1完整的作者列表请参阅贡献和致谢部分。 请将信件发送至 gemma-1-report@google.com。
Gemma:基于Gemini研究和技术的开放模型
摘要
这项工作介绍了 Gemma,这是一个轻量级、最先进的开放模型系列,由用于创建 Gemini 模型的研究和技术构建而成。 Gemma 模型在语言理解、推理和安全方面的学术基准上表现出了强劲的性能。 我们发布了两种规模的模型(20 亿和 70 亿个参数),并提供预训练和微调的检查点。 Gemma 在 18 个基于文本的任务中的 11 个上优于类似大小的开放模型,我们对模型的安全和责任方面进行了全面评估,并详细描述了模型开发。 我们相信,负责任地发布大语言模型对于提高前沿模型的安全性以及实现下一波大语言模型创新至关重要。
1简介
我们推出了 Gemma,这是一个基于 Google Gemini 模型的开放模型系列(Gemini Team,2023)。
我们使用与 Gemini 模型系列类似的架构、数据和训练方法,在多达 6T 的文本标记上训练 Gemma 模型。 与 Gemini 一样,这些模型在文本领域实现了强大的通才能力,同时还具有最先进的大规模理解和推理能力。 通过这项工作,我们发布了预先训练和微调的检查点,以及用于推理和服务的开源代码库。
Gemma 有两种尺寸:用于在 GPU 和 TPU 上高效部署和开发的 70 亿参数模型,以及用于 CPU 和设备上应用程序的 20 亿参数模型。 每种尺寸都旨在满足不同的计算限制、应用程序和开发人员要求。 在每个尺度上,我们都会发布原始的、预先训练的检查点,以及针对对话、指令遵循、帮助和安全性进行微调的检查点。 我们通过一系列定量和定性基准彻底评估我们模型的缺点。 我们相信,预训练和微调检查点的发布将使人们能够对当前指令调整机制的影响进行彻底的研究和调查,并开发出越来越安全和负责任的模型开发方法。
相对于可比规模(和一些更大)的开放模型,Gemma 提高了最先进的性能(Jiang 等人,2023;Touvron 等人,2023b,a;Almazrouei 等人,2023) 跨越广泛的领域,包括自动基准测试和人工评估。 示例领域包括问答 (Clark 等人,2019;Kwiatkowski 等人,2019)、常识推理 (Sakaguchi 等人,2019;Suzgun 等人,2022)、数学和科学(Cobbe 等人,2021;Hendrycks 等人,2020),以及编码(Austin 等人,2021;Chen 等人,2021)。 请参阅Evaluation部分中的完整详细信息。
与 Gemini 一样,Gemma 也建立在序列模型 (Sutskever 等人,2014 年) 和 Transformer (Vaswani 等人,2017 年)、基于神经网络的深度学习方法 (LeCun 等人、2015),以及分布式系统上的大规模训练技术(Barham 等人,2022;Roberts 等人,2023;Dean 等人,2012)。 Gemma 还建立在 Google 悠久的开放模型和生态系统基础上,包括 Word2Vec (Mikolov 等人,2013)、Transformer (Vaswani 等人,2017)、BERT (Devlin 等人,2018)、T5 (Raffel 等人,2019) 和 T5X (Roberts 等人,2022)。
我们相信,负责任地发布大语言模型对于提高前沿模型的安全性、确保公平地获得这一突破性技术、对当前技术进行严格评估和分析以及促进下一波创新的发展至关重要。 虽然已经对所有 Gemma 模型进行了全面测试,但测试无法涵盖可能使用 Gemma 的所有应用程序和场景。 考虑到这一点,所有 Gemma 用户都应在部署或使用之前针对其用例进行严格的安全测试。 有关我们安全方法的更多详细信息,请参阅Responsible Deployment部分。
在这份技术报告中,我们详细概述了 Gemma 的模型架构、训练基础设施以及预训练和微调方法,然后通过各种定量和定性基准对所有检查点进行了全面评估,以及标准学术基准和人类偏好评估。 然后,我们详细讨论我们的安全和负责任的部署方法。 最后,我们概述了 Gemma 的更广泛含义、其局限性和优点以及结论。
2模型架构
Gemma 模型架构基于 Transformer 解码器(Vaswani 等人,2017)。 表1总结了该架构的核心参数。 模型在 8192 个标记的上下文长度上进行训练。
| Parameters | 2B | 7B |
| d_model | 2048 | 3072 |
| Layers | 18 | 28 |
| Feedforward hidden dims | 32768 | 49152 |
| Num heads | 8 | 16 |
| Num KV heads | 1 | 16 |
| Head size | 256 | 256 |
| Vocab size | 256128 | 256128 |
我们还利用了原始 Transformer 论文之后提出的几项改进。 下面,我们列出了所包含的改进:
多查询注意力 (Shazeer,2019)。 值得注意的是,7B 模型使用多头注意力,而 2B 检查点使用多查询注意力(使用 ),基于消融研究,该研究揭示了各自的注意力变体在每个尺度上提高了性能(Shazeer, 2019)。
RoPE 嵌入 (Su 等人,2021)。 我们在每一层中使用旋转位置嵌入,而不是使用绝对位置嵌入;我们还在输入和输出之间共享嵌入,以减少模型大小。
GeGLU 激活 (Shazeer,2020)。 标准 ReLU 非线性被 GeGLU 激活函数取代。
RMSNorm。 我们使用 RMSNorm (Zhang and Sennrich, 2019) 对每个 Transformer 子层、注意力层和前馈层的输入进行归一化。
3 培训基础设施
我们使用 TPUv5e 训练 Gemma 模型; TPUv5e 部署在 256 个芯片的 Pod 中,配置为 16 x 16 芯片的 2D 环面。 对于 7B 模型,我们在 16 个 pod 中训练模型,总计 4096 个 TPUv5e。 我们在 2 个 pod 中预训练 2B 模型,总共 512 个 TPUv5e。 在 Pod 内,我们对 7B 模型使用 16 路模型分片和 16 路数据复制。 对于2B,我们简单地使用256路数据复制。 使用类似于 ZeRO-3 的技术进一步对优化器状态进行分片。 除了 Pod 之外,我们还使用 (Barham 等人,2022) 的 Pathways 方法在数据中心网络上执行数据副本缩减。
| Model | Embedding Parameters | Non-embedding Parameters |
| 2B | 524,550,144 | 1,981,884,416 |
| 7B | 786,825,216 | 7,751,248,896 |
与在 Gemini 中一样,我们利用 Jax (Roberts 等人,2023) 和 Pathways (Barham 等人,2022) 的“单控制器”编程范例来简化开发过程通过启用单个 Python 进程来编排整个训练运行;我们还利用 GSPMD 分区器 (Xu 等人, 2021) 进行训练步骤计算和 MegaScale XLA 编译器 (XLA, 2019)。
3.1碳足迹
我们估计预训练 Gemma 模型的碳排放量为 。 该值是根据我们的 TPU 数据中心直接报告的每小时能源使用量计算得出的;我们还缩放该值以考虑创建和维护数据中心所消耗的额外能源,从而为我们提供训练实验的总能源使用量。 我们通过将每小时的能源使用量与我们的数据中心报告的每小时每个电池的碳排放量数据相结合,将总能源使用量转换为碳排放量。
此外,Google 数据中心通过能源效率、可再生能源购买和碳抵消相结合来实现碳中和。 这种碳中和也适用于我们的实验以及用于运行这些实验的机器。
4预训练
4.1 训练数据
Gemma 2B 和 7B 分别针对来自网络文档、数学和代码的主要英语数据的 2T 和 6T 标记进行训练。 与 Gemini 不同,这些模型不是多模式的,也没有针对多语言任务的最先进性能进行训练。
我们使用 Gemini 的 SentencePiece tokenizer (Kudo 和 Richardson,2018) 的子集来实现兼容性。 它分割数字,不删除额外的空格,并依赖于未知标记的字节级编码,遵循 (Chowdhery 等人,2022) 和 (Gemini Team,2023)所使用的技术)。 词汇量大小为 256k 个标记。
4.2过滤
我们过滤预训练数据集以降低不需要或不安全言论的风险,并过滤掉某些个人信息和其他敏感数据。 这包括使用启发式和基于模型的分类器来删除有害或低质量的内容。 此外,我们从预训练数据混合物中过滤所有评估集,运行有针对性的污染分析以检查评估集泄漏,并通过最大限度地减少敏感输出的扩散来降低背诵的风险。
最终的数据混合是通过对 2B 和 7B 模型进行一系列消融来确定的。 与(Gemini Team,2023)中提倡的方法类似,我们在整个训练过程中进行训练以改变语料库混合物,以在训练结束时增加相关的高质量数据的权重。
5 配置参数
我们通过监督微调(SFT)对纯文本、纯英语合成和人类生成的提示响应对进行微调,并对 Gemma 2B 和 7B 进行微调,并根据人类反馈进行强化学习(RLHF),并在标记的奖励模型上进行训练仅英文偏好数据和基于一组高质量提示的政策。 我们发现这两个阶段对于提高下游自动评估和模型输出的人类偏好评估的性能都很重要。
5.1 监督微调
我们根据基于 LM 的并行评估选择数据混合物进行监督微调(Zheng 等人,2023)。 给定一组保留的提示,我们从测试模型生成响应,从基线模型生成相同提示的响应,随机排列这些响应,并要求更大的高性能模型来表达两个响应之间的偏好。 构建不同的提示集来突出特定的能力,例如遵循指令、真实性、创造力和安全性。 我们使用的不同的基于 LM 的自动判断采用了多种技术,例如思想链提示(Wei 等人,2022)以及标题和构成的使用(Bai 等人) ,2022),符合人类偏好。
5.2过滤
使用合成数据时,我们会对其进行多个阶段的过滤,删除显示某些个人信息的示例、不安全或有毒的模型输出、错误的自我识别数据或重复的示例。 继 Gemini 之后,我们发现,包含鼓励更好的上下文归因、对冲和拒绝以尽量减少幻觉的数据子集可以提高多个事实性指标的性能,而不会降低模型在其他指标上的性能。
最终的数据混合和监督微调配方(包括调整的超参数)是在提高有用性的基础上选择的,同时最大限度地减少与安全和幻觉相关的模型危害。
5.3格式化
指令调整模型使用特定的格式化程序进行训练,该格式化程序在训练和推理时用额外信息注释所有指令调整示例。 它有两个目的:1)指示对话中的角色,例如用户角色,2)描绘对话中的轮次,尤其是在多轮对话中。 为此目的,在标记器中保留了特殊的控制标记。 虽然在没有格式化程序的情况下可以获得一致的生成,但它会导致模型分布不均匀,并且很可能会生成更差的生成。
| Context | Relevant Token |
| User turn | user |
| Model turn | model |
| Start of conversation turn | <start_of_turn> |
| End of conversation turn | <end_of_turn> |
| User: | <start_of_turn>user |
| Knock knock.<end_of_turn> | |
| <start_of_turn>model | |
| Model: | Who’s there?<end_of_turn> |
| User: | <start_of_turn>user |
| Gemma.<end_of_turn> | |
| <start_of_turn>model | |
| Model: | Gemma who?<end_of_turn> |
5.4 根据人类反馈进行强化学习
我们使用RLHF进一步对监督微调模型进行微调(Christiano等人,2017;Ouyang等人,2022)。 我们从人类评分者那里收集了偏好对,并在 Bradley-Terry 模型(Bradley and Terry,1952)下训练了奖励函数,与 Gemini 类似。 该策略经过训练,使用 REINFORCE (Williams,1992) 的变体以及针对初始调整模型的 Kullback-Leibler 正则化项来优化此奖励函数。 与 SFT 阶段类似,为了调整超参数并另外减轻奖励黑客攻击(Amodei 等人,2016;Skalse 等人,2022),我们依靠高容量模型作为自动评估者并计算与基线模型的并排比较。
6评估
我们使用自动基准和人工评估在广泛的领域对 Gemma 进行评估。
6.1人类偏好评估
除了在微调模型上运行标准学术基准之外,我们还将最终版本候选者发送到人类评估研究,以与 Mistral v0.2 7B Instruct 模型(Jiang 等人,2023)进行比较。
在保留的约 1000 个提示集合中,这些提示旨在要求模型在创意写作任务、编码和遵循指令方面遵循指令,Gemma 7B IT 的正胜率为 51.7%,Gemma 2B IT 的胜率超过 Mistral 41.6% v0.2 7B 指导。 在面向测试基本安全协议的约 400 个提示集合中,Gemma 7B IT 的胜率是 58%,而 Gemma 2B IT 的胜率是 56.5%。 我们在表5中报告了相应的数字。
| Model | Safety | Instruction Following |
| Gemma 7B IT | 58% | 51.7% |
| 95% Conf. Interval | [55.9%, 60.1%] | [49.6%, 53.8%] |
| Win / Tie / Loss | 42.9% / 30.2% / 26.9% | 42.5% / 18.4% / 39.1% |
| Gemma 2B IT | 56.5% | 41.6% |
| 95% Conf. Interval | [54.4%, 58.6%] | [39.5%, 43.7%] |
| Win / Tie / Loss | 44.8% / 22.9% / 32.3% | 32.7% / 17.8% / 49.5% |
6.2 自动化基准
| LLaMA-2 | Mistral | Gemma | ||||
| Benchmark | metric | 7B | 13B | 7B | 2B | 7B |
| MMLU | 5-shot, top-1 | 45.3 | 54.8 | 62.5 | 42.3 | 64.3 |
| HellaSwag | 0-shot | 77.2 | 80.7 | 81.0 | 71.4 | 81.2 |
| PIQA | 0-shot | 78.8 | 80.5 | 82.2 | 77.3 | 81.2 |
| SIQA | 0-shot | 48.3 | 50.3 | 47.0 | 49.7 | 51.8 |
| Boolq | 0-shot | 77.4 | 81.7 | 83.2 | 69.4 | 83.2 |
| Winogrande | partial scoring | 69.2 | 72.8 | 74.2 | 65.4 | 72.3 |
| CQA | 7-shot | 57.8 | 67.3 | 66.3 | 65.3 | 71.3 |
| OBQA | 58.6 | 57.0 | 52.2 | 47.8 | 52.8 | |
| ARC-e | 75.2 | 77.3 | 80.5 | 73.2 | 81.5 | |
| ARC-c | 45.9 | 49.4 | 54.9 | 42.1 | 53.2 | |
| TriviaQA | 5-shot | 72.1 | 79.6 | 62.5 | 53.2 | 63.4 |
| NQ | 5-shot | 25.7 | 31.2 | 23.2 | 12.5 | 23.0 |
| HumanEval | pass@1 | 12.8 | 18.3 | 26.2 | 22.0 | 32.3 |
| MBPP | 3-shot | 20.8 | 30.6 | 40.2 | 29.2 | 44.4 |
| GSM8K | maj@1 | 14.6 | 28.7 | 35.4 | 17.7 | 46.4 |
| MATH | 4-shot | 2.5 | 3.9 | 12.7 | 11.8 | 24.3 |
| AGIEval | 29.3 | 39.1 | 41.2 | 24.2 | 41.7 | |
| BBH | 32.6 | 39.4 | 56.1 | 35.2 | 55.1 | |
| Average | 47.0 | 52.2 | 54.0 | 44.9 | 56.4 | |
我们衡量 Gemma 模型在物理推理(Bisk 等人,2019)、社交推理(Sap 等人,2019)、问题回答(Clark)等领域的表现等人,2019;Kwiatkowski 等人,2019),编码 (Austin 等人,2021;Chen 等人,2021),数学 (Cobbe 等人,2021)、常识推理(Sakaguchi 等人, 2019)、语言建模(Paperno 等人, 2016)、阅读理解(Joshi 等人, 2017) 等等。
| Mistral | Gemma | |
| Benchmark | 7B | 7B |
| ARC-c | 60.0 | 61.9 |
| HellaSwag | 83.3 | 82.2 |
| MMLU | 64.2 | 64.6 |
| TruthfulQA | 42.2 | 44.8 |
| Winogrande | 78.4 | 79.0 |
| GSM8K | 37.8 | 50.9 |
| Average | 61.0 | 63.8 |
对于大多数自动化基准测试,我们使用与 Gemini 相同的评估方法。 特别是对于那些我们报告与 Mistral 进行比较的性能的情况,我们尽可能地复制了 Mistral 技术报告中的方法。 这些具体基准是:ARC (Clark 等人,2018)、CommonsenseQA (Talmor 等人,2019)、Big Bench Hard (Suzgun 等人,2022) 和 AGI Eval(仅限英文)(Zhong 等人,2023)。 由于许可限制,我们无法对 LLaMA-2 进行任何评估,只能引用之前报告的那些指标(Touvron 等人,2023b)。
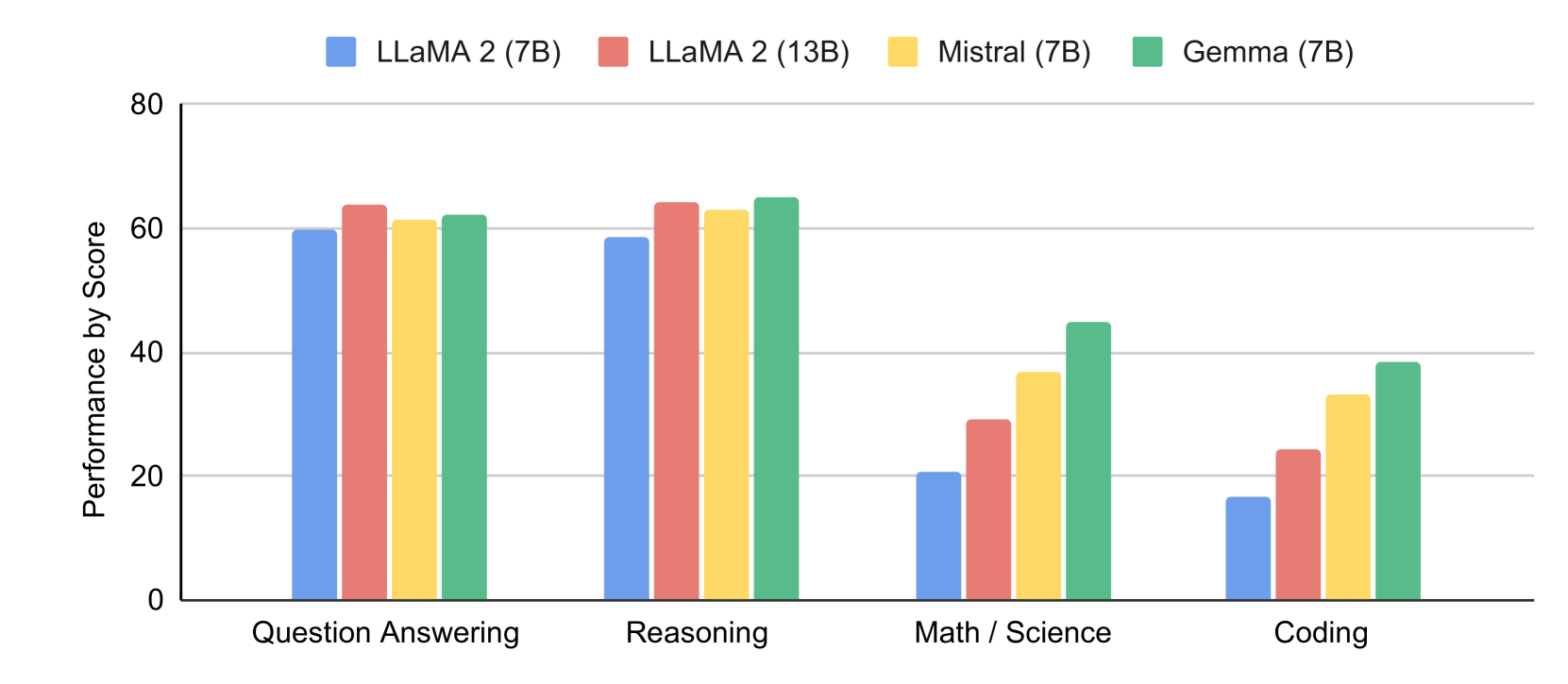
在 MMLU (Hendrycks 等人, 2020) 上,Gemma 7B 在相同或更小的规模下优于所有 OSS 替代品;它还优于几个较大的型号,包括 LLaMA2 13B。 然而,基准作者评估人类专家的表现为 89.8%;由于 Gemini Ultra 是第一个超过此阈值的型号,因此还有很大的持续改进空间以实现 Gemini 和人类水平的性能。
Gemma 模型在数学和编码基准方面表现出特别强大的性能。 在数学任务上,通常用于衡量模型的一般分析能力,Gemma 模型在 GSM8K (Cobbe 等人,2021) 和更困难的 MATH (Hendrycks 等人,2021) 基准。 同样,它们在 HumanEval (Chen 等人,2021) 上比替代开放模型至少高出 6 个点。 它们甚至超越了 MBPP 上经过代码微调的 CodeLLaMA-7B 模型的性能(CodeLLaMA 的得分为 41.4%,而 Gemma 7B 的得分为 44.4%)。
| Mistral | Gemma | |||
| Benchmark | metric | 7B* | 2B | 7B |
| RealToxicity | avg | 8.44 | 6.86 | 7.90 |
| BOLD | 38.21 | 45.57 | 49.08 | |
| CrowS-Pairs | top-1 | 32.76 | 45.82 | 51.33 |
| BBQ Ambig | 1-shot, top-1 | 97.53 | 62.58 | 92.54 |
| BBQ Disambig | top-1 | 84.45 | 54.62 | 71.99 |
| Winogender | top-1 | 64.3 | 51.25 | 54.17 |
| TruthfulQA | 44.2 | 44.84 | 31.81 | |
| Winobias 1_2 | 65.72 | 56.12 | 59.09 | |
| Winobias 2_2 | 84.53 | 91.1 | 92.23 | |
| Toxigen | 60.26 | 29.77 | 39.59 | |
由我们进行的评估。 请注意,由于许可限制,我们无法在 LLaMA-2 上运行评估;我们不会报告之前发布的 TruthfulQA 的 LLaMA-2 数据,因为我们使用不同的、不可比较的评估设置(我们使用 MC2,其中 LLaMA-2 使用 GPT-Judge)。
6.3 记忆评估
最近的研究表明,对齐模型可能容易受到新的对抗性攻击的影响,这些攻击可以绕过对齐(Nasr等人,2023)。 这些攻击可能会导致模型出现分歧,有时还会在训练过程中重复记忆的数据。 我们专注于可发现的记忆,它是模型记忆的合理上限(Nasr等人,2023),并且是多项研究中使用的通用定义(Carlini等)人, 2022; Anil 等人, 2023; Kudugunta 等人, 2023)。
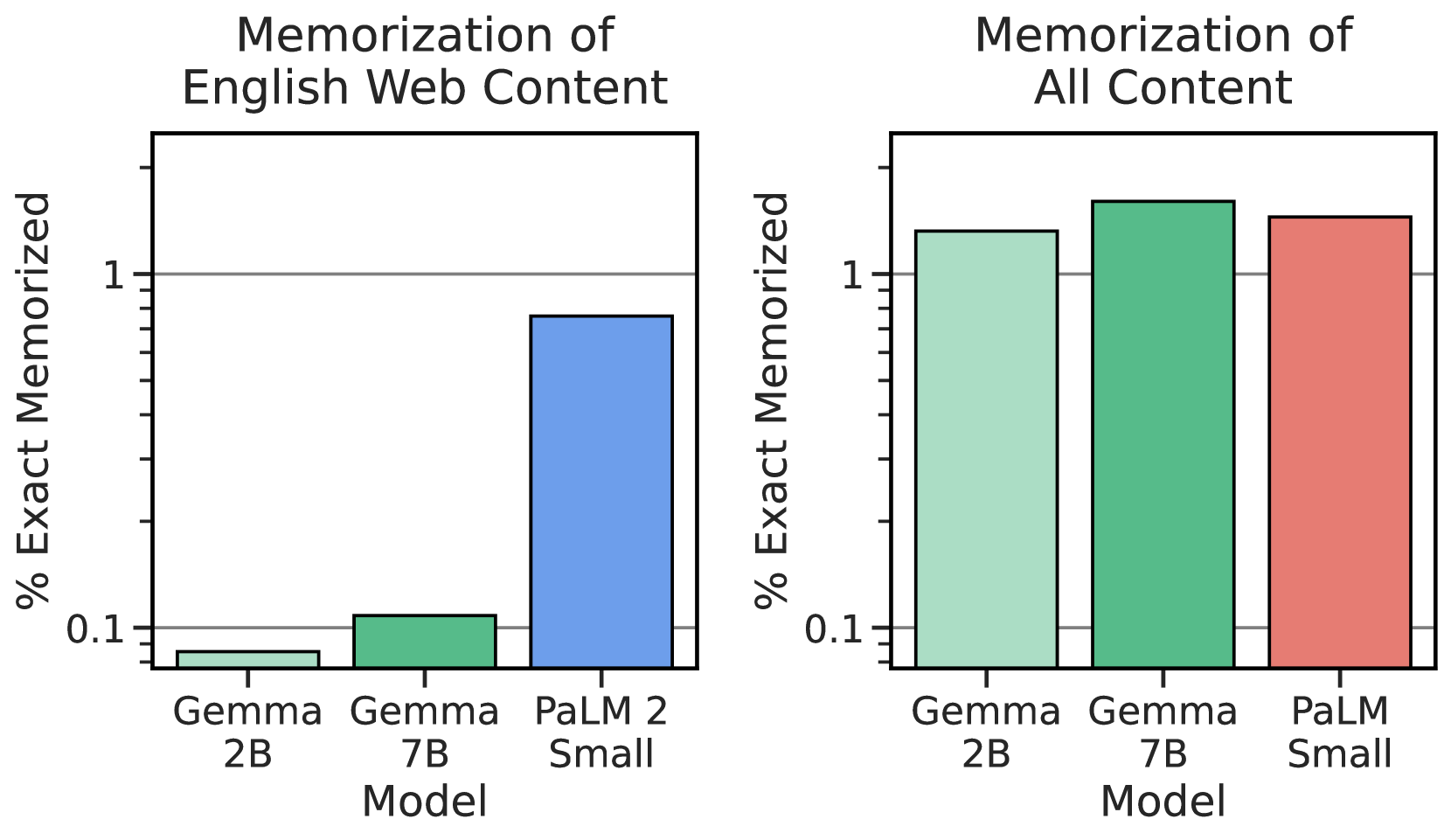
我们测试记忆力111我们对“记忆”的使用依赖于 www.genlaw.org/glossary.html 上该术语的定义。 使用与 Anil 等人 (2023) 中执行的方法相同的 Gemma 预训练模型。 我们从每个语料库中采样 10,000 个文档,并使用前 50 个标记作为模型的提示。 我们主要关注精确记忆,如果模型生成的后续 50 个标记与文本中的真实延续完全匹配,我们将文本分类为已记忆。 然而,为了更好地捕获潜在的释义记忆,我们使用 10% 编辑距离阈值进行近似记忆 (Ippolito 等人,2022)。 在图 2 中,我们将评估结果与尺寸最接近的 PaLM (Chowdhery 等人,2022) 和 PaLM 2 模型 (Anil 等人,2023)进行了比较)。
逐字记忆
通过评估训练语料库的共享子集,将 PaLM 2 与 PaLM 进行比较。 然而,Gemma 预训练数据与 PaLM 模型之间的重叠甚至更少,因此使用相同的方法,我们观察到记忆率要低得多(图 2 左)。 相反,我们发现估计整个预训练数据集的“总记忆”可以提供更可靠的估计(图 2 右),我们现在发现 Gemma 记忆训练数据的速度与 PaLM 相当。
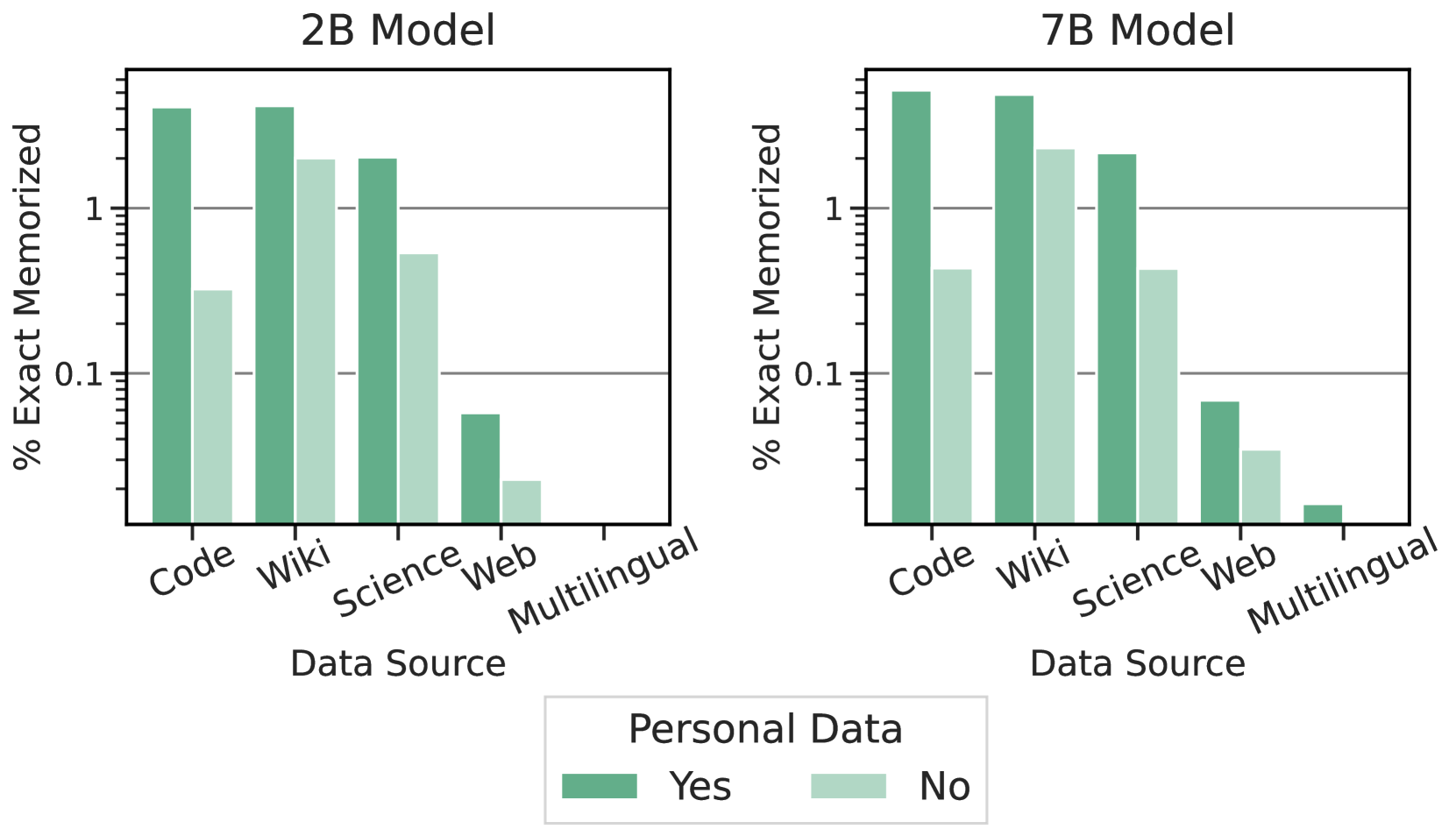
个人资料
也许更重要的是个人数据可能被记住的可能性。 为了使 Gemma 预训练模型安全可靠,我们使用自动化技术从训练集中过滤掉某些个人信息和其他敏感数据。
为了识别可能出现的个人数据,我们使用 Google Cloud 敏感数据保护222Available at: https://cloud.google.com/sensitive-data-protection。 该工具根据许多类别的个人数据(例如姓名、电子邮件等)输出三个严重级别。 我们将最高严重性分类为“敏感”,其余两个分类为“个人”。 然后,我们测量有多少存储的输出包含敏感或个人数据。 如图3所示, 我们没有观察到记忆敏感数据的情况。 我们确实发现该模型会记住一些我们根据上述分类为潜在“个人”的数据,尽管速度通常要低得多。 此外,值得注意的是,已知这些工具存在许多误报(因为它们只匹配模式而不考虑上下文),这意味着我们的结果可能高估了已识别的个人数据量。
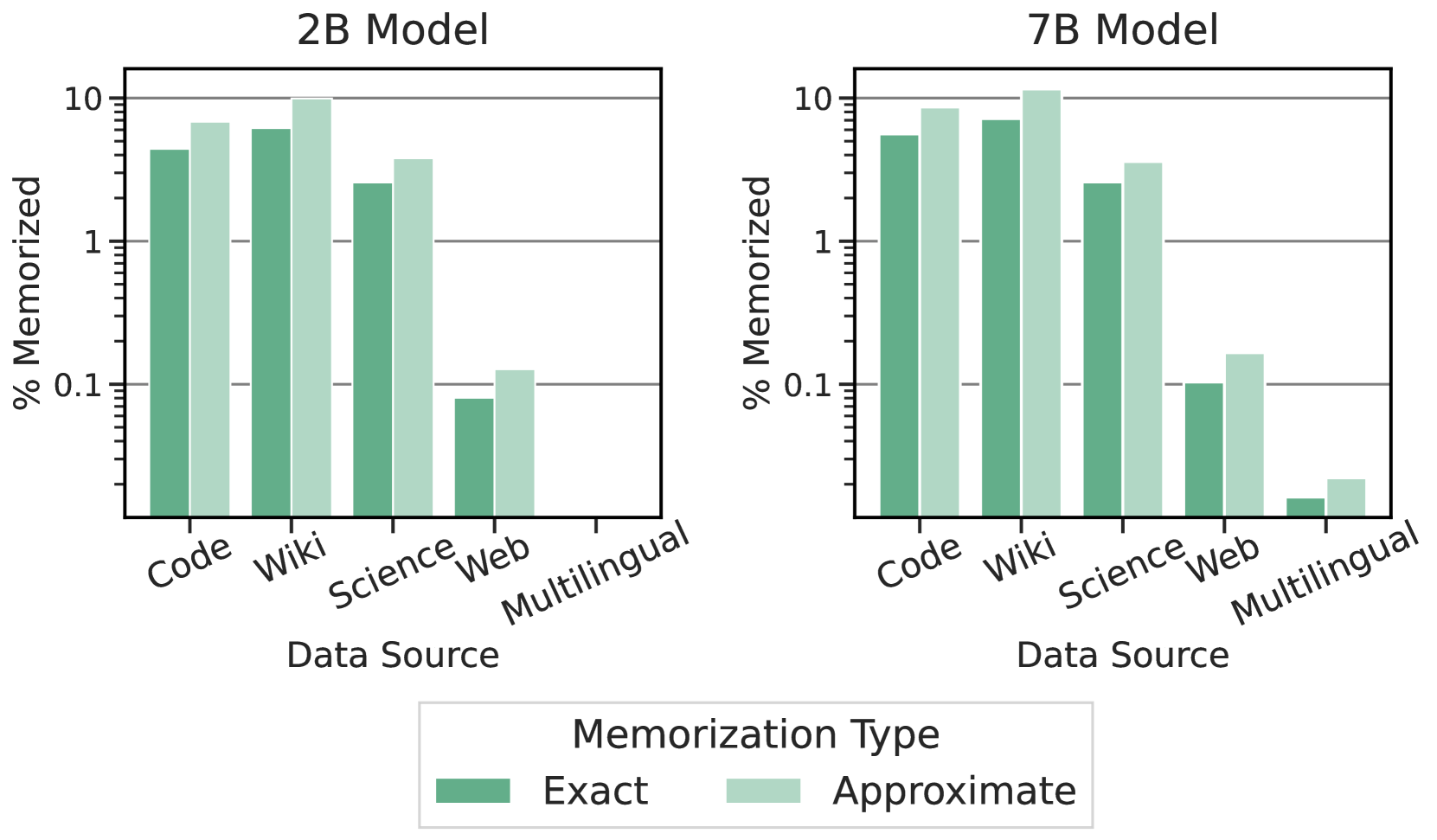
近似记忆
在图 4 中,我们观察到大约多出了 50% 的数据被记住(注意对数刻度),并且这在数据集的每个不同子类别中几乎是一致的。
7 负责任的部署
与之前发布的 Google 人工智能技术(Gemini Team,2023;Kavukcuoglu 等人,2022)一致,我们遵循结构化方法来负责任地开发和部署我们的模型,以便识别、衡量、并管理可预见的下游社会影响。 与我们最近发布的 Gemini 一样,这些都是基于先前有关语言模型风险的学术文献(Weidinger 等人,2021),以及整个行业之前进行的类似练习的结果(Anil 等人, 2023),与内部和外部专家的持续接触,以及发现新模型漏洞的非结构化尝试。
7.1好处
我们相信人工智能科技的开放可以带来显着的效益。 开源是科学和创新的重要驱动力,在大多数情况下也是一种负责任的做法。 但这需要与为行为者提供现在或将来造成伤害的工具的风险进行权衡。
Google 长期以来一直致力于提供更广泛的机会来获取成功的研究创新(GraphCast、Transformer、BERT、T5、Word2Vec),我们相信将 Gemma 释放到 AI 开发生态系统中将使下游开发人员能够在以下领域创建大量有益的应用程序:如科学、教育和艺术。 我们的指令调整产品应鼓励一系列开发人员利用 Gemma 的聊天和代码功能来支持他们自己有益的应用程序,同时允许自定义微调以针对特定用例专门化模型的功能。 为了确保 Gemma 支持广泛的开发人员需求,我们还发布了两种模型大小,以最佳地支持不同的环境,并使这些模型可跨多个平台使用(有关详细信息,请参阅 Kaggle)。 以这种方式提供对 Gemma 的广泛访问应该可以减少新企业或独立开发人员在将这些技术纳入其工作流程时所面临的经济和技术障碍。
除了为开发人员提供经过指令调整的模型外,我们还提供了对相应基础预训练模型的访问。 通过这样做,我们希望鼓励更多的人工智能安全研究和社区创新,为开发者提供更广泛的模型库,以社区已经受益的各种透明度和可解释性研究方法为基础(Pacchiardi 等人,2023 年;Zou 等人,2023 年)。
7.2风险
除了给人工智能开发生态系统带来好处外,我们意识到恶意使用大语言模型,例如创建深度伪造图像、人工智能生成的虚假信息以及非法和令人不安的材料,可能会对个人和机构层面造成伤害(Weidinger 等人,2021)。 此外,提供对模型权重的访问,而不是在 API 后面发布模型,给负责任的部署带来了新的挑战。
首先,我们无法阻止不良行为者出于恶意目的对 Gemma 进行微调,尽管其使用受到使用条款的约束,该使用条款禁止以违反我们的 Gemma 禁止使用政策的方式使用 Gemma 模型。 然而,我们认识到,需要进一步开展工作来建立更强大的缓解策略,以防止故意滥用开放系统,Google DeepMind 将继续在内部以及与更广泛的人工智能社区合作进行探索。
我们面临的第二个挑战是保护开发者和下游用户免受开放模型的意外行为的影响,包括产生有毒语言或延续歧视性社会危害、模型幻觉和泄露个人身份信息。 在 API 后面部署模型时,可以通过各种过滤方法来降低这些风险。
7.3缓解措施
如果没有 Gemma 系列模型的这一层防御,我们会根据 Gemini 方法过滤和测量预训练数据中的偏差,通过标准化 AI 安全基准评估安全性,内部红队合作以更好地防范这些风险。了解与外部使用 Gemma 相关的风险,并对模型进行严格的道德和安全评估,评估结果可参见8。
尽管我们在改进模型方面投入了大量资金,但我们也认识到它的局限性。 为了确保下游用户的透明度,我们发布了详细的模型卡,以帮助研究人员更全面地了解 Gemma。
我们还发布了 Generative AI Responsible Toolkit,以支持开发人员负责任地构建 AI。 这包含一系列资产,可帮助开发人员设计和实施负责任的人工智能最佳实践并确保其用户的安全。
发布开放权重模型的相对新颖性意味着这些模型的新用途和误用仍在被发现,这就是为什么 Google DeepMind 致力于在未来模型开发的同时不断研究和开发稳健的缓解策略。
7.4评估
最终,考虑到现有生态系统中可访问的大型系统的功能,我们相信 Gemma 的发布对整体人工智能风险组合的影响可以忽略不计。 有鉴于此,并考虑到这些模型在研究、审计和下游产品开发方面的实用性,我们相信 Gemma 对人工智能社区的好处超过了所描述的风险。
7.5继续前进
作为指导原则,Google DeepMind 努力采用与我们模型的潜在风险相称的评估和安全缓解措施。 在这种情况下,尽管我们相信 Gemma 模型将为社区带来净收益,但我们对安全性的强调源于此版本的不可逆转性。 由于开放模型带来的危害尚未明确,也没有针对此类模型的既定评估框架,我们将继续遵循这一先例,对开放模型的开发采取谨慎和谨慎的态度。 随着能力的进步,我们可能需要探索扩展测试、交错发布或替代访问机制,以确保负责任的人工智能开发。
随着生态系统的发展,我们敦促更广泛的人工智能社区超越简单化的“开放与封闭”辩论,避免夸大或最小化潜在危害,因为我们认为对风险和收益采取细致入微的协作方法至关重要。 在 Google DeepMind,我们致力于开发高质量的评估,并邀请社区加入我们的行列,以更深入地了解人工智能系统。
8讨论与结论
我们推出 Gemma,一个开放的文本和代码生成语言模型系列。 Gemma 推进了公开可用的语言模型性能、安全性和负责任的开发的最先进技术。
特别是,鉴于我们广泛的安全评估和缓解措施,我们相信 Gemma 模型将为社区带来净效益;然而,我们承认此发布是不可逆转的,并且开放模型造成的危害尚未明确定义,因此我们将继续采取与这些模型的潜在风险相称的评估和安全缓解措施。 此外,我们的模型在 6 个标准安全基准以及人类并行评估方面均优于竞争对手。
Gemma 模型提高了对话、推理、数学和代码生成等广泛领域的性能。 MMLU (64.3%) 和 MBPP (44.4%) 的结果证明了 Gemma 的高性能,以及公开可用的大语言模型性能的持续发展空间。
除了基准任务上最先进的性能衡量标准之外,我们很高兴看到社区中出现了哪些新用例,以及随着我们共同推进该领域而出现了哪些新功能。 我们希望研究人员使用 Gemma 来加速广泛的研究,我们希望开发人员创建有益的新应用程序、用户体验和其他功能。
Gemma 受益于 Gemini 模型程序的许多学习,包括代码、数据、架构、指令调整、来自人类反馈的强化学习和评估。 正如 Gemini 技术报告中所讨论的,我们重申了对大语言模型的使用的一系列非详尽的限制。 即使在基准任务上表现出色,仍需要进一步研究来创建可靠、按预期执行的稳健、安全的模型。 进一步研究领域的例子包括事实性、一致性、复杂推理和对抗性输入的鲁棒性。 正如 Gemini 所讨论的,我们注意到需要更具挑战性和稳健的基准。
9 贡献和致谢
核心贡献者
Thomas Mesnard
Cassidy Hardin
Robert Dadashi
Surya Bhupatiraju
Shreya Pathak
Laurent Sifre
Morgane里维埃尔
米希尔·桑杰·卡勒
朱丽叶·洛夫
普亚·塔夫蒂
莱昂纳德·胡赛诺
撰稿人
Aakanksha Chowdhery
Adam Roberts
Aditya Barua
Alex Botev
Alex Castro-罗斯
Ambrose Slone
Amélie Héliou
Andrea Tacchetti
Anna Bulanova
Antonia Paterson
Beth Tsai
Bobak Shahriari
Charline Le Lan
Christopher A.Choquette-Choo
Clément Crepy
Daniel Cer
Daphne Ippolito
David Reid
Elena Buchatskaya
Eric Ni
Eric Noland
Geng Yan
George Tucker
George-Christian Muraru
Grigory Rozhdestvenskiy
Henryk Michalewski
Ian Tenney
Ivan Grishchenko
Jacob Austin
James Keeling
Jane Labanowski
Jean-Baptiste Lespiau
Jeff Stanway
Jenny Brennan
Jeremy Chen
Johan Ferret
Justin Chiu
Justin Mao- Jones琼斯
Katherine Lee
Kathy Yu
Katie Millican
Lars Lowe Sjoesund
Lisa Lee
Lucas Dixon
Machel Reid
Maciej Mikuła
Mateo Wirth
Michael沙尔曼
Nikolai Chinaev
Nithum Thain
Olivier Bachem
Oscar Chang
Oscar Wahltinez
Paige Bailey
Paul Michel
Petko Yotov
Pier Giuseppe
Rahma Chaabouni
Ramona Comanescu
Reena Jana
Rohan Anil
Ross McIlroy
Ruibo Liu
Ryan Mullins
Samuel L Smith
Sebastian Borgeaud
Sertan Girgin
Sholto Douglas
Shree Pandya
Siamak Shakeri
Soham De
Ted Klimenko
Tom Hennigan
Vlad Feinberg
Wojciech Stokowiec
Yu-陈晖
扎法拉利-艾哈迈德
龚智涛
产品管理
Tris Warkentin
Ludovic Peran
项目管理
明江
执行赞助商
Clément Farabet
Oriol Vinyals
Jeff Dean
Koray Kavukcuoglu
Demis Hassabis
Zoubin Ghahramani
Douglas埃克
乔尔·巴拉尔
费尔南多·佩雷拉
伊莱·柯林斯
领先
阿曼德·朱林
诺亚·菲德尔
埃文·森特
技术主管
亚历克·安德烈夫
凯瑟琳·肯尼利
†† 同等贡献。
致谢
我们的工作得益于 Google 众多团队的奉献和努力。 我们要感谢以下团队的支持:Gemini、Gemini Safety、Gemini Infrastructure、Gemini Evaluation、Google Cloud、Google Research Responsible AI、Kaggle 和 Keras。
特别感谢 Adrian Hutter、Andreas Terzis、Andrei Kulik、Angelos Filos、Anushan Fernando、Aurelien Boffy、Danila Sinopalnikov、Edouard Leurent、Gabriela Surita、Geoffrey Cideron、Jilin Chen、Karthik Raveendran、Kathy Meier-Hellstern、Kehang Han、Kevin Robinson、Kritika Muralidharan、Le Hou、Leonard Berrada、Lev Proleev、何鲁恒、Marie Pellat、Mark Sherwood、Matt Hoffman、Matthias Grundmann、Nicola De Cao、Nikola Momchev、Nino Vieillard、Noah Constant、Peter Liu、Piotr Stanczyk、张桥、 Ruba Haroun、Seliem El-Sayed、Siddhartha Brahma、Tianhe (Kevin) Yu、Tom Le Paine、Yingjie Miao、Yuanzhong Xu 和 Yuting Sun。
参考
- Almazrouei et al. (2023) E. Almazrouei, H. Alobeidli, A. Alshamsi, A. Cappelli, R. Cojocaru, M. Debbah, Étienne Goffinet, D. Hesslow, J. Launay, Q. Malartic, D. Mazzotta, B. Noune, B. Pannier, and G. Penedo. The falcon series of open language models, 2023.
- Amodei et al. (2016) D. Amodei, C. Olah, J. Steinhardt, P. Christiano, J. Schulman, and D. Mané. Concrete problems in AI safety. arXiv preprint, 2016.
- Anil et al. (2023) R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Austin et al. (2021) J. Austin, A. Odena, M. I. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. J. Cai, M. Terry, Q. V. Le, and C. Sutton. Program synthesis with large language models. CoRR, abs/2108.07732, 2021. URL https://arxiv.org/abs/2108.07732.
- Bai et al. (2022) Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, C. Chen, C. Olsson, C. Olah, D. Hernandez, D. Drain, D. Ganguli, D. Li, E. Tran-Johnson, E. Perez, J. Kerr, J. Mueller, J. Ladish, J. Landau, K. Ndousse, K. Lukosuite, L. Lovitt, M. Sellitto, N. Elhage, N. Schiefer, N. Mercado, N. DasSarma, R. Lasenby, R. Larson, S. Ringer, S. Johnston, S. Kravec, S. E. Showk, S. Fort, T. Lanham, T. Telleen-Lawton, T. Conerly, T. Henighan, T. Hume, S. R. Bowman, Z. Hatfield-Dodds, B. Mann, D. Amodei, N. Joseph, S. McCandlish, T. Brown, and J. Kaplan. Constitutional ai: Harmlessness from ai feedback, 2022.
- Barham et al. (2022) P. Barham, A. Chowdhery, J. Dean, S. Ghemawat, S. Hand, D. Hurt, M. Isard, H. Lim, R. Pang, S. Roy, B. Saeta, P. Schuh, R. Sepassi, L. E. Shafey, C. A. Thekkath, and Y. Wu. Pathways: Asynchronous distributed dataflow for ml, 2022.
- Bisk et al. (2019) Y. Bisk, R. Zellers, R. L. Bras, J. Gao, and Y. Choi. PIQA: reasoning about physical commonsense in natural language. CoRR, abs/1911.11641, 2019. URL http://arxiv.org/abs/1911.11641.
- Bradley and Terry (1952) R. A. Bradley and M. E. Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39, 1952.
- Carlini et al. (2022) N. Carlini, D. Ippolito, M. Jagielski, K. Lee, F. Tramer, and C. Zhang. Quantifying memorization across neural language models. arXiv preprint arXiv:2202.07646, 2022.
- Chen et al. (2021) M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. de Oliveira Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, A. Ray, R. Puri, G. Krueger, M. Petrov, H. Khlaaf, G. Sastry, P. Mishkin, B. Chan, S. Gray, N. Ryder, M. Pavlov, A. Power, L. Kaiser, M. Bavarian, C. Winter, P. Tillet, F. P. Such, D. Cummings, M. Plappert, F. Chantzis, E. Barnes, A. Herbert-Voss, W. H. Guss, A. Nichol, A. Paino, N. Tezak, J. Tang, I. Babuschkin, S. Balaji, S. Jain, W. Saunders, C. Hesse, A. N. Carr, J. Leike, J. Achiam, V. Misra, E. Morikawa, A. Radford, M. Knight, M. Brundage, M. Murati, K. Mayer, P. Welinder, B. McGrew, D. Amodei, S. McCandlish, I. Sutskever, and W. Zaremba. Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021. URL https://arxiv.org/abs/2107.03374.
- Chowdhery et al. (2022) A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmann, P. Schuh, K. Shi, S. Tsvyashchenko, J. Maynez, A. Rao, P. Barnes, Y. Tay, N. Shazeer, V. Prabhakaran, E. Reif, N. Du, B. Hutchinson, R. Pope, J. Bradbury, J. Austin, M. Isard, G. Gur-Ari, P. Yin, T. Duke, A. Levskaya, S. Ghemawat, S. Dev, H. Michalewski, X. Garcia, V. Misra, K. Robinson, L. Fedus, D. Zhou, D. Ippolito, D. Luan, H. Lim, B. Zoph, A. Spiridonov, R. Sepassi, D. Dohan, S. Agrawal, M. Omernick, A. M. Dai, T. S. Pillai, M. Pellat, A. Lewkowycz, E. Moreira, R. Child, O. Polozov, K. Lee, Z. Zhou, X. Wang, B. Saeta, M. Diaz, O. Firat, M. Catasta, J. Wei, K. Meier-Hellstern, D. Eck, J. Dean, S. Petrov, and N. Fiedel. Palm: Scaling language modeling with pathways, 2022.
- Christiano et al. (2017) P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei. Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems, 30, 2017.
- Clark et al. (2019) C. Clark, K. Lee, M. Chang, T. Kwiatkowski, M. Collins, and K. Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. CoRR, abs/1905.10044, 2019. URL http://arxiv.org/abs/1905.10044.
- Clark et al. (2018) P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018.
- Cobbe et al. (2021) K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168.
- Dean et al. (2012) J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, M. Mao, M. a. Ranzato, A. Senior, P. Tucker, K. Yang, Q. Le, and A. Ng. Large scale distributed deep networks. In F. Pereira, C. Burges, L. Bottou, and K. Weinberger, editors, Advances in Neural Information Processing Systems, volume 25. Curran Associates, Inc., 2012. URL https://proceedings.neurips.cc/paper_files/paper/2012/file/6aca97005c68f1206823815f66102863-Paper.pdf.
- Devlin et al. (2018) J. Devlin, M. Chang, K. Lee, and K. Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805, 2018. URL http://arxiv.org/abs/1810.04805.
- Gemini Team (2023) Gemini Team. Gemini: A family of highly capable multimodal models, 2023.
- Hendrycks et al. (2020) D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt. Measuring massive multitask language understanding. CoRR, abs/2009.03300, 2020. URL https://arxiv.org/abs/2009.03300.
- Hendrycks et al. (2021) D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS, 2021.
- Ippolito et al. (2022) D. Ippolito, F. Tramèr, M. Nasr, C. Zhang, M. Jagielski, K. Lee, C. A. Choquette-Choo, and N. Carlini. Preventing verbatim memorization in language models gives a false sense of privacy. arXiv preprint arXiv:2210.17546, 2022.
- Jiang et al. (2023) A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed. Mistral 7b, 2023.
- Joshi et al. (2017) M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. CoRR, abs/1705.03551, 2017. URL http://arxiv.org/abs/1705.03551.
- Kavukcuoglu et al. (2022) K. Kavukcuoglu, P. Kohli, L. Ibrahim, D. Bloxwich, and S. Brown. How our principles helped define alphafold’s release, 2022.
- Kudo and Richardson (2018) T. Kudo and J. Richardson. SentencePiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In E. Blanco and W. Lu, editors, Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 66–71, Brussels, Belgium, Nov. 2018. Association for Computational Linguistics. 10.18653/v1/D18-2012. URL https://aclanthology.org/D18-2012.
- Kudugunta et al. (2023) S. Kudugunta, I. Caswell, B. Zhang, X. Garcia, C. A. Choquette-Choo, K. Lee, D. Xin, A. Kusupati, R. Stella, A. Bapna, et al. Madlad-400: A multilingual and document-level large audited dataset. arXiv preprint arXiv:2309.04662, 2023.
- Kwiatkowski et al. (2019) T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Lee, K. Toutanova, L. Jones, M. Kelcey, M.-W. Chang, A. M. Dai, J. Uszkoreit, Q. Le, and S. Petrov. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466, 2019. 10.1162/tacl_a_00276. URL https://aclanthology.org/Q19-1026.
- LeCun et al. (2015) Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. nature, 521(7553):436–444, 2015.
- Mikolov et al. (2013) T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. In Y. Bengio and Y. LeCun, editors, 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, May 2-4, 2013, Workshop Track Proceedings, 2013. URL http://arxiv.org/abs/1301.3781.
- Nasr et al. (2023) M. Nasr, N. Carlini, J. Hayase, M. Jagielski, A. F. Cooper, D. Ippolito, C. A. Choquette-Choo, E. Wallace, F. Tramèr, and K. Lee. Scalable extraction of training data from (production) language models. arXiv preprint arXiv:2311.17035, 2023.
- Ouyang et al. (2022) L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35, 2022.
- Pacchiardi et al. (2023) L. Pacchiardi, A. J. Chan, S. Mindermann, I. Moscovitz, A. Y. Pan, Y. Gal, O. Evans, and J. Brauner. How to catch an ai liar: Lie detection in black-box llms by asking unrelated questions, 2023.
- Paperno et al. (2016) D. Paperno, G. Kruszewski, A. Lazaridou, Q. N. Pham, R. Bernardi, S. Pezzelle, M. Baroni, G. Boleda, and R. Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context. CoRR, abs/1606.06031, 2016. URL http://arxiv.org/abs/1606.06031.
- Raffel et al. (2019) C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. CoRR, abs/1910.10683, 2019. URL http://arxiv.org/abs/1910.10683.
- Roberts et al. (2022) A. Roberts, H. W. Chung, A. Levskaya, G. Mishra, J. Bradbury, D. Andor, S. Narang, B. Lester, C. Gaffney, A. Mohiuddin, C. Hawthorne, A. Lewkowycz, A. Salcianu, M. van Zee, J. Austin, S. Goodman, L. B. Soares, H. Hu, S. Tsvyashchenko, A. Chowdhery, J. Bastings, J. Bulian, X. Garcia, J. Ni, A. Chen, K. Kenealy, J. H. Clark, S. Lee, D. Garrette, J. Lee-Thorp, C. Raffel, N. Shazeer, M. Ritter, M. Bosma, A. Passos, J. Maitin-Shepard, N. Fiedel, M. Omernick, B. Saeta, R. Sepassi, A. Spiridonov, J. Newlan, and A. Gesmundo. Scaling up models and data with t5x and seqio, 2022.
- Roberts et al. (2023) A. Roberts, H. W. Chung, G. Mishra, A. Levskaya, J. Bradbury, D. Andor, S. Narang, B. Lester, C. Gaffney, A. Mohiuddin, et al. Scaling up models and data with t5x and seqio. Journal of Machine Learning Research, 24(377):1–8, 2023.
- Sakaguchi et al. (2019) K. Sakaguchi, R. L. Bras, C. Bhagavatula, and Y. Choi. WINOGRANDE: an adversarial winograd schema challenge at scale. CoRR, abs/1907.10641, 2019. URL http://arxiv.org/abs/1907.10641.
- Sap et al. (2019) M. Sap, H. Rashkin, D. Chen, R. L. Bras, and Y. Choi. Socialiqa: Commonsense reasoning about social interactions. CoRR, abs/1904.09728, 2019. URL http://arxiv.org/abs/1904.09728.
- Shazeer (2019) N. Shazeer. Fast transformer decoding: One write-head is all you need. CoRR, abs/1911.02150, 2019. URL http://arxiv.org/abs/1911.02150.
- Shazeer (2020) N. Shazeer. GLU variants improve transformer. CoRR, abs/2002.05202, 2020. URL https://arxiv.org/abs/2002.05202.
- Skalse et al. (2022) J. M. V. Skalse, N. H. R. Howe, D. Krasheninnikov, and D. Krueger. Defining and characterizing reward gaming. In NeurIPS, 2022.
- Su et al. (2021) J. Su, Y. Lu, S. Pan, B. Wen, and Y. Liu. Roformer: Enhanced transformer with rotary position embedding. CoRR, abs/2104.09864, 2021. URL https://arxiv.org/abs/2104.09864.
- Sutskever et al. (2014) I. Sutskever, O. Vinyals, and Q. V. Le. Sequence to sequence learning with neural networks. CoRR, abs/1409.3215, 2014. URL http://arxiv.org/abs/1409.3215.
- Suzgun et al. (2022) M. Suzgun, N. Scales, N. Schärli, S. Gehrmann, Y. Tay, H. W. Chung, A. Chowdhery, Q. V. Le, E. H. Chi, D. Zhou, and J. Wei. Challenging big-bench tasks and whether chain-of-thought can solve them, 2022.
- Talmor et al. (2019) A. Talmor, J. Herzig, N. Lourie, and J. Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge, 2019.
- Touvron et al. (2023a) H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample. Llama: Open and efficient foundation language models, 2023a.
- Touvron et al. (2023b) H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korenev, P. S. Koura, M.-A. Lachaux, T. Lavril, J. Lee, D. Liskovich, Y. Lu, Y. Mao, X. Martinet, T. Mihaylov, P. Mishra, I. Molybog, Y. Nie, A. Poulton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M. Smith, R. Subramanian, X. E. Tan, B. Tang, R. Taylor, A. Williams, J. X. Kuan, P. Xu, Z. Yan, I. Zarov, Y. Zhang, A. Fan, M. Kambadur, S. Narang, A. Rodriguez, R. Stojnic, S. Edunov, and T. Scialom. Llama 2: Open foundation and fine-tuned chat models, 2023b.
- Vaswani et al. (2017) A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. CoRR, abs/1706.03762, 2017. URL http://arxiv.org/abs/1706.03762.
- Wei et al. (2022) J. Wei, X. Wang, D. Schuurmans, M. Bosma, E. H. Chi, Q. Le, and D. Zhou. Chain of thought prompting elicits reasoning in large language models. CoRR, abs/2201.11903, 2022. URL https://arxiv.org/abs/2201.11903.
- Weidinger et al. (2021) L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Uesato, P. Huang, M. Cheng, M. Glaese, B. Balle, A. Kasirzadeh, Z. Kenton, S. Brown, W. Hawkins, T. Stepleton, C. Biles, A. Birhane, J. Haas, L. Rimell, L. A. Hendricks, W. Isaac, S. Legassick, G. Irving, and I. Gabriel. Ethical and social risks of harm from language models. CoRR, abs/2112.04359, 2021. URL https://arxiv.org/abs/2112.04359.
- Williams (1992) R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8, 1992.
- XLA (2019) XLA. Xla: Optimizing compiler for tensorflow, 2019. URL https://www.tensorflow.org/xla.
- Xu et al. (2021) Y. Xu, H. Lee, D. Chen, B. A. Hechtman, Y. Huang, R. Joshi, M. Krikun, D. Lepikhin, A. Ly, M. Maggioni, R. Pang, N. Shazeer, S. Wang, T. Wang, Y. Wu, and Z. Chen. GSPMD: general and scalable parallelization for ML computation graphs. CoRR, abs/2105.04663, 2021. URL https://arxiv.org/abs/2105.04663.
- Zhang and Sennrich (2019) B. Zhang and R. Sennrich. Root mean square layer normalization. CoRR, abs/1910.07467, 2019. URL http://arxiv.org/abs/1910.07467.
- Zheng et al. (2023) L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023.
- Zhong et al. (2023) W. Zhong, R. Cui, Y. Guo, Y. Liang, S. Lu, Y. Wang, A. Saied, W. Chen, and N. Duan. Agieval: A human-centric benchmark for evaluating foundation models, 2023.
- Zou et al. (2023) A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowski, S. Goel, N. Li, M. J. Byun, Z. Wang, A. Mallen, S. Basart, S. Koyejo, D. Song, M. Fredrikson, J. Z. Kolter, and D. Hendrycks. Representation engineering: A top-down approach to ai transparency, 2023.