
- Zeng et al. (2023) Hansi Zeng, Chen Luo, Bowen Jin, Sheikh Muhammad Sarwar, Tianxin Wei, and Hamed Zamani. 2023. Scalable and effective generative information retrieval. ArXiv, abs/2311.09134.
- Zhao et al. (2023) Zirui Zhao, Wee Sun Lee, and David Hsu. 2023. Large language models as commonsense knowledge for large-scale task planning. In RSS 2023 Workshop on Learning for Task and Motion Planning.
- Zhou et al. (2023) Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. 2023. LIMA: Less is more for alignment.
- Zhou et al. (2022) Yujia Zhou, Jing Yao, Zhicheng Dou, Ledell Yu Wu, Peitian Zhang, and Ji rong Wen. 2022. Ultron: An ultimate retriever on corpus with a model-based indexer. ArXiv, abs/2208.09257.
- Zhu and Li (2023) Zeyuan Allen Zhu and Yuanzhi Li. 2023. Physics of language models: Part 3.1, knowledge storage and extraction. ArXiv, abs/2309.14316.
- Zhuang et al. (2022) Shengyao Zhuang, Houxing Ren, Linjun Shou, Jian Pei, Ming Gong, Guido Zuccon, and Daxin Jiang. 2022. Bridging the gap between indexing and retrieval for differentiable search index with query generation. arXiv preprint arXiv:2206.10128.
- Ziems et al. (2023) Noah Ziems, Wenhao Yu, Zhihan Zhang, and Meng Jiang. 2023. Large language models are built-in autoregressive search engines. In Findings of the Association for Computational Linguistics: ACL 2023, pages 2666–2678, Toronto, Canada. Association for Computational Linguistics.
附录A提示
A.1 完整背诵
给定一个键值对,提示如下:
= “文章{},内容:{}”
= “文章{}:这篇文章的内容是什么?” “{}”
A.2选择性背诵
在本实验中,我们遵循与相同的提示,如附录§A.1中所述,仅更改
= “文章{},内容:{}”
= “文章{}:本文的句子[{}]是什么?” “{}”
A.3 扎根问答实验
在本实验中,我们遵循与相同的提示,如附录§A.1中所述,仅将更改为与。 表示在答案之前背诵段落内容的情况。
= “文章{},内容:{}”
= “文章 {} \n 问题:{} \n 答案: ” “{}”
= “文章 {} \n 问题:{} \n 答案: ” “ {} ||答案:{}”
A.4开放域问答
在开放域问答实验的设置中,我们不再为每个文档预先分配 ID。 我们的 变成:
= “文档:{}”
同样,读取操作现在没有任何与之关联的 ID,而只有一个问题。 它变成:
= “问题:{q} \n 答案: ” “{ans}”
在背诵的情况下,我们训练模型的提示包括包含答案的段落。
= “问题:{q}” “相关文档:{} \n 答案:{ }”
附录B额外的选择性背诵实验
我们为背诵句子的选择性背诵任务提供了额外的实验结果。 所有实验都得出一致的结论:该模型无法从记忆的段落中随机提取句子。
在下面的两个实验中,我们包括 (1) 上下文中的设置:该段落包含在上下文窗口中。 (2) ID引导:提供段落ID的选择性背诵任务的基本版本。 (3) 短文背诵:先背短文,再背句子。
B.1 背诵第一/第二/最后一句话
| Recite First | Recite Second | Recite Last | ||||
|---|---|---|---|---|---|---|
| BLEU | EM | BLEU | EM | BLEU | EM | |
| In-context | 97.2 | 95.0 | 94.3 | 95.0 | 91.8 | 87.5 |
| ID-guided | 99.0 | 97.5 | 14.1 | 5.0 | 17.6 | 0.0 |
| Recitation | 99.6 | 95.0 | 98.8 | 87.5 | 98.7 | 85.0 |
作为选择性句子背诵任务的基本设置,我们提出诸如“第 123 条的[第一/第二/最后]句是什么?”。
结果如表6所示。 该模型几乎总是正确地背诵第一个句子,而第二个或最后一个句子的背诵性能显着下降。 这表明模型正在执行顺序访问:在文章ID之后,模型只能访问紧随ID之后的内容——第一句话。 它无法直接访问第二句或最后一句。
我们观察到,即使对于段落位于上下文窗口中的上下文设置,模型也不能完美执行,特别是在提取最后一个句子时。 这是因为模型还需要学习、或的含义,这涉及到统计索引的数值推理能力。 因此,在主要实验中,我们在句子的两端放置标记以降低任务难度。
B.2 背诵下一个/上一个句子
| Recite Next Sentence | Recite Previous Sentence | |||
|---|---|---|---|---|
| BLEU | EM | BLEU | EM | |
| In-context | 98.0 | 96.0 | 82.7 | 79.0 |
| ID-guided | 86.9 | 81.0 | 20.1 | 18.5 |
| Recitation | 98.4 | 85.0 | 96.5 | 81.0 |
我们进行实验来查找给定段落中输入句子之前和之后的句子。 换句话说,我们的操作变成了,其中是输入句子。 结果如表7所示。
我们注意到,找到输入句子之后的句子总是很容易,而反向任务则要困难得多。 这也表明模型是按顺序读取其内存的。 即使目标句子与输入句子相邻,它也无法随机访问输入之前的句子。
附录 C 其他开放域问答实验
为了确保我们的结论与不同的数据集大小保持一致,我们改变训练和验证文档以及问题的数量以观察性能差异。 对于 NQ,我们选择 5k 个训练和 5k 个验证 QA 对,形成包含大约 9k 个段落的语料库。 对于 Hotpot QA,我们在 distractor 子集中选择 5k 个训练问题和 5k 个验证问题,总共 18.2k 个段落。
在表8中,我们得到了类似的结论,即背诵大大提高了答题能力,并且由于背诵分数的提高,使用混合训练策略比连续训练更好。
| NQ | Hotpot QA | |||||
| EM | F1 | Recite BLEU | EM | F1 | Recite BLEU | |
| Closed-Book QA | 9.1 | 13.7 | - | 13.3 | 20.4 | - |
| Closed-Book QA w. Mixed Training | 11.5 | 17.2 | - | 15.9 | 23.6 | |
| Recitation | 15.7 | 19.7 | 29.1 | 20.8 | 28.4 | 50.9 |
| Closed-Book QA w. Continual Training | 10.3 | 15.5 | - | 15.1 | 22.8 | - |
| Recitation | 12.3 | 15.8 | 24.2 | 18.2 | 25.6 | 49.2 |
附录D大型语言模型实验
为了证明我们的结论可以推广到更大的模型,我们对 Qwen1.5-4b (Bai 等人, 2023) 和 Llama2-7b (Touvron 等人, 2023b)< 进行了额外的实验/t1>,分别有大约 40 亿和 70 亿个参数。 这些模型与 GPT2 属于同一仅解码器语言模型系列。 出于效率目的,我们使用 LoRA (Hu 等人, 2022),这是一种参数高效的方法来调节大型语言模型。
| Qwen1.5-4b | Llama2-7b | |||
|---|---|---|---|---|
| Setup | EM | BLEU | EM | BLEU |
| Baseline | 22.5 | 36.2 | 17.0 | 30.9 |
| Recitation | 100.0 | 100.0 | 95.5 | 98.6 |
| Permutation (first) | 99.5 | 100.0 | 99.0 | 99.4 |
| Permutation(random-4) | 90.0 | 92.7 | 86.5 | 90.4 |
选择性背诵
表9展示了选择性背诵任务的结果,这与较小的GPT2-large的结果一致。 进行背诵或排列可以增强对段落的随机访问并解决任务。 不过,与 GPT2 相比,基线和随机排列设置方面存在性能下降。 这是因为我们使用语义上有意义的段落标识符 Title,并且较大的模型可能在预训练期间记住了许多与标题实体相关的段落。 因此,更有可能生成不在我们预定义的段落集中的句子,这会降低性能,因为任务需要精确的再现。
| Qwen1.5-4b | Llama2-7b | |||
| Setup | EM | F1 | EM | F1 |
| w/o passage memorization | ||||
| Closed-Book QA | 19.0 | 28.9 | 26.3 | 37.6 |
| Open-Book QA | 84.0 | 90.9 | 83.7 | 91.5 |
| w/ passage memorization | ||||
| Grounded QA w/o ID | 20.7 | 30.7 | 27.3 | 38.7 |
| Grounded QA w/ Golden ID | 22.7 | 34.4 | 35.0 | 47.5 |
| Recitation | 45.7 | 54.2 | 63.7 | 70.1 |
接地气的问答
在表10中,我们显示了当ID类型是段落标题时的扎根QA性能。 我们发现,包括黄金标题(w/o ID vs. w/ Golden ID)仅略微提高了 Qwen 的性能,而 Llama 从提供的标题中受益更多,该标题通常是与问题相关的实体。 我们怀疑这是因为较大的模型在预训练期间学习了更多有关实体的知识。 然而,对于这两种模型,背诵和回答设置的性能都有显着提高,显示了背诵的有效性。
| NQ | Hotpot QA | ||||||
|---|---|---|---|---|---|---|---|
| Setup | EM | F1 | Rec-BLEU | EM | F1 | Rec-BLEU | |
| Llama2-7b | Closed-book QA | 26.4 | 39.0 | - | 24.1 | 33.8 | - |
| Recitation | 30.3 | 40.1 | 15.7 | 22.7 | 31.4 | 22.2 | |
| CBQA w. Mixed Training | 27.6 | 40.2 | - | 24.6 | 34.6 | - | |
| Recitation | 30.6 | 39.8 | 17.4 | 22.4 | 30.7 | 23.8 | |
| Qwen1.5-4b | Closed-book QA | 19.7 | 27.8 | - | 18.6 | 27.0 | - |
| Recitation | 16.3 | 24.1 | 11.4 | 16.7 | 24.5 | 17.4 | |
| CBQA w. Mixed Training | 21.2 | 29.4 | - | 19.3 | 28.3 | - | |
| Recitation | 17.4 | 24.1 | 13.6 | 18.4 | 25.1 | 32.7 | |
开放域问答
我们进一步将开放域问答的案例研究扩展到上述更大的模型。 与5.1节中的设置不同,我们不包括连续设置,因为我们根据经验发现模型遭受灾难性遗忘。 相反,我们引入了一种额外的设置(闭卷 QA + 背诵),其中模型在背诵和回答实例 () 上进行微调,但不会将任何段落写入内存。 此设置测试模型是否在预训练期间记住了相关段落,并在微调后学习背诵它们。 我们对所有实验使用 1e-4 的学习率。
附录E其他训练细节
我们在具有 NVIDIA Tesla A100 GPU(具有 40G 或 80G 内存)的集群中进行所有实验。 §3.2 中的实验在 4 个 GPU 上总共花费了 48 小时。 §3.3 和 §4 中的选择性句子背诵实验在 4 个 GPU 上总共花费了 41 个小时。 扎根 QA 实验在 4 个 GPU 上总共需要 132 小时。 开放域 QA 实验需要 3 天才能使用 32 个 GPU 完成。
我们使用 Hugging Face 转换器库进行所有实验。 对于GPT2模型的主要实验,我们使用3e-5的学习率。 我们为开放域 QA 实验设置了恒定的学习率计划。 对于所有其他实验,我们使用 0.05 的预热比率和线性衰减学习率。 我们在每个时期结束时评估模型在验证集上的性能,并报告性能最佳的模型。