Glyph-ByT5:用于精确视觉文本渲染的定制文本编码器
摘要
视觉文本渲染对当代文本到图像生成模型提出了根本性挑战,其核心问题在于文本编码器的缺陷。 为了实现准确的文本渲染,我们确定了文本编码器的两个关键要求:字符识别和字形对齐。 我们的解决方案涉及通过使用精心策划的配对字形文本数据集微调字符感知 ByT5 编码器来制作一系列定制文本编码器 Glyph-ByT5。 我们提出了一种将 Glyph-ByT5 与 SDXL 集成的有效方法,从而创建了用于设计图像生成的 Glyph-SDXL 模型。 这显着提高了文本渲染的准确性,在我们的设计图像基准测试中将其从低于 提高到接近 。 值得注意的是 Glyph-SDXL 新发现的文本段落渲染功能,通过自动多行布局实现数十到数百个字符的高拼写准确性。 最后,通过使用一小组具有视觉文本的高质量、真实感图像对 Glyph-SDXL 进行微调,我们展示了开放域真实图像中场景文本渲染能力的重大改进。 这些引人注目的结果旨在鼓励进一步探索为多样化和具有挑战性的任务设计定制文本编码器。
![[Uncaptioned image]](paragraph_1.png)
![[Uncaptioned image]](paragraph_2.png)
![[Uncaptioned image]](paragraph_3.png)
![[Uncaptioned image]](paragraph_4.png)
![[Uncaptioned image]](design_1.png)
![[Uncaptioned image]](design_5.png)
![[Uncaptioned image]](design_2.png)
![[Uncaptioned image]](design_3.png)
![[Uncaptioned image]](scene_1.png)
![[Uncaptioned image]](scene_2.png)
![[Uncaptioned image]](scene_3.png)
![[Uncaptioned image]](scene_5.png)
1简介
扩散模型已成为图像生成的主要方法。 值得注意的贡献,例如 DALLE3 [3, 19] 和稳定扩散系列 [24, 22],展示了在生成高质量图像方面的卓越能力响应用户提示的图像。 然而,它们准确渲染视觉文本的能力仍然存在重大限制,而视觉文本是各种图像生成应用程序中的关键要素。 这些应用范围从制作海报、卡片和小册子的设计图像到合成具有路标、广告牌或载有文本的 T 恤中的场景文本的现实世界图像。 实现精确文本渲染精度的挑战阻碍了图像生成模型在这些重要领域的实际部署。
我们认为阻碍视觉文本渲染性能的主要挑战在于文本编码器的局限性。 广泛使用的 CLIP 文本编码器经过训练,可以与视觉信号对齐,主要侧重于掌握图像概念,而不是深入研究图像细节。 相反,普遍采用的 T5 文本编码器是为全面理解语言而设计的,但缺乏与视觉信号的一致性。 我们认为,能够编码字符级信息并与视觉文本信号或字形对齐的文本编码器对于实现视觉文本渲染的高精度至关重要。 从字符感知 ByT5 编码器 [16] 中汲取灵感,我们的方法旨在对其进行自定义,以更好地与视觉文本或字形对齐。
为了构建所需的字符感知和字形对齐文本编码器,我们采用基于 ByT5 模型的微调方法,使用配对文本字形数据。 主要挑战来自于高质量配对文本字形数据的稀缺,我们通过建立一个可扩展的管道来克服这一挑战,该管道能够基于图形渲染生成几乎无限的配对数据。 此外,我们还采用了字形增强策略来增强文本编码器的字符感知,解决视觉文本渲染中常见的各种错误类型,如[16]中所述。 利用我们精心制作的数据集并采用创新的框级对比损失,我们有效地将 ByT5 调整为一系列用于字形生成的定制文本编码器,命名为 Glyph-ByT5。
| Method | #Params | Char-aware | Glyph-align | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | ||||
| M | ✗ | ✗ | |||||
| + T5-L | + M | ✗ | ✗ | ||||
| + ByT5-S | + M | ✓ | ✗ | ||||
| + Glyph-ByT5-S | + M | ✓ | ✓ | ||||
| + | + M | ✓ | ✓ | ||||
| B | ✗ | ✗ | |||||
| DALLE3 | Unknown | ✗ | ✗ | ||||
经过彻底的训练,Glyph-ByT5 使用高效的区域交叉注意力机制无缝集成到 SDXL 模型中,显着增强了原始扩散模型的文本渲染性能。 由此产生的 Glyph-SDXL 模型展示了卓越的拼写准确性,在生成文本丰富的设计图像方面优于其他最先进的模型,如表 1 所示。 此外,我们使用一组有限的场景文本图像对 Glyph-SDXL 进行了微调,显着增强了其生成场景文本图像的能力。 图 1 中的示例表明,改进后的模型能够熟练地将文本段落渲染为场景文本,而原始模型的图像生成能力没有明显下降。
我们的调查表明,通过定制文本编码器的训练和合适的信息注入机制的实现,我们可以将开放域图像生成器转变为出色的视觉文本渲染器。 当呈现数十到数百个字符的文本段落时,我们经过微调的扩散模型可以在指定区域内实现渲染的高拼写准确性,并完全自动处理多行布局。 从本质上讲,这项工作以三种不同但互补的方式做出了贡献。 首先,我们训练一个字符感知、字形对齐的文本编码器 Glyph-ByT5,作为准确视觉文本渲染问题的关键解决方案。 其次,我们详细介绍了 Glyph-SDXL 的架构和训练,Glyph-SDXL 是一种稳健的设计图像生成器,通过高效的区域交叉注意机制将 Glyph-ByT5 集成到 SDXL 中。 最后,我们展示了将 Glyph-SDXL 微调为场景文本图像生成器的潜力,为开发具有卓越视觉文本渲染功能的全面、开放域图像生成器奠定了基础。
2相关工作
2.1 视觉文本渲染
渲染清晰且视觉连贯的文本对基于扩散的图像生成模型提出了众所周知的限制和重大挑战。 值得注意的是,某些当代开放域图像生成模型,例如 Stable Diffusion 3 [10] 和 Ideogram 1.0111https://about.ideogram.ai/1.0,投入了大量精力来增强视觉文本渲染性能。 然而,渲染文本的拼写准确性仍然不能令人满意。 相反,也有人致力于视觉文本渲染,例如 GlyphControl、GlyphDraw 和 TextDiffuser 系列[29,17,16,6,7]。 虽然这些努力在拼写准确性方面取得了显着的进步,但令人失望的是,他们仍然专注于渲染单个单词或少于大约 20 个字符的文本行。 在这项研究中,我们的目标是解决精确的视觉文本渲染问题,特别是在处理超过一百个字符的文本内容时,在该领域提出了一个雄心勃勃的目标。
2.2 自定义文本编码器
最近的一些努力[12,5,32]已经针对面向文本的扩散模型做出了一些努力,并以不同的方式用定制的文本编码器替换或增强了原始的CLIP编码器。 然而,这些方法和它们的前身一样,仅限于处理一定长度的文本序列,UDiffText [32] 支持不超过 12 个字符的序列。 相比之下,我们的方法的独特之处在于它能够生成超过 100 个字符的文本序列,同时实现极高的准确度,达到接近 字级的准确度。 这一重大进展解决了以前方法的缺点,提供了更广泛的适用性并提高了文本生成任务的性能。 另一项密切相关的工作是计数感知 CLIP [21],它通过专门的图像文本计数数据集和以计数为中心的损失函数增强了原始 CLIP 文本编码器。 然而,他们的方法的一个重大限制是数据集缺乏可扩展性。 他们选择从头开始替换原始文本编码器和训练扩散模型,而我们的数据构建管道是可扩展的,我们优先考虑将 GlyphByT5 与原始文本编码器集成以提高效率。
我们的贡献我们的工作与前面提到的研究的见解相一致,发现大多数当前文本到图像生成模型的一个关键限制在于文本编码器。 我们工作的主要贡献在于提出了一种有效的策略来系统地解决字形渲染任务。 我们首先证明,利用图形渲染创建可扩展且准确的字形文本数据对于训练高质量、字形对齐、字符感知的文本编码器至关重要。 然后,我们介绍一种简单而强大的方法,将 Glyph-ByT5 文本编码器与 SDXL 中使用的原始 CLIP 文本编码器集成。 此外,我们还说明了如何通过执行设计到场景的对齐微调来将我们的方法应用于场景文本生成。 我们预计,在可扩展的高质量数据上训练定制文本编码器是克服空间意识和计算能力等基本限制的有希望的途径。
3 我们的方法
我们首先说明定制的字形对齐、字符感知文本编码器 Glyph-ByT5 的详细信息,该编码器使用配对字形图像和文本指令的大量数据集进行训练。 随后,我们演示了 Glyph-ByT5 在与用于设计文本渲染任务的 SDXL 模型集成时如何显着提高视觉文本渲染精度。 最后,我们引入了一种简单而有效的设计与场景对齐方法,使 Glyph-SDXL 能够适应精确的场景文本生成。
3.1 Glyph-ByT5:用于设计文本生成的定制字形对齐字符感知文本编码器
导致文本渲染不准确的一个关键因素是现代扩散模型中文本编码器的固有局限性,特别是在它们对字形图像的解释方面。 例如,最初的 CLIP 文本编码器是为概念层面上广泛的视觉语言语义对齐而定制的,而 T5/ByT5 文本编码器则专注于深度语言理解。 然而,尽管最近的工作表明 T5/ByT5 文本编码器有利于视觉文本渲染任务,但两者都没有针对字形图像解释进行明确的微调。 缺乏定制的文本编码器设计可能会导致各种应用程序中的文本呈现不太准确。
 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
 (e)
(e)
 (f)
(f)
 (g)
(g)
 (h)
(h)








为了弥合现有文本编码器(例如 CLIP 文本编码器或 T5/ByT5 文本编码器)和字形图像之间的差距,我们为一系列字形对齐的字符感知文本编码器提出了一种创新的字形对齐方法,即,字形-ByT5。 我们的方法专注于训练一系列字形感知文本编码器,专门设计用于协调字形图像和文本之间的差异。 受 LiT 框架 [30] 的启发,我们的策略涉及专门微调文本模型,同时保持预训练的图像模型冻结。 这种方法有效地迫使文本编码器进行适应,学习识别从已训练的图像模型中提取的视觉字形表示中编码的丰富信息。 对于视觉编码器组件,我们选择预先训练的 CLIP 视觉编码器或 DINOv2 模型,利用它们处理视觉数据的高级功能。 我们还探讨了采用专门为场景文本识别或其他任务量身定制的视觉编码器训练的影响,并且我们认为开发和用于视觉文本渲染的更先进的视觉编码器是未来的研究途径。
创建可扩展且准确的字形文本数据集为了启用自定义字形感知文本编码器的训练,我们首先创建一个高质量的字形文本数据集,表示为,由大约百万对合成数据组成。 该数据集是通过[13]最近的工作中引入的改进图形渲染来开发的。 我们根据在爬行的图形设计图像中找到的原始印刷属性(包括字体类型、颜色、大小、位置等)构建初始字形图像集。 我们编译了一个大型文本语料库,可以通过用从语料库中采样的随机文本替换单词来丰富字形图像集。 此外,我们随机修改每个文本框中的字体类型和颜色以进一步扩大数据集。 我们的字形文本数据集 包含几乎 不同的字体类型和 不同的字体颜色。 为了确保字形对齐的文本编码器仅关注视觉文本上的差异,我们默认都使用黑色背景。
我们给出与图3(a)所示的字形图像相对应的字形提示示例,详细说明字体类型、颜色和文本,如下所示:{Text“oh! 你要去的地方!”在[字体颜色-39]、[字体类型-90]中。 发短信“金毕业快乐!”在[字体颜色19][字体类型181]}中。 在此过程中,使用特殊标记来表示字体颜色和类型。 在将其输入 Glyph-ByT5 文本编码器之前,我们通过用丰富代码本中的一系列全局嵌入替换特殊标记(例如词符“[font-color-39]”)来预处理提示文本。 我们在三个不同尺度的 Glyph-Text 数据集上进行了实验,从 100K 扩展到 500K,最高可达 1M。 未来,我们的目标是显着扩展我们的数据集,在获得更多计算资源的情况下扩展到 100M。
创建段落字形文本数据集为了提高小字体的生成质量和定制文本编码器的段落级布局规划能力,我们额外编写了密集小段落-级别字形文本数据集,表示为。
我们将“段落”定义为无法容纳在一行中的文本内容块,通常由超过 10 个单词或 100 个字符组成。 段落字形渲染任务提出了更大的挑战,因为它不仅需要非常高的单词级拼写准确性,而且还需要对指定框区域内的单词级和行级布局进行细致的规划。 该数据集由 100,000 对合成数据 组成。 经验结果表明,使用 对最初使用 训练的模型进行微调,可以显着提高渲染小尺寸和段落级视觉文本的性能。
段落级布局规划的能力非常重要,我们凭经验证明扩散模型可以有效地规划多行排列并根据给定的文本框调整行或字间距,无论其大小或长宽比如何。 我们在图 3 中显示了段落字形文本数据的示例图像,说明每个图像至少包含一个超过 100 个字符的文本框。 有些图片甚至达到400个字符,以合理的间距排列成多行。 我们还构建了三个比例的段落字形文本数据集,包括 100K、500K 和 1M 字形文本对。
字形增强 与传统的 CLIP 模型不同,传统的 CLIP 模型仅将不同的字形文本对视为负样本,从而仅对由多个单词甚至由超过 这种方法构建了更多信息量的负样本,显着提高了训练效率。
所提出的字符级和单词级增强方案本质上由四种不同的字形增强策略的组合组成,包括字形替换、字形重复、字形删除 和 glyph add 在字符级和单词级。 我们将这些增强应用于 和 以确保一致性。 图 3 显示了这些增强策略的一些代表性示例。 我们还研究了为每个样本构建不同比例的信息负样本的效果。 我们独立地将这些增强应用到每个文本框。 我们在补充材料中提供了整个字形文本数据集和段落字形文本数据集的文本框、单词和字符数量的统计数据。
Glyph Text Encoder 为了有效捕获每个字符的文本特征,我们选择了字符感知的 ByT5 [28] 编码器作为 Glyph-CLIP 的默认文本编码器。 最初的 ByT5 模型具有强大的重型编码器和较轻的解码器。 ByT5 编码器使用 mC4 文本语料库中的官方预训练检查点进行初始化,如[27]中所述。
此外,我们还探讨了将文本编码器从小尺寸缩放到更大尺寸的影响。 这包括评估各种 ByT5 模型,例如 ByT5-Small(217M 参数)、ByT5-Base(415M 参数)和 ByT5-Large(864M 参数),检查其性能增强情况。 为了与原始 ByT5 系列区别,我们将这些文本编码器称为 Glyph-ByT5,表明它们专门致力于弥合字形图像与其相应文本提示之间的差距。
Glyph Vision Encoder 为了探索视觉编码器,我们分析了使用源自 CLIP [23] 或 DINOv2 [20, 9] 的视觉嵌入的影响,或为视觉文本识别任务定制的变体[31, 1]。 我们的观察表明 DINOv2 具有最佳性能。 还值得注意的是,CLIP 的视觉嵌入很难区分不同的字体类型。 这一发现与 [8, 34] 所讨论的最近的研究工作相一致,这些研究表明 DINOv2 在保存身份信息方面表现出色。 因此,DINOv2 被选为我们的主要视觉编码器。 此外,我们还探讨了将视觉编码器从小尺寸缩放到更大尺寸对性能的影响。 这包括评估 ViT-B/14(86M 参数)、ViT-L/14(300M 参数)和 ViT-g/14(1.1B 参数)等变体,并将它们与上述三个不同规模的 ByT5 文本编码器对齐。
框级对比损失 与将对比损失应用于整个图像的传统 CLIP 不同,我们建议应用框级对比损失,将每个文本框及其相应的文本提示视为一个实例。 根据文本框中的字符或单词的数量,我们可以将它们分类为单词文本框、句子文本框或段落文本框。 因此,我们的框级对比损失能够将文本与不同粒度级别的字形图像对齐。 这种对齐有助于我们定制的文本编码器获得段落级布局规划的能力。 我们将数学公式解释如下:
| (1) |
其中 表示同一批次中的所有图像文本对,其中第 个图像文本对由 框子文本对组成。 我们计算第 个图像文本对 中第 个框的框嵌入和子文本嵌入,如下所示: 和。 和分别表示视觉编码器和文本编码器。 我们设置了和之后的两个归一化因子。 是一个可学习的温度参数。
基于字形增强的硬阴性对比损失: 我们还计算了通过字形增强生成的硬阴性样本的对比损失,数学公式如下所示:
| (2) |
其中 和 这里, 表示基于框 和子文本 的增强训练数据>。 我们研究了消融实验中改变增强数据点数量的影响。
我们结合上述两个损失,即 ,以促进字形对齐预训练过程。 我们还凭经验证明,我们的设计优于消融实验中的图像级对比损失。 我们将卓越的性能归因于两个主要因素:大量有效训练样本的可用性,以及提供更准确视觉文本信息的框级视觉特征。 这些断言得到了先前两项研究结果的证实[4, 33]。 图4描绘了Glyph-ByT5的完整框架,展示了其集成了前面提到的关键组件的字形对齐预训练过程。
3.2 Glyph-SDXL:使用 Glyph-ByT5 增强 SDXL 以生成设计图像
为了验证我们的方法在设计图像中生成准确的文本内容以及规划每个文本框中的视觉段落布局的有效性,我们将 Glyph-ByT5 与最先进的开源文本到图像集成一代模型,SDXL [22]。 主要挑战在于将我们定制的文本编码器与现有的文本编码器集成,以利用两者的优势而不损害原始性能。 另一个挑战是缺乏用于在连贯背景图像层中渲染的训练设计文本生成模型的高质量图形设计数据集。
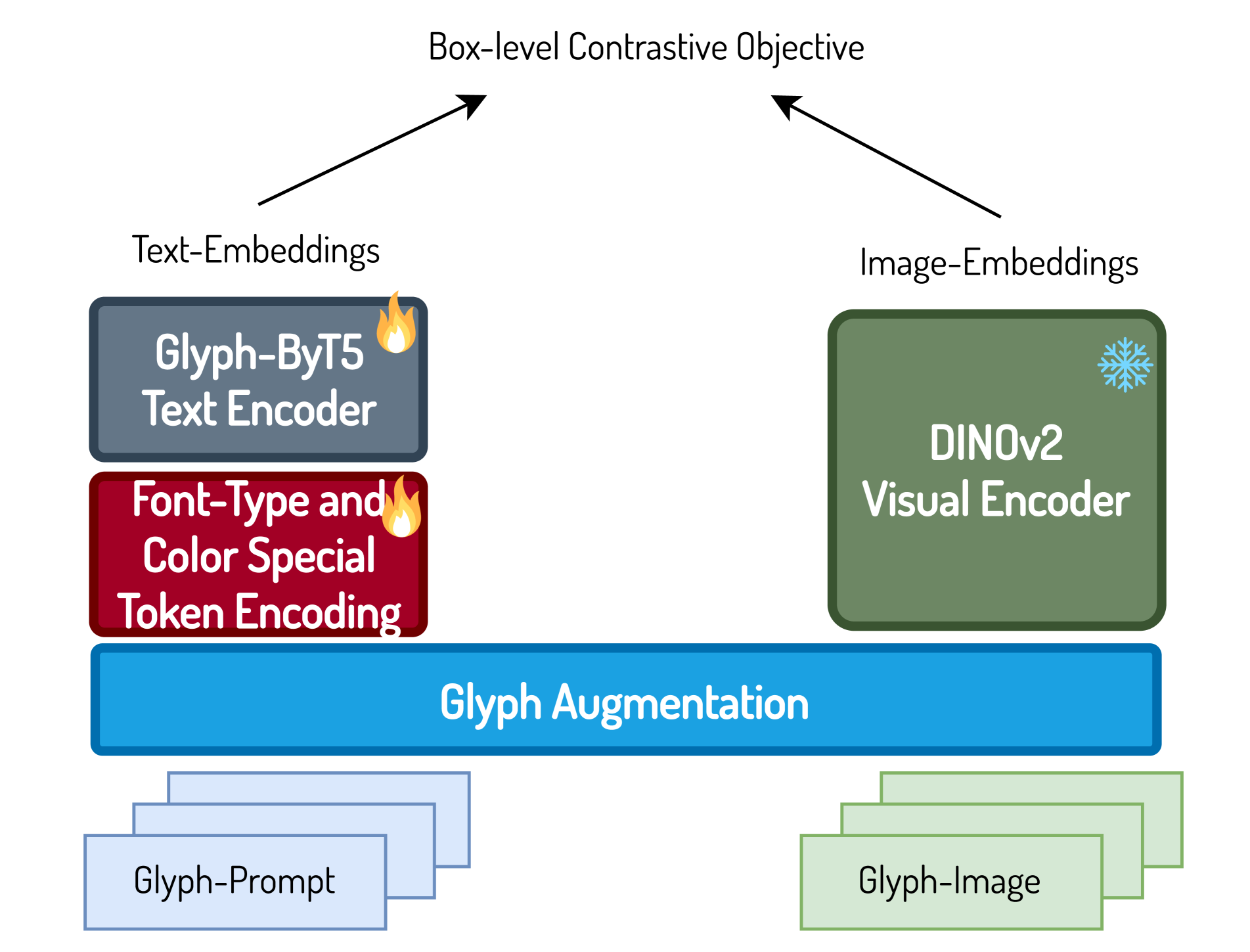 (一) 字形对齐预训练
(一) 字形对齐预训练
 (b) 区域级多文本编码器融合
(b) 区域级多文本编码器融合
为了解决上述两个挑战,我们首先引入了一种区域级多头交叉注意机制,将我们定制的文本编码器中编码的字形知识无缝地融合到目标排版框中的原始文本编码器所携带的先验知识中。排版框之外的区域。 此外,我们构建了一个高质量的图形设计数据集来训练我们的 Glyph-SDXL 生成模型,以实现准确的视觉文本渲染。 后续章节将详细讨论这两个关键贡献。
Region-wise Multi-head Cross-Attention 原始的多头交叉注意力是核心组件,负责将文本空间的丰富语义信息映射到图像空间的不同位置。 换句话说,它通过在不同层和时间步上持续应用多头交叉注意力来确定在哪里生成什么对象。
区域级多头交叉注意力的详细框架如图4右侧所示。 在我们的区域多头交叉注意机制中,我们首先将输入像素嵌入(查询)划分为多个组。 这些组对应于目标文本框,可以由用户指定,也可以利用 GPT-4 的规划功能自动预测。 同时,我们将文本提示(Key-Value)分为相应的子部分,其中包括全局提示和几组特定于字形的提示。 然后,我们专门指导目标文本框中的像素嵌入,以仅关注使用 Glyph-ByT5 提取的字形文本嵌入。 类似地,文本框外部的像素嵌入专门用于使用原始两个 CLIP 文本编码器提取的全局提示嵌入。
为了缩小 Glyph-ByT5 的输出嵌入空间与原始 SDXL 嵌入空间之间的差距,我们引入了一个轻量级映射器,即 ByT5-to-SDXL 映射器。 该映射器配备了四个 ByT5 Transformer 编码器层,每个层都使用随机权重进行初始化,并应用于预训练的 Glyph-ByT5 文本编码器的输出。 为了提高效率,我们通过使用掩模调制注意力图来实现上述区域级多头交叉注意力,该掩模确保像素嵌入和多个文本编码器嵌入之间的映射关系。 我们在训练期间增强了 Glyph-ByT5 文本编码器和 ByT5-to-SDXL 映射器的权重,这与之前的研究 [16] 一致,该研究强调了在扩散模型可以显着提高性能。
用于设计文本生成的视觉设计数据集 选择可靠的任务来访问设计文本渲染性能非常重要。 这项工作选择设计图像生成,因为这是文本密集型生成任务最具代表性的场景之一。 因此,我们首先通过从[13]之后的大量平面设计网站爬取,构建一个高质量的视觉设计图像数据集,在每个图像上渲染密集的段落级视觉文本。 这项任务提出了两个重大挑战,因为它不仅需要生成密集的视觉文本,还需要具有视觉吸引力的背景图像。 我们还创建了三个版本的图形设计数据集,大小分别为 100K、500K 和 1M,其中我们利用基于 Llama-B [25]的 LLaVA [15],为每个图形设计图像生成详细的标题,并可在原始数据中随时获取真实的字形文本。 我们还进行了数据清理,以确保很少有图形设计图像与用于字形对齐预训练的字形文本图像共享相同的版式。
Glyph-SDXL 我们在上面构建的设计文本数据集上训练 Glyph-SDXL。 为了保留 SDXL 的固有功能,我们锁定整个模型的权重,包括 UNet 架构和双 CLIP 文本编码器。 首先,我们专门在 UNet 组件上实现 LoRA [11] 模块。 其次,我们引入了一种区域级多文本编码器融合机制,旨在将 Glyph-ByT5 文本编码器的字形感知功能与两个原始 CLIP 文本编码器的强大优势相集成。 这种方法旨在协同每个文本编码器的独特功能,增强视觉文本渲染性能。 在实现中,我们只需要用我们的区域多头交叉注意相应地修改原始的多头交叉注意模块。
我们在补充材料中详细阐述了我们的方法与传统排版渲染工具之间的差异。 我们定制的 Glyph-ByT5 与传统工具的渲染精度相匹配,同时利用完全基于扩散的模型的功能。 这使得它能够处理超出标准渲染工具能力的场景文本生成任务。
3.3 设计到场景对齐:微调 Glyph-SDXL 以生成场景文本
之前构建的 Glyph-SDXL 主要针对图形设计图像进行训练,在生成保持连贯布局的场景文本时遇到困难。 此外,我们还注意到一种被称为“语言漂移”的现象,它稍微削弱了模型的原始熟练程度。 为了解决这些问题并促进创建卓越的场景文本生成模型,我们建议开发混合设计到场景对齐数据集。 该数据集结合了三种类型的高质量数据:来自 TextSeg [26] 的 4,000 个场景文本和设计文本图像、使用 SDXL 生成的 4,000 个合成图像以及 4,000 个设计图像。 我们只需在 epoch 的混合设计到场景对齐数据集上调整 Glyph-SDXL。 我们在三个公共基准测试中对我们的方法的场景文本渲染能力进行了彻底的评估,并报告了与之前最先进的方法相比显着的性能提升。 为了将其与原始的 Glyph-SDXL 区分开来,我们将设计到场景对齐数据集上的微调版本指定为 Glyph-SDXL-Scene。 此外,我们证明每个子集可用于三个组合目的:连贯的布局、准确的文本渲染和视觉质量,如补充材料中详述。
4实验
我们评估我们的方法在图形设计图像中生成准确的设计文本的能力,这些图像通常具有许多段落级文本框,以及逼真图像中的场景文本。 为了便于评估段落级视觉文本渲染,我们开发了 VisualParagraphy 基准测试。 该基准测试包括不同宽高比和比例的边界框中的多行视觉文本。
我们的评估将我们的方法与商业产品和最先进的视觉文本渲染技术(例如 DALL·E)在设计文本生成任务中进行比较。 我们报告客观的 OCR 指标并进行主观用户研究,从其他方面评估视觉质量。 对于场景文本生成任务,我们在三个公共基准测试中将我们的方法与代表性模型 GlyphControl [29] 和 TextDiffuser-2[7] 进行比较。
![[Uncaptioned image]](ours_1.png)
![[Uncaptioned image]](ours_2.png)
![[Uncaptioned image]](ours_3.png)
![[Uncaptioned image]](ours_4.png)
![[Uncaptioned image]](ours_5.png)
![[Uncaptioned image]](dalle_1.jpg)
![[Uncaptioned image]](dalle_2.jpg)
![[Uncaptioned image]](dalle_3.jpg)
![[Uncaptioned image]](dalle_4.jpg)
![[Uncaptioned image]](dalle_5.jpg) 图5: 定性比较结果。 我们分别在第一行和第二行中显示使用 Glyph-SDXL 和 DALLE3 生成的结果。
图5: 定性比较结果。 我们分别在第一行和第二行中显示使用 Glyph-SDXL 和 DALLE3 生成的结果。
此外,我们进行彻底的消融实验,以研究我们方法中每个组件的效果,并可视化交叉注意力图,以证明我们的定制文本编码器可以在扩散模型之前提供字形。 我们详细介绍了训练设置,并在补充材料中提供了其他比较结果。
4.1指标
在我们的大多数实验中,除了涉及 GlyphControl 和 TextDiffuser 的比较之外,我们默认报告区分大小写的字级精度。 在这些情况下,我们通过报告与案例无关的指标和图像级指标来与他们的原始方法保持一致。 例如,如表 8 所示,Case-Recall 用作区分大小写的度量来区分大小写字母。 相反,所有其他指标都与大小写无关。 准确度[IMG]用于表示图像级准确度,这取决于整个图像中每个视觉单词的准确拼写以获得良好的评估。 此外,我们还确定了 GlyphControl 中的 OCR 准确度指标和 TextDiffuser 中的召回指标之间的直接对应关系。 因此,为了确保 SimpleBench 和 CreativeBench 指标报告的一致性,我们通过选择 Recall 作为主要指标来统一方法。
4.2 视觉段落基准
我们构建了设计文本生成任务的基准,收集了大约 个设计文本提示,涵盖不同难度的不同数量的字符、渲染少于 20 个字符、渲染 20 到 50 个字符、渲染 50 到 100 个字符字符,并渲染超过100个字符。 我们在补充材料中提供了一些具有代表性的提示示例。 我们在与商业产品 DALLE3 进行比较时使用了大约 1,000 个设计文本提示,而默认情况下,在所有后续消融实验中使用大约 400 个设计文本提示的较小子集以提高效率。
4.3 与商业产品 DALL 的比较E3
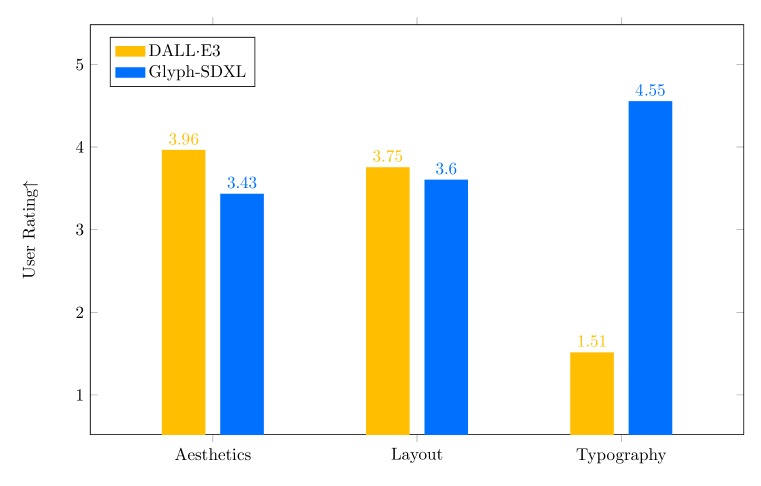
我们将我们的方法与视觉文本渲染任务中最强大的商业产品进行比较,即 VisualParagraphy 基准上的 DALLE3。 我们进行了一项用户研究,从三个关键方面评估结果:视觉美观、布局质量和排版准确性。 我们聘请了 10 位具有设计背景的用户,对生成的图像进行评分,评分范围为 1 到 5。 用户研究的结果如图6所示。 我们可以看到用户在排版方面的得分明显较高,而在其他两个方面的得分略低。 此外,我们在图 5 中显示了一些具有代表性的定性视觉比较结果。 我们发现我们的方法在设计文本渲染任务中表现出显着的优势。
| Method | SimpleBench | CreativeBench | MARIO-Eval | |||||||
| Recall | Case-Recall | Edit-Dis. | Recall | Case-Recall | Edit-Dis. | Accuracy [IMG] | Precision | Recall | F-measure | |
| DeepFloyd IF [14] | ||||||||||
| GlyphControl [29] | - | - | - | - | ||||||
| TextDiffuser [6] | - | - | - | - | - | - | ||||
| TextDiffuser-2 [7] | - | - | - | - | - | - | ||||
| Glyph-SDXL | ||||||||||
| Glyph-SDXL-Scene | ||||||||||
| Loss design | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | |
| IL-CL | ||||
| BL-CL | ||||
| IL-CL + BL-CL | ||||
| Glyph aug. ratio | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | |
| None | ||||
| 1:8 | ||||
| 1:16 | ||||
| 1:32 | ||||
| ByT5-to-SDXL mapper | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | |
| w/o mapper | ||||
| w/ mapper | ||||
| Text encoder | #Params | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | ||
| Glyph-ByT5-S | M | ||||
| Glyph-ByT5-B | M | ||||
| Glyph-ByT5-L | M | ||||
4.4与最先进技术的比较
我们的首要目标是确认我们的视觉文本生成模型的广泛适用性。 为此,我们仔细详细介绍了将我们的方法应用于早期研究中概述的代表性场景文本渲染基准所获得的结果,例如 TextDiffuser [6]、TextDiffuser-2 [7 ] 和 GlyphControl [29]。 这包括对 MARIO-Eval、SimpleBench 和 CreativeBench 等基准测试的全面测试。 比较结果总结在表8中。 根据这些比较结果,很明显,我们的 Glyph-SDXL-Scene 在这三个基准测试中明显优于之前的最先进技术。 我们方法的所有结果都代表零样本性能。
4.5 DALL 上的版式编辑E3
我们证明,我们的 Glyph-SDXL 能够按照补充材料中的 SDEdit [18] 编辑 DALLE3 生成的图像中的版式。
4.6消融实验
我们通过首先进行字形对齐预训练来进行所有消融研究,然后在我们的图形设计基准上训练 Glyph-SDXL 模型。 此外,除非另有说明,所有消融均在 Glyph-ByT5 和 Glyph-SDXL 模型的 K 个字形图像文本对上进行。
预训练视觉编码器选择我们研究了选择四种不同预训练视觉编码器的效果:CLIP视觉编码器[23]、DINOv2 [9]、ViTSTR [1] 和 CLIP4STR 视觉编码器 [31]。 我们在表8中报告了详细的比较结果。 值得注意的是,我们还观察到只有在使用 DINOv2 作为预训练的视觉编码器时才能实现准确的字体类型和颜色控制。
损失设计我们研究了选择不同训练损失设计的效果,并在表8中报告了详细的比较结果。 显然,所提出的盒级对比损失取得了良好的性能。





字形增强我们研究了字形对齐预训练期间字形增强的效果。 如表8所示,与非增强设置相比,字形增强提供了显着的改进,峰值在 1:16 左右。 值得注意的是,我们还观察到字体类型和颜色控制仅在比例达到或超过 1:16 时发生,也表明其有效性。
映射器、缩放字形文本数据集和文本编码器大小等 表 8 显示使用 ByT5 到 SDXL 映射器对齐间隙的重要性。 表 8 和表 8 验证了扩大字形文本数据集大小和文本编码器大小的好处。 我们在补充材料中提供了更多 Glyph-SDXL-Scene 的消融实验。
定性分析为了更深入地了解我们的 Glyph-ByT5 如何在视觉文本渲染任务中表现出色,我们进一步可视化字形文本提示和渲染图像之间的交叉注意力图,如图 7。 该可视化证实扩散模型有效地利用了 Glyph-ByT5 文本编码器中先前编码的字形对齐。
5结论
本文介绍了 Glyph-ByT5 文本编码器的设计和训练,该编码器专为使用扩散模型进行准确的视觉文本渲染而定制。 这项工作的核心是两个关键进展:创建可扩展的高质量字形文本数据集以及实施字形文本对齐预训练技术。 这些关键的进步有效地弥合了字形图像和文本提示之间的差距,有助于为文本丰富的设计图像和带有场景文本的开放域图像生成准确的文本。 我们提出的 Glyph-SDXL 模型所实现的引人注目的性能表明,专用文本编码器的开发代表了克服与扩散模型相关的一些基本挑战的有希望的途径,表明了该领域的一个重要趋势。
参考
- Atienza [2021] Rowel Atienza. Vision transformer for fast and efficient scene text recognition. In International Conference on Document Analysis and Recognition, pages 319–334. Springer, 2021.
- Avrahami et al. [2023] Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion. ACM Transactions on Graphics (TOG), 42(4):1–11, 2023.
- Betker et al. [2023] James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, Wesam Manassra, Prafulla Dhariwal, Casey Chu, Yunxin Jiao, and Aditya Ramesh. Improving image generation with better captions. 2023.
- Bica et al. [2024] Ioana Bica, Anastasija Ilić, Matthias Bauer, Goker Erdogan, Matko Bošnjak, Christos Kaplanis, Alexey A Gritsenko, Matthias Minderer, Charles Blundell, Razvan Pascanu, et al. Improving fine-grained understanding in image-text pre-training. arXiv preprint arXiv:2401.09865, 2024.
- [5] Haoxing Chen, Zhuoer Xu, Zhangxuan Gu, Jun Lan, Xing Zheng, Yaohui Li, Changhua Meng, Huijia Zhu, and Weiqiang Wang. Diffute: Universal text editing diffusion model.
- Chen et al. [2023a] Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, and Furu Wei. Textdiffuser: Diffusion models as text painters. arXiv preprint arXiv:2305.10855, 2023a.
- Chen et al. [2023b] Jingye Chen, Yupan Huang, Tengchao Lv, Lei Cui, Qifeng Chen, and Furu Wei. Textdiffuser-2: Unleashing the power of language models for text rendering. arXiv preprint arXiv:2311.16465, 2023b.
- Chen et al. [2023c] Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level image customization. arXiv preprint arXiv:2307.09481, 2023c.
- Darcet et al. [2023] Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers, 2023.
- Esser et al. [2024] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yannik Marek, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis, 2024.
- Hu et al. [2021] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Ji et al. [2023] Jiabao Ji, Guanhua Zhang, Zhaowen Wang, Bairu Hou, Zhifei Zhang, Brian Price, and Shiyu Chang. Improving diffusion models for scene text editing with dual encoders. arXiv preprint arXiv:2304.05568, 2023.
- Jia et al. [2023] Peidong Jia, Chenxuan Li, Zeyu Liu, Yichao Shen, Xingru Chen, Yuhui Yuan, Yinglin Zheng, Dong Chen, Ji Li, Xiaodong Xie, et al. Cole: A hierarchical generation framework for graphic design. arXiv preprint arXiv:2311.16974, 2023.
- Lab [2023] DeepFloyd Lab. Deepfloyd if. https://github.com/deep-floyd/IF, 2023.
- Liu et al. [2024] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024.
- Liu et al. [2022] Rosanne Liu, Daniel H Garrette, Chitwan Saharia, William Chan, Adam Roberts, Sharan Narang, Irina Blok, R. J. Mical, Mohammad Norouzi, and Noah Constant. Character-aware models improve visual text rendering. In Annual Meeting of the Association for Computational Linguistics, 2022.
- Ma et al. [2023] Jian Ma, Mingjun Zhao, Chen Chen, Ruichen Wang, Di Niu, Haonan Lu, and Xiaodong Lin. Glyphdraw: Learning to draw chinese characters in image synthesis models coherently. arXiv preprint arXiv:2303.17870, 2023.
- Meng et al. [2021] Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073, 2021.
- OpenAI [2023] OpenAI. Dall·e 3 system card. 2023.
- Oquab et al. [2023] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023.
- Paiss et al. [2023] Roni Paiss, Ariel Ephrat, Omer Tov, Shiran Zada, Inbar Mosseri, Michal Irani, and Tali Dekel. Teaching clip to count to ten. arXiv preprint arXiv:2302.12066, 2023.
- Podell et al. [2023] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Touvron et al. [2023] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Xu et al. [2021] Xingqian Xu, Zhifei Zhang, Zhaowen Wang, Brian Price, Zhonghao Wang, and Humphrey Shi. Rethinking text segmentation: A novel dataset and a text-specific refinement approach. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12045–12055, 2021.
- Xue et al. [2020] Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. mt5: A massively multilingual pre-trained text-to-text transformer. arXiv preprint arXiv:2010.11934, 2020.
- Xue et al. [2022] Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. Byt5: Towards a token-free future with pre-trained byte-to-byte models. Transactions of the Association for Computational Linguistics, 10:291–306, 2022.
- Yang et al. [2023] Yukang Yang, Dongnan Gui, Yuhui Yuan, Haisong Ding, Han Hu, and Kai Chen. Glyphcontrol: Glyph conditional control for visual text generation, 2023.
- Zhai et al. [2022] Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18123–18133, 2022.
- Zhao et al. [2023] Shuai Zhao, Xiaohan Wang, Linchao Zhu, and Yi Yang. Clip4str: A simple baseline for scene text recognition with pre-trained vision-language model. arXiv preprint arXiv:2305.14014, 2023.
- Zhao and Lian [2023] Yiming Zhao and Zhouhui Lian. Udifftext: A unified framework for high-quality text synthesis in arbitrary images via character-aware diffusion models. arXiv preprint arXiv:2312.04884, 2023.
- Zhong et al. [2022] Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chunyuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region-based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022.
- Zhou et al. [2023] Yufan Zhou, Ruiyi Zhang, Jiuxiang Gu, and Tong Sun. Customization assistant for text-to-image generation. arXiv preprint arXiv:2312.03045, 2023.
补充材料
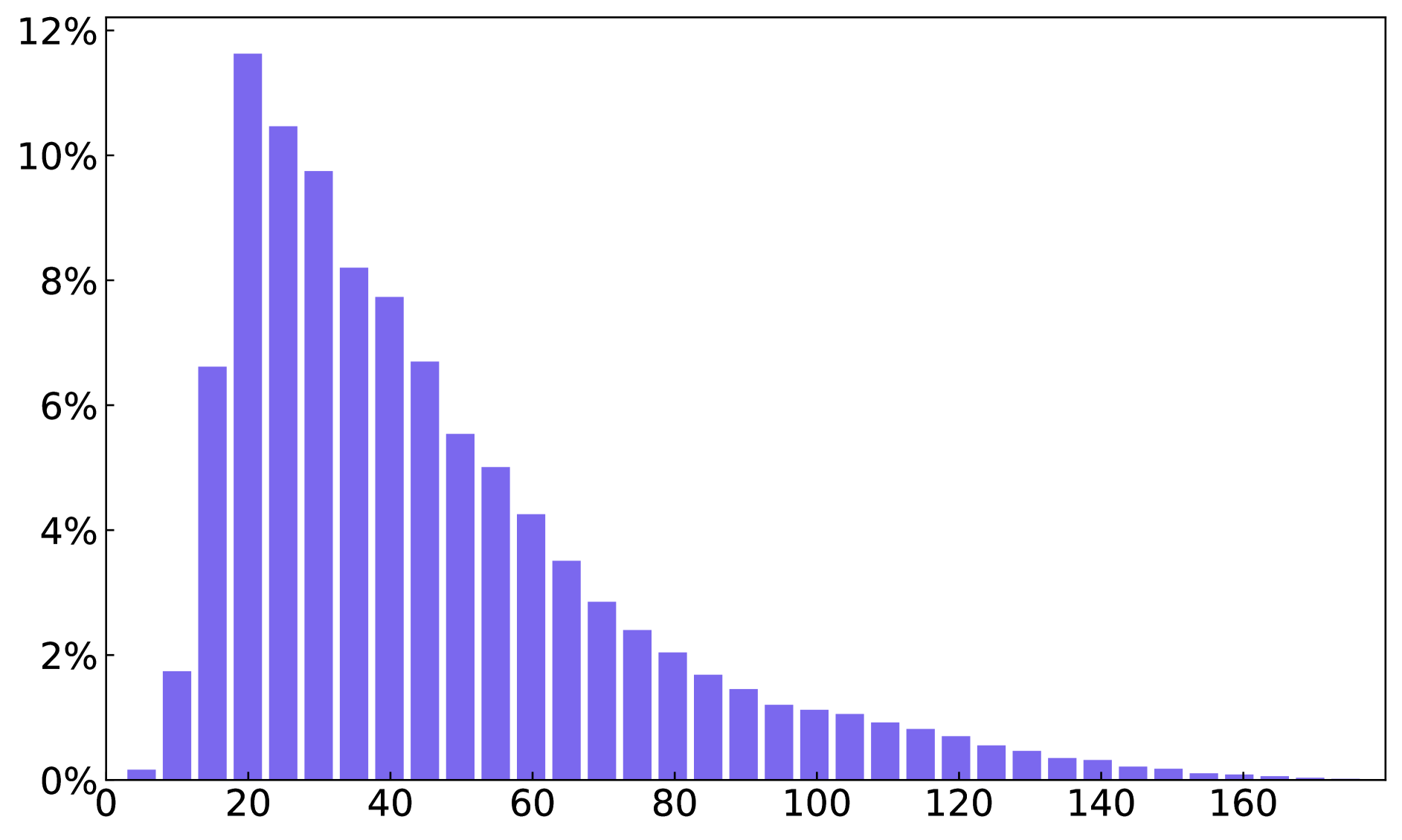
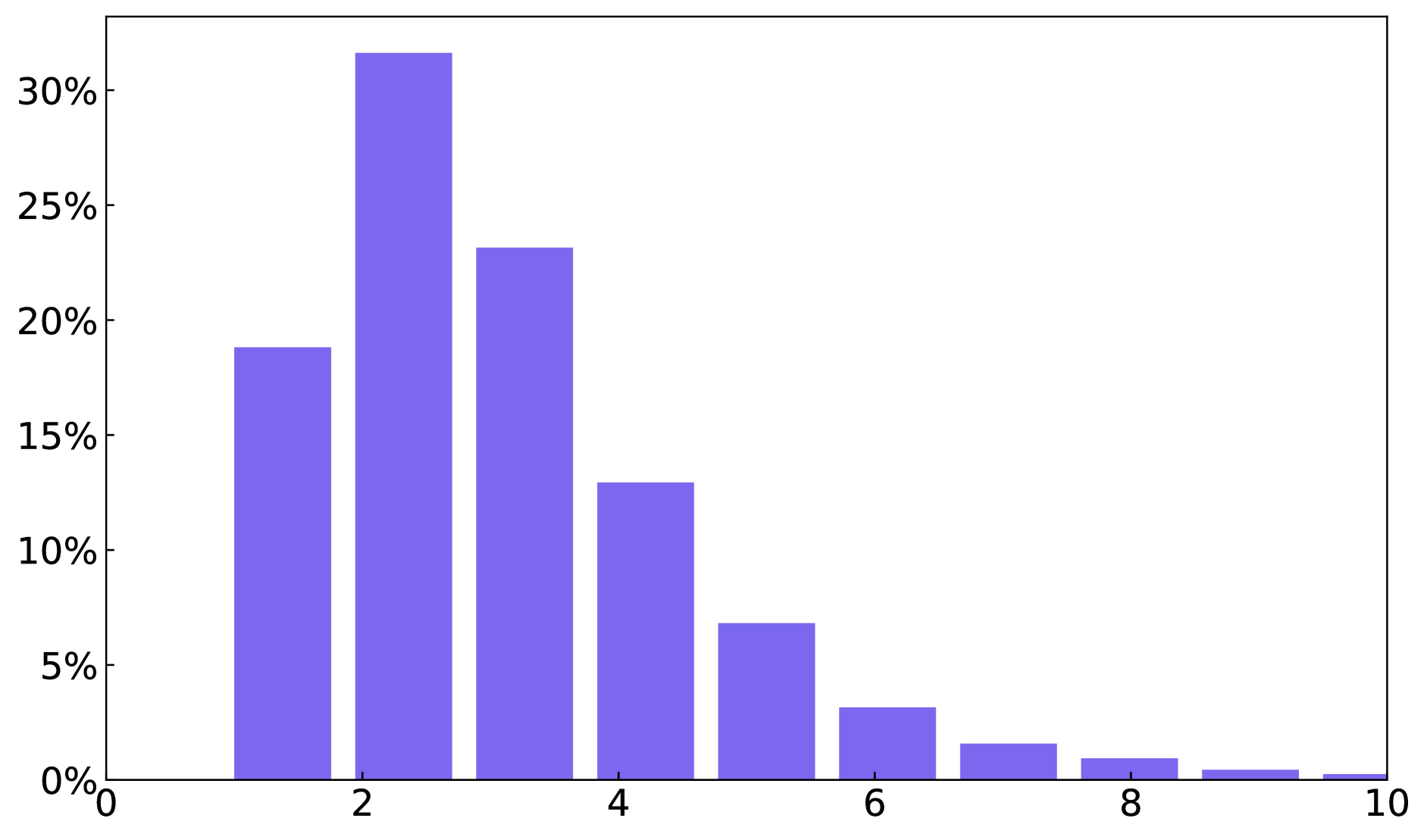
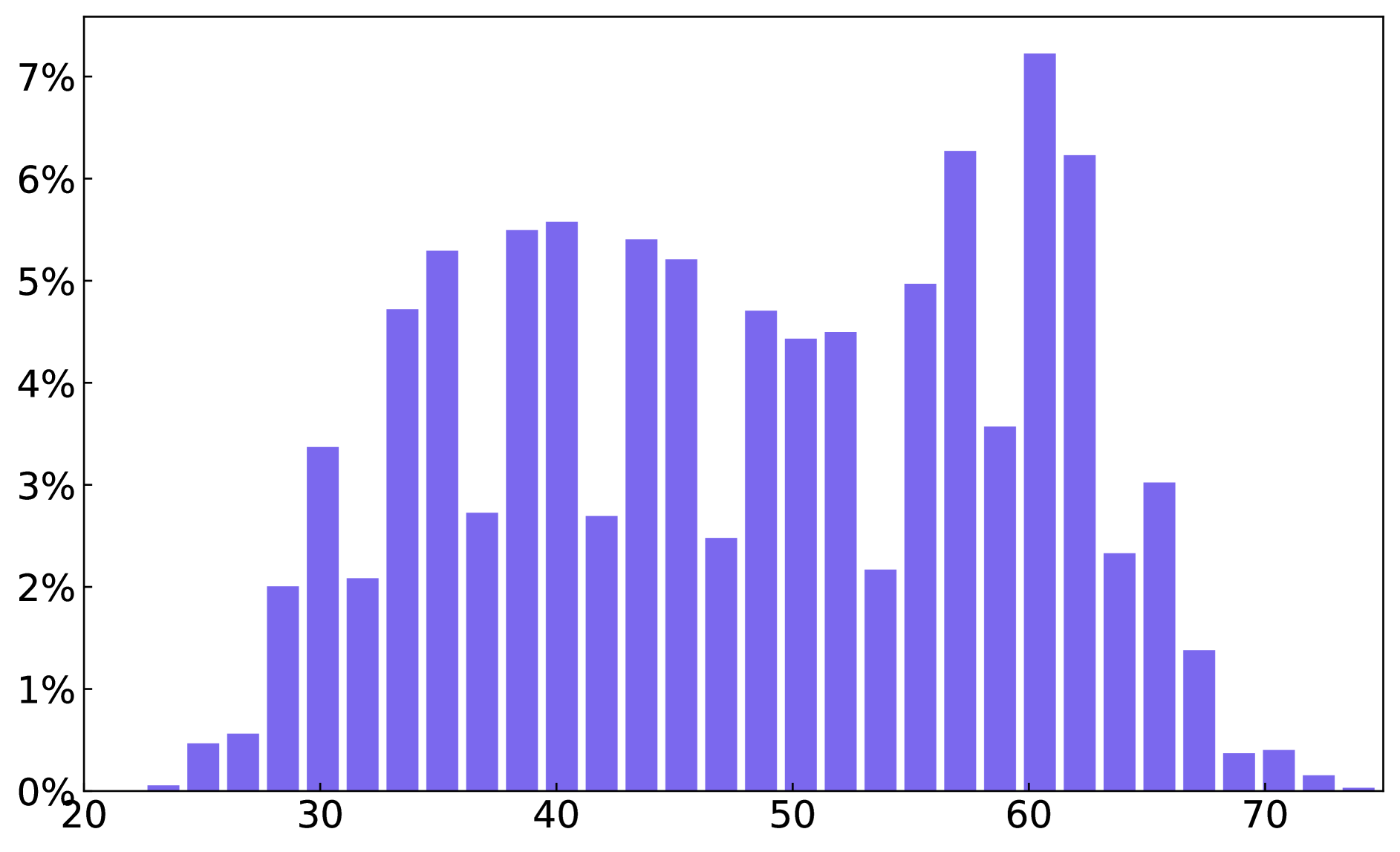
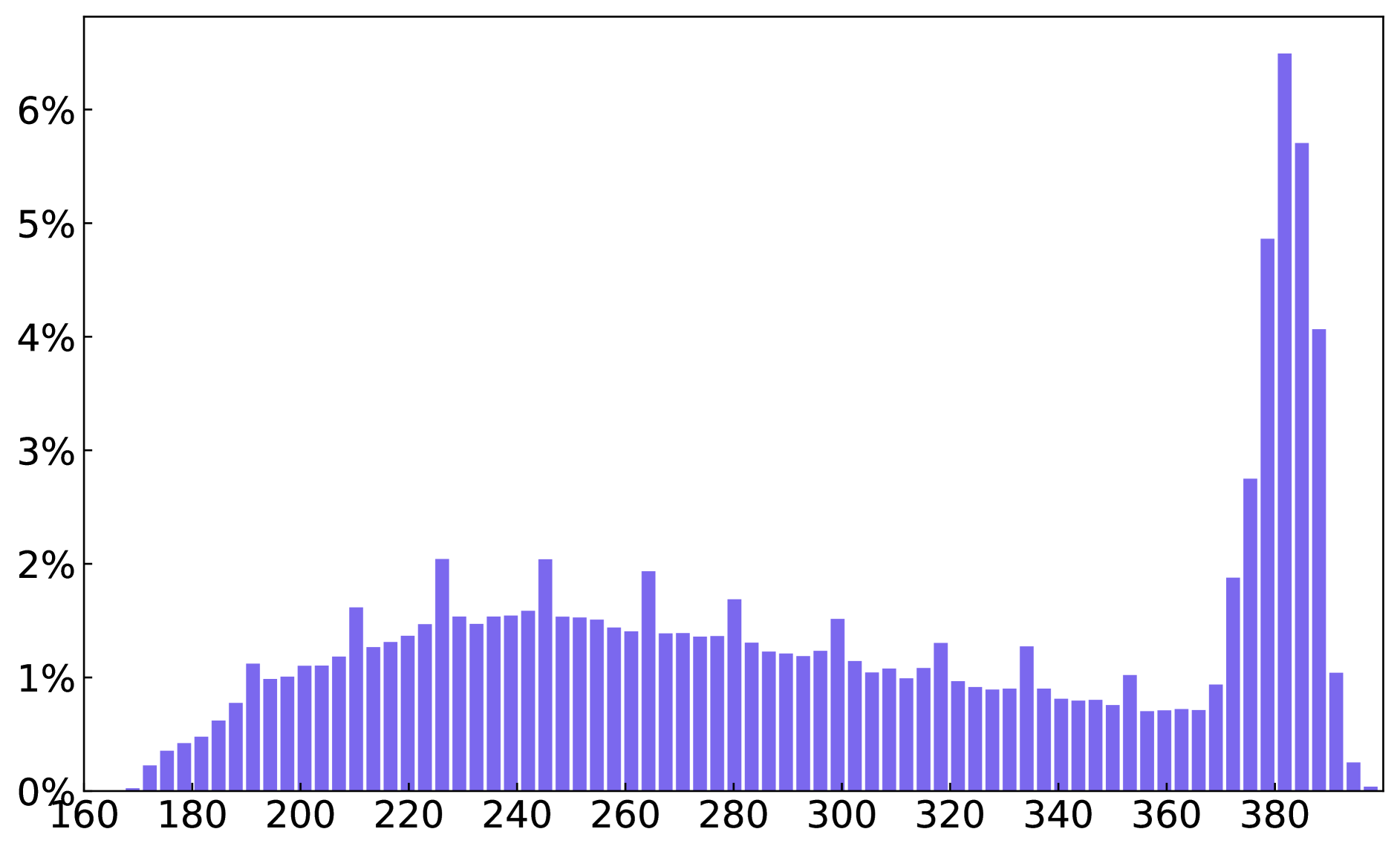
A. 数据集统计
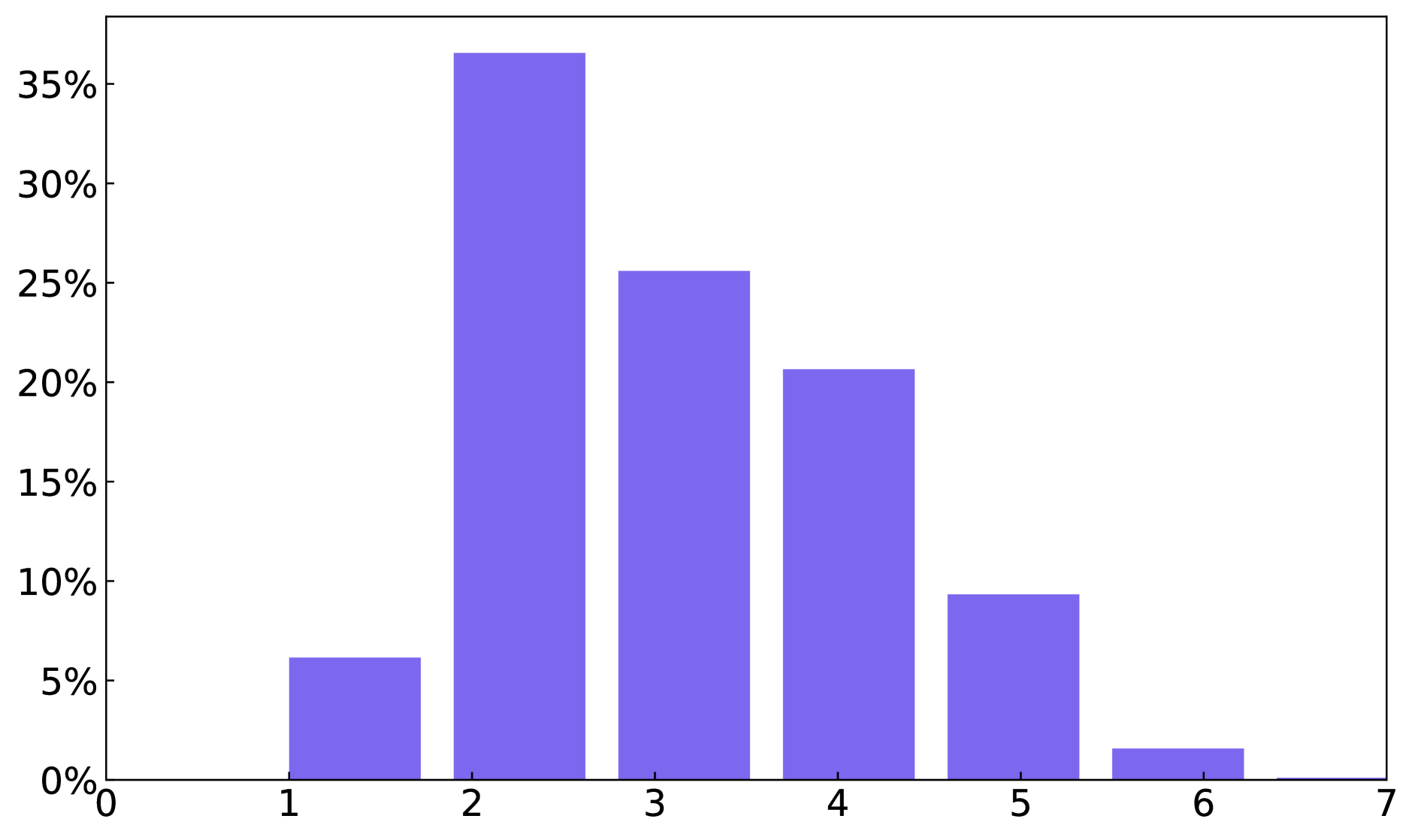
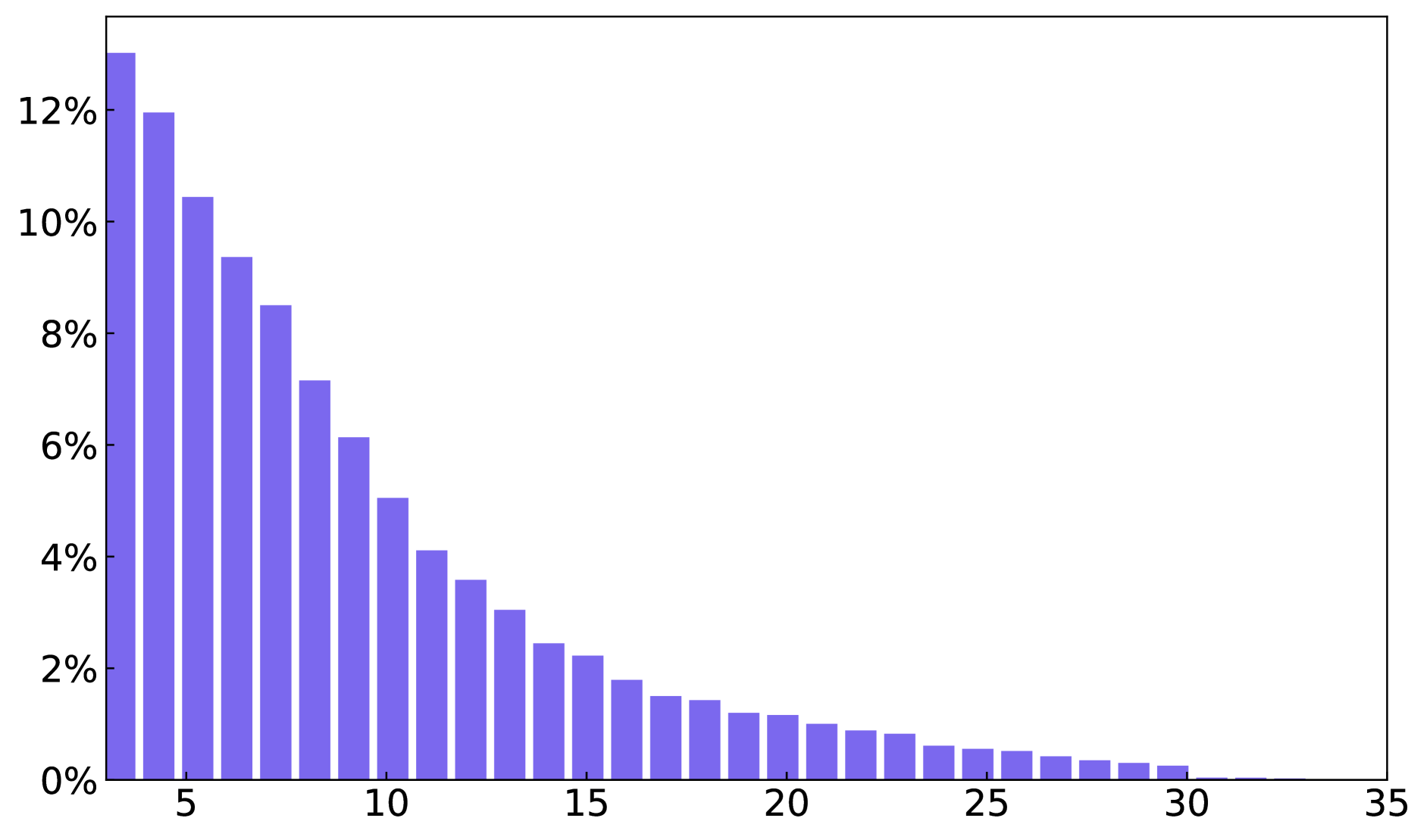
我们在图 8 中提供了整个字形文本数据集和段落字形文本数据集的文本框、单词和字符数量的统计数据。
 (一)
(一)
 (b)
(b)
 (c)
(c)
 (d)
(d)
 (e)
(e)
 (f)
(f)
B. 训练设置
| Hyperparameter | Glyph-CLIP-Small | Glyph-CLIP-Base | Glyph-CLIP-Large |
| Text Encoder | ByT5-Small | ByT5-Base | ByT5-Large |
| Vision Encoder | DINOv2 ViT-B/14 | DINOv2 ViT-L/14 | DINOv2 ViT-g/14 |
| Peak Learning-rate | 5.00E-04 | 5.00E-04 | 5.00E-04 |
| Batch Size | 1536 | 1024 | 768 |
| Epochs | 5 | 5 | 5 |
| Warmup Iterations | 100 | 100 | 100 |
| Weight Decay | 0.2 | 0.2 | 0.2 |
| Text-Encoder Dropout | 0.1 | 0.1 | 0.1 |
| Hyperparameter | Glyph-SDXL-Small | Glyph-SDXL-Base | Glyph-SDXL-Large |
| Text Encoder | Glyph-ByT5-Small | Glyph-ByT5-Base | Glyph-ByT5-Large |
| UNet Learning-rate | 5.00E-05 | 5.00E-05 | 5.00E-05 |
| Text Enoder Learning-rate | 1.00E-04 | 1.00E-04 | 1.00E-04 |
| Batch Size | 256 | 256 | 256 |
| Epochs | 10 | 10 | 10 |
| Weight Decay | 0.01 | 0.01 | 0.01 |
| Text-Encoder Weight Decay | 0.2 | 0.2 | 0.2 |
| Text-Encoder Dropout | 0.1 | 0.1 | 0.1 |
| Gradient Clipping | 1.0 | 1.0 | 1.0 |
| Text encoder fusion method | Precision () | |||
| 20 chars | 20-50 chars | 50-100 chars | 100 chars | |
| concatnate text embeddings | ||||
| region-wise cross-attention | ||||
C. 使用区域 SDEdit 进行版式编辑
受到 SDEdit [18] 和混合潜在扩散 [2] 成功的启发,我们引入了区域级 SDEdit 方案,将我们的 Glyph-SDXL 转变为精确且适应性强的可视化文本编辑器。 这使得能够在由最先进的 (SOTA) 生成模型(例如 DALL)生成的高质量图像中细化视觉文本E3。排版编辑结果如图10,展示了我们的方法在精确排版编辑方面的强大能力。
按区域划分的 SDEdit 方案: 对于任何给定的输入图像, 最初添加噪声步骤。 开始于 ,在噪声图像上迭代地采用 Glyph-SDXL 模型来执行去噪。 为了确保修改仅限于字形像素,从而保持背景像素不受影响,在此阶段仅字形区域进行去噪。 该过程一直进行到时间步 ,此时整个图像经过去噪以保证整体连贯性。 数字 10 描述了我们按区域划分的 SDEdit 方案的框架。
参数选择的影响:我们研究了和不同选择的效果。
我们首先修复并研究不同的影响。如图13所示,一个大的 对于确保字形潜在特征得到完全编辑至关重要。 较小 保留较大比例的原始潜在变量,从而导致冲突并降低性能。
此外,我们修复了并研究了不同选择的效果。如图13,较大的 确保字形框内部和外部像素之间更好的一致性,但会显着改变背景图像。 较小 相反,在牺牲连贯性的同时保持背景图像。

















 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
 (e)
(f) original
(e)
(f) original






 (a)
(a)
 (b)
(b)
 (c)
(c)
 (d)
(d)
 (e)
(e)
 (f)
(f)


















D. 设计与场景对齐的消融









































一、图15 进行了比较,证实了微调 Glyph-SDXL 与 SDXL 创建的合成图像的重要性。 这个过程显着 减轻仅使用图形设计数据进行微调时观察到的“语言漂移”现象。 此外,我们的分析表明,即使没有 SDXL 生成的图像,使用 TextSeg 和图形设计图像的组合数据集进行微调也是有益的。
E. 其他文本编码器融合方案的消融
人们可能会质疑连接来自不同文本编码器的文本嵌入的基本方法的有效性。 对比结果详见表 11. 根据经验,我们发现由于文本编码器之间存在巨大差异,该基线表现明显不佳。
F. 字体类型混合
我们展示了混合不同字体类型以创建新的看不见的字体类型的效果,以展示我们的 Glyph-SDXL 模型的外推能力。 如图所示 18,我们使用独特的 Creepster- 插入斜体 Brightwall-Italic 字体类型的嵌入常规字体类型,用于创建新的斜体混合字体类型,并包含Creepster-Regular的特殊效果。
G. 详细提示列表
我们在表12中说明了图1和图5所示生成图像的详细提示。
| Image |
Prompt |
| Fig 1, Row 1, Col1 | Background: Cards and invitations. The image features a white card adorned with blue flowers and greenery. Tags: blue, white, modern, simple, elegant, floral, illustration, professional, aesthetic, announcement. Text: Text ”It was the best of times, it was the worst of times. It was the age of wisdom, it was the age of foolishness.” in color-1, font-421. |
| Fig 1, Row 1, Col2 | Background: Cards and invitations. The image features a white card adorned with blue flowers and greenery. Tags: blue, white, modern, simple, elegant, floral, illustration, professional, aesthetic, announcement. Text: Text ”It was the best of times, it was the worst of times. It was the age of wisdom, it was the age of foolishness.” in color-1, font-469. |
| Fig 1, Row 1, Col3 | Background: Cards and invitations. The image features an endless lush green forest. Tags: elegant, illustration, professional, aesthetic, announcement. Text: Text ”It was the best of times, it was the worst of times.” in color-36, font-126. Text ”It was the age of wisdom, it was the age of foolishness.” in color-19, font-42. |
| Fig 1, Row 1, Col4 | Background: Blue Modern Stars Bookmark. The image features the stary universe with saturn, mars and other planets in aesthetic oil painting style. Tags: elegant, illustration, professional, aesthetic. Text: Text ”It was the best of times, it was the worst of times.” in color-0, font-47. Text ”It was the age of wisdom, it was the age of foolishness.” in color-38, font-420. |
| Fig 1, Row 2, Col1 | Background: Instagram Posts. The image features a stack of pancakes with syrup and strawberries on top. The pancakes are arranged in a visually appealing manner, with some pancakes placed on top of each other. The syrup is drizzled generously over the pancakes, and the strawberries are scattered around, adding a touch of color and freshness to the scene. The overall presentation of the pancakes is appetizing and inviting. Tags: brown, peach, grey, modern, minimalist, simple, colorful, illustration, Instagram post, instagram, post, national pancake day, international pancake day, happy pancake day, pancake day, pancake, sweet, cake, discount, sale. Text: Text ”Get 75% Discount for your first order” in color-3, font-25. Text ”Order Now” in color-0, font-97. Text ”National Pancake Day” in color-4, font-97. |
| Fig 1, Row 2, Col2 | Background: Cards and invitations. The image features a large gray elephant sitting in a field of flowers, holding a smaller elephant in its arms. The scene is quite serene and picturesque, with the two elephants being the main focus of the image. The field is filled with various flowers, creating a beautiful and vibrant backdrop for the elephants. Tags: Light green, orange, Illustration, watercolor, playful, Baby shower invitation, baby boy shower invitation, baby boy, welcoming baby boy, koala baby shower invitation, baby shower invitation for baby shower, baby boy invitation, background, playful baby shower card, baby shower, card, newborn, born, Baby Shirt Baby Shower Invitation. Text: Text ”RSVP to +123-456-7890” in color-18, font-100. Text ”Olivia Wilson” in color-99, font-210. Text ”Baby Shower” in color-53, font-210. Text ”Please Join Us For a” in color-18, font-100. Text ”In Honoring” in color-18, font-100. Text ”23 November, 2021 — 03:00 PM Fauget Hotels” in color-18, font-100. |
| Fig 1, Row 2, Col3 | Background: Flyers. The image features a purple background with a witch flying on a broomstick, surrounded by several pumpkins. The pumpkins are scattered throughout the scene, with some positioned closer to the witch and others further away. The combination of the purple background, the witch, and the pumpkins creates a festive and spooky atmosphere. Tags: purple, orange, colorful, illustration, creative, fun, dark, bold, playful, cute, cartoon, flyer, halloween, trick or treat, costume, party, spooky, pumpkin, trick, event. Text: Text ”Games” in color-27, font-197. Text ”Costume Party” in color-27, font-197. Text ”Candies” in color-27, font-197. Text ”October 31st 6 p.m. - 9 p.m. 123 Anywhere St., Any City, ST 12345” in color-51, font-197. Text ”Treat” in color-51, font-371. Text ”or” in color-51, font-371. Text ”Trick” in color-51, font-371. |
| Fig 1, Row 2, Col4 | Background: Instagram Posts. The image features a purple witch’s hat on a pumpkin, which is placed in front of a graveyard. The pumpkin is positioned in the center of the scene, and the hat is slightly tilted to the left. There are three ghosts in the background, with one on the left side, one on the right side, and another one in the middle. The ghosts are positioned at different heights, with the one on the left being the tallest, the one in the middle being the shortest, and the one on the right being slightly taller than the middle ghost. Tags: purple, orange, yellow, illustration, halloween, halloween day, halloween party, happy halloween, pumpkins, trick or treats, spooky, haunted, event, party, festive, witch, monster, scary, ghost, instagram post. Text: Text ”Big deals” in color-14. Text ”31 October 2022” in color-14. Text ”HALLOWEEN SALE” in color-57, font-252. Text ”ONLY FOR TODAY” in color-57, font-252. Text ”50% OFF” in color-57, font-252. |
| Fig 1, Row 1, Col4 | Background: A photo of a cute squirrel holding a sign, 4k, dslr. Text: Text ”Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”. |
| Fig 1, Row 1, Col4 | Background: A man standing in the midst of a vibrant sunflower field with a mountain range in the background under a blue sky, holding a sign that reads ”Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering” Vincent van Gogh style. Text: Text ”Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering”. |
| Fig 1, Row 1, Col4 | Background: An intriguing scene of a blank sign standing amidst a rocky landscape, with a backdrop of a clear sky and a palm tree. Text: Text ”Words on sign are”. Text ”CORRECT”. Text ”exactly with Glyph ByT5”. |
| Fig 1, Row 1, Col4 | Background: The image shows a sign with a stylized design, featuring a bird and branches. The sign is hanging from a ceiling, and it appears to be located outside a building. The design is simple and modern, with a limited color palette that includes shades of brown and white. The bird and branches are depicted in a minimalist style, with clean lines and a lack of detail that gives the sign a contemporary feel. The sign is likely intended to provide information or direction to passersby, but the specific content of the sign is not visible in the image. Text ”Glyph ByT5: A Customized Text Encoder for Accurate”. Text ”Visual Text Rendering”. |
| Fig 5, Row 1, Col1 | Background: The image features a decorative frame with a floral design, showcasing a variety of flowers. The frame is adorned with a combination of pink, yellow, and white flowers, creating a visually appealing and colorful display. The flowers are arranged in a way that fills the frame, giving the impression of a vibrant and lively scene. Text: Text ” ”Marriage does not guarantee you will be together forever, it’s only paper. It takes love, respect, trust, understanding, friendship, and faith in your relationship to make it last.”” in color-10, font-358. |
| Fig 5, Row 1, Col2 | Background: The image features a white background with a few plants and flowers scattered across it. There are three main plants in the scene, with one located on the left side, another in the middle, and the third on the right side. Additionally, there are two smaller plants in the upper part of the image. The plants are of various sizes and shapes, adding a sense of diversity to the scene. Text: Text ”Give yourself the same amount of care you selflessly give to others.” in color-7, font-196. |
| Fig 5, Row 1, Col3 | Background: Instagram Posts. The image features a woman sitting in a lotus position, also known as a yoga pose, with her legs crossed and her hands resting on her knees. She is surrounded by a serene environment, with trees in the background and a sun in the sky above her. The woman appears to be meditating or practicing yoga in a peaceful outdoor setting. Tags: WHITE, BROWN, BLUE, MODERN, meditation, exercise, fitness, yoga day, poster, health, illustration, international, position, concept, relaxation, yoga, woman. Text: Text ”” letś move to find healthy”” in color-2, font-30. Text ”YOGA DAY” in color-2, font-30. Text ”International” in color-2, font-500. |
| Fig 5, Row 1, Col4 | Background: The image features a white background with a circular frame made of colored pencils. The frame is filled with a variety of colored pencils, creating a visually appealing and artistic design. The pencils are arranged in different positions, with some overlapping and others standing alone. The combination of colors and the circular shape of the frame make the image a unique and creative piece of art. Text: Text ”I TOTALLY REMEMBERED YOUR BIRTHDAY!” in color-14, font-101. |
| Fig 5, Row 1, Col5 | Background: Facebook Post. The image features a man wearing a black shirt and blue overalls, holding a brown box. He is standing in front of a blue background, which has a few speech bubbles scattered around. The man appears to be smiling, possibly indicating that he is happy or excited about the box he is holding. Tags: Violet, purple, illustration, illustrated, corporate, professional, Courier, delivery, parcel, package, fast, free, express, shipping, vehicle, transportation, pickup, centre, man, character. Text: Text ”EXPRESS PARCEL SHIPPING” in color-0, font-4. Text ”www.reallygreatsite.comïn color-0, font-4. Text ”tel.: +123-456-7890” in color-0, font-4. Text ”over 1000 Delivery Centres” in color-0, font-4. Text ”Online Tracking” in color-0, font-4. Text ”10% off for New Clients” in color-0, font-4. Text ”FOR BUSINESS AND INDIVIDUALS” in color-123, font-4. Text ”DELIVERY” in color-123, font-54. Text ”COURIER” in color-0, font-54. |
H. 使用 GPT-4 进行版式布局规划
为了减少对手动提供的排版布局(例如目标文本框)的依赖,我们利用 GPT-4 的视觉规划功能来自动生成布局,并随后根据这些布局显示图像。 此外,我们利用 TextDiffuser-2 大语言模型的布局预测功能来确定目标文本框。 根据这些预测,我们实现 Glyph-SDXL 模型来生成可视文本图像,如图所示 18. 结果表明,GPT-4的布局能力明显比TextDiffuser-2的布局大语言模型更可靠。
此外,我们在图 18 中展示了 GPT-4 遇到的几个典型失败案例. 值得注意的是,GPT-4 倾向于将所有文本框均匀分布在同一列(第 1 列和第 2 列)中,将文本框聚集到一个角落(第 3 列和第 4 列),或者忽略文本语义隐含的布局约束,例如放置“Happy” ”和“父亲”在一起(第 5 栏和第 6 栏)。
























 GPT4
GPT4
 Human
Human
 GPT4
GPT4
 Human
Human
 GPT4
GPT4
 Human
Human