MedInsight:使用大型语言模型生成以患者为中心的医疗响应的多源上下文增强框架
摘要。
大型语言模型 (LLM) 在生成类似人类的响应方面表现出令人印象深刻的能力。 然而,它们缺乏特定领域的知识限制了它们在医疗保健环境中的适用性,在医疗保健环境中,上下文和全面的响应至关重要。 为了解决这一挑战并实现生成上下文相关且全面的以患者为中心的响应,我们提出了 MedInsight——一个新颖的检索增强框架,它使用来自多个来源的相关背景信息来增强 LLM 输入(提示)。 MedInsight 从患者的病历或咨询记录中提取相关细节。 然后,它根据患者的健康史和状况,从权威的医学教科书和精选的网络资源中整合信息。 通过构建一个将患者记录与相关医学知识相结合的增强上下文,MedInsight 生成丰富的、针对患者的响应,这些响应是针对诊断、治疗建议或患者教育等医疗保健应用量身定制的。 MTSamples 数据集上的实验验证了 MedInsight 在生成上下文相关的医学响应方面的有效性。 使用 Ragas 度量和 TruLens 对答案相似性和答案正确性进行定量评估证明了该模型的有效性。 此外,涉及主题专家 (SME) 的人工评估研究证实了 MedInsight 的效用,在生成响应的相关性和正确性方面具有适度的评分者间一致性。
1. 介绍
在医疗保健领域,提供针对个体患者量身定制的上下文和全面的医疗信息对于实现有效护理至关重要。 然而,由于医疗数据分散在多个来源,如患者记录、医学文献和在线资源,现有的方法通常难以提供个性化的回复。 尽管大型语言模型 (LLM) 的最新进展已证明其在理解和传达医学知识方面的潜力,但其下一个符元预测的训练目标会导致信息丢失、“记忆扭曲” (peng2023check, ),以及生成似是而非但错误的内容,即所谓的幻觉 (huang2023survey, )。 这些缺点凸显了需要使用来自不同来源的上下文相关信息来增强 LLM,以确保提供可靠且以患者为中心的回复。
为了应对将 LLM 适应医疗保健等专业领域这一挑战,出现了两种主要方法:微调和用外部知识增强模型。 微调是指在特定领域数据上进一步训练预训练的 LLM,以优化其针对目标应用的性能 (ovadia2023fine, )。 然而,这种方法可能计算量大,受数据可用性的限制,并且容易发生灾难性遗忘,即模型忘记之前学习的知识 (ovadia2023fine, ; kirkpatrick2017overcoming, ; goodfellow2013empirical, ; chen2020recall, ; luo2023empirical, )。 另一种方法是上下文学习 (ICL),其目标是通过修改输入提示来提高 LLM 在新任务上的有效性,而不改变模型权重 (chen2021meta, ; radford2019language, ; lampinen2022can, )。 ICL 的一个突出实现是检索增强生成 (RAG) (lewis2020retrieval, ; neelakantan2022text, ),其中信息检索技术用于从外部来源提取相关知识并将其整合到 LLM 生成的文本中。 通过用检索到的上下文信息增强模型的输入,RAG 可以将 LLM 适应特定领域的任务,而不会产生与微调相关的缺点。
虽然患者的医疗记录记录了他们的病史和当前状况,但全面护理所需的背景信息,例如有关疾病、症状、诊断和治疗的详细信息,通常分散在多个来源,例如医学文献、临床指南和在线知识库中。 相关医学知识的这种碎片化给提供针对患者独特背景的个性化回复带来了重大挑战。 为了应对这一挑战并有效地利用分散的信息来源,我们提出了 MedInsight,这是一个 RAG 框架,它能够通过将患者从其记录中获得的特定背景与从各种权威来源检索到的相关背景知识相结合,从而生成量身定制的医疗回复。
生成以患者为中心的医疗查询回复需要使用从权威来源提取的相关知识来增强患者的背景信息。 与专注于特定事实的任务不同,医疗问题通常需要更深入地了解跨越患者病史、当前症状、实验室检查结果和背景医学知识的多个上下文之间的关系。 例如,考虑以下问题 "对于出现慢性阻塞性肺病 (COPD) 恶化的患者,您会推荐哪些特定的管理策略或干预措施来改善呼吸症状和整体肺功能?" 有效地回答这个问题需要从患者的记录中理解整体患者背景,同时还要从医学知识来源中整合有关 COPD 恶化、治疗策略和呼吸管理的相关信息。 图 1 说明了 MedInsight 如何从多个来源增强背景信息以构建以患者为中心的回复。 提示(查询)与从患者医疗记录(即患者唯一上下文)和权威医学知识来源(如教科书)中提取的相关信息合并。 这将形成一个增强的上下文,将患者的详细信息与相关的医学概念结合起来,使 MedInsight 能够生成与上下文相关的、个性化的响应,以满足特定患者的需求。

通过将患者信息与医学知识相结合,我们为患者和护理人员提供了必要的见解和工具,以增强自我护理/患者护理并优化医疗保健服务。 我们的 RAG 方法利用患者的独特上下文生成以患者为中心的响应,并根据患者的病史提取与特定输入相关的医学知识。 这使患者和护理人员都能获得相关且个性化的信息,促进明智的决策并改善患者结局。
本文的主要贡献是:
-
•
我们证明了使用患者上下文(医疗记录和健康记录)为特定患者需求定制医疗建议的可能性。 这为护理人员提供了必要的知识和工具,以提升患者护理、增强治疗效果并优化医疗保健服务的效率。
-
•
我们构建了一个检索增强型问答系统,该系统利用患者的独特上下文生成以患者为中心的响应,并根据患者的病史提取与特定输入相关的医学知识。
-
•
我们展示并评估了 MedInsight 在生成准确且以患者为中心的响应方面的熟练程度,方法是采用定性和定量指标。
2. 背景与相关工作
本节首先介绍大型语言模型 (LLM) 和检索增强生成 (RAG) 的基础背景。 随后,我们将探讨在医疗保健领域利用这些方法的相关工作。
2.1. 大型语言模型
语言模型 (LM) 可以称为能够理解和生成人类语言的计算模型。 它们学习对文本的概率分布进行建模,随后预测词序列的可能性,或根据输入 (chang2023survey, ) 生成新的文本。 例如,传统的语言模型,如 N-gram (brown1992class, ),通过考虑其在先前文本中的上下文来估计一个词的概率。
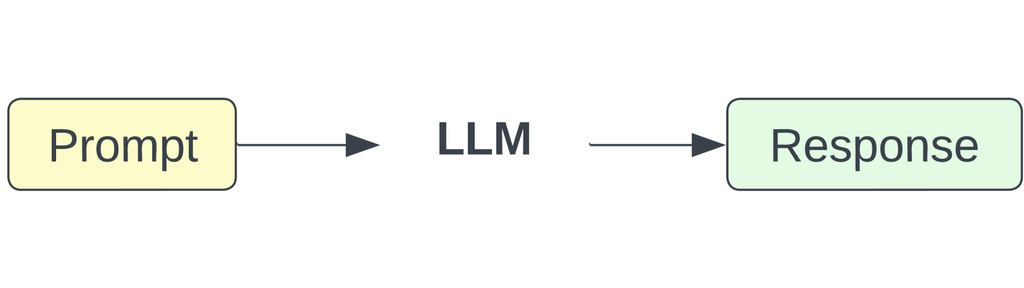
另一方面,大型语言模型 (LLM) 是在互联网文本的海量抓取上训练的先进语言模型,具有巨大的参数量和卓越的学习能力。 近年来,它们已成为多个研究领域的中心催化剂,包括但不限于自然语言处理 (NLP) (radford2019language, ; brown2020language, )、网络安全 (mitra2024localintel, ) 和推荐系统 (zhang2023recommendation, ; hou2023large, )。 最先进的 LLM,如 OpenAI GPT (radford2019language, )、Google 的 PaLM (chowdhery2022palm, )、Meta 的 LLMA2 (touvron2023llama, ) 主要利用 Transformer 架构 (vaswani2017attention, )。 现有的 LLM 遵循不同的 Transformer 架构和预训练目标,例如仅使用解码器(如 GPT-2 和 GPT-3 所见)、仅使用编码器(如 BERT 所示 (devlin2018bert, ) 和 RoBERTa (liu2019roberta, ))、或采用编码器-解码器结构(如 BART 所见)。 模型可以通过不同的方法进行训练:采用 自回归 方法,其目标是根据左手上下文预测后续的词;利用 掩蔽 技术,类似于填空题,其目标是使用两侧的上下文来预测被掩蔽的词;或者采用一种策略,其中序列被故意破坏,然后执行预测原始序列的任务。 这些模型在理解和生成语言方面表现出非凡的能力,产生与人类表达和意图非常相似的响应,例如 ChatGPT 等聊天机器人应用程序的出现。 LLM 有效地将它们所学到的知识和推理能力应用于处理各种下游任务,包括命名实体识别 (NER)、文本摘要、问答等。 图 1(a) 描述了这些下游任务的基本 LLM。 这种能力归因于 LLM 的内在特征,例如提示或上下文学习 (brown2020language, ),这是通过提供适当的指令或提示 (zhu2023large, ) 实现的。
2.2. 检索增强生成
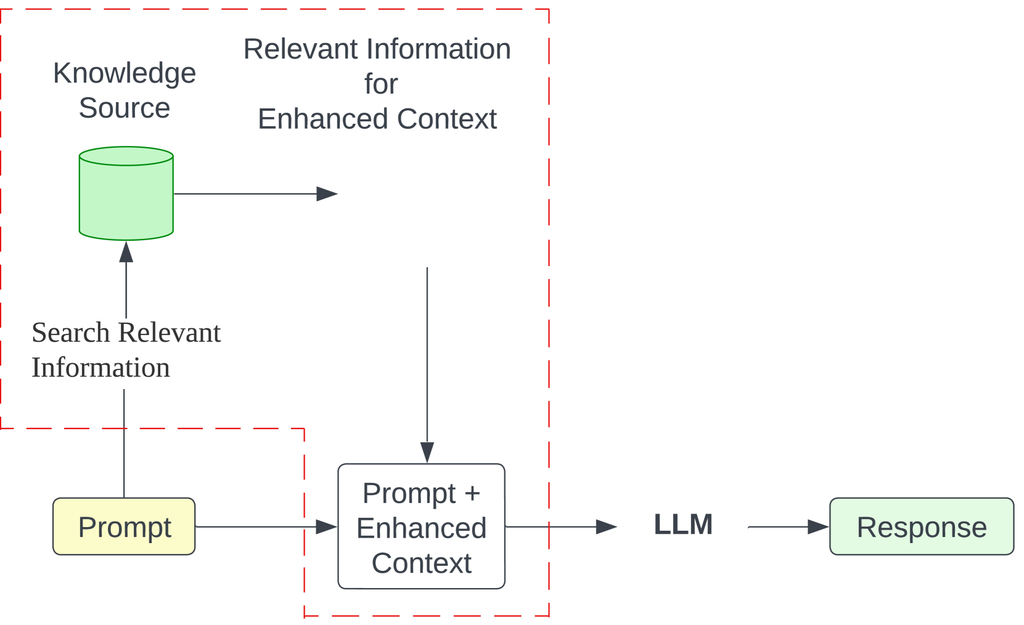
预训练的 LLM,包括 GPT 和 LLMA 等模型,已证明它们能够从训练数据中获取全面且详细的知识。 它们利用这些获得的知识根据提供的输入生成文本。 然而,这些模型面临着重大限制,阻碍了更广泛的部署。 例如,它们可能会产生看似合理的预测,但实际上并非事实,通常被称为幻觉 (huang2023survey, )。 当查询超出模型的训练数据或需要当前和更新的信息时,这种趋势尤为明显。 为了解决这一限制,一种很有前途的方法是检索增强生成 (RAG),由 (lewis2020retrieval, ) 在 2020 年中旬提出。 此方法将外部数据检索整合到生成过程中,从而增强模型提供精确和相关响应的能力。 图 1(b) 展示了一个简单的 RAG 的示例。
RAG 包括三个基本要素:知识库、检索器 和一个 LLM。 知识库能够容纳来自不同来源的大量文本,这些文本针对特定领域。 例如,在医疗领域,它可能包含有关医疗状况(疾病)、症状、预防措施、诊断和推荐药物等相关内容的信息。 检索器使用文本编码器为知识库中的每个文本计算一个嵌入向量。 当用户提出类似 “川崎病是什么,它对我的孩子健康有什么影响?” 的查询时,检索器使用文本编码器为问题输出一个嵌入向量,具体实现取决于检索组件,可能基于密集段检索 (DPR) (karpukhin2020dense, ),并可能遵循双编码器架构。 接下来,从医疗知识库中提取一小部分文本,例如 ,表示为检索文本,这些文本与给定问题的相似度最大,例如余弦相似度。 随后,这些 检索文本用作 LLM 生成所提供问题的答案的增强上下文。
2.3. 医疗保健中的 LLM
在自然语言处理 (NLP) 领域,LLM 因其在摘要、问答和自然语言生成 (NLG) (bubeck2023sparks, ) 等各种任务中的出色表现而掀起了一场革命 (bakker2022fine, )。 它们的多功能实用性促使研究人员积极探索在医疗保健领域的潜在应用。 ChatGPT 在美国医疗执照考试 (USMLE) (kung2023performance, ) 中取得了及格成绩,这证明了这一点。 此外,最近使用医疗数据微调的 Med-PaLM2 版本取得了最先进的结果,达到了人类临床医生的专业水平 (singhal2023towards, )。 尽管 LLM 在生成针对不同下游任务(如面向任务的问答)的人类化响应方面具有令人印象深刻的能力,但将 LLM 应用于医疗领域仍然具有挑战性。 这是因为大型语言模型 (LLM) 可能缺乏对其未接触过的医学知识的全面专业知识。 例如,一个仅用威廉·莎士比亚的文本训练的模型,在被问及某种疾病的症状时 (ovadia2023fine, ) 会难以表现良好。 为了缓解这个问题,研究人员目前正在用外部知识增强大型语言模型 (LLM)。 Zakka 等人 (zakka2023almanac, ) 推出了 Almanac,一个通过检索功能来增强医学指南和治疗建议的框架。 该框架是为了回答由五名委员会认证的临床医师和住院医师组成的专家小组提出的 130 个临床问题而创建的。 结果表明,Almanac 在真实性、安全性以及正确性方面超过了 GPT-4。 这表明,将检索系统整合到临床查询中会导致更精确和更可靠的响应。
同样,(kang2023knowledge, ) 中的作者提出了一种称为 KARD 的新方法。 该方法对小型大型语言模型 (LLM) 进行微调,以便生成从外部知识库或非参数内存中检索到的增强知识的语言模型获取的理由。 另一方面,Lozano 等人 (lozano2023clinfo, ) 推出了 Clinfo.ai,一个将端到端检索增强大型语言模型 (LLM) 链整合在一起的开源工作流程。 此工作流程专门设计用于查询、评估和将医学文献合成到简要摘要中,以按需解决问题。 为了提高 GPT-3/4 等大型语言模型 (LLM) 在生物医学数据上的准确性,(soong2023improving, ) 中的作者采用了检索方法。 随后,他们使用一组 19 个问题,定性地评估了 GPT-3.5 和 GPT-4 与定制的 RetA LLM 的性能。 结果表明,单独使用大型语言模型 (LLM) 比定制方法更可能出现幻觉现象。 为了将大型语言模型 (LLM) 中的通用知识纳入特定领域,Wang 等人 (wang2023augmenting, ) 提出了一种名为“用医学教科书增强的大型语言模型 (LLM-AMT)”的方法。 该方法将医学教科书作为外部数据库整合到问答系统中。 经验评估表明,在利用 LLM-AMT 时,响应的准确性有所提高。
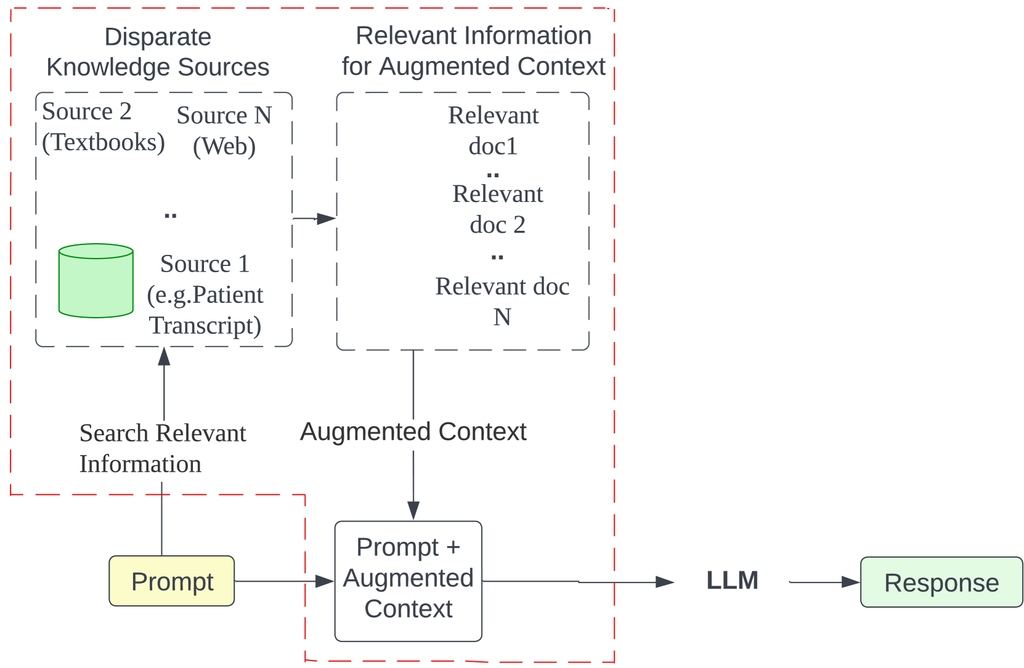
尽管上述方法在为医疗领域的大型语言模型 (LLM) 增强外部知识方面取得了显著进展,但它们通常依赖于单一知识源或专注于特定的医疗任务。 然而,在现实世界的医疗场景中,相关信息通常分布在多个碎片化的来源中,例如患者病历、临床指南、研究文献和在线知识库。 这种数据分割和知识来源的多样性给提供全面且个性化的医疗响应带来了重大挑战,这些响应需要根据患者的独特背景和病史进行定制。 如图 1(c) 所示,我们的框架通过整合来自多个来源的信息并将患者的详细信息与相关的医学知识联系起来,解决了这一挑战。 这种多源上下文增强方法使 MedInsight 能够克服依赖单一知识源的局限性,并提供个性化的医疗信息,从而考虑了医疗数据的碎片化性质。
3. MedInsight 架构与方法
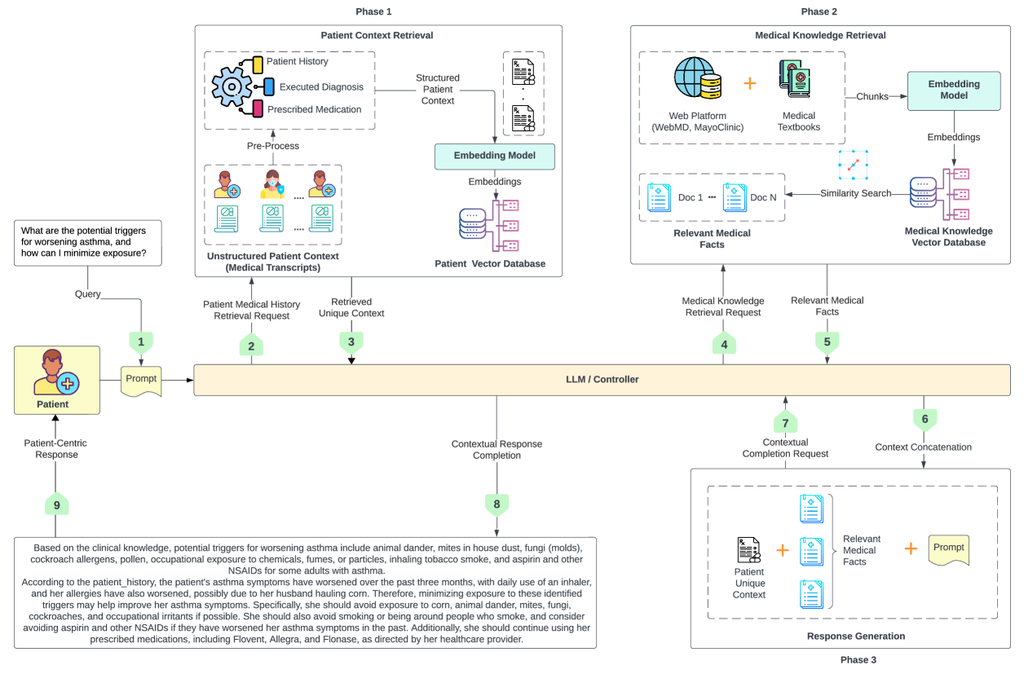
我们的框架 (称为 MedInsight) 的架构分为三个不可或缺的阶段,每个阶段在框架的功能中都发挥着不同的作用,如图 3 所示。 这三个阶段包括 患者上下文检索、医学知识检索 和 响应生成。 初始阶段围绕患者上下文检索展开,具体而言,重点利用患者的医疗记录构建一个全面且患者特异性的知识库。 在随后的阶段中,框架扩展了其范围,涵盖医学知识检索,利用可信的医学资源,例如医学教科书和网络平台 (例如,梅奥诊所和 WebMD)。 这一阶段确保我们的框架精通与医疗状况、治疗方法、药物以及一般健康和保健相关的各种学科知识。 最后阶段,响应生成,是将从患者数据或病史和医学知识中积累的上下文知识相结合以生成与上下文相关的以患者为中心的响应的综合点。 这三阶段方法保证了一个强大且适应性强的框架,能够提供上下文相关且相关的的信息,以满足患者和护理人员的多样化需求。
在接下来的几个小节中,我们将更详细地解释这些阶段。
3.1. 病人情况检索
在医疗保健领域,医疗保健提供者和患者进行对话以解决患者的健康问题。 随后,这些对话被转录以确保患者记录的准确性和完整性。 图 4(A) 展示了医患互动的一个例子。 在这种情况下,医疗记录可以定义为一个书面或打字的文档,它详细记录了患者的病史、诊断、治疗和相关细节。 这些记录是根据医疗保健专业人员(包括医生、护士或医疗记录员)的笔记制作的,可能源于患者与医疗保健提供者互动过程中的录音。 图 4(B) 展示了一个转录的医疗文档的代表性实例。 在这个阶段,我们开始将非结构化的医疗记录转换为结构化格式。 这种转换是通过使用 OpenAI 的 GPT-3.5-Turbo 的零样本提示策略实现的,通过 API 调用进行管理。 该过程包括将非结构化的医疗记录分类并标注为三个不同的类别:患者病史和症状、执行的诊断 以及 处方药物 以及 进一步的指示。 图 4(C) 提供了此过程生成的预处理和标注的独特患者情况的示例。 关于此过程使用的预处理技术和策略的更多见解将在第 4.1.1 节中讨论。
这个阶段的第二步是将结构化和标注的记录转换为向量数据库。 这个过程依赖于两个关键组件:嵌入模型和向量数据库。 嵌入指的是用于以捕捉自然语言词语和文档含义的方式表示它们的技巧。 这通常是一个低维空间中的实值向量。 在我们的 MedInsight 框架中,嵌入模型用于对患者的独特上下文进行向量化和预处理,并将它们存储在向量数据库中。 这使得能够执行 语义搜索 以检索相关知识。 同样,向量数据库(VD)是一种特定类型的数据库,它以高维向量的形式存储数据。 这些向量是从原始数据(例如非结构化文本)中推导出的数学表示,同时表示词级语义含义。 向量数据库的优势在于它可以根据向量距离快速进行相似性搜索和数据检索,这与传统的基于精确匹配或预定义标准进行搜索的数据库形成对比。 在我们的 MedInsight 框架中,Chroma DB111Chroma, Website: trychroma.com,一个内存中的 VD,允许根据提示的语义或上下文含义存储和检索最相关的预处理患者独特上下文。
3.2. 医疗知识检索
MedInsight 框架中的一个关键阶段是用从权威来源(如教科书和可信的网络平台(例如梅奥诊所、WebMD))检索到的相关医学知识全面增强患者的上下文。 医学教科书是关于疾病、症状、诊断和治疗的真实信息的权威资料库,而网络平台为专业人士和公众提供了各种可访问的医疗保健资源。 此上下文增强阶段将从患者医疗记录中提取的相关片段与用户的查询相结合,以建立更广泛的上下文。 然后,MedInsight 利用此综合上下文从可用资源中检索最相关的医学知识。
为了说明,图 5 提供了基于患者的独特情况和特定医疗查询的医疗知识检索的示例。 在这个特定场景中,患者的独特情况涉及一名男性患者经历过敏反应,他被开具了用于紧急情况的肾上腺素笔 。 但是,此患者的背景信息中没有说明如何使用肾上腺素笔的说明。 然后,医疗知识检索器搜索有关该主题的信息,并根据患者的背景信息和医疗查询返回最相关的文档。 MedInsight 能够根据提供的上下文和查询搜索相关信息,使其成为患者和护理人员的全面和支持性技术。 结果是个性化的,如图所示,患者正在寻求针对其特定情况量身定制的医疗建议。
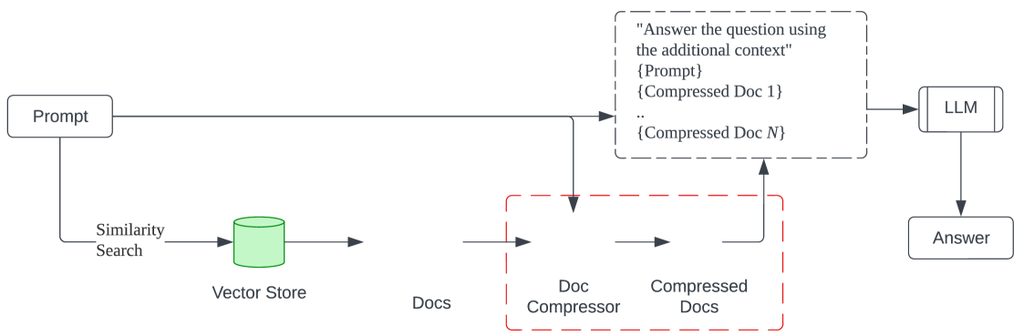
但是,传统的 RAG 管道在从各种来源检索证据时可能会遇到上下文溢出的挑战。 检索器通常不知道文档存储系统将面临的特定查询,导致相关信息可能隐藏在不相关文本中的情况。 传递完整文档在计算上可能很昂贵,并且可能降低性能。 为了解决这个问题,MedInsight 采用了通过 LangChain 提供的上下文压缩检索器,如图 6 所示。 这些检索器不是返回完整文档,而是使用查询上下文压缩内容,仅提取最相关的部分。 这种上下文压缩确保提取简洁、相关的医疗知识,从而促进 MedInsight 中随后的以患者为中心的响应生成阶段。
3.3. 响应生成
MedInsight 框架的最终阶段是响应生成,其任务是通过利用先前阶段从多个来源获得的增强上下文来生成全面、以患者为中心的响应。 如前所述,MedInsight 通过使用上下文压缩技术从权威教科书和可信的网络平台检索相关医学知识,来增强从患者医疗记录中提取的患者上下文。 此上下文增强过程确保响应生成阶段能够访问全面的、个性化的上下文,该上下文将个人的独特医疗细节与针对其特定状况和查询量身定制的相关背景信息相结合。
利用 LLM,此最终阶段根据用户提示和包含检索到的医疗文件和患者上下文的增强上下文,为单个患者或护理人员量身定制响应。 我们的方法整合了专有和开源 LLM 以进行响应生成。 最初,我们使用 OpenAI 的 GPT-3.5-Turbo 模型为 100 组问题生成响应(有关所选医疗专业的详细信息以及相应的问题,请参阅第 4.1 节)。 接下来,我们使用相同的管道使用 Mistral-7B-Instruct 生成响应,以便在以患者为中心的响应生成任务中对封闭源模型与开源模型进行比较评估。 此评估的结果在第 4.3.1 节中介绍。 图 7 展示了 MedInsight 生成的以患者为中心的响应的示例,该响应解决了医疗查询:“在紧急情况下如何使用处方 EpiPen®?” 该响应包含从患者记录中提取的患者医疗上下文、基于该上下文从外部知识源检索到的相关证据以及查询本身。 为清晰起见,从多个来源集成的上下文方面以红色突出显示。
4. 实验结果和讨论
我们的框架 MedInsight 可以作为患者的个性化支持系统,帮助他们理解自己的医疗状况,同时提供有关一般主题的更广泛的医疗信息。 此外,照护人员可以通过提出与患者相关的个性化问题,从该系统中受益,从而优化照护。 在这里,我们展示了一个概念验证实验,证明了我们框架的可行性。
4.1. 数据集准备和描述
由于 HIPAA 强加的严格隐私法规,获取公开的医疗数据的访问权限带来了挑战。 因此,在本研究中,我们利用从 MTSamples (mtsamples, ) 获得的医疗记录作为我们调查的基础数据集(或患者背景)。
MTSamples 数据集完全是合成的,这意味着它不包含任何实际的患者信息,并且是人工生成的。 该库包含 5000 份医疗报告的记录,涵盖了超过 40 种医疗专业的广泛领域。 从这个广泛的范围中,我们精心选择了 10 个特定的专业进行重点分析,包括 过敏/免疫学、肺/心血管、皮肤病学、胃肠病学、普通内科、骨科、神经科、足病学 和 儿科 - 新生儿,如表 1 所示。 在每个类别中,我们随机选择 5 个记录,这些记录代表患者的独特背景。 然后,我们为每个背景生成问题,采用 GPT-3.5-Turbo 的零样本提示策略。 这种方法使我们能够为每个不同的患者背景创建一对合成问题。 总之,我们整理了一个包含大约 100 个问题的集合,每个问题都专门针对单个患者量身定制。 所选记录涵盖了广泛的年龄范围,从 2 个月大的婴儿到 93 岁的成年人,并且代表了两种性别。 包含大的年龄组和性别使我们的数据集多样化,这反过来使得 MedInsight 更加全面。
为了检索医疗知识,我们仔细地为每个医疗专业策划了医疗教科书,以使我们的检索器更加全面(有关详细信息,请参阅第 3.2 节)。 总之,我们收集了 12 本 PDF 格式的医疗教科书,其中 10 本与特定医疗专业直接相关,2 本用作医疗百科全书。 值得注意的是,其中一些书籍超过了 8000 页。 表 1 显示了这些书籍的总符元计数。 有关这些扩展文本使用的拆分和分块策略的预处理的详细见解,请参阅第 4.2 节。
4.1.1. 数据集预处理
初始阶段涉及对从 MTSamples 数据集获得的合成原始数据的预处理。 这些原始数据包含没有标注的患者背景摘要。 通过上下文分析,我们将数据分为三个不同的组:病史、执行的诊断以及处方药物和进一步的说明。 此分类是引导 MedInsight 的检索器准确识别文本文档中相关信息的决定性因素。 因此,这种方法有助于生成与上下文相关的、以患者为中心的响应。 为了对原始数据进行预处理,我们采用了一种零样本提示策略,指示 GPT-3.5-Turbo 模型将提供的患者背景注释到上述三个类别中。 表 2 说明了患者背景的示例及其在应用零样本提示技术后的注释输出。
| Medical Speciality | # of Transcript(s) | # Selected | # of Token(s) |
| Allergy / Immunology | 7 | 5 | 335,807 |
| Pulmonary / cardiovascular | 372 | 5 | 643,733 |
| Dermatology | 29 | 5 | 652,882 |
| Gastroenterology | 230 | 5 | 108,893 |
| General Medicine | 259 | 5 | 541,243 |
| Orthopedic | 355 | 5 | 481,512 |
| Neurology | 223 | 5 | 1,921,963 |
| Podiatry | 47 | 5 | 82,270 |
| Urology | 158 | 5 | 791,163 |
| Pediatrics - Neonatal | 70 | 5 | 1,356,563 |
| Total | 1750 | 50 | 6,263,147 |
4.2. 实施细节
在我们的实验过程中,我们使用了 OpenAI 的专有 GPT-3.5-turbo 和开源 Mistral-7B-Instruct 作为我们框架的基础生成器。 模型的温度被故意设置为 0 以消除响应中的随机性。 通过其 API 访问的 GPT-3.5-turbo 使用零样本提示策略处理了患者上下文标注任务。 对于患者上下文检索和医疗知识检索,我们使用 Chroma 构建了一个向量数据库,但是,分块和拆分策略不同。 患者上下文规模相对较小,被分成 500 个块,重叠部分为 200。 相反,从网络平台和医学教科书中整理的医学上下文规模要大得多,一些医学书籍包含超过 8000 页。 因此,我们选择将医学知识检索器的块大小设置为 2500,重叠部分为 500。 我们 RAG 管道中的基本嵌入模型是 text-embedding-ada-002。 在证据检索阶段,我们使用了 LangChain 提供的 上下文压缩检索器。 该检索器不是直接返回检索到的文档,而是使用给定查询的上下文压缩这些文档,确保只返回相关信息。 这样的检索器提高了文档检索过程的效率和有效性,从而带来更好的用户体验和优化资源利用率。 上下文相关、以患者为中心的响应的生成涉及 GPT-3.5-Turbo 和 Mistral-7B-Instruct 8 位量化模型。 该实验在 Google Colab Jupiter 环境中进行,GPT-3.5-Turbo 使用标准 CPU 运行时。 Mistral-7B-Instruct 从 Huggingface(mistral, ) 下载,并在本地运行。 我们使用 Intel i9-12900 CPU、GPU GeForce RTX™ 3090 Ti(24 GB)和 128 GB RAM 运行 Mistral。 我们算法的概述见算法 1。
4.3. 评估
| Prompt Template | Unstructured Patient Context | Annotated Unique Patient Context |
|
prompt_template = """Given the following {medical transcript} of a patient, create a detailed summary by categories. The summary should be divided into the following categories: • Patient history and symptom • Executed diagnostics • 处方药物和说明: Medical Transcript: {transcript1.txt}""" |
An 83-year-old diabetic female presents today stating that she would like diabetic foot care.,O - ,On examination, the lateral aspect of her left great toenail is deeply ingrown. Her toenails are thick and opaque. Vibratory sensation appears to be intact. Dorsal pedal pulses are 1/4. There is no hair growth seen on her toes, feet or lower legs. Her feet are warm to the touch…discolored |
• 患者病史和症状:患者是一位 83 岁的糖尿病女性,主诉糖尿病足病护理……变色。 • Executed diagnostics: …the diagnosis made is onychocryptosis,… • Prescribed medications & Instruction: The transcript does not … prescribed medications… |
|
prompt_template = """Given the following {medical transcript} of a patient, create a detailed summary by categories. The summary should be divided into the following categories: • Patient history and symptom • Executed diagnostics • 处方药物和说明: Medical Transcript: {transcript2.txt}""" |
The patient is admitted for shortness of breath, continues to do fairly well. The patient has chronic atrial fibrillation, on anticoagulation, INR of 1.72…cardiologist regarding aortic stenosis. She may need a surgical intervention in this regard, which I explained to her. The patient will be discharged home on medical management and she has an appointment to see her cardiologist in the next few days.,In the interim, if she changes her mind or if she has any concerns, I have requested to call me back. |
• Patient history and symptom: The patient was admitted for shortness of breath…atrial fibrillation and is on anticoagulation with an INR of 1.72…severe aortic stenosis… • Executed diagnostics: Physical examination showed vital signs…systolic murmur in the aortic area,…impression was made of shortness… • 处方药物和说明:继续现有的药物……心脏病专家咨询主动脉瓣狭窄,因为可能需要手术干预。 |
我们的评估研究采用双管齐下的实验方法。 为了定量评估我们的框架在生成上下文相关响应方面的性能,我们采用了一套全面的指标,包括 Ragas 分数 (es2023ragas, ) 和 TruLens 分数 (TruLens, )。 在定量评估了我们模型的整体有效性之后,我们继续进行了一项主题专家 (SME) 评估研究,以验证 MedInsight 的答案生成能力。 由于这种评估的资源密集型特性,我们聘请了一个由四位住院医师组成的专家小组。 他们的任务包括对 100 个问题的答案进行评分,这些问题涵盖了所有医学专业,如第 4.1 节所述,并考虑了两个关键方面:事实正确性和与患者独特背景的相关性。
4.3.1. 定量评估
为了定量评估我们的 MedInsight 在生成上下文相关、以患者为中心的响应方面的性能,我们使用 RAGAS (es2023ragas, ) 和 TruLens (TruLens, ) 框架。 这些框架提供 提供专门为评估 RAG 管道而设计的综合指标。 我们选择这些框架 而不是像 BLEU (papineni2002bleu, ) 和 ROUGE (rouge2004package, ) 这样的流行替代方案,因为它们与我们的特定背景不符。 BLEU 主要用于评估机器翻译任务,而 ROUGE 专门用于评估文本摘要任务。 这两种指标都侧重于真实情况和生成句子之间的结构相似性,这可能不适合我们的情况,因为句子在结构上可能不同,但在事实上有相似之处。 传统指标无法捕捉到这种细微差别。 鉴于 MedInsight 主要作为一个基于 RAG 的问答系统,具有上下文映射功能,这些传统指标并不适合衡量其有效性。
| Evaluation Framework | Model | Average Similarity Score | Average Correctness Score |
| Ragas | gpt-3.5-turbo | 0.93 | 0.84 |
| Mistral-7B-Instruct | 0.92 | 0.77 | |
| TruLens | gpt-3.5-turbo | 0.90 | - |
| Mistral-7B-Instruct | 0.91 | - |
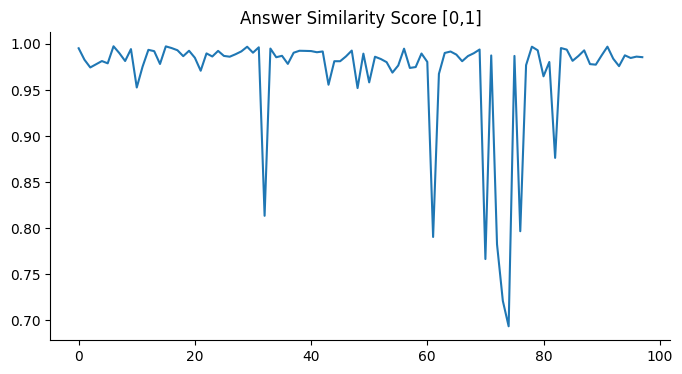
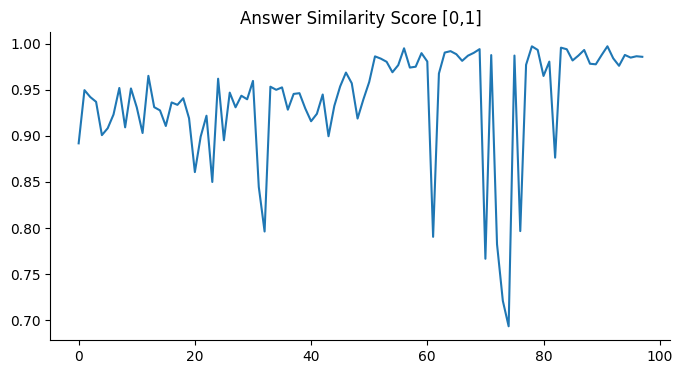
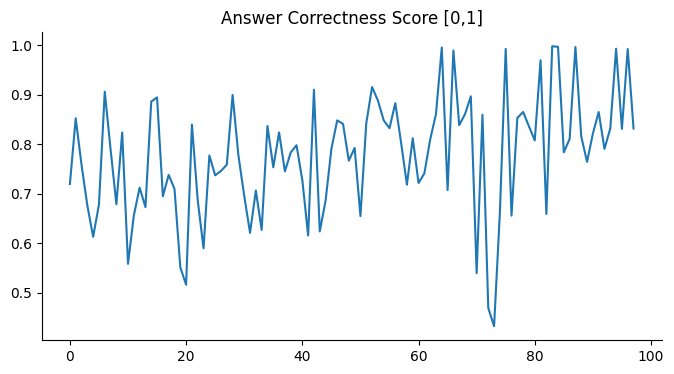
在我们的研究背景下,我们报告了 GPT-3.5-turbo 生成的答案在答案相似度方面的平均 RAGAS 得分为 0.93,在答案正确性方面的平均 RAGAS 得分为 0.8409。 图 7(a) 描述了答案相似度得分,图 7(b) 展示了 GPT-3.5-Turbo 生成的答案的答案正确性得分。 然而,在 Mistral-7B-Instruct 的情况下,我们报告了答案相似度方面的平均得分 0.92,答案正确性方面的平均得分 0.77。 图 7(c) 说明了答案相似度得分,而图 7(d) 展示了 Mistral-7B-Instruct 生成的响应的答案正确性得分。 同样,对于 TruLens,我们报告了 GPT-3.5-Turbo 生成的答案的平均答案相似度得分 0.91,Mistral-7B 生成的答案的平均答案相似度得分 0.90。 对于这两个框架,得分范围在 0 和 1 之间,其中 1 表示最佳生成。
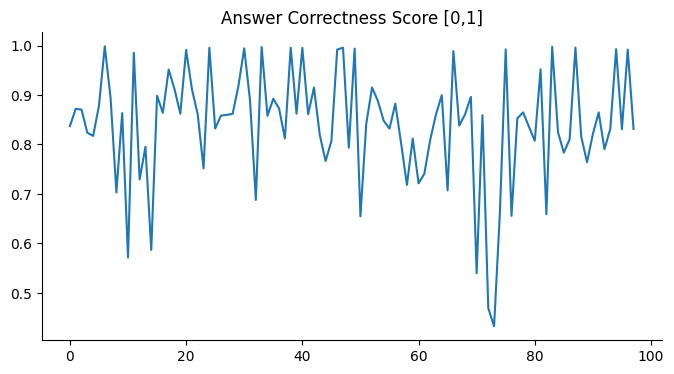
表 3 中突出显示的结果表明,在答案相似度方面,GPT 模型略微优于 Mistral-7B-Instruct。 此外,在与答案正确性相关的评估中,GPT 模型实现了显著的 7% 的准确率提高。 总体而言,结果强调了 MedInsight 在检索增强型问答任务框架内提供上下文相关答案的能力。
4.3.2. 定性评估
在通过定量指标评估我们模型的有效性之后,我们进行了一项人工评估研究,以验证 MedInsight 在以患者为中心的响应生成任务中的熟练程度。 鉴于此评估所涉及的巨额成本,我们聘请了一个由 4 名医疗专业人员组成的专家小组,包括医师和住院医师,使用评分机制来评估生成的响应。 评估集中在两个关键方面:事实正确性和上下文相关性。 第一个标准衡量生成答案对给定问题的准确性和相关性,而第二个标准则评估检索信息的上下文适宜性,同时考虑到问题和患者的独特背景。
医疗专家被提供了 10 个不同的医疗专业领域,每个领域包含 5 个独特的患者背景和 2 个问答对(有关问题的详细信息,请参见第 4.1 节)。 他们的任务是手动评估在总共 100 个问答对中生成的答案的质量。 为了评估事实正确性和上下文相关性,采用了一个 5 点李克特量表 (allen2007likert, ),范围从 1(表示“事实错误且上下文不相关”)到 5(表示“事实准确且上下文相关”)。 医疗专业人员被指示在这个量表上对响应进行评分。 获得的平均分为 5 分中的 4.66 分。 此步骤使我们能够为定量评估建立真实情况。 此外,我们使用弗莱斯卡帕测量 (mchugh2012interrater, ) 评估了评分者间的一致性,如表 4 所示。评估显示,医疗专家对生成响应的总体一致性中等,为 0.60,标准误为 0.029。
| Overall Categories | ||
| Overall Agreement | Kappa () | Standard Error |
| 0.600708945 | 0.029630951 | |
| a. Data contains 98 question-answer pairs evaluated by 4 raters using Fleiss Kappa. | ||
| b. Rating category values are case-sensitive. | ||
5. 结论和未来工作
大型语言模型在生成上下文响应方面拥有非凡的能力。 然而,由于缺乏领域特定知识,它们在医疗保健领域的应用受到限制。 为了解决这个问题,我们开发了一个名为 MedInsight 的新框架,帮助患者通过检索增强型问答更好地了解他们的病史、诊断和处方。 MedInsight 的主要目标是为患者提供洞察力,以改善和优化患者护理和医疗保健服务。
为了实现这一目标,MedInsight 采用了一种上下文增强方法,将来自医疗教科书和网络平台等多个来源的医疗知识与患者来自其记录的独特医疗上下文相结合。 开发的方法包括三个阶段:首先,从医疗记录和健康记录中提取相关细节,以了解患者的上下文。 其次,MedInsight 从 WebMD 和 Mayo Clinic 等外部资源中检索可信且相关的临床信息,以增强患者的上下文。 最后,利用增强的上下文(包括患者的详细信息和检索到的医疗知识)来生成以患者为中心的响应,以回应用户提示。
我们使用 MTSamples 数据集评估了 MedInsight 的上下文增强方法的有效性,该数据集包含十种医疗状况和五十种独特的患者上下文。 结果表明 MedInsight 在生成上下文相关响应方面有效。 RAGAS 框架揭示了答案相似度(GPT-3.5-turbo 为 0.93,Mistral-7B-Instruct 为 0.92)和答案正确性(GPT-3.5-turbo 为 0.84,Mistral-7B-Instruct 为 0.77)的有希望的分数。
在未来,我们旨在进一步优化检索器,并研究 RAG 方法在生成上下文相关的以患者为中心的响应时,在从多个来源增强上下文方面,相对于微调的有效性。
致谢
这项工作得到了密西西比州立大学计算机科学与工程系 PATENT 实验室(预测分析和技术集成实验室)的支持。 作者感谢 SME 对定性评估的帮助。 本文的观点和结论属于作者个人。
参考文献
- [1] Baolin Peng, Michel Galley, Pengcheng He, Hao Cheng, Yujia Xie, Yu Hu, Qiuyuan Huang, Lars Liden, Zhou Yu, Weizhu Chen, et al. Check your facts and try again: Improving large language models with external knowledge and automated feedback. arXiv preprint arXiv:2302.12813, 2023.
- [2] Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232, 2023.
- [3] Oded Ovadia, Menachem Brief, Moshik Mishaeli, and Oren Elisha. Fine-tuning or retrieval? comparing knowledge injection in llms. arXiv preprint arXiv:2312.05934, 2023.
- [4] James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13):3521–3526, 2017.
- [5] Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv preprint arXiv:1312.6211, 2013.
- [6] Sanyuan Chen, Yutai Hou, Yiming Cui, Wanxiang Che, Ting Liu, and Xiangzhan Yu. Recall and learn: Fine-tuning deep pretrained language models with less forgetting. arXiv preprint arXiv:2004.12651, 2020.
- [7] Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning. arXiv preprint arXiv:2308.08747, 2023.
- [8] Yanda Chen, Ruiqi Zhong, Sheng Zha, George Karypis, and He He. Meta-learning via language model in-context tuning. arXiv preprint arXiv:2110.07814, 2021.
- [9] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- [10] Andrew K Lampinen, Ishita Dasgupta, Stephanie CY Chan, Kory Matthewson, Michael Henry Tessler, Antonia Creswell, James L McClelland, Jane X Wang, and Felix Hill. Can language models learn from explanations in context? arXiv preprint arXiv:2204.02329, 2022.
- [11] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [12] Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, et al. Text and code embeddings by contrastive pre-training. arXiv preprint arXiv:2201.10005, 2022.
- [13] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109, 2023.
- [14] PF Brown, PV DeSouza, RL Mercer, VJ Della Pietra, and JC Lai. Class-based n-gram models of natural language. Comput. Linguist, (1950), 1992.
- [15] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [16] Shaswata Mitra, Subash Neupane, Trisha Chakraborty, Sudip Mittal, Aritran Piplai, Manas Gaur, and Shahram Rahimi. Localintel: Generating organizational threat intelligence from global and local cyber knowledge. arXiv preprint arXiv:2401.10036, 2024.
- [17] Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. Recommendation as instruction following: A large language model empowered recommendation approach. arXiv preprint arXiv:2305.07001, 2023.
- [18] Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. Large language models are zero-shot rankers for recommender systems. arXiv preprint arXiv:2305.08845, 2023.
- [19] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- [20] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [21] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [22] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [23] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [24] Yutao Zhu, Huaying Yuan, Shuting Wang, Jiongnan Liu, Wenhan Liu, Chenlong Deng, Zhicheng Dou, and Ji-Rong Wen. Large language models for information retrieval: A survey. arXiv preprint arXiv:2308.07107, 2023.
- [25] Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906, 2020.
- [26] Michiel Bakker, Martin Chadwick, Hannah Sheahan, Michael Tessler, Lucy Campbell-Gillingham, Jan Balaguer, Nat McAleese, Amelia Glaese, John Aslanides, Matt Botvinick, et al. Fine-tuning language models to find agreement among humans with diverse preferences. Advances in Neural Information Processing Systems, 35:38176–38189, 2022.
- [27] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- [28] Tiffany H Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepaño, Maria Madriaga, Rimel Aggabao, Giezel Diaz-Candido, James Maningo, et al. Performance of chatgpt on usmle: Potential for ai-assisted medical education using large language models. PLoS digital health, 2(2):e0000198, 2023.
- [29] Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Le Hou, Kevin Clark, Stephen Pfohl, Heather Cole-Lewis, Darlene Neal, et al. Towards expert-level medical question answering with large language models. arXiv preprint arXiv:2305.09617, 2023.
- [30] Cyril Zakka, Akash Chaurasia, Rohan Shad, Alex R Dalal, Jennifer L Kim, Michael Moor, Kevin Alexander, Euan Ashley, Jack Boyd, Kathleen Boyd, et al. Almanac: Retrieval-augmented language models for clinical medicine. Research Square, 2023.
- [31] Minki Kang, Seanie Lee, Jinheon Baek, Kenji Kawaguchi, and Sung Ju Hwang. Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks. arXiv preprint arXiv:2305.18395, 2023.
- [32] Alejandro Lozano, Scott L Fleming, Chia-Chun Chiang, and Nigam Shah. Clinfo. ai: An open-source retrieval-augmented large language model system for answering medical questions using scientific literature. In PACIFIC SYMPOSIUM ON BIOCOMPUTING 2024, pages 8–23. World Scientific, 2023.
- [33] David Soong, Sriram Sridhar, Han Si, Jan-Samuel Wagner, Ana Caroline Costa Sá, Christina Y Yu, Kubra Karagoz, Meijian Guan, Hisham Hamadeh, and Brandon W Higgs. Improving accuracy of gpt-3/4 results on biomedical data using a retrieval-augmented language model. arXiv preprint arXiv:2305.17116, 2023.
- [34] Yubo Wang, Xueguang Ma, and Wenhu Chen. Augmenting black-box llms with medical textbooks for clinical question answering. arXiv preprint arXiv:2309.02233, 2023.
- [35] [Online] MTSAMPLES. Transcribed medical transcription sample reports and examples. https://mtsamples.com/.
- [36] [Online] Hugging Face. Thebloke/mistral-7b-instruct-v0.2-gguf. https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.2-GGUF.
- [37] Shahul Es, Jithin James, Luis Espinosa-Anke, and Steven Schockaert. Ragas: Automated evaluation of retrieval augmented generation. arXiv preprint arXiv:2309.15217, 2023.
- [38] TruLens. Trulens: Don’t just vibe check your llm app!
- [39] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318, 2002.
- [40] Lin CY ROUGE. A package for automatic evaluation of summaries. In Proceedings of Workshop on Text Summarization of ACL, Spain, volume 5, 2004.
- [41] I Elaine Allen and Christopher A Seaman. Likert scales and data analyses. Quality progress, 40(7):64–65, 2007.
- [42] Mary L McHugh. Interrater reliability: the kappa statistic. Biochemia medica, 22(3):276–282, 2012.