AutoLoRA:基于元学习的低秩自适应自动调整矩阵秩
摘要
大规模预训练以及针对特定任务的微调在各种 NLP 任务中取得了巨大成功。 由于微调大型预训练模型的所有参数会带来巨大的计算和内存挑战,因此开发了几种有效的微调方法。 其中,低秩适应(LoRA)在冻结预训练权重的基础上对低秩增量更新矩阵进行微调,已被证明特别有效。 尽管如此,LoRA 在所有层上的统一排名分配,以及它对穷举搜索来寻找最佳排名的依赖,导致了较高的计算成本和次优的微调性能。 为了解决这些限制,我们引入了 AutoLoRA,这是一种基于元学习的框架,用于自动识别每个 LoRA 层的最佳排名。 AutoLoRA 将低秩更新矩阵中的每个秩 1 矩阵与选择变量相关联,该变量确定是否应丢弃秩 1 矩阵。 开发了一种基于元学习的方法来学习这些选择变量。 最佳排名是通过对这些变量的值进行阈值确定的。 我们在自然语言理解、生成和序列标记方面的综合实验证明了 AutoLoRA 的有效性。 该代码可在 https://anonymous.4open.science/r/AutoLoRA 上公开获取。
1简介
Large Language Models (大语言模型) Radford 等人 (2019); Brown 等人 (2020) 在各种 NLP 任务中展示了最先进的性能,从自然语言理解 (NLU) Wang 等人 (2018) 到 Natural语言生成 (NLG) Radev 等人 (2020),ChatGPT OpenAI (2023) 等模型的成功凸显了这一轨迹。 他们的成功很大程度上源于两个阶段的过程:对大量未标记文本进行初始预训练,然后对特定的下游任务进行微调。 然而,随着模型规模的扩大,例如从 RoBERTa-large 的 3.55 亿个参数 Liu 等人 (2019) 过渡到 GPT-3 的惊人的 1750 亿个参数 Brown 等人 (2020),微调在计算上变得非常昂贵。
为了应对这一挑战,人们开发了许多有效的微调方法Houlsby等人(2019)。 例如,Adapters 方法 Houlsby 等人 (2019) 将轻量级层(称为适配器)插入到预训练网络中。 在微调期间,仅更新这些适配器,而预训练层保持冻结。 此方法的一个限制是适配器在推理期间会产生额外的计算开销。 另一种方法是前缀调整 Lester 等人 (2021),引入可训练的前缀参数,这些前缀参数被添加到输入序列中,同时冻结预训练的模型参数。 然而,确定前缀的最佳长度可能很棘手。 太短的前缀无法捕获足够的信息,而太长的前缀可能会大大减少输入序列的最大长度。 为了解决这些限制,LoRA Hu 等人 (2022) 提出在预训练权重矩阵中添加低秩增量更新矩阵。 在微调期间,仅训练增量矩阵,而预训练矩阵被冻结。 低秩参数化显着减少了微调参数的数量。
虽然在不增加推理成本的情况下实现参数高效的微调,但 LoRA 有两个局限性。 首先,不同层的更新矩阵共享相同的秩,而不考虑跨层的不同属性。 预训练模型中的不同层对下游任务具有不同的重要性,并且应该进行不同的调整,这要求可训练参数的数量是特定于层的。 在所有层上采用统一的排名会损害这一目的,这会导致某些层参数化不足(导致微调性能不佳),而其他层则不必要地过度参数化(导致计算效率低下)。 其次,在 LoRA 中获得最佳排名通常涉及大量的手动超参数搜索,这非常耗时并且会带来可扩展性问题。
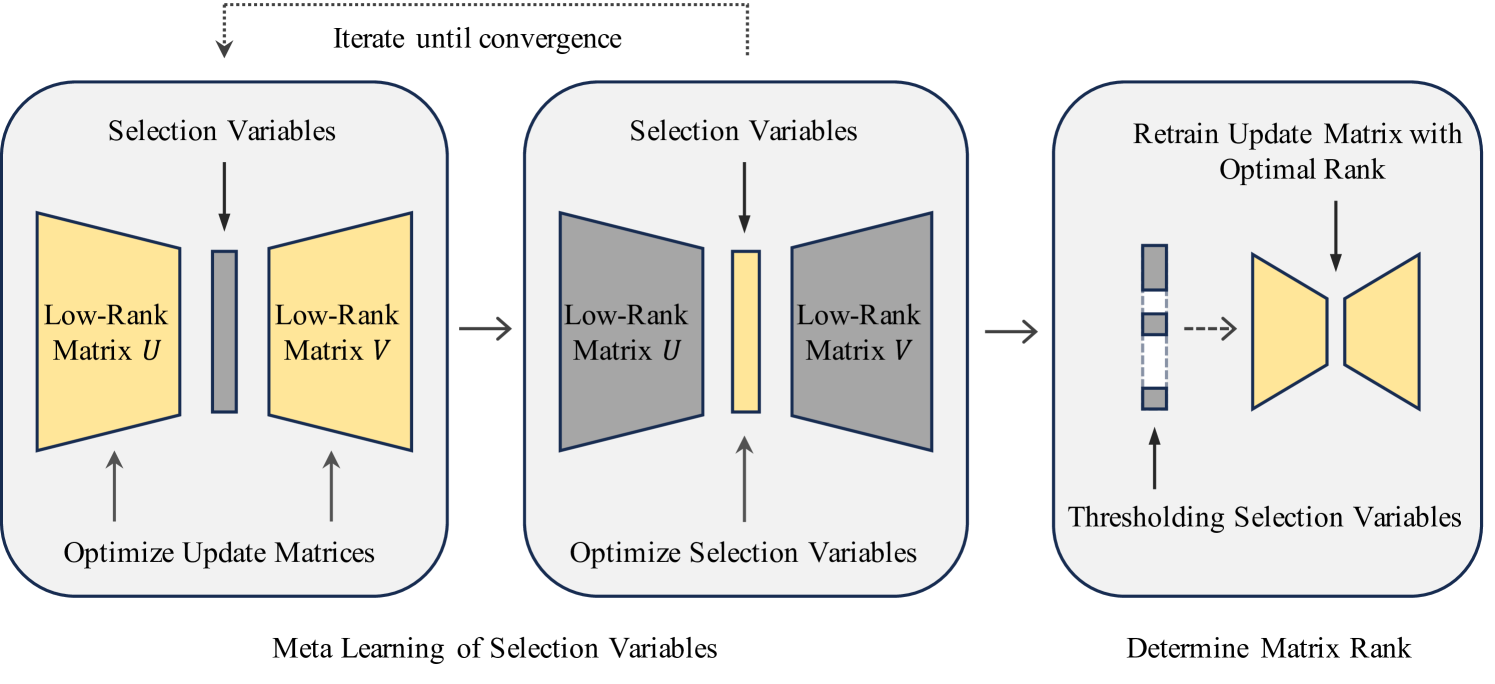
为了解决 LoRA 的上述局限性,我们引入了 AutoLoRA 框架来自动确定每个 LoRA 层的最佳等级。 在 AutoLoRA 中,我们首先将更新矩阵分解为两个低秩矩阵(秩为 )的乘积,这与 LoRA 方法一致。 该乘积可以表示为 1 阶矩阵的总和。 对于每个 1 阶矩阵,我们分配一个连续的可训练选择变量 指示矩阵在求和中的相对重要性。 学习后,如果接近于0,则从求和中删除相应的rank-1矩阵。 这些选择变量有效地控制更新矩阵的秩。 直接在训练数据集上结合更新矩阵学习 可能会导致过度拟合,并且以这种方式学习的网络缺乏泛化能力。 为了缓解这个问题,我们将 的搜索过程表述为元学习 Finn 等人 (2017) 问题。 首先,我们微调数据集上的训练矩阵中的权重。 其次,我们通过最小化验证数据集上的损失来优化 值。 这两个步骤迭代直至收敛。 随后,我们通过对学习到的 值进行阈值化,得出每个 LoRA 层的最佳排名。 一旦确定了每一层的最佳排名,低排名更新矩阵中的权重就会结合训练和验证数据进行重新训练。 我们提出的方法的概述如图1所示。
本文的主要贡献总结如下。
-
•
我们提出 AutoLoRA,一种基于元学习的方法,可以自动确定更新矩阵的最佳和特定层的等级,减轻像 LoRA 中那样手动调整它们的负担。
-
•
关于自然语言理解和生成任务的大量实验证明了 AutoLoRA 的有效性。
2相关作品
2.1 参数高效微调方法
人们已经开发了各种方法来有效地微调预训练模型。 这些方法仅更新大型预训练模型中权重的一小部分,而大多数参数被冻结。 根据 Aghajanyan 等人 (2021) 的说法,大型预训练模型中的权重矩阵往往具有较小的内在维度,为通过低维重新参数化微调预训练模型提供了理论直觉。 令人印象深刻的是,这些方法有时可以超越完全微调的性能,特别是在训练数据有限的下游任务中。
一些有效的微调方法通过更新可训练提示来微调预训练模型,同时保持其预训练参数冻结。 例如,Prompt-tuning Lester 等人 (2021) 学习语言模型的“软提示”来执行特定的下游任务。 前缀调优Li and Liang (2021)针对自然语言生成任务优化了一系列连续的特定于任务的向量。 P-tuning Liu 等人 (2023) 优化了一个小型神经网络,该网络生成连续的提示嵌入,以微调自然语言理解任务的 GPT 模型。 LLaMA-Adapter Zhang 等人 (2023b) 学习 LLaMA Touvron 等人 (2023a) 模型的可训练提示。 然而,选择合适的提示长度可能具有挑战性,因为短提示无法捕获足够的信息,而过长的提示会显着减少输入序列的长度。
另一项研究涉及通过将可训练模块插入到模型中来微调预训练模型,同时保持预训练参数冻结。 例如,Adapter Houlsby 等人 (2019) 建议将额外的可训练适配器层注入到预训练的 Transformer Vaswani 等人 (2017) 模型中。 IA3 Liu 等人 (2022) 将预训练模型中激活函数的输出与可训练向量相乘。 更紧凑的 mahabadi 等人 (2021) 将超复杂乘法层 Zhang 等人 (2021) 插入到预训练模型中,比 Adapters 提供更高的效率。 由于计算插入的模块,这些方法会产生额外的推理开销。
AdaLoRA Zhang 等人 (2023a) 旨在通过根据重要性分数自适应地分配预算来克服 LoRA 在所有 LoRA 层之间均匀分配更新预算的问题。 然而,由于重要性得分和更新矩阵都是在同一训练数据集上学习的,因此过度拟合的风险增加。
2.2 元学习
人们提出了各种元学习方法,以便用最少的训练数据更好地使模型适应新任务。 例如,与模型无关的元学习(MAML)Finn等人(2017)是一种基于梯度的元学习方法,旨在训练模型权重,以快速适应具有少量数据的新任务一些梯度下降步骤。 Meta-SGD 是 MAML Li 等人 (2018) 的扩展。 它不仅学习模型权重,还优化学习率以快速适应新任务。 Reptile Nichol 等人 (2018) 是一种一阶元学习算法,它是 MAML 的更简单的替代方案。 Reptile 反复将元参数的初始化移向在特定任务上训练的模型权重,从而避开二阶梯度计算。 与之前的这些方法正交,我们基于元学习的方法用于调整 LoRA 中的矩阵等级。
3 预赛
在LoRA Hu等人(2022)中,下游模型中层的权重矩阵被参数化为,其中 是预训练模型中 层的权重矩阵, 是增量更新矩阵。 被参数化为两个低秩矩阵的乘积:,其中 和 。 比和小得多,是的等级。 等价地, 可以写为 1 阶矩阵的总和:
| (1) |
其中 是 的 列和 的 行之间的外积。
4方法
4.1概述
4.2 重新参数化更新矩阵
我们将方程(1)中的每个秩1矩阵与选择变量相关联,并将重新参数化为加权1 阶矩阵之和:
| (2) |
可以理解为的重要性。 如果接近0,将从中删除,这有效地将的排名降低1。 换句话说,的排名相当于中非零值的数量。 通过根据这些选择变量对数据的适应性来学习这些选择变量,我们可以自动确定 的排名。 我们添加一个约束,即 的总和等于 1:。 这个约束使得的优化变得困难。 为了解决这个问题,我们不直接优化,而是使用softmax对它们进行参数化:
| (3) |
并学习无约束变量。
4.3 学习选择变量
4.4 确定矩阵秩
给定最优学习的选择变量,我们根据确定每个更新矩阵的排名。 对于每一层,我们计算中满足的条目数,其中表示阈值。 该数字将是 的最佳排名。 我们将 设置为 。 该阈值保证自动确定的排名至少为一。
4.5 重新训练更新矩阵
5实验
| Method | Params | CoLA | SST-2 | MRPC | QQP | MNLI | QNLI | RTE | STS-B | Avg. |
| Full FT | 125.0M | 61.6 | 94.8 | 89.3 | 90.3 | 86.7 | 92.8 | 76.9 | 91.2 | 85.5 |
| Adapter | 0.9M | 58.8 | 94.0 | 88.4 | 89.1 | 86.5 | 92.5 | 71.2 | 89.9 | 83.8 |
| LoRA | 0.3M | 59.0 | 94.5 | 89.1 | 89.6 | 86.9 | 92.9 | 75.8 | 91.1 | 84.9 |
| AdaLoRA | 0.3M | 58.8 | 94.0 | 89.4 | 89.9 | 87.0 | 93.0 | 75.9 | 90.6 | 85.0 |
| AutoLoRA | 0.3M | 61.3 | 94.9 | 89.4 | 90.3 | 87.0 | 92.9 | 77.0 | 90.8 | 85.5 |
5.1实验设置
本工作使用的基线方法包括 Adapter Houlsby 等人 (2019)、LoRA Hu 等人 (2022) 和 AdaLoRA Zhang 等人 (2023a).
我们通过微调 RoBERTa 基础模型 Liu 等人 (2019)、RoBERTa 大型模型和 GPT2 中模型 Radford 等人 (2019) 来检验 AutoLoRA 的有效性t1> 自然语言理解(NLU)、自然语言生成(NLG)和序列标记数据集。 我们在附录 B 中详细比较了这两个预训练模型。
Transformer Vaswani 等人 (2017) 模型由多个堆叠的 Transformer 块(层)组成,每个块包含一个多头注意力(MHA)模块和一个全连接神经网络。 MHA模块中的每个头包括查询投影层、键投影层和值投影层。 为了遵守 LoRA 中的标准设置,我们仅选择查询层和值投影层作为可训练的 LoRA 层,而其他层则保持冻结。 RoBERTa-base 和 GPT2-medium 都拥有 12 个 Transformer 层,从而产生 24 个可训练的 LoRA 层。 RoBERTa-large 模型有 24 个 Transformer 层,有 48 个可训练的 LoRA 层。
我们将每层选择变量的初始维度设置为8,即。 LoRA 基线中每层的等级设置为 4,从而产生与 AutoLoRA 中相似数量的可训练参数。 我们使用 AdamW Loshchilov 和 Hutter (2019) 作为 AutoLoRA 和基线方法的优化器。 我们将 NLU 和 NLG 任务的批量大小设置为 16,将序列标记任务的批量大小设置为 32。 我们将公式(4)中优化权重参数 的学习率设为 ,将公式(5)中优化选择变量 的学习率设为 。 所有实验均在 NVIDIA A100 GPU 上进行。 我们的实现基于 Pytorch Paszke 等人 (2019)、HuggingFace Transformers Wolf 等人 (2020) 和 Betty 库 Choe 等人 (2023).
5.2自然语言理解任务实验
我们对通用语言理解评估(GLUE)基准Wang等人(2018)的八个数据集进行了广泛的实验,以评估 AutoLoRA 在 NLU 任务上的性能。 GLUE 基准包含单句分类、句子对分类以及用于语言可接受性评估、情感分析、句子相似度测量和自然语言推理的回归任务。 我们使用准确性作为 SST-2、MRPC、QQP、MNLI、QNLI 和 RTE 任务的评估指标。 我们对 CoLA 任务使用 Matthew 相关性,对 STS-B 任务使用 Spearman 相关性。 由于 GLUE 基准的测试集并未公开,根据之前的研究 Zhang 等人 (2022),我们使用 AutoLoRA 框架在 GLUE 训练集上微调基于 RoBERTa 的模型并对其进行评估在 GLUE 开发套件上。 我们将原始训练集按照 1:1 的比例拆分为新的训练集和验证集,分别用作式中的 和 (4)和方程(5)分别。 请注意,基线方法是在原始训练集上进行训练的,我们的方法不会不公平地使用比基线更多的数据。
| E2E | WebNLG | ||||||||
| Method | Param | BLEU | NIST | MET | ROUGE-L | CIDEr | BLEU | MET | TER |
| Full FT | 354.9M | 68.0 | 8.61 | 46.1 | 69.0 | 2.38 | 46.5 | 38.0 | 0.53 |
| Adapter | 11.1M | 67.0 | 8.50 | 45.2 | 66.9 | 2.31 | 50.2 | 38.0 | 0.46 |
| LoRA | 0.3M | 67.1 | 8.54 | 45.7 | 68.0 | 2.33 | 50.7 | 39.5 | 0.46 |
| AdaLoRA | 0.3M | 67.0 | 8.55 | 45.5 | 68.1 | 2.32 | 50.6 | 39.4 | 0.44 |
| AutoLoRA | 0.3M | 67.9 | 8.68 | 46.0 | 68.9 | 2.37 | 50.8 | 39.6 | 0.44 |
表 1 显示了 AutoLoRA 在 GLUE 开发集上与基线方法相比的性能。 AutoLoRA 在 8 个数据集中的 6 个上实现了最佳性能,并获得了 85.5 的平均性能,优于所有基线方法。 由于 AutoLoRA 的平均性能优于 LoRA,因此我们可以得出结论,AutoLoRA 学习到的最佳排名优于 LoRA 中手动调整的排名。 原因有两个。 首先,AutoLoRA 允许不同的层具有不同的等级,充分考虑到不同层具有不同的属性并且需要具有特定于层的可调参数的事实。 相比之下,LoRA 对所有层统一使用相同的等级,而不考虑层之间的差异。 其次,AutoLoRA 通过梯度下降最大化验证数据的微调性能来学习连续选择变量(决定排名)。 搜索空间是连续的,这允许更全面地探索排名配置。 相比之下,LoRA 在离散空间中手动调整秩,其中秩配置的数量相对有限。
此外,AutoLoRA 的平均性能优于 AdaLoRA 基线。 原因是AdaLoRA使用单个数据集同时学习rank-1矩阵及其重要性分数,这很容易导致过度拟合。 相比之下,我们的方法将训练数据集分成两个不相交的集合,在一组上学习 1 级矩阵,并优化另一组上的选择变量,这对过度拟合更具弹性。
此外,我们还展示了对基于 RoBERTa 的模型进行全面微调的结果。 结果表明,AutoLoRA 的性能与完全微调方法相当,同时使用的参数显着减少。
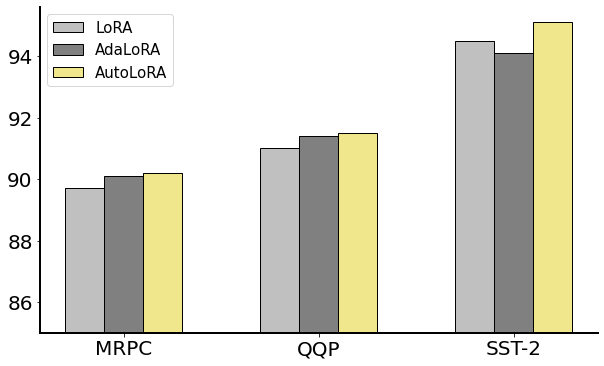
我们进一步检查 AutoLoRA 在更大的预训练模型上的功效。 具体来说,我们应用 AutoLoRA 在 MRPC、QQP 和 SST-2 数据集上微调 RoBERTa 大型模型 Liu 等人 (2019)。 RoBERTa-large 模型包含 3.55 亿个参数,而 RoBERTa-base 模型仅包含 1.25 亿个参数。 如图2所示,AutoLoRA 的性能在所有三个数据集上都超过了两种基线方法,这证明了 AutoLoRA 在微调各种尺寸的预训练模型方面具有强大的有效性。
5.3自然语言生成任务实验
除了 NLU 任务之外,我们还评估了 AutoLoRA 在 NLG 任务中的有效性。 实验在两个数据集上进行:E2E Novikova 等人 (2017) 和 WebNLG Gardent 等人 (2017)。 E2E数据集包含餐厅领域中的大约50,000个数据-句子对。 给定餐厅的数据记录,任务是生成餐厅的文本描述。 WebNLG 数据集包含从 DBpedia 中提取的 10,000 多个数据-句子对。 数据包含格式为(主语、属性、宾语)的三元组,任务是生成文本作为这些三元组的语言表达。 我们使用 BLEU Papineni 等人 (2002)、NIST Lin 和 Och (2004)、METEOR Banerjee 和 Lavie (2005)、ROUGE-L Lin 和 Hovy (2004) 和 CIDEr Vedantam 等人 (2015) 作为 E2E 数据集的评估指标。 对于WebNLG数据集,我们使用BLEU、METEOR和TER Snover等人(2006)作为评估指标。 AutoLoRA 用于微调 GPT 中模型。
| Method | Param | Precision | F1 |
| Full FT | 125.0M | 70.3 | 74.9 |
| Adapter | 0.9M | 66.9 | 71.3 |
| LoRA | 0.3M | 68.5 | 72.2 |
| AdaLoRA | 0.3M | 69.4 | 73.0 |
| AutoLoRA | 0.3M | 70.1 | 74.2 |
| Method | CoLA | SST-2 | MRPC | QQP | MNLI | QNLI | RTE | STS-B | Avg. |
| AutoLoRA (w/o cst.) | 61.0 | 93.7 | 88.5 | 90.0 | 87.2 | 92.1 | 77.5 | 90.5 | 85.1 |
| AutoLoRA (sigmoid) | 59.7 | 94.1 | 88.3 | 89.8 | 86.9 | 92.6 | 75.7 | 90.7 | 84.7 |
| AutoLoRA () | 61.2 | 94.8 | 89.3 | 90.1 | 87.1 | 92.8 | 77.3 | 90.5 | 85.2 |
| AutoLoRA | 61.3 | 94.9 | 89.4 | 90.3 | 87.0 | 92.9 | 77.0 | 90.8 | 85.5 |
5.4序列标记实验
在本节中,我们在序列标记任务上评估 AutoLoRA。 与 GLUE 任务对整个句子进行分类(侧重于捕获全局语义)不同,序列标记对句子中的每个词符进行分类(强调捕获局部上下文)。 实验在 BioNLP Collier and Kim (2004) 数据集上进行,该数据集是包含 DNA、RNA 和蛋白质等生物实体的命名实体识别数据集。 采用F1作为评价指标。 AutoLoRA 用于微调该任务的基于 RoBERTa 的模型。
表3显示了 AutoLoRA 在 BioNLP 测试集上与基线方法相比的性能。 AutoLoRA 在 F1 分数方面优于所有基线方法。 原因分析与5.2类似。 与我们之前关于 NLU 和 NLG 任务的发现一致,AutoLoRA 可以有效地微调序列标记的预训练模型。
5.5消融研究
在本节中,我们进行消融研究以调查我们方法中各个模块的有效性。 这些研究是在 GLUE 基准测试上进行的。
没有限制。
逐元素 Sigmoid。
元学习。
5.6定性分析
图3展示了AutoLoRA针对QQP、MNLI和E2E数据集确定的最佳排名。 对于 QQP 和 MNLI 数据集,我们使用 RoBERTa-base 主干网,而 E2E 数据集则使用 GPT2-medium 主干网。 在此图中,列 对应于预训练模型中的第 个 Transformer 块。 每行对应一个数据集和一个图层类型(查询投影和值投影图层)。 可以看出,AutoLoRA针对不同层学习到的最佳排名具有不同的值。 这与 1 节中讨论的假设一致,即不同层需要不同的矩阵秩。 Vanilla LoRA 忽略了这种差异,并在各层之间统一使用相同的等级,这导致性能较差。 我们的方法提供了一种计算有效的机制来学习这些特定于层的排名,这比网格搜索花费的时间少得多(如第 5.7 节所示)。
5.7计算成本
| Method | AdaLoRA | LoRA+Grid Search | AutoLoRA |
| Cost | x1 | x14.29 | x1.91 |
表 5 显示了 AutoLoRA 和两种基线方法在 SST-2、MNLI 和 QQP 数据集上的平均训练成本。 我们将AdaLoRA的平均训练时间标准化为1以供参考。 在LoRA中,我们使用网格搜索来调整排名,有16种配置。 可以看出,我们的方法比在 LoRA 中执行排名网格搜索要高效得多。 网格搜索是在离散空间中进行的。 对于每一个rank的配置,LoRA都需要从头开始运行,这是非常耗时的。 相比之下,我们的方法通过梯度方法在连续空间中执行搜索,可以有效地探索许多配置而无需重新启动。 与 AdaLoRA 相比,我们的方法具有明显更好的性能,如表 1、2 和 3 所示,并且没有大幅增加计算成本。
6 结论和未来的工作
在本文中,我们介绍了 AutoLoRA,这是一种基于元学习的框架,旨在自动搜索 LoRA 层的最佳排名。 我们的方法将 LoRA 更新中的每个 Rank-1 矩阵与选择变量相关联,并将排名调整问题表述为通过元学习优化选择变量。 应用阈值从连续选择变量中导出离散等级值,并执行重新训练以弥补阈值带来的差距。 综合实验显示了 AutoLoRA 在各种 NLP 任务中的功效。
与LoRA方法类似,AutoLoRA中的LoRA层是手动指定的,这可能不是最优的。 作为未来的工作,我们将通过开发类似于等式(5)中的元学习框架来研究如何自动选择 LoRA 层。
7 限制
与 AdaLoRA 等其他排名搜索技术相比,我们的方法确实引入了一些额外的计算和内存开销。 然而,如表5所示,训练成本的增加相对较小。 另一个限制是我们没有在最近的大型语言模型(大语言模型)上评估我们的方法,例如 LLaMA Touvron 等人 (2023a) 和 LLaMA-2 Touvron 等人 (2023b) )。 在这些大语言模型上应用 AutoLoRA 是有希望的,因为它们比以前的模型更强大。 我们也没有在非英语文本上预训练的大语言模型上评估我们的方法。 我们的目标是在未来的研究中解决这些局限性。
参考
- Aghajanyan et al. (2021) Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319–7328, Online. Association for Computational Linguistics.
- Banerjee and Lavie (2005) Satanjeev Banerjee and Alon Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65–72, Ann Arbor, Michigan. Association for Computational Linguistics.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Choe et al. (2023) Sang Keun Choe, Willie Neiswanger, Pengtao Xie, and Eric Xing. 2023. Betty: An automatic differentiation library for multilevel optimization. In The Eleventh International Conference on Learning Representations.
- Collier and Kim (2004) Nigel Collier and Jin-Dong Kim. 2004. Introduction to the bio-entity recognition task at JNLPBA. In Proceedings of the International Joint Workshop on Natural Language Processing in Biomedicine and its Applications (NLPBA/BioNLP), pages 73–78, Geneva, Switzerland. COLING.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1126–1135. PMLR.
- Gardent et al. (2017) Claire Gardent, Anastasia Shimorina, Shashi Narayan, and Laura Perez-Beltrachini. 2017. The WebNLG challenge: Generating text from RDF data. In Proceedings of the 10th International Conference on Natural Language Generation, pages 124–133, Santiago de Compostela, Spain. Association for Computational Linguistics.
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2790–2799. PMLR.
- Hu et al. (2022) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In ICLR.
- Hutter et al. (2011) Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. 2011. Sequential model-based optimization for general algorithm configuration. In Learning and Intelligent Optimization, pages 507–523, Berlin, Heidelberg. Springer Berlin Heidelberg.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online. Association for Computational Linguistics.
- Li et al. (2018) Zhenguo Li, Fuxin Zhou, Fei Chen, and Hang Li. 2018. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv preprint arXiv:1707.09835.
- Lin and Hovy (2004) Chin-Yew Lin and Eduard Hovy. 2004. Rouge: A package for automatic evaluation of summaries. In Workshop on Text Summarization Branches Out, Association for Computational Linguistics.
- Lin and Och (2004) Chin-Yew Lin and Franz Josef Och. 2004. Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL-04), pages 605–612, Barcelona, Spain.
- Lindauer et al. (2022) Marius Lindauer, Katharina Eggensperger, Matthias Feurer, André Biedenkapp, Difan Deng, Carolin Benjamins, Tim Ruhkopf, René Sass, and Frank Hutter. 2022. Smac3: A versatile bayesian optimization package for hyperparameter optimization. Journal of Machine Learning Research, 23(54):1–9.
- Liu et al. (2022) Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin Raffel. 2022. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. arXiv preprint arXiv:2205.05638.
- Liu et al. (2023) Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2023. Gpt understands, too. AI Open.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. ArXiv, abs/1907.11692.
- Loshchilov and Hutter (2019) Ilya Loshchilov and Frank Hutter. 2019. Decoupled weight decay regularization. In International Conference on Learning Representations.
- Maclaurin et al. (2015) Dougal Maclaurin, David Duvenaud, and Ryan P. Adams. 2015. Gradient-based hyperparameter optimization through reversible learning. In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, ICML’15, page 2113–2122. JMLR.org.
- mahabadi et al. (2021) Rabeeh Karimi mahabadi, James Henderson, and Sebastian Ruder. 2021. Compacter: Efficient low-rank hypercomplex adapter layers. In Advances in Neural Information Processing Systems.
- Nichol et al. (2018) Alex Nichol, Joshua Achiam, and John Schulman. 2018. On first-order meta-learning algorithms. arXiv preprint arXiv:1803.02999.
- Novikova et al. (2017) Jekaterina Novikova, Ondřej Dušek, and Verena Rieser. 2017. The E2E dataset: New challenges for end-to-end generation. In Proceedings of the 18th Annual SIGdial Meeting on Discourse and Dialogue, pages 201–206, Saarbrücken, Germany. Association for Computational Linguistics.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, page 311–318, USA. Association for Computational Linguistics.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. 2019. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Curran Associates Inc., Red Hook, NY, USA.
- Radev et al. (2020) Dragomir Radev, Ramesh Narasimhan, Ruochen Tang, Abhinand Sivaprasad, Xiangkai Zhang, Amr Saleh, Neha Krishnaswamy, Balazs Gliwa, Yunyao Qiu, Haoran Tang, Yash Vyas, and Rahul Nallapati. 2020. Dart: Open-domain structured data record to text generation. In Proceedings of the 28th International Conference on Computational Linguistics, pages 7492–7503.
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
- Snover et al. (2006) Matthew Snover, Bonnie Dorr, Richard Schwartz, Linnea Micciulla, and John Makhoul. 2006. Translation edit rate: A new metric for machine translation evaluation. In Proceedings of the Association for Machine Translation in the Americas (AMTA).
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open and efficient foundation language models.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023b. Llama 2: Open foundation and fine-tuned chat models.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Vedantam et al. (2015) Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. 2015. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belgium. Association for Computational Linguistics.
- Watanabe et al. (2023) S. Watanabe, A. Bansal, and F. Hutter. 2023. PED-ANOVA: Efficiently quantifying hyperparameter importance in arbitrary subspaces. International Joint Conference on Artificial Intelligence.
- Watanabe and Hutter (2023) S. Watanabe and F. Hutter. 2023. c-TPE: Tree-structured Parzen estimator with inequality constraints for expensive hyperparameter optimization. International Joint Conference on Artificial Intelligence.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online. Association for Computational Linguistics.
- Zhang et al. (2021) Aston Zhang, Yi Tay, SHUAI Zhang, Alvin Chan, Anh Tuan Luu, Siu Hui, and Jie Fu. 2021. Beyond fully-connected layers with quaternions: Parameterization of hypercomplex multiplications with $1/n$ parameters. In International Conference on Learning Representations.
- Zhang et al. (2022) Haojie Zhang, Ge Li, Jia Li, Zhongjin Zhang, YUQI ZHU, and Zhi Jin. 2022. Fine-tuning pre-trained language models effectively by optimizing subnetworks adaptively. In Advances in Neural Information Processing Systems.
- Zhang et al. (2023a) Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. 2023a. Adaptive budget allocation for parameter-efficient fine-tuning. In ICLR.
- Zhang et al. (2023b) Renrui Zhang, Jiaming Han, Chris Liu, Peng Gao, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, and Yu Qiao. 2023b. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199.
附录A数据集
| CoLA | RTE | QNLI | STS-B | MRPC | WNLI | SST-2 | MNLI (m/mm) | QQP | |
| Train | 8551 | 2490 | 104743 | 5749 | 3668 | 635 | 67349 | 392702 | 363871 |
| Dev | 1043 | 277 | 5463 | 1500 | 408 | 71 | 872 | 9815/9832 | 40432 |
表6显示了 GLUE 数据集的统计信息。
附录B预训练模型
RoBERTa 预训练了一个 Transformer 编码器,与 BERT Devlin 等人 (2019) 中的相同。 GPT2 模型预训练 Transformer 解码器。 RoBERTa 模型是通过屏蔽词符预测进行预训练的。 GPT2 模型是通过语言建模进行预训练的。 RoBERTa 通常用于自然语言理解 (NLU) 任务,而 GPT2 通常用于自然语言生成 (NLG) 任务。
附录C超参数优化
足够的超参数配置对于机器学习算法实现最佳性能至关重要。 与网格搜索和简单随机搜索相比,贝叶斯优化(BO)Lindauer等人(2022)和基于梯度的超参数优化Maclaurin等人(2015)已得到广泛应用因为他们的样本效率。 例如,SMAC Hutter 等人 (2011) 构建了一个概率模型来估计不同超参数配置的性能。 它依次选择下一组要评估的超参数,并使用预定义的获取函数来平衡超参数空间中的探索与利用。 SMAC3 Lindauer 等人 (2022) 通过使用更少的实例评估前景较差的超参数配置来改进 SMAC。 c-TPE Watanabe 和 Hutter (2023) 提出了一种受约束的树结构 Parzen 估计器来处理超参数配置的内存消耗和推理延迟等约束。 PED-ANOVA Watanabe 等人 (2023) 强调了良好的超参数搜索空间在超参数优化中的作用。 它推导出一种用皮尔逊散度计算超参数重要性的算法。 另一方面,Maclaurin等人(2015)计算了超参数的梯度,并提出了一种有效的方法来存储相关信息。