附录 参考
BEHAVIOR-1K:一个以人为本的具身人工智能基准,包含 1,000 种日常生活活动和逼真的模拟
摘要
我们提出了 BEHAVIOR-1K,这是一个面向以人为本的机器人技术的综合模拟基准。 BEHAVIOR-1K 包含两个部分,由一项关于“ 你希望机器人为你做什么? ”的广泛调查结果引导和驱动。 首先是定义 1,000 种日常生活活动,这些活动建立在 50 个场景(房屋、花园、餐厅、办公室等)的基础上,其中有超过 9,000 个物体被标注了丰富的物理和语义属性。 其次是 OmniGibson,一个新颖的模拟环境,通过逼真的刚体、可变形物体和液体的物理模拟和渲染来支持这些活动。 我们的实验表明,BEHAVIOR-1K 中的活动是长期的,并且依赖于复杂的操作技能,这两种都对最先进的机器人学习解决方案构成了挑战。 为了校准 BEHAVIOR-1K 的模拟到现实的差距,我们提供了一个初步研究,将使用移动机械手在模拟公寓中学习到的解决方案转移到其真实世界的对应物。 我们希望 BEHAVIOR-1K 的以人为本的本质、多样性和真实性使其成为具身人工智能和机器人学习研究的宝贵资源。 项目网站:https://behavior.stanford.edu。
† †* 表示同等贡献联系方式:{chengshu,zharu,jdwong,cgokmen,sanjana2}@stanford.edu
关键词: 具身 AI 基准,日常活动,移动操作
1 简介
受计算机视觉[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] 和自然语言处理[12, 13, 14, 15, 16] 领域取得的进展的启发,机器人学界在模拟[17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30] 中开发了多个基准。 这些基准的总体目标是促进通用、有效的机器人的发展,这些机器人能为人们的日常生活带来重大益处——以人为本的 AI,即“服务于人类需求、目标和价值观”[31, 32, 33, 34]。 尽管这些基准很有启发性,但它们中的任务和活动是由研究人员设计的;目前尚不清楚它们是否在解决人类的实际需求。
我们观察到,以人为本的机器人基准不仅应该为人类需求而设计,而且应该从人类需求中起源: 人们希望机器人为他们做哪些日常活动? 为此,我们对 1,461 名参与者进行了广泛的调查(参见第 2 节),对各种日常活动进行排名,以衡量参与者将这些活动委托给机器人的意愿。 我们还请非专业标注员提供这些活动的定义。 调查揭示了人们希望机器人执行的活动具有一定规律性,但更重要的是,突出了我们在设计机器人基准时应优先考虑的两个关键因素:场景、物体和活动类型的多样性,以及底层模拟环境的真实性。
调查显示,最需要的活动范围从“清洗地板”到“清洁浴缸”。显然,这些活动的多样性远远超出了现实世界的机器人挑战可能提供的范围[35,36,37,38, 39、40、41、42]。 开发模拟环境是一个自然的替代方案:可以在多种场景、物体和条件下高效、安全地训练和测试机器人代理,执行各种活动。 但是,要使这种范式有效,必须真实地模拟这些活动,准确地再现机器人可能在现实世界中遇到的情况。 尽管在特定领域[43, 44, 45]取得了重大进展,但在各种活动中实现真实性仍然是一个巨大的挑战,因为需要付出大量努力才能提供逼真的模型和模拟功能。
在这项工作中,我们介绍了BEHAVIOR-1K,这是一个在虚拟、交互式和生态环境中包含 1,000 个日常家庭活动的基准——这是 BEHAVIOR-100[27] 的下一代。 BEHAVIOR-1K 包含两个新颖的组件来满足对多样性和真实性的需求:多样化的BEHAVIOR-1K 数据集 和逼真的OmniGibson 模拟环境。 BEHAVIOR-1K 数据集 是一个大型数据集,包含 1) 针对 1,000 种活动的常识知识库,其中包含谓词逻辑定义(初始条件和目标条件),以及涉及的对象、它们的属性和状态转换,以及 2) 高质量的 3D 资产,包括 50 个场景和 9,000 多个具有丰富物理和语义注释的对象模型。
BEHAVIOR-1K 数据集 中的所有活动都在一个新的模拟环境 OmniGibson 中实例化,我们是在 Nvidia 的 Omniverse 和 PhysX 5 [46] 之上构建的,以提供刚体、可变形物体和流体的真实物理模拟和渲染。 OmniGibson 在 Omniverse 的功能基础上扩展了温度、切换、浸泡和脏污等一系列扩展对象状态。 它还包括生成有效的初始活动配置和基于活动定义区分有效目标解决方案的功能。 凭借所有这些逼真的模拟功能,OmniGibson 支持 BEHAVIOR-1K 数据集 中的 1,000 种不同活动。
我们评估了最先进的强化学习算法 [47, 48] 在 BEHAVIOR-1K 的几个活动中,既有原始动作空间中的视觉运动控制,也有利用基于采样的运动规划 [49] 的动作基元。 我们的分析表明,即使是 BEHAVIOR-1K 中的单一活动,对于当前的 AI 算法来说也是极具挑战性的,而基准只能在注入大量领域知识的情况下才能解决它。 具体来说,困难部分源于 BEHAVIOR-1K 活动的长度和所需物理操作的复杂性。 为了校准 BEHAVIOR-1K 的模拟到现实的差距,我们提供了一项初步研究,将使用移动机械手在模拟公寓中学习的解决方案转移到其实际世界的对应物。 我们希望 BEHAVIOR-1K 基准、我们的调查和我们的分析将有助于支持和指导未来具身 AI 代理和机器人的开发。
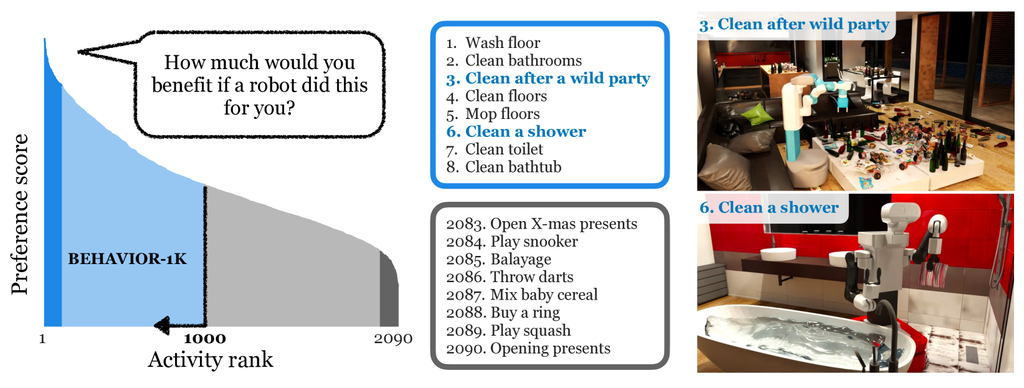
2 创建以人类需求为基础的基准:一项调查研究
大量的机器人研究都渴望满足人类的需求,但这些需求通常是假设或推测的。 以人为本的开发需要关于人类希望从自主代理中获得什么的直接信息[31]。 为了创建一个反映这些需求的基准,我们对美国普通人口进行了调查,询问: 你希望机器人为你做什么? 调查从时间利用调查[50, 51, 52]中获得了约 2,000 个活动,这些调查记录了人们如何花费时间,以及来自 WikiHow 文章[53]。 我们在 Amazon Mechanical Turk 上进行调查,共有 1,461 名受访者(人口统计信息见附录A.3),每个活动有 50 个 10 分制李克特量表响应。
调查结果总结在图1(左)中,我们根据人类偏好评分对活动进行排名。 活动的完整排名列表可以在我们的网站上找到。 分布显示出较大的统计分散性(基尼指数):人类希望机器人执行各种各样的活动,从清洁杂务到烹饪大型宴会。 像“擦洗浴室地板”这样的繁琐任务得分最高,而像游戏这样的娱乐活动得分最低。 在许多其他类别中,大约有 200 个清洁活动和 200 多个烹饪活动。
BEHAVIOR-1K 活动包括 909 个人类偏好评分最高的活动和来自 BEHAVIOR-100[27]的 91 个活动,总共 1,000 个排名最高的活动。 BEHAVIOR-1K 从其他具身 AI 基准中脱颖而出,因为它来自时间利用调查,并使用调查数据优先考虑人类认为最重要和最有用的活动,并包含一套极其多样化的活动。
3 相关工作:具身 AI 基准
| 行为-1K | 行为-100 | AI2THOR 视觉 房间重新布置 | TDW 运输 | 重新布置 T5 (Habitat) | ManipulaTHOR 臂点导航 | 交互式 Gibson 基准 | 虚拟家庭 | 阿尔弗雷德 | 栖息地2.0HAB | SAPIEN 玛尼技能 | 观看和帮助 | 射频宇宙 | 重新布置 T2 (OCRTOC) | 宜家家具组装 | RLBench | 元世界 | 机器人套件 | 软体健身房 | DeepMind 控制套件 | 开放人工智能健身房 | 栖息地1.0 | 吉布森 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mobile manipulation | Static manipulation | Navigation | ||||||||||||||||||||||||
|
||||||||||||||||||||||||||
|
1000 | 100 | 1 | 1 | 1 | 1 | 2 | 549 | 7 | 3 | 4 | 5 | 5 | 5 | 100 | 50 | 1 | 5 | 10 | 28 | 8 | 2 | 3 | |||
|
8 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |||
| Scenes / rooms | 50/373 | 15/100 | -/120 | 15/105 | 55 static/- | -/30 | 10/- | 6/24 | -/120 | 1/6 | 1/- | 7/29 | Gibson | 1/- | 1/- | 1/- | 1/- | 1/- | 1/- | 1/- | 1/- | HM3D | 572 static | |||
| Diversity |
|
1949 | 391 | 118 | 50 | YCB | 150 | 5 | 308 | 84 | 41+YCB | 4 | 117 | UNK | 12+YCB | 73+ | 28 | 7 | 10 | 4 | 4 | 4 | Mtpt. | N/A | ||
|
9318 | 1217 | 118 | 112 | YCB | 150 | 152 | UNK | 84 | 92+YCB | 162 | UNK | UNK | 101+YCB | 73+ | 28 | 80 | 10 | 4 | 4 | 4 | N/A | N/A | |||
|
3-47 | 3-34 | 5 | 7-9 | 2-5 | 2-3 | 10 | 1-24 | 2 | 5 | 1 | 2-8 | 1-6 | 5-10 | 1-2 | 1-2 | 1 | 1-3 | 1-3 | 1-3 | 1 | 0-1 | N/A | |||
|
2-11 | 2-8 | 4 | 4 | 4 | 2 | 1-3 | 1-7 | 2-3 | 1-2 | 1 | 1-3 | 1 | 1 | 1-3 | 1-4 | 4 | 1 | 1-3 | 1-2 | 1-2 | 1 | 1 | |||
|
N/A | N/A | ||||||||||||||||||||||||
|
- | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | ||||||||||
|
||||||||||||||||||||||||||
| Realism |
|
|||||||||||||||||||||||||
|
||||||||||||||||||||||||||
|
||||||||||||||||||||||||||
|
||||||||||||||||||||||||||
|
||||||||||||||||||||||||||
|
||||||||||||||||||||||||||
|
TP+C | TP+C | TP | TP+C | TP+C | TP+C | C | TP | TP | TP+C | C | TP | TP+C | TP+C | C | TP+C | C | C | C | C | C | C | C | |||
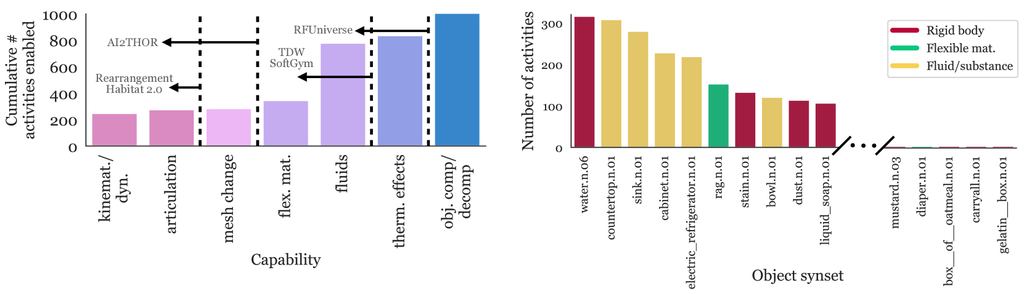
我们在表 1 中对 BEHAVIOR-1K 和其他嵌入式人工智能基准进行了广泛的比较,这些基准是在模拟中进行的 [17, 18, 19, 20, 21, 22, 23, 24, 25, 26]。 我们包括了有助于多样性和真实性的许多因素,并观察到 BEHAVIOR-1K 取得了重大进步。 首先,没有其他基准将其活动集建立在普通人的需求之上。 其他基准通常针对一组相对有限的活动,并且它们的模拟器仅在与这些任务相关的方面上是现实的。 事实上,我们经常观察到多样性与现实性的权衡。 例如,指令遵循基准,例如 VirtualHome [20] 和 ALFRED [20, 21] 在场景、物体和状态变化的数量上是多样的,但提供了有限的低级物理现实性。 另一方面,家庭重新布置基准,例如 Habitat 2.0 HAB [26]、TDW Transport [19] 和 SAPIEN ManiSkill [54, 55] 支持逼真的动作执行和刚体的精确物理模拟,但只包括少数任务。 同样,SoftGym [45] 和 RFUniverse [56] 具有与 OmniGibson 最接近的模拟功能,因此现实性更高,但它们也缺乏支持人类为中心的通用机器人开发所需的任务多样性。
与我们最相似的基准是上一代的 BEHAVIOR-100 [27]。 BEHAVIOR-100 推出了我们继承到 BEHAVIOR-1K 中的一些有益的设计选择,例如活动来源 (ATUS [50])、活动定义逻辑语言和评估指标。 然而,它在支持人类为中心的具身 AI 模拟基准所需的现实性和多样性方面存在不足,BEHAVIOR-1K 在这些方面实现了无与伦比的水平。 虽然 BEHAVIOR-100 包含 100 个由研究人员选择的活动,但我们的 BEHAVIOR-1K 通过一个数量级将多样性提升到 1,000 个活动,这些活动得益于我们独特的调查,这些活动以人类需求为基础。 此外,BEHAVIOR-100 仅包含 15 个场景(所有房屋)和 300 多个物体类别,而 BEHAVIOR-1K 增加到 50 个场景(房屋、商店、餐厅、办公室等)和 1,900 多个物体类别。 在现实性方面,BEHAVIOR-1K 通过 OmniGibson 扩展了可模拟的物理状态和过程:流体、柔性材料、混合物质等。 OmniGibson 为 BEHAVIOR-1K 渲染实现的现实性也明显高于 BEHAVIOR-100 和其他基准(参见图 3)。
4 BEHAVIOR-1K 数据集

一旦活动来源反映了人类需求,就需要在现实世界中以它们发生的方式进行具体定义和实例化。 我们构建了BEHAVIOR-1K 数据集,其中包括一个包含相关物体和物体状态的众包活动定义知识库,以及一个大型高质量交互式 3D 模型存储库。
我们通过众包的方式以 BEHAVIOR 领域定义语言 (BDDL) 的形式对活动进行具体定义 [27]。 BDDL 基于谓词逻辑,旨在让外行能够描述给定活动具体的初始条件和目标条件。 与几何、图像/视频或经验目标规范 [17, 18] 不同,BDDL 定义以物体和物体状态的形式存在,允许标注者在直观的语义级别进行定义。 语义符号还捕获了这样一个事实:多个物理状态可能是活动有效的初始化和解决方案。 参见附录中的清单 1、2 和 3 作为示例定义。
活动定义所构建的物体和物体状态空间被标注为具有生态学上的可能性。 物体空间源于 1,000 个活动的 5,000 篇 WikiHow 文章,并映射到 2,964 个来自 WordNet [57] 或自定义设计的叶子级同义词集。 通过众包工人、学生和 GPT-3 [58],我们还将每个物体与我们完全可模拟的物体状态相关联:例如,苹果 与 煮熟的 和 切片的 相关联,但不与 开启的 相关联。 许多物体属性对都通过参数进行增强,例如“苹果的煮熟温度”,利用了 OmniGibson 的连续扩展状态,使活动特别逼真。 最后,标注者和研究人员还创建了转换规则,例如将西红柿和盐变成酱汁,或者需要砂纸去除锈迹。 结果是一个知识库,其中包含数万个元素,这些元素是 1000 个生态学上合理的活动定义的基础。 我们通过让五位经验丰富的机器学习标注者验证所有类型的标注的子集,并获得极高的批准率 (96.8%) 来确保标注质量。 有关知识库的更多详细信息,请参见附录 B。
5 OmniGibson: 使用逼真的模拟实例化 BEHAVIOR-1K





BEHAVIOR-100 在 iGibson 2.0 [59] 中实现;然而,对 BEHAVIOR-1K 中各种活动的逼真模拟超出了 iGibson 2.0 的能力。 我们提出了一个新的模拟环境 OmniGibson,它提供了支持和实例化 BEHAVIOR-1K 所需的功能。 OmniGibson 建立在 Nvidia Omniverse 和 PhysX 5 之上,不仅模拟刚性物体,还模拟可变形物体、流体和柔性材料(参见图 4),同时生成高度逼真的光线追踪或路径追踪虚拟图像(参见图 3)。 这些特性显著提高了 BEHAVIOR-1K 与其他基准相比的真实度。
与 BEHAVIOR-100 相似,OmniGibson 还基于启发式方法(例如,当靠近一个打开的热源时,温度会升高)模拟了其他非运动学扩展物体状态(例如,温度、浸泡水平)。 OmniGibson 还实现了生成无限有效的物理配置的功能,这些配置满足活动的初始条件作为逻辑谓词(例如,食物 是 冷冻的),并基于物体的物理状态(姿态和关节配置)和扩展状态评估其目标条件(例如,食物 是 煮熟的 并且在 上面 一个 盘子,布 是 折叠的)。 奥姆吉布森 在场景初始化期间原生支持随机化,并且可以在物体模型及其姿态/状态之间进行采样。 OmniGibson 支持的扩展对象状态和逻辑谓词的完整细节可以在附录 E.1 中找到。
许多日常任务难以模拟,因为它们需要对复杂物理过程进行建模,例如折叠毛巾或倒一杯水。 OmniGibson 通过支持对流体、可变形物体和布料的逼真模拟来解锁它们(见图 2)。 事实上,如果没有这些功能,超过一半的 BEHAVIOR-1K 活动将无法模拟,这突出了这些功能对于捕捉日常活动的重要性。 OmniGibson 还捕捉了 Omniverse 本身无法模拟的多种物理过程,例如烤馅饼或将蔬菜泥。 除了上面提到的扩展状态外,我们还设计了一个模块化的 Transition Machine,它在满足特定条件时指定对象组之间的自定义转换。 例如,当放入烤箱中的面团达到一定温度阈值时,它会变成馅饼。 这进一步扩展了 OmniGibson 模拟复杂、逼真的活动的能力,而这些活动原本在物理上是无法完全模拟的。
6 实验: 在 BEHAVIOR-1K 中评估具身人工智能解决方案
在我们的实验中,我们旨在回答三个问题:现有的基于视觉的机器人学习算法在 BEHAVIOR-1K 中的表现如何,以及需要做出哪些假设才能提高它们的成功率? 当前 AI 对哪些活动元素最为棘手? BEHAVIOR-1K/OmniGibson 中模拟与现实差距的主要来源是什么? 我们的目标是指出有希望的研究方向,以提高 AI 在模拟中以及最终在现实世界中执行 BEHAVIOR-1K 活动的表现。
6.1 在 OmniGibson 中评估 BEHAVIOR-1K 解决方案
实验设置。
我们为我们的实验选择了三个典型的活动:CollectTrash,其中智能体收集空瓶和杯子,并将它们扔进垃圾桶(刚体操作);StoreDecoration,其中智能体将物品存放在抽屉里(铰接物体操作);以及 CleanTable,其中智能体用浸湿的布擦拭脏桌子(柔性材料和流体的操作)。 我们根据最先进的强化学习算法(RL)[60]评估了三种不同的基线:
-
•
RL-VMC,一种基于 Soft Actor-Critic (SAC)[48] 的视觉运动控制(从图像到低级关节命令)RL 解决方案;
-
•
RL-Prim.,一种基于 PPO[47] 的 RL 解决方案,它利用一组基于采样运动规划器[61, 62, 49] 的动作原语(pick、place、push、navigate、dip 和 wipe)。 该策略输出应用于物体的原语的离散选择;
-
•
RL-Prim.Hist.,RL-Prim. 的一个变体。 它将历史观察(3 步)作为附加输入,以帮助解开外观相似的状态。
所有智能体都使用稀疏的任务成功奖励进行训练,没有任何奖励工程。 遵循 BEHAVIOR-100[27] 中提出的指标,我们在表2 和4 中报告了成功率和效率指标(行驶距离、投入时间和造成的混乱),以及附录中表A.13 中的成功分数 Q。
| Method | Policy Features | Task success rate | |||
|---|---|---|---|---|---|
| Primitives | History | StoreDecoration | CollectTrash | CleanTable | |
| RL-VMC | |||||
| RL-Prim. | |||||
| RL-Prim.Hist. | |||||
结果:任务完成情况。
表 2 包含我们基线方法的任务成功率。 我们活动中极长的时域会导致视觉运动控制(RL-VMC)策略在所有三个活动中失败,这可能是由于信用分配 [65]、深度探索 [66, 67] 和消失梯度 [68] 等问题,如先前工作所报道。 我们使用时间扩展动作原语的基线(RL-Prim. 和 RL-Prim.Hist.) 取得了更好的成功,在所有三个活动中实现了超过 40% 的成功率。 我们观察到,更长期的活动更具挑战性:虽然 CleanTable 可以通过执行 6 个基本步骤的最佳序列来完成,但 CollectTrash 至少需要 。 这支持了这样的观点,即为了解决 BEHAVIOR-1K 的长期活动,必须采用某种形式的动作空间抽象,正如其他人所报道的那样 [27, 26, 69]。 在分析记忆的作用时,我们观察到 RL-Prim 取得了显著的性能提升。 相对于 RL-Prim.Hist.,尤其是在像 CollectTrash 这样的具有混淆观察结果的长期活动中。 在这项任务中,当机器人正在观察垃圾桶时,它需要额外的信息来了解哪些位置已经被清理过,以便继续前往其他位置。 我们的结果表明,在 BEHAVIOR-1K 的长期活动中,记忆对于具身 AI 将发挥至关重要的作用。
结果:效率。
除了成功之外,效率在具身 AI 的评估中也是至关重要的:如果一项成功的策略在模拟中需要很长时间或浪费太多能量,它在现实世界中可能是不可行的。 在表 4 中,我们报告了 Srivastava 等人提出的三个效率指标的结果 [27]。 我们观察到,使用记忆 (RL-Prim.Hist.) 提高了所有指标的效率:导航距离 (Dist. Nav. )、模拟时间 (Sim. Time) 和运动学对象混乱 (Kin. Dis. ),即由于机器人运动导致的对象位移量。
我们还评估了我们在训练期间引入的物理和驱动 (抓取、运动执行) 简化在多大程度上影响了 RL-Prim 的性能。 在评估时,当这些简化被移除时。 我们在表 4 中报告了结果。 我们观察到,在评估期间启用完全基于物理的抓取后,性能大幅下降。 因此,抓取是任何具身 AI 任务的关键组成部分,研究人员在训练期间简化其执行时应谨慎。 虽然 OmniGibson 支持完全基于物理的抓取,但为任意物体设计一个利用完全基于物理的抓取的 pick 动作原语本身就是一个开放的研究问题,我们留待未来工作。 相比之下,在评估期间启用完整的轨迹运动执行后,性能下降幅度要小得多。 此结果支持我们的假设,即通过假设运动规划在评估期间很可能提供可行的自由空间路径来加速训练过程是合理的。
| Method | Metrics in CollectTrash | ||
|---|---|---|---|
| Dist. Nav. [m] | Sim. Time [s] | Kin. Dis. [m] | |
| RL-VMC | |||
| RL-Prim. | |||
| RL-Prim.Hist. | |||
| Phys. Realism | Task success rate | |||
|---|---|---|---|---|
| Grasping | Full Motion | StoreDecoration | CollectTrash | CleanTable |
6.2 在真实机器人上评估 BEHAVIOR-1K 解决方案


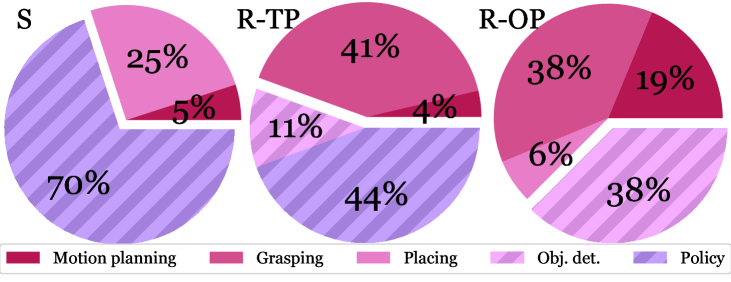
我们使用真实机器人进行了一系列实验来回答这个问题: 我们现实的模拟和真实世界之间主要的差异来源是什么? 为此,我们使用了模拟场景的真实世界对应场景,即模型公寓,用于 CollectTrash 活动。 我们扫描了公寓,并将其转换为虚拟的交互式场景。 我们使用真实的双臂移动机械手 Tiago,并利用其机载传感器获取的 RGB-D 图像和 YOLOv3 对象检测器 [70, 71] 在 3D 空间中定位物体,以便进行操作。 为了导航,机器人使用基于两个 LiDAR 传感器和公寓地图的粒子滤波器 [72] 进行定位。 动作基元是使用与模拟中相同的基于采样的运动规划算法 [62, 49] 实现的,并进行了额外的调整。 我们评估了两种在现实世界中选择动作原语的策略:一种基于人工输入的最优策略,以及一种基于视觉的策略(RL-Prim。) 在 OmniGibson 中训练。 为了促进模拟到现实的迁移,在训练过程中,我们还根据先前的工作 [73] 对观测结果应用了基于图像的数据增强(有关更多详细信息,请参见附录 G)。 使用最优策略,我们评估了模拟机器人和真实机器人之间驱动方式的差距;使用学习策略,我们还评估了视觉感知的差距。 我们在模拟(50 次运行,40% 成功率)和现实世界中分别使用最优策略(27 次运行,22% 成功率)和训练策略(26 次运行,0% 成功率)实现了不同的成功率,这暗示了模拟与现实之间的差距,我们将在下面进行分析。
图 5(右侧)展示了失败案例。 我们观察到,模拟中大多数失败是由于视觉策略(感知)造成的,而其他失败是由 place 原语中的随机性和基于采样的运动规划器造成的。 由于我们在模拟中使用辅助的 pick 原语进行评估,因此没有一个失败是由于抓取造成的。 抓取在现实世界中相当困难,对于训练策略和最优策略,它导致了约 40% 的失败。 对于学习策略,44% 的错误是由视觉策略选择错误的动作原语造成的,这是由于模拟图像和真实图像之间的差异造成的。 视觉差异源于未建模的影响,例如真实摄像头的动态范围较差(参见图 5,左侧和中间)以及物体建模不完善(例如,桌子上的精确木纹和表面反射率),这可以通过更具针对性的领域随机化来缓解。 有趣的是,真实机器人上的一些操作失败是由不利的机器人底座放置造成的,这是由于前一时间步的导航不准确导致的。 这种复合的错误来源在模拟中不存在,因为我们假设完美的位置定位和执行。
我们相信,这项分析提供了有关 OmniGibson 中 BEHAVIOR-1K 的模拟与现实差距的主要来源和严重程度的相关信息,并为未来的研究方向提供了见解。 我们的计划是利用这些见解中的一些来创建新颖的模拟到现实的解决方案,以在 BEHAVIOR-1K 上取得进展。
7 讨论和局限性
我们提出了 BEHAVIOR-1K,一个用于具身人工智能和机器人研究的基准,它基于人类需求,对 1000 种不同的活动进行了真实的模拟。 BEHAVIOR-1K 包含两个要素:BEHAVIOR-1K 数据集,一个关于日常活动的语义知识库,以及一个大型 3D 模型库;OmniGibson,一个提供刚体/可变形物体、柔性材料和流体的逼真渲染和物理模拟的环境。 在我们的评估中,我们观察到 BEHAVIOR-1K 是一个极具挑战性的基准:自主地解决这 1000 项活动超出了目前最先进的人工智能算法的能力。 我们研究并尝试使用动作原语来解决一些活动,以便深入了解最具挑战性的组成部分,为其他研究人员在我们基准上进行研究提供起点。 同样地,我们通过创建一个真实世界模拟公寓的数字孪生,以及通过使用模拟和真实移动机械臂在模拟和真实世界中对策略进行严格的评估和分析,探索了模拟-真实差距的来源。
限制:
我们继承了来自我们底层物理和渲染引擎英伟达 Omniverse 的一些限制。 在 OmniGibson 中,我们将渲染速度与视觉真实感(光线追踪)进行权衡,对于大约 60 个物体的房屋场景,达到约 60 fps(与 iGibson 2.0 中的约 100 fps 相比 [59])。 我们正在积极进行性能优化。 另一个限制是我们只包含不需要与人类交互的活动。 人类(行为、运动、外观)的真实模拟非常具有挑战性,是一个开放的研究领域。 我们计划在技术成熟后包含模拟人类。 最后,OmniGibson 仍然有改进的空间,以便进一步促进 sim2real 转移,例如将感知和致动的噪声模型纳入其中。
致谢
这项工作部分是在李成书、王约书亚和迈克尔·林格尔巴赫在英伟达研究院实习期间完成的。 这项工作部分由斯坦福以人为本的人工智能研究所 (HAI)、丰田研究院 (TRI)、NSF CCRI #2120095、NSF RI #2211258、NSF NRI #2024247、ONR MURI N00014-22-1-2740、ONR MURI N00014-21-1-2801、亚马逊、博世、Salesforce 和三星支持。 张若涵部分由吴蔡人类绩效联盟奖学金资助。 Sanjana Srivastava 部分由美国国家科学基金会研究生研究奖学金计划 (NSF GRFP) 资助。
参考文献
- Deng et al. [2009] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009.
- Lin et al. [2014] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision, pages 740–755. Springer, 2014.
- Everingham et al. [2010] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge. International Journal of Computer Vision, 88(2):303–338, 2010.
- Krishna et al. [2017] R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, S. Chen, Y. Kalantidis, L.-J. Li, D. A. Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123(1):32–73, 2017.
- Geiger et al. [2012] A. Geiger, P. Lenz, and R. Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In IEEE Conference on Computer Vision and Pattern Recognition, pages 3354–3361. IEEE, 2012.
- Goyal et al. [2017] R. Goyal, S. Ebrahimi Kahou, V. Michalski, J. Materzynska, S. Westphal, H. Kim, V. Haenel, I. Fruend, P. Yianilos, M. Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision, pages 5842–5850, 2017.
- Sigurdsson et al. [2018] G. A. Sigurdsson, A. Gupta, C. Schmid, A. Farhadi, and K. Alahari. Actor and observer: Joint modeling of first and third-person videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7396–7404, 2018.
- Xiang et al. [2017] Y. Xiang, T. Schmidt, V. Narayanan, and D. Fox. Posecnn: A convolutional neural network for 6d object pose estimation in cluttered scenes. arXiv preprint arXiv:1711.00199, 2017.
- Martín-Martín et al. [2021] R. Martín-Martín, M. Patel, H. Rezatofighi, A. Shenoi, J. Gwak, E. Frankel, A. Sadeghian, and S. Savarese. Jrdb: A dataset and benchmark of egocentric robot visual perception of humans in built environments. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
- Caba Heilbron et al. [2015] F. Caba Heilbron, V. Escorcia, B. Ghanem, and J. Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 961–970, 2015.
- Gurari et al. [2018] D. Gurari, Q. Li, A. J. Stangl, A. Guo, C. Lin, K. Grauman, J. Luo, and J. P. Bigham. Vizwiz grand challenge: Answering visual questions from blind people. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3608–3617, 2018.
- Marcinkiewicz [1994] M. A. Marcinkiewicz. Building a large annotated corpus of english: The penn treebank. Using Large Corpora, page 273, 1994.
- Wang et al. [2018] A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461, 2018.
- Rajpurkar et al. [2016] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv preprint arXiv:1606.05250, 2016.
- Socher et al. [2013] R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Y. Ng, and C. Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, 2013.
- Antol et al. [2015] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, pages 2425–2433, 2015.
- Batra et al. [2020] D. Batra, A. X. Chang, S. Chernova, A. J. Davison, J. Deng, V. Koltun, S. Levine, J. Malik, I. Mordatch, R. Mottaghi, M. Savva, and H. Su. Rearrangement: A challenge for embodied ai. arXiv preprint arXiv:2011.01975, 2020.
- Weihs et al. [2021] L. Weihs, M. Deitke, A. Kembhavi, and R. Mottaghi. Visual room rearrangement. arXiv preprint arXiv:2103.16544, 2021.
- Gan et al. [2021] C. Gan, S. Zhou, J. Schwartz, S. Alter, A. Bhandwaldar, D. Gutfreund, D. L. Yamins, J. J. DiCarlo, J. McDermott, A. Torralba, et al. The threedworld transport challenge: A visually guided task-and-motion planning benchmark for physically realistic embodied ai. arXiv preprint arXiv:2103.14025, 2021.
- Puig et al. [2018] X. Puig et al. Virtualhome: Simulating household activities via programs. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018.
- Shridhar et al. [2020] M. Shridhar, J. Thomason, D. Gordon, Y. Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 10740–10749, 2020.
- Xia et al. [2020] F. Xia, W. B. Shen, C. Li, P. Kasimbeg, M. E. Tchapmi, A. Toshev, R. Martín-Martín, and S. Savarese. Interactive gibson benchmark: A benchmark for interactive navigation in cluttered environments. IEEE Robotics and Automation Letters, 5(2):713–720, 2020.
- Yu et al. [2020] T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning, pages 1094–1100. PMLR, 2020.
- James et al. [2020] S. James, Z. Ma, D. Rovick Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters, 2020.
- Savva et al. [2019] M. Savva, A. Kadian, O. Maksymets, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V. Koltun, J. Malik, et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9339–9347, 2019.
- Szot et al. [2021] A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y. Zhao, J. Turner, N. Maestre, M. Mukadam, D. S. Chaplot, O. Maksymets, et al. Habitat 2.0: Training home assistants to rearrange their habitat. In Advances in Neural Information Processing Systems, volume 34, 2021.
- Srivastava et al. [2022] S. Srivastava, C. Li, M. Lingelbach, R. Martín-Martín, F. Xia, K. E. Vainio, Z. Lian, C. Gokmen, S. Buch, K. Liu, et al. Behavior: Benchmark for everyday household activities in virtual, interactive, and ecological environments. In Conference on Robot Learning, pages 477–490. PMLR, 2022.
- Zhu et al. [2020] Y. Zhu, J. Wong, A. Mandlekar, and R. Martín-Martín. robosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293, 2020.
- Tassa et al. [2018] Y. Tassa, Y. Doron, A. Muldal, T. Erez, Y. Li, D. d. L. Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancq, et al. Deepmind control suite. arXiv preprint arXiv:1801.00690, 2018.
- Brockman et al. [2016] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. Openai gym. arXiv preprint arXiv:1606.01540, 2016.
- Littman et al. [2021] M. L. Littman, I. Ajunwa, G. Berger, C. Boutilier, M. Currie, F. Doshi-Velez, G. Hadfield, M. C. Horowitz, C. Isbell, H. Kitano, et al. Gathering strength, gathering storms: The one hundred year study on artificial intelligence (AI100) 2021 study panel report. Technical report, Stanford University, 2021.
- Riedl [2019] M. O. Riedl. Human-centered artificial intelligence and machine learning. Human Behavior and Emerging Technologies, 1(1):33–36, 2019.
- Xu [2019] W. Xu. Toward human-centered ai: a perspective from human-computer interaction. Interactions, 26(4):42–46, 2019.
- Shneiderman [2020] B. Shneiderman. Bridging the gap between ethics and practice: guidelines for reliable, safe, and trustworthy human-centered ai systems. ACM Transactions on Interactive Intelligent Systems (TiiS), 10(4):1–31, 2020.
- Kitano et al. [1997] H. Kitano, M. Asada, Y. Kuniyoshi, I. Noda, E. Osawa, and H. Matsubara. Robocup: A challenge problem for ai. AI magazine, 18(1):73–73, 1997.
- Wisspeintner et al. [2009] T. Wisspeintner, T. Van Der Zant, L. Iocchi, and S. Schiffer. Robocup@home: Scientific competition and benchmarking for domestic service robots. Interaction Studies, 10(3):392–426, 2009.
- Iocchi et al. [2015] L. Iocchi, D. Holz, J. Ruiz-del Solar, K. Sugiura, and T. Van Der Zant. Robocup@ home: Analysis and results of evolving competitions for domestic and service robots. Artificial Intelligence, 229:258–281, 2015.
- Buehler et al. [2009] M. Buehler, K. Iagnemma, and S. Singh. The DARPA Urban Challenge: Autonomous Vehicles in City Traffic, volume 56. springer, 2009.
- Krotkov et al. [2017] E. Krotkov, D. Hackett, L. Jackel, M. Perschbacher, J. Pippine, J. Strauss, G. Pratt, and C. Orlowski. The darpa robotics challenge finals: Results and perspectives. Journal of Field Robotics, 34(2):229–240, 2017.
- Correll et al. [2016] N. Correll, K. E. Bekris, D. Berenson, O. Brock, A. Causo, K. Hauser, K. Okada, A. Rodriguez, J. M. Romano, and P. R. Wurman. Analysis and observations from the first amazon picking challenge. IEEE Transactions on Automation Science and Engineering, 15(1):172–188, 2016.
- Eppner et al. [2017] C. Eppner, S. Höfer, R. Jonschkowski, R. Martín-Martín, A. Sieverling, V. Wall, and O. Brock. Lessons from the amazon picking challenge: four aspects of building robotic systems. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, pages 4831–4835, 2017.
- Roa et al. [2021] M. A. Roa, M. Dogar, C. Vivas, A. Morales, N. Correll, M. Gorner, J. Rosell, S. Foix, R. Memmesheimer, F. Ferro, et al. Mobile manipulation hackathon: Moving into real world applications. IEEE Robotics & Automation Magazine, pages 2–14, 2021.
- Heiden et al. [2021] E. Heiden, M. Macklin, Y. Narang, D. Fox, A. Garg, and F. Ramos. Disect: A differentiable simulation engine for autonomous robotic cutting. arXiv preprint arXiv:2105.12244, 2021.
- Urakami et al. [2019] Y. Urakami, A. Hodgkinson, C. Carlin, R. Leu, L. Rigazio, and P. Abbeel. Doorgym: A scalable door opening environment and baseline agent. arXiv preprint arXiv:1908.01887, 2019.
- Lin et al. [2020] X. Lin, Y. Wang, J. Olkin, and D. Held. Softgym: Benchmarking deep reinforcement learning for deformable object manipulation. In Conference on Robot Learning, 2020.
- Nvidia, Corp. [2022] Nvidia, Corp. Physx. https://developer.nvidia.com/physx-sdk, 2022. Accessed: 2022-06-10.
- Schulman et al. [2017] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Haarnoja et al. [2018] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International Conference on Machine Learning, pages 1861–1870. PMLR, 2018.
- Jordan and Perez [2013] M. Jordan and A. Perez. Optimal bidirectional rapidly-exploring random trees. Technical Report MIT-CSAIL-TR-2013-021, Computer Science and Artificial Intelligence Laboratory, Massachusetts Institute of Technology, Cambridge, MA, 2013.
- U.S. Bureau of Labor Statistics [2019] U.S. Bureau of Labor Statistics. American Time Use Survey. https://www.bls.gov/tus/, 2019.
- European Commission [2010] European Commission. Harmonised european time use surveys. https://ec.europa.eu/eurostat/web/time-use-surveys, 2010.
- Gershuny et al. [2020] J. Gershuny, M. Vega-Rapun, and J. Lamote. Multinational time use study. https://www.timeuse.org/mtus, 2020.
- wikiHow, Inc. [2021] wikiHow, Inc. wikihow. https://www.wikihow.com, 2021. Accessed: 2021-06-16.
- Xiang et al. [2020] F. Xiang, Y. Qin, K. Mo, Y. Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y. Yuan, H. Wang, et al. SAPIEN: A simulated part-based interactive environment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11097–11107, 2020.
- Mu et al. [2021] T. Mu, Z. Ling, F. Xiang, D. Yang, X. Li, S. Tao, Z. Huang, Z. Jia, and H. Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations. arXiv preprint arXiv:2107.14483, 2021.
- Fu et al. [2022] H. Fu, W. Xu, H. Xue, H. Yang, R. Ye, Y. Huang, Z. Xue, Y. Wang, and C. Lu. Rfuniverse: A physics-based action-centric interactive environment for everyday household tasks. arXiv preprint arXiv:2202.00199, 2022.
- Miller [1995] G. A. Miller. Wordnet: a lexical database for english. Communications of the ACM, 38(11):39–41, 1995.
- Brown et al. [2020] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020.
- Li et al. [2021] C. Li, F. Xia, R. Martín-Martín, M. Lingelbach, S. Srivastava, B. Shen, K. E. Vainio, C. Gokmen, G. Dharan, T. Jain, A. Kurenkov, K. Liu, H. Gweon, J. Wu, L. Fei-Fei, and S. Savarese. igibson 2.0: Object-centric simulation for robot learning of everyday household tasks. In Annual Conference on Robot Learning, 2021.
- Barto and Mahadevan [2003] A. G. Barto and S. Mahadevan. Recent advances in hierarchical reinforcement learning. Discrete Event Dynamic Systems, 13(1):41–77, 2003.
- LaValle [2006] S. M. LaValle. Planning Algorithms. Cambridge University Press, 2006.
- Kuffner and LaValle [2000] J. J. Kuffner and S. M. LaValle. Rrt-connect: An efficient approach to single-query path planning. In Proceedings IEEE International Conference on Robotics and Automation, volume 2, pages 995–1001. IEEE, 2000.
- Ehsani et al. [2021] K. Ehsani, W. Han, A. Herrasti, E. VanderBilt, L. Weihs, E. Kolve, A. Kembhavi, and R. Mottaghi. Manipulathor: A framework for visual object manipulation. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 4497–4506, 2021.
- Li et al. [2020] C. Li, F. Xia, R. Martín-Martín, and S. Savarese. Hrl4in: Hierarchical reinforcement learning for interactive navigation with mobile manipulators. In Conference on Robot Learning, pages 603–616. PMLR, 2020.
- Alipov et al. [2021] V. Alipov, R. Simmons-Edler, N. Putintsev, P. Kalinin, and D. Vetrov. Towards practical credit assignment for deep reinforcement learning. arXiv preprint arXiv:2106.04499, 2021.
- Yang et al. [2021] T. Yang, H. Tang, C. Bai, J. Liu, J. Hao, Z. Meng, and P. Liu. Exploration in deep reinforcement learning: a comprehensive survey. arXiv preprint arXiv:2109.06668, 2021.
- Osband et al. [2019] I. Osband, B. V. Roy, D. J. Russo, and Z. Wen. Deep exploration via randomized value functions. Journal of Machine Learning Research, 20(124):1–62, 2019.
- Hochreiter [1998] S. Hochreiter. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst., 6(2):107–116, 1998.
- Xia et al. [2020] F. Xia, C. Li, R. Martín-Martín, O. Litany, A. Toshev, and S. Savarese. ReLMoGen: Leveraging motion generation in reinforcement learning for mobile manipulation. In IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020.
- Redmon and Farhadi [2018] J. Redmon and A. Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018.
- Bjelonic [2016–2018] M. Bjelonic. YOLO ROS: Real-time object detection for ROS. https://github.com/leggedrobotics/darknet_ros, 2016–2018.
- Thrun et al. [2005] S. Thrun, W. Burgard, and D. Fox. Probabilistic Robotics. MIT Press, 2005.
- Fan et al. [2021] L. Fan, G. Wang, D.-A. Huang, Z. Yu, L. Fei-Fei, Y. Zhu, and A. Anandkumar. Secant: Self-expert cloning for zero-shot generalization of visual policies. arXiv preprint arXiv:2106.09678, 2021.
- Koupaee and Wang [2018] M. Koupaee and W. Y. Wang. Wikihow: A large scale text summarization dataset. arXiv preprint arXiv:1810.09305, 2018.
- Likert [1932] R. Likert. A technique for the measurement of attitudes. Archives of psychology, 1932.
- Montgomery [2013] D. C. Montgomery. Design and analysis of experiments. John Wiley & Sons, Inc., Hoboken, NJ, eighth edition, 2013.
- Paolacci et al. [2010] G. Paolacci, J. Chandler, and P. G. Ipeirotis. Running experiments on amazon mechanical turk. Judgment and Decision making, 5(5):411–419, 2010.
- Center [2016] P. R. Center. Research in the crowdsourcing age, a case study. Technical report, Washington, D.C., July 2016. URL https://www.pewresearch.org/internet/2016/07/11/research-in-the-crowdsourcing-age-a-case-study/.
- Akbik et al. [2018] A. Akbik, D. Blythe, and R. Vollgraf. Contextual string embeddings for sequence labeling. In COLING 2018, 27th International Conference on Computational Linguistics, pages 1638–1649, 2018.
- Fox and Long [2003] M. Fox and D. Long. PDDL2.1: An extension to PDDL for expressing temporal planning domains. Journal of Artificial Intelligence Research, 20:61–124, dec 2003. doi:10.1613/jair.1129. URL https://doi.org/10.1613%2Fjair.1129.
- Wichlacz et al. [2019] J. Wichlacz, Álvaro Torralba, and J. Hoffmann. Construction-planning models in minecraft. In Proceedings of the 2nd ICAPS Workshop on Hierarchical Planning (HPlan 2019), pages 1–5, 2019.
- TurboSquid, Inc. [2022] TurboSquid, Inc. Turbosquid. https://www.turbosquid.com/, 2022. Accessed: 2022-06-24.
- Niantic, Inc. [2022] Niantic, Inc. Scaniverse. https://scaniverse.com, 2022. Accessed: 2022-06-24.
- Quigley et al. [2009] M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, A. Y. Ng, et al. Ros: an open-source robot operating system. In ICRA workshop on open source software, volume 3, page 5. Kobe, Japan, 2009.
- Baboolall et al. [2019] D. Baboolall, D. Pinder, and S. Stewart. How automation could affect employment for women in the united kingdom and minorities in the united states. McKinsey Digital, 2019. URL tinyurl.com/h883dm9n.
附录 A 调查
在本节中,我们提供了有关第 2 节中介绍的调查的更多信息,该调查指导了我们基准的开发。 我们将讨论如何选择作为调查一部分的活动,调查设计和执行以及有关调查参与者的人口统计信息。
A.1 活动来源
我们从时间使用调查和 WikiHow [74]的组合中获取活动。 时间使用调查是研究人口每天时间使用情况的研究 [50],使其成为体现智能的日常需求的良好替代。 我们结合了来自三项时间使用调查的信息——美国 [50]、协调欧洲 [51]和多国 [52] 时间使用调查——并获得了 540 种活动的初始集合。 时间使用调查侧重于频率足够高且需要大量时间的活动。 但是,还有一些其他活动对人类的日常生活至关重要,但未反映在时间使用调查中。 WikiHow 文章包括对人类重要的活动,他们会在其中寻求指导,即使这些活动不如时间使用调查中包含的活动频繁。 这表明有很大潜力获得更多有用的相关日常活动。 我们用 WikiHow 文章标题补充了时间使用调查中的活动,WikiHow 文章标题超过 180,000 个。 这些构成了一组原始的活动,这些活动按可行性进行过滤,如下一段所述。
可行性活动过滤:
模拟约束了从时间使用调查和 WikiHow 收集的哪些活动实际上可以在 BEHAVIOR-1K 中使用。 在调查之前,我们使用以下基于 OmniGibson 和 BDDL 约束的标准来过滤活动池:
| Filtering principle | Example activity filtered out |
|---|---|
| Activity requires physics or chemistry not supported in simulation | SteamingClothes, MakingSoap |
| Activity involves creating or consuming media | ReadingABook |
| Activity requires more than a day in real time | DryingSeedsOvernight |
| Activity requires non-visual perceptual modalities | SweeteningFood |
| Activity requires geometric configurations too fine-grained for BDDL | SettingUpANativityScene |
| Activity is predicated on branded items | SprayingWindex |
| Activity involves other people or live animals | AskingForARaise |
在过滤和消除重复项后,并包括来自 [27] 的活动,还有 2,090 项活动有待调查。
A.2 调查设计
我们的调查结构如下:
-
•
人口统计问题 请求有关家庭成员数量、职业、一般位置以及家庭工作、自动化和生计之间关系的信息(有关结果,请参见图 A.1)。
-
•
活动调查问题 请求受访者对一批活动的自动化价值的评估。 具体来说,本节包括:
-
50 个问题,每个活动一个问题
-
问题文本: 在 1(左)到 10(右)的范围内,评估您希望机器人为您做这项活动的程度。
-
每个回复都使用独立的李克特评分 [75],范围从 1(不太有益)到 10(最有益)。
-
我们对调查中关于两个设计决策的替代方案进行了试点:1) 问题措辞,以及 2) 问题格式。 关于问题的措辞,我们试点了三种替代方案来指定 代理:机器人、助手 和 自动化。 我们的目标是研究可能影响研究的关于机器人的任何可能的(误)解。 通过 30 个成对的 T 检验和 10 个方差分析 [76],我们没有发现使用这三种措辞获得的结果之间存在统计学上的显著差异。 关于问题的格式,我们试用了两种替代格式:10 点李克特量表和三元素最佳-最差评定。 通过肯德尔 τ [76],李克特评分确定的排名与最佳-最差评定的标准指标之间存在很强的相关性。 因此,我们得出结论,这两种方法都将给我们带来相似的排名,并选择更节省资源的选择(李克特量表)。
调查收集:
我们在亚马逊 Mechanical Turk 上部署了我们的调查 [77],并收集了每个活动 50 个独特的回复。 共有 1,461 名不同的受访者,他们的平均得分从 1.9 到 9.3,显示出高度的多样性。 平均得分为 5.16。 为了确保响应质量,我们在每份调查中重复了四个问题作为注意力检查。 如果一对重复项的响应差异超过两点,我们认为它失败了。 两次或多次失败会导致拒绝。 我们还拒绝了在对 50 个不同活动的所有响应中没有显著差异的调查响应。
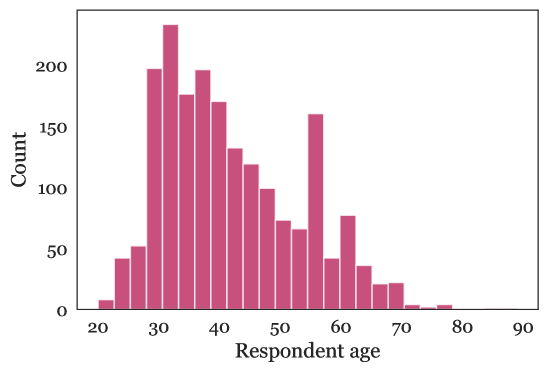
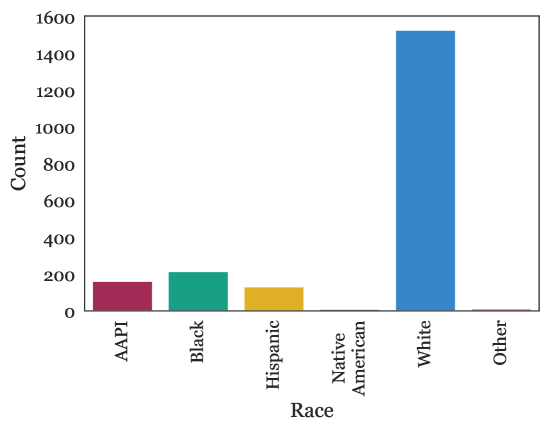
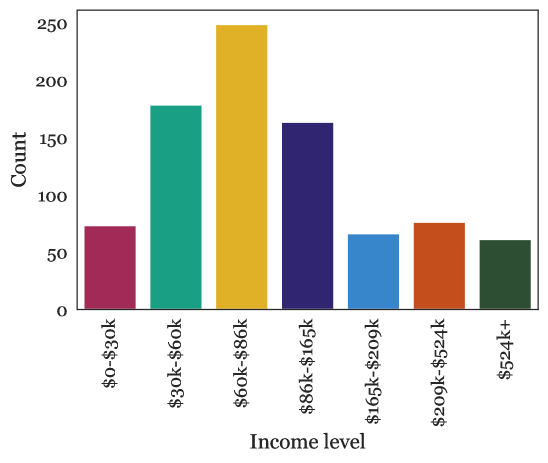
A.3 人口统计信息
图 A.1 描述了我们关于调查参与者的的人口统计问题的结果。 我们观察到,大多数成年人年龄段都有很好的代表性,特别是退休前年龄段,并且集中在 30-40 岁组。 种族方面,受访者约 75% 为白人,比例高于美国人口,但与 Mechanical Turk 的比例相似 [78]。 其他种族似乎在比例上与他们在 Mechanical Turk 和一般人口中的存在比例相似,但并不相同;这可能是由于他们在所有三个方面的人数都比较少 [78]。 有一些美洲原住民的代表,尽管在统计上并不显著。 从收入方面来看,受访者倾向于处于 30,000 美元至 150,000 美元的范围内,特别是在下半部分。
参与者的性别分布为 43.41% 女性,55.50% 男性,0.83% 非二元性别,0.26% 其他。 性别代表性不像美国人口那样均匀,但比 Mechanical Turk 工人人口更均匀 [78]。 非二元性别的代表人数很少。 在残疾状况方面,我们的参与者报告了 92.56% 无残疾,5.74% 残疾,1.70% 不愿回答。 因此,我们的调查包含了一些残疾人的代表性,但数量有限。 这类人群,以及老年人,通常被认为是可能从机器人努力中受益的人群;他们可以作为未来有针对性的调查的目标人群。
附录 B 活动标注
要获取 BDDL 中 1,000 种活动的定义,需要进行多个准备步骤来收集所需的知识。 这项知识也成为了 BEHAVIOR-1K 数据集 的一部分。 该流程在图 A.2 中概述。 现在,我们将详细介绍除调查以外的每个标注。 此外,这些标注的质量评估统计数据可以在第 B.1 节中找到。 我们发现,经验丰富的标注人员认为我们得到的 BEHAVIOR-1K 知识库非常准确。
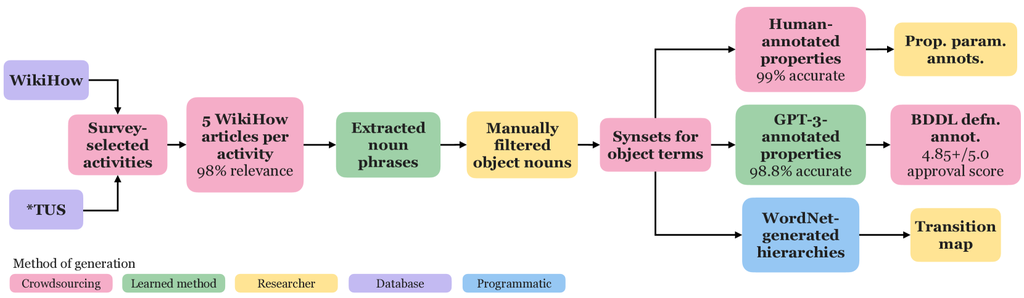
获取每个活动的物体列表(WikiHow 文章、名词短语提取和手动物体过滤):
我们的活动定义要求首先定义一组物体和属性,标注人员可以使用这些物体和属性来描述一项活动。 我们希望这些领域是自然的和生态的,包含人类可能认为一项任务所必需的所有相关物体。 为了获得每个活动在生态学上合理的对象空间,我们解析了 WikiHow 文章。 由于 WikiHow 是一个拥有广泛追随者和社区以及专家和同行评审的如何操作数据库,文章文本记录了活动中使用和操作的物体。 因此,我们要求 Upwork 平台上的众包工作者收集文章;为了稳健性,我们为每个活动收集了五篇文章。 我们使用了一个分块模型 [79] 从文章文本中提取名词短语,然后我们手动将名词短语过滤成有形的物体。
物体术语的同义词集和 WordNet 层次结构生成:
在为每个活动获取一个对象空间后,我们取它们的并集,并让众包工作者将每个空间与一个 WordNet [57] 同义词集匹配。 这消除了知识库中的词义歧义,并通过 WordNet 层级结构在整个对象空间中创建了一个层次结构。 此过程产生了 1,538 个 WordNet 叶级同义词集。 基于活动集的各种属性注释和需求,还有 1,426 个自定义同义词集,总共 2,964 个叶级同义词集。
属性注释:
每个作为 WordNet 层级结构中叶级同义词集的对象都与 BEHAVIOR-1K 中的一组对象属性相关联,这些属性中的每一个都可以在 OmniGibson 中完全模拟(属性的完整列表见表 A.1)。 这些属性定义了哪些谓词可以应用于该对象——例如,一个具有 cookable 属性的对象意味着它可以被 cooked 且 not cooked。 这种关联是与任务无关的,因为与特定活动无关或不希望有的对象/状态仍然会提供重要的学习信号。 所有适用于 2,964 个叶级同义词集中的许多同义词集的属性(因此需要大规模注释)都是由 GPT-3 [58] 或众包工作者完成的。 GPT-3 用于所有属性(总共 8 个),其中样本与人工标注的真实数据的汉明距离和假阳性率都小于 10%。 人工标注用于另外 5 个属性。 其余属性要么对模拟器实现敏感,因此需要手动标注,要么可以从其他标注中推断出来,并通过分析确定。
此标注仅针对叶级同义词集进行,然后从叶级标注推断出更高级同义词集的属性。 这可以防止定义不可解。 更详细地说:如图 A.2 所示,层次结构被应用于对象空间。 这允许活动定义标注者引用它们而不是叶级同义词集;例如,一个 PuttingAwayGroceries 定义可以包含“五个 edible_fruit.n.01”而不是“两个 apple.n.01 和三个 banana.n.01”,允许在活动实例化中具有更多变异,因为更多对象模型是有效的。 但是,三维物体模型通常只附加到叶级或接近叶级的同义词集,这意味着一个定义可能有一个更高级的同义词集,它附带了各种谓词,并且在模拟时,物体模型(与同义词集的后代之一相关联)必须模拟这些状态。 例如,当 container.n.01 被标注为 fillable 并且定义要求 container.n.01 被 filled 用 liquid,但实际上被采样到模拟器中以满足 container.n.01 的模型是一个布袋,不支持被 filled 用 liquid 时,就会出现问题。 因此,为了避免这种不可解性,任何非叶级同义词集的属性都是 所有其后代属性的交集。
| Object property | Annotation method | Prompt to annotator | Example objects |
| assembleable |
manual |
N/A |
desk.n.01, table.n.02 |
| breakable |
human |
Mark if the object can be broken into smaller pieces by a human dropping it on the floor without a tool. |
wine_bottle.n.01, room_light.n.01 |
| cloth |
manual |
N/A |
hammock.n.02, canvas.n.01 |
| coldSource |
GPT-3 |
Is [object] a source of cold? |
refrigerator.n.01, ice.n.01 |
| cookable |
GPT-3 |
Can a [object] be cooked? |
biscuit.n.01, pizza.n.01 |
| deformable |
prog. (all softBody, cloth, rope) |
N/A |
tortilla.n.01, clay.n.01 |
| diceable |
prog. (all sliceable’s derivative synsets |
N/A |
half__apricot.n.01, half__brisket.n.01 |
| drapeable |
prog. (all cloth, rope |
N/A |
dress.n.01, bath_towel.n.01 |
| fillable |
manual |
N/A |
stockpot.n.01, bucket.n.01 |
| fireSource |
GPT-3 |
Is a [object] designed to create fire? |
lighter.n.01, sparkler.n.01 |
| flammable |
human |
Mark if the object can catch fire (i.e. burn with a flame). |
candle.n.01, mail.n.01 |
| foldable |
prog. (all cloth, softBody) |
N/A |
tortilla.n.01, jean_jacket.n.01 |
| freezable |
prog. (all heatable) |
N/A |
olive_oil.n.01, ginger_beer.n.01 |
| heatable |
prog. (all rigid bodies) |
N/A |
oil.n.01, fish_knife.n.01 |
| heatSource |
GPT-3 |
Is a [object] a source of heat? |
oven.n.01, toaster.n.01 |
| liquid |
GPT-3 |
Is a [object] a liquid? |
gasoline.n.01, liquid_soap.n.01 |
| macroPhysicalSubstance |
manual |
N/A |
grated_cheese.n.01, blueberry.n.02 |
| meltable |
manual |
N/A |
cheese.n.01, chocolate.n.02 |
| microPhysicalSubstance |
manual |
N/A |
brown_sugar.n.01, cinnamon.n.03 |
| mixingTool |
manual |
N/A |
putty_knife.n.01, teaspoon.n.02 |
| needsOrientation |
manual |
N/A |
cumin__shaker.n.01, salt__shaker.n.01 |
| openable |
human |
Mark if the object is designed to be opened. |
mixer.n.04, keg.n.01 |
| particleApplier |
manual |
N/A |
pepper_mill.n.01, detergent__atomizer.n.01 |
| particleRemover |
GPT-3 |
Can a [object] absorb liquid? |
scrub_brush.n.01, broom.n.01 |
| particleSource |
manual (on top of particleApplier |
N/A |
sink.n.01 |
| particleSink |
manual (on top of particleRemover |
N/A |
sink.n.01 |
| rigidBody |
manual |
N/A |
tomato.n.01, desk.n.01 |
| rope |
manual |
N/A |
ribbon.n.01, fairy_light.n.01 |
| sliceable |
GPT-3 |
Can a [object] be sliced easily by a human with a knife? |
sweet_corn.n.01, sandwich.n.01 |
| slicingTool |
GPT-3 |
Can a [object] slice an apple? |
blade.n.09, razor.n.01 |
| softBody |
manual |
N/A |
dough.n.01, pillow.n.01 |
| substance |
prog. (all liquid, vis.Subst., phys.Subst.) |
N/A |
water.n.06, milk.n.01 |
| toggleable |
human |
The object can be switched between a finite number of discrete states and is designed to do so. |
hot_tub.n.01, light_bulb.n.01 |
| unfoldable |
prog. (all foldable) |
N/A |
tissue.n.02, foil.n.01 |
| visualSubstance |
manual |
N/A |
coriander.n.02, cocoa_powder.n.01 |
| waterCook |
manual (special case of cookable |
N/A |
chickpea.n.01, white_rice.n.01 |
属性参数标注:
BDDL 将对象和对象状态(即术语和谓词)分开,但模拟真实的“烹饪”或“填充”需要对象-对象属性元组的信息,而不仅仅是对象或对象属性本身。 例如,在现实世界中,apple.n.01 和 chicken.n.01 不会在相同的温度下被烹饪,因此仅仅知道它们都是 cookable 是不够的。 BEHAVIOR-1K 数据集 因此包括对几个属性参数的手动标注,这些参数是(对象,对象属性)特定的,例如 cookTemperature 适用于所有 cookable 对象。
对象-属性对和参数的示例:
-
•
cookable 对象从 (cooked object) = False 变为 (cooked object) = True 所需的温度
-
crab.n.05: 必须达到 63°C
-
squash.n.02: 必须达到 58°C
-
meatball.n.01: 必须达到 63°C
-
chicken_leg.n.01: 必须达到 74°C
-
-
•
由 heatSource 对象产生的温度。 对于 可切换热源,这可能需要 toggledOn(对象) = True
-
烤箱.n.01:产生 204°C
-
余烬.n.01:产生 1093°C
-
手持吹风机.n.01:产生 45°C
-
咖啡机.n.01:产生 93°C
-
过渡规则:
许多活动涉及复杂的化学和物理过程,这些过程超出了最先进的模拟技术的范围。 例如,将不同的水果混合成冰沙或打磨生锈的表面非常难以模拟,但代理完成这些任务的动作仍然在可及范围内,例如将水果放入搅拌机中。 因此,为了支持这类活动,我们创建了一套过渡规则,OmniGibson 将使用这些规则绕过底层物理,但仍然产生视觉上逼真的物理过渡,例如搅拌机开启后搅拌机内部产生的冰沙颗粒。
过渡规则示例:
-
•
物体的组成和分解
-
在 制作草莓冰沙 中使用的过渡规则
-
输入: 草莓.n.01,冰.n.01,柠檬汁.n.01,龙舌兰.n.01
-
过渡机: 搅拌机.n.01
-
输出: 冰沙.n.01
-
-
在 制作冷汤 中使用的转换规则
-
输入: 罗勒.n.03,盐.n.02,黑胡椒.n.02,番茄汁.n.01,黄瓜.n.02,水.n.06,柠檬汁.n.01
-
转换机器: 平底锅.n.01
-
输出: 冷汤.n.01
-
-
-
•
现实的清洁规则
-
在 清洁车库外部 中使用的转换规则
-
覆盖物体的物质: 油漆.n.01 或 喷漆.n.01
-
需要去除的物体: 颗粒清除器 浸泡在 (溶剂.n.01 或 丙酮.n.01) 中
-
-
在 清洁生锈的花园工具 中使用的转换规则
-
覆盖物体的物质: 锈.n.01 或 铜绿.n.01 或 切口.n.01(模拟为粒子,但向标注者展示为一元 刮伤 谓词)或 污垢.n.01(模拟为粒子,但向标注者展示为一元 变色 谓词)
-
需要去除的物体: 砂纸.n.01 或 磨刀石.n.01
-
-
BDDL 中的活动定义:
最后,将对象空间以及它们支持的相关属性和谓词提供给标记人员,以生成 BDDL 定义。 标记人员使用包含 BDDL 可视化版本的标记界面来构建活动定义 [27](关于 BDDL 中新功能的详细信息见第 C 节)。 标记界面强制执行使定义在逻辑上可解且格式良好的必要条件。 我们为每个活动收集一个定义,总共 1,000 个 BDDL 活动定义。
清单 1、2 和 3 显示了 BEHAVIOR-1K 活动定义的示例,而清单 4 和 5 显示了 BEHAVIOR-100 定义的示例。 我们看到,虽然对象和文字的数量相似,这说明这两个基准在其包含的活动方面已达到类似的规模和细节,但 BEHAVIOR-1K 的活动分布范围更大,也更详细。 BakingSugarCookies 活动涉及将 :init 中的配料转换为 :goal 中的司康饼的转换规则,此过程将需要 OmniGibson 中列出的搅拌器和烤箱。 相反,BEHAVIOR-100 中的烹饪仅限于单个对象从 not cooked 转换为 cooked;其他基准类似或完全没有烹饪。 CleanYourLaundryRoom 涉及使用特定的清洁剂来清洁霉菌,而 BEHAVIOR-100 清洁任务只有两种类型的“脏污”(stained 和 dusty),唯一规则是在 stained 的情况下使用水。 CleanTheBottomOfAnIron 也展示了针对锈迹的清洁(需要使用砂纸)。
B.1 BEHAVIOR-1K 标注的质量评估
| Article Collection | Object Extraction | Human Properties | GPT-3 / Machine Properties | |
| Accuracy (Approval Rate) | 0.974 | 0.968 | 0.990 | 0.988 |
| F1-score | 0.984 | 0.990 | 0.912 | 0.930 |
| False Discovery Rate | 0.026 | 0.032 | 0.031 | 0.029 |
| False Positive Rate | N/A | N/A | 0.002 | 0.003 |
| Activity Definition | ||||
|---|---|---|---|---|
| Question 1 | Question 2 | Question 3 | Question 4 | |
| Average Rating | 4.875 | 4.942 | 4.967 | 4.975 |
| Standard Deviation | 0.331 | 0.234 | 0.364 | 0.156 |
每个活动定义都根据每个问题的 1-5 分制进行评估,并列出了平均分数和标准差。 细粒度化的增加仍然反映了我们结果的高质量。
我们的质量控制调查表明,所有由众包工作者和 GPT-3 完成的标注都是最高质量的。 五位具有大型机器学习项目数据标注、编码或数据验证丰富经验的众包工作者证实了早期众包工作者的结果。 所有标注任务的准确率均超过 96%,F1 分数超过 91%,误报率和误发现率在 2-3% 之间,如表 A.2 所示。 我们注意到,同义词集验证的准确率略低于其他标注任务。 这可能是由于同义词集定义中的细微差别:例如,一个单词的“合理狭窄的上义词”,即使不在 WordNet [57] 中,也是可以接受的,例如“皂液分配器”的“分配器”,但对于什么是“合理狭窄”可能存在灰色区域(例如,“手工具”作为“皂液分配器”的替代品是否合理?)。
活动定义过程使用李克特量表和一系列问题进行了更细粒度的评估。 我们发现,响应值具有始终如一的较高平均值(非常接近 5 的最高分)和较低的标准差,如表 A.2 所示。 我们还发现,活动定义得分在不同主题(例如,与“清洁”相关的任务)之间没有显着差异,这表明 BDDL 定义在所有活动类别中得到一致的评分。
附录 C 新的 BDDL 功能
BEHAVIOR-1K 使用了 BEHAVIOR-100 [27] 中使用的 BDDL 的扩展版本,以支持新的多样化活动集。 这里有三个新特征:1)物质的表示,2)三值谓词,以及 3)对象的组合和分解。
物质的表示:
BEHAVIOR-1K 引入了 物质,这些物体是可以任意细分的,并且不遵守清晰的实例边界,例如 水。n.06 或 面粉。n.01。 传统的 PDDL/BDDL 难以处理缺乏实例边界的情况:例如,如果有两瓶橙汁,其中一瓶中的橙汁叫做 橙汁。n.01_1,另一瓶中的橙汁叫做 橙汁。n.01_2,那么任何颗粒的混合都会让智能体几乎无法满足与实例相关的 :目标 条件。 即使使用量化,像 存在(橙汁。n.01)(装满的 橙汁。n.01 玻璃。n.01_3) 这样的条件仍然不公平:如果智能体将来自两个不同 橙汁 实例的粒子混合在一起,使得它们一起 装满了 玻璃。n.01_3,但没有一个实例单独拥有足够的粒子在 玻璃。n.01_3 中装满它,那么 :目标 就不会实现。
我们只是强制规定在定义中最多只有一个 物质 实例。 标注者仍然可以通过在尽可能多的容器中生成物质来控制数量。 与单独标记每个粒子不同,这保持了一种紧凑的表示。 这不允许某些物质与其他物质不同(例如,一些橙汁是冷的,而一些是热的),但我们认为这是一个可以接受的限制。
此外,基于粒子的物体在模拟方面可能计算成本很高。 当标注者仅将 橙汁。n.01 用作橙汁的容器,而不是实际的粒子(例如,在 收纳杂货 活动中),这就会浪费计算资源。 因此,我们为每种物质引入了一个自定义容器同义词集,它与 瓶子。n.01 具有相同的属性和 WordNet 层次结构,并指导标注者在他们只想要容器时使用它。
三值谓词:
BEHAVIOR-100 活动中常见的一个问题是,涉及自然连续值数量的谓词的成功是突然且任意的:稍微敲开窗户就会突然从 未打开 变为 打开,并且活动从未完成变为完成——即使窗户不是人们通常认为的“打开”。 PDDL 2.1 [80] 具有数值变元和派生谓词,它们提供了连续状态。 然而,这种粒度对于 BEHAVIOR-1K 中的高级活动可能并不关键,并且该概念也很难向普通标注者传达。
因此,我们将某些谓词视为三值的,方法是使用两个布尔谓词,其中否定相同,例如 filled 和 empty(而不是仅 not filled)。 标注者仍然看到一个布尔谓词,在这种情况下是 filled,并对其取反来表达相反的意思,但我们假设当他们取反时,他们的意思是指绝对为空。 这是一个强烈的假设,但通常是安全的,因为人们往往不会添加看起来像常识的表达式。 无论我们在定义中看到谓词取反,我们都会将其替换为另一个谓词。 这适用于 filled/empty,open/closed,和 folded/unfolded。
为了确保切换后定义在逻辑上相同,底层的 BDDL 实现使用 De Morgan 定律转换定义,以便所有否定仅在切换发生之前应用于原子公式。
对象的组合和分解:
在标准 PDDL/ BDDL 中,:objects 中的对象被假定在整个活动中持续存在。 不存在创建未出现在 :init 中的新对象或明确销毁对象的的概念。
为了使我们的转换规则能够将某些对象变成其他对象,我们需要一种能够明确提供所需信息的表示。 :objects 部分不能仅从包含新对象的 :goal 中推断出来,因为 :goal 并不详尽。 因此,我们引入了 future 谓词,在 :init 中对所有未出现在代理进入场景时但必须存在才能满足 :goal 的对象使用。 future 谓词中的所有对象都出现在 :objects 中,并且它们不能出现在 :init 中的任何其他文字中。 这种方法借鉴了 [81],它更新对对象的引用(例如墙壁),因为随着更多子对象(例如块)被添加到其中,它会不断改变形式。
附录 D 场景和对象模型
在本节中,我们将提供有关 BEHAVIOR-1K 数据集 中提出的对象和场景模型的更多详细信息,包括选择、建模和标注过程。
在第 2 节概述的调查中,我们获得了一份人类希望机器人执行的 1000 项活动的清单。 然而,这些活动并不局限于某一特定类型的场景(例如,房屋)。 我们选择了涵盖 BEHAVIOR-1K 活动所需的场景类型,包括八种场景类型:房屋(15)、带花园的房屋(8)、酒店(3)、办公室(5)、杂货店(4)、普通大厅(4)、餐厅(6)和学校(5)(参见表 A.4)。 这些场景涵盖需要特定类型(例如,购物、烹饪、补货)的活动,以及在多种场景类型中可能发生的通用活动(例如,清洁)。 我们还标注了每种类型可以执行多少项活动,以指导我们应该在 BEHAVIOR-1K 数据集 中包含多少实例。 主要场景类型仍然是家庭:我们改进了 BEHAVIOR-100 中的 15 个家庭场景,并通过光源、新纹理等对其进行了进一步的标注。 然后,我们从 TurboSquid 等在线市场 [82] 中获得了每种场景类型的额外实例。
市场上的几个可用场景模型不包含执行 BEHAVIOR-1K 中自然活动所需的所有房间,例如,餐厅不包括厨房,办公室不包括洗手间,或者房屋不包括花园。 我们为这些房间收集了单独的模型,并委托专业的 3D 设计师将它们连接起来。
场景模型是与必要的物体模型一起获得的。 然而,它们不足以涵盖 BEHAVIOR-1K 中活动所需的物体。 我们获取了额外的模型来支持活动,如第 B 节描述的活动标注过程所示,总共从 1,900 多个类别中获取了 9,000 多个物体模型。 数据集中包含的物体类别的多样性可以在图 A.7 中观察到。
3D 供应商提供的场景和物体模型无法直接用于在 OmniGibson 中模拟 BEHAVIOR-1K 中的 1000 项活动,因为 1)缺乏类别标注,2)场景中缺乏(或错误)光源,3)部分分割不正确,4)缺乏关节,5)缺少按钮等交互元素,6)缺少用于采样的统一规范帧方向,以及 7)物理属性不佳,无法进行逼真的模拟。 我们手动清理并标注了所有场景和物体,以纠正这些元素。
我们将公开发布所有场景和模型,供其他研究人员使用。 这些模型将被加密,并且只能在 OmniGibson 中使用,以遵守模型作者的权利以及供应商协议。 我们将在网站上发布关于标注过程的文档以及管道源代码,使用户能够轻松地将他们自己的对象和场景导入到 OmniGibson 中,用于 BEHAVIOR-1K 活动。




|
Scene Type |
Scene Name |
Obj. Cnt. |
Syn. Cnt. |
Rm. Cnt. |
Room Types |
Example Activities |
|
BEHAVIOR-100 Houses |
Beechwood_0_int |
136 |
32 |
8 |
bathroom, corridor, dining_room, entryway, kitchen, living_room, private_office, utility_room |
clean a hot water dispenser, freeze lasagna, clean batting gloves |
|
Beechwood_1_int |
129 |
21 |
9 |
bathroom, bedroom, childs_room, closet, corridor, playroom, television_room |
clean your kitty litter box, store baby clothes, cleaning pet bed |
|
|
Benevolence_0_int |
21 |
10 |
4 |
bathroom, corridor, empty_room, entryway |
laying clothes out, pack a pencil case, sweeping outside entrance |
|
|
Benevolence_1_int |
74 |
22 |
5 |
corridor, dining_room, kitchen, living_room, storage_room |
hanging blinds, sorting volunteer materials, wash baby bottles |
|
|
Benevolence_2_int |
63 |
23 |
5 |
bathroom, bedroom, corridor |
clean walls, washing fabrics, folding clean laundry |
|
|
Ihlen_0_int |
68 |
21 |
7 |
bathroom, corridor, dining_room, garage, living_room, storage_room |
de-clutter your garage, sorting household items, set up a home office in your garage |
|
|
Ihlen_1_int |
147 |
27 |
9 |
bathroom, bedroom, corridor, dining_room, kitchen, living_room, staircase |
clean jewels, clean green beans, hanging up curtains |
|
|
Merom_0_int |
82 |
27 |
6 |
bathroom, childs_room, living_room, playroom, storage_room, utility_room |
changing dog’s water, wash a bra, wash a wool coat |
|
|
Merom_1_int |
123 |
28 |
8 |
bathroom, bedroom, childs_room, corridor, dining_room, kitchen, living_room, staircase |
store an uncooked turkey, drying table, clean flip flops |
|
|
Pomaria_0_int |
71 |
22 |
6 |
bathroom, bedroom, corridor, private_office, television_room |
prepare sea salt soak, clean sheets, dispose of medication |
|
|
Pomaria_1_int |
89 |
24 |
6 |
bathroom, corridor, kitchen, living_room, pantry_room, utility_room |
store brownies, clean a book, baking sugar cookies |
|
|
Pomaria_2_int |
42 |
18 |
3 |
bathroom, bedroom, corridor |
replacing screens, clean baby toys, putting up posters |
|
|
Rs_int |
72 |
32 |
5 |
bathroom, bedroom, entryway, kitchen, living_room |
dispose of a pizza box, putting food in fridge, putting out condiments |
|
|
Wainscott_0_int |
187 |
35 |
9 |
bathroom, bedroom, dining_room, kitchen, living_room |
make microwave popcorn, make frozen lemonade, make cake mix |
|
|
Wainscott_1_int |
150 |
26 |
10 |
bathroom, bedroom, corridor, exercise_room, playroom, private_office, utility_room |
decorating for religious ceremony, stash snacks in your room, disinfect laundry |
|
|
BEHAVIOR-100 Houses+Garden |
Beechwood_0_garden |
335 |
45 |
9 |
bathroom, corridor, dining_room, entryway, garden, kitchen, living_room, private_office, utility_room |
tidy your garden, opening doors, wash goalkeeper gloves |
|
Merom_0_garden |
197 |
51 |
8 |
bathroom, childs_room, garden, living_room, playroom, sauna, storage_room, utility_room |
clean your kitty litter box, clean a glass windshield, hang icicle lights |
|
|
Pomaria_0_garden |
260 |
49 |
7 |
bathroom, bedroom, corridor, garden, private_office, television_room |
putting up Christmas lights outside, prepare a hanging basket, clean a patio |
|
|
Rs_garden |
185 |
47 |
6 |
bathroom, bedroom, entryway, garden, kitchen, living_room |
cleaning driveway, clean a longboard, roast nuts |
|
|
Wainscott_0_garden |
712 |
61 |
10 |
bathroom, bedroom, dining_room, garden, kitchen, living_room |
clean an espresso machine, clearing food from table into fridge, painting porch |
|
|
New Houses |
house_single_floor |
1375 |
137 |
23 |
bathroom, bedroom, childs_room, closet, corridor, dining_room, empty_room, entryway, garden, kitchen, living_room, sauna, utility_room |
turning out all lights before sleep, iron curtains, packing hobby equipment |
|
house_double_floor_lower |
304 |
79 |
6 |
bathroom, corridor, garage, garden, kitchen, living_room |
wash towels, clean a fish, clean brass |
|
|
house_double_floor_upper |
325 |
78 |
5 |
bathroom, bedroom, television_room |
clean a saxophone, taking down curtains, clean walls |
|
|
Grocery Stores |
grocery_store_asian |
3402 |
79 |
2 |
bathroom, grocery_store |
buy alcohol, buy boxes for packing, buy a microwave oven |
|
grocery_store_cafe |
6994 |
71 |
4 |
bar , bathroom, dining_room, grocery_store |
defrost meat, clean reusable shopping bags, buy a good avocado |
|
|
grocery_store_convenience |
1889 |
82 |
2 |
bathroom, grocery_store |
washing windows, picking up prescriptions, buy food for vegetarians |
|
|
grocery_store_half_stocked |
3804 |
51 |
2 |
bathroom, grocery_store |
buying gardening supplies, buy basic garden tools, buy boxes for packing |
|
|
Halls |
hall_arch_wood |
78 |
11 |
2 |
bathroom, empty_room |
clean walls |
|
hall_train_station |
141 |
15 |
2 |
bathroom, empty_room |
clean cement | |
|
hall_glass_ceiling |
116 |
20 |
2 |
bathroom, empty_room |
preparing food for a fundraiser | |
|
hall_conference_large |
3372 |
26 |
2 |
bathroom, conference_hall |
distributing event T-shirts | |
|
Hotels |
hotel_gym_spa |
322 |
43 |
9 |
bathroom, corridor, gym , hammam , locker_room , sauna, spa |
turning on the hot tub, adding chemicals to hot tub, clean a sauna |
|
hotel_suite_large |
218 |
51 |
2 |
bathroom, bedroom |
clean vinyl shutters, cleaning computer, clean white marble |
|
|
hotel_suite_small |
48 |
28 |
2 |
bathroom, bedroom |
clean cork mats, putting out clean towels, clean a shower |
|
|
Offices |
office_bike |
479 |
49 |
3 |
bathroom, break_room, shared_office |
set up a webcam, set up two computer monitors, clean an office chair |
|
office_cubicles_left |
787 |
44 |
12 |
bathroom, conference_hall, copy_room, corridor, lobby, meeting_room, private_office, shared_office |
clean up your desk, clean a LED screen, laying out snacks at work |
|
|
office_cubicles_right |
406 |
37 |
11 |
bathroom, conference_hall, copy_room, corridor, lobby, meeting_room, private_office, shared_office |
making photocopies, clean a LED screen, clean a keyboard |
|
|
office_large |
1151 |
46 |
24 |
bathroom, break_room, conference_hall, copy_room, corridor, lobby, meeting_room, phone_room, private_office, shared_office |
emptying trash cans, putting meal in fridge at work, brewing coffee |
|
|
office_vendor_machine |
225 |
45 |
4 |
bathroom, break_room, meeting_room, shared_office |
clean a computer monitor, make the workplace exciting, dispose of glass |
|
|
Restaurants |
restaurant_asian |
1221 |
56 |
3 |
bathroom, dining_room, kitchen |
grill vegetables, cook tofu, clean clams |
|
restaurant_brunch |
1096 |
70 |
4 |
bar , bathroom, dining_room, kitchen |
stock a bar, cook squid, washing vegetables |
|
|
restaurant_cafeteria |
292 |
45 |
3 |
bathroom, dining_room, kitchen |
clean a popcorn machine, store coffee beans or ground coffee, roast meat |
|
|
restaurant_diner |
174 |
39 |
3 |
bar , bathroom, dining_room |
sweeping floors, installing smoke detectors, clean a lobster |
|
|
restaurant_hotel |
1080 |
81 |
4 |
bathroom, dining_room, kitchen, lobby |
clean eggs, setting table for coffee, clean a pizza stone |
|
|
restaurant_urban |
1368 |
90 |
4 |
bar , bathroom, dining_room, kitchen |
cook pumpkin seeds, putting roast in oven, thaw frozen fish |
|
|
Schools |
school_biology |
717 |
53 |
4 |
bathroom, biology_lab , corridor |
clean an eraser, turning sprinkler off, clean a glass pipe |
|
school_chemistry |
890 |
69 |
4 |
bathroom, chemistry_lab , corridor |
clean clear plastic, clean an eraser, clean a whiteboard |
|
|
school_comp_lab_infirmary |
828 |
61 |
6 |
bathroom, computer_lab, corridor, infirmary |
clean a computer monitor, prepare an emergency school kit, clean a keyboard |
|
|
school_geography |
556 |
42 |
5 |
bathroom, classroom, corridor |
clean gold, clean a glass pipe, clean an eraser |
|
|
school_gym |
853 |
36 |
7 |
bathroom, corridor, gym , locker_room |
clean a dirty baseball, dispose of glass, wash towels |
附录 E 模拟
E.1 OmniGibson 中的扩展对象状态和逻辑谓词
OmniGibson 扩展了 iGibson 2.0 [59] 中的扩展对象状态和逻辑谓词基础设施,以适应 BEHAVIOR-1K 的多样性和真实性。
E.1.1 与对象类别属性相关的扩展对象状态
出于计算效率的目的,并非所有扩展对象状态都需要针对每个对象维护和更新。 例如,像苹果这样的 可烹饪 对象需要跟踪它们的 温度,但桌子可能不需要,至少在模拟 BEHAVIOR-1K 活动时不需要。 因此,考虑到 BEHAVIOR-1K 数据集 中的对象类别属性标注(见表 A.1),OmniGibson 选择性地跟踪每个类别对象的扩展状态子集。 从对象类别属性到所需对象状态的映射可以在表 A.5 中找到。
| Object category property | Required extended object states |
|---|---|
| cookable |
MaxTemperature, Temperature |
| overcookable |
MaxTemperature, Temperature |
| freezable | Temperature |
| flammable | Temperature |
| heatable | Temperature |
| metable | Temperature |
| soakable | SoakedLevel |
| toggleable | ToggledState |
| sliceable | SlicedState |
| breakable | BrokenState |
| heatSource | ToggledState |
| fireSource | ToggledState |
| coldSource | ToggledState |
| waterSource | ToggledState |
E.1.2 对象模型属性
我们还需要对每个对象模型执行物理和语义标注,以便它们能够被真实地模拟并支持扩展对象状态的演化。 一些物理属性可以从 3D 资产中以编程方式生成,例如 形状、运动学结构 和 稳定方向,而其他一些则需要标注(包含在 BEHAVIOR-1K 数据集 中),例如 重量。 对象模型的 类型,它也是从 BEHAVIOR-1K 数据集 中的对象类别属性标注中推导出来的(见表 A.1),决定了对象将在 OmniGibson 中如何被模拟。 例如,布料和流体将使用底层粒子系统进行模拟。 此外,一些对象类别属性需要对该类别的每个模型进行额外的语义标注,例如,对于 水源 对象,需要 水源链接 来指示生成水的精确位置。 所有对象模型属性的详尽列表可以在表 A.6 中找到。
| Object model property | Relevant object category property | Description |
|---|---|---|
| Shape |
Model of the 3D shape of each link of the object |
|
| Weight |
Weight of the object |
|
| CenterOfMass |
Mean position of the matter in the object |
|
| MomentOfInertia |
Resistance of the object to change its angular velocity |
|
| KinematicStructure |
Structure of links and joints connecting them in the form of URDF (non-articulated objects are composed of one link) |
|
| StableOrientations |
A list of stable orientations assuming the object is placed on a flat surface, computed using a 3D geometry library |
|
| HeatSourceLink | heatSource |
Virtual (non-colliding) fixed link that generates heat |
| FireSourceLink | fireSource |
Virtual (non-colliding) fixed link that generates fire |
| CleaningToolLink | cleaningTool |
Fixed link that needs to contact dirt particles for the tool to clean them |
| WaterSourceLink | waterSource |
Virtual (non-colliding) fixed link that generates water |
| WaterSinkLink | waterSource |
Virtual (non-colliding) fixed link that absorbs water |
| TogglingLink | toggleable |
Virtual (non-colliding) fixed link that changes the toggled state of the object when contacted |
| SlicingLink | slicingTool |
Fixed link that changes the sliced state of another object if it contacts it with enough force |
| RelevantJoints | openable |
List of joints that are relevant to indicate whether an object is open |
| AttachmentKeypoints | assembleable |
List of keypoint locations that will be connected with those of other objects when they are close enough |
| ClothKeypoints |
foldable, unfoldable |
List of keypoint locations are used to determine if the object is folded (if they are close enough) or unfolded (if they are far enough) |
| ContainerVolume | fillable |
Virtual (non-colliding) fixed link that represents the inner volume of a fillable container. |
| Type |
cloth, deformable, liquid, rope, physicalSubstance, visualSubstance |
Type of the object, e.g. rigid body, fluid, physical/visual substance, cloth, deformable, which determines how it will be simulated in OmniGibson |
E.1.3 对象状态
虽然上述对象属性在模拟过程中保持不变(例如,苹果始终是 可烹饪的,水槽在其本地框架中始终具有相同的 WaterSourceLink 定义),但对象状态可能会发生变化。 底层的物理引擎处理运动学状态变化,例如 Pose、AABB、JointStates、ParticlePositions(用于流体和布料)等。除此之外,OmniGibson 处理对逻辑谓词至关重要的非运动学状态变化(下一小节描述)。 例如,OmniGibson 在每个模拟步骤中通过检查对象是否靠近/在任何 heatSource 或 coldSource 内来更新对象的 Temperature。 所有对象状态的详尽列表可以在表 A.7 中找到。
| Object State | Description and Update Rules |
|---|---|
| Pose |
6 DoF pose (position and orientation) of the object in world reference frame, updated by the underlying physics engine. |
| AABB |
Axis-aligned bounding box (coordinates of two opposite corners) of the object in the world reference frame, updated by the underlying physics engine. |
| JointStates |
State of all internal DoFs of the (articulated) object for the structure defined by KinematicStructure, updated by the underlying physics engine. |
| ParticlePositions |
Positions of all the underlying particles for cloth and fluid, updated by the underlying physics engine. |
| InContactObjs |
List of all objects in physical contact with the object, updated by the underlying physics engine. |
| ConnectedObjs |
List of all objects that are connected to the object, either via a fixed joint for rigid bodies or via an attachment for cloth and deformables. |
| InSamePositiveVerticalAxisObjs |
List of all objects in the positive vertical axis drawn from the object’s center of mass, updated by shooting a ray upwards in the positive z-axis and gather the objects hit by the ray. |
| InSameNegativeVerticalAxisObjs |
List of all objects in the negative vertical axis drawn from the object’s center of mass, updated by shooting a ray downwards in the negative z-axis and gather the objects hit by the ray. |
| InSameHorizontalPlaneObjs |
List of all objects in the horizontal plane drawn from the object’s center of mass, updated by shooting a number of ray in the x-y plane and gather the objects hit by the rays. |
|
Temperature, |
Object’s current temperature in C, updated by detecting if the object is affected by any heat source or heat sink. |
|
MaxTemperature, |
Maximum temperature of the object reached historically during this simulation run, updated by keeping track of all the Temperature in the history. |
|
SoakedLevel, |
Amount of liquid absorbed by the object corresponding to the number of liquid particles contacted, updated by detecting if the object is in contact with any liquid particle. This is maintained for every type of liquid separately. |
|
CoveredLevel, |
Amount of visualSubstance that covers the object, updated by detecting if the particles of the visualSubstance are in contact with anything that can potentially remove them from the object, e.g. cleaningTool. This is maintained for every type of visualSubstance separately. |
|
ToggledState, TS |
Binary state indicating if the object is currently on or off, updated by detecting if the agent is in contact with the TogglingLink. |
|
SlicedState, SS |
Binary state indicating whether the object has been sliced (irreversible), updated by detecting if the object is in contact with any SlicingTool that exerts a force above a certain threshold . We assume as default force threshold of , a value that can be configured per object category and model. |
|
BrokenState, BS |
Binary state indicating if the object is broken, updated by detecting if the object has a contact force with any other object above a certain threshold , a value that can be configured per object category and model. |
E.1.4 逻辑谓词作为检查函数
对于与 BEHAVIOR-1K 活动相关的每个逻辑谓词,我们定义一个检查函数,该函数将给定的物理状态(运动学和非运动学)映射到 BDDL 操作的二进制逻辑状态。 例如,OnTopOf 基于两个对象的姿势及其接触信息,而 Cooked 基于 Temperature。 所有逻辑谓词的检查函数的详细信息可以在表 A.8 中找到。
| Predicate | Description |
|---|---|
| InsideOf(,) |
Object is inside of object if we can find two orthogonal axes crossing at center of mass that intersect collision mesh in both directions. |
| OnTopOf(,) |
Object is on top of object if , where is the list of objects in the same positive/negative vertical axis as and is whether the two objects are in physical contact. |
| NextTo(,) |
Object is next to object if , where is a list of objects in the same horizontal plane as , is the L2 distance between the closest points of the two objects, and is a distance threshold that is proportional to the average size of the two objects. |
| InContactWith(,) |
Object is in contact with if their surfaces are in contact in at least one point, i.e., . |
| ConnectedWith(,) |
Object is connected with if . |
| Under(,) |
Object is under object if . |
| OnFloor(,) |
Object is on the room floor if and is of Room type. |
| Open(o) |
Any joints (internal articulated degrees of freedom) of object are open. Only joints that are relevant to consider an object Open are used in the predicate computation, e.g. the door of a microwave but not the buttons and controls. To select the relevant joints, object models of categories that can be Open undergo an additional annotation that produces a RelevantJoints list. A joint is considered open if its joint state is 5% over the lower limit, i.e. . |
| Cooked(o) |
The temperature of object was over the cooked threshold, , and under the burnt threshold, , at least once in the history of the simulation episode, i.e., . We annotate the cooked temperature for each object category that can be Cooked. |
| Burnt(o) |
The temperature of object was over the burnt threshold, , at least once in the history of the simulation episode, i.e., . We annotate the burnt temperature for each object category that can be Burnt. |
| OnFire(o) |
The temperature of object is above the on-fire threshold, , i.e., . We assume as default on-fire temperature , a value that can be adapted per object category and model. |
| Frozen(o) |
The temperature of object is under the freezing threshold, , i.e., . We assume as default freezing temperature , a value that can be adapted per object category and model. |
| Heated(o) |
The temperature of object is above the heated threshold, , i.e., . We assume as default heated temperature , a value that can be adapted per object category and model. |
| Boiled(l) |
The temperature of liquid is above the boiling point, , i.e., . We assume as default boiling point , a value that can be adapted per object category and model. |
| Soaked(o, l) |
The soaked level of the liquid for the object is over a threshold, , i.e., . The default value for the threshold is , (the object is soaked if it absorbs more than liquid particles), a value that can be adapted per object category and model and per liquid type. |
| Filled(o, l) |
Object is filled by liquid if the number of particles of that is inside the ContainerVolume of is above a certain threshold percentage of the total volume. The default value for the threshold is . |
| Covered(o, s) |
For visualSubstance , check if the covered level of for the object is over a threshold, , i.e., ; for physicalSubstance , check if the number of particles of that are in contact with the object is over the same threshold. The default value for the threshold is (50 substance particles), a value that can be adapted per object category and model, and per substance. |
| ToggledOn(o) |
Object is toggled on or off. It is a direct query of the object’s extended state , the toggled state. |
| Sliced(o) |
Object is sliced or not. It is a direct access of the object’s extended state , the sliced state. |
| Broken(o) |
Object is broken or not. It is a direct access of the object’s extended state , the broken state. |
| Folded(o) |
Object is folded if its corresponding ClothKeypoints are sufficiently close to each other. |
| Unfolded(o) |
Object is unfolded if its corresponding ClothKeypoints are sufficiently far from each other. |
| Assembled(o) |
Object is assembled if all of its parts have been correctly connected: every pair of parts and are connected (or not) with each other (i.e. ) in a specific way defined by each object model. |
| Hung(,) |
Object is hung onto object if they are connected, . |
| Blended( ... ) |
Objects to are blended if they are in contact with each other, i.e. for all pairs. |
| InFoVOfAgent(o) |
Object is in the field of view of the agent, i.e., at least one pixel of the image acquired by the agent’s onboard sensors corresponds to the surface of . |
| InHandOfAgent(o) |
Object is grasped by the agent’s hands (i.e. assistive grasping is activated on that object). |
| InReachOfAgent(o) |
Object is within meters away from the agent. |
| InSameRoomAsAgent(o) |
Object is located in the same room as the agent. |
E.1.5 逻辑谓词作为采样函数
对于每个与 BEHAVIOR-1K 活动相关的逻辑谓词,我们还定义了一个生成函数,该函数根据二进制逻辑状态采样有效的物理状态。 此功能对于无限活动初始化至关重要。 例如,如果活动初始条件要求将一个盘子放在一张餐桌的 OnTopOf 上,那么可以满足此条件的盘子的精确姿势将有无限多个。 我们的生成函数将找到一个有效的解决方案,并将盘子物理地放在桌子上。 其他例子包括将物体的 Temperature 设置为使它 Frozen 或将物体的关节配置设置为使它 Open。 所有逻辑谓词的采样函数的详细信息可以在表格 A.8 中找到。
| Predicate | Sampling Mechanism |
|---|---|
| InsideOf(,) |
Only InsideOf(,) = True can be sampled. is randomly sampled within using a ray-casting mechanism adopted from [27]. is guaranteed to be supported fully by a surface and free of collisions with any other object except . |
| OnTopOf(,) |
Only OnTopOf(,) = True can be sampled. is randomly sampled on top of using a ray-casting mechanism adopted from [27]. is guaranteed to be supported fully by a surface and free of collisions with any other object except . |
| ConnectedWith(,) |
Create a rigid joint between the two objects if they are both rigid bodies, or an attachment between them otherwise. |
| Under(,) |
Only Under(,) = True can be sampled. is randomly sampled on top of the floor region beneath using a ray-casting mechanism adopted from [27]. is guaranteed to be supported fully by a surface and free of collisions with any other object except the floor. |
| OnFloor(,) |
Only OnFloor(,) = True can be sampled. is randomly sampled on top of , which is the floor of a certain room, using the scene’s room segmentation mask. is guaranteed to be supported fully by a surface and free of collisions with any other object except . |
| Open(o) |
To sample an object with the predicate Open(o) = True, a subset of the object’s relevant joints (using the RelevantJoints model property) are selected, and each selected joint is moved to a uniformly random position between the openness threshold and the joint’s upper limit. To sample an object with the predicate Open(o) = False, all of the object’s relevant joints (using the RelevantJoints model property) are moved to a uniformly random position between the joint’s lower limit and the openness threshold. |
| Cooked(o) |
To sample an object with the predicate Cooked(o) = True, the object’s MaxTemperature is updated to . Similarly, to sample an object with the predicate Cooked(o) = False, the object’s MaxTemperature is updated to . |
| Burnt(o) |
To sample an object with the predicate Burnt(o) = True, the object’s MaxTemperature is updated to . Similarly, to sample an object with the predicate Cooked(o) = False, the object’s MaxTemperature is updated to . |
| OnFire(o) |
To sample an object with the predicate OnFire(o) = True, the object’s Temperature is updated to a uniformly random temperature between and . To sample an object with the predicate OnFire(o) = False, the object’s Temperature is updated to . |
| Frozen(o) |
To sample an object with the predicate Frozen(o) = True, the object’s Temperature is updated to a uniformly random temperature between and . To sample an object with the predicate Frozen(o) = False, the object’s Temperature is updated to . |
| Heated(o) |
To sample an object with the predicate Heated(o) = True, the object’s Temperature is updated to a uniformly random temperature between and . To sample an object with the predicate Heated(o) = False, the object’s Temperature is updated to . |
| Boiled(l) |
To sample a liquid type with the predicate Boiled(l) = True, the Temperature of all particles of is updated to a uniformly random temperature between and . To sample a liquid type with the predicate Boiled(o) = False, the Temperature of all particles of is updated to . |
| Soaked(o, l) |
To sample an object and a liquid type with the predicate Soaked(o, l) = True, the object’s SoakedLevel for is updated to match the Soaked threshold of . To sample an object and a liquid type with the predicate Soaked(o, l) = False, the object’s SoakedLevel is updated to 0. |
| Filled(o, l) |
To sample an object and a liquid type with the predicate Filled(o, l) = True, an appropriate number of particles of are sampled inside the ContainerVolume of so that they fill up enough of its volume (). To sample an object and a liquid type with the predicate Filled(o, l) = False, all particles of that are inside the ContainerVolume of (if any) are removed. |
| Covered(o, s) |
To sample an object and a substance with Covered(o, s) = True, a fixed number of particles of are randomly placed on the surface of using a ray-casting mechanism adopted from [27]. To sample an object and a visualSubstance with Covered(o, s) = False, all particles of is removed from and the corresponding CoveredLevel is set to 0. |
| ToggledOn(o) |
The ToggledState of the object is updated to match the required predicate value. |
| Sliced(o) |
The SlicedState of the object is updated to match the required predicate value. Also, the whole object are replaced with the two halves, that will be placed at the same location and inherit the extended states from the whole object (e.g. Temperature). |
| Broken(o) |
The BrokenState of the object is updated to match the required predicate value. Also, the whole object is broken down into pieces, that will be placed at the same location. |
E.2 AMT 视觉真实感研究
我们进行了一项 Amazon Mechanical Turk (AMT) 研究,以评估 OmniGibson 相对于多个其他模拟环境的视觉真实感。 我们从 OmniGibson、AI2-Thor、ThreeDWorld、Habitat 2.0 和 iGibson 2.0 中选择了 50 个代表性的 图像,并将它们随机打乱成 50 组,每组 5 张图像,其中每组都包含来自每个模拟环境的唯一图像。 对于每组图像,参与者被要求根据视觉真实度对图像进行排名,将组中最真实的图像分配给 ,并将后续图像分配给 。 图像洗牌在参与者之间是随机的。 在展示我们的结果时,我们将 60 位参与者的汇总均值和标准差反转,这样 的分数将代表视觉上最真实的图像。
我们选择图像的标准如下:(a)我们只包含从 完全交互式 场景拍摄的照片,以进行公平比较,以及(b)渲染必须来自模拟环境内部,无需定制调整(即,新用户可以期望这种视觉质量无需调整即可开箱即用)。





E.3 视觉模态
OmniGibson 提供了多种感知模块,以从代理的角度捕捉真实的传感器模态,包括 RGB、深度、语义分割、法线和光流图像,以及非视觉模态,如本体感受和 LiDAR 扫描(图 A.8)。 OmniGibson 还为代理动作空间提供了不同的抽象级别,包括低级控制、辅助操作和基本技能执行。 总体而言,这些模块旨在对广泛的具身 AI 研究社区有用,目标是加速 BEHAVIOR-1K 的突破。
E.4 性能基准
为了评估 OmniGibson 在不同条件下的性能,我们在两个具有代表性的场景 (Rs_int 和 house_single_floor) 中进行了严格的速度测试,这些场景在单个 GPU、单进程设置下具有不同数量的物体。 我们采用来自 Li 等人 [59] 和 Szot 等人 [26] 的“闲置”设置:一个机器人被放置在场景中(除了最后一行“- 机器人”),并且以零速度动作静止不动。 在每个时间步长,模拟器运行物理模拟、扩展物体状态更新和转换机更新循环,并渲染一个 RGB 图像。 我们使用 的动作时间步长和 的物理时间步长。 我们的基准测试运行在具有 Intel(R) Core(TM) i7-10700K CPU @ 5.10GHz 和一个 Nvidia GeForce RTX 3080 GPU 的 Ubuntu 机器上,在一个单进程设置中。 结果总结在表 A.10 中。
奥姆吉布森 在类似设置下,以与 iGibson 2.0 [59] 等先前作品相当的速度运行,但由于光线追踪,渲染质量更高。 即使对于包含 600 多个物体的庞大场景,它也保持着合理的速度。 奥姆吉布森 而且,它高度可配置,并为用户提供灵活的接口,以根据其用例和研究兴趣在模拟保真度和速度之间取得平衡。 如果用户对其任务中流体或织物不感兴趣,他们可以关闭这些功能以提高性能速度。 同样,如果用户只对运动学重排任务或非机器人具身 AI 应用(例如虚拟相机)感兴趣,他们可以分别关闭物体状态更新或移除机器人。 我们正在积极努力改进可以提供模拟加速的方面,例如在物体休眠、网格简化、更高效的物体状态更新等领域。 此外,由于实时光线追踪和流体/织物模拟仍然是一个活跃的研究领域,我们预计 Nvidia 即将推出的硬件和软件进步将在这些领域带来显著的性能提升。
| Eval. Conditions | Scene | |
|---|---|---|
| Rs_int (81 objs) | house_single_floor (621 objs) | |
| Full Feature Set | ||
| - Fluid and Cloth | ||
| - Object State Update | ||
| - Robot | ||
附录 F 基线详情
本节包含有关在主要论文中评估和分析的基线的补充信息:视觉运动控制基线以及使用动作原语的基线的两种变体,分别有无观察历史记录。

F.1 网络架构
对于 RL-Prim. 和 RL-Prim.Hist. 使用 PPO 作为底层 RL 算法,该架构由一个视觉特征提取器组成,该提取器以自我中心视觉观察作为输入,以及一个状态编码神经网络,该网络以机器人是否抓取物体作为输入。 图像输入使用每通道移动平均值进行归一化。 这两种编码传递到 MLP 模块,然后由值头处理以预测给定观察值的值,并由动作头处理以产生与在对象上执行的动作原语相对应的离散动作。 输入图像的大小为 。 特征提取器是 Conv-ReLU-MaxPooling-Flatten 的顺序架构。 MLP 将特征转换为 维向量。 RL-Prim. 网络架构的细节如 Fig. A.11 (b) 所示。 对于使用 SAC 作为底层 RL 算法的 RL-VMC,我们使用与 RL-Prim. 相同的特征提取器。RL-VMC 由一个 actor 网络、一个 critic 网络和一个目标 critic 网络组成。 它们都是具有 ReLU 激活函数的 MLP。 Fig. A.11 (a) 说明了 RL-VMC 网络架构的细节。 RL-VMC 具有连续动作空间,并直接输出低级控制动作。
F.2 任务设置
Fig. A.9 描述了我们在实验中考虑的三个活动:
-
•
StoreDecoration:一项整理活动,其中代理必须拿起并把万圣节装饰品存放到一个橱柜中,操作关节对象。 动作空间:navigate、pick、place、push。 目标是将两个南瓜放入抽屉中(见图 A.9 (a))。
-
•
CollectTrash: 一项收集活动,要求代理收集空瓶子和杯子,并将它们扔进垃圾桶。 动作空间: navigate, pick, place。 目标是将两个瓶子和两个杯子扔进垃圾桶(见图 A.9 (b))。
-
•
CleanTable: 一项清洁活动,涉及具有挑战性的布料操作和液体来清洁桌子。 动作空间: navigate, pick, dip, wipe。 目标是用浸湿的布清洁桌子(见图 A.9 (c))。
每项活动都发生在不同的 B1K 场景中,Rs_int, mockup_apt 和 restaurant_hotel。
F.3 训练细节
学习目标。
奖励函数。
我们使用 BDDL 活动定义提供的成功信号作为所有方法中训练策略的奖励函数。 例如,在 StoreDecorations 任务中,BDDL 任务目标定义为 Forall(decoration){Inside(decoration, cabinet)}。 当且仅当其中一个 decoration 被物理放置在 drawer 的 cabinet 内时,代理会收到一个正信号。 这是一个具有挑战性的稀疏奖励设置,因为代理需要计划多个步骤才能达到最终目标,而没有中间子目标奖励(例如,push 打开 drawer 必须在 pick 和 place decoration 之前发生,但不会对 push 打开操作给予任何奖励信号)。
超参数。
计算。
对于我们实验的每次运行,我们使用一个 Nvidia GeForce RTX 2080 Ti 或一个 Nvidia RTX A-6000 GPU,以及 Intel Xeon CPU 和 40GB 内存。 训练期间,GPU 内存使用量约为 9GB。 训练迭代总数根据任务的不同,在 10k 到 25k 之间,总训练时间在 3.75 到 7.5 小时之间。
| Learning Rate | |
|---|---|
| Buffer Size | |
| Batch Size | |
| Discount () | |
| Soft Update Coefficient |
| Learning Rate | |
|---|---|
| Buffer Size | |
| Batch Size | |
| Discount () | |
| GAE Parameter | |
| Clipping Parameter | |
| Entropy Coeff | |
| VF Coeff |
F.4 动作原语
BEHAVIOR-1K 活动是长期的,需要数百甚至数千个环境步骤(低级机器人控制信号)才能完成。 克服这一挑战的一种方法(例如,强化学习)是对原始动作空间进行修改,使用一组 动作原语,即对应于多个低级命令并实现预期结果的时间扩展动作,例如抓取物体或导航到某个位置。 对于我们的基线,我们定义了六个这样的原语,并使用基于采样的运动规划器实现了它们。
所有基元都是组合的:整个机器人导航到某个位置的无碰撞路径、机器人手臂通过末端执行器达到 6D_pose 的无碰撞路径,或预定义的手臂关节配置、末端执行器在笛卡尔空间中遵循线的轨迹(可能与环境发生碰撞/交互)以及打开/关闭的操作序列t3> 机器人的抓手保持该位置。 所有操作原语都以从收缩配置(折叠手臂)移动手臂到展开配置的轨迹开始,以便能够进行后续的手臂交互,并以从展开配置到收缩配置的逆向运动结束,以便能够进行后续的避碰导航。 动作原语以要执行动作的物体作为参数;我们假设可以访问物体的 3D 位置,以获得查询运动规划器所需的参数。 这种程序在真实机器人上被复制,我们结合了 YOLO 的检测 [70] 和 RGB-D 图像深度图的信息,来获得参数(见第 G 节)。 对于导航操作,我们假设有一组已知的相关位置可供导航(在图 A.9 中的矩形旁边)
我们在实验中使用的基元可以在图 A.10 中看到,包括:
-
一个)
navigate:整个机器人的无碰撞轨迹到一个位置。
-
b)
pick:由以下部分组成:1)到拾取目标上方的预抓取 6D_pose 的轨迹,2)在笛卡尔空间中向下朝向目标的 line 轨迹,当有接触时中断,3)closing 操作,4)第一个沿 line 向上回撤的轨迹,以及 5)第二个回撤轨迹以到达未收缩的关节配置。 只有当机器人当前未拾取其他物体时,该基元才会执行。
-
c)
place:由以下部分组成:1)到放置抓取目标上方的预放置 6D_pose 的轨迹,2)opening 操作,3)第二个回撤轨迹以到达未收缩的关节配置。 只有当机器人当前握住一个物体时,该基元才会执行。
-
d)
push:由以下部分组成:1)到推开目标上方的预推 6D_pose 的轨迹,2)在笛卡尔空间中向下朝向目标的 line 轨迹,如果有接触则中断,3)在笛卡尔空间中推开目标(例如,朝向机器人)的 line 轨迹,4)第一个沿 line 向上回撤的轨迹,以及 5)第二个回撤轨迹以到达未收缩的关节配置。
-
e)
dip:由以下部分组成:1)到浸入目标上方的预浸泡 6D_pose 的轨迹,2)在笛卡尔空间中向下朝向目标浸泡的 line 轨迹,3)在笛卡尔空间中向上移动的 line 轨迹,以及 4)回到初始关节配置的回撤轨迹。 只有当机器人当前握住一个物体时,该基元才会执行。
-
f)
wipe:由以下部分组成:1)到擦拭目标上方的预擦拭 6D_pose 的轨迹,2)在笛卡尔空间中向下朝向要擦拭的目标的 line 轨迹,当有接触时中断,3)在笛卡尔空间中水平擦拭左右的 line 轨迹,4)在笛卡尔空间中水平擦拭朝向机器人的 line 轨迹,4)第一个沿 line 向上回撤的轨迹,以及 5)第二个回撤轨迹以到达未收缩的关节配置。 该原语仅在机器人当前握持物体时执行。






F.5 附加指标:成功得分 Q
表 A.13 中报告了每个任务的成功得分 Q [27]。 我们观察到 Q 中的趋势与成功率相同。 这是我们方法有效性的另一个迹象。
| Method | Policy Features | Success score Q | |||
|---|---|---|---|---|---|
| Primitives | History | StoreDecoration | CollectTrash | CleanTable | |
| RL-VMC | |||||
| RL-Prim. | |||||
| RL-Prim.Hist. | |||||
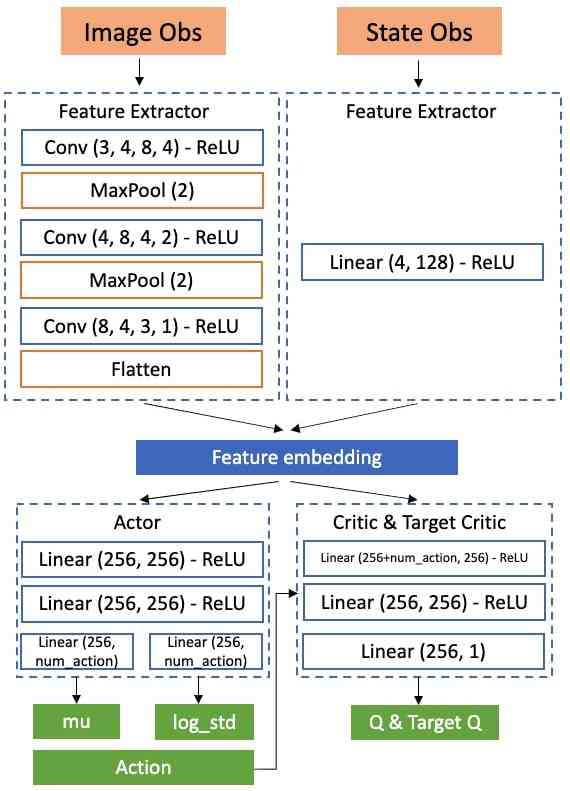 |
 |
| a) SAC Architecture | b) PPO Architecture |
附录 G 现实世界设置的详细信息
场景。
我们的现实世界实验是在我们实验室的一个模拟工作室公寓中进行的,该公寓包括一个卧室、一个客厅和一个餐厅。 为了 BEHAVIOR-1K,这个现实世界场景被模拟了一个数字对应物:mockup_apt 场景。 图 5 并排描绘了真实的和数字的孪生兄弟。 数字模型是首先使用手机和商业软件 [83] 扫描真实公寓创建的,然后,替换和投影墙壁、地板和天花板的纹理,最后,用我们 BEHAVIOR-1K 数据集 中的 3D 模型替换现有对象。 这个过程应该将真实世界和 3D 模型之间的差异造成的影响降到最低。 模拟机器人和真实机器人使用场景的相同 2D 地图进行定位。 这样,真实世界中的 2D 位置就对应于模拟中的相同 2D 位置。
机器人平台。
我们在实验中使用来自 PAL Robotics 的 Tiago++ 模型,该模型具有全向底座、两个带有平行旋转夹持器的 7 自由度手臂、一个 1 自由度棱柱形躯干、两个 SICK LiDAR 传感器(底座的背面和正面)以及一个安装在机器人头部上的 ASUS Xtion RGB-D 相机,该相机可以在偏航和俯仰方向上控制。 所有传感器和执行器都通过机器人操作系统 ROS [84] 连接。 代码运行在一台配备 Nvidia GTX 1070 的笔记本电脑上,该笔记本电脑将命令发送到板载机器人计算机以执行。
真实机器人上的动作原语。
我们在真实机器人上实现了动作原语的版本,包括 navigate、pick 和 place,类似于它们在 OmniGibson 中的实现。 对于导航,我们使用基于二维采样的运动规划器,该规划器在二维地图上进行,该地图用于定位,并且是从公寓的三维模型创建的。 为了在现实世界中进行操作,我们需要从传感器信号中获得规划操作原语(pick 和 place)所需的参数。 为此,我们首先从机器人相机获取的 RGB 图像中,使用 YOLO v3 [70] 物体检测器获得检测结果。 如果机器人试图对未检测到的物体执行动作原语,我们返回失败(在我们的分析中为 Object Detection Failure)。 如果要操作的物体已被检测到,我们查询深度图中对应于检测边界框中心处的 2121 窗口的像素,并使用此信息计算对应 3D 点的质心。 该位置将用作抓取或放置物体的目标位置。 这些信息足以使用基于采样的运动规划器 (RRT [62]) 创建一系列路径,类似于模拟中使用的路径。 运动规划器使用从深度传感器获得的场景体素表示。
实验设置。
我们在真实机器人的实验中随机化了三个参数:机器人的初始位置(从三个可能的活动位置中选择),物体在桌子上的位置以及物体的方向(直立或平躺)。 实验运行均匀地覆盖了这些参数。 此外,对于基于视觉的策略,我们评估了两种照明条件:全照明(包括天花板)和仅使用灯。 失败定义如下: 运动规划失败发生在机器人无法规划末端执行器轨迹来完成动作原语时。 这包括由于导航噪声引起的失败,其中机器人导航到任务位置后,距离目标物体太远,无法执行拾取或放置动作。 抓取失败包括在执行抓取过程中发生的错误,例如在尝试抓取时将物体推离桌子或由于物体滑落而丢失物体,以及机器人抓取物体后掉落物体。 放置失败包括机器人将物体放到错误的位置。 物体检测失败主要源于我们的物体检测器 YOLO v3 [70] 无法检测到要交互的物体;第二种,不太常见的物体检测失败对应于深度相机返回检测物体的无效测量值。 最后,当策略连续三次选择相同的无效动作时,我们认为策略失败,例如,当机器人已经在垃圾箱前面时,要求它导航到垃圾箱。 主要策略错误对应于策略重复选择相同的动作原语。 我们通过实验证明,即使策略选择在策略连续三次请求相同无效动作时呈现一些小的随机性,大多数后续调用也将是相同的无效动作,因此我们决定提前终止。
G.1 模拟与真实差距的进一步描述
我们进行了额外的实验来描述模拟与现实世界之间的差距。 在我们的实验中,我们将机器人移动到 mockup_apt 场景中的不同位置,并收集真实的传感器信号:RGB 图像、深度图和激光雷达测量值。 然后,我们将机器人移动到模拟中的相同位置,并收集虚拟传感器信号。 图 A.12 显示了一些图像。 我们观察到,由于我们高度逼真的模型,OmniGibson 提供了高保真的传感器信号,这些信号近似于现实世界的传感器信号。 但是,目前 OmniGibson 中没有对真实传感器中的一些噪声源进行建模,这会导致模拟与现实之间的差距,例如,RGB 相机的动态范围较差,或由于投影光机制导致深度图中的“阴影”效应。 这种分析表明,可以通过在 OmniGibson 中包含传感器噪声模型或利用模拟到现实的技术(例如,领域随机化、系统识别)来进一步缩小模拟与现实世界之间的传感器差距。
G.2 附加实验
除了 RL-Prim.Hist. 之外,我们还评估了 RL-VMC 和 RL-Prim.Hist. 在现实世界中,并且观察到在现实世界中与模拟中类似的性能趋势:RL-VMC < RL-Prim. < RL-Prim.Hist.. 由于训练期间的稀疏奖励和探索难度,RL-VMC 仍然没有取得成功。 RL-Prim。 的性能比 RL-Prim.Hist. 差。 :平均而言,使用 RL-Prim.Hist. 的机器人 成功放置了 0.64 个杯子/瓶,而使用 RL-Prim. 的机器人 放置了 0 个。 从定性角度看,RL-Prim. 往往陷入重复的动作循环中,因为代理不知道自己的动作历史。 这一初步结果让我们对 OmniGibson 能够成为未来模拟到现实机器人研究的可靠测试平台充满信心。


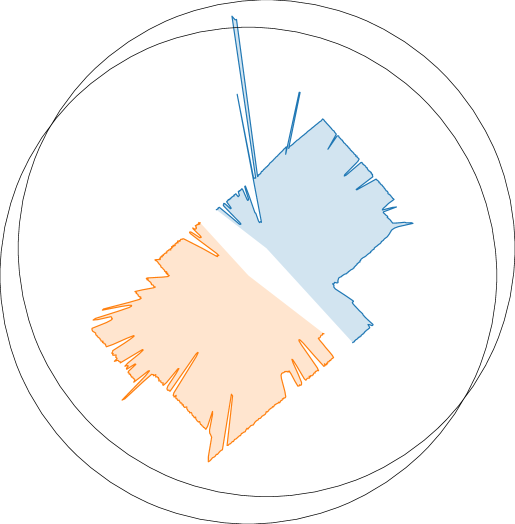





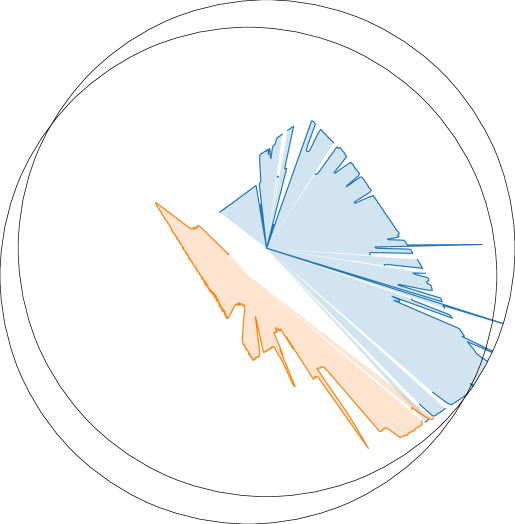


附录 H 伦理声明
BEHAVIOR-1K 旨在推动实现能够满足人类需求的具身人工智能解决方案。 因此,BEHAVIOR-1K 的主要伦理考量是用于确定这种需求的方法。 为了理解哪些活动对人类有用,我们在 Amazon Mechanical Turk 上对 1,461 名受访者进行了调查,并为每项活动收集了 50 份回复,旨在获得清晰的共识信号。 尽管这是一个庞大的群体,但结果仍然受到以下因素的影响:研究人员、标注者和数据提供者相对于这种技术的潜在用户群体而言只代表一小部分人口。 我们计划通过将 BEHAVIOR-1K 数据集 开源并邀请更广泛的社区为其知识库做出贡献来解决这些偏差。
此外,与美国人口相比,我们调查中的人口统计学特征偏向白人、男性、无残疾、中等五位数收入和 30-40 岁年龄段,其中该年龄段较高端的代表性更高,而较低端的代表性更低,更接近 Mechanical Turk 工作人员的人口统计特征。 这也使调查人口对某些回复产生偏差,从而造成潜在的伦理限制。
具体而言,这种偏差可能会影响调查对那些将最受自主代理影响的人群的代表性 [85]。 因此,我们提出了一些明确的问题,例如“你是否以家务劳动为生?”、“如果你以家务劳动为生,你是否会从帮助中受益?”、“你是否为别人付钱让他们为你做家务?”。 未来工作将涉及使用这些问题来指导基准开发。
语言 = C、basicstyle =、backgroundcolor =、stringstyle =、keywordstyle = [2]、keywordstyle = [3]、keywordstyle =、otherkeywords = ?、morekeywords = [2]ontop、inside、inroom、morekeywords = [3]define、问题、域、对象、init、目标、和、for_n_pairs、forall、:、存在、和、